
code
stringlengths 2.5k
150k
| kind
stringclasses 1
value |
|---|---|
ansible t_systems_mms.icinga_director.icinga_notification_template_info – Query notification templates in Icinga2 t\_systems\_mms.icinga\_director.icinga\_notification\_template\_info – Query notification templates in Icinga2
===============================================================================================================
Note
This plugin is part of the [t\_systems\_mms.icinga\_director collection](https://galaxy.ansible.com/t_systems_mms/icinga_director) (version 1.23.0).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install t_systems_mms.icinga_director`.
To use it in a playbook, specify: `t_systems_mms.icinga_director.icinga_notification_template_info`.
New in version 1.13.0: of t\_systems\_mms.icinga\_director
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get a list of notification template objects from Icinga2 through the director API.
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **client\_cert** path | | PEM formatted certificate chain file to be used for SSL client authentication. This file can also include the key as well, and if the key is included, `client_key` is not required. |
| **client\_key** path | | PEM formatted file that contains your private key to be used for SSL client authentication. If `client_cert` contains both the certificate and key, this option is not required. |
| **force** boolean | **Choices:*** **no** ←
* yes
| If `yes` do not get a cached copy. Alias `thirsty` has been deprecated and will be removed in 2.13.
aliases: thirsty |
| **force\_basic\_auth** boolean | **Choices:*** **no** ←
* yes
| Credentials specified with *url\_username* and *url\_password* should be passed in HTTP Header. |
| **http\_agent** string | **Default:**"ansible-httpget" | Header to identify as, generally appears in web server logs. |
| **query** string | **Default:**"" | Text to filter search results. The text is matched on object\_name. Only objects containing this text will be returned in the resultset. Requires Icinga Director 1.8.0+, in earlier versions this parameter is ignored and all objects are returned. |
| **resolved** boolean | **Choices:*** **no** ←
* yes
| Resolve all inherited object properties and omit templates in output. |
| **url** string / required | | HTTP, HTTPS, or FTP URL in the form (http|https|ftp)://[user[:pass]]@host.domain[:port]/path |
| **url\_password** string | | The password for use in HTTP basic authentication. If the *url\_username* parameter is not specified, the *url\_password* parameter will not be used. |
| **url\_username** string | | The username for use in HTTP basic authentication. This parameter can be used without *url\_password* for sites that allow empty passwords |
| **use\_gssapi** boolean added in 2.11 of ansible.builtin | **Choices:*** **no** ←
* yes
| Use GSSAPI to perform the authentication, typically this is for Kerberos or Kerberos through Negotiate authentication. Requires the Python library [gssapi](https://github.com/pythongssapi/python-gssapi) to be installed. Credentials for GSSAPI can be specified with *url\_username*/*url\_password* or with the GSSAPI env var `KRB5CCNAME` that specified a custom Kerberos credential cache. NTLM authentication is `not` supported even if the GSSAPI mech for NTLM has been installed. |
| **use\_proxy** boolean | **Choices:*** no
* **yes** ←
| If `no`, it will not use a proxy, even if one is defined in an environment variable on the target hosts. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If `no`, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* This module supports check mode.
Examples
--------
```
- name: Query a notification template in icinga
t_systems_mms.icinga_director.icinga_notification_template_info:
url: "{{ icinga_url }}"
url_username: "{{ icinga_user }}"
url_password: "{{ icinga_pass }}"
query: "foonotificationtemplate"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **objects** list / elements=string | always | A list of returned Director objects. The list contains all objects matching the query filter. If the filter does not match any object, the list will be empty. |
### Authors
* Martin Schurz (@schurzi)
ansible t_systems_mms.icinga_director.icinga_servicegroup_info – Query servicegroups in Icinga2 t\_systems\_mms.icinga\_director.icinga\_servicegroup\_info – Query servicegroups in Icinga2
============================================================================================
Note
This plugin is part of the [t\_systems\_mms.icinga\_director collection](https://galaxy.ansible.com/t_systems_mms/icinga_director) (version 1.23.0).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install t_systems_mms.icinga_director`.
To use it in a playbook, specify: `t_systems_mms.icinga_director.icinga_servicegroup_info`.
New in version 1.13.0: of t\_systems\_mms.icinga\_director
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get a list of servicegroup objects from Icinga2 through the director API.
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **client\_cert** path | | PEM formatted certificate chain file to be used for SSL client authentication. This file can also include the key as well, and if the key is included, `client_key` is not required. |
| **client\_key** path | | PEM formatted file that contains your private key to be used for SSL client authentication. If `client_cert` contains both the certificate and key, this option is not required. |
| **force** boolean | **Choices:*** **no** ←
* yes
| If `yes` do not get a cached copy. Alias `thirsty` has been deprecated and will be removed in 2.13.
aliases: thirsty |
| **force\_basic\_auth** boolean | **Choices:*** **no** ←
* yes
| Credentials specified with *url\_username* and *url\_password* should be passed in HTTP Header. |
| **http\_agent** string | **Default:**"ansible-httpget" | Header to identify as, generally appears in web server logs. |
| **query** string | **Default:**"" | Text to filter search results. The text is matched on object\_name. Only objects containing this text will be returned in the resultset. Requires Icinga Director 1.8.0+, in earlier versions this parameter is ignored and all objects are returned. |
| **resolved** boolean | **Choices:*** **no** ←
* yes
| Resolve all inherited object properties and omit templates in output. |
| **url** string / required | | HTTP, HTTPS, or FTP URL in the form (http|https|ftp)://[user[:pass]]@host.domain[:port]/path |
| **url\_password** string | | The password for use in HTTP basic authentication. If the *url\_username* parameter is not specified, the *url\_password* parameter will not be used. |
| **url\_username** string | | The username for use in HTTP basic authentication. This parameter can be used without *url\_password* for sites that allow empty passwords |
| **use\_gssapi** boolean added in 2.11 of ansible.builtin | **Choices:*** **no** ←
* yes
| Use GSSAPI to perform the authentication, typically this is for Kerberos or Kerberos through Negotiate authentication. Requires the Python library [gssapi](https://github.com/pythongssapi/python-gssapi) to be installed. Credentials for GSSAPI can be specified with *url\_username*/*url\_password* or with the GSSAPI env var `KRB5CCNAME` that specified a custom Kerberos credential cache. NTLM authentication is `not` supported even if the GSSAPI mech for NTLM has been installed. |
| **use\_proxy** boolean | **Choices:*** no
* **yes** ←
| If `no`, it will not use a proxy, even if one is defined in an environment variable on the target hosts. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If `no`, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* This module supports check mode.
Examples
--------
```
- name: Query a servicegroup in icinga
t_systems_mms.icinga_director.icinga_servicegroup_info:
url: "{{ icinga_url }}"
url_username: "{{ icinga_user }}"
url_password: "{{ icinga_pass }}"
query: "fooservicegroup"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **objects** list / elements=string | always | A list of returned Director objects. The list contains all objects matching the query filter. If the filter does not match any object, the list will be empty. |
### Authors
* Martin Schurz (@schurzi)
ansible Collections in the Wti Namespace Collections in the Wti Namespace
================================
These are the collections with docs hosted on [docs.ansible.com](https://docs.ansible.com/) in the **wti** namespace.
* [wti.remote](remote/index#plugins-in-wti-remote)
ansible wti.remote.cpm_interface_config – Set network interface parameters in WTI OOB and PDU devices wti.remote.cpm\_interface\_config – Set network interface parameters in WTI OOB and PDU devices
===============================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_interface_config`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Set network interface parameters in WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **interface** string | **Choices:*** eth0
* eth1
| This is the ethernet port name that is getting configured. |
| **ipv4address** string | | IPv4 format IP address for the defined interface Port. |
| **ipv4dhcpdefgateway** integer | **Choices:*** 0
* 1
| Enable or Disable this ports configuration as the default IPv4 route for the device. |
| **ipv4dhcpenable** integer | **Choices:*** 0
* 1
| Enable IPv4 DHCP request call to obtain confufuration information. |
| **ipv4dhcphostname** string | | Define IPv4 DHCP Hostname. |
| **ipv4dhcplease** integer | | IPv4 DHCP Lease Time. |
| **ipv4dhcpobdns** integer | **Choices:*** 0
* 1
| IPv6 DHCP Obtain DNS addresses auto. |
| **ipv4dhcpupdns** integer | **Choices:*** 0
* 1
| IPv4 DHCP DNS Server Update. |
| **ipv4gateway** string | | IPv4 format Gateway address for the defined interface Port. |
| **ipv4netmask** string | | IPv4 format Netmask for the defined interface Port. |
| **ipv6address** string | | IPv6 format IP address for the defined interface Port. |
| **ipv6gateway** string | | IPv6 format Gateway address for the defined interface Port. |
| **ipv6subnetprefix** string | | IPv6 format Subnet Prefix for the defined interface Port. |
| **negotiation** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
* 5
* 6
| This is the speed of the interface port being configured. 0=Auto, 1=10/half, 2=10/full, 3=100/half, 4=100/full, 5=1000/half, 6=1000/full |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.
Examples
--------
```
# Set Network Interface Parameters
- name: Set the Interface Parameters for port eth1 of a WTI device
cpm_interface_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
interface: "eth1"
ipv4address: "192.168.0.14"
ipv4netmask: "255.255.255.0"
ipv4gateway: "192.168.0.1"
negotiation: 0
# Set Network Interface Parameters
- name: Set the Interface Parameters for port eth1 to DHCP of a WTI device
cpm_interface_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
interface: "eth1"
negotiation: 0
ipv4dhcpenable: 1
ipv4dhcphostname: ""
ipv4dhcplease: -1
ipv4dhcpobdns: 0
ipv4dhcpupdns: 0
ipv4dhcpdefgateway: 0
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **interface** dictionary | always | Current k/v pairs of interface info for the WTI device after module execution. **Sample:** {'ietf-ipv4': {'address': [{'gateway': '', 'ip': '10.10.10.2', 'netmask': '255.255.255.0'}], 'dhcpclient': [{'enable': 0, 'hostname': '', 'lease': -1, 'obdns': 1, 'updns': 1}]}, 'ietf-ipv6': {'address': [{'gateway': '', 'ip': '', 'netmask': ''}]}, 'is\_gig': '1', 'is\_up': '0', 'mac\_address': '00-09-9b-02-45-db', 'name': 'eth1', 'negotiation': '0', 'speed': '10', 'type': '0'} |
| | **totalports** integer | success | Total interface ports requested of the WTI device. **Sample:** 1 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible Wti.Remote Wti.Remote
==========
Collection version 1.0.1
Plugin Index
------------
These are the plugins in the wti.remote collection
### Lookup Plugins
* [cpm\_metering](cpm_metering_lookup#ansible-collections-wti-remote-cpm-metering-lookup) – Get Power and Current data from WTI OOB/Combo and PDU devices
* [cpm\_status](cpm_status_lookup#ansible-collections-wti-remote-cpm-status-lookup) – Get status and parameters from WTI OOB and PDU devices.
### Modules
* [cpm\_alarm\_info](cpm_alarm_info_module#ansible-collections-wti-remote-cpm-alarm-info-module) – Get alarm information from WTI OOB and PDU devices
* [cpm\_config\_backup](cpm_config_backup_module#ansible-collections-wti-remote-cpm-config-backup-module) – Get parameters from WTI OOB and PDU devices
* [cpm\_config\_restore](cpm_config_restore_module#ansible-collections-wti-remote-cpm-config-restore-module) – Get parameters from WTI OOB and PDU devices
* [cpm\_current\_info](cpm_current_info_module#ansible-collections-wti-remote-cpm-current-info-module) – Get the Current Information of a WTI device
* [cpm\_firmware\_info](cpm_firmware_info_module#ansible-collections-wti-remote-cpm-firmware-info-module) – Get firmware information from WTI OOB and PDU devices
* [cpm\_interface\_config](cpm_interface_config_module#ansible-collections-wti-remote-cpm-interface-config-module) – Set network interface parameters in WTI OOB and PDU devices
* [cpm\_interface\_info](cpm_interface_info_module#ansible-collections-wti-remote-cpm-interface-info-module) – Get network interface parameters from WTI OOB and PDU devices
* [cpm\_iptables\_config](cpm_iptables_config_module#ansible-collections-wti-remote-cpm-iptables-config-module) – Set network IPTables parameters in WTI OOB and PDU devices
* [cpm\_iptables\_info](cpm_iptables_info_module#ansible-collections-wti-remote-cpm-iptables-info-module) – Get network IPTABLES parameters from WTI OOB and PDU devices
* [cpm\_plugconfig](cpm_plugconfig_module#ansible-collections-wti-remote-cpm-plugconfig-module) – Get and Set Plug Parameters on WTI OOB and PDU power devices
* [cpm\_plugcontrol](cpm_plugcontrol_module#ansible-collections-wti-remote-cpm-plugcontrol-module) – Get and Set Plug actions on WTI OOB and PDU power devices
* [cpm\_power\_info](cpm_power_info_module#ansible-collections-wti-remote-cpm-power-info-module) – Get the Power Information of a WTI device
* [cpm\_serial\_port\_config](cpm_serial_port_config_module#ansible-collections-wti-remote-cpm-serial-port-config-module) – Set Serial port parameters in WTI OOB and PDU devices
* [cpm\_serial\_port\_info](cpm_serial_port_info_module#ansible-collections-wti-remote-cpm-serial-port-info-module) – Get Serial port parameters in WTI OOB and PDU devices
* [cpm\_snmp\_config](cpm_snmp_config_module#ansible-collections-wti-remote-cpm-snmp-config-module) – Set network IPTables parameters in WTI OOB and PDU devices
* [cpm\_snmp\_info](cpm_snmp_info_module#ansible-collections-wti-remote-cpm-snmp-info-module) – Get network SNMP parameters from WTI OOB and PDU devices
* [cpm\_status\_info](cpm_status_info_module#ansible-collections-wti-remote-cpm-status-info-module) – Get general status information from WTI OOB and PDU devices
* [cpm\_temp\_info](cpm_temp_info_module#ansible-collections-wti-remote-cpm-temp-info-module) – Get temperature information from WTI OOB and PDU devices
* [cpm\_time\_config](cpm_time_config_module#ansible-collections-wti-remote-cpm-time-config-module) – Set Time/Date parameters in WTI OOB and PDU devices.
* [cpm\_time\_info](cpm_time_info_module#ansible-collections-wti-remote-cpm-time-info-module) – Get Time/Date parameters in WTI OOB and PDU devices
* [cpm\_user](cpm_user_module#ansible-collections-wti-remote-cpm-user-module) – Get various status and parameters from WTI OOB and PDU devices
See also
List of [collections](../../index#list-of-collections) with docs hosted here.
ansible wti.remote.cpm_snmp_info – Get network SNMP parameters from WTI OOB and PDU devices wti.remote.cpm\_snmp\_info – Get network SNMP parameters from WTI OOB and PDU devices
=====================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_snmp_info`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get network SNMP parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **interface** string | **Choices:*** eth0
* eth1
* ppp0
| This is the ethernet port name that is getting retrieved. It can include a single ethernet port name, multiple ethernet port names separated by commas or not defined for all ports. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the network SNMP Parameters for all interfaces of a WTI device.
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the network SNMP Parameters for eth0 of a WTI device.
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
interface: "eth0"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **snmpaccess** dictionary | always | Current k/v pairs of SNMP info for the WTI device after module execution. **Sample:** {'snmpaccess': [{'eth0': {'ietf-ipv4': [{'enable': 0, 'users': [{'authpass': 'testpass', 'authpriv': '1', 'authproto': '0', 'index': '1', 'privpass': 'testpass', 'privproto': '1', 'username': 'test10'}]}], 'ietf-ipv6': [{'enable': 0, 'users': [{'authpass': 'testpass', 'authpriv': '1', 'authproto': '0', 'index': '1', 'privpass': 'testpass', 'privproto': '1', 'username': 'test10'}]}]}}]} |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
| programming_docs |
ansible wti.remote.cpm_iptables_config – Set network IPTables parameters in WTI OOB and PDU devices wti.remote.cpm\_iptables\_config – Set network IPTables parameters in WTI OOB and PDU devices
=============================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_iptables_config`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Set network IPTables parameters in WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **clear** integer | **Choices:*** 0
* 1
| Removes all the iptables for the protocol being defined before setting the newly defined entry. |
| **command** list / elements=string / required | | Actual iptables command to send to the WTI device. |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **index** list / elements=string | | Index in which command should be inserted. If not defined entry will start at position one. |
| **protocol** integer | **Choices:*** 0
* 1
| The protocol that the iptables entry should be applied. 0 = ipv4, 1 = ipv6. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.
Examples
--------
```
# Set Network IPTables Parameters
- name: Set the an IPTables Parameter for a WTI device
cpm_iptables_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
command: "iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT"
# Sets multiple Network IPTables Parameters
- name: Set the IPTables Parameters a WTI device
cpm_iptables_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
index:
- 1
- 2
command:
- "iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT"
- "iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **iptables** dictionary | always | Current k/v pairs of interface info for the WTI device after module execution. **Sample:** [{'eth0': {'ietf-ipv4': {'clear': 1, 'entries': [{'entry': 'iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 443 -j ACCEPT', 'index': '1'}, {'entry': 'iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT', 'index': '2'}]}}}] |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_config_restore – Get parameters from WTI OOB and PDU devices wti.remote.cpm\_config\_restore – Get parameters from WTI OOB and PDU devices
=============================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_config_restore`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_filename** string / required | | This is the filename of the existing WTI device configuration file. |
| **cpm\_password** string / required | | This is the Password of the WTI device to get the parameters from. |
| **cpm\_path** string | **Default:**"/tmp/" | This is the directory path to the existing the WTI device configuration file. |
| **cpm\_url** string / required | | This is the URL of the WTI device to get the parameters from. |
| **cpm\_username** string / required | | This is the Username of the WTI device to get the parameters from. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Parameters for a WTI device
cpm_config_restore:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
cpm_path: "/tmp/"
cpm_filename: "wti-192-10-10-239-2020-02-13T16-05-57-xml"
use_https: true
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output XML configuration of the WTI device queried |
| | **filelength** integer | success | Length of the file uploaded in bytes **Sample:** [{'filelength': 329439}] |
| | **status** list / elements=string | success | List of status returns from backup operation **Sample:** [{'code': 0, 'text': 'ok', 'unittimestamp': '2020-02-14T00:18:57+00:00'}] |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_power_info – Get the Power Information of a WTI device wti.remote.cpm\_power\_info – Get the Power Information of a WTI device
=======================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_power_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get the Power Information of a WTI device
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_enddate** string | | End date of the range to look for power data |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_startdate** string | | Start date of the range to look for power data |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Power Information of a WTI device
cpm_power_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Power Information of a WTI device
cpm_power_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
startdate: 01-12-2020"
enddate: 02-16-2020"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **ats** string | success | Identifies if the WTI device is an ATS type of power device. **Sample:** 1 |
| | **outletmetering** string | success | Identifies if the WTI device has Poiwer Outlet metering. **Sample:** 1 |
| | **plugcount** string | success | Current outlet plug count of the WTI device after module execution. **Sample:** 8 |
| | **powerdata** dictionary | success | Power data of the WTI device after module execution. **Sample:** [{'branch1': [{'current1': '0.00', 'current2': '0.00', 'current3': '0.00', 'current4': '0.00', 'current5': '0.00', 'current6': '0.00', 'current7': '0.00', 'current8': '0.00', 'voltage1': '118.00'}], 'timestamp': '2020-02-24T21:45:18+00:00'}] |
| | **powerdatacount** string | success | Total powerdata samples returned after module execution. **Sample:** 1 |
| | **powereff** string | success | Power efficiency of the WTI device after module execution. **Sample:** 100 |
| | **powerfactor** string | success | Power factor of the WTI device after module execution. **Sample:** 100 |
| | **powerunit** string | success | Identifies if the WTI device is a power type device. **Sample:** 1 |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
| | **timestamp** string | success | Current timestamp of the WTI device after module execution. **Sample:** 2020-02-24T20:54:03+00:00 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_alarm_info – Get alarm information from WTI OOB and PDU devices wti.remote.cpm\_alarm\_info – Get alarm information from WTI OOB and PDU devices
================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_alarm_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get temperature alarm from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Alarm Information for a WTI device
cpm_alarm_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Alarm Information for a WTI device
cpm_alarm_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **alarms** dictionary | success | Current alarm status of the WTI device after module execution. **Sample:** [{'name': 'OVER CURRENT (INITIAL)', 'status': '0'}, {'name': 'OVER CURRENT (CRITICAL)', 'status': '0'}, {'name': 'OVER TEMPERATURE (INITIAL)', 'status': '0'}] |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_serial_port_info – Get Serial port parameters in WTI OOB and PDU devices wti.remote.cpm\_serial\_port\_info – Get Serial port parameters in WTI OOB and PDU devices
==========================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_serial_port_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get Serial port parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **port** list / elements=string / required | **Default:**["\*"] | This is the serial port number that is getting retrieved. It can include a single port number, multiple port numbers separated by commas, a list of port numbers, or an '\*' character for all ports. |
| **use\_https** boolean | **Choices:*** **no** ←
* yes
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** **no** ←
* yes
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Serial Port Parameters for port 2 of a WTI device
cpm_serial_port_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
port: 2
- name: Get the Serial Port Parameters for ports 2 and 4 of a WTI device
cpm_serial_port_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
port: 2,4
- name: Get the Serial Port Parameters for all ports of a WTI device
cpm_serial_port_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
port: "*"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **serialports** list / elements=string | success | List of data for each serial port **Sample:** [{'baud': 4, 'break': 1, 'cmd': 1, 'connstatus': 'Free', 'echo': 1, 'handshake': 2, 'logoff': '^X', 'mode': 1, 'parity': 3, 'port': 2, 'portname': 'switch', 'seq': 2, 'stopbits': 1, 'tout': 0}, {'baud': 3, 'break': 1, 'cmd': 1, 'connstatus': 'Free', 'echo': 1, 'handshake': 2, 'logoff': '^X', 'mode': 1, 'parity': 1, 'port': 4, 'portname': 'router', 'seq': 2, 'stopbits': 1, 'tout': 1}] |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_config_backup – Get parameters from WTI OOB and PDU devices wti.remote.cpm\_config\_backup – Get parameters from WTI OOB and PDU devices
============================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_config_backup`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to get the parameters from. |
| **cpm\_path** string | **Default:**"/tmp/" | This is the directory path to store the WTI device configuration file. |
| **cpm\_url** string / required | | This is the URL of the WTI device to get the parameters from. |
| **cpm\_username** string / required | | This is the Username of the WTI device to get the parameters from. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Parameters for a WTI device
cpm_config_backup:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The XML configuration of the WTI device queried |
| | **status** list / elements=string | success | List of status returns from backup operation **Sample:** [{'code': 0, 'savedfilename': '/tmp/wti-192-10-10-239-2020-02-13T16-05-57.xml', 'text': 'ok'}] |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
| programming_docs |
ansible wti.remote.cpm_snmp_config – Set network IPTables parameters in WTI OOB and PDU devices wti.remote.cpm\_snmp\_config – Set network IPTables parameters in WTI OOB and PDU devices
=========================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_snmp_config`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Set network IPTables parameters in WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **authpass** list / elements=string | | Sets the Authentication Password for SNMPv3 (V3 only). |
| **authpriv** list / elements=string | | Configures the Authentication and Privacy features for SNMPv3 communication, 0 = Auth/NoPriv, 1 = Auth/Priv (V3 only). |
| **authproto** list / elements=string | | Which authentication protocol will be used, 0 = MD5, 1 = SHA1 (V3 only). |
| **clear** integer | **Choices:*** 0
* 1
| Removes all the users for the protocol being defined before setting the newly defined entries. |
| **contact** string | | The name of the administrator responsible for SNMP issues. |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **enable** integer | **Choices:*** 0
* 1
| The activates SNMP polling for the specified interface and protocol. |
| **index** list / elements=string | | Index of the user being modified (V3 only). |
| **interface** string | **Choices:*** eth0
* eth1
* ppp0
| The ethernet port for the SNMP we are defining. |
| **location** string | | The location of the SNMP Server. |
| **privpass** list / elements=string | | Sets the Privacy Password for SNMPv3 (V3 only) (V3 only). |
| **privproto** list / elements=string | | Which privacy protocol will be used, 0 = DES, 1 = AES128 (V3 only). |
| **protocol** integer | **Choices:*** 0
* 1
| The protocol that the SNMP entry should be applied. 0 = ipv4, 1 = ipv6. |
| **readonly** integer | **Choices:*** 0
* 1
| Controls the ability to change configuration parameters with SNMP. |
| **rocommunity** string | | Read Only Community Password, not used for SNMP V3. |
| **rwcommunity** string | | Read/Write Community Password, not used for SNMP V3. |
| **systemname** string | | The hostname of the WTI Device. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **username** list / elements=string | | Sets the User Name for SNMPv3 access (V3 only). |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
| **version** integer | **Choices:*** 0
* 1
* 2
| Defined which version of SNMP the device will respond to 0 = V1/V2 Only, 1 = V3 Only, 2 = V1/V2/V3. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.
Examples
--------
```
# Sets the device SNMP Parameters
- name: Set the an SNMP Parameter for a WTI device
cpm_iptables_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
interface: "eth0"
use_https: true
validate_certs: false
protocol: 0
clear: 1
enable: 1
readonly: 0
version: 0
rocommunity: "ropassword"
rwcommunity: "rwpassword"
# Sets the device SNMP Parameters
- name: Set the SNMP Parameters a WTI device
cpm_iptables_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
version: 1
index:
- 1
- 2
username:
- "username1"
- "username2"
authpriv:
- 1
- 1
authpass:
- "authpass1"
- "uthpass2"
authproto:
- 1
- 1
privpass:
- "authpass1"
- "uthpass2"
privproto:
- 1
- 1
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **snmpaccess** dictionary | always | Current k/v pairs of interface info for the WTI device after module execution. **Sample:** [{'eth0': {'ietf-ipv4': {'clear': 1, 'enable': 0, 'readonly': 0, 'users': [{'authpass': 'testpass', 'authpriv': '1', 'authproto': '0', 'index': '1', 'privpass': 'privpass1', 'privproto': '0', 'username': 'username1'}], 'version': 0}}}] |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_interface_info – Get network interface parameters from WTI OOB and PDU devices wti.remote.cpm\_interface\_info – Get network interface parameters from WTI OOB and PDU devices
===============================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_interface_info`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get network interface parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **interface** list / elements=string | **Choices:*** eth0
* eth1
* ppp0
| This is the ethernet port name that is getting retrieved. It can include a single ethernet port name, multiple ethernet port names separated by commas or not defined for all ports. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the network interface Parameters for a WTI device for all interfaces
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the network interface Parameters for a WTI device for a specific interface
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
interface: "eth0,eth1"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **interface** dictionary | always | Current k/v pairs of interface info for the WTI device after module execution. **Sample:** {'ietf-ipv4': {'address': [{'gateway': '', 'ip': '10.10.10.2', 'netmask': '255.255.255.0'}], 'dhcpclient': [{'enable': 0, 'hostname': '', 'lease': -1, 'obdns': 1, 'updns': 1}]}, 'ietf-ipv6': {'address': [{'gateway': '', 'ip': '', 'netmask': ''}]}, 'is\_gig': '1', 'is\_up': '0', 'mac\_address': '00-09-9b-02-45-db', 'name': 'eth1', 'negotiation': '0', 'speed': '10', 'type': '0'} |
| | **totalports** integer | success | Total ethernet ports requested of the WTI device. **Sample:** 1 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_temp_info – Get temperature information from WTI OOB and PDU devices wti.remote.cpm\_temp\_info – Get temperature information from WTI OOB and PDU devices
=====================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_temp_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get temperature information from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Temperature Information of a WTI device
cpm_temp_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Temperature Information of a WTI device
cpm_temp_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **format** string | success | Current Temperature format (Celsius or Fahrenheit) of the WTI device after module execution. **Sample:** F |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
| | **temperature** string | success | Current Temperature of the WTI device after module execution. **Sample:** 76 |
| | **timestamp** string | success | Current timestamp of the WTI device after module execution. **Sample:** 2020-02-24T20:54:03+00:00 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_metering – Get Power and Current data from WTI OOB/Combo and PDU devices wti.remote.cpm\_metering – Get Power and Current data from WTI OOB/Combo and PDU devices
========================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_metering`.
New in version 2.7: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get Power and Current data from WTI OOB/Combo and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Configuration | Comments |
| --- | --- | --- | --- |
| **\_terms** string / required | **Choices:*** getpower
* getcurrent
| | This is the Action to send the module. |
| **cpm\_password** string / required | | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | | This is the Username of the WTI device to send the module. |
| **enddate** string | | | End date of the range to look for power data |
| **startdate** string | | | Start date of the range to look for power data |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| | Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** no
* **yes** ←
| | Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| | If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Examples
--------
```
# Get Power data
- name: Get Power data for a given WTI device
- debug:
var: lookup('cpm_metering',
'getpower',
validate_certs=true,
use_https=true,
cpm_url='rest.wti.com',
cpm_username='restpower',
cpm_password='restfulpowerpass12')
# Get Current data
- name: Get Current data for a given WTI device
- debug:
var: lookup('cpm_metering',
'getcurrent',
validate_certs=true,
use_https=true,
cpm_url='rest.wti.com',
cpm_username='restpower',
cpm_password='restfulpowerpass12')
# Get Power data for a date range
- name: Get Power data for a given WTI device given a certain date range
- debug:
var: lookup('cpm_metering',
'getpower',
validate_certs=true,
use_https=true,
cpm_url='rest.wti.com',
cpm_username='restpower',
cpm_password='restfulpowerpass12',
startdate='08-12-2018'
enddate='08-14-2018')
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this lookup:
| Key | Returned | Description |
| --- | --- | --- |
| **\_list** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_status – Get status and parameters from WTI OOB and PDU devices. wti.remote.cpm\_status – Get status and parameters from WTI OOB and PDU devices.
================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_status`.
New in version 2.7: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get various status and parameters from WTI OOB and PDU devices.
Parameters
----------
| Parameter | Choices/Defaults | Configuration | Comments |
| --- | --- | --- | --- |
| **\_terms** string / required | **Choices:*** temperature
* firmware
* status
* alarms
| | This is the Action to send the module. |
| **cpm\_password** string / required | | | This is the Basic Authentication Password of the WTI device to send the module. |
| **cpm\_url** string / required | | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | | This is the Basic Authentication Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| | Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** no
* **yes** ←
| | Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| | If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Examples
--------
```
# Get temperature
- name: run Get Device Temperature
- debug:
var: lookup('cpm_status',
'temperature',
validate_certs=true,
use_https=true,
cpm_url='rest.wti.com',
cpm_username='rest',
cpm_password='restfulpassword')
# Get firmware version
- name: Get the firmware version of a given WTI device
- debug:
var: lookup('cpm_status',
'firmware',
validate_certs=false,
use_https=true,
cpm_url="192.168.0.158",
cpm_username="super",
cpm_password="super")
# Get status output
- name: Get the status output from a given WTI device
- debug:
var: lookup('cpm_status',
'status',
validate_certs=true,
use_https=true,
cpm_url="rest.wti.com",
cpm_username="rest",
cpm_password="restfulpassword")
# Get Alarm output
- name: Get the alarms status of a given WTI device
- debug:
var: lookup('cpm_status',
'alarms',
validate_certs=false,
use_https=false,
cpm_url="192.168.0.158",
cpm_username="super",
cpm_password="super")
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this lookup:
| Key | Returned | Description |
| --- | --- | --- |
| **\_list** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
| programming_docs |
ansible wti.remote.cpm_plugconfig – Get and Set Plug Parameters on WTI OOB and PDU power devices wti.remote.cpm\_plugconfig – Get and Set Plug Parameters on WTI OOB and PDU power devices
=========================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_plugconfig`.
New in version 2.8: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get and Set Plug Parameters on WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_action** string / required | **Choices:*** getplugconfig
* setplugconfig
| This is the Action to send the module. |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **plug\_bootdelay** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
| On a reboot command, this is the time when a plug will turn on power, after it has been turned off. 0='0.5 Secs', 1='1 Sec', 2='2 Sec', 3='5 Sec', 4='15 Sec', 5='30 Sec', 6='1 Min', 7='2 Mins', - 8='3 Mins', 9='5 Mins'. |
| **plug\_bootpriority** integer | | Prioritizes which plug gets its state changed first. The lower the number the higher the priority. Valid value can from 1 to the maximum number of plugs of the WTI unit. |
| **plug\_default** integer | **Choices:*** 0
* 1
| What the Plugs default state is when the device starts. 0 - Off, 1 - On. |
| **plug\_id** string / required | | This is the plug number that is to be manipulated For the getplugconfig command, the plug\_id 'all' will return the status of all the plugs the user has rights to access. |
| **plug\_name** string | | The new name of the Plug. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Examples
--------
```
# Get Plug parameters for all ports
- name: Get the Plug parameters for ALL ports of a WTI Power device
cpm_plugconfig:
cpm_action: "getplugconfig"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
validate_certs: true
plug_id: "all"
# Get Plug parameters for port 2
- name: Get the Plug parameters for the given port of a WTI Power device
cpm_plugconfig:
cpm_action: "getplugconfig"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
validate_certs: false
plug_id: "2"
# Configure plug 5
- name: Configure parameters for Plug 5 on a given WTI Power device
cpm_plugconfig:
cpm_action: "setplugconfig"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
plug_id: "5"
plug_name: "NewPlugNameFive"
plug_bootdelay: "3"
plug_default: "0"
plug_bootpriority: "1"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_status_info – Get general status information from WTI OOB and PDU devices wti.remote.cpm\_status\_info – Get general status information from WTI OOB and PDU devices
==========================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_status_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get temperature general status from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Status Information for a WTI device
cpm_status_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Status Information for a WTI device
cpm_status_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **analogmodemphonenumber** string | success | Current Analog Modem (if installed) Phone number of the WTI device. **Sample:** 9495869959 |
| | **apacheversion** string | success | Current Apache Web version running on the WTI device. **Sample:** 2.4.41 |
| | **apirelease** string | success | Current Date of the API release of the WTI device. **Sample:** March 2020 |
| | **assettag** string | success | Current Asset Tag of the WTI device. **Sample:** ARTE121 |
| | **cpu\_boardprogramdate** string | success | Current Board and Program date of the WTI device. **Sample:** ARM, 4-30-2019 |
| | **currentmonitor** string | success | Identifies if the unit has current monitoring capabilites. **Sample:** Yes |
| | **energywise** string | success | Current Energywise version of the WTI device. **Sample:** 1.2.0 |
| | **gig\_dualphy** string | success | Identifies dual ethernet port and gigabyte ethernet ports in the WTI device. **Sample:** Yes, Yes |
| | **interface\_list** string | success | Current ethernet ports of the WTI device. **Sample:** eth0 |
| | **keylength** string | success | Current key length of the WTI device. **Sample:** 2048 |
| | **lineinputcount\_rating** string | success | Identifies total power inlets and their power rating. **Sample:** 1 , 20 Amps |
| | **macaddresses** dictionary | always | Current mac addresses of the WTI device. **Sample:** {'mac': '00-09-9b-02-9a-26'} |
| | **modeminstalled** string | success | Identifies if a modem is installed in the WTI device. **Sample:** Yes, 4G/LTE |
| | **modemmodel** string | success | Identifies the modem model number (if installed) in the WTI device. **Sample:** MTSMC-LVW2 |
| | **opensshversion** string | success | Current OpenSSH running on the WTI device. **Sample:** 8.2p1 |
| | **opensslversion** string | success | Current OpenSSL version running on the WTI device. **Sample:** 1.1.1d 10 Sep 2019 |
| | **option1/2** string | success | Various Identity options of the WTI. **Sample:** WPO-STRT-CPM8 / W4G-VZW-CPM8 |
| | **product** string | success | Current Product Part Number of the WTI device. **Sample:** CPM-800-1-CA |
| | **ram\_flash** string | success | Total RAM and FLASH installed in the WTI device.. **Sample:** 512 MB, 128 MB |
| | **restful** string | success | Current RESTful version of the WTI device. **Sample:** v1.0, v2 (Mar20) |
| | **serialnumber** string | success | Current Serial number of the WTI device. **Sample:** 12345678901234 |
| | **siteid** string | success | Current Site-ID of the WTI device. **Sample:** GENEVARACK |
| | **softwareversion** string | success | Expanded Firmware version of the WTI device. **Sample:** 6.60 19 Feb 2020 |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
| | **totalplugs** string | success | Total Power Outlet plugs of the WTI device. **Sample:** 8 |
| | **totalports** string | success | Total serial ports of the WTI device. **Sample:** 9 |
| | **uptime** string | success | Current uptime of the WTI device. **Sample:** 259308.26 |
| | **vendor** string | success | Identifies WTI device as a WTI device. **Sample:** wti |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_user – Get various status and parameters from WTI OOB and PDU devices wti.remote.cpm\_user – Get various status and parameters from WTI OOB and PDU devices
=====================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_user`.
New in version 2.7: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get/Add/Edit Delete Users from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_action** string / required | **Choices:*** getuser
* adduser
* edituser
* deleteuser
| This is the Action to send the module. |
| **cpm\_password** string / required | | This is the Basic Authentication Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Basic Authentication Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **user\_accessapi** integer | **Choices:*** 0
* 1
| If the user has access to the WTI device via RESTful APIs 0 No , 1 Yes |
| **user\_accesslevel** integer | **Choices:*** 0
* 1
* 2
* 3
| This is the access level that needs to be create/modified/deleted 0 View, 1 User, 2 SuperUser, 3 Administrator |
| **user\_accessmonitor** integer | **Choices:*** 0
* 1
| If the user has ability to monitor connection sessions 0 No , 1 Yes |
| **user\_accessoutbound** integer | **Choices:*** 0
* 1
| If the user has ability to initiate Outbound connection 0 No , 1 Yes |
| **user\_accessserial** integer | **Choices:*** 0
* 1
| If the user has access to the WTI device via Serial ports 0 No , 1 Yes |
| **user\_accessssh** integer | **Choices:*** 0
* 1
| If the user has access to the WTI device via SSH 0 No , 1 Yes |
| **user\_accessweb** integer | **Choices:*** 0
* 1
| If the user has access to the WTI device via Web 0 No , 1 Yes |
| **user\_callbackphone** string | | This is the Call Back phone number used for POTS modem connections |
| **user\_groupaccess** string | | If AccessLevel is lower than Administrator, which Groups the user has access |
| **user\_name** string / required | | This is the User Name that needs to be create/modified/deleted |
| **user\_pass** string | | This is the User Password that needs to be create/modified/deleted If the user is being Created this parameter is required |
| **user\_plugaccess** string | | If AccessLevel is lower than Administrator, which plugs the user has access |
| **user\_portaccess** string | | If AccessLevel is lower than Administrator, which ports the user has access |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Examples
--------
```
# Get User Parameters
- name: Get the User Parameters for the given user of a WTI device
cpm_user:
cpm_action: "getuser"
cpm_url: "rest.wti.com"
cpm_username: "restuser"
cpm_password: "restfuluserpass12"
use_https: true
validate_certs: true
user_name: "usernumberone"
# Create User
- name: Create a User on a given WTI device
cpm_user:
cpm_action: "adduser"
cpm_url: "rest.wti.com"
cpm_username: "restuser"
cpm_password: "restfuluserpass12"
use_https: true
validate_certs: false
user_name: "usernumberone"
user_pass: "complicatedpassword"
user_accesslevel: 2
user_accessssh: 1
user_accessserial: 1
user_accessweb: 0
user_accessapi: 1
user_accessmonitor: 0
user_accessoutbound: 0
user_portaccess: "10011111"
user_plugaccess: "00000111"
user_groupaccess: "00000000"
# Edit User
- name: Edit a User on a given WTI device
cpm_user:
cpm_action: "edituser"
cpm_url: "rest.wti.com"
cpm_username: "restuser"
cpm_password: "restfuluserpass12"
use_https: true
validate_certs: false
user_name: "usernumberone"
user_pass: "newpasswordcomplicatedpassword"
# Delete User
- name: Delete a User from a given WTI device
cpm_user:
cpm_action: "deleteuser"
cpm_url: "rest.wti.com"
cpm_username: "restuser"
cpm_password: "restfuluserpass12"
use_https: true
validate_certs: true
user_name: "usernumberone"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_iptables_info – Get network IPTABLES parameters from WTI OOB and PDU devices wti.remote.cpm\_iptables\_info – Get network IPTABLES parameters from WTI OOB and PDU devices
=============================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_iptables_info`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get network IPTABLES parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the network IPTABLES Parameters for a WTI device.
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the network IPTABLES Parameters for a WTI device.
cpm_interface_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **iptables** dictionary | always | Current k/v pairs of IPTABLES info for the WTI device after module execution. **Sample:** {'iptables': [{'eth0': {'ietf-ipv4': [{'clear': 0, 'entries': [{'entry': 'test10', 'index': '1'}, {'entry': '', 'index': '2'}]}], 'ietf-ipv6': [{'clear': 0, 'entries': [{'entry': 'test30', 'index': '1'}, {'entry': 'test40', 'index': '2'}]}]}}]} |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_firmware_info – Get firmware information from WTI OOB and PDU devices wti.remote.cpm\_firmware\_info – Get firmware information from WTI OOB and PDU devices
======================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_firmware_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get firmware information from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Firmware Information for a WTI device
cpm_firmware_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Firmware Information for a WTI device
cpm_firmware_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **family** string | success | Current family type (Console = 1 or Power = 0) of the WTI device. **Sample:** 1 |
| | **fips** string | success | If WTI device is a no FIPS only device. **Sample:** 2020-02-24T20:54:03+00:00 |
| | **firmware** string | success | Current Firmware version of the WTI device. **Sample:** 6.60 |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
| programming_docs |
ansible wti.remote.cpm_serial_port_config – Set Serial port parameters in WTI OOB and PDU devices wti.remote.cpm\_serial\_port\_config – Set Serial port parameters in WTI OOB and PDU devices
============================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_serial_port_config`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Set Serial port parameters in WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **baud** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10
| This is the baud rate to assign to the port. 0=300, 1=1200, 2=2400, 3=4800, 4=9600, 5=19200, 6=38400, 7=57600, 8=115200, 9=230400, 10=460800 |
| **break\_allow** boolean | **Choices:*** no
* yes
| This is if the break character is allowed to be passed through the port, 0=Off, 1=On |
| **cmd** integer | **Choices:*** 0
* 1
| This is the Admin Mode to assign to the port, 0=Deny, 1=Permit. |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **echo** boolean | **Choices:*** no
* yes
| -This is the command echo parameter to assign to the port, 0=Off, 1=On |
| **handshake** integer | **Choices:*** 0
* 1
* 2
* 3
| This is the handshake to assign to the port, 0=None, 1=XON/XOFF, 2=RTS/CTS, 3=Both. |
| **logoff** string | | This is the logout character to assign to the port If preceded by a ^ character, the sequence will be a control character. Used if seq is set to 0 or 1 |
| **mode** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
| This is the port mode to assign to the port, 0=Any-to-Any. 1=Passive, 2=Buffer, 3=Modem, 4=ModemPPP. |
| **parity** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
* 5
| This is the parity to assign to the port, 0=7-None, 1=7-Even, 2=7-Odd, 3=8-None, 4=8-Even, 5=8-Odd. |
| **port** integer / required | | This is the port number that is getting the action performed on. |
| **portname** string | | This is the Name of the Port that is displayed. |
| **seq** integer | **Choices:*** 1
* 2
* 3
| This is the type of Sequence Disconnect to assign to the port, 0=Three Characters (before and after), 1=One Character Only, 2=Off |
| **stopbits** integer | **Choices:*** 0
* 1
| This is the stop bits to assign to the port, 0=1 Stop Bit, 1=2 Stop Bit. |
| **tout** integer | **Choices:*** 0
* 1
* 2
* 3
* 4
* 5
| This is the Port Activity Timeout to assign to the port, 0=Off, 1=5 Min, 2=15 Min, 3=30 Min, 4=90 Min, 5=1 Min. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.
Examples
--------
```
# Set Serial Port Parameters
- name: Set the Port Parameters for port 2 of a WTI device
cpm_serial_port_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
port: "2"
portname: "RouterLabel"
baud: "7"
handshake: "1"
stopbits: "0"
parity: "0"
mode: "0"
cmd: "0"
seq: "1"
tout: "1"
echo: "0"
break_allow: "0"
logoff: "^H"
# Set Serial Port Port Name and Baud Rate Parameters
- name: Set New port name and baud rate (115k) for port 4 of a WTI device
cpm_serial_port_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
port: "4"
portname: "NewPortName1"
baud: "8"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_plugcontrol – Get and Set Plug actions on WTI OOB and PDU power devices wti.remote.cpm\_plugcontrol – Get and Set Plug actions on WTI OOB and PDU power devices
=======================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_plugcontrol`.
New in version 2.8: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get and Set Plug actions on WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_action** string / required | **Choices:*** getplugcontrol
* setplugcontrol
| This is the Action to send the module. |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **plug\_id** string / required | | This is the plug number or the plug name that is to be manipulated For the plugget command, the plug\_id 'all' will return the status of all the plugs the user has rights to access. |
| **plug\_state** string | **Choices:*** on
* off
* boot
* default
| This is what action to take on the plug. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Examples
--------
```
# Get Plug status for all ports
- name: Get the Plug status for ALL ports of a WTI device
cpm_plugcontrol:
cpm_action: "getplugcontrol"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
validate_certs: true
plug_id: "all"
# Get Plug status for port 2
- name: Get the Plug status for the given port of a WTI device
cpm_plugcontrol:
cpm_action: "getplugcontrol"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
validate_certs: false
plug_id: "2"
# Reboot plug 5
- name: Reboot Plug 5 on a given WTI device
cpm_plugcontrol:
cpm_action: "setplugcontrol"
cpm_url: "rest.wti.com"
cpm_username: "restpower"
cpm_password: "restfulpowerpass12"
use_https: true
plug_id: "5"
plug_state: "boot"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** string | always | The output JSON returned from the commands sent |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_time_info – Get Time/Date parameters in WTI OOB and PDU devices wti.remote.cpm\_time\_info – Get Time/Date parameters in WTI OOB and PDU devices
================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_time_info`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get Time/Date and NTP parameters from WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Time/Date Parameters for a WTI device
cpm_time_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Time/Date Parameters for a WTI device
cpm_time_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **date** string | success | Current Date of the WTI device after module execution. **Sample:** 11/14/2019 |
| | **ntp** dictionary | always | Current k/v pairs of ntp info of the WTI device after module execution. **Sample:** {'enable': '0', 'ietf-ipv4': {'address': [{'primary': '192.168.0.169', 'secondary': '12.34.56.78'}]}, 'ietf-ipv6': {'address': [{'primary': '', 'secondary': ''}]}, 'timeout': '4'} |
| | **time** string | success | Current Time of the WTI device after module execution. **Sample:** 12:12:00 |
| | **timezone** integer | success | Current Timezone of the WTI device after module execution. **Sample:** 5 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_current_info – Get the Current Information of a WTI device wti.remote.cpm\_current\_info – Get the Current Information of a WTI device
===========================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_current_info`.
New in version 2.9: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Get the Current Information of a WTI device
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_enddate** string | | End date of the range to look for current data |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_startdate** string | | Start date of the range to look for current data |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.)
Examples
--------
```
- name: Get the Current Information of a WTI device
cpm_current_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
- name: Get the Current Information of a WTI device
cpm_current_info:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: false
validate_certs: false
startdate: 01-12-2020"
enddate: 02-16-2020"
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **ats** string | success | Identifies if the WTI device is an ATS type of power device. **Sample:** 1 |
| | **outletmetering** string | success | Identifies if the WTI device has Poiwer Outlet metering. **Sample:** 1 |
| | **plugcount** string | success | Current outlet plug count of the WTI device after module execution. **Sample:** 8 |
| | **powerdata** dictionary | success | Power data of the WTI device after module execution. **Sample:** [{'branch1': [{'current1': '0.00', 'voltage1': '118.00'}], 'format': 'F', 'temperature': '90', 'timestamp': '2020-02-24T23:29:31+00:00'}] |
| | **powerdatacount** string | success | Total powerdata samples returned after module execution. **Sample:** 1 |
| | **powereff** string | success | Power efficiency of the WTI device after module execution. **Sample:** 100 |
| | **powerfactor** string | success | Power factor of the WTI device after module execution. **Sample:** 100 |
| | **powerunit** string | success | Identifies if the WTI device is a power type device. **Sample:** 1 |
| | **status** dictionary | always | Return status after module completion **Sample:** {'code': '0', 'text': 'OK'} |
| | **timestamp** string | success | Current timestamp of the WTI device after module execution. **Sample:** 2020-02-24T20:54:03+00:00 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
ansible wti.remote.cpm_time_config – Set Time/Date parameters in WTI OOB and PDU devices. wti.remote.cpm\_time\_config – Set Time/Date parameters in WTI OOB and PDU devices.
===================================================================================
Note
This plugin is part of the [wti.remote collection](https://galaxy.ansible.com/wti/remote) (version 1.0.1).
You might already have this collection installed if you are using the `ansible` package. It is not included in `ansible-core`. To check whether it is installed, run `ansible-galaxy collection list`.
To install it, use: `ansible-galaxy collection install wti.remote`.
To use it in a playbook, specify: `wti.remote.cpm_time_config`.
New in version 2.10: of wti.remote
* [Synopsis](#synopsis)
* [Parameters](#parameters)
* [Notes](#notes)
* [Examples](#examples)
* [Return Values](#return-values)
Synopsis
--------
* Set Time/Date and NTP parameters parameters in WTI OOB and PDU devices
Parameters
----------
| Parameter | Choices/Defaults | Comments |
| --- | --- | --- |
| **cpm\_password** string / required | | This is the Password of the WTI device to send the module. |
| **cpm\_url** string / required | | This is the URL of the WTI device to send the module. |
| **cpm\_username** string / required | | This is the Username of the WTI device to send the module. |
| **date** string | | Static date in the format of two digit month, two digit day, four digit year separated by a slash symbol. |
| **ipv4address** string | | Comma separated string of up to two addresses for a primary and secondary IPv4 base NTP server. |
| **ipv6address** string | | Comma separated string of up to two addresses for a primary and secondary IPv6 base NTP server. |
| **ntpenable** integer | **Choices:*** 0
* 1
| This enables or disables the NTP client service. |
| **time** string | | Static time in the format of two digit hour, two digit minute, two digit second separated by a colon symbol. |
| **timeout** integer | | Set the network timeout in seconds of contacting the NTP servers, valid options can be from 1-60. |
| **timezone** integer | | This is timezone that is assigned to the WTI device. |
| **use\_https** boolean | **Choices:*** no
* **yes** ←
| Designates to use an https connection or http connection. |
| **use\_proxy** boolean | **Choices:*** **no** ←
* yes
| Flag to control if the lookup will observe HTTP proxy environment variables when present. |
| **validate\_certs** boolean | **Choices:*** no
* **yes** ←
| If false, SSL certificates will not be validated. This should only be used on personally controlled sites using self-signed certificates. |
Notes
-----
Note
* Use `groups/cpm` in `module_defaults` to set common options used between CPM modules.
Examples
--------
```
# Set a static time/date and timezone of a WTI device
- name: Set known fixed time/date of a WTI device
cpm_time_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
date: "12/12/2019"
time: "09:23:46"
timezone: 5
# Enable NTP and set primary and seconday servers of a WTI device
- name: Set NTP primary and seconday servers of a WTI device
cpm_time_config:
cpm_url: "nonexist.wti.com"
cpm_username: "super"
cpm_password: "super"
use_https: true
validate_certs: false
timezone: 5
ntpenable: 1
ipv4address: "129.6.15.28.pool.ntp.org"
timeout: 15
```
Return Values
-------------
Common return values are documented [here](../../../reference_appendices/common_return_values#common-return-values), the following are the fields unique to this module:
| Key | Returned | Description |
| --- | --- | --- |
| **data** complex | always | The output JSON returned from the commands sent |
| | **date** string | success | Current Date of the WTI device after module execution. **Sample:** 11/14/2019 |
| | **ntp** dictionary | always | Current k/v pairs of ntp info of the WTI device after module execution. **Sample:** {'enable': '0', 'ietf-ipv4': {'address': [{'primary': '192.168.0.169', 'secondary': '12.34.56.78'}]}, 'ietf-ipv6': {'address': [{'primary': '', 'secondary': ''}]}, 'timeout': '4'} |
| | **time** string | success | Current Time of the WTI device after module execution. **Sample:** 12:12:00 |
| | **timezone** integer | success | Current Timezone of the WTI device after module execution. **Sample:** 5 |
### Authors
* Western Telematic Inc. (@wtinetworkgear)
| programming_docs |
ansible Configuring Ansible Configuring Ansible
===================
* [Configuration file](#configuration-file)
+ [Getting the latest configuration](#getting-the-latest-configuration)
* [Environmental configuration](#environmental-configuration)
* [Command line options](#command-line-options)
This topic describes how to control Ansible settings.
Configuration file
------------------
Certain settings in Ansible are adjustable via a configuration file (ansible.cfg). The stock configuration should be sufficient for most users, but there may be reasons you would want to change them. Paths where configuration file is searched are listed in [reference documentation](../reference_appendices/config#ansible-configuration-settings-locations).
### Getting the latest configuration
If installing Ansible from a package manager, the latest `ansible.cfg` file should be present in `/etc/ansible`, possibly as a `.rpmnew` file (or other) as appropriate in the case of updates.
If you installed Ansible from pip or from source, you may want to create this file in order to override default settings in Ansible.
An [example file is available on GitHub](https://github.com/ansible/ansible/blob/stable-2.11/examples/ansible.cfg).
For more details and a full listing of available configurations go to [configuration\_settings](../reference_appendices/config#ansible-configuration-settings). Starting with Ansible version 2.4, you can use the [ansible-config](../cli/ansible-config#ansible-config) command line utility to list your available options and inspect the current values.
For in-depth details, see [Ansible Configuration Settings](../reference_appendices/config#ansible-configuration-settings).
Environmental configuration
---------------------------
Ansible also allows configuration of settings using environment variables. If these environment variables are set, they will override any setting loaded from the configuration file.
You can get a full listing of available environment variables from [Ansible Configuration Settings](../reference_appendices/config#ansible-configuration-settings).
Command line options
--------------------
Not all configuration options are present in the command line, just the ones deemed most useful or common. Settings in the command line will override those passed through the configuration file and the environment.
The full list of options available is in [ansible-playbook](../cli/ansible-playbook#ansible-playbook) and [ansible](../cli/ansible#ansible).
ansible Installing Ansible Installing Ansible
==================
Ansible is an agentless automation tool that you install on a control node. From the control node, Ansible manages machines and other devices remotely (by default, over the SSH protocol).
To install Ansible for use at the command line, simply install the Ansible package on one machine (which could easily be a laptop). You do not need to install a database or run any daemons. Ansible can manage an entire fleet of remote machines from that one control node.
* [Prerequisites](#prerequisites)
+ [Control node requirements](#control-node-requirements)
+ [Managed node requirements](#managed-node-requirements)
* [Selecting an Ansible artifact and version to install](#selecting-an-ansible-artifact-and-version-to-install)
+ [Installing the Ansible community package](#installing-the-ansible-community-package)
+ [Installing `ansible-core`](#installing-ansible-core)
* [Installing and upgrading Ansible with `pip`](#installing-and-upgrading-ansible-with-pip)
+ [Prerequisites: Installing `pip`](#prerequisites-installing-pip)
+ [Installing Ansible with `pip`](#installing-ansible-with-pip)
+ [Installing Ansible in a virtual environment with `pip`](#installing-ansible-in-a-virtual-environment-with-pip)
+ [Upgrading Ansible with `pip`](#upgrading-ansible-with-pip)
- [Upgrading from 2.9 or earlier to 2.10](#upgrading-from-2-9-or-earlier-to-2-10)
- [Upgrading from Ansible 3 or ansible-core 2.10](#upgrading-from-ansible-3-or-ansible-core-2-10)
* [Installing Ansible on specific operating systems](#installing-ansible-on-specific-operating-systems)
+ [Installing Ansible on RHEL, CentOS, or Fedora](#installing-ansible-on-rhel-centos-or-fedora)
+ [Installing Ansible on Ubuntu](#installing-ansible-on-ubuntu)
+ [Installing Ansible on Debian](#installing-ansible-on-debian)
+ [Installing Ansible on Gentoo with portage](#installing-ansible-on-gentoo-with-portage)
+ [Installing Ansible on FreeBSD](#installing-ansible-on-freebsd)
+ [Installing Ansible on macOS](#installing-ansible-on-macos)
+ [Installing Ansible on Solaris](#installing-ansible-on-solaris)
+ [Installing Ansible on Arch Linux](#installing-ansible-on-arch-linux)
+ [Installing Ansible on Slackware Linux](#installing-ansible-on-slackware-linux)
+ [Installing Ansible on Clear Linux](#installing-ansible-on-clear-linux)
* [Installing and running the `devel` branch from source](#installing-and-running-the-devel-branch-from-source)
+ [Installing `devel` from GitHub with `pip`](#installing-devel-from-github-with-pip)
+ [Installing `devel` from GitHub by cloning](#installing-devel-from-github-by-cloning)
+ [Running the `devel` branch from a clone](#running-the-devel-branch-from-a-clone)
* [Confirming your installation](#confirming-your-installation)
* [Finding tarballs of tagged releases](#finding-tarballs-of-tagged-releases)
* [Adding Ansible command shell completion](#adding-ansible-command-shell-completion)
+ [Installing `argcomplete` on RHEL, CentOS, or Fedora](#installing-argcomplete-on-rhel-centos-or-fedora)
+ [Installing `argcomplete` with `apt`](#installing-argcomplete-with-apt)
+ [Installing `argcomplete` with `pip`](#installing-argcomplete-with-pip)
+ [Configuring `argcomplete`](#configuring-argcomplete)
- [Global configuration](#global-configuration)
- [Per command configuration](#per-command-configuration)
- [Using `argcomplete` with zsh or tcsh](#using-argcomplete-with-zsh-or-tcsh)
Prerequisites
-------------
Before you install Ansible, review the requirements for a control node. Before you use Ansible, review the requirements for managed nodes (those end devices you want to automate). Control nodes and managed nodes have different minimum requirements.
### Control node requirements
For your control node (the machine that runs Ansible), you can use any machine with Python 2 (version 2.7) or Python 3 (versions 3.5 and higher) installed. ansible-core 2.11 and Ansible 4.0.0 will make Python 3.8 a soft dependency for the control node, but will function with the aforementioned requirements. ansible-core 2.12 and Ansible 5.0.0 will require Python 3.8 or newer to function on the control node. Starting with ansible-core 2.11, the project will only be packaged for Python 3.8 and newer. This includes Red Hat, Debian, CentOS, macOS, any of the BSDs, and so on. Windows is not supported for the control node, read more about this in [Matt Davis’s blog post](http://blog.rolpdog.com/2020/03/why-no-ansible-controller-for-windows.html).
Warning
Please note that some plugins that run on the control node have additional requirements. These requirements should be listed in the plugin documentation.
When choosing a control node, remember that any management system benefits from being run near the machines being managed. If you are using Ansible to manage machines in a cloud, consider using a machine inside that cloud as your control node. In most cases Ansible will perform better from a machine on the cloud than from a machine on the open Internet.
Warning
Ansible 2.11 will make Python 3.8 a soft dependency for the control node, but will function with the aforementioned requirements. Ansible 2.12 will require Python 3.8 or newer to function on the control node. Starting with Ansible 2.11, the project will only be packaged for Python 3.8 and newer.
### Managed node requirements
Although you do not need a daemon on your managed nodes, you do need a way for Ansible to communicate with them. For most managed nodes, Ansible makes a connection over SSH and transfers modules using SFTP. If SSH works but SFTP is not available on some of your managed nodes, you can switch to SCP in [ansible.cfg](../reference_appendices/config#ansible-configuration-settings). For any machine or device that can run Python, you also need Python 2 (version 2.6 or later) or Python 3 (version 3.5 or later).
Warning
Please note that some modules have additional requirements that need to be satisfied on the ‘target’ machine (the managed node). These requirements should be listed in the module documentation.
Note
* If you have SELinux enabled on remote nodes, you will also want to install libselinux-python on them before using any copy/file/template related functions in Ansible. You can use the [yum module](../collections/ansible/builtin/yum_module#yum-module) or [dnf module](../collections/ansible/builtin/dnf_module#dnf-module) in Ansible to install this package on remote systems that do not have it.
* By default, before the first Python module in a playbook runs on a host, Ansible attempts to discover a suitable Python interpreter on that host. You can override the discovery behavior by setting the [ansible\_python\_interpreter](../user_guide/intro_inventory#ansible-python-interpreter) inventory variable to a specific interpreter, and in other ways. See [Interpreter Discovery](../reference_appendices/interpreter_discovery#interpreter-discovery) for details.
* Ansible’s [raw module](../collections/ansible/builtin/raw_module#raw-module), and the [script module](../collections/ansible/builtin/script_module#script-module), do not depend on a client side install of Python to run. Technically, you can use Ansible to install a compatible version of Python using the [raw module](../collections/ansible/builtin/raw_module#raw-module), which then allows you to use everything else. For example, if you need to bootstrap Python 2 onto a RHEL-based system, you can install it as follows:
```
$ ansible myhost --become -m raw -a "yum install -y python2"
```
Selecting an Ansible artifact and version to install
----------------------------------------------------
Starting with version 2.10, Ansible distributes two artifacts: a community package called `ansible` and a minimalist language and runtime called `ansible-core` (called `ansible-base` in version 2.10). Choose the Ansible artifact and version that matches your particular needs.
### Installing the Ansible community package
The `ansible` package includes the Ansible language and runtime plus a range of community curated Collections. It recreates and expands on the functionality that was included in Ansible 2.9.
You can choose any of the following ways to install the Ansible community package:
* Install the latest release with your OS package manager (for Red Hat Enterprise Linux (TM), CentOS, Fedora, Debian, or Ubuntu).
* Install with `pip` (the Python package manager).
### Installing `ansible-core`
Ansible also distributes a minimalist object called `ansible-core` (or `ansible-base` in version 2.10). It contains the Ansible language, runtime, and a short list of core modules and other plugins. You can build functionality on top of `ansible-core` by installing collections from Galaxy, Automation Hub, or any other source.
You can choose any of the following ways to install `ansible-core`:
* Install `ansible-core` (version 2.11 and greater) or `ansible-base` (version 2.10) with `pip`.
* Install `ansible-core` from source from the ansible/ansible GitHub repository to access the development (`devel`) version to develop or test the latest features.
Note
You should only run `ansible-core` from `devel` if you are modifying `ansible-core`, or trying out features under development. This is a rapidly changing source of code and can become unstable at any point.
Ansible generally creates new releases twice a year. See [Releases and maintenance](../reference_appendices/release_and_maintenance#release-and-maintenance) for information on release timing and maintenance of older releases.
Installing and upgrading Ansible with `pip`
-------------------------------------------
Ansible can be installed on many systems with `pip`, the Python package manager.
### Prerequisites: Installing `pip`
If `pip` is not already available on your system, run the following commands to install it:
```
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
$ python get-pip.py --user
```
You may need to perform some additional configuration before you are able to run Ansible. See the Python documentation on [installing to the user site](https://packaging.python.org/tutorials/installing-packages/#installing-to-the-user-site) for more information.
### Installing Ansible with `pip`
Note
If you have Ansible 2.9 or older installed or Ansible 3, see [Upgrading Ansible with pip](#pip-upgrade).
Once `pip` is installed, you can install Ansible [1](#id7):
```
$ python -m pip install --user ansible
```
In order to use the `paramiko` connection plugin or modules that require `paramiko`, install the required module [2](#id8):
```
$ python -m pip install --user paramiko
```
If you wish to install Ansible globally, run the following commands:
```
$ sudo python get-pip.py
$ sudo python -m pip install ansible
```
Note
Running `pip` with `sudo` will make global changes to the system. Since `pip` does not coordinate with system package managers, it could make changes to your system that leaves it in an inconsistent or non-functioning state. This is particularly true for macOS. Installing with `--user` is recommended unless you understand fully the implications of modifying global files on the system.
Note
Older versions of `pip` default to <http://pypi.python.org/simple>, which no longer works. Please make sure you have the latest version of `pip` before installing Ansible. If you have an older version of `pip` installed, you can upgrade by following [pip’s upgrade instructions](https://pip.pypa.io/en/stable/installing/#upgrading-pip) .
### Installing Ansible in a virtual environment with `pip`
Note
If you have Ansible 2.9 or older installed or Ansible 3, see [Upgrading Ansible with pip](#pip-upgrade).
Ansible can also be installed inside a new or existing `virtualenv`:
```
$ python -m virtualenv ansible # Create a virtualenv if one does not already exist
$ source ansible/bin/activate # Activate the virtual environment
$ python -m pip install ansible
```
### Upgrading Ansible with `pip`
#### Upgrading from 2.9 or earlier to 2.10
Starting in version 2.10, Ansible is made of two packages. When you upgrade from version 2.9 and older to version 2.10 or later, you need to uninstall the old Ansible version (2.9 or earlier) before upgrading. If you do not uninstall the older version of Ansible, you will see the following message, and no change will be performed:
```
Cannot install ansible-base with a pre-existing ansible==2.x installation.
Installing ansible-base with ansible-2.9 or older currently installed with
pip is known to cause problems. Please uninstall ansible and install the new
version:
pip uninstall ansible
pip install ansible-base
...
```
As explained by the message, to upgrade you must first remove the version of Ansible installed and then install it to the latest version.
```
$ pip uninstall ansible
$ pip install ansible
```
#### Upgrading from Ansible 3 or ansible-core 2.10
`ansible-base` only exists for version 2.10 and in Ansible 3. In 2.11 and later, the package is called `ansible-core`. Before installing `ansible-core` or Ansible 4, you must uninstall `ansible-base` if you have installed Ansible 3 or `ansible-base` 2.10.
To upgrade to `ansible-core`:
```
pip uninstall ansible-base
pip install ansible-core
```
To upgrade to Ansible 4:
```
pip uninstall ansible-base
pip install ansible
```
Installing Ansible on specific operating systems
------------------------------------------------
Follow these instructions to install the Ansible community package on a variety of operating systems.
### Installing Ansible on RHEL, CentOS, or Fedora
On Fedora:
```
$ sudo dnf install ansible
```
On RHEL:
```
$ sudo yum install ansible
```
On CentOS:
```
$ sudo yum install epel-release
$ sudo yum install ansible
```
RPMs for RHEL 7 and RHEL 8 are available from the [Ansible Engine repository](https://access.redhat.com/articles/3174981).
To enable the Ansible Engine repository for RHEL 8, run the following command:
```
$ sudo subscription-manager repos --enable ansible-2.9-for-rhel-8-x86_64-rpms
```
To enable the Ansible Engine repository for RHEL 7, run the following command:
```
$ sudo subscription-manager repos --enable rhel-7-server-ansible-2.9-rpms
```
RPMs for currently supported versions of RHEL and CentOS are also available from [EPEL](https://fedoraproject.org/wiki/EPEL).
Note
Since Ansible 2.10 for RHEL is not available at this time, continue to use Ansible 2.9.
Ansible can manage older operating systems that contain Python 2.6 or higher.
### Installing Ansible on Ubuntu
Ubuntu builds are available [in a PPA here](https://launchpad.net/~ansible/+archive/ubuntu/ansible).
To configure the PPA on your machine and install Ansible run these commands:
```
$ sudo apt update
$ sudo apt install software-properties-common
$ sudo add-apt-repository --yes --update ppa:ansible/ansible
$ sudo apt install ansible
```
Note
On older Ubuntu distributions, “software-properties-common” is called “python-software-properties”. You may want to use `apt-get` instead of `apt` in older versions. Also, be aware that only newer distributions (in other words, 18.04, 18.10, and so on) have a `-u` or `--update` flag, so adjust your script accordingly.
Debian/Ubuntu packages can also be built from the source checkout, run:
```
$ make deb
```
### Installing Ansible on Debian
Debian users may use the same source as the Ubuntu PPA (using the following table).
| Debian | | Ubuntu |
| --- | --- | --- |
| Debian 11 (Bullseye) | -> | Ubuntu 20.04 (Focal) |
| Debian 10 (Buster) | -> | Ubuntu 18.04 (Bionic) |
| Debian 9 (Stretch) | -> | Ubuntu 16.04 (Xenial) |
| Debian 8 (Jessie) | -> | Ubuntu 14.04 (Trusty) |
Note
As of Ansible 4.0.0, new releases will only be generated for Ubuntu 18.04 (Bionic) or later releases.
Add the following line to `/etc/apt/sources.list` or `/etc/apt/sources.list.d/ansible.list`:
```
deb http://ppa.launchpad.net/ansible/ansible/ubuntu MATCHING_UBUNTU_CODENAME_HERE main
```
Example for Debian 11 (Bullseye)
```
deb http://ppa.launchpad.net/ansible/ansible/ubuntu focal main
```
Then run these commands:
```
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
$ sudo apt update
$ sudo apt install ansible
```
### Installing Ansible on Gentoo with portage
```
$ emerge -av app-admin/ansible
```
To install the newest version, you may need to unmask the Ansible package prior to emerging:
```
$ echo 'app-admin/ansible' >> /etc/portage/package.accept_keywords
```
### Installing Ansible on FreeBSD
Though Ansible works with both Python 2 and 3 versions, FreeBSD has different packages for each Python version. So to install you can use:
```
$ sudo pkg install py27-ansible
```
or:
```
$ sudo pkg install py37-ansible
```
You may also wish to install from ports, run:
```
$ sudo make -C /usr/ports/sysutils/ansible install
```
You can also choose a specific version, for example `ansible25`.
Older versions of FreeBSD worked with something like this (substitute for your choice of package manager):
```
$ sudo pkg install ansible
```
### Installing Ansible on macOS
The preferred way to install Ansible on a Mac is with `pip`.
The instructions can be found in [Installing and upgrading Ansible with pip](#from-pip). If you are running macOS version 10.12 or older, then you should upgrade to the latest `pip` to connect to the Python Package Index securely. It should be noted that pip must be run as a module on macOS, and the linked `pip` instructions will show you how to do that.
Note
Note
If you have Ansible 2.9 or older installed or Ansible 3, see [Upgrading Ansible with pip](#pip-upgrade).
Note
macOS by default is configured for a small number of file handles, so if you want to use 15 or more forks you’ll need to raise the ulimit with `sudo launchctl limit maxfiles unlimited`. This command can also fix any “Too many open files” errors.
If you are installing on macOS Mavericks (10.9), you may encounter some noise from your compiler. A workaround is to do the following:
```
$ CFLAGS=-Qunused-arguments CPPFLAGS=-Qunused-arguments pip install --user ansible
```
### Installing Ansible on Solaris
Ansible is available for Solaris as [SysV package from OpenCSW](https://www.opencsw.org/packages/ansible/).
```
# pkgadd -d http://get.opencsw.org/now
# /opt/csw/bin/pkgutil -i ansible
```
### Installing Ansible on Arch Linux
Ansible is available in the Community repository:
```
$ pacman -S ansible
```
The AUR has a PKGBUILD for pulling directly from GitHub called [ansible-git](https://aur.archlinux.org/packages/ansible-git).
Also see the [Ansible](https://wiki.archlinux.org/index.php/Ansible) page on the ArchWiki.
### Installing Ansible on Slackware Linux
Ansible build script is available in the [SlackBuilds.org](https://slackbuilds.org/apps/ansible/) repository. Can be built and installed using [sbopkg](https://sbopkg.org/).
Create queue with Ansible and all dependencies:
```
# sqg -p ansible
```
Build and install packages from a created queuefile (answer Q for question if sbopkg should use queue or package):
```
# sbopkg -k -i ansible
```
### Installing Ansible on Clear Linux
Ansible and its dependencies are available as part of the sysadmin host management bundle:
```
$ sudo swupd bundle-add sysadmin-hostmgmt
```
Update of the software will be managed by the swupd tool:
```
$ sudo swupd update
```
Installing and running the `devel` branch from source
-----------------------------------------------------
In Ansible 2.10 and later, the [ansible/ansible repository](https://github.com/ansible/ansible) contains the code for basic features and functions, such as copying module code to managed nodes. This code is also known as `ansible-core`.
New features are added to `ansible-core` on a branch called `devel`. If you are testing new features, fixing bugs, or otherwise working with the development team on changes to the core code, you can install and run `devel`.
Note
You should only install and run the `devel` branch if you are modifying `ansible-core` or trying out features under development. This is a rapidly changing source of code and can become unstable at any point.
Note
If you want to use Ansible AWX as the control node, do not install or run the `devel` branch of Ansible. Use an OS package manager (like `apt` or `yum`) or `pip` to install a stable version.
If you are running Ansible from source, you may also wish to follow the [Ansible GitHub project](https://github.com/ansible/ansible). We track issues, document bugs, and share feature ideas in this and other related repositories.
For more information on getting involved in the Ansible project, see the [Ansible Community Guide](https://docs.ansible.com/ansible/latest/community/index.html#ansible-community-guide). For more information on creating Ansible modules and Collections, see the [Developer Guide](https://docs.ansible.com/ansible/latest/dev_guide/index.html#developer-guide).
### Installing `devel` from GitHub with `pip`
You can install the `devel` branch of `ansible-core` directly from GitHub with `pip`:
```
$ python -m pip install --user https://github.com/ansible/ansible/archive/devel.tar.gz
```
Note
If you have Ansible 2.9 or older installed or Ansible 3, see [Upgrading Ansible with pip](#pip-upgrade).
You can replace `devel` in the URL mentioned above, with any other branch or tag on GitHub to install older versions of Ansible (prior to `ansible-base` 2.10.), tagged alpha or beta versions, and release candidates. This installs all of Ansible.
```
$ python -m pip install --user https://github.com/ansible/ansible/archive/stable-2.9.tar.gz
```
See [Running the devel branch from a clone](#from-source) for instructions on how to run `ansible-core` directly from source.
### Installing `devel` from GitHub by cloning
You can install the `devel` branch of `ansible-core` by cloning the GitHub repository:
```
$ git clone https://github.com/ansible/ansible.git
$ cd ./ansible
```
The default branch is `devel`.
### Running the `devel` branch from a clone
`ansible-core` is easy to run from source. You do not need `root` permissions to use it and there is no software to actually install. No daemons or database setup are required.
Once you have installed the `ansible-core` repository by cloning, setup the Ansible environment:
Using Bash:
```
$ source ./hacking/env-setup
```
Using Fish:
```
$ source ./hacking/env-setup.fish
```
If you want to suppress spurious warnings/errors, use:
```
$ source ./hacking/env-setup -q
```
If you do not have `pip` installed in your version of Python, install it:
```
$ curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
$ python get-pip.py --user
```
Ansible also uses the following Python modules that need to be installed [1](#id7):
```
$ python -m pip install --user -r ./requirements.txt
```
To update the `devel` branch of `ansible-core` on your local machine, use pull-with-rebase so any local changes are replayed.
```
$ git pull --rebase
```
```
$ git pull --rebase #same as above
$ git submodule update --init --recursive
```
After you run the the env-setup script, you will be running from the source code. The default inventory file will be `/etc/ansible/hosts`. You can optionally specify an inventory file (see [How to build your inventory](../user_guide/intro_inventory#inventory)) other than `/etc/ansible/hosts`:
```
$ echo "127.0.0.1" > ~/ansible_hosts
$ export ANSIBLE_INVENTORY=~/ansible_hosts
```
You can read more about the inventory file at [How to build your inventory](../user_guide/intro_inventory#inventory).
Confirming your installation
----------------------------
Whatever method of installing Ansible you chose, you can test that it is installed correctly with a ping command:
```
$ ansible all -m ping --ask-pass
```
You can also use “sudo make install”.
Finding tarballs of tagged releases
-----------------------------------
If you are packaging Ansible or wanting to build a local package yourself, and you want to avoid a git checkout, you can use a tarball of a tagged release. You can download the latest stable release from PyPI’s [ansible package page](https://pypi.org/project/ansible/). If you need a specific older version, beta version, or release candidate, you can use the pattern `pypi.python.org/packages/source/a/ansible/ansible-{{VERSION}}.tar.gz`. VERSION must be the full version number, for example 3.1.0 or 4.0.0b2. You can make VERSION a variable in your package managing system that you update in one place whenever you package a new version.
Note
If you are creating your own Ansible package, you must also download or package `ansible-core` (or `ansible-base` for packages based on 2.10.x) from PyPI as part of your Ansible package. You must specify a particular version. Visit the PyPI project pages to download files for [ansible-core](https://pypi.org/project/ansible-core/) or [ansible-base](https://pypi.org/project/ansible-base/).
These releases are also tagged in the [git repository](https://github.com/ansible/ansible/releases) with the release version.
Adding Ansible command shell completion
---------------------------------------
As of Ansible 2.9, you can add shell completion of the Ansible command line utilities by installing an optional dependency called `argcomplete`. `argcomplete` supports bash, and has limited support for zsh and tcsh.
You can install `python-argcomplete` from EPEL on Red Hat Enterprise based distributions, and or from the standard OS repositories for many other distributions.
For more information about installation and configuration, see the [argcomplete documentation](https://kislyuk.github.io/argcomplete/).
### Installing `argcomplete` on RHEL, CentOS, or Fedora
On Fedora:
```
$ sudo dnf install python-argcomplete
```
On RHEL and CentOS:
```
$ sudo yum install epel-release
$ sudo yum install python-argcomplete
```
### Installing `argcomplete` with `apt`
```
$ sudo apt install python-argcomplete
```
### Installing `argcomplete` with `pip`
```
$ python -m pip install argcomplete
```
### Configuring `argcomplete`
There are 2 ways to configure `argcomplete` to allow shell completion of the Ansible command line utilities: globally or per command.
#### Global configuration
Global completion requires bash 4.2.
```
$ sudo activate-global-python-argcomplete
```
This will write a bash completion file to a global location. Use `--dest` to change the location.
#### Per command configuration
If you do not have bash 4.2, you must register each script independently.
```
$ eval $(register-python-argcomplete ansible)
$ eval $(register-python-argcomplete ansible-config)
$ eval $(register-python-argcomplete ansible-console)
$ eval $(register-python-argcomplete ansible-doc)
$ eval $(register-python-argcomplete ansible-galaxy)
$ eval $(register-python-argcomplete ansible-inventory)
$ eval $(register-python-argcomplete ansible-playbook)
$ eval $(register-python-argcomplete ansible-pull)
$ eval $(register-python-argcomplete ansible-vault)
```
You should place the above commands into your shells profile file such as `~/.profile` or `~/.bash_profile`.
#### Using `argcomplete` with zsh or tcsh
See the [argcomplete documentation](https://kislyuk.github.io/argcomplete/).
See also
[Introduction to ad hoc commands](../user_guide/intro_adhoc#intro-adhoc)
Examples of basic commands
[Working with playbooks](../user_guide/playbooks#working-with-playbooks)
Learning ansible’s configuration management language
[How do I handle the package dependencies required by Ansible package dependencies during Ansible installation ?](https://docs.ansible.com/ansible/latest/reference_appendices/faq.html#installation-faqs)
Ansible Installation related to FAQs
[Mailing List](https://groups.google.com/group/ansible-project)
Questions? Help? Ideas? Stop by the list on Google Groups
[irc.libera.chat](https://libera.chat/)
#ansible IRC chat channel
`1(1,2)`
If you have issues with the “pycrypto” package install on macOS, then you may need to try `CC=clang sudo -E pip install pycrypto`.
`2`
`paramiko` was included in Ansible’s `requirements.txt` prior to 2.8.
| programming_docs |
ansible Ansible Porting Guides Ansible Porting Guides
======================
Ansible Porting Guides are maintained in the `devel` branch only. Please go to [the devel Ansible Porting guides](https://docs.ansible.com/ansible/devel/porting_guides/porting_guides.html) for up to date information.
opentsdb Documentation for OpenTSDB 2.3 Documentation for OpenTSDB 2.3
==============================
Welcome to OpenTSDB 2.3, the scalable, distributed time series database. We recommend that you start with the [*User Guide*](user_guide/index) then test your understanding with an [*Installation*](installation) and read on the [*HTTP API*](api_http/index) if you need to develop against it.
opentsdb Additional Resources Additional Resources
====================
These are just some of the awesome front-ends, utilities, libraries and resources created by the OpenTSDB community. Please let us know if you have a project you'd like to see listed and if you don't see something you need, search for it on Github (new projects are popping up all the time) or your favorite search engine.
Monitoring
----------
* [Bosun](https://bosun.org/) - A monitoring and alerting system built on OpenTSDB from the folks at [Stack Exchange](http://stackexchange.com/).
Docker Images
-------------
* [petergrace/opentsdb-docker](https://registry.hub.docker.com/u/petergrace/opentsdb-docker/) - A prebuilt Docker image with HBase and OpenTSDB already configured and ready to run! If you have Docker installed, execute `docker run -d -p 4242:4242 petergrace/opentsdb-docker` to create an opentsdb instance running on port 4242.
* [opower/opentsdb](https://registry.hub.docker.com/u/opower/opentsdb/) - A Docker image containing OpenTSDB, HBase, and tcollector. Comes in both 2.0.1 and 2.1 versions (latest defaults to 2.1). Execute `docker run -d -p 4242:4242 opower/opentsdb` to create an OpenTSDB instance running on port 4242.
Front Ends
----------
* [Status Wolf](https://github.com/box/StatusWolf) - A PHP and MySQL based dashboard for creating and storing dynamic custom graphs with OpenTSDB data including anonmaly detection.
* [Metrilyx](https://github.com/Ticketmaster/metrilyx-2.0) - A Python and Django based dashboard system with dynamic graphs from Ticketmaster.
* [Opentsdb-Dashboard](https://github.com/clover/opentsdb-dashboard) - An HBase based dashboard system for OpenTSDB 1.x from Clover.
* [TSDash](https://github.com/facebook/tsdash) - A Java based UI and dashboard from Facebook.
* [OpenTSDB Dashboard](https://github.com/turn/opentsdb-dashboard) - A JQuery based dashboard from Turn.
* [Grafana](http://grafana.org) - A dashboard and graph editor with OpenTSDB support.
* [Graphite OpenTSDB Finder](https://github.com/mikebryant/graphite-opentsdb-finder) - A Graphite plugin to load TSDB data.
Utilities
---------
* [opentsdbjsonproxy](https://github.com/noca/opentsdbjsonproxy) - An HTTP proxy to convert 1.x ASCII output from the `/q` endpoint to JSON for use with High Charts or other libraries.
* [Collectd-opentsdb](https://github.com/auxesis/collectd-opentsdb) - A Collectd plugin to emmit stats to a TSD.
* [Collectd-opentsdb Java](https://github.com/dotcloud/collectd-opentsdb) - A Collectd plugin to that uses the OpenTSDB Java API to push data to a TSD.
* TSD\_proxy <<https://github.com/aravind/tsd_proxy>>`\_ - A buffering write proxy for OpenTSDB and alternate DBs.
* [Vacuumetrix](https://github.com/99designs/vacuumetrix) - Utility to pull data from various cloud services or APIs and store the results in backends such as Graphite, Ganglia and OpenTSDB.
* [JuJu Deployment Charm](https://github.com/charms/opentsdb) - Utility to compile OpenTSDB from GIT and deploy on a cluster.
* [Statsd Publisher](https://github.com/danslimmon/statsd-opentsdb-backend) - A statsd backend to publish data to a TSD.
* [OpenTSDB Proxy](https://github.com/nimbusproject/opentsdbproxy) - A Django based proxy with authentication and SSL support to run in front of the TSDs.
* [Puppet Module](https://github.com/mburger/puppet-opentsdb) - A puppet deployment module.
* [Flume Module](https://github.com/yandex/opentsdb-flume) - Write data from Flume to a TSD.
* [Chef Cookbook](https://github.com/looztra/opentsdb-cookbook) - Deploy from source via Chef.
* + [OpenTSDB Cookbook](https://github.com/acaiafa/opentsdb-cookbook) - A Chef cookbook for CentOS or Ubuntu.
* [Coda Hale Metrics Reporter](https://github.com/sps/metrics-opentsdb) - Writes data to OpenTSDB from the Java Metrics library.
* [Alternative Coda Hale Metrics Reporter](https://github.com/stuart-warren/metrics-opentsdb) - Writes data to OpenTSDB from the Java Metrics library.
* [opentsdb-snmp](https://github.com/frogmaster/opentsdb-snmp) - Fetches data from SNMP enabled devices and writes to OpenTSDB.
* [proxTSDB](https://github.com/worldline/proxyTSDB) - A metric data gateway capable of buffering data to RAM or disk if the TSD is down.
* [OpenTSDB Pig UDFs](https://github.com/santosh-d3vpl3x/opentsdb-udfs) - Integrate OpenTSDB with Apache Pig for large data set processing.
Clients
-------
* [R Client](https://github.com/holstius/opentsdbr) - A client to pull data from OpenTSDB into R.
* [Erlang Client](https://github.com/bradfordw/gen_opentsdb) - A simple client to publish data to a TSD from Erlang.
* [time-series](https://github.com/opower/time-series) - A Ruby client that supports both reading and writing to OpenTSDB 2.x - contains support for synthetic time series calculations.
* [Ruby](https://github.com/j05h/continuum) - A read-only client for querying data from the 1.x API.
* [Ruby](https://github.com/johnewart/ruby-opentsdb) A write-only client for pushing data to a TSD.
* [Go](https://github.com/bzub/go-opentsdb) - Work with OpenTSDB data in Go.
* [Potsdb](https://pypi.python.org/pypi/potsdb) - A Python client for writing data.
* [vert.x OpenTsDb](https://github.com/cyngn/vertx-opentsdb) - A library to write data to OpenTSDB from Vert.x.
References to OpenTSDB
----------------------
* [HBase in Action](http://www.manning.com/dimidukkhurana/) (Manning Publications) - Chapter 7: HBase by Example: OpenTSDB
* [Professional NoSQL](http://www.wrox.com/WileyCDA/WroxTitle/Professional-NoSQL.productCd-047094224X.html) (Wrox Publishing) - Mentioned in Chapter 17: Tools and Utilities
* [OSCon Data 2011](http://www.youtube.com/watch?v=WlsyqhrhRZA) - Presentation from Benoit Sigoure
* [Percona Live 2013](http://www.slideshare.net/geoffanderson/monitoring-mysql-with-opentsdb-19982758) Presentation from Geoffrey Anderson
* [HBaseCon 2013](http://www.hbasecon.com/sessions/opentsdb-at-scale/) - Presentation from Jonathan Creasy and Geoffrey Anderson
* [Strata 2011](http://strataconf.com/strata2011/public/schedule/detail/16996) - Presentation by Benoit Sigoure
Statistical Analysis Tools
--------------------------
* [GnuPlot](http://www.gnuplot.info/) - Graphing library used by OpenTSDB
* [R](http://www.r-project.org/) - Statistical computing framework
* [SciPy](http://www.scipy.org/) - Python libraries for dealing with numbers (Pandas library has time series support)
opentsdb Installation Installation
============
OpenTSDB may be compiled from source or installed from a package. Releases can be found on [Github](https://github.com/OpenTSDB/opentsdb/releases).
Runtime Requirements
--------------------
To actually run OpenTSDB, you'll need to meet the following:
* A Linux system (or Windows with manual building)
* Java Runtime Environment 1.6 or later
* HBase 0.92 or later
* GnuPlot 4.2 or later
Installation
------------
First, you need to setup HBase. If you are brand new to HBase and/or OpenTSDB we recommend you test with a stand-alone instance as this is the easiest to get up and running. The best place to start is to follow the [Apache Quick Start](https://hbase.apache.org/book/quickstart.html) guide. Alternatively you could try a packaged distribution such as [Cloudera's CDH](http://www.cloudera.com/content/cloudera/en/products-and-services/cloudera-express.html), [Hortonworks HDP](http://hortonworks.com/products/hdp-2/) or [`MapR<https://www.mapr.com/>`\_](#id2).
Before proceeding with OpenTSDB, make certain that Zookeeper is accessible. One method is to simply telnet to the proper port and execute the `stats` command.
```
root@host:~# telnet localhost 2181
Trying 127.0.0.1...
Connected to myhost.
Escape character is '^]'.
stats
Zookeeper version: 3.4.3-cdh4.0.1--1, built on 06/28/2012 23:59 GMT
Clients:
Latency min/avg/max: 0/0/677
Received: 4684478
Sent: 4687034
Outstanding: 0
Zxid: 0xb00187dd0
Mode: leader
Node count: 127182
Connection closed by foreign host.
```
If you can't connect to Zookeeper, check IPs and name resolution. HBase can be finicky.
If HBase is running, you can choose to install OpenTSDB from a package (available under [Releases](https://github.com/OpenTSDB/opentsdb/releases) in Github) or from source using GIT or a source tarball.
### Compiling From Source
Compilation requirements include:
* A Linux system
* Java Development Kit 1.6 or later
* GnuPlot 4.2 or later
* Autotools
* Make
* Python
* Git
* An Internet connection
Download the latest version using `git clone` command or download a release from the site or Github. Then just run the `build.sh` script. This script helps run all the processes needed to compile OpenTSDB: it runs `./bootstrap` (only once, when you first check out the code), followed by `./configure` and `make`. The output of the build process is put into a `build` folder and JARs required by OpenTSDB will be downloaded.
```
git clone git://github.com/OpenTSDB/opentsdb.git
cd opentsdb
./build.sh
```
If compilation was successfully, you should have a tsdb jar file in `./build` along with a `tsdb` script. You can now execute command-line tool by invoking `./build/tsdb` or you can run `make install` to install OpenTSDB on your system. Should you ever change your mind, there is also `make uninstall`, so there are no strings attached.
If you need to distribute OpenTSDB to machines without an Internet connection, call `./build.sh dist` to wrap the build directory into a tarball that you can then copy to additional machines.
### Source Layout
There are two main branches in the GIT repo. The `master` branch is the latest stable release along with any bug fixes that have been committed between releases. Currently, the `master` branch is OpenTSDB 2.0.1. The `next` branch is the next major or minor version of OpenTSDB with new features and development. When `next` is stable, it will be merged into `master`. Currently the `next` branch is 2.1.0 RC 1. Additional branches may be present and are used for testing or developing specific features.
### Debian Package
You can generate a Debian package by calling `sh build.sh debian`. The package will be located at `./build/opentsdb-2.x.x/opentsdb-2.x.x\_all.deb`. Then simply distribute the package and install it as you regularly would. For example `dpkg -i opentsdb-2.0.0\_all.deb`.
The Debian package will create the following directories:
* /etc/opentsdb - Configuration files
* /tmp/opentsdb - Temporary cache files
* /usr/share/opentsdb - Application files
* /usr/share/opentsdb/bin - The "tsdb" startup script that launches a TSD or command line tools
* /usr/share/opentsdb/lib - Java JAR library files
* /usr/share/opentsdb/plugins - Location for plugin files and dependencies
* /usr/share/opentsdb/static - Static files for the GUI
* /usr/share/opentsdb/tools - Scripts and other tools
* /var/log/opentsdb - Logs
Installation includes an init script at `/etc/init.d/opentsdb` that can start, stop and restart OpenTSDB. Simply call `service opentsdb start` to start the tsd and `service opentsdb stop` to gracefully shutdown. Note after install, the tsd will not be running so that you can edit the configuration file. Edit the config file, then start the TSD.
The Debian package also creates an `opentsdb` user and group for the TSD to run under for increased security. TSD only requires write permission to the temporary and logging directories. If you can't use the default locations, please change them in `/etc/opentsdb/opentsdb.conf` and `/etc/opentsdb/logback.xml` respectively and apply the proper permissions for the `opentsdb` user.
If you install OpenTSDB for the first time, you'll need to create the HBase tables using the script located at `/usr/share/opentsdb/tools/create\_table.sh`. Follow the steps below.
### Create Tables
If this is the first time that you are running OpenTSDB with your HBase instance, you first need to create the necessary HBase tables. A simple script is provided to create the proper tables with the ability to enable or disable compression. Execute:
```
env COMPRESSION=NONE HBASE_HOME=path/to/hbase-0.94.X ./src/create_table.sh
```
where the `COMPRESSION` value is either `NONE`, `LZO`, `GZIP` or `SNAPPY`. This will create four tables: `tsdb`, `tsdb-uid`, `tsdb-tree` and `tsdb-meta`. If you're just evaluating OpenTSDB, don't worry about compression for now. In production and at scale, make sure you use a valid compression library as it will save on storage tremendously.
### Start a TSD
OpenTSDB 2.3 works off a configuration file that is shared between the daemon and command line tools. If you compiled from source, copy the `./src/opentsdb.conf` file to a proper directory as documented in [*Configuration*](user_guide/configuration) and edit the following, required settings:
* **tsd.http.cachedir** - Path to write temporary files to
* **tsd.http.staticroot** - Path to the static GUI files found in `./build/staticroot`
* **tsd.storage.hbase.zk\_quorum** - If HBase and Zookeeper are not running on the same machine, specify the host and port here.
With the config file written, you can start a tsd with the command:
```
./build/tsdb tsd
```
Alternatively, you can also use the following commands to create a temporary directory and pass in only command line flags:
```
tsdtmp=${TMPDIR-'/tmp'}/tsd # For best performance, make sure
mkdir -p "$tsdtmp" # your temporary directory uses tmpfs
./build/tsdb tsd --port=4242 --staticroot=build/staticroot --cachedir="$tsdtmp" --zkquorum=myhost:2181
```
At this point you can access the TSD's web interface through <http://127.0.0.1:4242> (if it's running on your local machine).
Note
The **Cache Directory** stores temporary files generated when a graph is requested via the built-in GUI. These files should be purged periodically to free up space. OpenTSDB doesn't clean up after itself at this time but there is a script that should be run as a cron at least once a day located at `tools/clean\_cache.sh`.
Upgrading from 1.x
------------------
OpenTSDB 2.3 is fully backwards compatible with 1.x data. We've taken great pains to make sure you can download 2.3, compile, stop your old TSD and start the new one. Your existing tools will read and write to the TSD without a problem. 2.3 introduces two new tables to HBase schema for storing meta-data. From the directory where you downloaded the source (or the tools directory if installed with the Debian package), execute:
```
env COMPRESSION=NONE HBASE_HOME=path/to/hbase-0.94.X ./src/upgrade_1to2.sh
```
where `COMPRESSION` is the same as your existing production table compression format.
While you can start a 2.3 TSD with the same command line options as a 1.0 TSD, we highly recommend that you create a configuration file based on the config included at `./src/opentsdb.conf`. Or if you install from a package, you'll want to edit the included default config. The config file includes many more options than are accessible via command line and the file is shared with CLI tools. See [*Configuration*](user_guide/configuration) for details.
You do not have to upgrade all of your TSDs to 2.3 at the same time. Some users upgrade their read-only TSDs first to gain access to the full HTTP API and test the new features. Later on you can upgrade the write-only TSDs at leisure. You can also perform a rolling upgrade without issues. Simply stop traffic to one TSD, upgrade it, restore traffic, and continue on until you have upgraded all of your TSDs.
If you do perform a rolling upgrade where you have multiple TSDs, heed the following warning:
Warning
Do not write **Annotations** or **Data point with Millisecond Timestamps** while you run a mixture of 1.x and 2.x. Because these data are stored in the same rows as regular data points, they can affect compactions and queries.
Before upgrading to 2.x, you may want to upgrade all of your TSDs to OpenTSDB 1.2. This release is fully forwards compatible in that it will ignore annotations and millisecond timestamps and operate as expected. With 1.2 running, if you accidentally record an annotation or millisecond data point, your 1.2 TSDs will operate normally.
Upgrading from 2.x to a Later 2.x
---------------------------------
In general, upgrading within a single major release branch is simply a matter of updating the binaries or package and restarting a TSD. Within a branch we'll maintain settings, APIs and schema. However new features may be added with each minor version that include new configuration settings with useful defaults.
Note
The exception so far has been the introduction of salted rows in 2.2.0. Disabled by default, using this feature requires creating a new HBase table with a new set of pre-splits and modifying the configuration of every TSD to use the new table with salting enabled. The schema for salted and unsalted tables is incompatible so if users have a lot of data in a previous table, it may be best to leave a few TSDs running to query against the old table and new TSDs to write to and read from the new salted table. For smaller amounts of data, the [*scan*](user_guide/cli/scan) tool can be used to export and re-import your data.
Note
Likewise with 2.3, the introduction of new backends (Bigtable or Cassandra) requires setting up new storage tables and migrating data.
Downgrading
-----------
Because we've worked hard to maintain backwards compatibility, you can turn off a 2.x TSD and restart your old 1.x TSD. The only exceptions are if you have written annotations or milliseconds as you saw in the warning above. In these cases you must downgrade to 1.2 or later. You may also delete the `tsdb-tree` and `tsdb-meta` tables if you so desire.
Downgrades within a major version are idempotent.
Warning
If you wrote data using a salted table or changed the UID widths for metrics, tag keys or tag values then you cannot downgrade. Create a new table and export the data from the old table, then re-write the data to the new table using the older TSD version.
opentsdb What's New What's New
==========
OpenTSDB has a thriving community who contributed and requested a number of new features.
3.X (Planned)
-------------
While 3.0 is still a ways off, we'll be pushing some of the new features into a new branch of the repo. Some are in progress and other features are planned. If you have any features that you want to see, let us know.
* Distributed Queries - Based on the great work of Turn on [Splicer](https://github.com/turn/splicer) we have a distributed query layer to split queries amongst multiple TSDs for greater throughput.
* Query Caching - Improve queries with time-sharded caching of results.
* Improved Expressions - Perform group by, downsampling and arithmetic modifications in any order. Potentially support UDFs as well.
* Anomaly Processing/Forecasting - Integrate with modeling libraries (such as [EGADs](https://github.com/yahoo/egads)) for deeper time series analysis.
2.4 (Planned)
-------------
* Rollup/Pre-Aggregates - Support for storing and querying time-based rolled up data and/or pre-aggregated values.
* Distributed Percentile - Store histograms (or sketches) for calculating proper percentiles over multiple sources.
2.3
---
* Expressions - Query time computations using time series data. For example, dividing one metric by another.
* Graphite Style Functions - Additional filtering and mutation of data at query time using Graphite style functions.
* Calendar Based Downsampling - The ability to align downsampled data on Gregorian calendar boundaries.
* Bigtable Support - Run TSDB in the cloud using Google's hosted Bigtable service.
* Cassandra Support - Support for running OpenTSDB on legacy Cassandra clusters.
* Write Filters - Block or allow time series or UID assignments based on plugins or whitelists.
* New Aggregators - None for returning raw data. First and Last to return the first or last data points during downsampling.
* Meta Data Cache Plugin - A new API for caching meta data to improve query performance.
* Startup Plugins - APIs to help with service discovery on TSD startup.
* Example Java API usage classes.
2.2
---
* Appends - Support writing all data points for an hour in a single column. This saves the need for TSD compactions and reduces network traffic at query time.
* Salting - Enables greater distribution of writes for high cardinality metrics as well as asynchronous scanning for improved query speed. (Non backwards compatible)
* Random Metric UIDs - Enables better distribution of writes when creating new metrics
* Storage Exception Plugin - Enables various handling of data points when HBase is unavailable
* Secure AsyncHBase - Access HBase clusters requiring Kerberos or simple authentication along with optional encryption.
* Fill Policy - Enable emitting NaNs or Nulls via the JSON query endpoint when data points are "missing"
* Count and Percentiles - New aggregator functions
* More Stats - Gives greater insight into query performance via the query stats endpoint and new stats for threads, region clients and the JVM
* Annotations - Scan for multiple annotations only via the /api/annotations endpoint
* Query Filters - New filters for flexibility including case (in)sensitive literals, wildcards and regular expressions.
* Override Tag Widths - You can now override tag widths in the config instead of having to recompile the code.
* Compaction Tuning - New parameters allow for tuning the TSD compaction process.
* Delete Data And UIDs - Allow for deleting data at query time as well as removing UIDs from the system.
* Synchronous Writing - The HTTP Put API now supports synchronous writing to make sure data is flushed to HBase.
* Query Stats - Query details are now logged that include timing statistics. A new endpoint also shows running and completed queries.
2.1
---
* Downsampling - Timestamps are now aligned on modulus boundaries, reducing the need to interpolation across series.
* Last Data Point API - Query for the last data point for specific time series within a certain time window
* Duplicates - Handle duplicate data points at query time or during FSCK
* FSCK - An updated FSCK utility that iterates over the main data table, finding and fixing errors
* Read/Write Modes - Block assigning UIDs on individual TSDs for backup clusters
* UID Cache - Preload portions of the UID table on startup to improve writes
2.0
---
* Lock-less UID Assignment - Drastically improves write speed when storing new metrics, tag names, or values
* Restful API - Provides access to all of OpenTSDB's features as well as offering new options, defaulting to JSON
* Cross Origin Resource Sharing - For the API so you can make AJAX calls easily
* Store Data Via HTTP - Write data points over HTTP as an alternative to Telnet
* Configuration File - A key/value file shared by the TSD and command line tools
* Pluggable Serializers - Enable different inputs and outputs for the API
* Annotations - Record meta data about specific time series or data points
* Meta Data - Record meta data for each time series, metrics, tag names, or values
* Trees - Flatten metric and tag combinations into a single name for navigation or usage with different tools
* Search Plugins - Send meta data to search engines to delve into your data and figure out what's in your database
* Real-Time Publishing Plugin - Send data to external systems as they arrive to your TSD
* Ingest Plugins - Accept data points in different formats
* Millisecond Resolution - Optionally store data with millisecond precision
* Variable Length Encoding - Use less storage space for smaller integer values
* Non-Interpolating Aggregation Functions - For situations where you require raw data
* Rate Counter Calculations - Handle roll-over and anomaly supression
* Additional Statistics - Including the number of UIDs assigned and available
Thank you to everyone who has contributed to 2.3. Help us out by sharing your ideas and code at [GitHub](https://github.com/OpenTSDB)
| programming_docs |
opentsdb stats stats
=====
This command is similar to the HTTP [*/api/stats*](../api_http/stats/index) endpoint in that it will return a list of the TSD stats, one per line, in the `put` format. This command does not modify TSD in any way.
Request
-------
The command format is:
```
stats
```
Response
--------
A set of time series with data about the running TSD.
### Example
```
tsd.hbase.rpcs 1479600574 0 type=increment host=web01
tsd.hbase.rpcs 1479600574 0 type=delete host=web01
tsd.hbase.rpcs 1479600574 1 type=get host=web01
tsd.hbase.rpcs 1479600574 0 type=put host=web01
tsd.hbase.rpcs 1479600574 0 type=append host=web01
tsd.hbase.rpcs 1479600574 0 type=rowLock host=web01
tsd.hbase.rpcs 1479600574 0 type=openScanner host=web01
tsd.hbase.rpcs 1479600574 0 type=scan host=web01
tsd.hbase.rpcs.batched 1479600574 0 host=web01
```
opentsdb help help
====
Returns a list of the commands supported via the Telnet style API. This command does not modify TSD in any way.
Request
-------
The command format is:
```
help
```
Response
--------
A space separated list of commands supported.
### Example
```
available commands: put stats dropcaches version exit help diediedie
```
opentsdb Telnet Style API Telnet Style API
================
The original way of interacting with OpenTSDB was through a Telnet style API. A user or application simply had to open a socket to the TSD and start sending ASCII string commands and expect a response. This documentation lists the various commands provided by OpenTSDB.
Each command must be sent as a series of strings with a **new line** character terminating the request.
Note
Connections will be closed after a period of inactivity, typically 5 minutes.
If a command is sent to the API that is not supported or recognized, a response similar to the following will be shown:
```
unknown command: nosuchcommand. Try `help'.
```
At any time the connection can be closed by issuing the `exit` command.
* <put>
* <rollup>
* <stats>
* <version>
* <help>
* <dropcaches>
* <diediedie>
opentsdb diediedie diediedie
=========
This command will cause the running TSD to shutdown and the process to exit. Please use carefully.
Warning
As stated, when this command executes, the TSD will shutdown. You'll have to restart it manually, using a script, or use something like Daemontools or Runit.
Request
-------
The command format is:
```
diediedie
```
Response
--------
A response that it's cleaning up and exiting.
### Example
```
Cleaning up and exiting now.
```
opentsdb rollup rollup
======
Attempts to write a rolled up and/or pre-aggregated data point to storage. Note that UTF-8 characters may not be handled properly by the Telnet style API so use the [*/api/rollup*](../api_http/rollup) method instead or use the Java API directly. Also see the `../user\_guide/rollup` documentation for more information. This endpoint behaves in a similar manner to the [*put*](put) API.
Request
-------
The command format is:
```
rollup <rollup spec> <metric> <timestamp> <value> <tagk_1>=<tagv_1>[ <tagk_n>=<tagv_n>]
```
In this case the rollup spec is one of:
* `<interval>:<aggregator>` for a *raw* or *non-pre-aggregated* **rollup** over the interval.
* `<group\_by\_aggregator>` for a *raw* **pre-aggregated** value that has not been rolled up over time.
* `<interval>:<aggregator>:<group\_by\_aggregator>` for a *rolled up* *pre-aggregated* value.
Note:
* Because fields are space delimited, metrics and tag values may not contain spaces.
* The timestamp must be a positive Unix epoch timestamp. E.g. `1479496100` to represent `Fri, 18 Nov 2016 19:08:20 GMT`
* The value must be a number. It may be an integer (maximum and minimum values of Java's `long` data type), a floating point value or scientific notation (in the format `[-]<#>.<#>[e|E][-]<#>`).
* At least one tag pair must be present. Additional tag pairs can be added with spaces in between.
### Examples
```
rollup 1h:SUM sys.if.bytes.out 1479412800 1.3E3 host=web01 interface=eth0
rollup SUM sys.procs.running 1479496100 42 colo=lga
rollup 1h:SUM:SUM sys.procs.running 1479412800 24 colo=lga
```
Response
--------
A successful request will not return a response. Only on error will the socket return a line of data. Some examples appear below:
### Example Requests and Responses
```
rollup
rollup: illegal argument: not enough arguments (need least 5, got 1)
```
```
rollup SUM metric.foo notatime 42 host=web01
rollup: invalid value: Invalid character 'n' in notatime
```
The following will be returned if `tsd.core.auto\_create\_metrics` are disabled.
```
rollup SUM new.metric 1479496160 1.3e3 host=web01
rollup: unknown metric: No such name for 'metrics': 'new.metric'
```
opentsdb put put
===
Attempts to write a data point to storage. Note that UTF-8 characters may not be handled properly by the Telnet style API so use the [*/api/put*](../api_http/put) method instead or use the Java API directly.
Note
Because the socket is read and written to asynchronously, responses may be garbled. It's best to treat this similar to a UDP socket in that you may not always know if the data made it in. If you require truly synchronous writes with guarantees of the data making it to storage, please use the HTTP or Java APIs.
Request
-------
The command format is:
```
put <metric> <timestamp> <value> <tagk_1>=<tagv_1>[ <tagk_n>=<tagv_n>]
```
Note:
* Because fields are space delimited, metrics and tag values may not contain spaces.
* The timestamp must be a positive Unix epoch timestamp. E.g. `1479496100` to represent `Fri, 18 Nov 2016 19:08:20 GMT`
* The value must be a number. It may be an integer (maximum and minimum values of Java's `long` data type), a floating point value or scientific notation (in the format `[-]<#>.<#>[e|E][-]<#>`).
* At least one tag pair must be present. Additional tag pairs can be added with spaces in between.
### Examples
```
put sys.if.bytes.out 1479496100 1.3E3 host=web01 interface=eth0
put sys.procs.running 1479496100 42 host=web01
```
Response
--------
A successful request will not return a response. Only on error will the socket return a line of data. Some examples appear below:
### Example Requests and Responses
```
put
put: illegal argument: not enough arguments (need least 4, got 1)
```
```
put metric.foo notatime 42 host=web01
put: invalid value: Invalid character 'n' in notatime
```
The following will be returned if `tsd.core.auto\_create\_metrics` are disabled.
```
put new.metric 1479496160 1.3e3 host=web01
put: unknown metric: No such name for 'metrics': 'new.metric'
```
opentsdb version version
=======
This command is similar to the HTTP [*/api/version*](../api_http/version) endpoint in that it will return information about the currently running version of OpenTSDB. This command does not modify TSD in any way.
Request
-------
The command format is:
```
version
```
Response
--------
A set of lines with version information.
### Example
```
net.opentsdb.tools BuildData built at revision a7a0980 (MODIFIED)
Built on 2016/11/03 19:35:50 +0000 by clarsen@tsdvm:/Users/clarsen/Documents/opentsdb/opentsdb_dev
```
opentsdb dropcaches dropcaches
==========
Purges the metric, tag key and tag value UID to string and string to UID maps.
Request
-------
The command format is:
```
dropcaches
```
Response
--------
An acknowledgement after the caches have been purged.
### Example
```
Caches dropped.
```
opentsdb Plugins Plugins
=======
OpenTSDB implements a very simple plugin model to extend the application. Plugins use the *service* and *service provider* facilities built into Java 1.6 that allows for dynamically loading JAR files and instantiating plugin implementations after OpenTSDB has been started. While not as flexible as many framework implementations, all we need to do is load a plugin on startup, initialize the implementation, and start passing data to or through it.
To create a plugin, all you have to do is extend one of the *abstract* plugin classes, write a service description/manifest, compile, drop your JAR (along with any dependencies needed) into the OpenTSDB plugin folder, edit the TSD config and restart. That's all there is to it. No fancy frameworks, no worrying about loading and unloading at strange times, etc.
Manifest
--------
A plugin JAR requires a manifest with a special *services* folder and file to enable the [ServiceLoader](http://docs.oracle.com/javase/6/docs/api/java/util/ServiceLoader.html) to load it properly. Here are the steps for creating the proper files:
>
> * Create a `META-INF` directory under your `src` directory. Some IDEs can automatically generate this
> * Within the `META-INF` directory, create a file named `MANIFEST.MF`. Again some IDEs can generate this automatically.
> * Edit the `MANIFEST.MF` file and add:
>
>
> ```
> Manifest-Version: 1.0
>
> ```
>
> making sure to end with a blank line. You can add more manifest information if you like. This is the bare minimum to satisfy plugin requirements.
> * Create a `services` directory under `META-INF`
> * Within `services` create a file with the canonical class name of the abstract plugin class you are implementing. E.g. if you implement `net.opentsdb.search.SearchPlugin`, use that for the name of the file.
> * Edit the new file and put the canonical name of each class that implements the abstract interface on a new line of the file. E.g. if your implementation is called `net.opentsdb.search.ElasticSearch`, put that on a line. Some quick notes about this file:
>
>
> + You can put comments in the service implementation file. The comment character is the `#`, just like a Java properties file. E.g.:
>
>
> ```
> # ElasticSearch plugin written by John Doe
> # that sends data over HTTP to a number of ElasticSearch servers
> net.opentsdb.search.ElasticSearch
>
> ```
> + You can have more than one implementation of the same abstract class in one JAR and in this file. NOTE: If you have widely different implementations, start a different project and JAR. E.g. if you implement a search plugin for ElasticSearch and another for Solr, put Solr in a different project. However if you have two implementations that are very similar but slightly different, you can create one project. For example you could write an ElasticSearch plugin that uses HTTP for a protocol and another that uses Thrift. In that case, you could have a file like:
>
>
> ```
> # ElasticSearch HTTP
> net.opentsdb.search.ElasticSearchHTTP
> # ElasticSearch Thrift
> net.opentsdb.search.ElasticSearchThrift
>
> ```
> * Now compile your JAR and make sure to include the manifest file. Each IDE handles this differently. If you're going command line, try this:
>
>
> ```
> jar cvmf <path to MANIFEST.MF> <plugin jar name> <list of class files>
>
> ```
>
> Where the `<list of class files>` includes the services file that you created above. E.g.:
>
>
> ```
> jar cvmf META-INF/MANIFEST.MF searchplugin.jar ../bin/net/opentsdb/search/myplugin.class META-INF/services/net.opentsdb.search.SearchPlugin
>
> ```
>
>
>
Startup Plugins
---------------
Startup Plugins can be used to perform additional initialization steps during the OpenTSDB startup process.
There are four hooks available, and they are called in this order:
* Constructor
* Initialize
* Ready
* Shutdown
### Constructor
In the constructor for your plugin, you should initialize your plugin and make any external connections required here. For example, to connect to a service discovery tool such as Etcd or Curator.
### Initialize
The Initialize hook is called once OpenTSDB has fully read the configuration options, both from the file, and the command line. This is called prior to creating the TSDB object so you can modify the configuration at this time.
This hook could be used to register OpenTSDB with a service discovery mechanism or look up the location of an HBase cluster dynamically and populate the connfiguration. You could potentially create HBase tables if they do not exist at this time.
Note
You will want to make sure you set the status to PENDING or some other non-ready state in your service discovery system when this is called. TSDB has not been initialized yet at this point.
### Ready
This hook is called once OpenTSDB has been fully initialized and is ready to serve traffic. This hook could be used to set the status to READY in a service discovery system, change the state of in a load balancer or perform other tasks which require a fully functioning OpenTSDB instance.
### Shutdown
This hook is called when OpenTSDB is performing shutdown tasks. No work should be done here which requires a functioning and connected OpenTSDB instance. You could use this to update the status of this node within your service discovery mechanism.
opentsdb Development Development
===========
OpenTSDB has a strong and growing base of users running TSDs in production. There are also a number of talented developers creating tools for OpenTSDB or contributing code directly to the project. If you are interested in helping, by adding new features, fixing bugs, adding tools or simply updating documentation, please read the guidelines below. Then sign the contributors agreement and send us a pull request!
If you are looking to integrate OpenTSDB with your application, the compiled JAVA library has a consistent and well documented API. Please see [JAVA API Documentation](http://opentsdb.net/docs/javadoc/index.html).
Guidelines
----------
* Please file [issues on GitHub](https://github.com/OpenTSDB/opentsdb/issues) after checking to see if anyone has posted a bug already. Make sure your bug reports contain enough details so they can be easily understood by others and quickly fixed.
* Read the Development page for tips
* The best way to contribute code is to fork the main repo and [send a pull request](https://help.github.com/articles/using-pull-requests) on GitHub.
+ Bug fixes should be done in the `master` branch
+ New features or major changes should be done in the `next` branch
* Alternatively, you can send a plain-text patch to the [mailing list](https://groups.google.com/forum/#!forum/opentsdb).
* Before your code changes can be included, please file the [Contribution License Agreement](https://docs.google.com/spreadsheet/embeddedform?formkey=dFNiOFROLXJBbFBmMkQtb1hNMWhUUnc6MQ).
* Unlike, say, the Apache Software Foundation, we do not require every single code change to be attached to an issue. Feel free to send as many small fixes as you want.
* Please break down your changes into as many small commits as possible.
* Please *respect the coding style of the code* you're changing.
+ Indent code with 2 spaces, no tabs
+ Keep code to 80 columns
+ Curly brace on the same line as `if`, `for`, `while`, etc
+ Variables need descriptive names `like\_this` (instead of the typical Java style of `likeThis`)
+ Methods named `likeThis()` starting with lower case letters
+ Classes named `LikeThis`, starting with upper case letters
+ Use the `final` keyword as much as you can, particularly in method parameters and returns statements.
+ Avoid checked exceptions as much as possible
+ Always provide the most restrictive visibility to classes and members
+ Javadoc all of your classes and methods. Some folks make use the Java API directly and we'll build docs for the site, so the more the merrier
+ Don't add dependencies to the core OpenTSDB library unless absolutely necessary
+ Add unit tests for any classes/methods you create and verify that your change doesn't break existing unit tests. We know UTs aren't fun, but they are useful
Details
-------
* [General Development](development)
* [Plugins](plugins)
* [HTTP API](http_api)
opentsdb General Development General Development
===================
OpenTSDB isn't laid out like a typical Java project, instead it's a bit more like a C or C++ environment. This page is to help folks who want to modify OpenTSDB and provide updates back to the community.
Build System
------------
There are almost as many build systems as there are developers so it's impossible to satisfy everyone no matter which system or layout is chosen. Autotools and GNU Make were chosen early on for OpenTSDB because of their flexibility, portability, and especially speed and popular usage. It's not the easiest to configure but for our needs, it's really not too difficult. We'll spell out what you need to change below and give tips for IDE users who want to setup an environment. Note that the build script can now compile a `pom.xml` file for compiling with Maven and work is underway to provide better Maven support. However you still have to modify `Makefile.am` if you add or remove classes or dependencies and such.
Building
--------
OpenTSDB is built using the standard `./configure && make` model that is most commonly employed by many open-source projects. Fresh working copies checked out from Git must first be `./bootstraped`.
Alternatively, there is a `build.sh` script you can run that makes as it takes care of all the steps for you. You can give it a Make target in argument, e.g. `./build.sh distcheck` (the default target is `all`).
### Build Targets
The `build.sh` script will compile a JAR and the static GWT files for the front-end GUI if no parameters are passed. Additional parameters include:
* **check** - Executes unit tests and reports on the results. You can specify executing the checks in a specific file via `test\_SRC=<path>`, e.g. `./build.sh check test\_SRC=test/uid/TestNoSuchUniqueId.java`
* **pom.xml** - Compile a POM file to compile with Maven.
* **dist** - Downloads dependencies, compiles OpenTSDB and creates a tarball for distribution
* **distcheck** - Same as dist but also runs unit tests. This should be run before issuing pull requests to verify that everything performs correctly.
* **debian** - Compiles OpenTSDB and generates a Debian package
Adding a Dependency
-------------------
*Please try your best not to*. We're extremely picky on the dependencies and will require a code review before we start depending on a new library. The goal isn't to re-invent the wheel either, but we are very mindful about the number and quality of dependent libraries we pull in. If you absolutely must add a new dependency, here are the steps:
* Find the canonical source to download the dependent JAR file
* Find or create the proper directory under `third\_party/`
* In that directory, create a `<depdencency>.jar.md5` file
* Paste the MD5 hash of the entire jar in that file and save it
* Create or edit the `include.mk` file and copy the header info from another directory's file
* Add a `<DEPENDENCY>\_VERSION := <version>` e.g. `JACKSON\_VERSION := 1.9.4`
* Add a `<DEPENDENCY> := third\_parth/<DIR>/<dependency>$(<DEPENDENCY>\_VERSION).jar` line e.g. `JACKSON\_CORE := third\_party/jackson/jackson-core-lgpl-$(JACKSON\_CORE\_VERSION).jar`
* Add the canonical source URL in the format `<DEPENDENCY>\_BASE\_URL := <URL>` e.g. `JACKSON\_CORE\_BASE\_URL := http://repository.codehaus.org/org/codehaus/jackson/jackson-core-lgpl/$(JACKSON\_VERSION)` and note that the JAR name will be appended to the end of the URL
* Add the following lines
```
$(<DEPENDENCY>): $(J<DEPENDENCY>).md5
set dummy ``$(<DEPENDENCY>_BASE_URL)`` ``$(<DEPENDENCY>)``; shift; $(FETCH_DEPENDENCY)
```
e.g.
```
$(JACKSON_CORE): $(JACKSON_CORE).md5
set dummy ``$(JACKSON_CORE_BASE_URL)`` ``$(JACKSON_CORE)``; shift; $(FETCH_DEPENDENCY)
```
* Add a line `THIRD\_PARTY += $(<DEPENDENCY>)` e.g. `THIRD\_PARTY += $(JACKSON\_CORE)`
* Next, back in the `third\_party/` directory, edit the `include.mk` file and if you added a new directory for your dependency, insert a reference to the `.mk` file in the proper alphabetical position.
* Edit `Makefile.am`
+ Find the `tsdb\_DEPS = \` line
+ Add your new dependency in the proper alphabetical position in the format `$(<DEPENDENCY>)`, e.g. `$(JACKSON\_CORE>`. Note that if you put it the middle of the list, you must finish with the line continuation character, the backslash `\`. If your dependency goes at the end, do not add the backslash.
Note
If the dependency is only used for unit tests, then add it to the `test\_DEPS = \` list
+ Find the `pom.xml: pom.xml.in Makefile` line in the file
+ Add a sed line such as `-e 's/@<DEPENDENCY>\_VERSION@/$(<DEPENDENCY>\_VERSION)/' \` e.g. `-e 's/@JACKSON\_VERSION@/$(JACKSON\_VERSION)/' \`
Note
Unit test dependencies go here as well as regular items
* Edit `pom.xml.in`
+ Find the `<dependencies>` XML section
+ Copy and paste an existing dependency section and modify it for your variables
* Now run a build via `./build.sh` and verify that it fetches your dependency and builds without errors. \* Then run `./build.sh pom.xml` to verify that the POM is compiled properly and run a `mvn compile` to verify the Maven build works correctly.
Adding/Removing/Moving a Class
------------------------------
This is much easier than dealing with a dependency. You only need to modify `Makefile.am` and edit the `tsdb\_SRC := \` or the `test\_SRC := \` lists. If you're adding a class, put it in the proper alphabetical position and account for the proper directory and class name. It is case sensitive so make sure to get that right. If removing a class, just delete the line. If moving a class, add the new line and delete the old one. Be careful to handle the line continuation `\` backslashes. The last class in each list should NOT end with a backslash, the rest need it.
After editing, rebuild with `./build.sh` and verify that your class was compiled and included properly.
IDEs
----
Many devs use an IDE to work on Java projects and despite OpenTSDB's non-java-standard directory layout, working with an IDE is pretty easy. Here are some steps to get up and running with Eclipse though they should work with other environments. This example assumes you're using Eclipse.
* Clone the GIT repo to a location such as `/home/$USER/opentsdb`
* Build the repo with `./build.sh` from the directory
* Fire up Eclipse or your favorite IDE
* Create a new Java project with a name like `opentsdb\_dev` so that it winds up in `/home/$USER/opentsdb\_dev`
* Your dev directory should now have a `./src` directory
* Create a `net` directory under `./src` so that you have `./src/net` (some IDEs may create a `./src/java` dir, so add `./src/java/net`)
* Create a symlink to the GIT repo's `./src` directory from `./src/net/opentsdb`. E.g. `ln -s /home/$USER/opentsdb/src /home/$USER/opentsdb\_dev/src/net/opentdsb`
* Also, create a `tsd` directory under `./src` so that you have `./src/tsd`
* Create a symlink to the GIT repo's `./src/tsd/client` directory from `./src/tsd/client`. E.g. `ln -s /home/$USER/opentsdb/src/tsd/client /home/$USER/opentsdb\_dev/src/tsd/client`
* If your IDE didn't, create a `./test` directory under your dev project folder. This will be used for unit tests.
* Add a `net` directory under `./test` so you have `./test/net`
* Create a symlink to the GIT repo's `./test` directory from `./test/net/opentsdb`. E.g. `ln -s /home/$USER/opentsdb/test /home/$USER/opentsdb\_dev/test/net/opentdsb`
* Refresh the directory lists in Eclipse and you should see all of the source files
* Right click the `net.opentsdb.tsd.client` package under SRC and select `Build Path` then `Exclude` from the menu
* Now add the downloaded dependencies by clicking Project -> Properties, click the `Java Build Path` menu item and click `Add External JARs` button.
* Do that for each of the dependencies that were downloaded by the build script
* Copy the file `./build/src/BuildData.java` from the GIT repo, post build, to your `./src/net/opentsdb/` directory
* Now click Run (or Debug) -> Manage Configurations
* Under Java Application, right click and select New from the pop-up
* Under the Main tab, brows to your `opentsdb\_dev` project
* For the Main Class, search for `net.opentsdb.tools.TSDMain`
* Under Arguments, add the runtime arguments to select your Zookeeper quorum and the static and cache directories
* Run or Debug it and hopefully it worked
* Now edit away and when you're ready to publish changes, follow the directions above about modifying the build system (if necessary), publish to your own GitHub fork, and issue a pull request.
Note
This won't compile the GWT UI. If you want to do UI work and have made changes, recompile OpenTSDB or export it as a JAR from your IDE, then execute the following command (assuming the directory structure above):
```
java -cp ``<PATH_TO>gwt-dev-2.4.0.jar;<PATH_TO>gwt-user-2.4.0.jar;<PATH_TO>tsdb-1.1.0.jar;/home/$USER/opentsdb/src/net/opentsdb;/home/$USER/opentsdb/src`` com.google.gwt.dev.Compiler -ea -war <PATH_TO_STATIC_DIRECTORY> tsd.Queryui
```
| programming_docs |
opentsdb HTTP API HTTP API
========
These are some notes on adding to the HTTP API.
Reserved Query String Parameters
--------------------------------
The following is a list of query string parameters that are used by OpenTSDB across the entire API. Don't try to overload their use please:
| Parameter | Description |
| --- | --- |
| serializer | The name of a serializer to use for parsing input or formatting return data |
| method | Allows for overriding the HTTP verb when necessary |
opentsdb Quick Start Quick Start
===========
Once you have a TSD up and running (after following the [*Installation*](../installation) guide) you can follow the steps below to get some data into OpenTSDB. After you have some data stored, pull up the GUI and try generating some graphs.
Create Your First Metrics
-------------------------
Metrics need to be registered before you can start storing data points for them. This helps to avoid ingesting unwanted data and catch typos. You can enable auto-metric creation via configuration. To register one or more metrics, call the `mkmetric` CLI:
```
./tsdb mkmetric mysql.bytes_received mysql.bytes_sent
```
This will create 2 metrics: `mysql.bytes\_received` and `mysql.bytes\_sent`
New tags, on the other hand, are automatically registered whenever they're used for the first time. Right now OpenTSDB only allows you to have up to 2^24 = 16,777,216 different metrics, 16,777,216 different tag names and 16,777,216 different tag values. This is because each one of those is assigned a UID on 3 bytes. Metric names, tag names and tag values have their own UID spaces, which is why you can have 16,777,216 of each kind. The size of each space is configurable but there is no knob that exposes this configuration parameter right now. So bear in mind that using user ID or event ID as a tag value will not work right now if you have a large site.
Start Collecting Data
---------------------
So now that we have our 2 metrics, we can start sending data to the TSD. Let's write a little shell script to collect some data off of MySQL and send it to the TSD:
```
cat >mysql-collector.sh <<\EOF
#!/bin/bash
set -e
while true; do
mysql -u USER -pPASS --batch -N --execute "SHOW STATUS LIKE 'bytes%'" \
| awk -F"\t" -v now=`date +%s` -v host=`hostname` \
'{ print "put mysql." tolower($1) " " now " " $2 " host=" host }'
sleep 15
done | nc -w 30 host.name.of.tsd PORT
EOF
chmod +x mysql-collector.sh
nohup ./mysql-collector.sh &
```
Every 15 seconds, the script will collect 2 data points from MySQL and send them to the TSD. You can use a smaller sleep interval for greater granularity.
What does the script do? If you're not a big fan of shell and awk scripting, it may not be obvious how this works. But it's simple. The `set -e` command simply instructs bash to exit with an error if any of the commands fail. This simplifies error handling. The script then enters an infinite loop. In this loop, we query MySQL to retrieve 2 of its status variables:
```
$ mysql -u USER -pPASS --execute "SHOW STATUS LIKE 'bytes%'"
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| Bytes_received | 133 |
| Bytes_sent | 190 |
+----------------+-------+
```
The `--batch -N` flags ask the mysql command to remove the human friendly fluff so we don't have to filter it out ourselves. Then the output is piped to awk, which is told to split fields on tabs `-F"\t"` because with the `--batch` flag that's what mysql will use. We also create a couple of variables, one named `now` and initialize it to the current timestamp, the other named ``host` and set to the hostname of the local machine. Then, for every line, we print put ``mysql.`, followed by the lower-case form of the first word, then by a space, then by the current timestamp, then by the second word (the value), another space, and finally `host=` and the current hostname. Rinse and repeat every 15 seconds. The `-w 30` parameter given to `nc` simply sets a timeout on the connection to the TSD. Bear in mind, this is just an example, in practice you can use tcollector's MySQL collector.
If you don't have a MySQL server to monitor, you can try this instead to collect basic load metrics from your Linux servers:
```
cat >loadavg-collector.sh <<\EOF
#!/bin/bash
set -e
while true; do
awk -v now=`date +%s` -v host=`hostname` \
'{ print "put proc.loadavg.1m " now " " $1 " host=" host;
print "put proc.loadavg.5m " now " " $2 " host=" host }' /proc/loadavg
sleep 15
done | nc -w 30 host.name.of.tsd PORT
EOF
chmod +x loadavg-collector.sh
nohup ./loadavg-collector.sh &
```
This will store a reading of the 1-minute and 5-minute load average of your server in OpenTSDB by sending simple "telnet-style commands" to the TSD:
```
put proc.loadavg.1m 1288946927 0.36 host=foo
put proc.loadavg.5m 1288946927 0.62 host=foo
put proc.loadavg.1m 1288946942 0.43 host=foo
put proc.loadavg.5m 1288946942 0.62 host=foo
```
Batch Imports
-------------
Let's imagine that you have a cron job that crunches gigabytes of application logs every day or every hour to extract profiling data. For instance, you could be logging the time taken to process a request and your cron job would compute an average for every 30 second window. Maybe you're particularly interested in 2 types of requests handled by your application, so you'll compute separate averages for those requests, and an another average for every other request type. So your cron job may produce an output file that looks like this:
```
1288900000 42 foo
1288900000 51 bar
1288900000 69 other
1288900030 40 foo
1288900030 59 bar
1288900030 80 other
```
The first column is a timestamp, the second is the average latency for that 30 second window, and the third is the type of request we're talking about. If you run your cron job on a day worth of logs, you'll end up with 8640 such lines. In order to import those into OpenTSDB, you need to adjust your cron job slightly to produce its output in the following format:
```
myservice.latency.avg 1288900000 42 reqtype=foo
myservice.latency.avg 1288900000 51 reqtype=bar
myservice.latency.avg 1288900000 69 reqtype=other
myservice.latency.avg 1288900030 40 reqtype=foo
myservice.latency.avg 1288900030 59 reqtype=bar
myservice.latency.avg 1288900030 80 reqtype=other
```
Notice we're simply associating each data point with the name of a metric (myservice.latency.avg) and naming the tag that represents the request type. If each server has its own logs and you process them separately, you may want to add another tag to each line like the `host=foo` tag we saw in the previous section. This way you'll be able to plot the latency of each server individually, in addition to your average latency across the board and/or per request type. In order to import a data file in the format above (metric timestamp value tags) simply run the following command:
```
./tsdb import your-file
```
If your data file is large, consider gzip'ing it first. This can be as simple as piping the output of your cron job to `gzip -9 >output.gz` instead of writing directly to a file. The import command is able to read gzip'ed files and it greatly helps performance for large batch imports.
Self Monitoring
---------------
Each TSD exports some stats about itself through the simple stats command. You can collect those stats and feed them back to the TSD every few seconds. First, create the necessary metrics:
```
echo stats | nc -w 1 localhost 4242 \
| awk '{ print $1 }' | sort -u \
| xargs ./tsdb mkmetric
```
This requests the stats from the TSD (assuming it's running on the local host and listening to port 4242), extract the names of the metrics from the stats and assigns them UIDs. Then you can use this simple script to collect stats and store them in OpenTSDB:
```
#!/bin/bash
INTERVAL=15
while :; do
echo stats || exit
sleep $INTERVAL
done | nc -w 30 localhost $1 \
| sed 's/^/put /' \
| nc -w 30 localhost $1
```
This way you will collect and store stats from the TSD every 15 seconds.
Create a Graph
--------------
Once you've written some data using any of the methods above, you can now try to create a graph using that data. Pull up the GUI in your favorite browser. If you're running your TSD on the localhost, simply visit <http://127.0.0.1:4242>.
First, pick one of the metrics and put that in the `Metric` box. For example, `proc.loadavg.1m`. As you type, you should see auto-complete lines pop up and you can click on any of them.
Then click the `From` box at the top and a date-picker pop-up should appear. Select any time from yesterday and click on another box. At this point you should see "Loading graph.." very briefly followed by the actual graph. If the graph is empty, it may not have found the most recent data points so click the `(now)` link and the page should refresh.
This initial graph will aggregate all of the time series for the metric you selected. Try limiting your query to a specific host by adding `host` as a value in the left-hand box next to the `Tags` label (if it isn't already there) and add the specific host name (e.g. `foo`) in the right-hand box. After clicking in another box you should see the graph re-draw with different information.
opentsdb Plugins Plugins
=======
OpenTSDB 2.0 introduced a plugin framework, allowing varous contributors to quickly and easily customize their TSDs. This document gives you an overview of the plugin system and will link to some available implementations.
General
-------
Plugins are loaded at run time by a TSD or command line utility. Once the program or daemon is running, plugin configurations cannot be changed. You must restart the program for changes to take effect.
Plugins are JAR files that must be downloaded to a directory accessible by OpenTSDB. Once a directory is created, it must be specified in the `opentsdb.conf` config file via the `tsd.core.plugin\_path` property. If the plugin has dependency JARs that were not compiled into the plugin and are not located in the standard class path, they must be copied to this plugin directory as well.
Once the JARs are in place, they must be selected in the configuration file for the type of plugin specified. Usually this will be the fully qualified Java class name such as "net.opentsdb.search.ElasticSearch". Each plugin should have an "enabled" property as well that must be set to `true` for the plugin to be loaded. Plugins may also have configuration settings that must be added to the `opentsdb.conf` file before they can operate properly. See your plugin's documentation. See [*Configuration*](configuration) for details.
When starting a TSD or CLI tool, a number of errors may prevent a successful launch due to plugin issues. If something happens you should see an exception in the logs related to a plugin. Some things to troubleshoot include:
* Make sure the `tsd.core.plugin\_path` is configured
* Check that the path is readable for the user OpenTSDB is running under, i.e. check permissions
* Check for typos in the config file. Case matters for plugin names.
* The plugin may not have access to the dependencies it needs. If it has dependencies that are not included with OpenTSDB or packaged into it's own JAR you need to drop the dependencies in the plugin path.
* The plugin may be missing configuration settings required for it to be initialized. Read the docs and see if anything is missing.
Note
You should always test a new plugin in a development or QA environment before enabling them in production. Plugins may adversely affect write or read performance so be sure to do some load testing to avoid taking down your TSDs and losing data.
### Logging
Plugins and their dependencies can be pretty chatty so you may want to tweak your Logback settings to reduce the number of messages.
Serializers
-----------
The HTTP API provides a plugin interface for serializing and deserializing data in formats other than the default JSON formats. These plugins do not require a plugin name or enable flag in the configuration file. Instead simply drop the plugin in the plugin directory and it will be loaded when the TSD is launched. More than one serializer plugin can be loaded on startup. Serializer plugins may require configuration properties, so check the documentation before using them.
### Plugins
No implementations, aside from the default, at this time.
Startup and Service Discovery
-----------------------------
OpenTSDB is sometimes used within environments where additional initialization or registration is desired beyond what OpenTSDB typically can do out of the box. Startup plugins can be enabled which will be called when OpenTSDB is initializing, when it is ready to serve traffic, and when it is being shutdown. The `tsd.startup.plugin` property can be used to specify the plugin class and `tsd.startup.enable` will instruct OpenTSDB to attempt to load the startup plugin.
Note
Added in 2.3.0
### Plugins
* [Identity Plugin](https://github.com/inst-tech/opentsdb-discoveryplugins/blob/master/src/main/java/io/tsdb/opentsdb/discoveryplugins/IdentityPlugin.java) - An example plugin which does nothing but can be used as a starting point for future Startup Plugins and can be used to test the registration mechanism.
* [Apache Curator](https://github.com/inst-tech/opentsdb-discoveryplugins/blob/master/src/main/java/io/tsdb/opentsdb/discoveryplugins/CuratorPlugin.java) - A beta plugin which can be used to register OpenTSDB in Zookeeper using Apache Curator's Service Discovery mechanism
Search
------
OpenTSDB can emit meta data and annotations to a search engine for complex querying. A single search plugin can be enabled for a TSD to push data or execute queries. The `tsd.search.plugin` property lets you select a search plugin and `tsd.search.enable` will start sending data and queries. Search plugins will be loaded by TSDs and select command line tools such as the UID Manager tool.
### Plugins
* [Elastic Search](https://github.com/manolama/opentsdb-elasticsearch) - A beta plugin that connects to an Elastic Search cluster
Real Time Publishing
--------------------
Every data point received by a TSD can be sent to another destination for real time processing. One plugin for this type may be enabled at a time. The `tsd.rtpublisher.plugin` property lets you select a plugin and `tsd.rtpublisher.enable` will start sending data.
### Plugins
* [RabbitMQ](https://github.com/manolama/opentsdb-rtpub-rabbitmq) - A proof-of-concept plugin to publish to a RabbitMQ cluster by metric name
* [Skyline](https://github.com/gutefrage/OpenTsdbSkylinePublisher) - A proof-of-concept plugin to publish to an Etsy Skyline processor
RPC
---
Natively, OpenTSDB supports ingesting data points via Telnet or HTTP. The RPC plugin interface allows users to implement and choose alternative protocols such as Protobufs, Thrift, Memcache or any other means of storing information. More than one plugin can be loaded at a time via the `tsd.rpc.plugins` or tsd.http.rpc.plugins` configuration property. Simply list the class name of any RPC plugins you wish to load, separated by a comma if you have more than one. RPC plugins are only initialized when running a TSD.
### Plugins
No implementations at this time.
Storage Exception Handler
-------------------------
If a write to the underlying storage layer fails for any reason, an exception is raised. When this happens, if a a storage exception handler plugin is enabled, the data points that couldn't be written can be retried at a later date by spooling to disk or passing to a messaging system. (v2.2)
### Plugins
No implementations at this time.
HTTP RPC Plugin
---------------
This is an interface used to implement additional HTTP API endpoints for OpenTSDB. (v2.2)
### Plugins
No implementations at this time.
opentsdb Stats Stats
=====
OpenTSDB offers a number of metrics about its performance, accessible via various API endpoints. The main stats are accessible from the GUI via the "Stats" tab, from the Http API at `/api/stats` or the legacy API at `/stats`. The Telnet style API also supports the "stats" command for fetching over CLI. These can easily be published right back into OpenTSDB at any interval you like.
Additional stats available include JVM information, storage details (e.g. per-region-client HBase stats) and executed query details. See [*/api/stats*](../api_http/stats/index) for more details about the other endpoints.
All metrics from the main stats endpoint include a `host` tag that includes the name of the host where the TSD is running. If the `tsd.stats.canonical` configuration flag is set, this will change to `fqdn` and the TSD will try to resolve its host name to return the fully qualified domain name. Currently all stats are integer values. Each request for stats will fetch statistics in real time so the timestamp will reflect the current time on the TSD host.
Note
The `/api/stats` endpoint is a good place to execute a health check for your TSD as it will execute a query to storage for fetching UID stats. If the TSD is unable to reach the backing store, the API will return an exception.
| Metric | Tags | Type | Description |
| --- | --- | --- | --- |
| tsd.connectionmgr.connections | type=open | Gauge | The number of currently open Telnet and HTTP connections. |
| tsd.connectionmgr.connections | type=total | Counter | The total number of connections made to OpenTSDB. This includes all Telnet and HTTP connections. |
| tsd.connectionmgr.exceptions | type=closed | Counter | The total number of exceptions caused by writes to a channel that was already closed. This can occur if a query takes too long, the client closes their connection gracefully, and the TSD attempts to write to the socket. This includes all Telnet and HTTP connections. |
| tsd.connectionmgr.exceptions | type=reset | Counter | The total number of exceptions caused by a client disconnecting without closing the socket. This includes all Telnet and HTTP connections. |
| tsd.connectionmgr.exceptions | type=timeout | Counter | The total exceptions caused by a socket inactivity timeout, i.e. the TSD neither wrote nor received data from a socket within the timeout period. This includes all Telnet and HTTP connections. |
| tsd.connectionmgr.exceptions | type=unknown | Counter | The total exceptions with an unknown cause. Check the logs for details. This includes all Telnet and HTTP connections. |
| tsd.rpc.received | type=telnet | Counter | The total number of telnet RPC requests received |
| tsd.rpc.received | type=http | Counter | The total number of Http RPC requests received |
| tsd.rpc.received | type=http\_plugin | Counter | The total number of Http RPC requests received and handled by a plugin instead of the built-in APIs. (v2.2) |
| tsd.rpc.exceptions | | Counter | The total number exceptions caught during RPC calls. These may be user error or bugs. |
| tsd.http.latency\_50pct | type=all | Gauge | The time it took, in milliseconds, to answer HTTP requests for the 50th percentile cases |
| tsd.http.latency\_75pct | type=all | Gauge | The time it took, in milliseconds, to answer HTTP requests for the 75th percentile cases |
| tsd.http.latency\_90pct | type=all | Gauge | The time it took, in milliseconds, to answer HTTP requests for the 90th percentile cases |
| tsd.http.latency\_95pct | type=all | Gauge | The time it took, in milliseconds, to answer HTTP requests for the 95th percentile cases |
| tsd.http.latency\_50pct | type=graph | Gauge | The time it took, in milliseconds, to answer graphing requests for the 50th percentile cases |
| tsd.http.latency\_75pct | type=graph | Gauge | The time it took, in milliseconds, to answer graphing requests for the 75th percentile cases |
| tsd.http.latency\_90pct | type=graph | Gauge | The time it took, in milliseconds, to answer graphing requests for the 90th percentile cases |
| tsd.http.latency\_95pct | type=graph | Gauge | The time it took, in milliseconds, to answer graphing requests for the 95th percentile cases |
| tsd.http.latency\_50pct | type=gnuplot | Gauge | The time it took, in milliseconds, to generate the GnuPlot graphs for the 50th percentile cases |
| tsd.http.latency\_75pct | type=gnuplot | Gauge | The time it took, in milliseconds, to generate the GnuPlot graphs for the 75th percentile cases |
| tsd.http.latency\_90pct | type=gnuplot | Gauge | The time it took, in milliseconds, to generate the GnuPlot graphs for the 90th percentile cases |
| tsd.http.latency\_95pct | type=gnuplot | Gauge | The time it took, in milliseconds, to generate the GnuPlot graphs for the 95th percentile cases |
| tsd.http.graph.requests | cache=disk | Counter | The total number of graph requests satisfied from the disk cache |
| tsd.http.graph.requests | cache=miss | Counter | The total number of graph requests that were not cached and required a fetch from storage |
| tsd.http.query.invalid\_requests | | Counter | The total number data queries sent to the /api/query endpoint that were invalid due to user errors such as using the wrong HTTP method, missing parameters or using metrics and tags without UIDs. (v2.2) |
| tsd.http.query.exceptions | | Counter | The total number data queries sent to the /api/query endpoint that threw an exception due to bad user input or an underlying error. See logs for details. (v2.2) |
| tsd.http.query.success | | Counter | The total number data queries sent to the /api/query endpoint that completed successfully. Note that these may have returned an empty result. (v2.2) |
| tsd.rpc.received | type=put | Counter | The total number of `put` requests for writing data points |
| tsd.rpc.errors | type=hbase\_errors | Counter | The total number of RPC errors caused by HBase exceptions |
| tsd.rpc.errors | type=invalid\_values | Counter | The total number of RPC errors caused invalid `put` values from user requests, such as a string instead of a number |
| tsd.rpc.errors | type=illegal\_arguments | Counter | The total number of RPC errors caused by bad data from the user |
| tsd.rpc.errors | type=socket\_writes\_blocked | Counter | The total number of times the TSD was unable to write back to the telnet socket due to a full buffer. If this happens it likely means a number of exceptions were happening. (v2.2) |
| tsd.rpc.errors | type=unknown\_metrics | Counter | The total number of RPC errors caused by attempts to `put` a metric without an assigned UID. This only increments if *auto metrics* is disabled. |
| tsd.uid.cache-hit | kind=metrics | Counter | The total number of successful cache lookups for metric UIDs |
| tsd.uid.cache-miss | kind=metrics | Counter | The total number of failed cache lookups for metric UIDs that required a call to storage |
| tsd.uid.cache-size | kind=metrics | Gauge | The current number of cached metric UIDs |
| tsd.uid.ids-used | kind=metrics | Counter | The current number of assigned metric UIDs. (NOTE: if random metric UID generation is enabled ids-used will always be 0) |
| tsd.uid.ids-available | kind=metrics | Counter | The current number of available metric UIDs, decrements as UIDs are assigned. (NOTE: if random metric UID generation is enabled ids-used will always be 0) |
| tsd.uid.random-collisions | kind=metrics | Counter | How many times metric UIDs attempted a reassignment due to a collision with an existing UID. (v2.2) |
| tsd.uid.cache-hit | kind=tagk | Counter | The total number of successful cache lookups for tagk UIDs |
| tsd.uid.cache-miss | kind=tagk | Counter | The total number of failed cache lookups for tagk UIDs that required a call to storage |
| tsd.uid.cache-size | kind=tagk | Gauge | The current number of cached tagk UIDs |
| tsd.uid.ids-used | kind=tagk | Counter | The current number of assigned tagk UIDs |
| tsd.uid.ids-available | kind=tagk | Counter | The current number of available tagk UIDs, decrements as UIDs are assigned. |
| tsd.uid.cache-hit | kind=tagv | Counter | The total number of successful cache lookups for tagv UIDs |
| tsd.uid.cache-miss | kind=tagv | Counter | The total number of failed cache lookups for tagv UIDs that required a call to storage |
| tsd.uid.cache-size | kind=tagv | Gauge | The current number of cached tagv UIDs |
| tsd.uid.ids-used | kind=tagv | Counter | The current number of assigned tagv UIDs |
| tsd.uid.ids-available | kind=tagv | Counter | The current number of available tagv UIDs, decrements as UIDs are assigned. |
| tsd.jvm.ramfree | | Gauge | The number of bytes reported as free by the JVM's Runtime.freeMemory() |
| tsd.jvm.ramused | | Gauge | The number of bytes reported as used by the JVM's Runtime.totalMemory() |
| tsd.hbase.latency\_50pct | method=put | Gauge | The time it took, in milliseconds, to execute a Put call for the 50th percentile cases |
| tsd.hbase.latency\_75pct | method=put | Gauge | The time it took, in milliseconds, to execute a Put call for the 75th percentile cases |
| tsd.hbase.latency\_90pct | method=put | Gauge | The time it took, in milliseconds, to execute a Put call for the 90th percentile cases |
| tsd.hbase.latency\_95pct | method=put | Gauge | The time it took, in milliseconds, to execute a Put call for the 95th percentile cases |
| tsd.hbase.latency\_50pct | method=scan | Gauge | The time it took, in milliseconds, to execute a Scan call for the 50th percentile cases |
| tsd.hbase.latency\_75pct | method=scan | Gauge | The time it took, in milliseconds, to execute a Scan call for the 75th percentile cases |
| tsd.hbase.latency\_90pct | method=scan | Gauge | The time it took, in milliseconds, to execute a Scan call for the 90th percentile cases |
| tsd.hbase.latency\_95pct | method=scan | Gauge | The time it took, in milliseconds, to execute a Scan call for the 95th percentile cases |
| tsd.hbase.root\_lookups | | Counter | The total number of root lookups performed by the client |
| tsd.hbase.meta\_lookups | type=uncontended | Counter | The total number of uncontended meta table lookups performed by the client |
| tsd.hbase.meta\_lookups | type=contended | Counter | The total number of contended meta table lookups performed by the client |
| tsd.hbase.rpcs | type=increment | Counter | The total number of Increment requests performed by the client |
| tsd.hbase.rpcs | type=delete | Counter | The total number of Delete requests performed by the client |
| tsd.hbase.rpcs | type=get | Counter | The total number of Get requests performed by the client |
| tsd.hbase.rpcs | type=put | Counter | The total number of Put requests performed by the client |
| tsd.hbase.rpcs | type=rowLock | Counter | The total number of Row Lock requests performed by the client |
| tsd.hbase.rpcs | type=openScanner | Counter | The total number of Open Scanner requests performed by the client |
| tsd.hbase.rpcs | type=scan | Counter | The total number of Scan requests performed by the client. These indicate a scan->next() call. |
| tsd.hbase.rpcs.batched | | Counter | The total number of batched requests sent by the client |
| tsd.hbase.flushes | | Counter | The total number of flushes performed by the client |
| tsd.hbase.connections.created | | Counter | The total number of connections made by the client to region servers |
| tsd.hbase.nsre | | Counter | The total number of No Such Region Exceptions caught. These can happen when a region server crashes, is taken offline or when a region splits (?) |
| tsd.hbase.rpcs.rpcs\_delayed | | Counter | The total number of calls delayed due to an NSRE that were later successfully executed |
| tsd.hbase.rpcs.region\_clients.open | | Counter | The total number of connections opened to region servers since the TSD started. If this number is climbing the region servers may be crashing and restarting. (v2.2) |
| tsd.hbase.rpcs.region\_clients.idle\_closed | | Counter | The total number of connections to region servers that were closed due to idle connections. This indicates nothing was read from or written to a server in some time and the TSD will reconnect when it needs to. (v2.2) |
| tsd.compaction.count | type=trivial | Counter | The total number of trivial compactions performed by the TSD |
| tsd.compaction.count | type=complex | Counter | The total number of complex compactions performed by the TSD |
| tsd.compaction.duplicates | type=identical | Counter | The total number of data points found during compaction that were duplicates at the same time and with the same value. (v2.2) |
| tsd.compaction.duplicates | type=variant | Counter | The total number of data points found during compaction that were duplicates at the same time but with a different value. (v2.2) |
| tsd.compaction.queue.size | | Gauge | How many rows of data are currently in the queue to be compacted. (v2.2) |
| tsd.compaction.errors | type=read | Counter | The total number of rows that couldn't be read from storage due to an error of some sort. (v2.2) |
| tsd.compaction.errors | type=put | Counter | The total number of rows that couldn't be re-written to storage due to an error of some sort. (v2.2) |
| tsd.compaction.errors | type=delete | Counter | The total number of rows that couldn't have the old non-compacted data deleted from storage due to an error of some sort. (v2.2) |
| tsd.compaction.writes | type=read | Counter | The total number of writes back to storage of compacted values. (v2.2) |
| tsd.compaction.deletes | type=read | Counter | The total number of delete calls made to storage to remove old data that has been compacted. (v2.2) |
| programming_docs |
opentsdb User Guide User Guide
==========
These pages serve as a user and administration guide. We highly recommend that you start with the `writing` and [*Querying or Reading Data*](query/index) sections to understand how OpenTSDB handles its core purpose of storing and serving time series information. Then follow up with the [*Quick Start*](quickstart) section to play around with getting some data into your OpenTSDB instance. Finally follow up with the other pages for details on the other features of OpenTSDB.
* [Configuration](configuration)
* [Writing Data](writing/index)
* [Querying or Reading Data](query/index)
* [Rollup And Pre-Aggregates](rollups)
* [UIDs and TSUIDs](uids)
* [Metadata](metadata)
* [Trees](trees)
* [GUI](guis/index)
* [Plugins](plugins)
* [Stats](stats)
* [Definitions](definitions)
* [Storage](backends/index)
* [CLI Tools](cli/index)
* [Utilities](utilities/index)
* [Logging](logging)
* [Troubleshooting](troubleshooting)
opentsdb UIDs and TSUIDs UIDs and TSUIDs
===============
In OpenTSDB, when you write a timeseries data point, it is always associated with a metric and at least one tag name/value pair. Each metric, tag name and tag value is assigned a unique identifier (UID) the first time it is encountered or when explicitly assigned via the API or a CLI tool. The combination of metric and tag name/value pairs create a timeseries UID or TSUID.
UID
---
Types of UID objects include:
* **metric** - A metric such as `sys.cpu.0` or `trades.per.second`
* **tagk** - A tag name such as `host` or `symbol`. This is always the "key" (the first value) in a tag key/value pair.
* **tagv** - A tag value such as `web01` or `goog`. This is always the "value" (the second value) in a tag key/value pair.
### Assignment
The UID is a positive integer that is unique to the name of the UID object and it's type. Within the storage system there is a counter that is incremented for each `metric`, `tagk` and `tagv`. When you create a new `tsdb-uid` table, this counter is set to 0 for each type. So if you put a new data point with a metric of `sys.cpu.0` and a tag pair of `host=web01` you will have 3 new UID objects, each with a UID of 1.
UIDs are assigned automatically for new `tagk` and `tagv` objects when data points are written to a TSD. `metric` objects also receive new UIDs but only if the *auto metric* setting has been configured to `true`. Otherwise data points with new metrics are rejected. The UIDs are looked up in a cached map for every incoming data point. If the lookup fails, then the TSD will attempt to assign a new UID.
### Storage
By default, UIDs are encoded on 3 bytes in storage, giving a maximum unique ID of 16,777,215 for each UID type. This is done to reduce the amount of space taken up in storage and to reduce the memory footprint of a TSD. For the vast majority of users, 16 million unique metrics, 16 million unique tag names and 16 million unique tag values should be enough. But if you do need more of a particular type, you can modify the OpenTSDB source code and recompile with 4 bytes or more. As of version 2.2 you can override the UID size via the config file.
Warning
If you do adjust the byte encoding number, you must start with a fresh `tsdb` and fresh `tsdb-uid` table, otherwise the results will be unexpected. If you have data in an existing setup, you must export it, drop all tables, create them from scratch and re-import the data.
### Display
UIDs can be displayed in a few ways. The most common method is via the HTTP API where the 3 bytes of UID data are encoded as a hexadecimal string. For example, the UID of `1` would be written in binary as `000000000000000000000001`. As an array of unsigned byte values, you could imagine it as `[0, 0, 1]`. Encoded as a hex string, the value would be `000001` where the string is padded with 0s for each byte. The UID of 255 would result in a hex value of `0000FF` (or as a byte array, `[0, 0, 255]`. To convert between a decimal UID to a hex, use any kind of hex conversion tool you prefer and put 0s in front of the resulting value until you have a total of 6 characters. To convert from a hex UID to decimal, simply drop any 0s from the front, then use a tool to convert the hex string to a decimal.
In some CLI tools and log files, a UID may be displayed as an array of signed bytes (thanks to Java) such as the above example of `[0, 0, 1]` or `[0, 0, -28]`. To convert from this signed array to an an array of unsigned bytes, then to hex. For example, `-28` would be binary `10011100` which results in a decimal value of `156` and a hex value of `9C`.
### Modification
UIDs can be renamed or deleted. Renaming can be accomplished via the CLI and is generally safe but will affect EVERY time series that includes the renamed ID. E.g. if we have a series `sys.cpu.user host=web01` and another `apache.requests host=web01` and rename the `web01` tag value to `web01.mysite.org`, then both series will now reflect the new host name and all queries referring to the old name must be updated.. If a data point comes in that has the previous string, a new UID will be assigned.
Deleting UIDs can be tricky as of version 2.2. Deleting a metric is safe in that users may no longer query for the data and it won't show up in calls to the suggest API. However deleting a tag name or value can cause queries to fail. E.g. if you have time series for the metric `sys.cpu.user` with hosts `web01`, `web02`, `web03`, etc. and you delete the UID for `web02`, any query that would scan over data that includes the series `sys.cpu.user host=web02` will throw an exception to the user because the data remains in storage. We highly recommend you run an FSCK with a query to repair such issues.
### Why UIDs?
This question is asked often enough it's worth laying out the reasons here. Looking up or assigning a UID takes up precious cycles in the TSD so folks wonder if it wouldn't be faster to use the raw name of the metric or computer a hash. Indeed, from a write perspective it would be slightly faster, but there are a number of drawbacks that become apparent.
Raw Names
---------
Since OpenTSDB uses HBase as the storage layer, you could use strings as the row key. Following the current schema, you may have a row key that looked like `sys.cpu.0.user 1292148000 host=websv01.lga.mysite.com owner=operations`. Ordering would be similar to the existing schema, but now you're using up 70 bytes of storage each hour instead of 19. Additionally, the row key must be written and returned with every query to HBase, so you're increasing your network usage as well. So resorting to UIDs can help save space.
Hashes
------
Another idea is to simply bump up the UIDs to 4 bytes then calculate a hash on the strings and store the hash with forward and reverse maps as we currently do. This would certainly reduce the amount of time it takes to assign a UID, but there are a few problems. First, you will encounter collisions where different names return the same hash. You could try different algorithms and even try increasing the hash to 8 bytes, but you'll always have the issue of colliding hashes. Second, you are now adding a hash calculation to every data put since it would have to determine the hash, then lookup the hash in the UID table to see if it's been mapped yet. Right now, each data point only performs the lookup. Third, you can't pre-split your HBase regions as easily. If you know you will have roughly 800 metrics in your system (the tags are irrelevant for this purpose), you can pre-split your HBase table to evenly distribute those 800 metrics and increase your initial write performance.
TSUIDs
------
When a data point is written to OpenTSDB, the row key is formatted as `<metric\_UID><timestamp><tagk1\_UID><tagv1\_UID>[...<tagkN\_UID><tagvN\_UID>]`. By simply dropping the timestamp from the row key, we have a long array of UIDs that combined, form a unique timeseries ID. Encoding the bytes as a hex string will give us a useful TSUID that can be passed around various API calls. Thus from our UID example above where each metric, tag name and value has a UID of 1, our TSUID, encoded as a hexadecimal string, would be `000001000001000001`.
While this TSUID format may be long and ugly, particularly with all of the 0s for early UIDs, there are a few reasons why this is useful:
* If you know the width of each UID (by default 3 bytes as stated above), then you can easily parse the UID for each metric, tag name and value from the UID string.
* Assigning a unique numeric ID for each timeseries creates issues with lock contention and/or synchronization issues where a timeseries may be missed if the UID could not be incremented.
opentsdb Definitions Definitions
===========
When it comes to timeseries data, there are lots of terms tossed about that can lead to some confusion. This page is a sort of glossary that helps to define words related to the use of OpenTSDB.
Cardinality
-----------
Cardinality is a mathematical term defined as the number of elements in a set. In database lingo, it's often used to refer to the number of unique items in an index. With regards to OpenTSDB it can refer to:
* The number of unique time series for a given metric
* The number of unique tag values associated with a tag name
Due to the nature of the OpenTSDB storage schema, metrics with higher cardinality may take longer return results during query execution than those with lower cardinality. E.g. we may have metric `foo` with the tag name `datacenter` and there are 100 possible values for datacenter. Then we have metric `bar` with the tag `host` and 50,000 possible values for host. Metric `bar` has a higher cardinality than `foo`: 50,000 possible time series for `bar` an only 100 for `foo`.
Compaction
----------
An OpenTSDB compaction takes multiple columns in an HBase row and merges them into a single column to reduce disk space. This is not to be confused with HBase compactions where multiple edits to a region are merged into one. OpenTSDB compactions can occur periodically for a TSD after data has been written, or during a query.
Data Point
----------
Each of the metrics above can be recorded as a number at a specific time. For example, we could record that Sue worked 8 hours at the end of each day. Or that "mylogo.jpg" was downloaded 400 times in the past hour. Thus a datapoint consists of:
* A metric
* A numeric value
* A timestamp when the value was recorded
* One or more sets of tags
Metric
------
A metric is simply the name of a quantitative measurement. Metrics include things like:
* hours worked by an employee
* webserver downloads of a file
* snow accumulation in a region
Note
Notice that the `metric` did not include a specific number or a time. That is becaue a `metric` is just a label of what you are measuring. The actual measurements are called `datapoints`, as you'll see later.
Unfortunately OpenTSDB requires metrics to be named as a single, long word without spaces. Thus metrics are usually recorded using "dotted notation". For example, the metrics above would have names like:
* hours.worked
* webserver.downloads
* accumulation.snow
Tags
----
A `metric` should be descriptive of what is being measured, but with OpenTSDB, it should not be too specific. Instead, it is better to use `tags` to differentiate and organize different items that may share a common metric. Tags are pairs of words that provide a means of associating a metric with a specific item. Each pair consists of a `tagk` that represents the group or category of the following `tagv` that represents a specific item, object, location or other noun.
Expanding on the metric examples above:
* A business may have four employees, Sue, John, Kelly and Paul. Therefore we may configure a `tagk` of `employee` with their names as the `tagv`. These would be recorded as `employee=sue`, `employee=john` etc.
* Webservers usually have many files so we could have a `tagk` of `file` to arrive at `file=logo.jpg` or `file=index.php`
* Snow falls in many regions so we may record a `tagk` of `region` to get `region=new\_england` or `region=north\_west`
Time Series
-----------
A collection of two or more data points for a single metric and group of tag name/value pairs.
Timestamp
---------
Timestamps are simply the absolute time when a value for a given metric was recorded.
Value
-----
A value represents the actual numeric measurement of the given metric. One of our employees, Sue, worked 8 hours yesterday, thus the value would be `8`. There were 1,024 downloads of `logo.jpg` from our webserver in the past hour. And 12 inches of snow fell in New England today.
opentsdb Configuration Configuration
=============
OpenTSDB can be configured via a file on the local system, via command line arguments or a combination or both.
Configuration File
------------------
The configuration file conforms to the Java properties specification. Configuration names are lower-case, dotted strings without spaces. Each name is followed by an equals sign, then the value for the property. All OpenTSDB properties start with `tsd.` Comments or inactive configuration lines are blocked by a hash symbol `#`. For example:
```
# List of Zookeeper hosts that manage the HBase cluster
tsd.storage.hbase.zk_quorum = 192.168.1.100
```
will configure the TSD to connect to Zookeeper on `192.168.1.100`.
When combining configuration files and command line arguments, the order of processing is as follows:
1. Default values are loaded
2. Configuration file values are loaded, overriding default values
3. Command line parameters are loaded, overriding config file and default values
File Locations
--------------
You can use the `--config` command line argument to specify the full path to a configuration file. Otherwise if not specified, OpenTSDB and some of the command-line tools will attempt to search for a valid configuration file in the following locations:
* ./opentsdb.conf
* /etc/opentsdb.conf
* /etc/opentsdb/opentsdb.conf
* /opt/opentsdb/opentsdb.conf
In the event that a valid configuration file cannot be found and the required properties are not set, the TSD will not start. Please see the properties table below for a list of required configuration settings.
Properties
----------
The following is a table of configuration options for all tools. When applicable, the corresponding command line override is provided. Please note that individual command line tools may have their own values so see their documentation for details.
Note
For additional parameters used for tuning the AsyncHBase client, see [AsyncHBase Configuration](http://opentsdb.github.io/asynchbase/docs/build/html/configuration.html)
| Property | Type | Required | Description | Default | CLI |
| --- | --- | --- | --- | --- | --- |
| tsd.core.auto\_create\_metrics | Boolean | Optional | Whether or not a data point with a new metric will assign a UID to the metric. When false, a data point with a metric that is not in the database will be rejected and an exception will be thrown. | False | --auto-metric |
| tsd.core.auto\_create\_tagks *(2.1)* | Boolean | Optional | Whether or not a data point with a new tag name will assign a UID to the tagk. When false, a data point with a tag name that is not in the database will be rejected and an exception will be thrown. | True | |
| tsd.core.auto\_create\_tagvs *(2.1)* | Boolean | Optional | Whether or not a data point with a new tag value will assign a UID to the tagv. When false, a data point with a tag value that is not in the database will be rejected and an exception will be thrown. | True | |
| tsd.core.connections.limit *(2.3)* | Integer | Optional | Sets the maximum number of connections a TSD will handle, additional connections are immediately closed. | 0 | |
| tsd.core.enable\_api *(2.3)* | Boolean | Optional | Whether or not to allow the 2.x HTTP API to function. When disabled, calls to endpoints such as `/api/query` or `/api/suggest` will return a 404. | True | --disable-api |
| tsd.core.enable\_ui *(2.3)* | Boolean | Optional | Whether or not to allow the built-in GUI and legacy HTTP API to function. When disabled, calls to the root endpoint or other such as `/logs` or `/suggest` will return a 404. | True | --disable-ui |
| tsd.core.meta.enable\_realtime\_ts | Boolean | Optional | Whether or not to enable real-time TSMeta object creation. See [*Metadata*](metadata) | False | |
| tsd.core.meta.enable\_realtime\_uid | Boolean | Optional | Whether or not to enable real-time UIDMeta object creation. See [*Metadata*](metadata) | False | |
| tsd.core.meta.enable\_tsuid\_incrementing | Boolean | Optional | Whether or not to enable tracking of TSUIDs by incrementing a counter every time a data point is recorded. See [*Metadata*](metadata) (Overrides "tsd.core.meta.enable\_tsuid\_tracking") | False | |
| tsd.core.meta.enable\_tsuid\_tracking | Boolean | Optional | Whether or not to enable tracking of TSUIDs by storing a `1` with the current timestamp every time a data point is recorded. See [*Metadata*](metadata) | False | |
| tsd.core.plugin\_path | String | Optional | A path to search for plugins when the TSD starts. If the path is invalid, the TSD will fail to start. Plugins can still be enabled if they are in the class path. | | |
| tsd.core.preload\_uid\_cache *(2.1)* | Boolean | Optional | Enables pre-population of the UID caches when starting a TSD. | False | |
| tsd.core.preload\_uid\_cache.max\_entries *(2.1)* | Integer | Optional | The number of rows to scan for UID pre-loading. | 300,000 | |
| tsd.core.storage\_exception\_handler.enable *(2.2)* | Boolean | Optional | Whether or not to enable the configured storage exception handler plugin. | False | |
| tsd.core.storage\_exception\_handler.plugin *(2.2)* | String | Optional | The full class name of the storage exception handler plugin you wish to use. | | |
| tsd.core.timezone | String | Optional | A localized timezone identification string used to override the local system timezone used when converting absolute times to UTC when executing a query. This does not affect incoming data timestamps. E.g. America/Los\_Angeles | System Configured | |
| tsd.core.tree.enable\_processing | Boolean | Optional | Whether or not to enable processing new/edited TSMeta through tree rule sets | false | |
| tsd.core.uid.random\_metrics *(2.2)* | Boolean | Optional | Whether or not to randomly assign UIDs to new metrics as they are created | false | |
| tsd.core.bulk.allow\_out\_of\_order\_timestamps [\*](#id1)(2.3) | Boolean | Optional | Whether or not to allow out-of-order values when bulk importing data from a text file. | false | |
| tsd.http.cachedir | String | Required | The full path to a location where temporary files can be written. E.g. /tmp/opentsdb | | --cachedir |
| tsd.http.query.allow\_delete | Boolean | Optional | Whether or not to allow deleting data points from storage during query time. | False | |
| tsd.query.enable\_fuzzy\_filter | Boolean | Optional | Whether or not to enable the FuzzyRowFilter for HBase when making queries using the `explicitTags` flag. | True | |
| tsd.http.request.cors\_domains | String | Optional | A comma separated list of domain names to allow access to OpenTSDB when the `Origin` header is specified by the client. If empty, CORS requests are passed through without validation. The list may not contain the public wildcard `\*` and specific domains at the same time. | | |
| tsd.http.request.cors\_headers *(2.1)* | String | Optional | A comma separated list of headers sent to clients when executing a CORs request. The literal value of this option will be passed to clients. | Authorization, Content-Type, Accept, Origin, User-Agent, DNT, Cache-Control, X-Mx-ReqToken, Keep-Alive, X-Requested-With, If-Modified-Since | |
| tsd.http.request.enable\_chunked | Boolean | Optional | Whether or not to enable incoming chunk support for the HTTP RPC | false | |
| tsd.http.request.max\_chunk | Integer | Optional | The maximum request body size to support for incoming HTTP requests when chunking is enabled. | 4096 | |
| tsd.http.rpc.plugins *(2.2)* | String | Optional | A comma delimited list of RPC plugins to load when starting a TSD. Must contain the entire class name. | | |
| tsd.http.show\_stack\_trace | Boolean | Optional | Whether or not to return the stack trace with an API query response when an exception occurs. | false | |
| tsd.http.staticroot | String | Required | Location of a directory where static files, such as JavaScript files for the web interface, are located. E.g. /opt/opentsdb/staticroot | | --staticroot |
| tsd.mode *(2.1)* | String | Optional | Whether or not the TSD will allow writing data points. Must be either `rw` to allow writing data or `ro` to block data point writes. Note that meta data such as UIDs can still be written/modified. | rw | |
| tsd.network.async\_io | Boolean | Optional | Whether or not to use NIO or traditional blocking IO | True | --async-io |
| tsd.network.backlog | Integer | Optional | The connection queue depth for completed or incomplete connection requests depending on OS. The default may be limited by the 'somaxconn' kernel setting or set by Netty to 3072. | See Description | --backlog |
| tsd.network.bind | String | Optional | An IPv4 address to bind to for incoming requests. The default is to listen on all interfaces. E.g. 127.0.0.1 | 0.0.0.0 | --bind |
| tsd.network.keep\_alive | Boolean | Optional | Whether or not to allow keep-alive connections | True | |
| tsd.network.port | Integer | Required | The TCP port to use for accepting connections | | --port |
| tsd.network.reuse\_address | Boolean | Optional | Whether or not to allow reuse of the bound port within Netty | True | |
| tsd.network.tcp\_no\_delay | Boolean | Optional | Whether or not to disable TCP buffering before sending data | True | |
| tsd.network.worker\_threads | Integer | Optional | The number of asynchronous IO worker threads for Netty | *#CPU cores \* 2* | --worker-threads |
| tsd.no\_diediedie *(2.1)* | Boolean | Optional | Enable or disable the `diediedie` HTML and ASCII commands to shutdown a TSD. | False | |
| tsd.query.allow\_simultaneous\_duplicates *(2.2)* | Boolean | Optional | Whether or not to allow simultaneous duplicate queries from the same host. If disabled, a second query that comes in matching one already running will receive an exception. | False | |
| tsd.query.filter.expansion\_limit *(2.2)* | Integer | Optional | The maximum number of tag values to include in the regular expression sent to storage during scanning for data. A larger value means more computation on the HBase region servers. | 4096 | |
| tsd.query.skip\_unresolved\_tagvs *(2.2)* | Boolean | Optional | Whether or not to continue querying when the query includes a tag value that hasn't been assigned a UID yet and may not exist. | False | |
| tsd.query.timeout *(2.2)* | Integer | Optional | How long, in milliseconds, before canceling a running query. A value of 0 means queries will not timeout. | 0 | |
| tsd.rollups.enable *(2.4)* | Boolean | Optional | Whether or not to enable rollup and pre-aggregation storage and writing. | false | |
| tsd.rollups.tag\_raw *(2.4)* | Boolean | Optional | Whether or not to tag non-rolled-up and non-pre-aggregated values with the tag key configured in `tsd.rollups.agg\_tag\_key` and value configured in `tsd.rollups.raw\_agg\_tag\_value` | false | |
| tsd.rollups.agg\_tag\_key *(2.4)* | String | Optional | A special key to tag pre-aggregated data with when writing to storage | \_aggregate | |
| tsd.rollups.raw\_agg\_tag\_value *(2.4)* | String | Optional | A special tag value to non-rolled-up and non-pre-aggregated data with when writing to storage. `tsd.rollups.tag\_raw` must be set to true. | RAW | |
| tsd.rollups.block\_derived *(2.4)* | Boolean | Optional | Whether or not to block storing derived aggregations such as `AVG` and `DEV`. | true | |
| tsd.rpc.plugins | String | Optional | A comma delimited list of RPC plugins to load when starting a TSD. Must contain the entire class name. | | |
| tsd.rpc.telnet.return\_errors *(2.4)* | Boolean | Optional | Whether or not to return errors to the Telnet style socket when writing data via `put` or `rollup` | true | |
| tsd.rtpublisher.enable | Boolean | Optional | Whether or not to enable a real time publishing plugin. If true, you must supply a valid `tsd.rtpublisher.plugin` class name | False | |
| tsd.rtpublisher.plugin | String | Optional | The class name of a real time publishing plugin to instantiate. If `tsd.rtpublisher.enable` is set to false, this value is ignored. E.g. net.opentsdb.tsd.RabbitMQPublisher | | |
| tsd.search.enable | Boolean | Optional | Whether or not to enable search functionality. If true, you must supply a valid `tsd.search.plugin` class name | False | |
| tsd.search.plugin | String | Optional | The class name of a search plugin to instantiate. If `tsd.search.enable` is set to false, this value is ignored. E.g. net.opentsdb.search.ElasticSearch | | |
| tsd.stats.canonical | Boolean | Optional | Whether or not the FQDN should be returned with statistics requests. The default stats are returned with `host=<hostname>` which is not guaranteed to perform a lookup and return the FQDN. Setting this to true will perform a name lookup and return the FQDN if found, otherwise it may return the IP. The stats output should be `fqdn=<hostname>` | false | |
| tsd.storage.compaction.flush\_interval *(2.2)* | Integer | Optional | How long, in seconds, to wait in between compaction queue flush calls | 10 | |
| tsd.storage.compaction.flush\_speed *(2.2)* | Integer | Optional | A multiplier used to determine how quickly to attempt flushing the compaction queue. E.g. a value of 2 means it will try to flush the entire queue within 30 minutes. A value of 1 would take an hour. | 2 | |
| tsd.storage.compaction.max\_concurrent\_flushes *(2.2)* | Integer | Optional | The maximum number of compaction calls inflight to HBase at any given time | 10000 | |
| tsd.storage.compaction.min\_flush\_threshold *(2.2)* | Integer | Optional | Size of the compaction queue that must be exceeded before flushing is triggered | 100 | |
| tsd.storage.enable\_appends *(2.2)* | Boolean | Optional | Whether or not to append data to columns when writing data points instead of creating new columns for each value. Avoids the need for compactions after each hour but can use more resources on HBase. | False | |
| tsd.storage.enable\_compaction | Boolean | Optional | Whether or not to enable compactions | True | |
| tsd.storage.fix\_duplicates *(2.1)* | Boolean | Optional | Whether or not to accept the last written value when parsing data points with duplicate timestamps. When enabled in conjunction with compactions, a compacted column will be written with the latest data points. | False | |
| tsd.storage.flush\_interval | Integer | Optional | How often, in milliseconds, to flush the data point storage write buffer | 1000 | --flush-interval |
| tsd.storage.hbase.data\_table | String | Optional | Name of the HBase table where data points are stored | tsdb | --table |
| tsd.storage.hbase.meta\_table | String | Optional | Name of the HBase table where meta data are stored | tsdb-meta | |
| tsd.storage.hbase.prefetch\_meta *(2.2)* | Boolean | Optional | Whether or not to prefetch the regions for the TSDB tables before starting the network interface. This can improve performance. | False | |
| tsd.storage.hbase.tree\_table | String | Optional | Name of the HBase table where tree data are stored | tsdb-tree | |
| tsd.storage.hbase.uid\_table | String | Optional | Name of the HBase table where UID information is stored | tsdb-uid | --uidtable |
| tsd.storage.hbase.zk\_basedir | String | Optional | Path under which the znode for the -ROOT- region is located | /hbase | --zkbasedir |
| tsd.storage.hbase.zk\_quorum | String | Optional | A comma-separated list of ZooKeeper hosts to connect to, with or without port specifiers. E.g. `192.168.1.1:2181,192.168.1.2:2181` | localhost | --zkquorum |
| tsd.storage.repair\_appends *(2.2)* | Boolean | Optional | Whether or not to re-write appended data point columns at query time when the columns contain duplicate or out of order data. | False | |
| tsd.storage.max\_tags *(2.2)* | Integer | Optional | The maximum number of tags allowed per data point. **NOTE** Please be aware of the performance tradeoffs of overusing tags `writing` | 8 | |
| tsd.storage.salt.buckets *(2.2)* | Integer | Optional | The number of salt buckets used to distribute load across regions. **NOTE** Changing this value after writing data may cause TSUID based queries to fail. | 20 | |
| tsd.storage.salt.width *(2.2)* | Integer | Optional | The width, in bytes, of the salt prefix used to indicate which bucket a time series belongs in. A value of 0 means salting is disabled. **WARNING** Do not change after writing data to HBase or you will corrupt your tables and not be able to query any more. | 0 | |
| tsd.storage.uid.width.metric *(2.2)* | Integer | Optional | The width, in bytes, of metric UIDs. **WARNING** Do not change after writing data to HBase or you will corrupt your tables and not be able to query any more. | 3 | |
| tsd.storage.uid.width.tagk *(2.2)* | Integer | Optional | The width, in bytes, of tag name UIDs. **WARNING** Do not change after writing data to HBase or you will corrupt your tables and not be able to query any more. | 3 | |
| tsd.storage.uid.width.tagv *(2.2)* | Integer | Optional | The width, in bytes, of tag value UIDs. **WARNING** Do not change after writing data to HBase or you will corrupt your tables and not be able to query any more. | 3 | |
Data Types
----------
Some configuration values require special consideration:
* Booleans - The following literals will parse to `True`:
+ `1`
+ `true`
+ `yes`Any other values will result in a `False`. Parsing is case insensitive
* Strings - Strings, even those with spaces, do not require quotation marks, but some considerations apply:
+ Special characters must be escaped with a backslash include: `#`, `!`, `=`, and `:` E.g.:
```
my.property = Hello World\!
```
+ Unicode characters must be escaped with their hexadecimal representation, e.g.:
```
my.property = \u0009
```
| programming_docs |
opentsdb Trees Trees
=====
Along with metadata, OpenTSDB 2.0 introduces the concept of **trees**, a hierarchical method of organizing timeseries into an easily navigable structure that can be browsed similar to a file system on a computer. Users can define a number of trees with various rule sets that organize TSMeta objects into a tree structure. Then users can browse the resulting tree via an HTTP API endpoint. See [*/api/tree*](../api_http/tree/index) for details.
Tree Terminology
----------------
* **Branch** - Each branch is one node of a tree. It contains a list of child branches and leaves as well as a list of parent branches.
* **Leaf** - The end of a branch and represents a unique timeseries. The leaf will contain a TSUID value that can be used to generate a TSD query. A branch can, and likely will, have multiple leaves
* **Root** - The root branch is the start of the tree and all branches reach out from this root. It has a depth of 0.
* **Depth** - Each time a branch is added to another branch, the depth increases
* **Strict Matching** - When enabled, a timeseries must match a rule in every level of the rule set. If one or more levels fail to match, the timeseries will not be included in the tree.
* **Path** - The name and level of each branch above the current branch in the hierarchy.
Branch
------
Each node of a tree is recorded as a *branch* object. Each branch contains information such as:
* **Branch ID** - The ID of the branch. This is a hexadecimal value described below.
* **Display Name** - A name for the branch, parsed from a TSMeta object by the tree rule set.
* **Depth** - How deep within the hierarchy the branch resides.
* **Path** - The depth and name of each parent branch (includes the local branch).
* **Branches** - Child branches one depth level below this branch.
* **Leaves** - Leaves that belong to this branch.
Navigating a tree starts at the **root** branch which always has an ID that matches the ID of the tree the branch belongs to. The root should have one or more child branches that can be used to navigate down one level of the tree. Each child can be used to navigate to their children and so on. The root does not have any parent branches and is always at a depth of 0. If a tree has just been defined or enabled, it may not have a root branch yet, and by extension, there won't be any child branches.
Each branch will often have a list of child branches. However if a branch is at the end of a path, it may not have any child branches, but it should have a list of leaves.
### Branch IDs and Paths
Branch IDs are hexadecimal encoded byte arrays similar to TSUIDs but with a different format. Branch IDs always start with the ID of the tree encoded on 2 bytes. Root branches have a branch ID equal to the tree ID. Thus the root for tree `1` would have a branch ID of `0001`.
Each child branch has a `DisplayName` value and the hash of this value is used to generate a 32 bit integer ID for the branch. The hash function used is the Java `java.lang.String` hash function. The 4 bytes of the integer value are then encoded to 8 hexadecimal characters. For example, if we have a display name of `sys` for a branch, the hash returned will be 102093. The TSD will convert that value to hexadecimal `0001BECD`.
A branch ID is composed of the tree ID concatenated with the ID of each parent above the current branch, concatenated with the ID of the current branch. Thus, if our child branch `sys` is a child of the root, we would have a branch ID of `00010001BECD`.
Lets say there is a branch with a display name of `cpu` off of the `sys` child branch. `cpu` returns a hash of 98728 which converts to `000181A8` in hex. The ID of this child would be `00010001BECD000181A8`.
IDs are created this way primarily due to the method of branch and leaf storage but also as a way to navigate back up a tree from a branch anywhere in the tree structure. This can be particularly useful if you know the end branch of a path and want to move back up one level or more. Unfortunately a deep tree can create very long branch IDs, but a well designed tree really shouldn't be more than 5 to 10 levels deep. Most URI requests should support branches up to 100 levels deep before the URI character constraints are reached.
Leaves
------
A unique timeseries is represented as a *leaf* on the tree. A leaf can appear on any branch in the structure, including the root. But they will usually appear at the end of a series of branches in a branch that has one or more leaves but no child branches. Each leaf contains the TSUID for the timeseries to be used in a query as well as the metric and tag name/values. It also contains a *display name* that is parsed from the rule set but may not be identical to any of the metric, tag names or tag values.
Ideally a timeseries will only appear once on a tree. But if the TSMeta object for a timeseries, OR the UIDMeta for a metric or tag is modified, it may be processed a second time and a second leaf added. This can happen particularly in situations where a tree has a *custom* rule on the metric, tag name or tag value where the TSMeta has been processed then a user adds a custom field that matches the rule set. In these situations it is recommended to enable *strict matching* on the tree so that the timeseries will not show up until the custom data has been added.
Rules
-----
Each tree is dynamically built from a set of rules defined by the user. A rule set must contain at least one rule and usually will have more than one. Each set has multiple *levels* that determine the order of rule processing. Rules located at level 0 are processed first, then rules at level 1, and so on until all of the rules have been applied to a given timeseries. Each level in the rule set may have multiple rules to handle situations where metrics and tags may not have been planned out ahead of time or some arbitrary data may have snuck in. If multiple rules are stored in a level, the first one with a successful match will be applied and the others ignored. These rules are also ordered by the *order* field so that a rule with order 0 is processed first, then a rule with order 1 and so on. In logs and when using the test endpoint, rules are usually given IDs in the format of "[<treeId>:<level>:<order>:<type>]" such as "[1:0:1:0]" indicates the rule for tree 1, at level 0, order 1 of the type `METRIC`.
### Rule Types
Each rule acts on a single component of the timeseries data. Currently available types include:
| Type | ID | Description |
| --- | --- | --- |
| METRIC | 0 | Processes the name of the metric associated with the timeseries |
| METRIC\_CUSTOM | 1 | Searches the metric metadata custom tag list for the given secondary name. If matched, the value associated with the tag name will be processed. |
| TAGK | 2 | Searches the list of tagks for the given name. If matched, the tagv value associated with the tag name will be processed |
| TAGK\_CUSTOM | 3 | Searches the list of tagks for the given name. If matched, the tagk metadata custom tag list is searched for the given secondary name. If that matches, the value associated with the custom name will be processed. |
| TAGV\_CUSTOM | 4 | Searches the list of tagvs for the given name. If matched, the tagv metadata custom tag list is searched for the given secondary name. If that matches, the value associated with the custom name will be processed. |
### Rule Config
A single rule can either process a regex, a separator, or none. If a regex and a separator are defined for a rule, only the regex will be processed and the separator ignored.
All changes to a rule are validated to confirm that proper fields are filled out so that the rule can process data. The following fields must be filled out for each rule type:
| Type | field | customField |
| --- | --- | --- |
| Metric | | |
| Metric\_Custom | X | X |
| TagK | X | |
| TagK\_Custom | X | X |
| TagV\_Custom | X | X |
### Display Formatter
Occasionally the data extracted from a tag or metric may not be very descriptive. For example, an application may output a timeseries with a tag pair such as "port=80" or "port=443". With a standard rule that matched on the tagk value "port", we would have two branches with the names "80" and "443". The uninitiated may not know what these numbers mean. Thus users can define a token based formatter that will alter the output of the branch to display useful information. For example, we could declare a formatter of "{tag\_name}: {value}" and the branches will now display "port: 80" and "port: 443".
Tokens are case sensitive and must appear only one time per formatter. They must also appear exactly as deliniated in the table below:
| Token | Description | Applicable Rule Type |
| --- | --- | --- |
| {ovalue} | Original value processed by the rule. For example, if the rule uses a regex to extract a portion of the value but you do not want the extracted value, you could use the original here. | All |
| {value} | The processed value. If a rule has an extracted regex group or the value was split by a separator, this represents the value after that processing has occured. | All |
| {tag\_name} | The name of the tagk or custom tag associated with the value. | METRIC\_CUSTOM, TAGK\_CUSTOM, TAGV\_CUSTOM, TAGK |
| {tsuid} | the TSUID of the timeseries | All |
### Regex Rules
In some situations, you may want to extract only a component of a metric, tag or custom value to use for grouping. For example, if you have computers in mutiple data centers with fully qualified domain names that incorporate the name of the DC, but not all metrics include a DC tag, you could use a regex to extract the DC for grouping.
The `regex` rule parameter must be set with a valid regular expression that includes one or more extraction operators, i.e. the parentheses. If the regex matches on the value provided, the extracted data will be used to build the branch or leaf. If more than one extractions are provided in the regex, you can use the `regex\_group\_index` parameter to choose which extracted value to use. The index is 0 based and defaults to 0, so if you want to choose the output of the second extraction, you would set this index to 1. If the regex does not match on the value or the extraction fails to return a valid string, the rule will be considered a no match.
For example, if we have a host tagk with a tagv of `web01.nyc.mysite.com`, we could use a regex similar to `.\*\.(.\*)\..\*\..\*` to extract the "nyc" portion of the FQDN and group all of the servers in the "nyc" data center under the "nyc" branch.
### Separator Rules
The metrics for a number of systems are generally strings with a separator, such as a period, to deliniate components of the metric. For example, "sys.cpu.0.user". To build a useful tree, you can use a separator rule that will break apart the string based on a character sequence and create a branch or leaf from each individual value. Setting the separator to "." for the previous example would yield three branches "sys", "cpu", "0" and one leaf "user".
### Order of Precedence
Each rule can only process a regex, a separator, or neither. If the rule has both a "regex" and "separator" value in their respective fields, only the "regex" will be executed on the timeseries. The "separator" will be ignored. If neither "regex" or "separator" are defined, then when the rule's "field" is matched, the entire value for that field will be processed into a branch or leaf.
Tree Building
-------------
First, you must create the `tsdb-tree` table in HBase if you haven't already done so. If you enable tree processing and the table does not exist, the TSDs will not start.
A tree can be built in two ways. The `tsd.core.tree.enable\_processing` configuration setting enables real-time tree creation. Whenever a new TSMeta object is created or edited by a user, the TSMeta will be passed through every configured and enabled tree. The resulting branch will be recorded to storage. If a collision occurs or the TSUID failed to match on any rules, a warning will be logged and if the tree options configured, may be recorded to storage.
Alternatively you can periodically synchronize all TSMeta objects via the CLI `uid` tool. This will scan through the `tsdb-uid` table and pass each discovered TSMeta object through configured and enabled trees. See [*uid*](cli/uid) for details.
Note
For real-time tree building you need to enable the `tsd.core.meta.enable\_tracking` setting as well so that TSMeta objects are created when a timeseries is received.
The general process for creating and building a tree is as follows:
1. Create a new tree via the HTTP API
2. Assign one or more rules to the tree via the HTTP API
3. Test the rules with some TSMeta objects via the HTTP API
4. After veryfing the branches would appear correctly, set the tree's `enable` flag to `true`
5. Run the `uid` tool with the `treesync` sub command to synchronize existing TSMeta objects in the tree
Note
When you create a new tree, it will be disabled by default so TSMeta objects will not be processed through the rule set. This is so you have time to configure the rule set and test it to verify that the tree would be built as you expect it to.
### Rule Processing Order
A tree will usually have more than one rule in order for the resulting tree to be useful. As noted above, rules are organized into levels and orders. A TSMeta is processed through the rule set starting at level 0 and order 0. Processing proceedes through the rules on a level in increasing order. After the first rule on a level that successfully matches on the TSMeta data, processing skips to the next level. This means that rules on a level are effectively [``](#id1)or``ed. If level 0 has rules at order 0, 1, 2 and 3, and the TSMeta matches on the rule with an order of 1, the rules with order 2 and 3 will be skipped.
When editing rules, it may happen that some levels or orders are skipped or left empty. In these situations, processing simply skips the empty locations. You should do your best to keep things organized properly but the rule processor is a little forgiving.
### Strict Matching
All TSMeta objects are processed through every tree. If you only want a single, monolithic tree to organize all of your OpenTSDB timeseries, this isn't a problem. But if you want to create a number of trees for specific subsets of information, you may want to exclude some timeseries entries from creating leaves. The `strictMatch` flag on a tree helps to filter out timeseries that belong on one tree but not another. With strict matching enabled, a timeseries must match a rule on every level (that has one or more rules) in the rule set in order for it to be included in the tree. If the meta fails to match on any of the levels with rules, it will be recorded as a not matched entry and no leaf will be generated.
By default strict matching is disabled so that as many timeseries as possible can be captured in a tree. If you change this setting on a tree, you may want to delete the existing branches and run a re-sync.
Collisions
----------
Due to the flexibility of rule sets and the wide variety of metric, tag name and value naming, it is almost inevitable that two different TSMeta entries would try to create the same leaf on a tree. Each branch can only have one leaf with a given display name. For example, if a branch has a leaf named `user` with a tsuid of `010101` but the tree tries to add a new leaf named `user` with a tsuid of `020202`, the new leaf will not be added to the tree. Instead, a *collision* entry will be recorded for the tree to say that tsuid `0202020` collided with an existing leaf for tsuid `010101`. The HTTP API can then be used to query the collision list to see if a particular TSUID did not appear in the tree due to a collision.
Not Matched
-----------
When *strict matching* is enabled for a tree, a TSMeta must match on a rule on every level of the rule set in order to be added to the tree. If one or more levels fail to match, the TSUID will not be added. Similar to *collisions*, a not matched entry will be recorded for every TSUID that failed to be written to the tree. The entry will contain the TSUID and a brief message about which rule and level failed to match.
Examples
--------
Assume that our TSD has the following timeseries stored:
| TS# | Metric | Tags | TSUID |
| --- | --- | --- | --- |
| 1 | cpu.system | dc=dal, host=web01.dal.mysite.com | 0102040101 |
| 2 | cpu.system | dc=dal, host=web02.dal.mysite.com | 0102040102 |
| 3 | cpu.system | dc=dal, host=web03.dal.mysite.com | 0102040103 |
| 4 | app.connections | host=web01.dal.mysite.com | 010101 |
| 5 | app.errors | host=web01.dal.mysite.com, owner=doe | 0101010306 |
| 6 | cpu.system | dc=lax, host=web01.lax.mysite.com | 0102050101 |
| 7 | cpu.system | dc=lax, host=web02.lax.mysite.com | 0102050102 |
| 8 | cpu.user | dc=dal, host=web01.dal.mysite.com | 0202040101 |
| 9 | cpu.user | dc=dal, host=web02.dal.mysite.com | 0202040102 |
Note that for this example we won't be using any custom value rules so we don't need to show the TSMeta objects, but assume these values populate a TSMeta. Also, the TSUIDs are truncated with 1 byte per UID for illustration purposes.
Now let's setup a tree with `strictMatching` disabled and the following rules:
| Level | Order | Rule Type | Field (value) | Regex | Separator |
| --- | --- | --- | --- | --- | --- |
| 0 | 0 | TagK | dc | | |
| 0 | 1 | TagK | host | .\*\.(.\*)\.mysite\.com | |
| 1 | 0 | TagK | host | | \\. |
| 2 | 0 | Metric | | | \\. |
The goal for this set of rules is to order our timeseres by data center, then host, then by metric. Our company may have thousands of servers around the world so it doesn't make sense to display all of them in one branch of the tree, rather we want to group them by data center and let users drill down as needed.
In our example data, we had some old timeseries that didn't have a `dc` tag name. However the `host` tag does have a fully qualified domain name with the data center name embedded. Thus the first level of our rule set has two rules. The first will look for a `dc` tag, and if found, it will use that tag's value and the second rule is skipped. If the `dc` tag does not exist, then the second rule will scan the `host` tag's value and attempt to extract the data center name from the FQDN. The second level has one rule and that is used to group on the value of the `host` tag so that all metrics belonging to that host can be displayed in branches beneath it. The final level has the metric rule that includes a separator to further group the timeseries by the data contained. Since we have multiple CPU and application metrics, all deliniated by a period, it makes sense to add a separator at this point.
### Result
The resulting tree would look like this:
* dal
+ web01.dal.mysite.com
- app
* connections (tsuid=010101)
* errors (tsuid=0101010306)
- cpu
* system (tsuid=0102040101)
* user (tsuid=0202040101)
+ web02.dal.mysite.com
- cpu
* system (tsuid=0102040102)
* user (tsuid=0202040102)
+ web03.dal.mysite.com
- cpu
* system (tsuid=0102040103)
* lax
+ web01.lax.mysite.com
- cpu
* system (tsuid=0102050101)
+ web02.lax.mysite.com
- cpu
* system (tsuid=0102050102)
opentsdb Metadata Metadata
========
The primary purpose of OpenTSDB is to store timeseries data points and allow for various operations on that data. However it helps to know what kind of data is stored and provide some context when working with the information. OpenTSDB's metadata is data about the data points. Much of it is user configurable to provide tie-ins with external tools such as search engines or issue tracking systems. This chapter describes various metadata available and what it's used for.
UIDMeta
-------
Every data point stored in OpenTSDB has at least three UIDs associated with it. There will always be a `metric` and one or more tag pairs consisting of a `tagk` or tag name, and a `tagv` or tag value. When a new name for one of these UIDs comes into the system, a Unique ID is assigned so that there is always a UID name and numeric identifier pair.
Each UID may also have a metadata entry recorded in the `tsdb-uid` table. Data available for each UID includes immutable fields such as the `uid`, `type`, `name` and `created` timestamp that reflects the time when the UID was first assigned. Additionally some fields may be edited such as the `description`, `notes`, `displayName` and a set of `custom` key/value pairs to record extra information. For details on the fields, see the [*/api/uid/uidmeta*](../api_http/uid/uidmeta) endpoint.
Whenever a new UIDMeta object is created or modified, it will be pushed to the Search plugin if a plugin has been configured and loaded. For information about UID values, see [*UIDs and TSUIDs*](uids).
TSMeta
------
Each timeseries in OpenTSDB is uniquely identified by the combination of it's metric UID and tag name/value UIDs, creating a TSUID as per [*UIDs and TSUIDs*](uids). When a new timeseries is received, a TSMeta object can be recorded in the `tsdb-uid` table in a row identified by the TSUID. The meta object includes some immutable fields such as the `tsuid`, `metric`, `tags`, `lastReceived` and `created` timestamp that reflects the time when the TSMeta was first received. Additionally some fields can be edited such as a `description`, `notes` and others. See [*/api/uid/tsmeta*](../api_http/uid/tsmeta) for details.
Enabling Metadata
-----------------
If you want to use metadata in your OpenTSDB setup, you must explicitly enable real-time metadata tracking and/or use the CLI tools. There are multiple options for meta data generation due to impacts on performance, so before you enable any of these settings, please test the impact on your TSDs before enabling the settings in production.
Four options are available, starting with the least impact to the most.
* `tsd.core.meta.enable\_realtime\_uid` - When enabled, any time a new metric, tag name or tag value is assigned a UID, a UIDMeta object is generated and optionally sent to the configured search plugin. As UIDs are assigned fairly infrequently, this setting should not impact performance very much.
* `tsd.core.meta.enable\_tsuid\_tracking` - When enabled, every time a data point is recorded, a `1` is written to the `tsdb-meta` table with the timestamp of the given data point. Enabling this setting will generate twice the number of *puts* to storage and may require a greater amount of memory heap. For example a single TSD should be able to acheive 6,000 data points per second with about 2GB of heap.
* `tsd.core.meta.enable\_tsuid\_incrementing` - When this setting is enabled, every data point written will increment a counter in the `tsdb-meta` table corresponding to the time series the data point belongs to. As every data points spawns an increment request, this can generate a much larger load in a TSD and chew up heap space pretty quickly so only enable this if you can spread the load across multiple TSDs or your writes are fairly small. Enabling incrementing will override the `tsd.core.meta.enable\_tsuid\_tracking` setting. For example a single TSD should be able to acheive 3,000 data points per second with about 6GB of heap.
* `tsd.core.meta.enable\_realtime\_ts` - When enabled, any time a new time series arrives, a TSMeta object will be created and optionally sent to a configured search plugin. This option will also enabled the `tsd.core.meta.enable\_tsuid\_incrementing` setting even if it's explicitly set to `false` in the config. If you often push new time series to your TSDs, this option may incur a fair amount of overhead and require some garbage collection tuning. If you do not often push new time series, you should be able to enable this setting without a problem, but watch the memory usage of your TSDs.
Warning
Watch your JVM heap usage when enabling any of the real-time meta data settings.
For situations where a TSD crashes before metadata can be written to storage or if you do not enable real-time tracking, you can periodically use the `uid` CLI tool and the `metasync` sub command to generate missing UIDMeta and TSMeta objects. See [*uid*](cli/uid) for information.
Annotations
-----------
Another form of metadata is the *annotation*. Annotations are simple objects associated with a timestamp and, optionally, a timeseries. Annotations are meant to be a very basic means of recording an event. They are not intended as an event management or issue tracking system. Rather they can be used to link a timeseries to such an external system.
Every annotation is associated with a start timestamp. This determines where the note is stored in the backend and may be the start of an event with a beginning and end, or just used to record a note at a specific point in time. Optionally an end timestamp can be set if the note represents a time span, such as an issue that was resolved some time after the start.
Additionally, an annotation is defined by a TSUID. If the TSUID field is set to a valid TSUID, the annotation will be stored, and associated, along with the data points for the timeseries defined by the ID. This means that when creating a query for data points, any annotations stored within the requested timespan will be retrieved and optionally returned to the user. These annotations are considered "local".
If the TSUID is empty, the annotation is considered a "global" notation, something associated with all timeseries in the system. When querying, the user can specify that global annotations be fetched for the timespan of the query. These notes will then be returned along with "local" annotations.
Annotations should have a very brief *description*, limited to 25 characters or so since the note may appear on a graph. If the requested timespan has many annotations, the graph can become clogged with notes. User interfaces can then let the user select an annotation to retrieve greater detail. This detail may include lengthy "notes" and/or a custom map of key/value pairs.
Users can add, edit and delete annotations via the Http API at `../api\_http/annotation`.
An example GnuPlot graph with annotation markers appears below. Notice how only the `description` field appears in a box with a blue line recording the `start\_time`. Only the `start\_time` appears on the graph.
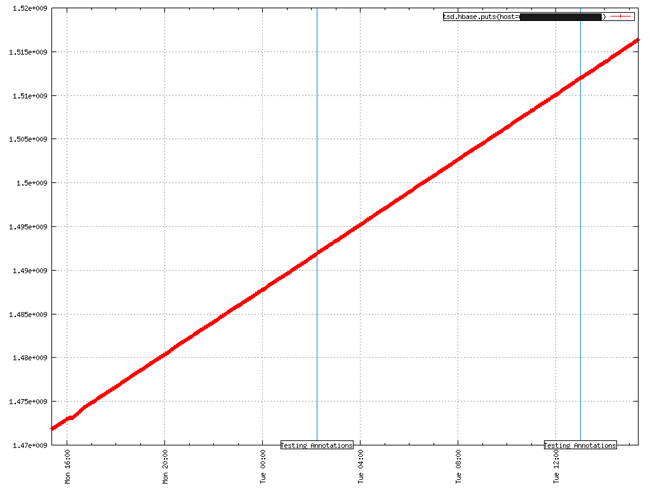
| programming_docs |
opentsdb Rollup And Pre-Aggregates Rollup And Pre-Aggregates
=========================
While TSDB is designed to store original, full resolution data as long as there is space, queries for wide time ranges or over many tag combinations can be quite painful. Such queries can take a long time to complete or, in the worst case, kill TSDs with out-of-memory exceptions. As of OpenTSDB 2.4, a set of new APIs allow for storing and querying lower resolution data to answer such queries much quicker. This page will give you an overview of what rollups and pre-aggregates are, how they work in TSDB and how best to use them. Look in the API's section for specific implementation details.
Note
OpenTSDB does not itself calculate and store rollup or pre-aggregated data. There are multiple ways to compute the results but they all have benefits and drawbacks depending on the scale and accuracy requirements. See the [Generating Rollups and Pre-Aggregates](#generating) section discussing how to create this data.
Example Data
------------
To help describe the lower resolution data, lets look at some full resolution (also known as *raw* data) example data. The first table defines the time series with a short-cut identifier.
| Series ID | Metric | Tag 1 | Tag 2 | Tag 3 |
| --- | --- | --- | --- | --- |
| ts1 | system.if.bytes.out | host=web01 | colo=lga | interface=eth0 |
| ts2 | system.if.bytes.out | host=web02 | colo=lga | interface=eth0 |
| ts3 | system.if.bytes.out | host=web03 | colo=sjc | interface=eth0 |
| ts4 | system.if.bytes.out | host=web04 | colo=sjc | interface=eth0 |
Notice that they all have the same `metric` and `interface` tag, but different `host` and `colo` tags.
Next for some data written at 15 minute intervals:
| Series ID | 12:00 | 12:15 | 12:30 | 12:45 | 13:00 | 13:15 | 13:30 | 13:45 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ts1 | 1 | 4 | -3 | 8 | 2 | -4 | 5 | 2 |
| ts2 | 7 | 2 | 8 | -9 | 4 | | 1 | 1 |
| ts3 | 9 | 3 | -2 | -1 | 6 | 3 | 8 | 2 |
| ts4 | | 2 | 5 | 2 | 8 | 5 | -4 | 7 |
Notice that some data points are missing. With those data sets, lets look at rollups first.
Rollups
-------
A "rollup" is defined, in OpenTSDB, as a **single** time series aggregated over time. It may also be called a "time-based aggregation". Rollups help to solve the problem of looking at wide time spans. For example, if you write a data point every 60 seconds and query for one year of data, a time series would return more than 525k individual data points. Graphing that many points could be pretty messy. Instead you may want to look at lower resolution data, say 1 hour data where you only have around 8k values to plot. Then you can identify anomalies and drill down for finer resolution data.
If you have already used OpenTSDB to query data, you are likely familiar with **downsamplers** that aggregate each time series into a smaller, or lower resolution, value. A rollup is essentially the result of a downsampler stored in the system and called up at will. Each rollup (or downsampler) requires two pieces of information:
* **Interval** - How much time is "rolled" up into the new value. For example, `1h` for one hour of data or `1d` for a day of data.
* **Aggregation Function** - What arithmetic was performed on the underlying values to arrive at the new value. E.g. `sum` to add all of the values or `max` to store the largest.
Warning
When storing rollups, it's best to avoid functions such as **average**, **median** or **deviation**. When performing further downsampling or grouping aggregations, such values become meaningless. Instead it's much better to always store the **sum** and **count** from which, at least, the **average** can be computed at query time. For more information, see the section below.
The timestamp of a rolled-up data point should snap to the top of the rollup interval. E.g. if the rollup interval is `1h` then it contains 1 hour of data and should snap to the top of the hour. (As all timestamps are written in Unix Epoch format, defined as the UTC timezone, this would be the start of an hour UTC time).
### Rollup Example
Given the series above, lets store the `sum` and `count` with an interval of `1h`.
| Series ID | 12:00 | 13:00 |
| --- | --- | --- |
| ts1 SUM | 10 | 5 |
| ts1 COUNT | 4 | 4 |
| ts2 SUM | 8 | 6 |
| ts2 COUNT | 4 | 3 |
| ts3 SUM | 9 | 19 |
| ts3 COUNT | 4 | 4 |
| ts4 SUM | 9 | 16 |
| ts4 COUNT | 3 | 4 |
Notice that all timestamps align to the top of the hour regardless of when the first data point in the interval "bucket" appears. Also notice that if a data point is not present for an interval, the count is lower.
In general, you should aim to compute and store the `MAX`, `MIN`, `SUM` and `COUNT` for each time series when storing rollups.
### Averaging Rollup Example
When rollups are enabled and you request a downsampler with the `avg` function from OpenTSDB, the TSD will scan storage for `SUM` and `COUNT` values. Then while iterating over the data it will accurately compute the average.
The timestamps for count and sum values must match. However, if the expected count value for a sum is missing, the sum will be kicked out of the results. Take the following example set from above where we're now missing a count data point in `ts2`.
| Series ID | 12:00 | 13:00 |
| --- | --- | --- |
| ts1 SUM | 10 | 5 |
| ts1 COUNT | 4 | 4 |
| ts2 SUM | 8 | 6 |
| ts2 COUNT | 4 | |
The resulting `avg` for a `2h` downsampling query would look like this:
| Series ID | 12:00 |
| --- | --- |
| ts1 AVG | 1.875 |
| ts2 AVG | 2 |
Pre-Aggregates
--------------
While rollups help with wide time span queries, you can still run into query performance issues with small ranges if the metric has high cardinality (i.e. the unique number of time series for the given metric). In the example above, we have 4 web servers. But lets say that we have 10,000 servers. Fetching the sum or average of interface traffic may be fairly slow. If users are often fetching the group by (or some think of it as the spatial aggregate) of large sets like this then it makes sense to store the aggregate and query that instead, fetching *much* less data.
Unlike rollups, pre-aggregates require only one extra piece of information:
* **Aggregation Function** - What arithmetic was performed on the underlying values to arrive at the new value. E.g. `sum` to add all of the time series or `max` to store the largest.
In OpenTSDB, pre-aggregates are differentiated from other time series with a special tag. The default tag key is `\_aggregate` (configurable via `tsd.rollups.agg\_tag\_key`). The **aggregation function** used to generate the data is then stored in the tag value in upper-case. Lets look at an example:
### Pre-Aggregate Example
Given the example set at the top, we may want to look at the total interface traffic by colo (data center). In that case, we can aggregate by `SUM` and `COUNT` similarly to the rollups. The result would be four **new** time series with meta data like:
| Series ID | Metric | Tag 1 | Tag 2 |
| --- | --- | --- | --- |
| ts1' | system.if.bytes.out | colo=lga | \_aggregate=SUM |
| ts2' | system.if.bytes.out | colo=lga | \_aggregate=COUNT |
| ts3' | system.if.bytes.out | colo=sjc | \_aggregate=SUM |
| ts4' | system.if.bytes.out | colo=sjc | \_aggregate=SUM |
Notice that these time series have dropped the tags for `host` and `interface`. That's because, during aggregation, multiple, different values of the `host` and `interface` have been wrapped up into this new series so it no longer makes sense to have them as tags. Also note that we injected the new `\_aggregate` tag in the stored data. Queries can now access this data by specifying an `\_aggregate` value.
Note
With rollups enabled, if you plan to use pre-aggregates, you may want to help differentiate raw data from pre-aggregates by having TSDB automatically inject `\_aggregate=RAW`. Just configure the `tsd.rollups.tag\_raw` setting to true.
Now for the resulting data:
| Series ID | 12:00 | 12:15 | 12:30 | 12:45 | 13:00 | 13:15 | 13:30 | 13:45 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ts1' | 8 | 6 | 5 | -1 | 6 | -4 | 6 | 3 |
| ts2' | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 2 |
| ts3' | 9 | 5 | 3 | 1 | 14 | 8 | 4 | 9 |
| ts4' | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
Since we're performing a group by aggregation (grouping by `colo`) we have a value for each timestamp from the original data set. We are *not* downsampling or performing a rollup in this situation.
Warning
As with rollups, when writing pre-aggregates, it's best to avoid functions such as **average**, **median** or **deviation**. Just store **sum** and **count**
Rolled-up Pre-Aggregates
------------------------
While pre-aggregates certainly help with high-cardinality metrics, users may still want to ask for wide time spans but run into slow queries. Thankfully you can roll up a pre-aggregate in the same way as raw data. Just generate the pre-aggregate, then roll it up using the information above.
Generating Rollups and Pre-Aggregates
-------------------------------------
Currently the TSDs do not generate the rollup or pre-aggregated data for you. The primary reason for this is that OpenTSDB is meant to handle huge amounts of time series data so individual TSDs are focused on getting their data into storage as quickly as possible.
### Problems
Because of the (essentially) stateless nature of the TSDs, they likely won't have the full set of data available to perform pre-aggregates. E.g., our sample `ts1` data may be written to `TSD\_A` while `ts2` is written to `TSD\_B`. Neither can perform a proper group-by without reading the data out of storage. We also don't know at what time we should perform the pre-aggregation. We could wait for 1 minute and pre-aggregate the data but miss anything that came in after that minute. Or we could wait an hour and queries over the pre-aggregates won't have data for the last hour. And what happens if data comes in much later?
Additionally for rollups, depending on how users write data to TSDs, for `ts1`, we may receive the `12:15` data point on `TSD\_A` but the `12:30` value arrives on `TSD\_B` so neither has the data required for the full hour. Time windowing constraints also apply to rollups.
### Solutions
Using rollups and pre-aggregates require some analysis and a choice between various trade-offs. Since some OpenTSDB users already have means in place for calculating this kind of data, we simply provide the API to store and query. However here are some tips on how to compute these on your own.
**Batch Processing**
One method that is commonly used by other time series databases is to read the data out of the database after some delay, calculate the pre-aggs and rollups, then write them. This is the easiest way of solving the problem and works well at small scales. However there are still a number of issues:
* As data grows, queries for generating the rollups grow as well to the point where the query load impacts write and user query performance. OpenTSDB runs into this same problem when data compactions are enabled under HBase.
* Also as data grows, more data means the batch processing time takes longer and must be sharded across multiple workers which can be a pain to coordinate and troubleshoot.
* Late or historical data may not be rolled up unless some means of tracking is in place to trigger a new batch on old data.
Some methods of improving batch processing include:
* Reading from replicated systems, e.g. if you setup HBase replication, you could have users query the master system and aggregations read from the replicated store.
* Read from alternate stores. One example is to mirror all data to another store such as HDFS and run batch jobs against that data.
**Queueing on TSDs**
Another option that some databases use is to queue all of the data in memory in the process and write the results after a configured time window has passed. But because TSDs are stateless and generally users put a load balancer in front of their TSDs, a single TSD may not get the full picture of the rollup or pre-agg to be calculated (as we mentioned above). For this method to work, upstream collectors would have to route all of the data required for a calculation to a specific TSD. It's not a difficult task but the problems faced include:
* Having enough RAM or disk space to spool the data locally on for each TSD.
* If a TSD process dies, you'll either loose the data for the aggregation or it must be bootstrapped from storage.
* Whenever the aggregation calculations are taking place, overall write throughput of the raw data can be affected.
* You still have the late/historical data issue.
* Since TSDB is JVM based, keeping all of that data in RAM and then running GC will hurt. A lot. (spooling to disk is better, but then you'll hit IO issues)
In general, queueing on a writer is a bad idea. Avoid the pain.
**Stream Processing**
A better way of dealing with rollups and pre-aggregates is to route the data into a stream processing system where it can be processed in near-real-time and written to the TSDs. It's similar to the *Queuing on TSDs* option but using one of the myriad stream processing frameworks (Storm, Flink, Spark, etc.) to handle message routing and in-memory storage. Then you simply write some code to compute the aggregates and spit the data out after a window has passed.
This is the solution used by many next-generation monitoring solutions such as that at Yahoo!. Yahoo is working to open source their stream processing system for others who need monitoring at massive scales and it plugs neatly into TSDB.
While stream processing is better you still have problems to deal with such as:
* Enough resources for the stream workers to do their job.
* A dead stream worker requires bootstrapping from storage.
* Late/historical data must be handled.
**Share**
If you have working code for calculating aggregations, please share with the OpenTSDB group. If your solution is open-source we may be able to incorporate it in the OpenTSDB ecosystem.
opentsdb Troubleshooting Troubleshooting
===============
This page lists common issues encountered by users of OpenTSDB along with various troubleshooting steps. If you run into an issue, please check the [OpenTSDB Google Group](https://groups.google.com/forum/#!forum/opentsdb) or the [Github Issues](https://github.com/OpenTSDB/opentsdb/issues). If you can't find an answer, please include your operating system, TSD version and HBase version in your question.
OpenTSDB compactions trigger large .tmp files and region server crashes in HBase
--------------------------------------------------------------------------------
This can be caused if you use millisecond timestamps and write thousands of data points for a single metric in a single hour. In this case, the column qualifier and row key can grow larger than the configured `hfile.index.block.max.size`. In this situation we recommend that you disable TSD compaction code. In the future we will support appends which will allow for compacted columns with small qualifiers.
TSDs are slow to respond after region splits or over long run times
-------------------------------------------------------------------
During region splits or region migrations, OpenTSDB's AsyncHBase client will buffer RPCs in memory and attempt to flush them once the regions are back online. Each region has a 10,000 RPC buffer by default and if many regions are down then the RPCs can eventually fill up the TSD heap and cause long garbage collection pauses. If this happens, you can either increase your heap to accommodate more region splits or decrease the NSRE queue size by modifying the `hbase.nsre.high\_watermark` config parameter in AsyncHBase 1.7 and OpenTSDB 2.2.
TSDs are stuck in GC or crashing due to Out of Memory Exceptions
----------------------------------------------------------------
There are a number of potential causes for this problem including:
* Multiple NSREs from HBase - See the section above about TSDs being slow to respond.
* Too many writes - If the rate of writes to TSD is high, queues can build up in AsyncHBase (see above) or in the compaction queue. If this is the case, check HBase performance and try disabling compactions.
* Large queries - A very large query with many time series or for a long range can cause the TSD to OOM. Try reducing query size or break large queries up into smaller chunks.
opentsdb Logging Logging
=======
OpenTSDB uses the [SLF4J](http://www.slf4j.org/) abstraction layer along with [Logback](http://logback.qos.ch/) for logging flexibility. Configuration is performed via an XML file and there are many different formatting, level and destination options.
Levels
------
Every log message is accompanied by a descriptive severity level. Levels employed by OpenTSDB include:
* **ERROR** - Something failed, be it invalid data, a failed connection or a bug in the code. You should pay attention to these and figure out what caused the error. Check with the user group for assistance.
* **WARN** - These are often caused by bad user data or something else that was wrong but not a critical error. Look for warnings if you are not receiving the results you expect when using OpenTSDB.
* **INFO** - Informational messages are notifications of expected or normal behavior. They can be useful during troubleshooting. Most logging appenders should be set to `INFO`.
* **DEBUG** - If you require further troubleshooting you can enable `DEBUG` logging that will give much greater detail about what OpenTSDB is doing under the hood. Be careful enabling this level as it can return a vast amount of data.
* **OFF** - To drop any logging messages from a class, simply set the level to `OFF`.
Configuration
-------------
A file called `logback.xml` is included in the `/src` directory and copied for distributions. On startup, OpenTSDB will search the class path for this file and if found, load the configuration. The default config from GIT will log INFO level events to console and store the 1,024 latest messages in a round-robin buffer to be accessed from the GUI. However by default, it won't log to disk. Packages built from GIT have file logging enabled by default. As of 2.2, all queries can be logged to a separate file for parsing and automating. This log is disabled by default but can be enabled by setting the proper log level.
### Appenders
Appenders are destinations where logging information is sent. Typically logging configs send results to the console and a file. Optionally you can send logs to Syslog, email, sockets, databases and more. Each appender section defines a destination, a format and an optional trigger. Read about appenders in the [Logback Manual](http://logback.qos.ch/manual/appenders.html).
### Loggers
Loggers determine what data and what level of data is routed to the appenders. Loggers can match a particular Java class namespace and affect all messages emitted from that space. The default OpenTSDB config explicitly lists some loggers for Zookeeper, AsyncHBase and the Async libraries to set their levels to `INFO` so as to avoid chatty outputs that are not relevant most of the time. If you enable a plugin and start seeing a lot of messages that you don't care about, add a logger entry to suppress the messages.
**Query Log** To enable the Query log, find the following section:
```
<logger name="QueryLog" level="OFF" additivity="false">
<appender-ref ref="QUERY_LOG"/>
</logger>
```
and set the `level` to `INFO`.
**Log File** To enable the main log file, find the following section:
```
<!--<appender-ref ref="FILE"/>-->
```
and remove the comments so it appears as `<appender-ref ref="FILE"/>`.
### Root
The root section is the catch-all logger that determines that default logging level for all messages that don't match an explicit logger. It also handles routing to the different appenders.
### Log to Rotating File
```
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/opentsdb/opentsdb.log</file>
<append>true</append>
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<fileNamePattern>/var/log/opentsdb/opentsdb.log.%i</fileNamePattern>
<minIndex>1</minIndex>
<maxIndex>3</maxIndex>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<maxFileSize>128MB</maxFileSize>
</triggeringPolicy>
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%logger{0}.%M] - %msg%n</pattern>
</encoder>
</appender>
```
This appender will write to a log file called `/var/log/opentsdb/opentsdb.log`. When the file reaches 128MB in size, it will rotate the log to `opentsdb.log.1` and start a new `opentsdb.log` file. Once the new log fills up, it bumps `.1` to `.2`, `.log` to `.1` and creates a new one. It repeats this until there are four log files in total. The next time the log fills up, the last log is deleted. This way you are gauranteed to only use up to 512MB of disk space. Many other appenders are available so see what fits your needs the best.
| programming_docs |
opentsdb GUI GUI
===
Currently OpenTSDB offers a simple built-in GUI accessible by opening your browser and navigating to the host and port where the TSD is running. For example, if you are running a TSD on your local computer on port 4242, simply navigate to `http://localhost:4242`. While the GUI won't win awards for beauty, it provides a quick means of building a useful graph with the data in your system.
Interface
---------
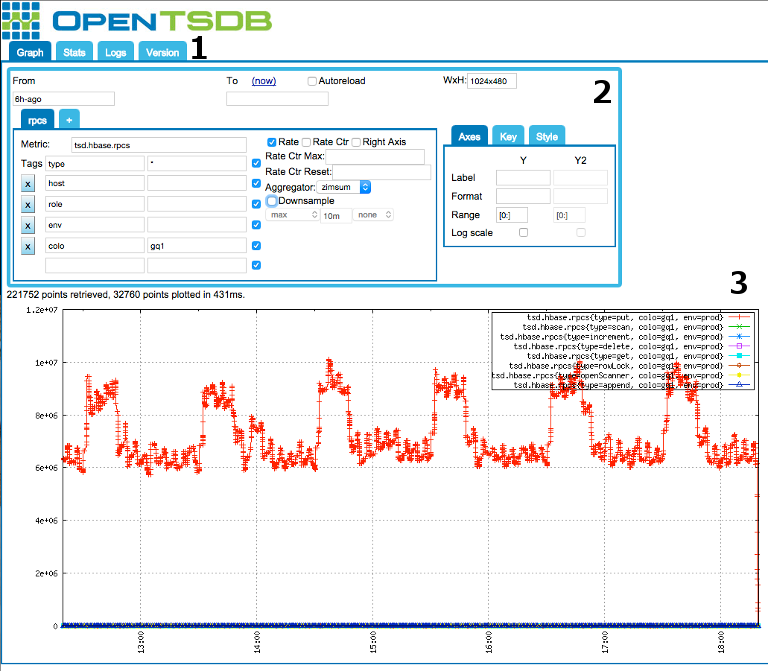 There are three main areas of the GUI:
1. The notification area and tab area that serves as a menu
2. The query builder that lets you select what will be displayed and how
3. The graph area that displays query results
### Menu
The menu is a group of tabs that can be clicked for different options.
* Graph - This is the default that lets you issue a query and generate a graph
* Stats - This tab will display a list of statistics about the running TSD. The same stats can be retrieved via the `/stats` or `/api/stats` endpoints.
* Logs - If Logback is configured, this tab will show you a list of the latest 1,024 log entries for the TSD.
* Version - Displays version information about the TSD
### Errors
When building a graph, if an error occurs, a message will appear above the menu. Click on the arrow to expand the message and determine what the error was.
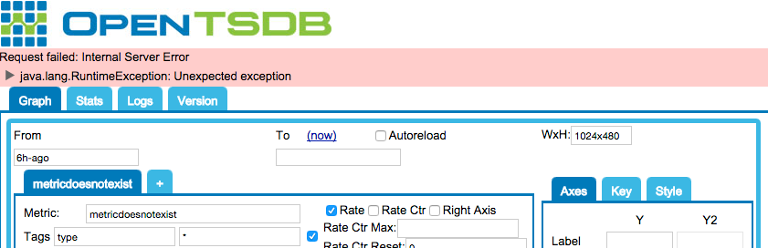 Query Builder
-------------
You'll likely spend a lot of time in this area since there are a number of options to play with. You'll likely want to start by choosing one or more metrics and tags to graph.
Note
If you start by picking a start and end time then as soon as you enter a metric, the TSD will start to graph *every time series for that metric*. This will show the `Loading Graph...` status and may take a long time before you can do anything else. So skip the times and choose your metrics first.
Note
Also note that changes to any field in this section will cause a graph reload, so be aware if you're graph takes a long time to load.
### Metrics Section
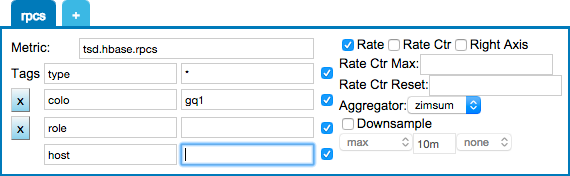 This area is where you choose the metrics, optional tags, aggregation function and a possible down sampler for your graph. Along the top are a pair of blue tabs. Each graph can display multiple metrics and the tabs organize the different sub queries. Each graph requires at least one metric so you'll choose that metric in the first tab. To add another metric to your graph, click the `+` tab and you'll be able to setup another sub query. If you have configured multiple metrics, simply click on the tab that corresponds to the metric you want to modify. The tab will display a subset of the metric name it is associated with.
The **Metric** box is where you'll choose a metric. This field auto-completes as you type just like a modern web browser. Auto-complete is generally case sensitive so only metrics matching the case provided will be displayed. By default, only the 25 top matching entries will be returned so you may not see all of the possible choices as you type. Either click on the entry you want when it appears or keep typing until you have entire metric in the box.
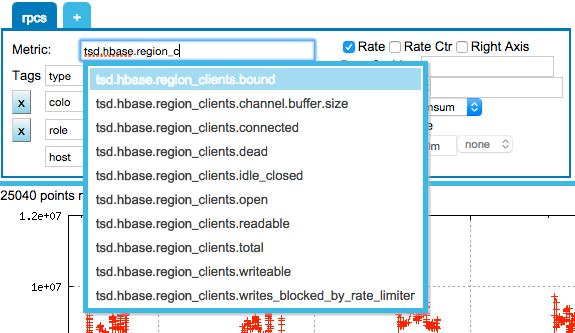 Recall from the [*Querying or Reading Data*](../query/index) documentation that if you only provide a metric without any tags, *every time series with that metric* will be aggregated in the results. If you want to drill down, supply one or more **Tags** to filter or group the results. A new metric section will have two boxes next to **Tags**. The left box is for the tag name or `tagk` value, e.g. `host` or `symbol`. The right hand box is for the tag value or `tagv`, e.g. `webserver01` or `google`. When you add a tag, another pair of boxes will appear so that you can keep adding tags to filter as much as necessary.
Both tag name and value boxes also auto-complete in the same way as the **Metric** box. However each auto-complete will show *all* of the results for the name or value, not just the values that would apply to a specific metric or tag name. In future versions we may be able to implement such a mapping feature but currently you'll have to sort through all of the values.
With version 2.2, a checkbox to the right of each pair of check boxes is used to determine if the results should be grouped by the tag filter (checked) or aggregated (unchecked). The boxes are checked by default to exhibit the behavior of TSD prior to 2.2.
The tag value box can use grouping operators such as the `\*` and the `|`. See [*Querying or Reading Data*](../query/index) for details. Tag value boxes can also use filters as of version 2.2. E.g. you can enter "wildcard(webserver\*)" as a tag value and it will match all hosts starting with "webserver".
The **Rate** box allows you to convert all of the time series for the metric to a rate of change value. By default this option is turned off.
**Rate ctr** Enables the rate options boxes below and indicate that the metric graphed is a monotonically increasing counter. If so, you can choose to supply a maximum value (**Rate Ctr Max**) for the counter so that when it rolls over, the graph will show the proper value instead of a negative number. Likewise you can choose to set a reset value (**Rate Ctr Reset**) to replace values with a zero if the rate is greater than the value. To avoid negative spikes it's generally save to set the rate counter with a reset value of 1.
For metrics or time series with different scales, you can select the **Right Axis** check box to add another axis to the right of the graph for the metric's time series. This can make graphs much more readable if the scales differ greatly.
The **Aggregator** box is a drop-down list of aggregation functions used to manipulate the data for multiple time series associated with the sub query. The default aggregator is *sum* but you can choose from a number of other options.
The **Downsample** section is used to reduce the number of data points displayed on the graph. By default, GnuPlot will place a character, such as the `+` or `x` at each data point of a graph. When the time span is wide and there are many data points, the graph can grow pretty thick and ugly. Use down sampling to reduce the number of points. Simply choose an aggregation function from the drop down list, then enter a time interval in the second box. The interval must follow the relative date format (without the `-ago` component). For example, to downsample on an hour, enter `1h`. The last selection box chooses a "fill policy" for the downsampled values when aggregated with other series. For graphing in the GUI, only the "zero" value makes a difference as it will substitute a zero for missing series. See [*Dates and Times*](../query/dates) for details.
 Downsampling Disabled
 Downsampling Enabled
### Time Section
 The time secion determines the timespan for all metrics and time series in your graph. The **Frome** time determines when your graph will start and the **End** time determines when it will stop. Both fields must be filled out for a query to execute. Times may be in human readable, absolute format or a relative format. See [*Dates and Times*](../query/dates) for details.
Clicking a time box will pop-up a utility to help you choose a time. Use the arrows at the top left of the box to navigate through the months, then click on a date. The relative links in the upper right are helpers to jump forward or backward 1 minute, 10 minutes, 1 hour, 1 day, 1 week or 30 days. The *now* link will update the time to the current time on your local system. The **HH** buttons let you choose an hour along with *AM* or *PM*. The MM buttons let you choose a normalized minute. You can also cut and paste a time into the any of the boxes or edit the times directly.
Note
Unix timestamps are not supported directly in the boxes. You can click in a box to display the calendar, then paste a Unix timestamp (in seconds) in the *UNIX Timestamp* box, then press the *TAB* key to convert to a human readable time stamp.
If the time stamp in a time box is invalid, the background will turn red. This may happen if your start time is greater than or equal to your end time.
The **To (now)** link will update the **End** box to the current time on your system.
Click the **Autoreload** check box to automatically refresh your graph periodically. This can be very useful for monitoring displays where you want to have the graph displayed for a number of people. When checked, the **End** box will disappear and be replaced by an **Every:** box that lets you choose the refresh rate in seconds. The default is to refresh every 15 seconds.
Graphing
--------
We'll make a quick detour here to talk about the actual graph section. Below the query building area is a spot where details about query results are displayed as well as the actual graph.
 A status line prints information about the results of a query including whether or not the results were cached in the TSD, how many raw data points were analyzed, how many data points were actually plotted (as per the results of aggregations and down sampling) and how long the query took to execute. When the browser is waiting for the results of a query, this message will show `Loading Graph...`.
Note
When using the built-in UI, graphs are cached on disk for 60 seconds. If auto-refresh is enabled and the default of 15s is used, the cached graph will be displayed until the 60 seconds have elapsed. If you have higher resolution data coming in and want to bypass the cache, simply append `&nocache` to the GUI URL.
Below the status line will be the actual graph. The graph is simply a PNG image generated by GnuPlot so you can copy the image and save it to your local machine or send it in an email.
You can also zoom in on a time range by clicking and dragging a red box across a section of the graph. Release and the query will be updated with the new time span. Note that the browser cursor doesn't change when you're over the graph, it will still remain the default arrow your browser or OS provides.
 ### Graph Style
Back in the query builder section you have the graphing style box to the right.
 The **WxH** box alters the dimensions of the graph. Simply enter the `<width>x<height>` in pixels such as `1024x768` then tab or click in another box to update the graph.
Below that are a few tabs for altering different parts of the graph.
### Axes Tab
This area deals with altering the Y axes of the graph. **Y** settings affect the axis on the left and **Y2** settings affect the axis on the right. Y2 settings are only enabled if at least one of the metrics has had the **Right Axis** check box checked.
The **Label** box will add the specified text to the graph alon the left or right Y axis. By default, no label is provided since OpenTSDB doesn't know what you're graphing.
The **Format** box can alter the numbers on the Y axis according to a custom algorithm or formatting. This can be useful to convert numbers to or from scientific notation and adjusting the scale for gigabytes if the data comes in as bytes. For example, you can supply a value of `%0.0f Reqs` and it will change the axis to show an integer value at each step with the string *Reqs* after it as in the following example.
 Read the [GnuPlot Manual](http://www.gnuplot.info/) for *Format Specifiers* to find out what is permissible.
The **Range** box allows you to effectively zoom horizontally, showing only the data points between a range of Y axis values. The format for this box is `[<starting value>:<optional end value>]`. For example, if I want to show only the data points with values between 700 and 800 I can enter `[700:800]`. This will produce a graph as below:
 The **Log Scale** check box will set a base ten log scale on the Y axis. An example appears below.
 ### Key Tab
The top half of the key tab's section deals with the location of the graph key. This is a series of buttons layed out to show you where the key will appear. A box surrounds some of the buttons indicating that the key will appear inside of the graph's box, overlaying the data. The default location is the top right inside of the graph box. Simply select a button to move the key box.
 By default, the key lists all of the different labels vertically. The **Horizontal Layout** check box will lay out the key horizontally first, then vertically if the dimensions of the graph wouldn't support it.
The **Box** check box will toggle a box outline around the key. This is on by default.
The **No Key** check box will hide the key altogether.
### Style Tab
The style tab currently has a single box, the **Smooth** check box. With this checked, the data point characters will be removed from the graph (showing the lines only) and the data will be smoothed with splines (at least three points need to be plotted). Some users prefer this over the default.
 Saving Your Work
----------------
As you make changes via the GUI you'll see that the URL reflects your edits. You can copy the URL, save it or email it around and pull it back up to pick up where you were. Unfortunately OpenTSDB doesn't include a built in dashboard so you'll have to save the URL somewhere manually.
opentsdb HBase Schema HBase Schema
============
Data Table Schema
-----------------
All OpenTSDB data points are stored in a single, massive table, named `tsdb` by default. This is to take advantage of HBase's ordering and region distribution. All values are stored in the `t` column family.
**Row Key** - Row keys are byte arrays comprised of an optional salt, the metric UID, a base timestamp and the UID for tagk/v pairs: `[salt]<metric\_uid><timestamp><tagk1><tagv1>[...<tagkN><tagvN>]`. By default, UIDs are encoded on 3 bytes.
With salting enabled (as of OpenTSDB 2.2) the first byte (or bytes) are a hashed salt ID to better distribute data across multiple regions and/or region servers.
The timestamp is a Unix epoch value in seconds encoded on 4 bytes. Rows are broken up into hour increments, reflected by the timestamp in each row. Thus each timestamp will be normalized to an hour value, e.g. *2013-01-01 08:00:00*. This is to avoid stuffing too many data points in a single row as that would affect region distribution. Also, since HBase sorts on the row key, data for the same metric and time bucket, but with different tags, will be grouped together for efficient queries.
Some example unsalted row keys, represented as hex are:
```
00000150E22700000001000001
00000150E22700000001000001000002000004
00000150E22700000001000002
00000150E22700000001000003
00000150E23510000001000001
00000150E23510000001000001000002000004
00000150E23510000001000002
00000150E23510000001000003
00000150E24320000001000001
00000150E24320000001000001000002000004
00000150E24320000001000002
00000150E24320000001000003
```
where:
```
00000150E22700000001000001
'----''------''----''----'
metric time tagk tagv
```
This represents a single metric but four time series across three hours. Note how there is one time series with two sets of tags:
```
00000150E22700000001000001000002000004
'----''------''----''----''----''----'
metric time tagk tagv tagk tagv
```
Tag names (tagk) are sorted alphabetically before storage, so the "host" tag will always appear first in the row key/TSUID ahead of "owner".
### Data Point Columns
By far the most common column are data points. These are the actual values recorded when data is sent to the TSD for storage.
**Column Qualifiers** - The qualifier is comprised of 2 or 4 bytes that encode an offset from the row's base time and flags to determine if the value is an integer or a decimal value. Qualifiers encode an offset from the row base time as well as the format and length of the data stored.
Columns with 2 byte qualifiers have an offset in seconds. The first 12 bits of the qualifier represent an integer that is a delta from the timestamp in the row key. For example, if the row key is normalized to `1292148000` and a data point comes in for `1292148123`, the recorded delta will be `123`. The last 4 bits are format flags
Columns with 4 byte qualifiers have an offset in milliseconds. The first 4 *bits* of the qualifier will always be set to `1` or `F` in hex. The next 22 bits encode the offset in milliseconds as an unsigned integer. The next 2 bits are reserved and the final 4 bits are format flags.
The last 4 bits of either column type describe the data stored. The first bit is a flag that indicates whether or not the value is an integer or floating point. A value of 0 indicates an integer, 1 indicates a float. The last 3 bits indicate the length of the data, offset by 1. A value of `000` indicates a 1 byte value while `010` indicates a 2 byte value. The length must reflect a value of 1, 2, 4 or 8. Anything else indicates an error.
For example, `0100` means the column value is an 8 byte, signed integer. `1011` indicates the column value is a 4 byte floating point value So the qualifier for the data point at `1292148123` with an integer value of 4294967296 would have a qualifier of `0000011110110100` or `07B4` in hex.
**Column Values** - 1 to 8 bytes encoded as indicated by the qualifier flag.
### Compactions
If compactions have been enabled for a TSD, a row may be compacted after it's base hour has passed or a query has run over the row. Compacted columns simply squash all of the data points together to reduce the amount of overhead consumed by disparate data points. Data is initially written to individual columns for speed, then compacted later for storage efficiency. Once a row is compacted, the individual data points are deleted. Data may be written back to the row and compacted again later.
Note
The OpenTSDB compaction process is entirely separate in scope and definition than the HBase idea of compactions.
**Column Qualifiers** - The qualifier for a compacted column will always be an even number of bytes and is simply a concatenation of the qualifiers for every data point that was in the row. Since we know each data point qualifier is 2 bytes, it's simple to split this up. A qualifier in hex with 2 data points may look like `07B407D4`.
**Column Values** - The value is also a concatenation of all of the individual data points. The qualifier is split first and the flags for each data point determine if the parser consumes 4 or 8 bytes
### Annotations or Other Objects
A row may store notes about the timeseries inline with the datapoints. Objects differ from data points by having an odd number of bytes in the qualifier.
**Column Qualifiers** - The qualifier is on 3 or 5 bytes with the first byte an ID that denotes the column as a qualifier. The first byte will always have a hex value of `0x01` for annotations (future object types will have a different prefix). The remaining bytes encode the timestamp delta from the row base time in a manner similar to a data point, though without the flags. If the qualifier is 3 bytes in length, the offset is in seconds. If the qualifier is 5 bytes in length, the offset is in milliseconds. Thus if we record an annotation at `1292148123`, the delta will be `123` and the qualifier, in hex, will be `01007B`.
**Column Values** - Annotation values are UTF-8 encoded JSON objects. Do not modify this value directly. The order of the fields is important, affecting CAS calls.
### Append Data Points
OpenTSDB 2.2 introduced the idea of writing numeric data points to OpenTSDB using the `append` method instead of the normal `put` method. This saves space in HBase by writing all data for a row in a single column, enabling the benefits of TSD compactions while avoiding problems with reading massive amounts of data back into TSDs and re-writing them to HBase. The drawback is that the schema is incompatible with regular data points and requires greater CPU usage on HBase region servers as they perform a read, modify, write operation for each value.
**Row Key** - Same as regular values.
**Column Qualifier** - The qualifier is always the object prefix `0x05` with an offset of 0 from the base time on two bytes. E.g. `0x050000`.
**Column Values** - Each column value is the concatenation of original data point qualifier offsets and values in the format `<offset1><value1><offset2><value2>...<offsetN><valueN>`. Values can appear in any order and are sorted at query time (with the option to re-write the sorted result back to HBase.).
UID Table Schema
----------------
A separate, smaller table called `tsdb-uid` stores UID mappings, both forward and reverse. Two columns exist, one named `name` that maps a UID to a string and another `id` mapping strings to UIDs. Each row in the column family will have at least one of three columns with mapping values. The standard column qualifiers are:
* `metrics` for mapping metric names to UIDs
* `tagk` for mapping tag names to UIDs
* `tagv` for mapping tag values to UIDs.
The `name` family may also contain additional meta-data columns if configured.
###
`id` Column Family
**Row Key** - This will be the string assigned to the UID. E.g. for a metric we may have a value of `sys.cpu.user` or for a tag value it may be `42`.
**Column Qualifiers** - One of the standard column types above.
**Column Value** - An unsigned integer encoded on 3 bytes by default reflecting the UID assigned to the string for the column type. If the UID length has been changed in the source code, the width may vary.
###
`name` Column Family
**Row Key** - The unsigned integer UID encoded on 3 bytes by default. If the UID length has been changed in the source code, the width may be different.
**Column Qualifiers** - One of the standard column types above OR one of `metrics\_meta`, `tagk\_meta` or `tagv\_meta`.
**Column Value** - For the standard qualifiers above, the string assigned to the UID. For a `\*\_meta` column, the value will be a UTF-8 encoded, JSON formatted UIDMeta Object as a string. Do not modify the column value outside of OpenTSDB. The order of the fields is important, affecting CAS calls.
### UID Assignment Row
Within the `id` column family is a row with a single byte key of `\x00`. This is the UID row that is incremented for the proper column type (metrics, tagk or tagv) when a new UID is assigned. The column values are 8 byte signed integers and reflect the maximum UID assigned for each type. On assignment, OpenTSDB calls HBase's atomic increment command on the proper column to fetch a new UID.
Meta Table Schema
-----------------
This table is an index of the different time series stored in OpenTSDB and can contain meta-data for each series as well as the number of data points stored for each series. Note that data will only be written to this table if OpenTSDB has been configured to track meta-data or the user creates a TSMeta object via the API. Only one column family is used, the `name` family and currently there are two types of columns, the meta column and the counter column.
### Row Key
This is the same as a data point table row key without the timestamp. E.g. `<metric\_uid><tagk1><tagv1>[...<tagkN><tagvN>]`. It is shared for all column types.
### TSMeta Column
These columns store UTF-8 encoded, JSON formatted objects similar to UIDMeta objects. The qualifier is always `ts\_meta`. Do not modify these column values outside of OpenTSDB or it may break CAS calls.
### Counter Column
These columns are atomic incrementers that count the number of data points stored for a time series. The qualifier is `ts\_counter` and the value is an 8 byte signed integer.
Tree Table Schema
-----------------
This table behaves as an index, organizing time series into a hierarchical structure similar to a file system for use with tools such as Graphite or other dashboards. A tree is defined by a set of rules that process a TSMeta object to determine where in the hierarchy, if at all, a time series should appear.
Each tree is assigned a Unique ID consisting of an unsigned integer starting with `1` for the first tree. All rows related to a tree are prefixed with this ID encoded as a two byte array. E.g. `\x00\x01` for UID `1`.
### Row Key
Tree definition rows are keyed with the ID of the tree on two bytes. Columns pertaining to the tree definition, as well as the root branch, appear in this row. Definitions are generated by the user.
Two special rows may be included. They are keyed on `<tree ID>\x01` for the `collisions` row and `<tree ID>\x02` for the `not matched` row. These are generated during tree processing and will be described later.
The remaining rows are branch and leaf rows containing information about the hierarchy. The rows are keyed on `<tree ID><branch ID>` where the `branch ID` is a concatenation of hashes of the branch display names. For example, if we have a flattened branch `dal.web01.myapp.bytes\_sent` where each branch name is separated by a period, we would have 3 levels of branching. `dal`, `web01` and `myapp`. The leaf would be named `bytes\_sent` and links to a TSUID. Hashing each branch name in Java returns a 4 byte integer and converting to hex for readability yields:
* `dal` = x00x01x83x8F
* `web01` = x06xBCx4Cx55
* `myapp` = x06x38x7CxF5
If this branch belongs to tree `1`, the row key for `dal` would be `\x00\x01\x00\x01\x83\x8F`. The branch for `myapp` would be `\x00\x01\x00\x01\x83\x8F\x06\xBC\x4C\x55\x06\x38\x7C\xF5`. This schema allows for navigation by providing a row key filter using a prefix including the tree ID and current branch level and a wild-card to match any number of child branch levels (usually only one level down).
### Tree Column
A Tree is defined as a UTF-8 encoded JSON object in the `tree` column of a tree row (identified by the tree's ID). The object contains descriptions and configuration settings for processing time series through the tree. Do not modify this object outside of OpenTSDB as it may break CAS calls.
### Rule Column
In the tree row there are 0 or more rule columns that define a specific processing task on a time series. These columns are also UTF-8 encoded JSON objects and are modified with CAS calls. The qualifier id of the format `rule:<level>:<order>` where `<level>` is the main processing order of a rule in the set (starting at 0) and `order` is the processing order of a rule (starting at 0) within a given level. For example `rule:1:0` defines a rule at level 1 and order 0.
### Tree Collision Column
If collision storage is enabled for a tree, a column is recorded for each time series that would have created a leaf that was already created for a previous time series. These columns are used to debug rule sets and only appear rin the collision row for a tree. The qualifier is of the format `tree\_collision:<tsuid>` where the TSUID is a byte array representing the time series identifier. This allows for a simple `getRequest` call to determine if a particular time series did not appear in a tree due to a collision. The value of a colission column is the byte array of the TSUID that was recorded as a leaf.
### Not Matched Column
Similar to collisions, when enabled for a tree, a column can be recorded for each time series that failed to match any rules in the rule set and therefore, did not appear in the tree. These columns only appear in the not matched row for a tree. The qualifier is of the format `tree\_not\_matched:<TSUID>` where the TSUID is a byte array representing the time series identifier. The value of a not matched column is the byte array of the TSUID that failed to match a rule.
### Branch Column
Branch columns have the qualifier `branch` and contain a UTF-8 JSON encoded object describing the current branch and any child branches that may exist. A branch column may appear in any row except the collision or not matched columns. Branches in the tree definition row are the `root` branch and link to the first level of child branches. These links are used to traverse the heirarchy.
### Leaf Column
Leaves are mappings to specific time series and represent the end of a hierarchy. Leaf columns have a qualifier format of `leaf:<TSUID>` where the TUID is a byte array representing the time series identifier. The value of a leaf is a UTF-8 encoded JSON object describing the leaf. Leaves may appear in any row other than the collision or not matched rows.
Rollup Tables Schema
--------------------
As of OpenTSDB 2.4 is the concept of rollup and pre-aggregation tables. While TSDB does a great job of storing raw values as long as you want, querying for wide timespans across massive amounts of raw data can slow queries to a crawl and potentially OOM a JVM. Instead, individual time series can be rolled up (or downsampled) by time and stored as separate values that allow for scanning much wider timespans at a lower resolution. Additionally, for metrics with high cardinalities, pre-aggregate groups can be stored to improve query speed dramatically.
There are three types of rolled up data:
* Rollup - This is a downsampled value across time for a single time series. It's similar to using a downsampler in query where the time series may have a data point every minute but is downsampled to a data point every hour using the `sum` aggregation. In that case, the resulting rolled up value is the sum of 60 values. E.g. if the value for each 1 minute data point is `1` then the resulting rollup value would be `60`.
* Pre-Aggregate - For a metric with high cardinality (many unique tag values), scanning for all of the series can be costly. Take a metric `system.interface.bytes.out` where there are 10,000 hosts spread across 5 data centers. If users often look at the total data output by data center ( the query would look similar to aggregation = sum and data\_center = [\*](#id2)) then pre-calculating the sum across each data center would result in 5 data points being fetched per time period from storage instead of 10K. The resulting pre-aggregate would have a different tag set than the raw time series. In the example above, each series would likely have a `host` tag along with a `data\_center` tag. After pre-aggregation, the `host` tag would be dropped, leaving only the `data\_center` tag.
* Rolled-up Pre-Aggregate - Pre-aggregated data can also be rolled up on time similar to raw time series. This can improve query speed for wide time spans over pre-aggregated data.
### Configuration
**TODO** - Settle on a config. Rollup configs consist of a table name, interval span and rollup interval. Raw pre-aggs can be stored in the data table or rollup tables as well.
### Pre-Aggregate Schema
In OpenTSDB's implementation, a new, users configurable tag is added to all time series when rollups are enabled. The default key is `\_aggegate` with a value of `raw` or an aggregation function. The tag is used to differentiate pre-aggregated data from raw (original) values. Therefore pre-aggregated data is stored in the same manner as original time series and can either be written to the original data table or stored in a separate table for greater query performance.
### Rollup Schema
Rolled up data must be stored in a separate table from the raw data as to avoid existing schema conflicts and to allow for more performant queries.
**Row Key** - The row key for rollups is in the same format as the original data table.
**Column Qualifier** - Columns are different for rolled up data and consist of `<aggregation\_function>:<time offset><type + length>` where the aggregation function is an upper-case string consisting of the function name used to generate the rollup and time offset is an offset from the row base time and the type + length describes the column value encoding.
* Aggregation Function - This is the name of a function such as `SUM`, `COUNT`, `MAX` or `MIN`.
* Time Offset - This is an offset based on the rollup table config, generally on 2 bytes. The offset is not a specific number of seconds or minutes from the base, instead it's the index of an interval of an offset. For example, if the table is configured to store 1 day of data at a resolution of 1 hour per row, then the base timestamp of the row key will align on daily boundaries (on Unix epoch timestamps). Then there would be a potential of 24 offsets (1 for each hour in the day) for the row. A data point at midnight for the given day would have an offset of 0 whereas the 23:00 hour value would have an offset of 22. Since rollup timestamps are aligned to time boundaries, qualifiers can save a fair amount of space.
* Type and Length - Similar to the original data table, the last 4 bits of each offset byte array contains the encoding of the data value including it's length and whether or not it's a floating point value.
An example column qualifier for the daily 1 hour interval table looks like:
```
SUM:0010
'-''---'
agg offset
```
Where the aggregator is `SUM`, the offset is `1` and the length is 1 byte of an integer value.
**Column Value** - The values are the same as in the main data table.
**TODOs** - Some further work that's needed:
* Compactions/Appends - The current schema does not support compacted or append data types. These can be implemented by denoting a single column per aggregation function (e.g. `SUM`, `COUNT`) and storing the offsets and values in the column value similar to the main data table.
* Additional Data Types - Currently only numeric data points are written to the pre-agg and rollup tables. We need to support rolling up annotations and other types of data.
| programming_docs |
opentsdb Storage Storage
=======
OpenTSDB currently supports Apache HBase as its main storage backend. As of version 2.3, OpenTSDB also works with Google's Bigtable in the cloud (fitting as OpenTSDB is descended from a monitoring system at Google and HBase is descended from HBase). Select the HBase link below to learn about the storage schema or Bigtable to find the configs and setup for use in the cloud.
* [HBase Schema](hbase)
+ [Data Table Schema](hbase#data-table-schema)
+ [UID Table Schema](hbase#uid-table-schema)
+ [Meta Table Schema](hbase#meta-table-schema)
+ [Tree Table Schema](hbase#tree-table-schema)
+ [Rollup Tables Schema](hbase#rollup-tables-schema)
* [Bigtable](bigtable)
+ [Setup](bigtable#setup)
+ [Configuration](bigtable#configuration)
* [Cassandra](cassandra)
+ [Setup](cassandra#setup)
+ [Configuration](cassandra#configuration)
opentsdb Cassandra Cassandra
=========
Cassandra is an eventually consistent key value store similar to HBase and Google`s Bigtable. It implements a distributed hash map with column families originally it supported a Thrift based API very close to HBase`s. Lately Cassandra has moved towards a SQL like query language with much more flexibility around data types, joints and filters. Thankfully the Thrift interface is still there so it`s easy to convert the OpenTSDB HBase schema and calls to Cassandra at a low level through the AsyncHBase `HBaseClient` API. [AsyncCassandra](https://github.com/OpenTSDB/asynccassandra) is a shim between OpenTSDB and Cassandra for trying out TSDB with an alternate backend.
Setup
-----
1. Setup a Cassandra cluster using the `ByteOrderedPartitioner`. This is critical as we require the row keys to be sorted. Because this setting affects the entire node, you may need to setup a cluster dedicated to OpenTSDB.
2. Create the proper keyspsaces and column families by using the cassandra-cli script:
```
create keyspace tsdb;
use tsdb;
create column family t with comparator = BytesType;
create keyspace tsdbuid;
use tsdbuid;
create column family id with comparator = BytesType;
create column family name with comparator = BytesType;
```
3. Build TSDB by executing sh build-cassandra.sh (or if you prefer Maven, sh build-cassandra.sh pom.xml)
4. Modify your opentsdb.conf file with the asynccassandra.seeds parameter, e.g. asynccassandra.seeds=127.0.0.1:9160.
5. In the config file, set tsd.storage.hbase.uid\_table=tsdbuid
6. Run the tsd via build/tsdb tsd --config=<path>/opentsdb.conf
If you intend to use meta data or tree features, repeat the keyspace creation with the proper table name.
Configuration
-------------
The following is a table with required and optional parameters to run OpenTSDB with Cassandra. These are in addition to the standard TSD configuration parameters from [*Configuration*](../configuration)
| Property | Type | Required | Description | Default |
| --- | --- | --- | --- | --- |
| asynccassandra.seeds | String | Required | The list of nodes in your Cassandra cluster. These can be formatted <hostname>:<port> | |
| asynccassandra.port | Integer | Optional | An optional port to use for all nodes if not configured in the seeds setting. | 9160 |
opentsdb Bigtable Bigtable
========
[Google Cloud Platform](https://cloud.google.com/) provides hosting of Google's Bigtable database, the original inspiration of HBase and many NoSQL storage systems. Because HBase is so similar to Bigtable, running OpenTSDB 2.3 and later with Google's backend is simple. Indeed, the schemas (see [*HBase Schema*](hbase)) are exactly the same so all you have to do is create your Bigtable instance, create your TSDB tables using the Bigtable HBase shell, and fire up the TSDs.
Note
The clients for Bigtable are in beta and undergoing a number of changes. Performance should improve as we adjust the code and uncover new tuning parameters. Please help us out on the mailing list or by modifying the code in GitHub.
Setup
-----
1. Setup your Google Cloud Platform account.
2. Follow the steps in [Creating a Cloud Bigtable Cluster](https://cloud.google.com/bigtable/docs/creating-cluster).
3. Follow the steps in [HBase Shell Quickstart](https://cloud.google.com/bigtable/docs/hbase-shell-quickstart), paying attention to where you download your JSON key file.
4. Set the HBASE\_HOME environment variable to your Bigtable shell directory, make sure the HBASE\_CLASSPATH, JAVA\_HOME, and GOOGLE\_APPLICATION\_CREDENTIALS environment variables have been set according to the values in Creating a Cloud BigTable Cluster document, and run the src/create\_table.sh script. If the script fails to launch the shell, try running the shell manually and execute the create statements substituting the proper values.
5. Build TSDB by executing sh build-bigtable.sh (or if you prefer Maven, sh build-bigtable.sh pom.xml)
6. Prepare the opentsdb.conf file with the required and/or optional configuration parameters below.
7. Run the TSD via build/tsdb tsd --config=<path>/opentsdb.conf
Configuration
-------------
The following is a table of required and optional parameters to run OpenTSDB with Bigtable. These are in addition to the standard TSD configuration parameters from [*Configuration*](../configuration).
| Property | Type | Required | Description | Default |
| --- | --- | --- | --- | --- |
| google.bigtable.project.id | String | Required | The project ID hosting your Bigtable cluster. | |
| google.bigtable.cluster.name | String | Required | The cluster ID you assigned to your Bigtable cluster at creation. | |
| google.bigtable.zone.name | String | Required | The zone where your Bigtable cluster is operating; chosen at creation. | |
| hbase.client.connection.impl | String | Required | The class that will be used to implement the HBase API AsyncBigtable will use as a shim between the Bigtable client and OpenTSDB. Set this to com.google.cloud.bigtable.hbase1\_0.BigtableConnection | |
| google.bigtable.auth.service.account.enable | Boolean | Required | Whether or not to use a Google cloud service account to connect. Set this to true | false |
| google.bigtable.auth.json.keyfile | String | Required | The full path to the JSON formatted key file associated with the service account you want to use for Bigtable access. Download this from your cloud console. | |
| google.bigtable.grpc.channel.count | Integer | Optional | The number of sockets opened to the Bigtable API for handling RPCs. For higher throughput consider increasing the channel count. | 4 |
Note
Google's Bigtable client communicates with their servers over HTTP2 with TLS using ALPN. As Java 7 and 8 (dunno about 9) lack native ALPN support, a [library](http://www.eclipse.org/jetty/documentation/current/alpn-chapter.html) must be loaded at JVM start to modify the JVM's bytecode. The build script for OpenTSDB will attempt to detect your JDK version and download the proper version of ALPN but if you have a custom JVM or something other than Hotspot or OpenJDK you may run into issues. Try different versions of the alpn-boot JAR to see what works for you.
opentsdb CLI Tools CLI Tools
=========
OpenTSDB consists of a single JAR file that uses a shell script to determine what actiosn the user wants to take. While the most common action is to start the TSD with the `tsd` command so that it can run all the time and process RPCs, other commands are available to work with OpenTSDB data. These commands include:
* <uid>
* <mkmetric>
* <import>
* <query>
* <fsck>
* <scan>
* <search>
* <tsd>
Accessing a CLI tool is performed from the location of the `tsdb` file, built after compiling OpenTSDB. By default the tsdb file will be located in the `build` directory so you may access it via `./build/tsdb`. Provide the name of the CLI utility as in `./build/tsdb tsd`.
Common Parameters
-----------------
All command line utilities share some common command line parameters:
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| --config | String | The full or relative path to an OpenTSDB [*Configuration*](../configuration) file. If this parameter is not provided, the command will attempt to load the default config file. | See [*Configuration*](../configuration) | --config=/usr/local/tempconfig.conf |
| --table | String | Name of the HBase table where datapoints are stored | tsdb | --table=prod-tsdb |
| --uidtable | String | Name of the HBase table where UID information is stored | tsdb-uid | --uidtable=prod-tsdb-uid |
| --verbose | Boolean | For some CLI tools, this command will allow for INFO and above logging per the logback.xml config. Otherwise without this flag, some tools may only log WARNing messages. | | |
| --zkbasedir | String | Path under which is the znode for the -ROOT- region | /hbase | --zkbasedir=/prod/hbase |
| --read-only | Boolean | Sets the mode for OpenTSDB | false | --read-only |
| --zkquorum | String | Specification of the ZooKeeper quorum to use, i.e. a list of servers and/or ports in the ZooKeeper cluster | localhost | --zkquorum=zkhost1,zkhost2,zkhost3 |
Site-specific Configuration
---------------------------
The common parameters above are required by all the CLI commands. It can be tedious to manually type them over and over again. You can instead store typically used values in a file `./tsdb.local`. This file is expected to be a shell script and will be sourced by `./tsdb` if it exists.
*Setting default values for common parameters*
If, for example, your ZooKeeper quorum is behind the DNS name "zookeeper.example.com" (a name with 5 A records), instead of always passing `--zkquorum=zookeeper.example.com` to the CLI tool each time you use it, you can create `./tsdb.local` with the following contents:
```
#!/bin/bash
MY_ARGS='--zkquorum=zookeeper'
set x $MY_ARGS "$@"
shift
```
*Overriding the timezone of the TSD*
Servers are frequently using UTC as their timezone. By default, the TSD renders graphs using the local timezone of the server. You can override this to have graphs in your local time by specifying a timezone in `./tsdb.local`. For example, if you're in California, this will force the TSD to use your timezone:
```
echo export TZ=PST8PDT >>tsdb.local
```
On most Linux and BSD systems, you can look under `/usr/share/zoneinfo` for names of timezones supported on your system.
*Changing JVM parameters*
You might want to adjust JVM parameters, for instance to turn on GC activity logging or to set the size of various memory regions. In order to do so, simply set the variable JVMARGS in `./tsdb.local`.
Here is an example that is recommended for production use:
```
GCARGS="-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps\
-XX:+PrintTenuringDistribution -Xloggc:/tmp/tsd-gc-`date +%s`.log"
if test -t 0; then # if stdin is a tty, don't turn on GC logging.
GCARGS=
fi
# The Sun JDK caches all name resolution results forever, which is stupid.
# This forces you to restart your application if any of the backends change
# IP. Instead tell it to cache names for only 10 minutes at most.
FIX_DNS='-Dsun.net.inetaddr.ttl=600'
JVMARGS="$JVMARGS $GCARGS $FIX_DNS"
```
opentsdb tsd tsd
===
The TSD command launches the OpenTSDB daemon in the foreground so that it can accept connections over TCP and HTTP. If successful, you should see a number of messages then:
```
2014-02-26 18:33:02,472 INFO [main] TSDMain: Ready to serve on 0.0.0.0:4242
```
The daemon will continue to run until killed via a Telnet or HTTP command is sent to tell it to stop. If an error occurred, such as failure to connect to Zookeeper or the inability to bind to the proper interface and port, an error will be logged and the daemon will exit.
Note that the daemon does not fork and run in the background.
opentsdb scan scan
====
The scan command is useful for debugging and exporting data points. Provide a start time, optional end time and one or more queries and the response will be raw byte data from storage or data points in a text format acceptable for use with the **import** command. Scan also provides a rudimentary means of deleting data. The scan command accepts common CLI arguments. Data is emitted to standard out.
Note that while queries require an aggregator, it is effectively ignored. If a query encompasses many time series, the scan output may be extremely large so be careful when crafting queries.
Parameters
----------
```
scan [--delete|--import] START-DATE [END-DATE] query [queries...]
```
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| --delete | Flag | Optional flag that deletes data in any row that matches the query. See warning below. | Not set | --delete |
| --import | flag | Optional flag that outputs results in a text format useful for importing or storing as a backup. | Not set | --import |
| START-DATE | String or Integer | Starting time for the query. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | | 1h-ago |
| END-DATE | String or Integer | Optional end time for the query. If not provided, the current time is used. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | Current timestamp | 2014/01/01-00:00:00 |
| query | String | One or more command line queries | | sum tsd.hbase.rpcs type=put |
Example:
```
scan --import 1h-ago now sum tsd.hbase.rpcs type=put sum tsd.hbase.rpcs type=scan
```
Warning
If you include the `--delete` flag, **ALL** data in 'any' row that matches on the query will be deleted permanently. Rows are separated on 1 hour boundaries so that if you issued a scan command with a start and end time that covered 10 minutes within a single hour, the entire hour of data will be deleted.
Deletions will also delete any Annotations or non-TSDB related data in a row.
Note
The scan command returns data on row boundaries (1 hour) so results may include data previous to and after the specified start and end times.
Raw Output
----------
The default output for `scan` is a raw dump of the rows and columns that match the given queries. This is useful in debugging situations such as data point collisions or encoding issues. As the output includes raw byte arrays and the format changes slightly depending on the data, it is not easily machine paresable.
Row keys, column qualifiers and column values are emitted as Java byte arrays. These are surrounded by square brackets and individual bytes are represented as signed integers (as Java does not have native unsigned ints). Row keys are printed first followed by a new line. Then each column is printed on it's own row and is indented with two spaces to indicate it belongs to the previous row. If a compacted column is found, the raw data and number of compacted values is printed followed by a new line. Each compacted data point is printed on it's own indented line. Annotations are also emitted in raw mode.
The various formats are listed below. The `\t` expression represents a tab. `space` indicates a space character.
### Row Key Format
```
[<row key>] <metric name> <row timestamp> (<datetime>) <tag/value pairs>
```
Where:
>
> * **row key** Is the raw byte array of the row key
> * **metric name** Is the decoded name of the metric the row represents
> * **row timestamp** Is the base timestamp of the row in seconds (on 1 hour boundaries)
> * **datetime** Is the system default formatted human readable timestamp
> * **tag/value pairs** Are the tags associated with the time series
>
>
>
Example:
```
[0, 0, 1, 80, -30, 39, 0, 0, 0, 1, 0, 0, 1] sys.cpu.user 1356998400 (Mon Dec 31 19:00:00 EST 2012) {host=web01}
```
### Single Data Point Column Format
```
<two spaces>[<qualifier>]\t[<value>]\t<offset>\t<l|f>\t<timestamp>\t(<datetime>)
```
Where:
>
> * **qualifier** Is the raw byte array of the column qualifier
> * **value** Is the raw byte array of the column value
> * **offset** Is the number of seconds or milliseconds (based on timestamp) of offset from the row base timestamp
> * **l|f** Is either `l` to indicate the value is an Integer (Java Long) or `f` for a floating point value.
> * **timestamp** Is the absolute timestamp of the data point in seconds or milliseconds
> * **datetime** Is the system default formatted human readable timestamp
>
>
>
Example:
```
[0, 17] [0, 17] [1, 1] 1 l 1356998401 (Mon Dec 31 19:00:01 EST 2012)
```
### Compacted Column Format
```
<two spaces>[<qualifier>]\t[<value>] = <number of datapoints> values:
```
Where:
>
> * **qualifier** Is the raw byte array of the column qualifier
> * **value** Is the raw byte array of the column value
> * **number of datapoints** Is the number of data points in the compacted column
>
>
>
Example:
```
[-16, 0, 0, 7, -16, 0, 2, 7, -16, 0, 1, 7] [0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, 6, 0] = 3 values:
```
Each data point within the compacted column follows the same format as a single column with the addition of two spaces of indentation.
### Annotation Column Format
```
<two spaces>[<qualifier>]\t[<value>]\t<offset>\t<JSON\>\t<timestamp\>\t(<datetime>)
```
Where:
>
> * **qualifier** Is the raw byte array of the column qualifier
> * **value** Is the raw byte array of the column value
> * **offset** Is the number of seconds or milliseconds (based on timestamp) of offset from the row base timestamp
> * **JSON** Is the decoded JSON data stored in the column
> * **timestamp** Is the absolute timestamp of the data point in seconds or milliseconds
> * **datetime** Is the system default formatted human readable timestamp
>
>
>
Example:
```
[1, 0, 0] [123, 34...] 0 {"tsuid":"000001000001000001","startTime":1356998400,"endTime":0,"description":"Annotation on seconds","notes":"","custom":null} 1356998416000 (Mon Dec 31 19:00:16 EST 2012)
```
Import Format
-------------
The import format is the same as a Telnet style `put` command.
```
<metric> <timestamp> <value> <tagk=tagv>[...<tagk=tagv>]
```
Where:
>
> * **metric** Is the name of the metric as a string
> * **timestamp** Is the absolute timestamp of the data point in seconds or milliseconds
> * **value** Is the value of the data point
> * **tagk=tagv** Are tag name/value pairs separated by spaces
>
>
>
Example:
```
sys.cpu.user 1356998400 42 host=web01 cpu=0
sys.cpu.user 1356998401 24 host=web01 cpu=0
```
opentsdb mkmetric mkmetric
========
mkmetric is a shortcut to the `uid assign metrics <metric>` command where you can provide multiple metric names in a single call and UIDs will be assigned or retrieved. If any of the metrics already exist, the assigned UID will be returned.
Parameters
----------
```
mkmetric metric [metrics]
```
Simply supply one or more space separate metric names in the call.
Example
```
mkmetric sys.cpu.user sys.cpu.nice sys.cpu.idle
```
Response
--------
The response is the literal "metrics" followed by the name of the metric and a Java formatted byte array representing the UID assigned or retrieved for each metric, one per line.
Example
```
metrics sys.cpu.user: [0, 0, -58]
metrics sys.cpu.nice: [0, 0, -57]
metrics sys.cpu.idle: [0, 0, -59]
```
opentsdb import import
======
The import command enables bulk loading of time series data into OpenTSDB. You provide one or more files and OpenTSDB will parse and load the data. Data must be formatted in the Telnet `put` style with one data point per line in a text file. Each file may optionally be compressed with GZip and if so, must end with the `.gz` extension.
For more information on storing data in OpenTSDB, please see `../writing`
Parameters
----------
```
import path [...paths]
```
Paths may be absolute or relative
Example
```
import /home/hobbes/timeseries1.gz /home/hobbes/timeseries2.gz
```
Input Format
------------
The format is the same as the Telnet `put` interface.
> <metric> <timestamp> <value> <tagk=tagv> [<tagkN=tagvN>]
>
Where:
>
> * **metric** Is the name of the metric. Note that the metric name may not include spaces.
> * **timestamp** Is the absolute timestamp of the data point in seconds or milliseconds
> * **value** Is the value to store
> * **tagk=tagv** Is a pair of one or more space sparate tag name and value pairs. Note that the tags may not have spaces in them.
>
>
>
Example:
> sys.cpu.user 1356998400 42 host=web01 cpu=0
>
Successful processing will result in responses like:
> 23:07:05.323 [main] INFO net.opentsdb.tools.TextImporter - Processed file in 22 ms, 2 data points (90.9 points/s)
>
However if an error occurs, the importer will stop and the errant line will be printed. For example:
> 23:07:06.375 [main] ERROR net.opentsdb.tools.TextImporter - Exception caught while processing file timeseries1.gz line=sys.cpu.system 1356998400 42 host=web02 novalue=
>
Warning
Data points processed up to the error are written to storage. You should edit the file and clear all data points up to the line where the error occurred. If you fix the line and restart the import, conflicts may occur with the existing data. Future updates to OpenTSDB will handle this situation gracefully.
| programming_docs |
opentsdb query query
=====
The query command line tool is meant to be a quick debugging tool for extracting data from OpenTSDB. The HTTP API will usually be much quicker when querying data as it incorprates caches and open connections to storage. Results are printed to stdout in a text format with one data point per line.
Note that a query may return data points before and after the timespan requested. These are used in downsampling and graphing.
Parameters
----------
```
query [Gnuplot opts] START-DATE [END-DATE] <aggregator> [rate] [counter,max,reset] [downsample N FUNC] <metric> [<tagk=tagv>] [...<tagk=tagv>] [...queries]
```
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| Gnuplot opts | Strings | Optional values used to generate Gnuplot scripts and graphs. Note that the actual graph PNG will not be generated, only the files (written to the temp directory) | | +wxh=1286x836 |
| START-DATE | String or Integer | Starting time for the query. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | | 1h-ago |
| END-DATE | String or Integer | Optional end time for the query. If not provided, the current time is used. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | Current timestamp | 2014/01/01-00:00:00 |
| aggregator | String | A function to use when multiple timeseries are included in the results | | sum |
| rate | String | The literal `rate` if the timeseries represents a counter and the results should be returned as delta per second | | rate |
| counter | String | Optional literal `counter` that indicates the underlying data is a monotonically increasong counter that may roll over | | counter |
| max | Integer | A positive integer representing the maximum value for the counter | Java Long.MaxValue | 65535 |
| resetValue | Integer | An optional value that, when exceeded, will cause the aggregator to return a 0 instead of the calculated rate. Useful when data sources are frequently reset to avoid spurious spikes. | | 65000 |
| downsample N FUNC | String | Optional downsampling specifier to group data into larger time spans and reduce the amount of data returned. Format is the literal `downsample` followed by a timespan in milliseconds and an aggregation function name | | downsample 300000 avg |
| metric | String | Required name of a metric to query for | | sys.cpu.user |
| tagk=tagv | String | Optional pairs of tag names and tag values | | host=web01 |
| additional queries | String | Optional additional queries to execute. Each query must follow the same format starting with an aggregator. All queries share the same start and end times. | | sum tsd.hbase.rpcs type=scan |
For more details on querying, please see [*Querying or Reading Data*](../query/index).
Example:
```
query 1h-ago now sum tsd.hbase.rpcs type=put sum tsd.hbase.rpcs type=scan
```
Output Format
-------------
Data is printed to stdout with one data point per line. If one or more Gnuplot options were specified, then scripts and data files for each query will be written to the configured temporary directory.
> <metric> <timestamp> <value> {<tagk=tagv>[,..<tagkN=tagvN>]}
>
Where:
>
> * **metric** Is the name of the metric queried
> * **timestamp** Is the absolute timestamp of the data point in seconds or milliseconds
> * **value** Is the data point value
> * **tagk=tagv** Is a list of common tag name and value pairs for all timeseries represented in the query
>
>
>
Example:
```
tsd.hbase.rpcs 1393376401000 28067146491 {type=put, fqdn=tsdb-data-1}
tsd.hbase.rpcs 1393376461000 28067526510 {type=put, fqdn=tsdb-data-1}
tsd.hbase.rpcs 1393376521000 28067826659 {type=put, fqdn=tsdb-data-1}
tsd.hbase.rpcs 1393376581000 28068126093 {type=put, fqdn=tsdb-data-1}
```
opentsdb search search
======
Note
Available in 2.1
The search command allows for searching OpenTSDB to reteive a list of time series or associated meta data. Search does not return actual data points or time series objects stored in the data table. Use the query tools to access that data. Currently only the `lookup` command is implemented.
Lookup
------
Lookup queries use either the meta data table or the main data table to determine what time series are associated with a given metric, tag name, tag value, tag pair or combination thereof. For example, if you want to know what metrics are available for a tag pair `host=web01` you can execute a lookup to find out.
Note
By default lookups are performed against the `tsdb-meta` table. You must enable real-time meta data creation or perform a `metasync` using the `uid` command in order to retreive data from a lookup. Alternatively you can lookup against the raw data table but this can take a very long time depending on how much data is in your system.
### Command Format
```
search lookup <query>
```
### Parameters
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| query | String | One or more command line queries similar to a data CLI query. See the query section below. | | tsd.hbase.rpcs type= |
| --use\_data\_table | Flag | Optional flag that will cause the lookup to run against the main `tsdb-data` table. *NOTE:* This can take a very long time to complete. | Not set | --use\_data\_table |
### Query Format
For details on crafting a query, see [*/api/search/lookup*](../../api_http/search/lookup). The CLI query is similar to an API query but spaces are used as separators instead of commas and curly braces are not used.
```
[<metric>] [[tagk]=[tagv]] ...[[tagk]=[tagv]]
```
At least one metric, tagk or tagv is required.
### Example Command
```
search lookup tsd.hbase.rpcs type=
```
### Output
During a lookup, the results will be printed to standard out. Note that if you have logging enabled, messages may be interspersed with the results. Set the logging level to WARN or ERROR in the `logback.xml` configuration to supress these warnings. You may want to run the lookup in the background and capture standard out to a file, particularly when running lookups against the data table as these may take a long time to complete.
```
<tsuid> <metric name> <tag/value pairs>
```
Where:
>
> * **tsuid** Is the hex encoded UID of the time series
> * **metric name** Is the decoded name of the metric the row represents
> * **tag/value pairs** Are the tags associated with the time series
>
>
>
### Example Response
```
0023E3000002017358000006017438 tsd.hbase.rpcs type=openScanner host=tsdb-1.mysite.com
```
Note
During scanning, if the UID for a metric, tag name or tag value cannot be resolved to a name, an exception will be thrown.
opentsdb uid uid
===
The UID utility provides various functions to search or modify information in the `tsdb-uid` table. This includes UID assignments for metrics, tag names and tag values as well as UID meta data, timeseries meta data and tree definitions or data.
Use the UID utility with the command line:
```
uid <subcommands> [arguments]
```
Common CLI Parameters
---------------------
Parameters specific to the UID utility include:
Lookup
------
The lookup command is the default for `uid` used to lookup the UID assigned to a name or the name assinged to a UID for a given type.
### Command Format
```
<kind> <name>
<kind> <UID>
```
### Example Command
```
./tsdb uid tagk host
```
### Example Response
```
tagk host: [0, 0, 1]
```
grep
----
The grep sub command performs a regular expression search for the given UID type and returns a list of all UID names that match the expression. Fields required for the grep command include:
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| kind | String | The type of the UID to search for. Must be one of `metrics`, `tagk` or `tagv` | | tagk |
| expression | String | The regex expression to search with | | disk.\*write |
### Command Format
```
grep <kind> '<expression>'
```
### Example Command
```
./tsdb uid grep metrics 'disk.*write'
```
### Example Response
```
metrics iostat.disk.msec_write: [0, 3, -67]
metrics iostat.disk.write_merged: [0, 3, -69]
metrics iostat.disk.write_requests: [0, 3, -70]
metrics iostat.disk.write_sectors: [0, 3, -68]
```
assign
------
This sub command is used to assign IDs to new unique names for metrics, tag names or tag values. Supply a list of one or more values to assign UIDs and the list of assignments will be returned.
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| kind | String | The type of the UID the names represent. Must be one of `metrics`, `tagk` or `tagv` | tagk |
| name | String | One or more names to assign UIDs to. Names must not be in quotes and cannot contain spaces. | owner |
### Command Format
```
assign <kind> <name> [<name>...]
```
### Example Command
```
./tsdb uid assign metrics disk.d0 disk.d1 disk.d2 disk.d3
```
### Example Response
rename
------
Changes the name of an already assigned UID. If the UID of the given type does not exist, an error will be returned.
Note
After changing a UID name you must flush the cache (see [*/api/dropcaches*](../../api_http/dropcaches)) or restart all TSDs for the change to take effect. TSDs do not periodically reload UID maps.
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| kind | String | The type of the UID the name represent. Must be one of `metrics`, `tagk` or `tagv` | tagk |
| name | String | The existing UID name | owner |
| newname | String | The new name UID name | server\_owner |
### Command Format
```
rename <kind> <name> <newname>
```
### Example Command
```
./tsdb uid rename metrics disk.d0 disk.d0.bytes_read
```
delete
------
Removes the mapping of the UID from the `tsdb-uid` table. Make sure all sources are no longer writing data using the UID and that sufficient time has passed so that users would not query for data that used the UIDs.
Note
After deleting a UID, it may still remain in the caches of running TSD servers. Make sure to flush their caches after deleting an entry.
Warning
Deleting a UID will not delete the underlying data associated with the UIDs (we're working on that). For metrics this is safe, it won't affect queries. But for tag names and values, if a query scans over data containing the old UID, the query will fail with an exception because it can no longer find the name mapping.
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| kind | String | The type of the UID the name represent. Must be one of `metrics`, `tagk` or `tagv` | tagk |
| name | String | The existing UID name | owner |
### Command Format
```
delete <kind> <name>
```
### Example Command
```
./tsdb uid delete disk.d0
```
fsck
----
The UID FSCK command will scan the entire UID table for errors pertaining to name and UID mappings. By default, the run will scan every column in the table and log any errors that were found. With version 2.1 it is possible to fix errors in the table by passing the "fix" flag. UIDMeta objects are skipped during scanning. Possible errors include:
| Error | Description | Fix |
| --- | --- | --- |
| Max ID for metrics is 42 but only 41 entries were found. Maybe 1 IDs were deleted? | This indicates one or more UIDs were not used for mapping entries. If a UID was deleted, this message is normal. If UIDs were not deleted, this can indicate wasted UIDs due to auto-assignments by TSDs where data was coming in too fast. Try assigning UIDs up-front as much as possible. | No fix necessary |
| We found an ID of 42 for metrics but the max ID is only 41! Future IDs may be double-assigned! | If this happens it is usually due to a corruption and indicates the max ID row was not updated properly. | Set the max ID row to the largest detected value |
| Invalid maximum ID for metrics: should be on 8 bytes | Indicates a corruption in the max ID row. | No fix yet. |
| Forward metrics mapping is missing reverse mapping: foo -> 000001 | This may occur if a TSD crashes before the reverse map is written and would only prevent queries from executing against time series using the UID as they would not be able to lookukp the name. | The fix is to restore the missing reverse map. |
| Forward metrics mapping bar -> 000001 is different than reverse mapping: 000001 -> foo | The reverse map points to a different name than the forward map and this should rarely happen. It will be paired with another message. | Depends on the second message |
| Inconsistent forward metrics mapping bar -> 000001 vs bar -> foo / foo -> 000001 | With a forward/reverse miss-match, it is possible that a UID was assigned to multiple names for the same type. If this occurs, then data for two different names has been written to the same time series and that data is effectively corrupt. | The fix is to delete the forward maps for all names that map to the same UID. Then the UID is given a new name that is a dot seperated concatenation of the previous names with an "fsck" prefix. E.g. in the example above we would have a new name of "fsck.bar.foo". This name may be used to access data from the corrupt time series. The next time data is written for the errant names, new UIDs will be assigned to each and new time series created. |
| Duplicate forward metrics mapping bar -> 000002 and null -> foo | In this case the UID was not used more than once but the reverse mapping was incorrect. | The reverse map will be restored, in this case: 000002 -> bar |
| Reverse metrics mapping is missing forward mapping: bar -> 000002 | A reverse map was found without a forward map. The UID may have been deleted. | Remove the reverse map |
| Inconsistent reverse metrics mapping 000003 -> foo vs 000001 -> foo / foo -> 000001 | If an orphaned reverse map points to a resolved forward map, this error occurs. | Remove the reverse map |
**Options**
* fix - Attempts to fix errors per the table above
* delete\_unknown - Removes any columns in the UID table that do not belong to OpenTSDB
### Command Format
```
fsck [fix] [delete_unknown]
```
### Example Command
```
./tsdb uid fsck fix
```
### Example Response
```
INFO [main] UidManager: ----------------------------------
INFO [main] UidManager: - Running fsck in FIX mode -
INFO [main] UidManager: - Remove Unknowns: false -
INFO [main] UidManager: ----------------------------------
INFO [main] UidManager: Maximum ID for metrics: 2
INFO [main] UidManager: Maximum ID for tagk: 4
INFO [main] UidManager: Maximum ID for tagv: 2
ERROR [main] UidManager: Forward tagk mapping is missing reverse mapping: bar -> 000004
INFO [main] UidManager: FIX: Restoring tagk reverse mapping: 000004 -> bar
ERROR [main] UidManager: Inconsistent reverse tagk mapping 000003 -> bar vs 000004 -> bar / bar -> 000004
INFO [main] UidManager: FIX: Removed tagk reverse mapping: 000003 -> bar
ERROR [main] UidManager: tagk: Found 2 errors.
INFO [main] UidManager: 17 KVs analyzed in 334ms (~50 KV/s)
WARN [main] UidManager: 2 errors found.
```
metasync
--------
This command will run through the entire data table, scanning each row of timeseries data and generate missing TSMeta objects and UIDMeta objects or update the created timestamps for each object type if necessary. Use this command after enabling meta tracking with existing data or if you suspect that some timeseries may not have been indexed properly. The command will also push new or updated meta entries to a search engine if a plugin has been configured. If existing meta is corrupted, meaning the TSD is unable to deserialize the object, it will be replaced with a new entry.
It is safe to run this command at any time as it will not destroy or overwrite valid data. (Unless you modify columns directly in HBase in a manner inconsistent with the meta data formats). The utility will split the data table into chunks processed by multiple threads so the more cores in your processor, the faster the command will complete.
### Command Format
```
metasync
```
### Example Command
```
./tsdb uid metasync
```
metapurge
---------
This sub command will mark all TSMeta and UIDMeta objects for deletion in the UID table. This is useful for downgrading from 2.0 to a 1.x version or simply flushing all meta data and starting over with a `metasync`.
### Command Format
```
metapurge
```
### Example Command
```
./tsdb uid metapurge
```
treesync
--------
Runs through the list of TSMeta objects in the UID table and processes each through all configured and enabled trees to compile branches. This command may be run at any time and will not affect existing objects.
### Command Format
```
treesync
```
### Example Command
```
./tsdb uid treesync
```
treepurge
---------
Removes all branches, collision, not matched data and optionally the tree definition itself for a given tree. Parameters include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| id | Integer | ID of the tree to purge | 1 |
| definition | Flag | Add this literal after the ID to delete the definition of the tree as well as the data | definition |
### Command Format
```
treepurge <id> [definition]
```
### Example Command
```
./tsdb uid treepurge 1
```
opentsdb fsck fsck
====
Similar to a file system check, the fsck command will scan and, optionally, attempt to repair problems with data points in OpenTSDB's data table. The fsck command only operates on the `tsdb` storage table, scanning the entire data table or any rows of data that match on a given query. Fsck can be used to repair errors and also reclaim space by compacting rows that were not compacted by a TSD and variable-length encoding data points from previous versions of OpenTSDB.
By default, running fsck will only report errors found by the query. No changes are made to the underlying data unless you supply the `--fix` or `--fix-all` flags. Generally you should run an fsck without a fix flag first and verify issues found in the log file. If you're confident in the repairs, add a fix flag. Not all errors can be repaired automatically.
Warning
Running fsck with `--fix` or `--fix-all` may delete data points, columns or entire rows and deleted data is unrecoverable unless you restore from a backup. (or perform some HBase trickery to restore the data before a major compaction)
Note
This page documents the OpenTSDB 2.1 fsck utility. For previous versions, only the `--fix` flag is available and only data within a query may be fsckd.
Parameters
----------
```
fsck [flags] [START-DATE [END-DATE] query [queries...]]
```
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| --fix | Flag | Optional flag that will attempt to repair errors. By itself, fix will only repair sign extension bugs, 8 byte floats with 4 byte qualifiers and VLE stand-alone data points. Use in conjunction with other flags to repair more issues. | Not set | --fix |
| --fix-all | Flag | Sets all repair flags to attempt to fix all issues at once. **Use with caution** | Not set | --fix |
| --compact | Flag | Compacts non-compacted rows during a repair. | Not Set | --compact |
| --delete-bad-compacts | Flag | Removes columns that appear to be compacted but failed parsing. If a column parses properly but the final byte of the value is not set to a 0 or a 1, the column will be left alone. | Not Set | --delete-bad-compacts |
| --delete-bad-rows | Flag | Removes any row that doesn't match the OpenTSDB row key format of a metric UID followed by a timestamp and tag UIDs. | Not Set | --delete-bad-rows |
| --delete-bad-values | Flag | Removes any stand-alone data points that could not be repaired or did not conform to the OpenTSDB specification. | Not Set | --delete-bad-values |
| --delete-orphans | Flag | Removes rows where one or more UIDs could not be resolved to a name. | Not Set | --delete-orphans |
| --delete-unknown\_columns | Flag | Removes any column that does not appear to be a compacted column, a stand-alone data point or a known or future OpenTSDB object. | Not Set | --delete-unknown-columns |
| --resolve-duplicates | Flag | Enables duplicate data point resolution by deleting all but the latest or oldest data point. Also see `--last-write-wins`. | Not Set | --resolve-duplicates |
| --last-write-wins | Flag | When set, deletes all but the most recently written data point when resolving duplicates. If the config value `tsd.storage.fix\_duplicates` is set to true, then the latest data point will be kept regardless of this value. | Not Set | --last-write-wins |
| --full-scan | Flag | Scans the entire data table. **Note:** This can take a very long time to complete. | Not Set | --full-scan |
| --threads | Integer | The number of threads to use when performing a full scan. The default is twice the number of CPU cores. | 2 x CPU Cores | --threads=16 |
| START-DATE | String or Integer | Starting time for the query. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | | 1h-ago |
| END-DATE | String or Integer | Optional end time for the query. If not provided, the current time is used. This may be an absolute or relative time. See [*Dates and Times*](../query/dates) for details | Current timestamp | 2014/01/01-00:00:00 |
| query | String | One or more command line queries | | sum tsd.hbase.rpcs type=put |
Examples
--------
**Query**
```
fsck --fix 1h-ago now sum tsd.hbase.rpcs type=put sum tsd.hbase.rpcs type=scan
```
**Full Table**
```
fsck --full-scan --threads=8 --fix --resolve-duplicates --compact
```
Full Table Vs Queries
---------------------
Using the `--full-scan` flag, the entire OpenTSDB `tsdb` data table will be scanned. By default the utility will launch `2 x CPU core` threads for optimal performance. Data is stored with the metric UID as the start of each row key so the utility will determine the maximum metric UID and split up the main data table equally among threads. If your data is distributed among metrics fairly evenly, then each thread should complete in roughly the same amount of time. However some metrics usually have more data or time series than others so these threads may be running much longer than others. Future updates to OpenTSDB will be able to divy up the workload in a more efficient manner.
Alternatively you can spcify a CLI query to fsck over a smaller timespan and look at a specific metric or time series. These queries will almost always complete much faster than a full scan and will uncover similar issues. However orphaned metrics will not found as the query will only operate on known time series. Orphans where tag names or values have been deleted will still be found.
Regardless of the method used, fsck only looks at the most recent column value in HBase. If the table is configured to store multiple versions, older versions of a column are ignored.
Results
-------
The results will be logged with settings in the `logback.xml` file. For long fscks, it's recommended to run in the background and configure LogBack to have plenty of space for writing data. On completion, statistics about the run will be printed. An example looks like:
```
2014-07-07 13:09:15,610 INFO [main] Fsck: Starting full table scan
2014-07-07 13:09:15,619 INFO [main] Fsck: Max metric ID is [0]
2014-07-07 13:09:15,619 INFO [main] Fsck: Spooling up [1] worker threads
2014-07-07 13:09:16,358 INFO [main] Fsck: Thread [0] Finished
2014-07-07 13:09:16,358 INFO [main] Fsck: Key Values Processed: 301
2014-07-07 13:09:16,358 INFO [main] Fsck: Rows Processed: 1
2014-07-07 13:09:16,359 INFO [main] Fsck: Valid Datapoints: 300
2014-07-07 13:09:16,359 INFO [main] Fsck: Annotations: 1
2014-07-07 13:09:16,359 INFO [main] Fsck: Invalid Row Keys Found: 0
2014-07-07 13:09:16,360 INFO [main] Fsck: Invalid Rows Deleted: 0
2014-07-07 13:09:16,360 INFO [main] Fsck: Duplicate Datapoints: 0
2014-07-07 13:09:16,360 INFO [main] Fsck: Duplicate Datapoints Resolved: 0
2014-07-07 13:09:16,361 INFO [main] Fsck: Orphaned UID Rows: 0
2014-07-07 13:09:16,361 INFO [main] Fsck: Orphaned UID Rows Deleted: 0
2014-07-07 13:09:16,361 INFO [main] Fsck: Possible Future Objects: 0
2014-07-07 13:09:16,362 INFO [main] Fsck: Unknown Objects: 0
2014-07-07 13:09:16,362 INFO [main] Fsck: Unknown Objects Deleted: 0
2014-07-07 13:09:16,362 INFO [main] Fsck: Unparseable Datapoint Values: 0
2014-07-07 13:09:16,362 INFO [main] Fsck: Unparseable Datapoint Values Deleted: 0
2014-07-07 13:09:16,363 INFO [main] Fsck: Improperly Encoded Floating Point Values: 0
2014-07-07 13:09:16,363 INFO [main] Fsck: Improperly Encoded Floating Point Values Fixed: 0
2014-07-07 13:09:16,363 INFO [main] Fsck: Unparseable Compacted Columns: 0
2014-07-07 13:09:16,364 INFO [main] Fsck: Unparseable Compacted Columns Deleted: 0
2014-07-07 13:09:16,364 INFO [main] Fsck: Datapoints Qualified for VLE : 0
2014-07-07 13:09:16,364 INFO [main] Fsck: Datapoints Compressed with VLE: 0
2014-07-07 13:09:16,365 INFO [main] Fsck: Bytes Saved with VLE: 0
2014-07-07 13:09:16,365 INFO [main] Fsck: Total Errors: 0
2014-07-07 13:09:16,366 INFO [main] Fsck: Total Correctable Errors: 0
2014-07-07 13:09:16,366 INFO [main] Fsck: Total Errors Fixed: 0
2014-07-07 13:09:16,366 INFO [main] Fsck: Completed fsck in [1] seconds
```
For the most part, these statistics should be self-explanatory. `Key Values Processed` indicates the number of individual columns in HBase. `VLE` referse to `variable length encoding`.
During a run, progress will be reported every 5 seconds so that you know the utility is still working. You should see lines similar to the following:
```
10:14:00.518 INFO [Fsck.run] - Processed 47689680000 rows, 449891670779 valid datapoints
10:14:01.518 INFO [Fsck.run] - Processed 47689730000 rows, 449892264237 valid datapoints
10:14:02.519 INFO [Fsck.run] - Processed 47689780000 rows, 449892880333 valid datapoints
```
Any time an error is found (and possibly fixed), the log will be updated immediately. Errors will usually include the column where the error was found in the output. Byte arrays are represented in either Java style signed bytes, e.g. `[0, 1, -42]` or hex encoded strings, e.g. `00000000000000040000000000000005`. Short-hand references include (k) for the row key, (q) for the qualifier and (v) for the value.
Types of Errors and Fixes
-------------------------
The following is a list of errors and/or fixes that can be found or performed with fsck.
### Bad Row Keys
If a row key is found that doesn't conform to the OpenTSDB data table specification `<metric\_UID><base\_timestamp><tagk1\_UID><tagv1\_UID>[...<tagkn\_UID><tagvn\_UID>]`, the entire row is considered invalid.
```
2014-07-07 15:03:46,483 ERROR [Fsck #0] Fsck: Invalid row key.
Key: 000001
```
*Fix:*
If `--delete-bad-rows` is set, then the entire row will be removed from HBase.
### Orphaned Rows
If a row key is parsed as a proper OpenTSDB row, then the UIDs for the time series ID (TSUID) of the row are resolved to their names. If any of the UIDs does not match a name in the `tsdb-uid` table, then the row is considered an orphan. This can happen if a UID is manually deleted from the UID table or a deletion does not complete properly.
```
2014-07-07 15:08:45,057 ERROR [Fsck #0] Fsck: Unable to resolve the metric from the row key.
Key: 00000150E22700000001000001
No such unique ID for 'metric': [0, 0, 1]
```
*Fix:*
If `--delete-orphans` is set, then the entire row will be removed from HBase.
### Compact Row
While it's not strictly an error, fsck can be used to compact rows into a single column. Compacting rows saves storage space by merging multiple columns into one. This cuts down on HBase overhead. If a TSD that is configured to compact columns crashes, some rows may be missed and remain in stand-alone data point form. As compaction can consume resources, you can use fsck to compact rows when the load on your cluster is reduced.
Specifying the `--compact` flag along with `--fix` will compact any row that has stand-alone data points within the query range. During compaction, any data points from old OpenTSDB versions that qualify for VLE will be re-encoded.
Note
If a row is repaired for any reason and has one or more compacted columns, the row will be re-compacted regardless of the `--compact` flag.
### Bad Compacted Column Error
These errors occur when compacted column is found that cannot be parsed into individual data points. This can happen if the qualifier appears correct but the number of bytes in the value array do not match the lengths encoded in the qualifier. Compacted columns with their data points out of order are not considered bad columns. Instead, the column will be sorted properly and re-written if the `--fix` or `--fix-all` flags are present.
```
2014-07-07 13:29:40,251 ERROR [Fsck #0] Fsck: Corrupted value: couldn't break down into individual values (consumed 20 bytes, but was expecting to consume 24): [k '00000150E22700000001000001' q '000700270033' v '00000000000000040000000000000005000000000000000600'], cells so far: [Cell([0, 7], [0, 0, 0, 0, 0, 0, 0, 4]), Cell([0, 39], [0, 0, 0, 0, 0, 0, 0, 5]), Cell([0, 51], [0, 0, 0, 0])]
```
*Fix:*
The only fix for this error is to delete the column by specifying the `--delete-bad-compacts` flag.
### Compacted Last Byte Error
The last byte of a compacted value is for storing meta data. It will usually be `0` if all of the data points are encoded in seconds or milliseconds. If there is a mixture of seconds and milliseconds will be set to `1`. If the value is something else then it may be from a future version of OpenTSDB or the column may be invalid.
```
18:13:35.979 [main] ERROR net.opentsdb.tools.Fsck - The last byte of a compacted should be 0 or 1. Either this value is corrupted or it was written by a future version of OpenTSDB.
[k '00000150E22700000001000001' q '00070027' v '00000000000000040000000000000005']
```
*Fix:*
Currently this is not repaired. You can manually set the last byte to 0 or 1 to prevent the error from being thrown. The `--delete-bad-compacts` flag will not remove these columns.
### Value Too Long Or Short
This may occur if a value is recorded on greater than 8 bytes for a single data point column. Individual data points are stored on 2 or 4 byte qualifiers. This error cannot happen for a data point within a compacted column. If it was compacted, the column would throw a bad compacted column error as it wouldn't be parseable.
```
2014-07-07 14:50:44,022 ERROR [Fsck #0] Fsck: This floating point value must be encoded either on 4 or 8 bytes, but it's on 9 bytes.
[k '00000150E22700000001000001' q 'F000020B' v '000000000000000005']
```
*Fix:*
`--delete-bad-values` will remove the column.
### Old Version Floats
Early OpenTSDB versions had a bug in the floating point value storage where the first 4 bytes of an 8 byte value were written with all bits set to 1. The value should be on the last four bytes as the qualifier encodes the length as four bytes. However if the invalid data was compacted, the data cannot be parsed properly and an error will be recorded.
```
18:43:35.297 [main] ERROR net.opentsdb.tools.Fsck - Floating point value with 0xFF most significant bytes, probably caused by sign extension bug present in revisions [96908436..607256fc].
[k '00000150E22700000001000001' q '002B' v 'FFFFFFFF43FA6666']
```
*Fix:*
The `--fix` flag will repair these errors by rewriting the value without the first four bytes. The qualifier remains unchanged.
### 4 Byte Floats with 8 Byte Value OK
Some versions of OpenTSDB may have encoded floating point values on 8 bytes when setting the qualifier length to 4 bytes. The first four bytes should be 0. If the value was compacted, the compacted column will be invalid as parsing is no longer possible.
```
2014-07-07 14:33:34,498 WARN [Fsck #0] Fsck: Floating point value was marked as 4 bytes long but was actually 8 bytes long
[k '00000150E22700000001000001' q '000B' v '0000000040866666']
```
*Fix:*
The `--fix` flag will repair these errors by rewriting the value without the first four bytes. The qualifier remains unchanged.
### 4 Byte Floats with 8 Byte Value Bad
In this case a value was encoded on 8 bytes with the first four bytes set to a non-zero value. It could be that the value is an 8 byte double since OpenTSDB never actually encoded on 8 bytes, the value is likely corrupt. If the value was compacted, the compacted column will be invalid as parsing is no longer possible.
```
2014-07-07 14:37:02,717 ERROR [Fsck #0] Fsck: Floating point value was marked as 4 bytes long but was actually 8 bytes long and the first four bytes were not zeroed
[k '00000150E22700000001000001' q '002B' v 'FB02F40F43FA6666']
```
*Fix:*
The `--delete-bad-values` flag will remove the column. You could try parsing the value as a Double manually and see if it looks valid, otherwise it's likely a corrupt column.
### Unknown Object
OpenTSDB 2.0 supports objects such as annotations in the data table. If a column is found that doesn't match an OpenTSDB object, a compacted column or a stand-alone data point, it is considered an unknown object and can likely be deleted.
```
2014-07-07 14:55:03,019 ERROR [Fsck #0] Fsck: Unknown qualifier, must be 2, 3, 5 or an even number of bytes.
[k '00000150E22700000001000001' q '00270401010101' v '0000000000000005']
```
*Fix:*
The `--delete-unknown-columns` flag will remove this column from the row.
### Future Object
Objects are encoded on 3 or 5 byte qualifiers and the type is determined by a prefix. If a prefix is found that OpenTSDB doesn't recognize, then it will report the object but it will not be deleted. Note that this may actually be an unknown or corrupted column as fsck only looks at the qualifier length and the first byte of the qualifier. If that is the case, you can safely delete this column manually.
```
2014-07-07 14:57:15,858 WARN [Fsck #0] Fsck: Found an object possibly from a future version of OpenTSDB
[k '00000150E22700000001000001' q '042704' v '467574757265204F626A656374']
```
*Fix:*
Future objects are left alone during fsck. Querying over the data with a TSD that doesn't support the object will throw an exception but versions that do support the object should procede normally.
### Duplicate Timestamps
Due to the use of encoding length and type for datapoints in qualifiers, it's possible to record a data point for the same timestamp with two different qualifiers. For example if you post an integer value for time `1` and then post a float value for time `1`, two different columns will be created. Duplicates can also happen if a row has been compacted and the TSD writes a new stand-alone column that matches a timestamp in the compacted column. At query time, an exception will be thrown as TSD does not know which value is the correct one.
```
2014-07-07 15:22:43,231 ERROR [Fsck #0] Fsck: More than one column had a value for the same timestamp: (1356998400000)
row key: (00000150E22700000001000001)
write time: (1388534400000) compacted: (false) qualifier: [0, 7] <--- Keep oldest
write time: (1388534400001) compacted: (false) qualifier: [0, 11]
write time: (1388534400002) compacted: (false) qualifier: [0, 3]
write time: (1388534400003) compacted: (false) qualifier: [0, 1]
```
*Fix:*
If `--resolve-duplicates` is set, then all data points except for the latest or the oldest value will be deleted. The fix applies to both stand-alone and compacted data points. If the `--last-write-wins` flag is set, then the latest value is saved. Without the `--last-write-wins` flag, then the oldest value is saved.
Note
If the `tsd.storage.fix\_duplicates` configuration value is set to `true` then the latest value will be saved regardless of `--last-write-wins`.
Note
With compactions enabled, it is possible (though unlikely) that a data point is written while a row is being compacted. In this case, the compacted column will have a *later* timestamp than a data point written during the compaction. Therefore the default result of `--resolve-duplicates` will keep the stand-alone data point or, if last writes win, then the compacted value.
### Variable-Length Encoding
Early OpenTSDB implementations always encoded integer values on 8 bytes. With 2.0, integers were written on the smallest number of bytes possible, either 1, 2, 4 or 8. During fsck, any 8 byte encoded integers detected will be re-written with VLE if the `--fix` or `--fix-all` flags are specified. This includes stand-alone and compacted values. At the end of a run, the number of bytes saved with VLE are displayed.
| programming_docs |
opentsdb clean_cache.sh clean\_cache.sh
===============
OpenTSDB uses a directory for caching graphs and gnuplot scripts. Unfortunately it doesn't clean up after itself at this time so a simple shell script is included to purge all files in the directory if drive where the directory resides drops below 10% of free space. Simply add this script as a cron entry and set it to run as often as you like.
Warning
This script will purge all files in the directory. Don't store anything important in the temp directory.
opentsdb Utilities Utilities
=========
This page lists some of the utilities or projects included with OpenTSDB or maintained by the OpenTSDB group. Additional utilities, such as front-ends, clients and publishers can be found on the [*Additional Resources*](../../resources) page or via a simple Google search.
* [TCollector](tcollector)
* [Collectors bundled with `tcollector`](tcollector#collectors-bundled-with-tcollector)
* [clean\_cache.sh](clean_cache)
* [tsddrain.py](tsddrain)
* [Load Balancing with Varnish](varnish)
* [Alerting with Nagios](nagios)
opentsdb TCollector TCollector
==========
[tcollector](https://github.com/OpenTSDB/tcollector/) is a client-side process that gathers data from local collectors and pushes the data to OpenTSDB. You run it on all your hosts, and it does the work of sending each host's data to the TSD.
OpenTSDB is designed to make it easy to collect and write data to it. It has a simple protocol, simple enough for even a shell script to start sending data. However, to do so reliably and consistently is a bit harder. What do you do when your TSD server is down? How do you make sure your collectors stay running? This is where tcollector comes in.
Tcollector does several things for you:
* Runs all of your data collectors and gathers their data
* Does all of the connection management work of sending data to the TSD
* You don't have to embed all of this code in every collector you write
* Does de-duplication of repeated values
* Handles all of the wire protocol work for you, as well as future enhancements
Deduplication
-------------
Typically you want to gather data about everything in your system. This generates a lot of datapoints, the majority of which don't change very often over time (if ever). However, you want fine-grained resolution when they do change. Tcollector remembers the last value and timestamp that was sent for all of the time series for all of the collectors it manages. If the value doesn't change between sample intervals, it suppresses sending that datapoint. Once the value does change (or 10 minutes have passed), it sends the last suppressed value and timestamp, plus the current value and timestamp. In this way all of your graphs and such are correct. Deduplication typically reduces the number of datapoints TSD needs to collect by a large fraction. This reduces network load and storage in the backend. A future OpenTSDB release however will improve on the storage format by using RLE (among other things), making it essentially free to store repeated values.
Collecting lots of metrics with tcollector
------------------------------------------
Collectors in tcollector can be written in any language. They just need to be executable and output the data to stdout. Tcollector will handle the rest. The collectors are placed in the `collectors` directory. Tcollector iterates over every directory named with a number in that directory and runs all the collectors in each directory. If you name the directory `60`, then tcollector will try to run every collector in that directory every 60 seconds. The shortest supported interval is 15 seconds, you should use a long-running collector in the 0 folder for intervals shorter than 15 seconds. TCollector will sleep for 15 seconds after each time it runs the collectors so intervals of 15 seconds are the only actually supported intervals. For example, this would allow you to run a collector every 15, 30, 45, 60, 75, or 90 seconds, but not 80 or 55 seconds. Use the directory `0` for any collectors that are long-lived and run continuously. Tcollector will read their output and respawn them if they die. Generally you want to write long-lived collectors since that has less overhead. OpenTSDB is designed to have lots of datapoints for each metric (for most metrics we send datapoints every 15 seconds).
If there any non-numeric named directories in the `collectors` directory, then they are ignored. We've included a `lib` and `etc` directory for library and config data used by all collectors.
Installation of tcollector
--------------------------
You need to clone tcollector from GitHub:
```
git clone git://github.com/OpenTSDB/tcollector.git
```
and edit 'tcollector/startstop' script to set following variable: `TSD\_HOST=dns.name.of.tsd`
To avoid having to run `mkmetric` for every metric that tcollector tracks you can to start TSD with the `--auto-metric` flag. This is useful to get started quickly, but it's not recommended to keep this flag in the long term, to avoid accidental metric creation.
opentsdb Load Balancing with Varnish Load Balancing with Varnish
===========================
[Varnish](https://www.varnish-cache.org/) is a powerful HTTP load balancer (reverse proxy), which is also very good at caching. When running multiple TSDs, Varnish comes in handy to distribute the HTTP traffic across the TSDs. Bear in mind that write traffic doesn't use the HTTP protocol by default, and as such you can only use Varnish for read queries. Using Varnish will help you easily scale the amount of read capacity of your TSD cluster.
The following is a sample Varnish configuration recommended for use with OpenTSDB. It uses a slightly custom load balancing strategy to achieve optimal cache hit rate at the TSD level. This configuration requires at least Varnish 2.1.0 to run, but using Varnish 3.0 or above is strongly recommended.
This sample configuration is for 2 backends, named `foo` and `bar`. You need to substitute at least the host names.
```
# VCL configuration for OpenTSDB.
backend foo {
.host = "foo";
.port = "4242";
.probe = {
.url = "/version";
.interval = 30s;
.timeout = 10s;
.window = 5;
.threshold = 3;
}
}
backend bar {
.host = "bar";
.port = "4242";
.probe = {
.url = "/version";
.interval = 30s;
.timeout = 10s;
.window = 5;
.threshold = 3;
}
}
# The `client' director will select a backend based on `client.identity'.
# It's normally used to implement session stickiness but here we abuse it
# to try to send pairs of requests to the same TSD, in order to achieve a
# higher cache hit rate. The UI sends queries first with a "&json" at the
# end, in order to get meta-data back about the results, and then it sends
# the same query again with "&png". If the second query goes to a different
# TSD, then that TSD will have to fetch the data from HBase again. Whereas
# if it goes to the same TSD that served the "&json" query, it'll hit the
# cache of that TSD and produce the PNG directly without using HBase.
#
# Note that we cannot use the `hash' director here, because otherwise Varnish
# would hash both the "&json" and the "&png" requests identically, and it
# would thus serve a cached JSON response to a "&png" request.
director tsd client {
{ .backend = foo; .weight = 100; }
{ .backend = bar; .weight = 100; }
}
sub vcl_recv {
set req.backend = tsd;
# Make sure we hit the same backend based on the URL requested,
# but ignore some parameters before hashing the URL.
set client.identity = regsuball(req.url, "&(o|ignore|png|json|html|y2?range|y2?label|y2?log|key|nokey)\b(=[^&]*)?", "");
}
sub vcl_hash {
# Remove the `ignore' parameter from the URL we hash, so that two
# identical requests modulo that parameter will hit Varnish's cache.
hash_data(regsuball(req.url, "&ignore\b(=[^&]*)?", ""));
if (req.http.host) {
hash_data(req.http.host);
} else {
hash_data(server.ip);
}
return (hash);
}
```
On many Linux distros (including Debian and Ubuntu), you need to put the configuration above in `/etc/varnish/default.vcl`. We also recommend tweaking the command-line parameters of `varnishd` in order to use a memory-backed cache of about 1GB if you can afford it. On Debian/Ubuntu systems, this is done by editing `/etc/default/varnish` to make sure that `-s malloc,1G` is passed to `varnishd`.
Read more about Varnish:
* [The VCL configuration language](http://www.varnish-cache.org/docs/trunk/reference/vcl.html)
* [Health checking backends](http://www.varnish-cache.org/trac/wiki/BackendPolling)
* [Tweaking the load balancing strategy](http://www.varnish-cache.org/trac/wiki/LoadBalancing)
Note
if you're using Varnish 2.x (which is not recommended as we would strongly encourage you to migrate to 3.x) you have to replace each function call `hash\_data(foo);` to set `req.hash += foo;` in the VCL configuration above.
opentsdb tsddrain.py tsddrain.py
===========
This is a simple utility for consuming data points from collectors while a TSD, HBase or HDFS is underoing maintenance. The script should be run on the same port as a TSD and accepts data in the `put` Telnet style. Data points are then written directly to disk in a format that can be used with the [*import*](../cli/import) command once HBase is back up.
Parameters
----------
```
tsddrain.py <port> <directory>
```
| Name | Data Type | Description | Default | Example |
| --- | --- | --- | --- | --- |
| port | Integer | The TCP port to listen on | | 4242 |
| directory | String | Path to a directory where data files should be written. A file is created for each client with the IP address of the client as the file name, | | /opt/temptsd/ |
Example
```
./tsddrain.py 4242 /opt/temptsd/
```
Results
-------
On succesfully binding to the default IPv4 address `0.0.0.0` and port it will simply print out the line below and start writing. When you're ready to resume using a TSD, simply kill the process.
```
Use Ctrl-C to stop me.
```
Warning
Tsddrain does not accept HTTP input at this time.
Warning
Test throughput on your systems to make sure it handles the load properly. Since it writes each point to disk immediately this can result in a huge disk IO load so very large OpenTSDB installations may require a larger number of drains than TSDs.
opentsdb Alerting with Nagios Alerting with Nagios
====================
OpenTSDB is great, but it's not (yet) a full monitoring platform. Now that you have a bunch of metrics in OpenTSDB, you want to start sending alerts when thresholds are getting too high. It's easy!
In the `tools` directory is a Python script `check\_tsd`. This script queries OpenTSDB and returns Nagios compatible output that gives you OK/WARNING/CRITICAL state.
Parameters
----------
```
Options:
-h, --help show this help message and exit
-H HOST, --host=HOST Hostname to use to connect to the TSD.
-p PORT, --port=PORT Port to connect to the TSD instance on.
-m METRIC, --metric=METRIC
Metric to query.
-t TAG, --tag=TAG Tags to filter the metric on.
-d SECONDS, --duration=SECONDS
How far back to look for data. Default 600s.
-D METHOD, --downsample=METHOD
Downsample function, e.g. one of avg, min, sum, max ... etc
-W SECONDS, --downsample-window=SECONDS
Window size over which to downsample.
-a METHOD, --aggregator=METHOD
Aggregation method: avg, min, sum (default), max .. etc
-x METHOD, --method=METHOD
Comparison method: gt, ge, lt, le, eq, ne.
-r, --rate Use rate value as comparison operand.
-w THRESHOLD, --warning=THRESHOLD
Threshold for warning. Uses the comparison method.
-c THRESHOLD, --critical=THRESHOLD
Threshold for critical. Uses the comparison method.
-v, --verbose Be more verbose.
-T SECONDS, --timeout=SECONDS
How long to wait for the response from TSD.
-E, --no-result-ok Return OK when TSD query returns no result.
-I SECONDS, --ignore-recent=SECONDS
Ignore data points that are that are that recent.
-P PERCENT, --percent-over=PERCENT
Only alarm if PERCENT of the data points violate the
threshold.
-N UTC, --now=UTC Set unix timestamp for "now", for testing
-S, --ssl Make queries to OpenTSDB via SSL (https)
```
For a complete list of downsample & aggregation modes, see [http://opentsdb.net/docs/build/html/user\_guide/query/aggregators.html#available-aggregators](../query/aggregators#available-aggregators)
Nagios Setup
------------
Drop the script into your Nagios path and set up a command like this:
```
define command{
command_name check_tsd
command_line $USER1$/check_tsd -H $HOSTADDRESS$ $ARG1$
}
```
Then define a host in nagios for your TSD server(s). You can give it a check\_command that is guaranteed to always return something if the backend is healthy.
```
define host{
host_name tsd
address tsd
check_command check_tsd!-d 60 -m rate:tsd.rpc.received -t type=put -x lt -c 1
[...]
}
```
Then define some service checks for the things you want to monitor.
```
define service{
host_name tsd
service_description Apache too many internal errors
check_command check_tsd!-d 300 -m rate:apache.stats.hits -t status=500 -w 1 -c 2
[...]
}
```
Testing
-------
If you have want to test your parameters against some specific point in time, you can use the `--now <UTC>` parameter to specify an explicit unix timestamp which is used as the current timestamp instead of the actual current time. If set, the script will fetch data starting at `UTC - duration`, ending at `UTC`.
To see the values retreived, and potentially ignored (due to duration), use the `--verbose` option.
opentsdb Query Details and Stats Query Details and Stats
=======================
With version 2.2 of OpenTSDB a number of details are now available around queries as we focus on improving flexibility and performance. Query details include who made the request (via headers and socket), what the response was (HTTP status codes and/or exceptions) and timing around the various processes the TSD takes.
Each HTTP query can include some of these details such as the original query and the timing information using the `showSummary` and `showQuery` parameters. Other details can be found in the `/api/stats/query` output including headers, status and exceptions. And full details (minus the actual result data) can be logged to disk via the logging config. This page details the various query sections and the information found therein.
Query
-----
This section is a serialization of the query given by the user. In the logs and stats page this will be the full query with timing and global options. When returned with the query results, only the sub query (metric and filters) are returned with the associated result set for identification purposes (e.g. if you request the same metric twice with two different aggregators, you need to know which data set corresponds to which aggregator).
For the fields and what they mean, see [*/api/query*](../../api_http/query/index). Some notes about the fields:
* The `tags` map should have the same number of entries as the `filters` array has `group\_by` entries. This is due to backwards compatibility with 2.1 and 1.0. Old style queries are converted into filtered queries and function the same way.
* A number of extra fields may be shown here with their default values such as `null`.
* You can copy and paste the query into a POST client to execute and find out what data was returned.
### Example
```
{
"start": "1455531250181",
"end": null,
"timezone": null,
"options": null,
"padding": false,
"queries": [{
"aggregator": "zimsum",
"metric": "tsd.connectionmgr.bytes.written",
"tsuids": null,
"downsample": "1m-avg",
"rate": true,
"filters": [{
"tagk": "colo",
"filter": "*",
"group_by": true,
"type": "wildcard"
}, {
"tagk": "env",
"filter": "prod",
"group_by": true,
"type": "literal_or"
}, {
"tagk": "role",
"filter": "frontend",
"group_by": true,
"type": "literal_or"
}],
"rateOptions": {
"counter": true,
"counterMax": 9223372036854775807,
"resetValue": 1,
"dropResets": false
},
"tags": {
"role": "literal_or(frontend)",
"env": "literal_or(prod)",
"colo": "wildcard(*)"
}
}, {
"aggregator": "zimsum",
"metric": "tsd.hbase.rpcs.cumulative_bytes_received",
"tsuids": null,
"downsample": "1m-avg",
"rate": true,
"filters": [{
"tagk": "colo",
"filter": "*",
"group_by": true,
"type": "wildcard"
}, {
"tagk": "env",
"filter": "prod",
"group_by": true,
"type": "literal_or"
}, {
"tagk": "role",
"filter": "frontend",
"group_by": true,
"type": "literal_or"
}],
"rateOptions": {
"counter": true,
"counterMax": 9223372036854775807,
"resetValue": 1,
"dropResets": false
},
"tags": {
"role": "literal_or(frontend)",
"env": "literal_or(prod)",
"colo": "wildcard(*)"
}
}],
"delete": false,
"noAnnotations": false,
"globalAnnotations": false,
"showTSUIDs": false,
"msResolution": false,
"showQuery": false,
"showStats": false,
"showSummary": false
}
```
Exception
---------
If the query failed, this field will include the message string and the first line of the stack trace for pinpointing. If the query was successful, this field will be null.
### Example
```
"exception": "No such name for 'metrics': 'nosuchmetric' net.opentsdb.uid.UniqueId$1GetIdCB.call(UniqueId.java:315)"
```
User
----
For future use, this field can be used to extract user information from queries and help debug who is using a TSD the most. It's fairly easy to modify the TSD code to extract the user from an HTTP header.
RequestHeaders
--------------
This is a map of the headers sent with the HTTP request. In a mediocre effort at security, the `Cookie` header field is obfuscated with asterisks in the case that it contains user identifiable or secure information. Each request is different so lookup the headers in the HTTP RFCs or your web browser or clients documentation.
### Example
```
"requestHeaders": {
"Accept-Language": "en-US,en;q=0.8",
"Host": "tsdhost:4242",
"Content-Length": "440",
"Referer": "http://tsdhost:8080/dashboard/db/tsdfrontend",
"Accept-Encoding": "gzip, deflate",
"X-Forwarded-For": "192.168.0.2",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.109 Safari/537.36",
"Origin": "http://tsdhost:8080",
"Content-Type": "application/json;charset=UTF-8",
"Accept": "application/json, text/plain, */*"
}
```
HttpResponse
------------
This field contains the numeric HTTP response code and a textual representation of that code.
### Example
```
"httpResponse": {
"code": 200,
"reasonPhrase": "OK"
}
```
Other Fields
------------
The output for log files and the stats page include other fields with single values as listed below:
| Metric | Type | Description |
| --- | --- | --- |
| executed | Counter | If the same query was executed multiple times (same times, same agent, etc) then this integer counter will increment. Use this to find out when a client may want to start caching results. |
| numRunningQueries | Gauge | How many queries were executing at the time the query was made (note that for the stats page this will always be up-to-date) |
| queryStartTimestamp | Timestamp (ms) | The timestamp (Unix epoch in milliseconds) when the query was received and started processing. |
| queryCompletedTimestamp | Timestamp (ms) | The timestamp (Unix epoch in milliseconds) when the query was finished and sent to the client. |
| sentToClient | boolean | Whether or not the query was successfully sent to the client. It may be blocked due to a socket exception or full write buffer. |
Stats
-----
A number of statistics are available around each query and more will be added over time. Various levels of detail are measured including:
* **Global** - Metrics pertaining to the entire query including max and average timings of each sub query.
* **Per-Sub Query** - Metrics pertaining to a single sub query (if multiple are present) including max and average timings of scanner.
* **Per-Scanner** - Metrics around each individual scanner (useful when salting is enabled)
Global stats are printed to the standard log, stats page. The full global, sub query and scanner details are available in the query log and via the query API when `showSummary` is present. Timing stats at a lower level are aggregated into max and average values at the upper level. Counters at each lower level are also aggregated at each upper level so you'll see the same counter metrics at each level. A table of stats and sections appears below.
Note
All timings in the table below are in milliseconds. Also note that times can be inflated by JVM GCs so make sure to enable GC logging if something seems off.
| Metric | Type | Section | Description |
| --- | --- | --- | --- |
| compactionTime | Float | Scanner | Cumulative time spent running each row through the compaction code to create a single column and manage duplicate values. |
| hbaseTime | Float | Scanner | Cumulative time spent waiting on HBase to return data. (Includes AsyncHBase deserialization time). |
| scannerId | String | Scanner | Details about the scanner including the table, start and end keys as well as filters used. |
| scannerTime | Float | Scanner | The total time from initialization of the scanner to when the scanner completed and closed. |
| scannerUidToStringTime | Float | Scanner | Cumulative time spent resolving UIDs from row keys to strings for use with regex and wildcard filters. If neither filter is used this value should be zero. |
| successfulScan | Integer | Scanner, Query, Global | How many scanners completed successfully. Per query, this should be equal to the number of salting buckets, or `1` if salting is disabled. |
| uidPairsResolved | Integer | Scanner | Total number of row key UIDs resolved to tag values when a regex or wildcard filter is used. If neither filter is used this value should be zero. |
| aggregationTime | Float | Query | Cumulative time spent aggregating data points including downsampling, multi-series aggregation and rate calculations. |
| groupByTime | Float | Query | Cumulative time spent sorting scanner results into groups for future aggregation. |
| queryScanTime | Float | Query | Total time spent waiting on the scanners to return results. This includes the `groupByTime`. |
| saltScannerMergeTime | Float | Query | Total time spent merging the salt scanner results into a single set prior to group by operations. |
| serializationTime | Float | Query | Total time spent serializing the query results. This includes `aggregationTime` and `uidToStringTime`. |
| uidToStringTime | Float | Query | Cumulative time spent resolving UIDs to strings for serialization. |
| emittedDPs | Integer | Query, Global | The total number of data points serialized in the output. Note that this may include NaNs or Nulls if the query specified such. |
| queryIndex | Integer | Query | The index of the sub query in the original user supplied query list. |
| processingPreWriteTime | Float | Global | Total time spent processing, fetching data and serializing results for the query until it is written over the wire. This value is sent in the API summary results and used as an estimate of the total time spent processing by the TSD. However it does not include the amount of time it took to send the value over the wire. |
| totalTime | Float | Global | Total time spent on the query including writing to the socket. This is only found in the log files and stats API. |
### Example
```
{
"statsSummary": {
"avgAggregationTime": 3.784976,
"avgHBaseTime": 8.530751,
"avgQueryScanTime": 10.964149,
"avgScannerTime": 8.588306,
"avgScannerUidToStringTime": 0.0,
"avgSerializationTime": 3.809661,
"emittedDPs": 1256,
"maxAggregationTime": 3.759478,
"maxHBaseTime": 9.904215,
"maxQueryScanTime": 10.320964,
"maxScannerUidtoStringTime": 0.0,
"maxSerializationTime": 3.779712,
"maxUidToStringTime": 0.197926,
"processingPreWriteTime": 20.170205,
"queryIdx_00": {
"aggregationTime": 3.784976,
"avgHBaseTime": 8.849337,
"avgScannerTime": 8.908597,
"avgScannerUidToStringTime": 0.0,
"emittedDPs": 628,
"groupByTime": 0.0,
"maxHBaseTime": 9.904215,
"maxScannerUidtoStringTime": 0.0,
"queryIndex": 0,
"queryScanTime": 10.964149,
"saltScannerMergeTime": 0.128234,
"scannerStats": {
"scannerIdx_00": {
"compactionTime": 0.048703,
"hbaseTime": 8.844783,
"scannerId": "Scanner(table=\"tsdb\", start_key=[0, 0, 2, 88, 86, -63, -25, -16], stop_key=[0, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.899045,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_01": {
"compactionTime": 0.066892,
"hbaseTime": 8.240165,
"scannerId": "Scanner(table=\"tsdb\", start_key=[1, 0, 2, 88, 86, -63, -25, -16], stop_key=[1, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.314855,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_02": {
"compactionTime": 0.01298,
"hbaseTime": 8.462203,
"scannerId": "Scanner(table=\"tsdb\", start_key=[2, 0, 2, 88, 86, -63, -25, -16], stop_key=[2, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.478315,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_03": {
"compactionTime": 0.036998,
"hbaseTime": 9.862741,
"scannerId": "Scanner(table=\"tsdb\", start_key=[3, 0, 2, 88, 86, -63, -25, -16], stop_key=[3, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.904215,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_04": {
"compactionTime": 0.058698,
"hbaseTime": 9.523481,
"scannerId": "Scanner(table=\"tsdb\", start_key=[4, 0, 2, 88, 86, -63, -25, -16], stop_key=[4, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.587324,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_05": {
"compactionTime": 0.041017,
"hbaseTime": 9.757787,
"scannerId": "Scanner(table=\"tsdb\", start_key=[5, 0, 2, 88, 86, -63, -25, -16], stop_key=[5, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.802395,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_06": {
"compactionTime": 0.062371,
"hbaseTime": 9.332585,
"scannerId": "Scanner(table=\"tsdb\", start_key=[6, 0, 2, 88, 86, -63, -25, -16], stop_key=[6, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.40264,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_07": {
"compactionTime": 0.063974,
"hbaseTime": 8.195105,
"scannerId": "Scanner(table=\"tsdb\", start_key=[7, 0, 2, 88, 86, -63, -25, -16], stop_key=[7, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.265713,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_08": {
"compactionTime": 0.062196,
"hbaseTime": 8.21871,
"scannerId": "Scanner(table=\"tsdb\", start_key=[8, 0, 2, 88, 86, -63, -25, -16], stop_key=[8, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.287582,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_09": {
"compactionTime": 0.051666,
"hbaseTime": 7.790636,
"scannerId": "Scanner(table=\"tsdb\", start_key=[9, 0, 2, 88, 86, -63, -25, -16], stop_key=[9, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.849597,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_10": {
"compactionTime": 0.036429,
"hbaseTime": 7.6472,
"scannerId": "Scanner(table=\"tsdb\", start_key=[10, 0, 2, 88, 86, -63, -25, -16], stop_key=[10, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.689386,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_11": {
"compactionTime": 0.044493,
"hbaseTime": 7.897932,
"scannerId": "Scanner(table=\"tsdb\", start_key=[11, 0, 2, 88, 86, -63, -25, -16], stop_key=[11, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.94793,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_12": {
"compactionTime": 0.025362,
"hbaseTime": 9.30409,
"scannerId": "Scanner(table=\"tsdb\", start_key=[12, 0, 2, 88, 86, -63, -25, -16], stop_key=[12, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.332411,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_13": {
"compactionTime": 0.057429,
"hbaseTime": 9.215958,
"scannerId": "Scanner(table=\"tsdb\", start_key=[13, 0, 2, 88, 86, -63, -25, -16], stop_key=[13, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.278104,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_14": {
"compactionTime": 0.102855,
"hbaseTime": 9.598685,
"scannerId": "Scanner(table=\"tsdb\", start_key=[14, 0, 2, 88, 86, -63, -25, -16], stop_key=[14, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.712258,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_15": {
"compactionTime": 0.0727,
"hbaseTime": 9.273193,
"scannerId": "Scanner(table=\"tsdb\", start_key=[15, 0, 2, 88, 86, -63, -25, -16], stop_key=[15, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.35403,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_16": {
"compactionTime": 0.025867,
"hbaseTime": 9.011146,
"scannerId": "Scanner(table=\"tsdb\", start_key=[16, 0, 2, 88, 86, -63, -25, -16], stop_key=[16, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.039663,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_17": {
"compactionTime": 0.066071,
"hbaseTime": 9.175692,
"scannerId": "Scanner(table=\"tsdb\", start_key=[17, 0, 2, 88, 86, -63, -25, -16], stop_key=[17, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 9.24738,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_18": {
"compactionTime": 0.090249,
"hbaseTime": 8.730833,
"scannerId": "Scanner(table=\"tsdb\", start_key=[18, 0, 2, 88, 86, -63, -25, -16], stop_key=[18, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.831461,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_19": {
"compactionTime": 0.039327,
"hbaseTime": 8.903825,
"scannerId": "Scanner(table=\"tsdb\", start_key=[19, 0, 2, 88, 86, -63, -25, -16], stop_key=[19, 0, 2, 88, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.947639,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
}
},
"serializationTime": 3.809661,
"successfulScan": 20,
"uidPairsResolved": 0,
"uidToStringTime": 0.197926
},
"queryIdx_01": {
"aggregationTime": 3.73398,
"avgHBaseTime": 8.212164,
"avgScannerTime": 8.268015,
"avgScannerUidToStringTime": 0.0,
"emittedDPs": 628,
"groupByTime": 0.0,
"maxHBaseTime": 8.986041,
"maxScannerUidtoStringTime": 0.0,
"queryIndex": 1,
"queryScanTime": 9.67778,
"saltScannerMergeTime": 0.095797,
"scannerStats": {
"scannerIdx_00": {
"compactionTime": 0.054894,
"hbaseTime": 8.708179,
"scannerId": "Scanner(table=\"tsdb\", start_key=[0, 0, 2, 76, 86, -63, -25, -16], stop_key=[0, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.770252,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_01": {
"compactionTime": 0.055956,
"hbaseTime": 8.666615,
"scannerId": "Scanner(table=\"tsdb\", start_key=[1, 0, 2, 76, 86, -63, -25, -16], stop_key=[1, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.730629,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_02": {
"compactionTime": 0.011224,
"hbaseTime": 8.474637,
"scannerId": "Scanner(table=\"tsdb\", start_key=[2, 0, 2, 76, 86, -63, -25, -16], stop_key=[2, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.487582,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_03": {
"compactionTime": 0.081926,
"hbaseTime": 8.894951,
"scannerId": "Scanner(table=\"tsdb\", start_key=[3, 0, 2, 76, 86, -63, -25, -16], stop_key=[3, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.986041,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_04": {
"compactionTime": 0.01882,
"hbaseTime": 8.209866,
"scannerId": "Scanner(table=\"tsdb\", start_key=[4, 0, 2, 76, 86, -63, -25, -16], stop_key=[4, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.231502,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_05": {
"compactionTime": 0.056902,
"hbaseTime": 8.709846,
"scannerId": "Scanner(table=\"tsdb\", start_key=[5, 0, 2, 76, 86, -63, -25, -16], stop_key=[5, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.772216,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_06": {
"compactionTime": 0.131424,
"hbaseTime": 8.033916,
"scannerId": "Scanner(table=\"tsdb\", start_key=[6, 0, 2, 76, 86, -63, -25, -16], stop_key=[6, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.181117,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_07": {
"compactionTime": 0.022517,
"hbaseTime": 8.006976,
"scannerId": "Scanner(table=\"tsdb\", start_key=[7, 0, 2, 76, 86, -63, -25, -16], stop_key=[7, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.032073,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_08": {
"compactionTime": 0.011527,
"hbaseTime": 8.591358,
"scannerId": "Scanner(table=\"tsdb\", start_key=[8, 0, 2, 76, 86, -63, -25, -16], stop_key=[8, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.604491,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_09": {
"compactionTime": 0.162222,
"hbaseTime": 8.25452,
"scannerId": "Scanner(table=\"tsdb\", start_key=[9, 0, 2, 76, 86, -63, -25, -16], stop_key=[9, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.435525,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_10": {
"compactionTime": 0.033886,
"hbaseTime": 7.973254,
"scannerId": "Scanner(table=\"tsdb\", start_key=[10, 0, 2, 76, 86, -63, -25, -16], stop_key=[10, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.011236,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_11": {
"compactionTime": 0.039491,
"hbaseTime": 7.959601,
"scannerId": "Scanner(table=\"tsdb\", start_key=[11, 0, 2, 76, 86, -63, -25, -16], stop_key=[11, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.003249,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_12": {
"compactionTime": 0.107793,
"hbaseTime": 8.177353,
"scannerId": "Scanner(table=\"tsdb\", start_key=[12, 0, 2, 76, 86, -63, -25, -16], stop_key=[12, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.298284,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_13": {
"compactionTime": 0.020697,
"hbaseTime": 8.124243,
"scannerId": "Scanner(table=\"tsdb\", start_key=[13, 0, 2, 76, 86, -63, -25, -16], stop_key=[13, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.147879,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_14": {
"compactionTime": 0.033261,
"hbaseTime": 8.145149,
"scannerId": "Scanner(table=\"tsdb\", start_key=[14, 0, 2, 76, 86, -63, -25, -16], stop_key=[14, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.182331,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_15": {
"compactionTime": 0.057804,
"hbaseTime": 8.17854,
"scannerId": "Scanner(table=\"tsdb\", start_key=[15, 0, 2, 76, 86, -63, -25, -16], stop_key=[15, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.243458,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_16": {
"compactionTime": 0.01212,
"hbaseTime": 8.070582,
"scannerId": "Scanner(table=\"tsdb\", start_key=[16, 0, 2, 76, 86, -63, -25, -16], stop_key=[16, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 8.084813,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_17": {
"compactionTime": 0.036777,
"hbaseTime": 7.919167,
"scannerId": "Scanner(table=\"tsdb\", start_key=[17, 0, 2, 76, 86, -63, -25, -16], stop_key=[17, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.959645,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_18": {
"compactionTime": 0.048097,
"hbaseTime": 7.87351,
"scannerId": "Scanner(table=\"tsdb\", start_key=[18, 0, 2, 76, 86, -63, -25, -16], stop_key=[18, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.926318,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
},
"scannerIdx_19": {
"compactionTime": 0.0,
"hbaseTime": 7.271033,
"scannerId": "Scanner(table=\"tsdb\", start_key=[19, 0, 2, 76, 86, -63, -25, -16], stop_key=[19, 0, 2, 76, 86, -62, 4, 16], columns={\"t\"}, populate_blockcache=true, max_num_rows=128, max_num_kvs=4096, region=null, filter=KeyRegexpFilter(\"(?s)^.{8}(?:.{7})*\\Q\u0000\u0000\u0005\\E(?:\\Q\u0000\u0000\u00006\\E)(?:.{7})*$\", ISO-8859-1), scanner_id=0x0000000000000000)",
"scannerTime": 7.271664,
"scannerUidToStringTime": 0.0,
"successfulScan": 1,
"uidPairsResolved": 0
}
},
"serializationTime": 3.749764,
"successfulScan": 20,
"uidPairsResolved": 0,
"uidToStringTime": 0.162088
},
"successfulScan": 40,
"uidPairsResolved": 0
}
}
```
| programming_docs |
opentsdb Querying or Reading Data Querying or Reading Data
========================
OpenTSDB offers a number of means to extract data such as CLI tools, an HTTP API and as a GnuPlot graph. Querying with OpenTSDB's tag based system can be a bit tricky so read through this document and checkout the following pages for deeper information. Example queries on this page follow the HTTP API format.
* [Dates and Times](dates)
* [Filters](filters)
* [Understanding Metrics and Time Series](timeseries)
* [Aggregators](aggregators)
* [Query Examples](examples)
* [Query Details and Stats](stats)
Query Components
----------------
OpenTSDB's query language is fairly simple but flexible. Each query has the following components:
| Parameter | Date Type | Required | Description | Example |
| --- | --- | --- | --- | --- |
| Start Time | String or Integer | Yes | Starting time for the query. This may be an absolute or relative time. See [*Dates and Times*](dates) for details | 24h-ago |
| End Time | String or Integer | No | An end time for the query. If the end time is not supplied, the current time on the TSD will be used. See [*Dates and Times*](dates) for details. | 1h-ago |
| Metric | String | Yes | The full name of a metric in the system. Must be the complete name. Case sensitive | sys.cpu.user |
| Aggregation Function | String | Yes | A mathematical function to use in combining multiple time series | sum |
| Tags | String | No | An optional set of tags for filtering or grouping | host=\*,dc=lax |
| Downsampler | String | No | An optional interval and function to reduce the number of data points returned | 1h-avg |
| Rate | String | No | An optional flag to calculate the rate of change for the result | rate |
Times
-----
Absolute time stamps are supported in human readable format or Unix style integers. Relative times may be used for refreshing dashboards. Currently, all queries are able to cover a single time span. In the future we hope to provide an offset query parameter that would allow for aggregations or graphing of a metric over different time periods, such as comparing last week to 1 year ago. See [*Dates and Times*](dates) for details on what is permissible.
While OpenTSDB can store data with millisecond resolution, most queries will return the data with second resolution to provide backwards compatibility for existing tools. Unless a down sampling algorithm has been specified with a query, the data will automatically be down sampled to 1 second using the same aggregation function specified in a query. This way, if multiple data points are stored for a given second, they will be aggregated and returned in a normal query correctly.
To extract data with millisecond resolution, use the `/api/query` endpoint and specify the `msResolution` (ms` is also okay, but not recommended) JSON parameter or query string flag and it will bypass down sampling (unless specified) and return all timestamps in Unix epoch millisecond resolution. Also, the `scan` commandline utility will return the timestamp as written in storage.
Tags
----
Every time series is comprised of a metric and one or more tag name/value pairs. Since tags are optional in queries, if you request only the metric name, then every metric with any number or value of tags will be returned in the aggregated results. For example, if we have a stored data set:
```
sys.cpu.user host=webserver01,cpu=0 1356998400 1
sys.cpu.user host=webserver01,cpu=1 1356998400 4
sys.cpu.user host=webserver02,cpu=0 1356998400 2
sys.cpu.user host=webserver02,cpu=1 1356998400 1
```
and simply craft a query `start=1356998400&m=sum:sys.cpu.user`, we will get a value of `8` at `1356998400` that incorporates all 4 time series.
If we want to aggregate the results for a specific group, we can filter on the `host` tag. The query `start=1356998400&m=sum:sys.cpu.user{host=webserver01}` will return a value of `5`, incorporating only the time series where `host=webserver01`. To drill down to a specific time series, you must include all of the tags for the series, e.g. `start=1356998400&m=sum:sys.cpu.user{host=webserver01,cpu=0}` will return `1`.
Note
Inconsistent tags can cause unexpected results when querying. See `../writing` for details.
Grouping
--------
A query can also aggregate time series with multiple tags into groups based on a tag value. Two special characters can be passed to the right of the equals symbol in a query:
* **\*** - The asterisk will return a separate result for each unique tag value
* **|** - The pipe will return a separate result *only* for the exact tag values specified
Let's take the following data set as an example:
```
sys.cpu.user host=webserver01,cpu=0 1356998400 1
sys.cpu.user host=webserver01,cpu=1 1356998400 4
sys.cpu.user host=webserver02,cpu=0 1356998400 2
sys.cpu.user host=webserver02,cpu=1 1356998400 1
sys.cpu.user host=webserver03,cpu=0 1356998400 5
sys.cpu.user host=webserver03,cpu=1 1356998400 3
```
If we want to query for the average CPU time across each server we can craft a query like `start=1356998400&m=avg:sys.cpu.user{host=\*}`. This will give us three results:
1. The aggregated average for `sys.cpu.user host=webserver01,cpu=0` and `sys.cpu.user host=webserver01,cpu=1`
2. The aggregated average for `sys.cpu.user host=webserver02,cpu=0` and `sys.cpu.user host=webserver02,cpu=1`
3. The aggregated average for `sys.cpu.user host=webserver03,cpu=0` and `sys.cpu.user host=webserver03,cpu=1`
However if we have many web servers in the system, this could create a ton of results. To filter on only the hosts we want you can use the pipe operator to select a subset of time series. For example `start=1356998400&m=avg:sys.cpu.user{host=webserver01|webserver03}` will return results only for `webserver01` and `webserver03`.
With version 2.2 you can enable or disable grouping per tag filter. Additional filters are also available including wildcards and regular expressions.
Explicit Tags
-------------
As of 2.3 and later, if you know all of the tag keys for a given metric query latency can be improved greatly by using the `explicitTags` feature and making sure `tsd.query.enable\_fuzzy\_filter` is enabled in the config. A special filter is given to HBase that enables skipping ahead to rows that we need for the query instead of iterating over every row key and comparing a regular expression.
For example, using the data set above, if we only care about metrics where `host=webserver02` and there are hundreds of hosts, you can craft a query such as `start=1356998400&m=avg:explicit\_tags:sys.cpu.user{host=webserver02,cpu=\*}`. Note that you must specify every tag included in the time series for this to work and you can decide whether or not to group by the additional tags.
Aggregation
-----------
A powerful feature of OpenTSDB is the ability to perform on-the-fly aggregations of multiple time series into a single set of data points. The original data is always available in storage but we can quickly extract the data in meaningful ways. Aggregation functions are means of merging two or more data points for a single time stamp into a single value. See [*Aggregators*](aggregators) for details.
Interpolation
-------------
When performing an aggregation, what happens if the time stamps of the data points for each time series fail to line up? Say we record the temperature every 5 minutes in different regions around the world. A sensor in Paris may send a temperature of `27c` at `1356998400`. Then a sensor in San Francisco may send a value of `18c` at `1356998430`, 30 seconds later. Antarctica may report `-29c` at `1356998529`. If we run a query requesting the average temperature, we want all of the data points averaged together into a single point. This is where **interpolation** comes into play. See [*Aggregators*](aggregators) for details.
Downsampling
------------
OpenTSDB can ingest a large amount of data, even a data point every second for a given time series. Thus queries may return a large number of data points. Accessing the results of a query with a large number of points from the API can eat up bandwidth. High frequencies of data can easily overwhelm Javascript graphing libraries, hence the choice to use GnuPlot. Graphs created by the GUI can be difficult to read, resulting in thick lines such as the graph below:
 Down sampling can be used at query time to reduce the number of data points returned so that you can extract better information from a graph or pass less data over a connection. Down sampling requires an **aggregation** function and a **time interval**. The aggregation function is used to compute a new data point across all of the data points in the specified interval with the proper mathematical function. For example, if the aggregation `sum` is used, then all of the data points within the interval will be summed together into a single value. If `avg` is chosen, then the average of all data points within the interval will be returned.
Intervals are specified by a number and a unit of time. For example, `30m` will aggregate data points every 30 minutes. `1h` will aggregate across an hour. See [*Dates and Times*](dates) for valid relative time units. Do not add the `-ago` to a down sampling query.
Using down sampling we can cleanup the previous graph to arrive at something much more useful:
 As of 2.1, downsampled timestamps are normalized based on the remainder of the original data point timestamp divided by the downsampling interval in milliseconds, i.e. the modulus. In Java the code is `timestamp - (timestamp % interval\_ms)`. For example, given a timestamp of `1388550980000`, or `1/1/2014 04:36:20 UTC` and an hourly interval that equates to 3600000 milliseconds, the resulting timestamp will be rounded to `1388548800000`. All data points between 4 and 5 UTC will wind up in the 4 AM bucket. If you query for a day's worth of data downsampling on 1 hour, you will receive 24 data points (assuming there is data for all 24 hours).
Normalization works very well for common queries such as a day's worth of data downsampled to 1 minute or 1 hour. However if you try to downsample on an odd interval, such as 36 minutes, then the timestamps may look a little strange due to the nature of the modulus calculation. Given an interval of 36 minutes and our example above, the interval would be `2160000` milliseconds and the resulting timestamp `1388549520` or `04:12:00 UTC`. All data points between `04:12` and `04:48` would wind up in a single bucket. Also note that OpenTSDB cannot currently normalize on non-UTC times and it cannot normalize on weekly or monthly boundaries.
With version 2.2 a downsampling query can emit a `NaN` or `null` when a downsample bucket is missing a value for all of the series involved. Because OpenTSDB does not allow for storing literal NaNs at this time, nor does it impose specific intervals on storage, this can be used to mimic systems that do such as RRDs.
Note
Previous to 2.1, timestamps were not normalized. The buckets were calculated based on the starting time of the first data point retreived for each series, then the series went through interpolation. This means a graph may show varying gaps between values and return more values than expected.
Rate
----
A number of data sources return values as constantly incrementing counters. One example is a web site hit counter. When you start a web server, it may have a hit counter of 0. After five minutes the value may be 1,024. After another five minutes it may be 2,048. The graph for a counter will be a somewhat straight line angling up to the right and isn't always very useful. OpenTSDB provides the **rate** key word that calculates the rate of change in values over time. This will transform counters into lines with spikes to show you when activity occurred and can be much more useful.
The rate is the first derivative of the values. It's defined as (v2 - v1) / (t2 - t1). Therefore you will get the rate of change per second. Currently the rate of change between millisecond values defaults to a per second calculation.
OpenTSDB 2.0 provides support for special monotonically increasing counter data handling including the ability to set a "rollover" value and suppress anomalous fluctuations. When the `counterMax` value is specified in a query, if a data point approaches this value and the point after is less than the previous, the max value will be used to calculate an accurate rate given the two points. For example, if we were recording an integer counter on 2 bytes, the maximum value would be 65,535. If the value at `t0` is `64000` and the value at `t1` is `1000`, the resulting rate per second would be calculated as `-63000`. However we know that it's likely the counter rolled over so we can set the max to `65535` and now the calculation will be `65535 - t0 + t1` to give us `2535`.
Systems that track data in counters often revert to 0 when restarted. When that happens and we could get a spurious result when using the max counter feature. For example, if the counter has reached `2000` at `t0` and someone reboots the server, the next value may be `500` at `t1`. If we set our max to `65535` the result would be `65535 - 2000 + 500` to give us `64035`. If the normal rate is a few points per second, this particular spike, with `30s` between points, would create a rate spike of `2,134.5`! To avoid this, we can set the `resetValue` which will, when the rate exceeds this value, return a data point of `0` so as to avoid spikes in either direction. For the example above, if we know that our rate almost never exceeds 100, we could configure a `resetValue` of `100` and when the data point above is calculated, it will return `0` instead of `2,134.5`. The default value of 0 means the reset value will be ignored, no rates will be suppressed.
Order of operations
-------------------
Understanding the order of operations is important. When returning query results the following is the order in which processing takes place:
1. Grouping
2. Down Sampling
3. Interpolation
4. Aggregation
5. Rate Calculation
opentsdb Aggregators Aggregators
===========
OpenTSDB was designed to efficiently combine multiple, distinct time series during query execution. But how do you merge individual time series into a single series of data? Aggregation functions provide the means of mathematically merging the different data series into one, giving you a choice of various mathematical operations. Since OpenTSDB doesn't know whether or not a query will return multiple time series, an aggregation function is always required just in case.
Aggregators have two methods of operation:
Aggregation
-----------
Since OpenTSDB doesn't know whether a query will return multiple time series until it scans through all of the data, an aggregation function must be specified for every query just in case. When more than one series is found, the two series are **aggregated** together into a single time series. For each timestamp in the different time series, the aggregator will perform it's computation for each value in every time series at that timestamp. That is, the aggregator will work *across* all of the time series at each timestamp. The following table illustrates the `sum` aggregator as it works across time series `A` and `B` to produce series `Output`.
| series | ts0 | ts0+10s | ts0+20s | ts0+30s | ts0+40s | ts0+50s |
| --- | --- | --- | --- | --- | --- | --- |
| A | 5 | 5 | 10 | 15 | 20 | 5 |
| B | 10 | 5 | 20 | 15 | 10 | 0 |
| Output | 15 | 10 | 30 | 30 | 30 | 5 |
For timestamp `ts0` the data points for `A` and `B` are summed, i.e. `5 + 10 == 15`. Next, the two values for `ts1` are summed together to get `10` and so on. Each aggregation function will perform a different mathematical operation.
### Interpolation
In the example above, both time series `A` and `B` had data points at every time stamp, they lined up neatly. However what happens when two series do not line up? It can be difficult, and sometimes undesired, to synchronize all sources of data to write at the exact same time. For example, if we have 10,000 servers sending 100 system metrics every 5 minutes, that would be a burst of 10M data points in a single second. We would need a pretty beefy network and cluster to accommodate that traffic. Not to mention the system would be sitting idle for the rest of 5 minutes. Instead it makes much more sense to splay the writes over time so that we have an average of 3,333 writes per second to reduce our hardware and network requirements.
Missing Data
By "missing" we simply mean that a time series does not have a data point for the timestamp requested. Usually the data is simply time shifted before or after the requested timestamp, but it could actually be missing if the source or the TSD encountered an error and the data wasn't recorded.
How do you *sum* or find the *avg* of a number and something that doesn't exist? One option is to simply ignore the data points for all time series at the time stamp where any series is missing data. But if you have two time series and they are simply miss-aligned, your query would return an empty data set even though there is good data in storage, so that's not very useful.
Another option is to define a scalar value (e.g. `0` or the maximum value for a Long) to use whenever a data point is missing. OpenTSDB 2.0 provides a few aggregation methods that substitute a scalar value for missing data points. These are useful when working with distinct value time series such as the number of sales in at a given time.
However sometimes it doesn't make sense to define a scalar for missing data. Often you may be recording a monotonically increasing counter such as the number of bytes transmitted from a network interface. With a counter, we can use **interpolation** to make a guess as to what the value would be at that point in time. Interpolation takes two points and the time span between them to calculate a *best guess* value at the time stamp requested.
Take a look at these two time series where the data is simply offset by 10 seconds:
| series | ts0 | ts0+10s | ts0+20s | ts0+30s | ts0+40s | ts0+50s | ts0+60s |
| --- | --- | --- | --- | --- | --- | --- | --- |
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
When OpenTSDB is calculating an aggregation it starts at the first data point found for any series, in this case it will be the data for `B` at `ts0`. We request a value for `A` at `ts0` but there isn't any data there. We know that there is data for `A` at `ts0+10s` but since we don't have any value before that, we can't make a guess as to what it would be. Thus we simply return the value for `B`.
Next we run across a value for `A` at time `ts0+10s`. We request a value for `ts0+10s` from time series `B` but there isn't one. But `B` knows there is a value at `ts0+20s` and we had a value at `ts0` so we can now calculate a guess for `ts0+10s`. The formula for linear interpolation is `y = y0 + (y1 - y0) \* ((x - x0) / (x1 - x0))` where, for series `B`, `y0 = 10`, `y1 = 20`, `x = ts0+10s (or 10)`, `x0 = ts0 (or 0)` and `x1 = ts0+20s (or 20)`. Thus we have `y = 10 + (20 - 10) \* ((10 - 0) / (20 - 0)` which will reduce to `y = 10 + 10 \* (10 / 20)` further reducing to `y = 10 + 10 \* .5` and `y = 10 + 5`. Therefore `B` will give us a *guestimated* value of `15` at `ts0+10s`.
Iteration continues over every timestamp for which a data point is found for every series returned as a part of the query. The resulting series, using the **sum** aggregator, will look like this:
| series | ts0 | ts0+10s | ts0+20s | ts0+30s | ts0+40s | ts0+50s | ts0+60s |
| --- | --- | --- | --- | --- | --- | --- | --- |
| A | na | 5 | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | 10 | na | 20 |
| Interpolated A | na | | 10 | | 10 | | |
| Interpolated B | | 15 | | 15 | | 15 | na |
| Summed Result | 10 | 20 | 30 | 25 | 20 | 20 | 20 |
**More Examples:** For the graphically inclined we have the following examples. An imaginary metric named `m` is recorded in OpenTSDB. The "sum of m" is the blue line at the top resulting from a query like `start=1h-ago&m=sum:m`. It's made of the sum of the red line for `host=foo` and the green line for `host=bar`:
 It seems intuitive from the image above that if you "stack up" the red line and the green line, you'd get the blue line. At any discrete point in time, the blue line has a value that is equal to the sum of the value of the red line and the value of the green line at that time. Without interpolation, you get something rather unintuitive that is harder to make sense of, and which is also a lot less meaningful and useful:
 Notice how the blue line drops down to the green data point at 18:46:48. No need to be a mathematician or to have taken advanced maths classes to see that interpolation is needed to properly aggregate multiple time series together and get meaningful results.
At the moment OpenTSDB primarily supports [linear interpolation](http://en.wikipedia.org/wiki/Linear_interpolation) (sometimes shortened "lerp") along with some aggregators that will simply substitute zeros or the max or min value. Patches are welcome for those who would like to add other interpolation methods.
Interpolation is only performed at query time when more than one time series are found to match a query. Many metrics collection systems interpolate on *write* so that you original value is never recorded. OpenTSDB stores your original value and lets you retrieve it at any time.
Here is another slightly more complicated example that came from the mailing list, depicting how multiple time series are aggregated by average:
[](../../_images/aggregation_average.png) The thick blue line with triangles is the an aggregation with the `avg` function of multiple time series as per the query `start=1h-ago&m=avg:duration\_seconds`. As we can see, the resulting time series has one data point at each timestamp of all the underlying time series it aggregates, and that data point is computed by taking the average of the values of all the time series at that timestamp. This is also true for the lonely data point of the squared-purple time series, that temporarily boosted the average until the next data point.
Note
Aggregation functions return integer or double values based on the input data points. If both source values are integers in storage, the resulting calculations will be integers. This means any fractional values resulting from the computation will be lopped off, no rounding will occur. If either data point is a floating point value, the result will be a floating point. However if downsampling or rates are enabled, the result will always be a float.
Downsampling
------------
The second method of operation for aggregation functions is `downsampling`. Since OpenTSDB stores data at the original resolution indefinitely, requesting data for a long time span can return millions of points. This can cause a burden on bandwidth or graphing libraries so it's common to request data at a lower resolution for longer spans. Downsampling breaks the long span of data into smaller spans and merges the data for the smaller span into a single data point. Aggregation functions will perform the same calculation as for an aggregation process but instead of working across data points for multiple time series at a single time stamp, downsampling works across multiple data points within a single time series over a given time span.
For example, take series `A` and `B` in the first table under **Aggregation**. The data points cover a 50 second time span. Let's say we want to downsample that to 30 seconds. This will give us two data points for each series:
| series | ts0 | ts0+10s | ts0+20s | ts0+30s | ts0+40s | ts0+50s |
| --- | --- | --- | --- | --- | --- | --- |
| A | 5 | 5 | 10 | 15 | 20 | 5 |
| A Downsampled | | | | 35 | | 25 |
| B | 10 | 5 | 20 | 15 | 10 | 0 |
| B Downsampled | | | | 50 | | 10 |
| Aggregated Result | | | | 85 | | 35 |
For early versions of OpenTSDB, the actual time stamps for the new data points will be an average of the time stamps for each data point in the time span. As of 2.1 and later, the timestamp for each point is aligned to the start of a time bucket based on a modulo of the current time and the downsample interval.
Note that when a query specifies a down sampling function and multiple time series are returned, downsampling occurs **before** aggregation. I.e. now that we have `A Downsampled` and `B Downsampled` we can aggregate the two series to come up with the aggregated result on the bottom line.
Fill Policies
-------------
With version 2.2 you can specify a fill policy when downsampling to substitute values for use in cross-series aggregations when data points are "missing". Because OpenTSDB does not impose constraints on time alignment or when values are supposed to exist, such constraints must be specified at query time. At serialization time, if all series are missing values for an expected timestamp, nothing is emitted. For example, if a series is writing data every minute from T0 to T4, but for some reason the source fails to write data at T3, only 4 values will be serialized when the user may expect 5. With fill policies you can now choose what value is emitted for T3.
When aggregating multiple series OpenTSDB generally performs linear interpolation when a series is missing a value at a timestamp present in one or more other series. Some aggregators substitute specific values such as zero, min or max values. With fill policies you can modify aggregation behavior by flagging a missing value as a NaN or a scalar such as zero. When a NaN is emitted for a series, it is skipped for all calculations. For example, if a query asks for the average of a metric and one or more series are missing values, substituting a 0 would drive down the average and lerping introduces non-extant values. However with NaNs we can flag the value as missing and skip it in the calculation.
Available polices include:
* None (`none`) - The default behavior that does not emit missing values during serialization and performs linear interpolation (or otherwise specified interpolation) when aggregating series.
* NaN (`nan`) - Emits a `NaN` in the serialization output when all values are missing in a series. Skips series in aggregations when the value is missing.
* Null (`null`) - Same behavior as NaN except that during serialization it emits a `null` instead of a `NaN`.
* Zero (`zero`) - Substitutes a zero when a timestamp is missing. The zero value will be incorporated in aggregated results.
(The terms in parentheses can be used in downsampling specifications, e.g. `1h-sum-nan`)
An example with the NaN fill policy and downsampling on 10 seconds:
| series | ts0 | ts0+10s | ts0+20s | ts0+30s | ts0+40s | ts0+50s | ts0+60s |
| --- | --- | --- | --- | --- | --- | --- | --- |
| A | na | na | na | 15 | na | 5 | na |
| B | 10 | na | 20 | na | na | na | 20 |
| Interpolated A | NaN | NaN | NaN | | NaN | | NaN |
| Interpolated B | | NaN | | NaN | NaN | NaN | |
| Summed Result | 10 | NaN | 20 | 15 | NaN | 5 | 20 |
Available Aggregators
---------------------
The following is a description of the aggregation functions available in OpenTSDB.
| Aggregator | Description | Interpolation |
| --- | --- | --- |
| avg | Averages the data points | Linear Interpolation |
| count | The number of raw data points in the set | Zero if missing |
| dev | Calculates the standard deviation | Linear Interpolation |
| ep50r3 | Calculates the estimated 50th percentile with the R-3 method \* | Linear Interpolation |
| ep50r7 | Calculates the estimated 50th percentile with the R-7 method \* | Linear Interpolation |
| ep75r3 | Calculates the estimated 75th percentile with the R-3 method \* | Linear Interpolation |
| ep75r7 | Calculates the estimated 75th percentile with the R-7 method \* | Linear Interpolation |
| ep90r3 | Calculates the estimated 90th percentile with the R-3 method \* | Linear Interpolation |
| ep90r7 | Calculates the estimated 90th percentile with the R-7 method \* | Linear Interpolation |
| ep95r3 | Calculates the estimated 95th percentile with the R-3 method \* | Linear Interpolation |
| ep95r7 | Calculates the estimated 95th percentile with the R-7 method \* | Linear Interpolation |
| ep99r3 | Calculates the estimated 99th percentile with the R-3 method \* | Linear Interpolation |
| ep99r7 | Calculates the estimated 99th percentile with the R-7 method \* | Linear Interpolation |
| ep999r3 | Calculates the estimated 999th percentile with the R-3 method \* | Linear Interpolation |
| ep999r7 | Calculates the estimated 999th percentile with the R-7 method \* | Linear Interpolation |
| first | Returns the first data point in the set. Only useful for downsampling, not aggregation. (2.3) | Indeterminate |
| last | Returns the last data point in the set. Only useful for downsampling, not aggregation. (2.3) | Indeterminate |
| mimmin | Selects the smallest data point | Maximum if missing |
| mimmax | Selects the largest data point | Minimum if missing |
| min | Selects the smallest data point | Linear Interpolation |
| max | Selects the largest data point | Linear Interpolation |
| none | Skips group by aggregation of all time series. (2.3) | Zero if missing |
| p50 | Calculates the 50th percentile | Linear Interpolation |
| p75 | Calculates the 75th percentile | Linear Interpolation |
| p90 | Calculates the 90th percentile | Linear Interpolation |
| p95 | Calculates the 95th percentile | Linear Interpolation |
| p99 | Calculates the 99th percentile | Linear Interpolation |
| p999 | Calculates the 999th percentile | Linear Interpolation |
| sum | Adds the data points together | Linear Interpolation |
| zimsum | Adds the data points together | Zero if missing |
\* For percentile calculations, see the [Wikipedia](http://en.wikipedia.org/wiki/Quantile) article. For high cardinality calculations, using the estimated percentiles may be more performant.
### Avg
Calculates the average of all values across the time span or across multiple time series. This function will perform linear interpolation across time series. It's useful for looking at gauge metrics. Note that even though the calculation will usually result in a float, if the data points are recorded as integers, an integer will be returned losing some precision.
### Count
Returns the number of data points stored in the series or range. When used to aggregate multiple series, zeros will be substituted. It's best to use this when downsampling.
### Dev
Calculates the [standard deviation](http://en.wikipedia.org/wiki/Standard_deviation) across a span or time series. This function will perform linear interpolation across time series. It's useful for looking at gauge metrics. Note that even though the calculation will usually result in a float, if the data points are recorded as integers, an integer will be returned losing some precision.
### Estimated Percentiles
Calculates various percentiles using a choice of algorithms. These are useful for series with many data points as some data may be kicked out of the calculation. When used to aggregate multiple series, the function will perform linear interpolation. See [Wikipedia](http://en.wikipedia.org/wiki/Quantile) for details. Implementation is through the [Apache Math library.](http://commons.apache.org/proper/commons-math/)
### First & Last
(2.3) These aggregators will return the first or the last data point in the downsampling interval. E.g. if a downsample bucket consists of the series `2, 6, 1, 7` then the `first` aggregator will return `1` and `last` will return `7`. Note that this aggregator is only useful for downsamplers. When used as a group-by aggregator, the results are indeterminate as the ordering of time series retrieved from storage and held in memory is not consistent from TSD to TSD or execution to execution.
### Max
The inverse of `min`, it returns the largest data point from all of the time series or within a time span. This function will perform linear interpolation across time series. It's useful for looking at the upper bounds of gauge metrics.
### MimMin
The "maximum if missing minimum" function returns only the smallest data point from all of the time series or within the time span. This function will *not* perform interpolation, instead it will return the maximum value for the type of data specified if the value is missing. This will return the Long.MaxValue for integer points or Double.MaxValue for floating point values. See [Primitive Data Types](http://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html) for details. It's useful for looking at the lower bounds of gauge metrics.
### MimMax
The "minimum if missing maximum" function returns only the largest data point from all of the time series or within the time span. This function will *not* perform interpolation, instead it will return the minimum value for the type of data specified if the value is missing. This will return the Long.MinValue for integer points or Double.MinValue for floating point values. See [Primitive Data Types](http://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html) for details. It's useful for looking at the upper bounds of gauge metrics.
### Min
Returns only the smallest data point from all of the time series or within the time span. This function will perform linear interpolation across time series. It's useful for looking at the lower bounds of gauge metrics.
### None
(2.3) Skips group by aggregation. This aggregator is useful for fetching the *raw* data from storage as it will return a result set for every time series matching the filters. Note that the query will throw an exception if used with a downsampler.
### Percentiles
Calculates various percentiles. When used to aggregate multiple series, the function will perform linear interpolation. Implementation is through the [Apache Math library.](http://commons.apache.org/proper/commons-math/)
### Sum
Calculates the sum of all data points from all of the time series or within the time span if down sampling. This is the default aggregation function for the GUI as it's often the most useful when combining multiple time series such as gauges or counters. It performs linear interpolation when data points fail to line up. If you have a distinct series of values that you want to sum and you do not need interpolation, look at `zimsum`
### ZimSum
Calculates the sum of all data points at the specified timestamp from all of the time series or within the time span. This function does *not* perform interpolation, instead it substitutes a `0` for missing data points. This can be useful when working with discrete values.
| programming_docs |
opentsdb Filters Filters
=======
In OpenTSDB 2.2 tag key and value filters were introduced. This makes it easier to extract only the data that you want from storage. The filter framework is plugable to allow for tying into external systems such as asset management or provisioning systems.
Multiple filters on the same tag key are allowed and when processed, they are *ANDed* together e.g. if we have two filters `host=literal\_or(web01)` and `host=literal\_or(web02)` the query will always return empty. If two or more filters are included for the same tag key and one has group by enabled but another does not, then group by will effectively be true for all filters on that tag key.
Note that some type of filters may cause queries to execute slower than others, e.g. the regex and wildcard filters. Before fetching data from storage, the filters are processed to create a database filter based on UIDs so using the case sensitive "literal or" filter is always faster than regex because we can resolve the strings to UIDs and send those to the storage system for filtering. Instead if you ask for regex or wildcards with pre, post or infix filtering the TSD must retrieve all of the rows from storage with the tag key UID, then for each unique row, resolve the UIDs back to strings and then run the filter over the results. Also, filter sets with a large list of literals will be processed post storage to avoid creating a massive filter for the backing store to process. This limit defaults to `4096` and can be configured via the `tsd.query.filter.expansion\_limit` parameter.
Built-in Filters
----------------
### literal\_or
Takes a single literal value or a pipe delimited list of values and returns any time series matching the results on a case sensitive bases. This is a very efficient filter as it can resolve the strings to UIDs and send that to the storage layer for pre-filtering.
*Examples*
`literal\_or(web01|web02|web03)` `literal\_or(web01)`
### ilteral\_or
The same as a `literal\_or` but is case insensitive. Note that this is not efficient like the literal or as it must post-process all rows from storage.
### not\_literal\_or
Case sensitive `literal\_or` that will return series that do **NOT** match the given list of values. Efficient as it can be pre-processed by storage.
### not\_iliteral\_or
Case insensitive `not\_literal\_or`.
### wildcard
Provides case sensitive postfix, prefix, infix and multi-infix filtering. The wildcard character is an asterisk (star) `\*`. Multiple wildcards can be used. If only the asterisk is given, the filter effectively returns any time series that include the tag key (and is an efficient filter that can be pre-processed).
*Examples* `wildcard(\*mysite.com)` `wildcard(web\*)` `wildcard(web\*mysite.com)` `wildcard(web\*mysite\*)` `wildcard(\*)`
### iwildcard
The same as `wildcard` but case insensitive.
### regexp
Filters using POSIX compliant regular expressions post fetching from storage. The filter uses Java's built-in regular expression operation. Be careful to escape special characters depending on the query method used.
*Examples* `regexp(web.\*)` `regexp(web[0-9].mysite.com)`
Plugins
-------
As developers add plugins we will list them here.
To develop a plugin, simply extend the `net.opentsdb.query.filter.TagVFilter` class, create JAR per the [*Plugins*](../../development/plugins) documentation and drop it in your plugins directory. On start, the TSD will search for the plugin and load it. If there was an error with the implementation the TSD will not start up and will log the exception.
opentsdb Understanding Metrics and Time Series Understanding Metrics and Time Series
=====================================
OpenTSDB is a time series database. A time series is a series of numeric data points of some particular metric over time. Each time series consists of a metric plus one or more tags associated with this metric (we'll cover tags in a bit). A metric is any particular piece of data (e.g. hits to an Apache hosted file) that you wish to track over time.
OpenTSDB is also a data plotting system. OpenTSDB plots things a bit differently than other systems. We'll discuss plotting in more detail below, but for now it's important to know that for OpenTSDB, the basis of any given plot is the metric. It takes that metric, finds all of the time series for the time range you select, aggregates those times series together (e.g. by summing them up) and plots the result. The plotting mechanism is very flexible and powerful and you can do much more than this, but for now let's talk about the key to the time series, which is the metric.
In OpenTSDB, a metric is named with a string, like `http.hits`. To be able to store all the different values for all the places where this metric exists, you tag the data with one or more tags when you send them to the TSD. TSD stores the timestamp, the value, and the tags. When you want to retrieve this data, TSD retrieves all of the values for the time span you supply, optionally with a tag filter you supply, aggregates all these values together how you want, and plots a graph of this value over time.
There's a bunch of things in here that we've introduced so far. To help you understand how things work, I'll start with a typical example. Let's say you have a bunch of web servers and you want to track two things: hits to the web server and load average of the system. Let's make up metric names to express this. For load average, let's call it `proc.loadavg.1min` (since on Linux you can easily get this data by reading `/proc/loadavg`). For many web servers, there is a way to ask the web server for a counter expressing the number of hits to the server since it started. This is a convenient counter upon which to use for a metric we'll call `http.hits`. I chose these two examples for two reasons. One, we'll get to see how OpenTSDB easily handles both counters (values that increase over time, except when they get reset by a restart/reboot or overflow) and how it handles normal values that go up and down, like load average. A great advantage of OpenTSDB is that you don't need to do any rate calculation of your counters. It will do it all for you. The second reason is that we can also show you how you can plot two different metrics with different scales on the same graph, which is a great way to correlate different metrics.
Your first datapoints
---------------------
Without going into too much detail on how collectors send data to the TSD , you write a collector that periodically sends the current value of these datapoints for each server to the TSD. So the TSD can aggregate the data from multiple hosts, you tag each value with a "host" tag. So, if you have web servers A, B, C, etc, they each periodically send something like this to the TSD:
```
put http.hits 1234567890 34877 host=A
put proc.loadavg.1min 1234567890 1.35 host=A
```
Here "1234567890" is the current epoch time (date +%s) in seconds. The next number is the value of the metric at this time. This is data from host A, so it's tagged with `host=A`. Data from host B would be tagged with `host=B`, and so forth. Over time, you'll get a bunch of time series stored in OpenTSDB.
Your first plot
---------------
Now, let's revisit what we talked about here at the beginning. A time series is a series of datapoints of some particular metric (and its tags) over time. For this example, each host is sending two time series to the TSD. If you had 3 boxes each sending these two time series, TSD would be collecting and storing 6 time series. Now that you have the data, let's start plotting.
To plot HTTP hits, you just go to the UI and enter `http.hits` as your metric name, and enter the time range. Check the "Rate" button since this particular metric is a rate counter, and voil?, you have a plot of the rate of HTTP hits to your web servers over time.
Aggregators
-----------
The default for the UI is to aggregate each time series for each host by adding them together (sum). What this means is, TSD is taking the three time series with this metric (host=A, B and C) and adding their values together to come up with the total hits by all web servers at a given time . Note you don't need to send your datapoints at exactly the same time, the TSD will figure it out. So, if each of your hosts was serving 1000 hits per second each at some point in time, the graph would show 3000. What if you wanted to show about how many hits each web server was serving? Two ways. If you just care about the average that each web server was serving, just change the Aggregator method from sum to avg. You can also try the others (max, min) to see the maximum or minimum value. More aggregation functions are in the works (percentiles, etc.). This is done on a per-interval basis , so if at some point in time one of your webservers was serving 50 QPS and the others were serving 100 and later a different webserver was serving 50 QPS and the others were serving 100, for these two points the Min would be 50. In other words it doesn't figure out which time series was the total minimum and just show you that host plot. The other way to see how many hits each web server is serving? This is where we look at the tag fields.
Downsampling
------------
To reduce the number of datapoints returned, you can specify a downsampling interval and method, such as 1h-avg or 1d-sum. This is also useful (such as when using the max and min) to find best and worst-case datapoints over a given period. Downsampling is most useful to make the graphing phase less intensive and more readable, especially when graphing more datapoints than screen pixels.
Tag Filters
-----------
In the UI you'll see that the TSD has filled one or more "Tags", the first one is host. What TSD is saying here that for this time range it sees that the data was tagged with a host tag. You can filter the graph so that it just plots the value of one host. If you fill in A in the host row, you'll just plot the values over time of host A. If you want to give a list of hosts to plot, fill in the list of hosts separated by the pipe symbol, e.g. A|B. This will give you two plots instead of one, one for A and one for B. Finally, you can also specify the special character [\*](#id1), which means to plot a line for every host.
Adding More Metrics
-------------------
So, now you have a plot of your web hits. How does that correlate against load average? On this same graph, click the "+" tab to add a new metric to this existing graph. Enter proc.loadavg.1min as your metric and click "Right Axis" so the Y axis is scaled separately and its labels on the right. Make sure "Rate" is unchecked, since load average is not a counter metric. Voil?! Now you can see how changes in the rate of web hits affects your system's load average.
Getting Fancy
-------------
Imagine each if your servers actually ran two webservers, say, one for static content and one for dynamic content. Rather than create another metric, just tag the http.hits metric with the server instance. Have your collector send stuff like:
`put http.hits 1234567890 34877 host=A webserver=static put http.hits 1234567890 4357 host=A webserver=dynamic put proc.loadavg.1min 1234567890 1.35 host=A`
Why do this instead of creating another metric? Well, what if sometimes you care about plotting total HTTP hits and sometimes you care about breaking out static vs. dynamic hits? With a tag, it's easy. With this new tag, you'll see a webserver tag appear in the UI when plotting this metric. You can leave it blank and it will aggregate up both values into one plot (according to your Aggregator setting) and you can see the total hits, or you can do webserver=\* to break out how much each of your static and dynamic instances are collectively doing across your web servers. You can even go deeper and specify webserver=\* and host=\* to see the full breakdown.
Guidelines When to Create Metrics
---------------------------------
Right now, you cannot combine two metrics into one plot line. This means you want a metric to be the biggest possible aggregation point. If you want to drill down to specifics within a metric, use tags.
Tags vs. Metrics
----------------
The metric should be a specific thing, like "Ethernet packets" but not be broken out into a particular instance of a thing. Generally you don't want to collect a metric like net.bytes.eth0, net.bytes.eth1, etc. Collect net.bytes and tag eth0 datapoints with iface=eth0, etc. Don't bother creating separate "in" and "out" metrics, either. Add the tag direction=in or direction=out. This way you can easily see the total network activity for a given box without having to plot a bunch of metrics. This still gives you the flexibility to drill down and just show activity for a particular interface, or just a particular direction.
Counters and Rates
------------------
If something is a counter, or is naturally something that is a rate, don't convert it to a rate before sending it to the TSD. There's two main reasons for this. First, doing your own rate calculation, reset/overflow handling, etc. is silly, since TSD can do it for you. You also don't have to worry about getting the units-per-second calculation correct based on a slightly inaccurate or changing sample interval. Secondly, if something happens where you lose a datapoint or more, if you are sending the current counter value then you won't lose data, just resolution of that data. The golden rule in TSD is, if your source data is a counter (some counter out of /proc or SNMP), keep it that way. Don't convert it. If you're writing your own collector (say, one that counts how often a particular error message appears in a tail -f of a log), don't reset your counter every sample interval. Let TSD to do the work for you.
Tags are your Friend
--------------------
In anything above a small environment, you probably have clusters or groups of machines doing the same thing. Over time these change, though. That's OK. Just use a tag when you send the data to TSD to pass this cluster info along. Add something like cluster=webserver to all the datapoints being sent from each of your webservers, and cluster=db for all your databases, etc.
Now when you plot CPU activity for your webserver cluster, you see all of them aggregated into one plot. Then let's say you add a webserver or even change it from a webserver to a database. All you have to do is make sure the right tag gets sent when its role changes, and now that box's CPU activity gets counted toward the right cluster. What's more, all of your historical data is still correct! This is the true power of OpenTSDB. Not only do you never lose resolution of your datapoints over time like RRD-based systems, but historical data doesn't get lost as your boxes shift around. You also don't have to put a bunch of cluster or grouping awareness logic into your dashboards.
Precisions on Metrics and Tags
------------------------------
The maximum number of tags allowed on a data point is defined by a constant (Const.MAX\_NUM\_TAGS), which at time of writing is 8. Metric names, tag names and tag values have to be made of alpha numeric characters, dash "-", underscore "\_", period ".", and forward slash "/", as is enforced by the package-private function Tags.validateString.
opentsdb Query Examples Query Examples
==============
The following is a list of example queries using an example data set. We'll illustrate a number of common query types that may be encountered so you can get an understanding of how the query system works. Each time series in the example set has only a single data point stored and the UIDs have been truncated to a single byte to make it easier to read. The example queries are all *Metric* queries from the HTTP API and only show the `m=` component. See [*/api/query*](../../api_http/query/index) for details. If you are using a CLI tool, the query format will differ slightly so read the documentation for the particular command.
Sample Data
-----------
**Time Series**
| TS# | Metric | Tags | TSUID |
| --- | --- | --- | --- |
| 1 | sys.cpu.system | dc=dal host=web01 | 0102040101 |
| 2 | sys.cpu.system | dc=dal host=web02 | 0102040102 |
| 3 | sys.cpu.system | dc=dal host=web03 | 0102040103 |
| 4 | sys.cpu.system | host=web01 | 010101 |
| 5 | sys.cpu.system | host=web01 owner=jdoe | 0101010306 |
| 6 | sys.cpu.system | dc=lax host=web01 | 0102050101 |
| 7 | sys.cpu.system | dc=lax host=web02 | 0102050102 |
| 8 | sys.cpu.user | dc=dal host=web01 | 0202040101 |
| 9 | sys.cpu.user | dc=dal host=web02 | 0202040102 |
**UIDs**
| Name | UID |
| --- | --- |
| **Metrics** | |
| cpu.system | 01 |
| cpu.user | 02 |
| **Tagks** | |
| host | 01 |
| dc | 02 |
| owner | 03 |
| **Tagvs** | |
| web01 | 01 |
| web02 | 02 |
| web03 | 03 |
| dal | 04 |
| lax | 05 |
| doe | 06 |
Warning
This isn't necesarily the best way to setup your metrics and tags, rather it's meant to be illustrative of how the query system works. In particular, TS #4 and 5, while legitimate timeseries, may screw up your queries unless you know how they work. In general, try to maintain the same number and type of tags for each timeseries.
Under the Hood
--------------
You may want to read up on how OpenTSDB stores timeseries data here: [*Storage*](../backends/index). Otherwise, remember that each row in storage has a unique key formatted:
```
<metricID><normalized_timestamp><tagkID1><tagvID1>[...<tagkIDN><tagvIDN>]
```
The data table above would be stored as:
```
01<ts>0101
01<ts>01010306
01<ts>02040101
01<ts>02040102
01<ts>02040103
01<ts>02050101
01<ts>02050102
02<ts>02040101
02<ts>02040102
```
When you query OpenTSDB, here's what happens under the hood.
* The query is parsed and verified to make sure that the format is correct and that the metrics, tag names and tag values exist. If a single metric, tag name or value doesn't exist in the system, it will kick back an error.
* Then it sets up a scanner for the underlying storage system.
+ If the query doesn't have any tags or tag values, then it will grab any rows of data that match `<metricID><timestamp>`, so if you have a ton of time series for a particular metric, this could be many, many rows.
+ If the query does have one or more tags defined, then it will still scan all of the rows matching `<metricID><timestamp>`, but also perform a regex to return only the rows that contain the requested tag.
* Once all of the data has been returned, OpenTSDB organizes it into groups, if required
* If downsampling was requested, each individual time series is down sampled into smaller time spans using the proper aggregator
* Then each group of data is aggregated using the specific aggregation function
* If the `rate` flag was detected, each aggregate will then be adjusted to get the rate.
* Results are returned to the caller
Query 1 - All Time Series for a Metric
--------------------------------------
```
m=sum:cpu.system
```
This is the simplest query to make. TSDB will setup a scanner to fetch all data points for the metric UID `01` between *<start>* and *<end>*. The result will be the a single dataset with time series #1 through #7 summed together. If you have thousands of unique tag combinations for a given metric, they will all be added together into one series.
```
[
{
"metric": "cpu.system",
"tags": {},
"aggregated_tags": [
"host"
],
"tsuids": [
"010101",
"0101010306",
"0102050101",
"0102040101",
"0102040102",
"0102040103",
"0102050102"
],
"dps": {
"1346846400": 130.29999923706055
}
}
]
```
Query 2 - Filter on a Tag
-------------------------
Usually aggregating all of the time series for a metric isn't particularly useful. Instead we can drill down a little by filtering for time series that contain a specific tagk/tagv pair combination. Simply put the pair in curly braces:
```
m=sum:cpu.system{host=web01}
```
This will return an aggregate of time series #1, #4, #5 and #6 since they're the only series that include `host=web01`.
```
[
{
"metric": "cpu.system",
"tags": {
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"010101",
"0101010306",
"0102040101",
"0102050101"
],
"dps": {
"1346846400": 63.59999942779541
}
}
]
```
Query 3 - Specific Time Series
------------------------------
What if you want a specific timeseries? You have to include every tag and coresponding value.
```
m=sum:cpu.system{host=web01,dc=lax}
```
This will return the data from timeseries #6 only.
```
[
{
"metric": "cpu.system",
"tags": {
"dc": "lax",
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"0102050101"
],
"dps": {
"1346846400": 15.199999809265137
}
}
]
```
Warning
This is where a tagging scheme will stand or fall. Let's say you want to get just the data from timeseries #4. With the current system, you are unable to. You would send in query #2 `m=sum:cpu.system{host=web01}` thinking that it will return just the data from #4, but as we saw, you'll get the aggregate results for #1, #4, #5 and #6. To prevent such an occurance, you would need to add another tag to #4 that differentiates it from other timeseries in the group. Or if you've already commited, you can use TSUID queries.
Query 4 - TSUID Query
---------------------
If you know the exact TSUID of the timeseries that you want to retrieve, you can simply pass it in like so:
```
tsuids=sum:0102040102
```
The results will be the data points that you requested.
```
[
{
"metric": "cpu.system",
"tags": {
"dc": "lax",
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"0102050101"
],
"dps": {
"1346846400": 15.199999809265137
}
}
]
```
Query 5 - Multi-TSUID Query
---------------------------
You can also aggregate multiple TSUIDs in the same query, provided they share the same metric. If you attempt to aggregate multiple metrics, the API will issue an error.
```
tsuids=sum:0102040101,0102050101
```
```
[
{
"metric": "cpu.system",
"tags": {
"host": "web01"
},
"aggregated_tags": [
"dc"
],
"tsuids": [
"0102040101",
"0102050101"
],
"dps": {
"1346846400": 33.19999980926514
}
}
]
```
Query 6 - Grouping
------------------
```
m=sum:cpu.system{host=*}
```
The `\*` (asterisk) is a grouping operator that will return a data set for each unique value of the tag name given. Every timeseries that includes the given metric and the given tag name, regardless of other tags or values, will be included in the results. After the individual timeseries results are grouped, they'll be aggregated and returned.
In this example, we will have 3 groups returned:
| Group | Time Series Included |
| --- | --- |
| web01 | #1, #4, #5, #6 |
| web02 | #2, #7 |
| web03 | #3 |
TSDB found 7 total timeseries that included the "host" tag. There were 3 unique values for that tag (web01, web02, and web03).
```
[
{
"metric": "cpu.system",
"tags": {
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"010101",
"0101010306",
"0102040101",
"0102050101"
],
"dps": {
"1346846400": 63.59999942779541
}
},
{
"metric": "cpu.system",
"tags": {
"host": "web02"
},
"aggregated_tags": [
"dc"
],
"tsuids": [
"0102040102",
"0102050102"
],
"dps": {
"1346846400": 24.199999809265137
}
},
{
"metric": "cpu.system",
"tags": {
"dc": "dal",
"host": "web03"
},
"aggregated_tags": [],
"tsuids": [
"0102040103"
],
"dps": {
"1346846400": 42.5
}
}
]
```
Query 7 - Group and Filter
--------------------------
Note that the in example #2, the `web01` group included the odd-ball timeseries #4 and #5. We can filter those out by specifying a second tag ala:
```
m=sum:cpu.nice{host=*,dc=dal}
```
Now we'll only get results for #1 - #3, but we lose the `dc=lax` values.
```
[
{
"metric": "cpu.system",
"tags": {
"dc": "dal",
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"0102040101"
],
"dps": {
"1346846400": 18
}
},
{
"metric": "cpu.system",
"tags": {
"dc": "dal",
"host": "web02"
},
"aggregated_tags": [],
"tsuids": [
"0102040102"
],
"dps": {
"1346846400": 9
}
},
{
"metric": "cpu.system",
"tags": {
"dc": "dal",
"host": "web03"
},
"aggregated_tags": [],
"tsuids": [
"0102040103"
],
"dps": {
"1346846400": 42.5
}
}
]
```
Query 8 - Grouping With OR
--------------------------
The `\*` operator is greedy and will return *all* values that are assigned to a tag name. If you only want a few tag values, you can use the `|` (pipe) operator instead.
```
m=sum:cpu.nice{host=web01|web02}
```
This will find all of the timeseries that include "host" values for "web01" OR "web02", then group them by value, similar to the `\*` operator. Our groups, this time, will look like this:
| Group | Time Series Included |
| --- | --- |
| web01 | #1, #4, #5, #6 |
| web02 | #2, #7 |
```
[
{
"metric": "cpu.system",
"tags": {
"host": "web01"
},
"aggregated_tags": [],
"tsuids": [
"010101",
"0101010306",
"0102040101",
"0102050101"
],
"dps": {
"1346846400": 63.59999942779541
}
},
{
"metric": "cpu.system",
"tags": {
"host": "web02"
},
"aggregated_tags": [
"dc"
],
"tsuids": [
"0102040102",
"0102050102"
],
"dps": {
"1346846400": 24.199999809265137
}
}
]
```
| programming_docs |
opentsdb Dates and Times Dates and Times
===============
OpenTSDB supports a number of date and time formats when querying for data. The following formats are supported in queries submitted through the GUI, CliQuery tool or HTTP API. Every query requires a **start time** and an optional **end time**. If the end time is not specified, the current time on the system where the TSD is running will be used.
Relative
--------
If you don't know the exact timestamp to request you can submit a time in the past relative to the time on the system where the TSD is running. Relative times follow the format `<amount><time unit>-ago` where `<amount>` is the number of time units and `<time unit>` is the unit of time, such as hours, days, etc. For example, if we provide a **start time** of `1h-ago` and leave out the **end time**, our query will return data start at 1 hour ago to the current time. Possible units of time include:
* ms - Milliseconds
* s - Seconds
* m - Minutes
* h - Hours
* d - Days (24 hours)
* w - Weeks (7 days)
* n - Months (30 days)
* y - Years (365 days)
Note
Relative times do not account for leap seconds, leap years or time zones. They simply calculate the number of seconds in the past from the current time.
Absolute Unix Time
------------------
Internally, all data is associated with a Unix (or POSIX) style timestamp. Unix times are defined as the number of seconds that have elapsed since January 1st, 1970 at 00:00:00 UTC time. Timestamps are represented as a positive integer such as `1364410924`, representing `ISO 8601:2013-03-27T19:02:04Z`. Since calls to store data in OpenTSDB require a Unix timestamp, it makes sense to support the format in queries. Thus you can supply an integer for a start or end time in a query.
Queries using Unix timestamps can also support millisecond precision by simply appending three digits. For example providing a start time of `1364410924000` and an end time of `1364410924250` will return data within a 250 millisecond window. Millisecond timestamps may also be supplied with a period separating the seconds from the milliseconds as in `1364410924.250`. Any integers with 13 (or 14) characters will be treated as a millisecond timestamp. Anything 10 characters or less represent seconds. Milliseconds may only be supplied with 3 digit precision. If your tool outputs more than 3 digits you must truncate or round the value.
Absolute Formatted Time
-----------------------
Since calculating a Unix time in your head is pretty difficult, OpenTSDB also supports human readable absolute date and times. Supported formats include:
* yyyy/MM/dd-HH:mm:ss
* yyyy/MM/dd HH:mm:ss
* yyyy/MM/dd-HH:mm
* yyyy/MM/dd HH:mm
* yyyy/MM/dd
`yyyy` represents the year as a four digit value, e.g. `2013`. `MM` represents the month of year starting at `01` for January to `12` for December. `dd` represents the day of the month starting at `01`. `HH` represents the hour of day in 24 hour format starting at `00` to `23`. `mm` represents the minutes starting at `00` to `59` and `ss` represents seconds starting at `00` to `59`. All months, days, hours, minutes and seconds that are single digits must be preceeded by a 0, e.g. the 5th day of the month must be given as `05`. When supplying on the data without a time, the system will assume midnight of the given day.
Examples include `2013/01/23-12:50:42` or `2013/01/23`. Formatted times are converted from the default timezone of the host running the TSD to UTC. HTTP API queries can accept a user supplied time zone to override the local zone.
Note
When using the CliQuery tool, you must use the format that separates the date from the time with a dash. This is because the command line is split on spaces, so if you put a space in the timestamp, it will fail to parse execute properly.
Time Zones
----------
When converting human readable timestamps, OpenTSDB will convert to UTC from the timezone configured on the system where the TSD is running. While many servers are configured to UTC, and we recommend that all systems running OpenTSDB use UTC, sometimes a local timezone is used.
Queries via query string to the HTTP API can specify a `tz` parameter with a timezone identification string in a format applicable to the localization settings of the system running the TSD. For example, we could specify `tz=America/Los\_Angeles` to convert our timestamp from Los Angeles local time to UTC.
Alternatively, if you are unable to change the system timezone, you can provide an override via the config file `tsd.core.timezone` property.
opentsdb Writing Data Writing Data
============
You may want to jump right in and start throwing data into your TSD, but to really take advantage of OpenTSDB's power and flexibility, you may want to pause and think about your naming schema. After you've done that, you can proceed to pushing data over the Telnet or HTTP APIs, or use an existing tool with OpenTSDB support such as 'tcollector'.
Naming Schema
-------------
Many metrics administrators are used to supplying a single name for their time series. For example, systems administrators used to RRD-style systems may name their time series `webserver01.sys.cpu.0.user`. The name tells us that the time series is recording the amount of time in user space for cpu `0` on `webserver01`. This works great if you want to retrieve just the user time for that cpu core on that particular web server later on.
But what if the web server has 64 cores and you want to get the average time across all of them? Some systems allow you to specify a wild card such as `webserver01.sys.cpu.\*.user` that would read all 64 files and aggregate the results. Alternatively, you could record a new time series called `webserver01.sys.cpu.user.all` that represents the same aggregate but you must now write '64 + 1' different time series. What if you had a thousand web servers and you wanted the average cpu time for all of your servers? You could craft a wild card query like `\*.sys.cpu.\*.user` and the system would open all 64,000 files, aggregate the results and return the data. Or you setup a process to pre-aggregate the data and write it to `webservers.sys.cpu.user.all`.
OpenTSDB handles things a bit differently by introducing the idea of 'tags'. Each time series still has a 'metric' name, but it's much more generic, something that can be shared by many unique time series. Instead, the uniqueness comes from a combination of tag key/value pairs that allows for flexible queries with very fast aggregations.
Note
Every time series in OpenTSDB must have at least one tag.
Take the previous example where the metric was `webserver01.sys.cpu.0.user`. In OpenTSDB, this may become `sys.cpu.user host=webserver01, cpu=0`. Now if we want the data for an individual core, we can craft a query like `sum:sys.cpu.user{host=webserver01,cpu=42}`. If we want all of the cores, we simply drop the cpu tag and ask for `sum:sys.cpu.user{host=webserver01}`. This will give us the aggregated results for all 64 cores. If we want the results for all 1,000 servers, we simply request `sum:sys.cpu.user`. The underlying data schema will store all of the `sys.cpu.user` time series next to each other so that aggregating the individual values is very fast and efficient. OpenTSDB was designed to make these aggregate queries as fast as possible since most users start out at a high level, then drill down for detailed information.
### Aggregations
While the tagging system is flexible, some problems can arise if you don't understand the querying side of OpenTSDB, hence the need for some forethought. Take the example query above: `sum:sys.cpu.user{host=webserver01}`. We recorded 64 unique time series for `webserver01`, one time series for each of the CPU cores. When we issued that query, all of the time series for metric `sys.cpu.user` with the tag `host=webserver01` were retrieved, averaged, and returned as one series of numbers. Let's say the resulting average was `50` for timestamp `1356998400`. Now we were migrating from another system to OpenTSDB and had a process that pre-aggregated all 64 cores so that we could quickly get the average value and simply wrote a new time series `sys.cpu.user host=webserver01`. If we run the same query, we'll get a value of `100` at `1356998400`. What happened? OpenTSDB aggregated all 64 time series *and* the pre-aggregated time series to get to that 100. In storage, we would have something like this:
```
sys.cpu.user host=webserver01 1356998400 50
sys.cpu.user host=webserver01,cpu=0 1356998400 1
sys.cpu.user host=webserver01,cpu=1 1356998400 0
sys.cpu.user host=webserver01,cpu=2 1356998400 2
sys.cpu.user host=webserver01,cpu=3 1356998400 0
...
sys.cpu.user host=webserver01,cpu=63 1356998400 1
```
OpenTSDB will *automatically* aggregate *all* of the time series for the metric in a query if no tags are given. If one or more tags are defined, the aggregate will 'include all' time series that match on that tag, regardless of other tags. With the query `sum:sys.cpu.user{host=webserver01}`, we would include `sys.cpu.user host=webserver01,cpu=0` as well as `sys.cpu.user host=webserver01,cpu=0,manufacturer=Intel`, `sys.cpu.user host=webserver01,foo=bar` and `sys.cpu.user host=webserver01,cpu=0,datacenter=lax,department=ops`. The moral of this example is: *be careful with your naming schema*.
### Time Series Cardinality
A critical aspect of any naming schema is to consider the cardinality of your time series. Cardinality is defined as the number of unique items in a set. In OpenTSDB's case, this means the number of items associated with a metric, i.e. all of the possible tag name and value combinations, as well as the number of unique metric names, tag names and tag values. Cardinality is important for two reasons outlined below.
**Limited Unique IDs (UIDs)**
There is a limited number of unique IDs to assign for each metric, tag name and tag value. By default there are just over 16 million possible IDs per type. If, for example, you ran a very popular web service and tried to track the IP address of clients as a tag, e.g. `web.app.hits clientip=38.26.34.10`, you may quickly run into the UID assignment limit as there are over 4 billion possible IP version 4 addresses. Additionally, this approach would lead to creating a very sparse time series as the user at address `38.26.34.10` may only use your app sporadically, or perhaps never again from that specific address.
The UID limit is usually not an issue, however. A tag value is assigned a UID that is completely disassociated from its tag name. If you use numeric identifiers for tag values, the number is assigned a UID once and can be used with many tag names. For example, if we assign a UID to the number `2`, we could store timeseries with the tag pairs `cpu=2`, `interface=2`, `hdd=2` and `fan=2` while consuming only 1 tag value UID (`2`) and 4 tag name UIDs (`cpu`, `interface`, `hdd` and `fan`).
If you think that the UID limit may impact you, first think about the queries that you want to execute. If we look at the `web.app.hits` example above, you probably only care about the total number of hits to your service and rarely need to drill down to a specific IP address. In that case, you may want to store the IP address as an annotation. That way you could still benefit from low cardinality but if you need to, you could search the results for that particular IP using external scripts. (Note: Support for annotation queries is expected in a *future* version of OpenTSDB.)
If you desperately need more than 16 million values, you can increase the number of bytes that OpenTSDB uses to encode UIDs from 3 bytes up to a maximum of 8 bytes. This change would require modifying the value in source code, recompiling, deploying your customized code to all TSDs which will access this data, and maintaining this customization across all future patches and releases.
Warning
It is possible that your situation requires this value to be increased. If you choose to modify this value, you must start with fresh data and a new UID table. Any data written with a TSD expecting 3-byte UID encoding will be incompatible with this change, so ensure that all of your TSDs are running the same modified code and that any data you have stored in OpenTSDB prior to making this change has been exported to a location where it can be manipulated by external tools. See the `TSDB.java` file for the values to change.
**Query Speed**
Cardinality also affects query speed a great deal, so consider the queries you will be performing frequently and optimize your naming schema for those. OpenTSDB creates a new row per time series per hour. If we have the time series `sys.cpu.user host=webserver01,cpu=0` with data written every second for 1 day, that would result in 86400 rows of data. However if we have 8 possible CPU cores for that host, now we have 691200 rows of data. This looks good because we can get easily a sum or average of CPU usage across all cores by issuing a query like `start=1d-ago&m=avg:sys.cpu.user{host=webserver01}`.
However what if we have 20,000 hosts, each with 8 cores? Now we will have 3.8 million rows per day due to a high cardinality of host values. Queries for the average core usage on host `webserver01` will be slower as it must pick out 691200 rows out of 3.8 million.
The benefits of this schema are that you have very deep granularity in your data, e.g., storing usage metrics on a per-core basis. You can also easily craft a query to get the average usage across all cores an all hosts: `start=1d-ago&m=avg:sys.cpu.user`. However queries against that particular metric will take longer as there are more rows to sift through.
Here are some common means of dealing with cardinality:
**Pre-Aggregate** - In the example above with `sys.cpu.user`, you generally care about the average usage on the host, not the usage per core. While the data collector may send a separate value per core with the tagging schema above, the collector could also send one extra data point such as `sys.cpu.user.avg host=webserver01`. Now you have a completely separate timeseries that would only have 24 rows per day and with 20K hosts, only 480K rows to sift through. Queries will be much more responsive for the per-host average and you still have per-core data to drill down to separately.
**Shift to Metric** - What if you really only care about the metrics for a particular host and don't need to aggregate across hosts? In that case you can shift the hostname to the metric. Our previous example becomes `sys.cpu.user.websvr01 cpu=0`. Queries against this schema are very fast as there would only be 192 rows per day for the metric. However to aggregate across hosts you would have to execute multiple queries and aggregate outside of OpenTSDB. (Future work will include this capability).
### Naming Conclusion
When you design your naming schema, keep these suggestions in mind:
* Be consistent with your naming to reduce duplication. Always use the same case for metrics, tag names and values.
* Use the same number and type of tags for each metric. E.g. don't store `my.metric host=foo` and `my.metric datacenter=lga`.
* Think about the most common queries you'll be executing and optimize your schema for those queries
* Think about how you may want to drill down when querying
* Don't use too many tags, keep it to a fairly small number, usually up to 4 or 5 tags (By default, OpenTSDB supports a maximum of 8 tags).
Data Specification
------------------
Every time series data point requires the following data:
* metric - A generic name for the time series such as `sys.cpu.user`, `stock.quote` or `env.probe.temp`.
* timestamp - A Unix/POSIX Epoch timestamp in seconds or milliseconds defined as the number of seconds that have elapsed since January 1st, 1970 at 00:00:00 UTC time. Only positive timestamps are supported at this time.
* value - A numeric value to store at the given timestamp for the time series. This may be an integer or a floating point value.
* tag(s) - A key/value pair consisting of a `tagk` (the key) and a `tagv` (the value). Each data point must have at least one tag.
### Timestamps
Data can be written to OpenTSDB with second or millisecond resolution. Timestamps must be integers and be no longer than 13 digits (See first [NOTE] below). Millisecond timestamps must be of the format `1364410924250` where the final three digits represent the milliseconds. Applications that generate timestamps with more than 13 digits (i.e., greater than millisecond resolution) must be rounded to a maximum of 13 digits before submitting or an error will be generated.
Timestamps with second resolution are stored on 2 bytes while millisecond resolution are stored on 4. Thus if you do not need millisecond resolution or all of your data points are on 1 second boundaries, we recommend that you submit timestamps with 10 digits for second resolution so that you can save on storage space. It's also a good idea to avoid mixing second and millisecond timestamps for a given time series. Doing so will slow down queries as iteration across mixed timestamps takes longer than if you only record one type or the other. OpenTSDB will store whatever you give it.
Note
When writing to the telnet interface, timestamps may optionally be written in the form `1364410924.250`, where three digits representing the milliseconds are placed after a period. Timestamps sent to the `/api/put` endpoint over HTTP *must* be integers and may not have periods. Data with millisecond resolution can only be extracted via the `/api/query` endpoint or CLI command at this time. See `query/index` for details.
Note
Providing millisecond resolution does not necessarily mean that OpenTSDB supports write speeds of 1 data point per millisecond over many time series. While a single TSD may be able to handle a few thousand writes per second, that would only cover a few time series if you're trying to store a point every millisecond. Instead OpenTSDB aims to provide greater measurement accuracy and you should generally avoid recording data at such a speed, particularly for long running time series.
### Metrics and Tags
The following rules apply to metric and tag values:
* Strings are case sensitive, i.e. "Sys.Cpu.User" will be stored separately from "sys.cpu.user"
* Spaces are not allowed
* Only the following characters are allowed: `a` to `z`, `A` to `Z`, `0` to `9`, `-`, `\_`, `.`, `/` or Unicode letters (as per the specification)
Metric and tags are not limited in length, though you should try to keep the values fairly short.
### Integer Values
If the value from a `put` command is parsed without a decimal point (`.`), it will be treated as a signed integer. Integers are stored, unsigned, with variable length encoding so that a data point may take as little as 1 byte of space or up to 8 bytes. This means a data point can have a minimum value of -9,223,372,036,854,775,808 and a maximum value of 9,223,372,036,854,775,807 (inclusive). Integers cannot have commas or any character other than digits and the dash (for negative values). For example, in order to store the maximum value, it must be provided in the form `9223372036854775807`.
### Floating Point Values
If the value from a `put` command is parsed with a decimal point (`.`) it will be treated as a floating point value. Currently all floating point values are stored on 4 bytes, single-precision, with support for 8 bytes planned for a future release. Floats are stored in IEEE 754 floating-point "single format" with positive and negative value support. Infinity and Not-a-Number values are not supported and will throw an error if supplied to a TSD. See [Wikipedia](https://en.wikipedia.org/wiki/IEEE_floating_point) and the [Java Documentation](http://docs.oracle.com/javase/specs/jls/se7/html/jls-4.html#jls-4.2.3) for details.
Note
Because OpenTSDB only supports floating point values, it is not suitable for storing measurements that require exact values like currency. This is why, when storing a value like `15.2` the database may return `15.199999809265137`.
### Ordering
Unlike other solutions, OpenTSDB allows for writing data for a given time series in any order you want. This enables significant flexibility in writing data to a TSD, allowing for populating current data from your systems, then importing historical data at a later time.
### Duplicate Data Points
Writing data points in OpenTSDB is generally idempotent within an hour of the original write. This means you can write the value `42` at timestamp `1356998400` and then write `42` again for the same time and nothing bad will happen. However if you have compactions enabled to reduce storage consumption and write the same data point after the row of data has been compacted, an exception may be returned when you query over that row. If you attempt to write two different values with the same timestamp, a duplicate data point exception may be thrown during query time. This is due to a difference in encoding integers on 1, 2, 4 or 8 bytes and floating point numbers. If the first value was an integer and the second a floating point, the duplicate error will always be thrown. However if both values were floats or they were both integers that could be encoded on the same length, then the original value may be overwritten if a compaction has not occurred on the row.
In most situations, if a duplicate data point is written it is usually an indication that something went wrong with the data source such as a process restarting unexpectedly or a bug in a script. OpenTSDB will fail "safe" by throwing an exception when you query over a row with one or more duplicates so you can down the issue.
With OpenTSDB 2.1 you can enable last-write-wins by setting the `tsd.storage.fix\_duplicates` configuration value to `true`. With this flag enabled, at query time, the most recent value recorded will be returned instead of throwing an exception. A warning will also be written to the log file noting a duplicate was found. If compaction is also enabled, then the original compacted value will be overwritten with the latest value.
Input Methods
-------------
There are currently three main methods to get data into OpenTSDB: Telnet API, HTTP API and batch import from a file. Alternatively you can use a tool that provides OpenTSDB support, or if you're extremely adventurous, use the Java library.
Warning
Don't try to write directly to the underlying storage system, e.g. HBase. Just don't. It'll get messy quickly.
Note
If the `tsd.mode` is set to `ro` instead of `rw`, the TSD will not accept data points through RPC calls. Telnet style calls will throw an exception and calls to the HTTP endpoint will return a 404 error. However it is still possible to write via the JAVA API when the mode is set to read only.
### Telnet
The easiest way to get started with OpenTSDB is to open up a terminal or telnet client, connect to your TSD and issue a `put` command and hit 'enter'. If you are writing a program, simply open a socket, print the string command with a new line and send the packet. The telnet command format is:
```
put <metric> <timestamp> <value> <tagk1=tagv1[ tagk2=tagv2 ...tagkN=tagvN]>
```
For example:
```
put sys.cpu.user 1356998400 42.5 host=webserver01 cpu=0
```
Each `put` can only send a single data point. Don't forget the newline character, e.g. `\n` at the end of your command.
Note
The Telnet method of writing is discouraged as it doesn't provide a way of determining which data points failed to write due to formatting or storage errors. Instead use the HTTP API.
### Http API
As of version 2.0, data can be sent over HTTP in formats supported by 'Serializer' plugins. Multiple, un-related data points can be sent in a single HTTP POST request to save bandwidth. See the `../api\_http/put` for details.
### Batch Import
If you are importing data from another system or you need to backfill historical data, you can use the `import` CLI utility. See `cli/import` for details.
Write Performance
-----------------
OpenTSDB can scale to writing millions of data points per 'second' on commodity servers with regular spinning hard drives. However users who fire up a VM with HBase in stand-alone mode and try to slam millions of data points at a brand new TSD are disappointed when they can only write data in the hundreds of points per second. Here's what you need to do to scale for brand new installs or testing and for expanding existing systems.
### UID Assignment
The first sticking point folks run into is ''uid assignment''. Every string for a metric, tag key and tag value must be assigned a UID before the data point can be stored. For example, the metric `sys.cpu.user` may be assigned a UID of `000001` the first time it is encountered by a TSD. This assignment takes a fair amount of time as it must fetch an available UID, write a UID to name mapping and a name to UID mapping, then use the UID to write the data point's row key. The UID will be stored in the TSD's cache so that the next time the same metric comes through, it can find the UID very quickly.
Therefore, we recommend that you 'pre-assign' UID to as many metrics, tag keys and tag values as you can. If you have designed a naming schema as recommended above, you'll know most of the values to assign. You can use the CLI tools `cli/mkmetric`, `cli/uid` or the HTTP API `../api\_http/uid/index` to perform pre-assignments. Any time you are about to send a bunch of new metrics or tags to a running OpenTSDB cluster, try to pre-assign or the TSDs will bog down a bit when they get the new data.
Note
If you restart a TSD, it will have to lookup the UID for every metric and tag so performance will be a little slow until the cache is filled.
### Random Metric UID Assignment
With 2.2 you can randomly assign UIDs to metrics for better region server write distribution. Because metric UIDs are located at the start of the row key, if a new set of busy metric are created, all writes for those metric will be on the same server until the region splits. With random UID generation enabled, the new metrics will be distributed across the key space and likely to wind up in different regions on different servers.
Random metric generation can be enabled or disabled at any time by modifying the `tsd.core.uid.random\_metrics` flag and data is backwards compatible all the way back to OpenTSDB 1.0. However it is recommended that you pre-split your TSDB data table according to the full metric UID space. E.g. if you use the default UID size in OpenTSDB, UIDs are 3 bytes wide, thus you can have 16,777,215 values. If you already have data in your TSDB table and choose to enable random UIDs, you may want to create new regions.
When generating random IDs, TSDB will try up to 10 times to assign a UID without a collision. Thus as the number of assigned metrics increases so too will the number of collisions and the likely hood that a data point may be dropped due to retries. If you enable random IDs and keep adding more metrics then you may want to increase the number of bytes on metric UIDs. Note that the UID change is not backwards compatible so you have to create a new table and migrate your old data.
### Salting
In 2.2 salting is supported to greatly increase write distribution across region servers. When enabled, a configured number of bytes are prepended to each row key. Each metric and combination of tags is then hashed into one "bucket", the ID of which is written to the salt bytes. Distribution is improved particularly for high-cardinality metrics (those with a large number of tag combinations) as the time series are split across the configured bucket count, thus routed to different regions and different servers. For example, without salting, a metric with 1 million series will be written to a single region on a single server. With salting enabled and a bucket size of 20, the series will be split across 20 regions (and 20 servers if the cluster has that many hosts) where each region has 50,000 series.
Warning
Because salting modifies the storage format, you cannot enable or disable salting at whim. If you have existing data, you must start a new data table and migrate data from the old table into the new one. Salted data cannot be read from previous versions of OpenTSDB.
To enable salting you must modify the config file parameter `tsd.storage.salt.width` and optionally `tsd.storage.salt.buckets`. We recommend setting the salt width to `1` and determine the number of buckets based on a factor of the number of region servers in your cluster. Note that at query time, the TSD will fire `tsd.storage.salt.buckets` number of scanners to fetch data. The proper number of salt buckets must be determined through experimentation as at some point query performance may suffer due to having too many scanners open and collating the results. In the future the salt width and buckets may be configurable but we didn't want folks changing settings on accident and losing data.
### Appends
Also in 2.2, writing to HBase columns via appends is now supported. This can improve both read and write performance in that TSDs will no longer maintain a queue of rows to compact at the end of each hour, thus preventing a massive read and re-write operation in HBase. However due to the way appends operate in HBase, an increase in CPU utilization, store file size and HDFS traffic will occur on the region servers. Make sure to monitor your HBase servers closely.
At read time, only one column is returned per row similar to post-TSD-compaction rows. However note that if the `tsd.storage.repair\_appends` is enabled, then when a column has duplicates or out of order data, it will be re-written to HBase. Also columns with many duplicates or ordering issues may slow queries as they must be resolved before answering the caller.
Appends can be enabled and disabled at any time. However versions of OpenTSDB prior to 2.2 will skip over appended values.
### Pre-Split HBase Regions
For brand new installs you will see much better performance if you pre-split the regions in HBase regardless of if you're testing on a stand-alone server or running a full cluster. HBase regions handle a defined range of row keys and are essentially a single file. When you create the `tsdb` table and start writing data for the first time, all of those data points are being sent to this one file on one server. As a region fills up, HBase will automatically split it into different files and move it to other servers in the cluster, but when this happens, the TSDs cannot write to the region and must buffer the data points. Therefore, if you can pre-allocate a number of regions before you start writing, the TSDs can send data to multiple files or servers and you'll be taking advantage of the linear scalability immediately.
The simplest way to pre-split your `tsdb` table regions is to estimate the number of unique metric names you'll be recording. If you have designed a naming schema, you should have a pretty good idea. Let's say that we will track 4,000 metrics in our system. That's not to say 4,000 time series, as we're not counting the tags yet, just the metric names such as "sys.cpu.user". Data points are written in row keys where the metric's UID comprises the first bytes, 3 bytes by default. The first metric will be assigned a UID of `000001` as a hex encoded value. The 4,000th metric will have a UID of `000FA0` in hex. You can use these as the start and end keys in the script from the [HBase Book](http://hbase.apache.org/book/perf.writing.html) to split your table into any number of regions. 256 regions may be a good place to start depending on how many time series share each metric.
TODO - include scripts for pre-splitting.
The simple split method above assumes that you have roughly an equal number of time series per metric (i.e. a fairly consistent cardinality). E.g. the metric with a UID of `000001` may have 200 time series and `000FA0` has about 150. If you have a wide range of time series per metric, e.g. `000001` has 10,000 time series while `000FA0` only has 2, you may need to develop a more complex splitting algorithm.
But don't worry too much about splitting. As stated above, HBase will automatically split regions for you so over time, the data will be distributed fairly evenly.
### Distributed HBase
HBase will run in stand-alone mode where it will use the local file system for storing files. It will still use multiple regions and perform as well as the underlying disk or raid array will let it. You'll definitely want a RAID array under HBase so that if a drive fails, you can replace it without losing data. This kind of setup is fine for testing or very small installations and you should be able to get into the low thousands of data points per second.
However if you want serious throughput and scalability you have to setup a Hadoop and HBase cluster with multiple servers. In a distributed setup HDFS manages region files, automatically distributing copies to different servers for fault tolerance. HBase assigns regions to different servers and OpenTSDB's client will send data points to the specific server where they will be stored. You're now spreading operations amongst multiple servers, increasing performance and storage. If you need even more throughput or storage, just add nodes or disks.
There are a number of ways to setup a Hadoop/HBase cluster and a ton of various tuning tweaks to make, so Google around and ask user groups for advice. Some general recommendations include:
* Dedicate a pair of high memory, low disk space servers for the Name Node. Set them up for high availability using something like Heartbeat and Pacemaker.
* Setup Zookeeper on at least 3 servers for fault tolerance. They must have a lot of RAM and a fairly fast disk for log writing. On small clusters, these can run on the Name node servers.
* JBOD for the HDFS data nodes
* HBase region servers can be collocated with the HDFS data nodes
* At least 1 gbps links between servers, 10 gbps preferable.
* Keep the cluster in a single data center
### Multiple TSDs
A single TSD can handle thousands of writes per second. But if you have many sources it's best to scale by running multiple TSDs and using a load balancer (such as Varnish or DNS round robin) to distribute the writes. Many users colocate TSDs on their HBase region servers when the cluster is dedicated to OpenTSDB.
### Persistent Connections
Enable keep-alives in the TSDs and make sure that any applications you are using to send time series data keep their connections open instead of opening and closing for every write. See `configuration` for details.
### Disable Meta Data and Real Time Publishing
OpenTSDB 2.0 introduced meta data for tracking the kinds of data in the system. When tracking is enabled, a counter is incremented for every data point written and new UIDs or time series will generate meta data. The data may be pushed to a search engine or passed through tree generation code. These processes require greater memory in the TSD and may affect throughput. Tracking is disabled by default so test it out before enabling the feature.
2.0 also introduced a real-time publishing plugin where incoming data points can be emitted to another destination immediately after they're queued for storage. This is disabled by default so test any plugins you are interested in before deploying in production.
| programming_docs |
opentsdb /api/serializers /api/serializers
================
This endpoint lists the serializer plugins loaded by the running TSD. Information given includes the name, implemented methods, content types and methods.
Verbs
-----
* GET
* POST
Requests
--------
No parameters are available, this is a read-only endpoint that simply returns system data.
Response
--------
The response is an array of serializer objects. Each object has the following fields:
| Field Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| serializer | String | The name of the serializer, suitable for use in the query string `serializer=<serializer\_name>` parameter | xml |
| formatters | Array<String> | An array of methods or endpoints that the serializer implements to convert response data. These usually map to an endpoint such as `/api/suggest` mapping to `Suggest`. If the serializer does not implement a certain method, the default formatter will respond. Each name also ends with the API version supported, e.g. `V1` will support version 1 API calls. | "Error","Suggest" |
| parsers | Array<String> | An array of methods or endpoints that the serializer implements to parse user input in the HTTP request body. These usually map to an endpoint such as `/api/suggest` will map to `Suggest`. If a serializer does not implement a parser, the default serializer will be used. Each name also ends with the API version supported, e.g. `V1` will support version 1 API calls. | "Suggest","Put" |
This endpoint should always return data with the JSON serializer as the default. If you think the TSD should have other formatters listed, check the plugin documentation to make sure you have the proper plugin and it's located in the right directory.
Example Response
----------------
```
[
{
"formatters": [
"SuggestV1",
"SerializersV1",
"ErrorV1",
"ErrorV1",
"NotFoundV1"
],
"serializer": "json",
"parsers": [
"SuggestV1"
],
"class": "net.opentsdb.tsd.HttpJsonSerializer",
"response_content_type": "application/json; charset=UTF-8",
"request_content_type": "application/json"
}
]
```
opentsdb HTTP API HTTP API
========
OpenTSDB provides an HTTP based application programming interface to enable integration with external systems. Almost all OpenTSDB features are accessiable via the API such as querying timeseries data, managing metadata and storing data points. Please read this entire page for important information about standard API behavior before investigating individual endpoints.
Overview
--------
The HTTP API is RESTful in nature but provides alternative access through various overrides since not all clients can adhere to a strict REST protocol. The default data exchange is via JSON though pluggable `formatters` may be accessed, via the request, to send or receive data in different formats. Standard HTTP response codes are used for all returned results and errors will be returned as content using the proper format.
Version 1.X to 2.x
------------------
OpenTSDB 1.x had a simple HTTP API that provided access to common behaviors such as querying for data, auto-complete queries and static file requests. OpenTSDB 2.0 introduces a new, formalized API as documented here. The 1.0 API is still accessible though most calls are deprecated and may be removed in version 3. All 2.0 API calls start with `/api/`.
Serializers
-----------
2.0 introduces pluggable serializers that allow for parsing user input and returning results in different formats such as XML or JSON. Serializers only apply to the 2.0 API calls, all 1.0 behave as before. For details on Serializers and options supported, please read [*HTTP Serializers*](serializers/index)
All API calls use the default JSON serializer unless overridden by query string or `Content-Type` header. To override:
* **Query String** - Supply a parameter such as `serializer=<serializer\_name>` where `<serializer\_name>` is the hard-coded name of the serializer as shown in the `/api/serializers` `serializer` output field.
Warning
If a serializer isn't found that matches the `<serializer\_name>` value, the query will return an error instead of processing further.
* **Content-Type** - If a query string is not given, the TSD will parse the `Content-Type` header from the HTTP request. Each serializer may supply a content type and if matched to the incoming request, the proper serializer will be used. If a serializer isn't located that maps to the content type, the default serializer will be used.
* **Default** - If no query string parameter is given or the content-type is missing or not matched, the default JSON serializer will be used.
The API documentation will display requests and responses using the JSON serializer. See plugin documentation for the ways in which serializers alter behavior.
Note
The JSON specification states that fields can appear in any order, so do not assume the ordering in given examples will be preserved. Arrays may be sorted and if so, this will be documented.
Authentication/Permissions
--------------------------
As of yet, OpenTSDB lacks an authentication and access control system. Therefore no authentication is required when accessing the API. If you wish to limit access to OpenTSDB, use network ACLs or firewalls to block access. We do not recommend running OpenTSDB on a machine with a public IP Address.
Response Codes
--------------
Every request will be returned with a standard HTTP response code. Most responses will include content, particularly error codes that will include details in the body about what went wrong. Successful codes returned from the API include:
| Code | Description |
| --- | --- |
| 200 | The request completed successfully |
| 204 | The server has completed the request successfully but is not returning content in the body. This is primarily used for storing data points as it is not necessary to return data to caller |
| 301 | This may be used in the event that an API call has migrated or should be forwarded to another server |
Common error response codes include:
| Code | Description |
| --- | --- |
| 400 | Information provided by the API user, via a query string or content data, was in error or missing. This will usually include information in the error body about what parameter caused the issue. Correct the data and try again. |
| 404 | The requested endpoint or file was not found. This is usually related to the static file endpoint. |
| 405 | The requested verb or method was not allowed. Please see the documentation for the endpoint you are attempting to access |
| 406 | The request could not generate a response in the format specified. For example, if you ask for a PNG file of the `logs` endpoing, you will get a 406 response since log entries cannot be converted to a PNG image (easily) |
| 408 | The request has timed out. This may be due to a timeout fetching data from the underlying storage system or other issues |
| 413 | The results returned from a query may be too large for the server's buffers to handle. This can happen if you request a lot of raw data from OpenTSDB. In such cases break your query up into smaller queries and run each individually |
| 500 | An internal error occured within OpenTSDB. Make sure all of the systems OpenTSDB depends on are accessible and check the bug list for issues |
| 501 | The requested feature has not been implemented yet. This may appear with formatters or when calling methods that depend on plugins |
| 503 | A temporary overload has occurred. Check with other users/applications that are interacting with OpenTSDB and determine if you need to reduce requests or scale your system. |
Errors
------
If an error occurs, the API will return a response with an error object formatted per the requested response type. Error object fields include:
| Field Name | Data Type | Always Present | Description | Example |
| --- | --- | --- | --- | --- |
| code | Integer | Yes | The HTTP status code | 400 |
| message | String | Yes | A descriptive error message about what went wrong | Missing required parameter |
| details | String | Optional | Details about the error, often a stack trace | Missing value: type |
| trace | String | Optional | A JAVA stack trace describing the location where the error was generated. This can be disabled via the `tsd.http.show\_stack\_trace` configuration option. The default for TSD is to show the stack trace. | See below |
All errors will return with a valid HTTP status error code and a content body with error details. The default formatter returns error messages as JSON with the `application/json` content-type. If a different formatter was requested, the output may be different. See the formatter documentation for details.
### Example Error Result
```
{
"error": {
"code": 400,
"message": "Missing parameter <code>type</code>",
"trace": "net.opentsdb.tsd.BadRequestException: Missing parameter <code>type</code>\r\n\tat net.opentsdb.tsd.BadRequestException.missingParameter(BadRequestException.java:78) ~[bin/:na]\r\n\tat net.opentsdb.tsd.HttpQuery.getRequiredQueryStringParam(HttpQuery.java:250) ~[bin/:na]\r\n\tat net.opentsdb.tsd.SuggestRpc.execute(SuggestRpc.java:63) ~[bin/:na]\r\n\tat net.opentsdb.tsd.RpcHandler.handleHttpQuery(RpcHandler.java:172) [bin/:na]\r\n\tat net.opentsdb.tsd.RpcHandler.messageReceived(RpcHandler.java:120) [bin/:na]\r\n\tat org.jboss.netty.channel.SimpleChannelUpstreamHandler.handleUpstream(SimpleChannelUpstreamHandler.java:75) [netty-3.5.9.Final.jar:na]\r\n\tat org.jboss.netty.channel.DefaultChannelPipeline.sendUpstream(DefaultChannelPipeline.java:565) [netty-3.5.9.Final.jar:na]
....\r\n\tat java.lang.Thread.run(Unknown Source) [na:1.6.0_26]\r\n"
}
}
```
Note that the stack trace is truncated. Also, the trace will include system specific line endings (in this case `\r\n` for Windows). If displaying for a user or writing to a log, be sure to replace the `\n` or `\r\n` and `\r` characters with new lines and tabs.
Verbs
-----
The HTTP API is RESTful in nature, meaning it does it's best to adhere to the REST protocol by using HTTP verbs to determine a course of action. For example, a `GET` request should only return data, a `PUT` or `POST` should modify data and `DELETE` should remove it. Documentation will reflect what verbs can be used on an endpoint and what they do.
However in some situations, verbs such as `DELETE` and `PUT` are blocked by firewalls, proxies or not implemented in clients. Furthermore, most developers are used to using `GET` and `POST` exclusively. Therefore, while the OpenTSDB API supports extended verbs, most requests can be performed with just `GET` by adding the query string parameter `method\_override`. This parameter allows clients to pass data for most API calls as query string values instead of body content. For example, you can delete an annotation by issuing a `GET` with a query string `/api/annotation?start\_time=1369141261&tsuid=010101&method\_override=delete`. The following table describes verb behavior and overrides.
| Verb | Description | Override |
| --- | --- | --- |
| GET | Used to retrieve data from OpenTSDB. Overrides can be provided to modify content. **Note**: Requests via GET can only use query string parameters; see the note below. | N/A |
| POST | Used to update or create an object in OpenTSDB using the content body from the request. Will use a formatter to parse the content body | method\_override=post |
| PUT | Replace an entire object in the system with the provided content | method\_override=put |
| DELETE | Used to delete data from the system | method\_override=delete |
If a method is not supported for a given API call, the TSD will return a 405 error.
Note
The HTTP specification states that there shouldn't be an association between data passed in a request body and the URI in a `GET` request. Thus OpenTSDB's API does not parse body content in `GET` requests. You can, however, provide a query string with data and an override for updating data in certain endpoints. But we recommend that you use `POST` for anything that writes data.
API Versioning
--------------
OpenTSDB 2.0's API call calls are versioned so that users can upgrade with gauranteed backwards compatability. To access a specific API version, you craft a URL such as `/api/v<version>/<endpoint>` such as `/api/v2/suggest`. This will access version 2 of the `suggest` endpoint. Versioning starts at 1 for OpenTSDB 2.0.0. Requests for a version that does not exist will result in calls to the latest version. Also, if you do not supply an explicit version, such as `/api/suggest`, the latest version will be used.
Query String Vs. Body Content
-----------------------------
Most of the API endpoints support query string parameters, particularly those that fetch data from the system. However due to the complexities of encoding some characters, and particularly Unicode, all endpoints also support access via POST content using formatters. The default format is JSON so clients can use their favorite means of generating a JSON object and send it to the OpenTSDB API via a `POST` request. `POST` requests will generally provided greater flexibility in the fields offered and fully Unicode support than query strings.
Compressed Requests
-------------------
The API can accept body content that has been compressed. Make sure to set the `Content-Encoding` header to `gzip` and pass the binary encoded data over the wire. This is particularly useful for posting data points to the `/api/put` endpoint. An example using curl:
```
$ gzip -9c clear-32k.json > gzip-32k.json
$ file gzip-32k.json
gzip-32k.json: gzip compressed data, was "clear-32k.json", from Unix, last modified: Thu Jan 16 15:31:55 2014
$ ls -l gzip-32k.json
-rw-r--r-- 1 root root 1666 févr. 4 09:57 gzip-32k.json
$ curl -X POST --data-binary "@gzip-32k.json" --header "Content-Type: application/json" --header "Content-Encoding: gzip" http://mytsdb1:4242/api/put?details
{"errors":[],"failed":0,"success":280}
```
CORS
----
OpenTSDB provides simple and preflight support for Cross-Origin Resource Sharing (CORS) requests. To enable CORS, you must supply either a wild card `\*` or a comma separated list of specific domains in the `tsd.http.request.cors\_domains` configuration setting and restart OpenTSDB. For example, you can supply a value of `\*` or you could provide a list of domains such as `beeblebrox.com,www.beeblebrox.com,aurtherdent.com`. The domain list is case insensitive but must fully match any value sent by clients.
When a `GET`, `POST`, `PUT` or `DELETE` request arrives with the `Origin` header set to a valid domain name, the server will compare the domain against the configured list. If the domain appears in the list or the wild card was set, the server will add the `Access-Control-Allow-Origin` and `Access-Control-Allow-Methods` headers to the response after processing is complete. The allowed methods will always be `GET, POST, PUT, DELETE`. It does not change per end point. If the request is a CORS preflight, i.e. the `OPTION` method is used, the response will be the same but with an empty content body and a 200 status code.
If the `Origin` domain did not match a domain in the configured list, the response will be a 200 status code and an Error (see above) for the content body stating that access was denied, regardless of whether the request was a preflight or a regular request. The request will not be processed any further.
By default, the `tsd.http.request.cors\_domains` list is empty and CORS is diabled. Requests are passed through without appending CORS specific headers. If an `Options` request arrives, it will receive a 405 error message.
Note
Do not rely on CORS for security. It is exceedingly easy to spoof a domain in an HTTP request and OpenTSDB does not perform reverse lookups or domain validation. CORS is only implemented as a means to make it easier JavaScript developers to work with the API.
Documentation
-------------
The documentation for each endpoint listed below will contain details about how to use that endpoint. Eahc page will contain a description of the endpoint, what verbs are supported, the fields in a request, fields in a respone and examples.
Request Parameters are a list of field names that you can pass in with your request. Each table has the following information:
* Name - The name of the field
* Data Type - The type of data you need to supply. E.g. `String` should be text, `Integer` must be a whole number (positive or negative), `Float` should be a decimal number. The data type may also be a complex object such as an array or map of values or objects. If you see `Present` in this column then simply adding the parameter to the query string sets the value to `true`, the actual value of the parameter is ignored. For example `/api/put?summary` will effectively set `summary=true`. If you request `/api/put?summary=false`, the API will still consider the request as `summary=true`.
* Required - Whether or not the parameter is required for a successful query. If the parameter is required, you'll see `Required` otherwise it will be `Optional`.
* Description - A detailed description of the parameter including what values are allowed if applicable.
* Default - The default value of the `Optional` parameter. If the data is required, this field will be blank.
* QS - If the parameter can be supplied via query string, this field will have a `Yes` in it, otherwise it will have a `No` meaning the parameter can only be supplied as part of the request body content.
* RW - Describes whether or not this parameter can result in an update to data stored in OpenTSDB. Possible values in this column are:
+ *empty* - This means that the field is for queries only and does not, necessarily, represent a field in the response.
+ **RO** - A field that appears in the response but is read only. The value passed along with a request will not alter the output field.
+ **RW** or **W** - A field that **will** result in an update to the data stored in the system
* Example - An example of the parameter value
Deprecated API
--------------
Read [*Deprecated HTTP API*](deprecated)
API Endpoints
-------------
* [/s](s)
* [/api/aggregators](aggregators)
* [/api/annotation](annotation/index)
* [/api/config](config/index)
* [/api/dropcaches](dropcaches)
* [/api/put](put)
* [/api/rollup](rollup)
* [/api/query](query/index)
* [/api/search](search/index)
* [/api/serializers](serializers)
* [/api/stats](stats/index)
* [/api/suggest](suggest)
* [/api/tree](tree/index)
* [/api/uid](uid/index)
* [/api/version](version)
opentsdb /api/aggregators /api/aggregators
================
This endpoint simply lists the names of implemented aggregation functions used in timeseries queries.
Verbs
-----
* GET
* POST
Requests
--------
This endpoint does not require any parameters via query string or body.
### Example Request
**Query String**
```
http://localhost:4242/api/aggregators
```
Response
--------
The response is an array of strings that are the names of aggregation functions that can be used in a timeseries query.
### Example Response
```
[
"min",
"sum",
"max",
"avg",
"dev"
]
```
opentsdb Deprecated HTTP API Deprecated HTTP API
===================
Version 1.0 of OpenTSDB included a rudimentary HTTP API that allowed for querying data, suggesting metric or tag names and a means of accessing static files. The 1.0 API has been carried over to 2.0 for backwards compatibility though most of the calls have been deprecated. Below is a list of the different endpoints and how to use them.
Warning
Version 3.0 may discard these deprecated methods so if you are developing tools against the HTTP API, make sure to use the 2.0 version.
If an endpoint is marked as (**Deprecated**) below, it should not be used for future development work.
Generalities
------------
Most of the endpoints can return data in one or more of the following formats:
* Plain Test - Or ASCII, the default for many requests will return a simple page of data with the Content-Type `text/plain`
* HTML - If a request is bad or there was an exception, the response will often be in HTML, hard-coded and not using templates
* JSON - Many calls can respond in a JSON format when the `json` query string parameter is appended
* PNG - Some requests, including exceptions and errors, can generate an image file. In these cases, an error is sent to GnuPlot and the resulting empty graph with a title consisting of the message is returned. Append the parameter `png` to the query string.
The correct Content-Type is returned for each response, e.g. `text/html; charset=UTF-8` for HTML, `application/json` for JSON and `image/png` for images.
Selecting a different output format is done with the `png` or `json` query string parameter. The value for the parameter is ignored. For example you can request `http://localhost:4242/suggest?type=metrics&q=sys&json` to return JSON data.
/
-
Requests the root which is the GWT generated OpenTSDB GUI. This endpoint only returns HTML and cannot return other data.
/aggregators (**Deprecated**)
-----------------------------
Returns a list of available aggregation functions in JSON format only. Other formats are ignored. This method does not accept any query string parameters.
Example Request:
```
http://localhost:4242/aggregators
```
Example Response:
```
["min","sum","max","avg"]
```
/diediedie (**Deprecated**)
---------------------------
Accessing this endpoint causes the TSD to perform a graceful shutdown and exit. A graceful shutdown prevents data loss by flushing all the buffered edits to HBase before exiting. The endpoint does not return any data and does not accept any parameters.
/dropcaches (**Deprecated**)
----------------------------
Clears all internal caches such as the UID to name and name to UID maps. It should be used if you have renamed a metric, tagk or tagv.
/logs (**Deprecated**)
----------------------
Returns the latest lines logged by the TSD internally, returning the most recent entries first. OpenTSDB uses LogBack and the `src/logback.xml` file must have a Cyclic Buffer appender configured for this endpoint to function. The XML configuration determines how many lines will be returned with each call. Output defaults to plain text with message components separated by tabs, or it can be returned as JSON with the proper query string.
This endpoint can also change the logging level of \_\_\_\_\_\_ at runtime. The query string parameter to use is `level=<logging\_level>`. For example, you can call `http://localhost:4242/logs?level=INFO` to set the log level to `INFO`. Valid parameter values are (from the most verbose to the least): `ALL` `TRACE` `DEBUG` `INFO` `WARN` `ERROR` `OFF` (names are case insensitive). Note that this method does not change the `logback.xml` configuration file and restarting the TSD will reload from that file.
/q (**Deprecated**)
-------------------
Queries the TSD for data.
/s
--
Serves static files, such as JavaScript generated by the GWT compiler or favicon.ico. The TSD needs a `--staticroot` or `tsd.http.staticroot` argument to start. This argument is the path to a directory that contains the files served by this end point.
When a request for `GET /s/queryui.nocache.js` comes in, for instance, the file `${staticroot}/queryui.nocache.js` is sent to the browser.
Note: The TSD will allow clients to cache static files for 1 year by default, and will report the age of the file on disk. If the file name contains nocache, then the TSD will tell clients to not cache the file (this idiom is used by GWT).
/stats (**Deprecated**)
-----------------------
Returns statistics about the running TSD
/suggest (**Deprecated**)
-------------------------
Used for auto-complete calls to match metrics, tag names or tag values on the given string. Returns JSON data only.
Parameters:
* type - The type of value to suggest. Must be either `metrics` for metrics, `tagk` for tag names or `tagv` for tag values.
* q - The string to match on. The match is case-sensitive and only matches on the first characters of each type of data. For example, `type=metrics&q=sys` would only return the names of metrics that start with `sys` such as `sys.cpu.0.system`
* max - An optional maximum number of results to return. The default is 25 and given values must be greater than 0.
Both parameters are required or you will receive an exception.
Example Request:
```
http://localhost:4242/suggest?type=metrics&q=df
```
Example Response:
```
[
"df.1kblocks.free",
"df.1kblocks.total",
"df.1kblocks.used",
"df.inodes.free",
"df.inodes.total",
"df.inodes.used"
]
```
/version (**Deprecated**)
-------------------------
Returns version information about the build of the running TSD. Can be returned in either the default of plain-text or JSON.
| programming_docs |
opentsdb /api/rollup /api/rollup
===========
This endpoint allows for storing rolled up and/or pre-aggregated data in OpenTSDB over HTTP. For details on rollups and pre-aggs, please see the user guide: [*Rollup And Pre-Aggregates*](../user_guide/rollups).
Also see the [*/api/put*](put) documentation for notes and common parameters that are shared with the `/api/rollup` endpoint. This page lays out the differences between the two.
Verbs
-----
* POST
Requests
--------
Rollup and pre-aggregate values are extensions of the `put` object with three additional fields. For completeness, all fields are listed below:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| metric | String | Required | The name of the metric you are storing | | | W | sys.cpu.nice |
| timestamp | Integer | Required | A Unix epoch style timestamp in seconds or milliseconds. The timestamp must not contain non-numeric characters. | | | W | 1365465600 |
| value | Integer, Float, String | Required | The value to record for this data point. It may be quoted or not quoted and must conform to the OpenTSDB value rules: `../../user\_guide/writing` | | | W | 42.5 |
| tags | Map | Required | A map of tag name/tag value pairs. At least one pair must be supplied. | | | W | {"host":"web01"} |
| interval | String | Optional\* | A time interval reflecting what timespan the **rollup** value represents. The interval consists of `<amount><unit>` similar to a downsampler or relative query timestamp. E.g. `6h` for 5 hours of data, `30m` for 30 minutes of data. | | | W | 1h |
| aggregator | String | Optional\* | An aggregation function used to generate the **rollup** value. Must match a supplied TSDB aggregator. | | | W | SUM |
| groupByAggregator | String | Optional\* | An aggregation function used to generate the **pre-aggregate** value. Must match a supplied TSDB aggregator. | | W | COUNT | |
While the aggregators and interval are marked as optional above, at least one of the combinations documented below must be satisfied for data to be recorded.
| interval | aggregator | groupByAggregator | Description |
| --- | --- | --- | --- |
| Set | Set | Empty | Data represents a *raw* or *non-pre-aggregated* **rollup** over the interval. |
| Empty | Empty | Set | Data represents a *raw* **pre-aggregated** value that has not been rolled up over time. |
| Set | Set | Set | Data represents a *rolled up* *pre-aggregated* value. |
### Example Single Data Point Put
You can supply a single data point in a request:
```
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
},
"interval": "1h",
"aggregator": "SUM",
"groupByAggregator", "SUM"
}
```
### Example Multiple Data Point Put
Multiple data points must be encased in an array:
```
[
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
},
"interval": "1h",
"aggregator": "SUM",
"groupByAggregator", "SUM"
},
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 9,
"tags": {
"host": "web02",
"dc": "lga"
},
"interval": "1h",
"aggregator": "SUM",
"groupByAggregator", "SUM"
}
]
```
Response
--------
Responses are handled in the same was as for the [*/api/put*](put) endpoint.
opentsdb /s /s
==
This endpoint was introduced in 1.0 as a means of accessing static files on the local system. `/s` will be maintained in the future and will not be deprecated. The static root is definied in the config file as `tsd.http.staticroot` or CLI via `--staticroot`.
By default, static files will be returned with a header telling clients to cache them for 1 year. Any file that contains `nocache` in the name (e.g. `queryui.nocache.js`, the idiom used by GWT) will not include the cache header.
Note
The TSD will attempt to return the correct **Content-Type** header for the requested file. However the TSD code doesn't support very many formats at this time, just HTML, JSON, Javascript and PNG. Let us know what formats you need or issue a pull request with your patches.
Warning
The code for this endpoint is very simple and does not include any security. Thus you should make sure that permissions on your static root directory are secure so that users can't write malicious files and serve them out of OpenTSDB. Users shouldn't be able to write files via OpenTSDB, but take precautions just to be safe.
Verbs
-----
All verbs are supported and simply ignored
Requests
--------
Query string and content body requests are ignored. Rather the requested file is a component of the path, e.g. `/s/index.html` will return the contents of the `index.html` file.
Example Request
---------------
**Query String**
```
http://localhost:4242/s/queryui.nocache.js
```
Response
--------
The response will be the contents of the requested file with appropriate HTTP headers configured.
opentsdb /api/suggest /api/suggest
============
This endpoint provides a means of implementing an "auto-complete" call that can be accessed repeatedly as a user types a request in a GUI. It does not offer full text searching or wildcards, rather it simply matches the entire string passed in the query on the first characters of the stored data. For example, passing a query of `type=metrics&q=sys` will return the top 25 metrics in the system that start with `sys`. Matching is case sensitive, so `sys` will not match `System.CPU`. Results are sorted alphabetically.
Verbs
-----
* GET
* POST
Requests
--------
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| type | String | Required | The type of data to auto complete on. Must be one of the following: **metrics**, **tagk** or **tagv** | | type | | metrics |
| q | String | Optional | A string to match on for the given type | | q | | web |
| max | Integer | Optional | The maximum number of suggested results to return. Must be greater than 0 | 25 | max | | 10 |
### Example Request
**Query String**
```
http://localhost:4242/api/suggest?type=metrics&q=sys&max=10
```
**JSON Content**
```
{
"type":"metrics",
"q":"sys",
"max":10
}
```
Response
--------
The response is an array of strings of the given type that match the query. If nothing was found to match the query, an empty array will be returned.
### Example Response
```
[
"sys.cpu.0.nice",
"sys.cpu.0.system",
"sys.cpu.0.user",
"sys.cpu.1.nice",
"sys.cpu.1.system",
"sys.cpu.1.user"
]
```
opentsdb /api/put /api/put
========
This endpoint allows for storing data in OpenTSDB over HTTP as an alternative to the Telnet interface. Put requests can only be performed via content associated with the POST method. The format of the content is dependent on the serializer selected. However there are some common parameters and responses as documented below.
To save on bandwidth, the put API allows clients to store multiple data points in a single request. The data points do not have to be related in any way. Each data point is processed individually and an error with one piece of data will not affect the storing of good data. This means if your request has 100 data points and 1 of them has an error, 99 data points will still be written and one will be rejected. See the Response section below for details on determining what data point was not stored.
Note
If the content you provide with the request cannot be parsed, such JSON content missing a quotation mark or curly brace, then all of the datapoints will be discarded. The API will return an error with details about what went wrong.
While the API does support multiple data points per request, the API will not return until every one has been processed. That means metric and tag names/values must be verified, the value parsed and the data queued for storage. If your put request has a large number of data points, it may take a long time for the API to respond, particularly if OpenTSDB has to assign UIDs to tag names or values. Therefore it is a good idea to limit the maximum number of data points per request; 50 per request is a good starting point.
Another recommendation is to enable keep-alives on your HTTP client so that you can re-use your connection to the server every time you put data.
Note
When using HTTP for puts, you may need to enable support for chunks if your HTTP client automatically breaks large requests into smaller packets. For example, CURL will break up messages larger than 2 or 3 data points and by default, OpenTSDB disables chunk support. Enable it by setting `tsd.http.request.enable\_chunked` to true in the config file.
Note
If the `tsd.mode` is set to `ro`, the `/api/put` endpoint will be unavailable and all calls will return a 404 error.
Verbs
-----
* POST
Requests
--------
Some query string parameters can be supplied that alter the response to a put request:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| summary | Present | Optional | Whether or not to return summary information | false | summary | | /api/put?summary |
| details | Present | Optional | Whether or not to return detailed information | false | details | | /api/put?details |
| sync | Boolean | Optional | Whether or not to wait for the data to be flushed to storage before returning the results. | false | sync | | /api/put?sync |
| sync\_timeout | Integer | Optional | A timeout, in milliseconds, to wait for the data to be flushed to storage before returning with an error. When a timeout occurs, using the `details` flag will tell how many data points failed and how many succeeded. `sync` must also be given for this to take effect. A value of 0 means the write will not timeout. | 0 | sync\_timeout | | /api/put/?sync&sync\_timeout=60000 |
If both `detailed` and `summary` are present in a query string, the API will respond with `detailed` information.
The fields and examples below refer to the default JSON serializer.
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| metric | String | Required | The name of the metric you are storing | | | W | sys.cpu.nice |
| timestamp | Integer | Required | A Unix epoch style timestamp in seconds or milliseconds. The timestamp must not contain non-numeric characters. | | | W | 1365465600 |
| value | Integer, Float, String | Required | The value to record for this data point. It may be quoted or not quoted and must conform to the OpenTSDB value rules: `../../user\_guide/writing` | | | W | 42.5 |
| tags | Map | Required | A map of tag name/tag value pairs. At least one pair must be supplied. | | | W | {"host":"web01"} |
### Example Single Data Point Put
You can supply a single data point in a request:
```
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
}
```
### Example Multiple Data Point Put
Multiple data points must be encased in an array:
```
[
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1346846400,
"value": 9,
"tags": {
"host": "web02",
"dc": "lga"
}
}
]
```
Response
--------
By default, the put endpoint will respond with a `204` HTTP status code and no content if all data points were stored successfully. If one or more datapoints had an error, the API will return a `400` with an error message in the content.
For debugging purposes, you can ask for the response to include a summary of how many data points were stored successfully and failed, or get details about what data points could not be stored and why so that you can fix your client code. Also, errors with a data point will be logged in the TSD's log file so you can look there for issues.
Fields present in `summary` or `detailed` responses include:
| Name | Data Type | Description |
| --- | --- | --- |
| success | Integer | The number of data points that were queued successfully for storage |
| failed | Integer | The number of data points that could not be queued for storage |
| errors | Array | A list of data points that failed be queued and why. Present in the `details` response only. |
### Example Response with Summary
```
{
"failed": 1,
"success": 0
}
```
### Example Response With Details
```
{
"errors": [
{
"datapoint": {
"metric": "sys.cpu.nice",
"timestamp": 1365465600,
"value": "NaN",
"tags": {
"host": "web01"
}
},
"error": "Unable to parse value to a number"
}
],
"failed": 1,
"success": 0
}
```
opentsdb /api/version /api/version
============
This endpoint returns information about the running version of OpenTSDB.
Verbs
-----
* GET
* POST
Requests
--------
This endpoint does not require any parameters via query string or body.
### Example Request
**Query String**
```
http://localhost:4242/api/version
```
Response
--------
The response is a hash map of version properties and values.
### Example Response
```
{
"timestamp": "1362712695",
"host": "localhost",
"repo": "/opt/opentsdb/build",
"full_revision": "11c5eefd79f0c800b703ebd29c10e7f924c01572",
"short_revision": "11c5eef",
"user": "localuser",
"repo_status": "MODIFIED",
"version": "2.0.0"
}
```
opentsdb /api/dropcaches /api/dropcaches
===============
This endpoint purges the in-memory data cached in OpenTSDB. This includes all UID to name and name to UID maps for metrics, tag names and tag values.
Note
This endpoint does not purge the on-disk temporary cache where graphs and other files are stored.
Verbs
-----
* GET
* POST
Requests
--------
This endpoint does not require any parameters via query string or body.
### Example Request
**Query String**
```
http://localhost:4242/api/dropcaches
```
Response
--------
The response is a hash map of information. Unless something goes wrong, this should always result in a `status` of `200` and a message of `Caches dropped`.
### Example Response
```
{
"message": "Caches dropped",
"status": "200"
}
```
opentsdb /api/tree /api/tree
=========
Trees are meta data used to organize time series in a heirarchical structure for browsing similar to a typical file system. A number of endpoints under the `/tree` root allow working with various tree related data:
Tree API Endpoints
------------------
* [/api/tree/branch](branch)
* [/api/tree/collisions](collisions)
* [/api/tree/notmatched](notmatched)
* [/api/tree/rule](rule)
* [/api/tree/rules](rules)
* [/api/tree/test](test)
The `/tree` endpoint allows for creating or modifying a tree definition. Tree definitions include configuration and meta data accessible via this endpoint, as well as the rule set accessiable via `/tree/rule` or `/tree/rules`.
Note
When creating a tree it will have the `enabled` field set to `false` by default. After creating a tree you should add rules then use the `tree/test` endpoint with a few TSUIDs to make sure the resulting tree will be what you expected. After you have verified the results, you can set the `enabled` field to `true` and new TSMeta objects or a tree synchronization will start to populate branches.
Verbs
-----
* GET - Retrieve one or more tree definitions
* POST - Edit tree fields
* PUT - Replace tree fields
* DELETE - Delete the results of a tree and/or the tree definition
Requests
--------
The following fields can be used for all tree endpoint requests:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Required\* | Used to fetch or modify a specific tree. [\*](#id1)When creating a new tree, the `tree` value must not be present. | | treeid | RO | 1 |
| name | String | Required\* | A brief, descriptive name for the tree. [\*](#id3)Required only when creating a tree. | | name | RW | Network Infrastructure |
| description | String | Optional | A longer description of what the tree contains | | description | RW | Tree containing all network gear |
| notes | String | Optional | Detailed notes about the tree | | notes | RW | |
| strictMatch | Boolean | Optional | Whether or not timeseries should be included in the tree if they fail to match one or more rule levels. | false | strict\_match | RW | true |
| enabled | Boolean | Optional | Whether or not TSMeta should be processed through the tree. By default this is set to `false` so that you can setup rules and test some objects before building branches. | false | enabled | RW | true |
| storeFailures | Boolean | Optional | Whether or not collisions and 'not matched' TSUIDs should be recorded. This can create very wide rows. | false | store\_failures | RW | true |
| definition | Boolean | Optional | Used only when `DELETE` ing a tree, if this flag is set to true, then the entire tree definition will be deleted along with all branches, collisions and not matched entries | false | definition | | true |
Response
--------
A successful response to a `GET`, `POST` or `PUT` request will return tree objects with optinally requested changes. Successful `DELETE` calls will return with a `204` status code and no body content. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the resposne will be a `304` without any body content. If the requested tree did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied an `400` error will be returned.
All **Request** fields will be present in the response in addition to others:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| rules | Map | A map or dictionary with rules defined for the tree organized by `level` and `order`. If no rules have been defined yet, the value will be `null` | *See Examples* |
| created | Integer | A Unix Epoch timestamp in seconds when the tree was originally created. | 1350425579 |
GET
---
A `GET` request to `/api/tree` without a tree ID will return a list of all of the trees configured in the system. The results will include configured rules for each tree. If no trees have been configured yet, the list will be empty.
### Example GET All Trees Query
```
http://localhost:4242/api/tree
```
### Example Response
```
[
{
"name": "Test Tree",
"description": "My Description",
"notes": "Details",
"rules": {
"0": {
"0": {
"type": "TAGK",
"field": "host",
"regex": "",
"separator": "",
"description": "Hostname rule",
"notes": "",
"level": 0,
"order": 0,
"treeId": 1,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
},
"1": {
"0": {
"type": "METRIC",
"field": "",
"regex": "",
"separator": "",
"description": "",
"notes": "Metric rule",
"level": 1,
"order": 0,
"treeId": 1,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
}
},
"created": 1356998400,
"treeId": 1,
"strictMatch": false,
"storeFailures": false,
"enabled": true
},
{
"name": "2nd Tree",
"description": "Other Tree",
"notes": "",
"rules": {
"0": {
"0": {
"type": "TAGK",
"field": "host",
"regex": "",
"separator": "",
"description": "",
"notes": "",
"level": 0,
"order": 0,
"treeId": 2,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
},
"1": {
"0": {
"type": "METRIC",
"field": "",
"regex": "",
"separator": "",
"description": "",
"notes": "",
"level": 1,
"order": 0,
"treeId": 2,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
}
},
"created": 1368964815,
"treeId": 2,
"strictMatch": false,
"storeFailures": false,
"enabled": false
}
]
```
To fetch a specific tree, supply a [``](#id5)treeId' value. The response will include the tree object if found. If the requested tree does not exist, a 404 exception will be returned.
### Example GET Single Tree
```
http://localhost:4242/api/treeId?tree=1
```
### Example Response
```
{
"name": "2nd Tree",
"description": "Other Tree",
"notes": "",
"rules": {
"0": {
"0": {
"type": "TAGK",
"field": "host",
"regex": "",
"separator": "",
"description": "",
"notes": "",
"level": 0,
"order": 0,
"treeId": 2,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
},
"1": {
"0": {
"type": "METRIC",
"field": "",
"regex": "",
"separator": "",
"description": "",
"notes": "",
"level": 1,
"order": 0,
"treeId": 2,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
}
},
"created": 1368964815,
"treeId": 2,
"strictMatch": false,
"storeFailures": false,
"enabled": false
}
```
POST/PUT
--------
Using the `POST` or `PUT` methods, you can create a new tree or edit most of the fields for an existing tree. New trees require a `name` value and for the `treeId' value to be empty. Existing trees require a valid ``treeId` ID and any fields that require modification. A successful request will return the modified tree object.
Note
A new tree will not have any rules. Your next call should probably be to `/tree/rule` or `/tree/rules`.
### Example POST Create Request
```
http://localhost:4242/api/tree?name=Network%20Tree&method_override=post
```
### Example Response
```
{
"name": "Network",
"description": "",
"notes": "",
"rules": null,
"created": 1368964815,
"treeId": 3,
"strictMatch": false,
"storeFailures": false,
"enabled": false
}
```
### Example POST Edit Request
```
http://localhost:4242/api/tree?treeId=3&description=Network%20Device%20Information&method_override=post
```
### Example Response
```
{
"name": "Network",
"description": "Network Device Information",
"notes": "",
"rules": null,
"created": 1368964815,
"treeId": 3,
"strictMatch": false,
"storeFailures": false,
"enabled": false
}
```
DELETE
------
Using the `DELETE` method will remove only collisions, not matched entries and branches for the given tree from storage. This endpoint starts a delete. Because the delete can take some time, the endpoint will return a successful 204 response without data if the delete completed. If the tree was not found, it will return a 404. If you want to delete the tree definition itself, you can supply the `defintion` flag in the query string with a value of `true` and the tree and rule definitions will be removed as well.
Warning
This method cannot be undone. Once executed, the purge will continue running unless the TSD is shutdown.
Note
Before executing a `DELETE` query, you should make sure that a manual tree syncronization is not running somehwere on your data. If it is, there may be some orphaned branches or leaves stored during the purge. Use the \_\_\_\_\_ CLi tool sometime after the delete to cleanup left over branches or leaves.
### Example DELETE Request
```
http://localhost:4242/api/tree?tree=1&method_override=delete
```
| programming_docs |
opentsdb /api/tree/collisions /api/tree/collisions
====================
When processing a TSMeta, if the resulting leaf would overwrite an existing leaf with a different TSUID, a collision will be recorded. This endpoint allows retreiving a list of the TSUIDs that were not included in a tree due to collisions. It is useful for debugging in that if you find a TSUID in this list, you can pass it through the `/tree/test` endpoint to get details on why the collision occurred.
Note
Calling this endpoint without a list of one or more TSUIDs will return all collisions in the tree. If you have a large number of timeseries in your system, the response can potentially be very large. Thus it is best to use this endpoint with specific TSUIDs.
Note
If `storeFailures` is diabled for the tree, this endpoint will not return any data. Collisions will still appear in the TSD's logs.
Verbs
-----
* GET
Requests
--------
The following fields are used for this endpoint
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Required | The ID of the tree to pass the TSMeta objects through | | treeid | | 1 |
| tsuids | String | Required | A list of one or more TSUIDs to search for collision entries. If requesting testing of more than one TSUID, they should be separted by a comma. | | tsuids | | 000001000001000001,00000200000200002 |
Response
--------
A successful response will return a map of key/value pairs where the unrecorded TSUID as the key and the existing leave's TSUID as the value. The response will only return collisions that were found. If one or more of the TSUIDs requested did not result in a collision, it will not be returned with the result. This may mean that the TSMeta has not been processed yet. Note that if no collisions have occurred or the tree hasn't processed any data yet, the result set will be empty. If the requested tree did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
### Example Request
> <http://localhost:4242/api/tree/collisions?treeId=1&tsuids=010101,020202>
>
### Example Response
```
{
"010101": "AAAAAA",
"020202": "BBBBBB"
}
```
opentsdb /api/tree/rules /api/tree/rules
===============
The rules endpoint is used for bulk merging, replacing or deleting the entire ruleset of a tree. Instead of calling the `tree/rule` endpoint multiple times for a single rule, you can supply a list of rules that will be merged into, or replace, the current rule set. Note that the `GET` verb is not supported for this endpoint. To fetch the ruleset, load the tree via the `/tree` endpoint. Also, all data must be provided in request content, query strings are not supported.
Verbs
-----
* POST - Merge rule sets
* PUT - Replace the entire rule set
* DELETE - Delete a rule
Requests
--------
A request to store data must be an array of objects in the content of the request. The same fields as required for the [*/api/tree/rule*](rule) endpoint are supported.
Response
--------
A successful response to a `POST` or `PUT` request will return a `204` response code without body content. Successful `DELETE` calls will return with a `204` status code and no body content. If a tree does not have any rules, the `DELETE` request will still return a `204`. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the response will be a `304` without any body content. If the requested tree did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
POST/PUT
--------
Issuing a `POST` will merge the given rule set with any that already exist. This means that if a rule already exists for one of the given rules, only the fields given will be modified in the existing rule. Using the `PUT` method will replace *all* of the rules for the given tree with the new set. Any existing rules for the tree will be deleted before the new rules are stored.
Note
All of the rules in the request array must belong to the same `treeId` or a `400` exception will be returned. Likewise, all of the rules will pass validation and must include the `level` and `order` fields.
### Example POST Request
```
http://localhost:4242/api/tree/rule?treeId=1&level=0&order=0&type=METRIC&separator=.&method_override=post
```
### Example Content Request
```
[
{
"treeId": 1,
"level": 0,
"order": 0,
"type": "METRIC",
"description": "Metric split rule",
"split": "\\."
},
{
"treeId": 1,
"level": 0,
"order": 1,
"type": "tagk",
"field": "fqdn",
"description": "Hostname for the device"
},
{
"treeId": 1,
"level": 1,
"order": 0,
"type": "tagk",
"field": "department"
"description": "Department that owns the device"
}
]
```
DELETE
------
Using the `DELETE` method will remove all rules from a tree. A successful deletion will respond with a `204` status code and no content body. If the tree did not exist, a `404` error will be returned.
Warning
This method cannot be undone.
### Example DELETE Request
```
http://localhost:4242/api/tree/rules?treeId=1&method_override=delete
```
opentsdb /api/tree/notmatched /api/tree/notmatched
====================
When processing a TSMeta, if the tree has `strictMatch` enabled and the meta fails to match on a rule in any level of the set, a *not matched* entry will be recorded. This endpoint allows for retrieving the list of TSUIDs that failed to match a rule set. It is useful for debugging in that if you find a TSUID in this list, you can pass it through the `/tree/test` endpoint to get details on why the meta failed to match.
Note
Calling this endpoint without a list of one or more TSUIDs will return all non-matched TSUIDs in the tree. If you have a large number of timeseries in your system, the response can potentially be very large. Thus it is best to use this endpoint with specific TSUIDs.
Note
If `storeFailures` is diabled for the tree, this endpoint will not return any data. Not Matched entries will still appear in the TSD's logs.
Verbs
-----
* GET
Requests
--------
The following fields are used for this endpoint
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Required | The ID of the tree to pass the TSMeta objects through | | treeid | | 1 |
| tsuids | String | Required | A list of one or more TSUIDs to search for not-matched entries. If requesting testing of more than one TSUID, they should be separted by a comma. | | tsuids | | 000001000001000001,00000200000200002 |
Response
--------
A successful response will return a map of key/value pairs where the unrecorded TSUID as the key and a message about which rule failed to match as the value. The response will only return not matched entries that were found. If one or more of the TSUIDs requested did not result in a not matched entry, it will not be returned with the result. This may mean that the TSMeta has not been processed yet. Note that if no failed matches have occurred or the tree hasn't processed any data yet, the result set will be empty. If the requested tree did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
### Example Request
> <http://localhost:4242/api/tree/notmatched?treeId=1&tsuids=010101,020202>
>
### Example Response
```
{
"010101": "Failed rule 0:0",
"020202": "Failed rule 1:1"
}
```
opentsdb /api/tree/test /api/tree/test
==============
For debugging a rule set, the test endpoint can be used to run a TSMeta object through a tree's rules and determine where in the heirarchy the leaf would appear. Or find out why a timeseries failed to match on a rule set or collided with an existing timeseries. The only method supported is `GET` and no changes will be made to the actual tree in storage when using this endpoint.
The `messages` field of the response contains information about what occurred during processing. If the TSUID did not exist or an error occurred, the reason will be found in this field. During processing, each rule that the TSMeta is processed through will generate a message. If a rule matched on the TSMeta successfully or failed, the reason will be recorded.
Verbs
-----
* GET
Requests
--------
The following fields are required for this endpoint.
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Required | The ID of the tree to pass the TSMeta objects through | | treeid | | 1 |
| tsuids | String | Required | A list of one or more TSUIDs to fetch TSMeta for. If requesting testing of more than one TSUID, they should be separted by a comma. | | tsuids | | 000001000001000001,00000200000200002 |
Response
--------
A successful response will return a list of JSON objects with a number of items including the TSMeta object, messages about the processing steps taken and a resulting branch. There will be one object for each TSUID requested with the TSUID as the object name. If the requested tree did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
Fields found in the response include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| messages | Array of Strings | A list of messages for each level and rule of the rule set | *See Below* |
| meta | Object | The TSMeta object loaded from storage | *See Below* |
| branch | Object | The full tree if successfully parsed | *See Below* |
### Example Request
> <http://localhost:4242/api/tree/test?treeId=1&tsuids=000001000001000001000002000002>
>
### Example Response
```
{
"000001000001000001000002000002": {
"messages": [
"Processing rule: [1:0:0:TAGK]",
"Matched tagk [host] for rule: [1:0:0:TAGK]",
"Processing rule: [1:1:0:METRIC]",
"Depth [3] Adding leaf [name: sys.cpu.0 tsuid: 000001000001000001000002000002] to parent branch [Name: [web-01.lga.mysite.com]]"
],
"meta": {
"tsuid": "000001000001000001000002000002",
"metric": {
"uid": "000001",
"type": "METRIC",
"name": "sys.cpu.0",
"description": "",
"notes": "",
"created": 1368979404,
"custom": null,
"displayName": ""
},
"tags": [
{
"uid": "000001",
"type": "TAGK",
"name": "host",
"description": "",
"notes": "",
"created": 1368979404,
"custom": null,
"displayName": ""
},
{
"uid": "000001",
"type": "TAGV",
"name": "web-01.lga.mysite.com",
"description": "",
"notes": "",
"created": 1368979404,
"custom": null,
"displayName": ""
},
{
"uid": "000002",
"type": "TAGK",
"name": "type",
"description": "",
"notes": "",
"created": 1368979404,
"custom": null,
"displayName": ""
},
{
"uid": "000002",
"type": "TAGV",
"name": "user",
"description": "",
"notes": "",
"created": 1368979404,
"custom": null,
"displayName": ""
}
],
"description": "",
"notes": "",
"created": 0,
"units": "",
"retention": 0,
"max": "NaN",
"min": "NaN",
"displayName": "",
"lastReceived": 0,
"totalDatapoints": 0,
"dataType": ""
},
"branch": {
"leaves": null,
"branches": [
{
"leaves": [
{
"metric": "",
"tags": null,
"tsuid": "000001000001000001000002000002",
"displayName": "sys.cpu.0"
}
],
"branches": null,
"path": {
"0": "ROOT",
"1": "web-01.lga.mysite.com"
},
"treeId": 1,
"displayName": "web-01.lga.mysite.com",
"branchId": "0001247F7202",
"numLeaves": 1,
"numBranches": 0,
"depth": 1
}
],
"path": {
"0": "ROOT"
},
"treeId": 1,
"displayName": "ROOT",
"branchId": "0001",
"numLeaves": 0,
"numBranches": 1,
"depth": 0
}
}
}
```
### Example Error Response
```
{
"000001000001000001000002000003": {
"branch": null,
"messages": [
"Unable to locate TSUID meta data"
],
"meta": null
}
}
```
opentsdb /api/tree/branch /api/tree/branch
================
A branch represents a level in the tree heirarchy and contains information about child branches and/or leaves. Branches are immutable from an API perspective and can only be created or modified by processing a TSMeta through tree rules via a CLI command or when a new timeseries is encountered or a TSMeta object modified. Therefore the `branch` endpoint only supports the `GET` verb.
A branch is identified by a `branchId`, a hexadecimal encoded string that represents the ID of the tree it belongs to as well as the IDs of each parent the branch stems from. All branches stem from the **ROOT** branch of a tree and this is usually the starting place when browsing. To fetch the **ROOT** just call this endpoingt with a valid `treeId`. The root branch ID is also a 4 character encoding of the tree ID.
Verbs
-----
* GET
Requests
--------
The following fields can be used to request a branch. Only one or the other may be used.
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Optional | Used to fetch the root branch of the tree. If used in combination with a branchId, the tree ID will be ignored. | | treeid | RO | 1 |
| branch | String | Required | A hexadecimal representation of the branch ID, required for all but the root branch request | | branch | RO | 000183A21C8F |
Response
--------
A successful response to a request will return the branch object using the requested serializer. If the requested tree or branch did not exist in the system, a `404` will be returned with an error message.
Fields returned with the response include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| treeId | Integer | The ID of the tree the branch belongs to | 1 |
| displayName | String | Name of the branch as determined by the rule set | sys |
| branchId | String | Hexadecimal encoded ID of the branch | 00010001BECD |
| depth | Integer | Depth of the branch within the tree, starting at *0* for the root branch | 1 |
| path | Map | List of parent branch names and their depth. | *See Below* |
| branches | Array | An array of child branch objects. May be `null`. | *See Below* |
| leaves | Array | An array of child leaf objects. May be `null`. | *See Leaves Below* |
**Leaves**
If a branch contains child leaves, i.e. timeseries stored in OpenTSDB, their metric, tags, TSUID and display name will be contained in the results. Leaf fields are as follows:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| metric | String | The name of the metric for the timeseries | sys.cpu.0 |
| tags | Map | A list of tag names and values representing the timeseries | *See Below* |
| tsuid | String | Hexadecimal encoded timeseries ID | 000001000001000001 |
| displayName | String | A name as parsed by the rule set | user |
GET
---
### Example Root GET Query
```
http://localhost:4242/api/tree/branch?treeid=1
```
### Example Response
```
{
"leaves": null,
"branches": [
{
"leaves": null,
"branches": null,
"path": {
"0": "ROOT",
"1": "sys"
},
"treeId": 1,
"displayName": "sys",
"branchId": "00010001BECD",
"depth": 1
}
],
"path": {
"0": "ROOT"
},
"treeId": 1,
"displayName": "ROOT",
"branchId": "0001",
"depth": 0
}
```
### Example Branch GET Query
```
http://localhost:4242/api/tree/branch?branchid=00010001BECD000181A8
```
### Example Response
```
{
"leaves": [
{
"metric": "sys.cpu.0.user",
"tags": {
"host": "web01"
},
"tsuid": "000001000001000001",
"displayName": "user"
}
],
"branches": [
{
"leaves": null,
"branches": null,
"path": {
"0": "ROOT",
"1": "sys",
"2": "cpu",
"3": "mboard"
},
"treeId": 1,
"displayName": "mboard",
"branchId": "00010001BECD000181A8BF992A99",
"depth": 3
}
],
"path": {
"0": "ROOT",
"1": "sys",
"2": "cpu"
},
"treeId": 1,
"displayName": "cpu",
"branchId": "00010001BECD000181A8",
"depth": 2
}
```
opentsdb /api/tree/rule /api/tree/rule
==============
Each rule in a tree is an individual object in storage, thus the `/api/tree/rule` endpoint allows for easy modification of a single rule in the set. Rules are addressed by their `tree` ID, `level` and `order` and all requests require these three parameters.
Note
If a manual tree synchronization is running somewhere or there is a large number of TSMeta objects being created or edited, the tree rule may be cached and modifications to a tree's rule set may take some time to propagate. If you make any modifications to the rule set, other than to meta information such as the `description` and `notes`, you may want to flush the tree data and perform a manual synchronization so that branches and leaves reflect the new rules.
Verbs
-----
* GET - Retrieve one or more rules
* POST - Create or modify a rule
* PUT - Create or replace a rule
* DELETE - Delete a rule
Requests
--------
The following fields can be used for all rule endpoint requests:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| treeId | Integer | Required | The tree the requested rule belongs to | | treeid | RO | 1 |
| level | Integer | Required | The level in the rule heirarchy where the rule resides. Must be 0 or greater. | 0 | level | RW | 2 |
| order | Integer | Required | The order within a level where the rule resides. Must be 0 or greater. | 0 | order | RW | 1 |
| description | String | Optional | A brief description of the rule's purpose | | description | RW | Split the metric by dot |
| notes | String | Optional | Detailed notes about the rule | | notes | RW | |
| type | String | Required\* | The type of rule represented. See [*Trees*](../../user_guide/trees). [\*](#id1)Required when creating a new rule. | | type | RW | METRIC |
| field | String | Optional | The name of a field for the rule to operate on | | field | RW | host |
| customField | String | Optional | The name of a `TSMeta` custom field for the rule to operate on. Note that the `field` value must also be configured or an exception will be raised. | | custom\_field | RW | owner |
| regex | String | Optional | A regular expression pattern to process the associated field or custom field value through. | | regex | RW | ^.\*\.([a-zA-Z]{3,4})[0-9]{0,1}\..\*\..\*$ |
| separator | String | Optional | If the field value should be split into multiple branches, provide the separation character. | | separator | RW | \. |
| regexGroupIdx | Integer | Optional | A group index for extracting a portion of a pattern from the given regular expression pattern. Must be 0 or greater. | 0 | regex\_group\_idx | RW | 1 |
| displayFormat | String | Optional | A display format string to alter the `display\_name` value of the resulting branch or leaf. See [*Trees*](../../user_guide/trees) | | display\_format | RW | Port: {ovalue} |
Note
When supplying a `separator` or a `regex` value, you must supply a valid regular expression. For separators, the most common use is to split dotted metrics into branches. E.g. you may want "sys.cpu.0.user" to be split into "sys", "cpu", "0" and "user" branches. You cannot supply just a "." for the separator value as that will not match properly. Instead, escape the period via ".". Note that if you are supplying JSON via a POST request, you must escape the backslash as well and supply "\.". GET request responses will escape all backslashes.
Response
--------
A successful response to a `GET`, `POST` or `PUT` request will return the full rule object with optional requested changes. Successful `DELETE` calls will return with a `204` status code and no body content. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the resposne will be a `304` without any body content. If the requested tree or rule did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
GET
---
A `GET` request requires a specific tree ID, rule level and order. Otherwise a `400` will be returned. To fetch all of the rules for a tree, use the `/api/tree` endpoint with a [``](#id3)treeId' value.
### Example GET Query
```
http://localhost:4242/api/tree/rule?treeId=1&level=0&order=0
```
### Example Response
```
{
"type": "METRIC",
"field": "",
"regex": "",
"separator": "\\.",
"description": "Split the metric on periods",
"notes": "",
"level": 1,
"order": 0,
"treeId": 1,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
```
POST/PUT
--------
Using the `POST` or `PUT` methods, you can create a new rule or edit an existing rule. New rules require a `type` value. Existing trees require a valid `treeId` ID and any fields that require modification. A successful request will return the modified rule object. Note that if a rule exists at the given level and order, any changes will be merged with or overwrite the existing rule.
### Example Query String Request
```
http://localhost:4242/api/tree/rule?treeId=1&level=0&order=0&type=METRIC&separator=\.&method_override=post
```
### Example Content Request
```
{
"type": "METRIC",
"separator": "\\.",
"description": "Split the metric on periods",
"level": 1,
"order": 0,
"treeId": 1
}
```
### Example Response
```
{
"type": "METRIC",
"field": "",
"regex": "",
"separator": "\\.",
"description": "Split the metric on periods",
"notes": "",
"level": 1,
"order": 0,
"treeId": 1,
"customField": "",
"regexGroupIdx": 0,
"displayFormat": ""
}
```
DELETE
------
Using the `DELETE` method will remove a rule from a tree. A successful deletion will respond with a `204` status code and no content body. If the rule did not exist, a `404` error will be returned.
Warning
This method cannot be undone.
### Example DELETE Request
```
http://localhost:4242/api/tree/rule?treeId=1&level=0&order=0&method_override=delete
```
| programming_docs |
opentsdb /api/config /api/config
===========
This endpoint returns information about the running configuration of the TSD. It is read only and cannot be used to set configuration options.
Conf API Endpoints
------------------
* [/api/config/filters](filters)
Verbs
-----
* GET
* POST
Requests
--------
This endpoint does not require any parameters via query string or body.
### Example Request
**Query String**
```
http://localhost:4242/api/config
```
Response
--------
The response is a hash map of configuration properties and values.
### Example Response
```
{
"tsd.search.elasticsearch.tsmeta_type": "tsmetadata",
"tsd.storage.flush_interval": "1000",
"tsd.network.tcp_no_delay": "true",
"tsd.search.tree.indexer.enable": "true",
"tsd.http.staticroot": "/usr/local/opentsdb/staticroot/",
"tsd.network.bind": "0.0.0.0",
"tsd.network.worker_threads": "",
"tsd.storage.hbase.zk_quorum": "localhost",
"tsd.network.port": "4242",
"tsd.rpcplugin.DummyRPCPlugin.port": "42",
"tsd.search.elasticsearch.hosts": "localhost",
"tsd.network.async_io": "true",
"tsd.rtpublisher.plugin": "net.opentsdb.tsd.RabbitMQPublisher",
"tsd.search.enableindexer": "false",
"tsd.rtpublisher.rabbitmq.user": "guest",
"tsd.search.enable": "false",
"tsd.search.plugin": "net.opentsdb.search.ElasticSearch",
"tsd.rtpublisher.rabbitmq.hosts": "localhost",
"tsd.core.tree.enable_processing": "false",
"tsd.stats.canonical": "true",
"tsd.http.cachedir": "/tmp/opentsdb/",
"tsd.http.request.max_chunk": "16384",
"tsd.http.show_stack_trace": "true",
"tsd.core.auto_create_metrics": "true",
"tsd.storage.enable_compaction": "true",
"tsd.rtpublisher.rabbitmq.pass": "guest",
"tsd.core.meta.enable_tracking": "true",
"tsd.mq.enable": "true",
"tsd.rtpublisher.rabbitmq.vhost": "/",
"tsd.storage.hbase.data_table": "tsdb",
"tsd.storage.hbase.uid_table": "tsdb-uid",
"tsd.http.request.enable_chunked": "true",
"tsd.core.plugin_path": "/usr/local/opentsdb/plugins",
"tsd.storage.hbase.zk_basedir": "/hbase",
"tsd.rtpublisher.enable": "false",
"tsd.rpcplugin.DummyRPCPlugin.hosts": "localhost",
"tsd.storage.hbase.tree_table": "tsdb-tree",
"tsd.network.keep_alive": "true",
"tsd.network.reuse_address": "true",
"tsd.rpc.plugins": "net.opentsdb.tsd.DummyRpcPlugin"
}
```
opentsdb /api/config/filters /api/config/filters
===================
**(Version 2.2 and later)** This endpoint lists the various filters loaded by the TSD and some information about how to use them.
Verbs
-----
* GET
* POST
Requests
--------
This endpoint does not require any parameters via query string or body.
### Example Request
**Query String**
```
http://localhost:4242/api/config/filters
```
Response
--------
The response is a map of filter names or types and sub maps of examples and descriptions. The examples show how to use them in both URI and JSON queries.
### Example Response
```
{
"iliteral_or": {
"examples": "host=iliteral_or(web01), host=iliteral_or(web01|web02|web03) {\"type\":\"iliteral_or\",\"tagk\":\"host\",\"filter\":\"web01|web02|web03\",\"groupBy\":false}",
"description": "Accepts one or more exact values and matches if the series contains any of them. Multiple values can be included and must be separated by the | (pipe) character. The filter is case insensitive and will not allow characters that TSDB does not allow at write time."
},
"wildcard": {
"examples": "host=wildcard(web*), host=wildcard(web*.tsdb.net) {\"type\":\"wildcard\",\"tagk\":\"host\",\"filter\":\"web*.tsdb.net\",\"groupBy\":false}",
"description": "Performs pre, post and in-fix glob matching of values. The globs are case sensitive and multiple wildcards can be used. The wildcard character is the * (asterisk). At least one wildcard must be present in the filter value. A wildcard by itself can be used as well to match on any value for the tag key."
},
"not_literal_or": {
"examples": "host=not_literal_or(web01), host=not_literal_or(web01|web02|web03) {\"type\":\"not_literal_or\",\"tagk\":\"host\",\"filter\":\"web01|web02|web03\",\"groupBy\":false}",
"description": "Accepts one or more exact values and matches if the series does NOT contain any of them. Multiple values can be included and must be separated by the | (pipe) character. The filter is case sensitive and will not allow characters that TSDB does not allow at write time."
},
"not_iliteral_or": {
"examples": "host=not_iliteral_or(web01), host=not_iliteral_or(web01|web02|web03) {\"type\":\"not_iliteral_or\",\"tagk\":\"host\",\"filter\":\"web01|web02|web03\",\"groupBy\":false}",
"description": "Accepts one or more exact values and matches if the series does NOT contain any of them. Multiple values can be included and must be separated by the | (pipe) character. The filter is case insensitive and will not allow characters that TSDB does not allow at write time."
},
"not_key": {
"examples": "host=not_key() {\"type\":\"not_key\",\"tagk\":\"host\",\"filter\":\"\",\"groupBy\":false}",
"description": "Skips any time series with the given tag key, regardless of the value. This can be useful for situations where a metric has inconsistent tag sets. NOTE: The filter value must be null or an empty string."
},
"iwildcard": {
"examples": "host=iwildcard(web*), host=iwildcard(web*.tsdb.net) {\"type\":\"iwildcard\",\"tagk\":\"host\",\"filter\":\"web*.tsdb.net\",\"groupBy\":false}",
"description": "Performs pre, post and in-fix glob matching of values. The globs are case insensitive and multiple wildcards can be used. The wildcard character is the * (asterisk). Case insensitivity is achieved by dropping all values to lower case. At least one wildcard must be present in the filter value. A wildcard by itself can be used as well to match on any value for the tag key."
},
"literal_or": {
"examples": "host=literal_or(web01), host=literal_or(web01|web02|web03) {\"type\":\"literal_or\",\"tagk\":\"host\",\"filter\":\"web01|web02|web03\",\"groupBy\":false}",
"description": "Accepts one or more exact values and matches if the series contains any of them. Multiple values can be included and must be separated by the | (pipe) character. The filter is case sensitive and will not allow characters that TSDB does not allow at write time."
},
"regexp": {
"examples": "host=regexp(.*) {\"type\":\"regexp\",\"tagk\":\"host\",\"filter\":\".*\",\"groupBy\":false}",
"description": "Provides full, POSIX compliant regular expression using the built in Java Pattern class. Note that an expression containing curly braces {} will not parse properly in URLs. If the pattern is not a valid regular expression then an exception will be raised."
}
```
}
opentsdb /api/uid /api/uid
========
Every metric, tag name and tag value is associated with a unique identifier (UID). Internally, the UID is a binary array assigned to a text value the first time it is encountered or via an explicit assignment request. This endpoint provides utilities for managing UIDs and their associated data. Please see the UID endpoint TOC below for information on what functions are implemented.
UIDs exposed via the API are encoded as hexadecimal strings. The UID `42` would be expressed as `00002A` given the default UID width of 3 bytes.
You may also edit meta data associated with timeseries or individual UID objects via the UID endpoint.
UID API Endpoints
-----------------
* [/api/uid/assign](assign)
* [/api/uid/tsmeta](tsmeta)
* [/api/uid/uidmeta](uidmeta)
opentsdb /api/uid/tsmeta /api/uid/tsmeta
===============
This endpoint enables searching, editing or deleting timeseries meta data information, that is meta data associated with a specific timeseries associated with a *metric* and one or more *tag name/value* pairs. Some fields are set by the TSD but others can be set by the user. When using the `POST` method, only the fields supplied with the request will be stored. Existing fields that are not included will be left alone. Using the `PUT` method will overwrite all user mutable fields with given values or defaults if a given field is not provided.
Please note that deleting a meta data entry will not delete the data points stored for the timeseries. Neither will it remove the UID assignments or associated UID meta objects.
Verbs
-----
* GET - Lookup one or more TS meta data
* POST - Updates only the fields provided
* PUT - Overwrites all user configurable meta data fields
* DELETE - Deletes the TS meta data
GET Requests
------------
A GET request can lookup the TS meta objects for one or more time series if they exist in the storage system. Two types of queries are supported:
* **tsuid** - A single hexadecimal TSUID may be supplied and a meta data object will be returned if located. The results will include a single object.
* **metric** - *(Version 2.1)* Similar to a data point query, you can supply a metric and one or more tag pairs. Any TS meta data matching the query will be returned. The results will be an array of one or more objects. Only one metric query may be supplied per call and wild cards or grouping operators are not supported.
### Example TSUID GET Request
```
http://localhost:4242/api/uid/tsmeta?tsuid=00002A000001000001
```
### Example Metric GET Request
```
http://localhost:4242/api/uid/tsmeta?m=sys.cpu.nice&dc=lga
```
POST/PUT Requests
-----------------
By default, you may only write data to a TS meta object if it already exists. TS meta data is created via the meta sync CLI command or in real-time as data points are written. If you attempt to write data to the tsmeta endpoint for a TSUID that does not exist, an error will be returned and no data will be saved.
Fields that can be supplied with a request include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| tsuid | String | Required | A hexadecimal representation of the timeseries UID | | tsuid | RO | 00002A000001000001 |
| description | String | Optional | A brief description of what the UID represents | | description | RW | System processor time |
| displayName | String | Optional | A short name that can be displayed in GUIs instead of the default name | | display\_name | RW | System CPU Time |
| notes | String | Optional | Detailed notes about what the UID represents | | notes | RW | Details |
| custom | Map | Optional | A key/value map to store custom fields and values | null | | RW | *See Below* |
| units | String | Optional | Units reflective of the data stored in the timeseries, may be used in GUIs or calculations | | units | RW | Mbps |
| dataType | String | Optional | The kind of data stored in the timeseries such as `counter`, `gauge`, `absolute`, etc. These may be defined later but they should be similar to Data Source Types in an [RRD](http://oss.oetiker.ch/rrdtool) | | data\_type | RW | counter |
| retention | Integer | Optional | The number of days of data points to retain for the given timeseries. **Not Implemented**. When set to 0, the default, data is retained indefinitely. | 0 | retention | RW | 365 |
| max | Float | Optional | An optional maximum value for this timeseries that may be used in calculations such as percent of maximum. If the default of `NaN` is present, the value is ignored. | NaN | max | RW | 1024 |
| min | Float | Optional | An optional minimum value for this timeseries that may be used in calculations such as percent of minimum. If the default of `NaN` is present, the value is ignored. | NaN | min | RW | 0 |
Note
Custom fields cannot be passed via query string. You must use the `POST` or `PUT` verbs.
Warning
If your request uses `PUT`, any fields that you do not supply with the request will be overwritten with their default values. For example, the `description` field will be set to an emtpy string and the `custom` field will be reset to `null`.
With OpenTSDB 2.1 you may supply a metric style query and, if UIDs exist for the given metric and tags, a new TS meta object will be stored. Data may be supplied via POST for the fields above as per a normal request, however the `tsuid` field must be left empty. Additionally two query string parameters must be supplied:
* **m** - A metric and tags similar to a GET request or data point query
* **create** - A flag with a value of `true`
For example:
```
http://localhost:4242/api/uid/tsmeta?display_name=Testing&m=sys.cpu.nice{host=web01,dc=lga}&create=true&method_override=post
```
If a TS meta object already exists in storage for the given metric and tags, the fields will be updated or overwritten.
### Example POST or PUT Request
*Query String:*
```
http://localhost:4242/api/uid/tsmeta?tsuid=00002A000001000001&method_override=post&display_name=System%20CPU%20Time
```
*JSON Content:*
```
{
"tsuid":"00002A000001000001",
"displayName":"System CPU Time for Webserver 01",
"custom": {
"owner": "Jane Doe",
"department": "Operations",
"assetTag": "12345"
}
}
```
### Example DELETE Request
*Query String:*
```
http://localhost:4242/api/uid/tsmeta?tsuid=00002A000001000001&method_override=delete
```
*JSON Content:*
```
{
"tsuid":"00002A000001000001"
}
```
Response
--------
A successful response to a `GET`, `POST` or `PUT` request will return the full TS meta data object with any given changes. Successful `DELETE` calls will return with a `204` status code and no body content. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the resposne will be a `304` without any body content. If the requested TSUID did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied an error will be returned.
All **Request** fields will be present in the response in addition to others:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| metric | UIDMeta | A UID meta data object representing information about the UID | *See Below* |
| tags | Array of UIDMeta | A list of tag name / tag value UID meta data objects associated with the timeseries. The `tagk` UID will be first followed by it's corresponding `tagv` object. | *See Below* |
| created | Integer | A Unix epoch timestamp, in seconds, when the timeseries was first recorded in the system. Note that if the TSD was upgraded or meta data recently enabled, this value may not be accurate. Run the [*uid*](../../user_guide/cli/uid) utility to synchronize meta data. | 1350425579 |
| lastReceived | Integer | A Unix epoch timestamp, in seconds, when a data point was last recieved. This is only updated on TSDs where meta data is enabled and it is not updated for every data point so there may be some lag. | 1350425579 |
| totalDatapoints | Integer | The total number of data points recorded for the timeseries. NOTE: This may not be accurate unless you have enabled metadata tracking since creating the TSDB tables. | 3242322 |
### Example Response
```
{
"tsuid": "00002A000001000001",
"metric": {
"uid": "00002A",
"type": "METRIC",
"name": "sys.cpu.0",
"description": "System CPU Time",
"notes": "",
"created": 1350425579,
"custom": null,
"displayName": ""
},
"tags": [
{
"uid": "000001",
"type": "TAGK",
"name": "host",
"description": "Server Hostname",
"notes": "",
"created": 1350425579,
"custom": null,
"displayName": "Hostname"
},
{
"uid": "000001",
"type": "TAGV",
"name": "web01.mysite.com",
"description": "Website hosting server",
"notes": "",
"created": 1350425579,
"custom": null,
"displayName": "Web Server 01"
}
],
"description": "Measures CPU activity",
"notes": "",
"created": 1350425579,
"units": "",
"retention": 0,
"max": "NaN",
"min": "NaN",
"custom": {
"owner": "Jane Doe",
"department": "Operations",
"assetTag": "12345"
},
"displayName": "",
"dataType": "absolute",
"lastReceived": 1350425590,
"totalDatapoints", 12532
}
```
opentsdb /api/uid/uidmeta /api/uid/uidmeta
================
This endpoint enables editing or deleting UID meta data information, that is meta data associated with *metrics*, *tag names* and *tag values*. Some fields are set by the TSD but others can be set by the user. When using the `POST` method, only the fields supplied with the request will be stored. Existing fields that are not included will be left alone. Using the `PUT` method will overwrite all user mutable fields with given values or defaults if a given field is not provided.
Note
Deleting a meta data entry will not delete the UID assignment nor will it delete any data points or associated timeseries information. Deletion only removes the specified meta data object, not the actual value. If you query for the same UID, you'll see the default meta data with empty fields.
Verbs
-----
* GET - Query string only
* POST - Updates only the fields provided
* PUT - Overwrites all user configurable meta data fields
* DELETE - Deletes the UID meta data
Requests
--------
Fields that can be supplied with a request include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| uid | String | Required | A hexadecimal representation of the UID | | uid | RO | 00002A |
| type | String | Required | The type of UID, must be `metric`, `tagk` or `tagv` | | type | RO | metric |
| description | String | Optional | A brief description of what the UID represents | | description | RW | System processor time |
| displayName | String | Optional | A short name that can be displayed in GUIs instead of the default name | | display\_name | RW | System CPU Time |
| notes | String | Optional | Detailed notes about what the UID represents | | notes | RW | Details |
| custom | Map | Optional | A key/value map to store custom fields and values | null | | RW | *See Below* |
Note
Custom fields cannot be passed via query string. You must use the `POST` or `PUT` verbs.
Warning
If your request uses `PUT`, any fields that you do not supply with the request will be overwritten with their default values. For example, the `description` field will be set to an emtpy string and the `custom` field will be reset to `null`.
### Example GET Request
```
http://localhost:4242/api/uid/uidmeta?uid=00002A&type=metric
```
### Example POST or PUT Request
*Query String:*
```
http://localhost:4242/api/uid/uidmeta?uid=00002A&type=metric&method=post&display_name=System%20CPU%20Time
```
*JSON Content:*
```
{
"uid":"00002A",
"type":"metric",
"displayName":"System CPU Time",
"custom": {
"owner": "Jane Doe",
"department": "Operations",
"assetTag": "12345"
}
}
```
### Example DELETE Request
*Query String:*
```
http://localhost:4242/api/uid/uidmeta?uid=00002A&type=metric&method=delete
```
*JSON Content:*
```
{
"uid":"00002A",
"type":"metric"
}
```
Response
--------
A successful response to a `GET`, `POST` or `PUT` request will return the full UID meta data object with any given changes. Successful `DELETE` calls will return with a `204` status code and no body content. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the response will be a `304` without any body content. If the requested UID did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied an error will be returned.
All **Request** fields will be present in the response in addition to a couple of others:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| name | String | The name of the UID as given when the data point was stored or the UID assigned | sys.cpu.0 |
| created | Integer | A Unix epoch timestamp in seconds when the UID was first created. If the meta data was not stored when the UID was assigned, this value may be 0. | 1350425579 |
### Example Response
```
{
"uid": "00002A",
"type": "TAGV",
"name": "web01.mysite.com",
"description": "Website hosting server",
"notes": "This server needs a new boot disk",
"created": 1350425579,
"custom": {
"owner": "Jane Doe",
"department": "Operations",
"assetTag": "12345"
},
"displayName": "Webserver 01"
}
```
| programming_docs |
opentsdb /api/uid/assign /api/uid/assign
===============
This endpoint enables assigning UIDs to new metrics, tag names and tag values. Multiple types and names can be provided in a single call and the API will process each name individually, reporting which names were assigned UIDs successfully, along with the UID assigned, and which failed due to invalid characters or had already been assigned. Assignment can be performed via query string or content data.
Verbs
-----
* GET
* POST
Requests
--------
Each request must have one or more of the following fields:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| metric | String | Optional | A list of metric names for assignment | | metric | RW | sys.cpu.0 |
| tagk | String | Optional | A list of tag names for assignment | | tagk | RW | host |
| tagv | String | Optional | A list of tag values for assignment | | tagv | RW | web01 |
When making a query string request, multiple names for a given type can be supplied in a comma separated fashion. E.g. `metric=sys.cpu.0,sys.cpu.1,sys.cpu.2,sys.cpu.3`. Naming conventions apply: see \_\_\_\_\_\_\_.
### Example Request
**Query String**
```
http://localhost:4242/api/uid/assign?metric=sys.cpu.0,sys.cpu.1&tagk=host&tagv=web01,web02,web03
```
**JSON Content**
```
{
"metric": [
"sys.cpu.0",
"sys.cpu.1",
"illegal!character"
],
"tagk": [
"host"
],
"tagv": [
"web01",
"web02",
"web03"
]
}
```
Response
--------
The response will contain a map of successful assignments along with the hex encoded UID value. If one or more values were not assigned, a separate map will contain a list of the values and the reason why they were not assigned. Maps with the type name and `<type>\_errors` will be generated only if one or more values for that type were provided.
When all values are assigned, the endpoint returns a 200 status code but if any value failed assignment, it will return a 400.
### Example Response
```
{
"metric": {},
"metric_errors": {
"sys.cpu.0": "Name already exists with UID: 000042",
"sys.cpu.1": "Name already exists with UID: 000043",
"illegal!character": "Invalid metric (illegal!character): illegal character: !",
},
"tagv": {},
"tagk_errors": {
"host": "Name already exists with UID: 0007E5"
},
"tagk": {
"web01": "000012",
"web02": "000013",
"web03": "000014"
}
}
```
opentsdb /api/annotation /api/annotation
===============
These endpoints provides a means of adding, editing or deleting annotations stored in the OpenTSDB backend. Annotations are very basic objects used to record a note of an arbitrary event at some point, optionally associated with a timeseries. Annotations are not meant to be used as a tracking or event based system, rather they are useful for providing links to such systems by displaying a notice on graphs or via API query calls.
When creating, modifying or deleting annotations, all changes will be propagated to the search plugin if configured.
Annotation API Endpoints
------------------------
* [/api/annotation/bulk](bulk)
The default `/annotation` endpoint deals with one notation at a time. The `/annotation/bulk` endpoint allows for adding or updating multiple annotations at a time.
Verbs
-----
* GET - Retrieve a single annotation
* POST - Create or modify an annotation
* PUT - Create or replace an annotation
* DELETE - Delete an annotation
Requests
--------
All annotations are identified by the `startTime` field and optionally the `tsuid` field. Each note can be global, meaning it is associated with all timeseries, or it can be local, meaning it's associated with a specific tsuid. If the tsuid is not supplied or has an empty value, the annotation is considered to be a global note.
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| startTime | Integer | Required | A Unix epoch timestamp, in seconds, marking the time when the annotation event should be recorded | | start\_time | RW | 1369141261 |
| endTime | Integer | Optional | An optional end time for the event if it has completed or been resolved | 0 | end\_time | RW | 1369141262 |
| tsuid | String | Optional | A TSUID if the annotation is associated with a timeseries. This may be null or empty if the note was for a global event | | tsuid | RW | 000001000001000001 |
| description | String | Optional | A brief description of the event. As this may appear on GnuPlot graphs, the description should be very short, ideally less than 25 characters. | | description | RW | Network Outage |
| notes | String | Optional | Detailed notes about the event | | notes | RW | Switch #5 died and was replaced |
| custom | Map | Optional | A key/value map to store custom fields and values | null | | RW | *See Below* |
Note
Custom fields cannot be passed via query string. You must use the `POST` or `PUT` verbs.
Warning
If your request uses `PUT`, any fields that you do not supply with the request will be overwritten with their default values. For example, the `description` field will be set to an empty string and the `custom` field will be reset to `null`.
### Example GET Request
```
http://localhost:4242/api/annotation?start_time=1369141261&tsuid=000001000001000001
```
### Example POST Request
```
{
"startTime":"1369141261",
"tsuid":"000001000001000001",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
}
}
```
Response
--------
A successful response to a `GET`, `POST` or `PUT` request will return the full object with the requested changes. Successful `DELETE` calls will return with a `204` status code and no body content. When modifying data, if no changes were present, i.e. the call did not provide any data to store, the response will be a `304` without any body content. If the requested annotation did not exist in the system, a `404` will be returned with an error message. If invalid data was supplied a `400` error will be returned.
### Example Response
```
{
"tsuid": "000001000001000001",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
},
"endTime": 0,
"startTime": 1369141261
}
```
opentsdb /api/annotation/bulk /api/annotation/bulk
====================
*NOTE: (Version 2.1)* The bulk endpoint enables adding, updating or deleting multiple annotations in a single call. Annotation updates must be sent over PUT or POST as content data. Query string requests are not supported for `POST` or `GET`. Each annotation is processed individually and synchronized with the backend. If one of the annotations has an error, such as a missing field, an exception will be returned and some of the annotations may not be written to storage. In such an event, the errant annotation should be fixed and all annotations sent again.
Annotations may also be deleted in bulk for a specified time span. If you supply a list of of one or more TSUIDs, annotations with a `start time` that falls within the specified timespan and belong to those TSUIDs will be removed. Alternatively the `global` flag can be set and any global annotations (those not associated with a time series) will be deleted within the range.
Verbs
-----
* POST - Create or modify annotations
* PUT - Create or replace annotations
* DELETE - Delete annotations within a time range
Requests
--------
Fields for posting or updating annotations are documented at [*/api/annotation*](index)
Fields for a bulk delete request are defined below:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| startTime | Integer | Required | A timestamp for the start of the request. The timestamp may be relative or absolute as per [*Dates and Times*](../../user_guide/query/dates). | | start\_time | RO | 1369141261 |
| endTime | Integer | Optional | An optional end time for the event if it has completed or been resolved. The timestamp may be relative or absolute as per [*Dates and Times*](../../user_guide/query/dates). | | end\_time | RO | 1369141262 |
| tsuids | Array | Optional | A list of TSUIDs with annotations that should be deleted. This may be empty or null (for JSON) in which case the `global` flag should be set. When using the query string, separate TSUIDs with commas. | | tsuids | RO | 000001000001000001, 000001000001000002 |
| global | Boolean | Optional | Whether or not global annotations should be deleted for the range | false | global | RO | true |
Warning
If your request uses `PUT`, any fields that you do not supply with the request will be overwritten with their default values. For example, the `description` field will be set to an empty string and the `custom` field will be reset to `null`.
### Example POST/PUT Request
```
[
{
"startTime":"1369141261",
"tsuid":"000001000001000001",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
}
},
{
"startTime":"1369141261",
"tsuid":"000001000001000002",
"description": "Second annotation on different TSUID",
"notes": "Additional details"
}
]
```
### Example DELETE QS Request
```
/api/annotation/bulk?start_time=1d-ago&end_time=1h-ago&method_override=delete&tsuids=000001000001000001,000001000001000002
```
### Example DELETE Request
```
{
"tsuids": [
"000001000001000001",
"000001000001000002"
],
"global": false,
"startTime": 1389740544690,
"endTime": 1389823344698,
"totalDeleted": 0
}
```
Response
--------
A successful response to a `POST` or `PUT` request will return the list of annotations after synchronization (i.e. if issuing a `POST` call, existing objects will be merged with the new objects). Delete requests will return an object with the delete query and a `totalDeleted` field with an integer number reflecting the total number of annotations deleted. If invalid data was supplied a `400` error will be returned along with the specific annotation that caused the error in the `details` field of the error object.
### Example POST/PUT Response
```
[
{
"tsuid": "000001000001000001",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
},
"endTime": 0,
"startTime": 1369141261
},
{
"tsuid": "000001000001000002",
"description": "Second annotation on different TSUID",
"notes": "Additional details",
"custom": null,
"endTime": 0,
"startTime": 1369141261
}
]
```
### Example DELETE Response
```
{
"tsuids": [
"000001000001000001",
"000001000001000002"
],
"global": false,
"startTime": 1389740544690,
"endTime": 1389823344698,
"totalDeleted": 42
}
```
opentsdb /api/search /api/search
===========
This endpoint provides a basic means of searching OpenTSDB meta data. Lookups can be performed against the `tsdb-meta` table when enabled. Optionally, a search plugin can be installed to send and retreive information from an external search indexing service such as Elastic Search. It is up to each search plugin to implement various parts of this endpoint and return data in a consistent format. The type of object searched and returned depends on the endpoint chosen.
Note
If the plugin is not configured or enabled, endpoints other than `/api/search/lookup` will return an exception.
Search API Endpoints
--------------------
* [*/api/search/lookup*](lookup)
* /api/search/tsmeta - [TSMETA Response](#tsmeta-endpoint)
* /api/search/tsmeta\_summary - [TSMETA\_SUMMARY Response](#tsmeta-summary-endpoint)
* /api/search/tsuids - [TSUIDS Response](#tsuids-endpoint)
* /api/search/uidmeta - [UIDMETA Response](#uidmeta-endpoint)
* /api/search/annotation - [Annotation Response](#annotation-endpoint)
Verbs
-----
* GET
* POST
Requests
--------
Parameters used by the search endpoint include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| query | String | Optional | The string based query to pass to the search engine. This will be parsed by the engine or plugin to perform the actual search. Allowable values depends on the plugin. Ignored for lookups. | | query | | name:sys.cpu.\* |
| limit | Integer | Optional | Limits the number of results returned per query so as not to override the TSD or search engine. Allowable values depends on the plugin. Ignored for lookups. | 25 | limit | | 100 |
| startIndex | Integer | Optional | Used in combination with the `limit` value to page through results. Allowable values depends on the plugin. Ignored for lookups. | 0 | start\_index | | 42 |
| metric | String | Optional | The name of a metric or a wildcard for lookup queries | \* | metric | | tsd.hbase.rpcs |
| tags | Array | Optional | One or more key/value objects with tag names and/or tag values for lookup queries. See [*/api/search/lookup*](lookup) | | tags | | See [*/api/search/lookup*](lookup) |
### Example Request
Query String:
```
http://localhost:4242/api/search/tsmeta?query=name:*&limit=3&start_index=0
```
POST:
```
{
"query": "name:*",
"limit": 4,
"startIndex": 5
}
```
Response
--------
Depending on the endpoint called, the output will change slightly. However common fields include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| type | String | The type of query submitted, i.e. the endpoint called. Will be one of the endpoints listed above. | TSMETA |
| query | String | The query string submitted. May be altered by the plugin | name:sys.cpu.\* |
| limit | Integer | The maximum number of items returned in the result set. Note that the actual number returned may be less than the limit. | 25 |
| startIndex | Integer | The starting index for the current result set as provided in the query | 0 |
| metric | String | The metric used for the lookup | *
|
| tags | Array | The list of tag pairs used for lookup queries. May be an empty list. | [ ] |
| time | Integer | The amount of time it took, in milliseconds, to complete the query | 120 |
| totalResults | Integer | The total number of results matched by the query | 1024 |
| results | Array | The result set. The format depends on the endpoint requested. | *See Below* |
This endpoint will almost always return a `200` with content body. If the query doesn't match any results, the `results` field will be an empty array and `totalResults` will be 0. If an error occurs, such as the plugin being disabled or not configured, an exception will be returned.
TSMETA Response
---------------
The TSMeta endpoint returns a list of matching TSMeta objects.
```
{
"type": "TSMETA",
"query": "name:*",
"metric": "*",
"tags": [],
"limit": 2,
"time": 675,
"results": [
{
"tsuid": "0000150000070010D0",
"metric": {
"uid": "000015",
"type": "METRIC",
"name": "app.apache.connections",
"description": "",
"notes": "",
"created": 1362655264,
"custom": null,
"displayName": ""
},
"tags": [
{
"uid": "000007",
"type": "TAGK",
"name": "fqdn",
"description": "",
"notes": "",
"created": 1362655264,
"custom": null,
"displayName": ""
},
{
"uid": "0010D0",
"type": "TAGV",
"name": "web01.mysite.com",
"description": "",
"notes": "",
"created": 1362720007,
"custom": null,
"displayName": ""
}
],
"description": "",
"notes": "",
"created": 1362740528,
"units": "",
"retention": 0,
"max": 0,
"min": 0,
"displayName": "",
"dataType": "",
"lastReceived": 0,
"totalDatapoints": 0
},
{
"tsuid": "0000150000070010D5",
"metric": {
"uid": "000015",
"type": "METRIC",
"name": "app.apache.connections",
"description": "",
"notes": "",
"created": 1362655264,
"custom": null,
"displayName": ""
},
"tags": [
{
"uid": "000007",
"type": "TAGK",
"name": "fqdn",
"description": "",
"notes": "",
"created": 1362655264,
"custom": null,
"displayName": ""
},
{
"uid": "0010D5",
"type": "TAGV",
"name": "web02.mysite.com",
"description": "",
"notes": "",
"created": 1362720007,
"custom": null,
"displayName": ""
}
],
"description": "",
"notes": "",
"created": 1362882263,
"units": "",
"retention": 0,
"max": 0,
"min": 0,
"displayName": "",
"dataType": "",
"lastReceived": 0,
"totalDatapoints": 0
}
],
"startIndex": 0,
"totalResults": 9688066
}
```
TSMETA\_SUMMARY Response
------------------------
The TSMeta Summary endpoint returns just the basic information associated with a timeseries including the TSUID, the metric name and tags. The search is run against the same index as the TSMeta query but returns a subset of the data.
```
{
"type": "TSMETA_SUMMARY",
"query": "name:*",
"metric": "*",
"tags": [],
"limit": 3,
"time": 565,
"results": [
{
"tags": {
"fqdn": "web01.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D0"
},
{
"tags": {
"fqdn": "web02.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D5"
},
{
"tags": {
"fqdn": "web03.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D6"
}
],
"startIndex": 0,
"totalResults": 9688066
}
```
TSUIDS Response
---------------
The TSUIDs endpoint returns a list of TSUIDS that match the query. The search is run against the same index as the TSMeta query but returns a subset of the data.
```
{
"type": "TSUIDS",
"query": "name:*",
"metric": "*",
"tags": [],
"limit": 3,
"time": 517,
"results": [
"0000150000070010D0",
"0000150000070010D5",
"0000150000070010D6"
],
"startIndex": 0,
"totalResults": 9688066
}
```
UIDMETA Response
----------------
The UIDMeta endpoint returns a list of UIDMeta objects that match the query.
```
{
"type": "UIDMETA",
"query": "name:*",
"metric": "*",
"tags": [],
"limit": 3,
"time": 517,
"results": [
{
"uid": "000007",
"type": "TAGK",
"name": "fqdn",
"description": "",
"notes": "",
"created": 1362655264,
"custom": null,
"displayName": ""
},
{
"uid": "0010D0",
"type": "TAGV",
"name": "web01.mysite.com",
"description": "",
"notes": "",
"created": 1362720007,
"custom": null,
"displayName": ""
},
{
"uid": "0010D5",
"type": "TAGV",
"name": "web02.mysite.com",
"description": "",
"notes": "",
"created": 1362720007,
"custom": null,
"displayName": ""
}
],
"startIndex": 0,
"totalResults": 9688066
}
```
Annotation Response
-------------------
The Annotation endpoint returns a list of Annotation objects that match the query.
```
{
"type": "ANNOTATION",
"query": "description:*",
"metric": "*",
"tags": [],
"limit": 25,
"time": 80,
"results": [
{
"tsuid": "000001000001000001",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
},
"endTime": 0,
"startTime": 1369141261
}
],
"startIndex": 0,
"totalResults": 1
}
```
| programming_docs |
opentsdb /api/search/lookup /api/search/lookup
==================
Note
Available in 2.1
Lookup queries use either the meta data table or the main data table to determine what time series are associated with a given metric, tag name, tag value, tag pair or combination thereof. For example, if you want to know what metrics are available for a tag pair `host=web01` you can execute a lookup to find out. Lookups do not require a search plugin to be installed.
Note
Lookups are performed against the `tsdb-meta` table. You must enable real-time meta data creation or perform a `metasync` using the `uid` command in order to retreive data from a lookup. Lookups can be executed against the raw data table using the CLI command only: [*search*](../../user_guide/cli/search)
Verbs
-----
* GET
* POST
Requests
--------
Parameters used by the lookup endpoint include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| query | String | Required | A lookup query as defined below. | | m | | tsd.hbase.rpcs{type=\*} |
| useMeta | Boolean | Optional | Whether or not to use the meta data table or the raw data table. The raw table will be much slower. | False | use\_meta | | True |
| limit | Integer | Optional | The maximum number of items returned in the result set. Currently the limit is ignored for lookup queries | 25 | | | 100 |
| startIndex | Integer | Optional | Ignored for lookup queries, always the default. | 0 | | | 10 |
### Lookup Queries
A lookup query consists of at least one metric, tag name (tagk) or tag value (tagv). Each value must be a literal name in the UID table. If a given name cannot be resolved to a UID, an exception will be returned. Only one metric can be supplied per query but multiple tagk, tagv or tag pairs may be provided.
Normally, tags a provided in the format `<tagk>=<tagv>` and a value is required on either side of the equals sign. However for lookups, one value may an asterisk `\*`, i.e. `<tagk>=\*` or `\*=<tagv>`. In these cases, the asterisk acts as a wildcard meaning any time series with the given tagk or tagv will be returned. For example, if we issue a query for `host=\*` then we will get all of the time series with a `host` tagk such as `host=web01` and `host=web02`.
For complex queries with multiple values, each type is `AND`'d with the other types and `OR`'d with it's own type.
```
<metric> AND (<tagk1>=[<tagv1>] OR <tagk1>=[<tagv2>]) AND ([<tagk2>]=<tagv3> OR [<tagk2>]=<tagv4>)
```
For example, the query `tsd.hbase.rpcs{type=\*,host=tsd1,host=tsd2,host=tsd3}` would return only the time series with the metric `tsd.hbase.rpcs` and the `type` tagk with any value and a `host` tag with either `tsd1` or `tsd2` or `tsd3`. Unlike a data query, you may supply multiple tagks with the same name as seen in the example above. Wildcards always take priority so if your query looked like `tsd.hbase.rpcs{type=\*,host=tsd1,host=tsd2,host=\*}`, then the query would effectively be treated as `tsd.hbase.rpcs{type=\*,host=\*}`.
To retreive a list of all time series with a specific tag value, e.g. a particular host, you could issue a query like `{\*=web01}` that will return all time series with a tag value of `web01`. This can be useful in debugging tag name issues such as some series having `host=web01` or `server=web01`.
### Example Request
Query String:
```
http://localhost:4242/api/search/lookup?m=tsd.hbase.rpcs{type=*}
```
POST:
JSON requests follow the search query format on the [*/api/search*](index) page. Limits and startNote that tags are supplied as a list of objects. The value for the `key` should be a `tagk` and the value for `value` should be a `tagv` or wildcard.
```
{
"metric": "tsd.hbase.rpcs",
"tags":[
{
"key": "type",
"value": "*"
}
]
}
```
Response
--------
Depending on the endpoint called, the output will change slightly. However common fields include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| type | String | The type of query submitted, i.e. the endpoint called. | LOOKUP |
| query | String | Ignored for lookup queries. | |
| limit | Integer | The maximum number of items returned in the result set. Currently the limit is ignored for lookup queries | 25 |
| startIndex | Integer | Ignored for lookup queries, always the default. | 0 |
| metric | String | The metric used for the lookup | \* |
| tags | Array | The list of tag pairs used for the lookup. May be an empty list. | [ ] |
| time | Integer | The amount of time it took, in milliseconds, to complete the query | 120 |
| totalResults | Integer | The total number of results matched by the query | 1024 |
| results | Array | The result set with the TSUID, metric and tags for each series. | *See Below* |
This endpoint will almost always return a `200` with content body. If the query doesn't match any results, the `results` field will be an empty array and `totalResults` will be 0. If an error occurs, such as a failure to resolve a metric or tag name to a UID, an exception will be returned.
Example Response
----------------
```
{
"type": "LOOKUP",
"metric": "tsd.hbase.rpcs",
"tags":[
{
"key": "type",
"value": "*"
}
]
"limit": 3,
"time": 565,
"results": [
{
"tags": {
"fqdn": "web01.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D0"
},
{
"tags": {
"fqdn": "web02.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D5"
},
{
"tags": {
"fqdn": "web03.mysite.com"
},
"metric": "app.apache.connections",
"tsuid": "0000150000070010D6"
}
],
"startIndex": 0,
"totalResults": 9688066
}
```
opentsdb HTTP Serializers HTTP Serializers
================
OpenTSDB supports common data formats via Serializers, plugins that can parse different data formats from an HTTP request and return data in the same format in an HTTP response. Below is a list of formatters included with OpenTSDB, descriptions and a list of formatter specific parameters.
* [*JSON Serializer*](json) - The default formatter for OpenTSDB handles parsing JSON requests and returns all data as JSON.
Please see [*HTTP API*](../index) for details on selecting a serializer.
opentsdb JSON Serializer JSON Serializer
===============
The default OpenTSDB serializer parses and returns JSON formatted data. Below you'll find details about the serializer and request parameters that affect only the the JSON serializer. If the serializer has extra parameters for a specific endpoint, they'll be listed below.
Serializer Name
---------------
`json`
Serializer Options
------------------
The following options are supported via query string:
| Parameter | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| jsonp | String | Optional | Wraps the response in a JavaScript function name passed to the parameter. | `empty` | jsonp=callback |
JSONP
-----
The JSON formatter can wrap responses in a JavaScript function using the `jsonp` query string parameter. Supply the name of the function you wish to use and the result will be wrapped.
### Example Request
```
http://localhost:4242/api/version?jsonp=callback
```
### Example Response
```
callback({
"timestamp": "1362712695",
"host": "DF81QBM1",
"repo": "/c/temp/a/opentsdb/build",
"full_revision": "11c5eefd79f0c800b703ebd29c10e7f924c01572",
"short_revision": "11c5eef",
"user": "df81qbm1_/clarsen",
"repo_status": "MODIFIED",
"version": "2.0.0"
})
```
api/query
---------
The JSON serializer allows some query string parameters that modify the output but have no effect on the data retrieved.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| arrays | Boolean | Optional | Returns the data points formatted as an array of arrays instead of a map of key/value pairs. Each array consists of the timestamp followed by the value. | false | arrays=true |
opentsdb /api/query/last /api/query/last
===============
This endpoint (2.1 and later) provides support for accessing the latest value of individual time series. It provides an optimization over a regular query when only the last data point is required. Locating the last point can be done with the timestamp of the meta data counter or by scanning backwards from the current system time.
Note
In order for this endpoint to function with metric string queries by scanning for matching time series, the meta data table must exist and have been populated with counters or TSMeta objects using one of the methods specified in [*Metadata*](../../user_guide/metadata). You must set either `tsd.core.meta.enable\_tsuid\_tracking` or `tsd.core.meta.enable\_realtime\_ts`. Queries with a backscan parameter will skip the meta table.
Similar to the standard query endpoint, there are two methods to use in selecting which time series should return data:
* **Metric Query** - Similar to a regular metric query, you can send a metric name and optionally a set of tag pairs. If the real-time meta has been enabled, the TSD will scan the meta data table to see if any time series match the query. For each time series that matches, it will scan for the latest data point and return it. However if meta is disabled, then the TSD will attempt a lookup for the exact set of metric and tags provided as long as a backscan value is given (as of 2.1.1).
* **TSUID Query** - If you know the TSUIDs for the time series that you want to access data for, simply provide a list of TSUIDs.
Additionally there are two ways to find the last data point for each time series located:
* **Counter Method** - If no backscan value is given and meta is enabled, the default is to lookup the data point counter in the meta data table for each time series. This counter records the time when the latest data point was written by a TSD. The endpoint looks up the timestamp and "gets" the proper data row, fetching the last point in the row. This will work most of the time, however please be aware that if you backfill older data (via an import or simply putting a data point with an old timestamp) the counter column timestamp may not be accurate. This method is best used for continuously updated data.
* **Back Scan** - Alternatively you can specify a number of hours to scan back in time starting at the current system time of the TSD where the query is being executed. For example, if you specify a back scan time of 24 hours, the TSD will first look for data in the row with the current hour. If that row is empty, it will look for data one hour before that. It will keep doing that until it finds a data point or it exceeds the hour limit. This method is useful if you often write data points out of order in time. Also note that the larger the backscan value, the longer it may take for queries to complete as they may scan further back in time for data.
All queries will return results only for time series that matched the query and for which a data point was found. The results are a list of individual data points per time series. Aggregation cannot be performed on individual data points as the timestamps may not align and the TSD will only return a single point so interpolation is impossible.
Verbs
-----
* GET
* POST
Requests
--------
Common parameters include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| queries | Array | Required | A list of one or more queries used to determine which time series to fetch the last data point for. | | timeseries | tsuids | | |
| resolveNames | Boolean | Optional | Whether or not to resolve the TSUIDs of results to their metric and tag names. | false | resolve | | true |
| backScan | Integer | Optional | A number of hours to search in the past for data. If set to 0 then the timestamp of the meta data counter for the time series is used. | 0 | back\_scan | | 24 |
Note that you can mix multiple metric and TSUID queries in one request.
### Metric Query String Format
The full specification for a metric query string sub query is as follows:
```
timeseries=<metric_name>[{<tag_name1>=<tag_value1>[,...<tag_nameN>=<tag_valueN>]}]
```
It is similar to a regular metric query but does not allow for aggregations, rates, down sampling or grouping operators. Note that if you supply a backscan value to avoid the meta table, then you must supply all of the tags and values to match the exact time series you are looking for. Backscan does not currently filter on the metric and tags given but will look for the specific series.
### TSUID Query String Format
TSUID queries are simpler than Metric queries. Simply pass a list of one or more hexadecimal encoded TSUIDs separated by commas:
```
tsuids=<tsuid1>[,...<tsuidN>]
```
### Example Query String Requests
```
http://localhost:4242/api/query/last?timeseries=proc.stat.cpu{host=foo,type=idle}×eries=proc.stat.mem{host=foo,type=idle}
http://localhost:4242/api/query/last?tsuids=000001000002000003,000001000002000004&back_scan=24&resolve=true
```
### Example Content Request
```
{
"queries": [
{
"metric": "sys.cpu.0",
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"tsuids": [
"000001000002000042",
"000001000002000043"
]
}
}
],
"resolveNames":true,
"backScan":24
}
```
Response
--------
The output will be an array of 0 or more data points depending on the data that was found. If a data point for a particular time series was not located within the time specified, it will not appear in the output. Output fields depend on whether or not the `resolve` flag was set.
| Name | Description |
| --- | --- |
| metric | Name of the metric for the time series. Only returned if `resolve` was set to true. |
| tags | A list of tags for the time series. Only returned if `resolve` was set to true. |
| timestamp | A Unix epoch timestamp, in milliseconds, when the data point was written |
| value | The value of the data point enclosed in quotation marks as a string |
| tsuid | The hexadecimal TSUID for the time series |
Unless there was an error with the query, you will generally receive a `200` status with content. However if your query couldn't find any data, it will return an empty result set. In the case of the JSON serializer, the result will be an empty array:
```
[]
```
### Example Responses
```
[
{
"timestamp": 1377118201000,
"value": "1976558550",
"tsuid": "0023E3000002000008000006000001"
},
{
"timestamp": 1377118201000,
"value": "1654587485",
"tsuid": "0023E3000002000008000006001656"
}
]
```
```
[
{
"metric": "tsd.hbase.rpcs",
"timestamp": 1377186301000,
"value": "2723265185",
"tags": {
"type": "put",
"host": "tsd1"
},
"tsuid": "0023E3000002000008000006000001"
},
{
"metric": "tsd.hbase.rpcs",
"timestamp": 1377186301000,
"value": "580720",
"tags": {
"type": "put",
"host": "tsd2"
},
"tsuid": "0023E3000002000008000006017438"
}
]
```
opentsdb /api/query /api/query
==========
Probably the most useful endpoint in the API, `/api/query` enables extracting data from the storage system in various formats determined by the serializer selected. Queries can be submitted via the 1.0 query string format or body content.
Query API Endpoints
-------------------
* [/api/query/exp](exp)
* [/api/query/gexp](gexp)
* [/api/query/last](last)
The `/query` endpoint is documented below. As of 2.2 data matching a query can be deleted by using the `DELETE` verb. The configuration parameter `tsd.http.query.allow\_delete` must be enabled to allow deletions. Data that is deleted will be returned in the query results. Executing the query a second time should return empty results.
Warning
Deleting data is permanent. Also beware that when deleting, some data outside the boundaries of the start and end times may be deleted as data is stored on an hourly basis.
Verbs
-----
* GET
* POST
* DELETE
Requests
--------
Request parameters include:
| Name | Data Type | Required | Description | Default | QS | RW | Example |
| --- | --- | --- | --- | --- | --- | --- | --- |
| start | String, Integer | Required | The start time for the query. This can be a relative or absolute timestamp. See [*Querying or Reading Data*](../../user_guide/query/index) for details. | | start | | 1h-ago |
| end | String, Integer | Optional | An end time for the query. If not supplied, the TSD will assume the local system time on the server. This may be a relative or absolute timestamp. See [*Querying or Reading Data*](../../user_guide/query/index) for details. | *current time* | end | | 1s-ago |
| queries | Array | Required | One or more sub queries used to select the time series to return. These may be metric `m` or TSUID `tsuids` queries | | m or tsuids | | *See below* |
| noAnnotations | Boolean | Optional | Whether or not to return annotations with a query. The default is to return annotations for the requested timespan but this flag can disable the return. This affects both local and global notes and overrides `globalAnnotations` | false | no\_annotations | | false |
| globalAnnotations | Boolean | Optional | Whether or not the query should retrieve global annotations for the requested timespan | false | global\_annotations | | true |
| msResolution (or ms) | Boolean | Optional | Whether or not to output data point timestamps in milliseconds or seconds. The msResolution flag is recommended. If this flag is not provided and there are multiple data points within a second, those data points will be down sampled using the query's aggregation function. | false | ms | | true |
| showTSUIDs | Boolean | Optional | Whether or not to output the TSUIDs associated with timeseries in the results. If multiple time series were aggregated into one set, multiple TSUIDs will be returned in a sorted manner | false | show\_tsuids | | true |
| showSummary | Boolean | Optional | Whether or not to show a summary of timings surrounding the query in the results. This creates another object in the map that is unlike the data point objects. | false | show\_summary | | true |
| showQuery | Boolean | Optional | Whether or not to return the original sub query with the query results. If the request contains many sub queries then this is a good way to determine which results belong to which sub query. Note that in the case of a `\*` or wildcard query, this can produce a lot of duplicate output. | false | show\_query | | true |
| delete | Boolean | Optional | Can be passed to the JSON with a POST to delete any data points that match the given query. | false | | W | true |
### Sub Queries
An OpenTSDB query requires at least one sub query, a means of selecting which time series should be included in the result set. There are two types:
* **Metric Query** - The full name of a metric is supplied along with an optional list of tags. This is optimized for aggregating multiple time series into one result.
* **TSUID Query** - A list of one or more TSUIDs that share a common metric. This is optimized for fetching individual time series where aggregation is not required.
A query can include more than one sub query and any mixture of the two types. When submitting a query via content body, if a list of TSUIDs is supplied, the metric and tags for that particular sub query will be ignored.
Each sub query can retrieve individual or groups of timeseries data, performing aggregation or grouping calculations on each set. Fields for each sub query include:
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| aggregator | String | Required | The name of an aggregation function to use. See [*/api/aggregators*](../aggregators) | | sum |
| metric | String | Required | The name of a metric stored in the system | | sys.cpu.0 |
| rate | Boolean | Optional | Whether or not the data should be converted into deltas before returning. This is useful if the metric is a continuously incrementing counter and you want to view the rate of change between data points. | false | true |
| rateOptions | Map | Optional | Monotonically increasing counter handling options | *See below* | *See below* |
| downsample | String | Optional | An optional downsampling function to reduce the amount of data returned. | *See below* | 5m-avg |
| tags | Map | Optional | To drill down to specific timeseries or group results by tag, supply one or more map values in the same format as the query string. Tags are converted to filters in 2.2. See the notes below about conversions. Note that if no tags are specified, all metrics in the system will be aggregated into the results. *Deprecated in 2.2* | | *See Below* |
| filters *(2.2)* | List | Optional | Filters the time series emitted in the results. Note that if no filters are specified, all time series for the given metric will be aggregated into the results. | | *See Below* |
| explicitTags *(2.3)* | Boolean | Optional | Returns the series that include only the tag keys provided in the filters. | false | true |
*Rate Options*
When passing rate options in a query string, the options must be enclosed in curly braces. For example: `m=sum:rate{counter,,1000}:if.octets.in`. If you wish to use the default `counterMax` but do want to supply a `resetValue`, you must add two commas as in the previous example. Additional fields in the `rateOptions` object include the following:
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| counter | Boolean | Optional | Whether or not the underlying data is a monotonically increasing counter that may roll over | false | true |
| counterMax | Integer | Optional | A positive integer representing the maximum value for the counter. | Java Long.MaxValue | 65535 |
| resetValue | Integer | Optional | An optional value that, when exceeded, will cause the aggregator to return a `0` instead of the calculated rate. Useful when data sources are frequently reset to avoid spurious spikes. | 0 | 65000 |
*Downsampling*
Downsample specifications const if an interval, a unit of time, an aggregator and (as of 2.2) an optional fill policy. The format of a downsample spec is:
```
<interval><units>-<aggregator>[-<fill policy>]
```
For example:
```
1h-sum
30m-avg-nan
24h-max-zero
```
See [*Aggregators*](../../user_guide/query/aggregators) for a list of supported fill policies.
*Filters*
New for 2.2, OpenTSDB includes expanded and plugable filters across tag key and value combinations. For a list of filters loaded in the TSD, see [*/api/config/filters*](../config/filters). For descriptions of the built-in filters see [*Filters*](../../user_guide/query/filters). Filters can be used in both query string and POST formatted queries. Multiple filters on the same tag key are allowed and when processed, they are *ANDed* together e.g. if we have two filters `host=literal\_or(web01)` and `host=literal\_or(web02)` the query will always return empty. If two or more filters are included for the same tag key and one has group by enabled but another does not, then group by will effectively be true for all filters on that tag key. Fields for POST queries pertaining to filters include:
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| type | String | Required | The name of the filter to invoke. See [*/api/config/filters*](../config/filters) | | regexp |
| tagk | String | Required | The tag key to invoke the filter on | | host |
| filter | String | Required | The filter expression to evaluate and depends on the filter being used | | web.\*.mysite.com |
| groupBy | Boolean | Optional | Whether or not to group the results by each value matched by the filter. By default all values matching the filter will be aggregated into a single series. | false | true |
For URI queries, the type precedes the filter expression in parentheses. The format is `<tagk>=<type>(<filter\_expression>)`. Whether or not results are grouped depends on which curly bracket the filter is in. Two curly braces are now supported per metric query. The first set is the *group by* filter and the second is a *non group by* filter, e.g. `{host=wildcard(web\*)}{colo=regexp(sjc.\*)}`. This specifies any metrics where the colo matches the regex expression "sjc.\*" and the host tag value starts with "web" and the results are grouped by host. If you only want to filter without grouping then the first curly set must be empty, e.g. `{}{host=wildcard(web\*),colo=regexp(sjc.\*)}`. This specifies nany metrics where colo matches the regex expression "sjc.\*" and the host tag value starts with "web" and the results are not grouped.
Note
Regular expression, wildcard filters with a pre/post/in-fix or literal ors with many values can cause queries to return slower as each row of data must be resolved to their string values then processed.
Note
When submitting a JSON query to OpenTSDB 2.2 or later, use either `tags` OR `filters`. Only one will take effect and the order is indeterminate as the JSON parser may deserialize one before the other. We recommend using filters for all future queries.
*Filter Conversions*
Values in the POST query `tags` map and the *group by* curly brace of URI queries are automatically converted to filters to provide backwards compatibility with existing systems. The auto conversions include:
| Example | Description |
| --- | --- |
| `<tagk>=\*` | Wildcard filter, effectively makes sure the tag key is present in the series |
| `<tagk>=value` | Case sensitive literal OR filter |
| `<tagk>=value1|value2|valueN` | Case sensitive literal OR filter |
| `<tagk>=va\*` | Case insensitive wildcard filter. An asterisk (star) with any other strings now becomes a wildcard filter shortcut |
### Metric Query String Format
The full specification for a metric query string sub query is as follows:
```
m=<aggregator>:[rate[{counter[,<counter_max>[,<reset_value>]]]}:][<down_sampler>:][explicit_tags:]<metric_name>[{<tag_name1>=<grouping filter>[,...<tag_nameN>=<grouping_filter>]}][{<tag_name1>=<non grouping filter>[,...<tag_nameN>=<non_grouping_filter>]}]
```
It can be a little daunting at first but you can break it down into components. If you're ever confused, try using the built-in GUI to plot a graph the way you want it, then look at the URL to see how the query is formatted. Changes to any of the form fields will update the URL (which you can actually copy and paste to share with other users). For examples, please see [*Query Examples*](../../user_guide/query/examples).
### TSUID Query String Format
TSUID queries are simpler than Metric queries. Simply pass a list of one or more hexadecimal encoded TSUIDs separated by commas:
```
tsuid=<aggregator>:<tsuid1>[,...<tsuidN>]
```
### Example Query String Requests
```
http://localhost:4242/api/query?start=1h-ago&m=sum:rate:proc.stat.cpu{host=foo,type=idle}
http://localhost:4242/api/query?start=1h-ago&tsuid=sum:000001000002000042,000001000002000043
```
### Example Content Request
Please see the serializer documentation for request information: [*HTTP Serializers*](../serializers/index). The following examples pertain to the default JSON serializer.
```
{
"start": 1356998400,
"end": 1356998460,
"queries": [
{
"aggregator": "sum",
"metric": "sys.cpu.0",
"rate": "true",
"tags": {
"host": "*",
"dc": "lga"
}
},
{
"aggregator": "sum",
"tsuids": [
"000001000002000042",
"000001000002000043"
]
}
}
]
}
```
2.2 query with filters
```
{
"start": 1356998400,
"end": 1356998460,
"queries": [
{
"aggregator": "sum",
"metric": "sys.cpu.0",
"rate": "true",
"filters": [
{
"type":"wildcard",
"tagk":"host",
"filter":"*",
"groupBy":true
},
{
"type":"literal_or",
"tagk":"dc",
"filter":"lga|lga1|lga2",
"groupBy":false
},
]
},
{
"aggregator": "sum",
"tsuids": [
"000001000002000042",
"000001000002000043"
]
}
}
]
}
```
Response
--------
The output generated for a query depends heavily on the chosen serializer [*HTTP Serializers*](../serializers/index). A request may result in multiple sets of data returned, particularly if the request included multiple queries or grouping was requested. Some common fields included with each data set in the response will be:
| Name | Description |
| --- | --- |
| metric | Name of the metric retrieved for the time series |
| tags | A list of tags only returned when the results are for a single time series. If results are aggregated, this value may be null or an empty map |
| aggregatedTags | If more than one timeseries were included in the result set, i.e. they were aggregated, this will display a list of tag names that were found in common across all time series. |
| dps | Retrieved data points after being processed by the aggregators. Each data point consists of a timestamp and a value, the format determined by the serializer. |
| annotations | If the query retrieved annotations for timeseries over the requested timespan, they will be returned in this group. Annotations for every timeseries will be merged into one set and sorted by `start\_time`. Aggregator functions do not affect annotations, all annotations will be returned for the span. |
| globalAnnotations | If requested by the user, the query will scan for global annotations during the timespan and the results returned in this group |
Unless there was an error with the query, you will generally receive a `200` status with content. However if your query couldn't find any data, it will return an empty result set. In the case of the JSON serializer, the result will be an empty array:
```
[]
```
For the JSON serializer, the timestamp will always be a Unix epoch style integer followed by the value as an integer or a floating point. For example, the default output is `"dps"{"<timestamp>":<value>}`. By default the timestamps will be in seconds. If the `msResolution` flag is set, then the timestamps will be in milliseconds.
### Example Aggregated Default Response
```
[
{
"metric": "tsd.hbase.puts",
"tags": {},
"aggregatedTags": [
"host"
],
"annotations": [
{
"tsuid": "00001C0000FB0000FB",
"description": "Testing Annotations",
"notes": "These would be details about the event, the description is just a summary",
"custom": {
"owner": "jdoe",
"dept": "ops"
},
"endTime": 0,
"startTime": 1365966062
}
],
"globalAnnotations": [
{
"description": "Notice",
"notes": "DAL was down during this period",
"custom": null,
"endTime": 1365966164,
"startTime": 1365966064
}
],
"tsuids": [
"0023E3000002000008000006000001"
],
"dps": {
"1365966001": 25595461080,
"1365966061": 25595542522,
"1365966062": 25595543979,
...
"1365973801": 25717417859
}
}
]
```
### Example Aggregated Array Response
```
[
{
"metric": "tsd.hbase.puts",
"tags": {},
"aggregatedTags": [
"host"
],
"dps": [
[
1365966001,
25595461080
],
[
1365966061,
25595542522
],
...
[
1365974221,
25722266376
]
]
}
]
```
### Example Multi-Set Response
For the following example, two TSDs were running and the query was: `http://localhost:4242/api/query?start=1h-ago&m=sum:tsd.hbase.puts{host=\*}`. This returns two explicit time series.
```
[
{
"metric": "tsd.hbase.puts",
"tags": {
"host": "tsdb-1.mysite.com"
},
"aggregatedTags": [],
"dps": {
"1365966001": 3758788892,
"1365966061": 3758804070,
...
"1365974281": 3778141673
}
},
{
"metric": "tsd.hbase.puts",
"tags": {
"host": "tsdb-2.mysite.com"
},
"aggregatedTags": [],
"dps": {
"1365966001": 3902179270,
"1365966062": 3902197769,
...
"1365974281": 3922266478
}
}
]
```
### Example With Show Summary and Query
```
[
{
"metric": "tsd.hbase.puts",
"tags": {},
"aggregatedTags": [
"host"
],
"query": {
"aggregator": "sum",
"metric": "tsd.hbase.puts",
"tsuids": null,
"downsample": null,
"rate": true,
"explicitTags": false,
"filters": [
{
"tagk": "host",
"filter": "*",
"group_by": true,
"type": "wildcard"
}
],
"rateOptions": null,
"tags": { }
},
"dps": {
"1365966001": 25595461080,
"1365966061": 25595542522,
"1365966062": 25595543979,
...
"1365973801": 25717417859
}
},
{
"statsSummary": {
"datapoints": 0,
"rawDatapoints": 56,
"aggregationTime": 0,
"serializationTime": 20,
"storageTime": 6,
"timeTotal": 26
}
}
]
```
| programming_docs |
opentsdb /api/query/gexp /api/query/gexp
===============
Graphite is an excellent storage system for time series data with a number of built in functions to manipulate the data. To support transitions from Graphite to OpenTSDB, the `/api/query/gexp` endpoint supports URI queries *similar* but not *identical* to Graphite`s expressions. Graphite functions are generally formatted as `func(<series>[, param1][, paramN])` with the ability to nest functions. TSD`s implementation follows the same pattern but uses an `m` style query (e.g. `sum:proc.stat.cpu{host=foo,type=idle}`) in place of the `<series>`. Nested functions are supported.
TSDB implements a subset of Graphite functions though we hope to add more in the future. For a list of Graphite functions and descriptions, see the [Documentation](http://graphite.readthedocs.org/en/latest/functions.html). TSD supported functions appear below.
Note
Supported as of version 2.3
Verbs
-----
* GET
Requests
--------
Queries can only be executed via GET using the URI at this time. (In the future, the [*/api/query/exp*](exp) endpoint will support more flexibility.) This is an extension of the main [*/api/query*](index) endpoint so parameters in the request table are also supported here. Additional parameters include:
| Name | Data Type | Required | Description | Example |
| --- | --- | --- | --- | --- |
| exp | String | Required | The Graphite style expression to execute. The first parameter of a function must either be another function or a URI formatted **Sub Query** | scale(sum:if.bytes\_in{host=\*},1024) |
### Example Query String Requests
```
http://localhost:4242/api/query/gexp?start=1h-ago&exp=scale(sum:if.bytes_in{host=*},1024)
```
Response
--------
The output is identical to [*/api/query*](index).
Functions
---------
Functions that accept a single metric query will operate across each time series result. E.g. if a query includes a group by on host such as `scale(sum:if.bytes\_in{host=\*},1024)`, and multiple hosts exist with that metric, then a series for each host will be emitted and the function applied. For functions that take multiple metrics, a union is performed across each metric and the function is executed across each resulting series with matching tags. E.g with the query `sum(sum:if.bytes\_in{host=\*},sum:if.bytes\_out{host=\*})`, assume two hosts exist, `web01` and `web02`. In this case, the output will be `if.bytes\_in{host=web01} + if.bytes\_out{host=web01}` and `if.bytes\_in{host=web02} + if.bytes\_out{host=web02}`. Missing series in any metric result set will be filled with the default fill value of the function.
Currently supported expressions include:
### absolute(<metric>)
Emits the results as absolute values, converting negative values to positive.
### diffSeries(<metric>[,<metricN>])
Returns the difference of all series in the list. Performs a UNION across tags in each metric result sets, defaulting to a fill value of zero. A maximum of 26 series are supported at this time.
### divideSeries(<metric>[,<metricN>])
Returns the quotient of all series in the list. Performs a UNION across tags in each metric result sets, defaulting to a fill value of zero. A maximum of 26 series are supported at this time.
### highestCurrent(<metric>,<n>)
Sorts all resulting time series by their most recent value and emits `n` number of series with the highest values. `n` must be a positive integer value.
### highestMax(<metric>,<n>)
Sorts all resulting time series by the maximum value for the time span and emits `n` number of series with the highest values. `n` must be a positive integer value.
### movingAverage(<metric>,<window>)
Emits a sliding window moving average for each data point and series in the metric. The `window` parameter may either be a positive integer that reflects the number of data points to maintain in the window (non-timed) or a time span specified by an integer followed by time unit such as ``60s`` or ``60m`` or ``24h``. Timed windows must be in single quotes.
### multiplySeries(<metric>[,<metricN>])
Returns the product of all series in the list. Performs a UNION across tags in each metric result sets, defaulting to a fill value of zero. A maximum of 26 series are supported at this time.
### scale(<metric>,<factor>)
Multiplies each series by the factor where the factor can be a positive or negative floating point or integer value.
### sumSeries(<metric>[,<metricN>])
Returns the sum of all series in the list. Performs a UNION across tags in each metric result sets, defaulting to a fill value of zero. A maximum of 26 series are supported at this time.
opentsdb /api/query/exp /api/query/exp
==============
This endpoint allows for querying data using expressions. The query is broken up into different sections.
Two set operations (or Joins) are allowed. The union of all time series ore the intersection.
For example we can compute "a + b" with a group by on the host field. Both metrics queried alone would emit a time series per host, e.g. maybe one for "web01", "web02" and "web03". Lets say metric "a" has values for all 3 hosts but metric "b" is missing "web03".
With the intersection operator, the expression will effectively add "a.web01 + b.web01" and "a.web02 + b.web02" but will skip emitting anything for "web03". Be aware of this if you see fewer outputs that you expected or you see errors about no series available after intersection.
With the union operator the expression will add the `web01` and `web02` series but for metric "b", it will substitute the metric's fill policy value for the results.
Note
Supported as of version 2.3
Verbs
-----
* POST
Requests
--------
The various sections implemented include:
### "time"
The time section is required and is a single JSON object. This affects the time range and optional reductions for all metrics requested.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| start | Integer | Required | The start time for the query. This may be relative, absolute human readable or absolute Unix Epoch. | | 1h-ago, 2015/05/05-00:00:00 |
| aggregator | String | Required | The global aggregation function to use for all metrics. It may be overridden on a per metric basis. | | sum |
| end | Integer | Optional | The end time for the query. If left out, the end is *now* | now | 1h-ago, 2015/05/05-00:00:00 |
| downsampler | Object | Optional | Reduces the number of data points returned. The format is defined below | None | See below |
| rate | Boolean | Optional | Whether or not to calculate all metrics as rates, i.e. value per second. This is computed before expressions. | false | true |
E.g.
```
"time":{ "start":"1h-ago", "end":"10m-ago", "downsampler":{"interval":"15m","aggregator":"max"}
```
**Downsampler**
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| interval | String | Required | A downsampling interval, i.e. what time span to rollup raw values into. The format is `<#><unit>`, e.g. `15m` | | 1h |
| aggregator | String | Required | The aggregation function to use for reducing the data points | | avg |
| fillPolicy | Object | Optional | A policy to use for filling buckets that are missing data points | None | See Below |
**Fill Policies**
These are used to replace "missing" values, i.e. when a data point was expected but couldn't be found in storage.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| policy | String | Required | The name of a policy to use. The values are listed in the table below | | zero |
| value | Double | Optional | For scalar fills, an optional value that can be used during substitution | NaN | 42 |
| Name | Description |
| --- | --- |
| nan | Emits a NaN if all values in the aggregation function were NaN or "missing". For aggregators, NaNs are treated as "sentinel" values that cause the function to skip over the values. Note that if a series emits a NaN in an expression, the NaN is infectious and will cause the output of that expression to be NaN. At serialization the NaN will be emitted. |
| null | Emits a Null at serialization time. During computation the values are treated as NaNs. |
| zero | Emits a zero when the value is missing |
| scalar | Emits a user defined value when a data point is missing. Must specify the value with `value`. The value can be an integer or floating point. |
Note that if you try to supply a value that is incompatible with the type the query will throw an exception. E.g. supplying a value with the NaN that isn't NaN will throw an error.
E.g.
```
{"policy":"scalar","value":"1"}
```
### "filters"
Filters are for selecting various time series based on the tag keys and values. At least one filter must be specified (for now) with at least an aggregation function supplied. Fields include:
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| id | String | Required | A unique ID for the filter. Cannot be the same as any metric or expression ID | | f1 |
| tags | Array | Optional | A list of filters on tag values | None | See below |
E.g.
```
"filters":[
"id":"f1",
"tags":[
{
"type":"wildcard",
"tagk":"host",
"filter":"*",
"groupBy":true
},
{
"type":"literal_or",
"tagk":"colo",
"filter":"lga",
"groupBy":false
}
]
]
```
**Filter Fields**
Within the "tags" field you can have one or more filter. The list of filters can be found via the [*/api/config/filters*](../config/filters) endpoint.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| type | String | Required | The name of the filter from the API | | regexp |
| tagk | String | Required | The tag key name such as *host* or *colo* that we filter on | | host |
| filter | String | Required | The value to filter on. This depends on the filter in use. See the API for details | | web.\*mysite.com |
| groupBy | Boolean | Optional | Whether or not to group results by the tag values matching this filter. E.g. grouping by host will return one result per host. Not grouping by host would aggregate (using the aggregation function) all results for the metric into one series | false | true |
### "metrics"
The metrics list determines which metrics are included in the expression. There must be at least one metric.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| id | String | Required | A unique ID for the metric. This MUST be a simple string, no punctuation or spaces | | cpunice |
| filter | String | Required | The filter to use when fetching this metric. It must match a filter in the filters array | | f1 |
| metric | String | Required | The name of a metric in OpenTSDB | | system.cpu.nice |
| aggregator | String | Optional | An optional aggregation function to overload the global function in `time` for just this metric | `time`'s aggregator | count |
| fillPolicy | Object | Optional | If downsampling is not used, this can be included to determine what to emit in calculations. It will also override the downsampling policy | zero fill | See above |
E.g.
```
{"id":"cpunice", "filter":"f1", "metric":"system.cpu.nice"}
```
### "expressions"
A list of one or more expressions over the metrics. The variables in an expression **MUST** refer to either a metric ID field or an expression ID field. Nested expressions are supported but exceptions will be thrown if a self reference or circular dependency is detected. So far only basic operations are supported such as addition, subtraction, multiplication, division, modulo
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| id | String | Required | A unique ID for the expression | | cpubusy |
| expr | String | Required | The expression to execute | | a + b / 1024 |
| join | Object | Optional | The set operation or "join" to perform for series across sets. | union | See below |
| fillPolicy | Object | Optional | An optional fill policy for the expression when it is used in a nested expression and doesn't have a value | NaN | See above |
E.g.
```
{
"id": "cpubusy",
"expr": "(((a + b + c + d + e + f + g) - g) / (a + b + c + d + e + f + g)) * 100",
"join": {
"operator": "intersection",
"useQueryTags": true,
"includeAggTags": false
}
}
```
**Joins**
The join object controls how the various time series for a given metric are merged within an expression. The two basic operations supported at this time are the union and intersection operators. Additional flags control join behavior.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| operator | String | Required | The operator to use, either union or intersection | | intersection |
| useQueryTags | Boolean | Optional | Whether or not to use just the tags explicitly defined in the filters when computing the join keys | false | true |
| includeAggTags | Boolean | Optional | Whether or not to include the tag keys that were aggregated out of a series in the join key | true | false |
### "outputs"
These determine the output behavior and allow you to eliminate some expressions from the results or include the raw metrics. By default, if this section is missing, all expressions and only the expressions will be serialized. The field is a list of one or more output objects. More fields will be added later with flags to affect the output.
| Name | Data Type | Required | Description | Default | Example |
| --- | --- | --- | --- | --- | --- |
| id | String | Required | The ID of the metric or expression | | e |
| alias | String | Optional | An optional descriptive name for series | | System Busy |
E.g.
```
{"id":"e", "alias":"System Busy"}
```
Note
The `id` field for all objects can not contain spaces, special characters or periods at this time.
**Complete Example**
```
{
"time": {
"start": "1y-ago",
"aggregator":"sum"
},
"filters": [
{
"tags": [
{
"type": "wildcard",
"tagk": "host",
"filter": "web*",
"groupBy": true
}
],
"id": "f1"
}
],
"metrics": [
{
"id": "a",
"metric": "sys.cpu.user",
"filter": "f1",
"fillPolicy":{"policy":"nan"}
},
{
"id": "b",
"metric": "sys.cpu.iowait",
"filter": "f1",
"fillPolicy":{"policy":"nan"}
}
],
"expressions": [
{
"id": "e",
"expr": "a + b"
},
{
"id":"e2",
"expr": "e * 2"
},
{
"id":"e3",
"expr": "e2 * 2"
},
{
"id":"e4",
"expr": "e3 * 2"
},
{
"id":"e5",
"expr": "e4 + e2"
}
],
"outputs":[
{"id":"e5", "alias":"Mega expression"},
{"id":"a", "alias":"CPU User"}
]
}
```
Response
--------
The output will contain a list of objects in the `outputs` array with the results in an array of arrays representing each time series followed by meta data for each series and the query overall. Also included is the original query and some summary statistics. The fields include:
| Name | Description |
| --- | --- |
| id | The expression ID the output matches |
| dps | The array of results. Each sub array starts with the timestamp in ms as the first (offset 0) value. The remaining values are the results for each series when a group by was applied. |
| dpsMeta | Meta data around the query including the first and last timestamps, number of result "sets", or sub arrays, and the number of series represented. |
| datapoints | The total number of data points returned to the user after aggregation |
| meta | Data about each time series in the result set. The fields are below |
The meta section contains ordered information about each time series in the output arrays. The first element in the array will always have a `metrics` value of `timestamp` and no other data.
| Name | Description |
| --- | --- |
| index | The index in the data point arrays that the meta refers to |
| metrics | The different metric names included in the expression |
| commonTags | Tag keys and values that were common across all time series that were aggregated in the resulting series |
| aggregatedTags | Tag keys that appeared in all series in the resulting series but had different values |
| dps | The number of data points emitted |
| rawDps | The number of raw values wrapped into the result |
### Example Responses
```
{
"outputs": [
{
"id": "Mega expression",
"dps": [
[
1431561600000,
1010,
1030
],
[
1431561660000,
"NaN",
"NaN"
],
[
1431561720000,
"NaN",
"NaN"
],
[
1431561780000,
1120,
1140
]
],
"dpsMeta": {
"firstTimestamp": 1431561600000,
"lastTimestamp": 1431561780000,
"setCount": 4,
"series": 2
},
"meta": [
{
"index": 0,
"metrics": [
"timestamp"
]
},
{
"index": 1,
"metrics": [
"sys.cpu",
"sys.iowait"
],
"commonTags": {
"host": "web01"
},
"aggregatedTags": []
},
{
"index": 2,
"metrics": [
"sys.cpu",
"sys.iowait"
],
"commonTags": {
"host": "web02"
},
"aggregatedTags": []
}
]
},
{
"id": "sys.cpu",
"dps": [
[
1431561600000,
1,
2
],
[
1431561660000,
3,
0
],
[
1431561720000,
5,
0
],
[
1431561780000,
7,
8
]
],
"dpsMeta": {
"firstTimestamp": 1431561600000,
"lastTimestamp": 1431561780000,
"setCount": 4,
"series": 2
},
"meta": [
{
"index": 0,
"metrics": [
"timestamp"
]
},
{
"index": 1,
"metrics": [
"sys.cpu"
],
"commonTags": {
"host": "web01"
},
"aggregatedTags": []
},
{
"index": 2,
"metrics": [
"sys.cpu"
],
"commonTags": {
"host": "web02"
},
"aggregatedTags": []
}
]
}
],
"statsSummary": {
"datapoints": 0,
"rawDatapoints": 0,
"aggregationTime": 0,
"serializationTime": 33,
"storageTime": 77,
"timeTotal": 148.63
},
"query": {
"name": null,
"time": {
"start": "1y-ago",
"end": null,
"timezone": null,
"downsampler": null,
"aggregator": "sum"
},
"filters": [
{
"id": "f1",
"tags": [
{
"tagk": "host",
"filter": "web*",
"group_by": true,
"type": "wildcard"
}
]
}
],
"metrics": [
{
"metric": "sys.cpu",
"id": "a",
"filter": "f1",
"aggregator": null,
"fillPolicy": {
"policy": "nan",
"value": "NaN"
},
"timeOffset": null
},
{
"metric": "sys.iowait",
"id": "b",
"filter": "f1",
"aggregator": null,
"fillPolicy": {
"policy": "nan",
"value": "NaN"
},
"timeOffset": null
}
],
"expressions": [
{
"id": "e",
"expr": "a + b"
},
{
"id": "e2",
"expr": "e * 2"
},
{
"id": "e3",
"expr": "e2 * 2"
},
{
"id": "e4",
"expr": "e3 * 2"
},
{
"id": "e5",
"expr": "e4 + e2"
}
],
"outputs": [
{
"id": "e5",
"alias": "Woot!"
},
{
"id": "a",
"alias": "Woot!2"
}
]
}
}
```
| programming_docs |
opentsdb /api/stats /api/stats
==========
This endpoint provides a list of statistics for the running TSD. Sub endpoints return details about other TSD components such as the JVM, thread states or storage client. All statistics are read only.
* [/api/stats/jvm](jvm)
* [/api/stats/query](query)
* [/api/stats/region\_clients](region_clients)
* [/api/stats/threads](threads)
Verbs
-----
* GET
* POST
Requests
--------
No parameters available.
### Example Request
**Query String**
```
http://localhost:4242/api/stats
```
Response
--------
The response is an array of objects. Fields in the response include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| metric | String | Name of the metric the statistic is recording | tsd.connectionmgr.connections |
| timestamp | Integer | Unix epoch timestamp, in seconds, when the statistic was collected and displayed | 1369350222 |
| value | Integer | The numeric value for the statistic | 42 |
| tags | Map | A list of key/value tag name/tag value pairs | *See Below* |
### Example Response
```
[
{
"metric": "tsd.connectionmgr.connections",
"timestamp": 1369350222,
"value": "1",
"tags": {
"host": "wtdb-1-4"
}
},
{
"metric": "tsd.connectionmgr.exceptions",
"timestamp": 1369350222,
"value": "0",
"tags": {
"host": "wtdb-1-4"
}
},
{
"metric": "tsd.rpc.received",
"timestamp": 1369350222,
"value": "0",
"tags": {
"host": "wtdb-1-4",
"type": "telnet"
}
}
]
```
opentsdb /api/stats/threads /api/stats/threads
==================
The threads endpoint is used for debugging the TSD and providing insight into the state and execution of various threads without having to resort to a JStack trace. (v2.2)
Verbs
-----
* GET
Requests
--------
No parameters available.
### Example Request
**Query String**
```
http://localhost:4242/api/stats/threads
```
Response
--------
The response is an array of objects. Fields in the response include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| threadID | Integer | Numeric ID of the thread | 1 |
| priority | Integer | Execution priority for the thread | 5 |
| name | String | String name of the thread, usually assigned by default | New I/O worker #23 |
| interrupted | Boolean | Whether or not the thread was interrupted | false |
| state | String | One of the valid Java thread states | RUNNABLE |
| stack | Array<String> | A stack trace showing where execution is currently located | *See Below* |
### Example Response
```
[
{
"threadID": 33,
"priority": 5,
"name": "AsyncHBase I/O Worker #23",
"interrupted": false,
"state": "RUNNABLE",
"stack": [
"sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)",
"sun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:136)",
"sun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:69)",
"sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:69)",
"sun.nio.ch.SelectorImpl.select(SelectorImpl.java:80)",
"org.jboss.netty.channel.socket.nio.SelectorUtil.select(SelectorUtil.java:68)",
"org.jboss.netty.channel.socket.nio.AbstractNioSelector.select(AbstractNioSelector.java:415)",
"org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:212)",
"org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:89)",
"org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)",
"org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)",
"org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)",
"java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895)",
"java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:918)",
"java.lang.Thread.run(Thread.java:695)"
]
},
{
"threadID": 6,
"priority": 9,
"name": "Signal Dispatcher",
"interrupted": false,
"state": "RUNNABLE",
"stack": []
},
{
"threadID": 21,
"priority": 5,
"name": "AsyncHBase I/O Worker #11",
"interrupted": false,
"state": "RUNNABLE",
"stack": [
"sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)",
"sun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:136)",
"sun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:69)",
"sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:69)",
"sun.nio.ch.SelectorImpl.select(SelectorImpl.java:80)",
"org.jboss.netty.channel.socket.nio.SelectorUtil.select(SelectorUtil.java:68)",
"org.jboss.netty.channel.socket.nio.AbstractNioSelector.select(AbstractNioSelector.java:415)",
"org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:212)",
"org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:89)",
"org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)",
"org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)",
"org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)",
"java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:895)",
"java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:918)",
"java.lang.Thread.run(Thread.java:695)"
]
},
{
"threadID": 2,
"priority": 10,
"name": "Reference Handler",
"interrupted": false,
"state": "WAITING",
"stack": [
"java.lang.Object.wait(Native Method)",
"java.lang.Object.wait(Object.java:485)",
"java.lang.ref.Reference$ReferenceHandler.run(Reference.java:116)"
]
},
{
"threadID": 44,
"priority": 5,
"name": "OpenTSDB Timer TSDB Timer #1",
"interrupted": false,
"state": "TIMED_WAITING",
"stack": [
"java.lang.Thread.sleep(Native Method)",
"org.jboss.netty.util.HashedWheelTimer$Worker.waitForNextTick(HashedWheelTimer.java:483)",
"org.jboss.netty.util.HashedWheelTimer$Worker.run(HashedWheelTimer.java:392)",
"org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)",
"java.lang.Thread.run(Thread.java:695)"
]
}
]
```
opentsdb /api/stats/query /api/stats/query
================
This endpoint can be used for tracking and troubleshooting queries executed against a TSD. It maintains an unbounded list of currently executing queries as well as a list of up to 256 completed queries (rotating the oldest queries out of memory). Information about each query includes the original query, request headers, response code, timing and an exception if thrown. (v2.2)
Verbs
-----
* GET
Requests
--------
No parameters available.
### Example Request
**Query String**
```
http://localhost:4242/api/stats/query
```
Response
--------
The response includes two arrays. `completed` lists the 256 most recent queries that have finished execution, whether successfully or with an error. The `running` array contains a list of queries currently executing. If this list is growing, the TSD is under heavy load. Note that the running list will not contain an exception, response code or timing details.
For information on the various sections and data from the stats endpoint, see [*Query Details and Stats*](../../user_guide/query/stats).
### Example Response
```
{
"completed": [{
"query": {
"start": "1455531250181",
"end": null,
"timezone": null,
"options": null,
"padding": false,
"queries": [{
"aggregator": "zimsum",
"metric": "tsd.connectionmgr.bytes.written",
"tsuids": null,
"downsample": "1m-avg",
"rate": true,
"filters": [{
"tagk": "colo",
"filter": "*",
"group_by": true,
"type": "wildcard"
}, {
"tagk": "env",
"filter": "prod",
"group_by": true,
"type": "literal_or"
}, {
"tagk": "role",
"filter": "frontend",
"group_by": true,
"type": "literal_or"
}],
"rateOptions": {
"counter": true,
"counterMax": 9223372036854775807,
"resetValue": 1,
"dropResets": false
},
"tags": {
"role": "literal_or(frontend)",
"env": "literal_or(prod)",
"colo": "wildcard(*)"
}
}, {
"aggregator": "zimsum",
"metric": "tsd.hbase.rpcs.cumulative_bytes_received",
"tsuids": null,
"downsample": "1m-avg",
"rate": true,
"filters": [{
"tagk": "colo",
"filter": "*",
"group_by": true,
"type": "wildcard"
}, {
"tagk": "env",
"filter": "prod",
"group_by": true,
"type": "literal_or"
}, {
"tagk": "role",
"filter": "frontend",
"group_by": true,
"type": "literal_or"
}],
"rateOptions": {
"counter": true,
"counterMax": 9223372036854775807,
"resetValue": 1,
"dropResets": false
},
"tags": {
"role": "literal_or(frontend)",
"env": "literal_or(prod)",
"colo": "wildcard(*)"
}
}],
"delete": false,
"noAnnotations": false,
"globalAnnotations": false,
"showTSUIDs": false,
"msResolution": false,
"showQuery": false,
"showStats": false,
"showSummary": false
},
"exception": "null",
"executed": 1,
"user": null,
"requestHeaders": {
"Accept-Language": "en-US,en;q=0.8",
"Host": "tsdhost:4242",
"Content-Length": "440",
"Referer": "http://tsdhost:8080/dashboard/db/tsdfrontend",
"Accept-Encoding": "gzip, deflate",
"X-Forwarded-For": "192.168.0.2",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.109 Safari/537.36",
"Origin": "http://tsdhost:8080",
"Content-Type": "application/json;charset=UTF-8",
"Accept": "application/json, text/plain, */*"
},
"numRunningQueries": 0,
"httpResponse": {
"code": 200,
"reasonPhrase": "OK"
},
"queryStartTimestamp": 1455552844368,
"queryCompletedTimestamp": 1455552844621,
"sentToClient": true,
"stats": {
"avgAggregationTime": 2.11416,
"avgHBaseTime": 200.267711,
"avgQueryScanTime": 242.037174,
"avgScannerTime": 200.474122,
"avgScannerUidToStringTime": 0.0,
"avgSerializationTime": 2.124153,
"emittedDPs": 716,
"maxAggregationTime": 2.093369,
"maxHBaseTime": 241.708782,
"maxQueryScanTime": 240.637231,
"maxScannerUidtoStringTime": 0.0,
"maxSerializationTime": 2.103411,
"maxUidToStringTime": 0.059345,
"processingPreWriteTime": 253.050907,
"successfulScan": 40,
"totalTime": 256.568992,
"uidPairsResolved": 0
}
}],
"running": []
}
```
opentsdb /api/stats/jvm /api/stats/jvm
==============
The threads endpoint is used for debugging the TSD's JVM process and includes stats about the garbage collector, system load and memory usage. (v2.2)
Note
The information printed will change depending on the JVM you are running the TSD under. In particular, the pools and GC sections will differ quite a bit.
Verbs
-----
* GET
Requests
--------
No parameters available.
### Example Request
**Query String**
```
http://localhost:4242/api/stats/jvm
```
Response
--------
The response is an object with multiple sub objects. Top level objects include
| Name | Data Type | Description |
| --- | --- | --- |
| os | Object | Information about the system |
| gc | Object | Information about the various garbage collectors such as how many times GC occurred and how long the process spent collecting. |
| runtime | Object | Details about the JVM including version and vendor, start timestamp (in millieconds) and the uptime. |
| pools | Object | Details about each of the memory pools, particularly when used with a generational collector. |
| memory | Object | Information about the JVM's memory usage. |
### Example Response
```
{
"os": {
"systemLoadAverage": 4.85
},
"gc": {
"parNew": {
"collectionTime": 26027510,
"collectionCount": 361039
},
"concurrentMarkSweep": {
"collectionTime": 333710,
"collectionCount": 396
}
},
"runtime": {
"startTime": 1441069233346,
"vmVersion": "24.60-b09",
"uptime": 1033439220,
"vmVendor": "Oracle Corporation",
"vmName": "Java HotSpot(TM) 64-Bit Server VM"
},
"pools": {
"cMSPermGen": {
"collectionUsage": {
"init": 21757952,
"used": 30044544,
"committed": 50077696,
"max": 85983232
},
"usage": {
"init": 21757952,
"used": 30045408,
"committed": 50077696,
"max": 85983232
},
"type": "NON_HEAP",
"peakUsage": {
"init": 21757952,
"used": 30045408,
"committed": 50077696,
"max": 85983232
}
},
"parSurvivorSpace": {
"collectionUsage": {
"init": 157024256,
"used": 32838400,
"committed": 157024256,
"max": 157024256
},
"usage": {
"init": 157024256,
"used": 32838400,
"committed": 157024256,
"max": 157024256
},
"type": "HEAP",
"peakUsage": {
"init": 157024256,
"used": 157024256,
"committed": 157024256,
"max": 157024256
}
},
"codeCache": {
"collectionUsage": null,
"usage": {
"init": 2555904,
"used": 8754368,
"committed": 8978432,
"max": 50331648
},
"type": "NON_HEAP",
"peakUsage": {
"init": 2555904,
"used": 8767040,
"committed": 8978432,
"max": 50331648
}
},
"cMSOldGen": {
"collectionUsage": {
"init": 15609561088,
"used": 1886862056,
"committed": 15609561088,
"max": 15609561088
},
"usage": {
"init": 15609561088,
"used": 5504187904,
"committed": 15609561088,
"max": 15609561088
},
"type": "HEAP",
"peakUsage": {
"init": 15609561088,
"used": 11849865176,
"committed": 15609561088,
"max": 15609561088
}
},
"parEdenSpace": {
"collectionUsage": {
"init": 1256259584,
"used": 0,
"committed": 1256259584,
"max": 1256259584
},
"usage": {
"init": 1256259584,
"used": 825272064,
"committed": 1256259584,
"max": 1256259584
},
"type": "HEAP",
"peakUsage": {
"init": 1256259584,
"used": 1256259584,
"committed": 1256259584,
"max": 1256259584
}
}
},
"memory": {
"objectsPendingFinalization": 0,
"nonHeapMemoryUsage": {
"init": 24313856,
"used": 38798912,
"committed": 59056128,
"max": 136314880
},
"heapMemoryUsage": {
"init": 17179869184,
"used": 6351794296,
"committed": 17022844928,
"max": 17022844928
}
}
}
```
opentsdb /api/stats/region_clients /api/stats/region\_clients
==========================
Returns information about the various HBase region server clients in AsyncHBase. This helps to identify issues with a particular region server. (v2.2)
Verbs
-----
* GET
Requests
--------
No parameters available.
### Example Request
**Query String**
```
http://localhost:4242/api/stats/region_clients
```
Response
--------
The response is an array of objects. Fields in the response include:
| Name | Data Type | Description | Example |
| --- | --- | --- | --- |
| pendingBreached | Integer | The total number of times writes to a new region client were discarded because it's pending RPC buffer was full. This should almost always be zero and a positive value indicates the TSD took a long time to connect to a region server. | 0 |
| writesBlocked | Integer | How many RPCs (batched or individual) in total were blocked due to the connection's send buffer being full. A positive value indicates a slow HBase server or poor network performance. | 0 |
| inflightBreached | Integer | The total number of times RPCs were blocked due to too many outstanding RPCs waiting for a response from HBase. A positive value indicates the region server is slow or network performance is poor. | 0 |
| dead | Boolean | Whether or not the region client is marked as dead due to a connection close event (such as region server going down) | false |
| rpcsInFlight | Integer | The current number of RPCs sent to HBase and awaiting a response. | 10 |
| rpcsSent | Integer | The total number of RPCs sent to HBase. | 424242 |
| rpcResponsesUnknown | Integer | The total number of responses received from HBase for which we couldn't find an RPC. This may indicate packet corruption or an incompatible HBase version. | 0 |
| pendingBatchedRPCs | Integer | The number of RPCs queued in the batched RPC awaiting the next flush or the batch limit. | 0 |
| endpoint | String | The IP and port of the region server in the format '/<ip>:<port>' | /127.0.0.1:35008 |
| rpcResponsesTimedout | Integer | The total number of responses from HBase for RPCs that have previously timedout. This means HBase may be catching up and responding to stale RPCs. | 0 |
| rpcid | Integer | The ID of the last RPC sent to HBase. This may be a negative number | 42 |
| rpcsTimedout | Integer | The total number of RPCs that have timed out. This may indicate a slow region server, poor network performance or GC issues with the TSD. | 0 |
| pendingRPCs | Integer | The number of RPCs queued and waiting for the connection handshake with the region server to complete | 0 |
### Example Response
```
[
{
"pendingBreached": 0,
"writesBlocked": 0,
"inflightBreached": 0,
"dead": false,
"rpcsInFlight": 0,
"rpcsSent": 35704,
"rpcResponsesUnknown": 0,
"pendingBatchedRPCs": 452,
"endpoint": "/127.0.0.1:35008",
"rpcResponsesTimedout": 0,
"rpcid": 35703,
"rpcsTimedout": 0,
"pendingRPCs": 0
}
]
```
gnuplot Plugins Plugins
=======
The set of functions available for plotting or for evaluating expressions can be extended through a plugin mechanism that imports executable functions from a shared library. For example, gnuplot versions through 5.4 do not provide a built-in implementation of the upper incomplete gamma function Q(a,x). *Q*(*a*, *x*) = [[IMAGE svg]](img11.svg)[[IMAGE svg]](img12.svg)*t*a-1*e*-t*dt* . You could define an approximation directly in gnuplot like this:
```
Q(a,x) = 1. - igamma(a,x)
```
However this has inherently limited precision as the value of Q approaches 1. If you need a more accurate implementation, it would be better to provide one via a plugin (see below). Once imported, the function can be used just as any other built-in or user-defined function in gnuplot. See **[import](import#import)**. The gnuplot distribution includes source code and instructions for creating a plugin library in the directory demo/plugin. You can modify the simple example file **demo\_plugin.c** by replacing one or more of the toy example functions with an implementation of the function you are interested in. This could include invocation of functions from an external mathematical library.
The demo/plugin directory also contains source for a plugin that implements Q(a,x). As noted above, this plugin allows earlier versions of gnuplot to provide the same function **uigamma** as the current development version.
```
import Q(a,x) from "uigamma_plugin"
uigamma(a,x) = ((x<1 || x<a) ? 1.0-igamma(a,x) : Q(a,x))
```
| programming_docs |
gnuplot Parallelaxes Parallelaxes
============
Parallel axis plots can highlight correlation in a multidimensional data set. Individual columns of input data are each associated with a separately scaled vertical axis. If all columns are drawn from a single file then each line on the plot represents values from a single row of data in that file. It is common to use some discrete categorization to assign line colors, allowing visual exploration of the correlation between this categorization and the axis dimensions. Syntax:
```
set style data parallelaxes
plot $DATA using col1{:varcol1} {at <xpos>} {<line properties}, \
$DATA using col2, ...
```
CHANGE: Version 5.4 of gnuplot introduces a change in the syntax for plot style parallelaxes. The revised syntax allows an unlimited number of parallel axes.
```
gnuplot 5.2: plot $DATA using 1:2:3:4:5 with parallelaxes
gnuplot 5.4: plot for [col=1:5] $DATA using col with parallelaxes
```
The new syntax also allows explicit placement of the parallel vertical axes along the x axis as in the example below. If no explicit x coordinate is provide axis N will be placed at x=N.
```
array xpos[5] = [1, 5, 6, 7, 11, 12]
plot for [col=1:5] $DATA using col with parallelaxes at xpos[col]
```
By default gnuplot will automatically determine the range and scale of the individual axes from the input data, but the usual **set axis range** commands can be used to customize this. See **[set paxis](set_show#set_paxis)**.
gnuplot Vfill Vfill
=====
Syntax:
```
vfill FILE using x:y:z:radius:(<expression>)
```
The **vfill** command acts analogously to a **plot** command except that instead of creating a plot it modifies voxels in the currently active voxel grid. For each point read from the input file, the voxel containing that point and also all other voxels within a sphere of given radius centered about (x,y,z) are incremented as follows:
* user variable VoxelDistance is set to the distance from (x,y,z) to that voxel's grid coordinates (vx,vy,vz).
* The expression provided in the 5th **using** specifier is evaluated. This expression can use the new value of VoxelDistance.
* voxel(vx,vy,vz) += result of evaluating <expression>
Example:
```
vfill "file.dat" using 1:2:3:(3.0):(1.0)
```
This command adds 1 to the value of every voxel within a sphere of radius 3.0 around each point in file.dat. Example:
```
vfill "file.dat" using 1:2:3:4:(VoxelDistance < 1 ? 1 : 1/VoxelDistance)
```
This command modifies all voxels in a sphere whose radius is determined for each point by the content of column 4. The increment added to a voxel decreases with its distance from the data point. Note that **vfill** always increments existing values in the current voxel grid. To reset them to zero, use **vclear**.
gnuplot Bee swarm plots Bee swarm plots
===============
"Bee swarm" plots result from applying jitter to separate overlapping points. A typical use is to compare the distribution of y values exhibited by two or more categories of points, where the category determines the x coordinate. See the **[set jitter](set_show#set_jitter)** command for how to control the overlap criteria and the displacement pattern used for jittering. The plots in the figure were created by the same plot command but different jitter settings.
```
set jitter
plot $data using 1:2:1 with points lc variable
```
gnuplot Evaluate Evaluate
========
The **evaluate** command executes the commands given as an argument string. Newline characters are not allowed within the string. Syntax:
```
eval <string expression>
```
This is especially useful for a repetition of similar commands.
Example:
```
set_label(x, y, text) \
= sprintf("set label '%s' at %f, %f point pt 5", text, x, y)
eval set_label(1., 1., 'one/one')
eval set_label(2., 1., 'two/one')
eval set_label(1., 2., 'one/two')
```
Please see **[substitution macros](substitution_command_line_m#substitution_macros)** for another way to execute commands from a string.
gnuplot Start-up (initialization) Start-up (initialization)
=========================
When gnuplot is run, it first looks for a system-wide initialization file **gnuplotrc**. The location of this file is determined when the program is built and is reported by **show loadpath**. The program then looks in the user's HOME directory for a file called **.gnuplot** on Unix-like systems or **GNUPLOT.INI** on other systems. (OS/2 will look for it in the directory named in the environment variable **GNUPLOT**; Windows will use **APPDATA**). Note: The program can be configured to look first in the current directory, but this is not recommended because it is bad security practice.
gnuplot Boxxyerror Boxxyerror
==========
The **boxxyerror** plot style is only relevant to 2D data plotting. It is similar to the **xyerrorbars** style except that it draws rectangular areas rather than crosses. It uses either 4 or 6 basic columns of input data. Additional input columns may be used to provide information such as variable line or fill color (see **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**).
```
4 columns: x y xdelta ydelta
6 columns: x y xlow xhigh ylow yhigh
```
The box width and height are determined from the x and y errors in the same way as they are for the **xyerrorbars** style — either from xlow to xhigh and from ylow to yhigh, or from x-xdelta to x+xdelta and from y-ydelta to y+ydelta, depending on how many data columns are provided.
The 6 column form of the command provides a convenient way to plot rectangles with arbitrary x and y bounds.
An additional (5th or 7th) input column may be used to provide variable (per-datapoint) color information (see **[linecolor](linetypes_colors_styles#linecolor)** and **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**).
The interior of the boxes is drawn according to the current fillstyle. See **[set style fill](set_show#set_style_fill)** and **[boxes](boxes#boxes)** for details. Alternatively a new fillstyle may be specified in the plot command.
gnuplot Reset Reset
=====
```
reset {bind | errors | session}
```
The **reset** command causes all graph-related options that can be set with the **set** command to return to their default values. This command can be used to restore the default settings after executing a loaded command file, or to return to a defined state after lots of settings have been changed.
The following are *not* affected by **reset**:
```
`set term` `set output` `set loadpath` `set linetype` `set fit`
`set encoding` `set decimalsign` `set locale` `set psdir`
`set overflow` `set multiplot`
```
Note that **reset** does not necessarily return settings to the state they were in at program entry, because the default values may have been altered by commands in the initialization files gnuplotrc or $HOME/.gnuplot. However, these commands can be re-executed by using the variant command **reset session**.
**reset session** deletes any user-defined variables and functions, restores default settings, and then re-executes the system-wide gnuplotrc initialization file and any private $HOME/.gnuplot preferences file. See **[initialization](start_up_initialization#initialization)**.
**reset errors** clears only the error state variables GPVAL\_ERRNO and GPVAL\_ERRMSG.
**reset bind** restores all hotkey bindings to their default state.
gnuplot Printerr Printerr
========
**printerr** is the same as print except that output is always sent to stderr even if a prior **set print** command remains in effect.
gnuplot Arrows Arrows
======
The 2D **arrows** style draws an arrow with specified length and orientation angle at each point (x,y). Additional input columns may be used to provide variable (per-datapoint) color information or arrow style. It is identical to the 2D style **with vectors** except that each the arrow head is positioned using length + angle rather than delta\_x + delta\_y. See **[with vectors](vectors#with_vectors)**.
```
4 columns: x y length angle
```
The keywords **with arrows** may be followed by inline arrow style properties, a reference to a predefined arrow style, or **arrowstyle variable** to load the index of the desired arrow style for each arrow from a separate column.
**length** > 0 is interpreted in x-axis coordinates. -1 < **length** < 0 is interpreted in horizontal graph coordinates; i.e. |length| is a fraction of the total graph width. The program will adjust for differences in x and y scaling or plot aspect ratio so that the visual length is independent of the orientation angle.
**angle** is always specified in degrees.
gnuplot System System
======
Syntax:
```
system "command string"
! command string
output = system("command string")
show variable GPVAL_SYSTEM
```
**system "command"** executes "command" in a subprocess by invoking the operating system's default shell. If called as a function, **system("command")** returns the character stream from the subprocess's stdout as a string. One trailing newline is stripped from the resulting string if present. See also **[backquotes](substitution_command_line_m#backquotes)**.
The exit status of the subprocess is reported in variables GPVAL\_SYSTEM\_ERRNO and GPVAL\_SYSTEM\_ERRMSG. Note that if the command string invokes more than one programs, the subprocess may return "Success" even if one of the programs produced an error. E.g. file = system("ls -1 \*.plt | tail -1") will return "Success" even if there are no \*.plt files because **tail** succeeds even if **ls** does not.
The system command can be used to import external functions into gnuplot as shown below, however this will force creation of a separate subprocess every time the function is invoked. For functions that will be invoked many times it would be better to import a directly callable subroutine from a shared library. See **[import](import#import)** and **plugin.dem**.
```
f(x) = real(system(sprintf("somecommand %f", x)))
```
gnuplot Pause Pause
=====
The **pause** command displays any text associated with the command and then waits a specified amount of time or until the carriage return is pressed. **pause** is especially useful in conjunction with **load** files. Syntax:
```
pause <time> {"<string>"}
pause mouse {<endcondition>}{, <endcondition>} {"<string>"}
pause mouse close
```
<time> may be any constant or floating-point expression. **pause -1** will wait until a carriage return is hit, zero (0) won't pause at all, and a positive number will wait the specified number of seconds. **pause 0** is synonymous with **print**.
If the current terminal supports **mousing**, then **pause mouse** will terminate on either a mouse click or on ctrl-C. For all other terminals, or if mousing is not active, **pause mouse** is equivalent to **pause -1**.
If one or more end conditions are given after **pause mouse**, then any one of the conditions will terminate the pause. The possible end conditions are **keypress**, **button1**, **button2**, **button3**, **close**, and **any**. If the pause terminates on a keypress, then the ascii value of the key pressed is returned in MOUSE\_KEY. The character itself is returned as a one character string in MOUSE\_CHAR. Hotkeys (bind command) are disabled if keypress is one of the end conditions. Zooming is disabled if button3 is one of the end conditions.
In all cases the coordinates of the mouse are returned in variables MOUSE\_X, MOUSE\_Y, MOUSE\_X2, MOUSE\_Y2. See **[mouse variables](mouse_input#mouse_variables)**.
Note: Since **pause** communicates with the operating system rather than the graphics, it may behave differently with different device drivers (depending upon how text and graphics are mixed).
Examples:
```
pause -1 # Wait until a carriage return is hit
pause 3 # Wait three seconds
pause -1 "Hit return to continue"
pause 10 "Isn't this pretty? It's a cubic spline."
pause mouse "Click any mouse button on selected data point"
pause mouse keypress "Type a letter from A-F in the active window"
pause mouse button1,keypress
pause mouse any "Any key or button will terminate"
```
The variant "pause mouse key" will resume after any keypress in the active plot window. If you want to wait for a particular key to be pressed, you can use a loop such as:
```
print "I will resume after you hit the Tab key in the plot window"
plot <something>
pause mouse key
while (MOUSE_KEY != 9) {
pause mouse key
}
```
Pause mouse close
-----------------
The command **pause mouse close** is a specific example of pausing to wait for an external event. In this case the program waits for a "close" event from the plot window. Exactly how to generate such an event varies with your desktop environment and configuration, but usually you can close the plot window by clicking on some widget on the window border or by typing a hot-key sequence such as <alt><F4> or <ctrl>q. If you are unsure whether a suitable widget or hot-key is available to the user, you may also want to define a hot-key sequence using gnuplot's own mechanism. See **[bind](mouse_input#bind)**. The command sequence below may be useful when running gnuplot from a script rather than from the command line.
```
plot <...whatever...>
bind all "alt-End" "exit gnuplot"
pause mouse close
```
gnuplot Continue Continue
========
The **continue** command is only meaningful inside the bracketed iteration clause of a **do** or **while** statement. It causes the remaining statements inside the bracketed clause to be skipped. Execution resumes at the start of the next iteration (if any remain in the loop condition). See also **[break](break#break)**.
gnuplot Layers Layers
======
A gnuplot plot is built up by drawing its various components in a fixed order. This order can be modified by assigning some components to a specific layer using the keywords **behind**, **back**, or **front**. For example, to replace the background color of the plot area you could define a colored rectangle with the attribute **behind**.
```
set object 1 rectangle from graph 0,0 to graph 1,1 fc rgb "gray" behind
```
The order of drawing is
```
behind
back
the plot itself
the plot legend (`key`)
front
```
Within each layer elements are drawn in the order
```
grid, axis, and border elements
pixmaps in numerical order
objects (rectangles, circles, ellipses, polygons) in numerical order
labels in numerical order
arrows in numerical order
```
In the case of multiple plots on a single page (multiplot mode) this order applies separately to each component plot, not to the multiplot as a whole.
gnuplot Stats (Statistical Summary) Stats (Statistical Summary)
===========================
Syntax:
```
stats {<ranges>} 'filename' {matrix | using N{:M}} {name 'prefix'} {{no}output}
```
This command prepares a statistical summary of the data in one or two columns of a file. The using specifier is interpreted in the same way as for plot commands. See **[plot](plot#plot)** for details on the **[index](plot#index)**, **[every](plot#every)**, and **[using](plot#using)** directives. Data points are filtered against both xrange and yrange before analysis. See **[set xrange](set_show#set_xrange)**. The summary is printed to the screen by default. Output can be redirected to a file by prior use of the command **set print**, or suppressed altogether using the **nooutput** option.
In addition to printed output, the program stores the individual statistics into three sets of variables. The first set of variables reports how the data is laid out in the file: The array of column headers is generated only if option **set datafile columnheaders** is in effect.
| | | |
| --- | --- | --- |
| `STATS_records` | *N* | total number *N* of in-range data records |
| `STATS_outofrange` | | number of records filtered out by range limits |
| `STATS_invalid` | | number of invalid/incomplete/missing records |
| `STATS_blank` | | number of blank lines in the file |
| `STATS_blocks` | | number of indexable blocks of data in the file |
| `STATS_columns` | | number of data columns in the first row of data |
| `STATS_column_header` | | array of strings holding column headers found |
The second set reports properties of the in-range data from a single column. This column is treated as y. If the y axis is autoscaled then no range limits are applied. Otherwise only values in the range [ymin:ymax] are considered.
If two columns are analysed jointly by a single **stats** command, the suffix "\_x" or "\_y" is appended to each variable name. I.e. STATS\_min\_x is the minimum value found in the first column, while STATS\_min\_y is the minimum value found in the second column. In this case points are filtered by testing against both xrange and yrange.
| | | | |
| --- | --- | --- | --- |
| `STATS_min` | | min(*y*) | minimum value of in-range data points |
| `STATS_max` | | max(*y*) | maximum value of in-range data points |
| `STATS_index_min` | | *i* | *y*i = min(*y*) | index i for which data[i] == STATS\_min |
| `STATS_index_max` | | *i* | *y*i = max(*y*) | index i for which data[i] == STATS\_max |
| `STATS_mean` | [[IMAGE svg]](img13.svg) = | [[IMAGE svg]](img14.svg)[[IMAGE svg]](img15.svg)*y* | mean value of the in-range data points |
| `STATS_stddev` | *σ*y = | [[IMAGE svg]](img16.svg) | population standard deviation of the in-range data |
| `STATS_ssd` | *s*y = | [[IMAGE svg]](img17.svg) | sample standard deviation of the in-range data |
| `STATS_lo_quartile` | | | value of the lower (1st) quartile boundary |
| `STATS_median` | | | median value |
| `STATS_up_quartile` | | | value of the upper (3rd) quartile boundary |
| `STATS_sum` | | [[IMAGE svg]](img15.svg)*y* | sum |
| `STATS_sumsq` | | [[IMAGE svg]](img15.svg)*y*2 | sum of squares |
| `STATS_skewness` | | [[IMAGE svg]](img18.svg)[[IMAGE svg]](img15.svg)(*y*-[[IMAGE svg]](img13.svg))3 | skewness of the in-range data points |
| `STATS_kurtosis` | | [[IMAGE svg]](img19.svg)[[IMAGE svg]](img15.svg)(*y*-[[IMAGE svg]](img13.svg))4 | kurtosis of the in-range data points |
| `STATS_adev` | | [[IMAGE svg]](img14.svg)[[IMAGE svg]](img15.svg)| *y*-[[IMAGE svg]](img13.svg)| | mean absolute deviation of the in-range data |
| `STATS_mean_err` | | *σ*y/[[IMAGE svg]](img20.svg) | standard error of the mean value |
| `STATS_stddev_err` | | *σ*y/[[IMAGE svg]](img21.svg) | standard error of the standard deviation |
| `STATS_skewness_err` | | [[IMAGE svg]](img22.svg) | standard error of the skewness |
| `STATS_kurtosis_err` | | [[IMAGE svg]](img23.svg) | standard error of the kurtosis |
The third set of variables is only relevant to analysis of two data columns.
| | | |
| --- | --- | --- |
| `STATS_correlation` | | sample correlation coefficient between x and y values |
| `STATS_slope` | | A corresponding to a linear fit y = Ax + B |
| `STATS_slope_err` | | uncertainty of A |
| `STATS_intercept` | | B corresponding to a linear fit y = Ax + B |
| `STATS_intercept_err` | | uncertainty of B |
| `STATS_sumxy` | | sum of x\*y |
| `STATS_pos_min_y` | | x coordinate of a point with minimum y value |
| `STATS_pos_max_y` | | x coordinate of a point with maximum y value |
Keyword **matrix** indicates that the input consists of a matrix (see **[matrix](splot#matrix)**); the usual statistics are generated by considering all matrix elements. The matrix dimensions are saved in variables STATS\_size\_x and STATS\_size\_y.
| | | |
| --- | --- | --- |
| `STATS_size_x` | | number of matrix columns |
| `STATS_size_y` | | number of matrix rows |
The index reported in STATS\_index\_xxx corresponds to the value of pseudo-column 0 ($0) in plot commands. I.e. the first point has index 0, the last point has index N-1.
Data values are sorted to find the median and quartile boundaries. If the total number of points N is odd, then the median value is taken as the value of data point (N+1)/2. If N is even, then the median is reported as the mean value of points N/2 and (N+2)/2. Equivalent treatment is used for the quartile boundaries.
For an example of using the **stats** command to annotate a subsequent plot, see [stats.dem.](http://www.gnuplot.info/demo/stats.html)
The **stats** command in this version of gnuplot can handle log-scaled data, but not the content of time/date fields (**set xdata time** or **set ydata time**). This restriction may be relaxed in a future version.
Name
----
It may be convenient to track the statistics from more than one file or data column in parallel. The **name** option causes the default prefix "STATS" to be replaced by a user-specified string. For example, the mean value of column 2 data from two different files could be compared by
```
stats "file1.dat" using 2 name "A"
stats "file2.dat" using 2 name "B"
if (A_mean < B_mean) {...}
```
Instead of providing a string constant as the name, the keyword **columnheader** or function **columnheader(N)** can be used to generate the name from whatever string is found in that column in the first row of the data file:
```
do for [COL=5:8] { stats 'datafile' using COL name columnheader }
```
| programming_docs |
gnuplot Mouse input Mouse input
===========
Many terminals allow interaction with the current plot using the mouse. Some also support the definition of hotkeys to activate pre-defined functions by hitting a single key while the mouse focus is in the active plot window. It is even possible to combine mouse input with **batch** command scripts, by invoking the command **pause mouse** and then using the mouse variables returned by mouse clicking as parameters for subsequent scripted actions. See **[bind](mouse_input#bind)** and **[mouse variables](mouse_input#mouse_variables)**. See also the command **[set mouse](set_show#set_mouse)**. Bind
----
Syntax:
```
bind {allwindows} [<key-sequence>] ["<gnuplot commands>"]
bind <key-sequence> ""
reset bind
```
The **bind** allows defining or redefining a hotkey, i.e. a sequence of gnuplot commands which will be executed when a certain key or key sequence is pressed while the driver's window has the input focus. Note that **bind** is only available if gnuplot was compiled with **mouse** support and it is used by all mouse-capable terminals. A user-specified binding supersedes any builtin bindings, except that <space> and 'q' cannot normally be rebound. For an exception, see **[bind space](mouse_input#bind_space)**.
Only mouse button 1 can be bound, and only for 2D plots.
You get the list of all hotkeys by typing **show bind** or **bind** or by typing the hotkey 'h' in the graph window.
Key bindings are restored to their default state by **reset bind**.
Note that multikey-bindings with modifiers must be given in quotes.
Normally hotkeys are only recognized when the currently active plot window has focus. **bind allwindows <key> ...** (short form: **bind all <key> ...**) causes the binding for <key> to apply to all gnuplot plot windows, active or not. In this case gnuplot variable MOUSE\_KEY\_WINDOW is set to the ID of the originating window, and may be used by the bound command.
Examples:
- set bindings:
```
bind a "replot"
bind "ctrl-a" "plot x*x"
bind "ctrl-alt-a" 'print "great"'
bind Home "set view 60,30; replot"
bind all Home 'print "This is window ",MOUSE_KEY_WINDOW'
```
- show bindings:
```
bind "ctrl-a" # shows the binding for ctrl-a
bind # shows all bindings
show bind # show all bindings
```
- remove bindings:
```
bind "ctrl-alt-a" "" # removes binding for ctrl-alt-a
(note that builtins cannot be removed)
reset bind # installs default (builtin) bindings
```
- bind a key to toggle something:
```
v=0
bind "ctrl-r" "v=v+1;if(v%2)set term x11 noraise; else set term x11 raise"
```
Modifiers (ctrl / alt) are case insensitive, keys not:
```
ctrl-alt-a == CtRl-alT-a
ctrl-alt-a != ctrl-alt-A
```
List of modifiers (alt == meta):
```
ctrl, alt, shift (only valid for Button1 Button2 Button3)
```
List of supported special keys:
```
"BackSpace", "Tab", "Linefeed", "Clear", "Return", "Pause", "Scroll_Lock",
"Sys_Req", "Escape", "Delete", "Home", "Left", "Up", "Right", "Down",
"PageUp", "PageDown", "End", "Begin",
```
```
"KP_Space", "KP_Tab", "KP_Enter", "KP_F1", "KP_F2", "KP_F3", "KP_F4",
"KP_Home", "KP_Left", "KP_Up", "KP_Right", "KP_Down", "KP_PageUp",
"KP_PageDown", "KP_End", "KP_Begin", "KP_Insert", "KP_Delete", "KP_Equal",
"KP_Multiply", "KP_Add", "KP_Separator", "KP_Subtract", "KP_Decimal",
"KP_Divide",
```
```
"KP_1" - "KP_9", "F1" - "F12"
```
The following are window events rather than actual keys
```
"Button1" "Button2" "Button3" "Close"
```
See also help for **[mouse](set_show#mouse)**.
### Bind space
If gnuplot was built with configuration option –enable-raise-console, then typing <space> in the plot window raises gnuplot's command window. This hotkey can be changed to ctrl-space by starting gnuplot as 'gnuplot -ctrlq', or by setting the XResource 'gnuplot\*ctrlq'. See **[x11 command-line-options](complete_list_terminals#x11_command-line-options)**. Mouse variables
---------------
When **mousing** is active, clicking in the active window will set several user variables that can be accessed from the gnuplot command line. The coordinates of the mouse at the time of the click are stored in MOUSE\_X MOUSE\_Y MOUSE\_X2 and MOUSE\_Y2. The mouse button clicked, and any meta-keys active at that time, are stored in MOUSE\_BUTTON MOUSE\_SHIFT MOUSE\_ALT and MOUSE\_CTRL. These variables are set to undefined at the start of every plot, and only become defined in the event of a mouse click in the active plot window. To determine from a script if the mouse has been clicked in the active plot window, it is sufficient to test for any one of these variables being defined.
```
plot 'something'
pause mouse
if (exists("MOUSE_BUTTON")) call 'something_else'; \
else print "No mouse click."
```
It is also possible to track keystrokes in the plot window using the mousing code.
```
plot 'something'
pause mouse keypress
print "Keystroke ", MOUSE_KEY, " at ", MOUSE_X, " ", MOUSE_Y
```
When **pause mouse keypress** is terminated by a keypress, then MOUSE\_KEY will contain the ascii character value of the key that was pressed. MOUSE\_CHAR will contain the character itself as a string variable. If the pause command is terminated abnormally (e.g. by ctrl-C or by externally closing the plot window) then MOUSE\_KEY will equal -1.
Note that after a zoom by mouse, you can read the new ranges as GPVAL\_X\_MIN, GPVAL\_X\_MAX, GPVAL\_Y\_MIN, and GPVAL\_Y\_MAX, see **[gnuplot-defined variables](expressions#gnuplot-defined_variables)**.
gnuplot Financebars Financebars
===========
The **financebars** style is only relevant for 2D data plotting of financial data. It requires 1 x coordinate (usually a date) and 4 y values (prices).
```
5 columns: date open low high close
```
An additional (6th) input column may be used to provide variable (per-record) color information (see **[linecolor](linetypes_colors_styles#linecolor)** and **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**).
The symbol is a vertical line segment, located horizontally at the x coordinate and limited vertically by the high and low prices. A horizontal tic on the left marks the opening price and one on the right marks the closing price. The length of these tics may be changed by **set errorbars**. The symbol will be unchanged if the high and low prices are interchanged. See **[set errorbars](set_show#set_errorbars)** and **[candlesticks](candlesticks#candlesticks)**, and also the [finance demo.](http://www.gnuplot.info/demo/finance.html)
gnuplot Unset Unset
=====
Options set using the **set** command may be returned to their default state by the corresponding **unset** command. The **unset** command may contain an optional iteration clause. See **[plot for](plot#plot_for)**. Examples:
```
set xtics mirror rotate by -45 0,10,100
...
unset xtics
```
```
# Unset labels numbered between 100 and 200
unset for [i=100:200] label i
```
Linetype
--------
Syntax:
```
unset linetype N
```
Remove all characteristics previously associated with a single linetype. Subsequent use of this linetype will use whatever characteristics and color that is native to the current terminal type (i.e. the default linetypes properties available in gnuplot versions prior to 4.6). Monochrome
----------
Switches the active set of linetypes from monochrome to color. Equivalent to **set color**. Output
------
Because some terminal types allow multiple plots to be written into a single output file, the output file is not automatically closed after plotting. In order to print or otherwise use the file safely, it should first be closed explicitly by using **unset output** or by using **set output** to close the previous file and then open a new one. Terminal
--------
The default terminal that is active at the time of program entry depends on the system platform, gnuplot build options, and the environmental variable GNUTERM. Whatever this default may be, gnuplot saves it to internal variable GNUTERM. The **unset terminal** command restores the initial terminal type. It is equivalent to **set terminal GNUTERM**. However if the string in GNUTERM contains terminal options in addition to the bare terminal name, you may want to instead use **set terminal @GNUTERM**.
gnuplot Splot Splot
=====
**splot** is the command for drawing 3D plots (well, actually projections on a 2D surface, but you knew that). It is the 3D equivalent of the **plot** command. **splot** provides only a single x, y, and z axis; there is no equivalent to the x2 and y2 secondary axes provided by **plot**. See the **[plot](plot#plot)** command for many options available in both 2D and 3D plots.
Syntax:
```
splot {<ranges>}
{<iteration>}
<function> | {{<file name> | <datablock name>} {datafile-modifiers}}
| <voxelgridname>
| keyentry
{<title-spec>} {with <style>}
{, {definitions{,}} <function> ...}
```
The **splot** command operates on a data generated by a function, read from a data file, or stored previously in a named data block. Data file names are usually provided as a quoted string. The function can be a mathematical expression, or a triple of mathematical expressions in parametric mode.
A new feature in version 5.4 is that **splot** can operate on voxel data. See **[voxel-grids](splot#voxel-grids)**, **[set vgrid](set_show#set_vgrid)**, **[vxrange](set_show#vxrange)**. At present voxel grids can be be plotted using styles **with dots**, **with points**, or **with isosurface**. Voxel grid values can also be referenced in the **using** specifiers of other plot styles, for example to assign colors.
By default **splot** draws the xy plane completely below the plotted data. The offset between the lowest ztic and the xy plane can be changed by **set xyplane**. The orientation of a **splot** projection is controlled by **set view**. See **[set view](set_show#set_view)** and **[set xyplane](set_show#set_xyplane)** for more information.
The syntax for setting ranges on the **splot** command is the same as for **plot**. In non-parametric mode, ranges must be given in the order
```
splot [<xrange>][<yrange>][<zrange>] ...
```
In parametric mode, the order is
```
splot [<urange>][<vrange>][<xrange>][<yrange>][<zrange>] ...
```
The **title** option is the same as in **plot**. The operation of **with** is also the same as in **plot** except that not all 2D plotting styles are available.
The **datafile** options have more differences.
As an alternative to surfaces drawn using parametric or function mode, the pseudo-file '++' can be used to generate samples on a grid in the xy plane.
See also **[show plot](set_show#show_plot)**, **[set view map](set_show#set_view_map)**, and **[sampling](plot#sampling)**.
Data-file
---------
**Splot**, like **plot**, can display from a file. Syntax:
```
splot '<file_name>' {binary <binary list>}
{{nonuniform} matrix}
{index <index list>}
{every <every list>}
{using <using list>}
```
The special filenames **""** and **"-"** are permitted, as in **plot**. See **[special-filenames](plot#special-filenames)**.
In brief, **binary** and **matrix** indicate that the data are in a special form, **index** selects which data sets in a multi-data-set file are to be plotted, **every** specifies which datalines (subsets) within a single data set are to be plotted, and **using** determines how the columns within a single record are to be interpreted.
The options **index** and **every** behave the same way as with **plot**; **using** does so also, except that the **using** list must provide three entries instead of two.
The **plot** option **smooth** is not available for **splot**, but **cntrparam** and **dgrid3d** provide limited smoothing capabilities.
Data file organization is essentially the same as for **plot**, except that each point is an (x,y,z) triple. If only a single value is provided, it will be used for z, the block number will be used for y, and the index of the data point in the block will be used for x. If two or four values are provided, **gnuplot** uses the last value for calculating the color in pm3d plots. Three values are interpreted as an (x,y,z) triple. Additional values are generally used as errors, which can be used by **fit**.
Single blank records separate blocks of data in a **splot** datafile; **splot** treats blocks as the equivalent of function y-isolines. No line will join points separated by a blank record. If all blocks contain the same number of points, **gnuplot** will draw cross-isolines between points in the blocks, connecting corresponding points. This is termed "grid data", and is required for drawing a surface, for contouring (**set contour**) and hidden-line removal (**set hidden3d**). See also **[splot grid\_data](splot#splot_grid_data)**.
It is no longer necessary to specify **parametric** mode for three-column **splot**s.
### Matrix
Gnuplot can interpret matrix data input in two different ways. The first of these assumes a uniform grid of x and y coordinates and assigns each value in the input matrix to one element M[i,j] of this uniform grid. The assigned x coordinates are the integers [0:NCOLS-1]. The assigned y coordinates are the integers [0:NROWS-1]. This is the default for text data input, but not for binary input. See **[matrix uniform](splot#matrix_uniform)** for examples and additional keywords.
The second interpretation assumes a non-uniform grid with explicit x and y coordinates. The first row of input data contains the y coordinates; the first column of input data contains the x coordinates. For binary input data, the first element of the first row must contain the number of columns. This is the default for **binary matrix** input, but requires an additional keyword **nonuniform** for text input data. See **[matrix nonuniform](splot#matrix_nonuniform)** for examples.
#### Uniform
Example commands for plotting uniform matrix data:
```
splot 'file' matrix using 1:2:3 # text input
splot 'file' binary general using 1:2:3 # binary input
```
In a uniform grid matrix the z-values are read in a row at a time, i. e.,
```
z11 z12 z13 z14 ...
z21 z22 z23 z24 ...
z31 z32 z33 z34 ...
```
and so forth. For text input, if the first row contains column labels rather than data, use the additional keyword **columnheaders**. Similarly if the first field in each row contains a label rather than data, use the additional keyword **rowheaders**. Here is an example that uses both:
```
$DATA << EOD
xxx A B C D
aa z11 z12 z13 z14
bb z21 z22 z23 z24
cc z31 z32 z33 z34
EOD
plot $DATA matrix columnheaders rowheaders with image
```
For text input, a blank line or comment line ends the matrix, and starts a new data block. You can select among the data blocks in a file by the **index** option to the **splot** command, as usual. The columnheaders option, if present, is applied only to the first data block.
#### Nonuniform
The first row of input data contains the y coordinates. The first column of input data contains the x coordinates. For binary input data, the first field of the first row must contain the number of columns. (This number is ignored for text input). Example commands for plotting non-uniform matrix data:
```
splot 'file' nonuniform matrix using 1:2:3 # text input
splot 'file' binary matrix using 1:2:3 # binary input
```
Thus the data organization for non-uniform matrix input is
```
<N+1> <x0> <x1> <x2> ... <xN>
<y0> <z0,0> <z0,1> <z0,2> ... <z0,N>
<y1> <z1,0> <z1,1> <z1,2> ... <z1,N>
: : : : ... :
```
which is then converted into triplets:
```
<x0> <y0> <z0,0>
<x0> <y1> <z0,1>
<x0> <y2> <z0,2>
: : :
<x0> <yN> <z0,N>
```
```
<x1> <y0> <z1,0>
<x1> <y1> <z1,1>
: : :
```
These triplets are then converted into **gnuplot** iso-curves and then **gnuplot** proceeds in the usual manner to do the rest of the plotting.
#### Every
The **every** keyword has special meaning when used with matrix data. Rather than applying to blocks of single points, it applies to rows and column values. Note that matrix rows and columns are indexed starting from 0, so the row with index N is the (N+1)th row. Syntax:
```
plot 'file' every {<column_incr>}
{:{<row_incr>}
{:{<start_column>}
{:{<start_row>}
{:{<end_column>}
{:<end_row>}}}}}
```
Examples:
```
plot 'file' matrix every :::N::N # plot all values in row with index N
plot 'file' matrix every ::3::7 # plot columns 3 to 7 for all rows
plot 'file' matrix every ::3:0:7:4 # submatrix bounded by [3,0] and [7,4]
```
#### Examples
A collection of matrix and vector manipulation routines (in C) is provided in **binary.c**. The routine to write binary data is
```
int fwrite_matrix(file,m,nrl,nrl,ncl,nch,row_title,column_title)
```
An example of using these routines is provided in the file **bf\_test.c**, which generates binary files for the demo file **demo/binary.dem**.
Usage in **plot**:
```
plot `a.dat` matrix
plot `a.dat` matrix using 1:3
plot 'a.gpbin' {matrix} binary using 1:3
```
will plot rows of the matrix, while using 2:3 will plot matrix columns, and using 1:2 the point coordinates (rather useless). Applying the **every** option you can specify explicit rows and columns. Example – rescale axes of a matrix in a text file:
```
splot `a.dat` matrix using (1+$1):(1+$2*10):3
```
Example – plot the 3rd row of a matrix in a text file:
```
plot 'a.dat' matrix using 1:3 every 1:999:1:2
```
(rows are enumerated from 0, thus 2 instead of 3). Gnuplot can read matrix binary files by use of the option **binary** appearing without keyword qualifications unique to general binary, i.e., **array**, **record**, **format**, or **filetype**. Other general binary keywords for translation should also apply to matrix binary. (See **[binary general](plot#binary_general)** for more details.)
### Example datafile
A simple example of plotting a 3D data file is
```
splot 'datafile.dat'
```
where the file "datafile.dat" might contain:
```
# The valley of the Gnu.
0 0 10
0 1 10
0 2 10
```
```
1 0 10
1 1 5
1 2 10
```
```
2 0 10
2 1 1
2 2 10
```
```
3 0 10
3 1 0
3 2 10
```
Note that "datafile.dat" defines a 4 by 3 grid ( 4 rows of 3 points each ). Rows (blocks) are separated by blank records.
Note also that the x value is held constant within each dataline. If you instead keep y constant, and plot with hidden-line removal enabled, you will find that the surface is drawn 'inside-out'.
Actually for grid data it is not necessary to keep the x values constant within a block, nor is it necessary to keep the same sequence of y values. **gnuplot** requires only that the number of points be the same for each block. However since the surface mesh, from which contours are derived, connects sequentially corresponding points, the effect of an irregular grid on a surface plot is unpredictable and should be examined on a case-by-case basis.
Grid data
---------
The 3D routines are designed for points in a grid format, with one sample, datapoint, at each mesh intersection; the datapoints may originate from either evaluating a function, see **[set isosamples](set_show#set_isosamples)**, or reading a datafile, see **[splot datafile](splot#splot_datafile)**. The term "isoline" is applied to the mesh lines for both functions and data. Note that the mesh need not be rectangular in x and y, as it may be parameterized in u and v, see **[set isosamples](set_show#set_isosamples)**. However, **gnuplot** does not require that format. In the case of functions, 'samples' need not be equal to 'isosamples', i.e., not every x-isoline sample need intersect a y-isoline. In the case of data files, if there are an equal number of scattered data points in each block, then "isolines" will connect the points in a block, and "cross-isolines" will connect the corresponding points in each block to generate a "surface". In either case, contour and hidden3d modes may give different plots than if the points were in the intended format. Scattered data can be converted to a {different} grid format with **set dgrid3d**.
The contour code tests for z intensity along a line between a point on a y-isoline and the corresponding point in the next y-isoline. Thus a **splot** contour of a surface with samples on the x-isolines that do not coincide with a y-isoline intersection will ignore such samples. Try:
```
set xrange [-pi/2:pi/2]; set yrange [-pi/2:pi/2]
set style function lp
set contour
set isosamples 10,10; set samples 10,10;
splot cos(x)*cos(y)
set samples 4,10; replot
set samples 10,4; replot
```
Splot surfaces
--------------
**splot** can display a surface as a collection of points, or by connecting those points. As with **plot**, the points may be read from a data file or result from evaluation of a function at specified intervals, see **[set isosamples](set_show#set_isosamples)**. The surface may be approximated by connecting the points with straight line segments, see **[set surface](set_show#set_surface)**, in which case the surface can be made opaque with **set hidden3d.** The orientation from which the 3d surface is viewed can be changed with **set view**. Additionally, for points in a grid format, **splot** can interpolate points having a common amplitude (see **[set contour](set_show#set_contour)**) and can then connect those new points to display contour lines, either directly with straight-line segments or smoothed lines (see **[set cntrparam](set_show#set_cntrparam)**). Functions are already evaluated in a grid format, determined by **set isosamples** and **set samples**, while file data must either be in a grid format, as described in **data-file**, or be used to generate a grid (see **[set dgrid3d](set_show#set_dgrid3d)**).
Contour lines may be displayed either on the surface or projected onto the base. The base projections of the contour lines may be written to a file, and then read with **plot**, to take advantage of **plot**'s additional formatting capabilities.
Voxel-grid
----------
Syntax:
```
splot $voxelgridname with {dots|points} {above <threshold>} ...
splot $voxelgridname with isosurface {level <threshold>} ...
```
Voxel data can be plotted with dots or points marking individual voxels whose value is above the specified threshold value (default threshold = 0). Color/pointtype/linewidth properties can be appended as usual.
At many view angles the voxel grid points will occlude each other or create Moiré artifacts on the display. These effects can be avoided by introducing jitter so that the displayed dot or point is displaced randomly from the true voxel grid coordinate. See **[set jitter](set_show#set_jitter)**.
Dense voxel grids can be down-sampled by using the **pointinterval** property (**pi** for short) to reduce the number of points drawn.
```
splot $vgrid with points pointtype 6 pointinterval 2
```
**with isosurface** will create a tessellated surface in 3D enclosing all voxels with value greater than the requested threshold. The surface placement is adjusted by linear interpolation to pass through the threshold value itself.
See **[set vgrid](set_show#set_vgrid)**, **[vfill](vfill#vfill)**. See demos **vplot.dem**, **isosurface.dem**.
| programming_docs |
gnuplot Image Image
=====
The **image**, **rgbimage**, and **rgbalpha** plotting styles all project a uniformly sampled grid of data values onto a plane in either 2D or 3D. The input data may be an actual bitmapped image, perhaps converted from a standard format such as PNG, or a simple array of numerical values. This figure illustrates generation of a heat map from an array of scalar values. The current palette is used to map each value onto the color assigned to the corresponding pixel.
```
plot '-' matrix with image
5 4 3 1 0
2 2 0 0 1
0 0 0 1 0
0 1 2 4 3
e
e
```
Each pixel (data point) of the input 2D image will become a rectangle or parallelipiped in the plot. The coordinates of each data point will determine the center of the parallelipiped. That is, an M x N set of data will form an image with M x N pixels. This is different from the pm3d plotting style, where an M x N set of data will form a surface of (M-1) x (N-1) elements. The scan directions for a binary image data grid can be further controlled by additional keywords. See **[binary keywords flipx](plot#binary_keywords_flipx)**, **[keywords center](plot#keywords_center)**, and **[keywords rotate](plot#keywords_rotate)**.
Image data can be scaled to fill a particular rectangle within a 2D plot coordinate system by specifying the x and y extent of each pixel. See **[binary keywords dx](plot#binary_keywords_dx)** and **[dy](plot#dy)**. To generate the figure at the right, the same input image was placed multiple times, each with a specified dx, dy, and origin. The input PNG image of a building is 50x128 pixels. The tall building was drawn by mapping this using **dx=0.5 dy=1.5**. The short building used a mapping **dx=0.5 dy=0.35**.
The **image** style handles input pixels containing a grayscale or color palette value. Thus 2D plots (**plot** command) require 3 columns of data (x,y,value), while 3D plots (**splot** command) require 4 columns of data (x,y,z,value).
The **rgbimage** style handles input pixels that are described by three separate values for the red, green, and blue components. Thus 5D data (x,y,r,g,b) is needed for **plot** and 6D data (x,y,z,r,g,b) for **splot**. The individual red, green, and blue components are assumed to lie in the range [0:255]. This matches the convention used in PNG and JPEG files (see **[binary filetype](plot#binary_filetype)**). However some data files use an alternative convention in which RGB components are floating point values in the range [0:1]. To use the **rgbimage** style with such data, first use the command **set rgbmax 1.0**.
The **rgbalpha** style handles input pixels that contain alpha channel (transparency) information in addition to the red, green, and blue components. Thus 6D data (x,y,r,g,b,a) is needed for **plot** and 7D data (x,y,z,r,g,b,a) for **splot**. The r, g, b, and alpha components are assumed to lie in the range [0:255]. To plot data for which RGBA components are floating point values in the range [0:1], first use the command **set rgbmax 1.0**.
If only a single data column is provided for the color components of either rgbimage or rgbalpha plots, it is interpreted as containing 32 bit packed ARGB data using the convention that alpha=0 means opaque and alpha=255 means fully transparent. Note that this is backwards from the alpha convention if alpha is supplied in a separate column, but matches the ARGB packing convention for individual commands to set color. See **[colorspec](linetypes_colors_styles#colorspec)**.
Transparency
------------
The **rgbalpha** plotting style assumes that each pixel of input data contains an alpha value in the range [0:255]. A pixel with alpha = 0 is purely transparent and does not alter the underlying contents of the plot. A pixel with alpha = 255 is purely opaque. All terminal types can handle these two extreme cases. A pixel with 0 < alpha < 255 is partially transparent. Terminal types that do not support partial transparency will round this value to 0 or 255. Image pixels
------------
Some terminals use device- or library-specific optimizations to render image data within a rectangular 2D area. This sometimes produces undesirable output, e.g. bad clipping or scaling, missing edges. The **pixels** keyword tells gnuplot to use generic code that renders the image pixel-by-pixel instead. This rendering mode is slower and may result in much larger output files, but should produce a consistent rendered view on all terminals. Example:
```
plot 'data' with image pixels
```
gnuplot Syntax Syntax
======
Options and any accompanying parameters are separated by spaces whereas lists and coordinates are separated by commas. Ranges are separated by colons and enclosed in brackets [], text and file names are enclosed in quotes, and a few miscellaneous things are enclosed in parentheses. Commas are used to separate coordinates on the **set** commands **arrow**, **key**, and **label**; the list of variables being fitted (the list after the **via** keyword on the **fit** command); lists of discrete contours or the loop parameters which specify them on the **set cntrparam** command; the arguments of the **set** commands **dgrid3d**, **dummy**, **isosamples**, **offsets**, **origin**, **samples**, **size**, **time**, and **view**; lists of tics or the loop parameters which specify them; the offsets for titles and axis labels; parametric functions to be used to calculate the x, y, and z coordinates on the **plot**, **replot** and **splot** commands; and the complete sets of keywords specifying individual plots (data sets or functions) on the **plot**, **replot** and **splot** commands.
Parentheses are used to delimit sets of explicit tics (as opposed to loop parameters) and to indicate computations in the **using** filter of the **fit**, **plot**, **replot** and **splot** commands.
(Parentheses and commas are also used as usual in function notation.)
Square brackets are used to delimit ranges given in **set**, **plot** or **splot** commands.
Colons are used to separate extrema in **range** specifications (whether they are given on **set**, **plot** or **splot** commands) and to separate entries in the **using** filter of the **plot**, **replot**, **splot** and **fit** commands.
Semicolons are used to separate commands given on a single command line.
Curly braces are used in the syntax for enhanced text mode and to delimit blocks in if/then/else statements. They are also used to denote complex numbers: {3,2} = 3 + 2i.
Quote Marks
-----------
Gnuplot uses three forms of quote marks for delimiting text strings, double-quote (ascii 34), single-quote (ascii 39), and backquote (ascii 96). Filenames may be entered with either single- or double-quotes. In this manual the command examples generally single-quote filenames and double-quote other string tokens for clarity.
String constants and text strings used for labels, titles, or other plot elements may be enclosed in either single quotes or double quotes. Further processing of the quoted text depends on the choice of quote marks.
Backslash processing of special characters like \n (newline) and \345 (octal character code) is performed only for double-quoted strings. In single-quoted strings, backslashes are just ordinary characters. To get a single-quote (ascii 39) in a single-quoted string, it must be doubled. Thus the strings "d \" s' b \ \" and 'd" s' ' b \' are completely equivalent.
Text justification is the same for each line of a multi-line string. Thus the center-justified string
```
"This is the first line of text.\nThis is the second line."
```
will produce
```
This is the first line of text.
This is the second line.
```
but
```
'This is the first line of text.\nThis is the second line.'
```
will produce
```
This is the first line of text.\nThis is the second line.
```
Enhanced text processing is performed for both double-quoted text and single-quoted text, but only by terminals supporting this mode. See **[enhanced text](enhanced_text_mode#enhanced_text)**.
Back-quotes are used to enclose system commands for substitution into the command line. See **[substitution](substitution_command_line_m#substitution)**.
gnuplot Toggle Toggle
======
Syntax:
```
toggle {<plotno> | "plottitle" | all}
```
This command has the same effect as left-clicking on the key entry for a plot currently displayed by an interactive terminal (qt, wxt, x11). If the plot is showing, it is toggled off; if it is currently hidden, it is toggled on. **toggle all** acts on all active plots, equivalent to the hotkey "i". **toggle "title"** requires an exact match to the plot title. **toggle "ti\*"** acts on the first plot whose title matches the characters before the final '\*'. If the current terminal is not interactive, the toggle command has no effect.
gnuplot Boxes Boxes
=====
In 2D plots the **boxes** style draws a rectangle centered about the given x coordinate that extends from the x axis, i.e. from y=0 not from the graph border, to the given y coordinate. The width of the box can be provided in an additional input column or controlled by **set boxwidth**. Otherwise each box extends to touch the adjacent boxes. In 3D plots the **boxes** style draws a box centered at the given [x,y] coordinate that extends from the plane at z=0 to the given z coordinate. The width of the box on x can be provided in a separate input column or via **set boxwidth**. The depth of the box on y is controlled by **set boxdepth**. Boxes do not automatically expand to touch each other as in 2D plots.
2D boxes
--------
**plot with boxes** uses 2 or 3 columns of basic data. Additional input columns may be used to provide information such as variable line or fill color. See **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**.
```
2 columns: x y
3 columns: x y x_width
```
The width of the box is obtained in one of three ways. If the input data has a third column, this will be used to set the box width. Otherwise if a width has been set using the **set boxwidth** command, this will be used. If neither of these is available, the width of each box will be calculated so that it touches the adjacent boxes.
The box interiors are drawn using the current fillstyle. Alternatively a fillstyle may be specified in the plot command. See **[set style fill](set_show#set_style_fill)**. If no fillcolor is given in the plot command, the current line color is used.
Examples:
To plot a data file with solid filled boxes with a small vertical space separating them (bargraph):
```
set boxwidth 0.9 relative
set style fill solid 1.0
plot 'file.dat' with boxes
```
To plot a sine and a cosine curve in pattern-filled boxes style:
```
set style fill pattern
plot sin(x) with boxes, cos(x) with boxes
```
The sin plot will use pattern 0; the cos plot will use pattern 1. Any additional plots would cycle through the patterns supported by the terminal driver.
To specify explicit fillstyles and fillcolors for each dataset:
```
plot 'file1' with boxes fs solid 0.25 fc 'cyan', \
'file2' with boxes fs solid 0.50 fc 'blue', \
'file3' with boxes fs solid 0.75 fc 'magenta', \
'file4' with boxes fill pattern 1, \
'file5' with boxes fill empty
```
3D boxes
--------
**splot with boxes** requires at least 3 columns of input data. Additional input columns may be used to provide information such as box width or fill color.
```
3 columns: x y z
4 columns: x y z [x_width or color]
5 columns: x y z x_width color
```
The last column is used as a color only if the splot command specifies a variable color mode. Examples
```
splot 'blue_boxes.dat' using 1:2:3 fc "blue"
splot 'rgb_boxes.dat' using 1:2:3:4 fc rgb variable
splot 'category_boxes.dat' using 1:2:3:4:5 lc variable
```
In the first example all boxes are blue and have the width previously set by **set boxwidth**. In the second example the box width is still taken from **set boxwidth** because the 4th column is interpreted as a 24-bit RGB color. The third example command reads box width from column 4 and interprets the value in column 5 as an integer linetype from which the color is derived.
By default boxes have no thickness; they consist of a single rectangle parallel to the xz plane at the specified y coordinate. You can change this to a true box with four sides and a top by setting a non-zero extent on y. See **[set boxdepth](set_show#set_boxdepth)**.
3D boxes are processed as pm3d quadrangles rather than as surfaces. Because of this the front/back order of drawing is not affected by **set hidden3d**. Similarly if you want each box face to have a border you must use **set pm3d border** rather than **set style fill border**. See **[set pm3d](set_show#set_pm3d)**. For best results use a combination of **set pm3d depthorder base** and **set pm3d lighting**.
gnuplot Environment Environment
===========
A number of shell environment variables are understood by **gnuplot**. None of these are required, but may be useful. GNUTERM, if defined, is used to set the terminal type on start-up. Starting with version 5.2 the entire string in GNUTERM is passed to "set term" so that terminal options may be included. E.g.
```
GNUTERM="postscript eps color size 5in, 3in"
```
This can be overridden by the ˜ /.gnuplot (or equivalent) start-up file (see **[startup](start_up_initialization#startup)**) and of course by later explicit **set term** commands. GNUHELP may be defined to be the pathname of the HELP file (gnuplot.gih).
On VMS, the logical name GNUPLOT$HELP should be defined as the name of the help library for **gnuplot**. The **gnuplot** help can be put inside any VMS system help library.
On Unix, HOME is used as the name of a directory to search for a .gnuplot file if none is found in the current directory. On MS-DOS, Windows and OS/2, GNUPLOT is used. On Windows, the NT-specific variable USERPROFILE is also tried. VMS, SYS$LOGIN: is used. Type **help startup**.
On Unix, PAGER is used as an output filter for help messages.
On Unix, SHELL is used for the **shell** command. On MS-DOS and OS/2, COMSPEC is used for the **shell** command.
**FIT\_SCRIPT** may be used to specify a **gnuplot** command to be executed when a fit is interrupted — see **[fit](fit#fit)**. **FIT\_LOG** specifies the default filename of the logfile maintained by fit.
GNUPLOT\_LIB may be used to define additional search directories for data and command files. The variable may contain a single directory name, or a list of directories separated by a platform-specific path separator, eg. ':' on Unix, or ';' on DOS/Windows/OS/2 platforms. The contents of GNUPLOT\_LIB are appended to the **loadpath** variable, but not saved with the **save** and **save set** commands.
Several gnuplot terminal drivers access TrueType fonts via the gd library. For these drivers the font search path is controlled by the environmental variable GDFONTPATH. Furthermore, a default font for these drivers may be set via the environmental variable GNUPLOT\_DEFAULT\_GDFONT.
The postscript terminal uses its own font search path. It is controlled by the environmental variable GNUPLOT\_FONTPATH.
GNUPLOT\_PS\_DIR is used by the postscript driver to search for external prologue files. Depending on the build process, gnuplot contains either a built-in copy of those files or a default hardcoded path. You can use this variable have the postscript terminal use custom prologue files rather than the default files. See **[postscript prologue](complete_list_terminals#postscript_prologue)**.
gnuplot Help Help
====
The **help** command displays built-in help. To specify information on a particular topic use the syntax:
```
help {<topic>}
```
If <topic> is not specified, a short message is printed about **gnuplot**. After help for the requested topic is given, a menu of subtopics is given; help for a subtopic may be requested by typing its name, extending the help request. After that subtopic has been printed, the request may be extended again or you may go back one level to the previous topic. Eventually, the **gnuplot** command line will return.
If a question mark (?) is given as the topic, the list of topics currently available is printed on the screen.
gnuplot gnuplot 5.4 − An Interactive Plotting Program gnuplot 5.4 − An Interactive Plotting Program
=============================================
Thomas Williams & Colin Kelley Version organized by: Ethan A Merritt and many others Major contributors (alphabetic order): Christoph Bersch, Hans-Bernhard Bröker, John Campbell, Robert Cunningham, David Denholm, Gershon Elber, Roger Fearick, Carsten Grammes, Lucas Hart, Lars Hecking, Péter Juhász, Thomas Koenig, David Kotz, Ed Kubaitis, Russell Lang, Timothée Lecomte, Alexander Lehmann, Jérôme Lodewyck, Alexander Mai, Bastian Märkisch, Ethan A Merritt, Petr Mikulík, Daniel Sebald, Carsten Steger, Shigeharu Takeno, Tom Tkacik, Jos Van der Woude, James R. Van Zandt, Alex Woo, Johannes Zellner Copyright © 1986 - 1993, 1998, 2004 Thomas Williams, Colin Kelley Copyright © 2004 - 2021 various authors Mailing list for comments: `[email protected]` Web site and issue trackers: `http://sourceforge.net/projects/gnuplot` This manual was originally prepared by Dick Crawford. Version 5.4 (May 2021)
gnuplot Fonts Fonts
=====
Gnuplot does not provide any fonts of its own. It relies on external font handling, the details of which unfortunately vary from one terminal type to another. Brief documentation of font mechanisms that apply to more than one terminal type is given here. For information on font use by other individual terminals, see the documentation for that terminal. Although it is possible to include non-alphabetic symbols by temporarily switching to a special font, e.g. the Adobe Symbol font, the preferred method is now to choose UTF-8 encoding and treat the symbol like any other character. Alternatively you can specify the unicode entry point for the desired symbol as an escape sequence in enhanced text mode. See **[encoding](set_show#encoding)**, **[unicode](enhanced_text_mode#unicode)**, **[locale](set_show#locale)**, and **[escape sequences](enhanced_text_mode#escape_sequences)**.
Cairo (pdfcairo, pngcairo, epscairo, wxt terminals)
---------------------------------------------------
These terminals find and access fonts using the external fontconfig tool set. Please see the [fontconfig user manual.](http://fontconfig.org/fontconfig-user.html) It is usually sufficient in gnuplot to request a font by a generic name and size, letting fontconfig substitute a similar font if necessary. The following will probably all work:
```
set term pdfcairo font "sans,12"
set term pdfcairo font "Times,12"
set term pdfcairo font "Times-New-Roman,12"
```
Gd (png, gif, jpeg, sixel terminals)
------------------------------------
Font handling for the png, gif, jpeg, and sixelgd terminals is done by the library libgd. Five basic fonts are provided directly by libgd. These are **tiny** (5x8 pixels), **small** (6x12 pixels), **medium**, (7x13 Bold), **large** (8x16) or **giant** (9x15 pixels). These fonts cannot be scaled or rotated. Use one of these keywords instead of the **font** keyword. E.g.
```
set term png tiny
```
On most systems libgd also provides access to Adobe Type 1 fonts (\*.pfa) and TrueType fonts (\*.ttf). You must give the name of the font file, not the name of the font inside it, in the form "<face> {,<pointsize>}". <face> is either the full pathname to the font file, or the first part of a filename in one of the directories listed in the GDFONTPATH environmental variable. That is, 'set term png font "Face"' will look for a font file named either <somedirectory>/Face.ttf or <somedirectory>/Face.pfa. For example, if GDFONTPATH contains **/usr/local/fonts/ttf:/usr/local/fonts/pfa** then the following pairs of commands are equivalent
```
set term png font "arial"
set term png font "/usr/local/fonts/ttf/arial.ttf"
set term png font "Helvetica"
set term png font "/usr/local/fonts/pfa/Helvetica.pfa"
```
To request a default font size at the same time:
```
set term png font "arial,11"
```
Both TrueType and Adobe Type 1 fonts are fully scalable and rotatable. If no specific font is requested in the "set term" command, gnuplot checks the environmental variable GNUPLOT\_DEFAULT\_GDFONT to see if there is a preferred default font.
Postscript (also encapsulated postscript \*.eps)
------------------------------------------------
PostScript font handling is done by the printer or viewing program. Gnuplot can create valid PostScript or encapsulated PostScript (\*.eps) even if no fonts at all are installed on your computer. Gnuplot simply refers to the font by name in the output file, and assumes that the printer or viewing program will know how to find or approximate a font by that name. All PostScript printers or viewers should know about the standard set of Adobe fonts **Times-Roman**, **Helvetica**, **Courier**, and **Symbol**. It is likely that many additional fonts are also available, but the specific set depends on your system or printer configuration. Gnuplot does not know or care about this; the output \*.ps or \*.eps files that it creates will simply refer to whatever font names you request.
Thus
```
set term postscript eps font "Times-Roman,12"
```
will produce output that is suitable for all printers and viewers. On the other hand
```
set term postscript eps font "Garamond-Premier-Pro-Italic"
```
will produce an output file that contains valid PostScript, but since it refers to a specialized font, only some printers or viewers will be able to display the specific font that was requested. Most will substitute a different font. However, it is possible to embed a specific font in the output file so that all printers will be able to use it. This requires that the a suitable font description file is available on your system. Note that some font files require specific licensing if they are to be embedded in this way. See **[postscript fontfile](complete_list_terminals#postscript_fontfile)** for more detailed description and examples.
| programming_docs |
gnuplot Dots Dots
====
The **dots** style plots a tiny dot at each point; this is useful for scatter plots with many points. Either 1 or 2 columns of input data are required in 2D. Three columns are required in 3D. For some terminals (post, pdf) the size of the dot can be controlled by changing the linewidth.
```
1 column y # x is row number
2 columns: x y
3 columns: x y z # 3D only (splot)
```
gnuplot Circles Circles
=======
The **circles** style plots a circle with an explicit radius at each data point. The radius is always interpreted in the units of the plot's horizontal axis (x or x2). The scale on y and the aspect ratio of the plot are both ignored. If the radius is not given in a separate column for each point it is taken from **set style circle**. In this case the radius may use graph or screen coordinates. Many combinations of per-point and previously set properties are possible. For 2D plots these include
```
using x:y
using x:y:radius
using x:y:color
using x:y:radius:color
using x:y:radius:arc_begin:arc_end
using x:y:radius:arc_begin:arc_end:color
```
By default a full circle will be drawn. It is possible to instead plot arc segments by specifying a start and end angle (in degrees) in columns 4 and 5.
A per-circle color may be provided in the last column of the using specifier. In this case the plot command must include a corresponding variable color term such as **lc variable** or **fillcolor rgb variable**.
For 3D plots the using specifier must contain
```
splot DATA using x:y:z:radius:color
```
where the variable color column is options. See **[set style circle](set_show#set_style_circle)** and **[set style fill](set_show#set_style_fill)**.
Examples:
```
# draws circles whose area is proportional to the value in column 3
set style fill transparent solid 0.2 noborder
plot 'data' using 1:2:(sqrt($3)) with circles, \
'data' using 1:2 with linespoints
```
```
# draws Pac-men instead of circles
plot 'data' using 1:2:(10):(40):(320) with circles
```
```
# draw a pie chart with inline data
set xrange [-15:15]
set style fill transparent solid 0.9 noborder
plot '-' using 1:2:3:4:5:6 with circles lc var
0 0 5 0 30 1
0 0 5 30 70 2
0 0 5 70 120 3
0 0 5 120 230 4
0 0 5 230 360 5
e
```
The result is similar to using a **points** plot with variable size points and pointstyle 7, except that the circles will scale with the x axis range. See also **[set object circle](set_show#set_object_circle)** and **[fillstyle](set_show#fillstyle)**.
gnuplot Load Load
====
The **load** command executes each line of the specified input file as if it had been typed in interactively. Files created by the **save** command can later be **load**ed. Any text file containing valid commands can be created and then executed by the **load** command. Files being **load**ed may themselves contain **load** or **call** commands. See **[comments](comments#comments)** for information about comments in commands. To **load** with arguments, see **[call](call#call)**. Syntax:
```
load "<input-file>"
```
The name of the input file must be enclosed in quotes.
The special filename "-" may be used to **load** commands from standard input. This allows a **gnuplot** command file to accept some commands from standard input. Please see help for **[batch/interactive](batch_interactive_operation#batch_interactive)** for more details.
On some systems which support a popen function (Unix), the load file can be read from a pipe by starting the file name with a '<'.
Examples:
```
load 'work.gnu'
load "func.dat"
load "< loadfile_generator.sh"
```
The **load** command is performed implicitly on any file names given as arguments to **gnuplot**. These are loaded in the order specified, and then **gnuplot** exits.
gnuplot Isosurface Isosurface
==========
This 3D plot style requires a populated voxel grid (see **[set vgrid](set_show#set_vgrid)**, **[vfill](vfill#vfill)**). Linear interpolation of voxel grid values is used to estimate fractional grid coordinates corresponding to the requested isolevel. These points are then used to generate a tessellated surface. The facets making up the surface are rendered as pm3d polygons, so the surface coloring, transparency, and border properties are controlled by **set pm3d**. In general the surface is easier to interpret visually if facets are given a thin border that is darker than the fill color. By default the tessellation uses a mixture of quadrangles and triangles. To use triangle only, see **[set isosurface](set_show#set_isosurface)**. Example:
```
set style fill solid 0.3
set pm3d depthorder border lc "blue" lw 0.2
splot $helix with isosurface level 10 fc "cyan"
```
gnuplot Polygons Polygons
========
```
splot DATA {using x:y:z} with polygons
{fillstyle <fillstyle spec>}
{fillcolor <colorspec>}
```
**splot with polygons** uses pm3d to render individual triangles, quadrangles, and larger polygons in 3D. These may be facets of a 3D surface or isolated shapes. The code assumes that the vertices lie in a plane. Vertices defining individual polygons are read from successive records of the input file. A blank line separates one polygon from the next. The fill style and color may be specified in the splot command, otherwise the global fillstyle from **set style fill** is used. Due to limitations in the pm3d code, a single border line style from **set pm3d border** is applied to all polygons. This restriction may be removed in a later gnuplot version.
pm3d sort order and lighting are applied to the faces. It is probably always desirable to use **set pm3d depthsort**.
```
set xyplane at 0
set view equal xyz
unset border
unset tics
set pm3d depth
set pm3d border lc "black" lw 1.5
splot 'icosahedron.dat' with polygons \
fs transparent solid 0.8 fc bgnd
```
gnuplot 3D plots 3D plots
========
3D plots are generated using the command **splot** rather than **plot**. Many of the 2D plot styles (points, images, impulse, labels, vectors) can also be used in 3D by providing an extra column of data containing z coordinate. Some plot types (pm3d coloring, surfaces, contours) must be generated using the **splot** command even if only a 2D projection is wanted. Surface plots
-------------
The styles **splot with lines** and **splot with surface** both generate a surface made from a grid of lines. Solid surfaces can be generated using the style **splot with pm3d**. Usually the surface is displayed at some convenient viewing angle, such that it clearly represents a 3D surface. See **[set view](set_show#set_view)**. In this case the X, Y, and Z axes are all visible in the plot. The illusion of 3D is enhanced by choosing hidden line removal. See **[hidden3d](set_show#hidden3d)**. The **splot** command can also calculate and draw contour lines corresponding to constant Z values. These contour lines may be drawn onto the surface itself, or projected onto the XY plane. See **[set contour](set_show#set_contour)**. 2D projection (set view map)
----------------------------
An important special case of the **splot** command is to map the Z coordinate onto a 2D surface by projecting the plot along the Z axis onto the xy plane. See **[set view map](set_show#set_view_map)**. This plot mode is useful for contour plots and heat maps. This figure shows contours plotted once with plot style **lines** and once with style **labels**. PM3D plots
----------
3D surfaces can also be drawn using solid pm3d quadrangles rather than lines. In this case there is no hidden surface removal, but if the component facets are drawn back-to-front then a similar effect is achieved. See **[set pm3d depthorder](set_show#set_pm3d_depthorder)**. While pm3d surfaces are by default colored using a smooth color palette (see **[set palette](set_show#set_palette)**), it is also possible to specify a solid color surface or to specify distinct solid colors for the top and bottom surfaces as in the figure shown here. See **[pm3d fillcolor](set_show#pm3d_fillcolor)**. Unlike the line-trimming in hidden3d mode, pm3d surfaces can be smoothly clipped to the current zrange. See **[set pm3d clipping](set_show#set_pm3d_clipping)**.
gnuplot Set-show Set-show
========
The **set** command can be used to set *lots* of options. No screen is drawn, however, until a **plot**, **splot**, or **replot** command is given. The **show** command shows their settings; **show all** shows all the settings.
Options changed using **set** can be returned to the default state by giving the corresponding **unset** command. See also the **[reset](reset#reset)** command, which returns all settable parameters to default values.
The **set** and **unset** commands may optionally contain an iteration clause. See **[plot for](plot#plot_for)**.
Angles
------
By default, **gnuplot** assumes the independent variable in polar graphs is in units of radians. If **set angles degrees** is specified before **set polar**, then the default range is [0:360] and the independent variable has units of degrees. This is particularly useful for plots of data files. The angle setting also applies to 3D mapping as set via the **set mapping** command. Syntax:
```
set angles {degrees | radians}
show angles
```
The angle specified in **set grid polar** is also read and displayed in the units specified by **set angles**.
**set angles** also affects the arguments of the machine-defined functions sin(x), cos(x) and tan(x), and the outputs of asin(x), acos(x), atan(x), atan2(x), and arg(x). It has no effect on the arguments of hyperbolic functions or Bessel functions. However, the output arguments of inverse hyperbolic functions of complex arguments are affected; if these functions are used, **set angles radians** must be in effect to maintain consistency between input and output arguments.
```
x={1.0,0.1}
set angles radians
y=sinh(x)
print y #prints {1.16933, 0.154051}
print asinh(y) #prints {1.0, 0.1}
```
but
```
set angles degrees
y=sinh(x)
print y #prints {1.16933, 0.154051}
print asinh(y) #prints {57.29578, 5.729578}
```
See also [poldat.dem: polar plot using **set angles** demo.](http://www.gnuplot.info/demo/poldat.html) Arrow
-----
Arbitrary arrows can be placed on a plot using the **set arrow** command. Syntax:
```
set arrow {<tag>} from <position> to <position>
set arrow {<tag>} from <position> rto <position>
set arrow {<tag>} from <position> length <coord> angle <ang>
set arrow <tag> arrowstyle | as <arrow_style>
set arrow <tag> {nohead | head | backhead | heads}
{size <headlength>,<headangle>{,<backangle>}} {fixed}
{filled | empty | nofilled | noborder}
{front | back}
{linestyle | ls <line_style>}
{linetype | lt <line_type>}
{linewidth | lw <line_width>}
{linecolor | lc <colorspec>}
{dashtype | dt <dashtype>}
```
```
unset arrow {<tag>}
show arrow {<tag>}
```
<tag> is an integer that identifies the arrow. If no tag is given, the lowest unused tag value is assigned automatically. The tag can be used to delete or change a specific arrow. To change any attribute of an existing arrow, use the **set arrow** command with the appropriate tag and specify the parts of the arrow to be changed.
The position of the first end point of the arrow is always specified by "from". The other end point can be specified using any of three different mechanisms. The <position>s are specified by either x,y or x,y,z, and may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. Unspecified coordinates default to 0. See **[coordinates](coordinates#coordinates)** for details. A coordinate system specifier does not carry over from the first endpoint description the second.
1) "to <position>" specifies the absolute coordinates of the other end.
2) "rto <position>" specifies an offset to the "from" position. For linear axes, **graph** and **screen** coordinates, the distance between the start and the end point corresponds to the given relative coordinate. For logarithmic axes, the relative given coordinate corresponds to the factor of the coordinate between start and end point. Thus, a negative relative value or zero are not allowed for logarithmic axes.
3) "length <coordinate> angle <angle>" specifies the orientation of the arrow in the plane of the graph. Again any of the coordinate systems can be used to specify the length. The angle is always in degrees.
Other characteristics of the arrow can either be specified as a pre-defined arrow style or by providing them in **set arrow** command. For a detailed explanation of arrow characteristics, see **[arrowstyle](set_show#arrowstyle)**.
Examples:
To set an arrow pointing from the origin to (1,2) with user-defined linestyle 5, use:
```
set arrow to 1,2 ls 5
```
To set an arrow from bottom left of plotting area to (-5,5,3), and tag the arrow number 3, use:
```
set arrow 3 from graph 0,0 to -5,5,3
```
To change the preceding arrow to end at 1,1,1, without an arrow head and double its width, use:
```
set arrow 3 to 1,1,1 nohead lw 2
```
To draw a vertical line from the bottom to the top of the graph at x=3, use:
```
set arrow from 3, graph 0 to 3, graph 1 nohead
```
To draw a vertical arrow with T-shape ends, use:
```
set arrow 3 from 0,-5 to 0,5 heads size screen 0.1,90
```
To draw an arrow relatively to the start point, where the relative distances are given in graph coordinates, use:
```
set arrow from 0,-5 rto graph 0.1,0.1
```
To draw an arrow with relative end point in logarithmic x axis, use:
```
set logscale x
set arrow from 100,-5 rto 10,10
```
This draws an arrow from 100,-5 to 1000,5. For the logarithmic x axis, the relative coordinate 10 means "factor 10" while for the linear y axis, the relative coordinate 10 means "difference 10". To delete arrow number 2, use:
```
unset arrow 2
```
To delete all arrows, use:
```
unset arrow
```
To show all arrows (in tag order), use:
```
show arrow
```
[arrows demos.](http://www.gnuplot.info/demo/arrowstyle.html)
Autoscale
---------
Autoscaling may be set individually on the x, y or z axis or globally on all axes. The default is to autoscale all axes. If you want to autoscale based on a subset of the plots in the figure, you can mark the other ones with the flag **noautoscale**. See **[datafile](plot#datafile)**. Syntax:
```
set autoscale {<axes>{|min|max|fixmin|fixmax|fix} | fix | keepfix}
set autoscale noextend
unset autoscale {<axes>}
show autoscale
```
where <axes> is either **x**, **y**, **z**, **cb**, **x2**, **y2**, **xy**, or **paxis {n}**. A keyword with **min** or **max** appended (this cannot be done with **xy**) tells **gnuplot** to autoscale just the minimum or maximum of that axis. If no keyword is given, all axes are autoscaled.
When autoscaling, the axis range is automatically computed and the dependent axis (y for a **plot** and z for **splot**) is scaled to include the range of the function or data being plotted.
If autoscaling of the dependent axis (y or z) is not set, the current y or z range is used.
Autoscaling the independent variables (x for **plot** and x,y for **splot**) is a request to set the domain to match any data file being plotted. If there are no data files, autoscaling an independent variable has no effect. In other words, in the absence of a data file, functions alone do not affect the x range (or the y range if plotting z = f(x,y)).
Please see **[set xrange](set_show#set_xrange)** for additional information about ranges.
The behavior of autoscaling remains consistent in parametric mode, (see **[set parametric](set_show#set_parametric)**). However, there are more dependent variables and hence more control over x, y, and z axis scales. In parametric mode, the independent or dummy variable is t for **plot**s and u,v for **splot**s. **autoscale** in parametric mode, then, controls all ranges (t, u, v, x, y, and z) and allows x, y, and z to be fully autoscaled.
When tics are displayed on second axes but no plot has been specified for those axes, x2range and y2range are inherited from xrange and yrange. This is done *before* applying offsets or autoextending the ranges to a whole number of tics, which can cause unexpected results. To prevent this you can explicitly link the secondary axis range to the primary axis range. See **[set link](set_show#set_link)**.
### Noextend
```
set autoscale noextend
```
By default autoscaling sets the axis range limits to the nearest tic label position that includes all the plot data. Keywords **fixmin**, **fixmax**, **fix** or **noextend** tell gnuplot to disable extension of the axis range to the next tic mark position. In this case the axis range limit exactly matches the coordinate of the most extreme data point. **set autoscale noextend** is a synonym for **set autoscale fix**. Range extension for a single axis can be disabled by appending the **noextend** keyword to the corresponding range command, e.g.
```
set yrange [0:*] noextend
```
**set autoscale keepfix** autoscales all axes while leaving the fix settings unchanged.
### Examples
Examples: This sets autoscaling of the y axis (other axes are not affected):
```
set autoscale y
```
This sets autoscaling only for the minimum of the y axis (the maximum of the y axis and the other axes are not affected):
```
set autoscale ymin
```
This disables extension of the x2 axis tics to the next tic mark, thus keeping the exact range as found in the plotted data and functions:
```
set autoscale x2fixmin
set autoscale x2fixmax
```
This sets autoscaling of the x and y axes:
```
set autoscale xy
```
This sets autoscaling of the x, y, z, x2 and y2 axes:
```
set autoscale
```
This disables autoscaling of the x, y, z, x2 and y2 axes:
```
unset autoscale
```
This disables autoscaling of the z axis only:
```
unset autoscale z
```
### Polar mode
When in polar mode (**set polar**), the xrange and the yrange may be left in autoscale mode. If **set rrange** is used to limit the extent of the polar axis, then xrange and yrange will adjust to match this automatically. However, explicit xrange and yrange commands can later be used to make further adjustments. See **[set rrange](set_show#set_rrange)**. See also [polar demos.](http://www.gnuplot.info/demo/poldat.html)
Bind
----
**show bind** shows the current state of all hotkey bindings. See **[bind](mouse_input#bind)**. Bmargin
-------
The command **set bmargin** sets the size of the bottom margin. Please see **[set margin](set_show#set_margin)** for details. Border
------
The **set border** and **unset border** commands control the display of the graph borders for the **plot** and **splot** commands. Note that the borders do not necessarily coincide with the axes; with **plot** they often do, but with **splot** they usually do not. Syntax:
```
set border {<integer>}
{front | back | behind}
{linestyle | ls <line_style>}
{linetype | lt <line_type>} {linewidth | lw <line_width>}
{linecolor | lc <colorspec>} {dashtype | dt <dashtype>}
{polar}
unset border
show border
```
With a **splot** displayed in an arbitrary orientation, like **set view 56,103**, the four corners of the x-y plane can be referred to as "front", "back", "left" and "right". A similar set of four corners exist for the top surface, of course. Thus the border connecting, say, the back and right corners of the x-y plane is the "bottom right back" border, and the border connecting the top and bottom front corners is the "front vertical". (This nomenclature is defined solely to allow the reader to figure out the table that follows.)
The borders are encoded in a 12-bit integer: the four low bits control the border for **plot** and the sides of the base for **splot**; the next four bits control the verticals in **splot**; the four high bits control the edges on top of an **splot**. The border settings is thus the sum of the appropriate entries from the following table:
| |
| --- |
| Graph Border Encoding |
| Bit | plot | splot |
| 1 | bottom | bottom left front |
| 2 | left | bottom left back |
| 4 | top | bottom right front |
| 8 | right | bottom right back |
| 16 | no effect | left vertical |
| 32 | no effect | back vertical |
| 64 | no effect | right vertical |
| 128 | no effect | front vertical |
| 256 | no effect | top left back |
| 512 | no effect | top right back |
| 1024 | no effect | top left front |
| 2048 | no effect | top right front |
| 4096 | polar | no effect |
The default setting is 31, which is all four sides for **plot**, and base and z axis for **splot**.
In 2D plots the border is normally drawn on top of all plots elements (**front**). If you want the border to be drawn behind the plot elements, use **set border back**.
In hidden3d plots the lines making up the border are normally subject to the same hidden3d processing as the plot elements. **set border behind** will override this default.
Using the optional <linestyle>, <linetype>, <linewidth>, <linecolor>, and <dashtype> specifiers, the way the border lines are drawn can be influenced (limited by what the current terminal driver supports). Besides the border itself, this line style is used for the tics, independent of whether they are plotted on the border or on the axes (see **[set xtics](set_show#set_xtics)**).
For **plot**, tics may be drawn on edges other than bottom and left by enabling the second axes – see **[set xtics](set_show#set_xtics)** for details.
If a **splot** draws only on the base, as is the case with "**unset surface; set contour base**", then the verticals and the top are not drawn even if they are specified.
The **set grid** options 'back', 'front' and 'layerdefault' also control the order in which the border lines are drawn with respect to the output of the plotted data.
The **polar** keyword enables a circular border for polar plots.
Examples:
Draw default borders:
```
set border
```
Draw only the left and bottom (**plot**) or both front and back bottom left (**splot**) borders:
```
set border 3
```
Draw a complete box around a **splot**:
```
set border 4095
```
Draw a topless box around a **splot**, omitting the front vertical:
```
set border 127+256+512 # or set border 1023-128
```
Draw only the top and right borders for a **plot** and label them as axes:
```
unset xtics; unset ytics; set x2tics; set y2tics; set border 12
```
Boxwidth
--------
The **set boxwidth** command is used to set the default width of boxes in the **boxes**, **boxerrorbars**, **boxplot**, **candlesticks** and **histograms** styles. Syntax:
```
set boxwidth {<width>} {absolute|relative}
show boxwidth
```
By default, adjacent boxes are extended in width until they touch each other. A different default width may be specified using the **set boxwidth** command. **Relative** widths are interpreted as being a fraction of this default width.
An explicit value for the boxwidth is interpreted as being a number of units along the current x axis (**absolute**) unless the modifier **relative** is given. If the x axis is a log-scale (see **[set log](set_show#set_log)**) then the value of boxwidth is truly "absolute" only at x=1; this physical width is maintained everywhere along the axis (i.e. the boxes do not become narrower the value of x increases). If the range spanned by a log scale x axis is far from x=1, some experimentation may be required to find a useful value of boxwidth.
The default is superseded by explicit width information taken from an extra data column in styles **boxes** or **boxerrorbars**. In a four-column data set, the fourth column will be interpreted as the box width unless the width is set to -2.0, in which case the width will be calculated automatically. See **[style boxes](boxes#style_boxes)** and **[style boxerrorbars](boxerrorbars#style_boxerrorbars)** for more details.
To set the box width to automatic use the command
```
set boxwidth
```
or, for four-column data,
```
set boxwidth -2
```
The same effect can be achieved with the **using** keyword in **plot**:
```
plot 'file' using 1:2:3:4:(-2)
```
To set the box width to half of the automatic size use
```
set boxwidth 0.5 relative
```
To set the box width to an absolute value of 2 use
```
set boxwidth 2 absolute
```
Boxdepth
--------
The **set boxdepth** command affects only 3D plots created by **splot with boxes**. It sets the extent of each box along the y axis, i.e. its thickness. Color
-----
Gnuplot supports two alternative sets of linetypes. The default set uses a different color for each linetype, although it also allows you to draw dotted or dashed lines in that color. The alternative monochrome set uses only dot/dash pattern or linewidth to distinguish linetypes. The **set color** command selects the color linetypes. See **[set monochrome](set_show#set_monochrome)**, **[set linetype](set_show#set_linetype)**, and **[set colorsequence](set_show#set_colorsequence)**. Colorsequence
-------------
Syntax:
```
set colorsequence {default|classic|podo}
```
**set colorsequence default** selects a terminal-independent repeating sequence of eight colors. See **[set linetype](set_show#set_linetype)**, **[colors](linetypes_colors_styles#colors)**.
**set colorsequence classic** lets each separate terminal type provide its own sequence of line colors. The number provided varies from 4 to more than 100, but most start with red/green/blue/magenta/cyan/yellow. This was the default behaviour prior to version 5.
**set colorsequence podo** selects eight colors drawn from a set recommended by Wong (2011) [Nature Methods 8:441] as being easily distinguished by color-blind viewers with either protanopia or deuteranopia.
In each case you can further customize the length of the sequence and the colors used. See **[set linetype](set_show#set_linetype)**, **[colors](linetypes_colors_styles#colors)**.
Clabel
------
This command is deprecated. Use **set cntrlabel** instead. **unset clabel** is replaced by **set cntrlabel onecolor**. **set clabel "format"** is replaced by **set cntrlabel format "format"**. Clip
----
Syntax:
```
set clip {points|one|two|radial}
unset clip {points|one|two|radial}
show clip
```
Default state:
```
unset clip points
set clip one
unset clip two
unset clip radial
```
Data points whose center lies inside the plot boundaries are normally drawn even if the finite size of the point symbol causes it to extend past a boundary line. **set clip points** causes such points to be clipped (i.e. not drawn) even though the point center is inside the boundaries of a 2D plot. Data points whose center lies outside the plot boundaries are never drawn.
**unset clip** causes a line segment in a plot not to be drawn if either end of that segment lies outside the plot boundaries (i.e. xrange and yrange).
**set clip one** causes **gnuplot** to draw the in-range portion of line segments with one endpoint in range and one endpoint out of range. **set clip two** causes **gnuplot** to draw the in-range portion of line segments with both endpoints out of range. Line segments that lie entirely outside the plot boundaries are never drawn.
**set clip radial** affects plotting only in polar mode. It clips lines against the radial bound established by **set rrange [0:MAX]**. This criteria is applied in conjunction with **set clip {one|two}**. I.e. the portion of a line between two points with R > RMAX that passes through the circle R = RMAX is drawn only if both **clip two** and **clip radial** are set.
Notes:
\* **set clip** affects only points and lines produced by plot styles **lines**, **linespoints**, **points**, **arrows**, and **vectors**.
\* Clipping of colored quadrangles drawn for pm3d surfaces and other solid objects is controlled **set pm3d clipping**. The default is smooth clipping against the current zrange.
\* Object clipping is controlled by the **clip** or **noclip** property of the individual object.
\* In the current version of gnuplot, "plot with vectors" in polar mode does not test or clip against the maximum radius.
Cntrlabel
---------
Syntax:
```
set cntrlabel {format "format"} {font "font"}
set cntrlabel {start <int>} {interval <int>}
set contrlabel onecolor
```
**set cntrlabel** controls the labeling of contours, either in the key (default) or on the plot itself in the case of **splot ... with labels**. In the latter case labels are placed along each contour line according to the **pointinterval** or **pointnumber** property of the label descriptor. By default a label is placed on the 5th line segment making up the contour line and repeated every 20th segment. These defaults are equivalent to
```
set cntrlabel start 5 interval 20
```
They can be changed either via the **set cntrlabel** command or by specifying the interval in the **splot** command itself
```
set contours; splot $FOO with labels point pointinterval -1
```
Setting the interval to a negative value means that the label appear only once per contour line. However if **set samples** or **set isosamples** is large then many contour lines may be created, each with a single label. A contour label is placed in the plot key for each linetype used. By default each contour level is given its own linetype, so a separate label appears for each. The command **set cntrlabel onecolor** causes all contours to be drawn using the same linetype, so only one label appears in the plot key. This command replaces an older command **unset clabel**.
Cntrparam
---------
**set cntrparam** controls the generation of contours and their smoothness for a contour plot. **show contour** displays current settings of **cntrparam** as well as **contour**. Syntax:
```
set cntrparam { { linear
| cubicspline
| bspline
| points <n>
| order <n>
| levels { <n>
| auto {<n>}
| discrete <z1> {,<z2>{,<z3>...}}
| incremental <start>, <incr> {,<end>}
}
{{un}sorted}
{firstlinetype N}
}
}
show contour
```
This command has two functions. First, it sets the values of z for which contours are to be determined. The number of contour levels <n> should be an integral constant expression. <z1>, <z2> ... are real-valued expressions. Second, it controls the appearance of the individual contour lines.
Keywords controlling the smoothness of contour lines:
**linear**, **cubicspline**, **bspline** — Controls type of approximation or interpolation. If **linear**, then straight line segments connect points of equal z magnitude. If **cubicspline**, then piecewise-linear contours are interpolated between the same equal z points to form somewhat smoother contours, but which may undulate. If **bspline**, a guaranteed-smoother curve is drawn, which only approximates the position of the points of equal-z.
**points** — Eventually all drawings are done with piecewise-linear strokes. This number controls the number of line segments used to approximate the **bspline** or **cubicspline** curve. Number of cubicspline or bspline segments (strokes) = **points** \* number of linear segments.
**order** — Order of the bspline approximation to be used. The bigger this order is, the smoother the resulting contour. (Of course, higher order bspline curves will move further away from the original piecewise linear data.) This option is relevant for **bspline** mode only. Allowed values are integers in the range from 2 (linear) to 10.
Keywords controlling the selection of contour levels:
**levels auto** — This is the default. <n> specifies a nominal number of levels; the actual number will be adjusted to give simple labels. If the surface is bounded by zmin and zmax, contours will be generated at integer multiples of dz between zmin and zmax, where dz is 1, 2, or 5 times some power of ten (like the step between two tic marks).
**levels discrete** — Contours will be generated at z = <z1>, <z2> ... as specified; the number of discrete levels sets the number of contour levels. In **discrete** mode, any **set cntrparam levels <n>** are ignored.
**levels incremental** — Contours are generated at values of z beginning at <start> and increasing by <increment>, until the number of contours is reached. <end> is used to determine the number of contour levels, which will be changed by any subsequent **set cntrparam levels <n>**. If the z axis is logarithmic, <increment> will be interpreted as a multiplicative factor, as it is for **set ztics**, and <end> should not be used.
Keywords controlling the assignment of linetype to contours:
By default the contours are generated in the reverse order specified (**unsorted**). Thus **set cntrparam levels increment 0, 10, 100** will create 11 contours levels starting with 100 and ending with 0. Adding the keyword **sorted** re-orders the contours by increasing numerical value, which in this case would mean the first contour is drawn at 0.
By default contours are drawn using successive linetypes starting with the next linetype after that used for the corresponding surface. Thus **splot x\*y lt 5** would use lt 6 for the first contour generated. If **hidden3d** mode is active then each surface uses two linetypes. In this case using default settings would cause the first contour to use the same linetype as the hidden surface, which is undesirable. This can be avoided in either of two ways. (1) Use **set hidden3d offset N** to change the linetype used for the hidden surface. A good choice would be **offset -1** since that will avoid all the contour linetypes. (2) Use the **set cntrparam firstlinetype N** option to specify a block of linetypes used for contour lines independent of whatever was used for the surface. This is particularly useful if you want to customize the set of contour linetypes. N <= 0 restores the default.
If the command **set cntrparam** is given without any arguments specified all options are reset to the default:
```
set cntrparam order 4 points 5
set cntrparam levels auto 5 unsorted
set cntrparam firstlinetype 0
```
### Examples
Examples:
```
set cntrparam bspline
set cntrparam points 7
set cntrparam order 10
```
To select levels automatically, 5 if the level increment criteria are met:
```
set cntrparam levels auto 5
```
To specify discrete levels at .1, .37, and .9:
```
set cntrparam levels discrete .1,1/exp(1),.9
```
To specify levels from 0 to 4 with increment 1:
```
set cntrparam levels incremental 0,1,4
```
To set the number of levels to 10 (changing an incremental end or possibly the number of auto levels):
```
set cntrparam levels 10
```
To set the start and increment while retaining the number of levels:
```
set cntrparam levels incremental 100,50
```
To define and use a customized block of contour linetypes
```
set linetype 100 lc "red" dt '....'
do for [L=101:199] {
if (L%10 == 0) {
set linetype L lc "black" dt solid lw 2
} else {
set linetype L lc "gray" dt solid lw 1
}
}
set cntrparam firstlinetype 100
set cntrparam sorted levels incremental 0, 1, 100
```
See also **[set contour](set_show#set_contour)** for control of where the contours are drawn, and **[set cntrlabel](set_show#set_cntrlabel)** for control of the format of the contour labels and linetypes.
See also [contours demo (contours.dem)](http://www.gnuplot.info/demo/contours.html)
and [contours with user defined levels demo (discrete.dem).](http://www.gnuplot.info/demo/discrete.html)
Color box
---------
The color scheme, i.e. the gradient of the smooth color with min\_z and max\_z values of **pm3d**'s **palette**, is drawn in a color box unless **unset colorbox**.
```
set colorbox
set colorbox {
{ vertical | horizontal } {{no}invert}
{ default | user }
{ origin x, y }
{ size x, y }
{ front | back }
{ noborder | bdefault | border [line style] }
}
show colorbox
unset colorbox
```
Color box position can be **default** or **user**. If the latter is specified the values as given with the **origin** and **size** subcommands are used. The box can be drawn after (**front**) or before (**back**) the graph or the surface.
The orientation of the color gradient can be switched by options **vertical** and **horizontal**.
**origin x, y** and **size x, y** are used only in combination with the **user** option. The x and y values are interpreted as screen coordinates by default, and this is the only legal option for 3D plots. 2D plots, including splot with **set view map**, allow any coordinate system to be specified. Try for example:
```
set colorbox horiz user origin .1,.02 size .8,.04
```
which will draw a horizontal gradient somewhere at the bottom of the graph. **border** turns the border on (this is the default). **noborder** turns the border off. If an positive integer argument is given after **border**, it is used as a line style tag which is used for drawing the border, e.g.:
```
set style line 2604 linetype -1 linewidth .4
set colorbox border 2604
```
will use line style **2604**, a thin line with the default border color (-1) for drawing the border. **bdefault** (which is the default) will use the default border line style for drawing the border of the color box. The axis of the color box is called **cb** and it is controlled by means of the usual axes commands, i.e. **set/unset/show** with **cbrange**, **[m]cbtics**, **format cb**, **grid [m]cb**, **cblabel**, and perhaps even **cbdata**, **[no]cbdtics**, **[no]cbmtics**.
**set colorbox** without any parameter switches the position to default. **unset colorbox** resets the default parameters for the colorbox and switches the colorbox off.
See also help for **[set pm3d](set_show#set_pm3d)**, **[set palette](set_show#set_palette)**, **[x11 pm3d](complete_list_terminals#x11_pm3d)**, and **[set style line](set_show#set_style_line)**.
Colornames
----------
Gnuplot knows a limited number of color names. You can use these to define the color range spanned by a pm3d palette, or to assign a terminal-independent color to a particular linetype or linestyle. To see the list of known color names, use the command **[show colornames](set_show#show_colornames)**. Example:
```
set style line 1 linecolor "sea-green"
```
Contour
-------
**set contour** enables contour drawing for surfaces. This option is available for **splot** only. It requires grid data, see **[grid\_data](splot#grid_data)** for more details. If contours are desired from non-grid data, **set dgrid3d** can be used to create an appropriate grid. Syntax:
```
set contour {base | surface | both}
unset contour
show contour
```
The three options specify where to draw the contours: **base** draws the contours on the grid base where the x/ytics are placed, **surface** draws the contours on the surfaces themselves, and **both** draws the contours on both the base and the surface. If no option is provided, the default is **base**.
See also **[set cntrparam](set_show#set_cntrparam)** for the parameters that affect the drawing of contours, and **[set cntrlabel](set_show#set_cntrlabel)** for control of labeling of the contours.
The surface can be switched off (see **[unset surface](set_show#unset_surface)**), giving a contour-only graph. Though it is possible to use **set size** to enlarge the plot to fill the screen, more control over the output format can be obtained by writing the contour information to a datablock, and rereading it as a 2D datafile plot:
```
unset surface
set contour
set cntrparam ...
set table $datablock
splot ...
unset table
# contour info now in $datablock
set term <whatever>
plot $datablock
```
In order to draw contours, the data should be organized as "grid data". In such a file all the points for a single y-isoline are listed, then all the points for the next y-isoline, and so on. A single blank line (a line containing no characters other than blank spaces and a carriage return and/or a line feed) separates one y-isoline from the next.
While **set contour** is in effect, **splot with <style>** will place the style elements (points, lines, impulses, labels, etc) along the contour lines. **with pm3d** will produce a pm3d surface and also contour lines. If you want to mix other plot elements, say labels read from a file, with the contours generated while **set contour** is active you must append the keyword **nocontours** after that clause in the splot command.
See also **[splot datafile](splot#splot_datafile)**.
See also [contours demo (contours.dem)](http://www.gnuplot.info/demo/contours.html)
and [contours with user defined levels demo (discrete.dem).](http://www.gnuplot.info/demo/discrete.html)
Dashtype
--------
The **set dashtype** command allows you to define a dash pattern that can then be referred to by its index. This is purely a convenience, as anywhere that would accept the dashtype by its numerical index would also accept an explicit dash pattern. Example:
```
set dashtype 5 (2,4,2,6) # define or redefine dashtype number 5
plot f1(x) dt 5 # plot using the new dashtype
plot f1(x) dt (2,4,2,6) # exactly the same plot as above
set linetype 5 dt 5 # always use this dash pattern with linetype 5
set dashtype 66 "..-" # define a new dashtype using a string
```
See also **[dashtype](linetypes_colors_styles#dashtype)**. Data style
----------
This form of the command is deprecated. Please see **[set style data](set_show#set_style_data)**. Datafile
--------
The **set datafile** command options control interpretation of fields read from input data files by the **plot**, **splot**, and **fit** commands. Several options are currently implemented. ### Set datafile columnheaders
The **set datafile columnheaders** command guarantees that the first row of input will be interpreted as column headers rather than as data values. It affects all input data sources to plot, splot, fit, and stats commands. If this setting is disabled by **unset datafile columnheaders**, the same effect is triggered on a per-file basis if there is an explicit columnheader() function in a using specifier or plot title associated with that file. See also **[set key autotitle](set_show#set_key_autotitle)** and **[columnheader](plot#columnheader)**. ### Set datafile fortran
The **set datafile fortran** command enables a special check for values in the input file expressed as Fortran D or Q constants. This extra check slows down the input process, and should only be selected if you do in fact have datafiles containing Fortran D or Q constants. The option can be disabled again using **unset datafile fortran**. ### Set datafile nofpe\_trap
The **set datafile nofpe\_trap** command tells gnuplot not to re-initialize a floating point exception handler before every expression evaluation used while reading data from an input file. This can significantly speed data input from very large files at the risk of program termination if a floating-point exception is generated. ### Set datafile missing
Syntax:
```
set datafile missing "<string>"
set datafile missing NaN
show datafile missing
unset datafile
```
The **set datafile missing** command tells **gnuplot** there is a special string used in input data files to denote a missing data entry. There is no default character for **missing**. Gnuplot makes a distinction between missing data and invalid data (e.g. "NaN", 1/0.). For example invalid data causes a gap in a line drawn through sequential data points; missing data does not.
Non-numeric characters found in a numeric field will usually be interpreted as invalid rather than as a missing data point unless they happen to match the **missing** string.
Conversely **set datafile missing NaN** causes all data or expressions evaluating to not-a-number (NaN) to be treated as missing data.
The example below shows differences between gnuplot version 4 and version 5. Example:
```
set style data linespoints
plot '-' title "(a)"
1 10
2 20
3 ?
4 40
5 50
e
set datafile missing "?"
plot '-' title "(b)"
1 10
2 20
3 ?
4 40
5 50
e
plot '-' using 1:2 title "(c)"
1 10
2 20
3 NaN
4 40
5 50
e
plot '-' using 1:($2) title "(d)"
1 10
2 20
3 NaN
4 40
5 50
e
```
Plot (a) differs in gnuplot 4 and gnuplot 5 because the third line contains only one valid number. Version 4 switched to a single-datum-on-a-line convention that the line number is "x" and the datum is "y", erroneously placing the point at(2,3).
Both the old and new gnuplot versions handle the same data correctly if the '?' character is designated as a marker for missing data (b).
Old gnuplot versions handled NaN differently depending of the form of the **using** clause, as shown in plots (c) and (d). Gnuplot now handles NaN the same whether the input column was specified as N or ($N). See also the [imageNaN demo.](http://www.gnuplot.info/demo/mgr.html)
Similarly gnuplot 5.4 will notice the missing value flag in column N whether the plot command specifies **using N** or **using ($N)** or **using (func($N))**. However if the "missing" value is encountered during evaluation of some more complicated expression, e.g. **using (column(strcol(1))**, it may evaluate to NaN and be treated as invalid data rather than as a missing data point. If you nevertheless want to treat this as missing data, use the command **set datafile missing NaN**.
### Set datafile separator
The command **set datafile separator** tells **gnuplot** that data fields in subsequent input files are separated by a specific character rather than by whitespace. The most common use is to read in csv (comma-separated value) files written by spreadsheet or database programs. By default data fields are separated by whitespace. Syntax:
```
set datafile separator {whitespace | tab | comma | "<chars>"}
```
Examples:
```
# Input file contains tab-separated fields
set datafile separator "\t"
```
```
# Input file contains comma-separated values fields
set datafile separator comma
```
```
# Input file contains fields separated by either * or |
set datafile separator "*|"
```
### Set datafile commentschars
The command **set datafile commentschars** specifies what characters can be used in a data file to begin comment lines. If the first non-blank character on a line is one of these characters then the rest of the data line is ignored. Default value of the string is "#!" on VMS and "#" otherwise. Syntax:
```
set datafile commentschars {"<string>"}
show datafile commentschars
unset commentschars
```
Then, the following line in a data file is completely ignored
```
# 1 2 3 4
```
but the following
```
1 # 3 4
```
will be interpreted as garbage in the 2nd column followed by valid data in the 3rd and 4th columns. Example:
```
set datafile commentschars "#!%"
```
### Set datafile binary
The **set datafile binary** command is used to set the defaults when reading binary data files. The syntax matches precisely that used for commands **plot** and **splot**. See **[binary matrix](splot#binary_matrix)** and **[binary general](plot#binary_general)** for details about the keywords that can be present in <binary list>. Syntax:
```
set datafile binary <binary list>
show datafile binary
show datafile
unset datafile
```
Examples:
```
set datafile binary filetype=auto
set datafile binary array=(512,512) format="%uchar"
```
```
show datafile binary # list current settings
```
Decimalsign
-----------
The **set decimalsign** command selects a decimal sign for numbers printed into tic labels or **set label** strings. Syntax:
```
set decimalsign {<value> | locale {"<locale>"}}
unset decimalsign
show decimalsign
```
The argument <value> is a string to be used in place of the usual decimal point. Typical choices include the period, '.', and the comma, ',', but others may be useful, too. If you omit the <value> argument, the decimal separator is not modified from the usual default, which is a period. Unsetting decimalsign has the same effect as omitting <value>.
Example:
Correct typesetting in most European countries requires:
```
set decimalsign ','
```
Please note: If you set an explicit string, this affects only numbers that are printed using gnuplot's gprintf() formatting routine, including axis tics. It does not affect the format expected for input data, and it does not affect numbers printed with the sprintf() formatting routine. To change the behavior of both input and output formatting, instead use the form
```
set decimalsign locale
```
This instructs the program to use both input and output formats in accordance with the current setting of the LC\_ALL, LC\_NUMERIC, or LANG environmental variables.
```
set decimalsign locale "foo"
```
This instructs the program to format all input and output in accordance with locale "foo", which must be installed. If locale "foo" is not found then an error message is printed and the decimal sign setting is unchanged. On linux systems you can get a list of the locales installed on your machine by typing "locale -a". A typical linux locale string is of the form "sl\_SI.UTF-8". A typical Windows locale string is of the form "Slovenian\_Slovenia.1250" or "slovenian". Please note that interpretation of the locale settings is done by the C library at runtime. Older C libraries may offer only partial support for locale settings such as the thousands grouping separator character.
```
set decimalsign locale; set decimalsign "."
```
This sets all input and output to use whatever decimal sign is correct for the current locale, but over-rides this with an explicit '.' in numbers formatted using gnuplot's internal gprintf() function.
Dgrid3d
-------
The **set dgrid3d** command enables, and can set parameters for, non-grid to grid data mapping. See **[splot grid\_data](splot#splot_grid_data)** for more details about the grid data structure. Syntax:
```
set dgrid3d {<rows>} {,{<cols>}}
{ splines |
qnorm {<norm>} |
(gauss | cauchy | exp | box | hann)
{kdensity} {<dx>} {,<dy>} }
unset dgrid3d
show dgrid3d
```
By default **dgrid3d** is disabled. When enabled, 3D data read from a file are always treated as a scattered data set. A grid with dimensions derived from a bounding box of the scattered data and size as specified by the row/col\_size parameters is created for plotting and contouring. The grid is equally spaced in x (rows) and in y (columns); the z values are computed as weighted averages or spline interpolations of the scattered points' z values. In other words, a regularly spaced grid is created and the a smooth approximation to the raw data is evaluated for all grid points. This approximation is plotted in place of the raw data.
The number of columns defaults to the number of rows, which defaults to 10.
Several algorithms are available to calculate the approximation from the raw data. Some of these algorithms can take additional parameters. These interpolations are such the closer the data point is to a grid point, the more effect it has on that grid point.
The **splines** algorithm calculates an interpolation based on "thin plate splines". It does not take additional parameters.
The **qnorm** algorithm calculates a weighted average of the input data at each grid point. Each data point is weighted by the inverse of its distance from the grid point raised to some power. The power is specified as an optional integer parameter that defaults to 1. This algorithm is the default.
Finally, several smoothing kernels are available to calculate weighted averages: z = Sum\_i w(d\_i) \* z\_i / Sum\_i w(d\_i), where z\_i is the value of the i-th data point and d\_i is the distance between the current grid point and the location of the i-th data point. All kernels assign higher weights to data points that are close to the current grid point and lower weights to data points further away.
The following kernels are available:
```
gauss : w(d) = exp(-d*d)
cauchy : w(d) = 1/(1 + d*d)
exp : w(d) = exp(-d)
box : w(d) = 1 if d<1
= 0 otherwise
hann : w(d) = 0.5*(1+cos(pi*d)) if d<1
w(d) = 0 otherwise
```
When using one of these five smoothing kernels, up to two additional numerical parameters can be specified: dx and dy. These are used to rescale the coordinate differences when calculating the distance: d\_i = sqrt( ((x-x\_i)/dx)\*\*2 + ((y-y\_i)/dy)\*\*2 ), where x,y are the coordinates of the current grid point and x\_i,y\_i are the coordinates of the i-th data point. The value of dy defaults to the value of dx, which defaults to 1. The parameters dx and dy make it possible to control the radius over which data points contribute to a grid point IN THE UNITS OF THE DATA ITSELF.
The optional keyword **kdensity**, which must come after the name of the kernel, but before the (optional) scale parameters, modifies the algorithm so that the values calculated for the grid points are not divided by the sum of the weights ( z = Sum\_i w(d\_i) \* z\_i ). If all z\_i are constant, this effectively plots a bivariate kernel density estimate: a kernel function (one of the five defined above) is placed at each data point, the sum of these kernels is evaluated at every grid point, and this smooth surface is plotted instead of the original data. This is similar in principle to + what the **smooth kdensity** option does to 1D datasets. (See kdensity2d.dem for usage demo)
A slightly different syntax is also supported for reasons of backwards compatibility. If no interpolation algorithm has been explicitly selected, the **qnorm** algorithm is assumed. Up to three comma-separated, optional parameters can be specified, which are interpreted as the the number of rows, the number of columns, and the norm value, respectively.
The **dgrid3d** option is a simple scheme which replaces scattered data with weighted averages on a regular grid. More sophisticated approaches to this problem exist and should be used to preprocess the data outside **gnuplot** if this simple solution is found inadequate.
See also [dgrid3d.dem: dgrid3d demo.](http://www.gnuplot.info/demo/dgrid3d.html)
and [scatter.dem: dgrid3d demo.](http://www.gnuplot.info/demo/scatter.html)
Dummy
-----
The **set dummy** command changes the default dummy variable names. Syntax:
```
set dummy {<dummy-var>} {,<dummy-var>}
show dummy
```
By default, **gnuplot** assumes that the independent, or "dummy", variable for the **plot** command is "t" if in parametric or polar mode, or "x" otherwise. Similarly the independent variables for the **splot** command are "u" and "v" in parametric mode (**splot** cannot be used in polar mode), or "x" and "y" otherwise.
It may be more convenient to call a dummy variable by a more physically meaningful or conventional name. For example, when plotting time functions:
```
set dummy t
plot sin(t), cos(t)
```
Examples:
```
set dummy u,v
set dummy ,s
```
The second example sets the second variable to s. To reset the dummy variable names to their default values, use
```
unset dummy
```
Encoding
--------
The **set encoding** command selects a character encoding. Syntax:
```
set encoding {<value>}
set encoding locale
show encoding
```
Valid values are
```
default - tells a terminal to use its default encoding
iso_8859_1 - the most common Western European encoding prior to UTF-8.
Known in the PostScript world as 'ISO-Latin1'.
iso_8859_15 - a variant of iso_8859_1 that includes the Euro symbol
iso_8859_2 - used in Central and Eastern Europe
iso_8859_9 - used in Turkey (also known as Latin5)
koi8r - popular Unix cyrillic encoding
koi8u - Ukrainian Unix cyrillic encoding
cp437 - codepage for MS-DOS
cp850 - codepage for OS/2, Western Europe
cp852 - codepage for OS/2, Central and Eastern Europe
cp950 - MS version of Big5 (emf terminal only)
cp1250 - codepage for MS Windows, Central and Eastern Europe
cp1251 - codepage for 8-bit Russian, Serbian, Bulgarian, Macedonian
cp1252 - codepage for MS Windows, Western Europe
cp1254 - codepage for MS Windows, Turkish (superset of Latin5)
sjis - shift-JIS Japanese encoding
utf8 - variable-length (multibyte) representation of Unicode
entry point for each character
```
The command **set encoding locale** is different from the other options. It attempts to determine the current locale from the runtime environment. On most systems this is controlled by the environmental variables LC\_ALL, LC\_CTYPE, or LANG. This mechanism is necessary, for example, to pass multibyte character encodings such as UTF-8 or EUC\_JP to the wxt and pdf terminals. This command does not affect the locale-specific representation of dates or numbers. See also **[set locale](set_show#set_locale)** and **[set decimalsign](set_show#set_decimalsign)**.
Generally you must set the encoding before setting the terminal type, as it may affect the choice of appropriate fonts.
Errorbars
---------
The **set errorbars** command controls the tics at the ends of error bars, and also at the end of the whiskers belonging to a boxplot. Syntax:
```
set errorbars {small | large | fullwidth | <size>} {front | back}
{line-properties}
unset errorbars
show errorbars
```
**small** is a synonym for 0.0 (no crossbar), and **large** for 1.0. The default is 1.0 if no size is given.
The keyword **fullwidth** is relevant only to boxplots and to histograms with errorbars. It sets the width of the errorbar ends to be the same as the width of the associated box. It does not change the width of the box itself.
The **front** and **back** keywords are relevant only to errorbars attached to filled rectangles (boxes, candlesticks, histograms).
Error bars are by default drawn using the same line properties as the border of the associated box. You can change this by providing a separate set of line properties for the error bars.
```
set errorbars linecolor black linewidth 0.5 dashtype '.'
```
Fit
---
The **set fit** command controls the options for the **fit** command. Syntax:
```
set fit {nolog | logfile {"<filename>"|default}}
{{no}quiet|results|brief|verbose}
{{no}errorvariables}
{{no}covariancevariables}
{{no}errorscaling}
{{no}prescale}
{maxiter <value>|default}
{limit <epsilon>|default}
{limit_abs <epsilon_abs>}
{start-lambda <value>|default}
{lambda-factor <value>|default}
{script {"<command>"|default}}
{v4 | v5}
unset fit
show fit
```
The **logfile** option defines where the **fit** command writes its output. The <filename> argument must be enclosed in single or double quotes. If no filename is given or **unset fit** is used the log file is reset to its default value "fit.log" or the value of the environmental variable **FIT\_LOG**. If the given logfile name ends with a / or \, it is interpreted to be a directory name, and the actual filename will be "fit.log" in that directory.
By default the information written to the log file is also echoed to the terminal session. **set fit quiet** turns off the echo, whereas **results** prints only final results. **brief** gives one line summaries for every iteration of the fit in addition. **verbose** yields detailed iteration reports as in version 4.
If the **errorvariables** option is turned on, the error of each fitted parameter computed by **fit** will be copied to a user-defined variable whose name is formed by appending "\_err" to the name of the parameter itself. This is useful mainly to put the parameter and its error onto a plot of the data and the fitted function, for reference, as in:
```
set fit errorvariables
fit f(x) 'datafile' using 1:2 via a, b
print "error of a is:", a_err
set label 1 sprintf("a=%6.2f +/- %6.2f", a, a_err)
plot 'datafile' using 1:2, f(x)
```
If the **errorscaling** option is specified, which is the default, the calculated parameter errors are scaled with the reduced chi square. This is equivalent to providing data errors equal to the calculated standard deviation of the fit (FIT\_STDFIT) resulting in a reduced chi square of one. With the **noerrorscaling** option the estimated errors are the unscaled standard deviations of the fit parameters. If no weights are specified for the data, parameter errors are always scaled.
If the **prescale** option is turned on, parameters are prescaled by their initial values before being passed to the Marquardt-Levenberg routine. This helps tremendously if there are parameters that differ in size by many orders of magnitude. Fit parameters with an initial value of exactly zero are never prescaled.
The maximum number of iterations may be limited with the **maxiter** option. A value of 0 or **default** means that there is no limit.
The **limit** option can be used to change the default epsilon limit (1e-5) to detect convergence. When the sum of squared residuals changes by a factor less than this number (epsilon), the fit is considered to have 'converged'. The **limit\_abs** option imposes an additional absolute limit in the change of the sum of squared residuals and defaults to zero.
If you need even more control about the algorithm, and know the Marquardt-Levenberg algorithm well, the following options can be used to influence it. The startup value of **lambda** is normally calculated automatically from the ML-matrix, but if you want to, you may provide your own using the **start\_lambda** option. Setting it to **default** will re-enable the automatic selection. The option **lambda\_factor** sets the factor by which **lambda** is increased or decreased whenever the chi-squared target function increased or decreased significantly. Setting it to **default** re-enables the default factor of 10.0.
The **script** option may be used to specify a **gnuplot** command to be executed when a fit is interrupted — see **[fit](fit#fit)**. This setting takes precedence over the default of **replot** and the environment variable **FIT\_SCRIPT**.
If the **covariancevariables** option is turned on, the covariances between final parameters will be saved to user-defined variables. The variable name for a certain parameter combination is formed by prepending "FIT\_COV\_" to the name of the first parameter and combining the two parameter names by "\_". For example given the parameters "a" and "b" the covariance variable is named "FIT\_COV\_a\_b".
In version 5 the syntax of the fit command changed and it now defaults to unitweights if no 'error' keyword is given. The **v4** option restores the default behavior of gnuplot version 4, see also **[fit](fit#fit)**.
Fontpath
--------
Syntax:
```
set fontpath "/directory/where/my/fonts/live"
set term postscript fontfile <filename>
```
[DEPRECATED in version 5.4]
The **fontpath** directory is relevant only for embedding fonts in postscript output produced by the postscript terminal. It has no effect on other gnuplot terminals. If you are not embedding fonts you do not need this command, and even if you are embedding fonts you only need it for fonts that cannot be found via the other paths below.
Earlier versions of gnuplot tried to emulate a font manager by tracking multiple directory trees containing fonts. This is now replaced by a search in the following places: (1) an absolute path given in the **set term postscript fontfile** command (2) the current directory (3) any of the directories specified by **set loadpath** (4) the directory specified by **set fontpath** (5) the directory provided in environmental variable GNUPLOT\_FONTPATH
Note: The search path for fonts specified by filename for the libgd terminals (png gif jpeg sixel) is controlled by environmental variable GDFONTPATH.
Format
------
The format of the tic-mark labels can be set with the **set format** command or with the **set tics format** or individual **set {axis}tics format** commands. Syntax:
```
set format {<axes>} {"<format-string>"} {numeric|timedate|geographic}
show format
```
where <axes> is either **x**, **y**, **xy**, **x2**, **y2**, **z**, **cb** or nothing (which applies the format to all axes). The following two commands are equivalent:
```
set format y "%.2f"
set ytics format "%.2f"
```
The length of the string is restricted to 100 characters. The default format is "% h", "$%h$" for LaTeX terminals. Other formats such as "%.2f" or "%3.0em" are often desirable. "set format" with no following string will restore the default.
If the empty string "" is given, tics will have no labels, although the tic mark will still be plotted. To eliminate the tic marks, use **unset xtics** or **set tics scale 0**.
Newline ( \n) and enhanced text markup is accepted in the format string. Use double-quotes rather than single-quotes in this case. See also **[syntax](syntax#syntax)**. Characters not preceded by "%" are printed verbatim. Thus you can include spaces and labels in your format string, such as "%g m", which will put " m" after each number. If you want "%" itself, double it: "%g %%".
See also **[set xtics](set_show#set_xtics)** for more information about tic labels, and **[set decimalsign](set_show#set_decimalsign)** for how to use non-default decimal separators in numbers printed this way. See also [electron demo (electron.dem).](http://www.gnuplot.info/demo/electron.html)
### Gprintf
The string function gprintf("format",x) uses gnuplot's own format specifiers, as do the gnuplot commands **set format**, **set timestamp**, and others. These format specifiers are not the same as those used by the standard C-language routine sprintf(). gprintf() accepts only a single variable to be formatted. Gnuplot also provides an sprintf("format",x1,x2,...) routine if you prefer. For a list of gnuplot's format options, see **[format specifiers](set_show#format_specifiers)**. ### Format specifiers
The acceptable formats (if not in time/date mode) are:
| |
| --- |
| Tic-mark label numerical format specifiers |
| Format | Explanation |
| `%f` | floating point notation |
| `%e` or `%E` | exponential notation; an "e" or "E" before the power |
| `%g` or `%G` | the shorter of `%e` (or `%E`) and `%f` |
| `%h` or `%H` | like `%g with "x10^{%S}" or "*10^{%S}" instead of "e%S"` |
| `%x` or `%X` | hex |
| `%o` or `%O` | octal |
| `%t` | mantissa to base 10 |
| `%l` | mantissa to base of current logscale |
| `%s` | mantissa to base of current logscale; scientific power |
| `%T` | power to base 10 |
| `%L` | power to base of current logscale |
| `%S` | scientific power |
| `%c` | character replacement for scientific power |
| `%b` | mantissa of ISO/IEC 80000 notation (ki, Mi, Gi, Ti, Pi, Ei, Zi, Yi) |
| `%B` | prefix of ISO/IEC 80000 notation (ki, Mi, Gi, Ti, Pi, Ei, Zi, Yi) |
| `%P` | multiple of pi |
A 'scientific' power is one such that the exponent is a multiple of three. Character replacement of scientific powers (**"%c"**) has been implemented for powers in the range -18 to +18. For numbers outside of this range the format reverts to exponential.
Other acceptable modifiers (which come after the "%" but before the format specifier) are "-", which left-justifies the number; "+", which forces all numbers to be explicitly signed; " " (a space), which makes positive numbers have a space in front of them where negative numbers have "-"; "#", which places a decimal point after floats that have only zeroes following the decimal point; a positive integer, which defines the field width; "0" (the digit, not the letter) immediately preceding the field width, which indicates that leading zeroes are to be used instead of leading blanks; and a decimal point followed by a non-negative integer, which defines the precision (the minimum number of digits of an integer, or the number of digits following the decimal point of a float).
Some systems may not support all of these modifiers but may also support others; in case of doubt, check the appropriate documentation and then experiment.
Examples:
```
set format y "%t"; set ytics (5,10) # "5.0" and "1.0"
set format y "%s"; set ytics (500,1000) # "500" and "1.0"
set format y "%+-12.3f"; set ytics(12345) # "+12345.000 "
set format y "%.2t*10^%+03T"; set ytic(12345)# "1.23*10^+04"
set format y "%s*10^{%S}"; set ytic(12345) # "12.345*10^{3}"
set format y "%s %cg"; set ytic(12345) # "12.345 kg"
set format y "%.0P pi"; set ytic(6.283185) # "2 pi"
set format y "%.0f%%"; set ytic(50) # "50%"
```
```
set log y 2; set format y '%l'; set ytics (1,2,3)
#displays "1.0", "1.0" and "1.5" (since 3 is 1.5 * 2^1)
```
There are some problem cases that arise when numbers like 9.999 are printed with a format that requires both rounding and a power.
If the data type for the axis is time/date, the format string must contain valid codes for the 'strftime' function (outside of **gnuplot**, type "man strftime"). See **[set timefmt](set_show#set_timefmt)** for a list of the allowed input format codes.
### Time/date specifiers
There are two groups of time format specifiers: time/date and relative time. These may be used to generate axis tic labels or to encode time in a string. See **[set xtics time](set_show#set_xtics_time)**, **[strftime](expressions#strftime)**, **[strptime](expressions#strptime)**. The time/date formats are
| |
| --- |
| Date Specifiers |
| Format | Explanation |
| `%a` | abbreviated name of day of the week |
| `%A` | full name of day of the week |
| `%b` or `%h` | abbreviated name of the month |
| `%B` | full name of the month |
| `%d` | day of the month, 01–31 |
| `%D` | shorthand for `"%m/%d/%y"` (only output) |
| `%F` | shorthand for `"%Y-%m-%d"` (only output) |
| `%k` | hour, 0–23 (one or two digits) |
| `%H` | hour, 00–23 (always two digits) |
| `%l` | hour, 1–12 (one or two digits) |
| `%I` | hour, 01–12 (always two digits) |
| `%j` | day of the year, 001–366 |
| `%m` | month, 01–12 |
| `%M` | minute, 00–60 |
| `%p` | "am" or "pm" |
| `%r` | shorthand for `"%I:%M:%S %p"` (only output) |
| `%R` | shorthand for `%H:%M"` (only output) |
| `%S` | second, integer 00–60 on output, (double) on input |
| `%s` | number of seconds since start of year 1970 |
| `%T` | shorthand for `"%H:%M:%S"` (only output) |
| `%U` | week of the year (CDC/MMWR "epi week") (ignored on input) |
| `%w` | day of the week, 0–6 (Sunday = 0) |
| `%W` | week of the year (ISO 8601 week date) (ignored on input) |
| `%y` | year, 0-99 in range 1969-2068 |
| `%Y` | year, 4-digit |
| `%z` | timezone, [+-]hh:mm |
| `%Z` | timezone name, ignored string |
For more information on the %W format (ISO week of year) see **[tm\_week](set_show#tm_week)**. The %U format (CDC/MMWR epidemiological week) is similar to %W except that it uses weeks that start on Sunday rather than Monday. Caveat: Both the %W and the %U formats were unreliable in gnuplot versions prior to 5.4.2. See unit test "week\_date.dem".
The relative time formats express the length of a time interval on either side of a zero time point. The relative time formats are
| |
| --- |
| Time Specifiers |
| Format | Explanation |
| `%tD` | +/- days relative to time=0 |
| `%tH` | +/- hours relative to time=0 (does not wrap at 24) |
| `%tM` | +/- minutes relative to time=0 |
| `%tS` | +/- seconds associated with previous tH or tM field |
Numerical formats may be preceded by a "0" ("zero") to pad the field with leading zeroes, and preceded by a positive digit to define the minimum field width. The %S, and %t formats also accept a precision specifier so that fractional hours/minutes/seconds can be written.
#### Examples
Examples of date format:
Suppose the x value in seconds corresponds a time slightly before midnight on 25 Dec 1976. The text printed for a tic label at this position would be
```
set format x # defaults to "12/25/76 \n 23:11"
set format x "%A, %d %b %Y" # "Saturday, 25 Dec 1976"
set format x "%r %D" # "11:11:11 pm 12/25/76"
```
Examples of time format:
The date format specifiers encode a time in seconds as a clock time on a particular day. So hours run only from 0-23, minutes from 0-59, and negative values correspond to dates prior to the epoch (1-Jan-1970). In order to report a time value in seconds as some number of hours/minutes/seconds relative to a time 0, use time formats %tH %tM %tS. To report a value of -3672.50 seconds
```
set format x # default date format "12/31/69 \n 22:58"
set format x "%tH:%tM:%tS" # "-01:01:12"
set format x "%.2tH hours" # "-1.02 hours"
set format x "%tM:%.2tS" # "-61:12.50"
```
### Tm\_week
The **tm\_week(t, standard)** function interprets its first argument t as a time in seconds from 1 Jan 1970. Despite the name of this function it does not report a field from the POSIX tm structure. If standard = 0 it returns the week number in the ISO 8601 "week date" system. This corresponds to gnuplot's %W time format. If standard = 1 it returns the CDC epidemiological week number ("epi week"). This corresponds to gnuplot's %U time format. For corresponding inverse functions that convert week dates to calendar time see **[weekdate\_iso](set_show#weekdate_iso)**, **[weekdate\_cdc](set_show#weekdate_cdc)**.
In brief, ISO Week 1 of year YYYY begins on the Monday closest to 1 Jan YYYY. This may place it in the previous calendar year. For example Tue 30 Dec 2008 has ISO week date 2009-W01-2 (2nd day of week 1 of 2009). Up to three days at the start of January may come before the Monday of ISO week 1; these days are assigned to the final week of the previous calendar year. E.g. Fri 1 Jan 2021 has ISO week date 2020-W53-05.
The US Center for Disease Control (CDC) epidemiological week is a similar week date convention that differs from the ISO standard by defining a week as starting on Sunday, rather than on Monday.
### Weekdate\_iso
Syntax:
```
time = weekdate_iso( year, week [, day] )
```
This function converts from the year, week, day components of a date in ISO 8601 "week date" format to the calendar date as a time in seconds since the epoch date 1 Jan 1970. Note that the nominal year in the week date system is not necessarily the same as the calendar year. The week is an integer from 1 to 53. The day parameter is optional. If it is omitted or equal to 0 the time returned is the start of the week. Otherwise day is an integer from 1 (Monday) to 2 (Sunday). See **[tm\_week](set_show#tm_week)** for additional information on an inverse function that converts from calendar date to week number in the ISO standard convention.
Example:
```
# Plot data from a file with column 1 containing ISO weeks
# Week cases deaths
# 2020-05 432 1
calendar_date(w) = weekdate_iso( int(w[1:4]), int(w[6:7]) )
set xtics time format "%b\n%Y"
plot FILE using (calendar_date(strcol(1))) : 2 title columnhead
```
### Weekdate\_cdc
Syntax:
```
time = weekdate_cdc( year, week [, day] )
```
This function converts from the year, week, day components of a date in the CDC/MMWR "epi week" format to the calendar date as a time in seconds since the epoch date 1 Jan 1970. The CDC week date convention differs from the ISO week date in that it is defined in terms of each week running from day 1 = Sunday to day 6 = Saturday. If the third parameter is 0 or is omitted, the time returned is the start of the week. See **[tm\_week](set_show#tm_week)** and **[weekdate\_iso](set_show#weekdate_iso)**.
Function style
--------------
This form of the command is deprecated. Please use **set style function**. Functions
---------
The **show functions** command lists all user-defined functions and their definitions. Syntax:
```
show functions
```
For information about the definition and usage of functions in **gnuplot**, please see **[expressions](expressions#expressions)**. See also [splines as user defined functions (spline.dem)](http://www.gnuplot.info/demo/spline.html)
and [use of functions and complex variables for airfoils (airfoil.dem).](http://www.gnuplot.info/demo/airfoil.html)
Grid
----
The **set grid** command allows grid lines to be drawn on the plot. Syntax:
```
set grid {{no}{m}xtics} {{no}{m}ytics} {{no}{m}ztics}
{{no}{m}x2tics} {{no}{m}y2tics} {{no}{m}rtics}
{{no}{m}cbtics}
{polar {<angle>}}
{layerdefault | front | back}
{{no}vertical}
{<line-properties-major> {, <line-properties-minor>}}
unset grid
show grid
```
The grid can be enabled and disabled for the major and/or minor tic marks on any axis, and the linetype and linewidth can be specified for major and minor grid lines, also via a predefined linestyle, as far as the active terminal driver supports this (see **[set style line](set_show#set_style_line)**).
A polar grid can be drawn for 2D plots. This is the default action of **set grid** if the program is already in polar mode, but can be enabled explicitly by **set grid polar <angle> rtics** whether or not the program is in polar mode. Circles are drawn to intersect major and/or minor tics along the r axis, and radial lines are drawn with a spacing of <angle>. Tic marks around the perimeter are controlled by **set ttics**, but these do not produce radial grid lines.
The pertinent tics must be enabled before **set grid** can draw them; **gnuplot** will quietly ignore instructions to draw grid lines at non-existent tics, but they will appear if the tics are subsequently enabled.
If no linetype is specified for the minor gridlines, the same linetype as the major gridlines is used. The default polar angle is 30 degrees.
If **front** is given, the grid is drawn on top of the graphed data. If **back** is given, the grid is drawn underneath the graphed data. Using **front** will prevent the grid from being obscured by dense data. The default setup, **layerdefault**, is equivalent to **back** for 2D plots. In 3D plots the default is to split up the grid and the graph box into two layers: one behind, the other in front of the plotted data and functions. Since **hidden3d** mode does its own sorting, it ignores all grid drawing order options and passes the grid lines through the hidden line removal machinery instead. These options actually affect not only the grid, but also the lines output by **set border** and the various ticmarks (see **[set xtics](set_show#set_xtics)**).
In 3D plots grid lines at x- and y- axis tic positions are by default drawn only on the base plane parallel to z=0. The **vertical** keyword activates drawing grid lines in the xz and yz planes also, running from zmin to zmax.
Z grid lines are drawn on the bottom of the plot. This looks better if a partial box is drawn around the plot — see **[set border](set_show#set_border)**.
Hidden3d
--------
The **set hidden3d** command enables hidden line removal for surface plotting (see **[splot](splot#splot)**). Some optional features of the underlying algorithm can also be controlled using this command. Syntax:
```
set hidden3d {defaults} |
{ {front|back}
{{offset <offset>} | {nooffset}}
{trianglepattern <bitpattern>}
{{undefined <level>} | {noundefined}}
{{no}altdiagonal}
{{no}bentover} }
unset hidden3d
show hidden3d
```
In contrast to the usual display in gnuplot, hidden line removal actually treats the given function or data grids as real surfaces that can't be seen through, so plot elements behind the surface will be hidden by it. For this to work, the surface needs to have 'grid structure' (see **[splot datafile](splot#splot_datafile)** about this), and it has to be drawn **with lines** or **with linespoints**.
When **hidden3d** is set, both the hidden portion of the surface and possibly its contours drawn on the base (see **[set contour](set_show#set_contour)**) as well as the grid will be hidden. Each surface has its hidden parts removed with respect to itself and to other surfaces, if more than one surface is plotted. Contours drawn on the surface (**set contour surface**) don't work.
**hidden3d** also affects 3D plotting styles **points**, **labels**, **vectors**, and **impulses** even if no surface is present in the graph. Unobscured portions of each vector are drawn as line segments (no arrowheads). Individual plots within the graph may be explicitly excluded from this processing by appending the extra option **nohidden3d** to the **with** specifier.
Hidden3d does not affect solid surfaces drawn using the pm3d mode. To achieve a similar effect purely for pm3d surfaces, use instead **set pm3d depthorder**. To mix pm3d surfaces with normal **hidden3d** processing, use the option **set hidden3d front** to force all elements included in hidden3d processing to be drawn after any remaining plot elements, including the pm3d surface.
Functions are evaluated at isoline intersections. The algorithm interpolates linearly between function points or data points when determining the visible line segments. This means that the appearance of a function may be different when plotted with **hidden3d** than when plotted with **nohidden3d** because in the latter case functions are evaluated at each sample. Please see **[set samples](set_show#set_samples)** and **[set isosamples](set_show#set_isosamples)** for discussion of the difference.
The algorithm used to remove the hidden parts of the surfaces has some additional features controllable by this command. Specifying **defaults** will set them all to their default settings, as detailed below. If **defaults** is not given, only explicitly specified options will be influenced: all others will keep their previous values, so you can turn on/off hidden line removal via **set {no}hidden3d**, without modifying the set of options you chose.
The first option, **offset**, influences the linetype used for lines on the 'back' side. Normally, they are drawn in a linetype one index number higher than the one used for the front, to make the two sides of the surface distinguishable. You can specify a different linetype offset to add instead of the default 1, by **offset <offset>**. Option **nooffset** stands for **offset 0**, making the two sides of the surface use the same linetype.
Next comes the option **trianglepattern <bitpattern>**. <bitpattern> must be a number between 0 and 7, interpreted as a bit pattern. Each bit determines the visibility of one edge of the triangles each surface is split up into. Bit 0 is for the 'horizontal' edges of the grid, Bit 1 for the 'vertical' ones, and Bit 2 for the diagonals that split each cell of the original grid into two triangles. The default pattern is 3, making all horizontal and vertical lines visible, but not the diagonals. You may want to choose 7 to see those diagonals as well.
The **undefined <level>** option lets you decide what the algorithm is to do with data points that are undefined (missing data, or undefined function values), or exceed the given x-, y- or z-ranges. Such points can either be plotted nevertheless, or taken out of the input data set. All surface elements touching a point that is taken out will be taken out as well, thus creating a hole in the surface. If <level> = 3, equivalent to option **noundefined**, no points will be thrown away at all. This may produce all kinds of problems elsewhere, so you should avoid this. <level> = 2 will throw away undefined points, but keep the out-of-range ones. <level> = 1, the default, will get rid of out-of-range points as well.
By specifying **noaltdiagonal**, you can override the default handling of a special case can occur if **undefined** is active (i.e. <level> is not 3). Each cell of the grid-structured input surface will be divided in two triangles along one of its diagonals. Normally, all these diagonals have the same orientation relative to the grid. If exactly one of the four cell corners is excluded by the **undefined** handler, and this is on the usual diagonal, both triangles will be excluded. However if the default setting of **altdiagonal** is active, the other diagonal will be chosen for this cell instead, minimizing the size of the hole in the surface.
The **bentover** option controls what happens to another special case, this time in conjunction with the **trianglepattern**. For rather crumply surfaces, it can happen that the two triangles a surface cell is divided into are seen from opposite sides (i.e. the original quadrangle is 'bent over'), as illustrated in the following ASCII art:
```
C----B
original quadrangle: A--B displayed quadrangle: |\ |
("set view 0,0") | /| ("set view 75,75" perhaps) | \ |
|/ | | \ |
C--D | \|
A D
```
If the diagonal edges of the surface cells aren't generally made visible by bit 2 of the <bitpattern> there, the edge CB above wouldn't be drawn at all, normally, making the resulting display hard to understand. Therefore, the default option of **bentover** will turn it visible in this case. If you don't want that, you may choose **nobentover** instead. See also [hidden line removal demo (hidden.dem)](http://www.gnuplot.info/demo/hidden.html)
and [complex hidden line demo (singulr.dem).](http://www.gnuplot.info/demo/singulr.html)
Historysize
-----------
(Deprecated). **set historysize N** is equivalent to **set history size N**. **unset historysize** is equivalent to **set history size -1**. History
-------
Syntax:
```
set history {size <N>} {quiet|numbers} {full|trim} {default}
```
When leaving gnuplot the value of history size limits the number of lines saved to the history file. **set history size -1** allows an unlimited number of lines to be written to the history file.
By default the **history** command prints a line number in front of each command. **history quiet** suppresses the number for this command only. **set history quiet** suppresses numbers for all future **history** commands.
The **trim** option reduces the number of duplicate lines in the history list by removing earlier instances of the current command.
Default settings: **set history size 500 numbers trim**.
Isosamples
----------
The isoline density (grid) for plotting functions as surfaces may be changed by the **set isosamples** command. Syntax:
```
set isosamples <iso_1> {,<iso_2>}
show isosamples
```
Each function surface plot will have <iso\_1> iso-u lines and <iso\_2> iso-v lines. If you only specify <iso\_1>, <iso\_2> will be set to the same value as <iso\_1>. By default, sampling is set to 10 isolines per u or v axis. A higher sampling rate will produce more accurate plots, but will take longer. These parameters have no effect on data file plotting.
An isoline is a curve parameterized by one of the surface parameters while the other surface parameter is fixed. Isolines provide a simple means to display a surface. By fixing the u parameter of surface s(u,v), the iso-u lines of the form c(v) = s(u0,v) are produced, and by fixing the v parameter, the iso-v lines of the form c(u) = s(u,v0) are produced.
When a function surface plot is being done without the removal of hidden lines, **set samples** controls the number of points sampled along each isoline; see **[set samples](set_show#set_samples)** and **[set hidden3d](set_show#set_hidden3d)**. The contour algorithm assumes that a function sample occurs at each isoline intersection, so change in **samples** as well as **isosamples** may be desired when changing the resolution of a function surface/contour.
Isosurface
----------
Syntax:
```
set isosurface {mixed|triangles}
set isosurface {no}insidecolor <n>
```
Surfaces plotted by the command **splot $voxelgrid with isosurface** are by default constructed from a mixture of quadrangles and triangles. The use of quadrangles creates a less complicated visual impression. This is the default. This command proveds an option to tessellate with only triangles. By default the inside of an isosurface is drawn in a separate color. The method of choosing that color is the same as for hidden3d surfaces, where an offset <n> is added to the base linetype. To draw both the inside and outside surfaces in the same color, use **set isosurface noinsidecolor**.
Jitter
------
Syntax:
```
set jitter {overlap <yposition>} {spread <factor>} {wrap <limit>}
{swarm|square|vertical}
```
Examples:
```
set jitter # jitter points within 1 character width
set jitter overlap 1.5 # jitter points within 1.5 character width
set jitter over 1.5 spread 0.5 # same but half the displacement on x
```
When one or both coordinates of a data set are restricted to discrete values then many points may lie exactly on top of each other. Jittering introduces an offset to the coordinates of these superimposed points that spreads them into a cluster. The threshold value for treating the points as being overlapped may be specified in character widths or any of the usual coordinate options. See **[coordinates](coordinates#coordinates)**. Jitter affects 2D plot styles **with points** and **with impulses**. It also affects 3D plotting of voxel grids.
The default jittering operation displaces points only along x. This produces a distinctive pattern sometimes called a "bee swarm plot". The optional keyword **square** adjusts the y coordinate of displaced points in addition to their x coordinate so that the points lie in distinct layers separated by at least the **overlap** distance.
To jitter along y (only) rather than along x, use keyword **vertical**.
The maximum displacement (in character units) can be limited using the **wrap** keyword.
Note that both the overlap criterion and the magnitude of jitter default to one character unit. Thus the plot appearance will change with the terminal font size, canvas size, or zoom factor. To avoid this you can specify the overlap criterion in the y axis coordinate system (the **first** keyword) and adjust the point size and spread multiplier as appropriate. See **[coordinates](coordinates#coordinates)**, **[pointsize](set_show#pointsize)**.
Caveat: jitter is incompatible with "pointsize variable".
**set jitter** is also useful in 3D plots of voxel data. Because voxel grids are regular lattices of evenly spaced points, many view angles cause points to overlap and/or generate Moiré patterns. These artifacts can be removed by displacing the symbol drawn at each grid point by a random amount.
Key
---
The **set key** command enables a key (or legend) containing a title and a sample (line, point, box) for each plot in the graph. The key may be turned off by requesting **set key off** or **unset key**. Individual key entries may be turned off by using the **notitle** keyword in the corresponding plot command. The text of the titles is controlled by the **set key autotitle** option or by the **title** keyword of individual **plot** and **splot** commands. See **[plot title](plot#plot_title)** for more information. Syntax:
```
set key {on|off} {default}
{{inside | outside | fixed} | {lmargin | rmargin | tmargin | bmargin}
| {at <position>}}
{left | right | center} {top | bottom | center}
{vertical | horizontal} {Left | Right}
{{no}enhanced}
{{no}opaque {fc <colorspec>}}
{{no}reverse} {{no}invert}
{samplen <sample_length>} {spacing <line_spacing>}
{width <width_increment>} {height <height_increment>}
{{no}autotitle {columnheader}}
{title {"<text>"} {{no}enhanced} {center | left | right}}
{font "<face>,<size>"} {textcolor <colorspec>}
{{no}box {linestyle <style> | linetype <type> | linewidth <width>}}
{maxcols {<max no. of columns> | auto}}
{maxrows {<max no. of rows> | auto}}
unset key
show key
```
Elements within the key are stacked according to **vertical** or **horizontal**. In the case of **vertical**, the key occupies as few columns as possible. That is, elements are aligned in a column until running out of vertical space at which point a new column is started. The vertical space may be limited using 'maxrows'. In the case of **horizontal**, the key occupies as few rows as possible. The horizontal space may be limited using 'maxcols'.
By default the key is placed in the upper right inside corner of the graph. The keywords **left**, **right**, **top**, **bottom**, **center**, **inside**, **outside**, **lmargin**, **rmargin**, **tmargin**, **bmargin** (, **above**, **over**, **below** and **under**) may be used to automatically place the key in other positions of the graph. Also an **at <position>** may be given to indicate precisely where the plot should be placed. In this case, the keywords **left**, **right**, **top**, **bottom** and **center** serve an analogous purpose for alignment. For more information, see **[key placement](set_show#key_placement)**.
Justification of the plot titles within the key is controlled by **Left** or **Right** (default). The text and sample can be reversed (**reverse**) and a box can be drawn around the key (**box {...}**) in a specified **linetype** and **linewidth**, or a user-defined **linestyle**.
The text in the key is set in **enhanced** mode by default, this can be changed with the **{no}enhanced** option, also independently for the key title only and for each individual plot.
By default the key is built up one plot at a time. That is, the key symbol and title are drawn at the same time as the corresponding plot. That means newer plots may sometimes place elements on top of the key. **set key opaque** causes the key to be generated after all the plots. In this case the key area is filled with background color or the requested fill color and then the key symbols and titles are written. The default can be restored by **set key noopaque**.
By default the first plot label is at the top of the key and successive labels are entered below it. The **invert** option causes the first label to be placed at the bottom of the key, with successive labels entered above it. This option is useful to force the vertical ordering of labels in the key to match the order of box types in a stacked histogram.
The <height\_increment> is a number of character heights to be added to or subtracted from the height of the key box. This is useful mainly when you are putting a box around the key and want larger borders around the key entries.
An overall title can be put on the key (**title "<text>"**) — see also **[syntax](syntax#syntax)** for the distinction between text in single- or double-quotes. The justification of the title defaults to center and can be changed by the keywords **right** or **left**
The defaults for **set key** are **on**, **right**, **top**, **vertical**, **Right**, **noreverse**, **noinvert**, **samplen 4**, **spacing 1**, **notitle**, and **nobox**. The default <linetype> is the same as that used for the plot borders. Entering **set key default** returns the key to its default configuration.
Each plot is represented in the key by a single line containing a line or symbol or shape representing the plot style and a corresponding title. Using the keyword **notitle** in the plot command will suppress generation of the line. Contour plots generated additional entries in the key, one for each contour (see **[cntrlabel](set_show#cntrlabel)**). You can add extra lines to the key by inserting a dummy plot command that uses the keyword **keyentry** rather than a filename or a function. See **[keyentry](set_show#keyentry)**.
When using the TeX/LaTeX group of terminals or terminals in which formatting information is embedded in the string, **gnuplot** can only estimate the width of the string for key positioning. If the key is to be positioned at the left, it may be convenient to use the combination **set key left Left reverse**.
### 3D key
Placement of the key for 3D plots (**splot**) by default uses the **fixed** option. Note: this is a change from gnuplot version 5.0 and earlier. **fixed** placement is very similar to **inside** placement with one important difference. The plot boundaries of a 3D plot change as the view point is rotated or scaled. If the key is positioned **inside** these boundaries then the key also moves when the view is changed. **fixed** positioning ignores changes to the view angles or scaling; i.e. the key remains fixed in one location on the canvas as the plot is rotated. For 2D plots the **fixed** option is exactly equivalent to **inside**.
If **splot** is being used to draw contours, by default a separate key entry is generated for each contour level with a distinct line type. To modify this see **[set cntrlabel](set_show#set_cntrlabel)**.
### Key examples
This places the key at the default location:
```
set key default
```
This disables the key:
```
unset key
```
This places a key at coordinates 2,3.5,2 in the default (first) coordinate system:
```
set key at 2,3.5,2
```
This places the key below the graph:
```
set key below
```
This places the key in the bottom left corner, left-justifies the text, gives it a title, and draws a box around it in linetype 3:
```
set key left bottom Left title 'Legend' box 3
```
### Extra key entries
Normally each plot autogenerates a single line entry in the key. If you need more control over what appears in the key you can use the **keyentry** keyword in the **plot** or **splot** command to insert extra lines. Instead of providing a filename or function to plot, use **keyentry** as a placeholder followed by plot style information (used to generate a key symbol) and a title. All the usual options for title font, text color, **at** coordinates, and enhanced text markup apply. Example:
```
plot $HEATMAP matrix with image notitle, \
keyentry with boxes fc palette cb 0 title "no effect", \
keyentry with boxes fc palette cb 1 title "threshold", \
keyentry with boxes fc palette cb 3 title "typical range", \
keyentry with labels nopoint title "as reported in [12]", \
keyentry with boxes fc palette cb 5 title "strong effect"
```
### Key autotitle
**set key autotitle** causes each plot to be identified in the key by the name of the data file or function used in the plot command. This is the default. **set key noautotitle** disables the automatic generation of plot titles. The command **set key autotitle columnheader** causes the first entry in each column of input data to be interpreted as a text string and used as a title for the corresponding plot. If the quantity being plotted is a function of data from several columns, gnuplot may be confused as to which column to draw the title from. In this case it is necessary to specify the column explicitly in the plot command, e.g.
```
plot "datafile" using (($2+$3)/$4) title columnhead(3) with lines
```
Note: The effect of **set key autotitle columnheader**, treatment of the first line in a data file as column headers rather than data applies even if the key is disabled by **unset key**. It also applies to **stats** and **fit** commands even though they generate no key. If you want the first line of data to be treated as column headers but *not* to use them for plot titles, use **set datafile columnheaders**.
In all cases an explicit **title** or **notitle** keyword in the plot command itself will override the default from **set key autotitle**.
### Key placement
This section describes placement of the primary, auto-generated key. To construct a secondary key or place plot titles elsewhere, see **[multiple keys](set_show#multiple_keys)**. To understand positioning, the best concept is to think of a region, i.e., inside/outside, or one of the margins. Along with the region, keywords **left/center/right** (l/c/r) and **top/center/bottom** (t/c/b) control where within the particular region the key should be placed.
When in **inside** mode, the keywords **left** (l), **right** (r), **top** (t), **bottom** (b), and **center** (c) push the key out toward the plot boundary as illustrated:
```
t/l t/c t/r
```
```
c/l c c/r
```
```
b/l b/c b/r
```
When in **outside** mode, automatic placement is similar to the above illustration, but with respect to the view, rather than the graph boundary. That is, a border is moved inward to make room for the key outside of the plotting area, although this may interfere with other labels and may cause an error on some devices. The particular plot border that is moved depends upon the position described above and the stacking direction. For options centered in one of the dimensions, there is no ambiguity about which border to move. For the corners, when the stack direction is **vertical**, the left or right border is moved inward appropriately. When the stack direction is **horizontal**, the top or bottom border is moved inward appropriately.
The margin syntax allows automatic placement of key regardless of stack direction. When one of the margins **lmargin** (lm), **rmargin** (rm), **tmargin** (tm), and **bmargin** (bm) is combined with a single, non-conflicting direction keyword, the following illustrated positions may contain the key:
```
l/tm c/tm r/tm
```
```
t/lm t/rm
```
```
c/lm c/rm
```
```
b/lm b/rm
```
```
l/bm c/bm r/bm
```
Keywords **above** and **over** are synonymous with **tmargin**. For version compatibility, **above** or **over** without an additional l/c/r or stack direction keyword uses **center** and **horizontal**. Keywords **below** and **under** are synonymous with **bmargin**. For compatibility, **below** or **under** without an additional l/c/r or stack direction keyword uses **center** and **horizontal**. A further compatibility issue is that **outside** appearing without an additional t/b/c or stack direction keyword uses **top**, **right** and **vertical** (i.e., the same as t/rm above).
The <position> can be a simple x,y,z as in previous versions, but these can be preceded by one of five keywords (**first**, **second**, **graph**, **screen**, **character**) which selects the coordinate system in which the position of the first sample line is specified. See **[coordinates](coordinates#coordinates)** for more details. The effect of **left**, **right**, **top**, **bottom**, and **center** when <position> is given is to align the key as though it were text positioned using the label command, i.e., **left** means left align with key to the right of <position>, etc.
### Key samples
By default, each plot on the graph generates a corresponding entry in the key. This entry contains a plot title and a sample line/point/box of the same color and fill properties as used in the plot itself. The font and textcolor properties control the appearance of the individual plot titles that appear in the key. Setting the textcolor to "variable" causes the text for each key entry to be the same color as the line or fill color for that plot. This was the default in some earlier versions of gnuplot. The length of the sample line can be controlled by **samplen**. The sample length is computed as the sum of the tic length and <sample\_length> times the character width. **samplen** also affects the positions of point samples in the key since these are drawn at the midpoint of the sample line, even if the sample line itself is not drawn.
Key entry lines are single-spaced based on the current font size. This can be adjusted by **set key spacing <line-spacing>**.
The <width\_increment> is a number of character widths to be added to or subtracted from the length of the string. This is useful only when you are putting a box around the key and you are using control characters in the text. **gnuplot** simply counts the number of characters in the string when computing the box width; this allows you to correct it.
### Multiple keys
It is possible to construct a legend/key manually rather than having the plot titles all appear in the auto-generated key. This allows, for example, creating a single legend for the component panels in a multiplot. Here is an example:
```
set multiplot layout 3,2 columnsfirst
set style data boxes
plot $D using 0:6 lt 1 title at 0.75, 0.20
plot $D using 0:12 lt 2 title at 0.75, 0.17
plot $D using 0:13 lt 3 title at 0.75, 0.14
plot $D using 0:14 lt 4 title at 0.75, 0.11
set label 1 at screen 0.75, screen 0.22 "Custom combined key area"
plot $D using 0:($6+$12+$13+$14) with linespoints title "total"
unset multiplot
```
Label
-----
Arbitrary labels can be placed on the plot using the **set label** command. Syntax:
```
set label {<tag>} {"<label text>"} {at <position>}
{left | center | right}
{norotate | rotate {by <degrees>}}
{font "<name>{,<size>}"}
{noenhanced}
{front | back}
{textcolor <colorspec>}
{point <pointstyle> | nopoint}
{offset <offset>}
{nobox} {boxed {bs <boxstyle>}}
{hypertext}
unset label {<tag>}
show label
```
The <position> is specified by either x,y or x,y,z, and may be preceded by **first**, **second**, **polar**, **graph**, **screen**, or **character** to indicate the coordinate system. See **[coordinates](coordinates#coordinates)** for details.
The tag is an integer that is used to identify the label. If no <tag> is given, the lowest unused tag value is assigned automatically. The tag can be used to delete or modify a specific label. To change any attribute of an existing label, use the **set label** command with the appropriate tag, and specify the parts of the label to be changed.
The <label text> can be a string constant, a string variable, or a string- valued expression. See **[strings](string_constants_string_var#strings)**, **[sprintf](expressions#sprintf)**, and **[gprintf](set_show#gprintf)**.
By default, the text is placed flush left against the point x,y,z. To adjust the way the label is positioned with respect to the point x,y,z, add the justification parameter, which may be **left**, **right** or **center**, indicating that the point is to be at the left, right or center of the text. Labels outside the plotted boundaries are permitted but may interfere with axis labels or other text.
Some terminals support enclosing the label in a box. See **[set style textbox](set_show#set_style_textbox)**. Not all terminals can handle boxes for rotated text.
If **rotate** is given, the label is written vertically. If **rotate by <degrees>** is given, the baseline of the text will be set to the specified angle. Some terminals do not support text rotation.
Font and its size can be chosen explicitly by **font "<name>{,<size>}"** if the terminal supports font settings. Otherwise the default font of the terminal will be used.
Normally the enhanced text mode string interpretation, if enabled for the current terminal, is applied to all text strings including label text. The **noenhanced** property can be used to exempt a specific label from the enhanced text mode processing. The can be useful if the label contains underscores, for example. See **[enhanced text](enhanced_text_mode#enhanced_text)**.
If **front** is given, the label is written on top of the graphed data. If **back** is given (the default), the label is written underneath the graphed data. Using **front** will prevent a label from being obscured by dense data.
**textcolor <colorspec>** changes the color of the label text. <colorspec> can be a linetype, an rgb color, or a palette mapping. See help for **[colorspec](linetypes_colors_styles#colorspec)** and **[palette](expressions#palette)**. **textcolor** may be abbreviated **tc**.
```
`tc default` resets the text color to its default state.
`tc lt <n>` sets the text color to that of line type <n>.
`tc ls <n>` sets the text color to that of line style <n>.
`tc palette z` selects a palette color corresponding to the label z position.
`tc palette cb <val>` selects a color corresponding to <val> on the colorbar.
`tc palette fraction <val>`, with 0<=val<=1, selects a color corresponding to
the mapping [0:1] to grays/colors of the `palette`.
`tc rgb "#RRGGBB"` or `tc rgb "0xRRGGBB"` sets an arbitrary 24-bit RGB color.
`tc rgb 0xRRGGBB` As above; a hexadecimal constant does not require quotes.
```
If a <pointstyle> is given, using keywords **lt**, **pt** and **ps**, see **[style](plot#style)**, a point with the given style and color of the given line type is plotted at the label position and the text of the label is displaced slightly. This option is used by default for placing labels in **mouse** enhanced terminals. Use **nopoint** to turn off the drawing of a point near the label (this is the default).
The displacement defaults to 1,1 in **pointsize** units if a <pointstyle> is given, 0,0 if no <pointstyle> is given. The displacement can be controlled by the optional **offset <offset>** where <offset> is specified by either x,y or x,y,z, and may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. See **[coordinates](coordinates#coordinates)** for details.
If one (or more) axis is timeseries, the appropriate coordinate should be given as a quoted time string according to the **timefmt** format string. See **[set xdata](set_show#set_xdata)** and **[set timefmt](set_show#set_timefmt)**.
The options available for **set label** are also available for the **labels** plot style. See **[labels](labels#labels)**. In this case the properties **textcolor**, **rotate**, and **pointsize** may be followed by keyword **variable** rather than by a fixed value. In this case the corresponding property of individual labels is determined by additional columns in the **using** specifier.
### Examples
Examples: To set a label at (1,2) to "y=x", use:
```
set label "y=x" at 1,2
```
To set a Sigma of size 24, from the Symbol font set, at the center of the graph, use:
```
set label "S" at graph 0.5,0.5 center font "Symbol,24"
```
To set a label "y=x`^`2" with the right of the text at (2,3,4), and tag the label as number 3, use:
```
set label 3 "y=x^2" at 2,3,4 right
```
To change the preceding label to center justification, use:
```
set label 3 center
```
To delete label number 2, use:
```
unset label 2
```
To delete all labels, use:
```
unset label
```
To show all labels (in tag order), use:
```
show label
```
To set a label on a graph with a timeseries on the x axis, use, for example:
```
set timefmt "%d/%m/%y,%H:%M"
set label "Harvest" at "25/8/93",1
```
To display a freshly fitted parameter on the plot with the data and the fitted function, do this after the **fit**, but before the **plot**:
```
set label sprintf("a = %3.5g",par_a) at 30,15
bfit = gprintf("b = %s*10^%S",par_b)
set label bfit at 30,20
```
To display a function definition along with its fitted parameters, use:
```
f(x)=a+b*x
fit f(x) 'datafile' via a,b
set label GPFUN_f at graph .05,.95
set label sprintf("a = %g", a) at graph .05,.90
set label sprintf("b = %g", b) at graph .05,.85
```
To set a label displaced a little bit from a small point:
```
set label 'origin' at 0,0 point lt 1 pt 2 ps 3 offset 1,-1
```
To set a label whose color matches the z value (in this case 5.5) of some point on a 3D splot colored using pm3d:
```
set label 'text' at 0,0,5.5 tc palette z
```
### Hypertext
Some terminals (wxt, qt, svg, canvas, win) allow you to attach hypertext to specific points on the graph or elsewhere on the canvas. When the mouse hovers over the anchor point, a pop-up box containing the text is displayed. Terminals that do not support hypertext will display nothing. You must enable the **point** attribute of the label in order for the hypertext to be anchored. Examples:
```
set label at 0,0 "Plot origin" hypertext point pt 1
plot 'data' using 1:2:0 with labels hypertext point pt 7 \
title 'mouse over point to see its order in data set'
```
For the wxt and qt terminals, left-click on a hypertext anchor after the text has appeared will copy the hypertext to the clipboard.
EXPERIMENTAL (implementation details may change) Text of the form "image{<xsize>,<ysize>}:<filename>{ \n<caption text>}" will trigger display of the image file in a pop-up box. The optional size overrides a default box size 300x200. The types of image file recognized may vary by terminal type, but \*.png should always work. Any additional text lines following the image filename are displayed as usual for hypertext. Example:
```
set label 7 "image:../figures/Fig7_inset.png\nFigure 7 caption..."
set label 7 at 10,100 hypertext point pt 7
```
Linetype
--------
The **set linetype** command allows you to redefine the basic linetypes used for plots. The command options are identical to those for "set style line". Unlike line styles, redefinitions by **set linetype** are persistent; they are not affected by **reset**. For example, whatever linetypes one and two look like to begin with, if you redefine them like this:
```
set linetype 1 lw 2 lc rgb "blue" pointtype 6
set linetype 2 lw 2 lc rgb "forest-green" pointtype 8
```
everywhere that uses lt 1 will now get a thick blue line. This includes uses such as the definition of a temporary linestyle derived from the base linetype 1. Similarly lt 2 will now produce a thick green line.
This mechanism can be used to define a set of personal preferences for the sequence of lines used in gnuplot. The recommended way to do this is to add to the run-time initialization file ˜ /.gnuplot a sequence of commands like
```
set linetype 1 lc rgb "dark-violet" lw 2 pt 1
set linetype 2 lc rgb "sea-green" lw 2 pt 7
set linetype 3 lc rgb "cyan" lw 2 pt 6 pi -1
set linetype 4 lc rgb "dark-red" lw 2 pt 5 pi -1
set linetype 5 lc rgb "blue" lw 2 pt 8
set linetype 6 lc rgb "dark-orange" lw 2 pt 3
set linetype 7 lc rgb "black" lw 2 pt 11
set linetype 8 lc rgb "goldenrod" lw 2
set linetype cycle 8
```
Every time you run gnuplot the line types will be initialized to these values. You may initialize as many linetypes as you like. If you do not redefine, say, linetype 3 then it will continue to have the default properties (in this case blue, pt 3, lw 1, etc).
Similar script files can be used to define theme-based color choices, or sets of colors optimized for a particular plot type or output device.
The command **set linetype cycle 8** tells gnuplot to re-use these definitions for the color and linewidth of higher-numbered linetypes. That is, linetypes 9-16, 17-24, and so on will use this same sequence of colors and widths. The point properties (pointtype, pointsize, pointinterval) are not affected by this command. **unset linetype cycle** disables this feature. If the line properties of a higher numbered linetype are explicitly defined, this takes precedence over the recycled low-number linetype properties.
Link
----
Syntax:
```
set link {x2 | y2} {via <expression1> inverse <expression2>}
unset link
```
The **set link** command establishes a mapping between the x and x2 axes, or the y and y2 axes. <expression1> maps primary axis coordinates onto the secondary axis. <expression2> maps secondary axis coordinates onto the primary axis.
Examples:
```
set link x2
```
This is the simplest form of the command. It forces the x2 axis to have identically the same range, scale, and direction as the x axis. Commands **set xrange**, **set x2range**, **set auto x**, etc will affect both the x and x2 axes.
```
set link x2 via x**2 inverse sqrt(x)
plot "sqrt_data" using 1:2 axes x2y1, "linear_data" using 1:2 axes x1y1
```
This command establishes forward and reverse mapping between the x and x2 axes. The forward mapping is used to generate x2 tic labels and x2 mouse coordinate The reverse mapping is used to plot coordinates given in the x2 coordinate system. Note that the mapping as given is valid only for x non-negative. When mapping to the y2 axis, both <expression1> and <expression2> must use y as dummy variable.
Lmargin
-------
The command **set lmargin** sets the size of the left margin. Please see **[set margin](set_show#set_margin)** for details. Loadpath
--------
The **loadpath** setting defines additional locations for data and command files searched by the **call**, **load**, **plot** and **splot** commands. If a file cannot be found in the current directory, the directories in **loadpath** are tried. Syntax:
```
set loadpath {"pathlist1" {"pathlist2"...}}
show loadpath
```
Path names may be entered as single directory names, or as a list of path names separated by a platform-specific path separator, eg. colon (':') on Unix, semicolon (';') on DOS/Windows/OS/2 platforms. The **show loadpath**, **save** and **save set** commands replace the platform-specific separator with a space character (' ').
If the environment variable GNUPLOT\_LIB is set, its contents are appended to **loadpath**. However, **show loadpath** prints the contents of **set loadpath** and GNUPLOT\_LIB separately. Also, the **save** and **save set** commands ignore the contents of GNUPLOT\_LIB.
Locale
------
The **locale** setting determines the language with which **{x,y,z}{d,m}tics** will write the days and months. Syntax:
```
set locale {"<locale>"}
```
<locale> may be any language designation acceptable to your installation. See your system documentation for the available options. The command **set locale ""** will try to determine the locale from the LC\_TIME, LC\_ALL, or LANG environment variables.
To change the decimal point locale, see **[set decimalsign](set_show#set_decimalsign)**. To change the character encoding to the current locale, see **[set encoding](set_show#set_encoding)**.
Logscale
--------
Syntax:
```
set logscale <axes> {<base>}
unset logscale <axes>
show logscale
```
where <axes> may be any combinations of **x**, **x2**, **y**, **y2**, **z**, **cb**, and **r** in any order. <base> is the base of the log scaling (default is base 10). If no axes are specified, the command affects all axes except **r**. The command **unset logscale** turns off log scaling for all axes. Note that the ticmarks generated for logscaled axes are not uniformly spaced. See **[set xtics](set_show#set_xtics)**.
Examples:
To enable log scaling in both x and z axes:
```
set logscale xz
```
To enable scaling log base 2 of the y axis:
```
set logscale y 2
```
To enable z and color log axes for a pm3d plot:
```
set logscale zcb
```
To disable z axis log scaling:
```
unset logscale z
```
Macros
------
In this version of gnuplot macro substitution is always enabled. Tokens in the command line of the form @<stringvariablename> will be replaced by the text string contained in <stringvariablename>. See **[substitution](substitution_command_line_m#substitution)**. Mapping
-------
If data are provided to **splot** in spherical or cylindrical coordinates, the **set mapping** command should be used to instruct **gnuplot** how to interpret them. Syntax:
```
set mapping {cartesian | spherical | cylindrical}
```
A cartesian coordinate system is used by default.
For a spherical coordinate system, the data occupy two or three columns (or **using** entries). The first two are interpreted as the azimuthal and polar angles theta and phi (or "longitude" and "latitude"), in the units specified by **set angles**. The radius r is taken from the third column if there is one, or is set to unity if there is no third column. The mapping is:
```
x = r * cos(theta) * cos(phi)
y = r * sin(theta) * cos(phi)
z = r * sin(phi)
```
Note that this is a "geographic" spherical system, rather than a "polar" one (that is, phi is measured from the equator, rather than the pole).
For a cylindrical coordinate system, the data again occupy two or three columns. The first two are interpreted as theta (in the units specified by **set angles**) and z. The radius is either taken from the third column or set to unity, as in the spherical case. The mapping is:
```
x = r * cos(theta)
y = r * sin(theta)
z = z
```
The effects of **mapping** can be duplicated with the **using** filter on the **splot** command, but **mapping** may be more convenient if many data files are to be processed. However even if **mapping** is used, **using** may still be necessary if the data in the file are not in the required order.
**mapping** has no effect on **plot**. [world.dem: mapping demos.](http://www.gnuplot.info/demo/world.html)
Margin
------
The **margin** is the distance between the plot border and the outer edge of the canvas. The size of the margin is chosen automatically, but can be overridden by the **set margin** commands. **show margin** shows the current settings. To alter the distance between the inside of the plot border and the data in the plot itself, see **[set offsets](set_show#set_offsets)**. Syntax:
```
set lmargin {{at screen} <margin>}
set rmargin {{at screen} <margin>}
set tmargin {{at screen} <margin>}
set bmargin {{at screen} <margin>}
set margins <left>, <right>, <bottom>, <top>
show margin
```
The default units of <margin> are character heights or widths, as appropriate. A positive value defines the absolute size of the margin. A negative value (or none) causes **gnuplot** to revert to the computed value. For 3D plots, only the left margin can be set using character units.
The keywords **at screen** indicates that the margin is specified as a fraction of the full drawing area. This can be used to precisely line up the corners of individual 2D and 3D graphs in a multiplot. This placement ignores the current values of **set origin** and **set size**, and is intended as an alternative method for positioning graphs within a multiplot.
Normally the margins of a plot are automatically calculated based on tics, tic labels, axis labels, the plot title, the timestamp and the size of the key if it is outside the borders. If, however, tics are attached to the axes (**set xtics axis**, for example), neither the tics themselves nor their labels will be included in either the margin calculation or the calculation of the positions of other text to be written in the margin. This can lead to tic labels overwriting other text if the axis is very close to the border.
Micro
-----
By default the "%c" format specifier for scientific notation used to generate axis tick labels uses a lower case u as a prefix to indicate "micro" (10`^`-6). The **set micro** command tells gnuplot to use a different typographic character (unicode U+00B5). The byte sequence used to represent this character depends on the current encoding. See **[format specifiers](set_show#format_specifiers)**, **[encoding](set_show#encoding)**. This command is EXPERIMENTAL. Implementation details may change.
Minussign
---------
Gnuplot uses the C language library routine sprintf() for most formatted input. However it also has its own formatting routine **gprintf()** that is used to generate axis tic labels. The C library routine always use a hyphen character (ascii \055) to indicate a negative number, as in -7. Many people prefer a different typographic minus sign character (unicode U+2212) for this purpose, as in −7. The command
```
set minussign
```
causes gprintf() to use this minus sign character rather than a hyphen in numeric output. In a utf-8 locale this is the multibyte sequence corresponding to unicode U+2212. In a Window codepage 1252 locale this is the 8-bit character ALT+150 ("en dash"). The **set minussign** command will affect axis tic labels and any labels that are created by explicitly invoking gprintf. It has no effect on other strings that contain a hyphen. See **[gprintf](set_show#gprintf)**.
Note that this command is ignored when you are using any of the LaTeX terminals, as LaTeX has its own mechanism for handling minus signs. It also is not necessary when using the postscript terminal because the postscript prologue output by gnuplot remaps the ascii hyphen code \055 to a different glyph named **minus**.
This command is EXPERIMENTAL. Implementation details may change.
Example (assumes utf8 locale):
```
set minus
A = -5
print "A = ",A # printed string will contain a hyphen
print gprintf("A = %g",A) # printed string will contain character U+2212
set label "V = -5" # label will contain a hyphen
set label sprintf("V = %g",-5) # label will contain a hyphen
set label gprintf("V = %g",-5) # label will contain character U+2212
```
Monochrome
----------
Syntax:
```
set monochrome {linetype N <linetype properties>}
```
The **set monochrome** command selects an alternative set of linetypes that differ by dot/dash pattern or line width rather than by color. This command replaces the monochrome option offered by certain terminal types in earlier versions of gnuplot. For backward compatibility these terminal types now implicitly invoke "set monochrome" if their own "mono" option is present. For example,
```
set terminal pdf mono
```
is equivalent to
```
set terminal pdf
set mono
```
Selecting monochrome mode does not prevent you from explicitly drawing lines using RGB or palette colors, but see also **[set palette gray](set_show#set_palette_gray)**. Six monochrome linetypes are defined by default. You can change their properties or add additional monochrome linetypes by using the full form of the command. Changes made to the monochrome linetypes do not affect the color linetypes and vice versa. To restore the usual set of color linetypes, use either **unset monochrome** or **set color**.
Mouse
-----
The command **set mouse** enables mouse actions for the current interactive terminal. It is usually enabled by default in interactive mode, but disabled by default if commands are being read from a file. There are two mouse modes. The 2D mode works for **plot** commands and for **splot** maps (i.e. **set view** with z-rotation 0, 90, 180, 270 or 360 degrees, including **set view map**). In this mode the mouse position is tracked and you can pan or zoom using the mouse buttons or arrow keys. Some terminals support toggling individual plots on/off by clicking on the corresponding key title or on a separate widget.
For 3D graphs **splot**, the view and scaling of the graph can be changed with mouse buttons 1 and 2, respectively. A vertical motion of Button 2 with the shift key held down changes the **xyplane**. If additionally to these buttons the modifier <ctrl> is held down, the coordinate axes are displayed but the data are suppressed. This is useful for large data sets. Mouse button 3 controls the azimuth of the z axis (see **[set view azimuth](set_show#set_view_azimuth)**).
Mousing is not available inside multiplot mode. When multiplot is completed using **unset multiplot**, then the mouse will be turned on again but acts only on the most recent plot within the multiplot (like replot does).
Syntax:
```
set mouse {doubleclick <ms>} {nodoubleclick}
{{no}zoomcoordinates}
{zoomfactors <xmultiplier>, <ymultiplier>}
{noruler | ruler {at x,y}}
{polardistance{deg|tan} | nopolardistance}
{format <string>}
{mouseformat <int> | <string> | function <f(x,y)>}
{{no}labels {"labeloptions"}}
{{no}zoomjump} {{no}verbose}
unset mouse
```
The options **noruler** and **ruler** switch the ruler off and on, the latter optionally setting the origin at the given coordinates. While the ruler is on, the distance in user units from the ruler origin to the mouse is displayed continuously. By default, toggling the ruler has the key binding 'r'.
The option **polardistance** determines if the distance between the mouse cursor and the ruler is also shown in polar coordinates (distance and angle in degrees or tangent (slope)). This corresponds to the default key binding '5'.
Choose the option **labels** to define persistent gnuplot labels using Button 2. The default is **nolabels**, which makes Button 2 draw only a temporary label at the mouse position. Labels are drawn with the current setting of **mouseformat**. The **labeloptions** string is passed to the **set label** command. The default is "point pointstyle 1" which will plot a small plus at the label position. Temporary labels will disappear at the next **replot** or mouse zoom operation. Persistent labels can be removed by holding the Ctrl-Key down while clicking Button 2 on the label's point. The threshold for how close you must be to the label is also determined by the **pointsize**.
If the option **verbose** is turned on the communication commands are shown during execution. This option can also be toggled by hitting **6** in the driver's window. **verbose** is off by default.
Press 'h' in the driver's window for a short summary of the mouse and key bindings. This will also display user defined bindings or **hotkeys** which can be defined using the **bind** command, see help for **[bind](mouse_input#bind)**. Note, that user defined **hotkeys** may override the default bindings. See also help for **[bind](mouse_input#bind)** and **[label](set_show#label)**.
### Doubleclick
The doubleclick resolution is given in milliseconds and used for Button 1, which copies the current mouse position to the **clipboard** on some terminals. The default value is 300 ms. Setting the value to 0 ms triggers the copy on a single click. ### Format
The **set mouse format** command specifies a format string for sprintf() which determines how the mouse cursor [x,y] coordinates are printed to the plot window and to the clipboard. The default is "% #g". This setting is superseded by "set mouse mouseformat".
### Mouseformat
Syntax:
```
set mouse mouseformat i
set mouse mouseformat "custom format"
set mouse mouseformat function string_valued_function(x, y)
```
This command controls the format used to report the current mouse position. An integer argument selects one of the format options in the table below. A string argument is used as a format for sprintf() in option 7 and should contain two float specifiers, one for x and one for y. Use of a custom function returning a string is EXPERIMENTAL. It allows readout of coordinate systems in which inverse mapping from screen coordinates to plot coordinates requires joint consideration of both x and y. See for example the map\_projection demo.
Example:
```
`set mouse mouseformat "mouse x,y = %5.2g, %10.3f"`.
```
Use **set mouse mouseformat ""** to turn this string off again. The following formats are available:
```
0 default (same as 1)
1 axis coordinates 1.23, 2.45
2 graph coordinates (from 0 to 1) /0.00, 1.00/
3 x = timefmt y = axis [(as set by `set timefmt`), 2.45]
4 x = date y = axis [31. 12. 1999, 2.45]
5 x = time y = axis [23:59, 2.45]
6 x = date time y = axis [31. 12. 1999 23:59, 2.45]
7 format from `set mouse mouseformat <format-string>`
8 format from `set mouse mouseformat function <func>`
```
### Scrolling
X and Y axis scaling in both 2D and 3D graphs can be adjusted using the mouse wheel. <wheel-up> scrolls up (increases both YMIN and YMAX by ten percent of the Y range, and increases both Y2MIN and Y2MAX likewise), and <wheel down> scrolls down. <shift-wheel-up> scrolls left (decreases both XMIN and XMAX, and both X2MIN and X2MAX), and <shift-wheel-down> scrolls right. <control-wheel-up> zooms in toward the center of the plot, and <control-wheel-down> zooms out. <shift-control-wheel-up> zooms in along the X and X2 axes only, and <shift-control-wheel-down> zooms out along the X and X2 axes only. ### X11 mouse
If multiple X11 plot windows have been opened using the **set term x11 <n>** terminal option, then only the current plot window supports the entire range of mouse commands and hotkeys. The other windows will, however, continue to display mouse coordinates at the lower left. ### Zoom
Zooming is usually accomplished by holding down the left mouse button and dragging the mouse to delineate a zoom region. Some platforms may require using a different mouse button. The original plot can be restored by typing the 'u' hotkey in the plot window. The hotkeys 'p' and 'n' step back and forth through a history of zoom operations. The option **zoomcoordinates** determines if the coordinates of the zoom box are drawn at the edges while zooming. This is on by default.
If the option **zoomjump** is on, the mouse pointer will be automatically offset a small distance after starting a zoom region with button 3. This can be useful to avoid a tiny (or even empty) zoom region. **zoomjump** is off by default.
Mttics
------
Minor tic marks around the perimeter of a polar plot are controlled by by **set mttics**. Please see **[set mxtics](set_show#set_mxtics)**. Multiplot
---------
The command **set multiplot** places **gnuplot** in the multiplot mode, in which several plots are placed next to each other on the same page or screen window. Syntax:
```
set multiplot
{ title <page title> {font <fontspec>} {enhanced|noenhanced} }
{ layout <rows>,<cols>
{rowsfirst|columnsfirst} {downwards|upwards}
{scale <xscale>{,<yscale>}} {offset <xoff>{,<yoff>}}
{margins <left>,<right>,<bottom>,<top>}
{spacing <xspacing>{,<yspacing>}}
}
set multiplot {next|previous}
unset multiplot
```
For some terminals, no plot is displayed until the command **unset multiplot** is given, which causes the entire page to be drawn and then returns gnuplot to its normal single-plot mode. For other terminals, each separate **plot** command produces an updated display.
The **clear** command is used to erase the rectangular area of the page that will be used for the next plot. This is typically needed to inset a small plot inside a larger plot.
Any labels or arrows that have been defined will be drawn for each plot according to the current size and origin (unless their coordinates are defined in the **screen** system). Just about everything else that can be **set** is applied to each plot, too. If you want something to appear only once on the page, for instance a single time stamp, you'll need to put a **set time**/**unset time** pair around one of the **plot**, **splot** or **replot** commands within the **set multiplot**/**unset multiplot** block.
The multiplot title is separate from the individual plot titles, if any. Space is reserved for it at the top of the page, spanning the full width of the canvas.
The commands **set origin** and **set size** must be used to correctly position each plot if no layout is specified or if fine tuning is desired. See **[set origin](set_show#set_origin)** and **[set size](set_show#set_size)** for details of their usage.
Example:
```
set multiplot
set size 0.4,0.4
set origin 0.1,0.1
plot sin(x)
set size 0.2,0.2
set origin 0.5,0.5
plot cos(x)
unset multiplot
```
This displays a plot of cos(x) stacked above a plot of sin(x).
**set size** and **set origin** refer to the entire plotting area used for each plot. Please also see **[set term size](canvas_size#set_term_size)**. If you want to have the axes themselves line up, you can guarantee that the margins are the same size with the **set margin** commands. See **[set margin](set_show#set_margin)** for their use. Note that the margin settings are absolute, in character units, so the appearance of the graph in the remaining space will depend on the screen size of the display device, e.g., perhaps quite different on a video display and a printer.
With the **layout** option you can generate simple multiplots without having to give the **set size** and **set origin** commands before each plot: Those are generated automatically, but can be overridden at any time. With **layout** the display will be divided by a grid with <rows> rows and <cols> columns. This grid is filled rows first or columns first depending on whether the corresponding option is given in the multiplot command. The stack of plots can grow **downwards** or **upwards**. Default is **rowsfirst** and **downwards**. The commands **set multiplot next** and **set multiplot previous** are relevant only in the context of using the layout option. **next** skips the next position in the grid, leaving a blank space. **prev** returns to the grid position immediately preceding the most recently plotted position.
Each plot can be scaled by **scale** and shifted with **offset**; if the y-values for scale or offset are omitted, the x-value will be used. **unset multiplot** will turn off the automatic layout and restore the values of **set size** and **set origin** as they were before **set multiplot layout**.
Example:
```
set size 1,1
set origin 0,0
set multiplot layout 3,2 columnsfirst scale 1.1,0.9
[ up to 6 plot commands here ]
unset multiplot
```
The above example will produce 6 plots in 2 columns filled top to bottom, left to right. Each plot will have a horizontal size of 1.1/2 and a vertical size of 0.9/3.
Another possibility is to set uniform margins for all plots in the layout with options **layout margins** and **spacing**, which must be used together. With **margins** you set the outer margins of the whole multiplot grid.
**spacing** gives the gap size between two adjacent subplots, and can also be given in **character** or **screen** units. If a single value is given, it is used for both x and y direction, otherwise two different values can be selected.
If one value has no unit, the one of the preceding margin setting is used.
Example:
```
set multiplot layout 2,2 margins 0.1, 0.9, 0.1, 0.9 spacing 0.0
```
In this case the two left-most subplots will have left boundaries at screen coordinate 0.1, the two right-most subplots will have right boundaries at screen coordinate 0.9, and so on. Because the spacing between subplots is given as 0, their inner boundaries will superimpose.
Example:
```
set multiplot layout 2,2 margins char 5,1,1,2 spacing screen 0, char 2
```
This produces a layout in which the boundary of both left subplots is 5 character widths from the left edge of the canvas, the right boundary of the right subplots is 1 character width from the canvas edge. The overall bottom margin is one character height and the overall top margin is 2 character heights. There is no horizontal gap between the two columns of subplots. The vertical gap between subplots is equal to 2 character heights.
Example:
```
set multiplot layout 2,2 columnsfirst margins 0.1,0.9,0.1,0.9 spacing 0.1
set ylabel 'ylabel'
plot sin(x)
set xlabel 'xlabel'
plot cos(x)
unset ylabel
unset xlabel
plot sin(2*x)
set xlabel 'xlabel'
plot cos(2*x)
unset multiplot
```
See also [multiplot demo (multiplt.dem)](http://www.gnuplot.info/demo/multiplt.html)
Mx2tics
-------
Minor tic marks along the x2 (top) axis are controlled by **set mx2tics**. Please see **[set mxtics](set_show#set_mxtics)**. Mxtics
------
Minor tic marks along the x axis are controlled by **set mxtics**. They can be turned off with **unset mxtics**. Similar commands control minor tics along the other axes. Syntax:
```
set mxtics {<freq> | default}
unset mxtics
show mxtics
```
The same syntax applies to **mytics**, **mztics**, **mx2tics**, **my2tics**, **mrtics**, **mttics** and **mcbtics**.
<freq> is the number of sub-intervals (NOT the number of minor tics) between major tics (the default for a linear axis is either two or five depending on the major tics, so there are one or four minor tics between major tics). Selecting **default** will return the number of minor ticks to its default value.
If the axis is logarithmic, the number of sub-intervals will be set to a reasonable number by default (based upon the length of a decade). This will be overridden if <freq> is given. However the usual minor tics (2, 3, ..., 8, 9 between 1 and 10, for example) are obtained by setting <freq> to 10, even though there are but nine sub-intervals.
To set minor tics at arbitrary positions, use the ("<label>" <pos> <level>, ...) form of **set {x|x2|y|y2|z}tics** with <label> empty and <level> set to 1.
The **set m{x|x2|y|y2|z}tics** commands work only when there are uniformly spaced major tics. If all major tics were placed explicitly by **set {x|x2|y|y2|z}tics**, then minor tic commands are ignored. Implicit major tics and explicit minor tics can be combined using **set {x|x2|y|y2|z}tics** and **set {x|x2|y|y2|z}tics add**.
Examples:
```
set xtics 0, 5, 10
set xtics add (7.5)
set mxtics 5
```
Major tics at 0,5,7.5,10, minor tics at 1,2,3,4,6,7,8,9
```
set logscale y
set ytics format ""
set ytics 1e-6, 10, 1
set ytics add ("1" 1, ".1" 0.1, ".01" 0.01, "10^-3" 0.001, \
"10^-4" 0.0001)
set mytics 10
```
Major tics with special formatting, minor tics at log positions By default, minor tics are off for linear axes and on for logarithmic axes. They inherit the settings for **axis|border** and **{no}mirror** specified for the major tics. Please see **[set xtics](set_show#set_xtics)** for information about these.
My2tics
-------
Minor tic marks along the y2 (right-hand) axis are controlled by **set my2tics**. Please see **[set mxtics](set_show#set_mxtics)**. Mytics
------
Minor tic marks along the y axis are controlled by **set mytics**. Please see **[set mxtics](set_show#set_mxtics)**. Mztics
------
Minor tic marks along the z axis are controlled by **set mztics**. Please see **[set mxtics](set_show#set_mxtics)**. Nonlinear
---------
Syntax:
```
set nonlinear <axis> via f(axis) inverse g(axis)
unset nonlinear <axis>
```
This command is similar to the **set link** command except that only one of the two linked axes is visible. The hidden axis remains linear. Coordinates along the visible axis are mapped by applying g(x) to hidden axis coordinates. f(x) maps the visible axis coordinates back onto the hidden linear axis. You must provide both the forward and inverse expressions.
To illustrate how this works, consider the case of a log-scale x2 axis.
```
set x2ange [1:1000]
set nonlinear x2 via log10(x) inverse 10**x
```
This achieves the same effect as **set log x2**. The hidden axis in this case has range [0:3], obtained by calculating [log10(xmin):log10(xmax)].
The transformation functions f() and g() must be defined using a dummy variable appropriate to the nonlinear axis:
```
axis: x x2 dummy variable x
axis: y y2 dummy variable y
axis: z cb dummy variable z
axis: r dummy variable r
```
Example:
```
set xrange [-3:3]
set nonlinear x via norm(x) inverse invnorm(x)
```
This example establishes a probability-scaled ("probit") x axis, such that plotting the cumulative normal function Phi(x) produces a straight line plot against a linear y axis.
Example:
```
logit(p) = log(p/(1-p))
logistic(a) = 1. / (1. + exp(-a))
set xrange [.001 : .999]
set nonlinear y via logit(y) inverse logistic(y)
plot logit(x)
```
This example establishes a logit-scaled y axis such that plotting logit(x) on a linear x axis produces a straight line plot.
Example:
```
f(x) = (x <= 100) ? x : (x < 500) ? NaN : x-390
g(x) = (x <= 100) ? x : x+390
set xrange [0:1000] noextend
set nonlinear x via f(x) inverse g(x)
set xtics add (100,500)
plot sample [x=1:100] x, [x=500:1000] x
```
This example creates a "broken axis". X coordinates 0-100 are at the left, X coordinates 500-1000 are at the right, there is a small gap (10 units) between them. So long as no data points with (100 < x < 500) are plotted, this works as expected.
Object
------
The **set object** command defines a single object which will appear in subsequent plots. You may define as many objects as you like. Currently the supported object types are **rectangle**, **circle**, **ellipse**, and **polygon**. Rectangles inherit a default set of style properties (fill, color, border) from those set by the command **set style rectangle**, but each object can also be given individual style properties. Circles, ellipses, and polygons inherit the fill style from **set style fill**. Objects to be drawn in 2D plots may be defined in any combination of axis, graph, polar, or screen coordinates. Object specifications in 3D plots cannot use graph coordinates. Rectangles and ellipses in 3D plots are limited to screen coordinates.
Syntax:
```
set object <index>
<object-type> <object-properties>
{front|back|behind|depthorder}
{clip|noclip}
{fc|fillcolor <colorspec>} {fs <fillstyle>}
{default} {lw|linewidth <width>} {dt|dashtype <dashtype>}
unset object <index>
```
<object-type> is either **rectangle**, **ellipse**, **circle**, or **polygon**. Each object type has its own set of characteristic properties.
The options **front**, **back**, **behind** control whether the object is drawn before or after the plot itself. See **[layers](layers#layers)**. Setting **front** will draw the object in front of all plot elements, but behind any labels that are also marked **front**. Setting **back** will place the object behind all plot curves and labels. Setting **behind** will place the object behind everything including the axes and **back** rectangles, thus
```
set object rectangle from screen 0,0 to screen 1,1 behind
```
can be used to provide a colored background for the entire graph or page. By default, objects are clipped to the graph boundary unless one or more vertices are given in screen coordinates. Setting **noclip** will disable clipping to the graph boundary, but will still clip against the screen size.
The fill color of the object is taken from the <colorspec>. **fillcolor** may be abbreviated **fc**. The fill style is taken from <fillstyle>. See **[colorspec](linetypes_colors_styles#colorspec)** and **[fillstyle](set_show#fillstyle)**. If the keyword **default** is given, these properties are inherited from the default settings at the time a plot is drawn. See **[set style rectangle](set_show#set_style_rectangle)**.
### Rectangle
Syntax:
```
set object <index> rectangle
{from <position> {to|rto} <position> |
center <position> size <w>,<h> |
at <position> size <w>,<h>}
```
The position of the rectangle may be specified by giving the position of two diagonal corners (bottom left and top right) or by giving the position of the center followed by the width and the height. In either case the positions may be given in axis, graph, or screen coordinates. See **[coordinates](coordinates#coordinates)**. The options **at** and **center** are synonyms.
Examples:
```
# Force the entire area enclosed by the axes to have background color cyan
set object 1 rect from graph 0, graph 0 to graph 1, graph 1 back
set object 1 rect fc rgb "cyan" fillstyle solid 1.0
```
```
# Position a red square with lower left at 0,0 and upper right at 2,3
set object 2 rect from 0,0 to 2,3 fc lt 1
```
```
# Position an empty rectangle (no fill) with a blue border
set object 3 rect from 0,0 to 2,3 fs empty border rgb "blue"
```
```
# Return fill and color to the default style but leave vertices unchanged
set object 2 rect default
```
Rectangle corners specified in screen coordinates may extend beyond the edge of the current graph. Otherwise the rectangle is clipped to fit in the graph.
### Ellipse
Syntax:
```
set object <index> ellipse {at|center} <position> size <w>,<h>
{angle <orientation>} {units xy|xx|yy}
{<other-object-properties>}
```
The position of the ellipse is specified by giving the center followed by the width and the height (actually the major and minor axes). The keywords **at** and **center** are synonyms. The center position may be given in axis, graph, or screen coordinates. See **[coordinates](coordinates#coordinates)**. The major and minor axis lengths must be given in axis coordinates. The orientation of the ellipse is specified by the angle between the horizontal axis and the major diameter of the ellipse. If no angle is given, the default ellipse orientation will be used instead (see **[set style ellipse](set_show#set_style_ellipse)**). The **units** keyword controls the scaling of the axes of the ellipse. **units xy** means that the major axis is interpreted in terms of units along the x axis, while the minor axis in that of the y axis. **units xx** means that both axes of the ellipses are scaled in the units of the x axis, while **units yy** means that both axes are in units of the y axis. The default is **xy** or whatever **set style ellipse units** was set to.
NB: If the x and y axis scales are not equal, (e.g. **units xy** is in effect) then the major/minor axis ratio will no longer be correct after rotation.
Note that **set object ellipse size <2r>,<2r>** does not in general produce the same result as **set object circle <r>**. The circle radius is always interpreted in terms of units along the x axis, and will always produce a circle even if the x and y axis scales are different and even if the aspect ratio of your plot is not 1. If **units** is set to **xy**, then 'set object ellipse' interprets the first <2r> in terms of x axis units and the second <2r> in terms of y axis units. This will only produce a circle if the x and y axis scales are identical and the plot aspect ratio is 1. On the other hand, if **units** is set to **xx** or **yy**, then the diameters specified in the 'set object' command will be interpreted in the same units, so the ellipse will have the correct aspect ratio, and it will maintain its aspect ratio even if the plot is resized.
### Circle
Syntax:
```
set object <index> circle {at|center} <position> size <radius>
{arc [<begin>:<end>]} {no{wedge}}
{<other-object-properties>}
```
The position of the circle is specified by giving the position of the center center followed by the radius. The keywords **at** and **center** are synonyms. In 2D plots the position and radius may be given in any coordinate system. See **[coordinates](coordinates#coordinates)**. Circles in 3D plots cannot use graph coordinates. In all cases the radius is calculated relative to the horizontal scale of the axis, graph, or canvas. Any disparity between the horizontal and vertical scaling will be corrected for so that the result is always a circle. If you want to draw a circle in plot coordinates (such that it will appear as an ellipse if the horizontal and vertical scales are different), use **set object ellipse** instead.
By default a full circle is drawn. The optional qualifier **arc** specifies a starting angle and ending angle, in degrees, for one arc of the circle. The arc is always drawn counterclockwise.
See also **[set style circle](set_show#set_style_circle)**, **[set object ellipse](set_show#set_object_ellipse)**.
### Polygon
Syntax:
```
set object <index> polygon
from <position> to <position> ... {to <position>}
```
or
```
from <position> rto <position> ... {rto <position>}
```
The position of the polygon may be specified by giving the position of a sequence of vertices. These may be given in any coordinate system. If relative coordinates are used (rto) then the coordinate type must match that of the previous vertex. See **[coordinates](coordinates#coordinates)**.
Example:
```
set object 1 polygon from 0,0 to 1,1 to 2,0
set object 1 fc rgb "cyan" fillstyle solid 1.0 border lt -1
```
#### Depthorder
The option **set object N depthorder** applies to 3D polygon objects only. Rather than assigning the object to layer front/back/behind it is included in the list of pm3d quadrangles sorted and rendered in order of depth by **set pm3d depthorder**. As with pm3d surfaces, two-sided coloring can be generated by specifying the object fillcolor as a linestyle. In this case the ordering of the first three vertices in the polygon determines the "side". If you set this property for an object that is not a 3D polygon it probably will not be drawn at all.
Offsets
-------
Autoscaling sets the x and y axis ranges to match the coordinates of the data that is plotted. Offsets provide a mechanism to expand these ranges to leave empty space between the data and the plot borders. Autoscaling then further extends each range to reach the next axis tic unless this has been suppressed by **set autoscale noextend** or **set xrange noextend**. See **[noextend](set_show#noextend)**. Offsets affect only scaling for the x1 and y1 axes. Syntax:
```
set offsets <left>, <right>, <top>, <bottom>
unset offsets
show offsets
```
Each offset may be a constant or an expression. Each defaults to 0. By default, the left and right offsets are given in units of the first x axis, the top and bottom offsets in units of the first y axis. Alternatively, you may specify the offsets as a fraction of the total graph dimension by using the keyword "graph". Only "graph" offsets are possible for nonlinear axes.
A positive offset expands the axis range in the specified direction, e.g. a positive bottom offset makes ymin more negative. Negative offsets interact badly with autoscaling and clipping.
Example:
```
set autoscale noextend
set offsets graph 0.05, 0, 2, 2
plot sin(x)
```
This graph of sin(x) will have y range [-3:3] because the function will be autoscaled to [-1:1] and the vertical offsets add 2 at each end of the range. The x range will be [-11:10] because the default is [-10:10] and it has been expanded to the left by 0.05 of that total range.
Origin
------
The **set origin** command is used to specify the origin of a plotting surface (i.e., the graph and its margins) on the screen. The coordinates are given in the **screen** coordinate system (see **[coordinates](coordinates#coordinates)** for information about this system). Syntax:
```
set origin <x-origin>,<y-origin>
```
Output
------
By default, screens are displayed to the standard output. The **set output** command redirects the display to the specified file or device. Syntax:
```
set output {"<filename>"}
show output
```
The filename must be enclosed in quotes. If the filename is omitted, any output file opened by a previous invocation of **set output** will be closed and new output will be sent to STDOUT. (If you give the command **set output "STDOUT"**, your output may be sent to a file named "STDOUT"! ["May be", not "will be", because some terminals, like **x11** or **wxt**, ignore **set output**.])
When both **set terminal** and **set output** are used together, it is safest to give **set terminal** first, because some terminals set a flag which is needed in some operating systems. This would be the case, for example, if the operating system needs a separate open command for binary files.
On platforms that support pipes, it may be useful to pipe terminal output. For instance,
```
set output "|lpr -Plaser filename"
set term png; set output "|display png:-"
```
On MSDOS machines, **set output "PRN"** will direct the output to the default printer. On VMS, output can be sent directly to any spooled device.
Overflow
--------
Syntax:
```
set overflow {float | NaN | undefined}
unset overflow
```
This version of gnuplot supports 64-bit integer arithmetic. This means that for values from 2`^`53 to 2`^`63 (roughly 10`^`16 to 10`^`19) integer evaluation preserves more precision than evaluation using IEEE 754 floating point arithmetic. However unlike the IEEE floating point representation, which sacrifices precision to span a total range of roughly [-10`^`307 : 10`^`307], integer operations that result in values outside the range [-2`^`63 : 2`^`63] overflow. The **set overflow** command lets you control what happens in case of overflow. See options below.
**set overflow** is the same as **set overflow float**. It causes the result to be returned as a real number rather than as an integer. This is the default.
The command **unset overflow** causes integer arithmetic overflow to be ignored. No error is shown. This may be desirable if your platform allows only 32-bit integer arithmetic and you want to approximate the behaviour of gnuplot versions prior to 5.4.
The **reset** command does not affect the state of overflow handling.
Earlier gnuplot versions were limited to 32-bit arithmetic and ignored integer overflow. Note, however, that some built-in operators did not use integer arithmetic at all, even when given integer arguments. This included the exponentiation operator N\*\*M and the summation operator (see **[summation](expressions#summation)**). These operations now return an integer value when given integer arguments, making them potentially susceptible to overflow and thus affected by the state of **set overflow**.
### Float
If an integer arithmetic expression overflows the limiting range, [-2`^`63 : 2`^`63] for 64-bit integers, the result is returned as a floating point value instead. This is not treated as an error. Example:
```
gnuplot> set overflow float
gnuplot> A = 2**62 - 1; print A, A+A, A+A+A
4611686018427387903 9223372036854775806 1.38350580552822e+19
```
### NaN
If an integer arithmetic expression overflows the limiting range, [-2`^`63 : 2`^`63] for 64-bit integers, the result is returned as NaN (Not a Number). This is not treated as an error. Example:
```
gnuplot> set overflow NaN
gnuplot> print 10**18, 10**19
1000000000000000000 NaN
```
### Undefined
If an integer arithmetic expression overflows the limiting range, [-2`^`63 : 2`^`63] for 64-bit integers, the result is undefined. This is treated as an error. Example:
```
gnuplot> set overflow undefined
gnuplot> A = 10**19
^
undefined value
```
### Affected operations
The **set overflow** state affects the arithmetic operators
```
+ - * / **
```
and the built-in summation operation **sum**. All of these operations will return an integer result if all of the arguments are integers, so long as no overflow occurs during evaluation.
The **set overflow** state does not affect logical or bit operations
```
<< >> | ^ &
```
If overflow occurs at any point during the course of evaluating of a summation **set overflow float** will cause the result to be returned as a real number even if the final sum is within the range of integer representation.
Palette
-------
The palette is a set of colors, usually ordered in the form of one or more stepped gradients, used for **pm3d** surfaces and other graph elements colored by z value. Colors in the current palette are automatically mapped from plot coordinates z values or an extra data column of gray values. Palette colors also can be accessed explicitly in a color specification (see **[colorspec](linetypes_colors_styles#colorspec)**) * as a **gray value** also known as **palette fraction** in the range [0:1]
* as a **z value** corresponding to the z coordinate of a plot element
* as a **cb value** in the range [cbmin:cbmax] (see **[set cbrange](set_show#set_cbrange)**)
The current palette is shown by default in a separate **colorbox** drawn next to plots that use plot style **pm3d**. The colorbox can be manually selected or disabled. See **[set colorbox](set_show#set_colorbox)**. Syntax:
```
set palette
set palette {
{ gray | color }
{ gamma <gamma> }
{ rgbformulae <r>,<g>,<b>
| defined { ( <gray1> <color1> {, <grayN> <colorN>}... ) }
| file '<filename>' {datafile-modifiers}
| functions <R>,<G>,<B>
}
{ cubehelix {start <val>} {cycles <val>} {saturation <val>} }
{ model { RGB | HSV | CMY } }
{ positive | negative }
{ nops_allcF | ps_allcF }
{ maxcolors <maxcolors> }
}
show palette
show palette palette <n> {{float | int}}
show palette gradient
show palette fit2rgbformulae
show palette rgbformulae
show colornames
```
**set palette** (i.e. without options) sets up the default values. Otherwise, the options can be given in any order. **show palette** shows the current palette properties.
**show palette gradient** displays the gradient defining the palette (if appropriate). **show palette rgbformulae** prints the available fixed gray –> color transformation formulae. **show colornames** prints the known color names.
**show palette palette <n>** prints to the screen or to the file given by **set print** a table of RGB triplets calculated for the current palette settings and a palette having <n> discrete colors. The default wide table can be limited to 3 columns of r,g,b float values [0..1] or integer values [0..255] by options float or int, respectively. This way, the current gnuplot color palette can be loaded into other imaging applications, for example Octave. Alternatively, the **test palette** command will plot the R,G,B profiles for the current palette and leave the profile values in a datablock $PALETTE.
The following options determine the coloring properties.
Figure using this palette can be **gray** or **color**. For instance, in **pm3d** color surfaces the gray of each small spot is obtained by mapping the averaged z-coordinate of the 4 corners of surface quadrangles into the range [min\_z,max\_z] providing range of grays [0:1]. This value can be used directly as the gray for gray maps. The color map requires a transformation gray –> (R,G,B), i.e. a mapping [0:1] –> ([0:1],[0:1],[0:1]).
Basically two different types of mappings can be used: Analytic formulae to convert gray to color, or discrete mapping tables which are interpolated. **palette rgbformulae** and **palette functions** use analytic formulae whereas **palette defined** and **palette file** use interpolated tables. **palette rgbformulae** reduces the size of postscript output to a minimum.
The command **show palette fit2rgbformulae** finds the best matching **set palette rgbformulae** for the current **set palette**. Naturally, it makes sense to use it for non-rgbformulae palettes. This command can be found useful mainly for external programs using the same rgbformulae definition of palettes as gnuplot, like zimg ( <http://zimg.sourceforge.net>
).
**set palette gray** switches to a gray only palette. **set palette rgbformulae**, **set palette defined**, **set palette file** and **set palette functions** switch to a color mapping. **set palette color** is an easy way to switch back from the gray palette to the last color mapping.
Automatic gamma correction via **set palette gamma <gamma>** can be done for gray maps (**set palette gray**) and for the **cubehelix** color palette schemes. Gamma = 1 produces a linear ramp of intensity. See **[test palette](test#test_palette)**.
Many terminals support only discrete number of colors (e.g. 256 colors in gif). After the default gnuplot linetype colors are allocated, the rest of the available colors are by default reserved for pm3d. Thus a multiplot using multiple palettes could fail because the first palette has used all the available color positions. You can mitigate this limitation by using **set palette maxcolors <N>** with a reasonably small value of N. This option causes N discrete colors to be selected from a continuous palette sampled at equally spaced intervals. If you want unequal spacing of N discrete colors, use **set palette defined** instead of a single continuous palette.
RGB color space might not be the most useful color space to work in. For that reason you may change the color space **model** to one of **RGB**, **HSV**, **CMY**. Using color names for **set palette defined** tables and a color space other than RGB will result in funny colors. All explanation have been written for RGB color space, so please note, that **R** can be **H**, or **C**, depending on the actual color space (**G** and **B** accordingly).
All values for all color spaces are limited to [0,1].
RGB stands for Red, Green, Blue; CMY stands for Cyan, Magenta, Yellow; HSV stands for Hue, Saturation, Value. For more information on color models see: <http://en.wikipedia.org/wiki/Color_space>
Note: Earlier gnuplot versions accepted YIQ and XYZ color space models also, but the implementation was never complete or correct.
### Rgbformulae
For **rgbformulae** three suitable mapping functions have to be chosen. This is done via **rgbformulae <r>,<g>,<b>**. The available mapping functions are listed by **show palette rgbformulae**. Default is **7,5,15**, some other examples are **3,11,6**, **21,23,3** or **3,23,21**. Negative numbers, like **3,-11,-6**, mean inverted color (i.e. 1-gray passed into the formula, see also **[positive](set_show#positive)** and **[negative](set_show#negative)** options below). Some nice schemes in RGB color space
```
7,5,15 ... traditional pm3d (black-blue-red-yellow)
3,11,6 ... green-red-violet
23,28,3 ... ocean (green-blue-white); try also all other permutations
21,22,23 ... hot (black-red-yellow-white)
30,31,32 ... color printable on gray (black-blue-violet-yellow-white)
33,13,10 ... rainbow (blue-green-yellow-red)
34,35,36 ... AFM hot (black-red-yellow-white)
```
A full color palette in HSV color space
```
3,2,2 ... red-yellow-green-cyan-blue-magenta-red
```
Please note that even if called **rgbformulae** the formulas might actually determine the <H>,<S>,<V> or <X>,<Y>,<Z> or ... color components as usual.
Use **positive** and **negative** to invert the figure colors.
Note that it is possible to find a set of the best matching rgbformulae for any other color scheme by the command
```
show palette fit2rgbformulae
```
### Defined
Gray-to-rgb mapping can be manually set by use of **palette defined**: A color gradient is defined and used to give the rgb values. Such a gradient is a piecewise linear mapping from gray values in [0,1] to the RGB space [0,1]x[0,1]x[0,1]. You must specify the gray values and the corresponding RGB values between which linear interpolation will be done. Syntax:
```
set palette defined { ( <gray1> <color1> {, <grayN> <colorN>}... ) }
```
<grayX> are gray values which are mapped to [0,1] and <colorX> are the corresponding rgb colors. The color can be specified in three different ways:
```
<color> := { <r> <g> <b> | '<color-name>' | '#rrggbb' }
```
Either by three numbers (each in [0,1]) for red, green and blue, separated by whitespace, or the name of the color in quotes or X style color specifiers also in quotes. You may freely mix the three types in a gradient definition, but the named color "red" will be something strange if RGB is not selected as color space. Use **show colornames** for a list of known color names.
Please note, that even if written as <r>, this might actually be the <H> component in HSV color space depending on the selected color model.
The <gray> values have to form an ascending sequence of real numbers; the sequence will be automatically rescaled to [0,1].
**set palette defined** (without a gradient definition in braces) switches to RGB color space and uses a preset full-spectrum color gradient. Use **show palette gradient** to display the gradient.
Examples:
To produce a gray palette (useless but instructive) use:
```
set palette model RGB
set palette defined ( 0 "black", 1 "white" )
```
To produce a blue yellow red palette use (all equivalent):
```
set palette defined ( 0 "blue", 1 "yellow", 2 "red" )
set palette defined ( 0 0 0 1, 1 1 1 0, 2 1 0 0 )
set palette defined ( 0 "#0000ff", 1 "#ffff00", 2 "#ff0000" )
```
To produce some rainbow-like palette use:
```
set palette defined ( 0 "blue", 3 "green", 6 "yellow", 10 "red" )
```
Full color spectrum within HSV color space:
```
set palette model HSV
set palette defined ( 0 0 1 1, 1 1 1 1 )
set palette defined ( 0 0 1 0, 1 0 1 1, 6 0.8333 1 1, 7 0.8333 0 1)
```
Approximate the default palette used by MATLAB:
```
set pal defined (1 '#00008f', 8 '#0000ff', 24 '#00ffff', \
40 '#ffff00', 56 '#ff0000', 64 '#800000')
```
To produce a palette with only a few, equally-spaced colors:
```
set palette model RGB maxcolors 4
set palette defined ( 0 "yellow", 1 "red" )
```
'Traffic light' palette (non-smooth color jumps at gray = 1/3 and 2/3).
```
set palette model RGB
set palette defined (0 "dark-green", 1 "green", \
1 "yellow", 2 "dark-yellow", \
2 "red", 3 "dark-red" )
```
### Functions
Use **set palette functions <Rexpr>, <Gexpr>, <Bexpr>** to define three formulae for the R(gray), G(gray) and B(gray) mapping. The three formulae may depend on the variable **gray** which will take values in [0,1] and should also produce values in [0,1]. Please note that <Rexpr> might be a formula for the H-value if HSV color space has been chosen (same for all other formulae and color spaces). Examples:
To produce a full color palette use:
```
set palette model HSV functions gray, 1, 1
```
A nice black to gold palette:
```
set palette model RGB functions 1.1*gray**0.25, gray**0.75, 0
```
A gamma-corrected black and white palette
```
gamma = 2.2
color(gray) = gray**(1./gamma)
set palette model RGB functions color(gray), color(gray), color(gray)
```
### Gray
**set palette gray** switches to a grayscale palette shading from 0.0 = black to 1.0 = white. **set palette color** is an easy way to switch back from the gray palette to the last color mapping. ### Cubehelix
The "cubehelix" option defines a family of palettes in which color (hue) varies along the standard color wheel while at the same time the net intensity increases monotonically as the gray value goes from 0 to 1.
```
D A Green (2011) http://arxiv.org/abs/1108.5083
```
**start** defines the starting point along the color wheel in radians. **cycles** defines how many color wheel cycles span the palette range. Larger values of **saturation** produce more saturated color; saturation > 1 may lead to clipping of the individual RGB components and to intensity becoming non-monotonic. The palette is also affected by **set palette gamma**. The default values are
```
set palette cubehelix start 0.5 cycles -1.5 saturation 1
set palette gamma 1.5
```
### File
**set palette file** is basically a **set palette defined (<gradient>)** where <gradient> is read from a datafile. Either 4 columns (gray,R,G,B) or just three columns (R,G,B) have to be selected via the **using** data file modifier. In the three column case, the line number will be used as gray. The gray range is automatically rescaled to [0,1]. The file is read as a normal data file, so all datafile modifiers can be used. Please note, that **R** might actually be e.g. **H** if HSV color space is selected. As usual <filename> may be **'-'** which means that the data follow the command inline and are terminated by a single **e** on a line of its own.
Use **show palette gradient** to display the gradient.
Examples:
Read in a palette of RGB triples each in range [0,255]:
```
set palette file 'some-palette' using ($1/255):($2/255):($3/255)
```
Equidistant rainbow (blue-green-yellow-red) palette:
```
set palette model RGB file "-"
0 0 1
0 1 0
1 1 0
1 0 0
e
```
Binary palette files are supported as well, see **[binary general](plot#binary_general)**. Example: put 64 triplets of R,G,B doubles into file palette.bin and load it by
```
set palette file "palette.bin" binary record=64 using 1:2:3
```
### Gamma correction
For gray mappings gamma correction can be turned on by **set palette gamma <gamma>**. <gamma> defaults to 1.5 which is quite suitable for most terminals. The gamma correction is applied to the cubehelix color palette family, but not to other palette coloring schemes. However, you may easily implement gamma correction for explicit color functions.
Example:
```
set palette model RGB
set palette functions gray**0.64, gray**0.67, gray**0.70
```
To use gamma correction with interpolated gradients specify intermediate gray values with appropriate colors. Instead of
```
set palette defined ( 0 0 0 0, 1 1 1 1 )
```
use e.g.
```
set palette defined ( 0 0 0 0, 0.5 .73 .73 .73, 1 1 1 1 )
```
or even more intermediate points until the linear interpolation fits the "gamma corrected" interpolation well enough.
### Postscript
In order to reduce the size of postscript files, the gray value and not all three calculated r,g,b values are written to the file. Therefore the analytical formulae are coded directly in the postscript language as a header just before the pm3d drawing, see /g and /cF definitions. Usually, it makes sense to write therein definitions of only the 3 formulae used. But for multiplot or any other reason you may want to manually edit the transformations directly in the postscript file. This is the default option **nops\_allcF**. Using the option **ps\_allcF** writes postscript definitions of all formulae. This you may find interesting if you want to edit the postscript file in order to have different palettes for different surfaces in one graph. Well, you can achieve this functionality by **multiplot** with fixed **origin** and **size**. If you are writing a pm3d surface to a postscript file, it may be possible to reduce the file size by up to 50% by the enclosed awk script **pm3dCompress.awk**. If the data lies on a rectangular grid, even greater compression may be possible using the script **pm3dConvertToImage.awk**. Usage:
```
awk -f pm3dCompress.awk thefile.ps >smallerfile.ps
awk -f pm3dConvertToImage.awk thefile.ps >smallerfile.ps
```
Parametric
----------
The **set parametric** command changes the meaning of **plot** (**splot**) from normal functions to parametric functions. The command **unset parametric** restores the plotting style to normal, single-valued expression plotting. Syntax:
```
set parametric
unset parametric
show parametric
```
For 2D plotting, a parametric function is determined by a pair of parametric functions operating on a parameter. An example of a 2D parametric function would be **plot sin(t),cos(t)**, which draws a circle (if the aspect ratio is set correctly — see **[set size](set_show#set_size)**). **gnuplot** will display an error message if both functions are not provided for a parametric **plot**.
For 3D plotting, the surface is described as x=f(u,v), y=g(u,v), z=h(u,v). Therefore a triplet of functions is required. An example of a 3D parametric function would be **cos(u)\*cos(v),cos(u)\*sin(v),sin(u)**, which draws a sphere. **gnuplot** will display an error message if all three functions are not provided for a parametric **splot**.
The total set of possible plots is a superset of the simple f(x) style plots, since the two functions can describe the x and y values to be computed separately. In fact, plots of the type t,f(t) are equivalent to those produced with f(x) because the x values are computed using the identity function. Similarly, 3D plots of the type u,v,f(u,v) are equivalent to f(x,y).
Note that the order the parametric functions are specified is xfunction, yfunction (and zfunction) and that each operates over the common parametric domain.
Also, the **set parametric** function implies a new range of values. Whereas the normal f(x) and f(x,y) style plotting assume an xrange and yrange (and zrange), the parametric mode additionally specifies a trange, urange, and vrange. These ranges may be set directly with **set trange**, **set urange**, and **set vrange**, or by specifying the range on the **plot** or **splot** commands. Currently the default range for these parametric variables is [-5:5]. Setting the ranges to something more meaningful is expected.
Paxis
-----
Syntax:
```
set paxis <axisno> {range <range-options> | tics <tic-options>}
set paxis <axisno> label <label-options> { offset <radial-offset> }
show paxis <axisno> {range | tics}
```
The **set paxis** command is equivalent to the **set xrange** and **set xtics** commands except that it acts on one of the axes p1, p2, ... used in parallel axis plots and spiderplots. See **[parallelaxes](parallelaxes#parallelaxes)**, **[set xrange](set_show#set_xrange)**, and **[set xtics](set_show#set_xtics)**. The normal options to the range and tics commands are accepted although not all options make sense for parallel axis plots. **set paxis <axisno> label <label-options>** is relevant to spiderplots but ignored otherwise. Axes of a parallel axis plot can be labeled using the **title** option of the plot command, which generates an xtic label. Note that this may require also **set xtics**.
The axis linetype properties are controlled using **[set style parallelaxis](set_show#set_style_parallelaxis)**.
Pixmap
------
Syntax:
```
set pixmap <index> "filename" at <position>
{width <w> | height <h> | size <w>,<h>}
{front|back|behind} {center}
show pixmaps
unset pixmaps
unset pixmap <index>
```
The **set pixmap** command is similar to **set object** in that it defines an object that will appear on subsequent plots. The rectangular array of red/green/blue/alpha values making up the pixmap are read from a png, jpeg, or gif file. The position and extent occupied by the pixmap in the gnuplot output may be specified in any coordinate system (see **[coordinates](coordinates#coordinates)**). The coordinates given by **at <position>** refer to the lower left corner of the pixmap unless keyword **center** is present.
If the x-extent of the rendered pixmap is set using **width <x-extent>** the aspect ratio of the original image is retained and neither the aspect ratio nor the orientation of the pixmap changes with axis scaling or rotation. Similarly if the y-extent is set using **height <y-extent>**. If both the x-extent and y-extent are given using **size <x-extent> <y-extent>** this overrides the original aspect ratio. If no size is set then the original size in pixels is used (the effective size is then terminal-dependent).
Pixmaps are not clipped to the border of the plot. As an exception to the general behaviour of objects and layers, a pixmap assigned to layer **behind** is rendered for only the first plot in a multiplot. This allows all panels in a multiplot to share a single background pixmap.
Examples:
```
# Use a gradient as the background for all plotting
# Both x and y will be resized to fill the entire canvas
set pixmap 1 "gradient.png"
set pixmap 1 at screen 0, 0 size screen 1, 1 behind
```
```
# Place a logo at the lower right of each page plotted
set pixmap 2 "logo.jpg"
set pixmap 2 at screen 0.95, 0 width screen 0.05 behind
```
```
# Place a small image at some 3D coordinate
# It will move as if attached to the surface being plotted
# but will always face forward and remain upright
set pixmap 3 "image.png" at my_x, my_y, f(my_x,my_y) width screen .05
splot f(x,y)
```
Plot
----
The **show plot** command shows the current plotting command as it results from the last **plot** and/or **splot** and possible subsequent **replot** commands. In addition, the **show plot add2history** command adds this current plot command into the **history**. It is useful if you have used **replot** to add more curves to the current plot and you want to edit the whole command now.
Pm3d
----
pm3d is an **splot** style for drawing palette-mapped 3d and 4d data as color/gray maps and surfaces. It allows plotting gridded or non-gridded data without preprocessing. pm3d style options also affect solid-fill polygons used to construct other 3D plot elements. Syntax (the options can be given in any order):
```
set pm3d {
{ at <position> }
{ interpolate <steps/points in scan, between scans> }
{ scansautomatic | scansforward | scansbackward
| depthorder {base} }
{ flush { begin | center | end } }
{ ftriangles | noftriangles }
{ clip {z} | clip1in | clip4in }
{ {no}clipcb }
{ corners2color
{ mean|geomean|harmean|rms|median|min|max|c1|c2|c3|c4 }
}
{ {no}lighting
{primary <fraction>} {specular <fraction>} {spec2 <fraction>}
}
{ border {<linestyle-options>}}
{ implicit | explicit }
{ map }
}
show pm3d
unset pm3d
```
Note that pm3d plots are plotted sequentially in the order given in the splot command. Thus earlier plots may be obscured by later plots. To avoid this you can use the **depthorder** scan option.
The pm3d surfaces can be projected onto the **top** or **bottom** of the view box. See **[pm3d position](set_show#pm3d_position)**. The following command draws three color surfaces at different altitudes:
```
set border 4095
set pm3d at s
splot 10*x with pm3d at b, x*x-y*y, x*x+y*y with pm3d at t
```
See also help for **[set palette](set_show#set_palette)**, **[set cbrange](set_show#set_cbrange)**, **[set colorbox](set_show#set_colorbox)**, and the demo file **demo/pm3d.dem**.
### Implicit
A pm3d color surface is drawn if the splot command specifies **with pm3d**, if the data or function **style** is set to pm3d globally, or if the pm3d mode is **set pm3d implicit**. In the latter two cases, the pm3d surface is draw in addition to the mesh produced by the style specified in the plot command. E.g.
```
splot 'fred.dat' with lines, 'lola.dat' with lines
```
would draw both a mesh of lines and a pm3d surface for each data set. If the option **explicit** is on (or **implicit** is off) only plots specified by the **with pm3d** attribute are plotted with a pm3d surface, e.g.:
```
splot 'fred.dat' with lines, 'lola.dat' with pm3d
```
would plot 'fred.dat' with lines (only) and 'lola.dat' with a pm3d surface. On gnuplot start-up, the mode is **explicit**. For historical and compatibility reasons, the commands **set pm3d;** (i.e. no options) and **set pm3d at X ...** (i.e. **at** is the first option) change the mode to **implicit**. The command **set pm3d;** sets other options to their default state.
If you set the default data or function style to **pm3d**, e.g.:
```
set style data pm3d
```
then the options **implicit** and **explicit** have no effect. ### Algorithm
Let us first describe how a map/surface is drawn. The input data come from an evaluated function or from an **splot data file**. Each surface consists of a sequence of separate scans (isolines). The pm3d algorithm fills the region between two neighbouring points in one scan with another two points in the next scan by a gray (or color) according to z-values (or according to an additional 'color' column, see help for **[using](plot#using)**) of these 4 corners; by default the 4 corner values are averaged, but this can be changed by the option **corners2color**. In order to get a reasonable surface, the neighbouring scans should not cross and the number of points in the neighbouring scans should not differ too much; of course, the best plot is with scans having same number of points. There are no other requirements (e.g. the data need not be gridded). Another advantage is that the pm3d algorithm does not draw anything outside of the input (measured or calculated) region.
Surface coloring works with the following input data:
1. splot of function or of data file with one or three data columns: The gray/color scale is obtained by mapping the averaged (or **corners2color**) z-coordinate of the four corners of the above-specified quadrangle into the range [min\_color\_z,max\_color\_z] of **zrange** or **cbrange** providing a gray value in the range [0:1]. This value can be used directly as the gray for gray maps. The normalized gray value can be further mapped into a color — see **[set palette](set_show#set_palette)** for the complete description.
2. splot of data file with two or four data columns: The gray/color value is obtained by using the last-column coordinate instead of the z-value, thus allowing the color and the z-coordinate be mutually independent. This can be used for 4d data drawing.
Other notes:
1. The term 'scan' referenced above is used more among physicists than the term 'iso\_curve' referenced in gnuplot documentation and sources. You measure maps recorded one scan after another scan, that's why.
2. The 'gray' or 'color' scale is a linear mapping of a continuous variable onto a smoothly varying palette of colors. The mapping is shown in a rectangle next to the main plot. This documentation refers to this as a "colorbox", and refers to the indexing variable as lying on the colorbox axis. See **[set colorbox](set_show#set_colorbox)**, **[set cbrange](set_show#set_cbrange)**.
### Lighting
By default the colors assigned to pm3d objects are not dependent on orientation or viewing angle. This state corresponds to **set pm3d nolighting**. The command **set pm3d lighting** selects a simple lighting model consisting of a single fixed source of illumination contributing 50% of the overall lighting. The strength of this light relative to the ambient illumination can be adjusted by **set pm3d lighting primary <fraction>**. Inclusion of specular highlighting can be adjusted by setting a fractional contribution:
```
set pm3d lighting primary 0.50 specular 0.0 # no highlights
set pm3d lighting primary 0.50 specular 0.6 # strong highlights
```
Solid-color pm3d surfaces tend to look very flat without specular highlights. Since the highlights from a single source only affect one side of the surface, a second spotlight source may be desirable to add specular highlights from the opposite direction. This is controlled by "spec2 <contribution>". EXPERIMENTAL (details may change in a future version): The second spotlight is a pure red light source that by default contributes nothing (spec2 0.0). See also hidden\_compare.dem [(comparison of hidden3d and pm3d treatment of solid-color surfaces)](http://www.gnuplot.info/demo_5.4/hidden_compare.html) ### Position
Color surface can be drawn at the base or top (then it is a gray/color planar map) or at z-coordinates of surface points (gray/color surface). This is defined by the **at** option with a string of up to 6 combinations of **b**, **t** and **s**. For instance, **at b** plots at bottom only, **at st** plots firstly surface and then top map, while **at bstbst** will never by seriously used. Colored quadrangles are plotted one after another. When plotting surfaces (**at s**), the later quadrangles overlap (overdraw) the previous ones. (Gnuplot is not virtual reality tool to calculate intersections of filled polygon meshes.) You may try to switch between **scansforward** and **scansbackward** to force the first scan of the data to be plotted first or last. The default is **scansautomatic** where gnuplot makes a guess about scans order. On the other hand, the **depthorder** option completely reorders the quadrangles. The rendering is performed after a depth sorting, which allows to visualize even complicated surfaces; see **[pm3d depthorder](set_show#pm3d_depthorder)** for more details.
### Scanorder
```
set pm3d {scansautomatic | scansforward | scansbackward | depthorder}
```
By default the quadrangles making up a pm3d solid surface are rendered in the order they are encountered along the surface grid points. This order may be controlled by the options **scansautomatic**|**scansforward**|**scansbackward**. These scan options are not in general compatible with hidden-surface removal.
If two successive scans do not have same number of points, then it has to be decided whether to start taking points for quadrangles from the beginning of both scans (**flush begin**), from their ends (**flush end**) or to center them (**flush center**). Note, that **flush (center|end)** are incompatible with **scansautomatic**: if you specify **flush center** or **flush end** and **scansautomatic** is set, it is silently switched to **scansforward**.
If two subsequent scans do not have the same number of points, the option **ftriangles** specifies whether color triangles are drawn at the scan tail(s) where there are not enough points in either of the scans. This can be used to draw a smooth map boundary.
Gnuplot does not do true hidden surface removal for solid surfaces, but often it is sufficient to render the component quadrangles in order from furthest to closest. This mode may be selected using the option
```
set pm3d depthorder
```
Note that the global option **set hidden3d** does not affect pm3d surfaces. The **depthorder** option by itself tends to produce bad results when applied to the long thin rectangles generated by **splot with boxes**. It works better to add the keyword **base**, which performs the depth sort using the intersection of the box with the plane at z=0. This type of plot is further improved by adding a lighing model. Example:
```
set pm3d depthorder base
set pm3d lighting
set boxdepth 0.4
splot $DATA using 1:2:3 with boxes
```
### Clipping
Syntax:
```
set pm3d {clip {z} | clip1in | clip4in}
set pm3d {no}clipcb
```
The component quadrangles of a pm3d surface or other 3D object are by default smoothly clipped against the current zrange. This is a change from earlier gnuplot versions.
Alternatively, surfaces can be clipped by rendering whole quadrangles but only those with all 4 corners in-range on x, y, and z (**set pm3d clip4in**), or only those with at least one corner in-range on x, y, and z (**set pm3d clip1in**). The options **clip**, **clip1in**, and **clip4in** are mutually exclusive.
Separate from clipping based on spatial x, y, and z coordinates, quadrangles can be rendered or not based on extreme palette color values. **clipcb**: (default) palette color values < cbmin are clipped to equal cbmin; palette color values > cbmax are clipped to equal cbmax. **noclipcb**: quadrangles with color value outside cbrange are not drawn at all.
### Color\_assignment
The default pm3d coloring assigns an individual color to each quadrangle of the surface grid. For alternative coloring schemes that assign uniform color to the entire surface, see **[pm3d fillcolor](set_show#pm3d_fillcolor)**. A single gray/color value (i.e. not a gradient) is assigned to each quadrangle. This value is calculated from the z-coordinates the four quadrangle corners according to **corners2color <option>**. The value is then used to select a color from the current palette. See **[set palette](set_show#set_palette)**. It is not possible to change palettes inside a single **splot** command.
If a fourth column of data is provided, the coloring of individual quadrangles works as above except that the color value is distinct from the z value. As a separate coloring option, the fourth data column may provide instead an RGB color. See **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**. In this case the plotting command must be
```
splot ... using 1:2:3:4 with pm3d lc rgb variable
```
Notice that ranges of z-values and color-values for surfaces are adjustable independently by **set zrange**, **set cbrange**, **set log z**, **set log cb**, etc.
### Corners2color
The color of each quadrangle in a pm3d surface is assigned based on the color values of its four bounding vertices. The options 'mean' (default), 'geomean', 'harmean, 'rms', and 'median' produce various kinds of surface color smoothing, while options 'min' and 'max' choose minimal or maximal value, respectively. This may not be desired for pixel images or for maps with sharp and intense peaks, in which case the options 'c1', 'c2', 'c3' or 'c4' can be used instead to assign the quadrangle color based on the z-coordinate of only one corner. Some experimentation may be needed to determine which corner corresponds to 'c1', as the orientation depends on the drawing direction. Because the pm3d algorithm does not extend the colored surface outside the range of the input data points, the 'c<j>' coloring options will result in pixels along two edges of the grid not contributing to the color of any quadrangle. For example, applying the pm3d algorithm to the 4x4 grid of data points in script **demo/pm3d.dem** (please have a look) produces only (4-1)x(4-1)=9 colored rectangles. ### Border
The option **set pm3d border {line-properties}** draws bounding lines around each quadrangle as it is rendered. Normally this is used in conjunction with the **depthorder** option to approximate hidden line removal. Note that the global option **set hidden3d** has no effect on pm3d plots. Default line properties (color, width) optionally follow the keyword **border**. These defaults can be overridden later in an splot command. Example of recommended usage:
```
set pm3d at s depthorder border lw 0.2 lt black
unset hidden3d
unset surf
splot x*x+y*y linecolor rgb "blue" # otherwise it would be black
```
### Fillcolor
```
splot FOO with pm3d fillcolor <colorspec>
```
Plot style **with pm3d** accepts an optional fillcolor in the splot command. This specification is applied to the entire pm3d surface. See **[colorspec](linetypes_colors_styles#colorspec)**. Most fillcolor specifications will result in a single solid color, which is hard to interpret visually unless there is also a lighting model present to distinguish surface components based on orientation. See **[pm3d lighting](set_show#pm3d_lighting)**.
There are a few special cases. **with pm3d fillcolor palette** would produce the same result as the default pm3d palette-based coloring, and is therefore not a useful option. **with pm3d fillcolor linestyle N** is more interesting. This variant assigns distinct colors to the top and bottom of the pm3d surface, similar to the color scheme used by gnuplot's **hidden3d** mode. Linestyle N is used for the top surface; linestyle N+1 for the bottom surface. Note that "top" and "bottom" depend on the scan order, so that the colors are inverted for **pm3d scansbackward** as compared to **pm3d scansforward**. This coloring option works best with **pm3d depthorder**, however, which unfortunately does not allow you to control the scan order so you may have to instead swap the colors defined for linestyles N and N+1.
### Interpolate
The option **interpolate m,n** will interpolate between grid points to generate a finer mesh. For data files, this smooths the color surface and enhances the contrast of spikes in the surface. When working with functions, interpolation makes little sense. It would usually make more sense to increase **samples** and **isosamples**. For positive m and n, each quadrangle or triangle is interpolated m-times and n-times in the respective direction. For negative m and n, the interpolation frequency is chosen so that there will be at least |m| and |n| points drawn; you can consider this as a special gridding function.
Note: **interpolate 0,0**, will automatically choose an optimal number of interpolated surface points.
Note: Currently color interpolation is always linear, even if corners2color is set to a nonlinear scheme such as the geometric mean.
### Deprecated\_options
The deprecated option **set pm3d map** was equivalent to **set pm3d at b; set view map; set style data pm3d; set style func pm3d;** The deprecated option **set pm3d hidden3d N** was equivalent to **set pm3d border ls N**.
Pointintervalbox
----------------
The **pointinterval** and **pointnumber** properties of a line type are used only in plot style **linespoints**. A negative value of pointinterval or pointnumber, e.g. -N, means that before the selected set of point symbols are drawn a box (actually circle) behind each point symbol is blanked out by filling with the background color. The command **set pointintervalbox** controls the radius of this blanked-out region. It is a multiplier for the default radius, which is equal to the point size. Pointsize
---------
The **set pointsize** command scales the size of the points used in plots. Syntax:
```
set pointsize <multiplier>
show pointsize
```
The default is a multiplier of 1.0. Larger pointsizes may be useful to make points more visible in bitmapped graphics.
The pointsize of a single plot may be changed on the **plot** command. See **[plot with](plot#plot_with)** for details.
Please note that the pointsize setting is not supported by all terminal types.
Polar
-----
The **set polar** command changes the meaning of the plot from rectangular coordinates to polar coordinates. Syntax:
```
set polar
unset polar
show polar
```
In polar coordinates, the dummy variable (t) represents an angle theta. The default range of t is [0:2\*pi], or [0:360] if degree units have been selected (see **[set angles](set_show#set_angles)**).
The command **unset polar** changes the meaning of the plot back to the default rectangular coordinate system.
The **set polar** command is not supported for **splot**s. See the **[set mapping](set_show#set_mapping)** command for similar functionality for **[splot](splot#splot)**s.
While in polar coordinates the meaning of an expression in t is really r = f(t), where t is an angle of rotation. The trange controls the domain (the angle) of the function. The r, x and y ranges control the extent of the graph in the x and y directions. Each of these ranges, as well as the rrange, may be autoscaled or set explicitly. For details, see **[set rrange](set_show#set_rrange)** and **[set xrange](set_show#set_xrange)**.
Example:
```
set polar
plot t*sin(t)
set trange [-2*pi:2*pi]
set rrange [0:3]
plot t*sin(t)
```
The first **plot** uses the default polar angular domain of 0 to 2\*pi. The radius and the size of the graph are scaled automatically. The second **plot** expands the domain, and restricts the size of the graph to the area within 3 units of the origin. This has the effect of limiting x and y to [-3:3].
By default polar plots are oriented such that theta=0 is at the far right, with theta increasing counterclockwise. You can change both the origin and the sense explicitly. See **[set theta](set_show#set_theta)**.
You may want to **set size square** to have **gnuplot** try to make the aspect ratio equal to unity, so that circles look circular. Tic marks around the perimeter can be specified using **set ttics**. See also [polar demos (polar.dem)](http://www.gnuplot.info/demo/polar.html)
and [polar data plot (poldat.dem).](http://www.gnuplot.info/demo/poldat.html)
Print
-----
The **set print** command redirects the output of the **print** command to a file. Syntax:
```
set print
set print "-"
set print "<filename>" [append]
set print "|<shell_command>"
set print $datablock [append]
```
**set print** with no parameters restores output to <STDERR>. The <filename> "-" means <STDOUT>. The **append** flag causes the file to be opened in append mode. A <filename> starting with "|" is opened as a pipe to the <shell\_command> on platforms that support piping.
The destination for **print** commands can also be a named data block. Data block names start with '$', see also **[inline data](inline_data_datablocks#inline_data)**. When printing a string to a data block, embedded newline characters are expanded to generate multiple data block entries. This is a CHANGE.
Psdir
-----
The **set psdir <directory>** command controls the search path used by the postscript terminal to find prologue.ps and character encoding files. You can use this mechanism to switch between different sets of locally-customized prolog files. The search order is
```
1) The directory specified by `set psdir`, if any
2) The directory specified by environmental variable GNUPLOT_PS_DIR
3) A built-in header or one from the default system directory
4) Directories set by `set loadpath`
```
Raxis
-----
The commands **set raxis** and **unset raxis** toggle whether the polar axis is drawn separately from grid lines and the x axis. If the minimum of the current rrange is non-zero (and not autoscaled), then a white circle is drawn at the center of the polar plot to indicate that the plot lines and axes do not reach 0. The axis line is drawn using the same line type as the plot border. See **[polar](set_show#polar)**, **[rrange](set_show#rrange)**, **[rtics](set_show#rtics)**, **[rlabel](set_show#rlabel)**, **[set grid](set_show#set_grid)**. Rgbmax
------
Syntax:
```
set rgbmax {1.0 | 255}
unset rgbmax
```
The red/green/blue color components of an rgbimage plot are by default interpreted as integers in the range [0:255]. **set rgbmax 1.0** tells the program that data values used to generate the color components of a plot with **rgbimage** or **rgbalpha** are floating point values in the range [0:1]. **unset rgbmax** returns to the default integer range [0:255]. Rlabel
------
This command places a label above the r axis. The label will be drawn whether or not the plot is in polar mode. See **[set xlabel](set_show#set_xlabel)** for additional keywords. Rmargin
-------
The command **set rmargin** sets the size of the right margin. Please see **[set margin](set_show#set_margin)** for details. Rrange
------
The **set rrange** command sets the range of the radial coordinate for a graph in polar mode. This has the effect of setting both xrange and yrange as well. The resulting xrange and yrange are both [-(rmax-rmin) : +(rmax-rmin)]. However if you later change the x or y range, for example by zooming, this does not change rrange, so data points continue to be clipped against rrange. Unlike other axes, autoscaling the raxis always results in rmin = 0. The **reverse** autoscaling flag is ignored. Note: Setting a negative value for rmin may produce unexpected results. Rtics
-----
The **set rtics** command places tics along the polar axis. The tics and labels are drawn to the right of the origin. The **mirror** keyword causes them to be drawn also to the left of the origin. See **[polar](set_show#polar)**, **[set xtics](set_show#set_xtics)**, and **[set mxtics](set_show#set_mxtics)** for discussion of keywords. Samples
-------
The default sampling rate of functions, or for interpolating data, may be changed by the **set samples** command. To change the sampling range for a particular plot, see **[plot sampling](plot#plot_sampling)**. Syntax:
```
set samples <samples_1> {,<samples_2>}
show samples
```
By default, sampling is set to 100 points. A higher sampling rate will produce more accurate plots, but will take longer. This parameter has no effect on data file plotting unless one of the interpolation/approximation options is used. See **[plot smooth](plot#plot_smooth)** re 2D data and **[set cntrparam](set_show#set_cntrparam)** and **[set dgrid3d](set_show#set_dgrid3d)** re 3D data.
When a 2D graph is being done, only the value of <samples\_1> is relevant.
When a surface plot is being done without the removal of hidden lines, the value of samples specifies the number of samples that are to be evaluated for the isolines. Each iso-v line will have <sample\_1> samples and each iso-u line will have <sample\_2> samples. If you only specify <samples\_1>, <samples\_2> will be set to the same value as <samples\_1>. See also **[set isosamples](set_show#set_isosamples)**.
Size
----
Syntax:
```
set size {{no}square | ratio <r> | noratio} {<xscale>,<yscale>}
show size
```
The <xscale> and <yscale> values are scale factors for the size of the plot, which includes the graph, labels, and margins.
Important note:
```
In earlier versions of gnuplot, some terminal types used the values from
`set size` to control also the size of the output canvas; others did not.
Almost all terminals now follow the following convention:
```
**set term <terminal\_type> size <XX>, <YY>** controls the size of the output file, or **canvas**. Please see individual terminal documentation for allowed values of the size parameters. By default, the plot will fill this canvas.
**set size <XX>, <YY>** scales the plot itself relative to the size of the canvas. Scale values less than 1 will cause the plot to not fill the entire canvas. Scale values larger than 1 will cause only a portion of the plot to fit on the canvas. Please be aware that setting scale values larger than 1 may cause problems on some terminal types.
**ratio** causes **gnuplot** to try to create a graph with an aspect ratio of <r> (the ratio of the y-axis length to the x-axis length) within the portion of the plot specified by <xscale> and <yscale>.
The meaning of a negative value for <r> is different. If <r>=-1, gnuplot tries to set the scales so that the unit has the same length on both the x and y axes. This is the 2D equivalent to the 3D command **set view equal xy**. If <r>=-2, the unit on y has twice the length of the unit on x, and so on.
The success of **gnuplot** in producing the requested aspect ratio depends on the terminal selected. The graph area will be the largest rectangle of aspect ratio <r> that will fit into the specified portion of the output (leaving adequate margins, of course).
**set size square** is a synonym for **set size ratio 1**.
Both **noratio** and **nosquare** return the graph to the default aspect ratio of the terminal, but do not return <xscale> or <yscale> to their default values (1.0).
**ratio** and **square** have no effect on 3D plots, but do affect 3D projections created using **set view map**. See also **[set view equal](set_show#set_view_equal)**, which forces the x and y axes of a 3D onto the same scale.
Examples:
To set the size so that the plot fills the available canvas:
```
set size 1,1
```
To make the graph half size and square use:
```
set size square 0.5,0.5
```
To make the graph twice as high as wide use:
```
set size ratio 2
```
Spiderplot
----------
The **set spiderplot** command switches interpretation of coordinates to a polar system in which each data point is mapped to a position along a radial axis. paxis 1 is always vertical; axes 2 to N proceed clockwise with even spacing. The command must be issued prior to plotting. It has additional effects equivalent to
```
set style data spiderplot
unset border
unset tics
set key noautotitle
set size ratio 1.0
```
Use **reset** to restore these after plotting. Style
-----
Default plotting styles are chosen with the **set style data** and **set style function** commands. See **[plot with](plot#plot_with)** for information about how to override the default plotting style for individual functions and data sets. See **plotting styles** or **[plot with](plot#plot_with)** for a complete list of styles. Syntax:
```
set style function <style>
set style data <style>
show style function
show style data
```
Default styles for specific plotting elements may also be set.
Syntax:
```
set style arrow <n> <arrowstyle>
set style boxplot <boxplot style options>
set style circle radius <size> {clip|noclip}
set style ellipse size <size> units {xy|xx|yy} {clip|noclip}
set style fill <fillstyle>
set style histogram <histogram style options>
set style line <n> <linestyle>
set style rectangle <object options> <linestyle> <fillstyle>
set style textbox {<n>} {opaque|transparent} {{no}border} {fillcolor}
```
### Set style arrow
Each terminal has a default set of arrow and point types, which can be seen by using the command **test**. **set style arrow** defines a set of arrow types and widths and point types and sizes so that you can refer to them later by an index instead of repeating all the information at each invocation. Syntax:
```
set style arrow <index> default
set style arrow <index> {nohead | head | backhead | heads}
{size <length>,<angle>{,<backangle>} {fixed}}
{filled | empty | nofilled | noborder}
{front | back}
{ {linestyle | ls <line_style>}
| {linetype | lt <line_type>}
{linewidth | lw <line_width}
{linecolor | lc <colorspec>}
{dashtype | dt <dashtype>} }
unset style arrow
show style arrow
```
<index> is an integer that identifies the arrowstyle.
If **default** is given all arrow style parameters are set to their default values.
If the linestyle <index> already exists, only the given parameters are changed while all others are preserved. If not, all undefined values are set to the default values.
Specifying **nohead** produces arrows drawn without a head — a line segment. This gives you yet another way to draw a line segment on the plot. By default, arrows have one head. Specifying **heads** draws arrow heads on both ends of the line.
Head size can be modified using **size <length>,<angle>** or **size <length>,<angle>,<backangle>**, where **<length>** defines length of each branch of the arrow head and **<angle>** the angle (in degrees) they make with the arrow. **<Length>** is in x-axis units; this can be changed by **first**, **second**, **graph**, **screen**, or **character** before the <length>; see **[coordinates](coordinates#coordinates)** for details.
By default the size of the arrow head is reduced for very short arrows. This can be disabled using the **fixed** keyword after the **size** command.
**<backangle>** is the angle (in degrees) the back branches make with the arrow (in the same direction as **<angle>**). It is ignored if the style is **nofilled**.
Specifying **filled** produces filled arrow heads with a border line around the arrow head. Specifying **noborder** produces filled arrow heads with no border. In this case the tip of the arrow head lies exactly on the endpoint of the vector and the arrow head is slightly smaller overall. Dashed arrows should always use **noborder**, since a dashed border is ugly. Not all terminals support filled arrow heads.
The line style may be selected from a user-defined list of line styles (see **[set style line](set_show#set_style_line)**) or may be defined here by providing values for **<line\_type>** (an index from the default list of styles) and/or **<line\_width>** (which is a multiplier for the default width).
Note, however, that if a user-defined line style has been selected, its properties (type and width) cannot be altered merely by issuing another **set style arrow** command with the appropriate index and **lt** or **lw**.
If **front** is given, the arrows are written on top of the graphed data. If **back** is given (the default), the arrow is written underneath the graphed data. Using **front** will prevent a arrow from being obscured by dense data.
Examples:
To draw an arrow without an arrow head and double width, use:
```
set style arrow 1 nohead lw 2
set arrow arrowstyle 1
```
See also **[set arrow](set_show#set_arrow)** for further examples.
### Boxplot
The **set style boxplot** command allows you to change the layout of plots created using the **boxplot** plot style. Syntax:
```
set style boxplot {range <r> | fraction <f>}
{{no}outliers} {pointtype <p>}
{candlesticks | financebars}
{medianlinewidth <width>}
{separation <x>}
{labels off | auto | x | x2}
{sorted | unsorted}
```
The box in the boxplot always spans the range of values from the first quartile to the third quartile of the data points. The limit of the whiskers that extend from the box can be controlled in two different ways. By default the whiskers extend from each end of the box for a range equal to 1.5 times the interquartile range (i.e. the vertical height of the box proper). Each whisker is truncated back toward the median so that it terminates at a y value belonging to some point in the data set. Since there may be no point whose value is exactly 1.5 times the interquartile distance, the whisker may be shorter than its nominal range. This default corresponds to
```
set style boxplot range 1.5
```
Alternatively, you can specify the fraction of the total number of points that the whiskers should span. In this case the range is extended symmetrically from the median value until it encompasses the requested fraction of the data set. Here again each whisker is constrained to end at a point in the data set. To span 95% of the points in the set
```
set style boxplot fraction 0.95
```
Any points that lie outside the range of the whiskers are considered outliers. By default these are drawn as individual circles (pointtype 7). The option **nooutliers** disables this. If outliers are not drawn they do not contribute to autoscaling.
By default boxplots are drawn in a style similar to candlesticks, but you have the option of using instead a style similar to finance bars.
A crossbar indicating the median is drawn using the same line type as box boundary. If you want a thicker line for the median
```
set style boxplot medianlinewidth 2.0
```
If you want no median line, set this to 0. If the using specification for a boxplot contains a fourth column, the values in that column will be interpreted as the discrete leveles of a factor variable. In this case more than one boxplots may be drawn, as many as the number of levels of the factor variable. These boxplots will be drawn next to each other, the distance between them is 1.0 by default (in x-axis units). This distance can be changed by the option **separation**.
The **labels** option governs how and where these boxplots (each representing a part of the dataset) are labeled. By default the value of the factor is put as a tick label on the horizontal axis – x or x2, depending on which one is used for the plot itself. This setting corresponds to option **labels auto**. The labels can be forced to use either of the x or x2 axes – options **labels x** and **labels x2**, respectively –, or they can be turned off altogether with the option **labels off**.
By default the boxplots corresponding to different levels of the factor variable are not sorted; they will be drawn in the same order the levels are encountered in the data file. This behavior corresponds to the **unsorted** option. If the **sorted** option is active, the levels are first sorted alphabetically, and the boxplots are drawn in the sorted order.
The **separation**, **labels**, **sorted** and **unsorted** option only have an effect if a fourth column is given the plot specification.
See **[boxplot](boxplot#boxplot)**, **[candlesticks](candlesticks#candlesticks)**, **[financebars](financebars#financebars)**.
### Set style data
The **set style data** command changes the default plotting style for data plots. Syntax:
```
set style data <plotting-style>
show style data
```
See **plotting styles** for the choices. **show style data** shows the current default data plotting style.
### Set style fill
The **set style fill** command is used to set the default style of the plot elements in plots with boxes, histograms, candlesticks and filledcurves. This default can be superseded by fillstyles attached to individual plots. Note that there is a separate default fill style for rectangles created by **set obj**. See **[set style rectangle](set_show#set_style_rectangle)**.
Syntax:
```
set style fill {empty
| {transparent} solid {<density>}
| {transparent} pattern {<n>}}
{border {lt} {lc <colorspec>} | noborder}
```
The **empty** option causes filled areas not to be filled. This is the default.
The **solid** option causes filling with a solid color, if the terminal supports that. The <density> parameter specifies the intensity of the fill color. At a <density> of 0.0, the box is empty, at <density> of 1.0, the inner area is of the same color as the current linetype. Some terminal types can vary the density continuously; others implement only a few levels of partial fill. If no <density> parameter is given, it defaults to 1.
The **pattern** option causes filling to be done with a fill pattern supplied by the terminal driver. The kind and number of available fill patterns depend on the terminal driver. If multiple datasets using filled boxes are plotted, the pattern cycles through all available pattern types, starting from pattern <n>, much as the line type cycles for multiple line plots.
Fill color (**fillcolor <colorspec>**) is distinct from fill style. I.e. plot elements or objects can share a fillstyle while retaining separate colors. In most places where a fillstyle is accepted you can also specify a fill color. Fillcolor may be abbreviated **fc**. Otherwise the fill color is take from the current linetype. Example:
```
plot FOO with boxes fillstyle solid 1.0 fillcolor "cyan"
```
#### Set style fill border
The bare keyword **border** causes the filled object to be surrounded by a solid line of the current linetype and color. You can change the color of this line by adding either a linetype or a linecolor. **noborder** specifies that no bounding line is drawn. Examples:
```
# Half-intensity fill, full intensity border in same color
set style fill solid 0.5 border
# Half-transparent fill, solid black border (linetype -1)
set style fill transparent solid 0.5 border -1
# Pattern fill in current color, border using color of linetype 5
plot ... with boxes fillstyle pattern 2 border lt 5
# Fill area in cyan, border in blue
plot ... with boxes fillcolor "cyan" fs solid border linecolor "blue"
```
Note: The border property of a fill style only affects plots drawn **with filledcurves** in the default mode (closed curve).
#### Set style fill transparent
Some terminals support the attribute **transparent** for filled areas. In the case of transparent solid fill areas, the **density** parameter is interpreted as an alpha value; that is, density 0 is fully transparent, density 1 is fully opaque. In the case of transparent pattern fill, the background of the pattern is either fully transparent or fully opaque. Note that there may be additional limitations on the creation or viewing of graphs containing transparent fill areas. For example, the png terminal can only use transparent fill if the "truecolor" option is set. Some pdf viewers may not correctly display the fill areas even if they are correctly described in the pdf file. Ghostscript/gv does not correctly display pattern-fill areas even though actual PostScript printers generally have no problem.
### Set style function
The **set style function** command changes the default plotting style for function plots (e.g. lines, points, filledcurves). See **plotting styles**. Syntax:
```
set style function <plotting-style>
show style function
```
### Set style increment
**Note**: This command has been deprecated. Instead please use the newer command **set linetype**, which redefines the linetypes themselves rather than searching for a suitable temporary line style to substitute. See **[set linetype](set_show#set_linetype)** Syntax:
```
set style increment {default|userstyles}
show style increment
```
By default, successive plots within the same graph will use successive linetypes from the default set for the current terminal type. However, choosing **set style increment user** allows you to step through the user-defined line styles rather than through the default linetypes.
Example:
```
set style line 1 lw 2 lc rgb "gold"
set style line 2 lw 2 lc rgb "purple"
set style line 4 lw 1 lc rgb "sea-green"
set style increment user
```
```
plot f1(x), f2(x), f3(x), f4(x)
```
should plot functions f1, f2, f4 in your 3 newly defined line styles. If a user-defined line style is not found then the corresponding default linetype is used instead. E.g. in the example above, f3(x) will be plotted using the default linetype 3.
### Set style line
Each terminal has a default set of line and point types, which can be seen by using the command **test**. **set style line** defines a set of line types and widths and point types and sizes so that you can refer to them later by an index instead of repeating all the information at each invocation. Syntax:
```
set style line <index> default
set style line <index> {{linetype | lt} <line_type> | <colorspec>}
{{linecolor | lc} <colorspec>}
{{linewidth | lw} <line_width>}
{{pointtype | pt} <point_type>}
{{pointsize | ps} <point_size>}
{{pointinterval | pi} <interval>}
{{pointnumber | pn} <max_symbols>}
{{dashtype | dt} <dashtype>}
{palette}
unset style line
show style line
```
**default** sets all line style parameters to those of the linetype with that same index.
If the linestyle <index> already exists, only the given parameters are changed while all others are preserved. If not, all undefined values are set to the default values.
Line styles created by this mechanism do not replace the default linetype styles; both may be used. Line styles are temporary. They are lost whenever you execute a **reset** command. To redefine the linetype itself, please see **[set linetype](set_show#set_linetype)**.
The line and point types default to the index value. The exact symbol that is drawn for that index value may vary from one terminal type to another.
The line width and point size are multipliers for the current terminal's default width and size (but note that <point\_size> here is unaffected by the multiplier given by the command**set pointsize**).
The **pointinterval** controls the spacing between points in a plot drawn with style **linespoints**. The default is 0 (every point is drawn). For example, **set style line N pi 3** defines a linestyle that uses pointtype N, pointsize and linewidth equal to the current defaults for the terminal, and will draw every 3rd point in plots using **with linespoints**. A negative value for the interval is treated the same as a positive value, except that some terminals will try to interrupt the line where it passes through the point symbol.
The **pointnumber** property is similar to **pointinterval** except that rather than plotting every Nth point it limits the total number of points to N.
Not all terminals support the **linewidth** and **pointsize** features; if not supported, the option will be ignored.
Terminal-independent colors may be assigned using either **linecolor <colorspec>** or **linetype <colorspec>**, abbreviated **lc** or **lt**. This requires giving a RGB color triple, a known palette color name, a fractional index into the current palette, or a constant value from the current mapping of the palette onto cbrange. See **[colors](linetypes_colors_styles#colors)**, **[colorspec](linetypes_colors_styles#colorspec)**, **[set palette](set_show#set_palette)**, **[colornames](set_show#colornames)**, **[cbrange](set_show#cbrange)**.
**set style line <n> linetype <lt>** will set both a terminal-dependent dot/dash pattern and color. The commands**set style line <n> linecolor <colorspec>** or **set style line <n> linetype <colorspec>** will set a new line color while leaving the existing dot-dash pattern unchanged.
In 3d mode (**splot** command), the special keyword **palette** is allowed as a shorthand for "linetype palette z". The color value corresponds to the z-value (elevation) of the splot, and varies smoothly along a line or surface.
Examples: Suppose that the default lines for indices 1, 2, and 3 are red, green, and blue, respectively, and the default point shapes for the same indices are a square, a cross, and a triangle, respectively. Then
```
set style line 1 lt 2 lw 2 pt 3 ps 0.5
```
defines a new linestyle that is green and twice the default width and a new pointstyle that is a half-sized triangle. The commands
```
set style function lines
plot f(x) lt 3, g(x) ls 1
```
will create a plot of f(x) using the default blue line and a plot of g(x) using the user-defined wide green line. Similarly the commands
```
set style function linespoints
plot p(x) lt 1 pt 3, q(x) ls 1
```
will create a plot of p(x) using the default triangles connected by a red line and q(x) using small triangles connected by a green line.
```
splot sin(sqrt(x*x+y*y))/sqrt(x*x+y*y) w l pal
```
creates a surface plot using smooth colors according to **palette**. Note, that this works only on some terminals. See also **[set palette](set_show#set_palette)**, **[set pm3d](set_show#set_pm3d)**.
```
set style line 10 linetype 1 linecolor rgb "cyan"
```
will assign linestyle 10 to be a solid cyan line on any terminal that supports rgb colors.
### Set style circle
Syntax:
```
set style circle {radius {graph|screen} <R>}
{{no}wedge}
{clip|noclip}
```
This command sets the default radius used in plot style "with circles". It applies to data plots with only 2 columns of data (x,y) and to function plots. The default is "set style circle radius graph 0.02". **Nowedge** disables drawing of the two radii that connect the ends of an arc to the center. The default is **wedge**. This parameter has no effect on full circles. **Clip** clips the circle at the plot boundaries, **noclip** disables this. Default is **clip**.
### Set style rectangle
Rectangles defined with the **set object** command can have individual styles. However, if the object is not assigned a private style then it inherits a default that is taken from the **set style rectangle** command.
Syntax:
```
set style rectangle {front|back} {lw|linewidth <lw>}
{fillcolor <colorspec>} {fs <fillstyle>}
```
See **[colorspec](linetypes_colors_styles#colorspec)** and **[fillstyle](set_show#fillstyle)**. **fillcolor** may be abbreviated as **fc**.
Examples:
```
set style rectangle back fc rgb "white" fs solid 1.0 border lt -1
set style rectangle fc linsestyle 3 fs pattern 2 noborder
```
The default values correspond to solid fill with the background color and a black border.
### Set style ellipse
Syntax:
```
set style ellipse {units xx|xy|yy}
{size {graph|screen} <a>, {{graph|screen} <b>}}
{angle <angle>}
{clip|noclip}
```
This command governs whether the diameters of ellipses are interpreted in the same units or not. Default is **xy**, which means that the major diameter (first axis) of ellipses will be interpreted in the same units as the x (or x2) axis, while the minor (second) diameter in those of the y (or y2) axis. In this mode the ratio of the ellipse axes depends on the scales of the plot axes and aspect ratio of the plot. When set to **xx** or **yy**, both axes of all ellipses will be interpreted in the same units. This means that the ratio of the axes of the plotted ellipses will be correct even after rotation, but either their vertical or horizontal extent will not be correct.
This is a global setting that affects all ellipses, both those defined as objects and those generated with the **plot** command, however, the value of **units** can also be redefined on a per-plot and per-object basis.
It is also possible to set a default size for ellipses with the **size** keyword. This default size applies to data plots with only 2 columns of data (x,y) and to function plots. The two values are interpreted as the major and minor diameters (as opposed to semi-major and semi-minor axes) of the ellipse.
The default is "set style ellipse size graph 0.05,0.03".
Last, but not least it is possible to set the default orientation with the **angle** keyword. The orientation, which is defined as the angle between the major axis of the ellipse and the plot's x axis, must be given in degrees.
**Clip** clips the ellipse at the plot boundaries, **noclip** disables this. Default is **clip**.
For defining ellipse objects, see **[set object ellipse](set_show#set_object_ellipse)**; for the 2D plot style, see **[ellipses](ellipses#ellipses)**.
### Set style parallelaxis
Syntax:
```
set style parallelaxis {front|back} {line-properties}
```
Determines the line type and layer for drawing the vertical axes in plots **with parallelaxes**. See **[with parallelaxes](parallelaxes#with_parallelaxes)**, **[set paxis](set_show#set_paxis)**.
### Set style spiderplot
Syntax:
```
set style spiderplot
{fillstyle <fillstyle-properties>}
{<line-properties> | <point-properties>}
```
This commands controls the default appearance of spider plots. The fill, line, and point properties can be modified in the first component of the plot command. The overall appearance of the plot is also affected by other settings such as **set grid spiderplot**. See also **[set paxis](set_show#set_paxis)**, **[spiderplot](spiderplot#spiderplot)**. Example:
```
# Default spider plot will be a polygon with a thick border but no fill
set style spiderplot fillstyle empty border lw 3
# This one will additionally place an open circle (pt 6) at each axis
plot for [i=1:6] DATA pointtype 6 pointsize 3
```
### Set style textbox
Syntax:
```
set style textbox {<boxstyle-index>}
{opaque|transparent} {fillcolor <color>}
{{no}border {<bordercolor>}}{linewidth <lw>}
{margins <xmargin>,<ymargin>}
```
This command controls the appearance of labels with the attribute 'boxed'. Terminal types that do not support boxed text will ignore this style. Note: Implementation for some terminals (svg, latex) is incomplete. Most terminals cannot place a box correctly around rotated text.
Three numbered textbox styles can be defined. If no boxstyle index <bs> is given, the default (unnumbered) style is changed. Example:
```
# default style has only a black border
set style textbox transparent border lc "black"
# style 2 (bs 2) has a light blue background with no border
set style textbox 2 opaque fc "light-cyan" noborder
set label 1 "I'm in a box" boxed
set label 2 "I'm blue" boxed bs 2
```
Surface
-------
The **set surface** command is only relevant for 3D plots (**splot**). Syntax:
```
set surface {implicit|explicit}
unset surface
show surface
```
**unset surface** will cause **splot** to not draw points or lines corresponding to any of the function or data file points. This is mainly useful for drawing only contour lines rather than the surface they were derived from. Contours may still be drawn on the surface, depending on the **set contour** option. To turn off the surface for an individual function or data file while leaving others active, use the **nosurface** keyword in the **splot** command. The combination **unset surface; set contour base** is useful for displaying contours on the grid base. See also **[set contour](set_show#set_contour)**.
If a 3D data set is recognizable as a mesh (grid) then by default the program implicitly treats the plot style **with lines** as requesting a gridded surface. See **[grid\_data](splot#grid_data)**. The command **set surface explicit** suppresses this expansion, plotting only the individual lines described by separate blocks of data in the input file. A gridded surface can still be plotted by explicitly requesting splot **with surface**.
Table
-----
When **table** mode is enabled, **plot** and **splot** commands print out a multicolumn text table of values
```
X Y {Z} <flag>
```
rather than creating an actual plot on the current terminal. The flag character is "i" if the point is in the active range, "o" if it is out-of-range, or "u" if it is undefined. The data format is determined by the format of the axis tickmarks (see **[set format](set_show#set_format)**), and the columns are separated by single spaces. This can be useful if you want to generate contours and then save them for further use. The same method can be used to save interpolated data (see **[set samples](set_show#set_samples)** and **[set dgrid3d](set_show#set_dgrid3d)**). Syntax:
```
set table {"outfile" | $datablock} {append}
{separator {whitespace|tab|comma|"<char>"}}
plot <whatever>
unset table
```
Subsequent tabular output is written to "outfile", if specified, otherwise it is written to stdout or other current value of **set output**. If **outfile** exists it will be replaced unless the **append** keyword is given. Alternatively, tabular output can be redirected to a named data block. Data block names start with '$', see also **[inline data](inline_data_datablocks#inline_data)**. You must explicitly **unset table** in order to go back to normal plotting on the current terminal.
The **separator** character can be used to output csv (comma separated value) files. This mode only affects plot style **with table**. See **[plot with table](set_show#plot_with_table)**.
### Plot with table
This discussion applies only to the special plot style **with table**. To avoid any style-dependent processing of the input data being tabulated (smoothing, errorbar expansion, secondary range checking, etc), or to increase the number of columns that can be tabulated, use the keyword "table" instead of a normal plot style. In this case the output does not contain an extra, last, column of flags **i**, **o**, **u** indicated inrange/outrange/undefined. The destination for output must first be specified with **set table <where>**. For example
```
set table $DATABLOCK1
plot <file> using 1:2:3:4:($5+$6):(func($7)):8:9:10 with table
```
Because there is no actual plot style in this case the columns do not correspond to specific axes. Therefore xrange, yrange, etc are ignored.
If a **using** term evaluates to a string, the string is tabulated. Numerical data is always written with format %g. If you want some other format use sprintf or gprintf to create a formatted string.
```
plot <file> using ("File 1"):1:2:3 with table
plot <file> using (sprintf("%4.2f",$1)) : (sprintf("%4.2f",$3)) with table
```
To create a csv file use
```
set table "tab.csv" separator comma
plot <foo> using 1:2:3:4 with table
```
[EXPERIMENTAL] To select only a subset of the data points for tabulation you can provide an input filter condition (**if <expression>**) at the end of the command. Note that the input filter may reference data columns that are not part of the output. This feature may change substantially before appearing in a released version of gnuplot.
```
plot <file> using 1:2:($4+$5) with table if (strcol(3) eq "Red")
plot <file> using 1:2:($4+$5) with table if (10. < $1 && $1 < 100.)
plot <file> using 1:2:($4+$5) with table if (filter($6,$7) != 0)
```
Terminal
--------
**gnuplot** supports many different graphics devices. Use **set terminal** to tell **gnuplot** what kind of output to generate. Use **set output** to redirect that output to a file or device. Syntax:
```
set terminal {<terminal-type> | push | pop}
show terminal
```
If <terminal-type> is omitted, **gnuplot** will list the available terminal types. <terminal-type> may be abbreviated.
If both **set terminal** and **set output** are used together, it is safest to give **set terminal** first, because some terminals set a flag which is needed in some operating systems.
Some terminals have many additional options. The options used by a previous invocation **set term <term> <options>** of a given **<term>** are remembered, thus subsequent **set term <term>** does not reset them. This helps in printing, for instance, when switching among different terminals — previous options don't have to be repeated.
The command **set term push** remembers the current terminal including its settings while **set term pop** restores it. This is equivalent to **save term** and **load term**, but without accessing the filesystem. Therefore they can be used to achieve platform independent restoring of the terminal after printing, for instance. After gnuplot's startup, the default terminal or that from **startup** file is pushed automatically. Therefore portable scripts can rely that **set term pop** restores the default terminal on a given platform unless another terminal has been pushed explicitly.
For more information, see the **[complete list of terminals](complete_list_terminals#complete_list_of_terminals)**.
Termoption
----------
The **set termoption** command allows you to change the behaviour of the current terminal without requiring a new **set terminal** command. Only one option can be changed per command, and only a small number of options can be changed this way. Currently the only options accepted are
```
set termoption {no}enhanced
set termoption font "<fontname>{,<fontsize>}"
set termoption fontscale <scale>
set termoption {linewidth <lw>}{lw <lw>}
```
Theta
-----
Polar coordinate plots are by default oriented such that theta = 0 is on the right side of the plot, with theta increasing as you proceed counterclockwise so that theta = 90 degrees is at the top. **set theta** allows you to change the origin and direction of the polar angular coordinate theta.
```
set theta {right|top|left|bottom}
set theta {clockwise|cw|counterclockwise|ccw}
```
**unset theta** restores the default state "set theta right ccw". Tics
----
The **set tics** command controls the tic marks and labels on all axes at once. The tics may be turned off with the **unset tics** command, and may be turned on (the default state) with **set tics**. Fine control of tics on individual axes is possible using the alternative commands **set xtics**, **set ztics**, etc.
Syntax:
```
set tics {axis | border} {{no}mirror}
{in | out} {front | back}
{{no}rotate {by <ang>}} {offset <offset> | nooffset}
{left | right | center | autojustify}
{format "formatstring"} {font "name{,<size>}"} {{no}enhanced}
{ textcolor <colorspec> }
set tics scale {default | <major> {,<minor>}}
unset tics
show tics
```
The options can be applied to a single axis (x, y, z, x2, y2, cb), e.g.
```
set xtics rotate by -90
unset cbtics
```
All tic marks are drawn using the same line properties as the plot border (see **[set border](set_show#set_border)**).
Set tics **back** or **front** applies to all axes at once, but only for 2D plots (not splot). It controls whether the tics are placed behind or in front of the plot elements, in the case that there is overlap.
**axis** or **border** tells **gnuplot** to put the tics (both the tics themselves and the accompanying labels) along the axis or the border, respectively. If the axis is very close to the border, the **axis** option will move the tic labels to outside the border in case the border is printed (see **[set border](set_show#set_border)**). The relevant margin settings will usually be sized badly by the automatic layout algorithm in this case.
**mirror** tells **gnuplot** to put unlabeled tics at the same positions on the opposite border. **nomirror** does what you think it does.
**in** and **out** change the tic marks to be drawn inwards or outwards.
**set tics scale** controls the size of the tic marks. The first value <major> controls the auto-generated or user-specified major tics (level 0). The second value controls the auto-generated or user-specified minor tics (level 1). <major> defaults to 1.0, <minor> defaults to <major>/2. Additional values control the size of user-specified tics with level 2, 3, ... Default tic sizes are restored by **set tics scale default**.
**rotate** asks **gnuplot** to rotate the text through 90 degrees, which will be done if the terminal driver in use supports text rotation. **norotate** cancels this. **rotate by <ang>** asks for rotation by <ang> degrees, supported by some terminal types.
The defaults are **border mirror norotate** for tics on the x and y axes, and **border nomirror norotate** for tics on the x2 and y2 axes. For the z axis, the default is **nomirror**.
The <offset> is specified by either x,y or x,y,z, and may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. <offset> is the offset of the tics texts from their default positions, while the default coordinate system is **character**. See **[coordinates](coordinates#coordinates)** for details. **nooffset** switches off the offset.
By default, tic labels are justified automatically depending on the axis and rotation angle to produce aesthetically pleasing results. If this is not desired, justification can be overridden with an explicit **left**, **right** or **center** keyword. **autojustify** restores the default behavior.
**set tics** with no options restores mirrored, inward-facing tic marks for the primary axes. All other settings are retained.
See also **[set xtics](set_show#set_xtics)** for more control of major (labeled) tic marks and **set mxtics** for control of minor tic marks. These commands provide control of each axis independently.
Ticslevel
---------
Deprecated. See **[set xyplane](set_show#set_xyplane)**. Ticscale
--------
The **set ticscale** command is deprecated, use **set tics scale** instead. Timestamp
---------
The command **set timestamp** places the current time and date in the plot margin. Syntax:
```
set timestamp {"<format>"} {top|bottom} {{no}rotate}
{offset <xoff>{,<yoff>}} {font "<fontspec>"}
{textcolor <colorspec>}
unset timestamp
show timestamp
```
The format string is used to write the date and time. Its default value is what asctime() uses: "%a %b %d %H:%M:%S %Y" (weekday, month name, day of the month, hours, minutes, seconds, four-digit year). With **top** or **bottom** you can place the timestamp along the top left or bottom left margin (default: bottom). **rotate** writes the timestamp vertically. The constants <xoff> and <yoff> are offsets that let you adjust the position more finely. <font> is used to specify the font with which the time is to be written.
The abbreviation **time** may be used in place of **timestamp**.
Example:
```
set timestamp "%d/%m/%y %H:%M" offset 80,-2 font "Helvetica"
```
See **[set timefmt](set_show#set_timefmt)** for more information about time format strings.
Timefmt
-------
This command sets the default format used to input time data. See **[set xdata time](set_show#set_xdata_time)**, **[timecolumn](expressions#timecolumn)**. Syntax:
```
set timefmt "<format string>"
show timefmt
```
The valid formats for both **timefmt** and **timecolumn** are:
| |
| --- |
| Time Series timedata Format Specifiers |
| Format | Explanation |
| `%d` | day of the month, 1–31 |
| `%m` | month of the year, 1–12 |
| `%y` | year, 0–99 |
| `%Y` | year, 4-digit |
| `%j` | day of the year, 1–365 |
| `%H` | hour, 0–24 |
| `%M` | minute, 0–60 |
| `%s` | seconds since the Unix epoch (1970-01-01 00:00 UTC) |
| `%S` | second, integer 0–60 on output, (double) on input |
| `%b` | three-character abbreviation of the name of the month |
| `%B` | name of the month |
| `%p` | two character match to one of: am AM pm PM |
Any character is allowed in the string, but must match exactly. \t (tab) is recognized. Backslash-octals ( \nnn) are converted to char. If there is no separating character between the time/date elements, then %d, %m, %y, %H, %M and %S read two digits each. If a decimal point immediately follows the field read by %S, the decimal and any following digits are interpreted as a fractional second. %Y reads four digits. %j reads three digits. %b requires three characters, and %B requires as many as it needs.
Spaces are treated slightly differently. A space in the string stands for zero or more whitespace characters in the file. That is, "%H %M" can be used to read "1220" and "12 20" as well as "12 20".
Each set of non-blank characters in the timedata counts as one column in the **using n:n** specification. Thus **11:11 25/12/76 21.0** consists of three columns. To avoid confusion, **gnuplot** requires that you provide a complete **using** specification if your file contains timedata.
If the date format includes the day or month in words, the format string must exclude this text. But it can still be printed with the "%a", "%A", "%b", or "%B" specifier. **gnuplot** will determine the proper month and weekday from the numerical values. See **[set format](set_show#set_format)** for more details about these and other options for printing time data.
When reading two-digit years with %y, values 69-99 refer to the 20th century, while values 00-68 refer to the 21st century. NB: This is in accordance with the UNIX98 spec, but conventions vary widely and two-digit year values are inherently ambiguous.
If the %p format returns "am" or "AM", hour 12 will be interpreted as hour 0. If the %p format returns "pm" or "PM", hours < 12 will be increased by 12.
See also **[set xdata](set_show#set_xdata)** and **[time/date](time_date_data#time_date)** for more information.
Example:
```
set timefmt "%d/%m/%Y\t%H:%M"
```
tells **gnuplot** to read date and time separated by tab. (But look closely at your data — what began as a tab may have been converted to spaces somewhere along the line; the format string must match what is actually in the file.) See also [time data demo.](http://www.gnuplot.info/demo/timedat.html) Title
-----
The **set title** command produces a plot title that is centered at the top of the plot. **set title** is a special case of **set label**. Syntax:
```
set title {"<title-text>"} {offset <offset>} {font "<font>{,<size>}"}
{{textcolor | tc} {<colorspec> | default}} {{no}enhanced}
show title
```
If <offset> is specified by either x,y or x,y,z the title is moved by the given offset. It may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. See **[coordinates](coordinates#coordinates)** for details. By default, the **character** coordinate system is used. For example, "**set title offset 0,-1**" will change only the y offset of the title, moving the title down by roughly the height of one character. The size of a character depends on both the font and the terminal.
<font> is used to specify the font with which the title is to be written; the units of the font <size> depend upon which terminal is used.
**textcolor <colorspec>** changes the color of the text. <colorspec> can be a linetype, an rgb color, or a palette mapping. See help for **[colorspec](linetypes_colors_styles#colorspec)** and **[palette](expressions#palette)**.
**noenhanced** requests that the title not be processed by the enhanced text mode parser, even if enhanced text mode is currently active.
**set title** with no parameters clears the title.
See **[syntax](syntax#syntax)** for details about the processing of backslash sequences and the distinction between single- and double-quotes.
Tmargin
-------
The command **set tmargin** sets the size of the top margin. Please see **[set margin](set_show#set_margin)** for details. Trange
------
Syntax: set trange [tmin:tmax] The range of the parametric variable t is useful in three contexts. 1) In parametric mode **plot** commands it limits the range of sampling
```
for both generating functions. See `set parametric`, `set samples`.
```
2) In polar mode **plot** commands it limits or defines the range of the
```
angular parameter theta. See `polar`.
```
3) In **plot** or **splot** commands using 1-dimensional sampled data via
```
the pseudofile "+". See `sampling 1D`, `special-filenames`.
```
Ttics
-----
The **set ttics** command places tics around the perimeter of a polar plot. This is the border if **set border polar** is enabled, otherwise the outermost circle of the polar grid drawn at the rightmost ticmark along the r axis. See **[set grid](set_show#set_grid)**, **[set rtics](set_show#set_rtics)**. The angular position is always labeled in degrees. The full perimeter can be labeled regardless of the current trange setting. The desired range of the tic labels should be given as shown below. Additional properties of the tic marks can be set. See **[xtics](set_show#xtics)**.
```
set ttics -180, 30, 180
set ttics add ("Theta = 0" 0)
set ttics font ":Italic" rotate
```
Urange
------
Syntax: set urange [umin:umax] The range of the parametric variables u and v is useful in two contexts. 1) **splot** in parametric mode. See **[set parametric](set_show#set_parametric)**, **[set isosamples](set_show#set_isosamples)**. 2) generating 2-dimension sampled data for either **plot** or **splot** using the pseudofile "++". See **[sampling 2D](plot#sampling_2D)**. Variables
---------
The **show variables** command lists the current value of user-defined and internal variables. Gnuplot internally defines variables whose names begin with GPVAL\_, MOUSE\_, FIT\_, and TERM\_. Syntax:
```
show variables # show variables that do not begin with GPVAL_
show variables all # show all variables including those beginning GPVAL_
show variables NAME # show only variables beginning with NAME
```
Version
-------
The **show version** command lists the version of gnuplot being run, its last modification date, the copyright holders, and email addresses for the FAQ, the gnuplot-info mailing list, and reporting bugs–in short, the information listed on the screen when the program is invoked interactively. Syntax:
```
show version {long}
```
When the **long** option is given, it also lists the operating system, the compilation options used when **gnuplot** was installed, the location of the help file, and (again) the useful email addresses.
Vgrid
-----
Syntax:
```
set vgrid $gridname {size N}
unset vgrid $gridname
show vgrid
```
If the named grid already exists, mark it as active (use it for subsequent **vfill** and **voxel** operations). If a new size is given, replace the existing content with a zero-filled N x N x N grid. If a grid with this name does not already exist, allocate an N x N x N grid (default N=100), zero the contents, and mark it as active. Note that grid names must begin with '$'.
**show vgrid** lists all currently defined voxel grids. Example output:
```
$vgrid1: (active)
size 100 X 100 X 100
vxrange [-4:4] vyrange[-4:4] vzrange[-4:4]
non-zero voxel values: min 0.061237 max 94.5604
number of zero voxels: 992070 (99.21%)
```
**unset vgrid $gridname** releases all data structures associated with that voxel grid. The data structures are also released by **reset session**. The function **voxel(x,y,z)** returns the value of the active grid point nearest that coordinate. See also **[splot voxel-grids](splot#splot_voxel-grids)**.
View
----
The **set view** command sets the viewing angle for **splot**s. It controls how the 3D coordinates of the plot are mapped into the 2D screen space. It provides controls for both rotation and scaling of the plotted data, but supports orthographic projections only. It supports both 3D projection or orthogonal 2D projection into a 2D plot-like map. Syntax:
```
set view <rot_x>{,{<rot_z>}{,{<scale>}{,<scale_z>}}}
set view map {scale <scale>}
set view projection {xy|xz|yz}
set view {no}equal {xy|xyz}
set view azimuth <angle>
show view
```
where <rot\_x> and <rot\_z> control the rotation angles (in degrees) in a virtual 3D coordinate system aligned with the screen such that initially (that is, before the rotations are performed) the screen horizontal axis is x, screen vertical axis is y, and the axis perpendicular to the screen is z. The first rotation applied is <rot\_x> around the x axis. The second rotation applied is <rot\_z> around the new z axis.
Command **set view map** is used to represent the drawing as a map. It is useful for **contour** plots or 2D heatmaps using pm3d mode rather than **with image**. In the latter case, take care that you properly use **zrange** and **cbrange** for input data point filtering and color range scaling, respectively.
<rot\_x> is bounded to the [0:180] range with a default of 60 degrees, while <rot\_z> is bounded to the [0:360] range with a default of 30 degrees. <scale> controls the scaling of the entire **splot**, while <scale\_z> scales the z axis only. Both scales default to 1.0.
Examples:
```
set view 60, 30, 1, 1
set view ,,0.5
```
The first sets all the four default values. The second changes only scale, to 0.5.
### Azimuth
```
set view azimuth <angle-in-degrees>
```
The setting of azimuth affects the orientation of the z axis in a 3D graph (splot). At the default azimuth = 0 the z axis of the plot lies in the plane orthogonal to the screen horizontal. I.e. the projection of the z axis lies along the screen vertical. Non-zero azimuth rotates the plot about the line of sight through the origin so that a projection of the z axis is no longer vertical. When azimuth = 90 the z axis is horizontal rather than vertical. ### Equal\_axes
The command **set view equal xy** forces the unit length of the x and y axes to be on the same scale, and chooses that scale so that the plot will fit on the page. The command **set view equal xyz** additionally sets the z axis scale to match the x and y axes; however there is no guarantee that the current z axis range will fit within the plot boundary. By default all three axes are scaled independently to fill the available area. See also **[set xyplane](set_show#set_xyplane)**.
### Projection
Syntax:
```
set view projection {xy|xz|yz}
```
Rotates the view angles of a 3D plot so that one of the primary planes xy, xz, or yz lies in the plane of the plot. Axis labels and tics positioning is adjusted accordingly; tics and labels on the third axis are disabled. The plot is scaled up to approximately match the size that 'plot' would generate for the same axis ranges. **set view projection xy** is equivalent to **set view map**. Vrange
------
Syntax: set vrange [vmin:vmax] The range of the parametric variables u and v is useful in two contexts. 1) **splot** in parametric mode. See **[set parametric](set_show#set_parametric)**, **[set isosamples](set_show#set_isosamples)**. 2) generating 2-dimension sampled data for either **plot** or **splot** using the pseudofile "++". See **[sampling 2D](plot#sampling_2D)**. Vxrange
-------
Syntax: set vxrange [vxmin:vxmax] Establishes the range of x coordinates spanned by the active voxel grid. Analogous commands **set vyrange** and **set vzrange** exist for the other two dimensions of the voxel grid. If no explicit ranges have been set prior to the first **vclear**, **vfill**, or **voxel(x,y,z) =** command, vmin and vmax will be copied from the current values of **xrange**.
Vyrange
-------
See **[set vxrange](set_show#set_vxrange)** Vzrange
-------
See **[set vxrange](set_show#set_vxrange)** Walls
-----
Syntax:
```
set walls
set wall {x0|y0|z0|x1|y1} {<fillstyle>} {fc <fillcolor>}
```
3D surfaces drawn by **[splot](splot#splot)** lie within a normalized unit cube regardless of the x y and z axis ranges. The bounding walls of this cube are described by the planes (graph coord x == 0), (graph coord x == 1), etc. The **set walls** command renders the walls x0 y0 and z0 as solid surfaces. By default these surfaces are semi-transparent (fillstyle transparent solid 0.5). You can customize which walls are drawn and also their individual color and fill style. If you choose to enable walls, you may also want to use **set xyplane 0**. Example:
```
set wall z0 fillstyle solid 1.0 fillcolor "gray"
```
X2data
------
The **set x2data** command sets data on the x2 (top) axis to timeseries (dates/times). Please see **[set xdata](set_show#set_xdata)**. X2dtics
-------
The **set x2dtics** command changes tics on the x2 (top) axis to days of the week. Please see **[set xdtics](set_show#set_xdtics)** for details. X2label
-------
The **set x2label** command sets the label for the x2 (top) axis. Please see **[set xlabel](set_show#set_xlabel)**. X2mtics
-------
The **set x2mtics** command changes tics on the x2 (top) axis to months of the year. Please see **[set xmtics](set_show#set_xmtics)** for details. X2range
-------
The **set x2range** command sets the horizontal range that will be displayed on the x2 (top) axis. See **[set xrange](set_show#set_xrange)** for the full set of command options. See also **[set link](set_show#set_link)**. X2tics
------
The **set x2tics** command controls major (labeled) tics on the x2 (top) axis. Please see **[set xtics](set_show#set_xtics)** for details. X2zeroaxis
----------
The **set x2zeroaxis** command draws a line at the origin of the x2 (top) axis (y2 = 0). For details, please see **[set zeroaxis](set_show#set_zeroaxis)**. Xdata
-----
This command controls interpretation of data on the x axis. An analogous command acts on each of the other axes. Syntax:
```
set xdata time
show xdata
```
The same syntax applies to **ydata**, **zdata**, **x2data**, **y2data** and **cbdata**.
The **time** option signals that data represents a time/date in seconds. The current version of gnuplot stores time to a millisecond precision.
If no option is specified, the data interpretation reverts to normal.
### Time
**set xdata time** indicates that the x coordinate represents a date or time to millisecond precision. There is an analogous command **set ydata time**. There are separate format mechanisms for interpretation of time data on input and output. Input data is read from a file either by using the global **timefmt** or by using the function timecolumn() as part of the plot command. These input mechanisms also apply to using time values to set an axis range. See **[set timefmt](set_show#set_timefmt)**, **[timecolumn](expressions#timecolumn)**.
Example:
```
set xdata time
set timefmt "%d-%b-%Y"
set xrange ["01-Jan-2013" : "31-Dec-2014"]
plot DATA using 1:2
```
or
```
plot DATA using (timecolumn(1,"%d-%b-%Y")):2
```
For output, i.e. tick labels along that axis or coordinates output by mousing, the function 'strftime' (type "man strftime" on unix to look it up) is used to convert from the internal time in seconds to a string representation of a date. **gnuplot** tries to figure out a reasonable format for this. You can customize the format using either **set format x** or **set xtics format**. See **[time\_specifiers](set_show#time_specifiers)** for a special set of time format specifiers. See also **[time/date](time_date_data#time_date)** for more information.
Xdtics
------
The **set xdtics** commands converts the x-axis tic marks to days of the week where 0=Sun and 6=Sat. Overflows are converted modulo 7 to dates. **set noxdtics** returns the labels to their default values. Similar commands do the same things for the other axes. Syntax:
```
set xdtics
unset xdtics
show xdtics
```
The same syntax applies to **ydtics**, **zdtics**, **x2dtics**, **y2dtics** and **cbdtics**.
See also the **[set format](set_show#set_format)** command.
Xlabel
------
The **set xlabel** command sets the x axis label. Similar commands set labels on the other axes. Syntax:
```
set xlabel {"<label>"} {offset <offset>} {font "<font>{,<size>}"}
{textcolor <colorspec>} {{no}enhanced}
{rotate by <degrees> | rotate parallel | norotate}
show xlabel
```
The same syntax applies to **x2label**, **ylabel**, **y2label**, **zlabel** and **cblabel**.
If <offset> is specified by either x,y or x,y,z the label is moved by the given offset. It may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. See **[coordinates](coordinates#coordinates)** for details. By default, the **character** coordinate system is used. For example, "**set xlabel offset -1,0**" will change only the x offset of the title, moving the label roughly one character width to the left. The size of a character depends on both the font and the terminal.
<font> is used to specify the font in which the label is written; the units of the font <size> depend upon which terminal is used.
**noenhanced** requests that the label text not be processed by the enhanced text mode parser, even if enhanced text mode is currently active.
To clear a label, put no options on the command line, e.g., "**set y2label**".
The default positions of the axis labels are as follows:
xlabel: The x-axis label is centered below the bottom of the plot.
ylabel: The y-axis label is centered to the left of the plot, defaulting to either horizontal or vertical orientation depending on the terminal type. The program may not reserve enough space to the left of the plot to hold long non-rotated ylabel text. You can adjust this with **set lmargin**.
zlabel: The z-axis label is centered along the z axis and placed in the space above the grid level.
cblabel: The color box axis label is centered along the box and placed below or to the right according to horizontal or vertical color box gradient.
y2label: The y2-axis label is placed to the right of the y2 axis. The position is terminal-dependent in the same manner as is the y-axis label.
x2label: The x2-axis label is placed above the plot but below the title. It is also possible to create an x2-axis label by using new-line characters to make a multi-line plot title, e.g.,
```
set title "This is the title\n\nThis is the x2label"
```
Note that double quotes must be used. The same font will be used for both lines, of course.
The orientation (rotation angle) of the x, x2, y and y2 axis labels in 2D plots can be changed by specifying **rotate by <degrees>**. The orientation of the x and y axis labels in 3D plots defaults to horizontal but can be changed to run parallel to the axis by specifying **rotate parallel**.
If you are not satisfied with the default position of an axis label, use **set label** instead–that command gives you much more control over where text is placed.
Please see **[syntax](syntax#syntax)** for further information about backslash processing and the difference between single- and double-quoted strings.
Xmtics
------
The **set xmtics** command converts the x-axis tic marks to months of the year where 1=Jan and 12=Dec. Overflows are converted modulo 12 to months. The tics are returned to their default labels by **unset xmtics**. Similar commands perform the same duties for the other axes. Syntax:
```
set xmtics
unset xmtics
show xmtics
```
The same syntax applies to **x2mtics**, **ymtics**, **y2mtics**, **zmtics** and **cbmtics**.
See also the **[set format](set_show#set_format)** command.
Xrange
------
The **set xrange** command sets the horizontal range that will be displayed. A similar command exists for each of the other axes, as well as for the polar radius r and the parametric variables t, u, and v. Syntax:
```
set xrange [{{<min>}:{<max>}}] {{no}reverse} {{no}writeback} {{no}extend}
| restore
show xrange
```
where <min> and <max> terms are constants, expressions or an asterisk to set autoscaling. If the data are time/date, you must give the range as a quoted string according to the **set timefmt** format. If <min> or <max> is omitted the current value will not be changed. See below for full autoscaling syntax. See also **[noextend](set_show#noextend)**.
The same syntax applies to **yrange**, **zrange**, **x2range**, **y2range**, **cbrange**, **rrange**, **trange**, **urange** and **vrange**.
See **[set link](set_show#set_link)** for options that link the ranges of x and x2, or y and y2.
The **reverse** option reverses the direction of an autoscaled axis. For example, if the data values range from 10 to 100, it will autoscale to the equivalent of set xrange [100:10]. The **reverse** flag has no effect if the axis is not autoscaled. NB: This is a change introduced in version 4.7.
Autoscaling: If <min> (the same applies for correspondingly to <max>) is an asterisk "\*" autoscaling is turned on. The range in which autoscaling is being performed may be limited by a lower bound <lb> or an upper bound <ub> or both. The syntax is
```
{ <lb> < } * { < <ub> }
```
For example,
```
0 < * < 200
```
sets <lb> = 0 and <ub> = 200. With such a setting <min> would be autoscaled, but its final value will be between 0 and 200 (both inclusive despite the '<' sign). If no lower or upper bound is specified, the '<' to also be omitted. If <ub> is lower than <lb> the constraints will be turned off and full autoscaling will happen. This feature is useful to plot measured data with autoscaling but providing a limit on the range, to clip outliers, or to guarantee a minimum range that will be displayed even if the data would not need such a big range. The **writeback** option essentially saves the range found by **autoscale** in the buffers that would be filled by **set xrange**. This is useful if you wish to plot several functions together but have the range determined by only some of them. The **writeback** operation is performed during the **plot** execution, so it must be specified before that command. To restore, the last saved horizontal range use **set xrange restore**. For example,
```
set xrange [-10:10]
set yrange [] writeback
plot sin(x)
set yrange restore
replot x/2
```
results in a yrange of [-1:1] as found only from the range of sin(x); the [-5:5] range of x/2 is ignored. Executing **show yrange** after each command in the above example should help you understand what is going on.
In 2D, **xrange** and **yrange** determine the extent of the axes, **trange** determines the range of the parametric variable in parametric mode or the range of the angle in polar mode. Similarly in parametric 3D, **xrange**, **yrange**, and **zrange** govern the axes and **urange** and **vrange** govern the parametric variables.
In polar mode, **rrange** determines the radial range plotted. <rmin> acts as an additive constant to the radius, whereas <rmax> acts as a clip to the radius — no point with radius greater than <rmax> will be plotted. **xrange** and **yrange** are affected — the ranges can be set as if the graph was of r(t)-rmin, with rmin added to all the labels.
Any range may be partially or totally autoscaled, although it may not make sense to autoscale a parametric variable unless it is plotted with data.
Ranges may also be specified on the **plot** command line. A range given on the plot line will be used for that single **plot** command; a range given by a **set** command will be used for all subsequent plots that do not specify their own ranges. The same holds true for **splot**.
### Examples
Examples: To set the xrange to the default:
```
set xrange [-10:10]
```
To set the yrange to increase downwards:
```
set yrange [10:-10]
```
To change zmax to 10 without affecting zmin (which may still be autoscaled):
```
set zrange [:10]
```
To autoscale xmin while leaving xmax unchanged:
```
set xrange [*:]
```
To autoscale xmin but keeping xmin positive:
```
set xrange [0<*:]
```
To autoscale x but keep minimum range of 10 to 50 (actual might be larger):
```
set xrange [*<10:50<*]
```
Autoscaling but limit maximum xrange to -1000 to 1000, i.e. autoscaling within [-1000:1000]
```
set xrange [-1000<*:*<1000]
```
Make sure xmin is somewhere between -200 and 100:
```
set xrange [-200<*<100:]
```
### Extend
**set xrange noextend** is the same as **set autoscale x noextend**. See **[noextend](set_show#noextend)**. Xtics
-----
Fine control of the major (labeled) tics on the x axis is possible with the **set xtics** command. The tics may be turned off with the **unset xtics** command, and may be turned on (the default state) with **set xtics**. Similar commands control the major tics on the y, z, x2 and y2 axes. Syntax:
```
set xtics {axis | border} {{no}mirror}
{in | out} {scale {default | <major> {,<minor>}}}
{{no}rotate {by <ang>}} {offset <offset> | nooffset}
{left | right | center | autojustify}
{add}
{ autofreq
| <incr>
| <start>, <incr> {,<end>}
| ({"<label>"} <pos> {<level>} {,{"<label>"}...) }
{format "formatstring"} {font "name{,<size>}"} {{no}enhanced}
{ numeric | timedate | geographic }
{{no}logscale}
{ rangelimited }
{ textcolor <colorspec> }
unset xtics
show xtics
```
The same syntax applies to **ytics**, **ztics**, **x2tics**, **y2tics** and **cbtics**.
**axis** or **border** tells **gnuplot** to put the tics (both the tics themselves and the accompanying labels) along the axis or the border, respectively. If the axis is very close to the border, the **axis** option will move the tic labels to outside the border. The relevant margin settings will usually be sized badly by the automatic layout algorithm in this case.
**mirror** tells **gnuplot** to put unlabeled tics at the same positions on the opposite border. **nomirror** does what you think it does.
**in** and **out** change the tic marks to be drawn inwards or outwards.
With **scale**, the size of the tic marks can be adjusted. If <minor> is not specified, it is 0.5\*<major>. The default size 1.0 for major tics and 0.5 for minor tics is requested by **scale default**.
**rotate** asks **gnuplot** to rotate the text through 90 degrees, which will be done if the terminal driver in use supports text rotation. **norotate** cancels this. **rotate by <ang>** asks for rotation by <ang> degrees, supported by some terminal types.
The defaults are **border mirror norotate** for tics on the x and y axes, and **border nomirror norotate** for tics on the x2 and y2 axes. For the z axis, the **{axis | border}** option is not available and the default is **nomirror**. If you do want to mirror the z-axis tics, you might want to create a bit more room for them with **set border**.
The <offset> is specified by either x,y or x,y,z, and may be preceded by **first**, **second**, **graph**, **screen**, or **character** to select the coordinate system. <offset> is the offset of the tics texts from their default positions, while the default coordinate system is **character**. See **[coordinates](coordinates#coordinates)** for details. **nooffset** switches off the offset.
Example:
Move xtics more closely to the plot.
```
set xtics offset 0,graph 0.05
```
By default, tic labels are justified automatically depending on the axis and rotation angle to produce aesthetically pleasing results. If this is not desired, justification can be overridden with an explicit **left**, **right** or **center** keyword. **autojustify** restores the default behavior.
**set xtics** with no options restores the default border or axis if xtics are being displayed; otherwise it has no effect. Any previously specified tic frequency or position {and labels} are retained.
Tic positions are calculated automatically by default or if the **autofreq** option is given.
A series of tic positions can be specified by giving either a tic interval alone, or a start point, interval, and end point (see **[xtics series](set_show#xtics_series)**).
Individual tic positions can be specified individually by providing an explicit list of positions, where each position may have an associated text label. See **[xtics list](set_show#xtics_list)**.
However they are specified, tics will only be plotted when in range.
Format (or omission) of the tic labels is controlled by **set format**, unless the explicit text of a label is included in the **set xtics ("<label>")** form.
Minor (unlabeled) tics can be added automatically by the **set mxtics** command, or at explicit positions by the **set xtics ("" <pos> 1, ...)** form.
The appearance of the tics (line style, line width etc.) is determined by the border line (see **[set border](set_show#set_border)**), even if the tics are drawn at the axes.
### Xtics series
Syntax:
```
set xtics <incr>
set xtics <start>, <incr>, <end>
```
The implicit <start>, <incr>, <end> form specifies that a series of tics will be plotted on the axis between the values <start> and <end> with an increment of <incr>. If <end> is not given, it is assumed to be infinity. The increment may be negative. If neither <start> nor <end> is given, <start> is assumed to be negative infinity, <end> is assumed to be positive infinity, and the tics will be drawn at integral multiples of <incr>. If the axis is logarithmic, the increment will be used as a multiplicative factor. If you specify to a negative <start> or <incr> after a numerical value (e.g., **rotate by <angle>** or **offset <offset>**), the parser fails because it subtracts <start> or <incr> from that value. As a workaround, specify **0-<start>** resp. **0-<incr>** in that case.
Example:
```
set xtics border offset 0,0.5 -5,1,5
```
Fails with 'invalid expression' at the last comma.
```
set xtics border offset 0,0.5 0-5,1,5
```
or
```
set xtics offset 0,0.5 border -5,1,5
```
Sets tics at the border, tics text with an offset of 0,0.5 characters, and sets the start, increment, and end to -5, 1, and 5, as requested. The **set grid** options 'front', 'back' and 'layerdefault' affect the drawing order of the xtics, too.
Examples:
Make tics at 0, 0.5, 1, 1.5, ..., 9.5, 10.
```
set xtics 0,.5,10
```
Make tics at ..., -10, -5, 0, 5, 10, ...
```
set xtics 5
```
Make tics at 1, 100, 1e4, 1e6, 1e8.
```
set logscale x; set xtics 1,100,1e8
```
### Xtics list
Syntax:
```
set xtics {add} ("label1" <pos1> <level1>, "label2" <pos2> <level2>, ...)
```
The explicit ("label" <pos> <level>, ...) form allows arbitrary tic positions or non-numeric tic labels. In this form, the tics do not need to be listed in numerical order. Each tic has a position, optionally with a label.
The label is a string enclosed by quotes or a string-valued expression. It may contain formatting information for converting the position into its label, such as "%3f clients", or it may be the empty string "". See **[set format](set_show#set_format)** for more information. If no string is given, the default label (numerical) is used.
An explicit tic mark has a third parameter, the level. The default is level 0, a major tic. Level 1 generates a minor tic. Labels are never printed for minor tics. Major and minor tics may be auto-generated by the program or specified explicitly by the user. Tics with level 2 and higher must be explicitly specified by the user, and take priority over auto-generated tics. The size of tics marks at each level is controlled by the command **set tics scale**.
Examples:
```
set xtics ("low" 0, "medium" 50, "high" 100)
set xtics (1,2,4,8,16,32,64,128,256,512,1024)
set ytics ("bottom" 0, "" 10, "top" 20)
set ytics ("bottom" 0, "" 10 1, "top" 20)
```
In the second example, all tics are labeled. In the third, only the end tics are labeled. In the fourth, the unlabeled tic is a minor tic.
Normally if explicit tics are given, they are used instead of auto-generated tics. Conversely if you specify **set xtics auto** or the like it will erase any previously specified explicit tics. You can mix explicit and auto- generated tics by using the keyword **add**, which must appear before the tic style being added.
Example:
```
set xtics 0,.5,10
set xtics add ("Pi" 3.14159)
```
This will automatically generate tic marks every 0.5 along x, but will also add an explicit labeled tic mark at pi.
### Xtics timedata
Times and dates are stored internally as a number of seconds. Input: Non-numeric time and date values are converted to seconds on input using the format specifier in **timefmt**. Axis positions and range limits also may be given as quoted dates or times interpreted using **timefmt**. If the <start>, <incr>, <end> form is used, <incr> must be in seconds. Use of **timefmt** to interpret input data, range, and tic positions is triggered by **set xdata time**.
Output: Axis tic labels are generated using a separate format specified either by **set format** or **set xtics format**. By default the usual numeric format specifiers are expected (**set xtics numeric**). Other options are geographic coordinates (**set xtics geographic**), or times or dates (**set xtics time**).
Note: For backward compatibility with earlier gnuplot versions, the command **set xdata time** will implicitly also do **set xtics time**, and **set xdata** or **unset xdata** will implicitly reset to **set xtics numeric**. However you can change this with a later call to **set xtics**.
Examples:
```
set xdata time # controls interpretation of input data
set timefmt "%d/%m" # format used to read input data
set xtics timedate # controls interpretation of output format
set xtics format "%b %d" # format used for tic labels
set xrange ["01/12":"06/12"]
set xtics "01/12", 172800, "05/12"
```
```
set xdata time
set timefmt "%d/%m"
set xtics format "%b %d" time
set xrange ["01/12":"06/12"]
set xtics ("01/12", "" "03/12", "05/12")
```
Both of these will produce tics "Dec 1", "Dec 3", and "Dec 5", but in the second example the tic at "Dec 3" will be unlabeled. ### Geographic
**set xtics geographic** indicates that x-axis values are to be interpreted as a geographic coordinate measured in degrees. Use **set xtics format** or **set format x** to specify the appearance of the axis tick labels. The format specifiers for geographic data are as follows:
```
%D = integer degrees
%<width.precision>d = floating point degrees
%M = integer minutes
%<width.precision>m = floating point minutes
%S = integer seconds
%<width.precision>s = floating point seconds
%E = label with E/W instead of +/-
%N = label with N/S instead of +/-
```
For example, the command **set format x "%Ddeg %5.2mmin %E"** will cause x coordinate -1.51 to be labeled as **" 1deg 30.60min W"**. If the xtics are left in the default state (**set xtics numeric**) the coordinate will be reported as a decimal number of degrees, and **format** will be assumed to contain normal numeric format specifiers rather than the special set above.
To output degrees/minutes/seconds in a context other than axis tics, such as placing labels on a map, you can use the relative time format specifiers %tH %tM %tS for strptime. See **[time\_specifiers](set_show#time_specifiers)**, **[strptime](expressions#strptime)**.
### Xtics logscale
If the **logscale** attribute is set for a tic series along a log-scaled axis, the tic interval is interpreted as a multiplicative factor rather than a constant. For example:
```
# generate a series of tics at y=20 y=200 y=2000 y=20000
set log y
set ytics 20, 10, 50000 logscale
```
Note that no tic is placed at y=50000 because it is not in the series 2\*10`^`x. If the logscale property is disabled, the tic increment will be treated as an additive constant even for a log-scaled axis. For example:
```
# generate a series of tics at y=20 y=40 y=60 ... y=200
set log y
set yrange [20:200]
set ytics 20 nologscale
```
The **logscale** attribute is set automatically by the **set log** command, so normally you do not need this keyword unless you want to force a constant tic interval as in the second example above. ### Xtics rangelimited
This option limits both the auto-generated axis tic labels and the corresponding plot border to the range of values actually present in the data that has been plotted. Note that this is independent of the current range limits for the plot. For example, suppose that the data in "file.dat" all lies in the range 2 < y < 4. Then the following commands will create a plot for which the left-hand plot border (y axis) is drawn for only this portion of the total y range, and only the axis tics in this region are generated. I.e., the plot will be scaled to the full range on y, but there will be a gap between 0 and 2 on the left border and another gap between 4 and 10. This style is sometimes referred to as a **range-frame** graph.
```
set border 3
set yrange [0:10]
set ytics nomirror rangelimited
plot "file.dat"
```
Xyplane
-------
The **set xyplane** command adjusts the position at which the xy plane is drawn in a 3D plot. The synonym "set ticslevel" is accepted for backwards compatibility. Syntax:
```
set xyplane at <zvalue>
set xyplane relative <frac>
set ticslevel <frac> # equivalent to set xyplane relative
show xyplane
```
The form **set xyplane relative <frac>** places the xy plane below the range in Z, where the distance from the xy plane to Zmin is given as a fraction of the total range in z. The default value is 0.5. Negative values are permitted, but tic labels on the three axes may overlap.
The alternative form **set xyplane at <zvalue>** fixes the placement of the xy plane at a specific Z value regardless of the current z range. Thus to force the x, y, and z axes to meet at a common origin one would specify **set xyplane at 0**.
See also **[set view](set_show#set_view)**, and **[set zeroaxis](set_show#set_zeroaxis)**.
Xzeroaxis
---------
The **set xzeroaxis** command draws a line at y = 0. For details, please see **[set zeroaxis](set_show#set_zeroaxis)**. Y2data
------
The **set y2data** command sets y2 (right-hand) axis data to timeseries (dates/times). Please see **[set xdata](set_show#set_xdata)**. Y2dtics
-------
The **set y2dtics** command changes tics on the y2 (right-hand) axis to days of the week. Please see **[set xdtics](set_show#set_xdtics)** for details. Y2label
-------
The **set y2label** command sets the label for the y2 (right-hand) axis. Please see **[set xlabel](set_show#set_xlabel)**. Y2mtics
-------
The **set y2mtics** command changes tics on the y2 (right-hand) axis to months of the year. Please see **[set xmtics](set_show#set_xmtics)** for details. Y2range
-------
The **set y2range** command sets the vertical range that will be displayed on the y2 (right) axis. See **[set xrange](set_show#set_xrange)** for the full set of command options. See also **[set link](set_show#set_link)**. Y2tics
------
The **set y2tics** command controls major (labeled) tics on the y2 (right-hand) axis. Please see **[set xtics](set_show#set_xtics)** for details. Y2zeroaxis
----------
The **set y2zeroaxis** command draws a line at the origin of the y2 (right-hand) axis (x2 = 0). For details, please see **[set zeroaxis](set_show#set_zeroaxis)**. Ydata
-----
The **set ydata** commands sets y-axis data to timeseries (dates/times). Please see **[set xdata](set_show#set_xdata)**. Ydtics
------
The **set ydtics** command changes tics on the y axis to days of the week. Please see **[set xdtics](set_show#set_xdtics)** for details. Ylabel
------
This command sets the label for the y axis. Please see **[set xlabel](set_show#set_xlabel)**. Ymtics
------
The **set ymtics** command changes tics on the y axis to months of the year. Please see **[set xmtics](set_show#set_xmtics)** for details. Yrange
------
The **set yrange** command sets the vertical range that will be displayed on the y axis. Please see **[set xrange](set_show#set_xrange)** for details. Ytics
-----
The **set ytics** command controls major (labeled) tics on the y axis. Please see **[set xtics](set_show#set_xtics)** for details. Yzeroaxis
---------
The **set yzeroaxis** command draws a line at x = 0. For details, please see **[set zeroaxis](set_show#set_zeroaxis)**. Zdata
-----
The **set zdata** command sets zaxis data to timeseries (dates/times). Please see **[set xdata](set_show#set_xdata)**. Zdtics
------
The **set zdtics** command changes tics on the z axis to days of the week. Please see **[set xdtics](set_show#set_xdtics)** for details. Zzeroaxis
---------
The **set zzeroaxis** command draws a line through (x=0,y=0). This has no effect on 2D plots, including splot with **set view map**. For details, please see **[set zeroaxis](set_show#set_zeroaxis)** and **[set xyplane](set_show#set_xyplane)**. Cbdata
------
Set color box axis data to timeseries (dates/times). Please see **[set xdata](set_show#set_xdata)**. Cbdtics
-------
The **set cbdtics** command changes tics on the color box axis to days of the week. Please see **[set xdtics](set_show#set_xdtics)** for details. Zero
----
The **zero** value is the default threshold for values approaching 0.0. Syntax:
```
set zero <expression>
show zero
```
**gnuplot** will not plot a point if its imaginary part is greater in magnitude than the **zero** threshold. This threshold is also used in various other parts of **gnuplot** as a (crude) numerical-error threshold. The default **zero** value is 1e-8. **zero** values larger than 1e-3 (the reciprocal of the number of pixels in a typical bitmap display) should probably be avoided, but it is not unreasonable to set **zero** to 0.0.
Zeroaxis
--------
The x axis may be drawn by **set xzeroaxis** and removed by **unset xzeroaxis**. Similar commands behave similarly for the y, x2, y2, and z axes. **set zeroaxis ...** (no prefix) acts on the x, y, and z axes jointly. Syntax:
```
set {x|x2|y|y2|z}zeroaxis { {linestyle | ls <line_style>}
| {linetype | lt <line_type>}
{linewidth | lw <line_width>}
{linecolor | lc <colorspec>}
{dashtype | dt <dashtype>} }
unset {x|x2|y|y2|z}zeroaxis
show {x|y|z}zeroaxis
```
By default, these options are off. The selected zero axis is drawn with a line of type <line\_type>, width <line\_width>, color <colorspec>, and dash type <dashtype> (if supported by the terminal driver currently in use), or a user-defined style <line\_style> (see **[set style line](set_show#set_style_line)**).
If no linetype is specified, any zero axes selected will be drawn using the axis linetype (linetype 0).
Examples:
To simply have the y=0 axis drawn visibly:
```
set xzeroaxis
```
If you want a thick line in a different color or pattern, instead:
```
set xzeroaxis linetype 3 linewidth 2.5
```
Zlabel
------
This command sets the label for the z axis. Please see **[set xlabel](set_show#set_xlabel)**. Zmtics
------
The **set zmtics** command changes tics on the z axis to months of the year. Please see **[set xmtics](set_show#set_xmtics)** for details. Zrange
------
The **set zrange** command sets the range that will be displayed on the z axis. The zrange is used only by **splot** and is ignored by **plot**. Please see **[set xrange](set_show#set_xrange)** for details. Ztics
-----
The **set ztics** command controls major (labeled) tics on the z axis. Please see **[set xtics](set_show#set_xtics)** for details. Cblabel
-------
This command sets the label for the color box axis. Please see **[set xlabel](set_show#set_xlabel)**. Cbmtics
-------
The **set cbmtics** command changes tics on the color box axis to months of the year. Please see **[set xmtics](set_show#set_xmtics)** for details. Cbrange
-------
The **set cbrange** command sets the range of values which are colored using the current **palette** by styles **with pm3d**, **with image** and **with palette**. Values outside of the color range use color of the nearest extreme. If the cb-axis is autoscaled in **splot**, then the colorbox range is taken from **zrange**. Points drawn in **splot ... pm3d|palette** can be filtered by using different **zrange** and **cbrange**.
Please see **[set xrange](set_show#set_xrange)** for details on **[set cbrange](set_show#set_cbrange)** syntax. See also **[set palette](set_show#set_palette)** and **[set colorbox](set_show#set_colorbox)**.
Cbtics
------
The **set cbtics** command controls major (labeled) tics on the color box axis. Please see **[set xtics](set_show#set_xtics)** for details.
| programming_docs |
gnuplot Polar plots Polar plots
===========
Polar plots are generated by changing the current coordinate system to polar before issuing a plot command. The option **set polar** tells gnuplot to interpret input 2D coordinates as <angle>,<radius> rather than <x>,<y>. Many, but not all, of the 2D plotting styles work in polar mode. The figure shows a combination of plot styles **lines** and **filledcurves**. See **[set polar](set_show#set_polar)**, **[set rrange](set_show#set_rrange)**, **[set size square](set_show#set_size_square)**, **[set theta](set_show#set_theta)**, **[set ttics](set_show#set_ttics)**.
gnuplot While While
=====
Syntax:
```
while (<expr>) {
<commands>
}
```
Execute a block of commands repeatedly so long as <expr> evaluates to a non-zero value. This command cannot be mixed with old-style (un-bracketed) if/else statements. See also **[do](do#do)**, **[continue](continue#continue)**, **[break](break#break)**.
gnuplot Refresh Refresh
=======
The **refresh** command is similar to **replot**, with two major differences. **refresh** reformats and redraws the current plot using the data already read in. This means that you can use **refresh** for plots with inline data (pseudo-device '-') and for plots from datafiles whose contents are volatile. You cannot use the **refresh** command to add new data to an existing plot. Mousing operations, in particular zoom and unzoom, will use **refresh** rather than **replot** if appropriate. Example:
```
plot 'datafile' volatile with lines, '-' with labels
100 200 "Special point"
e
# Various mousing operations go here
set title "Zoomed in view"
set term post
set output 'zoom.ps'
refresh
```
gnuplot Xerrorlines Xerrorlines
===========
The **xerrorlines** style is only relevant to 2D data plots. **xerrorlines** is like **linespoints**, except that a horizontal error line is also drawn. At each point (x,y), a line is drawn from (xlow,y) to (xhigh,y) or from (x-xdelta,y) to (x+xdelta,y), depending on how many data columns are provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**. The basic style requires either 3 or 4 columns:
```
3 columns: x y xdelta
4 columns: x y xlow xhigh
```
An additional input column (4th or 5th) may be used to provide information such as variable point color.
gnuplot Lines Lines
=====
The **lines** style connects adjacent points with straight line segments. It may be used in either 2D or 3D plots. The basic form requires 1, 2, or 3 columns of input data. Additional input columns may be used to provide information such as variable line color (see **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**). 2D form (no "using" spec)
```
1 column: y # implicit x from row number
2 columns: x y
```
3D form (no "using" spec)
```
1 column: z # implicit x from row, y from index
3 columns: x y z
```
See also **[linetype](set_show#linetype)**, **[linewidth](set_show#linewidth)**, and **[linestyle](set_show#linestyle)**.
gnuplot Undefine Undefine
========
Clear one or more previously defined user variables. This is useful in order to reset the state of a script containing an initialization test. A variable name can contain the wildcard character **\*** as last character. If the wildcard character is found, all variables with names that begin with the prefix preceding the wildcard will be removed. This is useful to remove several variables sharing a common prefix. Note that the wildcard character is only allowed at the end of the variable name! Specifying the wildcard character as sole argument to **undefine** has no effect.
Example:
```
undefine foo foo1 foo2
if (!exists("foo")) load "initialize.gp"
```
```
bar = 1; bar1 = 2; bar2 = 3
undefine bar* # removes all three variables
```
gnuplot Shell Shell
=====
The **shell** command spawns an interactive shell. To return to **gnuplot**, type **logout** if using VMS, **exit** or the END-OF-FILE character if using Unix, or **exit** if using MS-DOS or OS/2. The **shell** command ignores anything else on the gnuplot command line. If instead you want to pass a command string to a shell for immediate execution, use the **system** function or the shortcut **!**. See **[system](system#system)**.
Examples:
```
shell
system "print previous_plot.ps"
! print previous_plot.ps
current_time = system("date")
```
gnuplot Quit Quit
====
The **exit** and **quit** commands and END-OF-FILE character will exit **gnuplot**. Each of these commands will clear the output device (as does the **clear** command) before exiting.
gnuplot Replot Replot
======
The **replot** command without arguments repeats the last **plot** or **splot** command. This can be useful for viewing a plot with different **set** options, or when generating the same plot for several devices. Arguments specified after a **replot** command will be added onto the last **plot** or **splot** command (with an implied ',' separator) before it is repeated. **replot** accepts the same arguments as the **plot** and **splot** commands except that ranges cannot be specified. Thus you can use **replot** to plot a function against the second axes if the previous command was **plot** but not if it was **splot**.
N.B. — use of
```
plot '-' ; ... ; replot
```
is not recommended, because it will require that you type in the data all over again. In most cases you can use the **refresh** command instead, which will redraw the plot using the data previously read in.
Note that in multiplot mode, **replot** can only reproduce the most recent component plot, not the full set.
See also **[command-line-editing](command_line_editing#command-line-editing)** for ways to edit the last **[plot](plot#plot)** (**[splot](splot#splot)**) command.
See also **[show plot](set_show#show_plot)** to show the whole current plotting command, and the possibility to copy it into the **[history](history#history)**.
gnuplot Boxerrorbars Boxerrorbars
============
The **boxerrorbars** style is only relevant to 2D data plotting. It is a combination of the **boxes** and **yerrorbars** styles. It requires 3, 4, or 5 columns of data. An additional (4th, 5th or 6th) input column may be used to provide variable (per-datapoint) color information (see **[linecolor](linetypes_colors_styles#linecolor)** and **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**). The error bar will be drawn in the same color as the border of the box.
```
3 columns: x y ydelta
4 columns: x y ydelta xdelta # boxwidth != -2
4 columns: x y ylow yhigh # boxwidth == -2
5 columns: x y ylow yhigh xdelta
```
The boxwidth will come from the fourth column if the y errors are given as "ydelta" and the boxwidth was not previously set to -2.0 (**set boxwidth -2.0**) or from the fifth column if the y errors are in the form of "ylow yhigh". The special case **boxwidth = -2.0** is for four-column data with y errors in the form "ylow yhigh". In this case the boxwidth will be calculated so that each box touches the adjacent boxes. The width will also be calculated in cases where three-column data are used.
The box height is determined from the y error in the same way as it is for the **yerrorbars** style — either from y-ydelta to y+ydelta or from ylow to yhigh, depending on how many data columns are provided.
gnuplot Yerrorbars Yerrorbars
==========
The **yerrorbars** (or **errorbars**) style is only relevant to 2D data plots. **yerrorbars** is like **points**, except that a vertical error bar is also drawn. At each point (x,y), a line is drawn from (x,y-ydelta) to (x,y+ydelta) or from (x,ylow) to (x,yhigh), depending on how many data columns are provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**.
```
2 columns: [implicit x] y ydelta
3 columns: x y ydelta
4 columns: x y ylow yhigh
```
An additional input column (4th or 5th) may be used to provide information such as variable point color.
See also [errorbar demo.](http://www.gnuplot.info/demo/mgr.html)
gnuplot Fence plots Fence plots
===========
Fence plots combine several 2D plots by aligning their Y coordinates and separating them from each other by a displacement along X. Filling the area between a base value and each plot's series of Z values enhances the visual impact of the alignment on Y and comparison on Z. There are several ways such plots can be created in gnuplot. The simplest is to use the 5 column variant of the **zerrorfill** style. Suppose there are separate curves z = Fi(y) indexed by i. A fence plot is generated by **splot with zerrorfill** using input columns
```
i y z_base z_base Fi(y)
```
gnuplot Print Print
=====
The **print** command prints the value of <expression> to the screen. It is synonymous with **pause 0**. <expression> may be anything that **gnuplot** can evaluate that produces a number, or it can be a string. Syntax:
```
print <expression> {, <expression>, ...}
```
See **[expressions](expressions#expressions)**. The output file can be set with **set print**. See also **[printerr](printerr#printerr)**.
gnuplot Points Points
======
The **points** style displays a small symbol at each point. The command **set pointsize** may be used to change the default size of all points. The point type defaults to that of the linetype. See **[linetype](set_show#linetype)**. If no **using** spec is found in the plot command, input data columns are interpreted implicitly in the order
```
x y pointsize pointtype color
```
Any columns beyond the first two (x and y) are optional; they correspond to additional plot properties **pointsize variable**, **pointtype variable**, etc. The first 8 point types are shared by all terminals. Individual terminals may provide a much larger number of distinct point types. Use the **test** command to show what is provided by the current terminal settings.
Alternatively any single printable character may be given instead of a numerical point type, as in the example below. You may use any unicode character as the pointtype (assumes utf8 support). See **[escape sequences](enhanced_text_mode#escape_sequences)**. Longer strings may be plotted using plot style **labels** rather than **points**.
```
plot f(x) with points pt "#"
plot d(x) with points pt "\U+2299"
```
When using the keywords **pointtype**, **pointsize**, or **linecolor** in a plot command, the additional keyword **variable** may be given instead of a number. In this case the corresponding properties of each point are assigned by additional columns of input data. Variable pointsize is always taken from the first additional column provided in a **using** spec. Variable color is always taken from the last additional column. See **[colorspec](linetypes_colors_styles#colorspec)**. If all three properties are specified for each point, the order of input data columns is thus
```
plot DATA using x:y:pointsize:pointtype:color \
with points lc variable pt variable ps variable
```
Note: for information on user-defined program variables, see **[variables](expressions#variables)**.
gnuplot Linetypes, colors, and styles Linetypes, colors, and styles
=============================
In older gnuplot versions, each terminal type provided a set of distinct "linetypes" that could differ in color, in thickness, in dot/dash pattern, or in some combination of color and dot/dash. These colors and patterns were not guaranteed to be consistent across different terminal types although most used the color sequence red/green/blue/magenta/cyan/yellow. You can select this old behaviour via the command **set colorsequence classic**, but by default gnuplot version 5 uses a terminal-independent sequence of 8 colors. You can further customize the sequence of linetype properties interactively or in an initialization file. See **[set linetype](set_show#set_linetype)**. Several sample initialization files are provided in the distribution package.
The current linetype properties for a particular terminal can be previewed by issuing the **test** command after setting the terminal type.
Successive functions or datafiles plotted by a single command will be assigned successive linetypes in the current default sequence. You can override this for any individual function, datafile, or plot element by giving explicit line properties in the plot command.
Examples:
```
plot "foo", "bar" # plot two files using linetypes 1, 2
plot sin(x) linetype 4 # use linetype color 4
```
In general, colors can be specified using named colors, rgb (red, green, blue) components, hsv (hue, saturation, value) components, or a coordinate along the current pm3d palette.
Examples:
```
plot sin(x) lt rgb "violet" # one of gnuplot's named colors
plot sin(x) lt rgb "#FF00FF" # explicit RGB triple in hexadecimal
plot sin(x) lt palette cb -45 # whatever color corresponds to -45
# in the current cbrange of the palette
plot sin(x) lt palette frac 0.3 # fractional value along the palette
```
See **[colorspec](linetypes_colors_styles#colorspec)**, **[show colornames](set_show#show_colornames)**, **[hsv](expressions#hsv)**, **[set palette](set_show#set_palette)**, **[cbrange](set_show#cbrange)**. See also **[set monochrome](set_show#set_monochrome)**.
Linetypes also have an associated dot-dash pattern although not all terminal types are capable of using it. Gnuplot version 5 allows you to specify the dot-dash pattern independent of the line color. See **[dashtype](linetypes_colors_styles#dashtype)**.
Colorspec
---------
Many commands allow you to specify a linetype with an explicit color. Syntax:
```
... {linecolor | lc} {"colorname" | <colorspec> | <n>}
... {textcolor | tc} {<colorspec> | {linetype | lt} <n>}
... {fillcolor | fc} {<colorspec> | linetype <n> | linestyle <n>}
```
where <colorspec> has one of the following forms:
```
rgbcolor "colorname" # e.g. "blue"
rgbcolor "0xRRGGBB" # string containing hexadecimal constant
rgbcolor "0xAARRGGBB" # string containing hexadecimal constant
rgbcolor "#RRGGBB" # string containing hexadecimal in x11 format
rgbcolor "#AARRGGBB" # string containing hexadecimal in x11 format
rgbcolor <integer val> # integer value representing AARRGGBB
rgbcolor variable # integer value is read from input file
palette frac <val> # <val> runs from 0 to 1
palette cb <value> # <val> lies within cbrange
palette z
variable # color index is read from input file
bgnd # background color
black
```
The "<n>" is the linetype number the color of which is used, see **[test](test#test)**.
"colorname" refers to one of the color names built in to gnuplot. For a list of the available names, see **[show colornames](set_show#show_colornames)**.
Hexadecimal constants can be given in quotes as "#RRGGBB" or "0xRRGGBB", where RRGGBB represents the red, green, and blue components of the color and must be between 00 and FF. For example, magenta = full-scale red + full-scale blue could be represented by "0xFF00FF", which is the hexadecimal representation of (255 << 16) + (0 << 8) + (255).
"#AARRGGBB" represents an RGB color with an alpha channel (transparency) value in the high bits. An alpha value of 0 represents a fully opaque color; i.e., "#00RRGGBB" is the same as "#RRGGBB". An alpha value of 255 (FF) represents full transparency.
The color palette is a linear gradient of colors that smoothly maps a single numerical value onto a particular color. Two such mappings are always in effect. **palette frac** maps a fractional value between 0 and 1 onto the full range of the color palette. **palette cb** maps the range of the color axis onto the same palette. See **[set cbrange](set_show#set_cbrange)**. See also **[set colorbox](set_show#set_colorbox)**. You can use either of these to select a constant color from the current palette.
"palette z" maps the z value of each plot segment or plot element into the cbrange mapping of the palette. This allows smoothly-varying color along a 3d line or surface. It also allows coloring 2D plots by palette values read from an extra column of data (not all 2D plot styles allow an extra column). There are two special color specifiers: **bgnd** for background color and **black**.
### Background color
Most terminals allow you to set an explicit background color for the plot. The special linetype **bgnd** will draw in this color, and **bgnd** is also recognized as a color. Examples:
```
# This will erase a section of the canvas by writing over it in the
# background color
set term wxt background rgb "gray75"
set object 1 rectangle from x0,y0 to x1,y1 fillstyle solid fillcolor bgnd
# This will draw an "invisible" line along the x axis
plot 0 lt bgnd
```
### Linecolor variable
**lc variable** tells the program to use the value read from one column of the input data as a linetype index, and use the color belonging to that linetype. This requires a corresponding additional column in the **using** specifier. Text colors can be set similarly using **tc variable**. Examples:
```
# Use the third column of data to assign colors to individual points
plot 'data' using 1:2:3 with points lc variable
```
```
# A single data file may contain multiple sets of data, separated by two
# blank lines. Each data set is assigned as index value (see `index`)
# that can be retrieved via the `using` specifier `column(-2)`.
# See `pseudocolumns`. This example uses to value in column -2 to
# draw each data set in a different line color.
plot 'data' using 1:2:(column(-2)) with lines lc variable
```
### Rgbcolor variable
You can assign a separate color for each data point, line segment, or label in your plot. **lc rgbcolor variable** tells the program to read RGB color information for each line in the data file. This requires a corresponding additional column in the **using** specifier. The extra column is interpreted as a 24-bit packed RGB triple. If the value is provided directly in the data file it is easiest to give it as a hexadecimal value (see **[rgbcolor](linetypes_colors_styles#rgbcolor)**). Alternatively, the **using** specifier can contain an expression that evaluates to a 24-bit RGB color as in the example below. Text colors are similarly set using **tc rgbcolor variable**. Example:
```
# Place colored points in 3D at the x,y,z coordinates corresponding to
# their red, green, and blue components
rgb(r,g,b) = 65536 * int(r) + 256 * int(g) + int(b)
splot "data" using 1:2:3:(rgb($1,$2,$3)) with points lc rgb variable
```
Dashtype
--------
In gnuplot version 5 the dash pattern (**dashtype**) is a separate property associated with each line, analogous to **linecolor** or **linewidth**. It is not necessary to place the current terminal in a special mode just to draw dashed lines. I.e. the command **set term <termname> {solid|dashed}** is now ignored. If backwards compatibility with old scripts written for version 4 is required, the following lines can be used instead:
```
if (GPVAL_VERSION >= 5.0) set for [i=1:9] linetype i dashtype i
if (GPVAL_VERSION < 5.0) set termoption dashed
```
All lines have the property **dashtype solid** unless you specify otherwise. You can change the default for a particular linetype using the command **set linetype** so that it affects all subsequent commands, or you can include the desired dashtype as part of the **plot** or other command.
Syntax:
```
dashtype N # predefined dashtype invoked by number
dashtype "pattern" # string containing a combination of the characters
# dot (.) hyphen (-) underscore(_) and space.
dashtype (s1,e1,s2,e2,s3,e3,s4,e4) # dash pattern specified by 1 to 4
# numerical pairs <solid length>, <emptyspace length>
```
Example:
```
# Two functions using linetype 1 but distinguished by dashtype
plot f1(x) with lines lt 1 dt solid, f2(x) with lines lt 1 dt 3
```
Some terminals support user-defined dash patterns in addition to whatever set of predefined dash patterns they offer.
Examples:
```
plot f(x) dt 3 # use terminal-specific dash pattern 3
plot f(x) dt ".. " # construct a dash pattern on the spot
plot f(x) dt (2,5,2,15) # numerical representation of the same pattern
set dashtype 11 (2,4,4,7) # define new dashtype to be called by index
plot f(x) dt 11 # plot using our new dashtype
```
If you specify a dash pattern using a string the program will convert this to a sequence of <solid>,<empty> pairs. Dot "." becomes (2,5), dash "-" becomes (10,10), underscore "\_" becomes (20,10), and each space character " " adds 10 to the previous <empty> value. The command **show dashtype** will show both the original string and the converted numerical sequence.
Linestyles vs linetypes
-----------------------
A **linestyle** is a temporary association of properties linecolor, linewidth, dashtype, and pointtype. It is defined using the command **set style line**. Once you have defined a linestyle, you can use it in a plot command to control the appearance of one or more plot elements. In other words, it is just like a linetype except for its lifetime. Whereas **linetypes** are permanent (they last until you explicitly redefine them), **linestyles** last until the next reset of the graphics state. Examples:
```
# define a new line style with terminal-independent color cyan,
# linewidth 3, and associated point type 6 (a circle with a dot in it).
set style line 5 lt rgb "cyan" lw 3 pt 6
plot sin(x) with linespoints ls 5 # user-defined line style 5
```
| programming_docs |
gnuplot Pwd Pwd
===
The **pwd** command prints the name of the working directory to the screen. Note that if you wish to store the current directory into a string variable or use it in string expressions, then you can use variable GPVAL\_PWD, see **[show variables all](set_show#show_variables_all)**.
gnuplot Vectors Vectors
=======
The 2D **vectors** style draws a vector from (x,y) to (x+xdelta,y+ydelta). The 3D **vectors** style is similar, but requires six columns of basic data. In both cases, an additional input column (5th in 2D, 7th in 3D) may be used to provide variable (per-datapoint) color information. (see **[linecolor](linetypes_colors_styles#linecolor)** and **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**). A small arrowhead is drawn at the end of each vector.
```
4 columns: x y xdelta ydelta
6 columns: x y z xdelta ydelta zdelta
```
The keywords "with vectors" may be followed by an inline arrow style specifications, a reference to a predefined arrow style, or a request to read the index of the desired arrow style for each vector from a separate column. Note: If you choose "arrowstyle variable" it will fill in all arrow properties at the time the corresponding vector is drawn; you cannot mix this keyword with other line or arrow style qualifiers in the plot command.
```
plot ... with vectors filled heads
plot ... with vectors arrowstyle 3
plot ... using 1:2:3:4:5 with vectors arrowstyle variable
```
Example:
```
plot 'file.dat' using 1:2:3:4 with vectors head filled lt 2
splot 'file.dat' using 1:2:3:(1):(1):(1) with vectors filled head lw 2
```
splot with vectors is supported only for **set mapping cartesian**. **set clip one** and **set clip two** affect vectors drawn in 2D. See **[set clip](set_show#set_clip)** and **[arrowstyle](set_show#arrowstyle)**.
See also the 2D plot style **[with arrows](arrows#with_arrows)** that is identical to **[with vectors](vectors#with_vectors)** except that each arrow is specified using x:y:length:angle.
gnuplot Impulses Impulses
========
The **impulses** style displays a vertical line from y=0 to the y value of each point (2D) or from z=0 to the z value of each point (3D). Note that the y or z values may be negative. Data from additional columns can be used to control the color of each impulse. To use this style effectively in 3D plots, it is useful to choose thick lines (linewidth > 1). This approximates a 3D bar chart.
```
1 column: y
2 columns: x y # line from [x,0] to [x,y] (2D)
3 columns: x y z # line from [x,y,0] to [x,y,z] (3D)
```
gnuplot Differences between versions 4 and 5 Differences between versions 4 and 5
====================================
Some changes introduced in version 5 may cause certain scripts written for earlier versions of gnuplot to behave differently. \* Revised handling of input data containing NaN, inconsistent number of data columns, or other unexpected content. See Note under **[missing](set_show#missing)** for examples and figures.
\* Time coordinates are stored internally as the number of seconds relative to the standard unix epoch 1-Jan-1970. Earlier versions of gnuplot used a different epoch internally (1-Jan-2000). This change resolves inconsistencies introduced whenever time in seconds was generated externally. The epoch convention used by a particular gnuplot installation can be determined using the command **print strftime("%F",0)**. Time is now stored to at least millisecond precision.
\* The function **timecolumn(N,"timeformat")** now has 2 parameters. Because the new second parameter is not associated with any particular data axis, this allows using the **timecolumn** function to read time data for reasons other than specifying the x or y coordinate. This functionality replaces the command sequence **set xdata time; set timefmt "timeformat"**. It allows combining time data read from multiple files with different formats within a single plot.
\* The **reverse** keyword of the **set [axis]range** command affects only autoscaling. It does not invert or otherwise alter the meaning of a command such as **set xrange [0:1]**. If you want to reverse the direction of the x axis in such a case, say instead **set xrange [1:0]**.
\* The **call** command is provides a set of variables ARGC, ARG0, ..., ARG9. ARG0 holds the name of the script file being executed. ARG1 to ARG9 are string variables and thus may either be referenced directly or expanded as macros, e.g. @ARG1. The contents of ARG0 ... ARG9 may alternatively be accessed as array elements ARGV[0] ... ARGV[ARGC]. An older gnuplot convention of referencing call parameters as tokens $0 ... $9 is deprecated.
\* The optional bandwidth for the kernel density smoothing option is taken from a keyword rather than a data column. See **[smooth kdensity](plot#smooth_kdensity)**.
gnuplot Batch/Interactive Operation Batch/Interactive Operation
===========================
**Gnuplot** may be executed in either batch or interactive modes, and the two may even be mixed together on many systems. Any command-line arguments are assumed to be either program options (see command-line-options) or names of files containing **gnuplot** commands. Each file or command string will be executed in the order specified. The special filename "-" is indicates that commands are to be read from stdin. **Gnuplot** exits after the last file is processed. If no load files and no command strings are specified, **gnuplot** accepts interactive input from stdin.
Command line options
--------------------
Gnuplot accepts the following options on the command line
```
-V, --version
-h, --help
-p --persist
-d --default-settings
-s --slow
-e "command1; command2; ..."
-c scriptfile ARG1 ARG2 ...
```
-p tells the program not to close any remaining interactive plot windows when the program exits.
-d tells the program not to execute any private or system initialization (see **[initialization](start_up_initialization#initialization)**).
-s tells the program to wait for slow font initialization on startup. Otherwise it prints an error and continues with bad font metrics.
-e "command" tells gnuplot to execute that single command before continuing.
-c is equivalent to -e "call scriptfile ARG1 ARG2 ...". See **[call](call#call)**.
Examples
--------
To launch an interactive session:
```
gnuplot
```
To launch a batch session using two command files "input1" and "input2":
```
gnuplot input1 input2
```
To launch an interactive session after an initialization file "header" and followed by another command file "trailer":
```
gnuplot header - trailer
```
To give **gnuplot** commands directly in the command line, using the "-persist" option so that the plot remains on the screen afterwards:
```
gnuplot -persist -e "set title 'Sine curve'; plot sin(x)"
```
To set user-defined variables a and s prior to executing commands from a file:
```
gnuplot -e "a=2; s='file.png'" input.gpl
```
gnuplot Steps Steps
=====
The **steps** style is only relevant to 2D plotting. It connects consecutive points with two line segments: the first from (x1,y1) to (x2,y1) and the second from (x2,y1) to (x2,y2). The input column requires are the same as for plot styles **lines** and **points**. The difference between **fsteps** and **steps** is that **fsteps** traces first the change in y and then the change in x. **steps** traces first the change in x and then the change in y. To fill the area between the curve and the baseline at y=0, use **fillsteps**. See also [steps demo.](http://www.gnuplot.info/demo/steps.html)
gnuplot Inline data and datablocks Inline data and datablocks
==========================
There are two mechanisms for embedding data into a stream of gnuplot commands. If the special filename '-' appears in a plot command, then the lines immediately following the plot command are interpreted as inline data. See **[special-filenames](plot#special-filenames)**. Data provided in this way can only be used once, by the plot command it follows. The second mechanism defines a named data block as a here-document. The named data is persistent and may be referred to by more than one plot command. Example:
```
$Mydata << EOD
11 22 33 first line of data
44 55 66 second line of data
# comments work just as in a data file
77 88 99
EOD
stats $Mydata using 1:3
plot $Mydata using 1:3 with points, $Mydata using 1:2 with impulses
```
Data block names must begin with a $ character, which distinguishes them from other types of persistent variables. The end-of-data delimiter (EOD in the example) may be any sequence of alphanumeric characters.
The storage associated with named data blocks can be released using **undefine** command. **undefine $\*** frees all named data blocks at once.
gnuplot Yerrorlines Yerrorlines
===========
The **yerrorlines** (or **errorlines**) style is only relevant to 2D data plots. **yerrorlines** is like **linespoints**, except that a vertical error line is also drawn. At each point (x,y), a line is drawn from (x,y-ydelta) to (x,y+ydelta) or from (x,ylow) to (x,yhigh), depending on how many data columns are provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**. Either 3 or 4 input columns are required.
```
3 columns: x y ydelta
4 columns: x y ylow yhigh
```
An additional input column (4th or 5th) may be used to provide information such as variable point color.
See also [errorbar demo.](http://www.gnuplot.info/demo/mgr.html)
gnuplot Call Call
====
The **call** command is identical to the **load** command with one exception: the name of the file being loaded may be followed by up to nine parameters.
```
call "inputfile" <param-1> <param-2> <param-3> ... <param-9>
```
Previous versions of gnuplot performed macro-like substitution of the special tokens $0, $1, ... $9 with the literal contents of these parameters. This mechanism is now deprecated (see **[call old-style](call#call_old-style)**).
Gnuplot now provides a set of string variables ARG0, ARG1, ..., ARG9 and an integer variable ARGC. When a **call** command is executed ARG0 is set to the name of the input file, ARGC is set to the number of parameters present, and ARG1 to ARG9 are loaded from the parameters that follow it on the command line. Any existing contents of the ARG variables are saved and restored across a **call** command.
Because the parameters ARG1 ... ARG9 are stored in ordinary string variables they may be dereferenced by macro expansion (analogous to the older deprecated syntax). However in many cases it is more natural to use them as you would any other variable.
In parallel to the string parameters ARG1 ... ARG9, the passed parameters are stored in an array ARGV[9]. See **[argv](call#argv)**.
Argv[ ]
-------
When a gnuplot script is entered via the **call** command any parameters passed by the caller are available via two mechanisms. Each parameter is stored as a string in variables ARG1, ARG2, ... ARG9. Each parameter is also stored as one element of the array ARGV[9]. Numerical values are stored as complex variables. All other values are stored as strings. Thus after a call
```
call 'routine_1.gp' 1 pi "title"
```
The three arguments are available inside routine\_1.gp as follows
```
ARG1 = "1" ARGV[1] = 1.0
ARG2 = "3.14159" ARGV[2] = 3.14159265358979...
ARG3 = "title" ARGV[3] = "title"
```
In this example ARGV[1] and ARGV[2] have the full precision of a floating point variable. ARG2 lost precision in being stored as a string using format "%g".
Example
-------
```
Call site
MYFILE = "script1.gp"
FUNC = "sin(x)"
call MYFILE FUNC 1.23 "This is a plot title"
Upon entry to the called script
ARG0 holds "script1.gp"
ARG1 holds the string "sin(x)"
ARG2 holds the string "1.23"
ARG3 holds the string "This is a plot title"
ARGC is 3
The script itself can now execute
plot @ARG1 with lines title ARG3
print ARG2 * 4.56, @ARG2 * 4.56
print "This plot produced by script ", ARG0
```
Notice that because ARG1 is a string it must be dereferenced as a macro, but ARG2 may be dereferenced either as a macro (yielding a numerical constant) or a variable (yielding that same numerical value after auto-promotion of the string "1.23" to a real).
The same result could be obtained directly from a shell script by invoking gnuplot with the **-c** command line option:
```
gnuplot -persist -c "script1.gp" "sin(x)" 1.23 "This is a plot title"
```
Old-style
---------
This describes the deprecated call mechanism used by old versions of gnuplot.
```
call "<input-file>" <param-0> <param-1> ... <param-9>
```
The name of the input file must be enclosed in quotes. As each line is read from the input file, it is scanned for the following special character sequences: $0 $1 $2 $3 $4 $5 $6 $7 $8 $9 $#. If found, the sequence **$**+digit is replaced by the corresponding parameter from the **call** command line. Quote characters are not copied and string variable substitution is not performed. The character sequence **$#** is replaced by the number of passed parameters. **$** followed by any other character is treated as an escape sequence; use **$$** to get a single **$**.
Example:
If the file 'calltest.gp' contains the line:
```
print "argc=$# p0=$0 p1=$1 p2=$2 p3=$3 p4=$4 p5=$5 p6=$6 p7=x$7x"
```
entering the command:
```
call 'calltest.gp' "abcd" 1.2 + "'quoted'" -- "$2"
```
will display:
```
argc=7 p0=abcd p1=1.2 p2=+ p3='quoted' p4=- p5=- p6=$2 p7=xx
```
NOTES: This use of the **$** character conflicts both with gnuplot's own syntax for datafile columns and with the use of **$** to indicate environmental variables in a unix-like shell. The special sequence **$#** was mis-interpreted as a comment delimiter in gnuplot versions 4.5 through 4.6.3. Quote characters are ignored during substitution, so string constants are easily corrupted.
gnuplot Time/Date data Time/Date data
==============
**gnuplot** supports the use of time and/or date information as input data. This feature is activated by the commands **set xdata time**, **set ydata time**, etc. Internally all times and dates are converted to the number of seconds from the year 1970. The command **set timefmt** defines the default format for all inputs: data files, ranges, tics, label positions – anything that accepts a time data value defaults to receiving it in this format. Only one default format can be in effect at a given time. Thus if both x and y data in a file are time/date, by default they are interpreted in the same format. However this default can be replaced when reading any particular file or column of input using the **timecolumn** function in the corresponding **using** specifier.
The conversion to and from seconds assumes Universal Time (which is the same as Greenwich Standard Time). There is no provision for changing the time zone or for daylight savings. If all your data refer to the same time zone (and are all either daylight or standard) you don't need to worry about these things. But if the absolute time is crucial for your application, you'll need to convert to UT yourself.
Commands like **show xrange** will re-interpret the integer according to **timefmt**. If you change **timefmt**, and then **show** the quantity again, it will be displayed in the new **timefmt**. For that matter, if you reset the data type flag for that axis (e.g. **set xdata**), the quantity will be shown in its numerical form.
The commands **set format** or **set tics format** define the format that will be used for tic labels, whether or not input for the specified axis is time/date.
If time/date information is to be plotted from a file, the **using** option *must* be used on the **plot** or **splot** command. These commands simply use white space to separate columns, but white space may be embedded within the time/date string. If you use tabs as a separator, some trial-and-error may be necessary to discover how your system treats them.
The **time** function can be used to get the current system time. This value can be converted to a date string with the **strftime** function, or it can be used in conjunction with **timecolumn** to generate relative time/date plots. The type of the argument determines what is returned. If the argument is an integer, **time** returns the current time as an integer, in seconds from 1 Jan 1970. If the argument is real (or complex), the result is real as well. The precision of the fractional (sub-second) part depends on your operating system. If the argument is a string, it is assumed to be a format string, and it is passed to **strftime** to provide a formatted time/date string.
The following example demonstrates time/date plotting.
Suppose the file "data" contains records like
```
03/21/95 10:00 6.02e23
```
This file can be plotted by
```
set xdata time
set timefmt "%m/%d/%y"
set xrange ["03/21/95":"03/22/95"]
set format x "%m/%d"
set timefmt "%m/%d/%y %H:%M"
plot "data" using 1:3
```
which will produce xtic labels that look like "03/21".
Gnuplot tracks time to millisecond precision. Time formats have been modified to match this. Example: print the current time to msec precision
```
print strftime("%H:%M:%.3S %d-%b-%Y",time(0.0))
18:15:04.253 16-Apr-2011
```
See **[time\_specifiers](set_show#time_specifiers)**.
gnuplot Reread Reread
======
[DEPRECATED in version 5.4] This command is deprecated in favor of explicit iteration. See **[iterate](iteration#iterate)**. The **reread** command causes the current **gnuplot** command file, as specified by a **load** command, to be reset to its starting point before further commands are read from it. This essentially implements an endless loop of the commands from the beginning of the command file to the **reread** command. The **reread** command has no effect when reading interactively (from stdin).
gnuplot Filledcurves Filledcurves
============
The **filledcurves** style is only used for 2D plotting. It has three variants. The first two variants require either a single function or two columns (x,y) of input data, and may be further modified by the options listed below. Syntax:
```
plot ... with filledcurves [option]
```
where the option can be one of the following
```
[closed | {above | below}
{x1 | x2 | y | r}[=<a>] | xy=<x>,<y>]
```
The first variant, **closed**, treats the curve itself as a closed polygon. This is the default if there are two columns of input data.
The second variant is to fill the area between the curve and a given axis, a horizontal or vertical line, or a point.
```
filledcurves closed ... just filled closed curve,
filledcurves x1 ... x1 axis,
filledcurves x2 ... x2 axis, etc for y1 and y2 axes,
filledcurves y=42 ... line at y=42, i.e. parallel to x axis,
filledcurves xy=10,20 ... point 10,20 of x1,y1 axes (arc-like shape).
filledcurves above r=1.5 the area of a polar plot outside radius 1.5
```
The third variant fills the area between two curves sampled at the same set of x coordinates. It requires three columns of input data (x, y1, y2). This is the default if there are three or more columns of input data. If you have a y value in column 2 and an associated error value in column 3 the area of uncertainty can be represented by shading. See also the similar 3D plot style **[zerrorfill](zerrorfill#zerrorfill)**.
```
3 columns: x y yerror
```
```
plot $DAT using 1:($2-$3):($2+$3) with filledcurves, \
$DAT using 1:2 smooth mcs with lines
```
The **above** and **below** options apply both to commands of the form
```
... filledcurves above {x1|x2|y|r}=<val>
```
and to commands of the form
```
... using 1:2:3 with filledcurves below
```
In either case the option limits the filled area to one side of the bounding line or curve. Notes: Not all terminal types support this plotting mode.
```
The x= and y= keywords are ignored for 3 columns data plots
```
Zooming a filled curve drawn from a datafile may produce empty or incorrect areas because gnuplot is clipping points and lines, and not areas.
If the values <x>, <y>, or <a> are outside the drawing boundary they are moved to the graph boundary. Then the actual fill area in the case of option xy=<x>,<y> will depend on xrange and yrange.
Fill properties
---------------
Plotting **with filledcurves** can be further customized by giving a fillstyle (solid/transparent/pattern) or a fillcolor. If no fillstyle (**fs**) is given in the plot command then the current default fill style is used. See **[set style fill](set_show#set_style_fill)**. If no fillcolor (**fc**) is given in the plot command, the usual linetype color sequence is followed. The {{no}border} property of the fillstyle is honored by filledcurves mode **closed**, the default. It is ignored by all other filledcurves modes. Example:
```
plot 'data' with filledcurves fc "cyan" fs solid 0.5 border lc "blue"
```
| programming_docs |
gnuplot Xerrorbars Xerrorbars
==========
The **xerrorbars** style is only relevant to 2D data plots. **xerrorbars** is like **points**, except that a horizontal error bar is also drawn. At each point (x,y), a line is drawn from (xlow,y) to (xhigh,y) or from (x-xdelta,y) to (x+xdelta,y), depending on how many data columns are provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**. The basic style requires either 3 or 4 columns:
```
3 columns: x y xdelta
4 columns: x y xlow xhigh
```
An additional input column (4th or 5th) may be used to provide information such as variable point color.
gnuplot Fit Fit
===
The **fit** command fits a user-supplied real-valued expression to a set of data points, using the nonlinear least-squares Marquardt-Levenberg algorithm. There can be up to 12 independent variables, there is always 1 dependent variable, and any number of parameters can be fitted. Optionally, error estimates can be input for weighting the data points. The basic use of **fit** is best explained by a simple example:
```
f(x) = a + b*x + c*x**2
fit f(x) 'measured.dat' using 1:2 via a,b,c
plot 'measured.dat' u 1:2, f(x)
```
Syntax:
```
fit {<ranges>} <expression>
'<datafile>' {datafile-modifiers}
{{unitweights} | {y|xy|z}error | errors <var1>{,<var2>,...}}
via '<parameter file>' | <var1>{,<var2>,...}
```
Ranges may be specified to filter the data used in fitting. Out-of-range data points are ignored. The syntax is
```
[{dummy_variable=}{<min>}{:<max>}],
```
analogous to **plot**; see **[plot ranges](plot#plot_ranges)**. <expression> can be any valid **gnuplot** expression, although the most common is a previously user-defined function of the form f(x) or f(x,y). It must be real-valued. The names of the independent variables are set by the **set dummy** command, or in the <ranges> part of the command (see below); by default, the first two are called x and y. Furthermore, the expression should depend on one or more variables whose value is to be determined by the fitting procedure.
<datafile> is treated as in the **plot** command. All the **plot datafile** modifiers (**using**, **every**,...) except **smooth** are applicable to **fit**. See **[plot datafile](plot#plot_datafile)**.
The datafile contents can be interpreted flexibly by providing a **using** qualifier as with plot commands. For example to generate the independent variable x as the sum of columns 2 and 3, while taking z from column 6 and requesting equal weights:
```
fit ... using ($2+$3):6
```
In the absence of a **using** specification, the fit implicitly assumes there is only a single independent variable. If the file itself, or the using specification, contains only a single column of data, the line number is taken as the independent variable. If a **using** specification is given, there can be up to 12 independent variables (and more if specially configured at compile time).
The **unitweights** option, which is the default, causes all data points to be weighted equally. This can be changed by using the **errors** keyword to read error estimates of one or more of the variables from the data file. These error estimates are interpreted as the standard deviation s of the corresponding variable value and used to compute a weight for the datum as 1/s\*\*2.
In case of error estimates of the independent variables, these weights are further multiplied by fitting function derivatives according to the "effective variance method" (Jay Orear, Am. J. Phys., Vol. 50, 1982).
The **errors** keyword is to be followed by a comma-separated list of one or more variable names for which errors are to be input; the dependent variable z must always be among them, while independent variables are optional. For each variable in this list, an additional column will be read from the file, containing that variable's error estimate. Again, flexible interpretation is possible by providing the **using** qualifier. Note that the number of independent variables is thus implicitly given by the total number of columns in the **using** qualifier, minus 1 (for the dependent variable), minus the number of variables in the **errors** qualifier.
As an example, if one has 2 independent variables, and errors for the first independent variable and the dependent variable, one uses the **errors x,z** qualifier, and a **using** qualifier with 5 columns, which are interpreted as x:y:z:sx:sz (where x and y are the independent variables, z the dependent variable, and sx and sz the standard deviations of x and z).
A few shorthands for the **errors** qualifier are available: **yerrors** (for fits with 1 column of independent variable), and **zerrors** (for the general case) are all equivalent to **errors z**, indicating that there is a single extra column with errors of the dependent variable.
**xyerrors**, for the case of 1 independent variable, indicates that there are two extra columns, with errors of both the independent and the dependent variable. In this case the errors on x and y are treated by Orear's effective variance method.
Note that **yerror** and **xyerror** are similar in both form and interpretation to the **yerrorlines** and **xyerrorlines** 2D plot styles.
With the command **set fit v4** the fit command syntax is compatible with **gnuplot** version 4. In this case there must be two more **using** qualifiers (z and s) than there are independent variables, unless there is only one variable. **gnuplot** then uses the following formats, depending on the number of columns given in the **using** specification:
```
z # 1 independent variable (line number)
x:z # 1 independent variable (1st column)
x:z:s # 1 independent variable (3 columns total)
x:y:z:s # 2 independent variables (4 columns total)
x1:x2:x3:z:s # 3 independent variables (5 columns total)
x1:x2:x3:...:xN:z:s # N independent variables (N+2 columns total)
```
Please beware that this means that you have to supply z-errors s in a fit with two or more independent variables. If you want unit weights you need to supply them explicitly by using e.g. then format x:y:z:(1).
The dummy variable names may be changed when specifying a range as noted above. The first range corresponds to the first **using** spec, and so on. A range may also be given for z (the dependent variable), in which case data points for which f(x,...) is out of the z range will not contribute to the residual being minimized.
Multiple datasets may be simultaneously fit with functions of one independent variable by making y a 'pseudo-variable', e.g., the dataline number, and fitting as two independent variables. See **[fit multi-branch](fit#fit_multi-branch)**.
The **via** qualifier specifies which parameters are to be optimized, either directly, or by referencing a parameter file.
Examples:
```
f(x) = a*x**2 + b*x + c
g(x,y) = a*x**2 + b*y**2 + c*x*y
set fit limit 1e-6
fit f(x) 'measured.dat' via 'start.par'
fit f(x) 'measured.dat' using 3:($7-5) via 'start.par'
fit f(x) './data/trash.dat' using 1:2:3 yerror via a, b, c
fit g(x,y) 'surface.dat' using 1:2:3 via a, b, c
fit a0 + a1*x/(1 + a2*x/(1 + a3*x)) 'measured.dat' via a0,a1,a2,a3
fit a*x + b*y 'surface.dat' using 1:2:3 via a,b
fit [*:*][yaks=*:*] a*x+b*yaks 'surface.dat' u 1:2:3 via a,b
```
```
fit [][][t=*:*] a*x + b*y + c*t 'foo.dat' using 1:2:3:4 via a,b,c
```
```
set dummy x1, x2, x3, x4, x5
h(x1,x2,x3,x4,s5) = a*x1 + b*x2 + c*x3 + d*x4 + e*x5
fit h(x1,x2,x3,x4,x5) 'foo.dat' using 1:2:3:4:5:6 via a,b,c,d,e
```
After each iteration step, detailed information about the current state of the fit is written to the display. The same information about the initial and final states is written to a log file, "fit.log". This file is always appended to, so as to not lose any previous fit history; it should be deleted or renamed as desired. By using the command **set fit logfile**, the name of the log file can be changed.
If activated by using **set fit errorvariables**, the error for each fitted parameter will be stored in a variable named like the parameter, but with "\_err" appended. Thus the errors can be used as input for further computations.
If **set fit prescale** is activated, fit parameters are prescaled by their initial values. This helps the Marquardt-Levenberg routine converge more quickly and reliably in cases where parameters differ in size by several orders of magnitude.
The fit may be interrupted by pressing Ctrl-C (Ctrl-Break in wgnuplot). After the current iteration completes, you have the option to (1) stop the fit and accept the current parameter values, (2) continue the fit, (3) execute a **gnuplot** command as specified by **set fit script** or the environment variable **FIT\_SCRIPT**. The default is **replot**, so if you had previously plotted both the data and the fitting function in one graph, you can display the current state of the fit.
Once **fit** has finished, the **save fit** command may be used to store final values in a file for subsequent use as a parameter file. See **[save fit](save#save_fit)** for details.
Adjustable parameters
---------------------
There are two ways that **via** can specify the parameters to be adjusted, either directly on the command line or indirectly, by referencing a parameter file. The two use different means to set initial values. Adjustable parameters can be specified by a comma-separated list of variable names after the **via** keyword. Any variable that is not already defined is created with an initial value of 1.0. However, the fit is more likely to converge rapidly if the variables have been previously declared with more appropriate starting values.
In a parameter file, each parameter to be varied and a corresponding initial value are specified, one per line, in the form
```
varname = value
```
Comments, marked by '#', and blank lines are permissible. The special form
```
varname = value # FIXED
```
means that the variable is treated as a 'fixed parameter', initialized by the parameter file, but not adjusted by **fit**. For clarity, it may be useful to designate variables as fixed parameters so that their values are reported by **fit**. The keyword **# FIXED** has to appear in exactly this form.
Short introduction
------------------
**fit** is used to find a set of parameters that 'best' fits your data to your user-defined function. The fit is judged on the basis of the sum of the squared differences or 'residuals' (SSR) between the input data points and the function values, evaluated at the same places. This quantity is often called 'chisquare' (i.e., the Greek letter chi, to the power of 2). The algorithm attempts to minimize SSR, or more precisely, WSSR, as the residuals are 'weighted' by the input data errors (or 1.0) before being squared; see **[fit error\_estimates](fit#fit_error_estimates)** for details. That's why it is called 'least-squares fitting'. Let's look at an example to see what is meant by 'non-linear', but first we had better go over some terms. Here it is convenient to use z as the dependent variable for user-defined functions of either one independent variable, z=f(x), or two independent variables, z=f(x,y). A parameter is a user-defined variable that **fit** will adjust, i.e., an unknown quantity in the function declaration. Linearity/non-linearity refers to the relationship of the dependent variable, z, to the parameters which **fit** is adjusting, not of z to the independent variables, x and/or y. (To be technical, the second {and higher} derivatives of the fitting function with respect to the parameters are zero for a linear least-squares problem).
For linear least-squares (LLS), the user-defined function will be a sum of simple functions, not involving any parameters, each multiplied by one parameter. NLLS handles more complicated functions in which parameters can be used in a large number of ways. An example that illustrates the difference between linear and nonlinear least-squares is the Fourier series. One member may be written as
```
z=a*sin(c*x) + b*cos(c*x).
```
If a and b are the unknown parameters and c is constant, then estimating values of the parameters is a linear least-squares problem. However, if c is an unknown parameter, the problem is nonlinear. In the linear case, parameter values can be determined by comparatively simple linear algebra, in one direct step. However LLS is a special case which is also solved along with more general NLLS problems by the iterative procedure that **gnuplot** uses. **fit** attempts to find the minimum by doing a search. Each step (iteration) calculates WSSR with a new set of parameter values. The Marquardt-Levenberg algorithm selects the parameter values for the next iteration. The process continues until a preset criterion is met, either (1) the fit has "converged" (the relative change in WSSR is less than a certain limit, see **[set fit limit](set_show#set_fit_limit)**), or (2) it reaches a preset iteration count limit (see **[set fit maxiter](set_show#set_fit_maxiter)**). The fit may also be interrupted and subsequently halted from the keyboard (see **[fit](fit#fit)**). The user variable FIT\_CONVERGED contains 1 if the previous fit command terminated due to convergence; it contains 0 if the previous fit terminated for any other reason. FIT\_NITER contains the number of iterations that were done during the last fit.
Often the function to be fitted will be based on a model (or theory) that attempts to describe or predict the behaviour of the data. Then **fit** can be used to find values for the free parameters of the model, to determine how well the data fits the model, and to estimate an error range for each parameter. See **[fit error\_estimates](fit#fit_error_estimates)**.
Alternatively, in curve-fitting, functions are selected independent of a model (on the basis of experience as to which are likely to describe the trend of the data with the desired resolution and a minimum number of parameters\*functions.) The **fit** solution then provides an analytic representation of the curve.
However, if all you really want is a smooth curve through your data points, the **smooth** option to **plot** may be what you've been looking for rather than **fit**.
Error estimates
---------------
In **fit**, the term "error" is used in two different contexts, data error estimates and parameter error estimates. Data error estimates are used to calculate the relative weight of each data point when determining the weighted sum of squared residuals, WSSR or chisquare. They can affect the parameter estimates, since they determine how much influence the deviation of each data point from the fitted function has on the final values. Some of the **fit** output information, including the parameter error estimates, is more meaningful if accurate data error estimates have been provided.
The **statistical overview** describes some of the **fit** output and gives some background for the 'practical guidelines'.
### Statistical overview
The theory of non-linear least-squares (NLLS) is generally described in terms of a normal distribution of errors, that is, the input data is assumed to be a sample from a population having a given mean and a Gaussian (normal) distribution about the mean with a given standard deviation. For a sample of sufficiently large size, and knowing the population standard deviation, one can use the statistics of the chisquare distribution to describe a "goodness of fit" by looking at the variable often called "chisquare". Here, it is sufficient to say that a reduced chisquare (chisquare/degrees of freedom, where degrees of freedom is the number of datapoints less the number of parameters being fitted) of 1.0 is an indication that the weighted sum of squared deviations between the fitted function and the data points is the same as that expected for a random sample from a population characterized by the function with the current value of the parameters and the given standard deviations. If the standard deviation for the population is not constant, as in counting statistics where variance = counts, then each point should be individually weighted when comparing the observed sum of deviations and the expected sum of deviations.
At the conclusion **fit** reports 'stdfit', the standard deviation of the fit, which is the rms of the residuals, and the variance of the residuals, also called 'reduced chisquare' when the data points are weighted. The number of degrees of freedom (the number of data points minus the number of fitted parameters) is used in these estimates because the parameters used in calculating the residuals of the datapoints were obtained from the same data. If the data points have weights, **gnuplot** calculates the so-called p-value, i.e. one minus the cumulative distribution function of the chisquare-distribution for the number of degrees of freedom and the resulting chisquare, see **[practical\_guidelines](fit#practical_guidelines)**. These values are exported to the variables
```
FIT_NDF = Number of degrees of freedom
FIT_WSSR = Weighted sum-of-squares residual
FIT_STDFIT = sqrt(WSSR/NDF)
FIT_P = p-value
```
To estimate confidence levels for the parameters, one can use the minimum chisquare obtained from the fit and chisquare statistics to determine the value of chisquare corresponding to the desired confidence level, but considerably more calculation is required to determine the combinations of parameters which produce such values.
Rather than determine confidence intervals, **fit** reports parameter error estimates which are readily obtained from the variance-covariance matrix after the final iteration. By convention, these estimates are called "standard errors" or "asymptotic standard errors", since they are calculated in the same way as the standard errors (standard deviation of each parameter) of a linear least-squares problem, even though the statistical conditions for designating the quantity calculated to be a standard deviation are not generally valid for the NLLS problem. The asymptotic standard errors are generally over-optimistic and should not be used for determining confidence levels, but are useful for qualitative purposes.
The final solution also produces a correlation matrix indicating correlation of parameters in the region of the solution; The main diagonal elements, autocorrelation, are always 1; if all parameters were independent, the off-diagonal elements would be nearly 0. Two variables which completely compensate each other would have an off-diagonal element of unit magnitude, with a sign depending on whether the relation is proportional or inversely proportional. The smaller the magnitudes of the off-diagonal elements, the closer the estimates of the standard deviation of each parameter would be to the asymptotic standard error.
### Practical guidelines
If you have a basis for assigning weights to each data point, doing so lets you make use of additional knowledge about your measurements, e.g., take into account that some points may be more reliable than others. That may affect the final values of the parameters. Weighting the data provides a basis for interpreting the additional **fit** output after the last iteration. Even if you weight each point equally, estimating an average standard deviation rather than using a weight of 1 makes WSSR a dimensionless variable, as chisquare is by definition.
Each fit iteration will display information which can be used to evaluate the progress of the fit. (An '\*' indicates that it did not find a smaller WSSR and is trying again.) The 'sum of squares of residuals', also called 'chisquare', is the WSSR between the data and your fitted function; **fit** has minimized that. At this stage, with weighted data, chisquare is expected to approach the number of degrees of freedom (data points minus parameters). The WSSR can be used to calculate the reduced chisquare (WSSR/ndf) or stdfit, the standard deviation of the fit, sqrt(WSSR/ndf). Both of these are reported for the final WSSR.
If the data are unweighted, stdfit is the rms value of the deviation of the data from the fitted function, in user units.
If you supplied valid data errors, the number of data points is large enough, and the model is correct, the reduced chisquare should be about unity. (For details, look up the 'chi-squared distribution' in your favorite statistics reference.) If so, there are additional tests, beyond the scope of this overview, for determining how well the model fits the data.
A reduced chisquare much larger than 1.0 may be due to incorrect data error estimates, data errors not normally distributed, systematic measurement errors, 'outliers', or an incorrect model function. A plot of the residuals, e.g., **plot 'datafile' using 1:($2-f($1))**, may help to show any systematic trends. Plotting both the data points and the function may help to suggest another model.
Similarly, a reduced chisquare less than 1.0 indicates WSSR is less than that expected for a random sample from the function with normally distributed errors. The data error estimates may be too large, the statistical assumptions may not be justified, or the model function may be too general, fitting fluctuations in a particular sample in addition to the underlying trends. In the latter case, a simpler function may be more appropriate.
The p-value of the fit is one minus the cumulative distribution function of the chisquare-distribution for the number of degrees of freedom and the resulting chisquare. This can serve as a measure of the goodness-of-fit. The range of the p-value is between zero and one. A very small or large p-value indicates that the model does not describe the data and its errors well. As described above, this might indicate a problem with the data, its errors or the model, or a combination thereof. A small p-value might indicate that the errors have been underestimated and the errors of the final parameters should thus be scaled. See also **[set fit errorscaling](set_show#set_fit_errorscaling)**.
You'll have to get used to both **fit** and the kind of problems you apply it to before you can relate the standard errors to some more practical estimates of parameter uncertainties or evaluate the significance of the correlation matrix.
Note that **fit**, in common with most NLLS implementations, minimizes the weighted sum of squared distances (y-f(x))\*\*2. It does not provide any means to account for "errors" in the values of x, only in y. Also, any "outliers" (data points outside the normal distribution of the model) will have an exaggerated effect on the solution.
Control
-------
There are a number of environment variables that can be defined to affect **fit** before starting **gnuplot**, see **[fit control environment](fit#fit_control_environment)**. At run time adjustments to the **fit** command operation can be controlled by **set fit**. See **[fit control variables](fit#fit_control_variables)**. ### Control variables
DEPRECATED in version 5. These user variables used to affect fit behaviour.
```
FIT_LIMIT - use `set fit limit <epsilon>`
FIT_MAXITER - use `set fit maxiter <number_of_cycles>`
FIT_START_LAMBDA - use `set fit start-lambda <value>`
FIT_LAMBDA_FACTOR - use `set fit lambda-factor <value>`
FIT_SKIP - use the datafile `every` modifier
FIT_INDEX - See `fit multi-branch`
```
### Environment variables
The environment variables must be defined before **gnuplot** is executed; how to do so depends on your operating system.
```
FIT_LOG
```
changes the name (and/or path) of the file to which the fit log will be written from the default of "fit.log" in the working directory. The default value can be overwritten using the command **set fit logfile**.
```
FIT_SCRIPT
```
specifies a command that may be executed after an user interrupt. The default is **replot**, but a **plot** or **load** command may be useful to display a plot customized to highlight the progress of the fit. This setting can also be changed using **set fit script**. Multi-branch
------------
In multi-branch fitting, multiple data sets can be simultaneously fit with functions of one independent variable having common parameters by minimizing the total WSSR. The function and parameters (branch) for each data set are selected by using a 'pseudo-variable', e.g., either the dataline number (a 'column' index of -1) or the datafile index (-2), as the second independent variable. Example: Given two exponential decays of the form, z=f(x), each describing a different data set but having a common decay time, estimate the values of the parameters. If the datafile has the format x:z:s, then
```
f(x,y) = (y==0) ? a*exp(-x/tau) : b*exp(-x/tau)
fit f(x,y) 'datafile' using 1:-2:2:3 via a, b, tau
```
For a more complicated example, see the file "hexa.fnc" used by the "fit.dem" demo.
Appropriate weighting may be required since unit weights may cause one branch to predominate if there is a difference in the scale of the dependent variable. Fitting each branch separately, using the multi-branch solution as initial values, may give an indication as to the relative effect of each branch on the joint solution.
Starting values
---------------
Nonlinear fitting is not guaranteed to converge to the global optimum (the solution with the smallest sum of squared residuals, SSR), and can get stuck at a local minimum. The routine has no way to determine that; it is up to you to judge whether this has happened. **fit** may, and often will get "lost" if started far from a solution, where SSR is large and changing slowly as the parameters are varied, or it may reach a numerically unstable region (e.g., too large a number causing a floating point overflow) which results in an "undefined value" message or **gnuplot** halting.
To improve the chances of finding the global optimum, you should set the starting values at least roughly in the vicinity of the solution, e.g., within an order of magnitude, if possible. The closer your starting values are to the solution, the less chance of stopping at a false minimum. One way to find starting values is to plot data and the fitting function on the same graph and change parameter values and **replot** until reasonable similarity is reached. The same plot is also useful to check whether the fit found a false minimum.
Of course finding a nice-looking fit does not prove there is no "better" fit (in either a statistical sense, characterized by an improved goodness-of-fit criterion, or a physical sense, with a solution more consistent with the model.) Depending on the problem, it may be desirable to **fit** with various sets of starting values, covering a reasonable range for each parameter.
Tips
----
Here are some tips to keep in mind to get the most out of **fit**. They're not very organized, so you'll have to read them several times until their essence has sunk in. The two forms of the **via** argument to **fit** serve two largely distinct purposes. The **via "file"** form is best used for (possibly unattended) batch operation, where you supply the starting parameter values in a file.
The **via var1, var2, ...** form is best used interactively, where the command history mechanism may be used to edit the list of parameters to be fitted or to supply new startup values for the next try. This is particularly useful for hard problems, where a direct fit to all parameters at once won't work without good starting values. To find such, you can iterate several times, fitting only some of the parameters, until the values are close enough to the goal that the final fit to all parameters at once will work.
Make sure that there is no mutual dependency among parameters of the function you are fitting. For example, don't try to fit a\*exp(x+b), because a\*exp(x+b)=a\*exp(b)\*exp(x). Instead, fit either a\*exp(x) or exp(x+b).
A technical issue: The larger the ratio of the largest and the smallest absolute parameter values, the slower the fit will converge. If the ratio is close to or above the inverse of the machine floating point precision, it may take next to forever to converge, or refuse to converge at all. You will either have to adapt your function to avoid this, e.g., replace 'parameter' by '1e9\*parameter' in the function definition, and divide the starting value by 1e9 or use **set fit prescale** which does this internally according to the parameter starting values.
If you can write your function as a linear combination of simple functions weighted by the parameters to be fitted, by all means do so. That helps a lot, because the problem is no longer nonlinear and should converge with only a small number of iterations, perhaps just one.
Some prescriptions for analysing data, given in practical experimentation courses, may have you first fit some functions to your data, perhaps in a multi-step process of accounting for several aspects of the underlying theory one by one, and then extract the information you really wanted from the fitting parameters of those functions. With **fit**, this may often be done in one step by writing the model function directly in terms of the desired parameters. Transforming data can also quite often be avoided, though sometimes at the cost of a more difficult fit problem. If you think this contradicts the previous paragraph about simplifying the fit function, you are correct.
A "singular matrix" message indicates that this implementation of the Marquardt-Levenberg algorithm can't calculate parameter values for the next iteration. Try different starting values, writing the function in another form, or a simpler function.
Finally, a nice quote from the manual of another fitting package (fudgit), that kind of summarizes all these issues: "Nonlinear fitting is an art!"
| programming_docs |
gnuplot Glossary Glossary
========
Throughout this document an attempt has been made to maintain consistency of nomenclature. This cannot be wholly successful because as **gnuplot** has evolved over time, certain command and keyword names have been adopted that preclude such perfection. This section contains explanations of the way some of these terms are used. A "page" or "screen" or "canvas" is the entire area addressable by **gnuplot**. On a desktop it is a full window; on a plotter, it is a single sheet of paper; in svga mode it is the full monitor screen.
A screen may contain one or more "plots". A plot is defined by an abscissa and an ordinate, although these need not actually appear on it, as well as the margins and any text written therein.
A plot contains one "graph". A graph is defined by an abscissa and an ordinate, although these need not actually appear on it.
A graph may contain one or more "lines". A line is a single function or data set. "Line" is also a plotting style. The word will also be used in sense "a line of text". Presumably the context will remove any ambiguity.
The lines on a graph may have individual names. These may be listed together with a sample of the plotting style used to represent them in the "key", sometimes also called the "legend".
The word "title" occurs with multiple meanings in **gnuplot**. In this document, it will always be preceded by the adjective "plot", "line", or "key" to differentiate among them. A 2D graph may have up to four labeled **axes**. The names of the four axes are "x" for the axis along the bottom border of the plot, "y" for the axis along the left border, "x2" for the top border, and "y2" for the right border. See **[axes](plot#axes)**.
A 3D graph may have up to three labeled **axes** – "x", "y" and "z". It is not possible to say where on the graph any particular axis will fall because you can change the direction from which the graph is seen with **set view**.
When discussing data files, the term "record" will be resurrected and used to denote a single line of text in the file, that is, the characters between newline or end-of-record characters. A "point" is the datum extracted from a single record. A "block" of data is a set of consecutive records delimited by blank records. A line, when referred to in the context of a data file, is a subset of a block. Note that the term "data block" may also be used to refer to a named block inline data (see **[datablocks](inline_data_datablocks#datablocks)**).
gnuplot Histeps Histeps
=======
The **histeps** style is only relevant to 2D plotting. It is intended for plotting histograms. Y-values are assumed to be centered at the x-values; the point at x1 is represented as a horizontal line from ((x0+x1)/2,y1) to ((x1+x2)/2,y1). The lines representing the end points are extended so that the step is centered on at x. Adjacent points are connected by a vertical line at their average x, that is, from ((x1+x2)/2,y1) to ((x1+x2)/2,y2). The input column requires are the same as for plot styles **lines** and **points**. If **autoscale** is in effect, it selects the xrange from the data rather than the steps, so the end points will appear only half as wide as the others. See also [steps demo.](http://www.gnuplot.info/demo/steps.html)
gnuplot History History
=======
The **history** command prints or saves previous commands in the history list, or reexecutes a previous entry in the list. To modify the behavior of this command, see **[set history](set_show#set_history)**. Input lines with **history** as their first command are not stored in the command history.
Examples:
```
history # show the complete history
history 5 # show last 5 entries in the history
history quiet 5 # show last 5 entries without entry numbers
history "hist.gp" # write the complete history to file hist.gp
history "hist.gp" append # append the complete history to file hist.gp
history 10 "hist.gp" # write last 10 commands to file hist.gp
history 10 "|head -5 >>diary.gp" # write 5 history commands using pipe
history ?load # show all history entries starting with "load"
history ?"set c" # like above, several words enclosed in quotes
hist !"set xr" # like above, several words enclosed in quotes
hist !55 # reexecute the command at history entry 55
```
gnuplot Test Test
====
This command graphically tests or presents terminal and palette capabilities. Syntax:
```
test {terminal | palette}
```
**test** or **test terminal** creates a display of line and point styles and other useful things supported by the **terminal** you are currently using.
**test palette** plots profiles of R(z),G(z),B(z), where 0<=z<=1. These are the RGB components of the current color **palette**. It also plots the apparent net intensity as calculated using NTSC coefficients to map RGB onto a grayscale. The profile values are also loaded into a datablock named $PALETTE.
gnuplot Coordinates Coordinates
===========
The commands **set arrow**, **set key**, **set label** and **set object** allow you to draw something at an arbitrary position on the graph. This position is specified by the syntax:
```
{<system>} <x>, {<system>} <y> {,{<system>} <z>}
```
Each <system> can either be **first**, **second**, **polar**, **graph**, **screen**, or **character**.
**first** places the x, y, or z coordinate in the system defined by the left and bottom axes; **second** places it in the system defined by the x2,y2 axes (top and right); **graph** specifies the area within the axes — 0,0 is bottom left and 1,1 is top right (for splot, 0,0,0 is bottom left of plotting area; use negative z to get to the base — see **[set xyplane](set_show#set_xyplane)**); **screen** specifies the screen area (the entire area — not just the portion selected by **set size**), with 0,0 at bottom left and 1,1 at top right. **character** coordinates are used primarily for offsets, not absolute positions. The **character** vertical and horizontal size depend on the current font.
**polar** causes the first two values to be interpreted as angle theta and radius r rather than as x and y. This could be used, for example, to place labels on a 2D plot in polar coordinates or a 3D plot in cylindrical coordinates.
If the coordinate system for x is not specified, **first** is used. If the system for y is not specified, the one used for x is adopted.
In some cases, the given coordinate is not an absolute position but a relative value (e.g., the second position in **set arrow** ... **rto**). In most cases, the given value serves as difference to the first position. If the given coordinate belongs to a log-scaled axis, a relative value is interpreted as multiplier. For example,
```
set logscale x
set arrow 100,5 rto 10,2
```
plots an arrow from position 100,5 to position 1000,7 since the x axis is logarithmic while the y axis is linear.
If one (or more) axis is timeseries, the appropriate coordinate should be given as a quoted time string according to the **timefmt** format string. See **[set xdata](set_show#set_xdata)** and **[set timefmt](set_show#set_timefmt)**. **Gnuplot** will also accept an integer expression, which will be interpreted as seconds relative to 1 January 1970.
gnuplot Candlesticks Candlesticks
============
The **candlesticks** style can be used for 2D data plotting of financial data or for generating box-and-whisker plots of statistical data. The symbol is a rectangular box, centered horizontally at the x coordinate and limited vertically by the opening and closing prices. A vertical line segment at the x coordinate extends up from the top of the rectangle to the high price and another down to the low. The vertical line will be unchanged if the low and high prices are interchanged. Five columns of basic data are required:
```
financial data: date open low high close
whisker plot: x box_min whisker_min whisker_high box_high
```
The width of the rectangle can be controlled by the **set boxwidth** command. For backwards compatibility with earlier gnuplot versions, when the boxwidth parameter has not been set then the width of the candlestick rectangle is taken from **set errorbars <width>**.
Alternatively, an explicit width for each box-and-whiskers grouping may be specified in an optional 6th column of data. The width must be given in the same units as the x coordinate.
An additional (6th, or 7th if the 6th column is used for width data) input column may be used to provide variable (per-datapoint) color information (see **[linecolor](linetypes_colors_styles#linecolor)** and **[rgbcolor variable](linetypes_colors_styles#rgbcolor_variable)**).
By default the vertical line segments have no crossbars at the top and bottom. If you want crossbars, which are typically used for box-and-whisker plots, then add the keyword **whiskerbars** to the plot command. By default these whiskerbars extend the full horizontal width of the candlestick, but you can modify this by specifying a fraction of the full width.
The usual convention for financial data is that the rectangle is empty if (open < close) and solid fill if (close < open). This is the behavior you will get if the current fillstyle is set to "empty". See **[fillstyle](set_show#fillstyle)**. If you set the fillstyle to solid or pattern, then this will be used for all boxes independent of open and close values. See also **[set errorbars](set_show#set_errorbars)** and **[financebars](financebars#financebars)**. See also the [candlestick](http://www.gnuplot.info/demo/candlesticks.html)
and [finance](http://www.gnuplot.info/demo/finance.html)
demos.
Note: To place additional symbols, such as the median value, on a box-and-whisker plot requires additional plot commands as in this example:
```
# Data columns:X Min 1stQuartile Median 3rdQuartile Max
set errorbars 4.0
set style fill empty
plot 'stat.dat' using 1:3:2:6:5 with candlesticks title 'Quartiles', \
” using 1:4:4:4:4 with candlesticks lt -1 notitle
```
```
# Plot with crossbars on the whiskers, crossbars are 50% of full width
plot 'stat.dat' using 1:3:2:6:5 with candlesticks whiskerbars 0.5
```
See **[set boxwidth](set_show#set_boxwidth)**, **[set errorbars](set_show#set_errorbars)**, **[set style fill](set_show#set_style_fill)**, and **[boxplot](boxplot#boxplot)**.
gnuplot Save Save
====
Syntax:
```
save {functions | variables | terminal | set | fit} '<filename>'
```
If no option is specified, **gnuplot** saves functions, variables, **set** options and the last **plot** (**splot**) command.
**save**d files are written in text format and may be read by the **load** command. For **save** with the **set** option or without any option, the **terminal** choice and the **output** filename are written out as a comment, to get an output file that works in other installations of gnuplot, without changes and without risk of unwillingly overwriting files.
**save terminal** will write out just the **terminal** status, without the comment marker in front of it. This is mainly useful for switching the **terminal** setting for a short while, and getting back to the previously set terminal, afterwards, by loading the saved **terminal** status. Note that for a single gnuplot session you may rather use the other method of saving and restoring current terminal by the commands **set term push** and **set term pop**, see **[set term](set_show#set_term)**.
**save fit** saves only the variables used in the most recent **fit** command. The saved file may be used as a parameter file to initialize future fit commands using the **via** keyword.
The filename must be enclosed in quotes.
The special filename "-" may be used to **save** commands to standard output. On systems which support a popen function (Unix), the output of save can be piped through an external program by starting the file name with a '|'. This provides a consistent interface to **gnuplot**'s internal settings to programs which communicate with **gnuplot** through a pipe. Please see help for **[batch/interactive](batch_interactive_operation#batch_interactive)** for more details.
Examples:
```
save 'work.gnu'
save functions 'func.dat'
save var 'var.dat'
save set 'options.dat'
save term 'myterm.gnu'
save '-'
save '|grep title >t.gp'
```
gnuplot Xyerrorbars Xyerrorbars
===========
The **xyerrorbars** style is only relevant to 2D data plots. **xyerrorbars** is like **points**, except that horizontal and vertical error bars are also drawn. At each point (x,y), lines are drawn from (x,y-ydelta) to (x,y+ydelta) and from (x-xdelta,y) to (x+xdelta,y) or from (x,ylow) to (x,yhigh) and from (xlow,y) to (xhigh,y), depending upon the number of data columns provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**. Either 4 or 6 input columns are required.
```
4 columns: x y xdelta ydelta
6 columns: x y xlow xhigh ylow yhigh
```
If data are provided in an unsupported mixed form, the **using** filter on the **plot** command should be used to set up the appropriate form. For example, if the data are of the form (x,y,xdelta,ylow,yhigh), then you can use
```
plot 'data' using 1:2:($1-$3):($1+$3):4:5 with xyerrorbars
```
An additional input column (5th or 7th) may be used to provide variable (per-datapoint) color information.
gnuplot Complete list of terminals Complete list of terminals
==========================
Gnuplot supports a large number of output formats. These are selected by choosing an appropriate terminal type, possibly with additional modifying options. See **[set terminal](set_show#set_terminal)**. This document may describe terminal types that are not available to you because they were not configured or installed on your system. To see a list of terminals available on a particular gnuplot installation, type 'set terminal' with no modifiers.
Terminals marked **legacy** are not built by default in recent gnuplot versions and may not actually work.
Aifm
----
**NOTE: Legacy terminal**, originally written for Adobe Illustrator 3.0+. Since Adobe Illustrator understands PostScript level 1 commands directly, you should use **set terminal post level1** instead.
Syntax:
```
set terminal aifm {color|monochrome} {"<fontname>"} {<fontsize>}
```
Aqua
----
This terminal relies on AquaTerm.app for display on Mac OS X. Syntax:
```
set terminal aqua {<n>} {title "<wintitle>"} {size <x> <y>}
{font "<fontname>{,<fontsize>}"}
{linewidth <lw>}"}
{{no}enhanced} {solid|dashed} {dl <dashlength>}}
```
where <n> is the number of the window to draw in (default is 0), <wintitle> is the name shown in the title bar (default "Figure <n>"), <x> <y> is the size of the plot (default is 846x594 pt = 11.75x8.25 in).
Use <fontname> to specify the font (default is "Times-Roman"), and <fontsize> to specify the font size (default is 14.0 pt).
The aqua terminal supports enhanced text mode (see **[enhanced](enhanced_text_mode#enhanced)**), except for overprint. Font support is limited to the fonts available on the system. Character encoding can be selected by **set encoding** and currently supports iso\_latin\_1, iso\_latin\_2, cp1250, and UTF8 (default).
Lines can be drawn either solid or dashed, (default is solid) and the dash spacing can be modified by <dashlength> which is a multiplier > 0.
Be
--
The **be** terminal type is present if gnuplot is built for the **beos** operating system and for use with X servers. It is selected at program startup if the **DISPLAY** environment variable is set, if the **TERM** environment variable is set to **xterm**, or if the **-display** command line option is used. Syntax:
```
set terminal be {reset} {<n>}
```
Multiple plot windows are supported: **set terminal be <n>** directs the output to plot window number n. If n>0, the terminal number will be appended to the window title and the icon will be labeled **gplt <n>**. The active window may distinguished by a change in cursor (from default to crosshair.)
Plot windows remain open even when the **gnuplot** driver is changed to a different device. A plot window can be closed by pressing the letter q while that window has input focus, or by choosing **close** from a window manager menu. All plot windows can be closed by specifying **reset**, which actually terminates the subprocess which maintains the windows (unless **-persist** was specified).
Plot windows will automatically be closed at the end of the session unless the **-persist** option was given.
The size or aspect ratio of a plot may be changed by resizing the **gnuplot** window.
Linewidths and pointsizes may be changed from within **gnuplot** with **set linestyle**.
For terminal type **be**, **gnuplot** accepts (when initialized) the standard X Toolkit options and resources such as geometry, font, and name from the command line arguments or a configuration file. See the X(1) man page (or its equivalent) for a description of such options.
A number of other **gnuplot** options are available for the **be** terminal. These may be specified either as command-line options when **gnuplot** is invoked or as resources in the configuration file ".Xdefaults". They are set upon initialization and cannot be altered during a **gnuplot** session.
### Command-line\_options
In addition to the X Toolkit options, the following options may be specified on the command line when starting **gnuplot** or as resources in your ".Xdefaults" file:
| | |
| --- | --- |
| `-mono` | forces monochrome rendering on color displays. |
| `-gray` | requests grayscale rendering on grayscale or color displays. |
| | (Grayscale displays receive monochrome rendering by default.) |
| `-clear` | requests that the window be cleared momentarily before a |
| | new plot is displayed. |
| `-raise` | raises plot window after each plot. |
| `-noraise` | does not raise plot window after each plot. |
| `-persist` | plots windows survive after main gnuplot program exits. |
The options are shown above in their command-line syntax. When entered as resources in ".Xdefaults", they require a different syntax. Example:
```
gnuplot*gray: on
```
**gnuplot** also provides a command line option (**-pointsize <v>**) and a resource, **gnuplot\*pointsize: <v>**, to control the size of points plotted with the **points** plotting style. The value **v** is a real number (greater than 0 and less than or equal to ten) used as a scaling factor for point sizes. For example, **-pointsize 2** uses points twice the default size, and **-pointsize 0.5** uses points half the normal size.
### Monochrome\_options
For monochrome displays, **gnuplot** does not honor foreground or background colors. The default is black-on-white. **-rv** or **gnuplot\*reverseVideo: on** requests white-on-black. ### Color\_resources
For color displays, **gnuplot** honors the following resources (shown here with their default values) or the greyscale resources. The values may be color names as listed in the BE rgb.txt file on your system, hexadecimal RGB color specifications (see BE documentation), or a color name followed by a comma and an **intensity** value from 0 to 1. For example, **blue, 0.5** means a half intensity blue.
| | |
| --- | --- |
| | gnuplot\*background: white |
| | gnuplot\*textColor: black |
| | gnuplot\*borderColor: black |
| | gnuplot\*axisColor: black |
| | gnuplot\*line1Color: red |
| | gnuplot\*line2Color: green |
| | gnuplot\*line3Color: blue |
| | gnuplot\*line4Color: magenta |
| | gnuplot\*line5Color: cyan |
| | gnuplot\*line6Color: sienna |
| | gnuplot\*line7Color: orange |
| | gnuplot\*line8Color: coral |
The command-line syntax for these is, for example,
Example:
```
gnuplot -background coral
```
### Grayscale\_resources
When **-gray** is selected, **gnuplot** honors the following resources for grayscale or color displays (shown here with their default values). Note that the default background is black.
| | |
| --- | --- |
| | gnuplot\*background: black |
| | gnuplot\*textGray: white |
| | gnuplot\*borderGray: gray50 |
| | gnuplot\*axisGray: gray50 |
| | gnuplot\*line1Gray: gray100 |
| | gnuplot\*line2Gray: gray60 |
| | gnuplot\*line3Gray: gray80 |
| | gnuplot\*line4Gray: gray40 |
| | gnuplot\*line5Gray: gray90 |
| | gnuplot\*line6Gray: gray50 |
| | gnuplot\*line7Gray: gray70 |
| | gnuplot\*line8Gray: gray30 |
### Line\_resources
**gnuplot** honors the following resources for setting the width (in pixels) of plot lines (shown here with their default values.) 0 or 1 means a minimal width line of 1 pixel width. A value of 2 or 3 may improve the appearance of some plots.
| | |
| --- | --- |
| | gnuplot\*borderWidth: 2 |
| | gnuplot\*axisWidth: 0 |
| | gnuplot\*line1Width: 0 |
| | gnuplot\*line2Width: 0 |
| | gnuplot\*line3Width: 0 |
| | gnuplot\*line4Width: 0 |
| | gnuplot\*line5Width: 0 |
| | gnuplot\*line6Width: 0 |
| | gnuplot\*line7Width: 0 |
| | gnuplot\*line8Width: 0 |
**gnuplot** honors the following resources for setting the dash style used for plotting lines. 0 means a solid line. A two-digit number **jk** (**j** and **k** are >= 1 and <= 9) means a dashed line with a repeated pattern of **j** pixels on followed by **k** pixels off. For example, '16' is a "dotted" line with one pixel on followed by six pixels off. More elaborate on/off patterns can be specified with a four-digit value. For example, '4441' is four on, four off, four on, one off. The default values shown below are for monochrome displays or monochrome rendering on color or grayscale displays. For color displays, the default for each is 0 (solid line) except for **axisDashes** which defaults to a '16' dotted line.
| | |
| --- | --- |
| | gnuplot\*borderDashes: 0 |
| | gnuplot\*axisDashes: 16 |
| | gnuplot\*line1Dashes: 0 |
| | gnuplot\*line2Dashes: 42 |
| | gnuplot\*line3Dashes: 13 |
| | gnuplot\*line4Dashes: 44 |
| | gnuplot\*line5Dashes: 15 |
| | gnuplot\*line6Dashes: 4441 |
| | gnuplot\*line7Dashes: 42 |
| | gnuplot\*line8Dashes: 13 |
Caca
----
[EXPERIMENTAL] The **caca** terminal is a mostly-for-fun output mode that uses **libcaca** to plot using ascii characters. In contrast to the **dumb** terminal it includes support for color, box fill, images, rotated text, filled polygons, and mouse interaction. Syntax:
```
set terminal caca {{driver | format} {default | <driver> | list}}
{color | monochrome}
{{no}inverted}
{enhanced | noenhanced}
{background <rgb color>}
{title "<plot window title>"}
{size <width>,<height>}
{charset ascii|blocks|unicode}
```
The **driver** option selects the **libcaca** display driver or export **format**. Use **default** is to let **libcaca** choose the platform default display driver. The default driver can be changed by setting the environment variable CACA\_DRIVER before starting **gnuplot**. Use **set term caca driver list** to print a list of supported output modes.
The **color** and **monochrome** options select colored or mono output. Note that this also changes line symbols. Use the **inverted** option if you prefer a black background over the default white. This also changes the color of black default linetypes to white.
Enhanced text support can be activated using the **enhanced** option, see **[enhanced text](enhanced_text_mode#enhanced_text)**.
The title of the output window can be changed with the **title** option, if supported by the **libcaca** driver.
The **size** option selects the size of the canvas in characters. The default is 80 by 25. If supported by the backend, the canvas size will be automatically adjusted to the current window/terminal size. The default size of the "x11" and "gl" window can be controlled via the CACA\_GEOMETRY environment variable. The geometry of the window of the "win32" driver can be controlled and permanently changed via the app menu.
The **charset** option selects the character set used for lines, points, filling of polygons and boxes and dithering of images. Note that some backend/terminal/font combinations might not support some characters of the **blocks** or **unicode** character set. On Windows it is recommend to use a non-raster font such as "Lucida Console" or "Consolas".
The caca terminal supports mouse interaction. Please beware that some backends of **libcaca** (e.g. slang, ncurses) only update the mouse position on mouse clicks. Modifier keys (ctrl, alt, shift) are not supported by **libcaca** and are thus unavailable.
The default **encoding** of the **caca** terminal is utf8. It also supports the cp437 **encoding**.
The number of colors supported by **libcaca** backends differs. Most backends support 16 foreground and 16 background colors only, whereas e.g. the "x11" backend supports truecolor.
Depending on the terminal and **libcaca** backend, only 8 different background colors might be supported. Bright colors (with the most most significant bit of the background color set) are then interpreted as indicator for blinking text. Try using **background rgb "gray"** in that case.
See also the libcaca web site at <http://caca.zoy.org/wiki/libcaca>
and libcaca environment variables <http://caca.zoy.org/doxygen/libcaca/libcaca-env.html>
### Caca limitations and bugs
The **caca** terminal has known bugs and limitations: Unicode support depends on the driver and the terminal. The "x11" backend supports unicode since libcaca version 0.99.beta17. Due to a bug in **libcaca** <0.99.beta20, the "slang" driver does not support unicode. Note that **libcaca** <0.99.beta19 contains a bug which results in an endless loop if you supply illegal 8bit sequences.
Bright background colors may cause blinking.
Modifier keys are not supported for mousing, see **[term caca](complete_list_terminals#term_caca)**.
Rotated enhanced text, and transparency are not supported. The **size** option is not considered for on-screen display.
In order to correctly draw the key box, use
```
set key width 1 height 1
```
Alignment of enhanced text is wrong if it contains utf8 characters. Resizing of Windows console window does not work correctly due to a bug in libcaca. Closing the terminal window by clicking the "X" on the title line will terminate wgnuplot. Press "q" to close the window.
Cairolatex
----------
The **cairolatex** terminal device generates encapsulated PostScript (\*.eps), PDF, or PNG output using the cairo and pango support libraries and uses LaTeX for text output using the same routines as the **epslatex** terminal. Syntax:
```
set terminal cairolatex
{eps | pdf | png}
{standalone | input}
{blacktext | colortext | colourtext}
{header <header> | noheader}
{mono|color}
{{no}transparent} {{no}crop} {background <rgbcolor>}
{font <font>} {fontscale <scale>}
{linewidth <lw>} {rounded|butt|square} {dashlength <dl>}
{size <XX>{unit},<YY>{unit}}
{resolution <dpi>}
```
The cairolatex terminal prints a plot like **terminal epscairo** or **terminal pdfcairo** but transfers the texts to LaTeX instead of including them in the graph. For reference of options not explained here see **[pdfcairo](complete_list_terminals#pdfcairo)**.
**eps**, **pdf**, or **png** select the type of graphics output. Use **eps** with latex/dvips and **pdf** for pdflatex. If your plot has a huge number of points use **png** to keep the filesize down. When using the **png** option, the terminal accepts an extra option **resolution** to control the pixel density of the resulting PNG. The argument of **resolution** is an integer with the implied unit of DPI.
**blacktext** forces all text to be written in black even in color mode;
The **cairolatex** driver offers a special way of controlling text positioning: (a) If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically by LaTeX. (b) If the text string begins with '[', you need to continue it with: a position specification (up to two out of t,b,l,r,c), ']{', the text itself, and finally, '}'. The text itself may be anything LaTeX can typeset as an LR-box. \rule{}{}'s may help for best positioning. See also the documentation for the **[pslatex](complete_list_terminals#pslatex)** terminal driver. To create multiline labels, use \shortstack, for example
```
set ylabel '[r]{\shortstack{first line \\ second line}}'
```
The **back** option of **set label** commands is handled slightly different than in other terminals. Labels using 'back' are printed behind all other elements of the plot while labels using 'front' are printed above everything else.
The driver produces two different files, one for the eps, pdf, or png part of the figure and one for the LaTeX part. The name of the LaTeX file is taken from the **set output** command. The name of the eps/pdf/png file is derived by replacing the file extension (normally '.tex') with '.eps'/'.pdf'/'.png' instead. There is no LaTeX output if no output file is given! Remember to close the **output file** before next plot unless in **multiplot** mode.
In your LaTeX documents use ' \input{filename}' to include the figure. The '.eps'/'.pdf'/'.png' file is included by the command \includegraphics{...}, so you must also include \usepackage{graphicx} in the LaTeX preamble. If you want to use coloured text (option **colourtext**) you also have to include \usepackage{color} in the LaTeX preamble.
The behaviour concerning font selection depends on the header mode. In all cases, the given font size is used for the calculation of proper spacing. When not using the **standalone** mode the actual LaTeX font and font size at the point of inclusion is taken, so use LaTeX commands for changing fonts. If you use e.g. 12pt as font size for your LaTeX document, use '", 12"' as options. The font name is ignored. If using **standalone** the given font and font size are used, see below for a detailed description.
If text is printed coloured is controlled by the TeX booleans \ifGPcolor and \ifGPblacktext. Only if \ifGPcolor is true and \ifGPblacktext is false, text is printed coloured. You may either change them in the generated TeX file or provide them globally in your TeX file, for example by using
```
\newif\ifGPblacktext
\GPblacktexttrue
```
in the preamble of your document. The local assignment is only done if no global value is given. When using the cairolatex terminal give the name of the TeX file in the **set output** command including the file extension (normally ".tex"). The graph filename is generated by replacing the extension.
If using the **standalone** mode a complete LaTeX header is added to the LaTeX file; and "-inc" is added to the filename of the gaph file. The **standalone** mode generates a TeX file that produces output with the correct size when using dvips, pdfTeX, or VTeX. The default, **input**, generates a file that has to be included into a LaTeX document using the \input command.
If a font other than "" or "default" is given it is interpreted as LaTeX font name. It contains up to three parts, separated by a comma: 'fontname,fontseries,fontshape'. If the default fontshape or fontseries are requested, they can be omitted. Thus, the real syntax for the fontname is '{fontname}{,fontseries}{,fontshape}'. The naming convention for all parts is given by the LaTeX font scheme. The fontname is 3 to 4 characters long and is built as follows: One character for the font vendor, two characters for the name of the font, and optionally one additional character for special fonts, e.g., 'j' for fonts with old-style numerals or 'x' for expert fonts. The names of many fonts is described in <http://www.tug.org/fontname/fontname.pdf>
For example, 'cmr' stands for Computer Modern Roman, 'ptm' for Times-Roman, and 'phv' for Helvetica. The font series denotes the thickness of the glyphs, in most cases 'm' for normal ("medium") and 'bx' or 'b' for bold fonts. The font shape is 'n' for upright, 'it' for italics, 'sl' for slanted, or 'sc' for small caps, in general. Some fonts may provide different font series or shapes.
Examples:
Use Times-Roman boldface (with the same shape as in the surrounding text):
```
set terminal cairolatex font 'ptm,bx'
```
Use Helvetica, boldface, italics:
```
set terminal cairolatex font 'phv,bx,it'
```
Continue to use the surrounding font in slanted shape:
```
set terminal cairolatex font ',,sl'
```
Use small capitals:
```
set terminal cairolatex font ',,sc'
```
By this method, only text fonts are changed. If you also want to change the math fonts you have to use the "gnuplot.cfg" file or the **header** option, described below.
In **standalone** mode, the font size is taken from the given font size in the **set terminal** command. To be able to use a specified font size, a file "size<size>.clo" has to reside in the LaTeX search path. By default, 10pt, 11pt, and 12pt are supported. If the package "extsizes" is installed, 8pt, 9pt, 14pt, 17pt, and 20pt are added.
The **header** option takes a string as argument. This string is written into the generated LaTeX file. If using the **standalone** mode, it is written into the preamble, directly before the \begin{document} command. In the **input** mode, it is placed directly after the \begingroup command to ensure that all settings are local to the plot.
Examples:
Use T1 fontencoding, change the text and math font to Times-Roman as well as the sans-serif font to Helvetica:
```
set terminal cairolatex standalone header \
"\\usepackage[T1]{fontenc}\n\\usepackage{mathptmx}\n\\usepackage{helvet}"
```
Use a boldface font in the plot, not influencing the text outside the plot:
```
set terminal cairolatex input header "\\bfseries"
```
If the file "gnuplot.cfg" is found by LaTeX it is input in the preamble the LaTeX document, when using **standalone** mode. It can be used for further settings, e.g., changing the document font to Times-Roman, Helvetica, and Courier, including math fonts (handled by "mathptmx.sty"):
```
\usepackage{mathptmx}
\usepackage[scaled=0.92]{helvet}
\usepackage{courier}
```
The file "gnuplot.cfg" is loaded before the header information given by the **header** command. Thus, you can use **header** to overwrite some of settings performed using "gnuplot.cfg" Canvas
------
The **canvas** terminal creates a set of javascript commands that draw onto the HTML5 canvas element. Syntax:
```
set terminal canvas {size <xsize>, <ysize>} {background <rgb_color>}
{font {<fontname>}{,<fontsize>}} | {fsize <fontsize>}
{{no}enhanced} {linewidth <lw>}
{rounded | butt | square}
{dashlength <dl>}
{standalone {mousing} | name '<funcname>'}
{jsdir 'URL/for/javascripts'}
{title '<some string>'}
```
where <xsize> and <ysize> set the size of the plot area in pixels. The default size in standalone mode is 600 by 400 pixels. The default font size is 10.
NB: Only one font is available, the ascii portion of Hershey simplex Roman provided in the file canvastext.js. You can replace this with the file canvasmath.js, which contains also UTF-8 encoded Hershey simplex Greek and math symbols. For consistency with other terminals, it is also possible to use **font "name,size"**. Currently the font **name** is ignored, but browser support for named fonts is likely to arrive eventually.
The default **standalone** mode creates an html page containing javascript code that renders the plot using the HTML 5 canvas element. The html page links to two required javascript files 'canvastext.js' and 'gnuplot\_common.js'. An additional file 'gnuplot\_dashedlines.js' is needed to support dashed lines. By default these point to local files, on unix-like systems usually in directory /usr/local/share/gnuplot/<version>/js. See installation notes for other platforms. You can change this by using the **jsdir** option to specify either a different local directory or a general URL. The latter is usually appropriate if the plot is exported for viewing on remote client machines.
All plots produced by the canvas terminal are mouseable. The additional keyword **mousing** causes the **standalone** mode to add a mouse-tracking box underneath the plot. It also adds a link to a javascript file 'gnuplot\_mouse.js' and to a stylesheet for the mouse box 'gnuplot\_mouse.css' in the same local or URL directory as 'canvastext.js'.
The **name** option creates a file containing only javascript. Both the javascript function it contains and the id of the canvas element that it draws onto are taken from the following string parameter. The commands
```
set term canvas name 'fishplot'
set output 'fishplot.js'
```
will create a file containing a javascript function fishplot() that will draw onto a canvas with id=fishplot. An html page that invokes this javascript function must also load the canvastext.js function as described above. A minimal html file to wrap the fishplot created above might be:
```
<html>
<head>
<script src="canvastext.js"></script>
<script src="gnuplot_common.js"></script>
</head>
<body onload="fishplot();">
<script src="fishplot.js"></script>
<canvas id="fishplot" width=600 height=400>
<div id="err_msg">No support for HTML 5 canvas element</div>
</canvas>
</body>
</html>
```
The individual plots drawn on this canvas will have names fishplot\_plot\_1, fishplot\_plot\_2, and so on. These can be referenced by external javascript routines, for example gnuplot.toggle\_visibility("fishplot\_plot\_2").
Cgm
---
The **cgm** terminal generates a Computer Graphics Metafile, Version 1. This file format is a subset of the ANSI X3.122-1986 standard entitled "Computer Graphics - Metafile for the Storage and Transfer of Picture Description Information". Syntax:
```
set terminal cgm {color | monochrome} {solid | dashed} {{no}rotate}
{<mode>} {width <plot_width>} {linewidth <line_width>}
{font "<fontname>,<fontsize>"}
{background <rgb_color>}
[deprecated] {<color0> <color1> <color2> ...}
```
**solid** draws all curves with solid lines, overriding any dashed patterns; <mode> is **landscape**, **portrait**, or **default**; <plot\_width> is the assumed width of the plot in points; <line\_width> is the line width in points (default 1); <fontname> is the name of a font (see list of fonts below) <fontsize> is the size of the font in points (default 12).
The first six options can be in any order. Selecting **default** sets all options to their default values.
The mechanism of setting line colors in the **set term** command is deprecated. Instead you should set the background using a separate keyword and set the line colors using **set linetype**. The deprecated mechanism accepted colors of the form 'xrrggbb', where x is the literal character 'x' and 'rrggbb' are the red, green and blue components in hex. The first color was used for the background, subsequent colors are assigned to successive line types.
Examples:
```
set terminal cgm landscape color rotate dashed width 432 \
linewidth 1 'Helvetica Bold' 12 # defaults
set terminal cgm linewidth 2 14 # wider lines & larger font
set terminal cgm portrait "Times Italic" 12
set terminal cgm color solid # no pesky dashes!
```
### Cgm font
The first part of a Computer Graphics Metafile, the metafile description, includes a font table. In the picture body, a font is designated by an index into this table. By default, this terminal generates a table with the following 35 fonts, plus six more with **italic** replaced by **oblique**, or vice-versa (since at least the Microsoft Office and Corel Draw CGM import filters treat **italic** and **oblique** as equivalent):
| |
| --- |
| CGM fonts |
| | Helvetica | Hershey/Cartographic\_Roman |
| | Helvetica Bold | Hershey/Cartographic\_Greek |
| | Helvetica Oblique | Hershey/Simplex\_Roman |
| | Helvetica Bold Oblique | Hershey/Simplex\_Greek |
| | Times Roman | Hershey/Simplex\_Script |
| | Times Bold | Hershey/Complex\_Roman |
| | Times Italic | Hershey/Complex\_Greek |
| | Times Bold Italic | Hershey/Complex\_Italic |
| | Courier | Hershey/Complex\_Cyrillic |
| | Courier Bold | Hershey/Duplex\_Roman |
| | Courier Oblique | Hershey/Triplex\_Roman |
| | Courier Bold Oblique | Hershey/Triplex\_Italic |
| | Symbol | Hershey/Gothic\_German |
| | ZapfDingbats | Hershey/Gothic\_English |
| | Script | Hershey/Gothic\_Italian |
| | 15 | Hershey/Symbol\_Set\_1 |
| | | Hershey/Symbol\_Set\_2 |
| | | Hershey/Symbol\_Math |
The first thirteen of these fonts are required for WebCGM. The Microsoft Office CGM import filter implements the 13 standard fonts listed above, and also 'ZapfDingbats' and 'Script'. However, the script font may only be accessed under the name '15'. For more on Microsoft import filter font substitutions, check its help file which you may find here:
```
C:\Program Files\Microsoft Office\Office\Cgmimp32.hlp
```
and/or its configuration file, which you may find here:
```
C:\Program Files\Common Files\Microsoft Shared\Grphflt\Cgmimp32.cfg
```
In the **set term** command, you may specify a font name which does not appear in the default font table. In that case, a new font table is constructed with the specified font as its first entry. You must ensure that the spelling, capitalization, and spacing of the name are appropriate for the application that will read the CGM file. (Gnuplot and any MIL-D-28003A compliant application ignore case in font names.) If you need to add several new fonts, use several **set term** commands.
Example:
```
set terminal cgm 'Old English'
set terminal cgm 'Tengwar'
set terminal cgm 'Arabic'
set output 'myfile.cgm'
plot ...
set output
```
You cannot introduce a new font in a **set label** command.
### Cgm fontsize
Fonts are scaled assuming the page is 6 inches wide. If the **size** command is used to change the aspect ratio of the page or the CGM file is converted to a different width, the resulting font sizes will be scaled up or down accordingly. To change the assumed width, use the **width** option. ### Cgm linewidth
The **linewidth** option sets the width of lines in pt. The default width is 1 pt. Scaling is affected by the actual width of the page, as discussed under the **fontsize** and **width** options. ### Cgm rotate
The **norotate** option may be used to disable text rotation. For example, the CGM input filter for Word for Windows 6.0c can accept rotated text, but the DRAW editor within Word cannot. If you edit a graph (for example, to label a curve), all rotated text is restored to horizontal. The Y axis label will then extend beyond the clip boundary. With **norotate**, the Y axis label starts in a less attractive location, but the page can be edited without damage. The **rotate** option confirms the default behavior. ### Cgm solid
The **solid** option may be used to disable dashed line styles in the plots. This is useful when color is enabled and the dashing of the lines detracts from the appearance of the plot. The **dashed** option confirms the default behavior, which gives a different dash pattern to each line type. ### Cgm size
Default size of a CGM plot is 32599 units wide and 23457 units high for landscape, or 23457 units wide by 32599 units high for portrait. ### Cgm width
All distances in the CGM file are in abstract units. The application that reads the file determines the size of the final plot. By default, the width of the final plot is assumed to be 6 inches (15.24 cm). This distance is used to calculate the correct font size, and may be changed with the **width** option. The keyword should be followed by the width in points. (Here, a point is 1/72 inch, as in PostScript. This unit is known as a "big point" in TeX.) Gnuplot **expressions** can be used to convert from other units. Example:
```
set terminal cgm width 432 # default
set terminal cgm width 6*72 # same as above
set terminal cgm width 10/2.54*72 # 10 cm wide
```
### Cgm nofontlist
The default font table includes the fonts recommended for WebCGM, which are compatible with the Computer Graphics Metafile input filter for Microsoft Office and Corel Draw. Another application might use different fonts and/or different font names, which may not be documented. The **nofontlist** (synonym **winword6**) option deletes the font table from the CGM file. In this case, the reading application should use a default table. Gnuplot will still use its own default font table to select font indices. Thus, 'Helvetica' will give you an index of 1, which should get you the first entry in your application's default font table. 'Helvetica Bold' will give you its second entry, etc. Context
-------
ConTeXt is a macro package for TeX, highly integrated with Metapost (for drawing figures) and intended for creation of high-quality PDF documents. The terminal outputs Metafun source, which can be edited manually, but you should be able to configure most things from outside. For an average user of ConTeXt + gnuplot module it's recommended to refer to **Using ConTeXt** rather than reading this page or to read the manual of the gnuplot module for ConTeXt.
The **context** terminal supports the following options:
Syntax:
```
set term context {default}
{defaultsize | size <scale> | size <xsize>{in|cm}, <ysize>{in|cm}}
{input | standalone}
{timestamp | notimestamp}
{noheader | header "<header>"}
{color | colour | monochrome}
{rounded | mitered | beveled} {round | butt | squared}
{dashed | solid} {dashlength | dl <dl>}
{linewidth | lw <lw>}
{fontscale <fontscale>}
{mppoints | texpoints}
{inlineimages | externalimages}
{defaultfont | font "{<fontname>}{,<fontsize>}"}
```
In non-standalone (**input**) graphic only parameters **size** to select graphic size, **fontscale** to scale all the labels for a factor <fontscale> and font size, make sense, the rest is silently ignored and should be configured in the .tex file which inputs the graphic. It's highly recommended to set the proper fontsize if document font differs from 12pt, so that gnuplot will know how much space to reserve for labels.
**default** resets all the options to their default values.
**defaultsize** sets the plot size to 5in,3in. **size** <scale> sets the plot size to <scale> times <default value>. If two arguments are given (separated with ','), the first one sets the horizontal size and the second one the vertical size. Size may be given without units (in which case it means relative to the default value), with inches ('in') or centimeters ('cm').
**input** (default) creates a graphic that can be included into another ConTeXt document. **standalone** adds some lines, so that the document might be compiled as-is. You might also want to add **header** in that case.
Use **header** for any additional settings/definitions/macros that you might want to include in a standalone graphic. **noheader** is the default.
**notimestamp** prevents printing creation time in comments (if version control is used, one may prefer not to commit new version when only date changes).
**color** to make color plots is the default, but **monochrome** doesn't do anything special yet. If you have any good ideas how the behaviour should differ to suit the monochrome printers better, your suggestions are welcome.
**rounded** (default), **mitered** and **beveled** control the shape of line joins. **round** (default), **butt** and **squared** control the shape of line caps. See PostScript or PDF Reference Manual for explanation. For wild-behaving functions and thick lines it is better to use **rounded** and **round** to prevent sharp corners in line joins. (Some general support for this should be added to Gnuplot, so that the same options could be set for each line (style) separately).
**dashed** (default) uses different dash patterns for different line types, **solid** draws all plots with solid lines.
**dashlength** or **dl** scales the length of the dashed-line segments by <dl>. **linewidth** or **lw** scales all linewidths by <lw>. (lw 1 stands for 0.5bp, which is the default line width when drawing with Metapost.) **fontscale** scales text labels for factor <fontscale> relative to default document font.
**mppoints** uses predefined point shapes, drawn in Metapost. **texpoints** uses easily configurable set of symbols, defined with ConTeXt in the following way:
```
\defineconversion[my own points][+,{\ss x},\mathematics{\circ}]
\setupGNUPLOTterminal[context][points=tex,pointset=my own points]
```
**inlineimages** writes binary images to a string and only works in ConTeXt MKIV. **externalimages** writes PNG files to disk and also works with ConTeXt MKII. Gnuplot needs to have support for PNG images built in for this to work.
With **font** you can set font name and size in standalone graphics. In non-standalone (**input**) mode only the font size is important to reserve enough space for text labels. The command
```
set term context font "myfont,ss,10"
```
will result in
```
\setupbodyfont[myfont,ss,10pt]
```
If you additionally set **fontscale** to 0.8 for example, then the resulting font will be 8pt big and
```
set label ... font "myfont,12"
```
will come out as 9.6pt. It is your own responsibility to provide proper typescripts (and header), otherwise switching the font will have no effect. For a standard font in ConTeXt MKII (pdfTeX) you could use:
```
set terminal context standalone header '\usetypescript[iwona][ec]' \
font "iwona,ss,11"
```
Please take a look into ConTeXt documentation, wiki or mailing list (archives) for any up-to-date information about font usage. Examples:
```
set terminal context size 10cm, 5cm # 10cm, 5cm
set terminal context size 4in, 3in # 4in, 3in
```
For standalone (whole-page) plots with labels in UTF-8 encoding:
```
set terminal context standalone header '\enableregime[utf-8]'
```
### Requirements
You need gnuplot module for ConTeXt <http://ctan.org/pkg/context-gnuplot> and a recent version of ConTeXt. If you want to call gnuplot on-the-fly, you also need write18 enabled. In most TeX distributions this can be set with shell\_escape=t in texmf.cnf.
See <http://wiki.contextgarden.net/Gnuplot>
for details about this terminal and for more exhaustive help & examples.
### Calling gnuplot from ConTeXt
The easiest way to make plots in ConTeXt documents is
```
\usemodule[gnuplot]
\starttext
\title{How to draw nice plots with {\sc gnuplot}?}
\startGNUPLOTscript[sin]
set format y "%.1f"
plot sin(x) t '$\sin(x)$'
\stopGNUPLOTscript
\useGNUPLOTgraphic[sin]
\stoptext
```
This will run gnuplot automatically and include the resulting figure in the document. Corel
-----
Legacy terminal for CorelDraw (circa 1995). Syntax:
```
set terminal corel {monochrome | color} {"<font>" {<fontsize>}}
{<xsize> <ysize> {<linewidth> }}
```
where the fontsize and linewidth are specified in points and the sizes in inches. The defaults are monochrome, "SwitzerlandLight", 22, 8.2, 10 and 1.2.
Debug
-----
This terminal is provided to allow for the debugging of **gnuplot**. It is likely to be of use only for users who are modifying the source code. Domterm
-------
The **domterm** terminal device runs on the DomTerm terminal emulator including the domterm and qtdomterm programs. It supports SVG graphics embedded directly in the terminal output. See http://domterm.org . Please read the help for the **svg** terminal.
Dumb
----
The **dumb** terminal driver plots into a text block using ascii characters. It has an optional size specification and a trailing linefeed flag. Syntax:
```
set terminal dumb {size <xchars>,<ychars>} {[no]feed}
{aspect <htic>{,<vtic>}}
{[no]enhanced}
{mono|ansi|ansi256|ansirgb}
```
where <xchars> and <ychars> set the size of the text block. The default is 79 by 24. The last newline is printed only if **feed** is enabled.
The **aspect** option can be used to control the aspect ratio of the plot by setting the length of the horizontal and vertical tic marks. Only integer values are allowed. Default is 2,1 – corresponding to the aspect ratio of common screen fonts.
The **ansi**, **ansi256**, and **ansirgb** options will include escape sequences in the output to handle colors. Note that these might not be handled by your terminal. Default is **mono**. To obtain the best color match in **ansi** mode, you should use **set colorsequence classic**. Depending on the mode, the **dumb** terminal will emit the following sequences (without the additional whitespace):
```
ESC [ 0 m reset attributes to defaults
foreground color:
ESC [ 1 m set intense/bold
ESC [ 22 m intense/bold off
ESC [ <fg> m with color code 30 <= <fg> <= 37
ESC [ 39 m reset to default
ESC [ 38; 5; <c> m with palette index 16 <= <c> <= 255
ESC [ 38; 2; <r>; <g>; <b> m with components 0 <= <r,g,b> <= 255
background color:
ESC [ <bg> m with color code 40 <= <bg> <= 47
ESC [ 49 m reset to default
ESC [ 48; 5; <c> m with palette index 16 <= <c> <= 231
ESC [ 48; 2; <r>; <g>; <b> m with components 0 <= <r,g,b> <= 255
```
See also e.g. the description at <https://en.wikipedia.org/wiki/ANSI_escape_code#Colors>
Example:
```
set term dumb mono size 60,15 aspect 1
set tics nomirror scale 0.5
plot [-5:6.5] sin(x) with impulse ls -1
```
```
1 +-------------------------------------------------+
0.8 +|||++ ++||||++ |
0.6 +|||||+ ++|||||||+ sin(x) +----+ |
0.4 +||||||+ ++|||||||||+ |
0.2 +|||||||+ ++|||||||||||+ +|
0 ++++++++++++++++++++++++++++++++++++++++++++++++++|
-0.2 + +|||||||||||+ +|||||||||||+ |
-0.4 + +|||||||||+ +|||||||||+ |
-0.6 + +|||||||+ +|||||||+ |
-0.8 + ++||||+ ++||||+ |
-1 +---+--------+--------+-------+--------+--------+-+
-4 -2 0 2 4 6
```
Dxf
---
Terminal driver **dxf** for export to AutoCad (Release 10.x). It has no options. The default size is 120x80 AutoCad units. **dxf** uses seven colors (white, red, yellow, green, cyan, blue and magenta) that can be changed only by modifying the source file. If a black-and-white plotting device is used the colors are mapped to differing line thicknesses. Note: someone please update this terminal to the 2012 DXF standard! Dxy800a
-------
Note: legacy terminal. This terminal driver supports the Roland DXY800A plotter. It has no options. Eepic
-----
Note: Legacy terminal (not built by default). The latex, emtex, eepic, and tpic terminals in older versions of gnuplot provided minimal support for graphics styles beyond simple lines and points. They have been directly superseded by the **pict2e** terminal. For more capable TeX/LaTeX compatible terminal types see **[cairolatex](complete_list_terminals#cairolatex)**, **[context](complete_list_terminals#context)**, **[epslatex](complete_list_terminals#epslatex)**, **[mp](complete_list_terminals#mp)**, **[pstricks](complete_list_terminals#pstricks)**, and **[tikz](complete_list_terminals#tikz)**. The output of this terminal is intended for use with the "eepic.sty" macro package for LaTeX. To use it, you need "eepic.sty", "epic.sty" and a DVI driver that supports the "tpic" \specials. If your driver doesn't support those \specials, "eepicemu.sty" will enable you to use some of them. dvips and dvipdfm do support the "tpic" \specials, pdflatex does not.
Syntax:
```
set terminal eepic {default} {color|monochrome|dashed}
{rotate} {size XX,YY}
{small|tiny|<fontsize>}
```
**color** causes gnuplot to produce \color{...} commands so that the graphs are colored. Using this option, you must include \usepackage{color} in the preamble of your latex document.
**dashed** will allow dashed line types; without this option, only solid lines with varying thickness will be used. **dashed** and **color** are mutually exclusive; if **color** is specified, then **dashed** will be ignored.
**rotate** will enable true rotated text (by 90 degrees). Otherwise, rotated text will be typeset with letters stacked above each other. If you use this option you must include \usepackage{graphicx} in the preamble.
**small** will use \scriptsize symbols as point markers. Default is to use the default math size. **tiny** uses \scriptscriptstyle symbols.
The default size of an eepic plot is 5x3 inches. You can change this using the **size** terminal option.
<fontsize> is a number which specifies the font size inside the picture environment; the unit is pt (points), i.e., 10 pt equals approx. 3.5 mm. If fontsize is not specified, then all text inside the picture will be set in \footnotesize.
**default** resets all options to their defaults = no color, no dashed lines, pseudo-rotated (stacked) text, large point symbols.
Notes:
Remember to escape the # character (or other chars meaningful to (La-)TeX) by \ \ (2 backslashes).
It seems that dashed lines become solid lines when the vertices of a plot are too close. (I do not know if that is a general problem with the tpic specials, or if it is caused by a bug in eepic.sty or dvips/dvipdfm.)
Points, among other things, are drawn using the LaTeX commands " \Diamond", " \Box", etc. These commands no longer belong to the LaTeX2e core; they are included in the latexsym package, which is part of the base distribution and thus part of any LaTeX implementation. Please do not forget to use this package. Instead of latexsym, you can also include the amssymb package.
All drivers for LaTeX offer a special way of controlling text positioning: If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically. If the text string begins with '[', you need to follow this with a position specification (up to two out of t,b,l,r), ']{', the text itself, and finally '}'. The text itself may be anything LaTeX can typeset as an LR-box. ' \rule{}{}'s may help for best positioning.
Examples:
```
set term eepic
```
output graphs as eepic macros inside a picture environment; \input the resulting file in your LaTeX document.
```
set term eepic color tiny rotate 8
```
eepic macros with \color macros, \scripscriptsize point markers, true rotated text, and all text set with 8pt. About label positioning: Use gnuplot defaults (mostly sensible, but sometimes not really best):
```
set title '\LaTeX\ -- $ \gamma $'
```
Force centering both horizontally and vertically:
```
set label '{\LaTeX\ -- $ \gamma $}' at 0,0
```
Specify own positioning (top here):
```
set xlabel '[t]{\LaTeX\ -- $ \gamma $}'
```
The other label – account for long ticlabels:
```
set ylabel '[r]{\LaTeX\ -- $ \gamma $\rule{7mm}{0pt}}'
```
Emf
---
The **emf** terminal generates an Enhanced Metafile Format file. This file format is recognized by many Windows applications. Syntax:
```
set terminal emf {color | monochrome}
{enhanced {noproportional}}
{rounded | butt}
{linewidth <LW>} {dashlength <DL>}
{size XX,YY} {background <rgb_color>}
{font "<fontname>{,<fontsize>}"}
{fontscale <scale>}
```
In **monochrome** mode successive line types cycle through dash patterns. **linewidth <factor>** multiplies all line widths by this factor. **dashlength <factor>** is useful for thick lines. <fontname> is the name of a font; and **<fontsize>** is the size of the font in points.
The nominal size of the output image defaults to 1024x768 in arbitrary units. You may specify a different nominal size using the **size** option.
Enhanced text mode tries to approximate proportional character spacing. If you are using a monospaced font, or don't like the approximation, you can turn off this correction using the **noproportional** option.
The default settings are **color font "Arial,12" size 1024,768** Selecting **default** sets all options to their default values.
Examples:
```
set terminal emf 'Times Roman Italic, 12'
```
Emxvga
------
Note: legacy terminal. The **emxvga** and **emxvesa** terminal drivers support PCs with SVGA, VESA SVGA and VGA graphics boards, respectively. They are intended to be compiled with "emx-gcc" under either DOS or OS/2. They also need VESA and SVGAKIT maintained by Johannes Martin ([email protected]) with additions by David J. Liu ([email protected]). Syntax:
```
set terminal emxvga
set terminal emxvesa {vesa-mode}
```
The only option is the vesa mode for **emxvesa**, which defaults to G640x480x256.
Epscairo
--------
The **epscairo** terminal device generates encapsulated PostScript (\*.eps) using the cairo and pango support libraries. cairo version >= 1.6 is required. Please read the help for the **pdfcairo** terminal.
Epslatex
--------
The **epslatex** driver generates output for further processing by LaTeX. Syntax:
```
set terminal epslatex {default}
set terminal epslatex {standalone | input}
{oldstyle | newstyle}
{level1 | leveldefault | level3}
{color | colour | monochrome}
{background <rgbcolor> | nobackground}
{dashlength | dl <DL>}
{linewidth | lw <LW>} {pointscale | ps <PS>}
{rounded | butt}
{clip | noclip}
{palfuncparam <samples>{,<maxdeviation>}}
{size <XX>{unit},<YY>{unit}}
{header <header> | noheader}
{blacktext | colortext | colourtext}
{{font} "fontname{,fontsize}" {<fontsize>}}
{fontscale <scale>}
```
The epslatex terminal prints a plot as **terminal postscript eps** but transfers the texts to LaTeX instead of including in the PostScript code. Thus, many options are the same as in the **postscript terminal**.
The appearance of the epslatex terminal changed between versions 4.0 and 4.2 to reach better consistency with the postscript terminal: The plot size has been changed from 5 x 3 inches to 5 x 3.5 inches; the character width is now estimated to be 60% of the font size while the old epslatex terminal used 50%; now, the larger number of postscript linetypes and symbols are used. To reach an appearance that is nearly identical to the old one specify the option **oldstyle**. (In fact some small differences remain: the symbol sizes are slightly different, the tics are half as large as in the old terminal which can be changed using **set tics scale**, and the arrows have all features as in the postscript terminal.)
If you see the error message
```
"Can't find PostScript prologue file ... "
```
Please see and follow the instructions in **[postscript prologue](complete_list_terminals#postscript_prologue)**. The option **color** enables color, while **monochrome** prefers black and white drawing elements. Further, **monochrome** uses gray **palette** but it does not change color of objects specified with an explicit **colorspec**. **dashlength** or **dl** scales the length of dashed-line segments by <DL>, which is a floating-point number greater than zero. **linewidth** or **lw** scales all linewidths by <LW>.
By default the generated PostScript code uses language features that were introduced in PostScript Level 2, notably filters and pattern-fill of irregular objects such as filledcurves. PostScript Level 2 features are conditionally protected so that PostScript Level 1 interpreters do not issue errors but, rather, display a message or a PostScript Level 1 approximation. The **level1** option substitutes PostScript Level 1 approximations of these features and uses no PostScript Level 2 code. This may be required by some old printers and old versions of Adobe Illustrator. The flag **level1** can be toggled later by editing a single line in the PostScript output file to force PostScript Level 1 interpretation. In the case of files containing level 2 code, the above features will not appear or will be replaced by a note when this flag is set or when the interpreting program does not indicate that it understands level 2 PostScript or higher. The flag **level3** enables PNG encoding for bitmapped images, which can reduce the output size considerably.
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
**clip** tells PostScript to clip all output to the bounding box; **noclip** is the default.
**palfuncparam** controls how **set palette functions** are encoded as gradients in the output. Analytic color component functions (set via **set palette functions**) are encoded as linear interpolated gradients in the postscript output: The color component functions are sampled at <samples> points and all points are removed from this gradient which can be removed without changing the resulting colors by more than <maxdeviation>. For almost every useful palette you may safely leave the defaults of <samples>=2000 and <maxdeviation>=0.003 untouched.
The default size for postscript output is 10 inches x 7 inches. The default for eps output is 5 x 3.5 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possibly (currently only cm). The BoundingBox of the plot is correctly adjusted to contain the resized image. Screen coordinates always run from 0.0 to 1.0 along the full length of the plot edges as specified by the **size** option. NB: **this is a change from the previously recommended method of using the set size command prior to setting the terminal type**. The old method left the BoundingBox unchanged and screen coordinates did not correspond to the actual limits of the plot.
**blacktext** forces all text to be written in black even in color mode;
The epslatex driver offers a special way of controlling text positioning: (a) If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically by LaTeX. (b) If the text string begins with '[', you need to continue it with: a position specification (up to two out of t,b,l,r,c), ']{', the text itself, and finally, '}'. The text itself may be anything LaTeX can typeset as an LR-box. \rule{}{}'s may help for best positioning. See also the documentation for the **[pslatex](complete_list_terminals#pslatex)** terminal driver. To create multiline labels, use \shortstack, for example
```
set ylabel '[r]{\shortstack{first line \\ second line}}'
```
The **back** option of **set label** commands is handled slightly different than in other terminals. Labels using 'back' are printed behind all other elements of the plot while labels using 'front' are printed above everything else.
The driver produces two different files, one for the eps part of the figure and one for the LaTeX part. The name of the LaTeX file is taken from the **set output** command. The name of the eps file is derived by replacing the file extension (normally **.tex**) with **.eps** instead. There is no LaTeX output if no output file is given! Remember to close the **output file** before next plot unless in **multiplot** mode.
In your LaTeX documents use ' \input{filename}' to include the figure. The **.eps** file is included by the command \includegraphics{...}, so you must also include \usepackage{graphicx} in the LaTeX preamble. If you want to use coloured text (option **textcolour**) you also have to include \usepackage{color} in the LaTeX preamble.
Pdf files can be made from the eps file using 'epstopdf'. If the graphics package is properly configured, the LaTeX files can also be processed by pdflatex without changes, using the pdf files instead of the eps files. The behaviour concerning font selection depends on the header mode. In all cases, the given font size is used for the calculation of proper spacing. When not using the **standalone** mode the actual LaTeX font and font size at the point of inclusion is taken, so use LaTeX commands for changing fonts. If you use e.g. 12pt as font size for your LaTeX document, use '"" 12' as options. The font name is ignored. If using **standalone** the given font and font size are used, see below for a detailed description.
If text is printed coloured is controlled by the TeX booleans \ifGPcolor and \ifGPblacktext. Only if \ifGPcolor is true and \ifGPblacktext is false, text is printed coloured. You may either change them in the generated TeX file or provide them globally in your TeX file, for example by using
```
\newif\ifGPblacktext
\GPblacktexttrue
```
in the preamble of your document. The local assignment is only done if no global value is given. When using the epslatex terminal give the name of the TeX file in the **set output** command including the file extension (normally ".tex"). The eps filename is generated by replacing the extension by ".eps".
If using the **standalone** mode a complete LaTeX header is added to the LaTeX file; and "-inc" is added to the filename of the eps file. The **standalone** mode generates a TeX file that produces output with the correct size when using dvips, pdfTeX, or VTeX. The default, **input**, generates a file that has to be included into a LaTeX document using the \input command.
If a font other than "" or "default" is given it is interpreted as LaTeX font name. It contains up to three parts, separated by a comma: 'fontname,fontseries,fontshape'. If the default fontshape or fontseries are requested, they can be omitted. Thus, the real syntax for the fontname is '[fontname][,fontseries][,fontshape]'. The naming convention for all parts is given by the LaTeX font scheme. The fontname is 3 to 4 characters long and is built as follows: One character for the font vendor, two characters for the name of the font, and optionally one additional character for special fonts, e.g., 'j' for fonts with old-style numerals or 'x' for expert fonts. The names of many fonts is described in <http://www.tug.org/fontname/fontname.pdf>
For example, 'cmr' stands for Computer Modern Roman, 'ptm' for Times-Roman, and 'phv' for Helvetica. The font series denotes the thickness of the glyphs, in most cases 'm' for normal ("medium") and 'bx' or 'b' for bold fonts. The font shape is 'n' for upright, 'it' for italics, 'sl' for slanted, or 'sc' for small caps, in general. Some fonts may provide different font series or shapes.
Examples:
Use Times-Roman boldface (with the same shape as in the surrounding text):
```
set terminal epslatex 'ptm,bx'
```
Use Helvetica, boldface, italics:
```
set terminal epslatex 'phv,bx,it'
```
Continue to use the surrounding font in slanted shape:
```
set terminal epslatex ',,sl'
```
Use small capitals:
```
set terminal epslatex ',,sc'
```
By this method, only text fonts are changed. If you also want to change the math fonts you have to use the "gnuplot.cfg" file or the **header** option, described below.
In standalone mode, the font size is taken from the given font size in the **set terminal** command. To be able to use a specified font size, a file "size<size>.clo" has to reside in the LaTeX search path. By default, 10pt, 11pt, and 12pt are supported. If the package "extsizes" is installed, 8pt, 9pt, 14pt, 17pt, and 20pt are added.
The **header** option takes a string as argument. This string is written into the generated LaTeX file. If using the **standalone** mode, it is written into the preamble, directly before the \begin{document} command. In the **input** mode, it is placed directly after the \begingroup command to ensure that all settings are local to the plot.
Examples:
Use T1 fontencoding, change the text and math font to Times-Roman as well as the sans-serif font to Helvetica:
```
set terminal epslatex standalone header \
"\\usepackage[T1]{fontenc}\n\\usepackage{mathptmx}\n\\usepackage{helvet}"
```
Use a boldface font in the plot, not influencing the text outside the plot:
```
set terminal epslatex input header "\\bfseries"
```
If the file "gnuplot.cfg" is found by LaTeX it is input in the preamble the LaTeX document, when using **standalone** mode. It can be used for further settings, e.g., changing the document font to Times-Roman, Helvetica, and Courier, including math fonts (handled by "mathptmx.sty"):
```
\usepackage{mathptmx}
\usepackage[scaled=0.92]{helvet}
\usepackage{courier}
```
The file "gnuplot.cfg" is loaded before the header information given by the **header** command. Thus, you can use **header** to overwrite some of settings performed using "gnuplot.cfg" Epson\_180dpi
-------------
Note: only available if gnuplot is configured –with-bitmap-terminals. This driver supports a family of Epson printers and derivatives. **epson\_180dpi** and **epson\_60dpi** are drivers for Epson LQ-style 24-pin printers with resolutions of 180 and 60 dots per inch, respectively.
**epson\_lx800** is a generic 9-pin driver appropriate for printers like the Epson LX-800, the Star NL-10 and NX-1000, the PROPRINTER, and so forth.
**nec\_cp6** is generic 24-pin driver that can be used for printers like the NEC CP6 and the Epson LQ-800.
The **okidata** driver supports the 9-pin OKIDATA 320/321 Standard printers.
The **starc** driver is for the Star Color Printer.
The **tandy\_60dpi** driver is for the Tandy DMP-130 series of 9-pin, 60-dpi printers.
The **dpu414** driver is for the Seiko DPU-414 thermal printer.
**nec\_cp6** has the options:
Syntax:
```
set terminal nec_cp6 {monochrome | colour | draft}
```
which defaults to monochrome.
**dpu414** has the options:
Syntax:
```
set terminal dpu414 {small | medium | large} {normal | draft}
```
which defaults to medium (=font size) and normal. Preferred combinations are **medium normal** and **small draft**.
Excl
----
Note: legacy terminal. The **excl** terminal driver supports Talaris printers such as the EXCL Laser printer and the 1590. It has no options. Fig
---
The **fig** terminal device generates output in the Fig graphics language for import into the xfig interactive drawing tool. Notes:
```
The fig terminal was significantly revised in gnuplot version 5.3.
Currently only version 3.2 of the fig file format is supported.
Use of dash patterns may require Xfig 3.2.6 or newer.
```
Syntax:
```
set terminal fig {monochrome | color}
{small | big | size <xsize>{in|cm},<ysize>{in|cm}}
{landscape | portrait}
{font "<fontname>{,<fontsize>}"} {fontsize <size>}
{textnormal | {textspecial texthidden textrigid}}
{{linewidth|lw} <multiplier>}
```
The default settings are
```
set term fig color small landscape font "Times Roman,10" lw 1.0
```
**size** sets the size of the drawing area to <xsize>\*<ysize> in units of inches (default) or centimeters. The default is **size 5in,3in**. **small** is shorthand for **size 5in,3in** (3in,5in in portrait mode). **big** is shorthand for **size 8in,5in**.
**font** sets the text font face to <fontname> and its size to <fontsize> points. Choice is limited to the 35 standard PostScript fonts. **textnormal** resets the text flags and selects postscript fonts, **textspecial** sets the text flags for LaTeX specials, **texthidden** sets the hidden flag and **textrigid** the rigid flag.
**linewidth** is a multiplier for the linewidth property of all lines.
Additional point-plot symbols are also available in the **fig** driver. The symbols can be used through **pointtype** values % 100 above 50, with different fill intensities controlled by <pointtype> % 5 and outlines in black (for <pointtype> % 10 < 5) or in the current color. Available symbols are
```
50 - 59: circles
60 - 69: squares
70 - 79: diamonds
80 - 89: upwards triangles
90 - 99: downwards triangles
```
The size of these symbols scales with the font size. RGB colors will be replaced with gray unless they have been defined in a linetype prior to plotting or match a known named color or palette value. See **[colornames](set_show#colornames)**. E.g.
```
set linetype 999 lc rgb '#aabbcc'
plot $data with fillecurve fillcolor rgb '#aabbcc'
```
Ggi
---
Legacy terminal driver for the GGI (General Graphics Interface) project. Syntax:
```
set terminal ggi [acceleration <integer>] [[mode] {mode}]
```
In X the window cannot be resized using window manager handles, but the mode can be given with the mode option, e.g.:
```
- V1024x768
- V800x600
- V640x480
- V320x200
```
Please refer to the ggi documentation for other modes. The 'mode' keyword is optional. It is recommended to select the target by environment variables as explained in the libggi manual page. To get DGA on X, you should for example
```
bash> export GGI_DISPLAY=DGA
csh> setenv GGI_DISPLAY DGA
```
'acceleration' is only used for targets which report relative pointer motion events (e.g. DGA) and is a strictly positive integer multiplication factor for the relative distances. The default for acceleration is 7.
Examples:
```
set term ggi acc 10
set term ggi acc 1 mode V1024x768
set term ggi V1024x768
```
Gif
---
Syntax:
```
set terminal gif
{{no}enhanced}
{{no}transparent} {rounded|butt}
{linewidth <lw>} {dashlength <dl>}
{tiny | small | medium | large | giant}
{font "<face> {,<pointsize>}"} {fontscale <scale>}
{size <x>,<y>} {{no}crop}
{background <rgb_color>}
{animate {delay <d>} {loop <n>} {optimize}}
```
PNG, JPEG and GIF images are created using the external library libgd. GIF plots may be viewed interactively by piping the output to the 'display' program from the ImageMagick package as follows:
```
set term gif
set output '| display gif:-'
```
You can view the output from successive plot commands interactively by typing <space> in the display window. To save the current plot to a file, left click in the display window and choose **save**. **transparent** instructs the driver to make the background color transparent. Default is **notransparent**.
The **linewidth** and **dashlength** options are scaling factors that affect all lines drawn, i.e. they are multiplied by values requested in various drawing commands.
**butt** instructs the driver to use a line drawing method that does not overshoot the desired end point of a line. This setting is only applicable for line widths greater than 1. This setting is most useful when drawing horizontal or vertical lines. Default is **rounded**.
The output plot size <x,y> is given in pixels — it defaults to 640x480. Please see additional information under **[canvas](canvas_size#canvas)** and **[set size](set_show#set_size)**. Blank space at the edges of the finished plot may be trimmed using the **crop** option, resulting in a smaller final image size. Default is **nocrop**.
### Animate
```
set term gif animate {delay <d>} {loop <n>} {{no}optimize}}
```
The gif terminal **animate** option creates a single gif file containing multiple frames. The delay between display of successive frames may be specified in units of 1/100 second (default 5), but this value may or may not be honored accurately by a program used to view the animation later. The number of animation loops during playback can be specified, with the default of 0 meaning unlimited looping. Again this value may or may not be honored by the program later used for viewing. An animation sequence is terminated by the next **set output** or **set term** command.
The **optimize** option [DEPRECATED] is passed to the gd library when the output file is opened. It has two effects on the animation.
1) A single color map is used for the entire animation. This requires that all colors used in any frame of the animation are already defined in the first frame.
2) If possible, only the portions of a frame that differ from the previous frame are stored in the animation file. This space saving may not be possible if the animation uses transparency.
Both of these optimizations are intended to produce a smaller output file, but the decrease in size is probably only significant for long animations. Caveat: The implementation of optimization in libgd is known to be buggy. Therefore use of this option in gnuplot is not recommended.
Example showing continuous rotation:
```
set term gif animate loop 0
set output 'rotating_surface.gif'
do for [ang=1:359] {
set view 60, ang
splot f(x,y) with pm3d
}
unset output
```
### Fonts
The details of font selection are complicated. For more information please see the separate section under **[fonts gd](fonts#fonts_gd)**.
Examples:
```
set terminal gif medium noenhanced size 640,480 background '#ffffff'
```
Use the medium size built-in non-scaleable, non-rotatable font. Enhanced text mode will not work with this font. Use white (24 bit RGB in hexadecimal) for the non-transparent background.
```
set terminal gif font arial 14
```
Searches for a font with face name 'arial' and sets the font size to 14pt.
Gpic
----
The **gpic** terminal driver generates GPIC graphs in the Free Software Foundations's "groff" package. The default size is 5 x 3 inches. The only option is the origin, which defaults to (0,0). Syntax:
```
set terminal gpic {<x> <y>}
```
where **x** and **y** are in inches.
A simple graph can be formatted using
```
groff -p -mpic -Tps file.pic > file.ps.
```
The output from pic can be pipe-lined into eqn, so it is possible to put complex functions in a graph with the **set label** and **set {x/y}label** commands. For instance,
```
set ylab '@space 0 int from 0 to x alpha ( t ) roman d t@'
```
will label the y axis with a nice integral if formatted with the command:
```
gpic filename.pic | geqn -d@@ -Tps | groff -m[macro-package] -Tps
> filename.ps
```
Figures made this way can be scaled to fit into a document. The pic language is easy to understand, so the graphs can be edited by hand if need be. All co-ordinates in the pic-file produced by **gnuplot** are given as x+gnuplotx and y+gnuploty. By default x and y are given the value 0. If this line is removed with an editor in a number of files, one can put several graphs in one figure like this (default size is 5.0x3.0 inches):
```
.PS 8.0
x=0;y=3
copy "figa.pic"
x=5;y=3
copy "figb.pic"
x=0;y=0
copy "figc.pic"
x=5;y=0
copy "figd.pic"
.PE
```
This will produce an 8-inch-wide figure with four graphs in two rows on top of each other.
One can also achieve the same thing by specifying x and y in the command
```
set terminal gpic x y
```
Grass
-----
Note: legacy terminal. The **grass** terminal driver gives **gnuplot** capabilities to users of the GRASS geographic information system. Contact [email protected] for more information. Pages are written to the current frame of the GRASS Graphics Window. There are no options. Hp2623a
-------
The **hp2623a** terminal driver supports the Hewlett Packard HP2623A. It has no options. Hp2648
------
The **hp2648** terminal driver supports the Hewlett Packard HP2647 and HP2648. It has no options. Hp500c
------
Note: only available if gnuplot is configured –with-bitmap-terminals. The **hp500c** terminal driver supports the Hewlett Packard HP DeskJet 500c. It has options for resolution and compression. Syntax:
```
set terminal hp500c {<res>} {<comp>}
```
where **res** can be 75, 100, 150 or 300 dots per inch and **comp** can be "rle", or "tiff". Any other inputs are replaced by the defaults, which are 75 dpi and no compression. Rasterization at the higher resolutions may require a large amount of memory.
Hpgl
----
The **hpgl** driver produces HPGL output for devices like the HP7475A plotter. There are two options which can be set: the number of pens and **eject**, which tells the plotter to eject a page when done. The default is to use 6 pens and not to eject the page when done. The international character sets ISO-8859-1 and CP850 are recognized via **set encoding iso\_8859\_1** or **set encoding cp850** (see **[set encoding](set_show#set_encoding)** for details).
Syntax:
```
set terminal hpgl {<number_of_pens>} {eject}
```
The selection
```
set terminal hpgl 8 eject
```
is equivalent to the previous **hp7550** terminal, and the selection
```
set terminal hpgl 4
```
is equivalent to the previous **hp7580b** terminal. HPGL graphics can be imported by many software packages.
Hpljii
------
Note: only available if gnuplot is configured –with-bitmap-terminals. The **hpljii** terminal driver supports the HP Laserjet Series II printer. The **hpdj** driver supports the HP DeskJet 500 printer. These drivers allow a choice of resolutions. Syntax:
```
set terminal hpljii | hpdj {<res>}
```
where **res** may be 75, 100, 150 or 300 dots per inch; the default is 75. Rasterization at the higher resolutions may require a large amount of memory.
The **hp500c** terminal is similar to **hpdj**; **hp500c** additionally supports color and compression.
Hppj
----
Note: only available if gnuplot is configured –with-bitmap-terminals. The **hppj** terminal driver supports the HP PaintJet and HP3630 printers. The only option is the choice of font. Syntax:
```
set terminal hppj {FNT5X9 | FNT9X17 | FNT13X25}
```
with the middle-sized font (FNT9X17) being the default.
Imagen
------
The **imagen** terminal driver supports Imagen laser printers. It is capable of placing multiple graphs on a single page. Syntax:
```
set terminal imagen {<fontsize>} {portrait | landscape}
{[<horiz>,<vert>]}
```
where **fontsize** defaults to 12 points and the layout defaults to **landscape**. **<horiz>** and **<vert>** are the number of graphs in the horizontal and vertical directions; these default to unity.
Example:
```
set terminal imagen portrait [2,3]
```
puts six graphs on the page in three rows of two in portrait orientation.
Jpeg
----
Syntax:
```
set terminal jpeg
{{no}enhanced}
{{no}interlace}
{linewidth <lw>} {dashlength <dl>} {rounded|butt}
{tiny | small | medium | large | giant}
{font "<face> {,<pointsize>}"} {fontscale <scale>}
{size <x>,<y>} {{no}crop}
{background <rgb_color>}
```
PNG, JPEG and GIF images are created using the external library libgd. In most cases, PNG is to be preferred for single plots, and GIF for animations. Both are loss-less image formats, and produce better image quality than the lossy JPEG format. This is in particular noticeable for solid color lines against a solid background, i.e. exactly the sort of image typically created by gnuplot.
The **interlace** option creates a progressive JPEG image. Default is **nointerlace**.
The **linewidth** and **dashlength** options are scaling factors that affect all lines drawn, i.e. they are multiplied by values requested in various drawing commands.
**butt** instructs the driver to use a line drawing method that does not overshoot the desired end point of a line. This setting is only applicable for line widths greater than 1. This setting is most useful when drawing horizontal or vertical lines. Default is **rounded**.
The details of font selection are complicated. Two equivalent simple examples are given below:
```
set term jpeg font arial 11
set term jpeg font "arial,11"
```
For more information please see the separate section under **[fonts](fonts#fonts)**. The output plot size <x,y> is given in pixels — it defaults to 640x480. Please see additional information under **[canvas](canvas_size#canvas)** and **[set size](set_show#set_size)**. Blank space at the edges of the finished plot may be trimmed using the **crop** option, resulting in a smaller final image size. Default is **nocrop**.
Kyo
---
The **kyo** and **prescribe** terminal drivers support the Kyocera laser printer. The only difference between the two is that **kyo** uses "Helvetica" whereas **prescribe** uses "Courier". There are no options. Latex
-----
Note: Legacy terminal (not built by default). The latex, emtex, eepic, and tpic terminals in older versions of gnuplot provided minimal support for graphics styles beyond simple lines and points. They have been directly superseded by the **pict2e** terminal. For more capable TeX/LaTeX compatible terminal types see **[cairolatex](complete_list_terminals#cairolatex)**, **[context](complete_list_terminals#context)**, **[epslatex](complete_list_terminals#epslatex)**, **[mp](complete_list_terminals#mp)**, **[pstricks](complete_list_terminals#pstricks)**, and **[tikz](complete_list_terminals#tikz)**. Syntax:
```
set terminal {latex | emtex} {default | {courier|roman} {<fontsize>}}
{size <XX>{unit}, <YY>{unit}} {rotate | norotate}
{color | monochrome}
```
By default the plot will inherit font settings from the embedding document. You have the option of forcing either Courier (cmtt) or Roman (cmr) fonts instead. In this case you may also specify a fontsize. Unless your driver is capable of building fonts at any size (e.g. dvips), stick to the standard 10, 11 and 12 point sizes.
METAFONT users beware: METAFONT does not like odd sizes.
All drivers for LaTeX offer a special way of controlling text positioning: If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically. If the text string begins with '[', you need to follow this with a position specification (up to two out of t,b,l,r), ']{', the text itself, and finally '}'. The text itself may be anything LaTeX can typeset as an LR-box. ' \rule{}{}'s may help for best positioning.
Points, among other things, are drawn using the LaTeX commands " \Diamond" and " \Box". These commands no longer belong to the LaTeX2e core; they are included in the latexsym package, which is part of the base distribution and thus part of any LaTeX implementation. Please do not forget to use this package. Other point types use symbols from the amssymb package.
The default size for the plot is 5 inches by 3 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possible (currently only cm).
If **rotate** is specified, rotated text, especially a rotated y-axis label, is possible (the packages graphics or graphicx are needed). The 'stacked' y-axis label mechanism is then deactivated. This will also significantly improve the quality of line drawing, and is default since version 5.3.
The option **color** enables color, while **monochrome** uses only black and white drawing elements. You need to load the color or xcolor package in the preamble of your latex document.
Examples: About label positioning: Use gnuplot defaults (mostly sensible, but sometimes not really best):
```
set title '\LaTeX\ -- $ \gamma $'
```
Force centering both horizontally and vertically:
```
set label '{\LaTeX\ -- $ \gamma $}' at 0,0
```
Specify own positioning (top here):
```
set xlabel '[t]{\LaTeX\ -- $ \gamma $}'
```
The other label – account for long ticlabels:
```
set ylabel '[r]{\LaTeX\ -- $ \gamma $\rule{7mm}{0pt}}'
```
Linux console
-------------
Older gnuplot versions required special terminals **linux** or **vgagl** in order to display graphics on the linux console, i.e. in the absence of X11 or other windowing environment. These terminals have been deprecated. The recommended way to run gnuplot from the linux console is now to use a console terminal emulator such as yaft (https://github.com/uobikiemukot/yaft) that supports sixel graphics. With yaft as your console terminal you can run gnuplot and select a terminal with sixel output. See **[sixelgd](complete_list_terminals#sixelgd)**. As a fall-back option you could use **set term dumb**, but sixel graphics are much nicer.
Lua
---
The **lua** generic terminal driver works in conjunction with an external Lua script to create a target-specific plot file. Currently the only supported target is TikZ -> pdflatex. Information about Lua is available at http://www.lua.org .
Syntax:
```
set terminal lua <target name> | "<file name>"
{<script_args> ...}
{help}
```
A 'target name' or 'file name' (in quotes) for a script is mandatory. If a 'target name' for the script is given, the terminal will look for "gnuplot-<target name>.lua" in the local directory and on failure in the environmental variable GNUPLOT\_LUA\_DIR.
All arguments will be provided to the selected script for further evaluation. E.g. 'set term lua tikz help' will cause the script itself to print additional help on options and choices for the script.
Mf
--
The **mf** terminal driver creates an input file to the METAFONT program. Thus a figure may be used in the TeX document in the same way as is a character. To use a picture in a document, the METAFONT program must be run with the output file from **gnuplot** as input. Thus, the user needs a basic knowledge of the font creating process and the procedure for including a new font in a document. However, if the METAFONT program is set up properly at the local site, an unexperienced user could perform the operation without much trouble.
The text support is based on a METAFONT character set. Currently the Computer Modern Roman font set is input, but the user is in principal free to choose whatever fonts he or she needs. The METAFONT source files for the chosen font must be available. Each character is stored in a separate picture variable in METAFONT. These variables may be manipulated (rotated, scaled etc.) when characters are needed. The drawback is the interpretation time in the METAFONT program. On some machines (i.e. PC) the limited amount of memory available may also cause problems if too many pictures are stored.
The **mf** terminal has no options.
### METAFONT Instructions
- Set your terminal to METAFONT:
```
set terminal mf
```
- Select an output-file, e.g.:
```
set output "myfigures.mf"
```
- Create your pictures. Each picture will generate a separate character. Its default size will be 5\*3 inches. You can change the size by saying **set size 0.5,0.5** or whatever fraction of the default size you want to have. - Quit **gnuplot**.
- Generate a TFM and GF file by running METAFONT on the output of **gnuplot**. Since the picture is quite large (5\*3 in), you will have to use a version of METAFONT that has a value of at least 150000 for memmax. On Unix systems these are conventionally installed under the name bigmf. For the following assume that the command virmf stands for a big version of METAFONT. For example:
- Invoke METAFONT:
```
virmf '&plain'
```
- Select the output device: At the METAFONT prompt ('\*') type:
```
\mode:=CanonCX; % or whatever printer you use
```
- Optionally select a magnification:
```
mag:=1; % or whatever you wish
```
- Input the **gnuplot**-file:
```
input myfigures.mf
```
On a typical Unix machine there will usually be a script called "mf" that executes virmf '&plain', so you probably can substitute mf for virmf &plain. This will generate two files: mfput.tfm and mfput.$$$gf (where $$$ indicates the resolution of your device). The above can be conveniently achieved by typing everything on the command line, e.g.: virmf '&plain' ' \mode:=CanonCX; mag:=1; input myfigures.mf' In this case the output files will be named myfigures.tfm and myfigures.300gf. - Generate a PK file from the GF file using gftopk:
```
gftopk myfigures.300gf myfigures.300pk
```
The name of the output file for gftopk depends on the DVI driver you use. Ask your local TeX administrator about the naming conventions. Next, either install the TFM and PK files in the appropriate directories, or set your environment variables properly. Usually this involves setting TEXFONTS to include the current directory and doing the same thing for the environment variable that your DVI driver uses (no standard name here...). This step is necessary so that TeX will find the font metric file and your DVI driver will find the PK file. - To include your pictures in your document you have to tell TeX the font:
```
\font\gnufigs=myfigures
```
Each picture you made is stored in a single character. The first picture is character 0, the second is character 1, and so on... After doing the above step, you can use the pictures just like any other characters. Therefore, to place pictures 1 and 2 centered in your document, all you have to do is:
```
\centerline{\gnufigs\char0}
\centerline{\gnufigs\char1}
```
in plain TeX. For LaTeX you can, of course, use the picture environment and place the picture wherever you wish by using the \makebox and \put macros. This conversion saves you a lot of time once you have generated the font; TeX handles the pictures as characters and uses minimal time to place them, and the documents you make change more often than the pictures do. It also saves a lot of TeX memory. One last advantage of using the METAFONT driver is that the DVI file really remains device independent, because no \special commands are used as in the eepic and tpic drivers.
Mif
---
Note: Legacy terminal. The **mif** terminal driver produces Frame Maker MIF format version 3.00. It plots in MIF Frames with the size 15\*10 cm, and plot primitives with the same pen will be grouped in the same MIF group. Plot primitives in a **gnuplot** page will be plotted in a MIF Frame, and several MIF Frames are collected in one large MIF Frame. The MIF font used for text is "Times". Several options may be set in the MIF 3.00 driver.
Syntax:
```
set terminal mif {color | colour | monochrome} {polyline | vectors}
{help | ?}
```
**colour** plots lines with line types >= 0 in colour (MIF sep. 2–7) and **monochrome** plots all line types in black (MIF sep. 0). **polyline** plots curves as continuous curves and **vectors** plots curves as collections of vectors. **help** and **?** print online help on standard error output — both print a short description of the usage; **help** also lists the options.
Examples:
```
set term mif colour polylines # defaults
set term mif # defaults
set term mif vectors
set term mif help
```
Mp
--
The **mp** driver produces output intended to be input to the Metapost program. Running Metapost on the file creates EPS files containing the plots. By default, Metapost passes all text through TeX. This has the advantage of allowing essentially any TeX symbols in titles and labels.
Syntax:
```
set term mp {color | colour | monochrome}
{solid | dashed}
{notex | tex | latex}
{magnification <magsize>}
{psnfss | psnfss-version7 | nopsnfss}
{prologues <value>}
{a4paper}
{amstex}
{"<fontname> {,<fontsize>}"}
```
The option **color** causes lines to be drawn in color (on a printer or display that supports it), **monochrome** (or nothing) selects black lines. The option **solid** draws solid lines, while **dashed** (or nothing) selects lines with different patterns of dashes. If **solid** is selected but **color** is not, nearly all lines will be identical. This may occasionally be useful, so it is allowed.
The option **notex** bypasses TeX entirely, therefore no TeX code can be used in labels under this option. This is intended for use on old plot files or files that make frequent use of common characters like **$** and **%** that require special handling in TeX.
The option **tex** sets the terminal to output its text for TeX to process.
The option **latex** sets the terminal to output its text for processing by LaTeX. This allows things like \frac for fractions which LaTeX knows about but TeX does not. Note that you must set the environment variable TEX to the name of your LaTeX executable (normally latex) if you use this option or use **mpost –tex=<name of LaTeX executable> ...**. Otherwise metapost will try and use TeX to process the text and it won't work.
Changing font sizes in TeX has no effect on the size of mathematics, and there is no foolproof way to make such a change, except by globally setting a magnification factor. This is the purpose of the **magnification** option. It must be followed by a scaling factor. All text (NOT the graphs) will be scaled by this factor. Use this if you have math that you want at some size other than the default 10pt. Unfortunately, all math will be the same size, but see the discussion below on editing the MP output. **mag** will also work under **notex** but there seems no point in using it as the font size option (below) works as well.
The option **psnfss** uses postscript fonts in combination with LaTeX. Since this option only makes sense, if LaTeX is being used, the **latex** option is selected automatically. This option includes the following packages for LaTeX: inputenc(latin1), fontenc(T1), mathptmx, helvet(scaled=09.2), courier, latexsym and textcomp.
The option **psnfss-version7** uses also postscript fonts in LaTeX (option **latex** is also automatically selected), but uses the following packages with LaTeX: inputenc(latin1), fontenc(T1), times, mathptmx, helvet and courier.
The option **nopsnfss** is the default and uses the standard font (cmr10 if not otherwise specified).
The option **prologues** takes a value as an additional argument and adds the line **prologues:=<value>** to the metapost file. If a value of **2** is specified metapost uses postscript fonts to generate the eps-file, so that the result can be viewed using e.g. ghostscript. Normally the output of metapost uses TeX fonts and therefore has to be included in a (La)TeX file before you can look at it.
The option **noprologues** is the default. No additional line specifying the prologue will be added.
The option **a4paper** adds a **[a4paper]** to the documentclass. Normally letter paper is used (default). Since this option is only used in case of LaTeX, the **latex** option is selected automatically.
The option **amstex** automatically selects the **latex** option and includes the following LaTeX packages: amsfonts, amsmath(intlimits). By default these packages are not included.
A name in quotes selects the font that will be used when no explicit font is given in a **set label** or **set title**. A name recognized by TeX (a TFM file exists) must be used. The default is "cmr10" unless **notex** is selected, then it is "pcrr8r" (Courier). Even under **notex**, a TFM file is needed by Metapost. The file **pcrr8r.tfm** is the name given to Courier in LaTeX's psnfss package. If you change the font from the **notex** default, choose a font that matches the ASCII encoding at least in the range 32-126. **cmtt10** almost works, but it has a nonblank character in position 32 (space).
The size can be any number between 5.0 and 99.99. If it is omitted, 10.0 is used. It is advisable to use **magstep** sizes: 10 times an integer or half-integer power of 1.2, rounded to two decimals, because those are the most available sizes of fonts in TeX systems.
All the options are optional. If font information is given, it must be at the end, with size (if present) last. The size is needed to select a size for the font, even if the font name includes size information. For example, **set term mp "cmtt12"** selects cmtt12 shrunk to the default size 10. This is probably not what you want or you would have used cmtt10.
The following common ascii characters need special treatment in TeX:
```
$, &, #, %, _; |, <, >; ^, ~, \, {, and }
```
The five characters $, #, &, \_, and % can simply be escaped, e.g., **\$**. The three characters <, >, and | can be wrapped in math mode, e.g., **$<$**. The remainder require some TeX work-arounds. Any good book on TeX will give some guidance. If you type your labels inside double quotes, backslashes in TeX code need to be escaped (doubled). Using single quotes will avoid having to do this, but then you cannot use **\n** for line breaks. As of this writing, version 3.7 of gnuplot processes titles given in a **plot** command differently than in other places, and backslashes in TeX commands need to be doubled regardless of the style of quotes.
Metapost pictures are typically used in TeX documents. Metapost deals with fonts pretty much the same way TeX does, which is different from most other document preparation programs. If the picture is included in a LaTeX document using the graphics package, or in a plainTeX document via epsf.tex, and then converted to PostScript with dvips (or other dvi-to-ps converter), the text in the plot will usually be handled correctly. However, the text may not appear if you send the Metapost output as-is to a PostScript interpreter.
### Metapost Instructions
- Set your terminal to Metapost, e.g.:
```
set terminal mp mono "cmtt12" 12
```
- Select an output-file, e.g.:
```
set output "figure.mp"
```
- Create your pictures. Each plot (or multiplot group) will generate a separate Metapost beginfig...endfig group. Its default size will be 5 by 3 inches. You can change the size by saying **set size 0.5,0.5** or whatever fraction of the default size you want to have.
- Quit gnuplot.
- Generate EPS files by running Metapost on the output of gnuplot:
```
mpost figure.mp OR mp figure.mp
```
The name of the Metapost program depends on the system, typically **mpost** for a Unix machine and **mp** on many others. Metapost will generate one EPS file for each picture. - To include your pictures in your document you can use the graphics package in LaTeX or epsf.tex in plainTeX:
```
\usepackage{graphics} % LaTeX
\input epsf.tex % plainTeX
```
If you use a driver other than dvips for converting TeX DVI output to PS, you may need to add the following line in your LaTeX document:
```
\DeclareGraphicsRule{*}{eps}{*}{}
```
Each picture you made is in a separate file. The first picture is in, e.g., figure.0, the second in figure.1, and so on.... To place the third picture in your document, for example, all you have to do is:
```
\includegraphics{figure.2} % LaTeX
\epsfbox{figure.2} % plainTeX
```
The advantage, if any, of the mp terminal over a postscript terminal is editable output. Considerable effort went into making this output as clean as possible. For those knowledgeable in the Metapost language, the default line types and colors can be changed by editing the arrays **lt[]** and **col[]**. The choice of solid vs dashed lines, and color vs black lines can be change by changing the values assigned to the booleans **dashedlines** and **colorlines**. If the default **tex** option was in effect, global changes to the text of labels can be achieved by editing the **vebatimtex...etex** block. In particular, a LaTeX preamble can be added if desired, and then LaTeX's built-in size changing commands can be used for maximum flexibility. Be sure to set the appropriate MP configuration variable to force Metapost to run LaTeX instead of plainTeX.
Pbm
---
Note: only available if gnuplot is configured –with-bitmap-terminals. Syntax:
```
set terminal pbm {<fontsize>} {<mode>} {size <x>,<y>}
```
where <fontsize> is **small**, **medium**, or **large** and <mode> is **monochrome**, **gray** or **color**. The default plot size is 640 pixels wide and 480 pixels high. The output size is white-space padded to the nearest multiple of 8 pixels on both x and y. This empty space may be cropped later if needed.
The output of the **pbm** driver depends upon <mode>: **monochrome** produces a portable bitmap (one bit per pixel), **gray** a portable graymap (three bits per pixel) and **color** a portable pixmap (color, four bits per pixel).
The output of this driver can be used with various image conversion and manipulation utilities provided by NETPBM. Based on Jef Poskanzer's PBMPLUS package, NETPBM provides programs to convert the above PBM formats to GIF, TIFF, MacPaint, Macintosh PICT, PCX, X11 bitmap and many others. Complete information is available at http://netpbm.sourceforge.net/.
Examples:
```
set terminal pbm small monochrome # defaults
set terminal pbm color medium size 800,600
set output '| pnmrotate 45 | pnmtopng > tilted.png' # uses NETPBM
```
Pcl5
----
The **pcl5** driver supports PCL5e/PCL5c printers. It (mostly) uses the HP-GL/2 vector format. Syntax:
```
set terminal pcl5 {<mode>} {{no}enhanced}
{size <plotsize> | size <width>{unit},<height>{unit}}
{font "<fontname>,<size>"} {pspoints | nopspoints}
{fontscale <scale>} {pointsize <scale>} {linewidth <scale}
{rounded|butt} {color <number_of_pens>}
```
<mode> is **landscape** or **portrait**. <plotsize> is the physical plotting size of the plot, which can be one of the following formats: **letter** for standard (8 1/2" X 11") displays, **legal** for (8 1/2" X 14") displays, **noextended** for (36" X 48") displays (a letter size ratio), **extended** for (36" X 55") displays (almost a legal size ratio), or **a4** for (296mm X 210mm) displays. You can also explicitly specify the canvas size using the **width** and **height** options. Default unit is **in**. Default size is **letter**.
<fontname> can be one of stick, univers (default), albertus, antique\_olive, arial, avant\_garde\_gothic, bookman, zapf\_chancery, clarendon, coronet, courier courier\_ps, cg\_times, garamond\_antigua, helvetica, helvetica\_narrow, letter\_gothic, marigold, new\_century\_schlbk, cg\_omega, palatino, times\_new\_roman, times\_roman, zapf\_dingbats, truetype\_symbols, or wingdings. Font names are case-insensitive and underscores may be replaced by spaces or dashes or may be left out. <fontsize> is the font size in points.
The point type selection can be the a limited default set by specifying **nopspoints**, or the same set of point types as provided by the postscript terminal by specifying **pspoints** (default).
The **butt** option selects lines with butt ends and mitered joins (default), whereas **rounded** selects rounded line ends and joins.
Line widths, and point and font sizes can be scaled using the **linewidth**, **pointscale**, or **fontscale** options, respectively. **color** selects the number of pens <number\_of\_pens> used in plots. Default is 8, minimum 2.
Note that built-in support of some of these options is printer device dependent. For instance, all the fonts are supposedly supported by the HP Laserjet IV, but only a few (e.g. univers, stick) may be supported by the HP Laserjet III and the Designjet 750C. Also, color obviously won't work on monochrome devices, but newer ones will do grey-scale.
Defaults: landscape, a4, 8 pens, univers, 12 point, pspoints, butt, no scaling
The **pcl5** terminal will try to request fonts which match your **encoding**. Note that this has highest priority, so you might end up with a different font face. The terminal's default **encoding** is **HP Roman-8**.
Limitations:
This terminal does not support alpha transparency. Transparent filling is emulated using shading patterns. Boxed text is not implemented.
The support for UTF-8 is limited. Lacking the label mode for UTF-8 output in HP-GL/2, the driver reverts to PCL for strings containing 8bit characters. UTF-8 text is limited to angles of 0, 90, 180, and 270 degrees. Also vertical alignment might be off depending on the font.
Some enhanced text features (phantom box, overprinting) require using PCL features in addition to HP-GL/2. This conforms to the specs but may not work with your printer or software.
Pdf
---
[DEPRECATED] This terminal uses the non-free library PDFlib (GmbH Munchen) to produce files in Portable Document Format. Unless you have a commercial license for PDFlib and need some special feature it provides you would do better to use the cairo pdf terminal instead. Gnuplot can also export PDF files from wxt or qt interactive terminal sessions. Syntax:
```
set terminal pdf {monochrome|color|colour}
{{no}enhanced}
{fname "<font>"} {fsize <fontsize>}
{font "<fontname>{,<fontsize>}"} {fontscale <scale>}
{linewidth <lw>} {rounded|butt}
{dl <dashlength>}}
{size <XX>{unit},<YY>{unit}}
```
The default is to use a different color for each line type. Selecting **monochome** will use black for all linetypes, Even in in mono mode you can still use explicit colors for filled areas or linestyles.
where <font> is the name of the default font to use (default Helvetica) and <fontsize> is the font size (in points, default 12). For help on which fonts are available or how to install new ones, please see the documentation for your local installation of pdflib.
The **enhanced** option enables enhanced text processing features (subscripts, superscripts and mixed fonts). See **[enhanced](enhanced_text_mode#enhanced)**.
The width of all lines in the plot can be increased by the factor <n> specified in **linewidth**. Similarly **dashlength** is a multiplier for the default dash spacing.
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
The default size for PDF output is 5 inches by 3 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possible (currently only cm).
Pdfcairo
--------
The **pdfcairo** terminal device generates output in pdf. The actual drawing is done via cairo, a 2D graphics library, and pango, a library for laying out and rendering text. Syntax:
```
set term pdfcairo
{{no}enhanced} {mono|color}
{font <font>} {fontscale <scale>}
{linewidth <lw>} {rounded|butt|square} {dashlength <dl>}
{background <rgbcolor>}
{size <XX>{unit},<YY>{unit}}
```
This terminal supports an enhanced text mode, which allows font and other formatting commands (subscripts, superscripts, etc.) to be embedded in labels and other text strings. The enhanced text mode syntax is shared with other gnuplot terminal types. See **[enhanced](enhanced_text_mode#enhanced)** for more details.
The width of all lines in the plot can be modified by the factor <lw> specified in **linewidth**. The default linewidth is 0.5 points. (1 "PostScript" point = 1/72 inch = 0.353 mm)
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
The default size for the output is 5 inches x 3 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possible (currently only cm). Screen coordinates always run from 0.0 to 1.0 along the full length of the plot edges as specified by the **size** option.
<font> is in the format "FontFace,FontSize", i.e. the face and the size comma-separated in a single string. FontFace is a usual font face name, such as 'Arial'. If you do not provide FontFace, the pdfcairo terminal will use 'Sans'. FontSize is the font size, in points. If you do not provide it, the pdfcairo terminal will use a nominal font size of 12 points. However, the default fontscale parameter for this terminal is 0.5, so the apparent font size is smaller than this if the pdf output is viewed at full size.
```
For example :
set term pdfcairo font "Arial,12"
set term pdfcairo font "Arial" # to change the font face only
set term pdfcairo font ",12" # to change the font size only
set term pdfcairo font "" # to reset the font name and size
```
The fonts are retrieved from the usual fonts subsystems. Under Windows, those fonts are to be found and configured in the entry "Fonts" of the control panel. Under UNIX, they are handled by "fontconfig".
Pango, the library used to layout the text, is based on utf-8. Thus, the pdfcairo terminal has to convert from your encoding to utf-8. The default input encoding is based on your 'locale'. If you want to use another encoding, make sure gnuplot knows which one you are using. See **[encoding](set_show#encoding)** for more details.
Pango may give unexpected results with fonts that do not respect the unicode mapping. With the Symbol font, for example, the pdfcairo terminal will use the map provided by http://www.unicode.org/ to translate character codes to unicode. Note that "the Symbol font" is to be understood as the Adobe Symbol font, distributed with Acrobat Reader as "SY\_\_\_\_\_\_.PFB". Alternatively, the OpenSymbol font, distributed with OpenOffice.org as "opens\_\_\_.ttf", offers the same characters. Microsoft has distributed a Symbol font ("symbol.ttf"), but it has a different character set with several missing or moved mathematic characters. If you experience problems with your default setup (if the demo enhancedtext.dem is not displayed properly for example), you probably have to install one of the Adobe or OpenOffice Symbol fonts, and remove the Microsoft one. Other non-conform fonts, such as "wingdings" have been observed working.
The rendering of the plot cannot be altered yet. To obtain the best output possible, the rendering involves two mechanisms : antialiasing and oversampling. Antialiasing allows to display non-horizontal and non-vertical lines smoother. Oversampling combined with antialiasing provides subpixel accuracy, so that gnuplot can draw a line from non-integer coordinates. This avoids wobbling effects on diagonal lines ('plot x' for example).
Pict2e
------
The **pict2e** terminal uses the LaTeX2e variant of the picture environment. It replaces terminals which were based on the original LaTeX picture environment: **latex**, **emtex**, **tpic**, and **eepic**. (EXPERIMENTAL) Alternatives to this terminal with a more complete support of gnuplot's features are **tikz**, **pstricks**, **cairolatex**, **pslatex**, **epslatex** and **mp**.
Syntax:
```
set terminal pict2e
{font "{<fontname>}{,<fontsize>}"}
{size <XX>{unit}, <YY>{unit}}
{color | monochrome}
{linewidth <lw>} {rounded | butt}
{texarrows | gparrows} {texpoints | gppoints}
{smallpoints | tinypoints | normalpoints}
```
This terminal requires the following standard LaTeX packages: **pict2e**, **xcolor**, **graphics**/**graphicx** and **amssymb**. For pdflatex, the **transparent** package is used to support transparency.
By default the plot will inherit font settings from the embedding document. You have the option to force a font with the **font** option, like cmtt (Courier) or cmr (Roman), instead. In this case you may also force a specific fontsize. Otherwise the fontsize argument is used to estimate the required space for text. Unless your driver is capable of building fonts at any size (e.g. dvips), stick to the standard 10, 11 and 12 point sizes.
The default size for the plot is 5 inches by 3 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possible (currently only cm).
With **texpoints**, points are drawn using LaTeX commands like " \Diamond" and " \Box". These are provided by the the latexsym package, which is part of the base distribution and thus part of any LaTeX implementation. Other point types use symbols from the amssymb package. With **gppoints**, the terminal will use gnuplot's internal routines for drawing point symbols instead.
With the **texpoints** option, you can select three different point sizes: **normalpoints**, **smallpoints**, and **tinypoints**.
**color** causes gnuplot to produce \color{...} commands so that the graphs are colored. Using this option, you must include \usepackage{xcolor} in the preamble of your LaTeX document. **monochrome** will avoid the use of any color commands in the output. Transparent color fill is available if pdflatex is used.
**linewidth** sets the scale factor for the width of lines. **rounded** sets line caps and line joins to be rounded. **butt** sets butt caps and mitered joins and is the default.
**pict2e** only supports dotted lines, but not dashed lines. All default line types are solid. Use **set linetype** with the **dashtype** property to change.
**texarrows** draws **arrow**s using LaTeX commands which are shorter but do not offer all options. **gparrows** selects drawing arrows using gnuplot's own routine for full functionality instead.
Pm
--
The **pm** terminal driver provides an OS/2 Presentation Manager window in which the graph is plotted. The window is opened when the first graph is plotted. This window has its own online help as well as facilities for printing and copying to the clipboard. Syntax:
```
set terminal pm {{server} {n} | noserver}
{nopersist | persist}
{enhanced | noenhanced}
{font <fontspec>}
{nowidelines | widelines}
{fontscale <scale>}
{linewidth <scale>}
{pointscale <scale>}
{{title} "title"}
```
If **persist** is specified, each graph appears in its own window and all windows remain open after **gnuplot** exits. If **server** is specified, all graphs appear in the same window, which remains open when **gnuplot** exits. This option takes an optional numerical argument which specifies an instance of the server process. Thus multiple server windows can be in use at the same time.
If **widelines** is specified, all plots will be drawn with wide lines. If **enhanced** is specified, sub- and superscripts and multiple fonts are enabled (see **[enhanced text](enhanced_text_mode#enhanced_text)** for details). Font names for the core PostScript fonts may be abbreviated to a single letter (T/H/C/S for Times/Helvetica/Courier/Symbol).
**linewidth**, **fontscale**, **pointscale** can be used to scale the width of lines, the size of text, or the size of the point symbols.
If **title** is specified, it will be used as the title of the plot window. It will also be used as the name of the server instance, and will override the optional numerical argument.
The gnuplot outboard driver, gnupmdrv.exe, is searched in the same directory as gnuplot itself. You can override that by defining one of the environment variables GNUPLOT\_DRIVER\_DIR or GNUPLOT. As a last resort the current directory and the PATH are tried to locate gnupmdrv.exe.
Png
---
Syntax:
```
set terminal png
{{no}enhanced}
{{no}transparent} {{no}interlace}
{{no}truecolor} {rounded|butt}
{linewidth <lw>} {dashlength <dl>}
{tiny | small | medium | large | giant}
{font "<face> {,<pointsize>}"} {fontscale <scale>}
{size <x>,<y>} {{no}crop}
{background <rgb_color>}
```
PNG, JPEG and GIF images are created using the external library libgd. PNG plots may be viewed interactively by piping the output to the 'display' program from the ImageMagick package as follows:
```
set term png
set output '| display png:-'
```
You can view the output from successive plot commands interactively by typing <space> in the display window. To save the current plot to a file, left click in the display window and choose **save**. **transparent** instructs the driver to make the background color transparent. Default is **notransparent**.
**interlace** instructs the driver to generate interlaced PNGs. Default is **nointerlace**.
The **linewidth** and **dashlength** options are scaling factors that affect all lines drawn, i.e. they are multiplied by values requested in various drawing commands.
By default output png images use 256 indexed colors. The **truecolor** option instead creates TrueColor images with 24 bits of color information per pixel. Transparent fill styles require the **truecolor** option. See **[fillstyle](set_show#fillstyle)**. A transparent background is possible in either indexed or TrueColor images.
**butt** instructs the driver to use a line drawing method that does not overshoot the desired end point of a line. This setting is only applicable for line widths greater than 1. This setting is most useful when drawing horizontal or vertical lines. Default is **rounded**.
The details of font selection are complicated. Two equivalent simple examples are given below:
```
set term png font arial 11
set term png font "arial,11"
```
For more information please see the separate section under **[fonts](fonts#fonts)**. The output plot size <x,y> is given in pixels — it defaults to 640x480. Please see additional information under **[canvas](canvas_size#canvas)** and **[set size](set_show#set_size)**. Blank space at the edges of the finished plot may be trimmed using the **crop** option, resulting in a smaller final image size. Default is **nocrop**.
### Examples
```
set terminal png medium size 640,480 background '#ffffff'
```
Use the medium size built-in non-scaleable, non-rotatable font. Use white (24-bit RGB in hexadecimal) for the non-transparent background.
```
set terminal png font arial 14 size 800,600
```
Searches for a scalable font with face name 'arial' and sets the font size to 14pt. Please see **[fonts](fonts#fonts)** for details of how the font search is done.
```
set terminal png transparent truecolor enhanced
```
Use 24 bits of color information per pixel, with a transparent background. Use the **enhanced text** mode to control the layout of strings to be printed.
Pngcairo
--------
The **pngcairo** terminal device generates output in png. The actual drawing is done via cairo, a 2D graphics library, and pango, a library for laying out and rendering text. Syntax:
```
set term pngcairo
{{no}enhanced} {mono|color}
{{no}transparent} {{no}crop} {background <rgbcolor>
{font <font>} {fontscale <scale>}
{linewidth <lw>} {rounded|butt|square} {dashlength <dl>}
{pointscale <ps>}
{size <XX>{unit},<YY>{unit}}
```
This terminal supports an enhanced text mode, which allows font and other formatting commands (subscripts, superscripts, etc.) to be embedded in labels and other text strings. The enhanced text mode syntax is shared with other gnuplot terminal types. See **[enhanced](enhanced_text_mode#enhanced)** for more details.
The width of all lines in the plot can be modified by the factor <lw>.
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
The default size for the output is 640 x 480 pixels. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in pixels, but other units are possible (currently cm and inch). A size given in centimeters or inches will be converted into pixels assuming a resolution of 72 dpi. Screen coordinates always run from 0.0 to 1.0 along the full length of the plot edges as specified by the **size** option.
<font> is in the format "FontFace,FontSize", i.e. the face and the size comma-separated in a single string. FontFace is a usual font face name, such as 'Arial'. If you do not provide FontFace, the pngcairo terminal will use 'Sans'. FontSize is the font size, in points. If you do not provide it, the pngcairo terminal will use a size of 12 points.
```
For example :
set term pngcairo font "Arial,12"
set term pngcairo font "Arial" # to change the font face only
set term pngcairo font ",12" # to change the font size only
set term pngcairo font "" # to reset the font name and size
```
The fonts are retrieved from the usual fonts subsystems. Under Windows, those fonts are to be found and configured in the entry "Fonts" of the control panel. Under UNIX, they are handled by "fontconfig".
Pango, the library used to layout the text, is based on utf-8. Thus, the pngcairo terminal has to convert from your encoding to utf-8. The default input encoding is based on your 'locale'. If you want to use another encoding, make sure gnuplot knows which one you are using. See **[encoding](set_show#encoding)** for more detail.
Pango may give unexpected results with fonts that do not respect the unicode mapping. With the Symbol font, for example, the pngcairo terminal will use the map provided by http://www.unicode.org/ to translate character codes to unicode. Note that "the Symbol font" is to be understood as the Adobe Symbol font, distributed with Acrobat Reader as "SY\_\_\_\_\_\_.PFB". Alternatively, the OpenSymbol font, distributed with OpenOffice.org as "opens\_\_\_.ttf", offers the same characters. Microsoft has distributed a Symbol font ("symbol.ttf"), but it has a different character set with several missing or moved mathematic characters. If you experience problems with your default setup (if the demo enhancedtext.dem is not displayed properly for example), you probably have to install one of the Adobe or OpenOffice Symbol fonts, and remove the Microsoft one.
Rendering uses oversampling, antialiasing, and font hinting to the extent supported by the cairo and pango libraries.
Postscript
----------
Several options may be set in the **postscript** driver. Syntax:
```
set terminal postscript {default}
set terminal postscript {landscape | portrait | eps}
{enhanced | noenhanced}
{defaultplex | simplex | duplex}
{fontfile {add | delete} "<filename>"
| nofontfiles} {{no}adobeglyphnames}
{level1 | leveldefault | level3}
{color | colour | monochrome}
{background <rgbcolor> | nobackground}
{dashlength | dl <DL>}
{linewidth | lw <LW>} {pointscale | ps <PS>}
{rounded | butt}
{clip | noclip}
{palfuncparam <samples>{,<maxdeviation>}}
{size <XX>{unit},<YY>{unit}}
{blacktext | colortext | colourtext}
{{font} "fontname{,fontsize}" {<fontsize>}}
{fontscale <scale>}
```
If you see the error message
```
"Can't find PostScript prologue file ... "
```
Please see and follow the instructions in **[postscript prologue](complete_list_terminals#postscript_prologue)**. **landscape** and **portrait** choose the plot orientation. **eps** mode generates EPS (Encapsulated PostScript) output, which is just regular PostScript with some additional lines that allow the file to be imported into a variety of other applications. (The added lines are PostScript comment lines, so the file may still be printed by itself.) To get EPS output, use the **eps** mode and make only one plot per file. In **eps** mode the whole plot, including the fonts, is reduced to half of the default size.
**enhanced** enables enhanced text mode features (subscripts, superscripts and mixed fonts). See **[enhanced](enhanced_text_mode#enhanced)** for more information. **blacktext** forces all text to be written in black even in color mode;
Duplexing in PostScript is the ability of the printer to print on both sides of the same sheet of paper. With **defaultplex**, the default setting of the printer is used; with **simplex** only one side is printed; **duplex** prints on both sides (ignored if your printer can't do it).
**"<fontname>"** is the name of a valid PostScript font; and **<fontsize>** is the size of the font in PostScript points. In addition to the standard postscript fonts, an oblique version of the Symbol font, useful for mathematics, is defined. It is called "Symbol-Oblique".
**default** sets all options to their defaults: **landscape**, **monochrome**, **dl 1.0**, **lw 1.0**, **defaultplex**, **enhanced**, "Helvetica" and 14pt. Default size of a PostScript plot is 10 inches wide and 7 inches high. The option **color** enables color, while **monochrome** prefers black and white drawing elements. Further, **monochrome** uses gray **palette** but it does not change color of objects specified with an explicit **colorspec**. **dashlength** or **dl** scales the length of dashed-line segments by <DL>, which is a floating-point number greater than zero. **linewidth** or **lw** scales all linewidths by <LW>.
By default the generated PostScript code uses language features that were introduced in PostScript Level 2, notably filters and pattern-fill of irregular objects such as filledcurves. PostScript Level 2 features are conditionally protected so that PostScript Level 1 interpreters do not issue errors but, rather, display a message or a PostScript Level 1 approximation. The **level1** option substitutes PostScript Level 1 approximations of these features and uses no PostScript Level 2 code. This may be required by some old printers and old versions of Adobe Illustrator. The flag **level1** can be toggled later by editing a single line in the PostScript output file to force PostScript Level 1 interpretation. In the case of files containing level 2 code, the above features will not appear or will be replaced by a note when this flag is set or when the interpreting program does not indicate that it understands level 2 PostScript or higher. The flag **level3** enables PNG encoding for bitmapped images, which can reduce the output size considerably.
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
**clip** tells PostScript to clip all output to the bounding box; **noclip** is the default.
**palfuncparam** controls how **set palette functions** are encoded as gradients in the output. Analytic color component functions (set via **set palette functions**) are encoded as linear interpolated gradients in the postscript output: The color component functions are sampled at <samples> points and all points are removed from this gradient which can be removed without changing the resulting colors by more than <maxdeviation>. For almost every useful palette you may safely leave the defaults of <samples>=2000 and <maxdeviation>=0.003 untouched.
The default size for postscript output is 10 inches x 7 inches. The default for eps output is 5 x 3.5 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possibly (currently only cm). The BoundingBox of the plot is correctly adjusted to contain the resized image. Screen coordinates always run from 0.0 to 1.0 along the full length of the plot edges as specified by the **size** option. NB: **this is a change from the previously recommended method of using the set size command prior to setting the terminal type**. The old method left the BoundingBox unchanged and screen coordinates did not correspond to the actual limits of the plot.
Fonts listed by **fontfile** or **fontfile add** encapsulate the font definitions of the listed font from a postscript Type 1 or TrueType font file directly into the gnuplot output postscript file. Thus, the enclosed font can be used in labels, titles, etc. See the section **[postscript fontfile](complete_list_terminals#postscript_fontfile)** for more details. With **fontfile delete**, a fontfile is deleted from the list of embedded files. **nofontfiles** cleans the list of embedded fonts.
Examples:
```
set terminal postscript default # old postscript
set terminal postscript enhanced # old enhpost
set terminal postscript landscape 22 # old psbig
set terminal postscript eps 14 # old epsf1
set terminal postscript eps 22 # old epsf2
set size 0.7,1.4; set term post portrait color "Times-Roman" 14
set term post "VAGRoundedBT_Regular" 14 fontfile "bvrr8a.pfa"
```
Linewidths and pointsizes may be changed with **set style line**.
The **postscript** driver supports about 70 distinct pointtypes, selectable through the **pointtype** option on **plot** and **set style line**.
Several possibly useful files about **gnuplot**'s PostScript are included in the /docs/psdoc subdirectory of the **gnuplot** distribution and at the distribution sites. These are "ps\_symbols.gpi" (a **gnuplot** command file that, when executed, creates the file "ps\_symbols.ps" which shows all the symbols available through the **postscript** terminal), "ps\_guide.ps" (a PostScript file that contains a summary of the enhanced syntax and a page showing what the octal codes produce with text and symbol fonts), "ps\_file.doc" (a text file that contains a discussion of the organization of a PostScript file written by **gnuplot**), and "ps\_fontfile\_doc.tex" (a LaTeX file which contains a short documentation concerning the encapsulation of LaTeX fonts with a glyph table of the math fonts).
A PostScript file is editable, so once **gnuplot** has created one, you are free to modify it to your heart's desire. See the **[editing postscript](complete_list_terminals#editing_postscript)** section for some hints.
### Editing postscript
The PostScript language is a very complex language — far too complex to describe in any detail in this document. Nevertheless there are some things in a PostScript file written by **gnuplot** that can be changed without risk of introducing fatal errors into the file. For example, the PostScript statement "/Color true def" (written into the file in response to the command **set terminal postscript color**), may be altered in an obvious way to generate a black-and-white version of a plot. Similarly line colors, text colors, line weights and symbol sizes can also be altered in straight-forward ways. Text (titles and labels) can be edited to correct misspellings or to change fonts. Anything can be repositioned, and of course anything can be added or deleted, but modifications such as these may require deeper knowledge of the PostScript language.
The organization of a PostScript file written by **gnuplot** is discussed in the text file "ps\_file.doc" in the docs/ps subdirectory of the gnuplot source distribution.
### Postscript fontfile
```
set term postscript ... fontfile {add|delete} <filename>
```
The **fontfile** or **fontfile add** option takes one file name as argument and encapsulates this file into the postscript output in order to make this font available for text elements (labels, tic marks, titles, etc.). The **fontfile delete** option also takes one file name as argument. It deletes this file name from the list of encapsulated files. The postscript terminal understands some font file formats: Type 1 fonts in ASCII file format (extension ".pfa"), Type 1 fonts in binary file format (extension ".pfb"), and TrueType fonts (extension ".ttf"). pfa files are understood directly, pfb and ttf files are converted on the fly if appropriate conversion tools are installed (see below). You have to specify the full filename including the extension. Each **fontfile** option takes exact one font file name. This option can be used multiple times in order to include more than one font file.
The search order used to find font files is (1) absolute pathname or current working directory (2) any of the directories specified by **set loadpath** (3) the directory specified by **set fontpath** (4) the directory given in environmental variable GNUPLOT\_FONTPATH. NB: This is a CHANGE from earlier versions of gnuplot.
For using the encapsulated font file you have to specify the font name (which normally is not the same as the file name). When embedding a font file by using the **fontfile** option in interactive mode, the font name is printed on the screen. E.g.
```
Font file 'p052004l.pfb' contains the font 'URWPalladioL-Bold'. Location:
/usr/lib/X11/fonts/URW/p052004l.pfb
```
When using pfa or pfb fonts, you can also find it out by looking into the font file. There is a line similar to "/FontName /URWPalladioL-Bold def". The middle string without the slash is the fontname, here "URWPalladioL-Bold". For TrueType fonts, this is not so easy since the font name is stored in a binary format. In addition, they often have spaces in the font names which is not supported by Type 1 fonts (in which a TrueType is converted on the fly). The font names are changed in order to eliminate the spaces in the fontnames. The easiest way to find out which font name is generated for use with gnuplot, start gnuplot in interactive mode and type in "set terminal postscript fontfile '<filename.ttf>'".
For converting font files (either ttf or pfb) to pfa format, the conversion tool has to read the font from a file and write it to standard output. If the output cannot be written to standard output, on-the-fly conversion is not possible.
For pfb files "pfbtops" is a tool which can do this. If this program is installed on your system the on the fly conversion should work. Just try to encapsulate a pfb file. If the compiled in program call does not work correctly you can specify how this program is called by defining the environment variable GNUPLOT\_PFBTOPFA e.g. to "pfbtops %s". The **%s** will be replaced by the font file name and thus has to exist in the string.
If you don't want to do the conversion on the fly but get a pfa file of the font you can use the tool "pfb2pfa" which is written in simple c and should compile with any c compiler. It is available from many ftp servers, e.g. <ftp://ftp.dante.de/tex-archive/fonts/utilities/ps2mf/>
In fact, "pfbtopfa" and "pfb2ps" do the same job. "pfbtopfa" puts the resulting pfa code into a file, whereas "pfbtops" writes it to standard output.
TrueType fonts are converted into Type 1 pfa format, e.g. by using the tool "ttf2pt1" which is available from <http://ttf2pt1.sourceforge.net/>
If the builtin conversion does not work, the conversion command can be changed by the environment variable GNUPLOT\_TTFTOPFA. For usage with ttf2pt1 it may be set to "ttf2pt1 -a -e -W 0 %s - ". Here again, **%s** stands for the file name.
For special purposes you also can use a pipe (if available for your operating system). Therefore you start the file name definition with the character "<" and append a program call. This program has to write pfa data to standard output. Thus, a pfa file may be accessed by **set fontfile "< cat garamond.pfa"**.
For example, including Type 1 font files can be used for including the postscript output in LaTeX documents. The "european computer modern" font (which is a variant of the "computer modern" font) is available in pfb format from any CTAN server, e.g. <ftp://ftp.dante.de/tex-archive/fonts/ps-type1/cm-super/>
For example, the file "sfrm1000.pfb" contains the normal upright fonts with serifs in the design size 10pt (font name "SFRM1000"). The computer modern fonts, which are still necessary for mathematics, are available from <ftp://ftp.dante.de/tex-archive/fonts/cm/ps-type1/bluesky>
With these you can use any character available in TeX. However, the computer modern fonts have a strange encoding. (This is why you should not use cmr10.pfb for text, but sfrm1000.pfb instead.) The usage of TeX fonts is shown in one of the demos. The file "ps\_fontfile\_doc.tex" in the /docs/psdoc subdirectory of the **gnuplot** source distribution contains a table with glyphs of the TeX mathfonts.
If the font "CMEX10" is embedded (file "cmex10.pfb") gnuplot defines the additional font "CMEX10-Baseline". It is shifted vertically in order to fit better to the other glyphs (CMEX10 has its baseline at the top of the symbols).
### Postscript prologue
Each PostScript output file includes a %%Prolog section and possibly some additional user-defined sections containing, for example, character encodings. These sections are copied from a set of PostScript prologue files that are either compiled into the gnuplot executable or stored elsewhere on your computer. A default directory where these files live is set at the time gnuplot is built. However, you can override this default either by using the gnuplot command **set psdir** or by defining an environment variable GNUPLOT\_PS\_DIR. See **[set psdir](set_show#set_psdir)**. ### Postscript adobeglyphnames
This setting is only relevant to PostScript output with UTF-8 encoding. It controls the names used to describe characters with Unicode entry points higher than 0x00FF. That is, all characters outside of the Latin1 set. In general unicode characters do not have a unique name; they have only a unicode identification code. However, Adobe have a recommended scheme for assigning names to certain ranges of characters (extended Latin, Greek, etc). Some fonts use this scheme, others do not. By default, gnuplot will use the Adobe glyph names. E.g. the lower case Greek letter alpha will be called /alpha. If you specific **noadobeglyphnames** then instead gnuplot will use /uni03B1 to describe this character. If you get this setting wrong, the character may not be found even if it is present in the font. It is probably always correct to use the default for Adobe fonts, but for other fonts you may have to try both settings. See also **[fontfile](complete_list_terminals#fontfile)**. Pslatex and pstex
-----------------
The **pslatex** driver generates output for further processing by LaTeX, while the **pstex** driver generates output for further processing by TeX. **pslatex** uses \specials understandable by dvips and xdvi. Figures generated by **pstex** can be included in any plain-based format (including LaTeX). Syntax:
```
set terminal [pslatex | pstex] {default}
set terminal [pslatex | pstex]
{rotate | norotate}
{oldstyle | newstyle}
{auxfile | noauxfile}
{level1 | leveldefault | level3}
{color | colour | monochrome}
{background <rgbcolor> | nobackground}
{dashlength | dl <DL>}
{linewidth | lw <LW>} {pointscale | ps <PS>}
{rounded | butt}
{clip | noclip}
{palfuncparam <samples>{,<maxdeviation>}}
{size <XX>{unit},<YY>{unit}}
{<font_size>}
```
If you see the error message
```
"Can't find PostScript prologue file ... "
```
Please see and follow the instructions in **[postscript prologue](complete_list_terminals#postscript_prologue)**. The option **color** enables color, while **monochrome** prefers black and white drawing elements. Further, **monochrome** uses gray **palette** but it does not change color of objects specified with an explicit **colorspec**. **dashlength** or **dl** scales the length of dashed-line segments by <DL>, which is a floating-point number greater than zero. **linewidth** or **lw** scales all linewidths by <LW>.
By default the generated PostScript code uses language features that were introduced in PostScript Level 2, notably filters and pattern-fill of irregular objects such as filledcurves. PostScript Level 2 features are conditionally protected so that PostScript Level 1 interpreters do not issue errors but, rather, display a message or a PostScript Level 1 approximation. The **level1** option substitutes PostScript Level 1 approximations of these features and uses no PostScript Level 2 code. This may be required by some old printers and old versions of Adobe Illustrator. The flag **level1** can be toggled later by editing a single line in the PostScript output file to force PostScript Level 1 interpretation. In the case of files containing level 2 code, the above features will not appear or will be replaced by a note when this flag is set or when the interpreting program does not indicate that it understands level 2 PostScript or higher. The flag **level3** enables PNG encoding for bitmapped images, which can reduce the output size considerably.
**rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins.
**clip** tells PostScript to clip all output to the bounding box; **noclip** is the default.
**palfuncparam** controls how **set palette functions** are encoded as gradients in the output. Analytic color component functions (set via **set palette functions**) are encoded as linear interpolated gradients in the postscript output: The color component functions are sampled at <samples> points and all points are removed from this gradient which can be removed without changing the resulting colors by more than <maxdeviation>. For almost every useful palette you may safely leave the defaults of <samples>=2000 and <maxdeviation>=0.003 untouched.
The default size for postscript output is 10 inches x 7 inches. The default for eps output is 5 x 3.5 inches. The **size** option changes this to whatever the user requests. By default the X and Y sizes are taken to be in inches, but other units are possibly (currently only cm). The BoundingBox of the plot is correctly adjusted to contain the resized image. Screen coordinates always run from 0.0 to 1.0 along the full length of the plot edges as specified by the **size** option. NB: **this is a change from the previously recommended method of using the set size command prior to setting the terminal type**. The old method left the BoundingBox unchanged and screen coordinates did not correspond to the actual limits of the plot.
if **rotate** is specified, the y-axis label is rotated. <font\_size> is the size (in pts) of the desired font.
If **auxfile** is specified, it directs the driver to put the PostScript commands into an auxiliary file instead of directly into the LaTeX file. This is useful if your pictures are large enough that dvips cannot handle them. The name of the auxiliary PostScript file is derived from the name of the TeX file given on the **set output** command; it is determined by replacing the trailing **.tex** (actually just the final extent in the file name) with **.ps** in the output file name, or, if the TeX file has no extension, **.ps** is appended. The **.ps** is included into the **.tex** file by a \special{psfile=...} command. Remember to close the **output file** before next plot unless in **multiplot** mode.
Gnuplot versions prior to version 4.2 generated plots of the size 5 x 3 inches using the ps(la)tex terminal while the current version generates 5 x 3.5 inches to be consistent with the postscript eps terminal. In addition, the character width is now estimated to be 60% of the font size while the old epslatex terminal used 50%. To reach the old format specify the option **oldstyle**.
The pslatex driver offers a special way of controlling text positioning: (a) If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically by LaTeX. (b) If the text string begins with '[', you need to continue it with: a position specification (up to two out of t,b,l,r), ']{', the text itself, and finally, '}'. The text itself may be anything LaTeX can typeset as an LR-box. \rule{}{}'s may help for best positioning.
The options not described here are identical to the **Postscript terminal**. Look there if you want to know what they do.
Examples:
```
set term pslatex monochrome rotate # set to defaults
```
To write the PostScript commands into the file "foo.ps":
```
set term pslatex auxfile
set output "foo.tex"; plot ...; set output
```
About label positioning: Use gnuplot defaults (mostly sensible, but sometimes not really best):
```
set title '\LaTeX\ -- $ \gamma $'
```
Force centering both horizontally and vertically:
```
set label '{\LaTeX\ -- $ \gamma $}' at 0,0
```
Specify own positioning (top here):
```
set xlabel '[t]{\LaTeX\ -- $ \gamma $}'
```
The other label – account for long ticlabels:
```
set ylabel '[r]{\LaTeX\ -- $ \gamma $\rule{7mm}{0pt}}'
```
Linewidths and pointsizes may be changed with **set style line**.
Pstricks
--------
The **pstricks** driver is intended for use with the "pstricks.sty" macro package for LaTeX. It is an alternative to the **eepic** and **latex** drivers. You need "pstricks.sty", and, of course, a printer that understands PostScript, or a converter such as Ghostscript. PSTricks is available at [http://tug.org/PSTricks/.](http://tug.org/PSTricks/)
This driver definitely does not come close to using the full capability of the PSTricks package.
Syntax:
```
set terminal pstricks
{unit | size <XX>{unit},<YY>{unit}}
{standalone | input}
{blacktext | colortext | colourtext}
{linewidth <lw>} {rounded | butt}
{pointscale <ps>}
{psarrows | gparrows}
{background <rgbcolor>}
```
The **unit** option produces a plot with internal dimensions 1x1. The default is a plot of **size 5in,3in**.
**standalone** produces a LaTeX file with possibly multiple plots, ready to be compiled. The default is **input** to produce a TeX file which can be included.
**blacktext** forces all text to be written in black. **colortext** enables colored text. The default is **blacktext**.
**rounded** sets line caps and line joins to be rounded. **butt** sets butt caps and mitered joins and is the default.
**linewidth** and **pointscale** scale the width of lines and the size of point symbols, respectively.
**psarrows** draws **arrow**s using PSTricks commands which are shorter but do not offer all options. **gparrows** selects drawing arrows using gnuplot's own routine for full functionality instead.
The old **hacktext** option has been replaced by the new default format (%h), see **[format specifiers](set_show#format_specifiers)**.
Transparency requires support by Ghostscript or conversion to PDF.
Qms
---
The **qms** terminal driver supports the QMS/QUIC Laser printer, the Talaris 1200 and others. It has no options. Qt
--
The **qt** terminal device generates output in a separate window with the Qt library. Syntax:
```
set term qt {<n>}
{size <width>,<height>}
{position <x>,<y>}
{title "title"}
{font <font>} {{no}enhanced}
{linewidth <lw>} {dashlength <dl>}
{{no}persist} {{no}raise} {{no}ctrl}
{close}
{widget <id>}
```
Multiple plot windows are supported: **set terminal qt <n>** directs the output to plot window number n.
The default window title is based on the window number. This title can also be specified with the keyword "title".
Plot windows remain open even when the **gnuplot** driver is changed to a different device. A plot window can be closed by pressing the letter 'q' while that window has input focus, by choosing **close** from a window manager menu, or with **set term qt <n> close**.
The size of the plot area is given in pixels, it defaults to 640x480. In addition to that, the actual size of the window also includes the space reserved for the toolbar and the status bar. When you resize a window, the plot is immediately scaled to fit in the new size of the window. The **qt** terminal scales the whole plot, including fonts and linewidths, and keeps its global aspect ratio constant. If you type **replot**, click the **replot** icon in the terminal toolbar or type a new **plot** command, the new plot will completely fit in the window and the font size and the linewidths will be reset to their defaults.
The position option can be used to set the position of the plot window. The position option only applies to the first plot after the **set term** command.
The active plot window (the one selected by **set term qt <n>**) is interactive. Its behaviour is shared with other terminal types. See **[mouse](set_show#mouse)** for details. It also has some extra icons, which are supposed to be self-explanatory.
This terminal supports an enhanced text mode, which allows font and other formatting commands (subscripts, superscripts, etc.) to be embedded in labels and other text strings. The enhanced text mode syntax is shared with other gnuplot terminal types. See **[enhanced](enhanced_text_mode#enhanced)** for more details.
<font> is in the format "FontFace,FontSize", i.e. the face and the size comma-separated in a single string. FontFace is a usual font face name, such as 'Arial'. If you do not provide FontFace, the qt terminal will use 'Sans'. FontSize is the font size, in points. If you do not provide it, the qt terminal will use a size of 9 points.
```
For example :
set term qt font "Arial,12"
set term qt font "Arial" # to change the font face only
set term qt font ",12" # to change the font size only
set term qt font "" # to reset the font name and size
```
The dashlength affects only custom dash patterns, not Qt's built-in set.
To obtain the best output possible, the rendering involves three mechanisms : antialiasing, oversampling and hinting. Oversampling combined with antialiasing provides subpixel accuracy, so that gnuplot can draw a line from non-integer coordinates. This avoids wobbling effects on diagonal lines ('plot x' for example). Hinting avoids the blur on horizontal and vertical lines caused by oversampling. The terminal will snap these lines to integer coordinates so that a one-pixel-wide line will actually be drawn on one and only one pixel.
By default, the window is raised to the top of your desktop when a plot is drawn. This can be controlled with the keyword "raise". The keyword "persist" will prevent gnuplot from exiting before you explicitly close all the plot windows.
The <space> key raises the gnuplot console window [MS Windows only]. The 'q' key closes the plot window. These hot keys can be changed to ctrl-space and ctrl-q using the terminal option keyword "{no}ctrl". However the preferred way to select ctrl-q rather than 'q' is to use the toggle in the tools widget of the plot window.
The gnuplot outboard driver, gnuplot\_qt, is searched in a default place chosen when the program is compiled. You can override that by defining the environment variable GNUPLOT\_DRIVER\_DIR.
Regis
-----
Note: legacy terminal. The **regis** terminal device generates output in the REGIS graphics language. It has the option of using 4 (the default) or 16 colors. Syntax:
```
set terminal regis {4 | 16}
```
Sixelgd
-------
Syntax:
```
set terminal sixelgd
{{no}enhanced} {{no}truecolor}
{{no}transparent} {rounded|butt}
{linewidth <lw>} {dashlength <dl>}
{tiny | small | medium | large | giant}
{font "<face> {,<pointsize>}"} {fontscale <scale>}
{size <x>,<y>} {{no}crop} {animate}
{background <rgb_color>}
```
The **sixel** output format was originally used by DEC terminals and printers. This driver produces a sixel output stream by converting a PNG image created internally using the gd library. The sixel output stream can be viewed in the terminal as it is created or it can be written to a file so that it can be replayed later by echoing the file to the terminal.
The **animate** option resets the cursor position to the terminal top left at the start of every plot so that successive plots overwrite the same area on the screen rather than having earlier plots scroll off the top. This may be desirable in order to create an in-place animation.
**transparent** instructs the driver to make the background color transparent. Default is **notransparent**.
The **linewidth** and **dashlength** options are scaling factors that affect all lines drawn, i.e. they are multiplied by values requested in various drawing commands.
By default the sixel output uses 16 indexed colors. The **truecolor** option instead creates a TrueColor png image that is mapped down onto 256 colors in the output sixel image. Transparent fill styles require the **truecolor** option. See **[fillstyle](set_show#fillstyle)**. A **transparent** background is possible in either indexed or TrueColor images.
**butt** instructs the driver to use a line drawing method that does not overshoot the desired end point of a line. This setting is only applicable for line widths greater than 1. This setting is most useful when drawing horizontal or vertical lines. Default is **rounded**.
The details of font selection are complicated. For more information please see **[fonts](fonts#fonts)**.
The output plot size <x,y> is given in pixels — it defaults to 640x480. Please see additional information under **[canvas](canvas_size#canvas)** and **[set size](set_show#set_size)**. Blank space at the edges of the finished plot may be trimmed using the **crop** option, resulting in a smaller final image size. Default is **nocrop**. The terminal has been successfully tested with the xterm, mlterm and mintty terminals. The later two support the **truecolor** mode using 256 sixel colors out of box. Distributed copies of xterm may or may not have been configured to support sixel graphics and may be limited to 16 colors.
Svg
---
This terminal produces files in the W3C Scalable Vector Graphics format. Syntax:
```
set terminal svg {size <x>,<y> {|fixed|dynamic}}
{mouse} {standalone | jsdir <dirname>}
{name <plotname>}
{font "<fontname>{,<fontsize>}"} {{no}enhanced}
{fontscale <multiplier>}
{rounded|butt|square} {solid|dashed} {linewidth <lw>}
{background <rgb_color>}
```
where <x> and <y> are the size of the SVG plot to generate, **dynamic** allows a svg-viewer to resize plot, whereas the default setting, **fixed**, will request an absolute size.
**linewidth <w>** increases the width of all lines used in the figure by a factor of <w>.
<font> is the name of the default font to use (default Arial) and <fontsize> is the font size (in points, default 12). SVG viewing programs may substitute other fonts when the file is displayed.
The enhanced text mode syntax is shared with other gnuplot terminal types. See **[enhanced](enhanced_text_mode#enhanced)** for more details.
The **mouse** option tells gnuplot to add support for mouse tracking and for toggling individual plots on/off by clicking on the corresponding key entry. By default this is done by including a link that points to a script in a local directory, usually /usr/local/share/gnuplot/<version>/js. You can change this by using the **jsdir** option to specify either a different local directory or a general URL. The latter is usually appropriate if you are embedding the svg into a web page. Alternatively, the **standalone** option embeds the mousing code in the svg document itself rather than linking to an external resource.
When an SVG file will be used in conjunction with external files, e.g. if it is referenced by javascript code in a web page or parent document, then a unique name is required to avoid potential conflicting references to other SVG plots. Use the **name** option to ensure uniqueness.
Svga
----
Legacy terminal. The **svga** terminal driver supports PCs with SVGA graphics. It is typically only compiled with DJGPP and uses the GRX graphics library. There is also a variant for Windows 32bit, which is mainly used for debugging. The underlying library also supports X11, Linux console and SDL, but these targets are currently not supported. Syntax:
```
set terminal svga {font "<fontname>"}
{{no}enhanced}
{background <rgb color>}
{linewidth|lw <lw>}
{pointscale|ps <scale>}
{fontscale|fs <scale>}
```
Enhanced text support can be activated using the **enhanced** option, see **[enhanced text](enhanced_text_mode#enhanced_text)**. Note that changing the font size in enhanced text is currently not supported. Hence, super- and subscripts will have the same size.
The **linewidth** parameter scales the width of lines. The **pointscale** parameter sets the scale factor for point symbols. You can use **fontscale** to scale the bitmap font. This might be useful if you have a hi-res display. Note that integer factors give best results.
Tek40
-----
This family of terminal drivers supports a variety of VT-like terminals. **tek40xx** supports Tektronix 4010 and others as well as most TEK emulators. **vttek** supports VT-like tek40xx terminal emulators. The following are present only if selected when gnuplot is built: **kc-tek40xx** supports MS-DOS Kermit Tek4010 terminal emulators in color; **km-tek40xx** supports them in monochrome. **selanar** supports Selanar graphics. **bitgraph** supports BBN Bitgraph terminals. None have any options. Tek410x
-------
The **tek410x** terminal driver supports the 410x and 420x family of Tektronix terminals. It has no options. Texdraw
-------
The **texdraw** terminal driver supports the (La)TeX texdraw environment. It is intended for use with the texdraw package, see https://www.ctan.org/tex-archive/graphics/texdraw/ .
```
set terminal texdraw
{size <XX>{unit},<YY>{unit}}
{standalone | input}
{blacktext | colortext | colourtext}
{linewidth <lw>} {rounded | butt}
{pointscale <ps>}
{psarrows | gparrows} {texpoints | gppoints}
{background <rgbcolor>}
```
Note: Graphics are in grayscale only. Text is always black. Boxes and polygons are filled using solid gray levels only. Patterns are not available.
Points, among other things, are drawn using the LaTeX commands " \Diamond" and " \Box". These commands no longer belong to the LaTeX2e core; they are included in the latexsym package, which is part of the base distribution and thus part of any LaTeX implementation. Please do not forget to use this package. Other point types use symbols from the amssymb package. For compatibility with plain TeX you need to specify the **gppoints** option.
**standalone** produces a LaTeX file with possibly multiple plots, ready to be compiled. The default is **input** to produce a TeX file which can be included.
**blacktext** forces all text to be written in black. **colortext** enables "colored" text. The default is **blacktext** and "color" means grayscale really.
**rounded** sets line caps and line joins to be rounded; **butt** sets butt caps and mitered joins and is the default.
**linewidth** and **pointscale** scale the width of lines and the size of point symbols, respectively. **pointscale**only applies to **gppoints**.
**psarrows** draws **arrow**s using TeXdraw commands which are shorter but do not offer all options. **gparrows** selects drawing drawing arrows using gnuplot's own routine for full functionality instead. Similarly, **texpoints**, and **gppoints** select LaTeX symbols or gnuplot's point drawing routines.
Tgif
----
Legacy terminal (present only if gnuplot was configured –with-tgif). Tgif is/was an Xlib based interactive 2-D vector graphics drawing tool also capable of importing and marking up bitmap images. The **tgif** driver supports a choice of font and font size and multiple graphs on the page. The proportions of the axes are not changed.
Syntax:
```
set terminal tgif {portrait | landscape | default} {<[x,y]>}
{monochrome | color}
{{linewidth | lw} <LW>}
{solid | dashed}
{font "<fontname>{,<fontsize>}"}
```
where <[x,y]> specifies the number of graphs in the x and y directions on the page, **color** enables color, **linewidth** scales all linewidths by <LW>, "<fontname>" is the name of a valid PostScript font, and <fontsize> specifies the size of the PostScript font. **defaults** sets all options to their defaults: **portrait**, **[1,1]**, **color**, **linewidth 1.0**, **dashed**, **"Helvetica,18"**.
The **solid** option is usually preferred if lines are colored, as they often are in the editor. Hardcopy will be black-and-white, so **dashed** should be chosen for that.
Multiplot is implemented in two different ways.
The first multiplot implementation is the standard gnuplot multiplot feature:
```
set terminal tgif
set output "file.obj"
set multiplot
set origin x01,y01
set size xs,ys
plot ...
...
set origin x02,y02
plot ...
unset multiplot
```
See **[set multiplot](set_show#set_multiplot)** for further information.
The second version is the [x,y] option for the driver itself. The advantage of this implementation is that everything is scaled and placed automatically without the need for setting origins and sizes; the graphs keep their natural x/y proportions of 3/2 (or whatever is fixed by **set size**).
If both multiplot methods are selected, the standard method is chosen and a warning message is given.
Examples of single plots (or standard multiplot):
```
set terminal tgif # defaults
set terminal tgif "Times-Roman,24"
set terminal tgif landscape
set terminal tgif landscape solid
```
Examples using the built-in multiplot mechanism:
```
set terminal tgif portrait [2,4] # portrait; 2 plots in the x-
# and 4 in the y-direction
set terminal tgif [1,2] # portrait; 1 plot in the x-
# and 2 in the y-direction
set terminal tgif landscape [3,3] # landscape; 3 plots in both
# directions
```
Tikz
----
This driver creates output for use with the TikZ package of graphics macros in TeX. It is currently implemented via an external lua script, and **set term tikz** is a short form of the command **set term lua tikz**. See **[term lua](complete_list_terminals#term_lua)** for more information. Use the command **set term tikz help** to print terminal options. Tkcanvas
--------
This terminal driver generates Tk canvas widget commands in one of the following scripting languages: Tcl (default), Perl, Python, Ruby, or REXX. Syntax:
```
set terminal tkcanvas {tcl | perl | perltkx | python | ruby | rexx}
{standalone | input}
{interactive}
{rounded | butt}
{nobackground | background <rgb color>}
{{no}rottext}
{size <width>,<height>}
{{no}enhanced}
{externalimages | pixels}
```
Execute the following sequence of Tcl/Tk commands to display the result:
```
package require Tk
# the following two lines are only required to support external images
package require img::png
source resize.tcl
source plot.tcl
canvas .c -width 800 -height 600
pack .c
gnuplot .c
```
Or, for Perl/Tk use a program like this:
```
use Tk;
my $top = MainWindow->new;
my $c = $top->Canvas(-width => 800, -height => 600)->pack;
my $gnuplot = do "plot.pl";
$gnuplot->($c);
MainLoop;
```
Or, for Perl/Tkx use a program like this:
```
use Tkx;
my $top = Tkx::widget->new(".");
my $c = $top->new_tk__canvas(-width => 800, -height => 600);
$c->g_pack;
my $gnuplot = do "plot.pl";
$gnuplot->($c);
Tkx::MainLoop();
```
Or, for Python/Tkinter use a program like this:
```
from tkinter import *
from tkinter import font
root = Tk()
c = Canvas(root, width=800, height=600)
c.pack()
exec(open('plot.py').read())
gnuplot(c)
root.mainloop()
```
Or, for Ruby/Tk use a program like this:
```
require 'tk'
root = TkRoot.new { title 'Ruby/Tk' }
c = TkCanvas.new(root, 'width'=>800, 'height'=>600) { pack { } }
load('plot.rb')
gnuplot(c)
Tk.mainloop
```
Or, for Rexx/Tk use a program like this:
```
/**/
call RxFuncAdd 'TkLoadFuncs', 'rexxtk', 'TkLoadFuncs'
call TkLoadFuncs
cv = TkCanvas('.c', '-width', 800, '-height', 600)
call TkPack cv
call 'plot.rex' cv
do forever
cmd = TkWait()
if cmd = 'AWinClose' then leave
interpret 'call' cmd
end
```
The code generated by **gnuplot** (in the above examples, this code is written to "plot.<ext>") contains the following procedures:
gnuplot(canvas)
```
takes the name of a canvas as its argument.
When called, it clears the canvas, finds the size of the canvas and
draws the plot in it, scaled to fit.
```
gnuplot\_plotarea()
```
returns a list containing the borders of the plotting area
(xleft, xright, ytop, ybot) in canvas screen coordinates. It works only for 2-dimensional plotting (`plot`).
```
gnuplot\_axisranges()
```
returns the ranges of the two axes in plot coordinates
(x1min, x1max, y1min, y1max, x2min, x2max, y2min, y2max).
It works only for 2-dimensional plotting (`plot`).
```
You can create self-contained, minimal scripts using the **standalone** option. The default is **input** which creates scripts which have to be source'd (or loaded or called or whatever the adequate term is for the language selected).
If the **interactive** option is specified, mouse clicking on a line segment will print the coordinates of its midpoint to stdout. The user can supersede this behavior by supplying a procedure user\_gnuplot\_coordinates which takes the following arguments:
```
win id x1s y1s x2s y2s x1e y1e x2e y2e x1m y1m x2m y2m,
```
i.e. the name of the canvas and the id of the line segment followed by the coordinates of its start and end point in the two possible axis ranges; the coordinates of the midpoint are only filled for logarithmic axes. By default the canvas is **transparent**, but an explicit background color can be set with the **background** option.
**rounded** sets line caps and line joins to be rounded; **butt** is the default: butt caps and mitered joins.
Text at arbitrary angles can be activated with the **rottext** option, which requires Tcl/Tk 8.6 or later. The default is **norottext**.
The **size** option tries to optimize the tic and font sizes for the given canvas size. By default an output size of 800 x 600 pixels is assumed.
**enhanced** selects **enhanced text** processing (default), but is currently only available for Tcl.
The **pixels** (default) option selects the failsafe pixel-by-pixel image handler, see also **[image pixels](image#image_pixels)**. The **externalimages** option saves images as external png images, which are later loaded and scaled by the tkcanvas code. This option is only available for Tcl and display may be slow in some situations since the Tk image handler does not provide arbitrary scaling. Scripts need to source the provided rescale.tcl.
Interactive mode is not yet implemented for Python/Tk and Rexx/Tk. Interactive mode for Ruby/Tk does not yet support user\_gnuplot\_coordinates.
Tpic
----
Note: Legacy terminal (not built by default). The latex, emtex, eepic, and tpic terminals in older versions of gnuplot provided minimal support for graphics styles beyond simple lines and points. They have been directly superseded by the **pict2e** terminal. For more capable TeX/LaTeX compatible terminal types see **[cairolatex](complete_list_terminals#cairolatex)**, **[context](complete_list_terminals#context)**, **[epslatex](complete_list_terminals#epslatex)**, **[mp](complete_list_terminals#mp)**, **[pstricks](complete_list_terminals#pstricks)**, and **[tikz](complete_list_terminals#tikz)**. The **tpic** terminal driver supports the LaTeX picture environment with tpic \specials. Options are the point size, line width, and dot-dash interval.
Syntax:
```
set terminal tpic <pointsize> <linewidth> <interval>
```
where **pointsize** and **linewidth** are integers in milli-inches and **interval** is a float in inches. If a non-positive value is specified, the default is chosen: pointsize = 40, linewidth = 6, interval = 0.1.
All drivers for LaTeX offer a special way of controlling text positioning: If any text string begins with '{', you also need to include a '}' at the end of the text, and the whole text will be centered both horizontally and vertically by LaTeX. — If the text string begins with '[', you need to continue it with: a position specification (up to two out of t,b,l,r), ']{', the text itself, and finally, '}'. The text itself may be anything LaTeX can typeset as an LR-box. \rule{}{}'s may help for best positioning.
Examples: About label positioning: Use gnuplot defaults (mostly sensible, but sometimes not really best):
```
set title '\LaTeX\ -- $ \gamma $'
```
Force centering both horizontally and vertically:
```
set label '{\LaTeX\ -- $ \gamma $}' at 0,0
```
Specify own positioning (top here):
```
set xlabel '[t]{\LaTeX\ -- $ \gamma $}'
```
The other label – account for long ticlabels:
```
set ylabel '[r]{\LaTeX\ -- $ \gamma $\rule{7mm}{0pt}}'
```
VWS
---
Note: legacy terminal. The **VWS** terminal driver supports the VAX Windowing System. It has no options. It will sense the display type (monochrome, gray scale, or color.) All line styles are plotted as solid lines. Windows
-------
The **windows** terminal is a fast interactive terminal driver that uses the Windows GDI to draw and write text. The cross-platform **terminal wxt** and **terminal qt** are also supported on Windows. Syntax:
```
set terminal windows {<n>}
{color | monochrome}
{solid | dashed}
{rounded | butt}
{enhanced | noenhanced}
{font <fontspec>}
{fontscale <scale>}
{linewidth <scale>}
{pointscale <scale>}
{background <rgb color>}
{title "Plot Window Title"}
{{size | wsize} <width>,<height>}
{position <x>,<y>}
{docked {layout <rows>,<cols>} | standalone}
{close}
```
Multiple plot windows are supported: **set terminal win <n>** directs the output to plot window number n.
**color** and **monochrome** select colored or mono output, **dashed** and **solid** select dashed or solid lines. Note that **color** defaults to **solid**, whereas **monochrome** defaults to **dashed**. **rounded** sets line caps and line joins to be rounded; **butt** is the default, butt caps and mitered joins. **enhanced** enables enhanced text mode features (subscripts, superscripts and mixed fonts, see **[enhanced text](enhanced_text_mode#enhanced_text)** for more information). **<fontspec>** is in the format "<fontface>,<fontsize>", where "<fontface>" is the name of a valid Windows font, and <fontsize> is the size of the font in points and both components are optional. Note that in previous versions of gnuplot the **font** statement could be left out and <fontsize> could be given as a number without double quotes. This is no longer supported. **linewidth**, **fontscale**, **pointscale** can be used to scale the width of lines, the size of text, or the size of the point symbols. **title** changes the title of the graph window. **size** defines the width and height of the window's drawing area in pixels, **wsize** defines the actual size of the window itself and **position** defines the origin of the window i.e. the position of the top left corner on the screen (again in pixel). These options override any default settings from the **wgnuplot.ini** file.
**docked** embeds the graph window in the wgnuplot text window and the **size** and **position** options are ignored. Note that **docked** is not available for console-mode gnuplot. Setting this option changes the default for new windows. The initial default is **standalone**. The **layout** option allows to reserve a minimal number of columns and rows for graphs in docked mode. If there are more graphs than fit the given layout, additional rows will be added. Graphs are sorted by the numerical id, filling rows first.
Other options may be changed using the **graph-menu** or the initialization file **wgnuplot.ini**.
The Windows version normally terminates immediately as soon as the end of any files given as command line arguments is reached (i.e. in non-interactive mode), unless you specify **-** as the last command line option. It will also not show the text-window at all, in this mode, only the plot. By giving the optional argument **-persist** (same as for gnuplot under x11; former Windows-only options **/noend** or **-noend** are still accepted as well), will not close gnuplot. Contrary to gnuplot on other operating systems, gnuplot's interactive command line is accessible after the -persist option.
The plot window remains open when the gnuplot terminal is changed with a **set term** command. The plot window can be closed with **set term windows close**.
**gnuplot** supports different methods to create printed output on Windows, see **[windows printing](complete_list_terminals#windows_printing)**. The windows terminal supports data exchange with other programs via clipboard and EMF files, see **[graph-menu](complete_list_terminals#graph-menu)**. You can also use the **terminal emf** to create EMF files.
### Graph-menu
The **gnuplot graph** window has the following options on a pop-up menu accessed by pressing the right mouse button(\*) or selecting **Options** from the system menu or the toolbar: **Copy to Clipboard** copies a bitmap and an enhanced metafile picture.
**Save as EMF...** allows the user to save the current graph window as enhanced metafile (EMF or EMF+).
**Save as Bitmap...** allows the user to save a copy of the graph as bitmap file.
**Print...** prints the graphics windows using a Windows printer driver and allows selection of the printer and scaling of the output. See also **[windows printing](complete_list_terminals#windows_printing)**.
**Bring to Top** when checked raises the graph window to the top after every plot.
**Color** when checked enables color output. When unchecked it forces all grayscale output. This is e.g. useful to test appearance of monochrome printouts.
The **GDI backend** which uses the classic GDI API is deprecated and has been disabled in this version.
**GDI+ backend** draws to the screen using the GDI+ Windows API. It supports full antialiasing, oversampling, transparency and custom dash patterns. This was the default in versions 5.0 and 5.2.
**Direct2D backend** uses Direct2D & DirectWrite APIs to draw. It uses graphic card acceleration and is hence typically much faster. Since Direct2D can not create EMF data, saving and copying to clipboard of EMF data fall back to GDI+ while bitmap data is generated by D2d. This is the recommended and default backend since version 5.3.
**Oversampling** draws diagonal lines at fractional pixel positions to avoid "wobbling" effects. Vertical or horizontal lines are still snapped to integer pixel positions to avoid blurry lines.
**Antialiasing** enables smoothing of lines and edges. Note that this slows down drawing. **Antialiasing of polygons** is enabled by default but might slow down drawing with the GDI+ backend.
**Fast rotation** switches antialiasing temporarily off while rotating the graph with the mouse. This speeds up drawing considerably at the expense of an additional redraw after releasing the mouse button.
**Background...** sets the window background color.
**Choose Font...** selects the font used in the graphics window.
**Update wgnuplot.ini** saves the current window locations, window sizes, text window font, text window font size, graph window font, graph window font size, background color to the initialization file **wgnuplot.ini**.
(\*) Note that this menu is only available by pressing the right mouse button with **unset mouse**.
### Printing
In order of preference, graphs may be printed in the following ways: **1.** Use the **gnuplot** command **set terminal** to select a printer and **set output** to redirect output to a file.
**2.** Select the **Print...** command from the **gnuplot graph** window. An extra command **screendump** does this from the text window.
**3.** If **set output "PRN"** is used, output will go to a temporary file. When you exit from **gnuplot** or when you change the output with another **set output** command, a dialog box will appear for you to select a printer port. If you choose OK, the output will be printed on the selected port, passing unmodified through the print manager. It is possible to accidentally (or deliberately) send printer output meant for one printer to an incompatible printer.
### Text-menu
The **gnuplot text** window has the following options on a pop-up menu accessed by pressing the right mouse button or selecting **Options** from the system menu: **Copy to Clipboard** copies marked text to the clipboard.
**Paste** copies text from the clipboard as if typed by the user.
**Choose Font...** selects the font used in the text window.
**System Colors** when selected makes the text window honor the System Colors set using the Control Panel. When unselected, text is black or blue on a white background.
**Wrap long lines** when selected lines longer than the current window width are wrapped.
**Update wgnuplot.ini** saves the current settings to the initialisation file **wgnuplot.ini**, which is located in the user's application data directory.
### Wgnuplot.mnu
If the menu file **wgnuplot.mnu** is found in the same directory as **gnuplot**, then the menu specified in **wgnuplot.mnu** will be loaded. Menu commands:
```
[Menu] starts a new menu with the name on the following line.
[EndMenu] ends the current menu.
[--] inserts a horizontal menu separator.
[|] inserts a vertical menu separator.
[Button] puts the next macro on a push button instead of a menu.
```
Macros take two lines with the macro name (menu entry) on the first line and the macro on the second line. Leading spaces are ignored. Macro commands:
```
[INPUT] Input string with prompt terminated by [EOS] or {ENTER}
[EOS] End Of String terminator. Generates no output.
[OPEN] Get name of a file to open, with the title of the dialog
terminated by [EOS], followed by a default filename terminated
by [EOS] or {ENTER}.
[SAVE] Get name of a file to save. Parameters like [OPEN]
[DIRECTORY] Get name of a directory, with the title of the dialog
terminated by [EOS] or {ENTER}
```
Macro character substitutions:
```
{ENTER} Carriage Return '\r'
{TAB} Tab '\011'
{ESC} Escape '\033'
{^A} '\001'
...
{^_} '\031'
```
Macros are limited to 256 characters after expansion.
### Wgnuplot.ini
The Windows text window and the **windows** terminal will read some of their options from the **[WGNUPLOT]** section of **wgnuplot.ini**. This file is located in the user's application data directory. Here's a sample **wgnuplot.ini** file:
```
[WGNUPLOT]
TextOrigin=0 0
TextSize=640 150
TextFont=Consolas,9
TextWrap=1
TextLines=400
TextMaximized=0
SysColors=0
GraphOrigin=0 150
GraphSize=640 330
GraphFont=Tahoma,10
GraphColor=1
GraphToTop=1
GraphGDI+=1
GraphD2D=0
GraphGDI+Oversampling=1
GraphAntialiasing=1
GraphPolygonAA=1
GraphFastRotation=1
GraphBackground=255 255 255
DockVerticalTextFrac=350
DockHorizontalTextFrac=400
```
These settings apply to the wgnuplot text-window only. The **TextOrigin** and **TextSize** entries specify the location and size of the text window. If **TextMaximized** is non-zero, the window will be maximized.
The **TextFont** entry specifies the text window font and size.
The **TextWrap** entry selects wrapping of long text lines.
The **TextLines** entry specifies the number of (unwrapped) lines the internal buffer of the text window can hold. This value currently cannot be changed from within wgnuplot.
See **[text-menu](complete_list_terminals#text-menu)**.
**DockVerticalTextFrac** and **DockHorizontalTextFrac** set the fraction of the window reserved for the text window in permille of the vertical or horizontal layout.
The **GraphFont** entry specifies the font name and size in points.
See **[graph-menu](complete_list_terminals#graph-menu)**.
Wxt
---
The **wxt** terminal device generates output in a separate window. The window is created by the wxWidgets library, where the 'wxt' comes from. The actual drawing is done via cairo, a 2D graphics library, and pango, a library for laying out and rendering text. Syntax:
```
set term wxt {<n>}
{size <width>,<height>} {position <x>,<y>}
{background <rgb_color> | nobackground}
{{no}enhanced}
{font <font>} {fontscale <scale>}
{title "title"}
{linewidth <lw>} {butt|rounded|square}
{dashlength <dl>}
{{no}persist}
{{no}raise}
{{no}ctrl}
{close}
```
Multiple plot windows are supported: **set terminal wxt <n>** directs the output to plot window number n.
The default window title is based on the window number. This title can also be specified with the keyword "title".
Plot windows remain open even when the **gnuplot** driver is changed to a different device. A plot window can be closed by pressing the letter 'q' while that window has input focus, by choosing **close** from a window manager menu, or with **set term wxt <n> close**.
The size of the plot area is given in pixels, it defaults to 640x384. In addition to that, the actual size of the window also includes the space reserved for the toolbar and the status bar. When you resize a window, the plot is immediately scaled to fit in the new size of the window. Unlike other interactive terminals, the **wxt** terminal scales the whole plot, including fonts and linewidths, and keeps its global aspect ratio constant, leaving an empty space painted in gray. If you type **replot**, click the **replot** icon in the terminal toolbar or type a new **plot** command, the new plot will completely fit in the window and the font size and the linewidths will be reset to their defaults.
The position option can be used to set the position of the plot window. The position option only applies to the first plot after the **set term** command.
The active plot window (the one selected by **set term wxt <n>**) is interactive. Its behaviour is shared with other terminal types. See **[mouse](set_show#mouse)** for details. It also has some extra icons, which are supposed to be self-explanatory.
This terminal supports an enhanced text mode, which allows font and other formatting commands (subscripts, superscripts, etc.) to be embedded in labels and other text strings. The enhanced text mode syntax is shared with other gnuplot terminal types. See **[enhanced](enhanced_text_mode#enhanced)** for more details.
<font> is in the format "FontFace,FontSize", i.e. the face and the size comma-separated in a single string. FontFace is a usual font face name, such as 'Arial'. If you do not provide FontFace, the wxt terminal will use 'Sans'. FontSize is the font size, in points. If you do not provide it, the wxt terminal will use a size of 10 points.
```
For example :
set term wxt font "Arial,12"
set term wxt font "Arial" # to change the font face only
set term wxt font ",12" # to change the font size only
set term wxt font "" # to reset the font name and size
```
The fonts are retrieved from the usual fonts subsystems. Under Windows, those fonts are to be found and configured in the entry "Fonts" of the control panel. Under UNIX, they are handled by "fontconfig".
Pango, the library used to layout the text, is based on utf-8. Thus, the wxt terminal has to convert from your encoding to utf-8. The default input encoding is based on your 'locale'. If you want to use another encoding, make sure gnuplot knows which one you are using. See **[encoding](set_show#encoding)** for more details.
Pango may give unexpected results with fonts that do not respect the unicode mapping. With the Symbol font, for example, the wxt terminal will use the map provided by http://www.unicode.org/ to translate character codes to unicode. Pango will do its best to find a font containing this character, looking for your Symbol font, or other fonts with a broad unicode coverage, like the DejaVu fonts. Note that "the Symbol font" is to be understood as the Adobe Symbol font, distributed with Acrobat Reader as "SY\_\_\_\_\_\_.PFB". Alternatively, the OpenSymbol font, distributed with OpenOffice.org as "opens\_\_\_.ttf", offers the same characters. Microsoft has distributed a Symbol font ("symbol.ttf"), but it has a different character set with several missing or moved mathematic characters. If you experience problems with your default setup (if the demo enhancedtext.dem is not displayed properly for example), you probably have to install one of the Adobe or OpenOffice Symbol fonts, and remove the Microsoft one. Other non-conform fonts, such as "wingdings" have been observed working.
The rendering of the plot can be altered with a dialog available from the toolbar. To obtain the best output possible, the rendering involves three mechanisms : antialiasing, oversampling and hinting. Antialiasing allows to display non-horizontal and non-vertical lines smoother. Oversampling combined with antialiasing provides subpixel accuracy, so that gnuplot can draw a line from non-integer coordinates. This avoids wobbling effects on diagonal lines ('plot x' for example). Hinting avoids the blur on horizontal and vertical lines caused by oversampling. The terminal will snap these lines to integer coordinates so that a one-pixel-wide line will actually be drawn on one and only one pixel.
By default, the window is raised to the top of your desktop when a plot is drawn. This can be controlled with the keyword "raise". The keyword "persist" will prevent gnuplot from exiting before you explicitly close all the plot windows. Finally, by default the key <space> raises the gnuplot console window, and 'q' closes the plot window. The keyword "ctrl" allows you to replace those bindings by <ctrl>+<space> and <ctrl>+'q', respectively. These three keywords (raise, persist and ctrl) can also be set and remembered between sessions through the configuration dialog.
X11
---
Syntax:
```
set terminal x11 {<n> | window "<string>"}
{title "<string>"}
{{no}enhanced} {font <fontspec>}
{linewidth LW}
{{no}persist} {{no}raise} {{no}ctrlq}
{{no}replotonresize}
{close}
{size XX,YY} {position XX,YY}
set terminal x11 {reset}
```
Multiple plot windows are supported: **set terminal x11 <n>** directs the output to plot window number n. If n is not 0, the terminal number will be appended to the window title (unless a title has been supplied manually) and the icon will be labeled **Gnuplot <n>**. The active window may be distinguished by a change in cursor (from default to crosshair).
The **x11** terminal can connect to X windows previously created by an outside application via the option **window** followed by a string containing the X ID for the window in hexadecimal format. Gnuplot uses that external X window as a container since X does not allow for multiple clients selecting the ButtonPress event. In this way, gnuplot's mouse features work within the contained plot window.
```
set term x11 window "220001e"
```
The x11 terminal supports enhanced text mode (see **[enhanced](enhanced_text_mode#enhanced)**), subject to the available fonts. In order for font size commands embedded in text to have any effect, the default x11 font must be scalable. Thus the first example below will work as expected, but the second will not.
```
set term x11 enhanced font "arial,15"
set title '{/=20 Big} Medium {/=5 Small}'
```
```
set term x11 enhanced font "terminal-14"
set title '{/=20 Big} Medium {/=5 Small}'
```
Plot windows remain open even when the **gnuplot** driver is changed to a different device. A plot window can be closed by pressing the letter q while that window has input focus, or by choosing **close** from a window manager menu. All plot windows can be closed by specifying **reset**, which actually terminates the subprocess which maintains the windows (unless **-persist** was specified). The **close** command can be used to close individual plot windows by number. However, after a **reset**, those plot windows left due to persist cannot be closed with the command **close**. A **close** without a number closes the current active plot window.
The gnuplot outboard driver, gnuplot\_x11, is searched in a default place chosen when the program is compiled. You can override that by defining the environment variable GNUPLOT\_DRIVER\_DIR to point to a different location.
Plot windows will automatically be closed at the end of the session unless the **-persist** option was given.
The options **persist** and **raise** are unset by default, which means that the defaults (persist == no and raise == yes) or the command line options -persist / -raise or the Xresources are taken. If [no]persist or [no]raise are specified, they will override command line options and Xresources. Setting one of these options takes place immediately, so the behaviour of an already running driver can be modified. If the window does not get raised, see discussion in **[raise](raise#raise)**.
The option **replotonresize** (active by default) replots the data when the plot window is resized. Without this option, the even-aspect-ratio scaling may result in the plot filling only part of the window after resizing. With this option, gnuplot does a full replot on each resize event, resulting in better space utilization. This option is generally desirable, unless the potentially CPU-intensive replotting during resizing is a concern. Replots can be manually initiated with hotkey 'e' or the 'replot' command.
The option **title "<title name>"** will supply the title name of the window for the current plot window or plot window <n> if a number is given. Where (or if) this title is shown depends on your X window manager.
The size option can be used to set the size of the plot window. The size option will only apply to newly created windows.
The position option can be used to set the position of the plot window. The position option will only apply to newly created windows.
The size or aspect ratio of a plot may be changed by resizing the **gnuplot** window.
Linewidths and pointsizes may be changed from within **gnuplot** with **set linestyle**.
For terminal type **x11**, **gnuplot** accepts (when initialized) the standard X Toolkit options and resources such as geometry, font, and name from the command line arguments or a configuration file. See the X(1) man page (or its equivalent) for a description of such options.
A number of other **gnuplot** options are available for the **x11** terminal. These may be specified either as command-line options when **gnuplot** is invoked or as resources in the configuration file ".Xdefaults". They are set upon initialization and cannot be altered during a **gnuplot** session. (except **persist** and **raise**)
### X11\_fonts
Upon initial startup, the default font is taken from the X11 resources as set in the system or user .Xdefaults file or on the command line. Example:
```
gnuplot*font: lucidasans-bold-12
```
A new default font may be specified to the x11 driver from inside gnuplot using
```
`set term x11 font "<fontspec>"`
```
The driver first queries the X-server for a font of the exact name given. If this query fails, then it tries to interpret <fontspec> as "<font>,<size>,<slant>,<weight>" and to construct a full X11 font name of the form
```
-*-<font>-<weight>-<s>-*-*-<size>-*-*-*-*-*-<encoding>
```
```
<font> is the base name of the font (e.g. Times or Symbol)
<size> is the point size (defaults to 12 if not specified)
<s> is `i` if <slant>=="italic" `o` if <slant>=="oblique" `r` otherwise
<weight> is `medium` or `bold` if explicitly requested, otherwise `*`
<encoding> is set based on the current character set (see `set encoding`).
```
So **set term x11 font "arial,15,italic"** will be translated to -\*-arial-\*-i-\*-\*-15-\*-\*-\*-\*-\*-iso8859-1 (assuming default encoding). The <size>, <slant>, and <weight> specifications are all optional. If you do not specify <slant> or <weight> then you will get whatever font variant the font server offers first. You may set a default encoding via the corresponding X11 resource. E.g.
```
gnuplot*encoding: iso8859-15
```
The driver also recognizes some common PostScript font names and replaces them with possible X11 or TrueType equivalents. This same sequence is used to process font requests from **set label**. If your gnuplot was built with configuration option –enable-x11-mbfonts, you can specify multi-byte fonts by using the prefix "mbfont:" on the font name. An additional font may be given, separated by a semicolon. Since multi-byte font encodings are interpreted according to the locale setting, you must make sure that the environmental variable LC\_CTYPE is set to some appropriate locale value such as ja\_JP.eucJP, ko\_KR.EUC, or zh\_CN.EUC.
Example:
```
set term x11 font 'mbfont:kana14;k14'
# 'kana14' and 'k14' are Japanese X11 font aliases, and ';'
# is the separator of font names.
set term x11 font 'mbfont:fixed,16,r,medium'
# <font>,<size>,<slant>,<weight> form is also usable.
set title '(mb strings)' font 'mbfont:*-fixed-medium-r-normal--14-*'
```
The same syntax applies to the default font in Xresources settings, for example,
```
gnuplot*font: \
mbfont:-misc-fixed-medium-r-normal--14-*-*-*-c-*-jisx0208.1983-0
```
If gnuplot is built with –enable-x11-mbfonts, you can use two special PostScript font names 'Ryumin-Light-\*' and 'GothicBBB-Medium-\*' (standard Japanese PS fonts) without the prefix "mbfont:".
### Command-line\_options
In addition to the X Toolkit options, the following options may be specified on the command line when starting **gnuplot** or as resources in your ".Xdefaults" file (note that **raise** and **persist** can be overridden later by **set term x11 [no]raise [no]persist)**:
| | |
| --- | --- |
| `-mono` | forces monochrome rendering on color displays. |
| `-gray` | requests grayscale rendering on grayscale or color displays. |
| | (Grayscale displays receive monochrome rendering by default.) |
| `-clear` | requests that the window be cleared momentarily before a |
| | new plot is displayed. |
| `-tvtwm` | requests that geometry specifications for position of the |
| | window be made relative to the currently displayed portion |
| | of the virtual root. |
| `-raise` | raises plot window after each plot. |
| `-noraise` | does not raise plot window after each plot. |
| `-persist` | plot windows survive after main gnuplot program exits. |
The options are shown above in their command-line syntax. When entered as resources in ".Xdefaults", they require a different syntax. Example:
```
gnuplot*gray: on
gnuplot*ctrlq: on
```
**gnuplot** also provides a command line option (**-pointsize <v>**) and a resource, **gnuplot\*pointsize: <v>**, to control the size of points plotted with the **points** plotting style. The value **v** is a real number (greater than 0 and less than or equal to ten) used as a scaling factor for point sizes. For example, **-pointsize 2** uses points twice the default size, and **-pointsize 0.5** uses points half the normal size.
The **-ctrlq** switch changes the hot-key that closes a plot window from **q** to **<ctrl>q**. This is useful is you are using the keystroke-capture feature **pause mouse keystroke**, since it allows the character **q** to be captured just as all other alphanumeric characters. The **-ctrlq** switch similarly replaces the <space> hot-key with <ctrl><space> for the same reason.
### Color\_resources
NB: THIS SECTION IS LARGELY IRRELEVANT IN GNUPLOT VERSION 5 The X11 terminal honors the following resources (shown here with their default values) or the greyscale resources. The values may be color names as listed in the X11 rgb.txt file on your system, hexadecimal RGB color specifications (see X11 documentation), or a color name followed by a comma and an **intensity** value from 0 to 1. For example, **blue, 0.5** means a half intensity blue.
| | |
| --- | --- |
| | gnuplot\*background: white |
| | gnuplot\*textColor: black |
| | gnuplot\*borderColor: black |
| | gnuplot\*axisColor: black |
| | gnuplot\*line1Color: red |
| | gnuplot\*line2Color: green |
| | gnuplot\*line3Color: blue |
| | gnuplot\*line4Color: magenta |
| | gnuplot\*line5Color: cyan |
| | gnuplot\*line6Color: sienna |
| | gnuplot\*line7Color: orange |
| | gnuplot\*line8Color: coral |
The command-line syntax for these is simple only for background, which maps directly to the usual X11 toolkit option "-bg". All others can only be set on the command line by use of the generic "-xrm" resource override option
Examples:
```
gnuplot -background coral
```
to change the background color.
```
gnuplot -xrm 'gnuplot*line1Color:blue'
```
to override the first linetype color. ### Grayscale\_resources
When **-gray** is selected, **gnuplot** honors the following resources for grayscale or color displays (shown here with their default values). Note that the default background is black.
| | |
| --- | --- |
| | gnuplot\*background: black |
| | gnuplot\*textGray: white |
| | gnuplot\*borderGray: gray50 |
| | gnuplot\*axisGray: gray50 |
| | gnuplot\*line1Gray: gray100 |
| | gnuplot\*line2Gray: gray60 |
| | gnuplot\*line3Gray: gray80 |
| | gnuplot\*line4Gray: gray40 |
| | gnuplot\*line5Gray: gray90 |
| | gnuplot\*line6Gray: gray50 |
| | gnuplot\*line7Gray: gray70 |
| | gnuplot\*line8Gray: gray30 |
### Line\_resources
NB: THIS SECTION IS LARGELY IRRELEVANT IN GNUPLOT VERSION 5 **gnuplot** honors the following resources for setting the width (in pixels) of plot lines (shown here with their default values.) 0 or 1 means a minimal width line of 1 pixel width. A value of 2 or 3 may improve the appearance of some plots.
| | |
| --- | --- |
| | gnuplot\*borderWidth: 1 |
| | gnuplot\*axisWidth: 0 |
| | gnuplot\*line1Width: 0 |
| | gnuplot\*line2Width: 0 |
| | gnuplot\*line3Width: 0 |
| | gnuplot\*line4Width: 0 |
| | gnuplot\*line5Width: 0 |
| | gnuplot\*line6Width: 0 |
| | gnuplot\*line7Width: 0 |
| | gnuplot\*line8Width: 0 |
**gnuplot** honors the following resources for setting the dash style used for plotting lines. 0 means a solid line. A two-digit number **jk** (**j** and **k** are >= 1 and <= 9) means a dashed line with a repeated pattern of **j** pixels on followed by **k** pixels off. For example, '16' is a dotted line with one pixel on followed by six pixels off. More elaborate on/off patterns can be specified with a four-digit value. For example, '4441' is four on, four off, four on, one off. The default values shown below are for monochrome displays or monochrome rendering on color or grayscale displays. Color displays default to dashed:off
| | |
| --- | --- |
| | gnuplot\*dashed: off |
| | gnuplot\*borderDashes: 0 |
| | gnuplot\*axisDashes: 16 |
| | gnuplot\*line1Dashes: 0 |
| | gnuplot\*line2Dashes: 42 |
| | gnuplot\*line3Dashes: 13 |
| | gnuplot\*line4Dashes: 44 |
| | gnuplot\*line5Dashes: 15 |
| | gnuplot\*line6Dashes: 4441 |
| | gnuplot\*line7Dashes: 42 |
| | gnuplot\*line8Dashes: 13 |
### X11 pm3d\_resources
NB: THIS SECTION IS LARGELY IRRELEVANT IN GNUPLOT VERSION 5 Choosing the appropriate visual class and number of colors is a crucial point in X11 applications and a bit awkward, since X11 supports six visual types in different depths. By default **gnuplot** uses the default visual of the screen. The number of colors which can be allocated depends on the visual class chosen. On a visual class with a depth > 12bit, gnuplot starts with a maximal number of 0x200 colors. On a visual class with a depth > 8bit (but <= 12 bit) the maximal number of colors is 0x100, on <= 8bit displays the maximum number of colors is 240 (16 are left for line colors).
Gnuplot first starts to allocate the maximal number of colors as stated above. If this fails, the number of colors is reduced by the factor 2 until gnuplot gets all colors which are requested. If dividing **maxcolors** by 2 repeatedly results in a number which is smaller than **mincolors** **gnuplot** tries to install a private colormap. In this case the window manager is responsible for swapping colormaps when the pointer is moved in and out the x11 driver's window.
The default for **mincolors** is maxcolors / (num\_colormaps > 1 ? 2 : 8), where num\_colormaps is the number of colormaps which are currently used by gnuplot (usually 1, if only one x11 window is open).
Some systems support multiple (different) visual classes together on one screen. On these systems it might be necessary to force gnuplot to use a specific visual class, e.g. the default visual might be 8bit PseudoColor but the screen would also support 24bit TrueColor which would be the preferred choice.
The information about an Xserver's capabilities can be obtained with the program **xdpyinfo**. For the visual names below you can choose one of StaticGray, GrayScale, StaticColor, PseudoColor, TrueColor, DirectColor. If an Xserver supports a requested visual type at different depths, **gnuplot** chooses the visual class with the highest depth (deepest). If the requested visual class matches the default visual and multiple classes of this type are supported, the default visual is preferred.
Example: on an 8bit PseudoColor visual you can force a private color map by specifying **gnuplot\*maxcolors: 240** and **gnuplot\*mincolors: 240**.
| | |
| --- | --- |
| | gnuplot\*maxcolors: integer |
| | gnuplot\*mincolors: integer |
| | gnuplot\*visual: visual name |
### X11 other\_resources
By default the contents of the current plot window are exported to the X11 clipboard in response to X events in the window. Setting the resource 'gnuplot\*exportselection' to 'off' or 'false' will disable this. By default text rotation is done using a method that is fast, but can corrupt nearby colors depending on the background. If this is a problem, you can set the resource 'gnuplot.fastrotate' to 'off'
| | |
| --- | --- |
| | gnuplot\*exportselection: off |
| | gnuplot\*fastrotate: on |
| | gnuplot\*ctrlq: off |
Xlib
----
The **xlib** terminal driver supports the X11 Windows System. It generates gnuplot\_x11 commands, but sends them to the output file specified by **set output '<filename>'**. **set term x11** is equivalent to **set output "|gnuplot\_x11 -noevents"; set term xlib**. **xlib** takes the same set of options as **x11**.
| programming_docs |
gnuplot Import Import
======
The **import** command associates a user-defined function name with a function exported by an external shared object. This constitutes a plugin mechanism that extends the set of functions available in gnuplot. See **[plugins](plugins#plugins)**. Syntax:
```
import func(x[,y,z,...]) from "sharedobj[:symbol]"
```
Examples:
```
# make the function myfun, exported by "mylib.so" or "mylib.dll"
# available for plotting or numerical calculation in gnuplot
import myfun(x) from "mylib"
import myfun(x) from "mylib:myfun" # same as above
```
```
# make the function theirfun, defined in "theirlib.so" or "theirlib.dll"
# available under a different name
import myfun(x,y,z) from "theirlib:theirfun"
```
The program extends the name given for the shared object by either ".so" or ".dll" depending on the operating system, and searches for it first as a full path name and then as a path relative to the current directory. The operating system itself may also search any directories in LD\_LIBRARY\_PATH or DYLD\_LIBRARY\_PATH.
gnuplot Boxplot Boxplot
=======
Boxplots are a common way to represent a statistical distribution of values. Quartile boundaries are determined such that 1/4 of the points have a value equal or less than the first quartile boundary, 1/2 of the points have a value equal or less than the second quartile (median) value, etc. A box is drawn around the region between the first and third quartiles, with a horizontal line at the median value. Whiskers extend from the box to user-specified limits. Points that lie outside these limits are drawn individually. Examples
```
# Place a boxplot at x coordinate 1.0 representing the y values in column 5
plot 'data' using (1.0):5
```
```
# Same plot but suppress outliers and force the width of the boxplot to 0.3
set style boxplot nooutliers
plot 'data' using (1.0):5:(0.3)
```
By default only one boxplot is produced that represents all y values from the second column of the using specification. However, an additional (fourth) column can be added to the specification. If present, the values of that column will be interpreted as the discrete levels of a factor variable. As many boxplots will be drawn as there are levels in the factor variable. The separation between these boxplots is 1.0 by default, but it can be changed by **set style boxplot separation**. By default, the value of the factor variable is shown as a tic label below (or above) each boxplot.
Example
```
# Suppose that column 2 of 'data' contains either "control" or "treatment"
# The following example produces two boxplots, one for each level of the
# factor
plot 'data' using (1.0):5:(0):2
```
The default width of the box can be set via **set boxwidth <width>** or may be specified as an optional 3rd column in the **using** clause of the plot command. The first and third columns (x coordinate and width) are normally provided as constants rather than as data columns.
By default the whiskers extend from the ends of the box to the most distant point whose y value lies within 1.5 times the interquartile range. By default outliers are drawn as circles (point type 7). The width of the bars at the end of the whiskers may be controlled using **[set bars](set_show#set_bars)** or **[set errorbars](set_show#set_errorbars)**.
These default properties may be changed using the **set style boxplot** command. See **[set style boxplot](set_show#set_style_boxplot)**, **[bars](set_show#bars)**, **[boxwidth](set_show#boxwidth)**, **[fillstyle](set_show#fillstyle)**, **[candlesticks](candlesticks#candlesticks)**.
gnuplot Histograms Histograms
==========
The **histograms** style is only relevant to 2D plotting. It produces a bar chart from a sequence of parallel data columns. Each element of the **plot** command must specify a single input data source (e.g. one column of the input file), possibly with associated tic values or key titles. Four styles of histogram layout are currently supported.
```
set style histogram clustered {gap <gapsize>}
set style histogram errorbars {gap <gapsize>} {<linewidth>}
set style histogram rowstacked
set style histogram columnstacked
set style histogram {title font "name,size" tc <colorspec>}
```
The default style corresponds to **set style histogram clustered gap 2**. In this style, each set of parallel data values is collected into a group of boxes clustered at the x-axis coordinate corresponding to their sequential position (row #) in the selected datafile columns. Thus if <n> datacolumns are selected, the first cluster is centered about x=1, and contains <n> boxes whose heights are taken from the first entry in the corresponding <n> data columns. This is followed by a gap and then a second cluster of boxes centered about x=2 corresponding to the second entry in the respective data columns, and so on. The default gap width of 2 indicates that the empty space between clusters is equivalent to the width of 2 boxes. All boxes derived from any one column are given the same fill color and/or pattern (see **[set style fill](set_show#set_style_fill)**).
Each cluster of boxes is derived from a single row of the input data file. It is common in such input files that the first element of each row is a label. Labels from this column may be placed along the x-axis underneath the appropriate cluster of boxes with the **xticlabels** option to **using**.
The **errorbars** style is very similar to the **clustered** style, except that it requires additional columns of input for each entry. The first column holds the height (y value) of that box, exactly as for the **clustered** style.
```
2 columns: y yerr bar extends from y-yerr to y+err
3 columns: y ymin ymax bar extends from ymin to ymax
```
The appearance of the error bars is controlled by the current value of **set errorbars** and by the optional <linewidth> specification. Two styles of stacked histogram are supported, chosen by the command **set style histogram {rowstacked|columnstacked}**. In these styles the data values from the selected columns are collected into stacks of boxes. Positive values stack upwards from y=0; negative values stack downwards. Mixed positive and negative values will produce both an upward stack and a downward stack. The default stacking mode is **rowstacked**.
The **rowstacked** style places a box resting on the x-axis for each data value in the first selected column; the first data value results in a box a x=1, the second at x=2, and so on. Boxes corresponding to the second and subsequent data columns are layered on top of these, resulting in a stack of boxes at x=1 representing the first data value from each column, a stack of boxes at x=2 representing the second data value from each column, and so on. All boxes derived from any one column are given the same fill color and/or pattern (see **[set style fill](set_show#set_style_fill)**).
The **columnstacked** style is similar, except that each stack of boxes is built up from a single data column. Each data value from the first specified column yields a box in the stack at x=1, each data value from the second specified column yields a box in the stack at x=2, and so on. In this style the color of each box is taken from the row number, rather than the column number, of the corresponding data field.
Box widths may be modified using the **set boxwidth** command. Box fill styles may be set using the **set style fill** command.
Histograms always use the x1 axis, but may use either y1 or y2. If a plot contains both histograms and other plot styles, the non-histogram plot elements may use either the x1 or the x2 axis.
Examples: Suppose that the input file contains data values in columns 2, 4, 6, ... and error estimates in columns 3, 5, 7, ... This example plots the values in columns 2 and 4 as a histogram of clustered boxes (the default style). Because we use iteration in the plot command, any number of data columns can be handled in a single command. See **[plot for](plot#plot_for)**.
```
set boxwidth 0.9 relative
set style data histograms
set style histogram cluster
set style fill solid 1.0 border lt -1
plot for [COL=2:4:2] 'file.dat' using COL
```
This will produce a plot with clusters of two boxes (vertical bars) centered at each integral value on the x axis. If the first column of the input file contains labels, they may be placed along the x-axis using the variant command
```
plot for [COL=2:4:2] 'file.dat' using COL:xticlabels(1)
```
If the file contains both magnitude and range information for each value, then error bars can be added to the plot. The following commands will add error bars extending from (y-<error>) to (y+<error>), capped by horizontal bar ends drawn the same width as the box itself. The error bars and bar ends are drawn with linewidth 2, using the border linetype from the current fill style.
```
set errorbars fullwidth
set style fill solid 1 border lt -1
set style histogram errorbars gap 2 lw 2
plot for [COL=2:4:2] 'file.dat' using COL:COL+1
```
This shows how to plot the same data as a rowstacked histogram. Just to be different, this example lists the separate columns explicitly rather than using iteration.
```
set style histogram rowstacked
plot 'file.dat' using 2, ” using 4:xtic(1)
```
This will produce a plot in which each vertical bar corresponds to one row of data. Each vertical bar contains a stack of two segments, corresponding in height to the values found in columns 2 and 4 of the datafile.
Finally, the commands
```
set style histogram columnstacked
plot 'file.dat' using 2, ” using 4
```
will produce two vertical stacks, one for each column of data. The stack at x=1 will contain a box for each entry in column 2 of the datafile. The stack at x=2 will contain a box for each parallel entry in column 4 of the datafile.
Because this interchanges gnuplot's usual interpretation of input rows and columns, the specification of key titles and x-axis tic labels must also be modified accordingly. See the comments given below.
```
set style histogram columnstacked
plot ” u 5:key(1) # uses first column to generate key titles
plot ” u 5 title columnhead # uses first row to generate xtic labels
```
Note that the two examples just given present exactly the same data values, but in different formats.
Newhistogram
------------
Syntax:
```
newhistogram {"<title>" {font "name,size"} {tc <colorspec>}}
{lt <linetype>} {fs <fillstyle>} {at <x-coord>}
```
More than one set of histograms can appear in a single plot. In this case you can force a gap between them, and a separate label for each set, by using the **newhistogram** command. For example
```
set style histogram cluster
plot newhistogram "Set A", 'a' using 1, ” using 2, ” using 3, \
newhistogram "Set B", 'b' using 1, ” using 2, ” using 3
```
The labels "Set A" and "Set B" will appear beneath the respective sets of histograms, under the overall x axis label.
The newhistogram command can also be used to force histogram coloring to begin with a specific color (linetype). By default colors will continue to increment successively even across histogram boundaries. Here is an example using the same coloring for multiple histograms
```
plot newhistogram "Set A" lt 4, 'a' using 1, ” using 2, ” using 3, \
newhistogram "Set B" lt 4, 'b' using 1, ” using 2, ” using 3
```
Similarly you can force the next histogram to begin with a specified fillstyle. If the fillstyle is set to **pattern**, then the pattern used for filling will be incremented automatically.
The **at <x-coord>** option sets the x coordinate position of the following histogram to <x-coord>. For example
```
set style histogram cluster
set style data histogram
set style fill solid 1.0 border -1
set xtic 1 offset character 0,0.3
plot newhistogram "Set A", \
'file.dat' u 1 t 1, ” u 2 t 2, \
newhistogram "Set B" at 8, \
'file.dat' u 2 t 2, ” u 2 t 2
```
will position the second histogram to start at x=8.
Automated iteration over multiple columns
-----------------------------------------
If you want to create a histogram from many columns of data in a single file, it is very convenient to use the plot iteration feature. See **[plot for](plot#plot_for)**. For example, to create stacked histograms of the data in columns 3 through 8
```
set style histogram columnstacked
plot for [i=3:8] "datafile" using i title columnhead
```
gnuplot Persist Persist
=======
Many gnuplot terminals (aqua, pm, qt, x11, windows, wxt, ...) open separate display windows on the screen into which plots are drawn. The **persist** option tells gnuplot to leave these windows open when the main program exits. It has no effect on non-interactive terminal output. For example if you issue the command
```
gnuplot -persist -e 'plot [-5:5] sinh(x)'
```
gnuplot will open a display window, draw the plot into it, and then exit, leaving the display window containing the plot on the screen. You can also specify **persist** or **nopersist** when you set a new terminal.
```
set term qt persist size 700,500
```
Depending on the terminal type, some mousing operations may still be possible in the persistent window. However operations like zoom/unzoom that require redrawing the plot are not possible because the main program has exited. If you want to leave a plot window open and fully mouseable after creating the plot, for example when running gnuplot from a script file rather than interactively, see **[pause mouse close](pause#pause_mouse_close)**.
gnuplot Enhanced text mode Enhanced text mode
==================
Many terminal types support an enhanced text mode in which additional formatting information is embedded in the text string. For example, "x`^`2" will write x-squared as we are used to seeing it, with a superscript 2. This mode is selected by default when you set the terminal, but may be toggled afterward using "set termoption [no]enhanced", or by marking individual strings as in "set label 'x\_2' noenhanced".
| |
| --- |
| Enhanced Text Control Codes |
| Control | Example | Result | Explanation |
| `^` | `a^x` | *a*x | superscript |
| `_` | `a_x` | *a*x | subscript |
| `@` | `a@^b_{cd}` | *a*bcd | phantom box (occupies no width) |
| `&` | `d&{space}b` | db | inserts space of specified length |
| `~` | `~a{.8-}` | [[IMAGE svg]](img2.svg) | overprints '-' on 'a', raised by .8 |
| | | | times the current fontsize |
| | `{/Times abc}` | abc | print abc in font Times at current size |
| | `{/Times*2 abc}` | abc | print abc in font Times at twice current size |
| | `{/Times:Italic abc}` | *abc* | print abc in font Times with style italic |
| | `{/Arial:Bold=20 abc}` | abc | print abc in boldface Arial font size 20 |
| `\U+` | `\U+221E` | ∞ | Unicode point U+221E INFINITY |
The markup control characters act on the following single character or bracketed clause. The bracketed clause may contain a string of characters with no additional markup, e.g. 2`^`{10}, or it may contain additional markup that changes font properties. Font specifiers MUST be preceded by a '/' character that immediately follows the opening '{'. If a font name contains spaces it must be enclosed in single or double quotes.
Examples: The first example illustrates nesting one bracketed clause inside another to produce a boldface A with an italic subscript i, all in the current font. If the clause introduced by :Normal were omitted the subscript would be both italic and boldface. The second example illustrates the same markup applied to font "Times New Roman" at 20 point size.
```
{/:Bold A_{/:Normal{/:Italic i}}}
{/"Times New Roman":Bold=20 A_{/:Normal{/:Italic i}}}
```
The phantom box is useful for a@`^`b\_c to align superscripts and subscripts but does not work well for overwriting an accent on a letter. For the latter, it is much better to use an encoding (e.g. iso\_8859\_1 or utf8) that contains a large variety of letters with accents or other diacritical marks. See **[set encoding](set_show#set_encoding)**. Since the box is non-spacing, it is sensible to put the shorter of the subscript or superscript in the box (that is, after the @).
Space equal in length to a string can be inserted using the '&' character. Thus
```
'abc&{def}ghi'
```
would produce
```
'abc ghi'.
```
The '˜ ' character causes the next character or bracketed text to be overprinted by the following character or bracketed text. The second text will be horizontally centered on the first. Thus '˜ a/' will result in an 'a' with a slash through it. You can also shift the second text vertically by preceding the second text with a number, which will define the fraction of the current fontsize by which the text will be raised or lowered. In this case the number and text must be enclosed in brackets because more than one character is necessary. If the overprinted text begins with a number, put a space between the vertical offset and the text ('˜ {abc}{.5 000}'); otherwise no space is needed ('˜ {abc}{.5 — }'). You can change the font for one or both strings ('˜ a{.5 /\*.2 o}' — an 'a' with a one-fifth-size 'o' on top — and the space between the number and the slash is necessary), but you can't change it after the beginning of the string. Neither can you use any other special syntax within either string. You can, of course, use control characters by escaping them (see below), such as '˜ a{ \`^`}'
You can escape control characters using \, e.g., \ \, \{, and so on. See **[escape sequences](enhanced_text_mode#escape_sequences)** below.
Note that strings in double-quotes are parsed differently than those enclosed in single-quotes. The major difference is that backslashes may need to be doubled when in double-quoted strings.
The file "ps\_guide.ps" in the /docs/psdoc subdirectory of the gnuplot source distribution contains more examples of the enhanced syntax, as does the demo [**enhanced\_utf8.dem**](http://www.gnuplot.info/demo/enhanced_utf8.html)
Escape sequences
----------------
The backslash character \ is used to escape single byte character codes or Unicode entry points. The form \ooo (where ooo is a 3 character octal value) can be used to index a known character code in a specific font encoding. For example the Adobe Symbol font uses a custom encoding in which octal 245 represents the infinity symbol. You could embed this in an enhanced text string by giving the font name and the character code "{/Symbol \245}". This is mostly useful for the PostScript terminal, which cannot easily handle UTF-8 encoding.
You can specify a character by its Unicode code point as \U+hhhh, where hhhh is the 4 or 5 character hexadecimal code point. For example the code point for the infinity symbol is \U+221E. This will be converted to a UTF-8 byte sequence on output if appropriate. In a UTF-8 environment this mechanism is not needed for printable special characters since they are handled in a text string like any other character. However it is useful for combining forms or supplemental diacritical marks (e.g. an arrow over a letter to represent a vector). See **[set encoding](set_show#set_encoding)**, **[utf8](set_show#utf8)**, and the [online unicode demo.](http://www.gnuplot.info/demo_5.4/unicode.html)
gnuplot Clear Clear
=====
The **clear** command erases the current screen or output device as specified by **set terminal** and **set output**. This usually generates a formfeed on hardcopy devices. For some terminals **clear** erases only the portion of the plotting surface defined by **set size**, so for these it can be used in conjunction with **set multiplot** to create an inset.
Example:
```
set multiplot
plot sin(x)
set origin 0.5,0.5
set size 0.4,0.4
clear
plot cos(x)
unset multiplot
```
Please see **[set multiplot](set_show#set_multiplot)**, **[set size](set_show#set_size)**, and **[set origin](set_show#set_origin)** for details.
| programming_docs |
gnuplot Plotting Plotting
========
There are four **gnuplot** commands which actually create a plot: **plot**, **splot**, **replot**, and **refresh**. Other commands control the layout, style, and content of the plot that will eventually be created. **plot** generates 2D plots. **splot** generates 3D plots (actually 2D projections, of course). **replot** reexecutes the previous **plot** or **splot** command. **refresh** is similar to **replot** but it reuses any previously stored data rather than rereading data from a file or input stream. Each time you issue one of these four commands it will redraw the screen or generate a new page of output containing all of the currently defined axes, labels, titles, and all of the various functions or data sources listed in the original plot command. If instead you need to place several complete plots next to each other on the same page, e.g. to make a panel of sub-figures or to inset a small plot inside a larger plot, use the command **set multiplot** to suppress generation of a new page for each plot command.
Much of the general information about plotting can be found in the discussion of **plot**; information specific to 3D can be found in the **splot** section.
**plot** operates in either rectangular or polar coordinates – see **[set polar](set_show#set_polar)**. **splot** operates in Cartesian coordinates, but will accept azimuthal or cylindrical coordinates on input. See **[set mapping](set_show#set_mapping)**. **plot** also lets you use each of the four borders – x (bottom), x2 (top), y (left) and y2 (right) – as an independent axis. The **axes** option lets you choose which pair of axes a given function or data set is plotted against. A full complement of **set** commands exists to give you complete control over the scales and labeling of each axis. Some commands have the name of an axis built into their names, such as **set xlabel**. Other commands have one or more axis names as options, such as **set logscale xy**. Commands and options controlling the z axis have no effect on 2D graphs.
**splot** can plot surfaces and contours in addition to points and/or lines. See **[set isosamples](set_show#set_isosamples)** for information about defining the grid for a 3D function. See **[splot datafile](splot#splot_datafile)** for information about the requisite file structure for 3D data. For contours see **[set contour](set_show#set_contour)**, **[set cntrlabel](set_show#set_cntrlabel)**, and **[set cntrparam](set_show#set_cntrparam)**.
In **splot**, control over the scales and labels of the axes are the same as with **plot** except that there is also a z axis and labeling the x2 and y2 axes is possible only for pseudo-2D plots created using **set view map**.
gnuplot Command-line-editing Command-line-editing
====================
Command-line editing and command history are supported using either an external gnu readline library, an external BSD libedit library, or a built-in equivalent. This choice is a configuration option at the time gnuplot is built. The editing commands of the built-in version are given below. Please note that the action of the DEL key is system-dependent. The gnu readline and BSD libedit libraries have their own documentation.
| |
| --- |
| Command-line Editing Commands |
| Character | Function |
| | Line Editing |
| `^B` | move back a single character. |
| `^F` | move forward a single character. |
| `^A` | move to the beginning of the line. |
| `^E` | move to the end of the line. |
| `^H` | delete the previous character. |
| `DEL` | delete the current character. |
| `^D` | delete current character. EOF if line is empty. |
| `^K` | delete from current position to the end of line. |
| `^L` | redraw line in case it gets trashed. |
| `^U` | delete the entire line. |
| `^W` | delete previous word. |
| `^V` | inhibits the interpretation of the following key as editing command. |
| `TAB` | performs filename-completion. |
| | History |
| `^P` | move back through history. |
| `^N` | move forward through history. |
| `^R` | starts a backward-search. |
gnuplot Comments Comments
========
The comment character **#** may appear almost anywhere in a command line, and **gnuplot** will ignore the rest of that line. A **#** does not have this effect inside a quoted string. Note that if a commented line ends in ' \' then the subsequent line is also treated as part of the comment. See also **[set datafile commentschars](set_show#set_datafile_commentschars)** for specifying a comment character for data files.
gnuplot Raise Raise
=====
Syntax:
```
raise {plot_window_id}
lower {plot_window_id}
```
The **raise** and **lower** commands function only for a some terminal types and may depend also on your window manager and display preference settings. An example of use is shown here
```
set term wxt 123 # create first plot window
plot $FOO
lower # lower the only plot window that exists so far
set term wxt 456 # create 2nd plot window may occlude the first one
plot $BAZ
raise 123 # raise first plot window
```
These commands are known to be unreliable.
gnuplot Substitution and Command line macros Substitution and Command line macros
====================================
When a command line to gnuplot is first read, i.e. before it is interpreted or executed, two forms of lexical substitution are performed. These are triggered by the presence of text in backquotes (ascii character 96) or preceded by @ (ascii character 64). Substitution of system commands in backquotes
---------------------------------------------
Command-line substitution is specified by a system command enclosed in backquotes. This command is spawned and the output it produces replaces the backquoted text on the command line. Exit status of the system command is returned in variables GPVAL\_SYSTEM\_ERRNO and GPVAL\_SYSTEM\_ERRMSG. CHANGE (differs from versions 4 through 5.2): Internal carriage-return (' \r') and newline (' \n') characters are not stripped from the input stream during substitution. This change brings backquote substitution in line with the system() function.
Command-line substitution can be used anywhere on the **gnuplot** command line except inside strings delimited by single quotes.
Example:
This will run the program **leastsq** and replace **leastsq** (including backquotes) on the command line with its output:
```
f(x) = `leastsq`
```
or, in VMS
```
f(x) = `run leastsq`
```
These will generate labels with the current time and userid:
```
set label "generated on `date +%Y-%m-%d` by `whoami`" at 1,1
set timestamp "generated on %Y-%m-%d by `whoami`"
```
Substitution of string variables as macros
------------------------------------------
The character @ is used to trigger substitution of the current value of a string variable into the command line. The text in the string variable may contain any number of lexical elements. This allows string variables to be used as command line macros. Only string constants may be expanded using this mechanism, not string-valued expressions. For example:
```
style1 = "lines lt 4 lw 2"
style2 = "points lt 3 pt 5 ps 2"
range1 = "using 1:3"
range2 = "using 1:5"
plot "foo" @range1 with @style1, "bar" @range2 with @style2
```
The line containing @ symbols is expanded on input, so that by the time it is executed the effect is identical to having typed in full
```
plot "foo" using 1:3 with lines lt 4 lw 2, \
"bar" using 1:5 with points lt 3 pt 5 ps 2
```
The function exists() may be useful in connection with macro evaluation. The following example checks that C can safely be expanded as the name of a user-defined variable:
```
C = "pi"
if (exists(C)) print C," = ", @C
```
Macro expansion does not occur inside either single or double quotes. However macro expansion does occur inside backquotes.
Macro expansion is handled as the very first thing the interpreter does when looking at a new line of commands and is only done once. Therefore, code like the following will execute correctly:
```
A = "c=1"
@A
```
but this line will not, since the macro is defined on the same line and will not be expanded in time
```
A = "c=1"; @A # will not expand to c=1
```
Macro expansion inside a bracketed iteration occurs before the loop is executed; i.e. @A will always act as the original value of A even if A itself is reassigned inside the loop.
For execution of complete commands the **evaluate** command may also be handy.
String variables, macros, and command line substitution
-------------------------------------------------------
The interaction of string variables, backquotes and macro substitution is somewhat complicated. Backquotes do not block macro substitution, so
```
filename = "mydata.inp"
lines = ` wc --lines @filename | sed "s/ .*//" `
```
results in the number of lines in mydata.inp being stored in the integer variable lines. And double quotes do not block backquote substitution, so
```
mycomputer = "`uname -n`"
```
results in the string returned by the system command **uname -n** being stored in the string variable mycomputer.
However, macro substitution is not performed inside double quotes, so you cannot define a system command as a macro and then use both macro and backquote substitution at the same time.
```
machine_id = "uname -n"
mycomputer = "`@machine_id`" # doesn't work!!
```
This fails because the double quotes prevent @machine\_id from being interpreted as a macro. To store a system command as a macro and execute it later you must instead include the backquotes as part of the macro itself. This is accomplished by defining the macro as shown below. Notice that the sprintf format nests all three types of quotes.
```
machine_id = sprintf('"`uname -n`"')
mycomputer = @machine_id
```
gnuplot Linespoints Linespoints
===========
The **linespoints** style (short form **lp**) connects adjacent points with straight line segments and then goes back to draw a small symbol at each point. Points are drawn with the default size determined by **set pointsize** unless a specific point size is given in the plot command or a variable point size is provided in an additional column of input data. Additional input columns may also be used to provide information such as variable line color. See **[lines](lines#lines)** and **[points](points#points)**. Two keywords control whether or not every point in the plot is marked with a symbol, **pointinterval** (short form **pi**) and **pointnumber** (short form **pn**).
**pi N** or **pi -N** tells gnuplot to only place a symbol on every Nth point. A negative value for N will erase the portion of line segment that passes underneath the symbol. The size of the erased portion is controlled by **set pointintervalbox**.
**pn N** or **pn -N** tells gnuplot to label only N of the data points, evenly spaced over the data set. As with **pi**, a negative value for N will erase the portion of line segment that passes underneath the symbol.
gnuplot Xyerrorlines Xyerrorlines
============
The **xyerrorlines** style is only relevant to 2D data plots. **xyerrorlines** is like **linespoints**, except that horizontal and vertical error bars are also drawn. At each point (x,y), lines are drawn from (x,y-ydelta) to (x,y+ydelta) and from (x-xdelta,y) to (x+xdelta,y) or from (x,ylow) to (x,yhigh) and from (xlow,y) to (xhigh,y), depending upon the number of data columns provided. The appearance of the tic mark at the ends of the bar is controlled by **set errorbars**. Either 4 or 6 input columns are required.
```
4 columns: x y xdelta ydelta
6 columns: x y xlow xhigh ylow yhigh
```
If data are provided in an unsupported mixed form, the **using** filter on the **plot** command should be used to set up the appropriate form. For example, if the data are of the form (x,y,xdelta,ylow,yhigh), then you can use
```
plot 'data' using 1:2:($1-$3):($1+$3):4:5 with xyerrorlines
```
An additional input column (5th or 7th) may be used to provide variable (per-datapoint) color information.
gnuplot Vclear Vclear
======
Syntax:
```
vclear {$gridname}
```
Resets the value of all voxels in an existing grid to zero. If no grid name is given, clears the currently active grid.
gnuplot Ellipses Ellipses
========
The **ellipses** style plots an ellipse at each data point. This style is only relevant for 2D plotting. Each ellipse is described in terms of its center, major and minor diameters, and the angle between its major diameter and the x axis.
```
2 columns: x y
3 columns: x y major_diam
4 columns: x y major_diam minor_diam
5 columns: x y major_diam minor_diam angle
```
If only two input columns are present, they are taken as the coordinates of the centers, and the ellipses will be drawn with the default extent (see **[set style ellipse](set_show#set_style_ellipse)**). The orientation of the ellipse, which is defined as the angle between the major diameter and the plot's x axis, is taken from the default ellipse style (see **[set style ellipse](set_show#set_style_ellipse)**). If three input columns are provided, the third column is used for both diameters. The orientation angle defaults to zero. If four columns are present, they are interpreted as x, y, major diameter, minor diameter. Note that these are diameters, not radii. An optional 5th column may specify the orientation angle in degrees. The ellipses will also be drawn with their default extent if either of the supplied diameters in the 3-4-5 column form is negative.
In all of the above cases, optional variable color data may be given in an additional last (3th, 4th, 5th or 6th) column. See **[colorspec](linetypes_colors_styles#colorspec)**.
By default, the major diameter is interpreted in the units of the plot's horizontal axis (x or x2) while the minor diameter in that of the vertical (y or y2). If the x and y axis scales are not equal, the major/minor diameter ratio will no longer be correct after rotation. This can be changed with the **units** keyword, however.
There are three alternatives: if **units xy** is included in the plot specification, the axes will be scaled as described above. **units xx** ensures that both diameters are interpreted in units of the x axis, while **units yy** means that both diameters are interpreted in units of the y axis. In the latter two cases the ellipses will have the correct aspect ratio, even if the plot is resized. If **units** is omitted from the plot command, the setting from **set style ellipse** will be used.
Example (draws ellipses, cycling through the available line types):
```
plot 'data' using 1:2:3:4:(0):0 with ellipses
```
See also **[set object ellipse](set_show#set_object_ellipse)**, **[set style ellipse](set_show#set_style_ellipse)** and **[fillstyle](set_show#fillstyle)**.
gnuplot Zerrorfill Zerrorfill
==========
Syntax:
```
splot DATA using 1:2:3:4[:5] with zerrorfill {fc|fillcolor <colorspec>}
{lt|linetype <n>} {<line properties>}
```
The **zerrorfill** plot style is similar to one variant of the 2D plot style **filledcurves**. It fills the area between two functions or data lines that are sampled at the same x and y points. It requires 4 or 5 input columns:
```
4 columns: x y z zdelta
5 columns: x y z zlow zhigh
```
The area between zlow and zhigh is filled and then a line is drawn through the z values. By default both the line and the fill area use the same color, but you can change this in the splot command. The fill area properties are also affected by the global fill style; see **[set style fill](set_show#set_style_fill)**.
If there are multiple curves in the splot command each new curve may occlude all previous curves. To get proper depth sorting so that curves can only be occluded by curves closer to the viewer, use **set pm3d depthorder base**. Unfortunately this causes all the filled areas to be drawn after all of the corresponding lines of z values. In order to see both the lines and the depth-sorted fill areas you probably will need to make the fill areas partially transparent or use pattern fill rather than solid fill.
The fill area in the first two examples below is the same.
```
splot 'data' using 1:2:3:4 with zerrorfill fillcolor "grey" lt black
splot 'data' using 1:2:3:($3-$4):($3+$4) with zerrorfill
splot '+' using 1:(const):(func1($1)):(func2($1)) with zerrorfill
splot for [k=1:5] datafile[k] with zerrorfill lt black fc lt (k+1)
```
This plot style can also be used to create fence plots. See **[fenceplots](fence_plots#fenceplots)**.
gnuplot Expressions Expressions
===========
In general, any mathematical expression accepted by C, FORTRAN, Pascal, or BASIC is valid. The precedence of these operators is determined by the specifications of the C programming language. White space (spaces and tabs) is ignored inside expressions. Note that gnuplot uses both "real" and "integer" arithmetic, like FORTRAN and C. Integers are entered as "1", "-10", etc; reals as "1.0", "-10.0", "1e1", 3.5e-1, etc. The most important difference between the two forms is in division: division of integers truncates: 5/2 = 2; division of reals does not: 5.0/2.0 = 2.5. In mixed expressions, integers are "promoted" to reals before evaluation: 5/2e0 = 2.5. The result of division of a negative integer by a positive one may vary among compilers. Try a test like "print -5/2" to determine if your system always rounds down (-5/2 yields -3) or always rounds toward zero (-5/2 yields -2).
The integer expression "1/0" may be used to generate an "undefined" flag, which causes a point to be ignored. Or you can use the pre-defined variable NaN to achieve the same result. See **[using](plot#using)** for an example.
Gnuplot can also perform simple operations on strings and string variables. For example, the expression ("A" . "B" eq "AB") evaluates as true, illustrating the string concatenation operator and the string equality operator.
A string which contains a numerical value is promoted to the corresponding integer or real value if used in a numerical expression. Thus ("3" + "4" == 7) and (6.78 == "6.78") both evaluate to true. An integer, but not a real or complex value, is promoted to a string if used in string concatenation. A typical case is the use of integers to construct file names or other strings; e.g. ("file" . 4 eq "file4") is true.
Substrings can be specified using a postfixed range descriptor [beg:end]. For example, "ABCDEF"[3:4] == "CD" and "ABCDEF"[4:\*] == "DEF" The syntax "string"[beg:end] is exactly equivalent to calling the built-in string-valued function substr("string",beg,end), except that you cannot omit either beg or end from the function call.
Complex arithmetic
------------------
Arithmetic operations and most built-in functions support the use of complex arguments. Complex constants are expressed as {<real>,<imag>}, where <real> and <imag> must be numerical constants. Thus {0,1} represents 'i'. The real and imaginary components of complex value x can be extracted as real(x) and imag(x). The modulus is given by abs(x). Gnuplot's standard 2D and 3D plot styles can plot only real values; if you need to plot a complex-valued function f(x) with non-zero imaginary components you must choose between plotting real(f(x)) or abs(f(x)). For examples of representing complex values using color, see the [complex trigonometric function demos (complex\_trig.dem)](http://www.gnuplot.info/demo/complex_trig.html)
Constants
---------
Integer constants are interpreted via the C library routine strtoll(). This means that constants beginning with "0" are interpreted as octal, and constants beginning with "0x" or "0X" are interpreted as hexadecimal. Floating point constants are interpreted via the C library routine atof().
Complex constants are expressed as {<real>,<imag>}, where <real> and <imag> must be numerical constants. For example, {3,2} represents 3 + 2i; {0,1} represents 'i' itself. The curly braces are explicitly required here.
String constants consist of any sequence of characters enclosed either in single quotes or double quotes. The distinction between single and double quotes is important. See **[quotes](syntax#quotes)**.
Examples:
```
1 -10 0xffaabb # integer constants
1.0 -10. 1e1 3.5e-1 # floating point constants
{1.2, -3.4} # complex constant
"Line 1\nLine 2" # string constant (\n is expanded to newline)
'123\n456' # string constant (\ and n are ordinary characters)
```
Functions
---------
Arguments to math functions in **gnuplot** can be integer, real, or complex unless otherwise noted. Functions that accept or return angles (e.g. sin(x)) treat angle values as radians, but this may be changed to degrees using the command **set angles**.
| |
| --- |
| Math library functions |
| Function | Arguments | Returns |
| | | |
|
abs(x) | any | absolute value of *x*, | *x*|; same type |
| abs(x) | complex | length of *x*, [[IMAGE svg]](img3.svg) |
| acos(x) | any | cos-1*x* (inverse cosine) |
|
acosh(x) | any | cosh-1*x* (inverse hyperbolic cosine) in radians |
|
airy(x) | any | Airy function Ai(x) |
|
arg(x) | complex | the phase of *x* |
|
asin(x) | any | sin-1*x* (inverse sin) |
|
asinh(x) | any | sinh-1*x* (inverse hyperbolic sin) in radians |
|
atan(x) | any | tan-1*x* (inverse tangent) |
|
atan2(y,x) | int or real | tan-1(*y*/*x*) (inverse tangent) |
|
atanh(x) | any | tanh-1*x* (inverse hyperbolic tangent) in radians |
|
EllipticK(k) | real k ∈ (-1:1) | *K*(*k*) complete elliptic integral of the first kind |
|
EllipticE(k) | real k ∈ [-1:1] | *E*(*k*) complete elliptic integral of the second kind |
|
EllipticPi(n,k) | real n<1, real k ∈ (-1:1) | *Π*(*n*, *k*) complete elliptic integral of the third kind |
|
besj0(x) | int or real | *J*0 Bessel function of *x* in radians |
|
besj1(x) | int or real | *J*1 Bessel function of *x* in radians |
|
besjn(n,x) | int, real | *J*n Bessel function of *x* in radians |
|
besy0(x) | int or real | *Y*0 Bessel function of *x* in radians |
|
besy1(x) | int or real | *Y*1 Bessel function of *x* in radians |
|
besyn(n,x) | int, real | *Y*n Bessel function of *x* in radians |
|
besi0(x) | real | Modified Bessel function of order 0, *x* in radians |
|
besi1(x) | real | Modified Bessel function of order 1, *x* in radians |
|
besin(n,x) | int, real | Modified Bessel function of order n, *x* in radians |
|
ceil(x) | any | ⌈*x*⌉, smallest integer not less than *x* (real part) |
|
cos(x) | any | cos *x*, cosine of *x* |
|
cosh(x) | any | cosh *x*, hyperbolic cosine of *x* in radians |
|
erf(x) | any | erf(real(*x*)), error function of real(*x*) |
|
erfc(x) | any | erfc(real(*x*)), 1.0 - error function of real(*x*) |
|
exp(x) | any | *e*x, exponential function of *x* |
|
expint(n,x) | int *n*≥ 0, real *x*≥ 0 | *E*n(*x*) = [[IMAGE svg]](img4.svg)*t*-n*e*-xt d*t*, exponential integral of *x* |
|
floor(x) | any | ⌊*x*⌋, largest integer not greater than *x* (real part) |
|
gamma(x) | any | gamma(real(*x*)), gamma function of real(*x*) |
|
ibeta(p,q,x) | any | ibeta(real(*p*, *q*, *x*)), ibeta function of real(*p*,*q*,*x*) |
|
inverf(x) | any | inverse error function of real(*x*) |
|
igamma(a,x) | any | igamma(real(*a*, *x*)), igamma function of real(*a*,*x*) |
|
imag(x) | complex | imaginary part of *x* as a real number |
|
invnorm(x) | any | inverse normal distribution function of real(*x*) |
|
int(x) | real | integer part of *x*, truncated toward zero |
|
lambertw(x) | real | Lambert W function |
|
lgamma(x) | any | lgamma(real(*x*)), lgamma function of real(*x*) |
|
log(x) | any | loge*x*, natural logarithm (base *e*) of *x* |
|
log10(x) | any | log10*x*, logarithm (base 10) of *x* |
|
norm(x) | any | normal distribution (Gaussian) function of real(*x*) |
|
rand(x) | int | pseudo random number in the open interval (0:1) |
|
real(x) | any | real part of *x* |
|
sgn(x) | any | 1 if *x* > 0, -1 if *x* < 0, 0 if *x* = 0. imag(*x*) ignored |
|
sin(x) | any | sin *x*, sine of *x* |
|
sinh(x) | any | sinh *x*, hyperbolic sine of *x* in radians |
|
sqrt(x) | any | [[IMAGE svg]](img5.svg), square root of *x* |
|
tan(x) | any | tan *x*, tangent of *x* |
|
tanh(x) | any | tanh *x*, hyperbolic tangent of *x* in radians |
|
voigt(x,y) | real | Voigt/Faddeeva function [[IMAGE svg]](img6.svg)[[IMAGE svg]](img7.svg)[[IMAGE svg]](img8.svg)*dt* |
| | | Note: voigt(*x*, *y*) = *real* (faddeeva(*x* + *iy*)) |
| | | |
| |
| --- |
| Special functions from libcerf (only if available) |
| Function | Arguments | Returns |
| | | |
|
cerf(z) | complex | complex error function |
|
cdawson(z) | complex | complex extension of Dawson's integral *D*(*z*) = [[IMAGE svg]](img9.svg)*e*-z2*erfi*(*z*) |
|
faddeeva(z) | complex | rescaled complex error function *w*(*z*) = *e*-z2 *erfc*(- *iz*) |
|
erfi(x) | real | imaginary error function *erf* (*x*) = - *i*\**erf* (*ix*) |
|
VP(x,*σ*,*γ*) | real | Voigt profile *VP*(*x*, *σ*, *γ*) = [[IMAGE svg]](img10.svg)*G*(*x*′;*σ*)*L*(*x*-*x*′;*γ*)*dx*′ |
| | | |
| |
| --- |
| String functions |
| Function | Arguments | Returns |
|
gprintf("format",x,...) | any | string result from applying gnuplot's format parser |
|
sprintf("format",x,...) | multiple | string result from C-language sprintf |
|
strlen("string") | string | number of characters in string |
|
strstrt("string","key") | strings | int index of first character of substring "key" |
|
substr("string",beg,end) | multiple | string "string"[beg:end] |
|
strftime("timeformat",t) | any | string result from applying gnuplot's time parser |
|
strptime("timeformat",s) | string | seconds since year 1970 as given in string s |
|
system("command") | string | string containing output stream of shell command |
| trim(" string ") | string | string without leading or trailing whitespace |
| word("string",n) | string, int | returns the nth word in "string" |
| words("string") | string | returns the number of words in "string" |
| |
| --- |
| other **gnuplot** functions |
| Function | Arguments | Returns |
|
column(x) | int or string | column *x* during datafile manipulation. |
|
columnhead(x) | int | string containing first entry of column *x* in datafile. |
|
exists("X") | string | returns 1 if a variable named X is defined, 0 otherwise. |
|
hsv2rgb(h,s,v) | h,s,v ∈ [0:1] | 24bit RGB color value. |
|
palette(z) | double | RGB palette color mapped to z. |
|
stringcolumn(x) | int or string | content of column *x* as a string. |
|
timecolumn(N,"timeformat") | int, string | time data from column *N* during data input. |
|
tm\_hour(t) | time in sec | the hour (0..23) |
|
tm\_mday(t) | time in sec | the day of the month (1..31) |
|
tm\_min(t) | time in sec | the minute (0..59) |
|
tm\_mon(t) | time in sec | the month (0..11) |
|
tm\_sec(t) | time in sec | the second (0..59) |
|
tm\_wday(t) | time in sec | the day of the week (Sun..Sat) as (0..6) |
| tm\_week(t) | time in sec | week of year in ISO8601 "week date" system (1..53) |
|
tm\_yday(t) | time in sec | the day of the year (0..365) |
|
tm\_year(t) | time in sec | the year |
|
time(x) | any | the current system time in seconds |
|
valid(x) | int | test validity of column(*x*) during datafile manip. |
| value("name") | string | returns the value of the named variable. |
|
voxel(x,y,z) | real | value of the active grid voxel containing point (x,y,z) |
### Elliptic integrals
The **EllipticK(k)** function returns the complete elliptic integral of the first kind, i.e. the definite integral between 0 and pi/2 of the function **(1-(k\*sin(p))\*\*2)\*\*(-0.5)**. The domain of **k** is -1 to 1 (exclusive). The **EllipticE(k)** function returns the complete elliptic integral of the second kind, i.e. the definite integral between 0 and pi/2 of the function **(1-(k\*sin(p))\*\*2)\*\*0.5**. The domain of **k** is -1 to 1 (inclusive).
The **EllipticPi(n,k)** function returns the complete elliptic integral of the third kind, i.e. the definite integral between 0 and pi/2 of the function **(1-(k\*sin(p))\*\*2)\*\*(-0.5)/(1-n\*sin(p)\*\*2)**. The parameter **n** must be less than 1, while **k** must lie between -1 and 1 (exclusive). Note that by definition EllipticPi(0,k) == EllipticK(k) for all possible values of **k**.
### Random number generator
The function **rand()** produces a sequence of pseudo-random numbers between 0 and 1 using an algorithm from P. L'Ecuyer and S. Cote, "Implementing a random number package with splitting facilities", ACM Transactions on Mathematical Software, 17:98-111 (1991).
```
rand(0) returns a pseudo random number in the open interval (0:1)
generated from the current value of two internal
32-bit seeds.
rand(-1) resets both seeds to a standard value.
rand(x) for integer 0 < x < 2^31-1 sets both internal seeds
to x.
rand({x,y}) for integer 0 < x,y < 2^31-1 sets seed1 to x and
seed2 to y.
```
### Value
B = value("A") is effectively the same as B = A, where A is the name of a user-defined variable. This is useful when the name of the variable is itself held in a string variable. See **[user-defined variables](expressions#user-defined_variables)**. It also allows you to read the name of a variable from a data file. If the argument is a numerical expression, value() returns the value of that expression. If the argument is a string that does not correspond to a currently defined variable, value() returns NaN. ### Counting and extracting words
**word("string",n)** returns the nth word in string. For example, **word("one two three",2)** returns the string "two". **words("string")** returns the number of words in string. For example, **words(" a b c d")** returns 4.
The **word** and **words** functions provide limited support for quoted strings, both single and double quotes can be used:
```
print words("\"double quotes\" or 'single quotes'") # 3
```
A starting quote must either be preceded by a white space, or start the string. This means that apostrophes in the middle or at the end of words are considered as parts of the respective word:
```
print words("Alexis' phone doesn't work") # 4
```
Escaping quote characters is not supported. If you want to keep certain quotes, the respective section must be surrounded by the other kind of quotes:
```
s = "Keep \"'single quotes'\" or '\"double quotes\"'"
print word(s, 2) # 'single quotes'
print word(s, 4) # "double quotes"
```
Note, that in this last example the escaped quotes are necessary only for the string definition. **trim(" padded string ")** returns the original string stripped of leading and trailing whitespace. This is useful for string comparisons of input data fields that may contain extra whitespace. For example
```
plot FOO using 1:( trim(strcol(3)) eq "A" ? $2 : NaN )
```
Operators
---------
The operators in **gnuplot** are the same as the corresponding operators in the C programming language, except that all operators accept integer, real, and complex arguments, unless otherwise noted. The \*\* operator (exponentiation) is supported, as in FORTRAN. Parentheses may be used to change order of evaluation.
### Unary
The following is a list of all the unary operators and their usages:
| |
| --- |
| Unary Operators |
| Symbol | Example | Explanation |
| `-` | `-a` | unary minus |
| `+` | `+a` | unary plus (no-operation) |
| `~` | `~a` | \* one's complement |
| `!` | `!a` | \* logical negation |
| `!` | `a!` | \* factorial |
| `$` | `$3` | \* call arg/column during `using` manipulation |
| `|` | `|A|` | cardinality of array A |
(\*) Starred explanations indicate that the operator requires an integer argument.
Operator precedence is the same as in Fortran and C. As in those languages, parentheses may be used to change the order of operation. Thus -2\*\*2 = -4, but (-2)\*\*2 = 4.
The factorial operator returns an integer when N! is sufficiently small (N <= 20 for 64-bit integers). It returns a floating point approximation for larger values of N.
This operator returns the number of elements |A| when applied to array A. It returns the number of data lines |$DATA| when applied to datablock $DATA.
### Binary
The following is a list of all the binary operators and their usages:
| |
| --- |
| Binary Operators |
| Symbol | Example | Explanation |
| `**` | `a**b` | exponentiation |
| `*` | `a*b` | multiplication |
| `/` | `a/b` | division |
| `%` | `a%b` | \* modulo |
| `+` | `a+b` | addition |
| `-` | `a-b` | subtraction |
| `==` | `a==b` | equality |
| `!=` | `a!=b` | inequality |
| `<` | `a<b` | less than |
| `<=` | `a<=b` | less than or equal to |
| `>` | `a>b` | greater than |
| `>=` | `a>=b` | greater than or equal to |
| `<<` | `0xff<<1` | left shift unsigned |
| `>>` | `0xff>>1` | right shift unsigned |
| `&` | `a&b` | \* bitwise AND |
| `^` | `a^b` | \* bitwise exclusive OR |
| `|` | `a|b` | \* bitwise inclusive OR |
| `&&` | `a&&b` | \* logical AND |
| `||` | `a||b` | \* logical OR |
| `=` | `a = b` | assignment |
| `,` | `(a,b)` | serial evaluation |
| `.` | `A.B` | string concatenation |
| `eq` | `A eq B` | string equality |
| `ne` | `A ne B` | string inequality |
(\*) Starred explanations indicate that the operator requires integer arguments. Capital letters A and B indicate that the operator requires string arguments.
Logical AND (&&) and OR (||) short-circuit the way they do in C. That is, the second **&&** operand is not evaluated if the first is false; the second **||** operand is not evaluated if the first is true.
Serial evaluation occurs only in parentheses and is guaranteed to proceed in left to right order. The value of the rightmost subexpression is returned.
### Ternary
There is a single ternary operator:
| |
| --- |
| Ternary Operator |
| Symbol | Example | Explanation |
| `?:` | `a?b:c` | ternary operation |
The ternary operator behaves as it does in C. The first argument (a), which must be an integer, is evaluated. If it is true (non-zero), the second argument (b) is evaluated and returned; otherwise the third argument (c) is evaluated and returned.
The ternary operator is very useful both in constructing piecewise functions and in plotting points only when certain conditions are met.
Examples:
Plot a function that is to equal sin(x) for 0 <= x < 1, 1/x for 1 <= x < 2, and undefined elsewhere:
```
f(x) = 0<=x && x<1 ? sin(x) : 1<=x && x<2 ? 1/x : 1/0
plot f(x)
```
Note that **gnuplot** quietly ignores undefined values, so the final branch of the function (1/0) will produce no plottable points. Note also that f(x) will be plotted as a continuous function across the discontinuity if a line style is used. To plot it discontinuously, create separate functions for the two pieces. (Parametric functions are also useful for this purpose.) For data in a file, plot the average of the data in columns 2 and 3 against the datum in column 1, but only if the datum in column 4 is non-negative:
```
plot 'file' using 1:( $4<0 ? 1/0 : ($2+$3)/2 )
```
For an explanation of the **using** syntax, please see **[plot datafile using](plot#plot_datafile_using)**.
Summation
---------
A summation expression has the form
```
sum [<var> = <start> : <end>] <expression>
```
<var> is treated as an integer variable that takes on successive integral values from <start> to <end>. For each of these, the current value of <expression> is added to a running total whose final value becomes the value of the summation expression. Examples:
```
print sum [i=1:10] i
55.
# Equivalent to plot 'data' using 1:($2+$3+$4+$5+$6+...)
plot 'data' using 1 : (sum [col=2:MAXCOL] column(col))
```
It is not necessary that <expression> contain the variable <var>. Although <start> and <end> can be specified as variables or expressions, their value cannot be changed dynamically as a side-effect of carrying out the summation. If <end> is less than <start> then the value of the summation is zero. Gnuplot-defined variables
-------------------------
Gnuplot maintains a number of read-only variables that reflect the current internal state of the program and the most recent plot. These variables begin with the prefix "GPVAL\_". Examples include GPVAL\_TERM, GPVAL\_X\_MIN, GPVAL\_X\_MAX, GPVAL\_Y\_MIN. Type **show variables all** to display the complete list and current values. Values related to axes parameters (ranges, log base) are values used during the last plot, not those currently **set**. Example: To calculate the fractional screen coordinates of the point [X,Y]
```
GRAPH_X = (X - GPVAL_X_MIN) / (GPVAL_X_MAX - GPVAL_X_MIN)
GRAPH_Y = (Y - GPVAL_Y_MIN) / (GPVAL_Y_MAX - GPVAL_Y_MIN)
SCREEN_X = GPVAL_TERM_XMIN + GRAPH_X * (GPVAL_TERM_XMAX - GPVAL_TERM_XMIN)
SCREEN_Y = GPVAL_TERM_YMIN + GRAPH_Y * (GPVAL_TERM_YMAX - GPVAL_TERM_YMIN)
FRAC_X = SCREEN_X * GPVAL_TERM_SCALE / GPVAL_TERM_XSIZE
FRAC_Y = SCREEN_Y * GPVAL_TERM_SCALE / GPVAL_TERM_YSIZE
```
The read-only variable GPVAL\_ERRNO is set to a non-zero value if any gnuplot command terminates early due to an error. The most recent error message is stored in the string variable GPVAL\_ERRMSG. Both GPVAL\_ERRNO and GPVAL\_ERRMSG can be cleared using the command **reset errors**.
Interactive terminals with **mouse** functionality maintain read-only variables with the prefix "MOUSE\_". See **[mouse variables](mouse_input#mouse_variables)** for details.
The **fit** mechanism uses several variables with names that begin "FIT\_". It is safest to avoid using such names. When using **set fit errorvariables**, the error for each fitted parameter will be stored in a variable named like the parameter, but with "\_err" appended. See the documentation on **[fit](fit#fit)** and **[set fit](set_show#set_fit)** for details.
See **[user-defined variables](expressions#user-defined_variables)**, **[reset errors](reset#reset_errors)**, **[mouse variables](mouse_input#mouse_variables)**, and **[fit](fit#fit)**.
User-defined variables and functions
------------------------------------
New user-defined variables and functions of one through twelve variables may be declared and used anywhere, including on the **plot** command itself. User-defined function syntax:
```
<func-name>( <dummy1> {,<dummy2>} ... {,<dummy12>} ) = <expression>
```
where <expression> is defined in terms of <dummy1> through <dummy12>.
User-defined variable syntax:
```
<variable-name> = <constant-expression>
```
Examples:
```
w = 2
q = floor(tan(pi/2 - 0.1))
f(x) = sin(w*x)
sinc(x) = sin(pi*x)/(pi*x)
delta(t) = (t == 0)
ramp(t) = (t > 0) ? t : 0
min(a,b) = (a < b) ? a : b
comb(n,k) = n!/(k!*(n-k)!)
len3d(x,y,z) = sqrt(x*x+y*y+z*z)
plot f(x) = sin(x*a), a = 0.2, f(x), a = 0.4, f(x)
```
```
file = "mydata.inp"
file(n) = sprintf("run_%d.dat",n)
```
The final two examples illustrate a user-defined string variable and a user-defined string function.
Note that the variables **pi** (3.14159...) and **NaN** (IEEE "Not a Number") are already defined. You can redefine these to something else if you really need to. The original values can be recovered by setting:
```
NaN = GPVAL_NaN
pi = GPVAL_pi
```
Other variables may be defined under various gnuplot operations like mousing in interactive terminals or fitting; see **[gnuplot-defined variables](expressions#gnuplot-defined_variables)** for details.
You can check for existence of a given variable V by the exists("V") expression. For example
```
a = 10
if (exists("a")) print "a is defined"
if (!exists("b")) print "b is not defined"
```
Valid names are the same as in most programming languages: they must begin with a letter, but subsequent characters may be letters, digits, or "\_".
Each function definition is made available as a special string-valued variable with the prefix 'GPFUN\_'.
Example:
```
set label GPFUN_sinc at graph .05,.95
```
See **[show functions](set_show#show_functions)**, **[functions](plot#functions)**, **[gnuplot-defined variables](expressions#gnuplot-defined_variables)**, **[macros](substitution_command_line_m#macros)**, **[value](expressions#value)**.
Arrays
------
Arrays are implemented as indexed lists of user variables. The elements in an array are not limited to a single type of variable. Arrays must be created explicitly before being referenced. The size of an array cannot be changed after creation. All elements are initially undefined. In most places an array element can be used instead of a named user variable. The cardinality (number of elements) of array A is given by the expression |A|.
Example:
```
array A[6]
A[1] = 1
A[2] = 2.0
A[3] = {3.0, 3.0}
A[4] = "four"
A[6] = A[2]**3
array B[6] = [ 1, 2.0, A[3], "four", , B[2]**3 ]
```
```
do for [i=1:6] { print A[i], B[i] }
1 1
2.0 2.0
{3.0, 3.0} {3.0, 3.0}
four four
<undefined> <undefined>
8.0 8.0
```
Note: Arrays and variables share the same namespace. For example, assignment of a string variable named FOO will destroy any previously created array with name FOO.
The name of an array can be used in a **plot**, **splot**, **fit**, or **stats** command. This is equivalent to providing a file in which column 1 holds the array index (from 1 to size), column 2 holds the value of real(A[i]) and column 3 holds the value of imag(A[i]).
Example:
```
array A[200]
do for [i=1:200] { A[i] = sin(i * pi/100.) }
plot A title "sin(x) in centiradians"
```
When plotting the imaginary component of complex array values, it may be referenced either as imag(A[$1]) or as $3. These two commands are equivalent
```
plot A using (real(A[$1])) : (imag(A[$1]))
plot A using 2:3
```
| programming_docs |
gnuplot Plot Plot
====
**plot** is the primary command for drawing plots with **gnuplot**. It offers many different graphical representations for functions and data. **plot** is used to draw 2D functions and data. **splot** draws 2D projections of 3D surfaces and data. Syntax:
```
plot {<ranges>} <plot-element> {, <plot-element>, <plot-element>}
```
Each plot element consists of a definition, a function, or a data source together with optional properties or modifiers:
```
plot-element:
{<iteration>}
<definition> | {sampling-range} <function> | <data source>
| keyentry
{axes <axes>} {<title-spec>}
{with <style>}
```
The graphical representation of each plot element is determined by the keyword **with**, e.g. **with lines** or **with boxplot**. See **plotting styles**.
The data to be plotted is either generated by a function (two functions if in parametric mode), read from a data file, or read from a named data block that was defined previously. Multiple datafiles, data blocks, and/or functions may be plotted in a single plot command separated by commas. See **[data](plot#data)**, **[inline data](inline_data_datablocks#inline_data)**, **[functions](plot#functions)**.
A plot-element that contains the definition of a function or variable does not create any visible output, see third example below.
Examples:
```
plot sin(x)
plot sin(x), cos(x)
plot f(x) = sin(x*a), a = .2, f(x), a = .4, f(x)
plot "datafile.1" with lines, "datafile.2" with points
plot [t=1:10] [-pi:pi*2] tan(t), \
"data.1" using (tan($2)):($3/$4) smooth csplines \
axes x1y2 notitle with lines 5
plot for [datafile in "spinach.dat broccoli.dat"] datafile
```
See also **[show plot](set_show#show_plot)**.
Axes
----
There are four possible sets of axes available; the keyword <axes> is used to select the axes for which a particular line should be scaled. **x1y1** refers to the axes on the bottom and left; **x2y2** to those on the top and right; **x1y2** to those on the bottom and right; and **x2y1** to those on the top and left. Ranges specified on the **plot** command apply only to the first set of axes (bottom left). Binary
------
BINARY DATA FILES: It is necessary to provide the keyword **binary** after the filename. Adequate details of the file format must be given on the command line or extracted from the file itself for a supported binary **filetype**. In particular, there are two structures for binary files, binary matrix format and binary general format.
The **binary matrix** format contains a two dimensional array of 32 bit IEEE float values plus an additional column and row of coordinate values. In the **using** specifier of a plot command, column 1 refers to the matrix row coordinate, column 2 refers to the matrix column coordinate, and column 3 refers to the value stored in the array at those coordinates.
The **binary general** format contains an arbitrary number of columns for which information must be specified at the command line. For example, **array**, **record**, **format** and **using** can indicate the size, format and dimension of data. There are a variety of useful commands for skipping file headers and changing endianess. There are a set of commands for positioning and translating data since often coordinates are not part of the file when uniform sampling is inherent in the data. Unlike reading from a text or matrix binary file, general binary does not treat the generated columns as 1, 2 or 3 in the **using** list. Instead column 1 refers to column 1 of the file, or as specified in the **format** list.
There are global default settings for the various binary options which may be set using the same syntax as the options when used as part of the **(s)plot <filename> binary ...** command. This syntax is **set datafile binary ...**. The general rule is that common command-line specified parameters override file-extracted parameters which override default parameters.
**Binary matrix** is the default binary format when no keywords specific to **binary general** are given, i.e., **array**, **record**, **format**, **filetype**.
General binary data can be entered at the command line via the special file name '-'. However, this is intended for use through a pipe where programs can exchange binary data, not for keyboards. There is no "end of record" character for binary data. Gnuplot continues reading from a pipe until it has read the number of points declared in the **array** qualifier. See **[binary matrix](splot#binary_matrix)** or **[binary general](plot#binary_general)** for more details.
The **index** keyword is not supported, since the file format allows only one surface per file. The **every** and **using** filters are supported. **using** operates as if the data were read in the above triplet form. [Binary File Splot Demo.](http://www.gnuplot.info/demo/binary.html)
### General
The **binary** keyword appearing alone indicates a binary data file that contains both coordinate information describing a non-uniform grid and the value of each grid point (see **[binary matrix](splot#binary_matrix)**). Binary data in any other format requires additional keywords to describe the layout of the data. Unfortunately the syntax of these required additional keywords is convoluted. Nevertheless the general binary mode is particularly useful for application programs sending large amounts of data to gnuplot. Syntax:
```
plot '<file_name>' {binary <binary list>} ...
splot '<file_name>' {binary <binary list>} ...
```
General binary format is activated by keywords in <binary list> pertaining to information about file structure, i.e., **array**, **record**, **format** or **filetype**. Otherwise, non-uniform matrix binary format is assumed. (See **[binary matrix](splot#binary_matrix)** for more details.)
Gnuplot knows how to read a few standard binary file types that are fully self-describing, e.g. PNG images. Type **show datafile binary** at the command line for a list. Apart from these, you can think of binary data files as conceptually the same as text data. Each point has columns of information which are selected via the **using** specification. If no **format** string is specified, gnuplot will read in a number of binary values equal to the largest column given in the **<using list>**. For example, **using 1:3** will result in three columns being read, of which the second will be ignored. Certain plot types have an associated default using specification. For example, **with image** has a default of **using 1**, while **with rgbimage** has a default of **using 1:2:3**.
### Array
Describes the sampling array dimensions associated with the binary file. The coordinates will be generated by gnuplot. A number must be specified for each dimension of the array. For example, **array=(10,20)** means the underlying sampling structure is two-dimensional with 10 points along the first (x) dimension and 20 points along the second (y) dimension. A negative number indicates that data should be read until the end of file. If there is only one dimension, the parentheses may be omitted. A colon can be used to separate the dimensions for multiple records. For example, **array=25:35** indicates there are two one-dimensional records in the file. ### Record
This keyword serves the same function as **array** and has the same syntax. However, **record** causes gnuplot to not generate coordinate information. This is for the case where such information may be included in one of the columns of the binary data file. ### Skip
This keyword allows you to skip sections of a binary file. For instance, if the file contains a 1024 byte header before the start of the data region you would probably want to use
```
plot '<file_name>' binary skip=1024 ...
```
If there are multiple records in the file, you may specify a leading offset for each. For example, to skip 512 bytes before the 1st record and 256 bytes before the second and third records
```
plot '<file_name> binary record=356:356:356 skip=512:256:256 ...
```
### Format
The default binary format is a float. For more flexibility, the format can include details about variable sizes. For example, **format="%uchar%int%float"** associates an unsigned character with the first using column, an int with the second column and a float with the third column. If the number of size specifications is less than the greatest column number, the size is implicitly taken to be similar to the last given variable size. Furthermore, similar to the **using** specification, the format can include discarded columns via the **\*** character and have implicit repetition via a numerical repeat-field. For example, **format="%\*2int%3float"** causes gnuplot to discard two ints before reading three floats. To list variable sizes, type **show datafile binary datasizes**. There are a group of names that are machine dependent along with their sizes in bytes for the particular compilation. There is also a group of names which attempt to be machine independent.
### Endian
Often the endianess of binary data in the file does not agree with the endianess used by the platform on which gnuplot is running. Several words can direct gnuplot how to arrange bytes. For example **endian=little** means treat the binary file as having byte significance from least to greatest. The options are
```
little: least significant to greatest significance
big: greatest significance to least significance
default: assume file endianess is the same as compiler
swap (swab): Interchange the significance. (If things
don't look right, try this.)
```
Gnuplot can support "middle" ("pdp") endian if it is compiled with that option.
### Filetype
For some standard binary file formats gnuplot can extract all the necessary information from the file in question. As an example, "format=edf" will read ESRF Header File format files. For a list of the currently supported file formats, type **show datafile binary filetypes**. There is a special file type called **auto** for which gnuplot will check if the binary file's extension is a quasi-standard extension for a supported format.
Command line keywords may be used to override settings extracted from the file. The settings from the file override any defaults. See **[set datafile binary](set_show#set_datafile_binary)**.
#### Avs
**avs** is one of the automatically recognized binary file types for images. AVS is an extremely simple format, suitable mostly for streaming between applications. It consists of 2 longs (xwidth, ywidth) followed by a stream of pixels, each with four bytes of information alpha/red/green/blue. #### Edf
**edf** is one of the automatically recognized binary file types for images. EDF stands for ESRF Data Format, and it supports both edf and ehf formats (the latter means ESRF Header Format). More information on specifications can be found at
```
http://www.edfplus.info/specs
```
#### Png
If gnuplot was configured to use the libgd library for png/gif/jpeg output, then it can also be used to read these same image types as binary files. You can use an explicit command
```
plot 'file.png' binary filetype=png
```
Or the file type will be recognized automatically from the extension if you have previously requested
```
set datafile binary filetype=auto
```
### Keywords
The following keywords apply only when generating coordinates from binary data files. That is, the control mapping the individual elements of a binary array, matrix, or image to specific x/y/z positions. #### Scan
A great deal of confusion can arise concerning the relationship between how gnuplot scans a binary file and the dimensions seen on the plot. To lessen the confusion, conceptually think of gnuplot *always* scanning the binary file point/line/plane or fast/medium/slow. Then this keyword is used to tell gnuplot how to map this scanning convention to the Cartesian convention shown in plots, i.e., x/y/z. The qualifier for scan is a two or three letter code representing where point is assigned (first letter), line is assigned (second letter), and plane is assigned (third letter). For example, **scan=yx** means the fastest, point-by-point, increment should be mapped along the Cartesian y dimension and the middle, line-by-line, increment should be mapped along the x dimension. When the plotting mode is **plot**, the qualifier code can include the two letters x and y. For **splot**, it can include the three letters x, y and z.
There is nothing restricting the inherent mapping from point/line/plane to apply only to Cartesian coordinates. For this reason there are cylindrical coordinate synonyms for the qualifier codes where t (theta), r and z are analogous to the x, y and z of Cartesian coordinates.
#### Transpose
Shorthand notation for **scan=yx** or **scan=yxz**. I.e. it affects the assignment of pixels to scan lines during input. To instead transpose an image when it is displayed try
```
plot 'imagefile' binary filetype=auto flipx rotate=90deg with rgbimage
```
#### Dx, dy, dz
When gnuplot generates coordinates, it uses the spacing described by these keywords. For example **dx=10 dy=20** would mean space samples along the x dimension by 10 and space samples along the y dimension by 20. **dy** cannot appear if **dx** does not appear. Similarly, **dz** cannot appear if **dy** does not appear. If the underlying dimensions are greater than the keywords specified, the spacing of the highest dimension given is extended to the other dimensions. For example, if an image is being read from a file and only **dx=3.5** is given gnuplot uses a delta x and delta y of 3.5. The following keywords also apply only when generating coordinates. However they may also be used with matrix binary files.
#### Flipx, flipy, flipz
Sometimes the scanning directions in a binary datafile are not consistent with that assumed by gnuplot. These keywords can flip the scanning direction along dimensions x, y, z. #### Origin=
When gnuplot generates coordinates based upon transposition and flip, it attempts to always position the lower left point in the array at the origin, i.e., the data lies in the first quadrant of a Cartesian system after transpose and flip. To position the array somewhere else on the graph, the **origin** keyword directs gnuplot to position the lower left point of the array at a point specified by a tuple. The tuple should be a double for **plot** and a triple for **splot**. For example, **origin=(100,100):(100,200)** is for two records in the file and intended for plotting in two dimensions. A second example, **origin=(0,0,3.5)**, is for plotting in three dimensions.
#### Center
Similar to **origin**, this keyword will position the array such that its center lies at the point given by the tuple. For example, **center=(0,0)**. Center does not apply when the size of the array is **Inf**. #### Rotate
The transpose and flip commands provide some flexibility in generating and orienting coordinates. However, for full degrees of freedom, it is possible to apply a rotational vector described by a rotational angle in two dimensions. The **rotate** keyword applies to the two-dimensional plane, whether it be **plot** or **splot**. The rotation is done with respect to the positive angle of the Cartesian plane.
The angle can be expressed in radians, radians as a multiple of pi, or degrees. For example, **rotate=1.5708**, **rotate=0.5pi** and **rotate=90deg** are equivalent.
If **origin** is specified, the rotation is done about the lower left sample point before translation. Otherwise, the rotation is done about the array **center**.
#### Perpendicular
For **splot**, the concept of a rotational vector is implemented by a triple representing the vector to be oriented normal to the two-dimensional x-y plane. Naturally, the default is (0,0,1). Thus specifying both rotate and perpendicular together can orient data myriad ways in three-space. The two-dimensional rotation is done first, followed by the three-dimensional rotation. That is, if R' is the rotational 2 x 2 matrix described by an angle, and P is the 3 x 3 matrix projecting (0,0,1) to (xp,yp,zp), let R be constructed from R' at the upper left sub-matrix, 1 at element 3,3 and zeros elsewhere. Then the matrix formula for translating data is v' = P R v, where v is the 3 x 1 vector of data extracted from the data file. In cases where the data of the file is inherently not three-dimensional, logical rules are used to place the data in three-space. (E.g., usually setting the z-dimension value to zero and placing 2D data in the x-y plane.)
Data
----
Discrete data contained in a file can be displayed by specifying the name of the data file (enclosed in single or double quotes) on the **plot** command line. Syntax:
```
plot '<file_name>' {binary <binary list>}
{{nonuniform} matrix}
{index <index list> | index "<name>"}
{every <every list>}
{skip <number-of-lines>}
{using <using list>}
{smooth <option>}
{bins <options>}
{volatile} {noautoscale}
```
The modifiers **binary**, **index**, **every**, **skip**, **using**, **bins**, and **smooth** are discussed separately. In brief
* **skip N** tells the program to ignore N lines at the start of the input file
* **binary** indicates that the file contains binary data rather than text
* **index** selects which data sets in a multi-data-set file are to be plotted
* **every** specifies which points within a single data set are to be plotted
* **using** specifies which columns in the file are to be used in which order
* **smooth** performs simple filtering, interpolation, or curve-fitting of the data prior to plotting
* **bins** sorts individual input points into equal-sized intervals along x and plots a single accumulated value per interval
* **volatile** indicates that the content of the file may not be available to reread later and therefore it should be retained internally for re-use.
**splot** has a similar syntax but does not support **smooth** or **bins**.
The **noautoscale** keyword means that the points making up this plot will be ignored when automatically determining axis range limits.
TEXT DATA FILES:
Each non-empty line in a data file describes one data point, except that records beginning with **#** (and also with **!** on VMS) will be treated as comments and ignored.
Depending on the plot style and options selected, from one to eight values are read from each line and associated with a single data point. See **[using](plot#using)**.
The individual records on a single line of data must be separated by white space (one or more blanks or tabs) a special field separator character is is specified by the **set datafile** command. A single field may itself contain white space characters if the entire field is enclosed in a pair of double quotes, or if a field separator other than white space is in effect. Whitespace inside a pair of double quotes is ignored when counting columns, so the following datafile line has three columns:
```
1.0 "second column" 3.0
```
Data may be written in exponential format with the exponent preceded by the letter e or E. The fortran exponential specifiers d, D, q, and Q may also be used if the command **set datafile fortran** is in effect.
Blank records in a data file are significant. Single blank records designate discontinuities in a **plot**; no line will join points separated by a blank records (if they are plotted with a line style). Two blank records in a row indicate a break between separate data sets. See **[index](plot#index)**.
If autoscaling has been enabled (**set autoscale**), the axes are automatically extended to include all datapoints, with a whole number of tic marks if tics are being drawn. This has two consequences: i) For **splot**, the corner of the surface may not coincide with the corner of the base. In this case, no vertical line is drawn. ii) When plotting data with the same x range on a dual-axis graph, the x coordinates may not coincide if the x2tics are not being drawn. This is because the x axis has been autoextended to a whole number of tics, but the x2 axis has not. The following example illustrates the problem:
```
reset; plot '-', '-' axes x2y1
1 1
19 19
e
1 1
19 19
e
```
To avoid this, you can use the **noextend** modifier of the **set autoscale** or **set [axis]range** commands. This turns off extension of the axis range to include the next tic mark.
Label coordinates and text can also be read from a data file (see **[labels](labels#labels)**).
### Bins
Syntax:
```
plot 'DATA' using <XCOL> {:<YCOL>} bins{=<NBINS>}
{binrange [<LOW>:<HIGH>]} {binwidth=<width>}
{binvalue={sum|avg}
```
The **bins** option to a **plot** command first assigns the original data to equal width bins on x and then plots a single value per bin. The default number of bins is controlled by **set samples**, but this can be changed by giving an explicit number of bins in the command.
If no binrange is given, the range is taken from the extremes of the x values found in 'DATA'.
Given the range and the number of bins, bin width is calculated automatically and points are assigned to bins 0 to NBINS-1
```
BINWIDTH = (HIGH - LOW) / (NBINS-1)
xmin = LOW - BINWIDTH/2
xmax = HIGH + BINWIDTH/2
first bin holds points with (xmin <= x < xmin + BINWIDTH)
last bin holds points with (xmax-BINWIDTH <= x < xman)
each point is assigned to bin i = floor(NBINS * (x-xmin)/(xmax-xmin))
```
Alternatively you can provide a fixed bin width, in which case nbins is calculated as the smallest number of bins that will span the range.
On output bins are plotted or tabulated by midpoint. E.g. if the program calculates bin width as shown above, the x coordinate output for the first bin is x=LOW (not x=xmin).
If only a single column is given in the using clause then each data point contributes a count of 1 to the accumulation of total counts in the bin for that x coordinate value. If a second column is given then the value in that column is added to the accumulation for the bin. Thus the following two plot command are equivalent:
```
plot 'DATA" using N bins=20
set samples 20
plot 'DATA' using (column(N)):(1)
```
The y value plotted for each bin is the sum of the y values over all points in that bin. This corresponds to **binvalue=sum**. EXPERIMENTAL: **binvalue=avg** instead plots the mean y value for that bin.
For related plotting styles see **[smooth frequency](plot#smooth_frequency)** and **[smooth kdensity](plot#smooth_kdensity)**.
### Columnheaders
Extra lines at the start of a data file may be explicitly ignored using the **skip** keyword in the plot command. A single additional line containing text column headers may be present. It is skipped automatically if the plot command refers explicitly to column headers, e.g. by using them for titles. Otherwise you may need to skip it explicitly either by adding one to the skip count or by setting the attribute **set datafile columnheaders**. See **[skip](plot#skip)**, **[columnhead](expressions#columnhead)**, **[autotitle columnheader](set_show#autotitle_columnheader)**, **[set datafile](set_show#set_datafile)**. ### Csv files
Syntax:
```
set datafile separator {whitespace | tab | comma | "chars"}
```
"csv" is short for "comma-separated values". The term "csv file" is loosely applied to files in which data fields are delimited by a specific character, not necessarily a comma. To read data from a csv file you must tell gnuplot what the field-delimiting character is. For instance to read from a file using semicolon as a field delimiter:
```
set datafile separator ";"
```
See **[set datafile separator](set_show#set_datafile_separator)**. This applies only to files used for input. To create a csv file on output, use the corresponding **separator** option to **set table**.
### Every
The **every** keyword allows a periodic sampling of a data set to be plotted. For ordinary files a "point" single record (line); a "block" of data is a set of consecutive records with blank lines before and after the block.
For matrix data a "block" and "point" correspond to "row" and "column". See **[matrix every](splot#matrix_every)**.
Syntax:
```
plot 'file' every {<point_incr>}
{:{<block_incr>}
{:{<start_point>}
{:{<start_block>}
{:{<end_point>}
{:<end_block>}}}}}
```
The data points to be plotted are selected according to a loop from <**start\_point**> to <**end\_point**> with increment <**point\_incr**> and the blocks according to a loop from <**start\_block**> to <**end\_block**> with increment <**block\_incr**>.
The first datum in each block is numbered '0', as is the first block in the file.
Note that records containing unplottable information are counted.
Any of the numbers can be omitted; the increments default to unity, the start values to the first point or block, and the end values to the last point or block. ':' at the end of the **every** option is not permitted. If **every** is not specified, all points in all lines are plotted.
Examples:
```
every :::3::3 # selects just the fourth block ('0' is first)
every :::::9 # selects the first 10 blocks
every 2:2 # selects every other point in every other block
every ::5::15 # selects points 5 through 15 in each block
```
See [simple plot demos (simple.dem)](http://www.gnuplot.info/demo/simple.html)
, [Non-parametric splot demos](http://www.gnuplot.info/demo/surface1.html)
, and [Parametric splot demos](http://www.gnuplot.info/demo/surface2.html)
.
### Example datafile
This example plots the data in the file "population.dat" and a theoretical curve:
```
pop(x) = 103*exp((1965-x)/10)
set xrange [1960:1990]
plot 'population.dat', pop(x)
```
The file "population.dat" might contain:
```
# Gnu population in Antarctica since 1965
1965 103
1970 55
1975 34
1980 24
1985 10
```
Binary examples:
```
# Selects two float values (second one implicit) with a float value
# discarded between them for an indefinite length of 1D data.
plot '<file_name>' binary format="%float%*float" using 1:2 with lines
```
```
# The data file header contains all details necessary for creating
# coordinates from an EDF file.
plot '<file_name>' binary filetype=edf with image
plot '<file_name>.edf' binary filetype=auto with image
```
```
# Selects three unsigned characters for components of a raw RGB image
# and flips the y-dimension so that typical image orientation (start
# at top left corner) translates to the Cartesian plane. Pixel
# spacing is given and there are two images in the file. One of them
# is translated via origin.
plot '<file_name>' binary array=(512,1024):(1024,512) format='%uchar' \
dx=2:1 dy=1:2 origin=(0,0):(1024,1024) flipy u 1:2:3 w rgbimage
```
```
# Four separate records in which the coordinates are part of the
# data file. The file was created with a endianess different from
# the system on which gnuplot is running.
splot '<file_name>' binary record=30:30:29:26 endian=swap u 1:2:3
```
```
# Same input file, but this time we skip the 1st and 3rd records
splot '<file_name>' binary record=30:26 skip=360:348 endian=swap u 1:2:3
```
See also **[binary matrix](splot#binary_matrix)**.
### Index
The **index** keyword allows you to select specific data sets in a multi-data-set file for plotting. Syntax:
```
plot 'file' index { <m>{:<n>{:<p>}} | "<name>" }
```
Data sets are separated by pairs of blank records. **index <m>** selects only set <m>; **index <m>:<n>** selects sets in the range <m> to <n>; and **index <m>:<n>:<p>** selects indices <m>, <m>+<p>, <m>+2<p>, etc., but stopping at <n>. Following C indexing, the index 0 is assigned to the first data set in the file. Specifying too large an index results in an error message. If <p> is specified but <n> is left blank then every <p>-th dataset is read until the end of the file. If **index** is not specified, the entire file is plotted as a single data set.
Example:
```
plot 'file' index 4:5
```
For each point in the file, the index value of the data set it appears in is available via the pseudo-column **column(-2)**. This leads to an alternative way of distinguishing individual data sets within a file as shown below. This is more awkward than the **index** command if all you are doing is selecting one data set for plotting, but is very useful if you want to assign different properties to each data set. See **[pseudocolumns](plot#pseudocolumns)**, **[lc variable](linetypes_colors_styles#lc_variable)**.
Example:
```
plot 'file' using 1:(column(-2)==4 ? $2 : NaN) # very awkward
plot 'file' using 1:2:(column(-2)) linecolor variable # very useful!
```
**index '<name>'** selects the data set with name '<name>'. Names are assigned to data sets in comment lines. The comment character and leading white space are removed from the comment line. If the resulting line starts with <name>, the following data set is now named <name> and can be selected.
Example:
```
plot 'file' index 'Population'
```
Please note that every comment that starts with <name> will name the following data set. To avoid problems it may be useful to choose a naming scheme like '== Population ==' or '[Population]'.
### Skip
The **skip** keyword tells the program to skip lines at the start of a text (i.e. not binary) data file. The lines that are skipped do not count toward the line count used in processing the **every** keyword. Note that **skip N** skips lines only at the start of the file, whereas **every ::N** skips lines at the start of every block of data in the file. See also **[binary skip](plot#binary_skip)** for a similar option that applies to binary data files. ### Smooth
**gnuplot** includes a few general-purpose routines for filtering, interpolation and grouping data as it is input; these are grouped under the **smooth** option. More sophisticated data processing may be performed by preprocessing the data externally or by using **fit** with an appropriate model. Syntax:
```
smooth {unique | frequency | fnormal | cumulative | cnormal | bins
| kdensity {bandwidth} {period}
| csplines | acsplines | mcsplines | bezier | sbezier
| unwrap | zsort}
```
The **unique**, **frequency**, **fnormal**, **cumulative** and **cnormal** sort the data on x and then plot some aspect of the distribution of x values.
The spline and Bezier options determine coefficients describing a continuous curve between the endpoints of the data. This curve is then plotted in the same manner as a function, that is, by finding its value at uniform intervals along the abscissa (see **[set samples](set_show#set_samples)**) and connecting these points with straight line segments. If the data set is interrupted by blank lines or undefined values a separate continuous curve is fit for each uninterrupted subset of the data. Adjacent separately fit segments may be separated by a gap or discontinuity.
**unwrap** manipulates the data to avoid jumps of more than pi by adding or subtracting multiples of 2\*pi.
**zsort** uses a 3rd column of input to sort points prior to plotting.
If **autoscale** is in effect, axis ranges will be computed for the final curve rather than for the original data.
If **autoscale** is not in effect, and a spline curve is being generated, sampling of the spline fit is done across the intersection of the x range covered by the input data and the fixed abscissa range defined by **set xrange**.
If too few points are available to apply the requested smoothing operation an error message is produced.
The **smooth** options have no effect on function plots.
#### Acsplines
The **smooth acsplines** option approximates the data with a natural smoothing spline. After the data are made monotonic in x (see **[smooth unique](plot#smooth_unique)**), a curve is piecewise constructed from segments of cubic polynomials whose coefficients are found by fitting to the individual data points weighted by the value, if any, given in the third column of the using spec. The default is equivalent to
```
plot 'data-file' using 1:2:(1.0) smooth acsplines
```
Qualitatively, the absolute magnitude of the weights determines the number of segments used to construct the curve. If the weights are large, the effect of each datum is large and the curve approaches that produced by connecting consecutive points with natural cubic splines. If the weights are small, the curve is composed of fewer segments and thus is smoother; the limiting case is the single segment produced by a weighted linear least squares fit to all the data. The smoothing weight can be expressed in terms of errors as a statistical weight for a point divided by a "smoothing factor" for the curve so that (standard) errors in the file can be used as smoothing weights.
Example:
```
sw(x,S)=1/(x*x*S)
plot 'data_file' using 1:2:(sw($3,100)) smooth acsplines
```
#### Bezier
The **smooth bezier** option approximates the data with a Bezier curve of degree n (the number of data points) that connects the endpoints. #### Bins
**smooth bins** is the same as **bins**. See **[bins](plot#bins)**. For related plotting styles see **[smooth frequency](plot#smooth_frequency)** and **[smooth kdensity](plot#smooth_kdensity)**. #### Csplines
The **smooth csplines** option connects consecutive points by natural cubic splines after rendering the data monotonic (see **[smooth unique](plot#smooth_unique)**). #### Mcsplines
The **smooth mcsplines** option connects consecutive points by cubic splines constrained such that the smoothed function preserves the monotonicity and convexity of the original data points. This reduces the effect of outliers. FN Fritsch & RE Carlson (1980) "Monotone Piecewise Cubic Interpolation", SIAM Journal on Numerical Analysis 17: 238–246. #### Sbezier
The **smooth sbezier** option first renders the data monotonic (**unique**) and then applies the **bezier** algorithm. #### Unique
The **smooth unique** option makes the data monotonic in x; points with the same x-value are replaced by a single point having the average y-value. The resulting points are then connected by straight line segments. #### Unwrap
The **smooth unwrap** option modifies the input data so that any two successive points will not differ by more than pi; a point whose y value is outside this range will be incremented or decremented by multiples of 2pi until it falls within pi of the previous point. This operation is useful for making wrapped phase measurements continuous over time. #### Frequency
The **smooth frequency** option makes the data monotonic in x; points with the same x-value are replaced by a single point having the summed y-values. To plot a histogram of the number of data values in equal size bins, set the y-value to 1.0 so that the sum is a count of occurrences in that bin. This is done implicitly if only a single column is provided. Example:
```
binwidth = <something> # set width of x values in each bin
bin(val) = binwidth * floor(val/binwidth)
plot "datafile" using (bin(column(1))):(1.0) smooth frequency
plot "datafile" using (bin(column(1))) smooth frequency # same result
```
See also [smooth.dem](http://www.gnuplot.info/demo/smooth.html) #### Fnormal
The **smooth fnormal** option work just like the **frequency** option, but produces a normalized histogram. It makes the data monotonic in x and normalises the y-values so they all sum to 1. Points with the same x-value are replaced by a single point containing the sumed y-values. To plot a histogram of the number of data values in equal size bins, set the y-value to 1.0 so that the sum is a count of occurrences in that bin. This is done implicitly if only a single column is provided. See also [smooth.dem](http://www.gnuplot.info/demo/smooth.html) #### Cumulative
The **smooth cumulative** option makes the data monotonic in x; points with the same x-value are replaced by a single point containing the cumulative sum of y-values of all data points with lower x-values (i.e. to the left of the current data point). This can be used to obtain a cumulative distribution function from data. See also [smooth.dem](http://www.gnuplot.info/demo/smooth.html) #### Cnormal
The **smooth cnormal** option makes the data monotonic in x and normalises the y-values onto the range [0:1]. Points with the same x-value are replaced by a single point containing the cumulative sum of y-values of all data points with lower x-values (i.e. to the left of the current data point) divided by the total sum of all y-values. This can be used to obtain a normalised cumulative distribution function from data (useful when comparing sets of samples with differing numbers of members). See also [smooth.dem](http://www.gnuplot.info/demo/smooth.html) #### Kdensity
The **smooth kdensity** option generates and plots a kernel density estimate using Gaussian kernels for the distribution from which a set of values was drawn. Values are taken from the first data column, optional weights are taken from the second column. A Gaussian is placed at the location of each point and the sum of all these Gaussians is plotted as a function. To obtain a normalized histogram, each weight should be 1/number-of-points. Bandwidth: By default gnuplot calculates and uses the bandwidth which would be optimal for normally distributed data values.
```
default_bandwidth = sigma * (4/3N) ** (0.2)
```
This will usually be a very conservative, i.e. broad bandwidth. Alternatively, you can provide an explicit bandwidth.
```
plot $DATA smooth kdensity bandwidth <value> with boxes
```
The bandwidth used in the previous plot is stored in GPVAL\_KDENSITY\_BANDWIDTH. Period: For periodic data individual Gaussian components should be treated as repeating at intervals of one period. One example is data measured as a function of angle, where the period is 2pi. Another example is data indexed by day-of-year and measured over multiple years, where the period is 365. In such cases the period should be provided in the plot command:
```
plot $ANGULAR_DAT smooth kdensity period 2*pi with lines
```
#### Zsort
Syntax
```
plot FOO using x:y:z:color smooth zsort with points lc palette
```
The intended use is to filter presentation of 2D scatter plots with a huge number of points so that the distribution of high-scoring points remains evident. Sorting the points on z guarantees that points with a high z-value will not be obscured by points with lower z-values. Limited to plot style "with points". ### Special-filenames
There are a few filenames that have a special meaning: ' ', '-', '+' and '++'. The empty filename ' ' tells gnuplot to re-use the previous input file in the same plot command. So to plot two columns from the same input file:
```
plot 'filename' using 1:2, ” using 1:3
```
The filename can also be reused over subsequent plot commands, however **save** then only records the name in a comment.
The special filenames '+' and '++' are a mechanism to allow the full range of **using** specifiers and plot styles with inline functions. Normally a function plot can only have a single y (or z) value associated with each sampled point. The pseudo-file '+' treats the sampled points as column 1, and allows additional column values to be specified via a **using** specification, just as for a true input file. The number of samples is controlled via **set samples**. By default samples are generated over the range given by **set trange**, or if trange has not been set than over the full range of **set xrange**.
Note: The use of trange is a change from previous gnuplot versions. It allows the sampling range to differ from the x axis range.
```
plot '+' using ($1):(sin($1)):(sin($1)**2) with filledcurves
```
An independent sampling range can be provided immediately before the '+'. As in normal function plots, a name can be assigned to the independent variable. If given for the first plot element, the sampling range specifier has to be preceded by the **sample** keyword (see also **[plot sampling](plot#plot_sampling)**).
```
plot sample [beta=0:2*pi] '+' using (sin(beta)):(cos(beta)) with lines
```
Additionally, the range specifier of '+' supports giving a sampling increment.
```
plot $MYDATA, [t=-3:25:1] '+' using (t):(f(t))
```
The pseudo-file '++' returns 2 columns of data forming a regular grid of [u,v] coordinates with the number of points along u controlled by **set samples** and the number of points along v controlled by **set isosamples**. You must set urange and vrange before plotting '++'. However the x and y ranges can be autoscaled or can be explicitly set to different values than urange and vrange. Use of u and v to sample '++' is a CHANGE introduced in version 5.2 Examples:
```
splot '++' using 1:2:(sin($1)*sin($2)) with pm3d
plot '++' using 1:2:(sin($1)*sin($2)) with image
```
The special filename **'-'** specifies that the data are inline; i.e., they follow the command. Only the data follow the command; **plot** options like filters, titles, and line styles remain on the **plot** command line. This is similar to << in unix shell script, and $DECK in VMS DCL. The data are entered as though they are being read from a file, one data point per record. The letter "e" at the start of the first column terminates data entry.
**'-'** is intended for situations where it is useful to have data and commands together, e.g. when both are piped to **gnuplot** from another application. Some of the demos, for example, might use this feature. While **plot** options such as **index** and **every** are recognized, their use forces you to enter data that won't be used. For all but the simplest cases it is probably easier to first define a datablock and then read from it rather than from **'-'**. See **[datablocks](inline_data_datablocks#datablocks)**.
If you use **'-'** with **replot**, you may need to enter the data more than once. See **[replot](replot#replot)**, **[refresh](refresh#refresh)**. Here again it may be better to use a datablock.
A blank filename (' ') specifies that the previous filename should be reused. This can be useful with things like
```
plot 'a/very/long/filename' using 1:2, ” using 1:3, ” using 1:4
```
(If you use both **'-'** and **' '** on the same **plot** command, you'll need to have two sets of inline data, as in the example above.)
### Piped-data
On systems with a popen function, the datafile can be piped through a shell command by starting the file name with a '<'. For example,
```
pop(x) = 103*exp(-x/10)
plot "< awk '{print $1-1965, $2}' population.dat", pop(x)
```
would plot the same information as the first population example but with years since 1965 as the x axis. If you want to execute this example, you have to delete all comments from the data file above or substitute the following command for the first part of the command above (the part up to the comma):
```
plot "< awk '$0 !~ /^#/ {print $1-1965, $2}' population.dat"
```
While this approach is most flexible, it is possible to achieve simple filtering with the **using** keyword.
On systems with an fdopen() function, data can be read from an arbitrary file descriptor attached to either a file or pipe. To read from file descriptor **n** use **'<&n'**. This allows you to easily pipe in several data files in a single call from a POSIX shell:
```
$ gnuplot -p -e "plot '<&3', '<&4'" 3<data-3 4<data-4
$ ./gnuplot 5< <(myprogram -with -options)
gnuplot> plot '<&5'
```
### Using
The most common datafile modifier is **using**. It tells the program which columns of data in the input file are to be plotted. Syntax:
```
plot 'file' using <entry> {:<entry> {:<entry> ...}} {'format'}
```
If a format is specified, it is used to read in each datafile record using the C library 'scanf' function. Otherwise the record is interpreted as consisting of columns (fields) of data separated by whitespace (spaces and/or tabs), but see **[datafile separator](set_show#datafile_separator)**.
Each <entry> may be a simple column number that selects the value from one field of the input file, a string that matches a column label in the first line of a data set, an expression enclosed in parentheses, or a special function not enclosed in parentheses such as xticlabels(2).
If the entry is an expression in parentheses, then the function column(N) may be used to indicate the value in column N. That is, column(1) refers to the first item read, column(2) to the second, and so on. The special symbols $1, $2, ... are shorthand for column(1), column(2) ...
The special symbol $# evaluates to the total number of columns in the current line of input, so column($#) or stringcolumn($#) always returns the content of the final column even if the number of columns is unknown or different lines in the file contain different numbers of columns.
The function **valid(N)** tests whether column N contains a valid number. If each column of data in the input file contains a label in the first row rather than a data value, this label can be used to identify the column on input and/or in the plot legend. The column() function can be used to select an input column by label rather than by column number. For example, if the data file contains
```
Height Weight Age
val1 val1 val1
... ... ...
```
then the following plot commands are all equivalent
```
plot 'datafile' using 3:1, ” using 3:2
plot 'datafile' using (column("Age")):(column(1)), \
” using (column("Age")):(column(2))
plot 'datafile' using "Age":"Height", ” using "Age":"Weight"
```
The full string must match. Comparison is case-sensitive. To use column labels in the plot legend, use **set key autotitle columnhead**.
In addition to the actual columns 1...N in the input data file, gnuplot presents data from several "pseudo-columns" that hold bookkeeping information. E.g. $0 or column(0) returns the sequence number of this data record within a dataset. Please see **[pseudocolumns](plot#pseudocolumns)**.
An empty <entry> will default to its order in the list of entries. For example, **using ::4** is interpreted as **using 1:2:4**.
If the **using** list has only a single entry, that <entry> will be used for y and the data point number (pseudo-column $0) is used for x; for example, "**plot 'file' using 1**" is identical to "**plot 'file' using 0:1**". If the **using** list has two entries, these will be used for x and y. See **[set style](set_show#set_style)** and **[fit](fit#fit)** for details about plotting styles that make use of data from additional columns of input.
'scanf' accepts several numerical specifications but **gnuplot** requires all inputs to be double-precision floating-point variables, so "%lf" is essentially the only permissible specifier. A format string given by the user must contain at least one such input specifier, and no more than seven of them. 'scanf' expects to see white space — a blank, tab (" \t"), newline (" \n"), or formfeed (" \f") — between numbers; anything else in the input stream must be explicitly skipped.
Note that the use of " \t", " \n", or " \f" requires use of double-quotes rather than single-quotes.
#### Using\_examples
This creates a plot of the sum of the 2nd and 3rd data against the first: The format string specifies comma- rather than space-separated columns. The same result could be achieved by specifying **set datafile separator comma**.
```
plot 'file' using 1:($2+$3) '%lf,%lf,%lf'
```
In this example the data are read from the file "MyData" using a more complicated format:
```
plot 'MyData' using "%*lf%lf%*20[^\n]%lf"
```
The meaning of this format is:
```
%*lf ignore a number
%lf read a double-precision number (x by default)
%*20[^\n] ignore 20 non-newline characters
%lf read a double-precision number (y by default)
```
One trick is to use the ternary **?:** operator to filter data:
```
plot 'file' using 1:($3>10 ? $2 : 1/0)
```
which plots the datum in column two against that in column one provided the datum in column three exceeds ten. **1/0** is undefined; **gnuplot** quietly ignores undefined points, so unsuitable points are suppressed. Or you can use the pre-defined variable NaN to achieve the same result.
In fact, you can use a constant expression for the column number, provided it doesn't start with an opening parenthesis; constructs like **using 0+(complicated expression)** can be used. The crucial point is that the expression is evaluated once if it doesn't start with a left parenthesis, or once for each data point read if it does.
If timeseries data are being used, the time can span multiple columns. The starting column should be specified. Note that the spaces within the time must be included when calculating starting columns for other data. E.g., if the first element on a line is a time with an embedded space, the y value should be specified as column three.
It should be noted that (a) **plot 'file'**, (b) **plot 'file' using 1:2**, and (c) **plot 'file' using ($1):($2)** can be subtly different. The exact behaviour has changed in version 5. See **[missing](set_show#missing)**.
It is often possible to plot a file with lots of lines of garbage at the top simply by specifying
```
plot 'file' using 1:2
```
However, if you want to leave text in your data files, it is safer to put the comment character (#) in the first column of the text lines.
#### Pseudocolumns
Expressions in the **using** clause of a plot statement can refer to additional bookkeeping values in addition to the actual data values contained in the input file. These are contained in "pseudocolumns".
```
column(0) The sequential order of each point within a data set.
The counter starts at 0, increments on each non-blank,
non-comment line, and is reset by two sequential blank
records. The shorthand form $0 is available.
column(-1) This counter starts at 0, increments on a single blank line,
and is reset by two sequential blank lines.
This corresponds to the data line in array or grid data.
It can also be used to distinguish separate line segments
or polygons within a data set.
column(-2) Starts at 0 and increments on two sequential blank lines.
This is the index number of the current data set within a
file that contains multiple data sets. See `index`.
column($#) The special symbol $# evaluates to the total number of
columns available, so column($#) refers to the last
(rightmost) field in the current input line.
column($# - 1) would refer to the last-but-one column, etc.
```
#### Key
The layout of certain plot styles (column-stacked histograms, spider plots) is such that it would make no sense to generate plot titles from a data column header. Also it would make no sense to generate axis tic labels from the content of a data column (e.g. **using 2:3:xticlabels(1)**). These plots styles instead use the form **using 2:3:key(1)** to generate plot titles for the key from the text content of a data column, usually a first column of row headers. See the example given for **[spiderplot](spiderplot#spiderplot)**. #### Xticlabels
Axis tick labels can be generated via a string function, usually taking a data column as an argument. The simplest form uses the data column itself as a string. That is, xticlabels(N) is shorthand for xticlabels(stringcolumn(N)). This example uses the contents of column 3 as x-axis tick labels.
```
plot 'datafile' using <xcol>:<ycol>:xticlabels(3) with <plotstyle>
```
Axis tick labels may be generated for any of the plot axes: x x2 y y2 z. The **ticlabels(<labelcol>)** specifiers must come after all of the data coordinate specifiers in the **using** portion of the command. For each data point which has a valid set of X,Y[,Z] coordinates, the string value given to xticlabels() is added to the list of xtic labels at the same X coordinate as the point it belongs to. **xticlabels()** may be shortened to **xtic()** and so on.
Example:
```
splot "data" using 2:4:6:xtic(1):ytic(3):ztic(6)
```
In this example the x and y axis tic labels are taken from different columns than the x and y coordinate values. The z axis tics, however, are generated from the z coordinate of the corresponding point.
Example:
```
plot "data" using 1:2:xtic( $3 > 10. ? "A" : "B" )
```
This example shows the use of a string-valued function to generate x-axis tick labels. Each point in the data file generates a tick mark on x labeled either "A" or "B" depending on the value in column 3.
#### X2ticlabels
See **[plot using xticlabels](plot#plot_using_xticlabels)**. #### Yticlabels
See **[plot using xticlabels](plot#plot_using_xticlabels)**. #### Y2ticlabels
See **[plot using xticlabels](plot#plot_using_xticlabels)**. #### Zticlabels
See **[plot using xticlabels](plot#plot_using_xticlabels)**. #### Cbticlabels
EXPERIMENTAL (details may change in a future release version) 2D plots: colorbar labels are placed at the palette coordinate used by the plot for variable coloring "lc palette z". 3D plots: colorbar labels are placed at the z coordinate of the point. Note that in the case of a 3D heat map with variable color that does not match z, this is probably not the correct label. See also **[plot using xticlabels](plot#plot_using_xticlabels)**. ### Volatile
The **volatile** keyword in a plot command indicates that the data previously read from the input stream or file may not be available for re-reading. This tells the program to use **refresh** rather than **replot** commands whenever possible. See **[refresh](refresh#refresh)**. Errorbars
---------
Error bars are supported for 2D data file plots by reading one to four additional columns (or **using** entries); these additional values are used in different ways by the various errorbar styles. In the default situation, **gnuplot** expects to see three, four, or six numbers on each line of the data file — either
```
(x, y, ydelta),
(x, y, ylow, yhigh),
(x, y, xdelta),
(x, y, xlow, xhigh),
(x, y, xdelta, ydelta), or
(x, y, xlow, xhigh, ylow, yhigh).
```
The x coordinate must be specified. The order of the numbers must be exactly as given above, though the **using** qualifier can manipulate the order and provide values for missing columns. For example,
```
plot 'file' with errorbars
plot 'file' using 1:2:(sqrt($1)) with xerrorbars
plot 'file' using 1:2:($1-$3):($1+$3):4:5 with xyerrorbars
```
The last example is for a file containing an unsupported combination of relative x and absolute y errors. The **using** entry generates absolute x min and max from the relative error.
The y error bar is a vertical line plotted from (x, ylow) to (x, yhigh). If ydelta is specified instead of ylow and yhigh, ylow = y - ydelta and yhigh = y + ydelta are derived. If there are only two numbers on the record, yhigh and ylow are both set to y. The x error bar is a horizontal line computed in the same fashion. To get lines plotted between the data points, **plot** the data file twice, once with errorbars and once with lines (but remember to use the **notitle** option on one to avoid two entries in the key). Alternately, use the errorlines command (see **[errorlines](plot#errorlines)**).
The tic marks at the ends of the bar are controlled by **set errorbars**.
If autoscaling is on, the ranges will be adjusted to include the error bars.
See also [errorbar demos.](http://www.gnuplot.info/demo/mgr.html)
See **[plot using](plot#plot_using)**, **[plot with](plot#plot_with)**, and **[set style](set_show#set_style)** for more information.
Errorlines
----------
Lines with error bars are supported for 2D data file plots by reading one to four additional columns (or **using** entries); these additional values are used in different ways by the various errorlines styles. In the default situation, **gnuplot** expects to see three, four, or six numbers on each line of the data file — either
```
(x, y, ydelta),
(x, y, ylow, yhigh),
(x, y, xdelta),
(x, y, xlow, xhigh),
(x, y, xdelta, ydelta), or
(x, y, xlow, xhigh, ylow, yhigh).
```
The x coordinate must be specified. The order of the numbers must be exactly as given above, though the **using** qualifier can manipulate the order and provide values for missing columns. For example,
```
plot 'file' with errorlines
plot 'file' using 1:2:(sqrt($1)) with xerrorlines
plot 'file' using 1:2:($1-$3):($1+$3):4:5 with xyerrorlines
```
The last example is for a file containing an unsupported combination of relative x and absolute y errors. The **using** entry generates absolute x min and max from the relative error.
The y error bar is a vertical line plotted from (x, ylow) to (x, yhigh). If ydelta is specified instead of ylow and yhigh, ylow = y - ydelta and yhigh = y + ydelta are derived. If there are only two numbers on the record, yhigh and ylow are both set to y. The x error bar is a horizontal line computed in the same fashion.
The tic marks at the ends of the bar are controlled by **set errorbars**.
If autoscaling is on, the ranges will be adjusted to include the error bars.
See **[plot using](plot#plot_using)**, **[plot with](plot#plot_with)**, and **[set style](set_show#set_style)** for more information.
Functions
---------
Built-in or user-defined functions can be displayed by the **plot** and **splot** commands in addition to, or instead of, data read from a file. The requested function is evaluated by sampling at regular intervals spanning the independent axis range[s]. See **[set samples](set_show#set_samples)** and **[set isosamples](set_show#set_isosamples)**. Example:
```
approx(ang) = ang - ang**3 / (3*2)
plot sin(x) title "sin(x)", approx(x) title "approximation"
```
To set a default plot style for functions, see **[set style function](set_show#set_style_function)**. For information on built-in functions, see **[expressions functions](expressions#expressions_functions)**. For information on defining your own functions, see **[user-defined](expressions#user-defined)**.
Parametric
----------
When in parametric mode (**set parametric**) mathematical expressions must be given in pairs for **plot** and in triplets for **splot**. Examples:
```
plot sin(t),t**2
splot cos(u)*cos(v),cos(u)*sin(v),sin(u)
```
Data files are plotted as before, except any preceding parametric function must be fully specified before a data file is given as a plot. In other words, the x parametric function (**sin(t)** above) and the y parametric function (**t\*\*2** above) must not be interrupted with any modifiers or data functions; doing so will generate a syntax error stating that the parametric function is not fully specified.
Other modifiers, such as **with** and **title**, may be specified only after the parametric function has been completed:
```
plot sin(t),t**2 title 'Parametric example' with linespoints
```
See also [Parametric Mode Demos.](http://www.gnuplot.info/demo/param.html)
Ranges
------
This section describes only the optional axis ranges that may appear as the very first items in a **plot** command. If present, these ranges override any range limits established by a previous **set range** statement. For optional ranges elsewhere in a **plot** command that limit sampling of an individual plot component see **[sampling](plot#sampling)**. Syntax:
```
[{<dummy-var>=}{{<min>}:{<max>}}]
[{{<min>}:{<max>}}]
```
The first form applies to the independent variable (**xrange** or **trange**, if in parametric mode). The second form applies to dependent variables. <dummy-var> optionally establishes a new name for the independent variable. (The default name may be changed with **set dummy**.)
In non-parametric mode, ranges must be given in the order
```
plot [<xrange>][<yrange>][<x2range>][<y2range>] ...
```
In parametric mode, ranges must be given in the order
```
plot [<trange>][<xrange>][<yrange>][<x2range>][<y2range>] ...
```
The following **plot** command shows setting **trange** to [-pi:pi], **xrange** to [-1.3:1.3] and **yrange** to [-1:1] for the duration of the graph:
```
plot [-pi:pi] [-1.3:1.3] [-1:1] sin(t),t**2
```
**\*** can be used to allow autoscaling of either of min and max. Use an empty range **[]** as a placeholder if necessary.
Ranges specified on the **plot** or **splot** command line affect only that one graph; use the **set xrange**, **set yrange**, etc., commands to change the default ranges for future graphs.
The use of on-the-fly range specifiers in a plot command may not yield the expected result for linked axes (see **[set link](set_show#set_link)**).
For time data you must provide the range in quotes, using the same format used to read time from the datafile. See **[set timefmt](set_show#set_timefmt)**.
Examples:
This uses the current ranges:
```
plot cos(x)
```
This sets the x range only:
```
plot [-10:30] sin(pi*x)/(pi*x)
```
This is the same, but uses t as the dummy-variable:
```
plot [t = -10 :30] sin(pi*t)/(pi*t)
```
This sets both the x and y ranges:
```
plot [-pi:pi] [-3:3] tan(x), 1/x
```
This sets only the y range:
```
plot [ ] [-2:sin(5)*-8] sin(x)**besj0(x)
```
This sets xmax and ymin only:
```
plot [:200] [-pi:] $mydata using 1:2
```
This sets the x range for a timeseries:
```
set timefmt "%d/%m/%y %H:%M"
plot ["1/6/93 12:00":"5/6/93 12:00"] 'timedata.dat'
```
Sampling
--------
### 1D sampling (x or t axis)
By default, computed functions or data generated for the pseudo-file "+" are sampled over the entire range of the plot as set by a prior **set xrange** command, by an explicit global range specifier at the very start of the plot or splot command, or by autoscaling the xrange to span data seen in all the elements of this plot. However, individual plot components can be assigned a more restricted sampling range. Examples:
This establishes a total range on x running from 0 to 1000 and then plots data from a file and two functions each spanning a portion of the total range:
```
plot [0:1000] 'datafile', [0:200] func1(x), [200:500] func2(x)
```
This is similar except that the total range is established by the contents of the data file. In this case the sampled functions may or may not be entirely contained in the plot:
```
set autoscale x
plot 'datafile', [0:200] func1(x), [200:500] func2(x)
```
This command is ambiguous. The initial range will be interpreted as applying to the entire plot, not solely to the sampling of the first function as was probably the intent:
```
plot [0:10] f(x), [10:20] g(x), [20:30] h(x)
```
This command removes the ambiguity of the previous example by inserting the keyword **sample** so that the range is not applied to the entire plot:
```
plot sample [0:10] f(x), [10:20] g(x), [20:30] h(x)
```
This example shows one way of tracing out a helix in a 3D plot
```
splot [-2:2][-2:2] sample [h=1:10] '+' using (cos(h)):(sin(h)):(h)
```
### 2D sampling (u and v axes)
Computed functions or data generated for the pseudo-file '++' use samples generated along the u and v axes. This is a CHANGE from versions prior to 5.2 which sampled along the x and y axes. See **[special-filenames ++](plot#special-filenames_++)**. 2D sampling can be used in either **plot** or **splot** commands. Example of 2D sampling in a 2D **plot** command. These commands generated the plot shown for plotstyle **with vectors**. See **[vectors](vectors#vectors)**.
```
set urange [ -2.0 : 2.0 ]
set vrange [ -2.0 : 2.0 ]
plot '++' using ($1):($2):($2*0.4):(-$1*0.4) with vectors
```
Example of 2D sampling in a 3D **splot** command. These commands are similar to the ones used in **sampling.dem**. Note that the two surfaces are sampled over u and v ranges smaller than the full x and y ranges of the resulting plot.
```
set title "3D sampling range distinct from plot x/y range"
set xrange [1:100]
set yrange [1:100]
splot sample [u=30:70][v=0:50] '++' using 1:2:(u*v) lt 3, \
[u=40:80][v=30:60] '++' using (u):(v):(u*sqrt(v)) lt 4
```
The range specifiers for sampling on u and v can include an explicit sampling interval to control the number and spacing of samples:
```
splot sample [u=30:70:1][v=0:50:5] '++' using 1:2:(func($1,$2))
```
For loops in plot command
-------------------------
If many similar files or functions are to be plotted together, it may be convenient to do so by iterating over a shared plot command. Syntax:
```
plot for [<variable> = <start> : <end> {:<increment>}]
plot for [<variable> in "string of words"]
```
The scope of an iteration ends at the next comma or the end of the command, whichever comes first. An exception to this is that definitions are grouped with the following plot item even if there is an intervening comma. Note that iteration does not work for plots in parametric mode.
Example:
```
plot for [j=1:3] sin(j*x)
```
Example:
```
plot for [dataset in "apples bananas"] dataset."dat" title dataset
```
In this example iteration is used both to generate a file name and a corresponding title.
Example:
```
file(n) = sprintf("dataset_%d.dat",n)
splot for [i=1:10] file(i) title sprintf("dataset %d",i)
```
This example defines a string-valued function that generates file names, and plots ten such files together. The iteration variable ('i' in this example) is treated as an integer, and may be used more than once.
Example:
```
set key left
plot for [n=1:4] x**n sprintf("%d",n)
```
This example plots a family of functions.
Example:
```
list = "apple banana cabbage daikon eggplant"
item(n) = word(list,n)
plot for [i=1:words(list)] item[i].".dat" title item(i)
list = "new stuff"
replot
```
This example steps through a list and plots once per item. Because the items are retrieved dynamically, you can change the list and then replot.
Example:
```
list = "apple banana cabbage daikon eggplant"
plot for [i in list] i.".dat" title i
list = "new stuff"
replot
```
This example does exactly the same thing as the previous example, but uses the string iterator form of the command rather than an integer iterator.
If an iteration is to continue until all available data is consumed, use the symbol \* instead of an integer <end>. This can be used to process all columns in a line, all datasets (separated by 2 blank lines) in a file, or all files matching a template.
Examples:
```
plot for [i=2:*] 'datafile' using 1:i with histogram
splot for [i=0:*] 'datafile' index i using 1:2:3 with lines
plot for [i=1:*] file=sprintf("File_%03d.dat",i) file using 2 title file
```
Title
-----
By default each plot is listed in the key by the corresponding function or file name. You can give an explicit plot title instead using the **title** option. Syntax:
```
title <text> | notitle [<ignored text>]
title columnheader | title columnheader(N)
{at {beginning|end}} {{no}enhanced}
```
where <text> is a quoted string or an expression that evaluates to a string. The quotes will not be shown in the key. Note: Starting with gnuplot version 5.4, if <text> is an expression or function it it evaluated after the corresponding function or data stream is plotted. This allows the title to reference quantities calculated or input during plotting, which was not possible in earlier gnuplot versions.
There is also an option that will interpret the first entry in a column of input data (i.e. the column header) as a text field, and use it as the key title. See **[datastrings](datastrings#datastrings)**. This can be made the default by specifying **set key autotitle columnhead**.
The line title and sample can be omitted from the key by using the keyword **notitle**. A null title (**title ' '**) is equivalent to **notitle**. If only the sample is wanted, use one or more blanks (**title ' '**). If **notitle** is followed by a string this string is ignored.
If **key autotitles** is set (which is the default) and neither **title** nor **notitle** are specified the line title is the function name or the file name as it appears on the **plot** command. If it is a file name, any datafile modifiers specified will be included in the default title.
The layout of the key itself (position, title justification, etc.) can be controlled using **[set key](set_show#set_key)**.
The **at** keyword allows you to place the plot title somewhere outside the auto-generated key box. The title can be placed immediately before or after the line in the graph itself by using **at {beginning|end}**. This option may be useful when plotting **with lines** but makes little sense for most other styles.
To place the plot title at an arbitrary location on the page, use the form **at <x-position>,<y-position>**. By default the position is interpreted in screen coordinates; e.g. **at 0.5, 0.5** is always the middle of the screen regardless of plot axis scales or borders. The format of titles placed in this way is still affected by key options. See **[set key](set_show#set_key)**.
Examples:
This plots y=x with the title 'x':
```
plot x
```
This plots x squared with title "x`^`2" and file "data.1" with title "measured data":
```
plot x**2 title "x^2", 'data.1' t "measured data"
```
Plot multiple columns of data, each of which contains its own title on the first line of the file. Place the titles after the corresponding lines rather than in a separate key:
```
unset key
set offset 0, graph 0.1
plot for [i=1:4] 'data' using i with lines title columnhead at end
```
Create a single key area for two separate plots:
```
set key Left reverse
set multiplot layout 2,2
plot sin(x) with points pt 6 title "Left plot is sin(x)" at 0.5, 0.30
plot cos(x) with points pt 7 title "Right plot is cos(x)" at 0.5, 0.27
unset multiplot
```
With
----
Functions and data may be displayed in one of a large number of styles. The **with** keyword provides the means of selection. Syntax:
```
with <style> { {linestyle | ls <line_style>}
| {{linetype | lt <line_type>}
{linewidth | lw <line_width>}
{linecolor | lc <colorspec>}
{pointtype | pt <point_type>}
{pointsize | ps <point_size>}
{arrowstyle | as <arrowstyle_index>}
{fill | fs <fillstyle>} {fillcolor | fc <colorspec>}
{nohidden3d} {nocontours} {nosurface}
{palette}}
}
```
where <style> is one of
```
lines dots steps vectors yerrorlines
points impulses fsteps xerrorbar xyerrorbars
linespoints labels histeps xerrorlines xyerrorlines
financebars surface arrows yerrorbar parallelaxes
```
or
```
boxes boxplot ellipses histograms rgbalpha
boxerrorbars candlesticks filledcurves image rgbimage
boxxyerror circles fillsteps pm3d polygons
isosurface zerrorfill
```
or
```
table
```
The first group of styles have associated line, point, and text properties. The second group of styles also have fill properties. See **[fillstyle](set_show#fillstyle)**. Some styles have further sub-styles. See **plotting styles** for details of each. The **table** style produces tabular output rather than a plot. See **[set table](set_show#set_table)**.
A default style may be chosen by **set style function** and **set style data**.
By default, each function and data file will use a different line type and point type, up to the maximum number of available types. All terminal drivers support at least six different point types, and re-use them, in order, if more are required. To see the complete set of line and point types available for the current terminal, type **[test](test#test)**.
If you wish to choose the line or point type for a single plot, <line\_type> and <point\_type> may be specified. These are positive integer constants (or expressions) that specify the line type and point type to be used for the plot. Use **test** to display the types available for your terminal.
You may also scale the line width and point size for a plot by using <line\_width> and <point\_size>, which are specified relative to the default values for each terminal. The pointsize may also be altered globally — see **[set pointsize](set_show#set_pointsize)** for details. But note that both <point\_size> as set here and as set by **set pointsize** multiply the default point size — their effects are not cumulative. That is, **set pointsize 2; plot x w p ps 3** will use points three times default size, not six.
It is also possible to specify **pointsize variable** either as part of a line style or for an individual plot. In this case one extra column of input is required, i.e. 3 columns for a 2D plot and 4 columns for a 3D splot. The size of each individual point is determined by multiplying the global pointsize by the value read from the data file.
If you have defined specific line type/width and point type/size combinations with **set style line**, one of these may be selected by setting <line\_style> to the index of the desired style.
Both 2D and 3D plots (**plot** and **splot** commands) can use colors from a smooth palette set previously with the command **set palette**. The color value corresponds to the z-value of the point itself or to a separate color coordinate provided in an optional additional **using** colymn. Color values may be treated either as a fraction of the palette range (**palette frac**) or as a coordinate value mapped onto the colorbox range (**palette** or **palette z**). See **[colorspec](linetypes_colors_styles#colorspec)**, **[set palette](set_show#set_palette)**, **[linetype](set_show#linetype)**.
The keyword **nohidden3d** applies only to plots made with the **splot** command. Normally the global option **set hidden3d** applies to all plots in the graph. You can attach the **nohidden3d** option to any individual plots that you want to exclude from the hidden3d processing. The individual elements other than surfaces (i.e. lines, dots, labels, ...) of a plot marked **nohidden3d** will all be drawn, even if they would normally be obscured by other plot elements.
Similarly, the keyword **nocontours** will turn off contouring for an individual plot even if the global property **set contour** is active.
Similarly, the keyword **nosurface** will turn off the 3D surface for an individual plot even if the global property **set surface** is active.
The keywords may be abbreviated as indicated.
Note that the **linewidth**, **pointsize** and **palette** options are not supported by all terminals.
Examples:
This plots sin(x) with impulses:
```
plot sin(x) with impulses
```
This plots x with points, x\*\*2 with the default:
```
plot x w points, x**2
```
This plots tan(x) with the default function style, file "data.1" with lines:
```
plot [ ] [-2:5] tan(x), 'data.1' with l
```
This plots "leastsq.dat" with impulses:
```
plot 'leastsq.dat' w i
```
This plots the data file "population" with boxes:
```
plot 'population' with boxes
```
This plots "exper.dat" with errorbars and lines connecting the points (errorbars require three or four columns):
```
plot 'exper.dat' w lines, 'exper.dat' notitle w errorbars
```
Another way to plot "exper.dat" with errorlines (errorbars require three or four columns):
```
plot 'exper.dat' w errorlines
```
This plots sin(x) and cos(x) with linespoints, using the same line type but different point types:
```
plot sin(x) with linesp lt 1 pt 3, cos(x) with linesp lt 1 pt 4
```
This plots file "data" with points of type 3 and twice usual size:
```
plot 'data' with points pointtype 3 pointsize 2
```
This plots file "data" with variable pointsize read from column 4
```
plot 'data' using 1:2:4 with points pt 5 pointsize variable
```
This plots two data sets with lines differing only by weight:
```
plot 'd1' t "good" w l lt 2 lw 3, 'd2' t "bad" w l lt 2 lw 1
```
This plots filled curve of x\*x and a color stripe:
```
plot x*x with filledcurve closed, 40 with filledcurve y=10
```
This plots x\*x and a color box:
```
plot x*x, (x>=-5 && x<=5 ? 40 : 1/0) with filledcurve y=10 lt 8
```
This plots a surface with color lines:
```
splot x*x-y*y with line palette
```
This plots two color surfaces at different altitudes:
```
splot x*x-y*y with pm3d, x*x+y*y with pm3d at t
```
| programming_docs |
gnuplot Break Break
=====
The **break** command is only meaningful inside the bracketed iteration clause of a **do** or **while** statement. It causes the remaining statements inside the bracketed clause to be skipped and iteration is terminated. Execution resumes at the statement following the closing bracket. See also **[continue](continue#continue)**.
gnuplot If If
==
New syntax:
```
if (<condition>) { <commands>;
<commands>
<commands>
} else {
<commands>
}
```
Old syntax:
```
if (<condition>) <command-line> [; else if (<condition>) ...; else ...]
```
This version of gnuplot supports block-structured if/else statements. If the keyword **if** or **else** is immediately followed by an opening "{", then conditional execution applies to all statements, possibly on multiple input lines, until a matching "}" terminates the block. If commands may be nested.
The old single-line if/else syntax is still supported, but can not be mixed with the new block-structured syntax. See **[if-old](if#if-old)**.
If-old
------
Through gnuplot version 4.4, the scope of the if/else commands was limited to a single input line. Now a multi-line clause may be enclosed in curly brackets. The old syntax is still honored but cannot be used inside a bracketed clause. If no opening "{" follows the **if** keyword, the command(s) in <command-line> will be executed if <condition> is true (non-zero) or skipped if <condition> is false (zero). Either case will consume commands on the input line until the end of the line or an occurrence of **else**. Note that use of **;** to allow multiple commands on the same line will *not* end the conditionalized commands.
Examples:
```
pi=3
if (pi!=acos(-1)) print "?Fixing pi!"; pi=acos(-1); print pi
```
will display:
```
?Fixing pi!
3.14159265358979
```
but
```
if (1==2) print "Never see this"; print "Or this either"
```
will not display anything. else:
```
v=0
v=v+1; if (v%2) print "2" ; else if (v%3) print "3"; else print "fred"
```
(repeat the last line repeatedly!)
gnuplot Fsteps Fsteps
======
The **fsteps** style is only relevant to 2D plotting. It connects consecutive points with two line segments: the first from (x1,y1) to (x1,y2) and the second from (x1,y2) to (x2,y2). The input column requires are the same as for plot styles **lines** and **points**. The difference between **fsteps** and **steps** is that **fsteps** traces first the change in y and then the change in x. **steps** traces first the change in x and then the change in y. See also [steps demo.](http://www.gnuplot.info/demo/steps.html)
gnuplot Iteration Iteration
=========
gnuplot supports command iteration and block-structured if/else/while/do constructs. See **[if](if#if)**, **[while](while#while)**, and **[do](do#do)**. Simple iteration is possible inside **plot** or **set** commands. See **[plot for](plot#plot_for)**. General iteration spanning multiple commands is possible using a block construct as shown below. For a related new feature, see the **[summation](expressions#summation)** expression type. Here is an example using several of these new syntax features:
```
set multiplot layout 2,2
fourier(k, x) = sin(3./2*k)/k * 2./3*cos(k*x)
do for [power = 0:3] {
TERMS = 10**power
set title sprintf("%g term Fourier series",TERMS)
plot 0.5 + sum [k=1:TERMS] fourier(k,x) notitle
}
unset multiplot
```
Iteration is controlled by an iteration specifier with syntax
```
for [<var> in "string of N elements"]
```
or
```
for [<var> = <start> : <end> { : <increment> }]
```
In the first case <var> is a string variable that successively evaluates to single-word substrings 1 to N of the string in the iteration specifier. In the second case <start>, <end>, and <increment> are integers or integer expressions.
With one exception, gnuplot variables are global. There is a single, persistent, list of active variables indexed by name. Assignment to a variable creates or replaces an entry in that list. The only way to remove a variable from that list is the **undefine** command.
The single exception to this is the variable used in an iteration specifier. The scope of the iteration variable is private to that iteration. You cannot permanently change the value of the iteration variable inside the iterated clause. If the iteration variable has a value prior to iteration, that value will be retained or restored at the end of the iteration. For example, the following commands will print 1 2 3 4 5 6 7 8 9 10 A.
```
i = "A"
do for [i=1:10] { print i; i=10; }
print i
```
gnuplot Spiderplot Spiderplot
==========
Spider plots are essentially parallel axis plots in which the axes are arranged radially rather than vertically. Such plots are sometimes called **rader charts**. In gnuplot this requires working within a coordinate system established by the command **set spiderplot**, analogous to **set polar** except that the angular coordinate is determined implicitly by the parallel axis number. The appearance, labelling, and tic placement of the axes is controlled by **set paxis**. Further style choices are controlled using **[set style spiderplot](set_show#set_style_spiderplot)**, **[set grid](set_show#set_grid)**, and the individual components of the plot command. Because each spider plot corresponds to a row of data rather than a column, it would make no sense to generate key entry titles in the normal way. Instead, if a plot component contains a title the text is used to label the corresponding axis. This overrides any previous **set paxis n label "Foo"**. To place a title in the key, you can either use a separate **keyentry** command or extract text from a column in the input file with the **key(column)** using specifier. See **[keyentry](set_show#keyentry)**, **[using key](plot#using_key)**.
In this figure a spiderplot with 5 axes is used to compare multiple entities that are each characterized by five scores. Each line (row) in $DATA generates a new polygon on the plot.
```
set spiderplot
set style spiderplot fs transparent solid 0.2 border
set for [p=1:5] paxis p range [0:100]
set for [p=2:5] paxis p tics format ""
set paxis 1 tics font ",9"
set for [p=1:5] paxis p label sprintf("Score %d",p)
set grid spiderplot
plot for [i=1:5] $DATA using i:key(1)
```
Newspiderplot
-------------
Normally the sequential elements of a plot command **with spiderplot** each correspond to one vertex of a single polygon. In order to describe multiple polygons in the same plot command, they must be separated by **newspiderplot**. Example:
```
# One polygon with 10 vertices
plot for [i=1:5] 'A' using i, for [j=1:5] 'B' using j
# Two polygons with 5 vertices
plot for [i=1:5] 'A' using i, newspiderplot, for [j=1:5] 'B' using j
```
gnuplot Labels Labels
======
The **labels** style reads coordinates and text from a data file and places the text string at the corresponding 2D or 3D position. 3 or 4 input columns of basic data are required. Additional input columns may be used to provide properties that vary point by point such as text rotation angle (keywords **rotate variable**) or color (see **[textcolor variable](linetypes_colors_styles#textcolor_variable)**).
```
3 columns: x y string # 2D version
4 columns: x y z string # 3D version
```
The font, color, rotation angle and other properties of the printed text may be specified as additional command options (see **[set label](set_show#set_label)**). The example below generates a 2D plot with text labels constructed from the city whose name is taken from column 1 of the input file, and whose geographic coordinates are in columns 4 and 5. The font size is calculated from the value in column 3, in this case the population.
```
CityName(String,Size) = sprintf("{/=%d %s}", Scale(Size), String)
plot 'cities.dat' using 5:4:(CityName(stringcolumn(1),$3)) with labels
```
If we did not want to adjust the font size to a different size for each city name, the command would be much simpler:
```
plot 'cities.dat' using 5:4:1 with labels font "Times,8"
```
If the labels are marked as **hypertext** then the text only appears if the mouse is hovering over the corresponding anchor point. See **[hypertext](set_show#hypertext)**. In this case you must enable the label's **point** attribute so that there is a point to act as the hypertext anchor:
```
plot 'cities.dat' using 5:4:1 with labels hypertext point pt 7
```
The **labels** style can also be used in place of the **points** style when the set of predefined point symbols is not suitable or not sufficiently flexible. For example, here we define a set of chosen single-character symbols and assign one of them to each point in a plot based on the value in data column 3:
```
set encoding utf8
symbol(z) = "∙□+⊙♠♣♡♢"[int(z):int(z)]
splot 'file' using 1:2:(symbol($3)) with labels
```
This example shows use of labels with variable rotation angle in column 4 and textcolor ("tc") in column 5. Note that variable color is always taken from the last column in the **using** specifier.
```
plot $Data using 1:2:3:4:5 with labels tc variable rotate variable
```
gnuplot Fillsteps Fillsteps
=========
The **fillsteps** style is exactly like **steps** except that the area between the curve and y=0 is filled in the current fill style. See **[steps](steps#steps)**.
gnuplot Exit Exit
====
```
exit
exit message "error message text"
exit status <integer error code>
```
The commands **exit** and **quit**, as well as the END-OF-FILE character (usually Ctrl-D) terminate input from the current input stream: terminal session, pipe, or file input (pipe). If input streams are nested (inherited **load** scripts), then reading will continue in the parent stream. When the top level stream is closed, the program itself will exit.
The command **exit gnuplot** will immediately and unconditionally cause gnuplot to exit even if the input stream is multiply nested. In this case any open output files may not be completed cleanly. Example of use:
```
bind "ctrl-x" "unset output; exit gnuplot"
```
The command **exit error "error message"** simulates a program error. In interactive mode it prints the error message and returns to the command line, breaking out of all nested loops or calls. In non-interactive mode the program will exit.
When gnuplot exits to the controlling shell, the return value is not usually informative. This variant of the command allows you to return a specific value.
```
exit status <value>
```
See help for **[batch/interactive](batch_interactive_operation#batch_interactive)** for more details.
gnuplot Cd Cd
==
The **cd** command changes the working directory. Syntax:
```
cd '<directory-name>'
```
The directory name must be enclosed in quotes.
Examples:
```
cd 'subdir'
cd ".."
```
It is recommended that Windows users use single-quotes, because backslash [ \] has special significance inside double-quotes and has to be escaped. For example,
```
cd "c:\newdata"
```
fails, but
```
cd 'c:\newdata'
cd "c:\\newdata"
```
work as expected.
gnuplot Canvas size Canvas size
===========
This documentation uses the term "canvas" to mean the full drawing area available for positioning the plot and associated elements like labels, titles, key, etc. NB: For information about the HTML5 canvas terminal see **[set term canvas](complete_list_terminals#set_term_canvas)**.
In earlier versions of gnuplot, some terminal types used the values from **set size** to control also the size of the output canvas; others did not. The use of 'set size' for this purpose was deprecated in version 4. Almost all terminals now behave as follows:
**set term <terminal\_type> size <XX>, <YY>** controls the size of the output file, or "canvas". By default, the plot will fill this canvas.
**set size <XX>, <YY>** scales the plot itself relative to the size of the canvas. Scale values less than 1 will cause the plot to not fill the entire canvas. Scale values larger than 1 will cause only a portion of the plot to fit on the canvas. Please be aware that setting scale values larger than 1 may cause problems.
Example:
```
set size 0.5, 0.5
set term png size 600, 400
set output "figure.png"
plot "data" with lines
```
These commands produce an output file "figure.png" that is 600 pixels wide and 400 pixels tall. The plot will fill the lower left quarter of this canvas. This is consistent with the way multiplot mode has always worked.
gnuplot Do Do
==
Syntax:
```
do for <iteration-spec> {
<commands>
<commands>
}
```
Execute a sequence of commands multiple times. The commands must be enclosed in curly brackets, and the opening "{" must be on the same line as the **do** keyword. This command cannot be used with old-style (un-bracketed) if/else statements. See **[if](if#if)**. For examples of iteration specifiers, see **[iteration](iteration#iteration)**. Example:
```
set multiplot layout 2,2
do for [name in "A B C D"] {
filename = name . ".dat"
set title sprintf("Condition %s",name)
plot filename title name
}
unset multiplot
```
See also **[while](while#while)**, **[continue](continue#continue)**, **[break](break#break)**.
gnuplot For For
===
The **plot**, **splot**, **set** and **unset** commands may optionally contain an iteration for clause. This has the effect of executing the basic command multiple times, each time re-evaluating any expressions that make use of the iteration control variable. Iteration of arbitrary command sequences can be requested using the **do** command. Two forms of iteration clause are currently supported:
```
for [intvar = start:end{:increment}]
for [stringvar in "A B C D"]
```
Examples:
```
plot for [filename in "A.dat B.dat C.dat"] filename using 1:2 with lines
plot for [basename in "A B C"] basename.".dat" using 1:2 with lines
set for [i = 1:10] style line i lc rgb "blue"
unset for [tag = 100:200] label tag
```
Nested iteration is supported:
```
set for [i=1:9] for [j=1:9] label i*10+j sprintf("%d",i*10+j) at i,j
```
See additional documentation for **[iteration](iteration#iteration)**, **[do](do#do)**.
gnuplot String constants, string variables, and string functions String constants, string variables, and string functions
========================================================
In addition to string constants, most gnuplot commands also accept a string variable, a string expression, or a function that returns a string. For example, the following four methods of creating a plot all result in the same plot title:
```
four = "4"
graph4 = "Title for plot #4"
graph(n) = sprintf("Title for plot #%d",n)
```
```
plot 'data.4' title "Title for plot #4"
plot 'data.4' title graph4
plot 'data.4' title "Title for plot #".four
plot 'data.4' title graph(4)
```
Since integers are promoted to strings when operated on by the string concatenation operator ('.' character), the following method also works:
```
N = 4
plot 'data.'.N title "Title for plot #".N
```
In general, elements on the command line will only be evaluated as possible string variables if they are not otherwise recognizable as part of the normal gnuplot syntax. So the following sequence of commands is legal, although probably should be avoided so as not to cause confusion:
```
plot = "my_datafile.dat"
title = "My Title"
plot plot title title
```
Substrings
----------
Substrings can be specified by appending a range specifier to any string, string variable, or string-valued function. The range specifier has the form [begin:end], where begin is the index of the first character of the substring and end is the index of the last character of the substring. The first character has index 1. The begin or end fields may be empty, or contain '\*', to indicate the true start or end of the original string. E.g. str[:] and str[\*:\*] both describe the full string str. String operators
----------------
Three binary operators require string operands: the string concatenation operator ".", the string equality operator "eq" and the string inequality operator "ne". The following example will print TRUE.
```
if ("A"."B" eq "AB") print "TRUE"
```
String functions
----------------
Gnuplot provides several built-in functions that operate on strings. General formatting functions: see **[gprintf](set_show#gprintf)** **[sprintf](expressions#sprintf)**. Time formatting functions: see **[strftime](expressions#strftime)** **[strptime](expressions#strptime)**. String manipulation: see **[substr](expressions#substr)** **[strstrt](expressions#strstrt)** **[trim](expressions#trim)** **[word](expressions#word)** **[words](expressions#words)**. String encoding
---------------
Gnuplot's built-in string manipulation functions are sensitive to utf-8 encoding (see **[set encoding](set_show#set_encoding)**). For example
```
utf8string = "αβγ"
strlen(utf8string) returns 3 (number of characters, not number of bytes)
utf8string[2:2] evaluates to "β"
strstrt(utf8string,"β") evaluates to 2
```
gnuplot Datastrings Datastrings
===========
Data files may contain string data consisting of either an arbitrary string of printable characters containing no whitespace or an arbitrary string of characters, possibly including whitespace, delimited by double quotes. The following line from a datafile is interpreted to contain four columns, with a text field in column 3:
```
1.000 2.000 "Third column is all of this text" 4.00
```
Text fields can be positioned within a 2-D or 3-D plot using the commands:
```
plot 'datafile' using 1:2:4 with labels
splot 'datafile' using 1:2:3:4 with labels
```
A column of text data can also be used to label the ticmarks along one or more of the plot axes. The example below plots a line through a series of points with (X,Y) coordinates taken from columns 3 and 4 of the input datafile. However, rather than generating regularly spaced tics along the x axis labeled numerically, gnuplot will position a tic mark along the x axis at the X coordinate of each point and label the tic mark with text taken from column 1 of the input datafile.
```
set xtics
plot 'datafile' using 3:4:xticlabels(1) with linespoints
```
There is also an option that will interpret the first entry in a column of input data (i.e. the column heading) as a text field, and use it as the key title for data plotted from that column. The example given below will use the first entry in column 2 to generate a title in the key box, while processing the remainder of columns 2 and 4 to draw the required line:
```
plot 'datafile' using 1:(f($2)/$4) with lines title columnhead(2)
```
Another example:
```
plot for [i=2:6] 'datafile' using i title "Results for ".columnhead(i)
```
This use of column headings is automated by **set datafile columnheaders** or **set key autotitle columnhead**. See **[labels](labels#labels)**, **[using xticlabels](plot#using_xticlabels)**, **[plot title](plot#plot_title)**, **[using](plot#using)**, **[key autotitle](set_show#key_autotitle)**.
kotlin Kotlin Standard Library Kotlin Standard Library
=======================
The Kotlin Standard Library provides living essentials for everyday work with Kotlin. These include:
* Higher-order functions implementing idiomatic patterns ([let](api/latest/jvm/stdlib/kotlin/let), [apply](api/latest/jvm/stdlib/kotlin/apply), use, synchronized, etc).
* Extension functions providing querying operations for collections (eager) and sequences (lazy).
* Various utilities for working with strings and char sequences.
* Extensions for JDK classes making it convenient to work with files, IO, and threading.
Packages
--------
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin](api/latest/jvm/stdlib/kotlin/index)
Core functions and types, available on all supported platforms.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.annotation](api/latest/jvm/stdlib/kotlin.annotation/index)
Library support for the Kotlin annotation facility.
**Platform and version requirements:** JS (1.1) #### [kotlin.browser](api/latest/jvm/stdlib/kotlin.browser/index)
Access to top-level properties (`document`, `window` etc.) in the browser environment.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.collections](api/latest/jvm/stdlib/kotlin.collections/index)
Collection types, such as [Iterable](api/latest/jvm/stdlib/kotlin.collections/-iterable/index#kotlin.collections.Iterable), [Collection](api/latest/jvm/stdlib/kotlin.collections/-collection/index#kotlin.collections.Collection), [List](api/latest/jvm/stdlib/kotlin.collections/-list/index#kotlin.collections.List), [Set](api/latest/jvm/stdlib/kotlin.collections/-set/index#kotlin.collections.Set), [Map](api/latest/jvm/stdlib/kotlin.collections/-map/index#kotlin.collections.Map) and related top-level and extension functions.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.comparisons](api/latest/jvm/stdlib/kotlin.comparisons/index)
Helper functions for creating Comparator instances.
**Platform and version requirements:** JVM (1.0) #### [kotlin.concurrent](api/latest/jvm/stdlib/kotlin.concurrent/index)
Utility functions for concurrent programming.
**Platform and version requirements:** JVM (1.3), JS (1.3), Native (1.3) #### [kotlin.contracts](api/latest/jvm/stdlib/kotlin.contracts/index)
Experimental DSL for declaring custom function contracts.
**Platform and version requirements:** JVM (1.3), JS (1.3), Native (1.3) #### [kotlin.coroutines](api/latest/jvm/stdlib/kotlin.coroutines/index)
Basic primitives for creating and suspending coroutines: [Continuation](api/latest/jvm/stdlib/kotlin.coroutines/-continuation/index), [CoroutineContext](api/latest/jvm/stdlib/kotlin.coroutines/-coroutine-context/index) interfaces, coroutine creation and suspension top-level functions.
**Platform and version requirements:** JVM (1.4), JS (1.4), Native (1.4) #### [kotlin.coroutines.cancellation](api/latest/jvm/stdlib/kotlin.coroutines.cancellation/index)
**Platform and version requirements:** JVM (1.3), JS (1.3), Native (1.3) #### [kotlin.coroutines.intrinsics](api/latest/jvm/stdlib/kotlin.coroutines.intrinsics/index)
Low-level building blocks for libraries that provide coroutine-based APIs.
**Platform and version requirements:** JS (1.1) #### [kotlin.dom](api/latest/jvm/stdlib/kotlin.dom/index)
Utility functions for working with the browser DOM.
**Platform and version requirements:** JVM (1.8), JS (1.8), Native (1.8) #### [kotlin.enums](api/latest/jvm/stdlib/kotlin.enums/index)
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.experimental](api/latest/jvm/stdlib/kotlin.experimental/index)
Experimental APIs, subject to change in future versions of Kotlin.
**Platform and version requirements:** Native (1.7) #### [kotlin.internal](api/latest/jvm/stdlib/kotlin.internal/index)
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.io](api/latest/jvm/stdlib/kotlin.io/index)
IO API for working with files and streams.
**Platform and version requirements:** JVM (1.0), JRE7 (1.0) #### [kotlin.io.path](api/latest/jvm/stdlib/kotlin.io.path/index)
Convenient extensions for working with file system using [java.nio.file.Path](https://docs.oracle.com/javase/8/docs/api/java/nio/file/Path.html).
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.js](api/latest/jvm/stdlib/kotlin.js/index)
Functions and other APIs specific to the JavaScript platform.
**Platform and version requirements:** JVM (1.0), JS (1.0) #### [kotlin.jvm](api/latest/jvm/stdlib/kotlin.jvm/index)
Functions and annotations specific to the Java platform.
**Platform and version requirements:** JVM (1.8), JRE8 (1.8) #### [kotlin.jvm.optionals](api/latest/jvm/stdlib/kotlin.jvm.optionals/index)
Convenience extension functions for `java.util.Optional` to simplify Kotlin-Java interop.
**Platform and version requirements:** JVM (1.2), JS (1.2), Native (1.2) #### [kotlin.math](api/latest/jvm/stdlib/kotlin.math/index)
Mathematical functions and constants.
**Platform and version requirements:** Native (1.0) #### [kotlin.native](api/latest/jvm/stdlib/kotlin.native/index)
**Platform and version requirements:** Native (1.0) #### [kotlin.native.concurrent](api/latest/jvm/stdlib/kotlin.native.concurrent/index)
**Platform and version requirements:** Native (1.3) #### [kotlin.native.ref](api/latest/jvm/stdlib/kotlin.native.ref/index)
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.properties](api/latest/jvm/stdlib/kotlin.properties/index)
Standard implementations of delegates for [delegated properties](docs/delegated-properties) and helper functions for implementing custom delegates.
**Platform and version requirements:** JVM (1.3), JS (1.3), Native (1.3) #### [kotlin.random](api/latest/jvm/stdlib/kotlin.random/index)
Provides the default generator of pseudo-random values, the repeatable generator, and a base class for other RNG implementations.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.ranges](api/latest/jvm/stdlib/kotlin.ranges/index)
[Ranges](docs/ranges), Progressions and related top-level and extension functions.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.reflect](api/latest/jvm/stdlib/kotlin.reflect/index)
Runtime API for [Kotlin reflection](docs/reflection)
**Platform and version requirements:** JVM (1.1) #### [kotlin.reflect.full](api/latest/jvm/stdlib/kotlin.reflect.full/index)
Extensions for [Kotlin reflection](docs/reflection) provided by `kotlin-reflect` library.
**Platform and version requirements:** JVM (1.0) #### [kotlin.reflect.jvm](api/latest/jvm/stdlib/kotlin.reflect.jvm/index)
Runtime API for interoperability between [Kotlin reflection](docs/reflection) and Java reflection provided by `kotlin-reflect` library.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.sequences](api/latest/jvm/stdlib/kotlin.sequences/index)
[Sequence](api/latest/jvm/stdlib/kotlin.sequences/-sequence/index) type that represents lazily evaluated collections. Top-level functions for instantiating sequences and extension functions for sequences.
**Platform and version requirements:** JVM (1.2), JRE8 (1.2) #### [kotlin.streams](api/latest/jvm/stdlib/kotlin.streams/index)
Utility functions for working with Java 8 [streams](https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html).
**Platform and version requirements:** JVM (1.0), Native (1.0) #### [kotlin.system](api/latest/jvm/stdlib/kotlin.system/index)
System-related utility functions.
**Platform and version requirements:** JVM (1.0), JS (1.0), Native (1.0) #### [kotlin.text](api/latest/jvm/stdlib/kotlin.text/index)
Functions for working with text and regular expressions.
**Platform and version requirements:** JVM (1.3), JS (1.3), Native (1.3) #### [kotlin.time](api/latest/jvm/stdlib/kotlin.time/index)
API for representing [Duration](api/latest/jvm/stdlib/kotlin.time/-duration/index) values and experimental API for measuring time intervals.
**Platform and version requirements:** JS (1.4) #### [kotlinx.browser](api/latest/jvm/stdlib/kotlinx.browser/index)
**Platform and version requirements:** Native (1.3) #### [kotlinx.cinterop](api/latest/jvm/stdlib/kotlinx.cinterop/index)
**Platform and version requirements:** Native (1.3) #### [kotlinx.cinterop.internal](api/latest/jvm/stdlib/kotlinx.cinterop.internal/index)
**Platform and version requirements:** JS (1.4) #### [kotlinx.dom](api/latest/jvm/stdlib/kotlinx.dom/index)
**Platform and version requirements:** Native (1.3) #### [kotlinx.wasm.jsinterop](api/latest/jvm/stdlib/kotlinx.wasm.jsinterop/index)
**Platform and version requirements:** JS (1.1) #### [org.khronos.webgl](https://kotlinlang.org/api/latest/jvm/stdlib/org.khronos.webgl/index.html)
Kotlin JavaScript wrappers for the WebGL API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.css.masking](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.css.masking/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom/index.html)
Kotlin JavaScript wrappers for the DOM API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.clipboard](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.clipboard/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.css](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.css/index.html)
Kotlin JavaScript wrappers for the DOM CSS API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.encryptedmedia](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.encryptedmedia/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.events](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.events/index.html)
Kotlin JavaScript wrappers for the DOM events API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.mediacapture](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.mediacapture/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.mediasource](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.mediasource/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.parsing](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.parsing/index.html)
Kotlin JavaScript wrappers for the DOM parsing API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.pointerevents](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.pointerevents/index.html)
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.svg](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.svg/index.html)
Kotlin JavaScript wrappers for the DOM SVG API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.dom.url](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.dom.url/index.html)
Kotlin JavaScript wrappers for the DOM URL API.
**Platform and version requirements:** JS (1.1) #### [org.w3c.fetch](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.fetch/index.html)
Kotlin JavaScript wrappers for the [W3C fetch API](https://fetch.spec.whatwg.org).
**Platform and version requirements:** JS (1.1) #### [org.w3c.files](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.files/index.html)
Kotlin JavaScript wrappers for the [W3C file API](https://www.w3.org/TR/FileAPI/).
**Platform and version requirements:** JS (1.1) #### [org.w3c.notifications](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.notifications/index.html)
Kotlin JavaScript wrappers for the [Web Notifications API](https://www.w3.org/TR/notifications/).
**Platform and version requirements:** JS (1.1) #### [org.w3c.performance](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.performance/index.html)
Kotlin JavaScript wrappers for the [Navigation Timing API](https://www.w3.org/TR/navigation-timing/).
**Platform and version requirements:** JS (1.1) #### [org.w3c.workers](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.workers/index.html)
Kotlin JavaScript wrappers for the [Web Workers API](https://www.w3.org/TR/workers/).
**Platform and version requirements:** JS (1.1) #### [org.w3c.xhr](https://kotlinlang.org/api/latest/jvm/stdlib/org.w3c.xhr/index.html)
Kotlin JavaScript wrappers for the [XMLHttpRequest API](https://www.w3.org/TR/XMLHttpRequest/).
Index
-----
[All Types](https://kotlinlang.org/api/latest/jvm/stdlib/alltypes/index.html)
| programming_docs |
kotlin Concurrency and coroutines Concurrency and coroutines
==========================
When working with mobile platforms, you may need to write multithreaded code that runs in parallel. For this, you can use the [standard](#coroutines) `kotlinx.coroutines` library or its [multithreaded version](#multithreaded-coroutines) and [alternative solutions](#alternatives-to-kotlinx-coroutines).
Review the pros and cons of each solution and choose the one that works best for your situation.
Learn more about [concurrency, the current approach, and future improvements](multiplatform-mobile-concurrency-overview).
Coroutines
----------
Coroutines are light-weight threads that allow you to write asynchronous non-blocking code. Kotlin provides the [`kotlinx.coroutines`](https://github.com/Kotlin/kotlinx.coroutines) library with a number of high-level coroutine-enabled primitives.
The current version of `kotlinx.coroutines`, which can be used for iOS, supports usage only in a single thread. You cannot send work to other threads by changing a [dispatcher](#dispatcher-for-changing-threads).
For Kotlin 1.8.0, the recommended coroutines version is `1.6.4`.
You can suspend execution and do work on other threads while using a different mechanism for scheduling and managing that work. However, this version of `kotlinx.coroutines` cannot change threads on its own.
There is also [another version of `kotlinx.coroutines`](#multithreaded-coroutines) that provides support for multiple threads.
Get acquainted with the main concepts for using coroutines:
* [Asynchronous vs. parallel processing](#asynchronous-vs-parallel-processing)
* [Dispatcher for changing threads](#dispatcher-for-changing-threads)
* [Frozen captured data](#frozen-captured-data)
* [Frozen returned data](#frozen-returned-data)
### Asynchronous vs. parallel processing
Asynchronous and parallel processing are different.
Within a coroutine, the processing sequence may be suspended and resumed later. This allows for asynchronous, non-blocking code, without using callbacks or promises. That is asynchronous processing, but everything related to that coroutine can happen in a single thread.
The following code makes a network call using [Ktor](https://ktor.io/). In the main thread, the call is initiated and suspended, while another underlying process performs the actual networking. When completed, the code resumes in the main thread.
```
val client = HttpClient()
//Running in the main thread, start a `get` call
client.get<String>("https://example.com/some/rest/call")
//The get call will suspend and let other work happen in the main thread, and resume when the get call completes
```
That is different from parallel code that needs to be run in another thread. Depending on your purpose and the libraries you use, you may never need to use multiple threads.
### Dispatcher for changing threads
Coroutines are executed by a dispatcher that defines which thread the coroutine will be executed on. There are a number of ways in which you can specify the dispatcher, or change the one for the coroutine. For example:
```
suspend fun differentThread() = withContext(Dispatchers.Default){
println("Different thread")
}
```
`withContext` takes both a dispatcher as an argument and a code block that will be executed by the thread defined by the dispatcher. Learn more about [coroutine context and dispatchers](coroutine-context-and-dispatchers).
To perform work on a different thread, specify a different dispatcher and a code block to execute. In general, switching dispatchers and threads works similar to the JVM, but there are differences related to freezing captured and returned data.
### Frozen captured data
To run code on a different thread, you pass a `functionBlock`, which gets frozen and then runs in another thread.
```
fun <R> runOnDifferentThread(functionBlock: () -> R)
```
You will call that function as follows:
```
runOnDifferentThread {
//Code run in another thread
}
```
As described in the [concurrency overview](multiplatform-mobile-concurrency-overview), a state shared between threads in Kotlin/Native must be frozen. A function argument is a state itself, which will be frozen along with anything it captures.
Coroutine functions that cross threads use the same pattern. To allow function blocks to be executed on another thread, they are frozen.
In the following example, the data class instance `dc` will be captured by the function block and will be frozen when crossing threads. The `println` statement will print `true`.
```
val dc = DataClass("Hello")
withContext(Dispatchers.Default) {
println("${dc.isFrozen}")
}
```
When running parallel code, be careful with the captured state. Sometimes it's obvious when the state will be captured, but not always. For example:
```
class SomeModel(val id:IdRec){
suspend fun saveData() = withContext(Dispatchers.Default){
saveToDb(id)
}
}
```
The code inside `saveData` runs on another thread. That will freeze `id`, but because `id` is a property of the parent class, it will also freeze the parent class.
### Frozen returned data
Data returned from a different thread is also frozen. Even though it's recommended that you return immutable data, you can return a mutable state in a way that doesn't allow a returned value to be changed.
```
val dc = withContext(Dispatchers.Default) {
DataClass("Hello Again")
}
println("${dc.isFrozen}")
```
It may be a problem if a mutable state is isolated in a single thread and coroutine threading operations are used for communication. If you attempt to return data that retains a reference to the mutable state, it will also freeze the data by association.
Learn more about the [thread-isolated state](multiplatform-mobile-concurrent-mutability#thread-isolated-state).
Multithreaded coroutines
------------------------
A [special branch](https://github.com/Kotlin/kotlinx.coroutines/tree/native-mt) of the `kotlinx.coroutines` library provides support for using multiple threads. It is a separate branch for the reasons listed in the [future concurrency model blog post](https://blog.jetbrains.com/kotlin/2020/07/kotlin-native-memory-management-roadmap/).
However, you can still use the multithreaded version of `kotlinx.coroutines` in production, taking its specifics into account.
The current version for Kotlin 1.8.0 is `1.6.4-native-mt`.
To use the multithreaded version, add a dependency for the `commonMain` source set in `build.gradle(.kts)`:
```
val commonMain by getting {
dependencies {
implementation ("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4-native-mt")
}
}
```
```
commonMain {
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4-native-mt'
}
}
```
When using other libraries that also depend on `kotlinx.coroutines`, such as Ktor, make sure to specify the multithreaded version of `kotlinx-coroutines`. You can do this with `strictly`:
```
implementation ("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4-native-mt") {
version {
strictly("1.6.4-native-mt")
}
}
```
```
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4-native-mt' {
version {
strictly '1.6.4-native-mt'
}
}
```
Because the main version of `kotlinx.coroutines` is a single-threaded one, libraries will almost certainly rely on this version. If you see `InvalidMutabilityException` related to a coroutine operation, it's very likely that you are using the wrong version.
See a [complete example of using multithreaded coroutines in a Kotlin Multiplatform application](https://github.com/touchlab/KaMPKit).
Alternatives to kotlinx-coroutines
----------------------------------
There are a few alternative ways to run parallel code.
### CoroutineWorker
[`CoroutinesWorker`](https://github.com/Autodesk/coroutineworker) is a library published by AutoDesk that implements some features of coroutines across threads using the single-threaded version of `kotlinx.coroutines`.
For simple suspend functions this is a pretty good option, but it does not support Flow and other structures.
### Reaktive
[Reaktive](https://github.com/badoo/Reaktive) is an Rx-like library that implements Reactive extensions for Kotlin Multiplatform. It has some coroutine extensions but is primarily designed around RX and threads.
### Custom processor
For simpler background tasks, you can create your own processor with wrappers around platform specifics. See a [simple example](https://github.com/touchlab/KMMWorker).
### Platform concurrency
In production, you can also rely on the platform to handle concurrency. This could be helpful if the shared Kotlin code will be used for business logic or data operations rather than architecture.
To share a state in iOS across threads, that state needs to be [frozen](multiplatform-mobile-concurrency-overview#immutable-and-frozen-state). The concurrency libraries mentioned here will freeze your data automatically. You will rarely need to do so explicitly, if ever.
If you return data to the iOS platform that should be shared across threads, ensure that data is frozen before leaving the iOS boundary.
Kotlin has the concept of frozen only for Kotlin/Native platforms including iOS. To make `freeze` available in common code, you can create expect and actual implementations for `freeze`, or use [`stately-common`](https://github.com/touchlab/Stately#stately-common), which provides this functionality. In Kotlin/Native, `freeze` will freeze your state, while on the JVM it'll do nothing.
To use `stately-common`, add a dependency for the `commonMain` source set in `build.gradle(.kts)`:
```
val commonMain by getting {
dependencies {
implementation ("co.touchlab:stately-common:1.0.x")
}
}
```
```
commonMain {
dependencies {
implementation 'co.touchlab:stately-common:1.0.x'
}
}
```
*This material was prepared by [Touchlab](https://touchlab.co/) for publication by JetBrains.*
Last modified: 10 January 2023
[Concurrent mutability](multiplatform-mobile-concurrent-mutability) [Debugging Kotlin/Native](native-debugging)
kotlin Map-specific operations Map-specific operations
=======================
In [maps](collections-overview#map), types of both keys and values are user-defined. Key-based access to map entries enables various map-specific processing capabilities from getting a value by key to separate filtering of keys and values. On this page, we provide descriptions of the map processing functions from the standard library.
Retrieve keys and values
------------------------
For retrieving a value from a map, you must provide its key as an argument of the [`get()`](../api/latest/jvm/stdlib/kotlin.collections/-map/get) function. The shorthand `[key]` syntax is also supported. If the given key is not found, it returns `null`. There is also the function [`getValue()`](../api/latest/jvm/stdlib/kotlin.collections/get-value) which has slightly different behavior: it throws an exception if the key is not found in the map. Additionally, you have two more options to handle the key absence:
* [`getOrElse()`](../api/latest/jvm/stdlib/kotlin.collections/get-or-else) works the same way as for lists: the values for non-existent keys are returned from the given lambda function.
* [`getOrDefault()`](../api/latest/jvm/stdlib/kotlin.collections/get-or-default) returns the specified default value if the key is not found.
```
fun main() {
//sampleStart
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.get("one"))
println(numbersMap["one"])
println(numbersMap.getOrDefault("four", 10))
println(numbersMap["five"]) // null
//numbersMap.getValue("six") // exception!
//sampleEnd
}
```
To perform operations on all keys or all values of a map, you can retrieve them from the properties `keys` and `values` accordingly. `keys` is a set of all map keys and `values` is a collection of all map values.
```
fun main() {
//sampleStart
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap.keys)
println(numbersMap.values)
//sampleEnd
}
```
Filter
------
You can [filter](collection-filtering) maps with the [`filter()`](../api/latest/jvm/stdlib/kotlin.collections/filter) function as well as other collections. When calling `filter()` on a map, pass to it a predicate with a `Pair` as an argument. This enables you to use both the key and the value in the filtering predicate.
```
fun main() {
//sampleStart
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10}
println(filteredMap)
//sampleEnd
}
```
There are also two specific ways for filtering maps: by keys and by values. For each way, there is a function: [`filterKeys()`](../api/latest/jvm/stdlib/kotlin.collections/filter-keys) and [`filterValues()`](../api/latest/jvm/stdlib/kotlin.collections/filter-values). Both return a new map of entries which match the given predicate. The predicate for `filterKeys()` checks only the element keys, the one for `filterValues()` checks only values.
```
fun main() {
//sampleStart
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredKeysMap = numbersMap.filterKeys { it.endsWith("1") }
val filteredValuesMap = numbersMap.filterValues { it < 10 }
println(filteredKeysMap)
println(filteredValuesMap)
//sampleEnd
}
```
Plus and minus operators
------------------------
Due to the key access to elements, [`plus`](../api/latest/jvm/stdlib/kotlin.collections/plus) (`+`) and [`minus`](../api/latest/jvm/stdlib/kotlin.collections/minus) (`-`) operators work for maps differently than for other collections. `plus` returns a `Map` that contains elements of its both operands: a `Map` on the left and a `Pair` or another `Map` on the right. When the right-hand side operand contains entries with keys present in the left-hand side `Map`, the result map contains the entries from the right side.
```
fun main() {
//sampleStart
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap + Pair("four", 4))
println(numbersMap + Pair("one", 10))
println(numbersMap + mapOf("five" to 5, "one" to 11))
//sampleEnd
}
```
`minus` creates a `Map` from entries of a `Map` on the left except those with keys from the right-hand side operand. So, the right-hand side operand can be either a single key or a collection of keys: list, set, and so on.
```
fun main() {
//sampleStart
val numbersMap = mapOf("one" to 1, "two" to 2, "three" to 3)
println(numbersMap - "one")
println(numbersMap - listOf("two", "four"))
//sampleEnd
}
```
For details on using [`plusAssign`](../api/latest/jvm/stdlib/kotlin.collections/plus-assign) (`+=`) and [`minusAssign`](../api/latest/jvm/stdlib/kotlin.collections/minus-assign) (`-=`) operators on mutable maps, see [Map write operations](#map-write-operations) below.
Map write operations
--------------------
[Mutable](collections-overview#collection-types) maps offer map-specific write operations. These operations let you change the map content using the key-based access to the values.
There are certain rules that define write operations on maps:
* Values can be updated. In turn, keys never change: once you add an entry, its key is constant.
* For each key, there is always a single value associated with it. You can add and remove whole entries.
Below are descriptions of the standard library functions for write operations available on mutable maps.
### Add and update entries
To add a new key-value pair to a mutable map, use [`put()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-map/put). When a new entry is put into a `LinkedHashMap` (the default map implementation), it is added so that it comes last when iterating the map. In sorted maps, the positions of new elements are defined by the order of their keys.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap.put("three", 3)
println(numbersMap)
//sampleEnd
}
```
To add multiple entries at a time, use [`putAll()`](../api/latest/jvm/stdlib/kotlin.collections/put-all). Its argument can be a `Map` or a group of `Pair`s: `Iterable`, `Sequence`, or `Array`.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.putAll(setOf("four" to 4, "five" to 5))
println(numbersMap)
//sampleEnd
}
```
Both `put()` and `putAll()` overwrite the values if the given keys already exist in the map. Thus, you can use them to update values of map entries.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
val previousValue = numbersMap.put("one", 11)
println("value associated with 'one', before: $previousValue, after: ${numbersMap["one"]}")
println(numbersMap)
//sampleEnd
}
```
You can also add new entries to maps using the shorthand operator form. There are two ways:
* [`plusAssign`](../api/latest/jvm/stdlib/kotlin.collections/plus-assign) (`+=`) operator.
* the `[]` operator alias for `set()`.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2)
numbersMap["three"] = 3 // calls numbersMap.put("three", 3)
numbersMap += mapOf("four" to 4, "five" to 5)
println(numbersMap)
//sampleEnd
}
```
When called with the key present in the map, operators overwrite the values of the corresponding entries.
### Remove entries
To remove an entry from a mutable map, use the [`remove()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-map/remove) function. When calling `remove()`, you can pass either a key or a whole key-value-pair. If you specify both the key and value, the element with this key will be removed only if its value matches the second argument.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap.remove("one")
println(numbersMap)
numbersMap.remove("three", 4) //doesn't remove anything
println(numbersMap)
//sampleEnd
}
```
You can also remove entries from a mutable map by their keys or values. To do this, call `remove()` on the map's keys or values providing the key or the value of an entry. When called on values, `remove()` removes only the first entry with the given value.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3, "threeAgain" to 3)
numbersMap.keys.remove("one")
println(numbersMap)
numbersMap.values.remove(3)
println(numbersMap)
//sampleEnd
}
```
The [`minusAssign`](../api/latest/jvm/stdlib/kotlin.collections/minus-assign) (`-=`) operator is also available for mutable maps.
```
fun main() {
//sampleStart
val numbersMap = mutableMapOf("one" to 1, "two" to 2, "three" to 3)
numbersMap -= "two"
println(numbersMap)
numbersMap -= "five" //doesn't remove anything
println(numbersMap)
//sampleEnd
}
```
Last modified: 10 January 2023
[Set-specific operations](set-operations) [Scope functions](scope-functions)
kotlin Kotlin tips Kotlin tips
===========
Kotlin Tips is a series of short videos where members of the Kotlin team show how to use Kotlin in a more efficient and idiomatic way to have more fun when writing code.
[Subscribe to our YouTube channel](https://www.youtube.com/channel/UCP7uiEZIqci43m22KDl0sNw) to not miss new Kotlin Tips videos.
null + null in Kotlin
---------------------
What happens when you add `null + null` in Kotlin, and what does it return? Sebastian Aigner addresses this mystery in our latest quick tip. Along the way, he also shows why there's no reason to be scared of nullables:
Deduplicating collection items
------------------------------
Got a Kotlin collection that contains duplicates? Need a collection with only unique items? Let Sebastian Aigner show you how to remove duplicates from your lists, or turn them into sets in this Kotlin tip:
The suspend and inline mystery
------------------------------
How come functions like [`repeat()`](../api/latest/jvm/stdlib/kotlin/repeat), [`map()`](../api/latest/jvm/stdlib/kotlin.collections/map) and [`filter()`](../api/latest/jvm/stdlib/kotlin.collections/filter) accept suspending functions in their lambdas, even though their signatures aren't coroutines-aware? In this episode of Kotlin Tips Sebastian Aigner solves the riddle: it has something to do with the inline modifier:
Unshadowing declarations with their fully qualified name
--------------------------------------------------------
Shadowing means having two declarations in a scope have the same name. So, how do you pick? In this episode of Kotlin Tips Sebastian Aigner shows you a simple Kotlin trick to call exactly the function that you need, using the power of fully qualified names:
Return and throw with the Elvis operator
----------------------------------------
[Elvis](null-safety#elvis-operator) has entered the building once more! Sebastian Aigner explains why the operator is named after the famous singer, and how you can use `?:` in Kotlin to return or throw. The magic behind the scenes? [The Nothing type](../api/latest/jvm/stdlib/kotlin/-nothing).
Destructuring declarations
--------------------------
With [destructuring declarations](destructuring-declarations) in Kotlin, you can create multiple variables from a single object, all at once. In this video Sebastian Aigner shows you a selection of things that can be destructured – pairs, lists, maps, and more. And what about your own objects? Kotlin's component functions provide an answer for those as well:
Operator functions with nullable values
---------------------------------------
In Kotlin, you can override operators like addition and subtraction for your classes and supply your own logic. But what if you want to allow null values, both on their left and right sides? In this video, Sebastian Aigner answers this question:
Timing code
-----------
Watch Sebastian Aigner give a quick overview of the [`measureTimedValue()`](../api/latest/jvm/stdlib/kotlin.time/measure-timed-value) function, and learn how you can time your code:
Improving loops
---------------
In this video, Sebastian Aigner will demonstrate how to improve [loops](control-flow#for-loops) to make your code more readable, understandable, and concise:
Strings
-------
In this episode, Kate Petrova shows three tips to help you work with [Strings](strings) in Kotlin:
Doing more with the Elvis operator
----------------------------------
In this video, Sebastian Aigner will show how to add more logic to the [Elvis operator](null-safety#elvis-operator), such as logging to the right part of the operator:
Kotlin collections
------------------
In this episode, Kate Petrova shows three tips to help you work with [Kotlin Collections](collections-overview):
What's next?
------------
* See the complete list of Kotlin Tips in our [YouTube playlist](https://youtube.com/playlist?list=PLlFc5cFwUnmyDrc-mwwAL9cYFkSHoHHz7)
* Learn how to write [idiomatic Kotlin code for popular cases](idioms)
Last modified: 10 January 2023
[Kotlin Koans](koans) [Kotlin books](books)
| programming_docs |
kotlin Collection transformation operations Collection transformation operations
====================================
The Kotlin standard library provides a set of extension functions for collection *transformations*. These functions build new collections from existing ones based on the transformation rules provided. In this page, we'll give an overview of the available collection transformation functions.
Map
---
The *mapping* transformation creates a collection from the results of a function on the elements of another collection. The basic mapping function is [`map()`](../api/latest/jvm/stdlib/kotlin.collections/map). It applies the given lambda function to each subsequent element and returns the list of the lambda results. The order of results is the same as the original order of elements. To apply a transformation that additionally uses the element index as an argument, use [`mapIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/map-indexed).
```
fun main() {
//sampleStart
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
println(numbers.mapIndexed { idx, value -> value * idx })
//sampleEnd
}
```
If the transformation produces `null` on certain elements, you can filter out the `null`s from the result collection by calling the [`mapNotNull()`](../api/latest/jvm/stdlib/kotlin.collections/map-not-null) function instead of `map()`, or [`mapIndexedNotNull()`](../api/latest/jvm/stdlib/kotlin.collections/map-indexed-not-null) instead of `mapIndexed()`.
```
fun main() {
//sampleStart
val numbers = setOf(1, 2, 3)
println(numbers.mapNotNull { if ( it == 2) null else it * 3 })
println(numbers.mapIndexedNotNull { idx, value -> if (idx == 0) null else value * idx })
//sampleEnd
}
```
When transforming maps, you have two options: transform keys leaving values unchanged and vice versa. To apply a given transformation to keys, use [`mapKeys()`](../api/latest/jvm/stdlib/kotlin.collections/map-keys); in turn, [`mapValues()`](../api/latest/jvm/stdlib/kotlin.collections/map-values) transforms values. Both functions use the transformations that take a map entry as an argument, so you can operate both its key and value.
```
fun main() {
//sampleStart
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
println(numbersMap.mapKeys { it.key.uppercase() })
println(numbersMap.mapValues { it.value + it.key.length })
//sampleEnd
}
```
Zip
---
*Zipping* transformation is building pairs from elements with the same positions in both collections. In the Kotlin standard library, this is done by the [`zip()`](../api/latest/jvm/stdlib/kotlin.collections/zip) extension function.
When called on a collection or an array with another collection (or array) as an argument, `zip()` returns the `List` of `Pair` objects. The elements of the receiver collection are the first elements in these pairs.
If the collections have different sizes, the result of the `zip()` is the smaller size; the last elements of the larger collection are not included in the result.
`zip()` can also be called in the infix form `a zip b`.
```
fun main() {
//sampleStart
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors zip animals)
val twoAnimals = listOf("fox", "bear")
println(colors.zip(twoAnimals))
//sampleEnd
}
```
You can also call `zip()` with a transformation function that takes two parameters: the receiver element and the argument element. In this case, the result `List` contains the return values of the transformation function called on pairs of the receiver and the argument elements with the same positions.
```
fun main() {
//sampleStart
val colors = listOf("red", "brown", "grey")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal -> "The ${animal.replaceFirstChar { it.uppercase() }} is $color"})
//sampleEnd
}
```
When you have a `List` of `Pair`s, you can do the reverse transformation – *unzipping* – that builds two lists from these pairs:
* The first list contains the first elements of each `Pair` in the original list.
* The second list contains the second elements.
To unzip a list of pairs, call [`unzip()`](../api/latest/jvm/stdlib/kotlin.collections/unzip).
```
fun main() {
//sampleStart
val numberPairs = listOf("one" to 1, "two" to 2, "three" to 3, "four" to 4)
println(numberPairs.unzip())
//sampleEnd
}
```
Associate
---------
*Association* transformations allow building maps from the collection elements and certain values associated with them. In different association types, the elements can be either keys or values in the association map.
The basic association function [`associateWith()`](../api/latest/jvm/stdlib/kotlin.collections/associate-with) creates a `Map` in which the elements of the original collection are keys, and values are produced from them by the given transformation function. If two elements are equal, only the last one remains in the map.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
//sampleEnd
}
```
For building maps with collection elements as values, there is the function [`associateBy()`](../api/latest/jvm/stdlib/kotlin.collections/associate-by). It takes a function that returns a key based on an element's value. If two elements' keys are equal, only the last one remains in the map.
`associateBy()` can also be called with a value transformation function.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateBy { it.first().uppercaseChar() })
println(numbers.associateBy(keySelector = { it.first().uppercaseChar() }, valueTransform = { it.length }))
//sampleEnd
}
```
Another way to build maps in which both keys and values are somehow produced from collection elements is the function [`associate()`](../api/latest/jvm/stdlib/kotlin.collections/associate). It takes a lambda function that returns a `Pair`: the key and the value of the corresponding map entry.
Note that `associate()` produces short-living `Pair` objects which may affect the performance. Thus, `associate()` should be used when the performance isn't critical or it's more preferable than other options.
An example of the latter is when a key and the corresponding value are produced from an element together.
```
fun main() {
data class FullName (val firstName: String, val lastName: String)
fun parseFullName(fullName: String): FullName {
val nameParts = fullName.split(" ")
if (nameParts.size == 2) {
return FullName(nameParts[0], nameParts[1])
} else throw Exception("Wrong name format")
}
//sampleStart
val names = listOf("Alice Adams", "Brian Brown", "Clara Campbell")
println(names.associate { name -> parseFullName(name).let { it.lastName to it.firstName } })
//sampleEnd
}
```
Here we call a transform function on an element first, and then build a pair from the properties of that function's result.
Flatten
-------
If you operate nested collections, you may find the standard library functions that provide flat access to nested collection elements useful.
The first function is [`flatten()`](../api/latest/jvm/stdlib/kotlin.collections/flatten). You can call it on a collection of collections, for example, a `List` of `Set`s. The function returns a single `List` of all the elements of the nested collections.
```
fun main() {
//sampleStart
val numberSets = listOf(setOf(1, 2, 3), setOf(4, 5, 6), setOf(1, 2))
println(numberSets.flatten())
//sampleEnd
}
```
Another function – [`flatMap()`](../api/latest/jvm/stdlib/kotlin.collections/flat-map) provides a flexible way to process nested collections. It takes a function that maps a collection element to another collection. As a result, `flatMap()` returns a single list of its return values on all the elements. So, `flatMap()` behaves as a subsequent call of `map()` (with a collection as a mapping result) and `flatten()`.
```
data class StringContainer(val values: List<String>)
fun main() {
//sampleStart
val containers = listOf(
StringContainer(listOf("one", "two", "three")),
StringContainer(listOf("four", "five", "six")),
StringContainer(listOf("seven", "eight"))
)
println(containers.flatMap { it.values })
//sampleEnd
}
```
String representation
---------------------
If you need to retrieve the collection content in a readable format, use functions that transform the collections to strings: [`joinToString()`](../api/latest/jvm/stdlib/kotlin.collections/join-to-string) and [`joinTo()`](../api/latest/jvm/stdlib/kotlin.collections/join-to).
`joinToString()` builds a single `String` from the collection elements based on the provided arguments. `joinTo()` does the same but appends the result to the given [`Appendable`](../api/latest/jvm/stdlib/kotlin.text/-appendable/index) object.
When called with the default arguments, the functions return the result similar to calling `toString()` on the collection: a `String` of elements' string representations separated by commas with spaces.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers)
println(numbers.joinToString())
val listString = StringBuffer("The list of numbers: ")
numbers.joinTo(listString)
println(listString)
//sampleEnd
}
```
To build a custom string representation, you can specify its parameters in function arguments `separator`, `prefix`, and `postfix`. The resulting string will start with the `prefix` and end with the `postfix`. The `separator` will come after each element except the last.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString(separator = " | ", prefix = "start: ", postfix = ": end"))
//sampleEnd
}
```
For bigger collections, you may want to specify the `limit` – a number of elements that will be included into result. If the collection size exceeds the `limit`, all the other elements will be replaced with a single value of the `truncated` argument.
```
fun main() {
//sampleStart
val numbers = (1..100).toList()
println(numbers.joinToString(limit = 10, truncated = "<...>"))
//sampleEnd
}
```
Finally, to customize the representation of elements themselves, provide the `transform` function.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.joinToString { "Element: ${it.uppercase()}"})
//sampleEnd
}
```
Last modified: 10 January 2023
[Collection operations overview](collection-operations) [Filtering collections](collection-filtering)
kotlin Cancellation and timeouts Cancellation and timeouts
=========================
This section covers coroutine cancellation and timeouts.
Cancelling coroutine execution
------------------------------
In a long-running application you might need fine-grained control on your background coroutines. For example, a user might have closed the page that launched a coroutine and now its result is no longer needed and its operation can be cancelled. The [launch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/launch.html) function returns a [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) that can be used to cancel the running coroutine:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancel() // cancels the job
job.join() // waits for job's completion
println("main: Now I can quit.")
//sampleEnd
}
```
It produces the following output:
```
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.
```
As soon as main invokes `job.cancel`, we don't see any output from the other coroutine because it was cancelled. There is also a [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) extension function [cancelAndJoin](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel-and-join.html) that combines [cancel](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel.html) and [join](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/join.html) invocations.
Cancellation is cooperative
---------------------------
Coroutine cancellation is *cooperative*. A coroutine code has to cooperate to be cancellable. All the suspending functions in `kotlinx.coroutines` are *cancellable*. They check for cancellation of coroutine and throw [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html) when cancelled. However, if a coroutine is working in a computation and does not check for cancellation, then it cannot be cancelled, like the following example shows:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) { // computation loop, just wastes CPU
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}
```
Run it to see that it continues to print "I'm sleeping" even after cancellation until the job completes by itself after five iterations.
The same problem can be observed by catching a [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html) and not rethrowing it:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch(Dispatchers.Default) {
repeat(5) { i ->
try {
// print a message twice a second
println("job: I'm sleeping $i ...")
delay(500)
} catch (e: Exception) {
// log the exception
println(e)
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}
```
While catching `Exception` is an anti-pattern, this issue may surface in more subtle ways, like when using the [`runCatching`](../api/latest/jvm/stdlib/kotlin/run-catching) function, which does not rethrow [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html).
Making computation code cancellable
-----------------------------------
There are two approaches to making computation code cancellable. The first one is to periodically invoke a suspending function that checks for cancellation. There is a [yield](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/yield.html) function that is a good choice for that purpose. The other one is to explicitly check the cancellation status. Let us try the latter approach.
Replace `while (i < 5)` in the previous example with `while (isActive)` and rerun it.
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (isActive) { // cancellable computation loop
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}
```
As you can see, now this loop is cancelled. [isActive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/is-active.html) is an extension property available inside the coroutine via the [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) object.
Closing resources with finally
------------------------------
Cancellable suspending functions throw [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html) on cancellation, which can be handled in the usual way. For example, the `try {...} finally {...}` expression and Kotlin's `use` function execute their finalization actions normally when a coroutine is cancelled:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
println("job: I'm running finally")
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}
```
Both [join](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/join.html) and [cancelAndJoin](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel-and-join.html) wait for all finalization actions to complete, so the example above produces the following output:
```
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm running finally
main: Now I can quit.
```
Run non-cancellable block
-------------------------
Any attempt to use a suspending function in the `finally` block of the previous example causes [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html), because the coroutine running this code is cancelled. Usually, this is not a problem, since all well-behaving closing operations (closing a file, cancelling a job, or closing any kind of a communication channel) are usually non-blocking and do not involve any suspending functions. However, in the rare case when you need to suspend in a cancelled coroutine you can wrap the corresponding code in `withContext(NonCancellable) {...}` using [withContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-context.html) function and [NonCancellable](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-non-cancellable/index.html) context as the following example shows:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
withContext(NonCancellable) {
println("job: I'm running finally")
delay(1000L)
println("job: And I've just delayed for 1 sec because I'm non-cancellable")
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}
```
Timeout
-------
The most obvious practical reason to cancel execution of a coroutine is because its execution time has exceeded some timeout. While you can manually track the reference to the corresponding [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) and launch a separate coroutine to cancel the tracked one after delay, there is a ready to use [withTimeout](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout.html) function that does it. Look at the following example:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
withTimeout(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
//sampleEnd
}
```
It produces the following output:
```
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms
```
The `TimeoutCancellationException` that is thrown by [withTimeout](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout.html) is a subclass of [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html). We have not seen its stack trace printed on the console before. That is because inside a cancelled coroutine `CancellationException` is considered to be a normal reason for coroutine completion. However, in this example we have used `withTimeout` right inside the `main` function.
Since cancellation is just an exception, all resources are closed in the usual way. You can wrap the code with timeout in a `try {...} catch (e: TimeoutCancellationException) {...}` block if you need to do some additional action specifically on any kind of timeout or use the [withTimeoutOrNull](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout-or-null.html) function that is similar to [withTimeout](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout.html) but returns `null` on timeout instead of throwing an exception:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val result = withTimeoutOrNull(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
"Done" // will get cancelled before it produces this result
}
println("Result is $result")
//sampleEnd
}
```
There is no longer an exception when running this code:
```
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Result is null
```
Asynchronous timeout and resources
----------------------------------
The timeout event in [withTimeout](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout.html) is asynchronous with respect to the code running in its block and may happen at any time, even right before the return from inside of the timeout block. Keep this in mind if you open or acquire some resource inside the block that needs closing or release outside of the block.
For example, here we imitate a closeable resource with the `Resource` class that simply keeps track of how many times it was created by incrementing the `acquired` counter and decrementing the counter in its `close` function. Now let us let us create a lot of coroutines, each of which creates a `Resource` at the end of the `withTimeout` block and releases the resource outside the block. We add a small delay so that it is more likely that the timeout occurs right when the `withTimeout` block is already finished, which will cause a resource leak.
```
import kotlinx.coroutines.*
//sampleStart
var acquired = 0
class Resource {
init { acquired++ } // Acquire the resource
fun close() { acquired-- } // Release the resource
}
fun main() {
runBlocking {
repeat(100_000) { // Launch 100K coroutines
launch {
val resource = withTimeout(60) { // Timeout of 60 ms
delay(50) // Delay for 50 ms
Resource() // Acquire a resource and return it from withTimeout block
}
resource.close() // Release the resource
}
}
}
// Outside of runBlocking all coroutines have completed
println(acquired) // Print the number of resources still acquired
}
//sampleEnd
```
If you run the above code, you'll see that it does not always print zero, though it may depend on the timings of your machine. You may need to tweak the timeout in this example to actually see non-zero values.
To work around this problem you can store a reference to the resource in a variable instead of returning it from the `withTimeout` block.
```
import kotlinx.coroutines.*
var acquired = 0
class Resource {
init { acquired++ } // Acquire the resource
fun close() { acquired-- } // Release the resource
}
fun main() {
//sampleStart
runBlocking {
repeat(100_000) { // Launch 100K coroutines
launch {
var resource: Resource? = null // Not acquired yet
try {
withTimeout(60) { // Timeout of 60 ms
delay(50) // Delay for 50 ms
resource = Resource() // Store a resource to the variable if acquired
}
// We can do something else with the resource here
} finally {
resource?.close() // Release the resource if it was acquired
}
}
}
}
// Outside of runBlocking all coroutines have completed
println(acquired) // Print the number of resources still acquired
//sampleEnd
}
```
This example always prints zero. Resources do not leak.
Last modified: 10 January 2023
[Coroutines and channels − tutorial](coroutines-and-channels) [Composing suspending functions](composing-suspending-functions)
| programming_docs |
kotlin Kotlin Native Kotlin Native
=============
Kotlin/Native is a technology for compiling Kotlin code to native binaries which can run without a virtual machine. Kotlin/Native includes an [LLVM](https://llvm.org/)-based backend for the Kotlin compiler and a native implementation of the Kotlin standard library.
Why Kotlin/Native?
------------------
Kotlin/Native is primarily designed to allow compilation for platforms on which *virtual machines* are not desirable or possible, such as embedded devices or iOS. It is ideal for situations when a developer needs to produce a self-contained program that does not require an additional runtime or virtual machine.
Target platforms
----------------
Kotlin/Native supports the following platforms:
* macOS
* iOS, tvOS, watchOS
* Linux
* Windows (MinGW)
* Android NDK
[The full list of supported targets is available here](multiplatform-dsl-reference#targets).
Interoperability
----------------
Kotlin/Native supports two-way interoperability with native programming languages for different operating systems. The compiler creates:
* an executable for many [platforms](#target-platforms)
* a static library or [dynamic](native-dynamic-libraries) library with C headers for C/C++ projects
* an [Apple framework](apple-framework) for Swift and Objective-C projects
Kotlin/Native supports interoperability to use existing libraries directly from Kotlin/Native:
* static or dynamic [C libraries](native-c-interop)
* C, [Swift, and Objective-C](native-objc-interop) frameworks
It is easy to include compiled Kotlin code in existing projects written in C, C++, Swift, Objective-C, and other languages. It is also easy to use existing native code, static or dynamic [C libraries](native-c-interop), Swift/Objective-C [frameworks](native-objc-interop), graphical engines, and anything else directly from Kotlin/Native.
Kotlin/Native [libraries](native-platform-libs) help share Kotlin code between projects. POSIX, gzip, OpenGL, Metal, Foundation, and many other popular libraries and Apple frameworks are pre-imported and included as Kotlin/Native libraries in the compiler package.
Sharing code between platforms
------------------------------
[Multiplatform projects](multiplatform) allow sharing common Kotlin code between multiple platforms, including Android, iOS, JVM, JavaScript, and native. Multiplatform libraries provide required APIs for common Kotlin code and help develop shared parts of a project in Kotlin in one place and share it with some or all target platforms.
You can use [Kotlin Multiplatform Mobile](https://kotlinlang.org/lp/mobile/) to create multiplatform mobile applications with code shared between Android and iOS.
How to get started
------------------
### Tutorials and documentation
New to Kotlin? Take a look at [Getting started with Kotlin](getting-started).
Recommended documentation:
* [Kotlin Multiplatform Mobile documentation](multiplatform-mobile-getting-started)
* [Multiplatform documentation](multiplatform-get-started)
* [C interop](native-c-interop)
* [Swift/Objective-C interop](native-objc-interop)
Recommended tutorials:
* [Get started with Kotlin/Native](native-get-started)
* [Create your first cross-platform mobile application](multiplatform-mobile-create-first-app)
* [Types mapping between C and Kotlin/Native](mapping-primitive-data-types-from-c)
* [Kotlin/Native as a Dynamic Library](native-dynamic-libraries)
* [Kotlin/Native as an Apple Framework](apple-framework)
Last modified: 10 January 2023
[Kotlin for JavaScript](js-overview) [Kotlin for data science](data-science-overview)
kotlin Run code snippets Run code snippets
=================
Kotlin code is typically organized into projects with which you work in an IDE, a text editor, or another tool. However, if you want to quickly see how a function works or find an expression's value, there's no need to create a new project and build it. Check out these three handy ways to run Kotlin code instantly in different environments:
* [Scratch files and worksheets](#ide-scratches-and-worksheets) in the IDE.
* [Kotlin Playground](#browser-kotlin-playground) in the browser.
* [ki shell](#command-line-ki-shell) in the command line.
IDE: scratches and worksheets
-----------------------------
IntelliJ IDEA and Android Studio support Kotlin [scratch files and worksheets](https://www.jetbrains.com/help/idea/kotlin-repl.html#efb8fb32).
* *Scratch files* (or just *scratches*) let you create code drafts in the same IDE window as your project and run them on the fly. Scratches are not tied to projects; you can access and run all your scratches from any IntelliJ IDEA window on your OS.
To create a Kotlin scratch, click **File** | **New** | **Scratch File** and select the **Kotlin** type.
* *Worksheets* are project files: they are stored in project directories and tied to the project modules. Worksheets are useful for writing pieces of code that don't actually make a software unit but should still be stored together in a project, such as educational or demo materials.
To create a Kotlin worksheet in a project directory, right-click the directory in the project tree and select **New** | **Kotlin Worksheet**.
Syntax highlighting, auto-completion, and other IntelliJ IDEA code editing features are supported in scratches and worksheets. There's no need to declare the `main()` function – all the code you write is executed as if it were in the body of `main()`.
Once you have finished writing your code in a scratch or a worksheet, click **Run**. The execution results will appear in the lines opposite your code.
### Interactive mode
The IDE can run code from scratches and worksheets automatically. To get execution results as soon as you stop typing, switch on **Interactive mode**.
### Use modules
You can use classes or functions from a Kotlin project in your scratches and worksheets.
Worksheets automatically have access to classes and functions from the module where they reside.
To use classes or functions from a project in a scratch, import them into the scratch file with the `import` statement, as usual. Then write your code and run it with the appropriate module selected in the **Use classpath of module** list.
Both scratches and worksheets use the compiled versions of connected modules. So, if you modify a module's source files, the changes will propagate to scratches and worksheets when you rebuild the module. To rebuild the module automatically before each run of a scratch or a worksheet, select **Make module before Run**.
### Run as REPL
To evaluate each particular expression in a scratch or a worksheet, run it with **Use REPL** selected. The code lines will run sequentially, providing the results of each call. You can later use the results in the same file by reffering to their auto-generated `res*` names (they are shown in the corresponding lines).
Browser: Kotlin Playground
--------------------------
[Kotlin Playground](https://play.kotlinlang.org/) is an online application for writing, running, and sharing Kotlin code in your browser.
### Write and edit code
In the Playground's editor area, you can write code just as you would in a source file:
* Add your own classes, functions, and top-level declarations in an arbitrary order.
* Write the executable part in the body of the `main()` function.
As in typical Kotlin projects, the `main()` function in the Playground can have the `args` parameter or no parameters at all. To pass program arguments upon execution, write them in the **Program arguments** field.
The Playground highlights the code and shows code completion options as you type. It automatically imports declarations from the standard library and [`kotlinx.coroutines`](coroutines-overview).
### Choose execution environment
The Playground provides ways to customize the execution environment:
* Multiple Kotlin versions, including available [previews of future versions](eap).
* Multiple backends to run the code in: JVM, JS (legacy or [IR compiler](js-ir-compiler), or Canvas), or JUnit.
For JS backends, you can also see the generated JS code.
### Share code online
Use the Playground to share your code with others – click **Copy link** and send it to anyone you want to show the code to.
You can also embed code snippets from the Playground into other websites and even make them runnable. Click **Share code** to embed your sample into any web page or into a [Medium](https://medium.com/) article.
Command line: ki shell
----------------------
The [ki shell](https://github.com/Kotlin/kotlin-interactive-shell) (*Kotlin Interactive Shell*) is a command-line utility for running Kotlin code in the terminal. It's available for Linux, macOS, and Windows.
The ki shell provides basic code evaluation capabilities, along with advanced features such as:
* code completion
* type checks
* external dependencies
* paste mode for code snippets
* scripting support
See the [ki shell GitHub repository](https://github.com/Kotlin/kotlin-interactive-shell) for more details.
### Install and run ki shell
To install the ki shell, download the latest version of it from [GitHub](https://github.com/Kotlin/kotlin-interactive-shell) and unzip it in the directory of your choice.
On macOS, you can also install the ki shell with Homebrew by running the following command:
```
brew install ki
```
To start the ki shell, run `bin/ki.sh` on Linux and macOS (or just `ki` if the ki shell was installed with Homebrew) or `bin\ki.bat` on Windows.
Once the shell is running, you can immediately start writing Kotlin code in your terminal. Type `:help` (or `:h`) to see the commands that are available in the ki shell.
### Code completion and highlighting
The ki shell shows code completion options when you press **Tab**. It also provides syntax highlighting as you type. You can disable this feature by entering `:syntax off`.
When you press **Enter**, the ki shell evaluates the entered line and prints the result. Expression values are printed as variables with auto-generated names like `res*`. You can later use such variables in the code you run. If the construct entered is incomplete (for example, an `if` with a condition but without the body), the shell prints three dots and expects the remaining part.
### Check an expression's type
For complex expressions or APIs that you don't know well, the ki shell provides the `:type` (or `:t`) command, which shows the type of an expression:
### Load code
If the code you need is stored somewhere else, there are two ways to load it and use it in the ki shell:
* Load a source file with the `:load` (or `:l`) command.
* Copy and paste the code snippet in paste mode with the `:paste` (or `:p`) command.
The `ls` command shows available symbols (variables and functions).
### Add external dependencies
Along with the standard library, the ki shell also supports external dependencies. This lets you try out third-party libraries in it without creating a whole project.
To add a third-party library in the ki shell, use the `:dependsOn` command. By default, the ki shell works with Maven Central, but you can use other repositories if you connect them using the `:repository` command:
 Last modified: 10 January 2023
[Migrate to Kotlin code style](code-style-migration-guide) [Kotlin command-line compiler](command-line)
kotlin Annotations Annotations
===========
Annotations are means of attaching metadata to code. To declare an annotation, put the `annotation` modifier in front of a class:
```
annotation class Fancy
```
Additional attributes of the annotation can be specified by annotating the annotation class with meta-annotations:
* [`@Target`](../api/latest/jvm/stdlib/kotlin.annotation/-target/index) specifies the possible kinds of elements which can be annotated with the annotation (such as classes, functions, properties, and expressions);
* [`@Retention`](../api/latest/jvm/stdlib/kotlin.annotation/-retention/index) specifies whether the annotation is stored in the compiled class files and whether it's visible through reflection at runtime (by default, both are true);
* [`@Repeatable`](../api/latest/jvm/stdlib/kotlin.annotation/-repeatable/index) allows using the same annotation on a single element multiple times;
* [`@MustBeDocumented`](../api/latest/jvm/stdlib/kotlin.annotation/-must-be-documented/index) specifies that the annotation is part of the public API and should be included in the class or method signature shown in the generated API documentation.
```
@Target(AnnotationTarget.CLASS, AnnotationTarget.FUNCTION,
AnnotationTarget.TYPE_PARAMETER, AnnotationTarget.VALUE_PARAMETER,
AnnotationTarget.EXPRESSION)
@Retention(AnnotationRetention.SOURCE)
@MustBeDocumented
annotation class Fancy
```
Usage
-----
```
@Fancy class Foo {
@Fancy fun baz(@Fancy foo: Int): Int {
return (@Fancy 1)
}
}
```
If you need to annotate the primary constructor of a class, you need to add the `constructor` keyword to the constructor declaration, and add the annotations before it:
```
class Foo @Inject constructor(dependency: MyDependency) { ... }
```
You can also annotate property accessors:
```
class Foo {
var x: MyDependency? = null
@Inject set
}
```
Constructors
------------
Annotations can have constructors that take parameters.
```
annotation class Special(val why: String)
@Special("example") class Foo {}
```
Allowed parameter types are:
* Types that correspond to Java primitive types (Int, Long etc.)
* Strings
* Classes (`Foo::class`)
* Enums
* Other annotations
* Arrays of the types listed above
Annotation parameters cannot have nullable types, because the JVM does not support storing `null` as a value of an annotation attribute.
If an annotation is used as a parameter of another annotation, its name is not prefixed with the `@` character:
```
annotation class ReplaceWith(val expression: String)
annotation class Deprecated(
val message: String,
val replaceWith: ReplaceWith = ReplaceWith(""))
@Deprecated("This function is deprecated, use === instead", ReplaceWith("this === other"))
```
If you need to specify a class as an argument of an annotation, use a Kotlin class ([KClass](../api/latest/jvm/stdlib/kotlin.reflect/-k-class/index)). The Kotlin compiler will automatically convert it to a Java class, so that the Java code can access the annotations and arguments normally.
```
import kotlin.reflect.KClass
annotation class Ann(val arg1: KClass<*>, val arg2: KClass<out Any>)
@Ann(String::class, Int::class) class MyClass
```
Instantiation
-------------
In Java, an annotation type is a form of an interface, so you can implement it and use an instance. As an alternative to this mechanism, Kotlin lets you call a constructor of an annotation class in arbitrary code and similarly use the resulting instance.
```
annotation class InfoMarker(val info: String)
fun processInfo(marker: InfoMarker): Unit = TODO()
fun main(args: Array<String>) {
if (args.isNotEmpty())
processInfo(getAnnotationReflective(args))
else
processInfo(InfoMarker("default"))
}
```
Learn more about instantiation of annotation classes in [this KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/annotation-instantiation.md).
Lambdas
-------
Annotations can also be used on lambdas. They will be applied to the `invoke()` method into which the body of the lambda is generated. This is useful for frameworks like [Quasar](https://docs.paralleluniverse.co/quasar/), which uses annotations for concurrency control.
```
annotation class Suspendable
val f = @Suspendable { Fiber.sleep(10) }
```
Annotation use-site targets
---------------------------
When you're annotating a property or a primary constructor parameter, there are multiple Java elements which are generated from the corresponding Kotlin element, and therefore multiple possible locations for the annotation in the generated Java bytecode. To specify how exactly the annotation should be generated, use the following syntax:
```
class Example(@field:Ann val foo, // annotate Java field
@get:Ann val bar, // annotate Java getter
@param:Ann val quux) // annotate Java constructor parameter
```
The same syntax can be used to annotate the entire file. To do this, put an annotation with the target `file` at the top level of a file, before the package directive or before all imports if the file is in the default package:
```
@file:JvmName("Foo")
package org.jetbrains.demo
```
If you have multiple annotations with the same target, you can avoid repeating the target by adding brackets after the target and putting all the annotations inside the brackets:
```
class Example {
@set:[Inject VisibleForTesting]
var collaborator: Collaborator
}
```
The full list of supported use-site targets is:
* `file`
* `property` (annotations with this target are not visible to Java)
* `field`
* `get` (property getter)
* `set` (property setter)
* `receiver` (receiver parameter of an extension function or property)
* `param` (constructor parameter)
* `setparam` (property setter parameter)
* `delegate` (the field storing the delegate instance for a delegated property)
To annotate the receiver parameter of an extension function, use the following syntax:
```
fun @receiver:Fancy String.myExtension() { ... }
```
If you don't specify a use-site target, the target is chosen according to the `@Target` annotation of the annotation being used. If there are multiple applicable targets, the first applicable target from the following list is used:
* `param`
* `property`
* `field`
Java annotations
----------------
Java annotations are 100% compatible with Kotlin:
```
import org.junit.Test
import org.junit.Assert.*
import org.junit.Rule
import org.junit.rules.*
class Tests {
// apply @Rule annotation to property getter
@get:Rule val tempFolder = TemporaryFolder()
@Test fun simple() {
val f = tempFolder.newFile()
assertEquals(42, getTheAnswer())
}
}
```
Since the order of parameters for an annotation written in Java is not defined, you can't use a regular function call syntax for passing the arguments. Instead, you need to use the named argument syntax:
```
// Java
public @interface Ann {
int intValue();
String stringValue();
}
```
```
// Kotlin
@Ann(intValue = 1, stringValue = "abc") class C
```
Just like in Java, a special case is the `value` parameter; its value can be specified without an explicit name:
```
// Java
public @interface AnnWithValue {
String value();
}
```
```
// Kotlin
@AnnWithValue("abc") class C
```
### Arrays as annotation parameters
If the `value` argument in Java has an array type, it becomes a `vararg` parameter in Kotlin:
```
// Java
public @interface AnnWithArrayValue {
String[] value();
}
```
```
// Kotlin
@AnnWithArrayValue("abc", "foo", "bar") class C
```
For other arguments that have an array type, you need to use the array literal syntax or `arrayOf(...)`:
```
// Java
public @interface AnnWithArrayMethod {
String[] names();
}
```
```
@AnnWithArrayMethod(names = ["abc", "foo", "bar"])
class C
```
### Accessing properties of an annotation instance
Values of an annotation instance are exposed as properties to Kotlin code:
```
// Java
public @interface Ann {
int value();
}
```
```
// Kotlin
fun foo(ann: Ann) {
val i = ann.value
}
```
### Ability to not generate JVM 1.8+ annotation targets
If a Kotlin annotation has `TYPE` among its Kotlin targets, the annotation maps to `java.lang.annotation.ElementType.TYPE_USE` in its list of Java annotation targets. This is just like how the `TYPE_PARAMETER` Kotlin target maps to the `java.lang.annotation.ElementType.TYPE_PARAMETER` Java target. This is an issue for Android clients with API levels less than 26, which don't have these targets in the API.
To avoid generating the `TYPE_USE` and `TYPE_PARAMETER` annotation targets, use the new compiler argument `-Xno-new-java-annotation-targets`.
Repeatable annotations
----------------------
Just like [in Java](https://docs.oracle.com/javase/tutorial/java/annotations/repeating.html), Kotlin has repeatable annotations, which can be applied to a single code element multiple times. To make your annotation repeatable, mark its declaration with the [`@kotlin.annotation.Repeatable`](../api/latest/jvm/stdlib/kotlin.annotation/-repeatable/index) meta-annotation. This will make it repeatable both in Kotlin and Java. Java repeatable annotations are also supported from the Kotlin side.
The main difference with the scheme used in Java is the absence of a *containing annotation*, which the Kotlin compiler generates automatically with a predefined name. For an annotation in the example below, it will generate the containing annotation `@Tag.Container`:
```
@Repeatable
annotation class Tag(val name: String)
// The compiler generates the @Tag.Container containing annotation
```
You can set a custom name for a containing annotation by applying the [`@kotlin.jvm.JvmRepeatable`](../api/latest/jvm/stdlib/kotlin.jvm/-jvmrepeatable/index) meta-annotation and passing an explicitly declared containing annotation class as an argument:
```
@JvmRepeatable(Tags::class)
annotation class Tag(val name: String)
annotation class Tags(val value: Array<Tag>)
```
To extract Kotlin or Java repeatable annotations via reflection, use the [`KAnnotatedElement.findAnnotations()`](../api/latest/jvm/stdlib/kotlin.reflect.full/find-annotations) function.
Learn more about Kotlin repeatable annotations in [this KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/repeatable-annotations.md).
Last modified: 10 January 2023
[Coroutines](coroutines-overview) [Destructuring declarations](destructuring-declarations)
| programming_docs |
kotlin Coroutines Coroutines
==========
Asynchronous or non-blocking programming is an important part of the development landscape. When creating server-side, desktop, or mobile applications, it's important to provide an experience that is not only fluid from the user's perspective, but also scalable when needed.
Kotlin solves this problem in a flexible way by providing [coroutine](https://en.wikipedia.org/wiki/Coroutine) support at the language level and delegating most of the functionality to libraries.
In addition to opening the doors to asynchronous programming, coroutines also provide a wealth of other possibilities, such as concurrency and actors.
How to start
------------
New to Kotlin? Take a look at the [Getting started](getting-started) page.
### Documentation
* [Coroutines guide](coroutines-guide)
* [Basics](coroutines-basics)
* [Channels](channels)
* [Coroutine context and dispatchers](coroutine-context-and-dispatchers)
* [Shared mutable state and concurrency](shared-mutable-state-and-concurrency)
* [Asynchronous flow](flow)
### Tutorials
* [Asynchronous programming techniques](async-programming)
* [Introduction to coroutines and channels](coroutines-and-channels)
* [Debug coroutines using IntelliJ IDEA](debug-coroutines-with-idea)
* [Debug Kotlin Flow using IntelliJ IDEA – tutorial](debug-flow-with-idea)
* [Testing Kotlin coroutines on Android](https://developer.android.com/kotlin/coroutines/test)
Sample projects
---------------
* [kotlinx.coroutines examples and sources](https://github.com/Kotlin/kotlin-coroutines/tree/master/examples)
* [KotlinConf app](https://github.com/JetBrains/kotlinconf-app)
Last modified: 10 January 2023
[Asynchronous programming techniques](async-programming) [Annotations](annotations)
kotlin What's new in Kotlin 1.7.20 What's new in Kotlin 1.7.20
===========================
*[Release date: 29 September 2022](releases#release-details)*
The Kotlin 1.7.20 release is out! Here are some highlights from this release:
* [The new Kotlin K2 compiler supports `all-open`, SAM with receiver, Lombok, and other compiler plugins](#support-for-kotlin-k2-compiler-plugins)
* [We introduced the preview of the `..<` operator for creating open-ended ranges](#preview-of-the-operator-for-creating-open-ended-ranges)
* [The new Kotlin/Native memory manager is now enabled by default](#the-new-kotlin-native-memory-manager-enabled-by-default)
* [We introduced a new experimental feature for JVM: inline classes with a generic underlying type](#generic-inline-classes)
You can also find a short overview of the changes in this video:
Support for Kotlin K2 compiler plugins
--------------------------------------
The Kotlin team continues to stabilize the K2 compiler. K2 is still in **Alpha** (as announced in the [Kotlin 1.7.0 release](whatsnew17#new-kotlin-k2-compiler-for-the-jvm-in-alpha)), but it now supports several compiler plugins. You can follow [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-52604) to get updates from the Kotlin team on the new compiler.
Starting with this 1.7.20 release, the Kotlin K2 compiler supports the following plugins:
* [`all-open`](all-open-plugin)
* [`no-arg`](no-arg-plugin)
* [SAM with receiver](sam-with-receiver-plugin)
* [Lombok](lombok)
* AtomicFU
* `jvm-abi-gen`
Learn more about the new compiler and its benefits in the following videos:
* [The Road to the New Kotlin Compiler](https://www.youtube.com/watch?v=iTdJJq_LyoY)
* [K2 Compiler: a Top-Down View](https://www.youtube.com/watch?v=db19VFLZqJM)
### How to enable the Kotlin K2 compiler
To enable the Kotlin K2 compiler and test it, use the following compiler option:
```
-Xuse-k2
```
You can specify it in your `build.gradle(.kts)` file:
```
tasks.withType<KotlinCompile> {
kotlinOptions.useK2 = true
}
```
```
compileKotlin {
kotlinOptions.useK2 = true
}
```
Check out the performance boost on your JVM projects and compare it with the results of the old compiler.
### Leave your feedback on the new K2 compiler
We really appreciate your feedback in any form:
* Provide your feedback directly to K2 developers in Kotlin Slack: [get an invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up?_gl=1*ju6cbn*_ga*MTA3MTk5NDkzMC4xNjQ2MDY3MDU4*_ga_9J976DJZ68*MTY1ODMzNzA3OS4xMDAuMS4xNjU4MzQwODEwLjYw) and join the [#k2-early-adopters](https://kotlinlang.slack.com/archives/C03PK0PE257) channel.
* Report any problems you faced with the new K2 compiler to [our issue tracker](https://youtrack.jetbrains.com/newIssue?project=KT&c=Type%20Performance%20Problem&c=Subsystems%20Frontend.%20IR).
* [Enable the Send usage statistics option](https://www.jetbrains.com/help/idea/settings-usage-statistics.html) to allow JetBrains collecting anonymous data about K2 usage.
Language
--------
Kotlin 1.7.20 introduces preview versions for new language features, as well as puts restrictions on builder type inference:
* [Preview of the ..< operator for creating open-ended ranges](#preview-of-the-operator-for-creating-open-ended-ranges)
* [New data object declarations](#improved-string-representations-for-singletons-and-sealed-class-hierarchies-with-data-objects)
* [Builder type inference restrictions](#new-builder-type-inference-restrictions)
### Preview of the ..< operator for creating open-ended ranges
This release introduces the new `..<` operator. Kotlin has the `..` operator to express a range of values. The new `..<` operator acts like the `until` function and helps you define the open-ended range.
Our research shows that this new operator does a better job at expressing open-ended ranges and making it clear that the upper bound is not included.
Here is an example of using the `..<` operator in a `when` expression:
```
when (value) {
in 0.0..<0.25 -> // First quarter
in 0.25..<0.5 -> // Second quarter
in 0.5..<0.75 -> // Third quarter
in 0.75..1.0 -> // Last quarter <- Note closed range here
}
```
#### Standard library API changes
The following new types and operations will be introduced in the `kotlin.ranges` packages in the common Kotlin standard library:
##### New OpenEndRange interface
The new interface to represent open-ended ranges is very similar to the existing `ClosedRange<T>` interface:
```
interface OpenEndRange<T : Comparable<T>> {
// Lower bound
val start: T
// Upper bound, not included in the range
val endExclusive: T
operator fun contains(value: T): Boolean = value >= start && value < endExclusive
fun isEmpty(): Boolean = start >= endExclusive
}
```
##### Implementing OpenEndRange in the existing iterable ranges
When developers need to get a range with an excluded upper bound, they currently use the `until` function to effectively produce a closed iterable range with the same values. To make these ranges acceptable in the new API that takes `OpenEndRange<T>`, we want to implement that interface in the existing iterable ranges: `IntRange`, `LongRange`, `CharRange`, `UIntRange`, and `ULongRange`. So they will simultaneously implement both the `ClosedRange<T>` and `OpenEndRange<T>` interfaces.
```
class IntRange : IntProgression(...), ClosedRange<Int>, OpenEndRange<Int> {
override val start: Int
override val endInclusive: Int
override val endExclusive: Int
}
```
##### rangeUntil operators for the standard types
The `rangeUntil` operators will be provided for the same types and combinations currently defined by the `rangeTo` operator. We provide them as extension functions for prototype purposes, but for consistency, we plan to make them members later before stabilizing the open-ended ranges API.
#### How to enable the ..< operator
To use the `..<` operator or to implement that operator convention for your own types, enable the `-language-version 1.8` compiler option.
The new API elements introduced to support the open-ended ranges of the standard types require an opt-in, as usual for an experimental stdlib API: `@OptIn(ExperimentalStdlibApi::class)`. Alternatively, you could use the `-opt-in=kotlin.ExperimentalStdlibApi` compiler option.
[Read more about the new operator in this KEEP document](https://github.com/kotlin/KEEP/blob/open-ended-ranges/proposals/open-ended-ranges.md).
### Improved string representations for singletons and sealed class hierarchies with data objects
This release introduces a new type of `object` declaration for you to use: `data object`. [Data object](https://youtrack.jetbrains.com/issue/KT-4107) behaves conceptually identical to a regular `object` declaration but comes with a clean `toString` representation out of the box.
```
package org.example
object MyObject
data object MyDataObject
fun main() {
println(MyObject) // org.example.MyObject@1f32e575
println(MyDataObject) // MyDataObject
}
```
This makes `data object` declarations perfect for sealed class hierarchies, where you may use them alongside `data class` declarations. In this snippet, declaring `EndOfFile` as a `data object` instead of a plain `object` means that it will get a pretty `toString` without the need to override it manually, maintaining symmetry with the accompanying `data class` definitions:
```
sealed class ReadResult {
data class Number(val value: Int) : ReadResult()
data class Text(val value: String) : ReadResult()
data object EndOfFile : ReadResult()
}
fun main() {
println(ReadResult.Number(1)) // Number(value=1)
println(ReadResult.Text("Foo")) // Text(value=Foo)
println(ReadResult.EndOfFile) // EndOfFile
}
```
#### How to enable data objects
To use data object declarations in your code, enable the `-language-version 1.9` compiler option. In a Gradle project, you can do so by adding the following to your `build.gradle(.kts)`:
```
tasks.withType<org.jetbrains.kotlin.gradle.tasks.KotlinCompile>().configureEach {
// ...
kotlinOptions.languageVersion = "1.9"
}
```
```
compileKotlin {
// ...
kotlinOptions.languageVersion = '1.9'
}
```
Read more about data objects, and share your feedback on their implementation in the [respective KEEP document](https://github.com/Kotlin/KEEP/pull/316).
### New builder type inference restrictions
Kotlin 1.7.20 places some major restrictions on the [use of builder type inference](using-builders-with-builder-inference) that could affect your code. These restrictions apply to code containing builder lambda functions, where it's impossible to derive the parameter without analyzing the lambda itself. The parameter is used as an argument. Now, the compiler will always show an error for such code and ask you to specify the type explicitly.
This is a breaking change, but our research shows that these cases are very rare, and the restrictions shouldn't affect your code. If they do, consider the following cases:
* Builder inference with extension that hides members.
If your code contains an extension function with the same name that will be used during the builder inference, the compiler will show you an error:
```
class Data {
fun doSmth() {} // 1
}
fun <T> T.doSmth() {} // 2
fun test() {
buildList {
this.add(Data())
this.get(0).doSmth() // Resolves to 2 and leads to error
}
}
```
To fix the code, you should specify the type explicitly:
```
class Data {
fun doSmth() {} // 1
}
fun <T> T.doSmth() {} // 2
fun test() {
buildList<Data> { // Type argument!
this.add(Data())
this.get(0).doSmth() // Resolves to 1
}
}
```
* Builder inference with multiple lambdas and the type arguments are not specified explicitly.
If there are two or more lambda blocks in builder inference, they affect the type. To prevent an error, the compiler requires you to specify the type:
```
fun <T: Any> buildList(
first: MutableList<T>.() -> Unit,
second: MutableList<T>.() -> Unit
): List<T> {
val list = mutableListOf<T>()
list.first()
list.second()
return list
}
fun main() {
buildList(
first = { // this: MutableList<String>
add("")
},
second = { // this: MutableList<Int>
val i: Int = get(0)
println(i)
}
)
}
```
To fix the error, you should specify the type explicitly and fix the type mismatch:
```
fun main() {
buildList<Int>(
first = { // this: MutableList<Int>
add(0)
},
second = { // this: MutableList<Int>
val i: Int = get(0)
println(i)
}
)
}
```
If you haven't found your case mentioned above, [file an issue](https://kotl.in/issue) to our team.
See this [YouTrack issue](https://youtrack.jetbrains.com/issue/KT-53797) for more information about this builder inference update.
Kotlin/JVM
----------
Kotlin 1.7.20 introduces generic inline classes, adds more bytecode optimizations for delegated properties, and supports IR in the kapt stub generating task, making it possible to use all the newest Kotlin features with kapt:
* [Generic inline classes](#generic-inline-classes)
* [More optimized cases of delegated properties](#more-optimized-cases-of-delegated-properties)
* [Support for the JVM IR backend in kapt stub generating task](#support-for-the-jvm-ir-backend-in-kapt-stub-generating-task)
### Generic inline classes
Kotlin 1.7.20 allows the underlying type of JVM inline classes to be a type parameter. The compiler maps it to `Any?` or, generally, to the upper bound of the type parameter.
Consider the following example:
```
@JvmInline
value class UserId<T>(val value: T)
fun compute(s: UserId<String>) {} // Compiler generates fun compute-<hashcode>(s: Any?)
```
The function accepts the inline class as a parameter. The parameter is mapped to the upper bound, not the type argument.
To enable this feature, use the `-language-version 1.8` compiler option.
We would appreciate your feedback on this feature in [YouTrack](https://youtrack.jetbrains.com/issue/KT-52994).
### More optimized cases of delegated properties
In Kotlin 1.6.0, we optimized the case of delegating to a property by omitting the `$delegate` field and [generating immediate access to the referenced property](whatsnew16#optimize-delegated-properties-which-call-get-set-on-the-given-kproperty-instance). In 1.7.20, we've implemented this optimization for more cases. The `$delegate` field will now be omitted if a delegate is:
* A named object:
```
object NamedObject {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String = ...
}
val s: String by NamedObject
```
* A final `val` property with a [backing field](properties#backing-fields) and a default getter in the same module:
```
val impl: ReadOnlyProperty<Any?, String> = ...
class A {
val s: String by impl
}
```
* A constant expression, an enum entry, `this`, or `null`. Here's an example of `this`:
```
class A {
operator fun getValue(thisRef: Any?, property: KProperty<*>) ...
val s by this
}
```
Learn more about [delegated properties](delegated-properties).
We would appreciate your feedback on this feature in [YouTrack](https://youtrack.jetbrains.com/issue/KT-23397).
### Support for the JVM IR backend in kapt stub generating task
Before 1.7.20, the kapt stub generating task used the old backend, and [repeatable annotations](annotations#repeatable-annotations) didn't work with <kapt>. With Kotlin 1.7.20, we've added support for the [JVM IR backend](whatsnew15#stable-jvm-ir-backend) in the kapt stub generating task. This makes it possible to use all the newest Kotlin features with kapt, including repeatable annotations.
To use the IR backend in kapt, add the following option to your `gradle.properties` file:
```
kapt.use.jvm.ir=true
```
We would appreciate your feedback on this feature in [YouTrack](https://youtrack.jetbrains.com/issue/KT-49682).
Kotlin/Native
-------------
Kotlin 1.7.20 comes with the new Kotlin/Native memory manager enabled by default and gives you the option to customize the `Info.plist` file:
* [The new default memory manager](#the-new-kotlin-native-memory-manager-enabled-by-default)
* [Customizing the Info.plist file](#customizing-the-info-plist-file)
### The new Kotlin/Native memory manager enabled by default
This release brings further stability and performance improvements to the new memory manager, allowing us to promote the new memory manager to [Beta](components-stability).
The previous memory manager complicated writing concurrent and asynchronous code, including issues with implementing the `kotlinx.coroutines` library. This blocked the adoption of Kotlin Multiplatform Mobile because concurrency limitations created problems with sharing Kotlin code between iOS and Android platforms. The new memory manager finally paves the way to [promote Kotlin Multiplatform Mobile to Beta](https://blog.jetbrains.com/kotlin/2022/05/kotlin-multiplatform-mobile-beta-roadmap-update/).
The new memory manager also supports the compiler cache that makes compilation times comparable to previous releases. For more on the benefits of the new memory manager, see our original [blog post](https://blog.jetbrains.com/kotlin/2021/08/try-the-new-kotlin-native-memory-manager-development-preview/) for the preview version. You can find more technical details in the [documentation](native-memory-manager).
#### Configuration and setup
Starting with Kotlin 1.7.20, the new memory manager is the default. Not much additional setup is required.
If you've already turned it on manually, you can remove the `kotlin.native.binary.memoryModel=experimental` option from your `gradle.properties` or `binaryOptions["memoryModel"] = "experimental"` from the `build.gradle(.kts)` file.
If necessary, you can switch back to the legacy memory manager with the `kotlin.native.binary.memoryModel=strict` option in your `gradle.properties`. However, compiler cache support is no longer available for the legacy memory manager, so compilation times might worsen.
#### Freezing
In the new memory manager, freezing is deprecated. Don't use it unless you need your code to work with the legacy manager (where freezing is still required). This may be helpful for library authors that need to maintain support for the legacy memory manager or developers who want to have a fallback if they encounter issues with the new memory manager.
In such cases, you can temporarily support code for both new and legacy memory managers. To ignore deprecation warnings, do one of the following:
* Annotate usages of the deprecated API with `@OptIn(FreezingIsDeprecated::class)`.
* Apply `languageSettings.optIn("kotlin.native.FreezingIsDeprecated")` to all the Kotlin source sets in Gradle.
* Pass the compiler flag `-opt-in=kotlin.native.FreezingIsDeprecated`.
#### Calling Kotlin suspending functions from Swift/Objective-C
The new memory manager still restricts calling Kotlin `suspend` functions from Swift and Objective-C from threads other than the main one, but you can lift it with a new Gradle option.
This restriction was originally introduced in the legacy memory manager due to cases where the code dispatched a continuation to be resumed on the original thread. If this thread didn't have a supported event loop, the task would never run, and the coroutine would never be resumed.
In certain cases, this restriction is no longer required, but a check of all the necessary conditions can't be easily implemented. Because of this, we decided to keep it in the new memory manager while introducing an option for you to disable it. For this, add the following option to your `gradle.properties`:
```
kotlin.native.binary.objcExportSuspendFunctionLaunchThreadRestriction=none
```
The Kotlin team is very grateful to [Ahmed El-Helw](https://github.com/ahmedre) for implementing this option.
#### Leave your feedback
This is a significant change to our ecosystem. We would appreciate your feedback to help make it even better.
Try the new memory manager on your projects and [share feedback in our issue tracker, YouTrack](https://youtrack.jetbrains.com/issue/KT-48525).
### Customizing the Info.plist file
When producing a framework, the Kotlin/Native compiler generates the information property list file, `Info.plist`. Previously, it was cumbersome to customize its contents. With Kotlin 1.7.20, you can directly set the following properties:
| Property | Binary option |
| --- | --- |
| `CFBundleIdentifier` | `bundleId` |
| `CFBundleShortVersionString` | `bundleShortVersionString` |
| `CFBundleVersion` | `bundleVersion` |
To do that, use the corresponding binary option. Pass the `-Xbinary=$option=$value` compiler flag or set the `binaryOption(option, value)` Gradle DSL for the necessary framework.
The Kotlin team is very grateful to Mads Ager for implementing this feature.
Kotlin/JS
---------
Kotlin/JS has received some enhancements that improve the developer experience and boost performance:
* Klib generation is faster in both incremental and clean builds, thanks to efficiency improvements for the loading of dependencies.
* [Incremental compilation for development binaries](js-ir-compiler#incremental-compilation-for-development-binaries) has been reworked, resulting in major improvements in clean build scenarios, faster incremental builds, and stability fixes.
* We've improved `.d.ts` generation for nested objects, sealed classes, and optional parameters in constructors.
Gradle
------
The updates for the Kotlin Gradle plugin are focused on compatibility with the new Gradle features and the latest Gradle versions.
Kotlin 1.7.20 contains changes to support Gradle 7.1. Deprecated methods and properties were removed or replaced, reducing the number of deprecation warnings produced by the Kotlin Gradle plugin and unblocking future support for Gradle 8.0.
There are, however, some potentially breaking changes that may need your attention:
### Target configuration
* `org.jetbrains.kotlin.gradle.dsl.SingleTargetExtension` now has a generic parameter, `SingleTargetExtension<T : KotlinTarget>`.
* The `kotlin.targets.fromPreset()` convention has been deprecated. Instead, you can still use `kotlin.targets { fromPreset() }`, but we recommend using more [specialized ways to create targets](multiplatform-set-up-targets).
* Target accessors auto-generated by Gradle are no longer available inside the `kotlin.targets { }` block. Please use the `findByName("targetName")` method instead.
Note that such accessors are still available in the case of `kotlin.targets`, for example, `kotlin.targets.linuxX64`.
### Source directories configuration
The Kotlin Gradle plugin now adds Kotlin `SourceDirectorySet` as a `kotlin` extension to Java's `SourceSet` group. This makes it possible to configure source directories in the `build.gradle.kts` file similarly to how they are configured in [Java, Groovy, and Scala](https://docs.gradle.org/7.1/release-notes.html#easier-source-set-configuration-in-kotlin-dsl):
```
sourceSets {
main {
kotlin {
java.setSrcDirs(listOf("src/java"))
kotlin.setSrcDirs(listOf("src/kotlin"))
}
}
}
```
You no longer need to use a deprecated Gradle convention and specify the source directories for Kotlin.
Remember that you can also use the `kotlin` extension to access `KotlinSourceSet`:
```
kotlin {
sourceSets {
main {
// ...
}
}
}
```
### New method for JVM toolchain configuration
This release provides a new `jvmToolchain()` method for enabling the [JVM toolchain feature](gradle-configure-project#gradle-java-toolchains-support). If you don't need any additional [configuration fields](https://docs.gradle.org/current/javadoc/org/gradle/jvm/toolchain/JavaToolchainSpec.html), such as `implementation` or `vendor`, you can use this method from the Kotlin extension:
```
kotlin {
jvmToolchain(17)
}
```
This simplifies the Kotlin project setup process without any additional configuration. Before this release, you could specify the JDK version only in the following way:
```
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(17))
}
}
```
Standard library
----------------
Kotlin 1.7.20 offers new [extension functions](extensions#extension-functions) for the `java.nio.file.Path` class, which allows you to walk through a file tree:
* `walk()` lazily traverses the file tree rooted at the specified path.
* `fileVisitor()` makes it possible to create a `FileVisitor` separately. `FileVisitor` defines actions on directories and files when traversing them.
* `visitFileTree(fileVisitor: FileVisitor, ...)` consumes a ready `FileVisitor` and uses `java.nio.file.Files.walkFileTree()` under the hood.
* `visitFileTree(..., builderAction: FileVisitorBuilder.() -> Unit)` creates a `FileVisitor` with the `builderAction` and calls the `visitFileTree(fileVisitor, ...)` function.
* `FileVisitResult`, return type of `FileVisitor`, has the `CONTINUE` default value that continues the processing of the file.
Here are some things you can do with these new extension functions:
* Explicitly create a `FileVisitor` and then use:
```
val cleanVisitor = fileVisitor {
onPreVisitDirectory { directory, attributes ->
// Some logic on visiting directories
FileVisitResult.CONTINUE
}
onVisitFile { file, attributes ->
// Some logic on visiting files
FileVisitResult.CONTINUE
}
}
// Some logic may go here
projectDirectory.visitFileTree(cleanVisitor)
```
* Create a `FileVisitor` with the `builderAction` and use it immediately:
```
projectDirectory.visitFileTree {
// Definition of the builderAction:
onPreVisitDirectory { directory, attributes ->
// Some logic on visiting directories
FileVisitResult.CONTINUE
}
onVisitFile { file, attributes ->
// Some logic on visiting files
FileVisitResult.CONTINUE
}
}
```
* Traverse a file tree rooted at the specified path with the `walk()` function:
```
@OptIn(kotlin.io.path.ExperimentalPathApi::class)
fun traverseFileTree() {
val cleanVisitor = fileVisitor {
onPreVisitDirectory { directory, _ ->
if (directory.name == "build") {
directory.toFile().deleteRecursively()
FileVisitResult.SKIP_SUBTREE
} else {
FileVisitResult.CONTINUE
}
}
onVisitFile { file, _ ->
if (file.extension == "class") {
file.deleteExisting()
}
FileVisitResult.CONTINUE
}
}
val rootDirectory = createTempDirectory("Project")
rootDirectory.resolve("src").let { srcDirectory ->
srcDirectory.createDirectory()
srcDirectory.resolve("A.kt").createFile()
srcDirectory.resolve("A.class").createFile()
}
rootDirectory.resolve("build").let { buildDirectory ->
buildDirectory.createDirectory()
buildDirectory.resolve("Project.jar").createFile()
}
// Use walk function:
val directoryStructure = rootDirectory.walk(PathWalkOption.INCLUDE_DIRECTORIES)
.map { it.relativeTo(rootDirectory).toString() }
.toList().sorted()
assertPrints(directoryStructure, "[, build, build/Project.jar, src, src/A.class, src/A.kt]")
rootDirectory.visitFileTree(cleanVisitor)
val directoryStructureAfterClean = rootDirectory.walk(PathWalkOption.INCLUDE_DIRECTORIES)
.map { it.relativeTo(rootDirectory).toString() }
.toList().sorted()
assertPrints(directoryStructureAfterClean, "[, src, src/A.kt]")
//sampleEnd
}
```
As is usual for an experimental API, the new extensions require an opt-in: `@OptIn(kotlin.io.path.ExperimentalPathApi::class)` or `@kotlin.io.path.ExperimentalPathApi`. Alternatively, you can use a compiler option: `-opt-in=kotlin.io.path.ExperimentalPathApi`.
We would appreciate your feedback on the [`walk()` function](https://youtrack.jetbrains.com/issue/KT-52909) and the [visit extension functions](https://youtrack.jetbrains.com/issue/KT-52910) in YouTrack.
Documentation updates
---------------------
Since the previous release, the Kotlin documentation has received some notable changes:
### Revamped and improved pages
* [Basic types overview](basic-types) – learn about the basic types used in Kotlin: numbers, Booleans, characters, strings, arrays, and unsigned integer numbers.
* [IDEs for Kotlin development](kotlin-ide) – see the list of IDEs with official Kotlin support and tools that have community-supported plugins.
### New articles in the Kotlin Multiplatform journal
* [Native and cross-platform app development: how to choose?](native-and-cross-platform) – check out our overview and advantages of cross-platform app development and the native approach.
* [The six best cross-platform app development frameworks](cross-platform-frameworks) – read about the key aspects to help you choose the right framework for your cross-platform project.
### New and updated tutorials
* [Get started with Kotlin Multiplatform Mobile](multiplatform-mobile-getting-started) – learn about cross-platform mobile development with Kotlin and create an app that works on both Android and iOS.
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) – create an app using Kotlin throughout the whole stack, with a Kotlin/JVM server part and a Kotlin/JS web client.
* [Build a web application with React and Kotlin/JS](js-react) – create a browser app exploring Kotlin's DSLs and features of a typical React program.
### Changes in release documentation
We no longer provide a list of recommended kotlinx libraries for each release. This list included only the versions recommended and tested with Kotlin itself. It didn't take into account that some libraries depend on each other and require a special kotlinx version, which may differ from the recommended Kotlin version.
We're working on finding a way to provide information on how libraries interrelate and depend on each other so that it will be clear which kotlinx library version you should use when you upgrade the Kotlin version in your project.
Install Kotlin 1.7.20
---------------------
[IntelliJ IDEA](https://www.jetbrains.com/idea/download/) 2021.3, 2022.1, and 2022.2 automatically suggest updating the Kotlin plugin to 1.7.20.
The new command-line compiler is available for download on the [GitHub release page](https://github.com/JetBrains/kotlin/releases/tag/v1.7.20).
### Compatibility guide for Kotlin 1.7.20
Although Kotlin 1.7.20 is an incremental release, there are still incompatible changes we had to make to limit spread of the issues introduced in Kotlin 1.7.0.
Find the detailed list of such changes in the [Compatibility guide for Kotlin 1.7.20](compatibility-guide-1720).
Last modified: 10 January 2023
[What's new in Kotlin 1.8.0](whatsnew18) [What's new in Kotlin 1.7.0](whatsnew17)
| programming_docs |
kotlin Kotlin Symbol Processing API Kotlin Symbol Processing API
============================
Kotlin Symbol Processing (*KSP*) is an API that you can use to develop lightweight compiler plugins. KSP provides a simplified compiler plugin API that leverages the power of Kotlin while keeping the learning curve at a minimum. Compared to <kapt>, annotation processors that use KSP can run up to 2 times faster.
To learn more about how KSP compares to kapt, check out [why KSP](ksp-why-ksp). To get started writing a KSP processor, take a look at the [KSP quickstart](ksp-quickstart).
Overview
--------
The KSP API processes Kotlin programs idiomatically. KSP understands Kotlin-specific features, such as extension functions, declaration-site variance, and local functions. It also models types explicitly and provides basic type checking, such as equivalence and assign-compatibility.
The API models Kotlin program structures at the symbol level according to [Kotlin grammar](grammar). When KSP-based plugins process source programs, constructs like classes, class members, functions, and associated parameters are accessible for the processors, while things like `if` blocks and `for` loops are not.
Conceptually, KSP is similar to [KType](../api/latest/jvm/stdlib/kotlin.reflect/-k-type/index) in Kotlin reflection. The API allows processors to navigate from class declarations to corresponding types with specific type arguments and vice-versa. You can also substitute type arguments, specify variances, apply star projections, and mark nullabilities of types.
Another way to think of KSP is as a preprocessor framework of Kotlin programs. By considering KSP-based plugins as *symbol processors*, or simply *processors*, the data flow in a compilation can be described in the following steps:
1. Processors read and analyze source programs and resources.
2. Processors generate code or other forms of output.
3. The Kotlin compiler compiles the source programs together with the generated code.
Unlike a full-fledged compiler plugin, processors cannot modify the code. A compiler plugin that changes language semantics can sometimes be very confusing. KSP avoids that by treating the source programs as read-only.
You can also get an overview of KSP in this video:
How KSP looks at source files
-----------------------------
Most processors navigate through the various program structures of the input source code. Before diving into usage of the API, let's see at how a file might look from KSP's point of view:
```
KSFile
packageName: KSName
fileName: String
annotations: List<KSAnnotation> (File annotations)
declarations: List<KSDeclaration>
KSClassDeclaration // class, interface, object
simpleName: KSName
qualifiedName: KSName
containingFile: String
typeParameters: KSTypeParameter
parentDeclaration: KSDeclaration
classKind: ClassKind
primaryConstructor: KSFunctionDeclaration
superTypes: List<KSTypeReference>
// contains inner classes, member functions, properties, etc.
declarations: List<KSDeclaration>
KSFunctionDeclaration // top level function
simpleName: KSName
qualifiedName: KSName
containingFile: String
typeParameters: KSTypeParameter
parentDeclaration: KSDeclaration
functionKind: FunctionKind
extensionReceiver: KSTypeReference?
returnType: KSTypeReference
parameters: List<KSValueParameter>
// contains local classes, local functions, local variables, etc.
declarations: List<KSDeclaration>
KSPropertyDeclaration // global variable
simpleName: KSName
qualifiedName: KSName
containingFile: String
typeParameters: KSTypeParameter
parentDeclaration: KSDeclaration
extensionReceiver: KSTypeReference?
type: KSTypeReference
getter: KSPropertyGetter
returnType: KSTypeReference
setter: KSPropertySetter
parameter: KSValueParameter
```
This view lists common things that are declared in the file: classes, functions, properties, and so on.
SymbolProcessorProvider: the entry point
----------------------------------------
KSP expects an implementation of the `SymbolProcessorProvider` interface to instantiate `SymbolProcessor`:
```
interface SymbolProcessorProvider {
fun create(environment: SymbolProcessorEnvironment): SymbolProcessor
}
```
While `SymbolProcessor` is defined as:
```
interface SymbolProcessor {
fun process(resolver: Resolver): List<KSAnnotated> // Let's focus on this
fun finish() {}
fun onError() {}
}
```
A `Resolver` provides `SymbolProcessor` with access to compiler details such as symbols. A processor that finds all top-level functions and non-local functions in top-level classes might look something like the following:
```
class HelloFunctionFinderProcessor : SymbolProcessor() {
// ...
val functions = mutableListOf<String>()
val visitor = FindFunctionsVisitor()
override fun process(resolver: Resolver) {
resolver.getAllFiles().map { it.accept(visitor, Unit) }
}
inner class FindFunctionsVisitor : KSVisitorVoid() {
override fun visitClassDeclaration(classDeclaration: KSClassDeclaration, data: Unit) {
classDeclaration.getDeclaredFunctions().map { it.accept(this, Unit) }
}
override fun visitFunctionDeclaration(function: KSFunctionDeclaration, data: Unit) {
functions.add(function)
}
override fun visitFile(file: KSFile, data: Unit) {
file.declarations.map { it.accept(this, Unit) }
}
}
// ...
class Provider : SymbolProcessorProvider {
override fun create(environment: SymbolProcessorEnvironment): SymbolProcessor = TODO()
}
}
```
Resources
---------
* [Quickstart](ksp-quickstart)
* [Why use KSP?](ksp-why-ksp)
* [Examples](ksp-examples)
* [How KSP models Kotlin code](ksp-additional-details)
* [Reference for Java annotation processor authors](ksp-reference)
* [Incremental processing notes](ksp-incremental)
* [Multiple round processing notes](ksp-multi-round)
* [KSP on multiplatform projects](ksp-multiplatform)
* [Running KSP from command line](ksp-command-line)
* [FAQ](ksp-faq)
Supported libraries
-------------------
The table below includes a list of popular libraries on Android and their various stages of support for KSP.
| Library | Status | Tracking issue for KSP |
| --- | --- | --- |
| Room | [Officially supported](https://developer.android.com/jetpack/androidx/releases/room#2.3.0-beta02) | |
| Moshi | [Officially supported](https://github.com/square/moshi/) | |
| RxHttp | [Officially supported](https://github.com/liujingxing/rxhttp) | |
| Kotshi | [Officially supported](https://github.com/ansman/kotshi) | |
| Lyricist | [Officially supported](https://github.com/adrielcafe/lyricist) | |
| Lich SavedState | [Officially supported](https://github.com/line/lich/tree/master/savedstate) | |
| gRPC Dekorator | [Officially supported](https://github.com/mottljan/grpc-dekorator) | |
| EasyAdapter | [Officially supported](https://github.com/AmrDeveloper/EasyAdapter) | |
| Koin Annotations | [Officially supported](https://github.com/InsertKoinIO/koin-annotations) | |
| Auto Factory | Not yet supported | [Link](https://github.com/google/auto/issues/982) |
| Dagger | Not yet supported | [Link](https://github.com/google/dagger/issues/2349) |
| Hilt | Not yet supported | [Link](https://issuetracker.google.com/179057202) |
| Glide | [Officially supported](https://github.com/bumptech/glide) | |
| DeeplinkDispatch | [Supported via airbnb/DeepLinkDispatch#323](https://github.com/airbnb/DeepLinkDispatch/pull/323) | |
| Micronaut | In Progress | [Link](https://github.com/micronaut-projects/micronaut-core/issues/6781) |
Last modified: 10 January 2023
[Lombok compiler plugin](lombok) [KSP quickstart](ksp-quickstart)
kotlin Object expressions and declarations Object expressions and declarations
===================================
Sometimes you need to create an object that is a slight modification of some class, without explicitly declaring a new subclass for it. Kotlin can handle this with *object expressions* and *object declarations*.
Object expressions
------------------
*Object expressions* create objects of anonymous classes, that is, classes that aren't explicitly declared with the `class` declaration. Such classes are useful for one-time use. You can define them from scratch, inherit from existing classes, or implement interfaces. Instances of anonymous classes are also called *anonymous objects* because they are defined by an expression, not a name.
### Creating anonymous objects from scratch
Object expressions start with the `object` keyword.
If you just need an object that doesn't have any nontrivial supertypes, write its members in curly braces after `object`:
```
fun main() {
//sampleStart
val helloWorld = object {
val hello = "Hello"
val world = "World"
// object expressions extend Any, so `override` is required on `toString()`
override fun toString() = "$hello $world"
}
//sampleEnd
print(helloWorld)
}
```
### Inheriting anonymous objects from supertypes
To create an object of an anonymous class that inherits from some type (or types), specify this type after `object` and a colon (`:`). Then implement or override the members of this class as if you were [inheriting](inheritance) from it:
```
window.addMouseListener(object : MouseAdapter() {
override fun mouseClicked(e: MouseEvent) { /*...*/ }
override fun mouseEntered(e: MouseEvent) { /*...*/ }
})
```
If a supertype has a constructor, pass appropriate constructor parameters to it. Multiple supertypes can be specified as a comma-delimited list after the colon:
```
open class A(x: Int) {
public open val y: Int = x
}
interface B { /*...*/ }
val ab: A = object : A(1), B {
override val y = 15
}
```
### Using anonymous objects as return and value types
When an anonymous object is used as a type of a local or [private](visibility-modifiers#packages) but not [inline](inline-functions) declaration (function or property), all its members are accessible via this function or property:
```
class C {
private fun getObject() = object {
val x: String = "x"
}
fun printX() {
println(getObject().x)
}
}
```
If this function or property is public or private inline, its actual type is:
* `Any` if the anonymous object doesn't have a declared supertype
* The declared supertype of the anonymous object, if there is exactly one such type
* The explicitly declared type if there is more than one declared supertype
In all these cases, members added in the anonymous object are not accessible. Overridden members are accessible if they are declared in the actual type of the function or property:
```
interface A {
fun funFromA() {}
}
interface B
class C {
// The return type is Any. x is not accessible
fun getObject() = object {
val x: String = "x"
}
// The return type is A; x is not accessible
fun getObjectA() = object: A {
override fun funFromA() {}
val x: String = "x"
}
// The return type is B; funFromA() and x are not accessible
fun getObjectB(): B = object: A, B { // explicit return type is required
override fun funFromA() {}
val x: String = "x"
}
}
```
### Accessing variables from anonymous objects
The code in object expressions can access variables from the enclosing scope:
```
fun countClicks(window: JComponent) {
var clickCount = 0
var enterCount = 0
window.addMouseListener(object : MouseAdapter() {
override fun mouseClicked(e: MouseEvent) {
clickCount++
}
override fun mouseEntered(e: MouseEvent) {
enterCount++
}
})
// ...
}
```
Object declarations
-------------------
The [Singleton](https://en.wikipedia.org/wiki/Singleton_pattern) pattern can be useful in several cases, and Kotlin makes it easy to declare singletons:
```
object DataProviderManager {
fun registerDataProvider(provider: DataProvider) {
// ...
}
val allDataProviders: Collection<DataProvider>
get() = // ...
}
```
This is called an *object declaration*, and it always has a name following the `object` keyword. Just like a variable declaration, an object declaration is not an expression, and it cannot be used on the right-hand side of an assignment statement.
The initialization of an object declaration is thread-safe and done on first access.
To refer to the object, use its name directly:
```
DataProviderManager.registerDataProvider(...)
```
Such objects can have supertypes:
```
object DefaultListener : MouseAdapter() {
override fun mouseClicked(e: MouseEvent) { ... }
override fun mouseEntered(e: MouseEvent) { ... }
}
```
### Data objects
When printing a plain `object` declaration in Kotlin, you'll notice that its string representation contains both its name and the hash of the object:
```
object MyObject
fun main() {
println(MyObject) // MyObject@1f32e575
}
```
Just like [data classes](data-classes), you can mark your `object` declaration with the `data` modifier to get a nicely formatted string representation without having to manually provide an implementation for its `toString` function:
```
data object MyObject
fun main() {
println(MyObject) // MyObject
}
```
[Sealed class hierarchies](sealed-classes) are a particularly good fit for `data object` declarations, since they allow you to maintain symmetry with any data classes you might have defined alongside the object:
```
sealed class ReadResult {
data class Number(val value: Int): ReadResult()
data class Text(val value: String): ReadResult()
data object EndOfFile: ReadResult()
}
fun main() {
println(ReadResult.Number(1)) // Number(value=1)
println(ReadResult.Text("Foo")) // Text(value=Foo)
println(ReadResult.EndOfFile) // EndOfFile
}
```
### Companion objects
An object declaration inside a class can be marked with the `companion` keyword:
```
class MyClass {
companion object Factory {
fun create(): MyClass = MyClass()
}
}
```
Members of the companion object can be called simply by using the class name as the qualifier:
```
val instance = MyClass.create()
```
The name of the companion object can be omitted, in which case the name `Companion` will be used:
```
class MyClass {
companion object { }
}
val x = MyClass.Companion
```
Class members can access the private members of the corresponding companion object.
The name of a class used by itself (not as a qualifier to another name) acts as a reference to the companion object of the class (whether named or not):
```
class MyClass1 {
companion object Named { }
}
val x = MyClass1
class MyClass2 {
companion object { }
}
val y = MyClass2
```
Note that even though the members of companion objects look like static members in other languages, at runtime those are still instance members of real objects, and can, for example, implement interfaces:
```
interface Factory<T> {
fun create(): T
}
class MyClass {
companion object : Factory<MyClass> {
override fun create(): MyClass = MyClass()
}
}
val f: Factory<MyClass> = MyClass
```
However, on the JVM you can have members of companion objects generated as real static methods and fields if you use the `@JvmStatic` annotation. See the [Java interoperability](java-to-kotlin-interop#static-fields) section for more detail.
### Semantic difference between object expressions and declarations
There is one important semantic difference between object expressions and object declarations:
* Object expressions are executed (and initialized) *immediately*, where they are used.
* Object declarations are initialized *lazily*, when accessed for the first time.
* A companion object is initialized when the corresponding class is loaded (resolved) that matches the semantics of a Java static initializer.
Last modified: 10 January 2023
[Inline classes](inline-classes) [Delegation](delegation)
kotlin Set up a Kotlin/JS project Set up a Kotlin/JS project
==========================
Kotlin/JS projects use Gradle as a build system. To let developers easily manage their Kotlin/JS projects, we offer the `kotlin.js` Gradle plugin that provides project configuration tools together with helper tasks for automating routines typical for JavaScript development. For example, the plugin downloads the [Yarn](https://yarnpkg.com/) package manager for managing [npm](https://www.npmjs.com/) dependencies in background and can build a JavaScript bundle from a Kotlin project using [webpack](https://webpack.js.org/). Dependency management and configuration adjustments can be done to a large part directly from the Gradle build file, with the option to override automatically generated configurations for full control.
To create a Kotlin/JS project in IntelliJ IDEA, go to **File | New | Project**. Then select **Kotlin Multiplatform** and choose a Kotlin/JS target that suits you best. Don't forget to choose the language for the build script: Groovy or Kotlin.
Alternatively, you can apply the `org.jetbrains.kotlin.js` plugin to a Gradle project manually in the Gradle build file (`build.gradle` or `build.gradle.kts`).
```
plugins {
kotlin("js") version "1.8.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.js' version '1.8.0'
}
```
The Kotlin/JS Gradle plugin lets you manage aspects of your project in the `kotlin` section of the build script.
```
kotlin {
//...
}
```
Inside the `kotlin` section, you can manage the following aspects:
* [Target execution environment](#execution-environments): browser or Node.js
* [Project dependencies](#dependencies): Maven and npm
* [Run configuration](#run-task)
* [Test configuration](#test-task)
* [Bundling](#webpack-bundling) and [CSS support](#css) for browser projects
* [Target directory](#distribution-target-directory) and [module name](#module-name)
* [Project's `package.json` file](#package-json-customization)
Execution environments
----------------------
Kotlin/JS projects can target two different execution environments:
* Browser for client-side scripting in browsers
* [Node.js](https://nodejs.org/) for running JavaScript code outside of a browser, for example, for server-side scripting.
To define the target execution environment for a Kotlin/JS project, add the `js` section with `browser {}` or `nodejs {}` inside.
```
kotlin {
js {
browser {
}
binaries.executable()
}
}
```
The instruction `binaries.executable()` explicitly instructs the Kotlin compiler to emit executable `.js` files. This is the default behavior when using the current Kotlin/JS compiler, but the instruction is explicitly required if you are working with the [Kotlin/JS IR compiler](js-ir-compiler), or have set `kotlin.js.generate.executable.default=false` in your `gradle.properties`. In those cases, omitting `binaries.executable()` will cause the compiler to only generate Kotlin-internal library files, which can be used from other projects, but not run on their own. (This is typically faster than creating executable files, and can be a possible optimization when dealing with non-leaf modules of your project.)
The Kotlin/JS plugin automatically configures its tasks for working with the selected environment. This includes downloading and installing the required environment and dependencies for running and testing the application. This allows developers to build, run, and test simple projects without additional configuration. For projects targeting Node.js, there are also an option to use an existing Node.js installation. Learn how to [use pre-installed Node.js](#use-pre-installed-node-js).
Dependencies
------------
Like any other Gradle projects, Kotlin/JS projects support traditional Gradle [dependency declarations](https://docs.gradle.org/current/userguide/declaring_dependencies.html) in the `dependencies` section of the build script.
```
dependencies {
implementation("org.example.myproject", "1.1.0")
}
```
```
dependencies {
implementation 'org.example.myproject:1.1.0'
}
```
The Kotlin/JS Gradle plugin also supports dependency declarations for particular source sets in the `kotlin` section of the build script.
```
kotlin {
sourceSets["main"].dependencies {
implementation("org.example.myproject", "1.1.0")
}
}
```
```
kotlin {
sourceSets {
main {
dependencies {
implementation 'org.example.myproject:1.1.0'
}
}
}
}
```
Please note that not all libraries available for the Kotlin programming language are available when targeting JavaScript: Only libraries that include artifacts for Kotlin/JS can be used.
If the library you are adding has dependencies on [packages from npm](#npm-dependencies), Gradle will automatically resolve these transitive dependencies as well.
### Kotlin standard libraries
The dependency on the Kotlin/JS [standard library](../index) is mandatory for all Kotlin/JS projects, and as such is implicit – no artifacts need to be added.
If your project contains tests written in Kotlin, you should add a dependency on the [kotlin.test](https://kotlinlang.org/api/latest/kotlin.test/index.html) library:
```
dependencies {
testImplementation(kotlin("test-js"))
}
```
```
dependencies {
testImplementation 'org.jetbrains.kotlin:kotlin-test-js'
}
```
### npm dependencies
In the JavaScript world, the most common way to manage dependencies is [npm](https://www.npmjs.com/). It offers the biggest public repository of JavaScript modules.
The Kotlin/JS Gradle plugin lets you declare npm dependencies in the Gradle build script, analogous to how you would declare any other dependencies.
To declare an npm dependency, pass its name and version to the `npm()` function inside a dependency declaration. You can also specify one or multiple version range based on [npm's semver syntax](https://docs.npmjs.com/misc/semver#versions).
```
dependencies {
implementation(npm("react", "> 14.0.0 <=16.9.0"))
}
```
```
dependencies {
implementation npm('react', '> 14.0.0 <=16.9.0')
}
```
The plugin uses the [Yarn](https://yarnpkg.com/lang/en/) package manager to download and install NPM dependencies. It works out of the box without additional configuration, but you can tune it to specific needs. Learn how to [configure Yarn in Kotlin/JS Gradle plugin](#yarn).
Besides regular dependencies, there are three more types of dependencies that can be used from the Gradle DSL. To learn more about when each type of dependency can best be used, have a look at the official documentation linked from npm:
* [devDependencies](https://docs.npmjs.com/files/package.json#devdependencies), via `devNpm(...)`,
* [optionalDependencies](https://docs.npmjs.com/files/package.json#optionaldependencies) via `optionalNpm(...)`, and
* [peerDependencies](https://docs.npmjs.com/files/package.json#peerdependencies) via `peerNpm(...)`.
Once an npm dependency is installed, you can use its API in your code as described in [Calling JS from Kotlin](js-interop).
run task
--------
The Kotlin/JS plugin provides a `run` task that lets you run pure Kotlin/JS projects without additional configuration.
For running Kotlin/JS projects in the browser, this task is an alias for the `browserDevelopmentRun` task (which is also available in Kotlin multiplatform projects). It uses the [webpack-dev-server](https://webpack.js.org/configuration/dev-server/) to serve your JavaScript artifacts. If you want to customize the configuration used by `webpack-dev-server`, for example adjust the port the server runs on, use the [webpack configuration file](#webpack-bundling).
For running Kotlin/JS projects targeting Node.js, the `run` task is an alias for the `nodeRun` task (which is also available in Kotlin multiplatform projects).
To run a project, execute the standard lifecycle `run` task, or the alias to which it corresponds:
```
./gradlew run
```
To automatically trigger a re-build of your application after making changes to the source files, use the Gradle [continuous build](https://docs.gradle.org/current/userguide/command_line_interface.html#sec:continuous_build) feature:
```
./gradlew run --continuous
```
or
```
./gradlew run -t
```
Once the build of your project has succeeded, the `webpack-dev-server` will automatically refresh the browser page.
test task
---------
The Kotlin/JS Gradle plugin automatically sets up a test infrastructure for projects. For browser projects, it downloads and installs the [Karma](https://karma-runner.github.io/) test runner with other required dependencies; for Node.js projects, the [Mocha](https://mochajs.org/) test framework is used.
The plugin also provides useful testing features, for example:
* Source maps generation
* Test reports generation
* Test run results in the console
For running browser tests, the plugin uses [Headless Chrome](https://chromium.googlesource.com/chromium/src/+/lkgr/headless/README.md) by default. You can also choose other browser to run tests in, by adding the corresponding entries inside the `useKarma` section of the build script:
```
kotlin {
js {
browser {
testTask {
useKarma {
useIe()
useSafari()
useFirefox()
useChrome()
useChromeCanary()
useChromeHeadless()
usePhantomJS()
useOpera()
}
}
}
binaries.executable()
// . . .
}
}
```
Alternatively, you can add test targets for browsers in the `gradle.properties` file:
```
kotlin.js.browser.karma.browsers=firefox,safari
```
This approach allows you to define a list of browsers for all modules, and then add specific browsers in the build scripts of particular modules.
Please note that the Kotlin/JS Gradle plugin does not automatically install these browsers for you, but only uses those that are available in its execution environment. If you are executing Kotlin/JS tests on a continuous integration server, for example, make sure that the browsers you want to test against are installed.
If you want to skip tests, add the line `enabled = false` to the `testTask`.
```
kotlin {
js {
browser {
testTask {
enabled = false
}
}
binaries.executable()
// . . .
}
}
```
To run tests, execute the standard lifecycle `check` task:
```
./gradlew check
```
To specify environment variables used by your Node.js test runners (for example, to pass external information to your tests, or to fine-tune package resolution), use the `environment` function with a key-value pair inside the `testTask` block in your build script:
```
kotlin {
js {
nodejs {
testTask {
environment("key", "value")
}
}
}
}
```
### Karma configuration
The Kotlin/JS Gradle plugin automatically generates a Karma configuration file at build time which includes your settings from the [`kotlin.js.browser.testTask.useKarma` block](#test-task) in your `build.gradle(.kts)`. You can find the file at `build/js/packages/projectName-test/karma.conf.js`. To make adjustments to the configuration used by Karma, place your additional configuration files inside a directory called `karma.config.d` in the root of your project. All `.js` configuration files in this directory will be picked up and are automatically merged into the generated `karma.conf.js` at build time.
All karma configuration abilities are well described in Karma's [documentation](https://karma-runner.github.io/5.0/config/configuration-file.html).
webpack bundling
----------------
For browser targets, the Kotlin/JS plugin uses the widely known [webpack](https://webpack.js.org/) module bundler.
### webpack version
The Kotlin/JS plugin uses webpack 5.
If you have projects created with plugin versions earlier than 1.5.0, you can temporarily switch back to webpack 4 used in these versions by adding the following line to the project's `gradle.properties`:
```
kotlin.js.webpack.major.version=4
```
### webpack task
The most common webpack adjustments can be made directly via the `kotlin.js.browser.webpackTask` configuration block in the Gradle build file:
* `outputFileName` - the name of the webpacked output file. It will be generated in `<projectDir>/build/distributions/` after an execution of a webpack task. The default value is the project name.
* `output.libraryTarget` - the module system for the webpacked output. Learn more about [available module systems for Kotlin/JS projects](js-modules). The default value is `umd`.
```
webpackTask {
outputFileName = "mycustomfilename.js"
output.libraryTarget = "commonjs2"
}
```
You can also configure common webpack settings to use in bundling, running, and testing tasks in the `commonWebpackConfig` block.
### webpack configuration file
The Kotlin/JS Gradle plugin automatically generates a standard webpack configuration file at the build time. It is located in `build/js/packages/projectName/webpack.config.js`.
If you want to make further adjustments to the webpack configuration, place your additional configuration files inside a directory called `webpack.config.d` in the root of your project. When building your project, all `.js` configuration files will automatically be merged into the `build/js/packages/projectName/webpack.config.js` file. To add a new [webpack loader](https://webpack.js.org/loaders/), for example, add the following to a `.js` file inside the `webpack.config.d`:
```
config.module.rules.push({
test: /\.extension$/,
loader: 'loader-name'
});
```
All webpack configuration capabilities are well described in its [documentation](https://webpack.js.org/concepts/configuration/).
### Building executables
For building executable JavaScript artifacts through webpack, the Kotlin/JS plugin contains the `browserDevelopmentWebpack` and `browserProductionWebpack` Gradle tasks.
* `browserDevelopmentWebpack` creates development artifacts, which are larger in size, but take little time to create. As such, use the `browserDevelopmentWebpack` tasks during active development.
* `browserProductionWebpack` applies [dead code elimination](javascript-dce) to the generated artifacts and minifies the resulting JavaScript file, which takes more time, but generates executables that are smaller in size. As such, use the `browserProductionWebpack` task when preparing your project for production use.
Execute either of these tasks to obtain the respective artifacts for development or production. The generated files will be available in `build/distributions` unless [specified otherwise](#distribution-target-directory).
```
./gradlew browserProductionWebpack
```
Note that these tasks will only be available if your target is configured to generate executable files (via `binaries.executable()`).
CSS
---
The Kotlin/JS Gradle plugin also provides support for webpack's [CSS](https://webpack.js.org/loaders/css-loader/) and [style](https://webpack.js.org/loaders/style-loader/) loaders. While all options can be changed by directly modifying the [webpack configuration files](#webpack-bundling) that are used to build your project, the most commonly used settings are available directly from the `build.gradle(.kts)` file.
To turn on CSS support in your project, set the `cssSupport.enabled` option in the Gradle build file in the `commonWebpackConfig` block. This configuration is also enabled by default when creating a new project using the wizard.
```
browser {
commonWebpackConfig {
cssSupport {
enabled.set(true)
}
}
binaries.executable()
}
```
```
browser {
commonWebpackConfig {
cssSupport {
it.enabled.set(true)
}
}
binaries.executable()
}
```
Alternatively, you can add CSS support independently for `webpackTask`, `runTask`, and `testTask`.
```
browser {
webpackTask {
cssSupport {
enabled.set(true)
}
}
runTask {
cssSupport {
enabled.set(true)
}
}
testTask {
useKarma {
// . . .
webpackConfig.cssSupport {
enabled.set(true)
}
}
}
}
```
```
browser {
webpackTask {
cssSupport {
it.enabled.set(true)
}
}
runTask {
cssSupport {
it.enabled.set(true)
}
}
testTask {
useKarma {
// . . .
webpackConfig.cssSupport {
it.enabled.set(true)
}
}
}
}
```
Activating CSS support in your project helps prevent common errors that occur when trying to use style sheets from an unconfigured project, such as `Module parse failed: Unexpected character '@' (14:0)`.
You can use `cssSupport.mode` to specify how encountered CSS should be handled. The following values are available:
* `"inline"` (default): styles are added to the global `<style>` tag.
* `"extract"`: styles are extracted into a separate file. They can then be included from an HTML page.
* `"import"`: styles are processed as strings. This can be useful if you need access to the CSS from your code (such as `val styles = require("main.css")`).
To use different modes for the same project, use `cssSupport.rules`. Here, you can specify a list of `KotlinWebpackCssRules`, each of which define a mode, as well as [include](https://webpack.js.org/configuration/module/#ruleinclude) and [exclude](https://webpack.js.org/configuration/module/#ruleexclude) patterns.
Node.js
-------
For Kotlin/JS projects targeting Node.js, the plugin automatically downloads and installs the Node.js environment on the host. You can also use an existing Node.js instance if you have it.
### Use pre-installed Node.js
If Node.js is already installed on the host where you build Kotlin/JS projects, you can configure the Kotlin/JS Gradle plugin to use it instead of installing its own Node.js instance.
To use the pre-installed Node.js instance, add the following lines to your `build.gradle(.kts)`:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootExtension>().download = false
// or true for default behavior
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootExtension).download = false
}
```
Yarn
----
To download and install your declared dependencies at build time, the plugin manages its own instance of the [Yarn](https://yarnpkg.com/lang/en/) package manager. It works out of the box without additional configuration, but you can tune it or use Yarn already installed on your host.
### Additional Yarn features: .yarnrc
To configure additional Yarn features, place a `.yarnrc` file in the root of your project. At build time, it gets picked up automatically.
For example, to use a custom registry for npm packages, add the following line to a file called `.yarnrc` in the project root:
```
registry "http://my.registry/api/npm/"
```
To learn more about `.yarnrc`, please visit the [official Yarn documentation](https://classic.yarnpkg.com/en/docs/yarnrc/).
### Use pre-installed Yarn
If Yarn is already installed on the host where you build Kotlin/JS projects, you can configure the Kotlin/JS Gradle plugin to use it instead of installing its own Yarn instance.
To use the pre-installed Yarn instance, add the following lines to your `build.gradle(.kts)`:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().download = false
// or true for default behavior
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).download = false
}
```
### Version locking via kotlin-js-store
The `kotlin-js-store` directory in the project root is automatically generated by the Kotlin/JS Gradle plugin to hold the `yarn.lock` file, which is necessary for version locking. The lockfile is entirely managed by the Yarn plugin and gets updated during the execution of the `kotlinNpmInstall` Gradle task.
To follow a [recommended practice](https://classic.yarnpkg.com/blog/2016/11/24/lockfiles-for-all/), commit `kotlin-js-store` and its contents to your version control system. It ensures that your application is being built with the exact same dependency tree on all machines.
If needed, you can change both directory and lockfile names in the build script:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().lockFileDirectory =
project.rootDir.resolve("my-kotlin-js-store")
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().lockFileName = "my-yarn.lock"
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).lockFileDirectory =
file("my-kotlin-js-store")
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).lockFileName = 'my-yarn.lock'
}
```
To learn more about `yarn.lock`, please visit the [official Yarn documentation](https://classic.yarnpkg.com/lang/en/docs/yarn-lock/).
### Reporting that yarn.lock has been updated
Kotlin/JS provides Gradle settings that could notify you if the `yarn.lock` file has been updated. You can use these settings when you want to be notified if `yarn.lock` has been changed silently during the CI build process:
* `YarnLockMismatchReport`, which specifies how changes to the `yarn.lock` file are reported. You can use one of the following values:
+ `FAIL` fails the corresponding Gradle task. This is the default.
+ `WARNING` writes the information about changes in the warning log.
+ `NONE` disables reporting.
* `reportNewYarnLock`, which reports about the recently created `yarn.lock` file explicitly. By default, this option is disabled: it's a common practice to generate a new `yarn.lock` file at the first start. You can use this option to ensure that the file has been committed to your repository.
* `yarnLockAutoReplace`, which replaces `yarn.lock` automatically every time the Gradle task is run.
To use these options, update your build script file `build.gradle(.kts)` as follows:
```
import org.jetbrains.kotlin.gradle.targets.js.yarn.YarnLockMismatchReport
import org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin::class.java) {
rootProject.the<YarnRootExtension>().yarnLockMismatchReport =
YarnLockMismatchReport.WARNING // NONE | FAIL
rootProject.the<YarnRootExtension>().reportNewYarnLock = false // true
rootProject.the<YarnRootExtension>().yarnLockAutoReplace = false // true
}
```
```
import org.jetbrains.kotlin.gradle.targets.js.yarn.YarnLockMismatchReport
import org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).yarnLockMismatchReport =
YarnLockMismatchReport.WARNING // NONE | FAIL
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).reportNewYarnLock = false // true
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).yarnLockAutoReplace = false // true
}
```
### Installing npm dependencies with --ignore-scripts by default
To reduce the likelihood of executing malicious code from compromised npm packages, the Kotlin/JS Gradle plugin prevents the execution of [lifecycle scripts](https://docs.npmjs.com/cli/v8/using-npm/scripts#life-cycle-scripts) during the installation of npm dependencies by default.
You can explicitly enable lifecycle scripts execution by adding the following lines to `build.gradle(.kts)`:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().ignoreScripts = false
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).ignoreScripts = false
}
```
Distribution target directory
-----------------------------
By default, the results of a Kotlin/JS project build reside in the `/build/distribution` directory within the project root.
To set another location for project distribution files, add the `distribution` block inside `browser` in the build script and assign a value to the `directory` property. Once you run a project build task, Gradle will save the output bundle in this location together with project resources.
```
kotlin {
js {
browser {
distribution {
directory = File("$projectDir/output/")
}
}
binaries.executable()
// . . .
}
}
```
```
kotlin {
js {
browser {
distribution {
directory = file("$projectDir/output/")
}
}
binaries.executable()
// . . .
}
}
```
Module name
-----------
To adjust the name for the JavaScript *module* (which is generated in `build/js/packages/myModuleName`), including the corresponding `.js` and `.d.ts` files, use the `moduleName` option:
```
js {
moduleName = "myModuleName"
}
```
Note that this does not affect the webpacked output in `build/distributions`.
package.json customization
--------------------------
The `package.json` file holds the metadata of a JavaScript package. Popular package registries such as npm require all published packages to have such a file. They use it to track and manage package publications.
The Kotlin/JS Gradle plugin automatically generates `package.json` for Kotlin/JS projects during build time. By default, the file contains essential data: name, version, license, and dependencies, and some other package attributes.
Aside from basic package attributes, `package.json` can define how a JavaScript project should behave, for example, identifying scripts that are available to run.
You can add custom entries to the project's `package.json` via the Gradle DSL. To add custom fields to your `package.json`, use the `customField` function in the compilations `packageJson` block:
```
kotlin {
js {
compilations["main"].packageJson {
customField("hello", mapOf("one" to 1, "two" to 2))
}
}
}
```
When you build the project, this code will add the following block to the `package.json` file:
```
"hello": {
"one": 1,
"two": 2
}
```
Learn more about writing `package.json` files for npm registry in the [npm docs](https://docs.npmjs.com/cli/v6/configuring-npm/package-json).
Troubleshooting
---------------
When building a Kotlin/JS project using Kotlin 1.3.xx, you may encounter a Gradle error if one of your dependencies (or any transitive dependency) was built using Kotlin 1.4 or higher: `Could not determine the dependencies of task ':client:jsTestPackageJson'.`/`Cannot choose between the following variants`. This is a known problem, a workaround is provided [here](https://youtrack.jetbrains.com/issue/KT-40226).
Last modified: 10 January 2023
[Get started with Kotlin/JS for React](js-get-started) [Run Kotlin/JS](running-kotlin-js)
| programming_docs |
kotlin Booleans Booleans
========
The type `Boolean` represents boolean objects that can have two values: `true` and `false`.
`Boolean` has a nullable counterpart `Boolean?` that also has the `null` value.
Built-in operations on booleans include:
* `||` – disjunction (logical *OR*)
* `&&` – conjunction (logical *AND*)
* `!` – negation (logical *NOT*)
`||` and `&&` work lazily.
```
fun main() {
//sampleStart
val myTrue: Boolean = true
val myFalse: Boolean = false
val boolNull: Boolean? = null
println(myTrue || myFalse)
println(myTrue && myFalse)
println(!myTrue)
//sampleEnd
}
```
Last modified: 10 January 2023
[Numbers](numbers) [Characters](characters)
kotlin Make your Android application work on iOS – tutorial Make your Android application work on iOS – tutorial
====================================================
Learn how to make your existing Android application cross-platform so that it works both on Android and iOS. You'll be able to write code and test it for both Android and iOS only once, in one place.
This tutorial uses a [sample Android application](https://github.com/Kotlin/kmm-integration-sample) with a single screen for entering a username and password. The credentials are validated and saved to an in-memory database.
Prepare an environment for development
--------------------------------------
1. [Install all the necessary tools and update them to the latest versions](multiplatform-mobile-setup).
2. In Android Studio, create a new project from version control:
```
https://github.com/Kotlin/kmm-integration-sample
```
3. Switch to the **Project** view.

Make your code cross-platform
-----------------------------
To make your application work on iOS, you'll first make your code cross-platform, and then you'll reuse your cross-platform code in a new iOS application.
To make your code cross-platform:
1. [Decide what code to make cross-platform](#decide-what-code-to-make-cross-platform).
2. [Create a shared module for cross-platform code](#create-a-shared-module-for-cross-platform-code).
3. [Add a dependency on the shared module to your Android application](#add-a-dependency-on-the-shared-module-to-your-android-application).
4. [Make the business logic cross-platform](#make-the-business-logic-cross-platform).
5. [Run your cross-platform application on Android](#run-your-cross-platform-application-on-android).
### Decide what code to make cross-platform
Decide which code of your Android application is better to share for iOS and which to keep native. A simple rule is: share what you want to reuse as much as possible. The business logic is often the same for both Android and iOS, so it's a great candidate for reuse.
In your sample Android application, the business logic is stored in the package `com.jetbrains.simplelogin.androidapp.data`. Your future iOS application will use the same logic, so you should make it cross-platform, as well.
### Create a shared module for cross-platform code
The cross-platform code that is used for both iOS and Android *is stored* in the shared module. The Kotlin Multiplatform Mobile plugin provides a special wizard for creating such modules.
In your Android project, create a Kotlin Multiplatform shared module for your cross-platform code. Later you'll connect it to your existing Android application and your future iOS application.
1. In Android Studio, click **File** | **New** | **New Module**.
2. In the list of templates, select **Kotlin Multiplatform Shared Module**, enter the module name `shared`, and select the **Regular framework** in the list of iOS framework distribution options.
This is required for connecting the shared module to the iOS application.

3. Click **Finish**.
The wizard will create the Kotlin Multiplatform shared module, update the configuration files, and create files with classes that demonstrate the benefits of Kotlin Multiplatform. You can learn more about the [project structure](multiplatform-mobile-understand-project-structure).
### Add a dependency on the shared module to your Android application
To use cross-platform code in your Android application, connect the shared module to it, move the business logic code there, and make this code cross-platform.
1. In the `build.gradle.kts` file of the shared module, ensure that `compileSdk` and `minSdk` are the same as those in the `build.gradle` of your Android application in the `app` module.
If they are different, update them in the `build.gradle.kts` of the shared module. Otherwise, you'll encounter a compile error.
2. Add a dependency on the shared module to the `build.gradle` of your Android application.
```
dependencies {
implementation project(':shared')
}
```
3. Synchronize the Gradle files by clicking **Sync Now** in the notification.

4. In the `app/src/main/java/` directory, open the `LoginActivity` class in the `com.jetbrains.simplelogin.androidapp.ui.login` package.
5. To make sure that the shared module is successfully connected to your application, dump the `greeting()` function result to the log by updating the `onCreate()` method:
```
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
Log.i("Login Activity", "Hello from shared module: " + (Greeting().greeting()))
}
```
6. Follow Android Studio suggestions to import missing classes.
7. Debug the `app`. On the **Logcat** tab, search for `Hello` in the log, and you'll find the greeting from the shared module.

### Make the business logic cross-platform
You can now extract the business logic code to the Kotlin Multiplatform shared module and make it platform-independent. This is necessary for reusing the code for both Android and iOS.
1. Move the business logic code `com.jetbrains.simplelogin.androidapp.data` from the `app` directory to the `com.jetbrains.simplelogin.shared` package in the `shared/src/commonMain` directory. You can drag and drop the package or refactor it by moving everything from one directory to another.

2. When Android Studio asks what you'd like to do, select to move the package, and then approve the refactoring.

3. Ignore all warnings about platform-dependent code and click **Continue**.

4. Remove Android-specific code by replacing it with cross-platform Kotlin code or connecting to Android-specific APIs using [`expect` and `actual` declarations](multiplatform-connect-to-apis). See the following sections for details:
#### Replace Android-specific code with cross-platform code
To make your code work well on both Android and iOS, replace all JVM dependencies with Kotlin dependencies in the moved `data` directory wherever possible.
1. In the `LoginDataSource` class, replace `IOException` in the `login()` function with `RuntimeException`. `IOException` is not available in Kotlin.
```
// Before
return Result.Error(IOException("Error logging in", e))
```
```
// After
return Result.Error(RuntimeException("Error logging in", e))
```
2. In the `LoginDataValidator` class, replace the `Patterns` class from the `android.utils` package with a Kotlin regular expression matching the pattern for email validation:
```
// Before
private fun isEmailValid(email: String) = Patterns.EMAIL_ADDRESS.matcher(email).matches()
```
```
// After
private fun isEmailValid(email: String) = emailRegex.matches(email)
companion object {
private val emailRegex =
("[a-zA-Z0-9\\+\\.\\_\\%\\-\\+]{1,256}" +
"\\@" +
"[a-zA-Z0-9][a-zA-Z0-9\\-]{0,64}" +
"(" +
"\\." +
"[a-zA-Z0-9][a-zA-Z0-9\\-]{0,25}" +
")+").toRegex()
}
```
#### Connect to platform-specific APIs from the cross-platform code
In the `LoginDataSource` class, a universally unique identifier (UUID) for `fakeUser` is generated using the `java.util.UUID` class, which is not available for iOS.
```
val fakeUser = LoggedInUser(java.util.UUID.randomUUID().toString(), "Jane Doe")
```
Since the Kotlin standard library doesn't provide functionality for generating UUIDs, you still need to use platform-specific functionality for this case.
Provide the `expect` declaration for the `randomUUID()` function in the shared code and its `actual` implementations for each platform – Android and iOS – in the corresponding source sets. You can learn more about [connecting to platform-specific APIs](multiplatform-connect-to-apis).
1. Remove the `java.util.UUID` class from the common code:
```
val fakeUser = LoggedInUser(randomUUID(), "Jane Doe")
```
2. Create the `Utils.kt` file in the `com.jetbrains.simplelogin.shared` package of the `shared/src/commonMain` directory and provide the `expect` declaration:
```
package com.jetbrains.simplelogin.shared
expect fun randomUUID(): String
```
3. Create the `Utils.kt` file in the `com.jetbrains.simplelogin.shared` package of the `shared/src/androidMain` directory and provide the `actual` implementation for `randomUUID()` in Android:
```
package com.jetbrains.simplelogin.shared
import java.util.*
actual fun randomUUID() = UUID.randomUUID().toString()
```
4. Create the `Utils.kt` file in the `com.jetbrains.simplelogin.shared` of the `shared/src/iosMain` directory and provide the `actual` implementation for `randomUUID()` in iOS:
```
package com.jetbrains.simplelogin.shared
import platform.Foundation.NSUUID
actual fun randomUUID(): String = NSUUID().UUIDString()
```
5. All it's left to do is to explicitly import `randomUUID` in the `LoginDataSource.kt` file of the `shared/src/commonMain` directory:
```
import com.jetbrains.simplelogin.shared.randomUUID
```
For Android and iOS, Kotlin will use its different platform-specific implementations.
### Run your cross-platform application on Android
Run your cross-platform application for Android to make sure it works.
Make your cross-platform application work on iOS
------------------------------------------------
Once you've made your Android application cross-platform, you can create an iOS application and reuse the shared business logic in it.
1. [Create an iOS project in Xcode](#create-an-ios-project-in-xcode).
2. [Connect the framework to your iOS project](#connect-the-framework-to-your-ios-project).
3. [Use the shared module from Swift](#use-the-shared-module-from-swift).
### Create an iOS project in Xcode
1. In Xcode, click **File** | **New** | **Project**.
2. Select a template for an iOS app and click **Next**.

3. As the product name, specify **simpleLoginIOS** and click **Next**.

4. As the location for your project, select the directory that stores your cross-platform application, for example, `kmm-integration-sample`.
In Android Studio, you'll get the following structure:
You can rename the `simpleLoginIOS` directory to `iosApp` for consistency with other top-level directories of your cross-platform project.
### Connect the framework to your iOS project
Once you have the framework, you can connect it to your iOS project manually.
Connect your framework to the iOS project manually:
1. In Xcode, open the iOS project settings by double-clicking the project name.
2. On the **Build Phases** tab of the project settings, click the **+** and add **New Run Script Phase**.

3. Add the following script:
```
cd "$SRCROOT/.."
./gradlew :shared:embedAndSignAppleFrameworkForXcode
```

4. Move the **Run Script** phase before the **Compile Sources** phase.

5. On the **Build Settings** tab, switch to **All** build settings and specify the **Framework Search Path** under **Search Paths**:
```
$(SRCROOT)/../shared/build/xcode-frameworks/$(CONFIGURATION)/$(SDK_NAME)
```

6. On the **Build Settings** tab, specify the **Other Linker flags** under **Linking**:
```
$(inherited) -framework shared
```

7. Build the project in Xcode. If everything is set up correctly, the project will successfully build.
### Use the shared module from Swift
1. In Xcode, open the `ContentView.swift` file and import the `shared` module:
```
import shared
```
2. To check that it is properly connected, use the `greeting()` function from the shared module of your cross-platform app:
```
import SwiftUI
import shared
struct ContentView: View {
var body: some View {
Text(Greeting().greeting())
.padding()
}
}
```

3. In `ContentView.swift`, write code for using data from the shared module and rendering the application UI:
import SwiftUI import shared struct ContentView: View { @State private var username: String = "" @State private var password: String = "" @ObservedObject var viewModel: ContentView.ViewModel var body: some View { VStack(spacing: 15.0) { ValidatedTextField(titleKey: "Username", secured: false, text: $username, errorMessage: viewModel.formState.usernameError, onChange: { viewModel.loginDataChanged(username: username, password: password) }) ValidatedTextField(titleKey: "Password", secured: true, text: $password, errorMessage: viewModel.formState.passwordError, onChange: { viewModel.loginDataChanged(username: username, password: password) }) Button("Login") { viewModel.login(username: username, password: password) }.disabled(!viewModel.formState.isDataValid || (username.isEmpty && password.isEmpty)) } .padding(.all) } } struct ValidatedTextField: View { let titleKey: String let secured: Bool @Binding var text: String let errorMessage: String? let onChange: () -> () @ViewBuilder var textField: some View { if secured { SecureField(titleKey, text: $text) } else { TextField(titleKey, text: $text) } } var body: some View { ZStack { textField .textFieldStyle(RoundedBorderTextFieldStyle()) .autocapitalization(.none) .onChange(of: text) { \_ in onChange() } if let errorMessage = errorMessage { HStack { Spacer() FieldTextErrorHint(error: errorMessage) }.padding(.horizontal, 5) } } } } struct FieldTextErrorHint: View { let error: String @State private var showingAlert = false var body: some View { Button(action: { self.showingAlert = true }) { Image(systemName: "exclamationmark.triangle.fill") .foregroundColor(.red) } .alert(isPresented: $showingAlert) { Alert(title: Text("Error"), message: Text(error), dismissButton: .default(Text("Got it!"))) } } } extension ContentView { struct LoginFormState { let usernameError: String? let passwordError: String? var isDataValid: Bool { get { return usernameError == nil && passwordError == nil } } } class ViewModel: ObservableObject { @Published var formState = LoginFormState(usernameError: nil, passwordError: nil) let loginValidator: LoginDataValidator let loginRepository: LoginRepository init(loginRepository: LoginRepository, loginValidator: LoginDataValidator) { self.loginRepository = loginRepository self.loginValidator = loginValidator } func login(username: String, password: String) { if let result = loginRepository.login(username: username, password: password) as? ResultSuccess { print("Successful login. Welcome, \(result.data.displayName)") } else { print("Error while logging in") } } func loginDataChanged(username: String, password: String) { formState = LoginFormState( usernameError: (loginValidator.checkUsername(username: username) as? LoginDataValidator.ResultError)?.message, passwordError: (loginValidator.checkPassword(password: password) as? LoginDataValidator.ResultError)?.message) } } }
4. In `simpleLoginIOSApp.swift`, import the `shared` module and specify the arguments for the `ContentView()` function:
```
import SwiftUI
import shared
@main
struct SimpleLoginIOSApp: App {
var body: some Scene {
WindowGroup {
ContentView(viewModel: .init(loginRepository: LoginRepository(dataSource: LoginDataSource()), loginValidator: LoginDataValidator()))
}
}
}
```
Enjoy the results – update the logic only once
----------------------------------------------
Now your application is cross-platform. You can update the business logic in one place and see results on both Android and iOS.
1. In Android Studio, change the validation logic for a user's password in the `checkPassword()` function of the `LoginDataValidator` class:
```
package com.jetbrains.simplelogin.shared.data
class LoginDataValidator {
//...
fun checkPassword(password: String): Result {
return when {
password.length < 5 -> Result.Error("Password must be >5 characters")
password.lowercase() == "password" -> Result.Error("Password shouldn't be \"password\"")
else -> Result.Success
}
}
//...
}
```
2. Update `gradle.properties` to connect your iOS application to Android Studio for running it on a simulated or real device right there:
```
xcodeproj=iosApp/SimpleLoginIOS.xcodeproj
```
3. Synchronize the Gradle files by clicking **Sync Now** in the notification.

You will see the new run configuration **simpleLoginIOS** for running your iOS application right from Android Studio.
You can review the [final code for this tutorial](https://github.com/Kotlin/kmm-integration-sample/tree/final).
What else to share?
-------------------
You've shared the business logic of your application, but you can also decide to share other layers of your application. For example, the `ViewModel` class code is almost the same for [Android](https://github.com/Kotlin/kmm-integration-sample/blob/final/app/src/main/java/com/jetbrains/simplelogin/androidapp/ui/login/LoginViewModel.kt) and [iOS applications](https://github.com/Kotlin/kmm-integration-sample/blob/final/iosApp/SimpleLoginIOS/ContentView.swift#L84), and you can share it if your mobile applications should have the same presentation layer.
What's next?
------------
Once you've made your Android application cross-platform, you can move on and:
* [Add dependencies on multiplatform libraries](multiplatform-add-dependencies)
* [Add Android dependencies](multiplatform-mobile-android-dependencies)
* [Add iOS dependencies](multiplatform-mobile-ios-dependencies)
You can also check out community resources:
* [Video: 3 ways to get your Kotlin JVM code ready for Kotlin Multiplatform Mobile](https://www.youtube.com/watch?v=X6ckI1JWjqo)
Last modified: 10 January 2023
[Understand mobile project structure](multiplatform-mobile-understand-project-structure) [Publish your application](multiplatform-mobile-publish-apps)
| programming_docs |
kotlin What's new in Kotlin 1.6.0 What's new in Kotlin 1.6.0
==========================
*[Release date: 16 November 2021](releases#release-details)*
Kotlin 1.6.0 introduces new language features, optimizations and improvements to existing features, and a lot of improvements to the Kotlin standard library.
You can also find an overview of the changes in the [release blog post](https://blog.jetbrains.com/kotlin/2021/11/kotlin-1-6-0-is-released/).
Language
--------
Kotlin 1.6.0 brings stabilization to several language features introduced for preview in the previous 1.5.30 release:
* [Stable exhaustive when statements for enum, sealed and Boolean subjects](#stable-exhaustive-when-statements-for-enum-sealed-and-boolean-subjects)
* [Stable suspending functions as supertypes](#stable-suspending-functions-as-supertypes)
* [Stable suspend conversions](#stable-suspend-conversions)
* [Stable instantiation of annotation classes](#stable-instantiation-of-annotation-classes)
It also includes various type inference improvements and support for annotations on class type parameters:
* [Improved type inference for recursive generic types](#improved-type-inference-for-recursive-generic-types)
* [Changes to builder inference](#changes-to-builder-inference)
* [Support for annotations on class type parameters](#support-for-annotations-on-class-type-parameters)
### Stable exhaustive when statements for enum, sealed, and Boolean subjects
An *exhaustive* [`when`](control-flow#when-expression) statement contains branches for all possible types or values of its subject, or for some types plus an `else` branch. It covers all possible cases, making your code safer.
We will soon prohibit non-exhaustive `when` statements to make the behavior consistent with `when` expressions. To ensure smooth migration, Kotlin 1.6.0 reports warnings about non-exhaustive `when` statements with an enum, sealed, or Boolean subject. These warnings will become errors in future releases.
```
sealed class Contact {
data class PhoneCall(val number: String) : Contact()
data class TextMessage(val number: String) : Contact()
}
fun Contact.messageCost(): Int =
when(this) { // Error: 'when' expression must be exhaustive
is Contact.PhoneCall -> 42
}
fun sendMessage(contact: Contact, message: String) {
// Starting with 1.6.0
// Warning: Non exhaustive 'when' statements on Boolean will be
// prohibited in 1.7, add 'false' branch or 'else' branch instead
when(message.isEmpty()) {
true -> return
}
// Warning: Non exhaustive 'when' statements on sealed class/interface will be
// prohibited in 1.7, add 'is TextMessage' branch or 'else' branch instead
when(contact) {
is Contact.PhoneCall -> TODO()
}
}
```
See [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-47709) for a more detailed explanation of the change and its effects.
### Stable suspending functions as supertypes
Implementation of suspending functional types has become [Stable](components-stability) in Kotlin 1.6.0. A preview was available [in 1.5.30](whatsnew1530#suspending-functions-as-supertypes).
The feature can be useful when designing APIs that use Kotlin coroutines and accept suspending functional types. You can now streamline your code by enclosing the desired behavior in a separate class that implements a suspending functional type.
```
class MyClickAction : suspend () -> Unit {
override suspend fun invoke() { TODO() }
}
fun launchOnClick(action: suspend () -> Unit) {}
```
You can use an instance of this class where only lambdas and suspending function references were allowed previously: `launchOnClick(MyClickAction())`.
There are currently two limitations coming from implementation details:
* You can't mix ordinary functional types and suspending ones in the list of supertypes.
* You can't use multiple suspending functional supertypes.
### Stable suspend conversions
Kotlin 1.6.0 introduces [Stable](components-stability) conversions from regular to suspending functional types. Starting from 1.4.0, the feature supported functional literals and callable references. With 1.6.0, it works with any form of expression. As a call argument, you can now pass any expression of a suitable regular functional type where suspending is expected. The compiler will perform an implicit conversion automatically.
```
fun getSuspending(suspending: suspend () -> Unit) {}
fun suspending() {}
fun test(regular: () -> Unit) {
getSuspending { } // OK
getSuspending(::suspending) // OK
getSuspending(regular) // OK
}
```
### Stable instantiation of annotation classes
Kotlin 1.5.30 [introduced](whatsnew1530#instantiation-of-annotation-classes) experimental support for instantiation of annotation classes on the JVM platform. With 1.6.0, the feature is available by default both for Kotlin/JVM and Kotlin/JS.
Learn more about instantiation of annotation classes in [this KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/annotation-instantiation.md).
### Improved type inference for recursive generic types
Kotlin 1.5.30 introduced an improvement to type inference for recursive generic types, which allowed their type arguments to be inferred based only on the upper bounds of the corresponding type parameters. The improvement was available with the compiler option. In version 1.6.0 and later, it is enabled by default.
```
// Before 1.5.30
val containerA = PostgreSQLContainer<Nothing>(DockerImageName.parse("postgres:13-alpine")).apply {
withDatabaseName("db")
withUsername("user")
withPassword("password")
withInitScript("sql/schema.sql")
}
// With compiler option in 1.5.30 or by default starting with 1.6.0
val containerB = PostgreSQLContainer(DockerImageName.parse("postgres:13-alpine"))
.withDatabaseName("db")
.withUsername("user")
.withPassword("password")
.withInitScript("sql/schema.sql")
```
### Changes to builder inference
Builder inference is a type inference flavor which is useful when calling generic builder functions. It can infer the type arguments of a call with the help of type information from calls inside its lambda argument.
We're making multiple changes that are bringing us closer to fully stable builder inference. Starting with 1.6.0:
* You can make calls returning an instance of a not yet inferred type inside a builder lambda without specifying the `-Xunrestricted-builder-inference` compiler option [introduced in 1.5.30](whatsnew1530#eliminating-builder-inference-restrictions).
* With `-Xenable-builder-inference`, you can write your own builders without applying the [`@BuilderInference`](../api/latest/jvm/stdlib/kotlin/-builder-inference/index) annotation.
* With the `-Xenable-builder-inference`, builder inference automatically activates if a regular type inference cannot get enough information about a type.
[Learn how to write custom generic builders](using-builders-with-builder-inference).
### Support for annotations on class type parameters
Support for annotations on class type parameters looks like this:
```
@Target(AnnotationTarget.TYPE_PARAMETER)
annotation class BoxContent
class Box<@BoxContent T> {}
```
Annotations on all type parameters are emitted into JVM bytecode so annotation processors are able to use them.
For the motivating use case, read this [YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-43714).
Learn more about <annotations>.
Supporting previous API versions for a longer period
----------------------------------------------------
Starting with Kotlin 1.6.0, we will support development for three previous API versions instead of two, along with the current stable one. Currently, we support versions 1.3, 1.4, 1.5, and 1.6.
Kotlin/JVM
----------
For Kotlin/JVM, starting with 1.6.0, the compiler can generate classes with a bytecode version corresponding to JVM 17. The new language version also includes optimized delegated properties and repeatable annotations, which we had on the roadmap:
* [Repeatable annotations with runtime retention for 1.8 JVM target](#repeatable-annotations-with-runtime-retention-for-1-8-jvm-target)
* [Optimize delegated properties which call get/set on the given KProperty instance](#optimize-delegated-properties-which-call-get-set-on-the-given-kproperty-instance)
### Repeatable annotations with runtime retention for 1.8 JVM target
Java 8 introduced [repeatable annotations](https://docs.oracle.com/javase/tutorial/java/annotations/repeating.html), which can be applied multiple times to a single code element. The feature requires two declarations to be present in the Java code: the repeatable annotation itself marked with [`@java.lang.annotation.Repeatable`](https://docs.oracle.com/javase/8/docs/api/java/lang/annotation/Repeatable.html) and the containing annotation to hold its values.
Kotlin also has repeatable annotations, but requires only [`@kotlin.annotation.Repeatable`](../api/latest/jvm/stdlib/kotlin.annotation/-repeatable/index) to be present on an annotation declaration to make it repeatable. Before 1.6.0, the feature supported only `SOURCE` retention and was incompatible with Java's repeatable annotations. Kotlin 1.6.0 removes these limitations. `@kotlin.annotation.Repeatable` now accepts any retention and makes the annotation repeatable both in Kotlin and Java. Java's repeatable annotations are now also supported from the Kotlin side.
While you can declare a containing annotation, it's not necessary. For example:
* If an annotation `@Tag` is marked with `@kotlin.annotation.Repeatable`, the Kotlin compiler automatically generates a containing annotation class under the name of `@Tag.Container`:
```
@Repeatable
annotation class Tag(val name: String)
// The compiler generates @Tag.Container containing annotation
```
* To set a custom name for a containing annotation, apply the [`@kotlin.jvm.JvmRepeatable`](../api/latest/jvm/stdlib/kotlin.jvm/-jvmrepeatable/index) meta-annotation and pass the explicitly declared containing annotation class as an argument:
```
@JvmRepeatable(Tags::class)
annotation class Tag(val name: String)
annotation class Tags(val value: Array<Tag>)
```
Kotlin reflection now supports both Kotlin's and Java's repeatable annotations via a new function, [`KAnnotatedElement.findAnnotations()`](../api/latest/jvm/stdlib/kotlin.reflect.full/find-annotations).
Learn more about Kotlin repeatable annotations in [this KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/repeatable-annotations.md).
### Optimize delegated properties which call get/set on the given KProperty instance
We optimized the generated JVM bytecode by omitting the `$delegate` field and generating immediate access to the referenced property.
For example, in the following code
```
class Box<T> {
private var impl: T = ...
var content: T by ::impl
}
```
Kotlin no longer generates the field `content$delegate`. Property accessors of the `content` variable invoke the `impl` variable directly, skipping the delegated property's `getValue`/`setValue` operators and thus avoiding the need for the property reference object of the [`KProperty`](../api/latest/jvm/stdlib/kotlin.reflect/-k-property/index) type.
Thanks to our Google colleagues for the implementation!
Learn more about [delegated properties](delegated-properties).
Kotlin/Native
-------------
Kotlin/Native is receiving multiple improvements and component updates, some of them in the preview state:
* [Preview of the new memory manager](#preview-of-the-new-memory-manager)
* [Support for Xcode 13](#support-for-xcode-13)
* [Compilation of Windows targets on any host](#compilation-of-windows-targets-on-any-host)
* [LLVM and linker updates](#llvm-and-linker-updates)
* [Performance improvements](#performance-improvements)
* [Unified compiler plugin ABI with JVM and JS IR backends](#unified-compiler-plugin-abi-with-jvm-and-js-ir-backends)
* [Detailed error messages for klib linkage failures](#detailed-error-messages-for-klib-linkage-failures)
* [Reworked unhandled exception handling API](#reworked-unhandled-exception-handling-api)
### Preview of the new memory manager
With Kotlin 1.6.0, you can try the development preview of the new Kotlin/Native memory manager. It moves us closer to eliminating the differences between the JVM and Native platforms to provide a consistent developer experience in multiplatform projects.
One of the notable changes is the lazy initialization of top-level properties, like in Kotlin/JVM. A top-level property gets initialized when a top-level property or function from the same file is accessed for the first time. This mode also includes global interprocedural optimization (enabled only for release binaries), which removes redundant initialization checks.
We've recently published a [blog post](https://blog.jetbrains.com/kotlin/2021/08/try-the-new-kotlin-native-memory-manager-development-preview/) about the new memory manager. Read it to learn about the current state of the new memory manager and find some demo projects, or jump right to the [migration instructions](https://github.com/JetBrains/kotlin/blob/master/kotlin-native/NEW_MM.md) to try it yourself. Please check how the new memory manager works on your projects and share feedback in our issue tracker, [YouTrack](https://youtrack.jetbrains.com/issue/KT-48525).
### Support for Xcode 13
Kotlin/Native 1.6.0 supports Xcode 13 – the latest version of Xcode. Feel free to update your Xcode and continue working on your Kotlin projects for Apple operating systems.
### Compilation of Windows targets on any host
Starting from 1.6.0, you don't need a Windows host to compile the Windows targets `mingwX64` and `mingwX86`. They can be compiled on any host that supports Kotlin/Native.
### LLVM and linker updates
We've reworked the LLVM dependency that Kotlin/Native uses under the hood. This brings various benefits, including:
* Updated LLVM version to 11.1.0.
* Decreased dependency size. For example, on macOS it's now about 300 MB instead of 1200 MB in the previous version.
* [Excluded dependency on the `ncurses5` library](https://youtrack.jetbrains.com/issue/KT-42693) that isn't available in modern Linux distributions.
In addition to the LLVM update, Kotlin/Native now uses the [LLD](https://lld.llvm.org/) linker (a linker from the LLVM project) for MingGW targets. It provides various benefits over the previously used ld.bfd linker, and will allow us to improve runtime performance of produced binaries and support compiler caches for MinGW targets. Note that LLD [requires import libraries for DLL linkage](whatsnew1530#deprecation-of-linkage-against-dlls-without-import-libraries-for-mingw-targets). Learn more in [this Stack Overflow thread](https://stackoverflow.com/questions/3573475/how-does-the-import-library-work-details/3573527/#3573527).
### Performance improvements
Kotlin/Native 1.6.0 delivers the following performance improvements:
* Compilation time: compiler caches are enabled by default for `linuxX64` and `iosArm64` targets. This speeds up most compilations in debug mode (except the first one). Measurements showed about a 200% speed increase on our test projects. The compiler caches have been available for these targets since Kotlin 1.5.0 with [additional Gradle properties](whatsnew15#performance-improvements); you can remove them now.
* Runtime: iterating over arrays with `for` loops is now up to 12% faster thanks to optimizations in the produced LLVM code.
### Unified compiler plugin ABI with JVM and JS IR backends
In previous versions, authors of compiler plugins had to provide separate artifacts for Kotlin/Native because of the differences in the ABI.
Starting from 1.6.0, the Kotlin Multiplatform Gradle plugin is able to use the embeddable compiler jar – the one used for the JVM and JS IR backends – for Kotlin/Native. This is a step toward unification of the compiler plugin development experience, as you can now use the same compiler plugin artifacts for Native and other supported platforms.
This is a preview version of such support, and it requires an opt-in. To start using generic compiler plugin artifacts for Kotlin/Native, add the following line to `gradle.properties`: `kotlin.native.useEmbeddableCompilerJar=true`.
We're planning to use the embeddable compiler jar for Kotlin/Native by default in the future, so it's vital for us to hear how the preview works for you.
If you are an author of a compiler plugin, please try this mode and check if it works for your plugin. Note that depending on your plugin's structure, migration steps may be required. See [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-48595) for migration instructions and leave your feedback in the comments.
### Detailed error messages for klib linkage failures
The Kotlin/Native compiler now provides detailed error messages for klib linkage errors. The messages now have clear error descriptions, and they also include information about possible causes and ways to fix them.
For example:
* 1.5.30:
```
e: java.lang.IllegalStateException: IrTypeAliasSymbol expected: Unbound public symbol for public kotlinx.coroutines/CancellationException|null[0]
<stack trace>
```
* 1.6.0:
```
e: The symbol of unexpected type encountered during IR deserialization: IrClassPublicSymbolImpl, kotlinx.coroutines/CancellationException|null[0].
IrTypeAliasSymbol is expected.
This could happen if there are two libraries, where one library was compiled against the different version of the other library than the one currently used in the project.
Please check that the project configuration is correct and has consistent versions of dependencies.
The list of libraries that depend on "org.jetbrains.kotlinx:kotlinx-coroutines-core (org.jetbrains.kotlinx:kotlinx-coroutines-core-macosx64)" and may lead to conflicts:
<list of libraries and potential version mismatches>
Project dependencies:
<dependencies tree>
```
### Reworked unhandled exception handling API
We've unified the processing of unhandled exceptions throughout the Kotlin/Native runtime and exposed the default processing as the function `processUnhandledException(throwable: Throwable)` for use by custom execution environments, like `kotlinx.coroutines`. This processing is also applied to exceptions that escape operation in `Worker.executeAfter()`, but only for the new [memory manager](#preview-of-the-new-memory-manager).
API improvements also affected the hooks that have been set by `setUnhandledExceptionHook()`. Previously such hooks were reset after the Kotlin/Native runtime called the hook with an unhandled exception, and the program would always terminate right after. Now these hooks may be used more than once, and if you want the program to always terminate on an unhandled exception, either do not set an unhandled exception hook (`setUnhandledExceptionHook()`), or make sure to call `terminateWithUnhandledException()` at the end of your hook. This will help you send exceptions to a third-party crash reporting service (like Firebase Crashlytics) and then terminate the program. Exceptions that escape `main()` and exceptions that cross the interop boundary will always terminate the program, even if the hook did not call `terminateWithUnhandledException()`.
Kotlin/JS
---------
We're continuing to work on stabilizing the IR backend for the Kotlin/JS compiler. Kotlin/JS now has an [option to disable downloading of Node.js and Yarn](#option-to-use-pre-installed-node-js-and-yarn).
### Option to use pre-installed Node.js and Yarn
You can now disable downloading Node.js and Yarn when building Kotlin/JS projects and use the instances already installed on the host. This is useful for building on servers without internet connectivity, such as CI servers.
To disable downloading external components, add the following lines to your `build.gradle(.kts)`:
* Yarn:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().download = false // or true for default behavior
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).download = false
}
```
* Node.js:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootExtension>().download = false // or true for default behavior
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.nodejs.NodeJsRootExtension).download = false
}
```
Kotlin Gradle plugin
--------------------
In Kotlin 1.6.0, we changed the deprecation level of the `KotlinGradleSubplugin` class to 'ERROR'. This class was used for writing compiler plugins. In the following releases, we'll remove this class. Use the class `KotlinCompilerPluginSupportPlugin` instead.
We removed the `kotlin.useFallbackCompilerSearch` build option and the `noReflect` and `includeRuntime` compiler options. The `useIR` compiler option has been hidden and will be removed in upcoming releases.
Learn more about the [currently supported compiler options](gradle-compiler-options) in the Kotlin Gradle plugin.
Standard library
----------------
The new 1.6.0 version of the standard library stabilizes experimental features, introduces new ones, and unifies its behavior across the platforms:
* [New readline functions](#new-readline-functions)
* [Stable typeOf()](#stable-typeof)
* [Stable collection builders](#stable-collection-builders)
* [Stable Duration API](#stable-duration-api)
* [Splitting Regex into a sequence](#splitting-regex-into-a-sequence)
* [Bit rotation operations on integers](#bit-rotation-operations-on-integers)
* [Changes for replace() and replaceFirst() in JS](#changes-for-replace-and-replacefirst-in-js)
* [Improvements to the existing API](#improvements-to-the-existing-api)
* [Deprecations](#deprecations)
### New readline functions
Kotlin 1.6.0 offers new functions for handling standard input: [`readln()`](../api/latest/jvm/stdlib/kotlin.io/readln) and [`readlnOrNull()`](../api/latest/jvm/stdlib/kotlin.io/readln-or-null).
| **Earlier versions** | **1.6.0 alternative** | **Usage** |
| --- | --- | --- |
| `readLine()!!` | `readln()` | Reads a line from stdin and returns it, or throws a `RuntimeException` if EOF has been reached. |
| `readLine()` | `readlnOrNull()` | Reads a line from stdin and returns it, or returns `null` if EOF has been reached. |
We believe that eliminating the need to use `!!` when reading a line will improve the experience for newcomers and simplify teaching Kotlin. To make the read-line operation name consistent with its `println()` counterpart, we've decided to shorten the names of new functions to 'ln'.
```
println("What is your nickname?")
val nickname = readln()
println("Hello, $nickname!")
```
```
fun main() {
//sampleStart
var sum = 0
while (true) {
val nextLine = readlnOrNull().takeUnless {
it.isNullOrEmpty()
} ?: break
sum += nextLine.toInt()
}
println(sum)
//sampleEnd
}
```
The existing `readLine()` function will get a lower priority than `readln()` and `readlnOrNull()` in your IDE code completion. IDE inspections will also recommend using new functions instead of the legacy `readLine()`.
We're planning to gradually deprecate the `readLine()` function in future releases.
### Stable typeOf()
Version 1.6.0 brings a [Stable](components-stability) [`typeOf()`](../api/latest/jvm/stdlib/kotlin.reflect/type-of) function, closing one of the [major roadmap items](https://youtrack.jetbrains.com/issue/KT-45396).
[Since 1.3.40](https://blog.jetbrains.com/kotlin/2019/06/kotlin-1-3-40-released/), `typeOf()` was available on the JVM platform as an experimental API. Now you can use it in any Kotlin platform and get [`KType`](../api/latest/jvm/stdlib/kotlin.reflect/-k-type/index#kotlin.reflect.KType) representation of any Kotlin type that the compiler can infer:
```
inline fun <reified T> renderType(): String {
val type = typeOf<T>()
return type.toString()
}
fun main() {
val fromExplicitType = typeOf<Int>()
val fromReifiedType = renderType<List<Int>>()
}
```
### Stable collection builders
In Kotlin 1.6.0, collection builder functions have been promoted to [Stable](components-stability). Collections returned by collection builders are now serializable in their read-only state.
You can now use [`buildMap()`](../api/latest/jvm/stdlib/kotlin.collections/build-map), [`buildList()`](../api/latest/jvm/stdlib/kotlin.collections/build-list), and [`buildSet()`](../api/latest/jvm/stdlib/kotlin.collections/build-set) without the opt-in annotation:
```
fun main() {
//sampleStart
val x = listOf('b', 'c')
val y = buildList {
add('a')
addAll(x)
add('d')
}
println(y) // [a, b, c, d]
//sampleEnd
}
```
### Stable Duration API
The [Duration](../api/latest/jvm/stdlib/kotlin.time/-duration/index) class for representing duration amounts in different time units has been promoted to [Stable](components-stability). In 1.6.0, the Duration API has received the following changes:
* The first component of the [`toComponents()`](../api/latest/jvm/stdlib/kotlin.time/-duration/to-components) function that decomposes the duration into days, hours, minutes, seconds, and nanoseconds now has the `Long` type instead of `Int`. Before, if the value didn't fit into the `Int` range, it was coerced into that range. With the `Long` type, you can decompose any value in the duration range without cutting off the values that don't fit into `Int`.
* The `DurationUnit` enum is now standalone and not a type alias of `java.util.concurrent.TimeUnit` on the JVM. We haven't found any convincing cases in which having `typealias DurationUnit = TimeUnit` could be useful. Also, exposing the `TimeUnit` API through a type alias might confuse `DurationUnit` users.
* In response to community feedback, we're bringing back extension properties like `Int.seconds`. But we'd like to limit their applicability, so we put them into the companion of the `Duration` class. While the IDE can still propose extensions in completion and automatically insert an import from the companion, in the future we plan to limit this behavior to cases when the `Duration` type is expected.
```
import kotlin.time.Duration.Companion.seconds
fun main() {
//sampleStart
val duration = 10000
println("There are ${duration.seconds.inWholeMinutes} minutes in $duration seconds")
// There are 166 minutes in 10000 seconds
//sampleEnd
}
```
We suggest replacing previously introduced companion functions, such as `Duration.seconds(Int)`, and deprecated top-level extensions like `Int.seconds` with new extensions in `Duration.Companion`.
### Splitting Regex into a sequence
The `Regex.splitToSequence(CharSequence)` and `CharSequence.splitToSequence(Regex)` functions are promoted to [Stable](components-stability). They split the string around matches of the given regex, but return the result as a [Sequence](sequences) so that all operations on this result are executed lazily:
```
fun main() {
//sampleStart
val colorsText = "green, red, brown&blue, orange, pink&green"
val regex = "[,\\s]+".toRegex()
val mixedColor = regex.splitToSequence(colorsText)
// or
// val mixedColor = colorsText.splitToSequence(regex)
.onEach { println(it) }
.firstOrNull { it.contains('&') }
println(mixedColor) // "brown&blue"
//sampleEnd
}
```
### Bit rotation operations on integers
In Kotlin 1.6.0, the `rotateLeft()` and `rotateRight()` functions for bit manipulations became [Stable](components-stability). The functions rotate the binary representation of the number left or right by a specified number of bits:
```
fun main() {
//sampleStart
val number: Short = 0b10001
println(number
.rotateRight(2)
.toString(radix = 2)) // 100000000000100
println(number
.rotateLeft(2)
.toString(radix = 2)) // 1000100
//sampleEnd
}
```
### Changes for replace() and replaceFirst() in JS
Before Kotlin 1.6.0, the [`replace()`](../api/latest/jvm/stdlib/kotlin.text/-regex/replace) and [`replaceFirst()`](../api/latest/jvm/stdlib/kotlin.text/-regex/replace-first) Regex functions behaved differently in Java and JS when the replacement string contained a group reference. To make the behavior consistent across all target platforms, we've changed their implementation in JS.
Occurrences of `${name}` or `$index` in the replacement string are substituted with the subsequences corresponding to the captured groups with the specified index or a name:
* `$index` – the first digit after '$' is always treated as a part of the group reference. Subsequent digits are incorporated into the `index` only if they form a valid group reference.Only digits '0'–'9' are considered potential components of the group reference. Note that indexes of captured groups start from '1'. The group with index '0' stands for the whole match.
* `${name}` – the `name` can consist of Latin letters 'a'–'z', 'A'–'Z', or digits '0'–'9'. The first character must be a letter.
* To include the succeeding character as a literal in the replacement string, use the backslash character `\`:
```
fun main() {
//sampleStart
println(Regex("(.+)").replace("Kotlin", """\$ $1""")) // $ Kotlin
println(Regex("(.+)").replaceFirst("1.6.0", """\\ $1""")) // \ 1.6.0
//sampleEnd
}
```
You can use [`Regex.escapeReplacement()`](../api/latest/jvm/stdlib/kotlin.text/-regex/escape-replacement) if the replacement string has to be treated as a literal string.
### Improvements to the existing API
* Version 1.6.0 added the infix extension function for `Comparable.compareTo()`. You can now use the infix form for comparing two objects for order:
```
class WrappedText(val text: String) : Comparable<WrappedText> {
override fun compareTo(other: WrappedText): Int =
this.text compareTo other.text
}
```
* `Regex.replace()` in JS is now also not inline to unify its implementation across all platforms.
* The `compareTo()` and `equals()` String functions, as well as the `isBlank()` CharSequence function now behave in JS exactly the same way they do on the JVM. Previously there were deviations when it came to non-ASCII characters.
### Deprecations
In Kotlin 1.6.0, we're starting the deprecation cycle with a warning for some JS-only stdlib API.
#### concat(), match(), and matches() string functions
* To concatenate the string with the string representation of a given other object, use `plus()` instead of `concat()`.
* To find all occurrences of a regular expression within the input, use `findAll()` of the Regex class instead of `String.match(regex: String)`.
* To check if the regular expression matches the entire input, use `matches()` of the Regex class instead of `String.matches(regex: String)`.
#### sort() on arrays taking comparison functions
We've deprecated the `Array<out T>.sort()` function and the inline functions `ByteArray.sort()`, `ShortArray.sort()`, `IntArray.sort()`, `LongArray.sort()`, `FloatArray.sort()`, `DoubleArray.sort()`, and `CharArray.sort()`, which sorted arrays following the order passed by the comparison function. Use other standard library functions for array sorting.
See the [collection ordering](collection-ordering) section for reference.
Tools
-----
### Kover – a code coverage tool for Kotlin
With Kotlin 1.6.0, we're introducing Kover – a Gradle plugin for the [IntelliJ](https://github.com/JetBrains/intellij-coverage) and [JaCoCo](https://github.com/jacoco/jacoco) Kotlin code coverage agents. It works with all language constructs, including inline functions.
Learn more about Kover on its [GitHub repository](https://github.com/Kotlin/kotlinx-kover) or in this video:
Coroutines 1.6.0-RC
-------------------
`kotlinx.coroutines` [1.6.0-RC](https://github.com/Kotlin/kotlinx.coroutines/releases/tag/1.6.0-RC) is out with multiple features and improvements:
* Support for the [new Kotlin/Native memory manager](#preview-of-the-new-memory-manager)
* Introduction of dispatcher *views* API, which allows limiting parallelism without creating additional threads
* Migrating from Java 6 to Java 8 target
* `kotlinx-coroutines-test` with the new reworked API and multiplatform support
* Introduction of [`CopyableThreadContextElement`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-copyable-thread-context-element/index.html), which gives coroutines a thread-safe write access to [`ThreadLocal`](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/ThreadLocal.html) variables
Learn more in the [changelog](https://github.com/Kotlin/kotlinx.coroutines/releases/tag/1.6.0-RC).
Migrating to Kotlin 1.6.0
-------------------------
IntelliJ IDEA and Android Studio will suggest updating the Kotlin plugin to 1.6.0 once it is available.
To migrate existing projects to Kotlin 1.6.0, change the Kotlin version to `1.6.0` and reimport your Gradle or Maven project. [Learn how to update to Kotlin 1.6.0](releases#update-to-a-new-release).
To start a new project with Kotlin 1.6.0, update the Kotlin plugin and run the Project Wizard from **File** | **New** | **Project**.
The new command-line compiler is available for download on the [GitHub release page](https://github.com/JetBrains/kotlin/releases/tag/v1.6.0).
Kotlin 1.6.0 is a [feature release](kotlin-evolution#feature-releases-and-incremental-releases) and can, therefore, bring changes that are incompatible with your code written for earlier versions of the language. Find the detailed list of such changes in the [Compatibility Guide for Kotlin 1.6](compatibility-guide-16).
Last modified: 10 January 2023
[What's new in Kotlin 1.6.20](whatsnew1620) [What's new in Kotlin 1.5.30](whatsnew1530)
| programming_docs |
kotlin Generics: in, out, where Generics: in, out, where
========================
Classes in Kotlin can have type parameters, just like in Java:
```
class Box<T>(t: T) {
var value = t
}
```
To create an instance of such a class, simply provide the type arguments:
```
val box: Box<Int> = Box<Int>(1)
```
But if the parameters can be inferred, for example, from the constructor arguments, you can omit the type arguments:
```
val box = Box(1) // 1 has type Int, so the compiler figures out that it is Box<Int>
```
Variance
--------
One of the trickiest aspects of Java's type system is the wildcard types (see [Java Generics FAQ](http://www.angelikalanger.com/GenericsFAQ/JavaGenericsFAQ.html)). Kotlin doesn't have these. Instead, Kotlin has declaration-site variance and type projections.
Let's think about why Java needs these mysterious wildcards. The problem is explained well in [Effective Java, 3rd Edition](http://www.oracle.com/technetwork/java/effectivejava-136174.html), Item 31: *Use bounded wildcards to increase API flexibility*. First, generic types in Java are *invariant*, meaning that `List<String>` is *not* a subtype of `List<Object>`. If `List` were not *invariant*, it would have been no better than Java's arrays, as the following code would have compiled but caused an exception at runtime:
```
// Java
List<String> strs = new ArrayList<String>();
List<Object> objs = strs; // !!! A compile-time error here saves us from a runtime exception later.
objs.add(1); // Put an Integer into a list of Strings
String s = strs.get(0); // !!! ClassCastException: Cannot cast Integer to String
```
Java prohibits such things in order to guarantee run-time safety. But this has implications. For example, consider the `addAll()` method from the `Collection` interface. What's the signature of this method? Intuitively, you'd write it this way:
```
// Java
interface Collection<E> ... {
void addAll(Collection<E> items);
}
```
But then, you would not be able to do the following (which is perfectly safe):
```
// Java
void copyAll(Collection<Object> to, Collection<String> from) {
to.addAll(from);
// !!! Would not compile with the naive declaration of addAll:
// Collection<String> is not a subtype of Collection<Object>
}
```
(In Java, you probably learned this the hard way, see [Effective Java, 3rd Edition](http://www.oracle.com/technetwork/java/effectivejava-136174.html), Item 28: *Prefer lists to arrays*)
That's why the actual signature of `addAll()` is the following:
```
// Java
interface Collection<E> ... {
void addAll(Collection<? extends E> items);
}
```
The *wildcard type argument* `? extends E` indicates that this method accepts a collection of objects of `E` *or a subtype of* `E`, not just `E` itself. This means that you can safely *read* `E`'s from items (elements of this collection are instances of a subclass of E), but *cannot write* to it as you don't know what objects comply with that unknown subtype of `E`. In return for this limitation, you get the desired behavior: `Collection<String>` *is* a subtype of `Collection<? extends Object>`. In other words, the wildcard with an *extends*-bound (*upper* bound) makes the type *covariant*.
The key to understanding why this works is rather simple: if you can only *take* items from a collection, then using a collection of `String`s and reading `Object`s from it is fine. Conversely, if you can only *put* items into the collection, it's okay to take a collection of `Object`s and put `String`s into it: in Java there is `List<? super String>`, a *supertype* of `List<Object>`.
The latter is called *contravariance*, and you can only call methods that take `String` as an argument on `List<? super String>` (for example, you can call `add(String)` or `set(int, String)`). If you call something that returns `T` in `List<T>`, you don't get a `String`, but rather an `Object`.
Joshua Bloch gives the name *Producers* to objects you only *read from* and *Consumers* to those you only *write to*. He recommends:
### Declaration-site variance
Let's suppose that there is a generic interface `Source<T>` that does not have any methods that take `T` as a parameter, only methods that return `T`:
```
// Java
interface Source<T> {
T nextT();
}
```
Then, it would be perfectly safe to store a reference to an instance of `Source<String>` in a variable of type `Source<Object>` - there are no consumer-methods to call. But Java does not know this, and still prohibits it:
```
// Java
void demo(Source<String> strs) {
Source<Object> objects = strs; // !!! Not allowed in Java
// ...
}
```
To fix this, you should declare objects of type `Source<? extends Object>`. Doing so is meaningless, because you can call all the same methods on such a variable as before, so there's no value added by the more complex type. But the compiler does not know that.
In Kotlin, there is a way to explain this sort of thing to the compiler. This is called *declaration-site variance*: you can annotate the *type parameter* `T` of `Source` to make sure that it is only *returned* (produced) from members of `Source<T>`, and never consumed. To do this, use the `out` modifier:
```
interface Source<out T> {
fun nextT(): T
}
fun demo(strs: Source<String>) {
val objects: Source<Any> = strs // This is OK, since T is an out-parameter
// ...
}
```
The general rule is this: when a type parameter `T` of a class `C` is declared `out`, it may occur only in the *out*-position in the members of `C`, but in return `C<Base>` can safely be a supertype of `C<Derived>`.
In other words, you can say that the class `C` is *covariant* in the parameter `T`, or that `T` is a *covariant* type parameter. You can think of `C` as being a *producer* of `T`'s, and NOT a *consumer* of `T`'s.
The `out` modifier is called a *variance annotation*, and since it is provided at the type parameter declaration site, it provides *declaration-site variance*. This is in contrast with Java's *use-site variance* where wildcards in the type usages make the types covariant.
In addition to `out`, Kotlin provides a complementary variance annotation: `in`. It makes a type parameter *contravariant*, meaning it can only be consumed and never produced. A good example of a contravariant type is `Comparable`:
```
interface Comparable<in T> {
operator fun compareTo(other: T): Int
}
fun demo(x: Comparable<Number>) {
x.compareTo(1.0) // 1.0 has type Double, which is a subtype of Number
// Thus, you can assign x to a variable of type Comparable<Double>
val y: Comparable<Double> = x // OK!
}
```
The words *in* and *out* seem to be self-explanatory (as they've already been used successfully in C# for quite some time), and so the mnemonic mentioned above is not really needed. It can in fact be rephrased at a higher level of abstraction:
**[The Existential](https://en.wikipedia.org/wiki/Existentialism) Transformation: Consumer in, Producer out!**:-)
Type projections
----------------
### Use-site variance: type projections
It is very easy to declare a type parameter `T` as `out` and avoid trouble with subtyping on the use site, but some classes *can't* actually be restricted to only return `T`'s! A good example of this is `Array`:
```
class Array<T>(val size: Int) {
operator fun get(index: Int): T { ... }
operator fun set(index: Int, value: T) { ... }
}
```
This class can be neither co- nor contravariant in `T`. And this imposes certain inflexibilities. Consider the following function:
```
fun copy(from: Array<Any>, to: Array<Any>) {
assert(from.size == to.size)
for (i in from.indices)
to[i] = from[i]
}
```
This function is supposed to copy items from one array to another. Let's try to apply it in practice:
```
val ints: Array<Int> = arrayOf(1, 2, 3)
val any = Array<Any>(3) { "" }
copy(ints, any)
// ^ type is Array<Int> but Array<Any> was expected
```
Here you run into the same familiar problem: `Array<T>` is *invariant* in `T`, and so neither `Array<Int>` nor `Array<Any>` is a subtype of the other. Why not? Again, this is because `copy` could have an unexpected behavior, for example, it may attempt to write a `String` to `from`, and if you actually pass an array of `Int` there, a `ClassCastException` will be thrown later.
To prohibit the `copy` function from *writing* to `from`, you can do the following:
```
fun copy(from: Array<out Any>, to: Array<Any>) { ... }
```
This is *type projection*, which means that `from` is not a simple array, but is rather a restricted (*projected*) one. You can only call methods that return the type parameter `T`, which in this case means that you can only call `get()`. This is our approach to *use-site variance*, and it corresponds to Java's `Array<? extends Object>` while being slightly simpler.
You can project a type with `in` as well:
```
fun fill(dest: Array<in String>, value: String) { ... }
```
`Array<in String>` corresponds to Java's `Array<? super String>`. This means that you can pass an array of `CharSequence` or an array of `Object` to the `fill()` function.
### Star-projections
Sometimes you want to say that you know nothing about the type argument, but you still want to use it in a safe way. The safe way here is to define such a projection of the generic type, that every concrete instantiation of that generic type will be a subtype of that projection.
Kotlin provides so-called *star-projection* syntax for this:
* For `Foo<out T : TUpper>`, where `T` is a covariant type parameter with the upper bound `TUpper`, `Foo<*>` is equivalent to `Foo<out TUpper>`. This means that when the `T` is unknown you can safely *read* values of `TUpper` from `Foo<*>`.
* For `Foo<in T>`, where `T` is a contravariant type parameter, `Foo<*>` is equivalent to `Foo<in Nothing>`. This means there is nothing you can *write* to `Foo<*>` in a safe way when `T` is unknown.
* For `Foo<T : TUpper>`, where `T` is an invariant type parameter with the upper bound `TUpper`, `Foo<*>` is equivalent to `Foo<out TUpper>` for reading values and to `Foo<in Nothing>` for writing values.
If a generic type has several type parameters, each of them can be projected independently. For example, if the type is declared as `interface Function<in T, out U>` you could use the following star-projections:
* `Function<*, String>` means `Function<in Nothing, String>`.
* `Function<Int, *>` means `Function<Int, out Any?>`.
* `Function<*, *>` means `Function<in Nothing, out Any?>`.
Generic functions
-----------------
Classes aren't the only declarations that can have type parameters. Functions can, too. Type parameters are placed *before* the name of the function:
```
fun <T> singletonList(item: T): List<T> {
// ...
}
fun <T> T.basicToString(): String { // extension function
// ...
}
```
To call a generic function, specify the type arguments at the call site *after* the name of the function:
```
val l = singletonList<Int>(1)
```
Type arguments can be omitted if they can be inferred from the context, so the following example works as well:
```
val l = singletonList(1)
```
Generic constraints
-------------------
The set of all possible types that can be substituted for a given type parameter may be restricted by *generic constraints*.
### Upper bounds
The most common type of constraint is an *upper bound*, which corresponds to Java's `extends` keyword:
```
fun <T : Comparable<T>> sort(list: List<T>) { ... }
```
The type specified after a colon is the *upper bound*, indicating that only a subtype of `Comparable<T>` can be substituted for `T`. For example:
```
sort(listOf(1, 2, 3)) // OK. Int is a subtype of Comparable<Int>
sort(listOf(HashMap<Int, String>())) // Error: HashMap<Int, String> is not a subtype of Comparable<HashMap<Int, String>>
```
The default upper bound (if there was none specified) is `Any?`. Only one upper bound can be specified inside the angle brackets. If the same type parameter needs more than one upper bound, you need a separate *where*-clause:
```
fun <T> copyWhenGreater(list: List<T>, threshold: T): List<String>
where T : CharSequence,
T : Comparable<T> {
return list.filter { it > threshold }.map { it.toString() }
}
```
The passed type must satisfy all conditions of the `where` clause simultaneously. In the above example, the `T` type must implement *both* `CharSequence` and `Comparable`.
Type erasure
------------
The type safety checks that Kotlin performs for generic declaration usages are done at compile time. At runtime, the instances of generic types do not hold any information about their actual type arguments. The type information is said to be *erased*. For example, the instances of `Foo<Bar>` and `Foo<Baz?>` are erased to just `Foo<*>`.
### Generics type checks and casts
Due to the type erasure, there is no general way to check whether an instance of a generic type was created with certain type arguments at runtime, and the compiler prohibits such `is`-checks such as `ints is List<Int>` or `list is T` (type parameter). However, you can check an instance against a star-projected type:
```
if (something is List<*>) {
something.forEach { println(it) } // The items are typed as `Any?`
}
```
Similarly, when you already have the type arguments of an instance checked statically (at compile time), you can make an `is`-check or a cast that involves the non-generic part of the type. Note that angle brackets are omitted in this case:
```
fun handleStrings(list: MutableList<String>) {
if (list is ArrayList) {
// `list` is smart-cast to `ArrayList<String>`
}
}
```
The same syntax but with the type arguments omitted can be used for casts that do not take type arguments into account: `list as ArrayList`.
The type arguments of a generic function calls are also only checked at compile time. Inside the function bodies, the type parameters cannot be used for type checks, and type casts to type parameters (`foo as T`) are unchecked. The only exclusion is inline functions with [reified type parameters](inline-functions#reified-type-parameters), which have their actual type arguments inlined at each call site. This enables type checks and casts for the type parameters. However, the restrictions described above still apply for instances of generic types used inside checks or casts. For example, in the type check `arg is T`, if `arg` is an instance of a generic type itself, its type arguments are still erased.
```
//sampleStart
inline fun <reified A, reified B> Pair<*, *>.asPairOf(): Pair<A, B>? {
if (first !is A || second !is B) return null
return first as A to second as B
}
val somePair: Pair<Any?, Any?> = "items" to listOf(1, 2, 3)
val stringToSomething = somePair.asPairOf<String, Any>()
val stringToInt = somePair.asPairOf<String, Int>()
val stringToList = somePair.asPairOf<String, List<*>>()
val stringToStringList = somePair.asPairOf<String, List<String>>() // Compiles but breaks type safety!
// Expand the sample for more details
//sampleEnd
fun main() {
println("stringToSomething = " + stringToSomething)
println("stringToInt = " + stringToInt)
println("stringToList = " + stringToList)
println("stringToStringList = " + stringToStringList)
//println(stringToStringList?.second?.forEach() {it.length}) // This will throw ClassCastException as list items are not String
}
```
### Unchecked casts
Type casts to generic types with concrete type arguments such as `foo as List<String>` cannot be checked at runtime.
These unchecked casts can be used when type safety is implied by the high-level program logic but cannot be inferred directly by the compiler. See the example below.
```
fun readDictionary(file: File): Map<String, *> = file.inputStream().use {
TODO("Read a mapping of strings to arbitrary elements.")
}
// We saved a map with `Int`s into this file
val intsFile = File("ints.dictionary")
// Warning: Unchecked cast: `Map<String, *>` to `Map<String, Int>`
val intsDictionary: Map<String, Int> = readDictionary(intsFile) as Map<String, Int>
```
A warning appears for the cast in the last line. The compiler can't fully check it at runtime and provides no guarantee that the values in the map are `Int`.
To avoid unchecked casts, you can redesign the program structure. In the example above, you could use the `DictionaryReader<T>` and `DictionaryWriter<T>` interfaces with type-safe implementations for different types. You can introduce reasonable abstractions to move unchecked casts from the call site to the implementation details. Proper use of [generic variance](#variance) can also help.
For generic functions, using [reified type parameters](inline-functions#reified-type-parameters) makes casts like `arg as T` checked, unless `arg`'s type has *its own* type arguments that are erased.
An unchecked cast warning can be suppressed by [annotating](annotations) the statement or the declaration where it occurs with `@Suppress("UNCHECKED_CAST")`:
```
inline fun <reified T> List<*>.asListOfType(): List<T>? =
if (all { it is T })
@Suppress("UNCHECKED_CAST")
this as List<T> else
null
```
Underscore operator for type arguments
--------------------------------------
The underscore operator `_` can be used for type arguments. Use it to automatically infer a type of the argument when other types are explicitly specified:
```
abstract class SomeClass<T> {
abstract fun execute() : T
}
class SomeImplementation : SomeClass<String>() {
override fun execute(): String = "Test"
}
class OtherImplementation : SomeClass<Int>() {
override fun execute(): Int = 42
}
object Runner {
inline fun <reified S: SomeClass<T>, T> run() : T {
return S::class.java.getDeclaredConstructor().newInstance().execute()
}
}
fun main() {
// T is inferred as String because SomeImplementation derives from SomeClass<String>
val s = Runner.run<SomeImplementation, _>()
assert(s == "Test")
// T is inferred as Int because OtherImplementation derives from SomeClass<Int>
val n = Runner.run<OtherImplementation, _>()
assert(n == 42)
}
```
Last modified: 10 January 2023
[Sealed classes](sealed-classes) [Nested and inner classes](nested-classes)
kotlin Serialization Serialization
=============
*Serialization* is the process of converting data used by an application to a format that can be transferred over a network or stored in a database or a file. In turn, *deserialization* is the opposite process of reading data from an external source and converting it into a runtime object. Together they are an essential part of most applications that exchange data with third parties.
Some data serialization formats, such as [JSON](https://www.json.org/json-en.html) and [protocol buffers](https://developers.google.com/protocol-buffers) are particularly common. Being language-neutral and platform-neutral, they enable data exchange between systems written in any modern language.
In Kotlin, data serialization tools are available in a separate component, [kotlinx.serialization](https://github.com/Kotlin/kotlinx.serialization). It consists of two main parts: the Gradle plugin –`org.jetbrains.kotlin.plugin.serialization` and the runtime libraries.
Libraries
---------
`kotlinx.serialization` provides sets of libraries for all supported platforms – JVM, JavaScript, Native – and for various serialization formats – JSON, CBOR, protocol buffers, and others. You can find the complete list of supported serialization formats [below](#formats).
All Kotlin serialization libraries belong to the `org.jetbrains.kotlinx:` group. Their names start with `kotlinx-serialization-` and have suffixes that reflect the serialization format. Examples:
* `org.jetbrains.kotlinx:kotlinx-serialization-json` provides JSON serialization for Kotlin projects.
* `org.jetbrains.kotlinx:kotlinx-serialization-cbor` provides CBOR serialization.
Platform-specific artifacts are handled automatically; you don't need to add them manually. Use the same dependencies in JVM, JS, Native, and multiplatform projects.
Note that the `kotlinx.serialization` libraries use their own versioning structure, which doesn't match Kotlin's versioning. Check out the releases on [GitHub](https://github.com/Kotlin/kotlinx.serialization/releases) to find the latest versions.
Formats
-------
`kotlinx.serialization` includes libraries for various serialization formats:
* [JSON](https://www.json.org/): [`kotlinx-serialization-json`](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md#json)
* [Protocol buffers](https://developers.google.com/protocol-buffers): [`kotlinx-serialization-protobuf`](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md#protobuf)
* [CBOR](https://cbor.io/): [`kotlinx-serialization-cbor`](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md#cbor)
* [Properties](https://en.wikipedia.org/wiki/.properties): [`kotlinx-serialization-properties`](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md#properties)
* [HOCON](https://github.com/lightbend/config/blob/master/HOCON.md): [`kotlinx-serialization-hocon`](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md#hocon) (only on JVM)
Note that all libraries except JSON serialization (`kotlinx-serialization-core`) are [Experimental](components-stability), which means their API can be changed without notice.
There are also community-maintained libraries that support more serialization formats, such as [YAML](https://yaml.org/) or [Apache Avro](https://avro.apache.org/). For detailed information about available serialization formats, see the [`kotlinx.serialization` documentation](https://github.com/Kotlin/kotlinx.serialization/blob/master/formats/README.md).
Example: JSON serialization
---------------------------
Let's take a look at how to serialize Kotlin objects into JSON.
Before starting, you'll need to configure your build script so that you can use Kotlin serialization tools in your project:
1. Apply the Kotlin serialization Gradle plugin `org.jetbrains.kotlin.plugin.serialization` (or `kotlin("plugin.serialization")` in the Kotlin Gradle DSL).
```
plugins {
kotlin("jvm") version "1.8.0"
kotlin("plugin.serialization") version "1.8.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.jvm' version '1.8.0'
id 'org.jetbrains.kotlin.plugin.serialization' version '1.8.0'
}
```
2. Add the JSON serialization library dependency:`org.jetbrains.kotlinx:kotlinx-serialization-json:1.4.1`
```
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.4.1")
}
```
```
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-serialization-json:1.4.1'
}
```
Now you're ready to use the serialization API in your code. The API is located in the the `kotlinx.serialization` package and its format-specific subpackages such as `kotlinx.serialization.json`.
First, make a class serializable by annotating it with `@Serializable`.
```
import kotlinx.serialization.Serializable
@Serializable
data class Data(val a: Int, val b: String)
```
You can now serialize an instance of this class by calling `Json.encodeToString()`.
```
import kotlinx.serialization.Serializable
import kotlinx.serialization.json.Json
import kotlinx.serialization.encodeToString
@Serializable
data class Data(val a: Int, val b: String)
fun main() {
val json = Json.encodeToString(Data(42, "str"))
}
```
As a result, you get a string containing the state of this object in the JSON format: `{"a": 42, "b": "str"}`
You can also serialize object collections, such as lists, in a single call.
```
val dataList = listOf(Data(42, "str"), Data(12, "test"))
val jsonList = Json.encodeToString(dataList)
```
To deserialize an object from JSON, use the `decodeFromString()` function:
```
import kotlinx.serialization.Serializable
import kotlinx.serialization.json.Json
import kotlinx.serialization.decodeFromString
@Serializable
data class Data(val a: Int, val b: String)
fun main() {
val obj = Json.decodeFromString<Data>("""{"a":42, "b": "str"}""")
}
```
For more information about serialization in Kotlin, see the [Kotlin Serialization Guide](https://github.com/Kotlin/kotlinx.serialization/blob/master/docs/serialization-guide.md).
Last modified: 10 January 2023
[Debug Kotlin Flow using IntelliJ IDEA – tutorial](debug-flow-with-idea) [Lincheck guide](lincheck-guide)
| programming_docs |
kotlin Get started with Gradle and Kotlin/JVM Get started with Gradle and Kotlin/JVM
======================================
This tutorial demonstrates how to use IntelliJ IDEA and Gradle for creating a console application.
To get started, first download and install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
Create a project
----------------
1. In IntelliJ IDEA, select **File** | **New** | **Project**.
2. In the panel on the left, select **New Project**.
3. Name the new project and change its location, if necessary.
4. From the **Language** list, select **Kotlin**.

5. Select the **Gradle** build system.
6. From the **JDK list**, select the [JDK](https://www.oracle.com/java/technologies/downloads/) that you want to use in your project.
* If the JDK is installed on your computer, but not defined in the IDE, select **Add JDK** and specify the path to the JDK home directory.
* If you don't have the necessary JDK on your computer, select **Download JDK**.
7. From the **Gradle DSL** list, select **Kotlin**.
8. Select the **Add sample code** checkbox to create a file with a sample `"Hello World!"` application.
9. Click **Create**.
You have successfully created a project with Gradle.
Explore the build script
------------------------
Open the `build.gradle.kts` file. This is the Gradle Kotlin build script, which contains Kotlin-related artifacts and other parts required for the application:
```
// For `KotlinCompile` task below
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
plugins {
kotlin("jvm") version "1.8.0" // Kotlin version to use
application // Application plugin. Also see 1️⃣ below the code
}
group = "org.example" // A company name, for example, `org.jetbrains`
version = "1.0-SNAPSHOT" // Version to assign to the built artifact
repositories { // Sources of dependencies. See 2️⃣
mavenCentral() // Maven Central Repository. See 3️⃣
}
dependencies { // All the libraries you want to use. See 4️⃣
// Copy dependencies' names after you find them in a repository
testImplementation(kotlin("test")) // The Kotlin test library
}
tasks.test { // See 5️⃣
useJUnitPlatform() // JUnitPlatform for tests. See 6️⃣
}
kotlin { // Extension to make an easy setup
jvmToolchain(8) // Target version of generated JVM bytecode. See 7️⃣
}
application {
mainClass.set("MainKt") // The main class of the application
}
```
* 1️⃣ [Application plugin](https://docs.gradle.org/current/userguide/application_plugin.html) to add support for building CLI application in Java.
* 2️⃣ Lean more about [sources of dependencies](https://docs.gradle.org/current/userguide/declaring_repositories.html).
* 3️⃣ The [Maven Central Repository](https://search.maven.org/). It can also be [Google's Maven repository](https://maven.google.com/web/index.html) or your company's private repository.
* 4️⃣ Learn more about [declaring dependencies](https://docs.gradle.org/current/userguide/declaring_dependencies.html).
* 5️⃣ Learn more about [tasks](https://docs.gradle.org/current/dsl/org.gradle.api.Task.html).
* 6️⃣ [JUnitPlatform for tests](https://docs.gradle.org/current/javadoc/org/gradle/api/tasks/testing/Test.html#useJUnitPlatform).
* 7️⃣ Learn more about [setting up a Java toolchain](gradle-configure-project#gradle-java-toolchains-support).
As you can see, there are a few Kotlin-specific artifacts added to the Gradle build file:
1. In the `plugins` block, there is the `kotlin("jvm")` artifact – the plugin defines the version of Kotlin to be used in the project.
2. In the `dependencies` section, there is `testImplementation(kotlin("test"))`. Learn more about [setting dependencies on test libraries](gradle-configure-project#set-dependencies-on-test-libraries).
3. After the dependencies section, there is the `KotlinCompile` task configuration block. This is where you can add extra arguments to the compiler to enable or disable various language features.
Run the application
-------------------
Open the `Main.kt` file in `src/main/kotlin`.
The `src` directory contains Kotlin source files and resources. The `Main.kt` file contains sample code that will print `Hello World!`.
The easiest way to run the application is to click the green **Run** icon in the gutter and select **Run 'MainKt'**.
You can see the result in the **Run** tool window.
Congratulations! You have just run your first Kotlin application.
What's next?
------------
Learn more about:
* [Gradle build file properties](https://docs.gradle.org/current/dsl/org.gradle.api.Project.html#N14E9A).
* [Targeting different platforms and setting library dependencies](gradle-configure-project).
* [Compiler options and how to pass them](gradle-compiler-options).
* [Incremental compilation, caches support, build reports, and the Kotlin daemon](gradle-compilation-and-caches).
Last modified: 10 January 2023
[Gradle](gradle) [Configure a Gradle project](gradle-configure-project)
kotlin Keywords and operators Keywords and operators
======================
Hard keywords
-------------
The following tokens are always interpreted as keywords and cannot be used as identifiers:
* `as`
+ is used for [type casts](typecasts#unsafe-cast-operator).
+ specifies an [alias for an import](packages#imports)
* `as?` is used for [safe type casts](typecasts#safe-nullable-cast-operator).
* `break` [terminates the execution of a loop](returns).
* `class` declares a [class](classes).
* `continue` [proceeds to the next step of the nearest enclosing loop](returns).
* `do` begins a [do/while loop](control-flow#while-loops) (a loop with a postcondition).
* `else` defines the branch of an [if expression](control-flow#if-expression) that is executed when the condition is false.
* `false` specifies the 'false' value of the [Boolean type](booleans).
* `for` begins a [for loop](control-flow#for-loops).
* `fun` declares a [function](functions).
* `if` begins an [if expression](control-flow#if-expression).
* `in`
+ specifies the object being iterated in a [for loop](control-flow#for-loops).
+ is used as an infix operator to check that a value belongs to [a range](ranges), a collection, or another entity that [defines a 'contains' method](operator-overloading#in-operator).
+ is used in [when expressions](control-flow#when-expression) for the same purpose.
+ marks a type parameter as [contravariant](generics#declaration-site-variance).
* `!in`
+ is used as an operator to check that a value does NOT belong to [a range](ranges), a collection, or another entity that [defines a 'contains' method](operator-overloading#in-operator).
+ is used in [when expressions](control-flow#when-expression) for the same purpose.
* `interface` declares an [interface](interfaces).
* `is`
+ checks that [a value has a certain type](typecasts#is-and-is-operators).
+ is used in [when expressions](control-flow#when-expression) for the same purpose.
* `!is`
+ checks that [a value does NOT have a certain type](typecasts#is-and-is-operators).
+ is used in [when expressions](control-flow#when-expression) for the same purpose.
* `null` is a constant representing an object reference that doesn't point to any object.
* `object` declares [a class and its instance at the same time](object-declarations).
* `package` specifies the [package for the current file](packages).
* `return` [returns from the nearest enclosing function or anonymous function](returns).
* `super`
+ [refers to the superclass implementation of a method or property](inheritance#calling-the-superclass-implementation).
+ [calls the superclass constructor from a secondary constructor](classes#inheritance).
* `this`
+ refers to [the current receiver](this-expressions).
+ [calls another constructor of the same class from a secondary constructor](classes#constructors).
* `throw` [throws an exception](exceptions).
* `true` specifies the 'true' value of the [Boolean type](booleans).
* `try` [begins an exception-handling block](exceptions).
* `typealias` declares a [type alias](type-aliases).
* `typeof` is reserved for future use.
* `val` declares a read-only [property](properties) or [local variable](basic-syntax#variables).
* `var` declares a mutable [property](properties) or [local variable](basic-syntax#variables).
* `when` begins a [when expression](control-flow#when-expression) (executes one of the given branches).
* `while` begins a [while loop](control-flow#while-loops) (a loop with a precondition).
Soft keywords
-------------
The following tokens act as keywords in the context in which they are applicable, and they can be used as identifiers in other contexts:
* `by`
+ [delegates the implementation of an interface to another object](delegation).
+ [delegates the implementation of the accessors for a property to another object](delegated-properties).
* `catch` begins a block that [handles a specific exception type](exceptions).
* `constructor` declares a [primary or secondary constructor](classes#constructors).
* `delegate` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `dynamic` references a [dynamic type](dynamic-type) in Kotlin/JS code.
* `field` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `file` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `finally` begins a block that [is always executed when a try block exits](exceptions).
* `get`
+ declares the [getter of a property](properties#getters-and-setters).
+ is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `import` [imports a declaration from another package into the current file](packages).
* `init` begins an [initializer block](classes#constructors).
* `param` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `property` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `receiver`is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `set`
+ declares the [setter of a property](properties#getters-and-setters).
+ is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `setparam` is used as an [annotation use-site target](annotations#annotation-use-site-targets).
* `value` with the `class` keyword declares an [inline class](inline-classes).
* `where` specifies the [constraints for a generic type parameter](generics#upper-bounds).
Modifier keywords
-----------------
The following tokens act as keywords in modifier lists of declarations, and they can be used as identifiers in other contexts:
* `abstract` marks a class or member as [abstract](classes#abstract-classes).
* `actual` denotes a platform-specific implementation in [multiplatform projects](multiplatform).
* `annotation` declares an [annotation class](annotations).
* `companion` declares a [companion object](object-declarations#companion-objects).
* `const` marks a property as a [compile-time constant](properties#compile-time-constants).
* `crossinline` forbids [non-local returns in a lambda passed to an inline function](inline-functions#non-local-returns).
* `data` instructs the compiler to [generate canonical members for a class](data-classes).
* `enum` declares an [enumeration](enum-classes).
* `expect` marks a declaration as [platform-specific](multiplatform), expecting an implementation in platform modules.
* `external` marks a declaration as implemented outside of Kotlin (accessible through [JNI](java-interop#using-jni-with-kotlin) or in [JavaScript](js-interop#external-modifier)).
* `final` forbids [overriding a member](inheritance#overriding-methods).
* `infix` allows calling a function using [infix notation](functions#infix-notation).
* `inline` tells the compiler to [inline a function and the lambdas passed to it at the call site](inline-functions).
* `inner` allows referring to an outer class instance from a [nested class](nested-classes).
* `internal` marks a declaration as [visible in the current module](visibility-modifiers).
* `lateinit` allows initializing a [non-null property outside of a constructor](properties#late-initialized-properties-and-variables).
* `noinline` turns off [inlining of a lambda passed to an inline function](inline-functions#noinline).
* `open` allows [subclassing a class or overriding a member](classes#inheritance).
* `operator` marks a function as [overloading an operator or implementing a convention](operator-overloading).
* `out` marks a type parameter as [covariant](generics#declaration-site-variance).
* `override` marks a member as an [override of a superclass member](inheritance#overriding-methods).
* `private` marks a declaration as [visible in the current class or file](visibility-modifiers).
* `protected` marks a declaration as [visible in the current class and its subclasses](visibility-modifiers).
* `public` marks a declaration as [visible anywhere](visibility-modifiers).
* `reified` marks a type parameter of an inline function as [accessible at runtime](inline-functions#reified-type-parameters).
* `sealed` declares a [sealed class](sealed-classes) (a class with restricted subclassing).
* `suspend` marks a function or lambda as suspending (usable as a [coroutine](coroutines-overview)).
* `tailrec` marks a function as [tail-recursive](functions#tail-recursive-functions) (allowing the compiler to replace recursion with iteration).
* `vararg` allows [passing a variable number of arguments for a parameter](functions#variable-number-of-arguments-varargs).
Special identifiers
-------------------
The following identifiers are defined by the compiler in specific contexts, and they can be used as regular identifiers in other contexts:
* `field` is used inside a property accessor to refer to the [backing field of the property](properties#backing-fields).
* `it` is used inside a lambda to [refer to its parameter implicitly](lambdas#it-implicit-name-of-a-single-parameter).
Operators and special symbols
-----------------------------
Kotlin supports the following operators and special symbols:
* `+`, `-`, `*`, `/`, `%` - mathematical operators
+ `*` is also used to [pass an array to a vararg parameter](functions#variable-number-of-arguments-varargs).
* `=`
+ assignment operator.
+ is used to specify [default values for parameters](functions#default-arguments).
* `+=`, `-=`, `*=`, `/=`, `%=` - [augmented assignment operators](operator-overloading#augmented-assignments).
* `++`, `--` - [increment and decrement operators](operator-overloading#increments-and-decrements).
* `&&`, `||`, `!` - logical 'and', 'or', 'not' operators (for bitwise operations, use the corresponding [infix functions](numbers#operations-on-numbers) instead).
* `==`, `!=` - [equality operators](operator-overloading#equality-and-inequality-operators) (translated to calls of `equals()` for non-primitive types).
* `===`, `!==` - [referential equality operators](equality#referential-equality).
* `<`, `>`, `<=`, `>=` - [comparison operators](operator-overloading#comparison-operators) (translated to calls of `compareTo()` for non-primitive types).
* `[`, `]` - [indexed access operator](operator-overloading#indexed-access-operator) (translated to calls of `get` and `set`).
* `!!` [asserts that an expression is non-null](null-safety#the-operator).
* `?.` performs a [safe call](null-safety#safe-calls) (calls a method or accesses a property if the receiver is non-null).
* `?:` takes the right-hand value if the left-hand value is null (the [elvis operator](null-safety#elvis-operator)).
* `::` creates a [member reference](reflection#function-references) or a [class reference](reflection#class-references).
* `..` creates a [range](ranges).
* `:` separates a name from a type in a declaration.
* `?` marks a type as [nullable](null-safety#nullable-types-and-non-null-types).
* `->`
+ separates the parameters and body of a [lambda expression](lambdas#lambda-expression-syntax).
+ separates the parameters and return type declaration in a [function type](lambdas#function-types).
+ separates the condition and body of a [when expression](control-flow#when-expression) branch.
* `@`
+ introduces an [annotation](annotations#usage).
+ introduces or references a [loop label](returns#break-and-continue-labels).
+ introduces or references a [lambda label](returns#return-to-labels).
+ references a ['this' expression from an outer scope](this-expressions#qualified-this).
+ references an [outer superclass](inheritance#calling-the-superclass-implementation).
* `;` separates multiple statements on the same line.
* `$` references a variable or expression in a [string template](strings#string-templates).
* `_`
+ substitutes an unused parameter in a [lambda expression](lambdas#underscore-for-unused-variables).
+ substitutes an unused parameter in a [destructuring declaration](destructuring-declarations#underscore-for-unused-variables).
For operator precedence, see [this reference](grammar#expressions) in Kotlin grammar.
Last modified: 10 January 2023
[Sequential specification](sequential-specification) [Gradle](gradle)
kotlin KUG guidelines KUG guidelines
==============
A Kotlin User Group, or KUG, is a community that is dedicated to Kotlin and that offers you a place to share your Kotlin programming experience with like-minded people.
To become an KUG, your community should have some specific features shared by every KUG. It should:
* Provide Kotlin-related content, with regular meetups as the main form of activity.
* Host regular events (at least once every 3 months) with open registration and without any restriction for attendance.
* Be driven and organized by the community, and it should not use events to earn money or gain any other business benefits from members and attendees.
* Follow and ensure a code of conduct in order to provide a welcoming environment for attendees of any background and experience (check-out our recommended [Code of Conduct](https://confluence.jetbrains.com/display/ALL/JetBrains+Open+Source+and+Community+Code+of+Conduct)).
There are no limits regarding the format for KUG meetups. They can take place in whatever fashion works best for the community, whether that includes presentations, hands-on labs, lectures, hackathons, or informal beer-driven get-togethers.
How to run a KUG?
-----------------
* In order to promote group cohesion and prevent miscommunication, we recommend keeping to a limit of one KUG per city. Check out [the list of KUGs](https://kotlinlang.org/community/user-groups) to see if there is already a KUG in your area.
* Use the official KUG logo and branding. Check out [the branding guidelines](kotlin-brand-assets#kotlin-user-group-brand-assets).
* Keep your user group active. Run meetups regularly, at least once every 3 months.
* Announce your KUG meetups at least 2 weeks in advance. The announcement should contain a list of talks and the names of the speakers, as well as the location, timing, and any other crucial info about the event.
* KUG events should be free or, if you need to cover organizing expenses, limit prices to a maximum of 10 USD.
* Your group should have a code of conduct available for all members.
If your community has all the necessary features and follows these guidelines, you are ready to [Apply to be a new KUG](https://surveys.jetbrains.com/s3/submit-a-local-kotlin-user-group).
Have a question? [Contact us](mailto:[email protected])
Support for KUGs from JetBrains
-------------------------------
Active KUGs that host at least 1 meetup every 3 months can apply for the community support program, which includes:
* Official KUG branding.
* A special entry on the Kotlin website.
* Free licenses for JetBrains products to raffle off at meetups.
* Priority support for Kotlin events and campaigns.
* Help with recruiting Kotlin speakers for your events.
Support from JetBrains for other tech communities
-------------------------------------------------
If you organize any other tech communities, you can apply for support as well. By doing so, you may receive:
* Free licenses for JetBrains products to raffle off at meetups.
* Information about Kotlin official events and campaigns.
* Kotlin stickers.
* Help with recruiting Kotlin speakers for your events.
Last modified: 10 January 2023
[Contribution](contribute) [Kotlin Night guidelines](kotlin-night-guidelines)
| programming_docs |
kotlin CocoaPods overview and setup CocoaPods overview and setup
============================
Kotlin/Native provides integration with the [CocoaPods dependency manager](https://cocoapods.org/). You can add dependencies on Pod libraries as well as use a multiplatform project with native targets as a CocoaPods dependency.
You can manage Pod dependencies directly in IntelliJ IDEA and enjoy all the additional features such as code highlighting and completion. You can build the whole Kotlin project with Gradle and not ever have to switch to Xcode.
Use Xcode only when you need to write Swift/Objective-C code or run your application on a simulator or device. To work correctly with Xcode, you should [update your Podfile](#update-podfile-for-xcode).
Depending on your project and purposes, you can add dependencies between [a Kotlin project and a Pod library](native-cocoapods-libraries) as well as [a Kotlin Gradle project and an Xcode project](native-cocoapods-xcode).
Set up an environment to work with CocoaPods
--------------------------------------------
Install the [CocoaPods dependency manager](https://cocoapods.org/):
```
sudo gem install cocoapods
```
### If you use Kotlin prior to version 1.7.0
If your current version of Kotlin is earlier than 1.7.0, additionally install the [`cocoapods-generate`](https://github.com/square/cocoapods-generate) plugin:
```
sudo gem install cocoapods-generate
```
If you encounter problems during the installation, check the [Possible issues and solutions](#possible-issues-and-solutions) section.
Add and configure Kotlin CocoaPods Gradle plugin
------------------------------------------------
If your environment is set up correctly, you can [create a new Kotlin Multiplatform project](multiplatform-mobile-create-first-app) and choose **CocoaPods Dependency Manager** as the iOS framework distribution option. The plugin will automatically generate the project for you.
If you want to configure your project manually:
1. In `build.gradle(.kts)` of your project, apply the CocoaPods plugin as well as the Kotlin Multiplatform plugin:
```
plugins {
kotlin("multiplatform") version "1.8.0"
kotlin("native.cocoapods") version "1.8.0"
}
```
2. Configure `version`, `summary`, `homepage`, and `baseName` of the Podspec file in the `cocoapods` block:
```
plugins {
kotlin("multiplatform") version "1.8.0"
kotlin("native.cocoapods") version "1.8.0"
}
kotlin {
cocoapods {
// Required properties
// Specify the required Pod version here. Otherwise, the Gradle project version is used.
version = "1.0"
summary = "Some description for a Kotlin/Native module"
homepage = "Link to a Kotlin/Native module homepage"
// Optional properties
// Configure the Pod name here instead of changing the Gradle project name
name = "MyCocoaPod"
framework {
// Required properties
// Framework name configuration. Use this property instead of deprecated 'frameworkName'
baseName = "MyFramework"
// Optional properties
// Specify the framework linking type. It's dynamic by default.
isStatic = false
// Dependency export
export(project(":anotherKMMModule"))
transitiveExport = false // This is default.
// Bitcode embedding
embedBitcode(BITCODE)
}
// Maps custom Xcode configuration to NativeBuildType
xcodeConfigurationToNativeBuildType["CUSTOM_DEBUG"] = NativeBuildType.DEBUG
xcodeConfigurationToNativeBuildType["CUSTOM_RELEASE"] = NativeBuildType.RELEASE
}
}
```
3. Re-import the project.
4. Generate the [Gradle wrapper](https://docs.gradle.org/current/userguide/gradle_wrapper.html) to avoid compatibility issues during an Xcode build.
When applied, the CocoaPods plugin does the following:
* Adds both `debug` and `release` frameworks as output binaries for all macOS, iOS, tvOS, and watchOS targets.
* Creates a `podspec` task which generates a [Podspec](https://guides.cocoapods.org/syntax/podspec.html) file for the project.
The `Podspec` file includes a path to an output framework and script phases that automate building this framework during the build process of an Xcode project.
Update Podfile for Xcode
------------------------
If you want to import your Kotlin project in an Xcode project, you need to make some changes to your Podfile:
* If your project has any Git, HTTP, or custom Podspec repository dependencies, you should also specify the path to the Podspec in the Podfile.
For example, if you add a dependency on `podspecWithFilesExample`, declare the path to the Podspec in the Podfile:
```
target 'ios-app' do
# ... other dependencies ...
pod 'podspecWithFilesExample', :path => 'cocoapods/externalSources/url/podspecWithFilesExample'
end
```
The `:path` should contain the filepath to the Pod.
* When you add a library from the custom Podspec repository, you should also specify the [location](https://guides.cocoapods.org/syntax/podfile.html#source) of specs at the beginning of your Podfile:
```
source 'https://github.com/Kotlin/kotlin-cocoapods-spec.git'
target 'kotlin-cocoapods-xcproj' do
# ... other dependencies ...
pod 'example'
end
```
If you don't make these changes to the Podfile, the `podInstall` task will fail, and the CocoaPods plugin will show an error message in the log.
Check out the `withXcproject` branch of the [sample project](https://github.com/Kotlin/kmm-with-cocoapods-sample), which contains an example of Xcode integration with an existing Xcode project named `kotlin-cocoapods-xcproj`.
Possible issues and solutions
-----------------------------
### CocoaPods installation
#### Ruby installation
CocoaPods is built with Ruby, and you can install it with the default Ruby that should be available on macOS. Ruby 1.9 or later has a built-in RubyGems package management framework that help you install the [CocoaPods dependency manager](https://guides.cocoapods.org/using/getting-started.html#installation).
If you're experiencing problems installing CocoaPods and getting it to work, follow [this guide](https://www.ruby-lang.org/en/documentation/installation/) to install Ruby or refer to the [RubyGems website](https://rubygems.org/pages/download/) to install the framework.
#### Version compatibility
We recommend using the latest Kotlin version. If your current version is earlier than 1.7.0, you'll need to additionally install the [`cocoapods-generate`](#) plugin.
However, `cocoapods-generate` is not compatible with Ruby 3.0.0 or later. In this case, downgrade Ruby or upgrade Kotlin to 1.7.0 or later.
### Module not found
You may encounter a `module 'SomeSDK' not found` error that is connected with the [C-interop](native-c-interop) issue. Try these workarounds to avoid this error:
#### Specify the framework name
1. Find the `module.modulemap` file in the downloaded Pod directory:
```
[shared_module_name]/build/cocoapods/synthetic/IOS/Pods/[pod_name]
```
2. Check the framework name inside the module, for example `AppsFlyerLib {}`. If the framework name doesn't match the Pod name, specify it explicitly:
```
pod("AFNetworking") {
moduleName = "AppsFlyerLib"
}
```
#### Check the definition file
If the Pod doesn't contain a `.modulemap` file, like the `pod("NearbyMessages")`, in the generated `.def` file, replace modules with headers with the pointing main header:
```
tasks.named<org.jetbrains.kotlin.gradle.tasks.DefFileTask>("generateDefNearbyMessages").configure {
doLast {
outputFile.writeText("""
language = Objective-C
headers = GNSMessages.h
""".trimIndent())
}
}
```
Check the [CocoaPods documentation](https://guides.cocoapods.org/) for more information. If nothing works, and you still encounter this error, report an issue in [YouTrack](https://youtrack.jetbrains.com/newissue?project=kt).
Last modified: 10 January 2023
[Kotlin/Native as an Apple framework – tutorial](apple-framework) [Add dependencies on a Pod library](native-cocoapods-libraries)
kotlin Mapping function pointers from C – tutorial Mapping function pointers from C – tutorial
===========================================
This is the third post in the series. The very first tutorial is [Mapping primitive data types from C](mapping-primitive-data-types-from-c). There are also [Mapping struct and union types from C](mapping-struct-union-types-from-c) and [Mapping strings from C](mapping-strings-from-c) tutorials.
In this tutorial We will learn how to:
* [Pass Kotlin function as C function pointer](#pass-kotlin-function-as-c-function-pointer)
* [Use C function pointer from Kotlin](#use-the-c-function-pointer-from-kotlin)
Mapping function pointer types from C
-------------------------------------
The best way to understand the mapping between Kotlin and C is to try a tiny example. Declare a function that accepts a function pointer as a parameter and another function that returns a function pointer.
Kotlin/Native comes with the `cinterop` tool; the tool generates bindings between the C language and Kotlin. It uses a `.def` file to specify a C library to import. More details on this are in [Interop with C Libraries](native-c-interop).
The quickest way to try out C API mapping is to have all C declarations in the `interop.def` file, without creating any `.h` of `.c` files at all. Then place the C declarations in a `.def` file after the special `---` separator line:
```
---
int myFun(int i) {
return i+1;
}
typedef int (*MyFun)(int);
void accept_fun(MyFun f) {
f(42);
}
MyFun supply_fun() {
return myFun;
}
```
The `interop.def` file is enough to compile and run the application or open it in an IDE. Now it is time to create project files, open the project in [IntelliJ IDEA](https://jetbrains.com/idea) and run it.
Inspect generated Kotlin APIs for a C library
---------------------------------------------
While it is possible to use the command line, either directly or by combining it with a script file (such as `.sh` or `.bat` file), this approach doesn't scale well for big projects that have hundreds of files and libraries. It is then better to use the Kotlin/Native compiler with a build system, as it helps to download and cache the Kotlin/Native compiler binaries and libraries with transitive dependencies and run the compiler and tests. Kotlin/Native can use the [Gradle](https://gradle.org) build system through the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin.
We covered the basics of setting up an IDE compatible project with Gradle in the [A Basic Kotlin/Native Application](native-gradle) tutorial. Please check it out if you are looking for detailed first steps and instructions on how to start a new Kotlin/Native project and open it in IntelliJ IDEA. In this tutorial, we'll look at the advanced C interop related usages of Kotlin/Native and [multiplatform](multiplatform-discover-project#multiplatform-plugin) builds with Gradle.
First, create a project folder. All the paths in this tutorial will be relative to this folder. Sometimes the missing directories will have to be created before any new files can be added.
Use the following `build.gradle(.kts)` Gradle build file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
linuxX64("native") { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64("native") { // on Windows
val main by compilations.getting
val interop by main.cinterops.creating
binaries {
executable()
}
}
}
tasks.wrapper {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.BIN
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
linuxX64('native') { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64('native') { // on Windows
compilations.main.cinterops {
interop
}
binaries {
executable()
}
}
}
wrapper {
gradleVersion = '7.3'
distributionType = 'BIN'
}
```
The project file configures the C interop as an additional step of the build. Let's move the `interop.def` file to the `src/nativeInterop/cinterop` directory. Gradle recommends using conventions instead of configurations, for example, the source files are expected to be in the `src/nativeMain/kotlin` folder. By default, all the symbols from C are imported to the `interop` package, you may want to import the whole package in our `.kt` files. Check out the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin documentation to learn about all the different ways you could configure it.
Let's create a `src/nativeMain/kotlin/hello.kt` stub file with the following content to see how C function pointer declarations are visible from Kotlin:
```
import interop.*
fun main() {
println("Hello Kotlin/Native!")
accept_fun(https://kotlinlang.org/*fix me */)
val useMe = supply_fun()
}
```
Now you are ready to [open the project in IntelliJ IDEA](native-get-started) and to see how to fix the example project. While doing that, see how C functions are mapped into Kotlin/Native declarations.
C function pointers in Kotlin
-----------------------------
With the help of IntelliJ IDEA's **Go To** | **Declaration or Usages** or compiler errors, see the following declarations for the C functions:
```
fun accept_fun(f: MyFun? /* = CPointer<CFunction<(Int) -> Int>>? */)
fun supply_fun(): MyFun? /* = CPointer<CFunction<(Int) -> Int>>? */
fun myFun(i: kotlin.Int): kotlin.Int
typealias MyFun = kotlinx.cinterop.CPointer<kotlinx.cinterop.CFunction<(kotlin.Int) -> kotlin.Int>>
typealias MyFunVar = kotlinx.cinterop.CPointerVarOf<lib.MyFun>
```
You see that the function's `typedef` from C has been turned into Kotlin `typealias`. It uses `CPointer<..>` type to represent the pointer parameters, and `CFunction<(Int)->Int>` to represent the function signature. There is an `invoke` operator extension function available for all `CPointer<CFunction<..>` types, so that it is possible to call it as you would call any other function in Kotlin.
Pass Kotlin function as C function pointer
------------------------------------------
It is the time to try using C functions from the Kotlin program. Call the `accept_fun` function and pass the C function pointer to a Kotlin lambda:
```
fun myFun() {
accept_fun(staticCFunction<Int, Int> { it + 1 })
}
```
This call uses the `staticCFunction{..}` helper function from Kotlin/Native to wrap a Kotlin lambda function into a C function pointer. It only allows having unbound and non-capturing lambda functions. For example, it is not able to use a local variable from the function. You may only use globally visible declarations. Throwing exceptions from a `staticCFunction{..}` will end up in non-deterministic side-effects. It is vital to make sure that you code is not throwing any sudden exceptions from it.
Use the C function pointer from Kotlin
--------------------------------------
The next step is to call a C function pointer from a C pointer that you have from the `supply_fun()` call:
```
fun myFun2() {
val functionFromC = supply_fun() ?: error("No function is returned")
functionFromC(42)
}
```
Kotlin turns the function pointer return type into a nullable `CPointer<CFunction<..>` object. There is the need to explicitly check for `null` first. The [elvis operator](null-safety) for that in the code above. The `cinterop` tool helps us to turn a C function pointer into an easy to call object in Kotlin. This is what we did on the last line.
Fix the code
------------
You've seen all definitions and it is time to fix and run the code. Run the `runDebugExecutableNative` Gradle task [in the IDE](native-get-started) or use the following command to run the code:
```
./gradlew runDebugExecutableNative
```
The code in the `hello.kt` file may look like this:
```
import interop.*
import kotlinx.cinterop.*
fun main() {
println("Hello Kotlin/Native!")
val cFunctionPointer = staticCFunction<Int, Int> { it + 1 }
accept_fun(cFunctionPointer)
val funFromC = supply_fun() ?: error("No function is returned")
funFromC(42)
}
```
Next Steps
----------
Continue exploring more C language types and their representation in Kotlin/Native in next tutorials:
* [Mapping primitive data types from C](mapping-primitive-data-types-from-c)
* [Mapping struct and union types from C](mapping-struct-union-types-from-c)
* [Mapping strings from C](mapping-strings-from-c)
The [C Interop documentation](native-c-interop) covers more advanced scenarios of the interop.
Last modified: 10 January 2023
[Mapping struct and union types from C – tutorial](mapping-struct-union-types-from-c) [Mapping Strings from C – tutorial](mapping-strings-from-c)
kotlin Coroutines guide Coroutines guide
================
Kotlin, as a language, provides only minimal low-level APIs in its standard library to enable various other libraries to utilize coroutines. Unlike many other languages with similar capabilities, `async` and `await` are not keywords in Kotlin and are not even part of its standard library. Moreover, Kotlin's concept of *suspending function* provides a safer and less error-prone abstraction for asynchronous operations than futures and promises.
`kotlinx.coroutines` is a rich library for coroutines developed by JetBrains. It contains a number of high-level coroutine-enabled primitives that this guide covers, including `launch`, `async` and others.
This is a guide on core features of `kotlinx.coroutines` with a series of examples, divided up into different topics.
In order to use coroutines as well as follow the examples in this guide, you need to add a dependency on the `kotlinx-coroutines-core` module as explained [in the project README](https://github.com/Kotlin/kotlinx.coroutines/blob/master/README.md#using-in-your-projects).
Table of contents
-----------------
* [Coroutines basics](coroutines-basics)
* [Hands-on: Intro to coroutines and channels](https://play.kotlinlang.org/hands-on/Introduction%20to%20Coroutines%20and%20Channels)
* [Cancellation and timeouts](cancellation-and-timeouts)
* [Composing suspending functions](composing-suspending-functions)
* [Coroutine context and dispatchers](coroutine-context-and-dispatchers)
* [Asynchronous Flow](flow)
* [Channels](channels)
* [Coroutine exceptions handling](exception-handling)
* [Shared mutable state and concurrency](shared-mutable-state-and-concurrency)
* [Select expression (experimental)](select-expression)
* [Tutorial: Debug coroutines using IntelliJ IDEA](debug-coroutines-with-idea)
* [Tutorial: Debug Kotlin Flow using IntelliJ IDEA](debug-flow-with-idea)
Additional references
---------------------
* [Guide to UI programming with coroutines](https://github.com/Kotlin/kotlinx.coroutines/blob/master/ui/coroutines-guide-ui.md)
* [Coroutines design document (KEEP)](https://github.com/Kotlin/KEEP/blob/master/proposals/coroutines.md)
* [Full kotlinx.coroutines API reference](https://kotlinlang.org/api/kotlinx.coroutines/)
* [Best practices for coroutines in Android](https://developer.android.com/kotlin/coroutines/coroutines-best-practices)
* [Additional Android resources for Kotlin coroutines and flow](https://developer.android.com/kotlin/coroutines/additional-resources)
Last modified: 10 January 2023
[Opt-in requirements](opt-in-requirements) [Coroutines basics](coroutines-basics)
kotlin Kotlin for competitive programming Kotlin for competitive programming
==================================
This tutorial is designed both for competitive programmers that did not use Kotlin before and for Kotlin developers that did not participate in any competitive programming events before. It assumes the corresponding programming skills.
[Competitive programming](https://en.wikipedia.org/wiki/Competitive_programming) is a mind sport where contestants write programs to solve precisely specified algorithmic problems within strict constraints. Problems can range from simple ones that can be solved by any software developer and require little code to get a correct solution, to complex ones that require knowledge of special algorithms, data structures, and a lot of practice. While not being specifically designed for competitive programming, Kotlin incidentally fits well in this domain, reducing the typical amount of boilerplate that a programmer needs to write and read while working with the code almost to the level offered by dynamically-typed scripting languages, while having tooling and performance of a statically-typed language.
See [Get started with Kotlin/JVM](jvm-get-started) on how to set up development environment for Kotlin. In competitive programming, a single project is usually created and each problem's solution is written in a single source file.
Simple example: Reachable Numbers problem
-----------------------------------------
Let's take a look at a concrete example.
[Codeforces](https://codeforces.com/) Round 555 was held on April 26th for 3rd Division, which means it had problems fit for any developer to try. You can use [this link](https://codeforces.com/contest/1157) to read the problems. The simplest problem in the set is the [Problem A: Reachable Numbers](https://codeforces.com/contest/1157/problem/A). It asks to implement a straightforward algorithm described in the problem statement.
We'd start solving it by creating a Kotlin source file with an arbitrary name. `A.kt` will do well. First, you need to implement a function specified in the problem statement as:
Let's denote a function f(x) in such a way: we add 1 to x, then, while there is at least one trailing zero in the resulting number, we remove that zero.
Kotlin is a pragmatic and unopinionated language, supporting both imperative and function programming styles without pushing the developer towards either one. You can implement the function `f` in functional style, using such Kotlin features as [tail recursion](functions#tail-recursive-functions):
```
tailrec fun removeZeroes(x: Int): Int =
if (x % 10 == 0) removeZeroes(x / 10) else x
fun f(x: Int) = removeZeroes(x + 1)
```
Alternatively, you can write an imperative implementation of the function `f` using the traditional [while loop](control-flow) and mutable variables that are denoted in Kotlin with [var](basic-syntax#variables):
```
fun f(x: Int): Int {
var cur = x + 1
while (cur % 10 == 0) cur /= 10
return cur
}
```
Types in Kotlin are optional in many places due to pervasive use of type-inference, but every declaration still has a well-defined static type that is known at compilation.
Now, all is left is to write the main function that reads the input and implements the rest of the algorithm that the problem statement asks for — to compute the number of different integers that are produced while repeatedly applying function `f` to the initial number `n` that is given in the standard input.
By default, Kotlin runs on JVM and gives direct access to a rich and efficient collections library with general-purpose collections and data-structures like dynamically-sized arrays (`ArrayList`), hash-based maps and sets (`HashMap`/`HashSet`), tree-based ordered maps and sets (`TreeMap`/`TreeSet`). Using a hash-set of integers to track values that were already reached while applying function `f`, the straightforward imperative version of a solution to the problem can be written as shown below:
```
fun main() {
var n = readln().toInt() // read integer from the input
val reached = HashSet<Int>() // a mutable hash set
while (reached.add(n)) n = f(n) // iterate function f
println(reached.size) // print answer to the output
}
```
There is no need to handle the case of misformatted input in competitive programming. An input format is always precisely specified in competitive programming, and the actual input cannot deviate from the input specification in the problem statement. That's why you can use Kotlin's [`readln()`](../api/latest/jvm/stdlib/kotlin.io/readln) function. It asserts that the input string is present and throws an exception otherwise. Likewise, the [`String.toInt()`](../api/latest/jvm/stdlib/kotlin.text/to-int) function throws an exception if the input string is not an integer.
```
fun main() {
var n = readLine()!!.toInt() // read integer from the input
val reached = HashSet<Int>() // a mutable hash set
while (reached.add(n)) n = f(n) // iterate function f
println(reached.size) // print answer to the output
}
```
Note the use of Kotlin's [null-assertion operator](null-safety#the-operator) `!!` after the [readLine()](../api/latest/jvm/stdlib/kotlin.io/read-line) function call. Kotlin's `readLine()` function is defined to return a [nullable type](null-safety#nullable-types-and-non-null-types) `String?` and returns `null` on the end of the input, which explicitly forces the developer to handle the case of missing input.
There is no need to handle the case of misformatted input in competitive programming. In competitive programming, an input format is always precisely specified and the actual input cannot deviate from the input specification in the problem statement. That's what the null-assertion operator `!!` essentially does — it asserts that the input string is present and throws an exception otherwise. Likewise, the [String.toInt()](../api/latest/jvm/stdlib/kotlin.text/to-int).
All online competitive programming events allow the use of pre-written code, so you can define your own library of utility functions that are geared towards competitive programming to make your actual solution code somewhat easier to read and write. You would then use this code as a template for your solutions. For example, you can define the following helper functions for reading inputs in competitive programming:
```
private fun readStr() = readln() // string line
private fun readInt() = readStr().toInt() // single int
// similar for other types you'd use in your solutions
```
```
private fun readStr() = readLine()!! // string line
private fun readInt() = readStr().toInt() // single int
// similar for other types you'd use in your solutions
```
Note the use of `private` [visibility modifier](visibility-modifiers) here. While the concept of visibility modifier is not relevant for competitive programming at all, it allows you to place multiple solution files based on the same template without getting an error for conflicting public declarations in the same package.
Functional operators example: Long Number problem
-------------------------------------------------
For more complicated problems, Kotlin's extensive library of functional operations on collections comes in handy to minimize the boilerplate and turn the code into a linear top-to-bottom and left-to-right fluent data transformation pipeline. For example, the [Problem B: Long Number](https://codeforces.com/contest/1157/problem/B) problem takes a simple greedy algorithm to implement and it can be written using this style without a single mutable variable:
```
fun main() {
// read input
val n = readln().toInt()
val s = readln()
val fl = readln().split(" ").map { it.toInt() }
// define local function f
fun f(c: Char) = '0' + fl[c - '1']
// greedily find first and last indices
val i = s.indexOfFirst { c -> f(c) > c }
.takeIf { it >= 0 } ?: s.length
val j = s.withIndex().indexOfFirst { (j, c) -> j > i && f(c) < c }
.takeIf { it >= 0 } ?: s.length
// compose and write the answer
val ans =
s.substring(0, i) +
s.substring(i, j).map { c -> f(c) }.joinToString("") +
s.substring(j)
println(ans)
}
```
```
fun main() {
// read input
val n = readLine()!!.toInt()
val s = readLine()!!
val fl = readLine()!!.split(" ").map { it.toInt() }
// define local function f
fun f(c: Char) = '0' + fl[c - '1']
// greedily find first and last indices
val i = s.indexOfFirst { c -> f(c) > c }
.takeIf { it >= 0 } ?: s.length
val j = s.withIndex().indexOfFirst { (j, c) -> j > i && f(c) < c }
.takeIf { it >= 0 } ?: s.length
// compose and write the answer
val ans =
s.substring(0, i) +
s.substring(i, j).map { c -> f(c) }.joinToString("") +
s.substring(j)
println(ans)
}
```
In this dense code, in addition to collection transformations, you can see such handy Kotlin features as local functions and the [elvis operator](null-safety#elvis-operator) `?:` that allow to express <idioms> like "take the value if it is positive or else use length" with a concise and readable expressions like `.takeIf { it >= 0 } ?: s.length`, yet it is perfectly fine with Kotlin to create additional mutable variables and express the same code in imperative style, too.
To make reading the input in competitive programming tasks like this more concise, you can have the following list of helper input-reading functions:
```
private fun readStr() = readln() // string line
private fun readInt() = readStr().toInt() // single int
private fun readStrings() = readStr().split(" ") // list of strings
private fun readInts() = readStrings().map { it.toInt() } // list of ints
```
```
private fun readStr() = readLine()!! // string line
private fun readInt() = readStr().toInt() // single int
private fun readStrings() = readStr().split(" ") // list of strings
private fun readInts() = readStrings().map { it.toInt() } // list of ints
```
With these helpers, the part of code for reading input becomes simpler, closely following the input specification in the problem statement line by line:
```
// read input
val n = readInt()
val s = readStr()
val fl = readInts()
```
Note that in competitive programming it is customary to give variables shorter names than it is typical in industrial programming practice, since the code is to be written just once and not supported thereafter. However, these names are usually still mnemonic — `a` for arrays, `i`, `j`, and others for indices, `r`, and `c` for row and column numbers in tables, `x` and `y` for coordinates, and so on. It is easier to keep the same names for input data as it is given in the problem statement. However, more complex problems require more code which leads to using longer self-explanatory variable and function names.
More tips and tricks
--------------------
Competitive programming problems often have input like this:
The first line of the input contains two integers `n` and `k`
In Kotlin this line can be concisely parsed with the following statement using [destructuring declaration](destructuring-declarations) from a list of integers:
```
val (n, k) = readInts()
```
It might be temping to use JVM's `java.util.Scanner` class to parse less structured input formats. Kotlin is designed to interoperate well with JVM libraries, so that their use feels quite natural in Kotlin. However, beware that `java.util.Scanner` is extremely slow. So slow, in fact, that parsing 105 or more integers with it might not fit into a typical 2 second time-limit, which a simple Kotlin's `split(" ").map { it.toInt() }` would handle.
Writing output in Kotlin is usually straightforward with [println(...)](../api/latest/jvm/stdlib/kotlin.io/println) calls and using Kotlin's [string templates](strings#string-templates). However, care must be taken when output contains on order of 105 lines or more. Issuing so many `println` calls is too slow, since the output in Kotlin is automatically flushed after each line. A faster way to write many lines from an array or a list is using [joinToString()](../api/latest/jvm/stdlib/kotlin.collections/join-to-string) function with `"\n"` as the separator, like this:
```
println(a.joinToString("\n")) // each element of array/list of a separate line
```
Learning Kotlin
---------------
Kotlin is easy to learn, especially for those who already know Java. A short introduction to the basic syntax of Kotlin for software developers can be found directly in the reference section of the website starting from [basic syntax](basic-syntax).
IDEA has built-in [Java-to-Kotlin converter](https://www.jetbrains.com/help/idea/converting-a-java-file-to-kotlin-file.html). It can be used by people familiar with Java to learn the corresponding Kotlin syntactic constructions, but it is not perfect, and it is still worth familiarizing yourself with Kotlin and learning the [Kotlin idioms](idioms).
A great resource to study Kotlin syntax and API of the Kotlin standard library are [Kotlin Koans](koans).
Last modified: 10 January 2023
[Kotlin for data science](data-science-overview) [What's new in Kotlin 1.8.0](whatsnew18)
| programming_docs |
kotlin Iterators Iterators
=========
For traversing collection elements, the Kotlin standard library supports the commonly used mechanism of *iterators* – objects that provide access to the elements sequentially without exposing the underlying structure of the collection. Iterators are useful when you need to process all the elements of a collection one-by-one, for example, print values or make similar updates to them.
Iterators can be obtained for inheritors of the [`Iterable<T>`](../api/latest/jvm/stdlib/kotlin.collections/-iterable/index) interface, including `Set` and `List`, by calling the [`iterator()`](../api/latest/jvm/stdlib/kotlin.collections/-iterable/iterator) function.
Once you obtain an iterator, it points to the first element of a collection; calling the [`next()`](../api/latest/jvm/stdlib/kotlin.collections/-iterator/next) function returns this element and moves the iterator position to the following element if it exists.
Once the iterator passes through the last element, it can no longer be used for retrieving elements; neither can it be reset to any previous position. To iterate through the collection again, create a new iterator.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val numbersIterator = numbers.iterator()
while (numbersIterator.hasNext()) {
println(numbersIterator.next())
}
//sampleEnd
}
```
Another way to go through an `Iterable` collection is the well-known `for` loop. When using `for` on a collection, you obtain the iterator implicitly. So, the following code is equivalent to the example above:
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
for (item in numbers) {
println(item)
}
//sampleEnd
}
```
Finally, there is a useful `forEach()` function that lets you automatically iterate a collection and execute the given code for each element. So, the same example would look like this:
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
numbers.forEach {
println(it)
}
//sampleEnd
}
```
List iterators
--------------
For lists, there is a special iterator implementation: [`ListIterator`](../api/latest/jvm/stdlib/kotlin.collections/-list-iterator/index). It supports iterating lists in both directions: forwards and backwards.
Backward iteration is implemented by the functions [`hasPrevious()`](../api/latest/jvm/stdlib/kotlin.collections/-list-iterator/has-previous) and [`previous()`](../api/latest/jvm/stdlib/kotlin.collections/-list-iterator/previous). Additionally, the `ListIterator` provides information about the element indices with the functions [`nextIndex()`](../api/latest/jvm/stdlib/kotlin.collections/-list-iterator/next-index) and [`previousIndex()`](../api/latest/jvm/stdlib/kotlin.collections/-list-iterator/previous-index).
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val listIterator = numbers.listIterator()
while (listIterator.hasNext()) listIterator.next()
println("Iterating backwards:")
while (listIterator.hasPrevious()) {
print("Index: ${listIterator.previousIndex()}")
println(", value: ${listIterator.previous()}")
}
//sampleEnd
}
```
Having the ability to iterate in both directions, means the `ListIterator` can still be used after it reaches the last element.
Mutable iterators
-----------------
For iterating mutable collections, there is [`MutableIterator`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-iterator/index) that extends `Iterator` with the element removal function [`remove()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-iterator/remove). So, you can remove elements from a collection while iterating it.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four")
val mutableIterator = numbers.iterator()
mutableIterator.next()
mutableIterator.remove()
println("After removal: $numbers")
//sampleEnd
}
```
In addition to removing elements, the [`MutableListIterator`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list-iterator/index) can also insert and replace elements while iterating the list.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "four", "four")
val mutableListIterator = numbers.listIterator()
mutableListIterator.next()
mutableListIterator.add("two")
mutableListIterator.next()
mutableListIterator.set("three")
println(numbers)
//sampleEnd
}
```
Last modified: 10 January 2023
[Constructing collections](constructing-collections) [Ranges and progressions](ranges)
kotlin KSP with Kotlin Multiplatform KSP with Kotlin Multiplatform
=============================
For a quick start, see a [sample Kotlin Multiplatform project](https://github.com/google/ksp/tree/main/examples/multiplatform) defining a KSP processor.
Starting from KSP 1.0.1, applying KSP on a multiplatform project is similar to that on a single platform, JVM project. The main difference is that, instead of writing the `ksp(...)` configuration in dependencies, `add(ksp<Target>)` or `add(ksp<SourceSet>)` is used to specify which compilation targets need symbol processing, before compilation.
```
plugins {
kotlin("multiplatform")
id("com.google.devtools.ksp")
}
kotlin {
jvm {
withJava()
}
linuxX64() {
binaries {
executable()
}
}
sourceSets {
val commonMain by getting
val linuxX64Main by getting
val linuxX64Test by getting
}
}
dependencies {
add("kspCommonMainMetadata", project(":test-processor"))
add("kspJvm", project(":test-processor"))
add("kspJvmTest", project(":test-processor")) // Not doing anything because there's no test source set for JVM
// There is no processing for the Linux x64 main source set, because kspLinuxX64 isn't specified
add("kspLinuxX64Test", project(":test-processor"))
}
```
Compilation and processing
--------------------------
In a multiplatform project, Kotlin compilation may happen multiple times (`main`, `test`, or other build flavors) for each platform. So is symbol processing. A symbol processing task is created whenever there is a Kotlin compilation task and a corresponding `ksp<Target>` or `ksp<SourceSet>` configuration is specified.
For example, in the above `build.gradle.kts`, there are 4 compilation tasks: common/metadata, JVM main, Linux x64 main, Linux x64 test, and 3 symbol processing tasks: common/metadata, JVM main, Linux x64 test.
Avoid the ksp(...) configuration on KSP 1.0.1+
----------------------------------------------
Before KSP 1.0.1, there is only one, unified `ksp(...)` configuration available. Therefore, processors either applies to all compilation targets, or nothing at all. Note that the `ksp(...)` configuration not only applies to the main source set, but also the test source set if it exists, even on traditional, non-multiplatform projects. This brought unnecessary overheads to build time.
Starting from KSP 1.0.1, per-target configurations are provided as shown in the above example. In the future:
1. For multiplatform projects, the `ksp(...)` configuration will be deprecated and removed.
2. For single platform projects, the `ksp(...)` configuration will only apply to the main, default compilation. Other targets like `test` will need to specify `kspTest(...)` in order to apply processors.
Starting from KSP 1.0.1, there is an early access flag `-DallowAllTargetConfiguration=false` to switch to the more efficient behavior. If the current behavior is causing performance issues, please give it a try. The default value of the flag will be flipped from `true` to `false` on KSP 2.0.
Last modified: 10 January 2023
[Multiple round processing](ksp-multi-round) [Running KSP from command line](ksp-command-line)
kotlin How KSP models Kotlin code How KSP models Kotlin code
==========================
You can find the API definition in the [KSP GitHub repository](https://github.com/google/ksp/tree/main/api/src/main/kotlin/com/google/devtools/ksp). The diagram shows an overview of how Kotlin is [modeled](https://github.com/google/ksp/tree/main/api/src/main/kotlin/com/google/devtools/ksp/symbol/) in KSP:
Type and resolution
-------------------
The resolution takes most of the cost of the underlying API implementation. So type references are designed to be resolved by processors explicitly (with a few exceptions). When a *type* (such as `KSFunctionDeclaration.returnType` or `KSAnnotation.annotationType`) is referenced, it is always a `KSTypeReference`, which is a `KSReferenceElement` with annotations and modifiers.
```
interface KSFunctionDeclaration : ... {
val returnType: KSTypeReference?
// ...
}
interface KSTypeReference : KSAnnotated, KSModifierListOwner {
val type: KSReferenceElement
}
```
A `KSTypeReference` can be resolved to a `KSType`, which refers to a type in Kotlin's type system.
A `KSTypeReference` has a `KSReferenceElement`, which models Kotlin's program structure: namely, how the reference is written. It corresponds to the [`type`](grammar#type) element in Kotlin's grammar.
A `KSReferenceElement` can be a `KSClassifierReference` or `KSCallableReference`, which contains a lot of useful information without the need for resolution. For example, `KSClassifierReference` has `referencedName`, while `KSCallableReference` has `receiverType`, `functionArguments`, and `returnType`.
If the original declaration referenced by a `KSTypeReference` is needed, it can usually be found by resolving to `KSType` and accessing through `KSType.declaration`. Moving from where a type is mentioned to where its class is defined looks like this:
```
val ksType: KSType = ksTypeReference.resolve()
val ksDeclaration: KSDeclaration = ksType.declaration
```
Type resolution is costly and therefore has explicit form. Some of the information obtained from resolution is already available in `KSReferenceElement`. For example, `KSClassifierReference.referencedName` can filter out a lot of elements that are not interesting. You should resolve type only if you need specific information from `KSDeclaration` or `KSType`.
`KSTypeReference` pointing to a function type has most of its information in its element. Although it can be resolved to the family of `Function0`, `Function1`, and so on, these resolutions don't bring any more information than `KSCallableReference`. One use case for resolving function type references is dealing with the identity of the function's prototype.
Last modified: 10 January 2023
[KSP examples](ksp-examples) [Java annotation processing to KSP reference](ksp-reference)
kotlin Build a web application with React and Kotlin/JS — tutorial Build a web application with React and Kotlin/JS — tutorial
===========================================================
This tutorial will teach you how to build a browser application with Kotlin/JS and the [React](https://reactjs.org/) framework. You will:
* Complete common tasks associated with building a typical React application.
* Explore how [Kotlin's DSLs](type-safe-builders) can be used to help express concepts concisely and uniformly without sacrificing readability, allowing you to write a full-fledged application completely in Kotlin.
* Learn how to use ready-made npm components, use external libraries, and publish the final application.
The output will be a *KotlinConf Explorer* web app dedicated to the [KotlinConf](https://kotlinconf.com/) event, with links to conference talks. Users will be able to watch all the talks on one page and mark them as seen or unseen.
The tutorial assumes you have prior knowledge of Kotlin and basic knowledge of HTML and CSS. Understanding the basic concepts behind React may help you understand some sample code, but it is not strictly required.
Before you start
----------------
1. Download and install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
2. Clone the [project template](https://github.com/kotlin-hands-on/web-app-react-kotlin-js-gradle) and open it in IntelliJ IDEA. The template includes a basic Kotlin/JS Gradle project with all required configurations and dependencies
* Dependencies and tasks in the `build.gradle.kts` file:
```
dependencies {
// React, React DOM + Wrappers
implementation(enforcedPlatform("org.jetbrains.kotlin-wrappers:kotlin-wrappers-bom:1.0.0-pre.354"))
implementation("org.jetbrains.kotlin-wrappers:kotlin-react")
implementation("org.jetbrains.kotlin-wrappers:kotlin-react-dom")
// Kotlin React Emotion (CSS)
implementation("org.jetbrains.kotlin-wrappers:kotlin-emotion")
// Video Player
implementation(npm("react-player", "2.10.1"))
// Share Buttons
implementation(npm("react-share", "4.4.0"))
// Coroutines & serialization
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.3")
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.3.3")
}
```
* An HTML template page in `src/main/resources/index.html` for inserting JavaScript code that you'll be using in this tutorial:
```
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Hello, Kotlin/JS!</title>
</head>
<body>
<div id="root"></div>
<script src="confexplorer.js"></script>
</body>
</html>
```
Kotlin/JS projects are automatically bundled with all of your code and its dependencies into a single JavaScript file with the same name as the project, `confexplorer.js`, when you build them. As a typical [JavaScript convention](https://faqs.skillcrush.com/article/176-where-should-js-script-tags-be-linked-in-html-documents), the content of the body (including the `root` div) is loaded first to ensure that the browser loads all page elements before the scripts.
* A code snippet in `src/main/kotlin/Main.kt`:
```
import kotlinx.browser.document
fun main() {
document.bgColor = "red"
}
```
### Run the development server
By default, the Kotlin/JS Gradle plugin comes with support for an embedded `webpack-dev-server`, allowing you to run the application from the IDE without manually setting up any servers.
To test that the program successfully runs in the browser, start the development server by invoking the `run` or `browserDevelopmentRun` task (available in the `other` or `kotlin browser` directory) from the Gradle tool window inside IntelliJ IDEA:
To run the program from the Terminal, use `./gradlew run` instead.
When the project is compiled and bundled, a blank red page will appear in a browser window:
### Enable hot reload / continuous mode
Configure *[continuous compilation](dev-server-continuous-compilation)* mode so you don't have to manually compile and execute your project every time you make changes. Make sure to stop all running development server instances before proceeding.
1. Edit the run configuration that IntelliJ IDEA automatically generates after running the Gradle `run` task for the first time:

2. In the **Run/Debug Configurations** dialog, add the `--continuous` option to the arguments for the run configuration:
After applying the changes, you can use the **Run** button inside IntelliJ IDEA to start the development server back up. To run the continuous Gradle builds from the Terminal, use `./gradlew run --continuous` instead.
3. To test this feature, change the color of the page to blue in the `Main.kt` file while the Gradle task is running:
```
document.bgColor = "blue"
```
The project then recompiles, and after a reload the browser page will be the new color.
You can keep the development server running in continuous mode during the development process. It will automatically rebuild and reload the page when you make changes.
Create a web app draft
----------------------
### Add the first static page with React
To make your app display a simple message, replace the code in the `Main.kt` file with the following:
```
import kotlinx.browser.document
import react.*
import emotion.react.css
import csstype.Position
import csstype.px
import react.dom.html.ReactHTML.h1
import react.dom.html.ReactHTML.h3
import react.dom.html.ReactHTML.div
import react.dom.html.ReactHTML.p
import react.dom.html.ReactHTML.img
import react.dom.client.createRoot
import kotlinx.serialization.Serializable
fun main() {
val container = document.getElementById("root") ?: error("Couldn't find root container!")
createRoot(container).render(Fragment.create {
h1 {
+"Hello, React+Kotlin/JS!"
}
})
}
```
* The `render()` function instructs [kotlin-react-dom](https://github.com/JetBrains/kotlin-wrappers/tree/master/kotlin-react-dom) to render the first HTML element inside a [fragment](https://reactjs.org/docs/fragments.html) to the `root` element. This element is a container defined in `src/main/resources/index.html`, which was included in the template.
* The content is an `<h1>` header and uses a typesafe DSL to render HTML.
* `h1` is a function that takes a lambda parameter. When you add the `+` sign in front of a string literal, the `unaryPlus()` function is actually invoked using [operator overloading](operator-overloading). It appends the string to the enclosed HTML element.
When the project recompiles, the browser displays this HTML page:
### Convert HTML to Kotlin's typesafe HTML DSL
The Kotlin [wrappers](https://github.com/JetBrains/kotlin-wrappers/blob/master/kotlin-react/README.md) for React come with a [domain-specific language (DSL)](type-safe-builders) that makes it possible to write HTML in pure Kotlin code. In this way, it's similar to [JSX](https://reactjs.org/docs/introducing-jsx.html) from JavaScript. However, with this markup being Kotlin, you get all the benefits of a statically typed language, such as autocomplete or type checking.
Compare the classic HTML code for your future web app and its typesafe variant in Kotlin:
```
<h1>KotlinConf Explorer</h1>
<div>
<h3>Videos to watch</h3>
<p>John Doe: Building and breaking things</p>
<p>Jane Smith: The development process</p>
<p>Matt Miller: The Web 7.0</p>
<h3>Videos watched</h3>
<p>Tom Jerry: Mouseless development</p>
</div>
<div>
<h3>John Doe: Building and breaking things</h3>
<img src="https://via.placeholder.com/640x360.png?text=Video+Player+Placeholder">
</div>
```
```
h1 {
+"KotlinConf Explorer"
}
div {
h3 {
+"Videos to watch"
}
p {
+ "John Doe: Building and breaking things"
}
p {
+"Jane Smith: The development process"
}
p {
+"Matt Miller: The Web 7.0"
}
h3 {
+"Videos watched"
}
p {
+"Tom Jerry: Mouseless development"
}
}
div {
h3 {
+"John Doe: Building and breaking things"
}
img {
src = "https://via.placeholder.com/640x360.png?text=Video+Player+Placeholder"
}
}
```
Copy the Kotlin code and update the `Fragment.create()` function call inside the `main()` function, replacing the previous `h1` tag.
Wait for the browser to reload. The page should now look like this:
### Add videos using Kotlin constructs in markup
There are some advantages to writing HTML in Kotlin using this DSL. You can manipulate your app using regular Kotlin constructs, like loops, conditions, collections, and string interpolation.
You can now replace the hardcoded list of videos with a list of Kotlin objects:
1. In `Main.kt`, create a `Video` [data class](data-classes) to keep all video attributes in one place:
```
data class Video(
val id: Int,
val title: String,
val speaker: String,
val videoUrl: String
)
```
2. Fill up the two lists, for unwatched videos and watched videos, respectively. Add these declarations at file-level in `Main.kt`:
```
val unwatchedVideos = listOf(
Video(1, "Opening Keynote", "Andrey Breslav", "https://youtu.be/PsaFVLr8t4E"),
Video(2, "Dissecting the stdlib", "Huyen Tue Dao", "https://youtu.be/Fzt_9I733Yg"),
Video(3, "Kotlin and Spring Boot", "Nicolas Frankel", "https://youtu.be/pSiZVAeReeg")
)
val watchedVideos = listOf(
Video(4, "Creating Internal DSLs in Kotlin", "Venkat Subramaniam", "https://youtu.be/JzTeAM8N1-o")
)
```
3. To use these videos on the page, write a Kotlin `for` loop to iterate over the collection of unwatched `Video` objects. Replace the three `p` tags under "Videos to watch" with the following snippet:
```
for (video in unwatchedVideos) {
p {
+"${video.speaker}: ${video.title}"
}
}
```
4. Apply the same process to modify the code for the single tag following "Videos watched" as well:
```
for (video in watchedVideos) {
p {
+"${video.speaker}: ${video.title}"
}
}
```
Wait for the browser to reload. The layout should stay the same as before. You can add some more videos to the list to make sure that the loop is working.
### Add styles with typesafe CSS
The [kotlin-emotion](https://github.com/JetBrains/kotlin-wrappers/blob/master/kotlin-emotion/) wrapper for the [Emotion](https://emotion.sh/docs/introduction) library makes it possible to specify CSS attributes – even dynamic ones – right alongside HTML with JavaScript. Conceptually, that makes it similar to [CSS-in-JS](https://reactjs.org/docs/faq-styling.html#what-is-css-in-js) – but for Kotlin. The benefit of using a DSL is that you can use Kotlin code constructs to express formatting rules.
The template project for this tutorial already includes the dependency needed to use `kotlin-emotion`:
```
dependencies {
// ...
// Kotlin React Emotion (CSS) (chapter 3)
implementation("org.jetbrains.kotlin-wrappers:kotlin-emotion")
// ...
}
```
With `kotlin-emotion`, you can specify a `css` block inside HTML elements `div` and `h3`, where you can define the styles.
To move the video player to the top right-hand corner of the page, use CSS and adjust the code for the video player (the last `div` in the snippet):
```
div {
css {
position = Position.absolute
top = 10.px
right = 10.px
}
h3 {
+"John Doe: Building and breaking things"
}
img {
src = "https://via.placeholder.com/640x360.png?text=Video+Player+Placeholder"
}
}
```
Feel free to experiment with some other styles. For example, you could change the `fontFamily` or add some `color` to your UI.
Design app components
---------------------
The basic building blocks in React are called *[components](https://reactjs.org/docs/components-and-props.html)*. Components themselves can also be composed of other, smaller components. By combining components, you build your application. If you structure components to be generic and reusable, you'll be able to use them in multiple parts of the app without duplicating code or logic.
The content of the `render()` function generally describes a basic component. The current layout of your application looks like this:
If you decompose your application into individual components, you'll end up with a more structured layout in which each component handles its responsibilities:
Components encapsulate a particular functionality. Using components shortens source code and makes it easier to read and understand.
### Add the main component
To start creating the application's structure, first explicitly specify `App`, the main component for rendering to the `root`element:
1. Create a new `App.kt` file in the `src/main/kotlin` folder.
2. Inside this file, add the following snippet and move the typesafe HTML from `Main.kt` into it:
```
import kotlinx.coroutines.async
import react.*
import react.dom.*
import kotlinx.browser.window
import kotlinx.coroutines.*
import kotlinx.serialization.decodeFromString
import kotlinx.serialization.json.Json
import emotion.react.css
import csstype.Position
import csstype.px
import react.dom.html.ReactHTML.h1
import react.dom.html.ReactHTML.h3
import react.dom.html.ReactHTML.div
import react.dom.html.ReactHTML.p
import react.dom.html.ReactHTML.img
val App = FC<Props> {
// typesafe HTML goes here, starting with the first h1 tag!
}
```
The `FC` function creates a [function component](https://reactjs.org/docs/components-and-props.html#function-and-class-components).
3. In the `Main.kt` file, update the `main()` function as follows:
```
fun main() {
val container = document.getElementById("root") ?: error("Couldn't find root container!")
createRoot(container).render(App.create())
}
```
Now the program creates an instance of the `App` component and renders it to the specified container.
For more information about React concepts, see the [documentation and guides](https://reactjs.org/docs/hello-world.html#how-to-read-this-guide).
### Extract a list component
Since the `watchedVideos` and `unwatchedVideos` lists each contain a list of videos, it makes sense to create a single reusable component, and only adjust the content displayed in the lists.
The `VideoList` component follows the same pattern as the `App` component. It uses the `FC` builder function, and contains the code from the `unwatchedVideos` list.
1. Create a new `VideoList.kt` file in the `src/main/kotlin` folder and add the following code:
```
import kotlinx.browser.window
import react.*
import react.dom.*
import react.dom.html.ReactHTML.p
val VideoList = FC<Props> {
for (video in unwatchedVideos) {
p {
+"${video.speaker}: ${video.title}"
}
}
}
```
2. In `App.kt`, use the `VideoList` component by invoking it without parameters:
```
// . . .
div {
h3 {
+"Videos to watch"
}
VideoList()
h3 {
+"Videos watched"
}
VideoList()
}
// . . .
```
For now, the `App` component has no control over the content that is shown by the `VideoList` component. It's hard-coded, so you see the same list twice.
### Add props to pass data between components
Since you're going to reuse the `VideoList` component, you'll need to be able to fill it with different content. You can add the ability to pass the list of items as an attribute to the component. In React, these attributes are called *props*. When the props of a component are changed in React, the framework automatically re-renders the component.
For `VideoList`, you'll need a prop containing the list of videos to be shown. Define an interface that holds all the props which can be passed to a `VideoList` component:
1. Add the following definition to the `VideoList.kt` file:
```
external interface VideoListProps : Props {
var videos: List<Video>
}
```
The [external](js-interop#external-modifier) modifier tells the compiler that the interface's implementation is provided externally, so it doesn't try to generate JavaScript code from the declaration.
2. Adjust the class definition of `VideoList` to make use of the props that are passed into the `FC` block as a parameter:
```
val VideoList = FC<VideoListProps> { props ->
for (video in props.videos) {
p {
key = video.id.toString()
+"${video.speaker}: ${video.title}"
}
}
}
```
The `key` attribute helps the React renderer figure out what to do when the value of `props.videos` changes. It uses the key to determine which parts of a list need to be refreshed and which ones stay the same. You can find more information about lists and keys in the [React guide](https://reactjs.org/docs/lists-and-keys.html).
3. In the `App` component, make sure that the child components are instantiated with the proper attributes. In `App.kt`, replace the two loops underneath the `h3` elements with an invocation of `VideoList` together with the attributes for `unwatchedVideos` and `watchedVideos`. In the Kotlin DSL, you assign them inside a block belonging to the `VideoList` component:
```
h3 {
+"Videos to watch"
}
VideoList {
videos = unwatchedVideos
}
h3 {
+"Videos watched"
}
VideoList {
videos = watchedVideos
}
```
After a reload, the browser will show that the lists now render correctly.
### Make the list interactive
First, add an alert message that pops up when users click on a list entry. In `VideoList.kt`, add an `onClick` handler function that triggers an alert with the current video:
```
// . . .
p {
key = video.id.toString()
onClick = {
window.alert("Clicked $video!")
}
+"${video.speaker}: ${video.title}"
}
// . . .
```
If you click on one of the list items in the browser window, you'll get information about the video in an alert window like this:
### Add state to keep values
Instead of just alerting the user, you can add some functionality for highlighting the selected video with a ▶ triangle. To do that, introduce some *state* specific to this component.
State is one of core concepts in React. In modern React (which uses the so-called *Hooks API*), state is expressed using the [`useState` hook](https://reactjs.org/docs/hooks-state.html).
1. Add the following code to the top of the `VideoList` declaration:
```
val VideoList = FC<VideoListProps> { props ->
var selectedVideo: Video? by useState(null)
// . . .
```
* The `VideoList` functional component keeps state (a value that is independent of the current function invocation). State is nullable, and has the `Video?` type. Its default value is `null`.
* The `useState()` function from React instructs the framework to keep track of state across multiple invocations of the function. For example, even though you specify a default value, React makes sure that the default value is only assigned in the beginning. When state changes, the component will re-render based on the new state.
* The `by` keyword indicates that `useState()` acts as a [delegated property](delegated-properties). Like with any other variable, you read and write values. The implementation behind `useState()` takes care of the machinery required to make state work.To learn more about the State Hook, check out the [React documentation](https://reactjs.org/docs/hooks-state.html).
2. Change your implementation of the `VideoList` component to look as follows:
```
val VideoList = FC<VideoListProps> { props ->
var selectedVideo: Video? by useState(null)
for (video in props.videos) {
p {
key = video.id.toString()
onClick = {
selectedVideo = video
}
if (video == selectedVideo) {
+"▶ "
}
+"${video.speaker}: ${video.title}"
}
}
}
```
* When the user clicks a video, its value is assigned to the `selectedVideo` variable.
* When the selected list entry is rendered, the triangle is prepended.
You can find more details about state management in the [React FAQ](https://reactjs.org/docs/faq-state.html).
Check the browser and click an item in the list to make sure that everything is working correctly.
Compose components
------------------
Currently, the two video lists work on their own, meaning that each list keeps track of a selected video. Users can select two videos, one in the unwatched list and one in watched, even though there's only one player:
A list can't keep track of which video is selected both inside itself, and inside a sibling list. The reason is that the selected video is part not of the *list* state, but of the *application* state. This means you need to *lift* state out of the individual components.
### Lift state
React makes sure that props can only be passed from a parent component to its children. This prevents components from being hard-wired together.
If a component wants to change state of a sibling component, it needs to do so via its parent. At that point, state also no longer belongs to any of the child components but to the overarching parent component.
The process of migrating state from components to their parents is called *lifting state*. For your app, add `currentVideo` as state to the `App` component:
1. In `App.kt`, add the following to the top of the definition of the `App` component:
```
val App = FC<Props> {
var currentVideo: Video? by useState(null)
// . . .
}
```
The `VideoList` component no longer needs to keep track of state. It will receive the current video as a prop instead.
2. Remove the `useState()` call in `VideoList.kt`.
3. Prepare the `VideoList` component to receive the selected video as a prop. To do so, expand the `VideoListProps` interface to contain the `selectedVideo`:
```
external interface VideoListProps : Props {
var videos: List<Video>
var selectedVideo: Video?
}
```
4. Change the condition of the triangle so that it uses `props` instead of `state`:
```
if (video == props.selectedVideo) {
+"▶ "
}
```
### Pass handlers
At the moment, there's no way to assign a value to a prop, so the `onClick` function won't work the way it is currently set up. To change state of a parent component, you need to lift state again.
In React, state always flows from parent to child. So, to change the *application* state from one of the child components, you need to move the logic for handling user interaction to the parent component and then pass the logic in as a prop. Remember that in Kotlin, variables can have the [type of a function](lambdas#function-types).
1. Expand the `VideoListProps` interface again so that it contains a variable `onSelectVideo`, which is a function that takes a `Video` and returns `Unit`:
```
external interface VideoListProps : Props {
// ...
var onSelectVideo: (Video) -> Unit
}
```
2. In the `VideoList` component, use the new prop in the `onClick` handler:
```
onClick = {
props.onSelectVideo(video)
}
```
3. You can now go back to the `App` component and pass `selectedVideo` and a handler for `onSelectVideo` for each of the two video lists:
```
VideoList {
videos = unwatchedVideos // and watchedVideos respectively
selectedVideo = currentVideo
onSelectVideo = { video ->
currentVideo = video
}
}
```
4. Repeat the previous step for the watched videos list.
Switch back to your browser and make sure that when selecting a video the selection jumps between the two lists without duplication.
Add more components
-------------------
### Extract the video player component
You can now create another self-contained component, a video player, which is currently a placeholder image. Your video player needs to know the talk title, the author of the talk, and the link to the video. This information is already contained in each `Video` object, so you can pass it as a prop and access its attributes.
1. Create a new `VideoPlayer.kt` file and add the following implementation for the `VideoPlayer` component:
```
import csstype.*
import react.*
import emotion.react.css
import react.dom.html.ReactHTML.button
import react.dom.html.ReactHTML.div
import react.dom.html.ReactHTML.h3
import react.dom.html.ReactHTML.img
external interface VideoPlayerProps : Props {
var video: Video
}
val VideoPlayer = FC<VideoPlayerProps> { props ->
div {
css {
position = Position.absolute
top = 10.px
right = 10.px
}
h3 {
+"${props.video.speaker}: ${props.video.title}"
}
img {
src = "https://via.placeholder.com/640x360.png?text=Video+Player+Placeholder"
}
}
}
```
2. Because the `VideoPlayerProps` interface specifies that the `VideoPlayer` component takes a non-null `Video`, make sure to handle this in the `App` component accordingly.
In `App.kt`, replace the previous `div` snippet for the video player with the following:
```
currentVideo?.let { curr ->
VideoPlayer {
video = curr
}
}
```
The [`let` scope function](scope-functions#let) ensures that the `VideoPlayer` component is only added when `state.currentVideo` is not null.
Now clicking an entry in the list will bring up the video player and populate it with the information from the clicked entry.
### Add a button and wire it
To make it possible for users to mark a video as watched or unwatched and to move it between the two lists, add a button to the `VideoPlayer` component.
Since this button will move videos between two different lists, the logic handling state change needs to be *lifted* out of the `VideoPlayer` and passed in from the parent as a prop. The button should look different based on whether the video has been watched or not. This is also information you need to pass as a prop.
1. Expand the `VideoPlayerProps` interface in `VideoPlayer.kt` to include properties for those two cases:
```
external interface VideoPlayerProps : Props {
var video: Video
var onWatchedButtonPressed: (Video) -> Unit
var unwatchedVideo: Boolean
}
```
2. You can now add the button to the actual component. Copy the following snippet into the body of the `VideoPlayer` component, between the `h3` and `img` tags:
```
button {
css {
display = Display.block
backgroundColor = if (props.unwatchedVideo) NamedColor.lightgreen else NamedColor.red
}
onClick = {
props.onWatchedButtonPressed(props.video)
}
if (props.unwatchedVideo) {
+"Mark as watched"
} else {
+"Mark as unwatched"
}
}
```
With the help of Kotlin CSS DSL that make it possible to change styles dynamically, you can change the color of the button using a basic Kotlin `if` expression.
### Move video lists to the application state
Now it's time to adjust the `VideoPlayer` usage site in the `App` component. When the button is clicked, a video should be moved from the unwatched list to the watched list or vice versa. Since these lists can now actually change, move them into the application state:
1. In `App.kt`, add the following `useState()` calls to the top of the `App` component:
```
val App = FC<Props> {
var currentVideo: Video? by useState(null)
var unwatchedVideos: List<Video> by useState(listOf(
Video(1, "Opening Keynote", "Andrey Breslav", "https://youtu.be/PsaFVLr8t4E"),
Video(2, "Dissecting the stdlib", "Huyen Tue Dao", "https://youtu.be/Fzt_9I733Yg"),
Video(3, "Kotlin and Spring Boot", "Nicolas Frankel", "https://youtu.be/pSiZVAeReeg")
))
var watchedVideos: List<Video> by useState(listOf(
Video(4, "Creating Internal DSLs in Kotlin", "Venkat Subramaniam", "https://youtu.be/JzTeAM8N1-o")
))
// . . .
}
```
2. Since all the demo data is included in the default values for `watchedVideos` and `unwatchedVideos` directly, you no longer need the file-level declarations. In `Main.kt`, delete the declarations for `watchedVideos` and `unwatchedVideos`.
3. Change the call-site for `VideoPlayer` in the `App` component that belongs to the video player to look like this:
```
VideoPlayer {
video = curr
unwatchedVideo = curr in unwatchedVideos
onWatchedButtonPressed = {
if (video in unwatchedVideos) {
unwatchedVideos = unwatchedVideos - video
watchedVideos = watchedVideos + video
} else {
watchedVideos = watchedVideos - video
unwatchedVideos = unwatchedVideos + video
}
}
}
```
Go back to the browser, select a video, and press the button a few times. The video will jump between the two lists.
Use packages from npm
---------------------
To make the app usable, you still need a video player that actually plays videos and some buttons to help people share the content.
React has a rich ecosystem with a lot of pre-made components you can use instead of building this functionality yourself.
### Add the video player component
To replace the placeholder video component with an actual YouTube player, use the `react-player` package from npm. It can play videos and allows you to control the appearance of the player.
For the component documentation and the API description, see its [README](https://www.npmjs.com/package/react-player) in GitHub.
1. Check the `build.gradle.kts` file. The `react-player` package should be already included:
```
dependencies {
// ...
// Video Player
implementation(npm("react-player", "2.10.1"))
// ...
}
```
As you can see, npm dependencies can be added to a Kotlin/JS project by using the `npm()` function in the `dependencies` block of the build file. The Gradle plugin then takes care of downloading and installing these dependencies for you. To do so, it uses its own bundled installation of the [`yarn`](https://yarnpkg.com/) package manager.
2. To use the JavaScript package from inside the React application, it's necessary to tell the Kotlin compiler what to expect by providing it with [external declarations](js-interop).
Create a new `ReactYouTube.kt` file and add the following content:
```
@file:JsModule("react-player")
@file:JsNonModule
import react.*
@JsName("default")
external val ReactPlayer: ComponentClass<dynamic>
```
When the compiler sees an external declaration like `ReactPlayer`, it assumes that the implementation for the corresponding class is provided by the dependency and doesn't generate code for it.
The last two lines are equivalent to a JavaScript import like `require("react-player").default;`. They tell the compiler that it's certain that a component will conform to `ComponentClass<dynamic>` at runtime.
However, in this configuration, the generic type for the props accepted by `ReactPlayer` is set to `dynamic`. That means the compiler will accept any code, at the risk of breaking things at runtime.
A better alternative would be to create an `external interface` that specifies what kind of properties belong to the props for this external component. You can learn about the props' interface in the [README](https://www.npmjs.com/package/react-player) for the component. In this case, use the `url` and `controls` props:
1. Adjust the content of `ReactPlayer.kt` accordingly:
```
@file:JsModule("react-player")
@file:JsNonModule
import react.*
@JsName("default")
external val ReactPlayer: ComponentClass<ReactPlayerProps>
external interface ReactPlayerProps : Props {
var url: String
var controls: Boolean
}
```
2. You can now use the new `ReactPlayer` to replace the gray placeholder rectangle in the `VideoPlayer` component. In `VideoPlayer.kt`, replace the `img` tag with the following snippet:
```
ReactPlayer {
url = props.video.videoUrl
controls = true
}
```
### Add social share buttons
An easy way to share the application's content is to have social share buttons for messengers and email. You can use an off-the-shelf React component for this as well, for example, [react-share](https://github.com/nygardk/react-share/blob/master/README.md):
1. Check the `build.gradle.kts` file. This npm library should already be included:
```
dependencies {
// ...
// Share Buttons
implementation(npm("react-share", "4.4.0"))
// ...
}
```
2. To use `react-share` from Kotlin, you'll need to write more basic external declarations. The [examples on GitHub](https://github.com/nygardk/react-share/blob/master/demo/Demo.tsx#L61) show that a share button consists of two React components: `EmailShareButton` and `EmailIcon`, for example. Different types of share buttons and icons all have the same kind of interface. You'll create the external declarations for each component the same way you already did for the video player.
Add the following code to a new `ReactShare.kt` file:
```
@file:JsModule("react-share")
@file:JsNonModule
import react.ComponentClass
import react.Props
@JsName("EmailIcon")
external val EmailIcon: ComponentClass<IconProps>
@JsName("EmailShareButton")
external val EmailShareButton: ComponentClass<ShareButtonProps>
@JsName("TelegramIcon")
external val TelegramIcon: ComponentClass<IconProps>
@JsName("TelegramShareButton")
external val TelegramShareButton: ComponentClass<ShareButtonProps>
external interface ShareButtonProps : Props {
var url: String
}
external interface IconProps : Props {
var size: Int
var round: Boolean
}
```
3. Add new components into the user interface of the application. In `VideoPlayer.kt`, add two share buttons in a `div` right above the usage of `ReactPlayer`:
```
// . . .
div {
css {
position = Position.absolute
top = 10.px
right = 10.px
}
EmailShareButton {
url = props.video.videoUrl
EmailIcon {
size = 32
round = true
}
}
TelegramShareButton {
url = props.video.videoUrl
TelegramIcon {
size = 32
round = true
}
}
}
// . . .
```
You can now check your browser and see whether the buttons actually work. When clicking on the button, a *share window* should appear with the URL of the video. If the buttons don't show up or work, you may need to disable your ad and social media blocker.
Feel free to repeat this step with share buttons for other social networks available in [react-share](https://github.com/nygardk/react-share/blob/master/README.md#features).
Use an external REST API
------------------------
You can now replace the hard-coded demo data with some real data from a REST API in the app.
For this tutorial, there's a [small API](https://my-json-server.typicode.com/kotlin-hands-on/kotlinconf-json/videos/1). It offers only a single endpoint, `videos`, and takes a numeric parameter to access an element from the list. If you visit the API with your browser, you will see that the objects returned from the API have the same structure as `Video` objects.
### Use JS functionality from Kotlin
Browsers already come with a large variety of [Web APIs](https://developer.mozilla.org/en-US/docs/Web/API). You can also use them from Kotlin/JS, since it includes wrappers for these APIs out of the box. One example is the [fetch API](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API), which is used for making HTTP requests.
The first potential issue is that browser APIs like `fetch()` use [callbacks](https://developer.mozilla.org/en-US/docs/Glossary/Callback_function) to perform non-blocking operations. When multiple callbacks are supposed to run one after the other, they need to be nested. Naturally, the code gets heavily indented, with more and more pieces of functionality stacked inside each other, which makes it harder to read.
To overcome this, you can use Kotlin's coroutines, a better approach for such functionality.
The second issue arises from the dynamically typed nature of JavaScript. There are no guarantees about the type of data returned from the external API. To solve this, you can use the `kotlinx.serialization` library.
Check the `build.gradle.kts` file. The relevant snippet should already exist:
```
dependencies {
// . . .
// Coroutines & serialization
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.3")
}
```
### Add serialization
When you call an external API, you get back JSON-formatted text that still needs to be turned into a Kotlin object that can be worked with.
[`kotlinx.serialization`](https://github.com/Kotlin/kotlinx.serialization) is a library that makes it possible to write these types of conversions from JSON strings to Kotlin objects.
1. Check the `build.gradle.kts` file. The corresponding snippet should already exist:
```
plugins {
// . . .
kotlin("plugin.serialization") version "1.8.0"
}
dependencies {
// . . .
// Serialization
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.3.3")
}
```
2. As preparation for fetching the first video, it's necessary to tell the serialization library about the `Video` class. In `Main.kt`, add the `@Serializable` annotation to its definition:
```
@Serializable
data class Video(
val id: Int,
val title: String,
val speaker: String,
val videoUrl: String
)
```
### Fetch videos
To fetch a video from the API, add the following function in `App.kt` (or a new file):
```
suspend fun fetchVideo(id: Int): Video {
val response = window
.fetch("https://my-json-server.typicode.com/kotlin-hands-on/kotlinconf-json/videos/$id")
.await()
.text()
.await()
return Json.decodeFromString(response)
}
```
* *Suspending function* `fetch()`es a video with a given `id` from the API. This response may take a while, so you `await()` the result. Next, `text()`, which uses a callback, reads the body from the response. Then you `await()` its completion.
* Before returning the value of the function, you pass it to `Json.decodeFromString`, a function from `kotlinx.coroutines`. It converts the JSON text you received from the request into a Kotlin object with the appropriate fields.
* The `window.fetch` function call returns a `Promise` object. You normally would have to define a callback handler that gets invoked once the `Promise` is resolved and a result is available. However, with coroutines, you can `await()` those promises. Whenever a function like `await()` is called, the method stops (suspends) its execution. Its execution continues once the `Promise` can be resolved.
To give users a selection of videos, define the `fetchVideos()` function, which will fetch 25 videos from the same API as above. To run all the requests concurrently, use the [`async`](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/async.html) functionality provided by Kotlin's coroutines:
1. Add the following implementation to your `App.kt`:
```
suspend fun fetchVideos(): List<Video> = coroutineScope {
(1..25).map { id ->
async {
fetchVideo(id)
}
}.awaitAll()
}
```
Following the principle of [structured concurrency](coroutines-basics#structured-concurrency), the implementation is wrapped in a `coroutineScope`. You can then start 25 asynchronous tasks (one per request) and wait for all of them to complete.
2. You can now add data to your application. Add the definition for a `mainScope`, and change your `App` component so it starts with the following snippet. Don't forget to replace demo values with `emptyLists` instances as well:
```
val mainScope = MainScope()
val App = FC<Props> {
var currentVideo: Video? by useState(null)
var unwatchedVideos: List<Video> by useState(emptyList())
var watchedVideos: List<Video> by useState(emptyList())
useEffectOnce {
mainScope.launch {
unwatchedVideos = fetchVideos()
}
}
// . . .
```
* The [`MainScope()`](https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-main-scope.html) is a part of Kotlin's structured concurrency model and creates the scope for asynchronous tasks to run in.
* `useEffectOnce` is another React *hook* (specifically, a simplified version of the [useEffect](https://reactjs.org/docs/hooks-effect.html) hook). It indicates that the component performs a *side effect*. It doesn't just render itself but also communicates over the network.
Check your browser. The application should show actual data:
When you load the page:
* The code of the `App` component will be invoked. This starts the code in the `useEffectOnce` block.
* The `App` component is rendered with empty lists for the watched and unwatched videos.
* When the API requests finish, the `useEffectOnce` block assigns it to the `App` component's state. This triggers a re-render.
* The code of the `App` component will be invoked again, but the `useEffectOnce` block *will not* run for a second time.
If you want to get an in-depth understanding of how coroutines work, check out this [tutorial on coroutines](coroutines-and-channels).
Deploy to production and the cloud
----------------------------------
It's time to get the application published to the cloud and make it accessible to other people.
### Package a production build
To package all assets in production mode, run the `build` task in Gradle via the tool window in IntelliJ IDEA or by running `./gradlew build`. This generates an optimized project build, applying various improvements such as DCE (dead code elimination).
Once the build has finished, you can find all the files needed for deployment in `/build/distributions`. They include the JavaScript files, HTML files, and other resources required to run the application. You can put them on a static HTTP server, serve them using GitHub Pages, or host them on a cloud provider of your choice.
### Deploy to Heroku
Heroku makes it quite simple to spin up an application that is reachable under its own domain. Their free tier should be sufficient for development purposes.
1. [Create an account](https://signup.heroku.com/).
2. [Install and authenticate the CLI client](https://devcenter.heroku.com/articles/heroku-cli).
3. Create a Git repository and attach a Heroku app by running the following commands in the Terminal while in the project root:
```
git init
heroku create
git add .
git commit -m "initial commit"
```
4. Unlike a regular JVM application that would run on Heroku (one written with Ktor or Spring Boot, for example), your app generates static HTML pages and JavaScript files that need to be served accordingly. You can adjust the required buildpacks to serve the program properly:
```
heroku buildpacks:set heroku/gradle
heroku buildpacks:add https://github.com/heroku/heroku-buildpack-static.git
```
5. To allow the `heroku/gradle` buildpack to run properly, a `stage` task needs to be in the `build.gradle.kts` file. This task is equivalent to the `build` task, and the corresponding alias is already included at the bottom of the file:
```
// Heroku Deployment
tasks.register("stage") {
dependsOn("build")
}
```
6. Add a new `static.json` file to the project root to configure the `buildpack-static`.
7. Add the `root` property inside the file:
```
{
"root": "build/distributions"
}
```
8. You can now trigger a deployment, for example, by running the following command:
```
git add -A
git commit -m "add stage task and static content root configuration"
git push heroku master
```
If the deployment is successful, you will see the URL people can use to reach the application on the internet.
What's next
-----------
### Add more features
You can use the resulting app as a jumping-off point to explore more advanced topics in the realm of React, Kotlin/JS, and more.
* **Search**. You can add a search field to filter the list of talks – by title or by author, for example. Learn about how [HTML form elements work in React](https://reactjs.org/docs/forms.html).
* **Persistence**. Currently, the application loses track of the viewer's watch list every time the page gets reloaded. Consider building your own backend, using one of the web frameworks available for Kotlin (such as [Ktor](https://ktor.io/)). Alternatively, look into ways to [store information on the client](https://developer.mozilla.org/en-US/docs/Web/API/Window/localStorage).
* **Complex APIs**. Lots of datasets and APIs are available. You can pull all sorts of data into your application. For example, you can build a visualizer for [cat photos](https://thecatapi.com/) or a [royalty-free stock photo API](https://unsplash.com/developers).
### Improve the style: responsiveness and grids
The application design is still very simple and won't look great on mobile devices or in narrow windows. Explore more of the CSS DSL to make the app more accessible.
### Join the community and get help
The best way to report problems and get help is the [kotlin-wrappers issue tracker](https://github.com/JetBrains/kotlin-wrappers/issues). If you can't find a ticket for your issue, feel free to file a new one. You can also join the official [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up). There are channels for `#javascript` and `#react`.
### Learn more about coroutines
If you're interested in finding out more about how you can write concurrent code, check out the tutorial on [coroutines](coroutines-and-channels).
### Learn more about React
Now that you know the basic React concepts and how they translate to Kotlin, you can convert some other concepts outlined in the [official guides on React](https://reactjs.org/docs/) into Kotlin.
Last modified: 10 January 2023
[Samples](js-samples) [Get started with Kotlin/Native in IntelliJ IDEA](native-get-started)
| programming_docs |
kotlin Advent of Code puzzles in idiomatic Kotlin Advent of Code puzzles in idiomatic Kotlin
==========================================
[Advent of Code](https://adventofcode.com/) is an annual December event, where holiday-themed puzzles are published every day from December 1 to December 25. With the permission of [Eric Wastl](http://was.tl/), creator of Advent of Code, we'll show how to solve these puzzles using the idiomatic Kotlin style:
* [Advent of Code 2021](#advent-of-code-2021)
* [Advent of Code 2020](#advent-of-code-2020)
Advent of Code 2021
-------------------
* [Get ready](#get-ready)
* [Day 1: Sonar sweep](#day-1-sonar-sweep)
* [Day 2: Dive!](#day-2-dive)
* [Day 3: Binary diagnostic](#day-3-binary-diagnostic)
* [Day 4: Giant squid](#day-4-giant-squid)
### Get ready
We'll take you through the basic tips on how to get up and running with solving Advent of Code challenges with Kotlin:
* Read our [blog post about Advent of Code 2021](https://blog.jetbrains.com/kotlin/2021/11/advent-of-code-2021-in-kotlin/)
* Use [this GitHub template](https://github.com/kotlin-hands-on/advent-of-code-kotlin-template) to create projects
* Check out the welcome video by Kotlin Developer Advocate, Sebastian Aigner:
### Day 1: Sonar sweep
Apply windowed and count functions to work with pairs and triplets of integers.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2021/day/1)
* Check out the solution from Anton Arhipov on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/12/advent-of-code-2021-in-kotlin-day-1) or watch the video:
### Day 2: Dive!
Learn about destructuring declarations and the `when` expression.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2021/day/2)
* Check out the solution from Pasha Finkelshteyn on [GitHub](https://github.com/asm0dey/aoc-2021/blob/main/src/Day02.kt) or watch the video:
### Day 3: Binary diagnostic
Explore different ways to work with binary numbers.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2021/day/3)
* Check out the solution from Sebastian Aigner on [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/12/advent-of-code-2021-in-kotlin-day-3/) or watch the video:
### Day 4: Giant squid
Learn how to parse the input and introduce some domain classes for more convenient processing.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2021/day/4)
* Check out the solution from Anton Arhipov on the [GitHub](https://github.com/antonarhipov/advent-of-code-2021/blob/main/src/Day04.kt) or watch the video:
Advent of Code 2020
-------------------
* [Day 1: Report repair](#day-1-report-repair)
* [Day 2: Password philosophy](#day-2-password-philosophy)
* [Day 3: Toboggan trajectory](#day-3-toboggan-trajectory)
* [Day 4: Passport processing](#day-4-passport-processing)
* [Day 5: Binary boarding](#day-5-binary-boarding)
* [Day 6: Custom customs](#day-6-custom-customs)
* [Day 7: Handy haversacks](#day-7-handy-haversacks)
* [Day 8: Handheld halting](#day-8-handheld-halting)
* [Day 9: Encoding error](#day-9-encoding-error)
### Day 1: Report repair
Explore input handling, iterating over a list, different ways of building a map, and using the [`let`](scope-functions#let) function to simplify your code.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/1)
* Check out the solution from Svetlana Isakova on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/07/advent-of-code-in-idiomatic-kotlin/) or watch the video:
### Day 2: Password philosophy
Explore string utility functions, regular expressions, operations on collections, and how the [`let`](scope-functions#let) function can be helpful to transform your expressions.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/2)
* Check out the solution from Svetlana Isakova on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/07/advent-of-code-in-idiomatic-kotlin-day2/) or watch the video:
### Day 3: Toboggan trajectory
Compare imperative and more functional code styles, work with pairs and the [`reduce()`](../api/latest/jvm/stdlib/kotlin.collections/reduce) function, edit code in the column selection mode, and fix integer overflows.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/3)
* Check out the solution from Mikhail Dvorkin on [GitHub](https://github.com/kotlin-hands-on/advent-of-code-2020/blob/master/src/day03/day3.kt) or watch the video:
### Day 4: Passport processing
Apply the [`when`](control-flow#when-expression) expression and explore different ways of how to validate the input: utility functions, working with ranges, checking set membership, and matching a particular regular expression.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/4)
* Check out the solution from Sebastian Aigner on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/09/validating-input-advent-of-code-in-kotlin/) or watch the video:
### Day 5: Binary boarding
Use the Kotlin standard library functions (`replace()`, `toInt()`, `find()`) to work with the binary representation of numbers, explore powerful local functions, and learn how to use the `max()` function in Kotlin 1.5.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/5)
* Check out the solution from Svetlana Isakova on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/09/idiomatic-kotlin-binary-representation/) or watch the video:
### Day 6: Custom customs
Learn how to group and count characters in strings and collections using the standard library functions: `map()`, `reduce()`, `sumOf()`, `intersect()`, and `union()`.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/6)
* Check out the solution from Anton Arhipov on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/09/idiomatic-kotlin-set-operations/) or watch the video:
### Day 7: Handy haversacks
Learn how to use regular expressions, use Java's `compute()` method for HashMaps from Kotlin for dynamic calculations of the value in the map, use the `forEachLine()` function to read files, and compare two types of search algorithms: depth-first and breadth-first.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/7)
* Check out the solution from Pasha Finkelshteyn on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/09/idiomatic-kotlin-traversing-trees/) or watch the video:
### Day 8: Handheld halting
Apply sealed classes and lambdas to represent instructions, apply Kotlin sets to discover loops in the program execution, use sequences and the `sequence { }` builder function to construct a lazy collection, and try the experimental `measureTimedValue()` function to check performance metrics.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/8)
* Check out the solution from Sebastian Aigner on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/10/idiomatic-kotlin-simulating-a-console/) or watch the video:
### Day 9: Encoding error
Explore different ways to manipulate lists in Kotlin using the `any()`, `firstOrNull()`, `firstNotNullOfOrNull()`, `windowed()`, `takeIf()`, and `scan()` functions, which exemplify an idiomatic Kotlin style.
* Read the puzzle description on [Advent of Code](https://adventofcode.com/2020/day/9)
* Check out the solution from Svetlana Isakova on the [Kotlin Blog](https://blog.jetbrains.com/kotlin/2021/10/idiomatic-kotlin-working-with-lists/) or watch the video:
What's next?
------------
* Complete more tasks with [Kotlin Koans](koans)
* Create working applications with the free [Kotlin Basics track](https://hyperskill.org/join/fromdocstoJetSalesStat?redirect=true&next=/tracks/18)
Last modified: 10 January 2023
[Kotlin books](books) [Learning Kotlin with EduTools plugin](edu-tools-learner)
kotlin Create your first cross-platform app Create your first cross-platform app
====================================
Here you will learn how to create and run your first Kotlin Multiplatform Mobile application using Android Studio.
Create the project from a template
----------------------------------
1. In Android Studio, select **File | New | New Project**.
2. Select **Kotlin Multiplatform App** in the list of project templates, and click **Next**.

3. Specify a name for your first application, and click **Next**.

4. In the **iOS framework distribution** list, select the **Regular framework** option.

5. Keep the default names for the application and shared folders. Click **Finish**.
The project will be set up automatically. It may take some time to download and set up the required components when you do this for the first time.
Examine the project structure
-----------------------------
To view the full structure of your mobile multiplatform project, switch the view from **Android** to **Project**.
Each Kotlin Multiplatform Mobile project includes three modules:
* *shared* is a Kotlin module that contains the logic common for both Android and iOS applications – the code you share between platforms. It uses [Gradle](gradle) as the build system that helps you automate your build process. The *shared* module builds into an Android library and an iOS framework.
* *androidApp* is a Kotlin module that builds into an Android application. It uses Gradle as the build system. The *androidApp* module depends on and uses the shared module as a regular Android library.
* *iOSApp* is an Xcode project that builds into an iOS application. It depends on and uses the shared module as an iOS framework. The shared module can be used as a regular framework or as a [CocoaPods dependency](native-cocoapods), based on what you've chosen in the previous step in **iOS framework distribution**. In this tutorial, it's a regular framework dependency.
The shared module consists of three source sets: `androidMain`, `commonMain`, and `iosMain`. *Source set* is a Gradle concept for a number of files logically grouped together where each group has its own dependencies. In Kotlin Multiplatform, different source sets in a shared module can target different platforms.
Run your application
--------------------
You can run your multiplatform application on [Android](#run-your-application-on-android) or [iOS](#run-your-application-on-ios).
### Run your application on Android
1. Create an [Android virtual device](https://developer.android.com/studio/run/managing-avds#createavd).
2. In the list of run configurations, select **androidApp**.
3. Choose your Android virtual device and click **Run**.

#### Run on a different Android simulated device
Learn how to [configure the Android Emulator and run your application on a different simulated device](https://developer.android.com/studio/run/emulator#runningapp).
#### Run on a real Android device
Learn how to [configure and connect a hardware device and run your application on it](https://developer.android.com/studio/run/device).
### Run your application on iOS
1. Launch Xcode in a separate window. The first time you may also need to accept its license terms and allow it to perform some necessary initial tasks.
2. In Android Studio, select **iosApp** in the list of run configurations and click **Run**.
If you don't have an available iOS configuration in the list, add a [new iOS simulated device](#run-on-a-new-ios-simulated-device).

#### Run on a new iOS simulated device
If you want to run your application on a simulated device, you can add a new run configuration.
1. In the list of run configurations, click **Edit Configurations**.

2. Click the **+** button above the list of configurations and select **iOS Application**.

3. Name your configuration.
4. Select the **Xcode project file**. For that, navigate to your project, for example **KotlinMultiplatformSandbox**, open the`iosApp` folder and select the `.xcodeproj` file.
5. In the **Execution target** list, select a simulated device and click **OK**.

6. Click **Run** to run your application on the new simulated device.
#### Run on a real iOS device
1. Connect a real iPhone device to Xcode.
2. Make sure to code sign your app. For more information, see the [official Apple documentation](https://developer.apple.com/documentation/xcode/running-your-app-in-simulator-or-on-a-device/).
3. [Create a run configuration](#run-on-a-new-ios-simulated-device) by selecting iPhone in the **Execution target** list.
4. Click **Run** to run your application on the iPhone device.
Update your application
-----------------------
1. Open the `Greeting.kt` file in `shared/src/commonMain/kotlin`. This directory stores the shared code for both Android and iOS. If you make changes to the shared code, you will see them reflected in both applications.

2. Update the shared code by using `[reversed()](../api/latest/jvm/stdlib/kotlin.collections/reversed)`, the Kotlin standard library function for reversing text that works on all platforms:
```
class Greeting {
private val platform: Platform = getPlatform()
fun greeting(): String {
return "Guess what it is! > ${platform.name.reversed()}!"
}
}
```
3. Re-run the **androidApp** configuration to see the updated application in the Android simulated device.

4. In Android Studio, switch to **iosApp** and re-run it to see the updated application in the iOS simulated device.

Next step
---------
In the next part of the tutorial, you'll learn about dependencies and add a third-party library to expand the functionality of your project.
**[Proceed to the next part](multiplatform-mobile-dependencies)**
### See also
* See how to [create and run multiplatform tests](multiplatform-run-tests) to check that the code works correctly.
* Learn more about the [project structure](multiplatform-mobile-understand-project-structure), the shared module's artifacts, and how the Android and iOS apps are produced.
Get help
--------
* **Kotlin Slack**. Get an [invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) and join the [#multiplatform](https://kotlinlang.slack.com/archives/C3PQML5NU) channel.
* **Kotlin issue tracker**. [Report a new issue](https://youtrack.jetbrains.com/newIssue?project=KT).
Last modified: 10 January 2023
[Set up an environment](multiplatform-mobile-setup) [Add dependencies to your project](multiplatform-mobile-dependencies)
kotlin Constructing collections Constructing collections
========================
Construct from elements
-----------------------
The most common way to create a collection is with the standard library functions [`listOf<T>()`](../api/latest/jvm/stdlib/kotlin.collections/list-of), [`setOf<T>()`](../api/latest/jvm/stdlib/kotlin.collections/set-of), [`mutableListOf<T>()`](../api/latest/jvm/stdlib/kotlin.collections/mutable-list-of), [`mutableSetOf<T>()`](../api/latest/jvm/stdlib/kotlin.collections/mutable-set-of). If you provide a comma-separated list of collection elements as arguments, the compiler detects the element type automatically. When creating empty collections, specify the type explicitly.
```
val numbersSet = setOf("one", "two", "three", "four")
val emptySet = mutableSetOf<String>()
```
The same is available for maps with the functions [`mapOf()`](../api/latest/jvm/stdlib/kotlin.collections/map-of) and [`mutableMapOf()`](../api/latest/jvm/stdlib/kotlin.collections/mutable-map-of). The map's keys and values are passed as `Pair` objects (usually created with `to` infix function).
```
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key4" to 1)
```
Note that the `to` notation creates a short-living `Pair` object, so it's recommended that you use it only if performance isn't critical. To avoid excessive memory usage, use alternative ways. For example, you can create a mutable map and populate it using the write operations. The [`apply()`](scope-functions#apply) function can help to keep the initialization fluent here.
```
val numbersMap = mutableMapOf<String, String>().apply { this["one"] = "1"; this["two"] = "2" }
```
Create with collection builder functions
----------------------------------------
Another way of creating a collection is to call a builder function – [`buildList()`](../api/latest/jvm/stdlib/kotlin.collections/build-list), [`buildSet()`](../api/latest/jvm/stdlib/kotlin.collections/build-set), or [`buildMap()`](../api/latest/jvm/stdlib/kotlin.collections/build-map). They create a new, mutable collection of the corresponding type, populate it using [write operations](collection-write), and return a read-only collection with the same elements:
```
val map = buildMap { // this is MutableMap<String, Int>, types of key and value are inferred from the `put()` calls below
put("a", 1)
put("b", 0)
put("c", 4)
}
println(map) // {a=1, b=0, c=4}
```
Empty collections
-----------------
There are also functions for creating collections without any elements: [`emptyList()`](../api/latest/jvm/stdlib/kotlin.collections/empty-list), [`emptySet()`](../api/latest/jvm/stdlib/kotlin.collections/empty-set), and [`emptyMap()`](../api/latest/jvm/stdlib/kotlin.collections/empty-map). When creating empty collections, you should specify the type of elements that the collection will hold.
```
val empty = emptyList<String>()
```
Initializer functions for lists
-------------------------------
For lists, there is a constructor-like function that takes the list size and the initializer function that defines the element value based on its index.
```
fun main() {
//sampleStart
val doubled = List(3, { it * 2 }) // or MutableList if you want to change its content later
println(doubled)
//sampleEnd
}
```
Concrete type constructors
--------------------------
To create a concrete type collection, such as an `ArrayList` or `LinkedList`, you can use the available constructors for these types. Similar constructors are available for implementations of `Set` and `Map`.
```
val linkedList = LinkedList<String>(listOf("one", "two", "three"))
val presizedSet = HashSet<Int>(32)
```
Copy
----
To create a collection with the same elements as an existing collection, you can use copying functions. Collection copying functions from the standard library create *shallow* copy collections with references to the same elements. Thus, a change made to a collection element reflects in all its copies.
Collection copying functions, such as [`toList()`](../api/latest/jvm/stdlib/kotlin.collections/to-list), [`toMutableList()`](../api/latest/jvm/stdlib/kotlin.collections/to-mutable-list), [`toSet()`](../api/latest/jvm/stdlib/kotlin.collections/to-set) and others, create a snapshot of a collection at a specific moment. Their result is a new collection of the same elements. If you add or remove elements from the original collection, this won't affect the copies. Copies may be changed independently of the source as well.
```
class Person(var name: String)
fun main() {
//sampleStart
val alice = Person("Alice")
val sourceList = mutableListOf(alice, Person("Bob"))
val copyList = sourceList.toList()
sourceList.add(Person("Charles"))
alice.name = "Alicia"
println("First item's name is: ${sourceList[0].name} in source and ${copyList[0].name} in copy")
println("List size is: ${sourceList.size} in source and ${copyList.size} in copy")
//sampleEnd
}
```
These functions can also be used for converting collections to other types, for example, build a set from a list or vice versa.
```
fun main() {
//sampleStart
val sourceList = mutableListOf(1, 2, 3)
val copySet = sourceList.toMutableSet()
copySet.add(3)
copySet.add(4)
println(copySet)
//sampleEnd
}
```
Alternatively, you can create new references to the same collection instance. New references are created when you initialize a collection variable with an existing collection. So, when the collection instance is altered through a reference, the changes are reflected in all its references.
```
fun main() {
//sampleStart
val sourceList = mutableListOf(1, 2, 3)
val referenceList = sourceList
referenceList.add(4)
println("Source size: ${sourceList.size}")
//sampleEnd
}
```
Collection initialization can be used for restricting mutability. For example, if you create a `List` reference to a `MutableList`, the compiler will produce errors if you try to modify the collection through this reference.
```
fun main() {
//sampleStart
val sourceList = mutableListOf(1, 2, 3)
val referenceList: List<Int> = sourceList
//referenceList.add(4) //compilation error
sourceList.add(4)
println(referenceList) // shows the current state of sourceList
//sampleEnd
}
```
Invoke functions on other collections
-------------------------------------
Collections can be created in result of various operations on other collections. For example, [filtering](collection-filtering) a list creates a new list of elements that match the filter:
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3)
//sampleEnd
}
```
[Mapping](collection-transformations#map) produces a list of a transformation results:
```
fun main() {
//sampleStart
val numbers = setOf(1, 2, 3)
println(numbers.map { it * 3 })
println(numbers.mapIndexed { idx, value -> value * idx })
//sampleEnd
}
```
[Association](collection-transformations#associate) produces maps:
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
//sampleEnd
}
```
For more information about operations on collections in Kotlin, see [Collection operations overview](collection-operations).
Last modified: 10 January 2023
[Collections overview](collections-overview) [Iterators](iterators)
| programming_docs |
kotlin Data structure constraints Data structure constraints
==========================
Some data structures may require a part of operations not to be executed concurrently, such as single-producer single-consumer queues. Lincheck provides out-of-the-box support for such contracts, generating concurrent scenarios according to the restrictions.
Consider the [single-consumer queue](https://github.com/JCTools/JCTools/blob/66e6cbc9b88e1440a597c803b7df9bd1d60219f6/jctools-core/src/main/java/org/jctools/queues/atomic/MpscLinkedAtomicQueue.java) from the [JCTools library](https://github.com/JCTools/JCTools). Let's write a test to check correctness of its `poll()`, `peek()`, and `offer(x)` operations.
To meet the single-consumer restriction, ensure that all `poll()` and `peek()` consuming operations are called from a single thread. For that, declare a group of operations for *non-parallel* execution:
1. Declare `@OpGroupConfig` annotation to create a group of operations for non-parallel execution, name the group, and set `nonParallel` parameter to `true`.
2. Specify the group name in the `@Operation` annotation to add all non-parallel operations to this group.
Here is the resulting test:
```
import org.jctools.queues.atomic.*
import org.jetbrains.kotlinx.lincheck.annotations.*
import org.jetbrains.kotlinx.lincheck.check
import org.jetbrains.kotlinx.lincheck.strategy.stress.*
import org.junit.*
// Declare a group of operations that should not be executed in parallel:
@OpGroupConfig(name = "consumer", nonParallel = true)
class MPSCQueueTest {
private val queue = MpscLinkedAtomicQueue<Int>()
@Operation
fun offer(x: Int) = queue.offer(x)
@Operation(group = "consumer")
fun poll(): Int? = queue.poll()
@Operation(group = "consumer")
fun peek(): Int? = queue.peek()
@Test
fun stressTest() = StressOptions().check(this::class)
@Test
fun modelCheckingTest() = ModelCheckingOptions().check(this::class)
}
```
Here is an example of the scenario generated for this test:
```
= Iteration 15 / 100 =
Execution scenario (init part):
[offer(1), offer(4), peek(), peek(), offer(-6)]
Execution scenario (parallel part):
| poll() | offer(6) |
| poll() | offer(-1) |
| peek() | offer(-8) |
| offer(7) | offer(-5) |
| peek() | offer(3) |
Execution scenario (post part):
[poll(), offer(-6), peek(), peek(), peek()]
```
Note that all consuming `poll()` and `peek()` invocations are performed from a single thread, thus satisfying the "single-consumer" restriction.
Next step
---------
Learn how to [check your algorithm for progress guarantees](progress-guarantees) with the model checking strategy.
Last modified: 10 January 2023
[Modular testing](modular-testing) [Progress guarantees](progress-guarantees)
kotlin Build final native binaries Build final native binaries
===========================
By default, a Kotlin/Native target is compiled down to a `*.klib` library artifact, which can be consumed by Kotlin/Native itself as a dependency but cannot be executed or used as a native library.
To declare final native binaries such as executables or shared libraries, use the `binaries` property of a native target. This property represents a collection of native binaries built for this target in addition to the default `*.klib` artifact and provides a set of methods for declaring and configuring them.
Declare binaries
----------------
Use the following factory methods to declare elements of the `binaries` collection.
| Factory method | Binary kind | Available for |
| --- | --- | --- |
| `executable` | Product executable | All native targets |
| `test` | Test executable | All native targets |
| `sharedLib` | Shared native library | All native targets, except for `WebAssembly` |
| `staticLib` | Static native library | All native targets, except for `WebAssembly` |
| `framework` | Objective-C framework | macOS, iOS, watchOS, and tvOS targets only |
The simplest version doesn't require any additional parameters and creates one binary for each build type. Currently, two build types are available:
* `DEBUG` – produces a non-optimized binary with debug information
* `RELEASE` – produces an optimized binary without debug information
The following snippet creates two executable binaries, debug and release:
```
kotlin {
linuxX64 { // Define your target instead.
binaries {
executable {
// Binary configuration.
}
}
}
}
```
You can drop the lambda if there is no need for [additional configuration](multiplatform-dsl-reference#native-targets):
```
binaries {
executable()
}
```
You can specify for which build types to create binaries. In the following example, only the `debug` executable is created:
```
binaries {
executable(listOf(DEBUG)) {
// Binary configuration.
}
}
```
```
binaries {
executable([DEBUG]) {
// Binary configuration.
}
}
```
You can also declare binaries with custom names:
```
binaries {
executable("foo", listOf(DEBUG)) {
// Binary configuration.
}
// It's possible to drop the list of build types
// (in this case, all the available build types will be used).
executable("bar") {
// Binary configuration.
}
}
```
```
binaries {
executable('foo', [DEBUG]) {
// Binary configuration.
}
// It's possible to drop the list of build types
// (in this case, all the available build types will be used).
executable('bar') {
// Binary configuration.
}
}
```
The first argument sets a name prefix, which is the default name for the binary file. For example, for Windows the code produces the files `foo.exe` and `bar.exe`. You can also use the name prefix to [access the binary in the build script](#access-binaries).
Access binaries
---------------
You can access binaries to [configure them](multiplatform-dsl-reference#native-targets) or get their properties (for example, the path to an output file).
You can get a binary by its unique name. This name is based on the name prefix (if it is specified), build type, and binary kind following the pattern: `<optional-name-prefix><build-type><binary-kind>`, for example, `releaseFramework` or `testDebugExecutable`.
```
// Fails if there is no such binary.
binaries["fooDebugExecutable"]
binaries.getByName("fooDebugExecutable")
// Returns null if there is no such binary.
binaries.findByName("fooDebugExecutable")
```
```
// Fails if there is no such binary.
binaries['fooDebugExecutable']
binaries.fooDebugExecutable
binaries.getByName('fooDebugExecutable')
// Returns null if there is no such binary.
binaries.findByName('fooDebugExecutable')
```
Alternatively, you can access a binary by its name prefix and build type using typed getters.
```
// Fails if there is no such binary.
binaries.getExecutable("foo", DEBUG)
binaries.getExecutable(DEBUG) // Skip the first argument if the name prefix isn't set.
binaries.getExecutable("bar", "DEBUG") // You also can use a string for build type.
// Similar getters are available for other binary kinds:
// getFramework, getStaticLib and getSharedLib.
// Returns null if there is no such binary.
binaries.findExecutable("foo", DEBUG)
// Similar getters are available for other binary kinds:
// findFramework, findStaticLib and findSharedLib.
```
```
// Fails if there is no such binary.
binaries.getExecutable('foo', DEBUG)
binaries.getExecutable(DEBUG) // Skip the first argument if the name prefix isn't set.
binaries.getExecutable('bar', 'DEBUG') // You also can use a string for build type.
// Similar getters are available for other binary kinds:
// getFramework, getStaticLib and getSharedLib.
// Returns null if there is no such binary.
binaries.findExecutable('foo', DEBUG)
// Similar getters are available for other binary kinds:
// findFramework, findStaticLib and findSharedLib.
```
Export dependencies to binaries
-------------------------------
When building an Objective-C framework or a native library (shared or static), you may need to pack not just the classes of the current project, but also the classes of its dependencies. Specify which dependencies to export to a binary using the `export` method.
```
kotlin {
sourceSets {
macosMain.dependencies {
// Will be exported.
api(project(":dependency"))
api("org.example:exported-library:1.0")
// Will not be exported.
api("org.example:not-exported-library:1.0")
}
}
macosX64("macos").binaries {
framework {
export(project(":dependency"))
export("org.example:exported-library:1.0")
}
sharedLib {
// It's possible to export different sets of dependencies to different binaries.
export(project(':dependency'))
}
}
}
```
```
kotlin {
sourceSets {
macosMain.dependencies {
// Will be exported.
api project(':dependency')
api 'org.example:exported-library:1.0'
// Will not be exported.
api 'org.example:not-exported-library:1.0'
}
}
macosX64("macos").binaries {
framework {
export project(':dependency')
export 'org.example:exported-library:1.0'
}
sharedLib {
// It's possible to export different sets of dependencies to different binaries.
export project(':dependency')
}
}
}
```
For example, you implement several modules in Kotlin and want to access them from Swift. Usage of several Kotlin/Native frameworks in a Swift application is limited, but you can create an umbrella framework and export all these modules to it.
When you export a dependency, it includes all of its API to the framework API. The compiler adds the code from this dependency to the framework, even if you use a small fraction of it. This disables dead code elimination for the exported dependency (and for its dependencies, to some extent).
By default, export works non-transitively. This means that if you export the library `foo` depending on the library `bar`, only methods of `foo` are added to the output framework.
You can change this behavior using the `transitiveExport` option. If set to `true`, the declarations of the library `bar` are exported as well.
```
binaries {
framework {
export(project(":dependency"))
// Export transitively.
transitiveExport = true
}
}
```
```
binaries {
framework {
export project(':dependency')
// Export transitively.
transitiveExport = true
}
}
```
Build universal frameworks
--------------------------
By default, an Objective-C framework produced by Kotlin/Native supports only one platform. However, you can merge such frameworks into a single universal (fat) binary using the [`lipo` tool](https://llvm.org/docs/CommandGuide/llvm-lipo.html). This operation especially makes sense for 32-bit and 64-bit iOS frameworks. In this case, you can use the resulting universal framework on both 32-bit and 64-bit devices.
```
import org.jetbrains.kotlin.gradle.tasks.FatFrameworkTask
kotlin {
// Create and configure the targets.
val ios32 = iosArm32("ios32")
val ios64 = iosArm64("ios64")
configure(listOf(ios32, ios64)) {
binaries.framework {
baseName = "my_framework"
}
}
// Create a task to build a fat framework.
tasks.register<FatFrameworkTask>("debugFatFramework") {
// The fat framework must have the same base name as the initial frameworks.
baseName = "my_framework"
// The default destination directory is "<build directory>/fat-framework".
destinationDir = buildDir.resolve("fat-framework/debug")
// Specify the frameworks to be merged.
from(
ios32.binaries.getFramework("DEBUG"),
ios64.binaries.getFramework("DEBUG")
)
}
}
```
```
import org.jetbrains.kotlin.gradle.tasks.FatFrameworkTask
kotlin {
// Create and configure the targets.
targets {
iosArm32("ios32")
iosArm64("ios64")
configure([ios32, ios64]) {
binaries.framework {
baseName = "my_framework"
}
}
}
// Create a task building a fat framework.
tasks.register("debugFatFramework", FatFrameworkTask) {
// The fat framework must have the same base name as the initial frameworks.
baseName = "my_framework"
// The default destination directory is "<build directory>/fat-framework".
destinationDir = file("$buildDir/fat-framework/debug")
// Specify the frameworks to be merged.
from(
targets.ios32.binaries.getFramework("DEBUG"),
targets.ios64.binaries.getFramework("DEBUG")
)
}
}
```
Build XCFrameworks
------------------
All Kotlin Multiplatform projects can use XCFrameworks as an output to gather logic for all the target platforms and architectures in a single bundle. Unlike [universal (fat) frameworks](#build-universal-frameworks), you don't need to remove all unnecessary architectures before publishing the application to the App Store.
```
import org.jetbrains.kotlin.gradle.plugin.mpp.apple.XCFramework
plugins {
kotlin("multiplatform")
}
kotlin {
val xcf = XCFramework()
val iosTargets = listOf(iosX64(), iosArm64(), iosSimulatorArm64())
iosTargets.forEach {
it.binaries.framework {
baseName = "shared"
xcf.add(this)
}
}
}
```
```
import org.jetbrains.kotlin.gradle.plugin.mpp.apple.XCFrameworkConfig
plugins {
id 'org.jetbrains.kotlin.multiplatform'
}
kotlin {
def xcf = new XCFrameworkConfig(project)
def iosTargets = [iosX64(), iosArm64(), iosSimulatorArm64()]
iosTargets.forEach {
it.binaries.framework {
baseName = 'shared'
xcf.add(it)
}
}
}
```
When you declare XCFrameworks, Kotlin Gradle plugin will register three Gradle tasks:
* `assembleXCFramework`
* `assembleDebugXCFramework` (additionally debug artifact that contains [dSYMs](native-ios-symbolication))
* `assembleReleaseXCFramework`
If you're using [CocoaPods integration](native-cocoapods) in your projects, you can build XCFrameworks with the Kotlin CocoaPods Gradle plugin. It includes the following tasks that build XCFrameworks with all the registered targets and generate podspec files:
* `podPublishReleaseXCFramework`, which generates a release XCFramework along with a podspec file.
* `podPublishDebugXCFramework`, which generates a debug XCFramework along with a podspec file.
* `podPublishXCFramework`, which generates both debug and release XCFrameworks along with a podspec file.
This can help you distribute shared parts of your project separately from mobile apps through CocoaPods. You can also use XCFrameworks for publishing to private or public podspec repositories.
Customize the Info.plist file
-----------------------------
When producing a framework, the Kotlin/Native compiler generates the information property list file, `Info.plist`. You can customize its properties with the corresponding binary option:
| Property | Binary option |
| --- | --- |
| `CFBundleIdentifier` | `bundleId` |
| `CFBundleShortVersionString` | `bundleShortVersionString` |
| `CFBundleVersion` | `bundleVersion` |
To enable the feature, pass the `-Xbinary=$option=$value` compiler flag or set the `binaryOption("option", "value")` Gradle DSL for the specific framework:
```
binaries {
framework {
binaryOption("bundleId", "com.example.app")
binaryOption("bundleVersion", "2")
}
}
```
Last modified: 10 January 2023
[Build final native binaries (Experimental DSL)](multiplatform-native-artifacts) [Multiplatform Gradle DSL reference](multiplatform-dsl-reference)
kotlin Lombok compiler plugin Lombok compiler plugin
======================
The Kotlin Lombok compiler plugin allows the generation and use of Java's Lombok declarations by Kotlin code in the same mixed Java/Kotlin module. If you call such declarations from another module, then you don't need to use this plugin for the compilation of that module.
The Lombok compiler plugin cannot replace [Lombok](https://projectlombok.org/), but it helps Lombok work in mixed Java/Kotlin modules. Thus, you still need to configure Lombok as usual when using this plugin. Learn more about [how to configure the Lombok compiler plugin](#using-the-lombok-configuration-file).
Supported annotations
---------------------
The plugin supports the following annotations:
* `@Getter`, `@Setter`
* `@Builder`
* `@NoArgsConstructor`, `@RequiredArgsConstructor`, and `@AllArgsConstructor`
* `@Data`
* `@With`
* `@Value`
We're continuing to work on this plugin. To find out the detailed current state, visit the [Lombok compiler plugin's README](https://github.com/JetBrains/kotlin/tree/master/plugins/lombok).
Currently, we don't have plans to support the `@SuperBuilder` and `@Tolerate` annotations. However, we can consider this if you vote for [@SuperBuilder](https://youtrack.jetbrains.com/issue/KT-53563/Kotlin-Lombok-Support-SuperBuilder) and [@Tolerate](https://youtrack.jetbrains.com/issue/KT-53564/Kotlin-Lombok-Support-Tolerate) in YouTrack.
Gradle
------
Apply the `kotlin-plugin-lombok` Gradle plugin in the `build.gradle(.kts)` file:
```
plugins {
kotlin("plugin.lombok") version "1.8.0"
id("io.freefair.lombok") version "5.3.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.plugin.lombok' version '1.8.0'
id 'io.freefair.lombok' version '5.3.0'
}
```
See this [test project with examples of the Lombok compiler plugin in use](https://github.com/kotlin-hands-on/kotlin-lombok-examples/tree/master/kotlin_lombok_gradle/nokapt).
### Using the Lombok configuration file
If you use a [Lombok configuration file](https://projectlombok.org/features/configuration) `lombok.config`, you need to set the file's path so that the plugin can find it. The path must be relative to the module's directory. For example, add the following code to your `build.gradle(.kts)` file:
```
kotlinLombok {
lombokConfigurationFile(file("lombok.config"))
}
```
```
kotlinLombok {
lombokConfigurationFile file("lombok.config")
}
```
See this [test project with examples of the Lombok compiler plugin and `lombok.config` in use](https://github.com/kotlin-hands-on/kotlin-lombok-examples/tree/master/kotlin_lombok_gradle/withconfig).
Maven
-----
To use the Lombok compiler plugin, add the plugin `lombok` to the `compilerPlugins` section and the dependency `kotlin-maven-lombok` to the `dependencies` section. If you use a [Lombok configuration file](https://projectlombok.org/features/configuration) `lombok.config`, provide a path to it to the plugin in the `pluginOptions`. Add the following lines to the `pom.xml` file:
```
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<plugin>lombok</plugin>
</compilerPlugins>
<pluginOptions>
<option>lombok:config=${project.basedir}/lombok.config</option>
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-lombok</artifactId>
<version>${kotlin.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
<scope>provided</scope>
</dependency>
</dependencies>
</plugin>
```
See this [test project example of the Lombok compiler plugin and `lombok.config` in use](https://github.com/kotlin-hands-on/kotlin-lombok-examples/tree/master/kotlin_lombok_maven/nokapt).
Using with kapt
---------------
By default, the <kapt> compiler plugin runs all annotation processors and disables annotation processing by javac. To run [Lombok](https://projectlombok.org/) along with kapt, set up kapt to keep javac's annotation processors working.
If you use Gradle, add the option to the `build.gradle(.kts)` file:
```
kapt {
keepJavacAnnotationProcessors = true
}
```
In Maven, use the following settings to launch Lombok with Java's compiler:
```
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<annotationProcessorPaths>
<annotationProcessorPath>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</annotationProcessorPath>
</annotationProcessorPaths>
</configuration>
</plugin>
```
The Lombok compiler plugin works correctly with <kapt> if annotation processors don't depend on the code generated by Lombok.
Look through the test project examples of kapt and the Lombok compiler plugin in use:
* Using [Gradle](https://github.com/JetBrains/kotlin/tree/master/libraries/tools/kotlin-gradle-plugin-integration-tests/src/test/resources/testProject/lombokProject/yeskapt).
* Using [Maven](https://github.com/kotlin-hands-on/kotlin-lombok-examples/tree/master/kotlin_lombok_maven/yeskapt)
Command-line compiler
---------------------
Lombok compiler plugin JAR is available in the binary distribution of the Kotlin compiler. You can attach the plugin by providing the path to its JAR file using the `Xplugin` kotlinc option:
```
-Xplugin=$KOTLIN_HOME/lib/lombok-compiler-plugin.jar
```
If you want to use the `lombok.config` file, replace `<PATH_TO_CONFIG_FILE>` with a path to your `lombok.config`:
```
# The plugin option format is: "-P plugin:<plugin id>:<key>=<value>".
# Options can be repeated.
-P plugin:org.jetbrains.kotlin.lombok:config=<PATH_TO_CONFIG_FILE>
```
Last modified: 10 January 2023
[Using kapt](kapt) [Kotlin Symbol Processing API](ksp-overview)
| programming_docs |
kotlin Null safety Null safety
===========
Nullable types and non-null types
---------------------------------
Kotlin's type system is aimed at eliminating the danger of null references, also known as [The Billion Dollar Mistake](https://en.wikipedia.org/wiki/Null_pointer#History).
One of the most common pitfalls in many programming languages, including Java, is that accessing a member of a null reference will result in a null reference exception. In Java this would be the equivalent of a `NullPointerException`, or an *NPE* for short.
The only possible causes of an NPE in Kotlin are:
* An explicit call to `throw NullPointerException()`.
* Usage of the `!!` operator that is described below.
* Data inconsistency with regard to initialization, such as when:
+ An uninitialized `this` available in a constructor is passed and used somewhere (a "leaking `this`").
+ A [superclass constructor calls an open member](inheritance#derived-class-initialization-order) whose implementation in the derived class uses an uninitialized state.
* Java interoperation:
+ Attempts to access a member of a `null` reference of a [platform type](java-interop#null-safety-and-platform-types);
+ Nullability issues with generic types being used for Java interoperation. For example, a piece of Java code might add `null` into a Kotlin `MutableList<String>`, therefore requiring a `MutableList<String?>` for working with it.
+ Other issues caused by external Java code.
In Kotlin, the type system distinguishes between references that can hold `null` (nullable references) and those that cannot (non-null references). For example, a regular variable of type `String` cannot hold `null`:
```
fun main() {
//sampleStart
var a: String = "abc" // Regular initialization means non-null by default
a = null // compilation error
//sampleEnd
}
```
To allow nulls, you can declare a variable as a nullable string by writing `String?`:
```
fun main() {
//sampleStart
var b: String? = "abc" // can be set to null
b = null // ok
print(b)
//sampleEnd
}
```
Now, if you call a method or access a property on `a`, it's guaranteed not to cause an NPE, so you can safely say:
```
val l = a.length
```
But if you want to access the same property on `b`, that would not be safe, and the compiler reports an error:
```
val l = b.length // error: variable 'b' can be null
```
But you still need to access that property, right? There are a few ways to do so.
Checking for null in conditions
-------------------------------
First, you can explicitly check whether `b` is `null`, and handle the two options separately:
```
val l = if (b != null) b.length else -1
```
The compiler tracks the information about the check you performed, and allows the call to `length` inside the `if`. More complex conditions are supported as well:
```
fun main() {
//sampleStart
val b: String? = "Kotlin"
if (b != null && b.length > 0) {
print("String of length ${b.length}")
} else {
print("Empty string")
}
//sampleEnd
}
```
Note that this only works where `b` is immutable (meaning it is a local variable that is not modified between the check and its usage or it is a member `val` that has a backing field and is not overridable), because otherwise it could be the case that `b` changes to `null` after the check.
Safe calls
----------
Your second option for accessing a property on a nullable variable is using the safe call operator `?.`:
```
fun main() {
//sampleStart
val a = "Kotlin"
val b: String? = null
println(b?.length)
println(a?.length) // Unnecessary safe call
//sampleEnd
}
```
This returns `b.length` if `b` is not null, and `null` otherwise. The type of this expression is `Int?`.
Safe calls are useful in chains. For example, Bob is an employee who may be assigned to a department (or not). That department may in turn have another employee as a department head. To obtain the name of Bob's department head (if there is one), you write the following:
```
bob?.department?.head?.name
```
Such a chain returns `null` if any of the properties in it is `null`.
To perform a certain operation only for non-null values, you can use the safe call operator together with [`let`](../api/latest/jvm/stdlib/kotlin/let):
```
fun main() {
//sampleStart
val listWithNulls: List<String?> = listOf("Kotlin", null)
for (item in listWithNulls) {
item?.let { println(it) } // prints Kotlin and ignores null
}
//sampleEnd
}
```
A safe call can also be placed on the left side of an assignment. Then, if one of the receivers in the safe calls chain is `null`, the assignment is skipped and the expression on the right is not evaluated at all:
```
// If either `person` or `person.department` is null, the function is not called:
person?.department?.head = managersPool.getManager()
```
Nullable receiver
-----------------
Extension functions can be defined on a [nullable receiver](extensions#nullable-receiver). This way you can specify behaviour for null values without the need to use null-checking logic at each call-site.
For example, the [`toString()`](../api/latest/jvm/stdlib/kotlin/to-string) function is defined on a nullable receiver. It returns the String "null" (as opposed to a `null` value). This can be helpful in certain situations, for example, logging:
```
val person: Person? = null
logger.debug(person.toString()) // Logs "null", does not throw an exception
```
If you want your `toString()` invocation to return a nullable string, use the [safe-call operator `?.`](#safe-calls):
```
var timestamp: Instant? = null
val isoTimestamp = timestamp?.toString() // Returns a String? object which is `null`
if (isoTimestamp == null) {
// Handle the case where timestamp was `null`
}
```
Elvis operator
--------------
When you have a nullable reference, `b`, you can say "if `b` is not `null`, use it, otherwise use some non-null value":
```
val l: Int = if (b != null) b.length else -1
```
Instead of writing the complete `if` expression, you can also express this with the Elvis operator `?:`:
```
val l = b?.length ?: -1
```
If the expression to the left of `?:` is not `null`, the Elvis operator returns it, otherwise it returns the expression to the right. Note that the expression on the right-hand side is evaluated only if the left-hand side is `null`.
Since `throw` and `return` are expressions in Kotlin, they can also be used on the right-hand side of the Elvis operator. This can be handy, for example, when checking function arguments:
```
fun foo(node: Node): String? {
val parent = node.getParent() ?: return null
val name = node.getName() ?: throw IllegalArgumentException("name expected")
// ...
}
```
The !! operator
---------------
The third option is for NPE-lovers: the not-null assertion operator (`!!`) converts any value to a non-null type and throws an exception if the value is `null`. You can write `b!!`, and this will return a non-null value of `b` (for example, a `String` in our example) or throw an NPE if `b` is `null`:
```
val l = b!!.length
```
Thus, if you want an NPE, you can have it, but you have to ask for it explicitly and it won't appear out of the blue.
Safe casts
----------
Regular casts may result in a `ClassCastException` if the object is not of the target type. Another option is to use safe casts that return `null` if the attempt was not successful:
```
val aInt: Int? = a as? Int
```
Collections of a nullable type
------------------------------
If you have a collection of elements of a nullable type and want to filter non-null elements, you can do so by using `filterNotNull`:
```
val nullableList: List<Int?> = listOf(1, 2, null, 4)
val intList: List<Int> = nullableList.filterNotNull()
```
What's next?
------------
Learn how to [handle nullability in Java and Kotlin](java-to-kotlin-nullability-guide).
Last modified: 10 January 2023
[Using builders with builder type inference](using-builders-with-builder-inference) [Equality](equality)
kotlin Functions Functions
=========
Kotlin functions are declared using the `fun` keyword:
```
fun double(x: Int): Int {
return 2 * x
}
```
Function usage
--------------
Functions are called using the standard approach:
```
val result = double(2)
```
Calling member functions uses dot notation:
```
Stream().read() // create instance of class Stream and call read()
```
### Parameters
Function parameters are defined using Pascal notation - *name*: *type*. Parameters are separated using commas, and each parameter must be explicitly typed:
```
fun powerOf(number: Int, exponent: Int): Int { /*...*/ }
```
You can use a [trailing comma](coding-conventions#trailing-commas) when you declare function parameters:
```
fun powerOf(
number: Int,
exponent: Int, // trailing comma
) { /*...*/ }
```
### Default arguments
Function parameters can have default values, which are used when you skip the corresponding argument. This reduces the number of overloads:
```
fun read(
b: ByteArray,
off: Int = 0,
len: Int = b.size,
) { /*...*/ }
```
A default value is set by appending `=` to the type.
Overriding methods always use the base method's default parameter values. When overriding a method that has default parameter values, the default parameter values must be omitted from the signature:
```
open class A {
open fun foo(i: Int = 10) { /*...*/ }
}
class B : A() {
override fun foo(i: Int) { /*...*/ } // No default value is allowed.
}
```
If a default parameter precedes a parameter with no default value, the default value can only be used by calling the function with [named arguments](#named-arguments):
```
fun foo(
bar: Int = 0,
baz: Int,
) { /*...*/ }
foo(baz = 1) // The default value bar = 0 is used
```
If the last argument after default parameters is a [lambda](lambdas#lambda-expression-syntax), you can pass it either as a named argument or [outside the parentheses](lambdas#passing-trailing-lambdas):
```
fun foo(
bar: Int = 0,
baz: Int = 1,
qux: () -> Unit,
) { /*...*/ }
foo(1) { println("hello") } // Uses the default value baz = 1
foo(qux = { println("hello") }) // Uses both default values bar = 0 and baz = 1
foo { println("hello") } // Uses both default values bar = 0 and baz = 1
```
### Named arguments
You can name one or more of a function's arguments when calling it. This can be helpful when a function has many arguments and it's difficult to associate a value with an argument, especially if it's a boolean or `null` value.
When you use named arguments in a function call, you can freely change the order that they are listed in. If you want to use their default values, you can just leave these arguments out altogether.
Consider the `reformat()` function, which has 4 arguments with default values.
```
fun reformat(
str: String,
normalizeCase: Boolean = true,
upperCaseFirstLetter: Boolean = true,
divideByCamelHumps: Boolean = false,
wordSeparator: Char = ' ',
) { /*...*/ }
```
When calling this function, you don't have to name all its arguments:
```
reformat(
"String!",
false,
upperCaseFirstLetter = false,
divideByCamelHumps = true,
'_'
)
```
You can skip all the ones with default values:
```
reformat("This is a long String!")
```
You are also able to skip specific arguments with default values, rather than omitting them all. However, after the first skipped argument, you must name all subsequent arguments:
```
reformat("This is a short String!", upperCaseFirstLetter = false, wordSeparator = '_')
```
You can pass a [variable number of arguments (`vararg`)](#variable-number-of-arguments-varargs) with names using the `spread` operator:
```
fun foo(vararg strings: String) { /*...*/ }
foo(strings = *arrayOf("a", "b", "c"))
```
### Unit-returning functions
If a function does not return a useful value, its return type is `Unit`. `Unit` is a type with only one value - `Unit`. This value does not have to be returned explicitly:
```
fun printHello(name: String?): Unit {
if (name != null)
println("Hello $name")
else
println("Hi there!")
// `return Unit` or `return` is optional
}
```
The `Unit` return type declaration is also optional. The above code is equivalent to:
```
fun printHello(name: String?) { ... }
```
### Single-expression functions
When a function returns a single expression, the curly braces can be omitted and the body is specified after a `=` symbol:
```
fun double(x: Int): Int = x * 2
```
Explicitly declaring the return type is [optional](#explicit-return-types) when this can be inferred by the compiler:
```
fun double(x: Int) = x * 2
```
### Explicit return types
Functions with block body must always specify return types explicitly, unless it's intended for them to return `Unit`, [in which case specifying the return type is optional](#unit-returning-functions).
Kotlin does not infer return types for functions with block bodies because such functions may have complex control flow in the body, and the return type will be non-obvious to the reader (and sometimes even for the compiler).
### Variable number of arguments (varargs)
You can mark a parameter of a function (usually the last one) with the `vararg` modifier:
```
fun <T> asList(vararg ts: T): List<T> {
val result = ArrayList<T>()
for (t in ts) // ts is an Array
result.add(t)
return result
}
```
In this case, you can pass a variable number of arguments to the function:
```
val list = asList(1, 2, 3)
```
Inside a function, a `vararg`-parameter of type `T` is visible as an array of `T`, as in the example above, where the `ts` variable has type `Array<out T>`.
Only one parameter can be marked as `vararg`. If a `vararg` parameter is not the last one in the list, values for the subsequent parameters can be passed using named argument syntax, or, if the parameter has a function type, by passing a lambda outside the parentheses.
When you call a `vararg`-function, you can pass arguments individually, for example `asList(1, 2, 3)`. If you already have an array and want to pass its contents to the function, use the *spread* operator (prefix the array with `*`):
```
val a = arrayOf(1, 2, 3)
val list = asList(-1, 0, *a, 4)
```
If you want to pass a [primitive type array](arrays#primitive-type-arrays) into `vararg`, you need to convert it to a regular (typed) array using the `toTypedArray()` function:
```
val a = intArrayOf(1, 2, 3) // IntArray is a primitive type array
val list = asList(-1, 0, *a.toTypedArray(), 4)
```
### Infix notation
Functions marked with the `infix` keyword can also be called using the infix notation (omitting the dot and the parentheses for the call). Infix functions must meet the following requirements:
* They must be member functions or [extension functions](extensions).
* They must have a single parameter.
* The parameter must not [accept variable number of arguments](#variable-number-of-arguments-varargs) and must have no [default value](#default-arguments).
```
infix fun Int.shl(x: Int): Int { ... }
// calling the function using the infix notation
1 shl 2
// is the same as
1.shl(2)
```
Note that infix functions always require both the receiver and the parameter to be specified. When you're calling a method on the current receiver using the infix notation, use `this` explicitly. This is required to ensure unambiguous parsing.
```
class MyStringCollection {
infix fun add(s: String) { /*...*/ }
fun build() {
this add "abc" // Correct
add("abc") // Correct
//add "abc" // Incorrect: the receiver must be specified
}
}
```
Function scope
--------------
Kotlin functions can be declared at the top level in a file, meaning you do not need to create a class to hold a function, which you are required to do in languages such as Java, C#, and Scala ([top level definition is available since Scala 3](https://docs.scala-lang.org/scala3/book/taste-toplevel-definitions.html#inner-main)). In addition to top level functions, Kotlin functions can also be declared locally as member functions and extension functions.
### Local functions
Kotlin supports local functions, which are functions inside other functions:
```
fun dfs(graph: Graph) {
fun dfs(current: Vertex, visited: MutableSet<Vertex>) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v, visited)
}
dfs(graph.vertices[0], HashSet())
}
```
A local function can access local variables of outer functions (the closure). In the case above, `visited` can be a local variable:
```
fun dfs(graph: Graph) {
val visited = HashSet<Vertex>()
fun dfs(current: Vertex) {
if (!visited.add(current)) return
for (v in current.neighbors)
dfs(v)
}
dfs(graph.vertices[0])
}
```
### Member functions
A member function is a function that is defined inside a class or object:
```
class Sample {
fun foo() { print("Foo") }
}
```
Member functions are called with dot notation:
```
Sample().foo() // creates instance of class Sample and calls foo
```
For more information on classes and overriding members see [Classes](classes) and [Inheritance](classes#inheritance).
Generic functions
-----------------
Functions can have generic parameters, which are specified using angle brackets before the function name:
```
fun <T> singletonList(item: T): List<T> { /*...*/ }
```
For more information on generic functions, see [Generics](generics).
Tail recursive functions
------------------------
Kotlin supports a style of functional programming known as [tail recursion](https://en.wikipedia.org/wiki/Tail_call). For some algorithms that would normally use loops, you can use a recursive function instead without the risk of stack overflow. When a function is marked with the `tailrec` modifier and meets the required formal conditions, the compiler optimizes out the recursion, leaving behind a fast and efficient loop based version instead:
```
val eps = 1E-10 // "good enough", could be 10^-15
tailrec fun findFixPoint(x: Double = 1.0): Double =
if (Math.abs(x - Math.cos(x)) < eps) x else findFixPoint(Math.cos(x))
```
This code calculates the `fixpoint` of cosine, which is a mathematical constant. It simply calls `Math.cos` repeatedly starting at `1.0` until the result no longer changes, yielding a result of `0.7390851332151611` for the specified `eps` precision. The resulting code is equivalent to this more traditional style:
```
val eps = 1E-10 // "good enough", could be 10^-15
private fun findFixPoint(): Double {
var x = 1.0
while (true) {
val y = Math.cos(x)
if (Math.abs(x - y) < eps) return x
x = Math.cos(x)
}
}
```
To be eligible for the `tailrec` modifier, a function must call itself as the last operation it performs. You cannot use tail recursion when there is more code after the recursive call, within `try`/`catch`/`finally` blocks, or on open functions. Currently, tail recursion is supported by Kotlin for the JVM and Kotlin/Native.
**See also**:
* [Inline functions](inline-functions)
* [Extension functions](extensions)
* [Higher-order functions and lambdas](lambdas)
Last modified: 10 January 2023
[Type aliases](type-aliases) [High-order functions and lambdas](lambdas)
kotlin Publish your application Publish your application
========================
Once your mobile apps are ready for release, it's time to deliver them to the users by publishing them in app stores. Multiple stores are available for each platform. However, in this article we'll focus on the official ones: [Google Play Store](https://play.google.com/store) and [Apple App Store](https://www.apple.com/ios/app-store/). You'll learn how to prepare Kotlin Multiplatform Mobile applications for publishing, and we'll highlight the parts of this process that deserve special attention.
Android app
-----------
Since [Kotlin is the main language for Android development](https://developer.android.com/kotlin), Kotlin Multiplatform Mobile has no obvious effect on compiling the project and building the Android app. Both the Android library produced from the shared module and the Android app itself are typical Android Gradle modules; they are no different from other Android libraries and apps. Thus, publishing the Android app from a Kotlin Multiplatform project is no different from the usual process described in the [Android developer documentation](https://developer.android.com/studio/publish).
iOS app
-------
The iOS app from a Kotlin Multiplatform project is built from a typical Xcode project, so the main stages involved in publishing it are the same as described in the [iOS developer documentation](https://developer.apple.com/ios/submit/).
What is specific to Kotlin Multiplatform projects is compiling the shared Kotlin module into a framework and linking it to the Xcode project. Generally, all integration between the shared module and the Xcode project is done automatically by the [Kotlin Multiplatform Mobile plugin for Android Studio](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile). However, if you don't use the plugin, bear in mind the following when building and bundling the iOS project in Xcode:
* The shared Kotlin library compiles down to the native framework.
* You need to connect the framework compiled for the specific platform to the iOS app project.
* In the Xcode project settings, specify the path to the framework to search for the build system.
* After building the project, you should launch and test the app to make sure that there are no issues when working with the framework in runtime.
There are two ways you can connect the shared Kotlin module to the iOS project:
* Use the [Kotlin/Native CocoaPods plugin](native-cocoapods), which allows you to use a multiplatform project with native targets as a CocoaPods dependency in your iOS project.
* Manually configure your Multiplatform project to create an iOS framework and the Xcode project to obtain its latest version. The Kotlin Multiplatform Mobile plugin for Android Studio usually does this configuration. [Understand the project structure](multiplatform-mobile-understand-project-structure#ios-application) to implement it yourself.
### Symbolicating crash reports
To help developers make their apps better, iOS provides a means for analyzing app crashes. For detailed crash analysis, it uses special debug symbol (`.dSYM`) files that match memory addresses in crash reports with locations in the source code, such as functions or line numbers.
By default, the release versions of iOS frameworks produced from the shared Kotlin module have an accompanying `.dSYM` file. This helps you analyze crashes that happen in the shared module's code.
When an iOS app is rebuilt from bitcode, its `dSYM` file becomes invalid. For such cases, you can compile the shared module to a static framework that stores the debug information inside itself. For instructions on setting up crash report symbolication in binaries produced from Kotlin modules, see the [Kotlin/Native documentation](native-ios-symbolication).
Last modified: 10 January 2023
[Make your Android application work on iOS – tutorial](multiplatform-mobile-integrate-in-existing-app) [Create a multiplatform app using Ktor and SQLDelight – tutorial](multiplatform-mobile-ktor-sqldelight)
| programming_docs |
kotlin What's new in Kotlin 1.8.0-RC2 What's new in Kotlin 1.8.0-RC2
==============================
*[Release date: December 20, 2022](eap#build-details)*
The Kotlin 1.8.0-RC2 release is out! Here are some highlights from this release:
* [We removed the old backend for Kotlin/JVM](#kotlin-jvm)
* [We now support Xcode 14.1](#kotlin-native)
* [We ensured compatibility with Gradle 7.3](#gradle)
* [We introduced new experimental functions for JVM: recursively copy or delete directory content](#standard-library)
IDE support
-----------
Kotlin plugins that support 1.8.0-RC2 are available for:
| IDE | Supported versions |
| --- | --- |
| IntelliJ IDEA | 2021.3.x, 2022.1.x, 2022.2.x |
| Android Studio | Dolphin (213), Electric Eel (221), Flamingo (222) |
Kotlin/JVM
----------
* Removed the old backend. (The `-Xuse-old-backend` compiler option is no longer supported).
* Added support for Java 19 bytecode.
Kotlin/Native
-------------
* Added support for Xcode 14.1 and `watchosDeviceArm64` target.
* Added support for new annotations to improve Objective-C and Swift interoperability:
+ `@ObjCName`
+ `@HiddenFromObjC`
+ `@ShouldRefineInSwift`
* Added improvements to the CocoaPods Gradle plugin so that registered Kotlin frameworks are now dynamically linked by default.
Kotlin/JS
---------
* Stabilized the IR compiler and set incremental compilation to be used by default.
* Deprecated the old backend.
* Added additional reporting options for when `yarn.lock` is updated during the CI process.
* Updated the Gradle plugin so that `kotlin.js.browser.karma.browsers` property can be used to set browser test targets.
Kotlin Multiplatform
--------------------
* Added new Android source set layout that can be enabled in Gradle plugin with `kotlin.mpp.androidSourceSetLayoutVersion=2`.
* Added new naming schema for `KotlinSourceSet` entities.
* Changed the naming scheme of compilation configurations created by the Kotlin Multiplatform Gradle plugin.
Gradle
------
* Ensured compatibility with Gradle 7.3.
* Added the option to disable daemon fallback by using `kotlin.daemon.useFallbackStrategy`.
* Exposed available Kotlin compiler options as Gradle lazy properties.
* Updated minimum supported Gradle version to 6.8.3.
* Updated minimum supported Android Gradle plugin version to 4.1.3.
Compiler
--------
Updated the Lombok compiler plugin so that it now supports the `@Builder` annotation.
Standard library
----------------
* Updated the JVM target of the libraries in Kotlin distribution to version 1.8:
+ The contents of the artifacts `kotlin-stdlib-jdk7` and `kotlin-stdlib-jdk8` have been moved into `kotlin-stdlib`.
* Stabilized extension functions for `java.util.Optional`.
* Stabilized functions:
+ `cbrt()`
+ `toTimeUnit()`
+ `toDurationUnit()`
* Added new [experimental](components-stability#stability-levels-explained) extension functions for `java.nio.file.path` that can recursively copy or delete directory content. Opt-in is required (see details below), and you should use them only for evaluation purposes.
* Added new [experimental](components-stability#stability-levels-explained) functionality to `TimeMarks`, allowing `elapsedNow` to be read from multiple `TimeMarks` simultaneously. Opt-in is required (see details below), and you should use them only for evaluation purposes.
How to update to Kotlin 1.8.0-RC2
---------------------------------
You can install Kotlin 1.8.0-RC2 in the following ways:
* If you use the *Early Access Preview* update channel, the IDE will suggest automatically updating to 1.8.0-RC2 as soon as it becomes available.
* If you use the *Stable* update channel, you can change the channel to *Early Access Preview* at any time by selecting **Tools** | **Kotlin** | **Configure Kotlin Plugin Updates** in your IDE. You'll then be able to install the latest preview release. Check out [these instructions](install-eap-plugin) for details.
Once you've installed 1.8.0-RC2, don't forget to [change the Kotlin version](configure-build-for-eap) to 1.8.0-RC2 in your build scripts.
Learn more
----------
For more detail about the contents of this release, see our [changelog](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0-RC2).
Last modified: 10 January 2023
kotlin Wrap up your project Wrap up your project
====================
You've created your first Multiplatform Mobile app that works both on iOS and Android! Now you know how to set up an environment for cross-platform mobile development, create a project in Android Studio, run your app on devices, and expand its functionality.
Now that you've gained some experience with Kotlin Multiplatform Mobile, you can take a look at some advanced topics and take on additional cross-platform mobile development tasks:
| Next steps | Deep dive |
| --- | --- |
| * [Add tests to your Kotlin Multiplatform project](multiplatform-run-tests)
* [Publish your mobile application to app stores](multiplatform-mobile-publish-apps)
* [Introduce cross-platform mobile development to your team](multiplatform-mobile-introduce-your-team)
* [Check out the list of useful tools and libraries](https://github.com/terrakok/kmm-awesome)
| * [Kotlin Multiplatform Mobile project structure](multiplatform-mobile-understand-project-structure)
* [Interoperability with Objective-C frameworks and libraries](native-objc-interop)
* [Adding dependencies on multiplatform libraries](multiplatform-add-dependencies)
* [Adding Android dependencies](multiplatform-mobile-android-dependencies)
* [Adding iOS dependencies](multiplatform-mobile-ios-dependencies)
|
| Tutorials and samples | Community and feedback |
| --- | --- |
| * [Make your Android app cross-platform](multiplatform-mobile-integrate-in-existing-app)
* [Create a multiplatform app using Ktor and SQLDelight](multiplatform-mobile-ktor-sqldelight)
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app)
* [See the curated list of sample projects](multiplatform-mobile-samples)
| * [Join the #multiplatform channel in Kotlin Slack](https://kotlinlang.slack.com/archives/C3PQML5NU)
* [Subscribe to the "kotlin-multiplatform" tag on Stack Overflow](https://stackoverflow.com/questions/tagged/kotlin-multiplatform)
* [Subscribe to the Kotlin YouTube channel](https://www.youtube.com/playlist?list=PLlFc5cFwUnmy_oVc9YQzjasSNoAk4hk_C)
* [Report a problem to our issue tracker](https://youtrack.jetbrains.com/newIssue?project=KT)
|
Last modified: 10 January 2023
[Upgrade your app](multiplatform-mobile-upgrade-app) [Understand mobile project structure](multiplatform-mobile-understand-project-structure)
kotlin Introduce cross-platform mobile development to your team Introduce cross-platform mobile development to your team
========================================================
These recommendations will help you introduce your team to Kotlin Multiplatform Mobile:
* [Start with empathy](#start-with-empathy)
* [Explain how Kotlin Multiplatform Mobile works](#explain-how-it-works)
* [Show the value using case studies](#show-the-value)
* [Offer a proof by creating a sample project yourself](#offer-proof)
* [Prepare for questions from your team](#prepare-for-questions)
* [Support your team during the adaptation](#be-supportive)
Start with empathy
------------------
Software development is a team game, with each critical decision needing the approval of all team members. Integrating any cross-platform technology will significantly affect the development process for your mobile application. So before you start integrating Kotlin Multiplatform Mobile in your project, you'll need to introduce your team to the technology and guide them gently to see it's worth adopting.
Understanding the people who work on your project is the first step to successful integration. Your boss is responsible for delivering features with the best quality in the shortest time possible. To them, any new technology is a risk. Your colleagues have a different perspective, as well. They have experience building apps with the "native" technology stack. They know how to write the UI and business logic, work with dependencies, test, and debug code in the IDE, and they are already familiar with the language. Switching to a different ecosystem is very uncomfortable, as it always means leaving your comfort zone.
Given all that, be ready to face lots of biases and answer a lot of questions when advocating for the move to Kotlin Multiplatform Mobile. As you do, never lose sight of what your team needs. Some of the advice below might be useful for preparing your pitch.
Explain how it works
--------------------
At this stage, you need to get rid of any preexisting bad feelings about cross-platform mobile applications and show that using Kotlin Multiplatform in your project is not only possible but also won't bring regular cross-platform problems. You should explain why there won't be any problems, such as:
* *Limitations of using all iOS and Android features* – Whenever a task cannot be solved in the shared code or whenever you want to use specific native features, you can use the expect/actual pattern to seamlessly write platform-specific code.
* *Performance issues* – Shared code written in Kotlin is compiled to different output formats for different targets: to Java bytecode for Android and to native binaries for iOS. Thus, there is no additional runtime overhead when it comes to executing this code on platforms, and the performance is comparable to native apps.
* *Legacy code problems* – No matter how large your project is, your existing code will not prevent you from integrating Kotlin Multiplatform. You can start writing cross-platform code at any moment and connect it to your iOS and Android Apps as a regular dependency, or you can use the code you've already written and simply modify it to be compatible with iOS.
Being able to explain *how* technology works is important, as nobody likes when a discussion seems to rely on magic. People might think the worst if anything is unclear to them, so be careful not to make the mistake of thinking something is too obvious to warrant explanation. Instead, try to explain all the basic concepts before moving on to the next stage. This document on [multiplatform programming](multiplatform) could help you systemize your knowledge to prepare for this experience.
Show the value
--------------
Understanding how the technology works is necessary, but not enough. Your team needs to see the gains of using it, and the way you present these gains should be related to your product. Kotlin Multiplatform Mobile allows you to use a single codebase for the business logic of iOS and Android apps. So if you develop a very thin client and the majority of the code is UI logic, then the main power of Kotlin Multiplatform Mobile will be unused in your project. However, if your application has complex business logic, for example if you have features like networking, data storage, payments, complex computations, or data synchronization, then this logic could easily be written and shared between iOS and Android so you can experience the real power of the technology.
At this stage, you need to explain the main gains of using Kotlin Multiplatform in your product. One of the ways is to share stories of other companies who already benefit from the technology. The successful experience of these teams, especially ones with similar product objectives, could become a key factor in the final decision.
Citing case studies of different companies who already use Kotlin Multiplatform in production could significantly help you make a compelling argument:
* **[Chalk.com](https://kotlinlang.org/lp/mobile/case-studies/chalk)** – The UI for each of the Chalk.com apps is native to the platform, but otherwise almost everything for their apps can be shared with Kotlin Multiplatform Mobile.
* **[Cash App](https://kotlinconf.com/2019/talks/video/2019/116027/)** – A lot of the app's business logic, including the ability to search through all transactions, is implemented with Kotlin Multiplatform Mobile.
* **[Yandex.Disk](https://kotlinlang.org/lp/mobile/case-studies/yandex)** – They started out by experimenting with the integration of a small feature, and as the experiment was considered successful, they implemented their whole data synchronization logic in Kotlin Multiplatform Mobile.
Explore [the case studies page](https://kotlinlang.org/lp/mobile/case-studies) for inspirational references.
Offer proof
-----------
The theory is good, but putting it into practice is ultimately most important. As one option to make your case more convincing, you can take the risky choice of devoting some of your personal free time to creating something with Kotlin Multiplatform and then bringing in the results for your team to discuss. Your prototype could be some sort of test project, which you would write from scratch and which would demonstrate features that are needed in your application. [Create a multiplatform app using Ktor and SQLDelight – tutorial](multiplatform-mobile-ktor-sqldelight) can guide you well on this process.
The more relevant examples could be produced by experimenting with your current project. You could take one existing feature implemented in Kotlin and make it cross-platform, or you could even create a new Multiplatform Module in your existing project, take one non-priority feature from the bottom of the backlog, and implement it in the shared module. [Make your Android application work on iOS – tutorial](multiplatform-mobile-integrate-in-existing-app) provides a step-by-step guide based on a sample project.
The new [Kotlin Multiplatform Mobile plugin for Android Studio](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile) will allow you to accomplish either of these tasks in the shortest amount of time by using the **Kotlin Multiplatform App** or **Kotlin Multiplatform Library** wizards.
Prepare for questions
---------------------
No matter how detailed your pitch is, your team will have a lot of questions. Listen carefully, and try to answer them all patiently. You might expect the majority of the questions to come from the iOS part of the team, as they are the developers who aren't used to seeing Kotlin in their everyday developer routine. This list of some of the most common questions could help you here:
**Q: I heard applications based on cross-platform technologies can be rejected from the AppStore. Is taking this risk worth it?**
A: The Apple Store has strict guidelines for application publishing. One of the limitations is that apps may not download, install, or execute code which introduces or changes features or functionality of the app ([App Store Review Guideline 2.5.2](https://developer.apple.com/app-store/review/guidelines/#software-requirements)). This is relevant for some cross-platform technologies, but not for Kotlin Multiplatform Mobile. Shared Kotlin code compiles to native binaries with Kotlin/Native, bundles a regular iOS framework into your app, and doesn't provide the ability for dynamic code execution.
**Q: Multiplatform projects are built with Gradle, and Gradle has an extremely steep learning curve. Do I need to spend a lot of time now trying to configure my project?**
A: There's actually no need. There are various ways to organize the work process around building Kotlin mobile applications. First, only Android developers could be responsible for the builds, in which case the iOS team would only write code or even only consume the resulting artifact. You also can organize some workshops or practice pair programming while facing tasks that require working with Gradle, and this would increase your team's Gradle skills. You can explore different ways of and choose the one that's most appropriate for your team.
Also, in basic scenarios, you simply need to configure your project at the start, and then you just add dependencies to it. The new AS plugin makes configuring your project much easier, so it can now be done in a few clicks.
When only the Android part of the team works with shared code, the iOS developers don't even need to learn Kotlin. But when you are ready for your team to move to the next stage, where everyone contributes to the shared code, making the transition won't take much time. The similarities between the syntax and functionality of Swift and Kotlin greatly reduce the work required to learn how to read and write shared Kotlin code. [Try it yourself!](https://play.kotlinlang.org/koans/overview)
**Q: I heard that Kotlin Multiplatform Mobile is experimental technology. Does that mean that we shouldn't use it for production?**
A: Experimental status means we and the whole Kotlin community are just trying out an idea, but if it doesn't work, it may be dropped anytime. However, after the release of Kotlin 1.4, **Kotlin Multiplatform Mobile is in Alpha** status. This means the Kotlin team is fully committed to working to improve and evolve this technology and will not suddenly drop it. However, before going Beta, there could be some migration issues yet. But even experimental status doesn't prevent a feature from being used successfully in production, as long as you understand all the risks. Check [the Kotlin evolution page](kotlin-evolution) for information about the stability statuses of Kotlin Multiplatform components.
**Q: There are not enough multiplatform libraries to implement the business logic, it's much easier to find native alternatives.**
A: Of course, we can't compare the number of multiplatform libraries with React Native, for example. But it took five years for React Native to expand their ecosystem to its current size. Kotlin Multiplatform Mobile is still young, but the ecosystem has tremendous potential as there are already a lot of modern libraries written in Kotlin that can be easily ported to multiplatform.
It's also a great time to be an iOS developer in the Kotlin Multiplatform open-source community because the iOS experience is in demand and there are plenty of opportunities to gain recognition from iOS-specific contributions.
And the more your team digs into the technology, the more interesting and complex their questions will be. Don't worry if you don't have the answers – Kotlin Multiplatform has a large and [supportive community in the Kotlin Slack](https://kotlinlang.slack.com/archives/C3PQML5NU), where a lot of developers who already use it can help you. We would be very thankful if you could [share with us](mailto:[email protected]) the most popular questions asked by your team. This information will help us understand what topics need to be covered in the documentation.
Be supportive
-------------
After you decide to use Kotlin Multiplatform, there will be an adaptation period as your team experiments with the technology. And your mission will not be over yet! By providing continuous support for your teammates, you will reduce the time it takes for your team to dive into the technology and achieve their first results.
Here are some tips on how you can support your team at this stage:
* Collect the questions you were asked during the previous stage on the "Kotlin Multiplatform: Frequently asked questions" wiki page and share it with your team.
* Create a *#kotlin-multiplatform-support* Slack channel and become the most active user there.
* Organize an informal team building event with popcorn and pizza where you watch educational or inspirational videos about Kotlin Multiplatform. ["Shipping a Mobile Multiplatform Project on iOS & Android" by Ben Asher & Alec Strong](https://www.youtube.com/watch?v=je8aqW48JiA) could be a good choice.
The reality is that you probably will not change people's hearts and minds in a day or even a week. But patience and attentiveness to the needs of your colleagues will undoubtedly bring results.
The Kotlin Multiplatform Mobile team looks forward to hearing [your story](mailto:[email protected]).
*We'd like to thank the [Touchlab team](https://touchlab.co) for helping us write this article.*
Last modified: 10 January 2023
[FAQ](multiplatform-mobile-faq) [Get started with Kotlin/JVM](jvm-get-started)
| programming_docs |
kotlin Build final native binaries (Experimental DSL) Build final native binaries (Experimental DSL)
==============================================
[//]: # (title: Build final native binaries (Experimental DSL))
[Kotlin/Native targets](multiplatform-dsl-reference#native-targets) are compiled to the `*.klib` library artifacts, which can be consumed by Kotlin/Native itself as a dependency but cannot be used as a native library.
To declare final native binaries, use the new binaries format with the `kotlinArtifacts` DSL. It represents a collection of native binaries built for this target in addition to the default `*.klib` artifact and provides a set of methods for declaring and configuring them.
Kotlin artifact DSL can help you to solve a common issue: when you need to access multiple Kotlin modules from your app. Since the usage of several Kotlin/Native artifacts is limited, you can export multiple Kotlin modules into a single artifact with new DSL.
Declare binaries
----------------
The `kotlinArtifacts` element is the top-level block for artifact configuration in the Gradle build script. Use the following kinds of binaries to declare elements of the `kotlinArtifacts` DSL:
| Factory method | Binary kind | Available for |
| --- | --- | --- |
| `sharedLib` | [Shared native library](native-faq#how-do-i-create-a-shared-library) | All native targets, except for `WebAssembly` |
| `staticLib` | [Static native library](native-faq#how-do-i-create-a-static-library-or-an-object-file) | All native targets, except for `WebAssembly` |
| `framework` | Objective-C framework | macOS, iOS, watchOS, and tvOS targets only |
| `fatFramework` | Universal fat framework | macOS, iOS, watchOS, and tvOS targets only |
| `XCFramework` | XCFramework framework | macOS, iOS, watchOS, and tvOS targets only |
Inside the `kotlinArtifacts` element, you can write the following blocks:
* [Native.Library](#library)
* [Native.Framework](#framework)
* [Native.FatFramework](#fat-frameworks)
* [Native.XCFramework](#xcframeworks)
The simplest version requires the `target` (or `targets`) parameter for the selected build type. Currently, two build types are available:
* `DEBUG` – produces a non-optimized binary with debug information
* `RELEASE` – produces an optimized binary without debug information
In the `modes` parameter, you can specify build types for which you want to create binaries. The default value includes both `DEBUG` and `RELEASE` executable binaries:
```
kotlinArtifacts {
Native.Library {
target = iosX64 // Define your target instead
modes(DEBUG, RELEASE)
// Binary configuration
}
}
```
```
kotlinArtifacts {
it.native.Library {
target = iosX64 // Define your target instead
modes(DEBUG, RELEASE)
// Binary configuration
}
}
```
You can also declare binaries with custom names:
```
kotlinArtifacts {
Native.Library("mylib") {
// Binary configuration
}
}
```
```
kotlinArtifacts {
it.native.Library("mylib") {
// Binary configuration
}
}
```
The argument sets a name prefix, which is the default name for the binary file. For example, for Windows the code produces the `mylib.dll` file.
Configure binaries
------------------
For the binary configuration, the following common parameters are available:
| **Name** | **Description** |
| --- | --- |
| `isStatic` | Optional linking type that defines the library type. By default, it's `false` and the library is dynamic. |
| `modes` | Optional build types, `DEBUG` and `RELEASE`. |
| `kotlinOptions` | Optional compiler options applied to the compilation. See the list of available [compiler options](gradle-compiler-options). |
| `addModule` | In addition to the current module, you can add other modules to the resulting artifact. |
| `setModules` | You can override the list of all modules that will be added to the resulting artifact. |
### Libraries and frameworks
When building an Objective-C framework or a native library (shared or static), you may need to pack not just the classes of the current project but also the classes of any other multiplatform module into a single entity and export all these modules to it.
#### Library
For the library configuration, the additional `target` parameter is available:
| **Name** | **Description** |
| --- | --- |
| `target` | Declares a particular target of a project. The names of available targets are listed in the [Targets](multiplatform-dsl-reference#targets) section. |
```
kotlinArtifacts {
Native.Library("myslib") {
target = linuxX64
isStatic = false
modes(DEBUG)
addModule(project(":lib"))
kotlinOptions {
verbose = false
freeCompilerArgs += "-Xmen=pool"
}
}
}
```
```
kotlinArtifacts {
it.native.Library("myslib") {
target = linuxX64
it.static = false
modes(DEBUG)
addModule(project(":lib"))
kotlinOptions {
verbose = false
freeCompilerArgs += "-Xmen=pool"
}
}
}
```
The registered Gradle task is `assembleMyslibSharedLibrary` that assembles all types of registered "myslib" into a dynamic library.
#### Framework
For the framework configuration, the following additional parameters are available:
| **Name** | **Description** |
| --- | --- |
| `target` | Declares a particular target of a project. The names of available targets are listed in the [Targets](multiplatform-dsl-reference#targets) section. |
| `embedBitcode` | Declares the mode of bitcode embedding. Use `MARKER` to embed the bitcode marker (for debug builds) or `DISABLE` to turn off embedding. Bitcode embedding is not required for Xcode 14 and later. |
```
kotlinArtifacts {
Native.Framework("myframe") {
modes(DEBUG, RELEASE)
target = iosArm64
isStatic = false
embedBitcode = EmbedBitcodeMode.MARKER
kotlinOptions {
verbose = false
}
}
}
```
```
kotlinArtifacts {
it.native.Framework("myframe") {
modes(DEBUG, RELEASE)
target = iosArm64
it.static = false
embedBitcode = EmbedBitcodeMode.MARKER
kotlinOptions {
verbose = false
}
}
}
```
The registered Gradle task is `assembleMyframeFramework` that assembles all types of registered "myframe" framework.
### Fat frameworks
By default, an Objective-C framework produced by Kotlin/Native supports only one platform. However, you can merge such frameworks into a single universal (fat) binary. This especially makes sense for 32-bit and 64-bit iOS frameworks. In this case, you can use the resulting universal framework on both 32-bit and 64-bit devices.
For the fat framework configuration, the following additional parameters are available:
| **Name** | **Description** |
| --- | --- |
| `targets` | Declares all targets of the project. |
| `embedBitcode` | Declares the mode of bitcode embedding. Use `MARKER` to embed the bitcode marker (for debug builds) or `DISABLE` to turn off embedding. Bitcode embedding is not required for Xcode 14 and later. |
```
kotlinArtifacts {
Native.FatFramework("myfatframe") {
targets(iosX32, iosX64)
embedBitcode = EmbedBitcodeMode.DISABLE
kotlinOptions {
suppressWarnings = false
}
}
}
```
```
kotlinArtifacts {
it.native.FatFramework("myfatframe") {
targets(iosX32, iosX64)
embedBitcode = EmbedBitcodeMode.DISABLE
kotlinOptions {
suppressWarnings = false
}
}
}
```
The registered Gradle task is `assembleMyfatframeFatFramework` that assembles all types of registered "myfatframe" fat framework.
### XCFrameworks
All Kotlin Multiplatform projects can use XCFrameworks as an output to gather logic for all the target platforms and architectures in a single bundle. Unlike [universal (fat) frameworks](#fat-frameworks), you don't need to remove all unnecessary architectures before publishing the application to the App Store.
For the XCFrameworks configuration, the following additional parameters are available:
| **Name** | **Description** |
| --- | --- |
| `targets` | Declares all targets of the project. |
| `embedBitcode` | Declares the mode of bitcode embedding. Use `MARKER` to embed the bitcode marker (for debug builds) or `DISABLE` to turn off embedding. Bitcode embedding is not required for Xcode 14 and later. |
```
kotlinArtifacts {
Native.XCFramework("sdk") {
targets(iosX64, iosArm64, iosSimulatorArm64)
setModules(
project(":shared"),
project(":lib")
)
}
}
```
```
kotlinArtifacts {
it.native.XCFramework("sdk") {
targets(iosX64, iosArm64, iosSimulatorArm64)
setModules(
project(":shared"),
project(":lib")
)
}
}
```
The registered Gradle task is `assembleSdkXCFramework` that assembles all types of registered "sdk" XCFrameworks.
Last modified: 10 January 2023
[Configure compilations](multiplatform-configure-compilations) [Build final native binaries](multiplatform-build-native-binaries)
kotlin Incremental processing Incremental processing
======================
Incremental processing is a processing technique that avoids re-processing of sources as much as possible. The primary goal of incremental processing is to reduce the turn-around time of a typical change-compile-test cycle. For general information, see Wikipedia's article on [incremental computing](https://en.wikipedia.org/wiki/Incremental_computing).
To determine which sources are *dirty* (those that need to be reprocessed), KSP needs processors' help to identify which input sources correspond to which generated outputs. To help with this often cumbersome and error-prone process, KSP is designed to require only a minimal set of *root sources* that processors use as starting points to navigate the code structure. In other words, a processor needs to associate an output with the sources of the corresponding `KSNode` if the `KSNode` is obtained from any of the following:
* `Resolver.getAllFiles`
* `Resolver.getSymbolsWithAnnotation`
* `Resolver.getClassDeclarationByName`
* `Resolver.getDeclarationsFromPackage`
Incremental processing is currently enabled by default. To disable it, set the Gradle property `ksp.incremental=false`. To enable logs that dump the dirty set according to dependencies and outputs, use `ksp.incremental.log=true`. You can find these log files in the `build` output folder with a `.log` file extension.
Aggregating vs Isolating
------------------------
Similar to the concepts in [Gradle annotation processing](https://docs.gradle.org/current/userguide/java_plugin.html#sec:incremental_annotation_processing), KSP supports both *aggregating* and *isolating* modes. Note that unlike Gradle annotation processing, KSP categorizes each output as either aggregating or isolating, rather than the entire processor.
An aggregating output can potentially be affected by any input changes, except removing files that don't affect other files. This means that any input change results in a rebuild of all aggregating outputs, which in turn means reprocessing of all corresponding registered, new, and modified source files.
As an example, an output that collects all symbols with a particular annotation is considered an aggregating output.
An isolating output depends only on its specified sources. Changes to other sources do not affect an isolating output. Note that unlike Gradle annotation processing, you can define multiple source files for a given output.
As an example, a generated class that is dedicated to an interface it implements is considered isolating.
To summarize, if an output might depend on new or any changed sources, it is considered aggregating. Otherwise, the output is isolating.
Here's a summary for readers familiar with Java annotation processing:
* In an isolating Java annotation processor, all the outputs are isolating in KSP.
* In an aggregating Java annotation processor, some outputs can be isolating and some can be aggregating in KSP.
### How it is implemented
The dependencies are calculated by the association of input and output files, instead of annotations. This is a many-to-many relation.
The dirtiness propagation rules due to input-output associations are:
1. If an input file is changed, it will always be reprocessed.
2. If an input file is changed, and it is associated with an output, then all other input files associated with the same output will also be reprocessed. This is transitive, namely, invalidation happens repeatedly until there is no new dirty file.
3. All input files that are associated with one or more aggregating outputs will be reprocessed. In other words, if an input file isn't associated with any aggregating outputs, it won't be reprocessed (unless it meets 1. or 2. in the above).
Reasons are:
1. If an input is changed, new information can be introduced and therefore processors need to run again with the input.
2. An output is made out of a set of inputs. Processors may need all the inputs to regenerate the output.
3. `aggregating=true` means that an output may potentially depend on new information, which can come from either new files, or changed, existing files. `aggregating=false` means that processor is sure that the information only comes from certain input files and never from other or new files.
Example 1
---------
A processor generates `outputForA` after reading class `A` in `A.kt` and class `B` in `B.kt`, where `A` extends `B`. The processor got `A` by `Resolver.getSymbolsWithAnnotation` and then got `B` by `KSClassDeclaration.superTypes` from `A`. Because the inclusion of `B` is due to `A`, `B.kt` doesn't need to be specified in `dependencies` for `outputForA`. You can still specify `B.kt` in this case, but it is unnecessary.
```
// A.kt
@Interesting
class A : B()
// B.kt
open class B
// Example1Processor.kt
class Example1Processor : SymbolProcessor {
override fun process(resolver: Resolver) {
val declA = resolver.getSymbolsWithAnnotation("Interesting").first() as KSClassDeclaration
val declB = declA.superTypes.first().resolve().declaration
// B.kt isn't required, because it can be deduced as a dependency by KSP
val dependencies = Dependencies(aggregating = true, declA.containingFile!!)
// outputForA.kt
val outputName = "outputFor${declA.simpleName.asString()}"
// outputForA depends on A.kt and B.kt
val output = codeGenerator.createNewFile(dependencies, "com.example", outputName, "kt")
output.write("// $declA : $declB\n".toByteArray())
output.close()
}
// ...
}
```
Example 2
---------
Consider that a processor generates `outputA` after reading `sourceA` and `outputB` after reading `sourceB`.
When `sourceA` is changed:
* If `outputB` is aggregating, both `sourceA` and `sourceB` are reprocessed.
* If `outputB` is isolating, only `sourceA` is reprocessed.
When `sourceC` is added:
* If `outputB` is aggregating, both `sourceC` and `sourceB` are reprocessed.
* If `outputB` is isolating, only `sourceC` is reprocessed.
When `sourceA` is removed, nothing needs to be reprocessed.
When `sourceB` is removed, nothing needs to be reprocessed.
How file dirtiness is determined
--------------------------------
A dirty file is either directly *changed* by users or indirectly *affected* by other dirty files. KSP propagates dirtiness in two steps:
* Propagation by *resolution tracing*: Resolving a type reference (implicitly or explicitly) is the only way to navigate from one file to another. When a type reference is resolved by a processor, a changed or affected file that contains a change that may potentially affect the resolution result will affect the file containing that reference.
* Propagation by *input-output correspondence*: If a source file is changed or affected, all other source files having some output in common with that file are affected.
Note that both of them are transitive and the second forms equivalence classes.
Reporting bugs
--------------
To report a bug, please set Gradle properties `ksp.incremental=true` and `ksp.incremental.log=true`, and perform a clean build. This build produces two log files:
* `build/kspCaches/<source set>/logs/kspDirtySet.log`
* `build/kspCaches/<source set>/logs/kspSourceToOutputs.log`
You can then run successive incremental builds, which will generate two additional log files:
* `build/kspCaches/<source set>/logs/kspDirtySetByDeps.log`
* `build/kspCaches/<source set>/logs/kspDirtySetByOutputs.log`
These logs contain file names of sources and outputs, plus the timestamps of the builds.
Last modified: 10 January 2023
[Java annotation processing to KSP reference](ksp-reference) [Multiple round processing](ksp-multi-round)
kotlin Support for Gradle plugin variants Support for Gradle plugin variants
==================================
Gradle 7.0 introduced a new feature for Gradle plugin authors — [plugins with variants](https://docs.gradle.org/7.0/userguide/implementing_gradle_plugins.html#plugin-with-variants). This feature makes it easier to add support for latest Gradle features while maintaining compatibility with older Gradle versions. Learn more about [variant selection in Gradle](https://docs.gradle.org/current/userguide/variant_model.html).
With Gradle plugin variants, the Kotlin team can ship different Kotlin Gradle plugin (KGP) variants for different Gradle versions. The goal is to support the base Kotlin compilation in the `main` variant, which corresponds to the oldest supported versions of Gradle. Each variant will have implementations for Gradle features from a corresponding release. The latest variant will support the latest Gradle feature set. With this approach, it is possible to extend support for older Gradle versions with limited functionality.
Currently, there are the following variants of the Kotlin Gradle plugin:
| Variant's name | Corresponding Gradle versions |
| --- | --- |
| `main` | 6.8.3–6.9.3 |
| `gradle70` | 7.0 |
| `gradle71` | 7.1-7.4 |
| `gradle75` | 7.5 |
| `gradle76` | 7.6 and higher |
In future Kotlin releases, more variants will be probably added.
To check which variant your build uses, enable the [`--info` log level](https://docs.gradle.org/current/userguide/logging.html#sec:choosing_a_log_level) and find a string in the output starting with `Using Kotlin Gradle plugin`, for example, `Using Kotlin Gradle plugin main variant`.
Troubleshooting
---------------
### Gradle can't select a KGP variant in a custom configuration
This is an expected situation that Gradle can't select a KGP variant in a custom configuration. If you use a custom Gradle configuration:
```
configurations.register("customConfiguraton") {
...
}
```
```
configurations.register("customConfiguraton") {
...
}
```
and want to add a dependency on the Kotlin Gradle plugin, for example:
```
dependencies {
customConfiguration("org.jetbrains.kotlin:kotlin-gradle-plugin:1.8.0")
}
```
```
dependencies {
customConfiguration 'org.jetbrains.kotlin:kotlin-gradle-plugin:1.8.0'
}
```
You need to add the following attributes to your `customConfiguration`:
```
configurations {
customConfiguration {
attributes {
attribute(
Usage.USAGE_ATTRIBUTE,
project.objects.named(Usage.class, Usage.JAVA_RUNTIME)
)
attribute(
Category.CATEGORY_ATTRIBUTE,
project.objects.named(Category.class, Category.LIBRARY)
)
// If you want to depend on a specific KGP variant:
attribute(
GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
project.objects.named("7.0")
)
}
}
}
```
```
configurations {
customConfiguration {
attributes {
attribute(
Usage.USAGE_ATTRIBUTE,
project.objects.named(Usage, Usage.JAVA_RUNTIME)
)
attribute(
Category.CATEGORY_ATTRIBUTE,
project.objects.named(Category, Category.LIBRARY)
)
// If you want to depend on a specific KGP variant:
attribute(
GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
project.objects.named('7.0')
)
}
}
}
```
Otherwise, you will receive an error similar to this:
`> Could not resolve all files for configuration ':customConfiguraton'. > Could not resolve org.jetbrains.kotlin:kotlin-gradle-plugin:1.7.0. Required by: project : > Cannot choose between the following variants of org.jetbrains.kotlin:kotlin-gradle-plugin:1.7.0: - gradle70RuntimeElements - runtimeElements All of them match the consumer attributes: - Variant 'gradle70RuntimeElements' capability org.jetbrains.kotlin:kotlin-gradle-plugin:1.7.0: - Unmatched attributes:`
What's next?
------------
Learn more about [Gradle basics and specifics](https://docs.gradle.org/current/userguide/getting_started.html).
Last modified: 10 January 2023
[Compilation and caches in the Kotlin Gradle plugin](gradle-compilation-and-caches) [Maven](maven)
| programming_docs |
kotlin Configure a Gradle project Configure a Gradle project
==========================
To build a Kotlin project with [Gradle](https://docs.gradle.org/current/userguide/getting_started.html), you need to add the [Kotlin Gradle plugin](#apply-the-plugin) to your build script file `build.gradle(.kts)` and [configure the project's dependencies](#configure-dependencies) there.
Apply the plugin
----------------
To apply the Kotlin Gradle plugin, use the [`plugins` block](https://docs.gradle.org/current/userguide/plugins.html#sec:plugins_block) from the Gradle plugins DSL:
```
// replace `<...>` with the plugin name
plugins {
kotlin("<...>") version "1.8.0"
}
```
```
// replace `<...>` with the plugin name
plugins {
id 'org.jetbrains.kotlin.<...>' version '1.8.0'
}
```
When configuring your project, check the Kotlin Gradle plugin compatibility with available Gradle versions. In the following table, there are the minimum and maximum **fully supported** versions of Gradle and Android Gradle plugin:
| Kotlin version | Gradle min and max versions | Android Gradle plugin min and max versions |
| --- | --- | --- |
| 1.8.0 | 6.8.3 – 7.3.3 | 4.1.3 – 7.2.1 |
| 1.7.20 | 6.7.1 – 7.1.1 | 3.6.4 – 7.0.4 |
For example, the Kotlin Gradle plugin and the `kotlin-multiplatform` plugin 1.8.0 require the minimum Gradle version of 6.8.3 for your project to compile.
Similarly, the maximum fully supported version is 7.3.3. It doesn't have deprecated Gradle methods and properties, and supports all the current Gradle features.
Targeting the JVM
-----------------
To target the JVM, apply the Kotlin JVM plugin.
```
plugins {
kotlin("jvm") version "1.8.0"
}
```
```
plugins {
id "org.jetbrains.kotlin.jvm" version "1.8.0"
}
```
The `version` should be literal in this block, and it cannot be applied from another build script.
### Kotlin and Java sources
Kotlin sources and Java sources can be stored in the same folder, or they can be placed in different folders. The default convention is to use different folders:
```
project
- src
- main (root)
- kotlin
- java
```
The corresponding `sourceSets` property should be updated if you are not using the default convention:
```
sourceSets.main {
java.srcDirs("src/main/myJava", "src/main/myKotlin")
}
```
```
sourceSets {
main.kotlin.srcDirs += 'src/main/myKotlin'
main.java.srcDirs += 'src/main/myJava'
}
```
### Check for JVM target compatibility of related compile tasks
In the build module, you may have related compile tasks, for example:
* `compileKotlin` and `compileJava`
* `compileTestKotlin` and `compileTestJava`
For related tasks like these, the Kotlin Gradle plugin checks for JVM target compatibility. Different values of the [`jvmTarget` attribute](gradle-compiler-options#attributes-specific-to-jvm) in the `kotlin` extension or task and [`targetCompatibility`](https://docs.gradle.org/current/userguide/java_plugin.html#sec:java-extension) in the `java` extension or task cause JVM target incompatibility. For example: the `compileKotlin` task has `jvmTarget=1.8`, and the `compileJava` task has (or [inherits](https://docs.gradle.org/current/userguide/java_plugin.html#sec:java-extension)) `targetCompatibility=15`.
Configure the behavior of this check by setting the `kotlin.jvm.target.validation.mode` property in the `build.gradle` file to:
* `error` – the plugin will fail the build; the default value for projects on Gradle 8.0+.
* `warning` – the Kotlin Gradle plugin will print a warning message; the default value for projects on Gradle less than 8.0.
* `ignore` – the plugin will skip the check and won't produce any messages.
To avoid JVM target incompatibility, [configure a toolchain](#gradle-java-toolchains-support) or align JVM versions manually.
#### What can go wrong if not checking targets compatibility
There are two ways of manually setting JVM targets for Kotlin and Java source sets:
* The implicit way via [setting up a Java toolchain](#gradle-java-toolchains-support).
* The explicit way via setting the `jvmTarget` attribute in the `kotlin` extension or task and `targetCompatibility` in the `java` extension or task.
JVM target incompatibility occurs if you:
* Explicitly set different values of `jvmTarget` and `targetCompatibility`.
* Have a default configuration, and your JDK is not equal to `1.8`.
Let's consider a default configuration of JVM targets when you have only the Kotlin JVM plugin in your build script and no additional settings for JVM targets:
```
plugins {
kotlin("jvm") version "1.8.0"
}
```
```
plugins {
id "org.jetbrains.kotlin.jvm" version "1.8.0"
}
```
When there is no explicit information about the `jvmTarget` value in the build script, its default value is `null`, and the compiler translates it to the default value `1.8`. The `targetCompatibility` equals a current Gradle's JDK version, which is equal to your JDK version (unless you use a [Java toolchain approach](#gradle-java-toolchains-support)). Assume that this version is `11`. Your published library artifact will [declare the compatibility](https://docs.gradle.org/current/userguide/publishing_gradle_module_metadata.html) with JDK 11+: `org.gradle.jvm.version=11`, which is wrong. You will have to use Java 11 in your main project to add this library, although the bytecode's version is `1.8`. [Configure a toolchain](#gradle-java-toolchains-support) to solve this issue.
### Gradle Java toolchains support
Gradle 6.7 introduced [Java toolchains support](https://docs.gradle.org/current/userguide/toolchains.html). Using this feature, you can:
* Use a JDK and a JRE that are different from the ones in Gradle to run compilations, tests, and executables.
* Compile and test code with a not-yet-released language version.
With toolchains support, Gradle can autodetect local JDKs and install missing JDKs that Gradle requires for the build. Now Gradle itself can run on any JDK and still reuse the [remote build cache feature](gradle-compilation-and-caches#gradle-build-cache-support) for tasks that depend on a major JDK version.
The Kotlin Gradle plugin supports Java toolchains for Kotlin/JVM compilation tasks. JS and Native tasks don't use toolchains. The Kotlin compiler always runs on the JDK the Gradle daemon is running on. A Java toolchain:
* Sets the [`-jdk-home` option](compiler-reference#jdk-home-path) available for JVM targets.
* Sets the [`compilerOptions.jvmTarget`](gradle-compiler-options#attributes-specific-to-jvm) to the toolchain's JDK version if the user doesn't set the `jvmTarget` option explicitly. If the user doesn't configure the toolchain, the `jvmTarget` field uses the default value. Learn more about [JVM target compatibility](#check-for-jvm-target-compatibility-of-related-compile-tasks).
* Sets the toolchain to be used by any Java compile, test and javadoc tasks.
* Affects which JDK [`kapt` workers](kapt#running-kapt-tasks-in-parallel) are running on.
Use the following code to set a toolchain. Replace the placeholder `<MAJOR_JDK_VERSION>` with the JDK version you would like to use:
```
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
// Or shorter:
jvmToolchain(<MAJOR_JDK_VERSION>) // "8"
}
```
```
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
// Or shorter:
jvmToolchain(<MAJOR_JDK_VERSION>) // "8"
}
```
Note that setting a toolchain via the `kotlin` extension updates the toolchain for Java compile tasks as well.
You can set a toolchain via the `java` extension, and Kotlin compilation tasks will use it:
```
java {
toolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
}
```
```
java {
toolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
}
```
To set any JDK (even local) for the specific task, use the Task DSL.
### Setting JDK version with the Task DSL
The Task DSL allows setting any JDK version for any task implementing the `UsesKotlinJavaToolchain` interface. At the moment, these tasks are `KotlinCompile` and `KaptTask`. If you want Gradle to search for the major JDK version, replace the `<MAJOR_JDK_VERSION>` placeholder in your build script:
```
val service = project.extensions.getByType<JavaToolchainService>()
val customLauncher = service.launcherFor {
it.languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
project.tasks.withType<UsesKotlinJavaToolchain>().configureEach {
kotlinJavaToolchain.toolchain.use(customLauncher)
}
```
```
JavaToolchainService service = project.getExtensions().getByType(JavaToolchainService.class)
Provider<JavaLauncher> customLauncher = service.launcherFor {
it.languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
tasks.withType(UsesKotlinJavaToolchain::class).configureEach { task ->
task.kotlinJavaToolchain.toolchain.use(customLauncher)
}
```
Or you can specify the path to your local JDK and replace the placeholder `<LOCAL_JDK_VERSION>` with this JDK version:
```
tasks.withType<UsesKotlinJavaToolchain>().configureEach {
kotlinJavaToolchain.jdk.use(
"/path/to/local/jdk", // Put a path to your JDK
JavaVersion.<LOCAL_JDK_VERSION> // For example, JavaVersion.17
)
}
```
### Associate compiler tasks
You can *associate* compilations by setting up such a relationship between them that one compilation uses the compiled outputs of the other. Associating compilations establishes `internal` visibility between them.
The Kotlin compiler associates some compilations by default, such as the `test` and `main` compilations of each target. If you need to express that one of your custom compilations is connected to another, create your own associated compilation.
To make the IDE support associated compilations for inferring visibility between source sets, add the following code to your `build.gradle(.kts)`:
```
val integrationTestCompilation = kotlin.target.compilations.create("integrationTest") {
associateWith(kotlin.target.compilations.getByName("main"))
}
```
```
integrationTestCompilation {
kotlin.target.compilations.create("integrationTest") {
associateWith(kotlin.target.compilations.getByName("main"))
}
}
```
Here, the `integrationTest` compilation is associated with the `main` compilation that gives access to `internal` objects from functional tests.
Targeting multiple platforms
----------------------------
Projects targeting [multiple platforms](multiplatform-dsl-reference#targets), called [multiplatform projects](multiplatform-get-started), require the `kotlin-multiplatform` plugin. [Learn more about the plugin](multiplatform-discover-project#multiplatform-plugin).
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
```
Targeting Android
-----------------
It's recommended to use Android Studio for creating Android applications. [Learn how to use Android Gradle plugin](https://developer.android.com/studio/releases/gradle-plugin).
Targeting JavaScript
--------------------
When targeting only JavaScript, use the `kotlin-js` plugin. [Learn more](js-project-setup)
```
plugins {
kotlin("js") version "1.8.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.js' version '1.8.0'
}
```
### Kotlin and Java sources for JavaScript
This plugin only works for Kotlin files, so it is recommended that you keep Kotlin and Java files separate (if the project contains Java files). If you don't store them separately, specify the source folder in the `sourceSets` block:
```
kotlin {
sourceSets["main"].apply {
kotlin.srcDir("src/main/myKotlin")
}
}
```
```
kotlin {
sourceSets {
main.kotlin.srcDirs += 'src/main/myKotlin'
}
}
```
Triggering configuration actions with the KotlinBasePlugin interface
--------------------------------------------------------------------
To trigger some configuration action whenever any Kotlin Gradle plugin (JVM, JS, Multiplatform, Native, and others) is applied, use the `KotlinBasePlugin` interface that all Kotlin plugins inherit from:
```
import org.jetbrains.kotlin.gradle.plugin.KotlinBasePlugin
// ...
project.plugins.withType<KotlinBasePlugin>() {
// Configure your action here
}
```
```
import org.jetbrains.kotlin.gradle.plugin.KotlinBasePlugin
// ...
project.plugins.withType(KotlinBasePlugin.class) {
// Configure your action here
}
```
Configure dependencies
----------------------
To add a dependency on a library, set the dependency of the required [type](#dependency-types) (for example, `implementation`) in the `dependencies` block of the source sets DSL.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("com.example:my-library:1.0")
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation 'com.example:my-library:1.0'
}
}
}
}
```
Alternatively, you can [set dependencies at top level](#set-dependencies-at-top-level).
### Dependency types
Choose the dependency type based on your requirements.
| Type | Description | When to use |
| --- | --- | --- |
| `api` | Used both during compilation and at runtime and is exported to library consumers. | If any type from a dependency is used in the public API of the current module, use an `api` dependency. |
| `implementation` | Used during compilation and at runtime for the current module, but is not exposed for compilation of other modules depending on the one with the `implementation` dependency. | Use for dependencies needed for the internal logic of a module.
If a module is an endpoint application which is not published, use `implementation` dependencies instead of `api` dependencies. |
| `compileOnly` | Used for compilation of the current module and is not available at runtime nor during compilation of other modules. | Use for APIs which have a third-party implementation available at runtime. |
| `runtimeOnly` | Available at runtime but is not visible during compilation of any module. | |
### Dependency on the standard library
A dependency on the standard library (`stdlib`) is added automatically to each source set. The version of the standard library used is the same as the version of the Kotlin Gradle plugin.
For platform-specific source sets, the corresponding platform-specific variant of the library is used, while a common standard library is added to the rest. The Kotlin Gradle plugin selects the appropriate JVM standard library depending on the `compilerOptions.jvmTarget` [compiler option](gradle-compiler-options) of your Gradle build script.
If you declare a standard library dependency explicitly (for example, if you need a different version), the Kotlin Gradle plugin won't override it or add a second standard library.
If you do not need a standard library at all, you can add the opt-out option to the `gradle.properties`:
```
kotlin.stdlib.default.dependency=false
```
#### Versions alignment of transitive dependencies
If you explicitly write the Kotlin version 1.8.0 or higher in your dependencies, for example: `implementation("org.jetbrains.kotlin:kotlin-stdlib:1.8.0")`, then the Kotlin Gradle Plugin uses this Kotlin version for transitive `kotlin-stdlib-jdk7` and `kotlin-stdlib-jdk8` dependencies. This is for avoiding class duplication from different stdlib versions.[Learn more about [merging `kotlin-stdlib-jdk7` and `kotlin-stdlib-jdk8` into `kotlin-stdlib`](whatsnew18#updated-jvm-compilation-target). You can disable this behavior with the `kotlin.stdlib.jdk.variants.version.alignment` Gradle property:
```
`kotlin.stdlib.jdk.variants.version.alignment=false`
```
##### Other ways to align versions
* In case you have issues with versions alignment, align all versions via the Kotlin [BOM](https://docs.gradle.org/current/userguide/platforms.html#sub:bom_import). Declare a platform dependency on `kotlin-bom` in your build script:
```
implementation(platform("org.jetbrains.kotlin:kotlin-bom:1.8.0"))
```
```
implementation platform('org.jetbrains.kotlin:kotlin-bom:1.8.0')
```
* If you don't have a standard library explicitly: `kotlin.stdlib.default.dependency=false` in your `gradle.properties`, but one of your dependencies transitively brings some old Kotlin stdlib version, for example, `kotlin-stdlib-jdk7:1.7.20` and another dependency transitively brings `kotlin-stdlib:1.8+` – in this case, you can require `1.8.0` versions of these transitive libraries:
```
dependencies {
constraints {
add("implementation", "org.jetbrains.kotlin:kotlin-stdlib-jdk7") {
version {
require("1.8.0")
}
}
add("implementation", "org.jetbrains.kotlin:kotlin-stdlib-jdk8") {
version {
require("1.8.0")
}
}
}
}
```
```
dependencies {
constraints {
add("implementation", "org.jetbrains.kotlin:kotlin-stdlib-jdk7") {
version {
require("1.8.0")
}
}
add("implementation", "org.jetbrains.kotlin:kotlin-stdlib-jdk8") {
version {
require("1.8.0")
}
}
}
}
```
* If you have a Kotlin version equal to `1.8.0`: `implementation("org.jetbrains.kotlin:kotlin-stdlib:1.8.0")` and an old version (less than `1.8.0`) of a Kotlin Gradle plugin – update the Kotlin Gradle plugin:
```
// replace `<...>` with the plugin name
plugins {
kotlin("<...>") version "1.8.0"
}
```
```
// replace `<...>` with the plugin name
plugins {
id "org.jetbrains.kotlin.<...>" version "1.8.0"
}
```
* If you have an explicit old version (less than `1.8.0`) of `kotlin-stdlib-jdk7`/`kotlin-stdlib-jdk8`, for example, `implementation("org.jetbrains.kotlin:kotlin-stdlib-jdk7:SOME_OLD_KOTLIN_VERSION")`, and a dependency that transitively brings `kotlin-stdlib:1.8+`, [replace your `kotlin-stdlib-jdk<7/8>:SOME_OLD_KOTLIN_VERSION` with `kotlin-stdlib-jdk*:1.8.0`](whatsnew18#updated-jvm-compilation-target) or [exclude](https://docs.gradle.org/current/userguide/dependency_downgrade_and_exclude.html#sec:excluding-transitive-deps) a transitive `kotlin-stdlib:1.8+` from the library that brings it:
```
dependencies {
implementation("com.example:lib:1.0") {
exclude(group = "org.jetbrains.kotlin", module = "kotlin-stdlib")
}
}
```
```
dependencies {
implementation("com.example:lib:1.0") {
exclude group: "org.jetbrains.kotlin", module: "kotlin-stdlib"
}
}
```
### Set dependencies on test libraries
The [`kotlin.test`](https://kotlinlang.org/api/latest/kotlin.test/) API is available for testing Kotlin projects on all supported platforms. Add the dependency `kotlin-test` to the `commonTest` source set, so that the Gradle plugin can infer the corresponding test dependencies for each test source set:
* `kotlin-test-common` and `kotlin-test-annotations-common` for common source sets
* `kotlin-test-junit` for JVM source sets
* `kotlin-test-js` for Kotlin/JS source sets
Kotlin/Native targets do not require additional test dependencies, and the `kotlin.test` API implementations are built-in.
```
kotlin {
sourceSets {
val commonTest by getting {
dependencies {
implementation(kotlin("test")) // This brings all the platform dependencies automatically
}
}
}
}
```
```
kotlin {
sourceSets {
commonTest {
dependencies {
implementation kotlin("test") // This brings all the platform dependencies automatically
}
}
}
}
```
You can use the `kotlin-test` dependency in any shared or platform-specific source set as well.
For Kotlin/JVM, Gradle uses JUnit 4 by default. Therefore, the `kotlin("test")` dependency resolves to the variant for JUnit 4, namely `kotlin-test-junit`.
You can choose JUnit 5 or TestNG by calling [`useJUnitPlatform()`](https://docs.gradle.org/current/javadoc/org/gradle/api/tasks/testing/Test.html#useJUnitPlatform) or [`useTestNG()`](https://docs.gradle.org/current/javadoc/org/gradle/api/tasks/testing/Test.html#useTestNG) in the test task of your build script. The following example is for a Kotlin Multiplatform project:
```
kotlin {
jvm {
testRuns["test"].executionTask.configure {
useJUnitPlatform()
}
}
sourceSets {
val commonTest by getting {
dependencies {
implementation(kotlin("test"))
}
}
}
}
```
```
kotlin {
jvm {
testRuns["test"].executionTask.configure {
useJUnitPlatform()
}
}
sourceSets {
commonTest {
dependencies {
implementation kotlin("test")
}
}
}
}
```
The following example is for a JVM project:
```
dependencies {
testImplementation(kotlin("test"))
}
tasks {
test {
useTestNG()
}
}
```
```
dependencies {
testImplementation 'org.jetbrains.kotlin:kotlin-test'
}
test {
useTestNG()
}
```
[Learn how to test code using JUnit on the JVM](jvm-test-using-junit).
If you need to use a different JVM test framework, disable automatic testing framework selection by adding the line `kotlin.test.infer.jvm.variant=false` to the project's `gradle.properties` file. After doing this, add the framework as a Gradle dependency.
If you have used a variant of `kotlin("test")` in your build script explicitly and your project build stopped working with a compatibility conflict, see [this issue in the Compatibility Guide](compatibility-guide-15#do-not-mix-several-jvm-variants-of-kotlin-test-in-a-single-project).
### Set a dependency on a kotlinx library
If you use a kotlinx library and need a platform-specific dependency, you can use platform-specific variants of libraries with suffixes such as `-jvm` or `-js`, for example, `kotlinx-coroutines-core-jvm`. You can also use the library's base artifact name instead – `kotlinx-coroutines-core`.
```
kotlin {
sourceSets {
val jvmMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core-jvm:1.6.4")
}
}
}
}
```
```
kotlin {
sourceSets {
jvmMain {
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core-jvm:1.6.4'
}
}
}
}
```
If you use a multiplatform library and need to depend on the shared code, set the dependency only once, in the shared source set. Use the library's base artifact name, such as `kotlinx-coroutines-core` or `ktor-client-core`.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4'
}
}
}
}
```
### Set dependencies at top level
Alternatively, you can specify the dependencies at top level, using the following pattern for the configuration names: `<sourceSetName><DependencyType>`. This can be helpful for some Gradle built-in dependencies, like `gradleApi()`, `localGroovy()`, or `gradleTestKit()`, which are not available in the source sets' dependency DSL.
```
dependencies {
"commonMainImplementation"("com.example:my-library:1.0")
}
```
```
dependencies {
commonMainImplementation 'com.example:my-library:1.0'
}
```
What's next?
------------
Learn more about:
* [Compiler options and how to pass them](gradle-compiler-options).
* [Incremental compilation, caches support, build reports, and the Kotlin daemon](gradle-compilation-and-caches).
* [Gradle basics and specifics](https://docs.gradle.org/current/userguide/getting_started.html).
* [Support for Gradle plugin variants](gradle-plugin-variants).
Last modified: 10 January 2023
[Get started with Gradle and Kotlin/JVM](get-started-with-jvm-gradle-project) [Compiler options in the Kotlin Gradle plugin](gradle-compiler-options)
| programming_docs |
kotlin Kotlin/Native as an Apple framework – tutorial Kotlin/Native as an Apple framework – tutorial
==============================================
Kotlin/Native provides bi-directional interoperability with Objective-C/Swift. Objective-C frameworks and libraries can be used in Kotlin code. Kotlin modules can be used in Swift/Objective-C code too. Besides that, Kotlin/Native has [C Interop](native-c-interop). There is also the [Kotlin/Native as a Dynamic Library](native-dynamic-libraries) tutorial for more information.
In this tutorial, you will see how to use Kotlin/Native code from Objective-C and Swift applications on macOS and iOS.
In this tutorial you'll:
* [create a Kotlin Library](#create-a-kotlin-library) and compile it to a framework
* examine the generated [Objective-C and Swift API](#generated-framework-headers) code
* use the framework from [Objective-C](#use-the-code-from-objective-c) and [Swift](#use-the-code-from-swift)
* [Configure Xcode](#xcode-and-framework-dependencies) to use the framework for [macOS](#xcode-for-macos-target) and [iOS](#xcode-for-ios-targets)
Create a Kotlin library
-----------------------
The Kotlin/Native compiler can produce a framework for macOS and iOS out of the Kotlin code. The created framework contains all declarations and binaries needed to use it with Objective-C and Swift. The best way to understand the techniques is to try it for ourselves. Let's create a tiny Kotlin library first and use it from an Objective-C program.
Create the `hello.kt` file with the library contents:
```
package example
object Object {
val field = "A"
}
interface Interface {
fun iMember() {}
}
class Clazz : Interface {
fun member(p: Int): ULong? = 42UL
}
fun forIntegers(b: Byte, s: UShort, i: Int, l: ULong?) { }
fun forFloats(f: Float, d: Double?) { }
fun strings(str: String?) : String {
return "That is '$str' from C"
}
fun acceptFun(f: (String) -> String?) = f("Kotlin/Native rocks!")
fun supplyFun() : (String) -> String? = { "$it is cool!" }
```
While it is possible to use the command line, either directly or by combining it with a script file (such as `.sh` or `.bat` file), this approach doesn't scale well for big projects that have hundreds of files and libraries. It is therefore better to use the Kotlin/Native compiler with a build system, as it helps to download and cache the Kotlin/Native compiler binaries and libraries with transitive dependencies and run the compiler and tests. Kotlin/Native can use the [Gradle](https://gradle.org) build system through the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin.
We covered the basics of setting up an IDE compatible project with Gradle in the [A Basic Kotlin/Native Application](native-gradle) tutorial. Please check it out if you are looking for detailed first steps and instructions on how to start a new Kotlin/Native project and open it in IntelliJ IDEA. In this tutorial, we'll look at the advanced C interop related usages of Kotlin/Native and [multiplatform](multiplatform-discover-project#multiplatform-plugin) builds with Gradle.
First, create a project folder. All the paths in this tutorial will be relative to this folder. Sometimes the missing directories will have to be created before any new files can be added.
Use the following `build.gradle(.kts)` Gradle build file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
macosX64("native") {
binaries {
framework {
baseName = "Demo"
}
}
}
}
tasks.wrapper {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.ALL
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
macosX64("native") {
binaries {
framework {
baseName = "Demo"
}
}
}
}
wrapper {
gradleVersion = "7.3"
distributionType = "ALL"
}
```
Move the sources file into the `src/nativeMain/kotlin` folder under the project. That is the default path, where sources are located, when the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin is used. Use the following block to configure the project to generate a dynamic or shared library:
```
binaries {
framework {
baseName = "Demo"
}
}
```
Along with macOS `X64`, Kotlin/Native supports macos `arm64` and iOS `arm32`, `arm64` and `X64` targets. You may replace the `macosX64` with respective functions as shown in the table:
| Target platform/device | Gradle function |
| --- | --- |
| macOS x86\_64 | `macosX64()` |
| macOS ARM 64 | `macosArm64()` |
| iOS ARM 32 | `iosArm32()` |
| iOS ARM 64 | `iosArm64()` |
| iOS Simulator (x86\_64) | `iosX64()` |
Run the `linkNative` Gradle task to build the library [in the IDE](native-get-started) or by calling the following console command:
```
./gradlew linkNative
```
Depending on the variant, the build generates the framework into the `build/bin/native/debugFramework` and `build/bin/native/releaseFramework` folders. Let's see what is inside.
Generated framework headers
---------------------------
Each of the created frameworks contains the header file in `<Framework>/Headers/Demo.h`. The headers do not depend on the target platform (at least with Kotlin/Native v.0.9.2). It contains the definitions for our Kotlin code and a few Kotlin-wide declarations.
### Kotlin/Native runtime declarations
Take a look at Kotlin runtime declarations:
```
NS_ASSUME_NONNULL_BEGIN
@interface KotlinBase : NSObject
- (instancetype)init __attribute__((unavailable));
+ (instancetype)new __attribute__((unavailable));
+ (void)initialize __attribute__((objc_requires_super));
@end;
@interface KotlinBase (KotlinBaseCopying) <NSCopying>
@end;
__attribute__((objc_runtime_name("KotlinMutableSet")))
__attribute__((swift_name("KotlinMutableSet")))
@interface DemoMutableSet<ObjectType> : NSMutableSet<ObjectType>
@end;
__attribute__((objc_runtime_name("KotlinMutableDictionary")))
__attribute__((swift_name("KotlinMutableDictionary")))
@interface DemoMutableDictionary<KeyType, ObjectType> : NSMutableDictionary<KeyType, ObjectType>
@end;
@interface NSError (NSErrorKotlinException)
@property (readonly) id _Nullable kotlinException;
@end;
```
Kotlin classes have a `KotlinBase` base class in Objective-C, the class extends the `NSObject` class there. There are also have wrappers for collections and exceptions. Most of the collection types are mapped to similar collection types from the other side:
| Kotlin | Swift | Objective-C |
| --- | --- | --- |
| List | Array | NSArray |
| MutableList | NSMutableArray | NSMutableArray |
| Set | Set | NSSet |
| Map | Dictionary | NSDictionary |
| MutableMap | NSMutableDictionary | NSMutableDictionary |
### Kotlin numbers and NSNumber
The next part of the `<Framework>/Headers/Demo.h` contains number type mappings between Kotlin/Native and `NSNumber`. There is the base class called `DemoNumber` in Objective-C and `KotlinNumber` in Swift. It extends `NSNumber`. There are also child classes per Kotlin number type:
| Kotlin | Swift | Objective-C | Simple type |
| --- | --- | --- | --- |
| `-` | `KotlinNumber` | `<Package>Number` | `-` |
| `Byte` | `KotlinByte` | `<Package>Byte` | `char` |
| `UByte` | `KotlinUByte` | `<Package>UByte` | `unsigned char` |
| `Short` | `KotlinShort` | `<Package>Short` | `short` |
| `UShort` | `KotlinUShort` | `<Package>UShort` | `unsigned short` |
| `Int` | `KotlinInt` | `<Package>Int` | `int` |
| `UInt` | `KotlinUInt` | `<Package>UInt` | `unsigned int` |
| `Long` | `KotlinLong` | `<Package>Long` | `long long` |
| `ULong` | `KotlinULong` | `<Package>ULong` | `unsigned long long` |
| `Float` | `KotlinFloat` | `<Package>Float` | `float` |
| `Double` | `KotlinDouble` | `<Package>Double` | `double` |
| `Boolean` | `KotlinBoolean` | `<Package>Boolean` | `BOOL/Bool` |
Every number type has a class method to create a new instance from the related simple type. Also, there is an instance method to extract a simple value back. Schematically, declarations look like that:
```
__attribute__((objc_runtime_name("Kotlin__TYPE__")))
__attribute__((swift_name("Kotlin__TYPE__")))
@interface Demo__TYPE__ : DemoNumber
- (instancetype)initWith__TYPE__:(__CTYPE__)value;
+ (instancetype)numberWith__TYPE__:(__CTYPE__)value;
@end;
```
Where `__TYPE__` is one of the simple type names and `__CTYPE__` is the related Objective-C type, for example, `initWithChar(char)`.
These types are used to map boxed Kotlin number types into Objective-C and Swift. In Swift, you may simply call the constructor to create an instance, for example, `KotlinLong(value: 42)`.
### Classes and objects from Kotlin
Let's see how `class` and `object` are mapped to Objective-C and Swift. The generated `<Framework>/Headers/Demo.h` file contains the exact definitions for `Class`, `Interface`, and `Object`:
```
NS_ASSUME_NONNULL_BEGIN
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("Object")))
@interface DemoObject : KotlinBase
+ (instancetype)alloc __attribute__((unavailable));
+ (instancetype)allocWithZone:(struct _NSZone *)zone __attribute__((unavailable));
+ (instancetype)object __attribute__((swift_name("init()")));
@property (readonly) NSString *field;
@end;
__attribute__((swift_name("Interface")))
@protocol DemoInterface
@required
- (void)iMember __attribute__((swift_name("iMember()")));
@end;
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("Clazz")))
@interface DemoClazz : KotlinBase <DemoInterface>
- (instancetype)init __attribute__((swift_name("init()"))) __attribute__((objc_designated_initializer));
+ (instancetype)new __attribute__((availability(swift, unavailable, message="use object initializers instead")));
- (DemoLong * _Nullable)memberP:(int32_t)p __attribute__((swift_name("member(p:)")));
@end;
```
The code is full of Objective-C attributes, which are intended to help the use of the framework from both Objective-C and Swift languages. `DemoClazz`, `DemoInterface`, and `DemoObject` are created for `Clazz`, `Interface`, and `Object` respectively. The `Interface` is turned into `@protocol`, both a `class` and an `object` are represented as `@interface`. The `Demo` prefix comes from the `-output` parameter of the `kotlinc-native` compiler and the framework name. You can see here that the nullable return type `ULong?` is turned into `DemoLong*` in Objective-C.
### Global declarations from Kotlin
All global functions from Kotlin are turned into `DemoLibKt` in Objective-C and into `LibKt` in Swift, where `Demo` is the framework name and set by the `-output` parameter of `kotlinc-native`.
```
NS_ASSUME_NONNULL_BEGIN
__attribute__((objc_subclassing_restricted))
__attribute__((swift_name("LibKt")))
@interface DemoLibKt : KotlinBase
+ (void)forIntegersB:(int8_t)b s:(int16_t)s i:(int32_t)i l:(DemoLong * _Nullable)l __attribute__((swift_name("forIntegers(b:s:i:l:)")));
+ (void)forFloatsF:(float)f d:(DemoDouble * _Nullable)d __attribute__((swift_name("forFloats(f:d:)")));
+ (NSString *)stringsStr:(NSString * _Nullable)str __attribute__((swift_name("strings(str:)")));
+ (NSString * _Nullable)acceptFunF:(NSString * _Nullable (^)(NSString *))f __attribute__((swift_name("acceptFun(f:)")));
+ (NSString * _Nullable (^)(NSString *))supplyFun __attribute__((swift_name("supplyFun()")));
@end;
```
You see that Kotlin `String` and Objective-C `NSString*` are mapped transparently. Similarly, `Unit` type from Kotlin is mapped to `void`. We see primitive types are mapped directly. Non-nullable primitive types are mapped transparently. Nullable primitive types are mapped into `Kotlin<TYPE>*` types, as shown in the table [above](#kotlin-numbers-and-nsnumber). Both higher order functions `acceptFunF` and `supplyFun` are included, and accept Objective-C blocks.
More information about all other types mapping details can be found in the [Objective-C Interop](native-objc-interop) documentation article
Garbage collection and reference counting
-----------------------------------------
Objective-C and Swift use reference counting. Kotlin/Native has its own garbage collection too. Kotlin/Native garbage collection is integrated with Objective-C/Swift reference counting. You do not need to use anything special to control the lifetime of Kotlin/Native instances from Swift or Objective-C.
Use the code from Objective-C
-----------------------------
Let's call the framework from Objective-C. For that, create the `main.m` file with the following content:
```
#import <Foundation/Foundation.h>
#import <Demo/Demo.h>
int main(int argc, const char * argv[]) {
@autoreleasepool {
[[DemoObject object] field];
DemoClazz* clazz = [[ DemoClazz alloc] init];
[clazz memberP:42];
[DemoLibKt forIntegersB:1 s:1 i:3 l:[DemoULong numberWithUnsignedLongLong:4]];
[DemoLibKt forIntegersB:1 s:1 i:3 l:nil];
[DemoLibKt forFloatsF:2.71 d:[DemoDouble numberWithDouble:2.71]];
[DemoLibKt forFloatsF:2.71 d:nil];
NSString* ret = [DemoLibKt acceptFunF:^NSString * _Nullable(NSString * it) {
return [it stringByAppendingString:@" Kotlin is fun"];
}];
NSLog(@"%@", ret);
return 0;
}
}
```
Here you call Kotlin classes directly from Objective-C code. A Kotlin `object` has the class method function `object`, which allows us to get the only instance of the object and to call `Object` methods on it. The widespread pattern is used to create an instance of the `Clazz` class. You call the `[[ DemoClazz alloc] init]` on Objective-C. You may also use `[DemoClazz new]` for constructors without parameters. Global declarations from the Kotlin sources are scoped under the `DemoLibKt` class in Objective-C. All methods are turned into class methods of that class. The `strings` function is turned into `DemoLibKt.stringsStr` function in Objective-C, you can pass `NSString` directly to it. The return is visible as `NSString` too.
Use the code from Swift
-----------------------
The framework that you compiled with Kotlin/Native has helper attributes to make it easier to use with Swift. Convert the previous Objective-C example into Swift. As a result, you'll have the following code in `main.swift`:
```
import Foundation
import Demo
let kotlinObject = Object()
assert(kotlinObject === Object(), "Kotlin object has only one instance")
let field = Object().field
let clazz = Clazz()
clazz.member(p: 42)
LibKt.forIntegers(b: 1, s: 2, i: 3, l: 4)
LibKt.forFloats(f: 2.71, d: nil)
let ret = LibKt.acceptFun { "\($0) Kotlin is fun" }
if (ret != nil) {
print(ret!)
}
```
The Kotlin code is turned into very similar looking code in Swift. There are some small differences, though. In Kotlin any `object` has only one instance. Kotlin `object Object` now has a constructor in Swift, and we use the `Object()` syntax to access the only instance of it. The instance is always the same in Swift, so that `Object() === Object()` is true. Methods and property names are translated as-is. Kotlin `String` is turned into Swift `String` too. Swift hides `NSNumber*` boxing from us too. We can pass a Swift closure to Kotlin and call a Kotlin lambda function from Swift too.
More documentation on the types mapping can be found in the [Objective-C Interop](native-objc-interop) article.
Xcode and framework dependencies
--------------------------------
You need to configure an Xcode project to use our framework. The configuration depends on the target platform.
### Xcode for macOS target
First, in the **General** tab of the **target** configuration, under the **Linked Frameworks and Libraries** section, you need to include our framework. This will make Xcode look at our framework and resolve imports both from Objective-C and Swift.
The second step is to configure the framework search path of the produced binary. It is also known as `rpath` or [run-time search path](https://en.wikipedia.org/wiki/Rpath). The binary uses the path to look for the required frameworks. We do not recommend installing additional frameworks to the OS if it is not needed. You should understand the layout of your future application, for example, you may have the `Frameworks` folder under the application bundle with all the frameworks you use. The `@rpath` parameter can be configured in Xcode. You need to open the **project** configuration and find the **Runpath Search Paths** section. Here you specify the relative path to the compiled framework.
### Xcode for iOS targets
First, you need to include the compiled framework in the Xcode project. To do this, add the framework to the **Frameworks, Libraries, and Embedded Content** section of the **General** tab of the **target** configuration page.
The second step is to then include the framework path into the **Framework Search Paths** section of the **Build Settings** tab of the **target** configuration page. It is possible to use the `$(PROJECT_DIR)` macro to simplify the setup.
The iOS simulator requires a framework compiled for the `ios_x64` target, the `iOS_sim` folder in our case.
[This Stackoverflow thread](https://stackoverflow.com/questions/30963294/creating-ios-osx-frameworks-is-it-necessary-to-codesign-them-before-distributin) contains a few more recommendations. Also, the [CocoaPods](https://cocoapods.org/) package manager may be helpful to automate the process too.
Next steps
----------
Kotlin/Native has bidirectional interop with Objective-C and Swift languages. Kotlin objects integrate with Objective-C/Swift reference counting. Unused Kotlin objects are automatically removed. The [Objective-C Interop](native-objc-interop) article contains more information on the interop implementation details. Of course, it is possible to import an existing framework and use it from Kotlin. Kotlin/Native comes with a good set of pre-imported system frameworks.
Kotlin/Native supports C interop too. Check out the [Kotlin/Native as a Dynamic Library](native-dynamic-libraries) tutorial for that.
Last modified: 10 January 2023
[Interoperability with Swift/Objective-C](native-objc-interop) [CocoaPods overview and setup](native-cocoapods)
kotlin What's new in Kotlin 1.7.0 What's new in Kotlin 1.7.0
==========================
*[Release date: 9 June 2022](releases#release-details)*
Kotlin 1.7.0 has been released. It unveils the Alpha version of the new Kotlin/JVM K2 compiler, stabilizes language features, and brings performance improvements for the JVM, JS, and Native platforms.
Here is a list of the major updates in this version:
* [The new Kotlin K2 compiler is in Alpha now](#new-kotlin-k2-compiler-for-the-jvm-in-alpha), and it offers serious performance improvements. It is available only for the JVM, and none of the compiler plugins, including kapt, work with it.
* [A new approach to the incremental compilation in Gradle](#a-new-approach-to-incremental-compilation). Incremental compilation is now also supported for changes made inside dependent non-Kotlin modules and is compatible with Gradle.
* We've stabilized [opt-in requirement annotations](#stable-opt-in-requirements), [definitely non-nullable types](#stable-definitely-non-nullable-types), and [builder inference](#stable-builder-inference).
* [There's now an underscore operator for type args](#underscore-operator-for-type-arguments). You can use it to automatically infer a type of argument when other types are specified.
* [This release allows implementation by delegation to an inlined value of an inline class](#allow-implementation-by-delegation-to-an-inlined-value-of-an-inline-class). You can now create lightweight wrappers that do not allocate memory in most cases.
You can also find a short overview of the changes in this video:
New Kotlin K2 compiler for the JVM in Alpha
-------------------------------------------
This Kotlin release introduces the **Alpha** version of the new Kotlin K2 compiler. The new compiler aims to speed up the development of new language features, unify all of the platforms Kotlin supports, bring performance improvements, and provide an API for compiler extensions.
We've already published some detailed explanations of our new compiler and its benefits:
* [The Road to the New Kotlin Compiler](https://www.youtube.com/watch?v=iTdJJq_LyoY)
* [K2 Compiler: a Top-Down View](https://www.youtube.com/watch?v=db19VFLZqJM)
It's important to point out that with the Alpha version of the new K2 compiler we were primarily focused on performance improvements, and it only works with JVM projects. It doesn't support Kotlin/JS, Kotlin/Native, or other multi-platform projects, and none of compiler plugins, including <kapt>, work with it.
Our benchmarks show some outstanding results on our internal projects:
| Project | Current Kotlin compiler performance | New K2 Kotlin compiler performance | Performance boost |
| --- | --- | --- | --- |
| Kotlin | 2.2 KLOC/s | 4.8 KLOC/s | ~ x2.2 |
| YouTrack | 1.8 KLOC/s | 4.2 KLOC/s | ~ x2.3 |
| IntelliJ IDEA | 1.8 KLOC/s | 3.9 KLOC/s | ~ x2.2 |
| Space | 1.2 KLOC/s | 2.8 KLOC/s | ~ x2.3 |
You can check out the performance boost on your JVM projects and compare it with the results of the old compiler. To enable the Kotlin K2 compiler, use the following compiler option:
```
-Xuse-k2
```
Also, the K2 compiler [includes a number of bugfixes](https://youtrack.jetbrains.com/issues/KT?q=tag:%20FIR-preview-qa%20%23Resolved). Please note that even issues with **State: Open** from this list are in fact fixed in K2.
The next Kotlin releases will improve the stability of the K2 compiler and provide more features, so stay tuned!
If you face any performance issues with the Kotlin K2 compiler, please [report them to our issue tracker](https://youtrack.jetbrains.com/newIssue?project=KT&c=Type%20Performance%20Problem&c=Subsystems%20Frontend.%20IR).
Language
--------
Kotlin 1.7.0 introduces support for implementation by delegation and a new underscore operator for type arguments. It also stabilizes several language features introduced as previews in previous releases:
* [Implementation by delegation to inlined value of inline class](#allow-implementation-by-delegation-to-an-inlined-value-of-an-inline-class)
* [Underscore operator for type arguments](#underscore-operator-for-type-arguments)
* [Stable builder inference](#stable-builder-inference)
* [Stable opt-in requirements](#stable-opt-in-requirements)
* [Stable definitely non-nullable types](#stable-definitely-non-nullable-types)
### Allow implementation by delegation to an inlined value of an inline class
If you want to create a lightweight wrapper for a value or class instance, it's necessary to implement all interface methods by hand. Implementation by delegation solves this issue, but it did not work with inline classes before 1.7.0. This restriction has been removed, so you can now create lightweight wrappers that do not allocate memory in most cases.
```
interface Bar {
fun foo() = "foo"
}
@JvmInline
value class BarWrapper(val bar: Bar): Bar by bar
fun main() {
val bw = BarWrapper(object: Bar {})
println(bw.foo())
}
```
### Underscore operator for type arguments
Kotlin 1.7.0 introduces an underscore operator, `_`, for type arguments. You can use it to automatically infer a type argument when other types are specified:
```
abstract class SomeClass<T> {
abstract fun execute(): T
}
class SomeImplementation : SomeClass<String>() {
override fun execute(): String = "Test"
}
class OtherImplementation : SomeClass<Int>() {
override fun execute(): Int = 42
}
object Runner {
inline fun <reified S: SomeClass<T>, T> run(): T {
return S::class.java.getDeclaredConstructor().newInstance().execute()
}
}
fun main() {
// T is inferred as String because SomeImplementation derives from SomeClass<String>
val s = Runner.run<SomeImplementation, _>()
assert(s == "Test")
// T is inferred as Int because OtherImplementation derives from SomeClass<Int>
val n = Runner.run<OtherImplementation, _>()
assert(n == 42)
}
```
### Stable builder inference
Builder inference is a special kind of type inference that is useful when calling generic builder functions. It helps the compiler infer the type arguments of a call using the type information about other calls inside its lambda argument.
Starting with 1.7.0, builder inference is automatically activated if a regular type inference cannot get enough information about a type without specifying the `-Xenable-builder-inference` compiler option, which was [introduced in 1.6.0](whatsnew16#changes-to-builder-inference).
[Learn how to write custom generic builders](using-builders-with-builder-inference).
### Stable opt-in requirements
[Opt-in requirements](opt-in-requirements) are now [Stable](components-stability) and do not require additional compiler configuration.
Before 1.7.0, the opt-in feature itself required the argument `-opt-in=kotlin.RequiresOptIn` to avoid a warning. It no longer requires this; however, you can still use the compiler argument `-opt-in` to opt-in for other annotations, [module-wide](opt-in-requirements#module-wide-opt-in).
### Stable definitely non-nullable types
In Kotlin 1.7.0, definitely non-nullable types have been promoted to [Stable](components-stability). They provide better interoperability when extending generic Java classes and interfaces.
You can mark a generic type parameter as definitely non-nullable at the use site with the new syntax `T & Any`. The syntactic form comes from the notation for [intersection types](https://en.wikipedia.org/wiki/Intersection_type) and is now limited to a type parameter with nullable upper bounds on the left side of `&` and a non-nullable `Any` on the right side:
```
fun <T> elvisLike(x: T, y: T & Any): T & Any = x ?: y
fun main() {
// OK
elvisLike<String>("", "").length
// Error: 'null' cannot be a value of a non-null type
elvisLike<String>("", null).length
// OK
elvisLike<String?>(null, "").length
// Error: 'null' cannot be a value of a non-null type
elvisLike<String?>(null, null).length
}
```
Learn more about definitely non-nullable types in [this KEEP](https://github.com/Kotlin/KEEP/blob/c72601cf35c1e95a541bb4b230edb474a6d1d1a8/proposals/definitely-non-nullable-types.md).
Kotlin/JVM
----------
This release brings performance improvements for the Kotlin/JVM compiler and a new compiler option. Additionally, callable references to functional interface constructors have become Stable. Note that since 1.7.0, the default target version for Kotlin/JVM compilations is now `1.8`.
* [Compiler performance optimizations](#compiler-performance-optimizations)
* [New compiler option `-Xjdk-release`](#new-compiler-option-xjdk-release)
* [Stable callable references to functional interface constructors](#stable-callable-references-to-functional-interface-constructors)
* [Removed the JVM target version 1.6](#removed-jvm-target-version-1-6)
### Compiler performance optimizations
Kotlin 1.7.0 introduces performance improvements for the Kotlin/JVM compiler. According to our benchmarks, compilation time has been [reduced by 10% on average](https://youtrack.jetbrains.com/issue/KT-48233/Switching-to-JVM-IR-backend-increases-compilation-time-by-more-t#focus=Comments-27-6114542.0-0) compared to Kotlin 1.6.0. Projects with lots of usages of inline functions, for example, [projects using `kotlinx.html`](https://youtrack.jetbrains.com/issue/KT-51416/Compilation-of-kotlinx-html-DSL-should-still-be-faster), will compile faster thanks to the improvements to the bytecode postprocessing.
### New compiler option: -Xjdk-release
Kotlin 1.7.0 presents a new compiler option, `-Xjdk-release`. This option is similar to the [javac's command-line `--release` option](http://openjdk.java.net/jeps/247). The `-Xjdk-release` option controls the target bytecode version and limits the API of the JDK in the classpath to the specified Java version. For example, `kotlinc -Xjdk-release=1.8` won't allow referencing `java.lang.Module` even if the JDK in the dependencies is version 9 or higher.
Please leave your feedback on [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-29974/Add-a-compiler-option-Xjdk-release-similar-to-javac-s-release-to).
### Stable callable references to functional interface constructors
[Callable references](reflection#callable-references) to functional interface constructors are now [Stable](components-stability). Learn how to [migrate](fun-interfaces#migration-from-an-interface-with-constructor-function-to-a-functional-interface) from an interface with a constructor function to a functional interface using callable references.
Please report any issues you find in [YouTrack](https://youtrack.jetbrains.com/newissue?project=kt).
### Removed JVM target version 1.6
The default target version for Kotlin/JVM compilations is `1.8`. The `1.6` target has been removed.
Please migrate to JVM target 1.8 or above. Learn how to update the JVM target version for:
* [Gradle](gradle-compiler-options#attributes-specific-to-jvm)
* [Maven](maven#attributes-specific-to-jvm)
* [The command-line compiler](compiler-reference#jvm-target-version)
Kotlin/Native
-------------
Kotlin 1.7.0 includes changes to Objective-C and Swift interoperability and stabilizes features that were introduced in previous releases. It also brings performance improvements for the new memory manager along with other updates:
* [Performance improvements for the new memory manager](#performance-improvements-for-the-new-memory-manager)
* [Unified compiler plugin ABI with JVM and JS IR backends](#unified-compiler-plugin-abi-with-jvm-and-js-ir-backends)
* [Support for standalone Android executables](#support-for-standalone-android-executables)
* [Interop with Swift async/await: returning `Void` instead of `KotlinUnit`](#interop-with-swift-async-await-returning-void-instead-of-kotlinunit)
* [Prohibited undeclared exceptions through Objective-C bridges](#prohibited-undeclared-exceptions-through-objective-c-bridges)
* [Improved CocoaPods integration](#improved-cocoapods-integration)
* [Overriding of the Kotlin/Native compiler download URL](#overriding-the-kotlin-native-compiler-download-url)
### Performance improvements for the new memory manager
The new memory manager is still in Alpha, but it is on its way to becoming [Stable](components-stability). This release delivers significant performance improvements for the new memory manager, especially in garbage collection (GC). In particular, concurrent implementation of the sweep phase, [introduced in 1.6.20](whatsnew1620), is now enabled by default. This helps reduce the time the application is paused for GC. The new GC scheduler is better at choosing the GC frequency, especially for larger heaps.
Also, we've specifically optimized debug binaries, ensuring that the proper optimization level and link-time optimizations are used in the implementation code of the memory manager. This helped us improve execution time by roughly 30% for debug binaries on our benchmarks.
Try using the new memory manager in your projects to see how it works, and share your feedback with us in [YouTrack](https://youtrack.jetbrains.com/issue/KT-48525).
### Unified compiler plugin ABI with JVM and JS IR backends
Starting with Kotlin 1.7.0, the Kotlin Multiplatform Gradle plugin uses the embeddable compiler jar for Kotlin/Native by default. This [feature was announced in 1.6.0](whatsnew16#unified-compiler-plugin-abi-with-jvm-and-js-ir-backends) as Experimental, and now it's Stable and ready to use.
This improvement is very handy for library authors, as it improves the compiler plugin development experience. Before this release, you had to provide separate artifacts for Kotlin/Native, but now you can use the same compiler plugin artifacts for Native and other supported platforms.
### Support for standalone Android executables
Kotlin 1.7.0 provides full support for generating standard executables for Android Native targets. It was [introduced in 1.6.20](whatsnew1620#support-for-standalone-android-executables), and now it's enabled by default.
If you want to roll back to the previous behavior when Kotlin/Native generated shared libraries, use the following setting:
```
binaryOptions["androidProgramType"] = "nativeActivity"
```
### Interop with Swift async/await: returning Void instead of KotlinUnit
Kotlin `suspend` functions now return the `Void` type instead of `KotlinUnit` in Swift. This is the result of the improved interop with Swift's `async`/`await`. This feature was [introduced in 1.6.20](whatsnew1620#interop-with-swift-async-await-returning-void-instead-of-kotlinunit), and this release enables this behavior by default.
You don't need to use the `kotlin.native.binary.unitSuspendFunctionObjCExport=proper` property anymore to return the proper type for such functions.
### Prohibited undeclared exceptions through Objective-C bridges
When you call Kotlin code from Swift/Objective-C code (or vice versa) and this code throws an exception, it should be handled by the code where the exception occurred, unless you specifically allowed the forwarding of exceptions between languages with proper conversion (for example, using the `@Throws` annotation).
Previously, Kotlin had another unintended behavior where undeclared exceptions could "leak" from one language to another in some cases. Kotlin 1.7.0 fixes that issue, and now such cases lead to program termination.
So, for example, if you have a `{ throw Exception() }` lambda in Kotlin and call it from Swift, in Kotlin 1.7.0 it will terminate as soon as the exception reaches the Swift code. In previous Kotlin versions, such an exception could leak to the Swift code.
The `@Throws` annotation continues to work as before.
### Improved CocoaPods integration
Starting with Kotlin 1.7.0, you no longer need to install the `cocoapods-generate` plugin if you want to integrate CocoaPods in your projects.
Previously, you needed to install both the CocoaPods dependency manager and the `cocoapods-generate` plugin to use CocoaPods, for example, to handle [iOS dependencies](multiplatform-mobile-ios-dependencies#with-cocoapods) in Kotlin Multiplatform Mobile projects.
Now setting up the CocoaPods integration is easier, and we've resolved the issue when `cocoapods-generate` couldn't be installed on Ruby 3 and later. Now the newest Ruby versions that work better on Apple M1 are also supported.
See how to set up the [initial CocoaPods integration](native-cocoapods#set-up-an-environment-to-work-with-cocoapods).
### Overriding the Kotlin/Native compiler download URL
Starting with Kotlin 1.7.0, you can customize the download URL for the Kotlin/Native compiler. This is useful when external links on the CI are forbidden.
To override the default base URL `https://download.jetbrains.com/kotlin/native/builds`, use the following Gradle property:
```
kotlin.native.distribution.baseDownloadUrl=https://example.com
```
Kotlin/JS
---------
Kotlin/JS is receiving further improvements to the [JS IR compiler backend](js-ir-compiler) along with other updates that can make your development experience better:
* [Performance improvements for the new IR backend](#performance-improvements-for-the-new-ir-backend)
* [Minification for member names when using IR](#minification-for-member-names-when-using-ir)
* [Support for older browsers via polyfills in the IR backend](#support-for-older-browsers-via-polyfills-in-the-ir-backend)
* [Dynamically load JavaScript modules from js expressions](#dynamically-load-javascript-modules-from-js-expressions)
* [Specify environment variables for JavaScript test runners](#specify-environment-variables-for-javascript-test-runners)
### Performance improvements for the new IR backend
This release has some major updates that should improve your development experience:
* Incremental compilation performance of Kotlin/JS has been significantly improved. It takes less time to build your JS projects. Incremental rebuilds should now be roughly on par with the legacy backend in many cases now.
* The Kotlin/JS final bundle requires less space, as we have significantly reduced the size of the final artifacts. We've measured up to a 20% reduction in the production bundle size compared to the legacy backend for some large projects.
* Type checking for interfaces has been improved by orders of magnitude.
* Kotlin generates higher-quality JS code
### Minification for member names when using IR
The Kotlin/JS IR compiler now uses its internal information about the relationships of your Kotlin classes and functions to apply more efficient minification, shortening the names of functions, properties, and classes. This shrinks the resulting bundled applications.
This type of minification is automatically applied when you build your Kotlin/JS application in production mode and is enabled by default. To disable member name minification, use the `-Xir-minimized-member-names` compiler flag:
```
kotlin {
js(IR) {
compilations.all {
compileKotlinTask.kotlinOptions.freeCompilerArgs += listOf("-Xir-minimized-member-names=false")
}
}
}
```
### Support for older browsers via polyfills in the IR backend
The IR compiler backend for Kotlin/JS now includes the same polyfills as the legacy backend. This allows code compiled with the new compiler to run in older browsers that do not support all the methods from ES2015 used by the Kotlin standard library. Only those polyfills actually used by the project are included in the final bundle, which minimizes their potential impact on the bundle size.
This feature is enabled by default when using the IR compiler, and you don't need to configure it.
### Dynamically load JavaScript modules from js expressions
When working with the JavaScript modules, most applications use static imports, whose use is covered with the [JavaScript module integration](js-modules). However, Kotlin/JS was missing a mechanism to load JavaScript modules dynamically at runtime in your applications.
Starting with Kotlin 1.7.0, the `import` statement from JavaScript is supported in `js` blocks, allowing you to dynamically bring packages into your application at runtime:
```
val myPackage = js("import('my-package')")
```
### Specify environment variables for JavaScript test runners
To tune Node.js package resolution or pass external information to Node.js tests, you can now specify environment variables used by the JavaScript test runners. To define an environment variable, use the `environment()` function with a key-value pair inside the `testTask` block in your build script:
```
kotlin {
js {
nodejs {
testTask {
environment("key", "value")
}
}
}
}
```
Standard library
----------------
In Kotlin 1.7.0, the standard library has received a range of changes and improvements. They introduce new features, stabilize experimental ones, and unify support for named capturing groups for Native, JS, and the JVM:
* [min() and max() collection functions return as non-nullable](#min-and-max-collection-functions-return-as-non-nullable)
* [Regular expression matching at specific indices](#regular-expression-matching-at-specific-indices)
* [Extended support of previous language and API versions](#extended-support-for-previous-language-and-api-versions)
* [Access to annotations via reflection](#access-to-annotations-via-reflection)
* [Stable deep recursive functions](#stable-deep-recursive-functions)
* [Time marks based on inline classes for default time source](#time-marks-based-on-inline-classes-for-default-time-source)
* [New experimental extension functions for Java Optionals](#new-experimental-extension-functions-for-java-optionals)
* [Support for named capturing groups in JS and Native](#support-for-named-capturing-groups-in-js-and-native)
### min() and max() collection functions return as non-nullable
In [Kotlin 1.4.0](whatsnew14), we renamed the `min()` and `max()` collection functions to `minOrNull()` and `maxOrNull()`. These new names better reflect their behavior – returning null if the receiver collection is empty. It also helped align the functions' behavior with naming conventions used throughout the Kotlin collections API.
The same was true of `minBy()`, `maxBy()`, `minWith()`, and `maxWith()`, which all got their \*OrNull() synonyms in Kotlin 1.4.0. Older functions affected by this change were gradually deprecated.
Kotlin 1.7.0 reintroduces the original function names, but with a non-nullable return type. The new `min()`, `max()`, `minBy()`, `maxBy()`, `minWith()`, and `maxWith()` functions now strictly return the collection element or throw an exception.
```
fun main() {
val numbers = listOf<Int>()
println(numbers.maxOrNull()) // "null"
println(numbers.max()) // "Exception in... Collection is empty."
}
```
### Regular expression matching at specific indices
The `Regex.matchAt()` and `Regex.matchesAt()` functions, [introduced in 1.5.30](whatsnew1530#matching-with-regex-at-a-particular-position), are now Stable. They provide a way to check whether a regular expression has an exact match at a particular position in a `String` or `CharSequence`.
`matchesAt()` checks for a match and returns a boolean result:
```
fun main() {
val releaseText = "Kotlin 1.7.0 is on its way!"
// regular expression: one digit, dot, one digit, dot, one or more digits
val versionRegex = "\\d[.]\\d[.]\\d+".toRegex()
println(versionRegex.matchesAt(releaseText, 0)) // "false"
println(versionRegex.matchesAt(releaseText, 7)) // "true"
}
```
`matchAt()` returns the match if it's found, or `null` if it isn't:
```
fun main() {
val releaseText = "Kotlin 1.7.0 is on its way!"
val versionRegex = "\\d[.]\\d[.]\\d+".toRegex()
println(versionRegex.matchAt(releaseText, 0)) // "null"
println(versionRegex.matchAt(releaseText, 7)?.value) // "1.7.0"
}
```
We'd be grateful for your feedback on this [YouTrack issue](https://youtrack.jetbrains.com/issue/KT-34021).
### Extended support for previous language and API versions
To support library authors developing libraries that are meant to be consumable in a wide range of previous Kotlin versions, and to address the increased frequency of major Kotlin releases, we have extended our support for previous language and API versions.
With Kotlin 1.7.0, we're supporting three previous language and API versions rather than two. This means Kotlin 1.7.0 supports the development of libraries targeting Kotlin versions down to 1.4.0. For more information on backward compatibility, see [Compatibility modes](compatibility-modes).
### Access to annotations via reflection
The `KAnnotatedElement.[findAnnotations()](../api/latest/jvm/stdlib/kotlin.reflect.full/find-annotations)` extension function, which was first [introduced in 1.6.0](whatsnew16#repeatable-annotations-with-runtime-retention-for-1-8-jvm-target), is now [Stable](components-stability). This <reflection> function returns all annotations of a given type on an element, including individually applied and repeated annotations.
```
@Repeatable
annotation class Tag(val name: String)
@Tag("First Tag")
@Tag("Second Tag")
fun taggedFunction() {
println("I'm a tagged function!")
}
fun main() {
val x = ::taggedFunction
val foo = x as KAnnotatedElement
println(foo.findAnnotations<Tag>()) // [@Tag(name=First Tag), @Tag(name=Second Tag)]
}
```
### Stable deep recursive functions
Deep recursive functions have been available as an experimental feature since [Kotlin 1.4.0](https://blog.jetbrains.com/kotlin/2020/07/kotlin-1-4-rc-debugging-coroutines/#Defining_deep_recursive_functions_using_coroutines), and they are now [Stable](components-stability) in Kotlin 1.7.0. Using `DeepRecursiveFunction`, you can define a function that keeps its stack on the heap instead of using the actual call stack. This allows you to run very deep recursive computations. To call a deep recursive function, `invoke` it.
In this example, a deep recursive function is used to calculate the depth of a binary tree recursively. Even though this sample function calls itself recursively 100,000 times, no `StackOverflowError` is thrown:
```
class Tree(val left: Tree?, val right: Tree?)
val calculateDepth = DeepRecursiveFunction<Tree?, Int> { t ->
if (t == null) 0 else maxOf(
callRecursive(t.left),
callRecursive(t.right)
) + 1
}
fun main() {
// Generate a tree with a depth of 100_000
val deepTree = generateSequence(Tree(null, null)) { prev ->
Tree(prev, null)
}.take(100_000).last()
println(calculateDepth(deepTree)) // 100000
}
```
Consider using deep recursive functions in your code where your recursion depth exceeds 1000 calls.
### Time marks based on inline classes for default time source
Kotlin 1.7.0 improves the performance of time measurement functionality by changing the time marks returned by `TimeSource.Monotonic` into inline value classes. This means that calling functions like `markNow()`, `elapsedNow()`, `measureTime()`, and `measureTimedValue()` doesn't allocate wrapper classes for their `TimeMark` instances. Especially when measuring a piece of code that is part of a hot path, this can help minimize the performance impact of the measurement:
```
@OptIn(ExperimentalTime::class)
fun main() {
val mark = TimeSource.Monotonic.markNow() // Returned `TimeMark` is inline class
val elapsedDuration = mark.elapsedNow()
}
```
### New experimental extension functions for Java Optionals
Kotlin 1.7.0 comes with new convenience functions that simplify working with `Optional` classes in Java. These new functions can be used to unwrap and convert optional objects on the JVM and help make working with Java APIs more concise.
The `getOrNull()`, `getOrDefault()`, and `getOrElse()` extension functions allow you to get the value of an `Optional` if it's present. Otherwise, you get `null`, a default value, or a value returned by a function, respectively:
```
val presentOptional = Optional.of("I'm here!")
println(presentOptional.getOrNull())
// "I'm here!"
val absentOptional = Optional.empty<String>()
println(absentOptional.getOrNull())
// null
println(absentOptional.getOrDefault("Nobody here!"))
// "Nobody here!"
println(absentOptional.getOrElse {
println("Optional was absent!")
"Default value!"
})
// "Optional was absent!"
// "Default value!"
```
The `toList()`, `toSet()`, and `asSequence()` extension functions convert the value of a present `Optional` to a list, set, or sequence, or return an empty collection otherwise. The `toCollection()` extension function appends the `Optional` value to an already existing destination collection:
```
val presentOptional = Optional.of("I'm here!")
val absentOptional = Optional.empty<String>()
println(presentOptional.toList() + "," + absentOptional.toList())
// ["I'm here!"], []
println(presentOptional.toSet() + "," + absentOptional.toSet())
// ["I'm here!"], []
val myCollection = mutableListOf<String>()
absentOptional.toCollection(myCollection)
println(myCollection)
// []
presentOptional.toCollection(myCollection)
println(myCollection)
// ["I'm here!"]
val list = listOf(presentOptional, absentOptional).flatMap { it.asSequence() }
println(list)
// ["I'm here!"]
```
These extension functions are being introduced as Experimental in Kotlin 1.7.0. You can learn more about `Optional` extensions in [this KEEP](https://github.com/Kotlin/KEEP/pull/291). As always, we welcome your feedback in the [Kotlin issue tracker](https://kotl.in/issue).
### Support for named capturing groups in JS and Native
Starting with Kotlin 1.7.0, named capturing groups are supported not only on the JVM, but on the JS and Native platforms as well.
To give a name to a capturing group, use the (`?<name>group`) syntax in your regular expression. To get the text matched by a group, call the newly introduced [`MatchGroupCollection.get()`](../api/latest/jvm/stdlib/kotlin.text/get) function and pass the group name.
#### Retrieve matched group value by name
Consider this example for matching city coordinates. To get a collection of groups matched by the regular expression, use [`groups`](../api/latest/jvm/stdlib/kotlin.text/-match-result/groups). Compare retrieving a group's contents by its number (index) and by its name using `value`:
```
fun main() {
val regex = "\\b(?<city>[A-Za-z\\s]+),\\s(?<state>[A-Z]{2}):\\s(?<areaCode>[0-9]{3})\\b".toRegex()
val input = "Coordinates: Austin, TX: 123"
val match = regex.find(input)!!
println(match.groups["city"]?.value) // "Austin" — by name
println(match.groups[2]?.value) // "TX" — by number
}
```
#### Named backreferencing
You can now also use group names when backreferencing groups. Backreferences match the same text that was previously matched by a capturing group. For this, use the `\k<name>` syntax in your regular expression:
```
fun backRef() {
val regex = "(?<title>\\w+), yes \\k<title>".toRegex()
val match = regex.find("Do you copy? Sir, yes Sir!")!!
println(match.value) // "Sir, yes Sir"
println(match.groups["title"]?.value) // "Sir"
}
```
#### Named groups in replacement expressions
Named group references can be used with replacement expressions. Consider the [`replace()`](../api/latest/jvm/stdlib/kotlin.text/-regex/replace) function that substitutes all occurrences of the specified regular expression in the input with a replacement expression, and the [`replaceFirst()`](../api/latest/jvm/stdlib/kotlin.text/-regex/replace-first) function that swaps the first match only.
Occurrences of `${name}` in the replacement string are substituted with the subsequences corresponding to the captured groups with the specified name. You can compare replacements in group references by name and index:
```
fun dateReplace() {
val dateRegex = Regex("(?<dd>\\d{2})-(?<mm>\\d{2})-(?<yyyy>\\d{4})")
val input = "Date of birth: 27-04-2022"
println(dateRegex.replace(input, "\${yyyy}-\${mm}-\${dd}")) // "Date of birth: 2022-04-27" — by name
println(dateRegex.replace(input, "\$3-\$2-\$1")) // "Date of birth: 2022-04-27" — by number
}
```
Gradle
------
This release introduces new build reports, support for Gradle plugin variants, new statistics in kapt, and a lot more:
* [A new approach to incremental compilation](#a-new-approach-to-incremental-compilation)
* [New build reports for tracking compiler performance](#build-reports-for-kotlin-compiler-tasks)
* [Changes to the minimum supported versions of Gradle and the Android Gradle plugin](#bumping-minimum-supported-versions)
* [Support for Gradle plugin variants](#support-for-gradle-plugin-variants)
* [Updates in the Kotlin Gradle plugin API](#updates-in-the-kotlin-gradle-plugin-api)
* [Availability of the sam-with-receiver plugin via the plugins API](#the-sam-with-receiver-plugin-is-available-via-the-plugins-api)
* [Changes in compile tasks](#changes-in-compile-tasks)
* [New statistics of generated files by each annotation processor in kapt](#statistics-of-generated-files-by-each-annotation-processor-in-kapt)
* [Deprecation of the kotlin.compiler.execution.strategy system property](#deprecation-of-the-kotlin-compiler-execution-strategy-system-property)
* [Removal of deprecated options, methods, and plugins](#removal-of-deprecated-options-methods-and-plugins)
### A new approach to incremental compilation
In Kotlin 1.7.0, we've reworked incremental compilation for cross-module changes. Now incremental compilation is also supported for changes made inside dependent non-Kotlin modules, and it is compatible with the [Gradle build cache](https://docs.gradle.org/current/userguide/build_cache.html). Support for compilation avoidance has also been improved.
We expect you'll see the most significant benefit of the new approach if you use the build cache or frequently make changes in non-Kotlin Gradle modules. Our tests for the Kotlin project on the `kotlin-gradle-plugin` module show an improvement of greater than 80% for the changes after the cache hit.
To try this new approach, set the following option in your `gradle.properties`:
```
kotlin.incremental.useClasspathSnapshot=true
```
Learn how the new approach to incremental compilation is implemented under the hood in [this blog post](https://blog.jetbrains.com/kotlin/2022/07/a-new-approach-to-incremental-compilation-in-kotlin/).
Our plan is to stabilize this technology and add support for other backends (JS, for instance) and build systems. We'd appreciate your reports in [YouTrack](https://youtrack.jetbrains.com/issues/KT) about any issues or strange behavior you encounter in this compilation scheme. Thank you!
The Kotlin team is very grateful to [Ivan Gavrilovic](https://github.com/gavra0), [Hung Nguyen](https://github.com/hungvietnguyen), [Cédric Champeau](https://github.com/melix), and other external contributors for their help.
### Build reports for Kotlin compiler tasks
Kotlin 1.7.0 introduces build reports that help track compiler performance. Reports contain the durations of different compilation phases and reasons why compilation couldn't be incremental.
Build reports come in handy when you want to investigate issues with compiler tasks, for example:
* When the Gradle build takes too much time and you want to understand the root cause of the poor performance.
* When the compilation time for the same project differs, sometimes taking seconds, sometimes taking minutes.
To enable build reports, declare where to save the build report output in `gradle.properties`:
```
kotlin.build.report.output=file
```
The following values (and their combinations) are available:
* `file` saves build reports in a local file.
* `build_scan` saves build reports in the `custom values` section of the [build scan](https://scans.gradle.com/).
* `http` posts build reports using HTTP(S). The POST method sends metrics in the JSON format. Data may change from version to version. You can see the current version of the sent data in the [Kotlin repository](https://github.com/JetBrains/kotlin/blob/master/libraries/tools/kotlin-gradle-plugin/src/common/kotlin/org/jetbrains/kotlin/gradle/plugin/statistics/CompileStatisticsData.kt).
There are two common cases that analyzing build reports for long-running compilations can help you resolve:
* The build wasn't incremental. Analyze the reasons and fix underlying problems.
* The build was incremental, but took too much time. Try to reorganize source files — split big files, save separate classes in different files, refactor large classes, declare top-level functions in different files, and so on.
Learn more about new build reports in [this blog post](https://blog.jetbrains.com/kotlin/2022/06/introducing-kotlin-build-reports/).
You are welcome to try using build reports in your infrastructure. If you have any feedback, encounter any issues, or want to suggest improvements, please don't hesitate to report them in our [issue tracker](https://youtrack.jetbrains.com/newIssue). Thank you!
### Bumping minimum supported versions
Starting with Kotlin 1.7.0, the minimum supported Gradle version is 6.7.1. We had to [raise the version](https://youtrack.jetbrains.com/issue/KT-49733/Bump-minimal-supported-Gradle-version-to-6-7-1) to support [Gradle plugin variants](#support-for-gradle-plugin-variants) and the new Gradle API. In the future, we should not have to raise the minimum supported version as often, thanks to the Gradle plugin variants feature.
Also, the minimal supported Android Gradle plugin version is now 3.6.4.
### Support for Gradle plugin variants
Gradle 7.0 introduced a new feature for Gradle plugin authors — [plugins with variants](https://docs.gradle.org/7.0/userguide/implementing_gradle_plugins.html#plugin-with-variants). This feature makes it easier to add support for new Gradle features while maintaining compatibility for Gradle versions below 7.1. Learn more about [variant selection in Gradle](https://docs.gradle.org/current/userguide/variant_model.html).
With Gradle plugin variants, we can ship different Kotlin Gradle plugin variants for different Gradle versions. The goal is to support the base Kotlin compilation in the `main` variant, which corresponds to the oldest supported versions of Gradle. Each variant will have implementations for Gradle features from a corresponding release. The latest variant will support the widest Gradle feature set. With this approach, we can extend support for older Gradle versions with limited functionality.
Currently, there are only two variants of the Kotlin Gradle plugin:
* `main` for Gradle versions 6.7.1–6.9.3
* `gradle70` for Gradle versions 7.0 and higher
In future Kotlin releases, we may add more.
To check which variant your build uses, enable the [`--info` log level](https://docs.gradle.org/current/userguide/logging.html#sec:choosing_a_log_level) and find a string in the output starting with `Using Kotlin Gradle plugin`, for example, `Using Kotlin Gradle plugin main variant`.
Leave your feedback on [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-49227/Support-Gradle-plugins-variants).
### Updates in the Kotlin Gradle plugin API
The Kotlin Gradle plugin API artifact has received several improvements:
* There are new interfaces for Kotlin/JVM and Kotlin/kapt tasks with user-configurable inputs.
* There is a new `KotlinBasePlugin` interface that all Kotlin plugins inherit from. Use this interface when you want to trigger some configuration action whenever any Kotlin Gradle plugin (JVM, JS, Multiplatform, Native, and other platforms) is applied:
```
project.plugins.withType<org.jetbrains.kotlin.gradle.plugin.KotlinBasePlugin>() {
// Configure your action here
}
```
You can leave your feedback about the `KotlinBasePlugin` in [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-48008/Consider-offering-a-KotlinBasePlugin).
* We've laid the groundwork for the Android Gradle plugin to configure Kotlin compilation within itself, meaning you won't need to add the Kotlin Android Gradle plugin to your build. Follow [Android Gradle Plugin release announcements](https://developer.android.com/studio/releases/gradle-plugin) to learn about the added support and try it out!
### The sam-with-receiver plugin is available via the plugins API
The [sam-with-receiver compiler plugin](sam-with-receiver-plugin) is now available via the [Gradle plugins DSL](https://docs.gradle.org/current/userguide/plugins.html#sec:plugins_block):
```
plugins {
id("org.jetbrains.kotlin.plugin.sam.with.receiver") version "$kotlin_version"
}
```
### Changes in compile tasks
Compile tasks have received lots of changes in this release:
* Kotlin compile tasks no longer inherit the Gradle `AbstractCompile` task. They inherit only the `DefaultTask`.
* The `AbstractCompile` task has the `sourceCompatibility` and `targetCompatibility` inputs. Since the `AbstractCompile` task is no longer inherited, these inputs are no longer available in Kotlin users' scripts.
* The `SourceTask.stableSources` input is no longer available, and you should use the `sources` input. `setSource(...)` methods are still available.
* All compile tasks now use the `libraries` input for a list of libraries required for compilation. The `KotlinCompile` task still has the deprecated Kotlin property `classpath`, which will be removed in future releases.
* Compile tasks still implement the `PatternFilterable` interface, which allows the filtering of Kotlin sources. The `sourceFilesExtensions` input was removed in favor of using `PatternFilterable` methods.
* The deprecated `Gradle destinationDir: File` output was replaced with the `destinationDirectory: DirectoryProperty` output.
* The Kotlin/Native `AbstractNativeCompile` task now inherits the `AbstractKotlinCompileTool` base class. This is an initial step toward integrating Kotlin/Native build tools into all the other tools.
Please leave your feedback in [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-32805).
### Statistics of generated files by each annotation processor in kapt
The `kotlin-kapt` Gradle plugin already [reports performance statistics for each processor](https://github.com/JetBrains/kotlin/pull/4280). Starting with Kotlin 1.7.0, it can also report statistics on the number of generated files for each annotation processor.
This is useful to track if there are unused annotation processors as a part of the build. You can use the generated report to find modules that trigger unnecessary annotation processors and update the modules to prevent that.
Enable the statistics in two steps:
* Set the `showProcessorStats` flag to `true` in your `build.gradle.kts`:
```
kapt {
showProcessorStats = true
}
```
* Set the `kapt.verbose` Gradle property to `true` in your `gradle.properties`:
```
kapt.verbose=true
```
The statistics will appear in the logs with the `info` level. You'll see the `Annotation processor stats:` line followed by statistics on the execution time of each annotation processor. After these lines, there will be the `Generated files report:` line followed by statistics on the number of generated files for each annotation processor. For example:
```
[INFO] Annotation processor stats:
[INFO] org.mapstruct.ap.MappingProcessor: total: 290 ms, init: 1 ms, 3 round(s): 289 ms, 0 ms, 0 ms
[INFO] Generated files report:
[INFO] org.mapstruct.ap.MappingProcessor: total sources: 2, sources per round: 2, 0, 0
```
Please leave your feedback in [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-51132/KAPT-Support-reporting-the-number-of-generated-files-by-each-ann).
### Deprecation of the kotlin.compiler.execution.strategy system property
Kotlin 1.6.20 introduced [new properties for defining a Kotlin compiler execution strategy](whatsnew1620#properties-for-defining-kotlin-compiler-execution-strategy). In Kotlin 1.7.0, a deprecation cycle has started for the old system property `kotlin.compiler.execution.strategy` in favor of the new properties.
When using the `kotlin.compiler.execution.strategy` system property, you'll receive a warning. This property will be deleted in future releases. To preserve the old behavior, replace the system property with the Gradle property of the same name. You can do this in `gradle.properties`, for example:
```
kotlin.compiler.execution.strategy=out-of-process
```
You can also use the compile task property `compilerExecutionStrategy`. Learn more about this on the [Gradle page](gradle-compilation-and-caches#defining-kotlin-compiler-execution-strategy).
### Removal of deprecated options, methods, and plugins
#### Removal of the useExperimentalAnnotation method
In Kotlin 1.7.0, we completed the deprecation cycle for the `useExperimentalAnnotation` Gradle method. Use `optIn()` instead to opt in to using an API in a module.
For example, if your Gradle module is multiplatform:
```
sourceSets {
all {
languageSettings.optIn("org.mylibrary.OptInAnnotation")
}
}
```
Learn more about [opt-in requirements](opt-in-requirements) in Kotlin.
#### Removal of deprecated compiler options
We've completed the deprecation cycle for several compiler options:
* The `kotlinOptions.jdkHome` compiler option was deprecated in 1.5.30 and has been removed in the current release. Gradle builds now fail if they contain this option. We encourage you to use [Java toolchains](whatsnew1530#support-for-java-toolchains), which have been supported since Kotlin 1.5.30.
* The deprecated `noStdlib` compiler option has also been removed. The Gradle plugin uses the `kotlin.stdlib.default.dependency=true` property to control whether the Kotlin standard library is present.
#### Removal of deprecated plugins
In Kotlin 1.4.0, the `kotlin2js` and `kotlin-dce-plugin` plugins were deprecated, and they have been removed in this release. Instead of `kotlin2js`, use the new `org.jetbrains.kotlin.js` plugin. Dead code elimination (DCE) works when the Kotlin/JS Gradle plugin is [properly configured](javascript-dce).
In Kotlin 1.6.0, we changed the deprecation level of the `KotlinGradleSubplugin` class to `ERROR`. Developers used this class for writing compiler plugins. In this release, [this class has been removed](https://youtrack.jetbrains.com/issue/KT-48831/). Use the `KotlinCompilerPluginSupportPlugin` class instead.
#### Removal of the deprecated coroutines DSL option and property
We removed the deprecated `kotlin.experimental.coroutines` Gradle DSL option and the `kotlin.coroutines` property used in `gradle.properties`. Now you can just use *[suspending functions](coroutines-basics#extract-function-refactoring)* or [add the `kotlinx.coroutines` dependency](gradle-configure-project#set-a-dependency-on-a-kotlinx-library) to your build script.
Learn more about coroutines in the [Coroutines guide](coroutines-guide).
#### Removal of the type cast in the toolchain extension method
Before Kotlin 1.7.0, you had to do the type cast into the `JavaToolchainSpec` class when configuring the Gradle toolchain with Kotlin DSL:
```
kotlin {
jvmToolchain {
(this as JavaToolchainSpec).languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)
}
}
```
Now, you can omit the `(this as JavaToolchainSpec)` part:
```
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)
}
}
```
Migrating to Kotlin 1.7.0
-------------------------
### Install Kotlin 1.7.0
IntelliJ IDEA 2022.1 and Android Studio Chipmunk (212) automatically suggest updating the Kotlin plugin to 1.7.0.
The new command-line compiler is available for download on the [GitHub release page](https://github.com/JetBrains/kotlin/releases/tag/v1.7.0).
### Migrate existing or start a new project with Kotlin 1.7.0
* To migrate existing projects to Kotlin 1.7.0, change the Kotlin version to `1.7.0` and reimport your Gradle or Maven project. [Learn how to update to Kotlin 1.7.0](releases#update-to-a-new-release).
* To start a new project with Kotlin 1.7.0, update the Kotlin plugin and run the Project Wizard from **File** | **New** | **Project**.
### Compatibility guide for Kotlin 1.7.0
Kotlin 1.7.0 is a [feature release](kotlin-evolution#feature-releases-and-incremental-releases) and can, therefore, bring changes that are incompatible with your code written for earlier versions of the language. Find the detailed list of such changes in the [Compatibility guide for Kotlin 1.7.0](compatibility-guide-17).
Last modified: 10 January 2023
[What's new in Kotlin 1.7.20](whatsnew1720) [What's new in Kotlin 1.6.20](whatsnew1620)
| programming_docs |
kotlin Kotlin/JS IR compiler Kotlin/JS IR compiler
=====================
The Kotlin/JS IR compiler backend is the main focus of innovation around Kotlin/JS, and paves the way forward for the technology.
Rather than directly generating JavaScript code from Kotlin source code, the Kotlin/JS IR compiler backend leverages a new approach. Kotlin source code is first transformed into a [Kotlin intermediate representation (IR)](whatsnew14#unified-backends-and-extensibility), which is subsequently compiled into JavaScript. For Kotlin/JS, this enables aggressive optimizations, and allows improvements on pain points that were present in the previous compiler, such as generated code size (through dead code elimination), and JavaScript and TypeScript ecosystem interoperability, to name some examples.
The IR compiler backend is available starting with Kotlin 1.4.0 through the Kotlin/JS Gradle plugin. To enable it in your project, pass a compiler type to the `js` function in your Gradle build script:
```
kotlin {
js(IR) { // or: LEGACY, BOTH
// ...
binaries.executable() // not applicable to BOTH, see details below
}
}
```
* `IR` uses the new IR compiler backend for Kotlin/JS.
* `LEGACY` uses the default compiler backend.
* `BOTH` compiles your project with the new IR compiler as well as the default compiler backend. Use this mode for [authoring libraries compatible with both backends](#authoring-libraries-for-the-ir-compiler-with-backwards-compatibility).
The compiler type can also be set in the `gradle.properties` file, with the key `kotlin.js.compiler=ir`. This behaviour is overwritten by any settings in the `build.gradle(.kts)`, however.
Lazy initialization of top-level properties
-------------------------------------------
For better application startup performance, the Kotlin/JS IR compiler initializes top-level properties lazily. This way, the application loads without initializing all the top-level properties used in its code. It initializes only the ones needed at startup; other properties receive their values later when the code that uses them actually runs.
```
val a = run {
val result = // intensive computations
println(result)
result
} // value is computed upon the first usage
```
If for some reason you need to initialize a property eagerly (upon the application start), mark it with the [`@EagerInitialization`](../api/latest/jvm/stdlib/kotlin.js/-eager-initialization/index) annotation.
Incremental compilation for development binaries
------------------------------------------------
The JS IR compiler provides the *incremental compilation mode for development binaries* that speeds up the development process. In this mode, the compiler caches the results of `compileDevelopmentExecutableKotlinJs` Gradle task on the module level. It uses the cached compilation results for unchanged source files during subsequent compilations, making them complete faster, especially with small changes.
Incremental compilation is enabled by default. To disable incremental compilation for development binaries, add the following line to the project's `gradle.properties` or `local.properties`:
```
kotlin.incremental.js.ir=false // true by default
```
Output .js files: one per module or one for the whole project
-------------------------------------------------------------
As a compilation result, the JS IR compiler outputs separate `.js` files for each module of a project. Alternatively, you can compile the whole project into a single `.js` file by adding the following line to `gradle.properties`:
```
kotlin.js.ir.output.granularity=whole-program // 'per-module' is the default
```
Ignoring compilation errors
---------------------------
Kotlin/JS IR compiler provides a new compilation mode unavailable in the default backend – *ignoring compilation errors*. In this mode, you can try out your application even while its code contains errors. For example, when you're doing a complex refactoring or working on a part of the system that is completely unrelated to a compilation error in another part.
With this new compiler mode, the compiler ignores all broken code. Thus, you can run the application and try its parts that don't use the broken code. If you try to run the code that was broken during compilation, you'll get a runtime exception.
Choose between two tolerance policies for ignoring compilation errors in your code:
* `SEMANTIC`. The compiler will accept code that is syntactically correct but doesn't make sense semantically. For example, assigning a number to a string variable (type mismatch).
* `SYNTAX`. The compiler will accept any code, even if it contains syntax errors. Regardless of what you write, the compiler will still try to generate a runnable executable.
As an experimental feature, ignoring compilation errors requires an opt-in. To enable this mode, add the `-Xerror-tolerance-policy={SEMANTIC|SYNTAX}` compiler option:
```
kotlin {
js(IR) {
compilations.all {
compileTaskProvider.configure {
compilerOptions.freeCompilerArgs.add("-Xerror-tolerance-policy=SYNTAX")
}
}
}
}
```
Minification of member names in production
------------------------------------------
The Kotlin/JS IR compiler uses its internal information about the relationships of your Kotlin classes and functions to apply more efficient minification, shortening the names of functions, properties, and classes. This reduces the size of resulting bundled applications.
This type of minification is automatically applied when you build your Kotlin/JS application in [production](js-project-setup#building-executables) mode, and enabled by default. To disable member name minification, use the `-Xir-minimized-member-names` compiler option:
```
kotlin {
js(IR) {
compilations.all {
compileTaskProvider.configure {
compilerOptions.freeCompilerArgs.add("-Xir-minimized-member-names=false")
}
}
}
}
```
Preview: generation of TypeScript declaration files (d.ts)
----------------------------------------------------------
The Kotlin/JS IR compiler is capable of generating TypeScript definitions from your Kotlin code. These definitions can be used by JavaScript tools and IDEs when working on hybrid apps to provide autocompletion, support static analyzers, and make it easier to include Kotlin code in JavaScript and TypeScript projects.
Top-level declarations marked with [`@JsExport`](js-to-kotlin-interop#jsexport-annotation) in a project that produces executable files (`binaries.executable()`) will get a `.d.ts` file generated, which contains the TypeScript definitions for the exported Kotlin declarations. These declarations can be found in `build/js/packages/<package_name>/kotlin` alongside the corresponding un-webpacked JavaScript code.
Current limitations of the IR compiler
--------------------------------------
A major change with the new IR compiler backend is the **absence of binary compatibility** with the default backend. A library created with the new IR compiler uses a [`klib` format](native-libraries#library-format) and can't be used from the default backend. In the meantime, a library created with the old compiler is a `jar` with `js` files, which can't be used from the IR backend.
If you want to use the IR compiler backend for your project, you need to **update all Kotlin dependencies to versions that support this new backend**. Libraries published by JetBrains for Kotlin 1.4+ targeting Kotlin/JS already contain all artifacts required for usage with the new IR compiler backend.
**If you are a library author** looking to provide compatibility with the current compiler backend as well as the new IR compiler backend, additionally check out the [section about authoring libraries for the IR compiler](#authoring-libraries-for-the-ir-compiler-with-backwards-compatibility) section.
The IR compiler backend also has some discrepancies in comparison to the default backend. When trying out the new backend, it's good to be mindful of these possible pitfalls.
* Some **libraries that rely on specific characteristics** of the default backend, such as `kotlin-wrappers`, can display some problems. You can follow the investigation and progress [on YouTrack](https://youtrack.jetbrains.com/issue/KT-40525).
* The IR backend **does not make Kotlin declarations available to JavaScript** by default at all. To make Kotlin declarations visible to JavaScript, they **must be** annotated with [`@JsExport`](js-to-kotlin-interop#jsexport-annotation).
Migrating existing projects to the IR compiler
----------------------------------------------
Due to significant differences between the two Kotlin/JS compilers, making your Kotlin/JS code work with the IR compiler may require some adjustments. Learn how to migrate existing Kotlin/JS projects to the IR compiler in the [Kotlin/JS IR compiler migration guide](js-ir-migration).
Authoring libraries for the IR compiler with backwards compatibility
--------------------------------------------------------------------
If you're a library maintainer who is looking to provide compatibility with the default backend as well as the new IR compiler backend, a setting for the compiler selection is available that allows you to create artifacts for both backends, allowing you to keep compatibility for your existing users while providing support for the next generation of Kotlin compiler. This so-called `both`-mode can be turned on using the `kotlin.js.compiler=both` setting in your `gradle.properties` file, or can be set as one of the project-specific options inside your `js` block inside the `build.gradle(.kts)` file:
```
kotlin {
js(BOTH) {
// ...
}
}
```
When in `both` mode, the IR compiler backend and default compiler backend are both used when building a library from your sources (hence the name). This means that both `klib` files with Kotlin IR as well as `jar` files for the default compiler will be generated. When published under the same Maven coordinate, Gradle will automatically choose the right artifact depending on the use case – `js` for the old compiler, `klib` for the new one. This enables you to compile and publish your library for projects that are using either of the two compiler backends.
Last modified: 10 January 2023
[Kotlin/JS dead code elimination](javascript-dce) [Migrating Kotlin/JS projects to the IR compiler](js-ir-migration)
kotlin Share code on platforms Share code on platforms
=======================
With Kotlin Multiplatform, you can share the code using the mechanisms Kotlin provides:
* [Share code among all platforms used in your project](#share-code-on-all-platforms). Use it for sharing the common business logic that applies to all platforms.
* [Share code among some platforms](#share-code-on-similar-platforms) included in your project but not all. You can reuse much of the code in similar platforms using a hierarchical structure. You can use [target shortcuts](#use-target-shortcuts) for common combinations of targets or [create the hierarchical structure manually](#configure-the-hierarchical-structure-manually).
If you need to access platform-specific APIs from the shared code, use the Kotlin mechanism of [expected and actual declarations](multiplatform-connect-to-apis).
Share code on all platforms
---------------------------
If you have business logic that is common for all platforms, you don't need to write the same code for each platform – just share it in the common source set.
Some dependencies for source sets are set by default. You don't need to specify any `dependsOn` relations manually:
* For all platform-specific source sets that depend on the common source set, such as `jvmMain`, `macosX64Main`, and others.
* Between the `main` and `test` source sets of a particular target, such as `androidMain` and `androidTest`.
If you need to access platform-specific APIs from the shared code, use the Kotlin mechanism of [expected and actual declarations](multiplatform-connect-to-apis).
Share code on similar platforms
-------------------------------
You often need to create several native targets that could potentially reuse a lot of the common logic and third-party APIs.
For example, in a typical multiplatform project targeting iOS, there are two iOS-related targets: one is for iOS ARM64 devices, the other is for the x64 simulator. They have separate platform-specific source sets, but in practice there is rarely a need for different code for the device and simulator, and their dependencies are much the same. So iOS-specific code could be shared between them.
Evidently, in this setup it would be desirable to have a shared source set for two iOS targets, with Kotlin/Native code that could still directly call any of the APIs that are common to both the iOS device and the simulator.
In this case, you can share code across native targets in your project using the hierarchical structure. Since Kotlin 1.6.20, it's enabled by default. See [Hierarchical project structure](multiplatform-hierarchy) for more details.
There are two ways you can create the hierarchical structure:
* [Use target shortcuts](#use-target-shortcuts) to easily create the hierarchy structure for common combinations of native targets.
* [Configure the hierarchical structure manually](#configure-the-hierarchical-structure-manually).
Learn more about [sharing code in libraries](#share-code-in-libraries) and [using Native libraries in the hierarchical structure](#use-native-libraries-in-the-hierarchical-structure).
### Use target shortcuts
In a typical multiplatform project with two iOS-related targets – `iosArm64` and `iosX64`, the hierarchical structure includes an intermediate source set (`iosMain`), which is used by the platform-specific source sets.
The `kotlin-multiplatform` plugin provides target shortcuts for creating structures for common combinations of targets.
| Target shortcut | Targets |
| --- | --- |
| `ios` | `iosArm64`, `iosX64` |
| `watchos` | `watchosArm32`, `watchosArm64`, `watchosX64` |
| `tvos` | `tvosArm64`, `tvosX64` |
All shortcuts create similar hierarchical structures in the code. For example, the `ios` shortcut creates the following hierarchical structure:
```
kotlin {
sourceSets{
val commonMain by sourceSets.getting
val iosX64Main by sourceSets.getting
val iosArm64Main by sourceSets.getting
val iosMain by sourceSets.creating {
dependsOn(commonMain)
iosX64Main.dependsOn(this)
iosArm64Main.dependsOn(this)
}
}
}
```
```
kotlin {
sourceSets{
iosMain {
dependsOn(commonMain)
iosX64Main.dependsOn(it)
iosArm64Main.dependsOn(it)
}
}
}
```
#### Target shortcuts and ARM64 (Apple Silicon) simulators
The target shortcuts `ios`, `watchos`, and `tvos` don't include the simulator targets for ARM64 (Apple Silicon) platforms: `iosSimulatorArm64`, `watchosSimulatorArm64`, and `tvosSimulatorArm64`. If you use the target shortcuts and want to build the project for an Apple Silicon simulator, adjust the build script the following way:
1. Add the `*SimulatorArm64` simulator target you need.
2. Connect the simulator target with the shortcut using the source set dependencies (`dependsOn`).
```
kotlin {
ios()
// Add the ARM64 simulator target
iosSimulatorArm64()
val iosMain by sourceSets.getting
val iosTest by sourceSets.getting
val iosSimulatorArm64Main by sourceSets.getting
val iosSimulatorArm64Test by sourceSets.getting
// Set up dependencies between the source sets
iosSimulatorArm64Main.dependsOn(iosMain)
iosSimulatorArm64Test.dependsOn(iosTest)
}
```
```
kotlin {
ios()
// Add the ARM64 simulator target
iosSimulatorArm64()
// Set up dependencies between the source sets
sourceSets {
// ...
iosSimulatorArm64Main {
dependsOn(iosMain)
}
iosSimulatorArm64Test {
dependsOn(iosTest)
}
}
}
```
### Configure the hierarchical structure manually
To create the hierarchical structure manually, introduce an intermediate source set that holds the shared code for several targets and create a structure of the source sets including the intermediate one.
For example, if you want to share code among native Linux, Windows, and macOS targets – `linuxX64M`, `mingwX64`, and `macosX64`:
1. Add the intermediate source set `desktopMain` that holds the shared logic for these targets.
2. Specify the hierarchy of source sets using the `dependsOn` relation.
```
kotlin{
sourceSets {
val desktopMain by creating {
dependsOn(commonMain)
}
val linuxX64Main by getting {
dependsOn(desktopMain)
}
val mingwX64Main by getting {
dependsOn(desktopMain)
}
val macosX64Main by getting {
dependsOn(desktopMain)
}
}
}
```
```
kotlin {
sourceSets {
desktopMain {
dependsOn(commonMain)
}
linuxX64Main {
dependsOn(desktopMain)
}
mingwX64Main {
dependsOn(desktopMain)
}
macosX64Main {
dependsOn(desktopMain)
}
}
}
```
You can have a shared source set for the following combinations of targets:
* JVM or Android + JS + Native
* JVM or Android + Native
* JS + Native
* JVM or Android + JS
* Native
Kotlin doesn't currently support sharing a source set for these combinations:
* Several JVM targets
* JVM + Android targets
* Several JS targets
If you need to access platform-specific APIs from a shared native source set, IntelliJ IDEA will help you detect common declarations that you can use in the shared native code. For other cases, use the Kotlin mechanism of [expected and actual declarations](multiplatform-connect-to-apis).
### Share code in libraries
Thanks to the hierarchical project structure, libraries can also provide common APIs for a subset of targets. When a [library is published](multiplatform-publish-lib), the API of its intermediate source sets is embedded into the library artifacts along with information about the project structure. When you use this library, the intermediate source sets of your project access only those APIs of the library which are available to the targets of each source set.
For example, check out the following source set hierarchy from the `kotlinx.coroutines` repository:
The `concurrent` source set declares the function runBlocking and is compiled for the JVM and the native targets. Once the `kotlinx.coroutines` library is updated and published with the hierarchical project structure, you can depend on it and call `runBlocking` from a source set that is shared between the JVM and native targets since it matches the "targets signature" of the library's `concurrent` source set.
### Use native libraries in the hierarchical structure
You can use platform-dependent libraries like `Foundation`, `UIKit`, and `POSIX` in source sets shared among several native targets. This helps you share more native code without being limited by platform-specific dependencies.
Since Kotlin 1.6.20, the usage of platform-dependent libraries is available in shared source sets by default. No additional steps are required – IntelliJ IDEA will help you detect common declarations that you can use in the shared code. See [Hierarchical project structure](multiplatform-hierarchy) for more details.
In addition to [platform libraries](native-platform-libs) shipped with Kotlin/Native, this approach can also handle custom [`cinterop` libraries](native-c-interop) making them available in shared source sets. To enable this support, specify the additional `kotlin.mpp.enableCInteropCommonization` key:
```
kotlin.mpp.enableCInteropCommonization=true
```
What's next?
------------
* Check out examples of code sharing using the Kotlin mechanism of [expect and actual declarations](multiplatform-connect-to-apis)
* Learn more about [hierarchical project structure](multiplatform-hierarchy)
Last modified: 10 January 2023
[Publishing multiplatform libraries](multiplatform-publish-lib) [Connect to platform-specific APIs](multiplatform-connect-to-apis)
| programming_docs |
kotlin Data classes Data classes
============
It is not unusual to create classes whose main purpose is to hold data. In such classes, some standard functionality and some utility functions are often mechanically derivable from the data. In Kotlin, these are called *data classes* and are marked with `data`:
```
data class User(val name: String, val age: Int)
```
The compiler automatically derives the following members from all properties declared in the primary constructor:
* `equals()`/`hashCode()` pair
* `toString()` of the form `"User(name=John, age=42)"`
* [`componentN()` functions](destructuring-declarations) corresponding to the properties in their order of declaration.
* `copy()` function (see below).
To ensure consistency and meaningful behavior of the generated code, data classes have to fulfill the following requirements:
* The primary constructor needs to have at least one parameter.
* All primary constructor parameters need to be marked as `val` or `var`.
* Data classes cannot be abstract, open, sealed, or inner.
Additionally, the generation of data class members follows these rules with regard to the members' inheritance:
* If there are explicit implementations of `equals()`, `hashCode()`, or `toString()` in the data class body or `final` implementations in a superclass, then these functions are not generated, and the existing implementations are used.
* If a supertype has `componentN()` functions that are `open` and return compatible types, the corresponding functions are generated for the data class and override those of the supertype. If the functions of the supertype cannot be overridden due to incompatible signatures or due to their being final, an error is reported.
* Providing explicit implementations for the `componentN()` and `copy()` functions is not allowed.
Data classes may extend other classes (see [Sealed classes](sealed-classes) for examples).
```
data class User(val name: String = "", val age: Int = 0)
```
Properties declared in the class body
-------------------------------------
The compiler only uses the properties defined inside the primary constructor for the automatically generated functions. To exclude a property from the generated implementations, declare it inside the class body:
```
data class Person(val name: String) {
var age: Int = 0
}
```
Only the property `name` will be used inside the `toString()`, `equals()`, `hashCode()`, and `copy()` implementations, and there will only be one component function `component1()`. While two `Person` objects can have different ages, they will be treated as equal.
```
data class Person(val name: String) {
var age: Int = 0
}
fun main() {
//sampleStart
val person1 = Person("John")
val person2 = Person("John")
person1.age = 10
person2.age = 20
//sampleEnd
println("person1 == person2: ${person1 == person2}")
println("person1 with age ${person1.age}: ${person1}")
println("person2 with age ${person2.age}: ${person2}")
}
```
Copying
-------
Use the `copy()` function to copy an object, allowing you to alter *some* of its properties while keeping the rest unchanged. The implementation of this function for the `User` class above would be as follows:
```
fun copy(name: String = this.name, age: Int = this.age) = User(name, age)
```
You can then write the following:
```
val jack = User(name = "Jack", age = 1)
val olderJack = jack.copy(age = 2)
```
Data classes and destructuring declarations
-------------------------------------------
*Component functions* generated for data classes make it possible to use them in [destructuring declarations](destructuring-declarations):
```
val jane = User("Jane", 35)
val (name, age) = jane
println("$name, $age years of age") // prints "Jane, 35 years of age"
```
Standard data classes
---------------------
The standard library provides the `Pair` and `Triple` classes. In most cases, though, named data classes are a better design choice because they make the code more readable by providing meaningful names for the properties.
Last modified: 10 January 2023
[Extensions](extensions) [Sealed classes](sealed-classes)
kotlin Set up targets for Kotlin Multiplatform Set up targets for Kotlin Multiplatform
=======================================
You can add targets when [creating a project with the Project Wizard](multiplatform-library). If you need to add a target later, you can do this manually using target presets for [supported platforms](multiplatform-dsl-reference#targets).
Learn more about [additional settings for targets](multiplatform-dsl-reference#common-target-configuration).
```
kotlin {
jvm() // Create a JVM target with the default name 'jvm'
linuxX64() {
/* Specify additional settings for the 'linux' target here */
}
}
```
Each target can have one or more [compilations](multiplatform-configure-compilations). In addition to default compilations for test and production purposes, you can [create custom compilations](multiplatform-configure-compilations#create-a-custom-compilation).
Distinguish several targets for one platform
--------------------------------------------
You can have several targets for one platform in a multiplatform library. For example, these targets can provide the same API but use different libraries during runtime, such as testing frameworks and logging solutions. Dependencies on such a multiplatform library may fail to resolve because it isn't clear which target to choose.
To solve this, mark the targets on both the library author and consumer sides with a custom attribute, which Gradle uses during dependency resolution.
For example, consider a testing library that supports both JUnit and TestNG in the two targets. The library author needs to add an attribute to both targets as follows:
```
val testFrameworkAttribute = Attribute.of("com.example.testFramework", String::class.java)
kotlin {
jvm("junit") {
attributes.attribute(testFrameworkAttribute, "junit")
}
jvm("testng") {
attributes.attribute(testFrameworkAttribute, "testng")
}
}
```
```
def testFrameworkAttribute = Attribute.of('com.example.testFramework', String)
kotlin {
jvm('junit') {
attributes.attribute(testFrameworkAttribute, 'junit')
}
jvm('testng') {
attributes.attribute(testFrameworkAttribute, 'testng')
}
}
```
The consumer has to add the attribute to a single target where the ambiguity arises.
Last modified: 10 January 2023
[Understand Multiplatform project structure](multiplatform-discover-project) [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app)
kotlin Visibility modifiers Visibility modifiers
====================
Classes, objects, interfaces, constructors, and functions, as well as properties and their setters, can have *visibility modifiers*. Getters always have the same visibility as their properties.
There are four visibility modifiers in Kotlin: `private`, `protected`, `internal`, and `public`. The default visibility is `public`.
On this page, you'll learn how the modifiers apply to different types of declaring scopes.
Packages
--------
Functions, properties, classes, objects, and interfaces can be declared at the "top-level" directly inside a package:
```
// file name: example.kt
package foo
fun baz() { ... }
class Bar { ... }
```
* If you don't use a visibility modifier, `public` is used by default, which means that your declarations will be visible everywhere.
* If you mark a declaration as `private`, it will only be visible inside the file that contains the declaration.
* If you mark it as `internal`, it will be visible everywhere in the same [module](#modules).
* The `protected` modifier is not available for top-level declarations.
Examples:
```
// file name: example.kt
package foo
private fun foo() { ... } // visible inside example.kt
public var bar: Int = 5 // property is visible everywhere
private set // setter is visible only in example.kt
internal val baz = 6 // visible inside the same module
```
Class members
-------------
For members declared inside a class:
* `private` means that the member is visible inside this class only (including all its members).
* `protected` means that the member has the same visibility as one marked as `private`, but that it is also visible in subclasses.
* `internal` means that any client *inside this module* who sees the declaring class sees its `internal` members.
* `public` means that any client who sees the declaring class sees its `public` members.
If you override a `protected` or an `internal` member and do not specify the visibility explicitly, the overriding member will also have the same visibility as the original.
Examples:
```
open class Outer {
private val a = 1
protected open val b = 2
internal open val c = 3
val d = 4 // public by default
protected class Nested {
public val e: Int = 5
}
}
class Subclass : Outer() {
// a is not visible
// b, c and d are visible
// Nested and e are visible
override val b = 5 // 'b' is protected
override val c = 7 // 'c' is internal
}
class Unrelated(o: Outer) {
// o.a, o.b are not visible
// o.c and o.d are visible (same module)
// Outer.Nested is not visible, and Nested::e is not visible either
}
```
### Constructors
Use the following syntax to specify the visibility of the primary constructor of a class:
```
class C private constructor(a: Int) { ... }
```
Here the constructor is private. By default, all constructors are `public`, which effectively amounts to them being visible everywhere the class is visible (this means that a constructor of an `internal` class is only visible within the same module).
### Local declarations
Local variables, functions, and classes can't have visibility modifiers.
Modules
-------
The `internal` visibility modifier means that the member is visible within the same module. More specifically, a module is a set of Kotlin files compiled together, for example:
* An IntelliJ IDEA module.
* A Maven project.
* A Gradle source set (with the exception that the `test` source set can access the internal declarations of `main`).
* A set of files compiled with one invocation of the `<kotlinc>` Ant task.
Last modified: 10 January 2023
[Functional (SAM) interfaces](fun-interfaces) [Extensions](extensions)
kotlin Upgrade your app Upgrade your app
================
You've already implemented common logic using external dependencies. Now you can add more complex logic. Network requests and data serialization are the [most popular cases](https://kotlinlang.org/lp/mobile/) to share with Kotlin Multiplatform. Learn how to implement these in your first application, so that after completing this onboarding journey you can use them in future projects.
The updated app will retrieve data over the internet from a [SpaceX API](https://github.com/r-spacex/SpaceX-API/tree/master/docs#rspacex-api-docs) and display the date of the last successful launch of a SpaceX rocket.
Add more dependencies
---------------------
You'll need the following multiplatform libraries in your project:
* [`kotlinx.coroutines`](https://github.com/Kotlin/kotlinx.coroutines), for using coroutines to write asynchronous code, which allows simultaneous operations.
* [`kotlinx.serialization`](https://github.com/Kotlin/kotlinx.serialization), for deserializing JSON responses into objects of entity classes used to process network operations.
* [Ktor](https://ktor.io/), a framework as an HTTP client for retrieving data over the internet.
### kotlinx.coroutines
To add `kotlinx.coroutines` to your project, specify a dependency in the common source set. To do so, add the following line to the `build.gradle.kts` file of the shared module:
```
sourceSets {
val commonMain by getting {
dependencies {
// ...
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
}
}
}
```
The Multiplatform Gradle plugin automatically adds a dependency to the platform-specific (iOS and Android) parts of `kotlinx.coroutines`.
#### If you use Kotlin prior to version 1.7.20
If you use Kotlin 1.7.20 and later, you already have the new Kotlin/Native memory manager enabled by default. If it's not the case, add the following to the end of the `build.gradle.kts` file:
```
kotlin.targets.withType(org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget::class.java) {
binaries.all {
binaryOptions["memoryModel"] = "experimental"
}
}
```
### kotlinx.serialization
For `kotlinx.serialization`, you need the plugin required by the build system. The Kotlin serialization plugin is shipped with the Kotlin compiler distribution, and the IntelliJ IDEA plugin is bundled into the Kotlin plugin.
You can set up the serialization plugin with the Kotlin plugin using the Gradle plugins DSL by adding this line to the existing `plugins` block at the very beginning of the `build.gradle.kts` file in the shared module:
```
plugins {
//
kotlin("plugin.serialization") version "1.8.0"
}
```
### Ktor
You can add Ktor in the same way you've added the `kotlinx.coroutines` library. In addition to specifying the core dependency (`ktor-client-core`) in the common source set, you also need to:
* Add the ContentNegotiation functionality (`ktor-client-content-negotiation`), responsible for serializing/deserializing the content in a specific format.
* Add the `ktor-serialization-kotlinx-json` dependency to instruct Ktor to use the JSON format and `kotlinx.serialization` as a serialization library. Ktor will expect JSON data and deserialize it into a data class when receiving responses.
* Provide the platform engines by adding dependencies on the corresponding artifacts in the platform source sets (`ktor-client-android`, `ktor-client-darwin`).
```
val ktorVersion = "2.2.1"
sourceSets {
val commonMain by getting {
dependencies {
// ...
implementation("io.ktor:ktor-client-core:$ktorVersion")
implementation("io.ktor:ktor-client-content-negotiation:$ktorVersion")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
}
}
val androidMain by getting {
dependencies {
implementation("io.ktor:ktor-client-android:$ktorVersion")
}
}
val iosMain by creating {
// ...
dependencies {
implementation("io.ktor:ktor-client-darwin:$ktorVersion")
}
}
}
```
Synchronize the Gradle files by clicking **Sync Now** in the notification.
Create API requests
-------------------
You'll need the [SpaceX API](https://github.com/r-spacex/SpaceX-API/tree/master/docs#rspacex-api-docs) to retrieve data and a single method to get the list of all launches from the **v4/launches** endpoint.
### Add data model
In `shared/src/commonMain/kotlin`, create a new `RocketLaunch.kt` file and add a data class which stores data from the SpaceX API:
```
import kotlinx.serialization.SerialName
import kotlinx.serialization.Serializable
@Serializable
data class RocketLaunch (
@SerialName("flight_number")
val flightNumber: Int,
@SerialName("name")
val missionName: String,
@SerialName("date_utc")
val launchDateUTC: String,
@SerialName("success")
val launchSuccess: Boolean?,
)
```
* The `RocketLaunch` class is marked with the `@Serializable` annotation, so that the `kotlinx.serialization` plugin can automatically generate a default serializer for it.
* The `@SerialName` annotation allows you to redefine field names, making it possible to declare properties in data classes with more readable names.
### Connect HTTP client
1. In `Greeting.kt`, create a Ktor `HTTPClient` instance to execute network requests and parse the resulting JSON:
```
import io.ktor.client.*
import io.ktor.client.plugins.contentnegotiation.*
import io.ktor.serialization.kotlinx.json.*
import kotlinx.serialization.json.Json
class Greeting {
private val platform: Platform = getPlatform()
private val httpClient = HttpClient {
install(ContentNegotiation) {
json(Json {
prettyPrint = true
isLenient = true
ignoreUnknownKeys = true
})
}
}
}
```
To deserialize the result of the GET request, the [ContentNegotiation Ktor plugin](https://ktor.io/docs/serialization-client.html#register_json) and the JSON serializer are used.
2. In the `greeting()` function, retrieve the information about rocket launches by calling the `httpClient.get()` method and find the latest launch:
```
import io.ktor.client.call.*
import io.ktor.client.request.*
class Greeting {
// ...
@Throws(Exception::class)
suspend fun greeting(): String {
val rockets: List<RocketLaunch> =
httpClient.get("https://api.spacexdata.com/v4/launches").body()
val lastSuccessLaunch = rockets.last { it.launchSuccess == true }
return "Guess what it is! > ${platform.name.reversed()}!" +
"\nThere are only ${daysUntilNewYear()} left until New Year! 🎆" +
"\nThe last successful launch was ${lastSuccessLaunch.launchDateUTC} 🚀"
}
}
```
The `suspend` modifier in the `greeting()` function is necessary because it now contains a call to `get()`. It's a suspend function that has an asynchronous operation to retrieve data over the internet and can only be called from within a coroutine or another suspend function. The network request will be executed in the HTTP client's thread pool.
### Add internet access permission
To access the internet, the Android application needs appropriate permission. Since all network requests are made from the shared module, it makes sense to add the internet access permission to its manifest.
Update your `androidApp/src/main/AndroidManifest.xml` file as follows:
```
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.jetbrains.simplelogin.kotlinmultiplatformsandbox" >
<uses-permission android:name="android.permission.INTERNET"/>
</manifest>
```
Update Android and iOS apps
---------------------------
You've already updated the API of the shared module by adding the `suspend` modifier to the `greeting()` function. Now you need to update native (iOS, Android) parts of the project, so they can properly handle the result of calling the `greeting()` function.
### Android app
As both the shared module and the Android application are written in Kotlin, using shared code from Android is straightforward:
1. Add the `kotlinx.coroutines` library to the Android application by adding a line in the `build.gradle.kts` in the `androidApp` folder:
```
dependencies {
// ..
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-android:1.6.4")
}
```
2. Synchronize the Gradle files by clicking **Sync Now** in the notification.
3. In `androidApp/src/main/java`, locate the `MainActivity.kt` file and update the following class replacing previous implementation:
```
import androidx.compose.runtime.*
import kotlinx.coroutines.launch
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
MyApplicationTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colors.background
) {
val scope = rememberCoroutineScope()
var text by remember { mutableStateOf("Loading") }
LaunchedEffect(true) {
scope.launch {
text = try {
Greeting().greeting()
} catch (e: Exception) {
e.localizedMessage ?: "error"
}
}
}
GreetingView(text)
}
}
}
}
}
```
The `greeting()` function is now called in a coroutine inside `LaunchedEffect` to avoid recalling it on each recomposition.
### iOS app
For the iOS part of the project, you'll make use of [SwiftUI](https://developer.apple.com/xcode/swiftui/) to build the user interface and the [Model–view–viewmodel](#) pattern to connect the UI to the shared module, which contains all the business logic.
The module is already connected to the iOS project — the Android Studio plugin wizard did all the configuration. The module is already imported and used in `ContentView.swift` with `import shared`.
1. Launch your Xcode app and select **Open a project or file**.
2. Navigate to your project, for example **KotlinMultiplatformSandbox**, and select the `iosApp` folder. Click **Open**.
3. In `iosApp/iosApp.swift`, update the entry point for your app:
```
@main
struct iOSApp: App {
var body: some Scene {
WindowGroup {
ContentView(viewModel: ContentView.ViewModel())
}
}
}
```
4. In `iosApp/ContentView.swift`, create a `ViewModel` class for `ContentView`, which will prepare and manage data for it:
```
import SwiftUI
import shared
struct ContentView: View {
@ObservedObject private(set) var viewModel: ViewModel
var body: some View {
Text(viewModel.text)
}
}
extension ContentView {
class ViewModel: ObservableObject {
@Published var text = "Loading..."
init() {
// Data will be loaded here
}
}
}
```
* `ViewModel` is declared as an extension to `ContentView`, as they are closely connected.
* The [Combine framework](https://developer.apple.com/documentation/combine) connects the view model (`ContentView.ViewModel`) with the view (`ContentView`).
* `ContentView.ViewModel` is declared as an `ObservableObject`.
* The `@Published` wrapper is used for the `text` property.
* The `@ObservedObject` property wrapper is used to subscribe to the view model.Now the view model will emit signals whenever this property changes.
5. Call the `greeting()` function, which now also loads data from the SpaceX API, and save the result in the `text` property:
```
class ViewModel: ObservableObject {
@Published var text = "Loading..."
init() {
Greeting().greeting { greeting, error in
DispatchQueue.main.async {
if let greeting = greeting {
self.text = greeting
} else {
self.text = error?.localizedDescription ?? "error"
}
}
}
}
}
```
* Kotlin/Native [provides bidirectional interoperability with Objective-C](native-objc-interop#mappings), thus Kotlin concepts, including `suspend` functions, are mapped to the corresponding Swift/Objective-C concepts and vice versa. When you compile a Kotlin module into an Apple framework, suspending functions are available in it as functions with callbacks (`completionHandler`).
* The `greeting()` function was marked with the `@Throws(Exception::class)` annotation. So any exceptions that are instances of the `Exception` class or its subclass will be propagated as `NSError`, so you can handle them in the `completionHandler`.
* When calling Kotlin `suspend` functions from Swift, completion handlers might be called on threads other than main, see the [iOS integration](native-ios-integration#completion-handlers) in the Kotlin/Native memory manager. That's why `DispatchQueue.main.async` is used to update `text` property.
6. Re-run both **androidApp** and **iosApp** configurations from Android Studio to make sure your app's logic is synced:

Next step
---------
In the final part of the tutorial, you'll wrap up your project and see what steps to take next.
**[Proceed to the next part](multiplatform-mobile-wrap-up)**
### See also
* Explore various approaches to [composition of suspending functions](composing-suspending-functions).
* Learn more about the [interoperability with Objective-C frameworks and libraries](native-objc-interop).
* Complete this tutorial on [networking and data storage](multiplatform-mobile-ktor-sqldelight).
Get help
--------
* **Kotlin Slack**. Get an [invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) and join the [#multiplatform](https://kotlinlang.slack.com/archives/C3PQML5NU) channel.
* **Kotlin issue tracker**. [Report a new issue](https://youtrack.jetbrains.com/newIssue?project=KT).
Last modified: 10 January 2023
[Add dependencies to your project](multiplatform-mobile-dependencies) [Wrap up your project](multiplatform-mobile-wrap-up)
| programming_docs |
kotlin Run Kotlin/JS Run Kotlin/JS
=============
Since Kotlin/JS projects are managed with the Kotlin/JS Gradle plugin, you can run your project using the appropriate tasks. If you're starting with a blank project, ensure that you have some sample code to execute. Create the file `src/main/kotlin/App.kt` and fill it with a small "Hello, World"-type code snippet:
```
fun main() {
console.log("Hello, Kotlin/JS!")
}
```
Depending on the target platform, some platform-specific extra setup might be required to run your code for the first time.
Run the Node.js target
----------------------
When targeting Node.js with Kotlin/JS, you can simply execute the `run` Gradle task. This can be done for example via the command line, using the Gradle wrapper:
```
./gradlew run
```
If you're using IntelliJ IDEA, you can find the `run` action in the Gradle tool window:
On first start, the `kotlin.js` Gradle plugin will download all required dependencies to get you up and running. After the build is completed, the program is executed, and you can see the logging output in the terminal:
Run the browser target
----------------------
When targeting the browser, your project is required to have an HTML page. This page will be served by the development server while you are working on your application, and should embed your compiled Kotlin/JS file. Create and fill an HTML file `/src/main/resources/index.html`:
```
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Hello, Kotlin/JS!</title>
</head>
<body>
</body>
<script src="jsTutorial.js"></script>
</html>
```
By default, the name of your project's generated artifact (which is created through webpack) that needs to be referenced is your project name (in this case, `jsTutorial`). If you've named your project `followAlong`, make sure to embed `followAlong.js` instead of `jsTutorial.js`
After making these adjustments, start the integrated development server. You can do this from the command line via the Gradle wrapper:
```
./gradlew run
```
When working from IntelliJ IDEA, you can find the `run` action in the Gradle tool window.
After the project has been built, the embedded `webpack-dev-server` will start running, and will open a (seemingly empty) browser window pointing to the HTML file you specified previously. To validate that your program is running correctly, open the developer tools of your browser (for example by right-clicking and choosing the *Inspect* action). Inside the developer tools, navigate to the console, where you can see the results of the executed JavaScript code:
With this setup, you can recompile your project after each code change to see your changes. Kotlin/JS also supports a more convenient way of automatically rebuilding the application while you are developing it. To find out how to set up this *continuous mode*, check out the [corresponding tutorial](dev-server-continuous-compilation).
Last modified: 10 January 2023
[Set up a Kotlin/JS project](js-project-setup) [Development server and continuous compilation](dev-server-continuous-compilation)
kotlin Get started with Kotlin/Native using Gradle Get started with Kotlin/Native using Gradle
===========================================
[Gradle](https://gradle.org) is a build system that is very commonly used in the Java, Android, and other ecosystems. It is the default choice for Kotlin/Native and Multiplatform when it comes to build systems.
While most IDEs, including [IntelliJ IDEA](https://www.jetbrains.com/idea), can generate necessary Gradle files, this tutorial covers how to create them manually to provide a better understanding of how things work under the hood.
To get started, install the latest version of [Gradle](https://gradle.org/install/).
Create project files
--------------------
1. Create a project directory. Inside it, create `build.gradle` or `build.gradle.kts` Gradle build file with the following content:
```
// build.gradle.kts
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
macosX64("native") { // on macOS
// linuxX64("native") // on Linux
// mingwX64("native") // on Windows
binaries {
executable()
}
}
}
tasks.withType<Wrapper> {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.BIN
}
```
```
// build.gradle
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
macosX64('native') { // on macOS
// linuxX64('native') // on Linux
// mingwX64('native') // on Windows
binaries {
executable()
}
}
}
wrapper {
gradleVersion = '7.3'
distributionType = 'BIN'
}
```
You can use different [target presets](multiplatform-dsl-reference#targets), such as `macosX64`, `mingwX64`, `linuxX64`, `iosX64`, to define the corresponding target platform. The preset name describes a platform for which you are compiling your code. These target presets optionally take the target name as a parameter, which is `native` in this case. The target name is used to generate the source paths and task names in the project.
2. Create an empty `settings.gradle` or `settings.gradle.kts` file in the project directory.
3. Create a directory `src/nativeMain/kotlin` and place inside the `hello.kt` file with the following content:
```
fun main() {
println("Hello, Kotlin/Native!")
}
```
By convention, all sources are located in the `src/<target name>[Main|Test]/kotlin` directories, where `main` is for the source code and `test` is for tests. `<target name>` corresponds to the target platform (in this case `native`), as specified in the build file.
Now you are ready to build your project and run the application.
Build and run the application
-----------------------------
1. From the root project directory, run the build command:
```
gradle nativeBinaries
```
This command creates the `build/bin/native` directory with two directories inside: `debugExecutable` and `releaseExecutable`. They contain corresponding binary files.
By default, the name of the binary file is the same as the project directory.
2. To run the project, execute the following command:
```
build/bin/native/debugExecutable/<project_name>.kexe
```
Terminal prints "Hello, Kotlin/Native!".
Open the project in an IDE
--------------------------
Now you can open your project in any IDE that supports Gradle. If you use IntelliJ IDEA:
1. Select **File** | **Open...**.
2. Select the project directory and click **Open**.
IntelliJ IDEA will automatically detect it as Kotlin/Native project.
What's next?
------------
Learn how to [write Gradle build scripts for real-life Kotlin/Native projects](multiplatform-dsl-reference).
Last modified: 10 January 2023
[Get started with Kotlin/Native in IntelliJ IDEA](native-get-started) [Get started with Kotlin/Native using the command-line compiler](native-command-line-compiler)
kotlin iOS integration iOS integration
===============
Integration of Kotlin/Native garbage collector with Swift/Objective-C ARC is seamless and generally requires no additional work to be done. Learn more about [Swift/Objective-C interoperability](native-objc-interop).
However, there are some specifics you should keep in mind:
Threads
-------
### Deinitilizers
Deinit on the Swift/Objective-C objects and the objects they refer to is called on a different thread if these objects cross interop boundaries into Kotlin/Native, for example:
```
// Kotlin
class KotlinExample {
fun action(arg: Any) {
println(arg)
}
}
```
```
// Swift
class SwiftExample {
init() {
print("init on \(Thread.current)")
}
deinit {
print("deinit on \(Thread.current)")
}
}
func test() {
KotlinExample().action(arg: SwiftExample())
}
```
The resulting output:
```
init on <_NSMainThread: 0x600003bc0000>{number = 1, name = main}
shared.SwiftExample
deinit on <NSThread: 0x600003b9b900>{number = 7, name = (null)}
```
### Completion handlers
When calling Kotlin suspending functions from Swift, completion handlers might be called on threads other than the main one, for example:
```
// Kotlin
// coroutineScope, launch, and delay are from kotlinx.coroutines
suspend fun asyncFunctionExample() = coroutineScope {
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
```
```
// Swift
func test() {
print("Running test on \(Thread.current)")
PlatformKt.asyncFunctionExample(completionHandler: { _ in
print("Running completion handler on \(Thread.current)")
})
}
```
The resulting output:
```
Running test on <_NSMainThread: 0x600001b100c0>{number = 1, name = main}
Hello
World!
Running completion handler on <NSThread: 0x600001b45bc0>{number = 7, name = (null)}
```
### Calling Kotlin suspending functions
The Kotlin/Native memory manager has a restriction on calling Kotlin suspending functions from Swift and Objective-C from threads other than the main one.
This restriction was originally introduced in the legacy memory manager due to cases when the code dispatched a continuation to be resumed on the original thread. If this thread didn't have a supported event loop, the task would never run, and the coroutine would never be resumed.
In certain cases, this restriction is not required anymore. You can lift it by adding the following option to your `gradle.properties`:
```
kotlin.native.binary.objcExportSuspendFunctionLaunchThreadRestriction=none
```
Garbage collection and lifecycle
--------------------------------
### Object reclamation
An object is reclaimed only during the garbage collection. This applies to Swift/Objective-C objects that cross interop boundaries into Kotlin/Native, for example:
```
// Kotlin
class KotlinExample {
fun action(arg: Any) {
println(arg)
}
}
```
```
// Swift
class SwiftExample {
deinit {
print("SwiftExample deinit")
}
}
func test() {
swiftTest()
kotlinTest()
}
func swiftTest() {
print(SwiftExample())
print("swiftTestFinished")
}
func kotlinTest() {
KotlinExample().action(arg: SwiftExample())
print("kotlinTest finished")
}
```
The resulting output:
```
shared.SwiftExample
SwiftExample deinit
swiftTestFinished
shared.SwiftExample
kotlinTest finished
SwiftExample deinit
```
### Objective-C objects lifecycle
The Objective-C objects might live longer than they should, which sometimes might cause performance issues. For example, when a long-running loop creates several temporary objects that cross the Swift/Objective-C interop boundary on each iteration.
In the [GC logs](native-memory-manager#monitor-gc-performance), there's a number of stable refs in the root set. If this number keeps growing, it may indicate that the Swift/Objective-C objects are not freed up when they should. In this case, try the `autoreleasepool` block around loop bodies that do interop calls:
```
// Kotlin
fun growingMemoryUsage() {
repeat(Int.MAX_VALUE) {
NSLog("$it\n")
}
}
fun steadyMemoryUsage() {
repeat(Int.MAX_VALUE) {
autoreleasepool {
NSLog("$it\n")
}
}
}
```
### Garbage collection of Swift and Kotlin objects' chains
Consider the following example:
```
// Kotlin
interface Storage {
fun store(arg: Any)
}
class KotlinStorage(var field: Any? = null) : Storage {
override fun store(arg: Any) {
field = arg
}
}
class KotlinExample {
fun action(firstSwiftStorage: Storage, secondSwiftStorage: Storage) {
// Here, we create the following chain:
// firstKotlinStorage -> firstSwiftStorage -> secondKotlinStorage -> secondSwiftStorage.
val firstKotlinStorage = KotlinStorage()
firstKotlinStorage.store(firstSwiftStorage)
val secondKotlinStorage = KotlinStorage()
firstSwiftStorage.store(secondKotlinStorage)
secondKotlinStorage.store(secondSwiftStorage)
}
}
```
```
// Swift
class SwiftStorage : Storage {
let name: String
var field: Any? = nil
init(_ name: String) {
self.name = name
}
func store(arg: Any) {
field = arg
}
deinit {
print("deinit SwiftStorage \(name)")
}
}
func test() {
KotlinExample().action(
firstSwiftStorage: SwiftStorage("first"),
secondSwiftStorage: SwiftStorage("second")
)
}
```
It takes some time between "deinit SwiftStorage first" and "deinit SwiftStorage second" messages to appear in the log. The reason is that `firstKotlinStorage` and `secondKotlinStorage` are collected in different GC cycles. Here's the sequence of events:
1. `KotlinExample.action` finishes. `firstKotlinStorage` is considered "dead" because nothing references it, while `secondKotlinStorage` is not because it is referenced by `firstSwiftStorage`.
2. First GC cycle starts, and `firstKotlinStorage` is collected.
3. There are no references to `firstSwiftStorage`, so it is "dead" as well, and `deinit` is called.
4. Second GC cycle starts. `secondKotlinStorage` is collected because `firstSwiftStorage` is no longer referencing it.
5. `secondSwiftStorage` is finally reclaimed.
It requires two GC cycles to collect these four objects because deinitialization of Swift and Objective-C objects happens after the GC cycle. The limitation stems from `deinit`, which can call arbitrary code, including the Kotlin code that cannot be run during the GC pause.
Support for background state and App Extensions
-----------------------------------------------
The current memory manager does not track application state by default and does not integrate with [App Extensions](https://developer.apple.com/app-extensions/) out of the box.
It means that the memory manager doesn't adjust GC behavior accordingly, which might be harmful in some cases. To change this behavior, add the following [Experimental](components-stability) binary option to your `gradle.properties`:
```
kotlin.native.binary.appStateTracking=enabled
```
It turns off a timer-based invocation of the garbage collector when the application is in the background, so GC is called only when memory consumption becomes too high.
Last modified: 10 January 2023
[Kotlin/Native memory management](native-memory-manager) [Migrate to the new memory manager](native-migration-guide)
kotlin Connect to platform-specific APIs Connect to platform-specific APIs
=================================
If you're developing a multiplatform application that needs to access platform-specific APIs that implement the required functionality (for example, [generating a UUID](#generate-a-uuid)), use the Kotlin mechanism of *expected and actual declarations*.
With this mechanism, a common source set defines an *expected declaration*, and platform source sets must provide the *actual declaration* that corresponds to the expected declaration. This works for most Kotlin declarations, such as functions, classes, interfaces, enumerations, properties, and annotations.
The compiler ensures that every declaration marked with the `expect` keyword in the common module has the corresponding declarations marked with the `actual` keyword in all platform modules. The IDE provides tools that help you create the missing actual declarations.
Learn how to [add dependencies on platform-specific libraries](multiplatform-add-dependencies).
Examples
--------
For simplicity, the following examples use intuitive target names, like iOS and Android. However, in your Gradle build files, you need to use a specific target name from [the list of supported targets](multiplatform-dsl-reference#targets).
### Generate a UUID
Let's assume that you are developing iOS and Android applications using Kotlin Multiplatform Mobile and you want to generate a universally unique identifier (UUID):
For this purpose, declare the expected function `randomUUID()` with the `expect` keyword in the common module. Don't include any implementation code.
```
// Common
expect fun randomUUID(): String
```
In each platform-specific module (iOS and Android), provide the actual implementation for the function `randomUUID()` expected in the common module. Use the `actual` keyword to mark the actual implementation.
The following examples show the implementation of this for Android and iOS. Platform-specific code uses the `actual` keyword and the expected name for the function.
```
// Android
import java.util.*
actual fun randomUUID() = UUID.randomUUID().toString()
```
```
// iOS
import platform.Foundation.NSUUID
actual fun randomUUID(): String = NSUUID().UUIDString()
```
### Implement a logging framework
Another example of code sharing and interaction between the common and platform logic, JS and JVM in this case, in a minimalistic logging framework:
```
// Common
enum class LogLevel {
DEBUG, WARN, ERROR
}
internal expect fun writeLogMessage(message: String, logLevel: LogLevel)
fun logDebug(message: String) = writeLogMessage(message, LogLevel.DEBUG)
fun logWarn(message: String) = writeLogMessage(message, LogLevel.WARN)
fun logError(message: String) = writeLogMessage(message, LogLevel.ERROR)
```
```
// JVM
internal actual fun writeLogMessage(message: String, logLevel: LogLevel) {
println("[$logLevel]: $message")
}
```
For JavaScript, a completely different set of APIs is available, and the `actual` declaration will look like this.
```
// JS
internal actual fun writeLogMessage(message: String, logLevel: LogLevel) {
when (logLevel) {
LogLevel.DEBUG -> console.log(message)
LogLevel.WARN -> console.warn(message)
LogLevel.ERROR -> console.error(message)
}
}
```
### Send and receive messages from a WebSocket
Consider developing a chat platform for iOS and Android using Kotlin Multiplatform Mobile. Let's see how you can implement sending and receiving messages from a WebSocket.
For this purpose, define a common logic that you don't need to duplicate in all platform modules – just add it once to the common module. However, the actual implementation of the WebSocket class differs from platform to platform. That's why you should use `expect`/`actual` declarations for this class.
In the common module, declare the expected class `PlatformSocket()` with the `expect` keyword. Don't include any implementation code.
```
//Common
internal expect class PlatformSocket(
url: String
) {
fun openSocket(listener: PlatformSocketListener)
fun closeSocket(code: Int, reason: String)
fun sendMessage(msg: String)
}
interface PlatformSocketListener {
fun onOpen()
fun onFailure(t: Throwable)
fun onMessage(msg: String)
fun onClosing(code: Int, reason: String)
fun onClosed(code: Int, reason: String)
}
```
In each platform-specific module (iOS and Android), provide the actual implementation for the class `PlatformSocket()` expected in the common module. Use the `actual` keyword to mark the actual implementation.
The following examples show the implementation of this for Android and iOS.
```
//Android
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.Response
import okhttp3.WebSocket
internal actual class PlatformSocket actual constructor(url: String) {
private val socketEndpoint = url
private var webSocket: WebSocket? = null
actual fun openSocket(listener: PlatformSocketListener) {
val socketRequest = Request.Builder().url(socketEndpoint).build()
val webClient = OkHttpClient().newBuilder().build()
webSocket = webClient.newWebSocket(
socketRequest,
object : okhttp3.WebSocketListener() {
override fun onOpen(webSocket: WebSocket, response: Response) = listener.onOpen()
override fun onFailure(webSocket: WebSocket, t: Throwable, response: Response?) = listener.onFailure(t)
override fun onMessage(webSocket: WebSocket, text: String) = listener.onMessage(text)
override fun onClosing(webSocket: WebSocket, code: Int, reason: String) = listener.onClosing(code, reason)
override fun onClosed(webSocket: WebSocket, code: Int, reason: String) = listener.onClosed(code, reason)
}
)
}
actual fun closeSocket(code: Int, reason: String) {
webSocket?.close(code, reason)
webSocket = null
}
actual fun sendMessage(msg: String) {
webSocket?.send(msg)
}
}
```
Android implementation uses the third-party library [OkHttp](https://square.github.io/okhttp/). Add the corresponding dependency to `build.gradle(.kts)` in the shared module:
```
sourceSets {
val androidMain by getting {
dependencies {
implementation("com.squareup.okhttp3:okhttp:$okhttp_version")
}
}
}
```
```
commonMain {
dependencies {
implementation "com.squareup.okhttp3:okhttp:$okhttp_version"
}
}
```
iOS implementation uses `NSURLSession` from the standard Apple SDK and doesn't require additional dependencies.
```
//iOS
import platform.Foundation.*
import platform.darwin.NSObject
internal actual class PlatformSocket actual constructor(url: String) {
private val socketEndpoint = NSURL.URLWithString(url)!!
private var webSocket: NSURLSessionWebSocketTask? = null
actual fun openSocket(listener: PlatformSocketListener) {
val urlSession = NSURLSession.sessionWithConfiguration(
configuration = NSURLSessionConfiguration.defaultSessionConfiguration(),
delegate = object : NSObject(), NSURLSessionWebSocketDelegateProtocol {
override fun URLSession(
session: NSURLSession,
webSocketTask: NSURLSessionWebSocketTask,
didOpenWithProtocol: String?
) {
listener.onOpen()
}
override fun URLSession(
session: NSURLSession,
webSocketTask: NSURLSessionWebSocketTask,
didCloseWithCode: NSURLSessionWebSocketCloseCode,
reason: NSData?
) {
listener.onClosed(didCloseWithCode.toInt(), reason.toString())
}
},
delegateQueue = NSOperationQueue.currentQueue()
)
webSocket = urlSession.webSocketTaskWithURL(socketEndpoint)
listenMessages(listener)
webSocket?.resume()
}
private fun listenMessages(listener: PlatformSocketListener) {
webSocket?.receiveMessageWithCompletionHandler { message, nsError ->
when {
nsError != null -> {
listener.onFailure(Throwable(nsError.description))
}
message != null -> {
message.string?.let { listener.onMessage(it) }
}
}
listenMessages(listener)
}
}
actual fun closeSocket(code: Int, reason: String) {
webSocket?.cancelWithCloseCode(code.toLong(), null)
webSocket = null
}
actual fun sendMessage(msg: String) {
val message = NSURLSessionWebSocketMessage(msg)
webSocket?.sendMessage(message) { err ->
err?.let { println("send $msg error: $it") }
}
}
}
```
And here is the common logic in the common module that uses the platform-specific class `PlatformSocket()`.
```
//Common
class AppSocket(url: String) {
private val ws = PlatformSocket(url)
var socketError: Throwable? = null
private set
var currentState: State = State.CLOSED
private set(value) {
field = value
stateListener?.invoke(value)
}
var stateListener: ((State) -> Unit)? = null
set(value) {
field = value
value?.invoke(currentState)
}
var messageListener: ((msg: String) -> Unit)? = null
fun connect() {
if (currentState != State.CLOSED) {
throw IllegalStateException("The socket is available.")
}
socketError = null
currentState = State.CONNECTING
ws.openSocket(socketListener)
}
fun disconnect() {
if (currentState != State.CLOSED) {
currentState = State.CLOSING
ws.closeSocket(1000, "The user has closed the connection.")
}
}
fun send(msg: String) {
if (currentState != State.CONNECTED) throw IllegalStateException("The connection is lost.")
ws.sendMessage(msg)
}
private val socketListener = object : PlatformSocketListener {
override fun onOpen() {
currentState = State.CONNECTED
}
override fun onFailure(t: Throwable) {
socketError = t
currentState = State.CLOSED
}
override fun onMessage(msg: String) {
messageListener?.invoke(msg)
}
override fun onClosing(code: Int, reason: String) {
currentState = State.CLOSING
}
override fun onClosed(code: Int, reason: String) {
currentState = State.CLOSED
}
}
enum class State {
CONNECTING,
CONNECTED,
CLOSING,
CLOSED
}
}
```
Rules for expected and actual declarations
------------------------------------------
The main rules regarding expected and actual declarations are:
* An expected declaration is marked with the `expect` keyword; the actual declaration is marked with the `actual` keyword.
* `expect` and `actual` declarations have the same name and are located in the same package (have the same fully qualified name).
* `expect` declarations never contain any implementation code and are abstract by default.
* In interfaces, functions in `expect` declarations cannot have bodies, but their `actual` counterparts can be non-abstract and have a body. It allows the inheritors not to implement a particular function.
To indicate that common inheritors don't need to implement a function, mark it as `open`. All its `actual` implementations will be required to have a body:
```
// Common
expect interface Mascot {
open fun display(): String
}
class MascotImpl : Mascot {
// it's ok not to implement `display()`: all `actual`s are guaranteed to have a default implementation
}
// Platform-specific
actual interface Mascot {
actual fun display(): String {
TODO()
}
}
```
During each platform compilation, the compiler ensures that every declaration marked with the `expect` keyword in the common or intermediate source set has the corresponding declarations marked with the `actual` keyword in all platform source sets. The IDE provides tools that help you create the missing actual declarations.
If you have a platform-specific library that you want to use in shared code while providing your own implementation for another platform, you can provide a `typealias` to an existing class as the actual declaration:
```
expect class AtomicRef<V>(value: V) {
fun get(): V
fun set(value: V)
fun getAndSet(value: V): V
fun compareAndSet(expect: V, update: V): Boolean
}
```
```
actual typealias AtomicRef<V> = java.util.concurrent.atomic.AtomicReference<V>
```
Last modified: 10 January 2023
[Share code on platforms](multiplatform-share-on-platforms) [Hierarchical project structure](multiplatform-hierarchy)
| programming_docs |
kotlin Reflection Reflection
==========
*Reflection* is a set of language and library features that allows you to introspect the structure of your program at runtime. Functions and properties are first-class citizens in Kotlin, and the ability to introspect them (for example, learning the name or the type of a property or function at runtime) is essential when using a functional or reactive style.
JVM dependency
--------------
On the JVM platform, the Kotlin compiler distribution includes the runtime component required for using the reflection features as a separate artifact, `kotlin-reflect.jar`. This is done to reduce the required size of the runtime library for applications that do not use reflection features.
To use reflection in a Gradle or Maven project, add the dependency on `kotlin-reflect`:
* In Gradle:
```
dependencies {
implementation("org.jetbrains.kotlin:kotlin-reflect:1.8.0")
}
```
```
dependencies {
implementation "org.jetbrains.kotlin:kotlin-reflect:1.8.0"
}
```
* In Maven:
```
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-reflect</artifactId>
</dependency>
</dependencies>
```
If you don't use Gradle or Maven, make sure you have `kotlin-reflect.jar` in the classpath of your project. In other supported cases (IntelliJ IDEA projects that use the command-line compiler or Ant), it is added by default. In the command-line compiler and Ant, you can use the `-no-reflect` compiler option to exclude `kotlin-reflect.jar` from the classpath.
Class references
----------------
The most basic reflection feature is getting the runtime reference to a Kotlin class. To obtain the reference to a statically known Kotlin class, you can use the *class literal* syntax:
```
val c = MyClass::class
```
The reference is a [KClass](../api/latest/jvm/stdlib/kotlin.reflect/-k-class/index) type value.
### Bound class references
You can get the reference to the class of a specific object with the same `::class` syntax by using the object as a receiver:
```
val widget: Widget = ...
assert(widget is GoodWidget) { "Bad widget: ${widget::class.qualifiedName}" }
```
You will obtain the reference to the exact class of an object, for example, `GoodWidget` or `BadWidget`, regardless of the type of the receiver expression (`Widget`).
Callable references
-------------------
References to functions, properties, and constructors can also be called or used as instances of [function types](lambdas#function-types).
The common supertype for all callable references is [`KCallable<out R>`](../api/latest/jvm/stdlib/kotlin.reflect/-k-callable/index), where `R` is the return value type. It is the property type for properties, and the constructed type for constructors.
### Function references
When you have a named function declared as below, you can call it directly (`isOdd(5)`):
```
fun isOdd(x: Int) = x % 2 != 0
```
Alternatively, you can use the function as a function type value, that is, pass it to another function. To do so, use the `::` operator:
```
fun isOdd(x: Int) = x % 2 != 0
fun main() {
//sampleStart
val numbers = listOf(1, 2, 3)
println(numbers.filter(::isOdd))
//sampleEnd
}
```
Here `::isOdd` is a value of function type `(Int) -> Boolean`.
Function references belong to one of the [`KFunction<out R>`](../api/latest/jvm/stdlib/kotlin.reflect/-k-function/index) subtypes, depending on the parameter count. For instance, `KFunction3<T1, T2, T3, R>`.
`::` can be used with overloaded functions when the expected type is known from the context. For example:
```
fun main() {
//sampleStart
fun isOdd(x: Int) = x % 2 != 0
fun isOdd(s: String) = s == "brillig" || s == "slithy" || s == "tove"
val numbers = listOf(1, 2, 3)
println(numbers.filter(::isOdd)) // refers to isOdd(x: Int)
//sampleEnd
}
```
Alternatively, you can provide the necessary context by storing the method reference in a variable with an explicitly specified type:
```
val predicate: (String) -> Boolean = ::isOdd // refers to isOdd(x: String)
```
If you need to use a member of a class or an extension function, it needs to be qualified: `String::toCharArray`.
Even if you initialize a variable with a reference to an extension function, the inferred function type will have no receiver, but it will have an additional parameter accepting a receiver object. To have a function type with a receiver instead, specify the type explicitly:
```
val isEmptyStringList: List<String>.() -> Boolean = List<String>::isEmpty
```
#### Example: function composition
Consider the following function:
```
fun <A, B, C> compose(f: (B) -> C, g: (A) -> B): (A) -> C {
return { x -> f(g(x)) }
}
```
It returns a composition of two functions passed to it: `compose(f, g) = f(g(*))`. You can apply this function to callable references:
```
fun <A, B, C> compose(f: (B) -> C, g: (A) -> B): (A) -> C {
return { x -> f(g(x)) }
}
fun isOdd(x: Int) = x % 2 != 0
fun main() {
//sampleStart
fun length(s: String) = s.length
val oddLength = compose(::isOdd, ::length)
val strings = listOf("a", "ab", "abc")
println(strings.filter(oddLength))
//sampleEnd
}
```
### Property references
To access properties as first-class objects in Kotlin, use the `::` operator:
```
val x = 1
fun main() {
println(::x.get())
println(::x.name)
}
```
The expression `::x` evaluates to a `KProperty<Int>` type property object. You can read its value using `get()` or retrieve the property name using the `name` property. For more information, see the [docs on the `KProperty` class](../api/latest/jvm/stdlib/kotlin.reflect/-k-property/index).
For a mutable property such as `var y = 1`, `::y` returns a value with the [`KMutableProperty<Int>`](../api/latest/jvm/stdlib/kotlin.reflect/-k-mutable-property/index) type which has a `set()` method:
```
var y = 1
fun main() {
::y.set(2)
println(y)
}
```
A property reference can be used where a function with a single generic parameter is expected:
```
fun main() {
//sampleStart
val strs = listOf("a", "bc", "def")
println(strs.map(String::length))
//sampleEnd
}
```
To access a property that is a member of a class, qualify it as follows:
```
fun main() {
//sampleStart
class A(val p: Int)
val prop = A::p
println(prop.get(A(1)))
//sampleEnd
}
```
For an extension property:
```
val String.lastChar: Char
get() = this[length - 1]
fun main() {
println(String::lastChar.get("abc"))
}
```
### Interoperability with Java reflection
On the JVM platform, the standard library contains extensions for reflection classes that provide a mapping to and from Java reflection objects (see package `kotlin.reflect.jvm`). For example, to find a backing field or a Java method that serves as a getter for a Kotlin property, you can write something like this:
```
import kotlin.reflect.jvm.*
class A(val p: Int)
fun main() {
println(A::p.javaGetter) // prints "public final int A.getP()"
println(A::p.javaField) // prints "private final int A.p"
}
```
To get the Kotlin class that corresponds to a Java class, use the `.kotlin` extension property:
```
fun getKClass(o: Any): KClass<Any> = o.javaClass.kotlin
```
### Constructor references
Constructors can be referenced just like methods and properties. You can use them wherever the program expects a function type object that takes the same parameters as the constructor and returns an object of the appropriate type. Constructors are referenced by using the `::` operator and adding the class name. Consider the following function that expects a function parameter with no parameters and return type `Foo`:
```
class Foo
fun function(factory: () -> Foo) {
val x: Foo = factory()
}
```
Using `::Foo`, the zero-argument constructor of the class `Foo`, you can call it like this:
```
function(::Foo)
```
Callable references to constructors are typed as one of the [`KFunction<out R>`](../api/latest/jvm/stdlib/kotlin.reflect/-k-function/index) subtypes depending on the parameter count.
### Bound function and property references
You can refer to an instance method of a particular object:
```
fun main() {
//sampleStart
val numberRegex = "\\d+".toRegex()
println(numberRegex.matches("29"))
val isNumber = numberRegex::matches
println(isNumber("29"))
//sampleEnd
}
```
Instead of calling the method `matches` directly, the example uses a reference to it. Such a reference is bound to its receiver. It can be called directly (like in the example above) or used whenever a function type expression is expected:
```
fun main() {
//sampleStart
val numberRegex = "\\d+".toRegex()
val strings = listOf("abc", "124", "a70")
println(strings.filter(numberRegex::matches))
//sampleEnd
}
```
Compare the types of the bound and the unbound references. The bound callable reference has its receiver "attached" to it, so the type of the receiver is no longer a parameter:
```
val isNumber: (CharSequence) -> Boolean = numberRegex::matches
val matches: (Regex, CharSequence) -> Boolean = Regex::matches
```
A property reference can be bound as well:
```
fun main() {
//sampleStart
val prop = "abc"::length
println(prop.get())
//sampleEnd
}
```
You don't need to specify `this` as the receiver: `this::foo` and `::foo` are equivalent.
### Bound constructor references
A bound callable reference to a constructor of an [inner class](nested-classes#inner-classes) can be obtained by providing an instance of the outer class:
```
class Outer {
inner class Inner
}
val o = Outer()
val boundInnerCtor = o::Inner
```
Last modified: 10 January 2023
[Destructuring declarations](destructuring-declarations) [Get started with Kotlin Multiplatform Mobile](multiplatform-mobile-getting-started)
kotlin Ant Ant
===
Getting the Ant tasks
---------------------
Kotlin provides three tasks for Ant:
* `kotlinc`: Kotlin compiler targeting the JVM
* `kotlin2js`: Kotlin compiler targeting JavaScript
* `withKotlin`: Task to compile Kotlin files when using the standard *javac* Ant task
These tasks are defined in the *kotlin-ant.jar* library which is located in the `lib` folder in the [Kotlin Compiler](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0) archive. Ant version 1.8.2+ is required.
Targeting JVM with Kotlin-only source
-------------------------------------
When the project consists of exclusively Kotlin source code, the easiest way to compile the project is to use the `kotlinc` task:
```
<project name="Ant Task Test" default="build">
<typedef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<kotlinc src="hello.kt" output="hello.jar"/>
</target>
</project>
```
where `${kotlin.lib}` points to the folder where the Kotlin standalone compiler was unzipped.
Targeting JVM with Kotlin-only source and multiple roots
--------------------------------------------------------
If a project consists of multiple source roots, use `src` as elements to define paths:
```
<project name="Ant Task Test" default="build">
<typedef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<kotlinc output="hello.jar">
<src path="root1"/>
<src path="root2"/>
</kotlinc>
</target>
</project>
```
Targeting JVM with Kotlin and Java source
-----------------------------------------
If a project consists of both Kotlin and Java source code, while it is possible to use `kotlinc`, to avoid repetition of task parameters, it is recommended to use `withKotlin` task:
```
<project name="Ant Task Test" default="build">
<typedef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<delete dir="classes" failonerror="false"/>
<mkdir dir="classes"/>
<javac destdir="classes" includeAntRuntime="false" srcdir="src">
<withKotlin/>
</javac>
<jar destfile="hello.jar">
<fileset dir="classes"/>
</jar>
</target>
</project>
```
You can also specify the name of the module being compiled as the `moduleName` attribute:
```
<withKotlin moduleName="myModule"/>
```
Targeting JavaScript with single source folder
----------------------------------------------
```
<project name="Ant Task Test" default="build">
<typedef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<kotlin2js src="root1" output="out.js"/>
</target>
</project>
```
Targeting JavaScript with Prefix, PostFix and sourcemap options
---------------------------------------------------------------
```
<project name="Ant Task Test" default="build">
<taskdef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<kotlin2js src="root1" output="out.js" outputPrefix="prefix" outputPostfix="postfix" sourcemap="true"/>
</target>
</project>
```
Targeting JavaScript with single source folder and metaInfo option
------------------------------------------------------------------
The `metaInfo` option is useful, if you want to distribute the result of translation as a Kotlin/JavaScript library. If `metaInfo` was set to `true`, then during compilation additional JS file with binary metadata will be created. This file should be distributed together with the result of translation:
```
<project name="Ant Task Test" default="build">
<typedef resource="org/jetbrains/kotlin/ant/antlib.xml" classpath="${kotlin.lib}/kotlin-ant.jar"/>
<target name="build">
<!-- out.meta.js will be created, which contains binary metadata -->
<kotlin2js src="root1" output="out.js" metaInfo="true"/>
</target>
</project>
```
References
----------
Complete list of elements and attributes are listed below:
### Attributes common for kotlinc and kotlin2js
| Name | Description | Required | Default Value |
| --- | --- | --- | --- |
| `src` | Kotlin source file or directory to compile | Yes | |
| `nowarn` | Suppresses all compilation warnings | No | false |
| `noStdlib` | Does not include the Kotlin standard library into the classpath | No | false |
| `failOnError` | Fails the build if errors are detected during the compilation | No | true |
### kotlinc attributes
| Name | Description | Required | Default Value |
| --- | --- | --- | --- |
| `output` | Destination directory or .jar file name | Yes | |
| `classpath` | Compilation class path | No | |
| `classpathref` | Compilation class path reference | No | |
| `includeRuntime` | If `output` is a .jar file, whether Kotlin runtime library is included in the jar | No | true |
| `moduleName` | Name of the module being compiled | No | The name of the target (if specified) or the project |
### kotlin2js attributes
| Name | Description | Required |
| --- | --- | --- |
| `output` | Destination file | Yes |
| `libraries` | Paths to Kotlin libraries | No |
| `outputPrefix` | Prefix to use for generated JavaScript files | No |
| `outputSuffix` | Suffix to use for generated JavaScript files | No |
| `sourcemap` | Whether sourcemap file should be generated | No |
| `metaInfo` | Whether metadata file with binary descriptors should be generated | No |
| `main` | Should compiler generated code call the main function | No |
### Passing raw compiler arguments
To pass custom raw compiler arguments, you can use `<compilerarg>` elements with either `value` or `line` attributes. This can be done within the `<kotlinc>`, `<kotlin2js>`, and `<withKotlin>` task elements, as follows:
```
<kotlinc src="${test.data}/hello.kt" output="${temp}/hello.jar">
<compilerarg value="-Xno-inline"/>
<compilerarg line="-Xno-call-assertions -Xno-param-assertions"/>
<compilerarg value="-Xno-optimize"/>
</kotlinc>
```
The full list of arguments that can be used is shown when you run `kotlinc -help`.
Last modified: 10 January 2023
[Maven](maven) [IDEs for Kotlin development](kotlin-ide)
kotlin What's new in Kotlin 1.5.20 What's new in Kotlin 1.5.20
===========================
*[Release date: 24 June 2021](releases#release-details)*
Kotlin 1.5.20 has fixes for issues discovered in the new features of 1.5.0, and it also includes various tooling improvements.
You can find an overview of the changes in the [release blog post](https://blog.jetbrains.com/kotlin/2021/06/kotlin-1-5-20-released/) and this video:
Kotlin/JVM
----------
Kotlin 1.5.20 is receiving the following updates on the JVM platform:
* [String concatenation via invokedynamic](#string-concatenation-via-invokedynamic)
* [Support for JSpecify nullness annotations](#support-for-jspecify-nullness-annotations)
* [Support for calling Java's Lombok-generated methods within modules that have Kotlin and Java code](#support-for-calling-java-s-lombok-generated-methods-within-modules-that-have-kotlin-and-java-code)
### String concatenation via invokedynamic
Kotlin 1.5.20 compiles string concatenations into [dynamic invocations](https://docs.oracle.com/javase/7/docs/technotes/guides/vm/multiple-language-support.html#invokedynamic) (`invokedynamic`) on JVM 9+ targets, thereby keeping up with modern Java versions. More precisely, it uses [`StringConcatFactory.makeConcatWithConstants()`](https://docs.oracle.com/javase/9/docs/api/java/lang/invoke/StringConcatFactory.html#makeConcatWithConstants-java.lang.invoke.MethodHandles.Lookup-java.lang.String-java.lang.invoke.MethodType-java.lang.String-java.lang.Object...-) for string concatenation.
To switch back to concatenation via [`StringBuilder.append()`](https://docs.oracle.com/javase/9/docs/api/java/lang/StringBuilder.html#append-java.lang.String-) used in previous versions, add the compiler option `-Xstring-concat=inline`.
Learn how to add compiler options in [Gradle](gradle-compiler-options), [Maven](maven#specifying-compiler-options), and the [command-line compiler](compiler-reference#compiler-options).
### Support for JSpecify nullness annotations
The Kotlin compiler can read various types of [nullability annotations](java-interop#nullability-annotations) to pass nullability information from Java to Kotlin. Version 1.5.20 introduces support for the [JSpecify project](https://jspecify.dev/), which includes the standard unified set of Java nullness annotations.
With JSpecify, you can provide more detailed nullability information to help Kotlin keep null-safety interoperating with Java. You can set default nullability for the declaration, package, or module scope, specify parametric nullability, and more. You can find more details about this in the [JSpecify user guide](https://jspecify.dev/user-guide.html).
Here is the example of how Kotlin can handle JSpecify annotations:
```
// JavaClass.java
import org.jspecify.nullness.*;
@NullMarked
public class JavaClass {
public String notNullableString() { return ""; }
public @Nullable String nullableString() { return ""; }
}
```
```
// Test.kt
fun kotlinFun() = with(JavaClass()) {
notNullableString().length // OK
nullableString().length // Warning: receiver nullability mismatch
}
```
In 1.5.20, all nullability mismatches according to the JSpecify-provided nullability information are reported as warnings. Use the `-Xjspecify-annotations=strict` and `-Xtype-enhancement-improvements-strict-mode` compiler options to enable strict mode (with error reporting) when working with JSpecify. Please note that the JSpecify project is under active development. Its API and implementation can change significantly at any time.
[Learn more about null-safety and platform types](java-interop#null-safety-and-platform-types).
### Support for calling Java's Lombok-generated methods within modules that have Kotlin and Java code
Kotlin 1.5.20 introduces an experimental [Lombok compiler plugin](lombok). This plugin makes it possible to generate and use Java's [Lombok](https://projectlombok.org/) declarations within modules that have Kotlin and Java code. Lombok annotations work only in Java sources and are ignored if you use them in Kotlin code.
The plugin supports the following annotations:
* `@Getter`, `@Setter`
* `@NoArgsConstructor`, `@RequiredArgsConstructor`, and `@AllArgsConstructor`
* `@Data`
* `@With`
* `@Value`
We're continuing to work on this plugin. To find out the detailed current state, visit the [Lombok compiler plugin's README](https://github.com/JetBrains/kotlin/blob/master/plugins/lombok/lombok-compiler-plugin/README.md).
Currently, we don't have plans to support the `@Builder` annotation. However, we can consider this if you vote for [`@Builder` in YouTrack](https://youtrack.jetbrains.com/issue/KT-46959).
[Learn how to configure the Lombok compiler plugin](lombok#gradle).
Kotlin/Native
-------------
Kotlin/Native 1.5.20 offers a preview of the new feature and the tooling improvements:
* [Opt-in export of KDoc comments to generated Objective-C headers](#opt-in-export-of-kdoc-comments-to-generated-objective-c-headers)
* [Compiler bug fixes](#compiler-bug-fixes)
* [Improved performance of Array.copyInto() inside one array](#improved-performance-of-array-copyinto-inside-one-array)
### Opt-in export of KDoc comments to generated Objective-C headers
You can now set the Kotlin/Native compiler to export the [documentation comments (KDoc)](kotlin-doc) from Kotlin code to the Objective-C frameworks generated from it, making them visible to the frameworks' consumers.
For example, the following Kotlin code with KDoc:
```
/**
* Prints the sum of the arguments.
* Properly handles the case when the sum doesn't fit in 32-bit integer.
*/
fun printSum(a: Int, b: Int) = println(a.toLong() + b)
```
produces the following Objective-C headers:
```
/**
* Prints the sum of the arguments.
* Properly handles the case when the sum doesn't fit in 32-bit integer.
*/
+ (void)printSumA:(int32_t)a b:(int32_t)b __attribute__((swift_name("printSum(a:b:)")));
```
This also works well with Swift.
To try out this ability to export KDoc comments to Objective-C headers, use the `-Xexport-kdoc` compiler option. Add the following lines to `build.gradle(.kts)` of the Gradle projects you want to export comments from:
```
kotlin {
targets.withType<org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget> {
compilations.get("main").kotlinOptions.freeCompilerArgs += "-Xexport-kdoc"
}
}
```
```
kotlin {
targets.withType(org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget) {
compilations.get("main").kotlinOptions.freeCompilerArgs += "-Xexport-kdoc"
}
}
```
We would be very grateful if you would share your feedback with us using this [YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-38600).
### Compiler bug fixes
The Kotlin/Native compiler has received multiple bug fixes in 1.5.20. You can find the complete list in the [changelog](https://github.com/JetBrains/kotlin/releases/tag/v1.5.20).
There is an important bug fix that affects compatibility: in previous versions, string constants that contained incorrect UTF [surrogate pairs](https://en.wikipedia.org/wiki/Universal_Character_Set_characters#Surrogates) were losing their values during compilation. Now such values are preserved. Application developers can safely update to 1.5.20 – nothing will break. However, libraries compiled with 1.5.20 are incompatible with earlier compiler versions. See [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-33175) for details.
### Improved performance of Array.copyInto() inside one array
We've improved the way `Array.copyInto()` works when its source and destination are the same array. Now such operations finish up to 20 times faster (depending on the number of objects being copied) due to memory management optimizations for this use case.
Kotlin/JS
---------
With 1.5.20, we're publishing a guide that will help you migrate your projects to the new [IR-based backend](js-ir-compiler) for Kotlin/JS.
### Migration guide for the JS IR backend
The new [migration guide for the JS IR backend](js-ir-migration) identifies issues you may encounter during migration and provides solutions for them. If you find any issues that aren't covered in the guide, please report them to our [issue tracker](http://kotl.in/issue).
Gradle
------
Kotlin 1.5.20 introduces the following features that can improve the Gradle experience:
* [Caching for annotation processors classloaders in kapt](#caching-for-annotation-processors-classloaders-in-kapt)
* [Deprecation of the `kotlin.parallel.tasks.in.project` build property](#deprecation-of-the-kotlin-parallel-tasks-in-project-build-property)
### Caching for annotation processors' classloaders in kapt
There is now a new experimental feature that makes it possible to cache the classloaders of annotation processors in <kapt>. This feature can increase the speed of kapt for consecutive Gradle runs.
To enable this feature, use the following properties in your `gradle.properties` file:
```
# positive value will enable caching
# use the same value as the number of modules that use kapt
kapt.classloaders.cache.size=5
# disable for caching to work
kapt.include.compile.classpath=false
```
Learn more about <kapt>.
### Deprecation of the kotlin.parallel.tasks.in.project build property
With this release, Kotlin parallel compilation is controlled by the [Gradle parallel execution flag `--parallel`](https://docs.gradle.org/current/userguide/performance.html#parallel_execution). Using this flag, Gradle executes tasks concurrently, increasing the speed of compiling tasks and utilizing the resources more efficiently.
You no longer need to use the `kotlin.parallel.tasks.in.project` property. This property has been deprecated and will be removed in the next major release.
Standard library
----------------
Kotlin 1.5.20 changes the platform-specific implementations of several functions for working with characters and as a result brings unification across platforms:
* [Support for all Unicode digits in Char.digitToInt() for Kotlin/Native and Kotlin/JS](#support-for-all-unicode-digits-in-char-digittoint-in-kotlin-native-and-kotlin-js).
* [Unification of Char.isLowerCase()/isUpperCase() implementations across platforms](#unification-of-char-islowercase-isuppercase-implementations-across-platforms).
### Support for all Unicode digits in Char.digitToInt() in Kotlin/Native and Kotlin/JS
[`Char.digitToInt()`](../api/latest/jvm/stdlib/kotlin.text/digit-to-int) returns the numeric value of the decimal digit that the character represents. Before 1.5.20, the function supported all Unicode digit characters only for Kotlin/JVM: implementations on the Native and JS platforms supported only ASCII digits.
From now, both with Kotlin/Native and Kotlin/JS, you can call `Char.digitToInt()` on any Unicode digit character and get its numeric representation.
```
fun main() {
//sampleStart
val ten = '\u0661'.digitToInt() + '\u0039'.digitToInt() // ARABIC-INDIC DIGIT ONE + DIGIT NINE
println(ten)
//sampleEnd
}
```
### Unification of Char.isLowerCase()/isUpperCase() implementations across platforms
The functions [`Char.isUpperCase()`](../api/latest/jvm/stdlib/kotlin.text/is-upper-case) and [`Char.isLowerCase()`](../api/latest/jvm/stdlib/kotlin.text/is-lower-case) return a boolean value depending on the case of the character. For Kotlin/JVM, the implementation checks both the `General_Category` and the `Other_Uppercase`/`Other_Lowercase` [Unicode properties](https://en.wikipedia.org/wiki/Unicode_character_property).
Prior to 1.5.20, implementations for other platforms worked differently and considered only the general category. In 1.5.20, implementations are unified across platforms and use both properties to determine the character case:
```
fun main() {
//sampleStart
val latinCapitalA = 'A' // has "Lu" general category
val circledLatinCapitalA = 'Ⓐ' // has "Other_Uppercase" property
println(latinCapitalA.isUpperCase() && circledLatinCapitalA.isUpperCase())
//sampleEnd
}
```
Last modified: 10 January 2023
[What's new in Kotlin 1.5.30](whatsnew1530) [What's new in Kotlin 1.5.0](whatsnew15)
| programming_docs |
kotlin Strings in Java and Kotlin Strings in Java and Kotlin
==========================
This guide contains examples of how to perform typical tasks with strings in Java and Kotlin. It will help you migrate from Java to Kotlin and write your code in the authentically Kotlin way.
Concatenate strings
-------------------
In Java, you can do this in the following way:
```
// Java
String name = "Joe";
System.out.println("Hello, " + name);
System.out.println("Your name is " + name.length() + " characters long");
```
In Kotlin, use the dollar sign (`$`) before the variable name to interpolate the value of this variable into your string:
```
fun main() {
//sampleStart
// Kotlin
val name = "Joe"
println("Hello, $name")
println("Your name is ${name.length} characters long")
//sampleEnd
}
```
You can interpolate the value of a complicated expression by surrounding it with curly braces, like in `${name.length}`. See [string templates](strings#string-templates) for more information.
Build a string
--------------
In Java, you can use the [StringBuilder](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/StringBuilder.html):
```
// Java
StringBuilder countDown = new StringBuilder();
for (int i = 5; i > 0; i--) {
countDown.append(i);
countDown.append("\n");
}
System.out.println(countDown);
```
In Kotlin, use [buildString()](../api/latest/jvm/stdlib/kotlin.text/build-string) – an [inline function](inline-functions) that takes logic to construct a string as a lambda argument:
```
fun main() {
//sampleStart
// Kotlin
val countDown = buildString {
for (i in 5 downTo 1) {
append(i)
appendLine()
}
}
println(countDown)
//sampleEnd
}
```
Under the hood, the `buildString` uses the same `StringBuilder` class as in Java, and you access it via an implicit `this` inside the [lambda](lambdas#function-literals-with-receiver).
Learn more about [lambda coding conventions](coding-conventions#lambdas).
Create a string from collection items
-------------------------------------
In Java, you use the [Stream API](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/stream/package-summary.html) to filter, map, and then collect the items:
```
// Java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
String invertedOddNumbers = numbers
.stream()
.filter(it -> it % 2 != 0)
.map(it -> -it)
.map(Object::toString)
.collect(Collectors.joining("; "));
System.out.println(invertedOddNumbers);
```
In Kotlin, use the [joinToString()](../api/latest/jvm/stdlib/kotlin.collections/join-to-string) function, which Kotlin defines for every List:
```
fun main() {
//sampleStart
// Kotlin
val numbers = listOf(1, 2, 3, 4, 5, 6)
val invertedOddNumbers = numbers
.filter { it % 2 != 0 }
.joinToString(separator = ";") {"${-it}"}
println(invertedOddNumbers)
//sampleEnd
}
```
Learn more about [joinToString()](collection-transformations#string-representation) usage.
Set default value if the string is blank
----------------------------------------
In Java, you can use the [ternary operator](https://en.wikipedia.org/wiki/%3F:):
```
// Java
public void defaultValueIfStringIsBlank() {
String nameValue = getName();
String name = nameValue.isBlank() ? "John Doe" : nameValue;
System.out.println(name);
}
public String getName() {
Random rand = new Random();
return rand.nextBoolean() ? "" : "David";
}
```
Kotlin provides the inline function [ifBlank()](../api/latest/jvm/stdlib/kotlin.text/if-blank) that accepts the default value as an argument:
```
// Kotlin
import kotlin.random.Random
//sampleStart
fun main() {
val name = getName().ifBlank { "John Doe" }
println(name)
}
fun getName(): String =
if (Random.nextBoolean()) "" else "David"
//sampleEnd
```
Replace characters at the beginning and end of a string
-------------------------------------------------------
In Java, you can use the [replaceAll()](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/String.html#replaceAll(java.lang.String,java.lang.String)) function. The `replaceAll()` function in this case accepts regular expressions `^##` and `##$`, which define strings starting and ending with `##` respectively:
```
// Java
String input = "##place##holder##";
String result = input.replaceAll("^##|##$", "");
System.out.println(result);
```
In Kotlin, use the [removeSurrounding()](../api/latest/jvm/stdlib/kotlin.text/remove-surrounding) function with the string delimiter `##`:
```
fun main() {
//sampleStart
// Kotlin
val input = "##place##holder##"
val result = input.removeSurrounding("##")
println(result)
//sampleEnd
}
```
Replace occurrences
-------------------
In Java, you can use the [Pattern](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/regex/Pattern.html) and the [Matcher](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/regex/Matcher.html) classes, for example, to obfuscate some data:
```
// Java
String input = "login: Pokemon5, password: 1q2w3e4r5t";
Pattern pattern = Pattern.compile("\\w*\\d+\\w*");
Matcher matcher = pattern.matcher(input);
String replacementResult = matcher.replaceAll(it -> "xxx");
System.out.println("Initial input: '" + input + "'");
System.out.println("Anonymized input: '" + replacementResult + "'");
```
In Kotlin, you use the [Regex](../api/latest/jvm/stdlib/kotlin.text/-regex/index) class that simplifies working with regular expressions. Additionally, use [raw strings](strings#string-literals) to simplify a regex pattern by reducing the count of backslashes:
```
fun main() {
//sampleStart
// Kotlin
val regex = Regex("""\w*\d+\w*""") // raw string
val input = "login: Pokemon5, password: 1q2w3e4r5t"
val replacementResult = regex.replace(input, replacement = "xxx")
println("Initial input: '$input'")
println("Anonymized input: '$replacementResult'")
//sampleEnd
}
```
Split a string
--------------
In Java, to split a string with the period character (`.`), you need to use shielding (`\\`). This happens because the [split()](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/String.html#split(java.lang.String)) function of the `String` class accepts a regular expression as an argument:
```
// Java
System.out.println(Arrays.toString("Sometimes.text.should.be.split".split("\\.")));
```
In Kotlin, use the Kotlin function [split()](../api/latest/jvm/stdlib/kotlin.text/split), which accepts varargs of delimiters as input parameters:
```
fun main() {
//sampleStart
// Kotlin
println("Sometimes.text.should.be.split".split("."))
//sampleEnd
}
```
If you need to split with a regular expression, use the overloaded `split()` version that accepts the `Regex` as a parameter.
Take a substring
----------------
In Java, you can use the [substring()](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/String.html#substring(int)) function, which accepts an inclusive beginning index of a character to start taking the substring from. To take a substring after this character, you need to increment the index:
```
// Java
String input = "What is the answer to the Ultimate Question of Life, the Universe, and Everything? 42";
String answer = input.substring(input.indexOf("?") + 1);
System.out.println(answer);
```
In Kotlin, you use the [substringAfter()](../api/latest/jvm/stdlib/kotlin.text/substring-after) function and don't need to calculate the index of the character you want to take a substring after:
```
fun main() {
//sampleStart
// Kotlin
val input = "What is the answer to the Ultimate Question of Life, the Universe, and Everything? 42"
val answer = input.substringAfter("?")
println(answer)
//sampleEnd
}
```
Additionally, you can take a substring after the last occurrence of a character:
```
fun main() {
//sampleStart
// Kotlin
val input = "To be, or not to be, that is the question."
val question = input.substringAfterLast(",")
println(question)
//sampleEnd
}
```
Use multiline strings
---------------------
Before Java 15, there were several ways to create a multiline string. For example, using the [join()](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/String.html#join(java.lang.CharSequence,java.lang.CharSequence...)) function of the `String` class:
```
// Java
String lineSeparator = System.getProperty("line.separator");
String result = String.join(lineSeparator,
"Kotlin",
"Java");
System.out.println(result);
```
In Java 15, [text blocks](https://docs.oracle.com/en/java/javase/15/text-blocks/index.html) appeared. There is one thing to keep in mind: if you print a multiline string and the triple-quote is on the next line, there will be an extra empty line:
```
// Java
String result = """
Kotlin
Java
""";
System.out.println(result);
```
The output:
If you put the triple-quote on the same line as the last word, this difference in behavior disappears.
In Kotlin, you can format your line with the quotes on the new line, and there will be no extra empty line in the output. The left-most character of any line identifies the beginning of the line. The difference with Java is that Java automatically trims indents, and in Kotlin you should do it explicitly:
```
fun main() {
//sampleStart
// Kotlin
val result = """
Kotlin
Java
""".trimIndent()
println(result)
//sampleEnd
}
```
The output:
To have an extra empty line, you should add this empty line to your multiline string explicitly.
In Kotlin, you can also use the [trimMargin()](../api/latest/jvm/stdlib/kotlin.text/trim-margin) function to customize the indents:
```
// Kotlin
fun main() {
val result = """
# Kotlin
# Java
""".trimMargin("#")
println(result)
}
```
Learn more about [multiline strings](coding-conventions#strings).
What's next?
------------
* Look through other [Kotlin idioms](idioms).
* Learn how to convert existing Java code to Kotlin with the [Java to Kotlin converter](mixing-java-kotlin-intellij#converting-an-existing-java-file-to-kotlin-with-j2k).
If you have a favorite idiom, we invite you to share it by sending a pull request.
Last modified: 10 January 2023
[Using Java records in Kotlin](jvm-records) [Collections in Java and Kotlin](java-to-kotlin-collections-guide)
kotlin Compatibility guide for Kotlin 1.3 Compatibility guide for Kotlin 1.3
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.2 to Kotlin 1.3.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *Source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *Binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *Behavioral*: a change is said to be behavioral-incompatible if one and the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (e.g. from Java) is out of the scope of this document.
Incompatible changes
--------------------
### Evaluation order of constructor arguments regarding call
### Missing getter-targeted annotations on annotation constructor parameters
### Missing errors in class constructor's @get: annotations
### Nullability assertions on access to Java types annotated with @NotNull
### Unsound smartcasts on enum members
### val backing field reassignment in getter
### Array capturing before the for-loop where it is iterated
### Nested classifiers in enum entries
### Data class overriding copy
### Inner classes inheriting Throwable that capture generic parameters from the outer class
### Visibility rules regarding complex class hierarchies with companion objects
### Non-constant vararg annotation parameters
### Local annotation classes
### Smartcasts on local delegated properties
### mod operator convention
### Passing single element to vararg in named form
### Retention of annotations with target EXPRESSION
### Annotations with target PARAMETER shouldn't be applicable to parameter's type
### Array.copyOfRange throws an exception when indices are out of bounds instead of enlarging the returned array
### Progressions of ints and longs with a step of Int.MIN\_VALUE and Long.MIN\_VALUE are outlawed and won't be allowed to be instantiated
### Check for index overflow in operations on very long sequences
### Unify split by an empty match regex result across the platforms
### Discontinued deprecated artifacts in the compiler distribution
### Annotations in stdlib
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.4](compatibility-guide-14) [Compatibility modes](compatibility-modes)
kotlin Build a full-stack web app with Kotlin Multiplatform Build a full-stack web app with Kotlin Multiplatform
====================================================
This tutorial demonstrates how to build a connected full-stack application with IntelliJ IDEA. You will create a simple JSON API and learn how to use the API from a web app using Kotlin and React.
The application consists of a server part using Kotlin/JVM and a web client using Kotlin/JS. Both parts will be one Kotlin Multiplatform project. Since the whole app will be in Kotlin, you can share libraries and programming paradigms (such as using Coroutines for concurrency) on both the frontend and backend.
Using Kotlin throughout the whole stack also makes it possible to write classes and functions that can be used from both the JVM and JS targets of your application. In this tutorial, you'll primarily utilize this functionality to share a type-safe representation of the data between client and server.
You will also use popular Kotlin multiplatform libraries and frameworks:
* [`kotlinx.serialization`](https://github.com/Kotlin/kotlinx.serialization)
* [`kotlinx.coroutines`](https://github.com/Kotlin/kotlinx.coroutines)
* The [Ktor](https://ktor.io/) framework
Serialization and deserialization to and from type-safe objects is delegated to the `kotlinx.serialization` multiplatform library. This helps you make data communication safe and easy to implement.
The output will be a simple shopping list application that allows you to plan your grocery shopping.
* The user interface will be simple: a list of planned purchases and a field to enter new shopping items.
* If a user clicks on an item in the shopping list, it will be removed.
* The user can also specify a priority level for list entries by adding an exclamation point `!`. This information will help order the shopping list.
Create the project
------------------
Clone the [project repository](https://github.com/kotlin-hands-on/jvm-js-fullstack) from GitHub and open it in IntelliJ IDEA. This template already includes all of the configuration and required dependencies for all of the project parts: JVM, JS, and the common code.
You don't need to change the Gradle configuration throughout this tutorial. If you want to get right to programming, feel free to move on directly to the [next section](#build-the-backend).
Alternatively, you can get an understanding of the configuration and project setup in the `build.gradle.kts` file to prepare for other projects. Check out the sections about the Gradle structure below.
### Plugins
Like all Kotlin projects targeting more than one platform, your project uses the Kotlin Multiplatform Gradle plugin. It provides a single point of configuration for the application targets (in this case, Kotlin/JVM and Kotlin/JS) and exposes several lifecycle tasks for them.
Additionally, you'll need two more plugins:
* The [`application`](https://docs.gradle.org/current/userguide/application_plugin.html) plugin runs the server part of the application that uses JVM.
* The [`serialization`](https://github.com/Kotlin/kotlinx.serialization#gradle) plugin provides multiplatform conversions between Kotlin objects and their JSON text representation.
```
plugins {
kotlin("multiplatform") version "1.8.0"
application // to run the JVM part
kotlin("plugin.serialization") version "1.8.0"
}
```
### Targets
The target configuration inside the `kotlin` block is responsible for setting up the platforms you want to support with your project. Configure two targets: `jvm` (server) and `js` (client). Here you'll make further adjustments to target configurations.
```
jvm {
withJava()
}
js {
browser {
binaries.executable()
}
}
```
For more detailed information on targets, see [Understand Multiplatform project structure](multiplatform-discover-project#targets).
### Source sets
Kotlin source sets are a collection of Kotlin sources and their resources, dependencies, and language settings that belong to one or more targets. You use them to set up platform-specific and common dependency blocks.
```
sourceSets {
val commonMain by getting {
dependencies {
// ...
}
}
val jvmMain by getting {
dependencies {
// ...
}
}
val jsMain by getting {
dependencies {
// ...
}
}
}
```
Each source set also corresponds to a folder in the `src` directory. In your project, there are three folders, `commonMain`, `jsMain`, and `jvmMain`, which contain their own `resources` and `kotlin` folders.
For detailed information on source sets, see [Understand Multiplatform project structure](multiplatform-discover-project#source-sets).
Build the backend
-----------------
Let's begin by writing the server side of the application. The typical API server implements the [CRUD operations](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) – create, read, update, and delete. For the simple shopping list, you can focus solely on:
* Creating new entries in the list
* Reading entries using the API
* Deleting entries
To create the backend, you can use the Ktor framework, designed to build asynchronous servers and clients in connected systems. It can be set up quickly and grow as systems become more complex.
You can find more information about Ktor in its [documentation](https://ktor.io/docs/welcome.html).
### Run the embedded server
Instantiate a server with Ktor. You need to tell the [embedded server](https://ktor.io/docs/create-server.html#embedded-server) that ships with Ktor to use the `Netty` engine on a port, in this case, `9090`.
1. To define the entry point for the app, add the following code to `src/jvmMain/kotlin/Server.kt`:
```
import io.ktor.http.*
import io.ktor.serialization.kotlinx.json.*
import io.ktor.server.engine.*
import io.ktor.server.netty.*
import io.ktor.server.application.*
import io.ktor.server.plugins.compression.*
import io.ktor.server.plugins.contentnegotiation.*
import io.ktor.server.plugins.cors.routing.*
import io.ktor.server.request.*
import io.ktor.server.response.*
import io.ktor.server.http.content.*
import io.ktor.server.routing.*
fun main() {
embeddedServer(Netty, 9090) {
routing {
get("/hello") {
call.respondText("Hello, API!")
}
}
}.start(wait = true)
}
```
* The first API endpoint is an HTTP method, `get`, and the route under which it should be reachable, `/hello`.
* All imports that are needed for the rest of the tutorial have already been added.
2. To start the application and see that everything works, execute the Gradle `run` task. You can use the `./gradlew run` command in the terminal or run from the Gradle tool window:

3. Once the application has finished compiling and the server has started up, use a web browser to navigate to [`http://localhost:9090/hello`](http://localhost:9090/hello) to see the first route in action:

Later, like with the endpoint for GET requests to `/hello`, you'll be able to configure all of the endpoints for the API inside the [`routing`](https://ktor.io/docs/routing-in-ktor.html) block.
### Install Ktor plugins
Before continuing with the application development, install the required [plugins](https://ktor.io/docs/plugins.html) for the embedded servers. Ktor uses plugins to enable support for more features in the application like encoding, compression, logging, and authentication.
Add the following lines to the top of the `embeddedServer` block in `src/jvmMain/kotlin/Server.kt`:
```
install(ContentNegotiation) {
json()
}
install(CORS) {
allowMethod(HttpMethod.Get)
allowMethod(HttpMethod.Post)
allowMethod(HttpMethod.Delete)
anyHost()
}
install(Compression) {
gzip()
}
routing {
// ...
}
```
Each call to `install` adds one feature to the Ktor application:
* [`ContentNegotiation`](https://ktor.io/docs/serialization.html) provides automatic content conversion of requests based on their `Content-Type` and `Accept` headers. Together with the `json()` setting, this enables automatic serialization and deserialization to and from JSON, allowing you to delegate this task to the framework.
* [`CORS`](https://ktor.io/docs/cors.html) configures [Cross-Origin Resource Sharing](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS). CORS is needed to make calls from arbitrary JavaScript clients and helps prevent issues later.
* [`Compression`](https://ktor.io/docs/compression.html) greatly reduces the amount of data to be sent to the client by gzipping outgoing content when applicable.
#### Related Gradle configuration for Ktor
The artifacts required to use Ktor are a part of the `jvmMain` `dependencies` block in the `build.gradle.kts` file. This includes the server, logging, and supporting libraries for providing type-safe serialization support through `kotlinx.serialization`.
```
val jvmMain by getting {
dependencies {
implementation("io.ktor:ktor-serialization:$ktorVersion")
implementation("io.ktor:ktor-server-content-negotiation:$ktorVersion")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
implementation("io.ktor:ktor-server-cors:$ktorVersion")
implementation("io.ktor:ktor-server-compression:$ktorVersion")
implementation("io.ktor:ktor-server-core-jvm:$ktorVersion")
implementation("io.ktor:ktor-server-netty:$ktorVersion")
implementation("ch.qos.logback:logback-classic:$logbackVersion")
implementation("org.litote.kmongo:kmongo-coroutine-serialization:$kmongoVersion")
}
}
```
`kotlinx.serialization` and its integration with Ktor also requires a few common artifacts to be present, which you can find in the `commonMain` source set:
```
val commonMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:$serializationVersion")
implementation("io.ktor:ktor-client-core:$ktorVersion")
}
}
```
### Create a data model
Thanks to Kotlin Multiplatform, you can define the data model once as a common abstraction and refer to it from both the backend and frontend.
The data model for `ShoppingListItem` should have:
* A textual description of an item
* A numeric priority for an item
* An identifier
In `src/commonMain/`, create a `kotlin/ShoppingListItem.kt` file with the following content:
```
import kotlinx.serialization.Serializable
@Serializable
data class ShoppingListItem(val desc: String, val priority: Int) {
val id: Int = desc.hashCode()
companion object {
const val path = "/shoppingList"
}
}
```
* The `@Serializable` annotation comes from the multiplatform `kotlinx.serialization` library, which allows you to define models directly in common code.
* Once you use this serializable `ShoppingListItem` class from the JVM and JS platforms, code for each platform will be generated. This code takes care of serialization and deserialization.
* The `companion object` stores additional information about the model − in this case, the `path` under which you will be able to access it in the API. By referring to this variable instead of defining routes and requests as strings, you can change the `path` to model operations. Any changes to the endpoint name only need to be made here - the client and server are adjusted automatically.
### Add items to store
You can now use the `ShoppingListItem` model to instantiate some sample items and keep track of any additions or deletions made through the API.
Because there's currently no database, create a `MutableList` to temporarily store the `ShoppingListItem`s. For that, add the following file-level declaration to `src/jvmMain/kotlin/Server.kt`:
```
val shoppingList = mutableListOf(
ShoppingListItem("Cucumbers 🥒", 1),
ShoppingListItem("Tomatoes 🍅", 2),
ShoppingListItem("Orange Juice 🍊", 3)
)
```
The `common` classes are referred to as any other class in Kotlin – they are shared between all of the targets.
### Create routes for the JSON API
Add the routes that support the creation, retrieval, and deletion of `ShoppingListItem`s.
1. Inside `src/jvmMain/kotlin/Server.kt`, change your `routing` block to look as follows:
```
routing {
route(ShoppingListItem.path) {
get {
call.respond(shoppingList)
}
post {
shoppingList += call.receive<ShoppingListItem>()
call.respond(HttpStatusCode.OK)
}
delete("/{id}") {
val id = call.parameters["id"]?.toInt() ?: error("Invalid delete request")
shoppingList.removeIf { it.id == id }
call.respond(HttpStatusCode.OK)
}
}
}
```
Routes are grouped based on a common path. You don't have to specify the `route` path as a `String`. Instead, the `path` from the `ShoppingListItem` model is used. The code behaves as follows:
* A `get` request to the model's path (`/shoppingList`) responds with the whole shopping list.
* A `post` request to the model's path (`/shoppingList`) adds an entry to the shopping list.
* A `delete` request to the model's path and a provided `id` (`shoppingList/47`) removes an entry from the shopping list.
2. Check to ensure that everything is working as planned. Restart the application, head to [`http://localhost:9090/shoppingList`](http://localhost:9090/shoppingList), and validate that the data is properly served. You should see the example items in JSON formatting:

To test the `post` and `delete` requests, use an HTTP client that supports `.http` files. If you're using IntelliJ IDEA Ultimate Edition, you can do this right from the IDE.
1. In the project root, create a file called `AddShoppingListElement.http` and add a declaration of the HTTP POST request as follows:
```
POST http://localhost:9090/shoppingList
Content-Type: application/json
{
"desc": "Peppers 🌶",
"priority": 5
}
```
2. With the server running, execute the request using the run button in the gutter.
If everything goes well, the "run" tool window should show `HTTP/1.1 200 OK`, and you can visit [`http://localhost:9090/shoppingList`](http://localhost:9090/shoppingList) again to validate that the entry has been added properly:

3. Repeat this process for a file called `DeleteShoppingListElement.http`, which contains the following:
```
DELETE http://localhost:9090/shoppingList/AN_ID_GOES_HERE
```
To try this request, replace `AN_ID_GOES_HERE` with an existing ID.
Now you have a backend that can support all of the necessary operations for a functional shopping list. Move on to building a JavaScript frontend for the application, which will allow users to easily inspect, add, and check off elements from their shopping list.
Set up the frontend
-------------------
To make your version of the server usable, build a small Kotlin/JS web app that can query the server's API, display them in the form of a list, and allow the user to add and remove elements.
### Serve the frontend
Unless explicitly configured otherwise, a Kotlin Multiplatform project just means that you can build the application for each platform, in this case JVM and JavaScript. However, for the application to function properly, you need to have both the backend and the frontend compiled. In fact, you want the backend to also serve all of the assets belonging to the frontend – an HTML page and the corresponding `.js` file.
In the template project, the adjustments to the Gradle file have already been made. Whenever you run the server with the `run` Gradle task, the frontend is also built and included in the resulting artifacts. To learn more about how this works, see the [Relevant Gradle configuration](#relevant-gradle-configuration-for-the-frontend) section.
The template already comes with a boilerplate `index.html` file in the `src/commonMain/resources` folder. It has a `root` node for rendering components and a `script` tag that includes the application:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Full Stack Shopping List</title>
</head>
<body>
<div id="root"></div>
<script src="shoppinglist.js"></script>
</body>
</html>
```
This file is placed in the `common` resources instead of a `jvm` source set to make tasks for running the JS application in the browser (`jsBrowserDevelopmentRun` and `jsBrowserProductionRun`) accessible to the file as well. It's helpful if you need to run only the browser application without the backend.
While you don't need to make sure that the file is properly available on the server, you still need to instruct Ktor to provide the `.html` and `.js` files to the browser when requested.
#### Relevant Gradle configuration for the frontend
The Gradle configuration for the application contains a snippet that makes the execution and packaging of the server-side JVM application dependent on the build of your frontend application while respecting the settings regarding `development` and `production` from the environment variable. It makes sure that whenever a `jar` file is built from the application, it includes the Kotlin/JS code:
```
// include JS artifacts in any generated JAR
tasks.getByName<Jar>("jvmJar") {
val taskName = if (project.hasProperty("isProduction")
|| project.gradle.startParameter.taskNames.contains("installDist")
) {
"jsBrowserProductionWebpack"
} else {
"jsBrowserDevelopmentWebpack"
}
val webpackTask = tasks.getByName<KotlinWebpack>(taskName)
dependsOn(webpackTask) // make sure JS gets compiled first
from(File(webpackTask.destinationDirectory, webpackTask.outputFileName)) // bring output file along into the JAR
}
```
The `jvmJar` task modified here is called by the `application` plugin, which is responsible for the `run` task, and the `distributions` plugin, which is responsible for the `installDist` task, amongst others. This means that the combined build will work when you `run` your application, and also when you prepare it for deployment to another target system or cloud platform.
To ensure that the `run` task properly recognizes the JS artifacts, the classpath is adjusted as follows:
```
tasks.getByName<JavaExec>("run") {
classpath(tasks.getByName<Jar>("jvmJar")) // so that the JS artifacts generated by `jvmJar` can be found and served
}
```
### Serve HTML and JavaScript files from Ktor
For simplicity, the `index.html` file will be served on the root route `/` and expose the JavaScript artifact in the root directory.
1. In `src/jvmMain/kotlin/Server.kt`, add the corresponding routes to the `routing` block:
```
get("/") {
call.respondText(
this::class.java.classLoader.getResource("index.html")!!.readText(),
ContentType.Text.Html
)
}
static("/") {
resources("")
}
route(ShoppingListItem.path) {
// ...
}
```
2. To confirm that everything went as planned, run the application again with the Gradle `run` task.
3. Navigate to [`http://localhost:9090/`](http://localhost:9090/). You should see a page saying "Hello, Kotlin/JS":

### Edit configuration
While you are developing, the build system generates *development* artifacts. This means that no optimizations are applied when the Kotlin code is turned into JavaScript. That makes compile times faster but also results in larger JS files. When you deploy your application to the web, this is something you want to avoid.
To instruct Gradle to generate optimized production assets, set the necessary environment variable. If you are running your application on a deployment system, you can configure it to set this environment variable during the build. If you want to try out production mode locally, you can do it in the terminal or by adding the variable to the run configuration:
1. In IntelliJ IDEA, select the **Edit Configurations** action:

2. In the **Run/Debug Configurations** menu, set the environment variable:
```
ORG_GRADLE_PROJECT_isProduction=true
```

Subsequent builds with this run configuration will perform all available optimizations for the frontend part of the application, including eliminating dead code. They will still be slower than development builds, so it would be good to remove this flag again while you are developing.
Build the frontend
------------------
To render and manage user interface elements, use the popular framework [React](https://reactjs.org/) together with the available [wrappers](https://github.com/JetBrains/kotlin-wrappers/) for Kotlin. Setting up a full project with React will allow you to re-use it and its configuration as a starting point for more complex multiplatform applications.
For a more in-depth view of typical workflows and how apps are developed with React and Kotlin/JS, see the [Build a web application with React and Kotlin/JS](js-react) tutorial.
### Write the API client
To display data, you need to obtain it from the server. For this, build a small API client.
This API client will use the [`ktor-clients`](https://ktor.io/clients/index.html) library to send requests to HTTP endpoints. Ktor clients use Kotlin's coroutines to provide non-blocking networking and support plugins like the Ktor server.
In this configuration, the `JsonFeature` uses `kotlinx.serialization` to provide a way to create typesafe HTTP requests. It takes care of automatically converting between Kotlin objects and their JSON representation and vice versa.
By leveraging these properties, you can create an API wrapper as a set of suspending functions that either accept or return `ShoppingItems`. Create a file called `Api.kt` and implement them in `src/jsMain/kotlin`:
```
import io.ktor.http.*
import io.ktor.client.*
import io.ktor.client.call.*
import io.ktor.client.plugins.contentnegotiation.*
import io.ktor.client.request.*
import io.ktor.serialization.kotlinx.json.*
import kotlinx.browser.window
val jsonClient = HttpClient {
install(ContentNegotiation) {
json()
}
}
suspend fun getShoppingList(): List<ShoppingListItem> {
return jsonClient.get(ShoppingListItem.path).body()
}
suspend fun addShoppingListItem(shoppingListItem: ShoppingListItem) {
jsonClient.post(ShoppingListItem.path) {
contentType(ContentType.Application.Json)
setBody(shoppingListItem)
}
}
suspend fun deleteShoppingListItem(shoppingListItem: ShoppingListItem) {
jsonClient.delete(ShoppingListItem.path + "/${shoppingListItem.id}")
}
```
### Build the user interface
You've laid the groundwork on the client and have a clean API to access the data provided by the server. Now you can work on displaying the shopping list on the screen in a React application.
#### Configure an entry point for the application
Instead of rendering a simple "Hello, Kotlin/JS" string, make the application render a functional `App` component. For that, replace the content inside `src/jsMain/kotlin/Main.kt` with the following:
```
import kotlinx.browser.document
import react.create
import react.dom.client.createRoot
fun main() {
val container = document.getElementById("root") ?: error("Couldn't find container!")
createRoot(container).render(App.create())
}
```
#### Build and render the shopping list
Next, implement the `App` component. For the shopping list application, it needs to:
* Keep the "local state" of the shopping list to understand which elements to display.
* Load the shopping list elements from the server and set the state accordingly.
* Provide React with instructions on how to render the list.
Based on these requirements, you can implement the `App` component as follows:
1. Create and fill the `src/jsMain/kotlin/App.kt` file:
```
import react.*
import kotlinx.coroutines.*
import react.dom.html.ReactHTML.h1
import react.dom.html.ReactHTML.li
import react.dom.html.ReactHTML.ul
private val scope = MainScope()
val App = FC<Props> {
var shoppingList by useState(emptyList<ShoppingListItem>())
useEffectOnce {
scope.launch {
shoppingList = getShoppingList()
}
}
h1 {
+"Full-Stack Shopping List"
}
ul {
shoppingList.sortedByDescending(ShoppingListItem::priority).forEach { item ->
li {
key = item.toString()
+"[${item.priority}] ${item.desc} "
}
}
}
}
```
* Here, the Kotlin DSL is used to define the HTML representation of the application.
* `launch` is used to obtain the list of `ShoppingListItem`s from the API when the component is first initialized.
* The React hooks `useEffectOnce` and `useState` help you use React's functionality concisely. For more information on how React hooks work, check out the [official React documentation](https://reactjs.org/docs/hooks-overview.html). To learn more about React with Kotlin/JS, see the [Build a web application with React and Kotlin/JS](js-react) tutorial.
2. Start the application using the Gradle `run` task.
3. Navigate to [`http://localhost:9090/`](http://localhost:9090/) to see the list:

#### Add an input field component
Next, allow users to add new entries to the shopping list using a text input field. You'll need an input component that provides a callback when users submit their entry to the shopping list to receive input.
1. Create the `src/jsMain/kotlin/InputComponent.kt` file and fill it with the following definition:
```
import org.w3c.dom.HTMLFormElement
import react.*
import org.w3c.dom.HTMLInputElement
import react.dom.events.ChangeEventHandler
import react.dom.events.FormEventHandler
import react.dom.html.InputType
import react.dom.html.ReactHTML.form
import react.dom.html.ReactHTML.input
external interface InputProps : Props {
var onSubmit: (String) -> Unit
}
val inputComponent = FC<InputProps> { props ->
val (text, setText) = useState("")
val submitHandler: FormEventHandler<HTMLFormElement> = {
it.preventDefault()
setText("")
props.onSubmit(text)
}
val changeHandler: ChangeEventHandler<HTMLInputElement> = {
setText(it.target.value)
}
form {
onSubmit = submitHandler
input {
type = InputType.text
onChange = changeHandler
value = text
}
}
}
```
The `inputComponent` keeps track of its internal state (what the user has typed so far) and exposes an `onSubmit` handler that gets called when the user submits the form (usually by pressing the `Enter` key).
2. To use this `inputComponent` from the application, add the following snippet to `src/jsMain/kotlin/App.kt` at the bottom of the `FC` block (after the closing brace for the `ul` element):
```
inputComponent {
onSubmit = { input ->
val cartItem = ShoppingListItem(input.replace("!", ""), input.count { it == '!' })
scope.launch {
addShoppingListItem(cartItem)
shoppingList = getShoppingList()
}
}
}
```
* When users submit text, a new `ShoppingListItem` is created. Its priority is set to be the number of exclamation points in the input, and its description is the input with all exclamation points removed. This turns `Peaches!! 🍑` into a `ShoppingListItem(desc="Peaches 🍑", priority=2)`.
* The generated `ShoppingListItem` gets sent to the server with the client you've built before.
* Then, the UI is updated by obtaining the new list of `ShoppingListItem`s from the server, updating the application state, and letting React re-render the contents.
#### Implement item removal
Add the ability to remove the finished items from the list so that it doesn't get too long. You can modify an existing list rather than adding another UI element (like a "delete" button). When users click one of the items in the list, the app deletes it.
To achieve this, pass a corresponding handler to `onClick` of the list elements:
1. In `src/jsMain/kotlin/App.kt`, update the `li` block (inside the `ul` block):
```
li {
key = item.toString()
onClick = {
scope.launch {
deleteShoppingListItem(item)
shoppingList = getShoppingList()
}
}
+"[${item.priority}] ${item.desc} "
}
```
The API client is invoked along with the element that should be removed. The server updates the shopping list, which re-renders the user interface.
2. Start the application using the Gradle `run` task.
3. Navigate to [`http://localhost:9090/`](http://localhost:9090/), and try adding and removing elements from the list:

Include a database to store data
--------------------------------
Currently, the application doesn't save data, meaning that the shopping list vanishes when you terminate the server process. To fix that, use the MongoDB database to store and retrieve shopping list items even when the server shuts down.
MongoDB is simple, fast to set up, has library support for Kotlin, and provides simple, [NoSQL](https://en.wikipedia.org/wiki/NoSQL) document storage, which is more than enough for a basic application. You are free to equip your application with a different mechanism for data storage.
To provide all of the functionality used in this section, you'll need to include several libraries from the Kotlin and JavaScript (npm) ecosystems. See the `jsMain` dependency block in the `build.gradle.kts` file with the full setup.
### Set up MongoDB
Install MongoDB Community Edition on your local machine from the [official MongoDB website](https://docs.mongodb.com/manual/installation/#mongodb-community-edition-installation-tutorials). Alternatively, you can use a containerization tool like [podman](https://podman.io/) to run a containerized instance of MongoDB.
After installation, ensure that you are running the `mongodb-community` service for the rest of the tutorial. You'll use it to store and retrieve list entries.
### Include KMongo in the process
[KMongo](https://litote.org/kmongo/) is a community-created Kotlin framework that makes it easy to work with MongoDB from Kotlin/JVM code. It also works nicely with `kotlinx.serialization`, which is used to facilitate communication between client and server.
By making the code use an external database, you no longer need to keep a collection of `shoppingListItems` on the server. Instead, set up a database client and obtain a database and a collection from it.
1. Inside `src/jvmMain/kotlin/Server.kt`, remove the declaration for `shoppingList` and add the following three top-level variables:
```
val client = KMongo.createClient().coroutine
val database = client.getDatabase("shoppingList")
val collection = database.getCollection<ShoppingListItem>()
```
2. In `src/jvmMain/kotlin/Server.kt`, replace definitions for the GET, POST, and DELETE routes to a `ShoppingListItem` to make use of the available collection operations:
```
get {
call.respond(collection.find().toList())
}
post {
collection.insertOne(call.receive<ShoppingListItem>())
call.respond(HttpStatusCode.OK)
}
delete("/{id}") {
val id = call.parameters["id"]?.toInt() ?: error("Invalid delete request")
collection.deleteOne(ShoppingListItem::id eq id)
call.respond(HttpStatusCode.OK)
}
```
In the DELETE request, KMongo's [type-safe queries](https://litote.org/kmongo/typed-queries/) are used to obtain and remove the correct `ShoppingListItem` from the database.
3. Start the server using the `run` task, and navigate to [`http://localhost:9090/`](http://localhost:9090/). On the first start, you'll be greeted by an empty shopping list as is expected when querying an empty database.
4. Add some items to your shopping list. The server will save them to the database.
5. To check this, restart the server and reload the page.
### Inspect MongoDB
To see what kind of information is actually saved in the database, you can inspect the database using external tools.
If you have IntelliJ IDEA Ultimate Edition or DataGrip, you can inspect the database contents with these tools. Alternatively, you can use the [`mongosh`](https://www.mongodb.com/docs/mongodb-shell/) command-line client.
1. To connect to the local MongoDB instance, in IntelliJ IDEA Ultimate or DataGrip, go to the **Database** tab and select **+** | **Data Source** | **MongoDB**:

2. If it's your first time connecting to a MongoDB database this way, you might be prompted to download missing drivers:

3. When working with a local MongoDB installation that uses the default settings, no adjustments to the configuration are necessary. You can test the connection with the **Test Connection** button, which should output the MongoDB version and some additional information.
4. Click **OK**. Now you can use the **Database** window to navigate to your collection and look at everything stored in it:

#### Relevant Gradle configuration for Kmongo
Kmongo is added with a single dependency to the project, a specific version that includes coroutine and serialization support out of the box:
```
val jvmMain by getting {
dependencies {
// ...
implementation("org.litote.kmongo:kmongo-coroutine-serialization:$kmongoVersion")
}
}
```
Deploy to the cloud
-------------------
Instead of opening your app on `localhost`, you can bring it onto the web by deploying it to the cloud.
To get the application running on managed infrastructure (such as cloud providers), you need to integrate it with the environment variables provided by the selected platform and add any required configurations to the project. Specifically, pass the application port and MongoDB connection string.
### Specify the PORT variable
On managed platforms, the port on which the application should run is often determined externally and exposed through the `PORT` environment variable. If present, you can respect this setting by configuring `embeddedServer` in `src/jvmMain/kotlin/Server.kt`:
```
fun main() {
val port = System.getenv("PORT")?.toInt() ?: 9090
embeddedServer(Netty, port) {
// ...
}
}
```
Ktor also supports configuration files that can respect environment variables. To learn more about how to use them, check out the [official documentation](https://ktor.io/docs/configurations.html#hocon-overview).
### Specify the MONGODB\_URI variable
Managed platforms often expose connection strings through environment variables – for MongoDB, this might be the `MONGODB_URI` string, which needs to be used by the client to connect to the database. Depending on the specific MongoDB instance you're trying to connect to, you might need to append the `retryWrites=false` parameter to the connection string.
To properly satisfy these requirements, instantiate the `client` and `database` variables in `src/jvmMain/kotlin/Server.kt`:
```
val connectionString: ConnectionString? = System.getenv("MONGODB_URI")?.let {
ConnectionString("$it?retryWrites=false")
}
val client =
if (connectionString != null) KMongo.createClient(connectionString).coroutine else KMongo.createClient().coroutine
val database = client.getDatabase(connectionString?.database ?: "shoppingList")
```
This ensures that the `client` is created based on this information whenever the environment variables are set. Otherwise (for instance, on `localhost`), the database connection is instantiated as before.
### Create the Procfile
Managed cloud platforms like Heroku or PaaS implementations like [Dokku](https://github.com/dokku/dokku) also handle the lifecycle of your application. To do so, they require an "entry point" definition. These two platforms use a file called `Procfile` that you have in the project root directory. It points to the output generated by the `stage` task (which is included in the Gradle template already):
```
web: ./build/install/shoppingList/bin/shoppingList
```
### Turn on production mode
To turn on a compilation with optimizations for the JavaScript assets, pass another flag to the build process. In the **Run/Debug Configurations** menu, set the environment variable `ORG_GRADLE_PROJECT_isProduction` to `true`. You can set this environment variable when you deploy the application to the target environment.
#### Relevant Gradle configuration
The `stage` task is an alias for `installDist`:
```
// Alias "installDist" as "stage" (for cloud providers)
tasks.create("stage") {
dependsOn(tasks.getByName("installDist"))
}
// only necessary until https://youtrack.jetbrains.com/issue/KT-37964 is resolved
distributions {
main {
contents {
from("$buildDir/libs") {
rename("${rootProject.name}-jvm", rootProject.name)
into("lib")
}
}
}
}
```
What's next
-----------
### Add more features
See how your application can be expanded and improved:
* **Improve the design**. You could make use of `styled-components`, one of the libraries that have Kotlin wrappers provided. If you want to see `styled-components` in action, look at the [Build a web application with React and Kotlin/JS](js-react) tutorial.
* **Add crossing out list items**. For now, list items just vanish with no record of them existing. Instead of deleting an element, use crossing out.
* **Implement editing**. So far, an entry in the shopping list can't be edited. Consider adding an edit button.
### Join the community and get help
You can join the official Kotlin Slack channels, [#ktor](https://slack-chats.kotlinlang.org/c/ktor), [#javascript](https://slack-chats.kotlinlang.org/c/javascript), and others to get help with Kotlin related problems from the community.
### Learn more about Kotlin/JS
You can find additional learning materials targeting Kotlin/JS: [Set up a Kotlin/JS project](js-project-setup) and [Run Kotlin/JS](running-kotlin-js).
### Learn more about Ktor
For in-depth information about the Ktor framework, including demo projects, check out [ktor.io](https://ktor.io/).
If you run into trouble, check out the [Ktor issue tracker](https://youtrack.jetbrains.com/issues/KTOR) on YouTrack – and if you can't find your problem, don't hesitate to file a new issue.
### Learn more about Kotlin Multiplatform
Learn more about how [multiplatform code works in Kotlin](multiplatform).
Last modified: 10 January 2023
[Set up targets for Kotlin Multiplatform](multiplatform-set-up-targets) [Create and publish a multiplatform library – tutorial](multiplatform-library)
| programming_docs |
kotlin Nested and inner classes Nested and inner classes
========================
Classes can be nested in other classes:
```
class Outer {
private val bar: Int = 1
class Nested {
fun foo() = 2
}
}
val demo = Outer.Nested().foo() // == 2
```
You can also use interfaces with nesting. All combinations of classes and interfaces are possible: You can nest interfaces in classes, classes in interfaces, and interfaces in interfaces.
```
interface OuterInterface {
class InnerClass
interface InnerInterface
}
class OuterClass {
class InnerClass
interface InnerInterface
}
```
Inner classes
-------------
A nested class marked as `inner` can access the members of its outer class. Inner classes carry a reference to an object of an outer class:
```
class Outer {
private val bar: Int = 1
inner class Inner {
fun foo() = bar
}
}
val demo = Outer().Inner().foo() // == 1
```
See [Qualified `this` expressions](this-expressions) to learn about disambiguation of `this` in inner classes.
Anonymous inner classes
-----------------------
Anonymous inner class instances are created using an [object expression](object-declarations#object-expressions):
```
window.addMouseListener(object : MouseAdapter() {
override fun mouseClicked(e: MouseEvent) { ... }
override fun mouseEntered(e: MouseEvent) { ... }
})
```
Last modified: 10 January 2023
[Generics: in, out, where](generics) [Enum classes](enum-classes)
kotlin Compatibility guide for Kotlin 1.8 Compatibility guide for Kotlin 1.8
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.7 to Kotlin 1.8.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language
--------
### Prohibit the delegation of super calls to an abstract superclass member
### Deprecate confusing grammar in when-with-subject
### Prevent implicit coercions between different numeric types
### Make private constructors of sealed classes really private
### Prohibit using operator == on incompatible numeric types in builder inference context
### Prohibit if without else and non-exhaustive when in right hand side of elvis operator
### Prohibit upper bound violation in a generic type alias usage (one type parameter used in several type arguments of the aliased type)
### Prohibit upper bound violation in a generic type alias usage (a type parameter used in a generic type argument of a type argument of the aliased type)
### Prohibit using a type parameter declared for an extension property inside delegate
### Forbid @Synchronized annotation on suspend functions
### Prohibit using spread operator for passing arguments to non-vararg parameters
### Prohibit null-safety violation in lambdas passed to functions overloaded by lambda return type
### Keep nullability when approximating local types in public signatures
### Do not propagate deprecation through overrides
### Prohibit implicit inferring a type variable into an upper bound in the builder inference context
### Prohibit using collection literals in annotation classes anywhere except their parameters declaration
### Prohibit forward referencing of parameters with default values in default value expressions
### Prohibit extension calls on inline functional parameters
### Prohibit calls to infix functions named suspend with an anonymous function argument
### Prohibit using captured type parameters in inner classes against their variance
### Prohibit recursive call of a function without explicit return type in compound assignment operators
### Prohibit unsound calls with expected @NotNull T and given Kotlin generic parameter with nullable bound
### Prohibit access to members of a companion of an enum class from entry initializers of this enum
### Deprecate and remove Enum.declaringClass synthetic property
### Deprecate the enable and the compatibility modes of the compiler option -Xjvm-default
Standard library
----------------
### Warn about potential overload resolution change when Range/Progression starts implementing Collection
### Migrate declarations from kotlin.dom and kotlin.browser packages to kotlinx.\*
### Deprecate some JS-only API
Tools
-----
### Raise deprecation level of classpath property of KotlinCompile task
### Remove kapt.use.worker.api Gradle property
### Remove kotlin.compiler.execution.strategy system property
### Changes in compiler options
### Deprecate kotlin.internal.single.build.metrics.file property
Last modified: 10 January 2023
[Stability of Kotlin components (pre 1.4)](components-stability-pre-1-4) [Compatibility guide for Kotlin 1.7.20](compatibility-guide-1720)
kotlin Get started with Kotlin/Native using the command-line compiler Get started with Kotlin/Native using the command-line compiler
==============================================================
Obtain the compiler
-------------------
The Kotlin/Native compiler is available for macOS, Linux, and Windows. It is available as a command line tool and ships as part of the standard Kotlin distribution and can be downloaded from [GitHub Releases](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0). It supports different targets including iOS (arm32, arm64, simulator x86\_64), Windows (mingw32 and x86\_64), Linux (x86\_64, arm64, MIPS), macOS (x86\_64), Raspberry PI, STM32, WASM. [See the full list of targets here](native-overview). While cross-platform compilation is possible, which means using one platform to compile for a different one, in this Kotlin case we'll be targeting the same platform we're compiling on.
While the output of the compiler does not have any dependencies or virtual machine requirements, the compiler itself requires [Java 1.8 or higher runtime](https://jdk.java.net/11/).
Install the compiler by unpacking its archive to a directory of your choice and adding the path to its `/bin` directory to the `PATH` environment variable.
Write "Hello Kotlin/Native" program
-----------------------------------
The application will print "Hello Kotlin/Native" on the standard output. In a working directory of choice, create a file named `hello.kt` and enter the following contents:
```
fun main() {
println("Hello Kotlin/Native!")
}
```
Compile the code from the console
---------------------------------
To compile the application use the [downloaded](https://github.com/JetBrains/kotlin/releases) compiler to execute the following command:
```
kotlinc-native hello.kt -o hello
```
The value of `-o` option specifies the name of the output file, so this call should generate a `hello.kexe` (Linux and macOS) or `hello.exe` (Windows) binary file. For the full list of available compiler options, see the [compiler options reference](compiler-reference).
While compilation from the console seems to be easy and clear, it does not scale well for larger projects with hundreds of files and libraries. For real-world projects, it is recommended to use a [build system](native-gradle) and [IDE](native-get-started).
Last modified: 10 January 2023
[Get started with Kotlin/Native using Gradle](native-gradle) [Interoperability with C](native-c-interop)
kotlin Native and cross-platform app development: how to choose? Native and cross-platform app development: how to choose?
=========================================================
People spend much of their waking time on their mobile devices. They also [spend 4.8 hours per day on mobile applications](https://www.data.ai/en/insights/market-data/state-of-mobile-2022/), which makes them attractive to all kinds of businesses.
Mobile app development is constantly evolving, with new technologies and frameworks emerging every year. With various solutions on the market, it's often difficult to choose between them. You might have heard about the long-standing "native versus cross-platform" debate.
There are many factors to consider before building an app, such as development cost, time, and app functionality. This is especially true if you want to target both Android and iOS audiences. It may be challenging to decide which mobile development approach will be the best for your particular project. To help you choose between native and cross-platform app development, we've created a list of six essential things to keep in mind.
What is native mobile app development?
--------------------------------------
Native mobile development means that you build an app for a particular mobile operating system – in most cases Android or iOS. While working on native applications, developers use specific programming languages and tools. For example, you can create a native Android application with Kotlin or Java, or build an app for iOS with Objective-C or Swift.
Here are the core benefits and limitations.
| **Benefits** | **Limitations** |
| --- | --- |
| **High performance.** The core programming language and APIs used to build native apps make them fast and responsive. | **High cost.** Native app development requires two separate teams with different sets of skills, which adds to the time and cost of the development process. |
| **Intuitive user experience.** Mobile engineers develop native apps using native SDKs, which makes the UI look consistent. The interfaces of native apps are designed to work well with a specific platform, which makes them feel like an integrated part of the device and provides a more intuitive user experience. | **Big development team.** Managing large teams of multiple specialists can be challenging. The more people you have working on one project, the greater the effort required for communication and collaboration. |
| **Access to the full feature set of a particular device.** Native apps built for a particular operating system have direct access to the device's hardware, such as camera, microphone, and GPS location support. | **More errors in code.** More lines of code can leave more room for bugs. |
| | **Risks of having different logic on Android and iOS apps.** With native app development, the code written for one mobile platform cannot be tailored to another platform. For instance, Android and iOS apps might show different prices for the same item because of a mistake in the way the discount is calculated. |
What is cross-platform app development?
---------------------------------------
Cross-platform app development, also called multiplatform development, is the process of building mobile apps that are compatible with several operating systems. Instead of creating separate applications for iOS and Android, mobile engineers can share some or all of the source code between multiple platforms. This way, the applications will work the same on both iOS and Android.
There are various open-source frameworks for [cross-platform mobile app development](cross-platform-mobile-development) available today. Some of the most popular are Flutter, React Native, and Kotlin Multiplatform Mobile. Below are some of the key pros and cons.
| **Benefits** | **Limitations** |
| --- | --- |
| **Shareable code.** Developers create a single codebase without the need to write new code for each OS. | **Performance issues.** Some developers argue that the performance of multiplatform applications is low compared to native apps. |
| **Faster development.** You don't need to write or test as much code, which can help you accelerate the development process. | **Difficult to access native features of mobile devices.** Building a cross-platform app that needs to access platform-specific APIs requires more effort. |
| **Cost-effectiveness.** The cross-platform solution can be a good option to consider for startups and companies with smaller budgets because it allows them to reduce development costs. | **Limited UI consistency.** With cross-platform development frameworks that allow you to share the UI, applications may look and feel less native. |
| **New work opportunities.** You can attract new talent to your team with modern cross-platform technologies in a product's tech stack. Many developers want to tackle new challenges at work, which is why new technologies and tasks tend to increase developers' motivation and enjoyment while working. | **Challenging hiring process.** It can be harder to find professionals who can build multiplatform apps, compared to native app developers. For example, while writing this article, we found about 2,400 Android developer jobs versus 348 Flutter developer vacancies on Glassdoor. However, this situation may change as cross-platform technologies continually evolve and attract more mobile engineers. |
| **Shared logic.** Because this approach involves using a single codebase, you can be sure that you have the same application logic on different platforms. | | |
These are just a few of the key advantages of cross-platform app development. You can learn more about its benefits and use cases from global companies in our article about [cross-platform mobile development](cross-platform-mobile-development). As for the challenges of the approach – we'll discuss those in the following section.
### Debugging some popular myths about cross-platform app development
Multiplatform technology is constantly evolving. Some cross-platform development frameworks like [Kotlin Multiplatform Mobile](https://kotlinlang.org/lp/mobile/) provide the benefits of building both cross-platform and native apps and remove the limitations that are commonly associated with the approach.
#### 1. Cross-platform apps provide poorer performance than native apps.
Poor performance was long considered to be one of the main disadvantages of multiplatform applications. However, the performance and quality of your product largely depend on the tools you use to build the app. The latest cross-platform frameworks provide all the tools necessary to develop apps with a native-like user experience.
By using different compiler backends, [Kotlin](multiplatform#code-sharing-between-platforms) is compiled to platform formats – JVM bytecode for Android and native binaries for iOS. As a result, the performance of your shared code is the same as if you write them natively.
#### 2. Cross-platform frameworks are unsafe.
There's a common misconception that native apps are much more secure and reliable. However, modern cross-platform development tools allow developers to build safe apps that guarantee reliable data protection. Mobile engineers just need to [take additional measures to make their apps secure](https://appstronauts.co/blog/are-cross-platform-apps-as-fast-and-secure-as-native-apps/#:~:text=Unsecurity%20of%20cross%2Dplatform%20apps,a%20cross%2Dplatform%20app%27s%20code.).
#### 3. Cross-platform apps don't have access to all native functions of mobile devices.
It is true that not all cross-platform frameworks allow you to build apps with full access to the device's features. Nevertheless, some modern multiplatform frameworks can help you overcome this challenge. For example, Kotlin Multiplatform Mobile gives easy access to Android and iOS SDKs. It provides a [Kotlin mechanism of expected and actual declarations](multiplatform-connect-to-apis) to help you access the device's capabilities and features.
#### 4. It can often be difficult to manage cross-platform projects.
In fact, it's the opposite. Cross-platform solutions help you more effectively manage resources. Your development teams can learn how to write and reuse shared code. Android and iOS developers can achieve high efficiency and transparency by interacting and sharing knowledge.
Six key aspects to help you choose between cross-platform app development and the native approach
-------------------------------------------------------------------------------------------------
Now, let's take a look at important factors you need to consider when choosing between native and cross-platform solutions for mobile app development.
### 1. The type and purpose of your future app
One of the first steps is understanding what app you will be building, including its features and purpose. A complex application with many features will require a lot of programming, especially if it's something new that doesn't have any existing templates.
How crucial is the user interface of your app? Are you looking for outstanding visuals or is the UI less important? Will it require any specific hardware functionality and access to camera and GPS location support? You need to make sure the mobile development approach you choose provides the necessary tools to build the app you need and provide a great user experience.
### 2. Your team's experience in programming languages and tools
The developers on your team should have enough experience and expertise to work with particular frameworks. Pay close attention to what programming skills and languages the development tools require.
For example, developers need to know Objective-C or Swift to create native apps for iOS, and they need to know Kotlin or Java for Android. The cross-platform framework Flutter requires knowledge of Dart. If you use Kotlin Multiplatform Mobile, Kotlin syntax is easy for iOS developers to learn because it follows concepts similar to Swift.
### 3. Long-term viability
When choosing between different approaches and frameworks, you need to be confident that the platform vendor will continue supporting it over the long term. You can dig into the details about the provider, the size of their community, and adoption by global companies. For example, Kotlin Multiplatform Mobile was developed by JetBrains, Flutter by Google, and React Native by Facebook.
### 4. Development cost and your budget
As mentioned above, different mobile development solutions and tools come with different expenses. Depending on how flexible your budget is, you can choose the right solution for your project.
### 5. Adoption in the industry
You can always find out what other experts in the tech community are saying about different approaches. Reddit, StackOverflow, and Google Trends are a few good resources. Just take a look at search trends for the following two terms: "native mobile development" versus "cross-platform mobile development". Many users are still interested in learning about native app development, but it also seems like the cross-platform approach is gaining popularity.
If a technology is widely used by professionals, it has a strong ecosystem, many libraries, and best practices from the tech community, which makes development faster.
### 6. Visibility and learning resources
If you're considering trying cross-platform app development, one of the factors you should consider is how easy it is to find learning materials for the different multiplatform frameworks. Check their official documentation, books, and courses. Be sure they provide a [product roadmap](https://blog.jetbrains.com/kotlin/2022/06/what-to-expect-from-the-kotlin-team-in-202223/) with long-term plans.
When should you choose cross-platform app development?
------------------------------------------------------
Cross-platform solutions for mobile app development will save you time and effort when building applications for both Android and iOS.
In a nutshell, you should to opt for cross-platform solutions if:
* You need to build an app for both Android and iOS.
* You want to optimize development time.
* You want to have a single codebase for the app logic while keeping full control over UI elements. Not all cross-platform frameworks allow you to do this, but some, like Kotlin Multiplatform Mobile, provide this capability.
* You're eager to embrace a modern technology that continues to evolve.
When should you choose native app development?
----------------------------------------------
There may be a few specific cases when it makes sense to choose native mobile development. You should choose this approach if:
* Your app is targeting one specific audience – either Android or iOS.
* The user interface is critical to your future application. However, even if you take the native approach, you can try using multiplatform mobile app development solutions that allow you to share app logic, but not the UI, for your project.
* Your team is equipped with highly skilled Android and iOS developers, but you don't have time to introduce new technologies.
### Takeaways
Keep in mind all the aspects described above, your project's goals, and the end user. Whether you're better off with native or cross-platform development depends on your unique needs. Each solution has its strengths and weaknesses.
Nevertheless, keep an eye on what happens in the community. Knowing the latest mobile development trends will help you make the best choice for your project.
Last modified: 10 January 2023
[What is cross-platform mobile development?](cross-platform-mobile-development) [The Six Most Popular Cross-Platform App Development Frameworks](cross-platform-frameworks)
| programming_docs |
kotlin Samples Samples
=======
This is a curated list of Kotlin Multiplatform Mobile samples.
| Sample name | What's shared? | Popular libraries used | UI Framework | iOS integration | Platform APIs | Tests | Features |
| --- | --- | --- | --- | --- | --- | --- | --- |
| **[Kotlin Multiplatform Mobile Sample](https://github.com/Kotlin/kmm-basic-sample)** | Algorithms | - | XML, SwiftUI | Xcode build phases | ✅ | - | * `expect`/`actual` declarations
|
| **[KMM RSS Reader](https://github.com/Kotlin/kmm-production-sample)** | Models, Networking, Data Storage, UI State | SQLDelight, Ktor, DateTime, multiplatform-settings, Napier, kotlinx.serialization | Jetpack Compose, SwiftUI | Xcode build phases | ✅ | - | * Redux for sharing UI State
* Published to Google Play and App Store
|
| **[kmm-ktor-sample](https://github.com/KaterinaPetrova/kmm-ktor-sample)** | Networking | Ktor, kotlinx.serialization, Napier | XML, SwiftUI | Xcode build phases | - | - | * [Video tutorial](https://www.youtube.com/watch?v=_Q62iJoNOfg%26list=PLlFc5cFwUnmy_oVc9YQzjasSNoAk4hk_C%26index=2)
|
| **[todoapp](https://github.com/JetBrains/compose-jb/tree/master/examples/todoapp)** | Models, Networking, Presentation, Navigation and UI | SQLDelight, Decompose, MVIKotlin, Reaktive | Jetpack Compose, SwiftUI | Xcode build phases | - | ✅ | * 99% of the code is shared
* MVI architectural pattern
* Shared UI across Android, Desktop and Web via [Compose Multiplatform](https://www.jetbrains.com/lp/compose-mpp/)
|
| **[mpp-sample-lib](https://github.com/KaterinaPetrova/mpp-sample-lib)** | Algorithms | - | - | - | ✅ | - | * Demonstrates how to create a multiplatform library ([tutorial](https://dev.to/kathrinpetrova/series/11926))
|
| **[KaMPKit](https://github.com/touchlab/KaMPKit)** | Models, Networking, Data Storage, ViewModels | Koin, SQLDelight, Ktor, DateTime, multiplatform-settings, Kermit | Jetpack Compose, SwiftUI | CocoaPods | - | ✅ | - |
| **[PeopleInSpace](https://github.com/joreilly/PeopleInSpace)** | Models, Networking, Data Storage | Koin, SQLDelight, Ktor | Jetpack Compose, SwiftUI | CocoaPods, Swift Packages | - | ✅ | Target list:* Android Wear OS
* iOS
* watchOS
* macOS Desktop (Compose for Desktop)
* Web (Compose for Web)
* Web (Kotlin/JS + React Wrapper)
* JVM
|
| **[D-KMP-sample](https://github.com/dbaroncelli/D-KMP-sample)** | Networking, Data Storage, ViewModels, Navigation | SQLDelight, Ktor, DateTime, multiplatform-settings | Jetpack Compose, SwiftUI | Xcode build phases | - | ✅ | * Implements the MVI pattern and the unidirectional data flow
* Uses Kotlin's StateFlow to trigger UI layer recompositions
|
| **[Food2Fork Recipe App](https://github.com/mitchtabian/Food2Fork-KMM)** | Models, Networking, Data Storage, Interactors | SQLDelight, Ktor, DateTime | Jetpack Compose, SwiftUI | CocoaPods | - | - | - |
| **[Bookshelf](https://github.com/realm/realm-kotlin-samples/tree/main/Bookshelf)** | Models, Networking, Data Storage | Realm-Kotlin, Ktor, kotlinx.serialization | Jetpack Compose, SwiftUI | CocoaPods | - | - | * Uses [Realm](https://realm.io/) for data persistence
|
| **[Notflix](https://github.com/VictorKabata/Notflix)** | Models, Networking, Caching, ViewModels | Koin, Ktor, Multiplatform settings, kotlinx.coroutines, kotlinx.serialization, kotlinx.datetime, Napier | Jetpack Compose-Android, Compose Multiplatform-Desktop | - | ✅ | - | * Modular architecture
* Runs on desktop
* Sharing viewmodel
|
Last modified: 10 January 2023
[Multiplatform Gradle DSL reference](multiplatform-dsl-reference) [FAQ](multiplatform-mobile-faq)
kotlin Stability of Kotlin components (pre 1.4) Stability of Kotlin components (pre 1.4)
========================================
There can be different modes of stability depending of how quickly a component is evolving:
* **Moving fast (MF)**: no compatibility should be expected between even [incremental releases](kotlin-evolution#feature-releases-and-incremental-releases), any functionality can be added, removed or changed without warning.
* **Additions in Incremental Releases (AIR)**: things can be added in an incremental release, removals and changes of behavior should be avoided and announced in a previous incremental release if necessary.
* **Stable Incremental Releases (SIR)**: incremental releases are fully compatible, only optimizations and bug fixes happen. Any changes can be made in a [feature release](kotlin-evolution#feature-releases-and-incremental-releases).
* **Fully Stable (FS)**: incremental releases are fully compatible, only optimizations and bug fixes happen. Feature releases are backwards compatible.
Source and binary compatibility may have different modes for the same component, e.g. the source language can reach full stability before the binary format stabilizes, or vice versa.
The provisions of the [Kotlin evolution policy](kotlin-evolution) fully apply only to components that have reached Full Stability (FS). From that point on incompatible changes have to be approved by the Language Committee.
| **Component** | **Status Entered at version** | **Mode for Sources** | **Mode for Binaries** |
| --- | --- | --- | --- |
| Kotlin/JVM | 1.0 | FS | FS |
| kotlin-stdlib (JVM) | 1.0 | FS | FS |
| KDoc syntax | 1.0 | FS | N/A |
| Coroutines | 1.3 | FS | FS |
| kotlin-reflect (JVM) | 1.0 | SIR | SIR |
| Kotlin/JS | 1.1 | AIR | MF |
| Kotlin/Native | 1.3 | AIR | MF |
| Kotlin Scripts (\*.kts) | 1.2 | AIR | MF |
| dokka | 0.1 | MF | N/A |
| Kotlin Scripting APIs | 1.2 | MF | MF |
| Compiler Plugin API | 1.0 | MF | MF |
| Serialization | 1.3 | MF | MF |
| Multiplatform Projects | 1.2 | MF | MF |
| Inline classes | 1.3 | MF | MF |
| Unsigned arithmetics | 1.3 | MF | MF |
| **All other experimental features, by default** | N/A | **MF** | **MF** |
Last modified: 10 January 2023
[Stability of Kotlin components](components-stability) [Compatibility guide for Kotlin 1.8](compatibility-guide-18)
kotlin Interfaces Interfaces
==========
Interfaces in Kotlin can contain declarations of abstract methods, as well as method implementations. What makes them different from abstract classes is that interfaces cannot store state. They can have properties, but these need to be abstract or provide accessor implementations.
An interface is defined using the keyword `interface`:
```
interface MyInterface {
fun bar()
fun foo() {
// optional body
}
}
```
Implementing interfaces
-----------------------
A class or object can implement one or more interfaces:
```
class Child : MyInterface {
override fun bar() {
// body
}
}
```
Properties in interfaces
------------------------
You can declare properties in interfaces. A property declared in an interface can either be abstract or provide implementations for accessors. Properties declared in interfaces can't have backing fields, and therefore accessors declared in interfaces can't reference them:
```
interface MyInterface {
val prop: Int // abstract
val propertyWithImplementation: String
get() = "foo"
fun foo() {
print(prop)
}
}
class Child : MyInterface {
override val prop: Int = 29
}
```
Interfaces Inheritance
----------------------
An interface can derive from other interfaces, meaning it can both provide implementations for their members and declare new functions and properties. Quite naturally, classes implementing such an interface are only required to define the missing implementations:
```
interface Named {
val name: String
}
interface Person : Named {
val firstName: String
val lastName: String
override val name: String get() = "$firstName $lastName"
}
data class Employee(
// implementing 'name' is not required
override val firstName: String,
override val lastName: String,
val position: Position
) : Person
```
Resolving overriding conflicts
------------------------------
When you declare many types in your supertype list, you may inherit more than one implementation of the same method:
```
interface A {
fun foo() { print("A") }
fun bar()
}
interface B {
fun foo() { print("B") }
fun bar() { print("bar") }
}
class C : A {
override fun bar() { print("bar") }
}
class D : A, B {
override fun foo() {
super<A>.foo()
super<B>.foo()
}
override fun bar() {
super<B>.bar()
}
}
```
Interfaces *A* and *B* both declare functions *foo()* and *bar()*. Both of them implement *foo()*, but only *B* implements *bar()* (*bar()* is not marked as abstract in *A*, because this is the default for interfaces if the function has no body). Now, if you derive a concrete class *C* from *A*, you have to override *bar()* and provide an implementation.
However, if you derive *D* from *A* and *B*, you need to implement all the methods that you have inherited from multiple interfaces, and you need to specify how exactly *D* should implement them. This rule applies both to methods for which you've inherited a single implementation (*bar()*) and to those for which you've inherited multiple implementations (*foo()*).
Last modified: 10 January 2023
[Properties](properties) [Functional (SAM) interfaces](fun-interfaces)
kotlin Hierarchical project structure Hierarchical project structure
==============================
With Kotlin 1.6.20, every new multiplatform project comes with a hierarchical project structure. This means that source sets form a hierarchy for sharing the common code among several targets. It opens up a variety of opportunities, including using platform-dependent libraries in common source sets and the ability to share code when creating multiplatform libraries.
To get a default hierarchical project structure in your projects, [update to the latest release](releases#update-to-a-new-release). If you need to keep using an earlier version than 1.6.20, you can still enable this feature manually. For this, add the following to your `gradle.properties`:
```
kotlin.mpp.enableGranularSourceSetsMetadata=true
kotlin.native.enableDependencyPropagation=false
```
For multiplatform project authors
---------------------------------
With the new hierarchical project structure support, you can share code among some, but not all, [targets](multiplatform-dsl-reference#targets) in a multiplatform project.
You can also use platform-dependent libraries, such as `UIKit` and `POSIX`, in source sets shared among several native targets. One popular case is having access to iOS-specific dependencies like `Foundation` when sharing code across all iOS targets. The new structure helps you share more native code without being limited by platform-specific dependencies.
By using the hierarchical structure along with platform-dependent libraries in shared source sets, you can eliminate the need to use workarounds to get IDE support for sharing source sets among several native targets, for example `iosArm64` and `iosX64`:
// workaround 1: select iOS target platform depending on the Xcode environment variables kotlin { val iOSTarget: (String, KotlinNativeTarget.() -> Unit) -> KotlinNativeTarget = if (System.getenv("SDK\_NAME")?.startsWith("iphoneos") == true) ::iosArm64 else ::iosX64 iOSTarget("ios") }
# workaround 2: make symbolic links to use one source set for two targets ln -s iosMain iosArm64Main && ln -s iosMain iosX64Main
Instead of doing this, you can create a hierarchical structure with [target shortcuts](multiplatform-share-on-platforms#use-target-shortcuts) available for typical multi-target scenarios, or you can manually declare and connect the source sets. For example, you can create two iOS targets and a shared source set with the `ios()` shortcut:
```
kotlin {
ios() // iOS device and simulator targets; iosMain and iosTest source sets
}
```
The Kotlin toolchain will provide the correct default dependencies and locate the API surface area available in the shared code. This prevents cases like the use of a macOS-specific function in code shared for Windows.
For library authors
-------------------
A hierarchical project structure allows for reusing code in similar targets, as well as publishing and consuming libraries with granular APIs targeting similar platforms.
The Kotlin toolchain will automatically figure out the API available in the consumer source set while checking for unsafe usages, like using an API meant for the JVM in JS code.
* Libraries published with the new hierarchical project structure are only compatible with projects that already have a hierarchical project structure. To enable compatibility with non-hierarchical projects, add the following to the `gradle.properties` file in your library project:
```
kotlin.mpp.enableCompatibilityMetadataVariant=true
```
* Libraries published without the hierarchical project structure can't be used in a shared native source set. For example, users with `ios()` shortcuts in their `build.gradle.(kts)` files won't be able to use your library in their iOS-shared code.
See [Compatibility](#compatibility) for more details.
Compatibility
-------------
Compatibility between multiplatform projects and libraries is determined as follows:
| Library with hierarchical project structure | Project with hierarchical project structure | Compatibility |
| --- | --- | --- |
| Yes | Yes | ✅ |
| Yes | No | Need to enable with `enableCompatibilityMetadataVariant` in the library project |
| No | Yes | Library can't be used in a shared native source set |
| No | No | ✅ |
How to opt-out
--------------
To disable hierarchical structure support, set the following option to `false` in your `gradle.properties`:
```
kotlin.mpp.hierarchicalStructureSupport=false
```
As for the `kotlin.mpp.enableCompatibilityMetadataVariant` option that enables compatibility of libraries published with the hierarchical project structure and non-hierarchical projects – it's disabled by default. No additional steps are required.
Last modified: 10 January 2023
[Connect to platform-specific APIs](multiplatform-connect-to-apis) [Adding dependencies on multiplatform libraries](multiplatform-add-dependencies)
kotlin Scope functions Scope functions
===============
The Kotlin standard library contains several functions whose sole purpose is to execute a block of code within the context of an object. When you call such a function on an object with a [lambda expression](lambdas) provided, it forms a temporary scope. In this scope, you can access the object without its name. Such functions are called *scope functions*. There are five of them: `let`, `run`, `with`, `apply`, and `also`.
Basically, these functions do the same: execute a block of code on an object. What's different is how this object becomes available inside the block and what is the result of the whole expression.
Here's a typical usage of a scope function:
```
data class Person(var name: String, var age: Int, var city: String) {
fun moveTo(newCity: String) { city = newCity }
fun incrementAge() { age++ }
}
fun main() {
//sampleStart
Person("Alice", 20, "Amsterdam").let {
println(it)
it.moveTo("London")
it.incrementAge()
println(it)
}
//sampleEnd
}
```
If you write the same without `let`, you'll have to introduce a new variable and repeat its name whenever you use it.
```
data class Person(var name: String, var age: Int, var city: String) {
fun moveTo(newCity: String) { city = newCity }
fun incrementAge() { age++ }
}
fun main() {
//sampleStart
val alice = Person("Alice", 20, "Amsterdam")
println(alice)
alice.moveTo("London")
alice.incrementAge()
println(alice)
//sampleEnd
}
```
The scope functions do not introduce any new technical capabilities, but they can make your code more concise and readable.
Due to the similar nature of scope functions, choosing the right one for your case can be a bit tricky. The choice mainly depends on your intent and the consistency of use in your project. Below we'll provide detailed descriptions of the distinctions between scope functions and the conventions on their usage.
Function selection
------------------
To help you choose the right scope function for your purpose, we provide the table of key differences between them.
| Function | Object reference | Return value | Is extension function |
| --- | --- | --- | --- |
| `let` | `it` | Lambda result | Yes |
| `run` | `this` | Lambda result | Yes |
| `run` | - | Lambda result | No: called without the context object |
| `with` | `this` | Lambda result | No: takes the context object as an argument. |
| `apply` | `this` | Context object | Yes |
| `also` | `it` | Context object | Yes |
The detailed information about the differences is provided in the dedicated sections below.
Here is a short guide for choosing scope functions depending on the intended purpose:
* Executing a lambda on non-null objects: `let`
* Introducing an expression as a variable in local scope: `let`
* Object configuration: `apply`
* Object configuration and computing the result: `run`
* Running statements where an expression is required: non-extension `run`
* Additional effects: `also`
* Grouping function calls on an object: `with`
The use cases of different functions overlap, so that you can choose the functions based on the specific conventions used in your project or team.
Although the scope functions are a way of making the code more concise, avoid overusing them: it can decrease your code readability and lead to errors. Avoid nesting scope functions and be careful when chaining them: it's easy to get confused about the current context object and the value of `this` or `it`.
Distinctions
------------
Because the scope functions are all quite similar in nature, it's important to understand the differences between them. There are two main differences between each scope function:
* The way to refer to the context object.
* The return value.
### Context object: this or it
Inside the lambda of a scope function, the context object is available by a short reference instead of its actual name. Each scope function uses one of two ways to access the context object: as a lambda [receiver](lambdas#function-literals-with-receiver) (`this`) or as a lambda argument (`it`). Both provide the same capabilities, so we'll describe the pros and cons of each for different cases and provide recommendations on their use.
```
fun main() {
val str = "Hello"
// this
str.run {
println("The string's length: $length")
//println("The string's length: ${this.length}") // does the same
}
// it
str.let {
println("The string's length is ${it.length}")
}
}
```
#### this
`run`, `with`, and `apply` refer to the context object as a lambda receiver - by keyword `this`. Hence, in their lambdas, the object is available as it would be in ordinary class functions. In most cases, you can omit `this` when accessing the members of the receiver object, making the code shorter. On the other hand, if `this` is omitted, it can be hard to distinguish between the receiver members and external objects or functions. So, having the context object as a receiver (`this`) is recommended for lambdas that mainly operate on the object members: call its functions or assign properties.
```
data class Person(var name: String, var age: Int = 0, var city: String = "")
fun main() {
//sampleStart
val adam = Person("Adam").apply {
age = 20 // same as this.age = 20
city = "London"
}
println(adam)
//sampleEnd
}
```
#### it
In turn, `let` and `also` have the context object as a lambda argument. If the argument name is not specified, the object is accessed by the implicit default name `it`. `it` is shorter than `this` and expressions with `it` are usually easier for reading. However, when calling the object functions or properties you don't have the object available implicitly like `this`. Hence, having the context object as `it` is better when the object is mostly used as an argument in function calls. `it` is also better if you use multiple variables in the code block.
```
import kotlin.random.Random
fun writeToLog(message: String) {
println("INFO: $message")
}
fun main() {
//sampleStart
fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()
println(i)
//sampleEnd
}
```
Additionally, when you pass the context object as an argument, you can provide a custom name for the context object inside the scope.
```
import kotlin.random.Random
fun writeToLog(message: String) {
println("INFO: $message")
}
fun main() {
//sampleStart
fun getRandomInt(): Int {
return Random.nextInt(100).also { value ->
writeToLog("getRandomInt() generated value $value")
}
}
val i = getRandomInt()
println(i)
//sampleEnd
}
```
### Return value
The scope functions differ by the result they return:
* `apply` and `also` return the context object.
* `let`, `run`, and `with` return the lambda result.
These two options let you choose the proper function depending on what you do next in your code.
#### Context object
The return value of `apply` and `also` is the context object itself. Hence, they can be included into call chains as *side steps*: you can continue chaining function calls on the same object after them.
```
fun main() {
//sampleStart
val numberList = mutableListOf<Double>()
numberList.also { println("Populating the list") }
.apply {
add(2.71)
add(3.14)
add(1.0)
}
.also { println("Sorting the list") }
.sort()
//sampleEnd
println(numberList)
}
```
They also can be used in return statements of functions returning the context object.
```
import kotlin.random.Random
fun writeToLog(message: String) {
println("INFO: $message")
}
fun main() {
//sampleStart
fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()
//sampleEnd
}
```
#### Lambda result
`let`, `run`, and `with` return the lambda result. So, you can use them when assigning the result to a variable, chaining operations on the result, and so on.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three")
val countEndsWithE = numbers.run {
add("four")
add("five")
count { it.endsWith("e") }
}
println("There are $countEndsWithE elements that end with e.")
//sampleEnd
}
```
Additionally, you can ignore the return value and use a scope function to create a temporary scope for variables.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
val firstItem = first()
val lastItem = last()
println("First item: $firstItem, last item: $lastItem")
}
//sampleEnd
}
```
Functions
---------
To help you choose the right scope function for your case, we'll describe them in detail and provide usage recommendations. Technically, functions are interchangeable in many cases, so the examples show the conventions that define the common usage style.
### let
**The context object** is available as an argument (`it`). **The return value** is the lambda result.
`let` can be used to invoke one or more functions on results of call chains. For example, the following code prints the results of two operations on a collection:
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four", "five")
val resultList = numbers.map { it.length }.filter { it > 3 }
println(resultList)
//sampleEnd
}
```
With `let`, you can rewrite it:
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let {
println(it)
// and more function calls if needed
}
//sampleEnd
}
```
If the code block contains a single function with `it` as an argument, you can use the method reference (`::`) instead of the lambda:
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let(::println)
//sampleEnd
}
```
`let` is often used for executing a code block only with non-null values. To perform actions on a non-null object, use the [safe call operator `?.`](null-safety#safe-calls) on it and call `let` with the actions in its lambda.
```
fun processNonNullString(str: String) {}
fun main() {
//sampleStart
val str: String? = "Hello"
//processNonNullString(str) // compilation error: str can be null
val length = str?.let {
println("let() called on $it")
processNonNullString(it) // OK: 'it' is not null inside '?.let { }'
it.length
}
//sampleEnd
}
```
Another case for using `let` is introducing local variables with a limited scope for improving code readability. To define a new variable for the context object, provide its name as the lambda argument so that it can be used instead of the default `it`.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val modifiedFirstItem = numbers.first().let { firstItem ->
println("The first item of the list is '$firstItem'")
if (firstItem.length >= 5) firstItem else "!" + firstItem + "!"
}.uppercase()
println("First item after modifications: '$modifiedFirstItem'")
//sampleEnd
}
```
### with
A non-extension function: **the context object** is passed as an argument, but inside the lambda, it's available as a receiver (`this`). **The return value** is the lambda result.
We recommend `with` for calling functions on the context object without providing the lambda result. In the code, `with` can be read as "*with this object, do the following.*"
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
println("'with' is called with argument $this")
println("It contains $size elements")
}
//sampleEnd
}
```
Another use case for `with` is introducing a helper object whose properties or functions will be used for calculating a value.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three")
val firstAndLast = with(numbers) {
"The first element is ${first()}," +
" the last element is ${last()}"
}
println(firstAndLast)
//sampleEnd
}
```
### run
**The context object** is available as a receiver (`this`). **The return value** is the lambda result.
`run` does the same as `with` but invokes as `let` - as an extension function of the context object.
`run` is useful when your lambda contains both the object initialization and the computation of the return value.
```
class MultiportService(var url: String, var port: Int) {
fun prepareRequest(): String = "Default request"
fun query(request: String): String = "Result for query '$request'"
}
fun main() {
//sampleStart
val service = MultiportService("https://example.kotlinlang.org", 80)
val result = service.run {
port = 8080
query(prepareRequest() + " to port $port")
}
// the same code written with let() function:
val letResult = service.let {
it.port = 8080
it.query(it.prepareRequest() + " to port ${it.port}")
}
//sampleEnd
println(result)
println(letResult)
}
```
Besides calling `run` on a receiver object, you can use it as a non-extension function. Non-extension `run` lets you execute a block of several statements where an expression is required.
```
fun main() {
//sampleStart
val hexNumberRegex = run {
val digits = "0-9"
val hexDigits = "A-Fa-f"
val sign = "+-"
Regex("[$sign]?[$digits$hexDigits]+")
}
for (match in hexNumberRegex.findAll("+123 -FFFF !%*& 88 XYZ")) {
println(match.value)
}
//sampleEnd
}
```
### apply
**The context object** is available as a receiver (`this`). **The return value** is the object itself.
Use `apply` for code blocks that don't return a value and mainly operate on the members of the receiver object. The common case for `apply` is the object configuration. Such calls can be read as "*apply the following assignments to the object.*"
```
data class Person(var name: String, var age: Int = 0, var city: String = "")
fun main() {
//sampleStart
val adam = Person("Adam").apply {
age = 32
city = "London"
}
println(adam)
//sampleEnd
}
```
Having the receiver as the return value, you can easily include `apply` into call chains for more complex processing.
### also
**The context object** is available as an argument (`it`). **The return value** is the object itself.
`also` is good for performing some actions that take the context object as an argument. Use `also` for actions that need a reference to the object rather than its properties and functions, or when you don't want to shadow the `this` reference from an outer scope.
When you see `also` in the code, you can read it as "*and also do the following with the object.*"
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three")
numbers
.also { println("The list elements before adding new one: $it") }
.add("four")
//sampleEnd
}
```
takeIf and takeUnless
---------------------
In addition to scope functions, the standard library contains the functions `takeIf` and `takeUnless`. These functions let you embed checks of the object state in call chains.
When called on an object with a predicate provided, `takeIf` returns this object if it matches the predicate. Otherwise, it returns `null`. So, `takeIf` is a filtering function for a single object. In turn, `takeUnless` returns the object if it doesn't match the predicate and `null` if it does. The object is available as a lambda argument (`it`).
```
import kotlin.random.*
fun main() {
//sampleStart
val number = Random.nextInt(100)
val evenOrNull = number.takeIf { it % 2 == 0 }
val oddOrNull = number.takeUnless { it % 2 == 0 }
println("even: $evenOrNull, odd: $oddOrNull")
//sampleEnd
}
```
When chaining other functions after `takeIf` and `takeUnless`, don't forget to perform the null check or the safe call (`?.`) because their return value is nullable.
```
fun main() {
//sampleStart
val str = "Hello"
val caps = str.takeIf { it.isNotEmpty() }?.uppercase()
//val caps = str.takeIf { it.isNotEmpty() }.uppercase() //compilation error
println(caps)
//sampleEnd
}
```
`takeIf` and `takeUnless` are especially useful together with scope functions. A good case is chaining them with `let` for running a code block on objects that match the given predicate. To do this, call `takeIf` on the object and then call `let` with a safe call (`?`). For objects that don't match the predicate, `takeIf` returns `null` and `let` isn't invoked.
```
fun main() {
//sampleStart
fun displaySubstringPosition(input: String, sub: String) {
input.indexOf(sub).takeIf { it >= 0 }?.let {
println("The substring $sub is found in $input.")
println("Its start position is $it.")
}
}
displaySubstringPosition("010000011", "11")
displaySubstringPosition("010000011", "12")
//sampleEnd
}
```
This is how the same function looks without the standard library functions:
```
fun main() {
//sampleStart
fun displaySubstringPosition(input: String, sub: String) {
val index = input.indexOf(sub)
if (index >= 0) {
println("The substring $sub is found in $input.")
println("Its start position is $index.")
}
}
displaySubstringPosition("010000011", "11")
displaySubstringPosition("010000011", "12")
//sampleEnd
}
```
Last modified: 10 January 2023
[Map-specific operations](map-operations) [Opt-in requirements](opt-in-requirements)
| programming_docs |
kotlin Kotlin for Android Kotlin for Android
==================
Android mobile development has been Kotlin-first since Google I/O in 2019.
Using Kotlin for Android development, you can benefit from:
* **Less code combined with greater readability**. Spend less time writing your code and working to understand the code of others.
* **Mature language and environment**. Since its creation in 2011, Kotlin has developed continuously, not only as a language but as a whole ecosystem with robust tooling. Now it's seamlessly integrated in Android Studio and is actively used by many companies for developing Android applications.
* **Kotlin support in Android Jetpack and other libraries**. [KTX extensions](https://developer.android.com/kotlin/ktx) add Kotlin language features, such as coroutines, extension functions, lambdas, and named parameters, to existing Android libraries.
* **Interoperability with Java**. You can use Kotlin along with the Java programming language in your applications without needing to migrate all your code to Kotlin.
* **Support for multiplatform development**. You can use Kotlin for developing not only Android but also [iOS](https://kotlinlang.org/lp/mobile/), backend, and web applications. Enjoy the benefits of sharing the common code among the platforms.
* **Code safety**. Less code and better readability lead to fewer errors. The Kotlin compiler detects these remaining errors, making the code safe.
* **Easy learning**. Kotlin is very easy to learn, especially for Java developers.
* **Big community**. Kotlin has great support and many contributions from the community, which is growing all over the world. According to Google, over 60% of the top 1000 apps on the Play Store use Kotlin.
Many startups and Fortune 500 companies have already developed Android applications using Kotlin – see the list at [the Google website for Kotlin developers](https://developer.android.com/kotlin).
If you want to start using Kotlin for Android development, read [Google's recommendation for getting started with Kotlin on Android](https://developer.android.com/kotlin/get-started).
If you're new to Android and want to learn to create applications with Kotlin, check out [this Udacity course](https://www.udacity.com/course/developing-android-apps-with-kotlin--ud9012).
Last modified: 10 January 2023
[Kotlin for server side](server-overview) [Kotlin for JavaScript](js-overview)
kotlin Kotlin releases Kotlin releases
===============
We ship different types of releases:
* *Feature releases* (1.*x*) that bring major changes in the language.
* *Incremental releases* (1.*x*.*y*) that are shipped between feature releases and include updates in the tooling, performance improvements, and bug fixes.
* *Bug fix releases* (1.*x*.*yz*) that include bug fixes for incremental releases.
For example, for the feature release 1.3 we had several incremental releases including 1.3.10, 1.3.20, and 1.3.70. For 1.3.70, we had 2 bug fix releases – 1.3.71 and 1.3.72.
For each incremental and feature release, we also ship several preview (*EAP*) versions for you to try new features before they are released. See [Early Access Preview](eap) for details.
Learn more about [types of Kotlin releases and their compatibility](kotlin-evolution#feature-releases-and-incremental-releases).
Update to a new release
-----------------------
IntelliJ IDEA and Android Studio suggest updating to a new release once it is out. When you accept the suggestion, it automatically updates the Kotlin plugin to the new version. You can check the Kotlin version in **Tools** | **Kotlin** | **Configure Kotlin Plugin Updates**.
If you have projects created with earlier Kotlin versions, change the Kotlin version in your projects and update kotlinx libraries if necessary.
If you are migrating to the new feature release, Kotlin plugin's migration tools will help you with the migration.
IDE support
-----------
The IDE support for the latest version of the language is available for the following versions of IntelliJ IDEA and Android Studio:
* IntelliJ IDEA:
+ Latest stable
+ Previous stable
+ [Early access](https://www.jetbrains.com/resources/eap/) versions
* Android Studio:
+ [Latest released](https://developer.android.com/studio) version
+ [Early access](https://developer.android.com/studio/preview) versions
Release details
---------------
The following table lists details of the latest Kotlin releases.
You can also use [preview versions of Kotlin](eap#build-details).
| Build info | Build highlights |
| --- | --- |
| **1.8.0**
Released: **December 28, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0) | A feature release with improved kotlin-reflect performance, new recursively copy or delete directory content experimental functions for JVM, improved Objective-C/Swift interoperability.
Learn more in:* [What's new in Kotlin 1.8.0](whatsnew18)
* [Compatibility guide for Kotlin 1.8.0](compatibility-guide-18)
|
| **1.7.21**
Released: **November 9, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.7.21) | A bug fix release for Kotlin 1.7.20.
Learn more about Kotlin 1.7.20 in [What's new in Kotlin 1.7.20](whatsnew1720). |
| **1.7.20**
Released: **September 29, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.7.20) | An incremental release with new language features, the support for several compiler plugins in the Kotlin K2 compiler, the new Kotlin/Native memory manager enabled by default, and the support for Gradle 7.1.
Learn more in:* [What's new in Kotlin 1.7.20](whatsnew1720)
* [What's new in Kotlin YouTube video](https://youtu.be/OG9npowJgE8)
* [Compatibility guide for Kotlin 1.7.20](compatibility-guide-1720)
Learn more about [Kotlin 1.7.20](https://github.com/JetBrains/kotlin/releases/tag/v1.7.20). |
| **1.7.10**
Released: **July 7, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.7.10) | A bug fix release for Kotlin 1.7.0.
Learn more about [Kotlin 1.7.0](https://github.com/JetBrains/kotlin/releases/tag/v1.7.0). |
| **1.7.0**
Released: **June 9, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.7.0) | A feature release with Kotlin K2 compiler in Alpha for JVM, stabilized language features, performance improvements, and evolutionary changes such as stabilizing experimental APIs.
Learn more in:* [What's new in Kotlin 1.7.0](whatsnew17)
* [What's new in Kotlin YouTube video](https://youtu.be/54WEfLKtCGk)
* [Compatibility guide for Kotlin 1.7.0](compatibility-guide-17)
|
| **1.6.21**
Released: **April 20, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.6.21) | A bug fix release for Kotlin 1.6.20.
Learn more about [Kotlin 1.6.20](whatsnew1620). |
| **1.6.20**
Released: **April 4, 2022**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.6.20) | An incremental release with various improvements such as:* Prototype of context receivers
* Callable references to functional interface constructors
* Kotlin/Native: performance improvements for the new memory manager
* Multiplatform: hierarchical project structure by default
* Kotlin/JS: IR compiler improvements
* Gradle: compiler execution strategies
Learn more about [Kotlin 1.6.20](whatsnew1620). |
| **1.6.10**
Released: **December 14, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.6.10) | A bug fix release for Kotlin 1.6.0.
Learn more about [Kotlin 1.6.0](https://github.com/JetBrains/kotlin/releases/tag/v1.6.0). |
| **1.6.0**
Released: **November 16, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.6.0) | A feature release with new language features, performance improvements, and evolutionary changes such as stabilizing experimental APIs.
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2021/11/kotlin-1-6-0-is-released/)
* [What's new in Kotlin 1.6.0](whatsnew16)
* [Compatibility guide](compatibility-guide-16)
|
| **1.5.32**
Released: **November 29, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.32) | A bug fix release for Kotlin 1.5.31.
Learn more about [Kotlin 1.5.30](whatsnew1530). |
| **1.5.31**
Released: **September 20, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.31) | A bug fix release for Kotlin 1.5.30.
Learn more about [Kotlin 1.5.30](whatsnew1530). |
| **1.5.30**
Released: **August 23, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.30) | An incremental release with various improvements such as:* Instantiation of annotation classes on JVM
* Improved opt-in requirement mechanism and type inference
* Kotlin/JS IR backend in Beta
* Support for Apple Silicon targets
* Improved CocoaPods support
* Gradle: Java toolchain support and improved daemon configuration
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2021/08/kotlin-1-5-30-released/)
* [What's new in Kotlin 1.5.30](whatsnew1530)
|
| **1.5.21**
Released: **July 13, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.21) | A bug fix release for Kotlin 1.5.20.
Learn more about [Kotlin 1.5.20](whatsnew1520). |
| **1.5.20**
Released: **June 24, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.20) | An incremental release with various improvements such as:* String concatenation via `invokedynamic` on JVM by default
* Improved support for Lombok and support for JSpecify
* Kotlin/Native: KDoc export to Objective-C headers and faster `Array.copyInto()` inside one array
* Gradle: caching of annotation processors' classloaders and support for the `--parallel` Gradle property
* Aligned behavior of stdlib functions across platforms
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2021/06/kotlin-1-5-20-released/)
* [What's new in Kotlin 1.5.20](whatsnew1520)
|
| **1.5.10**
Released: **May 24, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.10) | A bug fix release for Kotlin 1.5.0.
Learn more about [Kotlin 1.5.0](https://blog.jetbrains.com/kotlin/2021/04/kotlin-1-5-0-released/). |
| **1.5.0**
Released: **May 5, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.5.0) | A feature release with new language features, performance improvements, and evolutionary changes such as stabilizing experimental APIs.
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2021/04/kotlin-1-5-0-released/)
* [What's new in Kotlin 1.5.0](whatsnew15)
* [Compatibility guide](compatibility-guide-15)
|
| **1.4.32**
Released: **March 22, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.32) | A bug fix release for Kotlin 1.4.30.
Learn more about [Kotlin 1.4.30](whatsnew1430). |
| **1.4.31**
Released: **February 25, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.31) | A bug fix release for Kotlin 1.4.30
Learn more about [Kotlin 1.4.30](whatsnew1430). |
| **1.4.30**
Released: **February 3, 2021**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.30) | An incremental release with various improvements such as:* New JVM backend, now in Beta
* Preview of new language features
* Improved Kotlin/Native performance
* Standard library API improvements
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2021/01/kotlin-1-4-30-released/)
* [What's new in Kotlin 1.4.30](whatsnew1430)
|
| **1.4.21**
Released: **December 7, 2020**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.21) | A bug fix release for Kotlin 1.4.20
Learn more about [Kotlin 1.4.20](whatsnew1420). |
| **1.4.20**
Released: **November 23, 2020**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.20) | An incremental release with various improvements such as:* Supporting new JVM features, like string concatenation via `invokedynamic`
* Improved performance and exception handling for Kotlin Multiplatform Mobile projects
* Extensions for JDK Path: `Path("dir") / "file.txt"`
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2020/11/kotlin-1-4-20-released/)
* [What's new in Kotlin 1.4.20](whatsnew1420)
|
| **1.4.10**
Released: **September 7, 2020**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.10) | A bug fix release for Kotlin 1.4.0.
Learn more about [Kotlin 1.4.0](https://blog.jetbrains.com/kotlin/2020/08/kotlin-1-4-released-with-a-focus-on-quality-and-performance/). |
| **1.4.0**
Released: **August 17, 2020**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.4.0) | A feature release with many features and improvements that mostly focus on quality and performance.
Learn more in:* [Release blog post](https://blog.jetbrains.com/kotlin/2020/08/kotlin-1-4-released-with-a-focus-on-quality-and-performance/)
* [What's new in Kotlin 1.4.0](whatsnew14)
* [Compatibility guide](compatibility-guide-14)
* [Migrating to Kotlin 1.4.0](whatsnew14#migrating-to-kotlin-1-4-0)
|
| **1.3.72**
Released: **April 15, 2020**
[Release on GitHub](https://github.com/JetBrains/kotlin/releases/tag/v1.3.72) | A bug fix release for Kotlin 1.3.70.
Learn more about [Kotlin 1.3.70](https://blog.jetbrains.com/kotlin/2020/03/kotlin-1-3-70-released/). |
Last modified: 10 January 2023
[Get started with Kotlin custom scripting – tutorial](custom-script-deps-tutorial) [Kotlin Multiplatform Mobile plugin releases](multiplatform-mobile-plugin-releases)
kotlin Packages and imports Packages and imports
====================
A source file may start with a package declaration:
```
package org.example
fun printMessage() { /*...*/ }
class Message { /*...*/ }
// ...
```
All the contents, such as classes and functions, of the source file are included in this package. So, in the example above, the full name of `printMessage()` is `org.example.printMessage`, and the full name of `Message` is `org.example.Message`.
If the package is not specified, the contents of such a file belong to the *default* package with no name.
Default imports
---------------
A number of packages are imported into every Kotlin file by default:
* [kotlin.\*](../api/latest/jvm/stdlib/kotlin/index)
* [kotlin.annotation.\*](../api/latest/jvm/stdlib/kotlin.annotation/index)
* [kotlin.collections.\*](../api/latest/jvm/stdlib/kotlin.collections/index)
* [kotlin.comparisons.\*](../api/latest/jvm/stdlib/kotlin.comparisons/index)
* [kotlin.io.\*](../api/latest/jvm/stdlib/kotlin.io/index)
* [kotlin.ranges.\*](../api/latest/jvm/stdlib/kotlin.ranges/index)
* [kotlin.sequences.\*](../api/latest/jvm/stdlib/kotlin.sequences/index)
* [kotlin.text.\*](../api/latest/jvm/stdlib/kotlin.text/index)
Additional packages are imported depending on the target platform:
* JVM:
+ java.lang.\*
+ [kotlin.jvm.\*](../api/latest/jvm/stdlib/kotlin.jvm/index)
* JS:
+ [kotlin.js.\*](../api/latest/jvm/stdlib/kotlin.js/index)
Imports
-------
Apart from the default imports, each file may contain its own `import` directives.
You can import either a single name:
```
import org.example.Message // Message is now accessible without qualification
```
or all the accessible contents of a scope: package, class, object, and so on:
```
import org.example.* // everything in 'org.example' becomes accessible
```
If there is a name clash, you can disambiguate by using `as` keyword to locally rename the clashing entity:
```
import org.example.Message // Message is accessible
import org.test.Message as testMessage // testMessage stands for 'org.test.Message'
```
The `import` keyword is not restricted to importing classes; you can also use it to import other declarations:
* top-level functions and properties
* functions and properties declared in [object declarations](object-declarations#object-declarations-overview)
* [enum constants](enum-classes)
Visibility of top-level declarations
------------------------------------
If a top-level declaration is marked `private`, it is private to the file it's declared in (see [Visibility modifiers](visibility-modifiers)).
Last modified: 10 January 2023
[Exceptions](exceptions) [Classes](classes)
kotlin Samples Samples
=======
This is a curated list of Kotlin/JS samples.
Do you have a great idea for a sample, or one you would like to add to the list? [Reach out](https://kotlinlang.slack.com/archives/C0B8L3U69) in Kotlin Slack ([get an invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up)) and tell us about it!
| Sample name | Popular libraries | Description | Features | npm dependencies | Project type | Tests | UI Components |
| --- | --- | --- | --- | --- | --- | --- | --- |
| **[full-stack-spring-collaborative-todo-list-sample](https://github.com/Kotlin/full-stack-spring-collaborative-todo-list-sample)** | Spring, React, ktor-client-js, Rsocket, kotlinx:kotlinx-serialization-json | A collaborative to-do list written with Kotlin/JS, Spring, and RSocket | * RSocket
* A fullstack web app for Spring and React
| ✅ | Multiplatform full-stack application | - | - |
| **[react-redux-js-ir-todo-list-sample](https://github.com/Kotlin/react-redux-js-ir-todo-list-sample)** | React, Redux | An implementation (translation) of the React Redux to-do list example project in Kotlin/JS | * RingUI for Kotlin components
* Redux for state management
| ✅ | Frontend web app | - | RingUI |
| **[full-stack-web-jetbrains-night-sample](https://github.com/Kotlin/full-stack-web-jetbrains-night-sample)** | kotlin-react, kotlinx-serialization, kotlinx-coroutines, Ktor (client, server) | A feed containing user-generated posts and comments. All data is stubbed by the fakeJSON and JSON Placeholder services | * expect/actual declarations
* modular architecture
* npm dependencies
| ✅ | Multiplatform full-stack application | - | RingUI |
Last modified: 10 January 2023
[Generation of external declarations with Dukat](js-external-declarations-with-dukat) [Build a web application with React and Kotlin/JS — tutorial](js-react)
kotlin No-arg compiler plugin No-arg compiler plugin
======================
The *no-arg* compiler plugin generates an additional zero-argument constructor for classes with a specific annotation.
The generated constructor is synthetic so it can't be directly called from Java or Kotlin, but it can be called using reflection.
This allows the Java Persistence API (JPA) to instantiate a class although it doesn't have the zero-parameter constructor from Kotlin or Java point of view (see the description of `kotlin-jpa` plugin [below](#jpa-support)).
Gradle
------
Add the plugin and specify the list of annotations that must lead to generating a no-arg constructor for the annotated classes.
```
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-noarg:$kotlin_version"
}
}
apply plugin: "kotlin-noarg"
```
Or using the Gradle plugins DSL:
```
plugins {
id "org.jetbrains.kotlin.plugin.noarg" version "1.8.0"
}
```
Then specify the list of no-arg annotations:
```
noArg {
annotation("com.my.Annotation")
}
```
Enable `invokeInitializers` option if you want the plugin to run the initialization logic from the synthetic constructor. By default, it is disabled.
```
noArg {
invokeInitializers = true
}
```
Maven
-----
```
<plugin>
<artifactId>kotlin-maven-plugin</artifactId>
<groupId>org.jetbrains.kotlin</groupId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<!-- Or "jpa" for JPA support -->
<plugin>no-arg</plugin>
</compilerPlugins>
<pluginOptions>
<option>no-arg:annotation=com.my.Annotation</option>
<!-- Call instance initializers in the synthetic constructor -->
<!-- <option>no-arg:invokeInitializers=true</option> -->
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-noarg</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
```
JPA support
-----------
As with the `kotlin-spring` plugin wrapped on top of `all-open`, `kotlin-jpa` is wrapped on top of `no-arg`. The plugin specifies [`@Entity`](https://docs.oracle.com/javaee/7/api/javax/persistence/Entity.html), [`@Embeddable`](https://docs.oracle.com/javaee/7/api/javax/persistence/Embeddable.html), and [`@MappedSuperclass`](https://docs.oracle.com/javaee/7/api/javax/persistence/MappedSuperclass.html) *no-arg* annotations automatically.
That's how you add the plugin in Gradle:
```
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-noarg:$kotlin_version"
}
}
apply plugin: "kotlin-jpa"
```
Or using the Gradle plugins DSL:
```
plugins {
id "org.jetbrains.kotlin.plugin.jpa" version "1.8.0"
}
```
In Maven, enable the `jpa` plugin:
```
<compilerPlugins>
<plugin>jpa</plugin>
</compilerPlugins>
```
Command-line compiler
---------------------
Add the plugin JAR file to the compiler plugin classpath and specify annotations or presets:
```
-Xplugin=$KOTLIN_HOME/lib/noarg-compiler-plugin.jar
-P plugin:org.jetbrains.kotlin.noarg:annotation=com.my.Annotation
-P plugin:org.jetbrains.kotlin.noarg:preset=jpa
```
Last modified: 10 January 2023
[All-open compiler plugin](all-open-plugin) [SAM-with-receiver compiler plugin](sam-with-receiver-plugin)
| programming_docs |
kotlin Symbolicating iOS crash reports Symbolicating iOS crash reports
===============================
Debugging an iOS application crash sometimes involves analyzing crash reports. More info about crash reports can be found in the [Apple documentation](https://developer.apple.com/library/archive/technotes/tn2151/_index.html).
Crash reports generally require symbolication to become properly readable: symbolication turns machine code addresses into human-readable source locations. The document below describes some specific details of symbolicating crash reports from iOS applications using Kotlin.
Producing .dSYM for release Kotlin binaries
-------------------------------------------
To symbolicate addresses in Kotlin code (e.g. for stack trace elements corresponding to Kotlin code) `.dSYM` bundle for Kotlin code is required.
By default, Kotlin/Native compiler produces `.dSYM` for release (i.e. optimized) binaries on Darwin platforms. This can be disabled with `-Xadd-light-debug=disable` compiler flag. At the same time, this option is disabled by default for other platforms. To enable it, use the `-Xadd-light-debug=enable` compiler option.
```
kotlin {
targets.withType<org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget> {
binaries.all {
freeCompilerArgs += "-Xadd-light-debug={enable|disable}"
}
}
}
```
```
kotlin {
targets.withType(org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget) {
binaries.all {
freeCompilerArgs += "-Xadd-light-debug={enable|disable}"
}
}
}
```
In projects created from IntelliJ IDEA or AppCode templates these `.dSYM` bundles are then discovered by Xcode automatically.
Make frameworks static when using rebuild from bitcode
------------------------------------------------------
Rebuilding Kotlin-produced framework from bitcode invalidates the original `.dSYM`. If it is performed locally, make sure the updated `.dSYM` is used when symbolicating crash reports.
If rebuilding is performed on App Store side, then `.dSYM` of rebuilt *dynamic* framework seems discarded and not downloadable from App Store Connect. In this case, it may be required to make the framework static.
```
kotlin {
targets.withType<org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget> {
binaries.withType<org.jetbrains.kotlin.gradle.plugin.mpp.Framework> {
isStatic = true
}
}
}
```
```
kotlin {
targets.withType(org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget) {
binaries.withType(org.jetbrains.kotlin.gradle.plugin.mpp.Framework) {
isStatic = true
}
}
}
```
Decode inlined stack frames
---------------------------
Xcode doesn't seem to properly decode stack trace elements of inlined function calls (these aren't only Kotlin `inline` functions but also functions that are inlined when optimizing machine code). So some stack trace elements may be missing. If this is the case, consider using `lldb` to process crash report that is already symbolicated by Xcode, for example:
```
$ lldb -b -o "script import lldb.macosx" -o "crashlog file.crash"
```
This command should output crash report that is additionally processed and includes inlined stack trace elements.
More details can be found in [LLDB documentation](https://lldb.llvm.org/use/symbolication.html).
Last modified: 10 January 2023
[Debugging Kotlin/Native](native-debugging) [Tips for improving Kotlin/Native compilation times](native-improving-compilation-time)
kotlin Kotlin plugin releases Kotlin plugin releases
======================
The [IntelliJ Kotlin plugin](https://plugins.jetbrains.com/plugin/6954-kotlin) and [IntelliJ IDEA](https://www.jetbrains.com/idea/) are on the same release cycle. To speed up the testing and delivery of new features, the plugin and the platform have been moved to the same codebase and ship simultaneously. Kotlin releases happen independently according to the [release cadence](https://blog.jetbrains.com/kotlin/2020/10/new-release-cadence-for-kotlin-and-the-intellij-kotlin-plugin/).
Kotlin and the Kotlin plugin have distinct sets of features:
* Kotlin releases contain language, compiler, and standard library features.
* Kotlin plugin releases introduce only IDE related features. For example, code formatting and debugging tools.
This also affects the versioning of the Kotlin plugin. Releases now have the same version as the simultaneous IntelliJ IDEA release.
Update to a new release
-----------------------
IntelliJ IDEA and Android Studio suggest updating to a new release once it is out. When you accept the suggestion, it automatically updates the Kotlin plugin to the new version. You can check the Kotlin plugin version in **Tools** | **Kotlin** | **Configure Kotlin Plugin Updates**.
If you are migrating to the new feature release, Kotlin plugin's migration tools will help you with the migration.
Release details
---------------
The following table lists the details of the latest Kotlin plugin releases:
| Release info | Release highlights |
| --- | --- |
| **2022.3**
Released: November 30, 2022 | * Support for Kotlin 1.7.20 features
* Improved IDE performance for Kotlin
Learn more in:* [What's New in IntelliJ IDEA 2022.3](https://www.jetbrains.com/idea/whatsnew/2022-3/)
|
| **2022.2**
Released: July 26, 2022 | * Data Flow Analysis in the debugger
* Fixed inconsistency between local and CI builds caused by the compiler versions mismatch
* Improved IDE performance
Learn more in:* [What's New in IntelliJ IDEA 2022.2](https://www.jetbrains.com/idea/whatsnew/2022-2/)
|
| **2022.1**
Released: April 12, 2022 | * Debugger improvements
* Improved IDE performance
* [Kover plugin](https://github.com/Kotlin/kotlinx-kover) integration
Learn more in:* [What's New in IntelliJ IDEA 2022.1](https://www.jetbrains.com/idea/whatsnew/2022-1/)
|
| **2021.3**
Released: November 30, 2021 | * Better debugging experience
* Performance improvements
* Editor inline hints
* New refactorings and improved inspections and intentions
Learn more in:* [What's New in IntelliJ IDEA 2021.3](https://www.jetbrains.com/idea/whatsnew/2021-3/)
|
| **2021.2**
Released: July 27, 2021 | * Performance improvements
* Better debugging experience
* Remote development support
Learn more in:* [What's New in IntelliJ IDEA 2021.2](https://www.jetbrains.com/idea/whatsnew/2021-2/)
|
| **2021.1**
Released: April 7, 2021 | * Performance improvements
* Evaluation of custom getters during debugging
* Improved Change Signature refactoring
* Code completion for type arguments
* UML diagrams for Kotlin classes
Learn more in:* [What's New in IntelliJ IDEA 2021.1](https://www.jetbrains.com/idea/whatsnew/2021-1/)
|
| **2020.3**
Released: December 1, 2020 | * New types of inline refactorings
* Structural search and replace
* EditorConfig support
* Project templates for Jetpack Compose for Desktop
Learn more in:* [IntelliJ IDEA 2020.3 release blog post](https://blog.jetbrains.com/idea/2020/12/intellij-idea-2020-3/)
|
Last modified: 10 January 2023
[Kotlin Multiplatform Mobile plugin releases](multiplatform-mobile-plugin-releases) [Kotlin roadmap](roadmap)
kotlin Collections in Java and Kotlin Collections in Java and Kotlin
==============================
*Collections* are groups of a variable number of items (possibly zero) that are significant to the problem being solved and are commonly operated on. This guide explains and compares collection concepts and operations in Java and Kotlin. It will help you migrate from Java to Kotlin and write your code in the authentically Kotlin way.
The first part of this guide contains a quick glossary of operations on the same collections in Java and Kotlin. It is divided into [operations that are the same](#operations-that-are-the-same-in-java-and-kotlin) and [operations that exist only in Kotlin](#operations-that-don-t-exist-in-java-s-standard-library). The second part of the guide, starting from [Mutability](#mutability), explains some of the differences by looking at specific cases.
For an introduction to collections, see the [Collections overview](collections-overview) or watch this [video](https://www.youtube.com/watch?v=F8jj7e-_jFA) by Sebastian Aigner, Kotlin Developer Advocate.
Operations that are the same in Java and Kotlin
-----------------------------------------------
In Kotlin, there are many operations on collections that look exactly the same as their counterparts in Java.
### Operations on lists, sets, queues, and deques
| Description | Common operations | More Kotlin alternatives |
| --- | --- | --- |
| Add an element or elements | `add()`, `addAll()` | Use the [`plusAssign`(`+=`) operator](collection-plus-minus): `collection += element`, `collection += anotherCollection`. |
| Check whether a collection contains an element or elements | `contains()`, `containsAll()` | Use the [`in` keyword](collection-elements#check-element-existence) to call `contains()` in the operator form: `element in collection`. |
| Check whether a collection is empty | `isEmpty()` | Use [`isNotEmpty()`](../api/latest/jvm/stdlib/kotlin.collections/is-not-empty) to check whether a collection is not empty. |
| Remove under a certain condition | `removeIf()` | |
| Leave only selected elements | `retainAll()` | |
| Remove all elements from a collection | `clear()` | |
| Get a stream from a collection | `stream()` | Kotlin has its own way to process streams: [sequences](#sequences) and methods like [`map()`](collection-filtering) and [`filter()`](#filter-elements). |
| Get an iterator from a collection | `iterator()` | |
### Operations on maps
| Description | Common operations | More Kotlin alternatives |
| --- | --- | --- |
| Add an element or elements | `put()`, `putAll()`, `putIfAbsent()` | In Kotlin, the assignment `map[key] = value` behaves the same as `put(key, value)`. Also, you may use the [`plusAssign`(`+=`) operator](collection-plus-minus): `map += Pair(key, value)` or `map += anotherMap`. |
| Replace an element or elements | `put()`, `replace()`, `replaceAll()` | Use the indexing operator `map[key] = value` instead of `put()` and `replace()`. |
| Get an element | `get()` | Use the indexing operator to get an element: `map[index]`. |
| Check whether a map contains an element or elements | `containsKey()`, `containsValue()` | Use the [`in` keyword](collection-elements#check-element-existence) to call `contains()` in the operator form: `element in map`. |
| Check whether a map is empty | `isEmpty()` | Use [`isNotEmpty()`](../api/latest/jvm/stdlib/kotlin.collections/is-not-empty) to check whether a map is not empty. |
| Remove an element | `remove(key)`, `remove(key, value)` | Use the [`minusAssign`(`-=`) operator](collection-plus-minus): `map -= key`. |
| Remove all elements from a map | `clear()` | |
| Get a stream from a map | `stream()` on entries, keys, or values | |
### Operations that exist only for lists
| Description | Common operations | More Kotlin alternatives |
| --- | --- | --- |
| Get an index of an element | `indexOf()` | |
| Get the last index of an element | `lastIndexOf()` | |
| Get an element | `get()` | Use the indexing operator to get an element: `list[index]`. |
| Take a sublist | `subList()` | |
| Replace an element or elements | `set()`, `replaceAll()` | Use the indexing operator instead of `set()`: `list[index] = value`. |
Operations that differ a bit
----------------------------
### Operations on any collection type
| Description | Java | Kotlin |
| --- | --- | --- |
| Get a collection's size | `size()` | `count()`, `size` |
| Get flat access to nested collection elements | `collectionOfCollections.forEach(flatCollection::addAll)` or `collectionOfCollections.stream().flatMap().collect()` | [`flatten()`](collection-transformations#flatten) or [`flatMap()`](../api/latest/jvm/stdlib/kotlin.collections/flat-map) |
| Apply the given function to every element | `stream().map().collect()` | [`map()`](collection-filtering) |
| Apply the provided operation to collection elements sequentially and return the accumulated result | `stream().reduce()` | [`reduce()`, `fold()`](collection-aggregate#fold-and-reduce) |
| Group elements by a classifier and count them | `stream().collect(Collectors.groupingBy(classifier, counting()))` | [`eachCount()`](collection-grouping) |
| Filter by a condition | `stream().filter().collect()` | [`filter()`](../api/latest/jvm/stdlib/kotlin.collections/filter) |
| Check whether collection elements satisfy a condition | `stream().noneMatch()`, `stream().anyMatch()`, `stream().allMatch()` | [`none()`, `any()`, `all()`](collection-filtering) |
| Sort elements | `stream().sorted().collect()` | [`sorted()`](collection-ordering#natural-order) |
| Take the first N elements | `stream().limit(N).collect()` | [`take(N)`](collection-parts#take-and-drop) |
| Take elements with a predicate | `stream().takeWhile().collect()` | [`takeWhile()`](collection-parts#take-and-drop) |
| Skip the first N elements | `stream().skip(N).collect()` | [`drop(N)`](collection-parts#take-and-drop) |
| Skip elements with a predicate | `stream().dropWhile().collect()` | [`dropWhile()`](collection-parts#take-and-drop) |
| Build maps from collection elements and certain values associated with them | `stream().collect(toMap(keyMapper, valueMapper))` | [`associate()`](collection-transformations#associate) |
To perform all of the operations listed above on maps, you first need to get an `entrySet` of a map.
### Operations on lists
| Description | Java | Kotlin |
| --- | --- | --- |
| Sort a list into natural order | `sort(null)` | `sort()` |
| Sort a list into descending order | `sort(comparator)` | `sortDescending()` |
| Remove an element from a list | `remove(index)`, `remove(element)` | `removeAt(index)`, `remove(element)` or [`collection -= element`](collection-plus-minus) |
| Fill all elements of a list with a certain value | `Collections.fill()` | [`fill()`](../api/latest/jvm/stdlib/kotlin.collections/fill) |
| Get unique elements from a list | `stream().distinct().toList()` | [`distinct()`](../api/latest/jvm/stdlib/kotlin.collections/distinct) |
Operations that don't exist in Java's standard library
------------------------------------------------------
* [`zip()`, `unzip()`](collection-transformations) – transform a collection.
* [`aggregate()`](collection-grouping) – group by a condition.
* [`takeLast()`, `takeLastWhile()`, `dropLast()`, `dropLastWhile()`](collection-parts#take-and-drop) – take or drop elements by a predicate.
* [`slice()`, `chunked()`, `windowed()`](collection-parts) – retrieve collection parts.
* [Plus (`+`) and minus (`-`) operators](collection-plus-minus) – add or remove elements.
If you want to take a deep dive into `zip()`, `chunked()`, `windowed()`, and some other operations, watch this video by Sebastian Aigner about advanced collection operations in Kotlin:
Mutability
----------
In Java, there are mutable collections:
```
// Java
// This list is mutable!
public List<Customer> getCustomers() { ... }
```
Partially mutable ones:
```
// Java
List<String> numbers = Arrays.asList("one", "two", "three", "four");
numbers.add("five"); // Fails in runtime with `UnsupportedOperationException`
```
And immutable ones:
```
// Java
List<String> numbers = new LinkedList<>();
// This list is immutable!
List<String> immutableCollection = Collections.unmodifiableList(numbers);
immutableCollection.add("five"); // Fails in runtime with `UnsupportedOperationException`
```
If you write the last two pieces of code in IntelliJ IDEA, the IDE will warn you that you're trying to modify an immutable object. This code will compile and fail in runtime with `UnsupportedOperationException`. You can't tell whether a collection is mutable by looking at its type.
Unlike in Java, in Kotlin you explicitly declare mutable or read-only collections depending on your needs. If you try to modify a read-only collection, the code won't compile:
```
// Kotlin
val numbers = mutableListOf("one", "two", "three", "four")
numbers.add("five") // This is OK
val immutableNumbers = listOf("one", "two")
//immutableNumbers.add("five") // Compilation error - Unresolved reference: add
```
Read more about immutability on the [Kotlin coding conventions](coding-conventions#immutability) page.
Covariance
----------
In Java, you can't pass a collection with a descendant type to a function that takes a collection of the ancestor type. For example, if `Rectangle` extends `Shape`, you can't pass a collection of `Rectangle` elements to a function that takes a collection of `Shape` elements. To make the code compilable, use the `? extends Shape` type so the function can take collections with any inheritors of `Shape`:
```
// Java
class Shape {}
class Rectangle extends Shape {}
public void doSthWithShapes(List<? extends Shape> shapes) {
/* If using just List<Shape>, the code won't compile when calling
this function with the List<Rectangle> as the argument as below */
}
public void main() {
var rectangles = List.of(new Rectangle(), new Rectangle());
doSthWithShapes(rectangles);
}
```
In Kotlin, read-only collection types are [covariant](generics#variance). This means that if a `Rectangle` class inherits from the `Shape` class, you can use the type `List<Rectangle>` anywhere the `List<Shape>` type is required. In other words, the collection types have the same subtyping relationship as the element types. Maps are covariant on the value type, but not on the key type. Mutable collections aren't covariant – this would lead to runtime failures.
```
// Kotlin
open class Shape(val name: String)
class Rectangle(private val rectangleName: String) : Shape(rectangleName)
fun doSthWithShapes(shapes: List<Shape>) {
println("The shapes are: ${shapes.joinToString { it.name }}")
}
fun main() {
val rectangles = listOf(Rectangle("rhombus"), Rectangle("parallelepiped"))
doSthWithShapes(rectangles)
}
```
Read more about [collection types](collections-overview#collection-types) here.
Ranges and progressions
-----------------------
In Kotlin, you can create intervals using [ranges](ranges#range). For example, `Version(1, 11)..Version(1, 30)` includes all of the versions from `1.11` to `1.30`. You can check that your version is in the range by using the `in` operator: `Version(0, 9) in versionRange`.
In Java, you need to manually check whether a `Version` fits both bounds:
```
// Java
class Version implements Comparable<Version> {
int major;
int minor;
Version(int major, int minor) {
this.major = major;
this.minor = minor;
}
@Override
public int compareTo(Version o) {
if (this.major != o.major) {
return this.major - o.major;
}
return this.minor - o.minor;
}
}
public void compareVersions() {
var minVersion = new Version(1, 11);
var maxVersion = new Version(1, 31);
System.out.println(
versionIsInRange(new Version(0, 9), minVersion, maxVersion));
System.out.println(
versionIsInRange(new Version(1, 20), minVersion, maxVersion));
}
public Boolean versionIsInRange(Version versionToCheck, Version minVersion,
Version maxVersion) {
return versionToCheck.compareTo(minVersion) >= 0
&& versionToCheck.compareTo(maxVersion) <= 0;
}
```
In Kotlin, you operate with a range as a whole object. You don't need to create two variables and compare a `Version` with them:
```
// Kotlin
class Version(val major: Int, val minor: Int): Comparable<Version> {
override fun compareTo(other: Version): Int {
if (this.major != other.major) {
return this.major - other.major
}
return this.minor - other.minor
}
}
fun main() {
val versionRange = Version(1, 11)..Version(1, 30)
println(Version(0, 9) in versionRange)
println(Version(1, 20) in versionRange)
}
```
As soon as you need to exclude one of the bounds, like to check whether a version is greater than or equal to (`>=`) the minimum version and less than (`<`) the maximum version, these inclusive ranges won't help.
Comparison by several criteria
------------------------------
In Java, to compare objects by several criteria, you may use the [`comparing()`](https://docs.oracle.com/javase/8/docs/api/java/util/Comparator.html#comparing-java.util.function.Function-) and [`thenComparingX()`](https://docs.oracle.com/javase/8/docs/api/java/util/Comparator.html#thenComparing-java.util.Comparator-) functions from the [`Comparator`](https://docs.oracle.com/javase/8/docs/api/java/util/Comparator.html) interface. For example, to compare people by their name and age:
```
class Person implements Comparable<Person> {
String name;
int age;
public String getName() {
return name;
}
public int getAge() {
return age;
}
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return this.name + " " + age;
}
}
public void comparePersons() {
var persons = List.of(new Person("Jack", 35), new Person("David", 30),
new Person("Jack", 25));
System.out.println(persons.stream().sorted(Comparator
.comparing(Person::getName)
.thenComparingInt(Person::getAge)).collect(toList()));
}
```
In Kotlin, you just enumerate which fields you want to compare:
```
data class Person(
val name: String,
val age: Int
)
fun main() {
val persons = listOf(Person("Jack", 35), Person("David", 30),
Person("Jack", 25))
println(persons.sortedWith(compareBy(Person::name, Person::age)))
}
```
Sequences
---------
In Java, you can generate a sequence of numbers this way:
```
// Java
int sum = IntStream.iterate(1, e -> e + 3)
.limit(10).sum();
System.out.println(sum); // Prints 145
```
In Kotlin, use *<sequences>*. Multi-step processing of sequences is executed lazily when possible – actual computing happens only when the result of the whole processing chain is requested.
```
fun main() {
//sampleStart
// Kotlin
val sum = generateSequence(1) {
it + 3
}.take(10).sum()
println(sum) // Prints 145
//sampleEnd
}
```
Sequences may reduce the number of steps that are needed to perform some filtering operations. See the [sequence processing example](sequences#sequence-processing-example), which shows the difference between `Iterable` and `Sequence`.
Removal of elements from a list
-------------------------------
In Java, the [`remove()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/List.html#remove(int)) function accepts an index of an element to remove.
When removing an integer element, use the `Integer.valueOf()` function as the argument for the `remove()` function:
```
// Java
public void remove() {
var numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(1);
numbers.remove(1); // This removes by index
System.out.println(numbers); // [1, 3, 1]
numbers.remove(Integer.valueOf(1));
System.out.println(numbers); // [3, 1]
}
```
In Kotlin, there are two types of element removal: by index with [`removeAt()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/remove-at) and by value with [`remove()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/remove).
```
fun main() {
//sampleStart
// Kotlin
val numbers = mutableListOf(1, 2, 3, 1)
numbers.removeAt(0)
println(numbers) // [2, 3, 1]
numbers.remove(1)
println(numbers) // [2, 3]
//sampleEnd
}
```
Traverse a map
--------------
In Java, you can traverse a map via [`forEach`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Map.html#forEach(java.util.function.BiConsumer)):
```
// Java
numbers.forEach((k,v) -> System.out.println("Key = " + k + ", Value = " + v));
```
In Kotlin, use a `for` loop or a `forEach`, similar to Java's `forEach`, to traverse a map:
```
// Kotlin
for ((k, v) in numbers) {
println("Key = $k, Value = $v")
}
// Or
numbers.forEach { (k, v) -> println("Key = $k, Value = $v") }
```
Get the first and the last items of a possibly empty collection
---------------------------------------------------------------
In Java, you can safely get the first and the last items by checking the size of the collection and using indices:
```
// Java
var list = new ArrayList<>();
//...
if (list.size() > 0) {
System.out.println(list.get(0));
System.out.println(list.get(list.size() - 1));
}
```
You can also use the [`getFirst()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Deque.html#getFirst()) and [`getLast()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Deque.html#getLast()) functions for [`Deque`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Deque.html) and its inheritors:
```
// Java
var deque = new ArrayDeque<>();
//...
if (deque.size() > 0) {
System.out.println(deque.getFirst());
System.out.println(deque.getLast());
}
```
In Kotlin, there are the special functions [`firstOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/first-or-null) and [`lastOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/last-or-null). Using the [`Elvis operator`](null-safety#elvis-operator), you can perform further actions right away depending on the result of a function. For example, `firstOrNull()`:
```
// Kotlin
val emails = listOf<String>() // Might be empty
val theOldestEmail = emails.firstOrNull() ?: ""
val theFreshestEmail = emails.lastOrNull() ?: ""
```
Create a set from a list
------------------------
In Java, to create a [`Set`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Set.html) from a [`List`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/List.html), you can use the [`Set.copyOf`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/Set.html#copyOf(java.util.Collection)) function:
```
// Java
public void listToSet() {
var sourceList = List.of(1, 2, 3, 1);
var copySet = Set.copyOf(sourceList);
System.out.println(copySet);
}
```
In Kotlin, use the function `toSet()`:
```
fun main() {
//sampleStart
// Kotlin
val sourceList = listOf(1, 2, 3, 1)
val copySet = sourceList.toSet()
println(copySet)
//sampleEnd
}
```
Group elements
--------------
In Java, you can group elements with the [Collectors](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/Collectors.html) function `groupingBy()`:
```
// Java
public void analyzeLogs() {
var requests = List.of(
new Request("https://kotlinlang.org/docs/home.html", 200),
new Request("https://kotlinlang.org/docs/home.html", 400),
new Request("https://kotlinlang.org/docs/comparison-to-java.html", 200)
);
var urlsAndRequests = requests.stream().collect(
Collectors.groupingBy(Request::getUrl));
System.out.println(urlsAndRequests);
}
```
In Kotlin, use the function [`groupBy()`](../api/latest/jvm/stdlib/kotlin.collections/group-by):
```
class Request(
val url: String,
val responseCode: Int
)
fun main() {
//sampleStart
// Kotlin
val requests = listOf(
Request("https://kotlinlang.org/docs/home.html", 200),
Request("https://kotlinlang.org/docs/home.html", 400),
Request("https://kotlinlang.org/docs/comparison-to-java.html", 200)
)
println(requests.groupBy(Request::url))
//sampleEnd
}
```
Filter elements
---------------
In Java, to filter elements from a collection, you need to use the [Stream API](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/package-summary.html). The Stream API has `intermediate` and `terminal` operations. `filter()` is an intermediate operation, which returns a stream. To receive a collection as the output, you need to use a terminal operation, like `collect()`. For example, to leave only those pairs whose keys end with `1` and whose values are greater than `10`:
```
// Java
public void filterEndsWith() {
var numbers = Map.of("key1", 1, "key2", 2, "key3", 3, "key11", 11);
var filteredNumbers = numbers.entrySet().stream()
.filter(entry -> entry.getKey().endsWith("1") && entry.getValue() > 10)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
System.out.println(filteredNumbers);
}
```
In Kotlin, filtering is built into collections, and `filter()` returns the same collection type that was filtered. So, all you need to write is the `filter()` and its predicate:
```
fun main() {
//sampleStart
// Kotlin
val numbers = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredNumbers = numbers.filter { (key, value) -> key.endsWith("1") && value > 10 }
println(filteredNumbers)
//sampleEnd
}
```
Learn more about [filtering maps](map-operations#filter) here.
### Filter elements by type
In Java, to filter elements by type and perform actions on them, you need to check their types with the [`instanceof`](https://docs.oracle.com/en/java/javase/17/language/pattern-matching-instanceof-operator.html) operator and then do the type cast:
```
// Java
public void objectIsInstance() {
var numbers = new ArrayList<>();
numbers.add(null);
numbers.add(1);
numbers.add("two");
numbers.add(3.0);
numbers.add("four");
System.out.println("All String elements in upper case:");
numbers.stream().filter(it -> it instanceof String)
.forEach( it -> System.out.println(((String) it).toUpperCase()));
}
```
In Kotlin, you just call [`filterIsInstance<NEEDED_TYPE>()`](../api/latest/jvm/stdlib/kotlin.collections/filter-is-instance) on your collection, and the type cast is done by [Smart casts](typecasts#smart-casts):
```
// Kotlin
fun main() {
//sampleStart
// Kotlin
val numbers = listOf(null, 1, "two", 3.0, "four")
println("All String elements in upper case:")
numbers.filterIsInstance<String>().forEach {
println(it.uppercase())
}
//sampleEnd
}
```
### Test predicates
Some tasks require you to check whether all, none, or any elements satisfy a condition. In Java, you can do all of these checks via the [Stream API](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/package-summary.html) functions [`allMatch()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/Stream.html#allMatch(java.util.function.Predicate)), [`noneMatch()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/Stream.html#noneMatch(java.util.function.Predicate)), and [`anyMatch()`](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/Stream.html#anyMatch(java.util.function.Predicate)):
```
// Java
public void testPredicates() {
var numbers = List.of("one", "two", "three", "four");
System.out.println(numbers.stream().noneMatch(it -> it.endsWith("e"))); // false
System.out.println(numbers.stream().anyMatch(it -> it.endsWith("e"))); // true
System.out.println(numbers.stream().allMatch(it -> it.endsWith("e"))); // false
}
```
In Kotlin, the [extension functions](extensions) `none()`, `any()`, and `all()` are available for every [Iterable](../api/latest/jvm/stdlib/kotlin.collections/-iterable/index#kotlin.collections.Iterable) object:
```
fun main() {
//sampleStart
// Kotlin
val numbers = listOf("one", "two", "three", "four")
println(numbers.none { it.endsWith("e") })
println(numbers.any { it.endsWith("e") })
println(numbers.all { it.endsWith("e") })
//sampleEnd
}
```
Learn more about [test predicates](collection-filtering#test-predicates).
Collection transformation operations
------------------------------------
### Zip elements
In Java, you can make pairs from elements with the same positions in two collections by iterating simultaneously over them:
```
// Java
public void zip() {
var colors = List.of("red", "brown");
var animals = List.of("fox", "bear", "wolf");
for (int i = 0; i < Math.min(colors.size(), animals.size()); i++) {
String animal = animals.get(i);
System.out.println("The " + animal.substring(0, 1).toUpperCase()
+ animal.substring(1) + " is " + colors.get(i));
}
}
```
If you want to do something more complex than just printing pairs of elements into the output, you can use [Records](https://blogs.oracle.com/javamagazine/post/records-come-to-java). In the example above, the record would be `record AnimalDescription(String animal, String color) {}`.
In Kotlin, use the [`zip()`](collection-transformations#zip) function to do the same thing:
```
fun main() {
//sampleStart
// Kotlin
val colors = listOf("red", "brown")
val animals = listOf("fox", "bear", "wolf")
println(colors.zip(animals) { color, animal ->
"The ${animal.replaceFirstChar { it.uppercase() }} is $color" })
//sampleEnd
}
```
`zip()` returns the List of [Pair](../api/latest/jvm/stdlib/kotlin/-pair/index) objects.
### Associate elements
In Java, you can use the [Stream API](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/package-summary.html) to associate elements with characteristics:
```
// Java
public void associate() {
var numbers = List.of("one", "two", "three", "four");
var wordAndLength = numbers.stream()
.collect(toMap(number -> number, String::length));
System.out.println(wordAndLength);
}
```
In Kotlin, use the [`associate()`](collection-transformations#associate) function:
```
fun main() {
//sampleStart
// Kotlin
val numbers = listOf("one", "two", "three", "four")
println(numbers.associateWith { it.length })
//sampleEnd
}
```
What's next?
------------
* Visit [Kotlin Koans](koans) – complete exercises to learn Kotlin syntax. Each exercise is created as a failing unit test and your job is to make it pass.
* Look through other [Kotlin idioms](idioms).
* Learn how to convert existing Java code to Kotlin with the [Java to Kotlin converter](mixing-java-kotlin-intellij#converting-an-existing-java-file-to-kotlin-with-j2k).
* Discover [collections in Kotlin](collections-overview).
If you have a favorite idiom, we invite you to share it by sending a pull request.
Last modified: 10 January 2023
[Strings in Java and Kotlin](java-to-kotlin-idioms-strings) [Nullability in Java and Kotlin](java-to-kotlin-nullability-guide)
| programming_docs |
kotlin Operator overloading Operator overloading
====================
Kotlin allows you to provide custom implementations for the predefined set of operators on types. These operators have predefined symbolic representation (like `+` or `*`) and precedence. To implement an operator, provide a [member function](functions#member-functions) or an [extension function](extensions) with a specific name for the corresponding type. This type becomes the left-hand side type for binary operations and the argument type for the unary ones.
To overload an operator, mark the corresponding function with the `operator` modifier:
```
interface IndexedContainer {
operator fun get(index: Int)
}
```
When [overriding](inheritance#overriding-methods) your operator overloads, you can omit `operator`:
```
class OrdersList: IndexedContainer {
override fun get(index: Int) { /*...*/ }
}
```
Unary operations
----------------
### Unary prefix operators
| Expression | Translated to |
| --- | --- |
| `+a` | `a.unaryPlus()` |
| `-a` | `a.unaryMinus()` |
| `!a` | `a.not()` |
This table says that when the compiler processes, for example, an expression `+a`, it performs the following steps:
* Determines the type of `a`, let it be `T`.
* Looks up a function `unaryPlus()` with the `operator` modifier and no parameters for the receiver `T`, that means a member function or an extension function.
* If the function is absent or ambiguous, it is a compilation error.
* If the function is present and its return type is `R`, the expression `+a` has type `R`.
As an example, here's how you can overload the unary minus operator:
```
data class Point(val x: Int, val y: Int)
operator fun Point.unaryMinus() = Point(-x, -y)
val point = Point(10, 20)
fun main() {
println(-point) // prints "Point(x=-10, y=-20)"
}
```
### Increments and decrements
| Expression | Translated to |
| --- | --- |
| `a++` | `a.inc()` + see below |
| `a--` | `a.dec()` + see below |
The `inc()` and `dec()` functions must return a value, which will be assigned to the variable on which the `++` or `--` operation was used. They shouldn't mutate the object on which the `inc` or `dec` was invoked.
The compiler performs the following steps for resolution of an operator in the *postfix* form, for example `a++`:
* Determines the type of `a`, let it be `T`.
* Looks up a function `inc()` with the `operator` modifier and no parameters, applicable to the receiver of type `T`.
* Checks that the return type of the function is a subtype of `T`.
The effect of computing the expression is:
* Store the initial value of `a` to a temporary storage `a0`.
* Assign the result of `a0.inc()` to `a`.
* Return `a0` as the result of the expression.
For `a--` the steps are completely analogous.
For the *prefix* forms `++a` and `--a` resolution works the same way, and the effect is:
* Assign the result of `a.inc()` to `a`.
* Return the new value of `a` as a result of the expression.
Binary operations
-----------------
### Arithmetic operators
| Expression | Translated to |
| --- | --- |
| `a + b` | `a.plus(b)` |
| `a - b` | `a.minus(b)` |
| `a * b` | `a.times(b)` |
| `a / b` | `a.div(b)` |
| `a % b` | `a.rem(b)` |
| `a..b` | `a.rangeTo(b)` |
For the operations in this table, the compiler just resolves the expression in the *Translated to* column.
Below is an example `Counter` class that starts at a given value and can be incremented using the overloaded `+` operator:
```
data class Counter(val dayIndex: Int) {
operator fun plus(increment: Int): Counter {
return Counter(dayIndex + increment)
}
}
```
### in operator
| Expression | Translated to |
| --- | --- |
| `a in b` | `b.contains(a)` |
| `a !in b` | `!b.contains(a)` |
For `in` and `!in` the procedure is the same, but the order of arguments is reversed.
### Indexed access operator
| Expression | Translated to |
| --- | --- |
| `a[i]` | `a.get(i)` |
| `a[i, j]` | `a.get(i, j)` |
| `a[i_1, ..., i_n]` | `a.get(i_1, ..., i_n)` |
| `a[i] = b` | `a.set(i, b)` |
| `a[i, j] = b` | `a.set(i, j, b)` |
| `a[i_1, ..., i_n] = b` | `a.set(i_1, ..., i_n, b)` |
Square brackets are translated to calls to `get` and `set` with appropriate numbers of arguments.
### invoke operator
| Expression | Translated to |
| --- | --- |
| `a()` | `a.invoke()` |
| `a(i)` | `a.invoke(i)` |
| `a(i, j)` | `a.invoke(i, j)` |
| `a(i_1, ..., i_n)` | `a.invoke(i_1, ..., i_n)` |
Parentheses are translated to calls to `invoke` with appropriate number of arguments.
### Augmented assignments
| Expression | Translated to |
| --- | --- |
| `a += b` | `a.plusAssign(b)` |
| `a -= b` | `a.minusAssign(b)` |
| `a *= b` | `a.timesAssign(b)` |
| `a /= b` | `a.divAssign(b)` |
| `a %= b` | `a.remAssign(b)` |
For the assignment operations, for example `a += b`, the compiler performs the following steps:
* If the function from the right column is available:
+ If the corresponding binary function (that means `plus()` for `plusAssign()`) is available too, `a` is a mutable variable, and the return type of `plus` is a subtype of the type of `a`, report an error (ambiguity).
+ Make sure its return type is `Unit`, and report an error otherwise.
+ Generate code for `a.plusAssign(b)`.
* Otherwise, try to generate code for `a = a + b` (this includes a type check: the type of `a + b` must be a subtype of `a`).
### Equality and inequality operators
| Expression | Translated to |
| --- | --- |
| `a == b` | `a?.equals(b) ?: (b === null)` |
| `a != b` | `!(a?.equals(b) ?: (b === null))` |
These operators only work with the function [`equals(other: Any?): Boolean`](../api/latest/jvm/stdlib/kotlin/-any/equals), which can be overridden to provide custom equality check implementation. Any other function with the same name (like `equals(other: Foo)`) will not be called.
The `==` operation is special: it is translated to a complex expression that screens for `null`'s. `null == null` is always true, and `x == null` for a non-null `x` is always false and won't invoke `x.equals()`.
### Comparison operators
| Expression | Translated to |
| --- | --- |
| `a > b` | `a.compareTo(b) > 0` |
| `a < b` | `a.compareTo(b) < 0` |
| `a >= b` | `a.compareTo(b) >= 0` |
| `a <= b` | `a.compareTo(b) <= 0` |
All comparisons are translated into calls to `compareTo`, that is required to return `Int`.
### Property delegation operators
`provideDelegate`, `getValue` and `setValue` operator functions are described in [Delegated properties](delegated-properties).
Infix calls for named functions
-------------------------------
You can simulate custom infix operations by using [infix function calls](functions#infix-notation).
Last modified: 10 January 2023
[Inline functions](inline-functions) [Type-safe builders](type-safe-builders)
kotlin Kotlin for JavaScript Kotlin for JavaScript
=====================
Kotlin/JS provides the ability to transpile your Kotlin code, the Kotlin standard library, and any compatible dependencies to JavaScript. The current implementation of Kotlin/JS targets [ES5](https://www.ecma-international.org/ecma-262/5.1/).
The recommended way to use Kotlin/JS is via the `kotlin.js` and `kotlin.multiplatform` Gradle plugins. They let you easily set up and control Kotlin projects targeting JavaScript in one place. This includes essential functionality such as controlling the bundling of your application, adding JavaScript dependencies directly from npm, and more. To get an overview of the available options, check out the [Kotlin/JS project setup](js-project-setup) documentation.
Kotlin/JS IR compiler
---------------------
The [Kotlin/JS IR compiler](js-ir-compiler) comes with a number of improvements over the old default compiler. For example, it reduces the size of generated executables via dead code elimination and provides smoother interoperability with the JavaScript ecosystem and its tooling.
By generating TypeScript declaration files (`d.ts`) from Kotlin code, the IR compiler makes it easier to create "hybrid" applications that mix TypeScript and Kotlin code and to leverage code-sharing functionality using Kotlin Multiplatform.
To learn more about the available features in the Kotlin/JS IR compiler and how to try it for your project, visit the [Kotlin/JS IR compiler documentation page](js-ir-compiler) and the [migration guide](js-ir-migration).
Use cases for Kotlin/JS
-----------------------
There are numerous ways to use Kotlin/JS. Here is a non-exhaustive list of scenarios in which you can use Kotlin/JS:
* **Write frontend web applications using Kotlin/JS**
+ Kotlin/JS allows you to **leverage powerful browser and web APIs** in a type-safe fashion. Create, modify, and interact with the elements in the Document Object Model (DOM), use Kotlin code to control the rendering of `canvas` or WebGL components, and enjoy access to many more features that modern browsers support.
+ Write **full, type-safe React applications with Kotlin/JS** using the [`kotlin-wrappers`](https://github.com/JetBrains/kotlin-wrappers) provided by JetBrains, which provide convenient abstractions and deep integrations for React and other popular JavaScript frameworks. `kotlin-wrappers` also provides support for a select number of adjacent technologies, like `react-redux`, `react-router`, and `styled-components`. Interoperability with the JavaScript ecosystem means that you can also use third-party React components and component libraries.
+ Use the **[Kotlin/JS frameworks](#kotlin-js-frameworks)**, which take full advantage of Kotlin concepts and its expressive power and conciseness.
* **Write server-side and serverless applications using Kotlin/JS**
+ The Node.js target provided by Kotlin/JS enables you to create applications that **run on a server** or are **executed on serverless infrastructure**. This gives you all the advantages of executing in a JavaScript runtime, such as **faster startup** and a **reduced memory footprint**. With [`kotlinx-nodejs`](https://github.com/Kotlin/kotlinx-nodejs), you have typesafe access to the [Node.js API](https://nodejs.org/docs/latest/api/) directly from your Kotlin code.
* **Use Kotlin's <multiplatform> projects to share code with other Kotlin targets**
+ All the functionality of Kotlin/JS can also be accessed when using the Kotlin `multiplatform` Gradle plugin.
+ If your backend is written in Kotlin, you can **share common code** such as data models or validation logic with a frontend written in Kotlin/JS, which allows you to **write and maintain full-stack web applications**.
+ You can also **share business logic between your web interface and mobile apps** for Android and iOS, and avoid duplicating commonly used functionality, like providing abstractions around REST API endpoints, user authentication, or your domain models.
* **Create libraries for use with JavaScript and TypeScript**
+ You don't have to write your whole application in Kotlin/JS – instead, you can **generate libraries from your Kotlin code** that can be consumed as modules from any code base written in JavaScript or TypeScript, regardless of the other frameworks or technologies you use. This approach of **creating hybrid applications** allows you to leverage the competencies that you and your team might already have around web development while helping you **reduce the amount of duplicated work**, making it easier to keep your web target consistent with other targets of your application.
Of course, this is not a complete list of all the ways you can use Kotlin/JS to your advantage, but merely some cherry-picked use cases. We invite you to experiment with different combinations and find out what works best for your project.
Whatever your specific use case, Kotlin/JS projects can use compatible **libraries from the Kotlin ecosystem**, as well as third-party **libraries from the JavaScript and TypeScript ecosystems**. To use the latter from Kotlin code, you can either provide your own typesafe wrappers, use community-maintained wrappers, or let [Dukat](js-external-declarations-with-dukat) automatically generate Kotlin declarations for you. Using the Kotlin/JS-exclusive [dynamic type](dynamic-type) allows you to loosen the constraints of Kotlin's type system and skip creating detailed library wrappers, though this comes at the expense of type safety.
Kotlin/JS is also compatible with the most common module systems: UMD, CommonJS, and AMD. The ability to [produce and consume modules](js-modules) means that you can interact with the JavaScript ecosystem in a structured manner.
Kotlin/JS frameworks
--------------------
Modern web development benefits significantly from frameworks that simplify building web applications. Here are a few examples of popular web frameworks for Kotlin/JS written by different authors:
### KVision
*KVision* is an object-oriented web framework that makes it possible to write applications in Kotlin/JS with ready-to-use components that can be used as building blocks for your application's user interface. You can use both reactive and imperative programming models to build your frontend, use connectors for Ktor, Spring Boot, and other frameworks to integrate it with your server-side applications, and share code using [Kotlin Multiplatform](multiplatform).
[Visit KVision site](https://kvision.io) for documentation, tutorials, and examples.
For updates and discussions about the framework, join the [#kvision](https://kotlinlang.slack.com/messages/kvision) and [#javascript](https://kotlinlang.slack.com/archives/C0B8L3U69) channels in the [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up).
### fritz2
*fritz2* is a standalone framework for building reactive web user interfaces. It provides its own type-safe DSL for building and rendering HTML elements, and it makes use of Kotlin's coroutines and flows to express components and their data bindings. It provides state management, validation, routing, and more out of the box, and integrates with Kotlin Multiplatform projects.
[Visit fritz2 site](https://www.fritz2.dev) for documentation, tutorials, and examples.
For updates and discussions about the framework, join the [#fritz2](https://kotlinlang.slack.com/messages/fritz2) and [#javascript](https://kotlinlang.slack.com/archives/C0B8L3U69) channels in the [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up).
### Doodle
*Doodle* is a vector-based UI framework for Kotlin/JS. Doodle applications use the browser's graphics capabilities to draw user interfaces instead of relying on DOM, CSS, or Javascript. By using this approach, Doodle gives you precise control over the rendering of arbitrary UI elements, vector shapes, gradients, and custom visualizations.
[Visit Doodle site](https://nacular.github.io/doodle/) for documentation, tutorials, and examples.
For updates and discussions about the framework, join the [#doodle](https://kotlinlang.slack.com/messages/doodle) and [#javascript](https://kotlinlang.slack.com/archives/C0B8L3U69) channels in the [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up).
### Compose for Web
*Compose for Web*, a part of Compose Multiplatform, brings [Google's Jetpack Compose UI toolkit](https://developer.android.com/jetpack/compose) to your browser. It allows you to build reactive web user interfaces using the concepts introduced by Jetpack Compose. It provides a DOM API to describe your website, as well as an experimental set of multiplatform layout primitives. Compose for Web also gives you the option to share parts of your UI code and logic across Android, desktop, and the web.
You can find more information about Compose Multiplatform on its [landing page](https://www.jetbrains.com/lp/compose-mpp/).
Join the [#compose-web](https://kotlinlang.slack.com/archives/C01F2HV7868) channel on the [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) to discuss Compose for Web, or [#compose](https://kotlinlang.slack.com/archives/CJLTWPH7S) for general Compose Multiplatform discussions.
Kotlin/JS, Today and Tomorrow
-----------------------------
In [this video](https://www.youtube.com/watch?v=fZUL8_kgHXg), Kotlin Developer Advocate Sebastian Aigner explains the main Kotlin/JS benefits, shares some tips and use cases, and talks about the plans and upcoming features for Kotlin/JS.
Get started with Kotlin/JS
--------------------------
If you're new to Kotlin, a good first step is to familiarize yourself with the [basic syntax](basic-syntax) of the language.
To start using Kotlin for JavaScript, please refer to [Set up a Kotlin/JS project](js-project-setup). You can also complete a [tutorial](#tutorials-for-kotlin-js) to work through or check out the list of [Kotlin/JS sample projects](#sample-projects-for-kotlin-js) for inspiration. They contain useful snippets and patterns and can serve as nice jump-off points for your own projects.
### Tutorials for Kotlin/JS
* [Build a web application with React and Kotlin/JS — tutorial](js-react) guides you through the process of building a simple web application using the React framework, shows how a type-safe Kotlin DSL for HTML makes it easy to build reactive DOM elements, and illustrates how to use third-party React components and obtain information from APIs, all while writing the whole application logic in pure Kotlin/JS.
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) teaches the concepts behind building an application that targets Kotlin/JVM and Kotlin/JS by building a client-server application that makes use of shared code, serialization, and other multiplatform paradigms. It also provides a brief introduction to working with Ktor both as a server- and client-side framework.
### Sample projects for Kotlin/JS
* [Full-stack Spring collaborative to-do list](https://github.com/Kotlin/full-stack-spring-collaborative-todo-list-sample) shows how to create a to-do list for collaborative work using `kotlin-multiplatform` with JS and JVM targets, Spring for the backend, Kotlin/JS with React for the frontend, and RSocket.
* [Kotlin/JS and React Redux to-do list](https://github.com/Kotlin/react-redux-js-ir-todo-list-sample) implements the React Redux to-do list using JS libraries (`react`, `react-dom`, `react-router`, `redux`, and `react-redux`) from npm and Webpack to bundle, minify, and run the project.
* [Full-stack demo application](https://github.com/Kotlin/full-stack-web-jetbrains-night-sample) guides you through the process of building an app with a feed containing user-generated posts and comments. All data is stubbed by the fakeJSON and JSON Placeholder services.
Join the Kotlin/JS community
----------------------------
You can also join the [#javascript](https://kotlinlang.slack.com/archives/C0B8L3U69) channel in the official [Kotlin Slack](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) to chat with the community and the team.
Last modified: 10 January 2023
[Kotlin for Android](android-overview) [Kotlin Native](native-overview)
kotlin Strings Strings
=======
Strings in Kotlin are represented by the type `String`. Generally, a string value is a sequence of characters in double quotes (`"`):
```
val str = "abcd 123"
```
Elements of a string are characters that you can access via the indexing operation: `s[i]`. You can iterate over these characters with a `for` loop:
```
fun main() {
val str = "abcd"
//sampleStart
for (c in str) {
println(c)
}
//sampleEnd
}
```
Strings are immutable. Once you initialize a string, you can't change its value or assign a new value to it. All operations that transform strings return their results in a new `String` object, leaving the original string unchanged:
```
fun main() {
//sampleStart
val str = "abcd"
println(str.uppercase()) // Create and print a new String object
println(str) // The original string remains the same
//sampleEnd
}
```
To concatenate strings, use the `+` operator. This also works for concatenating strings with values of other types, as long as the first element in the expression is a string:
```
fun main() {
//sampleStart
val s = "abc" + 1
println(s + "def")
//sampleEnd
}
```
String literals
---------------
Kotlin has two types of string literals:
* [Escaped strings](#escaped-strings)
* [Raw strings](#raw-strings)
### Escaped strings
*Escaped strings* can contain escaped characters.
Here's an example of an escaped string:
```
val s = "Hello, world!\n"
```
Escaping is done in the conventional way, with a backslash (`\`).
See [Characters](characters) page for the list of supported escape sequences.
### Raw strings
*Raw strings* can contain newlines and arbitrary text. It is delimited by a triple quote (`"""`), contains no escaping and can contain newlines and any other characters:
```
val text = """
for (c in "foo")
print(c)
"""
```
To remove leading whitespace from raw strings, use the [`trimMargin()`](../api/latest/jvm/stdlib/kotlin.text/trim-margin) function:
```
val text = """
|Tell me and I forget.
|Teach me and I remember.
|Involve me and I learn.
|(Benjamin Franklin)
""".trimMargin()
```
By default, a pipe symbol `|` is used as margin prefix, but you can choose another character and pass it as a parameter, like `trimMargin(">")`.
String templates
----------------
String literals may contain *template expressions* – pieces of code that are evaluated and whose results are concatenated into the string. A template expression starts with a dollar sign (`$`) and consists of either a name:
```
fun main() {
//sampleStart
val i = 10
println("i = $i") // Prints "i = 10"
//sampleEnd
}
```
or an expression in curly braces:
```
fun main() {
//sampleStart
val s = "abc"
println("$s.length is ${s.length}") // Prints "abc.length is 3"
//sampleEnd
}
```
You can use templates both in raw and escaped strings. To insert the dollar sign `$` in a raw string (which doesn't support backslash escaping) before any symbol, which is allowed as a beginning of an [identifier](grammar#identifiers), use the following syntax:
```
val price = """
${'$'}_9.99
"""
```
Last modified: 10 January 2023
[Characters](characters) [Arrays](arrays)
| programming_docs |
kotlin Run tests in Kotlin/JS Run tests in Kotlin/JS
======================
The Kotlin/JS Gradle plugin lets you run tests through a variety of test runners that can be specified via the Gradle configuration. In order to make test annotations and functionality available for the JavaScript target, add the correct platform artifact for [`kotlin.test`](https://kotlinlang.org/api/latest/kotlin.test/index.html) in `build.gradle.kts`:
```
dependencies {
// ...
testImplementation(kotlin("test-js"))
}
```
You can tune how tests are executed in Kotlin/JS by adjusting the settings available in the `testTask` block in the Gradle build script. For example, using the Karma test runner together with a headless instance of Chrome and an instance of Firefox looks like this:
```
target {
browser {
testTask {
useKarma {
useChromeHeadless()
useFirefox()
}
}
}
}
```
For a detailed description of the available functionality, check out the Kotlin/JS reference on [configuring the test task](js-project-setup#test-task).
Please note that by default, no browsers are bundled with the plugin. This means that you'll have to ensure they're available on the target system.
To check that tests are executed properly, add a file `src/test/kotlin/AppTest.kt` and fill it with this content:
```
import kotlin.test.Test
import kotlin.test.assertEquals
class AppTest {
@Test
fun thingsShouldWork() {
assertEquals(listOf(1,2,3).reversed(), listOf(3,2,1))
}
@Test
fun thingsShouldBreak() {
assertEquals(listOf(1,2,3).reversed(), listOf(1,2,3))
}
}
```
To run the tests in the browser, execute the `browserTest` task via IntelliJ IDEA, or use the gutter icons to execute all or individual tests:
Alternatively, if you want to run the tests via the command line, use the Gradle wrapper:
```
./gradlew browserTest
```
After running the tests from IntelliJ IDEA, the **Run** tool window will show the test results. You can click failed tests to see their stack trace, and navigate to the corresponding test implementation via a double-click.
After each test run, regardless of how you executed the test, you can find a properly formatted test report from Gradle in `build/reports/tests/browserTest/index.html`. Open this file in a browser to see another overview of the test results:
If you are using the set of example tests shown in the snippet above, one test passes, and one test breaks, which gives the resulting total of 50% successful tests. To get more information about individual test cases, you can navigate via the provided hyperlinks:
 Last modified: 10 January 2023
[Debug Kotlin/JS code](js-debugging) [Kotlin/JS dead code elimination](javascript-dce)
kotlin Aggregate operations Aggregate operations
====================
Kotlin collections contain functions for commonly used *aggregate operations* – operations that return a single value based on the collection content. Most of them are well known and work the same way as they do in other languages:
* [`minOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/min-or-null) and [`maxOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/max-or-null) return the smallest and the largest element respectively. On empty collections, they return `null`.
* [`average()`](../api/latest/jvm/stdlib/kotlin.collections/average) returns the average value of elements in the collection of numbers.
* [`sum()`](../api/latest/jvm/stdlib/kotlin.collections/sum) returns the sum of elements in the collection of numbers.
* [`count()`](../api/latest/jvm/stdlib/kotlin.collections/count) returns the number of elements in a collection.
```
fun main() {
val numbers = listOf(6, 42, 10, 4)
println("Count: ${numbers.count()}")
println("Max: ${numbers.maxOrNull()}")
println("Min: ${numbers.minOrNull()}")
println("Average: ${numbers.average()}")
println("Sum: ${numbers.sum()}")
}
```
There are also functions for retrieving the smallest and the largest elements by certain selector function or custom [`Comparator`](../api/latest/jvm/stdlib/kotlin/-comparator/index):
* [`maxByOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/max-by-or-null) and [`minByOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/min-by-or-null) take a selector function and return the element for which it returns the largest or the smallest value.
* [`maxWithOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/max-with-or-null) and [`minWithOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/min-with-or-null) take a `Comparator` object and return the largest or smallest element according to that `Comparator`.
* [`maxOfOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/max-of-or-null) and [`minOfOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/min-of-or-null) take a selector function and return the largest or the smallest return value of the selector itself.
* [`maxOfWithOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/max-of-with-or-null) and [`minOfWithOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/min-of-with-or-null) take a `Comparator` object and return the largest or smallest selector return value according to that `Comparator`.
These functions return `null` on empty collections. There are also alternatives – [`maxOf`](../api/latest/jvm/stdlib/kotlin.collections/max-of), [`minOf`](../api/latest/jvm/stdlib/kotlin.collections/min-of), [`maxOfWith`](../api/latest/jvm/stdlib/kotlin.collections/max-of-with), and [`minOfWith`](../api/latest/jvm/stdlib/kotlin.collections/min-of-with) – which do the same as their counterparts but throw a `NoSuchElementException` on empty collections.
```
fun main() {
//sampleStart
val numbers = listOf(5, 42, 10, 4)
val min3Remainder = numbers.minByOrNull { it % 3 }
println(min3Remainder)
val strings = listOf("one", "two", "three", "four")
val longestString = strings.maxWithOrNull(compareBy { it.length })
println(longestString)
//sampleEnd
}
```
Besides regular `sum()`, there is an advanced summation function [`sumOf()`](../api/latest/jvm/stdlib/kotlin.collections/sum-of) that takes a selector function and returns the sum of its application to all collection elements. Selector can return different numeric types: `Int`, `Long`, `Double`, `UInt`, and `ULong` (also `BigInteger` and `BigDecimal` on the JVM).
```
fun main() {
//sampleStart
val numbers = listOf(5, 42, 10, 4)
println(numbers.sumOf { it * 2 })
println(numbers.sumOf { it.toDouble() / 2 })
//sampleEnd
}
```
Fold and reduce
---------------
For more specific cases, there are the functions [`reduce()`](../api/latest/jvm/stdlib/kotlin.collections/reduce) and [`fold()`](../api/latest/jvm/stdlib/kotlin.collections/fold) that apply the provided operation to the collection elements sequentially and return the accumulated result. The operation takes two arguments: the previously accumulated value and the collection element.
The difference between the two functions is that `fold()` takes an initial value and uses it as the accumulated value on the first step, whereas the first step of `reduce()` uses the first and the second elements as operation arguments on the first step.
```
fun main() {
//sampleStart
val numbers = listOf(5, 2, 10, 4)
val simpleSum = numbers.reduce { sum, element -> sum + element }
println(simpleSum)
val sumDoubled = numbers.fold(0) { sum, element -> sum + element * 2 }
println(sumDoubled)
//incorrect: the first element isn't doubled in the result
//val sumDoubledReduce = numbers.reduce { sum, element -> sum + element * 2 }
//println(sumDoubledReduce)
//sampleEnd
}
```
The example above shows the difference: `fold()` is used for calculating the sum of doubled elements. If you pass the same function to `reduce()`, it will return another result because it uses the list's first and second elements as arguments on the first step, so the first element won't be doubled.
To apply a function to elements in the reverse order, use functions [`reduceRight()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-right) and [`foldRight()`](../api/latest/jvm/stdlib/kotlin.collections/fold-right). They work in a way similar to `fold()` and `reduce()` but start from the last element and then continue to previous. Note that when folding or reducing right, the operation arguments change their order: first goes the element, and then the accumulated value.
```
fun main() {
//sampleStart
val numbers = listOf(5, 2, 10, 4)
val sumDoubledRight = numbers.foldRight(0) { element, sum -> sum + element * 2 }
println(sumDoubledRight)
//sampleEnd
}
```
You can also apply operations that take element indices as parameters. For this purpose, use functions [`reduceIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-indexed) and [`foldIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/fold-indexed) passing element index as the first argument of the operation.
Finally, there are functions that apply such operations to collection elements from right to left - [`reduceRightIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-right-indexed) and [`foldRightIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/fold-right-indexed).
```
fun main() {
//sampleStart
val numbers = listOf(5, 2, 10, 4)
val sumEven = numbers.foldIndexed(0) { idx, sum, element -> if (idx % 2 == 0) sum + element else sum }
println(sumEven)
val sumEvenRight = numbers.foldRightIndexed(0) { idx, element, sum -> if (idx % 2 == 0) sum + element else sum }
println(sumEvenRight)
//sampleEnd
}
```
All reduce operations throw an exception on empty collections. To receive `null` instead, use their `*OrNull()` counterparts:
* [`reduceOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-or-null)
* [`reduceRightOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-right-or-null)
* [`reduceIndexedOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-indexed-or-null)
* [`reduceRightIndexedOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/reduce-right-indexed-or-null)
For cases where you want to save intermediate accumulator values, there are functions [`runningFold()`](../api/latest/jvm/stdlib/kotlin.collections/running-fold) (or its synonym [`scan()`](../api/latest/jvm/stdlib/kotlin.collections/scan)) and [`runningReduce()`](../api/latest/jvm/stdlib/kotlin.collections/running-reduce).
```
fun main() {
//sampleStart
val numbers = listOf(0, 1, 2, 3, 4, 5)
val runningReduceSum = numbers.runningReduce { sum, item -> sum + item }
val runningFoldSum = numbers.runningFold(10) { sum, item -> sum + item }
//sampleEnd
val transform = { index: Int, element: Int -> "N = ${index + 1}: $element" }
println(runningReduceSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningReduce:\n"))
println(runningFoldSum.mapIndexed(transform).joinToString("\n", "Sum of first N elements with runningFold:\n"))
}
```
If you need an index in the operation parameter, use [`runningFoldIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/running-fold-indexed) or [`runningReduceIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/running-reduce-indexed).
Last modified: 10 January 2023
[Ordering](collection-ordering) [Collection write operations](collection-write)
kotlin Kotlin and continuous integration with TeamCity Kotlin and continuous integration with TeamCity
===============================================
On this page, you'll learn how to set up [TeamCity](https://www.jetbrains.com/teamcity/) to build your Kotlin project. For more information and basics of TeamCity please check the [Documentation page](https://www.jetbrains.com/teamcity/documentation/) which contains information about installation, basic configuration, etc.
Kotlin works with different build tools, so if you're using a standard tool such as Ant, Maven or Gradle, the process for setting up a Kotlin project is no different to any other language or library that integrates with these tools. Where there are some minor requirements and differences is when using the internal build system of IntelliJ IDEA, which is also supported on TeamCity.
Gradle, Maven, and Ant
----------------------
If using Ant, Maven or Gradle, the setup process is straightforward. All that is needed is to define the Build Step. For example, if using Gradle, simply define the required parameters such as the Step Name and Gradle tasks that need executing for the Runner Type.
Since all the dependencies required for Kotlin are defined in the Gradle file, nothing else needs to be configured specifically for Kotlin to run correctly.
If using Ant or Maven, the same configuration applies. The only difference being that the Runner Type would be Ant or Maven respectively.
IntelliJ IDEA Build System
--------------------------
If using IntelliJ IDEA build system with TeamCity, make sure that the version of Kotlin being used by IntelliJ IDEA is the same as the one that TeamCity runs. You may need to download the specific version of the Kotlin plugin and install it on TeamCity.
Fortunately, there is a meta-runner already available that takes care of most of the manual work. If not familiar with the concept of TeamCity meta-runners, check the [documentation](https://www.jetbrains.com/help/teamcity/working-with-meta-runner.html). They are very easy and powerful way to introduce custom Runners without the need to write plugins.
### Download and install the meta-runner
The meta-runner for Kotlin is available on [GitHub](https://github.com/jonnyzzz/Kotlin.TeamCity). Download that meta-runner and import it from the TeamCity user interface
### Setup Kotlin compiler fetching step
Basically this step is limited to defining the Step Name and the version of Kotlin you need. Tags can be used.
The runner will set the value for the property `system.path.macro.KOTLIN.BUNDLED` to the correct one based on the path settings from the IntelliJ IDEA project. However, this value needs to be defined in TeamCity (and can be set to any value). Therefore, you need to define it as a system variable.
### Setup Kotlin compilation step
The final step is to define the actual compilation of the project, which uses the standard IntelliJ IDEA Runner Type.
With that, our project should now build and produce the corresponding artifacts.
Other CI servers
----------------
If using a continuous integration tool different to TeamCity, as long as it supports any of the build tools, or calling command line tools, compiling Kotlin and automating things as part of a CI process should be possible.
Last modified: 10 January 2023
[FAQ](ksp-faq) [Document Kotlin code: KDoc and Dokka](kotlin-doc)
kotlin Configure your build for EAP Configure your build for EAP
============================
If you create new projects using the EAP version of Kotlin, you don't need to perform any additional steps. The [Kotlin Plugin](install-eap-plugin) will do everything for you!
You only need to configure your build manually for existing projects — projects that were created before installing the EAP version.
To configure your build to use the EAP version of Kotlin, you need to:
* Specify the EAP version of Kotlin. [Available EAP versions are listed here](eap#build-details).
* Change the versions of dependencies to EAP ones. The EAP version of Kotlin may not work with the libraries of the previously released version.
The following procedures describe how to configure your build in Gradle and Maven:
* [Configure in Gradle](#configure-in-gradle)
* [Configure in Maven](#configure-in-maven)
Configure in Gradle
-------------------
This section describes how you can:
* [Adjust the Kotlin version](#adjust-the-kotlin-version)
* [Adjust versions in dependencies](#adjust-versions-in-dependencies)
### Adjust the Kotlin version
In the `plugins` block within `build.gradle(.kts)`, change the `KOTLIN-EAP-VERSION` to the actual EAP version, such as `1.8.0-RC2`. [Available EAP versions are listed here](eap#build-details).
Alternatively, you can specify the EAP version in the `pluginManagement` block in `settings.gradle(.kts)` – see [Gradle documentation](https://docs.gradle.org/current/userguide/plugins.html#sec:plugin_version_management) for details.
Here is an example for the Multiplatform project.
```
plugins {
java
kotlin("multiplatform") version "KOTLIN-EAP-VERSION"
}
repositories {
mavenCentral()
}
```
```
plugins {
id 'java'
id 'org.jetbrains.kotlin.multiplatform' version 'KOTLIN-EAP-VERSION'
}
repositories {
mavenCentral()
}
```
### Adjust versions in dependencies
If you use kotlinx libraries in your project, your versions of the libraries may not be compatible with the EAP version of Kotlin.
To resolve this issue, you need to specify the version of a compatible library in dependencies. For a list of compatible libraries, see [EAP build details](eap#build-details).
Here is an example.
For the **kotlinx.coroutines** library, add the version number – `1.6.0-RC3` – that is compatible with `1.8.0-RC2`.
```
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.0-RC3")
}
```
```
dependencies {
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.0-RC3"
}
```
Configure in Maven
------------------
In the sample Maven project definition, replace `KOTLIN-EAP-VERSION` with the actual version, such as `1.8.0-RC2`. [Available EAP versions are listed here](eap#build-details).
```
<project ...>
<properties>
<kotlin.version>KOTLIN-EAP-VERSION</kotlin.version>
</properties>
<repositories>
<repository>
<id>mavenCentral</id>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>mavenCentral</id>
<url>https://repo1.maven.org/maven2/</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
...
</plugin>
</plugins>
</build>
</project>
```
Last modified: 10 January 2023
[Install the EAP Plugin for IntelliJ IDEA or Android Studio](install-eap-plugin) [Basic syntax](basic-syntax)
kotlin Compatibility guide for Kotlin 1.4 Compatibility guide for Kotlin 1.4
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.3 to Kotlin 1.4.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language and stdlib
-------------------
### Unexpected behavior with in infix operator and ConcurrentHashMap
### Prohibit access to protected members inside public inline members
### Contracts on calls with implicit receivers
### Inconsistent behavior of floating-point number comparisons
### No smart cast on the last expression in a generic lambda
### Do not depend on the order of lambda arguments to coerce result to Unit
### Wrong common supertype between raw and integer literal type leads to unsound code
### Type safety problem because several equal type variables are instantiated with a different types
### Type safety problem because of incorrect subtyping for intersection types
### No type mismatch with an empty when expression inside lambda
### Return type Any inferred for lambda with early return with integer literal in one of possible return values
### Proper capturing of star projections with recursive types
### Common supertype calculation with non-proper type and flexible one leads to incorrect results
### Type safety problem because of lack of captured conversion against nullable type argument
### Preserve intersection type for covariant types after unchecked cast
### Type variable leaks from builder inference because of using this expression
### Wrong overload resolution for contravariant types with nullable type arguments
### Builder inference with non-nested recursive constraints
### Eager type variable fixation leads to a contradictory constraint system
### Prohibit tailrec modifier on open functions
### The INSTANCE field of a companion object more visible than the companion object class itself
### Outer finally block inserted before return is not excluded from thecatch interval of the inner try block without finally
### Use the boxed version of an inline class in return type position for covariant and generic-specialized overrides
### Do not declare checked exceptions in JVM bytecode when using delegation to Kotlin interfaces
### Changed behavior of signature-polymorphic calls to methods with a single vararg parameter to avoid wrapping the argument into another array
### Incorrect generic signature in annotations when KClass is used as a generic parameter
### Forbid spread operator in signature-polymorphic calls
### Change initialization order of default values for tail-recursive optimized functions
### Do not generate ConstantValue attribute for non-const vals
### Generated overloads for @JvmOverloads on open methods should be final
### Lambdas returning kotlin.Result now return boxed value instead of unboxed
### Unify exceptions from null checks
### Comparing floating-point values in array/list operations contains, indexOf, lastIndexOf: IEEE 754 or total order
### Gradually change the return type of collection min and max functions to non-nullable
### Deprecate appendln in favor of appendLine
### Deprecate conversions of floating-point types to Short and Byte
### Fail fast in Regex.findAll on an invalid startIndex
### Remove deprecated kotlin.coroutines.experimental
### Remove deprecated mod operator
### Hide Throwable.addSuppressed member and prefer extension instead
### capitalize should convert digraphs to title case
Tools
-----
### Compiler arguments with delimiter characters must be passed in double quotes on Windows
### KAPT: Names of synthetic $annotations() methods for properties have changed
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.5](compatibility-guide-15) [Compatibility guide for Kotlin 1.3](compatibility-guide-13)
| programming_docs |
kotlin Collection write operations Collection write operations
===========================
[Mutable collections](collections-overview#collection-types) support operations for changing the collection contents, for example, adding or removing elements. On this page, we'll describe write operations available for all implementations of `MutableCollection`. For more specific operations available for `List` and `Map`, see [List-specific Operations](list-operations) and [Map Specific Operations](map-operations) respectively.
Adding elements
---------------
To add a single element to a list or a set, use the [`add()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/add) function. The specified object is appended to the end of the collection.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4)
numbers.add(5)
println(numbers)
//sampleEnd
}
```
[`addAll()`](../api/latest/jvm/stdlib/kotlin.collections/add-all) adds every element of the argument object to a list or a set. The argument can be an `Iterable`, a `Sequence`, or an `Array`. The types of the receiver and the argument may be different, for example, you can add all items from a `Set` to a `List`.
When called on lists, `addAll()` adds new elements in the same order as they go in the argument. You can also call `addAll()` specifying an element position as the first argument. The first element of the argument collection will be inserted at this position. Other elements of the argument collection will follow it, shifting the receiver elements to the end.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 5, 6)
numbers.addAll(arrayOf(7, 8))
println(numbers)
numbers.addAll(2, setOf(3, 4))
println(numbers)
//sampleEnd
}
```
You can also add elements using the in-place version of the [`plus` operator](collection-plus-minus) - [`plusAssign`](../api/latest/jvm/stdlib/kotlin.collections/plus-assign) (`+=`) When applied to a mutable collection, `+=` appends the second operand (an element or another collection) to the end of the collection.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two")
numbers += "three"
println(numbers)
numbers += listOf("four", "five")
println(numbers)
//sampleEnd
}
```
Removing elements
-----------------
To remove an element from a mutable collection, use the [`remove()`](../api/latest/jvm/stdlib/kotlin.collections/remove) function. `remove()` accepts the element value and removes one occurrence of this value.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.remove(3) // removes the first `3`
println(numbers)
numbers.remove(5) // removes nothing
println(numbers)
//sampleEnd
}
```
For removing multiple elements at once, there are the following functions :
* [`removeAll()`](../api/latest/jvm/stdlib/kotlin.collections/remove-all) removes all elements that are present in the argument collection. Alternatively, you can call it with a predicate as an argument; in this case the function removes all elements for which the predicate yields `true`.
* [`retainAll()`](../api/latest/jvm/stdlib/kotlin.collections/retain-all) is the opposite of `removeAll()`: it removes all elements except the ones from the argument collection. When used with a predicate, it leaves only elements that match it.
* [`clear()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/clear) removes all elements from a list and leaves it empty.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers)
numbers.retainAll { it >= 3 }
println(numbers)
numbers.clear()
println(numbers)
val numbersSet = mutableSetOf("one", "two", "three", "four")
numbersSet.removeAll(setOf("one", "two"))
println(numbersSet)
//sampleEnd
}
```
Another way to remove elements from a collection is with the [`minusAssign`](../api/latest/jvm/stdlib/kotlin.collections/minus-assign) (`-=`) operator – the in-place version of [`minus`](collection-plus-minus). The second argument can be a single instance of the element type or another collection. With a single element on the right-hand side, `-=` removes the *first* occurrence of it. In turn, if it's a collection, *all* occurrences of its elements are removed. For example, if a list contains duplicate elements, they are removed at once. The second operand can contain elements that are not present in the collection. Such elements don't affect the operation execution.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "three", "four")
numbers -= "three"
println(numbers)
numbers -= listOf("four", "five")
//numbers -= listOf("four") // does the same as above
println(numbers)
//sampleEnd
}
```
Updating elements
-----------------
Lists and maps also provide operations for updating elements. They are described in [List-specific Operations](list-operations) and [Map Specific Operations](map-operations). For sets, updating doesn't make sense since it's actually removing an element and adding another one.
Last modified: 10 January 2023
[Aggregate operations](collection-aggregate) [List-specific operations](list-operations)
kotlin Conditions and loops Conditions and loops
====================
If expression
-------------
In Kotlin, `if` is an expression: it returns a value. Therefore, there is no ternary operator (`condition ? then : else`) because ordinary `if` works fine in this role.
```
var max = a
if (a < b) max = b
// With else
var max: Int
if (a > b) {
max = a
} else {
max = b
}
// As expression
val max = if (a > b) a else b
```
Branches of an `if` expression can be blocks. In this case, the last expression is the value of a block:
```
val max = if (a > b) {
print("Choose a")
a
} else {
print("Choose b")
b
}
```
If you're using `if` as an expression, for example, for returning its value or assigning it to a variable, the `else` branch is mandatory.
When expression
---------------
`when` defines a conditional expression with multiple branches. It is similar to the `switch` statement in C-like languages. Its simple form looks like this.
```
when (x) {
1 -> print("x == 1")
2 -> print("x == 2")
else -> {
print("x is neither 1 nor 2")
}
}
```
`when` matches its argument against all branches sequentially until some branch condition is satisfied.
`when` can be used either as an expression or as a statement. If it is used as an expression, the value of the first matching branch becomes the value of the overall expression. If it is used as a statement, the values of individual branches are ignored. Just like with `if`, each branch can be a block, and its value is the value of the last expression in the block.
The `else` branch is evaluated if none of the other branch conditions are satisfied.
If `when` is used as an *expression*, the `else` branch is mandatory, unless the compiler can prove that all possible cases are covered with branch conditions, for example, with [`enum` class](enum-classes) entries and [`sealed` class](sealed-classes) subtypes).
```
enum class Bit {
ZERO, ONE
}
val numericValue = when (getRandomBit()) {
Bit.ZERO -> 0
Bit.ONE -> 1
// 'else' is not required because all cases are covered
}
```
In `when` *statements*, the `else` branch is mandatory in the following conditions:
* `when` has a subject of an `Boolean`, [`enum`](enum-classes), or [`sealed`](sealed-classes) type, or their nullable counterparts.
* branches of `when` don't cover all possible cases for this subject.
```
enum class Color {
RED, GREEN, BLUE
}
when (getColor()) {
Color.RED -> println("red")
Color.GREEN -> println("green")
Color.BLUE -> println("blue")
// 'else' is not required because all cases are covered
}
when (getColor()) {
Color.RED -> println("red") // no branches for GREEN and BLUE
else -> println("not red") // 'else' is required
}
```
To define a common behavior for multiple cases, combine their conditions in a single line with a comma:
```
when (x) {
0, 1 -> print("x == 0 or x == 1")
else -> print("otherwise")
}
```
You can use arbitrary expressions (not only constants) as branch conditions
```
when (x) {
s.toInt() -> print("s encodes x")
else -> print("s does not encode x")
}
```
You can also check a value for being `in` or `!in` a [range](ranges) or a collection:
```
when (x) {
in 1..10 -> print("x is in the range")
in validNumbers -> print("x is valid")
!in 10..20 -> print("x is outside the range")
else -> print("none of the above")
}
```
Another option is checking that a value `is` or `!is` of a particular type. Note that, due to [smart casts](typecasts#smart-casts), you can access the methods and properties of the type without any extra checks.
```
fun hasPrefix(x: Any) = when(x) {
is String -> x.startsWith("prefix")
else -> false
}
```
`when` can also be used as a replacement for an `if`-`else` `if` chain. If no argument is supplied, the branch conditions are simply boolean expressions, and a branch is executed when its condition is true:
```
when {
x.isOdd() -> print("x is odd")
y.isEven() -> print("y is even")
else -> print("x+y is odd")
}
```
You can capture *when* subject in a variable using following syntax:
```
fun Request.getBody() =
when (val response = executeRequest()) {
is Success -> response.body
is HttpError -> throw HttpException(response.status)
}
```
The scope of variable introduced in *when* subject is restricted to the body of this *when*.
For loops
---------
The `for` loop iterates through anything that provides an iterator. This is equivalent to the `foreach` loop in languages like C#. The syntax of `for` is the following:
```
for (item in collection) print(item)
```
The body of `for` can be a block.
```
for (item: Int in ints) {
// ...
}
```
As mentioned before, `for` iterates through anything that provides an iterator. This means that it:
* has a member or an extension function `iterator()` that returns `Iterator<>`:
+ has a member or an extension function `next()`
+ has a member or an extension function `hasNext()` that returns `Boolean`.
All of these three functions need to be marked as `operator`.
To iterate over a range of numbers, use a [range expression](ranges):
```
fun main() {
//sampleStart
for (i in 1..3) {
println(i)
}
for (i in 6 downTo 0 step 2) {
println(i)
}
//sampleEnd
}
```
A `for` loop over a range or an array is compiled to an index-based loop that does not create an iterator object.
If you want to iterate through an array or a list with an index, you can do it this way:
```
fun main() {
val array = arrayOf("a", "b", "c")
//sampleStart
for (i in array.indices) {
println(array[i])
}
//sampleEnd
}
```
Alternatively, you can use the `withIndex` library function:
```
fun main() {
val array = arrayOf("a", "b", "c")
//sampleStart
for ((index, value) in array.withIndex()) {
println("the element at $index is $value")
}
//sampleEnd
}
```
While loops
-----------
`while` and `do-while` loops execute their body continuously while their condition is satisfied. The difference between them is the condition checking time:
* `while` checks the condition and, if it's satisfied, executes the body and then returns to the condition check.
* `do-while` executes the body and then checks the condition. If it's satisfied, the loop repeats. So, the body of `do-while` executes at least once regardless of the condition.
```
while (x > 0) {
x--
}
do {
val y = retrieveData()
} while (y != null) // y is visible here!
```
Break and continue in loops
---------------------------
Kotlin supports traditional `break` and `continue` operators in loops. See [Returns and jumps](returns).
Last modified: 10 January 2023
[Type checks and casts](typecasts) [Returns and jumps](returns)
kotlin Interoperability with Swift/Objective-C Interoperability with Swift/Objective-C
=======================================
This document covers some details of Kotlin/Native interoperability with Swift/Objective-C.
Usage
-----
Kotlin/Native provides bidirectional interoperability with Objective-C. Objective-C frameworks and libraries can be used in Kotlin code if properly imported to the build (system frameworks are imported by default). See [compilation configurations](multiplatform-configure-compilations#configure-interop-with-native-languages) for more details. A Swift library can be used in Kotlin code if its API is exported to Objective-C with `@objc`. Pure Swift modules are not yet supported.
Kotlin modules can be used in Swift/Objective-C code if compiled into a framework ([see here for how to declare binaries](multiplatform-build-native-binaries#declare-binaries)). See [Kotlin Multiplatform Mobile Sample](https://github.com/Kotlin/kmm-basic-sample) for an example.
### Hiding Kotlin declarations
If you don't want to export Kotlin declarations to Objective-C and Swift, use special annotations:
* `@HiddenFromObjC` hides a Kotlin declaration from Objective-C and Swift. The annotation disables a function or property export to Objective-C, making your Kotlin code more Objective-C/Swift-friendly.
* `@ShouldRefineInSwift` helps to replace a Kotlin declaration with a wrapper written in Swift. The annotation marks a function or property as `swift_private` in the generated Objective-C API. Such declarations get the `__` prefix, which makes them invisible from Swift.
You can still use these declarations in your Swift code to create a Swift-friendly API, but they won't be suggested in the Xcode autocomplete.
For more information on refining Objective-C declarations in Swift, see the [official Apple documentation](https://developer.apple.com/documentation/swift/improving-objective-c-api-declarations-for-swift).
Mappings
--------
The table below shows how Kotlin concepts are mapped to Swift/Objective-C and vice versa.
"->" and "<-" indicate that mapping only goes one way.
| Kotlin | Swift | Objective-C | Notes |
| --- | --- | --- | --- |
| `class` | `class` | `@interface` | [note](#name-translation) |
| `interface` | `protocol` | `@protocol` | |
| `constructor`/`create` | Initializer | Initializer | [note](#initializers) |
| Property | Property | Property | [note 1](#top-level-functions-and-properties), [note 2](#setters) |
| Method | Method | Method | [note 1](#top-level-functions-and-properties), [note 2](#method-names-translation) |
| `suspend`-> | `completionHandler:`/`async` | `completionHandler:` | [note 1](#errors-and-exceptions), [note 2](#suspending-functions) |
| `@Throws fun` | `throws` | `error:(NSError**)error` | [note](#errors-and-exceptions) |
| Extension | Extension | Category member | [note](#extensions-and-category-members) |
| `companion` member <- | Class method or property | Class method or property | |
| `null` | `nil` | `nil` | |
| `Singleton` | `shared` or `companion` property | `shared` or `companion` property | [note](#kotlin-singletons) |
| Primitive type | Primitive type / `NSNumber` | | [note](#nsnumber) |
| `Unit` return type | `Void` | `void` | |
| `String` | `String` | `NSString` | |
| `String` | `NSMutableString` | `NSMutableString` | [note](#nsmutablestring) |
| `List` | `Array` | `NSArray` | |
| `MutableList` | `NSMutableArray` | `NSMutableArray` | |
| `Set` | `Set` | `NSSet` | |
| `MutableSet` | `NSMutableSet` | `NSMutableSet` | [note](#collections) |
| `Map` | `Dictionary` | `NSDictionary` | |
| `MutableMap` | `NSMutableDictionary` | `NSMutableDictionary` | [note](#collections) |
| Function type | Function type | Block pointer type | [note](#function-types) |
| Inline classes | Unsupported | Unsupported | [note](#unsupported) |
### Name translation
Objective-C classes are imported into Kotlin with their original names. Protocols are imported as interfaces with `Protocol` name suffix, i.e. `@protocol Foo`-> `interface FooProtocol`. These classes and interfaces are placed into a package [specified in build configuration](#usage) (`platform.*` packages for preconfigured system frameworks).
The names of Kotlin classes and interfaces are prefixed when imported to Objective-C. The prefix is derived from the framework name.
Objective-C does not support packages in a framework. Thus, the Kotlin compiler renames Kotlin classes which have the same name but different package in the same framework. This algorithm is not stable yet and can change between Kotlin releases. As a workaround, you can rename the conflicting Kotlin classes in the framework.
To avoid renaming Kotlin declarations, use the `@ObjCName` annotation. It instructs the Kotlin compiler to use a custom Objective-C and Swift name for classes, interfaces, and other Kotlin concepts:
```
@ObjCName(swiftName = "MySwiftArray")
class MyKotlinArray {
@ObjCName("index")
fun indexOf(@ObjCName("of") element: String): Int = TODO()
}
// Usage with the ObjCName annotations
let array = MySwiftArray()
let index = array.index(of: "element")
```
### Initializers
Swift/Objective-C initializers are imported to Kotlin as constructors and factory methods named `create`. The latter happens with initializers declared in the Objective-C category or as a Swift extension, because Kotlin has no concept of extension constructors.
Kotlin constructors are imported as initializers to Swift/Objective-C.
### Setters
Writeable Objective-C properties overriding read-only properties of the superclass are represented as `setFoo()` method for the property `foo`. Same goes for a protocol's read-only properties that are implemented as mutable.
### Top-level functions and properties
Top-level Kotlin functions and properties are accessible as members of special classes. Each Kotlin file is translated into such a class. E.g.
```
// MyLibraryUtils.kt
package my.library
fun foo() {}
```
can be called from Swift like
```
MyLibraryUtilsKt.foo()
```
### Method names translation
Generally Swift argument labels and Objective-C selector pieces are mapped to Kotlin parameter names. Anyway these two concepts have different semantics, so sometimes Swift/Objective-C methods can be imported with a clashing Kotlin signature. In this case the clashing methods can be called from Kotlin using named arguments, e.g.:
```
[player moveTo:LEFT byMeters:17]
[player moveTo:UP byInches:42]
```
In Kotlin, it would be:
```
player.moveTo(LEFT, byMeters = 17)
player.moveTo(UP, byInches = 42)
```
The methods of `kotlin.Any` (`equals()`, `hashCode()` and `toString()`) are mapped to the methods `isEquals:`, `hash` and `description` in Objective-C, and to the method `isEquals(_:)` and the properties `hash`, `description` in Swift.
You can specify a more idiomatic name in Swift or Objective-C, instead of renaming the Kotlin declaration. Use the `@ObjCName` annotation that instructs the Kotlin compiler to use a custom Objective-C and Swift name for methods or parameters.
### Errors and exceptions
Kotlin has no concept of checked exceptions, all Kotlin exceptions are unchecked. Swift has only checked errors. So if Swift or Objective-C code calls a Kotlin method which throws an exception to be handled, then the Kotlin method should be marked with a `@Throws` annotation specifying a list of "expected" exception classes.
When compiling to Objective-C/Swift framework, non-`suspend` functions having or inheriting `@Throws` annotation are represented as `NSError*`-producing methods in Objective-C and as `throws` methods in Swift. Representations for `suspend` functions always have `NSError*`/`Error` parameter in completion handler.
When Kotlin function called from Swift/Objective-C code throws an exception which is an instance of one of the `@Throws`-specified classes or their subclasses, it is propagated as `NSError`. Other Kotlin exceptions reaching Swift/Objective-C are considered unhandled and cause program termination.
`suspend` functions without `@Throws` propagate only `CancellationException` as `NSError`. Non-`suspend` functions without `@Throws` don't propagate Kotlin exceptions at all.
Note that the opposite reversed translation is not implemented yet: Swift/Objective-C error-throwing methods aren't imported to Kotlin as exception-throwing.
### Suspending functions
Kotlin's [suspending functions](coroutines-basics) (`suspend`) are presented in the generated Objective-C headers as functions with callbacks, or [completion handlers](https://developer.apple.com/documentation/swift/calling_objective-c_apis_asynchronously) in Swift/Objective-C terminology.
Starting from Swift 5.5, Kotlin's `suspend` functions are also available for calling from Swift as `async` functions without using the completion handlers. Currently, this functionality is highly experimental and has certain limitations. See [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-47610) for details.
Learn more about the [`async`/`await` mechanism in Swift](https://docs.swift.org/swift-book/LanguageGuide/Concurrency.html).
### Extensions and category members
Members of Objective-C categories and Swift extensions are imported to Kotlin as extensions. That's why these declarations can't be overridden in Kotlin. And the extension initializers aren't available as Kotlin constructors.
Kotlin extensions to "regular" Kotlin classes are imported to Swift and Objective-C as extensions and category members respectively. Kotlin extensions to other types are treated as [top-level declarations](#top-level-functions-and-properties) with an additional receiver parameter. These types include:
* Kotlin `String` type
* Kotlin collection types and subtypes
* Kotlin `interface` types
* Kotlin primitive types
* Kotlin `inline` classes
* Kotlin `Any` type
* Kotlin function types and subtypes
* Objective-C classes and protocols
### Kotlin singletons
Kotlin singleton (made with an `object` declaration, including `companion object`) is imported to Swift/Objective-C as a class with a single instance.
The instance is available through the `shared` and `companion` properties.
For the following Kotlin code:
```
object MyObject {
val x = "Some value"
}
class MyClass {
companion object {
val x = "Some value"
}
}
```
Access these objects as follows:
```
MyObject.shared
MyObject.shared.x
MyClass.companion
MyClass.Companion.shared
```
### NSNumber
Kotlin primitive type boxes are mapped to special Swift/Objective-C classes. For example, `kotlin.Int` box is represented as `KotlinInt` class instance in Swift (or `${prefix}Int` instance in Objective-C, where `prefix` is the framework names prefix). These classes are derived from `NSNumber`, so the instances are proper `NSNumber`s supporting all corresponding operations.
`NSNumber` type is not automatically translated to Kotlin primitive types when used as a Swift/Objective-C parameter type or return value. The reason is that `NSNumber` type doesn't provide enough information about a wrapped primitive value type, i.e. `NSNumber` is statically not known to be `Byte`, `Boolean`, or `Double`. So Kotlin primitive values should be cast to/from `NSNumber` manually (see [below](#casting-between-mapped-types)).
### NSMutableString
`NSMutableString` Objective-C class is not available from Kotlin. All instances of `NSMutableString` are copied when passed to Kotlin.
### Collections
Kotlin collections are converted to Swift/Objective-C collections as described in the table above. Swift/Objective-C collections are mapped to Kotlin in the same way, except for `NSMutableSet` and `NSMutableDictionary`. `NSMutableSet` isn't converted to a Kotlin `MutableSet`. To pass an object for Kotlin `MutableSet`, you can create this kind of Kotlin collection explicitly by either creating it in Kotlin with e.g. `mutableSetOf()`, or using the `KotlinMutableSet` class in Swift (or `${prefix}MutableSet` in Objective-C, where `prefix` is the framework names prefix). The same holds for `MutableMap`.
### Function types
Kotlin function-typed objects (e.g. lambdas) are converted to Swift functions / Objective-C blocks. However, there is a difference in how types of parameters and return values are mapped when translating a function and a function type. In the latter case primitive types are mapped to their boxed representation. Kotlin `Unit` return value is represented as a corresponding `Unit` singleton in Swift/Objective-C. The value of this singleton can be retrieved in the same way as it is for any other Kotlin `object` (see singletons in the table above). To sum the things up:
```
fun foo(block: (Int) -> Unit) { ... }
```
would be represented in Swift as
```
func foo(block: (KotlinInt) -> KotlinUnit)
```
and can be called like
```
foo {
bar($0 as! Int32)
return KotlinUnit()
}
```
### Generics
Objective-C supports "lightweight generics" defined on classes, with a relatively limited feature set. Swift can import generics defined on classes to help provide additional type information to the compiler.
Generic feature support for Objective-C and Swift differ from Kotlin, so the translation will inevitably lose some information, but the features supported retain meaningful information.
#### Limitations
Objective-C generics do not support all features of either Kotlin or Swift, so there will be some information lost in the translation.
Generics can only be defined on classes, not on interfaces (protocols in Objective-C and Swift) or functions.
#### Nullability
Kotlin and Swift both define nullability as part of the type specification, while Objective-C defines nullability on methods and properties of a type. As such, the following:
```
class Sample<T>() {
fun myVal(): T
}
```
will (logically) look like this:
```
class Sample<T>() {
fun myVal(): T?
}
```
In order to support a potentially nullable type, the Objective-C header needs to define `myVal` with a nullable return value.
To mitigate this, when defining your generic classes, if the generic type should *never* be null, provide a non-null type constraint:
```
class Sample<T : Any>() {
fun myVal(): T
}
```
That will force the Objective-C header to mark `myVal` as non-null.
#### Variance
Objective-C allows generics to be declared covariant or contravariant. Swift has no support for variance. Generic classes coming from Objective-C can be force-cast as needed.
```
data class SomeData(val num: Int = 42) : BaseData()
class GenVarOut<out T : Any>(val arg: T)
```
```
let variOut = GenVarOut<SomeData>(arg: sd)
let variOutAny : GenVarOut<BaseData> = variOut as! GenVarOut<BaseData>
```
#### Constraints
In Kotlin, you can provide upper bounds for a generic type. Objective-C also supports this, but that support is unavailable in more complex cases, and is currently not supported in the Kotlin - Objective-C interop. The exception here being a non-null upper bound will make Objective-C methods/properties non-null.
#### To disable
To have the framework header written without generics, add the flag to the compiler config:
```
binaries.framework {
freeCompilerArgs += "-Xno-objc-generics"
}
```
Casting between mapped types
----------------------------
When writing Kotlin code, an object may need to be converted from a Kotlin type to the equivalent Swift/Objective-C type (or vice versa). In this case a plain old Kotlin cast can be used, e.g.
```
val nsArray = listOf(1, 2, 3) as NSArray
val string = nsString as String
val nsNumber = 42 as NSNumber
```
Subclassing
-----------
### Subclassing Kotlin classes and interfaces from Swift/Objective-C
Kotlin classes and interfaces can be subclassed by Swift/Objective-C classes and protocols.
### Subclassing Swift/Objective-C classes and protocols from Kotlin
Swift/Objective-C classes and protocols can be subclassed with a Kotlin `final` class. Non-`final` Kotlin classes inheriting Swift/Objective-C types aren't supported yet, so it is not possible to declare a complex class hierarchy inheriting Swift/Objective-C types.
Normal methods can be overridden using the `override` Kotlin keyword. In this case the overriding method must have the same parameter names as the overridden one.
Sometimes it is required to override initializers, e.g. when subclassing `UIViewController`. Initializers imported as Kotlin constructors can be overridden by Kotlin constructors marked with the `@OverrideInit` annotation:
```
class ViewController : UIViewController {
@OverrideInit constructor(coder: NSCoder) : super(coder)
...
}
```
The overriding constructor must have the same parameter names and types as the overridden one.
To override different methods with clashing Kotlin signatures, you can add a `@Suppress("CONFLICTING_OVERLOADS")` annotation to the class.
By default, the Kotlin/Native compiler doesn't allow calling a non-designated Objective-C initializer as a `super(...)` constructor. This behaviour can be inconvenient if the designated initializers aren't marked properly in the Objective-C library. Adding a `disableDesignatedInitializerChecks = true` to the `.def` file for this library would disable these compiler checks.
C features
----------
See [Interoperability with C](native-c-interop) for an example case where the library uses some plain C features, such as unsafe pointers, structs, and so on.
Export of KDoc comments to generated Objective-C headers
--------------------------------------------------------
By default, [KDocs](kotlin-doc) documentation comments are not translated into corresponding comments when generating an Objective-C header.
For example, the following Kotlin code with KDoc:
```
/**
* Prints the sum of the arguments.
* Properly handles the case when the sum doesn't fit in 32-bit integer.
*/
fun printSum(a: Int, b: Int) = println(a.toLong() + b)
```
will produce an Objective-C declaration without any comments:
```
+ (void)printSumA:(int32_t)a b:(int32_t)b __attribute__((swift_name("printSum(a:b:)")));
```
To enable export of KDoc comments, add the following compiler option to your `build.gradle(.kts)`:
```
kotlin {
targets.withType<org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget> {
compilations.get("main").compilerOptions.options.freeCompilerArgs.add("-Xexport-kdoc")
}
}
```
```
kotlin {
targets.withType(org.jetbrains.kotlin.gradle.plugin.mpp.KotlinNativeTarget) {
compilations.get("main").compilerOptions.options.freeCompilerArgs.add("-Xexport-kdoc")
}
}
```
After that the Objective-C header will contain a corresponding comment:
```
/**
* Prints the sum of the arguments.
* Properly handles the case when the sum doesn't fit in 32-bit integer.
*/
+ (void)printSumA:(int32_t)a b:(int32_t)b __attribute__((swift_name("printSum(a:b:)")));
```
Known limitations:
* Dependency documentation is not exported unless it is compiled with `-Xexport-kdoc` itself. The feature is experimental, so libraries compiled with this flag might be incompatible with other compiler versions.
* KDoc comments are mostly exported "as is" , many KDoc features (for example, `@property`) are not supported.
Unsupported
-----------
Some features of Kotlin programming language are not yet mapped into respective features of Objective-C or Swift. Currently, following features are not properly exposed in generated framework headers:
* inline classes (arguments are mapped as either underlying primitive type or `id`)
* custom classes implementing standard Kotlin collection interfaces (`List`, `Map`, `Set`) and other special classes
* Kotlin subclasses of Objective-C classes
Last modified: 10 January 2023
[Create an app using C Interop and libcurl – tutorial](native-app-with-c-and-libcurl) [Kotlin/Native as an Apple framework – tutorial](apple-framework)
| programming_docs |
kotlin Development server and continuous compilation Development server and continuous compilation
=============================================
Instead of manually compiling and executing a Kotlin/JS project every time you want to see the changes you made, you can use the *continuous compilation* mode. Instead of using the regular `run` command, invoke the Gradle wrapper in *continuous* mode:
```
./gradlew run --continuous
```
If you are working in IntelliJ IDEA, you can pass the same flag via the *run configuration*. After running the Gradle `run` task for the first time from the IDE, IntelliJ IDEA automatically generates a run configuration for it, which you can edit:
Enabling continuous mode via the **Run/Debug Configurations** dialog is as easy as adding the `--continuous` flag to the arguments for the run configuration:
When executing this run configuration, you can note that the Gradle process continues watching for changes to the program:
Once a change has been detected, the program will be recompiled automatically. If you still have the page open in the browser, the development server will trigger an automatic reload of the page, and the changes will become visible. This is thanks to the integrated `webpack-dev-server` that is managed by the Kotlin/JS Gradle plugin.
Last modified: 10 January 2023
[Run Kotlin/JS](running-kotlin-js) [Debug Kotlin/JS code](js-debugging)
kotlin Compatibility guide for Kotlin 1.7.20 Compatibility guide for Kotlin 1.7.20
=====================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
Usually incompatible changes happen only in feature releases, but this time we have to introduce two such changes in an incremental release to limit spread of the problems introduced by changes in Kotlin 1.7.
This document summarizes them, providing a reference for migration from Kotlin 1.7.0 and 1.7.10 to Kotlin 1.7.20.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language
--------
### Rollback attempt to fix proper constraints processing
### Forbid some builder inference cases to avoid problematic interaction with multiple lambdas and resolution
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.8](compatibility-guide-18) [Compatibility guide for Kotlin 1.7](compatibility-guide-17)
kotlin Get started with Kotlin Multiplatform Get started with Kotlin Multiplatform
=====================================
Support for multiplatform programming is one of Kotlin's key benefits. It reduces time spent writing and maintaining the same code for [different platforms](multiplatform-dsl-reference#targets) while retaining the flexibility and benefits of native programming.
Learn more about [Kotlin Multiplatform benefits](multiplatform).
Start from scratch
------------------
* [Create and publish a multiplatform library](multiplatform-library) teaches how to create a multiplatform library available for JVM, JS, and Native and which can be used from any other common code (for example, shared with Android and iOS). It also shows how to write tests which will be executed on all platforms and use an efficient implementation provided by a specific platform.
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) teaches the concepts behind building an application that targets Kotlin/JVM and Kotlin/JS by building a client-server application that makes use of shared code, serialization, and other multiplatform paradigms. It also provides a brief introduction to working with Ktor both as a server- and client-side framework.
* [Create your first Kotlin Multiplatform Mobile application](multiplatform-mobile-create-first-app) shows how to create a mobile application that works on Android and iOS with the help of the [Kotlin Multiplatform Mobile plugin for Android Studio](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile). Create, run, and test your first multiplatform mobile application.
Dive deep into Kotlin Multiplatform
-----------------------------------
Once you have gained some experience with Kotlin Multiplatform and want to know how to solve particular cross-platform development tasks:
* [Share code on platforms](multiplatform-share-on-platforms) in your Kotlin Multiplatform project.
* [Connect to platform-specific APIs](multiplatform-connect-to-apis) using the Kotlin mechanism of expected and actual declarations.
* [Set up targets manually](multiplatform-set-up-targets) for your Kotlin Multiplatform project.
* [Add dependencies](multiplatform-add-dependencies) on the standard, test, or another kotlinx library.
* [Configure compilations](multiplatform-configure-compilations) for production and test purposes in your project.
* [Run tests](multiplatform-run-tests) for JVM, JavaScript, Android, Linux, Windows, macOS, iOS, watchOS, and tvOS simulators.
* [Publish a multiplatform library](multiplatform-publish-lib) to the Maven repository.
* [Build native binaries](multiplatform-build-native-binaries) as executables or shared libraries, like universal frameworks or XCFrameworks.
Get help
--------
* **Kotlin Slack**: Get an [invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) and join the [#multiplatform](https://kotlinlang.slack.com/archives/C3PQML5NU) channel
* **StackOverflow**: Subscribe to the ["kotlin-multiplatform" tag](https://stackoverflow.com/questions/tagged/kotlin-multiplatform)
* **Kotlin issue tracker**: [Report a new issue](https://youtrack.jetbrains.com/newIssue?project=KT)
Last modified: 10 January 2023
[Create a multiplatform app using Ktor and SQLDelight – tutorial](multiplatform-mobile-ktor-sqldelight) [Understand Multiplatform project structure](multiplatform-discover-project)
kotlin Kotlin books Kotlin books
============
More and more authors write books for learning Kotlin in different languages. We are very thankful to all of them and appreciate all their efforts in helping us increase a number of professional Kotlin developers.
Here are just a few books we've reviewed and recommend you for learning Kotlin. You can find more books on [our community website](https://kotlin.link/).
| | |
| --- | --- |
| Atomic Kotlin | [Atomic Kotlin](https://www.atomickotlin.com/atomickotlin/) is for both beginning and experienced programmers!
From Bruce Eckel, author of the multi-award-winning Thinking in C++ and Thinking in Java, and Svetlana Isakova, Kotlin Developer Advocate at JetBrains, comes a book that breaks the language concepts into small, easy-to-digest "atoms", along with a free course consisting of exercises supported by hints and solutions directly inside IntelliJ IDEA! |
| Head First Kotlin | [Head First Kotlin](https://www.oreilly.com/library/view/head-first-kotlin/9781491996683/) is a complete introduction to coding in Kotlin. This hands-on book helps you learn the Kotlin language with a unique method that goes beyond syntax and how-to manuals and teaches you how to think like a great Kotlin developer.
You'll learn everything from language fundamentals to collections, generics, lambdas, and higher-order functions. Along the way, you'll get to play with both object-oriented and functional programming.
If you want to really understand Kotlin, this is the book for you. |
| Kotlin in Action | [Kotlin in Action](https://manning.com/books/kotlin-in-action) teaches you to use the Kotlin language for production-quality applications. Written for experienced Java developers, this example-rich book goes further than most language books, covering interesting topics like building DSLs with natural language syntax.
The book is written by Dmitry Jemerov and Svetlana Isakova, developers on the Kotlin team.
Chapter 6, covering the Kotlin type system, and chapter 11, covering DSLs, are available as a free preview on the [publisher web site](https://www.manning.com/books/kotlin-in-action#downloads). |
| Kotlin Programming: The Big Nerd Ranch Guide | [Kotlin Programming: The Big Nerd Ranch Guide](https://www.amazon.com/Kotlin-Programming-Nerd-Ranch-Guide/dp/0135161630)
In this book you will learn to work effectively with the Kotlin language through carefully considered examples designed to teach you Kotlin's elegant style and features.
Starting from first principles, you will work your way to advanced usage of Kotlin, empowering you to create programs that are more reliable with less code. |
| Programming Kotlin | [Programming Kotlin](https://pragprog.com/book/vskotlin/programming-kotlin) is written by Venkat Subramaniam.
Programmers don't just use Kotlin, they love it. Even Google has adopted it as a first-class language for Android development.
With Kotlin, you can intermix imperative, functional, and object-oriented styles of programming and benefit from the approach that's most suitable for the problem at hand.
Learn to use the many features of this highly concise, fluent, elegant, and expressive statically typed language with easy-to-understand examples.
Learn to write maintainable, high-performing JVM and Android applications, create DSLs, program asynchronously, and much more. |
| The Joy of Kotlin | [The Joy of Kotlin](https://www.manning.com/books/the-joy-of-kotlin) teaches you the right way to code in Kotlin.
In this insight-rich book, you'll master the Kotlin language while exploring coding techniques that will make you a better developer no matter what language you use. Kotlin natively supports a functional style of programming, so seasoned author Pierre-Yves Saumont begins by reviewing the FP principles of immutability, referential transparency, and the separation between functions and effects.
Then, you'll move deeper into using Kotlin in the real world, as you learn to handle errors and data properly, encapsulate shared state mutations, and work with laziness.
This book will change the way you code — and give you back some of the joy you had when you first started. |
Last modified: 10 January 2023
[Kotlin tips](kotlin-tips) [Advent of Code puzzles in idiomatic Kotlin](advent-of-code)
kotlin Migrating Kotlin/JS projects to the IR compiler Migrating Kotlin/JS projects to the IR compiler
===============================================
We replaced the current Kotlin/JS compiler with [the IR-based compiler](js-ir-compiler) in order to unify Kotlin's behavior on all platforms and to make it possible to implement new JS-specific optimizations, among other reasons. You can learn more about the internal differences between the two compilers in the blog post [Migrating our Kotlin/JS app to the new IR compiler](https://dev.to/kotlin/migrating-our-kotlin-js-app-to-the-new-ir-compiler-3o6i) by Sebastian Aigner.
Due to the significant differences between the compilers, switching your Kotlin/JS project from the old backend to the new one may require adjusting your code. On this page, we've compiled a list of known migration issues along with suggested solutions.
Note that this guide may change over time as we fix issues and find new ones. Please help us keep it complete – report any issues you encounter when switching to the IR compiler by submitting them to our issue tracker [YouTrack](https://kotl.in/issue) or filling out [this form](https://surveys.jetbrains.com/s3/ir-be-migration-issue).
Convert JS- and React-related classes and interfaces to external interfaces
---------------------------------------------------------------------------
**Issue**: Using Kotlin interfaces and classes (including data classes) that derive from pure JS classes, such as React's `State` and `Props`, can cause a `ClassCastException`. Such exceptions appear because the compiler attempts to work with instances of these classes as if they were Kotlin objects, when they actually come from JS.
**Solution**: convert all classes and interfaces that derive from pure JS classes to [external interfaces](js-interop#external-interfaces):
```
// Replace this
interface AppState : State { }
interface AppProps : Props { }
data class CustomComponentState(var name: String) : State
```
```
// With this
external interface AppState : State { }
external interface AppProps : Props { }
external interface CustomComponentState : State {
var name: String
}
```
In IntelliJ IDEA, you can use these [structural search and replace](https://www.jetbrains.com/help/idea/structural-search-and-replace.html) templates to automatically mark interfaces as `external`:
* [Template for `State`](https://gist.github.com/SebastianAigner/62119536f24597e630acfdbd14001b98)
* [Template for `Props`](https://gist.github.com/SebastianAigner/a47a77f5e519fc74185c077ba12624f9)
Convert properties of external interfaces to var
------------------------------------------------
**Issue**: properties of external interfaces in Kotlin/JS code can't be read-only (`val`) properties because their values can be assigned only after the object is created with `js()` or `jso()` (a helper function from [`kotlin-wrappers`](https://github.com/JetBrains/kotlin-wrappers)):
```
import kotlinx.js.jso
val myState = jso<CustomComponentState>()
myState.name = "name"
```
**Solution**: convert all properties of external interfaces to `var`:
```
// Replace this
external interface CustomComponentState : State {
val name: String
}
```
```
// With this
external interface CustomComponentState : State {
var name: String
}
```
Convert functions with receivers in external interfaces to regular functions
----------------------------------------------------------------------------
**Issue**: external declarations can't contain functions with receivers, such as extension functions or properties with corresponding functional types.
**Solution**: convert such functions and properties to regular functions by adding the receiver object as an argument:
```
// Replace this
external interface ButtonProps : Props {
var inside: StyledDOMBuilder<BUTTON>.() -> Unit
}
```
```
external interface ButtonProps : Props {
var inside: (StyledDOMBuilder<BUTTON>) -> Unit
}
```
Create plain JS objects for interoperability
--------------------------------------------
**Issue**: properties of a Kotlin object that implements an external interface are not *enumerable*. This means that they are not visible for operations that iterate over the object's properties, for example:
* `for (var name in obj)`
* `console.log(obj)`
* `JSON.stringify(obj)`
Although they are still accessible by the name: `obj.myProperty`
```
external interface AppProps { var name: String }
data class AppPropsImpl(override var name: String) : AppProps
fun main() {
val jsApp = js("{name: 'App1'}") as AppProps // plain JS object
println("Kotlin sees: ${jsApp.name}") // "App1"
println("JSON.stringify sees:" + JSON.stringify(jsApp)) // {"name":"App1"} - OK
val ktApp = AppPropsImpl("App2") // Kotlin object
println("Kotlin sees: ${ktApp.name}") // "App2"
// JSON sees only the backing field, not the property
println("JSON.stringify sees:" + JSON.stringify(ktApp)) // {"_name_3":"App2"}
}
```
**Solution 1**: create plain JavaScript objects with `js()` or `jso()` (a helper function from [`kotlin-wrappers`](https://github.com/JetBrains/kotlin-wrappers)):
```
external interface AppProps { var name: String }
data class AppPropsImpl(override var name: String) : AppProps
```
```
// Replace this
val ktApp = AppPropsImpl("App1") // Kotlin object
```
```
// With this
val jsApp = js("{name: 'App1'}") as AppProps // or jso {}
```
**Solution 2**: create objects with `kotlin.js.json()`:
```
// or with this
val jsonApp = kotlin.js.json(Pair("name", "App1")) as AppProps
```
Replace toString() calls on function references with .name
----------------------------------------------------------
**Issue**: in the IR backend, calling `toString()` on function references doesn't produce unique values.
**Solution**: use the `name` property instead of `toString()`.
Explicitly specify binaries.executable() in the build script
------------------------------------------------------------
**Issue**: the compiler doesn't produce executable `.js` files.
This may happen because the default compiler produces JavaScript executables by default while the IR compiler needs an explicit instruction to do this. Learn more in the [Kotlin/JS project setup instruction](js-project-setup#execution-environments).
**Solution**: add the line `binaries.executable()` to the project's `build.gradle(.kts)`.
```
kotlin {
js(IR) {
browser {
}
binaries.executable()
}
}
```
Additional troubleshooting tips when working with the Kotlin/JS IR compiler
---------------------------------------------------------------------------
These hints may help you when troubleshooting problems in your projects using the Kotlin/JS IR compiler.
### Make boolean properties nullable in external interfaces
**Issue**: when you call `toString` on a `Boolean` from an external interface, you're getting an error like `Uncaught TypeError: Cannot read properties of undefined (reading 'toString')`. JavaScript treats the `null` or `undefined` values of a boolean variable as `false`. If you rely on calling `toString` on a `Boolean` that may be `null` or `undefined` (for example when your code is called from JavaScript code you have no control over), be aware of this:
```
external interface SomeExternal {
var visible: Boolean
}
fun main() {
val empty: SomeExternal = js("{}")
println(empty.visible.toString()) // Uncaught TypeError: Cannot read properties of undefined (reading 'toString')
}
```
**Solution**: you can make your `Boolean` properties of external interfaces nullable (`Boolean?`):
```
// Replace this
external interface SomeExternal {
var visible: Boolean
}
```
```
// With this
external interface SomeExternal {
var visible: Boolean?
}
```
Last modified: 10 January 2023
[Kotlin/JS IR compiler](js-ir-compiler) [Browser and DOM API](browser-api-dom)
kotlin The Six Most Popular Cross-Platform App Development Frameworks The Six Most Popular Cross-Platform App Development Frameworks
==============================================================
Over the years, cross-platform app development has become one of the most popular ways to build mobile applications. A cross-platform, or multiplatform, approach allows developers to create apps that run similarly on different mobile platforms.
Interest has steadily increased over the period from 2010 to date, as this Google Trends chart illustrates:
The growing popularity of the rapidly advancing [cross-platform mobile development](cross-platform-mobile-development#kotlin-multiplatform-mobile) technology has resulted in many new tools emerging on the market. With many options available, it can be challenging to pick the one that will best suit your needs. To help you find the right tool, we've put together a list of the six best cross-platform app development frameworks and the features that make them great. At the end of this article, you will also find a few key things to pay attention to when choosing a multiplatform development framework for your business.
What is a cross-platform app development framework?
---------------------------------------------------
Mobile engineers use cross-platform mobile development frameworks to build native-looking applications for multiple platforms, such as Android and iOS, using a single codebase. Shareable code is one of the key advantages this approach has over native app development. Having one single codebase means that mobile engineers can save time by avoiding the need to write code for each operating system, accelerating the development process.
With demand for cross-platform solutions for mobile app development growing, the number of tools available on the market is increasing as well. In the following section, we provide an overview of the most widely used frameworks for building cross-platform mobile apps for iOS, Android, and other platforms. Our summaries include the programming languages these frameworks are based on, as well as their main features and advantages.
Popular cross-platform app development frameworks
-------------------------------------------------
This list of tools is not exhaustive; many other options are available on the market today. The important thing to realize is that there's no one-size-fits-all tool that will be ideal for everyone. The choice of framework largely depends on your particular project and your goals, as well as other specifics that we will cover at the end of the article.
Nevertheless, we've tried to pick out some of the best frameworks for cross-platform mobile development to give you a starting point for your decision.
### Flutter
Released by Google in 2017, Flutter is a popular framework for building mobile, web, and desktop apps from a single codebase. To build applications with Flutter, you will need to use Google's programming language called Dart.
**Programming language:** Dart.
**Mobile apps:** eBay, Alibaba, Google Pay, ByteDance apps.
**Key features:**
* Flutter's hot reload feature allows you to see how your application changes as soon as you modify your code, without you having to recompile it.
* Flutter supports Google's Material Design, a design system that helps developers build digital experiences. You can use multiple visual and behavioral widgets when building your app.
* Flutter doesn't rely on web browser technology. Instead, it has its own rendering engine for drawing widgets.
Flutter has a relatively active community of users around the world. It is widely used by many developers. According to the [Stack Overflow Developer Survey 2021](https://insights.stackoverflow.com/survey/2021#technology-most-loved-dreaded-and-wanted), Flutter is the second most-loved framework.
### React Native
An open-source UI software framework, React Native was developed in 2015 (a bit earlier than Flutter) by Meta Platforms, formerly Facebook. It's based on Facebook's JavaScript library React and allows developers to build natively rendered cross-platform mobile apps.
**Programming language:** JavaScript.
**Mobile apps:** Skype, Bloomberg, Shopify, various small modules in [Facebook and Instagram](https://itcraftapps.com/blog/7-react-native-myths-vs-reality/#facebook-instagram-in-react-native).
**Key features:**
* Developers can see their changes in their React components immediately, thanks to the Fast Refresh feature.
* One of React Native's advantages is a focus on the UI. React primitives render to native platform UI components, allowing you to build a customized and responsive user interface.
* In versions 0.62 and higher, integration between React Native and the mobile app debugger Flipper is enabled by default. Flipper is used to debug Android, iOS, and React native apps, and it provides tools like a log viewer, an interactive layout inspector, and a network inspector.
As one of the most popular cross-platform app development frameworks, React Native has a large and strong community of developers who share their technical knowledge. Thanks to this community, you can get the support you need when building mobile apps with the framework.
### Kotlin Multiplatform Mobile
Kotlin Multiplatform Mobile is an SDK developed by JetBrains for creating Android and iOS applications. It allows you to share common code between the two platforms and write platform-specific code only when it's necessary, for example, when you need to build native UI components or when you are working with platform-specific APIs.
**Programming language:** Kotlin.
**Mobile apps:** Philips, Baidu, Netflix, Leroy Merlin.
**Key features:**
* You can easily start using Multiplatform Mobile in existing projects.
* Kotlin Multiplatform Mobile provides you with full access over the user interface. You can utilize the latest UI frameworks, such as SwiftUI and Jetpack Compose.
* Developers have easy access to the Android and iOS SDKs without any restrictions.
Even though this cross-platform mobile development framework is the youngest on our list, it has a mature community. It's growing fast and is already making a distinct impression on today's market. Thanks to its regularly updated documentation and community support, you can always find answers to your questions. What's more, many [global companies and startups already use Kotlin Multiplatform Mobile](https://kotlinlang.org/lp/mobile/case-studies/) to develop multiplatform apps with a native-like user experience.
### Ionic
Ionic is an open-source UI toolkit that was released in 2013. It helps developers build hybrid mobile and desktop applications using a combination of native and web technologies, like HTML, CSS, and JavaScript, with integrations for the Angular, React, and Vue frameworks.
**Programming language:** JavaScript.
**Mobile apps:** T-Mobile, BBC (Children's & Education apps), EA Games.
**Key features:**
* Ionic is based on a SaaS UI framework designed specifically for mobile OS and provides multiple UI components for building applications.
* The Ionic framework uses the Cordova and Capacitor plugins to provide access to device's built-in features, such as the camera, flashlight, GPS, and audio recorder.
* Ionic has its own IDE called Ionic Studio, which was designed for building and prototyping apps with minimal coding.
There's constant activity on the Ionic Forum, where community members exchange knowledge and help each other overcome their development challenges.
### Xamarin
Xamarin was launched in 2011 and is now owned by Microsoft. It's an open-source cross-platform app development framework that uses the C# language and the .Net framework to develop apps for Android, iOS, and Windows.
**Programming language:** С#.
**Mobile apps:** UPS, Alaska Airlines, Academy Members (Academy of Motion Picture Arts and Sciences).
**Key features:**
* Xamarin applications use the Base Class Library, or .NET BCL, a large collection of classes that have a range of comprehensive features, including XML, database, IO, and networking support, and more. Existing C# code can be compiled for use in your app, giving you access to many libraries that add functionality beyond the BCL.
* With Xamarin.Forms, developers can utilize platform-specific UI elements to achieve a consistent look for their apps across different operating systems.
* Compiled bindings in Xamarin.Forms improve data binding performance. Using these bindings provides compile-time validation for all binding expressions. Because of this feature, mobile engineers get fewer runtime errors.
Xamarin is supported by many contributors across the globe and is especially popular among C, C++, and C# developers who create mobile applications.
### NativeScript
This open-source mobile application development framework was initially released in 2014. NativeScript allows you to build Android and iOS mobile apps using JavaScript or languages that transpile to JavaScript, like TypeScript, and frameworks like Angular and Vue.js.
**Programming language:** JavaScript, TypeScript.
**Mobile apps:** Daily Nanny, Strudel, Breethe.
**Key features:**
* NativeScript allows developers to easily access native Android and iOS APIs.
* The framework renders platform-native UIs. Apps built with NativeScript run directly on a native device without relying on WebViews, a system component for the Android OS that allows Android applications to show content from the web inside an app.
* NativeScript offers various plugins and pre-built app templates, eliminating the need for third-party solutions.
NativeScript is based on well-known web technologies like JavaScript and Angular, which is why many developers choose this framework. Nevertheless, it's usually used by small companies and startups.
How do you choose the right cross-platform app development framework for your project?
--------------------------------------------------------------------------------------
There are other cross-platform frameworks besides those mentioned above, and new tools will continue to appear on the market. Given the wide array of options, how can you find the right one for your next project? The first step is to understand your project's requirements and goals, and to get a clear idea of what you want your future app to look like. Next, you'll want to take the following important factors into account so you can decide on the best fit for your business.
### 1. The expertise of your team
Different cross-platform mobile development frameworks are based on different programming languages. Before adopting a framework, check what skills it requires and make sure your team of mobile engineers has enough knowledge and experience to work with it.
For example, if your team is equipped with highly skilled JavaScript developers, and you don't have enough resources to introduce new technologies, it may be worth choosing frameworks that use this language, such as React Native.
### 2. Vendor reliability and support
It's important to be sure that the maintainer of the framework will continue to support it in the long run. Learn more about the companies that develop and support the frameworks you're considering, and take a look at the mobile apps that have been built using them.
### 3. UI customization
Depending on how crucial the user interface is for your future app, you may need to know how easily you can customize the UI using a particular framework. For example, Kotlin Multiplatform Mobile provides you with full control over the UI and the ability to use the latest UI frameworks, such as SwiftUI and Jetpack Compose.
### 4. Framework maturity
Find out how frequently the public API and tooling for a prospective framework changes. For example, some changes to native operating system components break internal cross-platform behavior. It's better to be aware of possible challenges you may face when working with the mobile app development framework. You can also browse GitHub and check how many bugs the framework has and how these bugs are being handled.
### 5. Framework capabilities
Each framework has its own capabilities and limitations. Knowing what features and tools a framework provides is crucial to identifying the best solution for you. Does it have code analyzers and unit testing frameworks? How quickly and easily will you be able to build, debug, and test your app?
### 6. Consistency between different platforms
Providing consistency between multiple platforms can be challenging, given how much platforms like Android and iOS significantly differ, particularly in terms of the development experience. For example, tools and libraries aren't the same on these operating systems, so there may be many differences when it comes to the business logic. Some technologies, like Kotlin Multiplatform Mobile, allow you to write and share the app's business logic between Android and iOS platforms.
### 7. Security
Security and privacy are especially important when building a critical mobile app for business, for example, banking and e-commerce apps that include a payment system. According to [OWASP Mobile Top 10](https://owasp.org/www-project-mobile-top-10/), among the most critical security risks for mobile applications are insecure data storage, authentication, and authorization.
You need to ensure that the multiplatform mobile development framework of your choice provides the required level of security. One way to do this is to browse the security tickets on the framework's issue tracker if it has one that's publicly available.
### 8. Educational materials
The volume and quality of available learning resources about a framework can also help you understand how smooth your experience will be when working with it. Comprehensive official [documentation](home), online and offline conferences, and educational courses are a good sign that you will be able to find enough essential information about a product when you need it.
Key takeaways
-------------
Without considering these factors, it's difficult to choose the framework for cross-platform mobile development that will best meet your specific needs. Take a closer look at your future application requirements and weigh them against capabilities of various frameworks. Doing so will allow you to find the right cross-platform solution to help you deliver high-quality apps.
Last modified: 10 January 2023
[Native and cross-platform app development: how to choose?](native-and-cross-platform) [Security](security)
| programming_docs |
kotlin Teaching Kotlin with EduTools plugin Teaching Kotlin with EduTools plugin
====================================
With the [EduTools plugin](https://plugins.jetbrains.com/plugin/10081-edutools), available both in [Android Studio](https://developer.android.com/studio) and [IntelliJ IDEA](https://www.jetbrains.com/idea/), you can teach Kotlin through code practicing tasks. Take a look at the [Educator Start Guide](https://plugins.jetbrains.com/plugin/10081-edutools/docs/educator-start-guide.html?section=Kotlin) to learn how to create a simple Kotlin course that includes a set of programming tasks and integrated tests.
If you want to use the EduTools plugin to learn Kotlin, read [Learning Kotlin with EduTools plugin](edu-tools-learner).
Last modified: 10 January 2023
[Learning Kotlin with EduTools plugin](edu-tools-learner) [FAQ](faq)
kotlin Platform libraries Platform libraries
==================
To provide access to user's native operating system services, Kotlin/Native distribution includes a set of prebuilt libraries specific to each target. We call them **Platform Libraries**.
POSIX bindings
--------------
For all Unix- or Windows-based targets (including Android and iOS targets) we provide the `POSIX` platform lib. It contains bindings to platform's implementation of the [POSIX standard](https://en.wikipedia.org/wiki/POSIX).
To use the library, just import it:
```
import platform.posix.*
```
The only target for which it is not available is [WebAssembly](https://en.wikipedia.org/wiki/WebAssembly).
Note that the content of `platform.posix` is NOT identical on different platforms, in the same way as different `POSIX` implementations are a little different.
Popular native libraries
------------------------
There are many more platform libraries available for host and cross-compilation targets. Kotlin/Native distribution provides access to OpenGL, zlib and other popular native libraries on applicable platforms.
On Apple platforms, `objc` library is provided for interoperability with [Objective-C](https://en.wikipedia.org/wiki/Objective-C).
Inspect the contents of `dist/klib/platform/$target` of the distribution for the details.
Availability by default
-----------------------
The packages from platform libraries are available by default. No special link flags need to be specified to use them. Kotlin/Native compiler automatically detects which of the platform libraries have been accessed and automatically links the needed libraries.
On the other hand, the platform libs in the distribution are merely just wrappers and bindings to the native libraries. That means the native libraries themselves (`.so`, `.a`, `.dylib`, `.dll` etc) should be installed on the machine.
Last modified: 10 January 2023
[Kotlin/Native libraries](native-libraries) [Kotlin/Native as a dynamic library – tutorial](native-dynamic-libraries)
kotlin Kotlin/Native FAQ Kotlin/Native FAQ
=================
How do I run my program?
------------------------
Define a top-level function `fun main(args: Array<String>)` or just `fun main()` if you are not interested in passed arguments, please ensure it's not in a package. Also, compiler switch `-entry` could be used to make any function taking `Array<String>` or no arguments and return `Unit` as an entry point.
What is Kotlin/Native memory management model?
----------------------------------------------
Kotlin/Native uses an automated memory management scheme that is similar to what Java or Swift provide.
[Learn about the Kotlin/Native memory manager](native-memory-manager)
How do I create a shared library?
---------------------------------
Use the `-produce dynamic` compiler switch, or `binaries.sharedLib()` in Gradle.
```
kotlin {
iosArm64("mylib") {
binaries.sharedLib()
}
}
```
It will produce a platform-specific shared object (`.so` on Linux, `.dylib` on macOS, and `.dll` on Windows targets) and a C language header, allowing the use of all public APIs available in your Kotlin/Native program from C/C++ code.
How do I create a static library or an object file?
---------------------------------------------------
Use the `-produce static` compiler switch, or `binaries.staticLib()` in Gradle.
```
kotlin {
iosArm64("mylib") {
binaries.staticLib()
}
}
```
It will produce a platform-specific static object (`.a` library format) and a C language header, allowing you to use all the public APIs available in your Kotlin/Native program from C/C++ code.
How do I run Kotlin/Native behind a corporate proxy?
----------------------------------------------------
As Kotlin/Native needs to download a platform specific toolchain, you need to specify `-Dhttp.proxyHost=xxx -Dhttp.proxyPort=xxx` as the compiler's or `gradlew` arguments, or set it via the `JAVA_OPTS` environment variable.
How do I specify a custom Objective-C prefix/name for my Kotlin framework?
--------------------------------------------------------------------------
Use the `-module-name` compiler option or matching Gradle DSL statement.
```
kotlin {
iosArm64("myapp") {
binaries.framework {
freeCompilerArgs += listOf("-module-name", "TheName")
}
}
}
```
```
kotlin {
iosArm64("myapp") {
binaries.framework {
freeCompilerArgs += ["-module-name", "TheName"]
}
}
}
```
How do I rename the iOS framework?
----------------------------------
The default name is for an iOS framework is `<project name>.framework`. To set a custom name, use the `baseName` option. This will also set the module name.
```
kotlin {
iosArm64("myapp") {
binaries {
framework {
baseName = "TheName"
}
}
}
}
```
How do I enable bitcode for my Kotlin framework?
------------------------------------------------
By default gradle plugin adds it on iOS target.
* For debug build it embeds placeholder LLVM IR data as a marker.
* For release build it embeds bitcode as data.
Or commandline arguments: `-Xembed-bitcode` (for release) and `-Xembed-bitcode-marker` (debug)
Setting this in a Gradle DSL:
```
kotlin {
iosArm64("myapp") {
binaries {
framework {
// Use "marker" to embed the bitcode marker (for debug builds).
// Use "disable" to disable embedding.
embedBitcode("bitcode") // for release binaries.
}
}
}
}
```
These options have nearly the same effect as clang's `-fembed-bitcode`/`-fembed-bitcode-marker` and swiftc's `-embed-bitcode`/`-embed-bitcode-marker`.
Why do I see InvalidMutabilityException?
----------------------------------------
It likely happens, because you are trying to mutate a frozen object. An object can transfer to the frozen state either explicitly, as objects reachable from objects on which the `kotlin.native.concurrent.freeze` is called, or implicitly (i.e. reachable from `enum` or global singleton object - see the next question).
How do I make a singleton object mutable?
-----------------------------------------
Currently, singleton objects are immutable (i.e. frozen after creation), and it's generally considered good practise to have the global state immutable. If for some reason you need a mutable state inside such an object, use the `@konan.ThreadLocal` annotation on the object. Also, the `kotlin.native.concurrent.AtomicReference` class could be used to store different pointers to frozen objects in a frozen object and automatically update them.
How can I compile my project with unreleased versions of Kotlin/Native?
-----------------------------------------------------------------------
First, please consider trying [preview versions](eap).
In case you need an even more recent development version, you can build Kotlin/Native from source code: clone [Kotlin repository](https://github.com/JetBrains/kotlin) and follow [these steps](https://github.com/JetBrains/kotlin/blob/master/kotlin-native/README.md#building-from-source).
Last modified: 10 January 2023
[Tips for improving Kotlin/Native compilation times](native-improving-compilation-time) [Get started with Kotlin custom scripting – tutorial](custom-script-deps-tutorial)
kotlin Comparison to Java Comparison to Java
==================
Some Java issues addressed in Kotlin
------------------------------------
Kotlin fixes a series of issues that Java suffers from:
* Null references are [controlled by the type system](null-safety).
* [No raw types](java-interop#java-generics-in-kotlin)
* Arrays in Kotlin are [invariant](arrays)
* Kotlin has proper [function types](lambdas#function-types), as opposed to Java's SAM-conversions
* [Use-site variance](generics#use-site-variance-type-projections) without wildcards
* Kotlin does not have checked <exceptions>
What Java has that Kotlin does not
----------------------------------
* [Checked exceptions](exceptions)
* [Primitive types](basic-types) that are not classes. The byte-code uses primitives where possible, but they are not explicitly available.
* [Static members](classes) are replaced with [companion objects](object-declarations#companion-objects), [top-level functions](functions), [extension functions](extensions#extension-functions), or [@JvmStatic](java-to-kotlin-interop#static-methods).
* [Wildcard-types](generics) are replaced with [declaration-site variance](generics#declaration-site-variance) and [type projections](generics#type-projections).
* [Ternary-operator `a ? b : c`](control-flow#if-expression) is replaced with [if expression](control-flow#if-expression).
What Kotlin has that Java does not
----------------------------------
* [Lambda expressions](lambdas) + [Inline functions](inline-functions) = performant custom control structures
* [Extension functions](extensions)
* [Null-safety](null-safety)
* [Smart casts](typecasts)
* [String templates](strings)
* [Properties](properties)
* [Primary constructors](classes)
* [First-class delegation](delegation)
* [Type inference for variable and property types](basic-types)
* [Singletons](object-declarations)
* [Declaration-site variance & Type projections](generics)
* [Range expressions](ranges)
* [Operator overloading](operator-overloading)
* [Companion objects](classes#companion-objects)
* [Data classes](data-classes)
* [Separate interfaces for read-only and mutable collections](collections-overview)
* [Coroutines](coroutines-overview)
What's next?
------------
Learn how to:
* Perform [typical tasks with strings in Java and Kotlin](java-to-kotlin-idioms-strings).
* Perform [typical tasks with collections in Java and Kotlin](java-to-kotlin-collections-guide).
* [Handle nullability in Java and Kotlin](java-to-kotlin-nullability-guide).
Last modified: 10 January 2023
[Get started with Kotlin/JVM](jvm-get-started) [Calling Java from Kotlin](java-interop)
kotlin What's new in Kotlin 1.1 What's new in Kotlin 1.1
========================
*Release date: 15 February 2016*
Table of contents
-----------------
* [Coroutines](#coroutines-experimental)
* [Other language features](#other-language-features)
* [Standard library](#standard-library)
* [JVM backend](#jvm-backend)
* [JavaScript backend](#javascript-backend)
JavaScript
----------
Starting with Kotlin 1.1, the JavaScript target is no longer considered experimental. All language features are supported, and there are many new tools for integration with the frontend development environment. See [below](#javascript-backend) for a more detailed list of changes.
Coroutines (experimental)
-------------------------
The key new feature in Kotlin 1.1 is *coroutines*, bringing the support of `async`/`await`, `yield`, and similar programming patterns. The key feature of Kotlin's design is that the implementation of coroutine execution is part of the libraries, not the language, so you aren't bound to any specific programming paradigm or concurrency library.
A coroutine is effectively a light-weight thread that can be suspended and resumed later. Coroutines are supported through *[suspending functions](coroutines-basics#extract-function-refactoring)*: a call to such a function can potentially suspend a coroutine, and to start a new coroutine we usually use an anonymous suspending functions (i.e. suspending lambdas).
Let's look at `async`/`await` which is implemented in an external library, [kotlinx.coroutines](https://github.com/kotlin/kotlinx.coroutines):
```
// runs the code in the background thread pool
fun asyncOverlay() = async(CommonPool) {
// start two async operations
val original = asyncLoadImage("original")
val overlay = asyncLoadImage("overlay")
// and then apply overlay to both results
applyOverlay(original.await(), overlay.await())
}
// launches new coroutine in UI context
launch(UI) {
// wait for async overlay to complete
val image = asyncOverlay().await()
// and then show it in UI
showImage(image)
}
```
Here, `async { ... }` starts a coroutine and, when we use `await()`, the execution of the coroutine is suspended while the operation being awaited is executed, and is resumed (possibly on a different thread) when the operation being awaited completes.
The standard library uses coroutines to support *lazily generated sequences* with `yield` and `yieldAll` functions. In such a sequence, the block of code that returns sequence elements is suspended after each element has been retrieved, and resumed when the next element is requested. Here's an example:
```
import kotlin.coroutines.experimental.*
fun main(args: Array<String>) {
val seq = buildSequence {
for (i in 1..5) {
// yield a square of i
yield(i * i)
}
// yield a range
yieldAll(26..28)
}
// print the sequence
println(seq.toList())
}
```
Run the code above to see the result. Feel free to edit it and run again!
For more information, please refer to the [coroutines documentation](coroutines-overview) and [tutorial](coroutines-and-channels).
Note that coroutines are currently considered an **experimental feature**, meaning that the Kotlin team is not committing to supporting the backwards compatibility of this feature after the final 1.1 release.
Other language features
-----------------------
### Type aliases
A type alias allows you to define an alternative name for an existing type. This is most useful for generic types such as collections, as well as for function types. Here is an example:
```
//sampleStart
typealias OscarWinners = Map<String, String>
fun countLaLaLand(oscarWinners: OscarWinners) =
oscarWinners.count { it.value.contains("La La Land") }
// Note that the type names (initial and the type alias) are interchangeable:
fun checkLaLaLandIsTheBestMovie(oscarWinners: Map<String, String>) =
oscarWinners["Best picture"] == "La La Land"
//sampleEnd
fun oscarWinners(): OscarWinners {
return mapOf(
"Best song" to "City of Stars (La La Land)",
"Best actress" to "Emma Stone (La La Land)",
"Best picture" to "Moonlight" /* ... */)
}
fun main(args: Array<String>) {
val oscarWinners = oscarWinners()
val laLaLandAwards = countLaLaLand(oscarWinners)
println("LaLaLandAwards = $laLaLandAwards (in our small example), but actually it's 6.")
val laLaLandIsTheBestMovie = checkLaLaLandIsTheBestMovie(oscarWinners)
println("LaLaLandIsTheBestMovie = $laLaLandIsTheBestMovie")
}
```
See the [type aliases documentation](type-aliases) and [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/type-aliases.md) for more details.
### Bound callable references
You can now use the `::` operator to get a [member reference](reflection#function-references) pointing to a method or property of a specific object instance. Previously this could only be expressed with a lambda. Here's an example:
```
//sampleStart
val numberRegex = "\\d+".toRegex()
val numbers = listOf("abc", "123", "456").filter(numberRegex::matches)
//sampleEnd
fun main(args: Array<String>) {
println("Result is $numbers")
}
```
Read the [documentation](reflection) and [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/bound-callable-references.md) for more details.
### Sealed and data classes
Kotlin 1.1 removes some of the restrictions on sealed and data classes that were present in Kotlin 1.0. Now you can define subclasses of a top-level sealed class on the top level in the same file, and not just as nested classes of the sealed class. Data classes can now extend other classes. This can be used to define a hierarchy of expression classes nicely and cleanly:
```
//sampleStart
sealed class Expr
data class Const(val number: Double) : Expr()
data class Sum(val e1: Expr, val e2: Expr) : Expr()
object NotANumber : Expr()
fun eval(expr: Expr): Double = when (expr) {
is Const -> expr.number
is Sum -> eval(expr.e1) + eval(expr.e2)
NotANumber -> Double.NaN
}
val e = eval(Sum(Const(1.0), Const(2.0)))
//sampleEnd
fun main(args: Array<String>) {
println("e is $e") // 3.0
}
```
Read the [sealed classes documentation](sealed-classes) or KEEPs for [sealed class](https://github.com/Kotlin/KEEP/blob/master/proposals/sealed-class-inheritance.md) and [data class](https://github.com/Kotlin/KEEP/blob/master/proposals/data-class-inheritance.md) for more detail.
### Destructuring in lambdas
You can now use the [destructuring declaration](destructuring-declarations) syntax to unpack the arguments passed to a lambda. Here's an example:
```
fun main(args: Array<String>) {
//sampleStart
val map = mapOf(1 to "one", 2 to "two")
// before
println(map.mapValues { entry ->
val (key, value) = entry
"$key -> $value!"
})
// now
println(map.mapValues { (key, value) -> "$key -> $value!" })
//sampleEnd
}
```
Read the [destructuring declarations documentation](destructuring-declarations) and [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/destructuring-in-parameters.md) for more details.
### Underscores for unused parameters
For a lambda with multiple parameters, you can use the `_` character to replace the names of the parameters you don't use:
```
fun main(args: Array<String>) {
val map = mapOf(1 to "one", 2 to "two")
//sampleStart
map.forEach { _, value -> println("$value!") }
//sampleEnd
}
```
This also works in [destructuring declarations](destructuring-declarations):
```
data class Result(val value: Any, val status: String)
fun getResult() = Result(42, "ok").also { println("getResult() returns $it") }
fun main(args: Array<String>) {
//sampleStart
val (_, status) = getResult()
//sampleEnd
println("status is '$status'")
}
```
Read the [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/underscore-for-unused-parameters.md) for more details.
### Underscores in numeric literals
Just as in Java 8, Kotlin now allows to use underscores in numeric literals to separate groups of digits:
```
//sampleStart
val oneMillion = 1_000_000
val hexBytes = 0xFF_EC_DE_5E
val bytes = 0b11010010_01101001_10010100_10010010
//sampleEnd
fun main(args: Array<String>) {
println(oneMillion)
println(hexBytes.toString(16))
println(bytes.toString(2))
}
```
Read the [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/underscores-in-numeric-literals.md) for more details.
### Shorter syntax for properties
For properties with the getter defined as an expression body, the property type can now be omitted:
```
//sampleStart
data class Person(val name: String, val age: Int) {
val isAdult get() = age >= 20 // Property type inferred to be 'Boolean'
}
//sampleEnd
fun main(args: Array<String>) {
val akari = Person("Akari", 26)
println("$akari.isAdult = ${akari.isAdult}")
}
```
### Inline property accessors
You can now mark property accessors with the `inline` modifier if the properties don't have a backing field. Such accessors are compiled in the same way as [inline functions](inline-functions).
```
//sampleStart
public val <T> List<T>.lastIndex: Int
inline get() = this.size - 1
//sampleEnd
fun main(args: Array<String>) {
val list = listOf('a', 'b')
// the getter will be inlined
println("Last index of $list is ${list.lastIndex}")
}
```
You can also mark the entire property as `inline` - then the modifier is applied to both accessors.
Read the [inline functions documentation](inline-functions#inline-properties) and [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/inline-properties.md) for more details.
### Local delegated properties
You can now use the [delegated property](delegated-properties) syntax with local variables. One possible use is defining a lazily evaluated local variable:
```
import java.util.Random
fun needAnswer() = Random().nextBoolean()
fun main(args: Array<String>) {
//sampleStart
val answer by lazy {
println("Calculating the answer...")
42
}
if (needAnswer()) { // returns the random value
println("The answer is $answer.") // answer is calculated at this point
}
else {
println("Sometimes no answer is the answer...")
}
//sampleEnd
}
```
Read the [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/local-delegated-properties.md) for more details.
### Interception of delegated property binding
For [delegated properties](delegated-properties), it is now possible to intercept delegate to property binding using the `provideDelegate` operator. For example, if we want to check the property name before binding, we can write something like this:
```
class ResourceLoader<T>(id: ResourceID<T>) {
operator fun provideDelegate(thisRef: MyUI, prop: KProperty<*>): ReadOnlyProperty<MyUI, T> {
checkProperty(thisRef, prop.name)
... // property creation
}
private fun checkProperty(thisRef: MyUI, name: String) { ... }
}
fun <T> bindResource(id: ResourceID<T>): ResourceLoader<T> { ... }
class MyUI {
val image by bindResource(ResourceID.image_id)
val text by bindResource(ResourceID.text_id)
}
```
The `provideDelegate` method will be called for each property during the creation of a `MyUI` instance, and it can perform the necessary validation right away.
Read the [delegated properties documentation](delegated-properties) for more details.
### Generic enum value access
It is now possible to enumerate the values of an enum class in a generic way.
```
//sampleStart
enum class RGB { RED, GREEN, BLUE }
inline fun <reified T : Enum<T>> printAllValues() {
print(enumValues<T>().joinToString { it.name })
}
//sampleEnd
fun main(args: Array<String>) {
printAllValues<RGB>() // prints RED, GREEN, BLUE
}
```
### Scope control for implicit receivers in DSLs
The [`@DslMarker`](../api/latest/jvm/stdlib/kotlin/-dsl-marker/index) annotation allows to restrict the use of receivers from outer scopes in a DSL context. Consider the canonical [HTML builder example](type-safe-builders):
```
table {
tr {
td { + "Text" }
}
}
```
In Kotlin 1.0, code in the lambda passed to `td` has access to three implicit receivers: the one passed to `table`, to `tr` and to `td`. This allows you to call methods that make no sense in the context - for example to call `tr` inside `td` and thus to put a `<tr>` tag in a `<td>`.
In Kotlin 1.1, you can restrict that, so that only methods defined on the implicit receiver of `td` will be available inside the lambda passed to `td`. You do that by defining your annotation marked with the `@DslMarker` meta-annotation and applying it to the base class of the tag classes.
Read the [type safe builders documentation](type-safe-builders) and [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/scope-control-for-implicit-receivers.md) for more details.
### rem operator
The `mod` operator is now deprecated, and `rem` is used instead. See [this issue](https://youtrack.jetbrains.com/issue/KT-14650) for motivation.
Standard library
----------------
### String to number conversions
There is a bunch of new extensions on the String class to convert it to a number without throwing an exception on invalid number: `String.toIntOrNull(): Int?`, `String.toDoubleOrNull(): Double?` etc.
```
val port = System.getenv("PORT")?.toIntOrNull() ?: 80
```
Also integer conversion functions, like `Int.toString()`, `String.toInt()`, `String.toIntOrNull()`, each got an overload with `radix` parameter, which allows to specify the base of conversion (2 to 36).
### onEach()
`onEach` is a small, but useful extension function for collections and sequences, which allows to perform some action, possibly with side-effects, on each element of the collection/sequence in a chain of operations. On iterables it behaves like `forEach` but also returns the iterable instance further. And on sequences it returns a wrapping sequence, which applies the given action lazily as the elements are being iterated.
```
inputDir.walk()
.filter { it.isFile && it.name.endsWith(".txt") }
.onEach { println("Moving $it to $outputDir") }
.forEach { moveFile(it, File(outputDir, it.toRelativeString(inputDir))) }
```
### also(), takeIf(), and takeUnless()
These are three general-purpose extension functions applicable to any receiver.
`also` is like `apply`: it takes the receiver, does some action on it, and returns that receiver. The difference is that in the block inside `apply` the receiver is available as `this`, while in the block inside `also` it's available as `it` (and you can give it another name if you want). This comes handy when you do not want to shadow `this` from the outer scope:
```
class Block {
lateinit var content: String
}
//sampleStart
fun Block.copy() = Block().also {
it.content = this.content
}
//sampleEnd
// using 'apply' instead
fun Block.copy1() = Block().apply {
this.content = [email protected]
}
fun main(args: Array<String>) {
val block = Block().apply { content = "content" }
val copy = block.copy()
println("Testing the content was copied:")
println(block.content == copy.content)
}
```
`takeIf` is like `filter` for a single value. It checks whether the receiver meets the predicate, and returns the receiver, if it does or `null` if it doesn't. Combined with an elvis operator (?:) and early returns it allows writing constructs like:
```
val outDirFile = File(outputDir.path).takeIf { it.exists() } ?: return false
// do something with existing outDirFile
```
```
fun main(args: Array<String>) {
val input = "Kotlin"
val keyword = "in"
//sampleStart
val index = input.indexOf(keyword).takeIf { it >= 0 } ?: error("keyword not found")
// do something with index of keyword in input string, given that it's found
//sampleEnd
println("'$keyword' was found in '$input'")
println(input)
println(" ".repeat(index) + "^")
}
```
`takeUnless` is the same as `takeIf`, but it takes the inverted predicate. It returns the receiver when it *doesn't* meet the predicate and `null` otherwise. So one of the examples above could be rewritten with `takeUnless` as following:
```
val index = input.indexOf(keyword).takeUnless { it < 0 } ?: error("keyword not found")
```
It is also convenient to use when you have a callable reference instead of the lambda:
```
private fun testTakeUnless(string: String) {
//sampleStart
val result = string.takeUnless(String::isEmpty)
//sampleEnd
println("string = \"$string\"; result = \"$result\"")
}
fun main(args: Array<String>) {
testTakeUnless("")
testTakeUnless("abc")
}
```
### groupingBy()
This API can be used to group a collection by key and fold each group simultaneously. For example, it can be used to count the number of words starting with each letter:
```
fun main(args: Array<String>) {
val words = "one two three four five six seven eight nine ten".split(' ')
//sampleStart
val frequencies = words.groupingBy { it.first() }.eachCount()
//sampleEnd
println("Counting first letters: $frequencies.")
// The alternative way that uses 'groupBy' and 'mapValues' creates an intermediate map,
// while 'groupingBy' way counts on the fly.
val groupBy = words.groupBy { it.first() }.mapValues { (_, list) -> list.size }
println("Comparing the result with using 'groupBy': ${groupBy == frequencies}.")
}
```
### Map.toMap() and Map.toMutableMap()
These functions can be used for easy copying of maps:
```
class ImmutablePropertyBag(map: Map<String, Any>) {
private val mapCopy = map.toMap()
}
```
### Map.minus(key)
The operator `plus` provides a way to add key-value pair(s) to a read-only map producing a new map, however there was not a simple way to do the opposite: to remove a key from the map you have to resort to less straightforward ways to like `Map.filter()` or `Map.filterKeys()`. Now the operator `minus` fills this gap. There are 4 overloads available: for removing a single key, a collection of keys, a sequence of keys and an array of keys.
```
fun main(args: Array<String>) {
//sampleStart
val map = mapOf("key" to 42)
val emptyMap = map - "key"
//sampleEnd
println("map: $map")
println("emptyMap: $emptyMap")
}
```
### minOf() and maxOf()
These functions can be used to find the lowest and greatest of two or three given values, where values are primitive numbers or `Comparable` objects. There is also an overload of each function that take an additional `Comparator` instance if you want to compare objects that are not comparable themselves.
```
fun main(args: Array<String>) {
//sampleStart
val list1 = listOf("a", "b")
val list2 = listOf("x", "y", "z")
val minSize = minOf(list1.size, list2.size)
val longestList = maxOf(list1, list2, compareBy { it.size })
//sampleEnd
println("minSize = $minSize")
println("longestList = $longestList")
}
```
### Array-like List instantiation functions
Similar to the `Array` constructor, there are now functions that create `List` and `MutableList` instances and initialize each element by calling a lambda:
```
fun main(args: Array<String>) {
//sampleStart
val squares = List(10) { index -> index * index }
val mutable = MutableList(10) { 0 }
//sampleEnd
println("squares: $squares")
println("mutable: $mutable")
}
```
### Map.getValue()
This extension on `Map` returns an existing value corresponding to the given key or throws an exception, mentioning which key was not found. If the map was produced with `withDefault`, this function will return the default value instead of throwing an exception.
```
fun main(args: Array<String>) {
//sampleStart
val map = mapOf("key" to 42)
// returns non-nullable Int value 42
val value: Int = map.getValue("key")
val mapWithDefault = map.withDefault { k -> k.length }
// returns 4
val value2 = mapWithDefault.getValue("key2")
// map.getValue("anotherKey") // <- this will throw NoSuchElementException
//sampleEnd
println("value is $value")
println("value2 is $value2")
}
```
### Abstract collections
These abstract classes can be used as base classes when implementing Kotlin collection classes. For implementing read-only collections there are `AbstractCollection`, `AbstractList`, `AbstractSet` and `AbstractMap`, and for mutable collections there are `AbstractMutableCollection`, `AbstractMutableList`, `AbstractMutableSet` and `AbstractMutableMap`. On JVM, these abstract mutable collections inherit most of their functionality from JDK's abstract collections.
### Array manipulation functions
The standard library now provides a set of functions for element-by-element operations on arrays: comparison (`contentEquals` and `contentDeepEquals`), hash code calculation (`contentHashCode` and `contentDeepHashCode`), and conversion to a string (`contentToString` and `contentDeepToString`). They're supported both for the JVM (where they act as aliases for the corresponding functions in `java.util.Arrays`) and for JS (where the implementation is provided in the Kotlin standard library).
```
fun main(args: Array<String>) {
//sampleStart
val array = arrayOf("a", "b", "c")
println(array.toString()) // JVM implementation: type-and-hash gibberish
println(array.contentToString()) // nicely formatted as list
//sampleEnd
}
```
JVM Backend
-----------
### Java 8 bytecode support
Kotlin has now the option of generating Java 8 bytecode (`-jvm-target 1.8` command line option or the corresponding options in Ant/Maven/Gradle). For now this doesn't change the semantics of the bytecode (in particular, default methods in interfaces and lambdas are generated exactly as in Kotlin 1.0), but we plan to make further use of this later.
### Java 8 standard library support
There are now separate versions of the standard library supporting the new JDK APIs added in Java 7 and 8. If you need access to the new APIs, use `kotlin-stdlib-jre7` and `kotlin-stdlib-jre8` maven artifacts instead of the standard `kotlin-stdlib`. These artifacts are tiny extensions on top of `kotlin-stdlib` and they bring it to your project as a transitive dependency.
### Parameter names in the bytecode
Kotlin now supports storing parameter names in the bytecode. This can be enabled using the `-java-parameters` command line option.
### Constant inlining
The compiler now inlines values of `const val` properties into the locations where they are used.
### Mutable closure variables
The box classes used for capturing mutable closure variables in lambdas no longer have volatile fields. This change improves performance, but can lead to new race conditions in some rare usage scenarios. If you're affected by this, you need to provide your own synchronization for accessing the variables.
### javax.script support
Kotlin now integrates with the [javax.script API](https://docs.oracle.com/javase/8/docs/api/javax/script/package-summary.html) (JSR-223). The API allows to evaluate snippets of code at runtime:
```
val engine = ScriptEngineManager().getEngineByExtension("kts")!!
engine.eval("val x = 3")
println(engine.eval("x + 2")) // Prints out 5
```
See [here](https://github.com/JetBrains/kotlin/tree/master/libraries/examples/kotlin-jsr223-local-example) for a larger example project using the API.
### kotlin.reflect.full
To [prepare for Java 9 support](https://blog.jetbrains.com/kotlin/2017/01/kotlin-1-1-whats-coming-in-the-standard-library/), the extension functions and properties in the `kotlin-reflect.jar` library have been moved to the package `kotlin.reflect.full`. The names in the old package (`kotlin.reflect`) are deprecated and will be removed in Kotlin 1.2. Note that the core reflection interfaces (such as `KClass`) are part of the Kotlin standard library, not `kotlin-reflect`, and are not affected by the move.
JavaScript backend
------------------
### Unified standard library
A much larger part of the Kotlin standard library can now be used from code compiled to JavaScript. In particular, key classes such as collections (`ArrayList`, `HashMap` etc.), exceptions (`IllegalArgumentException` etc.) and a few others (`StringBuilder`, `Comparator`) are now defined under the `kotlin` package. On the JVM, the names are type aliases for the corresponding JDK classes, and on the JS, the classes are implemented in the Kotlin standard library.
### Better code generation
JavaScript backend now generates more statically checkable code, which is friendlier to JS code processing tools, like minifiers, optimisers, linters, etc.
### The external modifier
If you need to access a class implemented in JavaScript from Kotlin in a typesafe way, you can write a Kotlin declaration using the `external` modifier. (In Kotlin 1.0, the `@native` annotation was used instead.) Unlike the JVM target, the JS one permits to use external modifier with classes and properties. For example, here's how you can declare the DOM `Node` class:
```
external class Node {
val firstChild: Node
fun appendChild(child: Node): Node
fun removeChild(child: Node): Node
// etc
}
```
### Improved import handling
You can now describe declarations which should be imported from JavaScript modules more precisely. If you add the `@JsModule("<module-name>")` annotation on an external declaration it will be properly imported to a module system (either CommonJS or AMD) during the compilation. For example, with CommonJS the declaration will be imported via `require(...)` function. Additionally, if you want to import a declaration either as a module or as a global JavaScript object, you can use the `@JsNonModule` annotation.
For example, here's how you can import JQuery into a Kotlin module:
```
external interface JQuery {
fun toggle(duration: Int = definedExternally): JQuery
fun click(handler: (Event) -> Unit): JQuery
}
@JsModule("jquery")
@JsNonModule
@JsName("$")
external fun jquery(selector: String): JQuery
```
In this case, JQuery will be imported as a module named `jquery`. Alternatively, it can be used as a $-object, depending on what module system Kotlin compiler is configured to use.
You can use these declarations in your application like this:
```
fun main(args: Array<String>) {
jquery(".toggle-button").click {
jquery(".toggle-panel").toggle(300)
}
}
```
Last modified: 10 January 2023
[What's new in Kotlin 1.2](whatsnew12) [What's new in Kotlin 1.8.0-RC2](whatsnew-eap)
| programming_docs |
kotlin Compilation and caches in the Kotlin Gradle plugin Compilation and caches in the Kotlin Gradle plugin
==================================================
On this page, you can learn about the following topics:
* [Incremental compilation](#incremental-compilation)
* [Gradle build cache support](#gradle-build-cache-support)
* [Gradle configuration cache support](#gradle-configuration-cache-support)
* [The Kotlin daemon and how to use it with Gradle](#the-kotlin-daemon-and-how-to-use-it-with-gradle)
* [Defining Kotlin compiler execution strategy](#defining-kotlin-compiler-execution-strategy)
* [Kotlin compiler fallback strategy](#kotlin-compiler-fallback-strategy)
* [Build reports](#build-reports)
Incremental compilation
-----------------------
The Kotlin Gradle plugin supports incremental compilation. Incremental compilation tracks changes to source files between builds so that only the files affected by these changes are compiled.
Incremental compilation is supported for Kotlin/JVM and Kotlin/JS projects, and is enabled by default.
There are several ways to disable incremental compilation:
* Set `kotlin.incremental=false` for Kotlin/JVM.
* Set `kotlin.incremental.js=false` for Kotlin/JS projects.
* Use `-Pkotlin.incremental=false` or `-Pkotlin.incremental.js=false` as a command line parameter.
The parameter should be added to each subsequent build.
Note: Any build with incremental compilation disabled invalidates incremental caches. The first build is never incremental.
### A new approach to incremental compilation
The new approach to incremental compilation is available since Kotlin 1.7.0 for the JVM backend in the Gradle build system only. This approach supports changes made inside dependent non-Kotlin modules, includes an improved compilation avoidance, and is compatible with the [Gradle build cache](#gradle-build-cache-support).
All of these enhancements decrease the number of non-incremental builds, making the overall compilation time faster. You will receive the most benefit if you use the build cache, or, frequently make changes in non-Kotlin Gradle modules.
To enable this new approach, set the following option in your `gradle.properties`:
```
kotlin.incremental.useClasspathSnapshot=true
```
Learn how the new approach to incremental compilation is implemented under the hood in [this blog post](https://blog.jetbrains.com/kotlin/2022/07/a-new-approach-to-incremental-compilation-in-kotlin/).
Gradle build cache support
--------------------------
The Kotlin plugin uses the [Gradle build cache](https://docs.gradle.org/current/userguide/build_cache.html), which stores the build outputs for reuse in future builds.
To disable caching for all Kotlin tasks, set the system property `kotlin.caching.enabled` to `false` (run the build with the argument `-Dkotlin.caching.enabled=false`).
If you use <kapt>, note that kapt annotation processing tasks are not cached by default. However, you can [enable caching for them manually](kapt#gradle-build-cache-support).
Gradle configuration cache support
----------------------------------
The Kotlin plugin uses the [Gradle configuration cache](https://docs.gradle.org/current/userguide/configuration_cache.html), which speeds up the build process by reusing the results of the configuration phase.
See the [Gradle documentation](https://docs.gradle.org/current/userguide/configuration_cache.html#config_cache:usage) to learn how to enable the configuration cache. After you enable this feature, the Kotlin Gradle plugin automatically starts using it.
The Kotlin daemon and how to use it with Gradle
-----------------------------------------------
The Kotlin daemon:
* Runs with the Gradle daemon to compile the project.
* Runs separately from the Gradle daemon when you compile the project with an IntelliJ IDEA built-in build system.
The Kotlin daemon starts at the Gradle [execution stage](https://docs.gradle.org/current/userguide/build_lifecycle.html#sec:build_phases) when one of the Kotlin compile tasks starts to compile sources. The Kotlin daemon stops either with the Gradle daemon or after two idle hours with no Kotlin compilation.
The Kotlin daemon uses the same JDK that the Gradle daemon does.
### Setting Kotlin daemon's JVM arguments
Each of the following ways to set arguments overrides the ones that came before it:
* [Gradle daemon arguments inheritance](#gradle-daemon-arguments-inheritance)
* [`kotlin.daemon.jvm.options` system property](#kotlin-daemon-jvm-options-system-property)
* [`kotlin.daemon.jvmargs` property](#kotlin-daemon-jvmargs-property)
* [`kotlin` extension](#kotlin-extension)
* [Specific task definition](#specific-task-definition)
#### Gradle daemon arguments inheritance
If nothing is specified, the Kotlin daemon inherits arguments from the Gradle daemon. For example, in the `gradle.properties` file:
```
org.gradle.jvmargs=-Xmx1500m -Xms=500m
```
#### kotlin.daemon.jvm.options system property
If the Gradle daemon's JVM arguments have the `kotlin.daemon.jvm.options` system property – use it in the `gradle.properties` file:
```
org.gradle.jvmargs=-Dkotlin.daemon.jvm.options=-Xmx1500m,Xms=500m
```
When passing arguments, follow these rules:
* Use the minus sign `-` **only** before the arguments `Xmx`, `XX:MaxMetaspaceSize`, and `XX:ReservedCodeCacheSize`.
* Separate arguments with commas (`,`) *without* spaces. Arguments that come after a space will be used for the Gradle daemon, not for the Kotlin daemon.
#### kotlin.daemon.jvmargs property
You can add the `kotlin.daemon.jvmargs` property in the `gradle.properties` file:
```
kotlin.daemon.jvmargs=-Xmx1500m -Xms=500m
```
#### kotlin extension
You can specify arguments in the `kotlin` extension:
```
kotlin {
kotlinDaemonJvmArgs = listOf("-Xmx486m", "-Xms256m", "-XX:+UseParallelGC")
}
```
```
kotlin {
kotlinDaemonJvmArgs = ["-Xmx486m", "-Xms256m", "-XX:+UseParallelGC"]
}
```
#### Specific task definition
You can specify arguments for a specific task:
```
tasks.withType<CompileUsingKotlinDaemon>().configureEach {
kotlinDaemonJvmArguments.set(listOf("-Xmx486m", "-Xms256m", "-XX:+UseParallelGC"))
}
```
```
tasks.withType(CompileUsingKotlinDaemon::class).configureEach { task ->
task.kotlinDaemonJvmArguments.set(["-Xmx1g", "-Xms512m"])
}
```
### Kotlin daemon's behavior with JVM arguments
When configuring the Kotlin daemon's JVM arguments, note that:
* It is expected to have multiple instances of the Kotlin daemon running at the same time when different subprojects or tasks have different sets of JVM arguments.
* A new Kotlin daemon instance starts only when Gradle runs a related compilation task and existing Kotlin daemons do not have the same set of JVM arguments. Imagine that your project has a lot of subprojects. Most of them require some heap memory for a Kotlin daemon, but one module requires a lot (though it is rarely compiled). In this case, you should provide a different set of JVM arguments for such a module, so a Kotlin daemon with a larger heap size would start only for developers who touch this specific module.
* If the `Xmx` argument is not specified, the Kotlin daemon will inherit it from the Gradle daemon.
Defining Kotlin compiler execution strategy
-------------------------------------------
*Kotlin compiler execution strategy* defines where the Kotlin compiler is executed and if incremental compilation is supported in each case.
There are three compiler execution strategies:
| Strategy | Where Kotlin compiler is executed | Incremental compilation | Other characteristics and notes |
| --- | --- | --- | --- |
| Daemon | Inside its own daemon process | Yes | *The default and fastest strategy*. Can be shared between different Gradle daemons and multiple parallel compilations. |
| In process | Inside the Gradle daemon process | No | May share the heap with the Gradle daemon. The "In process" execution strategy is *slower* than the "Daemon" execution strategy. Each [worker](https://docs.gradle.org/current/userguide/worker_api.html) creates a separate Kotlin compiler classloader for each compilation. |
| Out of process | In a separate process for each compilation | No | The slowest execution strategy. Similar to the "In process", but additionally creates a separate Java process within a Gradle worker for each compilation. |
To define a Kotlin compiler execution strategy, you can use one of the following properties:
* The `kotlin.compiler.execution.strategy` Gradle property.
* The `compilerExecutionStrategy` compile task property.
The task property `compilerExecutionStrategy` takes priority over the Gradle property `kotlin.compiler.execution.strategy`.
The available values for the `kotlin.compiler.execution.strategy` property are:
1. `daemon` (default)
2. `in-process`
3. `out-of-process`
Use the Gradle property `kotlin.compiler.execution.strategy` in `gradle.properties`:
```
kotlin.compiler.execution.strategy=out-of-process
```
The available values for the `compilerExecutionStrategy` task property are:
1. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.DAEMON` (default)
2. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.IN_PROCESS`
3. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.OUT_OF_PROCESS`
Use the task property `compilerExecutionStrategy` in your build scripts:
```
import org.jetbrains.kotlin.gradle.tasks.CompileUsingKotlinDaemon
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy
// ...
tasks.withType<CompileUsingKotlinDaemon>().configureEach {
compilerExecutionStrategy.set(KotlinCompilerExecutionStrategy.IN_PROCESS)
}
```
```
import org.jetbrains.kotlin.gradle.tasks.CompileUsingKotlinDaemon
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy
// ...
tasks.withType(CompileUsingKotlinDaemon)
.configureEach {
compilerExecutionStrategy.set(KotlinCompilerExecutionStrategy.IN_PROCESS)
}
```
Kotlin compiler fallback strategy
---------------------------------
The Kotlin compiler's fallback strategy is to run a compilation outside a Kotlin daemon if the daemon somehow fails. If the Gradle daemon is on, the compiler uses the ["In process" strategy](#defining-kotlin-compiler-execution-strategy). If the Gradle daemon is off, the compiler uses the "Out of process" strategy.
When this fallback happens, you have the following warning lines in your Gradle's build output:
```
Failed to compile with Kotlin daemon: java.lang.RuntimeException: Could not connect to Kotlin compile daemon
[exception stacktrace]
Using fallback strategy: Compile without Kotlin daemon
Try ./gradlew --stop if this issue persists.
```
However, a silent fallback to another strategy can consume a lot of system resources or lead to non-deterministic builds, read more about this in this [YouTrack issue](https://youtrack.jetbrains.com/issue/KT-48843/Add-ability-to-disable-Kotlin-daemon-fallback-strategy). To avoid this, there is a Gradle property `kotlin.daemon.useFallbackStrategy`, whose default value is `true`. When the value is `false`, builds fail on problems with the daemon's startup or communication. Declare this property in `gradle.properties`:
```
kotlin.daemon.useFallbackStrategy=false
```
There is also a `useDaemonFallbackStrategy` property in Kotlin compile tasks, which takes priority over the Gradle property if you use both.
```
tasks {
compileKotlin {
useDaemonFallbackStrategy.set(false)
}
}
```
```
tasks.named("compileKotlin").configure {
useDaemonFallbackStrategy = false
}
```
If there is insufficient memory to run the compilation, you can see a message about it in the logs.
Build reports
-------------
Build reports for tracking compiler performance are available starting from Kotlin 1.7.0. Reports contain the durations of different compilation phases and reasons why compilation couldn't be incremental.
Use build reports to investigate performance issues when the compilation time is too long or when it differs for the same project.
Kotlin build reports help examine problems more efficiently than [Gradle build scans](https://scans.gradle.com/). Lots of engineers use them to investigate build performance, but the unit of granularity in Gradle scans is a single Gradle task.
There are two common cases that analyzing build reports for long-running compilations can help you resolve:
* The build wasn't incremental. Analyze the reasons and fix underlying problems.
* The build was incremental but took too much time. Try reorganizing source files — split big files, save separate classes in different files, refactor large classes, declare top-level functions in different files, and so on.
Learn [how to read build reports](https://blog.jetbrains.com/kotlin/2022/06/introducing-kotlin-build-reports/#how_to_read_build_reports) and [how JetBrains uses build reports](https://blog.jetbrains.com/kotlin/2022/06/introducing-kotlin-build-reports/#how_we_use_build_reports_in_jetbrains).
### Enabling build reports
To enable build reports, declare where to save the build report output in `gradle.properties`:
```
kotlin.build.report.output=file
```
The following values and their combinations are available for the output:
| Option | Description |
| --- | --- |
| `file` | Saves build reports in a human-readable format to a local file. By default, it's `${project_folder}/build/reports/kotlin-build/${project_name}-timestamp.txt` |
| `single_file` | Saves build reports in a format of an object to a specified local file |
| `build_scan` | Saves build reports in the `custom values` section of the [build scan](https://scans.gradle.com/). Note that the Gradle Enterprise plugin limits the number of custom values and their length. In big projects, some values could be lost | |
| `http` | Posts build reports using HTTP(S). The POST method sends metrics in JSON format. You can see the current version of the sent data in the [Kotlin repository](https://github.com/JetBrains/kotlin/blob/master/libraries/tools/kotlin-gradle-plugin/src/common/kotlin/org/jetbrains/kotlin/gradle/plugin/statistics/CompileStatisticsData.kt). You can find samples of HTTP endpoints in [this blog post](https://blog.jetbrains.com/kotlin/2022/06/introducing-kotlin-build-reports/#enable_build_reports) |
Here's the full list of available options for `kotlin.build.report`:
```
# Required outputs. Any combination is allowed
kotlin.build.report.output=file,single_file,http,build_scan
# Mandatory if single_file output is used. Where to put reports
# Use instead of the deprecated `kotlin.internal.single.build.metrics.file` property
kotlin.build.report.single_file=some_filename
# Optional. Output directory for file-based reports. Default: build/reports/kotlin-build/
kotlin.build.report.file.output_dir=kotlin-reports
# Mandatory if HTTP output is used. Where to post HTTP(S)-based reports
kotlin.build.report.http.url=http://127.0.0.1:8080
# Optional. User and password if the HTTP endpoint requires authentication
kotlin.build.report.http.user=someUser
kotlin.build.report.http.password=somePassword
# Optional. Label for marking your build report (for example, debug parameters)
kotlin.build.report.label=some_label
```
### Limit of custom values
To collect build scans' statistics, Kotlin build reports use [Gradle's custom values](https://docs.gradle.com/enterprise/tutorials/extending-build-scans/). Both you and different Gradle plugins can write data to custom values. The number of custom values has a limit. See the current maximum custom value count in the [Build scan plugin docs](https://docs.gradle.com/enterprise/gradle-plugin/#adding_custom_values).
If you have a big project, a number of such custom values may be quite big. If this number exceeds the limit, you can see the following message in the logs:
```
Maximum number of custom values (1,000) exceeded
```
To reduce the number of custom values the Kotlin plugin produces, you can use the following property in `gradle.properties`:
```
kotlin.build.report.build_scan.custom_values_limit=500
```
### Switching off collecting project and system properties
HTTP build statistic logs can contain some project and system properties. These properties can change builds' behavior, so it's useful to log them in build statistics. These properties can store sensitive data, for example, passwords or a project's full path.
You can disable collection of these statistics by adding the `kotlin.build.report.http.verbose_environment` property to your `gradle.properties`.
What's next?
------------
Learn more about:
* [Gradle basics and specifics](https://docs.gradle.org/current/userguide/getting_started.html).
* [Support for Gradle plugin variants](gradle-plugin-variants).
Last modified: 10 January 2023
[Compiler options in the Kotlin Gradle plugin](gradle-compiler-options) [Support for Gradle plugin variants](gradle-plugin-variants)
kotlin Coroutine context and dispatchers Coroutine context and dispatchers
=================================
Coroutines always execute in some context represented by a value of the [CoroutineContext](../api/latest/jvm/stdlib/kotlin.coroutines/-coroutine-context/index) type, defined in the Kotlin standard library.
The coroutine context is a set of various elements. The main elements are the [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) of the coroutine, which we've seen before, and its dispatcher, which is covered in this section.
Dispatchers and threads
-----------------------
The coroutine context includes a *coroutine dispatcher* (see [CoroutineDispatcher](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-dispatcher/index.html)) that determines what thread or threads the corresponding coroutine uses for its execution. The coroutine dispatcher can confine coroutine execution to a specific thread, dispatch it to a thread pool, or let it run unconfined.
All coroutine builders like [launch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/launch.html) and [async](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/async.html) accept an optional [CoroutineContext](../api/latest/jvm/stdlib/kotlin.coroutines/-coroutine-context/index) parameter that can be used to explicitly specify the dispatcher for the new coroutine and other context elements.
Try the following example:
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch { // context of the parent, main runBlocking coroutine
println("main runBlocking : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Default) { // will get dispatched to DefaultDispatcher
println("Default : I'm working in thread ${Thread.currentThread().name}")
}
launch(newSingleThreadContext("MyOwnThread")) { // will get its own new thread
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}
//sampleEnd
}
```
It produces the following output (maybe in different order):
```
Unconfined : I'm working in thread main
Default : I'm working in thread DefaultDispatcher-worker-1
newSingleThreadContext: I'm working in thread MyOwnThread
main runBlocking : I'm working in thread main
```
When `launch { ... }` is used without parameters, it inherits the context (and thus dispatcher) from the [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) it is being launched from. In this case, it inherits the context of the main `runBlocking` coroutine which runs in the `main` thread.
[Dispatchers.Unconfined](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-unconfined.html) is a special dispatcher that also appears to run in the `main` thread, but it is, in fact, a different mechanism that is explained later.
The default dispatcher is used when no other dispatcher is explicitly specified in the scope. It is represented by [Dispatchers.Default](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html) and uses a shared background pool of threads.
[newSingleThreadContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/new-single-thread-context.html) creates a thread for the coroutine to run. A dedicated thread is a very expensive resource. In a real application it must be either released, when no longer needed, using the [close](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-executor-coroutine-dispatcher/close.html) function, or stored in a top-level variable and reused throughout the application.
Unconfined vs confined dispatcher
---------------------------------
The [Dispatchers.Unconfined](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-unconfined.html) coroutine dispatcher starts a coroutine in the caller thread, but only until the first suspension point. After suspension it resumes the coroutine in the thread that is fully determined by the suspending function that was invoked. The unconfined dispatcher is appropriate for coroutines which neither consume CPU time nor update any shared data (like UI) confined to a specific thread.
On the other side, the dispatcher is inherited from the outer [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) by default. The default dispatcher for the [runBlocking](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) coroutine, in particular, is confined to the invoker thread, so inheriting it has the effect of confining execution to this thread with predictable FIFO scheduling.
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
delay(500)
println("Unconfined : After delay in thread ${Thread.currentThread().name}")
}
launch { // context of the parent, main runBlocking coroutine
println("main runBlocking: I'm working in thread ${Thread.currentThread().name}")
delay(1000)
println("main runBlocking: After delay in thread ${Thread.currentThread().name}")
}
//sampleEnd
}
```
Produces the output:
```
Unconfined : I'm working in thread main
main runBlocking: I'm working in thread main
Unconfined : After delay in thread kotlinx.coroutines.DefaultExecutor
main runBlocking: After delay in thread main
```
So, the coroutine with the context inherited from `runBlocking {...}` continues to execute in the `main` thread, while the unconfined one resumes in the default executor thread that the [delay](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/delay.html) function is using.
Debugging coroutines and threads
--------------------------------
Coroutines can suspend on one thread and resume on another thread. Even with a single-threaded dispatcher it might be hard to figure out what the coroutine was doing, where, and when if you don't have special tooling.
### Debugging with IDEA
The Coroutine Debugger of the Kotlin plugin simplifies debugging coroutines in IntelliJ IDEA.
The **Debug** tool window contains the **Coroutines** tab. In this tab, you can find information about both currently running and suspended coroutines. The coroutines are grouped by the dispatcher they are running on.
With the coroutine debugger, you can:
* Check the state of each coroutine.
* See the values of local and captured variables for both running and suspended coroutines.
* See a full coroutine creation stack, as well as a call stack inside the coroutine. The stack includes all frames with variable values, even those that would be lost during standard debugging.
* Get a full report that contains the state of each coroutine and its stack. To obtain it, right-click inside the **Coroutines** tab, and then click **Get Coroutines Dump**.
To start coroutine debugging, you just need to set breakpoints and run the application in debug mode.
Learn more about coroutines debugging in the [tutorial](tutorials/coroutines/debug-coroutines-with-idea).
### Debugging using logging
Another approach to debugging applications with threads without Coroutine Debugger is to print the thread name in the log file on each log statement. This feature is universally supported by logging frameworks. When using coroutines, the thread name alone does not give much of a context, so `kotlinx.coroutines` includes debugging facilities to make it easier.
Run the following code with `-Dkotlinx.coroutines.debug` JVM option:
```
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking<Unit> {
//sampleStart
val a = async {
log("I'm computing a piece of the answer")
6
}
val b = async {
log("I'm computing another piece of the answer")
7
}
log("The answer is ${a.await() * b.await()}")
//sampleEnd
}
```
There are three coroutines. The main coroutine (#1) inside `runBlocking` and two coroutines computing the deferred values `a` (#2) and `b` (#3). They are all executing in the context of `runBlocking` and are confined to the main thread. The output of this code is:
```
[main @coroutine#2] I'm computing a piece of the answer
[main @coroutine#3] I'm computing another piece of the answer
[main @coroutine#1] The answer is 42
```
The `log` function prints the name of the thread in square brackets, and you can see that it is the `main` thread with the identifier of the currently executing coroutine appended to it. This identifier is consecutively assigned to all created coroutines when the debugging mode is on.
Jumping between threads
-----------------------
Run the following code with the `-Dkotlinx.coroutines.debug` JVM option (see [debug](#debugging-coroutines-and-threads)):
```
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() {
//sampleStart
newSingleThreadContext("Ctx1").use { ctx1 ->
newSingleThreadContext("Ctx2").use { ctx2 ->
runBlocking(ctx1) {
log("Started in ctx1")
withContext(ctx2) {
log("Working in ctx2")
}
log("Back to ctx1")
}
}
}
//sampleEnd
}
```
It demonstrates several new techniques. One is using [runBlocking](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) with an explicitly specified context, and the other one is using the [withContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-context.html) function to change the context of a coroutine while still staying in the same coroutine, as you can see in the output below:
```
[Ctx1 @coroutine#1] Started in ctx1
[Ctx2 @coroutine#1] Working in ctx2
[Ctx1 @coroutine#1] Back to ctx1
```
Note that this example also uses the `use` function from the Kotlin standard library to release threads created with [newSingleThreadContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/new-single-thread-context.html) when they are no longer needed.
Job in the context
------------------
The coroutine's [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) is part of its context, and can be retrieved from it using the `coroutineContext[Job]` expression:
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
println("My job is ${coroutineContext[Job]}")
//sampleEnd
}
```
In the [debug mode](#debugging-coroutines-and-threads), it outputs something like this:
`My job is "coroutine#1":BlockingCoroutine{Active}@6d311334`
Note that [isActive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/is-active.html) in [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) is just a convenient shortcut for `coroutineContext[Job]?.isActive == true`.
Children of a coroutine
-----------------------
When a coroutine is launched in the [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) of another coroutine, it inherits its context via [CoroutineScope.coroutineContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/coroutine-context.html) and the [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html) of the new coroutine becomes a *child* of the parent coroutine's job. When the parent coroutine is cancelled, all its children are recursively cancelled, too.
However, this parent-child relation can be explicitly overriden in one of two ways:
1. When a different scope is explicitly specified when launching a coroutine (for example, `GlobalScope.launch`), then it does not inherit a `Job` from the parent scope.
2. When a different `Job` object is passed as the context for the new coroutine (as shown in the example below), then it overrides the `Job` of the parent scope.
In both cases, the launched coroutine is not tied to the scope it was launched from and operates independently.
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
// launch a coroutine to process some kind of incoming request
val request = launch {
// it spawns two other jobs
launch(Job()) {
println("job1: I run in my own Job and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// and the other inherits the parent context
launch {
delay(100)
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
}
delay(500)
request.cancel() // cancel processing of the request
println("main: Who has survived request cancellation?")
delay(1000) // delay the main thread for a second to see what happens
//sampleEnd
}
```
The output of this code is:
```
job1: I run in my own Job and execute independently!
job2: I am a child of the request coroutine
main: Who has survived request cancellation?
job1: I am not affected by cancellation of the request
```
Parental responsibilities
-------------------------
A parent coroutine always waits for completion of all its children. A parent does not have to explicitly track all the children it launches, and it does not have to use [Job.join](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/join.html) to wait for them at the end:
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
// launch a coroutine to process some kind of incoming request
val request = launch {
repeat(3) { i -> // launch a few children jobs
launch {
delay((i + 1) * 200L) // variable delay 200ms, 400ms, 600ms
println("Coroutine $i is done")
}
}
println("request: I'm done and I don't explicitly join my children that are still active")
}
request.join() // wait for completion of the request, including all its children
println("Now processing of the request is complete")
//sampleEnd
}
```
The result is going to be:
```
request: I'm done and I don't explicitly join my children that are still active
Coroutine 0 is done
Coroutine 1 is done
Coroutine 2 is done
Now processing of the request is complete
```
Naming coroutines for debugging
-------------------------------
Automatically assigned ids are good when coroutines log often and you just need to correlate log records coming from the same coroutine. However, when a coroutine is tied to the processing of a specific request or doing some specific background task, it is better to name it explicitly for debugging purposes. The [CoroutineName](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-name/index.html) context element serves the same purpose as the thread name. It is included in the thread name that is executing this coroutine when the [debugging mode](#debugging-coroutines-and-threads) is turned on.
The following example demonstrates this concept:
```
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking(CoroutineName("main")) {
//sampleStart
log("Started main coroutine")
// run two background value computations
val v1 = async(CoroutineName("v1coroutine")) {
delay(500)
log("Computing v1")
252
}
val v2 = async(CoroutineName("v2coroutine")) {
delay(1000)
log("Computing v2")
6
}
log("The answer for v1 / v2 = ${v1.await() / v2.await()}")
//sampleEnd
}
```
The output it produces with `-Dkotlinx.coroutines.debug` JVM option is similar to:
```
[main @main#1] Started main coroutine
[main @v1coroutine#2] Computing v1
[main @v2coroutine#3] Computing v2
[main @main#1] The answer for v1 / v2 = 42
```
Combining context elements
--------------------------
Sometimes we need to define multiple elements for a coroutine context. We can use the `+` operator for that. For example, we can launch a coroutine with an explicitly specified dispatcher and an explicitly specified name at the same time:
```
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
//sampleEnd
}
```
The output of this code with the `-Dkotlinx.coroutines.debug` JVM option is:
```
I'm working in thread DefaultDispatcher-worker-1 @test#2
```
Coroutine scope
---------------
Let us put our knowledge about contexts, children and jobs together. Assume that our application has an object with a lifecycle, but that object is not a coroutine. For example, we are writing an Android application and launch various coroutines in the context of an Android activity to perform asynchronous operations to fetch and update data, do animations, etc. All of these coroutines must be cancelled when the activity is destroyed to avoid memory leaks. We, of course, can manipulate contexts and jobs manually to tie the lifecycles of the activity and its coroutines, but `kotlinx.coroutines` provides an abstraction encapsulating that: [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html). You should be already familiar with the coroutine scope as all coroutine builders are declared as extensions on it.
We manage the lifecycles of our coroutines by creating an instance of [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) tied to the lifecycle of our activity. A `CoroutineScope` instance can be created by the [CoroutineScope()](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope.html) or [MainScope()](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-main-scope.html) factory functions. The former creates a general-purpose scope, while the latter creates a scope for UI applications and uses [Dispatchers.Main](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-main.html) as the default dispatcher:
```
class Activity {
private val mainScope = MainScope()
fun destroy() {
mainScope.cancel()
}
// to be continued ...
```
Now, we can launch coroutines in the scope of this `Activity` using the defined `scope`. For the demo, we launch ten coroutines that delay for a different time:
```
// class Activity continues
fun doSomething() {
// launch ten coroutines for a demo, each working for a different time
repeat(10) { i ->
mainScope.launch {
delay((i + 1) * 200L) // variable delay 200ms, 400ms, ... etc
println("Coroutine $i is done")
}
}
}
} // class Activity ends
```
In our main function we create the activity, call our test `doSomething` function, and destroy the activity after 500ms. This cancels all the coroutines that were launched from `doSomething`. We can see that because after the destruction of the activity no more messages are printed, even if we wait a little longer.
```
import kotlinx.coroutines.*
class Activity {
private val mainScope = CoroutineScope(Dispatchers.Default) // use Default for test purposes
fun destroy() {
mainScope.cancel()
}
fun doSomething() {
// launch ten coroutines for a demo, each working for a different time
repeat(10) { i ->
mainScope.launch {
delay((i + 1) * 200L) // variable delay 200ms, 400ms, ... etc
println("Coroutine $i is done")
}
}
}
} // class Activity ends
fun main() = runBlocking<Unit> {
//sampleStart
val activity = Activity()
activity.doSomething() // run test function
println("Launched coroutines")
delay(500L) // delay for half a second
println("Destroying activity!")
activity.destroy() // cancels all coroutines
delay(1000) // visually confirm that they don't work
//sampleEnd
}
```
The output of this example is:
```
Launched coroutines
Coroutine 0 is done
Coroutine 1 is done
Destroying activity!
```
As you can see, only the first two coroutines print a message and the others are cancelled by a single invocation of `job.cancel()` in `Activity.destroy()`.
### Thread-local data
Sometimes it is convenient to have an ability to pass some thread-local data to or between coroutines. However, since they are not bound to any particular thread, this will likely lead to boilerplate if done manually.
For [`ThreadLocal`](https://docs.oracle.com/javase/8/docs/api/java/lang/ThreadLocal.html), the [asContextElement](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/as-context-element.html) extension function is here for the rescue. It creates an additional context element which keeps the value of the given `ThreadLocal` and restores it every time the coroutine switches its context.
It is easy to demonstrate it in action:
```
import kotlinx.coroutines.*
val threadLocal = ThreadLocal<String?>() // declare thread-local variable
fun main() = runBlocking<Unit> {
//sampleStart
threadLocal.set("main")
println("Pre-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
val job = launch(Dispatchers.Default + threadLocal.asContextElement(value = "launch")) {
println("Launch start, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
yield()
println("After yield, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}
job.join()
println("Post-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
//sampleEnd
}
```
In this example we launch a new coroutine in a background thread pool using [Dispatchers.Default](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html), so it works on a different thread from the thread pool, but it still has the value of the thread local variable that we specified using `threadLocal.asContextElement(value = "launch")`, no matter which thread the coroutine is executed on. Thus, the output (with [debug](#debugging-coroutines-and-threads)) is:
```
Pre-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
Launch start, current thread: Thread[DefaultDispatcher-worker-1 @coroutine#2,5,main], thread local value: 'launch'
After yield, current thread: Thread[DefaultDispatcher-worker-2 @coroutine#2,5,main], thread local value: 'launch'
Post-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
```
It's easy to forget to set the corresponding context element. The thread-local variable accessed from the coroutine may then have an unexpected value, if the thread running the coroutine is different. To avoid such situations, it is recommended to use the [ensurePresent](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/ensure-present.html) method and fail-fast on improper usages.
`ThreadLocal` has first-class support and can be used with any primitive `kotlinx.coroutines` provides. It has one key limitation, though: when a thread-local is mutated, a new value is not propagated to the coroutine caller (because a context element cannot track all `ThreadLocal` object accesses), and the updated value is lost on the next suspension. Use [withContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-context.html) to update the value of the thread-local in a coroutine, see [asContextElement](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/as-context-element.html) for more details.
Alternatively, a value can be stored in a mutable box like `class Counter(var i: Int)`, which is, in turn, stored in a thread-local variable. However, in this case you are fully responsible to synchronize potentially concurrent modifications to the variable in this mutable box.
For advanced usage, for example for integration with logging MDC, transactional contexts or any other libraries which internally use thread-locals for passing data, see the documentation of the [ThreadContextElement](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-thread-context-element/index.html) interface that should be implemented.
Last modified: 10 January 2023
[Composing suspending functions](composing-suspending-functions) [Asynchronous Flow](flow)
| programming_docs |
kotlin Kotlin Multiplatform Mobile plugin releases Kotlin Multiplatform Mobile plugin releases
===========================================
Since Kotlin Multiplatform Mobile is now in [Beta](kotlin-evolution), we are working on stabilizing the corresponding [plugin for Android Studio](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile) and will be regularly releasing new versions that include new features, improvements, and bug fixes.
Ensure that you have the latest version of the Kotlin Multiplatform Mobile plugin!
Update to the new release
-------------------------
Android Studio will suggest updating to a new Kotlin Multiplatform Mobile plugin release as soon as it is available. If you accept the suggestion, it will automatically update the plugin to the latest version. You'll need to restart Android Studio to complete the plugin installation.
You can check the plugin version and update it manually in **Settings/Preferences** | **Plugins**.
You need a compatible version of Kotlin for the plugin to work correctly. You can find compatible versions in the [release details](#release-details). You can check your Kotlin version and update it in **Settings/Preferences** | **Plugins** or in **Tools** | **Kotlin** | **Configure Kotlin Plugin Updates**.
Release details
---------------
The following table lists the details of the latest Kotlin Multiplatform Mobile plugin releases:
| Release info | Release highlights | Compatible Kotlin version |
| --- | --- | --- |
| **0.5.1**
Released: 30 November, 2022 | * [Fixed new project generation: delete an excess "app" directory](https://youtrack.jetbrains.com/issue/KTIJ-23790).
| * [Kotlin 1.7.0—\*](releases#release-details)
|
| **0.5.0**
Released: 22 November, 2022 | * [Changed the default option for iOS framework distribution: now it is Regular framework](https://youtrack.jetbrains.com/issue/KT-54086).
* [Moved `MyApplicationTheme` to a separate file in a generated Android project](https://youtrack.jetbrains.com/issue/KT-53991).
* [Updated generated Android project](https://youtrack.jetbrains.com/issue/KT-54658).
* [Fixed an issue with unexpected erasing of new project directory](https://youtrack.jetbrains.com/issue/KTIJ-23707).
| * [Kotlin 1.7.0—\*](releases#release-details)
|
| **0.3.4**
Released: 12 September, 2022 | * [Migrated Android app to Jetpack Compose](https://youtrack.jetbrains.com/issue/KT-53162).
* [Removed outdated HMPP flags](https://youtrack.jetbrains.com/issue/KT-52248).
* [Removed package name from Android manifest](https://youtrack.jetbrains.com/issue/KTIJ-22633).
* [Updated `.gitignore` for Xcode projects](https://youtrack.jetbrains.com/issue/KT-53703).
* [Updated wizard project for better illustration expect/actual](https://youtrack.jetbrains.com/issue/KT-53928).
* [Updated compatibility with Canary build of Android Studio](https://youtrack.jetbrains.com/issue/KTIJ-22063).
* [Updated minimum Android SDK to 21 for Android app](https://youtrack.jetbrains.com/issue/KTIJ-22505).
* [Fixed an issue with the first launch after installation Xcode](https://youtrack.jetbrains.com/issue/KTIJ-22645).
* [Fixed an issues with Apple run configuration on M1](https://youtrack.jetbrains.com/issue/KTIJ-21781).
* [Fixed an issue with `local.properties` on Windows OS](https://youtrack.jetbrains.com/issue/KTIJ-22037).
* [Fixed an issue with Kotlin/Native debugger on Canary build of Android Studio](https://youtrack.jetbrains.com/issue/KT-53976).
| * [Kotlin 1.7.0—1.7.\*](releases#release-details)
|
| **0.3.3**
Released: 9 June, 2022 | * Updated dependency on Kotlin IDE plugin 1.7.0.
| * [Kotlin 1.7.0—1.7.\*](releases#release-details)
|
| **0.3.2**
Released: 4 April, 2022 | * Fixed the performance problem with the iOS application debug on Android Studio 2021.2 and 2021.3.
| * [Kotlin 1.5.0—1.6.\*](releases#release-details)
|
| **0.3.1**
Released: 15 February, 2022 | * [Enabled M1 iOS simulator in Kotlin Multiplatform Mobile wizards](https://youtrack.jetbrains.com/issue/KT-51105).
* Improved performance for indexing XcProjects: [KT-49777](https://youtrack.jetbrains.com/issue/KT-49777), [KT-50779](https://youtrack.jetbrains.com/issue/KT-50779).
* Build scripts clean up: use `kotlin("test")` instead of `kotlin("test-common")` and `kotlin("test-annotations-common")`.
* Increase compatibility range with [Kotlin plugin version](https://youtrack.jetbrains.com/issue/KTIJ-20167).
* [Fixed the problem with JVM debug on Windows host](https://youtrack.jetbrains.com/issue/KT-50699).
* [Fixed the problem with the invalid version after disabling the plugin](https://youtrack.jetbrains.com/issue/KT-50966).
| * [Kotlin 1.5.0—1.6.\*](releases#release-details)
|
| **0.3.0**
Released: 16 November, 2021 | * [New Kotlin Multiplatform Library wizard](https://youtrack.jetbrains.com/issue/KTIJ-19367).
* Support for the new type of Kotlin Multiplatform library distribution: [XCFramework](multiplatform-build-native-binaries#build-xcframeworks).
* Enabled [hierarchical project structure](multiplatform-share-on-platforms#configure-the-hierarchical-structure-manually) for new cross-platform mobile projects.
* Support for [explicit iOS targets declaration](https://youtrack.jetbrains.com/issue/KT-46861).
* [Enabled Kotlin Multiplatform Mobile plugin wizards on non-Mac machines](https://youtrack.jetbrains.com/issue/KT-48614).
* [Support for subfolders in the Kotlin Multiplatform module wizard](https://youtrack.jetbrains.com/issue/KT-47923).
* [Support for Xcode `Assets.xcassets` file](https://youtrack.jetbrains.com/issue/KT-49571).
* [Fixed the plugin classloader exception](https://youtrack.jetbrains.com/issue/KT-48103).
* Updated the CocoaPods Gradle Plugin template.
* Kotlin/Native debugger type evaluation improvements.
* Fixed iOS device launching with Xcode 13.
| * [Kotlin 1.6.0](releases#release-details)
|
| **0.2.7**
Released: August 2, 2021 | * [Added Xcode configuration option for AppleRunConfiguration](https://youtrack.jetbrains.com/issue/KTIJ-19054).
* [Added support Apple M1 simulators](https://youtrack.jetbrains.com/issue/KT-47618).
* [Added information about Xcode integration options in Project Wizard](https://youtrack.jetbrains.com/issue/KT-47466).
* [Added error notification after a project with CocoaPods was generated, but the CocoaPods gem has not been installed](https://youtrack.jetbrains.com/issue/KT-47329).
* [Added support Apple M1 simulator target in generated shared module with Kotlin 1.5.30](https://youtrack.jetbrains.com/issue/KT-47631).
* [Cleared generated Xcode project with Kotlin 1.5.20](https://youtrack.jetbrains.com/issue/KT-47465).
* Fixed launching Xcode Release configuration on a real iOS device.
* Fixed simulator launching with Xcode 12.5.
| * [Kotlin 1.5.10](releases#release-details)
|
| **0.2.6**
Released: June 10, 2021 | * Compatibility with Android Studio Bumblebee Canary 1.
* Support for [Kotlin 1.5.20](whatsnew1520): using the new framework-packing task for Kotlin/Native in the Project Wizard.
| * [Kotlin 1.5.10](releases#release-details)
|
| **0.2.5**
Released: May 25, 2021 | * [Fixed compatibility with Android Studio Arctic Fox 2020.3.1 Beta 1 and higher](https://youtrack.jetbrains.com/issue/KT-46834).
| * [Kotlin 1.5.10](releases#release-details)
|
| **0.2.4**
Released: May 5, 2021 | Use this version of the plugin with Android Studio 4.2 or Android Studio 2020.3.1 Canary 8 or higher.* Compatibility with [Kotlin 1.5.0](whatsnew15).
* [Ability to use the CocoaPods dependency manager in the Kotlin Multiplatform module for iOS integration](https://youtrack.jetbrains.com/issue/KT-45946).
| * [Kotlin 1.5.0](releases#release-details)
|
| **0.2.3**
Released: April 5, 2021 | * [The Project Wizard: improvements in naming modules](https://youtrack.jetbrains.com/issues?q=issue%20id:%20KT-43449,%20KT-44060,%20KT-41520,%20KT-45282).
* [Ability to use the CocoaPods dependency manager in the Project Wizard for iOS integration](https://youtrack.jetbrains.com/issue/KT-45478).
* [Better readability of gradle.properties in new projects](https://youtrack.jetbrains.com/issue/KT-42908).
* [Sample tests are no longer generated if "Add sample tests for Shared Module" is unchecked](https://youtrack.jetbrains.com/issue/KT-43441).
* [Fixes and other improvements](https://youtrack.jetbrains.com/issues?q=Subsystems:%20%7BKMM%20Plugin%7D%20Type:%20Feature,%20Bug%20State:%20-Obsolete,%20-%7BAs%20designed%7D,%20-Answered,%20-Incomplete%20resolved%20date:%202021-03-10%20..%202021-03-25).
| * [Kotlin 1.4.30](releases#release-details)
|
| **0.2.2**
Released: March 3, 2021 | * [Ability to open Xcode-related files in Xcode](https://youtrack.jetbrains.com/issue/KT-44970).
* [Ability to set up a location for the Xcode project file in the iOS run configuration](https://youtrack.jetbrains.com/issue/KT-44968).
* [Support for Android Studio 2020.3.1 Canary 8](https://youtrack.jetbrains.com/issue/KT-45162).
* [Fixes and other improvements](https://youtrack.jetbrains.com/issues?q=tag:%20KMM-0.2.2%20).
| * [Kotlin 1.4.30](releases#release-details)
|
| **0.2.1**
Released: February 15, 2021 | Use this version of the plugin with Android Studio 4.2.* Infrastructure improvements.
* [Fixes and other improvements](https://youtrack.jetbrains.com/issues?q=tag:%20KMM-0.2.1%20).
| * [Kotlin 1.4.30](releases#release-details)
|
| **0.2.0**
Released: November 23, 2020 | * [Support for iPad devices](https://youtrack.jetbrains.com/issue/KT-41932).
* [Support for custom scheme names that are configured in Xcode](https://youtrack.jetbrains.com/issue/KT-41677).
* [Ability to add custom build steps for the iOS run configuration](https://youtrack.jetbrains.com/issue/KT-41678).
* [Ability to debug a custom Kotlin/Native binary](https://youtrack.jetbrains.com/issue/KT-40954).
* [Simplified the code generated by Kotlin Multiplatform Mobile Wizards](https://youtrack.jetbrains.com/issue/KT-41712).
* [Removed support for the Kotlin Android Extensions plugin](https://youtrack.jetbrains.com/issue/KT-42121), which is deprecated in Kotlin 1.4.20.
* [Fixed saving physical device configuration after disconnecting from the host](https://youtrack.jetbrains.com/issue/KT-42390).
* Other fixes and improvements.
| * [Kotlin 1.4.20](releases#release-details)
|
| **0.1.3**
Released: October 2, 2020 | * Added compatibility with iOS 14 and Xcode 12.
* Fixed naming in platform tests created by the Kotlin Multiplatform Mobile Wizard.
| * [Kotlin 1.4.10](releases#release-details)
* [Kotlin 1.4.20](releases#release-details)
|
| **0.1.2**
Released: September 29, 2020 | * Fixed compatibility with [Kotlin 1.4.20-M1](eap#build-details).
* Enabled error reporting to JetBrains by default.
| * [Kotlin 1.4.10](releases#release-details)
* [Kotlin 1.4.20](releases#release-details)
|
| **0.1.1**
Released: September 10, 2020 | * Fixed compatibility with Android Studio Canary 8 and higher.
| * [Kotlin 1.4.10](releases#release-details)
* [Kotlin 1.4.20](releases#release-details)
|
| **0.1.0**
Released: August 31, 2020 | * The first version of the Kotlin Multiplatform Mobile plugin. Learn more in the [blog post](https://blog.jetbrains.com/kotlin/2020/08/kotlin-multiplatform-mobile-goes-alpha/).
| * [Kotlin 1.4.0](releases#release-details)
* [Kotlin 1.4.10](releases#release-details)
|
Last modified: 10 January 2023
[Kotlin releases](releases) [Kotlin plugin releases](plugin-releases)
kotlin Tips for improving Kotlin/Native compilation times Tips for improving Kotlin/Native compilation times
==================================================
The Kotlin/Native compiler is constantly receiving updates that improve its performance. With the latest Kotlin/Native compiler and a properly configured build environment, you can significantly improve the compilation times of your projects with Kotlin/Native targets.
Read on for our tips on how to speed up the Kotlin/Native compilation process.
General recommendations
-----------------------
* **Use the most recent version of Kotlin**. This way you will always have the latest performance improvements.
* **Avoid creating huge classes**. They take a long time to compile and load during execution.
* **Preserve downloaded and cached components between builds**. When compiling projects, Kotlin/Native downloads the required components and caches some results of its work to the `$USER_HOME/.konan` directory. The compiler uses this directory for subsequent compilations, making them take less time to complete.
When building in containers (such as Docker) or with continuous integration systems, the compiler may have to create the `~/.konan` directory from scratch for each build. To avoid this step, configure your environment to preserve `~/.konan` between builds. For example, redefine its location using the `KONAN_DATA_DIR` environment variable.
Gradle configuration
--------------------
The first compilation with Gradle usually takes more time than subsequent ones due to the need to download the dependencies, build caches, and perform additional steps. You should build your project at least twice to get an accurate reading of the actual compilation times.
Here are some recommendations for configuring Gradle for better compilation performance:
* **Increase the [Gradle heap size](https://docs.gradle.org/current/userguide/performance.html#adjust_the_daemons_heap_size)**. Add `org.gradle.jvmargs=-Xmx3g` to `gradle.properties`. If you use [parallel builds](https://docs.gradle.org/current/userguide/performance.html#parallel_execution), you might need to choose the right number of workers with the `org.gradle.workers.max` property or the `--max-workers` command-line option. The default value is the number of CPU processors.
* **Build only the binaries you need**. Don't run Gradle tasks that build the whole project, such as `build` or `assemble`, unless you really need to. These tasks build the same code more than once, increasing the compilation times. In typical cases such as running tests from IntelliJ IDEA or starting the app from Xcode, the Kotlin tooling avoids executing unnecessary tasks.
If you have a non-typical case or build configuration, you might need to choose the task yourself.
+ `linkDebug*`: To run your code during development, you usually need only one binary, so running the corresponding `linkDebug*` task should be enough. Keep in mind that compiling a release binary (`linkRelease*`) takes more time than compiling a debug one.
+ `packForXcode`: Since iOS simulators and devices have different processor architectures, it's a common approach to distribute a Kotlin/Native binary as a universal (fat) framework. During local development, it will be faster to build the `.framework` for only the platform you're using.
To build a platform-specific framework, call the `packForXcode` task generated by the [Kotlin Multiplatform Mobile project wizard](multiplatform-mobile-create-first-app).
* **Don't disable the [Gradle daemon](https://docs.gradle.org/current/userguide/gradle_daemon.html)** without having a good reason to. [Kotlin/Native runs from the Gradle daemon](https://blog.jetbrains.com/kotlin/2020/03/kotlin-1-3-70-released/#kotlin-native) by default. When it's enabled, the same JVM process is used and there is no need to warm it up for each compilation.
* **Don't use [transitiveExport = true](multiplatform-build-native-binaries#export-dependencies-to-binaries)**. Using transitive export disables dead code elimination in many cases: the compiler has to process a lot of unused code. It increases the compilation time. Use `export` explicitly for exporting the required projects and dependencies.
* **Use the Gradle [build caches](https://docs.gradle.org/current/userguide/build_cache.html)**:
+ **Local build cache**: Add `org.gradle.caching=true` to your `gradle.properties` or run with `--build-cache` on the command line.
+ **Remote build cache** in continuous integration environments. Learn how to [configure the remote build cache](https://docs.gradle.org/current/userguide/build_cache.html#sec:build_cache_configure_remote).
* **Enable previously disabled features of Kotlin/Native**. There are properties that disable the Gradle daemon and compiler caches – `kotlin.native.disableCompilerDaemon=true` and `kotlin.native.cacheKind=none`. If you had issues with these features before and added these lines to your `gradle.properties` or Gradle arguments, remove them and check whether the build completes successfully. It is possible that these properties were added previously to work around issues that have already been fixed.
Windows OS configuration
------------------------
* **Configure Windows Security**. Windows Security may slow down the Kotlin/Native compiler. You can avoid this by adding the `.konan` directory, which is located in `%USERPROFILE%` by default, to Windows Security exclusions. Learn how to [add exclusions to Windows Security](https://support.microsoft.com/en-us/windows/add-an-exclusion-to-windows-security-811816c0-4dfd-af4a-47e4-c301afe13b26).
Last modified: 10 January 2023
[Symbolicating iOS crash reports](native-ios-symbolication) [Kotlin/Native FAQ](native-faq)
kotlin Coroutine exceptions handling Coroutine exceptions handling
=============================
This section covers exception handling and cancellation on exceptions. We already know that a cancelled coroutine throws [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html) in suspension points and that it is ignored by the coroutines' machinery. Here we look at what happens if an exception is thrown during cancellation or multiple children of the same coroutine throw an exception.
Exception propagation
---------------------
Coroutine builders come in two flavors: propagating exceptions automatically ([launch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/launch.html) and [actor](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/actor.html)) or exposing them to users ([async](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/async.html) and [produce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/produce.html)). When these builders are used to create a *root* coroutine, that is not a *child* of another coroutine, the former builders treat exceptions as **uncaught** exceptions, similar to Java's `Thread.uncaughtExceptionHandler`, while the latter are relying on the user to consume the final exception, for example via [await](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-deferred/await.html) or [receive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-receive-channel/receive.html) ([produce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/produce.html) and [receive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-receive-channel/receive.html) are covered in [Channels](https://github.com/Kotlin/kotlinx.coroutines/blob/master/docs/channels.md) section).
It can be demonstrated by a simple example that creates root coroutines using the [GlobalScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-global-scope/index.html):
```
import kotlinx.coroutines.*
//sampleStart
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
val job = GlobalScope.launch { // root coroutine with launch
println("Throwing exception from launch")
throw IndexOutOfBoundsException() // Will be printed to the console by Thread.defaultUncaughtExceptionHandler
}
job.join()
println("Joined failed job")
val deferred = GlobalScope.async { // root coroutine with async
println("Throwing exception from async")
throw ArithmeticException() // Nothing is printed, relying on user to call await
}
try {
deferred.await()
println("Unreached")
} catch (e: ArithmeticException) {
println("Caught ArithmeticException")
}
}
//sampleEnd
```
The output of this code is (with [debug](https://github.com/Kotlin/kotlinx.coroutines/blob/master/docs/coroutine-context-and-dispatchers.md#debugging-coroutines-and-threads)):
```
Throwing exception from launch
Exception in thread "DefaultDispatcher-worker-2 @coroutine#2" java.lang.IndexOutOfBoundsException
Joined failed job
Throwing exception from async
Caught ArithmeticException
```
CoroutineExceptionHandler
-------------------------
It is possible to customize the default behavior of printing **uncaught** exceptions to the console. [CoroutineExceptionHandler](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-exception-handler/index.html) context element on a *root* coroutine can be used as a generic `catch` block for this root coroutine and all its children where custom exception handling may take place. It is similar to [`Thread.uncaughtExceptionHandler`](https://docs.oracle.com/javase/8/docs/api/java/lang/Thread.html#setUncaughtExceptionHandler(java.lang.Thread.UncaughtExceptionHandler)). You cannot recover from the exception in the `CoroutineExceptionHandler`. The coroutine had already completed with the corresponding exception when the handler is called. Normally, the handler is used to log the exception, show some kind of error message, terminate, and/or restart the application.
`CoroutineExceptionHandler` is invoked only on **uncaught** exceptions — exceptions that were not handled in any other way. In particular, all *children* coroutines (coroutines created in the context of another [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html)) delegate handling of their exceptions to their parent coroutine, which also delegates to the parent, and so on until the root, so the `CoroutineExceptionHandler` installed in their context is never used. In addition to that, [async](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/async.html) builder always catches all exceptions and represents them in the resulting [Deferred](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-deferred/index.html) object, so its `CoroutineExceptionHandler` has no effect either.
```
import kotlinx.coroutines.*
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
//sampleStart
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) { // root coroutine, running in GlobalScope
throw AssertionError()
}
val deferred = GlobalScope.async(handler) { // also root, but async instead of launch
throw ArithmeticException() // Nothing will be printed, relying on user to call deferred.await()
}
joinAll(job, deferred)
//sampleEnd
}
```
The output of this code is:
```
CoroutineExceptionHandler got java.lang.AssertionError
```
Cancellation and exceptions
---------------------------
Cancellation is closely related to exceptions. Coroutines internally use `CancellationException` for cancellation, these exceptions are ignored by all handlers, so they should be used only as the source of additional debug information, which can be obtained by `catch` block. When a coroutine is cancelled using [Job.cancel](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel.html), it terminates, but it does not cancel its parent.
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
val child = launch {
try {
delay(Long.MAX_VALUE)
} finally {
println("Child is cancelled")
}
}
yield()
println("Cancelling child")
child.cancel()
child.join()
yield()
println("Parent is not cancelled")
}
job.join()
//sampleEnd
}
```
The output of this code is:
```
Cancelling child
Child is cancelled
Parent is not cancelled
```
If a coroutine encounters an exception other than `CancellationException`, it cancels its parent with that exception. This behaviour cannot be overridden and is used to provide stable coroutines hierarchies for [structured concurrency](https://github.com/Kotlin/kotlinx.coroutines/blob/master/docs/composing-suspending-functions.md#structured-concurrency-with-async). [CoroutineExceptionHandler](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-exception-handler/index.html) implementation is not used for child coroutines.
The original exception is handled by the parent only when all its children terminate, which is demonstrated by the following example.
```
import kotlinx.coroutines.*
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
//sampleStart
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) {
launch { // the first child
try {
delay(Long.MAX_VALUE)
} finally {
withContext(NonCancellable) {
println("Children are cancelled, but exception is not handled until all children terminate")
delay(100)
println("The first child finished its non cancellable block")
}
}
}
launch { // the second child
delay(10)
println("Second child throws an exception")
throw ArithmeticException()
}
}
job.join()
//sampleEnd
}
```
The output of this code is:
```
Second child throws an exception
Children are cancelled, but exception is not handled until all children terminate
The first child finished its non cancellable block
CoroutineExceptionHandler got java.lang.ArithmeticException
```
Exceptions aggregation
----------------------
When multiple children of a coroutine fail with an exception, the general rule is "the first exception wins", so the first exception gets handled. All additional exceptions that happen after the first one are attached to the first exception as suppressed ones.
```
import kotlinx.coroutines.*
import java.io.*
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception with suppressed ${exception.suppressed.contentToString()}")
}
val job = GlobalScope.launch(handler) {
launch {
try {
delay(Long.MAX_VALUE) // it gets cancelled when another sibling fails with IOException
} finally {
throw ArithmeticException() // the second exception
}
}
launch {
delay(100)
throw IOException() // the first exception
}
delay(Long.MAX_VALUE)
}
job.join()
}
```
The output of this code is:
```
CoroutineExceptionHandler got java.io.IOException with suppressed [java.lang.ArithmeticException]
```
Cancellation exceptions are transparent and are unwrapped by default:
```
import kotlinx.coroutines.*
import java.io.*
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
//sampleStart
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) {
val inner = launch { // all this stack of coroutines will get cancelled
launch {
launch {
throw IOException() // the original exception
}
}
}
try {
inner.join()
} catch (e: CancellationException) {
println("Rethrowing CancellationException with original cause")
throw e // cancellation exception is rethrown, yet the original IOException gets to the handler
}
}
job.join()
//sampleEnd
}
```
The output of this code is:
```
Rethrowing CancellationException with original cause
CoroutineExceptionHandler got java.io.IOException
```
Supervision
-----------
As we have studied before, cancellation is a bidirectional relationship propagating through the whole hierarchy of coroutines. Let us take a look at the case when unidirectional cancellation is required.
A good example of such a requirement is a UI component with the job defined in its scope. If any of the UI's child tasks have failed, it is not always necessary to cancel (effectively kill) the whole UI component, but if the UI component is destroyed (and its job is cancelled), then it is necessary to cancel all child jobs as their results are no longer needed.
Another example is a server process that spawns multiple child jobs and needs to *supervise* their execution, tracking their failures and only restarting the failed ones.
### Supervision job
The [SupervisorJob](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-supervisor-job.html) can be used for these purposes. It is similar to a regular [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job.html) with the only exception that cancellation is propagated only downwards. This can easily be demonstrated using the following example:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val supervisor = SupervisorJob()
with(CoroutineScope(coroutineContext + supervisor)) {
// launch the first child -- its exception is ignored for this example (don't do this in practice!)
val firstChild = launch(CoroutineExceptionHandler { _, _ -> }) {
println("The first child is failing")
throw AssertionError("The first child is cancelled")
}
// launch the second child
val secondChild = launch {
firstChild.join()
// Cancellation of the first child is not propagated to the second child
println("The first child is cancelled: ${firstChild.isCancelled}, but the second one is still active")
try {
delay(Long.MAX_VALUE)
} finally {
// But cancellation of the supervisor is propagated
println("The second child is cancelled because the supervisor was cancelled")
}
}
// wait until the first child fails & completes
firstChild.join()
println("Cancelling the supervisor")
supervisor.cancel()
secondChild.join()
}
//sampleEnd
}
```
The output of this code is:
```
The first child is failing
The first child is cancelled: true, but the second one is still active
Cancelling the supervisor
The second child is cancelled because the supervisor was cancelled
```
### Supervision scope
Instead of [coroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/coroutine-scope.html), we can use [supervisorScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/supervisor-scope.html) for *scoped* concurrency. It propagates the cancellation in one direction only and cancels all its children only if it failed itself. It also waits for all children before completion just like [coroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/coroutine-scope.html) does.
```
import kotlin.coroutines.*
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
try {
supervisorScope {
val child = launch {
try {
println("The child is sleeping")
delay(Long.MAX_VALUE)
} finally {
println("The child is cancelled")
}
}
// Give our child a chance to execute and print using yield
yield()
println("Throwing an exception from the scope")
throw AssertionError()
}
} catch(e: AssertionError) {
println("Caught an assertion error")
}
//sampleEnd
}
```
The output of this code is:
```
The child is sleeping
Throwing an exception from the scope
The child is cancelled
Caught an assertion error
```
#### Exceptions in supervised coroutines
Another crucial difference between regular and supervisor jobs is exception handling. Every child should handle its exceptions by itself via the exception handling mechanism. This difference comes from the fact that child's failure does not propagate to the parent. It means that coroutines launched directly inside the [supervisorScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/supervisor-scope.html) *do* use the [CoroutineExceptionHandler](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-exception-handler/index.html) that is installed in their scope in the same way as root coroutines do (see the [CoroutineExceptionHandler](#coroutineexceptionhandler) section for details).
```
import kotlin.coroutines.*
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
supervisorScope {
val child = launch(handler) {
println("The child throws an exception")
throw AssertionError()
}
println("The scope is completing")
}
println("The scope is completed")
//sampleEnd
}
```
The output of this code is:
```
The scope is completing
The child throws an exception
CoroutineExceptionHandler got java.lang.AssertionError
The scope is completed
```
Last modified: 10 January 2023
[Channels](channels) [Shared mutable state and concurrency](shared-mutable-state-and-concurrency)
| programming_docs |
kotlin Create a RESTful web service with a database using Spring Boot – tutorial Create a RESTful web service with a database using Spring Boot – tutorial
=========================================================================
This tutorial walks you through the process of creating a simple application with Spring Boot and adding a database to store the information.
In this tutorial, you will:
* Create an application with an HTTP endpoint
* Learn how to return a data objects list in the JSON format
* Create a database for storing objects
* Use endpoints for writing and retrieving database objects
You can download and explore the [completed project](https://github.com/kotlin-hands-on/spring-time-in-kotlin-episode1) or watch a video of this tutorial:
Before you start
----------------
Download and install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
Bootstrap the project
---------------------
Use Spring Initializr to create a new project:
1. Open [Spring Initializr](https://start.spring.io/#!type=gradle-project&language=kotlin&platformVersion=2.7.3&packaging=jar&jvmVersion=11&groupId=com.example&artifactId=demo&name=demo&description=Demo%20project%20for%20Spring%20Boot&packageName=demo&dependencies=web,data-jdbc,h2). This link opens the page with the project settings for this tutorial already filled in. This project uses **Gradle**, **Kotlin**, **Spring Web**, **Spring Data JDBC**, and **H2 Database**:

2. Click **GENERATE** at the bottom of the screen. Spring Initializr will generate the project with the specified settings. The download starts automatically.
3. Unpack the **.zip** file and open it in IntelliJ IDEA.
The project has the following structure:
There are packages and classes under the `main/kotlin` folder that belong to the application. The entry point to the application is the `main()` method of the `DemoApplication.kt` file.
Explore the project build file
------------------------------
Open the `build.gradle.kts` file.
This is the Gradle Kotlin build script, which contains a list of the dependencies required for the application.
The Gradle file is standard for Spring Boot, but it also contains necessary Kotlin dependencies, including the [kotlin-spring](all-open-plugin#spring-support) Gradle plugin.
Explore the Spring Boot application
-----------------------------------
Open the `DemoApplication.kt` file:
```
package demo
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
@SpringBootApplication
class DemoApplication
fun main(args: Array<String>) {
runApplication<DemoApplication>(*args)
}
```
Note that the Kotlin application file differs from a Java application file:
* While Spring Boot looks for a public static `main()` method, the Kotlin application uses a [top-level function](functions#function-scope) defined outside `DemoApplication` class.
* The `DemoApplication` class is not declared as `open`, since the [kotlin-spring](all-open-plugin#spring-support) plugin does that automatically.
Create a data class and a controller
------------------------------------
To create an endpoint, add a [data class](data-classes) and a controller to your project:
1. In the `DemoApplication.kt` file, create a `Message` data class with two properties: `id` and `text`:
```
data class Message(val id: String?, val text: String)
```
2. In the same file, create a `MessageResource` class which will serve the requests and return a JSON document containing a collection of `Message` objects:
```
@RestController
class MessageResource {
@GetMapping("/")
fun index(): List<Message> = listOf(
Message("1", "Hello!"),
Message("2", "Bonjour!"),
Message("3", "Privet!"),
)
}
```
Full code of the `DemoApplication.kt`:
```
package demo
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.data.annotation.Id
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RestController
@SpringBootApplication
class DemoApplication
fun main(args: Array<String>) {
runApplication<DemoApplication>(*args)
}
@RestController
class MessageResource {
@GetMapping("/")
fun index(): List<Message> = listOf(
Message("1", "Hello!"),
Message("2", "Bonjour!"),
Message("3", "Privet!"),
)
}
data class Message(val id: String?, val text: String)
```
Run the application
-------------------
The application is now ready to run:
1. Click the green **Run** icon in the gutter beside the `main()` method or use the **Alt+Enter** shortcut to invoke the launch menu in IntelliJ IDEA:

2. Once the application starts, open the following URL: <http://localhost:8080>.
You will see a page with a collection of messages in JSON format:

Add database support
--------------------
To use a database in your application, first create two endpoints: one for saving messages and one for retrieving them:
1. Add the `@Table` annotation to the `Message` class to declare mapping to a database table. Add the `@Id` annotation before the `id` field. These annotations also require additional imports:
```
import org.springframework.data.annotation.Id
import org.springframework.data.relational.core.mapping.Table
@Table("MESSAGES")
data class Message(@Id val id: String?, val text: String)
```
2. Use the [Spring Data Repository API](https://docs.spring.io/spring-data/commons/docs/current/api/org/springframework/data/repository/CrudRepository.html) to access the database:
```
import org.springframework.data.jdbc.repository.query.Query
import org.springframework.data.repository.CrudRepository
interface MessageRepository : CrudRepository<Message, String>{
@Query("select * from messages")
fun findMessages(): List<Message>
}
```
When you call the `findMessages()` method on an instance of `MessageRepository`, it will execute the corresponding database query:
```
select * from messages
```
This query retrieves a list of all `Message` objects in the database table.
3. Create the `MessageService` class:
```
import org.springframework.stereotype.Service
@Service
class MessageService(val db: MessageRepository) {
fun findMessages(): List<Message> = db.findMessages()
fun post(message: Message){
db.save(message)
}
}
```
This class contains two methods:
* `post()` for writing a new `Message` object to the database
* `findMessages()` for getting all the messages from the database
4. Update the `MessageResource` class:
```
import org.springframework.web.bind.annotation.RequestBody
import org.springframework.web.bind.annotation.PostMapping
@RestController
class MessageResource(val service: MessageService) {
@GetMapping("/")
fun index(): List<Message> = service.findMessages()
@PostMapping
fun post(@RequestBody message: Message) {
service.post(message)
}
}
```
Now it uses `MessageService` to work with the database.
Configure the database
----------------------
Configure the database in the application:
1. Create a new folder called `sql` in the `src/main/resources` with the `schema.sql` file inside. It will store the database scheme:

2. Update the `src/main/resources/sql/schema.sql` file with the following code:
```
CREATE TABLE IF NOT EXISTS messages (
id VARCHAR(60) DEFAULT RANDOM_UUID() PRIMARY KEY,
text VARCHAR NOT NULL
);
```
It creates the `messages` table with two fields: `id` and `text`. The table structure matches the structure of the `Message` class.
3. Open the `application.properties` file located in the `src/main/resources` folder and add the following application properties:
```
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.url=jdbc:h2:file:./data/testdb
spring.datasource.username=sa
spring.datasource.password=password
spring.datasource.schema=classpath:sql/schema.sql
spring.datasource.initialization-mode=always
```
These settings enable the database for the Spring Boot application. See the full list of common application properties in the [Spring documentation](https://docs.spring.io/spring-boot/docs/current/reference/html/appendix-application-properties.html).
Execute HTTP requests
---------------------
You should use an HTTP client to work with previously created endpoints. In IntelliJ IDEA, you can use the embedded [HTTP client](https://www.jetbrains.com/help/idea/http-client-in-product-code-editor.html):
1. Run the application. Once the application is up and running, you can execute POST requests to store messages in the database.
2. Create the `requests.http` file and add the following HTTP requests:
```
### Post 'Hello!"
POST http://localhost:8080/
Content-Type: application/json
{
"text": "Hello!"
}
### Post "Bonjour!"
POST http://localhost:8080/
Content-Type: application/json
{
"text": "Bonjour!"
}
### Post "Privet!"
POST http://localhost:8080/
Content-Type: application/json
{
"text": "Privet!"
}
### Get all the messages
GET http://localhost:8080/
```
3. Execute all POST requests. Use the green **Run** icon in the gutter next to the request declaration. These requests write the text messages to the database.

4. Execute the GET request and see the result in the **Run** tool window:

### Alternative way to execute requests
You can also use any other HTTP client or cURL command-line tool. For example, you can run the following commands in the terminal to get the same result:
```
curl -X POST --location "http://localhost:8080" -H "Content-Type: application/json" -d "{ \"text\": \"Hello!\" }"
curl -X POST --location "http://localhost:8080" -H "Content-Type: application/json" -d "{ \"text\": \"Bonjour!\" }"
curl -X POST --location "http://localhost:8080" -H "Content-Type: application/json" -d "{ \"text\": \"Privet!\" }"
curl -X GET --location "http://localhost:8080"
```
Next step
---------
Get your personal language map to help you navigate Kotlin features and track your progress in studying the language. We will also send you language tips and useful materials on using Kotlin with Spring.
[](https://info.jetbrains.com/kotlin-tips.html)
### See also
For more tutorials, check out the Spring website:
* [Building web applications with Spring Boot and Kotlin](https://spring.io/guides/tutorials/spring-boot-kotlin/)
* [Spring Boot with Kotlin Coroutines and RSocket](https://spring.io/guides/tutorials/spring-webflux-kotlin-rsocket/)
Last modified: 10 January 2023
[Calling Kotlin from Java](java-to-kotlin-interop) [Test code using JUnit in JVM – tutorial](jvm-test-using-junit)
kotlin What's new in Kotlin 1.5.30 What's new in Kotlin 1.5.30
===========================
*[Release date: 24 August 2021](releases#release-details)*
Kotlin 1.5.30 offers language updates including previews of future changes, various improvements in platform support and tooling, and new standard library functions.
Here are some major improvements:
* Language features, including experimental sealed `when` statements, changes in using opt-in requirement, and others
* Native support for Apple silicon
* Kotlin/JS IR backend reaches Beta
* Improved Gradle plugin experience
You can also find a short overview of the changes in the [release blog post](https://blog.jetbrains.com/kotlin/2021/08/kotlin-1-5-30-released/) and this video:
Language features
-----------------
Kotlin 1.5.30 is presenting previews of future language changes and bringing improvements to the opt-in requirement mechanism and type inference:
* [Exhaustive when statements for sealed and Boolean subjects](#exhaustive-when-statements-for-sealed-and-boolean-subjects)
* [Suspending functions as supertypes](#suspending-functions-as-supertypes)
* [Requiring opt-in on implicit usages of experimental APIs](#requiring-opt-in-on-implicit-usages-of-experimental-apis)
* [Changes to using opt-in requirement annotations with different targets](#changes-to-using-opt-in-requirement-annotations-with-different-targets)
* [Improvements to type inference for recursive generic types](#improvements-to-type-inference-for-recursive-generic-types)
* [Eliminating builder inference restrictions](#eliminating-builder-inference-restrictions)
### Exhaustive when statements for sealed and Boolean subjects
An *exhaustive* [`when`](control-flow#when-expression) statement contains branches for all possible types or values of its subject or for some types plus an `else` branch. In other words, it covers all possible cases.
We're planning to prohibit non-exhaustive `when` statements soon to make the behavior consistent with `when` expressions. To ensure smooth migration, you can configure the compiler to report warnings about non-exhaustive `when` statements with a sealed class or a Boolean. Such warnings will appear by default in Kotlin 1.6 and will become errors later.
```
sealed class Mode {
object ON : Mode()
object OFF : Mode()
}
fun main() {
val x: Mode = Mode.ON
when (x) {
Mode.ON -> println("ON")
}
// WARNING: Non exhaustive 'when' statements on sealed classes/interfaces
// will be prohibited in 1.7, add an 'OFF' or 'else' branch instead
val y: Boolean = true
when (y) {
true -> println("true")
}
// WARNING: Non exhaustive 'when' statements on Booleans will be prohibited
// in 1.7, add a 'false' or 'else' branch instead
}
```
To enable this feature in Kotlin 1.5.30, use language version `1.6`. You can also change the warnings to errors by enabling [progressive mode](whatsnew13#progressive-mode).
```
kotlin {
sourceSets.all {
languageSettings.apply {
languageVersion = "1.6"
//progressiveMode = true // false by default
}
}
}
```
```
kotlin {
sourceSets.all {
languageSettings {
languageVersion = '1.6'
//progressiveMode = true // false by default
}
}
}
```
### Suspending functions as supertypes
Kotlin 1.5.30 provides a preview of the ability to use a `suspend` functional type as a supertype with some limitations.
```
class MyClass: suspend () -> Unit {
override suspend fun invoke() { TODO() }
}
```
Use the `-language-version 1.6` compiler option to enable the feature:
```
kotlin {
sourceSets.all {
languageSettings.apply {
languageVersion = "1.6"
}
}
}
```
```
kotlin {
sourceSets.all {
languageSettings {
languageVersion = '1.6'
}
}
}
```
The feature has the following restrictions:
* You can't mix an ordinary functional type and a `suspend` functional type as supertype. This is because of the implementation details of `suspend` functional types in the JVM backend. They are represented in it as ordinary functional types with a marker interface. Because of the marker interface, there is no way to tell which of the superinterfaces are suspended and which are ordinary.
* You can't use multiple `suspend` functional supertypes. If there are type checks, you also can't use multiple ordinary functional supertypes.
### Requiring opt-in on implicit usages of experimental APIs
The author of a library can mark an experimental API as [requiring opt-in](opt-in-requirements#create-opt-in-requirement-annotations) to inform users about its experimental state. The compiler raises a warning or error when the API is used and requires [explicit consent](opt-in-requirements#opt-in-to-using-api) to suppress it.
In Kotlin 1.5.30, the compiler treats any declaration that has an experimental type in the signature as experimental. Namely, it requires opt-in even for implicit usages of an experimental API. For example, if the function's return type is marked as an experimental API element, a usage of the function requires you to opt-in even if the declaration is not marked as requiring an opt-in explicitly.
```
// Library code
@RequiresOptIn(message = "This API is experimental.")
@Retention(AnnotationRetention.BINARY)
@Target(AnnotationTarget.CLASS)
annotation class MyDateTime // Opt-in requirement annotation
@MyDateTime
class DateProvider // A class requiring opt-in
// Client code
// Warning: experimental API usage
fun createDateSource(): DateProvider { /* ... */ }
fun getDate(): Date {
val dateSource = createDateSource() // Also warning: experimental API usage
// ...
}
```
Learn more about [opt-in requirements](opt-in-requirements).
### Changes to using opt-in requirement annotations with different targets
Kotlin 1.5.30 presents new rules for using and declaring opt-in requirement annotations on different [targets](../api/latest/jvm/stdlib/kotlin.annotation/-target/index). The compiler now reports an error for use cases that are impractical to handle at compile time. In Kotlin 1.5.30:
* Marking local variables and value parameters with opt-in requirement annotations is forbidden at the use site.
* Marking override is allowed only if its basic declaration is also marked.
* Marking backing fields and getters is forbidden. You can mark the basic property instead.
* Setting `TYPE` and `TYPE_PARAMETER` annotation targets is forbidden at the opt-in requirement annotation declaration site.
Learn more about [opt-in requirements](opt-in-requirements).
### Improvements to type inference for recursive generic types
In Kotlin and Java, you can define a recursive generic type, which references itself in its type parameters. In Kotlin 1.5.30, the Kotlin compiler can infer a type argument based only on upper bounds of the corresponding type parameter if it is a recursive generic. This makes it possible to create various patterns with recursive generic types that are often used in Java to make builder APIs.
```
// Kotlin 1.5.20
val containerA = PostgreSQLContainer<Nothing>(DockerImageName.parse("postgres:13-alpine")).apply {
withDatabaseName("db")
withUsername("user")
withPassword("password")
withInitScript("sql/schema.sql")
}
// Kotlin 1.5.30
val containerB = PostgreSQLContainer(DockerImageName.parse("postgres:13-alpine"))
.withDatabaseName("db")
.withUsername("user")
.withPassword("password")
.withInitScript("sql/schema.sql")
```
You can enable the improvements by passing the `-Xself-upper-bound-inference` or the `-language-version 1.6` compiler options. See other examples of newly supported use cases in [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-40804).
### Eliminating builder inference restrictions
Builder inference is a special kind of type inference that allows you to infer the type arguments of a call based on type information from other calls inside its lambda argument. This can be useful when calling generic builder functions such as [`buildList()`](../api/latest/jvm/stdlib/kotlin.collections/build-list) or [`sequence()`](../api/latest/jvm/stdlib/kotlin.sequences/sequence): `buildList { add("string") }`.
Inside such a lambda argument, there was previously a limitation on using the type information that the builder inference tries to infer. This means you can only specify it and cannot get it. For example, you cannot call [`get()`](../api/latest/jvm/stdlib/kotlin.collections/-list/get) inside a lambda argument of `buildList()` without explicitly specified type arguments.
Kotlin 1.5.30 removes these limitations with the `-Xunrestricted-builder-inference` compiler option. Add this option to enable previously prohibited calls inside a lambda argument of generic builder functions:
```
@kotlin.ExperimentalStdlibApi
val list = buildList {
add("a")
add("b")
set(1, null)
val x = get(1)
if (x != null) {
removeAt(1)
}
}
@kotlin.ExperimentalStdlibApi
val map = buildMap {
put("a", 1)
put("b", 1.1)
put("c", 2f)
}
```
Also, you can enable this feature with the `-language-version 1.6` compiler option.
Kotlin/JVM
----------
With Kotlin 1.5.30, Kotlin/JVM receives the following features:
* [Instantiation of annotation classes](#instantiation-of-annotation-classes)
* [Improved nullability annotation support configuration](#improved-nullability-annotation-support-configuration)
See the [Gradle](#gradle) section for Kotlin Gradle plugin updates on the JVM platform.
### Instantiation of annotation classes
With Kotlin 1.5.30 you can now call constructors of [annotation classes](annotations) in arbitrary code to obtain a resulting instance. This feature covers the same use cases as the Java convention that allows the implementation of an annotation interface.
```
annotation class InfoMarker(val info: String)
fun processInfo(marker: InfoMarker) = ...
fun main(args: Array<String>) {
if (args.size != 0)
processInfo(getAnnotationReflective(args))
else
processInfo(InfoMarker("default"))
}
```
Use the `-language-version 1.6` compiler option to enable this feature. Note that all current annotation class limitations, such as restrictions to define non-`val` parameters or members different from secondary constructors, remain intact.
Learn more about instantiation of annotation classes in [this KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/annotation-instantiation.md)
### Improved nullability annotation support configuration
The Kotlin compiler can read various types of [nullability annotations](java-interop#nullability-annotations) to get nullability information from Java. This information allows it to report nullability mismatches in Kotlin when calling Java code.
In Kotlin 1.5.30, you can specify whether the compiler reports a nullability mismatch based on the information from specific types of nullability annotations. Just use the compiler option `-Xnullability-annotations=@<package-name>:<report-level>`. In the argument, specify the fully qualified nullability annotations package and one of these report levels:
* `ignore` to ignore nullability mismatches
* `warn` to report warnings
* `strict` to report errors.
See the [full list of supported nullability annotations](java-interop#nullability-annotations) along with their fully qualified package names.
Here is an example showing how to enable error reporting for the newly supported [RxJava](https://github.com/ReactiveX/RxJava) 3 nullability annotations: `[email protected]:strict`. Note that all such nullability mismatches are warnings by default.
Kotlin/Native
-------------
Kotlin/Native has received various changes and improvements:
* [Apple silicon support](#apple-silicon-support)
* [Improved Kotlin DSL for the CocoaPods Gradle plugin](#improved-kotlin-dsl-for-the-cocoapods-gradle-plugin)
* [Experimental interoperability with Swift 5.5 async/await](#experimental-interoperability-with-swift-5-5-async-await)
* [Improved Swift/Objective-C mapping for objects and companion objects](#improved-swift-objective-c-mapping-for-objects-and-companion-objects)
* [Deprecation of linkage against DLLs without import libraries for MinGW targets](#deprecation-of-linkage-against-dlls-without-import-libraries-for-mingw-targets)
### Apple silicon support
Kotlin 1.5.30 introduces native support for [Apple silicon](https://support.apple.com/en-us/HT211814).
Previously, the Kotlin/Native compiler and tooling required the [Rosetta translation environment](https://developer.apple.com/documentation/apple-silicon/about-the-rosetta-translation-environment) for working on Apple silicon hosts. In Kotlin 1.5.30, the translation environment is no longer needed – the compiler and tooling can run on Apple silicon hardware without requiring any additional actions.
We've also introduced new targets that make Kotlin code run natively on Apple silicon:
* `macosArm64`
* `iosSimulatorArm64`
* `watchosSimulatorArm64`
* `tvosSimulatorArm64`
They are available on both Intel-based and Apple silicon hosts. All existing targets are available on Apple silicon hosts as well.
Note that in 1.5.30 we provide only basic support for Apple silicon targets in the `kotlin-multiplatform` Gradle plugin. Particularly, the new simulator targets aren't included in the [`ios`, `tvos`, and `watchos` target shortcuts](multiplatform-share-on-platforms#use-target-shortcuts). Learn how to [use Apple silicon targets with the target shortcuts](multiplatform-share-on-platforms#target-shortcuts-and-arm64-apple-silicon-simulators). We will keep working to improve the user experience with the new targets.
### Improved Kotlin DSL for the CocoaPods Gradle plugin
#### New parameters for Kotlin/Native frameworks
Kotlin 1.5.30 introduces the improved CocoaPods Gradle plugin DSL for Kotlin/Native frameworks. In addition to the name of the framework, you can specify other parameters in the pod configuration:
* Specify the dynamic or static version of the framework
* Enable export dependencies explicitly
* Enable Bitcode embedding
To use the new DSL, update your project to Kotlin 1.5.30, and specify the parameters in the `cocoapods` section of your `build.gradle(.kts)` file:
```
cocoapods {
frameworkName = "MyFramework" // This property is deprecated
// and will be removed in future versions
// New DSL for framework configuration:
framework {
// All Framework properties are supported
// Framework name configuration. Use this property instead of
// deprecated 'frameworkName'
baseName = "MyFramework"
// Dynamic framework support
isStatic = false
// Dependency export
export(project(":anotherKMMModule"))
transitiveExport = false // This is default.
// Bitcode embedding
embedBitcode(BITCODE)
}
}
```
#### Support custom names for Xcode configuration
The Kotlin CocoaPods Gradle plugin supports custom names in the Xcode build configuration. It will also help you if you're using special names for the build configuration in Xcode, for example `Staging`.
To specify a custom name, use the `xcodeConfigurationToNativeBuildType` parameter in the `cocoapods` section of your `build.gradle(.kts)` file:
```
cocoapods {
// Maps custom Xcode configuration to NativeBuildType
xcodeConfigurationToNativeBuildType["CUSTOM_DEBUG"] = NativeBuildType.DEBUG
xcodeConfigurationToNativeBuildType["CUSTOM_RELEASE"] = NativeBuildType.RELEASE
}
```
This parameter will not appear in the Podspec file. When Xcode runs the Gradle build process, the Kotlin CocoaPods Gradle plugin will select the necessary native build type.
### Experimental interoperability with Swift 5.5 async/await
We added [support for calling Kotlin's suspending functions from Objective-C and Swift in 1.4.0](whatsnew14#support-for-kotlin-s-suspending-functions-in-swift-and-objective-c), and now we're improving it to keep up with a new Swift 5.5 feature – [concurrency with `async` and `await` modifiers](https://github.com/apple/swift-evolution/blob/main/proposals/0296-async-await.md).
The Kotlin/Native compiler now emits the `_Nullable_result` attribute in the generated Objective-C headers for suspending functions with nullable return types. This makes it possible to call them from Swift as `async` functions with the proper nullability.
Note that this feature is experimental and can be affected in the future by changes in both Kotlin and Swift. For now, we're offering a preview of this feature that has certain limitations, and we are eager to hear what you think. Learn more about its current state and leave your feedback in [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-47610).
### Improved Swift/Objective-C mapping for objects and companion objects
Getting objects and companion objects can now be done in a way that is more intuitive for native iOS developers. For example, if you have the following objects in Kotlin:
```
object MyObject {
val x = "Some value"
}
class MyClass {
companion object {
val x = "Some value"
}
}
```
To access them in Swift, you can use the `shared` and `companion` properties:
```
MyObject.shared
MyObject.shared.x
MyClass.companion
MyClass.Companion.shared
```
Learn more about [Swift/Objective-C interoperability](native-objc-interop).
### Deprecation of linkage against DLLs without import libraries for MinGW targets
[LLD](https://lld.llvm.org/) is a linker from the LLVM project, which we plan to start using in Kotlin/Native for MinGW targets because of its benefits over the default ld.bfd – primarily its better performance.
However, the latest stable version of LLD doesn't support direct linkage against DLL for MinGW (Windows) targets. Such linkage requires using [import libraries](https://stackoverflow.com/questions/3573475/how-does-the-import-library-work-details/3573527#3573527). Although they aren't needed with Kotlin/Native 1.5.30, we're adding a warning to inform you that such usage is incompatible with LLD that will become the default linker for MinGW in the future.
Please share your thoughts and concerns about the transition to the LLD linker in [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-47605).
Kotlin Multiplatform
--------------------
1.5.30 brings the following notable updates to Kotlin Multiplatform:
* [Ability to use custom `cinterop` libraries in shared native code](#ability-to-use-custom-cinterop-libraries-in-shared-native-code)
* [Support for XCFrameworks](#support-for-xcframeworks)
* [New default publishing setup for Android artifacts](#new-default-publishing-setup-for-android-artifacts)
### Ability to use custom cinterop libraries in shared native code
Kotlin Multiplatform gives you an [option](multiplatform-share-on-platforms#use-native-libraries-in-the-hierarchical-structure) to use platform-dependent interop libraries in shared source sets. Before 1.5.30, this worked only with [platform libraries](native-platform-libs) shipped with Kotlin/Native distribution. Starting from 1.5.30, you can use it with your custom `cinterop` libraries. To enable this feature, add the `kotlin.mpp.enableCInteropCommonization=true` property in your `gradle.properties`:
```
kotlin.mpp.enableGranularSourceSetsMetadata=true
kotlin.native.enableDependencyPropagation=false
kotlin.mpp.enableCInteropCommonization=true
```
### Support for XCFrameworks
All Kotlin Multiplatform projects can now have XCFrameworks as an output format. Apple introduced XCFrameworks as a replacement for universal (fat) frameworks. With the help of XCFrameworks you:
* Can gather logic for all the target platforms and architectures in a single bundle.
* Don't need to remove all unnecessary architectures before publishing the application to the App Store.
XCFrameworks is useful if you want to use your Kotlin framework for devices and simulators on Apple M1.
To use XCFrameworks, update your `build.gradle(.kts)` script:
```
import org.jetbrains.kotlin.gradle.plugin.mpp.apple.XCFramework
plugins {
kotlin("multiplatform")
}
kotlin {
val xcf = XCFramework()
ios {
binaries.framework {
baseName = "shared"
xcf.add(this)
}
}
watchos {
binaries.framework {
baseName = "shared"
xcf.add(this)
}
}
tvos {
binaries.framework {
baseName = "shared"
xcf.add(this)
}
}
}
```
```
import org.jetbrains.kotlin.gradle.plugin.mpp.apple.XCFrameworkConfig
plugins {
id 'org.jetbrains.kotlin.multiplatform'
}
kotlin {
def xcf = new XCFrameworkConfig(project)
ios {
binaries.framework {
baseName = "shared"
xcf.add(it)
}
}
watchos {
binaries.framework {
baseName = "shared"
xcf.add(it)
}
}
tvos {
binaries.framework {
baseName = "shared"
xcf.add(it)
}
}
}
```
When you declare XCFrameworks, these new Gradle tasks will be registered:
* `assembleXCFramework`
* `assembleDebugXCFramework` (additionally debug artifact that [contains dSYMs](native-ios-symbolication))
* `assembleReleaseXCFramework`
Learn more about XCFrameworks in [this WWDC video](https://developer.apple.com/videos/play/wwdc2019/416/).
### New default publishing setup for Android artifacts
Using the `maven-publish` Gradle plugin, you can [publish your multiplatform library for the Android target](multiplatform-publish-lib#publish-an-android-library) by specifying [Android variant](https://developer.android.com/studio/build/build-variants) names in the build script. The Kotlin Gradle plugin will generate publications automatically.
Before 1.5.30, the generated publication [metadata](https://docs.gradle.org/current/userguide/publishing_gradle_module_metadata.html) included the build type attributes for every published Android variant, making it compatible only with the same build type used by the library consumer. Kotlin 1.5.30 introduces a new default publishing setup:
* If all Android variants that the project publishes have the same build type attribute, then the published variants won't have the build type attribute and will be compatible with any build type.
* If the published variants have different build type attributes, then only those with the `release` value will be published without the build type attribute. This makes the release variants compatible with any build type on the consumer side, while non-release variants will only be compatible with the matching consumer build types.
To opt-out and keep the build type attributes for all variants, you can set this Gradle property: `kotlin.android.buildTypeAttribute.keep=true`.
Kotlin/JS
---------
Two major improvements are coming to Kotlin/JS with 1.5.30:
* [JS IR compiler backend reaches Beta](#js-ir-compiler-backend-reaches-beta)
* [Better debugging experience for applications with the Kotlin/JS IR backend](#better-debugging-experience-for-applications-with-the-kotlin-js-ir-backend)
### JS IR compiler backend reaches Beta
The [IR-based compiler backend](whatsnew14#unified-backends-and-extensibility) for Kotlin/JS, which was introduced in 1.4.0 in [Alpha](components-stability), has reached Beta.
Previously, we published the [migration guide for the JS IR backend](js-ir-migration) to help you migrate your projects to the new backend. Now we would like to present the [Kotlin/JS Inspection Pack](https://plugins.jetbrains.com/plugin/17183-kotlin-js-inspection-pack/) IDE plugin, which displays the required changes directly in IntelliJ IDEA.
### Better debugging experience for applications with the Kotlin/JS IR backend
Kotlin 1.5.30 brings JavaScript source map generation for the Kotlin/JS IR backend. This will improve the Kotlin/JS debugging experience when the IR backend is enabled, with full debugging support that includes breakpoints, stepping, and readable stack traces with proper source references.
Learn how to [debug Kotlin/JS in the browser or IntelliJ IDEA Ultimate](js-debugging).
Gradle
------
As a part of our mission to [improve the Kotlin Gradle plugin user experience](https://youtrack.jetbrains.com/issue/KT-45778), we've implemented the following features:
* [Support for Java toolchains](#support-for-java-toolchains), which includes an [ability to specify a JDK home with the `UsesKotlinJavaToolchain` interface for older Gradle versions](#ability-to-specify-jdk-home-with-useskotlinjavatoolchain-interface)
* [An easier way to explicitly specify the Kotlin daemon's JVM arguments](#easier-way-to-explicitly-specify-kotlin-daemon-jvm-arguments)
### Support for Java toolchains
Gradle 6.7 introduced the ["Java toolchains support"](https://docs.gradle.org/current/userguide/toolchains.html) feature. Using this feature, you can:
* Run compilations, tests, and executables using JDKs and JREs that are different from the Gradle ones.
* Compile and test code with an unreleased language version.
With toolchains support, Gradle can autodetect local JDKs and install missing JDKs that Gradle requires for the build. Now Gradle itself can run on any JDK and still reuse the [build cache feature](gradle-compilation-and-caches#gradle-build-cache-support).
The Kotlin Gradle plugin supports Java toolchains for Kotlin/JVM compilation tasks. A Java toolchain:
* Sets the [`jdkHome` option](gradle-compiler-options#attributes-specific-to-jvm) available for JVM targets.
* Sets the [`kotlinOptions.jvmTarget`](gradle-compiler-options#attributes-specific-to-jvm) to the toolchain's JDK version if the user didn't set the `jvmTarget` option explicitly. If the toolchain is not configured, the `jvmTarget` field uses the default value. Learn more about [JVM target compatibility](gradle-configure-project#check-for-jvm-target-compatibility-of-related-compile-tasks).
* Affects which JDK [`kapt` workers](kapt#running-kapt-tasks-in-parallel) are running on.
Use the following code to set a toolchain. Replace the placeholder `<MAJOR_JDK_VERSION>` with the JDK version you would like to use:
```
kotlin {
jvmToolchain {
(this as JavaToolchainSpec).languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
}
```
```
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
}
```
Note that setting a toolchain via the `kotlin` extension will update the toolchain for Java compile tasks as well.
You can set a toolchain via the `java` extension, and Kotlin compilation tasks will use it:
```
java {
toolchain {
languageVersion.set(JavaLanguageVersion.of(<MAJOR_JDK_VERSION>)) // "8"
}
}
```
For information about setting any JDK version for `KotlinCompile` tasks, look through the docs about [setting the JDK version with the Task DSL](gradle-configure-project#setting-jdk-version-with-the-task-dsl).
For Gradle versions from 6.1 to 6.6, [use the `UsesKotlinJavaToolchain` interface to set the JDK home](#ability-to-specify-jdk-home-with-useskotlinjavatoolchain-interface).
### Ability to specify JDK home with UsesKotlinJavaToolchain interface
All Kotlin tasks that support setting the JDK via [`kotlinOptions`](gradle-compiler-options) now implement the `UsesKotlinJavaToolchain` interface. To set the JDK home, put a path to your JDK and replace the `<JDK_VERSION>` placeholder:
```
project.tasks
.withType<UsesKotlinJavaToolchain>()
.configureEach {
it.kotlinJavaToolchain.jdk.use(
"/path/to/local/jdk",
JavaVersion.<LOCAL_JDK_VERSION>
)
}
```
```
project.tasks
.withType(UsesKotlinJavaToolchain.class)
.configureEach {
it.kotlinJavaToolchain.jdk.use(
'/path/to/local/jdk',
JavaVersion.<LOCAL_JDK_VERSION>
)
}
```
Use the `UsesKotlinJavaToolchain` interface for Gradle versions from 6.1 to 6.6. Starting from Gradle 6.7, use the [Java toolchains](#support-for-java-toolchains) instead.
When using this feature, note that [kapt task workers](kapt#running-kapt-tasks-in-parallel) will only use [process isolation mode](https://docs.gradle.org/current/userguide/worker_api.html#changing_the_isolation_mode), and the `kapt.workers.isolation` property will be ignored.
### Easier way to explicitly specify Kotlin daemon JVM arguments
In Kotlin 1.5.30, there's a new logic for the Kotlin daemon's JVM arguments. Each of the options in the following list overrides the ones that came before it:
* If nothing is specified, the Kotlin daemon inherits arguments from the Gradle daemon (as before). For example, in the `gradle.properties` file:
```
org.gradle.jvmargs=-Xmx1500m -Xms=500m
```
* If the Gradle daemon's JVM arguments have the `kotlin.daemon.jvm.options` system property, use it as before:
```
org.gradle.jvmargs=-Dkotlin.daemon.jvm.options=-Xmx1500m -Xms=500m
```
* You can add the`kotlin.daemon.jvmargs` property in the `gradle.properties` file:
```
kotlin.daemon.jvmargs=-Xmx1500m -Xms=500m
```
* You can specify arguments in the `kotlin` extension:
```
kotlin {
kotlinDaemonJvmArgs = listOf("-Xmx486m", "-Xms256m", "-XX:+UseParallelGC")
}
```
```
kotlin {
kotlinDaemonJvmArgs = ["-Xmx486m", "-Xms256m", "-XX:+UseParallelGC"]
}
```
* You can specify arguments for a specific task:
```
tasks
.matching { it.name == "compileKotlin" && it is CompileUsingKotlinDaemon }
.configureEach {
(this as CompileUsingKotlinDaemon).kotlinDaemonJvmArguments.set(listOf("-Xmx486m", "-Xms256m", "-XX:+UseParallelGC"))
}
```
```
tasks
.matching {
it.name == "compileKotlin" && it instanceof CompileUsingKotlinDaemon
}
.configureEach {
kotlinDaemonJvmArguments.set(["-Xmx1g", "-Xms512m"])
}
```
For more information about the Kotlin daemon, see [the Kotlin daemon and using it with Gradle](gradle-compilation-and-caches#the-kotlin-daemon-and-how-to-use-it-with-gradle).
Standard library
----------------
Kotlin 1.5.30 is bringing improvements to the standard library's `Duration` and `Regex` APIs:
* [Changing `Duration.toString()` output](#changing-duration-tostring-output)
* [Parsing Duration from String](#parsing-duration-from-string)
* [Matching with Regex at a particular position](#matching-with-regex-at-a-particular-position)
* [Splitting Regex to a sequence](#splitting-regex-to-a-sequence)
### Changing Duration.toString() output
Before Kotlin 1.5.30, the [`Duration.toString()`](../api/latest/jvm/stdlib/kotlin.time/-duration/to-string) function would return a string representation of its argument expressed in the unit that yielded the most compact and readable number value. From now on, it will return a string value expressed as a combination of numeric components, each in its own unit. Each component is a number followed by the unit's abbreviated name: `d`, `h`, `m`, `s`. For example:
| **Example of function call** | **Previous output** | **Current output** |
| --- | --- | --- |
| Duration.days(45).toString() | `45.0d` | `45d` |
| Duration.days(1.5).toString() | `36.0h` | `1d 12h` |
| Duration.minutes(1230).toString() | `20.5h` | `20h 30m` |
| Duration.minutes(2415).toString() | `40.3h` | `1d 16h 15m` |
| Duration.minutes(920).toString() | `920m` | `15h 20m` |
| Duration.seconds(1.546).toString() | `1.55s` | `1.546s` |
| Duration.milliseconds(25.12).toString() | `25.1ms` | `25.12ms` |
The way negative durations are represented has also been changed. A negative duration is prefixed with a minus sign (`-`), and if it consists of multiple components, it is surrounded with parentheses: `-12m` and `-(1h 30m)`.
Note that small durations of less than one second are represented as a single number with one of the subsecond units. For example, `ms` (milliseconds), `us` (microseconds), or `ns` (nanoseconds): `140.884ms`, `500us`, `24ns`. Scientific notation is no longer used to represent them.
If you want to express duration in a single unit, use the overloaded `Duration.toString(unit, decimals)` function.
### Parsing Duration from String
In Kotlin 1.5.30, there are new functions in the Duration API:
* [`parse()`](../api/latest/jvm/stdlib/kotlin.time/-duration/parse), which supports parsing the outputs of:
+ [`toString()`](../api/latest/jvm/stdlib/kotlin.time/-duration/to-string).
+ [`toString(unit, decimals)`](../api/latest/jvm/stdlib/kotlin.time/-duration/to-string).
+ [`toIsoString()`](../api/latest/jvm/stdlib/kotlin.time/-duration/to-iso-string).
* [`parseIsoString()`](../api/latest/jvm/stdlib/kotlin.time/-duration/parse-iso-string), which only parses from the format produced by `toIsoString()`.
* [`parseOrNull()`](../api/latest/jvm/stdlib/kotlin.time/-duration/parse-or-null) and [`parseIsoStringOrNull()`](../api/latest/jvm/stdlib/kotlin.time/-duration/parse-iso-string-or-null), which behave like the functions above but return `null` instead of throwing `IllegalArgumentException` on invalid duration formats.
Here are some examples of `parse()` and `parseOrNull()` usages:
```
import kotlin.time.Duration
import kotlin.time.ExperimentalTime
@ExperimentalTime
fun main() {
//sampleStart
val isoFormatString = "PT1H30M"
val defaultFormatString = "1h 30m"
val singleUnitFormatString = "1.5h"
val invalidFormatString = "1 hour 30 minutes"
println(Duration.parse(isoFormatString)) // "1h 30m"
println(Duration.parse(defaultFormatString)) // "1h 30m"
println(Duration.parse(singleUnitFormatString)) // "1h 30m"
//println(Duration.parse(invalidFormatString)) // throws exception
println(Duration.parseOrNull(invalidFormatString)) // "null"
//sampleEnd
}
```
And here are some examples of `parseIsoString()` and `parseIsoStringOrNull()` usages:
```
import kotlin.time.Duration
import kotlin.time.ExperimentalTime
@ExperimentalTime
fun main() {
//sampleStart
val isoFormatString = "PT1H30M"
val defaultFormatString = "1h 30m"
println(Duration.parseIsoString(isoFormatString)) // "1h 30m"
//println(Duration.parseIsoString(defaultFormatString)) // throws exception
println(Duration.parseIsoStringOrNull(defaultFormatString)) // "null"
//sampleEnd
}
```
### Matching with Regex at a particular position
The new `Regex.matchAt()` and `Regex.matchesAt()` functions provide a way to check whether a regex has an exact match at a particular position in a `String` or `CharSequence`.
`matchesAt()` returns a boolean result:
```
fun main(){
//sampleStart
val releaseText = "Kotlin 1.5.30 is released!"
// regular expression: one digit, dot, one digit, dot, one or more digits
val versionRegex = "\\d[.]\\d[.]\\d+".toRegex()
println(versionRegex.matchesAt(releaseText, 0)) // "false"
println(versionRegex.matchesAt(releaseText, 7)) // "true"
//sampleEnd
}
```
`matchAt()` returns the match if one is found or `null` if one isn't:
```
fun main(){
//sampleStart
val releaseText = "Kotlin 1.5.30 is released!"
val versionRegex = "\\d[.]\\d[.]\\d+".toRegex()
println(versionRegex.matchAt(releaseText, 0)) // "null"
println(versionRegex.matchAt(releaseText, 7)?.value) // "1.5.30"
//sampleEnd
}
```
### Splitting Regex to a sequence
The new `Regex.splitToSequence()` function is a lazy counterpart of [`split()`](../api/latest/jvm/stdlib/kotlin.text/-regex/split). It splits the string around matches of the given regex, but it returns the result as a [Sequence](sequences) so that all operations on this result are executed lazily.
```
fun main(){
//sampleStart
val colorsText = "green, red , brown&blue, orange, pink&green"
val regex = "[,\\s]+".toRegex()
val mixedColor = regex.splitToSequence(colorsText)
.onEach { println(it) }
.firstOrNull { it.contains('&') }
println(mixedColor) // "brown&blue"
//sampleEnd
}
```
A similar function was also added to `CharSequence`:
```
val mixedColor = colorsText.splitToSequence(regex)
```
Serialization 1.3.0-RC
----------------------
`kotlinx.serialization` [1.3.0-RC](https://github.com/Kotlin/kotlinx.serialization/releases/tag/v1.3.0-RC) is here with new JSON serialization capabilities:
* Java IO streams serialization
* Property-level control over default values
* An option to exclude null values from serialization
* Custom class discriminators in polymorphic serialization
Learn more in the [changelog](https://github.com/Kotlin/kotlinx.serialization/releases/tag/v1.3.0-RC).
Last modified: 10 January 2023
[What's new in Kotlin 1.6.0](whatsnew16) [What's new in Kotlin 1.5.20](whatsnew1520)
| programming_docs |
kotlin Learning materials overview Learning materials overview
===========================
You can use the following materials and resources for learning Kotlin:
* [Basic syntax](basic-syntax) – get a quick overview of the Kotlin syntax.
* [Idioms](idioms) – learn how to write idiomatic Kotlin code for popular cases.
+ [Java to Kotlin migration guide: Strings](java-to-kotlin-idioms-strings) – learn how to perform typical tasks with strings in Java and Kotlin.
+ [Java to Kotlin migration guide: Collections](java-to-kotlin-collections-guide) — learn how to perform typical tasks with collections in Java and Kotlin.
+ [Java to Kotlin migration guide: Nullability](java-to-kotlin-nullability-guide) — learn how to handle nullability in Java and Kotlin.
* [Kotlin Koans](koans) – complete exercises to learn the Kotlin syntax. Each exercise is created as a failing unit test and your job is to make it pass. Recommended for developers with Java experience.
* [Kotlin by example](https://play.kotlinlang.org/byExample/overview) – review a set of small and simple annotated examples for the Kotlin syntax.
* [Kotlin Basics track](https://hyperskill.org/join/fromdocstoJetSalesStat?redirect=true&next=/tracks/18) – learn all the Kotlin essentials while creating working applications step by step on JetBrains Academy.
* [Kotlin books](books) – find books we've reviewed and recommend for learning Kotlin.
* [Kotlin tips](kotlin-tips) – watch short videos where the Kotlin team shows you how to use Kotlin in a more efficient and idiomatic way, so you can have more fun when writing code.
* [Advent of Code puzzles](advent-of-code) – learn idiomatic Kotlin and test your language skills by completing short and fun tasks.
* [Kotlin hands-on tutorials](https://play.kotlinlang.org/hands-on/overview) – complete long-form tutorials to fully grasp a technology. These tutorials guide you through a self-contained project related to a specific topic.
* [Kotlin for Java Developers](https://www.coursera.org/learn/kotlin-for-java-developers) – learn the similarities and differences between Java and Kotlin in this course on Coursera.
* [Kotlin documentation in PDF format](kotlin-pdf) – read our documentation offline.
Last modified: 10 January 2023
[Kotlin and OSGi](kotlin-osgi) [Kotlin Koans](koans)
kotlin Destructuring declarations Destructuring declarations
==========================
Sometimes it is convenient to *destructure* an object into a number of variables, for example:
```
val (name, age) = person
```
This syntax is called a *destructuring declaration*. A destructuring declaration creates multiple variables at once. You have declared two new variables: `name` and `age`, and can use them independently:
```
println(name)
println(age)
```
A destructuring declaration is compiled down to the following code:
```
val name = person.component1()
val age = person.component2()
```
The `component1()` and `component2()` functions are another example of the *principle of conventions* widely used in Kotlin (see operators like `+` and `*`, `for`-loops as an example). Anything can be on the right-hand side of a destructuring declaration, as long as the required number of component functions can be called on it. And, of course, there can be `component3()` and `component4()` and so on.
Destructuring declarations also work in `for`-loops:
```
for ((a, b) in collection) { ... }
```
Variables `a` and `b` get the values returned by `component1()` and `component2()` called on elements of the collection.
Example: returning two values from a function
---------------------------------------------
Assume that you need to return two things from a function - for example, a result object and a status of some sort. A compact way of doing this in Kotlin is to declare a [data class](data-classes) and return its instance:
```
data class Result(val result: Int, val status: Status)
fun function(...): Result {
// computations
return Result(result, status)
}
// Now, to use this function:
val (result, status) = function(...)
```
Since data classes automatically declare `componentN()` functions, destructuring declarations work here.
Example: destructuring declarations and maps
--------------------------------------------
Probably the nicest way to traverse a map is this:
```
for ((key, value) in map) {
// do something with the key and the value
}
```
To make this work, you should
* Present the map as a sequence of values by providing an `iterator()` function.
* Present each of the elements as a pair by providing functions `component1()` and `component2()`.
And indeed, the standard library provides such extensions:
```
operator fun <K, V> Map<K, V>.iterator(): Iterator<Map.Entry<K, V>> = entrySet().iterator()
operator fun <K, V> Map.Entry<K, V>.component1() = getKey()
operator fun <K, V> Map.Entry<K, V>.component2() = getValue()
```
So you can freely use destructuring declarations in `for`-loops with maps (as well as collections of data class instances or similar).
Underscore for unused variables
-------------------------------
If you don't need a variable in the destructuring declaration, you can place an underscore instead of its name:
```
val (_, status) = getResult()
```
The `componentN()` operator functions are not called for the components that are skipped in this way.
Destructuring in lambdas
------------------------
You can use the destructuring declarations syntax for lambda parameters. If a lambda has a parameter of the `Pair` type (or `Map.Entry`, or any other type that has the appropriate `componentN` functions), you can introduce several new parameters instead of one by putting them in parentheses:
```
map.mapValues { entry -> "${entry.value}!" }
map.mapValues { (key, value) -> "$value!" }
```
Note the difference between declaring two parameters and declaring a destructuring pair instead of a parameter:
```
{ a -> ... } // one parameter
{ a, b -> ... } // two parameters
{ (a, b) -> ... } // a destructured pair
{ (a, b), c -> ... } // a destructured pair and another parameter
```
If a component of the destructured parameter is unused, you can replace it with the underscore to avoid inventing its name:
```
map.mapValues { (_, value) -> "$value!" }
```
You can specify the type for the whole destructured parameter or for a specific component separately:
```
map.mapValues { (_, value): Map.Entry<Int, String> -> "$value!" }
map.mapValues { (_, value: String) -> "$value!" }
```
Last modified: 10 January 2023
[Annotations](annotations) [Reflection](reflection)
kotlin List-specific operations List-specific operations
========================
[`List`](collections-overview#list) is the most popular type of built-in collection in Kotlin. Index access to the elements of lists provides a powerful set of operations for lists.
Retrieve elements by index
--------------------------
Lists support all common operations for element retrieval: `elementAt()`, `first()`, `last()`, and others listed in [Retrieve single elements](collection-elements). What is specific for lists is index access to the elements, so the simplest way to read an element is retrieving it by index. That is done with the [`get()`](../api/latest/jvm/stdlib/kotlin.collections/-list/get) function with the index passed in the argument or the shorthand `[index]` syntax.
If the list size is less than the specified index, an exception is thrown. There are two other functions that help you avoid such exceptions:
* [`getOrElse()`](../api/latest/jvm/stdlib/kotlin.collections/get-or-else) lets you provide the function for calculating the default value to return if the index isn't present in the collection.
* [`getOrNull()`](../api/latest/jvm/stdlib/kotlin.collections/get-or-null) returns `null` as the default value.
```
fun main() {
//sampleStart
val numbers = listOf(1, 2, 3, 4)
println(numbers.get(0))
println(numbers[0])
//numbers.get(5) // exception!
println(numbers.getOrNull(5)) // null
println(numbers.getOrElse(5, {it})) // 5
//sampleEnd
}
```
Retrieve list parts
-------------------
In addition to common operations for [Retrieving Collection Parts](collection-parts), lists provide the [`subList()`](../api/latest/jvm/stdlib/kotlin.collections/-list/sub-list) function that returns a view of the specified elements range as a list. Thus, if an element of the original collection changes, it also changes in the previously created sublists and vice versa.
```
fun main() {
//sampleStart
val numbers = (0..13).toList()
println(numbers.subList(3, 6))
//sampleEnd
}
```
Find element positions
----------------------
### Linear search
In any lists, you can find the position of an element using the functions [`indexOf()`](../api/latest/jvm/stdlib/kotlin.collections/index-of) and [`lastIndexOf()`](../api/latest/jvm/stdlib/kotlin.collections/last-index-of). They return the first and the last position of an element equal to the given argument in the list. If there are no such elements, both functions return `-1`.
```
fun main() {
//sampleStart
val numbers = listOf(1, 2, 3, 4, 2, 5)
println(numbers.indexOf(2))
println(numbers.lastIndexOf(2))
//sampleEnd
}
```
There is also a pair of functions that take a predicate and search for elements matching it:
* [`indexOfFirst()`](../api/latest/jvm/stdlib/kotlin.collections/index-of-first) returns the *index of the first* element matching the predicate or `-1` if there are no such elements.
* [`indexOfLast()`](../api/latest/jvm/stdlib/kotlin.collections/index-of-last) returns the *index of the last* element matching the predicate or `-1` if there are no such elements.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4)
println(numbers.indexOfFirst { it > 2})
println(numbers.indexOfLast { it % 2 == 1})
//sampleEnd
}
```
### Binary search in sorted lists
There is one more way to search elements in lists – [binary search](https://en.wikipedia.org/wiki/Binary_search_algorithm). It works significantly faster than other built-in search functions but *requires the list to be [sorted](collection-ordering)* in ascending order according to a certain ordering: natural or another one provided in the function parameter. Otherwise, the result is undefined.
To search an element in a sorted list, call the [`binarySearch()`](../api/latest/jvm/stdlib/kotlin.collections/binary-search) function passing the value as an argument. If such an element exists, the function returns its index; otherwise, it returns `(-insertionPoint - 1)` where `insertionPoint` is the index where this element should be inserted so that the list remains sorted. If there is more than one element with the given value, the search can return any of their indices.
You can also specify an index range to search in: in this case, the function searches only between two provided indices.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println(numbers)
println(numbers.binarySearch("two")) // 3
println(numbers.binarySearch("z")) // -5
println(numbers.binarySearch("two", 0, 2)) // -3
//sampleEnd
}
```
#### Comparator binary search
When list elements aren't `Comparable`, you should provide a [`Comparator`](../api/latest/jvm/stdlib/kotlin/-comparator) to use in the binary search. The list must be sorted in ascending order according to this `Comparator`. Let's have a look at an example:
```
data class Product(val name: String, val price: Double)
fun main() {
//sampleStart
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch(Product("AppCode", 99.0), compareBy<Product> { it.price }.thenBy { it.name }))
//sampleEnd
}
```
Here's a list of `Product` instances that aren't `Comparable` and a `Comparator` that defines the order: product `p1` precedes product `p2` if `p1`'s price is less than `p2`'s price. So, having a list sorted ascending according to this order, we use `binarySearch()` to find the index of the specified `Product`.
Custom comparators are also handy when a list uses an order different from natural one, for example, a case-insensitive order for `String` elements.
```
fun main() {
//sampleStart
val colors = listOf("Blue", "green", "ORANGE", "Red", "yellow")
println(colors.binarySearch("RED", String.CASE_INSENSITIVE_ORDER)) // 3
//sampleEnd
}
```
#### Comparison binary search
Binary search with *comparison* function lets you find elements without providing explicit search values. Instead, it takes a comparison function mapping elements to `Int` values and searches for the element where the function returns zero. The list must be sorted in the ascending order according to the provided function; in other words, the return values of comparison must grow from one list element to the next one.
```
import kotlin.math.sign
//sampleStart
data class Product(val name: String, val price: Double)
fun priceComparison(product: Product, price: Double) = sign(product.price - price).toInt()
fun main() {
val productList = listOf(
Product("WebStorm", 49.0),
Product("AppCode", 99.0),
Product("DotTrace", 129.0),
Product("ReSharper", 149.0))
println(productList.binarySearch { priceComparison(it, 99.0) })
}
//sampleEnd
```
Both comparator and comparison binary search can be performed for list ranges as well.
List write operations
---------------------
In addition to the collection modification operations described in [Collection write operations](collection-write), [mutable](collections-overview#collection-types) lists support specific write operations. Such operations use the index to access elements to broaden the list modification capabilities.
### Add
To add elements to a specific position in a list, use [`add()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/add) and [`addAll()`](../api/latest/jvm/stdlib/kotlin.collections/add-all) providing the position for element insertion as an additional argument. All elements that come after the position shift to the right.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "five", "six")
numbers.add(1, "two")
numbers.addAll(2, listOf("three", "four"))
println(numbers)
//sampleEnd
}
```
### Update
Lists also offer a function to replace an element at a given position - [`set()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/set) and its operator form `[]`. `set()` doesn't change the indexes of other elements.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "five", "three")
numbers[1] = "two"
println(numbers)
//sampleEnd
}
```
[`fill()`](../api/latest/jvm/stdlib/kotlin.collections/fill) simply replaces all the collection elements with the specified value.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4)
numbers.fill(3)
println(numbers)
//sampleEnd
}
```
### Remove
To remove an element at a specific position from a list, use the [`removeAt()`](../api/latest/jvm/stdlib/kotlin.collections/-mutable-list/remove-at) function providing the position as an argument. All indices of elements that come after the element being removed will decrease by one.
```
fun main() {
//sampleStart
val numbers = mutableListOf(1, 2, 3, 4, 3)
numbers.removeAt(1)
println(numbers)
//sampleEnd
}
```
### Sort
In [Collection Ordering](collection-ordering), we describe operations that retrieve collection elements in specific orders. For mutable lists, the standard library offers similar extension functions that perform the same ordering operations in place. When you apply such an operation to a list instance, it changes the order of elements in that exact instance.
The in-place sorting functions have similar names to the functions that apply to read-only lists, but without the `ed/d` suffix:
* `sort*` instead of `sorted*` in the names of all sorting functions: [`sort()`](../api/latest/jvm/stdlib/kotlin.collections/sort), [`sortDescending()`](../api/latest/jvm/stdlib/kotlin.collections/sort-descending), [`sortBy()`](../api/latest/jvm/stdlib/kotlin.collections/sort-by), and so on.
* [`shuffle()`](../api/latest/jvm/stdlib/kotlin.collections/shuffle) instead of `shuffled()`.
* [`reverse()`](../api/latest/jvm/stdlib/kotlin.collections/reverse) instead of `reversed()`.
[`asReversed()`](../api/latest/jvm/stdlib/kotlin.collections/as-reversed) called on a mutable list returns another mutable list which is a reversed view of the original list. Changes in that view are reflected in the original list. The following example shows sorting functions for mutable lists:
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four")
numbers.sort()
println("Sort into ascending: $numbers")
numbers.sortDescending()
println("Sort into descending: $numbers")
numbers.sortBy { it.length }
println("Sort into ascending by length: $numbers")
numbers.sortByDescending { it.last() }
println("Sort into descending by the last letter: $numbers")
numbers.sortWith(compareBy<String> { it.length }.thenBy { it })
println("Sort by Comparator: $numbers")
numbers.shuffle()
println("Shuffle: $numbers")
numbers.reverse()
println("Reverse: $numbers")
//sampleEnd
}
```
Last modified: 10 January 2023
[Collection write operations](collection-write) [Set-specific operations](set-operations)
kotlin Stability of Kotlin components Stability of Kotlin components
==============================
The Kotlin language and toolset are divided into many components such as the compilers for the JVM, JS and Native targets, the Standard Library, various accompanying tools and so on. Many of these components were officially released as **Stable** which means that they are evolved in the backward-compatible way following the [principles](kotlin-evolution) of *Comfortable Updates* and *Keeping the Language Modern*. Among such stable components are, for example, the Kotlin compiler for the JVM, the Standard Library, and Coroutines.
Following the *Feedback Loop* principle we release many things early for the community to try out, so a number of components are not yet released as **Stable**. Some of them are very early stage, some are more mature. We mark them as **Experimental**, **Alpha** or **Beta** depending on how quickly each component is evolving and how much risk the users are taking when adopting it.
Stability levels explained
--------------------------
Here's a quick guide to these stability levels and their meaning:
**Experimental** means "try it only in toy projects":
* We are just trying out an idea and want some users to play with it and give feedback. If it doesn't work out, we may drop it any minute.
**Alpha** means "use at your own risk, expect migration issues":
* We decided to productize this idea, but it hasn't reached the final shape yet.
**Beta** means "you can use it, we'll do our best to minimize migration issues for you":
* It's almost done, user feedback is especially important now.
* Still, it's not 100% finished, so changes are possible (including ones based on your own feedback).
* Watch for deprecation warnings in advance for the best update experience.
We collectively refer to *Experimental*, *Alpha* and *Beta* as **pre-stable** levels.
**Stable** means "use it even in most conservative scenarios":
* It's done. We will be evolving it according to our strict [backward compatibility rules](https://kotlinfoundation.org/language-committee-guidelines/).
Please note that stability levels do not say anything about how soon a component will be released as Stable. Similarly, they do not indicate how much a component will be changed before release. They only say how fast a component is changing and how much risk of update issues users are running.
GitHub badges for Kotlin components
-----------------------------------
The [Kotlin GitHub organization](https://github.com/Kotlin) hosts different Kotlin-related projects. Some of them we develop full-time, while others are side projects.
Each Kotlin project has two GitHub badges describing its stability and support status:
* **Stability** status. This shows how quickly each project is evolving and how much risk the users are taking when adopting it. The stability status completely coincides with the [stability level of the Kotlin language features and its components](#stability-levels-explained):
+ stands for **Experimental**
+ stands for **Alpha**
+ stands for **Beta**
+ stands for **Stable**
* **Support** status. This shows our commitment to maintaining a project and helping users to solve their problems. The level of support is unified for all JetBrains products.
[See the JetBrains Confluence document for details](https://confluence.jetbrains.com/display/ALL/JetBrains+on+GitHub).
Stability of subcomponents
--------------------------
A stable component may have an experimental subcomponent, for example:
* a stable compiler may have an experimental feature;
* a stable API may include experimental classes or functions;
* a stable command-line tool may have experimental options.
We make sure to document precisely which subcomponents are not stable. We also do our best to warn users where possible and ask to opt in explicitly to avoid accidental usages of features that have not been released as stable.
Current stability of Kotlin components
--------------------------------------
| **Component** | **Status** | **Status since version** | **Comment** |
| --- | --- | --- | --- |
| Kotlin/JVM | Stable | 1.0 | |
| Kotlin K2 (JVM) | Alpha | 1.7 | |
| kotlin-stdlib (JVM) | Stable | 1.0 | |
| Coroutines | Stable | 1.3 | |
| kotlin-reflect (JVM) | Beta | 1.0 | |
| Kotlin/JS (Classic back-end) | Stable | 1.3 | Deprecated from 1.8.0, read the [IR migration guide](https://github.com/Kotlin/kotlinx.coroutines/blob/master/js-ir-migration.html) |
| Kotlin/JVM (IR-based) | Stable | 1.5 | |
| Kotlin/JS (IR-based) | Stable | 1.8 | |
| Kotlin/Native Runtime | Beta | 1.3 | |
| Kotlin/Native new memory manager | Beta | 1.7.20 | |
| klib binaries | Alpha | 1.4 | |
| Kotlin Multiplatform | Beta | 1.7.20 | |
| Kotlin/Native interop with C and Objective C | Beta | 1.3 | |
| CocoaPods integration | Beta | 1.3 | |
| Kotlin Multiplatform Mobile plugin for Android Studio | Alpha | 0.3.0 | [Versioned separately from the language](multiplatform-mobile-plugin-releases) |
| expect/actual language feature | Beta | 1.2 | |
| KDoc syntax | Stable | 1.0 | |
| Dokka | Beta | 1.6 | |
| Scripting syntax and semantics | Alpha | 1.2 | |
| Scripting embedding and extension API | Beta | 1.5 | |
| Scripting IDE support | Experimental | 1.2 | |
| CLI scripting | Alpha | 1.2 | |
| Compiler Plugin API | Experimental | 1.0 | |
| Serialization Compiler Plugin | Stable | 1.4 | |
| Serialization Core Library | Stable | 1.0.0 | Versioned separately from the language |
| Inline classes | Stable | 1.5 | |
| Unsigned arithmetic | Stable | 1.5 | |
| Contracts in stdlib | Stable | 1.3 | |
| User-defined contracts | Experimental | 1.3 | |
| **All other experimental components, by default** | Experimental | N/A | |
*[The pre-1.4 version of this page is available here](components-stability-pre-1-4).*
Last modified: 10 January 2023
[Kotlin Evolution](kotlin-evolution) [Stability of Kotlin components (pre 1.4)](components-stability-pre-1-4)
| programming_docs |
kotlin Compatibility guide for Kotlin 1.5 Compatibility guide for Kotlin 1.5
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.4 to Kotlin 1.5.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language and stdlib
-------------------
### Forbid spread operator in signature-polymorphic calls
### Forbid non-abstract classes containing abstract members invisible from that classes (internal/package-private)
### Forbid using array based on non-reified type parameters as reified type arguments on JVM
### Forbid secondary enum class constructors which do not delegate to the primary constructor
### Forbid exposing anonymous types from private inline functions
### Forbid passing non-spread arrays after arguments with SAM-conversion
### Support special semantics for underscore-named catch block parameters
### Change implementation strategy of SAM conversion from anonymous class-based to invokedynamic
### Performance issues with the JVM IR-based backend
### New field sorting in the JVM IR-based backend
### Generate nullability assertion for delegated properties with a generic call in the delegate expression
### Turn warnings into errors for calls with type parameters annotated by @OnlyInputTypes
### Use the correct order of arguments execution in calls with named vararg
### Use default value of the parameter in operator functional calls
### Produce empty reversed progressions in for loops if regular progression is also empty
### Straighten Char-to-code and Char-to-digit conversions out
### Inconsistent case-insensitive comparison of characters in kotlin.text functions
### Remove default locale-sensitive case conversion API
### Gradually change the return type of collection min and max functions to non-nullable
### Raise the deprecation level of conversions of floating-point types to Short and Byte
Tools
-----
### Do not mix several JVM variants of kotlin-test in a single project
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.6](compatibility-guide-16) [Compatibility guide for Kotlin 1.4](compatibility-guide-14)
kotlin Why KSP Why KSP
=======
Compiler plugins are powerful metaprogramming tools that can greatly enhance how you write code. Compiler plugins call compilers directly as libraries to analyze and edit input programs. These plugins can also generate output for various uses. For example, they can generate boilerplate code, and they can even generate full implementations for specially-marked program elements, such as `Parcelable`. Plugins have a variety of other uses and can even be used to implement and fine-tune features that are not provided directly in a language.
While compiler plugins are powerful, this power comes at a price. To write even the simplest plugin, you need to have some compiler background knowledge, as well as a certain level of familiarity with the implementation details of your specific compiler. Another practical issue is that plugins are often closely tied to specific compiler versions, meaning you might need to update your plugin each time you want to support a newer version of the compiler.
KSP makes creating lightweight compiler plugins easier
------------------------------------------------------
KSP is designed to hide compiler changes, minimizing maintenance efforts for processors that use it. KSP is designed not to be tied to the JVM so that it can be adapted to other platforms more easily in the future. KSP is also designed to minimize build times. For some processors, such as [Glide](https://github.com/bumptech/glide), KSP reduces full compilation times by up to 25% when compared to kapt.
KSP is itself implemented as a compiler plugin. There are prebuilt packages on Google's Maven repository that you can download and use without having to build the project yourself.
Comparison to kotlinc compiler plugins
--------------------------------------
`kotlinc` compiler plugins have access to almost everything from the compiler and therefore have maximum power and flexibility. On the other hand, because these plugins can potentially depend on anything in the compiler, they are sensitive to compiler changes and need to be maintained frequently. These plugins also require a deep understanding of `kotlinc`'s implementation, so the learning curve can be steep.
KSP aims to hide most compiler changes through a well-defined API, though major changes in compiler or even the Kotlin language might still require to be exposed to API users.
KSP tries to fulfill common use cases by providing an API that trades power for simplicity. Its capability is a strict subset of a general `kotlinc` plugin. For example, while `kotlinc` can examine expressions and statements and can even modify code, KSP cannot.
While writing a `kotlinc` plugin can be a lot of fun, it can also take a lot of time. If you aren't in a position to learn `kotlinc`'s implementation and do not need to modify source code or read expressions, KSP might be a good fit.
Comparison to reflection
------------------------
KSP's API looks similar to `kotlin.reflect`. The major difference between them is that type references in KSP need to be resolved explicitly. This is one of the reasons why the interfaces are not shared.
Comparison to kapt
------------------
<kapt> is a remarkable solution which makes a large amount of Java annotation processors work for Kotlin programs out-of-box. The major advantages of KSP over kapt are improved build performance, not tied to JVM, a more idiomatic Kotlin API, and the ability to understand Kotlin-only symbols.
To run Java annotation processors unmodified, kapt compiles Kotlin code into Java stubs that retain information that Java annotation processors care about. To create these stubs, kapt needs to resolve all symbols in the Kotlin program. The stub generation costs roughly 1/3 of a full `kotlinc` analysis and the same order of `kotlinc` code-generation. For many annotation processors, this is much longer than the time spent in the processors themselves. For example, Glide looks at a very limited number of classes with a predefined annotation, and its code generation is fairly quick. Almost all of the build overhead resides in the stub generation phase. Switching to KSP would immediately reduce the time spent in the compiler by 25%.
For performance evaluation, we implemented a [simplified version](https://github.com/google/ksp/releases/download/1.4.10-dev-experimental-20200924/miniGlide.zip) of [Glide](https://github.com/bumptech/glide) in KSP to make it generate code for the [Tachiyomi](https://github.com/inorichi/tachiyomi) project. While the total Kotlin compilation time of the project is 21.55 seconds on our test device, it took 8.67 seconds for kapt to generate the code, and it took 1.15 seconds for our KSP implementation to generate the code.
Unlike kapt, processors in KSP do not see input programs from Java's point of view. The API is more natural to Kotlin, especially for Kotlin-specific features such as top-level functions. Because KSP doesn't delegate to `javac` like kapt, it doesn't assume JVM-specific behaviors and can be used with other platforms potentially.
Limitations
-----------
While KSP tries to be a simple solution for most common use cases, it has made several trade-offs compared to other plugin solutions. The following are not goals of KSP:
* Examining expression-level information of source code.
* Modifying source code.
* 100% compatibility with the Java Annotation Processing API.
We are also exploring several additional features. These features are currently unavailable:
* IDE integration: Currently IDEs know nothing about the generated code.
Last modified: 10 January 2023
[KSP quickstart](ksp-quickstart) [KSP examples](ksp-examples)
kotlin Kotlin for data science Kotlin for data science
=======================
From building data pipelines to productionizing machine learning models, Kotlin can be a great choice for working with data:
* Kotlin is concise, readable, and easy to learn.
* Static typing and null safety help create reliable, maintainable code that is easy to troubleshoot.
* Being a JVM language, Kotlin gives you great performance and an ability to leverage an entire ecosystem of tried and true Java libraries.
Interactive editors
-------------------
Notebooks such as [Jupyter Notebook](https://jupyter.org/), [Datalore](http://jetbrains.com/datalore), and [Apache Zeppelin](https://zeppelin.apache.org/) provide convenient tools for data visualization and exploratory research. Kotlin integrates with these tools to help you explore data, share your findings with colleagues, or build up your data science and machine learning skills.
### Jupyter Kotlin kernel
The Jupyter Notebook is an open-source web application that allows you to create and share documents (aka "notebooks") that can contain code, visualizations, and Markdown text. [Kotlin-jupyter](https://github.com/Kotlin/kotlin-jupyter) is an open source project that brings Kotlin support to Jupyter Notebook.
Check out Kotlin kernel's [GitHub repo](https://github.com/Kotlin/kotlin-jupyter) for installation instructions, documentation, and examples.
### Kotlin Notebooks in Datalore
With Datalore, you can use Kotlin in the browser straight out of the box, no installation required. You can also collaborate on Kotlin notebooks in real time, get smart coding assistance when writing code, and share results as interactive or static reports. Check out a [sample report](https://datalore.jetbrains.com/view/report/9YLrg20eesVX2cQu1FKLiZ).
[Sign up and use Kotlin with a free Datalore Community account](https://datalore.jetbrains.com/).
### Zeppelin Kotlin interpreter
Apache Zeppelin is a popular web-based solution for interactive data analytics. It provides strong support for the Apache Spark cluster computing system, which is particularly useful for data engineering. Starting from [version 0.9.0](https://zeppelin.apache.org/docs/0.9.0-preview1/), Apache Zeppelin comes with bundled Kotlin interpreter.
Libraries
---------
The ecosystem of libraries for data-related tasks created by the Kotlin community is rapidly expanding. Here are some libraries that you may find useful:
### Kotlin libraries
* [Multik](https://github.com/Kotlin/multik): multidimensional arrays in Kotlin. The library provides Kotlin-idiomatic, type- and dimension-safe API for mathematical operations over multidimensional arrays. Multik offers swappable JVM and native computational engines, and a combination of the two for optimal performance.
* [KotlinDL](https://github.com/jetbrains/kotlindl) is a high-level Deep Learning API written in Kotlin and inspired by Keras. It offers simple APIs for training deep learning models from scratch, importing existing Keras models for inference, and leveraging transfer learning for tweaking existing pre-trained models to your tasks.
* [Kotlin DataFrame](https://github.com/Kotlin/dataframe) is a library for structured data processing. It aims to reconcile Kotlin's static typing with the dynamic nature of data by utilizing both the full power of the Kotlin language and the opportunities provided by intermittent code execution in Jupyter notebooks and REPLs.
* [Kotlin for Apache Spark](https://github.com/JetBrains/kotlin-spark-api) adds a missing layer of compatibility between Kotlin and Apache Spark. It allows Kotlin developers to use familiar language features such as data classes, and lambda expressions as simple expressions in curly braces or method references.
* [kotlin-statistics](https://github.com/thomasnield/kotlin-statistics) is a library providing extension functions for exploratory and production statistics. It supports basic numeric list/sequence/array functions (from `sum` to `skewness`), slicing operators (such as `countBy`, `simpleRegressionBy`), binning operations, discrete PDF sampling, naive bayes classifier, clustering, linear regression, and much more.
* [kmath](https://github.com/mipt-npm/kmath) is an experimental library that was intially inspired by [NumPy](https://numpy.org/) but evolved to more flexible abstractions. It implements mathematical operations combined in algebraic structures over Kotlin types, defines APIs for linear structures, expressions, histograms, streaming operations, provides interchangeable wrappers over existing Java and Kotlin libraries including [ND4J](https://github.com/eclipse/deeplearning4j/tree/master/nd4j), [Commons Math](https://commons.apache.org/proper/commons-math/), [Multik](https://github.com/Kotlin/multik), and others.
* [krangl](https://github.com/holgerbrandl/krangl) is a library inspired by R's [dplyr](https://dplyr.tidyverse.org/) and Python's [pandas](https://pandas.pydata.org/). This library provides functionality for data manipulation using a functional-style API; it also includes functions for filtering, transforming, aggregating, and reshaping tabular data.
* [lets-plot](https://github.com/JetBrains/lets-plot) is a plotting library for statistical data written in Kotlin. Lets-Plot is multiplatform and can be used not only with JVM, but also with JS and Python.
* [kravis](https://github.com/holgerbrandl/kravis) is another library for the visualization of tabular data inspired by R's [ggplot](https://ggplot2.tidyverse.org/).
* [londogard-nlp-toolkit](https://github.com/londogard/londogard-nlp-toolkit/) is a library that provides utilities when working with natural language processing such as word/subword/sentence embeddings, word-frequencies, stopwords, stemming, and much more.
### Java libraries
Since Kotlin provides first-class interop with Java, you can also use Java libraries for data science in your Kotlin code. Here are some examples of such libraries:
* [DeepLearning4J](https://deeplearning4j.konduit.ai) - a deep learning library for Java
* [ND4J](https://github.com/eclipse/deeplearning4j/tree/master/nd4j) - an efficient matrix math library for JVM
* [Dex](https://github.com/PatMartin/Dex) - a Java-based data visualization tool
* [Smile](https://github.com/haifengl/smile) - a comprehensive machine learning, natural language processing, linear algebra, graph, interpolation, and visualization system. Besides Java API, Smile also provides a functional [Kotlin API](https://haifengl.github.io/api/kotlin/smile-kotlin/index.html) along with Scala and Clojure API.
+ [Smile-NLP-kt](https://github.com/londogard/smile-nlp-kt) - a Kotlin rewrite of the Scala implicits for the natural language processing part of Smile in the format of extension functions and interfaces.
* [Apache Commons Math](https://commons.apache.org/proper/commons-math/) - a general math, statistics, and machine learning library for Java
* [NM Dev](https://nm.dev/) - a Java mathematical library that covers all of classical mathematics.
* [OptaPlanner](https://www.optaplanner.org/) - a solver utility for optimization planning problems
* [Charts](https://github.com/HanSolo/charts) - a scientific JavaFX charting library in development
* [Apache OpenNLP](https://opennlp.apache.org/) - a machine learning based toolkit for the processing of natural language text
* [CoreNLP](https://stanfordnlp.github.io/CoreNLP/) - a natural language processing toolkit
* [Apache Mahout](https://mahout.apache.org/) - a distributed framework for regression, clustering and recommendation
* [Weka](https://www.cs.waikato.ac.nz/ml/index.html) - a collection of machine learning algorithms for data mining tasks
* [Tablesaw](https://github.com/jtablesaw/tablesaw) - a Java dataframe. It includes a visualization library based on Plot.ly
If this list doesn't cover your needs, you can find more options in the **[Kotlin Machine Learning Demos](https://github.com/thomasnield/kotlin-machine-learning-demos)** GitHub repository with showcases from Thomas Nield.
Last modified: 10 January 2023
[Kotlin Native](native-overview) [Kotlin for competitive programming](competitive-programming)
kotlin FAQ FAQ
===
What is Kotlin Multiplatform Mobile?
------------------------------------
*Kotlin Multiplatform Mobile (KMM)* is an SDK for cross-platform mobile development. You can develop multiplatform mobile applications and share parts of your applications between Android and iOS, such as core layers, business logic, presentation logic, and more.
Kotlin Mobile uses the [multiplatform abilities of Kotlin](multiplatform) and the features designed for mobile development, such as CocoaPods integration and the [Android Studio Plugin](#what-is-the-kotlin-multiplatform-mobile-plugin).
You may want to watch this introductory [video](https://www.youtube.com/watch?v=mdN6P6RI__k), in which Kotlin Product Marketing Manager Ekaterina Petrova explains in detail what Kotlin Multiplatform Mobile is and how you can use it in your projects. With Ekaterina, you'll set up an environment and prepare for creating your first cross-platform mobile application with Kotlin Multiplatform Mobile.
What is the Kotlin Multiplatform Mobile plugin?
-----------------------------------------------
The *[Kotlin Multiplatform Mobile plugin](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile)* for Android Studio helps you develop applications that work on both Android and iOS.
With the Kotlin Multiplatform Mobile plugin, you can:
* Run, test, and debug the iOS part of your application on iOS targets straight from Android Studio.
* Quickly create a new multiplatform project.
* Add a multiplatform module into an existing project.
The Kotlin Multiplatform Mobile plugin works only on macOS. This is because iOS simulators, per the Apple requirement, can run only on macOS but not on any other operating systems, such as Microsoft Windows or Linux.
The good news is that you can work with cross-platform projects on Android even without the Kotlin Multiplatform Mobile plugin. If you are going to work with shared code or Android-specific code, you can work on any operating system supported by Android Studio.
What is Kotlin/Native and how does it relate to Kotlin Multiplatform Mobile?
----------------------------------------------------------------------------
*[Kotlin/Native](native-overview)* is a technology for compiling Kotlin code to native binaries, which can run without a virtual machine. It consists of an [LLVM](https://llvm.org/)-based backend for the Kotlin compiler and a native implementation of the Kotlin standard library.
Kotlin/Native is primarily designed to allow compilation for platforms where virtual machines are not desirable or possible, such as embedded devices and iOS. It is particularly suitable for situations when the developer needs to produce a self-contained program that does not require an additional runtime or virtual machine. And that is exactly the case with iOS development.
Shared code, written in Kotlin, is compiled to JVM bytecode for Android with Kotlin/JVM and to native binaries for iOS with Kotlin/Native. It makes the integration with Kotlin Multiplatform Mobile seamless on both platforms.
What are the plans for the technology evolution?
------------------------------------------------
Kotlin Multiplatform Mobile is one of the focus areas of the [Kotlin roadmap](roadmap). To see which parts we're working on right now, check out the [roadmap details](roadmap#roadmap-details). Most of the recent changes affect the **Kotlin Multiplatform** and **Kotlin/Native** sections.
The following video presents the current state and our plans for the Kotlin Multiplatform Mobile development:
Can I run an iOS application on Microsoft Windows or Linux?
-----------------------------------------------------------
If you want to write iOS-specific code and run an iOS application on a simulated or real device, use a Mac with a macOS ([use the Kotlin Multiplatform Mobile plugin for it](#what-is-the-kotlin-multiplatform-mobile-plugin)). This is because iOS simulators can run only on macOS, per the Apple requirement, but cannot run on other operating systems, such as Microsoft Windows or Linux.
If you are going to work with shared code or Android-specific code, you can work on any operating system supported by Android Studio.
Where can I get complete examples to play with?
-----------------------------------------------
* [Curated samples](multiplatform-mobile-samples)
* [Create a multiplatform app using Ktor and SQLDelight – tutorial](multiplatform-mobile-ktor-sqldelight)
In which IDE should I work on my cross-platform app?
----------------------------------------------------
You can work in [Android Studio](https://developer.android.com/studio). Android Studio allows the use of the [Kotlin Multiplatform Mobile plugin](#what-is-the-kotlin-multiplatform-mobile-plugin), which is a part of the Kotlin ecosystem. Enable the Kotlin Multiplatform Mobile plugin in Android Studio if you want to write iOS-specific code and launch an iOS application on a simulated or real device. The plugin can be used only on macOS.
Most of our adopters use Android Studio. However, if there is any reason for you not to use it, there is another option: you can use [IntelliJ IDEA](https://www.jetbrains.com/idea/download). IntelliJ IDEA provides the ability to create a multiplatform mobile application from the Project Wizard, but you won't be able to launch an iOS application from the IDE.
How can I write concurrent code in Kotlin Multiplatform Mobile projects?
------------------------------------------------------------------------
You can easily write concurrent code in your cross-platform mobile projects with the new [Kotlin/Native memory manager](native-memory-manager) that lifted previous limitations and aligned the behaviour between Kotlin/JVM and Kotlin/Native. The new memory manager has been enabled by default since Kotlin 1.7.20.
How can I speed up my Kotlin Multiplatform module compilation for iOS?
----------------------------------------------------------------------
See these [tips for improving Kotlin/Native compilation times](native-improving-compilation-time).
What platforms do you support?
------------------------------
Kotlin Multiplatform Mobile support development for:
* Android applications and libraries
* [Android NDK](https://developer.android.com/ndk) (ARM64 and ARM32)
* Apple iOS devices (ARM64 and ARM32) and simulators
* Apple watchOS devices (ARM64 and ARM32) and simulators
The [Kotlin Multiplatform](multiplatform) technology also supports [other platforms](multiplatform-dsl-reference#targets), including JavaScript, Linux, Windows, and WebAssembly.
Last modified: 10 January 2023
[Samples](multiplatform-mobile-samples) [Introduce cross-platform mobile development to your team](multiplatform-mobile-introduce-your-team)
| programming_docs |
kotlin Use JavaScript code from Kotlin Use JavaScript code from Kotlin
===============================
Kotlin was first designed for easy interoperation with the Java platform: it sees Java classes as Kotlin classes, and Java sees Kotlin classes as Java classes.
However, JavaScript is a dynamically typed language, which means it does not check types at compile time. You can freely talk to JavaScript from Kotlin via [dynamic](dynamic-type) types. If you want to use the full power of the Kotlin type system, you can create external declarations for JavaScript libraries which will be understood by the Kotlin compiler and the surrounding tooling.
An experimental tool to automatically create Kotlin external declarations for npm dependencies which provide type definitions (TypeScript / `d.ts`) called [Dukat](js-external-declarations-with-dukat) is also available.
Inline JavaScript
-----------------
You can inline some JavaScript code into your Kotlin code using the [`js()`](../api/latest/jvm/stdlib/kotlin.js/js) function. For example:
```
fun jsTypeOf(o: Any): String {
return js("typeof o")
}
```
Because the parameter of `js` is parsed at compile time and translated to JavaScript code "as-is", it is required to be a string constant. So, the following code is incorrect:
```
fun jsTypeOf(o: Any): String {
return js(getTypeof() + " o") // error reported here
}
fun getTypeof() = "typeof"
```
Note that invoking `js()` returns a result of type [`dynamic`](dynamic-type), which provides no type safety at the compile time.
external modifier
-----------------
To tell Kotlin that a certain declaration is written in pure JavaScript, you should mark it with the `external` modifier. When the compiler sees such a declaration, it assumes that the implementation for the corresponding class, function or property is provided externally (by the developer or via an [npm dependency](js-project-setup#npm-dependencies)), and therefore does not try to generate any JavaScript code from the declaration. This is also why `external` declarations can't have a body. For example:
```
external fun alert(message: Any?): Unit
external class Node {
val firstChild: Node
fun append(child: Node): Node
fun removeChild(child: Node): Node
// etc
}
external val window: Window
```
Note that the `external` modifier is inherited by nested declarations. This is why in the example `Node` class, there is no `external` modifier before member functions and properties.
The `external` modifier is only allowed on package-level declarations. You can't declare an `external` member of a non-`external` class.
### Declare (static) members of a class
In JavaScript you can define members either on a prototype or a class itself:
```
function MyClass() { ... }
MyClass.sharedMember = function() { /* implementation */ };
MyClass.prototype.ownMember = function() { /* implementation */ };
```
There is no such syntax in Kotlin. However, in Kotlin we have [`companion`](object-declarations#companion-objects) objects. Kotlin treats companion objects of `external` classes in a special way: instead of expecting an object, it assumes members of companion objects to be members of the class itself. `MyClass` from the example above can be described as follows:
```
external class MyClass {
companion object {
fun sharedMember()
}
fun ownMember()
}
```
### Declare optional parameters
If you are writing an external declaration for a JavaScript function which has an optional parameter, use `definedExternally`. This delegates the generation of the default values to the JavaScript function itself:
```
external fun myFunWithOptionalArgs(
x: Int,
y: String = definedExternally,
z: String = definedExternally
)
```
With this external declaration, you can call `myFunWithOptionalArgs` with one required argument and two optional arguments, where the default values are calculated by the JavaScript implementation of `myFunWithOptionalArgs`.
### Extend JavaScript classes
You can easily extend JavaScript classes as if they were Kotlin classes. Just define an `external open` class and extend it by a non-`external` class. For example:
```
open external class Foo {
open fun run()
fun stop()
}
class Bar: Foo() {
override fun run() {
window.alert("Running!")
}
fun restart() {
window.alert("Restarting")
}
}
```
There are some limitations:
* When a function of an external base class is overloaded by signature, you can't override it in a derived class.
* You can't override a function with default arguments.
* Non-external classes can't be extended by external classes.
### external interfaces
JavaScript does not have the concept of interfaces. When a function expects its parameter to support two methods `foo` and `bar`, you would just pass in an object that actually has these methods.
You can use interfaces to express this concept in statically typed Kotlin:
```
external interface HasFooAndBar {
fun foo()
fun bar()
}
external fun myFunction(p: HasFooAndBar)
```
A typical use case for external interfaces is to describe settings objects. For example:
```
external interface JQueryAjaxSettings {
var async: Boolean
var cache: Boolean
var complete: (JQueryXHR, String) -> Unit
// etc
}
fun JQueryAjaxSettings(): JQueryAjaxSettings = js("{}")
external class JQuery {
companion object {
fun get(settings: JQueryAjaxSettings): JQueryXHR
}
}
fun sendQuery() {
JQuery.get(JQueryAjaxSettings().apply {
complete = { (xhr, data) ->
window.alert("Request complete")
}
})
}
```
External interfaces have some restrictions:
* They can't be used on the right-hand side of `is` checks.
* They can't be passed as reified type arguments.
* They can't be used in class literal expressions (such as `I::class`).
* `as` casts to external interfaces always succeed. Casting to external interfaces produces the "Unchecked cast to external interface" compile time warning. The warning can be suppressed with the `@Suppress("UNCHECKED_CAST_TO_EXTERNAL_INTERFACE")` annotation.
IntelliJ IDEA can also automatically generate the `@Suppress` annotation. Open the intentions menu via the light bulb icon or Alt-Enter, and click the small arrow next to the "Unchecked cast to external interface" inspection. Here, you can select the suppression scope, and your IDE will add the annotation to your file accordingly.
### Casts
In addition to the ["unsafe" cast operator](typecasts#unsafe-cast-operator) `as`, which throws a `ClassCastException` in case a cast is not possible, Kotlin/JS also provides [`unsafeCast<T>()`](../api/latest/jvm/stdlib/kotlin.js/unsafe-cast). When using `unsafeCast`, *no type checking is done at all* during runtime. For example, consider the following two methods:
```
fun usingUnsafeCast(s: Any) = s.unsafeCast<String>()
fun usingAsOperator(s: Any) = s as String
```
They will be compiled accordingly:
```
function usingUnsafeCast(s) {
return s;
}
function usingAsOperator(s) {
var tmp$;
return typeof (tmp$ = s) === 'string' ? tmp$ : throwCCE();
}
```
Last modified: 10 January 2023
[Browser and DOM API](browser-api-dom) [Dynamic type](dynamic-type)
kotlin Extensions Extensions
==========
Kotlin provides the ability to extend a class or an interface with new functionality without having to inherit from the class or use design patterns such as *Decorator*. This is done via special declarations called *extensions*.
For example, you can write new functions for a class or an interface from a third-party library that you can't modify. Such functions can be called in the usual way, as if they were methods of the original class. This mechanism is called an *extension function*. There are also *extension properties* that let you define new properties for existing classes.
Extension functions
-------------------
To declare an extension function, prefix its name with a *receiver type*, which refers to the type being extended. The following adds a `swap` function to `MutableList<Int>`:
```
fun MutableList<Int>.swap(index1: Int, index2: Int) {
val tmp = this[index1] // 'this' corresponds to the list
this[index1] = this[index2]
this[index2] = tmp
}
```
The `this` keyword inside an extension function corresponds to the receiver object (the one that is passed before the dot). Now, you can call such a function on any `MutableList<Int>`:
```
val list = mutableListOf(1, 2, 3)
list.swap(0, 2) // 'this' inside 'swap()' will hold the value of 'list'
```
This function makes sense for any `MutableList<T>`, and you can make it generic:
```
fun <T> MutableList<T>.swap(index1: Int, index2: Int) {
val tmp = this[index1] // 'this' corresponds to the list
this[index1] = this[index2]
this[index2] = tmp
}
```
You need to declare the generic type parameter before the function name to make it available in the receiver type expression. For more information about generics, see [generic functions](generics).
Extensions are resolved statically
----------------------------------
Extensions do not actually modify the classes they extend. By defining an extension, you are not inserting new members into a class, only making new functions callable with the dot-notation on variables of this type.
Extension functions are dispatched *statically*, which means they are not virtual by receiver type. An extension function being called is determined by the type of the expression on which the function is invoked, not by the type of the result from evaluating that expression at runtime. For example:
```
fun main() {
//sampleStart
open class Shape
class Rectangle: Shape()
fun Shape.getName() = "Shape"
fun Rectangle.getName() = "Rectangle"
fun printClassName(s: Shape) {
println(s.getName())
}
printClassName(Rectangle())
//sampleEnd
}
```
This example prints *Shape*, because the extension function called depends only on the declared type of the parameter `s`, which is the `Shape` class.
If a class has a member function, and an extension function is defined which has the same receiver type, the same name, and is applicable to given arguments, the *member always wins*. For example:
```
fun main() {
//sampleStart
class Example {
fun printFunctionType() { println("Class method") }
}
fun Example.printFunctionType() { println("Extension function") }
Example().printFunctionType()
//sampleEnd
}
```
This code prints *Class method*.
However, it's perfectly OK for extension functions to overload member functions that have the same name but a different signature:
```
fun main() {
//sampleStart
class Example {
fun printFunctionType() { println("Class method") }
}
fun Example.printFunctionType(i: Int) { println("Extension function #$i") }
Example().printFunctionType(1)
//sampleEnd
}
```
Nullable receiver
-----------------
Note that extensions can be defined with a nullable receiver type. These extensions can be called on an object variable even if its value is null, and they can check for `this == null` inside the body.
This way, you can call `toString()` in Kotlin without checking for `null`, as the check happens inside the extension function:
```
fun Any?.toString(): String {
if (this == null) return "null"
// after the null check, 'this' is autocast to a non-null type, so the toString() below
// resolves to the member function of the Any class
return toString()
}
```
Extension properties
--------------------
Kotlin supports extension properties much like it supports functions:
```
val <T> List<T>.lastIndex: Int
get() = size - 1
```
Example:
```
val House.number = 1 // error: initializers are not allowed for extension properties
```
Companion object extensions
---------------------------
If a class has a [companion object](object-declarations#companion-objects) defined, you can also define extension functions and properties for the companion object. Just like regular members of the companion object, they can be called using only the class name as the qualifier:
```
class MyClass {
companion object { } // will be called "Companion"
}
fun MyClass.Companion.printCompanion() { println("companion") }
fun main() {
MyClass.printCompanion()
}
```
Scope of extensions
-------------------
In most cases, you define extensions on the top level, directly under packages:
```
package org.example.declarations
fun List<String>.getLongestString() { /*...*/}
```
To use an extension outside its declaring package, import it at the call site:
```
package org.example.usage
import org.example.declarations.getLongestString
fun main() {
val list = listOf("red", "green", "blue")
list.getLongestString()
}
```
See [Imports](packages#imports) for more information.
Declaring extensions as members
-------------------------------
You can declare extensions for one class inside another class. Inside such an extension, there are multiple *implicit receivers* - objects whose members can be accessed without a qualifier. An instance of a class in which the extension is declared is called a *dispatch receiver*, and an instance of the receiver type of the extension method is called an *extension receiver*.
```
class Host(val hostname: String) {
fun printHostname() { print(hostname) }
}
class Connection(val host: Host, val port: Int) {
fun printPort() { print(port) }
fun Host.printConnectionString() {
printHostname() // calls Host.printHostname()
print(":")
printPort() // calls Connection.printPort()
}
fun connect() {
/*...*/
host.printConnectionString() // calls the extension function
}
}
fun main() {
Connection(Host("kotl.in"), 443).connect()
//Host("kotl.in").printConnectionString() // error, the extension function is unavailable outside Connection
}
```
In the event of a name conflict between the members of a dispatch receiver and an extension receiver, the extension receiver takes precedence. To refer to the member of the dispatch receiver, you can use the [qualified `this` syntax](this-expressions#qualified-this).
```
class Connection {
fun Host.getConnectionString() {
toString() // calls Host.toString()
[email protected]() // calls Connection.toString()
}
}
```
Extensions declared as members can be declared as `open` and overridden in subclasses. This means that the dispatch of such functions is virtual with regard to the dispatch receiver type, but static with regard to the extension receiver type.
```
open class Base { }
class Derived : Base() { }
open class BaseCaller {
open fun Base.printFunctionInfo() {
println("Base extension function in BaseCaller")
}
open fun Derived.printFunctionInfo() {
println("Derived extension function in BaseCaller")
}
fun call(b: Base) {
b.printFunctionInfo() // call the extension function
}
}
class DerivedCaller: BaseCaller() {
override fun Base.printFunctionInfo() {
println("Base extension function in DerivedCaller")
}
override fun Derived.printFunctionInfo() {
println("Derived extension function in DerivedCaller")
}
}
fun main() {
BaseCaller().call(Base()) // "Base extension function in BaseCaller"
DerivedCaller().call(Base()) // "Base extension function in DerivedCaller" - dispatch receiver is resolved virtually
DerivedCaller().call(Derived()) // "Base extension function in DerivedCaller" - extension receiver is resolved statically
}
```
Note on visibility
------------------
Extensions utilize the same [visibility modifiers](visibility-modifiers) as regular functions declared in the same scope would. For example:
* An extension declared at the top level of a file has access to the other `private` top-level declarations in the same file.
* If an extension is declared outside its receiver type, it cannot access the receiver's `private` or `protected` members.
Last modified: 10 January 2023
[Visibility modifiers](visibility-modifiers) [Data classes](data-classes)
kotlin Adding iOS dependencies Adding iOS dependencies
=======================
Apple SDK dependencies (such as Foundation or Core Bluetooth) are available as a set of prebuilt libraries in Kotlin Multiplatform Mobile projects. They do not require any additional configuration.
You can also reuse other libraries and frameworks from the iOS ecosystem in your iOS source sets. Kotlin supports interoperability with Objective-C dependencies and Swift dependencies if their APIs are exported to Objective-C with the `@objc` attribute. Pure Swift dependencies are not yet supported.
Integration with the CocoaPods dependency manager is also supported with the same limitation – you cannot use pure Swift pods.
We recommend [using CocoaPods](#with-cocoapods) to handle iOS dependencies in Kotlin Multiplatform Mobile projects. [Manage dependencies manually](#without-cocoapods) only if you want to tune the interop process specifically or if you have some other strong reason to do so.
With CocoaPods
--------------
1. Perform [initial CocoaPods integration setup](native-cocoapods#set-up-an-environment-to-work-with-cocoapods).
2. Add a dependency on a Pod library from the CocoaPods repository that you want to use by including the `pod()` function call in `build.gradle.kts` (`build.gradle`) of your project.
```
kotlin {
cocoapods {
//..
pod("AFNetworking") {
version = "~> 4.0.1"
}
}
}
```
```
kotlin {
cocoapods {
//..
pod('AFNetworking') {
version = '~> 4.0.1'
}
}
}
```
You can add the following dependencies on a Pod library:
* [From the CocoaPods repository](native-cocoapods-libraries#from-the-cocoapods-repository)
* [On a locally stored library](native-cocoapods-libraries#on-a-locally-stored-library)
* [From a custom Git repository](native-cocoapods-libraries#from-a-custom-git-repository)
* [From a custom Podspec repository](native-cocoapods-libraries#from-a-custom-podspec-repository)
* [With custom cinterop options](native-cocoapods-libraries#with-custom-cinterop-options)
* [On a static Pod library](native-cocoapods-libraries#on-a-static-pod-library)
3. Re-import the project.
To use the dependency in your Kotlin code, import the package `cocoapods.<library-name>`. For the example above, it's:
```
import cocoapods.AFNetworking.*
```
Without CocoaPods
-----------------
If you don't want to use CocoaPods, you can use the cinterop tool to create Kotlin bindings for Objective-C or Swift declarations. This will allow you to call them from the Kotlin code.
The steps differ a bit for [libraries](#add-a-library-without-cocoapods) and [frameworks](#add-a-framework-without-cocoapods), but the idea remains the same.
1. Download your dependency.
2. Build it to get its binaries.
3. Create a special `.def` file that describes this dependency to cinterop.
4. Adjust your build script to generate bindings during the build.
### Add a library without CocoaPods
1. Download the library source code and place it somewhere where you can reference it from your project.
2. Build a library (library authors usually provide a guide on how to do this) and get a path to the binaries.
3. In your project, create a `.def` file, for example `DateTools.def`.
4. Add a first string to this file: `language = Objective-C`. If you want to use a pure C dependency, omit the language property.
5. Provide values for two mandatory properties:
* `headers` describes which headers will be processed by cinterop.
* `package` sets the name of the package these declarations should be put into.For example:
```
headers = DateTools.h
package = DateTools
```
6. Add information about interoperability with this library to the build script:
* Pass the path to the `.def` file. This path can be omitted if your `.def` file has the same name as cinterop and is placed in the `src/nativeInterop/cinterop/` directory.
* Tell cinterop where to look for header files using the `includeDirs` option.
* Configure linking to library binaries.
```
kotlin {
iosX64() {
compilations.getByName("main") {
val DateTools by cinterops.creating {
// Path to .def file
defFile("src/nativeInterop/cinterop/DateTools.def")
// Directories for header search (an analogue of the -I<path> compiler option)
includeDirs("include/this/directory", "path/to/another/directory")
}
val anotherInterop by cinterops.creating { /* ... */ }
}
binaries.all {
// Linker options required to link to the library.
linkerOpts("-L/path/to/library/binaries", "-lbinaryname")
}
}
}
```
```
kotlin {
iosX64 {
compilations.main {
cinterops {
DateTools {
// Path to .def file
defFile("src/nativeInterop/cinterop/DateTools.def")
// Directories for header search (an analogue of the -I<path> compiler option)
includeDirs("include/this/directory", "path/to/another/directory")
}
anotherInterop { /* ... */ }
}
}
binaries.all {
// Linker options required to link to the library.
linkerOpts "-L/path/to/library/binaries", "-lbinaryname"
}
}
}
```
7. Build the project.
Now you can use this dependency in your Kotlin code. To do that, import the package you've set up in the `package` property in the `.def` file. For the example above, this will be:
```
import DateTools.*
```
### Add a framework without CocoaPods
1. Download the framework source code and place it somewhere that you can reference it from your project.
2. Build the framework (framework authors usually provide a guide on how to do this) and get a path to the binaries.
3. In your project, create a `.def` file, for example `MyFramework.def`.
4. Add the first string to this file: `language = Objective-C`. If you want to use a pure C dependency, omit the language property.
5. Provide values for these two mandatory properties:
* `modules` – the name of the framework that should be processed by the cinterop.
* `package` – the name of the package these declarations should be put into.For example:
```
modules = MyFramework
package = MyFramework
```
6. Add information about interoperability with the framework to the build script:
* Pass the path to the .def file. This path can be omitted if your `.def` file has the same name as the cinterop and is placed in the `src/nativeInterop/cinterop/` directory.
* Pass the framework name to the compiler and linker using the `-framework` option. Pass the path to the framework sources and binaries to the compiler and linker using the `-F` option.
```
kotlin {
iosX64() {
compilations.getByName("main") {
val DateTools by cinterops.creating {
// Path to .def file
defFile("src/nativeInterop/cinterop/DateTools.def")
compilerOpts("-framework", "MyFramework", "-F/path/to/framework/")
}
val anotherInterop by cinterops.creating { /* ... */ }
}
binaries.all {
// Tell the linker where the framework is located.
linkerOpts("-framework", "MyFramework", "-F/path/to/framework/")
}
}
}
```
```
kotlin {
iosX64 {
compilations.main {
cinterops {
DateTools {
// Path to .def file
defFile("src/nativeInterop/cinterop/MyFramework.def")
compilerOpts("-framework", "MyFramework", "-F/path/to/framework/")
}
anotherInterop { /* ... */ }
}
}
binaries.all {
// Tell the linker where the framework is located.
linkerOpts("-framework", "MyFramework", "-F/path/to/framework/")
}
}
}
```
7. Build the project.
Now you can use this dependency in your Kotlin code. To do this, import the package you've set up in the package property in the `.def` file. For the example above, this will be:
```
import MyFramework.*
```
Learn more about [Objective-C and Swift interop](native-objc-interop) and [configuring cinterop from Gradle](multiplatform-dsl-reference#cinterops).
Workaround to enable IDE support for the shared iOS source set
--------------------------------------------------------------
Due to a [known issue](https://youtrack.jetbrains.com/issue/KT-40975), you won't be able to use IDE features, such as code completion and highlighting, for the shared iOS source set in a multiplatform project with [hierarchical structure support](multiplatform-share-on-platforms#share-code-on-similar-platforms) if your project depends on:
* Multiplatform libraries that don't support the hierarchical structure.
* Third-party iOS libraries, with the exception of [platform libraries](native-platform-libs) supported out of the box.
This issue applies only to the shared iOS source set. The IDE will correctly support the rest of the code.
To enable IDE support in these cases, you can work around the issue by adding the following code to `build.gradle.(kts)` in the `shared` directory of your project:
```
val iosTarget: (String, KotlinNativeTarget.() -> Unit) -> KotlinNativeTarget =
if (System.getenv("SDK_NAME")?.startsWith("iphoneos") == true)
::iosArm64
else
::iosX64
iosTarget("ios")
```
```
def iosTarget
if (System.getenv("SDK_NAME")?.startsWith("iphoneos")) {
iosTarget = kotlin.&iosArm64
} else {
iosTarget = kotlin.&iosX64
}
```
In this code sample, the configuration of iOS targets depends on the environment variable `SDK_NAME`, which is managed by Xcode. For each build, you'll have only one iOS target, named `ios`, that uses the `iosMain` source set. There will be no hierarchy of the `iosMain`, `iosArm64`, and `iosX64` source sets.
Alternatively, you can enable the support of platform-dependent interop libraries in shared source sets. In addition to [platform libraries](native-platform-libs) shipped with Kotlin/Native, this approach can also handle custom [`cinterop` libraries](native-c-interop) making them available in shared source sets. To enable this feature, add the `kotlin.mpp.enableCInteropCommonization=true` property in your `gradle.properties`:
```
kotlin.mpp.enableCInteropCommonization=true
```
What's next?
------------
Check out other resources on adding dependencies in multiplatform projects and learn more about:
* [Adding dependencies on multiplatform libraries or other multiplatform projects](multiplatform-add-dependencies)
* [Adding Android dependencies](multiplatform-mobile-android-dependencies)
Last modified: 10 January 2023
[Adding Android dependencies](multiplatform-mobile-android-dependencies) [Run tests with Kotlin Multiplatform](multiplatform-run-tests)
| programming_docs |
kotlin Delegated properties Delegated properties
====================
With some common kinds of properties, even though you can implement them manually every time you need them, it is more helpful to implement them once, add them to a library, and reuse them later. For example:
* *Lazy* properties: the value is computed only on first access.
* *Observable* properties: listeners are notified about changes to this property.
* Storing properties in a *map* instead of a separate field for each property.
To cover these (and other) cases, Kotlin supports *delegated properties*:
```
class Example {
var p: String by Delegate()
}
```
The syntax is: `val/var <property name>: <Type> by <expression>`. The expression after `by` is a *delegate*, because the `get()` (and `set()`) that correspond to the property will be delegated to its `getValue()` and `setValue()` methods. Property delegates don't have to implement an interface, but they have to provide a `getValue()` function (and `setValue()` for `var`s).
For example:
```
import kotlin.reflect.KProperty
class Delegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "$thisRef, thank you for delegating '${property.name}' to me!"
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
println("$value has been assigned to '${property.name}' in $thisRef.")
}
}
```
When you read from `p`, which delegates to an instance of `Delegate`, the `getValue()` function from `Delegate` is called. Its first parameter is the object you read `p` from, and the second parameter holds a description of `p` itself (for example, you can take its name).
```
val e = Example()
println(e.p)
```
This prints:
`Example@33a17727, thank you for delegating 'p' to me!`
Similarly, when you assign to `p`, the `setValue()` function is called. The first two parameters are the same, and the third holds the value being assigned:
```
e.p = "NEW"
```
This prints:
`NEW has been assigned to 'p' in Example@33a17727.`
The specification of the requirements to the delegated object can be found [below](#property-delegate-requirements).
You can declare a delegated property inside a function or code block; it doesn't have to be a member of a class. Below you can find [an example](#local-delegated-properties).
Standard delegates
------------------
The Kotlin standard library provides factory methods for several useful kinds of delegates.
### Lazy properties
[`lazy()`](../api/latest/jvm/stdlib/kotlin/lazy) is a function that takes a lambda and returns an instance of `Lazy<T>`, which can serve as a delegate for implementing a lazy property. The first call to `get()` executes the lambda passed to `lazy()` and remembers the result. Subsequent calls to `get()` simply return the remembered result.
```
val lazyValue: String by lazy {
println("computed!")
"Hello"
}
fun main() {
println(lazyValue)
println(lazyValue)
}
```
By default, the evaluation of lazy properties is *synchronized*: the value is computed only in one thread, but all threads will see the same value. If the synchronization of the initialization delegate is not required to allow multiple threads to execute it simultaneously, pass `LazyThreadSafetyMode.PUBLICATION` as a parameter to `lazy()`.
If you're sure that the initialization will always happen in the same thread as the one where you use the property, you can use `LazyThreadSafetyMode.NONE`. It doesn't incur any thread-safety guarantees and related overhead.
### Observable properties
[`Delegates.observable()`](../api/latest/jvm/stdlib/kotlin.properties/-delegates/observable) takes two arguments: the initial value and a handler for modifications.
The handler is called every time you assign to the property (*after* the assignment has been performed). It has three parameters: the property being assigned to, the old value, and the new value:
```
import kotlin.properties.Delegates
class User {
var name: String by Delegates.observable("<no name>") {
prop, old, new ->
println("$old -> $new")
}
}
fun main() {
val user = User()
user.name = "first"
user.name = "second"
}
```
If you want to intercept assignments and *veto* them, use [`vetoable()`](../api/latest/jvm/stdlib/kotlin.properties/-delegates/vetoable) instead of `observable()`. The handler passed to `vetoable` will be called *before* the assignment of a new property value.
Delegating to another property
------------------------------
A property can delegate its getter and setter to another property. Such delegation is available for both top-level and class properties (member and extension). The delegate property can be:
* A top-level property
* A member or an extension property of the same class
* A member or an extension property of another class
To delegate a property to another property, use the `::` qualifier in the delegate name, for example, `this::delegate` or `MyClass::delegate`.
```
var topLevelInt: Int = 0
class ClassWithDelegate(val anotherClassInt: Int)
class MyClass(var memberInt: Int, val anotherClassInstance: ClassWithDelegate) {
var delegatedToMember: Int by this::memberInt
var delegatedToTopLevel: Int by ::topLevelInt
val delegatedToAnotherClass: Int by anotherClassInstance::anotherClassInt
}
var MyClass.extDelegated: Int by ::topLevelInt
```
This may be useful, for example, when you want to rename a property in a backward-compatible way: introduce a new property, annotate the old one with the `@Deprecated` annotation, and delegate its implementation.
```
class MyClass {
var newName: Int = 0
@Deprecated("Use 'newName' instead", ReplaceWith("newName"))
var oldName: Int by this::newName
}
fun main() {
val myClass = MyClass()
// Notification: 'oldName: Int' is deprecated.
// Use 'newName' instead
myClass.oldName = 42
println(myClass.newName) // 42
}
```
Storing properties in a map
---------------------------
One common use case is storing the values of properties in a map. This comes up often in applications for things like parsing JSON or performing other dynamic tasks. In this case, you can use the map instance itself as the delegate for a delegated property.
```
class User(val map: Map<String, Any?>) {
val name: String by map
val age: Int by map
}
```
In this example, the constructor takes a map:
```
val user = User(mapOf(
"name" to "John Doe",
"age" to 25
))
```
Delegated properties take values from this map through string keys, which are associated with the names of properties:
```
class User(val map: Map<String, Any?>) {
val name: String by map
val age: Int by map
}
fun main() {
val user = User(mapOf(
"name" to "John Doe",
"age" to 25
))
//sampleStart
println(user.name) // Prints "John Doe"
println(user.age) // Prints 25
//sampleEnd
}
```
This also works for `var`'s properties if you use a `MutableMap` instead of a read-only `Map`:
```
class MutableUser(val map: MutableMap<String, Any?>) {
var name: String by map
var age: Int by map
}
```
Local delegated properties
--------------------------
You can declare local variables as delegated properties. For example, you can make a local variable lazy:
```
fun example(computeFoo: () -> Foo) {
val memoizedFoo by lazy(computeFoo)
if (someCondition && memoizedFoo.isValid()) {
memoizedFoo.doSomething()
}
}
```
The `memoizedFoo` variable will be computed on first access only. If `someCondition` fails, the variable won't be computed at all.
Property delegate requirements
------------------------------
For a *read-only* property (`val`), a delegate should provide an operator function `getValue()` with the following parameters:
* `thisRef` must be the same type as, or a supertype of, the *property owner* (for extension properties, it should be the type being extended).
* `property` must be of type `KProperty<*>` or its supertype.
`getValue()` must return the same type as the property (or its subtype).
```
class Resource
class Owner {
val valResource: Resource by ResourceDelegate()
}
class ResourceDelegate {
operator fun getValue(thisRef: Owner, property: KProperty<*>): Resource {
return Resource()
}
}
```
For a *mutable* property (`var`), a delegate has to additionally provide an operator function `setValue()` with the following parameters:
* `thisRef` must be the same type as, or a supertype of, the *property owner* (for extension properties, it should be the type being extended).
* `property` must be of type `KProperty<*>` or its supertype.
* `value` must be of the same type as the property (or its supertype).
```
class Resource
class Owner {
var varResource: Resource by ResourceDelegate()
}
class ResourceDelegate(private var resource: Resource = Resource()) {
operator fun getValue(thisRef: Owner, property: KProperty<*>): Resource {
return resource
}
operator fun setValue(thisRef: Owner, property: KProperty<*>, value: Any?) {
if (value is Resource) {
resource = value
}
}
}
```
`getValue()` and/or `setValue()` functions can be provided either as member functions of the delegate class or as extension functions. The latter is handy when you need to delegate a property to an object that doesn't originally provide these functions. Both of the functions need to be marked with the `operator` keyword.
You can create delegates as anonymous objects without creating new classes, by using the interfaces `ReadOnlyProperty` and `ReadWriteProperty` from the Kotlin standard library. They provide the required methods: `getValue()` is declared in `ReadOnlyProperty`; `ReadWriteProperty` extends it and adds `setValue()`. This means you can pass a `ReadWriteProperty` whenever a `ReadOnlyProperty` is expected.
```
fun resourceDelegate(resource: Resource = Resource()): ReadWriteProperty<Any?, Resource> =
object : ReadWriteProperty<Any?, Resource> {
var curValue = resource
override fun getValue(thisRef: Any?, property: KProperty<*>): Resource = curValue
override fun setValue(thisRef: Any?, property: KProperty<*>, value: Resource) {
curValue = value
}
}
val readOnlyResource: Resource by resourceDelegate() // ReadWriteProperty as val
var readWriteResource: Resource by resourceDelegate()
```
Translation rules for delegated properties
------------------------------------------
Under the hood, the Kotlin compiler generates auxiliary properties for some kinds of delegated properties and then delegates to them.
For example, for the property `prop` it generates the hidden property `prop$delegate`, and the code of the accessors simply delegates to this additional property:
```
class C {
var prop: Type by MyDelegate()
}
// this code is generated by the compiler instead:
class C {
private val prop$delegate = MyDelegate()
var prop: Type
get() = prop$delegate.getValue(this, this::prop)
set(value: Type) = prop$delegate.setValue(this, this::prop, value)
}
```
The Kotlin compiler provides all the necessary information about `prop` in the arguments: the first argument `this` refers to an instance of the outer class `C`, and `this::prop` is a reflection object of the `KProperty` type describing `prop` itself.
### Optimized cases for delegated properties
The `$delegate` field will be omitted if a delegate is:
* A referenced property:
```
class C<Type> {
private var impl: Type = ...
var prop: Type by ::impl
}
```
* A named object:
```
object NamedObject {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String = ...
}
val s: String by NamedObject
```
* A final `val` property with a backing field and a default getter in the same module:
```
val impl: ReadOnlyProperty<Any?, String> = ...
class A {
val s: String by impl
}
```
* A constant expression, enum entry, `this`, `null`. The example of `this`:
```
class A {
operator fun getValue(thisRef: Any?, property: KProperty<*>) ...
val s by this
}
```
### Translation rules when delegating to another property
When delegating to another property, the Kotlin compiler generates immediate access to the referenced property. This means that the compiler doesn't generate the field `prop$delegate`. This optimization helps save memory.
Take the following code, for example:
```
class C<Type> {
private var impl: Type = ...
var prop: Type by ::impl
}
```
Property accessors of the `prop` variable invoke the `impl` variable directly, skipping the delegated property's `getValue`and `setValue` operators, and thus the `KProperty` reference object is not needed.
For the code above, the compiler generates the following code:
```
class C<Type> {
private var impl: Type = ...
var prop: Type
get() = impl
set(value) {
impl = value
}
fun getProp$delegate(): Type = impl // This method is needed only for reflection
}
```
Providing a delegate
--------------------
By defining the `provideDelegate` operator, you can extend the logic for creating the object to which the property implementation is delegated. If the object used on the right-hand side of `by` defines `provideDelegate` as a member or extension function, that function will be called to create the property delegate instance.
One of the possible use cases of `provideDelegate` is to check the consistency of the property upon its initialization.
For example, to check the property name before binding, you can write something like this:
```
class ResourceDelegate<T> : ReadOnlyProperty<MyUI, T> {
override fun getValue(thisRef: MyUI, property: KProperty<*>): T { ... }
}
class ResourceLoader<T>(id: ResourceID<T>) {
operator fun provideDelegate(
thisRef: MyUI,
prop: KProperty<*>
): ReadOnlyProperty<MyUI, T> {
checkProperty(thisRef, prop.name)
// create delegate
return ResourceDelegate()
}
private fun checkProperty(thisRef: MyUI, name: String) { ... }
}
class MyUI {
fun <T> bindResource(id: ResourceID<T>): ResourceLoader<T> { ... }
val image by bindResource(ResourceID.image_id)
val text by bindResource(ResourceID.text_id)
}
```
The parameters of `provideDelegate` are the same as those of `getValue`:
* `thisRef` must be the same type as, or a supertype of, the *property owner* (for extension properties, it should be the type being extended);
* `property` must be of type `KProperty<*>` or its supertype.
The `provideDelegate` method is called for each property during the creation of the `MyUI` instance, and it performs the necessary validation right away.
Without this ability to intercept the binding between the property and its delegate, to achieve the same functionality you'd have to pass the property name explicitly, which isn't very convenient:
```
// Checking the property name without "provideDelegate" functionality
class MyUI {
val image by bindResource(ResourceID.image_id, "image")
val text by bindResource(ResourceID.text_id, "text")
}
fun <T> MyUI.bindResource(
id: ResourceID<T>,
propertyName: String
): ReadOnlyProperty<MyUI, T> {
checkProperty(this, propertyName)
// create delegate
}
```
In the generated code, the `provideDelegate` method is called to initialize the auxiliary `prop$delegate` property. Compare the generated code for the property declaration `val prop: Type by MyDelegate()` with the generated code [above](#translation-rules-for-delegated-properties) (when the `provideDelegate` method is not present):
```
class C {
var prop: Type by MyDelegate()
}
// this code is generated by the compiler
// when the 'provideDelegate' function is available:
class C {
// calling "provideDelegate" to create the additional "delegate" property
private val prop$delegate = MyDelegate().provideDelegate(this, this::prop)
var prop: Type
get() = prop$delegate.getValue(this, this::prop)
set(value: Type) = prop$delegate.setValue(this, this::prop, value)
}
```
Note that the `provideDelegate` method affects only the creation of the auxiliary property and doesn't affect the code generated for the getter or the setter.
With the `PropertyDelegateProvider` interface from the standard library, you can create delegate providers without creating new classes.
```
val provider = PropertyDelegateProvider { thisRef: Any?, property ->
ReadOnlyProperty<Any?, Int> {_, property -> 42 }
}
val delegate: Int by provider
```
Last modified: 10 January 2023
[Delegation](delegation) [Type aliases](type-aliases)
kotlin Kotlin Evolution Kotlin Evolution
================
Principles of Pragmatic Evolution
---------------------------------
Kotlin is designed to be a pragmatic tool for programmers. When it comes to language evolution, its pragmatic nature is captured by the following principles:
* Keep the language modern over the years.
* Stay in the constant feedback loop with the users.
* Make updating to new versions comfortable for the users.
As this is key to understanding how Kotlin is moving forward, let's expand on these principles.
**Keeping the Language Modern**. We acknowledge that systems accumulate legacy over time. What had once been cutting-edge technology can be hopelessly outdated today. We have to evolve the language to keep it relevant to the needs of the users and up-to-date with their expectations. This includes not only adding new features, but also phasing out old ones that are no longer recommended for production use and have altogether become legacy.
**Comfortable Updates**. Incompatible changes, such as removing things from a language, may lead to painful migration from one version to the next if carried out without proper care. We will always announce such changes well in advance, mark things as deprecated and provide automated migration tools *before the change happens*. By the time the language is changed we want most of the code in the world to be already updated and thus have no issues migrating to the new version.
**Feedback Loop**. Going through deprecation cycles requires significant effort, so we want to minimize the number of incompatible changes we'll be making in the future. Apart from using our best judgement, we believe that trying things out in real life is the best way to validate a design. Before casting things in stone we want them battle-tested. This is why we use every opportunity to make early versions of our designs available in production versions of the language, but in one of the *pre-stable* statuses: [Experimental, Alpha, or Beta](components-stability). Such features are not stable, they can be changed at any time, and the users that opt into using them do so explicitly to indicate that they are ready to deal with the future migration issues. These users provide invaluable feedback that we gather to iterate on the design and make it rock-solid.
Incompatible changes
--------------------
If, upon updating from one version to another, some code that used to work doesn't work any more, it is an *incompatible change* in the language (sometimes referred to as "breaking change"). There can be debates as to what "doesn't work any more" means precisely in some cases, but it definitely includes the following:
* Code that compiled and ran fine is now rejected with an error (at compile or link time). This includes removing language constructs and adding new restrictions.
* Code that executed normally is now throwing an exception.
The less obvious cases that belong to the "grey area" include handling corner cases differently, throwing an exception of a different type than before, changing behavior observable only through reflection, changes in undocumented/undefined behavior, renaming binary artifacts, etc. Sometimes such changes are very important and affect migration experience dramatically, sometimes they are insignificant.
Some examples of what definitely isn't an incompatible change include
* Adding new warnings.
* Enabling new language constructs or relaxing limitations for existing ones.
* Changing private/internal APIs and other implementation details.
The principles of Keeping the Language Modern and Comfortable Updates suggest that incompatible changes are sometimes necessary, but they should be introduced carefully. Our goal is to make the users aware of upcoming changes well in advance to let them migrate their code comfortably.
Ideally, every incompatible change should be announced through a compile-time warning reported in the problematic code (usually referred to as a *deprecation warning*) and accompanied with automated migration aids. So, the ideal migration workflow goes as follows:
* Update to version A (where the change is announced)
+ See warnings about the upcoming change
+ Migrate the code with the help of the tooling
* Update to version B (where the change happens)
+ See no issues at all
In practice some changes can't be accurately detected at compile time, so no warnings can be reported, but at least the users will be notified through Release notes of version A that a change is coming in version B.
### Dealing with compiler bugs
Compilers are complicated software and despite the best effort of their developers they have bugs. The bugs that cause the compiler itself to fail or report spurious errors or generate obviously failing code, though annoying and often embarrassing, are easy to fix, because the fixes do not constitute incompatible changes. Other bugs may cause the compiler to generate incorrect code that does not fail: e.g. by missing some errors in the source or simply generating wrong instructions. Fixes of such bugs are technically incompatible changes (some code used to compile fine, but now it won't any more), but we are inclined to fixing them as soon as possible to prevent the bad code patterns from spreading across user code. In our opinion, this serves the principle of Comfortable Updates, because fewer users have a chance of encountering the issue. Of course, this applies only to bugs that are found soon after appearing in a released version.
Decision making
---------------
[JetBrains](https://jetbrains.com), the original creator of Kotlin, is driving its progress with the help of the community and in accord with the [Kotlin Foundation](https://kotlinfoundation.org/).
All changes to the Kotlin Programming Language are overseen by the [Lead Language Designer](https://kotlinfoundation.org/structure/) (currently Roman Elizarov). The Lead Designer has the final say in all matters related to language evolution. Additionally, incompatible changes to fully stable components have to be approved to by the [Language Committee](https://kotlinfoundation.org/structure/) designated under the [Kotlin Foundation](https://kotlinfoundation.org/structure/) (currently comprised of Jeffrey van Gogh, William R. Cook and Roman Elizarov).
The Language Committee makes final decisions on what incompatible changes will be made and what exact measures should be taken to make user updates comfortable. In doing so, it relies on a set of guidelines available [here](https://kotlinfoundation.org/language-committee-guidelines/).
Feature releases and incremental releases
-----------------------------------------
Stable releases with versions 1.2, 1.3, etc. are usually considered to be *feature releases* bringing major changes in the language. Normally, we publish *incremental releases*, numbered 1.2.20, 1.2.30, etc, in between feature releases.
Incremental releases bring updates in the tooling (often including features), performance improvements and bug fixes. We try to keep such versions compatible with each other, so changes to the compiler are mostly optimizations and warning additions/removals. Pre-stable features may, of course, be added, removed or changed at any time.
Feature releases often add new features and may remove or change previously deprecated ones. Feature graduation from pre-stable to stable also happens in feature releases.
### EAP builds
Before releasing stable versions, we usually publish a number of preview builds dubbed EAP (for "Early Access Preview") that let us iterate faster and gather feedback from the community. EAPs of feature releases usually produce binaries that will be later rejected by the stable compiler to make sure that possible bugs in the binary format survive no longer than the preview period. Final Release Candidates normally do not bear this limitation.
### Pre-stable features
According to the Feedback Loop principle described above, we iterate on our designs in the open and release versions of the language where some features have one of the *pre-stable* statuses and *are supposed to change*. Such features can be added, changed or removed at any point and without warning. We do our best to ensure that pre-stable features can't be used accidentally by an unsuspecting user. Such features usually require some sort of an explicit opt-in either in the code or in the project configuration.
Pre-stable features usually graduate to the stable status after some iterations.
### Status of different components
To check the stability status of different components of Kotlin (Kotlin/JVM, JS, Native, various libraries, etc), please consult [this link](components-stability).
Libraries
---------
A language is nothing without its ecosystem, so we pay extra attention to enabling smooth library evolution.
Ideally, a new version of a library can be used as a "drop-in replacement" for an older version. This means that upgrading a binary dependency should not break anything, even if the application is not recompiled (this is possible under dynamic linking).
On the one hand, to achieve this, the compiler has to provide certain ABI stability guarantees under the constraints of separate compilation. This is why every change in the language is examined from the point of view of binary compatibility.
On the other hand, a lot depends on the library authors being careful about which changes are safe to make. Thus it's very important that library authors understand how source changes affect compatibility and follow certain best practices to keep both APIs and ABIs of their libraries stable. Here are some assumptions that we make when considering language changes from the library evolution standpoint:
* Library code should always specify return types of public/protected functions and properties explicitly thus never relying on type inference for public API. Subtle changes in type inference may cause return types to change inadvertently, leading to binary compatibility issues.
* Overloaded functions and properties provided by the same library should do essentially the same thing. Changes in type inference may result in more precise static types to be known at call sites causing changes in overload resolution.
Library authors can use the @Deprecated and [@RequiresOptIn](opt-in-requirements) annotations to control the evolution of their API surface. Note that @Deprecated(level=HIDDEN) can be used to preserve binary compatibility even for declarations removed from the API.
Also, by convention, packages named "internal" are not considered public API. All API residing in packages named "experimental" is considered pre-stable and can change at any moment.
We evolve the Kotlin Standard Library (kotlin-stdlib) for stable platforms according to the principles stated above. Changes to the contracts for its API undergo the same procedures as changes in the language itself.
Compiler keys
-------------
Command line keys accepted by the compiler are also a kind of public API, and they are subject to the same considerations. Supported flags (those that don't have the "-X" or "-XX" prefix) can be added only in feature releases and should be properly deprecated before removing them. The "-X" and "-XX" flags are experimental and can be added and removed at any time.
Compatibility tools
-------------------
As legacy features get removed and bugs fixed, the source language changes, and old code that has not been properly migrated may not compile any more. The normal deprecation cycle allows a comfortable period of time for migration, and even when it's over and the change ships in a stable version, there's still a way to compile unmigrated code.
### Compatibility flags
We provide the `-language-version X.Y` and `-api-version X.Y` flags that make a new version emulate the behavior of an old one for compatibility purposes. To give you more time for migration, we [support](compatibility-modes) the development for three previous language and API versions in addition to the latest stable one.
Using an older kotlin-stdlib or kotlin-reflect with a newer compiler without specifying compatibility flags is not recommended, and the compiler will report a [warning](compatibility-modes#binary-compatibility-warnings) when this happens.
Actively maintained code bases can benefit from getting bug fixes ASAP, without waiting for a full deprecation cycle to complete. Currently, such project can enable the `-progressive` flag and get such fixes enabled even in incremental releases.
All flags are available on the command line as well as [Gradle](gradle-compiler-options) and [Maven](maven#specifying-compiler-options).
### Evolving the binary format
Unlike sources that can be fixed by hand in the worst case, binaries are a lot harder to migrate, and this makes backwards compatibility very important in the case of binaries. Incompatible changes to binaries can make updates very uncomfortable and thus should be introduced with even more care than those in the source language syntax.
For fully stable versions of the compiler the default binary compatibility protocol is the following:
* All binaries are backwards compatible, i.e. a newer compiler can read older binaries (e.g. 1.3 understands 1.0 through 1.2),
* Older compilers reject binaries that rely on new features (e.g. a 1.0 compiler rejects binaries that use coroutines).
* Preferably (but we can't guarantee it), the binary format is mostly forwards compatible with the next feature release, but not later ones (in the cases when new features are not used, e.g. 1.3 can understand most binaries from 1.4, but not 1.5).
This protocol is designed for comfortable updates as no project can be blocked from updating its dependencies even if it's using a slightly outdated compiler.
Please note that not all target platforms have reached this level of stability (but Kotlin/JVM has).
Last modified: 10 January 2023
[FAQ](faq) [Stability of Kotlin components](components-stability)
| programming_docs |
kotlin Participate in the Kotlin Early Access Preview Participate in the Kotlin Early Access Preview
==============================================
You can participate in the Kotlin Early Access Preview (EAP) to try out the latest Kotlin features before they are released.
We ship a few Beta (*Beta*) and Release Candidate (*RC*) builds before every feature (*1.x*) and incremental (*1.x.y*) release.
We'll be very thankful if you find and report bugs to our issue tracker [YouTrack](https://kotl.in/issue). It is very likely that we'll be able to fix them before the final release, which means you won't need to wait until the next Kotlin release for your issues to be addressed.
By participating in the Early Access Preview and reporting bugs, you contribute to Kotlin and help us make it better for everyone in [the growing Kotlin community](https://kotlinlang.org/community/). We appreciate your help a lot!
If you have any questions and want to participate in discussions, you are welcome to join the [#eap channel in Kotlin Slack](https://app.slack.com/client/T09229ZC6/C0KLZSCHF). In this channel, you can also get notifications about new EAP builds.
**[Install the Kotlin EAP Plugin for IDEA or Android Studio](install-eap-plugin)**
If you have already installed the EAP version and want to work on projects that were created previously, check [our instructions on how to configure your build to support this version](configure-build-for-eap).
How the EAP can help you be more productive with Kotlin
-------------------------------------------------------
* **Prepare for the Stable release**. If you work on a complex multi-module project, participating in the EAP may streamline your experience when you adopt the Stable release version. The sooner you update to the Stable version, the sooner you can take advantage of its performance improvements and new language features.
The migration of huge and complex projects might take a while, not only because of their size but also because some specific use cases may not have been covered by the Kotlin team yet. By participating in the EAP and continuously testing new versions of Kotlin, you can provide us with early feedback about your specific use cases. This will help us address as many issues as possible and ensure you can safely update to the Stable version when it's released. [Check out how Slack benefits from testing Android, Kotlin, and Gradle pre-release versions](https://slack.engineering/shadow-jobs/).
* **Keep your library up-to-date**. If you're a library author, updating to the new Kotlin version is extremely important. Using older versions could block your users from updating Kotlin in their projects. Working with EAP versions allows you to support the latest Kotlin versions in your library almost immediately with the Stable release, which makes your users happier and your library more popular.
* **Share the experience**. If you're a Kotlin enthusiast and enjoy contributing to the Kotlin ecosystem by creating educational content, trying new features in the Kotin EAP allows you to be among the first to share the experience of using the new cool features with the community.
Build details
-------------
*No preview versions are currently available.*
Last modified: 10 January 2023
[What's new in Kotlin 1.8.0-RC2](whatsnew-eap) [Install the EAP Plugin for IntelliJ IDEA or Android Studio](install-eap-plugin)
kotlin Opt-in requirements Opt-in requirements
===================
The Kotlin standard library provides a mechanism for requiring and giving explicit consent for using certain elements of APIs. This mechanism lets library developers inform users of their APIs about specific conditions that require opt-in, for example, if an API is in the experimental state and is likely to change in the future.
To prevent potential issues, the compiler warns users of such APIs about these conditions and requires them to opt in before using the API.
Opt in to using API
-------------------
If a library author marks a declaration from a library's API as *[requiring opt-in](#require-opt-in-for-api)*, you should give an explicit consent for using it in your code. There are several ways to opt in to such APIs, all applicable without technical limitations. You are free to choose the way that you find best for your situation.
### Propagating opt-in
When you use an API in the code intended for third-party use (a library), you can propagate its opt-in requirement to your API as well. To do this, annotate your declaration with the *[opt-in requirement annotation](#create-opt-in-requirement-annotations)* of the API used in its body. This enables you to use API elements that require opt-in.
```
// Library code
@RequiresOptIn(message = "This API is experimental. It may be changed in the future without notice.")
@Retention(AnnotationRetention.BINARY)
@Target(AnnotationTarget.CLASS, AnnotationTarget.FUNCTION)
annotation class MyDateTime // Opt-in requirement annotation
@MyDateTime
class DateProvider // A class requiring opt-in
```
```
// Client code
fun getYear(): Int {
val dateProvider: DateProvider // Error: DateProvider requires opt-in
// ...
}
@MyDateTime
fun getDate(): Date {
val dateProvider: DateProvider // OK: the function requires opt-in as well
// ...
}
fun displayDate() {
println(getDate()) // Error: getDate() requires opt-in
}
```
As you can see in this example, the annotated function appears to be a part of the `@MyDateTime` API. So, such an opt-in propagates the opt-in requirement to the client code; its clients will see the same warning message and be required to consent as well.
Implicit usages of APIs that require opt-in also require opt-in. If an API element doesn't have an opt-in requirement annotation but its signature includes a type declared as requiring opt-in, its usage will still raise a warning. See the example below.
```
// Client code
fun getDate(dateProvider: DateProvider): Date { // Error: DateProvider requires opt-in
// ...
}
fun displayDate() {
println(getDate()) // Warning: the signature of getDate() contains DateProvider, which requires opt-in
}
```
To use multiple APIs that require opt-in, mark the declaration with all their opt-in requirement annotations.
### Non-propagating opt-in
In modules that don't expose their own API, such as applications, you can opt in to using APIs without propagating the opt-in requirement to your code. In this case, mark your declaration with [`@OptIn`](../api/latest/jvm/stdlib/kotlin/-opt-in/index) passing the opt-in requirement annotation as its argument:
```
// Library code
@RequiresOptIn(message = "This API is experimental. It may be changed in the future without notice.")
@Retention(AnnotationRetention.BINARY)
@Target(AnnotationTarget.CLASS, AnnotationTarget.FUNCTION)
annotation class MyDateTime // Opt-in requirement annotation
@MyDateTime
class DateProvider // A class requiring opt-in
```
```
// Client code
@OptIn(MyDateTime::class)
fun getDate(): Date { // Uses DateProvider; doesn't propagate the opt-in requirement
val dateProvider: DateProvider
// ...
}
fun displayDate() {
println(getDate()) // OK: opt-in is not required
}
```
When somebody calls the function `getDate()`, they won't be informed about the opt-in requirements for APIs used in its body.
Note that if `@OptIn` applies to the declaration whose signature contains a type declared as requiring opt-in, the opt-in will still propagate:
```
// Client code
@OptIn(MyDateTime::class)
fun getDate(dateProvider: DateProvider): Date { // Has DateProvider as a part of a signature; propagates the opt-in requirement
// ...
}
fun displayDate() {
println(getDate()) // Warning: getDate() requires opt-in
}
```
To use an API that requires opt-in in all functions and classes in a file, add the file-level annotation `@file:OptIn` to the top of the file before the package specification and imports.
```
// Client code
@file:OptIn(MyDateTime::class)
```
### Module-wide opt-in
If you don't want to annotate every usage of APIs that require opt-in, you can opt in to them for your whole module. To opt in to using an API in a module, compile it with the argument `-opt-in`, specifying the fully qualified name of the opt-in requirement annotation of the API you use: `-opt-in=org.mylibrary.OptInAnnotation`. Compiling with this argument has the same effect as if every declaration in the module had the annotation`@OptIn(OptInAnnotation::class)`.
If you build your module with Gradle, you can add arguments like this:
```
tasks.withType<org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask<*>>().configureEach {
compilerOptions.freeCompilerArgs.add("-opt-in=org.mylibrary.OptInAnnotation")
}
```
```
tasks.withType(org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask).configureEach {
compilerOptions {
freeCompilerArgs.add("-opt-in=org.mylibrary.OptInAnnotation")
}
}
```
If your Gradle module is a multiplatform module, use the `optIn` method:
```
sourceSets {
all {
languageSettings.optIn("org.mylibrary.OptInAnnotation")
}
}
```
```
sourceSets {
all {
languageSettings {
optIn('org.mylibrary.OptInAnnotation')
}
}
}
```
For Maven, it would be:
```
<build>
<plugins>
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<version>${kotlin.version}</version>
<executions>...</executions>
<configuration>
<args>
<arg>-opt-in=org.mylibrary.OptInAnnotation</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
```
To opt in to multiple APIs on the module level, add one of the described arguments for each opt-in requirement marker used in your module.
Require opt-in for API
----------------------
### Create opt-in requirement annotations
If you want to require explicit consent to using your module's API, create an annotation class to use as an *opt-in requirement annotation*. This class must be annotated with [@RequiresOptIn](../api/latest/jvm/stdlib/kotlin/-requires-opt-in/index):
```
@RequiresOptIn
@Retention(AnnotationRetention.BINARY)
@Target(AnnotationTarget.CLASS, AnnotationTarget.FUNCTION)
annotation class MyDateTime
```
Opt-in requirement annotations must meet several requirements:
* `BINARY` or `RUNTIME` [retention](../api/latest/jvm/stdlib/kotlin.annotation/-retention/index)
* No `EXPRESSION`, `FILE`, `TYPE`, or `TYPE_PARAMETER` among [targets](../api/latest/jvm/stdlib/kotlin.annotation/-target/index)
* No parameters.
An opt-in requirement can have one of two severity [levels](../api/latest/jvm/stdlib/kotlin/-requires-opt-in/-level/index):
* `RequiresOptIn.Level.ERROR`. Opt-in is mandatory. Otherwise, the code that uses marked API won't compile. Default level.
* `RequiresOptIn.Level.WARNING`. Opt-in is not mandatory, but advisable. Without it, the compiler raises a warning.
To set the desired level, specify the `level` parameter of the `@RequiresOptIn` annotation.
Additionally, you can provide a `message` to inform API users about special condition of using the API. The compiler will show it to users that use the API without opt-in.
```
@RequiresOptIn(level = RequiresOptIn.Level.WARNING, message = "This API is experimental. It can be incompatibly changed in the future.")
@Retention(AnnotationRetention.BINARY)
@Target(AnnotationTarget.CLASS, AnnotationTarget.FUNCTION)
annotation class ExperimentalDateTime
```
If you publish multiple independent features that require opt-in, declare an annotation for each. This makes the use of API safer for your clients: they can use only the features that they explicitly accept. This also lets you remove the opt-in requirements from the features independently.
### Mark API elements
To require an opt-in to using an API element, annotate its declaration with an opt-in requirement annotation:
```
@MyDateTime
class DateProvider
@MyDateTime
fun getTime(): Time {}
```
Note that for some language elements, an opt-in requirement annotation is not applicable:
* You cannot annotate a backing field or a getter of a property, just the property itself.
* You cannot annotate a local variable or a value parameter.
Opt-in requirements for pre-stable APIs
---------------------------------------
If you use opt-in requirements for features that are not stable yet, carefully handle the API graduation to avoid breaking the client code.
Once your pre-stable API graduates and is released in a stable state, remove its opt-in requirement annotations from declarations. The clients will be able to use them without restriction. However, you should leave the annotation classes in modules so that the existing client code remains compatible.
To let the API users update their modules accordingly (remove the annotations from their code and recompile), mark the annotations as [`@Deprecated`](../api/latest/jvm/stdlib/kotlin/-deprecated/index) and provide the explanation in the deprecation message.
```
@Deprecated("This opt-in requirement is not used anymore. Remove its usages from your code.")
@RequiresOptIn
annotation class ExperimentalDateTime
```
Last modified: 10 January 2023
[Scope functions](scope-functions) [Coroutines guide](coroutines-guide)
kotlin This expressions This expressions
================
To denote the current *receiver*, you use `this` expressions:
* In a member of a [class](classes#inheritance), `this` refers to the current object of that class.
* In an [extension function](extensions) or a [function literal with receiver](lambdas#function-literals-with-receiver) `this` denotes the *receiver* parameter that is passed on the left-hand side of a dot.
If `this` has no qualifiers, it refers to the *innermost enclosing scope*. To refer to `this` in other scopes, *label qualifiers* are used:
Qualified this
--------------
To access `this` from an outer scope (a [class](classes), [extension function](extensions), or labeled [function literal with receiver](lambdas#function-literals-with-receiver)) you write `this@label`, where `@label` is a [label](returns) on the scope `this` is meant to be from:
```
class A { // implicit label @A
inner class B { // implicit label @B
fun Int.foo() { // implicit label @foo
val a = this@A // A's this
val b = this@B // B's this
val c = this // foo()'s receiver, an Int
val c1 = this@foo // foo()'s receiver, an Int
val funLit = lambda@ fun String.() {
val d = this // funLit's receiver, a String
}
val funLit2 = { s: String ->
// foo()'s receiver, since enclosing lambda expression
// doesn't have any receiver
val d1 = this
}
}
}
}
```
Implicit this
-------------
When you call a member function on `this`, you can skip the `this.` part. If you have a non-member function with the same name, use this with caution because in some cases it can be called instead:
```
fun main() {
//sampleStart
fun printLine() { println("Top-level function") }
class A {
fun printLine() { println("Member function") }
fun invokePrintLine(omitThis: Boolean = false) {
if (omitThis) printLine()
else this.printLine()
}
}
A().invokePrintLine() // Member function
A().invokePrintLine(omitThis = true) // Top-level function
//sampleEnd()
}
```
Last modified: 10 January 2023
[Equality](equality) [Asynchronous programming techniques](async-programming)
kotlin Equality Equality
========
In Kotlin there are two types of equality:
* *Structural* equality (`==` - a check for `equals()`)
* *Referential* equality (`===` - two references point to the same object)
Structural equality
-------------------
Structural equality is checked by the `==` operation and its negated counterpart `!=`. By convention, an expression like `a == b` is translated to:
```
a?.equals(b) ?: (b === null)
```
If `a` is not `null`, it calls the `equals(Any?)` function, otherwise (`a` is `null`) it checks that `b` is referentially equal to `null`.
Note that there's no point in optimizing your code when comparing to `null` explicitly: `a == null` will be automatically translated to `a === null`.
To provide a custom equals check implementation, override the [`equals(other: Any?): Boolean`](../api/latest/jvm/stdlib/kotlin/-any/equals) function. Functions with the same name and other signatures, like `equals(other: Foo)`, don't affect equality checks with the operators `==` and `!=`.
Structural equality has nothing to do with comparison defined by the `Comparable<...>` interface, so only a custom `equals(Any?)` implementation may affect the behavior of the operator.
Referential equality
--------------------
Referential equality is checked by the `===` operation and its negated counterpart `!==`. `a === b` evaluates to true if and only if `a` and `b` point to the same object. For values represented by primitive types at runtime (for example, `Int`), the `===` equality check is equivalent to the `==` check.
Floating-point numbers equality
-------------------------------
When an equality check operands are statically known to be `Float` or `Double` (nullable or not), the check follows the [IEEE 754 Standard for Floating-Point Arithmetic](https://en.wikipedia.org/wiki/IEEE_754).
Otherwise, structural equality is used, which disagrees with the standard so that `NaN` is equal to itself, `NaN` is considered greater than any other element, including `POSITIVE_INFINITY`, and `-0.0` is not equal to `0.0`.
See: [Floating-point numbers comparison](numbers#floating-point-numbers-comparison).
Last modified: 10 January 2023
[Null safety](null-safety) [This expressions](this-expressions)
kotlin Functional (SAM) interfaces Functional (SAM) interfaces
===========================
An interface with only one abstract method is called a *functional interface*, or a *Single Abstract Method (SAM) interface*. The functional interface can have several non-abstract members but only one abstract member.
To declare a functional interface in Kotlin, use the `fun` modifier.
```
fun interface KRunnable {
fun invoke()
}
```
SAM conversions
---------------
For functional interfaces, you can use SAM conversions that help make your code more concise and readable by using [lambda expressions](lambdas#lambda-expressions-and-anonymous-functions).
Instead of creating a class that implements a functional interface manually, you can use a lambda expression. With a SAM conversion, Kotlin can convert any lambda expression whose signature matches the signature of the interface's single method into the code, which dynamically instantiates the interface implementation.
For example, consider the following Kotlin functional interface:
```
fun interface IntPredicate {
fun accept(i: Int): Boolean
}
```
If you don't use a SAM conversion, you will need to write code like this:
```
// Creating an instance of a class
val isEven = object : IntPredicate {
override fun accept(i: Int): Boolean {
return i % 2 == 0
}
}
```
By leveraging Kotlin's SAM conversion, you can write the following equivalent code instead:
```
// Creating an instance using lambda
val isEven = IntPredicate { it % 2 == 0 }
```
A short lambda expression replaces all the unnecessary code.
```
fun interface IntPredicate {
fun accept(i: Int): Boolean
}
val isEven = IntPredicate { it % 2 == 0 }
fun main() {
println("Is 7 even? - ${isEven.accept(7)}")
}
```
You can also use [SAM conversions for Java interfaces](java-interop#sam-conversions).
Migration from an interface with constructor function to a functional interface
-------------------------------------------------------------------------------
Starting from 1.6.20, Kotlin supports [callable references](reflection#callable-references) to functional interface constructors, which adds a source-compatible way to migrate from an interface with a constructor function to a functional interface. Consider the following code:
```
interface Printer {
fun print()
}
fun Printer(block: () -> Unit): Printer = object : Printer { override fun print() = block() }
```
With callable references to functional interface constructors enabled, this code can be replaced with just a functional interface declaration:
```
fun interface Printer {
fun print()
}
```
Its constructor will be created implicitly, and any code using the `::Printer` function reference will compile. For example:
```
documentsStorage.addPrinter(::Printer)
```
Preserve the binary compatibility by marking the legacy function `Printer` with the [`@Deprecated`](../api/latest/jvm/stdlib/kotlin/-deprecated/index) annotation with `DeprecationLevel.HIDDEN`:
```
@Deprecated(message = "Your message about the deprecation", level = DeprecationLevel.HIDDEN)
fun Printer(...) {...}
```
Functional interfaces vs. type aliases
--------------------------------------
You can also simply rewrite the above using a [type alias](type-aliases) for a functional type:
```
typealias IntPredicate = (i: Int) -> Boolean
val isEven: IntPredicate = { it % 2 == 0 }
fun main() {
println("Is 7 even? - ${isEven(7)}")
}
```
However, functional interfaces and [type aliases](type-aliases) serve different purposes. Type aliases are just names for existing types – they don't create a new type, while functional interfaces do. You can provide extensions that are specific to a particular functional interface to be inapplicable for plain functions or their type aliases.
Type aliases can have only one member, while functional interfaces can have multiple non-abstract members and one abstract member. Functional interfaces can also implement and extend other interfaces.
Functional interfaces are more flexible and provide more capabilities than type aliases, but they can be more costly both syntactically and at runtime because they can require conversions to a specific interface. When you choose which one to use in your code, consider your needs:
* If your API needs to accept a function (any function) with some specific parameter and return types – use a simple functional type or define a type alias to give a shorter name to the corresponding functional type.
* If your API accepts a more complex entity than a function – for example, it has non-trivial contracts and/or operations on it that can't be expressed in a functional type's signature – declare a separate functional interface for it.
Last modified: 10 January 2023
[Interfaces](interfaces) [Visibility modifiers](visibility-modifiers)
| programming_docs |
kotlin Asynchronous Flow Asynchronous Flow
=================
A suspending function asynchronously returns a single value, but how can we return multiple asynchronously computed values? This is where Kotlin Flows come in.
Representing multiple values
----------------------------
Multiple values can be represented in Kotlin using [collections](collections-overview). For example, we can have a `simple` function that returns a [List](../api/latest/jvm/stdlib/kotlin.collections/-list/index) of three numbers and then print them all using [forEach](../api/latest/jvm/stdlib/kotlin.collections/for-each):
```
fun simple(): List<Int> = listOf(1, 2, 3)
fun main() {
simple().forEach { value -> println(value) }
}
```
This code outputs:
```
1
2
3
```
### Sequences
If we are computing the numbers with some CPU-consuming blocking code (each computation taking 100ms), then we can represent the numbers using a [Sequence](../api/latest/jvm/stdlib/kotlin.sequences/index):
```
fun simple(): Sequence<Int> = sequence { // sequence builder
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it
yield(i) // yield next value
}
}
fun main() {
simple().forEach { value -> println(value) }
}
```
This code outputs the same numbers, but it waits 100ms before printing each one.
### Suspending functions
However, this computation blocks the main thread that is running the code. When these values are computed by asynchronous code we can mark the `simple` function with a `suspend` modifier, so that it can perform its work without blocking and return the result as a list:
```
import kotlinx.coroutines.*
//sampleStart
suspend fun simple(): List<Int> {
delay(1000) // pretend we are doing something asynchronous here
return listOf(1, 2, 3)
}
fun main() = runBlocking<Unit> {
simple().forEach { value -> println(value) }
}
//sampleEnd
```
This code prints the numbers after waiting for a second.
### Flows
Using the `List<Int>` result type, means we can only return all the values at once. To represent the stream of values that are being computed asynchronously, we can use a [`Flow<Int>`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow/index.html) type just like we would use a `Sequence<Int>` type for synchronously computed values:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow { // flow builder
for (i in 1..3) {
delay(100) // pretend we are doing something useful here
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
// Launch a concurrent coroutine to check if the main thread is blocked
launch {
for (k in 1..3) {
println("I'm not blocked $k")
delay(100)
}
}
// Collect the flow
simple().collect { value -> println(value) }
}
//sampleEnd
```
This code waits 100ms before printing each number without blocking the main thread. This is verified by printing "I'm not blocked" every 100ms from a separate coroutine that is running in the main thread:
```
I'm not blocked 1
1
I'm not blocked 2
2
I'm not blocked 3
3
```
Notice the following differences in the code with the [Flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow/index.html) from the earlier examples:
* A builder function of [Flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow/index.html) type is called [flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow.html).
* Code inside a `flow { ... }` builder block can suspend.
* The `simple` function is no longer marked with a `suspend` modifier.
* Values are *emitted* from the flow using an [emit](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) function.
* Values are *collected* from the flow using a [collect](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) function.
Flows are cold
--------------
Flows are *cold* streams similar to sequences — the code inside a [flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow.html) builder does not run until the flow is collected. This becomes clear in the following example:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
println("Flow started")
for (i in 1..3) {
delay(100)
emit(i)
}
}
fun main() = runBlocking<Unit> {
println("Calling simple function...")
val flow = simple()
println("Calling collect...")
flow.collect { value -> println(value) }
println("Calling collect again...")
flow.collect { value -> println(value) }
}
//sampleEnd
```
Which prints:
```
Calling simple function...
Calling collect...
Flow started
1
2
3
Calling collect again...
Flow started
1
2
3
```
This is a key reason the `simple` function (which returns a flow) is not marked with `suspend` modifier. The `simple()` call itself returns quickly and does not wait for anything. The flow starts afresh every time it is collected and that is why we see "Flow started" every time we call `collect` again.
Flow cancellation basics
------------------------
Flows adhere to the general cooperative cancellation of coroutines. As usual, flow collection can be cancelled when the flow is suspended in a cancellable suspending function (like [delay](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/delay.html)). The following example shows how the flow gets cancelled on a timeout when running in a [withTimeoutOrNull](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout-or-null.html) block and stops executing its code:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
withTimeoutOrNull(250) { // Timeout after 250ms
simple().collect { value -> println(value) }
}
println("Done")
}
//sampleEnd
```
Notice how only two numbers get emitted by the flow in the `simple` function, producing the following output:
```
Emitting 1
1
Emitting 2
2
Done
```
See [Flow cancellation checks](#flow-cancellation-checks) section for more details.
Flow builders
-------------
The `flow { ... }` builder from the previous examples is the most basic one. There are other builders that allow flows to be declared:
* The [flowOf](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow-of.html) builder defines a flow that emits a fixed set of values.
* Various collections and sequences can be converted to flows using the `.asFlow()` extension function.
For example, the snippet that prints the numbers 1 to 3 from a flow can be rewritten as follows:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
// Convert an integer range to a flow
(1..3).asFlow().collect { value -> println(value) }
//sampleEnd
}
```
Intermediate flow operators
---------------------------
Flows can be transformed using operators, in the same way as you would transform collections and sequences. Intermediate operators are applied to an upstream flow and return a downstream flow. These operators are cold, just like flows are. A call to such an operator is not a suspending function itself. It works quickly, returning the definition of a new transformed flow.
The basic operators have familiar names like [map](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/map.html) and [filter](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/filter.html). An important difference of these operators from sequences is that blocks of code inside these operators can call suspending functions.
For example, a flow of incoming requests can be mapped to its results with a [map](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/map.html) operator, even when performing a request is a long-running operation that is implemented by a suspending function:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
suspend fun performRequest(request: Int): String {
delay(1000) // imitate long-running asynchronous work
return "response $request"
}
fun main() = runBlocking<Unit> {
(1..3).asFlow() // a flow of requests
.map { request -> performRequest(request) }
.collect { response -> println(response) }
}
//sampleEnd
```
It produces the following three lines, each appearing one second after the previous:
```
response 1
response 2
response 3
```
### Transform operator
Among the flow transformation operators, the most general one is called [transform](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/transform.html). It can be used to imitate simple transformations like [map](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/map.html) and [filter](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/filter.html), as well as implement more complex transformations. Using the `transform` operator, we can [emit](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) arbitrary values an arbitrary number of times.
For example, using `transform` we can emit a string before performing a long-running asynchronous request and follow it with a response:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
suspend fun performRequest(request: Int): String {
delay(1000) // imitate long-running asynchronous work
return "response $request"
}
fun main() = runBlocking<Unit> {
//sampleStart
(1..3).asFlow() // a flow of requests
.transform { request ->
emit("Making request $request")
emit(performRequest(request))
}
.collect { response -> println(response) }
//sampleEnd
}
```
The output of this code is:
```
Making request 1
response 1
Making request 2
response 2
Making request 3
response 3
```
### Size-limiting operators
Size-limiting intermediate operators like [take](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/take.html) cancel the execution of the flow when the corresponding limit is reached. Cancellation in coroutines is always performed by throwing an exception, so that all the resource-management functions (like `try { ... } finally { ... }` blocks) operate normally in case of cancellation:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun numbers(): Flow<Int> = flow {
try {
emit(1)
emit(2)
println("This line will not execute")
emit(3)
} finally {
println("Finally in numbers")
}
}
fun main() = runBlocking<Unit> {
numbers()
.take(2) // take only the first two
.collect { value -> println(value) }
}
//sampleEnd
```
The output of this code clearly shows that the execution of the `flow { ... }` body in the `numbers()` function stopped after emitting the second number:
```
1
2
Finally in numbers
```
Terminal flow operators
-----------------------
Terminal operators on flows are *suspending functions* that start a collection of the flow. The [collect](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) operator is the most basic one, but there are other terminal operators, which can make it easier:
* Conversion to various collections like [toList](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/to-list.html) and [toSet](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/to-set.html).
* Operators to get the [first](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/first.html) value and to ensure that a flow emits a [single](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/single.html) value.
* Reducing a flow to a value with [reduce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/reduce.html) and [fold](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/fold.html).
For example:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
val sum = (1..5).asFlow()
.map { it * it } // squares of numbers from 1 to 5
.reduce { a, b -> a + b } // sum them (terminal operator)
println(sum)
//sampleEnd
}
```
Prints a single number:
```
55
```
Flows are sequential
--------------------
Each individual collection of a flow is performed sequentially unless special operators that operate on multiple flows are used. The collection works directly in the coroutine that calls a terminal operator. No new coroutines are launched by default. Each emitted value is processed by all the intermediate operators from upstream to downstream and is then delivered to the terminal operator after.
See the following example that filters the even integers and maps them to strings:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
(1..5).asFlow()
.filter {
println("Filter $it")
it % 2 == 0
}
.map {
println("Map $it")
"string $it"
}.collect {
println("Collect $it")
}
//sampleEnd
}
```
Producing:
```
Filter 1
Filter 2
Map 2
Collect string 2
Filter 3
Filter 4
Map 4
Collect string 4
Filter 5
```
Flow context
------------
Collection of a flow always happens in the context of the calling coroutine. For example, if there is a `simple` flow, then the following code runs in the context specified by the author of this code, regardless of the implementation details of the `simple` flow:
```
withContext(context) {
simple().collect { value ->
println(value) // run in the specified context
}
}
```
This property of a flow is called *context preservation*.
So, by default, code in the `flow { ... }` builder runs in the context that is provided by a collector of the corresponding flow. For example, consider the implementation of a `simple` function that prints the thread it is called on and emits three numbers:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
//sampleStart
fun simple(): Flow<Int> = flow {
log("Started simple flow")
for (i in 1..3) {
emit(i)
}
}
fun main() = runBlocking<Unit> {
simple().collect { value -> log("Collected $value") }
}
//sampleEnd
```
Running this code produces:
```
[main @coroutine#1] Started simple flow
[main @coroutine#1] Collected 1
[main @coroutine#1] Collected 2
[main @coroutine#1] Collected 3
```
Since `simple().collect` is called from the main thread, the body of `simple`'s flow is also called in the main thread. This is the perfect default for fast-running or asynchronous code that does not care about the execution context and does not block the caller.
### A common pitfall when using withContext
However, the long-running CPU-consuming code might need to be executed in the context of [Dispatchers.Default](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html) and UI-updating code might need to be executed in the context of [Dispatchers.Main](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-main.html). Usually, [withContext](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-context.html) is used to change the context in the code using Kotlin coroutines, but code in the `flow { ... }` builder has to honor the context preservation property and is not allowed to [emit](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) from a different context.
Try running the following code:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
// The WRONG way to change context for CPU-consuming code in flow builder
kotlinx.coroutines.withContext(Dispatchers.Default) {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
emit(i) // emit next value
}
}
}
fun main() = runBlocking<Unit> {
simple().collect { value -> println(value) }
}
//sampleEnd
```
This code produces the following exception:
```
Exception in thread "main" java.lang.IllegalStateException: Flow invariant is violated:
Flow was collected in [CoroutineId(1), "coroutine#1":BlockingCoroutine{Active}@5511c7f8, BlockingEventLoop@2eac3323],
but emission happened in [CoroutineId(1), "coroutine#1":DispatchedCoroutine{Active}@2dae0000, Dispatchers.Default].
Please refer to 'flow' documentation or use 'flowOn' instead
at ...
```
### flowOn operator
The exception refers to the [flowOn](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow-on.html) function that shall be used to change the context of the flow emission. The correct way to change the context of a flow is shown in the example below, which also prints the names of the corresponding threads to show how it all works:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
//sampleStart
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
log("Emitting $i")
emit(i) // emit next value
}
}.flowOn(Dispatchers.Default) // RIGHT way to change context for CPU-consuming code in flow builder
fun main() = runBlocking<Unit> {
simple().collect { value ->
log("Collected $value")
}
}
//sampleEnd
```
Notice how `flow { ... }` works in the background thread, while collection happens in the main thread:
Another thing to observe here is that the [flowOn](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow-on.html) operator has changed the default sequential nature of the flow. Now collection happens in one coroutine ("coroutine#1") and emission happens in another coroutine ("coroutine#2") that is running in another thread concurrently with the collecting coroutine. The [flowOn](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow-on.html) operator creates another coroutine for an upstream flow when it has to change the [CoroutineDispatcher](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-dispatcher/index.html) in its context.
Buffering
---------
Running different parts of a flow in different coroutines can be helpful from the standpoint of the overall time it takes to collect the flow, especially when long-running asynchronous operations are involved. For example, consider a case when the emission by a `simple` flow is slow, taking 100 ms to produce an element; and collector is also slow, taking 300 ms to process an element. Let's see how long it takes to collect such a flow with three numbers:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
import kotlin.system.*
//sampleStart
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // pretend we are asynchronously waiting 100 ms
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
val time = measureTimeMillis {
simple().collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")
}
//sampleEnd
```
It produces something like this, with the whole collection taking around 1200 ms (three numbers, 400 ms for each):
```
1
2
3
Collected in 1220 ms
```
We can use a [buffer](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/buffer.html) operator on a flow to run emitting code of the `simple` flow concurrently with collecting code, as opposed to running them sequentially:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
import kotlin.system.*
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // pretend we are asynchronously waiting 100 ms
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
//sampleStart
val time = measureTimeMillis {
simple()
.buffer() // buffer emissions, don't wait
.collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")
//sampleEnd
}
```
It produces the same numbers just faster, as we have effectively created a processing pipeline, having to only wait 100 ms for the first number and then spending only 300 ms to process each number. This way it takes around 1000 ms to run:
```
1
2
3
Collected in 1071 ms
```
### Conflation
When a flow represents partial results of the operation or operation status updates, it may not be necessary to process each value, but instead, only most recent ones. In this case, the [conflate](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/conflate.html) operator can be used to skip intermediate values when a collector is too slow to process them. Building on the previous example:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
import kotlin.system.*
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // pretend we are asynchronously waiting 100 ms
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
//sampleStart
val time = measureTimeMillis {
simple()
.conflate() // conflate emissions, don't process each one
.collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")
//sampleEnd
}
```
We see that while the first number was still being processed the second, and third were already produced, so the second one was *conflated* and only the most recent (the third one) was delivered to the collector:
```
1
3
Collected in 758 ms
```
### Processing the latest value
Conflation is one way to speed up processing when both the emitter and collector are slow. It does it by dropping emitted values. The other way is to cancel a slow collector and restart it every time a new value is emitted. There is a family of `xxxLatest` operators that perform the same essential logic of a `xxx` operator, but cancel the code in their block on a new value. Let's try changing [conflate](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/conflate.html) to [collectLatest](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect-latest.html) in the previous example:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
import kotlin.system.*
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // pretend we are asynchronously waiting 100 ms
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
//sampleStart
val time = measureTimeMillis {
simple()
.collectLatest { value -> // cancel & restart on the latest value
println("Collecting $value")
delay(300) // pretend we are processing it for 300 ms
println("Done $value")
}
}
println("Collected in $time ms")
//sampleEnd
}
```
Since the body of [collectLatest](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect-latest.html) takes 300 ms, but new values are emitted every 100 ms, we see that the block is run on every value, but completes only for the last value:
```
Collecting 1
Collecting 2
Collecting 3
Done 3
Collected in 741 ms
```
Composing multiple flows
------------------------
There are lots of ways to compose multiple flows.
### Zip
Just like the [Sequence.zip](../api/latest/jvm/stdlib/kotlin.sequences/zip) extension function in the Kotlin standard library, flows have a [zip](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/zip.html) operator that combines the corresponding values of two flows:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three") // strings
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string
.collect { println(it) } // collect and print
//sampleEnd
}
```
This example prints:
```
1 -> one
2 -> two
3 -> three
```
### Combine
When flow represents the most recent value of a variable or operation (see also the related section on [conflation](#conflation)), it might be needed to perform a computation that depends on the most recent values of the corresponding flows and to recompute it whenever any of the upstream flows emit a value. The corresponding family of operators is called [combine](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/combine.html).
For example, if the numbers in the previous example update every 300ms, but strings update every 400 ms, then zipping them using the [zip](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/zip.html) operator will still produce the same result, albeit results that are printed every 400 ms:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string with "zip"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//sampleEnd
}
```
However, when using a [combine](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/combine.html) operator here instead of a [zip](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/zip.html):
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking<Unit> {
//sampleStart
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.combine(strs) { a, b -> "$a -> $b" } // compose a single string with "combine"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//sampleEnd
}
```
We get quite a different output, where a line is printed at each emission from either `nums` or `strs` flows:
```
1 -> one at 452 ms from start
2 -> one at 651 ms from start
2 -> two at 854 ms from start
3 -> two at 952 ms from start
3 -> three at 1256 ms from start
```
Flattening flows
----------------
Flows represent asynchronously received sequences of values, and so it is quite easy to get into a situation where each value triggers a request for another sequence of values. For example, we can have the following function that returns a flow of two strings 500 ms apart:
```
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
```
Now if we have a flow of three integers and call `requestFlow` on each of them like this:
```
(1..3).asFlow().map { requestFlow(it) }
```
Then we will end up with a flow of flows (`Flow<Flow<String>>`) that needs to be *flattened* into a single flow for further processing. Collections and sequences have [flatten](../api/latest/jvm/stdlib/kotlin.sequences/flatten) and [flatMap](../api/latest/jvm/stdlib/kotlin.sequences/flat-map) operators for this. However, due to the asynchronous nature of flows they call for different *modes* of flattening, and hence, a family of flattening operators on flows exists.
### flatMapConcat
Concatenation of flows of flows is provided by the [flatMapConcat](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-concat.html) and [flattenConcat](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flatten-concat.html) operators. They are the most direct analogues of the corresponding sequence operators. They wait for the inner flow to complete before starting to collect the next one as the following example shows:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
fun main() = runBlocking<Unit> {
//sampleStart
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // emit a number every 100 ms
.flatMapConcat { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//sampleEnd
}
```
The sequential nature of [flatMapConcat](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-concat.html) is clearly seen in the output:
```
1: First at 121 ms from start
1: Second at 622 ms from start
2: First at 727 ms from start
2: Second at 1227 ms from start
3: First at 1328 ms from start
3: Second at 1829 ms from start
```
### flatMapMerge
Another flattening operation is to concurrently collect all the incoming flows and merge their values into a single flow so that values are emitted as soon as possible. It is implemented by [flatMapMerge](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-merge.html) and [flattenMerge](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flatten-merge.html) operators. They both accept an optional `concurrency` parameter that limits the number of concurrent flows that are collected at the same time (it is equal to [DEFAULT\_CONCURRENCY](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-d-e-f-a-u-l-t_-c-o-n-c-u-r-r-e-n-c-y.html) by default).
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
fun main() = runBlocking<Unit> {
//sampleStart
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapMerge { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//sampleEnd
}
```
The concurrent nature of [flatMapMerge](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-merge.html) is obvious:
```
1: First at 136 ms from start
2: First at 231 ms from start
3: First at 333 ms from start
1: Second at 639 ms from start
2: Second at 732 ms from start
3: Second at 833 ms from start
```
### flatMapLatest
In a similar way to the [collectLatest](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect-latest.html) operator, that was described in the section ["Processing the latest value"](#processing-the-latest-value), there is the corresponding "Latest" flattening mode where the collection of the previous flow is cancelled as soon as new flow is emitted. It is implemented by the [flatMapLatest](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-latest.html) operator.
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}
fun main() = runBlocking<Unit> {
//sampleStart
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapLatest { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
//sampleEnd
}
```
The output here in this example is a good demonstration of how [flatMapLatest](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flat-map-latest.html) works:
```
1: First at 142 ms from start
2: First at 322 ms from start
3: First at 425 ms from start
3: Second at 931 ms from start
```
Flow exceptions
---------------
Flow collection can complete with an exception when an emitter or code inside the operators throw an exception. There are several ways to handle these exceptions.
### Collector try and catch
A collector can use Kotlin's [`try/catch`](exceptions) block to handle exceptions:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
println("Emitting $i")
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
try {
simple().collect { value ->
println(value)
check(value <= 1) { "Collected $value" }
}
} catch (e: Throwable) {
println("Caught $e")
}
}
//sampleEnd
```
This code successfully catches an exception in [collect](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) terminal operator and, as we see, no more values are emitted after that:
```
Emitting 1
1
Emitting 2
2
Caught java.lang.IllegalStateException: Collected 2
```
### Everything is caught
The previous example actually catches any exception happening in the emitter or in any intermediate or terminal operators. For example, let's change the code so that emitted values are [mapped](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/map.html) to strings, but the corresponding code produces an exception:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<String> =
flow {
for (i in 1..3) {
println("Emitting $i")
emit(i) // emit next value
}
}
.map { value ->
check(value <= 1) { "Crashed on $value" }
"string $value"
}
fun main() = runBlocking<Unit> {
try {
simple().collect { value -> println(value) }
} catch (e: Throwable) {
println("Caught $e")
}
}
//sampleEnd
```
This exception is still caught and collection is stopped:
```
Emitting 1
string 1
Emitting 2
Caught java.lang.IllegalStateException: Crashed on 2
```
Exception transparency
----------------------
But how can code of the emitter encapsulate its exception handling behavior?
Flows must be *transparent to exceptions* and it is a violation of the exception transparency to [emit](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) values in the `flow { ... }` builder from inside of a `try/catch` block. This guarantees that a collector throwing an exception can always catch it using `try/catch` as in the previous example.
The emitter can use a [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html) operator that preserves this exception transparency and allows encapsulation of its exception handling. The body of the `catch` operator can analyze an exception and react to it in different ways depending on which exception was caught:
* Exceptions can be rethrown using `throw`.
* Exceptions can be turned into emission of values using [emit](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) from the body of [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html).
* Exceptions can be ignored, logged, or processed by some other code.
For example, let us emit the text on catching an exception:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun simple(): Flow<String> =
flow {
for (i in 1..3) {
println("Emitting $i")
emit(i) // emit next value
}
}
.map { value ->
check(value <= 1) { "Crashed on $value" }
"string $value"
}
fun main() = runBlocking<Unit> {
//sampleStart
simple()
.catch { e -> emit("Caught $e") } // emit on exception
.collect { value -> println(value) }
//sampleEnd
}
```
The output of the example is the same, even though we do not have `try/catch` around the code anymore.
### Transparent catch
The [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html) intermediate operator, honoring exception transparency, catches only upstream exceptions (that is an exception from all the operators above `catch`, but not below it). If the block in `collect { ... }` (placed below `catch`) throws an exception then it escapes:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
simple()
.catch { e -> println("Caught $e") } // does not catch downstream exceptions
.collect { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
}
//sampleEnd
```
A "Caught ..." message is not printed despite there being a `catch` operator:
```
Emitting 1
1
Emitting 2
Exception in thread "main" java.lang.IllegalStateException: Collected 2
at ...
```
### Catching declaratively
We can combine the declarative nature of the [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html) operator with a desire to handle all the exceptions, by moving the body of the [collect](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) operator into [onEach](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-each.html) and putting it before the `catch` operator. Collection of this flow must be triggered by a call to `collect()` without parameters:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
//sampleStart
simple()
.onEach { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
.catch { e -> println("Caught $e") }
.collect()
//sampleEnd
}
```
Now we can see that a "Caught ..." message is printed and so we can catch all the exceptions without explicitly using a `try/catch` block:
```
Emitting 1
1
Emitting 2
Caught java.lang.IllegalStateException: Collected 2
```
Flow completion
---------------
When flow collection completes (normally or exceptionally) it may need to execute an action. As you may have already noticed, it can be done in two ways: imperative or declarative.
### Imperative finally block
In addition to `try`/`catch`, a collector can also use a `finally` block to execute an action upon `collect` completion.
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
try {
simple().collect { value -> println(value) }
} finally {
println("Done")
}
}
//sampleEnd
```
This code prints three numbers produced by the `simple` flow followed by a "Done" string:
```
1
2
3
Done
```
### Declarative handling
For the declarative approach, flow has [onCompletion](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-completion.html) intermediate operator that is invoked when the flow has completely collected.
The previous example can be rewritten using an [onCompletion](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-completion.html) operator and produces the same output:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
//sampleStart
simple()
.onCompletion { println("Done") }
.collect { value -> println(value) }
//sampleEnd
}
```
The key advantage of [onCompletion](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-completion.html) is a nullable `Throwable` parameter of the lambda that can be used to determine whether the flow collection was completed normally or exceptionally. In the following example the `simple` flow throws an exception after emitting the number 1:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = flow {
emit(1)
throw RuntimeException()
}
fun main() = runBlocking<Unit> {
simple()
.onCompletion { cause -> if (cause != null) println("Flow completed exceptionally") }
.catch { cause -> println("Caught exception") }
.collect { value -> println(value) }
}
//sampleEnd
```
As you may expect, it prints:
```
1
Flow completed exceptionally
Caught exception
```
The [onCompletion](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-completion.html) operator, unlike [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html), does not handle the exception. As we can see from the above example code, the exception still flows downstream. It will be delivered to further `onCompletion` operators and can be handled with a `catch` operator.
### Successful completion
Another difference with [catch](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/catch.html) operator is that [onCompletion](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-completion.html) sees all exceptions and receives a `null` exception only on successful completion of the upstream flow (without cancellation or failure).
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
simple()
.onCompletion { cause -> println("Flow completed with $cause") }
.collect { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
}
//sampleEnd
```
We can see the completion cause is not null, because the flow was aborted due to downstream exception:
```
1
Flow completed with java.lang.IllegalStateException: Collected 2
Exception in thread "main" java.lang.IllegalStateException: Collected 2
```
Imperative versus declarative
-----------------------------
Now we know how to collect flow, and handle its completion and exceptions in both imperative and declarative ways. The natural question here is, which approach is preferred and why? As a library, we do not advocate for any particular approach and believe that both options are valid and should be selected according to your own preferences and code style.
Launching flow
--------------
It is easy to use flows to represent asynchronous events that are coming from some source. In this case, we need an analogue of the `addEventListener` function that registers a piece of code with a reaction for incoming events and continues further work. The [onEach](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/on-each.html) operator can serve this role. However, `onEach` is an intermediate operator. We also need a terminal operator to collect the flow. Otherwise, just calling `onEach` has no effect.
If we use the [collect](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) terminal operator after `onEach`, then the code after it will wait until the flow is collected:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
// Imitate a flow of events
fun events(): Flow<Int> = (1..3).asFlow().onEach { delay(100) }
fun main() = runBlocking<Unit> {
events()
.onEach { event -> println("Event: $event") }
.collect() // <--- Collecting the flow waits
println("Done")
}
//sampleEnd
```
As you can see, it prints:
```
Event: 1
Event: 2
Event: 3
Done
```
The [launchIn](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/launch-in.html) terminal operator comes in handy here. By replacing `collect` with `launchIn` we can launch a collection of the flow in a separate coroutine, so that execution of further code immediately continues:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
// Imitate a flow of events
fun events(): Flow<Int> = (1..3).asFlow().onEach { delay(100) }
//sampleStart
fun main() = runBlocking<Unit> {
events()
.onEach { event -> println("Event: $event") }
.launchIn(this) // <--- Launching the flow in a separate coroutine
println("Done")
}
//sampleEnd
```
It prints:
```
Done
Event: 1
Event: 2
Event: 3
```
The required parameter to `launchIn` must specify a [CoroutineScope](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-coroutine-scope/index.html) in which the coroutine to collect the flow is launched. In the above example this scope comes from the [runBlocking](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) coroutine builder, so while the flow is running, this [runBlocking](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) scope waits for completion of its child coroutine and keeps the main function from returning and terminating this example.
In actual applications a scope will come from an entity with a limited lifetime. As soon as the lifetime of this entity is terminated the corresponding scope is cancelled, cancelling the collection of the corresponding flow. This way the pair of `onEach { ... }.launchIn(scope)` works like the `addEventListener`. However, there is no need for the corresponding `removeEventListener` function, as cancellation and structured concurrency serve this purpose.
Note that [launchIn](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/launch-in.html) also returns a [Job](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/index.html), which can be used to [cancel](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel.html) the corresponding flow collection coroutine only without cancelling the whole scope or to [join](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-job/join.html) it.
### Flow cancellation checks
For convenience, the [flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow.html) builder performs additional [ensureActive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/ensure-active.html) checks for cancellation on each emitted value. It means that a busy loop emitting from a `flow { ... }` is cancellable:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun foo(): Flow<Int> = flow {
for (i in 1..5) {
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
foo().collect { value ->
if (value == 3) cancel()
println(value)
}
}
//sampleEnd
```
We get only numbers up to 3 and a [CancellationException](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-cancellation-exception/index.html) after trying to emit number 4:
```
Emitting 1
1
Emitting 2
2
Emitting 3
3
Emitting 4
Exception in thread "main" kotlinx.coroutines.JobCancellationException: BlockingCoroutine was cancelled; job="coroutine#1":BlockingCoroutine{Cancelled}@6d7b4f4c
```
However, most other flow operators do not do additional cancellation checks on their own for performance reasons. For example, if you use [IntRange.asFlow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/as-flow.html) extension to write the same busy loop and don't suspend anywhere, then there are no checks for cancellation:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun main() = runBlocking<Unit> {
(1..5).asFlow().collect { value ->
if (value == 3) cancel()
println(value)
}
}
//sampleEnd
```
All numbers from 1 to 5 are collected and cancellation gets detected only before return from `runBlocking`:
```
1
2
3
4
5
Exception in thread "main" kotlinx.coroutines.JobCancellationException: BlockingCoroutine was cancelled; job="coroutine#1":BlockingCoroutine{Cancelled}@3327bd23
```
#### Making busy flow cancellable
In the case where you have a busy loop with coroutines you must explicitly check for cancellation. You can add `.onEach { currentCoroutineContext().ensureActive() }`, but there is a ready-to-use [cancellable](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/cancellable.html) operator provided to do that:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
//sampleStart
fun main() = runBlocking<Unit> {
(1..5).asFlow().cancellable().collect { value ->
if (value == 3) cancel()
println(value)
}
}
//sampleEnd
```
With the `cancellable` operator only the numbers from 1 to 3 are collected:
```
1
2
3
Exception in thread "main" kotlinx.coroutines.JobCancellationException: BlockingCoroutine was cancelled; job="coroutine#1":BlockingCoroutine{Cancelled}@5ec0a365
```
Flow and Reactive Streams
-------------------------
For those who are familiar with [Reactive Streams](https://www.reactive-streams.org/) or reactive frameworks such as RxJava and project Reactor, design of the Flow may look very familiar.
Indeed, its design was inspired by Reactive Streams and its various implementations. But Flow main goal is to have as simple design as possible, be Kotlin and suspension friendly and respect structured concurrency. Achieving this goal would be impossible without reactive pioneers and their tremendous work. You can read the complete story in [Reactive Streams and Kotlin Flows](https://medium.com/@elizarov/reactive-streams-and-kotlin-flows-bfd12772cda4) article.
While being different, conceptually, Flow *is* a reactive stream and it is possible to convert it to the reactive (spec and TCK compliant) Publisher and vice versa. Such converters are provided by `kotlinx.coroutines` out-of-the-box and can be found in corresponding reactive modules (`kotlinx-coroutines-reactive` for Reactive Streams, `kotlinx-coroutines-reactor` for Project Reactor and `kotlinx-coroutines-rx2`/`kotlinx-coroutines-rx3` for RxJava2/RxJava3). Integration modules include conversions from and to `Flow`, integration with Reactor's `Context` and suspension-friendly ways to work with various reactive entities.
Last modified: 10 January 2023
[Coroutine context and dispatchers](coroutine-context-and-dispatchers) [Channels](channels)
| programming_docs |
kotlin Understand Multiplatform project structure Understand Multiplatform project structure
==========================================
Discover main parts of your multiplatform project:
* [Multiplatform plugin](#multiplatform-plugin)
* [Targets](#targets)
* [Source sets](#source-sets)
* [Compilations](#compilations)
Multiplatform plugin
--------------------
When you [create a multiplatform project](multiplatform-library), the Project Wizard automatically applies the `kotlin-multiplatform` Gradle plugin in the file `build.gradle`(`.kts`).
You can also apply it manually.
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
```
The `kotlin-multiplatform` plugin configures the project for creating an application or library to work on multiple platforms and prepares it for building on these platforms.
In the file `build.gradle`(`.kts`), it creates the `kotlin` extension at the top level, which includes configuration for [targets](#targets), [source sets](#source-sets), and dependencies.
Targets
-------
A multiplatform project is aimed at multiple platforms that are represented by different targets. A target is part of the build that is responsible for building, testing, and packaging the application for a specific platform, such as macOS, iOS, or Android. See the list of [supported platforms](multiplatform-dsl-reference#targets).
When you create a multiplatform project, targets are added to the `kotlin` block in the file `build.gradle` (`build.gradle.kts`).
```
kotlin {
jvm()
js {
browser {}
}
}
```
Learn how to [set up targets manually](multiplatform-set-up-targets).
Source sets
-----------
The project includes the directory `src` with Kotlin source sets, which are collections of Kotlin code files, along with their resources, dependencies, and language settings. A source set can be used in Kotlin compilations for one or more target platforms.
Each source set directory includes Kotlin code files (the `kotlin` directory) and `resources`. The Project Wizard creates default source sets for the `main` and `test` compilations of the common code and all added targets.
Source sets are added to the `sourceSets` block of the top-level `kotlin` block. For example, this is the source sets structure you get when creating a multiplatform library with the IntelliJ IDEA project wizard:
```
kotlin {
sourceSets {
val commonMain by getting
val commonTest by getting {
dependencies {
implementation(kotlin("test"))
}
}
val jvmMain by getting
val jvmTest by getting
val jsMain by getting
val jsTest by getting
val nativeMain by getting
val nativeTest by getting
}
}
```
```
kotlin {
sourceSets {
commonMain {
}
commonTest {
dependencies {
implementation kotlin('test')
}
}
jvmMain {
}
jvmTest {
}
jsMain {
}
jsTest {
}
nativeMain {
}
nativeTest {
}
}
}
```
Source sets form a hierarchy, which is used for sharing the common code. In a source set shared among several targets, you can use the platform-specific language features and dependencies that are available for all these targets.
For example, all Kotlin/Native features are available in the `desktopMain` source set, which targets the Linux (`linuxX64`), Windows (`mingwX64`), and macOS (`macosX64`) platforms.
Learn how to [build the hierarchy of source sets](multiplatform-share-on-platforms#share-code-on-similar-platforms).
Compilations
------------
Each target can have one or more compilations, for example, for production and test purposes.
For each target, default compilations include:
* `main` and `test` compilations for JVM, JS, and Native targets.
* A compilation per [Android build variant](https://developer.android.com/studio/build/build-variants), for Android targets.
Each compilation has a default source set, which contains sources and dependencies specific to that compilation.
Learn how to [configure compilations](multiplatform-configure-compilations).
Last modified: 10 January 2023
[Get started with Kotlin Multiplatform](multiplatform-get-started) [Set up targets for Kotlin Multiplatform](multiplatform-set-up-targets)
kotlin Mapping struct and union types from C – tutorial Mapping struct and union types from C – tutorial
================================================
This is the second post in the series. The very first tutorial of the series is [Mapping primitive data types from C](mapping-primitive-data-types-from-c). There are also the [Mapping function pointers from C](mapping-function-pointers-from-c) and [Mapping Strings from C](mapping-strings-from-c) tutorials.
In the tutorial, you will learn:
* [How struct and union types are mapped](#mapping-struct-and-union-c-types)
* [How to use struct and union type from Kotlin](#use-struct-and-union-types-from-kotlin)
Mapping struct and union C types
--------------------------------
The best way to understand the mapping between Kotlin and C is to try a tiny example. We will declare a struct and a union in the C language, to see how they are mapped into Kotlin.
Kotlin/Native comes with the `cinterop` tool, the tool generates bindings between the C language and Kotlin. It uses a `.def` file to specify a C library to import. More details are discussed in the [Interop with C Libraries](native-c-interop) tutorial.
In [the previous tutorial](mapping-primitive-data-types-from-c), you've created a `lib.h` file. This time, include those declarations directly into the `interop.def` file, after the `---` separator line:
```
---
typedef struct {
int a;
double b;
} MyStruct;
void struct_by_value(MyStruct s) {}
void struct_by_pointer(MyStruct* s) {}
typedef union {
int a;
MyStruct b;
float c;
} MyUnion;
void union_by_value(MyUnion u) {}
void union_by_pointer(MyUnion* u) {}
```
The `interop.def` file is enough to compile and run the application or open it in an IDE. Now it is time to create project files, open the project in [IntelliJ IDEA](https://jetbrains.com/idea) and run it.
Inspect Generated Kotlin APIs for a C library
---------------------------------------------
While it is possible to use the command line, either directly or by combining it with a script file (such as `.sh` or `.bat` file), this approach doesn't scale well for big projects that have hundreds of files and libraries. It is then better to use the Kotlin/Native compiler with a build system, as it helps to download and cache the Kotlin/Native compiler binaries and libraries with transitive dependencies and run the compiler and tests. Kotlin/Native can use the [Gradle](https://gradle.org) build system through the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin.
We covered the basics of setting up an IDE compatible project with Gradle in the [A Basic Kotlin/Native Application](native-gradle) tutorial. Please check it out if you are looking for detailed first steps and instructions on how to start a new Kotlin/Native project and open it in IntelliJ IDEA. In this tutorial, we'll look at the advanced C interop related usages of Kotlin/Native and [multiplatform](multiplatform-discover-project#multiplatform-plugin) builds with Gradle.
First, create a project folder. All the paths in this tutorial will be relative to this folder. Sometimes the missing directories will have to be created before any new files can be added.
Use the following `build.gradle(.kts)` Gradle build file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
linuxX64("native") { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64("native") { // on Windows
val main by compilations.getting
val interop by main.cinterops.creating
binaries {
executable()
}
}
}
tasks.wrapper {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.BIN
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
linuxX64('native') { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64('native') { // on Windows
compilations.main.cinterops {
interop
}
binaries {
executable()
}
}
}
wrapper {
gradleVersion = '7.3'
distributionType = 'BIN'
}
```
The project file configures the C interop as an additional step of the build. Let's move the `interop.def` file to the `src/nativeInterop/cinterop` directory. Gradle recommends using conventions instead of configurations, for example, the source files are expected to be in the `src/nativeMain/kotlin` folder. By default, all the symbols from C are imported to the `interop` package, you may want to import the whole package in our `.kt` files. Check out the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin documentation to learn about all the different ways you could configure it.
Create a `src/nativeMain/kotlin/hello.kt` stub file with the following content to see how C struct and union declarations are visible from Kotlin:
```
import interop.*
fun main() {
println("Hello Kotlin/Native!")
struct_by_value(/* fix me*/)
struct_by_pointer(/* fix me*/)
union_by_value(/* fix me*/)
union_by_pointer(/* fix me*/)
}
```
Now you are ready to [open the project in IntelliJ IDEA](native-get-started) and to see how to fix the example project. While doing that, see how C struct and union types are mapped into Kotlin/Native.
Struct and union types in Kotlin
--------------------------------
With the help of IntelliJ IDEA's **Go to | Declaration** or compiler errors, you see the following generated API for the C functions, `struct`, and `union`:
```
fun struct_by_value(s: CValue<MyStruct>)
fun struct_by_pointer(s: CValuesRef<MyStruct>?)
fun union_by_value(u: CValue<MyUnion>)
fun union_by_pointer(u: CValuesRef<MyUnion>?)
class MyStruct constructor(rawPtr: NativePtr /* = NativePtr */) : CStructVar {
var a: Int
var b: Double
companion object : CStructVar.Type
}
class MyUnion constructor(rawPtr: NativePtr /* = NativePtr */) : CStructVar {
var a: Int
val b: MyStruct
var c: Float
companion object : CStructVar.Type
}
```
You see that `cinterop` generated wrapper types for our `struct` and `union` types. For `MyStruct` and `MyUnion` type declarations in C, there are the Kotlin classes `MyStruct` and `MyUnion` generated respectively. The wrappers inherit from the `CStructVar` base class and declare all fields as Kotlin properties. It uses `CValue<T>` to represent a by-value structure parameter and `CValuesRef<T>?` to represent passing a pointer to a structure or a union.
Technically, there is no difference between `struct` and `union` types on the Kotlin side. Note that `a`, `b`, and `c` properties of `MyUnion` class in Kotlin use the same memory location to read/write their value just like `union` does in C language.
More details and advanced use-cases are presented in the
[C Interop documentation](native-c-interop)
Use struct and union types from Kotlin
--------------------------------------
It is easy to use the generated wrapper classes for C `struct` and `union` types from Kotlin. Thanks to the generated properties, it feels natural to use them in Kotlin code. The only question, so far, is how to create a new instance on those classes. As you see from the declarations of `MyStruct` and `MyUnion`, their constructors require a `NativePtr`. Of course, you are not willing to deal with pointers manually. Instead, you can use Kotlin API to have those objects instantiated for us.
Let's take a look at the generated functions that take our `MyStruct` and `MyUnion` as parameters. You see that by-value parameters are represented as `kotlinx.cinterop.CValue<T>`. And for typed pointer parameters you see `kotlinx.cinterop.CValuesRef<T>`. Kotlin provides us with an API to deal with both types easily, let's try it and see.
### Create a CValue
`CValue<T>` type is used to pass by-value parameters to a C function call. Use `cValue` function to create `CValue<T>` object instance. The function requires a [lambda function with a receiver](lambdas#function-literals-with-receiver) to initialize the underlying C type in-place. The function is declared as follows:
```
fun <reified T : CStructVar> cValue(initialize: T.() -> Unit): CValue<T>
```
Now it is time to see how to use `cValue` and pass by-value parameters:
```
fun callValue() {
val cStruct = cValue<MyStruct> {
a = 42
b = 3.14
}
struct_by_value(cStruct)
val cUnion = cValue<MyUnion> {
b.a = 5
b.b = 2.7182
}
union_by_value(cUnion)
}
```
### Create struct and union as CValuesRef
`CValuesRef<T>` type is used in Kotlin to pass a typed pointer parameter of a C function. First, you need an instance of `MyStruct` and `MyUnion` classes. Create them directly in the native memory. Use the
```
fun <reified T : kotlinx.cinterop.CVariable> alloc(): T
```
extension function on `kotlinx.cinterop.NativePlacement` type for this.
`NativePlacement` represents native memory with functions similar to `malloc` and `free`. There are several implementations of `NativePlacement`. The global one is called with `kotlinx.cinterop.nativeHeap` and don't forget to call the `nativeHeap.free(..)` function to free the memory after use.
Another option is to use the
```
fun <R> memScoped(block: kotlinx.cinterop.MemScope.() -> R): R
```
function. It creates a short-lived memory allocation scope, and all allocations will be cleaned up automatically at the end of the `block`.
Your code to call functions with pointers will look like this:
```
fun callRef() {
memScoped {
val cStruct = alloc<MyStruct>()
cStruct.a = 42
cStruct.b = 3.14
struct_by_pointer(cStruct.ptr)
val cUnion = alloc<MyUnion>()
cUnion.b.a = 5
cUnion.b.b = 2.7182
union_by_pointer(cUnion.ptr)
}
}
```
Note that this code uses the extension property `ptr` which comes from a `memScoped` lambda receiver type, to turn `MyStruct` and `MyUnion` instances into native pointers.
The `MyStruct` and `MyUnion` classes have the pointer to the native memory underneath. The memory will be released when a `memScoped` function ends, which is equal to the end of its `block`. Make sure that a pointer is not used outside of the `memScoped` call. You may use `Arena()` or `nativeHeap` for pointers that should be available longer, or are cached inside a C library.
### Conversion between CValue and CValuesRef
Of course, there are use cases when you need to pass a struct as a value to one call, and then, to pass the same struct as a reference to another call. This is possible in Kotlin/Native too. A `NativePlacement` will be needed here.
Let's see now `CValue<T>` is turned to a pointer first:
```
fun callMix_ref() {
val cStruct = cValue<MyStruct> {
a = 42
b = 3.14
}
memScoped {
struct_by_pointer(cStruct.ptr)
}
}
```
This code uses the extension property `ptr` which comes from `memScoped` lambda receiver type to turn `MyStruct` and `MyUnion` instances into native pointers. Those pointers are only valid inside the `memScoped` block.
For the opposite conversion, to turn a pointer into a by-value variable, we call the `readValue()` extension function:
```
fun callMix_value() {
memScoped {
val cStruct = alloc<MyStruct>()
cStruct.a = 42
cStruct.b = 3.14
struct_by_value(cStruct.readValue())
}
}
```
Run the code
------------
Now when you have learned how to use C declarations in your code, you are ready to try it out on a real example. Let's fix the code and see how it runs by calling the `runDebugExecutableNative` Gradle task [in the IDE](native-get-started) or by using the following console command:
```
./gradlew runDebugExecutableNative
```
The final code in the `hello.kt` file may look like this:
```
import interop.*
import kotlinx.cinterop.alloc
import kotlinx.cinterop.cValue
import kotlinx.cinterop.memScoped
import kotlinx.cinterop.ptr
import kotlinx.cinterop.readValue
fun main() {
println("Hello Kotlin/Native!")
val cUnion = cValue<MyUnion> {
b.a = 5
b.b = 2.7182
}
memScoped {
union_by_value(cUnion)
union_by_pointer(cUnion.ptr)
}
memScoped {
val cStruct = alloc<MyStruct> {
a = 42
b = 3.14
}
struct_by_value(cStruct.readValue())
struct_by_pointer(cStruct.ptr)
}
}
```
Next steps
----------
Continue exploring the C language types and their representation in Kotlin/Native in the related tutorials:
* [Mapping primitive data types from C](mapping-primitive-data-types-from-c)
* [Mapping function pointers from C](mapping-function-pointers-from-c)
* [Mapping strings from C](mapping-strings-from-c)
The [C Interop documentation](native-c-interop) covers more advanced scenarios of the interop.
Last modified: 10 January 2023
[Mapping primitive data types from C – tutorial](mapping-primitive-data-types-from-c) [Mapping function pointers from C – tutorial](mapping-function-pointers-from-c)
kotlin Exceptions Exceptions
==========
Exception classes
-----------------
All exception classes in Kotlin inherit the `Throwable` class. Every exception has a message, a stack trace, and an optional cause.
To throw an exception object, use the `throw` expression:
```
fun main() {
//sampleStart
throw Exception("Hi There!")
//sampleEnd
}
```
To catch an exception, use the `try`...`catch` expression:
```
try {
// some code
} catch (e: SomeException) {
// handler
} finally {
// optional finally block
}
```
There may be zero or more `catch` blocks, and the `finally` block may be omitted. However, at least one `catch` or `finally` block is required.
### Try is an expression
`try` is an expression, which means it can have a return value:
```
val a: Int? = try { input.toInt() } catch (e: NumberFormatException) { null }
```
The returned value of a `try` expression is either the last expression in the `try` block or the last expression in the `catch` block (or blocks). The contents of the `finally` block don't affect the result of the expression.
Checked exceptions
------------------
Kotlin does not have checked exceptions. There are many reasons for this, but we will provide a simple example that illustrates why it is the case.
The following is an example interface from the JDK implemented by the `StringBuilder` class:
```
Appendable append(CharSequence csq) throws IOException;
```
This signature says that every time I append a string to something (a `StringBuilder`, some kind of a log, a console, etc.), I have to catch the `IOExceptions`. Why? Because the implementation might be performing IO operations (`Writer` also implements `Appendable`). The result is code like this all over the place:
```
try {
log.append(message)
} catch (IOException e) {
// Must be safe
}
```
And that's not good. Just take a look at [Effective Java, 3rd Edition](https://www.oracle.com/technetwork/java/effectivejava-136174.html), Item 77: *Don't ignore exceptions*.
Bruce Eckel says this about checked exceptions:
And here are some additional thoughts on the matter:
* [Java's checked exceptions were a mistake](https://radio-weblogs.com/0122027/stories/2003/04/01/JavasCheckedExceptionsWereAMistake.html) (Rod Waldhoff)
* [The Trouble with Checked Exceptions](https://www.artima.com/intv/handcuffs.html) (Anders Hejlsberg)
If you want to alert callers about possible exceptions when calling Kotlin code from Java, Swift, or Objective-C, you can use the `@Throws` annotation. Read more about using this annotation [for Java](java-to-kotlin-interop#checked-exceptions) and [for Swift and Objective-C](native-objc-interop#errors-and-exceptions).
The Nothing type
----------------
`throw` is an expression in Kotlin, so you can use it, for example, as part of an Elvis expression:
```
val s = person.name ?: throw IllegalArgumentException("Name required")
```
The `throw` expression has the type `Nothing`. This type has no values and is used to mark code locations that can never be reached. In your own code, you can use `Nothing` to mark a function that never returns:
```
fun fail(message: String): Nothing {
throw IllegalArgumentException(message)
}
```
When you call this function, the compiler will know that the execution doesn't continue beyond the call:
```
val s = person.name ?: fail("Name required")
println(s) // 's' is known to be initialized at this point
```
You may also encounter this type when dealing with type inference. The nullable variant of this type, `Nothing?`, has exactly one possible value, which is `null`. If you use `null` to initialize a value of an inferred type and there's no other information that can be used to determine a more specific type, the compiler will infer the `Nothing?` type:
```
val x = null // 'x' has type `Nothing?`
val l = listOf(null) // 'l' has type `List<Nothing?>
```
Java interoperability
---------------------
Please see the section on exceptions in the [Java interoperability page](java-interop) for information about Java interoperability.
Last modified: 10 January 2023
[Returns and jumps](returns) [Packages and imports](packages)
| programming_docs |
kotlin Using Java records in Kotlin Using Java records in Kotlin
============================
*Records* are [classes](https://openjdk.java.net/jeps/395) in Java for storing immutable data. Records carry a fixed set of values – the *records components*. They have a concise syntax in Java and save you from having to write boilerplate code:
```
// Java
public record Person (String name, int age) {}
```
The compiler automatically generates a final class inherited from [`java.lang.Record`](https://docs.oracle.com/en/java/javase/16/docs/api/java.base/java/lang/Record.html) with the following members:
* a private final field for each record component
* a public constructor with parameters for all fields
* a set of methods to implement structural equality: `equals()`, `hashCode()`, `toString()`
* a public method for reading each record component
Records are very similar to Kotlin [data classes](data-classes).
Using Java records from Kotlin code
-----------------------------------
You can use record classes with components that are declared in Java the same way you would use classes with properties in Kotlin. To access the record component, just use its name like you do for [Kotlin properties](properties):
```
val newPerson = Person("Kotlin", 10)
val firstName = newPerson.name
```
Declare records in Kotlin
-------------------------
Kotlin supports record declaration only for data classes, and the data class must meet the [requirements](#requirements).
To declare a record class in Kotlin, use the `@JvmRecord` annotation:
```
@JvmRecord
data class Person(val name: String, val age: Int)
```
This JVM-specific annotation enables generating:
* the record components corresponding to the class properties in the class file
* the property accessor methods named according to the Java record naming convention
The data class provides `equals()`, `hashCode()`, and `toString()` method implementations.
### Requirements
To declare a data class with the `@JvmRecord` annotation, it must meet the following requirements:
* The class must be in a module that targets JVM 16 bytecode (or 15 if the `-Xjvm-enable-preview` compiler option is enabled).
* The class cannot explicitly inherit any other class (including `Any`) because all JVM records implicitly inherit `java.lang.Record`. However, the class can implement interfaces.
* The class cannot declare any properties with backing fields – except those initialized from the corresponding primary constructor parameters.
* The class cannot declare any mutable properties with backing fields.
* The class cannot be local.
* The primary constructor of the class must be as visible as the class itself.
### Enabling JVM records
JVM records require the `16` target version or higher of the generated JVM bytecode.
To specify it explicitly, use the `jvmTarget` compiler option in [Gradle](gradle-compiler-options#attributes-specific-to-jvm) or [Maven](maven#attributes-specific-to-jvm).
Further discussion
------------------
See this [language proposal for JVM records](https://github.com/Kotlin/KEEP/blob/master/proposals/jvm-records.md) for further technical details and discussion.
Last modified: 10 January 2023
[Mixing Java and Kotlin in one project – tutorial](mixing-java-kotlin-intellij) [Strings in Java and Kotlin](java-to-kotlin-idioms-strings)
kotlin Browser and DOM API Browser and DOM API
===================
The Kotlin/JS standard library lets you access browser-specific functionality using the `kotlinx.browser` package, which includes typical top-level objects such as `document` and `window`. The standard library provides typesafe wrappers for the functionality exposed by these objects wherever possible. As a fallback, the `dynamic` type is used to provide interaction with functions that do not map well into the Kotlin type system.
Interaction with the DOM
------------------------
For interaction with the Document Object Model (DOM), you can use the variable `document`. For example, you can set the background color of our website through this object:
```
document.bgColor = "FFAA12"
```
The `document` object also provides you a way to retrieve a specific element by ID, name, class name, tag name and so on. All returned elements are of type `Element?`. To access their properties, you need to cast them to their appropriate type. For example, assume that you have an HTML page with an email `<input>` field:
```
<body>
<input type="text" name="email" id="email"/>
<script type="text/javascript" src="tutorial.js"></script>
</body>
```
Note that your script is included at the bottom of the `body` tag. This ensures that the DOM is fully available before the script is loaded.
With this setup, you can access elements of the DOM. To access the properties of the `input` field, invoke `getElementById` and cast it to `HTMLInputElement`. You can then safely access its properties, such as `value`:
```
val email = document.getElementById("email") as HTMLInputElement
email.value = "[email protected]"
```
Much like you reference this `input` element, you can access other elements on the page, casting them to the appropriate types.
To see how to create and structure elements in the DOM in a concise way, check out the [Typesafe HTML DSL](typesafe-html-dsl).
Last modified: 10 January 2023
[Migrating Kotlin/JS projects to the IR compiler](js-ir-migration) [Use JavaScript code from Kotlin](js-interop)
kotlin Inheritance Inheritance
===========
All classes in Kotlin have a common superclass, `Any`, which is the default superclass for a class with no supertypes declared:
```
class Example // Implicitly inherits from Any
```
`Any` has three methods: `equals()`, `hashCode()`, and `toString()`. Thus, these methods are defined for all Kotlin classes.
By default, Kotlin classes are final – they can't be inherited. To make a class inheritable, mark it with the `open` keyword:
```
open class Base // Class is open for inheritance
```
To declare an explicit supertype, place the type after a colon in the class header:
```
open class Base(p: Int)
class Derived(p: Int) : Base(p)
```
If the derived class has a primary constructor, the base class can (and must) be initialized in that primary constructor according to its parameters.
If the derived class has no primary constructor, then each secondary constructor has to initialize the base type using the `super` keyword or it has to delegate to another constructor which does. Note that in this case different secondary constructors can call different constructors of the base type:
```
class MyView : View {
constructor(ctx: Context) : super(ctx)
constructor(ctx: Context, attrs: AttributeSet) : super(ctx, attrs)
}
```
Overriding methods
------------------
Kotlin requires explicit modifiers for overridable members and overrides:
```
open class Shape {
open fun draw() { /*...*/ }
fun fill() { /*...*/ }
}
class Circle() : Shape() {
override fun draw() { /*...*/ }
}
```
The `override` modifier is required for `Circle.draw()`. If it were missing, the compiler would complain. If there is no `open` modifier on a function, like `Shape.fill()`, declaring a method with the same signature in a subclass is not allowed, either with `override` or without it. The `open` modifier has no effect when added to members of a final class – a class without an `open` modifier.
A member marked `override` is itself open, so it may be overridden in subclasses. If you want to prohibit re-overriding, use `final`:
```
open class Rectangle() : Shape() {
final override fun draw() { /*...*/ }
}
```
Overriding properties
---------------------
The overriding mechanism works on properties in the same way that it does on methods. Properties declared on a superclass that are then redeclared on a derived class must be prefaced with `override`, and they must have a compatible type. Each declared property can be overridden by a property with an initializer or by a property with a `get` method:
```
open class Shape {
open val vertexCount: Int = 0
}
class Rectangle : Shape() {
override val vertexCount = 4
}
```
You can also override a `val` property with a `var` property, but not vice versa. This is allowed because a `val` property essentially declares a `get` method, and overriding it as a `var` additionally declares a `set` method in the derived class.
Note that you can use the `override` keyword as part of the property declaration in a primary constructor:
```
interface Shape {
val vertexCount: Int
}
class Rectangle(override val vertexCount: Int = 4) : Shape // Always has 4 vertices
class Polygon : Shape {
override var vertexCount: Int = 0 // Can be set to any number later
}
```
Derived class initialization order
----------------------------------
During the construction of a new instance of a derived class, the base class initialization is done as the first step (preceded only by evaluation of the arguments for the base class constructor), which means that it happens before the initialization logic of the derived class is run.
```
//sampleStart
open class Base(val name: String) {
init { println("Initializing a base class") }
open val size: Int =
name.length.also { println("Initializing size in the base class: $it") }
}
class Derived(
name: String,
val lastName: String,
) : Base(name.replaceFirstChar { it.uppercase() }.also { println("Argument for the base class: $it") }) {
init { println("Initializing a derived class") }
override val size: Int =
(super.size + lastName.length).also { println("Initializing size in the derived class: $it") }
}
//sampleEnd
fun main() {
println("Constructing the derived class(\"hello\", \"world\")")
Derived("hello", "world")
}
```
This means that when the base class constructor is executed, the properties declared or overridden in the derived class have not yet been initialized. Using any of those properties in the base class initialization logic (either directly or indirectly through another overridden `open` member implementation) may lead to incorrect behavior or a runtime failure. When designing a base class, you should therefore avoid using `open` members in the constructors, property initializers, or `init` blocks.
Calling the superclass implementation
-------------------------------------
Code in a derived class can call its superclass functions and property accessor implementations using the `super` keyword:
```
open class Rectangle {
open fun draw() { println("Drawing a rectangle") }
val borderColor: String get() = "black"
}
class FilledRectangle : Rectangle() {
override fun draw() {
super.draw()
println("Filling the rectangle")
}
val fillColor: String get() = super.borderColor
}
```
Inside an inner class, accessing the superclass of the outer class is done using the `super` keyword qualified with the outer class name: `super@Outer`:
```
open class Rectangle {
open fun draw() { println("Drawing a rectangle") }
val borderColor: String get() = "black"
}
//sampleStart
class FilledRectangle: Rectangle() {
override fun draw() {
val filler = Filler()
filler.drawAndFill()
}
inner class Filler {
fun fill() { println("Filling") }
fun drawAndFill() {
[email protected]() // Calls Rectangle's implementation of draw()
fill()
println("Drawn a filled rectangle with color ${[email protected]}") // Uses Rectangle's implementation of borderColor's get()
}
}
}
//sampleEnd
fun main() {
val fr = FilledRectangle()
fr.draw()
}
```
Overriding rules
----------------
In Kotlin, implementation inheritance is regulated by the following rule: if a class inherits multiple implementations of the same member from its immediate superclasses, it must override this member and provide its own implementation (perhaps, using one of the inherited ones).
To denote the supertype from which the inherited implementation is taken, use `super` qualified by the supertype name in angle brackets, such as `super<Base>`:
```
open class Rectangle {
open fun draw() { /* ... */ }
}
interface Polygon {
fun draw() { /* ... */ } // interface members are 'open' by default
}
class Square() : Rectangle(), Polygon {
// The compiler requires draw() to be overridden:
override fun draw() {
super<Rectangle>.draw() // call to Rectangle.draw()
super<Polygon>.draw() // call to Polygon.draw()
}
}
```
It's fine to inherit from both `Rectangle` and `Polygon`, but both of them have their implementations of `draw()`, so you need to override `draw()` in `Square` and provide a separate implementation for it to eliminate the ambiguity.
Last modified: 10 January 2023
[Classes](classes) [Properties](properties)
kotlin Kotlin/JS reflection Kotlin/JS reflection
====================
Kotlin/JS provides a limited support for the Kotlin [reflection API](reflection). The only supported parts of the API are:
* [class references](reflection#class-references) (`::class`).
* [`KType`](../api/latest/jvm/stdlib/kotlin.reflect/-k-type/index) and [`typeof()`](../api/latest/jvm/stdlib/kotlin.reflect/type-of) function.
Class references
----------------
The `::class` syntax returns a reference to the class of an instance, or the class corresponding to the given type. In Kotlin/JS, the value of a `::class` expression is a stripped-down [KClass](../api/latest/jvm/stdlib/kotlin.reflect/-k-class/index) implementation that supports only:
* [simpleName](../api/latest/jvm/stdlib/kotlin.reflect/-k-class/simple-name) and [isInstance()](../api/latest/jvm/stdlib/kotlin.reflect/-k-class/is-instance) members.
* [cast()](../api/latest/jvm/stdlib/kotlin.reflect/cast) and [safeCast()](../api/latest/jvm/stdlib/kotlin.reflect/safe-cast) extension functions.
In addition to that, you can use [KClass.js](../api/latest/jvm/stdlib/kotlin.js/js) to access the [JsClass](../api/latest/jvm/stdlib/kotlin.js/-js-class/index) instance corresponding to the class. The `JsClass` instance itself is a reference to the constructor function. This can be used to interoperate with JS functions that expect a reference to a constructor.
KType and typeOf()
------------------
The [`typeof()`](../api/latest/jvm/stdlib/kotlin.reflect/type-of) function constructs an instance of [`KType`](../api/latest/jvm/stdlib/kotlin.reflect/-k-type/index) for a given type. The `KType` API is fully supported in Kotlin/JS except for Java-specific parts.
Example
-------
Here is an example of the reflection usage in Kotlin/JS.
```
open class Shape
class Rectangle : Shape()
inline fun <reified T> accessReifiedTypeArg() =
println(typeOf<T>().toString())
fun main() {
val s = Shape()
val r = Rectangle()
println(r::class.simpleName) // Prints "Rectangle"
println(Shape::class.simpleName) // Prints "Shape"
println(Shape::class.js.name) // Prints "Shape"
println(Shape::class.isInstance(r)) // Prints "true"
println(Rectangle::class.isInstance(s)) // Prints "false"
val rShape = Shape::class.cast(r) // Casts a Rectangle "r" to Shape
accessReifiedTypeArg<Rectangle>() // Accesses the type via typeOf(). Prints "Rectangle"
}
```
Last modified: 10 January 2023
[JavaScript modules](js-modules) [Typesafe HTML DSL](typesafe-html-dsl)
kotlin Understand mobile project structure Understand mobile project structure
===================================
The purpose of the Kotlin Multiplatform Mobile technology is unifying the development of applications with common logic for Android and iOS platforms. To make this possible, it uses a mobile-specific structure of [Kotlin Multiplatform](multiplatform) projects.
This page describes the structure and components of a basic cross-platform mobile project: shared module, Android app, and an iOS app.
To view the complete structure of your mobile multiplatform project, switch the view from **Android** to **Project**.
Root project
------------
The root project is a Gradle project that holds the shared module and the Android application as its subprojects. They are linked together via the [Gradle multi-project mechanism](https://docs.gradle.org/current/userguide/multi_project_builds.html).

```
// settings.gradle.kts
include(":shared")
include(":androidApp")
```
```
// settings.gradle
include ':shared'
include ':androidApp'
```
The iOS application is produced from an Xcode project. It's stored in a separate directory within the root project. Xcode uses its own build system; thus, the iOS application project isn't connected with other parts of the Multiplatform Mobile project via Gradle. Instead, it uses the shared module as an external artifact – framework. For details on integration between the shared module and the iOS application, see [iOS application](#ios-application).
This is a basic structure of a cross-platform mobile project:
The root project does not hold source code. You can use it to store global configuration in its `build.gradle(.kts)` or `gradle.properties`, for example, add repositories or define global configuration variables.
For more complex projects, you can add more modules into the root project by creating them in the IDE and linking via `include` declarations in the Gradle settings.
Shared module
-------------
Shared module contains the core application logic used in both Android and iOS target platforms: classes, functions, and so on. This is a [Kotlin Multiplatform](multiplatform-get-started) module that compiles into an Android library and an iOS framework. It uses the Gradle build system with the Kotlin Multiplatform plugin applied and has targets for Android and iOS.
```
plugins {
kotlin("multiplatform") version "1.8.0"
// ..
}
kotlin {
android()
ios()
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
//..
}
kotlin {
android()
ios()
}
```
### Source sets
The shared module contains the code that is common for Android and iOS applications. However, to implement the same logic on Android and iOS, you sometimes need to write two platform-specific versions of it. To handle such cases, Kotlin offers the [expect/actual](multiplatform-connect-to-apis) mechanism. The source code of the shared module is organized in three source sets accordingly:
* `commonMain` stores the code that works on both platforms, including the `expect` declarations
* `androidMain` stores Android-specific parts, including `actual` implementations
* `iosMain` stores iOS-specific parts, including `actual` implementations
Each source set has its own dependencies. Kotlin standard library is added automatically to all source sets, you don't need to declare it in the build script.
```
kotlin {
sourceSets {
val commonMain by getting
val androidMain by getting {
dependencies {
implementation("androidx.core:core-ktx:1.2.0")
}
}
val iosMain by getting
// ...
}
}
```
```
kotlin {
sourceSets {
commonMain {
}
androidMain {
dependencies {
implementation 'androidx.core:core-ktx:1.2.0'
}
}
iosMain {
}
// ...
}
}
```
When you write your code, add the dependencies you need to the corresponding source sets. Read [Multiplatform documentation on adding dependencies](multiplatform-add-dependencies) for more information.
Along with `*Main` source sets, there are three matching test source sets:
* `commonTest`
* `androidTest`
* `iosTest`
Use them to store unit tests for common and platform-specific source sets accordingly. By default, they have dependencies on Kotlin test library, providing you with means for Kotlin unit testing: annotations, assertion functions and other. You can add dependencies on other test libraries you need.
```
kotlin {
sourceSets {
// ...
val commonTest by getting {
dependencies {
implementation(kotlin("test"))
}
}
val androidTest by getting
val iosTest by getting
}
}
```
```
kotlin {
sourceSets {
//...
commonTest {
dependencies {
implementation kotlin('test')
}
}
androidTest {
}
iosTest {
}
}
}
```
The main and test source sets described above are default. The Kotlin Multiplatform plugin generates them automatically upon target creation. In your project, you can add more source sets for specific purposes. For more information, see [Multiplatform DSL reference](multiplatform-dsl-reference#custom-source-sets).
### Android library
The configuration of the Android library produced from the shared module is typical for Android projects. To learn about Android libraries creation, see [Create an Android library](https://developer.android.com/studio/projects/android-library) in the Android developer documentation.
To produce the Android library, a separate Gradle plugin is used in addition to Kotlin Multiplatform:
```
plugins {
// ...
id("com.android.library")
}
```
```
plugins {
// ...
id 'com.android.library'
}
```
The configuration of Android library is stored in the `android {}` top-level block of the shared module's build script:
```
android {
compileSdk = 29
sourceSets["main"].manifest.srcFile("src/androidMain/AndroidManifest.xml")
defaultConfig {
minSdk = 24
targetSdk = 29
}
}
```
```
android {
compileSdk 29
sourceSets.main.manifest.srcFile 'src/androidMain/AndroidManifest.xml'
defaultConfig {
minSdk 24
targetSdk 29
}
}
```
It's typical for any Android project. You can edit it to suit your needs. To learn more, see the [Android developer documentation](https://developer.android.com/studio/build#module-level).
### iOS framework
For using in iOS applications, the shared module compiles into a framework – a kind of hierarchical directory with shared resources used on the Apple platforms. This framework connects to the Xcode project that builds into an iOS application.
The framework is produced via the [Kotlin/Native](native-overview) compiler. The framework configuration is stored in the `ios {}` block of the build script within `kotlin {}`. It defines the output type `framework` and the string identifier `baseName` that is used to form the name of the output artifact. Its default value matches the Gradle module name. For a real project, it's likely that you'll need a more complex configuration of the framework production. For details, see [Multiplatform documentation](multiplatform-build-native-binaries).
```
kotlin {
// ...
ios {
binaries {
framework {
baseName = "shared"
}
}
}
}
```
```
kotlin {
// ...
ios {
binaries {
framework {
baseName = 'shared'
}
}
}
}
```
Additionally, there is a Gradle task `embedAndSignAppleFrameworkForXcode`, that exposes the framework to the Xcode project the iOS application is built from. It uses the iOS application's project configuration to define the build mode (`debug` or `release`) and provide the appropriate framework version to the specified location.
The task is built into the multiplatform plugin. It executes upon each build of the Xcode project to provide the latest version of the framework for the iOS application. For details, see [iOS application](#ios-application).
Android application
-------------------
The Android application part of a Multiplatform Mobile project is a typical Android application written in Kotlin. In a basic cross-platform mobile project, it uses two Gradle plugins:
* Kotlin Android
* Android Application
```
plugins {
id("com.android.application")
kotlin("android")
}
```
```
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
}
```
To access the shared module code, the Android application uses it as a project dependency.
```
dependencies {
implementation(project(":shared"))
//..
}
```
```
dependencies {
implementation project(':shared')
//..
}
```
Besides this dependency, the Android application uses the Kotlin standard library (which is added automatically) and some common Android dependencies:
```
dependencies {
//..
implementation("androidx.core:core-ktx:1.2.0")
implementation("androidx.appcompat:appcompat:1.1.0")
implementation("androidx.constraintlayout:constraintlayout:1.1.3")
}
```
```
dependencies {
//..
implementation 'androidx.core:core-ktx:1.2.0'
implementation 'androidx.appcompat:appcompat:1.1.0'
implementation 'androidx.constraintlayout:constraintlayout:1.1.3'
}
```
Add your project's Android-specific dependencies to this block. The build configuration of the Android application is located in the `android {}` top-level block of the build script:
```
android {
compileSdk = 29
defaultConfig {
applicationId = "org.example.androidApp"
minSdk = 24
targetSdk = 29
versionCode = 1
versionName = "1.0"
}
buildTypes {
getByName("release") {
isMinifyEnabled = false
}
}
}
```
```
android {
compileSdk 29
defaultConfig {
applicationId 'org.example.androidApp'
minSdk 24
targetSdk 29
versionCode 1
versionName '1.0'
}
buildTypes {
'release' {
minifyEnabled false
}
}
}
```
It's typical for any Android project. You can edit it to suit your needs. To learn more, see the [Android developer documentation](https://developer.android.com/studio/build#module-level).
iOS application
---------------
The iOS application is produced from an Xcode project generated automatically by the New Project wizard. It resides in a separate directory within the root project.
For each build of the iOS application, the project obtains the latest version of the framework. To do this, it uses a **Run Script** build phase that executes the `embedAndSignAppleFrameworkForXcode` Gradle task from the shared module. This task generates the `.framework` with the required configuration, depending on the Xcode environment settings, and puts the artifact into the `DerivedData` Xcode directory.
* If you have a custom name for the Apple framework, use `embedAndSign<Custom-name>AppleFrameworkForXcode` as the name for this Gradle task.
* If you have a custom build configuration that is different from the default `Debug` or `Release`, on the **Build Settings** tab, add the `KOTLIN_FRAMEWORK_BUILD_TYPE` setting under **User-Defined** and set it to `Debug` or `Release`.
To embed framework into the application and make the declarations from the shared module available in the source code of the iOS application, the following build settings should be configured properly:
1. **Other Linker flags** under the **Linking** section:
```
$(inherited) -framework shared
```

2. **Framework Search Paths** under the **Search Paths** section:
```
$(SRCROOT)/../shared/build/xcode-frameworks/$(CONFIGURATION)/$(SDK_NAME)
```

In other aspects, the Xcode part of a cross-platform mobile project is a typical iOS application project. To learn more about creating iOS application, see the [Xcode documentation](https://developer.apple.com/documentation/xcode#topics).
Last modified: 10 January 2023
[Wrap up your project](multiplatform-mobile-wrap-up) [Make your Android application work on iOS – tutorial](multiplatform-mobile-integrate-in-existing-app)
| programming_docs |
kotlin Numbers Numbers
=======
Integer types
-------------
Kotlin provides a set of built-in types that represent numbers.
For integer numbers, there are four types with different sizes and, hence, value ranges:
| Type | Size (bits) | Min value | Max value |
| --- | --- | --- | --- |
| `Byte` | 8 | -128 | 127 |
| `Short` | 16 | -32768 | 32767 |
| `Int` | 32 | -2,147,483,648 (-231) | 2,147,483,647 (231 - 1) |
| `Long` | 64 | -9,223,372,036,854,775,808 (-263) | 9,223,372,036,854,775,807 (263 - 1) |
When you initialize a variable with no explicit type specification, the compiler automatically infers the type with the smallest range enough to represent the value. If it is not exceeding the range of `Int`, the type is `Int`. If it exceeds, the type is `Long`. To specify the `Long` value explicitly, append the suffix `L` to the value. Explicit type specification triggers the compiler to check the value not to exceed the range of the specified type.
```
val one = 1 // Int
val threeBillion = 3000000000 // Long
val oneLong = 1L // Long
val oneByte: Byte = 1
```
Floating-point types
--------------------
For real numbers, Kotlin provides floating-point types `Float` and `Double` that adhere to the [IEEE 754 standard](https://en.wikipedia.org/wiki/IEEE_754). `Float` reflects the IEEE 754 *single precision*, while `Double` reflects *double precision*.
These types differ in their size and provide storage for floating-point numbers with different precision:
| Type | Size (bits) | Significant bits | Exponent bits | Decimal digits |
| --- | --- | --- | --- | --- |
| `Float` | 32 | 24 | 8 | 6-7 |
| `Double` | 64 | 53 | 11 | 15-16 |
You can initialize `Double` and `Float` variables with numbers having a fractional part. It's separated from the integer part by a period (`.`) For variables initialized with fractional numbers, the compiler infers the `Double` type:
```
val pi = 3.14 // Double
// val one: Double = 1 // Error: type mismatch
val oneDouble = 1.0 // Double
```
To explicitly specify the `Float` type for a value, add the suffix `f` or `F`. If such a value contains more than 6-7 decimal digits, it will be rounded:
```
val e = 2.7182818284 // Double
val eFloat = 2.7182818284f // Float, actual value is 2.7182817
```
Unlike some other languages, there are no implicit widening conversions for numbers in Kotlin. For example, a function with a `Double` parameter can be called only on `Double` values, but not `Float`, `Int`, or other numeric values:
```
fun main() {
fun printDouble(d: Double) { print(d) }
val i = 1
val d = 1.0
val f = 1.0f
printDouble(d)
// printDouble(i) // Error: Type mismatch
// printDouble(f) // Error: Type mismatch
}
```
To convert numeric values to different types, use [explicit conversions](#explicit-number-conversions).
Literal constants for numbers
-----------------------------
There are the following kinds of literal constants for integral values:
* Decimals: `123`
* Longs are tagged by a capital `L`: `123L`
* Hexadecimals: `0x0F`
* Binaries: `0b00001011`
Kotlin also supports a conventional notation for floating-point numbers:
* Doubles by default: `123.5`, `123.5e10`
* Floats are tagged by `f` or `F`: `123.5f`
You can use underscores to make number constants more readable:
```
val oneMillion = 1_000_000
val creditCardNumber = 1234_5678_9012_3456L
val socialSecurityNumber = 999_99_9999L
val hexBytes = 0xFF_EC_DE_5E
val bytes = 0b11010010_01101001_10010100_10010010
```
Numbers representation on the JVM
---------------------------------
On the JVM platform, numbers are stored as primitive types: `int`, `double`, and so on. Exceptions are cases when you create a nullable number reference such as `Int?` or use generics. In these cases numbers are boxed in Java classes `Integer`, `Double`, and so on.
Nullable references to the same number can refer to different objects:
```
fun main() {
//sampleStart
val a: Int = 100
val boxedA: Int? = a
val anotherBoxedA: Int? = a
val b: Int = 10000
val boxedB: Int? = b
val anotherBoxedB: Int? = b
println(boxedA === anotherBoxedA) // true
println(boxedB === anotherBoxedB) // false
//sampleEnd
}
```
All nullable references to `a` are actually the same object because of the memory optimization that JVM applies to `Integer`s between `-128` and `127`. It doesn't apply to the `b` references, so they are different objects.
On the other hand, they are still equal:
```
fun main() {
//sampleStart
val b: Int = 10000
println(b == b) // Prints 'true'
val boxedB: Int? = b
val anotherBoxedB: Int? = b
println(boxedB == anotherBoxedB) // Prints 'true'
//sampleEnd
}
```
Explicit number conversions
---------------------------
Due to different representations, smaller types *are not subtypes* of bigger ones. If they were, we would have troubles of the following sort:
```
// Hypothetical code, does not actually compile:
val a: Int? = 1 // A boxed Int (java.lang.Integer)
val b: Long? = a // Implicit conversion yields a boxed Long (java.lang.Long)
print(b == a) // Surprise! This prints "false" as Long's equals() checks whether the other is Long as well
```
So equality would have been lost silently, not to mention identity.
As a consequence, smaller types *are NOT implicitly converted* to bigger types. This means that assigning a value of type `Byte` to an `Int` variable requires an explicit conversion:
```
fun main() {
//sampleStart
val b: Byte = 1 // OK, literals are checked statically
// val i: Int = b // ERROR
val i1: Int = b.toInt()
//sampleEnd
}
```
All number types support conversions to other types:
* `toByte(): Byte`
* `toShort(): Short`
* `toInt(): Int`
* `toLong(): Long`
* `toFloat(): Float`
* `toDouble(): Double`
In many cases, there is no need for explicit conversions because the type is inferred from the context, and arithmetical operations are overloaded for appropriate conversions, for example:
```
val l = 1L + 3 // Long + Int => Long
```
Operations on numbers
---------------------
Kotlin supports the standard set of arithmetical operations over numbers: `+`, `-`, `*`, `/`, `%`. They are declared as members of appropriate classes:
```
fun main() {
//sampleStart
println(1 + 2)
println(2_500_000_000L - 1L)
println(3.14 * 2.71)
println(10.0 / 3)
//sampleEnd
}
```
You can also override these operators for custom classes. See [Operator overloading](operator-overloading) for details.
### Division of integers
Division between integers numbers always returns an integer number. Any fractional part is discarded.
```
fun main() {
//sampleStart
val x = 5 / 2
//println(x == 2.5) // ERROR: Operator '==' cannot be applied to 'Int' and 'Double'
println(x == 2)
//sampleEnd
}
```
This is true for a division between any two integer types:
```
fun main() {
//sampleStart
val x = 5L / 2
println(x == 2L)
//sampleEnd
}
```
To return a floating-point type, explicitly convert one of the arguments to a floating-point type:
```
fun main() {
//sampleStart
val x = 5 / 2.toDouble()
println(x == 2.5)
//sampleEnd
}
```
### Bitwise operations
Kotlin provides a set of *bitwise operations* on integer numbers. They operate on the binary level directly with bits of the numbers' representation. Bitwise operations are represented by functions that can be called in infix form. They can be applied only to `Int` and `Long`:
```
val x = (1 shl 2) and 0x000FF000
```
Here is the complete list of bitwise operations:
* `shl(bits)` – signed shift left
* `shr(bits)` – signed shift right
* `ushr(bits)` – unsigned shift right
* `and(bits)` – bitwise **AND**
* `or(bits)` – bitwise **OR**
* `xor(bits)` – bitwise **XOR**
* `inv()` – bitwise inversion
### Floating-point numbers comparison
The operations on floating-point numbers discussed in this section are:
* Equality checks: `a == b` and `a != b`
* Comparison operators: `a < b`, `a > b`, `a <= b`, `a >= b`
* Range instantiation and range checks: `a..b`, `x in a..b`, `x !in a..b`
When the operands `a` and `b` are statically known to be `Float` or `Double` or their nullable counterparts (the type is declared or inferred or is a result of a [smart cast](typecasts#smart-casts)), the operations on the numbers and the range that they form follow the [IEEE 754 Standard for Floating-Point Arithmetic](https://en.wikipedia.org/wiki/IEEE_754).
However, to support generic use cases and provide total ordering, when the operands are **not** statically typed as floating point numbers (for example, `Any`, `Comparable<...>`, a type parameter), the operations use the `equals` and `compareTo` implementations for `Float` and `Double`, which disagree with the standard, so that:
* `NaN` is considered equal to itself
* `NaN` is considered greater than any other element including `POSITIVE_INFINITY`
* `-0.0` is considered less than `0.0`
Last modified: 10 January 2023
[Basic types](basic-types) [Booleans](booleans)
kotlin Mapping primitive data types from C – tutorial Mapping primitive data types from C – tutorial
==============================================
In this tutorial, you will learn what C data types are visible in Kotlin/Native and vice versa. You will:
* See what [Data types are in C language](#types-in-c-language).
* Create a [tiny C Library](#example-c-library) that uses those types in exports.
* [Inspect generated Kotlin APIs from a C library](#inspect-generated-kotlin-apis-for-a-c-library).
* Find how [Primitive types in Kotlin](#primitive-types-in-kotlin) are mapped to C.
Types in C language
-------------------
What types are there in the C language? Let's take the [C data types](https://en.wikipedia.org/wiki/C_data_types) article from Wikipedia as a basis. There are following types in the C programming language:
* basic types `char, int, float, double` with modifiers `signed, unsigned, short, long`
* structures, unions, arrays
* pointers
* function pointers
There are also more specific types:
* boolean type (from [C99](https://en.wikipedia.org/wiki/C99))
* `size_t` and `ptrdiff_t` (also `ssize_t`)
* fixed width integer types, such as `int32_t` or `uint64_t` (from [C99](https://en.wikipedia.org/wiki/C99))
There are also the following type qualifiers in the C language: `const`, `volatile`, `restruct`, `atomic`.
The best way to see what C data types are visible in Kotlin is to try it.
Example C library
-----------------
Create a `lib.h` file to see how C functions are mapped into Kotlin:
```
#ifndef LIB2_H_INCLUDED
#define LIB2_H_INCLUDED
void ints(char c, short d, int e, long f);
void uints(unsigned char c, unsigned short d, unsigned int e, unsigned long f);
void doubles(float a, double b);
#endif
```
The file is missing the `extern "C"` block, which is not needed for this example, but may be necessary if you use C++ and overloaded functions. The [C++ compatibility thread](https://stackoverflow.com/questions/1041866/what-is-the-effect-of-extern-c-in-c) on Stackoverflow contains more details on this.
For every set of `.h` files, you will be using the [`cinterop` tool](native-c-interop) from Kotlin/Native to generate a Kotlin/Native library, or `.klib`. The generated library will bridge calls from Kotlin/Native to C. It includes respective Kotlin declarations for the definitions form the `.h` files. It is only necessary to have a `.h` file to run the `cinterop` tool. And you do not need to create a `lib.c` file, unless you want to compile and run the example. More details on this are covered in the [C interop](native-c-interop) page. It is enough for the tutorial to create the `lib.def` file with the following content:
```
headers = lib.h
```
You may include all declarations directly into the `.def` file after a `---` separator. It can be helpful to include macros or other C defines into the code generated by the `cinterop` tool. Method bodies are compiled and fully included into the binary too. Use that feature to have a runnable example without a need for a C compiler. To implement that, you need to add implementations to the C functions from the `lib.h` file, and place these functions into a `.def` file. You will have the following `interop.def` result:
```
---
void ints(char c, short d, int e, long f) { }
void uints(unsigned char c, unsigned short d, unsigned int e, unsigned long f) { }
void doubles(float a, double b) { }
```
The `interop.def` file is enough to compile and run the application or open it in an IDE. Now it is time to create project files, open the project in [IntelliJ IDEA](https://jetbrains.com/idea) and run it.
Inspect generated Kotlin APIs for a C library
---------------------------------------------
While it is possible to use the command line, either directly or by combining it with a script file (such as `.sh` or `.bat` file), this approach doesn't scale well for big projects that have hundreds of files and libraries. It is then better to use the Kotlin/Native compiler with a build system, as it helps to download and cache the Kotlin/Native compiler binaries and libraries with transitive dependencies and run the compiler and tests. Kotlin/Native can use the [Gradle](https://gradle.org) build system through the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin.
We covered the basics of setting up an IDE compatible project with Gradle in the [A Basic Kotlin/Native Application](native-gradle) tutorial. Please check it out if you are looking for detailed first steps and instructions on how to start a new Kotlin/Native project and open it in IntelliJ IDEA. In this tutorial, we'll look at the advanced C interop related usages of Kotlin/Native and [multiplatform](multiplatform-discover-project#multiplatform-plugin) builds with Gradle.
First, create a project folder. All the paths in this tutorial will be relative to this folder. Sometimes the missing directories will have to be created before any new files can be added.
Use the following `build.gradle(.kts)` Gradle build file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
linuxX64("native") { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64("native") { // on Windows
val main by compilations.getting
val interop by main.cinterops.creating
binaries {
executable()
}
}
}
tasks.wrapper {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.BIN
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
linuxX64('native') { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64('native') { // on Windows
compilations.main.cinterops {
interop
}
binaries {
executable()
}
}
}
wrapper {
gradleVersion = '7.3'
distributionType = 'BIN'
}
```
The project file configures the C interop as an additional step of the build. Let's move the `interop.def` file to the `src/nativeInterop/cinterop` directory. Gradle recommends using conventions instead of configurations, for example, the source files are expected to be in the `src/nativeMain/kotlin` folder. By default, all the symbols from C are imported to the `interop` package, you may want to import the whole package in our `.kt` files. Check out the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin documentation to learn about all the different ways you could configure it.
Create a `src/nativeMain/kotlin/hello.kt` stub file with the following content to see how C primitive type declarations are visible from Kotlin:
```
import interop.*
fun main() {
println("Hello Kotlin/Native!")
ints(/* fix me*/)
uints(/* fix me*/)
doubles(/* fix me*/)
}
```
Now you are ready to [open the project in IntelliJ IDEA](native-get-started) and to see how to fix the example project. While doing that, see how C primitive types are mapped into Kotlin/Native.
Primitive types in kotlin
-------------------------
With the help of IntelliJ IDEA's **Go to | Declaration** or compiler errors, you see the following generated API for the C functions:
```
fun ints(c: Byte, d: Short, e: Int, f: Long)
fun uints(c: UByte, d: UShort, e: UInt, f: ULong)
fun doubles(a: Float, b: Double)
```
C types are mapped in the way we would expect, note that `char` type is mapped to `kotlin.Byte` as it is usually an 8-bit signed value.
| C | Kotlin |
| --- | --- |
| char | kotlin.Byte |
| unsigned char | kotlin.UByte |
| short | kotlin.Short |
| unsigned short | kotlin.UShort |
| int | kotlin.Int |
| unsigned int | kotlin.UInt |
| long long | kotlin.Long |
| unsigned long long | kotlin.ULong |
| float | kotlin.Float |
| double | kotlin.Double |
Fix the code
------------
You've seen all definitions and it is the time to fix the code. Run the `runDebugExecutableNative` Gradle task [in IDE](native-get-started) or use the following command to run the code:
```
./gradlew runDebugExecutableNative
```
The final code in the `hello.kt` file may look like that:
```
import interop.*
fun main() {
println("Hello Kotlin/Native!")
ints(1, 2, 3, 4)
uints(5, 6, 7, 8)
doubles(9.0f, 10.0)
}
```
Next steps
----------
Continue to explore more complicated C language types and their representation in Kotlin/Native in the next tutorials:
* [Mapping struct and union types from C](mapping-struct-union-types-from-c)
* [Mapping function pointers from C](mapping-function-pointers-from-c)
* [Mapping strings from C](mapping-strings-from-c)
The [C interop documentation](native-c-interop) covers more advanced scenarios of the interop.
Last modified: 10 January 2023
[Interoperability with C](native-c-interop) [Mapping struct and union types from C – tutorial](mapping-struct-union-types-from-c)
kotlin Ranges and progressions Ranges and progressions
=======================
Kotlin lets you easily create ranges of values using the [`rangeTo()`](../api/latest/jvm/stdlib/kotlin.ranges/range-to) function from the `kotlin.ranges` package and its operator form `..`. Usually, `rangeTo()` is complemented by `in` or `!in` functions.
```
fun main() {
val i = 1
//sampleStart
if (i in 1..4) { // equivalent of i >= 1 && i <= 4
print(i)
}
//sampleEnd
}
```
Integral type ranges ([`IntRange`](../api/latest/jvm/stdlib/kotlin.ranges/-int-range/index), [`LongRange`](../api/latest/jvm/stdlib/kotlin.ranges/-long-range/index), [`CharRange`](../api/latest/jvm/stdlib/kotlin.ranges/-char-range/index)) have an extra feature: they can be iterated over. These ranges are also [progressions](https://en.wikipedia.org/wiki/Arithmetic_progression) of the corresponding integral types.
Such ranges are generally used for iteration in `for` loops.
```
fun main() {
//sampleStart
for (i in 1..4) print(i)
//sampleEnd
}
```
To iterate numbers in reverse order, use the [`downTo`](../api/latest/jvm/stdlib/kotlin.ranges/down-to) function instead of `..`.
```
fun main() {
//sampleStart
for (i in 4 downTo 1) print(i)
//sampleEnd
}
```
It is also possible to iterate over numbers with an arbitrary step (not necessarily 1). This is done via the [`step`](../api/latest/jvm/stdlib/kotlin.ranges/step) function.
```
fun main() {
//sampleStart
for (i in 1..8 step 2) print(i)
println()
for (i in 8 downTo 1 step 2) print(i)
//sampleEnd
}
```
To iterate a number range which does not include its end element, use the [`until`](../api/latest/jvm/stdlib/kotlin.ranges/until) function:
```
fun main() {
//sampleStart
for (i in 1 until 10) { // i in 1 until 10, excluding 10
print(i)
}
//sampleEnd
}
```
Range
-----
A range defines a closed interval in the mathematical sense: it is defined by its two endpoint values which are both included in the range. Ranges are defined for comparable types: having an order, you can define whether an arbitrary instance is in the range between two given instances.
The main operation on ranges is `contains`, which is usually used in the form of `in` and `!in` operators.
To create a range for your class, call the `rangeTo()` function on the range start value and provide the end value as an argument. `rangeTo()` is often called in its operator form `..`.
```
class Version(val major: Int, val minor: Int): Comparable<Version> {
override fun compareTo(other: Version): Int {
if (this.major != other.major) {
return this.major - other.major
}
return this.minor - other.minor
}
}
fun main() {
//sampleStart
val versionRange = Version(1, 11)..Version(1, 30)
println(Version(0, 9) in versionRange)
println(Version(1, 20) in versionRange)
//sampleEnd
}
```
Progression
-----------
As shown in the examples above, the ranges of integral types, such as `Int`, `Long`, and `Char`, can be treated as [arithmetic progressions](https://en.wikipedia.org/wiki/Arithmetic_progression) of them. In Kotlin, these progressions are defined by special types: [`IntProgression`](../api/latest/jvm/stdlib/kotlin.ranges/-int-progression/index), [`LongProgression`](../api/latest/jvm/stdlib/kotlin.ranges/-long-progression/index), and [`CharProgression`](../api/latest/jvm/stdlib/kotlin.ranges/-char-progression/index).
Progressions have three essential properties: the `first` element, the `last` element, and a non-zero `step`. The first element is `first`, subsequent elements are the previous element plus a `step`. Iteration over a progression with a positive step is equivalent to an indexed `for` loop in Java/JavaScript.
```
for (int i = first; i <= last; i += step) {
// ...
}
```
When you create a progression implicitly by iterating a range, this progression's `first` and `last` elements are the range's endpoints, and the `step` is 1.
```
fun main() {
//sampleStart
for (i in 1..10) print(i)
//sampleEnd
}
```
To define a custom progression step, use the `step` function on a range.
```
fun main() {
//sampleStart
for (i in 1..8 step 2) print(i)
//sampleEnd
}
```
The `last` element of the progression is calculated this way:
* For a positive step: the maximum value not greater than the end value such that `(last - first) % step == 0`.
* For a negative step: the minimum value not less than the end value such that `(last - first) % step == 0`.
Thus, the `last` element is not always the same as the specified end value.
```
fun main() {
//sampleStart
for (i in 1..9 step 3) print(i) // the last element is 7
//sampleEnd
}
```
To create a progression for iterating in reverse order, use `downTo` instead of `..` when defining the range for it.
```
fun main() {
//sampleStart
for (i in 4 downTo 1) print(i)
//sampleEnd
}
```
If you already have a progression, you can iterate it in reverse order with the [`reversed`](../api/latest/jvm/stdlib/kotlin.ranges/reversed) function:
```
fun main() {
//sampleStart
for (i in (1..4).reversed()) print(i)
//sampleEnd
}
```
Progressions implement `Iterable<N>`, where `N` is `Int`, `Long`, or `Char` respectively, so you can use them in various [collection functions](collection-operations) like `map`, `filter`, and other.
```
fun main() {
//sampleStart
println((1..10).filter { it % 2 == 0 })
//sampleEnd
}
```
Last modified: 10 January 2023
[Iterators](iterators) [Sequences](sequences)
| programming_docs |
kotlin Compiler options in the Kotlin Gradle plugin Compiler options in the Kotlin Gradle plugin
============================================
Each release of Kotlin includes compilers for the supported targets: JVM, JavaScript, and native binaries for [supported platforms](native-overview#target-platforms).
These compilers are used by:
* The IDE, when you click the **Compile** or **Run** button for your Kotlin project.
* Gradle, when you call `gradle build` in a console or in the IDE.
* Maven, when you call `mvn compile` or `mvn test-compile` in a console or in the IDE.
You can also run Kotlin compilers manually from the command line as described in the [Working with command-line compiler](command-line) tutorial.
How to define options
---------------------
Kotlin compilers have a number of options for tailoring the compiling process.
Using a build script, you can specify additional compilation options. Use the `compilerOptions` property of a Kotlin compilation task for it. For example:
```
compileKotlin.compilerOptions.freeCompilerArgs.add("-Xexport-kdoc")
```
```
compileKotlin {
compilerOptions.freeCompilerArgs.add("-Xexport-kdoc")
}
//or
compileKotlin {
compilerOptions {
freeCompilerArgs.add("-Xexport-kdoc")
}
}
```
When targeting the JVM, the tasks are called `compileKotlin` for production code and `compileTestKotlin` for test code. The tasks for custom source sets are named according to their `compile<Name>Kotlin` patterns.
The names of the tasks in Android Projects contain [build variant](https://developer.android.com/studio/build/build-variants.html) names and follow the `compile<BuildVariant>Kotlin` pattern, for example, `compileDebugKotlin` or `compileReleaseUnitTestKotlin`.
When targeting JavaScript, the tasks are called `compileKotlinJs` for production code and `compileTestKotlinJs` for test code, and `compile<Name>KotlinJs` for custom source sets.
To configure a single task, use its name. Examples:
```
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask
// ...
val compileKotlin: KotlinCompilationTask<*> by tasks
compileKotlin.compilerOptions.suppressWarnings.set(true)
```
```
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask
// ...
tasks.named('compileKotlin', KotlinCompilationTask) {
compilerOptions {
suppressWarnings.set(true)
}
}
```
Note that with the Gradle Kotlin DSL, you should get the task from the project's `tasks` first.
Use the `Kotlin2JsCompile` and `KotlinCompileCommon` types for JS and common targets, respectively.
It is also possible to configure all of the Kotlin compilation tasks in the project:
```
tasks.withType<org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask<*>>().configureEach {
compilerOptions { /*...*/ }
}
```
```
tasks.withType(org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask).configureEach {
compilerOptions { /*...*/ }
}
```
Here is a complete list of options for Gradle tasks:
### Attributes specific to JVM
| Name | Description | Possible values | Default value |
| --- | --- | --- | --- |
| `javaParameters` | Generate metadata for Java 1.8 reflection on method parameters | | false |
| `jvmTarget` | Target version of the generated JVM bytecode | "1.8", "9", "10", ..., "19". Also, see [Types for compiler options](#types-for-compiler-options) | "1.8" |
| `noJdk` | Don't automatically include the Java runtime into the classpath | | false |
### Attributes common to JVM, JS, and JS DCE
| Name | Description | Possible values | Default value |
| --- | --- | --- | --- |
| `allWarningsAsErrors` | Report an error if there are any warnings | | false |
| `suppressWarnings` | Don't generate warnings | | false |
| `verbose` | Enable verbose logging output. Works only when the [Gradle debug log level enabled](https://docs.gradle.org/current/userguide/logging.html) | | false |
| `freeCompilerArgs` | A list of additional compiler arguments. You can use experimental `-X` arguments here too. See an [example](#example-of-additional-arguments-usage-via-freecompilerargs) | | [] |
#### Example of additional arguments usage via freeCompilerArgs
Use the attribute `freeCompilerArgs` to supply additional (including experimental) compiler arguments. You can add a single argument to this attribute or a list of arguments:
```
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask
// ...
val compileKotlin: KotlinCompilationTask<*> by tasks
// Single experimental argument
compileKotlin.compilerOptions.freeCompilerArgs.add("-Xexport-kdoc")
// Single additional argument, can be a key-value pair
compileKotlin.compilerOptions.freeCompilerArgs.add("-opt-in=org.mylibrary.OptInAnnotation")
// List of arguments
compileKotlin.compilerOptions.freeCompilerArgs.addAll(listOf("-Xno-param-assertions", "-Xno-receiver-assertions", "-Xno-call-assertions"))
```
```
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilationTask
// ...
tasks.named('compileKotlin', KotlinCompilationTask) {
compilerOptions {
// Single experimental argument
freeCompilerArgs.add("-Xexport-kdoc")
// Single additional argument, can be a key-value pair
freeCompilerArgs.add("-opt-in=org.mylibrary.OptInAnnotation")
// List of arguments
freeCompilerArgs.addAll(["-Xno-param-assertions", "-Xno-receiver-assertions", "-Xno-call-assertions"])
}
}
```
### Attributes common to JVM and JS
| Name | Description | Possible values | Default value |
| --- | --- | --- | --- |
| `apiVersion` | Restrict the use of declarations to those from the specified version of bundled libraries | "1.3" (DEPRECATED), "1.4" (DEPRECATED), "1.5", "1.6", "1.7", "1.8", "1.9" | |
| `languageVersion` | Provide source compatibility with the specified version of Kotlin | "1.4" (DEPRECATED), "1.5", "1.6", "1.7", "1.8", "1.9" | |
Also, see [Types for compiler options](#types-for-compiler-options).
### Attributes specific to JS
| Name | Description | Possible values | Default value |
| --- | --- | --- | --- |
| `friendModulesDisabled` | Disable internal declaration export | | false |
| `main` | Define whether the `main` function should be called upon execution | "call", "noCall". Also, see [Types for compiler options](#types-for-compiler-options) | "call" |
| `metaInfo` | Generate .meta.js and .kjsm files with metadata. Use to create a library | | true |
| `moduleKind` | The kind of JS module generated by the compiler | "umd", "commonjs", "amd", "plain", "es". Also, see [Types for compiler options](#types-for-compiler-options) | "umd" |
| `outputFile` | Destination \*.js file for the compilation result | | "<buildDir>/js/packages/<project.name>/kotlin/<project.name>.js" |
| `sourceMap` | Generate source map | | true |
| `sourceMapEmbedSources` | Embed source files into the source map | "never", "always", "inlining". Also, see [Types for compiler options](#types-for-compiler-options) | |
| `sourceMapPrefix` | Add the specified prefix to paths in the source map | | |
| `target` | Generate JS files for specific ECMA version | "v5" | "v5" |
| `typedArrays` | Translate primitive arrays to JS typed arrays | | true |
### Types for compiler options
Some of the `compilerOptions` use the new types instead of the `String` type:
| Option | Type | Example |
| --- | --- | --- |
| `jvmTarget` | [`JvmTarget`](https://github.com/JetBrains/kotlin/blob/1.8.0/libraries/tools/kotlin-gradle-compiler-types/src/generated/kotlin/org/jetbrains/kotlin/gradle/dsl/JvmTarget.kt) | `compilerOptions.jvmTarget.set(JvmTarget.JVM_11)` |
| `apiVersion` and `languageVersion` | [`KotlinVersion`](https://github.com/JetBrains/kotlin/blob/1.8.0/libraries/tools/kotlin-gradle-compiler-types/src/generated/kotlin/org/jetbrains/kotlin/gradle/dsl/KotlinVersion.kt) | `compilerOptions.languageVersion.set(KotlinVersion.KOTLIN_1_9)` |
| `main` | [`JsMainFunctionExecutionMode`](https://github.com/JetBrains/kotlin/blob/1.8.0/libraries/tools/kotlin-gradle-compiler-types/src/generated/kotlin/org/jetbrains/kotlin/gradle/dsl/JsMainFunctionExecutionMode.kt) | `compilerOptions.main.set(JsMainFunctionExecutionMode.NO_CALL)` |
| `moduleKind` | [`JsModuleKind`](https://github.com/JetBrains/kotlin/blob/1.8.0/libraries/tools/kotlin-gradle-compiler-types/src/generated/kotlin/org/jetbrains/kotlin/gradle/dsl/JsModuleKind.kt) | `compilerOptions.moduleKind.set(JsModuleKind.MODULE_ES)` |
| `sourceMapEmbedSources` | [`JsSourceMapEmbedMode`](https://github.com/JetBrains/kotlin/blob/1.8.0/libraries/tools/kotlin-gradle-compiler-types/src/generated/kotlin/org/jetbrains/kotlin/gradle/dsl/JsSourceMapEmbedMode.kt) | `compilerOptions.sourceMapEmbedSources.set(JsSourceMapEmbedMode.SOURCE_MAP_SOURCE_CONTENT_INLINING)` |
What's next?
------------
Learn more about:
* [Incremental compilation, caches support, build reports, and the Kotlin daemon](gradle-compilation-and-caches).
* [Gradle basics and specifics](https://docs.gradle.org/current/userguide/getting_started.html).
* [Support for Gradle plugin variants](gradle-plugin-variants).
Last modified: 10 January 2023
[Configure a Gradle project](gradle-configure-project) [Compilation and caches in the Kotlin Gradle plugin](gradle-compilation-and-caches)
kotlin Set up an environment Set up an environment
=====================
Before you create your first application that works on both iOS and Android, you'll need to set up an environment for Kotlin Multiplatform Mobile development.
Install the necessary tools
---------------------------
We recommend that you install the latest stable versions for compatibility and better performance.
| Tool | Comments |
| --- | --- |
| [Android Studio](https://developer.android.com/studio) | You will use Android Studio to create your multiplatform applications and run them on simulated or hardware devices. |
| [Xcode](https://apps.apple.com/us/app/xcode/id497799835) | Most of the time, Xcode will work in the background. You will use it to add Swift or Objective-C code to your iOS application. |
| [JDK](https://www.oracle.com/java/technologies/javase-downloads.html) | To check whether it's installed, run the following command in the Android Studio terminal or your command-line tool:
```
java -version
```
|
| [Kotlin Multiplatform Mobile plugin](multiplatform-mobile-plugin-releases) | In Android Studio, select **Settings/Preferences | Plugins**, search **Marketplace** for *Kotlin Multiplatform Mobile*, and then install it. |
| [Kotlin plugin](plugin-releases#update-to-a-new-release) | The Kotlin plugin is bundled with each Android Studio release. However, it still needs to be updated to the latest version to avoid compatibility issues.
To update the plugin, on the Android Studio welcome screen, select **Plugins | Installed**. Click **Update** next to Kotlin. You can also check the Kotlin version in **Tools | Kotlin | Configure Kotlin Plugin Updates**.
The Kotlin plugin should be compatible with the Kotlin Multiplatform Mobile plugin. Refer to the [compatibility table](multiplatform-mobile-plugin-releases#release-details). |
Check your environment
----------------------
To make sure everything works as expected, install and run the KDoctor tool:
1. In the Android Studio terminal or your command-line tool, run the following command to install the tool using Homebrew:
```
brew install kdoctor
```
If you don't have Homebrew yet, [install it](https://brew.sh/) or see the KDoctor [README](https://github.com/Kotlin/kdoctor#installation) for other ways to install it.
2. After the installation is completed, call KDoctor in the console:
```
kdoctor
```
3. If KDoctor diagnoses any problems while checking your environment, review the output for issues and possible solutions:
* Fix any failed checks (`[x]`). You can find problem descriptions and potential solutions after the `*` symbol.
* Check the warnings (`[!]`) and successful messages (`[v]`). They may contain useful notes and tips, as well.
Possible issues and solutions
-----------------------------
Android Studio
Make sure that you have Android Studio installed. You can get it from its [official website.](https://developer.android.com/studio)
Java and JDK
* Make sure that you have JDK installed. You can get it from its [official website](https://www.oracle.com/java/technologies/javase-downloads.html).
* Android Studio uses a bundled JDK to execute Gradle tasks. To configure the Gradle JDK in Android Studio, select **Settings/Preferences | Build, Execution, Deployment | Build Tools | Gradle**.
* You might encounter issues related to `JAVA_HOME`. This environment variable specifies the location of the Java binary required for Xcode and Gradle. If so, follow KDoctor's tips to fix the issues.
Xcode
* Make sure that you have Xcode installed. You can get it from its [official website](https://developer.apple.com/xcode/).
* Launch Xcode in a separate window to accept its license terms and allow it to perform some necessary initial tasks.
* `Error: can't grab Xcode schemes`. If you encounter an error like this, in Xcode, select **Settings/Preferences | Locations**. In the **Command Line Tools** field, select your Xcode.

Kotlin plugins
**Kotlin Multiplatform Mobile plugin**
* Make sure that the Kotlin Mobile Multiplatform plugin is installed and enabled. On the Android Studio welcome screen, select **Plugins | Installed**. Verify that you have the plugin enabled. If it's not in the **Installed** list, search **Marketplace** for it and install the plugin.
* If the plugin is outdated, click **Update** next to the plugin name. You can do the same in the **Settings/Preferences | Tools | Plugins** section.
* Check the compatibility of the Kotlin Multiplatform Mobile plugin with your version of Kotlin in the [Release details](multiplatform-mobile-plugin-releases#release-details) table.
**Kotlin plugin**
Make sure that the Kotlin plugin is updated to the latest version. To do that, on the Android Studio welcome screen, select **Plugins | Installed**. Click **Update** next to Kotlin.
You can also check the Kotlin version in **Tools | Kotlin | Configure Kotlin Plugin Updates**.
Command line
Make sure you have all the necessary tools installed:
* `command not found: brew` — [install Homebrew](https://brew.sh/).
* `command not found: java` — [install Java](https://www.oracle.com/java/technologies/javase-downloads.html).
Next step
---------
In the next part of the tutorial, you'll create your first cross-platform mobile application.
**[Proceed to the next part](multiplatform-mobile-create-first-app)**
Get help
--------
* **Kotlin Slack**. Get an [invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) and join the [#multiplatform](https://kotlinlang.slack.com/archives/C3PQML5NU) channel.
* **Kotlin issue tracker**. [Report a new issue](https://youtrack.jetbrains.com/newIssue?project=KT).
Last modified: 10 January 2023
[Get started with Kotlin Multiplatform Mobile](multiplatform-mobile-getting-started) [Create your first cross-platform app](multiplatform-mobile-create-first-app)
kotlin SAM-with-receiver compiler plugin SAM-with-receiver compiler plugin
=================================
The *sam-with-receiver* compiler plugin makes the first parameter of the annotated Java "single abstract method" (SAM) interface method a receiver in Kotlin. This conversion only works when the SAM interface is passed as a Kotlin lambda, both for SAM adapters and SAM constructors (see the [SAM conversions documentation](java-interop#sam-conversions) for more details).
Here is an example:
```
public @interface SamWithReceiver {}
@SamWithReceiver
public interface TaskRunner {
void run(Task task);
}
```
```
fun test(context: TaskContext) {
val runner = TaskRunner {
// Here 'this' is an instance of 'Task'
println("$name is started")
context.executeTask(this)
println("$name is finished")
}
}
```
Gradle
------
The usage is the same to [all-open](all-open-plugin) and [no-arg](no-arg-plugin), except the fact that sam-with-receiver does not have any built-in presets, and you need to specify your own list of special-treated annotations.
```
plugins {
id("org.jetbrains.kotlin.plugin.sam.with.receiver") version "$kotlin_version"
}
```
Then specify the list of SAM-with-receiver annotations:
```
samWithReceiver {
annotation("com.my.SamWithReceiver")
}
```
Maven
-----
```
<plugin>
<artifactId>kotlin-maven-plugin</artifactId>
<groupId>org.jetbrains.kotlin</groupId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<plugin>sam-with-receiver</plugin>
</compilerPlugins>
<pluginOptions>
<option>
sam-with-receiver:annotation=com.my.SamWithReceiver
</option>
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-sam-with-receiver</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
```
Command-line compiler
---------------------
Add the plugin JAR file to the compiler plugin classpath and specify the list of sam-with-receiver annotations:
```
-Xplugin=$KOTLIN_HOME/lib/sam-with-receiver-compiler-plugin.jar
-P plugin:org.jetbrains.kotlin.samWithReceiver:annotation=com.my.SamWithReceiver
```
Last modified: 10 January 2023
[No-arg compiler plugin](no-arg-plugin) [Using kapt](kapt)
kotlin Use dependencies from npm Use dependencies from npm
=========================
In Kotlin/JS projects, all dependencies can be managed through the Gradle plugin. This includes Kotlin/Multiplatform libraries such as `kotlinx.coroutines`, `kotlinx.serialization`, or `ktor-client`.
For depending on JavaScript packages from [npm](https://www.npmjs.com/), the Gradle DSL exposes an `npm` function that lets you specify packages you want to import from npm. Let's consider the import of an NPM package called [`is-sorted`](https://www.npmjs.com/package/is-sorted).
The corresponding part in the Gradle build file looks as follows:
```
dependencies {
// ...
implementation(npm("is-sorted", "1.0.5"))
}
```
Because JavaScript modules are usually dynamically typed and Kotlin is a statically typed language, you need to provide a kind of adapter. In Kotlin, such adapters are called *external declarations*. For the `is-sorted` package which offers only one function, this declaration is small to write. Inside the source folder, create a new file called `is-sorted.kt`, and fill it with these contents:
```
@JsModule("is-sorted")
@JsNonModule
external fun <T> sorted(a: Array<T>): Boolean
```
Please note that if you're using CommonJS as a target, the `@JsModule` and `@JsNonModule` annotations need to be adjusted accordingly.
This JavaScript function can now be used just like a regular Kotlin function. Because we provided type information in the header file (as opposed to simply defining parameter and return type to be `dynamic`), proper compiler support and type-checking is also available.
```
console.log("Hello, Kotlin/JS!")
console.log(sorted(arrayOf(1,2,3)))
console.log(sorted(arrayOf(3,1,2)))
```
Running these three lines either in the browser or Node.js, the output shows that the call to `sorted` was properly mapped to the function exported by the `is-sorted` package:
```
Hello, Kotlin/JS!
true
false
```
Because the JavaScript ecosystem has multiple ways of exposing functions in a package (for example through named or default exports), other npm packages might need a slightly altered structure for their external declarations.
To learn more about how to write declarations, please refer to [Calling JavaScript from Kotlin](js-interop).
Last modified: 10 January 2023
[Dynamic type](dynamic-type) [Use Kotlin code from JavaScript](js-to-kotlin-interop)
| programming_docs |
kotlin Adding dependencies on multiplatform libraries Adding dependencies on multiplatform libraries
==============================================
Every program requires a set of libraries to operate successfully. A Kotlin Multiplatform project can depend on multiplatform libraries that work for all target platforms, platform-specific libraries, and other multiplatform projects.
To add a dependency on a library, update your `build.gradle(.kts)` file in the `shared` directory of your project. Set a dependency of the required [type](gradle-configure-project#dependency-types) (for example, `implementation`) in the [`dependencies`](multiplatform-dsl-reference#dependencies) block:
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("com.example:my-library:1.0") // library shared for all source sets
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation 'com.example:my-library:1.0'
}
}
}
}
```
Alternatively, you can [set dependencies at the top level](gradle-configure-project#set-dependencies-at-top-level).
Dependency on a Kotlin library
------------------------------
### Standard library
A dependency on a standard library (`stdlib`) in each source set is added automatically. The version of the standard library is the same as the version of the `kotlin-multiplatform` plugin.
For platform-specific source sets, the corresponding platform-specific variant of the library is used, while a common standard library is added to the rest. The Kotlin Gradle plugin will select the appropriate JVM standard library depending on the `compilerOptions.jvmTarget` [compiler option](gradle-compiler-options) of your Gradle build script.
Learn how to [change the default behavior](gradle-configure-project#dependency-on-the-standard-library).
### Test libraries
The [`kotlin.test` API](https://kotlinlang.org/api/latest/kotlin.test/) is available for multiplatform tests. When you [create a multiplatform project](multiplatform-library), the Project Wizard automatically adds test dependencies to common and platform-specific source sets.
If you didn't use the Project Wizard to create your project, you can [add the dependencies manually](gradle-configure-project#set-dependencies-on-test-libraries).
### kotlinx libraries
If you use a multiplatform library and need to [depend on the shared code](#library-shared-for-all-source-sets), set the dependency only once in the shared source set. Use the library base artifact name, such as `kotlinx-coroutines-core`.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4'
}
}
}
}
```
If you use a kotlinx library and need a [platform-specific dependency](#library-used-in-specific-source-sets), you can use platform-specific variants of libraries with suffixes such as `-jvm` or `-js`, for example, `kotlinx-coroutines-core-jvm`.
```
kotlin {
sourceSets {
val jvmMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core-jvm:1.6.4")
}
}
}
}
```
```
kotlin {
sourceSets {
jvmMain {
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core-jvm:1.6.4'
}
}
}
}
```
Dependency on Kotlin Multiplatform libraries
--------------------------------------------
You can add dependencies on libraries that have adopted Kotlin Multiplatform technology, such as [SQLDelight](https://github.com/cashapp/sqldelight). The authors of these libraries usually provide guides for adding their dependencies to your project.
Check out this [community-maintained list of Kotlin Multiplatform libraries](https://libs.kmp.icerock.dev/).
### Library shared for all source sets
If you want to use a library from all source sets, you can add it only to the common source set. The Kotlin Multiplatform Mobile plugin will automatically add the corresponding parts to any other source sets.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("io.ktor:ktor-client-core:2.2.1")
}
}
val androidMain by getting {
dependencies {
// dependency to a platform part of ktor-client will be added automatically
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation 'io.ktor:ktor-client-core:2.2.1'
}
}
androidMain {
dependencies {
// dependency to platform part of ktor-client will be added automatically
}
}
}
}
```
### Library used in specific source sets
If you want to use a multiplatform library just for specific source sets, you can add it exclusively to them. The specified library declarations will then be available only in those source sets.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
// kotlinx.coroutines will be available in all source sets
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
}
}
val androidMain by getting {
dependencies {}
}
val iosMain by getting {
dependencies {
// SQLDelight will be available only in the iOS source set, but not in Android or common
implementation("com.squareup.sqldelight:native-driver:1.5.4")
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
// kotlinx.coroutines will be available in all source sets
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4'
}
}
androidMain {
dependencies {}
}
iosMain {
dependencies {
// SQLDelight will be available only in the iOS source set, but not in Android or common
implementation 'com.squareup.sqldelight:native-driver:1.5.4'
}
}
}
}
```
Dependency on another multiplatform project
-------------------------------------------
You can connect one multiplatform project to another as a dependency. To do this, simply add a project dependency to the source set that needs it. If you want to use a dependency in all source sets, add it to the common one. In this case, other source sets will get their versions automatically.
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation(project(":some-other-multiplatform-module"))
}
}
val androidMain by getting {
dependencies {
// platform part of :some-other-multiplatform-module will be added automatically
}
}
}
}
```
```
kotlin {
sourceSets {
commonMain {
dependencies {
implementation project(':some-other-multiplatform-module')
}
}
androidMain {
dependencies {
// platform part of :some-other-multiplatform-module will be added automatically
}
}
}
}
```
What's next?
------------
Check out other resources on adding dependencies in multiplatform projects and learn more about:
* [Adding Android dependencies](multiplatform-mobile-android-dependencies)
* [Adding iOS dependencies](multiplatform-mobile-ios-dependencies)
Last modified: 10 January 2023
[Hierarchical project structure](multiplatform-hierarchy) [Adding Android dependencies](multiplatform-mobile-android-dependencies)
kotlin What's new in Kotlin 1.2 What's new in Kotlin 1.2
========================
*Release date: 28 November 2017*
Table of contents
-----------------
* [Multiplatform projects](#multiplatform-projects-experimental)
* [Other language features](#other-language-features)
* [Standard library](#standard-library)
* [JVM backend](#jvm-backend)
* [JavaScript backend](#javascript-backend)
Multiplatform projects (experimental)
-------------------------------------
Multiplatform projects are a new **experimental** feature in Kotlin 1.2, allowing you to reuse code between target platforms supported by Kotlin – JVM, JavaScript, and (in the future) Native. In a multiplatform project, you have three kinds of modules:
* A *common* module contains code that is not specific to any platform, as well as declarations without implementation of platform-dependent APIs.
* A *platform* module contains implementations of platform-dependent declarations in the common module for a specific platform, as well as other platform-dependent code.
* A regular module targets a specific platform and can either be a dependency of platform modules or depend on platform modules.
When you compile a multiplatform project for a specific platform, the code for both the common and platform-specific parts is generated.
A key feature of the multiplatform project support is the possibility to express dependencies of common code on platform-specific parts through *expected* and *actual* declarations. An *expected* declaration specifies an API (class, interface, annotation, top-level declaration etc.). An *actual* declaration is either a platform-dependent implementation of the API or a type alias referring to an existing implementation of the API in an external library. Here's an example:
In the common code:
```
// expected platform-specific API:
expect fun hello(world: String): String
fun greet() {
// usage of the expected API:
val greeting = hello("multiplatform world")
println(greeting)
}
expect class URL(spec: String) {
open fun getHost(): String
open fun getPath(): String
}
```
In the JVM platform code:
```
actual fun hello(world: String): String =
"Hello, $world, on the JVM platform!"
// using existing platform-specific implementation:
actual typealias URL = java.net.URL
```
See the [multiplatform programming documentation](multiplatform) for details and steps to build a multiplatform project.
Other language features
-----------------------
### Array literals in annotations
Starting with Kotlin 1.2, array arguments for annotations can be passed with the new array literal syntax instead of the `arrayOf` function:
```
@CacheConfig(cacheNames = ["books", "default"])
public class BookRepositoryImpl {
// ...
}
```
The array literal syntax is constrained to annotation arguments.
### Lateinit top-level properties and local variables
The `lateinit` modifier can now be used on top-level properties and local variables. The latter can be used, for example, when a lambda passed as a constructor argument to one object refers to another object which has to be defined later:
```
class Node<T>(val value: T, val next: () -> Node<T>)
fun main(args: Array<String>) {
// A cycle of three nodes:
lateinit var third: Node<Int>
val second = Node(2, next = { third })
val first = Node(1, next = { second })
third = Node(3, next = { first })
val nodes = generateSequence(first) { it.next() }
println("Values in the cycle: ${nodes.take(7).joinToString { it.value.toString() }}, ...")
}
```
### Check whether a lateinit var is initialized
You can now check whether a lateinit var has been initialized using `isInitialized` on the property reference:
```
class Foo {
lateinit var lateinitVar: String
fun initializationLogic() {
//sampleStart
println("isInitialized before assignment: " + this::lateinitVar.isInitialized)
lateinitVar = "value"
println("isInitialized after assignment: " + this::lateinitVar.isInitialized)
//sampleEnd
}
}
fun main(args: Array<String>) {
Foo().initializationLogic()
}
```
### Inline functions with default functional parameters
Inline functions are now allowed to have default values for their inlined functional parameters:
```
//sampleStart
inline fun <E> Iterable<E>.strings(transform: (E) -> String = { it.toString() }) =
map { transform(it) }
val defaultStrings = listOf(1, 2, 3).strings()
val customStrings = listOf(1, 2, 3).strings { "($it)" }
//sampleEnd
fun main(args: Array<String>) {
println("defaultStrings = $defaultStrings")
println("customStrings = $customStrings")
}
```
### Information from explicit casts is used for type inference
The Kotlin compiler can now use information from type casts in type inference. If you're calling a generic method that returns a type parameter `T` and casting the return value to a specific type `Foo`, the compiler now understands that `T` for this call needs to be bound to the type `Foo`.
This is particularly important for Android developers, since the compiler can now correctly analyze generic `findViewById` calls in Android API level 26:
```
val button = findViewById(R.id.button) as Button
```
### Smart cast improvements
When a variable is assigned from a safe call expression and checked for null, the smart cast is now applied to the safe call receiver as well:
```
fun countFirst(s: Any): Int {
//sampleStart
val firstChar = (s as? CharSequence)?.firstOrNull()
if (firstChar != null)
return s.count { it == firstChar } // s: Any is smart cast to CharSequence
val firstItem = (s as? Iterable<*>)?.firstOrNull()
if (firstItem != null)
return s.count { it == firstItem } // s: Any is smart cast to Iterable<*>
//sampleEnd
return -1
}
fun main(args: Array<String>) {
val string = "abacaba"
val countInString = countFirst(string)
println("called on \"$string\": $countInString")
val list = listOf(1, 2, 3, 1, 2)
val countInList = countFirst(list)
println("called on $list: $countInList")
}
```
Also, smart casts in a lambda are now allowed for local variables that are only modified before the lambda:
```
fun main(args: Array<String>) {
//sampleStart
val flag = args.size == 0
var x: String? = null
if (flag) x = "Yahoo!"
run {
if (x != null) {
println(x.length) // x is smart cast to String
}
}
//sampleEnd
}
```
### Support for ::foo as a shorthand for this::foo
A bound callable reference to a member of `this` can now be written without explicit receiver, `::foo` instead of `this::foo`. This also makes callable references more convenient to use in lambdas where you refer to a member of the outer receiver.
### Breaking change: sound smart casts after try blocks
Earlier, Kotlin used assignments made inside a `try` block for smart casts after the block, which could break type- and null-safety and lead to runtime failures. This release fixes this issue, making the smart casts more strict, but breaking some code that relied on such smart casts.
To switch to the old smart casts behavior, pass the fallback flag `-Xlegacy-smart-cast-after-try` as the compiler argument. It will become deprecated in Kotlin 1.3.
### Deprecation: data classes overriding copy
When a data class derived from a type that already had the `copy` function with the same signature, the `copy` implementation generated for the data class used the defaults from the supertype, leading to counter-intuitive behavior, or failed at runtime if there were no default parameters in the supertype.
Inheritance that leads to a `copy` conflict has become deprecated with a warning in Kotlin 1.2 and will be an error in Kotlin 1.3.
### Deprecation: nested types in enum entries
Inside enum entries, defining a nested type that is not an `inner class` has been deprecated due to issues in the initialization logic. This causes a warning in Kotlin 1.2 and will become an error in Kotlin 1.3.
### Deprecation: single named argument for vararg
For consistency with array literals in annotations, passing a single item for a vararg parameter in the named form (`foo(items = i)`) has been deprecated. Please use the spread operator with the corresponding array factory functions:
```
foo(items = *arrayOf(1))
```
There is an optimization that removes redundant arrays creation in such cases, which prevents performance degradation. The single-argument form produces warnings in Kotlin 1.2 and is to be dropped in Kotlin 1.3.
### Deprecation: inner classes of generic classes extending Throwable
Inner classes of generic types that inherit from `Throwable` could violate type-safety in a throw-catch scenario and thus have been deprecated, with a warning in Kotlin 1.2 and an error in Kotlin 1.3.
### Deprecation: mutating backing field of a read-only property
Mutating the backing field of a read-only property by assigning `field = ...` in the custom getter has been deprecated, with a warning in Kotlin 1.2 and an error in Kotlin 1.3.
Standard library
----------------
### Kotlin standard library artifacts and split packages
The Kotlin standard library is now fully compatible with the Java 9 module system, which forbids split packages (multiple jar files declaring classes in the same package). In order to support that, new artifacts `kotlin-stdlib-jdk7` and `kotlin-stdlib-jdk8` are introduced, which replace the old `kotlin-stdlib-jre7` and `kotlin-stdlib-jre8`.
The declarations in the new artifacts are visible under the same package names from the Kotlin point of view, but have different package names for Java. Therefore, switching to the new artifacts will not require any changes to your source code.
Another change made to ensure compatibility with the new module system is removing the deprecated declarations in the `kotlin.reflect` package from the `kotlin-reflect` library. If you were using them, you need to switch to using the declarations in the `kotlin.reflect.full` package, which is supported since Kotlin 1.1.
### windowed, chunked, zipWithNext
New extensions for `Iterable<T>`, `Sequence<T>`, and `CharSequence` cover such use cases as buffering or batch processing (`chunked`), sliding window and computing sliding average (`windowed`) , and processing pairs of subsequent items (`zipWithNext`):
```
fun main(args: Array<String>) {
//sampleStart
val items = (1..9).map { it * it }
val chunkedIntoLists = items.chunked(4)
val points3d = items.chunked(3) { (x, y, z) -> Triple(x, y, z) }
val windowed = items.windowed(4)
val slidingAverage = items.windowed(4) { it.average() }
val pairwiseDifferences = items.zipWithNext { a, b -> b - a }
//sampleEnd
println("items: $items\n")
println("chunked into lists: $chunkedIntoLists")
println("3D points: $points3d")
println("windowed by 4: $windowed")
println("sliding average by 4: $slidingAverage")
println("pairwise differences: $pairwiseDifferences")
}
```
### fill, replaceAll, shuffle/shuffled
A set of extension functions was added for manipulating lists: `fill`, `replaceAll` and `shuffle` for `MutableList`, and `shuffled` for read-only `List`:
```
fun main(args: Array<String>) {
//sampleStart
val items = (1..5).toMutableList()
items.shuffle()
println("Shuffled items: $items")
items.replaceAll { it * 2 }
println("Items doubled: $items")
items.fill(5)
println("Items filled with 5: $items")
//sampleEnd
}
```
### Math operations in kotlin-stdlib
Satisfying the longstanding request, Kotlin 1.2 adds the `kotlin.math` API for math operations that is common for JVM and JS and contains the following:
* Constants: `PI` and `E`
* Trigonometric: `cos`, `sin`, `tan` and inverse of them: `acos`, `asin`, `atan`, `atan2`
* Hyperbolic: `cosh`, `sinh`, `tanh` and their inverse: `acosh`, `asinh`, `atanh`
* Exponentation: `pow` (an extension function), `sqrt`, `hypot`, `exp`, `expm1`
* Logarithms: `log`, `log2`, `log10`, `ln`, `ln1p`
* Rounding:
+ `ceil`, `floor`, `truncate`, `round` (half to even) functions
+ `roundToInt`, `roundToLong` (half to integer) extension functions
* Sign and absolute value:
+ `abs` and `sign` functions
+ `absoluteValue` and `sign` extension properties
+ `withSign` extension function
* `max` and `min` of two values
* Binary representation:
+ `ulp` extension property
+ `nextUp`, `nextDown`, `nextTowards` extension functions
+ `toBits`, `toRawBits`, `Double.fromBits` (these are in the `kotlin` package)
The same set of functions (but without constants) is also available for `Float` arguments.
### Operators and conversions for BigInteger and BigDecimal
Kotlin 1.2 introduces a set of functions for operating with `BigInteger` and `BigDecimal` and creating them from other numeric types. These are:
* `toBigInteger` for `Int` and `Long`
* `toBigDecimal` for `Int`, `Long`, `Float`, `Double`, and `BigInteger`
* Arithmetic and bitwise operator functions:
+ Binary operators `+`, `-`, `*`, `/`, `%` and infix functions `and`, `or`, `xor`, `shl`, `shr`
+ Unary operators `-`, `++`, `--`, and a function `inv`
### Floating point to bits conversions
New functions were added for converting `Double` and `Float` to and from their bit representations:
* `toBits` and `toRawBits` returning `Long` for `Double` and `Int` for `Float`
* `Double.fromBits` and `Float.fromBits` for creating floating point numbers from the bit representation
### Regex is now serializable
The `kotlin.text.Regex` class has become `Serializable` and can now be used in serializable hierarchies.
### Closeable.use calls Throwable.addSuppressed if available
The `Closeable.use` function calls `Throwable.addSuppressed` when an exception is thrown during closing the resource after some other exception.
To enable this behavior you need to have `kotlin-stdlib-jdk7` in your dependencies.
JVM backend
-----------
### Constructor calls normalization
Ever since version 1.0, Kotlin supported expressions with complex control flow, such as try-catch expressions and inline function calls. Such code is valid according to the Java Virtual Machine specification. Unfortunately, some bytecode processing tools do not handle such code quite well when such expressions are present in the arguments of constructor calls.
To mitigate this problem for the users of such bytecode processing tools, we've added a command-line compiler option (`-Xnormalize-constructor-calls=MODE`) that tells the compiler to generate more Java-like bytecode for such constructs. Here `MODE` is one of:
* `disable` (default) – generate bytecode in the same way as in Kotlin 1.0 and 1.1.
* `enable` – generate Java-like bytecode for constructor calls. This can change the order in which the classes are loaded and initialized.
* `preserve-class-initialization` – generate Java-like bytecode for constructor calls, ensuring that the class initialization order is preserved. This can affect overall performance of your application; use it only if you have some complex state shared between multiple classes and updated on class initialization.
The "manual" workaround is to store the values of sub-expressions with control flow in variables, instead of evaluating them directly inside the call arguments. It's similar to `-Xnormalize-constructor-calls=enable`.
### Java-default method calls
Before Kotlin 1.2, interface members overriding Java-default methods while targeting JVM 1.6 produced a warning on super calls: `Super calls to Java default methods are deprecated in JVM target 1.6. Recompile with '-jvm-target 1.8'`. In Kotlin 1.2, there's an **error** instead, thus requiring any such code to be compiled with JVM target 1.8.
### Breaking change: consistent behavior of x.equals(null) for platform types
Calling `x.equals(null)` on a platform type that is mapped to a Java primitive (`Int!`, `Boolean!`, `Short`!, `Long!`, `Float!`, `Double!`, `Char!`) incorrectly returned `true` when `x` was null. Starting with Kotlin 1.2, calling `x.equals(...)` on a null value of a platform type **throws an NPE** (but `x == ...` does not).
To return to the pre-1.2 behavior, pass the flag `-Xno-exception-on-explicit-equals-for-boxed-null` to the compiler.
### Breaking change: fix for platform null escaping through an inlined extension receiver
Inline extension functions that were called on a null value of a platform type did not check the receiver for null and would thus allow null to escape into the other code. Kotlin 1.2 forces this check at the call sites, throwing an exception if the receiver is null.
To switch to the old behavior, pass the fallback flag `-Xno-receiver-assertions` to the compiler.
JavaScript backend
------------------
### TypedArrays support enabled by default
The JS typed arrays support that translates Kotlin primitive arrays, such as `IntArray`, `DoubleArray`, into [JavaScript typed arrays](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays), that was previously an opt-in feature, has been enabled by default.
Tools
-----
### Warnings as errors
The compiler now provides an option to treat all warnings as errors. Use `-Werror` on the command line, or the following Gradle snippet:
```
compileKotlin {
kotlinOptions.allWarningsAsErrors = true
}
```
Last modified: 10 January 2023
[What's new in Kotlin 1.3](whatsnew13) [What's new in Kotlin 1.1](whatsnew11)
| programming_docs |
kotlin Grouping Grouping
========
The Kotlin standard library provides extension functions for grouping collection elements. The basic function [`groupBy()`](../api/latest/jvm/stdlib/kotlin.collections/group-by) takes a lambda function and returns a `Map`. In this map, each key is the lambda result and the corresponding value is the `List` of elements on which this result is returned. This function can be used, for example, to group a list of `String`s by their first letter.
You can also call `groupBy()` with a second lambda argument – a value transformation function. In the result map of `groupBy()` with two lambdas, the keys produced by `keySelector` function are mapped to the results of the value transformation function instead of the original elements.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four", "five")
println(numbers.groupBy { it.first().uppercase() })
println(numbers.groupBy(keySelector = { it.first() }, valueTransform = { it.uppercase() }))
//sampleEnd
}
```
If you want to group elements and then apply an operation to all groups at one time, use the function [`groupingBy()`](../api/latest/jvm/stdlib/kotlin.collections/grouping-by). It returns an instance of the [`Grouping`](../api/latest/jvm/stdlib/kotlin.collections/-grouping/index) type. The `Grouping` instance lets you apply operations to all groups in a lazy manner: the groups are actually built right before the operation execution.
Namely, `Grouping` supports the following operations:
* [`eachCount()`](../api/latest/jvm/stdlib/kotlin.collections/each-count) counts the elements in each group.
* [`fold()`](../api/latest/jvm/stdlib/kotlin.collections/fold) and [`reduce()`](../api/latest/jvm/stdlib/kotlin.collections/reduce) perform [fold and reduce](collection-aggregate#fold-and-reduce) operations on each group as a separate collection and return the results.
* [`aggregate()`](../api/latest/jvm/stdlib/kotlin.collections/aggregate) applies a given operation subsequently to all the elements in each group and returns the result. This is the generic way to perform any operations on a `Grouping`. Use it to implement custom operations when fold or reduce are not enough.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four", "five", "six")
println(numbers.groupingBy { it.first() }.eachCount())
//sampleEnd
}
```
Last modified: 10 January 2023
[Plus and minus operators](collection-plus-minus) [Retrieve collection parts](collection-parts)
kotlin What's new in Kotlin 1.6.20 What's new in Kotlin 1.6.20
===========================
*[Release date: 4 April 2022](releases#release-details)*
Kotlin 1.6.20 reveals previews of the future language features, makes the hierarchical structure the default for multiplatform projects, and brings evolutionary improvements to other components.
You can also find a short overview of the changes in this video:
Language
--------
In Kotlin 1.6.20, you can try two new language features:
* [Prototype of context receivers for Kotlin/JVM](#prototype-of-context-receivers-for-kotlin-jvm)
* [Definitely non-nullable types](#definitely-non-nullable-types)
### Prototype of context receivers for Kotlin/JVM
With Kotlin 1.6.20, you are no longer limited to having one receiver. If you need more, you can make functions, properties, and classes context-dependent (or *contextual*) by adding context receivers to their declaration. A contextual declaration does the following:
* It requires all declared context receivers to be present in a caller's scope as implicit receivers.
* It brings declared context receivers into its body scope as implicit receivers.
```
interface LoggingContext {
val log: Logger // This context provides a reference to a logger
}
context(LoggingContext)
fun startBusinessOperation() {
// You can access the log property since LoggingContext is an implicit receiver
log.info("Operation has started")
}
fun test(loggingContext: LoggingContext) {
with(loggingContext) {
// You need to have LoggingContext in a scope as an implicit receiver
// to call startBusinessOperation()
startBusinessOperation()
}
}
```
To enable context receivers in your project, use the `-Xcontext-receivers` compiler option. You can find a detailed description of the feature and its syntax in the [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/context-receivers.md#detailed-design).
Please note that the implementation is a prototype:
* With `-Xcontext-receivers` enabled, the compiler will produce pre-release binaries that cannot be used in production code
* The IDE support for context receivers is minimal for now
Try the feature in your toy projects and share your thoughts and experience with us in [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-42435). If you run into any problems, please [file a new issue](https://kotl.in/issue).
### Definitely non-nullable types
To provide better interoperability when extending generic Java classes and interfaces, Kotlin 1.6.20 allows you to mark a generic type parameter as definitely non-nullable on the use site with the new syntax `T & Any`. The syntactic form comes from a notation of [intersection types](https://en.wikipedia.org/wiki/Intersection_type) and is now limited to a type parameter with nullable upper bounds on the left side of `&` and non-nullable `Any` on the right side:
```
fun <T> elvisLike(x: T, y: T & Any): T & Any = x ?: y
fun main() {
// OK
elvisLike<String>("", "").length
// Error: 'null' cannot be a value of a non-null type
elvisLike<String>("", null).length
// OK
elvisLike<String?>(null, "").length
// Error: 'null' cannot be a value of a non-null type
elvisLike<String?>(null, null).length
}
```
Set the language version to `1.7` to enable the feature:
```
kotlin {
sourceSets.all {
languageSettings.apply {
languageVersion = "1.7"
}
}
}
```
```
kotlin {
sourceSets.all {
languageSettings {
languageVersion = '1.7'
}
}
}
```
Learn more about definitely non-nullable types in [the KEEP](https://github.com/Kotlin/KEEP/blob/c72601cf35c1e95a541bb4b230edb474a6d1d1a8/proposals/definitely-non-nullable-types.md).
Kotlin/JVM
----------
Kotlin 1.6.20 introduces:
* Compatibility improvements of default methods in JVM interfaces: [new `@JvmDefaultWithCompatibility` annotation for interfaces](#new-jvmdefaultwithcompatibility-annotation-for-interfaces) and [compatibility changes in the `-Xjvm-default` modes](#compatibility-changes-in-the-xjvm-default-modes)
* [Support for parallel compilation of a single module in the JVM backend](#support-for-parallel-compilation-of-a-single-module-in-the-jvm-backend)
* [Support for callable references to functional interface constructors](#support-for-callable-references-to-functional-interface-constructors)
### New @JvmDefaultWithCompatibility annotation for interfaces
Kotlin 1.6.20 introduces the new annotation [`@JvmDefaultWithCompatibility`](../api/latest/jvm/stdlib/kotlin.jvm/-jvm-default-with-compatibility/index): use it along with the `-Xjvm-default=all` compiler option [to create the default method in JVM interface](java-to-kotlin-interop#default-methods-in-interfaces) for any non-abstract member in any Kotlin interface.
If there are clients that use your Kotlin interfaces compiled without the `-Xjvm-default=all` option, they may be binary-incompatible with the code compiled with this option. Before Kotlin 1.6.20, to avoid this compatibility issue, the [recommended approach](https://blog.jetbrains.com/kotlin/2020/07/kotlin-1-4-m3-generating-default-methods-in-interfaces/#JvmDefaultWithoutCompatibility) was to use the `-Xjvm-default=all-compatibility` mode and also the `@JvmDefaultWithoutCompatibility` annotation for interfaces that didn't need this type of compatibility.
This approach had some disadvantages:
* You could easily forget to add the annotation when a new interface was added.
* Usually there are more interfaces in non-public parts than in the public API, so you end up having this annotation in many places in your code.
Now, you can use the `-Xjvm-default=all` mode and mark interfaces with the `@JvmDefaultWithCompatibility` annotation. This allows you to add this annotation to all interfaces in the public API once, and you won't need to use any annotations for new non-public code.
Leave your feedback about this new annotation in [this YouTrack ticket](https://youtrack.jetbrains.com/issue/KT-48217).
### Compatibility changes in the -Xjvm-default modes
Kotlin 1.6.20 adds the option to compile modules in the default mode (the `-Xjvm-default=disable` compiler option) against modules compiled with the `-Xjvm-default=all` or `-Xjvm-default=all-compatibility` modes. As before, compilations will also be successful if all modules have the `-Xjvm-default=all` or `-Xjvm-default=all-compatibility` modes. You can leave your feedback in this [YouTrack issue](https://youtrack.jetbrains.com/issue/KT-47000).
Kotlin 1.6.20 deprecates the `compatibility` and `enable` modes of the compiler option `-Xjvm-default`. There are changes in other modes' descriptions regarding the compatibility, but the overall logic remains the same. You can check out the [updated descriptions](java-to-kotlin-interop#compatibility-modes-for-default-methods).
For more information about default methods in the Java interop, see the [interoperability documentation](java-to-kotlin-interop#default-methods-in-interfaces) and [this blog post](https://blog.jetbrains.com/kotlin/2020/07/kotlin-1-4-m3-generating-default-methods-in-interfaces/).
### Support for parallel compilation of a single module in the JVM backend
We are continuing our work to [improve the new JVM IR backend compilation time](https://youtrack.jetbrains.com/issue/KT-46768). In Kotlin 1.6.20, we added the experimental JVM IR backend mode to compile all the files in a module in parallel. Parallel compilation can reduce the total compilation time by up to 15%.
Enable the experimental parallel backend mode with the [compiler option](compiler-reference#compiler-options) `-Xbackend-threads`. Use the following arguments for this option:
* `N` is the number of threads you want to use. It should not be greater than your number of CPU cores; otherwise, parallelization stops being effective because of switching context between threads
* `0` to use a separate thread for each CPU core
[Gradle](gradle) can run tasks in parallel, but this type of parallelization doesn't help a lot when a project (or a major part of a project) is just one big task from Gradle's perspective. If you have a very big monolithic module, use parallel compilation to compile more quickly. If your project consists of lots of small modules and has a build parallelized by Gradle, adding another layer of parallelization may hurt performance because of context switching.
### Support for callable references to functional interface constructors
Support for [callable references](reflection#callable-references) to functional interface constructors adds a source-compatible way to migrate from an interface with a constructor function to a [functional interface](fun-interfaces).
Consider the following code:
```
interface Printer {
fun print()
}
fun Printer(block: () -> Unit): Printer = object : Printer { override fun print() = block() }
```
With callable references to functional interface constructors enabled, this code can be replaced with just a functional interface declaration:
```
fun interface Printer {
fun print()
}
```
Its constructor will be created implicitly, and any code using the `::Printer` function reference will compile. For example:
```
documentsStorage.addPrinter(::Printer)
```
Preserve the binary compatibility by marking the legacy function `Printer` with the [`@Deprecated`](../api/latest/jvm/stdlib/kotlin/-deprecated/index) annotation with `DeprecationLevel.HIDDEN`:
```
@Deprecated(message = "Your message about the deprecation", level = DeprecationLevel.HIDDEN)
fun Printer(...) {...}
```
Use the compiler option `-XXLanguage:+KotlinFunInterfaceConstructorReference` to enable this feature.
Kotlin/Native
-------------
Kotlin/Native 1.6.20 marks continued development of its new components. We've taken another step toward consistent experience with Kotlin on other platforms:
* [An update on the new memory manager](#an-update-on-the-new-memory-manager)
* [Concurrent implementation for the sweep phase in new memory manager](#concurrent-implementation-for-the-sweep-phase-in-new-memory-manager)
* [Instantiation of annotation classes](#instantiation-of-annotation-classes)
* [Interop with Swift async/await: returning Swift's Void instead of KotlinUnit](#interop-with-swift-async-await-returning-void-instead-of-kotlinunit)
* [Better stack traces with libbacktrace](#better-stack-traces-with-libbacktrace)
* [Support for standalone Android executables](#support-for-standalone-android-executables)
* [Performance improvements](#performance-improvements)
* [Improved error handling during cinterop modules import](#improved-error-handling-during-cinterop-modules-import)
* [Support for Xcode 13 libraries](#support-for-xcode-13-libraries)
### An update on the new memory manager
With Kotlin 1.6.20, you can try the Alpha version of the new Kotlin/Native memory manager. It eliminates the differences between the JVM and Native platforms to provide a consistent developer experience in multiplatform projects. For example, you'll have a much easier time creating new cross-platform mobile applications that work on both Android and iOS.
The new Kotlin/Native memory manager lifts restrictions on object-sharing between threads. It also provides leak-free concurrent programming primitives that are safe and don't require any special management or annotations.
The new memory manager will become the default in future versions, so we encourage you to try it now. Check out our [blog post](https://blog.jetbrains.com/kotlin/2021/08/try-the-new-kotlin-native-memory-manager-development-preview/) to learn more about the new memory manager and explore demo projects, or jump right to the [migration instructions](https://github.com/JetBrains/kotlin/blob/master/kotlin-native/NEW_MM.md) to try it yourself.
Try using the new memory manager on your projects to see how it works and share feedback in our issue tracker, [YouTrack](https://youtrack.jetbrains.com/issue/KT-48525).
### Concurrent implementation for the sweep phase in new memory manager
If you have already switched to our new memory manager, which was [announced in Kotlin 1.6](whatsnew16#preview-of-the-new-memory-manager), you might notice a huge execution time improvement: our benchmarks show 35% improvement on average. Starting with 1.6.20, there is also a concurrent implementation for the sweep phase available for the new memory manager. This should also improve the performance and decrease the duration of garbage collector pauses.
To enable the feature for the new Kotlin/Native memory manager, pass the following compiler option:
```
-Xgc=cms
```
Feel free to share your feedback on the new memory manager performance in this [YouTrack issue](https://youtrack.jetbrains.com/issue/KT-48526).
### Instantiation of annotation classes
In Kotlin 1.6.0, instantiation of annotation classes became [Stable](components-stability) for Kotlin/JVM and Kotlin/JS. The 1.6.20 version delivers support for Kotlin/Native.
Learn more about [instantiation of annotation classes](annotations#instantiation).
### Interop with Swift async/await: returning Void instead of KotlinUnit
We've continued working on the [experimental interop with Swift's async/await](whatsnew1530#experimental-interoperability-with-swift-5-5-async-await) (available since Swift 5.5). Kotlin 1.6.20 differs from previous versions in the way it works with `suspend` functions with the `Unit` return type.
Previously, such functions were presented in Swift as `async` functions returning `KotlinUnit`. However, the proper return type for them is `Void`, similar to non-suspending functions.
To avoid breaking the existing code, we're introducing a Gradle property that makes the compiler translate `Unit`-returning suspend functions to `async` Swift with the `Void` return type:
```
# gradle.properties
kotlin.native.binary.unitSuspendFunctionObjCExport=proper
```
We plan to make this behavior the default in future Kotlin releases.
### Better stack traces with libbacktrace
Kotlin/Native is now able to produce detailed stack traces with file locations and line numbers for better debugging of `linux*` (except `linuxMips32` and `linuxMipsel32`) and `androidNative*` targets.
This feature uses the [libbacktrace](https://github.com/ianlancetaylor/libbacktrace) library under the hood. Take a look at the following code to see an example of the difference:
```
fun main() = bar()
fun bar() = baz()
inline fun baz() {
error("")
}
```
* **Before 1.6.20:**
Uncaught Kotlin exception: kotlin.IllegalStateException: at 0 example.kexe 0x227190 kfun:kotlin.Throwable#<init>(kotlin.String?){} + 96 at 1 example.kexe 0x221e4c kfun:kotlin.Exception#<init>(kotlin.String?){} + 92 at 2 example.kexe 0x221f4c kfun:kotlin.RuntimeException#<init>(kotlin.String?){} + 92 at 3 example.kexe 0x22234c kfun:kotlin.IllegalStateException#<init>(kotlin.String?){} + 92 at 4 example.kexe 0x25d708 kfun:#bar(){} + 104 at 5 example.kexe 0x25d68c kfun:#main(){} + 12
* **1.6.20 with libbacktrace:**
Uncaught Kotlin exception: kotlin.IllegalStateException: at 0 example.kexe 0x229550 kfun:kotlin.Throwable#<init>(kotlin.String?){} + 96 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Throwable.kt:24:37) at 1 example.kexe 0x22420c kfun:kotlin.Exception#<init>(kotlin.String?){} + 92 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:23:44) at 2 example.kexe 0x22430c kfun:kotlin.RuntimeException#<init>(kotlin.String?){} + 92 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:34:44) at 3 example.kexe 0x22470c kfun:kotlin.IllegalStateException#<init>(kotlin.String?){} + 92 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:70:44) at 4 example.kexe 0x25fac8 kfun:#bar(){} + 104 [inlined] (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/libraries/stdlib/src/kotlin/util/Preconditions.kt:143:56) at 5 example.kexe 0x25fac8 kfun:#bar(){} + 104 [inlined] (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:4:5) at 6 example.kexe 0x25fac8 kfun:#bar(){} + 104 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:2:13) at 7 example.kexe 0x25fa4c kfun:#main(){} + 12 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:1:14)
On Apple targets, which already had file locations and line numbers in stack traces, libbacktrace provides more details for inline function calls:
* **Before 1.6.20:**
Uncaught Kotlin exception: kotlin.IllegalStateException: at 0 example.kexe 0x10a85a8f8 kfun:kotlin.Throwable#<init>(kotlin.String?){} + 88 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Throwable.kt:24:37) at 1 example.kexe 0x10a855846 kfun:kotlin.Exception#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:23:44) at 2 example.kexe 0x10a855936 kfun:kotlin.RuntimeException#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:34:44) at 3 example.kexe 0x10a855c86 kfun:kotlin.IllegalStateException#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:70:44) at 4 example.kexe 0x10a8489a5 kfun:#bar(){} + 117 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:2:1) at 5 example.kexe 0x10a84891c kfun:#main(){} + 12 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:1:14) ...
* **1.6.20 with libbacktrace:**
Uncaught Kotlin exception: kotlin.IllegalStateException: at 0 example.kexe 0x10669bc88 kfun:kotlin.Throwable#<init>(kotlin.String?){} + 88 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Throwable.kt:24:37) at 1 example.kexe 0x106696bd6 kfun:kotlin.Exception#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:23:44) at 2 example.kexe 0x106696cc6 kfun:kotlin.RuntimeException#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:34:44) at 3 example.kexe 0x106697016 kfun:kotlin.IllegalStateException#<init>(kotlin.String?){} + 86 (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/kotlin-native/runtime/src/main/kotlin/kotlin/Exceptions.kt:70:44) at 4 example.kexe 0x106689d35 kfun:#bar(){} + 117 [inlined] (/opt/buildAgent/work/c3a91df21e46e2c8/kotlin/libraries/stdlib/src/kotlin/util/Preconditions.kt:143:56) >> at 5 example.kexe 0x106689d35 kfun:#bar(){} + 117 [inlined] (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:4:5) at 6 example.kexe 0x106689d35 kfun:#bar(){} + 117 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:2:13) at 7 example.kexe 0x106689cac kfun:#main(){} + 12 (/private/tmp/backtrace/src/commonMain/kotlin/app.kt:1:14) ...
To produce better stack traces with libbacktrace, add the following line to `gradle.properties`:
```
# gradle.properties
kotlin.native.binary.sourceInfoType=libbacktrace
```
Please tell us how debugging Kotlin/Native with libbacktrace works for you in [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-48424).
### Support for standalone Android executables
Previously, Android Native executables in Kotlin/Native were not actually executables but shared libraries that you could use as a NativeActivity. Now there's an option to generate standard executables for Android Native targets.
For that, in the `build.gradle(.kts)` part of your project, configure the executable block of your `androidNative` target. Add the following binary option:
```
kotlin {
androidNativeX64("android") {
binaries {
executable {
binaryOptions["androidProgramType"] = "standalone"
}
}
}
}
```
Note that this feature will become the default in Kotlin 1.7.0. If you want to preserve the current behavior, use the following setting:
```
binaryOptions["androidProgramType"] = "nativeActivity"
```
Thanks to Mattia Iavarone for the [implementation](https://github.com/jetbrains/kotlin/pull/4624)!
### Performance improvements
We are working hard on Kotlin/Native to [speed up the compilation process](https://youtrack.jetbrains.com/issue/KT-42294) and improve your developing experience.
Kotlin 1.6.20 brings some performance updates and bug fixes that affect the LLVM IR that Kotlin generates. According to the benchmarks on our internal projects, we achieved the following performance boosts on average:
* 15% reduction in execution time
* 20% reduction in the code size of both release and debug binaries
* 26% reduction in the compilation time of release binaries
These changes also provide a 10% reduction in compilation time for a debug binary on a large internal project.
To achieve this, we've implemented static initialization for some of the compiler-generated synthetic objects, improved the way we structure LLVM IR for every function, and optimized the compiler caches.
### Improved error handling during cinterop modules import
This release introduces improved error handling for cases where you import an Objective-C module using the `cinterop` tool (as is typical for CocoaPods pods). Previously, if you got an error while trying to work with an Objective-C module (for instance, when dealing with a compilation error in a header), you received an uninformative error message, such as `fatal error: could not build module $name`. We expanded upon this part of the `cinterop` tool, so you'll get an error message with an extended description.
### Support for Xcode 13 libraries
Libraries delivered with Xcode 13 have full support as of this release. Feel free to access them from anywhere in your Kotlin code.
Kotlin Multiplatform
--------------------
1.6.20 brings the following notable updates to Kotlin Multiplatform:
* [Hierarchical structure support is now default for all new multiplatform projects](#hierarchical-structure-support-for-multiplatform-projects)
* [Kotlin CocoaPods Gradle plugin received several useful features for CocoaPods integration](#kotlin-cocoapods-gradle-plugin)
### Hierarchical structure support for multiplatform projects
Kotlin 1.6.20 comes with hierarchical structure support enabled by default. Since [introducing it in Kotlin 1.4.0](whatsnew14#sharing-code-in-several-targets-with-the-hierarchical-project-structure), we've significantly improved the frontend and made IDE import stable.
Previously, there were two ways to add code in a multiplatform project. The first was to insert it in a platform-specific source set, which is limited to one target and can't be reused by other platforms. The second is to use a common source set shared across all the platforms that are currently supported by Kotlin.
Now you can [share source code](#better-code-sharing-in-your-project) among several similar native targets that reuse a lot of the common logic and third-party APIs. The technology will provide the correct default dependencies and find the exact API available in the shared code. This eliminates a complex build setup and having to use workarounds to get IDE support for sharing source sets among native targets. It also helps prevent unsafe API usages meant for a different target.
The technology will come in handy for [library authors](#more-opportunities-for-library-authors), too, as a hierarchical project structure allows them to publish and consume libraries with common APIs for a subset of targets.
By default, libraries published with the hierarchical project structure are compatible only with hierarchical structure projects. Learn more about [project-library compatibility](multiplatform-hierarchy#compatibility).
#### Better code-sharing in your project
Without hierarchical structure support, there is no straightforward way to share code across *some* but not *all* [Kotlin targets](multiplatform-dsl-reference#targets). One popular example is sharing code across all iOS targets and having access to iOS-specific [dependencies](multiplatform-share-on-platforms#use-native-libraries-in-the-hierarchical-structure), like `Foundation`.
Thanks to the hierarchical project structure support, you can now achieve this out of the box. In the new structure, source sets form a hierarchy. You can use platform-specific language features and dependencies available for each target that a given source set compiles to.
For example, consider a typical multiplatform project with two targets — `iosArm64` and `iosX64` for iOS devices and simulators. The Kotlin tooling understands that both targets have the same function and allows you to access that function from the intermediate source set, `iosMain`.
The Kotlin toolchain provides the correct default dependencies, like Kotlin/Native stdlib or native libraries. Moreover, Kotlin tooling will try its best to find exactly the API surface area available in the shared code. This prevents such cases as, for example, the use of a macOS-specific function in code shared for Windows.
#### More opportunities for library authors
When a multiplatform library is published, the API of its intermediate source sets is now properly published alongside it, making it available for consumers. Again, the Kotlin toolchain will automatically figure out the API available in the consumer source set while carefully watching out for unsafe usages, like using an API meant for the JVM in JS code. Learn more about [sharing code in libraries](multiplatform-share-on-platforms#share-code-in-libraries).
#### Configuration and setup
Starting with Kotlin 1.6.20, all your new multiplatform projects will have a hierarchical project structure. No additional setup is required.
* If you've already [turned it on manually](multiplatform-share-on-platforms#share-code-on-similar-platforms), you can remove the deprecated options from `gradle.properties`:
```
# gradle.properties
kotlin.mpp.enableGranularSourceSetsMetadata=true
kotlin.native.enableDependencyPropagation=false // or 'true', depending on your previous setup
```
* For Kotlin 1.6.20, we recommend using [Android Studio 2021.1.1](https://developer.android.com/studio) (Bumblebee) or later to get the best experience.
* You can also opt-out. To disable hierarchical structure support, set the following options in`gradle.properties`:
```
# gradle.properties
kotlin.mpp.hierarchicalStructureSupport=false
```
#### Leave your feedback
This is a significant change to the whole ecosystem. We would appreciate your feedback to help make it even better.
Try it now and report any difficulties you encounter to [our issue tracker](https://kotl.in/issue).
### Kotlin CocoaPods Gradle plugin
To simplify CocoaPods integration, Kotlin 1.6.20 delivers the following features:
* The CocoaPods plugin now has tasks that build XCFrameworks with all registered targets and generate the Podspec file. This can be useful when you don't want to integrate with Xcode directly, but you want to build artifacts and deploy them to your local CocoaPods repository.
Learn more about [building XCFrameworks](multiplatform-build-native-binaries#build-xcframeworks).
* If you use [CocoaPods integration](native-cocoapods) in your projects, you're used to specifying the required Pod version for the entire Gradle project. Now you have more options:
+ Specify the Pod version directly in the `cocoapods` block
+ Continue using a Gradle project versionIf none of these properties is configured, you'll get an error.
* You can now configure the CocoaPod name in the `cocoapods` block instead of changing the name of the whole Gradle project.
* The CocoaPods plugin introduces a new `extraSpecAttributes` property, which you can use to configure properties in a Podspec file that were previously hard-coded, like `libraries` or `vendored_frameworks`.
```
kotlin {
cocoapods {
version = "1.0"
name = "MyCocoaPod"
extraSpecAttributes["social_media_url"] = 'https://twitter.com/kotlin'
extraSpecAttributes["vendored_frameworks"] = 'CustomFramework.xcframework'
extraSpecAttributes["libraries"] = 'xml'
}
}
```
See the full Kotlin CocoaPods Gradle plugin [DSL reference](native-cocoapods-dsl-reference).
Kotlin/JS
---------
Kotlin/JS improvements in 1.6.20 mainly affect the IR compiler:
* [Incremental compilation for development binaries (IR)](#incremental-compilation-for-development-binaries-with-ir-compiler)
* [Lazy initialization of top-level properties by default (IR)](#lazy-initialization-of-top-level-properties-by-default-with-ir-compiler)
* [Separate JS files for project modules by default (IR)](#separate-js-files-for-project-modules-by-default-with-ir-compiler)
* [Char class optimization (IR)](#char-class-optimization)
* [Export improvements (both IR and legacy backends)](#improvements-to-export-and-typescript-declaration-generation)
* [@AfterTest guarantees for asynchronous tests](#aftertest-guarantees-for-asynchronous-tests)
### Incremental compilation for development binaries with IR compiler
To make Kotlin/JS development with the IR compiler more efficient, we're introducing a new *incremental compilation* mode.
When building **development binaries** with the `compileDevelopmentExecutableKotlinJs` Gradle task in this mode, the compiler caches the results of previous compilations on the module level. It uses the cached compilation results for unchanged source files during subsequent compilations, making them complete more quickly, especially with small changes. Note that this improvement exclusively targets the development process (shortening the edit-build-debug cycle) and doesn't affect the building of production artifacts.
To enable incremental compilation for development binaries, add the following line to the project's `gradle.properties`:
```
# gradle.properties
kotlin.incremental.js.ir=true // false by default
```
In our test projects, the new mode made incremental compilation up to 30% faster. However, the clean build in this mode became slower because of the need to create and populate the caches.
Please tell us what you think of using incremental compilation with your Kotlin/JS projects in [this YouTrack issue](https://youtrack.jetbrains.com/issue/KT-50203).
### Lazy initialization of top-level properties by default with IR compiler
In Kotlin 1.4.30, we presented a prototype of [lazy initialization of top-level properties](whatsnew1430#lazy-initialization-of-top-level-properties) in the JS IR compiler. By eliminating the need to initialize all properties when the application launches, lazy initialization reduces the startup time. Our measurements showed about a 10% speed-up on a real-life Kotlin/JS application.
Now, having polished and properly tested this mechanism, we're making lazy initialization the default for top-level properties in the IR compiler.
```
// lazy initialization
val a = run {
val result = // intensive computations
println(result)
result
} // run is executed upon the first usage of the variable
```
If for some reason you need to initialize a property eagerly (upon the application start), mark it with the [`@EagerInitialization`](../api/latest/jvm/stdlib/kotlin.native/-eager-initialization/index) annotation.
### Separate JS files for project modules by default with IR compiler
Previously, the JS IR compiler offered an [ability to generate separate `.js` files](https://youtrack.jetbrains.com/issue/KT-44319) for project modules. This was an alternative to the default option – a single `.js` file for the whole project. This file might be too large and inconvenient to use, because whenever you want to use a function from your project, you have to include the entire JS file as a dependency. Having multiple files adds flexibility and decreases the size of such dependencies. This feature was available with the `-Xir-per-module` compiler option.
Starting from 1.6.20, the JS IR compiler generates separate `.js` files for project modules by default.
Compiling the project into a single `.js` file is now available with the following Gradle property:
```
# gradle.properties
kotlin.js.ir.output.granularity=whole-program // `per-module` is the default
```
In previous releases, the experimental per-module mode (available via the `-Xir-per-module=true` flag) invoked `main()` functions in each module. This is inconsistent with the regular single `.js` mode. Starting with 1.6.20, the `main()` function will be invoked in the main module only in both cases. If you do need to run some code when a module is loaded, you can use top-level properties annotated with the `@EagerInitialization` annotation. See [Lazy initialization of top-level properties by default (IR)](#lazy-initialization-of-top-level-properties-by-default-with-ir-compiler).
### Char class optimization
The `Char` class is now handled by the Kotlin/JS compiler without introducing boxing (similar to [inline classes](inline-classes)). This speeds up operations on chars in Kotlin/JS code.
Aside from the performance improvement, this changes the way `Char` is exported to JavaScript: it's now translated to `Number`.
### Improvements to export and TypeScript declaration generation
Kotlin 1.6.20 is bringing multiple fixes and improvements to the export mechanism (the [`@JsExport`](../api/latest/jvm/stdlib/kotlin.js/-js-export/index) annotation), including the [generation of TypeScript declarations (`.d.ts`)](js-ir-compiler#preview-generation-of-typescript-declaration-files-d-ts). We've added the ability to export interfaces and enums, and we've fixed the export behavior in some corner cases that were reported to us previously. For more details, see the [list of export improvements in YouTrack](https://youtrack.jetbrains.com/issues?q=Project:%20Kotlin%20issue%20id:%20KT-45434,%20KT-44494,%20KT-37916,%20KT-43191,%20KT-46961,%20KT-40236).
Learn more about [using Kotlin code from JavaScript](js-to-kotlin-interop).
### @AfterTest guarantees for asynchronous tests
Kotlin 1.6.20 makes [`@AfterTest`](https://kotlinlang.org/api/latest/kotlin.test/kotlin.test/-after-test/) functions work properly with asynchronous tests on Kotlin/JS. If a test function's return type is statically resolved to [`Promise`](../api/latest/jvm/stdlib/kotlin.js/-promise/index), the compiler now schedules the execution of the `@AfterTest` function to the corresponding [`then()`](../api/latest/jvm/stdlib/kotlin.js/-promise/then) callback.
Security
--------
Kotlin 1.6.20 introduces a couple of features to improve the security of your code:
* [Using relative paths in klibs](#using-relative-paths-in-klibs)
* [Persisting yarn.lock for Kotlin/JS Gradle projects](#persisting-yarn-lock-for-kotlin-js-gradle-projects)
* [Installation of npm dependencies with `--ignore-scripts` by default](#installation-of-npm-dependencies-with-ignore-scripts-by-default)
### Using relative paths in klibs
A library in `klib` format [contains](native-libraries#library-format) a serialized IR representation of source files, which also includes their paths for generating proper debug information. Before Kotlin 1.6.20, stored file paths were absolute. Since the library author may not want to share absolute paths, the 1.6.20 version comes with an alternative option.
If you are publishing a `klib` and want to use only relative paths of source files in the artifact, you can now pass the `-Xklib-relative-path-base` compiler option with one or multiple base paths of source files:
```
tasks.withType(org.jetbrains.kotlin.gradle.dsl.KotlinCompile::class).configureEach {
// $base is a base path of source files
kotlinOptions.freeCompilerArgs += "-Xklib-relative-path-base=$base"
}
```
```
tasks.withType(org.jetbrains.kotlin.gradle.dsl.KotlinCompile).configureEach {
kotlinOptions {
// $base is a base path of source files
freeCompilerArgs += "-Xklib-relative-path-base=$base"
}
}
```
### Persisting yarn.lock for Kotlin/JS Gradle projects
The Kotlin/JS Gradle plugin now provides an ability to persist the `yarn.lock` file, making it possible to lock the versions of the npm dependencies for your project without additional Gradle configuration. The feature brings changes to the default project structure by adding the auto-generated `kotlin-js-store` directory to the project root. It holds the `yarn.lock` file inside.
We strongly recommend committing the `kotlin-js-store` directory and its contents to your version control system. Committing lockfiles to your version control system is a [recommended practice](https://classic.yarnpkg.com/blog/2016/11/24/lockfiles-for-all/) because it ensures your application is being built with the exact same dependency tree on all machines, regardless of whether those are development environments on other machines or CI/CD services. Lockfiles also prevent your npm dependencies from being silently updated when a project is checked out on a new machine, which is a security concern.
Tools like [Dependabot](https://github.com/dependabot) can also parse the `yarn.lock` files of your Kotlin/JS projects, and provide you with warnings if any npm package you depend on is compromised.
If needed, you can change both directory and lockfile names in the build script:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().lockFileDirectory =
project.rootDir.resolve("my-kotlin-js-store")
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().lockFileName = "my-yarn.lock"
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).lockFileDirectory =
file("my-kotlin-js-store")
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).lockFileName = 'my-yarn.lock'
}
```
### Installation of npm dependencies with --ignore-scripts by default
The Kotlin/JS Gradle plugin now prevents the execution of [lifecycle scripts](https://docs.npmjs.com/cli/v8/using-npm/scripts#life-cycle-scripts) during the installation of npm dependencies by default. The change is aimed at reducing the likelihood of executing malicious code from compromised npm packages.
To roll back to the old configuration, you can explicitly enable lifecycle scripts execution by adding the following lines to `build.gradle(.kts)`:
```
rootProject.plugins.withType<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin> {
rootProject.the<org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension>().ignoreScripts = false
}
```
```
rootProject.plugins.withType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnPlugin) {
rootProject.extensions.getByType(org.jetbrains.kotlin.gradle.targets.js.yarn.YarnRootExtension).ignoreScripts = false
}
```
Learn more about [npm dependencies of a Kotlin/JS Gradle project](js-project-setup#npm-dependencies).
Gradle
------
Kotlin 1.6.20 brings the following changes for the Kotlin Gradle Plugin:
* New [properties `kotlin.compiler.execution.strategy` and `compilerExecutionStrategy`](#properties-for-defining-kotlin-compiler-execution-strategy) for defining a Kotlin compiler execution strategy
* [Deprecation of the options `kapt.use.worker.api`, `kotlin.experimental.coroutines`, and `kotlin.coroutines`](#deprecation-of-build-options-for-kapt-and-coroutines)
* [Removal of the `kotlin.parallel.tasks.in.project` build option](#removal-of-the-kotlin-parallel-tasks-in-project-build-option)
### Properties for defining Kotlin compiler execution strategy
Before Kotlin 1.6.20, you used the system property `-Dkotlin.compiler.execution.strategy` to define a Kotlin compiler execution strategy. This property might have been inconvenient in some cases. Kotlin 1.6.20 introduces a Gradle property with the same name, `kotlin.compiler.execution.strategy`, and the compile task property `compilerExecutionStrategy`.
The system property still works, but it will be removed in future releases.
The current priority of properties is the following:
* The task property `compilerExecutionStrategy` takes priority over the system property and the Gradle property `kotlin.compiler.execution.strategy`.
* The Gradle property takes priority over the system property.
There are three compiler execution strategies that you can assign to these properties:
| Strategy | Where Kotlin compiler is executed | Incremental compilation | Other characteristics |
| --- | --- | --- | --- |
| Daemon | Inside its own daemon process | Yes | *The default strategy*. Can be shared between different Gradle daemons |
| In process | Inside the Gradle daemon process | No | May share the heap with the Gradle daemon |
| Out of process | In a separate process for each call | No | — |
Accordingly, the available values for `kotlin.compiler.execution.strategy` properties (both system and Gradle's) are:
1. `daemon` (default)
2. `in-process`
3. `out-of-process`
Use the Gradle property `kotlin.compiler.execution.strategy` in `gradle.properties`:
```
# gradle.properties
kotlin.compiler.execution.strategy=out-of-process
```
The available values for the `compilerExecutionStrategy` task property are:
1. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.DAEMON` (default)
2. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.IN_PROCESS`
3. `org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy.OUT_OF_PROCESS`
Use the task property `compilerExecutionStrategy` in the `build.gradle.kts` build script:
```
import org.jetbrains.kotlin.gradle.dsl.KotlinCompile
import org.jetbrains.kotlin.gradle.tasks.KotlinCompilerExecutionStrategy
// ...
tasks.withType<KotlinCompile>().configureEach {
compilerExecutionStrategy.set(KotlinCompilerExecutionStrategy.IN_PROCESS)
}
```
Please leave your feedback in [this YouTrack task](https://youtrack.jetbrains.com/issue/KT-49299).
### Deprecation of build options for kapt and coroutines
In Kotlin 1.6.20, we changed deprecation levels of the properties:
* We deprecated the ability to run <kapt> via the Kotlin daemon with `kapt.use.worker.api` – now it produces a warning to Gradle's output. By default, [kapt has been using Gradle workers](kapt#running-kapt-tasks-in-parallel) since the 1.3.70 release, and we recommend sticking to this method.
We are going to remove the option `kapt.use.worker.api` in future releases.
* We deprecated the `kotlin.experimental.coroutines` Gradle DSL option and the `kotlin.coroutines` property used in `gradle.properties`. Just use *suspending functions* or [add the `kotlinx.coroutines` dependency](gradle-configure-project#set-a-dependency-on-a-kotlinx-library) to your `build.gradle(.kts)` file.
Learn more about coroutines in the [Coroutines guide](coroutines-guide).
### Removal of the kotlin.parallel.tasks.in.project build option
In Kotlin 1.5.20, we announced [the deprecation of the build option `kotlin.parallel.tasks.in.project`](whatsnew1520#deprecation-of-the-kotlin-parallel-tasks-in-project-build-property). This option has been removed in Kotlin 1.6.20.
Depending on the project, parallel compilation in the Kotlin daemon may require more memory. To reduce memory consumption, [increase the heap size for the Kotlin daemon](gradle-compilation-and-caches#setting-kotlin-daemon-s-jvm-arguments).
Learn more about the [currently supported compiler options](gradle-compiler-options) in the Kotlin Gradle plugin.
Last modified: 10 January 2023
[What's new in Kotlin 1.7.0](whatsnew17) [What's new in Kotlin 1.6.0](whatsnew16)
| programming_docs |
kotlin Create and publish a multiplatform library – tutorial Create and publish a multiplatform library – tutorial
=====================================================
In this tutorial, you will learn how to create a multiplatform library for JVM, JS, and Native platforms, write common tests for all platforms, and publish the library to a local Maven repository.
This library converts raw data – strings and byte arrays – to the [Base64](https://en.wikipedia.org/wiki/Base64) format. It can be used on Kotlin/JVM, Kotlin/JS, and any available Kotlin/Native platform.
You will use different ways to implement the conversion to the Base64 format on different platforms:
* For JVM – the [`java.util.Base64` class](https://docs.oracle.com/javase/8/docs/api/java/util/Base64.html).
* For JS – the [`btoa()` function](https://developer.mozilla.org/docs/Web/API/WindowOrWorkerGlobalScope/btoa).
* For Kotlin/Native – your own implementation.
You will also test your code using common tests, and then publish the library to your local Maven repository.
Set up the environment
----------------------
You can complete this tutorial on any operating system. Download and install the [latest version of IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html) with the [latest Kotlin plugin](releases).
Create a project
----------------
1. In IntelliJ IDEA, select **File | New | Project**.
2. In the left-hand panel, select **Kotlin Multiplatform**.
3. Enter a project name, then in the **Multiplatform** section select **Library** as the project template.
By default, your project will use Gradle with Kotlin DSL as the build system.
4. Specify the [JDK](https://www.jetbrains.com/help/idea/sdk.html#jdk), which is required for developing Kotlin projects.
5. Click **Next** and then **Finish**.
Further project configuration
For more complex projects, you might need to add more modules and targets:
* To add modules, select **Project** and click the **+** icon. Choose the module type.
* To add target platforms, select **library** and click the **+** icon. Choose the target.
* Configure target settings, such as the target JVM version and test framework.

* If necessary, specify dependencies between modules:
+ Multiplatform and Android modules
+ Multiplatform and iOS modules
+ JVM modules
The wizard will create a sample multiplatform library with the following structure:
Write cross-platform code
-------------------------
Define the classes and interfaces you are going to implement in the common code.
1. In the `commonMain/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64.kt` file in the new package.
3. Define the `Base64Encoder` interface that converts bytes to the `Base64` format:
```
package org.jetbrains.base64
interface Base64Encoder {
fun encode(src: ByteArray): ByteArray
}
```
4. Define the `Base64Factory` object to provide an instance of the `Base64Encoder` interface to the common code:
```
expect object Base64Factory {
fun createEncoder(): Base64Encoder
}
```
The factory object is marked with the `expect` keyword in the cross-platform code. For each platform, you should provide an `actual` implementation of the `Base64Factory` object with the platform-specific encoder. Learn more about [platform-specific implementations](multiplatform-connect-to-apis).
Provide platform-specific implementations
-----------------------------------------
Now you will create the `actual` implementations of the `Base64Factory` object for each platform:
* [JVM](#jvm)
* [JS](#js)
* [Native](#native)
### JVM
1. In the `jvmMain/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64.kt` file in the new package.
3. Provide a simple implementation of the `Base64Factory` object that delegates to the `java.util.Base64` class:
```
package org.jetbrains.base64
import java.util.*
actual object Base64Factory {
actual fun createEncoder(): Base64Encoder = JvmBase64Encoder
}
object JvmBase64Encoder : Base64Encoder {
override fun encode(src: ByteArray): ByteArray = Base64.getEncoder().encode(src)
}
```
Pretty simple, right? You've provided a platform-specific implementation by using a straightforward delegation to a third-party implementation.
### JS
The JS implementation will be very similar to the JVM one.
1. In the `jsMain/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64.kt` file in the new package.
3. Provide a simple implementation of the `Base64Factory` object that delegates to the `btoa()` function.
```
package org.jetbrains.base64
import kotlinx.browser.window
actual object Base64Factory {
actual fun createEncoder(): Base64Encoder = JsBase64Encoder
}
object JsBase64Encoder : Base64Encoder {
override fun encode(src: ByteArray): ByteArray {
val string = src.decodeToString()
val encodedString = window.btoa(string)
return encodedString.encodeToByteArray()
}
}
```
### Native
Unfortunately, there is no third-party implementation available for all Kotlin/Native targets, so you need to write it yourself.
1. In the `nativeMain/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64.kt` file in the new package.
3. Provide your own implementation for the `Base64Factory` object:
```
package org.jetbrains.base64
private val BASE64_ALPHABET: String = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
private val BASE64_MASK: Byte = 0x3f
private val BASE64_PAD: Char = '='
private val BASE64_INVERSE_ALPHABET = IntArray(256) {
BASE64_ALPHABET.indexOf(it.toChar())
}
private fun Int.toBase64(): Char = BASE64_ALPHABET[this]
actual object Base64Factory {
actual fun createEncoder(): Base64Encoder = NativeBase64Encoder
}
object NativeBase64Encoder : Base64Encoder {
override fun encode(src: ByteArray): ByteArray {
fun ByteArray.getOrZero(index: Int): Int = if (index >= size) 0 else get(index).toInt()
// 4n / 3 is expected Base64 payload
val result = ArrayList<Byte>(4 * src.size / 3)
var index = 0
while (index < src.size) {
val symbolsLeft = src.size - index
val padSize = if (symbolsLeft >= 3) 0 else (3 - symbolsLeft) * 8 / 6
val chunk = (src.getOrZero(index) shl 16) or (src.getOrZero(index + 1) shl 8) or src.getOrZero(index + 2)
index += 3
for (i in 3 downTo padSize) {
val char = (chunk shr (6 * i)) and BASE64_MASK.toInt()
result.add(char.toBase64().code.toByte())
}
// Fill the pad with '='
repeat(padSize) { result.add(BASE64_PAD.code.toByte()) }
}
return result.toByteArray()
}
}
```
Test your library
-----------------
Now when you have `actual` implementations of the `Base64Factory` object for all platforms, it's time to test your multiplatform library.
To save time on testing, you can write common tests that will be executed on all platforms instead of testing each platform separately.
### Prerequisites
Before writing tests, add the `encodeToString` method with the default implementation to the `Base64Encoder` interface, which is defined in `commonMain/kotlin/org/jetbrains/base64/Base64.kt`. This implementation converts byte arrays to strings, which are much easier to test.
```
interface Base64Encoder {
fun encode(src: ByteArray): ByteArray
fun encodeToString(src: ByteArray): String {
val encoded = encode(src)
return buildString(encoded.size) {
encoded.forEach { append(it.toInt().toChar()) }
}
}
}
```
You can also provide a more efficient implementation of this method for a specific platform, for example, for JVM in `jvmMain/kotlin/org/jetbrains/base64/Base64.kt`:
```
object JvmBase64Encoder : Base64Encoder {
override fun encode(src: ByteArray): ByteArray = Base64.getEncoder().encode(src)
override fun encodeToString(src: ByteArray): String = Base64.getEncoder().encodeToString(src)
}
```
One of the benefits of a multiplatform library is having a default implementation with optional platform-specific overrides.
### Write common tests
Now you have a string-based API that you can cover with basic tests.
1. In the `commonTest/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64Test.kt` file in the new package.
3. Add tests to this file:
```
package org.jetbrains.base64
import kotlin.test.Test
import kotlin.test.assertEquals
class Base64Test {
@Test
fun testEncodeToString() {
checkEncodeToString("Kotlin is awesome", "S290bGluIGlzIGF3ZXNvbWU=")
}
@Test
fun testPaddedStrings() {
checkEncodeToString("", "")
checkEncodeToString("1", "MQ==")
checkEncodeToString("22", "MjI=")
checkEncodeToString("333", "MzMz")
checkEncodeToString("4444", "NDQ0NA==")
}
private fun checkEncodeToString(input: String, expectedOutput: String) {
assertEquals(expectedOutput, Base64Factory.createEncoder().encodeToString(input.asciiToByteArray()))
}
private fun String.asciiToByteArray() = ByteArray(length) {
get(it).code.toByte()
}
}
```
4. In the Terminal, execute the `check` Gradle task:
```
./gradlew check
```
The tests will run on all platforms (JVM, JS, and Native).
### Add platform-specific tests
You can also add tests that will be run only for a specific platform. For example, you can add UTF-16 tests on JVM:
1. In the `jvmTest/kotlin` directory, create the `org.jetbrains.base64` package.
2. Create the `Base64Test.kt` file in the new package.
3. Add tests to this file:
```
package org.jetbrains.base64
import kotlin.test.Test
import kotlin.test.assertEquals
class Base64JvmTest {
@Test
fun testNonAsciiString() {
val utf8String = "Gödel"
val actual = Base64Factory.createEncoder().encodeToString(utf8String.toByteArray())
assertEquals("R8O2ZGVs", actual)
}
}
```
This test will automatically run on the JVM platform in addition to the common tests.
Publish your library to the local Maven repository
--------------------------------------------------
Your multiplatform library is ready for publishing so that you can use it in other projects.
To publish your library, use the [`maven-publish` Gradle plugin](https://docs.gradle.org/current/userguide/publishing_maven.html).
1. In the `build.gradle.kts` file, apply the `maven-publish` plugin and specify the group and version of your library:
```
plugins {
kotlin("multiplatform") version "1.8.0"
id("maven-publish")
}
group = "org.jetbrains.base64"
version = "1.0.0"
```
2. In the Terminal, run the `publishToMavenLocal` Gradle task to publish your library to your local Maven repository:
```
./gradlew publishToMavenLocal
```
Your library will be published to the local Maven repository.
Publish your library to the external Maven Central repository
-------------------------------------------------------------
You can go public and release your multiplatform library to [Maven Central](https://search.maven.org/), a remote repository where maven artifacts are stored and managed. This way, other developers will be able to find it and add as a dependency to their projects.
### Register a Sonatype account and generate GPG keys
If this is your first library, or you used the sunset Bintray to do this before, you need first to register a Sonatype account.
You can use the GetStream article to create and set up your account. The [Registering a Sonatype account](https://getstream.io/blog/publishing-libraries-to-mavencentral-2021/#registering-a-sonatype-account) section describes how to:
1. Register a [Sonatype Jira account](https://issues.sonatype.org/secure/Signup!default.jspa).
2. Create a new issue. You can use [our issue](https://issues.sonatype.org/browse/OSSRH-65092) as an example.
3. Verify your domain ownership corresponding to the group ID you want to use to publish your artifacts.
Then, since artifacts published on Maven Central have to be signed, follow the [Generating a GPG key pair](https://getstream.io/blog/publishing-libraries-to-mavencentral-2021/#generating-a-gpg-key-pair) section to:
1. Generate a GPG key pair for signing your artifacts.
2. Publish your public key.
3. Export your private key.
When the Maven repository and signing keys for your library are ready, you can move on and set up your build to upload the library artifacts to a staging repository and then release them.
### Set up publication
Now you need to instruct Gradle how to publish the library. Most of the work is already done by the `maven-publish` and Kotlin Gradle plugins, all the required publications are created automatically. You already know the result when the library is published to a local Maven repository. To publish it to Maven Central, you need to take additional steps:
1. Configure the public Maven repository URL and credentials.
2. Provide a description and `javadocs` for all library components.
3. Sign publications.
You can handle all these tasks with Gradle scripts. Let's extract all the publication-related logic from the library module `build.script`, so you can easily reuse it for other modules in the future.
The most idiomatic and flexible way to do that is to use Gradle's [precompiled script plugins](https://docs.gradle.org/current/userguide/custom_plugins.html#sec:precompiled_plugins). All the build logic will be provided as a precompiled script plugin and could be applied by plugin ID to every module of our library.
To implement this, move the publication logic to a separate Gradle project:
1. Add a new Gradle project inside your library root project. For that, create a new folder named `convention-plugins` with `src/build.gradle.kts` in it.
2. Update this `build.gradle.kts` file with the following code:
```
plugins {
"kotlin-dsl" // Is needed to turn our build logic written in Kotlin into the Gradle Plugin
}
repositories {
gradlePluginPortal() // To use 'maven-publish' and 'signing' plugins in our own plugin
}
```
3. In the `convention-plugins/src` directory, create a `main/kotlin/convention.publication.gradle.kts` file to store all the publication logic.
4. Add all the required logic in the new file:
import org.gradle.api.publish.maven.MavenPublication import org.gradle.api.tasks.bundling.Jar import org.gradle.kotlin.dsl.`maven-publish` import org.gradle.kotlin.dsl.signing import java.util.\* plugins { 'maven-publish' signing } // Stub secrets to let the project sync and build without the publication values set up ext["signing.keyId"] = null ext["signing.password"] = null ext["signing.secretKeyRingFile"] = null ext["ossrhUsername"] = null ext["ossrhPassword"] = null // Grabbing secrets from local.properties file or from environment variables, which could be used on CI val secretPropsFile = project.rootProject.file("local.properties") if (secretPropsFile.exists()) { secretPropsFile.reader().use { Properties().apply { load(it) } }.onEach { (name, value) -> ext[name.toString()] = value } } else { ext["signing.keyId"] = System.getenv("SIGNING\_KEY\_ID") ext["signing.password"] = System.getenv("SIGNING\_PASSWORD") ext["signing.secretKeyRingFile"] = System.getenv("SIGNING\_SECRET\_KEY\_RING\_FILE") ext["ossrhUsername"] = System.getenv("OSSRH\_USERNAME") ext["ossrhPassword"] = System.getenv("OSSRH\_PASSWORD") } val javadocJar by tasks.registering(Jar::class) { archiveClassifier.set("javadoc") } fun getExtraString(name: String) = ext[name]?.toString() publishing { // Configure maven central repository repositories { maven { name = "sonatype" setUrl("https://s01.oss.sonatype.org/service/local/staging/deploy/maven2/") credentials { username = getExtraString("ossrhUsername") password = getExtraString("ossrhPassword") } } } // Configure all publications publications.withType<MavenPublication> { // Stub javadoc.jar artifact artifact(javadocJar.get()) // Provide artifacts information requited by Maven Central pom { name.set("MPP Sample library") description.set("Sample Kotlin Multiplatform library (jvm + ios + js) test") url.set("https://github.com/<your-github-repo>/mpp-sample-lib") licenses { license { name.set("MIT") url.set("https://opensource.org/licenses/MIT") } } developers { developer { id.set("<your-github-profile>") name.set("<your-name>") email.set("<your-email>") } } scm { url.set("https://github.com/<your-github-repo>/mpp-sample-lib") } } } } // Signing artifacts. Signing.\* extra properties values will be used signing { sign(publishing.publications) }
Applying just `maven-publish` is enough for publishing to the local Maven repository, but not to Maven Central. In the provided script, you get the credentials from `local.properties` or environment variables, do all the required configuration in the `publishing` section, and sign your publications with the signing plugin.
5. Go back to your library project. To ask Gradle to prebuild your plugins, update the root `settings.gradle.kts` with the following:
```
rootProject.name = "multiplatform-lib" // your project name
includeBuild("convention-plugins")
```
6. Now, you can apply this logic in the library's `build.script`. In the `plugins` section, replace `maven-publish` with `conventional.publication`:
```
plugins {
kotlin("multiplatform") version "1.8.0"
id("convention.publication")
}
```
7. Create a `local.properties` file with all the necessary credentials and make sure to add it to your `.gitignore`:
```
# The GPG key pair ID (last 8 digits of its fingerprint)
signing.keyId=...
# The passphrase of the key pair
signing.password=...
# Private key you exported earlier
signing.secretKeyRingFile=...
# Your credentials for the Jira account
ossrhUsername=...
ossrhPassword=...
```
8. Run `./gradlew clean` and sync the project.
New Gradle tasks related to the Sonatype repository should appear in the publishing group – that means that everything is ready for you to publish your library.
### Publish your library to Maven Central
To upload your library to the Sonatype repository, run the following program:
```
./gradlew publishAllPublicationsToSonatypeRepository
```
The staging repository will be created, and all the artifacts for all publications will be uploaded to that repository. All it's left to do is to check that all the artifacts you wanted to upload have made it there and to press the release button.
These steps are described in the [Your first release](https://getstream.io/blog/publishing-libraries-to-mavencentral-2021/#your-first-release) section. In short, you need to:
1. Go to <https://s01.oss.sonatype.org> and log in using your credentials in Sonatype Jira.
2. Find your repository in the **Staging repositories** section.
3. Close it.
4. Release the library.
5. To activate the sync to Maven Central, go back to the Jira issue you created and leave a comment saying that you've released your first component. This step is only needed if it's your first release.
Soon your library will be available at <https://repo1.maven.org/maven2>, and other developers will be able to add it as a dependency. In a couple of hours, other developers will be able to find it using [Maven Central Repository Search](https://search.maven.org/).
Add a dependency on the published library
-----------------------------------------
You can add your library to other multiplatform projects as a dependency.
In the `build.gradle.kts` file, add `mavenLocal()` or `MavenCentral()` (if the library was published to the external repository) and add a dependency on your library:
```
repositories {
mavenCentral()
mavenLocal()
}
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("org.jetbrains.base64:multiplatform-lib:1.0.0")
}
}
}
}
```
The `implementation` dependency consists of:
* The group ID and version — specified earlier in the `build.gradle.kts` file
* The artifact ID — by default, it's your project's name specified in the `settings.gradle.kts` file
For more details, see the [Gradle documentation](https://docs.gradle.org/current/userguide/publishing_maven.html) on the `maven-publish` plugin.
What's next?
------------
* Learn more about [publishing multiplatform libraries](multiplatform-publish-lib).
* Learn more about [Kotlin Multiplatform](multiplatform-get-started).
* [Create your first cross-platform mobile application – tutorial](multiplatform-mobile-create-first-app).
* [Build a full-stack web app with Kotlin Multiplatform – tutorial](multiplatform-full-stack-app).
Last modified: 10 January 2023
[Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) [Publishing multiplatform libraries](multiplatform-publish-lib)
| programming_docs |
kotlin Get started with Kotlin/JS for React Get started with Kotlin/JS for React
====================================
This tutorial demonstrates how to use IntelliJ IDEA for creating a frontend application with Kotlin/JS for React.
To get started, install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
Create an application
---------------------
Once you've installed IntelliJ IDEA, it's time to create your first frontend application based on Kotlin/JS with React.
1. In IntelliJ IDEA, select **File** | **New** | **Project**.
2. In the panel on the left, select **Kotlin Multiplatform**.
3. Enter a project name, select **React Application** as the project template, and click **Next**.
By default, your project will use Gradle with Kotlin DSL as the build system.
4. Accept the default configuration on the next screen and click **Finish**. Your project will open.

5. Open the `build.gradle.kts` file, the build script created by default based on your configuration. It includes the [`kotlin("js")` plugin and dependencies](js-project-setup) required for your frontend application. Ensure that you use the latest version of the plugin:
```
plugins {
kotlin("js") version "1.8.0"
}
```
Run the application
-------------------
Start the application by clicking **Run** next to the run configuration at the top of the screen.
Your default web browser opens the URL <http://localhost:8080/> with your frontend application.
Enter your name in the text box and accept the greetings from your application!
Update the application
----------------------
### Show your name backwards
1. Open the file `Welcome.kt` in `src/main/kotlin`.
The `src` directory contains Kotlin source files and resources. The file `Welcome.kt` includes sample code that renders the web page you've just seen.

2. Change the code of `div` to show your name backwards.
* Use the standard library function `reversed()` to reverse your name.
* Use a [string template](strings#string-templates) for your reversed name by adding a dollar sign `$` and enclosing it in curly braces – `${state.name.reversed()}`.
```
div {
css {
padding = 5.px
backgroundColor = rgb(8, 97, 22)
color = rgb(56, 246, 137)
}
+"Hello, $name"
+" Your name backwards is ${name.reversed()}!"
}
```
3. Save your changes to the file.
4. Go to the browser and enjoy the result.
You will see the changes only if your previous application is still running. If you've stopped your application, [run it again](#run-the-application).
### Add an image
1. Open the file `Welcome.kt` in `src/main/kotlin`.
2. Add a `div` container with a child image element `img` after the `input` block.
```
div {
img {
src = "https://placekitten.com/408/287"
}
}
```
3. Save your changes to the file.
4. Go to the browser and enjoy the result.
You will only see the changes if your previous application is still running. If you've stopped your application, [run it again](#run-the-application).
### Add a button that changes text
1. Open the file `Welcome.kt` in `src/main/kotlin`.
2. Add a `button` element with an `onClick` event handler.
```
button {
onClick = {
name = "Some name"
}
+"Change name"
}
```
3. Save your changes to the file.
4. Go to the browser and enjoy the result.
You will only see the changes if your previous application is still running. If you've stopped your application, [run it again](#run-the-application).
What's next?
------------
Once you have created your first application, you can complete long-form Kotlin/JS tutorials or check out the list of Kotlin/JS sample projects for inspiration. Both types of resources contain useful snippets and patterns and can serve as a nice jump-off point for your own projects.
### Tutorials
* [Build a web application with React and Kotlin/JS — tutorial](js-react) guides you through the process of building a simple web application using the React framework, shows how a type-safe Kotlin DSL for HTML makes it easy to build reactive DOM elements, and illustrates how to use third-party React components and obtain information from APIs, all while writing the whole application logic in pure Kotlin/JS.
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) teaches the concepts behind building an application that targets Kotlin/JVM and Kotlin/JS by building a client-server application that makes use of shared code, serialization, and other multiplatform paradigms. It also provides a brief introduction to working with Ktor both as a server- and client-side framework.
### Sample projects
* [Full-stack Spring collaborative to-do list](https://github.com/Kotlin/full-stack-spring-collaborative-todo-list-sample) shows how to create a to-do list for collaborative work using `kotlin-multiplatform` with JS and JVM targets, Spring for the backend, Kotlin/JS with React for the frontend, and RSocket.
* [Kotlin/JS and React Redux to-do list](https://github.com/Kotlin/react-redux-js-ir-todo-list-sample) implements the React Redux to-do list using JS libraries (`react`, `react-dom`, `react-router`, `redux`, and `react-redux`) from npm and Webpack to bundle, minify, and run the project.
* [Full-stack demo application](https://github.com/Kotlin/full-stack-web-jetbrains-night-sample) guides you through the process of building an app with a feed containing user-generated posts and comments. All data is stubbed by the fakeJSON and JSON Placeholder services.
Last modified: 10 January 2023
[Nullability in Java and Kotlin](java-to-kotlin-nullability-guide) [Set up a Kotlin/JS project](js-project-setup)
kotlin Adding Android dependencies Adding Android dependencies
===========================
The workflow for adding Android-specific dependencies to a Kotlin Multiplatform module is the same as it is for pure Android projects: declare the dependency in your Gradle file and import the project. After that, you can use this dependency in your Kotlin code.
We recommend declaring Android dependencies in Multiplatform Mobile projects by adding them to a specific Android source set. For that, update your `build.gradle(.kts)` file in the `shared` directory of your project:
```
sourceSets["androidMain"].dependencies {
implementation("com.example.android:app-magic:12.3")
}
```
```
sourceSets {
androidMain {
dependencies {
implementation 'com.example.android:app-magic:12.3'
}
}
}
```
Moving what was a top-level dependency in an Android project to a specific source set in a Multiplatform Mobile project might be difficult if the top-level dependency had a non-trivial configuration name. For example, to move a `debugImplementation` dependency from the top level of an Android project, you'll need to add an implementation dependency to the source set named `androidDebug`. To minimize the effort you have to put in to deal with migration problems like this, you can add a `dependencies` block inside the `android` block:
```
android {
//...
dependencies {
implementation("com.example.android:app-magic:12.3")
}
}
```
```
android {
//...
dependencies {
implementation 'com.example.android:app-magic:12.3'
}
}
```
Dependencies declared here will be treated exactly the same as dependencies from the top-level block, but declaring them this way will also separate Android dependencies visually in your build script and make it less confusing.
Putting dependencies into a standalone `dependencies` block at the end of the script, in a way that is idiomatic to Android projects, is also supported. However, we strongly recommend **against** doing this because configuring a build script with Android dependencies in the top-level block and other target dependencies in each source set is likely to cause confusion.
What's next?
------------
Check out other resources on adding dependencies in multiplatform projects and learn more about:
* [Adding dependencies in the official Android documentation](https://developer.android.com/studio/build/dependencies)
* [Adding dependencies on multiplatform libraries or other multiplatform projects](multiplatform-add-dependencies)
* [Adding iOS dependencies](multiplatform-mobile-ios-dependencies)
Last modified: 10 January 2023
[Adding dependencies on multiplatform libraries](multiplatform-add-dependencies) [Adding iOS dependencies](multiplatform-mobile-ios-dependencies)
kotlin Add dependencies to your project Add dependencies to your project
================================
You've already created your first cross-platform Kotlin Multiplatform Mobile project! Now let's learn how to add dependencies to third-party libraries, which is necessary for building successful cross-platform applications.
Dependency types
----------------
There are two types of dependencies that you can use in Multiplatform Mobile projects:
* *Multiplatform dependencies*. These are multiplatform libraries that support multiple targets and can be used in the common source set, `commonMain`.
Many modern Android libraries already have multiplatform support, like [Koin](https://insert-koin.io/), [Apollo](https://www.apollographql.com/), and [Okio](https://square.github.io/okio/).
* *Native dependencies*. These are regular libraries from relevant ecosystems. You usually work with them in native iOS projects using CocoaPods or another dependency manager and in Android projects using Gradle.
When you work with a shared module, you can also depend on native dependencies and use them in the native source sets, `androidMain` and `iosMain`. Typically, you'll need these dependencies when you want to work with platform APIs, for example security storage, and there is common logic.
For both types of dependencies, you can use local and external repositories.
Add a multiplatform dependency
------------------------------
Let's now go back to the app and make the greeting a little more festive. In addition to the device information, add a function to display the number of days left until New Year's Day. The `kotlinx-datetime` library, which has full multiplatform support, is the most convenient way to work with dates in your shared code.
1. Navigate to the `build.gradle.kts` file in the `shared` directory.
2. Add the following dependency to the `commonMain` source set dependencies:
```
kotlin {
sourceSets {
val commonMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-datetime:0.4.0")
}
}
}
}
```
3. Synchronize the Gradle files by clicking **Sync Now** in the notification.

4. In `shared/src/commonMain/kotlin`, create a new file `NewYear.kt` and update it with a short function that calculates the number of days from today until the new year using the `date-time` date arithmetic:
```
import kotlinx.datetime.*
fun daysUntilNewYear(): Int {
val today = Clock.System.todayIn(TimeZone.currentSystemDefault())
val closestNewYear = LocalDate(today.year + 1, 1, 1)
return today.daysUntil(closestNewYear)
}
```
5. In `Greeting.kt`, update the `greeting()` function to see the result:
```
class Greeting {
private val platform: Platform = getPlatform()
fun greeting(): String {
return "Guess what it is! > ${platform.name.reversed()}!" +
"\nThere are only ${daysUntilNewYear()} days left until New Year! 🎆"
}
}
```
6. To see the results, re-run your **androidApp** and **iosApp** configurations from Android Studio:
Next step
---------
In the next part of the tutorial, you'll add more dependencies and more complex logic to your project.
**[Proceed to the next part](multiplatform-mobile-upgrade-app)**
### See also
* Discover how to work with multiplatform dependencies of all kinds: [Kotlin libraries, Kotlin Multiplatform libraries, and other multiplatform projects](multiplatform-add-dependencies).
* Learn how to [add Android dependencies](multiplatform-mobile-android-dependencies) and [iOS dependencies with or without CocoaPods](multiplatform-mobile-ios-dependencies) for use in platform-specific source sets.
* Check out the examples of [how to use Android and iOS libraries](multiplatform-mobile-samples) in sample projects (be sure to check the Platform APIs column).
Get help
--------
* **Kotlin Slack**. Get an [invite](https://surveys.jetbrains.com/s3/kotlin-slack-sign-up) and join the [#multiplatform](https://kotlinlang.slack.com/archives/C3PQML5NU) channel.
* **Kotlin issue tracker**. [Report a new issue](https://youtrack.jetbrains.com/newIssue?project=KT).
Last modified: 10 January 2023
[Create your first cross-platform app](multiplatform-mobile-create-first-app) [Upgrade your app](multiplatform-mobile-upgrade-app)
kotlin Kotlin/Native memory management Kotlin/Native memory management
===============================
Kotlin/Native uses a modern memory manager that is similar to JVM, Go, and other mainstream technologies:
* Objects are stored in a shared heap and can be accessed from any thread.
* Tracing garbage collector (GC) is executed periodically to collect objects that are not reachable from the "roots", like local and global variables.
The memory manager is the same across all the Kotlin/Native targets, except for wasm32, which is only supported in the [legacy memory manager](#legacy-memory-manager).
Garbage collector
-----------------
The exact algorithm of GC is constantly evolving. As of 1.7.20, it is the Stop-the-World Mark and Concurrent Sweep collector that does not separate heap into generations.
GC is executed on a separate thread and kicked off based on the timer and memory pressure heuristics, or can be [called manually](#enable-garbage-collection-manually).
### Enable garbage collection manually
To force start garbage collector, call `kotlin.native.internal.GC.collect()`. It triggers a new collection and waits for its completion.
### Monitor GC performance
There are no special instruments to monitor the GC performance yet. However, it's still possible to look through GC logs for diagnosis. To enable logging, set the following compilation flag in the Gradle build script:
```
-Xruntime-logs=gc=info
```
Currently, the logs are only printed to `stderr`.
### Disable garbage collection
It's recommended to keep GC enabled. However, you can disable it in certain cases, for example, for testing purposes or if you encounter issues and have a short-lived program. To do that, set the following compilation flag in the Gradle build script:
```
-Xgc=noop
```
Memory consumption
------------------
If there are no memory leaks in the program, but you still see unexpectedly high memory consumption, try updating Kotlin to the latest version. We're constantly improving the memory manager, so even a simple compiler update might improve memory consumption.
Another way to fix high memory consumption is related to [`mimalloc`](https://github.com/microsoft/mimalloc), the default memory allocator for many targets. It pre-allocates and holds onto the system memory to improve the allocation speed.
To avoid that at the cost of performance, a couple of options are available:
* Switch the memory allocator from `mimalloc` to the system allocator. For that, set the `-Xallocator=std` compilation option in your Gradle build script.
* Since Kotlin 1.8.0-Beta, you can also instruct `mimalloc` to promptly release memory back to the system. It's a smaller performance cost, but it gives less definitive results.
For that, enable the following binary option in your `gradle.properties` file:
```
kotlin.native.binary.mimallocUseCompaction=true
```
If none of these options improved the memory consumption, report an issue in [YouTrack](https://youtrack.jetbrains.com/newissue?project=kt).
Unit tests in the background
----------------------------
In unit tests, nothing processes the main thread queue, so don't use `Dispatchers.Main` unless it was mocked, which can be done by calling `Dispatchers.setMain` from `kotlinx-coroutines-test`.
If you don't rely on `kotlinx.coroutines` or `Dispatchers.setMain` doesn't work for you for some reason, try the following workaround for implementing the test launcher:
package testlauncher import platform.CoreFoundation.\* import kotlin.native.concurrent.\* import kotlin.native.internal.test.\* import kotlin.system.\* fun mainBackground(args: Array<String>) { val worker = Worker.start(name = "main-background") worker.execute(TransferMode.SAFE, { args.freeze() }) { val result = testLauncherEntryPoint(it) exitProcess(result) } CFRunLoopRun() error("CFRunLoopRun should never return") }
Then, compile the test binary with the `-e testlauncher.mainBackground` compiler flag.
Legacy memory manager
---------------------
If it's necessary, you can switch back to the legacy memory manager. Set the following option in your `gradle.properties`:
```
kotlin.native.binary.memoryModel=strict
```
If you encounter issues with migrating from the legacy memory manager, or you want to temporarily support both the current and legacy memory managers, see our recommendations in the [migration guide](native-migration-guide).
What's next
-----------
* [Migrate from the legacy memory manager](native-migration-guide)
* [Configure integration with iOS](native-ios-integration)
Last modified: 10 January 2023
[Kotlin/Native as a dynamic library – tutorial](native-dynamic-libraries) [iOS integration](native-ios-integration)
kotlin All-open compiler plugin All-open compiler plugin
========================
Kotlin has classes and their members `final` by default, which makes it inconvenient to use frameworks and libraries such as Spring AOP that require classes to be `open`. The *all-open* compiler plugin adapts Kotlin to the requirements of those frameworks and makes classes annotated with a specific annotation and their members open without the explicit `open` keyword.
For instance, when you use Spring, you don't need all the classes to be open, but only classes annotated with specific annotations like `@Configuration` or `@Service`. *All-open* allows to specify such annotations.
We provide *all-open* plugin support both for Gradle and Maven with the complete IDE integration.
Gradle
------
Add the plugin artifact to the build script dependencies and apply the plugin:
```
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-allopen:$kotlin_version"
}
}
apply plugin: "kotlin-allopen"
```
As an alternative, you can enable it using the `plugins` block:
```
plugins {
id "org.jetbrains.kotlin.plugin.allopen" version "1.8.0"
}
```
Then specify the list of annotations that will make classes open:
```
allOpen {
annotation("com.my.Annotation")
// annotations("com.another.Annotation", "com.third.Annotation")
}
```
If the class (or any of its superclasses) is annotated with `com.my.Annotation`, the class itself and all its members will become open.
It also works with meta-annotations:
```
@com.my.Annotation
annotation class MyFrameworkAnnotation
@MyFrameworkAnnotation
class MyClass // will be all-open
```
`MyFrameworkAnnotation` is annotated with the all-open meta-annotation `com.my.Annotation`, so it becomes an all-open annotation as well.
Maven
-----
Here's how to use all-open with Maven:
```
<plugin>
<artifactId>kotlin-maven-plugin</artifactId>
<groupId>org.jetbrains.kotlin</groupId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<!-- Or "spring" for the Spring support -->
<plugin>all-open</plugin>
</compilerPlugins>
<pluginOptions>
<!-- Each annotation is placed on its own line -->
<option>all-open:annotation=com.my.Annotation</option>
<option>all-open:annotation=com.their.AnotherAnnotation</option>
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-allopen</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
```
Please refer to the [Gradle](#gradle) section for the detailed information about how all-open annotations work.
Spring support
--------------
If you use Spring, you can enable the *kotlin-spring* compiler plugin instead of specifying Spring annotations manually. The kotlin-spring is a wrapper on top of all-open, and it behaves exactly the same way.
As with all-open, add the plugin to the build script dependencies:
```
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-allopen:$kotlin_version"
}
}
apply plugin: "kotlin-spring" // instead of "kotlin-allopen"
```
Or using the Gradle plugins DSL:
```
plugins {
id "org.jetbrains.kotlin.plugin.spring" version "1.8.0"
}
```
In Maven, the `spring` plugin is provided by the `kotlin-maven-allopen` plugin dependency, so to enable it:
```
<compilerPlugins>
<plugin>spring</plugin>
</compilerPlugins>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-allopen</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
```
The plugin specifies the following annotations:
* [`@Component`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/stereotype/Component.html)
* [`@Async`](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/scheduling/annotation/Async.html)
* [`@Transactional`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/transaction/annotation/Transactional.html)
* [`@Cacheable`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/cache/annotation/Cacheable.html)
* [`@SpringBootTest`](https://docs.spring.io/spring-boot/docs/current/api/org/springframework/boot/test/context/SpringBootTest.html)
Thanks to meta-annotations support, classes annotated with [`@Configuration`](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/context/annotation/Configuration.html), [`@Controller`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/stereotype/Controller.html), [`@RestController`](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/web/bind/annotation/RestController.html), [`@Service`](https://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/stereotype/Service.html) or [`@Repository`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/stereotype/Repository.html) are automatically opened since these annotations are meta-annotated with [`@Component`](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/stereotype/Component.html).
Of course, you can use both `kotlin-allopen` and `kotlin-spring` in the same project.
Note that if you use the project template generated by the [start.spring.io](https://start.spring.io/#!language=kotlin) service, the `kotlin-spring` plugin will be enabled by default.
Command-line compiler
---------------------
All-open compiler plugin JAR is available in the binary distribution of the Kotlin compiler. You can attach the plugin by providing the path to its JAR file using the `Xplugin` kotlinc option:
```
-Xplugin=$KOTLIN_HOME/lib/allopen-compiler-plugin.jar
```
You can specify all-open annotations directly, using the `annotation` plugin option, or enable the "preset". The presets available now for all-open are `spring`, `micronaut`, and `quarkus`.
```
# The plugin option format is: "-P plugin:<plugin id>:<key>=<value>".
# Options can be repeated.
-P plugin:org.jetbrains.kotlin.allopen:annotation=com.my.Annotation
-P plugin:org.jetbrains.kotlin.allopen:preset=spring
```
Last modified: 10 January 2023
[Kotlin compiler options](compiler-reference) [No-arg compiler plugin](no-arg-plugin)
| programming_docs |
kotlin Properties Properties
==========
Declaring properties
--------------------
Properties in Kotlin classes can be declared either as mutable, using the `var` keyword, or as read-only, using the `val` keyword.
```
class Address {
var name: String = "Holmes, Sherlock"
var street: String = "Baker"
var city: String = "London"
var state: String? = null
var zip: String = "123456"
}
```
To use a property, simply refer to it by its name:
```
fun copyAddress(address: Address): Address {
val result = Address() // there's no 'new' keyword in Kotlin
result.name = address.name // accessors are called
result.street = address.street
// ...
return result
}
```
Getters and setters
-------------------
The full syntax for declaring a property is as follows:
```
var <propertyName>[: <PropertyType>] [= <property_initializer>]
[<getter>]
[<setter>]
```
The initializer, getter, and setter are optional. The property type is optional if it can be inferred from the initializer or the getter's return type, as shown below:
```
var initialized = 1 // has type Int, default getter and setter
// var allByDefault // ERROR: explicit initializer required, default getter and setter implied
```
The full syntax of a read-only property declaration differs from a mutable one in two ways: it starts with `val` instead of `var` and does not allow a setter:
```
val simple: Int? // has type Int, default getter, must be initialized in constructor
val inferredType = 1 // has type Int and a default getter
```
You can define custom accessors for a property. If you define a custom getter, it will be called every time you access the property (this way you can implement a computed property). Here's an example of a custom getter:
```
//sampleStart
class Rectangle(val width: Int, val height: Int) {
val area: Int // property type is optional since it can be inferred from the getter's return type
get() = this.width * this.height
}
//sampleEnd
fun main() {
val rectangle = Rectangle(3, 4)
println("Width=${rectangle.width}, height=${rectangle.height}, area=${rectangle.area}")
}
```
You can omit the property type if it can be inferred from the getter:
```
val area get() = this.width * this.height
```
If you define a custom setter, it will be called every time you assign a value to the property, except its initialization. A custom setter looks like this:
```
var stringRepresentation: String
get() = this.toString()
set(value) {
setDataFromString(value) // parses the string and assigns values to other properties
}
```
By convention, the name of the setter parameter is `value`, but you can choose a different name if you prefer.
If you need to annotate an accessor or change its visibility, but you don't need to change the default implementation, you can define the accessor without defining its body:
```
var setterVisibility: String = "abc"
private set // the setter is private and has the default implementation
var setterWithAnnotation: Any? = null
@Inject set // annotate the setter with Inject
```
### Backing fields
In Kotlin, a field is only used as a part of a property to hold its value in memory. Fields cannot be declared directly. However, when a property needs a backing field, Kotlin provides it automatically. This backing field can be referenced in the accessors using the `field` identifier:
```
var counter = 0 // the initializer assigns the backing field directly
set(value) {
if (value >= 0)
field = value
// counter = value // ERROR StackOverflow: Using actual name 'counter' would make setter recursive
}
```
The `field` identifier can only be used in the accessors of the property.
A backing field will be generated for a property if it uses the default implementation of at least one of the accessors, or if a custom accessor references it through the `field` identifier.
For example, there would be no backing field in the following case:
```
val isEmpty: Boolean
get() = this.size == 0
```
### Backing properties
If you want to do something that does not fit into this *implicit backing field* scheme, you can always fall back to having a *backing property*:
```
private var _table: Map<String, Int>? = null
public val table: Map<String, Int>
get() {
if (_table == null) {
_table = HashMap() // Type parameters are inferred
}
return _table ?: throw AssertionError("Set to null by another thread")
}
```
Compile-time constants
----------------------
If the value of a read-only property is known at compile time, mark it as a *compile time constant* using the `const` modifier. Such a property needs to fulfil the following requirements:
* It must be a top-level property, or a member of an [`object` declaration](object-declarations#object-declarations-overview) or a *[companion object](object-declarations#companion-objects)*.
* It must be initialized with a value of type `String` or a primitive type
* It cannot be a custom getter
The compiler will inline usages of the constant, replacing the reference to the constant with its actual value. However, the field will not be removed and therefore can be interacted with using <reflection>.
Such properties can also be used in annotations:
```
const val SUBSYSTEM_DEPRECATED: String = "This subsystem is deprecated"
@Deprecated(SUBSYSTEM_DEPRECATED) fun foo() { ... }
```
Late-initialized properties and variables
-----------------------------------------
Normally, properties declared as having a non-null type must be initialized in the constructor. However, it is often the case that doing so is not convenient. For example, properties can be initialized through dependency injection, or in the setup method of a unit test. In these cases, you cannot supply a non-null initializer in the constructor, but you still want to avoid null checks when referencing the property inside the body of a class.
To handle such cases, you can mark the property with the `lateinit` modifier:
```
public class MyTest {
lateinit var subject: TestSubject
@SetUp fun setup() {
subject = TestSubject()
}
@Test fun test() {
subject.method() // dereference directly
}
}
```
This modifier can be used on `var` properties declared inside the body of a class (not in the primary constructor, and only when the property does not have a custom getter or setter), as well as for top-level properties and local variables. The type of the property or variable must be non-null, and it must not be a primitive type.
Accessing a `lateinit` property before it has been initialized throws a special exception that clearly identifies the property being accessed and the fact that it hasn't been initialized.
### Checking whether a lateinit var is initialized
To check whether a `lateinit var` has already been initialized, use `.isInitialized` on the [reference to that property](reflection#property-references):
```
if (foo::bar.isInitialized) {
println(foo.bar)
}
```
This check is only available for properties that are lexically accessible when declared in the same type, in one of the outer types, or at top level in the same file.
Overriding properties
---------------------
See [Overriding properties](inheritance#overriding-properties)
Delegated properties
--------------------
The most common kind of property simply reads from (and maybe writes to) a backing field, but custom getters and setters allow you to use properties so one can implement any sort of behavior of a property. Somewhere in between the simplicity of the first kind and variety of the second, there are common patterns for what properties can do. A few examples: lazy values, reading from a map by a given key, accessing a database, notifying a listener on access.
Such common behaviors can be implemented as libraries using [delegated properties](delegated-properties).
Last modified: 10 January 2023
[Inheritance](inheritance) [Interfaces](interfaces)
kotlin Progress guarantees Progress guarantees
===================
Many concurrent algorithms provide non-blocking progress guarantees, such as lock-freedom and wait-freedom. As they are usually non-trivial, it's easy to add a bug that blocks the algorithm. Lincheck can help you find liveness bugs using the model checking strategy.
To check the progress guarantee of the algorithm, enable the `checkObstructionFreedom` option in `ModelCheckingOptions()`:
```
ModelCheckingOptions().checkObstructionFreedom()
```
For example, consider `ConcurrentHashMap<K, V>` from the Java standard library. Here is the Lincheck test to detect that `put(key: K, value: V)` is a blocking operation:
```
class ConcurrentHashMapTest {
private val map = ConcurrentHashMap<Int, Int>()
@Operation
public fun put(key: Int, value: Int) = map.put(key, value)
@Test
fun modelCheckingTest() = ModelCheckingOptions()
.actorsBefore(1) // To init the HashMap
.actorsPerThread(1)
.actorsAfter(0)
.minimizeFailedScenario(false)
.checkObstructionFreedom()
.check(this::class)
}
```
Run the `modelCheckingTest()`. You should get the following result:
```
= Obstruction-freedom is required but a lock has been found =
Execution scenario (init part):
[put(2, 6)]
Execution scenario (parallel part):
| put(-6, -8) | put(1, 4) |
= The following interleaving leads to the error =
Parallel part trace:
| | put(1, 4) |
| | put(1,4) at ConcurrentHashMapTest.put(ConcurrentMapTest.kt:34) |
| | putVal(1,4,false) at ConcurrentHashMap.put(ConcurrentHashMap.java:1006) |
| | table.READ: Node[]@1 at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1014) |
| | tabAt(Node[]@1,0): Node@1 at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1018) |
| | MONITORENTER at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1031) |
| | tabAt(Node[]@1,0): Node@1 at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1032) |
| | next.READ: null at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1046) |
| | switch |
| put(-6, -8) | |
| put(-6,-8) at ConcurrentHashMapTest.put(ConcurrentMapTest.kt:34) | |
| putVal(-6,-8,false) at ConcurrentHashMap.put(ConcurrentHashMap.java:1006) | |
| table.READ: Node[]@1 at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1014) | |
| tabAt(Node[]@1,0): Node@1 at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1018) | |
| MONITORENTER at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1031) | |
| | MONITOREXIT at ConcurrentHashMap.putVal(ConcurrentHashMap.java:1065) |
```
Now let's write a test for the non-blocking `ConcurrentSkipListMap<K, V>`, expecting the test to pass successfully:
```
class ConcurrentSkipListMapTest {
private val map = ConcurrentSkipListMap<Int, Int>()
@Operation
public fun put(key: Int, value: Int) = map.put(key, value)
@Test
fun modelCheckingTest() = ModelCheckingOptions()
.checkObstructionFreedom()
.check(this::class)
}
```
At the moment, Lincheck supports only the obstruction-freedom progress guarantees. However, most real-life liveness bugs add unexpected blocking code, so the obstruction-freedom check will also help with lock-free and wait-free algorithms.
Next step
---------
Learn how to [specify the sequential specification](sequential-specification) of the testing algorithm explicitly, improving the Lincheck tests robustness.
Last modified: 10 January 2023
[Data structure constraints](constraints) [Sequential specification](sequential-specification)
kotlin Mixing Java and Kotlin in one project – tutorial Mixing Java and Kotlin in one project – tutorial
================================================
Kotlin provides the first-class interoperability with Java, and modern IDEs make it even better. In this tutorial, you'll learn how to use both Kotlin and Java sources in the same project in IntelliJ IDEA. To learn how to start a new Kotlin project in IntelliJ IDEA, see [Getting started with IntelliJ IDEA](jvm-get-started).
Adding Java source code to an existing Kotlin project
-----------------------------------------------------
Adding Java classes to a Kotlin project is pretty straightforward. All you need to do is create a new Java file. Select a directory or a package inside your project and go to **File** | **New** | **Java Class** or use the **Alt + Insert**/**Cmd + N** shortcut.
If you already have the Java classes, you can just copy them to the project directories.
You can now consume the Java class from Kotlin or vice versa without any further actions.
For example, adding the following Java class:
```
public class Customer {
private String name;
public Customer(String s){
name = s;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void placeOrder() {
System.out.println("A new order is placed by " + name);
}
}
```
lets you call it from Kotlin like any other type in Kotlin.
```
val customer = Customer("Phase")
println(customer.name)
println(customer.placeOrder())
```
Adding Kotlin source code to an existing Java project
-----------------------------------------------------
Adding a Kotlin file to an existing Java project is pretty much the same.
If this is the first time you're adding a Kotlin file to this project, IntelliJ IDEA will automatically add the required Kotlin runtime.
You can also open the Kotlin runtime configuration manually from **Tools** | **Kotlin** | **Configure Kotlin in Project**.
Converting an existing Java file to Kotlin with J2K
---------------------------------------------------
The Kotlin plugin also bundles a Java to Kotlin converter (*J2K*) that automatically converts Java files to Kotlin. To use J2K on a file, click **Convert Java File to Kotlin File** in its context menu or in the **Code** menu of IntelliJ IDEA.
While the converter is not fool-proof, it does a pretty decent job of converting most boilerplate code from Java to Kotlin. Some manual tweaking however is sometimes required.
Last modified: 10 January 2023
[Test code using JUnit in JVM – tutorial](jvm-test-using-junit) [Using Java records in Kotlin](jvm-records)
kotlin Collection operations overview Collection operations overview
==============================
The Kotlin standard library offers a broad variety of functions for performing operations on collections. This includes simple operations, such as getting or adding elements, as well as more complex ones including search, sorting, filtering, transformations, and so on.
Extension and member functions
------------------------------
Collection operations are declared in the standard library in two ways: [member functions](classes#class-members) of collection interfaces and [extension functions](extensions#extension-functions).
Member functions define operations that are essential for a collection type. For example, [`Collection`](../api/latest/jvm/stdlib/kotlin.collections/-collection/index) contains the function [`isEmpty()`](../api/latest/jvm/stdlib/kotlin.collections/-collection/is-empty) for checking its emptiness; [`List`](../api/latest/jvm/stdlib/kotlin.collections/-list/index) contains [`get()`](../api/latest/jvm/stdlib/kotlin.collections/-list/get) for index access to elements, and so on.
When you create your own implementations of collection interfaces, you must implement their member functions. To make the creation of new implementations easier, use the skeletal implementations of collection interfaces from the standard library: [`AbstractCollection`](../api/latest/jvm/stdlib/kotlin.collections/-abstract-collection/index), [`AbstractList`](../api/latest/jvm/stdlib/kotlin.collections/-abstract-list/index), [`AbstractSet`](../api/latest/jvm/stdlib/kotlin.collections/-abstract-set/index), [`AbstractMap`](../api/latest/jvm/stdlib/kotlin.collections/-abstract-map/index), and their mutable counterparts.
Other collection operations are declared as extension functions. These are filtering, transformation, ordering, and other collection processing functions.
Common operations
-----------------
Common operations are available for both [read-only and mutable collections](collections-overview#collection-types). Common operations fall into these groups:
* [Transformations](collection-transformations)
* [Filtering](collection-filtering)
* [`plus` and `minus` operators](collection-plus-minus)
* [Grouping](collection-grouping)
* [Retrieving collection parts](collection-parts)
* [Retrieving single elements](collection-elements)
* [Ordering](collection-ordering)
* [Aggregate operations](collection-aggregate)
Operations described on these pages return their results without affecting the original collection. For example, a filtering operation produces a *new collection* that contains all the elements matching the filtering predicate. Results of such operations should be either stored in variables, or used in some other way, for example, passed in other functions.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
numbers.filter { it.length > 3 } // nothing happens with `numbers`, result is lost
println("numbers are still $numbers")
val longerThan3 = numbers.filter { it.length > 3 } // result is stored in `longerThan3`
println("numbers longer than 3 chars are $longerThan3")
//sampleEnd
}
```
For certain collection operations, there is an option to specify the *destination* object. Destination is a mutable collection to which the function appends its resulting items instead of returning them in a new object. For performing operations with destinations, there are separate functions with the `To` postfix in their names, for example, [`filterTo()`](../api/latest/jvm/stdlib/kotlin.collections/filter-to) instead of [`filter()`](../api/latest/jvm/stdlib/kotlin.collections/filter) or [`associateTo()`](../api/latest/jvm/stdlib/kotlin.collections/associate-to) instead of [`associate()`](../api/latest/jvm/stdlib/kotlin.collections/associate). These functions take the destination collection as an additional parameter.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val filterResults = mutableListOf<String>() //destination object
numbers.filterTo(filterResults) { it.length > 3 }
numbers.filterIndexedTo(filterResults) { index, _ -> index == 0 }
println(filterResults) // contains results of both operations
//sampleEnd
}
```
For convenience, these functions return the destination collection back, so you can create it right in the corresponding argument of the function call:
```
fun main() {
val numbers = listOf("one", "two", "three", "four")
//sampleStart
// filter numbers right into a new hash set,
// thus eliminating duplicates in the result
val result = numbers.mapTo(HashSet()) { it.length }
println("distinct item lengths are $result")
//sampleEnd
}
```
Functions with destination are available for filtering, association, grouping, flattening, and other operations. For the complete list of destination operations see the [Kotlin collections reference](../api/latest/jvm/stdlib/kotlin.collections/index).
Write operations
----------------
For mutable collections, there are also *write operations* that change the collection state. Such operations include adding, removing, and updating elements. Write operations are listed in the [Write operations](collection-write) and corresponding sections of [List-specific operations](list-operations#list-write-operations) and [Map specific operations](map-operations#map-write-operations).
For certain operations, there are pairs of functions for performing the same operation: one applies the operation in-place and the other returns the result as a separate collection. For example, [`sort()`](../api/latest/jvm/stdlib/kotlin.collections/sort) sorts a mutable collection in-place, so its state changes; [`sorted()`](../api/latest/jvm/stdlib/kotlin.collections/sorted) creates a new collection that contains the same elements in the sorted order.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four")
val sortedNumbers = numbers.sorted()
println(numbers == sortedNumbers) // false
numbers.sort()
println(numbers == sortedNumbers) // true
//sampleEnd
}
```
Last modified: 10 January 2023
[Sequences](sequences) [Collection transformation operations](collection-transformations)
| programming_docs |
kotlin Ordering Ordering
========
The order of elements is an important aspect of certain collection types. For example, two lists of the same elements are not equal if their elements are ordered differently.
In Kotlin, the orders of objects can be defined in several ways.
First, there is *natural* order. It is defined for implementations of the [`Comparable`](../api/latest/jvm/stdlib/kotlin/-comparable/index) interface. Natural order is used for sorting them when no other order is specified.
Most built-in types are comparable:
* Numeric types use the traditional numerical order: `1` is greater than `0`; `-3.4f` is greater than `-5f`, and so on.
* `Char` and `String` use the [lexicographical order](https://en.wikipedia.org/wiki/Lexicographical_order): `b` is greater than `a`; `world` is greater than `hello`.
To define a natural order for a user-defined type, make the type an implementer of `Comparable`. This requires implementing the `compareTo()` function. `compareTo()` must take another object of the same type as an argument and return an integer value showing which object is greater:
* Positive values show that the receiver object is greater.
* Negative values show that it's less than the argument.
* Zero shows that the objects are equal.
Below is a class for ordering versions that consist of the major and the minor part.
```
class Version(val major: Int, val minor: Int): Comparable<Version> {
override fun compareTo(other: Version): Int = when {
this.major != other.major -> this.major compareTo other.major // compareTo() in the infix form
this.minor != other.minor -> this.minor compareTo other.minor
else -> 0
}
}
fun main() {
println(Version(1, 2) > Version(1, 3))
println(Version(2, 0) > Version(1, 5))
}
```
*Custom* orders let you sort instances of any type in a way you like. Particularly, you can define an order for non-comparable objects or define an order other than natural for a comparable type. To define a custom order for a type, create a [`Comparator`](../api/latest/jvm/stdlib/kotlin/-comparator/index) for it. `Comparator` contains the `compare()` function: it takes two instances of a class and returns the integer result of the comparison between them. The result is interpreted in the same way as the result of a `compareTo()` as is described above.
```
fun main() {
//sampleStart
val lengthComparator = Comparator { str1: String, str2: String -> str1.length - str2.length }
println(listOf("aaa", "bb", "c").sortedWith(lengthComparator))
//sampleEnd
}
```
Having the `lengthComparator`, you are able to arrange strings by their length instead of the default lexicographical order.
A shorter way to define a `Comparator` is the [`compareBy()`](../api/latest/jvm/stdlib/kotlin.comparisons/compare-by) function from the standard library. `compareBy()` takes a lambda function that produces a `Comparable` value from an instance and defines the custom order as the natural order of the produced values.
With `compareBy()`, the length comparator from the example above looks like this:
```
fun main() {
//sampleStart
println(listOf("aaa", "bb", "c").sortedWith(compareBy { it.length }))
//sampleEnd
}
```
The Kotlin collections package provides functions for sorting collections in natural, custom, and even random orders. On this page, we'll describe sorting functions that apply to [read-only](collections-overview#collection-types) collections. These functions return their result as a new collection containing the elements of the original collection in the requested order. To learn about functions for sorting [mutable](collections-overview#collection-types) collections in place, see the [List-specific operations](list-operations#sort).
Natural order
-------------
The basic functions [`sorted()`](../api/latest/jvm/stdlib/kotlin.collections/sorted) and [`sortedDescending()`](../api/latest/jvm/stdlib/kotlin.collections/sorted-descending) return elements of a collection sorted into ascending and descending sequence according to their natural order. These functions apply to collections of `Comparable` elements.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println("Sorted ascending: ${numbers.sorted()}")
println("Sorted descending: ${numbers.sortedDescending()}")
//sampleEnd
}
```
Custom orders
-------------
For sorting in custom orders or sorting non-comparable objects, there are the functions [`sortedBy()`](../api/latest/jvm/stdlib/kotlin.collections/sorted-by) and [`sortedByDescending()`](../api/latest/jvm/stdlib/kotlin.collections/sorted-by-descending). They take a selector function that maps collection elements to `Comparable` values and sort the collection in natural order of that values.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val sortedNumbers = numbers.sortedBy { it.length }
println("Sorted by length ascending: $sortedNumbers")
val sortedByLast = numbers.sortedByDescending { it.last() }
println("Sorted by the last letter descending: $sortedByLast")
//sampleEnd
}
```
To define a custom order for the collection sorting, you can provide your own `Comparator`. To do this, call the [`sortedWith()`](../api/latest/jvm/stdlib/kotlin.collections/sorted-with) function passing in your `Comparator`. With this function, sorting strings by their length looks like this:
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println("Sorted by length ascending: ${numbers.sortedWith(compareBy { it.length })}")
//sampleEnd
}
```
Reverse order
-------------
You can retrieve the collection in the reversed order using the [`reversed()`](../api/latest/jvm/stdlib/kotlin.collections/reversed) function.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.reversed())
//sampleEnd
}
```
`reversed()` returns a new collection with the copies of the elements. So, if you change the original collection later, this won't affect the previously obtained results of `reversed()`.
Another reversing function - [`asReversed()`](../api/latest/jvm/stdlib/kotlin.collections/as-reversed)
* returns a reversed view of the same collection instance, so it may be more lightweight and preferable than `reversed()` if the original list is not going to change.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(reversedNumbers)
//sampleEnd
}
```
If the original list is mutable, all its changes reflect in its reversed views and vice versa.
```
fun main() {
//sampleStart
val numbers = mutableListOf("one", "two", "three", "four")
val reversedNumbers = numbers.asReversed()
println(reversedNumbers)
numbers.add("five")
println(reversedNumbers)
//sampleEnd
}
```
However, if the mutability of the list is unknown or the source is not a list at all, `reversed()` is more preferable since its result is a copy that won't change in the future.
Random order
------------
Finally, there is a function that returns a new `List` containing the collection elements in a random order - [`shuffled()`](../api/latest/jvm/stdlib/kotlin.collections/shuffled). You can call it without arguments or with a [`Random`](../api/latest/jvm/stdlib/kotlin.random/-random/index) object.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.shuffled())
//sampleEnd
}
```
Last modified: 10 January 2023
[Retrieve single elements](collection-elements) [Aggregate operations](collection-aggregate)
kotlin Running KSP from command line Running KSP from command line
=============================
KSP is a Kotlin compiler plugin and needs to run with Kotlin compiler. Download and extract them.
```
#!/bin/bash
# Kotlin compiler
wget https://github.com/JetBrains/kotlin/releases/download/v1.8.0/kotlin-compiler-1.8.0.zip
unzip kotlin-compiler-1.8.0.zip
# KSP
wget https://github.com/google/ksp/releases/download/1.8.0-1.0.8/artifacts.zip
unzip artifacts.zip
```
To run KSP with `kotlinc`, pass the `-Xplugin` option to `kotlinc`.
`-Xplugin=/path/to/symbol-processing-cmdline-1.8.0-1.0.8.jar`
This is different from the `symbol-processing-1.8.0-1.0.8.jar`, which is designed to be used with `kotlin-compiler-embeddable` when running with Gradle. The command line `kotlinc` needs `symbol-processing-cmdline-1.8.0-1.0.8.jar`.
You'll also need the API jar.
`-Xplugin=/path/to/symbol-processing-api-1.8.0-1.0.8.jar`
See the complete example:
```
#!/bin/bash
KSP_PLUGIN_ID=com.google.devtools.ksp.symbol-processing
KSP_PLUGIN_OPT=plugin:$KSP_PLUGIN_ID
KSP_PLUGIN_JAR=./com/google/devtools/ksp/symbol-processing-cmdline/1.8.0-1.0.8/symbol-processing-cmdline-1.8.0-1.0.8.jar
KSP_API_JAR=./com/google/devtools/ksp/symbol-processing-api/1.8.0-1.0.8/symbol-processing-api-1.8.0-1.0.8.jar
KOTLINC=./kotlinc/bin/kotlinc
AP=/path/to/your-processor.jar
mkdir out
$KOTLINC \
-Xplugin=$KSP_PLUGIN_JAR \
-Xplugin=$KSP_API_JAR \
-Xallow-no-source-files \
-P $KSP_PLUGIN_OPT:apclasspath=$AP \
-P $KSP_PLUGIN_OPT:projectBaseDir=. \
-P $KSP_PLUGIN_OPT:classOutputDir=./out \
-P $KSP_PLUGIN_OPT:javaOutputDir=./out \
-P $KSP_PLUGIN_OPT:kotlinOutputDir=./out \
-P $KSP_PLUGIN_OPT:resourceOutputDir=./out \
-P $KSP_PLUGIN_OPT:kspOutputDir=./out \
-P $KSP_PLUGIN_OPT:cachesDir=./out \
-P $KSP_PLUGIN_OPT:incremental=false \
-P $KSP_PLUGIN_OPT:apoption=key1=value1 \
-P $KSP_PLUGIN_OPT:apoption=key2=value2 \
$*
```
Last modified: 10 January 2023
[KSP with Kotlin Multiplatform](ksp-multiplatform) [FAQ](ksp-faq)
kotlin Dynamic type Dynamic type
============
Being a statically typed language, Kotlin still has to interoperate with untyped or loosely typed environments, such as the JavaScript ecosystem. To facilitate these use cases, the `dynamic` type is available in the language:
```
val dyn: dynamic = ...
```
The `dynamic` type basically turns off Kotlin's type checker:
* A value of the `dynamic` type can be assigned to any variable or passed anywhere as a parameter.
* Any value can be assigned to a variable of the `dynamic` type or passed to a function that takes `dynamic` as a parameter.
* `null`-checks are disabled for the `dynamic` type values.
The most peculiar feature of `dynamic` is that we are allowed to call **any** property or function with any parameters on a `dynamic` variable:
```
dyn.whatever(1, "foo", dyn) // 'whatever' is not defined anywhere
dyn.whatever(*arrayOf(1, 2, 3))
```
On the JavaScript platform this code will be compiled "as is": `dyn.whatever(1)` in Kotlin becomes `dyn.whatever(1)` in the generated JavaScript code.
When calling functions written in Kotlin on values of `dynamic` type, keep in mind the name mangling performed by the Kotlin to JavaScript compiler. You may need to use the [@JsName annotation](js-to-kotlin-interop#jsname-annotation) to assign well-defined names to the functions that you need to call.
A dynamic call always returns `dynamic` as a result, so you can chain such calls freely:
```
dyn.foo().bar.baz()
```
When you pass a lambda to a dynamic call, all of its parameters by default have the type `dynamic`:
```
dyn.foo {
x -> x.bar() // x is dynamic
}
```
Expressions using values of `dynamic` type are translated to JavaScript "as is", and do not use the Kotlin operator conventions. The following operators are supported:
* binary: `+`, `-`, `*`, `/`, `%`, `>`, `<` `>=`, `<=`, `==`, `!=`, `===`, `!==`, `&&`, `||`
* unary
+ prefix: `-`, `+`, `!`
+ prefix and postfix: `++`, `--`
* assignments: `+=`, `-=`, `*=`, `/=`, `%=`
* indexed access:
+ read: `d[a]`, more than one argument is an error
+ write: `d[a1] = a2`, more than one argument in `[]` is an error
`in`, `!in` and `..` operations with values of type `dynamic` are forbidden.
For a more technical description, see the [spec document](https://github.com/JetBrains/kotlin/blob/master/spec-docs/dynamic-types.md).
Last modified: 10 January 2023
[Use JavaScript code from Kotlin](js-interop) [Use dependencies from npm](using-packages-from-npm)
kotlin Coding conventions Coding conventions
==================
Commonly known and easy-to-follow coding conventions are vital for any programming language. Here we provide guidelines on the code style and code organization for projects that use Kotlin.
Configure style in IDE
----------------------
Two most popular IDEs for Kotlin - [IntelliJ IDEA](https://www.jetbrains.com/idea/) and [Android Studio](https://developer.android.com/studio/) provide powerful support for code styling. You can configure them to automatically format your code in consistence with the given code style.
### Apply the style guide
1. Go to **Settings/Preferences | Editor | Code Style | Kotlin**.
2. Click **Set from...**.
3. Select **Kotlin style guide**.
### Verify that your code follows the style guide
1. Go to **Settings/Preferences | Editor | Inspections | General**.
2. Switch on **Incorrect formatting** inspection. Additional inspections that verify other issues described in the style guide (such as naming conventions) are enabled by default.
Source code organization
------------------------
### Directory structure
In pure Kotlin projects, the recommended directory structure follows the package structure with the common root package omitted. For example, if all the code in the project is in the `org.example.kotlin` package and its subpackages, files with the `org.example.kotlin` package should be placed directly under the source root, and files in `org.example.kotlin.network.socket` should be in the `network/socket` subdirectory of the source root.
### Source file names
If a Kotlin file contains a single class or interface (potentially with related top-level declarations), its name should be the same as the name of the class, with the `.kt` extension appended. It applies to all types of classes and interfaces. If a file contains multiple classes, or only top-level declarations, choose a name describing what the file contains, and name the file accordingly. Use [upper camel case](https://en.wikipedia.org/wiki/Camel_case) with an uppercase first letter (also known as Pascal case), for example, `ProcessDeclarations.kt`.
The name of the file should describe what the code in the file does. Therefore, you should avoid using meaningless words such as `Util` in file names.
### Source file organization
Placing multiple declarations (classes, top-level functions or properties) in the same Kotlin source file is encouraged as long as these declarations are closely related to each other semantically, and the file size remains reasonable (not exceeding a few hundred lines).
In particular, when defining extension functions for a class which are relevant for all clients of this class, put them in the same file with the class itself. When defining extension functions that make sense only for a specific client, put them next to the code of that client. Avoid creating files just to hold all extensions of some class.
### Class layout
The contents of a class should go in the following order:
1. Property declarations and initializer blocks
2. Secondary constructors
3. Method declarations
4. Companion object
Do not sort the method declarations alphabetically or by visibility, and do not separate regular methods from extension methods. Instead, put related stuff together, so that someone reading the class from top to bottom can follow the logic of what's happening. Choose an order (either higher-level stuff first, or vice versa) and stick to it.
Put nested classes next to the code that uses those classes. If the classes are intended to be used externally and aren't referenced inside the class, put them in the end, after the companion object.
### Interface implementation layout
When implementing an interface, keep the implementing members in the same order as members of the interface (if necessary, interspersed with additional private methods used for the implementation).
### Overload layout
Always put overloads next to each other in a class.
Naming rules
------------
Package and class naming rules in Kotlin are quite simple:
* Names of packages are always lowercase and do not use underscores (`org.example.project`). Using multi-word names is generally discouraged, but if you do need to use multiple words, you can either just concatenate them together or use camel case (`org.example.myProject`).
* Names of classes and objects start with an uppercase letter and use camel case:
```
open class DeclarationProcessor { /*...*/ }
object EmptyDeclarationProcessor : DeclarationProcessor() { /*...*/ }
```
### Function names
Names of functions, properties and local variables start with a lowercase letter and use camel case and no underscores:
```
fun processDeclarations() { /*...*/ }
var declarationCount = 1
```
Exception: factory functions used to create instances of classes can have the same name as the abstract return type:
```
interface Foo { /*...*/ }
class FooImpl : Foo { /*...*/ }
fun Foo(): Foo { return FooImpl() }
```
### Names for test methods
In tests (and **only** in tests), you can use method names with spaces enclosed in backticks. Note that such method names are currently not supported by the Android runtime. Underscores in method names are also allowed in test code.
```
class MyTestCase {
@Test fun `ensure everything works`() { /*...*/ }
@Test fun ensureEverythingWorks_onAndroid() { /*...*/ }
}
```
### Property names
Names of constants (properties marked with `const`, or top-level or object `val` properties with no custom `get` function that hold deeply immutable data) should use uppercase underscore-separated ([screaming snake case](https://en.wikipedia.org/wiki/Snake_case)) names:
```
const val MAX_COUNT = 8
val USER_NAME_FIELD = "UserName"
```
Names of top-level or object properties which hold objects with behavior or mutable data should use camel case names:
```
val mutableCollection: MutableSet<String> = HashSet()
```
Names of properties holding references to singleton objects can use the same naming style as `object` declarations:
```
val PersonComparator: Comparator<Person> = /*...*/
```
For enum constants, it's OK to use either uppercase underscore-separated names ([screaming snake case](https://en.wikipedia.org/wiki/Snake_case)) (`enum class Color { RED, GREEN }`) or upper camel case names, depending on the usage.
### Names for backing properties
If a class has two properties which are conceptually the same but one is part of a public API and another is an implementation detail, use an underscore as the prefix for the name of the private property:
```
class C {
private val _elementList = mutableListOf<Element>()
val elementList: List<Element>
get() = _elementList
}
```
### Choose good names
The name of a class is usually a noun or a noun phrase explaining what the class *is*: `List`, `PersonReader`.
The name of a method is usually a verb or a verb phrase saying what the method *does*: `close`, `readPersons`. The name should also suggest if the method is mutating the object or returning a new one. For instance `sort` is sorting a collection in place, while `sorted` is returning a sorted copy of the collection.
The names should make it clear what the purpose of the entity is, so it's best to avoid using meaningless words (`Manager`, `Wrapper`) in names.
When using an acronym as part of a declaration name, capitalize it if it consists of two letters (`IOStream`); capitalize only the first letter if it is longer (`XmlFormatter`, `HttpInputStream`).
Formatting
----------
### Indentation
Use four spaces for indentation. Do not use tabs.
For curly braces, put the opening brace in the end of the line where the construct begins, and the closing brace on a separate line aligned horizontally with the opening construct.
```
if (elements != null) {
for (element in elements) {
// ...
}
}
```
### Horizontal whitespace
* Put spaces around binary operators (`a + b`). Exception: don't put spaces around the "range to" operator (`0..i`).
* Do not put spaces around unary operators (`a++`).
* Put spaces between control flow keywords (`if`, `when`, `for`, and `while`) and the corresponding opening parenthesis.
* Do not put a space before an opening parenthesis in a primary constructor declaration, method declaration or method call.
```
class A(val x: Int)
fun foo(x: Int) { ... }
fun bar() {
foo(1)
}
```
* Never put a space after `(`, `[`, or before `]`, `)`
* Never put a space around `.` or `?.`: `foo.bar().filter { it > 2 }.joinToString()`, `foo?.bar()`
* Put a space after `//`: `// This is a comment`
* Do not put spaces around angle brackets used to specify type parameters: `class Map<K, V> { ... }`
* Do not put spaces around `::`: `Foo::class`, `String::length`
* Do not put a space before `?` used to mark a nullable type: `String?`
As a general rule, avoid horizontal alignment of any kind. Renaming an identifier to a name with a different length should not affect the formatting of either the declaration or any of the usages.
### Colon
Put a space before `:` in the following cases:
* when it's used to separate a type and a supertype
* when delegating to a superclass constructor or a different constructor of the same class
* after the `object` keyword
Don't put a space before `:` when it separates a declaration and its type.
Always put a space after `:`.
```
abstract class Foo<out T : Any> : IFoo {
abstract fun foo(a: Int): T
}
class FooImpl : Foo() {
constructor(x: String) : this(x) { /*...*/ }
val x = object : IFoo { /*...*/ }
}
```
### Class headers
Classes with a few primary constructor parameters can be written in a single line:
```
class Person(id: Int, name: String)
```
Classes with longer headers should be formatted so that each primary constructor parameter is in a separate line with indentation. Also, the closing parenthesis should be on a new line. If you use inheritance, the superclass constructor call or the list of implemented interfaces should be located on the same line as the parenthesis:
```
class Person(
id: Int,
name: String,
surname: String
) : Human(id, name) { /*...*/ }
```
For multiple interfaces, the superclass constructor call should be located first and then each interface should be located in a different line:
```
class Person(
id: Int,
name: String,
surname: String
) : Human(id, name),
KotlinMaker { /*...*/ }
```
For classes with a long supertype list, put a line break after the colon and align all supertype names horizontally:
```
class MyFavouriteVeryLongClassHolder :
MyLongHolder<MyFavouriteVeryLongClass>(),
SomeOtherInterface,
AndAnotherOne {
fun foo() { /*...*/ }
}
```
To clearly separate the class header and body when the class header is long, either put a blank line following the class header (as in the example above), or put the opening curly brace on a separate line:
```
class MyFavouriteVeryLongClassHolder :
MyLongHolder<MyFavouriteVeryLongClass>(),
SomeOtherInterface,
AndAnotherOne
{
fun foo() { /*...*/ }
}
```
Use regular indent (four spaces) for constructor parameters. This ensures that properties declared in the primary constructor have the same indentation as properties declared in the body of a class.
### Modifiers order
If a declaration has multiple modifiers, always put them in the following order:
```
public / protected / private / internal
expect / actual
final / open / abstract / sealed / const
external
override
lateinit
tailrec
vararg
suspend
inner
enum / annotation / fun // as a modifier in `fun interface`
companion
inline / value
infix
operator
data
```
Place all annotations before modifiers:
```
@Named("Foo")
private val foo: Foo
```
Unless you're working on a library, omit redundant modifiers (for example, `public`).
### Annotations
Place annotations on separate lines before the declaration to which they are attached, and with the same indentation:
```
@Target(AnnotationTarget.PROPERTY)
annotation class JsonExclude
```
Annotations without arguments may be placed on the same line:
```
@JsonExclude @JvmField
var x: String
```
A single annotation without arguments may be placed on the same line as the corresponding declaration:
```
@Test fun foo() { /*...*/ }
```
### File annotations
File annotations are placed after the file comment (if any), before the `package` statement, and are separated from `package` with a blank line (to emphasize the fact that they target the file and not the package).
```
/** License, copyright and whatever */
@file:JvmName("FooBar")
package foo.bar
```
### Functions
If the function signature doesn't fit on a single line, use the following syntax:
```
fun longMethodName(
argument: ArgumentType = defaultValue,
argument2: AnotherArgumentType,
): ReturnType {
// body
}
```
Use regular indent (four spaces) for function parameters. It helps ensure consistency with constructor parameters.
Prefer using an expression body for functions with the body consisting of a single expression.
```
fun foo(): Int { // bad
return 1
}
fun foo() = 1 // good
```
### Expression bodies
If the function has an expression body whose first line doesn't fit on the same line as the declaration, put the `=` sign on the first line and indent the expression body by four spaces.
```
fun f(x: String, y: String, z: String) =
veryLongFunctionCallWithManyWords(andLongParametersToo(), x, y, z)
```
### Properties
For very simple read-only properties, consider one-line formatting:
```
val isEmpty: Boolean get() = size == 0
```
For more complex properties, always put `get` and `set` keywords on separate lines:
```
val foo: String
get() { /*...*/ }
```
For properties with an initializer, if the initializer is long, add a line break after the `=` sign and indent the initializer by four spaces:
```
private val defaultCharset: Charset? =
EncodingRegistry.getInstance().getDefaultCharsetForPropertiesFiles(file)
```
### Control flow statements
If the condition of an `if` or `when` statement is multiline, always use curly braces around the body of the statement. Indent each subsequent line of the condition by four spaces relative to statement begin. Put the closing parentheses of the condition together with the opening curly brace on a separate line:
```
if (!component.isSyncing &&
!hasAnyKotlinRuntimeInScope(module)
) {
return createKotlinNotConfiguredPanel(module)
}
```
This helps align the condition and statement bodies.
Put the `else`, `catch`, `finally` keywords, as well as the `while` keyword of a `do-while` loop, on the same line as the preceding curly brace:
```
if (condition) {
// body
} else {
// else part
}
try {
// body
} finally {
// cleanup
}
```
In a `when` statement, if a branch is more than a single line, consider separating it from adjacent case blocks with a blank line:
```
private fun parsePropertyValue(propName: String, token: Token) {
when (token) {
is Token.ValueToken ->
callback.visitValue(propName, token.value)
Token.LBRACE -> { // ...
}
}
}
```
Put short branches on the same line as the condition, without braces.
```
when (foo) {
true -> bar() // good
false -> { baz() } // bad
}
```
### Method calls
In long argument lists, put a line break after the opening parenthesis. Indent arguments by four spaces. Group multiple closely related arguments on the same line.
```
drawSquare(
x = 10, y = 10,
width = 100, height = 100,
fill = true
)
```
Put spaces around the `=` sign separating the argument name and value.
### Wrap chained calls
When wrapping chained calls, put the `.` character or the `?.` operator on the next line, with a single indent:
```
val anchor = owner
?.firstChild!!
.siblings(forward = true)
.dropWhile { it is PsiComment || it is PsiWhiteSpace }
```
The first call in the chain usually should have a line break before it, but it's OK to omit it if the code makes more sense that way.
### Lambdas
In lambda expressions, spaces should be used around the curly braces, as well as around the arrow which separates the parameters from the body. If a call takes a single lambda, pass it outside of parentheses whenever possible.
```
list.filter { it > 10 }
```
If assigning a label for a lambda, do not put a space between the label and the opening curly brace:
```
fun foo() {
ints.forEach lit@{
// ...
}
}
```
When declaring parameter names in a multiline lambda, put the names on the first line, followed by the arrow and the newline:
```
appendCommaSeparated(properties) { prop ->
val propertyValue = prop.get(obj) // ...
}
```
If the parameter list is too long to fit on a line, put the arrow on a separate line:
```
foo {
context: Context,
environment: Env
->
context.configureEnv(environment)
}
```
### Trailing commas
A trailing comma is a comma symbol after the last item of a series of elements:
```
class Person(
val firstName: String,
val lastName: String,
val age: Int, // trailing comma
)
```
Using trailing commas has several benefits:
* It makes version-control diffs cleaner – as all the focus is on the changed value.
* It makes it easy to add and reorder elements – there is no need to add or delete the comma if you manipulate elements.
* It simplifies code generation, for example, for object initializers. The last element can also have a comma.
Trailing commas are entirely optional – your code will still work without them. The Kotlin style guide encourages the use of trailing commas at the declaration site and leaves it at your discretion for the call site.
To enable trailing commas in the IntelliJ IDEA formatter, go to **Settings/Preferences | Editor | Code Style | Kotlin**, open the **Other** tab and select the **Use trailing comma** option.
#### Enumerations
```
enum class Direction {
NORTH,
SOUTH,
WEST,
EAST, // trailing comma
}
```
#### Value arguments
```
fun shift(x: Int, y: Int) { /*...*/ }
shift(
25,
20, // trailing comma
)
val colors = listOf(
"red",
"green",
"blue", // trailing comma
)
```
#### Class properties and parameters
```
class Customer(
val name: String,
val lastName: String, // trailing comma
)
class Customer(
val name: String,
lastName: String, // trailing comma
)
```
#### Function value parameters
```
fun powerOf(
number: Int,
exponent: Int, // trailing comma
) { /*...*/ }
constructor(
x: Comparable<Number>,
y: Iterable<Number>, // trailing comma
) {}
fun print(
vararg quantity: Int,
description: String, // trailing comma
) {}
```
#### Parameters with optional type (including setters)
```
val sum: (Int, Int, Int) -> Int = fun(
x,
y,
z, // trailing comma
): Int {
return x + y + x
}
println(sum(8, 8, 8))
```
#### Indexing suffix
```
class Surface {
operator fun get(x: Int, y: Int) = 2 * x + 4 * y - 10
}
fun getZValue(mySurface: Surface, xValue: Int, yValue: Int) =
mySurface[
xValue,
yValue, // trailing comma
]
```
#### Parameters in lambdas
```
fun main() {
val x = {
x: Comparable<Number>,
y: Iterable<Number>, // trailing comma
->
println("1")
}
println(x)
}
```
#### when entry
```
fun isReferenceApplicable(myReference: KClass<*>) = when (myReference) {
Comparable::class,
Iterable::class,
String::class, // trailing comma
-> true
else -> false
}
```
#### Collection literals (in annotations)
```
annotation class ApplicableFor(val services: Array<String>)
@ApplicableFor([
"serializer",
"balancer",
"database",
"inMemoryCache", // trailing comma
])
fun run() {}
```
#### Type arguments
```
fun <T1, T2> foo() {}
fun main() {
foo<
Comparable<Number>,
Iterable<Number>, // trailing comma
>()
}
```
#### Type parameters
```
class MyMap<
MyKey,
MyValue, // trailing comma
> {}
```
#### Destructuring declarations
```
data class Car(val manufacturer: String, val model: String, val year: Int)
val myCar = Car("Tesla", "Y", 2019)
val (
manufacturer,
model,
year, // trailing comma
) = myCar
val cars = listOf<Car>()
fun printMeanValue() {
var meanValue: Int = 0
for ((
_,
_,
year, // trailing comma
) in cars) {
meanValue += year
}
println(meanValue/cars.size)
}
printMeanValue()
```
Documentation comments
----------------------
For longer documentation comments, place the opening `/**` on a separate line and begin each subsequent line with an asterisk:
```
/**
* This is a documentation comment
* on multiple lines.
*/
```
Short comments can be placed on a single line:
```
/** This is a short documentation comment. */
```
Generally, avoid using `@param` and `@return` tags. Instead, incorporate the description of parameters and return values directly into the documentation comment, and add links to parameters wherever they are mentioned. Use `@param` and `@return` only when a lengthy description is required which doesn't fit into the flow of the main text.
```
// Avoid doing this:
/**
* Returns the absolute value of the given number.
* @param number The number to return the absolute value for.
* @return The absolute value.
*/
fun abs(number: Int): Int { /*...*/ }
// Do this instead:
/**
* Returns the absolute value of the given [number].
*/
fun abs(number: Int): Int { /*...*/ }
```
Avoid redundant constructs
--------------------------
In general, if a certain syntactic construction in Kotlin is optional and highlighted by the IDE as redundant, you should omit it in your code. Do not leave unnecessary syntactic elements in code just "for clarity".
### Unit return type
If a function returns Unit, the return type should be omitted:
```
fun foo() { // ": Unit" is omitted here
}
```
### Semicolons
Omit semicolons whenever possible.
### String templates
Don't use curly braces when inserting a simple variable into a string template. Use curly braces only for longer expressions.
```
println("$name has ${children.size} children")
```
Idiomatic use of language features
----------------------------------
### Immutability
Prefer using immutable data to mutable. Always declare local variables and properties as `val` rather than `var` if they are not modified after initialization.
Always use immutable collection interfaces (`Collection`, `List`, `Set`, `Map`) to declare collections which are not mutated. When using factory functions to create collection instances, always use functions that return immutable collection types when possible:
```
// Bad: use of mutable collection type for value which will not be mutated
fun validateValue(actualValue: String, allowedValues: HashSet<String>) { ... }
// Good: immutable collection type used instead
fun validateValue(actualValue: String, allowedValues: Set<String>) { ... }
// Bad: arrayListOf() returns ArrayList<T>, which is a mutable collection type
val allowedValues = arrayListOf("a", "b", "c")
// Good: listOf() returns List<T>
val allowedValues = listOf("a", "b", "c")
```
### Default parameter values
Prefer declaring functions with default parameter values to declaring overloaded functions.
```
// Bad
fun foo() = foo("a")
fun foo(a: String) { /*...*/ }
// Good
fun foo(a: String = "a") { /*...*/ }
```
### Type aliases
If you have a functional type or a type with type parameters which is used multiple times in a codebase, prefer defining a type alias for it:
```
typealias MouseClickHandler = (Any, MouseEvent) -> Unit
typealias PersonIndex = Map<String, Person>
```
If you use a private or internal type alias for avoiding name collision, prefer the `import ... as ...` mentioned in [Packages and Imports](packages).
### Lambda parameters
In lambdas which are short and not nested, it's recommended to use the `it` convention instead of declaring the parameter explicitly. In nested lambdas with parameters, always declare parameters explicitly.
### Returns in a lambda
Avoid using multiple labeled returns in a lambda. Consider restructuring the lambda so that it will have a single exit point. If that's not possible or not clear enough, consider converting the lambda into an anonymous function.
Do not use a labeled return for the last statement in a lambda.
### Named arguments
Use the named argument syntax when a method takes multiple parameters of the same primitive type, or for parameters of `Boolean` type, unless the meaning of all parameters is absolutely clear from context.
```
drawSquare(x = 10, y = 10, width = 100, height = 100, fill = true)
```
### Conditional statements
Prefer using the expression form of `try`, `if`, and `when`.
```
return if (x) foo() else bar()
```
```
return when(x) {
0 -> "zero"
else -> "nonzero"
}
```
The above is preferable to:
```
if (x)
return foo()
else
return bar()
```
```
when(x) {
0 -> return "zero"
else -> return "nonzero"
}
```
### if versus when
Prefer using `if` for binary conditions instead of `when`. For example, use this syntax with `if`:
```
if (x == null) ... else ...
```
instead of this one with `when`:
```
when (x) {
null -> // ...
else -> // ...
}
```
Prefer using `when` if there are three or more options.
### Nullable Boolean values in conditions
If you need to use a nullable `Boolean` in a conditional statement, use `if (value == true)` or `if (value == false)` checks.
### Loops
Prefer using higher-order functions (`filter`, `map` etc.) to loops. Exception: `forEach` (prefer using a regular `for` loop instead, unless the receiver of `forEach` is nullable or `forEach` is used as part of a longer call chain).
When making a choice between a complex expression using multiple higher-order functions and a loop, understand the cost of the operations being performed in each case and keep performance considerations in mind.
### Loops on ranges
Use the `until` function to loop over an open range:
```
for (i in 0..n - 1) { /*...*/ } // bad
for (i in 0 until n) { /*...*/ } // good
```
### Strings
Prefer string templates to string concatenation.
Prefer multiline strings to embedding `\n` escape sequences into regular string literals.
To maintain indentation in multiline strings, use `trimIndent` when the resulting string does not require any internal indentation, or `trimMargin` when internal indentation is required:
```
fun main() {
//sampleStart
println("""
Not
trimmed
text
"""
)
println("""
Trimmed
text
""".trimIndent()
)
println()
val a = """Trimmed to margin text:
|if(a > 1) {
| return a
|}""".trimMargin()
println(a)
//sampleEnd
}
```
Learn the difference between [Java and Kotlin multiline strings](java-to-kotlin-idioms-strings#use-multiline-strings).
### Functions vs properties
In some cases functions with no arguments might be interchangeable with read-only properties. Although the semantics are similar, there are some stylistic conventions on when to prefer one to another.
Prefer a property over a function when the underlying algorithm:
* does not throw
* is cheap to calculate (or cached on the first run)
* returns the same result over invocations if the object state hasn't changed
### Extension functions
Use extension functions liberally. Every time you have a function that works primarily on an object, consider making it an extension function accepting that object as a receiver. To minimize API pollution, restrict the visibility of extension functions as much as it makes sense. As necessary, use local extension functions, member extension functions, or top-level extension functions with private visibility.
### Infix functions
Declare a function as `infix` only when it works on two objects which play a similar role. Good examples: `and`, `to`, `zip`. Bad example: `add`.
Do not declare a method as `infix` if it mutates the receiver object.
### Factory functions
If you declare a factory function for a class, avoid giving it the same name as the class itself. Prefer using a distinct name making it clear why the behavior of the factory function is special. Only if there is really no special semantics, you can use the same name as the class.
```
class Point(val x: Double, val y: Double) {
companion object {
fun fromPolar(angle: Double, radius: Double) = Point(...)
}
}
```
If you have an object with multiple overloaded constructors that don't call different superclass constructors and can't be reduced to a single constructor with default argument values, prefer to replace the overloaded constructors with factory functions.
### Platform types
A public function/method returning an expression of a platform type must declare its Kotlin type explicitly:
```
fun apiCall(): String = MyJavaApi.getProperty("name")
```
Any property (package-level or class-level) initialized with an expression of a platform type must declare its Kotlin type explicitly:
```
class Person {
val name: String = MyJavaApi.getProperty("name")
}
```
A local value initialized with an expression of a platform type may or may not have a type declaration:
```
fun main() {
val name = MyJavaApi.getProperty("name")
println(name)
}
```
### Scope functions apply/with/run/also/let
Kotlin provides a set of functions to execute a block of code in the context of a given object: `let`, `run`, `with`, `apply`, and `also`. For the guidance on choosing the right scope function for your case, refer to [Scope Functions](scope-functions).
Coding conventions for libraries
--------------------------------
When writing libraries, it's recommended to follow an additional set of rules to ensure API stability:
* Always explicitly specify member visibility (to avoid accidentally exposing declarations as public API)
* Always explicitly specify function return types and property types (to avoid accidentally changing the return type when the implementation changes)
* Provide [KDoc](kotlin-doc) comments for all public members, with the exception of overrides that do not require any new documentation (to support generating documentation for the library)
Last modified: 10 January 2023
[Idioms](idioms) [Basic types](basic-types)
| programming_docs |
kotlin What is cross-platform mobile development? What is cross-platform mobile development?
==========================================
Nowadays, many companies are facing the challenge of needing to build mobile apps for multiple platforms, specifically for both Android and iOS. This is why cross-platform mobile development solutions have emerged as one of the most popular software development trends.
According to Statista, there were 3.48 million mobile apps available on the Google Play Store and 2.22 million apps on the App Store in the first quarter of 2021, with Android and iOS now accounting for [99% of the worldwide mobile operating system market](https://gs.statcounter.com/os-market-share/mobile/worldwide).
How do you go about creating a mobile app that can reach Android and iOS audiences? In this article, you will find out why more and more mobile engineers are choosing a cross-platform, or multiplatform, mobile development approach.
Cross-platform mobile development: definition and solutions
-----------------------------------------------------------
Multiplatform mobile development is an approach that allows you to build a single mobile application that runs smoothly on several operating systems. In cross-platform apps, some or even all of the source code can be shared. This means that developers can create and deploy mobile assets that work on both Android and iOS without having to recode them for each individual platform.
### Different approaches to mobile app development
There are four main ways to create an application for both Android and iOS.
#### 1. Separate native apps for each operating system
When creating native apps, developers build an application for a particular operating system and rely on tools and programming languages designed specifically for one platform: Kotlin or Java for Android, Objective-C or Swift for iOS.
These tools and languages give you access to the features and capabilities of a given OS and allow you to craft responsive apps with intuitive interfaces. But if you want to reach both Android and iOS audiences, you will have to create separate applications, and that takes a lot of time and effort.
#### 2. Progressive web apps (PWAs)
Progressive web apps combine the features of mobile apps with solutions used in web development. Roughly speaking, they offer a mix of a website and a mobile application. Developers build PWAs using web technologies, such as JavaScript, HTML, CSS, and WebAssembly.
Web applications do not require separate bundling or distribution and can be published online. They are accessible via the browser on your computer, smartphone, and tablet, and don't need to be installed via Google Play or the App Store.
The drawback here is that a user cannot utilize all of their device's functionality, for example, contacts, calendars, the phone, and other assets, which results in a limited user experience. In terms of app performance, native apps have the lead.
#### 3. Cross-platform apps
As mentioned earlier, multiplatform apps are designed to run identically on different mobile platforms. Cross-platform frameworks allow you to write shareable and reusable code for the purpose of developing these apps.
This approach has several benefits, such as efficiency with respect to both time and cost. We'll take a closer look at the pros and cons of cross-platform mobile development in a later section.
#### 4. Hybrid apps
When browsing websites and forums, you may notice that some people use the terms *"cross-platform mobile development"* and *"hybrid mobile development"* interchangeably. Doing so, however, is not entirely accurate.
When it comes to cross-platform apps, mobile engineers can write code once and then reuse it on different platforms. Hybrid app development, on the other hand, is an approach that combines native and web technologies. It requires you to embed code written in a web development language like HTML, CSS, or JavaScript into a native app. You can do this with the help of frameworks, such as Ionic Capacitor and Apache Cordova, using additional plugins to get access to the native functionalities of platforms.
The only similarity between cross-platform and hybrid development is code shareability. In terms of performance, hybrid applications are not on par with native apps. Because hybrid apps deploy a single code base, some features are specific to a particular OS and don't function well on others.
### Native or cross-platform app development: a longstanding debate
[The debate around native and cross-platform development](native-and-cross-platform) remains unresolved in the tech community. Both of these technologies are in constant evolution and come with their own benefits and limitations.
Some experts still prefer native mobile development over multiplatform solutions, identifying the stronger performance and better user experience of native apps as some of the most important benefits.
However, many modern businesses need to reduce the time to market and the cost of per platform development while still aiming to have a presence both on Android and iOS. This is where cross-platform development frameworks like [Kotlin Multiplatform Mobile](https://kotlinlang.org/lp/mobile/) can help, as David Henry and Mel Yahya, a pair of senior software engineers from Netflix, [note](https://netflixtechblog.com/netflix-android-and-ios-studio-apps-kotlin-multiplatform-d6d4d8d25d23):
Is cross-platform mobile development right for you?
---------------------------------------------------
Choosing a mobile development approach that is right for you depends on many factors, like business requirements, objectives, and tasks. Like any other solution, cross-platform mobile development has its pros and cons.
### Benefits of cross-platform development
There are plenty of reasons businesses choose this approach over other options.
#### 1. Reusable code
With cross-platform programming, mobile engineers don't need to write new code for every operating system. Using a single codebase allows developers to cut down on time spent doing repetitive tasks, such as API calls, data storage, data serialization, and analytics implementation.
In our Kotlin Multiplatform survey from Q3-Q4 2021, we asked the Kotlin community about the parts of code they were able to share between different platforms.
#### 2. Time savings
Due to code reusability, cross-platform applications require less code, and when it comes to coding, less code is more. Time saved is because you do not have to write as much code. Additionally, with fewer lines of code, there are fewer places for bugs to emerge, resulting in less time spent testing and maintaining your code.
#### 3. Effective resource management
Building separate applications is expensive. Having a single codebase helps you effectively manage your resources. Both your Android and your iOS development teams can learn how to write and use shared code.
#### 4. Attractive opportunities for developers
Many mobile engineers view modern cross-platform technologies as desirable elements in a product's tech stack. Developers may get bored at work due to repetitive and routine tasks, such as JSON parsing. However, new technologies and tasks can bring back their excitement, motivation, and joy for work tasks. This means that having a modern tech stack can actually simplify the hiring process for your mobile team.
#### 5. Opportunity to reach wider audiences
You don't have to choose between different platforms. Since your app is compatible with multiple operating systems, you can satisfy the needs of both Android and iOS audiences and maximize your reach.
#### 6. Quicker time to market and customization
Since you don't need to build different apps for different platforms, you can develop and launch your product much faster. What's more, if your application needs to be customized or transformed, it will be easier for programmers to make small changes to specific parts of your codebase. This will also allow you to be more responsive to user feedback.
### Challenges of a cross-platform development approach
All solutions come with their own limitations. What issues might you encounter with cross-platform programming? Some individuals in the tech community argue that multiplatform development still struggles with glitches related to performance. Furthermore, project leads might have fears that their aim to optimize the development process will have a negative impact on the user experience of an application. However, with improvements to the technologies, cross-platform solutions are becoming increasingly stable, adaptable, and flexible.
In our [Kotlin Multiplatform survey from Q1-Q2 2021](https://blog.jetbrains.com/kotlin/2021/10/multiplatform-survey-q1-q2-2021/), we asked survey participants whether they were satisfied with the quality of their apps after adopting Kotlin Multiplatform Mobile. When asked whether they were satisfied with their apps' performance, binary size, and appearance, as many as 98.3% of respondents answered positively.
Another concern is the inability to seamlessly support the native features of applications. Nevertheless, if you're building a multiplatform app that needs to access platform-specific APIs, you can use Kotlin's [expected and actual declarations](multiplatform-connect-to-apis). They allow you to define in common code that you "expect" to be able to call the same function across multiple platforms and provide the "actual" implementations, which can interact with any platform-specific libraries thanks to Kotlin interoperability with Java and Objective-C/Swift.
These issues raise the question of whether the end-user will notice a difference between native and cross-platform apps.
As modern multiplatform frameworks continue to evolve, they increasingly allow mobile engineers to craft a native-like experience. If an application is well written, the user will not be able to notice the difference. However, the quality of your product will heavily depend on the cross-platform app development tools you choose.
The most popular cross-platform solutions
-----------------------------------------
[The most popular cross-platform frameworks](cross-platform-frameworks) include Flutter, React Native, and Kotlin Multiplatform Mobile. Each of these frameworks has its own capabilities and strengths. Depending on the tool you use, your development process and the outcome may vary.
### Flutter
Flutter is a cross-platform development framework that was created by Google and uses the Dart programming language. Flutter supports native features, such as location services, camera functionality, and hard drive access. If you need to create a specific app feature that's not supported in Flutter, you can write platform-specific code using the [Platform Channel technology](https://brightmarbles.io/blog/platform-channel-in-flutter-benefits-and-limitations/).
Apps built with Flutter need to share all of their UX and UI layers, which is why they may not always feel 100% native. One of the best things about this framework is its Hot Reload feature, which allows developers to make changes and view them instantly.
This framework may be the best option in the following situations:
* You want to share UI components between your apps but you want your applications to look close to native.
* The app is expected to put a heavy load on CPU/GPU.
* You need to develop an MVP application.
Among the most popular apps built with Flutter are Google Ads, Xianyu by Alibaba, eBay Motors, and Hamilton.
### React Native
Facebook introduced React Native in 2015 as an open-source framework designed to help mobile engineers build hybrid native/cross-platform apps. It's based on ReactJS – a JavaScript library for building user interfaces. In other words, it uses JavaScript to build mobile apps for Android and iOS systems.
React Native provides access to several third-party UI libraries with ready-to-use components, helping mobile engineers save time during the development process. Like Flutter, it allows you to see all your changes immediately, thanks to the Fast Refresh feature.
You should consider using React Native for your app in the following cases:
* Your application is relatively simple and is expected to be lightweight.
* The development team is fluent in JavaScript or React.
Applications built with React Native include Facebook, Instagram, Skype, and Uber Eats.
### Kotlin Multiplatform Mobile
Kotlin Multiplatform Mobile is an SDK for cross-platform mobile development provided by JetBrains. It allows you to create Android and iOS apps with shared logic. Its key benefits include:
* Smooth integration with existing projects.
* Full control over the UI, along with the ability to use the latest UI frameworks, such as SwiftUI and Jetpack Compose.
* Easy access to Android and iOS SDKs without any restrictions.
Global companies and start-ups alike have already leveraged Kotlin Multiplatform Mobile to optimize and accelerate their mobile development efforts. The benefits of this approach are apparent from the stories of the companies that have already adopted it.
* The development team from the award-winning to-do list app Todoist started using Kotlin Multiplatform Mobile to synchronize their app's sorting logic on multiple platforms, and in doing so they combined the benefits of creating cross-platform and native apps. You can learn more about their experience in this [video](https://www.youtube.com/watch?v=z-o9MqN86eE).
* The introduction of Kotlin Multiplatform allowed Philips to [become faster at implementing new features](https://kotlinlang.org/lp/mobile/case-studies/philips) and increased the interaction between their Android and iOS developers.
* Shopify was able to use Kotlin Multiplatform to [share an astounding 95% of their code](https://shopify.engineering/managing-native-code-react-native), which also delivered a significant performance improvement. Similarly, the startup company Down Dog is using Kotlin Multiplatform to [increase the development speed for the apps](https://kotlinlang.org/lp/mobile/case-studies/down-dog) by maximizing the amount of code shared between all the platforms: JVM, Native, and JS.
Conclusion
----------
As cross-platform development solutions continue to evolve, their limitations have begun to pale in comparison to the benefits they provide. A variety of technologies are available on the market, all suited to different sets of workflows and requirements. Each of the tools discussed in this article offers extensive support for teams thinking about giving cross-platform a try.
Ultimately, carefully considering your specific business needs, objectives, and tasks, and developing clear goals that you want to achieve with your app, will help you identify the best solution for you.
Last modified: 10 January 2023
[Compatibility modes](compatibility-modes) [Native and cross-platform app development: how to choose?](native-and-cross-platform)
kotlin Configure compilations Configure compilations
======================
Kotlin multiplatform projects use compilations for producing artifacts. Each target can have one or more compilations, for example, for production and test purposes.
For each target, default compilations include:
* `main` and `test` compilations for JVM, JS, and Native targets.
* A [compilation](#compilation-for-android) per [Android build variant](https://developer.android.com/studio/build/build-variants), for Android targets.
If you need to compile something other than production code and unit tests, for example, integration or performance tests, you can [create a custom compilation](#create-a-custom-compilation).
You can configure how artifacts are produced in:
* [All compilations](#configure-all-compilations) in your project at once.
* [Compilations for one target](#configure-compilations-for-one-target) since one target can have multiple compilations.
* [A specific compilation](#configure-one-compilation).
See the [list of compilation parameters](multiplatform-dsl-reference#compilation-parameters) and [compiler options](gradle-compiler-options) available for all or specific targets.
Configure all compilations
--------------------------
```
kotlin {
targets.all {
compilations.all {
compilerOptions.configure {
allWarningsAsErrors.set(true)
}
}
}
}
```
Configure compilations for one target
-------------------------------------
```
kotlin {
targets.jvm.compilations.all {
compilerOptions.configure {
sourceMap.set(true)
metaInfo.set(true)
}
}
}
```
```
kotlin {
jvm().compilations.all {
compilerOptions.configure {
sourceMap.set(true)
metaInfo.set(true)
}
}
}
```
Configure one compilation
-------------------------
```
kotlin {
jvm {
val main by compilations.getting {
compilerOptions.configure {
jvmTarget.set(JvmTarget.JVM_1_8)
}
}
}
}
```
```
kotlin {
jvm().compilations.main {
compilerOptions.configure {
jvmTarget.set(JvmTarget.JVM_1_8)
}
}
}
```
Create a custom compilation
---------------------------
If you need to compile something other than production code and unit tests, for example, integration or performance tests, create a custom compilation.
For example, to create a custom compilation for integration tests of the `jvm()` target, add a new item to the `compilations` collection.
```
kotlin {
jvm() {
compilations {
val main by getting
val integrationTest by compilations.creating {
defaultSourceSet {
dependencies {
// Compile against the main compilation's compile classpath and outputs:
implementation(main.compileDependencyFiles + main.output.classesDirs)
implementation(kotlin("test-junit"))
/* ... */
}
}
// Create a test task to run the tests produced by this compilation:
tasks.register<Test>("integrationTest") {
// Run the tests with the classpath containing the compile dependencies (including 'main'),
// runtime dependencies, and the outputs of this compilation:
classpath = compileDependencyFiles + runtimeDependencyFiles + output.allOutputs
// Run only the tests from this compilation's outputs:
testClassesDirs = output.classesDirs
}
}
}
}
}
```
```
kotlin {
jvm() {
compilations.create('integrationTest') {
defaultSourceSet {
dependencies {
def main = compilations.main
// Compile against the main compilation's compile classpath and outputs:
implementation(main.compileDependencyFiles + main.output.classesDirs)
implementation kotlin('test-junit')
/* ... */
}
}
// Create a test task to run the tests produced by this compilation:
tasks.register('jvmIntegrationTest', Test) {
// Run the tests with the classpath containing the compile dependencies (including 'main'),
// runtime dependencies, and the outputs of this compilation:
classpath = compileDependencyFiles + runtimeDependencyFiles + output.allOutputs
// Run only the tests from this compilation's outputs:
testClassesDirs = output.classesDirs
}
}
}
}
```
You also need to create a custom compilation in other cases, for example, if you want to combine compilations for different JVM versions in your final artifact, or you have already set up source sets in Gradle and want to migrate to a multiplatform project.
Use Java sources in JVM compilations
------------------------------------
When [creating a project with the Project Wizard](multiplatform-library), Java sources are included in the compilations of the JVM target.
In the build script, the following section applies the Gradle `java` plugin and configures the target to cooperate with it:
```
kotlin {
jvm {
withJava()
}
}
```
The Java source files are placed in the child directories of the Kotlin source roots. For example, the paths are:
The common source sets cannot include Java sources.
Due to current limitations, the Kotlin plugin replaces some tasks configured by the Java plugin:
* The target's JAR task instead of `jar` (for example, `jvmJar`).
* The target's test task instead of `test` (for example, `jvmTest`).
* The resources are processed by the equivalent tasks of the compilations instead of `*ProcessResources` tasks.
The publication of this target is handled by the Kotlin plugin and doesn't require steps that are specific for the Java plugin.
Configure interop with native languages
---------------------------------------
Kotlin provides [interoperability with native languages](native-c-interop) and DSL to configure this for a specific compilation.
| Native language | Supported platforms | Comments |
| --- | --- | --- |
| C | All platforms, except for WebAssembly | |
| Objective-C | Apple platforms (macOS, iOS, watchOS, tvOS) | |
| Swift via Objective-C | Apple platforms (macOS, iOS, watchOS, tvOS) | Kotlin can use only Swift declarations marked with the `@objc` attribute. |
A compilation can interact with several native libraries. Configure interoperability in the `cinterops` block of the compilation with [available parameters](multiplatform-dsl-reference#cinterops).
```
kotlin {
linuxX64 { // Replace with a target you need.
compilations.getByName("main") {
val myInterop by cinterops.creating {
// Def-file describing the native API.
// The default path is src/nativeInterop/cinterop/<interop-name>.def
defFile(project.file("def-file.def"))
// Package to place the Kotlin API generated.
packageName("org.sample")
// Options to be passed to compiler by cinterop tool.
compilerOpts("-Ipath/to/headers")
// Directories to look for headers.
includeDirs.apply {
// Directories for header search (an equivalent of the -I<path> compiler option).
allHeaders("path1", "path2")
// Additional directories to search headers listed in the 'headerFilter' def-file option.
// -headerFilterAdditionalSearchPrefix command line option equivalent.
headerFilterOnly("path1", "path2")
}
// A shortcut for includeDirs.allHeaders.
includeDirs("include/directory", "another/directory")
}
val anotherInterop by cinterops.creating { /* ... */ }
}
}
}
```
```
kotlin {
linuxX64 { // Replace with a target you need.
compilations.main {
cinterops {
myInterop {
// Def-file describing the native API.
// The default path is src/nativeInterop/cinterop/<interop-name>.def
defFile project.file("def-file.def")
// Package to place the Kotlin API generated.
packageName 'org.sample'
// Options to be passed to compiler by cinterop tool.
compilerOpts '-Ipath/to/headers'
// Directories for header search (an eqivalent of the -I<path> compiler option).
includeDirs.allHeaders("path1", "path2")
// Additional directories to search headers listed in the 'headerFilter' def-file option.
// -headerFilterAdditionalSearchPrefix command line option equivalent.
includeDirs.headerFilterOnly("path1", "path2")
// A shortcut for includeDirs.allHeaders.
includeDirs("include/directory", "another/directory")
}
anotherInterop { /* ... */ }
}
}
}
}
```
Compilation for Android
-----------------------
The compilations created for an Android target by default are tied to [Android build variants](https://developer.android.com/studio/build/build-variants): for each build variant, a Kotlin compilation is created under the same name.
Then, for each [Android source set](https://developer.android.com/studio/build/build-variants#sourcesets) compiled for each of the variants, a Kotlin source set is created under that source set name prepended by the target name, like the Kotlin source set `androidDebug` for an Android source set `debug` and the Kotlin target named `android`. These Kotlin source sets are added to the variants' compilations accordingly.
The default source set `commonMain` is added to each production (application or library) variant's compilation. The `commonTest` source set is similarly added to the compilations of unit test and instrumented test variants.
Annotation processing with [`kapt`](kapt) is also supported, but due to current limitations it requires that the Android target is created before the `kapt` dependencies are configured, which needs to be done in a top-level `dependencies` block rather than within Kotlin source set dependencies.
```
kotlin {
android { /* ... */ }
}
dependencies {
kapt("com.my.annotation:processor:1.0.0")
}
```
Compilation of the source set hierarchy
---------------------------------------
Kotlin can build a [source set hierarchy](multiplatform-share-on-platforms#share-code-on-similar-platforms) with the `dependsOn` relation.
If the source set `jvmMain` depends on a source set `commonMain` then:
* Whenever `jvmMain` is compiled for a certain target, `commonMain` takes part in that compilation as well and is also compiled into the same target binary form, such as JVM class files.
* Sources of `jvmMain` 'see' the declarations of `commonMain`, including internal declarations, and also see the [dependencies](multiplatform-add-dependencies) of `commonMain`, even those specified as `implementation` dependencies.
* `jvmMain` can contain platform-specific implementations for the [expected declarations](multiplatform-connect-to-apis) of `commonMain`.
* The resources of `commonMain` are always processed and copied along with the resources of `jvmMain`.
* The [language settings](multiplatform-dsl-reference#language-settings) of `jvmMain` and `commonMain` should be consistent.
Language settings are checked for consistency in the following ways:
* `jvmMain` should set a `languageVersion` that is greater than or equal to that of `commonMain`.
* `jvmMain` should enable all unstable language features that `commonMain` enables (there's no such requirement for bugfix features).
* `jvmMain` should use all experimental annotations that `commonMain` uses.
* `apiVersion`, bugfix language features, and `progressiveMode` can be set arbitrarily.
Last modified: 10 January 2023
[Run tests with Kotlin Multiplatform](multiplatform-run-tests) [Build final native binaries (Experimental DSL)](multiplatform-native-artifacts)
| programming_docs |
kotlin Sequences Sequences
=========
Along with collections, the Kotlin standard library contains another type – *sequences* ([`Sequence<T>`](../api/latest/jvm/stdlib/kotlin.sequences/-sequence/index)). Unlike collections, sequences don't contain elements, they produce them while iterating. Sequences offer the same functions as [`Iterable`](../api/latest/jvm/stdlib/kotlin.collections/-iterable/index) but implement another approach to multi-step collection processing.
When the processing of an `Iterable` includes multiple steps, they are executed eagerly: each processing step completes and returns its result – an intermediate collection. The following step executes on this collection. In turn, multi-step processing of sequences is executed lazily when possible: actual computing happens only when the result of the whole processing chain is requested.
The order of operations execution is different as well: `Sequence` performs all the processing steps one-by-one for every single element. In turn, `Iterable` completes each step for the whole collection and then proceeds to the next step.
So, the sequences let you avoid building results of intermediate steps, therefore improving the performance of the whole collection processing chain. However, the lazy nature of sequences adds some overhead which may be significant when processing smaller collections or doing simpler computations. Hence, you should consider both `Sequence` and `Iterable` and decide which one is better for your case.
Construct
---------
### From elements
To create a sequence, call the [`sequenceOf()`](../api/latest/jvm/stdlib/kotlin.sequences/sequence-of) function listing the elements as its arguments.
```
val numbersSequence = sequenceOf("four", "three", "two", "one")
```
### From an Iterable
If you already have an `Iterable` object (such as a `List` or a `Set`), you can create a sequence from it by calling [`asSequence()`](../api/latest/jvm/stdlib/kotlin.collections/as-sequence).
```
val numbers = listOf("one", "two", "three", "four")
val numbersSequence = numbers.asSequence()
```
### From a function
One more way to create a sequence is by building it with a function that calculates its elements. To build a sequence based on a function, call [`generateSequence()`](../api/latest/jvm/stdlib/kotlin.sequences/generate-sequence) with this function as an argument. Optionally, you can specify the first element as an explicit value or a result of a function call. The sequence generation stops when the provided function returns `null`. So, the sequence in the example below is infinite.
```
fun main() {
//sampleStart
val oddNumbers = generateSequence(1) { it + 2 } // `it` is the previous element
println(oddNumbers.take(5).toList())
//println(oddNumbers.count()) // error: the sequence is infinite
//sampleEnd
}
```
To create a finite sequence with `generateSequence()`, provide a function that returns `null` after the last element you need.
```
fun main() {
//sampleStart
val oddNumbersLessThan10 = generateSequence(1) { if (it < 8) it + 2 else null }
println(oddNumbersLessThan10.count())
//sampleEnd
}
```
### From chunks
Finally, there is a function that lets you produce sequence elements one by one or by chunks of arbitrary sizes – the [`sequence()`](../api/latest/jvm/stdlib/kotlin.sequences/sequence) function. This function takes a lambda expression containing calls of [`yield()`](../api/latest/jvm/stdlib/kotlin.sequences/-sequence-scope/yield) and [`yieldAll()`](../api/latest/jvm/stdlib/kotlin.sequences/-sequence-scope/yield-all) functions. They return an element to the sequence consumer and suspend the execution of `sequence()` until the next element is requested by the consumer. `yield()` takes a single element as an argument; `yieldAll()` can take an `Iterable` object, an `Iterator`, or another `Sequence`. A `Sequence` argument of `yieldAll()` can be infinite. However, such a call must be the last: all subsequent calls will never be executed.
```
fun main() {
//sampleStart
val oddNumbers = sequence {
yield(1)
yieldAll(listOf(3, 5))
yieldAll(generateSequence(7) { it + 2 })
}
println(oddNumbers.take(5).toList())
//sampleEnd
}
```
Sequence operations
-------------------
The sequence operations can be classified into the following groups regarding their state requirements:
* *Stateless* operations require no state and process each element independently, for example, [`map()`](collection-transformations#map) or [`filter()`](collection-filtering). Stateless operations can also require a small constant amount of state to process an element, for example, [`take()` or `drop()`](collection-parts).
* *Stateful* operations require a significant amount of state, usually proportional to the number of elements in a sequence.
If a sequence operation returns another sequence, which is produced lazily, it's called *intermediate*. Otherwise, the operation is *terminal*. Examples of terminal operations are [`toList()`](constructing-collections#copy) or [`sum()`](collection-aggregate). Sequence elements can be retrieved only with terminal operations.
Sequences can be iterated multiple times; however some sequence implementations might constrain themselves to be iterated only once. That is mentioned specifically in their documentation.
Sequence processing example
---------------------------
Let's take a look at the difference between `Iterable` and `Sequence` with an example.
### Iterable
Assume that you have a list of words. The code below filters the words longer than three characters and prints the lengths of first four such words.
```
fun main() {
//sampleStart
val words = "The quick brown fox jumps over the lazy dog".split(" ")
val lengthsList = words.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars:")
println(lengthsList)
//sampleEnd
}
```
When you run this code, you'll see that the `filter()` and `map()` functions are executed in the same order as they appear in the code. First, you see `filter:` for all elements, then `length:` for the elements left after filtering, and then the output of the two last lines.
This is how the list processing goes:
### Sequence
Now let's write the same with sequences:
```
fun main() {
//sampleStart
val words = "The quick brown fox jumps over the lazy dog".split(" ")
//convert the List to a Sequence
val wordsSequence = words.asSequence()
val lengthsSequence = wordsSequence.filter { println("filter: $it"); it.length > 3 }
.map { println("length: ${it.length}"); it.length }
.take(4)
println("Lengths of first 4 words longer than 3 chars")
// terminal operation: obtaining the result as a List
println(lengthsSequence.toList())
//sampleEnd
}
```
The output of this code shows that the `filter()` and `map()` functions are called only when building the result list. So, you first see the line of text `"Lengths of.."` and then the sequence processing starts. Note that for elements left after filtering, the map executes before filtering the next element. When the result size reaches 4, the processing stops because it's the largest possible size that `take(4)` can return.
The sequence processing goes like this:
In this example, the sequence processing takes 18 steps instead of 23 steps for doing the same with lists.
Last modified: 10 January 2023
[Ranges and progressions](ranges) [Collection operations overview](collection-operations)
kotlin Compatibility guide for Kotlin 1.6 Compatibility guide for Kotlin 1.6
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.5 to Kotlin 1.6.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language
--------
### Make when statements with enum, sealed, and Boolean subjects exhaustive by default
### Deprecate confusing grammar in when-with-subject
### Prohibit access to class members in the super constructor call of its companion and nested objects
### Type nullability enhancement improvements
### Prevent implicit coercions between different numeric types
### Prohibit declarations of repeatable annotation classes whose container annotation violates JLS
### Prohibit declaring a nested class named Container in a repeatable annotation class
### Prohibit @JvmField on a property in the primary constructor that overrides an interface property
### Deprecate the enable and the compatibility modes of the compiler option -Xjvm-default
### Prohibit super calls from public-abi inline functions
### Prohibit protected constructor calls from public inline functions
### Prohibit exposing private nested types from private-in-file types
### Annotation target is not analyzed in several cases for annotations on a type
### Prohibit calls to functions named suspend with a trailing lambda
Standard library
----------------
### Remove brittle contains optimization in minus/removeAll/retainAll
### Change value generation algorithm in Random.nextLong
### Gradually change the return type of collection min and max functions to non-nullable
### Deprecate floating-point array functions: contains, indexOf, lastIndexOf
### Migrate declarations from kotlin.dom and kotlin.browser packages to kotlinx.\*
### Make Regex.replace function not inline in Kotlin/JS
### Different behavior of the Regex.replace function in JVM and JS when replacement string contains group reference
### Use the Unicode case folding in JS Regex
### Deprecate some JS-only API
### Hide implementation- and interop-specific functions from the public API of classes in Kotlin/JS
Tools
-----
### Deprecate KotlinGradleSubplugin class
### Remove kotlin.useFallbackCompilerSearch build option
### Remove several compiler options
### Deprecate useIR compiler option
### Deprecate kapt.use.worker.api Gradle property
### Remove kotlin.parallel.tasks.in.project Gradle property
### Deprecate kotlin.experimental.coroutines Gradle DSL option and kotlin.coroutines Gradle property
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.7](compatibility-guide-17) [Compatibility guide for Kotlin 1.5](compatibility-guide-15)
kotlin Security Security
========
We do our best to make sure our products are free of security vulnerabilities. To reduce the risk of introducing a vulnerability, you can follow these best practices:
* Always use the latest Kotlin release. For security purposes, we sign our releases published on [Maven Central](https://search.maven.org/search?q=g:org.jetbrains.kotlin) with these PGP keys:
+ Key ID: **[email protected]**
+ Fingerprint: **2FBA 29D0 8D2E 25EE 84C1 32C3 0729 A0AF F899 9A87**
+ Key size: **RSA 3072**
* Use the latest versions of your application's dependencies. If you need to use a specific version of a dependency, periodically check if any new security vulnerabilities have been discovered. You can follow [the guidelines from GitHub](https://help.github.com/en/github/managing-security-vulnerabilities/managing-vulnerabilities-in-your-projects-dependencies) or browse known vulnerabilities in the [CVE base](https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=kotlin).
We are very eager and grateful to hear about any security issues you find. To report vulnerabilities that you discover in Kotlin, please post a message directly to our [issue tracker](https://youtrack.jetbrains.com/newIssue?project=KT&c=Type%20Security%20Problem) or send us an [email](mailto:[email protected]).
For more information on how our responsible disclosure process works, please check the [JetBrains Coordinated Disclosure Policy](https://www.jetbrains.com/legal/terms/coordinated-disclosure.html).
Last modified: 10 January 2023
[The Six Most Popular Cross-Platform App Development Frameworks](cross-platform-frameworks) [Kotlin documentation as PDF](kotlin-pdf)
kotlin Get started with Kotlin/JVM Get started with Kotlin/JVM
===========================
This tutorial demonstrates how to use IntelliJ IDEA for creating a console application.
To get started, first download and install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
Create a project
----------------
1. In IntelliJ IDEA, select **File** | **New** | **Project**.
2. In the panel on the left, select **New Project**.
3. Name the new project and change its location if necessary.
4. From the **Language** list, select **Kotlin**.

5. Select the **IntelliJ** build system. It's a native builder that doesn't require downloading additional artifacts.
If you want to create a more complex project that needs further configuration, select Maven or Gradle. For Gradle, choose a language for the build script: Kotlin or Groovy.
6. From the **JDK list**, select the [JDK](https://www.oracle.com/java/technologies/downloads/) that you want to use in your project.
* If the JDK is installed on your computer, but not defined in the IDE, select **Add JDK** and specify the path to the JDK home directory.
* If you don't have the necessary JDK on your computer, select **Download JDK**.
7. Enable the **Add sample code** option to create a file with a sample `"Hello World!"` application.
8. Click **Create**.
Create an application
---------------------
1. Open the `Main.kt` file in `src/main/kotlin`.
The `src` directory contains Kotlin source files and resources. The `Main.kt` file contains sample code that will print `Hello World!`.

2. Modify the code so that it requests your name and says `Hello` to you alone, and not to the whole world:
* Introduce a local variable `name` with the keyword `val`. It will get its value from an input where you will enter your name – [`readln()`](../api/latest/jvm/stdlib/kotlin.io/readln).
* Use a string template by adding a dollar sign `$` before this variable name directly in the text output like this – `$name`.
```
fun main() {
println("What's your name?")
val name = readln()
println("Hello, $name!")
}
```

Run the application
-------------------
Now the application is ready to run. The easiest way to do this is to click the green **Run** icon in the gutter and select **Run 'MainKt'**.
You can see the result in the **Run** tool window.
Enter your name and accept the greetings from your application!
Congratulations! You have just run your first Kotlin application.
What's next?
------------
Once you've created this application, you can start to dive deeper into Kotlin syntax:
* Add sample code from [Kotlin examples](https://play.kotlinlang.org/byExample/overview)
* Install the [EduTools plugin](https://plugins.jetbrains.com/plugin/10081-edutools) for IDEA and complete exercises from the [Kotlin Koans course](https://plugins.jetbrains.com/plugin/10081-edutools/docs/learner-start-guide.html?section=Kotlin%20Koans)
Last modified: 10 January 2023
[Introduce cross-platform mobile development to your team](multiplatform-mobile-introduce-your-team) [Comparison to Java](comparison-to-java)
kotlin Kotlin command-line compiler Kotlin command-line compiler
============================
Every Kotlin release ships with a standalone version of the compiler. You can download the latest version manually or via a package manager.
Install the compiler
--------------------
### Manual install
1. Download the latest version (`kotlin-compiler-1.8.0.zip`) from [GitHub Releases](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0).
2. Unzip the standalone compiler into a directory and optionally add the `bin` directory to the system path. The `bin` directory contains the scripts needed to compile and run Kotlin on Windows, macOS, and Linux.
### SDKMAN!
An easier way to install Kotlin on UNIX-based systems, such as macOS, Linux, Cygwin, FreeBSD, and Solaris, is [SDKMAN!](https://sdkman.io). It also works in Bash and ZSH shells. [Learn how to install SDKMAN!](https://sdkman.io/install).
To install the Kotlin compiler via SDKMAN!, run the following command in the terminal:
```
sdk install kotlin
```
### Homebrew
Alternatively, on macOS you can install the compiler via [Homebrew](https://brew.sh/):
```
brew update
brew install kotlin
```
### Snap package
If you use [Snap](https://snapcraft.io/) on Ubuntu 16.04 or later, you can install the compiler from the command line:
```
sudo snap install --classic kotlin
```
Create and run an application
-----------------------------
1. Create a simple application in Kotlin that displays `"Hello, World!"`. In your favorite editor, create a new file called `hello.kt` with the following lines:
```
fun main() {
println("Hello, World!")
}
```
2. Compile the application using the Kotlin compiler:
```
kotlinc hello.kt -include-runtime -d hello.jar
```
The `-d` option indicates the output path for generated class files, which may be either a directory or a *.jar* file. The `-include-runtime` option makes the resulting *.jar* file self-contained and runnable by including the Kotlin runtime library in it.
To see all available options, run
```
kotlinc -help
```
3. Run the application.
```
java -jar hello.jar
```
Compile a library
-----------------
If you're developing a library to be used by other Kotlin applications, you can build the *.jar* file without including the Kotlin runtime in it:
```
kotlinc hello.kt -d hello.jar
```
Since binaries compiled this way depend on the Kotlin runtime, you should make sure the latter is present in the classpath whenever your compiled library is used.
You can also use the `kotlin` script to run binaries produced by the Kotlin compiler:
```
kotlin -classpath hello.jar HelloKt
```
`HelloKt` is the main class name that the Kotlin compiler generates for the file named `hello.kt`.
Run the REPL
------------
You can run the compiler without parameters to have an interactive shell. In this shell, you can type any valid Kotlin code and see the results.
Run scripts
-----------
Kotlin can also be used as a scripting language. A script is a Kotlin source file (`.kts`) with top-level executable code.
```
import java.io.File
// Get the passed in path, i.e. "-d some/path" or use the current path.
val path = if (args.contains("-d")) args[1 + args.indexOf("-d")]
else "."
val folders = File(path).listFiles { file -> file.isDirectory() }
folders?.forEach { folder -> println(folder) }
```
To run a script, pass the `-script` option to the compiler with the corresponding script file:
```
kotlinc -script list_folders.kts -- -d <path_to_folder_to_inspect>
```
Kotlin provides experimental support for script customization, such as adding external properties, providing static or dynamic dependencies, and so on. Customizations are defined by so-called *Script definitions* - annotated kotlin classes with the appropriate support code. The script filename extension is used to select the appropriate definition. Learn more about [Kotlin custom scripting](custom-script-deps-tutorial).
Properly prepared script definitions are detected and applied automatically when the appropriate jars are included in the compilation classpath. Alternatively, you can specify definitions manually by passing the `-script-templates` option to the compiler:
```
kotlinc -script-templates org.example.CustomScriptDefinition -script custom.script1.kts
```
For additional details, please consult the [KEEP-75](https://github.com/Kotlin/KEEP/blob/master/proposals/scripting-support.md).
Last modified: 10 January 2023
[Run code snippets](run-code-snippets) [Kotlin compiler options](compiler-reference)
| programming_docs |
kotlin Compatibility guide for Kotlin 1.7 Compatibility guide for Kotlin 1.7
==================================
*[Keeping the Language Modern](kotlin-evolution)* and *[Comfortable Updates](kotlin-evolution)* are among the fundamental principles in Kotlin Language Design. The former says that constructs which obstruct language evolution should be removed, and the latter says that this removal should be well-communicated beforehand to make code migration as smooth as possible.
While most of the language changes were already announced through other channels, like update changelogs or compiler warnings, this document summarizes them all, providing a complete reference for migration from Kotlin 1.6 to Kotlin 1.7.
Basic terms
-----------
In this document we introduce several kinds of compatibility:
* *source*: source-incompatible change stops code that used to compile fine (without errors or warnings) from compiling anymore
* *binary*: two binary artifacts are said to be binary-compatible if interchanging them doesn't lead to loading or linkage errors
* *behavioral*: a change is said to be behavioral-incompatible if the same program demonstrates different behavior before and after applying the change
Remember that those definitions are given only for pure Kotlin. Compatibility of Kotlin code from the other languages perspective (for example, from Java) is out of the scope of this document.
Language
--------
### Make safe call result always nullable
### Prohibit the delegation of super calls to an abstract superclass member
### Prohibit exposing non-public types through public properties declared in a non-public primary constructor
### Prohibit access to uninitialized enum entries qualified with the enum name
### Prohibit computing constant values of complex boolean expressions in when condition branches and conditions of loops
### Make when statements with enum, sealed, and Boolean subjects exhaustive by default
### Deprecate confusing grammar in when-with-subject
### Type nullability enhancement improvements
### Prevent implicit coercions between different numeric types
### Deprecate the enable and the compatibility modes of the compiler option -Xjvm-default
### Prohibit calls to functions named suspend with a trailing lambda
### Prohibit smart cast on a base class property if the base class is from another module
### Do not neglect meaningful constraints during type inference
Standard library
----------------
### Gradually change the return type of collection min and max functions to non-nullable
### Deprecate floating-point array functions: contains, indexOf, lastIndexOf
### Migrate declarations from kotlin.dom and kotlin.browser packages to kotlinx.\*
### Deprecate some JS-only API
Tools
-----
### Remove KotlinGradleSubplugin class
### Remove useIR compiler option
### Deprecate kapt.use.worker.api Gradle property
### Remove kotlin.experimental.coroutines Gradle DSL option and kotlin.coroutines Gradle property
### Deprecate useExperimentalAnnotation compiler option
### Deprecate kotlin.compiler.execution.strategy system property
### Remove kotlinOptions.jdkHome compiler option
### Remove noStdlib compiler option
### Remove kotlin2js and kotlin-dce-plugin plugins
### Changes in compile tasks
Last modified: 10 January 2023
[Compatibility guide for Kotlin 1.7.20](compatibility-guide-1720) [Compatibility guide for Kotlin 1.6](compatibility-guide-16)
kotlin Filtering collections Filtering collections
=====================
Filtering is one of the most popular tasks in collection processing. In Kotlin, filtering conditions are defined by *predicates* – lambda functions that take a collection element and return a boolean value: `true` means that the given element matches the predicate, `false` means the opposite.
The standard library contains a group of extension functions that let you filter collections in a single call. These functions leave the original collection unchanged, so they are available for both [mutable and read-only](collections-overview#collection-types) collections. To operate the filtering result, you should assign it to a variable or chain the functions after filtering.
Filter by predicate
-------------------
The basic filtering function is [`filter()`](../api/latest/jvm/stdlib/kotlin.collections/filter). When called with a predicate, `filter()` returns the collection elements that match it. For both `List` and `Set`, the resulting collection is a `List`, for `Map` it's a `Map` as well.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val longerThan3 = numbers.filter { it.length > 3 }
println(longerThan3)
val numbersMap = mapOf("key1" to 1, "key2" to 2, "key3" to 3, "key11" to 11)
val filteredMap = numbersMap.filter { (key, value) -> key.endsWith("1") && value > 10}
println(filteredMap)
//sampleEnd
}
```
The predicates in `filter()` can only check the values of the elements. If you want to use element positions in the filter, use [`filterIndexed()`](../api/latest/jvm/stdlib/kotlin.collections/filter-indexed). It takes a predicate with two arguments: the index and the value of an element.
To filter collections by negative conditions, use [`filterNot()`](../api/latest/jvm/stdlib/kotlin.collections/filter-not). It returns a list of elements for which the predicate yields `false`.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val filteredIdx = numbers.filterIndexed { index, s -> (index != 0) && (s.length < 5) }
val filteredNot = numbers.filterNot { it.length <= 3 }
println(filteredIdx)
println(filteredNot)
//sampleEnd
}
```
There are also functions that narrow the element type by filtering elements of a given type:
* [`filterIsInstance()`](../api/latest/jvm/stdlib/kotlin.collections/filter-is-instance) returns collection elements of a given type. Being called on a `List<Any>`, `filterIsInstance<T>()` returns a `List<T>`, thus allowing you to call functions of the `T` type on its items.
```
fun main() {
//sampleStart
val numbers = listOf(null, 1, "two", 3.0, "four")
println("All String elements in upper case:")
numbers.filterIsInstance<String>().forEach {
println(it.uppercase())
}
//sampleEnd
}
```
* [`filterNotNull()`](../api/latest/jvm/stdlib/kotlin.collections/filter-not-null) returns all non-null elements. Being called on a `List<T?>`, `filterNotNull()` returns a `List<T: Any>`, thus allowing you to treat the elements as non-null objects.
```
fun main() {
//sampleStart
val numbers = listOf(null, "one", "two", null)
numbers.filterNotNull().forEach {
println(it.length) // length is unavailable for nullable Strings
}
//sampleEnd
}
```
Partition
---------
Another filtering function – [`partition()`](../api/latest/jvm/stdlib/kotlin.collections/partition) – filters a collection by a predicate and keeps the elements that don't match it in a separate list. So, you have a `Pair` of `List`s as a return value: the first list containing elements that match the predicate and the second one containing everything else from the original collection.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val (match, rest) = numbers.partition { it.length > 3 }
println(match)
println(rest)
//sampleEnd
}
```
Test predicates
---------------
Finally, there are functions that simply test a predicate against collection elements:
* [`any()`](../api/latest/jvm/stdlib/kotlin.collections/any) returns `true` if at least one element matches the given predicate.
* [`none()`](../api/latest/jvm/stdlib/kotlin.collections/none) returns `true` if none of the elements match the given predicate.
* [`all()`](../api/latest/jvm/stdlib/kotlin.collections/all) returns `true` if all elements match the given predicate. Note that `all()` returns `true` when called with any valid predicate on an empty collection. Such behavior is known in logic as *[vacuous truth](https://en.wikipedia.org/wiki/Vacuous_truth)*.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
println(numbers.any { it.endsWith("e") })
println(numbers.none { it.endsWith("a") })
println(numbers.all { it.endsWith("e") })
println(emptyList<Int>().all { it > 5 }) // vacuous truth
//sampleEnd
}
```
`any()` and `none()` can also be used without a predicate: in this case they just check the collection emptiness. `any()` returns `true` if there are elements and `false` if there aren't; `none()` does the opposite.
```
fun main() {
//sampleStart
val numbers = listOf("one", "two", "three", "four")
val empty = emptyList<String>()
println(numbers.any())
println(empty.any())
println(numbers.none())
println(empty.none())
//sampleEnd
}
```
Last modified: 10 January 2023
[Collection transformation operations](collection-transformations) [Plus and minus operators](collection-plus-minus)
kotlin CocoaPods Gradle plugin DSL reference CocoaPods Gradle plugin DSL reference
=====================================
Kotlin CocoaPods Gradle plugin is a tool for creating Podspec files. These files are necessary to integrate your Kotlin project with the [CocoaPods dependency manager](https://cocoapods.org/).
This reference contains the complete list of blocks, functions, and properties for the Kotlin CocoaPods Gradle plugin that you can use when working with the [CocoaPods integration](native-cocoapods).
* Learn how to [set up the environment](native-cocoapods#set-up-an-environment-to-work-with-cocoapods) and [configure the Kotlin CocoaPods Gradle plugin](native-cocoapods#add-and-configure-kotlin-cocoapods-gradle-plugin).
* Depending on your project and purposes, you can add dependencies between [a Kotlin project and a Pod library](native-cocoapods-libraries) as well as [a Kotlin Gradle project and an Xcode project](native-cocoapods-xcode).
Enable the plugin
-----------------
To apply the CocoaPods plugin, add the following lines to the `build.gradle(.kts)` file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
kotlin("native.cocoapods") version "1.8.0"
}
```
The plugin versions match the [Kotlin release versions](releases). The latest stable version is 1.8.0.
cocoapods block
---------------
The `cocoapods` block is the top-level block for the CocoaPods configuration. It contains general information on the Pod, including required information like the Pod version, summary, and homepage, as well as optional features.
You can use the following blocks, functions, and properties inside it:
| **Name** | **Description** |
| --- | --- |
| `version` | The version of the Pod. If this is not specified, a Gradle project version is used. If none of these properties are configured, you'll get an error. |
| `summary` | A required description of the Pod built from this project. |
| `homepage` | A required link to the homepage of the Pod built from this project. |
| `authors` | Specifies authors of the Pod built from this project. |
| `podfile` | Configures the existing `Podfile` file. |
| `noPodspec()` | Sets up the plugin not to produce a Podspec file for the `cocoapods` section. |
| `useLibraries()` | Sets up `cocoapods-generate` to produce `xcodeproj` compatible with static libraries. |
| `name` | The name of the Pod built from this project. If not provided, the project name is used. |
| `license` | The license of the Pod built from this project, its type, and the text. |
| `framework` | The framework block configures the framework produced by the plugin. |
| `source` | The location of the Pod built from this project. |
| `extraSpecAttributes` | Configures other Podspec attributes like `libraries` or `vendored_frameworks`. |
| `xcodeConfigurationToNativeBuildType` | Maps custom Xcode configuration to NativeBuildType: "Debug" to `NativeBuildType.DEBUG` and "Release" to `NativeBuildType.RELEASE`. |
| `publishDir` | Configures the output directory for Pod publishing. |
| `pods` | Returns a list of Pod dependencies. |
| `pod()` | Adds a CocoaPods dependency to the Pod built from this project. |
| `specRepos` | Adds a specification repository using `url()`. This is necessary when a private Pod is used as a dependency. See the [CocoaPods documentation](https://guides.cocoapods.org/making/private-cocoapods.html) for more information. |
### Targets
* `ios`
* `osx`
* `tvos`
* `watchos`
For each target, use the `deploymentTarget` property to specify the minimum target version for the Pod library.
When applied, CocoaPods adds both `debug` and `release` frameworks as output binaries for all of the targets.
```
kotlin {
ios()
cocoapods {
version = "2.0"
name = "MyCocoaPod"
summary = "CocoaPods test library"
homepage = "https://github.com/JetBrains/kotlin"
extraSpecAttributes["vendored_frameworks"] = 'CustomFramework.xcframework'
license = "{ :type => 'MIT', :text => 'License text'}"
source = "{ :git => '[email protected]:vkormushkin/kmmpodlibrary.git', :tag => '$version' }"
authors = "Kotlin Dev"
specRepos {
url("https://github.com/Kotlin/kotlin-cocoapods-spec.git")
}
pod("example")
xcodeConfigurationToNativeBuildType["CUSTOM_RELEASE"] = NativeBuildType.RELEASE
}
}
```
### framework() block
The `framework` block is nested inside `cocoapods` and configures the framework properties of the Pod built from the project.
| **Name** | **Description** |
| --- | --- |
| `baseName` | A required framework name. Use this property instead of the deprecated `frameworkName`. |
| `isStatic` | Defines the framework linking type. It's dynamic by default. |
| `transitiveExport` | Enables dependency export. |
```
kotlin {
cocoapods {
framework {
baseName = "MyFramework"
isStatic = false
export(project(":anotherKMMModule"))
transitiveExport = true
}
}
}
```
pod() function
--------------
The `pod()` function call adds a CocoaPods dependency to the Pod built from this project. Each dependency requires a separate function call.
You can specify the name of a Pod library in the function parameters and additional parameter values, like the `version` and `source` of the library, in its configuration block.
| **Name** | **Description** |
| --- | --- |
| `version` | The library version. To use the latest version of the library, omit the parameter. |
| `source` | Configures the Pod from: * The Git repository using `git()`. In the block after `git()`, you can specify `commit` to use a specific commit, `tag` to use a specific tag, and `branch` to use a specific branch from the repository
* The local repository using `path()`
* An archived (tar, jar, zip) Pod folder using `url()`
|
| `packageName` | Specifies the package name. |
| `extraOpts` | Specifies the list of options for a Pod library. For example, specific flags:
```
extraOpts = listOf("-compiler-option")
```
. |
```
kotlin {
ios()
cocoapods {
summary = "CocoaPods test library"
homepage = "https://github.com/JetBrains/kotlin"
ios.deploymentTarget = "13.5"
pod("pod_dependency") {
version = "1.0"
source = path(project.file("../pod_dependency"))
}
}
}
```
Last modified: 10 January 2023
[Use a Kotlin Gradle project as a CocoaPods dependency](native-cocoapods-xcode) [Kotlin/Native libraries](native-libraries)
kotlin Kotlin Koans Kotlin Koans
============
Kotlin Koans are a series of exercises designed primarily for Java developers, to help you become familiar with the Kotlin syntax. Each exercise is created as a failing unit test, and your job is to make it pass. You can complete the Kotlin Koans tasks in one of the following ways:
* You can play with [Koans online](https://play.kotlinlang.org/koans).
* You can perform the tasks right inside IntelliJ IDEA or Android Studio by [installing the EduTools plugin](https://plugins.jetbrains.com/plugin/10081-edutools/docs/install-edutools-plugin.html) and [choosing the Kotlin Koans course](https://plugins.jetbrains.com/plugin/10081-edutools/docs/learner-start-guide.html?section=Kotlin%20Koans).
Whatever way you choose to solve koans, you can see the solution for each task:
* In the online version, click **Show answer**.
* For the EduTools plugin, try to complete the task first and then choose **Peek solution** if your answer is incorrect.
We recommend you check the solution after implementing the task to compare your answer with the proposed one. Make sure you don't cheat!
Last modified: 10 January 2023
[Learning materials overview](learning-materials-overview) [Kotlin tips](kotlin-tips)
kotlin Basic syntax Basic syntax
============
This is a collection of basic syntax elements with examples. At the end of every section, you'll find a link to a detailed description of the related topic.
You can also learn all the Kotlin essentials with the free [Kotlin Basics track](https://hyperskill.org/join/fromdocstoJetSalesStat?redirect=true&next=/tracks/18) on JetBrains Academy.
Package definition and imports
------------------------------
Package specification should be at the top of the source file.
```
package my.demo
import kotlin.text.*
// ...
```
It is not required to match directories and packages: source files can be placed arbitrarily in the file system.
See [Packages](packages).
Program entry point
-------------------
An entry point of a Kotlin application is the `main` function.
```
fun main() {
println("Hello world!")
}
```
Another form of `main` accepts a variable number of `String` arguments.
```
fun main(args: Array<String>) {
println(args.contentToString())
}
```
Print to the standard output
----------------------------
`print` prints its argument to the standard output.
```
fun main() {
//sampleStart
print("Hello ")
print("world!")
//sampleEnd
}
```
`println` prints its arguments and adds a line break, so that the next thing you print appears on the next line.
```
fun main() {
//sampleStart
println("Hello world!")
println(42)
//sampleEnd
}
```
Functions
---------
A function with two `Int` parameters and `Int` return type.
```
//sampleStart
fun sum(a: Int, b: Int): Int {
return a + b
}
//sampleEnd
fun main() {
print("sum of 3 and 5 is ")
println(sum(3, 5))
}
```
A function body can be an expression. Its return type is inferred.
```
//sampleStart
fun sum(a: Int, b: Int) = a + b
//sampleEnd
fun main() {
println("sum of 19 and 23 is ${sum(19, 23)}")
}
```
A function that returns no meaningful value.
```
//sampleStart
fun printSum(a: Int, b: Int): Unit {
println("sum of $a and $b is ${a + b}")
}
//sampleEnd
fun main() {
printSum(-1, 8)
}
```
`Unit` return type can be omitted.
```
//sampleStart
fun printSum(a: Int, b: Int) {
println("sum of $a and $b is ${a + b}")
}
//sampleEnd
fun main() {
printSum(-1, 8)
}
```
See [Functions](functions).
Variables
---------
Read-only local variables are defined using the keyword `val`. They can be assigned a value only once.
```
fun main() {
//sampleStart
val a: Int = 1 // immediate assignment
val b = 2 // `Int` type is inferred
val c: Int // Type required when no initializer is provided
c = 3 // deferred assignment
//sampleEnd
println("a = $a, b = $b, c = $c")
}
```
Variables that can be reassigned use the `var` keyword.
```
fun main() {
//sampleStart
var x = 5 // `Int` type is inferred
x += 1
//sampleEnd
println("x = $x")
}
```
You can declare variables at the top level.
```
//sampleStart
val PI = 3.14
var x = 0
fun incrementX() {
x += 1
}
//sampleEnd
fun main() {
println("x = $x; PI = $PI")
incrementX()
println("incrementX()")
println("x = $x; PI = $PI")
}
```
See also [Properties](properties).
Creating classes and instances
------------------------------
To define a class, use the `class` keyword.
```
class Shape
```
Properties of a class can be listed in its declaration or body.
```
class Rectangle(var height: Double, var length: Double) {
var perimeter = (height + length) * 2
}
```
The default constructor with parameters listed in the class declaration is available automatically.
```
class Rectangle(var height: Double, var length: Double) {
var perimeter = (height + length) * 2
}
fun main() {
//sampleStart
val rectangle = Rectangle(5.0, 2.0)
println("The perimeter is ${rectangle.perimeter}")
//sampleEnd
}
```
Inheritance between classes is declared by a colon (`:`). Classes are final by default; to make a class inheritable, mark it as `open`.
```
open class Shape
class Rectangle(var height: Double, var length: Double): Shape() {
var perimeter = (height + length) * 2
}
```
See <classes> and [objects and instances](object-declarations).
Comments
--------
Just like most modern languages, Kotlin supports single-line (or *end-of-line*) and multi-line (*block*) comments.
```
// This is an end-of-line comment
/* This is a block comment
on multiple lines. */
```
Block comments in Kotlin can be nested.
```
/* The comment starts here
/* contains a nested comment */
and ends here. */
```
See [Documenting Kotlin Code](kotlin-doc) for information on the documentation comment syntax.
String templates
----------------
```
fun main() {
//sampleStart
var a = 1
// simple name in template:
val s1 = "a is $a"
a = 2
// arbitrary expression in template:
val s2 = "${s1.replace("is", "was")}, but now is $a"
//sampleEnd
println(s2)
}
```
See [String templates](strings#string-templates) for details.
Conditional expressions
-----------------------
```
//sampleStart
fun maxOf(a: Int, b: Int): Int {
if (a > b) {
return a
} else {
return b
}
}
//sampleEnd
fun main() {
println("max of 0 and 42 is ${maxOf(0, 42)}")
}
```
In Kotlin, `if` can also be used as an expression.
```
//sampleStart
fun maxOf(a: Int, b: Int) = if (a > b) a else b
//sampleEnd
fun main() {
println("max of 0 and 42 is ${maxOf(0, 42)}")
}
```
See [`if`-expressions](control-flow#if-expression).
for loop
--------
```
fun main() {
//sampleStart
val items = listOf("apple", "banana", "kiwifruit")
for (item in items) {
println(item)
}
//sampleEnd
}
```
or
```
fun main() {
//sampleStart
val items = listOf("apple", "banana", "kiwifruit")
for (index in items.indices) {
println("item at $index is ${items[index]}")
}
//sampleEnd
}
```
See [for loop](control-flow#for-loops).
while loop
----------
```
fun main() {
//sampleStart
val items = listOf("apple", "banana", "kiwifruit")
var index = 0
while (index < items.size) {
println("item at $index is ${items[index]}")
index++
}
//sampleEnd
}
```
See [while loop](control-flow#while-loops).
when expression
---------------
```
//sampleStart
fun describe(obj: Any): String =
when (obj) {
1 -> "One"
"Hello" -> "Greeting"
is Long -> "Long"
!is String -> "Not a string"
else -> "Unknown"
}
//sampleEnd
fun main() {
println(describe(1))
println(describe("Hello"))
println(describe(1000L))
println(describe(2))
println(describe("other"))
}
```
See [when expression](control-flow#when-expression).
Ranges
------
Check if a number is within a range using `in` operator.
```
fun main() {
//sampleStart
val x = 10
val y = 9
if (x in 1..y+1) {
println("fits in range")
}
//sampleEnd
}
```
Check if a number is out of range.
```
fun main() {
//sampleStart
val list = listOf("a", "b", "c")
if (-1 !in 0..list.lastIndex) {
println("-1 is out of range")
}
if (list.size !in list.indices) {
println("list size is out of valid list indices range, too")
}
//sampleEnd
}
```
Iterate over a range.
```
fun main() {
//sampleStart
for (x in 1..5) {
print(x)
}
//sampleEnd
}
```
Or over a progression.
```
fun main() {
//sampleStart
for (x in 1..10 step 2) {
print(x)
}
println()
for (x in 9 downTo 0 step 3) {
print(x)
}
//sampleEnd
}
```
See [Ranges and progressions](ranges).
Collections
-----------
Iterate over a collection.
```
fun main() {
val items = listOf("apple", "banana", "kiwifruit")
//sampleStart
for (item in items) {
println(item)
}
//sampleEnd
}
```
Check if a collection contains an object using `in` operator.
```
fun main() {
val items = setOf("apple", "banana", "kiwifruit")
//sampleStart
when {
"orange" in items -> println("juicy")
"apple" in items -> println("apple is fine too")
}
//sampleEnd
}
```
Using lambda expressions to filter and map collections:
```
fun main() {
//sampleStart
val fruits = listOf("banana", "avocado", "apple", "kiwifruit")
fruits
.filter { it.startsWith("a") }
.sortedBy { it }
.map { it.uppercase() }
.forEach { println(it) }
//sampleEnd
}
```
See [Collections overview](collections-overview).
Nullable values and null checks
-------------------------------
A reference must be explicitly marked as nullable when `null` value is possible. Nullable type names have `?` at the end.
Return `null` if `str` does not hold an integer:
```
fun parseInt(str: String): Int? {
// ...
}
```
Use a function returning nullable value:
```
fun parseInt(str: String): Int? {
return str.toIntOrNull()
}
//sampleStart
fun printProduct(arg1: String, arg2: String) {
val x = parseInt(arg1)
val y = parseInt(arg2)
// Using `x * y` yields error because they may hold nulls.
if (x != null && y != null) {
// x and y are automatically cast to non-nullable after null check
println(x * y)
}
else {
println("'$arg1' or '$arg2' is not a number")
}
}
//sampleEnd
fun main() {
printProduct("6", "7")
printProduct("a", "7")
printProduct("a", "b")
}
```
or
```
fun parseInt(str: String): Int? {
return str.toIntOrNull()
}
fun printProduct(arg1: String, arg2: String) {
val x = parseInt(arg1)
val y = parseInt(arg2)
//sampleStart
// ...
if (x == null) {
println("Wrong number format in arg1: '$arg1'")
return
}
if (y == null) {
println("Wrong number format in arg2: '$arg2'")
return
}
// x and y are automatically cast to non-nullable after null check
println(x * y)
//sampleEnd
}
fun main() {
printProduct("6", "7")
printProduct("a", "7")
printProduct("99", "b")
}
```
See [Null-safety](null-safety).
Type checks and automatic casts
-------------------------------
The `is` operator checks if an expression is an instance of a type. If an immutable local variable or property is checked for a specific type, there's no need to cast it explicitly:
```
//sampleStart
fun getStringLength(obj: Any): Int? {
if (obj is String) {
// `obj` is automatically cast to `String` in this branch
return obj.length
}
// `obj` is still of type `Any` outside of the type-checked branch
return null
}
//sampleEnd
fun main() {
fun printLength(obj: Any) {
println("Getting the length of '$obj'. Result: ${getStringLength(obj) ?: "Error: The object is not a string"} ")
}
printLength("Incomprehensibilities")
printLength(1000)
printLength(listOf(Any()))
}
```
or
```
//sampleStart
fun getStringLength(obj: Any): Int? {
if (obj !is String) return null
// `obj` is automatically cast to `String` in this branch
return obj.length
}
//sampleEnd
fun main() {
fun printLength(obj: Any) {
println("Getting the length of '$obj'. Result: ${getStringLength(obj) ?: "Error: The object is not a string"} ")
}
printLength("Incomprehensibilities")
printLength(1000)
printLength(listOf(Any()))
}
```
or even
```
//sampleStart
fun getStringLength(obj: Any): Int? {
// `obj` is automatically cast to `String` on the right-hand side of `&&`
if (obj is String && obj.length > 0) {
return obj.length
}
return null
}
//sampleEnd
fun main() {
fun printLength(obj: Any) {
println("Getting the length of '$obj'. Result: ${getStringLength(obj) ?: "Error: The object is not a string"} ")
}
printLength("Incomprehensibilities")
printLength("")
printLength(1000)
}
```
See [Classes](classes) and [Type casts](typecasts).
Last modified: 10 January 2023
[Configure your build for EAP](configure-build-for-eap) [Idioms](idioms)
| programming_docs |
kotlin Interoperability with C Interoperability with C
=======================
Kotlin/Native follows the general tradition of Kotlin to provide excellent existing platform software interoperability. In the case of a native platform, the most important interoperability target is a C library. So Kotlin/Native comes with a `cinterop` tool, which can be used to quickly generate everything needed to interact with an external library.
The following workflow is expected when interacting with the native library:
1. Create a `.def` file describing what to include into bindings.
2. Use the `cinterop` tool to produce Kotlin bindings.
3. Run the Kotlin/Native compiler on an application to produce the final executable.
The interoperability tool analyses C headers and produces a "natural" mapping of the types, functions, and constants into the Kotlin world. The generated stubs can be imported into an IDE for the purpose of code completion and navigation.
Interoperability with Swift/Objective-C is provided too and covered in [Objective-C interop](native-objc-interop).
Platform libraries
------------------
Note that in many cases there's no need to use custom interoperability library creation mechanisms described below, as for APIs available on the platform standardized bindings called [platform libraries](native-platform-libs) could be used. For example, POSIX on Linux/macOS platforms, Win32 on Windows platform, or Apple frameworks on macOS/iOS are available this way.
Simple example
--------------
Install libgit2 and prepare stubs for the git library:
```
cd samples/gitchurn
../../dist/bin/cinterop -def src/nativeInterop/cinterop/libgit2.def \
-compiler-option -I/usr/local/include -o libgit2
```
Compile the client:
```
../../dist/bin/kotlinc src/gitChurnMain/kotlin \
-library libgit2 -o GitChurn
```
Run the client:
```
./GitChurn.kexe ../..
```
Create bindings for a new library
---------------------------------
To create bindings for a new library, start from creating a `.def` file. Structurally it's a simple property file, which looks like this:
```
headers = png.h
headerFilter = png.h
package = png
```
Then run the `cinterop` tool with something like this (note that for host libraries that are not included in the sysroot search paths, headers may be needed):
```
cinterop -def png.def -compiler-option -I/usr/local/include -o png
```
This command will produce a `png.klib` compiled library and `png-build/kotlin` directory containing Kotlin source code for the library.
If the behavior for a certain platform needs to be modified, you can use a format like `compilerOpts.osx` or `compilerOpts.linux` to provide platform-specific values to the options.
Note that the generated bindings are generally platform-specific, so if you are developing for multiple targets, the bindings need to be regenerated.
After the generation of bindings, they can be used by the IDE as a proxy view of the native library.
For a typical Unix library with a config script, the `compilerOpts` will likely contain the output of a config script with the `--cflags` flag (maybe without exact paths).
The output of a config script with `--libs` will be passed as a `-linkedArgs` `kotlinc` flag value (quoted) when compiling.
### Select library headers
When library headers are imported to a C program with the `#include` directive, all of the headers included by these headers are also included in the program. So all header dependencies are included in generated stubs as well.
This behavior is correct but it can be very inconvenient for some libraries. So it is possible to specify in the `.def` file which of the included headers are to be imported. The separate declarations from other headers can also be imported in case of direct dependencies.
#### Filter headers by globs
It is possible to filter headers by globs using filter properties from the `.def` file. They are treated as a space-separated list of globs.
* To include declarations from headers, use the `headerFilter` property. If the included header matches any of the globs, the declarations are included in the bindings.
The globs are applied to the header paths relative to the appropriate include path elements, for example, `time.h` or `curl/curl.h`. So if the library is usually included with `#include <SomeLibrary/Header.h>`, it would probably be correct to filter headers with the following filter:
```
headerFilter = SomeLibrary/**
```
If `headerFilter` is not provided, all the headers are included. However, we encourage you to use `headerFilter` and specify the glob as precisely as possible. In this case, the generated library contains only the necessary declarations. It can help avoid various issues when upgrading Kotlin or tools in your development environment.
* To exclude specific headers, use the `excludeFilter` property.
It can be helpful to remove redundant or problematic headers and optimize compilation, as declarations from the specified headers are not included into the bindings.
```
excludeFilter = SomeLibrary/time.h
```
#### Filter headers by module maps
Some libraries have proper `module.modulemap` or `module.map` files in their headers. For example, macOS and iOS system libraries and frameworks do. The [module map file](https://clang.llvm.org/docs/Modules.html#module-map-language) describes the correspondence between header files and modules. When the module maps are available, the headers from the modules that are not included directly can be filtered out using the experimental `excludeDependentModules` option of the `.def` file:
```
headers = OpenGL/gl.h OpenGL/glu.h GLUT/glut.h
compilerOpts = -framework OpenGL -framework GLUT
excludeDependentModules = true
```
When both `excludeDependentModules` and `headerFilter` are used, they are applied as an intersection.
### C compiler and linker options
Options passed to the C compiler (used to analyze headers, such as preprocessor definitions) and the linker (used to link final executables) can be passed in the definition file as `compilerOpts` and `linkerOpts` respectively. For example:
```
compilerOpts = -DFOO=bar
linkerOpts = -lpng
```
Target-specific options only applicable to the certain target can be specified as well:
```
compilerOpts = -DBAR=bar
compilerOpts.linux_x64 = -DFOO=foo1
compilerOpts.mac_x64 = -DFOO=foo2
```
With such a configuration, C headers will be analyzed with `-DBAR=bar -DFOO=foo1` on Linux and with `-DBAR=bar -DFOO=foo2` on macOS . Note that any definition file option can have both common and the platform-specific part.
### Add custom declarations
Sometimes it is required to add custom C declarations to the library before generating bindings (e.g., for [macros](#macros)). Instead of creating an additional header file with these declarations, you can include them directly to the end of the `.def` file, after a separating line, containing only the separator sequence `---`:
```
headers = errno.h
---
static inline int getErrno() {
return errno;
}
```
Note that this part of the `.def` file is treated as part of the header file, so functions with the body should be declared as `static`. The declarations are parsed after including the files from the `headers` list.
### Include a static library in your klib
Sometimes it is more convenient to ship a static library with your product, rather than assume it is available within the user's environment. To include a static library into `.klib` use `staticLibrary` and `libraryPaths` clauses. For example:
```
headers = foo.h
staticLibraries = libfoo.a
libraryPaths = /opt/local/lib /usr/local/opt/curl/lib
```
When given the above snippet the `cinterop` tool will search `libfoo.a` in `/opt/local/lib` and `/usr/local/opt/curl/lib`, and if it is found include the library binary into `klib`.
When using such `klib` in your program, the library is linked automatically.
Bindings
--------
### Basic interop types
All the supported C types have corresponding representations in Kotlin:
* Signed, unsigned integral, and floating point types are mapped to their Kotlin counterpart with the same width.
* Pointers and arrays are mapped to `CPointer<T>?`.
* Enums can be mapped to either Kotlin enum or integral values, depending on heuristics and the [definition file hints](#definition-file-hints).
* Structs and unions are mapped to types having fields available via the dot notation, i.e. `someStructInstance.field1`.
* `typedef` are represented as `typealias`.
Also, any C type has the Kotlin type representing the lvalue of this type, i.e., the value located in memory rather than a simple immutable self-contained value. Think C++ references, as a similar concept. For structs (and `typedef`s to structs) this representation is the main one and has the same name as the struct itself, for Kotlin enums it is named `${type}Var`, for `CPointer<T>` it is `CPointerVar<T>`, and for most other types it is `${type}Var`.
For types that have both representations, the one with a "lvalue" has a mutable `.value` property for accessing the value.
#### Pointer types
The type argument `T` of `CPointer<T>` must be one of the "lvalue" types described above, e.g., the C type `struct S*` is mapped to `CPointer<S>`, `int8_t*` is mapped to `CPointer<int_8tVar>`, and `char**` is mapped to `CPointer<CPointerVar<ByteVar>>`.
C null pointer is represented as Kotlin's `null`, and the pointer type `CPointer<T>` is not nullable, but the `CPointer<T>?` is. The values of this type support all the Kotlin operations related to handling `null`, e.g. `?:`, `?.`, `!!` etc.:
```
val path = getenv("PATH")?.toKString() ?: ""
```
Since the arrays are also mapped to `CPointer<T>`, it supports the `[]` operator for accessing values by index:
```
fun shift(ptr: CPointer<BytePtr>, length: Int) {
for (index in 0 .. length - 2) {
ptr[index] = ptr[index + 1]
}
}
```
The `.pointed` property for `CPointer<T>` returns the lvalue of type `T`, pointed by this pointer. The reverse operation is `.ptr`: it takes the lvalue and returns the pointer to it.
`void*` is mapped to `COpaquePointer` – the special pointer type which is the supertype for any other pointer type. So if the C function takes `void*`, then the Kotlin binding accepts any `CPointer`.
Casting a pointer (including `COpaquePointer`) can be done with `.reinterpret<T>`, e.g.:
```
val intPtr = bytePtr.reinterpret<IntVar>()
```
or
```
val intPtr: CPointer<IntVar> = bytePtr.reinterpret()
```
As is with C, these reinterpret casts are unsafe and can potentially lead to subtle memory problems in the application.
Also, there are unsafe casts between `CPointer<T>?` and `Long` available, provided by the `.toLong()` and `.toCPointer<T>()` extension methods:
```
val longValue = ptr.toLong()
val originalPtr = longValue.toCPointer<T>()
```
Note that if the type of the result is known from the context, the type argument can be omitted as usual due to the type inference.
### Memory allocation
The native memory can be allocated using the `NativePlacement` interface, e.g.
```
val byteVar = placement.alloc<ByteVar>()
```
or
```
val bytePtr = placement.allocArray<ByteVar>(5)
```
The most "natural" placement is in the object `nativeHeap`. It corresponds to allocating native memory with `malloc` and provides an additional `.free()` operation to free allocated memory:
```
val buffer = nativeHeap.allocArray<ByteVar>(size)
<use buffer>
nativeHeap.free(buffer)
```
However, the lifetime of allocated memory is often bound to the lexical scope. It is possible to define such scope with `memScoped { ... }`. Inside the braces, the temporary placement is available as an implicit receiver, so it is possible to allocate native memory with `alloc` and `allocArray`, and the allocated memory will be automatically freed after leaving the scope.
For example, the C function returning values through pointer parameters can be used like
```
val fileSize = memScoped {
val statBuf = alloc<stat>()
val error = stat("/", statBuf.ptr)
statBuf.st_size
}
```
### Pass pointers to bindings
Although C pointers are mapped to the `CPointer<T>` type, the C function pointer-typed parameters are mapped to `CValuesRef<T>`. When passing `CPointer<T>` as the value of such a parameter, it is passed to the C function as is. However, the sequence of values can be passed instead of a pointer. In this case the sequence is passed "by value", i.e., the C function receives the pointer to the temporary copy of that sequence, which is valid only until the function returns.
The `CValuesRef<T>` representation of pointer parameters is designed to support C array literals without explicit native memory allocation. To construct the immutable self-contained sequence of C values, the following methods are provided:
* `${type}Array.toCValues()`, where `type` is the Kotlin primitive type
* `Array<CPointer<T>?>.toCValues()`, `List<CPointer<T>?>.toCValues()`
* `cValuesOf(vararg elements: ${type})`, where `type` is a primitive or pointer
For example:
C:
```
void foo(int* elements, int count);
...
int elements[] = {1, 2, 3};
foo(elements, 3);
```
Kotlin:
```
foo(cValuesOf(1, 2, 3), 3)
```
### Strings
Unlike other pointers, the parameters of type `const char*` are represented as a Kotlin `String`. So it is possible to pass any Kotlin string to a binding expecting a C string.
There are also some tools available to convert between Kotlin and C strings manually:
* `fun CPointer<ByteVar>.toKString(): String`
* `val String.cstr: CValuesRef<ByteVar>`.
To get the pointer, `.cstr` should be allocated in native memory, e.g.
`val cString = kotlinString.cstr.getPointer(nativeHeap)`
In all cases, the C string is supposed to be encoded as UTF-8.
To skip automatic conversion and ensure raw pointers are used in the bindings, a `noStringConversion` statement in the `.def` file could be used, i.e.
```
noStringConversion = LoadCursorA LoadCursorW
```
This way any value of type `CPointer<ByteVar>` can be passed as an argument of `const char*` type. If a Kotlin string should be passed, code like this could be used:
```
memScoped {
LoadCursorA(null, "cursor.bmp".cstr.ptr) // for ASCII version
LoadCursorW(null, "cursor.bmp".wcstr.ptr) // for Unicode version
}
```
### Scope-local pointers
It is possible to create a scope-stable pointer of C representation of `CValues<T>` instance using the `CValues<T>.ptr` extension property, available under `memScoped { ... }`. It allows using the APIs which require C pointers with a lifetime bound to a certain `MemScope`. For example:
```
memScoped {
items = arrayOfNulls<CPointer<ITEM>?>(6)
arrayOf("one", "two").forEachIndexed { index, value -> items[index] = value.cstr.ptr }
menu = new_menu("Menu".cstr.ptr, items.toCValues().ptr)
...
}
```
In this example, all values passed to the C API `new_menu()` have a lifetime of the innermost `memScope` it belongs to. Once the control flow leaves the `memScoped` scope the C pointers become invalid.
### Pass and receive structs by value
When a C function takes or returns a struct / union `T` by value, the corresponding argument type or return type is represented as `CValue<T>`.
`CValue<T>` is an opaque type, so the structure fields cannot be accessed with the appropriate Kotlin properties. It should be possible, if an API uses structures as handles, but if field access is required, there are the following conversion methods available:
* `fun T.readValue(): CValue<T>`. Converts (the lvalue) `T` to a `CValue<T>`. So to construct the `CValue<T>`, `T` can be allocated, filled, and then converted to `CValue<T>`.
* `CValue<T>.useContents(block: T.() -> R): R`. Temporarily places the `CValue<T>` to memory, and then runs the passed lambda with this placed value `T` as receiver. So to read a single field, the following code can be used:
```
val fieldValue = structValue.useContents { field }
```
### Callbacks
To convert a Kotlin function to a pointer to a C function, `staticCFunction(::kotlinFunction)` can be used. It is also able to provide the lambda instead of a function reference. The function or lambda must not capture any values.
#### Pass user data to callbacks
Often C APIs allow passing some user data to callbacks. Such data is usually provided by the user when configuring the callback. It is passed to some C function (or written to the struct) as e.g. `void*`. However, references to Kotlin objects can't be directly passed to C. So they require wrapping before configuring the callback and then unwrapping in the callback itself, to safely swim from Kotlin to Kotlin through the C world. Such wrapping is possible with `StableRef` class.
To wrap the reference:
```
val stableRef = StableRef.create(kotlinReference)
val voidPtr = stableRef.asCPointer()
```
where the `voidPtr` is a `COpaquePointer` and can be passed to the C function.
To unwrap the reference:
```
val stableRef = voidPtr.asStableRef<KotlinClass>()
val kotlinReference = stableRef.get()
```
where `kotlinReference` is the original wrapped reference.
The created `StableRef` should eventually be manually disposed using the `.dispose()` method to prevent memory leaks:
```
stableRef.dispose()
```
After that it becomes invalid, so `voidPtr` can't be unwrapped anymore.
See the `samples/libcurl` for more details.
### Macros
Every C macro that expands to a constant is represented as a Kotlin property. Other macros are not supported. However, they can be exposed manually by wrapping them with supported declarations. E.g. function-like macro `FOO` can be exposed as function `foo` by [adding the custom declaration](#add-custom-declarations) to the library:
```
headers = library/base.h
---
static inline int foo(int arg) {
return FOO(arg);
}
```
### Definition file hints
The `.def` file supports several options for adjusting the generated bindings.
* `excludedFunctions` property value specifies a space-separated list of the names of functions that should be ignored. This may be required because a function declared in the C header is not generally guaranteed to be really callable, and it is often hard or impossible to figure this out automatically. This option can also be used to workaround a bug in the interop itself.
* `strictEnums` and `nonStrictEnums` properties values are space-separated lists of the enums that should be generated as a Kotlin enum or as integral values correspondingly. If the enum is not included into any of these lists, then it is generated according to the heuristics.
* `noStringConversion` property value is space-separated lists of the functions whose `const char*` parameters shall not be auto-converted as Kotlin string
### Portability
Sometimes the C libraries have function parameters or struct fields of a platform-dependent type, e.g. `long` or `size_t`. Kotlin itself doesn't provide neither implicit integer casts nor C-style integer casts (e.g. `(size_t) intValue`), so to make writing portable code in such cases easier, the `convert` method is provided:
```
fun ${type1}.convert<${type2}>(): ${type2}
```
where each of `type1` and `type2` must be an integral type, either signed or unsigned.
`.convert<${type}>` has the same semantics as one of the `.toByte`, `.toShort`, `.toInt`, `.toLong`, `.toUByte`, `.toUShort`, `.toUInt` or `.toULong` methods, depending on `type`.
The example of using `convert`:
```
fun zeroMemory(buffer: COpaquePointer, size: Int) {
memset(buffer, 0, size.convert<size_t>())
}
```
Also, the type parameter can be inferred automatically and so may be omitted in some cases.
### Object pinning
Kotlin objects could be pinned, i.e. their position in memory is guaranteed to be stable until unpinned, and pointers to such objects inner data could be passed to the C functions. For example
```
fun readData(fd: Int): String {
val buffer = ByteArray(1024)
buffer.usePinned { pinned ->
while (true) {
val length = recv(fd, pinned.addressOf(0), buffer.size.convert(), 0).toInt()
if (length <= 0) {
break
}
// Now `buffer` has raw data obtained from the `recv()` call.
}
}
}
```
Here we use service function `usePinned`, which pins an object, executes block and unpins it on normal and exception paths.
Last modified: 10 January 2023
[Get started with Kotlin/Native using the command-line compiler](native-command-line-compiler) [Mapping primitive data types from C – tutorial](mapping-primitive-data-types-from-c)
| programming_docs |
kotlin Channels Channels
========
Deferred values provide a convenient way to transfer a single value between coroutines. Channels provide a way to transfer a stream of values.
Channel basics
--------------
A [Channel](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-channel/index.html) is conceptually very similar to `BlockingQueue`. One key difference is that instead of a blocking `put` operation it has a suspending [send](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-send-channel/send.html), and instead of a blocking `take` operation it has a suspending [receive](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-receive-channel/receive.html).
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val channel = Channel<Int>()
launch {
// this might be heavy CPU-consuming computation or async logic, we'll just send five squares
for (x in 1..5) channel.send(x * x)
}
// here we print five received integers:
repeat(5) { println(channel.receive()) }
println("Done!")
//sampleEnd
}
```
The output of this code is:
```
1
4
9
16
25
Done!
```
Closing and iteration over channels
-----------------------------------
Unlike a queue, a channel can be closed to indicate that no more elements are coming. On the receiver side it is convenient to use a regular `for` loop to receive elements from the channel.
Conceptually, a [close](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-send-channel/close.html) is like sending a special close token to the channel. The iteration stops as soon as this close token is received, so there is a guarantee that all previously sent elements before the close are received:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val channel = Channel<Int>()
launch {
for (x in 1..5) channel.send(x * x)
channel.close() // we're done sending
}
// here we print received values using `for` loop (until the channel is closed)
for (y in channel) println(y)
println("Done!")
//sampleEnd
}
```
Building channel producers
--------------------------
The pattern where a coroutine is producing a sequence of elements is quite common. This is a part of *producer-consumer* pattern that is often found in concurrent code. You could abstract such a producer into a function that takes channel as its parameter, but this goes contrary to common sense that results must be returned from functions.
There is a convenient coroutine builder named [produce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/produce.html) that makes it easy to do it right on producer side, and an extension function [consumeEach](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/consume-each.html), that replaces a `for` loop on the consumer side:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun CoroutineScope.produceSquares(): ReceiveChannel<Int> = produce {
for (x in 1..5) send(x * x)
}
fun main() = runBlocking {
//sampleStart
val squares = produceSquares()
squares.consumeEach { println(it) }
println("Done!")
//sampleEnd
}
```
Pipelines
---------
A pipeline is a pattern where one coroutine is producing, possibly infinite, stream of values:
```
fun CoroutineScope.produceNumbers() = produce<Int> {
var x = 1
while (true) send(x++) // infinite stream of integers starting from 1
}
```
And another coroutine or coroutines are consuming that stream, doing some processing, and producing some other results. In the example below, the numbers are just squared:
```
fun CoroutineScope.square(numbers: ReceiveChannel<Int>): ReceiveChannel<Int> = produce {
for (x in numbers) send(x * x)
}
```
The main code starts and connects the whole pipeline:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val numbers = produceNumbers() // produces integers from 1 and on
val squares = square(numbers) // squares integers
repeat(5) {
println(squares.receive()) // print first five
}
println("Done!") // we are done
coroutineContext.cancelChildren() // cancel children coroutines
//sampleEnd
}
fun CoroutineScope.produceNumbers() = produce<Int> {
var x = 1
while (true) send(x++) // infinite stream of integers starting from 1
}
fun CoroutineScope.square(numbers: ReceiveChannel<Int>): ReceiveChannel<Int> = produce {
for (x in numbers) send(x * x)
}
```
Prime numbers with pipeline
---------------------------
Let's take pipelines to the extreme with an example that generates prime numbers using a pipeline of coroutines. We start with an infinite sequence of numbers.
```
fun CoroutineScope.numbersFrom(start: Int) = produce<Int> {
var x = start
while (true) send(x++) // infinite stream of integers from start
}
```
The following pipeline stage filters an incoming stream of numbers, removing all the numbers that are divisible by the given prime number:
```
fun CoroutineScope.filter(numbers: ReceiveChannel<Int>, prime: Int) = produce<Int> {
for (x in numbers) if (x % prime != 0) send(x)
}
```
Now we build our pipeline by starting a stream of numbers from 2, taking a prime number from the current channel, and launching new pipeline stage for each prime number found:
```
numbersFrom(2) -> filter(2) -> filter(3) -> filter(5) -> filter(7) ...
```
The following example prints the first ten prime numbers, running the whole pipeline in the context of the main thread. Since all the coroutines are launched in the scope of the main [runBlocking](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) coroutine we don't have to keep an explicit list of all the coroutines we have started. We use [cancelChildren](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/cancel-children.html) extension function to cancel all the children coroutines after we have printed the first ten prime numbers.
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
var cur = numbersFrom(2)
repeat(10) {
val prime = cur.receive()
println(prime)
cur = filter(cur, prime)
}
coroutineContext.cancelChildren() // cancel all children to let main finish
//sampleEnd
}
fun CoroutineScope.numbersFrom(start: Int) = produce<Int> {
var x = start
while (true) send(x++) // infinite stream of integers from start
}
fun CoroutineScope.filter(numbers: ReceiveChannel<Int>, prime: Int) = produce<Int> {
for (x in numbers) if (x % prime != 0) send(x)
}
```
The output of this code is:
```
2
3
5
7
11
13
17
19
23
29
```
Note that you can build the same pipeline using [`iterator`](../api/latest/jvm/stdlib/kotlin.sequences/iterator) coroutine builder from the standard library. Replace `produce` with `iterator`, `send` with `yield`, `receive` with `next`, `ReceiveChannel` with `Iterator`, and get rid of the coroutine scope. You will not need `runBlocking` either. However, the benefit of a pipeline that uses channels as shown above is that it can actually use multiple CPU cores if you run it in [Dispatchers.Default](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-dispatchers/-default.html) context.
Anyway, this is an extremely impractical way to find prime numbers. In practice, pipelines do involve some other suspending invocations (like asynchronous calls to remote services) and these pipelines cannot be built using `sequence`/`iterator`, because they do not allow arbitrary suspension, unlike `produce`, which is fully asynchronous.
Fan-out
-------
Multiple coroutines may receive from the same channel, distributing work between themselves. Let us start with a producer coroutine that is periodically producing integers (ten numbers per second):
```
fun CoroutineScope.produceNumbers() = produce<Int> {
var x = 1 // start from 1
while (true) {
send(x++) // produce next
delay(100) // wait 0.1s
}
}
```
Then we can have several processor coroutines. In this example, they just print their id and received number:
```
fun CoroutineScope.launchProcessor(id: Int, channel: ReceiveChannel<Int>) = launch {
for (msg in channel) {
println("Processor #$id received $msg")
}
}
```
Now let us launch five processors and let them work for almost a second. See what happens:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking<Unit> {
//sampleStart
val producer = produceNumbers()
repeat(5) { launchProcessor(it, producer) }
delay(950)
producer.cancel() // cancel producer coroutine and thus kill them all
//sampleEnd
}
fun CoroutineScope.produceNumbers() = produce<Int> {
var x = 1 // start from 1
while (true) {
send(x++) // produce next
delay(100) // wait 0.1s
}
}
fun CoroutineScope.launchProcessor(id: Int, channel: ReceiveChannel<Int>) = launch {
for (msg in channel) {
println("Processor #$id received $msg")
}
}
```
The output will be similar to the the following one, albeit the processor ids that receive each specific integer may be different:
```
Processor #2 received 1
Processor #4 received 2
Processor #0 received 3
Processor #1 received 4
Processor #3 received 5
Processor #2 received 6
Processor #4 received 7
Processor #0 received 8
Processor #1 received 9
Processor #3 received 10
```
Note that cancelling a producer coroutine closes its channel, thus eventually terminating iteration over the channel that processor coroutines are doing.
Also, pay attention to how we explicitly iterate over channel with `for` loop to perform fan-out in `launchProcessor` code. Unlike `consumeEach`, this `for` loop pattern is perfectly safe to use from multiple coroutines. If one of the processor coroutines fails, then others would still be processing the channel, while a processor that is written via `consumeEach` always consumes (cancels) the underlying channel on its normal or abnormal completion.
Fan-in
------
Multiple coroutines may send to the same channel. For example, let us have a channel of strings, and a suspending function that repeatedly sends a specified string to this channel with a specified delay:
```
suspend fun sendString(channel: SendChannel<String>, s: String, time: Long) {
while (true) {
delay(time)
channel.send(s)
}
}
```
Now, let us see what happens if we launch a couple of coroutines sending strings (in this example we launch them in the context of the main thread as main coroutine's children):
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val channel = Channel<String>()
launch { sendString(channel, "foo", 200L) }
launch { sendString(channel, "BAR!", 500L) }
repeat(6) { // receive first six
println(channel.receive())
}
coroutineContext.cancelChildren() // cancel all children to let main finish
//sampleEnd
}
suspend fun sendString(channel: SendChannel<String>, s: String, time: Long) {
while (true) {
delay(time)
channel.send(s)
}
}
```
The output is:
```
foo
foo
BAR!
foo
foo
BAR!
```
Buffered channels
-----------------
The channels shown so far had no buffer. Unbuffered channels transfer elements when sender and receiver meet each other (aka rendezvous). If send is invoked first, then it is suspended until receive is invoked, if receive is invoked first, it is suspended until send is invoked.
Both [Channel()](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-channel.html) factory function and [produce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/produce.html) builder take an optional `capacity` parameter to specify *buffer size*. Buffer allows senders to send multiple elements before suspending, similar to the `BlockingQueue` with a specified capacity, which blocks when buffer is full.
Take a look at the behavior of the following code:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking<Unit> {
//sampleStart
val channel = Channel<Int>(4) // create buffered channel
val sender = launch { // launch sender coroutine
repeat(10) {
println("Sending $it") // print before sending each element
channel.send(it) // will suspend when buffer is full
}
}
// don't receive anything... just wait....
delay(1000)
sender.cancel() // cancel sender coroutine
//sampleEnd
}
```
It prints "sending" *five* times using a buffered channel with capacity of *four*:
```
Sending 0
Sending 1
Sending 2
Sending 3
Sending 4
```
The first four elements are added to the buffer and the sender suspends when trying to send the fifth one.
Channels are fair
-----------------
Send and receive operations to channels are *fair* with respect to the order of their invocation from multiple coroutines. They are served in first-in first-out order, e.g. the first coroutine to invoke `receive` gets the element. In the following example two coroutines "ping" and "pong" are receiving the "ball" object from the shared "table" channel.
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
//sampleStart
data class Ball(var hits: Int)
fun main() = runBlocking {
val table = Channel<Ball>() // a shared table
launch { player("ping", table) }
launch { player("pong", table) }
table.send(Ball(0)) // serve the ball
delay(1000) // delay 1 second
coroutineContext.cancelChildren() // game over, cancel them
}
suspend fun player(name: String, table: Channel<Ball>) {
for (ball in table) { // receive the ball in a loop
ball.hits++
println("$name $ball")
delay(300) // wait a bit
table.send(ball) // send the ball back
}
}
//sampleEnd
```
The "ping" coroutine is started first, so it is the first one to receive the ball. Even though "ping" coroutine immediately starts receiving the ball again after sending it back to the table, the ball gets received by the "pong" coroutine, because it was already waiting for it:
```
ping Ball(hits=1)
pong Ball(hits=2)
ping Ball(hits=3)
pong Ball(hits=4)
```
Note that sometimes channels may produce executions that look unfair due to the nature of the executor that is being used. See [this issue](https://github.com/Kotlin/kotlinx.coroutines/issues/111) for details.
Ticker channels
---------------
Ticker channel is a special rendezvous channel that produces `Unit` every time given delay passes since last consumption from this channel. Though it may seem to be useless standalone, it is a useful building block to create complex time-based [produce](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/produce.html) pipelines and operators that do windowing and other time-dependent processing. Ticker channel can be used in [select](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.selects/select.html) to perform "on tick" action.
To create such channel use a factory method [ticker](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/ticker.html). To indicate that no further elements are needed use [ReceiveChannel.cancel](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-receive-channel/cancel.html) method on it.
Now let's see how it works in practice:
```
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
//sampleStart
fun main() = runBlocking<Unit> {
val tickerChannel = ticker(delayMillis = 100, initialDelayMillis = 0) // create ticker channel
var nextElement = withTimeoutOrNull(1) { tickerChannel.receive() }
println("Initial element is available immediately: $nextElement") // no initial delay
nextElement = withTimeoutOrNull(50) { tickerChannel.receive() } // all subsequent elements have 100ms delay
println("Next element is not ready in 50 ms: $nextElement")
nextElement = withTimeoutOrNull(60) { tickerChannel.receive() }
println("Next element is ready in 100 ms: $nextElement")
// Emulate large consumption delays
println("Consumer pauses for 150ms")
delay(150)
// Next element is available immediately
nextElement = withTimeoutOrNull(1) { tickerChannel.receive() }
println("Next element is available immediately after large consumer delay: $nextElement")
// Note that the pause between `receive` calls is taken into account and next element arrives faster
nextElement = withTimeoutOrNull(60) { tickerChannel.receive() }
println("Next element is ready in 50ms after consumer pause in 150ms: $nextElement")
tickerChannel.cancel() // indicate that no more elements are needed
}
//sampleEnd
```
It prints following lines:
```
Initial element is available immediately: kotlin.Unit
Next element is not ready in 50 ms: null
Next element is ready in 100 ms: kotlin.Unit
Consumer pauses for 150ms
Next element is available immediately after large consumer delay: kotlin.Unit
Next element is ready in 50ms after consumer pause in 150ms: kotlin.Unit
```
Note that [ticker](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/ticker.html) is aware of possible consumer pauses and, by default, adjusts next produced element delay if a pause occurs, trying to maintain a fixed rate of produced elements.
Optionally, a `mode` parameter equal to [TickerMode.FIXED\_DELAY](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.channels/-ticker-mode/-f-i-x-e-d_-d-e-l-a-y/index.html) can be specified to maintain a fixed delay between elements.
Last modified: 10 January 2023
[Asynchronous Flow](flow) [Coroutine exceptions handling](exception-handling)
kotlin Concurrent mutability Concurrent mutability
=====================
When it comes to working with iOS, [Kotlin/Native's state and concurrency model](multiplatform-mobile-concurrency-overview) has [two simple rules](multiplatform-mobile-concurrency-overview#rules-for-state-sharing).
1. A mutable, non-frozen state is visible to only one thread at a time.
2. An immutable, frozen state can be shared between threads.
The result of following these rules is that you can't change [global states](multiplatform-mobile-concurrency-overview#global-state), and you can't change the same shared state from multiple threads. In many cases, simply changing your approach to how you design your code will work fine, and you don't need concurrent mutability. States were mutable from multiple threads in JVM code, but they didn't *need* to be.
However, in many other cases, you may need arbitrary thread access to a state, or you may have *service* objects that should be available to the entire application. Or maybe you simply don't want to go through the potentially costly exercise of redesigning existing code. Whatever the reason, *it will not always be feasible to constrain a mutable state to a single thread*.
There are various techniques that help you work around these restrictions, each with their own pros and cons:
* [Atomics](#atomics)
* [Thread-isolated states](#thread-isolated-state)
* [Low-level capabilities](#low-level-capabilities)
Atomics
-------
Kotlin/Native provides a set of Atomic classes that can be frozen while still supporting changes to the value they contain. These classes implement a special-case handling of states in the Kotlin/Native runtime. This means that you can change values inside a frozen state.
The Kotlin/Native runtime includes a few different variations of Atomics. You can use them directly or from a library.
Kotlin provides an experimental low-level [`kotlinx.atomicfu`](https://github.com/Kotlin/kotlinx.atomicfu) library that is currently used only for internal purposes and is not supported for general usage. You can also use [Stately](https://github.com/touchlab/Stately), a utility library for multiplatform compatibility with Kotlin/Native-specific concurrency, developed by [Touchlab](https://touchlab.co).
### AtomicInt/AtomicLong
The first two are simple numerics: `AtomicInt` and `AtomicLong`. They allow you to have a shared `Int` or `Long` that can be read and changed from multiple threads.
```
object AtomicDataCounter {
val count = AtomicInt(3)
fun addOne() {
count.increment()
}
}
```
The example above is a global `object`, which is frozen by default in Kotlin/Native. In this case, however, you can change the value of `count`. It's important to note that you can change the value of `count` *from any thread*.
### AtomicReference
`AtomicReference` holds an object instance, and you can change that object instance. The object you put in `AtomicReference` must be frozen, but you can change the value that `AtomicReference` holds. For example, the following won't work in Kotlin/Native:
```
data class SomeData(val i: Int)
object GlobalData {
var sd = SomeData(0)
fun storeNewValue(i: Int) {
sd = SomeData(i) //Doesn't work
}
}
```
According to the [rules of global state](multiplatform-mobile-concurrency-overview#global-state), global `object` values are frozen in Kotlin/Native, so trying to modify `sd` will fail. You could implement it instead with `AtomicReference`:
```
data class SomeData(val i: Int)
object GlobalData {
val sd = AtomicReference(SomeData(0).freeze())
fun storeNewValue(i: Int) {
sd.value = SomeData(i).freeze()
}
}
```
The `AtomicReference` itself is frozen, which lets it live inside something that is frozen. The data in the `AtomicReference` instance is explicitly frozen in the code above. However, in the multiplatform libraries, the data will be frozen automatically. If you use the Kotlin/Native runtime's `AtomicReference`, you *should* remember to call `freeze()` explicitly.
`AtomicReference` can be very useful when you need to share a state. There are some drawbacks to consider, however.
Accessing and changing values in an `AtomicReference` is very costly performance-wise *relative to* a standard mutable state. If performance is a concern, you may want to consider using another approach involving a [thread-isolated state](#thread-isolated-state).
There is also a potential issue with memory leaks, which will be resolved in the future. In situations where the object kept in the `AtomicReference` has cyclical references, it may leak memory if you don't explicitly clear it out:
* If you have state that may have cyclic references and needs to be reclaimed, you should use a nullable type in the `AtomicReference` and set it to null explicitly when you're done with it.
* If you're keeping `AtomicReference` in a global object that never leaves scope, this won't matter (because the memory never needs to be reclaimed during the life of the process).
```
class Container(a:A) {
val atom = AtomicReference<A?>(a.freeze())
/**
* Call when you're done with Container
*/
fun clear(){
atom.value = null
}
}
```
Finally, there's also a consistency concern. Setting/getting values in `AtomicReference` is itself atomic, but if your logic requires a longer chain of thread exclusion, you'll need to implement that yourself. For example, if you have a list of values in an `AtomicReference` and you want to scan them first before adding a new one, you'll need to have some form of concurrency management that `AtomicReference` alone does not provide.
The following won't protect against duplicate values in the list if called from multiple threads:
```
object MyListCache {
val atomicList = AtomicReference(listOf<String>().freeze())
fun addEntry(s:String){
val l = atomicList.value
val newList = mutableListOf<String>()
newList.addAll(l)
if(!newList.contains(s)){
newList.add(s)
}
atomicList.value = newList.freeze()
}
}
```
You will need to implement some form of locking or check-and-set logic to ensure proper concurrency.
Thread-isolated state
---------------------
[Rule 1 of Kotlin/Native state](multiplatform-mobile-concurrency-overview#rule-1-mutable-state-1-thread) is that a mutable state is visible to only one thread. Atomics allow mutability from any thread. Isolating a mutable state to a single thread, and allowing other threads to communicate with that state, is an alternative method for achieving concurrent mutability.
To do this, create a work queue that has exclusive access to a thread, and create a mutable state that lives in just that thread. Other threads communicate with the mutable thread by scheduling *work* on the work queue.
Data that goes in or comes out, if any, needs to be frozen, but the mutable state hidden in the worker thread remains mutable.
Conceptually it looks like the following: one thread pushes a frozen state into the state worker, which stores it in the mutable state container. Another thread later schedules work that takes that state out.
Implementing thread-isolated states is somewhat complex, but there are libraries that provide this functionality.
### AtomicReference vs. thread-isolated state
For simple values, `AtomicReference` will likely be an easier option. For cases with significant states, and potentially significant state changes, using a thread-isolated state may be a better choice. The main performance penalty is actually crossing over threads. But in performance tests with collections, for example, a thread-isolated state significantly outperforms a mutable state implemented with `AtomicReference`.
The thread-isolated state also avoids the consistency issues that `AtomicReference` has. Because all operations happen in the state thread, and because you're scheduling work, you can perform operations with multiple steps and guarantee consistency without managing thread exclusion. Thread isolation is a design feature of the Kotlin/Native state rules, and isolating mutable states works with those rules.
The thread-isolated state is also more flexible insofar as you can make mutable states concurrent. You can use any type of mutable state, rather than needing to create complex concurrent implementations.
Low-level capabilities
----------------------
Kotlin/Native has some more advanced ways of sharing concurrent states. To achieve high performance, you may need to avoid the concurrency rules altogether.
Kotlin/Native runs on top of C++ and provides interop with C and Objective-C. If you are running on iOS, you can also pass lambda arguments into your shared code from Swift. All of this native code runs outside of the Kotlin/Native state restrictions.
That means that you can implement a concurrent mutable state in a native language and have Kotlin/Native talk to it.
You can use [Objective-C interop](native-c-interop) to access low-level code. You can also use Swift to implement Kotlin interfaces or pass in lambdas that Kotlin code can call from any thread.
One of the benefits of a platform-native approach is performance. On the negative side, you'll need to manage concurrency on your own. Objective-C does not know about `frozen`, but if you store states from Kotlin in Objective-C structures, and share them between threads, the Kotlin states definitely need to be frozen. Kotlin/Native's runtime will generally warn you about issues, but it's possible to cause concurrency problems in native code that are very, very difficult to track down. It is also very easy to create memory leaks.
Since in the Kotlin Multiplatform application you are also targeting the JVM, you'll need alternate ways to implement anything you use platform native code for. This will obviously take more work and may lead to platform inconsistencies.
*This material was prepared by [Touchlab](https://touchlab.co/) for publication by JetBrains.*
Last modified: 10 January 2023
[Concurrency overview](multiplatform-mobile-concurrency-overview) [Concurrency and coroutines](multiplatform-mobile-concurrency-and-coroutines)
| programming_docs |
kotlin Sequential specification Sequential specification
========================
To be sure that the algorithm provides correct sequential behavior, you can define its *sequential specification* by writing a straightforward sequential implementation of the testing data structure.
To provide a sequential specification of the algorithm for verification:
1. Implement a sequential version of all the testing methods.
2. Pass the class with sequential implementation to the `sequentialSpecification()` option:
```
StressOptions().sequentialSpecification(SequentialQueue::class)
```
For example, here is the test to check correctness of `j.u.c.ConcurrentLinkedQueue` from the Java standard library.
```
import org.jetbrains.kotlinx.lincheck.*
import org.jetbrains.kotlinx.lincheck.annotations.*
import org.jetbrains.kotlinx.lincheck.annotations.Operation
import org.jetbrains.kotlinx.lincheck.strategy.stress.*
import org.jetbrains.kotlinx.lincheck.verifier.*
import org.junit.*
import java.util.*
import java.util.concurrent.*
class ConcurrentLinkedQueueTest {
private val s = ConcurrentLinkedQueue<Int>()
@Operation
fun add(value: Int) = s.add(value)
@Operation
fun poll(): Int? = s.poll()
@Test
fun stressTest() = StressOptions()
.sequentialSpecification(SequentialQueue::class.java)
.check(this::class)
}
class SequentialQueue {
val s = LinkedList<Int>()
fun add(x: Int) = s.add(x)
fun poll(): Int? = s.poll()
}
```
Last modified: 10 January 2023
[Progress guarantees](progress-guarantees) [Keywords and operators](keyword-reference)
kotlin Set-specific operations Set-specific operations
=======================
The Kotlin collections package contains extension functions for popular operations on sets: finding intersections, merging, or subtracting collections from each other.
To merge two collections into one, use the [`union()`](../api/latest/jvm/stdlib/kotlin.collections/union) function. It can be used in the infix form `a union b`. Note that for ordered collections the order of the operands is important: in the resulting collection, the elements of the first operand go before the elements of the second.
To find an intersection between two collections (elements present in both of them), use [`intersect()`](../api/latest/jvm/stdlib/kotlin.collections/intersect). To find collection elements not present in another collection, use [`subtract()`](../api/latest/jvm/stdlib/kotlin.collections/subtract). Both these functions can be called in the infix form as well, for example, `a intersect b`.
```
fun main() {
//sampleStart
val numbers = setOf("one", "two", "three")
println(numbers union setOf("four", "five"))
println(setOf("four", "five") union numbers)
println(numbers intersect setOf("two", "one"))
println(numbers subtract setOf("three", "four"))
println(numbers subtract setOf("four", "three")) // same output
//sampleEnd
}
```
You can also apply `union`, `intersect`, and `subtract` to `List`. However, their result is *always* a `Set`, even on lists. In this result, all the duplicate elements are merged into one and the index access is not available.
```
fun main() {
//sampleStart
val list1 = listOf(1, 1, 2 ,3, 5, 8, -1)
val list2 = listOf(1, 1, 2, 2 ,3, 5)
println(list1 intersect list2) // result on two lists is a Set
println(list1 union list2) // equal elements are merged into one
//sampleEnd
}
```
Last modified: 10 January 2023
[List-specific operations](list-operations) [Map-specific operations](map-operations)
kotlin Kotlin and OSGi Kotlin and OSGi
===============
To enable Kotlin [OSGi](https://www.osgi.org/) support in your Kotlin project, include `kotlin-osgi-bundle` instead of the regular Kotlin libraries. It is recommended to remove `kotlin-runtime`, `kotlin-stdlib` and `kotlin-reflect` dependencies as `kotlin-osgi-bundle` already contains all of them. You also should pay attention in case when external Kotlin libraries are included. Most regular Kotlin dependencies are not OSGi-ready, so you shouldn't use them and should remove them from your project.
Maven
-----
To include the Kotlin OSGi bundle to a Maven project:
```
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-osgi-bundle</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
```
To exclude the standard library from external libraries (notice that "star exclusion" works in Maven 3 only):
```
<dependency>
<groupId>some.group.id</groupId>
<artifactId>some.library</artifactId>
<version>some.library.version</version>
<exclusions>
<exclusion>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
```
Gradle
------
To include `kotlin-osgi-bundle` to a Gradle project:
```
compile "org.jetbrains.kotlin:kotlin-osgi-bundle:$kotlinVersion"
```
To exclude default Kotlin libraries that comes as transitive dependencies you can use the following approach:
```
dependencies {
compile (
[group: 'some.group.id', name: 'some.library', version: 'someversion'],
.....) {
exclude group: 'org.jetbrains.kotlin'
}
```
FAQ
---
### Why not just add required manifest options to all Kotlin libraries
Even though it is the most preferred way to provide OSGi support, unfortunately it couldn't be done for now due to so called ["package split" issue](http://wiki.osgi.org/wiki/Split_Packages) that couldn't be easily eliminated and such a big change is not planned for now. There is `Require-Bundle` feature but it is not the best option too and not recommended to use. So it was decided to make a separate artifact for OSGi.
Last modified: 10 January 2023
[Document Kotlin code: KDoc and Dokka](kotlin-doc) [Learning materials overview](learning-materials-overview)
kotlin What's new in Kotlin 1.4.20 What's new in Kotlin 1.4.20
===========================
*[Release date: 23 November 2020](releases#release-details)*
Kotlin 1.4.20 offers a number of new experimental features and provides fixes and improvements for existing features, including those added in 1.4.0.
You can also learn about new features with more examples in [this blog post](https://blog.jetbrains.com/kotlin/2020/11/kotlin-1-4-20-released/).
Kotlin/JVM
----------
Improvements of Kotlin/JVM are intended to keep it up with the features of modern Java versions:
* [Java 15 target](#java-15-target)
* [invokedynamic string concatenation](#invokedynamic-string-concatenation)
### Java 15 target
Now Java 15 is available as a Kotlin/JVM target.
### invokedynamic string concatenation
Kotlin 1.4.20 can compile string concatenations into [dynamic invocations](https://docs.oracle.com/javase/7/docs/technotes/guides/vm/multiple-language-support.html#invokedynamic) on JVM 9+ targets, therefore improving the performance.
Currently, this feature is experimental and covers the following cases:
* `String.plus` in the operator (`a + b`), explicit (`a.plus(b)`), and reference (`(a::plus)(b)`) form.
* `toString` on inline and data classes.
* string templates except for ones with a single non-constant argument (see [KT-42457](https://youtrack.jetbrains.com/issue/KT-42457)).
To enable `invokedynamic` string concatenation, add the `-Xstring-concat` compiler option with one of the following values:
* `indy-with-constants` to perform `invokedynamic` concatenation on strings with [StringConcatFactory.makeConcatWithConstants()](https://docs.oracle.com/javase/9/docs/api/java/lang/invoke/StringConcatFactory.html#makeConcatWithConstants-java.lang.invoke.MethodHandles.Lookup-java.lang.String-java.lang.invoke.MethodType-java.lang.String-java.lang.Object...-).
* `indy` to perform `invokedynamic` concatenation on strings with [StringConcatFactory.makeConcat()](https://docs.oracle.com/javase/9/docs/api/java/lang/invoke/StringConcatFactory.html#makeConcat-java.lang.invoke.MethodHandles.Lookup-java.lang.String-java.lang.invoke.MethodType-).
* `inline` to switch back to the classic concatenation via `StringBuilder.append()`.
Kotlin/JS
---------
Kotlin/JS keeps evolving fast, and in 1.4.20 you can find a number experimental features and improvements:
* [Gradle DSL changes](#gradle-dsl-changes)
* [New Wizard templates](#new-wizard-templates)
* [Ignoring compilation errors with IR compiler](#ignoring-compilation-errors-with-ir-compiler)
### Gradle DSL changes
The Gradle DSL for Kotlin/JS receives a number of updates which simplify project setup and customization. This includes webpack configuration adjustments, modifications to the auto-generated `package.json` file, and improved control over transitive dependencies.
#### Single point for webpack configuration
A new configuration block `commonWebpackConfig` is available for the browser target. Inside it, you can adjust common settings from a single point, instead of having to duplicate configurations for the `webpackTask`, `runTask`, and `testTask`.
To enable CSS support by default for all three tasks, add the following snippet in the `build.gradle(.kts)` of your project:
```
browser {
commonWebpackConfig {
cssSupport.enabled = true
}
binaries.executable()
}
```
Learn more about [configuring webpack bundling](js-project-setup#webpack-bundling).
#### package.json customization from Gradle
For more control over your Kotlin/JS package management and distribution, you can now add properties to the project file [`package.json`](https://nodejs.dev/learn/the-package-json-guide) via the Gradle DSL.
To add custom fields to your `package.json`, use the `customField` function in the compilation's `packageJson` block:
```
kotlin {
js(BOTH) {
compilations["main"].packageJson {
customField("hello", mapOf("one" to 1, "two" to 2))
}
}
}
```
Learn more about [`package.json` customization](js-project-setup#package-json-customization).
#### Selective yarn dependency resolutions
Kotlin 1.4.20 provides a way of configuring Yarn's [selective dependency resolutions](https://classic.yarnpkg.com/en/docs/selective-version-resolutions/) - the mechanism for overriding dependencies of the packages you depend on.
You can use it through the `YarnRootExtension` inside the `YarnPlugin` in Gradle. To affect the resolved version of a package for your project, use the `resolution` function passing in the package name selector (as specified by Yarn) and the version to which it should resolve.
```
rootProject.plugins.withType<YarnPlugin> {
rootProject.the<YarnRootExtension>().apply {
resolution("react", "16.0.0")
resolution("processor/decamelize", "3.0.0")
}
}
```
Here, *all* of your npm dependencies which require `react` will receive version `16.0.0`, and `processor` will receive its dependency `decamelize` as version `3.0.0`.
#### Disabling granular workspaces
To speed up build times, the Kotlin/JS Gradle plugin only installs the dependencies which are required for a particular Gradle task. For example, the `webpack-dev-server` package is only installed when you execute one of the `*Run` tasks, and not when you execute the assemble task. Such behavior can potentially bring problems when you run multiple Gradle processes in parallel. When the dependency requirements clash, the two installations of npm packages can cause errors.
To resolve this issue, Kotlin 1.4.20 includes an option to disable these so-called *granular workspaces*. This feature is currently available through the `YarnRootExtension` inside the `YarnPlugin` in Gradle. To use it, add the following snippet to your `build.gradle.kts` file:
```
rootProject.plugins.withType<YarnPlugin> {
rootProject.the<YarnRootExtension>().disableGranularWorkspaces()
}
```
### New Wizard templates
To give you more convenient ways to customize your project during creation, the project wizard for Kotlin comes with new templates for Kotlin/JS applications:
* **Browser Application** - a minimal Kotlin/JS Gradle project that runs in the browser.
* **React Application** - a React app that uses the appropriate `kotlin-wrappers`. It provides options to enable integrations for style-sheets, navigational components, or state containers.
* **Node.js Application** - a minimal project for running in a Node.js runtime. It comes with the option to directly include the experimental `kotlinx-nodejs` package.
Learn how to [create Kotlin/JS applications from templates](js-get-started).
### Ignoring compilation errors with IR compiler
The [IR compiler](js-ir-compiler) for Kotlin/JS comes with a new experimental mode - *compilation with errors*. In this mode, you can run you code even if it contains errors, for example, if you want to try certain things it when the whole application is not ready yet.
There are two tolerance policies for this mode:
* `SEMANTIC`: the compiler will accept code which is syntactically correct, but doesn't make sense semantically, such as `val x: String = 3`.
* `SYNTAX`: the compiler will accept any code, even if it contains syntax errors.
To allow compilation with errors, add the `-Xerror-tolerance-policy=` compiler option with one of the values listed above.
Learn more about [ignoring compilation errors](js-ir-compiler#ignoring-compilation-errors) with Kotlin/JS IR compiler.
Kotlin/Native
-------------
Kotlin/Native's priorities in 1.4.20 are performance and polishing existing features. These are the notable improvements:
* [Escape analysis](#escape-analysis)
* [Performance improvements and bug fixes](#performance-improvements-and-bug-fixes)
* [Opt-in wrapping of Objective-C exceptions](#opt-in-wrapping-of-objective-c-exceptions)
* [CocoaPods plugin improvements](#cocoapods-plugin-improvements)
* [Support for Xcode 12 libraries](#support-for-xcode-12-libraries)
### Escape analysis
Kotlin/Native receives a prototype of the new [escape analysis](https://en.wikipedia.org/wiki/Escape_analysis) mechanism. It improves the runtime performance by allocating certain objects on the stack instead of the heap. This mechanism shows a 10% average performance increase on our benchmarks, and we continue improving it so that it speeds up the program even more.
The escape analysis runs in a separate compilation phase for the release builds (with the `-opt` compiler option).
If you want to disable the escape analysis phase, use the `-Xdisable-phases=EscapeAnalysis` compiler option.
### Performance improvements and bug fixes
Kotlin/Native receives performance improvements and bug fixes in various components, including the ones added in 1.4.0, for example, the [code sharing mechanism](multiplatform-share-on-platforms#share-code-on-similar-platforms).
### Opt-in wrapping of Objective-C exceptions
Kotlin/Native now can handle exceptions thrown from Objective-C code in runtime to avoid program crashes.
You can opt in to wrap `NSException`'s into Kotlin exceptions of type `ForeignException`. They hold the references to the original `NSException`'s. This lets you get the information about the root cause and handle it properly.
To enable wrapping of Objective-C exceptions, specify the `-Xforeign-exception-mode objc-wrap` option in the `cinterop` call or add `foreignExceptionMode = objc-wrap` property to `.def` file. If you use [CocoaPods integration](native-cocoapods), specify the option in the `pod {}` build script block of a dependency like this:
```
pod("foo") {
extraOpts = listOf("-Xforeign-exception-mode", "objc-wrap")
}
```
The default behavior remains unchanged: the program terminates when an exception is thrown from the Objective-C code.
### CocoaPods plugin improvements
Kotlin 1.4.20 continues the set of improvements in CocoaPods integration. Namely, you can try the following new features:
* [Improved task execution](#improved-task-execution)
* [Extended DSL](#extended-dsl)
* [Updated integration with Xcode](#updated-integration-with-xcode)
#### Improved task execution
CocoaPods plugin gets an improved task execution flow. For example, if you add a new CocoaPods dependency, existing dependencies are not rebuilt. Adding an extra target also doesn't affect rebuilding dependencies for existing ones.
#### Extended DSL
The DSL of adding [CocoaPods](native-cocoapods) dependencies to your Kotlin project receives new capabilites.
In addition to local Pods and Pods from the CocoaPods repository, you can add dependencies on the following types of libraries:
* A library from a custom spec repository.
* A remote library from a Git repository.
* A library from an archive (also available by arbitrary HTTP address).
* A static library.
* A library with custom cinterop options.
Learn more about [adding CocoaPods dependencies](native-cocoapods-libraries) in Kotlin projects. Find examples in the [Kotlin with CocoaPods sample](https://github.com/Kotlin/kmm-with-cocoapods-sample).
#### Updated integration with Xcode
To work correctly with Xcode, Kotlin requires some Podfile changes:
* If your Kotlin Pod has any Git, HTTP, or specRepo Pod dependency, you should also specify it in the Podfile.
* When you add a library from the custom spec, you also should specify the [location](https://guides.cocoapods.org/syntax/podfile.html#source) of specs at the beginning of your Podfile.
Now integration errors have a detailed description in IDEA. So if you have problems with your Podfile, you will immediately know how to fix them.
Learn more about [creating Kotlin pods](native-cocoapods-xcode).
### Support for Xcode 12 libraries
We have added support for new libraries delivered with Xcode 12. Now you can use them from the Kotlin code.
Kotlin Multiplatform
--------------------
### Updated structure of multiplatform library publications
Starting from Kotlin 1.4.20, there is no longer a separate metadata publication. Metadata artifacts are now included in the *root* publication which stands for the whole library and is automatically resolved to the appropriate platform-specific artifacts when added as a dependency to the common source set.
Learn more about [publishing a multiplatform library](multiplatform-publish-lib).
#### Compatibility with earlier versions
This change of structure breaks the compatibility between projects with [hierarchical project structure](multiplatform-share-on-platforms#share-code-on-similar-platforms). If a multiplatform project and a library it depends on both have the hierarchical project structure, then you need to update them to Kotlin 1.4.20 or higher simultaneously. Libraries published with Kotlin 1.4.20 are not available for using from project published with earlier versions.
Projects and libraries without the hierarchical project structure remain compatible.
Standard library
----------------
The standard library of Kotlin 1.4.20 offers new extensions for working with files and a better performance.
* [Extensions for java.nio.file.Path](#extensions-for-java-nio-file-path)
* [Improved String.replace function performance](#improved-string-replace-function-performance)
### Extensions for java.nio.file.Path
Now the standard library provides experimental extensions for `java.nio.file.Path`. Working with the modern JVM file API in an idiomatic Kotlin way is now similar to working with `java.io.File` extensions from the `kotlin.io` package.
```
// construct path with the div (/) operator
val baseDir = Path("/base")
val subDir = baseDir / "subdirectory"
// list files in a directory
val kotlinFiles: List<Path> = Path("/home/user").listDirectoryEntries("*.kt")
```
The extensions are available in the `kotlin.io.path` package in the `kotlin-stdlib-jdk7` module. To use the extensions, [opt-in](opt-in-requirements) to the experimental annotation `@ExperimentalPathApi`.
### Improved String.replace function performance
The new implementation of `String.replace()` speeds up the function execution. The case-sensitive variant uses a manual replacement loop based on `indexOf`, while the case-insensitive one uses regular expression matching.
Kotlin Android Extensions
-------------------------
In 1.4.20 the Kotlin Android Extensions plugin becomes deprecated and `Parcelable` implementation generator moves to a separate plugin.
* [Deprecation of synthetic views](#deprecation-of-synthetic-views)
* [New plugin for Parcelable implementation generator](#new-plugin-for-parcelable-implementation-generator)
### Deprecation of synthetic views
*Synthetic views* were presented in the Kotlin Android Extensions plugin a while ago to simplify the interaction with UI elements and reduce boilerplate. Now Google offers a native mechanism that does the same - Android Jetpack's [view bindings](https://developer.android.com/topic/libraries/view-binding), and we're deprecating synthetic views in favor of those.
We extract the Parcelable implementations generator from `kotlin-android-extensions` and start the deprecation cycle for the rest of it - synthetic views. For now, they will keep working with a deprecation warning. In the future, you'll need to switch your project to another solution. Here are the [guidelines](https://goo.gle/kotlin-android-extensions-deprecation) that will help you migrate your Android project from synthetics to view bindings.
### New plugin for Parcelable implementation generator
The `Parcelable` implementation generator is now available in the new `kotlin-parcelize` plugin. Apply this plugin instead of `kotlin-android-extensions`.
The `@Parcelize` annotation is moved to the `kotlinx.parcelize` package.
Learn more about `Parcelable` implementation generator in the [Android documentation](https://developer.android.com/kotlin/parcelize).
Last modified: 10 January 2023
[What's new in Kotlin 1.4.30](whatsnew1430) [What's new in Kotlin 1.4](whatsnew14)
| programming_docs |
kotlin Characters Characters
==========
Characters are represented by the type `Char`. Character literals go in single quotes: `'1'`.
Special characters start from an escaping backslash `\`. The following escape sequences are supported:
* `\t` – tab
* `\b` – backspace
* `\n` – new line (LF)
* `\r` – carriage return (CR)
* `\'` – single quotation mark
* `\"` – double quotation mark
* `\\` – backslash
* `\$` – dollar sign
To encode any other character, use the Unicode escape sequence syntax: `'\uFF00'`.
```
fun main() {
//sampleStart
val aChar: Char = 'a'
println(aChar)
println('\n') // Prints an extra newline character
println('\uFF00')
//sampleEnd
}
```
If a value of character variable is a digit, you can explicitly convert it to an `Int` number using the [`digitToInt()`](../api/latest/jvm/stdlib/kotlin.text/digit-to-int) function.
Last modified: 10 January 2023
[Booleans](booleans) [Strings](strings)
kotlin Mapping Strings from C – tutorial Mapping Strings from C – tutorial
=================================
This is the last tutorial in the series. The first tutorial of the series is [Mapping primitive data types from C](mapping-primitive-data-types-from-c). There are also [Mapping struct and union types from C](mapping-struct-union-types-from-c) and [Mapping function pointers from C](mapping-function-pointers-from-c) tutorials.
In this tutorial, you'll see how to deal with C strings in Kotlin/Native. You will learn how to:
* [Pass a Kotlin string to C](#pass-kotlin-string-to-c)
* [Read a C string in Kotlin](#read-c-strings-in-kotlin)
* [Receive C string bytes into a Kotlin string](#receive-c-string-bytes-from-kotlin)
Working with C strings
----------------------
There is no dedicated type in C language for strings. A developer knows from a method signature or the documentation, whether a given `char *` means a C string in the context. Strings in the C language are null-terminated, a trailing zero character `\0` is added at the end of a bytes sequence to mark a string termination. Usually, [UTF-8 encoded strings](https://en.wikipedia.org/wiki/UTF-8) are used. The UTF-8 encoding uses variable width characters, and it is backward compatible with [ASCII](https://en.wikipedia.org/wiki/ASCII). Kotlin/Native uses UTF-8 character encoding by default.
The best way to understand the mapping between C and Kotlin languages is to try it out on a small example. Create a small library headers for that. First, create a `lib.h` file with the following declaration of functions that deal with the C strings:
```
#ifndef LIB2_H_INCLUDED
#define LIB2_H_INCLUDED
void pass_string(char* str);
char* return_string();
int copy_string(char* str, int size);
#endif
```
In the example, you see the most popular ways to pass or receive a string in the C language. Take the return of `return_string` with care. In general, it is best to make sure you use the right function to dispose the returned `char*` with the right `free(..)` function call.
Kotlin/Native comes with the `cinterop` tool; the tool generates bindings between the C language and Kotlin. It uses a `.def` file to specify a C library to import. More details on this are in the [Interop with C Libraries](native-c-interop) tutorial. The quickest way to try out C API mapping is to have all C declarations in the `interop.def` file, without creating any `.h` of `.c` files at all. Then place the C declarations in a `interop.def` file after the special `---` separator line:
```
headers = lib.h
---
void pass_string(char* str) {
}
char* return_string() {
return "C stirng";
}
int copy_string(char* str, int size) {
*str++ = 'C';
*str++ = ' ';
*str++ = 'K';
*str++ = '/';
*str++ = 'N';
*str++ = 0;
return 0;
}
```
The `interop.def` file is enough to compile and run the application or open it in an IDE. Now it is time to create project files, open the project in [IntelliJ IDEA](https://jetbrains.com/idea) and run it.
Inspect generated Kotlin APIs for a C library
---------------------------------------------
While it is possible to use the command line, either directly or by combining it with a script file (such as `.sh` or `.bat` file), this approach doesn't scale well for big projects that have hundreds of files and libraries. It is then better to use the Kotlin/Native compiler with a build system, as it helps to download and cache the Kotlin/Native compiler binaries and libraries with transitive dependencies and run the compiler and tests. Kotlin/Native can use the [Gradle](https://gradle.org) build system through the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin.
We covered the basics of setting up an IDE compatible project with Gradle in the [A Basic Kotlin/Native Application](native-gradle) tutorial. Please check it out if you are looking for detailed first steps and instructions on how to start a new Kotlin/Native project and open it in IntelliJ IDEA. In this tutorial, we'll look at the advanced C interop related usages of Kotlin/Native and [multiplatform](multiplatform-discover-project#multiplatform-plugin) builds with Gradle.
First, create a project folder. All the paths in this tutorial will be relative to this folder. Sometimes the missing directories will have to be created before any new files can be added.
Use the following `build.gradle(.kts)` Gradle build file:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
repositories {
mavenCentral()
}
kotlin {
linuxX64("native") { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64("native") { // on Windows
val main by compilations.getting
val interop by main.cinterops.creating
binaries {
executable()
}
}
}
tasks.wrapper {
gradleVersion = "7.3"
distributionType = Wrapper.DistributionType.BIN
}
```
```
plugins {
id 'org.jetbrains.kotlin.multiplatform' version '1.8.0'
}
repositories {
mavenCentral()
}
kotlin {
linuxX64('native') { // on Linux
// macosX64("native") { // on x86_64 macOS
// macosArm64("native") { // on Apple Silicon macOS
// mingwX64('native') { // on Windows
compilations.main.cinterops {
interop
}
binaries {
executable()
}
}
}
wrapper {
gradleVersion = '7.3'
distributionType = 'BIN'
}
```
The project file configures the C interop as an additional step of the build. Let's move the `interop.def` file to the `src/nativeInterop/cinterop` directory. Gradle recommends using conventions instead of configurations, for example, the source files are expected to be in the `src/nativeMain/kotlin` folder. By default, all the symbols from C are imported to the `interop` package, you may want to import the whole package in our `.kt` files. Check out the [kotlin-multiplatform](multiplatform-discover-project#multiplatform-plugin) plugin documentation to learn about all the different ways you could configure it.
Let's create a `src/nativeMain/kotlin/hello.kt` stub file with the following content to see how C string declarations are visible from Kotlin:
```
import interop.*
fun main() {
println("Hello Kotlin/Native!")
pass_string(/*fix me*/)
val useMe = return_string()
val useMe2 = copy_string(/*fix me*/)
}
```
Now you are ready to [open the project in IntelliJ IDEA](native-get-started) and to see how to fix the example project. While doing that, see how C strings are mapped into Kotlin/Native.
Strings in Kotlin
-----------------
With the help of IntelliJ IDEA's **Go to | Declaration** or compiler errors, you see the following generated API for the C functions:
```
fun pass_string(str: CValuesRef<ByteVar /* = ByteVarOf<Byte> */>?)
fun return_string(): CPointer<ByteVar /* = ByteVarOf<Byte> */>?
fun copy_string(str: CValuesRef<ByteVar /* = ByteVarOf<Byte> */>?, size: Int): Int
```
These declarations look clear. All `char *` pointers are turned into `str: CValuesRef<ByteVar>?` for parameters and to `CPointer<ByteVar>?` in return types. Kotlin turns `char` type into `kotlin.Byte` type, as it is usually an 8-bit signed value.
In the generated Kotlin declarations, you see that `str` is represented as `CValuesRef<ByteVar/>?`. The type is nullable, and you can simply pass Kotlin `null` as the parameter value.
Pass Kotlin string to C
-----------------------
Let's try to use the API from Kotlin. Call `pass_string` first:
```
fun passStringToC() {
val str = "this is a Kotlin String"
pass_string(str.cstr)
}
```
Passing a Kotlin string to C is easy, thanks to the fact that there is `String.cstr` [extension property](extensions#extension-properties) in Kotlin for it. There is also `String.wcstr` for cases when you need UTF-16 wide characters.
Read C Strings in Kotlin
------------------------
This time you'll take a returned `char *` from the `return_string` function and turn it into a Kotlin string. For that, do the following in Kotlin:
```
fun passStringToC() {
val stringFromC = return_string()?.toKString()
println("Returned from C: $stringFromC")
}
```
This code uses the `toKString()` extension function above. Please do not miss out the `toString()` function. The `toKString()` has two overloaded extension functions in Kotlin:
```
fun CPointer<ByteVar>.toKString(): String
fun CPointer<ShortVar>.toKString(): String
```
The first extension takes a `char *` as a UTF-8 string and turns it into a String. The second function does the same but for wide UTF-16 strings.
Receive C string bytes from Kotlin
----------------------------------
This time we will ask a C function to write us a C string to a given buffer. The function is called `copy_string`. It takes a pointer to the location writing characters and the allowed buffer size. The function returns something to indicate if it has succeeded or failed. Let's assume `0` means it succeeded, and the supplied buffer was big enough:
```
fun sendString() {
val buf = ByteArray(255)
buf.usePinned { pinned ->
if (copy_string(pinned.addressOf(0), buf.size - 1) != 0) {
throw Error("Failed to read string from C")
}
}
val copiedStringFromC = buf.decodeToString()
println("Message from C: $copiedStringFromC")
}
```
First of all, you need to have a native pointer to pass to the C function. Use the `usePinned` extension function to temporarily pin the native memory address of the byte array. The C function fills in the byte array with data. Use another extension function `ByteArray.decodeToString()` to turn the byte array into a Kotlin `String`, assuming UTF-8 encoding.
Fix the Code
------------
You've now seen all the definitions and it is time to fix the code. Run the `runDebugExecutableNative` Gradle task [in the IDE](native-get-started) or use the following command to run the code:
```
./gradlew runDebugExecutableNative
```
The code in the final `hello.kt` file may look like this:
```
import interop.*
import kotlinx.cinterop.*
fun main() {
println("Hello Kotlin/Native!")
val str = "this is a Kotlin String"
pass_string(str.cstr)
val useMe = return_string()?.toKString() ?: error("null pointer returned")
println(useMe)
val copyFromC = ByteArray(255).usePinned { pinned ->
val useMe2 = copy_string(pinned.addressOf(0), pinned.get().size - 1)
if (useMe2 != 0) throw Error("Failed to read string from C")
pinned.get().decodeToString()
}
println(copyFromC)
}
```
Next steps
----------
Continue to explore more C language types and their representation in Kotlin/Native in our other tutorials:
* [Mapping primitive data types from C](mapping-primitive-data-types-from-c)
* [Mapping struct and union types from C](mapping-struct-union-types-from-c)
* [Mapping function pointers from C](mapping-function-pointers-from-c)
The [C Interop documentation](native-c-interop) documentation covers more advanced scenarios of the interop.
Last modified: 10 January 2023
[Mapping function pointers from C – tutorial](mapping-function-pointers-from-c) [Create an app using C Interop and libcurl – tutorial](native-app-with-c-and-libcurl)
kotlin Debug Kotlin Flow using IntelliJ IDEA – tutorial Debug Kotlin Flow using IntelliJ IDEA – tutorial
================================================
This tutorial demonstrates how to create Kotlin Flow and debug it using IntelliJ IDEA.
The tutorial assumes you have prior knowledge of the [coroutines](coroutines-guide) and [Kotlin Flow](flow#flows) concepts.
Create a Kotlin flow
--------------------
Create a Kotlin [flow](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/flow.html) with a slow emitter and a slow collector:
1. Open a Kotlin project in IntelliJ IDEA. If you don't have a project, [create one](jvm-get-started#create-a-project).
2. To use the `kotlinx.coroutines` library in a Gradle project, add the following dependency to `build.gradle(.kts)`:
```
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
}
```
```
dependencies {
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4'
}
```
For other build systems, see instructions in the [`kotlinx.coroutines` README](https://github.com/Kotlin/kotlinx.coroutines#using-in-your-projects).
3. Open the `Main.kt` file in `src/main/kotlin`.
The `src` directory contains Kotlin source files and resources. The `Main.kt` file contains sample code that will print `Hello World!`.
4. Create the `simple()` function that returns a flow of three numbers:
* Use the [`delay()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/delay.html) function to imitate CPU-consuming blocking code. It suspends the coroutine for 100 ms without blocking the thread.
* Produce the values in the `for` loop using the [`emit()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/-flow-collector/emit.html) function.
```
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
import kotlin.system.*
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
emit(i)
}
}
```
5. Change the code in the `main()` function:
* Use the [`runBlocking()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/run-blocking.html) block to wrap a coroutine.
* Collect the emitted values using the [`collect()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/collect.html) function.
* Use the [`delay()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/delay.html) function to imitate CPU-consuming code. It suspends the coroutine for 300 ms without blocking the thread.
* Print the collected value from the flow using the [`println()`](../api/latest/jvm/stdlib/kotlin.io/println) function.
```
fun main() = runBlocking {
simple()
.collect { value ->
delay(300)
println(value)
}
}
```
6. Build the code by clicking **Build Project**.

Debug the coroutine
-------------------
1. Set a breakpoint at the line where the `emit()` function is called:

2. Run the code in debug mode by clicking **Debug** next to the run configuration at the top of the screen.
The **Debug** tool window appears:
* The **Frames** tab contains the call stack.
* The **Variables** tab contains variables in the current context. It tells us that the flow is emitting the first value.
* The **Coroutines** tab contains information on running or suspended coroutines.
3. Resume the debugger session by clicking **Resume Program** in the **Debug** tool window. The program stops at the same breakpoint.
Now the flow emits the second value.

### Optimized-out variables
If you use `suspend` functions, in the debugger, you might see the "was optimized out" text next to a variable's name:
This text means that the variable's lifetime was decreased, and the variable doesn't exist anymore. It is difficult to debug code with optimized variables because you don't see their values. You can disable this behavior with the `-Xdebug` compiler option.
Add a concurrently running coroutine
------------------------------------
1. Open the `Main.kt` file in `src/main/kotlin`.
2. Enhance the code to run the emitter and collector concurrently:
* Add a call to the [`buffer()`](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines.flow/buffer.html) function to run the emitter and collector concurrently. `buffer()` stores emitted values and runs the flow collector in a separate coroutine.
```
fun main() = runBlocking<Unit> {
simple()
.buffer()
.collect { value ->
delay(300)
println(value)
}
}
```
3. Build the code by clicking **Build Project**.
Debug a Kotlin flow with two coroutines
---------------------------------------
1. Set a new breakpoint at `println(value)`.
2. Run the code in debug mode by clicking **Debug** next to the run configuration at the top of the screen.
The **Debug** tool window appears.
In the **Coroutines** tab, you can see that there are two coroutines running concurrently. The flow collector and emitter run in separate coroutines because of the `buffer()` function. The `buffer()` function buffers emitted values from the flow. The emitter coroutine has the **RUNNING** status, and the collector coroutine has the **SUSPENDED** status.
3. Resume the debugger session by clicking **Resume Program** in the **Debug** tool window.
Now the collector coroutine has the **RUNNING** status, while the emitter coroutine has the **SUSPENDED** status.
You can dig deeper into each coroutine to debug your code.
Last modified: 10 January 2023
[Debug coroutines using IntelliJ IDEA – tutorial](debug-coroutines-with-idea) [Serialization](serialization)
kotlin Coroutines and channels − tutorial Coroutines and channels − tutorial
==================================
In this tutorial, you'll learn how to use coroutines in IntelliJ IDEA to perform network requests without blocking the underlying thread or callbacks.
You'll learn:
* Why and how to use suspending functions to perform network requests.
* How to send requests concurrently using coroutines.
* How to share information between different coroutines using channels.
For network requests, you'll need the [Retrofit](https://square.github.io/retrofit/) library, but the approach shown in this tutorial works similarly for any other libraries that support coroutines.
Before you start
----------------
1. Download and install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html).
2. Clone the [project template](http://github.com/kotlin-hands-on/intro-coroutines) by choosing **Get from VCS** on the Welcome screen or selecting **File | New | Project from Version Control**.
You can also clone it from the command line:
```
git clone https://github.com/kotlin-hands-on/intro-coroutines
```
### Generate a GitHub developer token
You'll be using the GitHub API in your project. To get access, provide your GitHub account name and either a password or a token. If you have two-factor authentication enabled, a token will be enough.
Generate a new GitHub token to use the GitHub API with [your account](https://github.com/settings/tokens/new):
1. Specify the name of your token, for example, `coroutines-tutorial`:

2. Do not select any scopes. Click **Generate token** at the bottom of the page.
3. Copy the generated token.
### Run the code
The program loads the contributors for all of the repositories under the given organization (named “kotlin” by default). Later you'll add logic to sort the users by the number of their contributions.
1. Open the `src/contributors/main.kt` file and run the `main()` function. You'll see the following window:
If the font is too small, adjust it by changing the value of `setDefaultFontSize(18f)` in the `main()` function.
2. Provide your GitHub username and token (or password) in the corresponding fields.
3. Make sure that the *BLOCKING* option is selected in the *Variant* dropdown menu.
4. Click *Load contributors*. The UI should freeze for some time and then show the list of contributors.
5. Open the program output to ensure the data has been loaded. The list of contributors is logged after each successful request.
There are different ways of implementing this logic: by using [blocking requests](#blocking-requests) or [callbacks](#callbacks). You'll compare these solutions with one that uses [coroutines](#coroutines) and see how [channels](#channels) can be used to share information between different coroutines.
Blocking requests
-----------------
You will use the [Retrofit](https://square.github.io/retrofit/) library to perform HTTP requests to GitHub. It allows requesting the list of repositories under the given organization and the list of contributors for each repository:
```
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
fun getOrgReposCall(
@Path("org") org: String
): Call<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
fun getRepoContributorsCall(
@Path("owner") owner: String,
@Path("repo") repo: String
): Call<List<User>>
}
```
This API is used by the `loadContributorsBlocking()` function to fetch the list of contributors for the given organization.
1. Open `src/tasks/Request1Blocking.kt` to see its implementation:
```
fun loadContributorsBlocking(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgReposCall(req.org) // #1
.execute() // #2
.also { logRepos(req, it) } // #3
.body() ?: emptyList() // #4
return repos.flatMap { repo ->
service
.getRepoContributorsCall(req.org, repo.name) // #1
.execute() // #2
.also { logUsers(repo, it) } // #3
.bodyList() // #4
}.aggregate()
}
```
* At first, you get a list of the repositories under the given organization and store it in the `repos` list. Then for each repository, the list of contributors is requested, and all of the lists are merged into one final list of contributors.
* `getOrgReposCall()` and `getRepoContributorsCall()` both return an instance of the `*Call` class (`#1`). At this point, no request is sent.
* `*Call.execute()` is then invoked to perform the request (`#2`). `execute()` is a synchronous call that blocks the underlying thread.
* When you get the response, the result is logged by calling the specific `logRepos()` and `logUsers()` functions (`#3`). If the HTTP response contains an error, this error will be logged here.
* Finally, get the response's body, which contains the data you need. For this tutorial, you'll use an empty list as a result in case there is an error, and you'll log the corresponding error (`#4`).
2. To avoid repeating `.body() ?: emptyList()`, an extension function `bodyList()` is declared:
```
fun <T> Response<List<T>>.bodyList(): List<T> {
return body() ?: emptyList()
}
```
3. Run the program again and take a look at the system output in IntelliJ IDEA. It should have something like this:
```
1770 [AWT-EventQueue-0] INFO Contributors - kotlin: loaded 40 repos
2025 [AWT-EventQueue-0] INFO Contributors - kotlin-examples: loaded 23 contributors
2229 [AWT-EventQueue-0] INFO Contributors - kotlin-koans: loaded 45 contributors
...
```
* The first item on each line is the number of milliseconds that have passed since the program started, then the thread name in square brackets. You can see from which thread the loading request is called.
* The final item on each line is the actual message: how many repositories or contributors were loaded.This log output demonstrates that all of the results were logged from the main thread. When you run the code with a *BLOCKING* option, the window freezes and doesn't react to input until the loading is finished. All of the requests are executed from the same thread as the one called `loadContributorsBlocking()` is from, which is the main UI thread (in Swing, it's an AWT event dispatching thread). This main thread becomes blocked, and that's why the UI is frozen:
After the list of contributors has loaded, the result is updated.
4. In `src/contributors/Contributors.kt`, find the `loadContributors()` function responsible for choosing how the contributors are loaded and look at how `loadContributorsBlocking()` is called:
```
when (getSelectedVariant()) {
BLOCKING -> { // Blocking UI thread
val users = loadContributorsBlocking(service, req)
updateResults(users, startTime)
}
}
```
* The `updateResults()` call goes right after the `loadContributorsBlocking()` call.
* `updateResults()` updates the UI, so it must always be called from the UI thread.
* Since `loadContributorsBlocking()` is also called from the UI thread, the UI thread becomes blocked and the UI is frozen.
### Task 1
The first task helps you familiarize yourself with the task domain. Currently, each contributor's name is repeated several times, once for every project they have taken part in. Implement the `aggregate()` function combining the users so that each contributor is added only once. The `User.contributions` property should contain the total number of contributions of the given user to *all* the projects. The resulting list should be sorted in descending order according to the number of contributions.
Open `src/tasks/Aggregation.kt` and implement the `List<User>.aggregate()` function. Users should be sorted by the total number of their contributions.
The corresponding test file `test/tasks/AggregationKtTest.kt` shows an example of the expected result.
After implementing this task, the resulting list for the "kotlin" organization should be similar to the following:

#### Solution for task 1
1. To group users by login, use [`groupBy()`](../api/latest/jvm/stdlib/kotlin.collections/group-by), which returns a map from a login to all occurrences of the user with this login in different repositories.
2. For each map entry, count the total number of contributions for each user and create a new instance of the `User` class by the given name and total of contributions.
3. Sort the resulting list in descending order:
```
fun List<User>.aggregate(): List<User> =
groupBy { it.login }
.map { (login, group) -> User(login, group.sumOf { it.contributions }) }
.sortedByDescending { it.contributions }
```
An alternative solution is to use the [`groupingBy()`](../api/latest/jvm/stdlib/kotlin.collections/grouping-by) function instead of `groupBy()`.
Callbacks
---------
The previous solution works, but it blocks the thread and therefore freezes the UI. A traditional approach that avoids this is to use *callbacks*.
Instead of calling the code that should be invoked right after the operation is completed, you can extract it into a separate callback, often a lambda, and pass that lambda to the caller in order for it to be called later.
To make the UI responsive, you can either move the whole computation to a separate thread or switch to the Retrofit API which uses callbacks instead of blocking calls.
### Use a background thread
1. Open `src/tasks/Request2Background.kt` and see its implementation. First, the whole computation is moved to a different thread. The `thread()` function starts a new thread:
```
thread {
loadContributorsBlocking(service, req)
}
```
Now that all of the loading has been moved to a separate thread, the main thread is free and can be occupied by other tasks:

2. The signature of the `loadContributorsBackground()` function changes. It takes an `updateResults()` callback as the last argument to call it after all the loading completes:
```
fun loadContributorsBackground(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
)
```
3. Now when the `loadContributorsBackground()` is called, the `updateResults()` call goes in the callback, not immediately afterward as it did before:
```
loadContributorsBackground(service, req) { users ->
SwingUtilities.invokeLater {
updateResults(users, startTime)
}
}
```
By calling `SwingUtilities.invokeLater`, you ensure that the `updateResults()` call, which updates the results, happens on the main UI thread (AWT event dispatching thread).
However, if you try to load the contributors via the `BACKGROUND` option, you can see that the list is updated but nothing changes.
### Task 2
Fix the `loadContributorsBackground()` function in `src/tasks/Request2Background.kt` so that the resulting list is shown in the UI.
#### Solution for task 2
If you try to load the contributors, you can see in the log that the contributors are loaded but the result isn't displayed. To fix this, call `updateResults()` on the resulting list of users:
```
thread {
updateResults(loadContributorsBlocking(service, req))
}
```
Make sure to call the logic passed in the callback explicitly. Otherwise, nothing will happen.
### Use the Retrofit callback API
In the previous solution, the whole loading logic is moved to the background thread, but that still isn't the best use of resources. All of the loading requests go sequentially and the thread is blocked while waiting for the loading result, while it could have been occupied by other tasks. Specifically, the thread could start loading another request to receive the entire result earlier.
Handling the data for each repository should then be divided into two parts: loading and processing the resulting response. The second *processing* part should be extracted into a callback.
The loading for each repository can then be started before the result for the previous repository is received (and the corresponding callback is called):
The Retrofit callback API can help achieve this. The `Call.enqueue()` function starts an HTTP request and takes a callback as an argument. In this callback, you need to specify what needs to be done after each request.
Open `src/tasks/Request3Callbacks.kt` and see the implementation of `loadContributorsCallbacks()` that uses this API:
```
fun loadContributorsCallbacks(
service: GitHubService, req: RequestData,
updateResults: (List<User>) -> Unit
) {
service.getOrgReposCall(req.org).onResponse { responseRepos -> // #1
logRepos(req, responseRepos)
val repos = responseRepos.bodyList()
val allUsers = mutableListOf<User>()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers -> // #2
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
}
}
}
// TODO: Why doesn't this code work? How to fix that?
updateResults(allUsers.aggregate())
}
```
* For convenience, this code fragment uses the `onResponse()` extension function declared in the same file. It takes a lambda as an argument rather than an object expression.
* The logic for handling the responses is extracted into callbacks: the corresponding lambdas start at lines `#1` and `#2`.
However, the provided solution doesn't work. If you run the program and load contributors by choosing the *CALLBACKS* option, you'll see that nothing is shown. However, the tests that immediately return the result pass.
Think about why the given code doesn't work as expected and try to fix it, or see the solutions below.
### Task 3 (optional)
Rewrite the code in the `src/tasks/Request3Callbacks.kt` file so that the loaded list of contributors is shown.
#### The first attempted solution for task 3
In the current solution, many requests are started concurrently, which decreases the total loading time. However, the result isn't loaded. This is because the `updateResults()` callback is called right after all of the loading requests are started, before the `allUsers` list has been filled with the data.
You could try to fix this with a change like the following:
```
val allUsers = mutableListOf<User>()
for ((index, repo) in repos.withIndex()) { // #1
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (index == repos.lastIndex) { // #2
updateResults(allUsers.aggregate())
}
}
}
```
* First, you iterate over the list of repos with an index (`#1`).
* Then, from each callback, you check whether it's the last iteration (`#2`).
* And if that's the case, the result is updated.
However, this code also fails to achieve our objective. Try to find the answer yourself, or see the solution below.
#### The second attempted solution for task 3
Since the loading requests are started concurrently, there's no guarantee that the result for the last one comes last. The results can come in any order.
Thus, if you compare the current index with the `lastIndex` as a condition for completion, you risk losing the results for some repos.
If the request that processes the last repo returns faster than some prior requests (which is likely to happen), all of the results for requests that take more time will be lost.
One way to fix this is to introduce an index and check whether all of the repositories have already been processed:
```
val allUsers = Collections.synchronizedList(mutableListOf<User>())
val numberOfProcessed = AtomicInteger()
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
logUsers(repo, responseUsers)
val users = responseUsers.bodyList()
allUsers += users
if (numberOfProcessed.incrementAndGet() == repos.size) {
updateResults(allUsers.aggregate())
}
}
}
```
This code uses a synchronized version of the list and `AtomicInteger()` because, in general, there's no guarantee that different callbacks that process `getRepoContributors()` requests will always be called from the same thread.
#### The third attempted solution for task 3
An even better solution is to use the `CountDownLatch` class. It stores a counter initialized with the number of repositories. This counter is decremented after processing each repository. It then waits until the latch is counted down to zero before updating the results:
```
val countDownLatch = CountDownLatch(repos.size)
for (repo in repos) {
service.getRepoContributorsCall(req.org, repo.name)
.onResponse { responseUsers ->
// processing repository
countDownLatch.countDown()
}
}
countDownLatch.await()
updateResults(allUsers.aggregate())
```
The result is then updated from the main thread. This is more direct than delegating the logic to the child threads.
After reviewing these three attempts at a solution, you can see that writing correct code with callbacks is non-trivial and error-prone, especially when several underlying threads and synchronization occur.
Suspending functions
--------------------
You can implement the same logic using suspending functions. Instead of returning `Call<List<Repo>>`, define the API call as a [suspending function](composing-suspending-functions) as follows:
```
interface GitHubService {
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): List<Repo>
}
```
* `getOrgRepos()` is defined as a `suspend` function. When you use a suspending function to perform a request, the underlying thread isn't blocked. More details about how this works will come in later sections.
* `getOrgRepos()` returns the result directly instead of returning a `Call`. If the result is unsuccessful, an exception is thrown.
Alternatively, Retrofit allows returning the result wrapped in `Response`. In this case, the result body is provided, and it is possible to check for errors manually. This tutorial uses the versions that return `Response`.
In `src/contributors/GitHubService.kt`, add the following declarations to the `GitHubService` interface:
```
interface GitHubService {
// getOrgReposCall & getRepoContributorsCall declarations
@GET("orgs/{org}/repos?per_page=100")
suspend fun getOrgRepos(
@Path("org") org: String
): Response<List<Repo>>
@GET("repos/{owner}/{repo}/contributors?per_page=100")
suspend fun getRepoContributors(
@Path("owner") owner: String,
@Path("repo") repo: String
): Response<List<User>>
}
```
### Task 4
Your task is to change the code of the function that loads contributors to make use of two new suspending functions, `getOrgRepos()` and `getRepoContributors()`. The new `loadContributorsSuspend()` function is marked as `suspend` to use the new API.
1. Copy the implementation of `loadContributorsBlocking()` that is defined in `src/tasks/Request1Blocking.kt` into the `loadContributorsSuspend()` that is defined in `src/tasks/Request4Suspend.kt`.
2. Modify the code so that the new suspending functions are used instead of the ones that return `Call`s.
3. Run the program by choosing the *SUSPEND* option and ensure that the UI is still responsive while the GitHub requests are performed.
#### Solution for task 4
Replace `.getOrgReposCall(req.org).execute()` with `.getOrgRepos(req.org)` and repeat the same replacement for the second "contributors" request:
```
suspend fun loadContributorsSuspend(service: GitHubService, req: RequestData): List<User> {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
return repos.flatMap { repo ->
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}.aggregate()
}
```
* `loadContributorsSuspend()` should be defined as a `suspend` function.
* You no longer need to call `execute`, which returned the `Response` before, because now the API functions return the `Response` directly. Note that this detail is specific to the Retrofit library. With other libraries, the API will be different, but the concept is the same.
Coroutines
----------
The code with suspending functions looks similar to the "blocking" version. The major difference from the blocking version is that instead of blocking the thread, the coroutine is suspended:
```
block -> suspend
thread -> coroutine
```
### Starting a new coroutine
If you look at how `loadContributorsSuspend()` is used in `src/contributors/Contributors.kt`, you can see that it's called inside `launch`. `launch` is a library function that takes a lambda as an argument:
```
launch {
val users = loadContributorsSuspend(req)
updateResults(users, startTime)
}
```
Here `launch` starts a new computation that is responsible for loading the data and showing the results. The computation is suspendable – when performing network requests, it is suspended and releases the underlying thread. When the network request returns the result, the computation is resumed.
Such a suspendable computation is called a *coroutine*. So, in this case, `launch` *starts a new coroutine* responsible for loading data and showing the results.
Coroutines run on top of threads and can be suspended. When a coroutine is suspended, the corresponding computation is paused, removed from the thread, and stored in memory. Meanwhile, the thread is free to be occupied by other tasks:
When the computation is ready to be continued, it is returned to a thread (not necessarily the same one).
In the `loadContributorsSuspend()` example, each "contributors" request now waits for the result using the suspension mechanism. First, the new request is sent. Then, while waiting for the response, the whole "load contributors" coroutine that was started by the `launch` function is suspended.
The coroutine resumes only after the corresponding response is received:
While the response is waiting to be received, the thread is free to be occupied by other tasks. The UI stays responsive, despite all the requests taking place on the main UI thread:
1. Run the program using the *SUSPEND* option. The log confirms that all of the requests are sent to the main UI thread:
```
2538 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2729 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - ts2kt: loaded 11 contributors
3029 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-koans: loaded 45 contributors
...
11252 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin-coroutines-workshop: loaded 1 contributors
```
2. The log can show you which coroutine the corresponding code is running on. To enable it, open **Run | Edit configurations** and add the `-Dkotlinx.coroutines.debug` VM option:
The coroutine name will be attached to the thread name while `main()` is run with this option. You can also modify the template for running all of the Kotlin files and enable this option by default.
Now all of the code runs on one coroutine, the "load contributors" coroutine mentioned above, denoted as `@coroutine#1`. While waiting for the result, you shouldn't reuse the thread for sending other requests because the code is written sequentially. The new request is sent only when the previous result is received.
Suspending functions treat the thread fairly and don't block it for "waiting". However, this doesn't yet bring any concurrency into the picture.
Concurrency
-----------
Kotlin coroutines are much less resource-intensive than threads. Each time you want to start a new computation asynchronously, you can create a new coroutine instead.
To start a new coroutine, use one of the main *coroutine builders*: `launch`, `async`, or `runBlocking`. Different libraries can define additional coroutine builders.
`async` starts a new coroutine and returns a `Deferred` object. `Deferred` represents a concept known by other names such as `Future` or `Promise`. It stores a computation, but it *defers* the moment you get the final result; it *promises* the result sometime in the *future*.
The main difference between `async` and `launch` is that `launch` is used to start a computation that isn't expected to return a specific result. `launch` returns a `Job` that represents the coroutine. It is possible to wait until it completes by calling `Job.join()`.
`Deferred` is a generic type that extends `Job`. An `async` call can return a `Deferred<Int>` or a `Deferred<CustomType>`, depending on what the lambda returns (the last expression inside the lambda is the result).
To get the result of a coroutine, you can call `await()` on the `Deferred` instance. While waiting for the result, the coroutine that this `await()` is called from is suspended:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}
```
`runBlocking` is used as a bridge between regular and suspending functions, or between the blocking and non-blocking worlds. It works as an adaptor for starting the top-level main coroutine. It is intended primarily to be used in `main()` functions and tests.
If there is a list of deferred objects, you can call `awaitAll()` to await the results of all of them:
```
import kotlinx.coroutines.*
fun main() = runBlocking {
val deferreds: List<Deferred<Int>> = (1..3).map {
async {
delay(1000L * it)
println("Loading $it")
it
}
}
val sum = deferreds.awaitAll().sum()
println("$sum")
}
```
When each "contributors" request is started in a new coroutine, all of the requests are started asynchronously. A new request can be sent before the result for the previous one is received:
The total loading time is approximately the same as in the *CALLBACKS* version, but it doesn't need any callbacks. What's more, `async` explicitly emphasizes which parts run concurrently in the code.
### Task 5
In the `Request5Concurrent.kt` file, implement a `loadContributorsConcurrent()` function by using the previous `loadContributorsSuspend()` function.
#### Tip for task 5
You can only start a new coroutine inside a coroutine scope. Copy the content from `loadContributorsSuspend()` to the `coroutineScope` call so that you can call `async` functions there:
```
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
}
```
Base your solution on the following scheme:
```
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
// load contributors for each repo
}
}
deferreds.awaitAll() // List<List<User>>
```
#### Solution for task 5
Wrap each "contributors" request with `async` to create as many coroutines as there are repositories. `async` returns `Deferred<List<User>>`. This is not an issue because creating new coroutines is not very resource-intensive, so you can create as many as you need.
1. You can no longer use `flatMap` because the `map` result is now a list of `Deferred` objects, not a list of lists. `awaitAll()` returns `List<List<User>>`, so call `flatten().aggregate()` to get the result:
```
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val deferreds: List<Deferred<List<User>>> = repos.map { repo ->
async {
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
}
deferreds.awaitAll().flatten().aggregate()
}
```
2. Run the code and check the log. All of the coroutines still run on the main UI thread because multithreading hasn't been employed yet, but you can already see the benefits of running coroutines concurrently.
3. To change this code to run "contributors" coroutines on different threads from the common thread pool, specify `Dispatchers.Default` as the context argument for the `async` function:
```
async(Dispatchers.Default) { }
```
* `CoroutineDispatcher` determines what thread or threads the corresponding coroutine should be run on. If you don't specify one as an argument, `async` will use the dispatcher from the outer scope.
* `Dispatchers.Default` represents a shared pool of threads on the JVM. This pool provides a means for parallel execution. It consists of as many threads as there are CPU cores available, but it will still have two threads if there's only one core.
4. Modify the code in the `loadContributorsConcurrent()` function to start new coroutines on different threads from the common thread pool. Also, add additional logging before sending the request:
```
async(Dispatchers.Default) {
log("starting loading for ${repo.name}")
service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
}
```
5. Run the program once again. In the log, you can see that each coroutine can be started on one thread from the thread pool and resumed on another:
```
1946 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
1946 [DefaultDispatcher-worker-3 @coroutine#5] INFO Contributors - starting loading for dokka
1946 [DefaultDispatcher-worker-1 @coroutine#3] INFO Contributors - starting loading for ts2kt
...
2178 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
2569 [DefaultDispatcher-worker-1 @coroutine#5] INFO Contributors - dokka: loaded 36 contributors
2821 [DefaultDispatcher-worker-2 @coroutine#3] INFO Contributors - ts2kt: loaded 11 contributors
```
For instance, in this log excerpt, `coroutine#4` is started on the `worker-2` thread and continued on the `worker-1` thread.
In `src/contributors/Contributors.kt`, check the implementation of the *CONCURRENT* option:
1. To run the coroutine only on the main UI thread, specify `Dispatchers.Main` as an argument:
```
launch(Dispatchers.Main) {
updateResults()
}
```
* If the main thread is busy when you start a new coroutine on it, the coroutine becomes suspended and scheduled for execution on this thread. The coroutine will only resume when the thread becomes free.
* It's considered good practice to use the dispatcher from the outer scope rather than explicitly specifying it on each end-point. If you define `loadContributorsConcurrent()` without passing `Dispatchers.Default` as an argument, you can call this function in any context: with a `Default` dispatcher, with the main UI thread, or with a custom dispatcher.
* As you'll see later, when calling `loadContributorsConcurrent()` from tests, you can call it in the context with `TestDispatcher`, which simplifies testing. That makes this solution much more flexible.
2. To specify the dispatcher on the caller side, apply the following change to the project while letting `loadContributorsConcurrent` start coroutines in the inherited context:
```
launch(Dispatchers.Default) {
val users = loadContributorsConcurrent(service, req)
withContext(Dispatchers.Main) {
updateResults(users, startTime)
}
}
```
* `updateResults()` should be called on the main UI thread, so you call it with the context of `Dispatchers.Main`.
* `withContext()` calls the given code with the specified coroutine context, is suspended until it completes, and returns the result. An alternative but more verbose way to express this would be to start a new coroutine and explicitly wait (by suspending) until it completes: `launch(context) { ... }.join()`.
3. Run the code and ensure that the coroutines are executed on the threads from the thread pool.
Structured concurrency
----------------------
* The *coroutine scope* is responsible for the structure and parent-child relationships between different coroutines. New coroutines usually need to be started inside a scope.
* The *coroutine context* stores additional technical information used to run a given coroutine, like the coroutine custom name, or the dispatcher specifying the threads the coroutine should be scheduled on.
When `launch`, `async`, or `runBlocking` are used to start a new coroutine, they automatically create the corresponding scope. All of these functions take a lambda with a receiver as an argument, and `CoroutineScope` is the implicit receiver type:
```
launch { /* this: CoroutineScope */ }
```
* New coroutines can only be started inside a scope.
* `launch` and `async` are declared as extensions to `CoroutineScope`, so an implicit or explicit receiver must always be passed when you call them.
* The coroutine started by `runBlocking` is the only exception because `runBlocking` is defined as a top-level function. But because it blocks the current thread, it's intended primarily to be used in `main()` functions and tests as a bridge function.
A new coroutine inside `runBlocking`, `launch`, or `async` is started automatically inside the scope:
```
import kotlinx.coroutines.*
fun main() = runBlocking { /* this: CoroutineScope */
launch { /* ... */ }
// the same as:
this.launch { /* ... */ }
}
```
When you call `launch` inside `runBlocking`, it's called as an extension to the implicit receiver of the `CoroutineScope` type. Alternatively, you could explicitly write `this.launch`.
The nested coroutine (started by `launch` in this example) can be considered as a child of the outer coroutine (started by `runBlocking`). This "parent-child" relationship works through scopes; the child coroutine is started from the scope corresponding to the parent coroutine.
It's possible to create a new scope without starting a new coroutine, by using the `coroutineScope` function. To start new coroutines in a structured way inside a `suspend` function without access to the outer scope, you can create a new coroutine scope that automatically becomes a child of the outer scope that this `suspend` function is called from. `loadContributorsConcurrent()`is a good example.
You can also start a new coroutine from the global scope using `GlobalScope.async` or `GlobalScope.launch`. This will create a top-level "independent" coroutine.
The mechanism behind the structure of the coroutines is called *structured concurrency*. It provides the following benefits over global scopes:
* The scope is generally responsible for child coroutines, whose lifetime is attached to the lifetime of the scope.
* The scope can automatically cancel child coroutines if something goes wrong or a user changes their mind and decides to revoke the operation.
* The scope automatically waits for the completion of all child coroutines. Therefore, if the scope corresponds to a coroutine, the parent coroutine does not complete until all the coroutines launched in its scope have completed.
When using `GlobalScope.async`, there is no structure that binds several coroutines to a smaller scope. Coroutines started from the global scope are all independent – their lifetime is limited only by the lifetime of the whole application. It's possible to store a reference to the coroutine started from the global scope and wait for its completion or cancel it explicitly, but that won't happen automatically as it would with structured concurrency.
### Canceling the loading of contributors
Consider two versions of the `loadContributorsConcurrent()` function. The first uses `coroutineScope` to start all of the child coroutines, whereas the second uses `GlobalScope`. Compare how both versions behave when you try to cancel the parent coroutine.
1. Copy the implementation of `loadContributorsConcurrent()` from `Request5Concurrent.kt` to `loadContributorsNotCancellable()` in `Request5NotCancellable.kt`, and then remove the creation of a new `coroutineScope`.
2. The `async` calls now fail to resolve, so start them by using `GlobalScope.async`:
```
suspend fun loadContributorsNotCancellable(
service: GitHubService,
req: RequestData
): List<User> { // #1
// ...
GlobalScope.async { // #2
log("starting loading for ${repo.name}")
// load repo contributors
}
// ...
return deferreds.awaitAll().flatten().aggregate() // #3
}
```
* The function now returns the result directly, not as the last expression inside the lambda (lines `#1` and `#3`).
* All of the "contributors" coroutines are started inside the `GlobalScope`, not as children of the coroutine scope ( line `#2`).
3. Add a 3-second delay to all of the coroutines that send requests, so that there's enough time to cancel the loading after the coroutines are started but before the requests are sent:
```
suspend fun loadContributorsConcurrent(
service: GitHubService,
req: RequestData
): List<User> = coroutineScope {
// ...
GlobalScope.async {
log("starting loading for ${repo.name}")
delay(3000)
// load repo contributors
}
// ...
}
```
4. Run the program and choose the *CONCURRENT* option to load the contributors.
5. Wait until all of the "contributors" coroutines are started, and then click *Cancel*. The log shows no new results, which means that all of the requests were indeed canceled:
```
2896 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 40 repos
2901 [DefaultDispatcher-worker-2 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2909 [DefaultDispatcher-worker-5 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* click on 'cancel' */
/* no requests are sent */
```
6. Repeat step 5, but this time choose the `NOT_CANCELLABLE` option:
```
2570 [AWT-EventQueue-0 @coroutine#1] INFO Contributors - kotlin: loaded 30 repos
2579 [DefaultDispatcher-worker-1 @coroutine#4] INFO Contributors - starting loading for kotlin-koans
...
2586 [DefaultDispatcher-worker-6 @coroutine#36] INFO Contributors - starting loading for mpp-example
/* click on 'cancel' */
/* but all the requests are still sent: */
6402 [DefaultDispatcher-worker-5 @coroutine#4] INFO Contributors - kotlin-koans: loaded 45 contributors
...
9555 [DefaultDispatcher-worker-8 @coroutine#36] INFO Contributors - mpp-example: loaded 8 contributors
```
In this case, no coroutines are canceled, and all the requests are still sent.
7. Check how the cancellation is triggered in the "contributors" program. When the *Cancel* button is clicked, the main "loading" coroutine is explicitly canceled and the child coroutines are canceled automatically:
```
interface Contributors {
fun loadContributors() {
// ...
when (getSelectedVariant()) {
CONCURRENT -> {
launch {
val users = loadContributorsConcurrent(service, req)
updateResults(users, startTime)
}.setUpCancellation() // #1
}
}
}
private fun Job.setUpCancellation() {
val loadingJob = this // #2
// cancel the loading job if the 'cancel' button was clicked:
val listener = ActionListener {
loadingJob.cancel() // #3
updateLoadingStatus(CANCELED)
}
// add a listener to the 'cancel' button:
addCancelListener(listener)
// update the status and remove the listener
// after the loading job is completed
}
}
```
The `launch` function returns an instance of `Job`. `Job` stores a reference to the "loading coroutine", which loads all of the data and updates the results. You can call the `setUpCancellation()` extension function on it (line `#1`), passing an instance of `Job` as a receiver.
Another way you could express this would be to explicitly write:
```
val job = launch { }
job.setUpCancellation()
```
* For readability, you could refer to the `setUpCancellation()` function receiver inside the function with the new `loadingJob` variable (line `#2`).
* Then you could add a listener to the *Cancel* button so that when it's clicked, the `loadingJob` is canceled (line `#3`).
With structured concurrency, you only need to cancel the parent coroutine and this automatically propagates cancellation to all of the child coroutines.
### Using the outer scope's context
When you start new coroutines inside the given scope, it's much easier to ensure that all of them run with the same context. It is also much easier to replace the context if needed.
Now it's time to learn how using the dispatcher from the outer scope works. The new scope created by the `coroutineScope` or by the coroutine builders always inherits the context from the outer scope. In this case, the outer scope is the scope the `suspend loadContributorsConcurrent()` function was called from:
```
launch(Dispatchers.Default) { // outer scope
val users = loadContributorsConcurrent(service, req)
// ...
}
```
All of the nested coroutines are automatically started with the inherited context. The dispatcher is a part of this context. That's why all of the coroutines started by `async` are started with the context of the default dispatcher:
```
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// this scope inherits the context from the outer scope
// ...
async { // nested coroutine started with the inherited context
// ...
}
// ...
}
```
With structured concurrency, you can specify the major context elements (like dispatcher) once, when creating the top-level coroutine. All the nested coroutines then inherit the context and modify it only if needed.
Showing progress
----------------
Despite the information for some repositories being loaded rather quickly, the user only sees the resulting list after all of the data has been loaded. Until then, the loader icon runs showing the progress, but there's no information about the current state or what contributors are already loaded.
You can show the intermediate results earlier and display all of the contributors after loading the data for each of the repositories:
To implement this functionality, in the `src/tasks/Request6Progress.kt`, you'll need to pass the logic updating the UI as a callback, so that it's called on each intermediate state:
```
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
// loading the data
// calling `updateResults()` on intermediate states
}
```
On the call site in `Contributors.kt`, the callback is passed to update the results from the `Main` thread for the *PROGRESS* option:
```
launch(Dispatchers.Default) {
loadContributorsProgress(service, req) { users, completed ->
withContext(Dispatchers.Main) {
updateResults(users, startTime, completed)
}
}
}
```
* The `updateResults()` parameter is declared as `suspend` in `loadContributorsProgress()`. It's necessary to call `withContext`, which is a `suspend` function inside the corresponding lambda argument.
* `updateResults()` callback takes an additional Boolean parameter as an argument specifying whether the loading has completed and the results are final.
### Task 6
In the `Request6Progress.kt` file, implement the `loadContributorsProgress()` function that shows the intermediate progress. Base it on the `loadContributorsSuspend()` function from `Request4Suspend.kt`.
* Use a simple version without concurrency; you'll add it later in the next section.
* The intermediate list of contributors should be shown in an "aggregated" state, not just the list of users loaded for each repository.
* The total number of contributions for each user should be increased when the data for each new repository is loaded.
#### Solution for task 6
To store the intermediate list of loaded contributors in the "aggregated" state, define an `allUsers` variable which stores the list of users, and then update it after contributors for each new repository are loaded:
```
suspend fun loadContributorsProgress(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
var allUsers = emptyList<User>()
for ((index, repo) in repos.withIndex()) {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, index == repos.lastIndex)
}
}
```
#### Consecutive vs concurrent
An `updateResults()` callback is called after each request is completed:
This code doesn't include concurrency. It's sequential, so you don't need synchronization.
The best option would be to send requests concurrently and update the intermediate results after getting the response for each repository:
To add concurrency, use *channels*.
Channels
--------
Writing code with a shared mutable state is quite difficult and error-prone (like in the solution using callbacks). A simpler way is to share information by communication rather than by using a common mutable state. Coroutines can communicate with each other through *channels*.
Channels are communication primitives that allow data to be passed between coroutines. One coroutine can *send* some information to a channel, while another can *receive* that information from it:
A coroutine that sends (produces) information is often called a producer, and a coroutine that receives (consumes) information is called a consumer. One or multiple coroutines can send information to the same channel, and one or multiple coroutines can receive data from it:
When many coroutines receive information from the same channel, each element is handled only once by one of the consumers. Once an element is handled, it is immediately removed from the channel.
You can think of a channel as similar to a collection of elements, or more precisely, a queue, in which elements are added to one end and received from the other. However, there's an important difference: unlike collections, even in their synchronized versions, a channel can *suspend* `send()`and `receive()` operations. This happens when the channel is empty or full. The channel can be full if the channel size has an upper bound.
`Channel` is represented by three different interfaces: `SendChannel`, `ReceiveChannel`, and `Channel`, with the latter extending the first two. You usually create a channel and give it to producers as a `SendChannel` instance so that only they can send information to the channel. You give a channel to consumers as a `ReceiveChannel` instance so that only they can receive from it. Both `send` and `receive` methods are declared as `suspend`:
```
interface SendChannel<in E> {
suspend fun send(element: E)
fun close(): Boolean
}
interface ReceiveChannel<out E> {
suspend fun receive(): E
}
interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
```
The producer can close a channel to indicate that no more elements are coming.
Several types of channels are defined in the library. They differ in how many elements they can internally store and whether the `send()` call can be suspended or not. For all of the channel types, the `receive()` call behaves similarly: it receives an element if the channel is not empty; otherwise, it is suspended.
Unlimited channel
An unlimited channel is the closest analog to a queue: producers can send elements to this channel and it will keep growing indefinitely. The `send()` call will never be suspended. If the program runs out of memory, you'll get an `OutOfMemoryException`. The difference between an unlimited channel and a queue is that when a consumer tries to receive from an empty channel, it becomes suspended until some new elements are sent.

Buffered channel
The size of a buffered channel is constrained by the specified number. Producers can send elements to this channel until the size limit is reached. All of the elements are internally stored. When the channel is full, the next `send` call on it is suspended until more free space becomes available.

Rendezvous channel
The "Rendezvous" channel is a channel without a buffer, the same as a buffered channel with zero size. One of the functions (`send()` or `receive()`) is always suspended until the other is called.
If the `send()` function is called and there's no suspended `receive` call ready to process the element, then `send()` is suspended. Similarly, if the `receive` function is called and the channel is empty or, in other words, there's no suspended `send()` call ready to send the element, the `receive()` call is suspended.
The "rendezvous" name ("a meeting at an agreed time and place") refers to the fact that `send()` and `receive()` should "meet on time".

Conflated channel
A new element sent to the conflated channel will overwrite the previously sent element, so the receiver will always get only the latest element. The `send()` call is never suspended.

When you create a channel, specify its type or the buffer size (if you need a buffered one):
```
val rendezvousChannel = Channel<String>()
val bufferedChannel = Channel<String>(10)
val conflatedChannel = Channel<String>(CONFLATED)
val unlimitedChannel = Channel<String>(UNLIMITED)
```
By default, a "Rendezvous" channel is created.
In the following task, you'll create a "Rendezvous" channel, two producer coroutines, and a consumer coroutine:
```
import kotlinx.coroutines.channels.Channel
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val channel = Channel<String>()
launch {
channel.send("A1")
channel.send("A2")
log("A done")
}
launch {
channel.send("B1")
log("B done")
}
launch {
repeat(3) {
val x = channel.receive()
log(x)
}
}
}
fun log(message: Any?) {
println("[${Thread.currentThread().name}] $message")
}
```
### Task 7
In `src/tasks/Request7Channels.kt`, implement the function `loadContributorsChannels()` that requests all of the GitHub contributors concurrently and shows intermediate progress at the same time.
Use the previous functions, `loadContributorsConcurrent()` from `Request5Concurrent.kt` and `loadContributorsProgress()` from `Request6Progress.kt`.
#### Tip for task 7
Different coroutines that concurrently receive contributor lists for different repositories can send all of the received results to the same channel:
```
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = TODO()
// ...
channel.send(users)
}
}
```
Then the elements from this channel can be received one by one and processed:
```
repeat(repos.size) {
val users = channel.receive()
// ...
}
```
Since the `receive()` calls are sequential, no additional synchronization is needed.
#### Solution for task 7
As with the `loadContributorsProgress()` function, you can create an `allUsers` variable to store the intermediate states of the "all contributors" list. Each new list received from the channel is added to the list of all users. You aggregate the result and update the state using the `updateResults` callback:
```
suspend fun loadContributorsChannels(
service: GitHubService,
req: RequestData,
updateResults: suspend (List<User>, completed: Boolean) -> Unit
) = coroutineScope {
val repos = service
.getOrgRepos(req.org)
.also { logRepos(req, it) }
.bodyList()
val channel = Channel<List<User>>()
for (repo in repos) {
launch {
val users = service.getRepoContributors(req.org, repo.name)
.also { logUsers(repo, it) }
.bodyList()
channel.send(users)
}
}
var allUsers = emptyList<User>()
repeat(repos.size) {
val users = channel.receive()
allUsers = (allUsers + users).aggregate()
updateResults(allUsers, it == repos.lastIndex)
}
}
```
* Results for different repositories are added to the channel as soon as they are ready. At first, when all of the requests are sent, and no data is received, the `receive()` call is suspended. In this case, the whole "load contributors" coroutine is suspended.
* Then, when the list of users is sent to the channel, the "load contributors" coroutine resumes, the `receive()` call returns this list, and the results are immediately updated.
You can now run the program and choose the *CHANNELS* option to load the contributors and see the result.
Although neither coroutines nor channels completely remove the complexity that comes with concurrency, they make life easier when you need to understand what's going on.
Testing coroutines
------------------
Let's now test all solutions to check that the solution with concurrent coroutines is faster than the solution with the `suspend` functions, and check that the solution with channels is faster than the simple "progress" one.
In the following task, you'll compare the total running time of the solutions. You'll mock a GitHub service and make this service return results after the given timeouts:
```
repos request - returns an answer within 1000 ms delay
repo-1 - 1000 ms delay
repo-2 - 1200 ms delay
repo-3 - 800 ms delay
```
The sequential solution with the `suspend` functions should take around 4000 ms (4000 = 1000 + (1000 + 1200 + 800)). The concurrent solution should take around 2200 ms (2200 = 1000 + max(1000, 1200, 800)).
For the solutions that show progress, you can also check the intermediate results with timestamps.
The corresponding test data is defined in `test/contributors/testData.kt`, and the files `Request4SuspendKtTest`, `Request7ChannelsKtTest`, and so on contain the straightforward tests that use mock service calls.
However, there are two problems here:
* These tests take too long to run. Each test takes around 2 to 4 seconds, and you need to wait for the results each time. It's not very efficient.
* You can't rely on the exact time the solution runs because it still takes additional time to prepare and run the code. You could add a constant, but then the time would differ from machine to machine. The mock service delays should be higher than this constant so you can see a difference. If the constant is 0.5 sec, making the delays 0.1 sec won't be enough.
A better way would be to use special frameworks to test the timing while running the same code several times (which increases the total time even more), but that is complicated to learn and set up.
To solve these problems and make sure that solutions with provided test delays behave as expected, one faster than the other, use *virtual* time with a special test dispatcher. This dispatcher keeps track of the virtual time passed from the start and runs everything immediately in real time. When you run coroutines on this dispatcher, the `delay` will return immediately and advance the virtual time.
Tests that use this mechanism run fast, but you can still check what happens at different moments in virtual time. The total running time drastically decreases:
To use virtual time, replace the `runBlocking` invocation with a `runTest`. `runTest` takes an extension lambda to `TestScope` as an argument. When you call `delay` in a `suspend` function inside this special scope, `delay` will increase the virtual time instead of delaying in real time:
```
@Test
fun testDelayInSuspend() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
foo()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 6 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun foo() {
delay(1000) // auto-advances without delay
println("foo") // executes eagerly when foo() is called
}
```
You can check the current virtual time using the `currentTime` property of `TestScope`.
The actual running time in this example is several milliseconds, whereas virtual time equals the delay argument, which is 1000 milliseconds.
To get the full effect of "virtual" `delay` in child coroutines, start all of the child coroutines with `TestDispatcher`. Otherwise, it won't work. This dispatcher is automatically inherited from the other `TestScope`, unless you provide a different dispatcher:
```
@Test
fun testDelayInLaunch() = runTest {
val realStartTime = System.currentTimeMillis()
val virtualStartTime = currentTime
bar()
println("${System.currentTimeMillis() - realStartTime} ms") // ~ 11 ms
println("${currentTime - virtualStartTime} ms") // 1000 ms
}
suspend fun bar() = coroutineScope {
launch {
delay(1000) // auto-advances without delay
println("bar") // executes eagerly when bar() is called
}
}
```
If `launch` is called with the context of `Dispatchers.Default` in the example above, the test will fail. You'll get an exception saying that the job has not been completed yet.
You can test the `loadContributorsConcurrent()` function this way only if it starts the child coroutines with the inherited context, without modifying it using the `Dispatchers.Default` dispatcher.
You can specify the context elements like the dispatcher when *calling* a function rather than when *defining* it, which allows for more flexibility and easier testing.
By default, the compiler shows warnings if you use the experimental testing API. To suppress these warnings, annotate the test function or the whole class containing the tests with `@OptIn(ExperimentalCoroutinesApi::class)`. Add the compiler argument instructing the compiler that you're using the experimental API:
```
compileTestKotlin {
kotlinOptions {
freeCompilerArgs += "-Xuse-experimental=kotlin.Experimental"
}
}
```
In the project corresponding to this tutorial, the compiler argument has already been added to the Gradle script.
### Task 8
Refactor the following tests in `tests/tasks/` to use virtual time instead of real time:
* Request4SuspendKtTest.kt
* Request5ConcurrentKtTest.kt
* Request6ProgressKtTest.kt
* Request7ChannelsKtTest.kt
Compare the total running times before and after applying your refactoring.
#### Tip for task 8
1. Replace the `runBlocking` invocation with `runTest`, and replace `System.currentTimeMillis()` with `currentTime`:
```
@Test
fun test() = runTest {
val startTime = currentTime
// action
val totalTime = currentTime - startTime
// testing result
}
```
2. Uncomment the assertions that check the exact virtual time.
3. Don't forget to add `@UseExperimental(ExperimentalCoroutinesApi::class)`.
#### Solution for task 8
Here are the solutions for the concurrent and channels cases:
```
fun testConcurrent() = runTest {
val startTime = currentTime
val result = loadContributorsConcurrent(MockGithubService, testRequestData)
Assert.assertEquals("Wrong result for 'loadContributorsConcurrent'", expectedConcurrentResults.users, result)
val totalTime = currentTime - startTime
Assert.assertEquals(
"The calls run concurrently, so the total virtual time should be 2200 ms: " +
"1000 for repos request plus max(1000, 1200, 800) = 1200 for concurrent contributors requests)",
expectedConcurrentResults.timeFromStart, totalTime
)
}
```
First, check that the results are available exactly at the expected virtual time, and then check the results themselves:
```
fun testChannels() = runTest {
val startTime = currentTime
var index = 0
loadContributorsChannels(MockGithubService, testRequestData) { users, _ ->
val expected = concurrentProgressResults[index++]
val time = currentTime - startTime
Assert.assertEquals(
"Expected intermediate results after ${expected.timeFromStart} ms:",
expected.timeFromStart, time
)
Assert.assertEquals("Wrong intermediate results after $time:", expected.users, users)
}
}
```
The first intermediate result for the last version with channels becomes available sooner than the progress version, and you can see the difference in tests that use virtual time.
What's next
-----------
* Check out the [Asynchronous Programming with Kotlin](https://kotlinconf.com/workshops/) workshop at KotlinConf.
* Find out more about using [virtual time and the experimental testing package](https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-test/).
Last modified: 10 January 2023
[Coroutines basics](coroutines-basics) [Cancellation and timeouts](cancellation-and-timeouts)
| programming_docs |
kotlin Kotlin brand assets Kotlin brand assets
===================
Kotlin Logo
-----------
Our logo consists of a mark and a typeface. The full-color version is the main one and should be used in the vast majority of cases.
[Download all versions](https://resources.jetbrains.com/storage/products/kotlin/docs/kotlin_logos.zip)
Our logo and mark have a protective field. Please position the logo so that other design elements do not come into the box. The minimum size of the protective field is half the height of the mark.
Pay special attention to the following restrictions concerning the use of the logo:
* Do not separate the mark from the text. Do not swap elements.
* Do not change the transparency of the logo.
* Do not outline the logo.
* Do not repaint the logo in third-party colors.
* Do not change the text.
* Do not set the logo against a complex background. Do not place the logo in front of a bright background.
Kotlin User Group brand assets
------------------------------
We provide Kotlin user groups with a logo that is specifically designed to be recognizable and convey a reference to Kotlin.
* The official Kotlin logo is associated with the language itself. It should not be used otherwise in different scopes, as this could cause confusion. The same applies to its close derivatives.
* User groups logo also means that the opinions and actions of the community are independent of the Kotlin team.
* Your opinions don't have to agree with ours, and we think this is the most beneficial model for a creative and strong community.
[Download all assets](https://drive.google.com/drive/folders/0B3Zi34svOj1RZ2sxZExhblRJc1k)
### Style for user groups
Since the launch of the Kotlin community support program at the beginning of 2017, the number of user groups has multiplied, with around 2-4 new user groups joining us every month. Please check out the complete list of groups in the **Kotlin User Groups** section to find one in your area.
We provide new Kotlin user groups with a user group logo and a profile picture.
There are two main reasons why we are doing it:
* Firstly, we received numerous requests from the community asking for special Kotlin style branded materials to help them be recognized as officially dedicated user groups.
* Secondly, we wanted to provide a distinct style for the user group and community content to make it clear which Kotlin-related materials are from the official team and which are created by the community.
### Create the logo of your user group
To create a logo of your users group:
1. Copy the Kotlin user group [logo file](https://docs.google.com/drawings/d/1IcJp8Z2jAwEliXrHB-l9RNK_2LrqGTkNuPPtjrW1iIU/edit) to your Google drive (you have to be signed in to your Google account).
2. Replace the **Your City** text with the name of your user group.
3. Download the picture and use it for the user group materials.
*Belarusian Kotlin User Group Profile Picture sample*
You can download a [set of graphics](https://drive.google.com/drive/folders/0B3Zi34svOj1RZ2sxZExhblRJc1k) including vector graphics and samples of cover pictures for social networks.
### Create your group's profile picture for different platforms
To create your group's profile picture:
1. Make a copy of the Kotlin user group profile [picture file](https://docs.google.com/drawings/d/1buhwccmllb7wFS0OIAub0WC4DIuSHRiDpjEQhB4tkPs/edit) to your Google Drive (you have to be signed in to your Google account).
2. Add a shortened name of the user group's location (up to 4 capital symbols according to our default sample).
3. Download the picture and use it for your profiles on Facebook, Twitter, or any other platform.
### Create meetup.com cover photo
To create a cover photo with a group's logo for meetup.com:
1. Make a copy of the [picture file](https://drive.google.com/file/d/1g_0Plf_do6vrXvy1R-Hx430vfV2CPVKN/view) to your Google Drive (you have to be signed in to your Google account).
2. Add a shortened name of the user group's location to the logo on the right upper corner of the picture. If you want to replace the general pattern with a custom picture, click on the background pattern-picture, choose 'Replace Image', then 'Upload from Computer' or any other source.
3. Download the picture and use it for your profile on [meetup.com](https://meetup.com).
Kotlin Night brand assets
-------------------------
JetBrains provides branding and materials for Kotlin Night events. Our team will prepare digital assets for the event promotion and ship your merchandise pack containing stickers and t-shirts. Check out what we have to make your Kotlin Night fun!
[Download all assets](https://drive.google.com/drive/folders/1wTJ-PiO6VvbY6XdACGLsWZ_N8KHI0Nvr)
### Social media
Stickers can be used to brand any media necessary for a Kotlin Night. Just stick them on anything you can get your hands on. It's fun!
### Branding stickers
Stickers can be used to brand assets for a Kotlin Night. Just stick them on anything you can get your hands on. It is funny!
### Press-wall
You can decorate a press wall with stickers for unforgettable event pictures.
### Sticky badges
Use stickers as badges for the attendees and boost networking at the event!
### Board for stickers
Or you can provide a board where your guests can paste stickers with their impressions, feedback, and wishes.
### T-shirts
Guests of the event are offered to paste stickers on the board with their impressions of the meeting. What does it mean for you?
 Last modified: 10 January 2023
[Kotlin Night guidelines](kotlin-night-guidelines)
kotlin IDEs for Kotlin development IDEs for Kotlin development
===========================
JetBrains provides the official Kotlin plugin for two Integrated Development Environments (IDEs): [IntelliJ IDEA](#intellij-idea) and [Android Studio](#android-studio).
Other IDEs and source editors, such as [Eclipse](#eclipse), Visual Studio Code, and Atom, have Kotlin community-supported plugins.
IntelliJ IDEA
-------------
[IntelliJ IDEA](https://www.jetbrains.com/idea/download/) is an IDE for JVM languages designed to maximize developer productivity. It does the routine and repetitive tasks for you by providing clever code completion, static code analysis, and refactorings, and lets you focus on the bright side of software development, making it not only productive but also an enjoyable experience.
Kotlin plugin is bundled with each IntelliJ IDEA release.
Read more about IntelliJ IDEA in the [official documentation](https://www.jetbrains.com/help/idea/discover-intellij-idea.html).
Android Studio
--------------
[Android Studio](https://developer.android.com/studio) is the official IDE for Android app development, based on [IntelliJ IDEA](https://www.jetbrains.com/idea/). On top of IntelliJ's powerful code editor and developer tools, Android Studio offers even more features that enhance your productivity when building Android apps.
Kotlin plugin is bundled with each Android Studio release.
Read more about Android Studio in the [official documentation](https://developer.android.com/studio/intro).
Eclipse
-------
[Eclipse](https://eclipseide.org/release/) is an IDE that is used to develop applications in different programming languages, including Kotlin. Eclipse also has the Kotlin plugin: originally developed by JetBrains, now the Kotlin plugin is supported by the Kotlin community contributors.
You can install the [Kotlin plugin manually from the Eclipse Marketplace](https://marketplace.eclipse.org/content/kotlin-plugin-eclipse).
The Kotlin team manages the development and contribution process to the Kotlin plugin for Eclipse. If you want to contribute to the plugin, send a pull request to the [Kotlin for Eclipse repository on GitHub](https://github.com/Kotlin/kotlin-eclipse).
Compatibility with the Kotlin language versions
-----------------------------------------------
For IntelliJ IDEA and Android Studio the Kotlin plugin is bundled with each IDE release. When the new Kotlin version is released, these IDEs will suggest updating Kotlin to the latest version automatically. See the latest supported language version for each IDE in [Kotlin releases](releases#ide-support).
Other IDEs support
------------------
JetBrains doesn't provide the Kotlin plugin for other IDEs. However, some of the other IDEs and source editors, such as Eclipse, Visual Studio Code, and Atom, have their own Kotlin plugins supported by the Kotlin community.
You can use any text editor to write the Kotlin code, but without IDE-related features: code formatting, debugging tools, and so on. To use Kotlin in text editors, you can download the latest Kotlin command-line compiler (`kotlin-compiler-1.8.0.zip`) from Kotlin [GitHub Releases](https://github.com/JetBrains/kotlin/releases/tag/v1.8.0) and [install it manually](command-line#manual-install). Also, you could use package managers, such as [Homebrew](command-line#homebrew), [SDKMAN!](command-line#sdkman), and [Snap package](command-line#snap-package).
What's next?
------------
* [Start your first project using IntelliJ IDEA IDE](jvm-get-started)
* [Create your first cross-platform mobile app using Android Studio](multiplatform-mobile-create-first-app)
* Learn how to [install EAP version of the Kotlin plugin](install-eap-plugin)
Last modified: 10 January 2023
[Ant](ant) [Migrate to Kotlin code style](code-style-migration-guide)
kotlin What's new in Kotlin 1.3 What's new in Kotlin 1.3
========================
*Release date: 29 October 2018*
Coroutines release
------------------
After some long and extensive battle testing, coroutines are now released! It means that from Kotlin 1.3 the language support and the API are [fully stable](components-stability). Check out the new [coroutines overview](coroutines-overview) page.
Kotlin 1.3 introduces callable references on suspend-functions and support of coroutines in the reflection API.
Kotlin/Native
-------------
Kotlin 1.3 continues to improve and polish the Native target. See the [Kotlin/Native overview](native-overview) for details.
Multiplatform projects
----------------------
In 1.3, we've completely reworked the model of multiplatform projects in order to improve expressiveness and flexibility, and to make sharing common code easier. Also, Kotlin/Native is now supported as one of the targets!
The key differences to the old model are:
* In the old model, common and platform-specific code needed to be placed in separate modules, linked by `expectedBy` dependencies. Now, common and platform-specific code is placed in different source roots of the same module, making projects easier to configure.
* There is now a large number of [preset platform configurations](multiplatform-dsl-reference#targets) for different supported platforms.
* The [dependencies configuration](multiplatform-add-dependencies) has been changed; dependencies are now specified separately for each source root.
* Source sets can now be shared between an arbitrary subset of platforms (for example, in a module that targets JS, Android and iOS, you can have a source set that is shared only between Android and iOS).
* [Publishing multiplatform libraries](multiplatform-publish-lib) is now supported.
For more information, please refer to the [multiplatform programming documentation](multiplatform).
Contracts
---------
The Kotlin compiler does extensive static analysis to provide warnings and reduce boilerplate. One of the most notable features is smartcasts — with the ability to perform a cast automatically based on the performed type checks:
```
fun foo(s: String?) {
if (s != null) s.length // Compiler automatically casts 's' to 'String'
}
```
However, as soon as these checks are extracted in a separate function, all the smartcasts immediately disappear:
```
fun String?.isNotNull(): Boolean = this != null
fun foo(s: String?) {
if (s.isNotNull()) s.length // No smartcast :(
}
```
To improve the behavior in such cases, Kotlin 1.3 introduces experimental mechanism called *contracts*.
*Contracts* allow a function to explicitly describe its behavior in a way which is understood by the compiler. Currently, two wide classes of cases are supported:
* Improving smartcasts analysis by declaring the relation between a function's call outcome and the passed arguments values:
```
fun require(condition: Boolean) {
// This is a syntax form which tells the compiler:
// "if this function returns successfully, then the passed 'condition' is true"
contract { returns() implies condition }
if (!condition) throw IllegalArgumentException(...)
}
fun foo(s: String?) {
require(s is String)
// s is smartcast to 'String' here, because otherwise
// 'require' would have thrown an exception
}
```
* Improving the variable initialization analysis in the presence of high-order functions:
```
fun synchronize(lock: Any?, block: () -> Unit) {
// It tells the compiler:
// "This function will invoke 'block' here and now, and exactly one time"
contract { callsInPlace(block, EXACTLY_ONCE) }
}
fun foo() {
val x: Int
synchronize(lock) {
x = 42 // Compiler knows that lambda passed to 'synchronize' is called
// exactly once, so no reassignment is reported
}
println(x) // Compiler knows that lambda will be definitely called, performing
// initialization, so 'x' is considered to be initialized here
}
```
### Contracts in stdlib
`stdlib` already makes use of contracts, which leads to improvements in the analyses described above. This part of contracts is **stable**, meaning that you can benefit from the improved analysis right now without any additional opt-ins:
```
//sampleStart
fun bar(x: String?) {
if (!x.isNullOrEmpty()) {
println("length of '$x' is ${x.length}") // Yay, smartcast to not-null!
}
}
//sampleEnd
fun main() {
bar(null)
bar("42")
}
```
### Custom contracts
It is possible to declare contracts for your own functions, but this feature is **experimental,** as the current syntax is in a state of early prototype and will most probably be changed. Also please note that currently the Kotlin compiler does not verify contracts, so it's the responsibility of the programmer to write correct and sound contracts.
Custom contracts are introduced by a call to `contract` stdlib function, which provides DSL scope:
```
fun String?.isNullOrEmpty(): Boolean {
contract {
returns(false) implies (this@isNullOrEmpty != null)
}
return this == null || isEmpty()
}
```
See the details on the syntax as well as the compatibility notice in the [KEEP](https://github.com/Kotlin/KEEP/blob/master/proposals/kotlin-contracts.md).
Capturing when subject in a variable
------------------------------------
In Kotlin 1.3, it is now possible to capture the `when` subject into a variable:
```
fun Request.getBody() =
when (val response = executeRequest()) {
is Success -> response.body
is HttpError -> throw HttpException(response.status)
}
```
While it was already possible to extract this variable just before `when`, `val` in `when` has its scope properly restricted to the body of `when`, and so preventing namespace pollution. [See the full documentation on `when` here](control-flow#when-expression).
@JvmStatic and @JvmField in companions of interfaces
----------------------------------------------------
With Kotlin 1.3, it is possible to mark members of a `companion` object of interfaces with annotations `@JvmStatic` and `@JvmField`. In the classfile, such members will be lifted to the corresponding interface and marked as `static`.
For example, the following Kotlin code:
```
interface Foo {
companion object {
@JvmField
val answer: Int = 42
@JvmStatic
fun sayHello() {
println("Hello, world!")
}
}
}
```
It is equivalent to this Java code:
```
interface Foo {
public static int answer = 42;
public static void sayHello() {
// ...
}
}
```
Nested declarations in annotation classes
-----------------------------------------
In Kotlin 1.3, it is possible for annotations to have nested classes, interfaces, objects, and companions:
```
annotation class Foo {
enum class Direction { UP, DOWN, LEFT, RIGHT }
annotation class Bar
companion object {
fun foo(): Int = 42
val bar: Int = 42
}
}
```
Parameterless main
------------------
By convention, the entry point of a Kotlin program is a function with a signature like `main(args: Array<String>)`, where `args` represent the command-line arguments passed to the program. However, not every application supports command-line arguments, so this parameter often ends up not being used.
Kotlin 1.3 introduced a simpler form of `main` which takes no parameters. Now "Hello, World" in Kotlin is 19 characters shorter!
```
fun main() {
println("Hello, world!")
}
```
Functions with big arity
------------------------
In Kotlin, functional types are represented as generic classes taking a different number of parameters: `Function0<R>`, `Function1<P0, R>`, `Function2<P0, P1, R>`, ... This approach has a problem in that this list is finite, and it currently ends with `Function22`.
Kotlin 1.3 relaxes this limitation and adds support for functions with bigger arity:
```
fun trueEnterpriseComesToKotlin(block: (Any, Any, ... /* 42 more */, Any) -> Any) {
block(Any(), Any(), ..., Any())
}
```
Progressive mode
----------------
Kotlin cares a lot about stability and backward compatibility of code: Kotlin compatibility policy says that breaking changes (e.g., a change which makes the code that used to compile fine, not compile anymore) can be introduced only in the major releases (**1.2**, **1.3**, etc.).
We believe that a lot of users could use a much faster cycle where critical compiler bug fixes arrive immediately, making the code more safe and correct. So, Kotlin 1.3 introduces the *progressive* compiler mode, which can be enabled by passing the argument `-progressive` to the compiler.
In the progressive mode, some fixes in language semantics can arrive immediately. All these fixes have two important properties:
* They preserve backward compatibility of source code with older compilers, meaning that all the code which is compilable by the progressive compiler will be compiled fine by non-progressive one.
* They only make code *safer* in some sense — e.g., some unsound smartcast can be forbidden, behavior of the generated code may be changed to be more predictable/stable, and so on.
Enabling the progressive mode can require you to rewrite some of your code, but it shouldn't be too much — all the fixes enabled under progressive are carefully handpicked, reviewed, and provided with tooling migration assistance. We expect that the progressive mode will be a nice choice for any actively maintained codebases which are updated to the latest language versions quickly.
Inline classes
--------------
Kotlin 1.3 introduces a new kind of declaration — `inline class`. Inline classes can be viewed as a restricted version of the usual classes, in particular, inline classes must have exactly one property:
```
inline class Name(val s: String)
```
The Kotlin compiler will use this restriction to aggressively optimize runtime representation of inline classes and substitute their instances with the value of the underlying property where possible removing constructor calls, GC pressure, and enabling other optimizations:
```
inline class Name(val s: String)
//sampleStart
fun main() {
// In the next line no constructor call happens, and
// at the runtime 'name' contains just string "Kotlin"
val name = Name("Kotlin")
println(name.s)
}
//sampleEnd
```
See [reference](inline-classes) for inline classes for details.
Unsigned integers
-----------------
Kotlin 1.3 introduces unsigned integer types:
* `kotlin.UByte`: an unsigned 8-bit integer, ranges from 0 to 255
* `kotlin.UShort`: an unsigned 16-bit integer, ranges from 0 to 65535
* `kotlin.UInt`: an unsigned 32-bit integer, ranges from 0 to 2^32 - 1
* `kotlin.ULong`: an unsigned 64-bit integer, ranges from 0 to 2^64 - 1
Most of the functionality of signed types are supported for unsigned counterparts too:
```
fun main() {
//sampleStart
// You can define unsigned types using literal suffixes
val uint = 42u
val ulong = 42uL
val ubyte: UByte = 255u
// You can convert signed types to unsigned and vice versa via stdlib extensions:
val int = uint.toInt()
val byte = ubyte.toByte()
val ulong2 = byte.toULong()
// Unsigned types support similar operators:
val x = 20u + 22u
val y = 1u shl 8
val z = "128".toUByte()
val range = 1u..5u
//sampleEnd
println("ubyte: $ubyte, byte: $byte, ulong2: $ulong2")
println("x: $x, y: $y, z: $z, range: $range")
}
```
See [reference](unsigned-integer-types) for details.
@JvmDefault
-----------
Kotlin targets a wide range of the Java versions, including Java 6 and Java 7, where default methods in the interfaces are not allowed. For your convenience, the Kotlin compiler works around that limitation, but this workaround isn't compatible with the `default` methods, introduced in Java 8.
This could be an issue for Java-interoperability, so Kotlin 1.3 introduces the `@JvmDefault` annotation. Methods annotated with this annotation will be generated as `default` methods for JVM:
```
interface Foo {
// Will be generated as 'default' method
@JvmDefault
fun foo(): Int = 42
}
```
Standard library
----------------
### Multiplatform random
Prior to Kotlin 1.3, there was no uniform way to generate random numbers on all platforms — we had to resort to platform-specific solutions like `java.util.Random` on JVM. This release fixes this issue by introducing the class `kotlin.random.Random`, which is available on all platforms:
```
import kotlin.random.Random
fun main() {
//sampleStart
val number = Random.nextInt(42) // number is in range [0, limit)
println(number)
//sampleEnd
}
```
### isNullOrEmpty and orEmpty extensions
`isNullOrEmpty` and `orEmpty` extensions for some types are already present in stdlib. The first one returns `true` if the receiver is `null` or empty, and the second one falls back to an empty instance if the receiver is `null`. Kotlin 1.3 provides similar extensions on collections, maps, and arrays of objects.
### Copy elements between two existing arrays
The `array.copyInto(targetArray, targetOffset, startIndex, endIndex)` functions for the existing array types, including the unsigned arrays, make it easier to implement array-based containers in pure Kotlin.
```
fun main() {
//sampleStart
val sourceArr = arrayOf("k", "o", "t", "l", "i", "n")
val targetArr = sourceArr.copyInto(arrayOfNulls<String>(6), 3, startIndex = 3, endIndex = 6)
println(targetArr.contentToString())
sourceArr.copyInto(targetArr, startIndex = 0, endIndex = 3)
println(targetArr.contentToString())
//sampleEnd
}
```
### associateWith
It is quite a common situation to have a list of keys and want to build a map by associating each of these keys with some value. It was possible to do it before with the `associate { it to getValue(it) }` function, but now we're introducing a more efficient and easy to explore alternative: `keys.associateWith { getValue(it) }`.
```
fun main() {
//sampleStart
val keys = 'a'..'f'
val map = keys.associateWith { it.toString().repeat(5).capitalize() }
map.forEach { println(it) }
//sampleEnd
}
```
### ifEmpty and ifBlank functions
Collections, maps, object arrays, char sequences, and sequences now have an `ifEmpty` function, which allows specifying a fallback value that will be used instead of the receiver if it is empty:
```
fun main() {
//sampleStart
fun printAllUppercase(data: List<String>) {
val result = data
.filter { it.all { c -> c.isUpperCase() } }
.ifEmpty { listOf("<no uppercase>") }
result.forEach { println(it) }
}
printAllUppercase(listOf("foo", "Bar"))
printAllUppercase(listOf("FOO", "BAR"))
//sampleEnd
}
```
Char sequences and strings in addition have an `ifBlank` extension that does the same thing as `ifEmpty` but checks for a string being all whitespace instead of empty.
```
fun main() {
//sampleStart
val s = " \n"
println(s.ifBlank { "<blank>" })
println(s.ifBlank { null })
//sampleEnd
}
```
### Sealed classes in reflection
We've added a new API to `kotlin-reflect` that can be used to enumerate all the direct subtypes of a `sealed` class, namely `KClass.sealedSubclasses`.
### Smaller changes
* `Boolean` type now has companion.
* `Any?.hashCode()` extension that returns 0 for `null`.
* `Char` now provides `MIN_VALUE` and `MAX_VALUE` constants.
* `SIZE_BYTES` and `SIZE_BITS` constants in primitive type companions.
Tooling
-------
### Code style support in IDE
Kotlin 1.3 introduces support for the [recommended code style](coding-conventions) in IntelliJ IDEA. Check out [this page](code-style-migration-guide) for the migration guidelines.
### kotlinx.serialization
[kotlinx.serialization](https://github.com/Kotlin/kotlinx.serialization) is a library which provides multiplatform support for (de)serializing objects in Kotlin. Previously, it was a separate project, but since Kotlin 1.3, it ships with the Kotlin compiler distribution on par with the other compiler plugins. The main difference is that you don't need to manually watch out for the Serialization IDE Plugin being compatible with the Kotlin IDE plugin version you're using: now the Kotlin IDE plugin already includes serialization!
See here for [details](https://github.com/Kotlin/kotlinx.serialization#current-project-status).
### Scripting update
Kotlin 1.3 continues to evolve and improve scripting API, introducing some experimental support for scripts customization, such as adding external properties, providing static or dynamic dependencies, and so on.
For additional details, please consult the [KEEP-75](https://github.com/Kotlin/KEEP/blob/master/proposals/scripting-support.md).
### Scratches support
Kotlin 1.3 introduces support for runnable Kotlin *scratch files*. *Scratch file* is a kotlin script file with the .kts extension that you can run and get evaluation results directly in the editor.
Consult the general [Scratches documentation](https://www.jetbrains.com/help/idea/scratches.html) for details.
Last modified: 10 January 2023
[What's new in Kotlin 1.4](whatsnew14) [What's new in Kotlin 1.2](whatsnew12)
| programming_docs |
kotlin Get started with Kotlin/Native in IntelliJ IDEA Get started with Kotlin/Native in IntelliJ IDEA
===============================================
This tutorial demonstrates how to use IntelliJ IDEA for creating a Kotlin/Native application.
To get started, install the latest version of [IntelliJ IDEA](https://www.jetbrains.com/idea/download/index.html). The tutorial is applicable to both IntelliJ IDEA Community Edition and the Ultimate Edition.
Create a new Kotlin/Native project in IntelliJ IDEA
---------------------------------------------------
1. In IntelliJ IDEA, select **File** | **New** | **Project**.
2. In the panel on the left, select **Kotlin Multiplatform**.
3. Enter a project name, select **Native Application** as the project template, and click **Next**.
By default, your project will use Gradle with Kotlin DSL as the build system.
4. Accept the default configuration on the next screen and click **Finish**. Your project will open.
By default, the wizard creates the necessary `Main.kt` file with code that prints "Hello, Kotlin/Native!" to the standard output.
5. Open the `build.gradle.kts` file, the build script that contains the project settings. To create Kotlin/Native applications, you need the Kotlin Multiplatform Gradle plugin installed. Ensure that you use the latest version of the plugin:
```
plugins {
kotlin("multiplatform") version "1.8.0"
}
```
Build and run the application
-----------------------------
1. Click **Build Project** next to the run configuration at the top of the screen:

2. In the IntelliJ IDEA terminal or your command-line tool, run the following command:
```
build/bin/native/debugExecutable/<your_app_name>.kexe
```
IntelliJ IDEA prints "Hello, Kotlin/Native!".
You can [configure IntelliJ IDEA](https://www.jetbrains.com/help/idea/compiling-applications.html#auto-build) to build your project automatically:
1. Go to **Settings/Preferences | Build, Execution, Deployment | Compiler**.
2. On the **Compiler** page, select **Build project automatically**.
3. Apply the changes.
Now when you make changes in the class files or save the file (**Ctrl + S**/**Cmd + S**), IntelliJ IDEA automatically performs the incremental build of the project.
Update the application
----------------------
### Count the letters in your name
1. Open the file `Main.kt` in `src/nativeMain/kotlin`.
The `src` directory contains the Kotlin source files and resources. The file `Main.kt` includes sample code that prints "Hello, Kotlin/Native!" using the [`println()`](../api/latest/jvm/stdlib/kotlin.io/println) function.
2. Add code to read the input. Use the [`readln()`](../api/latest/jvm/stdlib/kotlin.io/readln) function to read the input value and assign it to the `name` variable:
```
fun main() {
// Read the input value.
println("Hello, enter your name:")
val name = readln()
}
```
3. Eliminate the whitespaces and count the letters:
* Use the [`replace()`](../api/latest/jvm/stdlib/kotlin.text/replace) function to remove the empty spaces in the name.
* Use the scope function [`let`](scope-functions#let) to run the function within the object context.
* Use a [string template](strings#string-templates) to insert your name length into the string by adding a dollar sign `$` and enclosing it in curly braces – `${it.length}`. `it` is the default name of a [lambda parameter](coding-conventions#lambda-parameters).
```
fun main() {
// Read the input value.
println("Hello, enter your name:")
val name = readln()
// Count the letters in the name.
name.replace(" ", "").let {
println("Your name contains ${it.length} letters")
}
}
```
4. Save the changes and run the following command in the IntelliJ IDEA terminal or your command-line tool:
```
build/bin/native/debugExecutable/<your_app_name>.kexe
```
5. Enter your name and enjoy the result:

### Count the unique letters in your name
1. Open the file `Main.kt` in `src/nativeMain/kotlin`.
2. Declare the new [extension function](extensions#extension-functions) `countDistinctCharacters()` for `String`:
* Convert the name to lowercase using the [`lowercase()`](../api/latest/jvm/stdlib/kotlin.text/lowercase) function.
* Convert the input string to a list of characters using the [`toList()`](../api/latest/jvm/stdlib/kotlin.text/to-list) function.
* Select only the distinct characters in your name using the [`distinct()`](../api/latest/jvm/stdlib/kotlin.collections/distinct) function.
* Count the distinct characters using the [`count()`](../api/latest/jvm/stdlib/kotlin.collections/count) function.
```
fun String.countDistinctCharacters() = lowercase().toList().distinct().count()
```
3. Use the `countDistinctCharacters()` function to count the unique letters in your name:
```
fun String.countDistinctCharacters() = lowercase().toList().distinct().count()
fun main() {
// Read the input value.
println("Hello, enter your name:")
val name = readln()
// Count the letters in the name.
name.replace(" ", "").let {
println("Your name contains ${it.length} letters")
// Print the number of unique letters.
println("Your name contains ${it.countDistinctCharacters()} unique letters")
}
}
```
4. Save the changes and run the following command in the IntelliJ IDEA terminal or your command-line tool:
```
build/bin/native/debugExecutable/<your_app_name>.kexe
```
5. Enter your name and enjoy the result:

What's next?
------------
Once you have created your first application, you can complete our long-form tutorial on Kotlin/Native, [Create an app using C Interop and libcurl](native-app-with-c-and-libcurl) that explains how to create a native HTTP client and interoperate with C libraries.
Last modified: 10 January 2023
[Build a web application with React and Kotlin/JS — tutorial](js-react) [Get started with Kotlin/Native using Gradle](native-gradle)
kotlin Nullability in Java and Kotlin Nullability in Java and Kotlin
==============================
*Nullability* is the ability of a variable to hold a `null` value. When a variable contains `null`, an attempt to dereference the variable leads to a `NullPointerException`. There are many ways to write code in order to minimize the probability of receiving null pointer exceptions.
This guide covers differences between Java's and Kotlin's approaches to handling possibly nullable variables. It will help you migrate from Java to Kotlin and write your code in authentic Kotlin style.
The first part of this guide covers the most important difference – support for nullable types in Kotlin and how Kotlin processes [types from Java code](#platform-types). The second part, starting from [Checking the result of a function call](#checking-the-result-of-a-function-call), examines several specific cases to explain certain differences.
[Learn more about null safety in Kotlin](null-safety).
Support for nullable types
--------------------------
The most important difference between Kotlin's and Java's type systems is Kotlin's explicit support for [nullable types](null-safety). It is a way to indicate which variables can possibly hold a `null` value. If a variable can be `null`, it's not safe to call a method on the variable because this can cause a `NullPointerException`. Kotlin prohibits such calls at compile time and thereby prevents lots of possible exceptions. At runtime, objects of nullable types and objects of non-nullable types are treated the same: A nullable type isn't a wrapper for a non-nullable type. All checks are performed at compile time. That means there's almost no runtime overhead for working with nullable types in Kotlin.
In Java, if you don't write null checks, methods may throw a `NullPointerException`:
```
// Java
int stringLength(String a) {
return a.length();
}
void main() {
stringLength(null); // Throws a `NullPointerException`
}
```
This call will have the following output:
```
java.lang.NullPointerException: Cannot invoke "String.length()" because "a" is null
at test.java.Nullability.stringLength(Nullability.java:8)
at test.java.Nullability.main(Nullability.java:12)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
at java.base/java.util.ArrayList.forEach(ArrayList.java:1511)
```
In Kotlin, all regular types are non-nullable by default unless you explicitly mark them as nullable. If you don't expect `a` to be `null`, declare the `stringLength()` function as follows:
```
// Kotlin
fun stringLength(a: String) = a.length
```
The parameter `a` has the `String` type, which in Kotlin means it must always contain a `String` instance and it cannot contain `null`. Nullable types in Kotlin are marked with a question mark `?`, for example, `String?`. The situation with a `NullPointerException` at runtime is impossible if `a` is `String` because the compiler enforces the rule that all arguments of `stringLength()` not be `null`.
An attempt to pass a `null` value to the `stringLength(a: String)` function will result in a compile-time error, "Null can not be a value of a non-null type String":
If you want to use this function with any arguments, including `null`, use a question mark after the argument type `String?` and check inside the function body to ensure that the value of the argument is not `null`:
```
// Kotlin
fun stringLength(a: String?): Int = if (a != null) a.length else 0
```
After the check is passed successfully, the compiler treats the variable as if it were of the non-nullable type `String` in the scope where the compiler performs the check.
If you don't perform this check, the code will fail to compile with the following message: "Only [safe (?.)](null-safety#safe-calls) or [non-null asserted (!!.) calls](null-safety#the-operator) are allowed on a [nullable receiver](extensions#nullable-receiver) of type String?".
You can write the same shorter – use the [safe-call operator ?. (If-not-null shorthand)](idioms#if-not-null-shorthand), which allows you to combine a null check and a method call into a single operation:
```
// Kotlin
fun stringLength(a: String?): Int = a?.length ?: 0
```
Platform types
--------------
In Java, you can use annotations showing whether a variable can or cannot be `null`. Such annotations aren't part of the standard library, but you can add them separately. For example, you can use the JetBrains annotations `@Nullable` and `@NotNull` (from the `org.jetbrains.annotations` package) or annotations from Eclipse (`org.eclipse.jdt.annotation`). Kotlin can recognize such annotations when you're [calling Java code from Kotlin code](java-interop#nullability-annotations) and will treat types according to their annotations.
If your Java code doesn't have these annotations, then Kotlin will treat Java types as *platform types*. But since Kotlin doesn't have nullability information for such types, its compiler will allow all operations on them. You will need to decide whether to perform null checks, because:
* Just as in Java, you'll get a `NullPointerException` if you try to perform an operation on `null`.
* The compiler won't highlight any redundant null checks, which it normally does when you perform a null-safe operation on a value of a non-nullable type.
Learn more about [calling Java from Kotlin in regard to null-safety and platform types](java-interop#null-safety-and-platform-types).
Checking the result of a function call
--------------------------------------
One of the most common situations where you need to check for `null` is when you obtain a result from a function call.
In the following example, there are two classes, `Order` and `Customer`. `Order` has a reference to an instance of `Customer`. The `findOrder()` function returns an instance of the `Order` class, or `null` if it can't find the order. The objective is to process the customer instance of the retrieved order.
Here are the classes in Java:
```
//Java
record Order (Customer customer) {}
record Customer (String name) {}
```
In Java, call the function and do an if-not-null check on the result to proceed with the dereferencing of the required property:
```
// Java
Order order = findOrder();
if (order != null) {
processCustomer(order.getCustomer());
}
```
Converting the Java code above to Kotlin code directly results in the following:
```
// Kotlin
data class Order(val customer: Customer)
data class Customer(val name: String)
val order = findOrder()
// Direct conversion
if (order != null){
processCustomer(order.customer)
}
```
Use the [safe-call operator `?.` (If-not-null shorthand)](idioms#if-not-null-shorthand) in combination with any of the [scope functions](scope-functions) from the standard library. The `let` function is usually used for this:
```
// Kotlin
val order = findOrder()
order?.let {
processCustomer(it.customer)
}
```
Here is a shorter version of the same:
```
// Kotlin
findOrder()?.customer?.let(::processCustomer)
```
Default values instead of null
------------------------------
Checking for `null` is often used in combination with [setting the default value](functions#default-arguments) in case the null check is successful.
The Java code with a null check:
```
// Java
Order order = findOrder();
if (order == null) {
order = new Order(new Customer("Antonio"))
}
```
To express the same in Kotlin, use the [Elvis operator (If-not-null-else shorthand)](null-safety#elvis-operator):
```
// Kotlin
val order = findOrder() ?: Order(Customer("Antonio"))
```
Functions returning a value or null
-----------------------------------
In Java, you need to be careful when working with list elements. You should always check whether an element exists at an index before you attempt to use the element:
```
// Java
var numbers = new ArrayList<Integer>();
numbers.add(1);
numbers.add(2);
System.out.println(numbers.get(0));
//numbers.get(5) // Exception!
```
The Kotlin standard library often provides functions whose names indicate whether they can possibly return a `null` value. This is especially common in the collections API:
```
fun main() {
//sampleStart
// Kotlin
// The same code as in Java:
val numbers = listOf(1, 2)
println(numbers[0]) // Can throw IndexOutOfBoundsException if the collection is empty
//numbers.get(5) // Exception!
// More abilities:
println(numbers.firstOrNull())
println(numbers.getOrNull(5)) // null
//sampleEnd
}
```
Aggregate operations
--------------------
When you need to get the biggest element or `null` if there are no elements, in Java you would use the [Stream API](https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/util/stream/package-summary.html):
```
// Java
var numbers = new ArrayList<Integer>();
var max = numbers.stream().max(Comparator.naturalOrder()).orElse(null);
System.out.println("Max: " + max);
```
In Kotlin, use [aggregate operations](collection-aggregate):
```
// Kotlin
val numbers = listOf<Int>()
println("Max: ${numbers.maxOrNull()}")
```
Learn more about [collections in Java and Kotlin](java-to-kotlin-collections-guide).
Casting types safely
--------------------
When you need to safely cast a type, in Java you would use the `instanceof` operator and then check how well it worked:
```
// Java
int getStringLength(Object y) {
return y instanceof String x ? x.length() : -1;
}
void main() {
System.out.println(getStringLength(1)); // Prints `-1`
}
```
To avoid exceptions in Kotlin, use the [safe cast operator](typecasts#safe-nullable-cast-operator) `as?`, which returns `null` on failure:
```
// Kotlin
fun main() {
println(getStringLength(1)) // Prints `-1`
}
fun getStringLength(y: Any): Int {
val x: String? = y as? String // null
return x?.length ?: -1 // Returns -1 because `x` is null
}
```
What's next?
------------
* Browse other [Kotlin idioms](idioms).
* Learn how to convert existing Java code to Kotlin with the [Java-to-Kotlin (J2K) converter](mixing-java-kotlin-intellij#converting-an-existing-java-file-to-kotlin-with-j2k).
* Check out other migration guides:
+ [Strings in Java and Kotlin](java-to-kotlin-idioms-strings)
+ [Collections in Java and Kotlin](java-to-kotlin-collections-guide).
If you have a favorite idiom, feel free to share it with us by sending a pull request!
Last modified: 10 January 2023
[Collections in Java and Kotlin](java-to-kotlin-collections-guide) [Get started with Kotlin/JS for React](js-get-started)
kotlin Kotlin Multiplatform Kotlin Multiplatform
====================
The Kotlin Multiplatform technology is designed to simplify the development of cross-platform projects. It reduces time spent writing and maintaining the same code for [different platforms](#kotlin-multiplatform-use-cases) while retaining the flexibility and benefits of native programming.
Kotlin Multiplatform use cases
------------------------------
### Android and iOS applications
Sharing code between mobile platforms is one of the major Kotlin Multiplatform use cases. With Kotlin Multiplatform Mobile, you can build cross-platform mobile applications and share common code between Android and iOS, such as business logic, connectivity, and more.
Check out the [Get started with Kotlin Multiplatform Mobile](multiplatform-mobile-getting-started) and [Create a multiplatform app using Ktor and SQLDelight](multiplatform-mobile-ktor-sqldelight) tutorials, where you will create applications for Android and iOS that include a module with shared code for both platforms.
### Full-stack web applications
Another scenario when code sharing may bring benefits is a connected application where the logic can be reused on both the server and the client side running in the browser. This is covered by Kotlin Multiplatform as well.
See [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app) tutorial, where you will create a connected application consisting of a server part, using Kotlin/JVM and a web client, using Kotlin/JS.
### Multiplatform libraries
Kotlin Multiplatform is also useful for library authors. You can create a multiplatform library with common code and its platform-specific implementations for JVM, JS, and Native platforms. Once published, a multiplatform library can be used in other cross-platform projects as a dependency.
See the [Create and publish a multiplatform library](multiplatform-library) tutorial, where you will create a multiplatform library, test it, and publish it to Maven.
### Common code for mobile and web applications
One more popular case for using Kotlin Multiplatform is sharing the same code across Android, iOS, and web apps. It reduces the amount of business logic coded by frontend developers and helps implement products more efficiently, decreasing the coding and testing efforts.
See the [RSS Reader](https://github.com/Kotlin/kmm-production-sample/tree/c6a0d9182802490d17729ae634fb59268f68a447) sample project — a cross-platform application for iOS and Android with desktop and web clients implemented as experimental features.
How Kotlin Multiplatform works
------------------------------
* **Common Kotlin** includes the language, core libraries, and basic tools. Code written in common Kotlin works everywhere on all platforms.
* With Kotlin Multiplatform libraries, you can reuse the multiplatform logic in common and platform-specific code. Common code can rely on a set of libraries that cover everyday tasks such as [HTTP](https://ktor.io/clients/http-client/multiplatform.html), [serialization](https://github.com/Kotlin/kotlinx.serialization), and [managing coroutines](https://github.com/Kotlin/kotlinx.coroutines).
* To interop with platforms, use platform-specific versions of Kotlin. **Platform-specific versions of Kotlin** (Kotlin/JVM, Kotlin/JS, Kotlin/Native) include extensions to the Kotlin language, and platform-specific libraries and tools.
* Through these platforms you can access the **platform native code** (JVM, JS, and Native) and leverage all native capabilities.
### Code sharing between platforms
With Kotlin Multiplatform, spend less time on writing and maintaining the same code for [different platforms](multiplatform-dsl-reference#targets) – just share it using the mechanisms Kotlin provides:
* [Share code among all platforms used in your project](multiplatform-share-on-platforms#share-code-on-all-platforms). Use it for sharing the common business logic that applies to all platforms.
* [Share code among some platforms](multiplatform-share-on-platforms#share-code-on-similar-platforms) included in your project but not all. Do this when you can reuse much of the code in similar platforms:

* If you need to access platform-specific APIs from the shared code, use the Kotlin mechanism of [expected and actual declarations](multiplatform-connect-to-apis).
Get started
-----------
* Start with the [Get started with Kotlin Multiplatform Mobile](multiplatform-mobile-getting-started) if you want to create iOS and Android applications with shared code
* Look through [sharing code principles and examples](multiplatform-share-on-platforms) if you want to create applications or libraries targeting other platforms
### Sample projects
Look through cross-platform application samples to understand how Kotlin Multiplatform works:
* [Kotlin Multiplatform Mobile samples](multiplatform-mobile-samples)
* [KotlinConf app](https://github.com/JetBrains/kotlinconf-app)
* [KotlinConf Spinner app](https://github.com/jetbrains/kotlinconf-spinner)
* [Build a full-stack web app with Kotlin Multiplatform](multiplatform-full-stack-app)
Last modified: 10 January 2023
[Get started with Kotlin](getting-started) [Kotlin for server side](server-overview)
| programming_docs |
kotlin Publishing multiplatform libraries Publishing multiplatform libraries
==================================
You can publish a multiplatform library to a local Maven repository with the [`maven-publish` Gradle plugin](https://docs.gradle.org/current/userguide/publishing_maven.html). Specify the group, version, and the [repositories](https://docs.gradle.org/current/userguide/publishing_maven.html#publishing_maven:repositories) where the library should be published. The plugin creates publications automatically.
```
plugins {
//...
id("maven-publish")
}
group = "com.example"
version = "1.0"
publishing {
repositories {
maven {
//...
}
}
}
```
To get hands-on experience, as well as learn how to publish a multiplatform library to the external Maven Central repository, see the [Create and publish a multiplatform library](multiplatform-library) tutorial.
Structure of publications
-------------------------
When used with `maven-publish`, the Kotlin plugin automatically creates publications for each target that can be built on the current host, except for the Android target, which needs an [additional step to configure publishing](#publish-an-android-library).
Publications of a multiplatform library include an additional *root* publication `kotlinMultiplatform` that stands for the whole library and is automatically resolved to the appropriate platform-specific artifacts when added as a dependency to the common source set. Learn more about [adding dependencies](multiplatform-add-dependencies).
This `kotlinMultiplatform` publication includes metadata artifacts and references the other publications as its variants.
The `kotlinMultiplatform` publication may also need the sources and documentation artifacts if that is required by the repository. In that case, add those artifacts by using [`artifact(...)`](https://docs.gradle.org/current/javadoc/org/gradle/api/publish/maven/MavenPublication.html#artifact-java.lang.Object-) in the publication's scope.
Avoid duplicate publications
----------------------------
To avoid duplicate publications of modules that can be built on several platforms (like JVM and JS), configure the publishing tasks for these modules to run conditionally.
You can detect the platform in the script, introduce a flag such as `isMainHost` and set it to `true` for the main target platform. Alternatively, you can pass the flag from an external source, for example, from CI configuration.
This simplified example ensures that publications are only uploaded when `isMainHost=true` is passed. This means that a publication that can be published from multiple platforms will be published only once – from the main host.
```
kotlin {
jvm()
js()
mingwX64()
linuxX64()
val publicationsFromMainHost =
listOf(jvm(), js()).map { it.name } + "kotlinMultiplatform"
publishing {
publications {
matching { it.name in publicationsFromMainHost }.all {
val targetPublication = this@all
tasks.withType<AbstractPublishToMaven>()
.matching { it.publication == targetPublication }
.configureEach { onlyIf { findProperty("isMainHost") == "true" } }
}
}
}
}
```
```
kotlin {
jvm()
js()
mingwX64()
linuxX64()
def publicationsFromMainHost =
[jvm(), js()].collect { it.name } + "kotlinMultiplatform"
publishing {
publications {
matching { it.name in publicationsFromMainHost }.all { targetPublication ->
tasks.withType(AbstractPublishToMaven)
.matching { it.publication == targetPublication }
.configureEach { onlyIf { findProperty("isMainHost") == "true" } }
}
}
}
}
```
By default, each publication includes a sources JAR that contains the sources used by the main compilation of the target.
Publish an Android library
--------------------------
To publish an Android library, you need to provide additional configuration.
By default, no artifacts of an Android library are published. To publish artifacts produced by a set of [Android variants](https://developer.android.com/studio/build/build-variants), specify the variant names in the Android target block:
```
kotlin {
android {
publishLibraryVariants("release", "debug")
}
}
```
The example works for Android libraries without [product flavors](https://developer.android.com/studio/build/build-variants#product-flavors). For a library with product flavors, the variant names also contain the flavors, like `fooBarDebug` or `fooBazRelease`.
The default publishing setup is as follows:
* If the published variants have the same build type (for example, all of them are `release` or`debug`), they will be compatible with any consumer build type.
* If the published variants have different build types, then only the release variants will be compatible with consumer build types that are not among the published variants. All other variants (such as `debug`) will only match the same build type on the consumer side, unless the consumer project specifies the [matching fallbacks](https://developer.android.com/reference/tools/gradle-api/4.2/com/android/build/api/dsl/BuildType).
If you want to make every published Android variant compatible with only the same build type used by the library consumer, set this Gradle property: `kotlin.android.buildTypeAttribute.keep=true`.
You can also publish variants grouped by the product flavor, so that the outputs of the different build types are placed in a single module, with the build type becoming a classifier for the artifacts (the release build type is still published with no classifier). This mode is disabled by default and can be enabled as follows:
```
kotlin {
android {
publishLibraryVariantsGroupedByFlavor = true
}
}
```
Last modified: 10 January 2023
[Create and publish a multiplatform library – tutorial](multiplatform-library) [Share code on platforms](multiplatform-share-on-platforms)
kotlin Create a multiplatform app using Ktor and SQLDelight – tutorial Create a multiplatform app using Ktor and SQLDelight – tutorial
===============================================================
This tutorial demonstrates how to use Android Studio to create a mobile application for iOS and Android using Kotlin Multiplatform Mobile with Ktor and SQLDelight.
The application will include a module with shared code for both the iOS and Android platforms. The business logic and data access layers will be implemented only once in the shared module, while the UI of both applications will be native.
The output will be an app that retrieves data over the internet from the public [SpaceX API](https://docs.spacexdata.com/?version=latest), saves it in a local database, and displays a list of SpaceX rocket launches together with the launch date, results, and a detailed description of the launch:
You will use the following multiplatform libraries in the project:
* [Ktor](https://ktor.io/docs/create-client.html) as an HTTP client for retrieving data over the internet.
* [`kotlinx.serialization`](https://github.com/Kotlin/kotlinx.serialization) to deserialize JSON responses into objects of entity classes.
* [`kotlinx.coroutines`](https://github.com/Kotlin/kotlinx.coroutines) to write asynchronous code.
* [SQLDelight](https://github.com/cashapp/sqldelight) to generate Kotlin code from SQL queries and create a type-safe database API.
Before you start
----------------
1. Download and install [Android Studio](https://developer.android.com/studio/).
2. Search for the [Kotlin Multiplatform Mobile plugin](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile) in the Android Studio Marketplace and install it.

3. Download and install [Xcode](https://developer.apple.com/xcode/).
For more details, see the [Set up the environment](multiplatform-mobile-setup) section.
Create a Multiplatform project
------------------------------
1. In Android Studio, select **File** | **New** | **New Project**. In the list of project templates, select **Kotlin Multiplatform App** and then click **Next**.

2. Name your application and click **Next**.
3. Select **Regular framework** in the list of **iOS framework distribution** options.

4. Keep all other options default. Click **Finish**.
5. To view the complete structure of the multiplatform mobile project, switch the view from **Android** to **Project**.

For more on project features and how to use them, see [Understand the project structure](multiplatform-mobile-understand-project-structure).
Add dependencies to the multiplatform library
---------------------------------------------
To add a multiplatform library to the shared module, you need to add dependency instructions (`implementation`) for all libraries to the `dependencies` block of the relevant source sets in the `build.gradle.kts` file.
Both the `kotlinx.serialization` and SQLDelight libraries also require additional configurations.
1. In the `shared` directory, specify the dependencies on all the required libraries in the `build.gradle.kts` file:
```
val coroutinesVersion = "1.6.4"
val ktorVersion = "2.2.1"
val sqlDelightVersion = "1.5.4"
val dateTimeVersion = "0.4.0"
sourceSets {
val commonMain by getting {
dependencies {
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:$coroutinesVersion")
implementation("io.ktor:ktor-client-core:$ktorVersion")
implementation("io.ktor:ktor-client-content-negotiation:$ktorVersion")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
implementation("com.squareup.sqldelight:runtime:$sqlDelightVersion")
}
}
val androidMain by getting {
dependencies {
implementation("io.ktor:ktor-client-android:$ktorVersion")
implementation("com.squareup.sqldelight:android-driver:$sqlDelightVersion")
}
}
val iosMain by creating {
// ...
dependencies {
implementation("io.ktor:ktor-client-darwin:$ktorVersion")
implementation("com.squareup.sqldelight:native-driver:$sqlDelightVersion")
}
}
}
```
* Each library requires a core artifact in the common source set.
* Both the SQLDelight and Ktor libraries need platform drivers in the iOS and Android source sets, as well.
* In addition, Ktor needs the [serialization feature](https://ktor.io/docs/serialization-client.html) to use `kotlinx.serialization` for processing network requests and responses.
2. At the very beginning of the `build.gradle.kts` file in the same `shared` directory, add the following lines to the `plugins` block:
```
plugins {
// ...
kotlin("plugin.serialization") version "1.8.0"
id("com.squareup.sqldelight")
}
```
3. Now go to the `build.gradle.kts` file in the project *root directory* and specify the classpath for the plugin in the build system dependencies:
```
buildscript {
// ...
val sqlDelightVersion = "1.5.4"
dependencies {
// ...
classpath("com.squareup.sqldelight:gradle-plugin:$sqlDelightVersion")
}
}
```
4. Finally, define the SQLDelight version in the `gradle.properties` file in the project *root directory* to ensure that the SQLDelight versions of the plugin and the libraries are the same:
```
sqlDelightVersion=1.5.4
```
5. Sync the Gradle project.
Learn more about adding [dependencies on multiplatform libraries](multiplatform-add-dependencies).
Create an application data model
--------------------------------
The Kotlin Multiplatform app will contain the public `SpaceXSDK` class, the facade over networking and cache services. The application data model will have three entity classes with:
* General information about the launch
* A URL to external information
* Information about the rocket
1. In `shared/src/commonMain/kotlin`, add the `com.jetbrains.handson.kmm.shared.entity` package.
2. Create the `Entity.kt` file inside the package.
3. Declare all the data classes for basic entities:
import kotlinx.serialization.SerialName import kotlinx.serialization.Serializable @Serializable data class RocketLaunch( @SerialName("flight\_number") val flightNumber: Int, @SerialName("mission\_name") val missionName: String, @SerialName("launch\_year") val launchYear: Int, @SerialName("launch\_date\_utc") val launchDateUTC: String, @SerialName("rocket") val rocket: Rocket, @SerialName("details") val details: String?, @SerialName("launch\_success") val launchSuccess: Boolean?, @SerialName("links") val links: Links ) @Serializable data class Rocket( @SerialName("rocket\_id") val id: String, @SerialName("rocket\_name") val name: String, @SerialName("rocket\_type") val type: String ) @Serializable data class Links( @SerialName("mission\_patch") val missionPatchUrl: String?, @SerialName("article\_link") val articleUrl: String? )
Each serializable class must be marked with the `@Serializable` annotation. The `kotlinx.serialization` plugin automatically generates a default serializer for `@Serializable` classes unless you explicitly pass a link to a serializer through the annotation argument.
However, you don't need to do that in this case. The `@SerialName` annotation allows you to redefine field names, which helps to declare properties in data classes with more easily readable names.
Configure SQLDelight and implement cache logic
----------------------------------------------
### Configure SQLDelight
The SQLDelight library allows you to generate a type-safe Kotlin database API from SQL queries. During compilation, the generator validates the SQL queries and turns them into Kotlin code that can be used in the shared module.
The library is already in the project. To configure it, go to the `shared` directory and add the `sqldelight` block to the end of the `build.gradle.kts` file. The block will contain a list of databases and their parameters:
```
sqldelight {
database("AppDatabase") {
packageName = "com.jetbrains.handson.kmm.shared.cache"
}
}
```
The `packageName` parameter specifies the package name for the generated Kotlin sources.
### Generate the database API
First, create the `.sq` file, which will contain all the needed SQL queries. By default, the SQLDelight plugin reads `.sq` from the `sqldelight` folder:
1. In `shared/src/commonMain`, create a new `sqldelight` directory and add the `com.jetbrains.handson.kmm.shared.cache` package.
2. Inside the package, create an `.sq` file with the name of the database, `AppDatabase.sq`. All the SQL queries for the application will be in this file.
3. The database will contain two tables with data about launches and rockets. To create the tables, add the following code to the `AppDatabase.sq` file:
```
CREATE TABLE Launch (
flightNumber INTEGER NOT NULL,
missionName TEXT NOT NULL,
launchYear INTEGER AS Int NOT NULL DEFAULT 0,
rocketId TEXT NOT NULL,
details TEXT,
launchSuccess INTEGER AS Boolean DEFAULT NULL,
launchDateUTC TEXT NOT NULL,
missionPatchUrl TEXT,
articleUrl TEXT
);
CREATE TABLE Rocket (
id TEXT NOT NULL PRIMARY KEY,
name TEXT NOT NULL,
type TEXT NOT NULL
);
```
4. To insert data into the tables, declare SQL insert functions:
```
insertLaunch:
INSERT INTO Launch(flightNumber, missionName, launchYear, rocketId, details, launchSuccess, launchDateUTC, missionPatchUrl, articleUrl)
VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?);
insertRocket:
INSERT INTO Rocket(id, name, type)
VALUES(?, ?, ?);
```
5. To clear data in the tables, declare SQL delete functions:
```
removeAllLaunches:
DELETE FROM Launch;
removeAllRockets:
DELETE FROM Rocket;
```
6. In the same way, declare functions to retrieve data. For data about a rocket, use its identifier and select information about all its launches using a JOIN statement:
```
selectRocketById:
SELECT * FROM Rocket
WHERE id = ?;
selectAllLaunchesInfo:
SELECT Launch.*, Rocket.*
FROM Launch
LEFT JOIN Rocket ON Rocket.id == Launch.rocketId;
```
After the project is compiled, the generated Kotlin code will be stored in the `shared/build/generated/sqldelight` directory. The generator will create an interface named `AppDatabase`, as specified in `build.gradle.kts`.
### Create platform database drivers
To initialize `AppDatabase`, pass an `SqlDriver` instance to it. SQLDelight provides multiple platform-specific implementations of the SQLite driver, so you need to create them for each platform separately. You can do this by using [expected and actual declarations](multiplatform-connect-to-apis).
1. Create an abstract factory for database drivers. To do this, in `shared/src/commonMain/kotlin`, create the `com.jetbrains.handson.kmm.shared.cache` package and the `DatabaseDriverFactory` class inside it:
```
package com.jetbrains.handson.kmm.shared.cache
import com.squareup.sqldelight.db.SqlDriver
expect class DatabaseDriverFactory {
fun createDriver(): SqlDriver
}
```
Now provide `actual` implementations for this expected class.
2. On Android, the `AndroidSqliteDriver` class implements the SQLite driver. Pass the database information and the link to the context to the `AndroidSqliteDriver` class constructor.
For this, in the `shared/src/androidMain/kotlin` directory, create the `com.jetbrains.handson.kmm.shared.cache` package and a `DatabaseDriverFactory` class inside it with the actual implementation:
```
package com.jetbrains.handson.kmm.shared.cache
import android.content.Context
import com.squareup.sqldelight.android.AndroidSqliteDriver
import com.squareup.sqldelight.db.SqlDriver
actual class DatabaseDriverFactory(private val context: Context) {
actual fun createDriver(): SqlDriver {
return AndroidSqliteDriver(AppDatabase.Schema, context, "test.db")
}
}
```
3. On iOS, the SQLite driver implementation is the `NativeSqliteDriver` class. In the `shared/src/iosMain/kotlin` directory, create a `com.jetbrains.handson.kmm.shared.cache` package and a `DatabaseDriverFactory` class inside it with the actual implementation:
```
package com.jetbrains.handson.kmm.shared.cache
import com.squareup.sqldelight.db.SqlDriver
import com.squareup.sqldelight.drivers.native.NativeSqliteDriver
actual class DatabaseDriverFactory {
actual fun createDriver(): SqlDriver {
return NativeSqliteDriver(AppDatabase.Schema, "test.db")
}
}
```
Instances of these factories will be created later in the code of your Android and iOS projects.
You can navigate through the `expect` declarations and `actual` realizations by clicking the handy gutter icon:
### Implement cache
So far, you have added platform database drivers and an `AppDatabase` class to perform database operations. Now create a `Database` class, which will wrap the `AppDatabase` class and contain the caching logic.
1. In the common source set `shared/src/commonMain/kotlin`, create a new `Database` class in the `com.jetbrains.handson.kmm.shared.cache` package. It will be common to both platform logics.
2. To provide a driver for `AppDatabase`, pass an abstract `DatabaseDriverFactory` to the `Database` class constructor:
```
package com.jetbrains.handson.kmm.shared.cache
import com.jetbrains.handson.kmm.shared.entity.Links
import com.jetbrains.handson.kmm.shared.entity.Rocket
import com.jetbrains.handson.kmm.shared.entity.RocketLaunch
internal class Database(databaseDriverFactory: DatabaseDriverFactory) {
private val database = AppDatabase(databaseDriverFactory.createDriver())
private val dbQuery = database.appDatabaseQueries
}
```
This class's [visibility](visibility-modifiers#class-members) is set to internal, which means it is only accessible from within the multiplatform module.
3. Inside the `Database` class, implement some data handling operations. Add a function to clear all the tables in the database in a single SQL transaction:
```
internal fun clearDatabase() {
dbQuery.transaction {
dbQuery.removeAllRockets()
dbQuery.removeAllLaunches()
}
}
```
4. Create a function to get a list of all the rocket launches:
```
import com.jetbrains.handson.kmm.shared.entity.Links
import com.jetbrains.handson.kmm.shared.entity.Patch
import com.jetbrains.handson.kmm.shared.entity.RocketLaunch
internal fun getAllLaunches(): List<RocketLaunch> {
return dbQuery.selectAllLaunchesInfo(::mapLaunchSelecting).executeAsList()
}
private fun mapLaunchSelecting(
flightNumber: Long,
missionName: String,
launchYear: Int,
rocketId: String,
details: String?,
launchSuccess: Boolean?,
launchDateUTC: String,
missionPatchUrl: String?,
articleUrl: String?,
rocket_id: String?,
name: String?,
type: String?
): RocketLaunch {
return RocketLaunch(
flightNumber = flightNumber.toInt(),
missionName = missionName,
launchYear = launchYear,
details = details,
launchDateUTC = launchDateUTC,
launchSuccess = launchSuccess,
rocket = Rocket(
id = rocketId,
name = name!!,
type = type!!
),
links = Links(
missionPatchUrl = missionPatchUrl,
articleUrl = articleUrl
)
)
}
```
The argument passed to `selectAllLaunchesInfo` is a function that maps the database entity class to another type, which in this case is the `RocketLaunch` data model class.
5. Add a function to insert data into the database:
```
internal fun createLaunches(launches: List<RocketLaunch>) {
dbQuery.transaction {
launches.forEach { launch ->
val rocket = dbQuery.selectRocketById(launch.rocket.id).executeAsOneOrNull()
if (rocket == null) {
insertRocket(launch)
}
insertLaunch(launch)
}
}
}
private fun insertRocket(launch: RocketLaunch) {
dbQuery.insertRocket(
id = launch.rocket.id,
name = launch.rocket.name,
type = launch.rocket.type
)
}
private fun insertLaunch(launch: RocketLaunch) {
dbQuery.insertLaunch(
flightNumber = launch.flightNumber.toLong(),
missionName = launch.missionName,
launchYear = launch.launchYear,
rocketId = launch.rocket.id,
details = launch.details,
launchSuccess = launch.launchSuccess ?: false,
launchDateUTC = launch.launchDateUTC,
missionPatchUrl = launch.links.missionPatchUrl,
articleUrl = launch.links.articleUrl
)
}
```
The `Database` class instance will be created later, along with the SDK facade class.
Implement an API service
------------------------
To retrieve data over the internet, you'll need the [SpaceX public API](https://github.com/r-spacex/SpaceX-API/tree/master/docs#rspacex-api-docs) and a single method to retrieve the list of all launches from the `v5/launches` endpoint.
Create a class that will connect the application to the API:
1. In the common source set `shared/src/commonMain/kotlin`, create the `com.jetbrains.handson.kmm.shared.network` package and the `SpaceXApi` class inside it:
```
package com.jetbrains.handson.kmm.shared.network
import com.jetbrains.handson.kmm.shared.entity.RocketLaunch
import io.ktor.client.*
import io.ktor.client.call.*
import io.ktor.client.plugins.contentnegotiation.*
import io.ktor.client.request.*
import io.ktor.serialization.kotlinx.json.*
import kotlinx.serialization.json.Json
class SpaceXApi {
private val httpClient = HttpClient {
install(ContentNegotiation) {
json(Json {
ignoreUnknownKeys = true
useAlternativeNames = false
})
}
}
}
```
* This class executes network requests and deserializes JSON responses into entities from the `entity` package. The Ktor `HttpClient` instance initializes and stores the `httpClient` property.
* This code uses the [Ktor `ContentNegotiation` plugin](https://ktor.io/docs/serialization-client.html) to deserialize the `GET` request result. The plugin processes the request and the response payload as JSON, serializing and deserializing them using a special serializer.
2. Declare the data retrieval function that will return the list of `RocketLaunch`es:
```
suspend fun getAllLaunches(): List<RocketLaunch> {
return httpClient.get("https://api.spacexdata.com/v3/launches").body()
}
```
* The `getAllLaunches` function has the `suspend` modifier because it contains a call of the suspend function `get()`, which includes an asynchronous operation to retrieve data over the internet and can only be called from a coroutine or another suspend function. The network request will be executed in the HTTP client's thread pool.
* The URL is defined inside the `get()` function to send requests.
### Add internet access permission
To access the internet, the Android application needs the appropriate permission. Since all network requests are made from the shared module, adding the internet access permission to this module's manifest makes sense.
In the `androidApp/src/main/AndroidManifest.xml` file, add the following permission to the manifest:
```
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android" package="com.jetbrains.handson.androidApp">
<uses-permission android:name="android.permission.INTERNET" />
</manifest>
```
Build an SDK
------------
Your iOS and Android applications will communicate with the SpaceX API through the shared module, which will provide a public class.
1. In the `com.jetbrains.handson.kmm.shared` package of the common source set, create the `SpaceXSDK` class:
```
package com.jetbrains.handson.kmm.shared
import com.jetbrains.handson.kmm.shared.cache.Database
import com.jetbrains.handson.kmm.shared.cache.DatabaseDriverFactory
import com.jetbrains.handson.kmm.shared.network.SpaceXApi
class SpaceXSDK(databaseDriverFactory: DatabaseDriverFactory) {
private val database = Database(databaseDriverFactory)
private val api = SpaceXApi()
}
```
This class will be the facade over the `Database` and `SpaceXApi` classes.
2. To create a `Database` class instance, you'll need to provide the `DatabaseDriverFactory` platform instance to it, so you'll inject it from the platform code through the `SpaceXSDK` class constructor.
```
import com.jetbrains.handson.kmm.shared.entity.RocketLaunch
@Throws(Exception::class)
suspend fun getLaunches(forceReload: Boolean): List<RocketLaunch> {
val cachedLaunches = database.getAllLaunches()
return if (cachedLaunches.isNotEmpty() && !forceReload) {
cachedLaunches
} else {
api.getAllLaunches().also {
database.clearDatabase()
database.createLaunches(it)
}
}
}
```
* The class contains one function for getting all launch information. Depending on the value of `forceReload`, it returns cached values or loads the data from the internet and then updates the cache with the results. If there is no cached data, it loads the data from the internet independently of the `forceReload` flag’s value.
* Clients of your SDK could use a `forceReload` flag to load the latest information about the launches, which would allow the user to use the pull-to-refresh gesture.
* To handle exceptions produced by the Ktor client in Swift, the function is marked with the `@Throws` annotation.All Kotlin exceptions are unchecked, while Swift has only checked errors. Thus, to make your Swift code aware of expected exceptions, Kotlin functions should be marked with the `@Throws` annotation specifying a list of potential exception classes.
Create the Android application
------------------------------
The Kotlin Multiplatform Mobile plugin for Android Studio has already handled the configuration for you, so the Kotlin Multiplatform shared module is already connected to your Android application.
Before implementing the UI and the presentation logic, add all the required dependencies to the `androidApp/build.gradle.kts`:
```
// ...
dependencies {
implementation(project(":shared"))
implementation("com.google.android.material:material:1.6.1")
implementation("androidx.appcompat:appcompat:1.4.2")
implementation("androidx.constraintlayout:constraintlayout:2.1.4")
implementation("androidx.swiperefreshlayout:swiperefreshlayout:1.1.0")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-android:1.6.2")
implementation("androidx.core:core-ktx:1.8.0")
implementation("androidx.recyclerview:recyclerview:1.2.1")
implementation("androidx.cardview:cardview:1.0.0")
}
// ...
```
### Implement the UI: display the list of rocket launches
1. To implement the UI, create the `layout/activity_main.xml` file in `androidApp/src/main/res`.
The screen is based on the `ConstraintLayout` with the `SwipeRefreshLayout` inside it, which contains `RecyclerView` and `FrameLayout` with a background with a `ProgressBar` across its center:
<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" android:layout\_width="match\_parent" android:layout\_height="match\_parent"> <androidx.swiperefreshlayout.widget.SwipeRefreshLayout android:id="@+id/swipeContainer" android:layout\_width="match\_parent" android:layout\_height="match\_parent" app:layout\_constraintBottom\_toBottomOf="parent" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toTopOf="parent"> <androidx.recyclerview.widget.RecyclerView android:id="@+id/launchesListRv" android:layout\_width="match\_parent" android:layout\_height="match\_parent" /> </androidx.swiperefreshlayout.widget.SwipeRefreshLayout> <FrameLayout android:id="@+id/progressBar" android:layout\_width="0dp" android:layout\_height="0dp" android:background="#fff" app:layout\_constraintBottom\_toBottomOf="parent" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toTopOf="parent"> <ProgressBar android:layout\_width="wrap\_content" android:layout\_height="wrap\_content" android:layout\_gravity="center" /> </FrameLayout> </androidx.constraintlayout.widget.ConstraintLayout>
2. In `androidApp/src/main/java`, replace the implementation of the `MainActivity` class, adding the properties for the UI elements:
```
class MainActivity : AppCompatActivity() {
private lateinit var launchesRecyclerView: RecyclerView
private lateinit var progressBarView: FrameLayout
private lateinit var swipeRefreshLayout: SwipeRefreshLayout
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
title = "SpaceX Launches"
setContentView(R.layout.activity_main)
launchesRecyclerView = findViewById(R.id.launchesListRv)
progressBarView = findViewById(R.id.progressBar)
swipeRefreshLayout = findViewById(R.id.swipeContainer)
}
}
```
3. For the `RecyclerView` element to work, you need to create an adapter (as a subclass of `RecyclerView.Adapter`) that will convert raw data into list item views. To do this, create a separate `LaunchesRvAdapter` class:
```
class LaunchesRvAdapter(var launches: List<RocketLaunch>) : RecyclerView.Adapter<LaunchesRvAdapter.LaunchViewHolder>() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): LaunchViewHolder {
return LayoutInflater.from(parent.context)
.inflate(R.layout.item_launch, parent, false)
.run(::LaunchViewHolder)
}
override fun getItemCount(): Int = launches.count()
override fun onBindViewHolder(holder: LaunchViewHolder, position: Int) {
holder.bindData(launches[position])
}
inner class LaunchViewHolder(itemView: View) : RecyclerView.ViewHolder(itemView) {
// ...
fun bindData(launch: RocketLaunch) {
// ...
}
}
}
```
4. Create an `item_launch.xml` resource file in `androidApp/src/main/res/layout/` with the items view layout:
<?xml version="1.0" encoding="utf-8"?> <androidx.cardview.widget.CardView xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:card\_view="http://schemas.android.com/tools" android:layout\_width="match\_parent" android:layout\_height="wrap\_content" android:layout\_marginHorizontal="16dp" android:layout\_marginVertical="8dp" card\_view:cardCornerRadius="8dp"> <androidx.constraintlayout.widget.ConstraintLayout android:layout\_width="match\_parent" android:layout\_height="wrap\_content" android:paddingBottom="16dp"> <TextView android:id="@+id/missionName" android:layout\_width="0dp" android:layout\_height="wrap\_content" android:layout\_margin="8dp" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toTopOf="parent" /> <TextView android:id="@+id/launchSuccess" android:layout\_width="0dp" android:layout\_height="wrap\_content" android:layout\_margin="8dp" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toBottomOf="@+id/missionName" /> <TextView android:id="@+id/launchYear" android:layout\_width="0dp" android:layout\_height="wrap\_content" android:layout\_margin="8dp" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toBottomOf="@+id/launchSuccess" /> <TextView android:id="@+id/details" android:layout\_width="0dp" android:layout\_height="wrap\_content" android:layout\_margin="8dp" app:layout\_constraintEnd\_toEndOf="parent" app:layout\_constraintStart\_toStartOf="parent" app:layout\_constraintTop\_toBottomOf="@+id/launchYear" /> </androidx.constraintlayout.widget.ConstraintLayout> </androidx.cardview.widget.CardView>
5. In `androidApp/src/main/res/values/`, either create your appearance of the app or copy the following styles:
```
<?xml version="1.0" encoding="utf-8"?>
<resources>
<color name="colorPrimary">#37474f</color>
<color name="colorPrimaryDark">#102027</color>
<color name="colorAccent">#62727b</color>
<color name="colorSuccessful">#4BB543</color>
<color name="colorUnsuccessful">#FC100D</color>
<color name="colorNoData">#615F5F</color>
</resources>
```
```
<?xml version="1.0" encoding="utf-8"?>
<resources>
<string name="app_name">SpaceLaunches</string>
<string name="successful">Successful</string>
<string name="unsuccessful">Unsuccessful</string>
<string name="no_data">No data</string>
<string name="launch_year_field">Launch year: %s</string>
<string name="mission_name_field">Launch name: %s</string>
<string name="launch_success_field">Launch success: %s</string>
<string name="details_field">Launch details: %s</string>
</resources>
```
```
<resources>
<!-- Base application theme. -->
<style name="AppTheme" parent="Theme.AppCompat.Light.DarkActionBar">
<!-- Customize your theme here. -->
<item name="colorPrimary">@color/colorPrimary</item>
<item name="colorPrimaryDark">@color/colorPrimaryDark</item>
<item name="colorAccent">@color/colorAccent</item>
</style>
</resources>
```
6. Complete the implementation of the `RecyclerView.Adapter`:
```
class LaunchesRvAdapter(var launches: List<RocketLaunch>) : RecyclerView.Adapter<LaunchesRvAdapter.LaunchViewHolder>() {
// ...
inner class LaunchViewHolder(itemView: View) : RecyclerView.ViewHolder(itemView) {
private val missionNameTextView = itemView.findViewById<TextView>(R.id.missionName)
private val launchYearTextView = itemView.findViewById<TextView>(R.id.launchYear)
private val launchSuccessTextView = itemView.findViewById<TextView>(R.id.launchSuccess)
private val missionDetailsTextView = itemView.findViewById<TextView>(R.id.details)
fun bindData(launch: RocketLaunch) {
val ctx = itemView.context
missionNameTextView.text = ctx.getString(R.string.mission_name_field, launch.missionName)
launchYearTextView.text = ctx.getString(R.string.launch_year_field, launch.launchYear.toString())
missionDetailsTextView.text = ctx.getString(R.string.details_field, launch.details ?: "")
val launchSuccess = launch.launchSuccess
if (launchSuccess != null ) {
if (launchSuccess) {
launchSuccessTextView.text = ctx.getString(R.string.successful)
launchSuccessTextView.setTextColor((ContextCompat.getColor(itemView.context, R.color.colorSuccessful)))
} else {
launchSuccessTextView.text = ctx.getString(R.string.unsuccessful)
launchSuccessTextView.setTextColor((ContextCompat.getColor(itemView.context, R.color.colorUnsuccessful)))
}
} else {
launchSuccessTextView.text = ctx.getString(R.string.no_data)
launchSuccessTextView.setTextColor((ContextCompat.getColor(itemView.context, R.color.colorNoData)))
}
}
}
}
```
7. Update the `MainActivity` class as follows:
```
class MainActivity : AppCompatActivity() {
// ...
private val launchesRvAdapter = LaunchesRvAdapter(listOf())
override fun onCreate(savedInstanceState: Bundle?) {
// ...
launchesRecyclerView.adapter = launchesRvAdapter
launchesRecyclerView.layoutManager = LinearLayoutManager(this)
swipeRefreshLayout.setOnRefreshListener {
swipeRefreshLayout.isRefreshing = false
displayLaunches(true)
}
displayLaunches(false)
}
private fun displayLaunches(needReload: Boolean) {
// TODO: Presentation logic
}
}
```
Here you create an instance of `LaunchesRvAdapter`, configure the `RecyclerView` component, and implement all the `LaunchesListView` interface functions. To catch the screen refresh gesture, you add a listener to the `SwipeRefreshLayout`.
### Implement the presentation logic
1. Create an instance of the `SpaceXSDK` class from the shared module and inject an instance of `DatabaseDriverFactory` in it:
```
class MainActivity : AppCompatActivity() {
// ...
private val sdk = SpaceXSDK(DatabaseDriverFactory(this))
}
```
2. Implement the private function `displayLaunches(needReload: Boolean)`. It runs the `getLaunches()` function inside the coroutine launched in the main `CoroutineScope`, handles exceptions, and displays the error text in the toast message:
```
class MainActivity : AppCompatActivity() {
private val mainScope = MainScope()
// ...
override fun onDestroy() {
super.onDestroy()
mainScope.cancel()
}
// ...
private fun displayLaunches(needReload: Boolean) {
progressBarView.isVisible = true
mainScope.launch {
kotlin.runCatching {
sdk.getLaunches(needReload)
}.onSuccess {
launchesRvAdapter.launches = it
launchesRvAdapter.notifyDataSetChanged()
}.onFailure {
Toast.makeText(this@MainActivity, it.localizedMessage, Toast.LENGTH_SHORT).show()
}
progressBarView.isVisible = false
}
}
}
```
3. Select **androidApp** from the run configurations menu, choose an emulator, and click the run button:
You've just created an Android application that has its business logic implemented in the Kotlin Multiplatform Mobile module.
Create the iOS application
--------------------------
For the iOS part of the project, you'll make use of [SwiftUI](https://developer.apple.com/xcode/swiftui/) to build the user interface and the "Model View View-Model" pattern to connect the UI to the shared module, which contains all the business logic.
The shared module is already connected to the iOS project because the Android Studio plugin wizard has done all the configuration. You can import it the same way you would regular iOS dependencies: `import shared`.
### Implement the UI
First, you'll create a `RocketLaunchRow` SwiftUI view for displaying an item from the list. It will be based on the `HStack` and `VStack` views. There will be extensions on the `RocketLaunchRow` structure with useful helpers for displaying the data.
1. Launch your Xcode app and select **Open a project or file**.
2. Navigate to your project and select the `iosApp` folder. Click **Open**.
3. In your Xcode project, create a new Swift file with the type **SwiftUI View**, name it `RocketLaunchRow`, and update it with the following code:
```
import SwiftUI
import shared
struct RocketLaunchRow: View {
var rocketLaunch: RocketLaunch
var body: some View {
HStack() {
VStack(alignment: .leading, spacing: 10.0) {
Text("Launch name: \(rocketLaunch.missionName)")
Text(launchText).foregroundColor(launchColor)
Text("Launch year: \(String(rocketLaunch.launchYear))")
Text("Launch details: \(rocketLaunch.details ?? "")")
}
Spacer()
}
}
}
extension RocketLaunchRow {
private var launchText: String {
if let isSuccess = rocketLaunch.launchSuccess {
return isSuccess.boolValue ? "Successful" : "Unsuccessful"
} else {
return "No data"
}
}
private var launchColor: Color {
if let isSuccess = rocketLaunch.launchSuccess {
return isSuccess.boolValue ? Color.green : Color.red
} else {
return Color.gray
}
}
}
```
The list of launches will be displayed in the `ContentView`, which the project wizard has already created.
4. Create a `ViewModel` class for the `ContentView`, which will prepare and manage the data. Declare it as an extension to the `ContentView`, as they are closely connected, and then add the following code to `ContentView.swift`:
```
// ...
extension ContentView {
enum LoadableLaunches {
case loading
case result([RocketLaunch])
case error(String)
}
class ViewModel: ObservableObject {
@Published var launches = LoadableLaunches.loading
}
}
```
* The [Combine framework](https://developer.apple.com/documentation/combine) connects the view model (`ContentView.ViewModel`) with the view (`ContentView`).
* `ContentView.ViewModel` is declared as an `ObservableObject` and `@Published` wrapper is used for the `launches` property, so the view model will emit signals whenever this property changes.
5. Implement the body of the `ContentView` file and display the list of launches:
```
struct ContentView: View {
@ObservedObject private(set) var viewModel: ViewModel
var body: some View {
NavigationView {
listView()
.navigationBarTitle("SpaceX Launches")
.navigationBarItems(trailing:
Button("Reload") {
self.viewModel.loadLaunches(forceReload: true)
})
}
}
private func listView() -> AnyView {
switch viewModel.launches {
case .loading:
return AnyView(Text("Loading...").multilineTextAlignment(.center))
case .result(let launches):
return AnyView(List(launches) { launch in
RocketLaunchRow(rocketLaunch: launch)
})
case .error(let description):
return AnyView(Text(description).multilineTextAlignment(.center))
}
}
}
```
The `@ObservedObject` property wrapper is used to subscribe to the view model.
6. To make it compile, the `RocketLaunch` class needs to confirm the `Identifiable` protocol, as it is used as a parameter for initializing the `List` Swift UIView. The `RocketLaunch` class already has a property named `id`, so add the following to the bottom of `ContentView.swift`:
```
extension RocketLaunch: Identifiable { }
```
### Load the data
To retrieve the data about the rocket launches in the view model, you'll need an instance of `SpaceXSDK` from the Multiplatform library.
1. In `ContentView.swift`, pass it in through the constructor:
```
extension ContentView {
// ...
class ViewModel: ObservableObject {
let sdk: SpaceXSDK
@Published var launches = LoadableLaunches.loading
init(sdk: SpaceXSDK) {
self.sdk = sdk
self.loadLaunches(forceReload: false)
}
func loadLaunches(forceReload: Bool) {
// TODO: retrieve data
}
}
}
```
2. Call the `getLaunches()` function from the `SpaceXSDK` class and save the result in the `launches` property:
```
func loadLaunches(forceReload: Bool) {
self.launches = .loading
sdk.getLaunches(forceReload: forceReload, completionHandler: { launches, error in
if let launches = launches {
self.launches = .result(launches)
} else {
self.launches = .error(error?.localizedDescription ?? "error")
}
})
}
```
* When you compile a Kotlin module into an Apple framework, [suspending functions](whatsnew14#support-for-kotlin-s-suspending-functions-in-swift-and-objective-c) are available in it as functions with callbacks (`completionHandler`).
* Since the `getLaunches` function is marked with the `@Throws(Exception::class)` annotation, any exceptions that are instances of the `Exception` class or its subclass will be propagated as `NSError`. Therefore, all such errors can be handled in the `completionHandler` function.
3. Go to the entry point of the app, `iOSApp.swift`, and initialize the SDK, view, and view model:
```
import SwiftUI
import shared
@main
struct iOSApp: App {
let sdk = SpaceXSDK(databaseDriverFactory: DatabaseDriverFactory())
var body: some Scene {
WindowGroup {
ContentView(viewModel: .init(sdk: sdk))
}
}
}
```
4. In Android Studio, switch to the **iosApp** configuration, choose an emulator, and run it to see the result:
What's next?
------------
This tutorial features some potentially resource-heavy operations, like parsing JSON and making requests to the database in the main thread. To learn about how to write concurrent code and optimize your app, see [How to work with concurrency](multiplatform-mobile-concurrency-overview).
You can also check out these additional learning materials:
* [Use the Ktor HTTP client in multiplatform projects](https://ktor.io/docs/http-client-engines.html#mpp-config)
* [Make your Android application work on iOS](multiplatform-mobile-integrate-in-existing-app)
* [Introduce your team to Kotlin Multiplatform Mobile](multiplatform-mobile-introduce-your-team)
Last modified: 10 January 2023
[Publish your application](multiplatform-mobile-publish-apps) [Get started with Kotlin Multiplatform](multiplatform-get-started)
| programming_docs |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.