
code
stringlengths 2.5k
150k
| kind
stringclasses 1
value |
|---|---|
```
# Import conventions we'll be using here. See Part 1
import matplotlib
# matplotlib.use('nbagg')
import matplotlib.pyplot as plt
import numpy as np
```
# Limits, Legends, and Layouts
In this section, we'll focus on what happens around the edges of the axes: Ticks, ticklabels, limits, layouts, and legends.
# Limits and autoscaling
By default, Matplotlib will attempt to determine limits for you that encompasses all the data you have plotted. This is the "autoscale" feature. For image plots, the limits are not padded while plots such as scatter plots and bar plots are given some padding.
```
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=plt.figaspect(0.5))
ax1.plot([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax2.scatter([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
plt.show()
```
### `ax.margins(...)`
If you'd like to add a bit of "padding" to a plot, `ax.margins(<some_small_fraction>)` is a very handy way to do so. Instead of choosing "even-ish" numbers as min/max ranges for each axis, `margins` will make Matplotlib calculate the min/max of each axis by taking the range of the data and adding on a fractional amount of padding.
As an example:
```
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=plt.figaspect(0.5))
ax1.plot([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax2.scatter([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax1.margins(x=0.0, y=0.1) # 10% padding in the y-direction only
ax2.margins(0.05) # 5% padding in all directions
plt.show()
```
### `ax.axis(...)`
The `ax.axis(...)` method is a convienent way of controlling the axes limits and enabling/disabling autoscaling.
If you ever need to get all of the current plot limits, calling `ax.axis()` with no arguments will return the xmin/max/etc:
xmin, xmax, ymin, ymax = ax.axis()
If you'd like to manually set all of the x/y limits at once, you can use `ax.axis` for this, as well (note that we're calling it with a single argument that's a sequence, not 4 individual arguments):
ax.axis([xmin, xmax, ymin, ymax])
However, you'll probably use `axis` mostly with either the `"tight"` or `"equal"` options. There are other options as well; see the documentation for full details. In a nutshell, though:
* *tight*: Set axes limits to the exact range of the data
* *equal*: Set axes scales such that one cm/inch in the y-direction is the same as one cm/inch in the x-direction. In Matplotlib terms, this sets the aspect ratio of the plot to 1. That _doesn't_ mean that the axes "box" will be square.
And as an example:
```
fig, axes = plt.subplots(nrows=3)
for ax in axes:
ax.plot([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
axes[0].set_title('Normal Autoscaling', y=0.7, x=0.8)
axes[1].set_title('ax.axis("tight")', y=0.7, x=0.8)
axes[1].axis('tight')
axes[2].set_title('ax.axis("equal")', y=0.7, x=0.8)
axes[2].axis('equal')
plt.show()
```
### Manually setting only one limit
Another trick with limits is to specify only half of a limit. When done **after** a plot is made, this has the effect of allowing the user to anchor a limit while letting Matplotlib autoscale the rest of it.
```
# Good -- setting limits after plotting is done
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=plt.figaspect(0.5))
ax1.plot([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax2.scatter([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax1.set_ylim(bottom=-10)
ax2.set_xlim(right=25)
plt.show()
# Bad -- Setting limits before plotting is done
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=plt.figaspect(0.5))
ax1.set_ylim(bottom=-10)
ax2.set_xlim(right=25)
ax1.plot([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
ax2.scatter([-10, -5, 0, 5, 10, 15], [-1.2, 2, 3.5, -0.3, -4, 1])
plt.show()
```
# Legends
As you've seen in some of the examples so far, the X and Y axis can also be labeled, as well as the subplot itself via the title.
However, another thing you can label is the line/point/bar/etc that you plot. You can provide a label to your plot, which allows your legend to automatically build itself.
```
fig, ax = plt.subplots()
ax.plot([1, 2, 3, 4], [10, 20, 25, 30], label='Philadelphia')
ax.plot([1, 2, 3, 4], [30, 23, 13, 4], label='Boston')
ax.set(ylabel='Temperature (deg C)', xlabel='Time', title='A tale of two cities')
ax.legend()
plt.show()
```
In `classic` mode, legends will go in the upper right corner by default (you can control this with the `loc` kwarg). As of v2.0, by default Matplotlib will choose a location to avoid overlapping plot elements as much as possible. To force this option, you can pass in:
ax.legend(loc="best")
Also, if you happen to be plotting something that you do not want to appear in the legend, just set the label to "\_nolegend\_".
```
fig, ax = plt.subplots(1, 1)
ax.bar([1, 2, 3, 4], [10, 20, 25, 30], label="Foobar", align='center', color='lightblue')
ax.plot([1, 2, 3, 4], [10, 20, 25, 30], label="_nolegend_", marker='o', color='darkred')
ax.legend(loc='best')
plt.show()
```
# Exercise 4.1
Once again, let's use a bit of what we've learned. Try to reproduce the following figure:
<img src="images/exercise_4-1.png">
Hint: You'll need to combine `ax.axis(...)` and `ax.margins(...)`. Here's the data and some code to get you started:
```
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(0, 2 * np.pi, 150)
x1, y1 = np.cos(t), np.sin(t)
x2, y2 = 2 * x1, 2 * y1
colors = ['darkred', 'darkgreen']
# Try to plot the two circles, scale the axes as shown and add a legend
# Hint: it's easiest to combine `ax.axis(...)` and `ax.margins(...)` to scale the axes
%load solutions/4.1-legends_and_scaling.py
```
# Dealing with the boundaries: Layout, ticks, spines, etc
One key thing we haven't talked about yet is all of the annotation on the outside of the axes, the borders of the axes, and how to adjust the amount of space around the axes. We won't go over every detail, but this next section should give you a reasonable working knowledge of how to configure what happens around the edges of your axes.
## Ticks, Tick Lines, Tick Labels and Tickers
This is a constant source of confusion:
* A Tick is the *location* of a Tick Label.
* A Tick Line is the line that denotes the location of the tick.
* A Tick Label is the text that is displayed at that tick.
* A [`Ticker`](http://matplotlib.org/api/ticker_api.html#module-matplotlib.ticker) automatically determines the ticks for an Axis and formats the tick labels.
[`tick_params()`](https://matplotlib.org/api/axes_api.html#ticks-and-tick-labels) is often used to help configure your tickers.
```
fig, ax = plt.subplots()
ax.plot([1, 2, 3, 4], [10, 20, 25, 30])
# Manually set ticks and tick labels *on the x-axis* (note ax.xaxis.set, not ax.set!)
ax.xaxis.set(ticks=range(1, 5), ticklabels=[3, 100, -12, "foo"])
# Make the y-ticks a bit longer and go both in and out...
ax.tick_params(axis='y', direction='inout', length=10)
plt.show()
```
A commonly-asked question is "How do I plot categories?"
Starting in version 2.0 of mpl, just like any other data.
For example:
```
data = [('apples', 2), ('oranges', 3), ('peaches', 1)]
fruit, value = zip(*data)
fig, ax = plt.subplots()
ax.bar(fruit, value, align='center', color='gray')
plt.show()
```
## Subplot Spacing
The spacing between the subplots can be adjusted using [`fig.subplots_adjust()`](http://matplotlib.org/api/pyplot_api.html?#matplotlib.pyplot.subplots_adjust). Play around with the example below to see how the different arguments affect the spacing.
```
fig, axes = plt.subplots(2, 2, figsize=(9, 9))
fig.subplots_adjust(wspace=0.5, hspace=0.3,
left=0.125, right=0.9,
top=0.9, bottom=0.1)
plt.show()
```
A common "gotcha" is that the labels are not automatically adjusted to avoid overlapping those of another subplot. Matplotlib does not currently have any sort of robust layout engine, as it is a design decision to minimize the amount of "magical plotting". We intend to let users have complete, 100% control over their plots. LaTeX users would be quite familiar with the amount of frustration that can occur with automatic placement of figures in their documents.
That said, there have been some efforts to develop tools that users can use to help address the most common compaints. The "[Tight Layout](http://matplotlib.org/users/tight_layout_guide.html)" feature, when invoked, will attempt to resize margins and subplots so that nothing overlaps.
If you have multiple subplots, and want to avoid overlapping titles/axis labels/etc, `fig.tight_layout` is a great way to do so:
```
def example_plot(ax):
ax.plot([1, 2])
ax.set_xlabel('x-label', fontsize=16)
ax.set_ylabel('y-label', fontsize=8)
ax.set_title('Title', fontsize=24)
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
example_plot(ax1)
example_plot(ax2)
example_plot(ax3)
example_plot(ax4)
# Enable fig.tight_layout to compare...
fig.tight_layout()
plt.show()
```
## GridSpec
Under the hood, Matplotlib utilizes [`GridSpec`](http://matplotlib.org/api/gridspec_api.html) to lay out the subplots. While `plt.subplots()` is fine for simple cases, sometimes you will need more advanced subplot layouts. In such cases, you should use GridSpec directly. GridSpec is outside the scope of this tutorial, but it is handy to know that it exists. [Here](http://matplotlib.org/users/gridspec.html) is a guide on how to use it.
## Sharing axes
There will be times when you want to have the x axis and/or the y axis of your subplots to be "shared". Sharing an axis means that the axis in one or more subplots will be tied together such that any change in one of the axis changes all of the other shared axes. This works very nicely with autoscaling arbitrary datasets that may have overlapping domains. Furthermore, when interacting with the plots (panning and zooming), all of the shared axes will pan and zoom automatically.
```
fig, (ax1, ax2) = plt.subplots(1, 2, sharex=True, sharey=True)
ax1.plot([1, 2, 3, 4], [1, 2, 3, 4])
ax2.plot([3, 4, 5, 6], [6, 5, 4, 3])
plt.show()
```
## "Twinning" axes
Sometimes one may want to overlay two plots on the same axes, but the scales may be entirely different. You can simply treat them as separate plots, but then twin them.
```
fig, ax1 = plt.subplots(1, 1)
ax1.plot([1, 2, 3, 4], [1, 2, 3, 4])
ax2 = ax1.twinx()
ax2.scatter([1, 2, 3, 4], [60, 50, 40, 30])
ax1.set(xlabel='X', ylabel='First scale')
ax2.set(ylabel='Other scale')
plt.show()
```
# Axis Spines
Spines are the axis lines for a plot. Each plot can have four spines: "top", "bottom", "left" and "right". By default, they are set so that they frame the plot, but they can be individually positioned and configured via the [`set_position()`](http://matplotlib.org/api/spines_api.html#matplotlib.spines.Spine.set_position) method of the spine. Here are some different configurations.
```
fig, ax = plt.subplots()
ax.plot([-2, 2, 3, 4], [-10, 20, 25, 5])
ax.spines['top'].set_visible(False)
ax.xaxis.set_ticks_position('bottom') # no ticklines at the top
ax.spines['right'].set_visible(False)
ax.yaxis.set_ticks_position('left') # no ticklines on the right
# "outward"
# Move the two remaining spines "out" away from the plot by 10 points
#ax.spines['bottom'].set_position(('outward', 10))
#ax.spines['left'].set_position(('outward', 10))
# "data"
# Have the spines stay intersected at (0,0)
#ax.spines['bottom'].set_position(('data', 0))
#ax.spines['left'].set_position(('data', 0))
# "axes"
# Have the two remaining spines placed at a fraction of the axes
#ax.spines['bottom'].set_position(('axes', 0.75))
#ax.spines['left'].set_position(('axes', 0.3))
plt.show()
```
# Exercise 4.2
This one is a bit trickier. Once again, try to reproduce the figure below:
<img src="images/exercise_4-2.png">
A few key hints: The two subplots have no vertical space between them (this means that the `hspace` is `0`). Note that the bottom spine is at 0 in data coordinates and the tick lines are missing from the right and top sides.
Because you're going to be doing a lot of the same things to both subplots, to avoid repitive code you might consider writing a function that takes an `Axes` object and makes the spine changes, etc to it.
```
import matplotlib.pyplot as plt
import numpy as np
# Try to reproduce the figure shown in images/exercise_4.2.png
# This one is a bit trickier!
# Here's the data...
data = [('dogs', 4, 4), ('frogs', -3, 1), ('cats', 1, 5), ('goldfish', -2, 2)]
animals, friendliness, popularity = zip(*data)
%load solutions/4.2-spines_ticks_and_subplot_spacing.py
```
| github_jupyter |
<a href="https://colab.research.google.com/github/piyushjain220/TSAI/blob/main/NLP/Resources/EVA_P2S3.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
#Imports
```
import numpy as np
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from IPython import display
plt.style.use('seaborn-white')
```
# Read and process data.
Download the file from this URL: https://drive.google.com/file/d/1UWWIi-sz9g0x3LFvkIZjvK1r2ZaCqgGS/view?usp=sharing
```
data = open('text.txt', 'r').read()
```
Process data and calculate indices
```
chars = list(set(data))
data_size, X_size = len(data), len(chars)
print("Corona Virus article has %d characters, %d unique characters" %(data_size, X_size))
char_to_idx = {ch:i for i,ch in enumerate(chars)}
idx_to_char = {i:ch for i,ch in enumerate(chars)}
```
# Constants and Hyperparameters
```
Hidden_Layer_size = 10 #size of the hidden layer
Time_steps = 10 # Number of time steps (length of the sequence) used for training
learning_rate = 1e-1 # Learning Rate
weight_sd = 0.1 #Standard deviation of weights for initialization
z_size = Hidden_Layer_size + X_size #Size of concatenation(H, X) vector
```
# Activation Functions and Derivatives
```
def sigmoid(x): # sigmoid function
return # write your code here
def dsigmoid(y): # derivative of sigmoid function
return # write your code here
def tanh(x): # tanh function
return # write your code here
def dtanh(y): # derivative of tanh
return # write your code here
```
# Quiz Question 1
What is the value of sigmoid(0) calculated from your code? (Answer up to 1 decimal point, e.g. 4.2 and NOT 4.29999999, no rounding off).
# Quiz Question 2
What is the value of dsigmoid(sigmoid(0)) calculated from your code?? (Answer up to 2 decimal point, e.g. 4.29 and NOT 4.29999999, no rounding off).
# Quiz Question 3
What is the value of tanh(dsigmoid(sigmoid(0))) calculated from your code?? (Answer up to 5 decimal point, e.g. 4.29999 and NOT 4.29999999, no rounding off).
# Quiz Question 4
What is the value of dtanh(tanh(dsigmoid(sigmoid(0)))) calculated from your code?? (Answer up to 5 decimal point, e.g. 4.29999 and NOT 4.29999999, no rounding off).
# Parameters
```
class Param:
def __init__(self, name, value):
self.name = name
self.v = value # parameter value
self.d = np.zeros_like(value) # derivative
self.m = np.zeros_like(value) # momentum for Adagrad
```
We use random weights with normal distribution (0, weight_sd) for tanh activation function and (0.5, weight_sd) for `sigmoid` activation function.
Biases are initialized to zeros.
# LSTM
You are making this network, please note f, i, c and o (also "v") in the image below:

Please note that we are concatenating the old_hidden_vector and new_input.
# Quiz Question 4
In the class definition below, what should be size_a, size_b, and size_c? ONLY use the variables defined above.
```
size_a = # write your code here
size_b = # write your code here
size_c = # write your code here
class Parameters:
def __init__(self):
self.W_f = Param('W_f', np.random.randn(size_a, size_b) * weight_sd + 0.5)
self.b_f = Param('b_f', np.zeros((size_a, 1)))
self.W_i = Param('W_i', np.random.randn(size_a, size_b) * weight_sd + 0.5)
self.b_i = Param('b_i', np.zeros((size_a, 1)))
self.W_C = Param('W_C', np.random.randn(size_a, size_b) * weight_sd)
self.b_C = Param('b_C', np.zeros((size_a, 1)))
self.W_o = Param('W_o', np.random.randn(size_a, size_b) * weight_sd + 0.5)
self.b_o = Param('b_o', np.zeros((size_a, 1)))
#For final layer to predict the next character
self.W_v = Param('W_v', np.random.randn(X_size, size_a) * weight_sd)
self.b_v = Param('b_v', np.zeros((size_c, 1)))
def all(self):
return [self.W_f, self.W_i, self.W_C, self.W_o, self.W_v,
self.b_f, self.b_i, self.b_C, self.b_o, self.b_v]
parameters = Parameters()
```
Look at these operations which we'll be writing:
**Concatenation of h and x:**
$z\:=\:\left[h_{t-1},\:x\right]$
$f_t=\sigma\left(W_f\cdot z\:+\:b_f\:\right)$
$i_i=\sigma\left(W_i\cdot z\:+\:b_i\right)$
$\overline{C_t}=\tanh\left(W_C\cdot z\:+\:b_C\right)$
$C_t=f_t\ast C_{t-1}+i_t\ast \overline{C}_t$
$o_t=\sigma\left(W_o\cdot z\:+\:b_i\right)$
$h_t=o_t\ast\tanh\left(C_t\right)$
**Logits:**
$v_t=W_v\cdot h_t+b_v$
**Softmax:**
$\hat{y}=softmax\left(v_t\right)$
```
def forward(x, h_prev, C_prev, p = parameters):
assert x.shape == (X_size, 1)
assert h_prev.shape == (Hidden_Layer_size, 1)
assert C_prev.shape == (Hidden_Layer_size, 1)
z = np.row_stack((h_prev, x))
f = # write your code here
i = # write your code here
C_bar = # write your code here
C = # write your code here
o = # write your code here
h = # write your code here
v = # write your code here
y = np.exp(v) / np.sum(np.exp(v)) #softmax
return z, f, i, C_bar, C, o, h, v, y
```
You must finish the function above before you can attempt the questions below.
# Quiz Question 5
What is the output of 'print(len(forward(np.zeros((X_size, 1)), np.zeros((Hidden_Layer_size, 1)), np.zeros((Hidden_Layer_size, 1)), parameters)))'?
# Quiz Question 6.
Assuming you have fixed the forward function, run this command:
z, f, i, C_bar, C, o, h, v, y = forward(np.zeros((X_size, 1)), np.zeros((Hidden_Layer_size, 1)), np.zeros((Hidden_Layer_size, 1)))
Now, find these values:
1. print(z.shape)
2. print(np.sum(z))
3. print(np.sum(f))
Copy and paste exact values you get in the logs into the quiz.
```
z, f, i, C_bar, C, o, h, v, y = forward(np.zeros((X_size, 1)), np.zeros((Hidden_Layer_size, 1)), np.zeros((Hidden_Layer_size, 1)))
```
# Backpropagation
Here we are defining the backpropagation. It's too complicated, here is the whole code. (Please note that this would work only if your earlier code is perfect).
```
def backward(target, dh_next, dC_next, C_prev,
z, f, i, C_bar, C, o, h, v, y,
p = parameters):
assert z.shape == (X_size + Hidden_Layer_size, 1)
assert v.shape == (X_size, 1)
assert y.shape == (X_size, 1)
for param in [dh_next, dC_next, C_prev, f, i, C_bar, C, o, h]:
assert param.shape == (Hidden_Layer_size, 1)
dv = np.copy(y)
dv[target] -= 1
p.W_v.d += np.dot(dv, h.T)
p.b_v.d += dv
dh = np.dot(p.W_v.v.T, dv)
dh += dh_next
do = dh * tanh(C)
do = dsigmoid(o) * do
p.W_o.d += np.dot(do, z.T)
p.b_o.d += do
dC = np.copy(dC_next)
dC += dh * o * dtanh(tanh(C))
dC_bar = dC * i
dC_bar = dtanh(C_bar) * dC_bar
p.W_C.d += np.dot(dC_bar, z.T)
p.b_C.d += dC_bar
di = dC * C_bar
di = dsigmoid(i) * di
p.W_i.d += np.dot(di, z.T)
p.b_i.d += di
df = dC * C_prev
df = dsigmoid(f) * df
p.W_f.d += np.dot(df, z.T)
p.b_f.d += df
dz = (np.dot(p.W_f.v.T, df)
+ np.dot(p.W_i.v.T, di)
+ np.dot(p.W_C.v.T, dC_bar)
+ np.dot(p.W_o.v.T, do))
dh_prev = dz[:Hidden_Layer_size, :]
dC_prev = f * dC
return dh_prev, dC_prev
```
# Forward and Backward Combined Pass
Let's first clear the gradients before each backward pass
```
def clear_gradients(params = parameters):
for p in params.all():
p.d.fill(0)
```
Clip gradients to mitigate exploding gradients
```
def clip_gradients(params = parameters):
for p in params.all():
np.clip(p.d, -1, 1, out=p.d)
```
Calculate and store the values in forward pass. Accumulate gradients in backward pass and clip gradients to avoid exploding gradients.
input, target are list of integers, with character indexes.
h_prev is the array of initial h at h−1 (size H x 1)
C_prev is the array of initial C at C−1 (size H x 1)
Returns loss, final hT and CT
```
def forward_backward(inputs, targets, h_prev, C_prev):
global paramters
# To store the values for each time step
x_s, z_s, f_s, i_s, = {}, {}, {}, {}
C_bar_s, C_s, o_s, h_s = {}, {}, {}, {}
v_s, y_s = {}, {}
# Values at t - 1
h_s[-1] = np.copy(h_prev)
C_s[-1] = np.copy(C_prev)
loss = 0
# Loop through time steps
assert len(inputs) == Time_steps
for t in range(len(inputs)):
x_s[t] = np.zeros((X_size, 1))
x_s[t][inputs[t]] = 1 # Input character
(z_s[t], f_s[t], i_s[t],
C_bar_s[t], C_s[t], o_s[t], h_s[t],
v_s[t], y_s[t]) = \
forward(x_s[t], h_s[t - 1], C_s[t - 1]) # Forward pass
loss += -np.log(y_s[t][targets[t], 0]) # Loss for at t
clear_gradients()
dh_next = np.zeros_like(h_s[0]) #dh from the next character
dC_next = np.zeros_like(C_s[0]) #dh from the next character
for t in reversed(range(len(inputs))):
# Backward pass
dh_next, dC_next = \
backward(target = targets[t], dh_next = dh_next,
dC_next = dC_next, C_prev = C_s[t-1],
z = z_s[t], f = f_s[t], i = i_s[t], C_bar = C_bar_s[t],
C = C_s[t], o = o_s[t], h = h_s[t], v = v_s[t],
y = y_s[t])
clip_gradients()
return loss, h_s[len(inputs) - 1], C_s[len(inputs) - 1]
```
# Sample the next character
```
def sample(h_prev, C_prev, first_char_idx, sentence_length):
x = np.zeros((X_size, 1))
x[first_char_idx] = 1
h = h_prev
C = C_prev
indexes = []
for t in range(sentence_length):
_, _, _, _, C, _, h, _, p = forward(x, h, C)
idx = np.random.choice(range(X_size), p=p.ravel())
x = np.zeros((X_size, 1))
x[idx] = 1
indexes.append(idx)
return indexes
```
# Training (Adagrad)
Update the graph and display a sample output
```
def update_status(inputs, h_prev, C_prev):
#initialized later
global plot_iter, plot_loss
global smooth_loss
# Get predictions for 200 letters with current model
sample_idx = sample(h_prev, C_prev, inputs[0], 200)
txt = ''.join(idx_to_char[idx] for idx in sample_idx)
# Clear and plot
plt.plot(plot_iter, plot_loss)
display.clear_output(wait=True)
plt.show()
#Print prediction and loss
print("----\n %s \n----" % (txt, ))
print("iter %d, loss %f" % (iteration, smooth_loss))
```
# Update Parameters
\begin{align}
\theta_i &= \theta_i - \eta\frac{d\theta_i}{\sum dw_{\tau}^2} \\
d\theta_i &= \frac{\partial L}{\partial \theta_i}
\end{align}
```
def update_paramters(params = parameters):
for p in params.all():
p.m += p.d * p.d # Calculate sum of gradients
#print(learning_rate * dparam)
p.v += -(learning_rate * p.d / np.sqrt(p.m + 1e-8))
```
To delay the keyboard interrupt to prevent the training from stopping in the middle of an iteration
```
# Exponential average of loss
# Initialize to a error of a random model
smooth_loss = -np.log(1.0 / X_size) * Time_steps
iteration, pointer = 0, 0
# For the graph
plot_iter = np.zeros((0))
plot_loss = np.zeros((0))
```
# Training Loop
```
iter = 1000
while iter > 0:
# Reset
if pointer + Time_steps >= len(data) or iteration == 0:
g_h_prev = np.zeros((Hidden_Layer_size, 1))
g_C_prev = np.zeros((Hidden_Layer_size, 1))
pointer = 0
inputs = ([char_to_idx[ch]
for ch in data[pointer: pointer + Time_steps]])
targets = ([char_to_idx[ch]
for ch in data[pointer + 1: pointer + Time_steps + 1]])
loss, g_h_prev, g_C_prev = \
forward_backward(inputs, targets, g_h_prev, g_C_prev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001
# Print every hundred steps
if iteration % 100 == 0:
update_status(inputs, g_h_prev, g_C_prev)
update_paramters()
plot_iter = np.append(plot_iter, [iteration])
plot_loss = np.append(plot_loss, [loss])
pointer += Time_steps
iteration += 1
iter = iter -1
```
# Quiz Question 7.
Run the above code for 50000 iterations making sure that you have 100 hidden layers and time_steps is 40. What is the loss value you're seeing?
| github_jupyter |
## QE methods and QE_utils
In this tutorial, we will explore various methods needed to handle Quantum Espresso (QE) calculations - to run them, prepare input, and extract output. All that will be done with the help of the **QE_methods** and **QE_utils** modules, which contains the following functions:
**QE_methods**
* cryst2cart(a1,a2,a3,r)
* [Topic 2](#topic-2) read_qe_schema(filename, verbose=0)
* [Topic 3](#topic-3) read_qe_index(filename, orb_list, verbose=0)
* [Topic 4](#topic-4) read_qe_wfc_info(filename, verbose=0)
* [Topic 9](#topic-9) read_qe_wfc_grid(filename, verbose=0)
* [Topic 5](#topic-5) read_qe_wfc(filename, orb_list, verbose=0)
* read_md_data(filename)
* read_md_data_xyz(filename, PT, dt)
* read_md_data_xyz2(filename, PT)
* read_md_data_cell(filename)
* out2inp(out_filename,templ_filename,wd,prefix,t0,tmax,dt)
* out2pdb(out_filename,T,dt,pdb_prefix)
* out2xyz(out_filename,T,dt,xyz_filename)
* xyz2inp(out_filename,templ_filename,wd,prefix,t0,tmax,dt)
* get_QE_normal_modes(filename, verbosity=0)
* [Topic 1](#topic-1) run_qe(params, t, dirname0, dirname1)
* read_info(params)
* read_all(params)
* read_wfc_grid(params)
**QE_utils**
* get_value(params,key,default,typ)
* split_orbitals_energies(C, E)
* [Topic 7](#topic-7) merge_orbitals(Ca, Cb)
* post_process(coeff, ene, issoc)
* [Topic 6](#topic-6) orthogonalize_orbitals(C)
* [Topic 8](#topic-8) orthogonalize_orbitals2(Ca,Cb)
```
import os
import sys
import math
import copy
if sys.platform=="cygwin":
from cyglibra_core import *
elif sys.platform=="linux" or sys.platform=="linux2":
from liblibra_core import *
#from libra_py import *
from libra_py import units
from libra_py import QE_methods
from libra_py import QE_utils
from libra_py import scan
from libra_py import hpc_utils
from libra_py import data_read
from libra_py import data_outs
from libra_py import data_conv
from libra_py.workflows.nbra import step2
import py3Dmol # molecular visualization
import matplotlib.pyplot as plt # plots
%matplotlib inline
plt.rc('axes', titlesize=24) # fontsize of the axes title
plt.rc('axes', labelsize=20) # fontsize of the x and y labels
plt.rc('legend', fontsize=20) # legend fontsize
plt.rc('xtick', labelsize=16) # fontsize of the tick labels
plt.rc('ytick', labelsize=16) # fontsize of the tick labels
plt.rc('figure.subplot', left=0.2)
plt.rc('figure.subplot', right=0.95)
plt.rc('figure.subplot', bottom=0.13)
plt.rc('figure.subplot', top=0.88)
colors = {}
colors.update({"11": "#8b1a0e"}) # red
colors.update({"12": "#FF4500"}) # orangered
colors.update({"13": "#B22222"}) # firebrick
colors.update({"14": "#DC143C"}) # crimson
colors.update({"21": "#5e9c36"}) # green
colors.update({"22": "#006400"}) # darkgreen
colors.update({"23": "#228B22"}) # forestgreen
colors.update({"24": "#808000"}) # olive
colors.update({"31": "#8A2BE2"}) # blueviolet
colors.update({"32": "#00008B"}) # darkblue
colors.update({"41": "#2F4F4F"}) # darkslategray
clrs_index = ["11", "21", "31", "41", "12", "22", "32", "13","23", "14", "24"]
```
First, lets prepare the working directories and run simple SCF calculations to generate the output files
```
PWSCF = os.environ['PWSCF62']
# Setup the calculations
params = {}
# I run the calculations on laptop, so no BATCH system
params["BATCH_SYSTEM"] = None
# The number of processors to use
params["NP"] = 1
# The QE executable
params["EXE"] = F"{PWSCF}/pw.x"
# The executable to generate the wavefunction files
params["EXE_EXPORT"] = F"{PWSCF}/pw_export.x" #"/mnt/c/cygwin/home/Alexey-user/Soft/espresso/bin/pw_export.x"
# The type of the calculations to be performed - in this case only a single SCF with spin-polarization
params["nac_method"] = 1
# The prefix of the input file
params["prefix0"] = "x0.scf"
# Working directory - where all stuff happen
params["wd"] = os.getcwd()+"/wd"
# Remove the previous results and temporary working directory from the previous runs
os.system(F"rm -r {params['wd']}")
os.system(F"mkdir {params['wd']}")
# Copy the input files into the working directory
# also, notice how the SCF input file name has been changed
os.system(F"cp x0.scf.in {params['wd']}/x0.scf.0.in")
os.system(F"cp x0.exp.in {params['wd']}")
os.system(F"cp Li.pbe-sl-kjpaw_psl.1.0.0.UPF {params['wd']}")
os.system(F"cp H.pbe-rrkjus_psl.1.0.0.UPF {params['wd']}")
```
<a name="topic-1"></a>
### 1. run_qe(params, t, dirname0, dirname1)
Use it to actually run the calculations
Comment this out if you have already done the calculations
```
help(QE_methods.run_qe)
!pwd
os.chdir("wd")
QE_methods.run_qe(params, 0, "res", "res2")
os.chdir("../")
```
<a name="topic-2"></a>
### 2. read_qe_schema(filename, verbose=0)
Can be used to read the information about the completed run
```
pwd
info = QE_methods.read_qe_schema("wd/res/x0.save/data-file-schema.xml", verbose=0)
print(info)
nat = info["nat"]
R, F = info["coords"], info["forces"]
for at in range(nat):
print(F"Atom {at} \t {info['atom_labels'][at]} \t\
x={R.get(3*at+0):.5f}, y={R.get(3*at+1):.5f}, z={R.get(3*at+2):.5f}\
fx={F.get(3*at+0):.5f}, fy={F.get(3*at+1):.5f}, fz={F.get(3*at+2):.5f}")
```
<a name="topic-3"></a>
### 3. read_qe_index(filename, orb_list, verbose=0)
Is analogous to **read_qe_schema** in many regards, it just extracts a bit different info, including orbital energies.
One would also need to specify which energy levels we want to extract, so one would need that info beforehands.
In this example, we have just 4 electrons, so:
1 - HOMO-1
2 - HOMO
3 - LUMO
4 - LUMO+1
Lets try just the 4 orbitals
```
info2, all_e = QE_methods.read_qe_index("wd/res/x0.export/index.xml", [1,2,3,4], verbose=1)
print( info2)
print(all_e)
e_alp = all_e[0]
e_bet = all_e[1]
for i in range(4):
print(F"E_{i}^alpha = {e_alp.get(i,i).real:12.8f} \t E_{i}^beta = {e_bet.get(i,i).real:12.8f}")
```
<a name="topic-4"></a>
### 4. read_qe_wfc_info(filename, verbose=0)
Can be used to extract some descriptors of the wavefunctions produced
```
wfc_info1 = QE_methods.read_qe_wfc_info("wd/res/x0.export/wfc.1", verbose=1)
wfc_info2 = QE_methods.read_qe_wfc_info("wd/res/x0.export/wfc.2", verbose=1)
print(wfc_info1)
print(wfc_info2)
```
<a name="topic-5"></a>
### 5. read_qe_wfc(filename, orb_list, verbose=0)
Can be used to read in the actual wavefunctions produced
```
alpha = QE_methods.read_qe_wfc("wd/res/x0.export/wfc.1", [1,2,3,4], verbose=0)
beta = QE_methods.read_qe_wfc("wd/res/x0.export/wfc.2", [1,2,3,4], verbose=0)
print(alpha)
print(alpha.num_of_rows, alpha.num_of_cols)
print(beta)
print(beta.num_of_rows, beta.num_of_cols)
```
Orthogonality and normalization
Below we can see that MO overlaps <alpha(i)|alpha(j)> are almost orthonormal - the diagonal elements are coorectly 1.0
But the off-diagonal elements are not quite 0.0
Same is true for <beta(i)|beta(j)>
However, there is no any expectation about the orthogonality or normalization across the two sets
```
S_aa = alpha.H() * alpha
S_bb = beta.H() * beta
S_ab = alpha.H() * beta
def print_mat(X):
nr, nc = X.num_of_rows, X.num_of_cols
for i in range(nr):
line = ""
for j in range(nc):
line = line + "%8.5f " % (X.get(i,j).real)
print(line)
print("S_aa")
print_mat(S_aa)
print("S_bb")
print_mat(S_bb)
print("S_ab")
print_mat(S_ab)
```
<a name="topic-6"></a>
### 6. QE_utils.orthogonalize_orbitals(C)
Can be used to orthogonalize orbitals if they are not.
So lets transform alpha and beta orbitals such they are now orthonormal within each set.
The resulting orbitals are not orthonormal across the two sets still
```
alp = QE_utils.orthogonalize_orbitals(alpha)
bet = QE_utils.orthogonalize_orbitals(beta)
S_aa = alp.H() * alp
S_bb = bet.H() * bet
S_ab = alp.H() * bet
print("S_aa")
print_mat(S_aa)
print("S_bb")
print_mat(S_bb)
print("S_ab")
print_mat(S_ab)
```
<a name="topic-7"></a>
### 7. QE_utils.merge_orbitals(Ca, Cb)
Sometimes (usually in the non-collinear case), we want to have a single set of orbitals (many are nearly doubly degenerate), not just alpha and beta components. We can prepare the single set from the spinor components using this function. In this example, we just gonna mimic non-collinear SOC calculations, pretending that alpha and beta orbital sets are the spinor components.
```
C = QE_utils.merge_orbitals(alpha, beta)
S = C.H() * C
print_mat(S)
```
<a name="topic-8"></a>
### 8. QE_utils.orthogonalize_orbitals2(Ca, Cb)
This is a special orthogonalization procedure - the one for 2-component spinors. The inputs are assumed to be the components for each orbital. The orthogonalization works such that it is S_aa + S_bb = I
```
alpha = QE_methods.read_qe_wfc("wd/res/x0.export/wfc.1", [1,2,3,4], verbose=0)
beta = QE_methods.read_qe_wfc("wd/res/x0.export/wfc.2", [1,2,3,4], verbose=0)
alp, bet = QE_utils.orthogonalize_orbitals2(alpha, beta)
S_aa = alp.H() * alp
S_bb = bet.H() * bet
print("S_aa")
print_mat(S_aa)
print("S_bb")
print_mat(S_bb)
print("S_aa + S_bb")
print_mat(S_aa + S_bb)
S_ab = alp.H() * bet
print("S_ab")
print_mat(S_ab)
```
<a name="topic-9"></a>
### 9. read_qe_wfc_grid(filename, verbose=0)
Can be used to read the grid points for the given PW representation.
```
G1 = QE_methods.read_qe_wfc_grid("wd/res/x0.export/grid.1", verbose=0)
print(len(G1))
for i in range(10):
print(F"{i} \t {G1[i].x} \t {G1[i].y} \t {G1[i].z}")
```
| github_jupyter |
___
<img style="float: right; margin: 0px 0px 15px 15px;" src="https://upload.wikimedia.org/wikipedia/commons/thumb/4/4a/Python3-powered_hello-world.svg/1000px-Python3-powered_hello-world.svg.png" width="300px" height="100px" />
# <font color= #8A0829> Simulación matemática.</font>
#### <font color= #2E9AFE> `Miércoles-Viernes (Videoconferencia) de 13:00 a 15:00 hrs`</font>
- <Strong> Esteban Jiménez Rodríguez </Strong>
- <Strong> Año </Strong>: 2021
- <Strong> Copyright: </Strong> MIT, excepto donde se indique lo contrario.
- <Strong> Email: </Strong> <font color="blue"> `[email protected], [email protected]` </font>
___
### `Presentación mía`
___
### `Presentación de ustedes`
___
### `Algunas reglas de juego`
[Normas mínimas disciplinarias](https://www.dropbox.com/s/sbez0e0rv34na14/NORMAS_MINIMAS_DISCIPLINARIAS.pdf?dl=0)
- Todas las entregas deben hacerse através de los espacios provistos en canvas, a menos que se especifique lo contrario.
- No se recibirán entregas por ningún otro medio. Sin excepción.
___
### `Horario de asesoría`
A convenir.
___
### `Descripción de la asignatura`
*Este es un curso básico de simulación utilizando python, por ende vamos a iniciar elaborando programas simples y conforme avancemos el nivel de exigencia aumentará.*
- Problemas de ingeniería: requieren soluciones adecuadas, eficientes y óptimas.
- La simulación matemática de escenarios es una estrategia relevante para resolver tales problemas, consiste en modelar numéricamente los principios físicos y matemáticos que rigen un fenómeno mediante el uso de lenguajes de modelado y herramientas de tecnologías de información.
- La asignatura está diseñada para que logres dichos propósitos e inicies un proceso que te permita apropiarte de desempeños profesionales muy útiles en tu formación profesional y en tu futuro, al incorporarte a la industria u organizaciones que te demandarán resolver e implementar la simulación de escenarios bajo diferentes situaciones a través de la sistematización de la solución al problema planteado.
#### `OBJETIVO GENERAL `
> <p style='text-align: justify;'> A partir de la modelación de fenómenos físicos desarrollarás las competencias necesarias para reproducir escenarios de aplicación profesional que representen de manera más cercana el fenómeno objetivo. Podrás además realizar inferencias que ayuden a la óptima toma de decisiones en la solución de problemas.</p>
`Módulo 1.` **Optimización**
> Se evaluará una presentación de **proyecto.**
1. ¿Qué es una simulación?
- Introducción e instalación de software
- Uso de Markdown
- Control de versiones con git
2. Optimización de funciones de variable escalar con SymPy
3. Programación Lineal
5. Ajuste de curvas
7. Clasificación binaria
`Módulo 2.` **Montecarlo**
> Se evaluará una presentación de **proyecto.**
1. Generación de números aleatorios
- Generación de variables aleatorias (Uniforme, triangular, exponencial).
- Simulación de una fila un servidor (fila de un banco, cafetería, etc).
2. Caminata aleatoria
3. Integrales
4. Fractales aleatorios
5. Bajar y organizar datos de Yahoo Finance (Pandas)
6. Probabilidad precio-umbral
`Módulo 2.` **Ecuaciones diferenciales**
> Se evaluará una presentación de **proyecto.**
1. Introducción a ecuaciones diferenciales
2. ¿Cómo se muve un péndulo?
3. ¿Cómo funciona la suspensión de un auto?
4. ¿Cómo crece una población?
5. Modelo del rendimiento de una cuenta de ahorro
### `Evaluación`
- 3 Proyectos (trabajo en equipo) 45%
- Cada proyecto tiene un valor del 15%
- La evaluación de cada proyecto se divide en dos partes
- Reporte 7.5%
- Exposición 7.5%
- Equipos de 2 integrantes mínimo y 3 máximo. *Esto no se negocia*.
- Si durante algún proyecto las cosas no funcionan entre los integrantes, para el siguiente proyecto se pueden formar equipos nuevos.
- Examen final 19%
- Quices 16%
- Tareas 20%
- La evaluación de cada tarea se divide en dos partes
- Primera entrega 30%
- Segunda entrega 70%
- Si sacan 100 en la primera entrega, no es necesario hacer la segunda entrega.
- Si sacan menos de 100 en la primera entrega, y no realizan las correcciones para la segunda entrega, se calificará como si no se hubiera hecho segunda entrega.
- Si sacan menos de 100 en la primera entrega, y no realizan segunda entrega, se calificará como si no se hubiera hecho segunda entrega.
- Para tener derecho a segunda entrega, deben realizar la primera entrega.
### `Bibliografía `
- Process Dynamics: Modeling, Analysis and Simulation by B. Wayne Bequette
- Stochastic Simulation and Applications in Financewith MATLAB Programs by HuuTueHuynh
- Fluent Python by Ramalho, Luciano
- Python for Finance by Hilpisch, Yves
- Python for Scientists by Stewart, John M.
- Mathematical Modeling in Continuum Mechanics by Temam & Miranville
Estos y muchos mas libros los pueden encontrar en la Biblioteca.
<script>
$(document).ready(function(){
$('div.prompt').hide();
$('div.back-to-top').hide();
$('nav#menubar').hide();
$('.breadcrumb').hide();
$('.hidden-print').hide();
});
</script>
<footer id="attribution" style="float:right; color:#808080; background:#fff;">
Created with Jupyter by Esteban Jiménez Rodríguez.
</footer>
| github_jupyter |
```
import matplotlib.pyplot as plt
import BondGraphTools
from BondGraphTools.config import config
from BondGraphTools.reaction_builder import Reaction_Network
julia = config.julia
```
# `BondGraphTools`
## Modelling Network Bioenergetics.
https://github.com/peter-cudmore/seminars/ANZIAM-2019
Dr. Peter Cudmore.
Systems Biology Labratory,
The School of Chemical and Biomedical Engineering,
The University of Melbourne.
In this talk i discuss
* Problems in compartmental modelling of cellular processes,
* Some solutions from engineering and physics,
* Software to make life easier.
For this talk; a *model* is a set of ordinary differential equations.
## Part 1: Problems in Cellular Process Modelling.
<center> <img src="images/map.png"> </center>
<center><i>Parameters (or the lack thereof) are the bane of the mathematical biologists existence!</i></center>
Consinder $S + E = ES = E + P$ (one 'edge' of metabolism).
Assuming mass action, the dynamics are:
$$\begin{align}
\dot{[S]} &= k_1^b[ES] - k_1^f[E][S],\\
\dot{[E]} &= (k_1^b + k_2^f)[ES] - [E](k_1^f[S] + k_2^b[P]),\\
\dot{[ES]} &= -(k_1^b + k_2^f)[ES] + [E](k_1^f[S] + k_2^b[P]),\\
\dot{[P]} &= k_2^f[ES] - k_2^f[E][P].
\end{align}
$$
*What are the kinetic parameters $k_1^b, k_1^f, k_2^b, k_2^f$?*
*How do we find them for large systems?*
Can kinetic parameters be estimated from available data?
<center><h3>No!</h3></center>
When fitting data to a system of kinetics parameters may be:
- unobservable (for example, rate constants from equilibrium data),
- or *sloppy* (aways underdetermined for a set of data).
Do kinetic parameters generalise across different experiments (and hence can be tabulated)?
<center><h3>No!</h3></center>
At the very least kinetic parameters fail to generalise across temperatures.
For example; physiological conditions are around $37^\circ C$ while labs are around $21^\circ C$.
Do kinetic parameters violate the laws physics?
<center><h3>Often!</h3></center>
_The principal of detailed balance_ requires that at equilibirum each simple process should be balanced by its reverse process.
This puts constraints on the kinetic parameters which are often broken, for example, by setting $k^b_i = 0$ (no back reaction for that step).
An alternative is to think of kinetic parameters as derived from physical constants!
For instance:
- Oster, G. and Perelson, A. and Katchalsy, A. *Network Thermodynamics*. Nature 1971; 234:5329.
- Erderer, M. and Gilles, E. D. *Thermodynamically Feasible Kinetic Models of Reaction Networks*. Biophys J. 2007; 92(6): 1846–1857.
- Saa, P. A. and Nielsen, L. K. *Construction of feasible and accurate kinetic models of metabolism: A Bayesian approach.* Sci Rep. 2016;6:29635.
# Part 2: A Solution via Network Thermodynamics
<center> <img src="images/map.png"> </center>
### Network Thermodynamics
Partitions $S + B = P$ into _components_.
1. Energy Storage.
2. Dissipative Processes.
3. Conservation Laws.
Here:
- Chem. potential acts like _pressure_ or _voltage_.
- Molar flow acts like _velocity_ or _current_.
```
# Reaction Network from BondGraphTools
reaction = Reaction_Network(
"S + B = P", name="One Step Reaction"
)
model = reaction.as_network_model()
# Basic Visualisation.
from BondGraphTools import draw
figure = draw(model, size=(8,6))
```
### Kinetic parameters from Network Thermodynamics.
Partitions $S + B = P$ into _components_.
1. Energy Storage Compartments:
$S$, $B$ and $P$.
2. Dissipative Processes: (The chemical reaction itself).
3. Conservation Laws: (The flow from A is the flow from B and is equal to the flow into reaction).
Gibbs Energy:
$$\mathrm{d}G = P\mathrm{d}v +S\mathrm{d}T + \sum_i\mu_i\mathrm{d}n_i$$
- $\mu_i$ is the Chemical Potential of species $A_i$
- $n_i$ is the amount (in mols) of $A_i$
Chemical Potential is usually modelled as
$$\mu_i = PT\ln\left(\frac{k_in_i}{V}\right)$$ where $$k_i = \frac{1}{c^\text{ref}}\exp\left[\frac{\mu_i^\text{ref}}{PT}\right]$$
- $P$, $T$ and $V$ are pressure, temperature and volume respectively.
- $c^\text{ref}$ is the reference concentration (often $10^{-9} \text{mol/L}$).
- $\mu_i^\text{ref}$ is the reference potential.
<center><i> The reference potential can be tabulated, approximated and (in somecase) directly measured!</i> </center>
Reaction flow $v$ is assumed to obey the Marcelin-de Donder formula:
$$ v \propto \exp\left(\frac{A_f}{PT}\right) - \exp\left(\frac{A_r}{PT}\right)$$
where $A_f, A_r$ are the forward and reverse chemical affinities.
For $S + B = P$, $$A_f = \mu_S + \mu_B \quad \text{and}\quad A_r = \mu_P.$$
### Kinetic parameters from Network Thermodynamics.
For the equation $S + B= P$, in thermodynamic parameters:
$$
\dot{[P]} = \kappa(k_Sk_B[S][B] - k_P[P])
$$
Here $$k^f = \kappa k_Sk_B, \quad k^b = \kappa k_P, \quad \text{with} \quad k_i = \frac{1}{c^\text{ref}}\exp\left[\frac{\mu_i^\text{ref}}{PT}\right], \quad \kappa > 0.$$
*$k^f$ and $k^b$ are now related to physical constants!*
# Part 3: Network Thermodynamics with `BondGraphTools`
<center> <img src="images/map.png"> </center>
```
import BondGraphTools
help(BondGraphTools)
```
### Network Energetics
Network Energetics, which includes Network Thermodynamics partitions $S + B = P$ into _components_.
1. Energy Storage Compartments: $C: S$, $C: B$ and $C: P$.
2. Dissipative Processes: $R: r_{1;0}$
3. Conservation Laws: $1$ (common flow).
*Bond Graphs represent of energy networks.*
```
#from BondGraphTools.reaction_builder
# import Reaction_Network
reaction = Reaction_Network(
"S + B = P", name="One Step Reaction"
)
model = reaction.as_network_model()
# Basic Visualisation.
from BondGraphTools import draw
figure = draw(model, size=(8,6))
# Initialise latex printing
from sympy import init_printing
init_printing()
# Print the equations of motion
model.constitutive_relations
figure
for v in model.state_vars:
(component, local_v) = model.state_vars[v]
meta_data = component.state_vars[local_v]
print(f"{v} is {component}\'s {meta_data}")
#
#
figure
```
### A peak under the hood
In `BondGraphTools`, components have a number of power ports defined such that the power $P_i$ entering the $i$th port is $P_i = e_if_i$
The power vaiables $(e,f)$ are related to the component state variables $(x, \mathrm{d}x)$ by _constitutive relations_.
```
from BondGraphTools import new
chemical_potential = new("Ce", library="BioChem")
chemical_potential.constitutive_relations
figure
```
##### A peak under the hood (cont.)
The harpoons represent _shared power variables_.
For example the harpoon from port 1 on $R: r_{1;0}$ to $C:P$ indiciates that
$$
f^{C:P}_0 = - f^{R:r_{1;0}}_1 \qquad
e^{C:P}_0 = e^{R:r_{1;0}}_1
$$
so that power is conserved through the connection
$$
P^{C:P}_0 + P^{R:r_{1;0}}_1 = 0
$$
```
figure
```
##### A peak under the hood (cont.)
The resulting system is of the form:
$$
LX + V(X) = 0
$$
where
$$
X = \left(\frac{\mathrm{d}\mathbf{x}}{\mathrm{d}t},
\mathbf{e},
\mathbf{f},
\mathbf{x},
\mathbf{u}\right)^T
$$
- $\mathbf{e},\mathbf{f}$ vectors of power variables
- $\mathrm{d}\mathbf{x}, \mathbf{x}$ similarly state variables.
- and $\mathbf{u}$ control variables
- $L$ is a sparse matrix
- $V$ is a nonlinear vector field.
### So what does this have to do with parameters?
Having a network energetics library allows for:
- automation via dataflow scripting (eq; `request`, `xlrd`),
- 'computational modularity' for model/parameter reuse,
- intergration with existing parameter estimators,
- use with your favourite data analysis technology.
*Enables the tabuation of paramaters!*
### Why Python?
- open source, commonly available and commonly used
- 'executable pseudocode' (easy to read) and excellent for rapid development
- great libraries for both science and general purpose computing
- excellent quality management tools
- pacakge management, version control
*`BondGraphTools` is developed with sustainable development practices.*
## `BondGraphTools` now and in the future.
#### Current Version
Version 0.3.6 (on PyPI) is being used by in the Systems Biology Lab:
- Prof. Peter Gawrthop (mitochondrial electron transport).
- Michael Pan (ionic homeostasis).
- Myself (coupled oscillators, synthetic biology)
#### Features Already Implemented
- Component libraries, (mechotronic and biochem)
- Numerical simulations,
- Control variables,
- Stiochiometric analysis
The big challenge: _scaling up_!
# Thanks for Listening!
Thanks to:
- Prof. Edmund Crampin Prof. Peter Gawthrop, Michael Pan & The Systems Biology Lab.
- The University of Melbourne
- The ARC Center of Excellence for Convergent Bio-Nano Science.
- ANZIAM Organisers and sessions chairs, and Victoria University.
Please check out `BondGraphTools`
- documentation at [bondgraphtools.readthedocs.io](http://bondgraphtools.readthedocs.io)
- source at [https://github.com/BondGraphTools](https://github.com/BondGraphTools)
| github_jupyter |
# Naive-Bayes Classifier
```
#Baseline SVM with PCA classifier
import sklearn
import numpy as np
import sklearn.datasets as skd
import ast
from sklearn.feature_extraction import DictVectorizer
from sklearn import linear_model
from sklearn import naive_bayes
from sklearn.metrics import precision_recall_fscore_support
from sklearn.neighbors.nearest_centroid import NearestCentroid
from sklearn.metrics.pairwise import pairwise_distances
from sklearn.metrics import confusion_matrix
from scipy.sparse import vstack
import matplotlib.pyplot as plt
import itertools
import pickle
file = open("mr_train.obj",'rb')
mr_train = pickle.load(file)
file.close()
file = open("mr_test.obj",'rb')
mr_test = pickle.load(file)
file.close()
file = open("mr_cv.obj",'rb')
mr_cv = pickle.load(file)
file.close()
'''
file = open("b_train.obj",'rb')
b = pickle.load(file)
file.close()
file = open("c_cv.obj",'rb')
c = pickle.load(file)
file.close()
file = open("d_test.obj",'rb')
d = pickle.load(file)
file.close()
'''
file = open("x_train.obj",'rb')
x_train = pickle.load(file)
file.close()
file = open("x_test.obj",'rb')
x_test = pickle.load(file)
file.close()
file = open("x_cv.obj",'rb')
x_cv = pickle.load(file)
file.close()
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
plt.figure(figsize=(20,10))
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45,fontsize=10)
plt.yticks(tick_marks, classes,fontsize=10)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
print("Training data has %d malware samples and %d features" % (x_train.shape[0], x_train.shape[1]))
print("Crossval data has %d malware samples and %d features" % (x_cv.shape[0], x_cv.shape[1]))
print("Test data has %d malware samples and %d features" % (x_test.shape[0], x_test.shape[1]))
print("Performing IG Feature selection...")
indices=np.argsort(np.asarray(x_train.sum(axis=0)).ravel(),axis=0)[::-1]
x_train_ig = x_train[:,indices]
x_cv_ig = x_cv[:,indices]
x_test_ig = x_test[:,indices]
print("Training NB Classifier with top 5000 IG features ...")
NB = sklearn.naive_bayes.MultinomialNB()
NB.fit(x_train_ig,mr_train.target)
print("Obtaining predictions on test data...")
y_pred_cv=NB.predict(x_cv_ig)
y_pred_test=NB.predict(x_test_ig)
prec_cv, rec_cv, fsc_cv, sup_cv = precision_recall_fscore_support(mr_cv.target, y_pred_cv, average='weighted')
prec_test, rec_test, fsc_test, sup_test = precision_recall_fscore_support(mr_test.target, y_pred_test, average='weighted')
print("Precision on crossval data is %.4f" % prec_cv)
print("Recall on crossval data is %.4f" % rec_cv)
print("Precision on test data is %.4f" % prec_test)
print("Recall on test data is %.4f" % rec_test)
#Distance measure to class centroids
#Confusion Matrices
print("Finding class centroids and computing distance of samples to centroids")
clf = NearestCentroid()
clf.fit(x_train_ig,mr_train.target)
dist_train = pairwise_distances(x_train_ig, clf.centroids_)
dist_test = pairwise_distances(x_test_ig, clf.centroids_)
print("Calculating drift_l2 thresholds...")
m = np.resize(np.array([]),8)
var = np.resize(np.array([]),8)
thresh = np.resize(np.array([]),8)
for i in range(8):
m[i] = np.mean(dist_train[np.where(np.argmin(dist_train,axis=1)==i)][:,i])
var[i] = np.sqrt(np.std(dist_train[np.where(np.argmin(dist_train,axis=1)==i)][:,i]))
thresh[i] = m[i]+var[i]
test_drift_l2 = np.resize(np.array([]),8)
test_total = np.resize(np.array([]),8)
test_d_per = np.resize(np.array([]),8)
"Calculating drift_l2 on test data with new classes..."
for r in range(8):
test_drift_l2[r]=sum(dist_test[np.where(np.argmin(dist_test,axis=1)==r)][:,r] > thresh[r])
test_total[r]= sum(np.argmin(dist_test,axis=1)==r)
if test_total[r]!=0:
test_d_per[r]=test_drift_l2[r]/test_total[r]
else:
test_d_per[r]='nan'
print("In test set there are %d drift_l2ed malware of a total of %d samples, total drift_l2 percentage is %.4f" % (sum(test_drift_l2), sum(test_total), sum(test_drift_l2)/sum(test_total)))
print("Selecting drift_l2ed malware samples from test set...")
ind_array_test = np.array([])
indices_test = np.array([])
for i in range(8):
ind_array_test = np.where(np.argmin(dist_test,axis=1)==i)
indices_test = np.append(indices_test,ind_array_test[0][dist_test[np.where(np.argmin(dist_test,axis=1)==i)][:,i] > thresh[i]])
print("Appending drift_l2ed malware samples from test set to training set, and re-labelling...")
x_train_drift_l2 = vstack([x_train_ig,x_test_ig[indices_test.astype(int)]])
mr_train_drift_l2_target = np.append(mr_train.target,mr_test.target[indices_test.astype(int)],axis=0)
print("Training drift_l2-Aware SVM classifier with new training set...")
NB_drift_l2 = sklearn.naive_bayes.MultinomialNB()
NB_drift_l2.fit(x_train_drift_l2,mr_train_drift_l2_target)
print("Computing predictions on test data with newly trained model...")
y_drift_l2 = NB_drift_l2.predict(x_test_ig)
prec_drift_l2, rec_drift_l2, fsc_drift_l2, sup_drift_l2 = precision_recall_fscore_support(mr_test.target,y_drift_l2, average='weighted')
print("Precision on test data with new classes with original model was %.4f" %prec_test)
print("Recall on test data with new classes with original model was %.4f" %rec_test)
print("Precision on test data with new classes with concept drift_l2-aware model %.4f" %prec_drift_l2)
print("Recall on test data with new classes with concept drift_l2-aware model %.4f" %rec_drift_l2)
# Computing intersections of flagged samples and actual new class samples for l2 centroid drift
intersection = np.intersect1d(np.sort(indices_test),np.flatnonzero(mr_test.target > 7))
print(intersection.shape)
print("Precision with mean + 1std threshold is %.4f, recall is %.4f, flagged samples are %d, percentage of samples flagged is %.4f and percentage of flagged samples that actually belong to new families is %.4f" % (prec_drift_l2,rec_drift_l2,len(indices_test),np.double(len(indices_test))/np.double(len(mr_test.data)),np.double(intersection.shape[0])/np.double(np.flatnonzero(mr_test.target > 7).size)))
#Confusion Matrices
plt.figure(figsize=(50,30))
print("Computing confusion matrices...")
cnf_matrix_cv = confusion_matrix(mr_cv.target, y_pred_cv)
cnf_matrix_test = confusion_matrix(mr_test.target,y_pred_test)
cnf_matrix_drift_l2 = confusion_matrix(mr_test.target,y_drift_l2)
print("Plotting confusion matrix for crossvalidation data")
np.set_printoptions(precision=2)
plt.figure()
plot_confusion_matrix(cnf_matrix_cv, classes=mr_cv.target_names,
title='Confusion matrix, without normalization, crossval data')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix_cv, classes=mr_cv.target_names, normalize=True,
title='Normalized confusion matrix, crossval data')
plt.show()
print("Plotting confusion matrix for test data in base model")
np.set_printoptions(precision=2)
plt.figure()
plot_confusion_matrix(cnf_matrix_test, classes=mr_test.target_names,
title='Confusion matrix, without normalization, test data')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix_test, classes=mr_test.target_names, normalize=True,
title='Normalized confusion matrix, test data')
plt.show()
print("Plotting confusion matrix for test data in drift-aware l2 model")
np.set_printoptions(precision=2)
plt.figure()
plot_confusion_matrix(cnf_matrix_drift_l2, classes=mr_test.target_names,
title='Confusion matrix, without normalization, l2 model')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix_drift_l2, classes=mr_test.target_names, normalize=True,
title='Normalized confusion matrix, l2 model')
plt.show()
from sklearn.metrics import confusion_matrix
C = confusion_matrix(mr_test.target_names,cnf_matrix_drift_l2)
# Normalize the confusion matrix
Csum = np.sum(C,1)
C = C / Csum[None,:]
# Print the confusion matrix
print(np.array_str(C, precision=3, suppress_small=True))
plt.imshow(C, interpolation='none')
plt.colorbar()
```
| github_jupyter |
# A Whale off the Port(folio)
---
In this assignment, you'll get to use what you've learned this week to evaluate the performance among various algorithmic, hedge, and mutual fund portfolios and compare them against the S&P 500 Index.
```
# Initial imports
import pandas as pd
import numpy as np
import datetime as dt
from pathlib import Path
%matplotlib inline
```
# Data Cleaning
In this section, you will need to read the CSV files into DataFrames and perform any necessary data cleaning steps. After cleaning, combine all DataFrames into a single DataFrame.
Files:
* `whale_returns.csv`: Contains returns of some famous "whale" investors' portfolios.
* `algo_returns.csv`: Contains returns from the in-house trading algorithms from Harold's company.
* `sp500_history.csv`: Contains historical closing prices of the S&P 500 Index.
## Whale Returns
Read the Whale Portfolio daily returns and clean the data
```
# Reading whale returns
# Count nulls
# Drop nulls
```
## Algorithmic Daily Returns
Read the algorithmic daily returns and clean the data
```
# Reading algorithmic returns
# Count nulls
# Drop nulls
```
## S&P 500 Returns
Read the S&P 500 historic closing prices and create a new daily returns DataFrame from the data.
```
# Reading S&P 500 Closing Prices
# Check Data Types
# Fix Data Types
# Calculate Daily Returns
# Drop nulls
# Rename `Close` Column to be specific to this portfolio.
```
## Combine Whale, Algorithmic, and S&P 500 Returns
```
# Join Whale Returns, Algorithmic Returns, and the S&P 500 Returns into a single DataFrame with columns for each portfolio's returns.
```
---
# Conduct Quantitative Analysis
In this section, you will calculate and visualize performance and risk metrics for the portfolios.
## Performance Anlysis
#### Calculate and Plot the daily returns.
```
# Plot daily returns of all portfolios
```
#### Calculate and Plot cumulative returns.
```
# Calculate cumulative returns of all portfolios
# Plot cumulative returns
```
---
## Risk Analysis
Determine the _risk_ of each portfolio:
1. Create a box plot for each portfolio.
2. Calculate the standard deviation for all portfolios
4. Determine which portfolios are riskier than the S&P 500
5. Calculate the Annualized Standard Deviation
### Create a box plot for each portfolio
```
# Box plot to visually show risk
```
### Calculate Standard Deviations
```
# Calculate the daily standard deviations of all portfolios
```
### Determine which portfolios are riskier than the S&P 500
```
# Calculate the daily standard deviation of S&P 500
# Determine which portfolios are riskier than the S&P 500
```
### Calculate the Annualized Standard Deviation
```
# Calculate the annualized standard deviation (252 trading days)
```
---
## Rolling Statistics
Risk changes over time. Analyze the rolling statistics for Risk and Beta.
1. Calculate and plot the rolling standard deviation for all portfolios using a 21-day window
2. Calculate the correlation between each stock to determine which portfolios may mimick the S&P 500
3. Choose one portfolio, then calculate and plot the 60-day rolling beta between it and the S&P 500
### Calculate and plot rolling `std` for all portfolios with 21-day window
```
# Calculate the rolling standard deviation for all portfolios using a 21-day window
# Plot the rolling standard deviation
```
### Calculate and plot the correlation
```
# Calculate the correlation
# Display de correlation matrix
```
### Calculate and Plot Beta for a chosen portfolio and the S&P 500
```
# Calculate covariance of a single portfolio
# Calculate variance of S&P 500
# Computing beta
# Plot beta trend
```
## Rolling Statistics Challenge: Exponentially Weighted Average
An alternative way to calculate a rolling window is to take the exponentially weighted moving average. This is like a moving window average, but it assigns greater importance to more recent observations. Try calculating the [`ewm`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.ewm.html) with a 21-day half-life.
```
# Use `ewm` to calculate the rolling window
```
---
# Sharpe Ratios
In reality, investment managers and thier institutional investors look at the ratio of return-to-risk, and not just returns alone. After all, if you could invest in one of two portfolios, and each offered the same 10% return, yet one offered lower risk, you'd take that one, right?
### Using the daily returns, calculate and visualize the Sharpe ratios using a bar plot
```
# Annualized Sharpe Ratios
# Visualize the sharpe ratios as a bar plot
```
### Determine whether the algorithmic strategies outperform both the market (S&P 500) and the whales portfolios.
Write your answer here!
---
# Create Custom Portfolio
In this section, you will build your own portfolio of stocks, calculate the returns, and compare the results to the Whale Portfolios and the S&P 500.
1. Choose 3-5 custom stocks with at last 1 year's worth of historic prices and create a DataFrame of the closing prices and dates for each stock.
2. Calculate the weighted returns for the portfolio assuming an equal number of shares for each stock
3. Join your portfolio returns to the DataFrame that contains all of the portfolio returns
4. Re-run the performance and risk analysis with your portfolio to see how it compares to the others
5. Include correlation analysis to determine which stocks (if any) are correlated
## Choose 3-5 custom stocks with at last 1 year's worth of historic prices and create a DataFrame of the closing prices and dates for each stock.
For this demo solution, we fetch data from three companies listes in the S&P 500 index.
* `GOOG` - [Google, LLC](https://en.wikipedia.org/wiki/Google)
* `AAPL` - [Apple Inc.](https://en.wikipedia.org/wiki/Apple_Inc.)
* `COST` - [Costco Wholesale Corporation](https://en.wikipedia.org/wiki/Costco)
```
# Reading data from 1st stock
# Reading data from 2nd stock
# Reading data from 3rd stock
# Combine all stocks in a single DataFrame
# Reset Date index
# Reorganize portfolio data by having a column per symbol
# Calculate daily returns
# Drop NAs
# Display sample data
```
## Calculate the weighted returns for the portfolio assuming an equal number of shares for each stock
```
# Set weights
weights = [1/3, 1/3, 1/3]
# Calculate portfolio return
# Display sample data
```
## Join your portfolio returns to the DataFrame that contains all of the portfolio returns
```
# Join your returns DataFrame to the original returns DataFrame
# Only compare dates where return data exists for all the stocks (drop NaNs)
```
## Re-run the risk analysis with your portfolio to see how it compares to the others
### Calculate the Annualized Standard Deviation
```
# Calculate the annualized `std`
```
### Calculate and plot rolling `std` with 21-day window
```
# Calculate rolling standard deviation
# Plot rolling standard deviation
```
### Calculate and plot the correlation
```
# Calculate and plot the correlation
```
### Calculate and Plot Rolling 60-day Beta for Your Portfolio compared to the S&P 500
```
# Calculate and plot Beta
```
### Using the daily returns, calculate and visualize the Sharpe ratios using a bar plot
```
# Calculate Annualzied Sharpe Ratios
# Visualize the sharpe ratios as a bar plot
```
### How does your portfolio do?
Write your answer here!
| github_jupyter |
# Basics of probability
We'll start by reviewing some basics of probability theory. I will use some simple examples - dice and roullete - to illustrate basic probability concepts. We'll also use these simple examples to build intuition on several properties of probabilities - the law of total probability, independence, conditional probability, and Bayes's rule - that can be generalized, and will be used throughout the course.
# Probability Spaces
To work with probabilites we need to define three things:
1. A sample space, $\Omega$
2. An event space, $\mathcal F$
3. A probability function, $P$
Read more about probability spaces on <a href="https://en.wikipedia.org/wiki/Probability_space"> Wikipedia</a>
## Discrete Sample Space
**Roulette**
A simple example to illustrate the concept or probability spaces is the roullete. Here we'll consider an American Roullete with 38 equally-probably numbers.

- ***Sample Space***:<br>
The sample space is the space of all possible outcomes.
$$\Omega=\{\color{green}{00},\color{green}0,\color{red}1,2,\color{red}3,4,\ldots, \color{red}{36}\}$$
- ***Event Space:***<br>
The event space is the set of all subsets of the sample space:
$$\mathcal F=\left\{
\{\color{green}{00}\},
\{\color{green}{0}\},
\{\color{red}1\},
\{2\},\{\color{red}3\}\ldots,
\{\color{green}{00},\color{green}0\},\ldots,
\{ \color{red}1,\ldots,
\color{red}36\}\right\}$$
- ***Probability:***<br>
For a roullete the probability is defined as $P=1/38$ for each of the 38 possible outcomes in the sample space. Each event also has an associated probability
We note a couple of things. The Sample space and the event space do not uniquely define the probability. For example, we could have a biased roullete (perhaps using a magnet and a metal ball), such that the ball is more likely to fall on particular numbers. In that case, the probability of individual outcomes in the sample space may not be equal. However, as we discusss more below, the total sum of probabilities across the possible outcomes still has to equal 1, unless there is a chance that the ball falls off the roullete table and none of the outcomes is hit.
Note also that outcomes are different from events. A single outcome, e.g. a roullete roll of $\color{green}{00}$ is associated with multiple possible events. It helps to think of an event as a possible bet , and the event space as *the space of all possible bets*. Any bet you make on the roullete can be expressed as a subset of $\mathcal F$, and has a probability associated with it.
For example, consider a bet on a single number (e.g. on $\color{red}7$), also called a straight-up bet. This event is equivalent to the outcome of the roullete being in the set $E_1=\{\color{red}1\}$. The probability of this event is $P(E_1)$=1/38.

Alternatively consider a bet on red. This event is equivalent to the outcome being in $E_2=\left\{\color{red}{1},\color{red}{2},\color{red}{3},\ldots,\color{red}{36}\right\}$, and its probability is $P(E_2)=18/38$.

*Note*: Formally, the event space is a $\sigma$-algebra, and the probability function is a measure.
## Infinite Sample Spaces
Why do we need to go through these definitions of event spaces and sample spaces? For probability spaces with a finite number of possibl outcomes we can assign a probability to each outcome and it becomes trivial to compute the probability of events. However, that is no longer the case when we start working with infinite sample spaces, such as an interval on the real line. For example, if the sample space of a random process is the interval $\Omega=[0,1]\in \mathbb R$, there are an infinite number of possible outcomes, and thus not all of them can have finite (non-zero) probability. In that case, we can only assign finite probabilities to sub-intervals, or subsets of the sample space. In other words, *in the most general case we can only assign finite probabilities to member of the event space $\mathcal E$*. However, the same rules of probabilites apply for both infinite and finite samples spaces, and it is easier to get an intuition for them on small, finite spaces.
For purposes of this class, we don't need to worry about probability spaces, event spaces, and probability functions. However, simple examples such as these are useful in illustrating some very general properties of probabilities that we *will* use extensively in the class, especially in the chapters on statistical inference and Bayesian data analysis.
<hr style="border:1px solid black
"> </hr>
# Calculus of Probabilities
## Combining probabilities
The probability of roullete bets illustrates a general rule about combining probabilities. How do we compute the probability of an event? Consider two friends Alice and Bob, betting on the roullete, and say we want to compute the probability that at least one of them wins. We'll call this event $E$.
First, let's say each of them bets one of the green zeros. Rolling a green zero is equivalent to rolling either $\color{green}0$ OR $\color{green}{00}$. The two friends going home with some money is associated with the subset $E=\{\color{green}0,\color{green}{00}\}$of the event space. If we allso associate Alice winning with event $A$ with rolling $\color{green}{00}$ and Bob winning event $B$ with rolling $\color{green}{00}$, we can write:
$$P(E)=P(A \text{ OR } B)\equiv P(A \lor B)$$
Notice that
- $\{\color{green}{00,0}\}$=$\{\color{green}{00}\}\cup\{\color{green}{0}\}$
- $\{\color{green}{00}\}\cap\{\color{green}{0}\}=0$
- $P(\{\color{green}{00}\}\cup\{\color{green}{0}\})=P(\{\color{green}{00}\})+P(\{\color{green}{0}\})$
On the other hand, consider a case where Alice bets on all the numbers between $1-6$, with win probability $P(A)=6/38$ and the Bob bets on his favourite numbers, $3$ and $33$, with win probability $P(B)=2/38$ Them winning something is associated with $E=\{1,2,3,4,5,6,33\}$, with $P(E)=7/38$. Notice that in thise $P(E)\neq P(A)+P(B)$
```{important}
Thus, the general rule of combining probabilities is:
$$P(A \text{ OR } B)=P(A \cup B)=P(A)+P(B)-P(A\cap B)$$
with
$$P(A \text{ OR } B)=P(A \cup B)=P(A)+P(B)\text{, if } P(A\cap B)=\phi$$
```
## Valid Probability Functions
In order for a function on the event space to be a valid probability function, it neeeds to obey the following properties
```{important}
- $P:\Omega \rightarrow [0,1]$
- $P(\phi)=0$, where $\phi$ is the null-set
- $P(\Omega)=1$
- If $E_1$ and and $E_2$ are mutually exclusive events (i.e. $E_1 \cap E_2=\phi$), then the probability of $E_1$ OR $E_2$ occuring is
$$P(E_1 \text{ OR } E_2)=P(E_1\cup E_2)=P(E_1)+P(E_2)$$
```
## Joint Probabilities
The joint probability of two events is the probability of both being true simultaneously. Consider the probability of both Alice AND Bob winning. We would denote this as
$$P(A\text{ AND }B)\equiv P(A\land B)\equiv P(A,B)$$
The latter notation is the one we will be using a lot throughout the course. If each of them bets on one of the zeros, and there is thus no overlap between their bets, the probability of both winning is zero. In the second case, where Alice bets on $1$ through $6$ and Bob bets on $3$ and $33$, the probability of both of them winning is the probability of rolling a $3$, whith the intersection of the two events. This is a general rule of probability calculus:
```{imporatant}
The joint probability of two events is the probability of their intersection:
- $P(A,B)=P(A\cap B)$
- $P(A,B)=0 \text{ if } A\cap B=\phi$, and we would say that $A$ and $B$ are mutually exclusive
```
<hr style="border:1px solid black
"> </hr>
# Conditional Probabilities & Independence
Here we'll review some definitions and properties of conditional probabilities and independence that we will use throughout the course. This is more easily done when we have two random processes occuring simultaneously. So we will consider the roll of two independent and *fair* dice.
The sample space, $\Omega$ is illustrated by the following table:

The event space is the set of all subsets of $\Omega$ and the probability function for a fair dice is a constant functoin $P=1/36$.
For example the *event* $E$="a total roll of 3" is the intersection of two different outcome "red dice rolls 1 and greeen dice rolls 2" is different from "red dice rolls 2 and green dice rolls 1", i.e. $\{\color{red}1,\color{green}2\} ,\{\color{green}2,\color{red}1\}$ The probability of rolling a 3 is thus $P(\{\color{red}1,\color{green}2\})+P(\{\color{green}1,\color{red}2)\}=2/36$.
We can also define events applicable to a single dice. For example, "the red dice rolled a 1". The probability of the red dice rolling a 1 is 1/6, and it can also be written as the union of all the six outcomes in which the red dice rolls 1.
## Independent Events
The role of one dice should not affect the role of the other. The two dice are ***independent***.
Example: what is the probability of rolling a <span style="color:blue">⚅</span> <span style="color:red">⚅</span> is 1/36. It is also the probability of rolling both a <span style="color:blue">⚅</span> and a <span style="color:red">⚅</span> at the same time. The probability for each dice 1/6, so their combined probability is
$P($<span style="color:blue">⚅</span> <span style="color:red">⚅</span>$)=P($<span style="color:blue">⚅</span>$)P($<span style="color:red">⚅</span>$)$
```{important}
<b>Definition</b>: Two events are independent iff:
$$P(A \text{ AND } B)=P(A,B)=P(A)P(B)$$
```
Fun sidenote: although it's harder, we can define independent events for a single dice! Consider the two events:
- A: "Green dice rolled even" with probability $P(A)=1/2$
- B: "Green dice rolled less than three", with probability $P(B)=1/3$<br>
The joint probability of both events happening is the probability of the dice rolling a 2, so it is $P(A,B)=1/6=P(A)P(B)$
## Conditional Probability
Consider the previous example, with two independent events. How can two events on the same dice be independent? It's easier to think through this process sequentially, or *conditionally*. Think of the probability of both "rolling even" and "rolling less than three" as "the probability of rolling even" and, subsequently, also "rolling less than three". The truth values of those statemetns do not change if you look at them one at a time.
If you roll even, the probability of rolling less than 3 is 1/3, i.e. the probability of rolling a 2.
If you roll odd, the probability of rolling <3 is still 1/3, i.e. the probability of rolling a 1.
So whether you roll odd or even does not impact the P of rolling less than three. Thus, the two events are independent.
This notion of whether the realization of one event affects the probability of another event is quantified using conditoinal probabilities.
***Notation***: $P(A|B)$=The conditional probability of event $A$ being true **given** that event $B$ is true.
Examples: What is the probability of the event "A" ="rolling a combined 10"? It is the probability of the events consisting of {{<span style="color:blue">⚃</span> <span style="color:red">⚅</span>},{<span style="color:blue">⚄</span> <span style="color:red">⚄</span>},{<span style="color:blue">⚅</span> <span style="color:red">⚃</span>}} and it is 3/36. Now, what is the probability of rolling a combined 10, **given** that the red dice rolled a 4. Well, it is the probability of the green dice rolling a 6, which is 1/6.
- $P("10")=3/36$
- $P("10"|$<span style="color:red">⚃</span>$)=1/6$
Let's use our sequential thinking to come up with a very useful properties of conditional probabilities. Consider the joint event of "A"="rolling a combined "10" and "B" the red dice rolling 4.
The probabiliy of both being true is equal to 1/36. But you can think of it as the probability of rolling a 4 with the red dice (P(B)=1/6), and then rolling a "10" given that the red dice rolled 4 P(A|B)=1/6).
```{important}
<b>Definition</b>: The following relationships hold between joint and conditional probabilities:
$$P(A,B)=P(A|B)P(B)$$
$$P(A|B)=\frac{P(A,B)}{P(B)}$$
```
## Bayes Rule
The above relation between conditional probabilities and joint probabilities leads us to one of the most useful formulas in statistics: Bayes' Rule.
Notice that we can write $P(A,B)$ as either $P(A|B)P(B)$ or $P(B|A)P(A)$. We can manipulate this relation to understand how the relation between the conditional probability of A given B and the conditional probability of B given A
$$P(A,B)=P(A|B)P(B)=P(B|A)P(A)$$
```{important}
**Bayes' Rule**:
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$
```
## Law of Total probability
```{important}
The law of total probability says that if we have a partition of the sample space, $A_n$ such that $A_i\cap A_j=\phi$ if $i\neq j$. and $\cap_{n} A_n = \Omega$, then
$$P(E)=\sum_n P(E|A_n)P(A_n)$$
```
This should be intuitive with the fair dice example. For example, let $E$ be the event 'A total roll $D=6$ was rolled'. A partition $A_n$ could be 'the dice $X$ rolled n' for $n$ between 1 and 6. Thus, the total probability of $D=6$ is the sum of the probability of rolling a seven given that $X$ rolled 1, plus the probability of rolling a seven given that $X$ rolled a 2, and so on....
<hr style="border:1px solid black
"> </hr>
# Random variables
***Definition***: A random variable is a real-valued function whose whose values depend on outcomes of a random phenomenon.**
$$X:\Omega \rightarrow \mathbb R$$
Consider the case of a single fair dice, with possible values, i.e. sample space:
$$\Omega=\{1,2,3,4,5,6\}$$
We can define a random variable $X$ whose value is equal to the dice roll. This random variable could take ***discrete*** values between 1 and 6.
$$X:\{1,2,3,4,5,6\} \rightarrow \{1,2,3,4,5,6\} $$
If the dice is fair, than the probability of X taking each value is the same, and equal to 1/6. We would call this a discrete uniform random variable.
At this point it may seem like I'm inventing new terminology. For example, why do we need to call $X$ a random variable, and talk about the possibility that it takes on different values? It seems like the probability of X taking on each value is just the probability of each event in $\Omega$?
Here is another example of a random variable on the same sample space: $Z$ is a random variable which takes the value $Z=0$ if the dice roll is odd and $Z=1$ if the dice roll is even. Thus, even though $X$ and $Z$ are associated with the same sample space and events, they take on different values. In this case, since $Z$ takes on only two values, 0 and 1 $Z$ would be called a Bernoulli random variable.
$$Z:\{1,2,3,4,5,6\} \rightarrow \{1,2\} $$
| github_jupyter |
```
# A simple example of an animated plot
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
fig, ax = plt.subplots()
# Initial plot
x = np.arange(0., 10., 0.2)
y = np.arange(0., 10., 0.2)
line, = ax.plot(x, y)
plt.rcParams["figure.figsize"] = (10,8)
plt.ylabel("Price")
plt.xlabel("Size (sq.ft)")
plt.plot([1, 1.2, 3], [3, 3.5, 4.7], 'go', label='Training data')
#ax.plot(test_house_size, test_house_price, 'mo', label='Testing data')
def animate(i):
print(i)
x = np.arange(0., 6, 0.05)
line.set_xdata(x) # update the data
line.set_ydata( x ** (1 + (i/10.0))) # update the data
return line,
# Init only required for blitting to give a clean slate.
def init():
line.set_ydata(y)
return line,
ani = animation.FuncAnimation(fig, animate, frames=np.arange(1, 10), init_func=init, interval=1000, blit=True)
plt.show()
```
#1. Carregar imagem
Nas próximas seções, iremos aprender como carregar imagens de duas fontes distintas para exibí-las através de nosso código: (a) Internet e (b) diretório de seu próprio google drive. Também, veremos qual vantagem cada uma das formas de aquisição.
## 1.1 URLs
A vantagem de carregarmos imagens diretamente de *urls* é que ela não precisamos nos preocupar com a aquisição ou armazenamento dela de forma direta. Ou seja, podemos acessá-la e exibí-la diretamente através de seu *link*. Será mostrado duas formas de acessá-las e exibí-las logo a seguir
### 1.1.1 OpenCV + matplot + urllib
```
#Importação das bibliotecas que iremos utilizar
import cv2
import numpy as np
import urllib
import matplotlib.pyplot as plt
I = url_to_image("https://live.staticflickr.com/65535/48055207731_98367225e3_m.jpg")
# se conseguiu carregar a imagem
if(I is not None):
# exibe a imagem
plt.show()
def url_to_image(url):
# Abre a url para acessar o dado
resp = urllib.request.urlopen(url)
# conversão da imagem para array de bytes do tamanho de inteiros de 8 bits
image_array = np.asarray(bytearray(resp.read()), dtype="uint8")
# conversão do array para imagem
image = cv2.imdecode(image_array, cv2.IMREAD_COLOR)
# verifica se a imagem possui 3 dimensões: altura, largura e número de canais
if (len(image.shape)==3):
# remove os informações dos eixos de coordenadas
plt.axis("off")
# converte a imagem de bgr para rgb
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# adiciona a imagem no plot
plt.imshow(image_rgb)
# retorna
return image_rgb
# caso não possua as 3 informações, então ou o link é inválido ou o dado
# não é imagem
else:
print('Erro to load image !!')
return None
```
### 1.1.2 Pil.Image + comandos Linux
```
import PIL.Image
def show_results(content_path, max_dim):
#plt.figure(figsize=(10, 5))
content = img = PIL.Image.open(content_path)
long = max(img.size)
scale = max_dim/long
img = img.resize((round(img.size[0]*scale), round(img.size[1]*scale)), PIL.Image.ANTIALIAS)
#plt.subplot(1, 2, 1)
plt.imshow(img)
!wget --quiet -P /tmp/nst/ https://live.staticflickr.com/65535/48055207731_98367225e3_m.jpg
show_results("/tmp/nst/48055207731_98367225e3_m.jpg", 256)
```
## 1.2 Arquivos no gdrive
A vantagem de carregarmos imagens diretamente do gdrive pessoal é que não precisamos nos preocupar com o fato da página estar acessível ou não. No entanto, é necessário seguir os seguintes passos:
- executar o código
- clicar no *link* que aparecer
- dar autorização
- copiar o código gerado e
- colar na barra que apareceu colab
É importante informar que outras pessoas não terão acesso as imagens dessa forma, mesmo que você torne as imagens públicas.
```
from google.colab import drive
drive.mount('/content/gdrive')
```
### 1.2.1 Usando OpenCV + Matplotlib
```
import cv2
import matplotlib.pyplot as plt
# carrega a imagem
bgr_img = cv2.imread('/content/gdrive/My Drive/Colab Notebooks/docencia/MLP/figuras/decisao_linear.png')
plt.axis("off")
# adiciona a imagem no plot e exibe
plt.imshow(cv2.cvtColor(bgr_img, cv2.COLOR_BGR2RGB))
plt.show()
```
### 1.2.2 Usando Ipython.display
```
from IPython.display import Image
# carrega, adiciona no display e exibe
Image(filename="/content/gdrive/My Drive/Colab Notebooks/docencia/MLP/figuras/decisao_linear.png")
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation, rc
from IPython.display import HTML
fig, ax = plt.subplots()
ax.set_xlim(( 0, 2))
ax.set_ylim((-2, 2))
line, = ax.plot([], [], lw=2)
def init():
line.set_data([], [])
return (line,)
def animate(i):
x = np.linspace(0, 2, 1000)
y = np.sin(2 * np.pi * (x - 0.01 * i))
line.set_data(x, y)
return (line,)
anim = animation.FuncAnimation(fig, animate, init_func=init,
frames=100, interval=20,
blit=True)
#plt.show()
#rc('animation', html='jshtml')
HTML(anim.to_jshtml())
#anim
```
#2. Matplotlib
Essa seção fornece algumas dicas básicas para utilização da biblioteca matplotlib, principal biblioteca utilizada para exibição de imagens e gráficos no python
```
# Testei ams não funcionou. Não apareceu UI
!jupyter nbextension install https://bitbucket.org/ipre/calico/downloads/calico-document-tools-1.0.zip
!jupyter nbextension enable calico-document-tools
#%matplotlib inline
#from IPython.core.magics.display import Javascript
#Javascript(""""load_extensions": {"calico-spell-check":true,
# "calico-document-tools":true,
# "calico-cell-tools":true""")
#%#javascript
#IPython.notebook.config.update({
# "load_extensions": {"calico-spell-check":true,
# "calico-document-tools":true,
# "calico-cell-tools":true
# }
#})
# Testei ams não funcionou. Não apareceu UI
# https://github.com/takluyver/cite2c
# https://pypi.org/project/cite2c/
#!pip install cite2c
#!python -m cite2c.install
!sudo apt-get install texlive-latex-extra
!sudo apt-get install texlive-bibtex-extra
```
AAAAAAAAAAAAAA <cite data-cite="PER-GRA:2007">(Granger, 2013)</cite>
<figure>
<a href="https://www.fullstackpython.com/img/logos/markdown.png">
<img src="https://www.fullstackpython.com/img/logos/markdown.png" alt="You can use Markdown to add images to Jupyter Notebook files, such as this image of the Markdown logo. Source: Full Stack Python."></a>
<figcaption> You can use Markdown to add images to Jupyter Notebook files, such as this image of the Markdown logo. Source: Full Stack Python.
</figcaption>
</figure>
@article{PER-GRA:2007,
Author = {P\'erez, Fernando and Granger, Brian E.},
Title = {{IP}ython: a System for Interactive Scientific Computing},
Journal = {Computing in Science and Engineering},
Volume = {9},
Number = {3},
Pages = {21--29},
month = may,
year = 2007,
url = "http://ipython.org",
ISSN = "1521-9615",
doi = {10.1109/MCSE.2007.53},
publisher = {IEEE Computer Society},
}
Referências citation <a name="ref-1"/>[(Pérez and Granger, 2007)](#cite-PER-GRA:2007)
[1] https://www.datacamp.com/community/tutorials/matplotlib-tutorial-python#anatomy
<cite data-cite="granger2013">(Granger, 2013)</cite>
<strong data-cite="granger2013">(Granger, 2013)</strong>
```
# nbconvert funcionou. No entanto, os outros comandos não
%%bash
ls
jupyter nbconvert aula_utils.ipynb --to latex
#python latex aula_utils.tex
#!python bibtex aula_utils.aux
#!python pdflatex aula_utils.tex
#!python pdflatex aula_utils.tex
pdflatex aula_utils.tex
%%bash
# mudar para o diretório onde está o notebook que será convertido
%cd "/content/drive/My Drive/Colab Experimental/mltutorial/"
ipython nbconvert mynotebook.ipynb --to latex --template citations.tplx
latex mynotebook.tex
bibtex mynotebook.aux
pdflatex mynotebook.tex
pdflatex mynotebook.tex
pdflatex mynotebook.tex
#!pip install cite2c
#!python3 -m cite2c.install
```
<!--bibtex
@Article{PER-GRA:2007,
Author = {P\'erez, Fernando and Granger, Brian E.},
Title = {{IP}ython: a System for Interactive Scientific Computing},
Journal = {Computing in Science and Engineering},
Volume = {9},
Number = {3},
Pages = {21--29},
month = may,
year = 2007,
url = "http://ipython.org",
ISSN = "1521-9615",
doi = {10.1109/MCSE.2007.53},
publisher = {IEEE Computer Society},
}
-->
```
# NÃO FINCIONOU - não carrega o arquivo com o comando load
# - o colab abre arquivos somente como leitura. Não dá para editar
# - tentei gambi para editar o conf.py, deu
# - tentei gambi para jogar o notebook na pasta source do projeto sphinx e encontrei 2 problemas:
# - 1: tudo copiado para a pasta Files é deletado quando você sai
# - 2:
# https://sphinxcontrib-bibtex.readthedocs.io/en/latest/quickstart.html#overview
#!pip install sphinxcontrib-bibtex
#!sphinx-quickstart
#!cd /content/docs/source/
#%load conf.py
#%pycat code.py
#!rm code.py
#%%writefile conf.py
# -*- coding: utf-8 -*-
#
# Configuration file for the Sphinx documentation builder.
#
# This file does only contain a selection of the most common options. For a
# full list see the documentation:
# http://www.sphinx-doc.org/en/master/config
# -- Path setup --------------------------------------------------------------
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
sys.path.insert(0, os.path.abspath('../..'))
sys.setrecursionlimit(1500)
# -- Project information -----------------------------------------------------
project = u'teste_sphinxlib'
copyright = u'2019, Thales'
author = u'Thales'
# The short X.Y version
version = u''
# The full version, including alpha/beta/rc tags
release = u'0.0.1'
# -- General configuration ---------------------------------------------------
# If your documentation needs a minimal Sphinx version, state it here.
#
# needs_sphinx = '1.0'
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.ifconfig',
'sphinx.ext.viewcode',
'sphinx.ext.githubpages',
'sphinxcontrib.bibtex',
]
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
# The suffix(es) of source filenames.
# You can specify multiple suffix as a list of string:
#
# source_suffix = ['.rst', '.md']
source_suffix = '.rst'
# The master toctree document.
master_doc = 'index'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
#
# This is also used if you do content translation via gettext catalogs.
# Usually you set "language" from the command line for these cases.
language = None
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
exclude_patterns = []
# The name of the Pygments (syntax highlighting) style to use.
pygments_style = None
# -- Options for HTML output -------------------------------------------------
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
html_theme = 'alabaster'
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
# documentation.
#
# html_theme_options = {}
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
html_static_path = ['_static']
# Custom sidebar templates, must be a dictionary that maps document names
# to template names.
#
# The default sidebars (for documents that don't match any pattern) are
# defined by theme itself. Builtin themes are using these templates by
# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
# 'searchbox.html']``.
#
# html_sidebars = {}
# -- Options for HTMLHelp output ---------------------------------------------
# Output file base name for HTML help builder.
htmlhelp_basename = 'teste_sphinxlibdoc'
# -- Options for LaTeX output ------------------------------------------------
latex_elements = {
# The paper size ('letterpaper' or 'a4paper').
#
# 'papersize': 'letterpaper',
# The font size ('10pt', '11pt' or '12pt').
#
# 'pointsize': '10pt',
# Additional stuff for the LaTeX preamble.
#
# 'preamble': '',
# Latex figure (float) alignment
#
# 'figure_align': 'htbp',
}
# Grouping the document tree into LaTeX files. List of tuples
# (source start file, target name, title,
# author, documentclass [howto, manual, or own class]).
latex_documents = [
(master_doc, 'teste_sphinxlib.tex', u'teste\\_sphinxlib Documentation',
u'Thales', 'manual'),
]
# -- Options for manual page output ------------------------------------------
# One entry per manual page. List of tuples
# (source start file, name, description, authors, manual section).
man_pages = [
(master_doc, 'teste_sphinxlib', u'teste_sphinxlib Documentation',
[author], 1)
]
# -- Options for Texinfo output ----------------------------------------------
# Grouping the document tree into Texinfo files. List of tuples
# (source start file, target name, title, author,
# dir menu entry, description, category)
texinfo_documents = [
(master_doc, 'teste_sphinxlib', u'teste_sphinxlib Documentation',
author, 'teste_sphinxlib', 'One line description of project.',
'Miscellaneous'),
]
# -- Options for Epub output -------------------------------------------------
# Bibliographic Dublin Core info.
epub_title = project
# The unique identifier of the text. This can be a ISBN number
# or the project homepage.
#
# epub_identifier = ''
# A unique identification for the text.
#
# epub_uid = ''
# A list of files that should not be packed into the epub file.
epub_exclude_files = ['search.html']
# -- Extension configuration -------------------------------------------------
```
See :cite:`1987:nelson` for an introduction to non-standard analysis.
.. bibliography:: refs.bib
:cited:
Here is a link :func:`time.time`.
.,,.
,;;*;;;;,
.-'``;-');;.
/' .-. /*;;
.' \d \;; .;;;,
/ o ` \; ,__. ,;*;;;*;,
\__, _.__,' \_.-') __)--.;;;;;*;;;;,
`""`;;;\ /-')_) __) `\' ';;;;;;
;*;;; -') `)_) |\ | ;;;;*;
;;;;| `---` O | | ;;*;;;
*;*;\| O / ;;;;;*
;;;;;/| .-------\ / ;*;;;;;
;;;*;/ \ | '. (`. ;;;*;;;
;;;;;'. ; | ) \ | ;;;;;;
,;*;;;;\/ |. / /` | ';;;*;
;;;;;;/ |/ / /__/ ';;;
'*jgs/ | / | ;*;
`""""` `""""` ;'
```
%cd source
```
%load conf.py
```
%load conf.py
# acessar google drive
from os.path import join
from google.colab import drive
ROOT = "/content/drive"
drive.mount(ROOT)
# criar um diretório para seus projetos
PROJ = "My Drive/Colab Experimental/Workspace" # This is a custom path.
PROJECT_PATH = join(ROOT, PROJ)
!mkdir "{PROJECT_PATH}"
# Iniciar o git no diretório
!git init "{PROJECT_PATH}"
#%%bash
%cd "/content/drive/My Drive/Colab Experimental/Workspace/"
!ls
!git clone git://github.com/schlaicha/jupyter-publication-scripts.git jupyter-publication-scripts
%cd jupyter-publication-scripts
!ls
%cd "/content/drive/My Drive/Colab Experimental/Workspace/jupyter-publication-scripts/"
!ls
!python setup.py install
!python -m jupyterpublicationscripts
#Change IPython/Jupyter notebook working directory
# default : /root/.local/share/jupyter
%%bash
jupyter -h
\(ax^2 + \sqrt{bx} + c = 0 \)
```
---
---
```
#How to use MathJax
# centered:
```
1. $$ x = {-b \pm \sqrt{b^2-4ac} \over 2a} $$
2. \\[ x = {-b \pm \sqrt{b^2-4ac} \over 2a} \\]
3. $$\begin{vmatrix}a & b\\
c & d
## \end{vmatrix}=ad-bc$$
```
# Inline:
```
1. \\( ax^2 + \sqrt{bx} + c = 0 \\)
<p align="center">
<b>Some Links:</b><br>
<a href="#">Link 1</a> |
<a href="#">Link 2</a> |
<a href="#">Link 3</a>
<br><br>
<img src="http://s.4cdn.org/image/title/105.gif">
</p>
#Como referenciar outro notebook contido no drive
[Aula CNN](1pbbIqPmZiLoFKDYvmZiF4tHNspTmLi42#scrollTo=tfgzKfNFgxmB)
# Como criar hiperlink
[link](http://example.com "Title").
Some text with [a link][1] and
another [link][2].
[1]: http://example.com/ "Title"
[2]: http://example.org/ "Title"

![Alt2][3]
[3]: https://segredosdomundo.r7.com/wp-content/uploads/2017/09/7-41.jpg "EXAMPLE2"
Linked logo: 
(http://wordpress.com/ "Title")
- [x] Write the press release
- [ ] Update the website
- [ ] Contact the media
| github_jupyter |
##### Copyright 2020 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# TensorFlow Addons 画像 : 操作
<table class="tfo-notebook-buttons" align="left">
<td><a target="_blank" href="https://www.tensorflow.org/addons/tutorials/image_ops"><img src="https://www.tensorflow.org/images/tf_logo_32px.png"> TensorFlow.orgで表示</a></td>
<td><a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ja/addons/tutorials/image_ops.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png"> Google Colab で実行</a></td>
<td><a target="_blank" href="https://github.com/tensorflow/docs-l10n/blob/master/site/ja/addons/tutorials/image_ops.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png">GitHub でソースを表示{</a></td>
<td><a href="https://storage.googleapis.com/tensorflow_docs/docs-l10n/site/ja/addons/tutorials/image_ops.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png">ノートブックをダウンロード/a0}</a></td>
</table>
## 概要
このノートブックでは、TensorFlow Addons で画像操作を使用する方法をいくつか紹介します。
この例では、以下の画像操作について説明します。
- `tfa.image.mean_filter2d`
- `tfa.image.rotate`
- `tfa.image.transform`
- `tfa.image.random_hsv_in_yiq`
- `tfa.image.adjust_hsv_in_yiq`
- `tfa.image.dense_image_warp`
- `tfa.image.euclidean_dist_transform`
# セットアップ
```
!pip install -U tensorflow-addons
import tensorflow as tf
import numpy as np
import tensorflow_addons as tfa
import matplotlib.pyplot as plt
```
# 画像を準備して検査する
## 画像をダウンロードする
```
img_path = tf.keras.utils.get_file('tensorflow.png','https://tensorflow.org/images/tf_logo.png')
```
## 画像を検査する
### TensorFlow のアイコン
```
img_raw = tf.io.read_file(img_path)
img = tf.io.decode_image(img_raw)
img = tf.image.convert_image_dtype(img, tf.float32)
img = tf.image.resize(img, [500,500])
plt.title("TensorFlow Logo with shape {}".format(img.shape))
_ = plt.imshow(img)
```
### 白黒バージョンを作成する
```
bw_img = 1.0 - tf.image.rgb_to_grayscale(img)
plt.title("Mask image with shape {}".format(bw_img.shape))
_ = plt.imshow(bw_img[...,0], cmap='gray')
```
# tfa.image を使って遊ぶ
## 平均フィルタリング
平均フィルタリングはフィルタリング技術の 1 つで、画像や信号のノイズ除去によく使用されます。この考え方は、画像をピクセル単位で処理し、隣接するピクセルの平均値で置き換えるというものです。
```
mean = tfa.image.mean_filter2d(img, filter_shape=11)
_ = plt.imshow(mean)
```
## 回転
この操作は、特定の画像をユーザーが入力した角度(ラジアン単位)に回転させます。
```
rotate = tfa.image.rotate(img, tf.constant(np.pi/8))
_ = plt.imshow(rotate)
```
## 変換
この操作は、特定の画像をユーザーが指定した変換ベクトルに基づいて変換します。
```
transform = tfa.image.transform(img, [1.0, 1.0, -250, 0.0, 1.0, 0.0, 0.0, 0.0])
_ = plt.imshow(transform)
```
## YIQ でランダムに HSV 変換する
この操作は、特定の RGB 画像のカラースケールを YIQ に変更しますが、ここではデルタ色相と彩度の値を指定された範囲からランダムに選択します。
```
delta = 0.5
lower_saturation = 0.1
upper_saturation = 0.9
lower_value = 0.2
upper_value = 0.8
rand_hsvinyiq = tfa.image.random_hsv_in_yiq(img, delta, lower_saturation, upper_saturation, lower_value, upper_value)
_ = plt.imshow(rand_hsvinyiq)
```
## YIQ で HSV を調整する
この操作は、特定の RGB 画像のカラースケールを YIQ に変更しますが、ここではランダムに選択するのではなく、デルタ色相と彩度の値はユーザーの入力値です。
```
delta = 0.5
saturation = 0.3
value = 0.6
adj_hsvinyiq = tfa.image.adjust_hsv_in_yiq(img, delta, saturation, value)
_ = plt.imshow(adj_hsvinyiq)
```
## 高密度画像ワープ
この操作は、オフセットベクトルのフローフィールドで指定された任意の画像の非線形ワープを行います(例えば、ここではランダムな値を使用します)。
```
input_img = tf.image.convert_image_dtype(tf.expand_dims(img, 0), tf.dtypes.float32)
flow_shape = [1, input_img.shape[1], input_img.shape[2], 2]
init_flows = np.float32(np.random.normal(size=flow_shape) * 2.0)
dense_img_warp = tfa.image.dense_image_warp(input_img, init_flows)
dense_img_warp = tf.squeeze(dense_img_warp, 0)
_ = plt.imshow(dense_img_warp)
```
## ユークリッド距離変換
この操作は、前景ピクセルから背景ピクセルまでのピクセル値をユークリッド距離で更新します。
- 注意: これは二値化画像のみを受け取り、結果は変換された画像になります。異なる画像を指定した場合は、結果は単一の値の画像になります。
```
gray = tf.image.convert_image_dtype(bw_img,tf.uint8)
# The op expects a batch of images, so add a batch dimension
gray = tf.expand_dims(gray, 0)
eucid = tfa.image.euclidean_dist_transform(gray)
eucid = tf.squeeze(eucid, (0, -1))
_ = plt.imshow(eucid, cmap='gray')
```
| github_jupyter |
# Logistic Regression with a Neural Network mindset
Welcome to your first (required) programming assignment! You will build a logistic regression classifier to recognize cats. This assignment will step you through how to do this with a Neural Network mindset, and so will also hone your intuitions about deep learning.
**Instructions:**
- Do not use loops (for/while) in your code, unless the instructions explicitly ask you to do so.
**You will learn to:**
- Build the general architecture of a learning algorithm, including:
- Initializing parameters
- Calculating the cost function and its gradient
- Using an optimization algorithm (gradient descent)
- Gather all three functions above into a main model function, in the right order.
## 1 - Packages ##
First, let's run the cell below to import all the packages that you will need during this assignment.
- [numpy](https://www.numpy.org/) is the fundamental package for scientific computing with Python.
- [h5py](http://www.h5py.org) is a common package to interact with a dataset that is stored on an H5 file.
- [matplotlib](http://matplotlib.org) is a famous library to plot graphs in Python.
- [PIL](http://www.pythonware.com/products/pil/) and [scipy](https://www.scipy.org/) are used here to test your model with your own picture at the end.
```
import numpy as np
import matplotlib.pyplot as plt
import h5py
import scipy
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset
%matplotlib inline
```
## 2 - Overview of the Problem set ##
**Problem Statement**: You are given a dataset ("data.h5") containing:
- a training set of m_train images labeled as cat (y=1) or non-cat (y=0)
- a test set of m_test images labeled as cat or non-cat
- each image is of shape (num_px, num_px, 3) where 3 is for the 3 channels (RGB). Thus, each image is square (height = num_px) and (width = num_px).
You will build a simple image-recognition algorithm that can correctly classify pictures as cat or non-cat.
Let's get more familiar with the dataset. Load the data by running the following code.
```
# Loading the data (cat/non-cat)
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
```
We added "_orig" at the end of image datasets (train and test) because we are going to preprocess them. After preprocessing, we will end up with train_set_x and test_set_x (the labels train_set_y and test_set_y don't need any preprocessing).
Each line of your train_set_x_orig and test_set_x_orig is an array representing an image. You can visualize an example by running the following code. Feel free also to change the `index` value and re-run to see other images.
```
# Example of a picture
index = 25
plt.imshow(train_set_x_orig[index])
print ("y = " + str(train_set_y[:, index]) + ", it's a '" + classes[np.squeeze(train_set_y[:, index])].decode("utf-8") + "' picture.")
```
Many software bugs in deep learning come from having matrix/vector dimensions that don't fit. If you can keep your matrix/vector dimensions straight you will go a long way toward eliminating many bugs.
**Exercise:** Find the values for:
- m_train (number of training examples)
- m_test (number of test examples)
- num_px (= height = width of a training image)
Remember that `train_set_x_orig` is a numpy-array of shape (m_train, num_px, num_px, 3). For instance, you can access `m_train` by writing `train_set_x_orig.shape[0]`.
```
### START CODE HERE ### (≈ 3 lines of code)
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
### END CODE HERE ###
print ("Number of training examples: m_train = " + str(m_train))
print ("Number of testing examples: m_test = " + str(m_test))
print ("Height/Width of each image: num_px = " + str(num_px))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_set_x shape: " + str(train_set_x_orig.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x shape: " + str(test_set_x_orig.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
```
**Expected Output for m_train, m_test and num_px**:
<table style="width:15%">
<tr>
<td>**m_train**</td>
<td> 209 </td>
</tr>
<tr>
<td>**m_test**</td>
<td> 50 </td>
</tr>
<tr>
<td>**num_px**</td>
<td> 64 </td>
</tr>
</table>
For convenience, you should now reshape images of shape (num_px, num_px, 3) in a numpy-array of shape (num_px $*$ num_px $*$ 3, 1). After this, our training (and test) dataset is a numpy-array where each column represents a flattened image. There should be m_train (respectively m_test) columns.
**Exercise:** Reshape the training and test data sets so that images of size (num_px, num_px, 3) are flattened into single vectors of shape (num\_px $*$ num\_px $*$ 3, 1).
A trick when you want to flatten a matrix X of shape (a,b,c,d) to a matrix X_flatten of shape (b$*$c$*$d, a) is to use:
```python
X_flatten = X.reshape(X.shape[0], -1).T # X.T is the transpose of X
```
```
# Reshape the training and test examples
### START CODE HERE ### (≈ 2 lines of code)
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
### END CODE HERE ###
print ("train_set_x_flatten shape: " + str(train_set_x_flatten.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x_flatten shape: " + str(test_set_x_flatten.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
print ("sanity check after reshaping: " + str(train_set_x_flatten[0:5,0]))
```
**Expected Output**:
<table style="width:35%">
<tr>
<td>**train_set_x_flatten shape**</td>
<td> (12288, 209)</td>
</tr>
<tr>
<td>**train_set_y shape**</td>
<td>(1, 209)</td>
</tr>
<tr>
<td>**test_set_x_flatten shape**</td>
<td>(12288, 50)</td>
</tr>
<tr>
<td>**test_set_y shape**</td>
<td>(1, 50)</td>
</tr>
<tr>
<td>**sanity check after reshaping**</td>
<td>[17 31 56 22 33]</td>
</tr>
</table>
To represent color images, the red, green and blue channels (RGB) must be specified for each pixel, and so the pixel value is actually a vector of three numbers ranging from 0 to 255.
One common preprocessing step in machine learning is to center and standardize your dataset, meaning that you substract the mean of the whole numpy array from each example, and then divide each example by the standard deviation of the whole numpy array. But for picture datasets, it is simpler and more convenient and works almost as well to just divide every row of the dataset by 255 (the maximum value of a pixel channel).
<!-- During the training of your model, you're going to multiply weights and add biases to some initial inputs in order to observe neuron activations. Then you backpropogate with the gradients to train the model. But, it is extremely important for each feature to have a similar range such that our gradients don't explode. You will see that more in detail later in the lectures. !-->
Let's standardize our dataset.
```
train_set_x = train_set_x_flatten/255.
test_set_x = test_set_x_flatten/255.
```
<font color='blue'>
**What you need to remember:**
Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, ...)
- Reshape the datasets such that each example is now a vector of size (num_px \* num_px \* 3, 1)
- "Standardize" the data
## 3 - General Architecture of the learning algorithm ##
It's time to design a simple algorithm to distinguish cat images from non-cat images.
You will build a Logistic Regression, using a Neural Network mindset. The following Figure explains why **Logistic Regression is actually a very simple Neural Network!**
<img src="images/LogReg_kiank.png" style="width:650px;height:400px;">
**Mathematical expression of the algorithm**:
For one example $x^{(i)}$:
$$z^{(i)} = w^T x^{(i)} + b \tag{1}$$
$$\hat{y}^{(i)} = a^{(i)} = sigmoid(z^{(i)})\tag{2}$$
$$ \mathcal{L}(a^{(i)}, y^{(i)}) = - y^{(i)} \log(a^{(i)}) - (1-y^{(i)} ) \log(1-a^{(i)})\tag{3}$$
The cost is then computed by summing over all training examples:
$$ J = \frac{1}{m} \sum_{i=1}^m \mathcal{L}(a^{(i)}, y^{(i)})\tag{6}$$
**Key steps**:
In this exercise, you will carry out the following steps:
- Initialize the parameters of the model
- Learn the parameters for the model by minimizing the cost
- Use the learned parameters to make predictions (on the test set)
- Analyse the results and conclude
## 4 - Building the parts of our algorithm ##
The main steps for building a Neural Network are:
1. Define the model structure (such as number of input features)
2. Initialize the model's parameters
3. Loop:
- Calculate current loss (forward propagation)
- Calculate current gradient (backward propagation)
- Update parameters (gradient descent)
You often build 1-3 separately and integrate them into one function we call `model()`.
### 4.1 - Helper functions
**Exercise**: Using your code from "Python Basics", implement `sigmoid()`. As you've seen in the figure above, you need to compute $sigmoid( w^T x + b) = \frac{1}{1 + e^{-(w^T x + b)}}$ to make predictions. Use np.exp().
```
# GRADED FUNCTION: sigmoid
def sigmoid(z):
"""
Compute the sigmoid of z
Arguments:
z -- A scalar or numpy array of any size.
Return:
s -- sigmoid(z)
"""
### START CODE HERE ### (≈ 1 line of code)
s = 1 / (1 + np.exp(-z))
### END CODE HERE ###
return s
print ("sigmoid([0, 2]) = " + str(sigmoid(np.array([0,2]))))
```
**Expected Output**:
<table>
<tr>
<td>**sigmoid([0, 2])**</td>
<td> [ 0.5 0.88079708]</td>
</tr>
</table>
### 4.2 - Initializing parameters
**Exercise:** Implement parameter initialization in the cell below. You have to initialize w as a vector of zeros. If you don't know what numpy function to use, look up np.zeros() in the Numpy library's documentation.
```
# GRADED FUNCTION: initialize_with_zeros
def initialize_with_zeros(dim):
"""
This function creates a vector of zeros of shape (dim, 1) for w and initializes b to 0.
Argument:
dim -- size of the w vector we want (or number of parameters in this case)
Returns:
w -- initialized vector of shape (dim, 1)
b -- initialized scalar (corresponds to the bias)
"""
### START CODE HERE ### (≈ 1 line of code)
w = np.zeros(shape=(dim, 1))
b = 0
### END CODE HERE ###
assert(w.shape == (dim, 1))
assert(isinstance(b, float) or isinstance(b, int))
return w, b
dim = 2
w, b = initialize_with_zeros(dim)
print ("w = " + str(w))
print ("b = " + str(b))
```
**Expected Output**:
<table style="width:15%">
<tr>
<td> ** w ** </td>
<td> [[ 0.]
[ 0.]] </td>
</tr>
<tr>
<td> ** b ** </td>
<td> 0 </td>
</tr>
</table>
For image inputs, w will be of shape (num_px $\times$ num_px $\times$ 3, 1).
### 4.3 - Forward and Backward propagation
Now that your parameters are initialized, you can do the "forward" and "backward" propagation steps for learning the parameters.
**Exercise:** Implement a function `propagate()` that computes the cost function and its gradient.
**Hints**:
Forward Propagation:
- You get X
- You compute $A = \sigma(w^T X + b) = (a^{(1)}, a^{(2)}, ..., a^{(m-1)}, a^{(m)})$
- You calculate the cost function: $J = -\frac{1}{m}\sum_{i=1}^{m}y^{(i)}\log(a^{(i)})+(1-y^{(i)})\log(1-a^{(i)})$
Here are the two formulas you will be using:
$$ \frac{\partial J}{\partial w} = \frac{1}{m}X(A-Y)^T\tag{7}$$
$$ \frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^m (a^{(i)}-y^{(i)})\tag{8}$$
```
# GRADED FUNCTION: propagate
def propagate(w, b, X, Y):
"""
Implement the cost function and its gradient for the propagation explained above
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of size (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if non-cat, 1 if cat) of size (1, number of examples)
Return:
cost -- negative log-likelihood cost for logistic regression
dw -- gradient of the loss with respect to w, thus same shape as w
db -- gradient of the loss with respect to b, thus same shape as b
Tips:
- Write your code step by step for the propagation. np.log(), np.dot()
"""
m = X.shape[1]
# FORWARD PROPAGATION (FROM X TO COST)
### START CODE HERE ### (≈ 2 lines of code)
A = sigmoid(np.dot(w.T,X) + b)# compute activation
cost = (- 1 / m) * np.sum(Y * np.log(A) + (1 - Y) * (np.log(1 - A)))# compute cost
### END CODE HERE ###
# BACKWARD PROPAGATION (TO FIND GRAD)
### START CODE HERE ### (≈ 2 lines of code)
dw = (1 / m) * np.dot(X, (A - Y).T)
db = (1 / m) * np.sum(A- Y)
### END CODE HERE ###
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ())
grads = {"dw": dw,
"db": db}
return grads, cost
w, b, X, Y = np.array([[1.],[2.]]), 2., np.array([[1.,2.,-1.],[3.,4.,-3.2]]), np.array([[1,0,1]])
grads, cost = propagate(w, b, X, Y)
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print ("cost = " + str(cost))
```
**Expected Output**:
<table style="width:50%">
<tr>
<td> ** dw ** </td>
<td> [[ 0.99845601]
[ 2.39507239]]</td>
</tr>
<tr>
<td> ** db ** </td>
<td> 0.00145557813678 </td>
</tr>
<tr>
<td> ** cost ** </td>
<td> 5.801545319394553 </td>
</tr>
</table>
### 4.4 - Optimization
- You have initialized your parameters.
- You are also able to compute a cost function and its gradient.
- Now, you want to update the parameters using gradient descent.
**Exercise:** Write down the optimization function. The goal is to learn $w$ and $b$ by minimizing the cost function $J$. For a parameter $\theta$, the update rule is $ \theta = \theta - \alpha \text{ } d\theta$, where $\alpha$ is the learning rate.
```
# GRADED FUNCTION: optimize
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False):
"""
This function optimizes w and b by running a gradient descent algorithm
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of shape (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if non-cat, 1 if cat), of shape (1, number of examples)
num_iterations -- number of iterations of the optimization loop
learning_rate -- learning rate of the gradient descent update rule
print_cost -- True to print the loss every 100 steps
Returns:
params -- dictionary containing the weights w and bias b
grads -- dictionary containing the gradients of the weights and bias with respect to the cost function
costs -- list of all the costs computed during the optimization, this will be used to plot the learning curve.
Tips:
You basically need to write down two steps and iterate through them:
1) Calculate the cost and the gradient for the current parameters. Use propagate().
2) Update the parameters using gradient descent rule for w and b.
"""
costs = []
for i in range(num_iterations):
# Cost and gradient calculation (≈ 1-4 lines of code)
### START CODE HERE ###
grads, cost = propagate(w, b, X, Y)
### END CODE HERE ###
# Retrieve derivatives from grads
dw = grads["dw"]
db = grads["db"]
# update rule (≈ 2 lines of code)
### START CODE HERE ###
w = w - learning_rate * dw
b = b - learning_rate * db
### END CODE HERE ###
# Record the costs
if i % 100 == 0:
costs.append(cost)
# Print the cost every 100 training iterations
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
params, grads, costs = optimize(w, b, X, Y, num_iterations= 100, learning_rate = 0.009, print_cost = False)
print ("w = " + str(params["w"]))
print ("b = " + str(params["b"]))
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
```
**Expected Output**:
<table style="width:40%">
<tr>
<td> **w** </td>
<td>[[ 0.19033591]
[ 0.12259159]] </td>
</tr>
<tr>
<td> **b** </td>
<td> 1.92535983008 </td>
</tr>
<tr>
<td> **dw** </td>
<td> [[ 0.67752042]
[ 1.41625495]] </td>
</tr>
<tr>
<td> **db** </td>
<td> 0.219194504541 </td>
</tr>
</table>
**Exercise:** The previous function will output the learned w and b. We are able to use w and b to predict the labels for a dataset X. Implement the `predict()` function. There are two steps to computing predictions:
1. Calculate $\hat{Y} = A = \sigma(w^T X + b)$
2. Convert the entries of a into 0 (if activation <= 0.5) or 1 (if activation > 0.5), stores the predictions in a vector `Y_prediction`. If you wish, you can use an `if`/`else` statement in a `for` loop (though there is also a way to vectorize this).
```
# GRADED FUNCTION: predict
def predict(w, b, X):
'''
Predict whether the label is 0 or 1 using learned logistic regression parameters (w, b)
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of size (num_px * num_px * 3, number of examples)
Returns:
Y_prediction -- a numpy array (vector) containing all predictions (0/1) for the examples in X
'''
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0], 1)
# Compute vector "A" predicting the probabilities of a cat being present in the picture
### START CODE HERE ### (≈ 1 line of code)
A = sigmoid(np.dot(w.T, X) + b)
### END CODE HERE ###
for i in range(A.shape[1]):
# Convert probabilities A[0,i] to actual predictions p[0,i]
### START CODE HERE ### (≈ 4 lines of code)
Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
### END CODE HERE ###
assert(Y_prediction.shape == (1, m))
return Y_prediction
w = np.array([[0.1124579],[0.23106775]])
b = -0.3
X = np.array([[1.,-1.1,-3.2],[1.2,2.,0.1]])
print ("predictions = " + str(predict(w, b, X)))
```
**Expected Output**:
<table style="width:30%">
<tr>
<td>
**predictions**
</td>
<td>
[[ 1. 1. 0.]]
</td>
</tr>
</table>
<font color='blue'>
**What to remember:**
You've implemented several functions that:
- Initialize (w,b)
- Optimize the loss iteratively to learn parameters (w,b):
- computing the cost and its gradient
- updating the parameters using gradient descent
- Use the learned (w,b) to predict the labels for a given set of examples
## 5 - Merge all functions into a model ##
You will now see how the overall model is structured by putting together all the building blocks (functions implemented in the previous parts) together, in the right order.
**Exercise:** Implement the model function. Use the following notation:
- Y_prediction_test for your predictions on the test set
- Y_prediction_train for your predictions on the train set
- w, costs, grads for the outputs of optimize()
```
# GRADED FUNCTION: model
def model(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False):
"""
Builds the logistic regression model by calling the function you've implemented previously
Arguments:
X_train -- training set represented by a numpy array of shape (num_px * num_px * 3, m_train)
Y_train -- training labels represented by a numpy array (vector) of shape (1, m_train)
X_test -- test set represented by a numpy array of shape (num_px * num_px * 3, m_test)
Y_test -- test labels represented by a numpy array (vector) of shape (1, m_test)
num_iterations -- hyperparameter representing the number of iterations to optimize the parameters
learning_rate -- hyperparameter representing the learning rate used in the update rule of optimize()
print_cost -- Set to true to print the cost every 100 iterations
Returns:
d -- dictionary containing information about the model.
"""
### START CODE HERE ###
# initialize parameters with zeros (≈ 1 line of code)
w, b = initialize_with_zeros(X_train.shape[0])
# Gradient descent (≈ 1 line of code)
parameters, grads, costs = parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
# Retrieve parameters w and b from dictionary "parameters"
w = parameters["w"]
b = parameters["b"]
# Predict test/train set examples (≈ 2 lines of code)
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
### END CODE HERE ###
# Print train/test Errors
print("train accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations}
return d
```
Run the following cell to train your model.
```
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 2000, learning_rate = 0.005, print_cost = True)
```
**Expected Output**:
<table style="width:40%">
<tr>
<td> **Cost after iteration 0 ** </td>
<td> 0.693147 </td>
</tr>
<tr>
<td> <center> $\vdots$ </center> </td>
<td> <center> $\vdots$ </center> </td>
</tr>
<tr>
<td> **Train Accuracy** </td>
<td> 99.04306220095694 % </td>
</tr>
<tr>
<td>**Test Accuracy** </td>
<td> 70.0 % </td>
</tr>
</table>
**Comment**: Training accuracy is close to 100%. This is a good sanity check: your model is working and has high enough capacity to fit the training data. Test accuracy is 68%. It is actually not bad for this simple model, given the small dataset we used and that logistic regression is a linear classifier. But no worries, you'll build an even better classifier next week!
Also, you see that the model is clearly overfitting the training data. Later in this specialization you will learn how to reduce overfitting, for example by using regularization. Using the code below (and changing the `index` variable) you can look at predictions on pictures of the test set.
```
# Example of a picture that was wrongly classified.
index = 1
plt.imshow(test_set_x[:,index].reshape((num_px, num_px, 3)))
print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[d["Y_prediction_test"][0,index]].decode("utf-8") + "\" picture.")
```
Let's also plot the cost function and the gradients.
```
# Plot learning curve (with costs)
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
```
**Interpretation**:
You can see the cost decreasing. It shows that the parameters are being learned. However, you see that you could train the model even more on the training set. Try to increase the number of iterations in the cell above and rerun the cells. You might see that the training set accuracy goes up, but the test set accuracy goes down. This is called overfitting.
## 6 - Further analysis (optional/ungraded exercise) ##
Congratulations on building your first image classification model. Let's analyze it further, and examine possible choices for the learning rate $\alpha$.
#### Choice of learning rate ####
**Reminder**:
In order for Gradient Descent to work you must choose the learning rate wisely. The learning rate $\alpha$ determines how rapidly we update the parameters. If the learning rate is too large we may "overshoot" the optimal value. Similarly, if it is too small we will need too many iterations to converge to the best values. That's why it is crucial to use a well-tuned learning rate.
Let's compare the learning curve of our model with several choices of learning rates. Run the cell below. This should take about 1 minute. Feel free also to try different values than the three we have initialized the `learning_rates` variable to contain, and see what happens.
```
learning_rates = [0.01, 0.001, 0.0001]
models = {}
for i in learning_rates:
print ("learning rate is: " + str(i))
models[str(i)] = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 1500, learning_rate = i, print_cost = False)
print ('\n' + "-------------------------------------------------------" + '\n')
for i in learning_rates:
plt.plot(np.squeeze(models[str(i)]["costs"]), label= str(models[str(i)]["learning_rate"]))
plt.ylabel('cost')
plt.xlabel('iterations (hundreds)')
legend = plt.legend(loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()
```
**Interpretation**:
- Different learning rates give different costs and thus different predictions results.
- If the learning rate is too large (0.01), the cost may oscillate up and down. It may even diverge (though in this example, using 0.01 still eventually ends up at a good value for the cost).
- A lower cost doesn't mean a better model. You have to check if there is possibly overfitting. It happens when the training accuracy is a lot higher than the test accuracy.
- In deep learning, we usually recommend that you:
- Choose the learning rate that better minimizes the cost function.
- If your model overfits, use other techniques to reduce overfitting. (We'll talk about this in later videos.)
## 7 - Test with your own image (optional/ungraded exercise) ##
Congratulations on finishing this assignment. You can use your own image and see the output of your model. To do that:
1. Click on "File" in the upper bar of this notebook, then click "Open" to go on your Coursera Hub.
2. Add your image to this Jupyter Notebook's directory, in the "images" folder
3. Change your image's name in the following code
4. Run the code and check if the algorithm is right (1 = cat, 0 = non-cat)!
```
## START CODE HERE ## (PUT YOUR IMAGE NAME)
my_image = "my_image.jpg" # change this to the name of your image file
## END CODE HERE ##
# We preprocess the image to fit your algorithm.
fname = "images/" + my_image
image = np.array(ndimage.imread(fname, flatten=False))
image = image/255.
my_image = scipy.misc.imresize(image, size=(num_px,num_px)).reshape((1, num_px*num_px*3)).T
my_predicted_image = predict(d["w"], d["b"], my_image)
plt.imshow(image)
print("y = " + str(np.squeeze(my_predicted_image)) + ", your algorithm predicts a \"" + classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
```
<font color='blue'>
**What to remember from this assignment:**
1. Preprocessing the dataset is important.
2. You implemented each function separately: initialize(), propagate(), optimize(). Then you built a model().
3. Tuning the learning rate (which is an example of a "hyperparameter") can make a big difference to the algorithm. You will see more examples of this later in this course!
Finally, if you'd like, we invite you to try different things on this Notebook. Make sure you submit before trying anything. Once you submit, things you can play with include:
- Play with the learning rate and the number of iterations
- Try different initialization methods and compare the results
- Test other preprocessings (center the data, or divide each row by its standard deviation)
Bibliography:
- http://www.wildml.com/2015/09/implementing-a-neural-network-from-scratch/
- https://stats.stackexchange.com/questions/211436/why-do-we-normalize-images-by-subtracting-the-datasets-image-mean-and-not-the-c
| github_jupyter |
```
import numpy as np
import pandas as pd
import tensorflow as tf
import os
import warnings
warnings.filterwarnings('ignore')
from tensorflow import keras
from sklearn.preprocessing import RobustScaler, MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import f1_score, accuracy_score
from Models import SAE, CNN_AE, LSTM_AE, GRU_AE, Bi_LSTM_AE, CNN_Bi_LSTM_AE, Causal_CNN_AE, Wavenet, Attention_Bi_LSTM_AE, Attention_CNN_Bi_LSTM_AE, Attention_Wavenet
np.random.seed(7)
tf.random.set_seed(7)
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID";
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only allocate 1GB of memory on the first GPU
try:
tf.config.experimental.set_virtual_device_configuration(
gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Virtual devices must be set before GPUs have been initialized
print(e)
svm_reg = SVR(gamma='scale')
from sklearn.metrics import mean_squared_error as mse
from sklearn.metrics import r2_score
dataset_path = './datasets/regression/'
def n_steps_reshape(X_train_full, y_train_full, n_steps=10, for_rnn=False):
new_data = []
new_label = []
columns = X_train_full.columns
for i in range(X_train_full.shape[0]-n_steps):
new_instance = []
train_data = X_train_full[i:i+n_steps]
for c in columns:
for v in train_data[c].values:
new_instance.append(v)
# for _, row in train_data.iterrows():
# for c in columns:
# new_instance.append(row[c])
new_label.append(y_train_full[i+n_steps])
new_data.append(new_instance)
scaler = RobustScaler()
new_data = scaler.fit_transform(new_data)
new_label = scaler.fit_transform(np.array(new_label).reshape(-1,1))
if for_rnn:
return np.array(new_data).reshape(len(new_data), n_steps, columns.shape[0]), new_label
else:
return np.array(new_data), new_label
def LSTM_Model(n_steps, n_features):
return keras.models.Sequential([
keras.layers.LSTM(128, return_sequences=True, input_shape=[n_steps, n_features]),
keras.layers.LSTM(128),
keras.layers.Dense(1, activation=keras.layers.LeakyReLU(alpha=0.5))
])
results = []
from TRepNet import TRepNet
def get_codings(X_train, n_steps, n_features):
# X_train, X_test, n_steps = flatten_ts(train_x, test_x)
# X_train, X_test = rnn_reshape(X_train, X_test, n_steps // n_features, n_features)
encoder, decoder = TRepNet(n_steps, n_features, activation='elu')
model = keras.models.Sequential([encoder, decoder])
model.compile(loss="mae", optimizer=keras.optimizers.Nadam(lr=0.001, clipnorm=1.), metrics=['mae'])
history = model.fit(X_train, X_train, epochs=500, batch_size=16, validation_split=0.20, callbacks=[es], verbose=1, shuffle=False)
# Codings
return encoder.predict(X_train)
es = keras.callbacks.EarlyStopping(patience=5, restore_best_weights=True)
# for fn in [SAE, CNN_AE, LSTM_AE, GRU_AE, Bi_LSTM_AE, CNN_Bi_LSTM_AE, Causal_CNN_AE, Wavenet, TRepNet]:
# results = []
# print(fn.__name__)
# name = 'Solar Generation'
# solar_data = pd.read_csv(dataset_path + 'Solar/data.csv', quotechar='"').fillna(0)
# solar_data_X = solar_data.drop(columns=['SITE_NO', 'DATE', 'TIME'])
# solar_data_y = solar_data['GEN_ENERGY']
# X_train_full, y_train_full = n_steps_reshape(solar_data_X, solar_data_y, 10, for_rnn=True)
# X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
# X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
# svm_reg.fit(X_train, y_train)
# pred = svm_reg.predict(X_test)
# print(mse(y_test, pred))
# results.append({'dataset': name, 'MSE': mse(y_test, pred)})
# name = 'Beijing PM 2.5'
# beijing_data = pd.read_csv(dataset_path + 'Beijing-PM25.csv').dropna().drop(columns=['No', 'year']).reset_index(drop=True)
# beijing_data_X = pd.get_dummies(beijing_data, columns=['cbwd'])
# beijing_data_y = beijing_data['pm2.5']
# X_train_full, y_train_full = n_steps_reshape(beijing_data_X, beijing_data_y, 10, for_rnn=True)
# X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
# X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
# svm_reg.fit(X_train, y_train)
# pred = svm_reg.predict(X_test)
# print(mse(y_test, pred))
# results.append({'dataset': name, 'MSE': mse(y_test, pred)})
# name = 'Appliance Energy Prediction'
# energy_data = pd.read_csv(dataset_path + 'energydata_complete.csv')
# enery_data_X = energy_data.drop(columns=['date'])
# enery_data_y = energy_data['Appliances']
# X_train_full, y_train_full = n_steps_reshape(enery_data_X, enery_data_y, 10, for_rnn=True)
# X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
# X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
# svm_reg.fit(X_train, y_train)
# pred = svm_reg.predict(X_test)
# print(mse(y_test, pred))
# results.append({'dataset': name, 'MSE': mse(y_test, pred)})
# name = 'Parking Birmingham'
# parking_data = pd.read_csv(dataset_path + 'Parking Birmingham.csv')
# parking_data_X = parking_data.drop(columns=['SystemCodeNumber', 'LastUpdated'])
# parking_data_y = parking_data['Occupancy']
# X_train_full, y_train_full = n_steps_reshape(parking_data_X, parking_data_y, 10, for_rnn=True)
# X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
# X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
# svm_reg.fit(X_train, y_train)
# pred = svm_reg.predict(X_test)
# print(mse(y_test, pred))
# results.append({'dataset': name, 'MSE': mse(y_test, pred)})
# name = 'Daily Deemand Forecasting'
# demand_data = pd.read_csv(dataset_path + 'Daily_Demand_Forecasting_Orders.csv', sep=';')
# demand_data_X = demand_data
# demand_data_y = demand_data['Target']
# X_train_full, y_train_full = n_steps_reshape(demand_data_X, demand_data_y, 10, for_rnn=True)
# X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
# X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
# svm_reg.fit(X_train, y_train)
# pred = svm_reg.predict(X_test)
# print(mse(y_test, pred))
# results.append({'dataset': name, 'MSE': mse(y_test, pred)})
# pd.DataFrame(results).to_csv('./results/regression-'+ fn.__name__ +'-results.csv', index=False)
# print('END')
```
### Solar Generation
```
solar_data = pd.read_csv(dataset_path + 'Solar/data.csv', quotechar='"').fillna(0)
solar_data_X = solar_data.drop(columns=['SITE_NO', 'DATE', 'TIME'])
solar_data_y = solar_data['GEN_ENERGY']
X_train_full, y_train_full = n_steps_reshape(solar_data_X, solar_data_y, 10)
X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
svm_reg.fit(X_train, y_train)
pred = svm_reg.predict(X_test)
print(mse(y_test, pred))
X_train, X_test = X_train.reshape(X_train.shape[0], 10, solar_data_X.shape[1]), X_test.reshape(X_test.shape[0], 10, solar_data_X.shape[1])
model = LSTM_Model(X_train.shape[1], X_train.shape[2])
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
history = model.fit(X_train, y_train, epochs=10, validation_split=0.1, shuffle=False, callbacks=[es])
pred = model.predict(X_test)
mse(y_test, pred)
```
### Beijing PM 2.5
```
beijing_data = pd.read_csv(dataset_path + 'Beijing-PM25.csv').dropna().drop(columns=['No', 'year']).reset_index(drop=True)
beijing_data_X = pd.get_dummies(beijing_data, columns=['cbwd'])
beijing_data_y = beijing_data['pm2.5']
X_train_full, y_train_full = n_steps_reshape(beijing_data_X, beijing_data_y, 10)
X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
svm_reg.fit(X_train, y_train)
pred = svm_reg.predict(X_test)
print(mse(y_test, pred))
X_train, X_test, y_train, y_test = X_train.reshape(X_train.shape[0], 10, beijing_data_X.shape[1]), X_test.reshape(X_test.shape[0], 10, beijing_data_X.shape[1]), np.array(y_train), np.array(y_test)
model = LSTM_Model(X_train.shape[1], X_train.shape[2])
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
history = model.fit(X_train, y_train, epochs=10, validation_split=0.1, shuffle=False, callbacks=[es])
pred = model.predict(X_test)
mse(y_test, pred)
```
### Energy Data
```
energy_data = pd.read_csv(dataset_path + 'energydata_complete.csv')
enery_data_X = energy_data.drop(columns=['date'])
enery_data_y = energy_data['Appliances']
X_train_full, y_train_full = n_steps_reshape(enery_data_X, enery_data_y, 10, for_rnn=True)
X_train_full = get_codings(X_train_full, 10, X_train_full.shape[2])
X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
svm_reg.fit(X_train, y_train)
pred = svm_reg.predict(X_test)
print(mse(y_test, pred))
X_train, X_test, y_train, y_test = X_train.reshape(X_train.shape[0], 10, enery_data_X.shape[1]), X_test.reshape(X_test.shape[0], 10, enery_data_X.shape[1]), np.array(y_train), np.array(y_test)
model = LSTM_Model(X_train.shape[1], X_train.shape[2])
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
history = model.fit(X_train, y_train, epochs=10, validation_split=0.1, shuffle=False, callbacks=[es])
pred = model.predict(X_test)
mse(y_test, pred)
```
### Parking Birmingham
```
parking_data = pd.read_csv(dataset_path + 'Parking Birmingham.csv')
parking_data_X = parking_data.drop(columns=['SystemCodeNumber', 'LastUpdated'])
parking_data_y = parking_data['Occupancy']
X_train_full, y_train_full = n_steps_reshape(parking_data_X, parking_data_y, 10)
X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
svm_reg.fit(X_train, y_train)
pred = svm_reg.predict(X_test)
print(mse(y_test, pred))
X_train, X_test, y_train, y_test = X_train.reshape(X_train.shape[0], 10, parking_data_X.shape[1]), X_test.reshape(X_test.shape[0], 10, parking_data_X.shape[1]), np.array(y_train), np.array(y_test)
model = LSTM_Model(X_train.shape[1], X_train.shape[2])
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
history = model.fit(X_train, y_train, epochs=10, validation_split=0.1, shuffle=False, callbacks=[es])
pred = model.predict(X_test)
mse(y_test, pred)
```
### Daily Demand
```
demand_data = pd.read_csv(dataset_path + 'Daily_Demand_Forecasting_Orders.csv', sep=';')
demand_data_X = demand_data
demand_data_y = demand_data['Target']
X_train_full, y_train_full = n_steps_reshape(demand_data_X, demand_data_y, 10)
X_train, X_test, y_train, y_test = train_test_split(X_train_full, y_train_full, test_size=0.20, random_state=7)
svm_reg.fit(X_train, y_train)
pred = svm_reg.predict(X_test)
print(mse(y_test, pred))
X_train, X_test, y_train, y_test = X_train.reshape(X_train.shape[0], 10, demand_data_X.shape[1]), X_test.reshape(X_test.shape[0], 10, demand_data_X.shape[1]), np.array(y_train), np.array(y_test)
model = LSTM_Model(X_train.shape[1], X_train.shape[2])
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
history = model.fit(X_train, y_train, epochs=10, validation_split=0.1, shuffle=False, callbacks=[es])
pred = model.predict(X_test)
mse(y_test, pred)
```
| github_jupyter |
# ACA-Py & ACC-Py Basic Template
## Copy this template into the root folder of your notebook workspace to get started
### Imports
```
from aries_cloudcontroller import AriesAgentController
import os
from termcolor import colored
```
### Initialise the Agent Controller
```
api_key = os.getenv("ACAPY_ADMIN_API_KEY")
admin_url = os.getenv("ADMIN_URL")
print(f"Initialising a controller with admin api at {admin_url} and an api key of {api_key}")
agent_controller = AriesAgentController(admin_url,api_key)
```
### Start a Webhook Server
```
webhook_port = int(os.getenv("WEBHOOK_PORT"))
webhook_host = "0.0.0.0"
await agent_controller.init_webhook_server(webhook_host, webhook_port)
print(f"Listening for webhooks from agent at http://{webhook_host}:{webhook_port}")
```
## Register Agent Event Listeners
You can see some examples within the webhook_listeners recipe. Copy any relevant cells across and fill in additional logic as needed.
```
listeners = []
## YOUR LISTENERS HERE
# Receive connection messages
def connections_handler(payload):
state = payload['state']
connection_id = payload["connection_id"]
their_role = payload["their_role"]
routing_state = payload["routing_state"]
print("----------------------------------------------------------")
print("Connection Webhook Event Received")
print("Connection ID : ", connection_id)
print("State : ", state)
print("Routing State : ", routing_state)
print("Their Role : ", their_role)
print("----------------------------------------------------------")
if state == "active":
# Your business logic
print(colored("Connection ID: {0} is now active.".format(connection_id), "green", attrs=["bold"]))
connection_listener = {
"handler": connections_handler,
"topic": "connections"
}
listeners.append(connection_listener)
def issuer_handler(payload):
connection_id = payload['connection_id']
exchange_id = payload['credential_exchange_id']
state = payload['state']
role = payload['role']
print("\n---------------------------------------------------\n")
print("Handle Issue Credential Webhook")
print(f"Connection ID : {connection_id}")
print(f"Credential exchange ID : {exchange_id}")
print("Agent Protocol Role : ", role)
print("Protocol State : ", state )
print("\n---------------------------------------------------\n")
if state == "offer_sent":
proposal = payload["credential_proposal_dict"]
attributes = proposal['credential_proposal']['attributes']
print(f"Offering credential with attributes : {attributes}")
## YOUR LOGIC HERE
elif state == "request_received":
print("Request for credential received")
## YOUR LOGIC HERE
elif state == "credential_sent":
print("Credential Sent")
## YOUR LOGIC HERE
issuer_listener = {
"topic": "issue_credential",
"handler": issuer_handler
}
listeners.append(issuer_listener)
agent_controller.register_listeners(listeners)
```
## Store Issuing Schema and Cred Def Identifiers
If you intend for this agent to issue credentials you should first initialise your agent as an issuer and author the relevant identifiers to the public ledger. The issuer_initialisation recipe notebook can be duplicated and used as a starting point.
Once schema and cred def identifiers are created copy across and store in variables as illustrated in the cell below. Be sure to use unique names for each variable.
```
schema_id='ABsZzHjqQSfKUCEquCaAkN:2:aries_playground:0.0.1'
cred_def_id='ABsZzHjqQSfKUCEquCaAkN:3:CL:9916:default'
# %store <schema_id>
# %store <cred_def_id>
```
## Load any Identifiers from Store
If you are writing your logic across multiple notebooks, which I have found can make it easier to break things up, then rather than defining the schema and cred def identifiers every time it can be easier to load them from the jupyter store. Note: this assumes they have been written to the store in a previous notebook during the time the current docker containers have been running.
```
# %store -r <schema_id>
# %store -r <cred_def_id>
```
## Establish Connection with the Holder (PORT 8889)
Before you can issue a credential you must first establish a connection across which the credential will be issued to a holder. (see recipes/connection)
```
# Alias for invited connection
alias = None
auto_accept = "true"
# Use public DID?
public = "false"
# Should this invitation be usable by multiple invitees?
multi_use = "false"
invitation_response = await agent_controller.connections.create_invitation(alias, auto_accept, public, multi_use)
# Is equivalent to above. Arguments are optionally
# invitation_response = await agent_controller.connections.create_invitation()
# You will use this identifier to issue a credential across this connection
connection_id = invitation_response["connection_id"]
```
## Copy Invitation Object to Holder Notebook
```
invitation = invitation_response["invitation"]
## Copy this output
print(invitation)
```
## OPTIONAL: Display Invite as QR Code
This is useful if you wish to issue a credential to a mobile wallet.
```
import qrcode
# Link for connection invitation
invitation_url = invitation_response["invitation_url"]
# Creating an instance of qrcode
qr = qrcode.QRCode(
version=1,
box_size=5,
border=5)
qr.add_data(invitation_url)
qr.make(fit=True)
img = qr.make_image(fill='black', back_color='white')
img
```
## Populate Credential Attributes
Before you can issue a credential, you must define the values that will be issued in this credential. The attribute names **MUST** match those in the schem identified by the <schema_id> value.
Make sure to change all code enclosed with <>.
```
comment=input("Please enter some comment: ")
credential_attributes = [
{"name": "comment", "value": comment},
]
print(credential_attributes)
```
## Send Credential
This is the easiest way to issue a credential because it automates the rest of the protocol steps.
Note: The `connection_id` must be in the active state before a credential can be sent.
```
# Do you want the ACA-Py instance to trace it's processes (for testing/timing analysis)
trace = False
comment = ""
# Remove credential record after issued?
auto_remove = True
# Change <schema_id> and <cred_def_id> to correct pair. Cred_def_id must identify a definition to which your agent has corresponding private issuing key.
send_cred_response = await agent_controller.issuer.send_credential(connection_id, schema_id, cred_def_id, credential_attributes, comment, auto_remove, trace)
# Note last three args are optional.
# await agent_controller.issuer.send_credential(connection_id, <schema_id>, <cred_def_id, credential_attributes)
```
## Now Request a Proof of this Credential Through the Verifier Notebook (Port 8891)
## Terminate Controller
Whenever you have finished with this notebook, be sure to terminate the controller. This is especially important if your business logic runs across multiple notebooks.
```
await agent_controller.terminate()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/100rab-S/Tensorflow-Developer-Certificate/blob/main/S%2BP_Week_4_Lesson_1.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
<a href="https://colab.research.google.com/github/lmoroney/dlaicourse/blob/master/TensorFlow%20In%20Practice/Course%204%20-%20S%2BP/S%2BP%20Week%204%20Lesson%201.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
def trend(time, slope=0):
return slope * time
def seasonal_pattern(season_time):
"""Just an arbitrary pattern, you can change it if you wish"""
return np.where(season_time < 0.4,
np.cos(season_time * 2 * np.pi),
1 / np.exp(3 * season_time))
def seasonality(time, period, amplitude=1, phase=0):
"""Repeats the same pattern at each period"""
season_time = ((time + phase) % period) / period
return amplitude * seasonal_pattern(season_time)
def noise(time, noise_level=1, seed=None):
rnd = np.random.RandomState(seed)
return rnd.randn(len(time)) * noise_level
time = np.arange(4 * 365 + 1, dtype="float32")
baseline = 10
series = trend(time, 0.1)
baseline = 10
amplitude = 40
slope = 0.05
noise_level = 5
# Create the series
series = baseline + trend(time, slope) + seasonality(time, period=365, amplitude=amplitude)
# Update with noise
series += noise(time, noise_level, seed=42)
split_time = 1000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]
window_size = 20
batch_size = 32
shuffle_buffer_size = 1000
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
series = tf.expand_dims(series, axis=-1)
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
ds = ds.map(lambda w: (w[:-1], w[1:]))
return ds.batch(batch_size).prefetch(1)
def model_forecast(model, series, window_size):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecast
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
window_size = 30
train_set = windowed_dataset(x_train, window_size, batch_size=128, shuffle_buffer=shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=5,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 200)
])
lr_schedule = tf.keras.callbacks.LearningRateScheduler(
lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(train_set, epochs=100, callbacks=[lr_schedule], verbose=2)
plt.semilogx(history.history["lr"], history.history["loss"])
plt.axis([1e-8, 1e-4, 0, 30])
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
#batch_size = 16
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=3,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 200)
])
optimizer = tf.keras.optimizers.SGD(lr=1e-5, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(dataset,epochs=500)
rnn_forecast = model_forecast(model, series[..., np.newaxis], window_size)
rnn_forecast = rnn_forecast[split_time - window_size:-1, -1, 0]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, rnn_forecast)
tf.keras.metrics.mean_absolute_error(x_valid, rnn_forecast).numpy()
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
mae=history.history['mae']
loss=history.history['loss']
epochs=range(len(loss)) # Get number of epochs
#------------------------------------------------
# Plot MAE and Loss
#------------------------------------------------
plt.plot(epochs, mae, 'r')
plt.plot(epochs, loss, 'b')
plt.title('MAE and Loss')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["MAE", "Loss"])
plt.figure()
epochs_zoom = epochs[200:]
mae_zoom = mae[200:]
loss_zoom = loss[200:]
#------------------------------------------------
# Plot Zoomed MAE and Loss
#------------------------------------------------
plt.plot(epochs_zoom, mae_zoom, 'r')
plt.plot(epochs_zoom, loss_zoom, 'b')
plt.title('MAE and Loss')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["MAE", "Loss"])
plt.figure()
```
| github_jupyter |
Program: 08_kmeans_test.R
Date: September, 2019
Programmer: Hillary Mulder
Purpose: Show K means doesnt work well with harmonized trials data
```
library(cluster)
library(caret)
library(purrr)
library(dplyr)
library(boot)
#library(table1)
library(Hmisc)
data=read.csv("Data/analysis_ds.csv")
data$allhat=ifelse(data$study.1=='ALLHAT', 1, 0)
data$aimhigh=ifelse(data$study.1=='AIMHIGH', 1, 0)
data$accord=ifelse(data$study.1=='ACCORD', 1, 0)
train=data[which(data$train==1),]
base_nmiss=train[complete.cases(train[, c(1:3, 5, 6, 9:19, 20:22, 50, 51, 56:58)]), c(1:3, 5, 6, 9:19, 20:22, 50, 51, 56:58)]
studyn=base_nmiss$study.1
enrolid=base_nmiss[,1]
base_nmiss=base_nmiss[, -c(1,20,21)]
#base_nmiss=base_nmiss[, -c(1,9,10,22,23)]
colnames(base_nmiss)
ppr=preProcess(base_nmiss, method=c('center','scale'))
#apply transformations
base_scale=predict(ppr, newdata=base_nmiss)
#base_scale=scale(base_nmiss)
test=data[which(data$test==1),]
test_nmiss=test[complete.cases(test[, c(1:3, 5, 6, 9:19, 20:22, 50, 51, 56:58)]), c(1:3, 5, 6, 9:19, 20:22, 50, 51, 56:58)]
test_studyn=test_nmiss$study.1
test_enrolid=test_nmiss[,1]
test_nmiss=test_nmiss[, -c(1,20,21)]
#base_nmiss=base_nmiss[, -c(1,9,10,22,23)]
#test_scale=scale(_nmiss)
test_scale=predict(ppr, newdata=test_nmiss)
set.seed(123)
# function to compute total within-cluster sum of square
wss <- function(k) {
kmeans(base_scale, k, iter.max=20, nstart = 4)$tot.withinss
}
# Compute and plot wss for k = 1 to k = 15
k.values <- 2:15
# extract wss for 2-15 clusters
wss_values <- map_dbl(k.values, wss)
plot(k.values, wss_values,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters K",
ylab="Total within-clusters sum of squares")
#going to use 4 or 5 clusters
set.seed(123)
cluster1 <- kmeans(base_scale, 4, iter.max=15, nstart = 6)
cluster2 <- kmeans(base_scale, 5, iter.max=15, nstart = 6)
base_nmiss %>%
mutate(Cluster = cluster1$cluster) %>%
group_by(Cluster) %>%
summarise_all("mean")
base_nmiss %>%
mutate(Cluster = cluster2$cluster) %>%
group_by(Cluster) %>%
summarise_all("mean")
#table(base_nmiss$studyn, final$cluster)
check=data.frame(person_id=enrolid, study=studyn, cluster1=cluster1$cluster, cluster2=cluster2$cluster)
#head(check)
table(check$study, check$cluster1)
table(check$study, check$cluster2)
#table(base_nmiss$studyn, final$cluster)
predict.kmeans <- function(object,
newdata,
method = c("centers", "classes")) {
method <- match.arg(method)
centers <- object$centers
ss_by_center <- apply(centers, 1, function(x) {
colSums((t(newdata) - x) ^ 2)
})
best_clusters <- apply(ss_by_center, 1, which.min)
if (method == "centers") {
centers[best_clusters, ]
} else {
best_clusters
}
}
pred1=predict.kmeans(cluster1, newdata=test_scale, method="classes")
pred2=predict.kmeans(cluster2, newdata=test_scale, method="classes")
std=data.frame(person_id=test_enrolid, study=test_studyn, cluster1=pred1, cluster2=pred2)
#head(std)
table(std$study, std$cluster1)
table(std$study, std$cluster2)
#train2=left_join(x=train, y=check, by='person_id')
#colnames(train)
#head(train)
#test2=left_join(x=test, y=std, by='person_id')
#all=rbind(train2, test2)
#head(all)
#write.csv(all, file='Data/analysis_ds_clusters.csv', quote = FALSE, row.names = FALSE)
base_new=base_scale[,-(19:21)]
test_new=test_scale[,-c(19:21)]
set.seed(123)
cluster3 <- kmeans(base_new, 4, iter.max=15, nstart = 6)
cluster4 <- kmeans(base_new, 5, iter.max=15, nstart = 6)
#table(base_nmiss$studyn, final$cluster)
check=data.frame(person_id=enrolid, study=studyn, cluster3=cluster3$cluster, cluster4=cluster4$cluster)
#head(check)
table(check$study, check$cluster3)
table(check$study, check$cluster4)
pred3=predict.kmeans(cluster3, newdata=test_new, method="classes")
pred4=predict.kmeans(cluster4, newdata=test_new, method="classes")
std=data.frame(person_id=test_enrolid, study=test_studyn, cluster3=pred3, cluster4=pred4)
#head(std)
table(std$study, std$cluster3)
table(std$study, std$cluster4)
```
| github_jupyter |
# 作业3:设计并训练KNN算法对图片进行分类。
## example1:
```
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
k=7
test_num=int(input('请输入需要测试的数据数量:'))
#加载TFRecord训练集的数据
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["/home/srhyme/ML project/DS/train.tfrecords"])
_, example = reader.read(filename_queue)
features = tf.parse_single_example(
example,features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
})
train_images = tf.decode_raw(features['image_raw'], tf.uint8)
train_labels = tf.cast(features['label'], tf.int32)
train_pixels = tf.cast(features['pixels'], tf.int32)
#加载TFRecord测试集的数据
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["/home/srhyme/ML project/DS/test.tfrecords"])
_, example = reader.read(filename_queue)
features = tf.parse_single_example(
example,features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
})
test_images = tf.decode_raw(features['image_raw'], tf.uint8)
test_labels = tf.cast(features['label'], tf.int32)
test_pixels = tf.cast(features['pixels'], tf.int32)
tri_list=[]
tei_list=[]
trl_list=[]
tel_list=[]
#转换TFRecord里面的类型格式
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(sess.run(train_pixels)):
image,label=sess.run([train_images,train_labels])
tri_list.append(image)
trl=np.zeros((1,10))
trl[0][label]=1
trl_list.append(trl[0])
train_labels=np.array(trl_list)
train_images=np.array(tri_list)
print('训练集已加载完毕')
for i in range(test_num):
image,label=sess.run([test_images,test_labels])
tei_list.append(image)
tel=np.zeros((1,10))
tel[0][label]=1
tel_list.append(tel[0])
test_labels=np.array(tel_list)
test_images=np.array(tei_list)
print('测试集已加载完毕')
sess.close()
x_train = tf.placeholder(tf.float32)
x_test = tf.placeholder(tf.float32)
y_train = tf.placeholder(tf.float32)
# 欧式距离
euclidean_distance = tf.sqrt(tf.reduce_sum(tf.square(x_train - x_test), 1))
# 计算最相近的k个样本的索引
_, nearest_index = tf.nn.top_k(-euclidean_distance, k)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
predicted_num = 0
# 对每个图片进行预测
for i in range(test_images.shape[0]):
# 最近k个样本的标记索引
nearest_index_res = sess.run(
nearest_index,
feed_dict={
x_train: train_images,
y_train: train_labels,
x_test: test_images[i]})
# 最近k个样本的标记
nearest_label = []
for j in range(k):
nearest_label.append(list(train_labels[nearest_index_res[j]]))
predicted_class = sess.run(tf.argmax(tf.reduce_sum(nearest_label, 0), 0))
true_class = sess.run(tf.argmax(test_labels[i]))
if predicted_class == true_class:
predicted_num += 1
if i % 100 == 0:
print('step is %d accuracy is %.4f' % (i, predicted_num / (i+1)))
print('accuracy is %.4f' % (predicted_num / test_num))
```
## example2:
```
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
from collections import Counter
#训练集数据的引入
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["/home/srhyme/ML project/DS/train.tfrecords"])
_, example = reader.read(filename_queue)
features = tf.parse_single_example(
example,features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
})
train_images = tf.decode_raw(features['image_raw'], tf.uint8)
train_labels = tf.cast(features['label'], tf.int32)
train_pixels = tf.cast(features['pixels'], tf.int32)
#测试集数据的引入
reader = tf.TFRecordReader()
filename_queue = tf.train.string_input_producer(["/home/srhyme/ML project/DS/test.tfrecords"])
_, example = reader.read(filename_queue)
features = tf.parse_single_example(
example,features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
})
test_images = tf.decode_raw(features['image_raw'], tf.uint8)
test_labels = tf.cast(features['label'], tf.int32)
test_pixels = tf.cast(features['pixels'], tf.int32)
#设置变量
testnum=int(input('请输入需要测试的数据集数量:'))
k=5
correct_probability=testnum
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
test_num=sess.run(test_pixels)
train_num=sess.run(train_pixels)
#生成一个训练标签的列表,方便索引
c_labels=[]
for n in range(train_num):
train_label=sess.run(train_labels)
c_labels.append(train_label)
#生成一个测试标签的列表,方便索引
g_labels=[]
for n in range(test_num):
test_label=sess.run(test_labels)
g_labels.append(test_label)
for i in range(testnum):#测试集数量
test_image=sess.run(test_images)
#生成每个测试集的距离列表
min_label=[]
for j in range(train_num):#训练集数量
train_image=sess.run(train_images)
euclidean_distance =np.sqrt(np.sum(np.square(train_image - test_image)))
min_label.append(-euclidean_distance)
#生成最近k个点的位置
min_labels=tf.constant([min_label])
_, nearest_index = tf.nn.top_k(min_labels, k)
#生成一个最近k点标签列表
nearest_label=[]
near=nearest_index
for m in range(k):
nearest_label.append(c_labels[sess.run(near[0,m])])#在训练标签中找到该位置的标签
#生成该测试集经过knn训练后拟合的标签
nearset_dict=Counter(nearest_label)
key_list=[]
value_list=[]
for key,value in nearset_dict.items():
key_list.append(key)
value_list.append(value)
max_value=max(value_list)
get_value_index = value_list.index(max_value)
guess = key_list[get_value_index]
#判断正确率
correct=g_labels[i]
if correct != guess:
correct_probability=correct_probability - 1
print('正确率为',(correct_probability/testnum))
```
| github_jupyter |
# Continuous Delivery Explained
> "An introduction to the devops practice of CI/CD."
- toc: false
- branch: master
- badges: true
- comments: true
- categories: [devops, continuous-delivery]
- image: images/copied_from_nb/img/devops/feedback-cycle.png

> *I wrote this back in September 2014 and never published it, but since it's an introductory piece it stands its ground, so let this serve as an initial post…*
## CD in a Nutshell
A typical mission statement for Continuous Delivery is this…
> *Our highest priority is to satisfy the customer,*
> *through early and **continuous delivery** of valuable software.*
Continuous Delivery strives to improve the process of software delivery, by applying Continuous Deployment paired with automated testing and Continuous Integration. The goal is creating software developed to a high standard and easily packaged and deployed to test environments, resulting in the ability to rapidly, reliably and repeatedly push out enhancements and bug fixes to customers in small increments, at low risk and with minimal manual overhead.
CD is effective because it facilitates an explorative approach by providing real, valuable measurements of the output of the process, and feeding those results back into the process. It's the next logical step after applying Agile principles to development, by expanding the scope to the whole software life-cycle and all involved parties, from inception to going live and then maintaining the product for a substantial amount of time in fast-paced iterations.
## Some More Details
Continuous Delivery means that your software is production-ready from day one of your project (even when it's not “feature complete”), and that you can release to users on demand at the push of a button. There are several practices and patterns that enable this, but the foundation is formed in particular by excellent configuration management, continuous integration, and comprehensive automated testing at all levels. The key pattern is the deployment pipeline, which is effectively the extension of continuous integration out to production, whereby every check-in produces a release candidate which is assessed for its fitness to be released to production through a series of automated and then manual tests.
In order to be able to perform these validations against every build, your regression tests must be automated — both at the unit and acceptance level. Humans then perform tasks such as exploratory testing, usability testing, and showcases as later validations against builds that have already passed the automated tests. Builds can be deployed automatically on demand to testing, staging and production environments by the people authorized to do so — note that this means deployments are triggered by humans and performed by machines.
Through these practices, teams can get fast feedback on whether the software being delivered is useful, reduce the risk of release, and achieve a much more predictable, reliable process for software delivery. The backbone of CD is a culture in which everybody, if somehow involved in the delivery process, collaborates throughout the life-cycle of the product — developers, testers, infrastructure, operators, DBAs, managers, and customers alike.
## Where to Go From Here?
Here are some resources for diving deeper into the topic:
- [Jez Humble's Blog · Continuous Delivery](https://continuousdelivery.com/about/)
- [CD Foundation](https://cd.foundation/) – A Neutral Home for the Next Generation of Continuous Delivery Collaboration.
- [IT Revolution DevOps Blog](https://itrevolution.com/devops-blog/)
- [Devops Weekly Mailing List](https://www.devopsweekly.com/) (by [@garethr](https://twitter.com/garethr))
- [Team Topologies](https://teamtopologies.com/)
> 👍 *Credits:* [Devops-toolchain](https://commons.wikimedia.org/wiki/File:Devops-toolchain.svg)
| github_jupyter |
<center>
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/IDSNlogo.png" width="300" alt="cognitiveclass.ai logo" />
</center>
# String Operations
Estimated time needed: **15** minutes
## Objectives
After completing this lab you will be able to:
* Work with Strings
* Perform operations on String
* Manipulate Strings using indexing and escape sequences
<h2>Table of Contents</h2>
<div class="alert alert-block alert-info" style="margin-top: 20px">
<ul>
<li>
<a href="https://#strings">What are Strings?</a>
</li>
<li>
<a href="https://#index">Indexing</a>
<ul>
<li><a href="https://neg/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01">Negative Indexing</a></li>
<li><a href="https://slice/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01">Slicing</a></li>
<li><a href="https://stride/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01">Stride</a></li>
<li><a href="https://concat/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01">Concatenate Strings</a></li>
</ul>
</li>
<li>
<a href="https://#escape">Escape Sequences</a>
</li>
<li>
<a href="https://#operations">String Operations</a>
</li>
<li>
<a href="https://#quiz">Quiz on Strings</a>
</li>
</ul>
</div>
<hr>
<h2 id="strings">What are Strings?</h2>
The following example shows a string contained within 2 quotation marks:
```
# Use quotation marks for defining string
"Michael Jackson"
```
We can also use single quotation marks:
```
# Use single quotation marks for defining string
'Michael Jackson'
```
A string can be a combination of spaces and digits:
```
# Digitals and spaces in string
'1 2 3 4 5 6 '
```
A string can also be a combination of special characters :
```
# Special characters in string
'@#2_#]&*^%$'
```
We can print our string using the print statement:
```
# Print the string
print("hello!")
```
We can bind or assign a string to another variable:
```
# Assign string to variable
name = "Michael Jackson"
print(name)
```
<hr>
<h2 id="index">Indexing</h2>
It is helpful to think of a string as an ordered sequence. Each element in the sequence can be accessed using an index represented by the array of numbers:
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%201/images/StringsIndex.png" width="600" align="center" />
The first index can be accessed as follows:
<hr/>
<div class="alert alert-success alertsuccess" style="margin-top: 20px">
[Tip]: Because indexing starts at 0, it means the first index is on the index 0.
</div>
<hr/>
```
# Print the first element in the string
print(name[0])
```
We can access index 6:
```
# Print the element on index 6 in the string
print(name[6])
```
Moreover, we can access the 13th index:
```
# Print the element on the 13th index in the string
print(name[13])
```
<h3 id="neg">Negative Indexing</h3>
We can also use negative indexing with strings:
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%201/images/StringsNeg.png" width="600" align="center" />
Negative index can help us to count the element from the end of the string.
The last element is given by the index -1:
```
# Print the last element in the string
print(name[-1])
```
The first element can be obtained by index -15:
```
# Print the first element in the string
print(name[-15])
```
We can find the number of characters in a string by using <code>len</code>, short for length:
```
# Find the length of string
len("Michael Jackson")
```
<h3 id="slice">Slicing</h3>
We can obtain multiple characters from a string using slicing, we can obtain the 0 to 4th and 8th to the 12th element:
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%201/images/StringsSlice.png" width="600" align="center" />
<hr/>
<div class="alert alert-success alertsuccess" style="margin-top: 20px">
[Tip]: When taking the slice, the first number means the index (start at 0), and the second number means the length from the index to the last element you want (start at 1)
</div>
<hr/>
```
# Take the slice on variable name with only index 0 to index 3
name[0:4]
# Take the slice on variable name with only index 8 to index 11
name[8:12]
```
<h3 id="stride">Stride</h3>
We can also input a stride value as follows, with the '2' indicating that we are selecting every second variable:
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%201/images/StringsStride.png" width="600" align="center" />
```
# Get every second element. The elments on index 1, 3, 5 ...
name[::2]
```
We can also incorporate slicing with the stride. In this case, we select the first five elements and then use the stride:
```
# Get every second element in the range from index 0 to index 4
name[0:5:2]
```
<h3 id="concat">Concatenate Strings</h3>
We can concatenate or combine strings by using the addition symbols, and the result is a new string that is a combination of both:
```
# Concatenate two strings
statement = name + "is the best"
statement
```
To replicate values of a string we simply multiply the string by the number of times we would like to replicate it. In this case, the number is three. The result is a new string, and this new string consists of three copies of the original string:
```
# Print the string for 3 times
3 * "Michael Jackson"
```
You can create a new string by setting it to the original variable. Concatenated with a new string, the result is a new string that changes from Michael Jackson to “Michael Jackson is the best".
```
# Concatenate strings
name = "Michael Jackson"
name = name + " is the best"
name
```
<hr>
<h2 id="escape">Escape Sequences</h2>
Back slashes represent the beginning of escape sequences. Escape sequences represent strings that may be difficult to input. For example, back slash "n" represents a new line. The output is given by a new line after the back slash "n" is encountered:
```
# New line escape sequence
print(" Michael Jackson \n is the best" )
```
Similarly, back slash "t" represents a tab:
```
# Tab escape sequence
print(" Michael Jackson \t is the best" )
```
If you want to place a back slash in your string, use a double back slash:
```
# Include back slash in string
print(" Michael Jackson \\ is the best" )
```
We can also place an "r" before the string to display the backslash:
```
# r will tell python that string will be display as raw string
print(r" Michael Jackson \ is the best" )
```
<hr>
<h2 id="operations">String Operations</h2>
There are many string operation methods in Python that can be used to manipulate the data. We are going to use some basic string operations on the data.
Let's try with the method <code>upper</code>; this method converts lower case characters to upper case characters:
```
# Convert all the characters in string to upper case
a = "Thriller is the sixth studio album"
print("before upper:", a)
b = a.upper()
print("After upper:", b)
```
The method <code>replace</code> replaces a segment of the string, i.e. a substring with a new string. We input the part of the string we would like to change. The second argument is what we would like to exchange the segment with, and the result is a new string with the segment changed:
```
# Replace the old substring with the new target substring is the segment has been found in the string
a = "Michael Jackson is the best"
b = a.replace('Michael', 'Janet')
b
```
The method <code>find</code> finds a sub-string. The argument is the substring you would like to find, and the output is the first index of the sequence. We can find the sub-string <code>jack</code> or <code>el<code>.
<img src="https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%201/images/StringsFind.png" width="600" align="center" />
```
# Find the substring in the string. Only the index of the first elment of substring in string will be the output
name = "Michael Jackson"
name.find('el')
# Find the substring in the string.
name.find('Jack')
```
If the sub-string is not in the string then the output is a negative one. For example, the string 'Jasdfasdasdf' is not a substring:
```
# If cannot find the substring in the string
name.find('Jasdfasdasdf')
```
<hr>
<h2 id="quiz">Quiz on Strings</h2>
What is the value of the variable <code>a</code> after the following code is executed?
```
# Write your code below and press Shift+Enter to execute
a = "1"
```
<details><summary>Click here for the solution</summary>
```python
"1"
```
</details>
What is the value of the variable <code>b</code> after the following code is executed?
```
# Write your code below and press Shift+Enter to execute
b = "2"
```
<details><summary>Click here for the solution</summary>
```python
"2"
```
</details>
What is the value of the variable <code>c</code> after the following code is executed?
```
# Write your code below and press Shift+Enter to execute
c = a + b
```
<details><summary>Click here for the solution</summary>
```python
"12"
```
</details>
<hr>
Consider the variable <code>d</code> use slicing to print out the first three elements:
```
# Write your code below and press Shift+Enter to execute
d = "ABCDEFG"
print(d[:3])
```
<details><summary>Click here for the solution</summary>
```python
print(d[:3])
# or
print(d[0:3])
```
</details>
<hr>
Use a stride value of 2 to print out every second character of the string <code>e</code>:
```
# Write your code below and press Shift+Enter to execute
e = 'clocrkr1e1c1t'
print(e[::2])
```
<details><summary>Click here for the solution</summary>
```python
print(e[::2])
```
</details>
<hr>
Print out a backslash:
```
# Write your code below and press Shift+Enter to execute
print("\\")
```
<details><summary>Click here for the solution</summary>
```python
print("\\\\")
or
print(r"\ ")
```
</details>
<hr>
Convert the variable <code>f</code> to uppercase:
```
# Write your code below and press Shift+Enter to execute
f = "You are wrong"
f.upper()
```
<details><summary>Click here for the solution</summary>
```python
f.upper()
```
</details>
<hr>
Consider the variable <code>g</code>, and find the first index of the sub-string <code>snow</code>:
```
# Write your code below and press Shift+Enter to execute
g = "Mary had a little lamb Little lamb, little lamb Mary had a little lamb \
Its fleece was white as snow And everywhere that Mary went Mary went, Mary went \
Everywhere that Mary went The lamb was sure to go"
g.find('snow')
```
<details><summary>Click here for the solution</summary>
```python
g.find("snow")
```
</details>
In the variable <code>g</code>, replace the sub-string <code>Mary</code> with <code>Bob</code>:
```
# Write your code below and press Shift+Enter to execute
g.replace("Mary", "Bob")
```
<details><summary>Click here for the solution</summary>
```python
g.replace("Mary", "Bob")
```
</details>
<hr>
<h2>The last exercise!</h2>
<p>Congratulations, you have completed your first lesson and hands-on lab in Python. However, there is one more thing you need to do. The Data Science community encourages sharing work. The best way to share and showcase your work is to share it on GitHub. By sharing your notebook on GitHub you are not only building your reputation with fellow data scientists, but you can also show it off when applying for a job. Even though this was your first piece of work, it is never too early to start building good habits. So, please read and follow <a href="https://cognitiveclass.ai/blog/data-scientists-stand-out-by-sharing-your-notebooks/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01" target="_blank">this article</a> to learn how to share your work.
<hr>
## Author
<a href="https://www.linkedin.com/in/joseph-s-50398b136/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkPY0101ENSkillsNetwork19487395-2021-01-01" target="_blank">Joseph Santarcangelo</a>
## Change Log
| Date (YYYY-MM-DD) | Version | Changed By | Change Description |
| ----------------- | ------- | ---------- | ----------------------------------- |
| 2020-11-11 | 2.1 | Aije | Updated variable names to lowercase |
| 2020-08-26 | 2.0 | Lavanya | Moved lab to course repo in GitLab |
## <h3 align="center"> © IBM Corporation 2020. All rights reserved. <h3/>
| github_jupyter |
**[Pandas Home Page](https://www.kaggle.com/learn/pandas)**
---
# Introduction
In this set of exercises we will work with the [Wine Reviews dataset](https://www.kaggle.com/zynicide/wine-reviews).
Run the following cell to load your data and some utility functions (including code to check your answers).
```
import pandas as pd
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
from learntools.core import binder; binder.bind(globals())
from learntools.pandas.indexing_selecting_and_assigning import *
print("Setup complete.")
```
Look at an overview of your data by running the following line.
```
reviews.head()
```
# Exercises
## 1.
Select the `description` column from `reviews` and assign the result to the variable `desc`.
```
# Your code here
desc = reviews['description'] #or reviews.description
# Check your answer
q1.check()
```
Follow-up question: what type of object is `desc`? If you're not sure, you can check by calling Python's `type` function: `type(desc)`.
```
#q1.hint()
#q1.solution()
type(desc)
```
## 2.
Select the first value from the description column of `reviews`, assigning it to variable `first_description`.
```
first_description = reviews.description[0]
# Check your answer
q2.check()
first_description
#q2.hint()
#q2.solution()
```
## 3.
Select the first row of data (the first record) from `reviews`, assigning it to the variable `first_row`.
```
first_row = reviews.iloc[0]
# Check your answer
q3.check()
first_row
#q3.hint()
#q3.solution()
```
## 4.
Select the first 10 values from the `description` column in `reviews`, assigning the result to variable `first_descriptions`.
Hint: format your output as a pandas Series.
```
first_descriptions = reviews.loc[:9, 'description']
# Check your answer
q4.check()
first_descriptions
#q4.hint()
#q4.solution()
```
## 5.
Select the records with index labels `1`, `2`, `3`, `5`, and `8`, assigning the result to the variable `sample_reviews`.
In other words, generate the following DataFrame:

```
sample_reviews = reviews.loc[[1, 2, 3, 5, 8]]
# Check your answer
q5.check()
sample_reviews
q5.hint()
#q5.solution()
```
## 6.
Create a variable `df` containing the `country`, `province`, `region_1`, and `region_2` columns of the records with the index labels `0`, `1`, `10`, and `100`. In other words, generate the following DataFrame:

```
df = reviews.loc[[0, 1, 10, 100], ['country', 'province', 'region_1', 'region_2']]
# Check your answer
q6.check()
df
#q6.hint()
#q6.solution()
```
## 7.
Create a variable `df` containing the `country` and `variety` columns of the first 100 records.
Hint: you may use `loc` or `iloc`. When working on the answer this question and the several of the ones that follow, keep the following "gotcha" described in the tutorial:
> `iloc` uses the Python stdlib indexing scheme, where the first element of the range is included and the last one excluded.
`loc`, meanwhile, indexes inclusively.
> This is particularly confusing when the DataFrame index is a simple numerical list, e.g. `0,...,1000`. In this case `df.iloc[0:1000]` will return 1000 entries, while `df.loc[0:1000]` return 1001 of them! To get 1000 elements using `loc`, you will need to go one lower and ask for `df.iloc[0:999]`.
```
df = reviews.loc[0:99, ['country', 'variety']]
# Check your answer
q7.check()
df
#q7.hint()
#q7.solution()
```
## 8.
Create a DataFrame `italian_wines` containing reviews of wines made in `Italy`. Hint: `reviews.country` equals what?
```
italian_wines = reviews.loc[reviews.country == "Italy"]
# Check your answer
q8.check()
italian_wines
#q8.hint()
#q8.solution()
```
## 9.
Create a DataFrame `top_oceania_wines` containing all reviews with at least 95 points (out of 100) for wines from Australia or New Zealand.
```
top_oceania_wines = reviews.loc[(reviews.country.isin(["Australia", "New Zealand"])) & (reviews.points >= 95)]
# Check your answer
q9.check()
top_oceania_wines
q9.hint()
#q9.solution()
```
# Keep going
Move on to learn about **[summary functions and maps](https://www.kaggle.com/residentmario/summary-functions-and-maps)**.
---
**[Pandas Home Page](https://www.kaggle.com/learn/pandas)**
*Have questions or comments? Visit the [Learn Discussion forum](https://www.kaggle.com/learn-forum/161299) to chat with other Learners.*
| github_jupyter |
# Content-based recommender using Deep Structured Semantic Model
An example of how to build a Deep Structured Semantic Model (DSSM) for incorporating complex content-based features into a recommender system. See [Learning Deep Structured Semantic Models for Web Search using Clickthrough Data](https://www.microsoft.com/en-us/research/publication/learning-deep-structured-semantic-models-for-web-search-using-clickthrough-data/). This example does not attempt to provide a datasource or train a model, but merely show how to structure a complex DSSM network.
```
import warnings
import mxnet as mx
from mxnet import gluon, nd, autograd, sym
import numpy as np
from sklearn.random_projection import johnson_lindenstrauss_min_dim
# Define some constants
max_user = int(1e5)
title_vocab_size = int(3e4)
query_vocab_size = int(3e4)
num_samples = int(1e4)
hidden_units = 128
epsilon_proj = 0.25
ctx = mx.gpu() if mx.context.num_gpus() > 0 else mx.cpu()
```
## Bag of words random projection
A previous version of this example contained a bag of word random projection example, it is kept here for reference but not used in the next example.
Random Projection is a dimension reduction technique that guarantees the disruption of the pair-wise distance between your original data point within a certain bound.
What is even more interesting is that the dimension to project onto to guarantee that bound does not depend on the original number of dimension but solely on the total number of datapoints.
You can see more explanation [in this blog post](http://jasonpunyon.com/blog/2017/12/02/fun-with-random-numbers-random-projection/)
```
proj_dim = johnson_lindenstrauss_min_dim(num_samples, epsilon_proj)
print("To keep a distance disruption ~< {}% of our {} samples we need to randomly project to at least {} dimensions".format(epsilon_proj*100, num_samples, proj_dim))
class BagOfWordsRandomProjection(gluon.HybridBlock):
def __init__(self, vocab_size, output_dim, random_seed=54321, pad_index=0):
"""
:param int vocab_size: number of element in the vocabulary
:param int output_dim: projection dimension
:param int ramdon_seed: seed to use to guarantee same projection
:param int pad_index: index of the vocabulary used for padding sentences
"""
super(BagOfWordsRandomProjection, self).__init__()
self._vocab_size = vocab_size
self._output_dim = output_dim
proj = self._random_unit_vecs(vocab_size=vocab_size, output_dim=output_dim, random_seed=random_seed)
# we set the projection of the padding word to 0
proj[pad_index, :] = 0
self.proj = self.params.get_constant('proj', value=proj)
def _random_unit_vecs(self, vocab_size, output_dim, random_seed):
rs = np.random.RandomState(seed=random_seed)
W = rs.normal(size=(vocab_size, output_dim))
Wlen = np.linalg.norm(W, axis=1)
W_unit = W / Wlen[:,None]
return W_unit
def hybrid_forward(self, F, x, proj):
"""
:param nd or sym F:
:param nd.NDArray x: index of tokens
returns the sum of the projected embeddings of each token
"""
embedded = F.Embedding(x, proj, input_dim=self._vocab_size, output_dim=self._output_dim)
return embedded.sum(axis=1)
bowrp = BagOfWordsRandomProjection(1000, 20)
bowrp.initialize()
bowrp(mx.nd.array([[10, 50, 100], [5, 10, 0]]))
```
With padding:
```
bowrp(mx.nd.array([[10, 50, 100, 0], [5, 10, 0, 0]]))
```
# Content-based recommender / ranking system using DSSM
For example in the search result ranking problem:
You have users, that have performed text-based searches. They were presented with results, and selected one of them.
Results are composed of a title and an image.
Your positive examples will be the clicked items in the search results, and the negative examples are sampled from the non-clicked examples.
The network will jointly learn embeddings for users and query text making up the "Query", title and image making the "Item" and learn how similar they are.
After training, you can index the embeddings for your items and do a knn search with your query embeddings using the cosine similarity to return ranked items
```
proj_dim = 128
class DSSMRecommenderNetwork(gluon.HybridBlock):
def __init__(self, query_vocab_size, proj_dim, max_user, title_vocab_size, hidden_units, random_seed=54321, p=0.5):
super(DSSMRecommenderNetwork, self).__init__()
with self.name_scope():
# User/Query pipeline
self.user_embedding = gluon.nn.Embedding(max_user, proj_dim)
self.user_mlp = gluon.nn.Dense(hidden_units, activation="relu")
# Instead of bag of words, we use learned embeddings + stacked biLSTM average
self.query_text_embedding = gluon.nn.Embedding(query_vocab_size, proj_dim)
self.query_lstm = gluon.rnn.LSTM(hidden_units, 2, bidirectional=True)
self.query_text_mlp = gluon.nn.Dense(hidden_units, activation="relu")
self.query_dropout = gluon.nn.Dropout(p)
self.query_mlp = gluon.nn.Dense(hidden_units, activation="relu")
# Item pipeline
# Instead of bag of words, we use learned embeddings + stacked biLSTM average
self.title_embedding = gluon.nn.Embedding(title_vocab_size, proj_dim)
self.title_lstm = gluon.rnn.LSTM(hidden_units, 2, bidirectional=True)
self.title_mlp = gluon.nn.Dense(hidden_units, activation="relu")
# You could use vgg here for example
self.image_embedding = gluon.model_zoo.vision.resnet18_v2(pretrained=False).features
self.image_mlp = gluon.nn.Dense(hidden_units, activation="relu")
self.item_dropout = gluon.nn.Dropout(p)
self.item_mlp = gluon.nn.Dense(hidden_units, activation="relu")
def hybrid_forward(self, F, user, query_text, title, image):
# Query
user = self.user_embedding(user)
user = self.user_mlp(user)
query_text = self.query_text_embedding(query_text)
query_text = self.query_lstm(query_text.transpose((1,0,2)))
# average the states
query_text = query_text.mean(axis=0)
query_text = self.query_text_mlp(query_text)
query = F.concat(user, query_text)
query = self.query_dropout(query)
query = self.query_mlp(query)
# Item
title_text = self.title_embedding(title)
title_text = self.title_lstm(title_text.transpose((1,0,2)))
# average the states
title_text = title_text.mean(axis=0)
title_text = self.title_mlp(title_text)
image = self.image_embedding(image)
image = self.image_mlp(image)
item = F.concat(title_text, image)
item = self.item_dropout(item)
item = self.item_mlp(item)
# Cosine Similarity
query = query.expand_dims(axis=2)
item = item.expand_dims(axis=2)
sim = F.batch_dot(query, item, transpose_a=True) / (query.norm(axis=1) * item.norm(axis=1) + 1e-9).expand_dims(axis=2)
return sim.squeeze(axis=2)
network = DSSMRecommenderNetwork(
query_vocab_size,
proj_dim,
max_user,
title_vocab_size,
hidden_units
)
network.initialize(mx.init.Xavier(), ctx)
# Load pre-trained vgg16 weights
with network.name_scope():
network.image_embedding = gluon.model_zoo.vision.resnet18_v2(pretrained=True, ctx=ctx).features
```
It is quite hard to visualize the network since it is relatively complex but you can see the two-pronged structure, and the resnet18 branch
```
mx.viz.plot_network(network(
mx.sym.var('user'), mx.sym.var('query_text'), mx.sym.var('title'), mx.sym.var('image')),
shape={'user': (1,1), 'query_text': (1,30), 'title': (1,30), 'image': (1,3,224,224)},
node_attrs={"fixedsize":"False"})
```
We can print the summary of the network using dummy data. We can see it is already training on 32M parameters!
```
user = mx.nd.array([[200], [100]], ctx)
query = mx.nd.array([[10, 20, 0, 0, 0], [40, 50, 0, 0, 0]], ctx) # Example of an encoded text
title = mx.nd.array([[10, 20, 0, 0, 0], [40, 50, 0, 0, 0]], ctx) # Example of an encoded text
image = mx.nd.random.uniform(shape=(2,3, 224,224), ctx=ctx) # Example of an encoded image
network.summary(user, query, title, image)
network(user, query, title, image)
```
The output is the similarity, if we wanted to train it on real data, we would need to minimize the Cosine loss, 1 - cosine_similarity.
| github_jupyter |
# Plots for logistic regression, consistent vs inconsistent noiseless AT, increasing epsilon
```
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches
import dotenv
import pandas as pd
import mlflow
import plotly
import plotly.graph_objects as go
import plotly.express as px
import plotly.subplots
import plotly.io as pio
import typing
import os
import shutil
import sys
import warnings
EXPORT = False
SHOW_TITLES = not EXPORT
EXPORT_DIR_NAME = 'eps_increase_separate_legend'
EXPERIMENT_NAME = 'logistic_regression_inconsistent_consistent_increase_epsilon'
# Load environment variables
dotenv.load_dotenv()
# Enable loading of the project module
MODULE_DIR = os.path.join(os.path.abspath(os.path.join(os.path.curdir, os.path.pardir, os.pardir)), 'src')
sys.path.append(MODULE_DIR)
%load_ext autoreload
%autoreload 2
import interpolation_robustness as ir
FIGURE_SIZE = (2.75, 1.4)
LEGEND_FIGURE_SIZE = (2.75, 0.7)
LEGEND_FONT_SIZE = ir.plots.FONT_SIZE_SMALL_PT
ir.plots.setup_matplotlib(show_titles=SHOW_TITLES)
if EXPORT:
EXPORT_DIR = os.path.join(ir.util.REPO_ROOT_DIR, 'logs', f'export_{EXPORT_DIR_NAME}')
print('Using export directory', EXPORT_DIR)
if os.path.exists(EXPORT_DIR):
shutil.rmtree(EXPORT_DIR)
os.makedirs(EXPORT_DIR)
def export_fig(fig: plt.Figure, filename: str):
# If export is disabled then do nothing
if EXPORT:
export_path = os.path.join(EXPORT_DIR, filename)
fig.savefig(export_path)
print('Exported figure at', export_path)
```
## Load experiment data
```
client = mlflow.tracking.MlflowClient()
experiment = client.get_experiment_by_name(EXPERIMENT_NAME)
runs = mlflow.search_runs(
experiment.experiment_id
)
runs = runs.set_index('run_id', drop=False) # set index, but keep column to not break stuff depending on it
# Convert some parameters to numbers and sort accordingly
runs['params.data_dim'] = runs['params.data_dim'].astype(int)
runs['params.data_num_train_samples'] = runs['params.data_num_train_samples'].astype(int)
runs['params.train_attack_epsilon'] = runs['params.train_attack_epsilon'].astype(np.float)
runs['params.test_attack_epsilon'] = runs['params.test_attack_epsilon'].astype(np.float)
runs['params.l2_lambda'] = runs['params.l2_lambda'].astype(np.float)
runs['params.label_noise'] = runs['params.label_noise'].astype(np.float)
runs['metrics.train_robust_risk'] = 1.0 - runs['metrics.train_robust_accuracy']
assert runs['params.l2_lambda'].eq(0).all()
runs['metrics.train_robust_log_loss'] = runs['metrics.training_loss']
runs = runs.sort_values(['params.label_noise'], ascending=True)
print('Loaded', len(runs), 'runs')
assert runs['status'].eq('FINISHED').all()
assert runs['params.label_noise'].eq(0).all()
grouping_keys = ['params.data_dim', 'params.l2_lambda', 'params.train_consistent_attacks', 'params.train_attack_epsilon', 'params.data_num_train_samples']
aggregate_metrics = ('metrics.true_robust_risk', 'metrics.train_robust_log_loss')
runs_agg = runs.groupby(grouping_keys, as_index=False).aggregate({metric: ['mean', 'std'] for metric in aggregate_metrics})
```
## Plots
```
robust_consistent_color_idx = 1
robust_inconsistent_color_idx = 2
population_linestyle = ir.plots.LINESTYLE_MAP[0]
training_linestyle = ir.plots.LINESTYLE_MAP[2]
BASELINE_LAMBDA = 0
warnings.simplefilter(action='ignore', category=pd.errors.PerformanceWarning)
fig, ax = plt.subplots(figsize=FIGURE_SIZE)
target_num_samples = 1000
current_runs = runs_agg[runs_agg['params.data_num_train_samples'] == target_num_samples]
assert current_runs['params.l2_lambda'].eq(0).all()
data_dim, = current_runs['params.data_dim'].unique()
current_consistent_runs = current_runs[current_runs['params.train_consistent_attacks'] == 'True']
current_inconsistent_runs = current_runs[current_runs['params.train_consistent_attacks'] == 'False']
ax.errorbar(
current_consistent_runs['params.train_attack_epsilon'],
current_consistent_runs[('metrics.true_robust_risk', 'mean')],
yerr=current_consistent_runs[('metrics.true_robust_risk', 'std')],
label=fr'Robust risk, cons.',
c=f'C{robust_consistent_color_idx}',
ls=population_linestyle,
zorder=2
)
ax.errorbar(
current_inconsistent_runs['params.train_attack_epsilon'],
current_inconsistent_runs[('metrics.true_robust_risk', 'mean')],
yerr=current_inconsistent_runs[('metrics.true_robust_risk', 'std')],
label=fr'Robust risk, incons.',
c=f'C{robust_inconsistent_color_idx}',
ls=population_linestyle,
zorder=2
)
ax.errorbar(
current_consistent_runs['params.train_attack_epsilon'],
current_consistent_runs[('metrics.train_robust_log_loss', 'mean')],
yerr=current_consistent_runs[('metrics.train_robust_log_loss', 'std')],
label=fr'Training loss, cons.',
c=f'C{robust_consistent_color_idx}',
ls=training_linestyle,
zorder=2
)
ax.errorbar(
current_inconsistent_runs['params.train_attack_epsilon'],
current_inconsistent_runs[('metrics.train_robust_log_loss', 'mean')],
yerr=current_inconsistent_runs[('metrics.train_robust_log_loss', 'std')],
label=fr'Training loss, incons.',
c=f'C{robust_inconsistent_color_idx}',
ls=training_linestyle,
zorder=2
)
ax.set_xlabel('Train and test $\epsilon$')
ax.set_ylim(bottom=-0.005)
ax.set_xlim(left=-0.001)
if SHOW_TITLES:
fig.suptitle(f'Consistent vs inconsistent AT, fixed d {data_dim} and n {target_num_samples}')
export_fig(fig, f'eps_increase.pdf')
plt.show()
# Legend
legend_fig = plt.figure(figsize=LEGEND_FIGURE_SIZE)
handles, labels = ax.get_legend_handles_labels()
ir.plots.errorbar_legend(
legend_fig,
handles,
labels,
loc='center',
ncol=2,
mode='expand',
frameon=True,
fontsize=LEGEND_FONT_SIZE,
borderpad=0.7
)
export_fig(legend_fig, f'eps_increase_legend.pdf')
```
| github_jupyter |
# RNN - LSTM - Toxic Comments
A corpus of manually labeled comments - classifying each comment by its type of toxicity is available on Kaggle. We will aim to do a binary classification of whether a comment is toxic or not.
Approach:
- Learning Embedding with the Task
- LSTM
- BiLSTM
```
import numpy as np
import pandas as pd
import keras
import matplotlib.pyplot as plt
%matplotlib inline
import vis
```
### Get the Data
Uncomment these shell lines to get the data
```
# !wget http://bit.do/deep_toxic_train -P data/
# !mv data/deep_toxic_train data/train.zip
df = pd.read_csv("data/train.zip")
df.head()
```
### Import the required libraries
```
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
```
### Create the Input & Output Data
```
train_sentences = df["comment_text"]
train_sentences.head()
```
**Pre-processing the train data**
- Tokenization: "This is an apple" -> ["This", "is", "an", "apple"]
- Indexing: {0: "This", 1: "is", 2: "an", 3: "apple"}
- Index Representation: [0, 1, 2, 3]
```
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Tokenizer
max_words = 20000
tokenizer = Tokenizer(num_words=max_words, oov_token='UNK')
tokenizer.fit_on_texts(list(train_sentences))
```
Tokenizer Fix from https://github.com/keras-team/keras/issues/8092
```
tokenizer.word_index = {e:i for e,i in tokenizer.word_index.items() if i <= max_words} # <= because tokenizer is 1 indexed
tokenizer.word_index[tokenizer.oov_token] = max_words + 1
# Index Representation
tokenized_train = tokenizer.texts_to_sequences(train_sentences)
# Selecting Padding
# find length of each sentence and plot the length
number_of_words = [len(comment) for comment in tokenized_train]
plt.hist(number_of_words, bins = np.arange(0, 500, 10));
# Padding to make it uniform
maxlen = 200
X = pad_sequences(tokenized_train, maxlen = maxlen)
labels = df.iloc[:,2].values
# Baseline Benchmark
1 - df.iloc[:,2].sum()/df.iloc[:,2].count()
from keras.utils import to_categorical
y = to_categorical(labels)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
```
### Step 2: Create the Model Architecture
```
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding, Dropout, Bidirectional
model = Sequential()
model.add(Embedding(max_words, output_dim=128, mask_zero=True))
model.add(LSTM(60))
model.add(Dropout(0.1))
model.add(Dense(2, activation='sigmoid'))
```
### Step 3: Compile the Model & Fit on the Data
```
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
output = model.fit(X_train, y_train, batch_size=128, epochs=5, validation_split=0.2)
```
### Step 4: Evaluate the Model
```
vis.metrics(output.history)
score = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
```
### Step 5: Visualise evaluation & Make a prediction
```
predict_classes = model.predict_classes(X_test)
actual_classes = np.dot(y_test,np.array([[0],[1]])).reshape(-1)
pd.crosstab(actual_classes, predict_classes)
```
| github_jupyter |
## Mask Adaptivity Detection Using YOLO
Mask became an essential accessory post COVID-19. Most of the countries are making face masks mandatory to avail services like transport, fuel and any sort of outside activity. It is become utmost necessary to keep track of the adaptivity of the crowd. This notebook contains implementation of a face mask adaptivity tracker using YOLO.

```
import warnings
import numpy as np
import argparse
import time
import cv2
import os
warnings.filterwarnings("ignore")
```
### Prepare DarkNet Environment
```
# Create DarkNet Environment
def prepare_environment():
os.environ['PATH'] += ':/usr/local/cuda/bin'
!rm -fr darknet
!git clone https://github.com/AlexeyAB/darknet/
!apt install gcc-5 g++-5 -y
!ln -s /usr/bin/gcc-5 /usr/local/cuda/bin/gcc
!ln -s /usr/bin/g++-5 /usr/local/cuda/bin/g++
%cd darknet
!sed -i 's/GPU=0/GPU=1/g' Makefile
!sed -i 's/OPENCV=0/OPENCV=1/g' Makefile
!make
# get yolov3 weights
#!wget https://pjreddie.com/media/files/darknet53.conv.74.weights
!chmod a+x ./darknet
!apt install ffmpeg libopencv-dev libgtk-3-dev python-numpy python3-numpy libdc1394-22 libdc1394-22-dev libjpeg-dev libtiff5-dev libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libv4l-dev libtbb-dev qtbase5-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils unzip
status='Completed'
return status
prepare_environment()
from google.colab import drive
drive.mount('/content/drive')
os.listdir('/content/drive/My Drive/darknet/YOLO_Custom')
```
### Get Tiny YOLO Weight (Skip if Resuming Training)
```
!wget --header="Host: pjreddie.com" --header="User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36" --header="Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9" --header="Accept-Language: en-US,en;q=0.9" --header="Referer: https://github.com/AlexeyAB/darknet" --header="Cookie: __utma=134107727.1364647705.1589636782.1589689587.1589901067.3; __utmz=134107727.1589901067.3.3.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided)" --header="Connection: keep-alive" "https://pjreddie.com/media/files/yolov3-tiny.weights" -c -O 'yolov3-tiny.weights'
!./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
```
### Copy Required Files from Drive
```
# Copy fils from Google Drive to the VM local filesystem
!cp -r "/content/drive/My Drive/darknet/YOLO_Custom" /content/darknet/YOLO_Custom
```
### Train
Use the below command to train yolo:
!./darknet detector train data_file_path config_file_path training_weights_path log_path
To train yolov3 instead of tiny yolo, replace the following files:
use ***yolov3_train_cfg*** instead of ***yolov3-tiny_obj_train.cfg***
use ***yolov3_test_cfg*** instead of ***yolov3-tiny_obj_test.cfg*** for testing purpose.
Replace the yolov3 weight link with the tiny yolo weight link
```
!./darknet detector train "/content/darknet/YOLO_Custom/obj.data" "/content/darknet/YOLO_Custom/yolov3-tiny_obj_train.cfg" "/content/darknet/yolov3-tiny.conv.15" "train.log" -dont_show
```
### Utility Functions
```
# Define threshold for confidence score and Non max supression here
confthres=0.2
nmsthres=0.1
path="./"
def get_labels(label_dir):
return open(label_dir).read().split('\n')
def get_colors(LABELS):
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),dtype="uint8")
return COLORS
def get_weights(weights_path):
# derive the paths to the YOLO weights and model configuration
weightsPath = os.path.sep.join([yolo_path, weights_path])
return weightsPath
def get_config(config_path):
configPath = os.path.sep.join([yolo_path, config_path])
return configPath
def load_model(configpath,weightspath):
# load our YOLO object detector trained on COCO dataset (80 classes)
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configpath, weightspath)
return net
#https://medium.com/analytics-vidhya/object-detection-using-yolo-v3-and-deploying-it-on-docker-and-minikube-c1192e81ae7a
def get_predection(image,net,LABELS,COLORS):
(H, W) = image.shape[:2]
# determine only the *output* layer names that we need from YOLO
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# construct a blob from the input image and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes and
# associated probabilities
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
#print(layerOutputs[0])
end = time.time()
# show timing information on YOLO
#print("[INFO] YOLO took {:.6f} seconds".format(end - start))
# initialize our lists of detected bounding boxes, confidences, and
# class IDs, respectively
boxes = []
confidences = []
classIDs = []
num_class_0 = 0
num_class_1 = 0
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability) of
# the current object detection
scores = detection[5:]
#print(detection)
classID = np.argmax(scores)
# print(classID)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > confthres:
# scale the bounding box coordinates back relative to the
# size of the image, keeping in mind that YOLO actually
# returns the center (x, y)-coordinates of the bounding
# box followed by the boxes' width and height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top and
# and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates, confidences,
# and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
if(classID==0):
num_class_0 +=1
elif(classID==1):
num_class_1 +=1
# apply non-maxima suppression to suppress weak, overlapping bounding
# boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, confthres,
nmsthres)
if(num_class_0>0 or num_class_1>0):
index= num_class_0/(num_class_0+num_class_1)
else:
index=-1
#print(index,)
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# draw a bounding box rectangle and label on the image
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
text = "{}".format(LABELS[classIDs[i]])
#print(boxes)
#print(classIDs)
#cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,0.5, color=(69, 60, 90), thickness=2)
cv2.rectangle(image, (x, y-5), (x+62, y-15), color, cv2.FILLED)
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,0.5, (0,0,0), 1)
if(index!=-1 and index<.50):
cv2.rectangle(image, (40, 46), (220, 16), (0,0,255), cv2.FILLED)
cv2.putText(image,'Mask Adaptivity: POOR',(40,40),cv2.FONT_HERSHEY_SIMPLEX,0.5, (0,255,255), 1)
elif(index>=.50 and index<.70):
cv2.rectangle(image, (40, 46), (255, 16), (0, 165, 255), cv2.FILLED)
cv2.putText(image,'Mask Adaptivity: MODERATE',(40,40),cv2.FONT_HERSHEY_SIMPLEX,0.5, (0,0,0), 1)
elif(index>=0.70):
cv2.rectangle(image, (40, 46), (220, 16), (42,236,42), cv2.FILLED)
cv2.putText(image,'Mask Adaptivity: HIGH',(40,40),cv2.FONT_HERSHEY_SIMPLEX,0.5, (0,0,0), 1)
return image
# Method to predict Image
def predict_image(img_path):
image = cv2.imread(img_path)
nets=load_model(CFG,Weights)
#Colors=get_colors(Lables)
Colors=[(42,236,42),(0,0,255)]
res=get_predection(image,nets,Lables,Colors)
# image=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
# show the output image
cv2_imshow(res)
cv2.waitKey()
# Method to predict Video
def predict_video(input_path,output_path):
vid = cv2.VideoCapture(input_path)
op=output_path
height, width = None, None
writer = None
print('[Info] processing Video (It may take several minutes to Run)..')
while True:
grabbed, frame = vid.read()
# Checking if the complete video is read
if not grabbed:
break
if width is None or height is None:
height, width = frame.shape[:2]
frame=get_predection(frame,nets,Lables,Colors)
if writer is None:
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter(op, fourcc, 27,(frame.shape[1], frame.shape[0]), True)
writer.write(frame)
print ("[INFO] Cleaning up...")
writer.release()
vid.release()
print ("[INFO] Prediction Completed.")
# This will not work in colab, as colab can't access local hardware
import time
def predict_web_cam():
#stream = cv2.VideoCapture(0)
sess = K.get_session()
while True:
# Capture frame-by-frame
grabbed, frame = stream.read()
if not grabbed:
break
# Run detection
start = time.time()
image = Image.fromarray(frame)
output_image = get_predection(image,nets,Lables,Colors)
end = time.time()
print("Inference time: {:.2f}s".format(end - start))
# Display the resulting frame
cv2.imshow('Web Cam',np.asarray(output_image))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
stream.release()
cv2.destroyAllWindows()
```
### Set the Variables (Must before Prediction)
```
# Set the pah for test config file, label directory and weights
CFG='/content/darknet/YOLO_Custom/yolov3-tiny_obj_test.cfg'
label_dir='/content/darknet/YOLO_Custom/obj.names'
#cfgpath=test_config_path
Weights='/content/darknet/YOLO_Custom/yolov3-tiny_obj_train_tiny8.weights'
Lables=get_labels(label_dir)
```
### Predict Image
```
from google.colab.patches import cv2_imshow
img_path='/content/buckey.jpg'
predict_image(img_path)
```
### Predict Video
```
input_path='/content/in.mp4'
output_path='/content/out.mp4'
predict_video(input_path,output_path)
```
| github_jupyter |
## Precision-Recall Curves in Multiclass
For multiclass classification, we have 2 options:
- determine a PR curve for each class.
- determine the overall PR curve as the micro-average of all classes
Let's see how to do both.
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.multiclass import OneVsRestClassifier
# to convert the 1-D target vector in to a matrix
from sklearn.preprocessing import label_binarize
from sklearn.metrics import precision_recall_curve
from yellowbrick.classifier import PrecisionRecallCurve
```
## Load data (multiclass)
```
# load data
data = load_wine()
data = pd.concat([
pd.DataFrame(data.data, columns=data.feature_names),
pd.DataFrame(data.target, columns=['target']),
], axis=1)
data.head()
# target distribution:
# multiclass and (fairly) balanced
data.target.value_counts(normalize=True)
# separate dataset into train and test
X_train, X_test, y_train, y_test = train_test_split(
data.drop(labels=['target'], axis=1), # drop the target
data['target'], # just the target
test_size=0.3,
random_state=0)
X_train.shape, X_test.shape
# the target is a vector with the 3 classes
y_test[0:10]
```
## Train ML models
The dataset we are using is very, extremely simple, so I am creating dumb models intentionally, that is few trees and very shallow for the random forests and few iterations for the logit. This is, so that we can get the most out of the PR curves by inspecting them visually.
### Random Forests
The Random Forests in sklearn are not trained as a 1 vs Rest. So in order to produce a 1 vs rest probability vector for each class, we need to wrap this estimator with another one from sklearn:
- [OneVsRestClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsRestClassifier.html)
```
# set up the model, wrapped by the OneVsRestClassifier
rf = OneVsRestClassifier(
RandomForestClassifier(
n_estimators=10, random_state=39, max_depth=1, n_jobs=4,
)
)
# train the model
rf.fit(X_train, y_train)
# produce the predictions (as probabilities)
y_train_rf = rf.predict_proba(X_train)
y_test_rf = rf.predict_proba(X_test)
# note that the predictions are an array of 3 columns
# first column: the probability of an observation of being of class 0
# second column: the probability of an observation of being of class 1
# third column: the probability of an observation of being of class 2
y_test_rf[0:10, :]
pd.DataFrame(y_test_rf).sum(axis=1)[0:10]
# The final prediction is that of the biggest probabiity
rf.predict(X_test)[0:10]
```
### Logistic Regression
The Logistic regression supports 1 vs rest automatically though its multi_class parameter:
```
# set up the model
logit = LogisticRegression(
random_state=0, multi_class='ovr', max_iter=10,
)
# train
logit.fit(X_train, y_train)
# obtain the probabilities
y_train_logit = logit.predict_proba(X_train)
y_test_logit = logit.predict_proba(X_test)
# note that the predictions are an array of 3 columns
# first column: the probability of an observation of being of class 0
# second column: the probability of an observation of being of class 1
# third column: the probability of an observation of being of class 2
y_test_logit[0:10, :]
# The final prediction is that of the biggest probabiity
logit.predict(X_test)[0:10]
```
## Precision-Recall Curve
### Per class with Sklearn
```
# with label_binarize we transform the target vector
# into a multi-label matrix, so that it matches the
# outputs of the models
# then we have 1 class per column
y_test = label_binarize(y_test, classes=[0, 1, 2])
y_test[0:10, :]
# now we determine the precision and recall at different thresholds
# considering only the probability vector for class 2 and the true
# target for class 2
# so we treat the problem as class 2 vs rest
p, r, thresholds = precision_recall_curve(y_test[:, 2], y_test_rf[:, 2])
# precision values
p
# recall values
r
# threhsolds examined
thresholds
```
Go ahead and examine the precision and recall for the other classes see how these values change.
```
# now let's do these for all classes and capture the results in
# dictionaries, so we can plot the values afterwards
# determine the Precision and recall
# at various thresholds of probability
# in a 1 vs all fashion, for each class
precision_rf = dict()
recall_rf = dict()
# for each class
for i in range(3):
# determine precision and recall at various thresholds
# in a 1 vs all fashion
precision_rf[i], recall_rf[i], _ = precision_recall_curve(
y_test[:, i], y_test_rf[:, i])
precision_rf
# plot the curves for each class
for i in range(3):
plt.plot(recall_rf[i], precision_rf[i], label='class {}'.format(i))
plt.xlabel("recall")
plt.ylabel("precision")
plt.legend(loc="best")
plt.title("precision vs. recall curve")
plt.show()
# and now for the logistic regression
precision_lg = dict()
recall_lg = dict()
# for each class
for i in range(3):
# determine precision and recall at various thresholds
# in a 1 vs all fashion
precision_lg[i], recall_lg[i], _ = precision_recall_curve(
y_test[:, i], y_test_logit[:, i])
plt.plot(recall_lg[i], precision_lg[i], label='class {}'.format(i))
plt.xlabel("recall")
plt.ylabel("precision")
plt.legend(loc="best")
plt.title("precision vs. recall curve")
plt.show()
# and now, just because it is a bit difficult to compare
# between models, we plot the PR curves class by class,
# but the 2 models in the same plot
# for each class
for i in range(3):
plt.plot(recall_lg[i], precision_lg[i], label='logit class {}'.format(i))
plt.plot(recall_rf[i], precision_rf[i], label='rf class {}'.format(i))
plt.xlabel("recall")
plt.ylabel("precision")
plt.legend(loc="best")
plt.title("precision vs. recall curve for class{}".format(i))
plt.show()
```
We see that the Random Forest does a better job for all classes.
### Micro-average with sklearn
In order to do this, we concatenate all the probability vectors 1 after the other, and so we do with the real values.
```
# probability vectors for all classes in 1-d vector
y_test_rf.ravel()
# see that the unravelled prediction vector has 3 times the size
# of the origina target
len(y_test), len(y_test_rf.ravel())
# A "micro-average": quantifying score on all classes jointly
# for random forests
precision_rf["micro"], recall_rf["micro"], _ = precision_recall_curve(
y_test.ravel(), y_test_rf.ravel(),
)
# for logistic regression
precision_lg["micro"], recall_lg["micro"], _ = precision_recall_curve(
y_test.ravel(), y_test_logit.ravel(),
)
# now we plot them next to each other
i = "micro"
plt.plot(recall_lg[i], precision_lg[i], label='logit micro {}')
plt.plot(recall_rf[i], precision_rf[i], label='rf micro {}')
plt.xlabel("recall")
plt.ylabel("precision")
plt.legend(loc="best")
plt.title("precision vs. recall curve for class{}".format(i))
plt.show()
```
## Yellowbrick
### Per class with Yellobrick
https://www.scikit-yb.org/en/latest/api/classifier/prcurve.html
**Note:**
In the cells below, we are passing to Yellobrick classes a model that is already fit. When we fit() the Yellobrick class, it will check if the model is fit, in which case it will do nothing.
If we pass a model that is not fit, and a multiclass target, Yellowbrick will wrap the model automatically with a 1 vs Rest classifier.
Check Yellobrick's documentation for more details.
```
visualizer = PrecisionRecallCurve(
rf, per_class=True, cmap="cool", micro=False,
)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show() # Finalize and show the figure
visualizer = PrecisionRecallCurve(
logit, per_class=True, cmap="cool", micro=False,
)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show() # Finalize and show the figure
```
### Micro yellowbrick
```
visualizer = PrecisionRecallCurve(
rf, cmap="cool", micro=True,
)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show() # Finalize and show the figure
visualizer = PrecisionRecallCurve(
logit, cmap="cool", micro=True,
)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show() # Finalize and show the figure
```
That's all for PR curves
| github_jupyter |
```
"""Flow around a hole in a porous medium."""
from fenics import *
import numpy as np
def make_mesh(Theta, a, b, nr, nt, s):
mesh = RectangleMesh(Point(a, 0), Point(b, 1),
nr, nt, 'crossed')
# Define markers for Dirichket boundaries
tol = 1E-14
# x=a becomes the inner borehole boundary
class Inner(SubDomain):
def inside(self, x, on_boundary):
return on_boundary and abs(x[0] - a) < tol
# x=b becomes the outer borehole boundary
class Outer(SubDomain):
def inside(self, x, on_boundary):
return on_boundary and abs(x[0] - b) < tol
inner = Inner(); outer = Outer();
markers = MeshFunction('size_t', mesh, mesh.topology().dim() - 1)
markers.set_all(0)
inner.mark(markers, 1)
outer.mark(markers, 2)
# --- Deform mesh ---
# First make a denser mesh towards r=a
x = mesh.coordinates()[:,0]
y = mesh.coordinates()[:,1]
def denser(x, y):
return [a + (b-a)*((x-a)/(b-a))**s, y]
x_bar, y_bar = denser(x, y)
xy_bar_coor = np.array([x_bar, y_bar]).transpose()
mesh.coordinates()[:] = xy_bar_coor
# Then map onto to a "piece of cake"
def cylinder(r, s):
return [r*np.cos(Theta*s), r*np.sin(Theta*s)]
x_hat, y_hat = cylinder(x_bar, y_bar)
xy_hat_coor = np.array([x_hat, y_hat]).transpose()
mesh.coordinates()[:] = xy_hat_coor
return mesh, markers
def solver(
mesh,
markers, # MeshFunctions for Dirichlet conditions
alpha, # Diffusion coefficient
u_a, # Inner pressure
u_b, # Outer pressure
degree, # Element polynomial degree
filename, # Name of VTK file
):
V = FunctionSpace(mesh, 'P', degree)
bc_inner = DirichletBC(V, u_a, markers, 1)
bc_outer = DirichletBC(V, u_b, markers, 2)
bcs = [bc_inner, bc_outer]
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
a = alpha*dot(grad(u), grad(v))*dx
L = Constant(0)*v*dx # L = 0*v*dx = 0 does not work...
# Compute solution
u = Function(V)
solve(a == L, u, bcs)
f = File("mesh.xml")
f << mesh
# Save solution to file in VTK format
vtkfile = File(filename + '.pvd')
vtkfile << u
u.rename('u', 'u'); plot(u); plot(mesh)
import matplotlib.pyplot as plt
plt.show()
return u
def problem():
mesh, markers = make_mesh(Theta=25*pi/180, a=1, b=2,
nr=20, nt=20, s=1.9)
beta = 5
solver(mesh, markers, alpha=1, u_a=1, u_b=0, degree=1, filename='tmp')
if __name__ == '__main__':
problem()
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.model_selection import StratifiedShuffleSplit, cross_val_score, cross_val_predict, GridSearchCV
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
#skill position and matchup data for 2016-2017 nfl season
receivers = pd.read_csv('WKReceiving2016.csv')
rz_receiving = pd.read_csv('RZReceiving2016.csv')
team_off = pd.read_csv('TeamOff2016.csv')
tight_ends = pd.read_csv('WKTE2016.csv')
running_backs = pd.read_csv('WKRB2016.csv')
pass_def = pd.read_csv('PassD16.csv')
run_def = pd.read_csv('RunD16.csv')
#Concat positional data
frames = [receivers, tight_ends, running_backs]
rec = pd.concat(frames)
rec[rec['Pos'] =='TE'].head(10)
#data cleaning
#replace missing data with zero
mask = rec['YAC'] == '-'
column_name = 'YAC'
rec.loc[mask, column_name] = 0
mask = rec['YPT'] == '-'
column_name = 'YPT'
rec.loc[mask, column_name] = 0
mask = rec['YPR'] == '-'
column_name = 'YPR'
rec.loc[mask, column_name] = 0
mask = rec['C %'] == '-'
column_name = 'C %'
rec.loc[mask, column_name] = 0
mask = rec['aDOT'] == '-'
column_name = 'aDOT'
rec.loc[mask, column_name] = 0
rec[rec['Pos'] =='TE'].head(10)
#convert column data to floats
rec['YAC'] = rec['YAC'].astype(float)
rec['YPT'] = rec['YPT'].astype(float)
rec['YPR'] = rec['YPR'].astype(float)
rec['C %'] = rec['C %'].astype(float)
rec['aDOT'] = rec['aDOT'].astype(float)
rec[rec['Pos'] =='TE'].head(10)
#merge matchup and positional data
#run defense
rec = pd.merge(rec, run_def, on=['Opp'], how='inner')
rec.tail(10)
#pass defense
rec = pd.merge(rec, pass_def, on=['Opp'], how='inner')
rec.head(10)
#exploration
#17.8% of samples scored a passing touchdown
#massive effect on fantasy points accured
#more than half of all tds by wide receivers
print('Total: ', rec['TD'].sum())
print('Score: ', rec['Score'].mean())
print('FPTS: ', rec.FPTS.mean())
print('TD0 ', rec[rec['TD']==0].FPTS.mean())
print('TD1 ', rec[rec['TD']==1].FPTS.mean())
print('WR TDs: ', rec[rec['Pos']=='WR'].TD.sum())
print('TE TDs: ', rec[rec['Pos']=='TE'].TD.sum())
print('RB TDs: ', rec[rec['Pos']=='RB'].TD.sum())
#data reflects skill players with atleast one snap, rb waters down frequencies
rec['Pos'].value_counts().to_frame()
#filter for skill players with at least 1 target
rec = rec[rec['Tgt']>0]
rec['Pos'].value_counts().to_frame()
#fantasy points by position
print('WR FPTS: ', rec[rec['Pos']=='WR'].FPTS.mean())
print('TE FPTS: ', rec[rec['Pos']=='TE'].FPTS.mean())
print('RB FPTS: ', rec[rec['Pos']=='RB'].FPTS.mean())
# visual of positional scoring frequency
plt.style.use('seaborn')
f,ax=plt.subplots(figsize=(8,4))
rec['Score'].groupby(rec['Pos']).sum().plot.pie(autopct='%1.1f%%', shadow=True)
ax.set_title('Positional Scoring')
ax.set_ylabel('')
plt.show()
#visual of positional frequency
f,ax=plt.subplots(figsize=(8,4))
sns.countplot('Pos', data=rec)
ax.set_title('Positional Sample')
plt.show()
#length of dataset -- skill players receiving at least one target in a game
print(len(rec))
#WR outpreformed positional frequency relative to scoring frequency -- 63.6% > 50.1%
print('WR frequency: ', 1826/3645)
print('TE frequency: ', 856/3645)
print('RB frequency: ', 963/3645)
#scoring efficiency
#wr ~33% success rate
#te ~25% success rate
#rb ~10% success rate
f,ax=plt.subplots(1,2, figsize=(18,8))
rec['Score'].groupby(rec['Pos']).value_counts().plot.pie(autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Touchdown Success by Position')
ax[0].set_ylabel('')
sns.countplot('Pos', hue='Score', data=rec, ax=ax[1])
ax[1].set_title('TD Success by Position')
plt.show()
#opportunity as a measure of touchdowns is significant across all positions
#this implies scoring requires more than just a positional component
f,ax=plt.subplots(figsize=(9,5))
sns.barplot('Pos','Tgt', data=rec, hue='Score')
ax.set_title('Expected Targets')
plt.show()
#target distance as a weighted measure of opportunity is significant for wr and te in scoring touchdowns
#rb routes are generally shorter patterns, so this is to be expected
f,ax=plt.subplots(figsize=(9,5))
sns.barplot('Pos','aDOT', data=rec, hue='Score')
ax.set_title('Expected aDOT')
plt.show()
#rb average target distance less than one yard
#46.2% increase in target distance observed for scoring outcomes
print('Score=0: ', rec[rec['Score']==0].aDOT.mean())
print('Score=1: ', rec[rec['Score']==1].aDOT.mean())
print('Score=1: ', rec[rec['Pos']=='RB'].aDOT.mean())
print((10.704-7.32)/7.32)
#receiving yards as a function of touchdowns is significant across positions
f,ax=plt.subplots(figsize=(9,5))
sns.barplot('Pos','Yds', data=rec, hue='Score')
ax.set_title('Expected Yards')
plt.show()
#110% average increase in receiving yards for scoring events
print('Score=0: ', rec[rec['Score']==0].Yds.mean())
print('Score=1: ', rec[rec['Score']==1].Yds.mean())
print((60.37-28.76)/28.76)
#receptions as a function of touchdowns is significant across positions
f,ax=plt.subplots(figsize=(9,5))
sns.barplot('Pos','Rec', data=rec, hue='Score')
ax.set_title('Expected Rec')
plt.show()
#68.1% expected increase in receptions for scoring events
print('Score=0: ', rec[rec['Score']==0].Rec.mean())
print('Score=1: ', rec[rec['Score']==1].Rec.mean())
print((4.54-2.7)/2.7)
#opportunity has huge role in touchdown expectation
#average targets for player who scores a touchdown ~ 6
#touchdown expectation for players receiving at least 6 targets = 33%
#this will be the baseline for model evaluation
print('Score=0: ', rec[rec['Score']==0].Tgt.mean())
print('Score=1: ', rec[rec['Score']==1].Tgt.mean())
print((6.32-3.8)/3.8)
print('Targets>=10: ', rec[rec['Tgt']>=6].Score.mean())
#more data cleaning
#convert team names to ordinal rank based on matchup data
#convert position names to arbitrary values for processing
rec['Opp'].replace(['DEN','HST', 'MIN', 'ARZ', 'JAX', 'BUF', 'CHI', 'SEA', 'BLT',
'LA', 'CIN', 'NE', 'PHI', 'SF', 'MIA', 'PIT', 'NYJ', 'KC', 'DET',
'SD', 'CLV', 'TB', 'NYG', 'OAK', 'WAS', 'DAL', 'IND', 'ATL', 'CAR',
'TEN', 'GB', 'NO'], [1, 2, 3 , 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32], inplace=True)
rec['Team'].replace(['ATL', 'NO', 'NE', 'GB', 'DAL', 'ARZ', 'OAK', 'IND', 'SD',
'PIT', 'BUF', 'WAS', 'KC', 'TEN', 'CAR', 'PHI', 'MIA', 'SEA',
'TB', 'DET', 'BLT', 'DEN', 'MIN', 'CIN', 'JAX', 'NYG', 'SF',
'CHI', 'HST', 'NYJ', 'CLV', 'LA'], [1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
11, 12, 13, 14, 15, 16, 17, 18, 19,
20, 21, 22, 23, 24, 25, 26, 27, 28,
29, 30, 31, 32], inplace=True)
rec['Pos'].replace(['WR', 'TE', 'RB'], [0, 1, 2], inplace=True)
print(rec.info())
#convert matchup ranking to a range for better interpretation
rec['Opp_range'] = 0
rec.loc[rec['Opp']<=6, 'Opp_range'] = 0
rec.loc[(rec['Opp']>6) & (rec['Opp']<=12), 'Opp_range'] = 1
rec.loc[(rec['Opp']>12) & (rec['Opp']<=18), 'Opp_range'] = 2
rec.loc[(rec['Opp']>18) & (rec['Opp']<=24), 'Opp_range'] = 3
rec.loc[rec['Opp']>24, 'Opp_range'] = 4
#Reorder features for convenience
data = rec[['Score','Opp_range','Pos', 'Tgt','aDOT','Yds']]
#ready for processing
X=data[['Opp_range','Pos', 'Tgt','aDOT','Yds']] #features
#X=np.c_[X,X.values[:,0]*X.values[:,1]]
y=data['Score'] #label
data.tail(10)
#skill positional scoring less about matchup and more about volume
f,ax = plt.subplots(figsize=(10,10))
corr = data.corr()
cmap = sns.diverging_palette(150,275, as_cmap=True)
sns.heatmap(corr,cmap=cmap, square=True,annot=True)
plt.show()
#how predictive are receivers fantasy output relative to TE in terms of mkt share, etc.
#use groupby week and filter for target threshold in relation to fantasy output rank
#examine fantasy output rank in relation to TD for week - how big is impact of TD on fantasy output rank
#examine variation in volume by position
#examine significance of snaps for TE
#filter volume for TE by week
#filter TD scored relative to volume by week for each position
#examine avg volume per week by position
#examine weekly production of >25 touches for rb
#split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=0)
print(len(X_train))
print(len(X_test))
print(len(y_train))
print(len(y_test))
#train model using accuracy as evaluation metric
accuracy_train=[]
std_dev=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
m=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(),
DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier()]
for i in m:
score = cross_val_score(i, X_train, y_train, cv=3, scoring='accuracy')
accuracy_train.append(score.mean())
std_dev.append(score.std())
mods = pd.DataFrame({'Acc': acc_results, 'Std': std_results}, index=classifiers)
mods
#little variation wrt accuracy for models likely due to skew of dataset towards non-scoring outcomes ~80% of dataset
#train model using f1 score as evaluation metric
#visual of confusion matrix for each classifier
f,ax=plt.subplots(2,4,figsize=(13,7))
pred = cross_val_predict(svm.SVC(kernel='rbf'),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[0,0],annot=True,fmt='2.0f')
ax[0,0].set_title('Matrix for rbf-SVM')
pred = cross_val_predict(svm.SVC(kernel='linear'),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[0,1],annot=True,fmt='2.0f')
ax[0,1].set_title('Matrix for Linear-SVM')
pred = cross_val_predict(KNeighborsClassifier(),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[0,2],annot=True,fmt='2.0f')
ax[0,2].set_title('Matrix for KNN')
pred = cross_val_predict(RandomForestClassifier(),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[0,3],annot=True,fmt='2.0f')
ax[0,3].set_title('Matrix for Random-Forests')
pred = cross_val_predict(LogisticRegression(),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[1,0],annot=True,fmt='2.0f')
ax[1,0].set_title('Matrix for Logistic Regression')
pred = cross_val_predict(DecisionTreeClassifier(),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[1,1],annot=True,fmt='2.0f')
ax[1,1].set_title('Matrix for Decision Tree')
pred = cross_val_predict(GaussianNB(),X_train,y_train,cv=3)
sns.heatmap(metrics.confusion_matrix(y_train,pred),ax=ax[1,2],annot=True,fmt='2.0f')
ax[1,2].set_title('Matrix for Naive Bayes')
plt.subplots_adjust(hspace=0.2,wspace=0.2)
plt.show()
#f-scores for training set
f_scores=[]
classifiers=['Linear Svm','Radial Svm','Logistic Regression','KNN','Decision Tree','Naive Bayes','Random Forest']
m=[svm.SVC(kernel='linear'),svm.SVC(kernel='rbf'),LogisticRegression(),KNeighborsClassifier(),
DecisionTreeClassifier(),GaussianNB(),RandomForestClassifier()]
for i in m:
pred = cross_val_predict(i, X_train, y_train, cv=3)
f_scores.append(metrics.f1_score(y_train, pred))
f_ones = pd.DataFrame({'Models': classifiers ,'F': f_scores})
f_ones
f,ax=plt.subplots(figsize=(12,5))
sns.barplot('Models', 'F', data=f_ones, ci=None)
ax.set_title('F1 Scores')
plt.show()
#hyperparameter tuning and test set evaluation
accuracy = []
f1_scores = []
models = []
accuracy.append(0.33)
f1_scores.append(0.33)
models.append('Baseline')
#logistic reg
model = LogisticRegression()
model.fit(X_train, y_train)
p1 = model.predict(X_test)
print('Logistic Regression accuracy: ', metrics.accuracy_score(p1, y_test))
print('Logistic Regression f1-score: ', metrics.f1_score(y_test, p1))
accuracy.append(0.811197916667)
f1_scores.append(metrics.f1_score(y_test, p1))
models.append('LR')
#SVM hyperparameter tuning
Cs = [0.01 ,0.1, 0.25, 1, 5, 7, 10]
gammas = [0.01, 0.1, 0.25, 0.5, 0.75, 1]
kernels = ['linear', 'rbf']
param_grid = {'C': Cs, 'gamma': gammas, 'kernel': kernels}
grid_search = GridSearchCV(svm.SVC(), param_grid, cv=3)
grid_search.fit(X,y)
print(grid_search.best_params_)
#rbf svm
model = svm.SVC(kernel='rbf', C=5, gamma=0.1)
model.fit(X_train, y_train)
p2 = model.predict(X_test)
print('RBF SVM accuracy: ', metrics.accuracy_score(p2, y_test))
print('RBF SVM f1-score: ', metrics.f1_score(y_test, p2))
accuracy.append(0.807291666667)
f1_scores.append(metrics.f1_score(y_test, p2))
models.append('RBF-SVM')
#Decision Tree hyperparameter tuning
model = DecisionTreeClassifier()
depth = [2, 4, 6, 8, 10]
param_grid = {"max_depth": depth}
grid_search = GridSearchCV(model, param_grid, cv=3)
grid_search.fit(X,y)
print(grid_search.best_params_)
#decision tree
model = DecisionTreeClassifier(max_depth=4)
model.fit(X_train, y_train)
p3 = model.predict(X_test)
print('Decision Tree accuracy: ', metrics.accuracy_score(p3, y_test))
print('Decision Tree f1-score: ', metrics.f1_score(y_test, p3))
accuracy.append(0.791666666667)
f1_scores.append(metrics.f1_score(y_test, p3))
models.append('Decision Tree')
#knn hyperparameter tuning
model = KNeighborsClassifier()
neighbors = list(range(1,21,1))
param_grid = {"n_neighbors": neighbors}
grid_search = GridSearchCV(model, param_grid, cv=3)
grid_search.fit(X,y)
print(grid_search.best_params_)
#knn
model = KNeighborsClassifier(n_neighbors=10)
model.fit(X_train, y_train)
p4 = model.predict(X_test)
print('KNeighbors accuracy: ', metrics.accuracy_score(p4, y_test))
print('KNeighbors f1-score: ', metrics.f1_score(y_test, p4))
accuracy.append(0.802083333333)
f1_scores.append(metrics.f1_score(y_test, p4))
models.append('KNN')
#naive bayes
model = GaussianNB()
model.fit(X_train, y_train)
p5 = model.predict(X_test)
print('GaussianNB accuracy: ', metrics.accuracy_score(p5, y_test))
print('GaussianNB f1-score: ', metrics.f1_score(y_test, p5))
accuracy.append(0.813443072702)
f1_scores.append(metrics.f1_score(y_test, p5))
models.append('GaussianNB')
#random forest
model = RandomForestClassifier()
model.fit(X_train, y_train)
p6 = model.predict(X_test)
print('Random Forest accuracy: ', metrics.accuracy_score(p6, y_test))
print('Random Forest f1-score: ', metrics.f1_score(y_test, p6))
accuracy.append(0.810699588477)
f1_scores.append(metrics.f1_score(y_test, p6))
models.append('Random Forest')
ml_acc_results = pd.DataFrame({'Models': models, 'Results': accuracy})
ml_f1_results = pd.DataFrame({'Models': models, 'Results': f1_scores})
print(models)
print(accuracy)
print(f1_scores)
f,ax=plt.subplots(figsize=(12,5))
sns.barplot('Models','Results', data=ml_acc_results, ci=None)
ax.set_title('Test Set Accuracy')
plt.show()
f,ax=plt.subplots(figsize=(12,5))
sns.barplot('Models','Results', data=ml_f1_results, ci=None)
ax.set_title('Test Set F1 Scores')
plt.show()
```
| github_jupyter |
#### Copyright 2017 Google LLC.
```
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
# Synthetic Features and Outliers
**Learning Objectives:**
* Create a synthetic feature that is the ratio of two other features
* Use this new feature as an input to a linear regression model
* Improve the effectiveness of the model by identifying and clipping (removing) outliers out of the input data
Let's revisit our model from the previous First Steps with TensorFlow exercise.
First, we'll import the California housing data into a *pandas* `DataFrame`:
## Setup
```
from __future__ import print_function
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.metrics as metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.ERROR)
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.1f}'.format
california_housing_dataframe = pd.read_csv("https://storage.googleapis.com/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index))
california_housing_dataframe["median_house_value"] /= 1000.0
california_housing_dataframe
```
Next, we'll set up our input function, and define the function for model training:
```
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
"""Trains a linear regression model of one feature.
Args:
features: pandas DataFrame of features
targets: pandas DataFrame of targets
batch_size: Size of batches to be passed to the model
shuffle: True or False. Whether to shuffle the data.
num_epochs: Number of epochs for which data should be repeated. None = repeat indefinitely
Returns:
Tuple of (features, labels) for next data batch
"""
# Convert pandas data into a dict of np arrays.
features = {key:np.array(value) for key,value in dict(features).items()}
# Construct a dataset, and configure batching/repeating.
ds = Dataset.from_tensor_slices((features,targets)) # warning: 2GB limit
ds = ds.batch(batch_size).repeat(num_epochs)
# Shuffle the data, if specified.
if shuffle:
ds = ds.shuffle(buffer_size=10000)
# Return the next batch of data.
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def train_model(learning_rate, steps, batch_size, input_feature):
"""Trains a linear regression model.
Args:
learning_rate: A `float`, the learning rate.
steps: A non-zero `int`, the total number of training steps. A training step
consists of a forward and backward pass using a single batch.
batch_size: A non-zero `int`, the batch size.
input_feature: A `string` specifying a column from `california_housing_dataframe`
to use as input feature.
Returns:
A Pandas `DataFrame` containing targets and the corresponding predictions done
after training the model.
"""
periods = 10
steps_per_period = steps / periods
my_feature = input_feature
my_feature_data = california_housing_dataframe[[my_feature]].astype('float32')
my_label = "median_house_value"
targets = california_housing_dataframe[my_label].astype('float32')
# Create input functions.
training_input_fn = lambda: my_input_fn(my_feature_data, targets, batch_size=batch_size)
predict_training_input_fn = lambda: my_input_fn(my_feature_data, targets, num_epochs=1, shuffle=False)
# Create feature columns.
feature_columns = [tf.feature_column.numeric_column(my_feature)]
# Create a linear regressor object.
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=feature_columns,
optimizer=my_optimizer
)
# Set up to plot the state of our model's line each period.
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
plt.title("Learned Line by Period")
plt.ylabel(my_label)
plt.xlabel(my_feature)
sample = california_housing_dataframe.sample(n=300)
plt.scatter(sample[my_feature], sample[my_label])
colors = [cm.coolwarm(x) for x in np.linspace(-1, 1, periods)]
# Train the model, but do so inside a loop so that we can periodically assess
# loss metrics.
print("Training model...")
print("RMSE (on training data):")
root_mean_squared_errors = []
for period in range (0, periods):
# Train the model, starting from the prior state.
linear_regressor.train(
input_fn=training_input_fn,
steps=steps_per_period,
)
# Take a break and compute predictions.
predictions = linear_regressor.predict(input_fn=predict_training_input_fn)
predictions = np.array([item['predictions'][0] for item in predictions])
# Compute loss.
root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(predictions, targets))
# Occasionally print the current loss.
print(" period %02d : %0.2f" % (period, root_mean_squared_error))
# Add the loss metrics from this period to our list.
root_mean_squared_errors.append(root_mean_squared_error)
# Finally, track the weights and biases over time.
# Apply some math to ensure that the data and line are plotted neatly.
y_extents = np.array([0, sample[my_label].max()])
weight = linear_regressor.get_variable_value('linear/linear_model/%s/weights' % input_feature)[0]
bias = linear_regressor.get_variable_value('linear/linear_model/bias_weights')
x_extents = (y_extents - bias) / weight
x_extents = np.maximum(np.minimum(x_extents,
sample[my_feature].max()),
sample[my_feature].min())
y_extents = weight * x_extents + bias
plt.plot(x_extents, y_extents, color=colors[period])
print("Model training finished.")
# Output a graph of loss metrics over periods.
plt.subplot(1, 2, 2)
plt.ylabel('RMSE')
plt.xlabel('Periods')
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(root_mean_squared_errors)
# Create a table with calibration data.
calibration_data = pd.DataFrame()
calibration_data["predictions"] = pd.Series(predictions)
calibration_data["targets"] = pd.Series(targets)
display.display(calibration_data.describe())
print("Final RMSE (on training data): %0.2f" % root_mean_squared_error)
return calibration_data
```
## Task 1: Try a Synthetic Feature
Both the `total_rooms` and `population` features count totals for a given city block.
But what if one city block were more densely populated than another? We can explore how block density relates to median house value by creating a synthetic feature that's a ratio of `total_rooms` and `population`.
In the cell below, create a feature called `rooms_per_person`, and use that as the `input_feature` to `train_model()`.
What's the best performance you can get with this single feature by tweaking the learning rate? (The better the performance, the better your regression line should fit the data, and the lower
the final RMSE should be.)
**NOTE**: You may find it helpful to add a few code cells below so you can try out several different learning rates and compare the results. To add a new code cell, hover your cursor directly below the center of this cell, and click **CODE**.
```
#
# YOUR CODE HERE
#
california_housing_dataframe["rooms_per_person"] =
calibration_data = train_model(
learning_rate=0.00005,
steps=500,
batch_size=5,
input_feature="rooms_per_person"
)
```
### Solution
Click below for a solution.
```
california_housing_dataframe["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] / california_housing_dataframe["population"])
calibration_data = train_model(
learning_rate=0.05,
steps=500,
batch_size=5,
input_feature="rooms_per_person")
```
## Task 2: Identify Outliers
We can visualize the performance of our model by creating a scatter plot of predictions vs. target values. Ideally, these would lie on a perfectly correlated diagonal line.
Use Pyplot's [`scatter()`](https://matplotlib.org/gallery/shapes_and_collections/scatter.html) to create a scatter plot of predictions vs. targets, using the rooms-per-person model you trained in Task 1.
Do you see any oddities? Trace these back to the source data by looking at the distribution of values in `rooms_per_person`.
```
# YOUR CODE HERE
```
### Solution
Click below for the solution.
```
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
plt.scatter(calibration_data["predictions"], calibration_data["targets"])
```
The calibration data shows most scatter points aligned to a line. The line is almost vertical, but we'll come back to that later. Right now let's focus on the ones that deviate from the line. We notice that they are relatively few in number.
If we plot a histogram of `rooms_per_person`, we find that we have a few outliers in our input data:
```
plt.subplot(1, 2, 2)
_ = california_housing_dataframe["rooms_per_person"].hist()
```
## Task 3: Clip Outliers
See if you can further improve the model fit by setting the outlier values of `rooms_per_person` to some reasonable minimum or maximum.
For reference, here's a quick example of how to apply a function to a Pandas `Series`:
clipped_feature = my_dataframe["my_feature_name"].apply(lambda x: max(x, 0))
The above `clipped_feature` will have no values less than `0`.
```
# YOUR CODE HERE
```
### Solution
Click below for the solution.
The histogram we created in Task 2 shows that the majority of values are less than `5`. Let's clip `rooms_per_person` to 5, and plot a histogram to double-check the results.
```
california_housing_dataframe["rooms_per_person"] = (
california_housing_dataframe["rooms_per_person"]).apply(lambda x: min(x, 5))
_ = california_housing_dataframe["rooms_per_person"].hist()
```
To verify that clipping worked, let's train again and print the calibration data once more:
```
calibration_data = train_model(
learning_rate=0.05,
steps=500,
batch_size=5,
input_feature="rooms_per_person")
_ = plt.scatter(calibration_data["predictions"], calibration_data["targets"])
```
| github_jupyter |
## A motivating example: harmonic oscillator
### created by Yuying Liu, 11/02/2019
```
# imports
import os
import sys
import torch
import numpy as np
import scipy as sp
from scipy import integrate
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings('ignore')
module_path = os.path.abspath(os.path.join('../../src/'))
if module_path not in sys.path:
sys.path.append(module_path)
import VaryingStepRKNN as net
# # # # # # # # # # # # # # # # # #
# global constants, paths, etc. #
# # # # # # # # # # # # # # # # # #
load_data = False
load_model = False
data_dir = '../data/VaryingStep/Linear/'
model_dir = '../../model/VaryingStep/Linear/'
```
### simulation
```
np.random.seed(2)
train_steps = 10000
test_steps = 2**15
n_train = 500
n_test = 50
n_steps = 5
dt = 0.002;
n = 2
A = np.array([[0, -1], [1, 0]])
def harmonic_oscillator_rhs(x):
# rhs of harmonic oscillator
return A.dot(x)
if load_data:
# # # # # # # # # # # # # # # # # # # #
# load simulated data from directory #
# # # # # # # # # # # # # # # # # # # #
train_data = np.load(os.path.join(data_dir, 'trainBig.npy'))
test_data = np.load(os.path.join(data_dir, 'testBig.npy'))
n_train = train_data.shape[0]
n_test = test_data.shape[0]
else:
# # # # # # # # # # # # # # # # #
# simulate harmonic oscillator #
# # # # # # # # # # # # # # # # #
# simulate training trials
train_data = np.zeros((n_train, train_steps, n))
print('generating training trials ...')
for i in tqdm(range(n_train)):
x_init = np.random.uniform(-1, 1, n)
t = np.linspace(0, (train_steps-1)*dt, train_steps)
sol = sp.integrate.solve_ivp(lambda _, x: harmonic_oscillator_rhs(x), [0, (train_steps-1)*dt], x_init, t_eval=t)
train_data[i, :, :] = sol.y.T
# simulate test trials
test_data = np.zeros((n_test, test_steps, n))
print('generating testing trials ...')
for i in tqdm(range(n_test)):
x_init = np.random.uniform(-1, 1, n)
t = np.linspace(0, (test_steps-1)*dt, test_steps)
sol = sp.integrate.solve_ivp(lambda _, x: harmonic_oscillator_rhs(x), [0, (test_steps-1)*dt], x_init, t_eval=t)
test_data[i, :, :] = sol.y.T
# save data
np.save(os.path.join(data_dir, 'trainBig.npy'), train_data)
np.save(os.path.join(data_dir, 'testBig.npy'), test_data)
```
### visualize & load data
```
# load the data to dataset object
datasets = list()
step_sizes = list()
print('Dt\'s: ')
for i in range(2, 10):
step_size = 2**i
print(step_size * dt)
step_sizes.append(step_size)
datasets.append(net.VaryingStepDataSet(train_data, test_data, dt, n_steps=n_steps, step_size=step_size))
# # # # # # # # #
# visualization #
# # # # # # # # #
# visualize time series & samples
t = np.linspace(0, (test_steps-1)*dt, test_steps)
fig = plt.figure(figsize=(12, 8))
gs = gridspec.GridSpec(nrows=3, ncols=2, hspace=0.5)
ax0 = fig.add_subplot(gs[0, :])
ax0.plot(t, test_data[0, :, :], linewidth=2.0)
ax0.set_title('sampled trajectory', fontsize=20)
ax0.tick_params(axis='both', which='major', labelsize=15)
ax1 = fig.add_subplot(gs[1:, 0])
ax2 = fig.add_subplot(gs[1:, 1])
for i in range(n_train):
ax1.scatter(datasets[0].train_ys[i, 0:100, 0], datasets[0].train_ys[i, 0:100, 1], marker='.', s=30)
ax2.scatter(datasets[-1].train_ys[i, 0:100, 0], datasets[-1].train_ys[i, 0:100, 1], marker='.', s=30)
ax1.set_title('high res samples', fontsize=20)
ax1.tick_params(axis='both', which='major', labelsize=15)
ax2.set_title('low res samples', fontsize=20)
ax2.tick_params(axis='both', which='major', labelsize=15)
```
### RKNN with varying timesteps
```
models = list()
max_epoch=10000
if load_model:
# load the model
for step_size in step_sizes:
models.append(torch.load(os.path.join(model_dir, 'model_D{}.pt'.format(step_size)), map_location='cpu'))
# fix model consistencies trained on gpus (optional)
for model in models:
model.device = 'cpu'
model._modules['vector_field']._modules['activation'] = torch.nn.ReLU()
else:
for (step_size, dataset) in zip(step_sizes, datasets):
# set up the network
model = net.VaryingTimeStepper(arch=[2, 20, 40, 40, 20, 2], dt=dt)
# training
print('training model_D{} ...'.format(step_size))
model.train_net(dataset, max_epoch=max_epoch, batch_size=n_train, lr=1e-3,
model_path=os.path.join(model_dir, 'model_D{}.pt'.format(step_size)))
models.append(model)
# uniscale forecast
n_steps = 1000
preds_mse = list()
criterion = torch.nn.MSELoss(reduction='none')
for (model, dataset) in tqdm(zip(models, datasets)):
y_preds, _ = model.forecast(dataset.test_x, n_steps=n_steps)
preds_mse.append(criterion(dataset.test_ys[:, 0:n_steps, :], y_preds).mean(-1))
# visualize forecasting error at each time step
fig = plt.figure(figsize=(20, 6))
t = [dt*step for step in range(n_steps)]
colors=iter(plt.cm.rainbow(np.linspace(0, 1, 8)))
for k in range(len(preds_mse)):
err = preds_mse[k]
mean = err.mean(0).detach().numpy()
rgb = next(colors)
plt.plot(t, np.log(mean), linestyle='-', color=rgb, linewidth=3.0, label='$\Delta\ t$={}'.format(step_sizes[k]*dt))
plt.legend(fontsize=20, loc='upper right')
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
# multiscale forecast
n_steps = 1000
criterion = torch.nn.MSELoss(reduction='none')
y_preds, _ = net.multiscale_forecast(datasets[0].test_x, n_steps=n_steps, models=models[3:])
multiscale_preds_mse = criterion(datasets[0].test_ys[:, 0:n_steps, :], y_preds).mean(-1)
# visualize multiscale forecasting error at each time step
fig = plt.figure(figsize=(20, 6))
t = [dt*step for step in range(n_steps)]
# visualize forecasting error at each time step
fig = plt.figure(figsize=(20, 6))
t = [dt*step for step in range(n_steps)]
colors=iter(plt.cm.rainbow(np.linspace(0, 1, 8)))
multiscale_err = multiscale_preds_mse.mean(0).detach().numpy()
for k in range(len(preds_mse)):
err = preds_mse[k]
mean = err.mean(0).detach().numpy()
rgb = next(colors)
plt.plot(t, np.log(mean), linestyle='-', color=rgb, linewidth=3.0, alpha=0.5, label='$\Delta\ t$={}'.format(step_sizes[k]*dt))
plt.plot(t, np.log(multiscale_err), linestyle='-', color='k', linewidth=3.0, label='multiscale'.format(step_sizes[0]))
plt.legend(fontsize=20, loc='upper right')
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
```
### Table 1
```
diff_scale_mse = torch.zeros(len(models)+1, len(step_sizes))
for i in range(len(models)):
for j in range(len(step_sizes)):
step_size = step_sizes[j]
diff_scale_mse[i, j] = preds_mse[i][:, 0:5*step_size:step_size].mean()
for j in range(len(step_sizes)):
diff_scale_mse[-1, j] = multiscale_preds_mse[:, 0:5*step_size:step_size].mean()
np.set_printoptions(precision=2, suppress=False)
print(diff_scale_mse.detach().numpy())
```
### Flow maps
```
xvalues, yvalues = np.meshgrid(np.arange(-1.0,1.0,0.02), np.arange(-1.0,1.0,0.02))
inits = np.stack([xvalues, yvalues], 2)
t = [0.] + [10 * dt * step_size for step_size in step_sizes]
flow = np.zeros((inits.shape[0], inits.shape[1], len(t), 2))
for i in range(inits.shape[0]):
for j in range(inits.shape[1]):
init = inits[i, j]
sol = sp.integrate.solve_ivp(lambda _, x: harmonic_oscillator_rhs(x), [0, 10*step_sizes[-1]*dt], init, t_eval=t)
flow[i, j, :] = sol.y.T
to_plots = list()
vmin = float('inf')
vmax = float('-inf')
for i in range(1, len(t)):
vmin = min(np.min(flow[:, :, i, 1] - flow[:, :, 0, 1]), vmin)
vmax = max(np.max(flow[:, :, i, 1] - flow[:, :, 0, 1]), vmax)
to_plots.append((flow[:, :, i, 1] - flow[:, :, 0, 1]))
for im in to_plots:
plt.figure(figsize=(10, 8))
plt.imshow(im, extent=[-1,1,-1,1], vmin=vmin, vmax=vmax)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
# plt.figure(figsize=(10, 8))
# plt.imshow(im, extent=[-1,1,-1,1], vmin=vmin, vmax=vmax)
# plt.xticks(fontsize=20)
# plt.yticks(fontsize=20)
# cbar = plt.colorbar()
# cbar.ax.tick_params(labelsize=20)
```
| github_jupyter |
<a href="https://colab.research.google.com/github/gmshashank/Deep_Flow_Prediction/blob/main/supervised_airfoils_normalized.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Supervised training for RANS flows around airfoils
## Overview
For this example of supervised training
we have a turbulent airflow around wing profiles, and we'd like to know the average motion
and pressure distribution around this airfoil for different Reynolds numbers and angles of attack.
Thus, given an airfoil shape, Reynolds numbers, and angle of attack, we'd like to obtain
a velocity field and a pressure field around the airfoil.
This is classically approximated with _Reynolds-Averaged Navier Stokes_ (RANS) models, and this
setting is still one of the most widely used applications of Navier-Stokes solver in industry.
However, instead of relying on traditional numerical methods to solve the RANS equations,
we now aim for training a surrogate model via a neural network that completely bypasses the numerical solver,
and produces the solution in terms of velocity and pressure.
[[run in colab]](https://colab.research.google.com/github/tum-pbs/pbdl-book/blob/main/supervised-airfoils.ipynb)
## Formulation
With the supervised formulation from {doc}`supervised`, our learning task is pretty straight-forward, and can be written as
$$\begin{aligned}
\text{arg min}_{\theta} \sum_i ( f(x_i ; \theta)-y^*_i )^2 ,
\end{aligned}$$
where $x$ and $y^*$ each consist of a set of physical fields,
and the index $i$ evaluates the difference across all discretization points in our data sets.
The goal is to infer velocity $\mathbf{u} = u_x,u_y$ and a pressure field $p$ in a computational domain $\Omega$
around the airfoil in the center of $\Omega$.
$u_x,u_y$ and $p$ each have a dimension of $128^2$.
As inputs we have the Reynolds number $\text{Re} \in \mathbb{R}$, the angle of attack
$\alpha \in \mathbb{R}$, and the airfoil shape $\mathbf{s}$ encoded as a rasterized grid with $128^2$.
Both constant, scalar inputs $\text{Re}$ and $\alpha$ are likewise extended to a size of $128^2$.
Thus, put together, both input and output have the same dimensions: $x,y^* \in \mathbb{R}^{3\times128\times128}$.
This is exactly what we'll specify as input and output dimensions for the NN below.
A point to keep in mind here is that our quantities of interest in $y^*$ contain three different physical fields. While the two velocity components are quite similar in spirit, the pressure field typically has a different behavior with an approximately squared scaling with respect to the velocity (cf. [Bernoulli](https://en.wikipedia.org/wiki/Bernoulli%27s_principle)). This implies that we need to be careful with simple summations (as in the minimization problem above), and that we should take care to normalize the data.
## Code coming up...
Let's get started with the implementation. Note that we'll skip the data generation process here. The code below is adapted from {cite}`thuerey2020dfp` and [this codebase](https://github.com/thunil/Deep-Flow-Prediction), which you can check out for details. Here, we'll simply download a small set of training data generated with a Spalart-Almaras RANS simulation in [OpenFOAM](https://openfoam.org/).
```
# import numpy as np
# import os.path, random
# import torch
# from torch.utils.data import Dataset
# print("Torch version {}".format(torch.__version__))
# # get training data
# dir = "./"
# if True:
# # download
# if not os.path.isfile('data-airfoils.npz'):
# import requests
# print("Downloading training data (300MB), this can take a few minutes the first time...")
# with open("data-airfoils.npz", 'wb') as datafile:
# resp = requests.get('https://dataserv.ub.tum.de/s/m1615239/download?path=%2F&files=dfp-data-400.npz', verify=False)
# datafile.write(resp.content)
# else:
# # alternative: load from google drive (upload there beforehand):
# from google.colab import drive
# drive.mount('/content/gdrive')
# dir = "./gdrive/My Drive/"
# npfile=np.load(dir+'data-airfoils.npz')
# print("Loaded data, {} training, {} validation samples".format(len(npfile["inputs"]),len(npfile["vinputs"])))
# print("Size of the inputs array: "+format(npfile["inputs"].shape))
```
If you run this notebook in colab, the `else` statement above (which is deactivated by default) might be interesting for you: instead of downloading the training data anew every time, you can manually download it once and store it in your google drive. We assume it's stored in the root directory as `data-airfoils.npz`. Afterwards, you can use the code above to load the file from your google drive, which is typically much faster. This is highly recommended if you want to experiment more extensively via colab.
```
!git clone https://github.com/thunil/Deep-Flow-Prediction.git
%cd /content/Deep-Flow-Prediction
# Reduced data set with 6.4k samples plus test data (1.2GB)
# https://dataserv.ub.tum.de/s/m1470791/download?path=%2F&files=data_6k.tar.gz
import requests
with open("data_6k.tar.gz", 'wb') as datafile:
resp = requests.get('https://dataserv.ub.tum.de/s/m1470791/download?path=%2F&files=data_6k.tar.gz', verify=False)
datafile.write(resp.content)
!tar -xvf data_6k.tar.gz
# # Full data set with 53.8k samples plus test data (10GB):
# # https://dataserv.ub.tum.de/s/m1459172/download?path=%2F&files=data_full.tar.gz
# with open("data_full.tar.gz", 'wb') as datafile:
# resp = requests.get('https://dataserv.ub.tum.de/s/m1459172/download?path=%2F&files=data_full.tar.gz', verify=False)
# datafile.write(resp.content)
# %cd train
# !python ./runTrain.py
```
## Dataset generation using OpenFoam
```
# !git clone https://github.com/thunil/Deep-Flow-Prediction.git
# !pip install torch numpy
# # !apt-get install openfoam5 gmsh
# %%bash
# sh -c "wget -O - http://dl.openfoam.org/gpg.key | apt-key add -"
# add-apt-repository http://dl.openfoam.org/ubuntu
# apt-get update
# apt-get -y install openfoam6 gmsh
# %%bash
# sh -c "wget -O - http://dl.openfoam.org/gpg.key | apt-key add -"
# sh -c "wget -O - http://dl.openfoam.org/gpg.key | apt-key add -"
# add-apt-repository http://dl.openfoam.org/ubuntu
# apt-get update
# apt-get -y install openfoam6
# pip install PyFoam
# apt-get -y install gmsh
# %%bash
# /opt/openfoam6/etc/bashrc
# cp -r $FOAM_TUTORIALS/incompressible/icoFoam/cavity/cavity ./
# %%bash
# ./opt/openfoam6/etc/bashrc
# cd ./cavity
# blockMesh >log.blockMesh 2>&1
# icoFoam >log.icoFoam 2>&1
# ls
# %cd /content/Deep-Flow-Prediction/data
# !./download_airfoils.sh
# !python ./dataGen.py
```
## RANS training data
Now we have some training data. In general it's very important to understand the data we're working with as much as possible (for any ML task the _garbage-in-gargabe-out_ principle definitely holds). We should at least understand the data in terms of dimensions and rough statistics, but ideally also in terms of content. Otherwise we'll have a very hard time interpreting the results of a training run. And despite all the DL magic: if you can't make out any patterns in your data, NNs surely won't find any useful ones.
Hence, let's look at one of the training samples... The following is just some helper code to show images side by side.
```
import pylab
# helper to show three target channels: normalized, with colormap, side by side
def showSbs(a1,a2, stats=False, bottom="NN Output", top="Reference", title=None):
c=[]
for i in range(3):
b = np.flipud( np.concatenate((a2[i],a1[i]),axis=1).transpose())
min, mean, max = np.min(b), np.mean(b), np.max(b);
if stats: print("Stats %d: "%i + format([min,mean,max]))
b -= min; b /= (max-min)
c.append(b)
fig, axes = pylab.subplots(1, 1, figsize=(16, 5))
axes.set_xticks([]); axes.set_yticks([]);
im = axes.imshow(np.concatenate(c,axis=1), origin='upper', cmap='magma')
pylab.colorbar(im); pylab.xlabel('p, ux, uy'); pylab.ylabel('%s %s'%(bottom,top))
if title is not None: pylab.title(title)
# NUM=72
# showSbs(npfile["inputs"][NUM],npfile["targets"][NUM], stats=False, bottom="Target Output", top="Inputs", title="3 inputs are shown at the top (mask, in-ux, in-uy), with the 3 output channels (p,ux,uy) at the bottom")
```
Next, let's define a small helper class `DfpDataset` to organize inputs and targets. We'll transfer the corresponding data to the pytorch `DataLoader` class.
We also set up some globals to control training parameters, maybe most importantly: the learning rate `LR`, i.e. $\eta$ from the previous setions. When your training run doesn't converge this is the first parameter to experiment with.
Here, we'll keep it relatively small throughout. (Using _learning rate decay_ would be better, i.e. potentially give an improved convergence, but is omitted here for clarity.)
```
# # some global training constants
# # number of training epochs
# EPOCHS = 100
# # batch size
# BATCH_SIZE = 10
# # learning rate
# LR = 0.00002
# class DfpDataset():
# def __init__(self, inputs,targets):
# self.inputs = inputs
# self.targets = targets
# def __len__(self):
# return len(self.inputs)
# def __getitem__(self, idx):
# return self.inputs[idx], self.targets[idx]
# tdata = DfpDataset(npfile["inputs"],npfile["targets"])
# vdata = DfpDataset(npfile["vinputs"],npfile["vtargets"])
# trainLoader = torch.utils.data.DataLoader(tdata, batch_size=BATCH_SIZE, shuffle=True , drop_last=True)
# valiLoader = torch.utils.data.DataLoader(vdata, batch_size=BATCH_SIZE, shuffle=False, drop_last=True)
# print("Training & validation batches: {} , {}".format(len(trainLoader),len(valiLoader) ))
################
#
# Deep Flow Prediction - N. Thuerey, K. Weissenov, H. Mehrotra, N. Mainali, L. Prantl, X. Hu (TUM)
#
# Dataset handling
#
################
import torch
from torch.utils.data import Dataset
import numpy as np
from os import listdir
import random
# global switch, use fixed max values for dim-less airfoil data?
fixedAirfoilNormalization = True
# global switch, make data dimensionless?
makeDimLess = True
# global switch, remove constant offsets from pressure channel?
removePOffset = True
## helper - compute absolute of inputs or targets
def find_absmax(data, use_targets, x):
maxval = 0
for i in range(data.totalLength):
if use_targets == 0:
temp_tensor = data.inputs[i]
else:
temp_tensor = data.targets[i]
temp_max = np.max(np.abs(temp_tensor[x]))
if temp_max > maxval:
maxval = temp_max
return maxval
######################################## DATA LOADER #########################################
# also normalizes data with max , and optionally makes it dimensionless #
def LoaderNormalizer(data, isTest = False, shuffle = 0, dataProp = None):
"""
# data: pass TurbDataset object with initialized dataDir / dataDirTest paths
# train: when off, process as test data (first load regular for normalization if needed, then replace by test data)
# dataProp: proportions for loading & mixing 3 different data directories "reg", "shear", "sup"
# should be array with [total-length, fraction-regular, fraction-superimposed, fraction-sheared],
# passing None means off, then loads from single directory
"""
if dataProp is None:
# load single directory
files = listdir(data.dataDir)
files.sort()
for i in range(shuffle):
random.shuffle(files)
if isTest:
print("Reducing data to load for tests")
files = files[0:min(10, len(files))]
data.totalLength = len(files)
data.inputs = np.empty((len(files), 3, 128, 128))
data.targets = np.empty((len(files), 3, 128, 128))
for i, file in enumerate(files):
npfile = np.load(data.dataDir + file)
d = npfile['a']
data.inputs[i] = d[0:3]
data.targets[i] = d[3:6]
print("Number of data loaded:", len(data.inputs) )
else:
# load from folders reg, sup, and shear under the folder dataDir
data.totalLength = int(dataProp[0])
data.inputs = np.empty((data.totalLength, 3, 128, 128))
data.targets = np.empty((data.totalLength, 3, 128, 128))
files1 = listdir(data.dataDir + "reg/")
files1.sort()
files2 = listdir(data.dataDir + "sup/")
files2.sort()
files3 = listdir(data.dataDir + "shear/" )
files3.sort()
for i in range(shuffle):
random.shuffle(files1)
random.shuffle(files2)
random.shuffle(files3)
temp_1, temp_2 = 0, 0
for i in range(data.totalLength):
if i >= (1-dataProp[3])*dataProp[0]:
npfile = np.load(data.dataDir + "shear/" + files3[i-temp_2])
d = npfile['a']
data.inputs[i] = d[0:3]
data.targets[i] = d[3:6]
elif i >= (dataProp[1])*dataProp[0]:
npfile = np.load(data.dataDir + "sup/" + files2[i-temp_1])
d = npfile['a']
data.inputs[i] = d[0:3]
data.targets[i] = d[3:6]
temp_2 = i + 1
else:
npfile = np.load(data.dataDir + "reg/" + files1[i])
d = npfile['a']
data.inputs[i] = d[0:3]
data.targets[i] = d[3:6]
temp_1 = i + 1
temp_2 = i + 1
print("Number of data loaded (reg, sup, shear):", temp_1, temp_2 - temp_1, i+1 - temp_2)
################################## NORMALIZATION OF TRAINING DATA ##########################################
if removePOffset:
for i in range(data.totalLength):
data.targets[i,0,:,:] -= np.mean(data.targets[i,0,:,:]) # remove offset
data.targets[i,0,:,:] -= data.targets[i,0,:,:] * data.inputs[i,2,:,:] # pressure * mask
# make dimensionless based on current data set
if makeDimLess:
for i in range(data.totalLength):
# only scale outputs, inputs are scaled by max only
v_norm = ( np.max(np.abs(data.inputs[i,0,:,:]))**2 + np.max(np.abs(data.inputs[i,1,:,:]))**2 )**0.5
data.targets[i,0,:,:] /= v_norm**2
data.targets[i,1,:,:] /= v_norm
data.targets[i,2,:,:] /= v_norm
# normalize to -1..1 range, from min/max of predefined
if fixedAirfoilNormalization:
# hard coded maxima , inputs dont change
data.max_inputs_0 = 100.
data.max_inputs_1 = 38.12
data.max_inputs_2 = 1.0
# targets depend on normalization
if makeDimLess:
data.max_targets_0 = 4.65
data.max_targets_1 = 2.04
data.max_targets_2 = 2.37
print("Using fixed maxima "+format( [data.max_targets_0,data.max_targets_1,data.max_targets_2] ))
else: # full range
data.max_targets_0 = 40000.
data.max_targets_1 = 200.
data.max_targets_2 = 216.
print("Using fixed maxima "+format( [data.max_targets_0,data.max_targets_1,data.max_targets_2] ))
else: # use current max values from loaded data
data.max_inputs_0 = find_absmax(data, 0, 0)
data.max_inputs_1 = find_absmax(data, 0, 1)
data.max_inputs_2 = find_absmax(data, 0, 2) # mask, not really necessary
print("Maxima inputs "+format( [data.max_inputs_0,data.max_inputs_1,data.max_inputs_2] ))
data.max_targets_0 = find_absmax(data, 1, 0)
data.max_targets_1 = find_absmax(data, 1, 1)
data.max_targets_2 = find_absmax(data, 1, 2)
print("Maxima targets "+format( [data.max_targets_0,data.max_targets_1,data.max_targets_2] ))
data.inputs[:,0,:,:] *= (1.0/data.max_inputs_0)
data.inputs[:,1,:,:] *= (1.0/data.max_inputs_1)
data.targets[:,0,:,:] *= (1.0/data.max_targets_0)
data.targets[:,1,:,:] *= (1.0/data.max_targets_1)
data.targets[:,2,:,:] *= (1.0/data.max_targets_2)
###################################### NORMALIZATION OF TEST DATA #############################################
if isTest:
files = listdir(data.dataDirTest)
files.sort()
data.totalLength = len(files)
data.inputs = np.empty((len(files), 3, 128, 128))
data.targets = np.empty((len(files), 3, 128, 128))
for i, file in enumerate(files):
npfile = np.load(data.dataDirTest + file)
d = npfile['a']
data.inputs[i] = d[0:3]
data.targets[i] = d[3:6]
if removePOffset:
for i in range(data.totalLength):
data.targets[i,0,:,:] -= np.mean(data.targets[i,0,:,:]) # remove offset
data.targets[i,0,:,:] -= data.targets[i,0,:,:] * data.inputs[i,2,:,:] # pressure * mask
if makeDimLess:
for i in range(len(files)):
v_norm = ( np.max(np.abs(data.inputs[i,0,:,:]))**2 + np.max(np.abs(data.inputs[i,1,:,:]))**2 )**0.5
data.targets[i,0,:,:] /= v_norm**2
data.targets[i,1,:,:] /= v_norm
data.targets[i,2,:,:] /= v_norm
data.inputs[:,0,:,:] *= (1.0/data.max_inputs_0)
data.inputs[:,1,:,:] *= (1.0/data.max_inputs_1)
data.targets[:,0,:,:] *= (1.0/data.max_targets_0)
data.targets[:,1,:,:] *= (1.0/data.max_targets_1)
data.targets[:,2,:,:] *= (1.0/data.max_targets_2)
print("Data stats, input mean %f, max %f; targets mean %f , max %f " % (
np.mean(np.abs(data.targets), keepdims=False), np.max(np.abs(data.targets), keepdims=False) ,
np.mean(np.abs(data.inputs), keepdims=False) , np.max(np.abs(data.inputs), keepdims=False) ) )
return data
######################################## DATA SET CLASS #########################################
class TurbDataset(Dataset):
# mode "enum" , pass to mode param of TurbDataset (note, validation mode is not necessary anymore)
TRAIN = 0
TEST = 2
def __init__(self, dataProp=None, mode=TRAIN, dataDir="../data/train/", dataDirTest="../data/test/", shuffle=0, normMode=0):
global makeDimLess, removePOffset
"""
:param dataProp: for split&mix from multiple dirs, see LoaderNormalizer; None means off
:param mode: TRAIN|TEST , toggle regular 80/20 split for training & validation data, or load test data
:param dataDir: directory containing training data
:param dataDirTest: second directory containing test data , needs training dir for normalization
:param normMode: toggle normalization
"""
if not (mode==self.TRAIN or mode==self.TEST):
print("Error - TurbDataset invalid mode "+format(mode) ); exit(1)
if normMode==1:
print("Warning - poff off!!")
removePOffset = False
if normMode==2:
print("Warning - poff and dimless off!!!")
makeDimLess = False
removePOffset = False
self.mode = mode
self.dataDir = dataDir
self.dataDirTest = dataDirTest # only for mode==self.TEST
# load & normalize data
self = LoaderNormalizer(self, isTest=(mode==self.TEST), dataProp=dataProp, shuffle=shuffle)
if not self.mode==self.TEST:
# split for train/validation sets (80/20) , max 400
targetLength = self.totalLength - min( int(self.totalLength*0.2) , 400)
self.valiInputs = self.inputs[targetLength:]
self.valiTargets = self.targets[targetLength:]
self.valiLength = self.totalLength - targetLength
self.inputs = self.inputs[:targetLength]
self.targets = self.targets[:targetLength]
self.totalLength = self.inputs.shape[0]
def __len__(self):
return self.totalLength
def __getitem__(self, idx):
return self.inputs[idx], self.targets[idx]
# reverts normalization
def denormalize(self, data, v_norm):
a = data.copy()
a[0,:,:] /= (1.0/self.max_targets_0)
a[1,:,:] /= (1.0/self.max_targets_1)
a[2,:,:] /= (1.0/self.max_targets_2)
if makeDimLess:
a[0,:,:] *= v_norm**2
a[1,:,:] *= v_norm
a[2,:,:] *= v_norm
return a
# simplified validation data set (main one is TurbDataset above)
class ValiDataset(TurbDataset):
def __init__(self, dataset):
self.inputs = dataset.valiInputs
self.targets = dataset.valiTargets
self.totalLength = dataset.valiLength
def __len__(self):
return self.totalLength
def __getitem__(self, idx):
return self.inputs[idx], self.targets[idx]
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
seed = random.randint(0, 2**32 - 1)
print("Random seed: {}".format(seed))
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if device.type == 'cuda':
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_reserved(0)/1024**3,1), 'GB')
torch.cuda.manual_seed_all(seed)
#torch.backends.cudnn.deterministic=True # warning, slower
print(device)
######## Settings ########
# number of training iterations
# iterations = 10000
# batch size
# batch_size = 10
# learning rate, generator
lrG = 0.0006
# decay learning rate?
decayLr = True
# channel exponent to control network size
expo = 5
# data set config
prop=None # by default, use all from "../data/train"
#prop=[1000,0.75,0,0.25] # mix data from multiple directories
# save txt files with per epoch loss?
saveL1 = False
##########################
prefix = ""
# if len(sys.argv)>1:
# prefix = sys.argv[1]
# print("Output prefix: {}".format(prefix))
dropout = 0. # note, the original runs from https://arxiv.org/abs/1810.08217 used slight dropout, but the effect is minimal; conv layers "shouldn't need" dropout, hence set to 0 here.
doLoad = "" # optional, path to pre-trained model
print("LR: {}".format(lrG))
print("LR decay: {}".format(decayLr))
# print("Iterations: {}".format(iterations))
print("Dropout: {}".format(dropout))
##########################
# some global training constants
# number of training epochs
EPOCHS = 100
# batch size
BATCH_SIZE = 10
# # learning rate
# LR = 0.00002
# create pytorch data object with dfp dataset
data = TurbDataset(prop, shuffle=1,dataDir="data/train/",dataDirTest="data/test/" )
trainLoader = torch.utils.data.DataLoader(data, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
print("Training batches: {}".format(len(trainLoader)))
dataValidation = ValiDataset(data)
valiLoader = torch.utils.data.DataLoader(dataValidation, batch_size=BATCH_SIZE, shuffle=False, drop_last=True)
print("Validation batches: {}".format(len(valiLoader)))
print("Training & validation batches: {} , {}".format(len(trainLoader),len(valiLoader) ))
# EPOCHS = 2
```
## Network setup
Now we can set up the architecture of our neural network, we'll use a fully convolutional U-net. This is a widely used architecture that uses a stack of convolutions across different spatial resolutions. The main deviation from a regular conv-net is to introduce _skip connection_ from the encoder to the decoder part. This ensures that no information is lost during feature extraction. (Note that this only works if the network is to be used as a whole. It doesn't work in situations where we'd, e.g., want to use the decoder as a standalone component.)
Here's a overview of the architecure:

First, we'll define a helper to set up a convolutional block in the network, `blockUNet`. Note, we don't use any pooling! Instead we use strides and transpose convolutions (these need to be symmetric for the decoder part, i.e. have an uneven kernel size), following [best practices](https://distill.pub/2016/deconv-checkerboard/). The full pytroch neural network is managed via the `DfpNet` class.
```
import os, sys, random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.autograd
import torch.utils.data
def blockUNet(in_c, out_c, name, transposed=False, bn=True, relu=True, size=4, pad=1, dropout=0.):
block = nn.Sequential()
if relu:
block.add_module('%s_relu' % name, nn.ReLU(inplace=True))
else:
block.add_module('%s_leakyrelu' % name, nn.LeakyReLU(0.2, inplace=True))
if not transposed:
block.add_module('%s_conv' % name, nn.Conv2d(in_c, out_c, kernel_size=size, stride=2, padding=pad, bias=True))
else:
block.add_module('%s_upsam' % name, nn.Upsample(scale_factor=2, mode='bilinear'))
# reduce kernel size by one for the upsampling (ie decoder part)
block.add_module('%s_tconv' % name, nn.Conv2d(in_c, out_c, kernel_size=(size-1), stride=1, padding=pad, bias=True))
if bn:
block.add_module('%s_bn' % name, nn.BatchNorm2d(out_c))
if dropout>0.:
block.add_module('%s_dropout' % name, nn.Dropout2d( dropout, inplace=True))
return block
class TurbNetG(nn.Module):
def __init__(self, channelExponent=6, dropout=0.):
super(TurbNetG, self).__init__()
channels = int(2 ** channelExponent + 0.5)
self.layer1 = nn.Sequential()
self.layer1.add_module('layer1', nn.Conv2d(3, channels, 4, 2, 1, bias=True))
self.layer2 = blockUNet(channels , channels*2, 'enc_layer2', transposed=False, bn=True, relu=False, dropout=dropout )
self.layer3 = blockUNet(channels*2, channels*2, 'enc_layer3', transposed=False, bn=True, relu=False, dropout=dropout )
self.layer4 = blockUNet(channels*2, channels*4, 'enc_layer4', transposed=False, bn=True, relu=False, dropout=dropout )
self.layer5 = blockUNet(channels*4, channels*8, 'enc_layer5', transposed=False, bn=True, relu=False, dropout=dropout )
self.layer6 = blockUNet(channels*8, channels*8, 'enc_layer6', transposed=False, bn=True, relu=False, dropout=dropout , size=2,pad=0)
self.layer7 = blockUNet(channels*8, channels*8, 'enc_layer7', transposed=False, bn=True, relu=False, dropout=dropout , size=2,pad=0)
# note, kernel size is internally reduced by one for the decoder part
self.dlayer7 = blockUNet(channels*8, channels*8, 'dec_layer7', transposed=True, bn=True, relu=True, dropout=dropout , size=2,pad=0)
self.dlayer6 = blockUNet(channels*16,channels*8, 'dec_layer6', transposed=True, bn=True, relu=True, dropout=dropout , size=2,pad=0)
self.dlayer5 = blockUNet(channels*16,channels*4, 'dec_layer5', transposed=True, bn=True, relu=True, dropout=dropout )
self.dlayer4 = blockUNet(channels*8, channels*2, 'dec_layer4', transposed=True, bn=True, relu=True, dropout=dropout )
self.dlayer3 = blockUNet(channels*4, channels*2, 'dec_layer3', transposed=True, bn=True, relu=True, dropout=dropout )
self.dlayer2 = blockUNet(channels*4, channels , 'dec_layer2', transposed=True, bn=True, relu=True, dropout=dropout )
self.dlayer1 = nn.Sequential()
self.dlayer1.add_module('dec_layer1_relu', nn.ReLU(inplace=True))
self.dlayer1.add_module('dec_layer1_tconv', nn.ConvTranspose2d(channels*2, 3, 4, 2, 1, bias=True))
def forward(self, x):
# note, this Unet stack could be allocated with a loop, of course...
out1 = self.layer1(x)
out2 = self.layer2(out1)
out3 = self.layer3(out2)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
out6 = self.layer6(out5)
out7 = self.layer7(out6)
# ... bottleneck ...
dout6 = self.dlayer7(out7)
dout6_out6 = torch.cat([dout6, out6], 1)
dout6 = self.dlayer6(dout6_out6)
dout6_out5 = torch.cat([dout6, out5], 1)
dout5 = self.dlayer5(dout6_out5)
dout5_out4 = torch.cat([dout5, out4], 1)
dout4 = self.dlayer4(dout5_out4)
dout4_out3 = torch.cat([dout4, out3], 1)
dout3 = self.dlayer3(dout4_out3)
dout3_out2 = torch.cat([dout3, out2], 1)
dout2 = self.dlayer2(dout3_out2)
dout2_out1 = torch.cat([dout2, out1], 1)
dout1 = self.dlayer1(dout2_out1)
return dout1
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
```
Next, we can initialize an instance of the `DfpNet`.
Below, the `EXPO` parameter here controls the exponent for the feature maps of our Unet: this directly scales the network size (3 gives a network with ca. 150k parameters). This is relatively small for a generative NN with $3 \times 128^2 = \text{ca. }49k$ outputs, but yields fast training times and prevents overfitting given the relatively small data set we're using here. Hence it's a good starting point.
```
# channel exponent to control network size
# EXPO = 5
# setup network
netG = TurbNetG(channelExponent=expo, dropout=dropout)
#print(netG) # to double check the details...
nn_parameters = filter(lambda p: p.requires_grad, netG.parameters())
params = sum([np.prod(p.size()) for p in nn_parameters])
# crucial parameter to keep in view: how many parameters do we have?
print("Trainable params: {} -> crucial! always keep in view... ".format(params))
netG.apply(weights_init)
if len(doLoad)>0:
netG.load_state_dict(torch.load(doLoad))
print("Loaded model "+doLoad)
netG.to(device)
criterionL1 = nn.L1Loss()
criterionL1.to(device)
# optimizerG = optim.Adam(netG.parameters(), lr=LR, betas=(0.5, 0.999), weight_decay=0.0)
optimizerG = optim.Adam(netG.parameters(), lr=lrG, betas=(0.5, 0.999), weight_decay=0.0)
inputs = torch.autograd.Variable(torch.FloatTensor(BATCH_SIZE, 3, 128, 128))
inputs = inputs.to(device)
targets = torch.autograd.Variable(torch.FloatTensor(BATCH_SIZE, 3, 128, 128))
targets = targets.to(device)
```
With an exponent of 3, this network has 147555 trainable parameters. As the subtle hint in the print statement indicates, this is a crucial number to always have in view when training NNs. It's easy to change settings, and get a network that has millions of parameters, and as a result probably all kinds of convergence and overfitting problems. The number of parameters definitely has to be matched with the amount of training data, and should also scale with the depth of the network. How these three relate to each other exactly is problem dependent, though.
## Training
Finally, we can train the NN. This step can take a while, as the training runs over all 320 samples 100 times, and continually evaluates the validation samples to keep track of how well the current state of the NN is doing.
```
# history_L1 = []
# history_L1val = []
# if os.path.isfile("network"):
# print("Found existing network, loading & skipping training")
# net.load_state_dict(torch.load("network")) # optionally, load existing network
# else:
# print("Training from scratch")
# for epoch in range(EPOCHS):
# net.train()
# L1_accum = 0.0
# for i, traindata in enumerate(trainLoader, 0):
# inputs_curr, targets_curr = traindata
# inputs.data.copy_(inputs_curr.float())
# targets.data.copy_(targets_curr.float())
# net.zero_grad()
# gen_out = net(inputs)
# lossL1 = criterionL1(gen_out, targets)
# lossL1.backward()
# optimizerG.step()
# L1_accum += lossL1.item()
# # validation
# net.eval()
# L1val_accum = 0.0
# for i, validata in enumerate(valiLoader, 0):
# inputs_curr, targets_curr = validata
# inputs.data.copy_(inputs_curr.float())
# targets.data.copy_(targets_curr.float())
# outputs = net(inputs)
# outputs_curr = outputs.data.cpu().numpy()
# lossL1val = criterionL1(outputs, targets)
# L1val_accum += lossL1val.item()
# # data for graph plotting
# history_L1.append( L1_accum / len(trainLoader) )
# history_L1val.append( L1val_accum / len(valiLoader) )
# # if epoch<3 or epoch%20==0:
# print( "Epoch: {}, L1 train: {:7.5f}, L1 vali: {:7.5f}".format(epoch, history_L1[-1], history_L1val[-1]) )
# torch.save(net.state_dict(), "network" )
# print("Training done, saved network")
print(device)
print(inputs.device)
print(targets.device)
# utils.py
################
#
# Deep Flow Prediction - N. Thuerey, K. Weissenov, H. Mehrotra, N. Mainali, L. Prantl, X. Hu (TUM)
#
# Helper functions for image output
#
################
import math, re, os
import numpy as np
from PIL import Image
from matplotlib import cm
# add line to logfiles
def log(file, line, doPrint=True):
f = open(file, "a+")
f.write(line + "\n")
f.close()
if doPrint: print(line)
# reset log file
def resetLog(file):
f = open(file, "w")
f.close()
# compute learning rate with decay in second half
def computeLR(i,epochs, minLR, maxLR):
if i < epochs*0.5:
return maxLR
e = (i/float(epochs)-0.5)*2.
# rescale second half to min/max range
fmin = 0.
fmax = 6.
e = fmin + e*(fmax-fmin)
f = math.pow(0.5, e)
return minLR + (maxLR-minLR)*f
# image output
def imageOut(filename, _outputs, _targets, saveTargets=False, normalize=False, saveMontage=True):
outputs = np.copy(_outputs)
targets = np.copy(_targets)
s = outputs.shape[1] # should be 128
if saveMontage:
new_im = Image.new('RGB', ( (s+10)*3, s*2) , color=(255,255,255) )
BW_im = Image.new('RGB', ( (s+10)*3, s*3) , color=(255,255,255) )
for i in range(3):
outputs[i] = np.flipud(outputs[i].transpose())
targets[i] = np.flipud(targets[i].transpose())
min_value = min(np.min(outputs[i]), np.min(targets[i]))
max_value = max(np.max(outputs[i]), np.max(targets[i]))
if normalize:
outputs[i] -= min_value
targets[i] -= min_value
max_value -= min_value
outputs[i] /= max_value
targets[i] /= max_value
else: # from -1,1 to 0,1
outputs[i] -= -1.
targets[i] -= -1.
outputs[i] /= 2.
targets[i] /= 2.
if not saveMontage:
suffix = ""
if i==0:
suffix = "_pressure"
elif i==1:
suffix = "_velX"
else:
suffix = "_velY"
im = Image.fromarray(cm.magma(outputs[i], bytes=True))
im = im.resize((512,512))
im.save(filename + suffix + "_pred.png")
im = Image.fromarray(cm.magma(targets[i], bytes=True))
if saveTargets:
im = im.resize((512,512))
im.save(filename + suffix + "_target.png")
if saveMontage:
im = Image.fromarray(cm.magma(targets[i], bytes=True))
new_im.paste(im, ( (s+10)*i, s*0))
im = Image.fromarray(cm.magma(outputs[i], bytes=True))
new_im.paste(im, ( (s+10)*i, s*1))
im = Image.fromarray(targets[i] * 256.)
BW_im.paste(im, ( (s+10)*i, s*0))
im = Image.fromarray(outputs[i] * 256.)
BW_im.paste(im, ( (s+10)*i, s*1))
imE = Image.fromarray( np.abs(targets[i]-outputs[i]) * 10. * 256. )
BW_im.paste(imE, ( (s+10)*i, s*2))
if saveMontage:
new_im.save(filename + ".png")
BW_im.save( filename + "_bw.png")
# save single image
def saveAsImage(filename, field_param):
field = np.copy(field_param)
field = np.flipud(field.transpose())
min_value = np.min(field)
max_value = np.max(field)
field -= min_value
max_value -= min_value
field /= max_value
im = Image.fromarray(cm.magma(field, bytes=True))
im = im.resize((512, 512))
im.save(filename)
# read data split from command line
def readProportions():
flag = True
while flag:
input_proportions = input("Enter total numer for training files and proportions for training (normal, superimposed, sheared respectively) seperated by a comma such that they add up to 1: ")
input_p = input_proportions.split(",")
prop = [ float(x) for x in input_p ]
if prop[1] + prop[2] + prop[3] == 1:
flag = False
else:
print( "Error: poportions don't sum to 1")
print("##################################")
return(prop)
# helper from data/utils
def makeDirs(directoryList):
for directory in directoryList:
if not os.path.exists(directory):
os.makedirs(directory)
history_L1 = []
history_L1val = []
if os.path.isfile("network"):
print("Found existing network, loading & skipping training")
net.load_state_dict(torch.load("network")) # optionally, load existing network
else:
print("Training from scratch")
for epoch in range(EPOCHS):
# print("Starting epoch {} / {}".format((epoch+1),EPOCHS))
netG.train()
L1_accum = 0.0
for i, traindata in enumerate(trainLoader, 0):
inputs_cpu, targets_cpu = traindata
targets_cpu, inputs_cpu = targets_cpu.float().cuda(), inputs_cpu.float().cuda()
inputs.data.resize_as_(inputs_cpu).copy_(inputs_cpu)
targets.data.resize_as_(targets_cpu).copy_(targets_cpu)
# compute LR decay
if decayLr:
# currLr = utils.computeLR(epoch, EPOCHS, lrG*0.1, lrG)
currLr = computeLR(epoch, EPOCHS, lrG*0.1, lrG)
if currLr < lrG:
for g in optimizerG.param_groups:
g['lr'] = currLr
netG.zero_grad()
gen_out = netG(inputs)
lossL1 = criterionL1(gen_out, targets)
lossL1.backward()
optimizerG.step()
L1_accum += lossL1.item()
# validation
netG.eval()
L1val_accum = 0.0
for i, validata in enumerate(valiLoader, 0):
inputs_cpu, targets_cpu = validata
targets_cpu, inputs_cpu = targets_cpu.float().cuda(), inputs_cpu.float().cuda()
inputs.data.resize_as_(inputs_cpu).copy_(inputs_cpu)
targets.data.resize_as_(targets_cpu).copy_(targets_cpu)
outputs = netG(inputs)
outputs_cpu = outputs.data.cpu().numpy()
lossL1val = criterionL1(outputs, targets)
L1val_accum += lossL1val.item()
if i==0:
input_ndarray = inputs_cpu.cpu().numpy()[0]
v_norm = ( np.max(np.abs(input_ndarray[0,:,:]))**2 + np.max(np.abs(input_ndarray[1,:,:]))**2 )**0.5
outputs_denormalized = data.denormalize(outputs_cpu[0], v_norm)
targets_denormalized = data.denormalize(targets_cpu.cpu().numpy()[0], v_norm)
# utils.makeDirs(["results_train"])
# utils.imageOut("results_train/epoch{}_{}".format(epoch, i), outputs_denormalized, targets_denormalized, saveTargets=True)
makeDirs(["results_train"])
imageOut("results_train/epoch{}_{}".format(epoch, i), outputs_denormalized, targets_denormalized, saveTargets=True)
# data for graph plotting
history_L1.append( L1_accum / len(trainLoader) )
history_L1val.append( L1val_accum / len(valiLoader) )
# if epoch<3 or epoch%20==0:
print( f"Epoch: {epoch+1}, L1 train: {history_L1[-1]}, L1 vali: {history_L1val[-1]}")
if (epoch+1)%20==0:
# torch.save(netG.state_dict(), f"network_{epoch+1}" )
torch.save({
'epoch': epoch,
'model_state_dict': netG.state_dict(),
'optimizer_state_dict': optimizerG.state_dict(),
'loss': lossL1,
...
}, f"network_{epoch+1}.pth")
torch.save(netG.state_dict(), "network" )
print("Training done, saved network")
```
The NN is finally trained! The losses should have nicely gone down in terms of absolute values: With the standard settings from an initial value of around 0.2 for the validation loss, to ca. 0.02 after 100 epochs.
Let's look at the graphs to get some intuition for how the training progressed over time. This is typically important to identify longer-term trends in the training. In practice it's tricky to spot whether the overall trend of 100 or so noisy numbers in a command line log is going slightly up or down - this is much easier to spot in a visualization.
```
import matplotlib.pyplot as plt
l1train = np.asarray(history_L1)
l1vali = np.asarray(history_L1val)
plt.plot(np.arange(l1train.shape[0]),l1train,'b',label='Training loss')
plt.plot(np.arange(l1vali.shape[0] ),l1vali ,'g',label='Validation loss')
plt.legend()
plt.show()
```
You should see a curve that goes down for ca. 40 epochs, and then starts to flatten out. In the last part, it's still slowly decreasing, and most importantly, the validation loss is not increasing. This would be a certain sign of overfitting, and something that we should avoid. (Try decreasing the amount of training data artificially, then you should be able to intentionally cause overfitting.)
## Training progress and validation
If you look closely at this graph, you should spot something peculiar:
_Why is the validation loss lower than the training loss_?
The data is similar to the training data of course, but in a way it's slightly "tougher", because the network certainly never received any validation samples during training. It is natural that the validation loss slightly deviates from the training loss, but how can the L1 loss be _lower_ for these inputs?
This is a subtlety of the training loop above: it runs a training step first, and the loss for each point in the graph is measured with the evolving state of the network in an epoch. The network is updated, and afterwards runs through the validation samples. Thus all validation samples are using a state that is definitely different (and hopefully a bit better) than the initial states of the epoch. Hence, the validation loss can be slightly lower.
A general word of caution here: never evaluate your network with training data! That won't tell you much because overfitting is a very common problem. At least use data the network hasn't seen before, i.e. validation data, and if that looks good, try some more different (at least slightly out-of-distribution) inputs, i.e., _test data_. The next cell runs the trained network over the validation data, and displays one of them with the `showSbs` function.
```
netG.eval()
for i, validata in enumerate(valiLoader, 0):
inputs_curr, targets_curr = validata
inputs.data.copy_(inputs_curr.float())
targets.data.copy_(targets_curr.float())
outputs = netG(inputs)
outputs_curr = outputs.data.cpu().numpy()
if i<1: showSbs(targets_curr[0] , outputs_curr[0], title="Validation sample %d"%(i*BATCH_SIZE))
```
Visually, there should at least be a rough resemblance here between input out network output. We'll save the more detailed evaluation for the test data, though.
## Test evaluation
Now let's look at actual test samples: In this case we'll use new airfoil shapes as out-of-distribution (OOD) data. These are shapes that the network never saw in any training samples, and hence it tells us a bit about how well the NN generalizes to unseen inputs (the validation data wouldn't suffice to draw conclusions about generalization).
We'll use the same visualization as before, and as indicated by the Bernoulli equation, especially the _pressure_ in the first column is a challenging quantity for the network. Due to it's cubic scaling w.r.t. the input freestream velocity and localized peaks, it is the toughest quantity to infer for the network.
The cell below first downloads a smaller archive with these test data samples, and then runs them through the network. The evaluation loop also computes the accumulated L1 error such that we can quantify how well the network does on the test samples.
```
# testdata = TurbDataset(prop, shuffle=1,mode=2, dataDir="data/train/",dataDirTest="data/test/" )
# testLoader = torch.utils.data.DataLoader(testdata, batch_size=1, shuffle=False, drop_last=True)
# print("Training batches: {}".format(len(testLoader)))
# if not os.path.isfile('data-airfoils-test.npz'):
# import urllib.request
# url="https://physicsbaseddeeplearning.org/data/data_test.npz"
# print("Downloading test data, this should be fast...")
# urllib.request.urlretrieve(url, 'data-airfoils-test.npz')
# nptfile=np.load('data-airfoils-test.npz')
# print("Loaded {}/{} test samples\n".format(len(nptfile["test_inputs"]),len(nptfile["test_targets"])))
# testdata = DfpDataset(nptfile["test_inputs"],nptfile["test_targets"])
testdata = TurbDataset(prop, shuffle=1,mode=2, dataDir="data/train/",dataDirTest="data/test/" )
testLoader = torch.utils.data.DataLoader(testdata, batch_size=1, shuffle=False, drop_last=True)
netG.eval()
L1t_accum = 0.
for i, validata in enumerate(testLoader, 0):
inputs_curr, targets_curr = validata
inputs.data.copy_(inputs_curr.float())
targets.data.copy_(targets_curr.float())
outputs = netG(inputs)
outputs_curr = outputs.data.cpu().numpy()
lossL1t = criterionL1(outputs, targets)
L1t_accum += lossL1t.item()
if i<3: showSbs(targets_curr[0] , outputs_curr[0], title="Test sample %d"%(i))
print("\nAverage test error: {}".format( L1t_accum/len(testLoader) ))
```
The average test error with the default settings should be ca. 0.03. As the inputs are normalized, this means the average error across all three fields is 3% w.r.t. the maxima of each quantity. This is not too bad for new shapes, but clearly leaves room for improvement.
Looking at the visualizations, you'll notice that especially high-pressure peaks and pockets of larger y-velocities are missing in the outputs. This is primarily caused by the small network, which does not have enough resources to reconstruct details.
Nonetheless, we have successfully replaced a fairly sophisticated RANS solver with a very small and fast neural network architecture. It has GPU support "out-of-the-box" (via pytorch), is differentiable, and introduces an error of only a few per-cent.
---
## Next steps
There are many obvious things to try here (see the suggestions below), e.g. longer training, larger data sets, larger networks etc.
* Experiment with learning rate, dropout, and network size to reduce the error on the test set. How small can you make it with the given training data?
* The setup above uses normalized data. Instead you can recover [the original fields by undoing the normalization](https://github.com/thunil/Deep-Flow-Prediction) to check how well the network does w.r.t. the original quantities.
* As you'll see, it's a bit limited here what you can get out of this dataset, head over to [the main github repo of this project](https://github.com/thunil/Deep-Flow-Prediction) to download larger data sets, or generate own data.
```
torch.save({
'epoch': epoch,
'model_state_dict': netG.state_dict(),
'optimizer_state_dict': optimizerG.state_dict(),
'loss': lossL1,
# ...
}, f"network_{epoch+1}.pth")
!zip results_train.zip /content/Deep-Flow-Prediction/results_train/*
```
| github_jupyter |
Decoding with ANOVA + SVM: face vs house in the Haxby dataset
===============================================================
This example does a simple but efficient decoding on the Haxby dataset:
using a feature selection, followed by an SVM.
```
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
%matplotlib inline
```
Retrieve the files of the Haxby dataset
----------------------------------------
```
from nilearn import datasets
# By default 2nd subject will be fetched
haxby_dataset = datasets.fetch_haxby()
# print basic information on the dataset
print('Mask nifti image (3D) is located at: %s' % haxby_dataset.mask)
print('Functional nifti image (4D) is located at: %s' %
haxby_dataset.func[0])
```
Load the behavioral data
-------------------------
```
import pandas as pd
# Load target information as string and give a numerical identifier to each
behavioral = pd.read_csv(haxby_dataset.session_target[0], sep=" ")
conditions = behavioral['labels']
# Restrict the analysis to faces and places
condition_mask = behavioral['labels'].isin(['face', 'house'])
conditions = conditions[condition_mask]
# Confirm that we now have 2 conditions
print(conditions.unique())
# Record these as an array of sessions, with fields
# for condition (face or house) and run
session = behavioral[condition_mask].to_records(index=False)
print(session.dtype.names)
```
Prepare the fMRI data: smooth and apply the mask
-------------------------------------------------
```
from nilearn.input_data import NiftiMasker
mask_filename = haxby_dataset.mask
# For decoding, standardizing is often very important
# note that we are also smoothing the data
masker = NiftiMasker(mask_img=mask_filename, smoothing_fwhm=4,
standardize=True, memory="nilearn_cache", memory_level=1)
func_filename = haxby_dataset.func[0]
X = masker.fit_transform(func_filename)
# Apply our condition_mask
X = X[condition_mask]
```
Build the decoder
------------------
Define the prediction function to be used.
Here we use a Support Vector Classification, with a linear kernel
```
from sklearn.svm import SVC
svc = SVC(kernel='linear')
# Define the dimension reduction to be used.
# Here we use a classical univariate feature selection based on F-test,
# namely Anova. When doing full-brain analysis, it is better to use
# SelectPercentile, keeping 5% of voxels
# (because it is independent of the resolution of the data).
from sklearn.feature_selection import SelectPercentile, f_classif
feature_selection = SelectPercentile(f_classif, percentile=5)
# We have our classifier (SVC), our feature selection (SelectPercentile),and now,
# we can plug them together in a *pipeline* that performs the two operations
# successively:
from sklearn.pipeline import Pipeline
anova_svc = Pipeline([('anova', feature_selection), ('svc', svc)])
```
Fit the decoder and predict
----------------------------
```
anova_svc.fit(X, conditions)
y_pred = anova_svc.predict(X)
```
Obtain prediction scores via cross validation
-----------------------------------------------
```
from sklearn.model_selection import LeaveOneGroupOut, cross_val_score
# Define the cross-validation scheme used for validation.
# Here we use a LeaveOneGroupOut cross-validation on the session group
# which corresponds to a leave-one-session-out
cv = LeaveOneGroupOut()
# Compute the prediction accuracy for the different folds (i.e. session)
cv_scores = cross_val_score(anova_svc, X, conditions, cv=cv, groups=session)
# Return the corresponding mean prediction accuracy
classification_accuracy = cv_scores.mean()
# Print the results
print("Classification accuracy: %.4f / Chance level: %f" %
(classification_accuracy, 1. / len(conditions.unique())))
# Classification accuracy: 0.70370 / Chance level: 0.5000
```
Visualize the results
----------------------
Look at the SVC's discriminating weights
```
coef = svc.coef_
# reverse feature selection
coef = feature_selection.inverse_transform(coef)
# reverse masking
weight_img = masker.inverse_transform(coef)
# Use the mean image as a background to avoid relying on anatomical data
from nilearn import image
mean_img = image.mean_img(func_filename)
# Create the figure
from nilearn.plotting import plot_stat_map, show
plot_stat_map(weight_img, mean_img, title='SVM weights')
# Saving the results as a Nifti file may also be important
weight_img.to_filename('haxby_face_vs_house.nii')
show()
```
***Exercise:***
What do you see?
| github_jupyter |
# Python Flair Basics
**(C) 2018-2020 by [Damir Cavar](http://damir.cavar.me/)**
**Version:** 0.3, February 2020
**Download:** This and various other Jupyter notebooks are available from my [GitHub repo](https://github.com/dcavar/python-tutorial-for-ipython).
**License:** [Creative Commons Attribution-ShareAlike 4.0 International License](https://creativecommons.org/licenses/by-sa/4.0/) ([CA BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
This material was used in my Advanced Topics in AI class, introduction to Deep Learning environments in Spring 2019 at Indiana University.
Two types of central objects:
- Sentence
- Token
A Sentence holds a textual sentence and is essentially a list of Token objects.
For creating a Sentence object we first import the Sentence class from the *flair.data* module:
```
from flair.data import Sentence
```
We can now define a sentence:
```
sentence = Sentence('The grass is green .')
print(sentence)
```
We can access the tokens of a sentence via their token id or with their index:
```
print(sentence.get_token(4))
print(sentence[3])
```
We can also iterate over all tokens in a sentence:
```
for token in sentence:
print(token)
```
## Tokenization
There is a simple tokenizer included in the library using the lightweight segtok library to tokenize your text for such a Sentence definition. In the Sentence constructor use the flag *use_tokenize* to tokenize the input string before instantiating a Sentence object:
```
sentence = Sentence('The grass is green.', use_tokenizer=True)
print(sentence)
```
## Tags on Tokens
A Token has fields for linguistic annotation:
- lemma
- part-of-speech tag
- named entity tag
We can add a tag by specifying the tag type and the tag value.
We will adding an NER tag of type 'color' to the word 'green'. This means that we've tagged this word as an entity of type color:
```
sentence[3].add_tag('ner', 'color')
print(sentence.to_tagged_string())
```
Each tag is of class Label. An associated score indicates confidence:
```
from flair.data import Label
tag: Label = sentence[3].get_tag('ner')
print(f'"{sentence[3]}" is tagged as "{tag.value}" with confidence score "{tag.score}"')
```
The manually added color tag has a score of 1.0. A tag predicted by a sequence labeler will have a score value that indicates the classifier confidence.
A Sentence can have one or multiple labels that can for example be used in text classification tasks. For instance, the example below shows how we add the label 'sports' to a sentence, thereby labeling it as belonging to the sports category.
```
sentence = Sentence('France is the current world cup winner.')
sentence.add_label('sports')
sentence.add_labels(['sports', 'world cup'])
sentence = Sentence('France is the current world cup winner.', labels=['sports', 'world cup'])
```
Labels are also of the Label class. So, you can print a sentence's labels like this:
```
sentence = Sentence('France is the current world cup winner.', labels=['sports', 'world cup'])
print(sentence)
for label in sentence.labels:
print(label)
```
## Tagging Text
### Using Pre-Trained Sequence Tagging Models
Flair has numerous pre-trained models. For the named entity recognition (NER) task there is a model that was trained on the English CoNLL-03 task and can recognize 4 different entity types. Import it using:
```
from flair.models import SequenceTagger
tagger = SequenceTagger.load('ner')
```
We use the predict() method of the tagger on a sentence to add predicted tags to the tokens in the sentence:
```
sentence = Sentence('Washington went to New York .')
tagger.predict(sentence)
print(sentence.to_tagged_string())
```
Getting annotated spans for multi-word expressions can be achieved using the following command:
```
for entity in sentence.get_spans('ner'):
print(entity)
```
Which indicates that "George Washington" is a person (PER) and "Washington" is a location (LOC). Each such Span has a text, a tag value, its position in the sentence and "score" that indicates how confident the tagger is that the prediction is correct. You can also get additional information, such as the position offsets of each entity in the sentence by calling:
```
print(sentence.to_dict(tag_type='ner'))
print(sentence.to_dict())
```
Flair contains various sequence tagger models. You choose which pre-trained model you load by passing the appropriate string to the load() method of the SequenceTagger class. Currently, the following pre-trained models are provided:
As indicated in the list above, we also provide pre-trained models for languages other than English. Currently, we support German, French, and Dutch other languages are forthcoming. To tag a German sentence, just load the appropriate model:
```
tagger = SequenceTagger.load('de-ner')
sentence = Sentence('George Washington ging nach Washington .')
tagger.predict(sentence)
print(sentence.to_tagged_string())
```
Flair offers access to multi-lingual models for multi-lingual text.
```
tagger = SequenceTagger.load('pos-multi')
sentence = Sentence('George Washington lebte in Washington . Dort kaufte er a horse .')
tagger.predict(sentence)
print(sentence.to_tagged_string())
```
## Semantic Frames
For English, Flair provides a pre-trained model that detects semantic frames in text, trained using Propbank 3.0 frames. This provides some sort of word sense disambiguation for frame evoking words.
```
tagger = SequenceTagger.load('frame')
sentence_1 = Sentence('George returned to Berlin to return his hat .')
sentence_2 = Sentence('He had a look at different hats .')
tagger.predict(sentence_1)
tagger.predict(sentence_2)
print(sentence_1.to_tagged_string())
print(sentence_2.to_tagged_string())
```
The frame detector makes a distinction in sentence 1 between two different meanings of the word 'return'. 'return.01' means returning to a location, while 'return.02' means giving something back.
Similarly, in sentence 2 the frame detector finds a light verb construction in which 'have' is the light verb and 'look' is a frame evoking word.
## Sentence Tagging
To tag an entire text corpus, one needs to split the corpus into sentences and pass a list of Sentence objects to the .predict() method.
```
text = "This is a sentence. John read a book. This is another sentence. I love Berlin."
from segtok.segmenter import split_single
sentences = [Sentence(sent, use_tokenizer=True) for sent in split_single(text)]
tagger: SequenceTagger = SequenceTagger.load('ner')
tagger.predict(sentences)
for i in sentences:
print(i.to_tagged_string())
```
Using the mini_batch_size parameter of the .predict() method, you can set the size of mini batches passed to the tagger. Depending on your resources, you might want to play around with this parameter to optimize speed.
## Pre-Trained Text Classification Models
Flair provides a pre-trained model for detecting positive or negative comments. It was trained on the IMDB dataset and it can recognize positive and negative sentiment in English text. The IMDB data set can be downloaded from the [linked site](http://ai.stanford.edu/~amaas/data/sentiment/).
```
from flair.models import TextClassifier
classifier = TextClassifier.load('en-sentiment')
```
We call the predict() method of the classifier on a sentence. This will add the predicted label to the sentence:
```
sentence = Sentence('This film hurts. It is so bad that I am confused.')
classifier.predict(sentence)
print(sentence.labels)
sentence = Sentence('This film is fantastic. I love it.')
classifier.predict(sentence)
print(sentence.labels)
```
Flair has a pre-trained German and English model.
## Using Word Embeddings
Flair provides a set of classes with which we can embed the words in sentences in various ways.
All word embedding classes inherit from the TokenEmbeddings class and implement the embed() method which we need to call to embed our text. This means that for most users of Flair, the complexity of different embeddings remains hidden behind this interface. Simply instantiate the embedding class we require and call embed() to embed our text.
All embeddings produced with Flair's methods are Pytorch vectors, so they can be immediately used for training and fine-tuning.
Classic word embeddings are static and word-level, meaning that each distinct word gets exactly one pre-computed embedding. Most embeddings fall under this class, including the popular GloVe or Komninos embeddings.
We instantiate the WordEmbeddings class and pass a string identifier of the embedding we wish to load. If we want to use GloVe embeddings, we pass the string 'glove' to the constructor:
```
from flair.embeddings import WordEmbeddings
glove_embedding = WordEmbeddings('glove')
```
We create an example sentence and call the embedding's embed() method. We can also pass a list of sentences to this method since some embedding types make use of batching to increase speed.
```
sentence = Sentence('The grass is green .')
glove_embedding.embed(sentence)
for token in sentence:
print(token)
print(token.embedding)
```
GloVe embeddings are Pytorch vectors of dimensionality 100.
We choose which pre-trained embeddings we want to load by passing the appropriate id string to the constructor of the WordEmbeddings class. We would use the two-letter language code to init an embedding, so 'en' for English and 'de' for German and so on. By default, this will initialize FastText embeddings trained over Wikipedia. We can also always use FastText embeddings over Web crawls, by instantiating with '-crawl'. The 'de-crawl' option would use embeddings trained over German web crawls.
For English, Flair provides a few more options. We can choose between instantiating 'en-glove', 'en-extvec' and so on.
If we want to load German FastText embeddings, instantiate as follows:
```
german_embedding = WordEmbeddings('de')
```
If we want to load German FastText embeddings trained over crawls, we instantiate as follows:
```
german_embedding = WordEmbeddings('de-crawl')
```
If the models are not locally available, Flair will automatically download them and install them into the local user cache.
It is recommended to use the FastText embeddings, or GloVe if we want a smaller model.
If we want to use any other embeddings (not listed in the list above), we can load those by calling:
```
custom_embedding = WordEmbeddings('path/to/your/custom/embeddings.gensim')
```
If we want to load custom embeddings, we need to make sure that the custom embeddings are correctly formatted to gensim.
We can, for example, convert FastText embeddings to gensim using the following code snippet:
```
import gensim
word_vectors = gensim.models.KeyedVectors.load_word2vec_format('/path/to/fasttext/embeddings.txt', binary=False)
word_vectors.save('/path/to/converted')
```
## Character Embeddings
Some embeddings - such as character-features - are not pre-trained but rather trained on the downstream task. Normally this requires an implementation of a hierarchical embedding architecture.
With Flair, we don't need to worry about such things. Just choose the appropriate embedding class and the character features will then automatically train during downstream task training.
```
from flair.embeddings import CharacterEmbeddings
embedding = CharacterEmbeddings()
sentence = Sentence('The grass is green .')
embedding.embed(sentence)
```
### Sub-Word Embeddings
Flair now also includes the byte pair embeddings calulated by @bheinzerling that segment words into subsequences. This can dramatically reduce the model size vis-a-vis using normal word embeddings at nearly the same accuracy. So, if we want to train small models try out the new BytePairEmbeddings class.
We initialize with a language code (275 languages supported), a number of 'syllables', and a number of dimensions (one of 50, 100, 200 or 300). The following initializes and uses byte pair embeddings for English:
```
from flair.embeddings import BytePairEmbeddings
embedding = BytePairEmbeddings('en')
sentence = Sentence('The grass is green .')
embedding.embed(sentence)
```
[Sub-word embeddings](https://nlp.h-its.org/bpemb/) are interesting, since
[BPEmb](https://nlp.h-its.org/bpemb/) is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
- subwords allow guessing the meaning of unknown / out-of-vocabulary words. E.g., the suffix -shire in Melfordshire indicates a location.
- Byte-Pair Encoding gives a subword segmentation that is often good enough, without requiring tokenization or morphological analysis. In this case the BPE segmentation might be something like melf ord shire.
- Pre-trained byte-pair embeddings work surprisingly well, while requiring no tokenization and being much smaller than alternatives: an 11 MB BPEmb English model matches the results of the 6 GB FastText model in our evaluation.
If you are using word embeddings like word2vec or GloVe, you have probably encountered out-of-vocabulary words, i.e., words for which no embedding exists. A makeshift solution is to replace such words with an UNK token and train a generic embedding representing such unknown words.
Subword approaches try to solve the unknown word problem differently, by assuming that you can reconstruct a word's meaning from its parts. For example, the suffix -shire lets you guess that Melfordshire is probably a location, or the suffix -osis that Myxomatosis might be a sickness.
There are many ways of splitting a word into subwords. A simple method is to split into characters and then learn to transform this character sequence into a vector representation by feeding it to a convolutional neural network (CNN) or a recurrent neural network (RNN), usually a long-short term memory (LSTM). This vector representation can then be used like a word embedding.
Another, more linguistically motivated way is a morphological analysis, but this requires tools and training data which might not be available for your language and domain of interest.
Enter Byte-Pair Encoding (BPE) [Sennrich et al, 2016], an unsupervised subword segmentation method. BPE starts with a sequence of symbols, for example characters, and iteratively merges the most frequent symbol pair into a new symbol.
For example, applying BPE to English might first merge the characters h and e into a new symbol he, then t and h into th, then t and he into the, and so on.
Learning these merge operations from a large corpus (e.g. all Wikipedia articles in a given language) often yields reasonable subword segementations. For example, a BPE model trained on English Wikipedia splits melfordshire into mel, ford, and shire.
### Stacked Embeddings
Stacked embeddings are one of the most important concepts of Flair. We can use them to combine different embeddings together, for instance if we want to use both traditional embeddings together with contextual string embeddings (see below). Stacked embeddings allow us to mix and match. We find that a combination of embeddings often gives best results.
All we need to do is use the StackedEmbeddings class and instantiate it by passing a list of embeddings that we wish to combine. For instance, lets combine classic GloVe embeddings with character embeddings. This is effectively the architecture proposed in (Lample et al., 2016).
```
from flair.embeddings import WordEmbeddings, CharacterEmbeddings
glove_embedding = WordEmbeddings('glove')
character_embeddings = CharacterEmbeddings()
```
Now instantiate the StackedEmbeddings class and pass it a list containing these two embeddings.
```
from flair.embeddings import StackedEmbeddings
stacked_embeddings = StackedEmbeddings(
embeddings=[glove_embedding, character_embeddings])
```
We use this embedding like all the other embeddings, i.e. call the embed() method over our sentences.
```
sentence = Sentence('The grass is green .')
stacked_embeddings.embed(sentence)
for token in sentence:
print(token)
print(token.embedding)
```
Words are now embedded using a concatenation of two different embeddings. This means that the resulting embedding vector is still a single PyTorch vector.
## Other Embeddings: BERT, ELMo, Flair
Next to standard WordEmbeddings and CharacterEmbeddings, Flair also provides classes for BERT, ELMo and Flair embeddings. These embeddings enable us to train truly state-of-the-art NLP models.
All word embedding classes inherit from the TokenEmbeddings class and implement the embed() method which we need to call to embed our text. This means that for most users of Flair, the complexity of different embeddings remains hidden behind this interface. We instantiate the embedding class we require and call embed() to embed our text.
All embeddings produced with Flair's methods are Pytorch vectors, so they can be immediately used for training and fine-tuning.
### Flair Embeddings
Contextual string embeddings are powerful embeddings that capture latent syntactic-semantic information that goes beyond standard word embeddings. Key differences are: (1) they are trained without any explicit notion of words and thus fundamentally model words as sequences of characters. And (2) they are contextualized by their surrounding text, meaning that the same word will have different embeddings depending on its contextual use.
Recent advances in language modeling using recurrent neural networks have made it viable to model language as distributions over characters. By learning to predict the next character on the basis of previous characters, such models have been shown to automatically internalize linguistic concepts such as words, sentences, subclauses and even sentiment. In Flair the internal states of a trained character language model is leveraged to produce a novel type of word embedding which the authors refer to as contextual string embeddings. The proposed embeddings have the distinct properties that they (a) are trained without any explicit notion of words and thus fundamentally model words as sequences of characters, and (b) are contextualized by their surrounding text, meaning that the same word will have different embeddings depending on its contextual use. The authors conduct a comparative evaluation against previous embeddings and find that their embeddings are highly useful for downstream tasks: across four classic sequence labeling tasks they consistently outperform the previous state-of-the-art. In particular, they significantly outperform previous work on English and German named entity recognition (NER), allowing them to report new state-of-the-art F1-scores on the CONLL03 shared task.
With Flair, we can use these embeddings simply by instantiating the appropriate embedding class, same as standard word embeddings:
```
from flair.embeddings import FlairEmbeddings
flair_embedding_forward = FlairEmbeddings('news-forward')
sentence = Sentence('The grass is green .')
flair_embedding_forward.embed(sentence)
```
We can choose which embeddings we load by passing the appropriate string to the constructor of the FlairEmbeddings class. Currently, there are numerous contextual string embeddings provided in models (more coming). See [list](https://github.com/zalandoresearch/flair/blob/master/resources/docs/TUTORIAL_4_ELMO_BERT_FLAIR_EMBEDDING.md).
The recommendation is to combine both forward and backward Flair embeddings. Depending on the task, it is also recommended to add standard word embeddings into the mix. So, the recommendation is to use StackedEmbedding for most English tasks:
```
from flair.embeddings import WordEmbeddings, FlairEmbeddings, StackedEmbeddings
stacked_embeddings = StackedEmbeddings([
WordEmbeddings('glove'),
FlairEmbeddings('news-forward'),
FlairEmbeddings('news-backward'),
])
```
We would use this embedding like all the other embeddings, i.e. call the embed() method over our sentences.
### BERT Embeddings
BERT embeddings were developed by Devlin et al. (2018) and are a different kind of powerful word embedding based on a bidirectional transformer architecture. Flair is using the implementation of huggingface. The embeddings are wrapped into our simple embedding interface, so that they can be used like any other embedding.
```
from flair.embeddings import BertEmbeddings
embedding = BertEmbeddings()
sentence = Sentence('The grass is green .')
embedding.embed(sentence)
for i in sentence:
print(i, i.embedding)
```
We can load any of the pre-trained BERT models by providing the model string during initialization:
- 'bert-base-uncased': English; 12-layer, 768-hidden, 12-heads, 110M parameters
- 'bert-large-uncased': English; 24-layer, 1024-hidden, 16-heads, 340M parameters
- 'bert-base-cased': English; 12-layer, 768-hidden, 12-heads , 110M parameters
- 'bert-large-cased': English; 24-layer, 1024-hidden, 16-heads, 340M parameters
- 'bert-base-multilingual-cased': 104 languages; 12-layer, 768-hidden, 12-heads, 110M parameters
- 'bert-base-chinese': Chinese Simplified and Traditional; 12-layer, 768-hidden, 12-heads, 110M parameters
### ELMo Embeddings
ELMo embeddings were presented by Peters et al. in 2018. They are using a bidirectional recurrent neural network to predict the next word in a text. Flair is using the implementation of AllenNLP. As this implementation comes with a lot of sub-dependencies, which Flair authors don't want to include in Flair, you need to first install the library via `pip install allennlp` before we can use it in Flair. Using the embeddings is as simple as using any other embedding type. To specify the correct model, pick one of *small*, *medium*, *portugese*, *original*:
```
from flair.embeddings import ELMoEmbeddings
embedding = ELMoEmbeddings(model="small")
sentence = Sentence('The grass is green .')
embedding.embed(sentence)
```
AllenNLP provides the following pre-trained models. To use any of the following models inside Flair simple specify the embedding id when initializing the ELMoEmbeddings.
- 'small': English; 1024-hidden, 1 layer, 14.6M parameters
- 'medium': English; 2048-hidden, 1 layer, 28.0M parameters
- 'original': English; 4096-hidden, 2 layers, 93.6M parameters
- 'pt': Portuguese
- 'pubmed': English biomedical data; more information
### BERT and Flair Combined
We can very easily mix and match Flair, ELMo, BERT and classic word embeddings. We instantiate each embedding we wish to combine and use them in a StackedEmbedding.
For instance, let's say we want to combine the multilingual Flair and BERT embeddings to train a hyper-powerful multilingual downstream task model.
First, instantiate the embeddings we wish to combine:
```
from flair.embeddings import FlairEmbeddings, BertEmbeddings
flair_forward_embedding = FlairEmbeddings('multi-forward')
flair_backward_embedding = FlairEmbeddings('multi-backward')
bert_embedding = BertEmbeddings('bert-base-multilingual-cased')
```
Now we instantiate the StackedEmbeddings class and pass it a list containing these three embeddings:
```
from flair.embeddings import StackedEmbeddings
stacked_embeddings = StackedEmbeddings(
embeddings=[flair_forward_embedding, flair_backward_embedding, bert_embedding])
```
We use this embedding like all the other embeddings, i.e. call the embed() method over our sentences.
```
sentence = Sentence('The grass is green .')
stacked_embeddings.embed(sentence)
for token in sentence:
print(token)
print(token.embedding)
```
Words are now embedded using a concatenation of three different embeddings. This means that the resulting embedding vector is still a single PyTorch vector.
## Document Embeddings
Document embeddings are different from word embeddings in that they provide one embedding for an entire text, whereas word embeddings provide embeddings for individual words.
...
**(C) 2018-2020 by [Damir Cavar](http://damir.cavar.me/)**
| github_jupyter |
```
import datetime
import lightgbm as lgb
import numpy as np
import os
import pandas as pd
import random
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import haversine
import catboost as cb
random_seed = 174
random.seed(random_seed)
np.random.seed(random_seed)
# Load data
train = pd.read_csv('data/taxi/train.csv')
test = pd.read_csv('data/taxi/test.csv')
ss = pd.read_csv('data/taxi/sample_submission.csv')
train.head()
def rmsle(y_true, y_pred):
assert len(y_true) == len(y_pred)
return np.sqrt(np.mean(np.power(np.log1p(y_true + 1) - np.log1p(y_pred + 1), 2)))
def extract_features(df):
df['hdistance'] = df.apply(lambda r: haversine.haversine((r['pickup_latitude'],r['pickup_longitude']),(r['dropoff_latitude'], r['dropoff_longitude'])), axis=1)
df['distance'] = np.sqrt(np.power(df['dropoff_longitude'] - df['pickup_longitude'], 2) + np.power(df['dropoff_latitude'] - df['pickup_latitude'], 2))
df['log_distance'] = np.log(df['distance'] + 1)
df['month'] = df['pickup_datetime'].apply(lambda x: int(x.split(' ')[0].split('-')[1]))
df['day'] = df['pickup_datetime'].apply(lambda x: int(x.split(' ')[0].split('-')[2]))
df['hour'] = df['pickup_datetime'].apply(lambda x: int(x.split(' ')[1].split(':')[0]))
df['minutes'] = df['pickup_datetime'].apply(lambda x: int(x.split(' ')[1].split(':')[1]))
df['is_weekend'] = ((df.pickup_datetime.astype('datetime64[ns]').dt.dayofweek) // 4 == 1).astype(float)
df['weekday'] = df.pickup_datetime.astype('datetime64[ns]').dt.dayofweek
df['is_holyday'] = df.apply(lambda row: 1 if (row['month']==1 and row['day']==1) or (row['month']==7 and row['day']==4) or (row['month']==11 and row['day']==11) or (row['month']==12 and row['day']==25) or (row['month']==1 and row['day'] >= 15 and row['day'] <= 21 and row['weekday'] == 0) or (row['month']==2 and row['day'] >= 15 and row['day'] <= 21 and row['weekday'] == 0) or (row['month']==5 and row['day'] >= 25 and row['day'] <= 31 and row['weekday'] == 0) or (row['month']==9 and row['day'] >= 1 and row['day'] <= 7 and row['weekday'] == 0) or (row['month']==10 and row['day'] >= 8 and row['day'] <= 14 and row['weekday'] == 0) or (row['month']==11 and row['day'] >= 22 and row['day'] <= 28 and row['weekday'] == 3) else 0, axis=1)
df['is_day_before_holyday'] = df.apply(lambda row: 1 if (row['month']==12 and row['day']==31) or (row['month']==7 and row['day']==3) or (row['month']==11 and row['day']==10) or (row['month']==12 and row['day']==24) or (row['month']==1 and row['day'] >= 14 and row['day'] <= 20 and row['weekday'] == 6) or (row['month']==2 and row['day'] >= 14 and row['day'] <= 20 and row['weekday'] == 6) or (row['month']==5 and row['day'] >= 24 and row['day'] <= 30 and row['weekday'] == 6) or ((row['month']==9 and row['day'] >= 1 and row['day'] <= 6) or (row['month']==8 and row['day'] == 31) and row['weekday'] == 6) or (row['month']==10 and row['day'] >= 7 and row['day'] <= 13 and row['weekday'] == 6) or (row['month']==11 and row['day'] >= 21 and row['day'] <= 27 and row['weekday'] == 2) else 0, axis=1)
df['store_and_fwd_flag'] = df['store_and_fwd_flag'].map(lambda x: 0 if x =='N' else 1)
df.drop('day', axis=1, inplace=True)
# Extract features
print('Extracting train features')
extract_features(train)
print('Extracting test features')
extract_features(test)
train.head()
# Prepare data
X = np.array(train.drop(['id', 'pickup_datetime', 'dropoff_datetime', 'store_and_fwd_flag', 'trip_duration'], axis=1))
y = np.log(train['trip_duration'].values)
median_trip_duration = np.median(train['trip_duration'].values)
print('X.shape = ' + str(X.shape))
print('y.shape = ' + str(y.shape))
X_test = np.array(test.drop(['id', 'pickup_datetime', 'store_and_fwd_flag'], axis=1))
print('X_test.shape = ' + str(X_test.shape))
#Сделаем скейлинг данных
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X)
#Преобразуем тренировочные данные
X_scaled = scaler.transform(X)
#Преобразуем тестовые данные
X_te_scaled = scaler.transform(X_test)
print('Training and making predictions')
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmsle',
'max_depth': 6,
'learning_rate': 0.4,
'num_leaves': 45,
'max_bin': 250
}
n_estimators = 300
n_iters = 5
preds_buf = []
err_buf = []
for i in range(n_iters): #[9, 52, 100, 145, 174, 176, 184]: подборка с 0.38
x_train, x_valid, y_train, y_valid = train_test_split(X_scaled, y, test_size=0.1, random_state=i) ############
d_train = lgb.Dataset(x_train, label=y_train)
d_valid = lgb.Dataset(x_valid, label=y_valid)
watchlist = [d_valid]
#model = cb.CatBoostRegressor()
#model.fit(x_train, y_train)
model = lgb.train(params, d_train, n_estimators, watchlist, verbose_eval=1)
preds = model.predict(x_valid)
preds = np.exp(preds)
preds[preds < 0] = median_trip_duration
err = rmsle(np.exp(y_valid), preds)
err_buf.append(err)
print(str(i) + ' random_state, ' + ' RMSLE = ' + str(err))
preds = model.predict(X_te_scaled)#################################
preds = np.exp(preds)
preds[preds < 0] = median_trip_duration
preds_buf.append(preds)
print('Mean RMSLE = ' + str(np.mean(err_buf)) + ' +/- ' + str(np.std(err_buf)))
# Average predictions
preds = np.mean(preds_buf, axis=0)
# Prepare submission
subm = pd.DataFrame()
subm['id'] = test.id.values
subm['trip_duration'] = preds
subm.to_csv('submission_taxi_lgbm.csv', index=False)
```
| github_jupyter |
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.

# Automated Machine Learning
_**Remote Execution with DataStore**_
## Contents
1. [Introduction](#Introduction)
1. [Setup](#Setup)
1. [Data](#Data)
1. [Train](#Train)
1. [Results](#Results)
1. [Test](#Test)
## Introduction
This sample accesses a data file on a remote DSVM through DataStore. Advantages of using data store are:
1. DataStore secures the access details.
2. DataStore supports read, write to blob and file store
3. AutoML natively supports copying data from DataStore to DSVM
Make sure you have executed the [configuration](../../../configuration.ipynb) before running this notebook.
In this notebook you would see
1. Storing data in DataStore.
2. get_data returning data from DataStore.
## Setup
As part of the setup you have already created a <b>Workspace</b>. For AutoML you would need to create an <b>Experiment</b>. An <b>Experiment</b> is a named object in a <b>Workspace</b>, which is used to run experiments.
```
import logging
import os
import time
import numpy as np
import pandas as pd
import azureml.core
from azureml.core.compute import DsvmCompute
from azureml.core.experiment import Experiment
from azureml.core.workspace import Workspace
from azureml.train.automl import AutoMLConfig
ws = Workspace.from_config()
# choose a name for experiment
experiment_name = 'automl-remote-datastore-file'
# project folder
project_folder = './sample_projects/automl-remote-datastore-file'
experiment=Experiment(ws, experiment_name)
output = {}
output['SDK version'] = azureml.core.VERSION
output['Subscription ID'] = ws.subscription_id
output['Workspace'] = ws.name
output['Resource Group'] = ws.resource_group
output['Location'] = ws.location
output['Project Directory'] = project_folder
output['Experiment Name'] = experiment.name
pd.set_option('display.max_colwidth', -1)
outputDf = pd.DataFrame(data = output, index = [''])
outputDf.T
```
### Create a Remote Linux DSVM
Note: If creation fails with a message about Marketplace purchase eligibilty, go to portal.azure.com, start creating DSVM there, and select "Want to create programmatically" to enable programmatic creation. Once you've enabled it, you can exit without actually creating VM.
**Note**: By default SSH runs on port 22 and you don't need to specify it. But if for security reasons you can switch to a different port (such as 5022), you can append the port number to the address. [Read more](https://docs.microsoft.com/en-us/azure/virtual-machines/troubleshooting/detailed-troubleshoot-ssh-connection) on this.
```
compute_target_name = 'mydsvmc'
try:
while ws.compute_targets[compute_target_name].provisioning_state == 'Creating':
time.sleep(1)
dsvm_compute = DsvmCompute(workspace=ws, name=compute_target_name)
print('found existing:', dsvm_compute.name)
except:
dsvm_config = DsvmCompute.provisioning_configuration(vm_size="Standard_D2_v2")
dsvm_compute = DsvmCompute.create(ws, name=compute_target_name, provisioning_configuration=dsvm_config)
dsvm_compute.wait_for_completion(show_output=True)
print("Waiting one minute for ssh to be accessible")
time.sleep(90) # Wait for ssh to be accessible
```
## Data
### Copy data file to local
Download the data file.
```
if not os.path.isdir('data'):
os.mkdir('data')
from sklearn.datasets import fetch_20newsgroups
import csv
remove = ('headers', 'footers', 'quotes')
categories = [
'alt.atheism',
'talk.religion.misc',
'comp.graphics',
'sci.space',
]
data_train = fetch_20newsgroups(subset = 'train', categories = categories,
shuffle = True, random_state = 42,
remove = remove)
pd.DataFrame(data_train.data).to_csv("data/X_train.tsv", index=False, header=False, quoting=csv.QUOTE_ALL, sep="\t")
pd.DataFrame(data_train.target).to_csv("data/y_train.tsv", index=False, header=False, sep="\t")
```
### Upload data to the cloud
Now make the data accessible remotely by uploading that data from your local machine into Azure so it can be accessed for remote training. The datastore is a convenient construct associated with your workspace for you to upload/download data, and interact with it from your remote compute targets. It is backed by Azure blob storage account.
The data.tsv files are uploaded into a directory named data at the root of the datastore.
```
#blob_datastore = Datastore(ws, blob_datastore_name)
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
# ds.upload_files("data.tsv")
ds.upload(src_dir='./data', target_path='data', overwrite=True, show_progress=True)
```
### Configure & Run
First let's create a DataReferenceConfigruation object to inform the system what data folder to download to the compute target.
The path_on_compute should be an absolute path to ensure that the data files are downloaded only once. The get_data method should use this same path to access the data files.
```
from azureml.core.runconfig import DataReferenceConfiguration
dr = DataReferenceConfiguration(datastore_name=ds.name,
path_on_datastore='data',
path_on_compute='/tmp/azureml_runs',
mode='download', # download files from datastore to compute target
overwrite=False)
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
import pkg_resources
# create a new RunConfig object
conda_run_config = RunConfiguration(framework="python")
# Set compute target to the Linux DSVM
conda_run_config.target = dsvm_compute
# set the data reference of the run coonfiguration
conda_run_config.data_references = {ds.name: dr}
pandas_dependency = 'pandas==' + pkg_resources.get_distribution("pandas").version
cd = CondaDependencies.create(pip_packages=['azureml-sdk[automl]'], conda_packages=['numpy','py-xgboost<=0.80',pandas_dependency])
conda_run_config.environment.python.conda_dependencies = cd
```
### Create Get Data File
For remote executions you should author a get_data.py file containing a get_data() function. This file should be in the root directory of the project. You can encapsulate code to read data either from a blob storage or local disk in this file.
The *get_data()* function returns a [dictionary](README.md#getdata).
The read_csv uses the path_on_compute value specified in the DataReferenceConfiguration call plus the path_on_datastore folder and then the actual file name.
```
if not os.path.exists(project_folder):
os.makedirs(project_folder)
%%writefile $project_folder/get_data.py
import pandas as pd
def get_data():
X_train = pd.read_csv("/tmp/azureml_runs/data/X_train.tsv", delimiter="\t", header=None, quotechar='"')
y_train = pd.read_csv("/tmp/azureml_runs/data/y_train.tsv", delimiter="\t", header=None, quotechar='"')
return { "X" : X_train.values, "y" : y_train[0].values }
```
## Train
You can specify automl_settings as **kwargs** as well. Also note that you can use the get_data() symantic for local excutions too.
<i>Note: For Remote DSVM and Batch AI you cannot pass Numpy arrays directly to AutoMLConfig.</i>
|Property|Description|
|-|-|
|**primary_metric**|This is the metric that you want to optimize. Classification supports the following primary metrics: <br><i>accuracy</i><br><i>AUC_weighted</i><br><i>average_precision_score_weighted</i><br><i>norm_macro_recall</i><br><i>precision_score_weighted</i>|
|**iteration_timeout_minutes**|Time limit in minutes for each iteration|
|**iterations**|Number of iterations. In each iteration Auto ML trains a specific pipeline with the data|
|**n_cross_validations**|Number of cross validation splits|
|**max_concurrent_iterations**|Max number of iterations that would be executed in parallel. This should be less than the number of cores on the DSVM
|**preprocess**| *True/False* <br>Setting this to *True* enables Auto ML to perform preprocessing <br>on the input to handle *missing data*, and perform some common *feature extraction*|
|**enable_cache**|Setting this to *True* enables preprocess done once and reuse the same preprocessed data for all the iterations. Default value is True.|
|**max_cores_per_iteration**| Indicates how many cores on the compute target would be used to train a single pipeline.<br> Default is *1*, you can set it to *-1* to use all cores|
```
automl_settings = {
"iteration_timeout_minutes": 60,
"iterations": 4,
"n_cross_validations": 5,
"primary_metric": 'AUC_weighted',
"preprocess": True,
"max_cores_per_iteration": 1,
"verbosity": logging.INFO
}
automl_config = AutoMLConfig(task = 'classification',
debug_log = 'automl_errors.log',
path=project_folder,
run_configuration=conda_run_config,
#compute_target = dsvm_compute,
data_script = project_folder + "/get_data.py",
**automl_settings
)
```
For remote runs the execution is asynchronous, so you will see the iterations get populated as they complete. You can interact with the widgets/models even when the experiment is running to retreive the best model up to that point. Once you are satisfied with the model you can cancel a particular iteration or the whole run.
```
remote_run = experiment.submit(automl_config, show_output=False)
remote_run
```
## Results
#### Widget for monitoring runs
The widget will sit on "loading" until the first iteration completed, then you will see an auto-updating graph and table show up. It refreshed once per minute, so you should see the graph update as child runs complete.
You can click on a pipeline to see run properties and output logs. Logs are also available on the DSVM under /tmp/azureml_run/{iterationid}/azureml-logs
NOTE: The widget displays a link at the bottom. This links to a web-ui to explore the individual run details.
```
from azureml.widgets import RunDetails
RunDetails(remote_run).show()
# Wait until the run finishes.
remote_run.wait_for_completion(show_output = True)
```
#### Retrieve All Child Runs
You can also use sdk methods to fetch all the child runs and see individual metrics that we log.
```
children = list(remote_run.get_children())
metricslist = {}
for run in children:
properties = run.get_properties()
metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)}
metricslist[int(properties['iteration'])] = metrics
rundata = pd.DataFrame(metricslist).sort_index(1)
rundata
```
### Canceling Runs
You can cancel ongoing remote runs using the *cancel()* and *cancel_iteration()* functions
```
# Cancel the ongoing experiment and stop scheduling new iterations
# remote_run.cancel()
# Cancel iteration 1 and move onto iteration 2
# remote_run.cancel_iteration(1)
```
### Pre-process cache cleanup
The preprocess data gets cache at user default file store. When the run is completed the cache can be cleaned by running below cell
```
remote_run.clean_preprocessor_cache()
```
### Retrieve the Best Model
Below we select the best pipeline from our iterations. The *get_output* method returns the best run and the fitted model. There are overloads on *get_output* that allow you to retrieve the best run and fitted model for *any* logged metric or a particular *iteration*.
```
best_run, fitted_model = remote_run.get_output()
```
#### Best Model based on any other metric
```
# lookup_metric = "accuracy"
# best_run, fitted_model = remote_run.get_output(metric=lookup_metric)
```
#### Model from a specific iteration
```
# iteration = 1
# best_run, fitted_model = remote_run.get_output(iteration=iteration)
```
## Test
```
# Load test data.
from pandas_ml import ConfusionMatrix
data_test = fetch_20newsgroups(subset = 'test', categories = categories,
shuffle = True, random_state = 42,
remove = remove)
X_test = np.array(data_test.data).reshape((len(data_test.data),1))
y_test = data_test.target
# Test our best pipeline.
y_pred = fitted_model.predict(X_test)
y_pred_strings = [data_test.target_names[i] for i in y_pred]
y_test_strings = [data_test.target_names[i] for i in y_test]
cm = ConfusionMatrix(y_test_strings, y_pred_strings)
print(cm)
cm.plot()
```
| github_jupyter |
# Assignment 3: Question Answering
Welcome to this week's assignment of course 4. In this you will explore question answering. You will implement the "Text to Text Transfer from Transformers" (better known as T5). Since you implemented transformers from scratch last week you will now be able to use them.
<img src = "qa.png">
## Outline
- [Overview](#0)
- [Part 0: Importing the Packages](#0)
- [Part 1: C4 Dataset](#1)
- [1.1 Pre-Training Objective](#1.1)
- [1.2 Process C4](#1.2)
- [1.2.1 Decode to natural language](#1.2.1)
- [1.3 Tokenizing and Masking](#1.3)
- [Exercise 01](#ex01)
- [1.4 Creating the Pairs](#1.4)
- [Part 2: Transfomer](#2)
- [2.1 Transformer Encoder](#2.1)
- [2.1.1 The Feedforward Block](#2.1.1)
- [Exercise 02](#ex02)
- [2.1.2 The Encoder Block](#2.1.2)
- [Exercise 03](#ex03)
- [2.1.3 The Transformer Encoder](#2.1.3)
- [Exercise 04](#ex04)
<a name='0'></a>
### Overview
This assignment will be different from the two previous ones. Due to memory and time constraints of this environment you will not be able to train a model and use it for inference. Instead you will create the necessary building blocks for the transformer encoder model and will use a pretrained version of the same model in two ungraded labs after this assignment.
After completing these 3 (1 graded and 2 ungraded) labs you will:
* Implement the code neccesary for Bidirectional Encoder Representation from Transformer (BERT).
* Understand how the C4 dataset is structured.
* Use a pretrained model for inference.
* Understand how the "Text to Text Transfer from Transformers" or T5 model works.
<a name='0'></a>
# Part 0: Importing the Packages
```
import ast
import string
import textwrap
import itertools
import numpy as np
import trax
from trax import layers as tl
from trax.supervised import decoding
# Will come handy later.
wrapper = textwrap.TextWrapper(width=70)
# Set random seed
np.random.seed(42)
```
<a name='1'></a>
## Part 1: C4 Dataset
The [C4](https://www.tensorflow.org/datasets/catalog/c4) is a huge data set. For the purpose of this assignment you will use a few examples out of it which are present in `data.txt`. C4 is based on the [common crawl](https://commoncrawl.org/) project. Feel free to read more on their website.
Run the cell below to see how the examples look like.
```
# load example jsons
example_jsons = list(map(ast.literal_eval, open('data.txt')))
# Printing the examples to see how the data looks like
for i in range(5):
print(f'example number {i+1}: \n\n{example_jsons[i]} \n')
```
Notice the `b` before each string? This means that this data comes as bytes rather than strings. Strings are actually lists of bytes so for the rest of the assignments the name `strings` will be used to describe the data.
To check this run the following cell:
```
type(example_jsons[0].get('text'))
```
<a name='1.1'></a>
### 1.1 Pre-Training Objective
**Note:** The word "mask" will be used throughout this assignment in context of hiding/removing word(s)
You will be implementing the BERT loss as shown in the following image.
<img src = "loss.png" width="600" height = "400">
Assume you have the following text: <span style = "color:blue"> **Thank you <span style = "color:red">for inviting </span> me to your party <span style = "color:red">last</span> week** </span>
Now as input you will mask the words in red in the text:
<span style = "color:blue"> **Input:**</span> Thank you **X** me to your party **Y** week.
<span style = "color:blue">**Output:**</span> The model should predict the words(s) for **X** and **Y**.
**Z** is used to represent the end.
<a name='1.2'></a>
### 1.2 Process C4
C4 only has the plain string `text` field, so you will tokenize and have `inputs` and `targets` out of it for supervised learning. Given your inputs, the goal is to predict the targets during training.
You will now take the `text` and convert it to `inputs` and `targets`.
```
# Grab text field from dictionary
natural_language_texts = [example_json['text'] for example_json in example_jsons]
# First text example
natural_language_texts[4]
```
<a name='1.2.1'></a>
#### 1.2.1 Decode to natural language
The following functions will help you `detokenize` and`tokenize` the text data.
The `sentencepiece` vocabulary was used to convert from text to ids. This vocabulary file is loaded and used in this helper functions.
`natural_language_texts` has the text from the examples we gave you.
Run the cells below to see what is going on.
```
# Special tokens
PAD, EOS, UNK = 0, 1, 2
def detokenize(np_array):
return trax.data.detokenize(
np_array,
vocab_type='sentencepiece',
vocab_file='sentencepiece.model',
vocab_dir='.')
def tokenize(s):
# The trax.data.tokenize function operates on streams,
# that's why we have to create 1-element stream with iter
# and later retrieve the result with next.
return next(trax.data.tokenize(
iter([s]),
vocab_type='sentencepiece',
vocab_file='sentencepiece.model',
vocab_dir='.'))
# printing the encoding of each word to see how subwords are tokenized
tokenized_text = [(tokenize(word).tolist(), word) for word in natural_language_texts[0].split()]
print(tokenized_text, '\n')
# We can see that detokenize successfully undoes the tokenization
print(f"tokenized: {tokenize('Beginners')}\ndetokenized: {detokenize(tokenize('Beginners'))}")
```
As you can see above, you were able to take a piece of string and tokenize it.
Now you will create `input` and `target` pairs that will allow you to train your model. T5 uses the ids at the end of the vocab file as sentinels. For example, it will replace:
- `vocab_size - 1` by `<Z>`
- `vocab_size - 2` by `<Y>`
- and so forth.
It assigns every word a `chr`.
The `pretty_decode` function below, which you will use in a bit, helps in handling the type when decoding. Take a look and try to understand what the function is doing.
Notice that:
```python
string.ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
```
**NOTE:** Targets may have more than the 52 sentinels we replace, but this is just to give you an idea of things.
```
vocab_size = trax.data.vocab_size(
vocab_type='sentencepiece',
vocab_file='sentencepiece.model',
vocab_dir='.')
def get_sentinels(vocab_size=vocab_size, display=False):
sentinels = {}
for i, char in enumerate(reversed(string.ascii_letters), 1):
decoded_text = detokenize([vocab_size - i])
# Sentinels, ex: <Z> - <a>
sentinels[decoded_text] = f'<{char}>'
if display:
print(f'The sentinel is <{char}> and the decoded token is:', decoded_text)
return sentinels
sentinels = get_sentinels(vocab_size, display=True)
def pretty_decode(encoded_str_list, sentinels=sentinels):
# If already a string, just do the replacements.
if isinstance(encoded_str_list, (str, bytes)):
for token, char in sentinels.items():
encoded_str_list = encoded_str_list.replace(token, char)
return encoded_str_list
# We need to decode and then prettyfy it.
return pretty_decode(detokenize(encoded_str_list))
pretty_decode("I want to dress up as an Intellectual this halloween.")
```
The functions above make your `inputs` and `targets` more readable. For example, you might see something like this once you implement the masking function below.
- <span style="color:red"> Input sentence: </span> Younes and Lukasz were working together in the lab yesterday after lunch.
- <span style="color:red">Input: </span> Younes and Lukasz **Z** together in the **Y** yesterday after lunch.
- <span style="color:red">Target: </span> **Z** were working **Y** lab.
<a name='1.3'></a>
### 1.3 Tokenizing and Masking
You will now implement the `tokenize_and_mask` function. This function will allow you to tokenize and mask input words with a noise probability. We usually mask 15% of the words.
<a name='ex01'></a>
### Exercise 01
```
# UNQ_C1
# GRADED FUNCTION: tokenize_and_mask
def tokenize_and_mask(text, vocab_size=vocab_size, noise=0.15,
randomizer=np.random.uniform, tokenize=tokenize):
"""Tokenizes and masks a given input.
Args:
text (str or bytes): Text input.
vocab_size (int, optional): Size of the vocabulary. Defaults to vocab_size.
noise (float, optional): Probability of masking a token. Defaults to 0.15.
randomizer (function, optional): Function that generates random values. Defaults to np.random.uniform.
tokenize (function, optional): Tokenizer function. Defaults to tokenize.
Returns:
tuple: Tuple of lists of integers associated to inputs and targets.
"""
# current sentinel number (starts at 0)
cur_sentinel_num = 0
# inputs
inps = []
# targets
targs = []
### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###
# prev_no_mask is True if the previous token was NOT masked, False otherwise
# set prev_no_mask to True
prev_no_mask = None
# loop through tokenized `text`
for token in tokenize(text):
# check if the `noise` is greater than a random value (weighted coin flip)
if randomizer() < noise:
# check to see if the previous token was not masked
if prev_no_mask==True: # add new masked token at end_id
# number of masked tokens increases by 1
cur_sentinel_num += None
# compute `end_id` by subtracting current sentinel value out of the total vocabulary size
end_id = None - None
# append `end_id` at the end of the targets
targs.append(None)
# append `end_id` at the end of the inputs
inps.append(None)
# append `token` at the end of the targets
targs.append(None)
# set prev_no_mask accordingly
prev_no_mask = None
else: # don't have two masked tokens in a row
# append `token ` at the end of the inputs
inps.append(None)
# set prev_no_mask accordingly
prev_no_mask = None
### END CODE HERE ###
return inps, targs
# Some logic to mock a np.random value generator
# Needs to be in the same cell for it to always generate same output
def testing_rnd():
def dummy_generator():
vals = np.linspace(0, 1, 10)
cyclic_vals = itertools.cycle(vals)
for _ in range(100):
yield next(cyclic_vals)
dumr = itertools.cycle(dummy_generator())
def dummy_randomizer():
return next(dumr)
return dummy_randomizer
input_str = natural_language_texts[0]
print(f"input string:\n\n{input_str}\n")
inps, targs = tokenize_and_mask(input_str, randomizer=testing_rnd())
print(f"tokenized inputs:\n\n{inps}\n")
print(f"targets:\n\n{targs}")
```
#### **Expected Output:**
```CPP
b'Beginners BBQ Class Taking Place in Missoula!\nDo you want to get better at making delicious BBQ? You will have the opportunity, put this on your calendar now. Thursday, September 22nd join World Class BBQ Champion, Tony Balay from Lonestar Smoke Rangers. He will be teaching a beginner level class for everyone who wants to get better with their culinary skills.\nHe will teach you everything you need to know to compete in a KCBS BBQ competition, including techniques, recipes, timelines, meat selection and trimming, plus smoker and fire information.\nThe cost to be in the class is $35 per person, and for spectators it is free. Included in the cost will be either a t-shirt or apron and you will be tasting samples of each meat that is prepared.'
tokenized inputs:
[31999, 15068, 4501, 3, 12297, 3399, 16, 5964, 7115, 31998, 531, 25, 241, 12, 129, 394, 44, 492, 31997, 58, 148, 56, 43, 8, 1004, 6, 474, 31996, 39, 4793, 230, 5, 2721, 6, 1600, 1630, 31995, 1150, 4501, 15068, 16127, 6, 9137, 2659, 5595, 31994, 782, 3624, 14627, 15, 12612, 277, 5, 216, 31993, 2119, 3, 9, 19529, 593, 853, 21, 921, 31992, 12, 129, 394, 28, 70, 17712, 1098, 5, 31991, 3884, 25, 762, 25, 174, 12, 214, 12, 31990, 3, 9, 3, 23405, 4547, 15068, 2259, 6, 31989, 6, 5459, 6, 13618, 7, 6, 3604, 1801, 31988, 6, 303, 24190, 11, 1472, 251, 5, 37, 31987, 36, 16, 8, 853, 19, 25264, 399, 568, 31986, 21, 21380, 7, 34, 19, 339, 5, 15746, 31985, 8, 583, 56, 36, 893, 3, 9, 3, 31984, 9486, 42, 3, 9, 1409, 29, 11, 25, 31983, 12246, 5977, 13, 284, 3604, 24, 19, 2657, 31982]
targets:
[31999, 12847, 277, 31998, 9, 55, 31997, 3326, 15068, 31996, 48, 30, 31995, 727, 1715, 31994, 45, 301, 31993, 56, 36, 31992, 113, 2746, 31991, 216, 56, 31990, 5978, 16, 31989, 379, 2097, 31988, 11, 27856, 31987, 583, 12, 31986, 6, 11, 31985, 26, 16, 31984, 17, 18, 31983, 56, 36, 31982, 5]
```
You will now use the inputs and the targets from the `tokenize_and_mask` function you implemented above. Take a look at the masked sentence using your `inps` and `targs` from the sentence above.
```
print('Inputs: \n\n', pretty_decode(inps))
print('\nTargets: \n\n', pretty_decode(targs))
```
<a name='1.4'></a>
### 1.4 Creating the Pairs
You will now create pairs using your dataset. You will iterate over your data and create (inp, targ) pairs using the functions that we have given you.
```
# Apply tokenize_and_mask
inputs_targets_pairs = [tokenize_and_mask(text) for text in natural_language_texts]
def display_input_target_pairs(inputs_targets_pairs):
for i, inp_tgt_pair in enumerate(inputs_targets_pairs, 1):
inps, tgts = inp_tgt_pair
inps, tgts = pretty_decode(inps), pretty_decode(tgts)
print(f'[{i}]\n\n'
f'inputs:\n{wrapper.fill(text=inps)}\n\n'
f'targets:\n{wrapper.fill(text=tgts)}\n\n\n\n')
display_input_target_pairs(inputs_targets_pairs)
```
<a name='2'></a>
# Part 2: Transfomer
We now load a Transformer model checkpoint that has been pre-trained using the above C4 dataset and decode from it. This will save you a lot of time rather than have to train your model yourself. Later in this notebook, we will show you how to fine-tune your model.
<img src = "fulltransformer.png" width="300" height="600">
Start by loading in the model. We copy the checkpoint to local dir for speed, otherwise initialization takes a very long time. Last week you implemented the decoder part for the transformer. Now you will implement the encoder part. Concretely you will implement the following.
<img src = "encoder.png" width="300" height="600">
<a name='2.1'></a>
### 2.1 Transformer Encoder
You will now implement the transformer encoder. Concretely you will implement two functions. The first function is `FeedForwardBlock`.
<a name='2.1.1'></a>
#### 2.1.1 The Feedforward Block
The `FeedForwardBlock` function is an important one so you will start by implementing it. To do so, you need to return a list of the following:
- [`tl.LayerNorm()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.normalization.LayerNorm) = layer normalization.
- [`tl.Dense(d_ff)`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.core.Dense) = fully connected layer.
- [`activation`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.activation_fns.Relu) = activation relu, tanh, sigmoid etc.
- `dropout_middle` = we gave you this function (don't worry about its implementation).
- [`tl.Dense(d_model)`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.core.Dense) = fully connected layer with same dimension as the model.
- `dropout_final` = we gave you this function (don't worry about its implementation).
You can always take a look at [trax documentation](https://trax-ml.readthedocs.io/en/latest/) if needed.
**Instructions**: Implement the feedforward part of the transformer. You will be returning a list.
<a name='ex02'></a>
### Exercise 02
```
# UNQ_C2
# GRADED FUNCTION: FeedForwardBlock
def FeedForwardBlock(d_model, d_ff, dropout, dropout_shared_axes, mode, activation):
"""Returns a list of layers implementing a feed-forward block.
Args:
d_model: int: depth of embedding
d_ff: int: depth of feed-forward layer
dropout: float: dropout rate (how much to drop out)
dropout_shared_axes: list of integers, axes to share dropout mask
mode: str: 'train' or 'eval'
activation: the non-linearity in feed-forward layer
Returns:
A list of layers which maps vectors to vectors.
"""
dropout_middle = tl.Dropout(rate=dropout,
shared_axes=dropout_shared_axes,
mode=mode)
dropout_final = tl.Dropout(rate=dropout,
shared_axes=dropout_shared_axes,
mode=mode)
### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###
ff_block = [
# trax Layer normalization
None,
# trax Dense layer using `d_ff`
None,
# activation() layer - you need to call (use parentheses) this func!
None,
# dropout middle layer
None,
# trax Dense layer using `d_model`
None,
# dropout final layer
None,
]
### END CODE HERE ###
return ff_block
# Print the block layout
feed_forward_example = FeedForwardBlock(d_model=512, d_ff=2048, dropout=0.8, dropout_shared_axes=0, mode = 'train', activation = tl.Relu)
print(feed_forward_example)
```
#### **Expected Output:**
```CPP
[LayerNorm, Dense_2048, Relu, Dropout, Dense_512, Dropout]
```
<a name='2.1.2'></a>
#### 2.1.2 The Encoder Block
The encoder block will use the `FeedForwardBlock`.
You will have to build two residual connections. Inside the first residual connection you will have the `tl.layerNorm()`, `attention`, and `dropout_` layers. The second residual connection will have the `feed_forward`.
You will also need to implement `feed_forward`, `attention` and `dropout_` blocks.
So far you haven't seen the [`tl.Attention()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.attention.Attention) and [`tl.Residual()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.combinators.Residual) layers so you can check the docs by clicking on them.
<a name='ex03'></a>
### Exercise 03
```
# UNQ_C3
# GRADED FUNCTION: EncoderBlock
def EncoderBlock(d_model, d_ff, n_heads, dropout, dropout_shared_axes,
mode, ff_activation, FeedForwardBlock=FeedForwardBlock):
"""
Returns a list of layers that implements a Transformer encoder block.
The input to the layer is a pair, (activations, mask), where the mask was
created from the original source tokens to prevent attending to the padding
part of the input.
Args:
d_model (int): depth of embedding.
d_ff (int): depth of feed-forward layer.
n_heads (int): number of attention heads.
dropout (float): dropout rate (how much to drop out).
dropout_shared_axes (int): axes on which to share dropout mask.
mode (str): 'train' or 'eval'.
ff_activation (function): the non-linearity in feed-forward layer.
FeedForwardBlock (function): A function that returns the feed forward block.
Returns:
list: A list of layers that maps (activations, mask) to (activations, mask).
"""
### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###
# Attention block
attention = tl.Attention(
# Use dimension of the model
d_feature=None,
# Set it equal to number of attention heads
n_heads=None,
# Set it equal `dropout`
dropout=None,
# Set it equal `mode`
mode=None
)
# Call the function `FeedForwardBlock` (implemented before) and pass in the parameters
feed_forward = FeedForwardBlock(
None,
None,
None,
None,
None,
None
)
# Dropout block
dropout_ = tl.Dropout(
# set it equal to `dropout`
rate=None,
# set it equal to the axes on which to share dropout mask
shared_axes=None,
# set it equal to `mode`
mode=None
)
encoder_block = [
# add `Residual` layer
tl.Residual(
# add norm layer
None,
# add attention
None,
# add dropout
None,
),
# add another `Residual` layer
tl.Residual(
# add feed forward
None,
),
]
### END CODE HERE ###
return encoder_block
# Print the block layout
encoder_example = EncoderBlock(d_model=512, d_ff=2048, n_heads=6, dropout=0.8, dropout_shared_axes=0, mode = 'train', ff_activation=tl.Relu)
print(encoder_example)
```
#### **Expected Output:**
```CPP
[Serial_in2_out2[
Branch_in2_out3[
None
Serial_in2_out2[
LayerNorm
Serial_in2_out2[
Dup_out2
Dup_out2
Serial_in4_out2[
Parallel_in3_out3[
Dense_512
Dense_512
Dense_512
]
PureAttention_in4_out2
Dense_512
]
]
Dropout
]
]
Add_in2
], Serial[
Branch_out2[
None
Serial[
LayerNorm
Dense_2048
Relu
Dropout
Dense_512
Dropout
]
]
Add_in2
]]
```
<a name='2.1.3'></a>
### 2.1.3 The Transformer Encoder
Now that you have implemented the `EncoderBlock`, it is time to build the full encoder. BERT, or Bidirectional Encoder Representations from Transformers is one such encoder.
You will implement its core code in the function below by using the functions you have coded so far.
The model takes in many hyperparameters, such as the `vocab_size`, the number of classes, the dimension of your model, etc. You want to build a generic function that will take in many parameters, so you can use it later. At the end of the day, anyone can just load in an API and call transformer, but we think it is important to make sure you understand how it is built. Let's get started.
**Instructions:** For this encoder you will need a `positional_encoder` first (which is already provided) followed by `n_layers` encoder blocks, which are the same encoder blocks you previously built. Once you store the `n_layers` `EncoderBlock` in a list, you are going to encode a `Serial` layer with the following sublayers:
- [`tl.Branch`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.combinators.Branch): helps with the branching and has the following sublayers:
- `positional_encoder`.
- [`tl.PaddingMask()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.attention.PaddingMask): layer that maps integer sequences to padding masks.
- Your list of `EncoderBlock`s
- [`tl.Select([0], n_in=2)`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.combinators.Select): Copies, reorders, or deletes stack elements according to indices.
- [`tl.LayerNorm()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.normalization.LayerNorm).
- [`tl.Mean()`](https://trax-ml.readthedocs.io/en/latest/trax.layers.html#trax.layers.core.Mean): Mean along the first axis.
- `tl.Dense()` with n_units set to n_classes.
- `tl.LogSoftmax()`
Please refer to the [trax documentation](https://trax-ml.readthedocs.io/en/latest/) for further information.
<a name='ex04'></a>
### Exercise 04
```
# UNQ_C4
# GRADED FUNCTION: TransformerEncoder
def TransformerEncoder(vocab_size=vocab_size,
n_classes=10,
d_model=512,
d_ff=2048,
n_layers=6,
n_heads=8,
dropout=0.1,
dropout_shared_axes=None,
max_len=2048,
mode='train',
ff_activation=tl.Relu,
EncoderBlock=EncoderBlock):
"""
Returns a Transformer encoder model.
The input to the model is a tensor of tokens.
Args:
vocab_size (int): vocab size. Defaults to vocab_size.
n_classes (int): how many classes on output. Defaults to 10.
d_model (int): depth of embedding. Defaults to 512.
d_ff (int): depth of feed-forward layer. Defaults to 2048.
n_layers (int): number of encoder/decoder layers. Defaults to 6.
n_heads (int): number of attention heads. Defaults to 8.
dropout (float): dropout rate (how much to drop out). Defaults to 0.1.
dropout_shared_axes (int): axes on which to share dropout mask. Defaults to None.
max_len (int): maximum symbol length for positional encoding. Defaults to 2048.
mode (str): 'train' or 'eval'. Defaults to 'train'.
ff_activation (function): the non-linearity in feed-forward layer. Defaults to tl.Relu.
EncoderBlock (function): Returns the encoder block. Defaults to EncoderBlock.
Returns:
trax.layers.combinators.Serial: A Transformer model as a layer that maps
from a tensor of tokens to activations over a set of output classes.
"""
positional_encoder = [
tl.Embedding(vocab_size, d_model),
tl.Dropout(rate=dropout, shared_axes=dropout_shared_axes, mode=mode),
tl.PositionalEncoding(max_len=max_len)
]
### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###
# Use the function `EncoderBlock` (implemented above) and pass in the parameters over `n_layers`
encoder_blocks = [None for _ in range(None)]
# Assemble and return the model.
return tl.Serial(
# Encode
tl.Branch(
# Use `positional_encoder`
None,
# Use trax padding mask
None,
),
# Use `encoder_blocks`
None,
# Use select layer
None,
# Use trax layer normalization
None,
# Map to output categories.
# Use trax mean. set axis to 1
None,
# Use trax Dense using `n_classes`
None,
# Use trax log softmax
None,
)
### END CODE HERE ###
# Run this cell to see the structure of your model
# Only 1 layer is used to keep the output readable
TransformerEncoder(n_layers=1)
```
#### **Expected Output:**
```CPP
Serial[
Branch_out2[
[Embedding_32000_512, Dropout, PositionalEncoding]
PaddingMask(0)
]
Serial_in2_out2[
Branch_in2_out3[
None
Serial_in2_out2[
LayerNorm
Serial_in2_out2[
Dup_out2
Dup_out2
Serial_in4_out2[
Parallel_in3_out3[
Dense_512
Dense_512
Dense_512
]
PureAttention_in4_out2
Dense_512
]
]
Dropout
]
]
Add_in2
]
Serial[
Branch_out2[
None
Serial[
LayerNorm
Dense_2048
Relu
Dropout
Dense_512
Dropout
]
]
Add_in2
]
Select[0]_in2
LayerNorm
Mean
Dense_10
LogSoftmax
]
```
**NOTE Congratulations! You have completed all of the graded functions of this assignment.** Since the rest of the assignment takes a lot of time and memory to run we are providing some extra ungraded labs for you to see this model in action.
**Keep it up!**
To see this model in action continue to the next 2 ungraded labs. **We strongly recommend you to try the colab versions of them as they will yield a much smoother experience.** The links to the colabs can be found within the ungraded labs or if you already know how to open files within colab here are some shortcuts (if not, head to the ungraded labs which contain some extra instructions):
[BERT Loss Model Colab](https://drive.google.com/file/d/1EHAbMnW6u-GqYWh5r3Z8uLbz4KNpKOAv/view?usp=sharing)
[T5 SQuAD Model Colab](https://drive.google.com/file/d/1c-8KJkTySRGqCx_JjwjvXuRBTNTqEE0N/view?usp=sharing)
| github_jupyter |
```
#default_exp dataset_torch
```
# dataset_torch
> Module to load the slates dataset into a Pytorch Dataset and Dataloaders with default train/valid test splits.
```
#export
import torch
import recsys_slates_dataset.data_helper as data_helper
from torch.utils.data import Dataset, DataLoader
import torch
import json
import numpy as np
import logging
logging.basicConfig(format='%(asctime)s %(message)s', level='INFO')
class SequentialDataset(Dataset):
''' A Pytorch Dataset for the FINN Recsys Slates Dataset.
Attributes:
data: [Dict] A dictionary with tensors of the dataset. First dimension in each tensor must be the batch dimension. Requires the keys "click" and "slate". Additional elements can be added.
sample_candidate_items: [int] Number of negative item examples sampled from the item universe for each interaction. If positive, the dataset provide an additional dictionary item "allitem". Often also called uniform candidate sampling. See Eide et. al. 2021 for more information.
'''
def __init__(self, data, sample_candidate_items=0):
self.data = data
self.num_items = self.data['slate'].max()+1
self.sample_candidate_items = sample_candidate_items
self.mask2ind = {'train' : 1, 'valid' : 2, 'test' : 3}
logging.info(
"Loading dataset with slate size={} and number of negative samples={}"
.format(self.data['slate'].size(), self.sample_candidate_items))
# Performs some checks on the dataset to make sure it is valid:
assert "slate" in data.keys(), "Slate tensor is not in dataset. This is required."
assert "click" in data.keys(), "Click tensor is not in dataset. This is required."
assert all([val.size(0)==data['slate'].size(0) for key, val in data.items()]), "Not all data tensors have the same batch dimension"
def __getitem__(self, idx):
batch = {key: val[idx] for key, val in self.data.items()}
if self.sample_candidate_items:
# Sample actions uniformly (3 is the first non-special item)
batch['allitem'] = torch.randint(
size=(batch['click'].size(0), self.sample_candidate_items),
low=3, high=self.num_items, device = batch['click'].device
)
return batch
def __len__(self):
return len(self.data['click'])
#export
def load_dataloaders(data_dir= "dat",
batch_size=1024,
num_workers= 0,
sample_candidate_items=False,
valid_pct= 0.05,
test_pct= 0.05,
t_testsplit= 5,
limit_num_users=None,
seed=0):
"""
Loads pytorch dataloaders to be used in training. If used with standard settings, the train/val/test split is equivalent to Eide et. al. 2021.
Attributes:
data_dir: [str] where download and store data if not already downloaded.
batch_size: [int] Batch size given by dataloaders.
num_workers: [int] How many threads should be used to prepare batches of data.
sample_candidate_items: [int] Number of negative item examples sampled from the item universe for each interaction. If positive, the dataset provide an additional dictionary item "allitem". Often also called uniform candidate sampling. See Eide et. al. 2021 for more information.
valid_pct: [float] Percentage of users allocated to validation dataset.
test_pct: [float] Percentage of users allocated to test dataset.
t_testsplit: [int] For users allocated to validation and test datasets, how many initial interactions should be part of the training dataset.
limit_num_users: [int] For debugging purposes, only return some users.
seed: [int] Seed used to sample users/items.
"""
logging.info("Download data if not in data folder..")
data_helper.download_data_files(data_dir=data_dir)
logging.info('Load data..')
with np.load("{}/data.npz".format(data_dir)) as data_np:
data = {key: torch.tensor(val) for key, val in data_np.items()}
if limit_num_users is not None:
logging.info("Limiting dataset to only return the first {} users.".format(limit_num_users))
data = {key : val[:limit_num_users] for key, val in data.items()}
with open('{}/ind2val.json'.format(data_dir), 'rb') as handle:
# Use string2int object_hook found here: https://stackoverflow.com/a/54112705
ind2val = json.load(
handle,
object_hook=lambda d: {
int(k) if k.lstrip('-').isdigit() else k: v
for k, v in d.items()
}
)
num_users = len(data['click'])
num_validusers = int(num_users * valid_pct)
num_testusers = int(num_users * test_pct)
torch.manual_seed(seed)
perm_user = torch.randperm(num_users)
valid_user_idx = perm_user[:num_validusers]
test_user_idx = perm_user[num_validusers:(num_validusers+num_testusers)]
train_user_idx = perm_user[(num_validusers+num_testusers):]
# Split dictionary into train/valid/test with a phase mask that shows which interactions are in different sets
# (as some users have both train and valid data)
data_train = data
data_train['phase_mask'] = torch.ones_like(data['click']).bool()
data_train['phase_mask'][test_user_idx,t_testsplit:]=False
data_train['phase_mask'][valid_user_idx,t_testsplit:]=False
data_valid = {key: val[valid_user_idx] for key, val in data.items()}
data_valid['phase_mask'] = torch.zeros_like(data_valid['click']).bool()
data_valid['phase_mask'][:,t_testsplit:] = True
data_test = {key: val[test_user_idx] for key, val in data.items()}
data_test['phase_mask'] = torch.zeros_like(data_test['click']).bool()
data_test['phase_mask'][:,t_testsplit:] = True
data_dicts = {
"train" : data_train,
"valid" : data_valid,
"test" : data_test}
datasets = {
phase : SequentialDataset(data, sample_candidate_items)
for phase, data in data_dicts.items()
}
# Build dataloaders for each data subset:
dataloaders = {
phase: DataLoader(ds, batch_size=batch_size, shuffle=(phase=="train"), num_workers=num_workers)
for phase, ds in datasets.items()
}
for key, dl in dataloaders.items():
logging.info(
"In {}: num_users: {}, num_batches: {}".format(key, len(dl.dataset), len(dl))
)
# Load item attributes:
with np.load('{}/itemattr.npz'.format(data_dir), mmap_mode=None) as itemattr_file:
itemattr = {key : val for key, val in itemattr_file.items()}
return ind2val, itemattr, dataloaders
#slow
ind2val, itemattr, dataloaders = load_dataloaders()
```
| github_jupyter |
# Collaborative filtering on the MovieLense Dataset
###### This notebook is based on part of Chapter 9 of [BigQuery: The Definitive Guide](https://www.oreilly.com/library/view/google-bigquery-the/9781492044451/ "http://shop.oreilly.com/product/0636920207399.do") by Lakshmanan and Tigani.
### MovieLens dataset
To illustrate recommender systems in action, let’s use the MovieLens dataset. This is a dataset of movie reviews released by GroupLens, a research lab in the Department of Computer Science and Engineering at the University of Minnesota, through funding by the US National Science Foundation.
Download the data and load it as a BigQuery table using:
```
import os
PROJECT = "your-project-here" # REPLACE WITH YOUR PROJECT ID
BUCKET = "your-bucket-here" # REPLACE WITH YOUR BUCKET NAME
REGION = "us-central1" # REPLACE WITH YOUR BUCKET REGION e.g. us-central1
# Do not change these
os.environ["PROJECT"] = PROJECT
os.environ["BUCKET"] = BUCKET
os.environ["REGION"] = REGION
os.environ["TFVERSION"] = "1.14"
%%bash
rm -r bqml_data
mkdir bqml_data
cd bqml_data
curl -O 'http://files.grouplens.org/datasets/movielens/ml-20m.zip'
unzip ml-20m.zip
bq --location=US mk --dataset \
--description 'Movie Recommendations' \
$PROJECT:movielens
bq --location=US load --source_format=CSV \
--autodetect movielens.ratings ml-20m/ratings.csv
bq --location=US load --source_format=CSV \
--autodetect movielens.movies_raw ml-20m/movies.csv
```
## Exploring the data
Two tables should now be available in <a href="https://console.cloud.google.com/bigquery">BigQuery</a>.
Collaborative filtering provides a way to generate product recommendations for users, or user targeting for products. The starting point is a table, <b>movielens.ratings</b>, with three columns: a user id, an item id, and the rating that the user gave the product. This table can be sparse -- users don’t have to rate all products. Then, based on just the ratings, the technique finds similar users and similar products and determines the rating that a user would give an unseen product. Then, we can recommend the products with the highest predicted ratings to users, or target products at users with the highest predicted ratings.
```
%%bigquery --project $PROJECT
SELECT *
FROM movielens.ratings
LIMIT 10
```
A quick exploratory query yields that the dataset consists of over 138 thousand users, nearly 27 thousand movies, and a little more than 20 million ratings, confirming that the data has been loaded successfully.
```
%%bigquery --project $PROJECT
SELECT
COUNT(DISTINCT userId) numUsers,
COUNT(DISTINCT movieId) numMovies,
COUNT(*) totalRatings
FROM movielens.ratings
```
On examining the first few movies using the query following query, we can see that the genres column is a formatted string:
```
%%bigquery --project $PROJECT
SELECT *
FROM movielens.movies_raw
WHERE movieId < 5
```
We can parse the genres into an array and rewrite the table as follows:
```
%%bigquery --project $PROJECT
CREATE OR REPLACE TABLE movielens.movies AS
SELECT * REPLACE(SPLIT(genres, "|") AS genres)
FROM movielens.movies_raw
%%bigquery --project $PROJECT
SELECT *
FROM movielens.movies
WHERE movieId < 5
```
## Matrix factorization
Matrix factorization is a collaborative filtering technique that relies on factorizing the ratings matrix into two vectors called the user factors and the item factors. The user factors is a low-dimensional representation of a user_id and the item factors similarly represents an item_id.
We can create the recommender model using (<b>Optional</b>, takes 30 minutes. Note: we have a model we already trained if you want to skip this step):
```
%%bigquery --project $PROJECT
CREATE OR REPLACE MODEL movielens.recommender
options(model_type='matrix_factorization',
user_col='userId', item_col='movieId', rating_col='rating')
AS
SELECT
userId, movieId, rating
FROM movielens.ratings
%%bigquery --project $PROJECT
SELECT *
-- Note: remove cloud-training-demos if you are using your own model:
FROM ML.TRAINING_INFO(MODEL `cloud-training-demos.movielens.recommender`)
```
Note that we create a model as usual, except that the model_type is matrix_factorization and that we have to identify which columns play what roles in the collaborative filtering setup.
What did you get? Our model took an hour to train, and the training loss starts out extremely bad and gets driven down to near-zero over next the four iterations:
<table>
<tr>
<th>Iteration</th>
<th>Training Data Loss</th>
<th>Evaluation Data Loss</th>
<th>Duration (seconds)</th>
</tr>
<tr>
<td>4</td>
<td>0.5734</td>
<td>172.4057</td>
<td>180.99</td>
</tr>
<tr>
<td>3</td>
<td>0.5826</td>
<td>187.2103</td>
<td>1,040.06</td>
</tr>
<tr>
<td>2</td>
<td>0.6531</td>
<td>4,758.2944</td>
<td>219.46</td>
</tr>
<tr>
<td>1</td>
<td>1.9776</td>
<td>6,297.2573</td>
<td>1,093.76</td>
</tr>
<tr>
<td>0</td>
<td>63,287,833,220.5795</td>
<td>168,995,333.0464</td>
<td>1,091.21</td>
</tr>
</table>
However, the evaluation data loss is quite high, and much higher than the training data loss. This indicates that overfitting is happening, and so we need to add some regularization. Let’s do that next. Note the added l2_reg=0.2 (<b>Optional</b>, takes 30 minutes):
```
%%bigquery --project $PROJECT
CREATE OR REPLACE MODEL movielens.recommender_l2
options(model_type='matrix_factorization',
user_col='userId', item_col='movieId',
rating_col='rating', l2_reg=0.2)
AS
SELECT
userId, movieId, rating
FROM movielens.ratings
%%bigquery --project $PROJECT
SELECT *
-- Note: remove cloud-training-demos if you are using your own model:
FROM ML.TRAINING_INFO(MODEL `cloud-training-demos.movielens.recommender_l2`)
```
Now, we get faster convergence (three iterations instead of five), and a lot less overfitting. Here are our results:
<table>
<tr>
<th>Iteration</th>
<th>Training Data Loss</th>
<th>Evaluation Data Loss</th>
<th>Duration (seconds)</th>
</tr>
<tr>
<td>2</td>
<td>0.6509</td>
<td>1.4596</td>
<td>198.17</td>
</tr>
<tr>
<td>1</td>
<td>1.9829</td>
<td>33,814.3017</td>
<td>1,066.06</td>
</tr>
<tr>
<td>0</td>
<td>481,434,346,060.7928</td>
<td>2,156,993,687.7928</td>
<td>1,024.59</td>
</tr>
</table>
By default, BigQuery sets the number of factors to be the log2 of the number of rows. In our case, since we have 20 million rows in the table, the number of factors would have been chosen to be 24. As with the number of clusters in K-Means clustering, this is a reasonable default but it is often worth experimenting with a number about 50% higher (36) and a number that is about a third lower (16):
```
%%bigquery --project $PROJECT
CREATE OR REPLACE MODEL movielens.recommender_16
options(model_type='matrix_factorization',
user_col='userId', item_col='movieId',
rating_col='rating', l2_reg=0.2, num_factors=16)
AS
SELECT
userId, movieId, rating
FROM movielens.ratings
%%bigquery --project $PROJECT
SELECT *
-- Note: remove cloud-training-demos if you are using your own model:
FROM ML.TRAINING_INFO(MODEL `cloud-training-demos.movielens.recommender_16`)
```
When we did that, we discovered that the evaluation loss was lower (0.97) with num_factors=16 than with num_factors=36 (1.67) or num_factors=24 (1.45). We could continue experimenting, but we are likely to see diminishing returns with further experimentation. So, let’s pick this as the final matrix factorization model and move on.
## Making recommendations
With the trained model, we can now provide recommendations. For example, let’s find the best comedy movies to recommend to the user whose userId is 903. In the query below, we are calling ML.PREDICT passing in the trained recommendation model and providing a set of movieId and userId to carry out the predictions on. In this case, it’s just one userId (903), but all movies whose genre includes Comedy.
```
%%bigquery --project $PROJECT
SELECT * FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender_16`, (
SELECT
movieId, title, 903 AS userId
FROM movielens.movies, UNNEST(genres) g
WHERE g = 'Comedy'
))
ORDER BY predicted_rating DESC
LIMIT 5
```
## Filtering out already rated movies
Of course, this includes movies the user has already seen and rated in the past. Let’s remove them:
```
%%bigquery --project $PROJECT
SELECT * FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender_16`, (
WITH seen AS (
SELECT ARRAY_AGG(movieId) AS movies
FROM movielens.ratings
WHERE userId = 903
)
SELECT
movieId, title, 903 AS userId
FROM movielens.movies, UNNEST(genres) g, seen
WHERE g = 'Comedy' AND movieId NOT IN UNNEST(seen.movies)
))
ORDER BY predicted_rating DESC
LIMIT 5
```
For this user, this happens to yield the same set of movies -- the top predicted ratings didn’t include any of the movies the user has already seen.
## Customer targeting
In the previous section, we looked at how to identify the top-rated movies for a specific user. Sometimes, we have a product and have to find the customers who are likely to appreciate it. Suppose, for example, we wish to get more reviews for movieId=96481 which has only one rating and we wish to send coupons to the 5 users who are likely to rate it the highest. We can identify those users using:
```
%%bigquery --project $PROJECT
SELECT * FROM
ML.PREDICT(MODEL `cloud-training-demos.movielens.recommender_16`, (
WITH allUsers AS (
SELECT DISTINCT userId
FROM movielens.ratings
)
SELECT
96481 AS movieId,
(SELECT title FROM movielens.movies WHERE movieId=96481) title,
userId
FROM
allUsers
))
ORDER BY predicted_rating DESC
LIMIT 5
```
### Batch predictions for all users and movies
What if we wish to carry out predictions for every user and movie combination? Instead of having to pull distinct users and movies as in the previous query, a convenience function is provided to carry out batch predictions for all movieId and userId encountered during training. A limit is applied here, otherwise, all user-movie predictions will be returned and will crash the notebook.
```
%%bigquery --project $PROJECT
SELECT *
FROM ML.RECOMMEND(MODEL `cloud-training-demos.movielens.recommender_16`)
LIMIT 10
```
As seen in a section above, it is possible to filter out movies the user has already seen and rated in the past. The reason already seen movies aren’t filtered out by default is that there are situations (think of restaurant recommendations, for example) where it is perfectly expected that we would need to recommend restaurants the user has liked in the past.
Copyright 2019 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| github_jupyter |
```
import neuroglancer
# Use this in IPython to allow external viewing
# neuroglancer.set_server_bind_address(bind_address='192.168.158.128',
# bind_port=80)
from nuggt.utils import ngutils
viewer = neuroglancer.Viewer()
viewer
import numpy as np
import zarr
import os
# working_dir = '/media/jswaney/Drive/Justin/coregistration/whole_brain_tde'
working_dir = '/home/jswaney/coregistration'
fixed_path = 'fixed/zarr_stack/8_8_8'
moving_path = 'moving/zarr_stack/8_8_8'
fixed_store = zarr.NestedDirectoryStore(os.path.join(working_dir, fixed_path))
moving_store = zarr.NestedDirectoryStore(os.path.join(working_dir, moving_path))
fixed_img = zarr.open(fixed_store, mode='r')
moving_img = zarr.open(moving_store, mode='r')
print(fixed_img.shape)
print(moving_img.shape)
normalization = 2000
def plot_image(img, viewer, layer, shader):
with viewer.txn() as txn:
source = neuroglancer.LocalVolume(img.astype(np.float32))
txn.layers[layer] = neuroglancer.ImageLayer(source=source, shader=shader)
def plot_fixed(fixed_img, viewer):
fixed_shader = ngutils.red_shader % (1 / normalization)
plot_image(fixed_img, viewer, 'fixed', fixed_shader)
def plot_moving(moving_img, viewer):
moving_shader = ngutils.green_shader % (1 / normalization)
plot_image(moving_img, viewer, 'moving', moving_shader)
def plot_both(fixed_img, moving_img, viewer):
plot_fixed(fixed_img, viewer)
plot_moving(moving_img, viewer)
plot_both(fixed_img, moving_img, viewer)
```
# Downsampling Zarr
```
from phathom.io.zarr import downsample_zarr
factors = (8, 8, 8)
output_path = os.path.join(working_dir, 'fixed/zarr_down8')
nb_workers = 1
downsample_zarr(fixed_img, factors, output_path, nb_workers)
factors = (8, 8, 8)
output_path = os.path.join(working_dir, 'moving/zarr_down8')
nb_workers = 1
downsample_zarr(moving_img, factors, output_path, nb_workers)
```
# Downsampling ndarray
```
from skimage.measure import block_reduce
factors = (16, 16, 16)
def downsample_mean(img, factors):
return block_reduce(img, factors, np.mean, 0)
def downsample_max(img, factors):
return block_reduce(img, factors, np.max, 0)
fixed_downsample = downsample_mean(fixed_img, factors)
moving_downsample = downsample_mean(moving_img, factors)
plot_both(fixed_downsample, moving_downsample, viewer)
```
# Gaussian smoothing
```
from skimage.filters import gaussian
sigma = 1.0
fixed_smooth = gaussian(fixed_downsample, sigma, preserve_range=True)
moving_smooth = gaussian(moving_downsample, sigma, preserve_range=True)
plot_both(fixed_smooth, moving_smooth, viewer)
```
# Destriping
```
import pystripe
import multiprocessing
import tqdm
bandwidth = [64, 64]
wavelet = 'db4'
def _filter_streaks(img):
return pystripe.filter_streaks(img, sigma=bandwidth, wavelet=wavelet)
with multiprocessing.Pool(12) as pool:
rf = list(tqdm.tqdm(pool.imap(_filter_streaks, fixed_smooth), total=len(fixed_smooth)))
rm = list(tqdm.tqdm(pool.imap(_filter_streaks, moving_smooth), total=len(moving_smooth)))
fixed_destripe = np.array(rf).T
moving_destripe = np.array(rm).T
with multiprocessing.Pool(12) as pool:
rf = list(tqdm.tqdm(pool.imap(_filter_streaks, fixed_destripe), total=len(fixed_smooth)))
rm = list(tqdm.tqdm(pool.imap(_filter_streaks, moving_destripe), total=len(moving_smooth)))
fixed_destripe = np.array(rf).T
moving_destripe = np.array(rm).T
plot_both(fixed_destripe, moving_destripe, viewer)
```
# Rigid transformation
```
from phathom.registration import coarse, pcloud
from phathom import utils
from scipy.ndimage import map_coordinates
t = np.array([0, 0, 0])
thetas = np.array([np.pi/4, 0, 0])
def rigid_warp(img, t, thetas, center, output_shape):
r = pcloud.rotation_matrix(thetas)
idx = np.indices(output_shape)
pts = np.reshape(idx, (idx.shape[0], idx.size//idx.shape[0])).T
warped_pts = coarse.rigid_transformation(t, r, pts, center)
interp_values = map_coordinates(img, warped_pts.T)
transformed = np.reshape(interp_values, output_shape)
return transformed
transformed = rigid_warp(fixed_downsample,
t,
thetas,
np.zeros(3),
moving_downsample.shape)
plot_fixed(transformed, viewer)
from scipy.ndimage.measurements import center_of_mass
def center_mass(img):
return np.asarray(center_of_mass(img))
fixed_com = center_mass(fixed_downsample)
moving_com = center_mass(moving_downsample)
print(fixed_com)
print(moving_com)
```
# Optimization
```
def ncc(fixed, transformed, nonzero=False):
if nonzero:
idx = np.where(transformed)
a = fixed[idx]
b = transformed[idx]
else:
a = fixed
b = transformed
return np.sum((a-a.mean())*(b-b.mean())/((a.size-1)*a.std()*b.std()))
def ssd(fixed, transformed):
return np.mean((fixed-transformed)**2)
def registration_objective(x, fixed_img, moving_img, t):
transformed_img = rigid_warp(moving_img,
t=t,
thetas=x,
center=fixed_com,
output_shape=moving_img.shape)
return ssd(moving_img, transformed_img)
def callback(x, f, accept):
pass
from scipy.optimize import basinhopping
niter = 4
t_star = moving_com-fixed_com
bounds = [(0, np.pi/2) for _ in range(3)]
res = basinhopping(registration_objective,
x0=np.zeros(3),
niter=niter,
T=1.0,
stepsize=1.0,
interval=5,
minimizer_kwargs={
'method': 'L-BFGS-B',
# 'method': 'Nelder-Mead',
'args': (fixed_smooth,
moving_smooth,
t_star),
'bounds': bounds,
'tol': 0.01,
'options': {'disp': False}
},
disp=True)
theta_star = res.x
print(res)
registered = rigid_warp(fixed_smooth, t_star, theta_star, fixed_com, moving_destripe.shape)
plot_fixed(registered, viewer)
```
# Contour
```
import matplotlib.pyplot as plt
plt.hist(fixed_downsample.ravel(), bins=100)
plt.xlim([0, 1000])
plt.ylim([0, 100000])
plt.show()
plt.hist(moving_downsample.ravel(), bins=100)
plt.xlim([0, 1000])
plt.ylim([0, 100000])
plt.show()
threshold = 150
fixed_mask = fixed_downsample > threshold
moving_mask = moving_downsample > threshold
plot_both(1000*fixed_mask, 1000*moving_mask, viewer)
```
# Convex hull
```
from skimage.morphology import convex_hull_image
import tqdm
fixed_hull = np.zeros_like(fixed_mask)
for i, f in enumerate(tqdm.tqdm(fixed_mask)):
if not np.all(f == 0):
fixed_hull[i] = convex_hull_image(f)
moving_hull = np.zeros_like(moving_mask)
for i, m in enumerate(tqdm.tqdm(moving_mask)):
if not np.all(m == 0):
moving_hull[i] = convex_hull_image(m)
plot_both(1000*fixed_hull, 1000*moving_hull, viewer)
from scipy.ndimage.morphology import distance_transform_edt
fixed_distance = distance_transform_edt(fixed_mask)
moving_distance = distance_transform_edt(moving_mask)
plot_both(100*fixed_distance, 100*moving_distance, viewer)
niter = 3
from scipy.optimize import basinhopping
fixed_com = center_mass(fixed_mask)
moving_com = center_mass(moving_mask)
t0 = moving_com-fixed_com
bounds = [(-s, s) for s in moving_distance.shape]+[(-np.pi, np.pi) for _ in range(3)]
# bounds = [(-np.pi, np.pi) for _ in range(3)]
def absolute_difference(img1, img2):
return np.mean(np.abs(img1-img2))
def registration_objective(x, fixed_img, moving_img):
transformed_img = rigid_warp(moving_img,
t= x[:3],
thetas= x[3:],
center=fixed_com,
output_shape=fixed_img.shape)
return absolute_difference(fixed_img, transformed_img)
# return ssd(fixed_img, transformed_img)
def callback(x, f, accept):
print(x)
res = basinhopping(registration_objective,
x0=np.concatenate((t0, np.zeros(3))),
niter=niter,
T=0.5,
stepsize=0.5,
interval=5,
minimizer_kwargs={
'method': 'L-BFGS-B',
'args': (fixed_distance,
moving_distance),
'bounds': bounds,
'tol': 0.001,
'options': {'disp': False}
},
callback=callback,
disp=True)
t_star = res.x[:3]
theta_star = res.x[3:]
print(res)
reg_distance = rigid_warp(moving_distance,
t_star,
theta_star,
fixed_com,
moving_distance.shape)
plot_moving(100*reg_distance, viewer)
```
Sum of squared differences seems to provide slightly better registration than Normalized cross-correlation in the case of distance transformed convex hulls. This might be because NCC is indifferent to intensity difference and only considers correlations in the intensities, whereas SSD will penalize for any difference in intensity. In a multi-modal setting, this is usually not desired, but since we are dealing with the same brain in both images, the overall shape (and therefore distance transforms) should take similar values (not just correlated).
Also, it was necessary to include the translation component in the optimization procedure because our center of mass estimate for the center of rotation is not accurate. This causes the optimization for our rigid transformation to be partially constrained to inaccurate values, making it hard to converge to a rotation
# Coarse Registration
```
registered = rigid_warp(moving_downsample,
t_star,
theta_star,
fixed_com,
moving_downsample.shape)
plot_both(fixed_downsample, registered, viewer)
```
We need to convert the downsampled transformation into an approprate transformation for the original resolution image. The rotation matrix is scale invariant, but we need to make sure the center of rotation and translation are upsampled by the same amount that we downsampled
```
print('Converged rigid transformation for downsampled image')
print('Rotation (deg):', theta_star*180/np.pi)
print('Center (px):', fixed_com)
print('Translation (px):', t_star)
fixed_fullres_path = os.path.join(working_dir, 'fixed/zarr_stack/8_8_8')
fixed_fullres_store = zarr.NestedDirectoryStore(fixed_fullres_path)
fixed_fullres = zarr.open(fixed_fullres_store, mode='r')
theta = theta_star
true_factors = np.array(fixed_fullres.shape) / np.array(fixed_downsample.shape)
t, center = coarse._scale_rigid_params(t_star,
fixed_com,
true_factors)
print('Converged rigid transformation for original image')
print('Rotation (deg):', theta*180/np.pi)
print('Center (px):', center)
print('Translation (px):', t)
plot_both(fixed_img, moving_img, viewer)
registered = rigid_warp(moving_img,
t,
theta,
center,
fixed_img.shape)
plot_moving(registered, viewer)
np.save('rigid_8_8_8.npy', registered)
```
# Save the transformation
```
from phathom.utils import pickle_save
transformation_dict = {'t': t,
'center': center,
'theta': theta}
pickle_save(os.path.join(working_dir, 'rigid_transformation.pkl'),
transformation_dict)
from phathom.utils import pickle_load
transformation_dict = pickle_load(os.path.join(working_dir, 'rigid_transformation.pkl'))
transformation_dict
```
| github_jupyter |
```
## plot plasma density
%pylab inline
import numpy as np
from matplotlib import pyplot as plt
from ReadBinary import *
fileSuffix = "-10"
folder = "../data/LargePeriodicLattice-GaussianPlasma/fp=1THz/"
#folder = "../data/2D/"
filename = folder+"Wp2-x{}.data".format(fileSuffix)
arrayInfo = GetArrayInfo(filename)
print("typeCode: ", arrayInfo["typeCode"])
print("typeSize: ", arrayInfo["typeSize"])
print("shape: ", arrayInfo["shape"])
print("numOfArrays: ", arrayInfo["numOfArrays"])
Wp2 = GetArrays(filename, 0, 1)[0,0,:,:]
print("shape: ", Wp2.shape)
shape = Wp2.shape
plt.figure(figsize=(6, 6*(shape[0]/shape[1])))
plt.imshow(np.real(Wp2[:,:]), cmap="rainbow", origin='lower', aspect='auto')
plt.contour(np.real(Wp2[:,:]), cmap="Greys", linewidths=0.5)
plt.show()
## animate Electric field
%pylab tk
import numpy as np
from matplotlib import pyplot as plt
import matplotlib.animation as animation
from ReadBinary import *
filename = folder+"E-x{}.data".format(fileSuffix)
arrayInfo = GetArrayInfo(filename)
print("typeCode: ", arrayInfo["typeCode"])
print("typeSize: ", arrayInfo["typeSize"])
print("shape: ", arrayInfo["shape"])
print("numOfArrays: ", arrayInfo["numOfArrays"])
E = GetArrays(filename, indStart=0, indEnd=None)[:, 0, :, :]
print("shape: ", E.shape)
shape = E.shape[1:]
print("Max E: ", np.max(np.abs(E)))
animate = True
save_animation = True
if animate:
def animate_E(n):
plt.clf()
fig = plt.imshow(np.real(E[n, :,:]), cmap="rainbow", origin='lower', aspect='auto')
plt.colorbar()
plt.contour(np.real(Wp2[:,:]), cmap="Greys", linewidths=0.5)
plt.xticks([])
plt.yticks([])
plt.pause(0.05)
return fig
if not save_animation:
plt.ion()
plt.figure(figsize=(7,6*(shape[0]/shape[1])))
for n in range(E.shape[0]):
animate_E(n)
else:
fig = plt.figure(figsize=(7,6*(shape[0]/shape[1])))
anim = animation.FuncAnimation(fig, animate_E, frames=E.shape[0], interval=1, repeat=False)
anim.save(folder + 'Efield-anim.mp4', writer="ffmpeg", fps=15, dpi=200)
%pylab inline
E = GetArrays(folder+"E-x-slice{}.data".format(fileSuffix), indStart=0, indEnd=None)[:, 0, :, :]
print("shape: ", E.shape)
shape = E.shape[1:]
E_ty = E[:, :, 0]
plt.imshow(np.real(E_ty).T, cmap="rainbow", origin='lower', aspect='auto')
plt.colorbar()
plt.show()
Nt, Ny = E_ty.shape
N_pts = 50
E_f_ty = np.fft.fftshift(np.fft.fft2(E_ty))[Nt//2-N_pts:Nt//2+N_pts, Ny//2-N_pts:Ny//2+N_pts]
plt.imshow(np.abs(E_f_ty), cmap="rainbow", origin='lower', aspect='auto')
plt.show()
%pylab inline
plt.figure()
E_t = np.sum(E_ty, axis=1)[700:]
plt.plot(E_t)
plt.show()
Nt = len(E_t)
N_pts = 30
plt.figure()
E_f_t = np.fft.fftshift(np.fft.fft(E_t))[Nt//2-N_pts:Nt//2+N_pts]
plt.plot(np.abs(E_f_t))
plt.show()
Nw = 200
w_max = 5
w = np.linspace(0, w_max, Nw)
dt = 0.01*0.95/np.sqrt(2.0)
Nt = len(E_t)
t = np.linspace(0, Nt*dt, Nt)
E_f_t = np.zeros(Nw, dtype=complex)
for i in range(len(w)):
w_i = w[i]
E_f_t[i] = np.sum(E_t * np.exp(-1j*w_i*t))/Nt
plot(w, np.abs(E_f_t))
show()
from scipy import constants
pitch = 124
plot(w*(constants.c/(pitch*constants.micro))/constants.tera/(2.0*np.pi), np.abs(E_f_t))
show()
%pylab inline
import numpy as np
from matplotlib import pyplot as plt
import os
from scipy import constants
from ReadBinary import *
folder = "../data/LargePeriodicLattice-GaussianPlasma/fp=1THz/"
file_list = os.listdir(folder)
suffixes = sorted([f[9:f.find(".data")] for f in file_list if "slice" in f])
print(suffixes)
angles = [float(sfx[1:]) for sfx in suffixes]
print(angles)
sorted_keys = sorted(range(len(angles)), key=lambda k: angles[k])
suffixes = [suffixes[i] for i in sorted_keys]
print(suffixes)
filename = folder+"E-x-slice{}.data".format(suffixes[0])
arrayInfo = GetArrayInfo(filename)
Ny = arrayInfo["shape"][1]
Nt = arrayInfo["numOfArrays"]
print("Nt: {}, Ny: {}".format(Nt, Ny))
Nw = 200
def get_spectrum_si(E_t):
w_max = 5
w = np.linspace(0, w_max, Nw)
dt = 0.01*0.95/np.sqrt(2.0)
Nt = len(E_t)
t = np.linspace(0, Nt*dt, Nt)
E_f_t = np.zeros(Nw, dtype=complex)
for i in range(len(w)):
w_i = w[i]
E_f_t[i] = np.sum(E_t * np.exp(-1j*w_i*t))/Nt
pitch = 124
f_si = w*(constants.c/(pitch*constants.micro))/constants.tera/(2.0*np.pi)
return f_si, E_f_t
E = GetArrays(folder+"E-x-slice{}.data".format(suffixes[0]), indStart=0, indEnd=None)[:, 0, :, :]
E_ty = E[:, :, 0]
E_t = np.sum(E_ty, axis=1)[700:]
f_si, E_f_t = get_spectrum_si(E_t)
plot(f_si, np.abs(E_f_t))
show()
n_files = len(suffixes)
gap_spec = np.zeros((Nw, n_files), dtype=complex)
for i in range(n_files):
E = GetArrays(folder+"E-x-slice{}.data".format(suffixes[i]), indStart=0, indEnd=None)[:, 0, :, :]
E_ty = E[:, :, 0]
E_t = np.sum(E_ty, axis=1)[700:]
f_si, E_f_t = get_spectrum_si(E_t)
gap_spec[:, i] = E_f_t
print(suffixes[i], end=" ")
imshow(np.abs(gap_spec), cmap="rainbow", origin='lower', aspect='auto')
font = {'family' : 'serif', 'weight' : 'normal', 'size' : 14}
matplotlib.rc('font', **font)
imshow(np.abs(gap_spec[0:100,:]), cmap="rainbow", interpolation=None, origin='lower', aspect='auto', \
extent=[0, 45, 0, f_si[100]], vmax=None)
#contour(np.abs(gap_spec[0:100,:]), extent=[0, 45, 0, f_si[100]])
xlabel(r"$\theta$ (degrees)")
ylabel(r"f (THz)")
savefig(folder+'E-r-spectrum.png', bbox_inches='tight', pad_inches=0.5)
```
| github_jupyter |
```
import pandas as pd
from pylab import rcParams
import seaborn as sb
import matplotlib.pyplot as plt
import sklearn
from sklearn.cluster import DBSCAN
from collections import Counter
import datetime
from sklearn.preprocessing import LabelEncoder
from collections import defaultdict
from functools import reduce
import math
to_milliseconds = lambda seconds : seconds * 60 * 1000
class BinaryDataAnalysis:
"""Convert non-nummeric values in the dataframe to numbers so that the dataframe can be used to fit a model
Args (all optional):
eps: The epsilon in minutes (starting minimum distance between datapoints to cluster them together)
cluster_degregation: The next epsilon divider to use if clusters are too large
(if eps=5 and cluster_degregation=2 then the next eps will be 2.5, and the next 1.25 etc.)
max_cluster_distance: the maximum size of a cluster in minutes
weeks: the amount of weeks to analyze,
a minimum of 1 needed,
a minimum of 2 is recommended
decay_strength: how much the next week counts for predicting relevant groups
e.g. with a decay_strength of 0.5, ech week before last week will
count half as strong for predicting if the groups are still relevant
cluster_threshold: from how many occourences (in one week) should it get 'self.threshold_percentage'
as percentage that it is a group...
More occourences will result in a higher persentage than 'self.threshold_percentage'
Less occourences will result in a lower persentage
threshold_percentage: the persentage to give a group if the amount of occourences is 'self.cluster_threshold'
"""
def __init__(self,
eps=5,
cluster_degregation=2,
max_cluster_distance=7.5, #minutes
weeks=5,
decay_strength=0.5,
cluster_threshold=25,
threshold_percentage=90):
self.eps = eps
self.cluster_degregation = cluster_degregation
self.max_cluster_distance = max_cluster_distance
self.weeks = weeks
self.decay_strength = decay_strength
self.cluster_threshold = cluster_threshold
self.threshold_percentage = threshold_percentage
def analyze(self, df):
"""Analyze a dataframe and return a list of predicted groups & relevant groups
Args:
df: the dataframe to analyze
Returns:
result: an array of predicted groups in the following format:
[
{
item_ids: a list of item-id's that are predicted to be a group,
is_predicted_group_percentage: the percentage chance that this is a group,
is_relevant_group_percentage: the percentage chance that this group is still relevant
(depending on how much it has been used lately)
},
{...},
{...}
]
"""
# todo? cut off trailing days?
self.lookup_table = self.create_lookup_table(
df=df
)
df_fit = self.clean_dataframe(
df=df
)
week_hashcodes = self.get_week_clusters_hash_codes(
df=df_fit
)
hashcode_occurances = self.get_hashcode_occurances_per_week(
week_hashcodes=week_hashcodes
)
predicted_groups = self.calculate_groups(
hashcode_occurances_per_week=hashcode_occurances
)
result = []
for key in predicted_groups:
items = self.get_lookup_values(
hashcode=key
)
result.append({
'item_ids': items,
'is_predicted_group_percentage': predicted_groups[key]['is_predicted_group_percentage'],
'is_relevant_group_percentage': predicted_groups[key]['is_relevant_group_percentage']
})
return result
def create_lookup_table(self, df):
"""Creates a lookup table for all unique row-id's
Args:
df: the dataframe containing an id column with several diffrent devices creating events
Returns:
lookup_dict: a dictionary where each id corresponds to an index e.g.
{ 0: 1743, 1: 1749, 2: 1803, 3: 1890, 4: 1911}
"""
df_lookup = pd.DataFrame(data={ 'id': pd.Series(df['id']).unique() })
df_lookup['hashcode'] = self.clean_dataframe(
df=df_lookup
)['id']
lookup_dict = dict()
for index, row in df_lookup.iterrows():
lookup_dict[row['hashcode']] = row['id']
return lookup_dict
def clean_dataframe(self, df):
"""Convert non-nummeric values in the dataframe to numbers so that the dataframe can be used to fit a model
Args:
df: The dataframe to clean.
Returns:
df_fit: The dataframe with nummeric values
"""
d = defaultdict(LabelEncoder)
df_fit = df.apply(lambda x: d[x.name].fit_transform(x))
if 'state' in df.columns:
df_fit['state'] = df['state']
if 'time' in df.columns:
df_fit['time'] = df['time']
return df_fit
def get_week_clusters_hash_codes(self, df):
"""Get Cluster for a dataframe per week
Args:
df: The dataframe with more than one week of timestamps to cluster.
Returns:
week_hashcodes: A multidimentional array where each array is one week, and in one week array
are a list of clusters represented by a hashcode.
A hashcode is the reversed binary representation of a cluster,
e.g.
hashcode 3
is binary 00000011
is reversed 11000000
means devices with index 0 and 1 (from the lookup table) are grouped
Example output:
[[3, 5, 20], [3, 3, 20]]
means:
amount of weeks: 2
clusters in week 1:
3 (00000011) = a group with device 0 & 1
5 (00000101) = a group with device 0 & 2
20 (00010100) = a group with device 2 & 4
clusters in week 2:
3 (00000011) = a group with device 0 & 1
3 (00000011) = another group with device 0 & 1
21 (00010101) = a group with device 0, 2 & 4
"""
one_week_in_milliseconds = (1000 * 60 * 60 * 24 * 7)
last_timestamp = df['time'].max()
week_hashcodes = []
for week in range(self.weeks):
week_hashcodes.append([])
df_week = df[df['time'] >= last_timestamp - ((week + 1) * one_week_in_milliseconds)]
df_week = df_week[df_week['time'] < last_timestamp - (week * one_week_in_milliseconds)]
if not df_week.empty:
cluster_arr = self.split_dataframe_on_state_and_get_cluster_arr(
df=df_week,
starting_eps=self.eps
)
for idx, df_week in enumerate(cluster_arr):
cluster = []
for row in df_week.iterrows():
index, data = row
cluster.append(data['id'].tolist())
cluster = list(set(cluster))
hashcode = 0
for lamp in cluster:
hashcode += pow(2, lamp)
if(len(cluster) > 1):
week_hashcodes[week].append(hashcode)
else:
print(
'WARNING!!! There are not',
self.weeks,
'weeks in the dataset... amount_of_weeks HAS BEEN CHANGED TO',
week
)
self.weeks = week
break
return week_hashcodes
def split_dataframe_on_state_and_get_cluster_arr(self, df, starting_eps):
"""Split a dataframe into 2 seperate dataframes (one with state=0, the other with state=1)
and get the clusters for both of the dataframes
Args:
df: The dataframe to split & get clusters from.
Returns:
cluster_arr: an array that holds 0 or more dataframes (clusters)
"""
df_1 = df.loc[df['state'] == 1]
df_0 = df.loc[df['state'] == 0]
cluster_arr1 = self.get_clusters_recursive(df=df_1.copy(), eps=self.eps)
cluster_arr2 = self.get_clusters_recursive(df=df_0.copy(), eps=self.eps)
cluster_arr = cluster_arr1 + cluster_arr2
return cluster_arr
def get_clusters_recursive(self, df, eps, iteration=0, cluster_arr=None):
"""Get clusters for a single dataframe
Args:
df: The dataframe
eps: the epsilon to start with (maximum distance between two datapoints)
Returns:
cluster_arr: An array of dataframes (each one represents a cluster)e.g.
[DataFrame, DataFrame, DataFrame, ...]
"""
if cluster_arr is None:
cluster_arr = []
model = self.fit_model(df, eps)
cluster_dict = self.get_clusters(df=df, model=model)
for idx, df in cluster_dict['too_large'].items():
cluster_arr + self.get_clusters_recursive(
df=cluster_dict['too_large'][idx],
eps=eps / self.cluster_degregation,
iteration=iteration + 1,
cluster_arr=cluster_arr
)
for idx, df in cluster_dict['perfect_size'].items():
cluster_arr.append(df)
return cluster_arr
def fit_model(self, df, eps):
"""Fit the dataframe in the DBSCAN algoritm and return the model
more information: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
Args:
df: The dataframe to run the algorithm on
eps: the epsilon (maximum distance between two datapoints)
Returns:
model: The fitted DBSCAN model
"""
model = DBSCAN(
eps=to_milliseconds(eps),
min_samples=2
).fit(df)
return model
def get_clusters(self, df, model):
"""Get clusters for a single dataframe
Args:
df: The dataframe
model: the fitted model
Returns:
dict: A dictionary with 2 keys, each of wich is another dictionary which contains all dataframes (one per cluster)
e.g.
{
'too_large': {
0: DataFrame,
1: DataFrame,
2: DataFrame
},
'perfect_size': {
0: DataFrame,
1: DataFrame
}
}
"""
df['cluster'] = model.labels_
cluster_dict_too_large = {}
cluster_dict_perfect_size = {}
# Calculate amount of clusters
cluster_data_count = Counter(model.labels_)
if -1 in cluster_data_count:
cluster_data_count.pop(-1) # don't count outliers as a cluster
if (bool(cluster_data_count)):
amount_of_clusters = max(cluster_data_count) + 1
else:
amount_of_clusters = 0;
for idx in range(amount_of_clusters):
cluster_df = df.loc[df['cluster'] == idx].drop(columns=['cluster'])
first_time = cluster_df['time'].iloc[0]
last_time = cluster_df['time'].iloc[cluster_df['time'].size - 1]
diffrence_in_miliseconds = last_time - first_time
if diffrence_in_miliseconds > to_milliseconds(self.max_cluster_distance):
cluster_dict_too_large[idx] = cluster_df
else:
cluster_dict_perfect_size[idx] = cluster_df
return {
'too_large': cluster_dict_too_large,
'perfect_size': cluster_dict_perfect_size
}
def get_hashcode_occurances_per_week(self, week_hashcodes):
"""Count all occourences of hashcodes per week
Args:
week_hashcodes: The week_hashcodes (generated from self.get_week_clusters_hash_codes())
Returns:
count_dict: A dictionary with an index for each hashcode, with all
occourences per week (last week = 0, the week before that = 1).
e.g.
{
'3': {
'occurance_week': {
'0': 24,
'1': 56,
'2': 32,
'3': 12
}
},
'5': { 'occurance_week': { ... } },
'20': { 'occurance_week': { ... } },
...
}
"""
count_dict = {}
for week, hashcodes_arr in enumerate(week_hashcodes):
for i in hashcodes_arr:
if i in count_dict:
count_dict[i]['occurance_week'][str(week)] += 1
else:
count_dict[i] = {}
count_dict[i]['occurance_week'] = {}
for w in range(self.weeks):
count_dict[i]['occurance_week'][str(w)] = 0
return count_dict
def calculate_groups(self, hashcode_occurances_per_week):
"""Calculate the predicted groups & relevant groups persentages from the amount of occourences.
Args:
hashcode_occurances_per_week: The hashcode occurances per week
(generated from self.get_hashcode_occurances_per_week())
Returns:
count_dict: A dictionary with an index for each hashcode and the predicted groups & relevant groups persentages
e.g.
{
'3': {
'is_predicted_group_percentage': 92.3,
'is_relevant_group_percentage': 72.1,
},
'5': {
'is_predicted_group_percentage': 42.9,
'is_relevant_group_percentage': 51.8,
},
'20': { ... },
...
}
"""
count_dict = hashcode_occurances_per_week
for key,val in count_dict.items():
threshold = self.cluster_threshold * self.weeks
total_occurances = 0
for week in range(self.weeks):
total_occurances += val['occurance_week'][str(week)]
if total_occurances >= threshold:
div = (total_occurances / threshold)
count = 1
perc = self.threshold_percentage
while div > 1:
div /= 2
perc += ((100 - self.threshold_percentage) / 2) * (1 / count)
count *= 2
else:
perc = (total_occurances / threshold) * self.threshold_percentage
count_dict[key]['is_predicted_group_percentage'] = round(perc, 2)
for key,val in count_dict.items():
total = 0
current = 0
for week in range(self.weeks):
perc = 0
if val['occurance_week'][str(week)] >= self.cluster_threshold:
div = (val['occurance_week'][str(week)] / self.cluster_threshold)
count = 1
perc = self.threshold_percentage
while div > 1:
div /= 2
perc += ((100 - self.threshold_percentage) / 2) * (1 / count)
count *= 2
else:
perc = (val['occurance_week'][str(week)] / self.cluster_threshold) * self.threshold_percentage
total += 100 * (0.5) / pow(2, week * self.decay_strength)
current += perc * (0.5) / pow(2, week * self.decay_strength)
count_dict[key]['is_relevant_group_percentage'] = round((current / total) * 100, 2)
count_dict[key].pop('occurance_week', None)
return count_dict
def get_lookup_values(self, hashcode):
"""Get the individual item-indexes for a given hashcode
Args:
hashcode: The dataframe hashcode
e.g. 21
Returns:
items: An array of items
e.g. [0, 2, 4]
e.g.
hashcode 21
= 00010101 in binary
= 10101000 reversed
= item 0 = true,
item 1 = false
item 2 = true
item 3 = false
item 4 = true
item 5 = false
item 6 = false
item 7 = false
= a group with device 0, 2 & 4
"""
def bitfield(n):
return [int(digit) for digit in bin(n)[2:]]
bits = bitfield(hashcode)[::-1]
items = []
for idx, bit in enumerate(bits):
if bit == 1:
items.append(self.lookup_table[idx])
return items
class DataFrameValidator:
"""Validate a Dataframe for use in BinaryDataAnalisys
Be aware: the values for the time column are expected to be timestamps in milliseconds
"""
time_column = 'time'
expected_columns = ['id', 'state', time_column]
minimum_days_of_data_needed = 7
def validate(self, df):
"""Validate a dataframe with the values specified above
Args:
df: the dataframe to validate
Returns:
boolean: if it's valid or not
"""
columns_valid = self.validate_columns(df)
if not columns_valid:
return False
min_amount_of_data_valid = self.validate_minimum_days_of_data_needed(df)
if not min_amount_of_data_valid:
return False
return True
def validate_columns(self, df):
"""Validate a dataframe's columns with the values specified above
Args:
df: the dataframe to validate
Returns:
boolean: if the columns are valid or not
"""
expected_df_columns = pd.DataFrame(columns=self.expected_columns)
columns_too_many = df.columns.difference(expected_df_columns.columns)
if not len(columns_too_many) == 0:
print('The provided dataframe has too many columns:', *columns_too_many, sep='\n')
columns_too_few = expected_df_columns.columns.difference(df.columns)
if not len(columns_too_few) == 0:
print('The provided dataframe is missing the following columns:', *columns_too_few, sep='\n')
return len(columns_too_many) + len(columns_too_few) == 0
def validate_minimum_days_of_data_needed(self, df):
"""Validate a dataframe's amount of data with the values specified above
Args:
df: the dataframe to validate
Returns:
boolean: if the data is valid or not
"""
df_time = df.sort_values(by=[self.time_column])[self.time_column]
first_timestamp = df_time.values[0]
last_timestamp = df_time.values[-1]
diff = last_timestamp - first_timestamp
days = diff / 1000 / 60 / 60 / 24
enough_data = days > self.minimum_days_of_data_needed
if not enough_data:
print(
'There is a minimum of ' +
str(self.minimum_days_of_data_needed) +
' days of data needed, only ' +
str(math.floor(days * 100) / 100) +
' days of data was given!'
)
return enough_data
```
### get data & transform 'name' column into 'id' column
```
address = './datasets/staandelamp_realistic_huge.json'
df_data = pd.read_json(address)
df_data = df_data.sort_values(by=['time'])
df_data['id'] = df_data['name']
df_data = df_data.drop(columns=['name'])
print(df_data.shape)
df_data.head()
```
### Validate Dataframe
```
validator = DataFrameValidator()
dataframe_is_valid = validator.validate(df_data)
if dataframe_is_valid:
print('Valid!')
else:
print('WARNING! Dataframe validation failed!')
if dataframe_is_valid:
BDASCAN = BinaryDataAnalysis()
result = BDASCAN.analyze(df_data)
print(result[:5])
```
| github_jupyter |
# Quantum tomography for n-qubit
Init state: general GHZ
Target state: 1 layer
Here is the case for n-qubit with $n>1$.
The state that need to reconstruct is GHZ state:
$
|G H Z\rangle=\frac{1}{\sqrt{2}}(|0 \ldots 0\rangle+|1 \ldots 1\rangle)=\frac{1}{\sqrt{2}}\left[\begin{array}{c}
1 \\
0 \\
\ldots \\
1
\end{array}\right]
$
$
|G H Z\rangle\langle G H Z|=\frac{1}{2}\left[\begin{array}{cccc}
1 & 0 & \ldots & 1 \\
0 & \ldots & \ldots & 0 \\
\ldots & \ldots & \ldots & \ldots \\
1 & 0 & \ldots & 1
\end{array}\right]
$
In general, the elements that have value 1 can be lower or greater base on $\theta$. The below image is the construct GHZ state circuit in case of 4-qubits:
<img src="../../images/general_ghz.png" width=500px/>
The reconstructed circuit will be include $R_X, R_Z$ and $CNOT$ gates:
<img src="../../images/1layer.png"/>
```
import qiskit
import numpy as np
import matplotlib.pyplot as plt
import sys
sys.path.insert(1, '../')
import qtm.base, qtm.constant, qtm.ansatz
num_qubits = 3
thetas = np.zeros((2*num_qubits*3))
theta = np.random.uniform(0, 2*np.pi)
# Init quantum tomography n qubit
qc = qiskit.QuantumCircuit(num_qubits, num_qubits)
# qc = qtm.ansatz.create_ghz_state(qc, theta)
qc = qtm.ansatz.u_cluster_nqubit(qc, thetas)
qc.draw('mpl', scale = 6)
# Init parameters
num_qubits = 3
thetas = np.zeros((2*num_qubits*3))
theta = np.random.uniform(0, 2*np.pi)
# Init quantum tomography n qubit
qc = qiskit.QuantumCircuit(num_qubits, num_qubits)
qc = qtm.ansatz.create_ghz_state(qc)
# Reduce loss value in 100 steps
thetas, loss_values = qtm.base.fit(
qc, num_steps = 200, thetas = thetas,
create_circuit_func = qtm.ansatz.u_cluster_nqubit,
grad_func = qtm.base.grad_loss,
loss_func = qtm.loss.loss_basis,
optimizer = qtm.optimizer.sgd,
verbose = 1
)
# Plot loss value in 100 steps
plt.plot(loss_values)
plt.xlabel("Step")
plt.ylabel("Loss value")
plt.show()
plt.plot(loss_values)
plt.xlabel("Step")
plt.ylabel("Loss value")
plt.savefig('ghz_init2', dpi = 600)
# Get statevector from circuit
psi = qiskit.quantum_info.Statevector.from_instruction(qc)
rho_psi = qiskit.quantum_info.DensityMatrix(psi)
psi_hat = qiskit.quantum_info.Statevector(qtm.base.get_u_hat(
thetas = thetas,
create_circuit_func = qtm.ansatz.u_cluster_nqubit,
num_qubits = qc.num_qubits
))
rho_psi_hat = qiskit.quantum_info.DensityMatrix(psi_hat)
# Calculate the metrics
trace, fidelity = qtm.base.get_metrics(psi, psi_hat)
print("Trace: ", trace)
print("Fidelity: ", fidelity)
qiskit.visualization.plot_state_city(rho_psi, title = 'rho_psi')
qiskit.visualization.plot_state_city(rho_psi_hat, title = 'rho_psi_hat')
```
| github_jupyter |
```
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import warnings
warnings.filterwarnings('ignore')
df1 = pd.read_csv('monday.csv', sep = ";")
df2 = pd.read_csv('tuesday.csv', sep = ";")
df3 = pd.read_csv('wednesday.csv', sep = ";")
df4 = pd.read_csv('thursday.csv', sep = ";")
df5 = pd.read_csv('friday.csv', sep = ";")
df = pd.concat([df1, df2, df3, df4, df5], ignore_index=True)
df_unique = pd.read_csv('df_unique.csv', index_col=None)
df_unique.drop('Unnamed: 0', axis=1, inplace=True)
# 5. Simulate a single customer
# 5.1 create transition probability matrix
# create table with transition for each timestamp
# two columns (from-->to)
# concat/append this yourney for each customer
# count individual transitions from each location
# (from fruit -> drinks (87 people in total)
# (from fruit -> spices (45 people in total) ...
# those are the probabilities for each location)
df_journey = df_unique.groupby(['customer_unique', 'location', 'date']).count().sort_values(by = ['customer_unique', 'date'])
entry_point = df_journey.reset_index(1).index.get_level_values(level=0).unique()
entry_list= []
for i in entry_point:
entry_list.append(df_journey.reset_index(1).xs(i)['location'][0])
df_journey.reset_index(inplace=True)
# count entry location
import collections
entry_dict = collections.Counter(entry_list)
entry_p = []
for i in list(entry_dict.values()):
entry_p.append(i/(sum(entry_dict.values())))
states_ = ['fruit', 'dairy', 'spices', 'drinks']
entry_dic = zip(states_,entry_p)
list(entry_dic)
sum(entry_p)
df_trans = df_journey[['location']]
df_trans['_to'] = df_journey[['location']].shift(periods=-1, fill_value='checkout')
indexlist = df_trans[df_trans['location'] == 'checkout'].index
df_trans.drop(indexlist, inplace=True)
df_trans['transition'] = df_trans['location'] + "_" + df_trans['_to']
df_trans
labels, trans = pd.factorize(df_trans['transition'])
df_trans['trans_fac'] = labels
len(labels)
trans_dict = df_trans['transition'].value_counts(ascending=True)
values = [value for (key, value) in sorted(trans_dict.items())]
keys = [key for (key, value) in sorted(trans_dict.items())]
sorted_trans_dict = dict(zip(keys, values))
sorted_trans_dict
df_unique.head()
trans_matrix = pd.DataFrame.from_dict({'entrance': [0,0,0,0,0,0],
'fruit': [0,0,0,0,0,0],
'spices': [0,0,0,0,0,0],
'dairy': [0,0,0,0,0,0],
'drinks': [0,0,0,0,0,0],
'checkout': [0,0,0,0,0,0]})
trans_matrix.set_index([pd.Index(['entrance', 'fruit', 'spices', 'dairy', 'drinks', 'checkout'])], inplace=True)
trans_matrix
for f in sorted_trans_dict.items():
origin = str(f[0].split('_')[0])
dest = str(f[0].split('_')[1])
count_ = int(f[1])
trans_matrix.loc[origin][dest] = count_
row_sum = trans_matrix.sum(axis=1)
prob_matrix = trans_matrix.T/row_sum
prob_matrix.loc['checkout']['checkout']=1
#prob_matrix.loc['entrance']['entrance']=1
prob_matrix
prob_matrix.fillna(0, inplace=True)
prob_dict = dict(prob_matrix)
# check:
prob_matrix.T.loc['spices'].sum()
prob_matrix
# add 0 probability for going to checkout from entrance
entry_p.append(0)
entry_p.insert(0,0)
entry_p
# adding entrance probability
prob_matrix['entrance'] = entry_p
```
```
prob_matrix
# Average number of steps during journey
# counting every stage (including ideling customers)
(df_journey.shape[0]-1)/df_journey['customer_unique'].nunique()
df_journey['customer_unique'].nunique()
len(set(df_journey['customer_unique'].values))
# counting every different stage
df.shape[0]/df_journey['customer_unique'].nunique()
# calculate probabilities at entrance
# by counting first stage of all unique customers
# cal. percentage value
# use this number in markov.next_state('XXX') function
x = prob_dict.keys()
list(x)[5]
```
_______________________________
```
class Customer(object):
def __init__(self, transition_prob):
"""
Initialize the MarkovChain instance.
Parameters
----------
transition_prob: dict
A dict object representing the transition
probabilities in Markov Chain.
Should be of the form:
{'state1': {'state1': 0.1, 'state2': 0.4},
'state2': {...}}
"""
self.transition_prob = transition_prob
self.states = list(transition_prob.keys())
self.first_state = 'entrance'
def next_state(self, current_state):
return np.random.choice(
self.states,
p=[self.transition_prob[current_state][next_state]
for next_state in self.states])
def generate_states(self, current_state='entrance', no=50):
future_states = []
for i in range(no):
next_state = self.next_state(current_state)
future_states.append(next_state)
current_state = next_state
if future_states[-1] == self.states[-1]:
break
return future_states
```
```
markow = Customer(prob_dict)
markow.generate_states()
markov.transition_prob
```
| github_jupyter |
# Chapter 2 - Small Worlds vs Large Wolrds
[Recorded Classes 2019 Chap2 by Richard McElreath](https://www.youtube.com/watch?v=XoVtOAN0htU&list=PLDcUM9US4XdNM4Edgs7weiyIguLSToZRI&index=2)
The **Small World** represents the scientific model itself, and the **Large World**
represents the broader context in which one deploys a model.
**Bayesian inference** is just counting and comparing of possibilities. Consider
by analogy Jorge Luis Borges’ short story “The Garden of Forking Paths.”
In order to make good inference about what actually happened, it helps to consider
everything that could have happened. A Bayesian analysis is a garden of forking data,
in which alternative sequences of events are cultivated.
**The approach cannot guarantee a correct answer**, on large world terms. But it can
guarantee the best possible answer, on small world terms, that could be derived
from the information fed into it.
The goal of the Bayesian approach is to figure out which of the conjectures for a
certain context is **the most plausible**, given some evidence (data).
By comparing these counts, we have part of a solution
for a way to rate the relative plausibility of each conjecture.
But it’s only a part of a solution, because in order to compare these counts
we first have to decide how many ways each conjecture could itself be realized.
We might argue that when we have no reason to assume otherwise, we can just consider
each conjecture equally plausible and compare the counts directly, **Principle of Indifference**.
But often we do have reason to assume otherwise.
> ***Principle of indifference***: When there is no reason to say that one conjecture is more plausible
> than another, weigh all of the conjectures equally.
To grasp a solution, suppose we’re willing to say each conjecture is equally plausible
at the start. Then, we just compare the counts of ways
in which each conjecture is compatible with the observed data. So, comparing them can suggest
that ones are more plausible, than others. Since these are our initial counts, and
probably they are going to update later, they are labeled **prior**.
Then when we get more evidence or observations, we can update the conjectures' plausibility.
Only if they new data is independent of the previous data,
> To update the plausibility ***p*** of a conjecture ***C*** that is produced in ***W<sub>prior</sub>***
> ways based on previous data ***D<sub>prior</sub>*** after providing more evidence ***D<sub>new</sub>***
> is as follows:
>
> $\Large P_c \propto W_{prior} \times W_{new} $
Why multiplication? Because it's a shortcut for counting all possible paths.
## From counting to probability
It’s hard to use these counts though, so almost always they are standardized in a way that
transforms them into probabilities.
The meaning would be the same, it’s just the relative values that matter. Second,
as the amount of data grows, the counts will very quickly grow very large and become difficult
to manipulate.
Then, for any value p can take, we judge the plausibility of that value p
as proportional to the number of ways it can get through the garden of forking data.
Finally, we construct probabilities by standardizing the plausibility so that the sum of
the plausibilities for all possible conjectures will be one. All you need to do in order to
standardize is to add up all of the products, one for each value p can take, and then divide each
product by the sum of products:
Being ***p*** the proportion of a feature,
\begin{align*}
\Large P_p={\frac {W_{{p}_{new}} \times P_{prior}}{\sum \small products}}
\end{align*}
## Example 2.1
There is a bag with four marbles, and we only know that they are <span style="color:blue">blue [B]</span> and
<span style="color:grey">white [W]</span>. A marble is picked from the bag putting it back after finishing, after
doing this four times we got the sequence [<span style="color:blue">B</span> <span style="color:grey">W</span> <span style="color:blue">B</span>] .
So if ***p*** is defined as the proportion of marbles that are blue, for [<span style="color:blue">B </span><span style="color:grey">W W W</span>]
with ***D<sub>new</sub>*** = [<span style="color:blue">B</span> <span style="color:grey">W</span> <span style="color:blue">B</span>],
we can say that:
> plausability of ***p*** after ***D<sub>new</sub>*** $\propto$ was ***p*** can produce
> ***D<sub>new</sub>*** $\times$ prior plausability of ***p***
The above just means that for any value p can take, we judge the plausibility of that value p
as proportional to the number of ways it can get through the garden of forking data.
| Composition | p (prop.) | Ways (W) | Plausability (P) |
| --- | --- | --- | --- |
| [ <span style="color:grey">W W W W</span> ] | 0 | 0 | 0 |
| [ <span style="color:blue">B </span><span style="color:grey">W W W</span> ] | 0.25 | 3 | 0.15 |
| [ <span style="color:blue">B B</span><span style="color:grey"> W W</span> ] | 0.5 | 8 | 0.4 |
| [ <span style="color:blue">B B B </span><span style="color:grey">W</span> ] | 0.75 | 9 | 0.45 |
| [ <span style="color:blue">B B B B</span> ] | 1 | 0 | 0 |
* A conjectured proportion of blue marbles, p, is usually called a ***parameter*** value.
It’s just a way of indexing possible explanations of the data.
* The relative number of ways that a value p can produce the data is usually called
a ***likelihood***. It is derived by enumerating all the possible data sequences that
could have happened and then eliminating those sequences inconsistent with the
data.
* The prior plausibility of any specific p is usually called the ***prior probability***.
* The new, updated plausibility of any specific p is usually called the ***posterior
probability***.
## Libraries import
```
import numpy as np
from scipy import stats
import random
import matplotlib.pyplot as plt
%matplotlib inline
np.set_printoptions(suppress=True)
```
*2.1.1- How to calculate this plausibilities of the example 2.1 in Python?*
```
Ways=np.array([0,3,8,9,0])
# Prior plausibility of p is 1 (it didn't change). So,
Ways/Ways.sum()
```
## 2.1 Building a model
By working with probabilities instead of raw counts, Bayesian inference is made much
easier, but it looks much harder.
To get the logic moving, we need to make assumptions, and these assumptions constitute
the model. Designing a simple Bayesian model benefits from a design loop with three steps.
1. Data story: Motivate the model by narrating how the data might arise.
2. Update: Educate your model by feeding it the data.
3. Evaluate: All statistical models require supervision, leading possibly to model revision.
### 2.1.1. A data story
Bayesian data analysis usually means producing a story for how the data came to be. This story may be descriptive, specifying associations that can be used to
predict outcomes, given observations. Or it may be causal, a theory of how some events produce other events.
Typically, any story you intend to be causal may also be descriptive. But many descriptive stories are hard to interpret causally. But all data stories are complete,
in the sense that they are sufficient for specifying an algorithm for simulating new data.
### 2.1.2 Bayesian updating
Using the evidence to decide among different possible conjectures, like the marbles on the bag previously. Each possible proportion may be more or less plausible, given the evidence.
A Bayesian model begins with one set of plausibilities assigned to each of these possibilities.
These are the prior plausibilities. Then it updates them in light of the data, to produce the
posterior plausibilities. This updating process is a kind of learning, called ***Bayesian Updating***.
Notice that every updated set of plausibilities becomes the initial plausibilities for the
next observation. Every conclusion is the starting point for future inference. However, this
updating process works backwards, as well as forwards.
Given the final set of plausibilities, it is possible
to mathematically divide out the observation, to infer the previous plausibility curve. So the
data could be presented to your model in any order, or all at once even. In most cases, you
will present the data all at once, for the sake of convenience. But it’s important to realize that
this merely represents abbreviation of an ***Iterated Learning Process***.
### 2.1.3 Evaluate
The Bayesian model learns in a way that is demonstrably optimal, provided
that the real, large world is accurately described by the model. This is to say that your
Bayesian machine guarantees perfect inference, within the small world. No other way of
using the available information, and beginning with the same state of information, could do
better.
However, the calculations may malfunction, so results always have to be checked. And if
there are important differences between the model and reality, then there is no logical
guarantee of large world performance. And even if the two worlds did match, any particular
sample of data could still be misleading. So it’s worth keeping in mind at least two cautious principles:
1. *First, the model’s certainty is no guarantee that the model is a good one.*
2. *Supervise and critique your model’s work.*
Moreover, models do not need to be exactly true in order to produce highly precise and useful inferences.
This is because models are essentially information processing machines, and there are some surprising aspects of
information that cannot be easily captured by framing the problem in terms of the truth of
assumptions.
Instead, the objective is to check the model’s adequacy for some purpose. This usually
means asking and answering additional questions, beyond those that originally constructed
the model. Both the questions and answers will depend upon the scientific context.
## 2.2 Components of the model
Consider three different kinds of things we counted in the previous sections.
1. The number of ways each conjecture could produce an observation
2. The accumulated number of ways each conjecture could produce the entire data
3. The initial plausibility of each conjectured cause of the data
Each of these things has a direct analog in conventional probability theory. And so the usual way we build a statistical model involves
choosing distributions and devices for each that represent the relative numbers of ways things can happen.
1. Variables. Variables are just symbols that can take on different values. In a scientific context,
variables include things we wish to infer, such as proportions and rates, as well as things we might observe, the data. The first variable is our target of inference, *p*, *e.g. the proportion of marbles in the bag*. This variable cannot be observed. Unobserved variables are usually called ***PARAMETERS***. But while *p* itself is unobserved, we can infer it from the other variables.
> *When we observe a sample of variables, we need to say how likely that exact sample is, out of the universe of potential samples of the same length.*
2. Definitions. Once we have all the variables we need to define each, we build a model that relates the variables to one to another. The
goal is count all the ways the data could arise, given the assumptions.
1. ***Observed variables***. Define how plausible any combination of this variables is. Each specific value of ***p*** corresponds to aspecific plausibility of the data. In conventional statistics, a distribution function assigned to an observed variable is usually landcalled a likelihood. That term has special meaning in non-Bayesian statistics, however.
2. ***Unobserved variables***. The distributions we assign to the observed variables typically have their own variables. In the binomial below, there is $p$, the probability of sampling water. Since p is not observed, we usually call it a ***PARAMETER***. or every parameter you intend your Bayesian machine to consider, you must provide a
distribution of prior plausibility, its ***PRIOR***.
### 2.2.1 Prior
When you have a previous estimate to provide, that can become the prior. As a result, each estimate becomes the prior for the next step.
But this doesn’t resolve the problem of providing a prior, because at the dawn of time, when $N = 0$, the machine still had an initial state of information for the parameter $p$: *a flat line specifying equal plausibility for every possible value*.
*So where do priors come from?* They are both engineering assumptions, chosen to help the machine learn, and scientific assumptions, chosen to reflect what we know about a phenomenon. The flat prior is very common, but it is hardly ever the best prior.
There is a school of Bayesian inference that emphasizes choosing priors based upon the personal beliefs of the analyst. While this subjective Bayesian approach thrives in some statistics and philosophy and economics programs, it is rare in the sciences. Within Bayesian data analysis in the natural and social sciences, the prior is considered to be just part of the model. As such it should be chosen, evaluated, and revised just like all of the other components of the model. In practice, the subjectivist and the non-subjectivist will often analyze data in nearly the same way.
Beyond all of the above, there’s no law mandating we use only one prior. If you don’t have a strong argument for any particular prior, then try different ones. Because the prior is an assumption, it should be interrogated like other assumptions: by altering it and checking how sensitive inference is to the assumption.
## Example 2.2
Suppose you have a globe representing our planet, the Earth. This version of the world is small enough to hold in your hands. You are curious how much of the surface is covered in water. You adopt the following strategy: You will toss the globe up in the air. When you catch it, you will record whether or not the surface under your right index finger is water or land. Then you toss the globe up in the air again and repeat the procedure. This strategy generates a sequence of surface samples from the globe, where *W* indicates water and *L* indicates land.
In this case, once we add our assumptions that (1) every toss is independent of the other tosses and (2) the probability of W is the same on every toss, probability theory provides a unique answer, known as the binomial distribution. This is the common “coin tossing” distribution. And so the probability of observing W waters and L lands, with a probability p of water on each toss, is:
\begin{align*}
\Large Pr(W, L|p)={\frac {(W + L)!}{W!L!}}p^W(1-p)^L
\end{align*}
> The counts of “water” W and “land’ L are distributed binomially, with prob-
ability p of “water” on each toss.
### Binom probability mass function
\begin{align*}
\Large f(k)={{n}\choose{k}}p^k(1-p)^{n-k},
\end{align*}
\begin{align*} k \in \{0, 1,..., n\} , 0 \leq p \leq 1
\end{align*}
> Being $n$ the size of the sample or the *#samples*, $k$ the #times that a value has been selected in the sample, and $p$ the probability of that variable.
Binom takes $n$ and $p$ as shape parameters, where $p$ is the probability of a single success $1 - p$ and is the probability of a single failure.
The probability mass function above is defined in the “standardized” form. To shift distribution use the loc parameter. Specifically, ```binom.pmf(k, n, p, loc)``` is identically equivalent to ```binom.pmf(k - loc, n, p)```
*How compute compute the likelihood of the data—six W’s in nine tosses—under any value of p with?*
```
stats.binom.pmf(k=6, n=9, p=0.5)
```
That number is the relative number of ways to get 6 water (in our globe-tossing model, holding $p$ at 0.5 and $N = W + L$ at nine.
With all the above work, we can now summarize out model. The observed variables $W$ and $L$ are given relative counts through the binomial distribution. So, we can write, as a shortcut:
\begin{align*}
\Large W \sim Binomial(N,p)
\end{align*}
where $N = W + L$. The above is just a convention for communicating the assumption that the relative counts of ways to realize W in N trials with probability p on each trial comes from the binomial distribution. And the unobserved parameter p similarly gets:
\begin{align*}
\Large p \sim Uniform(0,1)
\end{align*}
This means that p has a uniform—flat—prior over its entire possible range, from zero to one.
## 2.4 Making the model
Once you have named all the variables and chosen definitions for each, a Bayesian model can update all of the prior distributions to their purely logical consequences: the ***POSTERIOR DISTRIBUTION***.
For every unique combination of data, likelihood, parameters, and prior, there is a unique posterior distribution.The posterior distribution takes the form of the probability of the parameters, conditional on the data.
For the proportion of water case case, it would be $Pr(p|W, L)$, the probability of each possible value of p, conditional on the specific $W$ and $L$ that we observed.
## 2.4.1 ***Baye's Theorem***
The mathematical definition of the posterior distribution arises from ***BAYES’ THEOREM***.
\begin{align*}
\Large Posterior={\frac {Probability_{data} \times Prior}{Average \space probability_{data}}}
\end{align*}
Bayes’ theorem postulates that the probability of any particular value of p, considering the data, is equal to the product of the relative plausibility of the data, conditional on p, and the prior plausibility of p, divided by this thing $Pr(W, L)$, which I’ll call the ***average probability of the data***, sometimes called *“evidence”* or the *“average likelihood”*.
The posterior is proportional to the product of the prior and the probability of the data. Because for each specific value of $p$, the number of paths through the garden of forking data is the product of the prior number of paths and the new number of paths. Multiplication is just compressed counting.
### 2.4.2 Motors
Various numerical techniques are needed to approximate the mathematics that follows from the definition of Bayes’ theorem. One is the ***Grid Aprroximation***.
## Grid Approximation
While most parameters are continuous, capable of taking on an infinite number of values, it turns out that we can achieve an excellent approximation of the continuous posterior distribution by considering only a finite grid of parameter values.
At any particular value of a parameter, $p'$ , it’s a simple matter to compute the posterior probability: just multiply the prior probability of $p'$ by the likelihood at $p'$ . Repeating this procedure for each value in the grid generates an approximate picture of the exact posterior distribution.
> *In most of real modeling, grid approximation isn’t practical. The reason is that it scales very poorly, as the number of parameters increases.*
Summarizing:
- The posterior probability is the *standarized product* of (1) probability of the data $\times$ (2) prior probability
- *Standarized* means: add up all the products and divide each by this sum:
\begin{align*}
\Large posterior\{0...n\} = \sum_{i=1}^n {posterior}_i \times {probability}_{data_i}
\end{align*}
\begin{align*}
\Large post\_standarized_{i} = {\frac {{posterior}_i} {\sum_{j=1}^n posteriors_j}}
\end{align*}
- Grid approximation uses *finite grid* of parameter values instead of continuous space
- Too expensive with more than a few parameters
In the context of the globe tossing problem, grid approximation works extremely well. So let’s build a grid approximation for the model we’ve constructed so far. Here is the recipe:
1. Define the grid. This means you decide how many points to use in estimating the
posterior, and then you make a list of the parameter values on the grid.
2. Compute the value of the prior at each parameter value on the grid.
3. Compute the likelihood at each parameter value.
4. Compute the unstandardized posterior at each parameter value, by multiplying the
prior by the likelihood.
5. Finally, standardize the posterior, by dividing each value by the sum of all values.

## Example 2.3
Following the example of globe tossing, we have as data:
```python
['W','L','W','W','W','L','W','L','W']
````
So that means $k=7$, $n=9$
```
def grid_approximation(k, n, points, prior, showDesc=False):
#k=#success, n=#samples, points=#of point to aprroximate
#Define grid
grid = np.linspace(0, 1, points)
#Define prior. For uniform=1, bc we assume all values are equally probable when N=0
if type(prior) is int or type(prior) is float:
prior = np.repeat(prior, points)
#Compute likelihood at each value in the grid
likelihood = stats.binom.pmf(k, n, grid)
#Compute product of likelihood and prior
posterior = likelihood * prior
#Standarize the posterior, so it sums to 1
posterior_std = posterior / np.sum(posterior)
if(showDesc):
print('Likelihood matrix {}'.format(likelihood))
print('Posterior matrix {}'.format(posterior))
print('Posterior standarize matrix {}'.format(posterior_std))
return grid, posterior_std
k, n = 6, 9
grid, posterior = grid_approximation(k, n, 100, 1)
fig, ax = plt.subplots(1, 1, figsize=(16,10))
ax.plot(grid, posterior,'-', label='binom pmf', color='grey')
ax.fill_between(grid, posterior, color='turquoise', alpha=.5)
ax.set_title('Grid Aprrox After 6/9 Successes with 100 points of estimation', fontsize=20)
ax.set_xlabel('Proportion of Earth is Water', fontsize=15)
ax.set_ylabel('Posterior Probability', fontsize=15);
def plot_likelihood(k, n, points, xlabel, ylabel, prior, showPrevious=False, showGridDesc=False):
cols_per_row = 3
from math import ceil
if type(points) is list:
m = len(points)
if len(points) > cols_per_row:
rows = ceil(m/cols_per_row)
cols = cols_per_row
else:
cols = len(points)
cols_per_row = len(points)
rows = 1
fig, axs = plt.subplots(nrows=rows, ncols=cols, sharey=False, sharex=False)
if rows == 1:
axs = np.array(axs).reshape(1, cols)
fig.set_size_inches(12*cols,8*rows)
else:
m = 1
fig, axs = plt.subplots(1, m, sharey=False, sharex=False)
fig.set_size_inches(15,8)
if type(points) is list:
j = 0
l = 0
for i in points:
grid, posterior = grid_approximation(k, n, i, prior, showDesc=showGridDesc)
axs[l][j].plot(grid, posterior,'-', label='binom pmf', color='grey')
axs[l][j].set_title(str(i)+' estimation points', fontsize=25)
if j == 0 and l==0:
axs[l][j].set_ylabel(ylabel+'\n', fontsize=25)
axs[l][j].legend(['Probability'])
axs[l][j].fill_between(grid, posterior, color='turquoise')
if showPrevious and (j,l) != (0,0):
axs[l][j].legend(['Previous Probability','Current Probility'])
j+=1
if j == cols_per_row:
j=0
l+=1
if showPrevious and (l*cols_per_row+j) < m:
axs[l][j].plot(grid, posterior,':', label='binom pmf', color='red')
if rows > 1:
axs[l][j-1].set_xlabel(xlabel+'\n\n\n ', fontsize=25)
while j < cols_per_row:
axs[l][j].set_visible(False)
j+=1
fig.suptitle('Grid Aprroximation After {}/{} Successes'.format(k,n), fontsize=35);
else:
if points < 3:
points = 50
print('Number of aprroximation points is to low. \nSetting default #points of approximation to 50')
grid, posterior = grid_approximation(k, n, points, prior, showDesc=showGridDesc)
axs.plot(grid, posterior,'-', label='binom pmf', color='grey')
axs.fill_between(grid, posterior, color='turquoise', alpha=.5)
fig.suptitle('Grid Aprroximation After {}/{} Successes'.format(k,n), fontsize=35)
axs.set_xlabel(xlabel+'\n\n\n ', fontsize=25)
axs.set_ylabel(ylabel+'\n', fontsize=25);
point_lst = [4,10,50,75,100,200,1000]
k, n = 6, 9
plot_likelihood(k, n, point_lst,'Proportion of Earth is Water','Posterior Probability',1, showPrevious=True)
```
> After a certain amount of points the difference between approximation is minimal.
More points means more precision, but at certain amount of points there won’t be much change in inference, in this case after the first 100.
### Example 2.5
Let's try the prior where we assume a 0% chance of the true proportion of water being less than 50%.
```
points = 100
k, n = 6, 9
prior = (np.linspace(0, 1, points) >= .5).astype(int)
plot_likelihood(k, n, points, 'Proportion of Earth is Water','Posterior Probability', prior, showPrevious=True)
```
### 2.4.4 Quadratic approximation
It's a model that makes stronger assumptions than the *Grid Approximation*, because the main disadvatange of the Grid Approximation is that the number of unique values to consider in the grid grows rapidly as the number of parameters in your model increases. For two parameters approximated by 100 values each, that’s
already 100 2 = 10000 values to compute. For 10 parameters, the grid becomes many billions of values. These days, it’s routine to have models with hundreds or thousands of parameters. The grid approximation strategy scales very poorly with model complexity, so it won’t get very far.
A useful approach is ***QUADRATIC APPROXIMATION***. Under quite general conditions, the region near the peak of the posterior distribution will be nearly Gaussian—or “normal”—in shape. This means the posterior distribution can be usefully approximated by a Gaussian distribution. A Gaussian distribution is convenient, because it can be completely described by only two numbers: the location of its center (mean) and its spread (variance). A Gaussian approximation is called “quadratic approximation” because the logarithm of a Gaussian distribution forms a parabola. And a parabola is a quadratic function. So this approximation essentially represents any log-posterior with a parabola.
For many of the most common procedures in applied statistics—linear regression, for example—the approximation works very well. Often, it is even exactly correct, not actually an approximation at all. Computationally, quadratic approximation is very inexpensive, at least compared to grid approximation and MCMC (discussed next).
# Problems
## Easy
| github_jupyter |
# Self-Driving Car Engineer Nanodegree
## Deep Learning
## Project: Build a Traffic Sign Recognition Classifier
In this notebook, a template is provided for you to implement your functionality in stages, which is required to successfully complete this project. If additional code is required that cannot be included in the notebook, be sure that the Python code is successfully imported and included in your submission if necessary.
> **Note**: Once you have completed all of the code implementations, you need to finalize your work by exporting the iPython Notebook as an HTML document. Before exporting the notebook to html, all of the code cells need to have been run so that reviewers can see the final implementation and output. You can then export the notebook by using the menu above and navigating to \n",
"**File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.
In addition to implementing code, there is a writeup to complete. The writeup should be completed in a separate file, which can be either a markdown file or a pdf document. There is a [write up template](https://github.com/udacity/CarND-Traffic-Sign-Classifier-Project/blob/master/writeup_template.md) that can be used to guide the writing process. Completing the code template and writeup template will cover all of the [rubric points](https://review.udacity.com/#!/rubrics/481/view) for this project.
The [rubric](https://review.udacity.com/#!/rubrics/481/view) contains "Stand Out Suggestions" for enhancing the project beyond the minimum requirements. The stand out suggestions are optional. If you decide to pursue the "stand out suggestions", you can include the code in this Ipython notebook and also discuss the results in the writeup file.
>**Note:** Code and Markdown cells can be executed using the **Shift + Enter** keyboard shortcut. In addition, Markdown cells can be edited by typically double-clicking the cell to enter edit mode.
---
## Step 0: Load The Data
```
# Load pickled data
import pickle
# TODO: Fill this in based on where you saved the training and testing data
training_file = './traffic-signs-data/train.p'
validation_file = './traffic-signs-data/valid.p'
testing_file = './traffic-signs-data/test.p'
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
```
---
## Step 1: Dataset Summary & Exploration
The pickled data is a dictionary with 4 key/value pairs:
- `'features'` is a 4D array containing raw pixel data of the traffic sign images, (num examples, width, height, channels).
- `'labels'` is a 1D array containing the label/class id of the traffic sign. The file `signnames.csv` contains id -> name mappings for each id.
- `'sizes'` is a list containing tuples, (width, height) representing the original width and height the image.
- `'coords'` is a list containing tuples, (x1, y1, x2, y2) representing coordinates of a bounding box around the sign in the image. **THESE COORDINATES ASSUME THE ORIGINAL IMAGE. THE PICKLED DATA CONTAINS RESIZED VERSIONS (32 by 32) OF THESE IMAGES**
Complete the basic data summary below. Use python, numpy and/or pandas methods to calculate the data summary rather than hard coding the results. For example, the [pandas shape method](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.shape.html) might be useful for calculating some of the summary results.
### Provide a Basic Summary of the Data Set Using Python, Numpy and/or Pandas
```
### Replace each question mark with the appropriate value.
### Use python, pandas or numpy methods rather than hard coding the results
# TODO: Number of training examples
n_train = X_train.shape[0] # shape is a tuple: (num_samples, width, height, channel)
# TODO: Number of validation examples
n_validation = X_valid.shape[0]
# TODO: Number of testing examples.
n_test = X_test.shape[0]
# TODO: What's the shape of an traffic sign image?
image_shape = X_train[0].shape
# TODO: How many unique classes/labels there are in the dataset.
n_classes = len(set(y_train))
print("Number of training examples =", n_train)
print("Number of testing examples =", n_test)
print("Image data shape =", image_shape)
print("Number of classes =", n_classes)
```
### Include an exploratory visualization of the dataset
Visualize the German Traffic Signs Dataset using the pickled file(s). This is open ended, suggestions include: plotting traffic sign images, plotting the count of each sign, etc.
The [Matplotlib](http://matplotlib.org/) [examples](http://matplotlib.org/examples/index.html) and [gallery](http://matplotlib.org/gallery.html) pages are a great resource for doing visualizations in Python.
**NOTE:** It's recommended you start with something simple first. If you wish to do more, come back to it after you've completed the rest of the sections. It can be interesting to look at the distribution of classes in the training, validation and test set. Is the distribution the same? Are there more examples of some classes than others?
```
### Data exploration visualization code goes here.
### Feel free to use as many code cells as needed.
import matplotlib.pyplot as plt
import numpy as np
import random
# Visualizations will be shown in the notebook.
%matplotlib inline
ROW = 4
COL = 6
def plot_data(data, label, channel=None, row=ROW, col=COL):
fig, axes = plt.subplots(row, col, figsize=(12, 10))
fig.subplots_adjust(hspace=0.01, wspace=0.1)
axes = axes.flatten()
for i in range(row * col):
index = random.randint(0, len(data))
if channel == 'gray':
gray_image = data[index].squeeze()
axes[i].imshow(gray_image, cmap='gray')
else:
axes[i].imshow(data[index])
axes[i].set_title(label[index])
axes[i].set_axis_off()
plot_data(X_train, y_train)
# histogram of label frequency (once again, before data augmentation)
hist, bins = np.histogram(y_train, bins=n_classes)
width = 0.7 * (bins[1] - bins[0])
center = (bins[:-1] + bins[1:]) / 2
plt.bar(center, hist, align='center', width=width)
plt.show()
```
----
## Step 2: Design and Test a Model Architecture
Design and implement a deep learning model that learns to recognize traffic signs. Train and test your model on the [German Traffic Sign Dataset](http://benchmark.ini.rub.de/?section=gtsrb&subsection=dataset).
The LeNet-5 implementation shown in the [classroom](https://classroom.udacity.com/nanodegrees/nd013/parts/fbf77062-5703-404e-b60c-95b78b2f3f9e/modules/6df7ae49-c61c-4bb2-a23e-6527e69209ec/lessons/601ae704-1035-4287-8b11-e2c2716217ad/concepts/d4aca031-508f-4e0b-b493-e7b706120f81) at the end of the CNN lesson is a solid starting point. You'll have to change the number of classes and possibly the preprocessing, but aside from that it's plug and play!
With the LeNet-5 solution from the lecture, you should expect a validation set accuracy of about 0.89. To meet specifications, the validation set accuracy will need to be at least 0.93. It is possible to get an even higher accuracy, but 0.93 is the minimum for a successful project submission.
There are various aspects to consider when thinking about this problem:
- Neural network architecture (is the network over or underfitting?)
- Play around preprocessing techniques (normalization, rgb to grayscale, etc)
- Number of examples per label (some have more than others).
- Generate fake data.
Here is an example of a [published baseline model on this problem](http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf). It's not required to be familiar with the approach used in the paper but, it's good practice to try to read papers like these.
### Pre-process the Data Set (normalization, grayscale, etc.)
Minimally, the image data should be normalized so that the data has mean zero and equal variance. For image data, `(pixel - 128)/ 128` is a quick way to approximately normalize the data and can be used in this project.
Other pre-processing steps are optional. You can try different techniques to see if it improves performance.
Use the code cell (or multiple code cells, if necessary) to implement the first step of your project.
```
### Preprocess the data here. It is required to normalize the data. Other preprocessing steps could include
### converting to grayscale, etc.
### Feel free to use as many code cells as needed.
# shuffle dataset
def unison_shuffle(x, y, seed=101):
"""
In-place unison shuffling
"""
rand_state = np.random.RandomState(seed)
rand_state.shuffle(x)
# re-seeding to get the same ordering
rand_state.seed(seed)
rand_state.shuffle(y)
def normalize(x):
return (x - 128) / 128
def grayscale(x):
return np.sum(x/3, axis=3, keepdims=True)
def preprocess(x):
return normalize(grayscale(x))
# Testing grayscaling
gray = grayscale(X_valid)
plot_data(gray, y_valid, channel='gray')
### Preprocessing Data
prev_mean = np.mean(X_train)
print("Training data shape before preprocessing: ", X_train.shape)
print("Training data mean before preprocessing: ", prev_mean)
X_train = preprocess(X_train)
X_valid = preprocess(X_valid)
X_test = preprocess(X_test)
proc_mean = np.mean(X_train)
print("Training data shape after preprocessing: ", X_train.shape)
print("Training data mean after preprocessing: ", proc_mean)
```
### Labeling
```
import tensorflow as tf
import csv
NUM_CHANNEL = 1
with open( './signnames.csv', 'rt') as f:
reader = csv.reader(f)
label_name = list(reader)
x = tf.placeholder(tf.float32, (None, 32, 32, NUM_CHANNEL))
y = tf.placeholder(tf.int32, (None))
keep_prob = tf.placeholder(tf.float32)
one_hot_y = tf.one_hot(y, n_classes)
```
### Model Architecture
```
from tensorflow.contrib.layers import flatten
def LeNet(x, mu=0, sigma= 0.1):
# Layer 1: Convolutional. Input = 32x32x3. Output = 28x28x6.
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, NUM_CHANNEL, 6), mean = mu, stddev = sigma))
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
# Activation.
conv1 = tf.nn.relu(conv1)
# Pooling. Input = 28x28x6. Output = 14x14x6.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# Layer 2: Convolutional. Output = 10x10x16.
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
# Activation.
conv2 = tf.nn.relu(conv2)
# Pooling. Input = 10x10x16. Output = 5x5x16.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# Flatten. Input = 5x5x16. Output = 400.
fc0 = flatten(conv2)
# Layer 3: Fully Connected. Input = 400. Output = 120.
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# Activation and drop out
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, keep_prob)
# Layer 4: Fully Connected. Input = 120. Output = 86.
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 86), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(86))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# Activation and drop out
fc2 = tf.nn.relu(fc2)
fc2 = tf.nn.dropout(fc2, keep_prob)
# Layer 5: Fully Connected. Input = 86. Output = 43.
fc3_W = tf.Variable(tf.truncated_normal(shape=(86, n_classes), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(n_classes))
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
```
### Train, Validate and Test the Model
A validation set can be used to assess how well the model is performing. A low accuracy on the training and validation
sets imply underfitting. A high accuracy on the training set but low accuracy on the validation set implies overfitting.
### Setting up Pipeline
```
LR = 0.001
EPOCHS = 50
BATCH_SIZE = 128
KEEP_PROB = 0.5
# Arguments used for tf.truncated_normal, randomly defines variables for the weights and biases for each layer
MU = 0
SIGMA = 0.1
# Saving output graphs in local directory
GRAPH_FILENAME = './img/curr_training_curve.png'
logits = LeNet(x, MU, SIGMA)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot_y, logits=logits)
loss_operation = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate = LR)
training_operation = optimizer.minimize(loss_operation)
```
### Validating
```
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(one_hot_y, 1))
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
sess = tf.get_default_session()
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_data[offset:end], y_data[offset:end]
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: 1.0})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examples
```
### Training
```
class Plot(object):
def __init__(self):
self.train_accuracy_over_epoch = []
self.valid_accuracy_over_epoch = []
def plot_graph(self):
assert len(self.train_accuracy_over_epoch) == len(self.valid_accuracy_over_epoch)
x = range(len(self.valid_accuracy_over_epoch))
y1 = self.train_accuracy_over_epoch
y2 = self.valid_accuracy_over_epoch
plt.plot(x, y1,'b-', label='Training Accuray')
plt.plot(x, y2,'r:', label='Validation Accuray')
# Create empty plot with blank marker containing the extra label
plt.plot([],[], ' ', label="LEARNING_RATE: {}".format(LR))
plt.plot([],[], ' ', label="BATCH_SIZE: {}".format(BATCH_SIZE))
plt.plot([],[], ' ', label="KEEP_PROB: {}".format(KEEP_PROB))
plt.plot([],[], ' ', label="Mu: {}".format(MU))
plt.plot([],[], ' ', label="Sigma: {}".format(SIGMA))
plt.title('Accuracy Over Time', fontsize=12)
plt.xlabel('Epoch', fontsize=10)
plt.ylabel('Accuracy', fontsize=10)
plt.legend(loc='lower right', fontsize=6)
plt.savefig(GRAPH_FILENAME)
plt.show()
p = Plot()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train)
steps_per_epoch = int(num_examples / BATCH_SIZE)
accum_entropy_loss = 0
print("Training...\n")
for i in range(EPOCHS):
unison_shuffle(X_train, y_train)
acc_training_accuracy = 0
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
_, batch_accuracy = sess.run([training_operation, accuracy_operation],
feed_dict={x: batch_x, y: batch_y, keep_prob: KEEP_PROB})
acc_training_accuracy += batch_accuracy
avg_training_accuray = acc_training_accuracy / steps_per_epoch
validation_accuracy = evaluate(X_valid, y_valid)
p.train_accuracy_over_epoch.append(avg_training_accuray)
p.valid_accuracy_over_epoch.append(validation_accuracy)
print("EPOCH {} : Training Accuray {:.1f}%, Validation Accuracy {:.1f}%".format(i, 100*avg_training_accuray, 100*validation_accuracy))
p.plot_graph()
saver.save(sess, './lenet')
print("Model saved")
```
### Log:
1. 5/18/2018 - Training accuracy 99.4%, Validation Accuracy 92.3%
- preprocessing: simple normalization: (pixel - 128)/128
- lr: 0.001, batch: 128, epoch: 50, mu: 0, sigma: 0.1
- Seems to be overfitting
2. 5/18/2018 - Training accuracy 89.9%, Validation Accuracy 91.1%
- added drop out at the fully connected layers
- lr: 0.0015, batch: 128, epoch: 50, mu: 0, sigma: 0.1
3. 5/18/2018 - Training Accuray 94.2%, Validation Accuracy 92.6%
- preprocessing: normalization and grayscaling
- everything else remains the same
4. 5/18/2018 - Training Accuray 94.9% Validation Accuracy 94.1%
- preprocessing: same
- hyperparameter: everything stays the same except batch becomes 200
- Try increasing learning rate
5. 5/19/2018 - Training Accuray 85.0%, Validation Accuracy 86.7%
- preprocessing: same
- lr: 0.003 and everything else is the same
6. 5/19/2018 - Training Accuray 97.0%, Validation Accuracy 96.4%
- preprocessing: find bugs in preprocessing: didn't divide properly
- pixel - 128/128 instead of (pixel - 128)/128
- lr: 0.001 and everything else is the same
- Much better convergence
### Test Model
```
with tf.Session() as sess:
saver = tf.train.import_meta_graph('./lenet.meta')
saver.restore(sess, tf.train.latest_checkpoint('.'))
test_accuracy = evaluate(X_test, y_test)
print("Test Set Accuracy {:.1f}%".format(100*test_accuracy))
```
### Test Result
The accuracy of the model on the test set is **94.2%**. Comparing to the training accuracy of 97.6% and validation accuracy of 96.9%, the model seems to be overfitting. This can be due to the fact that the data set has unequal distribution across all 43 traffic signs. We can improve by generating more images for the scarce labels in the data set.
---
## Step 3: Test a Model on New Images
To give yourself more insight into how your model is working, download at least five pictures of German traffic signs from the web and use your model to predict the traffic sign type.
You may find `signnames.csv` useful as it contains mappings from the class id (integer) to the actual sign name.
### Load and Output the Images
```
### Load the images and plot them here.
### Feel free to use as many code cells as needed.
import matplotlib.image as mpimg
import cv2
downloaded_img_names = ['30kph','children-crossing','keep-right','road-work','stop']
X_download = []
for name in downloaded_img_names:
filepath = './downloaded_img/' + name + '.jpg'
image = (mpimg.imread(filepath))
X_download.append(cv2.resize(image, (32,32), interpolation=cv2.INTER_AREA))
fig, axes = plt.subplots(1, 5, figsize=(20, 13), subplot_kw={'xticks': [], 'yticks': []})
fig.subplots_adjust(hspace=0.3, wspace=0.05)
for ax, i in zip(axes.flat, range(5)):
ax.imshow(X_download[i])
ax.set_title(downloaded_img_names[i])
plt.show()
```
### Predict the Sign Type for Each Image
```
### Run the predictions here and use the model to output the prediction for each image.
### Make sure to pre-process the images with the same pre-processing pipeline used earlier.
### Feel free to use as many code cells as needed.
X_download = preprocess(np.array(X_download))
y_download = np.array([1, 28, 38, 25, 14])
X_download.shape
predict_operation = tf.nn.top_k(tf.nn.softmax(logits), k=5)
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('.'))
prob, indices = sess.run(predict_operation, feed_dict={x: X_download, y: y_download, keep_prob: 1.0})
# print(scores, indices)
for i, image in enumerate(X_download):
corr_label = label_name[y_download[i]+1]
print("Image", i + 1, "- correct label:", corr_label)
for j in range(5):
percent = prob[i][j] * 100
label = label_name[indices[i][j] + 1]
print('{:9.2f}% {}'.format(percent, label[1]))
# print("Accuracy on Downloaded Images {:.1f}%".format(100*test_accuracy))
```
### Analyze Performance
The accuracy on the downloaded image is **80%**.
### Project Writeup
Once you have completed the code implementation, document your results in a project writeup using this [template](https://github.com/udacity/CarND-Traffic-Sign-Classifier-Project/blob/master/writeup_template.md) as a guide. The writeup can be in a markdown or pdf file.
> **Note**: Once you have completed all of the code implementations and successfully answered each question above, you may finalize your work by exporting the iPython Notebook as an HTML document. You can do this by using the menu above and navigating to \n",
"**File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.
| github_jupyter |
# Example 1: How to Generate Synthetic Data (MarginalSynthesizer)
In this notebook we show you how to create a simple synthetic dataset.
# Environment
## Library Imports
```
import numpy as np
import pandas as pd
from pathlib import Path
import os
import sys
```
## Jupyter-specific Imports and Settings
```
# set printing options
np.set_printoptions(threshold=sys.maxsize)
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
pd.set_option('display.expand_frame_repr', False)
# Display all cell outputs
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
from IPython import get_ipython
ipython = get_ipython()
# autoreload extension
if 'autoreload' not in ipython.extension_manager.loaded:
get_ipython().run_line_magic('load_ext', 'autoreload')
get_ipython().run_line_magic('autoreload', '2')
from importlib import reload
```
## Import Synthesizer
For this example we use the MarginalSynthesizer algorithm. As the name suggests, this algorithm generates data via the marginal distributions of each column in the input dataset. In other words, the output synthetic data will have similar counts for each column but the statistical patterns between columns are likely not preserved. While this method is rather naive, it will work with data of any shape or size - and run relatively quickly as well.
```
from synthesis.synthesizers import MarginalSynthesizer
```
# Synthetic Data Generation
Let's load a dataset to see how the generation process works.
In this case, we will use the adult dataset - source: https://archive.ics.uci.edu/ml/datasets/adult
```
df_original = pd.read_csv('../data/original/adult.csv')
df_original.head()
```
We will now import our synthesizer and fit it on the input data.
Additionally we can specify the 'epsilon' value, which according to the definition of differential privacy is used to quantify the privacy risk posed by releasing statistics computed on sensitive data. More on that here: https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
In short, a lower value of epsilon will result in more randomness and v.v.
```
epsilon = 1 # set to float(np.inf) if you'd like to compute without differential privacy.
synthesizer = MarginalSynthesizer(epsilon=epsilon)
synthesizer.fit(df_original)
```
After our synthesizer has fitted the structure of the original data source, we can now use it to generate a new dataset.
```
# we can specify the number of records by sample(n_records=...),
# default it generates the same number of records as the input data
df_synthetic = synthesizer.sample()
```
We now obtained a new dataset which looks very similar to the original one.
```
df_synthetic.head()
```
# Evaluation
We can see that the synthetic data has a similar structure the original. We can also evaluate whether it has retained the statistical distributions of the original data. We use the SyntheticDataEvaluator class to compare the synthetic data to the original by applying various metrics.
Note: for more elaborate evaluation techniques we refer to the example notebook on 'evaluating synthetic data'.
```
from synthesis.evaluation import SyntheticDataEvaluator
evaluator = SyntheticDataEvaluator()
evaluator.fit(df_original, df_synthetic)
evaluator.score()
evaluator.plot()
```
Observe that the marginal distributions are preserved quite well - especially for columns with low dimensionality. When using differentialy private algorithms (like MarginalSynthesizer) it is advised to reduce the dimensionality of the original data by generalizing columns.
Also observe that the last plot shows the synthetic data did not capture any of the correlations in the original data. This is expected as MarginalSynthesizer synthesizes data by columns independently.
# Conclusion
We hope that gave you a quick introduction on synthetic data generation. Now go try it on your own data!
In the next example notebook we show how a more sophisticated algorithm is able to preserve statistical patterns between columns in the original data.
| github_jupyter |
# Mapping QTL in BXD mice using R/qtl2
[Karl Broman](https://kbroman.org)
[<img style="display:inline-block;" src="https://orcid.org/sites/default/files/images/orcid_16x16(1).gif">](https://orcid.org/0000-0002-4914-6671),
[Department of Biostatistics & Medical Informatics](https://www.biostat.wisc.edu),
[University of Wisconsin–Madison](https://www.wisc.edu)
Our aim in this tutorial is to demonstrate how to map quantitative trait loci (QTL) in the BXD mouse recombinant inbred lines using the [R/qtl2](https://kbroman.org/qtl2) software. We will first show how to download BXD phenotypes from [GeneNetwork2](http://gn2.genenetwork.org) using its API, via the R package [R/GNapi](https://github.com/rqtl/GNapi). At the end, we will use the [R/qtl2browse](https://github.com/rqtl/qtl2browse) package to display genome scan results using the [Genetics Genome Browser](https://github.com/chfi/purescript-genome-browser).
## Acquiring phenotypes with the GeneNetwork API
We will first use the [GeneNetwork2](http://gn2.genenetwork.org) API to acquire BXD phenotypes to use for mapping. We will use the R package [R/GNapi](https://github.com/rqtl/GNapi).
We first need to install the package, which is not available on [CRAN](https://cran.r-project.org), but is available via a private repository.
```r
install.packages("GNapi", repos="http://rqtl.org/qtl2cran")
```
We then load the package using `library()`.
```
library(GNapi)
```
The [R/GNapi](https://github.com/kbroman/GNapi) has a variety of functions. For an overview, see [its vignette](http://kbroman.org/GNapi/GNapi.html). Here we will just do one thing: use the function `get_pheno()` to grab BXD phenotype data. You provide a data set and a phenotype. Phenotype 10038 concerns "habituation", measured as a difference in locomotor activity between day 1 and day 3 in a 5 minute test trial.
```
phe <- get_pheno("BXD", "10038")
head(phe)
```
We will use just the column "value", but we need to include the strain names so that R/qtl2 can line up these phenotypes with the genotypes.
```
pheno <- setNames(phe$value, phe$sample_name)
head(pheno)
```
## Acquiring genotype data with R/qtl2
We now want to get genotype data for the BXD panel. We first need to install the [R/qtl2](https://kbroman.org/qtl2) package. As with R/GNapi, it is not available on CRAN, but rather is distributed via a private repository.
```r
install.packages("qtl2", repos="http://rqtl.org/qtl2cran")
```
We then load the package with `library()`.
```
library(qtl2)
```
R/qtl2 uses a special file format for QTL data ([described here](https://kbroman.org/qtl2/assets/vignettes/input_files.html)). There are a variety of sample datasets [on Github](https://github.com/rqtl/qtl2data), including genotypes for the [mouse BXD lines](https://github.com/rqtl/qtl2data/tree/master/BXD), taken from [GeneNetwork2](http://gn2.genenetwork.org). We'll load those data directly into R using the function `read_cross2()`.
```
bxd_file <- "https://raw.githubusercontent.com/rqtl/qtl2data/master/BXD/bxd.zip"
bxd <- read_cross2(bxd_file)
```
We get a warning message about heterozygous genotypes being omitted. A number of the newer BXD lines have considerable heterozygosity. But these lines weren't among those phenotyped in the data we downloaded above, and so we don't need to worry about it here.
The data are read into the object `bxd`, which has class `"cross2"`. It contains the genotypes and well as genetic and physical marker maps. There are also phenotype data (which we will ignore).
We can get a quick summary of the dataset with `summary()`. For reasons that I don't understand, it gets printed as a big mess within this Jupyter notebook, and so here we need to surround it with `print()` to get the intended output.
```
print( summary(bxd) )
```
## QTL mapping in R/qtl2
The first step in QTL analysis is to calculate genotype probabilities at putative QTL positions across the genome, conditional on the observed marker data. This allows us that consider positions between the genotyped markers and to allow for the presence of genotyping errors.
First, we need to define the positions that we will consider. We will take the observed marker positions and insert a set of "pseudomarkers" (marker-like positions that are not actually markers). We do this with the function `insert_pseudomarkers()`. We pull the genetic map (`gmap`) out of the `bxd` data as our basic map; `step=0.2` and `stepwidth="max"` mean to insert pseudomarkers so that no two adjacent markers or pseudomarkers are more than 0.2 cM apart. That is, in any marker interval that is greater than 0.2 cM, we will insert one or more evenly spaced pseudomarkers, so that the intervals between markers and pseudomarkers are no more than 0.2 cM.
```
gmap <- insert_pseudomarkers(bxd$gmap, step=0.2, stepwidth="max")
```
We will be interested in results with respect to the physical map (in Mbp), and so we need to create a corresponding map that includes the pseudomarker positions. We do this with the function `interp_map()`, which uses linear interpolation to get estimated positions for the inserted pseudomarkers.
```
pmap <- interp_map(gmap, bxd$gmap, bxd$pmap)
```
We can now proceed with calculating genotype probabilities for all BXD strains at all markers and pseudomarkers, conditional on the observed marker genotypes and assuming a 0.2% genotyping error rate. We use the [Carter-Falconer](https://doi.org/10.1007/BF02996226) map function to convert between cM and recombination fractions; it assumes a high degree of crossover interference, appropriate for the mouse.
```
pr <- calc_genoprob(bxd, gmap, error_prob=0.002, map_function="c-f")
```
In the QTL analysis, we will fit a linear mixed model to account for polygenic background effects. We will use the "leave one chromosome out" (LOCO) method for this. When we scan a chromosome for a QTL, we include a polygenic term with a kinship matrix derived from all other chromosomes.
We first need to calculate this set of kinship matrices, which we do with the function `calc_kinship()`. The second argument, `"loco"`, indicates that we want to calculate a vector of kinship matrices, each derived from the genotype probabilities but leaving one chromosome out.
```
k <- calc_kinship(pr, "loco")
```
Now, finally, we're ready to perform the genome scan, which we do with the function `scan1()`. It takes the genotype probabilities and a set of phenotypes (here, just one phenotype). If kinship matrices are provided (here, as `k`), the scan is performed using a linear mixed model. To make the calculations faster, the residual polygenic variance is first estimated without including any QTL effect and is then taking to be fixed and known during the scan.
```
out <- scan1(pr, pheno, k)
```
The output of `scan1()` is a matrix of LOD scores; the rows are marker/pseudomarker positions and the columns are phenotypes. We can plot the results using `plot.scan1()`, and we can just use `plot()` because it uses the class of its input to determine what plot to make.
Here I'm using the package [repr](https://cran.r-project.org/package=repr) to control the height and width of the plot that's created. I installed it with `install.packages("repr")`. You can ignore that part, if you want.
```
library(repr)
options(repr.plot.height=4, repr.plot.width=8)
par(mar=c(5.1, 4.1, 0.6, 0.6))
plot(out, pmap)
```
There's a clear QTL on chromosome 8. We can make a plot of just that chromosome with the argument `chr=15`.
```
par(mar=c(5.1, 4.1, 0.6, 0.6))
plot(out, pmap, chr=15)
```
Let's create a plot of the phenotype vs the genotype at the inferred QTL. We first need to identify the QTL location, which we can do using `max()`. We then use `maxmarg()` to get inferred genotypes at the inferred QTL.
```
mx <- max(out, pmap)
g_imp <- maxmarg(pr, pmap, chr=mx$chr, pos=mx$pos, return_char=TRUE)
```
We can use `plot_pxg()` to plot the phenotype as a function of QTL genotype. We use `swap_axes=TRUE` to have the phenotype on the x-axis and the genotype on the y-axis, rather than the other way around. Here we see that the BB and DD genotypes are completely separated, phenotypically.
```
par(mar=c(5.1, 4.1, 0.6, 0.6))
plot_pxg(g_imp, pheno, swap_axes=TRUE, xlab="Habituation phenotype")
```
## Browsing genome scan results with the Genetics Genome Browser
The [Genetics Genome Browser](https://github.com/chfi/purescript-genome-browser) is a fast, lightweight, [purescript]-based genome browser developed for browsing GWAS or QTL analysis results. We'll use the R package [R/qtl2browse](https://github.com/rqtl/qtl2browse) to view our QTL mapping results in the GGB.
We first need to install the R/qtl2browse package, again from a private [CRAN](https://cran.r-project.org)-like repository.
```r
install.packages("qtl2browse", repos="http://rqtl.org/qtl2cran")
```
We then load the package and use its one function, `browse()`, which takes the `scan1()` output and corresponding physical map (in Mbp). This will open the Genetics Genome Browser in a separate tab in your web browser.
```
library(qtl2browse)
browse(out, pmap)
```
| github_jupyter |
# Simplifying Codebases
Param's just a Python library, and so anything you can do with Param you can do "manually". So, why use Param?
The most immediate benefit to using Param is that it allows you to greatly simplify your codebases, making them much more clear, readable, and maintainable, while simultaneously providing robust handling against error conditions.
Param does this by letting a programmer explicitly declare the types and values of parameters accepted by the code. Param then ensures that only suitable values of those parameters ever make it through to the underlying code, removing the need to handle any of those conditions explicitly.
To see how this works, let's create a Python class with some attributes without using Param:
```
class OrdinaryClass(object):
def __init__(self, a=2, b=3, title="sum"):
self.a = a
self.b = b
self.title = title
def __call__(self):
return self.title + ": " + str(self.a + self.b)
```
As this is just standard Python, we can of course instantiate this class, modify its variables, and call it:
```
o1 = OrdinaryClass(b=4, title="Sum")
o1.a=4
o1()
```
The same code written using Param would look like:
```
import param
class ParamClass(param.Parameterized):
a = param.Integer(2, bounds=(0,1000), doc="First addend")
b = param.Integer(3, bounds=(0,1000), doc="Second addend")
title = param.String(default="sum", doc="Title for the result")
def __call__(self):
return self.title + ": " + str(self.a + self.b)
o2 = ParamClass(b=4, title="Sum")
o2()
```
As you can see, the Parameters here are used precisely like normal attributes once they are defined, so the code for `__call__` and for invoking the constructor are the same in both cases. It's thus generally quite straightforward to migrate an existing class into Param. So, why do that?
Well, with fewer lines of code than the ordinary class, you've now unlocked a whole wealth of features and better behavior! For instance, what happens if a user tries to supply some inappropriate data? With Param, such errors will be caught immediately:
```
with param.exceptions_summarized():
o3 = ParamClass()
o3.b = -5
```
Of course, you could always add more code to an ordinary Python class to check for errors like that, but it quickly gets unwieldy:
```
class OrdinaryClass2(object):
def __init__(self, a=2, b=3, title="sum"):
if type(a) is not int:
raise ValueError("'a' must be an integer")
if type(b) is not int:
raise ValueError("'b' must be an integer")
if a<0:
raise ValueError("'a' must be at least `0`")
if b<0:
raise ValueError("'b' must be at least `0`")
if type(title) is not str:
raise ValueError("'title' must be a string")
self.a = a
self.b = b
self.title = title
def __call__(self):
return self.title + ": " + str(self.a + self.b)
with param.exceptions_summarized():
OrdinaryClass2(a="f")
```
Unfortunately, catching errors in the constructor like that won't help if someone modifies the attribute directly, which won't be detected as an error:
```
o4 = OrdinaryClass2()
o4.a = "four"
```
Python will happily accept this incorrect value and will continue processing. It may only be much later, in a very different part of your code, that you see a mysterious error message that's then very difficult to relate back to the actual problem you need to fix:
```
with param.exceptions_summarized():
o4()
```
Here there's no problem with the code in the cell above; `o4()` is fully valid Python; the real problem is in the preceding cell, which could have been in a completely different file or library. The error message is also obscure and confusing at this level, because the user of `o4` may have no idea why strings and integers are getting concatenated.
To get a better error message, you _could_ move those checks into the `__call__` method, which would make sure that errors are always eventually detected:
```
class OrdinaryClass3(object):
def __init__(self, a=2, b=3, title="sum"):
self.a = a
self.b = b
self.title = title
def __call__(self):
if type(self.a) is not int:
raise ValueError("'a' must be an integer")
if type(self.b) is not int:
raise ValueError("'b' must be an integer")
if self.a<0:
raise ValueError("'a' must be at least `0`")
if self.b<0:
raise ValueError("'b' must be at least `0`")
if type(self.title) is not str:
raise ValueError("'title' must be a string")
return self.title + ": " + str(self.a + self.b)
o5 = OrdinaryClass3()
o5.a = "four"
with param.exceptions_summarized():
o5()
```
But you'd now have to check for errors in _every_ _single_ _method_ that might use those parameters. Worse, you still only detect the problem very late, far from where it was first introduced. Any distance between the error and the error report makes it much more difficult to address, as the user then has to track down where in the code `a` might have gotten set to a non-integer.
With Param you can catch such problems at their start, as soon as an incorrect value is provided, when it is still simple to detect and correct it. To get those same features in hand-written Python code, you would need to provide explicit getters and setters, which is made easier with Python properties and decorators, but is still quite unwieldy:
```
class OrdinaryClass4(object):
def __init__(self, a=2, b=3, title="sum"):
self.a = a
self.b = b
self.title = title
@property
def a(self): return self.__a
@a.setter
def a(self, a):
if type(a) is not int:
raise ValueError("'a' must be an integer")
if a < 0:
raise ValueError("'a' must be at least `0`")
self.__a = a
@property
def b(self): return self.__b
@b.setter
def b(self, b):
if type(b) is not int:
raise ValueError("'a' must be an integer")
if b < 0:
raise ValueError("'a' must be at least `0`")
self.__b = b
@property
def title(self): return self.__title
def title(self, b):
if type(title) is not string:
raise ValueError("'title' must be a string")
self.__title = title
def __call__(self):
return self.title + ": " + str(self.a + self.b)
o5=OrdinaryClass4()
o5()
with param.exceptions_summarized():
o5=OrdinaryClass4()
o5.b=-6
```
Note that this code has an easily overlooked mistake in it, reporting `a` rather than `b` as the problem. This sort of error is extremely common in copy-pasted validation code of this type, because tests rarely exercise all of the error conditions involved.
As you can see, even getting close to the automatic validation already provided by Param requires 8 methods and >30 highly repetitive lines of code, even when using relatively esoteric Python features like properties and decorators, and still doesn't yet implement other Param features like automatic documentation, attribute inheritance, or dynamic values. With Param, the corresponding `ParamClass` code only requires 6 lines and no fancy techniques beyond Python classes. Most importantly, the Param version lets readers and program authors focus directly on what this code actually does, which is to compute a function from three provided parameters:
```
class ParamClass(param.Parameterized):
a = param.Integer(2, bounds=(0,1000), doc="First addend")
b = param.Integer(3, bounds=(0,1000), doc="Second addend")
title = param.String(default="sum", doc="Title for the result")
def __call__(self):
return self.title + ": " + str(self.a + self.b)
```
Even a quick skim of this code reveals what parameters are available, what values they will accept, what the default values are, and how those parameters will be used in the method. Plus the actual code of the method stands out immediately, as all the code is either parameters or actual functionality. In contrast, users of OrdinaryClass3 will have to read through dozens of lines of code to discern even basic information about usage, or else authors of the code will need to create and maintain docstrings that may or may not match the actual code over time and will further increase the amount of text to write and maintain.
## Programming contracts
If you think about the examples above, you can see how Param makes it simple for programmers to make a contract with their users, being explicit and clear what will be accepted and rejected, while also allowing programmers to make safe assumptions about what inputs the code may ever receive. There is no need for `__call__` _ever_ to check for the type of one of its parameters, whether it's in the range allowed, or any other property that can be enforced by Param. Your custom code can then be much more linear and straightforward, getting right to work with the actual task at hand, without having to have reams of `if` statements and `asserts()` that disrupt the flow of the source file and make the reader get sidetracked in error-handling code. Param lets you once and for all declare what this code accepts, which is both clear documentation to the user and a guarantee that the programmer can forget about any other possible value a user might someday supply.
Crucially, these contracts apply not just between the user and a given piece of code, but also between components of the system itself. When validation code is expensive, as in ordinary Python, programmers will typically do it only at the edges of the system, where input from the user is accepted. But expressing types and ranges is so easy in Param, it can be done for any major component in the system. The Parameter list declares very clearly what that component accepts, which lets the code for that component ignore all potential inputs that are disallowed by the Parameter specifications, while correctly advertising to the rest of the codebase what inputs are allowed. Programmers can thus focus on their particular components of interest, knowing precisely what inputs will ever be let through, without having to reason about the flow of configuration and data throughout the whole system.
Without Param, you should expect Python code to be full of confusing error checking and handling of different input types, while still only catching a small fraction of the possible incorrect inputs that could be provided. But Param-based code should be dramatically easier to read, easier to maintain, easier to develop, and nearly bulletproof against mistaken or even malicious usage.
| github_jupyter |
Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.
- Author: Sebastian Raschka
- GitHub Repository: https://github.com/rasbt/deeplearning-models
```
!pip install -q IPython
!pip install -q ipykernel
!pip install -q watermark
!pip install -q matplotlib
!pip install -q sklearn
!pip install -q pandas
!pip install -q pydot
!pip install -q hiddenlayer
!pip install -q graphviz
%load_ext watermark
%watermark -a 'Sebastian Raschka' -v -p torch
```
- Runs on CPU (not recommended here) or GPU (if available)
# Model Zoo -- Convolutional Neural Network (VGG19 Architecture)
Implementation of the VGG-19 architecture on Cifar10.
Reference for VGG-19:
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
The following table (taken from Simonyan & Zisserman referenced above) summarizes the VGG19 architecture:

## Imports
```
import numpy as np
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
```
## Settings and Dataset
```
##########################
### SETTINGS
##########################
# Device
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('Device:', DEVICE)
# Hyperparameters
random_seed = 1
learning_rate = 0.001
num_epochs = 20
batch_size = 128
# Architecture
num_features = 784
num_classes = 10
##########################
### MNIST DATASET
##########################
# Note transforms.ToTensor() scales input images
# to 0-1 range
train_dataset = datasets.CIFAR10(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.CIFAR10(root='data',
train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
```
## Model
```
##########################
### MODEL
##########################
class VGG16(torch.nn.Module):
def __init__(self, num_features, num_classes):
super(VGG16, self).__init__()
# calculate same padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
# (1(32-1)- 32 + 3)/2 = 1
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64,
out_channels=64,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_2 = nn.Sequential(
nn.Conv2d(in_channels=64,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128,
out_channels=128,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_3 = nn.Sequential(
nn.Conv2d(in_channels=128,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256,
out_channels=256,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_4 = nn.Sequential(
nn.Conv2d(in_channels=256,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.block_5 = nn.Sequential(
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512,
out_channels=512,
kernel_size=(3, 3),
stride=(1, 1),
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2))
)
self.classifier = nn.Sequential(
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096, num_classes)
)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
#n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
#m.weight.data.normal_(0, np.sqrt(2. / n))
m.weight.detach().normal_(0, 0.05)
if m.bias is not None:
m.bias.detach().zero_()
elif isinstance(m, torch.nn.Linear):
m.weight.detach().normal_(0, 0.05)
m.bias.detach().detach().zero_()
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
x = self.block_4(x)
x = self.block_5(x)
logits = self.classifier(x.view(-1, 512))
probas = F.softmax(logits, dim=1)
return logits, probas
torch.manual_seed(random_seed)
model = VGG16(num_features=num_features,
num_classes=num_classes)
model = model.to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
import hiddenlayer as hl
hl.build_graph(model, torch.zeros([128, 3, 32, 32]).to(DEVICE))
```
## Training
```
def compute_accuracy(model, data_loader):
model.eval()
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
def compute_epoch_loss(model, data_loader):
model.eval()
curr_loss, num_examples = 0., 0
with torch.no_grad():
for features, targets in data_loader:
features = features.to(DEVICE)
targets = targets.to(DEVICE)
logits, probas = model(features)
loss = F.cross_entropy(logits, targets, reduction='sum')
num_examples += targets.size(0)
curr_loss += loss
curr_loss = curr_loss / num_examples
return curr_loss
start_time = time.time()
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %04d/%04d | Cost: %.4f'
%(epoch+1, num_epochs, batch_idx,
len(train_loader), cost))
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
print('Epoch: %03d/%03d | Train: %.3f%% | Loss: %.3f' % (
epoch+1, num_epochs,
compute_accuracy(model, train_loader),
compute_epoch_loss(model, train_loader)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
```
## Evaluation
```
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader)))
%watermark -iv
```
| github_jupyter |
# Changing the input current when solving PyBaMM models
This notebook shows you how to change the input current when solving PyBaMM models. It also explains how to load in current data from a file, and how to add a user-defined current function. For more examples of different drive cycles see [here](https://github.com/pybamm-team/PyBaMM/tree/master/results/drive_cycles).
### Table of Contents
1. [Constant current](#constant)
1. [Loading in current data](#data)
1. [Adding your own current function](#function)
## Constant current <a name="constant"></a>
In this notebook we will use the SPM as the example model, and change the input current from the default option. If you are not familiar with running a model in PyBaMM, please see [this](./models/SPM.ipynb) notebook for more details.
In PyBaMM, the current function is set using the parameter "Current function [A]". Below we load the SPM with the default parameters, and then change the the current function to be an input parameter, so that we can change it easily later.
```
%pip install pybamm -q # install PyBaMM if it is not installed
import pybamm
import numpy as np
import os
os.chdir(pybamm.__path__[0]+'/..')
# create the model
model = pybamm.lithium_ion.DFN()
# set the default model parameters
param = model.default_parameter_values
# change the current function to be an input parameter
param["Current function [A]"] = "[input]"
```
We can set up a simulation in the usual way, making sure we pass in our updated parameters. We choose to solve with a 1.6A current. In order to do this we must pass a dictionary of inputs whose keys are the parameter names and values are the values we want to use for that call to solve
```
# set up simlation
simulation = pybamm.Simulation(model, parameter_values=param)
# solve the model at the given time points, passing the current as an input
t_eval = np.linspace(0, 600, 300)
simulation.solve(t_eval, inputs={"Current function [A]": 1.6})
# plot
simulation.plot()
```
PyBaMM can also simulate rest behaviour by setting the current function to zero:
```
# solve the model at the given time points
simulation.solve(t_eval, inputs={"Current function [A]": 0})
# plot
simulation.plot()
```
## Loading in current data <a name="data"></a>
To run drive cycles from data we can create an interpolant and pass it as the current function.
```
import pandas as pd # needed to read the csv data file
model = pybamm.lithium_ion.DFN()
# import drive cycle from file
drive_cycle = pd.read_csv("pybamm/input/drive_cycles/US06.csv", comment="#", header=None).to_numpy()
# load parameter values
param = model.default_parameter_values
# create interpolant - must be a function of *dimensional* time
timescale = param.evaluate(model.timescale)
current_interpolant = pybamm.Interpolant(drive_cycle, timescale * pybamm.t)
# set drive cycle
param["Current function [A]"] = current_interpolant
# set up simulation - for drive cycles we recommend using the CasadiSolver in "fast" mode
solver = pybamm.CasadiSolver(mode="fast")
simulation = pybamm.Simulation(model, parameter_values=param, solver=solver)
```
Note that when simulating drive cycles there is no need to pass a list of times at which to return the solution, the results are automatically returned at the time points in the data. If you would like the solution returned at times different to those in the data then you can pass an array of times `t_eval` to `solve` in the usual way.
```
# simulate US06 drive cycle (duration 600 seconds)
simulation.solve()
# plot
simulation.plot()
```
Note that some solvers try to evaluate the model equations at a very large value of `t` during the first step. This may raise a warning if the time requested by the solver is outside of the range of the data provided. However, this does not affect the solve since this large timestep is rejected by the solver, and a suitable shorter initial step is taken.
## Adding your own current function <a name="function"></a>
A user defined current function can be passed to any model by specifying either a function or a set of data points for interpolation.
For example, you may want to simulate a sinusoidal current with amplitude A and frequency omega. In order to do so you must first define the method
```
# create user-defined function
def my_fun(A, omega):
def current(t):
return A * pybamm.sin(2 * np.pi * omega * t)
return current
```
Note that the function returns a function which takes the input time.
Then the model may be loaded and the "Current function" parameter updated to `my_fun` called with a specific value of `A` and `omega`
```
model = pybamm.lithium_ion.SPM()
# load default parameter values
param = model.default_parameter_values
# set user defined current function
A = model.param.I_typ
omega = 0.1
param["Current function [A]"] = my_fun(A,omega)
```
Note that when `my_fun` is evaluated with `A` and `omega`, this creates a new function `current(t)` which can then be used in the expression tree. The model may then be solved in the usual way
```
# set up simulation
simulation = pybamm.Simulation(model, parameter_values=param)
# Example: simulate for 30 seconds
simulation_time = 30 # end time in seconds
npts = int(50 * simulation_time * omega) # need enough timesteps to resolve output
t_eval = np.linspace(0, simulation_time, npts)
solution = simulation.solve(t_eval)
label = ["Frequency: {} Hz".format(omega)]
# plot current and voltage
output_variables = ["Current [A]", "Terminal voltage [V]"]
simulation.plot(output_variables, labels=label)
```
| github_jupyter |
## Discretisation
Discretisation is the process of transforming continuous variables into discrete variables by creating a set of contiguous intervals that span the range of the variable's values. Discretisation is also called **binning**, where bin is an alternative name for interval.
### Discretisation helps handle outliers and may improve value spread in skewed variables
Discretisation helps handle outliers by placing these values into the lower or higher intervals, together with the remaining inlier values of the distribution. Thus, these outlier observations no longer differ from the rest of the values at the tails of the distribution, as they are now all together in the same interval / bucket. In addition, by creating appropriate bins or intervals, discretisation can help spread the values of a skewed variable across a set of bins with equal number of observations.
### Discretisation approaches
There are several approaches to transform continuous variables into discrete ones. Discretisation methods fall into 2 categories: **supervised and unsupervised**. Unsupervised methods do not use any information, other than the variable distribution, to create the contiguous bins in which the values will be placed. Supervised methods typically use target information in order to create the bins or intervals.
#### Unsupervised discretisation methods
- Equal width discretisation
- Equal frequency discretisation
- K-means discretisation
#### Supervised discretisation methods
- Discretisation using decision trees
In this lecture, I will describe **equal frequency discretisation**.
## Equal frequency discretisation
Equal frequency discretisation divides the scope of possible values of the variable into N bins, where each bin carries the same amount of observations. This is particularly useful for skewed variables as it spreads the observations over the different bins equally. We find the interval boundaries by determining the quantiles.
Equal frequency discretisation using quantiles consists of dividing the continuous variable into N quantiles, N to be defined by the user.
Equal frequency binning is straightforward to implement and by spreading the values of the observations more evenly it may help boost the algorithm's performance. This arbitrary binning may also disrupt the relationship with the target.
## In this demo
We will learn how to perform equal frequency discretisation using the Titanic dataset with
- pandas and NumPy
- Feature-engine
- Scikit-learn
## Titanic dataset
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import KBinsDiscretizer
from feature_engine.discretisers import EqualFrequencyDiscretiser
# load the numerical variables of the Titanic Dataset
data = pd.read_csv('../titanic.csv',
usecols=['age', 'fare', 'survived'])
data.head()
# Let's separate into train and test set
X_train, X_test, y_train, y_test = train_test_split(
data[['age', 'fare']],
data['survived'],
test_size=0.3,
random_state=0)
X_train.shape, X_test.shape
```
The variables Age and Fare contain missing data, that I will fill by extracting a random sample of the variable.
```
def impute_na(data, variable):
# function to fill NA with a random sample
df = data.copy()
# random sampling
df[variable+'_random'] = df[variable]
# extract the random sample to fill the na
random_sample = X_train[variable].dropna().sample(
df[variable].isnull().sum(), random_state=0)
# pandas needs to have the same index in order to merge datasets
random_sample.index = df[df[variable].isnull()].index
df.loc[df[variable].isnull(), variable+'_random'] = random_sample
return df[variable+'_random']
# replace NA in both train and test sets
X_train['age'] = impute_na(data, 'age')
X_test['age'] = impute_na(data, 'age')
X_train['fare'] = impute_na(data, 'fare')
X_test['fare'] = impute_na(data, 'fare')
# let's explore the distribution of age
X_train[['age', 'fare']].hist(bins=30, figsize=(8,4))
plt.show()
```
## Equal frequency discretisation with pandas and NumPy
The interval limits are the quantile limits. We can find those out with pandas qcut.
```
# let's use pandas qcut (quantile cut) and I indicate that
# we want 10 bins.
# retbins = True indicates that I want to capture the limits
# of each interval (so I can then use them to cut the test set)
Age_disccretised, intervals = pd.qcut(
X_train['age'], 10, labels=None, retbins=True, precision=3, duplicates='raise')
pd.concat([Age_disccretised, X_train['age']], axis=1).head(10)
```
We can see in the above output how by discretising using quantiles, we placed each Age observation within one interval. For example, age 29 was placed in the 26-30 interval, whereas age 63 was placed into the 49-80 interval.
Note how the interval widths are different.
We can visualise the interval cut points below:
```
intervals
```
And because we generated the bins using the quantile cut method, we should have roughly the same amount of observations per bin. See below.
```
# roughly the same number of passengers per interval
Age_disccretised.value_counts()
# we can also add labels instead of having the interval boundaries, to the bins, as follows:
labels = ['Q'+str(i) for i in range(1,11)]
labels
Age_disccretised, intervals = pd.qcut(X_train['age'], 10, labels=labels,
retbins=True,
precision=3, duplicates='raise')
Age_disccretised.head()
# to transform the test set:
# we use pandas cut method (instead of qcut) and
# pass the quantile edges calculated in the training set
X_test['Age_disc_label'] = pd.cut(x = X_test['age'], bins=intervals, labels=labels)
X_test['Age_disc'] = pd.cut(x = X_test['age'], bins=intervals)
X_test.head(10)
# let's check that we have equal frequency (equal number of observations per bin)
X_test.groupby('Age_disc')['age'].count().plot.bar()
```
We can see that the top intervals have less observations. This may happen with skewed distributions if we try to divide in a high number of intervals. To make the value spread more homogeneous, we should discretise in less intervals.
## Equal frequency discretisation with Feature-Engine
```
# Let's separate into train and test set
X_train, X_test, y_train, y_test = train_test_split(
data[['age', 'fare']],
data['survived'],
test_size=0.3,
random_state=0)
X_train.shape, X_test.shape
# replace NA in both train and test sets
X_train['age'] = impute_na(data, 'age')
X_test['age'] = impute_na(data, 'age')
X_train['fare'] = impute_na(data, 'fare')
X_test['fare'] = impute_na(data, 'fare')
# with feature engine we can automate the process for many variables
# in one line of code
disc = EqualFrequencyDiscretiser(q=10, variables = ['age', 'fare'])
disc.fit(X_train)
# in the binner dict, we can see the limits of the intervals. Note
# that the intervals have different widths
disc.binner_dict_
# transform train and text
train_t = disc.transform(X_train)
test_t = disc.transform(X_test)
train_t.head()
# and now let's explore the number of observations per bucket
t1 = train_t.groupby(['age'])['age'].count() / len(train_t)
t2 = test_t.groupby(['age'])['age'].count() / len(test_t)
tmp = pd.concat([t1, t2], axis=1)
tmp.columns = ['train', 'test']
tmp.plot.bar()
plt.xticks(rotation=0)
plt.ylabel('Number of observations per bin')
t1 = train_t.groupby(['fare'])['fare'].count() / len(train_t)
t2 = test_t.groupby(['fare'])['fare'].count() / len(test_t)
tmp = pd.concat([t1, t2], axis=1)
tmp.columns = ['train', 'test']
tmp.plot.bar()
plt.xticks(rotation=0)
plt.ylabel('Number of observations per bin')
```
Note how equal frequency discretisation obtains a better value spread across the different intervals.
## Equal frequency discretisation with Scikit-learn
```
# Let's separate into train and test set
X_train, X_test, y_train, y_test = train_test_split(
data[['age', 'fare']],
data['survived'],
test_size=0.3,
random_state=0)
X_train.shape, X_test.shape
# replace NA in both train and test sets
X_train['age'] = impute_na(data, 'age')
X_test['age'] = impute_na(data, 'age')
X_train['fare'] = impute_na(data, 'fare')
X_test['fare'] = impute_na(data, 'fare')
disc = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='quantile')
disc.fit(X_train[['age', 'fare']])
disc.bin_edges_
train_t = disc.transform(X_train[['age', 'fare']])
train_t = pd.DataFrame(train_t, columns = ['age', 'fare'])
train_t.head()
test_t = disc.transform(X_test[['age', 'fare']])
test_t = pd.DataFrame(test_t, columns = ['age', 'fare'])
t1 = train_t.groupby(['age'])['age'].count() / len(train_t)
t2 = test_t.groupby(['age'])['age'].count() / len(test_t)
tmp = pd.concat([t1, t2], axis=1)
tmp.columns = ['train', 'test']
tmp.plot.bar()
plt.xticks(rotation=0)
plt.ylabel('Number of observations per bin')
t1 = train_t.groupby(['fare'])['fare'].count() / len(train_t)
t2 = test_t.groupby(['fare'])['fare'].count() / len(test_t)
tmp = pd.concat([t1, t2], axis=1)
tmp.columns = ['train', 'test']
tmp.plot.bar()
plt.xticks(rotation=0)
plt.ylabel('Number of observations per bin')
```
| github_jupyter |
This baseline has reached Top %11 with rank of #457/4540 Teams at Private Leader Board (missed Bronze with only 2 places)
```
import numpy as np
import pandas as pd
import sys
import gc
from scipy.signal import hilbert
from scipy.signal import hann
from scipy.signal import convolve
pd.options.display.precision = 15
train_set = pd.read_csv('../input/train.csv', dtype={'acoustic_data': np.int16, 'time_to_failure': np.float32})
segments = int(np.floor(train_set.shape[0] / 150000))
X_train = pd.DataFrame(index=range(segments), dtype=np.float64)
y_train = pd.DataFrame(index=range(segments), dtype=np.float64, columns=['time_to_failure'])
def feature_generate(df,x,seg):
df.loc[seg, 'ave'] = x.mean()
df.loc[seg, 'std'] = x.std()
df.loc[seg, 'max'] = x.max()
df.loc[seg, 'min'] = x.min()
df.loc[seg, 'sum'] = x.sum()
df.loc[seg, 'mad'] = x.mad()
df.loc[seg, 'kurtosis'] = x.kurtosis()
df.loc[seg, 'skew'] = x.skew()
df.loc[seg, 'quant0_01'] = np.quantile(x,0.01)
df.loc[seg, 'quant0_05'] = np.quantile(x,0.05)
df.loc[seg, 'quant0_95'] = np.quantile(x,0.95)
df.loc[seg, 'quant0_99'] = np.quantile(x,0.99)
df.loc[seg, 'abs_min'] = np.abs(x).min()
df.loc[seg, 'abs_max'] = np.abs(x).max()
df.loc[seg, 'abs_mean'] = np.abs(x).mean()
df.loc[seg, 'abs_std'] = np.abs(x).std()
df.loc[seg, 'mean_change_abs'] = np.mean(np.diff(x))
df.loc[seg, 'max_to_min'] = x.max() / np.abs(x.min())
df.loc[seg, 'max_to_min_diff'] = x.max() - np.abs(x.min())
df.loc[seg, 'count_big'] = len(x[np.abs(x) > 500])
df.loc[seg, 'average_first_10000'] = x[:10000].mean()
df.loc[seg, 'average_last_10000'] = x[-10000:].mean()
df.loc[seg, 'average_first_50000'] = x[:50000].mean()
df.loc[seg, 'average_last_50000'] = x[-50000:].mean()
df.loc[seg, 'std_first_10000'] = x[:10000].std()
df.loc[seg, 'std_last_10000'] = x[-10000:].std()
df.loc[seg, 'std_first_50000'] = x[:50000].std()
df.loc[seg, 'std_last_50000'] = x[-50000:].std()
df.loc[seg, '10q'] = np.percentile(x, 0.10)
df.loc[seg, '25q'] = np.percentile(x, 0.25)
df.loc[seg, '50q'] = np.percentile(x, 0.50)
df.loc[seg, '75q'] = np.percentile(x, 0.75)
df.loc[seg, '90q'] = np.percentile(x, 0.90)
df.loc[seg, 'abs_1q'] = np.percentile(x, np.abs(0.01))
df.loc[seg, 'abs_5q'] = np.percentile(x, np.abs(0.05))
df.loc[seg, 'abs_30q'] = np.percentile(x, np.abs(0.30))
df.loc[seg, 'abs_60q'] = np.percentile(x, np.abs(0.60))
df.loc[seg, 'abs_95q'] = np.percentile(x, np.abs(0.95))
df.loc[seg, 'abs_99q'] = np.percentile(x, np.abs(0.99))
df.loc[seg, 'hilbert_mean'] = np.abs(hilbert(x)).mean()
df.loc[seg, 'hann_window_mean'] = (convolve(x, hann(150), mode = 'same') / sum(hann(150))).mean()
for windows in [10, 100, 1000]:
x_roll_std = x.rolling(windows).std().dropna().values
x_roll_mean = x.rolling(windows).mean().dropna().values
df.loc[seg, 'avg_roll_std' + str(windows)] = x_roll_std.mean()
df.loc[seg, 'std_roll_std' + str(windows)] = x_roll_std.std()
df.loc[seg, 'max_roll_std' + str(windows)] = x_roll_std.max()
df.loc[seg, 'min_roll_std' + str(windows)] = x_roll_std.min()
df.loc[seg, '1q_roll_std' + str(windows)] = np.quantile(x_roll_std, 0.01)
df.loc[seg, '5q_roll_std' + str(windows)] = np.quantile(x_roll_std, 0.05)
df.loc[seg, '95q_roll_std' + str(windows)] = np.quantile(x_roll_std, 0.95)
df.loc[seg, '99q_roll_std' + str(windows)] = np.quantile(x_roll_std, 0.99)
df.loc[seg, 'av_change_abs_roll_std' + str(windows)] = np.mean(np.diff(x_roll_std))
df.loc[seg, 'abs_max_roll_std' + str(windows)] = np.abs(x_roll_std).max()
df.loc[seg, 'avg_roll_mean' + str(windows)] = x_roll_mean.mean()
df.loc[seg, 'std_roll_mean' + str(windows)] = x_roll_mean.std()
df.loc[seg, 'max_roll_mean' + str(windows)] = x_roll_mean.max()
df.loc[seg, 'min_roll_mean' + str(windows)] = x_roll_mean.min()
df.loc[seg, '1q_roll_mean' + str(windows)] = np.quantile(x_roll_mean, 0.01)
df.loc[seg, '5q_roll_mean' + str(windows)] = np.quantile(x_roll_mean, 0.05)
df.loc[seg, '95q_roll_mean' + str(windows)] = np.quantile(x_roll_mean, 0.95)
df.loc[seg, '99q_roll_mean' + str(windows)] = np.quantile(x_roll_mean, 0.99)
df.loc[seg, 'av_change_abs_roll_mean' + str(windows)] = np.mean(np.diff(x_roll_mean))
df.loc[seg, 'abs_max_roll_mean' + str(windows)] = np.abs(x_roll_mean).max()
return df
for s in range(segments):
seg = train_set.iloc[s*150000:s*150000+150000]
x = pd.Series(seg['acoustic_data'].values)
y = seg['time_to_failure'].values[-1]
y_train.loc[s, 'time_to_failure'] = y
X_train = feature_generate(X_train,x,s)
columns=X_train.columns
del train_set
gc.collect()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
y_train = y_train.values.flatten()
gc.collect()
import xgboost as xgb
model = xgb.XGBRegressor(objective = 'reg:linear',
metric = 'mae',
tree_method = 'gpu_hist',
verbosity = 0)
%%time
model.fit(X_train,y_train)
from matplotlib import pyplot
print(model.feature_importances_)
pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show()
from xgboost import plot_importance
plot_importance(model)
pyplot.show()
submission = pd.read_csv('../input/sample_submission.csv', index_col='seg_id')
X_test = pd.DataFrame(columns=columns, dtype=np.float64, index=submission.index)
for s in X_test.index:
seg = pd.read_csv('../input/test/' + s + '.csv')
x = pd.Series(seg['acoustic_data'].values)
X_test = feature_generate(X_test,x,s)
X_test = scaler.transform(X_test)
submission['time_to_failure'] = model.predict(X_test).clip(0, 16)
submission.to_csv('submission.csv')
```
| github_jupyter |
# Exercise 4 - Optimizing Model Training
In [the previous exercise](./03%20-%20Compute%20Contexts.ipynb), you created cloud-based compute and used it when running a model training experiment. The benefit of cloud compute is that it offers a cost-effective way to scale out your experiment workflow and try different algorithms and parameters in order to optimize your model's performance; and that's what we'll explore in this exercise.
> **Important**: This exercise assumes you have completed the previous exercises in this series - specifically, you must have:
>
> - Created an Azure ML Workspace.
> - Uploaded the diabetes.csv data file to the workspace's default datastore.
> - Registered a **Diabetes Dataset** dataset in the workspace.
> - Provisioned an Azure ML Compute resource named **cpu-cluster**.
>
> If you haven't done that, now would be a good time - nobody's going to do it for you!
## Task 1: Connect to Your Workspace
The first thing you need to do is to connect to your workspace using the Azure ML SDK. Let's start by ensuring you still have the latest version installed (if you ended and restarted your Azure Notebooks session, the environment may have been reset)
```
!pip install --upgrade azureml-sdk[notebooks,automl,explain]
import azureml.core
print("Ready to use Azure ML", azureml.core.VERSION)
```
Now you're ready to connect to your workspace. When you created it in the previous exercise, you saved its configuration; so now you can simply load the workspace from its configuration file.
> **Note**: If the authenticated session with your Azure subscription has expired since you completed the previous exercise, you'll be prompted to reauthenticate.
```
from azureml.core import Workspace
# Load the workspace from the saved config file
ws = Workspace.from_config()
print('Ready to work with', ws.name)
```
Now let's get the Azure ML compute resource you created previously (or recreate it if you deleted it!)
```
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
cpu_cluster_name = "cpu-cluster"
# Verify that cluster does not exist already
try:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
# Create an AzureMl Compute resource (a container cluster)
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
vm_priority='lowpriority',
max_nodes=4)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
cpu_cluster.wait_for_completion(show_output=True)
```
## Task 2: Use *Hyperdrive* to Determine Optimal Parameter Values
The remote compute you created is a four-node cluster, and you can take advantage of this to execute multiple experiment runs in parallel. One key reason to do this is to try training a model with a range of different hyperparameter values.
Azure ML includes a feature called *hyperdrive* that enables you to randomly try different values for one or more hyperparameters, and find the best performing trained model based on a metric that you specify - such as *Accuracy* or *Area Under the Curve (AUC)*.
> **More Information**: For more information about Hyperdrive, see the [Azure ML documentation](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-tune-hyperparameters).
Let's run a Hyperdrive experiment on the remote compute you have provisioned. First, we'll create the experiment and its associated folder.
```
import os
from azureml.core import Experiment
# Create an experiment
experiment_name = 'diabetes_training'
experiment = Experiment(workspace = ws, name = experiment_name)
# Create a folder for the experiment files
experiment_folder = './' + experiment_name
os.makedirs(experiment_folder, exist_ok=True)
print("Experiment:", experiment.name)
```
Now we'll create the Python script our experiment will run in order to train a model.
```
%%writefile $experiment_folder/diabetes_training.py
# Import libraries
import argparse
import joblib
from azureml.core import Workspace, Dataset, Experiment, Run
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
# Set regularization parameter
parser = argparse.ArgumentParser()
parser.add_argument('--regularization', type=float, dest='reg_rate', default=0.01, help='regularization rate')
args = parser.parse_args()
reg = args.reg_rate
# Get the experiment run context
run = Run.get_context()
# load the diabetes dataset
dataset_name = 'Diabetes Dataset'
print("Loading data from " + dataset_name)
diabetes = Dataset.get_by_name(workspace=run.experiment.workspace, name=dataset_name).to_pandas_dataframe()
# Separate features and labels
X, y = diabetes[['Pregnancies','PlasmaGlucose','DiastolicBloodPressure','TricepsThickness','SerumInsulin','BMI','DiabetesPedigree','Age']].values, diabetes['Diabetic'].values
# Split data into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)
# Train a logistic regression model
print('Training a logistic regression model with regularization rate of', reg)
run.log('Regularization Rate', np.float(reg))
model = LogisticRegression(C=1/reg, solver="liblinear").fit(X_train, y_train)
# calculate accuracy
y_hat = model.predict(X_test)
acc = np.average(y_hat == y_test)
print('Accuracy:', acc)
run.log('Accuracy', np.float(acc))
# calculate AUC
y_scores = model.predict_proba(X_test)
auc = roc_auc_score(y_test,y_scores[:,1])
print('AUC: ' + str(auc))
run.log('AUC', np.float(auc))
# plot ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
fig = plt.figure(figsize=(6, 4))
# Plot the diagonal 50% line
plt.plot([0, 1], [0, 1], 'k--')
# Plot the FPR and TPR achieved by our model
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
run.log_image(name = "ROC", plot = fig)
plt.show()
os.makedirs('outputs', exist_ok=True)
# note file saved in the outputs folder is automatically uploaded into experiment record
joblib.dump(value=model, filename='outputs/diabetes_model.pkl')
run.complete()
```
Now, we'll use the *Hyperdrive* feature of Azure ML to run multiple experiments in parallel, using different values for the **regularization** parameter to find the optimal value for our data.
```
from azureml.train.hyperdrive import GridParameterSampling, BanditPolicy, HyperDriveConfig, PrimaryMetricGoal
from azureml.train.hyperdrive import choice
from azureml.widgets import RunDetails
from azureml.train.sklearn import SKLearn
# Sample a range of parameter values
params = GridParameterSampling(
{
# There's only one parameter, so grid sampling will try each value - with multiple parameters it would try every combination
'--regularization': choice(0.001, 0.005, 0.01, 0.05, 0.1, 1.0)
}
)
# Set evaluation policy to stop poorly performing training runs early
policy = BanditPolicy(evaluation_interval=2, slack_factor=0.1)
# Create an estimator that uses the remote compute
hyper_estimator = SKLearn(source_directory=experiment_folder,
compute_target = cpu_cluster,
conda_packages=['pandas','ipykernel','matplotlib'],
pip_packages=['azureml-sdk','argparse','pyarrow'],
entry_script='diabetes_training.py')
# Configure hyperdrive settings
hyperdrive = HyperDriveConfig(estimator=hyper_estimator,
hyperparameter_sampling=params,
policy=policy,
primary_metric_name='AUC',
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=6,
max_concurrent_runs=4)
# Run the experiment
run = experiment.submit(config=hyperdrive)
# Show the status in the notebook as the experiment runs
RunDetails(run).show()
```
When all of the runs have finished, you can find the best one based on the performance metric you specified (in this case, the one with the best AUC).
```
best_run = run.get_best_run_by_primary_metric()
best_run_metrics = best_run.get_metrics()
parameter_values = best_run.get_details() ['runDefinition']['arguments']
print('Best Run Id: ', best_run.id)
print(' -AUC:', best_run_metrics['AUC'])
print(' -Accuracy:', best_run_metrics['Accuracy'])
print(' -Regularization Rate:',parameter_values)
```
Since we've found the best run, we can register the model it trained.
```
from azureml.core import Model
# Register model
best_run.register_model(model_path='outputs/diabetes_model.pkl', model_name='diabetes_model', tags={'Training context':'Hyperdrive'}, properties={'AUC': best_run_metrics['AUC'], 'Accuracy': best_run_metrics['Accuracy']})
# List registered models
for model in Model.list(ws):
print(model.name, 'version:', model.version)
for tag_name in model.tags:
tag = model.tags[tag_name]
print ('\t',tag_name, ':', tag)
for prop_name in model.properties:
prop = model.properties[prop_name]
print ('\t',prop_name, ':', prop)
print('\n')
```
## Task 3: Use *Auto ML* to Find the Best Model
Hyperparameter tuning has helped us find the optimal regularization rate for our logistic regression model, but we might get better results by trying a different algorithm, and by performing some basic feature-engineering, such as scaling numeric feature values. You could just create lots of different training scripts that apply various scikit-learn algorithms, and try them all until you find the best result; but Azure ML provides a feature called *Automated Machine Learning* (or *Auto ML*) that can do this for you.
First, let's create a folder for a new experiment.
```
# Create a project folder if it doesn't exist
automl_folder = "automl_experiment"
if not os.path.exists(automl_folder):
os.makedirs(automl_folder)
print(automl_folder, 'folder created')
```
You don't need to create a training script (Auto ML will do that for you), but you do need to load the training data; and when using remote compute, this is best achieved by creating a script containing a **get_data** function.
```
%%writefile $automl_folder/get_data.py
#Write the get_data file.
from azureml.core import Run, Workspace, Dataset
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
def get_data():
# load the diabetes dataset
run = Run.get_context()
dataset_name = 'Diabetes Dataset'
diabetes = Dataset.get_by_name(workspace=run.experiment.workspace, name=dataset_name).to_pandas_dataframe()
# Separate features and labels
X, y = diabetes[['Pregnancies','PlasmaGlucose','DiastolicBloodPressure','TricepsThickness','SerumInsulin','BMI','DiabetesPedigree','Age']].values, diabetes['Diabetic'].values
# Split data into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)
return { "X" : X_train, "y" : y_train, "X_valid" : X_test, "y_valid" : y_test }
```
Now you're ready to confifure the Auto ML experiment. To do this, you'll need a run configuration that includes the required packages for the experiment environment, and a set of configuration settings that tells Auto ML how many options to try, which metric to use when evaluating models, and so on.
> **More Information**: For more information about options when using Auto ML, see the [Azure ML documentation](https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-configure-auto-train).
```
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.train.automl import AutoMLConfig
import time
import logging
automl_run_config = RunConfiguration(framework="python")
automl_run_config.environment.docker.enabled = True
auto_ml_dependencies = CondaDependencies.create(
pip_packages=["azureml-sdk", "pyarrow", "pandas", "scikit-learn", "numpy"])
automl_run_config.environment.python.conda_dependencies = auto_ml_dependencies
automl_settings = {
"name": "Diabetes_AutoML_{0}".format(time.time()),
"iteration_timeout_minutes": 10,
"iterations": 10,
"primary_metric": 'AUC_weighted',
"preprocess": False,
"max_concurrent_iterations": 4,
"verbosity": logging.INFO
}
automl_config = AutoMLConfig(task='classification',
debug_log='automl_errors.log',
path=automl_folder,
compute_target=cpu_cluster,
run_configuration=automl_run_config,
data_script=automl_folder + "/get_data.py",
model_explainability=True,
**automl_settings,
)
```
OK, we're ready to go. Let's start the Auto ML run, which will generate child runs for different algorithms.
> **Note**: This will take some time. Progress will be displayed as each child run completes, and then a widget showing the results will be displayed.
```
from azureml.core.experiment import Experiment
from azureml.widgets import RunDetails
automl_experiment = Experiment(ws, 'diabetes_automl')
automl_run = automl_experiment.submit(automl_config, show_output=True)
RunDetails(automl_run).show()
```
View the output of the experiment in the widget, and click the run that produced the best result to see its details.
Then click the link to view the experiment details in the Azure portal and view the overall experiment details before viewing the details for the individual run that produced the best result. There's lots of information here about the performance of the model generated and how its features were used.
Let's get the best run and the model that was generated (you can ignore any warnings about Azure ML package versions that might appear).
```
best_run, fitted_model = automl_run.get_output()
print(best_run)
print(fitted_model)
best_run_metrics = best_run.get_metrics()
for metric_name in best_run_metrics:
metric = best_run_metrics[metric_name]
print(metric_name, metric)
```
One of the options you used was to include model *explainability*. This uses a test dataset to evaluate the importance of each feature. You can view this data in the notebook widget or the portal, and you can also retrieve it from the run.
```
from azureml.train.automl.automlexplainer import retrieve_model_explanation
shap_values, expected_values, overall_summary, overall_imp, per_class_summary, per_class_imp = retrieve_model_explanation(best_run)
# Overall feature importance (the Feature value is the column index in the training data)
print("Feature\tImportance")
for i in range(len(overall_imp)):
print(overall_imp[i], '\t', overall_summary[i])
```
Finally, having found the best performing model, you can register it.
```
# Register model
best_run.register_model(model_path='outputs/model.pkl', model_name='diabetes_model', tags={'Training context':'Auto ML'}, properties={'AUC': best_run_metrics['AUC_weighted'], 'Accuracy': best_run_metrics['accuracy']})
# List registered models
for model in Model.list(ws):
print(model.name, 'version:', model.version)
for tag_name in model.tags:
tag = model.tags[tag_name]
print ('\t',tag_name, ':', tag)
for prop_name in model.properties:
prop = model.properties[prop_name]
print ('\t',prop_name, ':', prop)
print('\n')
```
Now you've seen several ways to leverage the high-scale compute capabilities of the cloud to experiment with model training and find the best performing model for your data. In the next exerise, you'll deploy a registered model into production.
| github_jupyter |
# Numpy实现浅层神经网络
实践部分将搭建神经网络,包含一个隐藏层,实验将会展现出与Logistic回归的不同之处。
实验将使用两层神经网络实现对“花”型图案的分类,如图所示,图中的点包含红点(y=0)和蓝点(y=1)还有点的坐标信息,实验将通过以下步骤完成对两种点的分类,使用Numpy实现。
- 输入样本;
- 搭建神经网络;
- 初始化参数;
- 训练,包括前向传播与后向传播(即BP算法);
- 得出训练后的参数;
- 根据训练所得参数,绘制两类点边界曲线。
<img src="image/data.png" style="width:400px;height:300px;">
该实验将使用Python原生库实现两层神经网络的搭建,完成分类。
## 1 - 引用库
首先,载入几个需要用到的库,它们分别是:
- numpy:一个python的基本库,用于科学计算
- planar_utils:定义了一些工具函数
- matplotlib.pyplot:用于生成图,在验证模型准确率和展示成本变化趋势时会使用到
- sklearn:用于数据挖掘和数据分析
```
import numpy as np
import sklearn
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(1)
```
## 2 - 载入数据并观察纬度
载入数据后,输出维度
```
#载入数据
train_x, train_y, test_x, test_y = load_planar_dataset()
#输出维度
shape_X = train_x.shape
shape_Y = train_y.shape
print ('The shape of X is: ' + str(shape_X))
print ('The shape of Y is: ' + str(shape_Y))
```
由输出可知每组输入坐标包含两个值,包含一个值,共320组数据(测试集在训练集基础上增加80组数据,共400组)。
## 3 - 简单逻辑回归实验
使用逻辑回归处理该数据,观察分类结果
```
#训练逻辑回归分类器
clf = sklearn.linear_model.LogisticRegressionCV();
clf.fit(train_x.T, train_y.T);
#绘制逻辑回归分类边界
plot_decision_boundary(lambda x: clf.predict(x), train_x, train_y)
plt.title("Logistic Regression")
#输出准确率
LR_predictions = clf.predict(train_x.T)
print ('Accuracy of logistic regression:%d ' % float((np.dot(train_y,LR_predictions) + np.dot(1-train_y,1-LR_predictions))/float(train_y.size)*100) +
'% ' + "(percentage of correctly labelled datapoints)")
```
可以看出逻辑回归效果并不好,这是因为逻辑回归网络结构只包含输入层和输出层,无法拟合更为复杂的模型,下面尝试神经网络模型。
## 4 - 神经网络模型
下面开始搭建神经网络模型,我们采用两层神经网络实验,隐藏层包含4个节点,使用tanh激活函数;输出层包含一个节点,使用Sigmoid激活函数,结果小于0.5即认为是0,否则认为是1。
** 神经网络结构 **
下面用代码实现神经网络结构,首先确定神经网络的结构,即获取相关数据维度,并设置隐藏层节点个数(本实验设置4个隐藏层节点),用以初始化参数
```
#定义各层规模函数
def layer_sizes(X, Y):
"""
参数含义:
X -- 输入的数据
Y -- 输出值
返回值:
n_x -- 输入层节点数
n_h -- 隐藏层节点数
n_y -- 输出层节点数
"""
n_x = X.shape[0] #输入层大小(节点数)
n_h = 4
n_y = Y.shape[0] #输出层大小(节点数)
return (n_x, n_h, n_y)
```
** 初始化模型参数 **
获取相关维度信息后,开始初始化参数,定义相关函数
```
# 定义函数:初始化参数
def initialize_parameters(n_x, n_h, n_y):
"""
参数:
n_x -- 输入层大小
n_h -- 隐藏层大小
n_y -- 输出层大小
返回值:
params -- 一个包含所有参数的python字典:
W1 -- (隐藏层)权重,维度是 (n_h, n_x)
b1 -- (隐藏层)偏移量,维度是 (n_h, 1)
W2 -- (输出层)权重,维度是 (n_y, n_h)
b2 -- (输出层)偏移量,维度是 (n_y, 1)
"""
np.random.seed(2) # 设置随机种子
#随机初始化参数
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
```
** 前向传播与后向传播 **
获取输入数据,参数初始化完成后,可以开始前向传播的计算
```
# 定义函数:前向传播
def forward_propagation(X, parameters):
"""
参数:
X -- 输入值
parameters -- 一个python字典,包含计算所需全部参数(是initialize_parameters函数的输出)
返回值:
A2 -- 模型输出值
cache -- 一个字典,包含 "Z1", "A1", "Z2" and "A2"
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#计算中间量和节点值
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = 1/(1+np.exp(-Z2))
assert(A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
```
前向传播最后可得出模型输出值(即代码中的A2),即可计算成本函数cost
```
# 定义函数:成本函数
def compute_cost(A2, Y, parameters):
"""
根据第三章给出的公式计算成本
参数:
A2 -- 模型输出值
Y -- 真实值
parameters -- 一个python字典包含参数 W1, b1, W2和b2
返回值:
cost -- 成本函数
"""
m = Y.shape[1] #样本个数
#计算成本
logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 - A2), 1 - Y)
cost = -1. / m * np.sum(logprobs)
cost = np.squeeze(cost) # 确保维度的正确性
assert(isinstance(cost, float))
return cost
```
计算了成本函数,可以开始后向传播的计算
```
# 定义函数:后向传播
def backward_propagation(parameters, cache, X, Y):
"""
参数:
parameters -- 一个python字典,包含所有参数
cache -- 一个python字典包含"Z1", "A1", "Z2"和"A2".
X -- 输入值
Y -- 真实值
返回值:
grads -- 一个python字典包含所有参数的梯度
"""
m = X.shape[1]
#首先从"parameters"获取W1,W2
W1 = parameters["W1"]
W2 = parameters["W2"]
# 从"cache"中获取A1,A2
A1 = cache["A1"]
A2 = cache["A2"]
#后向传播: 计算dW1, db1, dW2, db2.
dZ2 = A2 - Y
dW2 = 1. / m * np.dot(dZ2, A1.T)
db2 = 1. / m * np.sum(dZ2, axis = 1, keepdims = True)
dZ1 = np.dot(W2.T, dZ2) * (1 - np.power(A1, 2))
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 1. / m * np.sum(dZ1, axis = 1, keepdims = True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
```
通过后向传播获取梯度后,可以根据梯度下降公式更新参数
```
def update_parameters(parameters, grads, learning_rate = 1.2):
"""
使用梯度更新参数
参数:
parameters -- 包含所有参数的python字典
grads -- 包含所有参数梯度的python字典
返回值:
parameters -- 包含更新后参数的python
"""
#从"parameters"中读取全部参数
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# 从"grads"中读取全部梯度
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
#更新参数
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
```
** 神经网络模型 **
前向传播、成本函数计算和后向传播构成一个完整的神经网络,将上述函数组合,构建一个神经网络模型
```
#定义函数:神经网络模型
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
"""
参数:
X -- 输入值
Y -- 真实值
n_h -- 隐藏层大小/节点数
num_iterations -- 训练次数
print_cost -- 设置为True,则每1000次训练打印一次成本函数值
返回值:
parameters -- 训练结束,更新后的参数值
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
#根据n_x, n_h, n_y初始化参数,并取出W1,b1,W2,b2
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(0, num_iterations):
#前向传播, 输入: "X, parameters". 输出: "A2, cache".
A2, cache = forward_propagation(X, parameters)
#成本计算. 输入: "A2, Y, parameters". 输出: "cost".
cost = compute_cost(A2, Y, parameters)
#后向传播, 输入: "parameters, cache, X, Y". 输出: "grads".
grads = backward_propagation(parameters, cache, X, Y)
#参数更新. 输入: "parameters, grads". 输出: "parameters".
parameters = update_parameters(parameters, grads)
#每1000次训练打印一次成本函数值
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
```
** 预测 **
通过上述模型可以训练得出最后的参数,此时需检测其准确率,用训练后的参数预测训练的输出,大于0.5的值视作1,否则视作0
```
#定义函数:预测
def predict(parameters, X):
"""
使用训练所得参数,对每个训练样本进行预测
参数:
parameters -- 保安所有参数的python字典
X -- 输入值
返回值:
predictions -- 模型预测值向量(红色: 0 / 蓝色: 1)
"""
#使用训练所得参数进行前向传播计算,并将模型输出值转化为预测值(大于0.5视作1,即True)
A2, cache = forward_propagation(X, parameters)
predictions = A2 > 0.5
return predictions
```
下面对获取的数据进行训练,并输出准确率
```
#建立神经网络模型
parameters = nn_model(train_x, train_y, n_h = 4, num_iterations = 10000, print_cost=True)
#绘制分类边界
plot_decision_boundary(lambda x: predict(parameters, x.T), train_x, train_y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, train_x)
# 预测训练集
print('Train Accuracy: %d' % float((np.dot(train_y, predictions.T) +
np.dot(1 - train_y, 1 - predictions.T)) /
float(train_y.size) * 100) + '%')
# 预测测试集
predictions = predict(parameters, test_x)
print('Test Accuracy: %d' % float((np.dot(test_y, predictions.T) +
np.dot(1 - test_y, 1 - predictions.T)) /
float(test_y.size) * 100) + '%')
```
对比逻辑回归47%的准确率和分类结果图,神经网络分类的结果提高了不少,这是因为神经网络增加的隐藏层,为模型训练提供了更多选择,使得神经网络能拟合更加复杂的模型,对于更加复杂的图案分类更加准确。
| github_jupyter |
# What's this TensorFlow business?
You've written a lot of code in this assignment to provide a whole host of neural network functionality. Dropout, Batch Norm, and 2D convolutions are some of the workhorses of deep learning in computer vision. You've also worked hard to make your code efficient and vectorized.
For the last part of this assignment, though, we're going to leave behind your beautiful codebase and instead migrate to one of two popular deep learning frameworks: in this instance, TensorFlow (or PyTorch, if you choose to work with that notebook).
#### What is it?
TensorFlow is a system for executing computational graphs over Tensor objects, with native support for performing backpropogation for its Variables. In it, we work with Tensors which are n-dimensional arrays analogous to the numpy ndarray.
#### Why?
* Our code will now run on GPUs! Much faster training. Writing your own modules to run on GPUs is beyond the scope of this class, unfortunately.
* We want you to be ready to use one of these frameworks for your project so you can experiment more efficiently than if you were writing every feature you want to use by hand.
* We want you to stand on the shoulders of giants! TensorFlow and PyTorch are both excellent frameworks that will make your lives a lot easier, and now that you understand their guts, you are free to use them :)
* We want you to be exposed to the sort of deep learning code you might run into in academia or industry.
## How will I learn TensorFlow?
TensorFlow has many excellent tutorials available, including those from [Google themselves](https://www.tensorflow.org/get_started/get_started).
Otherwise, this notebook will walk you through much of what you need to do to train models in TensorFlow. See the end of the notebook for some links to helpful tutorials if you want to learn more or need further clarification on topics that aren't fully explained here.
**NOTE: This notebook is meant to teach you the latest version of Tensorflow 2.0. Most examples on the web today are still in 1.x, so be careful not to confuse the two when looking up documentation**.
## Install Tensorflow 2.0
Tensorflow 2.0 is still not in a fully 100% stable release, but it's still usable and more intuitive than TF 1.x. Please make sure you have it installed before moving on in this notebook! Here are some steps to get started:
1. Have the latest version of Anaconda installed on your machine.
2. Create a new conda environment starting from Python 3.7. In this setup example, we'll call it `tf_20_env`.
3. Run the command: `source activate tf_20_env`
4. Then pip install TF 2.0 as described here: https://www.tensorflow.org/install/pip
A guide on creating Anaconda enviornments: https://uoa-eresearch.github.io/eresearch-cookbook/recipe/2014/11/20/conda/
This will give you an new enviornemnt to play in TF 2.0. Generally, if you plan to also use TensorFlow in your other projects, you might also want to keep a seperate Conda environment or virtualenv in Python 3.7 that has Tensorflow 1.9, so you can switch back and forth at will.
# Table of Contents
This notebook has 5 parts. We will walk through TensorFlow at **three different levels of abstraction**, which should help you better understand it and prepare you for working on your project.
1. Part I, Preparation: load the CIFAR-10 dataset.
2. Part II, Barebone TensorFlow: **Abstraction Level 1**, we will work directly with low-level TensorFlow graphs.
3. Part III, Keras Model API: **Abstraction Level 2**, we will use `tf.keras.Model` to define arbitrary neural network architecture.
4. Part IV, Keras Sequential + Functional API: **Abstraction Level 3**, we will use `tf.keras.Sequential` to define a linear feed-forward network very conveniently, and then explore the functional libraries for building unique and uncommon models that require more flexibility.
5. Part V, CIFAR-10 open-ended challenge: please implement your own network to get as high accuracy as possible on CIFAR-10. You can experiment with any layer, optimizer, hyperparameters or other advanced features.
We will discuss Keras in more detail later in the notebook.
Here is a table of comparison:
| API | Flexibility | Convenience |
|---------------|-------------|-------------|
| Barebone | High | Low |
| `tf.keras.Model` | High | Medium |
| `tf.keras.Sequential` | Low | High |
# Part I: Preparation
First, we load the CIFAR-10 dataset. This might take a few minutes to download the first time you run it, but after that the files should be cached on disk and loading should be faster.
In previous parts of the assignment we used CS231N-specific code to download and read the CIFAR-10 dataset; however the `tf.keras.datasets` package in TensorFlow provides prebuilt utility functions for loading many common datasets.
For the purposes of this assignment we will still write our own code to preprocess the data and iterate through it in minibatches. The `tf.data` package in TensorFlow provides tools for automating this process, but working with this package adds extra complication and is beyond the scope of this notebook. However using `tf.data` can be much more efficient than the simple approach used in this notebook, so you should consider using it for your project.
```
import os
import tensorflow as tf
import numpy as np
import math
import timeit
import matplotlib.pyplot as plt
%matplotlib inline
def load_cifar10(num_training=49000, num_validation=1000, num_test=10000):
"""
Fetch the CIFAR-10 dataset from the web and perform preprocessing to prepare
it for the two-layer neural net classifier. These are the same steps as
we used for the SVM, but condensed to a single function.
"""
# Load the raw CIFAR-10 dataset and use appropriate data types and shapes
cifar10 = tf.keras.datasets.cifar10.load_data()
(X_train, y_train), (X_test, y_test) = cifar10
X_train = np.asarray(X_train, dtype=np.float32)
y_train = np.asarray(y_train, dtype=np.int32).flatten()
X_test = np.asarray(X_test, dtype=np.float32)
y_test = np.asarray(y_test, dtype=np.int32).flatten()
# Subsample the data
mask = range(num_training, num_training + num_validation)
X_val = X_train[mask]
y_val = y_train[mask]
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask]
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask]
# Normalize the data: subtract the mean pixel and divide by std
mean_pixel = X_train.mean(axis=(0, 1, 2), keepdims=True)
std_pixel = X_train.std(axis=(0, 1, 2), keepdims=True)
X_train = (X_train - mean_pixel) / std_pixel
X_val = (X_val - mean_pixel) / std_pixel
X_test = (X_test - mean_pixel) / std_pixel
return X_train, y_train, X_val, y_val, X_test, y_test
# If there are errors with SSL downloading involving self-signed certificates,
# it may be that your Python version was recently installed on the current machine.
# See: https://github.com/tensorflow/tensorflow/issues/10779
# To fix, run the command: /Applications/Python\ 3.7/Install\ Certificates.command
# ...replacing paths as necessary.
# Invoke the above function to get our data.
NHW = (0, 1, 2)
X_train, y_train, X_val, y_val, X_test, y_test = load_cifar10()
print('Train data shape: ', X_train.shape)
print('Train labels shape: ', y_train.shape, y_train.dtype)
print('Validation data shape: ', X_val.shape)
print('Validation labels shape: ', y_val.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
class Dataset(object):
def __init__(self, X, y, batch_size, shuffle=False):
"""
Construct a Dataset object to iterate over data X and labels y
Inputs:
- X: Numpy array of data, of any shape
- y: Numpy array of labels, of any shape but with y.shape[0] == X.shape[0]
- batch_size: Integer giving number of elements per minibatch
- shuffle: (optional) Boolean, whether to shuffle the data on each epoch
"""
assert X.shape[0] == y.shape[0], 'Got different numbers of data and labels'
self.X, self.y = X, y
self.batch_size, self.shuffle = batch_size, shuffle
def __iter__(self):
N, B = self.X.shape[0], self.batch_size
idxs = np.arange(N)
if self.shuffle:
np.random.shuffle(idxs)
return iter((self.X[i:i+B], self.y[i:i+B]) for i in range(0, N, B))
train_dset = Dataset(X_train, y_train, batch_size=64, shuffle=True)
val_dset = Dataset(X_val, y_val, batch_size=64, shuffle=False)
test_dset = Dataset(X_test, y_test, batch_size=64)
# We can iterate through a dataset like this:
for t, (x, y) in enumerate(train_dset):
print(t, x.shape, y.shape)
if t > 5: break
```
You can optionally **use GPU by setting the flag to True below**. It's not neccessary to use a GPU for this assignment; if you are working on Google Cloud then we recommend that you do not use a GPU, as it will be significantly more expensive.
```
# Set up some global variables
USE_GPU = False
if USE_GPU:
device = '/device:GPU:0'
else:
device = '/cpu:0'
# Constant to control how often we print when training models
print_every = 100
print('Using device: ', device)
```
# Part II: Barebones TensorFlow
TensorFlow ships with various high-level APIs which make it very convenient to define and train neural networks; we will cover some of these constructs in Part III and Part IV of this notebook. In this section we will start by building a model with basic TensorFlow constructs to help you better understand what's going on under the hood of the higher-level APIs.
**"Barebones Tensorflow" is important to understanding the building blocks of TensorFlow, but much of it involves concepts from TensorFlow 1.x.** We will be working with legacy modules such as `tf.Variable`.
Therefore, please read and understand the differences between legacy (1.x) TF and the new (2.0) TF.
### Historical background on TensorFlow 1.x
TensorFlow 1.x is primarily a framework for working with **static computational graphs**. Nodes in the computational graph are Tensors which will hold n-dimensional arrays when the graph is run; edges in the graph represent functions that will operate on Tensors when the graph is run to actually perform useful computation.
Before Tensorflow 2.0, we had to configure the graph into two phases. There are plenty of tutorials online that explain this two-step process. The process generally looks like the following for TF 1.x:
1. **Build a computational graph that describes the computation that you want to perform**. This stage doesn't actually perform any computation; it just builds up a symbolic representation of your computation. This stage will typically define one or more `placeholder` objects that represent inputs to the computational graph.
2. **Run the computational graph many times.** Each time the graph is run (e.g. for one gradient descent step) you will specify which parts of the graph you want to compute, and pass a `feed_dict` dictionary that will give concrete values to any `placeholder`s in the graph.
### The new paradigm in Tensorflow 2.0
Now, with Tensorflow 2.0, we can simply adopt a functional form that is more Pythonic and similar in spirit to PyTorch and direct Numpy operation. Instead of the 2-step paradigm with computation graphs, making it (among other things) easier to debug TF code. You can read more details at https://www.tensorflow.org/guide/eager.
The main difference between the TF 1.x and 2.0 approach is that the 2.0 approach doesn't make use of `tf.Session`, `tf.run`, `placeholder`, `feed_dict`. To get more details of what's different between the two version and how to convert between the two, check out the official migration guide: https://www.tensorflow.org/alpha/guide/migration_guide
Later, in the rest of this notebook we'll focus on this new, simpler approach.
### TensorFlow warmup: Flatten Function
We can see this in action by defining a simple `flatten` function that will reshape image data for use in a fully-connected network.
In TensorFlow, data for convolutional feature maps is typically stored in a Tensor of shape N x H x W x C where:
- N is the number of datapoints (minibatch size)
- H is the height of the feature map
- W is the width of the feature map
- C is the number of channels in the feature map
This is the right way to represent the data when we are doing something like a 2D convolution, that needs spatial understanding of where the intermediate features are relative to each other. When we use fully connected affine layers to process the image, however, we want each datapoint to be represented by a single vector -- it's no longer useful to segregate the different channels, rows, and columns of the data. So, we use a "flatten" operation to collapse the `H x W x C` values per representation into a single long vector.
Notice the `tf.reshape` call has the target shape as `(N, -1)`, meaning it will reshape/keep the first dimension to be N, and then infer as necessary what the second dimension is in the output, so we can collapse the remaining dimensions from the input properly.
**NOTE**: TensorFlow and PyTorch differ on the default Tensor layout; TensorFlow uses N x H x W x C but PyTorch uses N x C x H x W.
```
def flatten(x):
"""
Input:
- TensorFlow Tensor of shape (N, D1, ..., DM)
Output:
- TensorFlow Tensor of shape (N, D1 * ... * DM)
"""
N = tf.shape(x)[0]
return tf.reshape(x, (N, -1))
def test_flatten():
# Construct concrete values of the input data x using numpy
x_np = np.arange(24).reshape((2, 3, 4))
print('x_np:\n', x_np, '\n')
# Compute a concrete output value.
x_flat_np = flatten(x_np)
print('x_flat_np:\n', x_flat_np, '\n')
test_flatten()
```
### Barebones TensorFlow: Define a Two-Layer Network
We will now implement our first neural network with TensorFlow: a fully-connected ReLU network with two hidden layers and no biases on the CIFAR10 dataset. For now we will use only low-level TensorFlow operators to define the network; later we will see how to use the higher-level abstractions provided by `tf.keras` to simplify the process.
We will define the forward pass of the network in the function `two_layer_fc`; this will accept TensorFlow Tensors for the inputs and weights of the network, and return a TensorFlow Tensor for the scores.
After defining the network architecture in the `two_layer_fc` function, we will test the implementation by checking the shape of the output.
**It's important that you read and understand this implementation.**
```
def two_layer_fc(x, params):
"""
A fully-connected neural network; the architecture is:
fully-connected layer -> ReLU -> fully connected layer.
Note that we only need to define the forward pass here; TensorFlow will take
care of computing the gradients for us.
The input to the network will be a minibatch of data, of shape
(N, d1, ..., dM) where d1 * ... * dM = D. The hidden layer will have H units,
and the output layer will produce scores for C classes.
Inputs:
- x: A TensorFlow Tensor of shape (N, d1, ..., dM) giving a minibatch of
input data.
- params: A list [w1, w2] of TensorFlow Tensors giving weights for the
network, where w1 has shape (D, H) and w2 has shape (H, C).
Returns:
- scores: A TensorFlow Tensor of shape (N, C) giving classification scores
for the input data x.
"""
w1, w2 = params # Unpack the parameters
x = flatten(x) # Flatten the input; now x has shape (N, D)
h = tf.nn.relu(tf.matmul(x, w1)) # Hidden layer: h has shape (N, H)
scores = tf.matmul(h, w2) # Compute scores of shape (N, C)
return scores
def two_layer_fc_test():
hidden_layer_size = 42
# Scoping our TF operations under a tf.device context manager
# lets us tell TensorFlow where we want these Tensors to be
# multiplied and/or operated on, e.g. on a CPU or a GPU.
with tf.device(device):
x = tf.zeros((64, 32, 32, 3))
w1 = tf.zeros((32 * 32 * 3, hidden_layer_size))
w2 = tf.zeros((hidden_layer_size, 10))
# Call our two_layer_fc function for the forward pass of the network.
scores = two_layer_fc(x, [w1, w2])
print(scores.shape)
two_layer_fc_test()
```
### Barebones TensorFlow: Three-Layer ConvNet
Here you will complete the implementation of the function `three_layer_convnet` which will perform the forward pass of a three-layer convolutional network. The network should have the following architecture:
1. A convolutional layer (with bias) with `channel_1` filters, each with shape `KW1 x KH1`, and zero-padding of two
2. ReLU nonlinearity
3. A convolutional layer (with bias) with `channel_2` filters, each with shape `KW2 x KH2`, and zero-padding of one
4. ReLU nonlinearity
5. Fully-connected layer with bias, producing scores for `C` classes.
**HINT**: For convolutions: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/nn/conv2d; be careful with padding!
**HINT**: For biases: https://www.tensorflow.org/performance/xla/broadcasting
```
def three_layer_convnet(x, params):
"""
A three-layer convolutional network with the architecture described above.
Inputs:
- x: A TensorFlow Tensor of shape (N, H, W, 3) giving a minibatch of images
- params: A list of TensorFlow Tensors giving the weights and biases for the
network; should contain the following:
- conv_w1: TensorFlow Tensor of shape (KH1, KW1, 3, channel_1) giving
weights for the first convolutional layer.
- conv_b1: TensorFlow Tensor of shape (channel_1,) giving biases for the
first convolutional layer.
- conv_w2: TensorFlow Tensor of shape (KH2, KW2, channel_1, channel_2)
giving weights for the second convolutional layer
- conv_b2: TensorFlow Tensor of shape (channel_2,) giving biases for the
second convolutional layer.
- fc_w: TensorFlow Tensor giving weights for the fully-connected layer.
Can you figure out what the shape should be?
- fc_b: TensorFlow Tensor giving biases for the fully-connected layer.
Can you figure out what the shape should be?
"""
conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b = params
scores = None
############################################################################
# TODO: Implement the forward pass for the three-layer ConvNet. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# I know that padding = "SAME" ends up the same <i> for this examples </i> but the problem explicitely states: "and zero-padding of two"
padding = [[0,0], [2,2], [2,2], [0,0]]
x = tf.pad(x, padding)
x = tf.nn.conv2d(x, conv_w1, strides=(1,1), padding="VALID")
x = tf.nn.relu(x + conv_b1)
padding = [[0,0], [1,1], [1,1], [0,0]]
x = tf.pad(x, padding)
x = tf.nn.conv2d(x, conv_w2, strides=(1,1), padding="VALID")
x = tf.nn.relu(x + conv_b2)
x = flatten(x)
scores = tf.matmul(x, fc_w) + fc_b # Compute scores of shape (N, C)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return scores
```
After defing the forward pass of the three-layer ConvNet above, run the following cell to test your implementation. Like the two-layer network, we run the graph on a batch of zeros just to make sure the function doesn't crash, and produces outputs of the correct shape.
When you run this function, `scores_np` should have shape `(64, 10)`.
```
def three_layer_convnet_test():
with tf.device(device):
x = tf.zeros((64, 32, 32, 3))
conv_w1 = tf.zeros((5, 5, 3, 6))
conv_b1 = tf.zeros((6,))
conv_w2 = tf.zeros((3, 3, 6, 9))
conv_b2 = tf.zeros((9,))
fc_w = tf.zeros((32 * 32 * 9, 10))
fc_b = tf.zeros((10,))
params = [conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b]
scores = three_layer_convnet(x, params)
# Inputs to convolutional layers are 4-dimensional arrays with shape
# [batch_size, height, width, channels]
print('scores_np has shape: ', scores.shape)
three_layer_convnet_test()
```
### Barebones TensorFlow: Training Step
We now define the `training_step` function performs a single training step. This will take three basic steps:
1. Compute the loss
2. Compute the gradient of the loss with respect to all network weights
3. Make a weight update step using (stochastic) gradient descent.
We need to use a few new TensorFlow functions to do all of this:
- For computing the cross-entropy loss we'll use `tf.nn.sparse_softmax_cross_entropy_with_logits`: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/nn/sparse_softmax_cross_entropy_with_logits
- For averaging the loss across a minibatch of data we'll use `tf.reduce_mean`:
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/reduce_mean
- For computing gradients of the loss with respect to the weights we'll use `tf.GradientTape` (useful for Eager execution): https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/GradientTape
- We'll mutate the weight values stored in a TensorFlow Tensor using `tf.assign_sub` ("sub" is for subtraction): https://www.tensorflow.org/api_docs/python/tf/assign_sub
```
def training_step(model_fn, x, y, params, learning_rate):
with tf.GradientTape() as tape:
scores = model_fn(x, params) # Forward pass of the model
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=scores)
total_loss = tf.reduce_mean(loss)
grad_params = tape.gradient(total_loss, params)
# Make a vanilla gradient descent step on all of the model parameters
# Manually update the weights using assign_sub()
for w, grad_w in zip(params, grad_params):
w.assign_sub(learning_rate * grad_w)
return total_loss
def train_part2(model_fn, init_fn, learning_rate):
"""
Train a model on CIFAR-10.
Inputs:
- model_fn: A Python function that performs the forward pass of the model
using TensorFlow; it should have the following signature:
scores = model_fn(x, params) where x is a TensorFlow Tensor giving a
minibatch of image data, params is a list of TensorFlow Tensors holding
the model weights, and scores is a TensorFlow Tensor of shape (N, C)
giving scores for all elements of x.
- init_fn: A Python function that initializes the parameters of the model.
It should have the signature params = init_fn() where params is a list
of TensorFlow Tensors holding the (randomly initialized) weights of the
model.
- learning_rate: Python float giving the learning rate to use for SGD.
"""
params = init_fn() # Initialize the model parameters
for t, (x_np, y_np) in enumerate(train_dset):
# Run the graph on a batch of training data.
loss = training_step(model_fn, x_np, y_np, params, learning_rate)
# Periodically print the loss and check accuracy on the val set.
if t % print_every == 0:
print('Iteration %d, loss = %.4f' % (t, loss))
check_accuracy(val_dset, x_np, model_fn, params)
def check_accuracy(dset, x, model_fn, params):
"""
Check accuracy on a classification model, e.g. for validation.
Inputs:
- dset: A Dataset object against which to check accuracy
- x: A TensorFlow placeholder Tensor where input images should be fed
- model_fn: the Model we will be calling to make predictions on x
- params: parameters for the model_fn to work with
Returns: Nothing, but prints the accuracy of the model
"""
num_correct, num_samples = 0, 0
for x_batch, y_batch in dset:
scores_np = model_fn(x_batch, params).numpy()
y_pred = scores_np.argmax(axis=1)
num_samples += x_batch.shape[0]
num_correct += (y_pred == y_batch).sum()
acc = float(num_correct) / num_samples
print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))
```
### Barebones TensorFlow: Initialization
We'll use the following utility method to initialize the weight matrices for our models using Kaiming's normalization method.
[1] He et al, *Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
*, ICCV 2015, https://arxiv.org/abs/1502.01852
```
def create_matrix_with_kaiming_normal(shape):
if len(shape) == 2:
fan_in, fan_out = shape[0], shape[1]
elif len(shape) == 4:
fan_in, fan_out = np.prod(shape[:3]), shape[3]
return tf.keras.backend.random_normal(shape) * np.sqrt(2.0 / fan_in)
```
### Barebones TensorFlow: Train a Two-Layer Network
We are finally ready to use all of the pieces defined above to train a two-layer fully-connected network on CIFAR-10.
We just need to define a function to initialize the weights of the model, and call `train_part2`.
Defining the weights of the network introduces another important piece of TensorFlow API: `tf.Variable`. A TensorFlow Variable is a Tensor whose value is stored in the graph and persists across runs of the computational graph; however unlike constants defined with `tf.zeros` or `tf.random_normal`, the values of a Variable can be mutated as the graph runs; these mutations will persist across graph runs. Learnable parameters of the network are usually stored in Variables.
You don't need to tune any hyperparameters, but you should achieve validation accuracies above 40% after one epoch of training.
```
def two_layer_fc_init():
"""
Initialize the weights of a two-layer network, for use with the
two_layer_network function defined above.
You can use the `create_matrix_with_kaiming_normal` helper!
Inputs: None
Returns: A list of:
- w1: TensorFlow tf.Variable giving the weights for the first layer
- w2: TensorFlow tf.Variable giving the weights for the second layer
"""
hidden_layer_size = 4000
w1 = tf.Variable(create_matrix_with_kaiming_normal((3 * 32 * 32, 4000)))
w2 = tf.Variable(create_matrix_with_kaiming_normal((4000, 10)))
return [w1, w2]
learning_rate = 1e-2
train_part2(two_layer_fc, two_layer_fc_init, learning_rate)
```
### Barebones TensorFlow: Train a three-layer ConvNet
We will now use TensorFlow to train a three-layer ConvNet on CIFAR-10.
You need to implement the `three_layer_convnet_init` function. Recall that the architecture of the network is:
1. Convolutional layer (with bias) with 32 5x5 filters, with zero-padding 2
2. ReLU
3. Convolutional layer (with bias) with 16 3x3 filters, with zero-padding 1
4. ReLU
5. Fully-connected layer (with bias) to compute scores for 10 classes
You don't need to do any hyperparameter tuning, but you should see validation accuracies above 43% after one epoch of training.
```
def three_layer_convnet_init():
"""
Initialize the weights of a Three-Layer ConvNet, for use with the
three_layer_convnet function defined above.
You can use the `create_matrix_with_kaiming_normal` helper!
Inputs: None
Returns a list containing:
- conv_w1: TensorFlow tf.Variable giving weights for the first conv layer
- conv_b1: TensorFlow tf.Variable giving biases for the first conv layer
- conv_w2: TensorFlow tf.Variable giving weights for the second conv layer
- conv_b2: TensorFlow tf.Variable giving biases for the second conv layer
- fc_w: TensorFlow tf.Variable giving weights for the fully-connected layer
- fc_b: TensorFlow tf.Variable giving biases for the fully-connected layer
"""
params = None
############################################################################
# TODO: Initialize the parameters of the three-layer network. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
conv_w1 = tf.Variable(create_matrix_with_kaiming_normal((5, 5, 3, 32)))
conv_w2 = tf.Variable(create_matrix_with_kaiming_normal((3, 3, 32, 16)))
conv_b1 = tf.Variable(tf.zeros(32))
conv_b2 = tf.Variable(tf.zeros(16))
fc_w = tf.Variable(create_matrix_with_kaiming_normal((16 * 32 * 32, 10)))
fc_b = tf.Variable(tf.zeros(10))
params = (conv_w1, conv_b1, conv_w2, conv_b2, fc_w, fc_b)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return params
learning_rate = 3e-3
train_part2(three_layer_convnet, three_layer_convnet_init, learning_rate)
```
# Part III: Keras Model Subclassing API
Implementing a neural network using the low-level TensorFlow API is a good way to understand how TensorFlow works, but it's a little inconvenient - we had to manually keep track of all Tensors holding learnable parameters. This was fine for a small network, but could quickly become unweildy for a large complex model.
Fortunately TensorFlow 2.0 provides higher-level APIs such as `tf.keras` which make it easy to build models out of modular, object-oriented layers. Further, TensorFlow 2.0 uses eager execution that evaluates operations immediately, without explicitly constructing any computational graphs. This makes it easy to write and debug models, and reduces the boilerplate code.
In this part of the notebook we will define neural network models using the `tf.keras.Model` API. To implement your own model, you need to do the following:
1. Define a new class which subclasses `tf.keras.Model`. Give your class an intuitive name that describes it, like `TwoLayerFC` or `ThreeLayerConvNet`.
2. In the initializer `__init__()` for your new class, define all the layers you need as class attributes. The `tf.keras.layers` package provides many common neural-network layers, like `tf.keras.layers.Dense` for fully-connected layers and `tf.keras.layers.Conv2D` for convolutional layers. Under the hood, these layers will construct `Variable` Tensors for any learnable parameters. **Warning**: Don't forget to call `super(YourModelName, self).__init__()` as the first line in your initializer!
3. Implement the `call()` method for your class; this implements the forward pass of your model, and defines the *connectivity* of your network. Layers defined in `__init__()` implement `__call__()` so they can be used as function objects that transform input Tensors into output Tensors. Don't define any new layers in `call()`; any layers you want to use in the forward pass should be defined in `__init__()`.
After you define your `tf.keras.Model` subclass, you can instantiate it and use it like the model functions from Part II.
### Keras Model Subclassing API: Two-Layer Network
Here is a concrete example of using the `tf.keras.Model` API to define a two-layer network. There are a few new bits of API to be aware of here:
We use an `Initializer` object to set up the initial values of the learnable parameters of the layers; in particular `tf.initializers.VarianceScaling` gives behavior similar to the Kaiming initialization method we used in Part II. You can read more about it here: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/initializers/VarianceScaling
We construct `tf.keras.layers.Dense` objects to represent the two fully-connected layers of the model. In addition to multiplying their input by a weight matrix and adding a bias vector, these layer can also apply a nonlinearity for you. For the first layer we specify a ReLU activation function by passing `activation='relu'` to the constructor; the second layer uses softmax activation function. Finally, we use `tf.keras.layers.Flatten` to flatten the output from the previous fully-connected layer.
```
class TwoLayerFC(tf.keras.Model):
def __init__(self, hidden_size, num_classes):
super(TwoLayerFC, self).__init__()
initializer = tf.initializers.VarianceScaling(scale=2.0)
self.fc1 = tf.keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=initializer)
self.fc2 = tf.keras.layers.Dense(num_classes, activation='softmax',
kernel_initializer=initializer)
self.flatten = tf.keras.layers.Flatten()
def call(self, x, training=False):
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
return x
def test_TwoLayerFC():
""" A small unit test to exercise the TwoLayerFC model above. """
input_size, hidden_size, num_classes = 50, 42, 10
x = tf.zeros((64, input_size))
model = TwoLayerFC(hidden_size, num_classes)
with tf.device(device):
scores = model(x)
print(scores.shape)
test_TwoLayerFC()
```
### Keras Model Subclassing API: Three-Layer ConvNet
Now it's your turn to implement a three-layer ConvNet using the `tf.keras.Model` API. Your model should have the same architecture used in Part II:
1. Convolutional layer with 5 x 5 kernels, with zero-padding of 2
2. ReLU nonlinearity
3. Convolutional layer with 3 x 3 kernels, with zero-padding of 1
4. ReLU nonlinearity
5. Fully-connected layer to give class scores
6. Softmax nonlinearity
You should initialize the weights of your network using the same initialization method as was used in the two-layer network above.
**Hint**: Refer to the documentation for `tf.keras.layers.Conv2D` and `tf.keras.layers.Dense`:
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Conv2D
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dense
```
class ThreeLayerConvNet(tf.keras.Model):
def __init__(self, channel_1, channel_2, num_classes):
super(ThreeLayerConvNet, self).__init__()
########################################################################
# TODO: Implement the __init__ method for a three-layer ConvNet. You #
# should instantiate layer objects to be used in the forward pass. #
########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.conv1 = tf.keras.layers.Conv2D(filters=channel_1, kernel_size=5, strides=(1,1), padding='valid', activation='relu')
self.conv2 = tf.keras.layers.Conv2D(filters=channel_2, kernel_size=3, strides=(1,1), padding='valid', activation='relu')
self.flatten = tf.keras.layers.Flatten()
self.fc = tf.keras.layers.Dense(num_classes, activation='softmax')
# self.softmax = tf.keras.layers.Activation(tf.keras.activations.softmax)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
########################################################################
# END OF YOUR CODE #
########################################################################
def call(self, x, training=False):
scores = None
########################################################################
# TODO: Implement the forward pass for a three-layer ConvNet. You #
# should use the layer objects defined in the __init__ method. #
########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
padding = [[0,0], [2,2], [2,2], [0,0]]
x = tf.pad(x, padding)
x = self.conv1(x)
padding = [[0,0], [1,1], [1,1], [0,0]]
x = tf.pad(x, padding)
x = self.conv2(x)
x = self.flatten(x)
x = self.fc(x)
scores = x
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
########################################################################
# END OF YOUR CODE #
########################################################################
return scores
```
Once you complete the implementation of the `ThreeLayerConvNet` above you can run the following to ensure that your implementation does not crash and produces outputs of the expected shape.
```
def test_ThreeLayerConvNet():
channel_1, channel_2, num_classes = 12, 8, 10
model = ThreeLayerConvNet(channel_1, channel_2, num_classes)
with tf.device(device):
x = tf.zeros((64, 3, 32, 32))
scores = model(x)
print(scores.shape)
test_ThreeLayerConvNet()
```
### Keras Model Subclassing API: Eager Training
While keras models have a builtin training loop (using the `model.fit`), sometimes you need more customization. Here's an example, of a training loop implemented with eager execution.
In particular, notice `tf.GradientTape`. Automatic differentiation is used in the backend for implementing backpropagation in frameworks like TensorFlow. During eager execution, `tf.GradientTape` is used to trace operations for computing gradients later. A particular `tf.GradientTape` can only compute one gradient; subsequent calls to tape will throw a runtime error.
TensorFlow 2.0 ships with easy-to-use built-in metrics under `tf.keras.metrics` module. Each metric is an object, and we can use `update_state()` to add observations and `reset_state()` to clear all observations. We can get the current result of a metric by calling `result()` on the metric object.
```
def train_part34(model_init_fn, optimizer_init_fn, num_epochs=1, is_training=False):
"""
Simple training loop for use with models defined using tf.keras. It trains
a model for one epoch on the CIFAR-10 training set and periodically checks
accuracy on the CIFAR-10 validation set.
Inputs:
- model_init_fn: A function that takes no parameters; when called it
constructs the model we want to train: model = model_init_fn()
- optimizer_init_fn: A function which takes no parameters; when called it
constructs the Optimizer object we will use to optimize the model:
optimizer = optimizer_init_fn()
- num_epochs: The number of epochs to train for
Returns: Nothing, but prints progress during trainingn
"""
with tf.device(device):
# Compute the loss like we did in Part II
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
model = model_init_fn()
optimizer = optimizer_init_fn()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
val_loss = tf.keras.metrics.Mean(name='val_loss')
val_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='val_accuracy')
t = 0
for epoch in range(num_epochs):
# Reset the metrics - https://www.tensorflow.org/alpha/guide/migration_guide#new-style_metrics
train_loss.reset_states()
train_accuracy.reset_states()
for x_np, y_np in train_dset:
with tf.GradientTape() as tape:
# Use the model function to build the forward pass.
scores = model(x_np, training=is_training)
loss = loss_fn(y_np, scores)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# Update the metrics
train_loss.update_state(loss)
train_accuracy.update_state(y_np, scores)
if t % print_every == 0:
val_loss.reset_states()
val_accuracy.reset_states()
for test_x, test_y in val_dset:
# During validation at end of epoch, training set to False
prediction = model(test_x, training=False)
t_loss = loss_fn(test_y, prediction)
val_loss.update_state(t_loss)
val_accuracy.update_state(test_y, prediction)
template = 'Iteration {}, Epoch {}, Loss: {}, Accuracy: {}, Val Loss: {}, Val Accuracy: {}'
print (template.format(t, epoch+1,
train_loss.result(),
train_accuracy.result()*100,
val_loss.result(),
val_accuracy.result()*100))
t += 1
```
### Keras Model Subclassing API: Train a Two-Layer Network
We can now use the tools defined above to train a two-layer network on CIFAR-10. We define the `model_init_fn` and `optimizer_init_fn` that construct the model and optimizer respectively when called. Here we want to train the model using stochastic gradient descent with no momentum, so we construct a `tf.keras.optimizers.SGD` function; you can [read about it here](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/optimizers/SGD).
You don't need to tune any hyperparameters here, but you should achieve validation accuracies above 40% after one epoch of training.
```
hidden_size, num_classes = 4000, 10
learning_rate = 1e-2
def model_init_fn():
return TwoLayerFC(hidden_size, num_classes)
def optimizer_init_fn():
return tf.keras.optimizers.SGD(learning_rate=learning_rate)
train_part34(model_init_fn, optimizer_init_fn)
```
### Keras Model Subclassing API: Train a Three-Layer ConvNet
Here you should use the tools we've defined above to train a three-layer ConvNet on CIFAR-10. Your ConvNet should use 32 filters in the first convolutional layer and 16 filters in the second layer.
To train the model you should use gradient descent with Nesterov momentum 0.9.
**HINT**: https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/optimizers/SGD
You don't need to perform any hyperparameter tuning, but you should achieve validation accuracies above 50% after training for one epoch.
```
learning_rate = 3e-3
channel_1, channel_2, num_classes = 32, 16, 10
def model_init_fn():
model = None
############################################################################
# TODO: Complete the implementation of model_fn. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
model = ThreeLayerConvNet(channel_1, channel_2, num_classes)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return model
def optimizer_init_fn():
optimizer = None
############################################################################
# TODO: Complete the implementation of model_fn. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9, nesterov=True)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return optimizer
train_part34(model_init_fn, optimizer_init_fn)
```
# Part IV: Keras Sequential API
In Part III we introduced the `tf.keras.Model` API, which allows you to define models with any number of learnable layers and with arbitrary connectivity between layers.
However for many models you don't need such flexibility - a lot of models can be expressed as a sequential stack of layers, with the output of each layer fed to the next layer as input. If your model fits this pattern, then there is an even easier way to define your model: using `tf.keras.Sequential`. You don't need to write any custom classes; you simply call the `tf.keras.Sequential` constructor with a list containing a sequence of layer objects.
One complication with `tf.keras.Sequential` is that you must define the shape of the input to the model by passing a value to the `input_shape` of the first layer in your model.
### Keras Sequential API: Two-Layer Network
In this subsection, we will rewrite the two-layer fully-connected network using `tf.keras.Sequential`, and train it using the training loop defined above.
You don't need to perform any hyperparameter tuning here, but you should see validation accuracies above 40% after training for one epoch.
```
learning_rate = 1e-2
def model_init_fn():
input_shape = (32, 32, 3)
hidden_layer_size, num_classes = 4000, 10
initializer = tf.initializers.VarianceScaling(scale=2.0)
layers = [
tf.keras.layers.Flatten(input_shape=input_shape),
tf.keras.layers.Dense(hidden_layer_size, activation='relu',
kernel_initializer=initializer),
tf.keras.layers.Dense(num_classes, activation='softmax',
kernel_initializer=initializer),
]
model = tf.keras.Sequential(layers)
return model
def optimizer_init_fn():
return tf.keras.optimizers.SGD(learning_rate=learning_rate)
train_part34(model_init_fn, optimizer_init_fn)
```
### Abstracting Away the Training Loop
In the previous examples, we used a customised training loop to train models (e.g. `train_part34`). Writing your own training loop is only required if you need more flexibility and control during training your model. Alternately, you can also use built-in APIs like `tf.keras.Model.fit()` and `tf.keras.Model.evaluate` to train and evaluate a model. Also remember to configure your model for training by calling `tf.keras.Model.compile.
You don't need to perform any hyperparameter tuning here, but you should see validation and test accuracies above 42% after training for one epoch.
```
model = model_init_fn()
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate),
loss='sparse_categorical_crossentropy',
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
model.fit(X_train, y_train, batch_size=64, epochs=1, validation_data=(X_val, y_val))
model.evaluate(X_test, y_test)
```
### Keras Sequential API: Three-Layer ConvNet
Here you should use `tf.keras.Sequential` to reimplement the same three-layer ConvNet architecture used in Part II and Part III. As a reminder, your model should have the following architecture:
1. Convolutional layer with 32 5x5 kernels, using zero padding of 2
2. ReLU nonlinearity
3. Convolutional layer with 16 3x3 kernels, using zero padding of 1
4. ReLU nonlinearity
5. Fully-connected layer giving class scores
6. Softmax nonlinearity
You should initialize the weights of the model using a `tf.initializers.VarianceScaling` as above.
You should train the model using Nesterov momentum 0.9.
You don't need to perform any hyperparameter search, but you should achieve accuracy above 45% after training for one epoch.
```
def model_init_fn():
model = None
############################################################################
# TODO: Construct a three-layer ConvNet using tf.keras.Sequential. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=5, padding="same", activation='relu'))
model.add(tf.keras.layers.Conv2D(filters=16, kernel_size=3, padding="same", activation='relu'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=10, activation='softmax'))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return model
learning_rate = 5e-4
def optimizer_init_fn():
optimizer = None
############################################################################
# TODO: Complete the implementation of model_fn. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9, nesterov=True)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return optimizer
train_part34(model_init_fn, optimizer_init_fn)
```
We will also train this model with the built-in training loop APIs provided by TensorFlow.
```
model = model_init_fn()
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=[tf.keras.metrics.sparse_categorical_accuracy])
model.fit(X_train, y_train, batch_size=64, epochs=1, validation_data=(X_val, y_val))
model.evaluate(X_test, y_test)
```
## Part IV: Functional API
### Demonstration with a Two-Layer Network
In the previous section, we saw how we can use `tf.keras.Sequential` to stack layers to quickly build simple models. But this comes at the cost of losing flexibility.
Often we will have to write complex models that have non-sequential data flows: a layer can have **multiple inputs and/or outputs**, such as stacking the output of 2 previous layers together to feed as input to a third! (Some examples are residual connections and dense blocks.)
In such cases, we can use Keras functional API to write models with complex topologies such as:
1. Multi-input models
2. Multi-output models
3. Models with shared layers (the same layer called several times)
4. Models with non-sequential data flows (e.g. residual connections)
Writing a model with Functional API requires us to create a `tf.keras.Model` instance and explicitly write input tensors and output tensors for this model.
```
def two_layer_fc_functional(input_shape, hidden_size, num_classes):
initializer = tf.initializers.VarianceScaling(scale=2.0)
inputs = tf.keras.Input(shape=input_shape)
flattened_inputs = tf.keras.layers.Flatten()(inputs)
fc1_output = tf.keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=initializer)(flattened_inputs)
scores = tf.keras.layers.Dense(num_classes, activation='softmax',
kernel_initializer=initializer)(fc1_output)
# Instantiate the model given inputs and outputs.
model = tf.keras.Model(inputs=inputs, outputs=scores)
return model
def test_two_layer_fc_functional():
""" A small unit test to exercise the TwoLayerFC model above. """
input_size, hidden_size, num_classes = 50, 42, 10
input_shape = (50,)
x = tf.zeros((64, input_size))
model = two_layer_fc_functional(input_shape, hidden_size, num_classes)
with tf.device(device):
scores = model(x)
print(scores.shape)
test_two_layer_fc_functional()
```
### Keras Functional API: Train a Two-Layer Network
You can now train this two-layer network constructed using the functional API.
You don't need to perform any hyperparameter tuning here, but you should see validation accuracies above 40% after training for one epoch.
```
input_shape = (32, 32, 3)
hidden_size, num_classes = 4000, 10
learning_rate = 1e-2
def model_init_fn():
return two_layer_fc_functional(input_shape, hidden_size, num_classes)
def optimizer_init_fn():
return tf.keras.optimizers.SGD(learning_rate=learning_rate)
train_part34(model_init_fn, optimizer_init_fn)
```
# Part V: CIFAR-10 open-ended challenge
In this section you can experiment with whatever ConvNet architecture you'd like on CIFAR-10.
You should experiment with architectures, hyperparameters, loss functions, regularization, or anything else you can think of to train a model that achieves **at least 70%** accuracy on the **validation** set within 10 epochs. You can use the built-in train function, the `train_part34` function from above, or implement your own training loop.
Describe what you did at the end of the notebook.
### Some things you can try:
- **Filter size**: Above we used 5x5 and 3x3; is this optimal?
- **Number of filters**: Above we used 16 and 32 filters. Would more or fewer do better?
- **Pooling**: We didn't use any pooling above. Would this improve the model?
- **Normalization**: Would your model be improved with batch normalization, layer normalization, group normalization, or some other normalization strategy?
- **Network architecture**: The ConvNet above has only three layers of trainable parameters. Would a deeper model do better?
- **Global average pooling**: Instead of flattening after the final convolutional layer, would global average pooling do better? This strategy is used for example in Google's Inception network and in Residual Networks.
- **Regularization**: Would some kind of regularization improve performance? Maybe weight decay or dropout?
### NOTE: Batch Normalization / Dropout
If you are using Batch Normalization and Dropout, remember to pass `is_training=True` if you use the `train_part34()` function. BatchNorm and Dropout layers have different behaviors at training and inference time. `training` is a specific keyword argument reserved for this purpose in any `tf.keras.Model`'s `call()` function. Read more about this here : https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/BatchNormalization#methods
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers/Dropout#methods
### Tips for training
For each network architecture that you try, you should tune the learning rate and other hyperparameters. When doing this there are a couple important things to keep in mind:
- If the parameters are working well, you should see improvement within a few hundred iterations
- Remember the coarse-to-fine approach for hyperparameter tuning: start by testing a large range of hyperparameters for just a few training iterations to find the combinations of parameters that are working at all.
- Once you have found some sets of parameters that seem to work, search more finely around these parameters. You may need to train for more epochs.
- You should use the validation set for hyperparameter search, and save your test set for evaluating your architecture on the best parameters as selected by the validation set.
### Going above and beyond
If you are feeling adventurous there are many other features you can implement to try and improve your performance. You are **not required** to implement any of these, but don't miss the fun if you have time!
- Alternative optimizers: you can try Adam, Adagrad, RMSprop, etc.
- Alternative activation functions such as leaky ReLU, parametric ReLU, ELU, or MaxOut.
- Model ensembles
- Data augmentation
- New Architectures
- [ResNets](https://arxiv.org/abs/1512.03385) where the input from the previous layer is added to the output.
- [DenseNets](https://arxiv.org/abs/1608.06993) where inputs into previous layers are concatenated together.
- [This blog has an in-depth overview](https://chatbotslife.com/resnets-highwaynets-and-densenets-oh-my-9bb15918ee32)
### Have fun and happy training!
```
class CustomConvNet(tf.keras.Model):
def __init__(self):
super(CustomConvNet, self).__init__()
############################################################################
# TODO: Construct a model that performs well on CIFAR-10 #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# https://www.tensorflow.org/tutorials/images/cnn
self.conv1 = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), strides=(1,1), padding='valid', activation='relu')
self.dropout1 = tf.keras.layers.Dropout(0.3)
self.conv2 = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=(1,1), padding='valid', activation='relu')
self.dropout2 = tf.keras.layers.Dropout(0.3)
self.conv3 = tf.keras.layers.Conv2D(filters=64, kernel_size=(3, 3), strides=(1,1), padding='valid', activation='relu')
self.dropout3 = tf.keras.layers.Dropout(0.3)
self.flatten = tf.keras.layers.Flatten()
self.bn1 = tf.keras.layers.BatchNormalization()
self.fc1 = tf.keras.layers.Dense(64, activation='relu')
self.bn2 = tf.keras.layers.BatchNormalization()
self.fc2 = tf.keras.layers.Dense(num_classes, activation='softmax')
self.maxpool = tf.keras.layers.MaxPool2D()
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
def call(self, input_tensor, training=False):
############################################################################
# TODO: Construct a model that performs well on CIFAR-10 #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x = self.conv1(input_tensor)
# if training:
# x = self.dropout1(x, training=training)
x = self.maxpool(x)
x = self.conv2(x)
# if training:
# x = self.dropout2(x, training=training)
x = self.maxpool(x)
x = self.conv3(x)
# if training:
# x = self.dropout3(x, training=training)
# x = self.maxpool(x)
x = self.flatten(x)
# if training:
# x = self.bn1(x, training=training)
x = self.fc1(x)
# if training:
# x = self.bn2(x, training=training)
x = self.fc2(x)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return x
device = '/device:GPU:0' # Change this to a CPU/GPU as you wish!
# device = '/cpu:0' # Change this to a CPU/GPU as you wish!
print_every = 700
num_epochs = 10
model = CustomConvNet()
def model_init_fn():
return CustomConvNet()
def optimizer_init_fn():
learning_rate = 1e-3
return tf.keras.optimizers.Adam(learning_rate)
train_part34(model_init_fn, optimizer_init_fn, num_epochs=num_epochs, is_training=True)
```
## Describe what you did
In the cell below you should write an explanation of what you did, any additional features that you implemented, and/or any graphs that you made in the process of training and evaluating your network.
TODO: Tell us what you did
Tried Dropout, BatchNorm but just regular conv + pool into fully connected layers worked best and produced a model with > 70% val accuracy after 5 epochs.
| github_jupyter |
# Trump Tweets at the Internet Archive
So Trump's Twitter account is gone. At least at twitter.com. But (fortunately for history) there has probably never been a more heavily archived social media account at the Internet Archive and elsewhere on the web. There are also a plethora of online "archives" like [The Trump Archive](https://www.thetrumparchive.com/) which have collected these tweets as data. But seeing the tweets as they appeared in the browser is important. Of course you can go view the account in the Wayback Machine and [browse around](https://web.archive.org/web/20210107055108/https://twitter.com/realDonaldTrump) but what if we wanted a list of all the Trump tweets? How many times were these tweets actually archived?
## CDX API
The Wayback Machine (and many other web archives) have a service called the [CDX API](https://github.com/internetarchive/wayback/tree/master/wayback-cdx-server). Think of it as the index to the archive. You can give it a URL and it'll tell you what snapshots it has for it. You can also ask the CDX API to search for a *url prefix* and it will tell you what snapshots it has that start with that string. Lets use the handy [wayback](https://wayback.readthedocs.io/en/stable/usage.html) Python module to search for tweet URLs in the Wayback machine. So URLs that look like:
https://twitter.com/realDonaldTrump/status/{id}
```
! pip install wayback
```
The search() method handles paging through the API results using a resumption token behind the scenes. Lets look at the first 100 results just to see what they look like.
```
from wayback import WaybackClient
wb = WaybackClient()
count = 0
for result in wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix'):
print(result.url)
count += 1
if count > 100:
break
```
So there are some weird URLs in there, that look like the result of buggy automated archive processes that aren't constructing URLs properly?
* https://twitter.com/realDonaldTrump/status/%22/SyakibPutera/status/636601131339087872%22
* https://twitter.com/realDonaldTrump/status/'+twitter_id+
And then we can see lots of results for the same URL such as https://twitter.com/realDonaldTrump/status/1000061992042975232 repeated over and over. This is because that URL was archived at multiple points in time. So lets improve on this to filter out the URLs that don't look like tweet URLs, and to only emit the unique ones. But still we'll just look at the first 100 results to make sure things are working properly.
```
import re
seen = set()
for result in wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix'):
if re.search(r'/realDonaldTrump/status/\d+', result.url):
if result.url not in seen:
print(result.url)
seen.add(result.url)
if len(seen) > 100:
break
```
This list shows that some tweet URLs can have query strings, which modify the presentation of the tweet in various ways. For example to change the language of the user interface:
* https://twitter.com/realDonaldTrump/status/1000114139136606209?lang=en-gb
Or to highlight certain information:
* https://twitter.com/realDonaldTrump/status/1000114139136606209?conversation_id=1000114139136606209
The query parameters are essential for finding the right view in the Wayback Machine. But the different variants don't really matter if we are simply wanting to count the number of tweets that are archived. Also it looks like some URLs aren't for the tweets themselves, but for components of the tweet, like video:
* https://twitter.com/realDonaldTrump/status/1000114139136606209/video/1
The process can be adjusted to parse the URL to ensure the path is for an actual tweet, not a tweet component. The tweet id can also be extracted from the path in order to track whether it has been seen before.
```
from urllib.parse import urlparse
seen = set()
for result in wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix'):
uri = urlparse(result.url)
m = re.match(r'^/realDonaldTrump/status/(\d+)/?$', uri.path, re.IGNORECASE)
if not m:
continue
tweet_id = m.group(1)
if tweet_id not in seen:
print(result.url)
seen.add(tweet_id)
if len(seen) > 100:
break
```
It looks like this is actually working pretty good. For completeness we can store a mapping of the tweet id to all the results for that tweet id. This will allow us to track how many tweet have been archiving, while letting us examing how many times that tweet was archived, and what their precise URLs are for playback.
This time we can let it keep running to get all the results.
```
from collections import defaultdict
tweets = defaultdict(list)
for result in wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix'):
uri = urlparse(result.url)
m = re.match(r'^/realDonaldTrump/status/(\d{8,})/?$', uri.path, re.IGNORECASE)
if not m:
continue
tweet_id = m.group(1)
tweets[tweet_id].append(result)
```
Now we can see the tweet ids. Instead of printing them all out we can just look at the first 100:
```
list(tweets.keys())[0:100]
```
And we can look at when a given tweet was archived too, irrespective of the various query strings that can be part of it. Here we get all the snapshots for tweet id 1002298565299965953 and print out the times that it was archived, in descending order.
```
for result in sorted(tweets['1002298565299965953'], key=lambda r: r.timestamp, reverse=True):
print(result.timestamp)
len(tweets['1002298565299965953'])
```
So this particular URL was archived 252 times! The snapshots start on May 31, 2018 and most of the snapshots are from a few days of that. But there are also a handful of snapshots in 2019 and 2020. Examining [one of the snapshots] shows that it was sent on May 31st at 2:19 PM. It's hard to tell what time zone the display was generated for. But since the first snapshot was at May 31, 2018 at 21:19:36 UTC it is safe to assume that the display is for -07:00 UTC, or (given the time of year) Pacific Daylight Time.
The [overview](https://web.archive.org/web/20180101000000*/twitter.com/realDonaldTrump/status/1002298565299965953) gives a picture of some of these snapshots. But the nice thing about our index is that it factors in the way that the tweet ID is expressed in the URL. So we know more than what the URL specific overview shows. For example here are all the various URLs that were collected.
```
for result in sorted(tweets['1002298565299965953'], key=lambda r: r.timestamp, reverse=True):
print(result.url)
```
What was the most archived tweet?
```
sorted(tweets, key=lambda r: len(tweets[r]), reverse=True)[0]
len(tweets['1006837823469735936'])
```
So https://twitter.com/realDonaldTrump/status/1006837823469735936 was archived 23,419 times?! It's interesting that the [overview page](https://web.archive.org/web/*/twitter.com/realDonaldTrump/status/1006837823469735936) only says 595 times, because it is looking at that exact URL. Looking at [the content](https://web.archive.org/web/20180613095659/twitter.com/realDonaldTrump/status/1006837823469735936) of the tweet it is understandable why this one was archived so much.
## Missing Data?
So what does the coverage look like? Before Trump's account was suspended [his profile](https://web.archive.org/web/20210107045727/https://twitter.com/realDonaldTrump/) indicated he has sent 59.6K tweets. The [TrumpTweetArchive](https://www.thetrumparchive.com/) also shows 56,571 tweets. How many tweet IDs did we find?
```
len(tweets)
```
That is *a lot* less than what we should have found. So either there is a problem with my code, or the wayback module isn't paging results properly, or the CDX API isn't functioning properly, or not all of Trumps tweets have been archived?
In conversation with [Rob Brackett](https://robbrackett.com/) who is the principal author of the Python [wayback](https://pypi.org/project/wayback) library it seems that using the `limit` parameter can help return more results. So instead of doing:
wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix')
the `limit` parameter should be used:
wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix', limit=500000)
Here's Rob's explanation, which kind of begs more questions:
> Basically what’s happening here is that, without the `limit` parameter, the first page of results hits the maximum size and then, in that situation, does not include a resume key for moving on to the next page. Including a low enough limit (I think anything less than 1.5 million, but not sure) prevents you from hitting that ceiling and lets you successfully page through everything. When I do that, I get 64,329 tweet IDs across 16,253,658 CDX records (but the default Colab instance doesn’t have enough memory to store every record like you’re doing, so I had to just store the first record for each ID).
So lets give this a try. Rob noted that we're likely to consume all working memory storing all these CDX records in RAM. So lets persist them to a sqlite database instead.
```
import pathlib
data = pathlib.Path("data")
db_path = data / "trump-tweets.sqlite3"
import sqlite3
# only generate the sqlite db if it's not already there
if not db_path.is_file():
db = sqlite3.connect(db_path)
db.execute(
'''
CREATE TABLE tweets (
tweet_id TEXT,
url TEXT,
timestamp DATETIME,
mime_type TEXT,
status_code INTEGER,
digest TEXT,
length INTEGER
)
'''
)
count = 0
for result in wb.search('twitter.com/realDonaldTrump/status/', matchType='prefix', limit=500000):
uri = urlparse(result.url)
m = re.match(r'^/realDonaldTrump/status/(\d{8,})/?$', uri.path, re.IGNORECASE)
if not m:
continue
tweet_id = m.group(1)
db.execute('INSERT INTO tweets VALUES (?, ?, ?, ?, ?, ?, ?)', [
tweet_id,
result.url,
result.timestamp,
result.mime_type,
result.status_code,
result.digest,
result.length
])
count += 1
if count % 1000 == 0:
db.commit()
db.close()
```
Unfortunately GitHub won't let you upload the 3GB sqlite file--even with git-lfs enabled.
```
db = sqlite3.connect("data/trump-tweets.sqlite3")
db.execute('SELECT COUNT(DISTINCT(tweet_id)) FROM tweets').fetchall()
```
So 65,314 tweets were found. That's quite a bit more than the 59k suggested by the Twitter display and the 56,571 by the Trump Archive. Let's limit to snapshots that had a 200 OK HTTP response. As we saw above it's possible people tried to archive bogus tweet URLs.
```
db.execute(
'''
SELECT COUNT(DISTINCT(tweet_id))
FROM tweets
WHERE status_code = 200
''').fetchall()
```
That seems a lot more like it. So what were the most archived tweet? Let's get the top 10.
```
cursor = db.execute(
'''
SELECT tweet_id,
COUNT(*) AS total
FROM tweets
WHERE status_code = 200
GROUP by tweet_id
ORDER BY total DESC
LIMIT 10
'''
)
for row in cursor.fetchall():
print(row)
```
So the most archived URL was archived 56,571 times:
https://web.archive.org/web/20200521045242/https://twitter.com/realDonaldTrump/status/704834185471598592
The interface indicates it was archived 1,616 times, but remember we factored in alternate forms of the tweet URL. Lets see what those were.
```
cursor = db.execute(
'''
SELECT url,
COUNT(*) as total
FROM tweets
WHERE tweet_id = "704834185471598592"
AND status_code = 200
GROUP BY url
ORDER BY total DESC
'''
)
for row in cursor.fetchall():
print(row)
```
Now that is kind of fascinating. Why would there be 1,349 captures of each of those language specific URLs for this tweet? This seems like some kind of automation?
## Missing from Trump Archive?
So what tweets were found in the Internet Archive that are not in the Trump Archive. To figure this out we can first load in the Trump Archive tweets. This is relatively easy to do using the Google Drive download from their FAQ page.
```
import pandas
df = pandas.read_csv('https://drive.google.com/uc?export=download&id=1xRKHaP-QwACMydlDnyFPEaFdtskJuBa6'
)
trump_archive = set([str(tweet_id) for tweet_id in df['id']])
len(trump_archive)
```
Now we need the tweet ids from our sqlite db. Tweets will return a 200 OK and retweets will 301 Moved Permanently to the original tweet so we will include both here.
```
cursor = db.execute(
'''
SELECT DISTINCT(tweet_id)
FROM tweets
WHERE status_code in (200, 301)
'''
)
wayback = set([r[0] for r in cursor.fetchall()])
len(wayback)
```
Now we can see what tweet ids are in the Wayback Machine but not in the Trump Archive.
```
len(wayback - trump_archive)
```
Wow. so 3592 tweets are in the Wayback Machine but not in the Trump Archive?! Let's spot check one of them to see if this is the case. Lets generate the Wayback URLs for the first 25 of these ids.
https://web.archive.org/web/{datetime}/{url}
```
ids = list(wayback - trump_archive)[0:25]
cursor = db.execute(
'''
SELECT
"https://web.archive.org/web/"
|| STRFTIME('%Y%m%d%H%M%S', timestamp)
|| "/"
|| url
FROM tweets
WHERE tweet_id IN ({})
'''.format(",".join(["?"] * 25)),
ids
)
for row in cursor.fetchall():
print(row[0])
```
The first 5 of these seem to generate a *Something Went Wrong Page*. Perhaps there were tweets there and the Wayback Machine failed fetch them properly? Or maybe the data is there but failing to play back? It's hard to say with confidence.
https://web.archive.org/web/20201108045542/https://twitter.com/realDonaldTrump/status/1080839175392321541
<img src="images/twitter-something-went-wrong.png">
But then at least some of these appear to work such as:
* https://web.archive.org/web/20201106091445/https://twitter.com/realDonaldTrump/status/667434942826156032
* https://web.archive.org/web/20200307194518/https://twitter.com/realdonaldtrump/status/646009823356690432
The Trump Archive API can tell if they have these two:
https://www.thetrumparchive.com/tweets/{tweet-id}
* https://www.thetrumparchive.com/tweets/667434942826156032
* https://www.thetrumparchive.com/tweets/646009823356690432
So it looks like there are definitely some realDonaldTrump tweets in the Internet Archive's Wayback Machine that are not in the Trump Archive. Some number less than 3,592. It would be necessary to somehow verify these to be sure. Here's a CSV of all the tweet IDs to see if they can be curated.
```
import csv
out = csv.writer(open('data/trump-tweets-missing-from-archive.csv', 'w'))
out.writerow(['tweet_url', 'archive_url'])
for tweet_id in wayback - trump_archive:
sql = """
SELECT
url,
STRFTIME('%Y%m%d%H%M%S', timestamp) AS timestamp
FROM tweets
WHERE tweet_id = ?
ORDER BY timestamp DESC
LIMIT 1
"""
[tweet_url, timestamp] = db.execute(sql, [tweet_id]).fetchone()
out.writerow([
tweet_url,
"https://web.archive.org/web/{}/{}".format(timestamp, tweet_url)
])
print(tweet_url)
```
## Missing from Internet Archive?
How about the other angle: are there any tweet ids in the Trump Archive that didn't come back from the CDX API?
```
len(trump_archive - wayback)
```
It appears yes?
```
trump_archive - wayback
```
Lets examing the first one: 1175115230457802752. Is it in the Trump Archive?
https://www.thetrumparchive.com/tweets/1175115230457802752
Yes. It looks like a retweet of @FLOTUS:
RT @FLOTUS: Welcome to the @WhiteHouse PM Morrison and Mrs. Morrison! 🇺🇸🇦🇺 https://t.co/kYznIkJf9H
But the redirect of the retweet is not in the Internet Archive:
https://web.archive.org/web/*/https://twitter.com/realDonaldTrump/1175115230457802752
This in itself isn't too surprising because people wouldn't typically archive the retweet redirect. Are there any non-retweets in the Trump Archive but not in the Wayback Machine? To test that we need to examine the text of these tweets. Luckily we can look those up pretty easily using The Trump Archive API.
```
import requests
for tweet_id in trump_archive - wayback:
url = "https://www.thetrumparchive.com/tweets/{}".format(tweet_id)
resp = requests.get(url)
if resp.status_code == 200:
tweet = resp.json()
if tweet['isRetweet'] == False:
print("id: {}\ndate: {}\n{}\n".format(
tweet['id'],
tweet['date'],
tweet['text']
))
for tweet_id in trump_archive - wayback:
url = "https://www.thetrumparchive.com/tweets/{}".format(tweet_id)
resp = requests.get(url)
if resp.status_code == 200:
tweet = resp.json()
if not re.match(r'^"?RT', tweet['text']):
print("id: {}\ndate: {}\ndeleted: {}\n{}\n".format(
tweet['id'],
tweet['date'],
tweet['isDeleted'],
tweet['text']
))
```
We can verify by looking in our database for a tweet id like 1281926278845812736:
```
db.execute('SELECT * FROM tweets WHERE tweet_id = ?', ["1281926278845812736"]).fetchall()
```
Sure enough, it looks like Internet Archive wasn't quite quick enough to pick this one up. It's hard to say when the tweet was deleted, but it was archived on 2020-11-15 which was well after when it was sent on 2020-07-11.
But this is truly remarkable that the Wayback Machine only seems to be missing three original tweets (non-retweets), at least with respect with the Trump Archive. But since the Trump Archive appears to be missing at least some content that is present in the Wayback Machine its not exactly clear how accurate this is. In the end this highlights why it is important for Twitter to make an archival snapshot available.
## Archiving Activity
We can use our little SQLite database to plot the archiving activity related to Trump's tweets over time.
```
sql = \
'''
SELECT
STRFTIME('%Y%m%d', timestamp) AS day,
COUNT(*) AS "snapshots"
FROM tweets
GROUP BY day
ORDER BY day ASC
'''
df = pandas.read_sql_query(sql, db, parse_dates=['day'])
df.head()
```
Lets fill in the blanks for days where there was no archiving of Trump's tweets.
```
dates = pandas.date_range(min(df.day), max(df.day))
df = df.set_index('day').reindex(dates).fillna(0)
df.head()
```
Now we can try a plot!
```
df.plot(
kind='line',
title="Archiving Trump's Tweets at the Internet Archive",
figsize=(10, 4),
legend=False,
xlabel='Time',
ylabel='Snapshots per Day'
)
```
Kinda noisy. Maybe it will look better as tweets-per-week?
```
df = df.resample('W').sum().rename_axis('time')
df.plot(
kind='line',
title="Archiving Trump's Tweets at the Internet Archive",
figsize=(10, 4),
legend=False,
xlabel='Time',
ylabel='Snapshots per Week'
)
```
## Trump Archive URLs
To help media organizations update their links to point at snapshots at the Internet Archive I thought it could be useful to create a CSV dataset of the tweet ids and links. It's important to limit to known good tweets (within a particular range) and ones that returned a 200 OK. The latest snapshot will provide a picture of what interaction with that tweet looked like when the tweets were removed.
The situation is a bit tricky because just because there is a 200 OK response for a tweet URL in the Internet Archive doesn't mean its a good one to link to. For example this one seems to be OK but doesn't render: because of playback issues.
https://web.archive.org/web/20201112035441/https://twitter.com/realdonaldtrump/status/1698308935?s=21
What we can do is create a little function to make sure that it renders:
```
import requests_html
http = requests_html.AsyncHTMLSession()
async def response_ok(url, tries=10):
global http
try:
resp = await http.get(url)
await resp.html.arender(timeout=60)
match = resp.html.search("Something went wrong")
if match:
return False
return True
except Exception as e:
if tries == 0:
raise e
else:
http = requests_html.AsyncHTMLSession()
return await response_ok(url, tries - 1)
await response_ok('https://web.archive.org/web/20201112035441/https://twitter.com/realdonaldtrump/status/1698308935?s=21')
await response_ok('https://web.archive.org/web/20201106114341/https://twitter.com/realDonaldTrump/status/1776419923')
sql = \
"""
SELECT DISTINCT(CAST(tweet_id AS NUMERIC)) AS tweet_num
FROM tweets
WHERE tweet_num > 1698308934
AND tweet_num < 1351984482019115009
ORDER BY tweet_num ASC
"""
out = csv.writer(open('data/trump-tweet-archive.csv', 'w'))
out.writerow(['tweet_url', 'archive_url'])
count = 0
for row in db.execute(sql):
tweet_id = row[0]
sql = \
"""
SELECT url, STRFTIME('%Y%m%d%H%M%S', timestamp)
FROM tweets
WHERE tweet_id = ?
AND status_code = 200
ORDER BY timestamp DESC
"""
for [url, timestamp] in db.execute(sql, [tweet_id]):
archive_url = 'https://web.archive.org/web/{}/{}'.format(timestamp, url)
print('checking {}'.format(archive_url))
if await response_ok(archive_url):
tweet_url = 'https://twitter.com/realDonaldTrump/status/{}'.format(tweet_id)
print('ok {} {}'.format(tweet_url, archive_url))
out.writerow([tweet_url, archive_url])
break
```
## Top 10
What were the top 10 most archived tweets?
```
import sqlite3
import pandas
db = sqlite3.connect('data/trump-tweets.sqlite3')
df = pandas.read_csv('data/trump-archive.csv')
def get_text(tweet_id):
v = df[df['id'] == tweet_id].text.values
if len(v) != 0:
return v[0]
else:
return "???"
get_text(1698308935)
sql = '''
SELECT tweet_id,
COUNT(*) AS total
FROM tweets
GROUP BY tweet_id
ORDER By total DESC
LIMIT 10
'''
for [tweet_id, total] in db.execute(sql):
print('* [{}]({}) {}'.format(
get_text(int(tweet_id)),
'https://web.archive.org/web/*/https://twitter.com/realDonaldTrump/status/{}'.format(tweet_id),
total
))
```
## Politwoops
Just as a last exercise its interesting to see which tweets in Politwoops for Trump are in (or not in the Internet Archive). We saw one of them above when we were analyzing The Trump Twitter Archive.
First we need all the politwoops ids. We can use Politwoops API:
```
import requests
politwoops = set()
page = 1
while True:
url = "https://projects.propublica.org/politwoops/user/realDonaldTrump"
data = requests.get(url, params={"format": "json", "page": page}).json()
if not data or len(data["tweets"]) == 0:
break
for tweet in data["tweets"]:
politwoops.add(tweet["id"])
page += 1
len(politwoops)
wayback_missing = politwoops - wayback
len(wayback_missing)
len(wayback_missing) / len(politwoops)
```
So it looks like there are 179 tweets in Politwoops that are missing from Wayback Machine? Lets take a look at the URLs to spot check a few.
```
for tweet_id in wayback_missing:
politwoops_url = "https://projects.propublica.org/politwoops/tweet/{}".format(tweet_id)
wayback_url = "https://web.archive.org/web/*/http://twitter.com/realDonaldTrump/status/{}".format(tweet_id)
print(politwoops_url)
print(wayback_url)
print()
```
Looking at some of these it becomes clear that politwoops are lumping together realDonaldTrump and POTUS. But we didn't collect Wayback data for POTUS. We can collect the Politwoops data again but filter out the POTUS data.
```
politwoops = set()
page = 1
while True:
url = "https://projects.propublica.org/politwoops/user/realDonaldTrump"
data = requests.get(url, params={"format": "json", "page": page}).json()
if not data or len(data["tweets"]) == 0:
break
for tweet in data["tweets"]:
# make sure the user is realdonaldtrump and not potus
if tweet["user_name"].lower() == "realdonaldtrump":
politwoops.add(tweet["id"])
page += 1
len(politwoops)
wayback_missing = politwoops - wayback
len(wayback_missing)
for tweet_id in wayback_missing:
politwoops_url = "https://projects.propublica.org/politwoops/tweet/{}".format(tweet_id)
wayback_url = "https://web.archive.org/web/*/http://twitter.com/realDonaldTrump/status/{}".format(tweet_id)
print(politwoops_url)
print(wayback_url)
print()
out = csv.writer(open('data/trump-politwoops-wayback.csv', 'w'))
out.writerow(['tweet_id', 'politwoops_url', 'wayback_url'])
for tweet_id in wayback_missing:
politwoops_url = "https://projects.propublica.org/politwoops/tweet/{}".format(tweet_id)
wayback_url = "https://web.archive.org/web/*/http://twitter.com/realDonaldTrump/status/{}".format(tweet_id)
out.writerow([tweet_id, politwoops_url, wayback_url])
```
| github_jupyter |
## Profiling sequential code
I profiled the sequential code `count_spacers_with_ED.py` using the `cProfile` Python package. I ran `count_spacers_with_ED.py` with a control file of 100 sequences (*Genome-Pos-3T3-Unsorted_100_seqs.txt*) and an experimental file of 100 sequences (*Genome-Pos-3T3-Bot10_100_seqs.txt*). Each of these input files contained 75 sequencing reads that could be perfectly matched to my database of 80,000 guide sequences, and 25 sequencing reads that needed an edit distance calculation. This breakdown was representative of the proportion of sequencing reads in the full input files that require an edit distance calculation because ~25% of sequencing reads cannot be perfectly matched to one of the 80,000 guide sequences.
The exact command I ran was <br>
`python -m cProfile -o 100_seq_stats.profile count_spacers_with_ED.py -g ../data/Brie_CRISPR_library_with_controls_FOR_ANALYSIS.csv -u ../data/Genome-Pos-3T3-Unsorted_100_seqs.txt -s ../data/Genome-Pos-3T3-Bot10_100_seqs.txt -o cProfile_test_output`
This code was run on my Macbook Pro, which has a 2.2 GHz Intel Core i7 processor with 6 cores.
The profiling information was saved in a file called *100_seq_stats.profile*. I will now use the `pstats` package to see what parts of my code are taking the longest and if they can be parallelized.
```python
print
```
```
import pstats
p = pstats.Stats('100_seq_stats.profile'); #read in profiling stats
p.strip_dirs(); #remove the extraneous path from all the module names
#sort according to time spent within each function, and then print the statistics for the top 20 functions.
p.sort_stats('time').print_stats(20)
```
As you can see from the table above, most of the runtime for our sequential code is spent within the `editDistDP` function. 534 of the 537 seconds, which accounts for 99.4% of our runtime, are spent calculating the edit distance between 50 sequencing reads and 80,000 guides. Generally, the input files contain ~10M sequencing reads, and about 25% of the sequences cannot be matched perfectly to one of the 80,000 guides. Thus for two input files of ~10M sequencing reads (~20M reads total), there are ~4-5M sequencing reads for which the edit distance calculations must be performed. If this code was run sequentially, this would require 10,000 hours of runtime. Therefore, we need to parallelize this portion of the code.
The edit distance calculation is currently nested within the function `count_spacers`, which matches each sequencing read from the input files to one of the 80,000 guides. For 200 sequencing reads provided as input, 1.4 seconds are spent performing the matching, which is only 0.007 seconds per sequencing read (I am using the 1.4 seconds from the *tottime* column because the *cumtime* takes into account the edit distance calculation). This number grows large if we have 20M sequencing reads we need to match because it would take $\dfrac{0.007\text{seconds/read} \cdot 20\text{M reads}}{3600\text{seconds/hour}} = 39\text{hours}$. Thus, the entire matching process of our workflow needs to be parallelized.
We want to parallelize this matching process by using a Spark cluster to have access to as many cores as possible to perform both the matching process and edit distance calculation (if needed). We will partition each input file into many tasks, and each task will run on a single core of the Spark cluster so a single core will perform both the matching process and edit distance for the sequencing reads in a partition. From what we have determined, there is not an easy way to parallelize the actual edit distance calculation between two strings. However, for a given sequencing read, we should be able to parallelize the 80,000 edit distance calculations that need to be performed between the sequencing read and the 80,000 guides by using Python multi-threading or possibly a GPU.
## Overheads
Since we do not know which sequences from our input files we will need to perform edit distance calculations for, load-balancing is the main overhead we anticipate dealing with because we do not want one or two cores slowed down with having to compute too many edit distance calculations. We would like to spread the number of edit distance calculations out evenly between the cores by tuning the number of Spark tasks. It may be good to shuffle the order of the sequencing reads because sometimes many sequences that require edit distance calculations are adjacent to each other in the input file.
If we try to use a GPU to perform the 80,000 edit distance calculations in parallel, memory-transfer (input/output) to the GPU would also be an overhead. For a single sequencing read, multiple transfers would need to be performed because we would not be able to perform the 80,000 calculations in parallel because we are limited by the number of cores on the GPU. Currently, we do not have a good way of mitigating this overhead if we were to use GPUs.
## Scaling
The sequence matching and edit distance portion of our code accounts for 99.4% of the runtime in our small example. With larger problem sizes, this percentage should only increase because the number of operations performed after the sequence matching and edit distance section is constant.
Amdahl's Law states that potential program speedup $S_t$ is defined by the fraction of code $c$ that can be parallelized, according to the formula
$$
S_t = \dfrac{1}{(1-c)+\frac{c}{p}}
$$
where $p$ is the number of processors/cores. In our case, $c=0.994$ and the table below shows the speed-ups for $2$, $4$, $8$, $64$, and $128$ processors/cores:
|processors|speed-up|
|----------|--------|
|2|1.98x|
|4|3.93x|
|8|7.68x|
|64|46.44x|
|128|72.64x|
Thus, our strong-scaling is almost linear when $p$ is small, but we observe that this begins to break down because we only get 73x speed-up if we were to use 128 processors/cores.
Gustafson's Law states larger systems should be used to solve larger problems because there should ideally be a fixed amount of parallel work per processor. The speed-up $S_t$ is calculated by
$$
S_t = 1 - c +c\cdot p
$$
where $p$ is the number of processors/cores. In our case, $c=0.994$ and the table below shows the speed-ups for $2$, $4$, $8$, $64$, and $128$ processors/cores:
|processors|speed-up|
|----------|--------|
|2|1.994x|
|4|3.98x|
|8|7.96x|
|64|63.62x|
|128|127.23x|
Thus, we almost achieve perfect weak-scaling because we can split up larger problem-sizes (which would be larger input files in our case) over more processors to achieve about the same runtime.
| github_jupyter |
## Bayesian Optimization with Scikit-Optimize
In this notebook, we will perform **Bayesian Optimization** with Gaussian Processes in Parallel, utilizing various CPUs, to speed up the search.
This is useful to reduce search times.
https://scikit-optimize.github.io/stable/auto_examples/parallel-optimization.html#example
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from skopt import Optimizer # for the optimization
from joblib import Parallel, delayed # for the parallelization
from skopt.space import Real, Integer, Categorical
from skopt.utils import use_named_args
# load dataset
breast_cancer_X, breast_cancer_y = load_breast_cancer(return_X_y=True)
X = pd.DataFrame(breast_cancer_X)
y = pd.Series(breast_cancer_y).map({0:1, 1:0})
X.head()
# the target:
# percentage of benign (0) and malign tumors (1)
y.value_counts() / len(y)
# split dataset into a train and test set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0)
X_train.shape, X_test.shape
```
## Define the Hyperparameter Space
Scikit-optimize provides an utility function to create the range of values to examine for each hyperparameters. More details in [skopt.Space](https://scikit-optimize.github.io/stable/modules/generated/skopt.Space.html)
```
# determine the hyperparameter space
param_grid = [
Integer(10, 120, name="n_estimators"),
Integer(1, 5, name="max_depth"),
Real(0.0001, 0.1, prior='log-uniform', name='learning_rate'),
Real(0.001, 0.999, prior='log-uniform', name="min_samples_split"),
Categorical(['deviance', 'exponential'], name="loss"),
]
# Scikit-optimize parameter grid is a list
type(param_grid)
```
## Define the model
```
# set up the gradient boosting classifier
gbm = GradientBoostingClassifier(random_state=0)
```
## Define the objective function
This is the hyperparameter response space, the function we want to minimize.
```
# We design a function to maximize the accuracy, of a GBM,
# with cross-validation
# the decorator allows our objective function to receive the parameters as
# keyword arguments. This is a requirement for scikit-optimize.
@use_named_args(param_grid)
def objective(**params):
# model with new parameters
gbm.set_params(**params)
# optimization function (hyperparam response function)
value = np.mean(
cross_val_score(
gbm,
X_train,
y_train,
cv=3,
n_jobs=-4,
scoring='accuracy')
)
# negate because we need to minimize
return -value
```
## Optimization with Gaussian Process
```
# We use the Optimizer
optimizer = Optimizer(
dimensions = param_grid, # the hyperparameter space
base_estimator = "GP", # the surrogate
n_initial_points=10, # the number of points to evaluate f(x) to start of
acq_func='EI', # the acquisition function
random_state=0,
n_jobs=4,
)
# we will use 4 CPUs (n_points)
# if we loop 10 times using 4 end points, we perform 40 searches in total
for i in range(10):
x = optimizer.ask(n_points=4) # x is a list of n_points points
y = Parallel(n_jobs=4)(delayed(objective)(v) for v in x) # evaluate points in parallel
optimizer.tell(x, y)
# the evaluated hyperparamters
optimizer.Xi
# the accuracy
optimizer.yi
# all together in one dataframe, so we can investigate further
dim_names = ['n_estimators', 'max_depth', 'min_samples_split', 'learning_rate', 'loss']
tmp = pd.concat([
pd.DataFrame(optimizer.Xi),
pd.Series(optimizer.yi),
], axis=1)
tmp.columns = dim_names + ['accuracy']
tmp.head()
```
## Evaluate convergence of the search
```
tmp['accuracy'].sort_values(ascending=False).reset_index(drop=True).plot()
```
The trade-off with parallelization, is that we will not optimize the search after each evaluation of f(x), instead after, in this case 4, evaluations of f(x). Thus, we may need to perform more evaluations to find the optima. But, because we do it in parallel, overall, we reduce wall time.
```
tmp.sort_values(by='accuracy', ascending=True)
```
| github_jupyter |
## Control Flow
Generally, a program is executed sequentially and once executed it is not repeated again. There may be a situation when you need to execute a piece of code n number of times, or maybe even execute certain piece of code based on a particular condition.. this is where the control flow statements come in.
In this section, we will be covering:
- Conditional statements -- if, else, and elif
- Loop statements -- for, while
- Loop control statements -- break, continue, pass
### Conditional Statements
Conditionals statements are used to change the flow of execution. You can use the relational operators, logical operators and membership operators for performing condition checks
```
result = 1
if result == 1:
print("Best Match")
elif result <= 3:
print("Close Enough")
else:
print("This is Blasphemy!")
```
The logic is very simple.. *`if`* < `condition_is_met` >, *`then`* do something; *`else`* do something else.
Python adopts the `if`-`else` clause as it is used in many languages.. However the `elif` part is unique to python. `elif` simply is a contraction for `else if`.
### Loop Statements
These statements are used when we want to execute a piece of code multiple times. Python has two types of loops -- `for` loop and `while` loop.
```
for i in [0,1,2]:
print("{}".format(i))
```
In `for` loop, we specify the variable we want to use, the `iterator` we want to loop over, and use the `in` (membership) operator to link them together.
```
i = 2
while i >= 0:
print("{}".format(i))
i -= 1
```
As you can see, they both serve different purposes. For loop is used when you want to run something for fixed amount of times, whereas while loop can theoretically run forever (if you use something like `while True:` .. *dont!* ).
One of the most commonly used `iterator` with for loop is the `range` object which is used to generate the sequence of numbers
```
list(range(10))
```
The `range` requires the *stop* argument. It can also accept *start* (at first position) and *step* (at third position) as arguments but if not passed, it creates a sequence of numbers from `0` till `stop - 1`. Remember, the *stop* is not included in the output
```
# With start and stop
list(range(2, 20))
# With start, stop and step
list(range(2, 20, 2))
```
When you have an iterator of iterators .. for example a list of lists .. then you can use what is known as nested loops to flatten the list.
```
# This is not the best way.. but for the sake of completion of
# topic, this example is included.
arr = [range(3), range(3, 6)]
for lists in arr:
for elem in lists:
print(elem)
```
### Loop Control Statements
Loop control statements change the executing of loop from its normal sequence.
#### Break
It terminates the current loop and resumes the execution at the next statement. The most common use for break is when some external condition is triggered requiring a hasty exit from a loop. The break statement can be used in both while and for loops.
```
for i in range(1, 10):
if i == 5:
print('Condition satisfied')
break
print(i) # What would happen if this is placed before if condition?
```
#### Continue
Continue statement returns the control to the beginning of the loop. The continue statement rejects all the remaining statements in the current iteration of the loop and moves the control back to the top of the loop.
```
for i in range(1, 10):
if i == 5:
print('Condition satisfied')
continue
print("whatever.. I won't get printed anyways.")
print(i)
```
#### Pass
Pass is used when a statement is required syntactically but performs a null operation i.e. nothing happens when the statement is executed.
```
for i in range(1, 10):
if i == 5:
print('Condition satisfied')
pass
print(i)
```
As you can see execution of pass statement had no effect on the flow of the code. It wouldn't have mattered if it was not there.
It is generally used as a temporary placeholder for an unimplemented logic. For example lets say you have written a function (we'll learn about functions a little later) and want to test the remaining part of code without actually running your function.. You can use pass statement in such cases. Python interpreter will read that and skip that part and get on with further execution.
### Loops with else
Python's Loop statements can be accompanies with an else block in cases where a certain block of code needs to be executed after the loop has successfully completed its execution i.e. iff the loop didn't `break` out in the middle of execution
```
best = 11
for i in range(10):
if i >= best:
print("Excellent")
break
else:
continue
else:
print("Couldn't find the best match")
```
Now if we change the `best` to something less than `10`
```
best = 9
for i in range(10):
if i >= best:
print("Excellent")
break
else:
continue
else:
print("Couldn't find the best match")
```
You can implement similar functionality using the `while` loop.
| github_jupyter |
# Smart Queue Monitoring System - Retail Scenario
## Overview
Now that you have your Python script and job submission script, you're ready to request an **IEI Tank-870** edge node and run inference on the different hardware types (CPU, GPU, VPU, FPGA).
After the inference is completed, the output video and stats files need to be retrieved and stored in the workspace, which can then be viewed within the Jupyter Notebook.
## Objectives
* Submit inference jobs to Intel's DevCloud using the `qsub` command.
* Retrieve and review the results.
* After testing, go back to the proposal doc and update your original proposed hardware device.
## Step 0: Set Up
#### IMPORTANT: Set up paths so we can run Dev Cloud utilities
You *must* run this every time you enter a Workspace session.
(Tip: select the cell and use **Shift+Enter** to run the cell.)
```
%env PATH=/opt/conda/bin:/opt/spark-2.4.3-bin-hadoop2.7/bin:/opt/conda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/intel_devcloud_support
import os
import sys
sys.path.insert(0, os.path.abspath('/opt/intel_devcloud_support'))
sys.path.insert(0, os.path.abspath('/opt/intel'))
```
### Step 0.1: (Optional-step): Original Video
If you are curious to see the input video, run the following cell to view the original video stream we'll be using for inference.
```
import videoHtml
videoHtml.videoHTML('Retail', ['original_videos/Retail.mp4'])
```
## Step 1 : Inference on a Video
In the next few cells, You'll submit your job using the `qsub` command and retrieving the results for each job. Each of the cells below should submit a job to different edge compute nodes.
The output of the cell is the `JobID` of your job, which you can use to track progress of a job with `liveQStat`.
You will need to submit a job for each of the following hardware types:
* **CPU**
* **GPU**
* **VPU**
* **FPGA**
**Note** You will have to submit each job one at a time and retrieve their results.
After submission, they will go into a queue and run as soon as the requested compute resources become available.
(Tip: **shift+enter** will run the cell and automatically move you to the next cell.)
If your job successfully runs and completes, once you retrieve your results, it should output a video and a stats text file in the `results/retail/<DEVICE>` directory.
For example, your **CPU** job should output its files in this directory:
> **results/retail/cpu**
**Note**: To get the queue labels for the different hardware devices, you can go to [this link](https://devcloud.intel.com/edge/get_started/devcloud/).
The following arguments should be passed to the job submission script after the `-F` flag:
* Model path - `/data/models/intel/person-detection-retail-0013/<MODEL PRECISION>/`. You will need to adjust this path based on the model precision being using on the hardware.
* Device - `CPU`, `GPU`, `MYRIAD`, `HETERO:FPGA,CPU`
* Manufacturing video path - `/data/resources/retail.mp4`
* Manufacturing queue_param file path - `/data/queue_param/retail.npy`
* Output path - `/output/results/retail/<DEVICE>` This should be adjusted based on the device used in the job.
* Max num of people - This is the max number of people in queue before the system would redirect them to another queue.
## Step 1.1: Submit to an Edge Compute Node with an Intel CPU
In the cell below, write a script to submit a job to an <a
href="https://software.intel.com/en-us/iot/hardware/iei-tank-dev-kit-core">IEI
Tank* 870-Q170</a> edge node with an <a
href="https://ark.intel.com/products/88186/Intel-Core-i5-6500TE-Processor-6M-Cache-up-to-3-30-GHz-">Intel® Core™ i5-6500TE processor</a>. The inference workload should run on the CPU.
```
#Submit job to the queue
cpu_job_id = !qsub queue_job.sh -d . -l nodes=1:tank-870:i5-6500te -F "/data/models/intel/person-detection-retail-0013/FP32/person-detection-retail-0013 CPU /data/resources/retail.mp4 /data/queue_param/retail.npy /output/results/retail/cpu 2"
print(cpu_job_id[0])
```
#### Check Job Status
To check on the job that was submitted, use `liveQStat` to check the status of the job.
Column `S` shows the state of your running jobs.
For example:
- If `JOB ID`is in Q state, it is in the queue waiting for available resources.
- If `JOB ID` is in R state, it is running.
```
import liveQStat
liveQStat.liveQStat()
```
#### Get Results
Run the next cell to retrieve your job's results.
```
import get_results
get_results.getResults(cpu_job_id[0], filename='output.tgz', blocking=True)
```
#### Unpack your output files and view stdout.log
```
!tar zxf output.tgz
!cat stdout.log
```
#### View stderr.log
This can be used for debugging
```
!cat stderr.log
```
#### View Output Video
Run the cell below to view the output video. If inference was successfully run, you should see a video with bounding boxes drawn around each person detected.
```
import videoHtml
videoHtml.videoHTML('Retail CPU', ['results/retail/cpu/output_video.mp4'])
```
## Step 1.2: Submit to an Edge Compute Node with a CPU and IGPU
In the cell below, write a script to submit a job to an <a
href="https://software.intel.com/en-us/iot/hardware/iei-tank-dev-kit-core">IEI
Tank* 870-Q170</a> edge node with an <a href="https://ark.intel.com/products/88186/Intel-Core-i5-6500TE-Processor-6M-Cache-up-to-3-30-GHz-">Intel® Core i5-6500TE</a>. The inference workload should run on the **Intel® HD Graphics 530** integrated GPU.
```
#Submit job to the queue
gpu_job_id = !qsub queue_job.sh -d . -l nodes=1:tank-870:i5-6500te:intel-hd-530 -F "/data/models/intel/person-detection-retail-0013/FP16/person-detection-retail-0013 GPU /data/resources/retail.mp4 /data/queue_param/retail.npy /output/results/retail/gpu 2"
print(gpu_job_id[0])
```
### Check Job Status
To check on the job that was submitted, use `liveQStat` to check the status of the job.
Column `S` shows the state of your running jobs.
For example:
- If `JOB ID`is in Q state, it is in the queue waiting for available resources.
- If `JOB ID` is in R state, it is running.
```
import liveQStat
liveQStat.liveQStat()
```
#### Get Results
Run the next cell to retrieve your job's results.
```
import get_results
get_results.getResults(gpu_job_id[0], filename='output.tgz', blocking=True)
```
#### Unpack your output files and view stdout.log
```
!tar zxf output.tgz
!cat stdout.log
```
#### View stderr.log
This can be used for debugging
```
!cat stderr.log
```
#### View Output Video
Run the cell below to view the output video. If inference was successfully run, you should see a video with bounding boxes drawn around each person detected.
```
import videoHtml
videoHtml.videoHTML('Retail GPU', ['results/retail/gpu/output_video.mp4'])
```
## Step 1.3: Submit to an Edge Compute Node with an Intel® Neural Compute Stick 2
In the cell below, write a script to submit a job to an <a
href="https://software.intel.com/en-us/iot/hardware/iei-tank-dev-kit-core">IEI
Tank 870-Q170</a> edge node with an <a href="https://ark.intel.com/products/88186/Intel-Core-i5-6500TE-Processor-6M-Cache-up-to-3-30-GHz-">Intel Core i5-6500te CPU</a>. The inference workload should run on an <a
href="https://software.intel.com/en-us/neural-compute-stick">Intel Neural Compute Stick 2</a> installed in this node.
```
#Submit job to the queue
vpu_job_id = !qsub queue_job.sh -d . -l nodes=1:tank-870:i5-6500te:intel-ncs2 -F "/data/models/intel/person-detection-retail-0013/FP16/person-detection-retail-0013 MYRIAD /data/resources/retail.mp4 /data/queue_param/retail.npy /output/results/retail/vpu 2"
print(vpu_job_id[0])
```
### Check Job Status
To check on the job that was submitted, use `liveQStat` to check the status of the job.
Column `S` shows the state of your running jobs.
For example:
- If `JOB ID`is in Q state, it is in the queue waiting for available resources.
- If `JOB ID` is in R state, it is running.
```
import liveQStat
liveQStat.liveQStat()
```
#### Get Results
Run the next cell to retrieve your job's results.
```
import get_results
get_results.getResults(vpu_job_id[0], filename='output.tgz', blocking=True)
```
#### Unpack your output files and view stdout.log
```
!tar zxf output.tgz
!cat stdout.log
```
#### View stderr.log
This can be used for debugging
```
!cat stderr.log
```
#### View Output Video
Run the cell below to view the output video. If inference was successfully run, you should see a video with bounding boxes drawn around each person detected.
```
import videoHtml
videoHtml.videoHTML('Retail VPU', ['results/retail/vpu/output_video.mp4'])
```
## Step 1.4: Submit to an Edge Compute Node with IEI Mustang-F100-A10
In the cell below, write a script to submit a job to an <a
href="https://software.intel.com/en-us/iot/hardware/iei-tank-dev-kit-core">IEI
Tank 870-Q170</a> edge node with an <a href="https://ark.intel.com/products/88186/Intel-Core-i5-6500TE-Processor-6M-Cache-up-to-3-30-GHz-">Intel Core™ i5-6500te CPU</a> . The inference workload will run on the <a href="https://www.ieiworld.com/mustang-f100/en/"> IEI Mustang-F100-A10 </a> FPGA card installed in this node.
```
#Submit job to the queue
fpga_job_id = !qsub queue_job.sh -d . -l nodes=1:tank-870:i5-6500te:iei-mustang-f100-a10 -F "/data/models/intel/person-detection-retail-0013/FP16/person-detection-retail-0013 HETERO:FPGA,CPU /data/resources/retail.mp4 /data/queue_param/retail.npy /output/results/retail/fpga 2"
print(fpga_job_id[0])
```
### Check Job Status
To check on the job that was submitted, use `liveQStat` to check the status of the job.
Column `S` shows the state of your running jobs.
For example:
- If `JOB ID`is in Q state, it is in the queue waiting for available resources.
- If `JOB ID` is in R state, it is running.
```
import liveQStat
liveQStat.liveQStat()
```
#### Get Results
Run the next cell to retrieve your job's results.
```
import get_results
get_results.getResults(fpga_job_id[0], filename='output.tgz', blocking=True)
```
#### Unpack your output files and view stdout.log
```
!tar zxf output.tgz
!cat stdout.log
```
#### View stderr.log
This can be used for debugging
```
!cat stderr.log
```
#### View Output Video
Run the cell below to view the output video. If inference was successfully run, you should see a video with bounding boxes drawn around each person detected.
```
import videoHtml
videoHtml.videoHTML('Retail FPGA', ['results/retail/fpga/output_video.mp4'])
```
***Wait!***
Please wait for all the inference jobs and video rendering to complete before proceeding to the next step.
## Step 2: Assess Performance
Run the cells below to compare the performance across all 4 devices. The following timings for the model are being comapred across all 4 devices:
- Model Loading Time
- Average Inference Time
- FPS
```
import matplotlib.pyplot as plt
device_list=['cpu', 'gpu', 'fpga', 'vpu']
inference_time=[]
fps=[]
model_load_time=[]
for device in device_list:
with open('results/retail/'+device+'/stats.txt', 'r') as f:
inference_time.append(float(f.readline().split("\n")[0]))
fps.append(float(f.readline().split("\n")[0]))
model_load_time.append(float(f.readline().split("\n")[0]))
plt.bar(device_list, inference_time)
plt.xlabel("Device Used")
plt.ylabel("Total Inference Time in Seconds")
plt.show()
plt.bar(device_list, fps)
plt.xlabel("Device Used")
plt.ylabel("Frames per Second")
plt.show()
plt.bar(device_list, model_load_time)
plt.xlabel("Device Used")
plt.ylabel("Model Loading Time in Seconds")
plt.show()
```
# Step 3: Update Proposal Document
Now that you've completed your hardware testing, you should go back to the proposal document and validate or update your originally proposed hardware. Once you've updated your proposal, you can move onto the next scenario.
| github_jupyter |
## MatrixTable Tutorial
If you've gotten this far, you're probably thinking:
- "Can't I do all of this in `pandas` or `R`?"
- "What does this have to do with biology?"
The two crucial features that Hail adds are _scalability_ and the _domain-specific primitives_ needed to work easily with biological data. Fear not! You've learned most of the basic concepts of Hail and now are ready for the bit that makes it possible to represent and compute on genetic matrices: the [MatrixTable](https://hail.is/docs/0.2/hail.MatrixTable.html).
In the last example of the [Table Joins Tutorial](https://hail.is/docs/0.2/tutorials/08-joins.html), the ratings table had a compound key: `movie_id` and `user_id`. The ratings were secretly a movie-by-user matrix!
However, since this matrix is very sparse, it is reasonably represented in a so-called "coordinate form" `Table`, where each row of the table is an entry of the sparse matrix. For large and dense matrices (like sequencing data), the per-row overhead of coordinate reresentations is untenable. That's why we built `MatrixTable`, a 2-dimensional generalization of `Table`.
### MatrixTable Anatomy
Recall that `Table` has two kinds of fields:
- global fields
- row fields
`MatrixTable` has four kinds of fields:
- global fields
- row fields
- column fields
- entry fields
Row fields are fields that are stored once per row. These can contain information about the rows, or summary data calculated per row.
Column fields are stored once per column. These can contain information about the columns, or summary data calculated per column.
Entry fields are the piece that makes this structure a matrix -- there is an entry for each (row, column) pair.
### Importing and Reading
Like tables, matrix tables can be [imported](https://hail.is/docs/0.2/methods/impex.html) from a variety of formats: VCF, (B)GEN, PLINK, TSV, etc. Matrix tables can also be *read* from a "native" matrix table format. Let's read a sample of prepared [1KG](https://en.wikipedia.org/wiki/1000_Genomes_Project) data.
```
import hail as hl
from bokeh.io import output_notebook, show
output_notebook()
hl.utils.get_1kg('data/')
mt = hl.read_matrix_table('data/1kg.mt')
mt.describe()
```
There are a few things to note:
- There is a single column field `s`. This is the sample ID from the VCF. It is also the column key.
- There is a compound row key: `locus` and `alleles`.
- `locus` has type `locus<GRCh37>`
- `alleles` has type `array<str>`
- GT has type `call`. That's a genotype call!
Whereas table expressions could be indexed by nothing or indexed by rows, matrix table expression have four options: nothing, indexed by row, indexed by column, or indexed by row and column (the entries). Let's see some examples.
```
mt.s.describe()
mt.GT.describe()
```
### MatrixTable operations
We belabored the operations on tables because they all have natural analogs (sometimes several) on matrix tables. For example:
- `count` => `count_{rows, cols}` (and `count` which returns both)
- `filter` => `filter_{rows, cols, entries}`
- `annotate` => `annotate_{rows, cols, entries}` (and globals for both)
- `select` => `select_{rows, cols, entries}` (and globals for both)
- `transmute` => `transmute_{rows, cols, entries}` (and globals for both)
- `group_by` => `group_{rows, cols}_by`
- `explode` => `expode_{rows, cols}`
- `aggregate` => `aggregate_{rows, cols, entries}`
Some operations are unique to `MatrixTable`:
- The row fields can be accessed as a `Table` with [rows](https://hail.is/docs/0.2/hail.MatrixTable.html#hail.MatrixTable.rows)
- The column fields can be accessed as a `Table` with [cols](https://hail.is/docs/0.2/hail.MatrixTable.html#hail.MatrixTable.cols).
- The entire field space of a `MatrixTable` can be accessed as a coordinate-form `Table` with [entries](https://hail.is/docs/0.2/hail.MatrixTable.html#hail.MatrixTable.entries). Be careful with this! While it's fast to aggregate or query, trying to write this `Table` to disk could produce files _thousands of times larger_ than the corresponding `MatrixTable`.
Let's explore `mt` using these tools. Let's get the size of the dataset.
```
mt.count() # (rows, cols)
```
Let's look at the first few row keys (variants) and column keys (sample IDs).
```
mt.rows().select().show()
mt.s.show()
```
Let's investigate the genotypes and the call rate. Let's look at the first few genotypes:
```
mt.GT.show()
```
All homozygous reference, which is not surprising. Let's look at the distribution of genotype calls:
```
mt.aggregate_entries(hl.agg.counter(mt.GT.n_alt_alleles()))
```
Let's compute the overall call rate directly, and then plot the distribution of call rate per variant.
```
mt.aggregate_entries(hl.agg.fraction(hl.is_defined(mt.GT)))
```
Here's a nice trick: you can use an aggregator inside `annotate_rows` and it will aggregate over columns, that is, summarize the values in the row using the aggregator. Let's compute and plot call rate per variant.
```
mt2 = mt.annotate_rows(call_rate = hl.agg.fraction(hl.is_defined(mt.GT)))
mt2.describe()
p = hl.plot.histogram(mt2.call_rate, range=(0,1.0), bins=100,
title='Variant Call Rate Histogram', legend='Call Rate')
show(p)
```
### Exercise: GQ vs DP
In this exercise, you'll use Hail to investigate a strange property of sequencing datasets.
The `DP` field is the sequencing depth (the number of reads).
Let's first plot a histogram of `DP`:
```
p = hl.plot.histogram(mt.DP, range=(0,40), bins=40, title='DP Histogram', legend='DP')
show(p)
```
Now, let's do the same thing for GQ.
The `GQ` field is the phred-scaled "genotype quality". The formula to convert to a linear-scale confidence (0 to 1) is `10 ** -(mt.GQ / 10)`. GQ is truncated to lie between 0 and 99.
```
p = hl.plot.histogram(mt.GQ, range=(0,100), bins=100, title='GQ Histogram', legend='GQ')
show(p)
```
Whoa! That's a strange distribution! There's a big spike at 100. The rest of the values have roughly the same shape as the DP distribution, but form a [Dimetrodon](https://en.wikipedia.org/wiki/Dimetrodon). Use Hail to figure out what's going on!
| github_jupyter |
```
# 1. Loading Libraries
# Importing NumPy and Panda
import pandas as pd
import numpy as np
# ---------Import libraries & modules for data visualizaiton
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
# Importing scit-learn module to split the dataset into train/test sub-datasets
from sklearn.model_selection import train_test_split
# Importing scit-learn module for the algorith/model: Linear Regression
from sklearn.linear_model import LogisticRegression
# Importing sci-Learn module for K-fole cross-validation - algorithm/modle evaluation & validation
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# Importing scit-learn module fro classification report
from sklearn.metrics import classification_report
# 2. Specifing data file location
filename = 'C:/Data Sets/Iris.csv'
# Loading the data into a Pandas DataFrame
df = pd.read_csv(filename)
# 4 Preprocess Dataset
# 4.1 Cleaning Data: Find & Mark Missing Values
# Zero values cannot be use in these columns
# Marking and updating zero values as missing or NaN
df[['SepalLengthCm', 'SepalWidthCm', 'SepalWidthCm', 'PetalWidthCm']] \
= df[['SepalLengthCm', 'SepalWidthCm', 'SepalWidthCm', 'PetalWidthCm']].replace(0, np.NaN)
# count the number of NaN values in each column
print(df.isnull().sum())
# 5. Performing Exploratory Data Analysis on Dataset
# Get the dimensions or Shape of the dataset
# i.e. number of records/rows x number of variables/columns
print(df.shape)
# Getting the data types of all the variables/attributes of the data set
# The resutls shows
print(df.dtypes)
# Getting several records/rows at he top fo the dataset
# Get the first five records
print(df.head(5))
# Get the summary statistics of the numerica variables/attributes fo the dataset
print(df.describe())
# class distribution
# i.e. how many records for each class
# This dataset is a good candidate for the classification issues
print(df.groupby('Species').size())
# Plot historgram for each numerica variable/attribute of the dataset
# VIP NOTES: The first variable ID is also plotted. However, the plot should be ignored
df.hist(figsize=(12, 8))
pyplot.show()
# Density plots
# IMPORTANT NOTES: 5 numerica variables -->> at least 5 plots -->> layout (2, 3): 2 rows, each row with 3 plots
df.plot(kind='density', subplots=True, layout=(3,3), sharex=False, legend=True, fontsize=1, figsize=(12, 16))
pyplot.show()
df.plot(kind='box', subplots=True, layout=(3, 3), sharex=False, sharey=False, figsize=(12, 8))
pyplot.show()
# scatter plot matirx
scatter_matrix(df, alpha=0.8, figsize=(15,15))
pyplot.show()
# Store datafram values into a numpy array
array = df.values
# separate array into input and output components by slicign
# For X (input)[:, 1:5] --> all the rows, columns from 1 -4 (5 - 1)
X = array[:,1:5]
# For Y (input)[:, 5] --> all the rows, column 5
Y = array[:,5]
# Splittling the dataset --> training sub-dataset: 67%; test sub-dataset: 33%
test_size = 0.33
# Selection of records to include in which sub-dataset mush be done randomely
# Use this seed for randomizzation
seed = 7
# Split the dataset (both input & output) into training/testing datasets
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# Building the model
model = LogisticRegression()
# Train the model using the training sub-dataset
model.fit(X_train, Y_train)
# Print the classification report
# Ref: Section 10.2.5 Book: Machine Learning Mastery with Python
predicted = model.predict(X_test)
report = classification_report(Y_test, predicted)
print(report)
# Finding the Accuracy Leve
# score the accuracy level
result = model.score(X_test, Y_test)
# Print out the results
print(("Accuracy: %.3f%%") % (result*100))
# 10. Classify/Predict
model.predict([[5.3, 3.0, 4.5, 1.5]])
```
| github_jupyter |
# COCO Reader
Reader operator that reads a COCO dataset (or subset of COCO), which consists of an annotation file and the images directory.
`DALI_EXTRA_PATH` environment variable should point to the place where data from [DALI extra repository](https://github.com/NVIDIA/DALI_extra) is downloaded. Please make sure that the proper release tag is checked out.
```
from nvidia.dali.pipeline import Pipeline
import nvidia.dali.ops as ops
import nvidia.dali.types as types
import numpy as np
from time import time
import os.path
test_data_root = os.environ['DALI_EXTRA_PATH']
file_root = os.path.join(test_data_root, 'db', 'coco', 'images')
annotations_file = os.path.join(test_data_root, 'db', 'coco', 'instances.json')
num_gpus = 1
batch_size = 16
class COCOPipeline(Pipeline):
def __init__(self, batch_size, num_threads, device_id):
super(COCOPipeline, self).__init__(batch_size, num_threads, device_id, seed = 15)
self.input = ops.COCOReader(file_root = file_root, annotations_file = annotations_file,
shard_id = device_id, num_shards = num_gpus, ratio=True)
self.decode = ops.ImageDecoder(device = "mixed", output_type = types.RGB)
def define_graph(self):
inputs, bboxes, labels = self.input()
images = self.decode(inputs)
return (images, bboxes, labels)
start = time()
pipes = [COCOPipeline(batch_size=batch_size, num_threads=2, device_id = device_id) for device_id in range(num_gpus)]
for pipe in pipes:
pipe.build()
total_time = time() - start
print("Computation graph built and dataset loaded in %f seconds." % total_time)
pipe_out = [pipe.run() for pipe in pipes]
images_cpu = pipe_out[0][0].as_cpu()
bboxes_cpu = pipe_out[0][1]
labels_cpu = pipe_out[0][2]
```
Bounding boxes returned by the operator are lists of floats containing composed of **\[x, y, width, height]** (`ltrb` is set to `False` by default).
```
bboxes = bboxes_cpu.at(4)
bboxes
```
Let's see the ground truth bounding boxes drawn on the image.
```
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import random
img_index = 4
img = images_cpu.at(img_index)
H = img.shape[0]
W = img.shape[1]
fig,ax = plt.subplots(1)
ax.imshow(img)
bboxes = bboxes_cpu.at(img_index)
labels = labels_cpu.at(img_index)
categories_set = set()
for label in labels:
categories_set.add(label[0])
category_id_to_color = dict([ (cat_id , [random.uniform(0, 1) ,random.uniform(0, 1), random.uniform(0, 1)]) for cat_id in categories_set])
for bbox, label in zip(bboxes, labels):
rect = patches.Rectangle((bbox[0]*W,bbox[1]*H),bbox[2]*W,bbox[3]*H,linewidth=1,edgecolor=category_id_to_color[label[0]],facecolor='none')
ax.add_patch(rect)
plt.show()
```
| github_jupyter |
```
import numpy as np
np.random.seed(123)
import os
from keras.models import Model
from keras.layers import Input, Convolution2D, MaxPooling2D, BatchNormalization
from keras.layers import Flatten, Dense, Dropout, ZeroPadding2D, Reshape, UpSampling2D
from keras.layers.local import LocallyConnected1D
from keras.layers.noise import GaussianDropout
from keras.optimizers import SGD
from keras.regularizers import l2
from keras import backend as K
from keras.utils.layer_utils import print_summary
import tensorflow as tf
import cv2
import h5py
import matplotlib.pyplot as plt
%matplotlib inline
#os.environ["CUDA_VISIBLE_DEVICES"] = "" # uncomment this line to run the code on the CPU
filter_id = 470 # candle class
N = 3200 # feature vector size
def max_loss(y_true, y_pred):
return (1.-K.sum(tf.mul(y_true,y_pred),axis=-1))
def max_metric(y_true, y_pred):
return (1.-max_loss(y_true,y_pred))
def get_model():
# generator
inputs = Input(shape=(N,), name='input')
g0 = Reshape((N,1))(inputs)
g0 = GaussianDropout(0.05)(g0)
g1 = LocallyConnected1D(nb_filter=1, filter_length=1,
init='one', activation='relu', bias=False,
border_mode='valid',W_regularizer=l2(0.1))(g0)
g2 = Reshape((128,5,5))(g1)
g3 = UpSampling2D(size=(2, 2))(g2) # 10x10
g3 = Convolution2D(512,2,2,activation='relu',border_mode='valid')(g3) # 9x9
g3 = BatchNormalization(mode = 0 , axis = 1)(g3)
g3 = Convolution2D(512,2,2,activation='relu',border_mode='same')(g3) # 9x9
g3 = BatchNormalization(mode = 0 , axis = 1)(g3)
g4 = UpSampling2D(size=(2, 2))(g3) # 18x18
g4 = Convolution2D(256,3,3,activation='relu',border_mode='valid')(g4) # 16x16
g4 = BatchNormalization(mode = 0 , axis = 1)(g4)
g4 = Convolution2D(256,3,3,activation='relu',border_mode='same')(g4) # 16x16
g4 = BatchNormalization(mode = 0 , axis = 1)(g4)
g5 = UpSampling2D(size=(2, 2))(g4) # 32x32
g5 = Convolution2D(256,3,3,activation='relu',border_mode='valid')(g5)# 30x30
g5 = BatchNormalization(mode = 0 , axis = 1)(g5)
g5 = Convolution2D(256,3,3,activation='relu',border_mode='same')(g5) # 30x30
g5 = BatchNormalization(mode = 0 , axis = 1)(g5)
g6 = UpSampling2D(size=(2, 2))(g5) # 60x60
g6 = Convolution2D(128,3,3,activation='relu',border_mode='valid')(g6) # 58x58
g6 = BatchNormalization(mode = 0 , axis = 1)(g6)
g6 = Convolution2D(128,3,3,activation='relu',border_mode='same')(g6) # 58x58
g6 = BatchNormalization(mode = 0 , axis = 1)(g6)
g7 = UpSampling2D(size=(2, 2))(g6) # 116x116
g7 = Convolution2D(128,4,4,activation='relu',border_mode='valid')(g7) # 113x113
g7 = BatchNormalization(mode = 0 , axis = 1)(g7)
g7 = Convolution2D(128,4,4,activation='relu',border_mode='same')(g7) # 113x113
g7 = BatchNormalization(mode = 0 , axis = 1)(g7)
g8 = UpSampling2D(size=(2, 2))(g7) # 226x226
g8 = Convolution2D(64,3,3,activation='relu',border_mode='valid')(g8) # 224x224
g8 = BatchNormalization(mode = 0 , axis = 1)(g8)
g8 = Convolution2D(64,3,3,activation='relu',border_mode='same')(g8) # 224x224
g8 = BatchNormalization(mode = 0 , axis = 1)(g8)
g8 = Convolution2D(3,3,3,activation='linear',border_mode='same')(g8) # 224x224
g8 = BatchNormalization(mode = 0, axis = 1, name='image')(g8)
temp = Model(input=inputs, output=g8)
offset = len(temp.layers)
# discriminator
vgg1 = ZeroPadding2D((1,1),input_shape=(3,224,224))(g8)
vgg2 = Convolution2D(64, 3, 3, activation='relu')(vgg1)
vgg3 = ZeroPadding2D((1,1))(vgg2)
vgg4 = Convolution2D(64, 3, 3, activation='relu')(vgg3)
vgg5 = MaxPooling2D((2,2), strides=(2,2))(vgg4)
vgg6 = ZeroPadding2D((1,1))(vgg5)
vgg7 = Convolution2D(128, 3, 3, activation='relu')(vgg6)
vgg8 = ZeroPadding2D((1,1))(vgg7)
vgg9 = Convolution2D(128, 3, 3, activation='relu')(vgg8)
vgg10 = MaxPooling2D((2,2), strides=(2,2))(vgg9)
vgg11 = ZeroPadding2D((1,1))(vgg10)
vgg12 = Convolution2D(256, 3, 3, activation='relu')(vgg11)
vgg13 = ZeroPadding2D((1,1))(vgg12)
vgg14 = Convolution2D(256, 3, 3, activation='relu')(vgg13)
vgg15 = ZeroPadding2D((1,1))(vgg14)
vgg16 = Convolution2D(256, 3, 3, activation='relu')(vgg15)
vgg17 = MaxPooling2D((2,2), strides=(2,2))(vgg16)
vgg18 = ZeroPadding2D((1,1))(vgg17)
vgg19 = Convolution2D(512, 3, 3, activation='relu')(vgg18)
vgg20 = ZeroPadding2D((1,1))(vgg19)
vgg21 = Convolution2D(512, 3, 3, activation='relu')(vgg20)
vgg22 = ZeroPadding2D((1,1))(vgg21)
vgg23 = Convolution2D(512, 3, 3, activation='relu')(vgg22)
vgg24 = MaxPooling2D((2,2), strides=(2,2))(vgg23)
vgg25 = ZeroPadding2D((1,1))(vgg24)
vgg26 = Convolution2D(512, 3, 3, activation='relu')(vgg25)
vgg27 = ZeroPadding2D((1,1))(vgg26)
vgg28 = Convolution2D(512, 3, 3, activation='relu')(vgg27)
vgg29 = ZeroPadding2D((1,1))(vgg28)
vgg30 = Convolution2D(512, 3, 3, activation='relu')(vgg29)
vgg31 = MaxPooling2D((2,2), strides=(2,2))(vgg30)
vgg32 = Flatten()(vgg31)
vgg33 = Dense(4096, activation='relu')(vgg32)
vgg34 = Dropout(0.5)(vgg33)
vgg35 = Dense(4096, activation='relu')(vgg34)
vgg36 = Dropout(0.5)(vgg35)
vgg37 = Dense(1000, activation='relu', name='vgg_class')(vgg36)
# create model
model = Model(input=inputs, output=[vgg37,g8])
# set generator weights
enc_size = 30
f = h5py.File('decoder_weights.h5')
for k, l in enumerate(f.attrs['layer_names']):
if(k<enc_size):
continue
g = f[l]
weight_names = [n.decode('utf8') for n in g.attrs['weight_names']]
weights = [g[weight_name] for weight_name in weight_names]
model.layers[k-enc_size+4].set_weights(weights)
model.layers[k-enc_size+4].trainable = False
f.close()
# set discriminator weights (vgg)
f = h5py.File('vgg16_weights.h5')
for k in range(f.attrs['nb_layers']):
g = f['layer_{}'.format(k)]
weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])]
model.layers[k+offset].set_weights(weights)
model.layers[k+offset].trainable = False
f.close()
# set the locally connected layer weights to trainable
model.layers[3].trainable = True
# compile model
sgd = SGD(lr=0.01, decay=0.0, momentum=0.1, nesterov=True)
model.compile(optimizer=sgd, loss=[max_loss, 'mse'], metrics=['mse'], loss_weights=[1.,0.])
return model
# create neural network
model = get_model()
print_summary(model.layers)
def reconstruct_image(im):
im2 = np.squeeze(im)*1
im2 = im2.transpose((1,2,0))
im2[:,:,0] += 103.939
im2[:,:,1] += 116.779
im2[:,:,2] += 123.68
im2 = im2.astype(np.uint8)
return cv2.cvtColor(im2,cv2.COLOR_BGR2RGB)
def print_img(model,z=None):
if(z is None):
z = np.random.uniform(0,1,size=(1,N))
out = model.predict(z, batch_size=z.shape[0])
activ = out[0][0]
img = out[1][0]
# change to RGB colors and rescale image
img -= np.min(img)
img /= np.max(img)
img *= 256.
img = cv2.cvtColor(img.astype('uint8').transpose(1,2,0), cv2.COLOR_BGR2RGB)
plt.figure(figsize=(6,6))
plt.imshow(np.flipud(img))
plt.title('filter activation: '+str(activ[filter_id]))
plt.axis('off')
plt.show()
return img
_ = print_img(model)
# training the model
batch_size = 1
n_samples = 40
dummy_labels2 = np.zeros(shape=(n_samples,3,224,224))
vgg_nclasses = 1000
z = np.ones(shape=(n_samples,N))
IMG = np.zeros((30,224,224,3))
for k in np.arange(0,30):
dummy_labels1 = np.ones(shape=(n_samples,vgg_nclasses))*(-10./vgg_nclasses) # put a penalty to the other classes
dummy_labels1[:,filter_id] = 1. # give a positive unit weight for the target class
out = model.fit(z, [dummy_labels1,dummy_labels2], batch_size=batch_size, nb_epoch=1, verbose=1)
IMG[k,:,:,:] = print_img(model, z[0:1])
# plotting the median of the last 10 iterations gives a smoother final image
plt.figure()
plt.imshow(np.flipud(np.median(IMG[20:,:,:,:],axis=0).astype('uint8')))
plt.axis('off')
plt.show()
```
| github_jupyter |

<a href="https://hub.callysto.ca/jupyter/hub/user-redirect/git-pull?repo=https%3A%2F%2Fgithub.com%2Fcallysto%2Fcurriculum-notebooks&branch=master&subPath=Mathematics/PatternsAndRelations/patterns-and-relations.ipynb&depth=1" target="_parent"><img src="https://raw.githubusercontent.com/callysto/curriculum-notebooks/master/open-in-callysto-button.svg?sanitize=true" width="123" height="24" alt="Open in Callysto"/></a>
```
from IPython.display import HTML
HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
The raw code for this IPython notebook is by default hidden for easier reading.
To toggle on/off the raw code, click <a href="javascript:code_toggle()">here</a>.''')
# Modules
import string
import numpy as np
import pandas as pd
import qgrid as q
import matplotlib.pyplot as plt
# Widgets & Display modules, etc..
from ipywidgets import widgets as w
from ipywidgets import Button, Layout, widgets
from IPython.display import display, Javascript, Markdown
# grid features for interactive grids
grid_features = { 'fullWidthRows': True,
'syncColumnCellResize': True,
'forceFitColumns': True,
'rowHeight': 40,
'enableColumnReorder': True,
'enableTextSelectionOnCells': True,
'editable': True,
'filterable': False,
'sortable': False,
'highlightSelectedRow': True}
from ipywidgets import Button , Layout , interact,widgets
from IPython.display import Javascript, display
# Function: executes previous cell on button widget click event and hides achievement indicators message
def run_current(ev):
display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+0,IPython.notebook.get_selected_index()+1)'))
# Counter for toggling achievement indicator on/off
button_ctr = 0
# Achievement Indicators
line_1 = "#### Achievement Indicators"
line_2 = "**General Outcome: **"
line_3 = "* Create a table of values from a linear relation, graph the table of values, and analyze the graph to draw conclusions and solve problems"
# Use to print lines, then save in lines_list
def print_lines(n):
lines_str = ""
for i in range(1,n+1):
lines_str = lines_str + "line_"+str(i)+","
lines_str = lines_str[:-1]
print(lines_str)
lines_list = [line_1,line_2,line_3]
# Show/Hide buttons
ai_button_show = widgets.Button(button_style='info',description="Show Achievement Indicators", layout=Layout(width='25%', height='30px') )
ai_button_hide = widgets.Button(button_style='info',description="Hide Achievement Indicators", layout=Layout(width='25%', height='30px') )
display(Markdown("For instructors:"))
button_ctr += 1
if(button_ctr % 2 == 0):
for line in lines_list:
display(Markdown(line))
display(ai_button_hide)
ai_button_hide.on_click( run_current )
else:
display(ai_button_show)
ai_button_show.on_click( run_current )
# Import libraires
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import operator
import qgrid as q
from ipywidgets import widgets
from ipywidgets import Button, Layout,interact_manual,interact
from IPython.display import display, Javascript, Markdown
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from ipywidgets import widgets as w
from ipywidgets import Button, Layout
from IPython.display import display, Javascript, Markdown
```
<h1 align='center'>Patterns & Relations</h1>
<h4 align = 'center'> $\mid$ Grade 7 $\mid$ Math $\mid$</h4>
<h2 align='center'>Introduction</h2>
In this notebook we will learn what an ordered pair is and how we can use a table of values to represent them. We will work with simple linear equations (relations) and tabulate values for them.
We will also learn what a plane and coordinate plane are and explore the relationship between an equation and a coordinate plane is.
We will then have an opportunity to practice the concepts we learned via a set of exercises that will help us build and plot a few points for a given linear relation.
This notebook is one in a series of notebooks that explore the use patterns to describe the world and to solve problems. Please refer to notebook CC-63 for specific outcome 1.
We begin with a few definitions.
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> An **ordered pair** $(n_1,n_2)$ is a pair of numbers where *order* matters.
</font>
</div>
For example, the pair $(1,2)$ is different from the pair $(2,1)$.
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> An **equation** (also referred to as a **relation**) is an expression asserting that two quantities are equal.
</font>
</div>
For example,
$y = x + 2$
$y = 3x$
$y = 2$
are all equations.
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> An **linear equation** (or **linear relation**) is an equation of the form $$y = ax + b$$, where $a,b$ are fixed values.
</font>
</div>
For example,
| a | b|Linear Relation |
|---|--|-----------|
|1|2|$$y = x + 2$$|
| 3 |1|$$y = 3x + 1$$|
|5|0|$$y = 5x$$ |
|0|0|$$y = 0$$|
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> A **table of values** is a set of ordered pairs usually resulting from substituting numbers into an equation. </font>
</div>
For example, if we consider the equation
$$y = x + 1$$
and the values $x = 1,2,3$, the table of values corresponds to
| Value for x | Value for y|Ordered Pair (x,y)|
|---|--|-----|
|1|2|(1,2)|
|2|3|(2,3)|
|3|4|(3,4)|
Let us illustrate this with an example you can interact with.
<h2 align='center'>Interactive Example: Generating a table of values from a linear relation</h2>
Let us take the relation
$$y = x + 3$$
and suppose that $x$ is an integer. We can then obtain different values for $y$, depending on the value of $x$.
Then, if we consider the following values for x:
| | | | |
|---------|--|--|--|
| x = ||0|1|2|3|4|5|
We can substitute each in the equation to obtain a new value of y.
**Activity**
Let us try all entries to illustrate. Using the widget below change the value of $x$. What is the value for $y$ as $x$ changes?
```
%matplotlib inline
style = {'description_width': 'initial'}
@interact(x_value=widgets.IntSlider(value=0,
min=0,
max=5,
step=1,
description='Value for x',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d',
style =style
))
def plug_and_play(x_value):
fig = plt.figure(figsize=(16,5))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
ax1.text(0.4,0.5,"x = " + str(x_value),fontsize=30)
ax2.text(0.34,0.7,"y = x + 3",fontsize=30)
ax2.text(0.34,0.5,"y =" + str(x_value) + " + 3",fontsize=30)
ax2.text(0.34,0.3,"y =" + str(x_value + 3),fontsize=30)
ax3.text(0.4,0.5,"(" + str(x_value) + "," + str(x_value + 3) + ")",fontsize=30)
ax1.set_title("Value for x",fontsize=30)
ax2.set_title("Value for y",fontsize=30)
ax3.set_title("Ordered Pair",fontsize=30)
ax1.set_xticklabels([]),ax1.set_yticklabels([])
ax2.set_xticklabels([]),ax2.set_yticklabels([])
ax3.set_xticklabels([]),ax3.set_yticklabels([])
ax1.axis("Off"),ax2.axis("Off"),ax3.axis("Off")
plt.show()
```
**Question**
Knowing that the linear relation is $y = x + 3$, what is the value for y, when $x = 2$? Use the widget above to help you find the answer.
```
s = {'description_width': 'initial'}
from ipywidgets import interact_manual
def question_q(answer):
if answer=="Select option":
print("Click on the correct value for y.")
elif answer=="5":
ret="Correct!"
return ret
elif answer != "5" or answer != "Select Option":
ret = "Not quite.Recall y = x + 3. We know x = 2. What does 2 + 3 equal to?"
return ret
answer_q = interact(question_q,answer=widgets.Select(
options=["Select option","2",\
"10","3",\
"5"],
value='Select option',
description="y value",
disabled=False,
style=s
))
```
**Question**
Using the correct answer above, what is the corresponding ordered pair? Recall that an ordered pair is of the form $(x,y)$.
```
s = {'description_width': 'initial'}
from ipywidgets import interact_manual
def question_q(answer):
if answer=="Select option":
print("Click on the correct ordered pair (x,y).")
elif answer=="(2,5)":
ret="Correct!"
return ret
elif answer != "(2,5)" or answer != "Select Option":
ret = "Not quite.Recall x = 2, y = 5. The correct ordered pair is of the form (x,y)."
return ret
answer_q = interact(question_q,answer=widgets.Select(
options=["Select option","(2,5)",\
"(2,1)","(5,2)",\
"(5,3)"],
value='Select option',
description="Ordered pair (x,y)",
disabled=False,
style=s
))
```
Memorizing all different values for $x$ and $y$ is unnecessary.
We can organize the $x,y$ values along with the corresponding pairs $(x,y)$ in a table as follows.
```
### Create dataframe
#df_num_rows = int(dropdown_widget.value)
grid_features = { 'fullWidthRows': False,
'syncColumnCellResize': True,
'forceFitColumns': True,
'rowHeight': 40,
'enableColumnReorder': True,
'enableTextSelectionOnCells': True,
'editable': False,
'filterable': False,
'sortable': False,
'highlightSelectedRow': True}
# Set up data input for dataframe
x_values = np.array([0,1,2,3,4])
y_values = x_values + 3
ordered = [(x_values[i],y_values[i]) for i in range(len(x_values))]
y_equals = ["y = " + str(x_values[i]) + "+3" for i in range(len(x_values))]
df_num_rows = len(x_values)
empty_list = [ '' for i in range(df_num_rows) ]
category_list = [ i+1 for i in range(df_num_rows) ]
df_dict = {'Entry Number':category_list,\
'Values for x': empty_list, 'y = x + 3':empty_list,'Values for y': empty_list,\
'Ordered pairs': empty_list}
feature_list = ['Entry Number','Values for x','y = x + 3','Values for y','Ordered pairs']
student_df = pd.DataFrame(data = df_dict,columns=feature_list)
student_df.set_index('Entry Number',inplace=True)
student_df["Values for y"] = y_values
student_df["Values for x"] = x_values
student_df["y = x + 3"] = y_equals
student_df["Ordered pairs"] = ordered
# Set up & display as Qgrid
q_student_df = q.show_grid( student_df , grid_options = grid_features )
display(q_student_df)
```
Once we compute a few ordered pairs, we can represent them visually. We define the following two concepts.
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> A **plane** is a flat surface that extends infinitely in all directions.
</font>
</div>
```
point = np.array([1, 1, 1])
normal = np.array([0, 0, 1])
# a plane is a*x+b*y+c*z+d=0
# [a,b,c] is the normal. Thus, we have to calculate
# d and we're set
d = -point.dot(normal)
# create x,y
xx, yy = np.meshgrid(range(10), range(10))
# calculate corresponding z
z = (-normal[0] * xx - normal[1] * yy - d) * 1. /normal[2]
# plot the surface
plt3d = plt.figure(figsize=(15,10)).gca(projection='3d')
plt3d.plot_surface(xx, yy, z,color="#518900",edgecolor="white")
plt3d.grid(False)
plt3d.axis("Off")
plt.show()
```
<div class="alert alert-warning">
<font color="black"><b>Definition.</b> A **coordinate plane** is a plane formed by a horizontal number line (the x-axis) and a vertical number line (the y-axis) that intersect at a point called the origin.
</font>
</div>
We can plot points on the coordinate plane. We use ordered pairs to encode information on where points are located.
Recall that an ordered pair is of the form $(x,y)$. The first entry on the pair denotes how far from the origin along the x-axis the point is, the second entry denotes how far from the origin along the y-axis the point is.
Let's see a simple example for the ordered pair $(1,4)$.
```
fig = plt.figure(figsize=(16,5))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
ax2.set_xticks(np.arange(-5,6)),ax2.set_yticks(np.arange(-5,6))
ax2.set_xlim(0,5)
ax2.set_ylim(0,5)
ax1.axis("Off"),ax2.axis("On"),ax3.axis("Off")
ax2.axhline(y=0, color='blue')
ax2.axvline(x=0, color='blue')
ax2.text(5.1,0.1,"x-axis",fontsize=20)
ax2.text(0.1,5.1,"y-axis",fontsize=20)
ax2.grid(True)
x_value,y_value = 1,4
x_or,y_or = 0,0
ax2.scatter(x_value,y_value,color="black",s=120)
ax2.scatter(x_or,y_or,color="black",s=220)
ax2.text(x_value + 0.1,y_value + 0.5,"(" +str(x_value) + "," + str(y_value) + ")")
ax2.text(x_or + 0.1,y_or + 0.3,"origin")
ax2.plot([-5,x_value], [y_value,y_value], color='green', marker='o', linestyle='dashed',
linewidth=2, markersize=2)
ax2.plot([x_value,x_value], [-5,y_value], color='green', marker='o', linestyle='dashed',
linewidth=2, markersize=2)
plt.show()
```
Notice why the order matters. Indeed, if we consider the pair $(4,1)$ we see that it is different.
```
fig = plt.figure(figsize=(16,5))
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
ax2.set_xticks(np.arange(-5,6)),ax2.set_yticks(np.arange(-5,6))
ax2.set_xlim(0,5)
ax2.set_ylim(0,5)
ax1.axis("Off"),ax2.axis("On"),ax3.axis("Off")
ax2.axhline(y=0, color='blue')
ax2.axvline(x=0, color='blue')
ax2.text(5.1,0.1,"x-axis",fontsize=20)
ax2.text(0.1,5.1,"y-axis",fontsize=20)
ax2.grid(True)
x_value,y_value = 4,1
x_or,y_or = 0,0
ax2.scatter(x_value,y_value,color="black",s=120)
ax2.scatter(x_or,y_or,color="black",s=220)
ax2.text(x_value + 0.1,y_value + 0.5,"(" +str(x_value) + "," + str(y_value) + ")")
ax2.text(x_or + 0.1,y_or + 0.3,"origin")
ax2.plot([-5,x_value], [y_value,y_value], color='green', marker='o', linestyle='dashed',
linewidth=2, markersize=2)
ax2.plot([x_value,x_value], [-5,y_value], color='green', marker='o', linestyle='dashed',
linewidth=2, markersize=2)
plt.show()
```
Let us take the table we computed previously for the relation
$$y = x +3$$
along with the ordered pairs we computed.
We can then represent the ordered pairs in the coordinate plane.
**Activity**
Use the widget below to see the relationship between the different ordered pairs and the points on the coordinate plane.
```
%matplotlib inline
@interact(x_value=widgets.IntSlider(value=0,
min=0,
max=5,
step=1,
description='Value for x',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d',
style =style
))
def show_points(x_value):
x_values = np.array([0,1,2,3,4,5])
y_values = x_values + 3
fig = plt.figure()
plt.subplots_adjust(left=14, bottom=0.2, right=16, top=1.5,
wspace=0.1, hspace=0.2)
ax1 = fig.add_subplot(1, 2, 1)
ax1.text(0.1,0.8,"x = " + str(x_value),fontsize=20)
ax1.text(0.1,0.6,"y = " + str(x_value) +"+ 3 = " + str(x_value + 3),fontsize=20)
ax1.text(0.1,0.4,"Ordered pair (" + str(x_value) +"," + str(x_value + 3) + ")",fontsize=20)
ax1.set_title("Values for x and y", fontsize=25)
ax2 = fig.add_subplot(1, 2, 2)
ax2.set_xticks(np.arange(-6,11)),ax2.set_yticks(np.arange(-6,11))
ax2.set_xlim(0,6)
ax2.set_ylim(0,9)
ax1.axis("Off"),ax2.axis("On")
ax2.axhline(y=0, color='blue')
ax2.axvline(x=0, color='blue')
ax2.text(6.5,0.2,"x-axis",fontsize=20)
ax2.text(0.5,9.5,"y-axis",fontsize=20)
ax2.grid(True)
# for i in range(len(x_values)):
# ax2.text(x_values[i] - 0.5,y_values[i]-0.7,"(" + str(x_values[i]) + "," + str(y_values[i]) + ")")
points = ax2.scatter(x_values,y_values,color="black",s=60)
ax2.scatter(x_value,x_value + 3,color="red",s=120)
#datacursor(points)
plt.show()
```
### <h4>Conclusion</h4>
From this graph we conclude that the relation between $x$ and $y$ is linear. This makes sense given the equation is of the form
$$y = ax + b$$
where $a,b$ are integers and in this particular case, $a = 1, b =3$.
Points which are of interest are the intersection between $y$ and the x-axis as well as $x$ and the $y$ axis. The former happens exactly when $y = 0$ while the latter occurs when $x=0$.
We observe that $y$ does not intersect the x axis for positive values of $x$. We also observe that $x$ intersects the y-axis when $x=0$. Such intersection can be observed in the ordered pair $(0,3)$.
```
# Create button and dropdown widget
def rerun_cell( b ):
display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1,IPython.notebook.get_selected_index()+2)'))
style = {'description_width': 'initial'}
number_of_cat = 13
dropdown_options = [ str(i+1) for i in range(number_of_cat) ]
dropdown_widget = widgets.Dropdown( options = dropdown_options , value = '3' , description = 'Number of entries' , disabled=False,style=style )
categories_button = widgets.Button(button_style='info',description="Enter", layout=Layout(width='15%', height='30px'))
# Display widgets
#display(dropdown_widget)
#display(categories_button)
#categories_button.on_click( rerun_cell )
```
<h2 align='center'>Practice Area</h2>
<h4>Exercise</h4>
We will repeat a similar exercise as above, only this time, we will use a different linear relation.
$$y = 2x +4$$
Let us begin by building a simple table.
Answer the questions below to complete a similar table.
### Question 1
Knowing that $y = 2x + 4$, what is the value of $y$ when $x = 3$? In other words, what does $2(3) + 4$ equal to?
```
s = {'description_width': 'initial'}
from ipywidgets import interact_manual
def question_q(answer):
if answer=="Select option":
print("Click on the correct value of y.")
elif answer=="10":
ret="Correct!"
return ret
elif answer != "10" or answer != "Select Option":
ret = "You are close to the answer but need to improve your result.Recall 2(3) = 6. What does 6 + 4 equal to?"
return ret
answer_q = interact(question_q,answer=widgets.Select(
options=["Select option","1",\
"10","3",\
"0"],
value='Select option',
description="y value",
disabled=False,
style=s
))
```
### Question 2
Knowing that $y = 2x + 4$, what is the value of $y$ when $x=0$?
```
s = {'description_width': 'initial'}
from ipywidgets import interact_manual
def question_p(answer):
if answer=="Select option":
print("Click on the correct value of y.")
elif answer=="4":
ret="Correct!"
return ret
elif answer != "4" or answer != "Select Option":
ret = "You are close to the answer but need to improve your result.Recall y = x + 4. What does 0 + 4 equal to?"
return ret
answer_p = interact(question_p,answer=widgets.Select(
options=["Select option","-1",\
"10","4",\
"0"],
value='Select option',
description="y value",
disabled=False,
style=s
))
```
### Question 3
What is the ordered pair obtained when $x = 2$?
```
s = {'description_width': 'initial'}
from ipywidgets import interact_manual
def question_s(answer):
if answer=="Select option":
print("Click on the correct ordered pair (x,y)")
elif answer=="(2,8)":
ret="Correct!"
return ret
elif answer != "(2,8)" or answer != "Select Option":
ret = "You are close to the answer but need to improve your result.We know y = 8 and x = 2. We also know an ordered pair is of the form (x,y)."
return ret
answer_s = interact(question_s,answer=widgets.Select(
options=["Select option","(2,6)",\
"(2,8)","(8,2)",\
"(2,-2)"],
value='Select option',
description="Ordered pair (x,y)",
disabled=False,
style=s
))
def math_function(relation,x_val):
y_val = relation["+"](relation["Coef1"]*x_val,relation["Coef2"])
return y_val
def table_of_values_quad(range_val,relation):
empty_list = [ '' for i in range(range_val + 1) ]
category_list = [ i+1 for i in range(range_val + 1) ]
# Set up data input for dataframe
df_dict = {'Entry Number':category_list,\
'Values for x': empty_list, \
'y ='+ str(relation['Coef1']) + "x + " \
+ str(relation['Coef2']):empty_list,\
'Values for y': empty_list,\
'Ordered pairs': empty_list}
feature_list = ['Entry Number','Values for x',\
'y ='+ str(relation['Coef1']) \
+ "x + " + str(relation['Coef2']),\
'Values for y','Ordered pairs']
student_df = pd.DataFrame(data = df_dict,columns=feature_list)
student_df.set_index('Entry Number',inplace=True)
x_values = np.array(np.arange(range_val+1))
y_values = math_function(relation,x_values)
ordered = [(x_values[i],y_values[i]) for i in range(range_val+1)]
y_equals = ["y = " + str(relation['Coef1']) +"(" + str(x_values[i]) + ")" \
+ "+" + str(relation['Coef2'])
for i in range(len(x_values))]
student_df["Values for y"] = y_values
student_df["Values for x"] = x_values
student_df['y ='+ str(relation['Coef1']) + \
"x + " + str(relation['Coef2'])] = y_equals
student_df["Ordered pairs"] = ordered
q_student_df = q.show_grid( student_df , grid_options = grid_features )
display(q_student_df)
def generate_tab(value):
if value==True:
if "Correct!" in str(answer_p.widget.children)\
and "Correct!" in str(answer_q.widget.children)\
and "Correct!" in str(answer_s.widget.children):
relation_ar = {"Coef1":2,"Coef2":4,"+": operator.add}
table_of_values_quad(4,relation_ar)
else:
print("At least one of your answers is not correct. Compare your answers with the table.")
relation_ar = {"Coef1":2,"Coef2":4,"+": operator.add}
table_of_values_quad(4,relation_ar)
interact(generate_tab,value = widgets.ToggleButton(
value=False,
description='Generate Table',
disabled=False,
button_style='info', # 'success', 'info', 'warning', 'danger' or ''
tooltip='Description',
icon='check'
));
```
### Question 4
Using the information on the table and the widget below, identify and select what ordered pairs belong to the relation
$$y = 2x + 4$$
Select one of the four following options. The correct answer will plot all points, the incorrect answer will print a message.
```
def plot_answer(relation):
x_values = np.array([0,1,2,3,4])
y_values = relation["Coef1"]*x_values + relation["Coef2"]
fig = plt.figure()
plt.subplots_adjust(left=14, bottom=0.2, right=16, top=1.5,
wspace=0.1, hspace=0.2)
ax2 = fig.add_subplot(1, 1, 1)
ax2.set_xticks(np.arange(-6,11))
ax2.set_yticks(np.arange(-6,relation["Coef1"]*x_values[-1] + relation["Coef2"]+2))
ax2.set_xlim(0,5)
ax2.set_ylim(0,relation["Coef1"]*x_values[-1] + relation["Coef2"]+1)
ax2.text(x_values[-1] + 1,0.001,"x-axis",fontsize=20)
ax2.text(0.1,y_values[-1] + 1,"y-axis",fontsize=20)
ax2.grid(True)
# for i in range(len(x_values)):
# ax2.text(x_values[i] - 0.5,y_values[i]-0.7,"(" + str(x_values[i]) + "," + str(y_values[i]) + ")")
points = ax2.scatter(x_values,y_values,color="black",s=60)
#ax2.scatter(x_value,x_value + 3,color="red",s=120)
#datacursor(points)
plt.show()
def choose_points(value):
if value=="(3,10),(5,14),(0,4)":
print("Correct!")
rel = {"Coef1":2,"Coef2":4,"+": operator.add}
plot_answer(rel)
else:
print("Those do not look like the ordered pairs in our table. Try again.")
interact(choose_points,
value = widgets.RadioButtons(
options=[
"(3,11),(5,11),(2,8)",\
"(0,0),(1,2),(2,2)",\
"(3,10),(5,14),(0,4)",\
"(10,10),(10,8),(1,6)"],
# value='pineapple',
description='Ordered Pairs:',
disabled=False,
style = style
));
```
### Question 5: Conclusions
What can you conclude from the table above? Use the following statements to guide your answer and add any other observations you make.
| Statement |
|-----------|
|The relation between $x$ and $y$ is linear|
|There is an intersection between the y-axis and $x$ at the ordered pair ... |
|There is an intersection between the x-axis and $y$ at the ordered pair ... |
```
emma1_text = widgets.Textarea( value='', placeholder='Write your answer here. Press Record Answer when you finish.', description='', disabled=False , layout=Layout(width='100%', height='75px') )
emma1_button = widgets.Button(button_style='info',description="Record Answer", layout=Layout(width='15%', height='30px'))
display(emma1_text)
display(emma1_button)
emma1_button.on_click( rerun_cell )
emma1_input = emma1_text.value
if(emma1_input != ''):
emma1_text.close()
emma1_button.close()
display(Markdown("### Your answer for Question 6: Conclusions"))
display(Markdown(emma1_input))
```
<h2 align='center'>Experiment</h2>
In this section you will have an opportunity to explore linear relations parameterized by you, to create their respective tables of values and to plot the ordered pairs. In the end, use what you learned in this notebook to make observations about your findings.
Recall that a linear equation is of the form
$$y = ax + b$$
Use the widget below to choose new values for $a,b$.
```
def choose(a,b):
print("Equation: " + str(a) + "x + " + str(b))
return [a,b]
coeff = interact(choose,a=widgets.IntSlider(value=0,
min=0,
max=15,
step=1,
description='Value for a',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d',
style =style)
,b=widgets.IntSlider(value=0,
min=0,
max=15,
step=1,
description='Value for b',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d',
style =style));
def rerun_cell( b ):
display(Javascript('IPython.notebook.execute_cell_range(IPython.notebook.get_selected_index()+1,IPython.notebook.get_selected_index()+3)'))
table_button = widgets.Button(button_style='info',description="Generate Table of Values and Plot", layout=Layout(width='25%', height='30px'))
display(table_button)
table_button.on_click( rerun_cell )
relation_ar = {"Coef1":coeff.widget.kwargs['a'],"Coef2":coeff.widget.kwargs['b'],"+": operator.add}
table_of_values_quad(4,relation_ar)
plot_answer(relation_ar)
```
<h2 align='center'>Interactive Example: Find the relation from a table of values</h2>
What if, instead of knowing what the relation is, we are only given a table of values or a plot?
If we know that the values belong to a linear relation, this along with the values is enough to determine what the relation is.
Consider the table and the plotted ordered pairs below.
```
def tabulate_to_eq(relation):
x_values = np.array([0,1,2,3,4])
y_values = relation["Coef1"]*x_values + relation["Coef2"]
ordered = [(x_values[i],y_values[i]) for i in range(len(x_values))]
df_num_rows = len(x_values)
empty_list = [ '' for i in range(df_num_rows) ]
category_list = [ i+1 for i in range(df_num_rows) ]
df_dict_2 = {'Entry Number':category_list,\
'Values for x': empty_list,'Values for y': empty_list,\
'Ordered pairs': empty_list}
feature_list = ['Entry Number','Values for x','Values for y','Ordered pairs']
student_df_2 = pd.DataFrame(data = df_dict_2,columns=feature_list)
student_df_2.set_index('Entry Number',inplace=True)
student_df_2["Values for y"] = y_values
student_df_2["Values for x"] = x_values
student_df_2["Ordered pairs"] = ordered
# Set up & display as Qgrid
q_student_df_2 = q.show_grid( student_df_2 , grid_options = grid_features )
display(q_student_df_2)
rels = {"Coef1":2,"Coef2":1,"+": operator.add}
tabulate_to_eq(rels)
plot_answer(rels)
```
Can you determine what the equation is based on the ordered pairs?
In the questions below we will walk towards the solution.
## Observation #1
Using the table or the plot, find what the value of $y$ is when $x = 0$. Enter your answer in the box. When you think you have the correct answer, press the Run Interact button.
```
s = {'description_width': 'initial'}
@interact_manual(answer =widgets.Textarea(
value=' ',
placeholder='Type something',
description='Your Answer:',
disabled=False,
style=s))
def get_answer_one(answer):
if "1" in answer:
print("Correct!")
else:
print("HINT: Look at Entry Number 1 in the table. What is the value for y?")
```
### Observation #2
Recall that a linear relation is of the form $$y = ax + b$$
Use this information along with the answer to Observation #1, to deduce the value of $b$.
Enter your answer in the box below. When you think you have found an answer, press the Run Interact button.
```
s = {'description_width': 'initial'}
@interact_manual(answer =widgets.Textarea(
value=' ',
placeholder='Type something',
description='Your Answer:',
disabled=False,
style=s))
def get_answer_one(answer):
if "1" in answer:
print("Correct!")
else:
print("HINT: y = ax + b. When x = 0, y = 0 + b = 1. This means that 0 + b = 1. What is the value of b?")
```
From the observation above, we determined that the value of $b = 1$, as
$$y = ax + b$$
and when $x =0$, we observe $y = 1$. Via algebraic manipulation, this means that $ 0 +b = 1$ which means $b = 1$.
We now know our equation is of the form
$$ y =ax + 1$$
There is only one loose end. We want to get the value of $a$.
### Observation #3
Observe Entry Number 2. In there we see that the ordered pair is $(1,3)$. This means that if $x = 1$, then $y = 3$.
In our equation, this looks as follows:
$$y = a(1) + 1 = 3$$
Which is equivalent to
$$y = a + 1 = 3$$
What is the value of $a$?
```
s = {'description_width': 'initial'}
@interact_manual(answer =widgets.Textarea(
value=' ',
placeholder='Type something',
description='Your Answer:',
disabled=False,
style=s))
def get_answer_one(answer):
if "2" in answer:
print("Correct!")
else:
print("HINT: a + 1 = 3. What value, when added to 1, results in 3? ")
```
### Recap
Observe that all we needed to find the linear equation were the first two entries in the table.
Indeed, we used Entry Number 1, x = 0, y = 1 to determine that b = 1.
We then used this, along with Entry Number 2 x = 1, y = 3, to determine that a = 2.
This yields to the linear equation
$$y = 2x + 1$$
Use the widget below to verify that this linear equation generates the adequate table of values.
```
@interact(x_value=widgets.IntSlider(value=0,
min=0,
max=4,
step=1,
description='Value for x',
disabled=False,
continuous_update=False,
orientation='horizontal',
readout=True,
readout_format='d',
style =style
))
def verify_points(x_value):
relation = {"Coef1":2,"Coef2":1,"+": operator.add}
x_values = np.array([0,1,2,3,4])
y_values = relation["Coef1"]*x_values + relation["Coef2"]
fig = plt.figure()
plt.subplots_adjust(left=14, bottom=0.2, right=16, top=1.5,
wspace=0.1, hspace=0.2)
ax1 = fig.add_subplot(1, 2, 1)
ax1.text(0.1,0.8,"x = " + str(x_value),fontsize=20)
ax1.text(0.1,0.6,"y = " + str(relation["Coef1"]) + "x + "+ str(relation["Coef2"]),fontsize=20)
ax1.text(0.1,0.4,"y = 2(" + str(x_value) + ") + 1 = " + str(2*x_value)+ " + 1 = " + str(relation["Coef1"]*x_value+ relation["Coef2"]),fontsize=20)
ax1.text(0.1,0.2,"Ordered pair (" +str(x_value) + "," + str(relation["Coef1"]*x_value+ relation["Coef2"]) + ")",fontsize=20)
ax1.set_title("Values for x and y", fontsize=25)
ax2 = fig.add_subplot(1, 2, 2)
ax2.set_xticks(np.arange(-6,x_values[-1]+2)),ax2.set_yticks(np.arange(-6,y_values[-1]+2))
ax2.set_xlim(0,x_values[-1]+1)
ax2.set_ylim(0,y_values[-1]+1)
ax1.axis("Off"),ax2.axis("On")
ax2.axhline(y=0, color='blue')
ax2.axvline(x=0, color='blue')
ax2.text(x_values[-1]+1,0.2,"x-axis",fontsize=20)
ax2.text(0.1,y_values[-1]+1,"y-axis",fontsize=20)
ax2.grid(True)
# for i in range(len(x_values)):
# ax2.text(x_values[i] - 0.5,y_values[i]-0.7,"(" + str(x_values[i]) + "," + str(y_values[i]) + ")")
points = ax2.scatter(x_values,y_values,color="black",s=60)
ax2.scatter(x_value,relation["Coef1"]*x_value+ relation["Coef2"] ,color="red",s=120)
#datacursor(points)
plt.show()
tabulate_to_eq({"Coef1":2,"Coef2":1,"+": operator.add})
```
Why do you think equations of the form
$$y = ax + b$$
are called "linear"?
Use the box below to enter your answer.
```
emma1_text = w.Textarea( value='', placeholder='Write your answer here. Press Record Answer when you finish.', description='', disabled=False , layout=Layout(width='100%', height='75px') )
emma1_button = w.Button(button_style='info',description="Record Answer", layout=Layout(width='15%', height='30px'))
display(emma1_text)
display(emma1_button)
emma1_button.on_click( rerun_cell )
```
<h2 align='center'>Conclusion</h2>
In this notebook we learned what an ordered pair is. We also learned what a table of values is as well as a plane and a coordinate plane. Furthermore, we learned that given a relation between x and y, we can track and represent the relation between x and y via a table of values or a coordinate plane.
We analyzed basic linear relations, tabulated their values and plotted on a coordinate plane. We explored the pairs that intersected the y and x axis and made remarks based on our observations.
[](https://github.com/callysto/curriculum-notebooks/blob/master/LICENSE.md)
| github_jupyter |
# Python code til udregning af data fra ATP
```
#Imports
```
# Udregninger
## Alder for at kunne blive tilbudt tidlig pension
```
#Årgange født i 1955-1960 har adgang til at søge i 2021.
#Man skal være fyldt 61 for at søge.
print(2021-61, "kan anmode om tidlig pension")
#Der indgår personer fra 6 1⁄2 årgange
print(2021-66, "sidste år inden folkepension indtræder")
#da personer født 1.halvår 1955 har nået folkepensionsalderen inden 1. januar 2022.
```
## Forventede ansøgning
```
#Omkring 38.000 helårspersoner forventes at opnå ret til at gå på tidligt pension i 2022.
#Det dækker over muligheden for at 1, 2 eller 3 år.
#22.000 vil benytte sig af retten i 2022, 6000 fra beskæftigelse.
ansøgning = 38100 #personer
benyttelse = 22000 #benytter tidlig pension
print("Det vil sige, at dem der afstår retten til tidlig pension er", ansøgning-benyttelse, "personer")
```
## Personer med 44+ på arbejdsmarkedet
```
#Personer med 44+ år på arbejdsmarkedet har automatisk fuld anciennitet.
automatisk_behandling = 1.7+7.1
berettiget = 33.9
procent = round(automatisk_behandling/berettiget*100)
print(automatisk_behandling, "af de", round(automatisk_behandling/berettiget*100),
"% af ansøgerne har automatisk fuld anciennitet er", round(ansøgning/100*procent), "personer")
#8,8 ud af 33,9 = 26 % af ansøgerne har automatisk fuld anciennitet. 26% af 38.100 = 9906 personer.
```
## Manuel håndtering
```
#Personer der har 42 eller 43 års anciennitet på arbejdsmarkedet kræver manuel håndtering.
resterende = 74
#74% af 38.100 ansøgere = 28.194 ansøgere kræver manuel håndtering
print(round(ansøgning/100*resterende),"ansøgere kræver manuel håndtering")
```
## Supplerende dokumentation
```
#Vi forventer, at 50% af ansøgerne der kræver manuel behandling indsender supplerende dokumentation.
halvdelen = 2
manuel_håndtering = 28194
#50% af 28.194 = 14.097 personer.
print(round(manuel_håndtering/halvdelen))
```
## Uger i ansøgningsperioden
```
#Hvor mange uger er der i perioden d. 1. august – 31. december?
antal_uger = 52 #uger
uger_i_perioden = 31 #uger
print(antal_uger-uger_i_perioden,"uger ansøgningsperioden")
```
## Arbejdstimer
```
#Hvor mange arbejdstimer er der behov for i perioden?
#ATP har et erfaringsbaseret estimat for tidsforbruget ifm. manuel behandling af en typisk ansøgning,
#svarende til 30 minutter.
supplerende = 14097 #antal ansøgning der kræver
halvtime = 2 #halv time
print(supplerende/halvtime," antal arbejdstimer")
```
## antal medarbejder
```
#Hvor mange timer om ugen er det rimeligt at sige at hver medarbejder bruger på sagsbehandling?
#Der går også timer på administration, interne møder og andet.
uger_ansøgning = 21 #uger
årsværk_ATP = 1356 #timer
procent_år = 40.38 #procent
print(uger_ansøgning/antal_uger*100, "% af et år, af de 1356 timer =", round(årsværk_ATP*0.404),"timer")
print(round((supplerende/halvtime)/548),"medarbejder")
```
| github_jupyter |
# Speed comparison between PyPairs and the R verison - PyPairs
Here we ran the sandbag part of the original Pairs method on the oscope dataset for a growing subset of genes. Taking note of the required execution time. Single cored time is taken. For the result please see: [2.3 Differences in code - Python](./2.3%20Differences%20in%20code%20-%20R.ipynb)
<div id="toc"></div>
## Neccessary Imports
```
%%javascript
$.getScript('https://kmahelona.github.io/ipython_notebook_goodies/ipython_notebook_toc.js')
import sys
code = "./../../code/"
data = "./../../data/"
sys.path.append(code)
import pandas
import pypairs as pairs
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import plotly.graph_objs as go
import numpy as np
from pathlib import Path
from tqdm import tqdm_notebook as tqdm
import helper
import timeit
init_notebook_mode(connected=True)
```
## Loading Oscope Dataset
```
# Load matrix
oscope_gencounts = pandas.read_csv(Path(data + "data/GSE64016_H1andFUCCI_normalized_EC_human.csv"))
# Set index right
oscope_gencounts.set_index("Unnamed: 0", inplace=True)
# Subset sorted
oscope_gencounts_sorted = oscope_gencounts.iloc[:, [oscope_gencounts.columns.get_loc(c) for c in oscope_gencounts.columns if "G1_" in c or "G2_" in c or "S_" in c]]
# Define annotation
is_G1 = [oscope_gencounts_sorted.columns.get_loc(c) for c in oscope_gencounts_sorted.columns if "G1_" in c]
is_S = [oscope_gencounts_sorted.columns.get_loc(c) for c in oscope_gencounts_sorted.columns if "S_" in c]
is_G2M = [oscope_gencounts_sorted.columns.get_loc(c) for c in oscope_gencounts_sorted.columns if "G2_" in c]
annotation = {
"G1": list(is_G1),
"S": list(is_S),
"G2M": list(is_G2M)
}
no_genes = len(oscope_gencounts_sorted.index) - 1
print("Total number of genes in oscope dataset {}".format(no_genes))
```
## Running sandbag with increasing number of genes
Notice: Long runtime, result stored in magic please see [Results](#Results)
```
t = []
genes = [10,100,500,1000,5000,10000,19000]
for g in tqdm(genes):
sub = helper.random_subset(range(0, no_genes), g)
subset = oscope_gencounts_sorted.iloc[sub, :]
start = timeit.default_timer()
oscope_marker_pairs = pairs.sandbag(x=subset, phases=annotation, fraction=0.65, processes=1, verbose=True)
time_sandbag = timeit.default_timer() - start
t.append(time_sandbag)
%store t
```
## Results
Python times are feched from store magic, R times were copied manually
```
%store -r
t_python = t
t_r = [0.01, 0.08, 1.49, 6.37, 180.56, 803.64, 2761.00]
# Create traces
trace0 = go.Scatter(
x= [10,100,500,1000,5000,10000,19000],
y= t_python,
mode='markers+lines',
marker=dict(
symbol='circle',
size=10,
color='green',
),
name='PyPairs'
)
trace1 = go.Scatter(
x= [10,100,500,1000,5000,10000,19000],
y= t_r,
mode='markers+lines',
marker=dict(
symbol='square',
size=10,
color='blue',
),
name='R Version'
)
layout = go.Layout(
title='Speed comparison: R implementation vs PyPairs',
xaxis=dict(
title='No. of genes',
),
yaxis=dict(
title='Time in ms',
)
)
data = go.Figure(data=[trace0, trace1], layout=layout)
iplot(data)
```
| github_jupyter |
# Practice Notebook: Methods and Classes
The code below defines an *Elevator* class. The elevator has a current floor, it also has a top and a bottom floor that are the minimum and maximum floors it can go to. Fill in the blanks to make the elevator go through the floors requested.
```
class Elevator:
def __init__(self, bottom, top, current):
"""Initializes the Elevator instance."""
self.bottom=bottom
self.top=top
self.current=current
def __str__(self):
"""Information about Current floor"""
return "Current floor: {}".format(self.current)
def up(self):
"""Makes the elevator go up one floor."""
if self.current<10:
self.current+=1
def down(self):
"""Makes the elevator go down one floor."""
if self.current > 0:
self.current -= 1
def go_to(self, floor):
"""Makes the elevator go to the specific floor."""
if floor >= self.bottom and floor <= self.top:
self.current = floor
elif floor < 0:
self.current = 0
else:
self.current = 10
elevator = Elevator(-1, 10, 0)
```
This class is pretty empty and doesn't do much. To test whether your *Elevator* class is working correctly, run the code blocks below.
```
elevator.up()
elevator.current #should output 1
elevator.down()
elevator.current #should output 0
elevator.go_to(10)
elevator.current #should output 10
```
If you get a **<font color =red>NameError</font>** message, be sure to run the *Elevator* class definition code block first. If you get an **<font color =red>AttributeError</font>** message, be sure to initialize *self.current* in your *Elevator* class.
Once you've made the above methods output 1, 0 and 10, you've successfully coded the *Elevator* class and its methods. Great work!
<br><br>
For the up and down methods, did you take into account the top and bottom floors? Keep in mind that the elevator shouldn't go above the top floor or below the bottom floor. To check that out, try the code below and verify if it's working as expected. If it's not, then go back and modify the methods so that this code behaves correctly.
```
# Go to the top floor. Try to go up, it should stay. Then go down.
elevator.go_to(10)
elevator.up()
elevator.down()
print(elevator.current) # should be 9
# Go to the bottom floor. Try to go down, it should stay. Then go up.
elevator.go_to(-1)
elevator.down()
elevator.down()
elevator.up()
elevator.up()
print(elevator.current) # should be 1
```
Now add the __str__ method to your *Elevator* class definition above so that when printing the elevator using the **print( )** method, we get the current floor together with a message. For example, in the 5th floor it should say "Current floor: 5"
```
elevator.go_to(5)
print(elevator)
```
Remember, Python uses the default method, that prints the position where the object is stored in the computer’s memory. If your output is something like: <br>
> <__main__.Elevator object at 0x7ff6a9ff3fd0>
Then you will need to add the special __str__ method, which returns the string that you want to print. Try again until you get the desired output, "Current floor: 5".
Once you have successfully produced the desired output, you are all done with this practice notebook. Awesome!
| github_jupyter |
# PTN Template
This notebook serves as a template for single dataset PTN experiments
It can be run on its own by setting STANDALONE to True (do a find for "STANDALONE" to see where)
But it is intended to be executed as part of a *papermill.py script. See any of the
experimentes with a papermill script to get started with that workflow.
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import os, json, sys, time, random
import numpy as np
import torch
from torch.optim import Adam
from easydict import EasyDict
import matplotlib.pyplot as plt
from steves_models.steves_ptn import Steves_Prototypical_Network
from steves_utils.lazy_iterable_wrapper import Lazy_Iterable_Wrapper
from steves_utils.iterable_aggregator import Iterable_Aggregator
from steves_utils.ptn_train_eval_test_jig import PTN_Train_Eval_Test_Jig
from steves_utils.torch_sequential_builder import build_sequential
from steves_utils.torch_utils import get_dataset_metrics, ptn_confusion_by_domain_over_dataloader
from steves_utils.utils_v2 import (per_domain_accuracy_from_confusion, get_datasets_base_path)
from steves_utils.PTN.utils import independent_accuracy_assesment
from steves_utils.stratified_dataset.episodic_accessor import Episodic_Accessor_Factory
from steves_utils.ptn_do_report import (
get_loss_curve,
get_results_table,
get_parameters_table,
get_domain_accuracies,
)
from steves_utils.transforms import get_chained_transform
```
# Required Parameters
These are allowed parameters, not defaults
Each of these values need to be present in the injected parameters (the notebook will raise an exception if they are not present)
Papermill uses the cell tag "parameters" to inject the real parameters below this cell.
Enable tags to see what I mean
```
required_parameters = {
"experiment_name",
"lr",
"device",
"seed",
"dataset_seed",
"labels_source",
"labels_target",
"domains_source",
"domains_target",
"num_examples_per_domain_per_label_source",
"num_examples_per_domain_per_label_target",
"n_shot",
"n_way",
"n_query",
"train_k_factor",
"val_k_factor",
"test_k_factor",
"n_epoch",
"patience",
"criteria_for_best",
"x_transforms_source",
"x_transforms_target",
"episode_transforms_source",
"episode_transforms_target",
"pickle_name",
"x_net",
"NUM_LOGS_PER_EPOCH",
"BEST_MODEL_PATH",
"torch_default_dtype"
}
standalone_parameters = {}
standalone_parameters["experiment_name"] = "STANDALONE PTN"
standalone_parameters["lr"] = 0.0001
standalone_parameters["device"] = "cuda"
standalone_parameters["seed"] = 1337
standalone_parameters["dataset_seed"] = 1337
standalone_parameters["num_examples_per_domain_per_label_source"]=100
standalone_parameters["num_examples_per_domain_per_label_target"]=100
standalone_parameters["n_shot"] = 3
standalone_parameters["n_query"] = 2
standalone_parameters["train_k_factor"] = 1
standalone_parameters["val_k_factor"] = 2
standalone_parameters["test_k_factor"] = 2
standalone_parameters["n_epoch"] = 100
standalone_parameters["patience"] = 10
standalone_parameters["criteria_for_best"] = "target_accuracy"
standalone_parameters["x_transforms_source"] = ["unit_power"]
standalone_parameters["x_transforms_target"] = ["unit_power"]
standalone_parameters["episode_transforms_source"] = []
standalone_parameters["episode_transforms_target"] = []
standalone_parameters["torch_default_dtype"] = "torch.float32"
standalone_parameters["x_net"] = [
{"class": "nnReshape", "kargs": {"shape":[-1, 1, 2, 256]}},
{"class": "Conv2d", "kargs": { "in_channels":1, "out_channels":256, "kernel_size":(1,7), "bias":False, "padding":(0,3), },},
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm2d", "kargs": {"num_features":256}},
{"class": "Conv2d", "kargs": { "in_channels":256, "out_channels":80, "kernel_size":(2,7), "bias":True, "padding":(0,3), },},
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm2d", "kargs": {"num_features":80}},
{"class": "Flatten", "kargs": {}},
{"class": "Linear", "kargs": {"in_features": 80*256, "out_features": 256}}, # 80 units per IQ pair
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm1d", "kargs": {"num_features":256}},
{"class": "Linear", "kargs": {"in_features": 256, "out_features": 256}},
]
# Parameters relevant to results
# These parameters will basically never need to change
standalone_parameters["NUM_LOGS_PER_EPOCH"] = 10
standalone_parameters["BEST_MODEL_PATH"] = "./best_model.pth"
# uncomment for CORES dataset
from steves_utils.CORES.utils import (
ALL_NODES,
ALL_NODES_MINIMUM_1000_EXAMPLES,
ALL_DAYS
)
standalone_parameters["labels_source"] = ALL_NODES
standalone_parameters["labels_target"] = ALL_NODES
standalone_parameters["domains_source"] = [1]
standalone_parameters["domains_target"] = [2,3,4,5]
standalone_parameters["pickle_name"] = "cores.stratified_ds.2022A.pkl"
# Uncomment these for ORACLE dataset
# from steves_utils.ORACLE.utils_v2 import (
# ALL_DISTANCES_FEET,
# ALL_RUNS,
# ALL_SERIAL_NUMBERS,
# )
# standalone_parameters["labels_source"] = ALL_SERIAL_NUMBERS
# standalone_parameters["labels_target"] = ALL_SERIAL_NUMBERS
# standalone_parameters["domains_source"] = [8,20, 38,50]
# standalone_parameters["domains_target"] = [14, 26, 32, 44, 56]
# standalone_parameters["pickle_name"] = "oracle.frame_indexed.stratified_ds.2022A.pkl"
# standalone_parameters["num_examples_per_domain_per_label_source"]=1000
# standalone_parameters["num_examples_per_domain_per_label_target"]=1000
# Uncomment these for Metahan dataset
# standalone_parameters["labels_source"] = list(range(19))
# standalone_parameters["labels_target"] = list(range(19))
# standalone_parameters["domains_source"] = [0]
# standalone_parameters["domains_target"] = [1]
# standalone_parameters["pickle_name"] = "metehan.stratified_ds.2022A.pkl"
# standalone_parameters["n_way"] = len(standalone_parameters["labels_source"])
# standalone_parameters["num_examples_per_domain_per_label_source"]=200
# standalone_parameters["num_examples_per_domain_per_label_target"]=100
standalone_parameters["n_way"] = len(standalone_parameters["labels_source"])
# Parameters
parameters = {
"experiment_name": "tuned_1v2:oracle.run2_limited",
"device": "cuda",
"lr": 0.0001,
"labels_source": [
"3123D52",
"3123D65",
"3123D79",
"3123D80",
"3123D54",
"3123D70",
"3123D7B",
"3123D89",
"3123D58",
"3123D76",
"3123D7D",
"3123EFE",
"3123D64",
"3123D78",
"3123D7E",
"3124E4A",
],
"labels_target": [
"3123D52",
"3123D65",
"3123D79",
"3123D80",
"3123D54",
"3123D70",
"3123D7B",
"3123D89",
"3123D58",
"3123D76",
"3123D7D",
"3123EFE",
"3123D64",
"3123D78",
"3123D7E",
"3124E4A",
],
"episode_transforms_source": [],
"episode_transforms_target": [],
"domains_source": [8, 32, 50],
"domains_target": [14, 20, 26, 38, 44],
"num_examples_per_domain_per_label_source": 2000,
"num_examples_per_domain_per_label_target": 2000,
"n_shot": 3,
"n_way": 16,
"n_query": 2,
"train_k_factor": 3,
"val_k_factor": 2,
"test_k_factor": 2,
"torch_default_dtype": "torch.float32",
"n_epoch": 50,
"patience": 3,
"criteria_for_best": "target_accuracy",
"x_net": [
{"class": "nnReshape", "kargs": {"shape": [-1, 1, 2, 256]}},
{
"class": "Conv2d",
"kargs": {
"in_channels": 1,
"out_channels": 256,
"kernel_size": [1, 7],
"bias": False,
"padding": [0, 3],
},
},
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm2d", "kargs": {"num_features": 256}},
{
"class": "Conv2d",
"kargs": {
"in_channels": 256,
"out_channels": 80,
"kernel_size": [2, 7],
"bias": True,
"padding": [0, 3],
},
},
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm2d", "kargs": {"num_features": 80}},
{"class": "Flatten", "kargs": {}},
{"class": "Linear", "kargs": {"in_features": 20480, "out_features": 256}},
{"class": "ReLU", "kargs": {"inplace": True}},
{"class": "BatchNorm1d", "kargs": {"num_features": 256}},
{"class": "Linear", "kargs": {"in_features": 256, "out_features": 256}},
],
"NUM_LOGS_PER_EPOCH": 10,
"BEST_MODEL_PATH": "./best_model.pth",
"pickle_name": "oracle.Run2_10kExamples_stratified_ds.2022A.pkl",
"x_transforms_source": ["unit_mag"],
"x_transforms_target": ["unit_mag"],
"dataset_seed": 7,
"seed": 7,
}
# Set this to True if you want to run this template directly
STANDALONE = False
if STANDALONE:
print("parameters not injected, running with standalone_parameters")
parameters = standalone_parameters
if not 'parameters' in locals() and not 'parameters' in globals():
raise Exception("Parameter injection failed")
#Use an easy dict for all the parameters
p = EasyDict(parameters)
supplied_keys = set(p.keys())
if supplied_keys != required_parameters:
print("Parameters are incorrect")
if len(supplied_keys - required_parameters)>0: print("Shouldn't have:", str(supplied_keys - required_parameters))
if len(required_parameters - supplied_keys)>0: print("Need to have:", str(required_parameters - supplied_keys))
raise RuntimeError("Parameters are incorrect")
###################################
# Set the RNGs and make it all deterministic
###################################
np.random.seed(p.seed)
random.seed(p.seed)
torch.manual_seed(p.seed)
torch.use_deterministic_algorithms(True)
###########################################
# The stratified datasets honor this
###########################################
torch.set_default_dtype(eval(p.torch_default_dtype))
###################################
# Build the network(s)
# Note: It's critical to do this AFTER setting the RNG
# (This is due to the randomized initial weights)
###################################
x_net = build_sequential(p.x_net)
start_time_secs = time.time()
###################################
# Build the dataset
###################################
if p.x_transforms_source == []: x_transform_source = None
else: x_transform_source = get_chained_transform(p.x_transforms_source)
if p.x_transforms_target == []: x_transform_target = None
else: x_transform_target = get_chained_transform(p.x_transforms_target)
if p.episode_transforms_source == []: episode_transform_source = None
else: raise Exception("episode_transform_source not implemented")
if p.episode_transforms_target == []: episode_transform_target = None
else: raise Exception("episode_transform_target not implemented")
eaf_source = Episodic_Accessor_Factory(
labels=p.labels_source,
domains=p.domains_source,
num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_source,
iterator_seed=p.seed,
dataset_seed=p.dataset_seed,
n_shot=p.n_shot,
n_way=p.n_way,
n_query=p.n_query,
train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),
pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),
x_transform_func=x_transform_source,
example_transform_func=episode_transform_source,
)
train_original_source, val_original_source, test_original_source = eaf_source.get_train(), eaf_source.get_val(), eaf_source.get_test()
eaf_target = Episodic_Accessor_Factory(
labels=p.labels_target,
domains=p.domains_target,
num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_target,
iterator_seed=p.seed,
dataset_seed=p.dataset_seed,
n_shot=p.n_shot,
n_way=p.n_way,
n_query=p.n_query,
train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),
pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),
x_transform_func=x_transform_target,
example_transform_func=episode_transform_target,
)
train_original_target, val_original_target, test_original_target = eaf_target.get_train(), eaf_target.get_val(), eaf_target.get_test()
transform_lambda = lambda ex: ex[1] # Original is (<domain>, <episode>) so we strip down to episode only
train_processed_source = Lazy_Iterable_Wrapper(train_original_source, transform_lambda)
val_processed_source = Lazy_Iterable_Wrapper(val_original_source, transform_lambda)
test_processed_source = Lazy_Iterable_Wrapper(test_original_source, transform_lambda)
train_processed_target = Lazy_Iterable_Wrapper(train_original_target, transform_lambda)
val_processed_target = Lazy_Iterable_Wrapper(val_original_target, transform_lambda)
test_processed_target = Lazy_Iterable_Wrapper(test_original_target, transform_lambda)
datasets = EasyDict({
"source": {
"original": {"train":train_original_source, "val":val_original_source, "test":test_original_source},
"processed": {"train":train_processed_source, "val":val_processed_source, "test":test_processed_source}
},
"target": {
"original": {"train":train_original_target, "val":val_original_target, "test":test_original_target},
"processed": {"train":train_processed_target, "val":val_processed_target, "test":test_processed_target}
},
})
# Some quick unit tests on the data
from steves_utils.transforms import get_average_power, get_average_magnitude
q_x, q_y, s_x, s_y, truth = next(iter(train_processed_source))
assert q_x.dtype == eval(p.torch_default_dtype)
assert s_x.dtype == eval(p.torch_default_dtype)
print("Visually inspect these to see if they line up with expected values given the transforms")
print('x_transforms_source', p.x_transforms_source)
print('x_transforms_target', p.x_transforms_target)
print("Average magnitude, source:", get_average_magnitude(q_x[0].numpy()))
print("Average power, source:", get_average_power(q_x[0].numpy()))
q_x, q_y, s_x, s_y, truth = next(iter(train_processed_target))
print("Average magnitude, target:", get_average_magnitude(q_x[0].numpy()))
print("Average power, target:", get_average_power(q_x[0].numpy()))
###################################
# Build the model
###################################
model = Steves_Prototypical_Network(x_net, device=p.device, x_shape=(2,256))
optimizer = Adam(params=model.parameters(), lr=p.lr)
###################################
# train
###################################
jig = PTN_Train_Eval_Test_Jig(model, p.BEST_MODEL_PATH, p.device)
jig.train(
train_iterable=datasets.source.processed.train,
source_val_iterable=datasets.source.processed.val,
target_val_iterable=datasets.target.processed.val,
num_epochs=p.n_epoch,
num_logs_per_epoch=p.NUM_LOGS_PER_EPOCH,
patience=p.patience,
optimizer=optimizer,
criteria_for_best=p.criteria_for_best,
)
total_experiment_time_secs = time.time() - start_time_secs
###################################
# Evaluate the model
###################################
source_test_label_accuracy, source_test_label_loss = jig.test(datasets.source.processed.test)
target_test_label_accuracy, target_test_label_loss = jig.test(datasets.target.processed.test)
source_val_label_accuracy, source_val_label_loss = jig.test(datasets.source.processed.val)
target_val_label_accuracy, target_val_label_loss = jig.test(datasets.target.processed.val)
history = jig.get_history()
total_epochs_trained = len(history["epoch_indices"])
val_dl = Iterable_Aggregator((datasets.source.original.val,datasets.target.original.val))
confusion = ptn_confusion_by_domain_over_dataloader(model, p.device, val_dl)
per_domain_accuracy = per_domain_accuracy_from_confusion(confusion)
# Add a key to per_domain_accuracy for if it was a source domain
for domain, accuracy in per_domain_accuracy.items():
per_domain_accuracy[domain] = {
"accuracy": accuracy,
"source?": domain in p.domains_source
}
# Do an independent accuracy assesment JUST TO BE SURE!
# _source_test_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.test, p.device)
# _target_test_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.test, p.device)
# _source_val_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.val, p.device)
# _target_val_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.val, p.device)
# assert(_source_test_label_accuracy == source_test_label_accuracy)
# assert(_target_test_label_accuracy == target_test_label_accuracy)
# assert(_source_val_label_accuracy == source_val_label_accuracy)
# assert(_target_val_label_accuracy == target_val_label_accuracy)
experiment = {
"experiment_name": p.experiment_name,
"parameters": dict(p),
"results": {
"source_test_label_accuracy": source_test_label_accuracy,
"source_test_label_loss": source_test_label_loss,
"target_test_label_accuracy": target_test_label_accuracy,
"target_test_label_loss": target_test_label_loss,
"source_val_label_accuracy": source_val_label_accuracy,
"source_val_label_loss": source_val_label_loss,
"target_val_label_accuracy": target_val_label_accuracy,
"target_val_label_loss": target_val_label_loss,
"total_epochs_trained": total_epochs_trained,
"total_experiment_time_secs": total_experiment_time_secs,
"confusion": confusion,
"per_domain_accuracy": per_domain_accuracy,
},
"history": history,
"dataset_metrics": get_dataset_metrics(datasets, "ptn"),
}
ax = get_loss_curve(experiment)
plt.show()
get_results_table(experiment)
get_domain_accuracies(experiment)
print("Source Test Label Accuracy:", experiment["results"]["source_test_label_accuracy"], "Target Test Label Accuracy:", experiment["results"]["target_test_label_accuracy"])
print("Source Val Label Accuracy:", experiment["results"]["source_val_label_accuracy"], "Target Val Label Accuracy:", experiment["results"]["target_val_label_accuracy"])
json.dumps(experiment)
```
| github_jupyter |
# Worksheet 0.1.2: Python syntax (`while` loops)
<div class="alert alert-block alert-info">
This worksheet will invite you to tinker with the examples, as they are live code cells. Instead of the normal fill-in-the-blank style of notebook, feel free to mess with the code directly. Remember that -- to test things out -- the <a href = "../sandbox/CMPSC%20100%20-%20Week%2000%20-%20Sandbox.ipynb"><b>Sandbox</b></a> is available to you as well.
</div>
<div class="alert alert-block alert-warning" id = "warning">
The work this week also offers the opportunity to tie up the server in loopish operations. Should you be unable to run cells, simply locate the <b>Kernel</b> menu at the top of the screen and click <b>Interrupt Kernel</b>. This should jumpstart the kernel again and clear out the infinite loop behavior.</div>
## Feeling a bit loopy?
If you're not, you might start to during this worksheet.
We've mostly covered cases in which events or calculations need to happen one at a time or just one time in total. Occasionally -- much more than occasionally, really -- programs need to repeat instructions more than once until some given condition is met.
If you read the word "condition" above and have started thinking `booleans` are involved: you're right yet again.
While casually referred to as a "loop" structure, the technical term for this repetition is _iteration_ -- the process of repeating a set of statements until a given condition is no longer `True`. In the case of `while` loops, we can rephrase the statement above to read "while the condition is true, repeat some statements"
`while` loops recall syntax similar to `if` statements:
```python
while CONDITION:
# Repeat
# these
# statements
```
Again, notice that indentation plays a part here: everything indented underneat the `while` statement "belongs to" that `while` loop, and will be subject to repetition.
For example, a simple countdown:
```
# Initialize starting number
seconds = 10
# Start while loop
while seconds > 0:
print(seconds)
seconds -= 1
print("Liftoff!")
```
In the above block of code, we start by telling the program where to, well, start. Then we print that number followed by an instruction `seconds -= 1` to _decrement_ (decrease) that number by one _each time the loop runs_ (on each _iteration_). By the time we reach the end, the last run notices that `seconds == 0`, therefore `seconds` _is not_ greater than `0` anymore and it breaks out of the loop, executing the next statement after the loop.
Like Worksheet 0 this week, we can use any combination of expressions that `boolean` values can muster, be they _relational operators_ testing `integers`, `floating point numbers`, `strings`, or _logical operators_ looking for combinations of `boolean` expressions.
### `while` loops and the flow of control
Here's that control topic back to haunt us.
Again, the technical flow of the program's instructions (i.e. code) doesn't change. It's still technically top-down. However, something interesting happens when we hit a loop or _iteration_. Consider our countdown above:

As the diagram points out, the flow of control changes when we encounter a `while` loop. Statements _in the loop_ execute from `top -> bottom -> top` until the condition cited is no longer true (in this case, until the moment that `seconds` dips below `1`.
## Detour into user input
Why user input and why now? As we'll see in future weeks, other kinds of loops can fulfill the same purpose as `while` loops. However, there's something unique that `while` loops can do that others aren't so well-suited to: handing user input.
This relies on our understanding of _functions_ as we're about to learn a new one: `input()` -- a function which allows us to prompt users to enter data so that our programs can do an operation called "parsing" (understanding/reading) it.
It's always helpful to put some `string` value in the parenthesis as the _argument_, to give a user some sense of what they're being requested to type. In fact, the general format of the function is, like others we've seen:
```python
# Where ARGUMENT will evaluate to a string
input(ARGUMENT)
```
In order to effectively use it, we need to _assign_ the result of the function to a variable to store it in memory. Run the following cell for an example:
```
name = input("What is your name: ")
print("Hello, " + name + ".")
```
_Because we stored the result_ in `name`, we can use it -- whether that's to `print` it or test it:
```
if name == "The Professor":
print("The Professor is in the house!")
else:
print("Oh, you're not the professor. Forget it.")
```
One thing of particular note:
```
# The identifier "str_value" is arbitrary here, no real significance
str_value = input("Enter a numeric value of any kind: ")
print(type(str_value))
```
No matter what we enter here, the result will always be a `string` type. That's because the Python language is rigged to do its best with _whatever_ a user writes in the prompt. This means handling characters/symbols (`!@#^!%#@$` -- I promise I'm not swearing here), letters (`a`,`b`,`c`), or numbers (either `integer` or `float`).
This means that, to make it useful, we might have to _convert_ it if we want a numeric value from it:
```
float_value = float(str_value)
print(type(float_value))
```
However, insofar as user input is concerned, we can test it _or_ we can use it as something called a "sentinel" value. Using word "sentinel" here means exactly what it means in normal speech -- something to watch out for, like the following:
```
# Setup choice
choice = ""
# Do the loop
while choice != "E":
# Print message to relay the user's choice
print("The loop is running.")
choice = input("[C]ontinue or [E]xit? ")
print("You chose to exit!")
```
## Mean`while`
The conclusion we should draw from our little detour is this: `while` statements are exceptionally good at handling all kinds of `boolean` conditions. When it's merely simple counting, like our countdown example above, it's OK, too -- but, as we'll see in the near future, counting and other more complex tests are better suited by other loop types.
## Infinite loops
<div class="alert alert-block alert-danger">
Most programmers fall prey to an infinite loop from time to time. The examples below are not code cells, because if you were to run them, they would -- well -- loop infinitely. If you think you're stuck in an infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop infinite loop, don't hesistate to take the advice in the <a href = "#warning">warning</a> above.
</div>
There are times when conditions _can't_ be met. For example:
```python
count = 0
while True:
count += 1
```
Now, there _is_ an application for something like this. However, note that if we say `while True`, the condition is literally hard-coded to be `True` _all the time_ -- it can never change. Another example:
```python
sum = 0
limit = 5
while sum < limit:
sum -=1
```
Here, we're actually _counting backwards_, so `sum` will never be `+5`. It might be `-5` (at some point), but it will continue on to `-∞`, and never stop. In essence, `sum` will always be less than `limit`.
## The sum of its parts
First things first: this program is a one-trick pony: it only adds numbers.
I'm asking you to use what we have learned in this worksheet to write a program whose sole purpose is to present the sum of a set of user-entered numbers. The user should be able to enter as many numbers as they want, provided that:
* all of the numbers are integers
* uses `number` to store user input
* users can choose to quit by entering an `0` at the prompt
* `if number = 0`, don't add the number to `count`
* non-hint hint: there are at least 3 ways to do this
* the program output the sum in the following format:
```
The sum of these # numbers -> ###
```
* The "proof" of this program is to add the following numbers when you grade the worksheet:
* `4`,`8`,`15`,`16`,`23`,`42`
I'll start you out.
```
# NOTE: YOU MUST RUN THIS CELL TO MAKE THESE VARIABLES AVAILABLE
# NOTE 2: RUN THIS CELL TO RESET ALL NUMBERS AS WELL
# Setup variable to handle input
number = ""
# Setup variable to keep running total
sum = 0
# Setup a count variable to track the count
count = 0
# TODO: Write code to complete activity using knowledge you've gained about while loops
```
## Finishing this activity
If the program above runs and you've finished the worksheet, be sure to run `gradle grade` to do one final check!
| github_jupyter |
# "# backtesting with grid search"
> "Easily backtest a grid of parameters in a given trading strategy"
- toc: true
- branch: master
- badges: true
- comments: true
- author: Jerome de Leon
- categories: [grid search, backtest]
<a href="https://colab.research.google.com/github/enzoampil/fastquant/blob/master/examples/2020-04-20-backtest_with_grid_search.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# uncomment to install in colab
# !pip3 install fastquant
```
## backtest SMAC
`fastquant` offers a convenient way to backtest several trading strategies. To backtest using Simple Moving Average Crossover (`SMAC`), we do the following.
```python
backtest('smac', dcv_data, fast_period=15, slow_period=40)
```
`fast_period` and `slow_period` are two `SMAC` parameters that can be changed depending on the user's preferences. A simple way to fine tune these parameters is to run `backtest` on a grid of values and find which combination of `fast_period` and `slow_period` yields the highest net profit.
First, we fetch `JFC`'s historical data comprised of date, close price, and volume.
```
from fastquant import get_stock_data, backtest
symbol='JFC'
dcv_data = get_stock_data(symbol,
start_date='2018-01-01',
end_date='2020-04-28',
format='cv',
)
dcv_data.head()
import matplotlib.pyplot as pl
pl.style.use("default")
from fastquant import backtest
results = backtest("smac",
dcv_data,
fast_period=15,
slow_period=40,
verbose=False,
plot=True
)
```
The plot above is optional. `backtest` returns a dataframe of parameters and corresponding metrics:
```
results.head()
```
## define the search space
Second, we specify the range of reasonable values to explore for `fast_period` and `slow_period`. Let's take between 1 and 20 trading days (roughly a month) in steps of 1 day for `fast_period`, and between 21 and 240 trading days (roughly a year) in steps of 5 days for `slow_period`.
```
import numpy as np
fast_periods = np.arange(1,20,1, dtype=int)
slow_periods = np.arange(20,241,5, dtype=int)
# make a grid of 0's (placeholder)
period_grid = np.zeros(shape=(len(fast_periods),len(slow_periods)))
period_grid.shape
```
## run grid search
Third, we run backtest for each iteration over each pair of `fast_period` and `slow_period`, saving each time the net profit to the `period_grid` variable.
Note: Before running backtest over a large grid, try measuring how long it takes your machine to run one backtest instance.
```python
%timeit
backtest(...)
```
In my machine with 8 cores, `backtest` takes
```
101 ms ± 8.3 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
```
from time import time
init_cash=100000
start_time = time()
for i,fast_period in enumerate(fast_periods):
for j,slow_period in enumerate(slow_periods):
results = backtest('smac',
dcv_data,
fast_period=fast_period,
slow_period=slow_period,
init_cash=100000,
verbose=False,
plot=False
)
net_profit = results.final_value.values[0]-init_cash
period_grid[i,j] = net_profit
end_time = time()
time_basic = end_time-start_time
print("Basic grid search took {:.1f} sec".format(time_basic))
```
## visualize the period grid
Next, we visualize `period_grid` as a 2D matrix.
```
import matplotlib.colors as mcolors
import matplotlib.pyplot as pl
pl.style.use("default")
fig, ax = pl.subplots(1,1, figsize=(8,4))
xmin, xmax = slow_periods[0],slow_periods[-1]
ymin, ymax = fast_periods[0],fast_periods[-1]
#make a diverging color map such that profit<0 is red and blue otherwise
cmap = pl.get_cmap('RdBu')
norm = mcolors.TwoSlopeNorm(vmin=period_grid.min(),
vmax = period_grid.max(),
vcenter=0
)
#plot matrix
cbar = ax.imshow(period_grid,
origin='lower',
interpolation='none',
extent=[xmin, xmax, ymin, ymax],
cmap=cmap,
norm=norm
)
pl.colorbar(cbar, ax=ax, shrink=0.9,
label='net profit', orientation="horizontal")
# search position with highest net profit
y, x = np.unravel_index(np.argmax(period_grid), period_grid.shape)
best_slow_period = slow_periods[x]
best_fast_period = fast_periods[y]
# mark position
# ax.annotate(f"max profit={period_grid[y, x]:.0f}@({best_slow_period}, {best_fast_period}) days",
# (best_slow_period+5,best_fast_period+1)
# )
ax.axvline(best_slow_period, 0, 1, c='k', ls='--')
ax.axhline(best_fast_period+0.5, 0, 1, c='k', ls='--')
# add labels
ax.set_aspect(5)
pl.setp(ax,
xlim=(xmin,xmax),
ylim=(ymin,ymax),
xlabel='slow period (days)',
ylabel='fast period (days)',
title='JFC w/ SMAC',
);
print(f"max profit={period_grid[y, x]:.0f} @ ({best_slow_period},{best_fast_period}) days")
```
From the plot above, there are only a few period combinations which we can guarantee non-negative net profit using SMAC strategy. The best result is achieved with (105,30) for period_slow and period_fast, respectively.
In fact SMAC strategy is so bad such that there is only 9% chance it will yield profit when using any random period combinations in our grid, which is smaller than the 12% chance it will yield break even at least.
```
percent_positive_profit=(period_grid>0).sum()/np.product(period_grid.shape)*100
percent_positive_profit
percent_breakeven=(period_grid==0).sum()/np.product(period_grid.shape)*100
percent_breakeven
```
Anyway, let's check the results of backtest using the `best_fast_period` and `best_slow_period`.
```
results = backtest('smac',
dcv_data,
fast_period=best_fast_period,
slow_period=best_slow_period,
verbose=True,
plot=True
)
net_profit = results.final_value.values[0]-init_cash
net_profit
```
There are only 6 cross-over events of which only the latest transaction yielded positive gains resulting to a 7% net profit. Is 7% profit over a ~two-year baseline better than the market benchmark?
## built-in grid search in fastquant
The good news is `backtest` provides a built-in grid search if strategy parameters are lists. Let's re-run `backtest` with a grid we used above.
```
from fastquant import backtest
start_time = time()
results = backtest("smac",
dcv_data,
fast_period=fast_periods,
slow_period=slow_periods,
verbose=False,
plot=False
)
end_time = time()
time_optimized = end_time-start_time
print("Optimized grid search took {:.1f} sec".format(time_optimized))
```
`results` is automatically ranked based on `rnorm` which is a proxy for performance. In this case, the best `fast_period`,`slow_period`=(8,200) d.
The returned parameters are should have `len(fast_periods)`x`len(slow_periods)` (19x45=855 in this case).
```
results.shape
results.head()
```
Now, we recreate the 2D matrix before, but this time using scatter plot.
```
fig, ax = pl.subplots(1,1, figsize=(8,4))
#make a diverging color map such that profit<0 is red and blue otherwise
cmap = pl.get_cmap('RdBu')
norm = mcolors.TwoSlopeNorm(vmin=period_grid.min(),
vmax = period_grid.max(),
vcenter=0
)
#plot scatter
results['net_profit'] = results['final_value']-results['init_cash']
df = results[['slow_period','fast_period','net_profit']]
ax2 = df.plot.scatter(x='slow_period', y='fast_period', c='net_profit',
norm=norm, cmap=cmap, ax=ax
)
ymin,ymax = df.fast_period.min(), df.fast_period.max()
xmin,xmax = df.slow_period.min(), df.slow_period.max()
# best performance (instead of highest profit)
best_fast_period, best_slow_period, net_profit = df.loc[0,['fast_period','slow_period','net_profit']]
# mark position
# ax.annotate(f"max profit={net_profit:.0f}@({best_slow_period}, {best_fast_period}) days",
# (best_slow_period-100,best_fast_period+1), color='r'
# )
ax.axvline(best_slow_period, 0, 1, c='r', ls='--')
ax.axhline(best_fast_period+0.5, 0, 1, c='r', ls='--')
ax.set_aspect(5)
pl.setp(ax,
xlim=(xmin,xmax),
ylim=(ymin,ymax),
xlabel='slow period (days)',
ylabel='fast period (days)',
title='JFC w/ SMAC',
);
# fig.colorbar(ax2, orientation="horizontal", shrink=0.9, label='net profit')
print(f"max profit={net_profit:.0f} @ ({best_slow_period},{best_fast_period}) days")
```
Note also that built-in grid search in `backtest` is optimized and slightly faster than the basic loop-based grid search.
```
#time
time_basic/time_optimized
```
## Final notes
While it is tempting to do a grid search over larger search space and finer resolutions, it is computationally expensive, inefficient, and prone to overfitting. There are better methods than brute force grid search which we will tackle in the next example.
As an exercise, it is good to try the following:
* Use different trading strategies and compare their results
* Use a longer data baseline
| github_jupyter |
## Preprocessing
```
# Import our dependencies
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
import tensorflow as tf
# Import and read the charity_data.csv.
import pandas as pd
application_df = pd.read_csv("Resources/charity_data.csv")
application_df.head()
# Drop the non-beneficial ID columns, 'EIN' and 'NAME'.
application_df = application_df.drop(columns = ['EIN','NAME'])
application_df.head()
# Determine the number of unique values in each column.
application_df.nunique()
# Look at APPLICATION_TYPE value counts for binning
app_type = application_df['APPLICATION_TYPE'].value_counts()
app_type
# Choose a cutoff value and create a list of application types to be replaced
# use the variable name `application_types_to_replace`
application_types_to_replace = list(app_type[ app_type < 500].index)
# Replace in dataframe
for app in application_types_to_replace:
application_df['APPLICATION_TYPE'] = application_df['APPLICATION_TYPE'].replace(app,"Other")
# Check to make sure binning was successful
application_df['APPLICATION_TYPE'].value_counts()
# Look at CLASSIFICATION value counts for binning
class_type = application_df['CLASSIFICATION'].value_counts()
class_type
# You may find it helpful to look at CLASSIFICATION value counts >1
class_type_greaterthan1 = class_type[class_type > 1]
class_type_greaterthan1.value_counts()
# Choose a cutoff value and create a list of classifications to be replaced
# use the variable name `classifications_to_replace`
classifications_to_replace = list(class_type[class_type < 100].index)
# Replace in dataframe
for cls in classifications_to_replace:
application_df['CLASSIFICATION'] = application_df['CLASSIFICATION'].replace(cls,"Other")
# Check to make sure binning was successful
application_df['CLASSIFICATION'].value_counts()
# Convert categorical data to numeric with `pd.get_dummies`
dummy_app_df = pd.get_dummies(application_df)
dummy_app_df.head()
# Split our preprocessed data into our features and target arrays
y = dummy_app_df['IS_SUCCESSFUL']
X = dummy_app_df.drop(columns=['IS_SUCCESSFUL'])
# Split the preprocessed data into a training and testing dataset
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 28)
# Create a StandardScaler instances
scaler = StandardScaler()
# Fit the StandardScaler
X_scaler = scaler.fit(X_train)
# Scale the data
X_train_scaled = X_scaler.transform(X_train)
X_test_scaled = X_scaler.transform(X_test)
print(X_train_scaled.shape)
```
## Compile, Train and Evaluate the Model
```
# Define the model - deep neural net, i.e., the number of input features and hidden nodes for each layer.
nn = tf.keras.models.Sequential()
# First hidden layer
nn.add(tf.keras.layers.Dense(units=80, activation ='relu', input_dim = 45))
# Second hidden layer
nn.add(tf.keras.layers.Dense(units=30, activation ='relu', input_dim = 45))
# Output layer
nn.add(tf.keras.layers.Dense(units=1, activation ='sigmoid'))
# Check the structure of the model
nn.summary()
# Compile the model
nn.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ["accuracy"])
# Train the model
nn_fit = nn.fit(X_train_scaled,y_train,epochs= 100)
# Evaluate the model using the test data
model_loss, model_accuracy = nn.evaluate(X_test_scaled,y_test,verbose=2)
print(f"Loss: {model_loss}, Accuracy: {model_accuracy}")
# Export our model to HDF5 file
nn.save('AlphabetSoupCharity.h5')
```
## Attempt 2
```
# Define the model - deep neural net, i.e., the number of input features and hidden nodes for each layer.
nn = tf.keras.models.Sequential()
# First hidden layer
nn.add(tf.keras.layers.Dense(units=80, activation ='relu', input_dim = 45))
# Second hidden layer
nn.add(tf.keras.layers.Dense(units=30, activation ='relu', input_dim = 45))
# Third hidden layer
nn.add(tf.keras.layers.Dense(units=5, activation ='relu', input_dim = 45))
# Output layer
nn.add(tf.keras.layers.Dense(units=1, activation ='sigmoid'))
# Check the structure of the model
nn.summary()
# Compile the model
nn.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ["accuracy"])
nn_fit = nn.fit(X_train_scaled,y_train,epochs= 100)
# Evaluate the model using the test data
model_loss, model_accuracy = nn.evaluate(X_test_scaled,y_test,verbose=2)
print(f"Loss: {model_loss}, Accuracy: {model_accuracy}")
# Export our model to HDF5 file
nn.save('AlphabetSoupCharity_Optimization.h5')
```
## Attempt 3
```
# Define the model - deep neural net, i.e., the number of input features and hidden nodes for each layer.
nn = tf.keras.models.Sequential()
# First hidden layer
nn.add(tf.keras.layers.Dense(units=80, activation ='relu', input_dim = 45))
# Second hidden layer
nn.add(tf.keras.layers.Dense(units=30, activation ='sigmoid', input_dim = 45))
# Third hidden layer
nn.add(tf.keras.layers.Dense(units=5, activation ='sigmoid', input_dim = 45))
# Output layer
nn.add(tf.keras.layers.Dense(units=1, activation ='sigmoid'))
# Check the structure of the model
nn.summary()
# Compile the model
nn.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ["accuracy"])
nn_fit = nn.fit(X_train_scaled,y_train,epochs= 200)
# Evaluate the model using the test data
model_loss, model_accuracy = nn.evaluate(X_test_scaled,y_test,verbose=2)
print(f"Loss: {model_loss}, Accuracy: {model_accuracy}")
# Export our model to HDF5 file
nn.save('AlphabetSoupCharity_Optimization2.h5')
```
| github_jupyter |
# Tabular Q-Learning From Scratch
### Custom Environment to train our model on
```
import gym
from gym import spaces
import numpy as np
import random
from copy import deepcopy
class gridworld_custom(gym.Env):
"""Custom Environment that follows gym interface"""
metadata = {'render.modes': ['human']}
def __init__(self, *args, **kwargs):
super(gridworld_custom, self).__init__()
self.current_step = 0
self.reward_range = (-10, 100)
self.action_space = spaces.Discrete(2)
self.observation_space = spaces.Box(low=np.array(
[0, 0]), high=np.array([4, 4]), dtype=np.int64)
self.target_coord = (4, 4)
self.death_coord = [(3, 1), (4, 2)]
def Reward_Function(self, obs):
if (obs[0] == self.target_coord[0] and obs[1] == self.target_coord[1]):
return 20
elif (obs[0] == self.death_coord[0][0] and obs[1] == self.death_coord[0][1]) or \
(obs[0] == self.death_coord[1][0] and obs[1] == self.death_coord[1][1]):
return -10
else:
return -1
return 0
def reset(self):
self.current_step = 0
self.prev_obs = [random.randint(0, 4), random.randint(0, 4)]
if (self.prev_obs[0] == self.target_coord[0] and self.prev_obs[1] == self.target_coord[1]):
return self.reset()
return self.prev_obs
def step(self, action):
action = int(action)
self.current_step += 1
obs = deepcopy(self.prev_obs)
if(action == 0):
if(self.prev_obs[0] < 4):
obs[0] = obs[0] + 1
else:
obs[0] = obs[0]
if(action == 1):
if(self.prev_obs[0] > 0):
obs[0] = obs[0] - 1
else:
obs[0] = obs[0]
if(action == 2):
if(self.prev_obs[1] < 4):
obs[1] = obs[1] + 1
else:
obs[1] = obs[1]
if(action == 3):
if(self.prev_obs[1] > 0):
obs[1] = obs[1] - 1
else:
obs[1] = obs[1]
reward = self.Reward_Function(obs)
if (obs[0] == self.target_coord[0] and obs[1] == self.target_coord[1]) or (self.current_step >= 250):
done = True
else:
done = False
self.prev_obs = obs
return obs, reward, done, {}
def render(self, mode='human', close=False):
for i in range(0, 5):
for j in range(0, 5):
if i == self.prev_obs[0] and j == self.prev_obs[1]:
print("*", end=" ")
elif i == self.target_coord[0] and j == self.target_coord[1]:
print("w", end=" ")
elif (i == self.death_coord[0][0] and j == self.death_coord[0][1]) or \
(i == self.death_coord[1][0] and j == self.death_coord[1][1]):
print("D", end=" ")
else:
print("_", end=" ")
print()
print()
print()
```
### Import Required Packages
```
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
import pandas as pd
#from tqdm.auto import tqdm
from tqdm import tqdm
```
### Build the q-learning class which contains the table storing all the q values for all states and actions
```
class q_learning():
def __init__(self):
self.q_table = pd.DataFrame(columns=['state', 'q_val_0', 'q_val_1', 'q_val_2', 'q_val_3'])
for i in range(5):
for j in range(5):
state_str = "("+str(i)+","+str(j)+")"
X = pd.DataFrame([[state_str, 0, 0, 0, 0]], columns=['state', 'q_val_0', 'q_val_1', 'q_val_2', 'q_val_3'])
self.q_table = self.q_table.append(X, ignore_index=True)
self.q_table = self.q_table.set_index('state')
self.gamma = 1
self.step_size = 0.8
def update_q_value(self, curr_state, prev_state, action, reward):
curr_state_str = "("+str(curr_state[0])+","+str(curr_state[1])+")"
prev_state_str = "("+str(prev_state[0])+","+str(prev_state[1])+")"
action_str = "q_val_"+str(action)
q_pred = self.q_table.loc[prev_state_str][action_str]
q_target = reward + self.gamma * np.max(self.q_table.loc[curr_state_str].to_numpy())
self.q_table.loc[prev_state_str][action_str] = q_pred + self.step_size * (q_target - q_pred)
def choose_action(self, curr_state):
curr_state_str = "("+str(curr_state[0])+","+str(curr_state[1])+")"
action = np.argmax(self.q_table.loc[curr_state_str].to_numpy())
return action
```
#### Check up the functionality of epsilon greedy. Just for reference.
```
epsilon = 1
epsilon_decay = 0.9997
episodes = 10000
epsilon_copy = deepcopy(epsilon)
eps = []
for i in range(episodes):
epsilon_copy = epsilon_copy * epsilon_decay
eps.append(epsilon_copy)
plt.plot(eps)
plt.show()
```
### Run everything.
```
env = gridworld_custom()
agent = q_learning()
pbar = tqdm(range(episodes))
for episode in pbar:
prev_obs = env.reset()
done = False
epsilon = epsilon * epsilon_decay
while not(done):
if(random.uniform(0, 1) > epsilon):
action = agent.choose_action(prev_obs)
else:
action = random.randint(0,3)
obs, reward, done, _ = env.step(action)
agent.update_q_value(obs, prev_obs, action, reward)
prev_obs = deepcopy(obs)
```
### Take a look at the Q Table after training. Gives us an understanding as to how the model might function
```
agent.q_table
```
### Test the trained model
```
prev_obs = env.reset()
done = False
env.render()
while not(done):
action = agent.choose_action(prev_obs)
obs, reward, done, _ = env.step(action)
prev_obs = obs
env.render()
```
| github_jupyter |
# Abstractive Summarization
### Loading Pre-processed Dataset
The Data is preprocessed in [Data_Pre-Processing.ipynb](https://github.com/JRC1995/Abstractive-Summarization/blob/master/Data_Pre-Processing.ipynb)
Dataset source: https://www.kaggle.com/snap/amazon-fine-food-reviews
```
import json
with open('Processed_Data/Amazon_Reviews_Processed.json') as file:
for json_data in file:
saved_data = json.loads(json_data)
vocab2idx = saved_data["vocab"]
embd = saved_data["embd"]
train_batches_text = saved_data["train_batches_text"]
test_batches_text = saved_data["test_batches_text"]
val_batches_text = saved_data["val_batches_text"]
train_batches_summary = saved_data["train_batches_summary"]
test_batches_summary = saved_data["test_batches_summary"]
val_batches_summary = saved_data["val_batches_summary"]
train_batches_true_text_len = saved_data["train_batches_true_text_len"]
val_batches_true_text_len = saved_data["val_batches_true_text_len"]
test_batches_true_text_len = saved_data["test_batches_true_text_len"]
train_batches_true_summary_len = saved_data["train_batches_true_summary_len"]
val_batches_true_summary_len = saved_data["val_batches_true_summary_len"]
test_batches_true_summary_len = saved_data["test_batches_true_summary_len"]
break
idx2vocab = {v:k for k,v in vocab2idx.items()}
```
## Hyperparameters
```
hidden_size = 300
learning_rate = 0.001
epochs = 5
max_summary_len = 16 # should be summary_max_len as used in data_preprocessing with +1 (+1 for <EOS>)
D = 5 # D determines local attention window size
window_len = 2*D+1
l2=1e-6
```
## Tensorflow Placeholders
```
import tensorflow as tf
embd_dim = len(embd[0])
tf_text = tf.placeholder(tf.int32, [None, None])
tf_embd = tf.placeholder(tf.float32, [len(vocab2idx),embd_dim])
tf_true_summary_len = tf.placeholder(tf.int32, [None])
tf_summary = tf.placeholder(tf.int32,[None, None])
tf_train = tf.placeholder(tf.bool)
```
## Embed vectorized text
Dropout used for regularization
(https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf)
```
embd_text = tf.nn.embedding_lookup(tf_embd, tf_text)
embd_text = tf.layers.dropout(embd_text,rate=0.3,training=tf_train)
```
## LSTM function
More info:
<br>
https://dl.acm.org/citation.cfm?id=1246450,
<br>
https://www.bioinf.jku.at/publications/older/2604.pdf,
<br>
https://en.wikipedia.org/wiki/Long_short-term_memory
```
def LSTM(x,hidden_state,cell,input_dim,hidden_size,scope):
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
w = tf.get_variable("w", shape=[4,input_dim,hidden_size],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
u = tf.get_variable("u", shape=[4,hidden_size,hidden_size],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
b = tf.get_variable("bias", shape=[4,1,hidden_size],
dtype=tf.float32,
trainable=True,
initializer=tf.zeros_initializer())
input_gate = tf.nn.sigmoid( tf.matmul(x,w[0]) + tf.matmul(hidden_state,u[0]) + b[0])
forget_gate = tf.nn.sigmoid( tf.matmul(x,w[1]) + tf.matmul(hidden_state,u[1]) + b[1])
output_gate = tf.nn.sigmoid( tf.matmul(x,w[2]) + tf.matmul(hidden_state,u[2]) + b[2])
cell_ = tf.nn.tanh( tf.matmul(x,w[3]) + tf.matmul(hidden_state,u[3]) + b[3])
cell = forget_gate*cell + input_gate*cell_
hidden_state = output_gate*tf.tanh(cell)
return hidden_state, cell
```
## Bi-Directional LSTM Encoder
(https://maxwell.ict.griffith.edu.au/spl/publications/papers/ieeesp97_schuster.pdf)
More Info: https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
Bi-directional LSTM encoder has a forward encoder and a backward encoder. The forward encoder encodes a text sequence from start to end, and the backward encoder encodes the text sequence from end to start.
The final output is a combination (in this case, a concatenation) of the forward encoded text and the backward encoded text
## Forward Encoding
```
S = tf.shape(embd_text)[1] #text sequence length
N = tf.shape(embd_text)[0] #batch_size
i=0
hidden=tf.zeros([N, hidden_size], dtype=tf.float32)
cell=tf.zeros([N, hidden_size], dtype=tf.float32)
hidden_forward=tf.TensorArray(size=S, dtype=tf.float32)
#shape of embd_text: [N,S,embd_dim]
embd_text_t = tf.transpose(embd_text,[1,0,2])
#current shape of embd_text: [S,N,embd_dim]
def cond(i, hidden, cell, hidden_forward):
return i < S
def body(i, hidden, cell, hidden_forward):
x = embd_text_t[i]
hidden,cell = LSTM(x,hidden,cell,embd_dim,hidden_size,scope="forward_encoder")
hidden_forward = hidden_forward.write(i, hidden)
return i+1, hidden, cell, hidden_forward
_, _, _, hidden_forward = tf.while_loop(cond, body, [i, hidden, cell, hidden_forward])
```
## Backward Encoding
```
i=S-1
hidden=tf.zeros([N, hidden_size], dtype=tf.float32)
cell=tf.zeros([N, hidden_size], dtype=tf.float32)
hidden_backward=tf.TensorArray(size=S, dtype=tf.float32)
def cond(i, hidden, cell, hidden_backward):
return i >= 0
def body(i, hidden, cell, hidden_backward):
x = embd_text_t[i]
hidden,cell = LSTM(x,hidden,cell,embd_dim,hidden_size,scope="backward_encoder")
hidden_backward = hidden_backward.write(i, hidden)
return i-1, hidden, cell, hidden_backward
_, _, _, hidden_backward = tf.while_loop(cond, body, [i, hidden, cell, hidden_backward])
```
## Merge Forward and Backward Encoder Hidden States
```
hidden_forward = hidden_forward.stack()
hidden_backward = hidden_backward.stack()
encoder_states = tf.concat([hidden_forward,hidden_backward],axis=-1)
encoder_states = tf.transpose(encoder_states,[1,0,2])
encoder_states = tf.layers.dropout(encoder_states,rate=0.3,training=tf_train)
final_encoded_state = tf.layers.dropout(tf.concat([hidden_forward[-1],hidden_backward[-1]],axis=-1),rate=0.3,training=tf_train)
```
## Implementation of attention scoring function
Given a sequence of encoder states ($H_s$) and the decoder hidden state ($H_t$) of current timestep $t$, the equation for computing attention score is:
$$Score = (H_s.W_a).H_t^T $$
($W_a$ = trainable parameters)
(https://nlp.stanford.edu/pubs/emnlp15_attn.pdf)
```
def attention_score(encoder_states,decoder_hidden_state,scope="attention_score"):
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
Wa = tf.get_variable("Wa", shape=[2*hidden_size,2*hidden_size],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
encoder_states = tf.reshape(encoder_states,[N*S,2*hidden_size])
encoder_states = tf.reshape(tf.matmul(encoder_states,Wa),[N,S,2*hidden_size])
decoder_hidden_state = tf.reshape(decoder_hidden_state,[N,2*hidden_size,1])
return tf.reshape(tf.matmul(encoder_states,decoder_hidden_state),[N,S])
```
## Local Attention Function
Based on: https://nlp.stanford.edu/pubs/emnlp15_attn.pdf
```
def align(encoder_states, decoder_hidden_state,scope="attention"):
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
Wp = tf.get_variable("Wp", shape=[2*hidden_size,125],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
Vp = tf.get_variable("Vp", shape=[125,1],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
positions = tf.cast(S-window_len,dtype=tf.float32) # Maximum valid attention window starting position
# Predict attention window starting position
ps = positions*tf.nn.sigmoid(tf.matmul(tf.tanh(tf.matmul(decoder_hidden_state,Wp)),Vp))
# ps = (soft-)predicted starting position of attention window
pt = ps+D # pt = center of attention window where the whole window length is 2*D+1
pt = tf.reshape(pt,[N])
i = 0
gaussian_position_based_scores = tf.TensorArray(size=S,dtype=tf.float32)
sigma = tf.constant(D/2,dtype=tf.float32)
def cond(i,gaussian_position_based_scores):
return i < S
def body(i,gaussian_position_based_scores):
score = tf.exp(-((tf.square(tf.cast(i,tf.float32)-pt))/(2*tf.square(sigma))))
# (equation (10) in https://nlp.stanford.edu/pubs/emnlp15_attn.pdf)
gaussian_position_based_scores = gaussian_position_based_scores.write(i,score)
return i+1,gaussian_position_based_scores
i,gaussian_position_based_scores = tf.while_loop(cond,body,[i,gaussian_position_based_scores])
gaussian_position_based_scores = gaussian_position_based_scores.stack()
gaussian_position_based_scores = tf.transpose(gaussian_position_based_scores,[1,0])
gaussian_position_based_scores = tf.reshape(gaussian_position_based_scores,[N,S])
scores = attention_score(encoder_states,decoder_hidden_state)*gaussian_position_based_scores
scores = tf.nn.softmax(scores,axis=-1)
return tf.reshape(scores,[N,S,1])
```
## LSTM Decoder With Local Attention
```
with tf.variable_scope("decoder",reuse=tf.AUTO_REUSE):
SOS = tf.get_variable("sos", shape=[1,embd_dim],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
# SOS represents starting marker
# It tells the decoder that it is about to decode the first word of the output
# I have set SOS as a trainable parameter
Wc = tf.get_variable("Wc", shape=[4*hidden_size,embd_dim],
dtype=tf.float32,
trainable=True,
initializer=tf.glorot_uniform_initializer())
SOS = tf.tile(SOS,[N,1]) #now SOS shape: [N,embd_dim]
inp = SOS
hidden=final_encoded_state
cell=tf.zeros([N, 2*hidden_size], dtype=tf.float32)
decoder_outputs=tf.TensorArray(size=max_summary_len, dtype=tf.float32)
outputs=tf.TensorArray(size=max_summary_len, dtype=tf.int32)
for i in range(max_summary_len):
inp = tf.layers.dropout(inp,rate=0.3,training=tf_train)
attention_scores = align(encoder_states,hidden)
encoder_context_vector = tf.reduce_sum(encoder_states*attention_scores,axis=1)
hidden,cell = LSTM(inp,hidden,cell,embd_dim,2*hidden_size,scope="decoder")
hidden_ = tf.layers.dropout(hidden,rate=0.3,training=tf_train)
concated = tf.concat([hidden_,encoder_context_vector],axis=-1)
linear_out = tf.nn.tanh(tf.matmul(concated,Wc))
decoder_output = tf.matmul(linear_out,tf.transpose(tf_embd,[1,0]))
# produce unnormalized probability distribution over vocabulary
decoder_outputs = decoder_outputs.write(i,decoder_output)
# Pick out most probable vocab indices based on the unnormalized probability distribution
next_word_vec = tf.cast(tf.argmax(decoder_output,1),tf.int32)
next_word_vec = tf.reshape(next_word_vec, [N])
outputs = outputs.write(i,next_word_vec)
next_word = tf.nn.embedding_lookup(tf_embd, next_word_vec)
inp = tf.reshape(next_word, [N, embd_dim])
decoder_outputs = decoder_outputs.stack()
outputs = outputs.stack()
decoder_outputs = tf.transpose(decoder_outputs,[1,0,2])
outputs = tf.transpose(outputs,[1,0])
```
## Define Cross Entropy Cost Function and L2 Regularization
```
filtered_trainables = [var for var in tf.trainable_variables() if
not("Bias" in var.name or "bias" in var.name
or "noreg" in var.name)]
regularization = tf.reduce_sum([tf.nn.l2_loss(var) for var
in filtered_trainables])
with tf.variable_scope("loss"):
epsilon = tf.constant(1e-9, tf.float32)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf_summary, logits=decoder_outputs)
pad_mask = tf.sequence_mask(tf_true_summary_len,
maxlen=max_summary_len,
dtype=tf.float32)
masked_cross_entropy = cross_entropy*pad_mask
cost = tf.reduce_mean(masked_cross_entropy) + \
l2*regularization
cross_entropy = tf.reduce_mean(masked_cross_entropy)
```
## Accuracy
```
# Comparing predicted sequence with labels
comparison = tf.cast(tf.equal(outputs, tf_summary),
tf.float32)
# Masking to ignore the effect of pads while calculating accuracy
pad_mask = tf.sequence_mask(tf_true_summary_len,
maxlen=max_summary_len,
dtype=tf.bool)
masked_comparison = tf.boolean_mask(comparison, pad_mask)
# Accuracy
accuracy = tf.reduce_mean(masked_comparison)
```
## Define Optimizer
```
all_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
optimizer = tf.contrib.opt.NadamOptimizer(
learning_rate=learning_rate)
gvs = optimizer.compute_gradients(cost, var_list=all_vars)
capped_gvs = [(tf.clip_by_norm(grad, 5), var) for grad, var in gvs] # Gradient Clipping
train_op = optimizer.apply_gradients(capped_gvs)
```
## Training and Validation
```
import pickle
import random
with tf.Session() as sess: # Start Tensorflow Session
display_step = 100
patience = 5
load = input("\nLoad checkpoint? y/n: ")
print("")
saver = tf.train.Saver()
if load.lower() == 'y':
print('Loading pre-trained weights for the model...')
saver.restore(sess, 'Model_Backup/Seq2seq_summarization.ckpt')
sess.run(tf.global_variables())
sess.run(tf.tables_initializer())
with open('Model_Backup/Seq2seq_summarization.pkl', 'rb') as fp:
train_data = pickle.load(fp)
covered_epochs = train_data['covered_epochs']
best_loss = train_data['best_loss']
impatience = 0
print('\nRESTORATION COMPLETE\n')
else:
best_loss = 2**30
impatience = 0
covered_epochs = 0
init = tf.global_variables_initializer()
sess.run(init)
sess.run(tf.tables_initializer())
epoch=0
while (epoch+covered_epochs)<epochs:
print("\n\nSTARTING TRAINING\n\n")
batches_indices = [i for i in range(0, len(train_batches_text))]
random.shuffle(batches_indices)
total_train_acc = 0
total_train_loss = 0
for i in range(0, len(train_batches_text)):
j = int(batches_indices[i])
cost,prediction,\
acc, _ = sess.run([cross_entropy,
outputs,
accuracy,
train_op],
feed_dict={tf_text: train_batches_text[j],
tf_embd: embd,
tf_summary: train_batches_summary[j],
tf_true_summary_len: train_batches_true_summary_len[j],
tf_train: True})
total_train_acc += acc
total_train_loss += cost
if i % display_step == 0:
print("Iter "+str(i)+", Cost= " +
"{:.3f}".format(cost)+", Acc = " +
"{:.2f}%".format(acc*100))
if i % 500 == 0:
idx = random.randint(0,len(train_batches_text[j])-1)
text = " ".join([idx2vocab.get(vec,"<UNK>") for vec in train_batches_text[j][idx]])
predicted_summary = [idx2vocab.get(vec,"<UNK>") for vec in prediction[idx]]
actual_summary = [idx2vocab.get(vec,"<UNK>") for vec in train_batches_summary[j][idx]]
print("\nSample Text\n")
print(text)
print("\nSample Predicted Summary\n")
for word in predicted_summary:
if word == '<EOS>':
break
else:
print(word,end=" ")
print("\n\nSample Actual Summary\n")
for word in actual_summary:
if word == '<EOS>':
break
else:
print(word,end=" ")
print("\n\n")
print("\n\nSTARTING VALIDATION\n\n")
total_val_loss=0
total_val_acc=0
for i in range(0, len(val_batches_text)):
if i%100==0:
print("Validating data # {}".format(i))
cost, prediction,\
acc = sess.run([cross_entropy,
outputs,
accuracy],
feed_dict={tf_text: val_batches_text[i],
tf_embd: embd,
tf_summary: val_batches_summary[i],
tf_true_summary_len: val_batches_true_summary_len[i],
tf_train: False})
total_val_loss += cost
total_val_acc += acc
avg_val_loss = total_val_loss/len(val_batches_text)
print("\n\nEpoch: {}\n\n".format(epoch+covered_epochs))
print("Average Training Loss: {:.3f}".format(total_train_loss/len(train_batches_text)))
print("Average Training Accuracy: {:.2f}".format(100*total_train_acc/len(train_batches_text)))
print("Average Validation Loss: {:.3f}".format(avg_val_loss))
print("Average Validation Accuracy: {:.2f}".format(100*total_val_acc/len(val_batches_text)))
if (avg_val_loss < best_loss):
best_loss = avg_val_loss
save_data={'best_loss':best_loss,'covered_epochs':covered_epochs+epoch+1}
impatience=0
with open('Model_Backup/Seq2seq_summarization.pkl', 'wb') as fp:
pickle.dump(save_data, fp)
saver.save(sess, 'Model_Backup/Seq2seq_summarization.ckpt')
print("\nModel saved\n")
else:
impatience+=1
if impatience > patience:
break
epoch+=1
```
### Future Works
* Beam Search
* Pointer Mechanisms
* BLEU\ROUGE evaluation
* Implement Testing
* Complete Training and Optimize Hyperparameters
| github_jupyter |
```
import pandas as pd
import numpy as np
import lightgbm as lgb
from collections import OrderedDict
from sklearn.metrics import roc_auc_score
from tqdm import tqdm
from copy import deepcopy
from autowoe import ReportDeco, AutoWoE
```
### Чтение и подготовка обучающей выборки
```
train = pd.read_csv("./example_data/train_demo.csv",
low_memory=False,
index_col="line_id",
parse_dates = ["datetime_" + str(i) for i in range(2)],)
train = train.iloc[:, 50:100]
num_col = list(filter(lambda x: "numb" in x, train.columns))
num_feature_type = {x: "real" for x in num_col}
date_col = filter(lambda x: "datetime" in x, train.columns)
for col in date_col:
train[col + "_year"] = train[col].map(lambda x: x.year)
train[col + "_weekday"] = train[col].map(lambda x: x.weekday())
train[col + "_month"] = train[col].map(lambda x: x.month)
```
### Чтение и подготовка тестовой выборки
```
test = pd.read_csv("./example_data/test_demo.csv",
index_col="line_id",
parse_dates = ["datetime_" + str(i) for i in range(2)])
date_col = filter(lambda x: "datetime" in x, test.columns)
for col in date_col:
test[col + "_year"] = test[col].map(lambda x: x.year)
test[col + "_weekday"] = test[col].map(lambda x: x.weekday())
test[col + "_month"] = test[col].map(lambda x: x.month)
test_target = pd.read_csv("./example_data/test-target_demo.csv")["target"]
test["target"] = test_target.values
```
### Параметры модели
Для обучения модели рекомендуется указать тип признаков для обучения.
Поэтому создается словарь features_type с ключами:
"real" -- вещественный признак,
"cat" -- категориальный.
Для признаков, которые не размечены, типы будут определены автоматом. Такой вариант будет работать, но качество порядочно просядет
#### features_type
```
cat_col = list(filter(lambda x: "str" in x, train.columns))
cat_feature_type = {x: "cat" for x in cat_col}
year_col = list(filter(lambda x: "_year" in x, train.columns))
year_feature_type = {x: "cat" for x in year_col}
weekday_col = list(filter(lambda x: "_weekday" in x, train.columns))
weekday_feature_type = {x: "cat" for x in weekday_col}
month_col = list(filter(lambda x: "_month" in x, train.columns))
month_feature_type = {x: "cat" for x in month_col}
features = cat_col + year_col + weekday_col + month_col + num_col
```
#### Feature level constrains
```
features_type = dict(**num_feature_type,
**cat_feature_type,
**year_feature_type,
**weekday_feature_type,
**month_feature_type)
```
- `features_monotone_constraints` - также можно указать зависимость целевой переменной от признака. Если заранее известно, что при возрастании признака feature_1, то эту информацию можно учесть в модели, добавив в словарь пару {feature_1: "1"}. Если же зависимость признака от целевой переменной обратная, то можно указать {feature_1: "-1"} Если про зависимость ничего неизвестно, но хочется, чтобы она была монотонная, можно указать 'auto'. Можно указать {feature_1: "0"}, в случае, если установлено общее ограничение на монотонность, чтобы не распространять его на эту фичу. Если специальных условий нет, то можно не собирать этот дикт
Рекомендуемое использование:
1) В случае, если задано общее условие на монотонность, то можно собрать дикт {feature_1: "0", feature_2: "0"}, чтобы игнорировать это ограничение для признаков feature_1, feature_2
2) В случае, если не задано общее условие на монотонность, то можно собрать дикт {feature_1: "auto", feature_2: "auto"}, чтобы установить это ограничение для признаков feature_1, feature_2
```
features_monotone_constraints = {'number_74': 'auto', 'number_83': 'auto'}
```
- `max_bin_count` - через словарь max_bin_count можно задать число бинов для WoE кодирования, если для какого-то признака оно отлично от общего.
```
max_bin_count = {'number_47': 3, 'number_51': 2}
```
#### Рекомендация
В общем случае, в первый момент построения модели лучше не указывать специальных ограничений в features_monotone_constraints и max_bin_count. Если в результате анализа полученной модели разбиение оказалось неинтерпретируемым или нестабильным по отдельным признакам, но в целом по модели ок, то ограничить сложность разбиения отдельных призаков имеет смысл. Если разбивка большинства признаков в модели оказалась неудовлетворительная, то рекомендуется в первую очередь настраивать глобальные ограничения (см параметры модели max_bin_count, monotonic, min_bin_size и др ниже)
#### Общие параметры модели
- `interpreted_model` - требуется ли интерпретируемость модели (условие на знак в коэффициентах логистической регрессии)
- `monotonic` - Глобальное условие на монотонность. Если указано True, то для всех признаков по умолчанию будут строится только монотонные разбиения. Указать специальные условия для отдельных признаков можно используя features_monotone_constraints аргумент метода .fit
- `max_bin_count` - Глобальное ограничение на число бинов. Указать специальные условия для отдельных признаков можно используя max_bin_count аргумент метода .fit
- `select_type` - способ ПРЕДВАРИТЕЛЬНОГО!!! (ЭТО ВАЖНО) отбора признаков. Если указать None, то будут отобраны признаки, у которых importance больше imp_th. Если указвать, например 50, то после предварительного отобра останется только 50 признаков самых важных признаков. Крайне не рекомендуется сильно ограничивать
- `pearson_th` - пороговое значение для корреляции Пирсона. Используется на финальной стадии отбора признаков.
Если корреляция вух признаков по модулю больше pearson_th, то будет выброшен тот, у которого
информативность меньше
- `auc_th` - пороговое значение для одномерной оценки качества признака
- `vif_th` - пороговое значение для VIF признака
- `imp_th` - порог по которому будет произведен отбор признаков, если указать select_type=None (см. ниже).
- `th_const` порог по которому признак будет считаться константным. Все константные признаки в модели не учитываются. Если число валидных значений больше трешхолда, то колонка не константная (int). В случае указания float, трешхолд будет определяться как размер_выборки * th_const
- `force_single_split` - иногда в силу ограничений на min_bin_size невозможно построить ни одной группировки на переменную. force_single_split=True заставит в этом случае построить единственно возмоджный сплит, в случае если при этом выделяется группа размера более чем th_const. False будет выкидывать этот признак
- `th_nan` - порог по которому будет выделена отдельная категория для пропусков в данных.
Если число пропусков меньше чем th_nan, то WoE значения для пропусков берется равным нулю.
В противном случае пропущенные значения будут выделены в отдельную группу и для них отдельно
будет рассчитано WoE значение.
Так же влияет на редкие категории (менее th_cat). Если суммарно таких категорий будет менее th_nan, то обработка будет производиться по принципу отпределенному в `cat_merge_to`, иначе оценено по группе
- `th_cat` - порог, по которой немногочисленные категории в категориальных признаках будут объединятся в отдельную группу
- `woe_diff_th` - Возмодность смеджить наны и редкие категории с каким-то бином, если разница в вое менее woe_diff_th
- `min_bin_size` - минимальный размер бина при группировке. Возможно int как число наблюдений и float как доля от выбрки
- `min_bin_mults` - в ходе построения бинов будут протестированы возможные значения min_bin_size,
min_bin_size * min_bin_mults[0], min_bin_size * min_bin_mults[1] ... . Ждем float > 1. Дефолт - (2, 4), в принципе можно не трогать
- `min_gains_to_split` - возможные значения регуляризатора, которые будут протестированы в ходе построения биннинга
- `auc_tol` - Чувствительность к AUC. Считаем, что можем пожертвовать auc_tol качества от максимального, чтобы сделать модель проще
- `cat_alpha` - Регуляризатор для кодировщика категорий
- `cat_merge_to` - группа для редких (менее th_cat) категорий либо новых на тесте
"to_nan" -- в группу nan,
"to_woe_0" -- отдельная группа с WoE = 0,
"to_maxfreq" - в самую большую группу,
"to_maxp" - в группу с наибольшей вероятностью события,
"to_minp" - в группу с наименьшей вероятностью события
- `nan_merge_to` - группа для НаНов
"to_woe_0" -- отдельная группа с WoE = 0,
"to_maxfreq" - в самую большую группу,
"to_maxp" - в группу с наибольшей вероятностью события,
"to_minp" - в группу с наименьшей вероятностью события
- `oof_woe` - если указать oof_woe=True, то WoE кодирование будет происходить по кросс-валидации. Если же False, то сразу на всей обучающей выборке.
- `n_folds` - количество фолдов для внутренней кроссвалидации
- `n_jobs` - число процессов, которое будет использовать модель
- `l1_grid_size` - в данной модели на одном из шагов используется отбор признаков LASSO. l1_base_step -- размер сетки для перебора C
- `l1_exp_scale` - шкала сетки для L1 отбора. 4 соответствует макс значению C порядка 3-4. Увеличивать, если необходимо сделать менее регуляризованную модель
- `imp_type` - способ определения значимости признаков -- features importance ("feature_imp" - в общем случае более сложная модель) или permutation importance ("perm_imp" - в общем случае более простая модель)
- `regularized_refit` - после отбора признаков полученная модель пересчитывается на всех данных. Стоит ли включать L1 при этом. Если нет, то в интерпретируемом режиме модель будет итеративно переобучаться, пока все веса не станут отрицательны. Если да - то аналогичное будет получаться закручиванием L1. Может быть полезно ставить False если нужна стат модель, те p-value на оценки
- `p_val` - допустимый уровень p_value на оценки модели при условии обучении стат модели (regularized_refit=False)
```
auto_woe = AutoWoE(interpreted_model=True,
monotonic=False,
max_bin_count=5,
select_type=None,
pearson_th=0.9,
auc_th=.505,
vif_th=10.,
imp_th=0,
th_const=32,
force_single_split=True,
th_nan=0.01,
th_cat=0.005,
woe_diff_th=0.01,
min_bin_size=0.01,
min_bin_mults=(2, 4),
min_gains_to_split=(0.0, 0.5, 1.0),
auc_tol=1e-4,
cat_alpha=100,
cat_merge_to="to_woe_0",
nan_merge_to="to_woe_0",
oof_woe=True,
n_folds=6,
n_jobs=4,
l1_grid_size=20,
l1_exp_scale=6,
imp_type="feature_imp",
regularized_refit=False,
p_val=0.05,
debug=False,
verbose=0
)
auto_woe = ReportDeco(auto_woe)
```
- `train` обучающая выборка
- `target_name` - название целевой переменной
- `features_type` - см выше описание дикта features_type. Возможно указание None для автозаполнения, но не рекомендуется
- `group_kf` - название колонки-группы для GroupKFold https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GroupKFold.html
- `max_bin_count` - см выше описание дикта max_bin_count. Можно ничего не передавать, если специальных условий не предусмотрено. Общее для всех условние задано в __init__
- `features_monotone_constraints` - см выше описание дикта features_monotone_constraints. Можно ничего не передавать, если специальных условий не предусмотрено. Общее для всех условние задано в __init__
- `validation` - возможность использовать валидацию в построении/отборе признаков. Можно не передавать. На текущий момент используется для 1) отбора признаков по p-value при построении стат модели
```
auto_woe.fit(train[features + ['target']],
target_name="target",
features_type=features_type,
group_kf=None,
max_bin_count=max_bin_count,
features_monotone_constraints=features_monotone_constraints,
validation=test
)
pred = auto_woe.predict_proba(test)
roc_auc_score(test['target'], pred)
pred = auto_woe.predict_proba(test[['number_72']], report=False)
roc_auc_score(test['target'], pred)
print(auto_woe.get_sql_inference_query('table'))
```
### Полезные методы модели
- `private_features_type` - типизация признаков
- `get_woe` - рабиение на бины и WoE значения в них
- `get_split` - границы разбиения. Особо полезен для категориальных признаков
##### Замечание:
ReportDeco - обертка для построения отчета. Она не обязательна для обучения и применения модели, но обязательна для построения отчета (см последнюю ячейку).
Для доступа к атрибутам самой модели необходимо обратится к атрибуту auto_woe.model декоратора
Все атрибуты объекта-модели так же доступны через объект-отчета.
Однако в пикл отчета будет весить существенно больше, так что для сохранения модели на инференс стоит сохранять только auto_woe.model
### Формирование отчета
```
report_params = {"automl_date_column": "report_month", # колонка с датой в формате params['datetimeFormat']
"output_path": "./AUTOWOE_REPORT_1", # папка, куда сгенерится отчет и сложатся нужные файлы
"report_name": "___НАЗВАНИЕ ОТЧЕТА___",
"report_version_id": 1,
"city": "Воронеж",
"model_aim": "___ЦЕЛЬ ПОСТРОЕНИЯ МОДЕЛИ___",
"model_name": "___НАЗВАНИЕ МОДЕЛИ___",
"zakazchik": "___ЗАКАЗЧИК___",
"high_level_department": "___ПОДРАЗДЕЛЕНИЕ___",
"ds_name": "___РАЗРАБОТЧИК МОДЕЛИ___",
"target_descr": "___ОПИСАНИЕ ЦЕЛЕВОГО СОБЫТИЯ___",
"non_target_descr": "___ОПИСАНИЕ НЕЦЕЛЕВОГО СОБЫТИЯ___"}
auto_woe.generate_report(report_params)
```
| github_jupyter |
Discussion Analysis
===
Notebook for analysis of discussion done in Evidence and Reconsider tasks via the annotation web client.
```
import os
import re
import pandas as pd
import numpy as np
import sklearn
import sklearn.metrics
from collections import Counter
import itertools
import sqlite3
import sys
sys.path.append("../annotation_data")
import responsibility as responsibility_utils
from utils import get_webclient_url
annotation_web_client_database = "/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/cbAnnotator.sqlite"
def get_annotation_db():
db = sqlite3.connect(
annotation_web_client_database,
detect_types=sqlite3.PARSE_DECLTYPES
)
db.row_factory = sqlite3.Row
return db
def get_discussion_entries(responsibility, phase, evidence_user, reconsider_user):
try:
db = get_annotation_db()
cursor = db.execute(
"""SELECT * FROM discussionEntry
WHERE responsibility = ? AND phase = ? AND evidence_username = ? AND reconsider_username = ?
GROUP BY site_id, journal_oid
ORDER BY id DESC""",
(responsibility, phase, evidence_user, reconsider_user)
)
results = cursor.fetchall()
if results is None or len(results) == 0:
return None
data = []
for result in results:
site_id, journal_oid = result['site_id'], result['journal_oid']
highlighted_text, additional_discussion = result['highlighted_text'], result['additional_discussion']
is_annotation_changed = result['is_annotation_changed'] == 1
if additional_discussion.startswith("You indicated that this post does not contain the responsibility."):
if not is_annotation_changed:
print("WARNING: Forcibly changed is_annotation_changed based on assumption of looping.")
is_annotation_changed = True
data.append({
"phase": phase,
"responsibility": responsibility,
"site_id": site_id,
"journal_oid": journal_oid,
"highlighted_text": highlighted_text,
"additional_discussion": additional_discussion,
"is_annotation_changed": is_annotation_changed,
"evidence_username": evidence_user,
"reconsider_username": reconsider_user
})
return data
finally:
db.close()
```
### Experiment metadata
```
responsibility_list = ["coordinating_support",
"symptom_management",
"preparation",
"managing_transitions",
"info_filtering",
"continued_monitoring",
"clinical_decisions"]
user1 = "luoxx498"
user2 = "eriks074"
evidence_phase = "evidence"
reconsider_phase = "reconsider"
```
### Load data
```
all_rows = []
for phase in [evidence_phase, reconsider_phase]:
for users in [(user1, user2), (user2, user1)]:
evidence_username, reconsider_username = users
for responsibility in responsibility_list:
new_rows = get_discussion_entries(responsibility, phase, evidence_username, reconsider_username)
if new_rows is None:
print(responsibility, phase, evidence_username, reconsider_username)
continue
all_rows += new_rows
len(all_rows)
df = pd.DataFrame(all_rows)
df.head(n=4)
indices_to_drop = []
for key, group in df.groupby(by=("site_id", "journal_oid", "responsibility")):
assert len(group) <= 2, len(group)
if len(group) == 2:
evidence = group[group.phase == evidence_phase]
assert len(evidence) == 1
if evidence.iloc[0].is_annotation_changed:
indices_to_drop.append(evidence.index.values[0])
len(indices_to_drop)
orig_size = len(df)
df = df.drop(indices_to_drop)
new_size = len(df)
orig_size, new_size
```
### Analysis
```
# first, how many fall into the three conditions?
print("Evidence phase annotation changes")
for u1, u2 in [(user1, user2), (user2, user1)]:
print("Evidence tasks:", u1)
print("Reconsider tasks:", u2)
print("="*40)
for responsibility in responsibility_list:
df_subset = df[(df.phase == evidence_phase)
& (df.responsibility == responsibility)
& (df.evidence_username == u1)
& (df.reconsider_username == u2)]
total_changed = np.sum(df_subset.is_annotation_changed)
total = len(df_subset)
pct_changed = total_changed / total
print(f"{responsibility:20}{' ':10}{total_changed:2}/{total:2}{' ':10}{pct_changed*100:.1f}%")
print()
print("Reconsider phase annotation changes")
for u1, u2 in [(user1, user2), (user2, user1)]:
print("Evidence tasks:", u1)
print("Reconsider tasks:", u2)
print("="*40)
for responsibility in responsibility_list:
df_subset = df[(df.phase == reconsider_phase)
& (df.responsibility == responsibility)
& (df.evidence_username == u1)
& (df.reconsider_username == u2)]
total_changed = np.sum(df_subset.is_annotation_changed)
total = len(df_subset)
pct_changed = total_changed / total if total > 0 else 0
print(f"{responsibility:20}{' ':10}{total_changed:2}/{total:2}{' ':10}{pct_changed*100:.1f}%")
print()
```
### Irresolvable case analysis
```
print("Irresolvable disagreements from reconsider phase")
print("="*50)
u1_all_irresolvable = 0
u2_all_irresolvable = 0
u1_all_total = 0
u2_all_total = 0
for responsibility in responsibility_list:
df_subset = df[(df.phase == reconsider_phase)
& (df.responsibility == responsibility)
& (df.evidence_username == user1)
& (df.reconsider_username == user2)]
u2_irresolvable_count = np.sum(~df_subset.is_annotation_changed)
u2_total = len(df_subset)
df_subset = df[(df.phase == reconsider_phase)
& (df.responsibility == responsibility)
& (df.evidence_username == user2)
& (df.reconsider_username == user1)]
u1_irresolvable_count = np.sum(~df_subset.is_annotation_changed)
u1_total = len(df_subset)
u1_all_irresolvable += u1_irresolvable_count
u2_all_irresolvable += u2_irresolvable_count
u1_all_total += u1_total
u2_all_total += u2_total
print(f"{responsibility:20}{' ':5}{u2_irresolvable_count:2}/{u2_total:2}{' ':5}{u1_irresolvable_count:2}/{u1_total:2}{' ':5}{u1_irresolvable_count+u2_irresolvable_count:2}/{u1_total + u2_total:2}")
print()
pct_irresolvable = (u1_all_irresolvable+u2_all_irresolvable)/(u1_all_total + u2_all_total) * 100
print(f"{'Total':20}{' ':5}{u2_all_irresolvable:2}/{u2_all_total:2}{' ':5}{u1_all_irresolvable:2}/{u1_all_total:2}{' ':5}{u1_all_irresolvable+u2_all_irresolvable:2}/{u1_all_total + u2_all_total:2} ({pct_irresolvable:.2f}%)")
print()
# the original submission draft reports 26.3% of the updates as irresolvable,
# but I'm not actually sure where that number's coming from. Should probably be 25.7, so updated accordingly
df[(df.additional_discussion != "") & (df.phase == reconsider_phase) & (~df.is_annotation_changed)][["responsibility", "additional_discussion", "evidence_username", "reconsider_username", "is_annotation_changed"]]
```
Themes in comments:
- Evidence to me of a different responsibility (and thus not this one)
Takeaway: A problem with soft boundaries? Evidence that lies in margins especially hard to interpret
- Not clear enough (in other words, ambiguous)
- An edge case that falls just outside the boundary
Qualitative analysis of annotator comments in irresolvable cases reveals two primary themes: (1) disagreement about the directness of supporting evidence needed to assign a responsibility and (2) disagreement about which responsibility a piece of evidence indicates. These themes align with two significant dimensions of ambiguity identified by Chen et al.: (a) data ambiguity, meaning multiple reasonable interpretations, often due to missing or unclear context, and (b) human subjectivity, meaning distinct interpretations resulting from ''different levels of understanding or sets of experiences'' among annotators \cite{chen_using_2018}. Chen et al. further utilize disagreement between coders as a proxy for ambiguity, and the lower IRR scores relative to the phases indicates a higher degree of ambiguity. Could the primary dimension of ambiguity leading to low IRR scores be human subjectivity? Because the annotators are the same for both phases and responsibilities, it is unlikely.
Is data ambiguity excacerbated by soft boundaries in the codebook? The irresolvable cases suggest that it could, and that further attempts to clarify the boundaries between responsibilities and the types of evidence that constitute a responsibility could decrease ambiguity and improve IRR. However, expert feedback indicates that our operationalization is reasonable. These points of evidence suggest an inherent ambiguity to the classification task. Only real option is to choose a different classification task! (I think that's what I believe, sadly...)
These qualitative observations align with conceptualizations of ambiguity by Chen et al... and the low IRR indicates this!
Further, since the set of annotators for the phases and responsibilities are the same, along with comments from the coders, indicates that it may be primarily data ambiguity at play.
Coders are bad?
Same coders for phases and responsibilities, so they can't be!
Operationalization is wrong?
But experts think its fine!
Answer: there's inherently ambiguity! Chen et al indicates that low IRR indicates this!
### Discussion analysis
```
pd.set_option('display.max_colwidth', 255)
df[(df.additional_discussion != "") & (df.phase == evidence_phase)][["responsibility", "highlighted_text", "additional_discussion", "evidence_username", "reconsider_username", "is_annotation_changed"]]
df[(df.additional_discussion != "") & (df.phase == reconsider_phase)][["responsibility", "additional_discussion", "evidence_username", "reconsider_username", "is_annotation_changed"]]
```
| github_jupyter |
_Lambda School Data Science, Unit 2_
# Regression 2 Sprint Challenge: Predict drugstore sales 🏥
For your Sprint Challenge, you'll use real-world sales data from a German drugstore chain, from Jan 2, 2013 — July 31, 2015.
You are given three dataframes:
- `train`: historical sales data for 100 stores
- `test`: historical sales data for 100 different stores
- `store`: supplemental information about the stores
The train and test set do _not_ have different date ranges. But they _do_ have different store ids. Your task is _not_ to forecast future sales from past sales. **Your task is to predict sales at unknown stores, from sales at known stores.**
```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import category_encoders as ce
import eli5
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_squared_log_error
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from xgboost import XGBRegressor
from pdpbox.pdp import pdp_isolate, pdp_plot
from pdpbox.pdp import pdp_interact, pdp_interact_plot
from eli5.sklearn import PermutationImportance
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import pandas as pd
train = pd.read_csv('https://drive.google.com/uc?export=download&id=1E9rgiGf1f_WL2S4-V6gD7ZhB8r8Yb_lE')
test = pd.read_csv('https://drive.google.com/uc?export=download&id=1vkaVptn4TTYC9-YPZvbvmfDNHVR8aUml')
store = pd.read_csv('https://drive.google.com/uc?export=download&id=1rZD-V1mWydeytptQfr-NL7dBqre6lZMo')
assert train.shape == (78400, 7)
assert test.shape == (78400, 7)
assert store.shape == (200, 10)
```
The dataframes have a variety of columns:
- **Store** - a unique Id for each store
- **DayOfWeek** - integer, 1-6
- **Date** - the date, from Jan 2, 2013 — July 31, 2015.
- **Sales** - the units of inventory sold on a given date (this is the target you are predicting)
- **Customers** - the number of customers on a given date
- **Promo** - indicates whether a store is running a promo on that day
- **SchoolHoliday** - indicates the closure of public schools
- **StoreType** - differentiates between 4 different store models: a, b, c, d
- **Assortment** - describes an assortment level: a = basic, b = extra, c = extended
- **CompetitionDistance** - distance in meters to the nearest competitor store
- **CompetitionOpenSince[Month/Year]** - gives the approximate year and month of the time the nearest competitor was opened
- **Promo2** - Promo2 is a continuing and consecutive promotion for some stores: 0 = store is not participating, 1 = store is participating
- **Promo2Since[Year/Week]** - describes the year and calendar week when the store started participating in Promo2
- **PromoInterval** - describes the consecutive intervals Promo2 is started, naming the months the promotion is started anew. E.g. "Feb,May,Aug,Nov" means each round starts in February, May, August, November of any given year for that store
This Sprint Challenge has three parts. To demonstrate mastery on each part, do all the required instructions. To earn a score of "3" for the part, also do the stretch goals.
## 1. Wrangle relational data, Log-transform the target
- Merge the `store` dataframe with the `train` and `test` dataframes.
- Arrange the X matrix and y vector for the train and test sets.
- Log-transform the target for the train and test set.
- Plot the target's distribution for the train set, before and after the transformation.
#### Stretch goals
- Engineer 3+ more features.
```
store.head()
train.head()
test.head()
```
### Merge train, test and store
```
# Wrangle train, validation, and test sets
def wrangle(X):
X = X.copy()
# Engineer date features
X['Date'] = pd.to_datetime(X['Date'], infer_datetime_format=True)
X['date_year'] = X['Date'].dt.year
X['date_month'] = X['Date'].dt.month
X['date_day'] = X['Date'].dt.day
X = X.drop(columns='Date')
# Merge data
X = (X.merge(store, how='left').fillna(0))
return X
train = wrangle(train)
test = wrangle(test)
train.shape, test.shape
```
### Arrange X matrix and y target for train and test
```
target = 'Sales'
X_train = train.drop(columns=target)
X_test = test.drop(columns=target)
y_train = train[target]
y_test = test[target]
X_train.shape, X_test.shape, y_train.shape, y_test.shape
```
### log transform train and test target
```
y_train_log = np.log1p(y_train)
y_test_log = np.log1p(y_test)
```
### plot distribution of train target before and after transformation
```
sns.distplot(y_train);
sns.distplot(y_train_log);
```
## 2. Fit and validate your model
- **Use Gradient Boosting** or any type of regression model.
- **Beat the baseline:** The estimated baseline Root Mean Squared Logarithmic Error is 0.90, if we guessed the mean sales for every prediction. Remember that RMSE with the log-transformed target is equivalent to RMSLE with the original target. Try to get your error below 0.20.
- **To validate your model, choose any one of these options:**
- Split the train dataframe into train and validation sets. Put all dates for a given store into the same set. Use xgboost `early_stopping_rounds` with the validation set.
- Or, use scikit-learn `cross_val_score`. Put all dates for a given store into the same fold.
- Or, use scikit-learn `RandomizedSearchCV` for hyperparameter optimization. Put all dates for a given store into the same fold.
- **Get the Validation Error** (multiple times if you try multiple iterations) **and Test Error** (one time, at the end).
#### Stretch goal
- Optimize 3+ hyperparameters by searching 10+ "candidates" (possible combinations of hyperparameters).
```
def rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true, y_pred))
def rmsle(y_true, y_pred):
return np.sqrt(mean_squared_log_error(y_true, y_pred))
```
### Build baseline model
```
y_base = np.full_like(y_test_log, fill_value=y_train_log.mean())
print('Validation RMSLE, Mean Baseline:', rmse(y_test_log, y_base))
```
### Split train data into train and validate, put all dates for a given store in the same set
```
stores = train['Store'].unique()
train_stores, val_stores = train_test_split(
stores, random_state=42
)
train_stores = train[train.Store.isin(train_stores)]
val_stores = train[train.Store.isin(val_stores)]
assert train_stores.shape[0] + val_stores.shape[0] == train.shape[0]
target = 'Sales'
X_train = train_stores.drop(columns=target)
X_val = val_stores.drop(columns=target)
y_train = train_stores[target]
y_val = val_stores[target]
y_train_log = np.log1p(y_train)
y_val_log = np.log1p(y_val)
X_train.shape, X_val.shape
```
### Use XGBoost to predict target
```
# Make pipeline
pipeline = make_pipeline(
ce.OrdinalEncoder(),
XGBRegressor(
n_estimators=1000,
n_jobs=-1,
eval_metric='rmse',
early_stopping_rounds=10
)
)
# Fit
pipeline.fit(X_train, y_train_log)
# Validate
y_pred_log = pipeline.predict(X_val)
print('Validation Error', rmse(y_val_log, y_pred_log))
```
### Get the test error
```
y_pred_test = pipeline.predict(X_test)
print('Test Error', rmse(y_test_log, y_pred_test))
```
## 3. Plot model interpretation visualizations
- Choose any one of these options:
- Permutation Importances plot
- Partial Dependency Plot, 1 feature isolation
- Partial Dependency Plot, 2 feature interaction
#### Stretch goals
- Plot 2+ visualizations.
- Use permutation importances for feature selection.
```
X_val.columns
features = [
'date_month',
'date_day',
'DayOfWeek'
]
for feature in features:
isolated = pdp_isolate(
model=pipeline,
dataset=X_val,
model_features=X_val.columns,
feature=feature
)
pdp_plot(isolated, feature_name=feature);
```
| github_jupyter |
<a href="https://colab.research.google.com/github/olgOk/QCircuit/blob/master/tutorials/Deutsch_Algorithm.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Deutsch Algorithm
by Olga Okrut
Install frameworks, and import libraries
```
!pip install tensornetwork jax jaxlib colorama qcircuit
from qcircuit import QCircuit as qc
```
Now, after we have learned how quantum gates work and how to build a quantum circuit, we will jump to the first quantum algorithm. We begin with a very simple quantum algorithm - Deutsch algorithm, named after its inventor David Deutsch, which serves as an excellent proof of the supremacy of quantum computers and algorithms over classical.
The problem Deutsch algorithm tackles can now be stated as follows. Given a black box *Uf* implementing
some unknown binary function *f* that maps {0, 1} into {0, 1}.
We have to clasify *f* as “constant” or “balanced” function.
Here, constant means function always outputs the same bit, i.e. f(0) = f(1) = 1 or f(0) = f(1) = 0:

Balanced means function outputs different bits on different inputs, i.e. f(0) != f(1):

The circuit for Deutsch’s algoritm is given below. The steps for the Deutsch algorithm:
1. Prepare two qubits, one in state `1|0> + 0|1>` and the other in state `0|0> + 1|1>` (apply *X* gate on the second qubit).
2. Apply the Hadamard gate (*H*) on both qubits to bring them to superposition.
3. The output after the Hadamard transformation will be send through the gate *Uf*. The values of the *Uf* matrix depends on the *f(x)* function. That means that the state vector after the gate *Uf* depends on the function, e.g. constant or balanced function.
4. The output from the *Uf* transormation is send to the gates Hadarard again. It will collapse the state vector from the superposition to one of the possible state depending on the function *f(x)*.
5. The output from the Hadamard transformation will be a two qubit register. If all four possible function values are tested, it is revealed that the final output will be either `(0, 0), (0, 1), (1, 0), or (1, 1)` with probability of 1. The output value will depend on *f(x)*. The two qubits are entangled in the end, so only one of their values can be measured. This prevents us from known exactly which *f(x)* is being used. However, the first qubit in the pair will always be 1 if the function *f(x)* is **balanced**. If *f(x)* is **constant**, the algorithm outputs 0.

Now, let's create the quantum circuit above. We will use built-in method
```
Uf(function)
```
which translates a classcal binary function *f(x)* into a unitary matrix *U*, and applies it to the circuit. As a parameter, it takes a function that needs to be tested for being balanced or constant. I will use a set of predefined functions to show the validity of the algorithm.
```
# define binary functions. Some of them are constant, other balanced
def f1(x):
return x
def f2(x):
return 1
def f3(x):
return 0
def f4(x):
return not x
def f5(x):
return x ** 2
def f6(x):
return not (x ** 3)
def f7(x):
return (x % 3 == 2)
def f8(x):
return not (x % 3 == 2)
# check if the function constant
def is_const(func):
deutsch = qc.QCircuit(2)
deutsch.X(0)
deutsch.H(1)
deutsch.H(0)
deutsch.Uf(func)
deutsch.H(0)
deutsch.H(1)
# get output state vector
# decide if a function constanta or balanced
output_state = deutsch.get_state_vector()
if abs(output_state[0]) == 1.+0.j or abs(output_state[1]) == 1.+0.j:
return True
else:
return False
functions = [f1, f2, f3, f4, f5, f6, f7, f8]
for func in range(len(functions)):
print('function f{} is {}'.format(func+1, 'constant' if is_const(functions[func]) else 'balansed'))
```
| github_jupyter |
<h1>Table of Contents<span class="tocSkip"></span></h1>
<div class="toc"><ul class="toc-item"><li><span><a href="#Stop-Reinventing-Pandas" data-toc-modified-id="Stop-Reinventing-Pandas-1"><span class="toc-item-num">1 </span>Stop Reinventing Pandas</a></span></li><li><span><a href="#First-Hacks!" data-toc-modified-id="First-Hacks!-2"><span class="toc-item-num">2 </span>First Hacks!</a></span><ul class="toc-item"><li><span><a href="#Beautiful-pipes!" data-toc-modified-id="Beautiful-pipes!-2.1"><span class="toc-item-num">2.1 </span>Beautiful pipes!</a></span></li><li><span><a href="#The-Penny-Drops" data-toc-modified-id="The-Penny-Drops-2.2"><span class="toc-item-num">2.2 </span>The Penny Drops</a></span></li><li><span><a href="#Map-with-dict" data-toc-modified-id="Map-with-dict-2.3"><span class="toc-item-num">2.3 </span>Map with dict</a></span></li></ul></li><li><span><a href="#Time-Series" data-toc-modified-id="Time-Series-3"><span class="toc-item-num">3 </span>Time Series</a></span><ul class="toc-item"><li><span><a href="#Resample" data-toc-modified-id="Resample-3.1"><span class="toc-item-num">3.1 </span>Resample</a></span><ul class="toc-item"><li><span><a href="#The-Old-Way" data-toc-modified-id="The-Old-Way-3.1.1"><span class="toc-item-num">3.1.1 </span>The Old Way</a></span></li><li><span><a href="#A-Better-Way" data-toc-modified-id="A-Better-Way-3.1.2"><span class="toc-item-num">3.1.2 </span>A Better Way</a></span></li></ul></li><li><span><a href="#Slice-Easily" data-toc-modified-id="Slice-Easily-3.2"><span class="toc-item-num">3.2 </span>Slice Easily</a></span></li><li><span><a href="#Time-Windows:-Rolling,-Expanding,-EWM" data-toc-modified-id="Time-Windows:-Rolling,-Expanding,-EWM-3.3"><span class="toc-item-num">3.3 </span>Time Windows: Rolling, Expanding, EWM</a></span><ul class="toc-item"><li><span><a href="#With-Apply" data-toc-modified-id="With-Apply-3.3.1"><span class="toc-item-num">3.3.1 </span>With Apply</a></span></li></ul></li><li><span><a href="#Combine-with-GroupBy-🤯" data-toc-modified-id="Combine-with-GroupBy-🤯-3.4"><span class="toc-item-num">3.4 </span>Combine with GroupBy 🤯</a></span></li></ul></li><li><span><a href="#Sorting" data-toc-modified-id="Sorting-4"><span class="toc-item-num">4 </span>Sorting</a></span><ul class="toc-item"><li><span><a href="#By-Values" data-toc-modified-id="By-Values-4.1"><span class="toc-item-num">4.1 </span>By Values</a></span></li><li><span><a href="#By-Index" data-toc-modified-id="By-Index-4.2"><span class="toc-item-num">4.2 </span>By Index</a></span></li><li><span><a href="#By-Both-(New-in-0.23)" data-toc-modified-id="By-Both-(New-in-0.23)-4.3"><span class="toc-item-num">4.3 </span>By Both <span style="color: red">(New in 0.23)</span></a></span></li></ul></li><li><span><a href="#Stack,-Unstack" data-toc-modified-id="Stack,-Unstack-5"><span class="toc-item-num">5 </span>Stack, Unstack</a></span><ul class="toc-item"><li><span><a href="#Unstack" data-toc-modified-id="Unstack-5.1"><span class="toc-item-num">5.1 </span>Unstack</a></span><ul class="toc-item"><li><span><a href="#The-Old-way" data-toc-modified-id="The-Old-way-5.1.1"><span class="toc-item-num">5.1.1 </span>The Old way</a></span></li><li><span><a href="#A-better-way" data-toc-modified-id="A-better-way-5.1.2"><span class="toc-item-num">5.1.2 </span>A better way</a></span></li></ul></li><li><span><a href="#Unstack" data-toc-modified-id="Unstack-5.2"><span class="toc-item-num">5.2 </span>Unstack</a></span><ul class="toc-item"><li><span><a href="#Some-More-Hacks" data-toc-modified-id="Some-More-Hacks-5.2.1"><span class="toc-item-num">5.2.1 </span>Some More Hacks</a></span></li></ul></li></ul></li><li><span><a href="#GroupBy" data-toc-modified-id="GroupBy-6"><span class="toc-item-num">6 </span>GroupBy</a></span><ul class="toc-item"><li><span><a href="#Old-Ways" data-toc-modified-id="Old-Ways-6.1"><span class="toc-item-num">6.1 </span>Old Ways</a></span><ul class="toc-item"><li><span><a href="#List-Aggregates" data-toc-modified-id="List-Aggregates-6.1.1"><span class="toc-item-num">6.1.1 </span>List Aggregates</a></span></li><li><span><a href="#Dict-aggregate" data-toc-modified-id="Dict-aggregate-6.1.2"><span class="toc-item-num">6.1.2 </span>Dict aggregate</a></span></li><li><span><a href="#With-Rename" data-toc-modified-id="With-Rename-6.1.3"><span class="toc-item-num">6.1.3 </span>With Rename</a></span></li></ul></li><li><span><a href="#Named-Aggregations-(New-in-0.25)" data-toc-modified-id="Named-Aggregations-(New-in-0.25)-6.2"><span class="toc-item-num">6.2 </span>Named Aggregations <span style="color: red">(New in 0.25)</span></a></span></li></ul></li><li><span><a href="#Clip" data-toc-modified-id="Clip-7"><span class="toc-item-num">7 </span>Clip</a></span><ul class="toc-item"><li><span><a href="#The-Old-Way" data-toc-modified-id="The-Old-Way-7.1"><span class="toc-item-num">7.1 </span>The Old Way</a></span></li><li><span><a href="#A-better-way" data-toc-modified-id="A-better-way-7.2"><span class="toc-item-num">7.2 </span>A better way</a></span></li></ul></li><li><span><a href="#Reindex" data-toc-modified-id="Reindex-8"><span class="toc-item-num">8 </span>Reindex</a></span></li><li><span><a href="#Method-Chaining" data-toc-modified-id="Method-Chaining-9"><span class="toc-item-num">9 </span>Method Chaining</a></span><ul class="toc-item"><li><span><a href="#Assign" data-toc-modified-id="Assign-9.1"><span class="toc-item-num">9.1 </span>Assign</a></span><ul class="toc-item"><li><span><a href="#With-a-callable" data-toc-modified-id="With-a-callable-9.1.1"><span class="toc-item-num">9.1.1 </span>With a callable</a></span></li></ul></li><li><span><a href="#Pipe" data-toc-modified-id="Pipe-9.2"><span class="toc-item-num">9.2 </span>Pipe</a></span></li></ul></li><li><span><a href="#Beautiful-Code-Tells-a-Story" data-toc-modified-id="Beautiful-Code-Tells-a-Story-10"><span class="toc-item-num">10 </span>Beautiful Code Tells a Story</a></span></li><li><span><a href="#Bonus!" data-toc-modified-id="Bonus!-11"><span class="toc-item-num">11 </span>Bonus!</a></span><ul class="toc-item"><li><span><a href="#Percent-Change" data-toc-modified-id="Percent-Change-11.1"><span class="toc-item-num">11.1 </span>Percent Change</a></span></li><li><span><a href="#Interval-Index" data-toc-modified-id="Interval-Index-11.2"><span class="toc-item-num">11.2 </span>Interval Index</a></span></li><li><span><a href="#Split-Strings" data-toc-modified-id="Split-Strings-11.3"><span class="toc-item-num">11.3 </span>Split Strings</a></span></li><li><span><a href="#Toy-Examples-with-Pandas-Testing" data-toc-modified-id="Toy-Examples-with-Pandas-Testing-11.4"><span class="toc-item-num">11.4 </span>Toy Examples with Pandas Testing</a></span></li></ul></li><li><span><a href="#Research-with-Style!" data-toc-modified-id="Research-with-Style!-12"><span class="toc-item-num">12 </span>Research with Style!</a></span><ul class="toc-item"><li><span><a href="#Basic" data-toc-modified-id="Basic-12.1"><span class="toc-item-num">12.1 </span>Basic</a></span></li><li><span><a href="#Gradient" data-toc-modified-id="Gradient-12.2"><span class="toc-item-num">12.2 </span>Gradient</a></span></li><li><span><a href="#Custom" data-toc-modified-id="Custom-12.3"><span class="toc-item-num">12.3 </span>Custom</a></span></li><li><span><a href="#Bars" data-toc-modified-id="Bars-12.4"><span class="toc-item-num">12.4 </span>Bars</a></span></li></ul></li><li><span><a href="#You-don't-have-to-memorize-this" data-toc-modified-id="You-don't-have-to-memorize-this-13"><span class="toc-item-num">13 </span>You don't have to memorize this</a></span></li><li><span><a href="#Resources" data-toc-modified-id="Resources-14"><span class="toc-item-num">14 </span>Resources</a></span></li></ul></div>
# Stop Reinventing Pandas
The following post was presented as a talk for the [IE@DS](https://www.facebook.com/groups/173376299978861/) community, and for the [PyData meetup](https://www.meetup.com/PyData-Tel-Aviv/events/256232456/).
All the resources for this post, including a runable notebook, can be found in the [github repo](https://github.com/DeanLa/dont_reinvent_pandas)
blog post version here:
<span style="font-size:2em"> [DeanLa.com](http://deanla.com/)</span>

This notebook aims to show some nice ways modern Pandas makes your life easier. It is not about efficiency. I'm Pandas' built-in methods will be more efficient than reinventing pandas, but the main goal is to make the code easier to read, and more imoprtant - easier to write.

```
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['classic', 'ggplot', 'seaborn-poster', 'dean.style'])
%load_ext autoreload
%autoreload 2
import my_utils
import warnings
warnings.simplefilter("ignore")
```
# First Hacks!
Reading the data and a few housekeeping tasks. is the first place we can make our code more readable.
```
df_io = pd.read_csv('./bear_data.csv', index_col=0, parse_dates=['date_'])
df_io.head()
df = df_io.copy().sort_values('date_').set_index('date_').drop(columns='val_updated')
df.head()
```
## Beautiful pipes!
One line method chaining is hard to read and prone to human error, chaining each method in its own line makes it a lot more readable.
```
df_io\
.copy()\
.sort_values('date_')\
.set_index('date_')\
.drop(columns='val_updated')\
.head()
```
But it has a problem. You can't comment out and even comment in between
```
# This block will result in an error
df_io\
.copy()\ # This is an inline comment
# This is a regular comment
.sort_values('date_')\
# .set_index('date_')\
.drop(columns='val_updated')\
.head()
```
Even an unnoticeable space character may break everything
```
# This block will result in an error
df_io\
.copy()\
.sort_values('date_')\
.set_index('date_')\
.drop(columns='val_updated')\
.head()
```
## The Penny Drops
I like those "penny dropping" moments, when you realize you knew everything that is presented, yet it is presented in a new way you never thought of.
```
# We can split these value inside ()
users = (134856, 195373, 295817, 294003, 262166, 121066, 129678, 307120, 258759, 277922, 220794, 192312,
318486, 314631, 306448, 297059,206892,
169046, 181703, 146200, 199876, 247904, 250884, 282989, 234280, 202520,
138064, 133577, 301053, 242157)
# Penny Drop: We can also Split here
df = (df_io
.copy() # This is an inline comment
# This is a regular comment
.sort_values('date_')
.set_index('date_')
.drop(columns='val_updated')
)
df.head()
```
## Map with dict
A dict is a callable with $f(key) = value$, there for you can call `.map` with it. In this example I want to make int key codes into letter.
```
df.bear_type.map(lambda x: x+3).head()
# A dict is also a callable
bears = {
1: 'Grizzly',
2: 'Sun',
3: 'Pizzly',
4: 'Sloth',
5: 'Polar',
6: 'Cave',
7: 'Black',
8: 'Panda'
}
df['bear_type'] = df.bear_type.map(bears)
df.head()
```
# Time Series
## Resample
Task: How many events happen each hour?
### The Old Way
```
bad = df.copy()
bad['day'] = bad.index.date
bad['hour'] = bad.index.hour
(bad
.groupby(['day','hour'])
.count()
)
```
* Many lines of code
* unneeded columns
* Index is not a time anymore
* **missing rows** (Did you notice?)
### A Better Way
```
df.resample('H').count() # H is for Hour
```
But it's even better on non-round intervals
```
rs = df.resample('10T').count()
# T is for Minute, and pandas understands 10 T, it will also under stand 11T if you wonder
rs.head()
```
[Complete list of Pandas' time abbrevations](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Period.strftime.html)
## Slice Easily
Pandas will automatically make string into timestamps, and it will understand what you want it to do.
```
# Take only timestamp in the hour of 21:00.
rs.loc['2018-10-09 21',:]
# Take all time stamps before 18:31
rs.loc[:'2018-10-09 18:31',:]
```
## Time Windows: Rolling, Expanding, EWM
If your Dataframe is indexed on a time index (Which we have)
```
fig, ax = plt.subplots()
rs.rename(columns = {'bear_type':'bears'}).plot(ax=ax,linestyle='--')
(rs
.rolling('90T')
.mean()
.rename(columns = {'bear_type':'rolling mean'})
.plot(ax=ax)
)
rs.expanding().mean().rename(columns = {'bear_type':'expanding mean'}).plot(ax=ax)
rs.ewm(6).mean().rename(columns = {'bear_type':'ewm mean'}).plot(ax=ax)
plt.show()
```
### With Apply
Intuitively, windows are like GroupBy, so you can apply anything you want after the grouping, e.g.: geometric mean.
```
fig, ax = plt.subplots()
rs.plot(ax=ax,linestyle='--')
(rs
.rolling(6)
.apply(lambda x: np.power(np.product(x),1/len(x)),raw=True)
.rename(columns = {'bear_type':'Rolling Geometric Mean'})
.plot(ax=ax)
)
plt.show()
```
## Combine with GroupBy 🤯
Pandas has no problem with groupby and resample together. It's as simple as `groupby[col1,col2]`. In our specific case, we want to cound events in an interval per event type.
```
per_bear = (df
.groupby('bear_type')
.resample('15T')
.apply('count')
.rename(columns={'bear_type':'amount'})
)
per_bear.groupby('bear_type').head(2)
```
# Sorting
## By Values
```
per_bear.sort_values(by=['amount'], ascending=False).head(10)
```
## By Index
```
per_bear.sort_index().head(7)
per_bear.sort_index(level=1).head(7)
```
## By Both <span style="color:red">(New in 0.23)</span>
`Index` has a name. Modern Pandas knows to address this index by name just like a regular column.
```
per_bear.sort_values(['amount','bear_type'], ascending=(False, True)).head(10)
```
# Stack, Unstack
## Unstack
In this case, working with a wide format indexed on intervals, with event types as columns, will make a lot more sense.
### The Old way
Pivot table in modern pandas is more robust than it used to be. Still, it requires you to specify everything.
```
pt = pd.pivot_table(per_bear,values = 'amount',columns='bear_type',index='date_')
pt.head()
```
### A better way
When you have just one column of values, unstack does the same easily
```
pt = per_bear.unstack('bear_type')
pt.columns = pt.columns.droplevel() # Unstack creates a multiindex on columns
pt.head()
```
## Unstack
And some extra tricks
```
pt.stack().head()
```
This looks kind of what we had expected but:
* It's a series, not a DataFrame
* The levels of the index are "reversed" to before
* The main sort is on the date, yet it used to be on the event type
### Some More Hacks
```
stack_back = (pt
.stack()
.to_frame('amount') # Turn Series to DF without calling the DF constructor
.swaplevel() # Swaps the levels of the index
.sort_index()
)
stack_back.head()
stack_back.equals(per_bear)
```
# GroupBy
```sql
select min(B), avg(B), geometric_mean(B), min(C), max(C)
from pt
group by A
```
```
pt
```
## Old Ways
```
pt.groupby('Grizzly')['Polar'].agg(['min','mean']).head()
```
### List Aggregates
```
pt.groupby('Grizzly')[['Polar','Black']].agg(['min','mean',lambda x: x.prod()/len(x),'max']).head()
```
* Not what we wanted
* MultiIndex
* Names are not unique
* How do you access `<lambda_0>`
### Dict aggregate
```
pt.groupby('Grizzly').agg({'Polar':['min','mean',lambda x: x.prod()/len(x)],'Black':['min','max']})
```
### With Rename
```
pt.groupby('Grizzly').Polar.agg({'min_Polar':'min'})
warnings.simplefilter("ignore")
pt.groupby('Grizzly').agg({
'Polar':{'min_Polar':'min','avg_Polar':'mean','geo_Polar':lambda x: x.prod()/len(x)},
'Black':{'min_Black':'min','max_Black':'max'}
})
warnings.simplefilter("default")
```
Still a MultiIndex
## Named Aggregations <span style="color:red">(New in 0.25)</span>
This is also the way to go from `1.0.0` as others will be depracated
```
def geo(x):
return x.prod()/len(x)
pt.groupby('Grizzly').agg(
min_Polar = pd.NamedAgg(column='Polar', aggfunc='min'),
avg_Polar = pd.NamedAgg(column='Polar', aggfunc='mean'),
geo_Polar = pd.NamedAgg('Polar', geo),
# But actually NamedAgg is optional
min_Black = ('Black','min'),
max_Black = ('Black','max')
)
```
# Clip
Let's say, we know from domain knowledge the that an bear walks around a minimum of 3 and maximum of 12 times at each timestamp. We would like to fix that.
In a real world example, we many time want to turn negative numbers to zeroes or some truly big numbers to sum known max.
## The Old Way
Iterate over columns and change values that meet condition.
```
cl = pt.copy()
lb = 3
ub = 12
# Needed A loop of 3 lines
for col in ['Grizzly','Polar','Black']:
cl['clipped_{}'.format(col)] = cl[col]
cl.loc[cl[col] < lb,'clipped_{}'.format(col)] = lb
cl.loc[cl[col] > ub,'clipped_{}'.format(col)] = ub
my_utils.plot_clipped(cl) # my_utils can be found in the github repo
```
## A better way
`.clip(lb,ub)`
```
cl = pt.copy()
cl['Grizzly'] = cl.Grizzly.clip(3,12)
cl = pt.copy()
# Beutiful One Liner
cl[['clipped_Grizzly','clipped_Polar','clipped_Black']] = cl.clip(5,12)
my_utils.plot_clipped(cl) # my_utils can be found in the github repo
```
# Reindex
Now we have 3 types of bears 17:00 to 23:00. But we were at the the park from 16:00 to 00:00. We've also been told that this park as Panda bears and Cave bears.
In the old way we would have this column assignment with a loop, and for the rows we would have maybe create a columns and do some join. A lot of work.
```
etypes = ['Grizzly','Polar','Black','Panda','Cave'] # New columns
# Define a date range - Pandas will automatically make this into an index
idx = pd.date_range(start='2018-10-09 16:00:00',end='2018-10-09 23:59:00',freq=pt.index.freq,tz='UTC')
type(idx)
pt.reindex(index=idx, columns=etypes, fill_value=0).head(8)
### Let's put this in a function - This will help us later.
def get_all_types_and_timestamps(df, min_date='2018-10-09 16:00:00',
max_date='2018-10-09 23:59:00',
etypes=['Grizzly','Polar','Black','Panda','Cave']):
ret = df.copy()
time_idx = pd.date_range(start=min_date,end=max_date,freq='15T',tz='UTC')
# Indices work like set. This is a good practive so we don't override our intended index
idx = ret.index.union(time_idx)
etypes = df.columns.union(set(etypes))
ret = ret.reindex(idx, columns=etypes, fill_value=0)
return ret
```
# Method Chaining
## Assign
Assign is for creating new columns on the dataframes. This is instead of
`df[new_col] = function(df[old_col])`. They are both one lines, but `.assign` doesn't break the flow.
```
pt.assign(mean_all = pt.mean(axis=1)).head()
```
### With a callable
This is good when we have a filtering phase before.
```
pt.assign(mean_all = lambda x: x.mean(axis=1)).head()
```
## Pipe
Think R's `%>%`, `.pipe` is a method that accepts a function. `pipe`, by default, assumes the first argument of this function is a dataframe and passes the current dataframe down the pipeline. The function should return a dataframe also, if you want to continue with the chaining. Yet, it can also return any other value if you put it in the last step.
This is incredibly valueable because it takes you one step further from "sql" where you do things "in reverse".
$f(g(h($ `df` $)))$ = `df.pipe(h).pipe(g).pipe(f)`
```
def add_to_col(df, col='Grizzly', n = 200):
ret = df.copy()
# A dataframe is mutable, if you don't copy it first, this is prone to many errors.
# I always copy when I enter a function, even if I'm sure it shouldn't change anything.
ret[col] = ret[col] + n
return ret
add_to_col(add_to_col(add_to_col(pt), 'Polar', 100), 'Black',500).head()
(pt
.pipe(add_to_col)
.pipe(add_to_col, col='Polar', n=100)
.pipe(add_to_col, col='Black', n=500)
.head(5))
```
You can always do this with multiple lines of `df = do_something(df)` but I think this method is more elegant.
# Beautiful Code Tells a Story
Your code is not just about making the computer do things. It's about telling a story of what you wish to happen. Sometimes other people will want to read you code. Most time, it is you 3 monhts in the future who will want to read it. Some say good code documents itself. I'm not that extreme, yet storytelling with code may save you from many lines of unnecessary comments.
The next and final block tells the story in one block. It's elegant, it tells a story. If you build utility functions and `pipe` them while following meaningful naming, they help tell a story. if you `assign` columns with meaningful names, they tell a story. you `drop`, you `apply`, you `read`, you `groupby` and you `resample` - they all tell a story.
(Well... Maybe they could have gone with better naming for `resample`)
```
df = (pd
.read_csv ('./bear_data.csv', index_col=0, parse_dates=['date_'])
.assign (bear_type=lambda df: df.bear_type.map(bears))
.sort_values ('date_')
.set_index ('date_')
.drop (columns='val_updated')
.groupby ('bear_type')
.resample ('15T')
.apply ('count')
.rename (columns={'bear_type': 'amount'})
.unstack ('bear_type')
.pipe (my_utils.remove_multi_index)
.pipe (get_all_types_and_timestamps) # Remember this from before?
.assign (mean_bears=lambda x: x.mean(axis=1))
.loc [:, ['mean_bears']]
.pipe (my_utils.make_sliding_time_windows, steps_back=6)
.dropna ()
)
df.head()
```
# Bonus!
Cool methods I've found but did not fit in the talk's flow.
<span style="font-size:2em"> [No Time?](#You-don't-have-to-memorize-this)</span>
```
src = df.copy().loc[:,['mean_bears']]
```
## Percent Change
```
src.assign(pct = src.pct_change()).head(11)
```
## Interval Index
Helps creating a "common language" when talking about time series aggregations.
```
src = df.copy()
ir = pd.interval_range(start=df.index.min(),
end=df.index.max() + df.index.freq,
freq=df.index.freq)
type(ir)
ir
try:
df.loc['2018-10-09 18:37',:] # Datetime Index
except Exception as e:
print (type(e), e)
# Will result error
src.index = ir # Interval Index
src.loc['2018-10-09 18:37',:]
src.loc['2018-10-09 18:37':'2018-10-09 19:03',:]
```
## Split Strings
The entire concept of strings is different in `1.0.0`
```
txt = pd.DataFrame({'text':['hello','dean langsam','diving into pandas is better than reinventing it']})
txt
txt.text.str.split()
txt.text.str.split(expand = True) # Expand to make it a dataframe
```
## Toy Examples with Pandas Testing
```
import pandas.util.testing as tm
tm.N, tm.K = 15, 10
st = pd.util.testing.makeTimeDataFrame() * 100
st
```
# Research with Style!

```
stnan = st.copy()
stnan[np.random.rand(*stnan.shape) < 0.05] = np.nan # Put some nans in it
```
## Basic
```
(stnan
.style
.highlight_null('red')
.highlight_max(color='steelblue', axis = 0) # Max each row
.highlight_min(color ='gold', axis = 1) # Min each columns
)
```
## Gradient
```
st.clip(0,100).style.background_gradient( cmap='Purples')
```
## Custom
```
def custom_style(val):
if val < -100:
return 'background-color:red'
elif val > 100:
return 'background-color:green'
elif abs(val) <20:
return 'background-color:yellow'
else:
return ''
st.style.applymap(custom_style)
```
## Bars
```
(st.style
.bar(subset=['A','D'],color='steelblue')
.bar(subset=['J'],color=['indianred','limegreen'], align='mid')
)
```
# You don't have to memorize this
Just put this in the back of your mind and remember that modern Pandas has so many superpowers. Just remember they exist, and google them when you actually need them.
Always, when I feel I'm insecure about Pandas, I go back to [Greg Reda](https://twitter.com/gjreda)'s [tweet](https://twitter.com/gjreda/status/1049694953687924737):

# Resources
* [Modern Pandas](https://tomaugspurger.github.io/modern-1-intro.html) by Tom Augspurger
* [Basic Time Series Manipulation with Pandas](https://towardsdatascience.com/basic-time-series-manipulation-with-pandas-4432afee64ea) by Laura Fedoruk
* [Pandas Docs](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.clip.html). You don't have to thoroughly go over everything, just randomly open a page in the docs and you're sure to learn a new thing.
| github_jupyter |
# Interacting with ProtoDash
In this notebook we'll combine the ProtoDash and the Partial Effects to obtain feature importances on the digits classifications task.
ProtoDash was proposed in _Gurumoorthy, Karthik & Dhurandhar, Amit & Cecchi, Guillermo & Aggarwal, Charu. (2019). Efficient Data Representation by Selecting Prototypes with Importance Weights. 260-269. 10.1109/ICDM.2019.00036_.
```
import numpy as np
import pandas as pd
# automatically differentiable implementation of numpy
import jax.numpy as jnp # v0.2.13
import shap #0.34.0
from sklearn.metrics import classification_report
from sklearn import datasets
from sklearn.model_selection import train_test_split
from IPython.display import display
import matplotlib.pyplot as plt
from itea.classification import ITEA_classifier
from itea.inspection import *
from sklearn.preprocessing import OneHotEncoder
from aix360.algorithms.protodash import ProtodashExplainer #0.2.1
import warnings
warnings.filterwarnings(action='ignore', module=r'itea')
digits_data = datasets.load_digits(n_class=10)
X, y = digits_data['data'], digits_data['target']
labels = digits_data['feature_names']
targets = digits_data['target_names']
X /= X.max(axis=1).reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
tfuncs = {
'id' : lambda x: x,
'sin': jnp.sin,
'cos': jnp.cos,
'tan': jnp.tan
}
clf = ITEA_classifier(
gens = 100,
popsize = 100,
max_terms = 40,
expolim = (0, 2),
verbose = 10,
tfuncs = tfuncs,
labels = labels,
simplify_method = None,
random_state = 42,
fit_kw = {'max_iter' : 5}
).fit(X_train, y_train)
final_itexpr = clf.bestsol_
final_itexpr.selected_features_
print(classification_report(
y_test,
final_itexpr.predict(X_test),
target_names=[str(t) for t in targets]
))
```
We can use the ``ITEA_summarizer`` to inspect the convergence during the evolution. In the cell below, we'll create 3 plots, one for the fitness (classification accuracy), one for the complexity (number of nodes if the IT expression was converted to a symbolic tree) and number of terms (number of IT terms of the solutions in the population for each generation).
```
fig, ax = plt.subplots(3, 1, figsize=(10, 8), sharex=True)
summarizer = ITEA_summarizer(itea=clf).fit(X_train, y_train).plot_convergence(
data=['fitness', 'complexity', 'n_terms'],
ax=ax,
show=False
)
plt.tight_layout()
plt.show()
# features are named pixel_x_y. Lets extract those coordinates and
# paint in a figure to show the selected features
selected_features = np.zeros((8, 8))
for feature_name, feature_importance in zip(
final_itexpr.selected_features_,
np.sum(final_itexpr.feature_importances_, axis=0)
):
x, y = feature_name[-3], feature_name[-1]
selected_features[int(x), int(y)] = feature_importance
fig, axs = plt.subplots(1, 1, figsize=(3,3))
axs.imshow(selected_features, cmap='gray_r')
axs.set_title(f"Selected features")
plt.tight_layout()
plt.show()
onehot_encoder = OneHotEncoder(sparse=False)
onehot_encoded = onehot_encoder.fit_transform(
np.hstack( (X_train, y_train.reshape(-1, 1)) ) )
explainer = ProtodashExplainer()
# call protodash explainer. We'll select 10 prototypes
# S contains indices of the selected prototypes
# W contains importance weights associated with the selected prototypes
(W, S, _) = explainer.explain(onehot_encoded, onehot_encoded, m=10)
from matplotlib import cm
fig, axs = plt.subplots(2, 5, figsize=(12,5))
# Showing 10 prototypes
for s, ax in zip(S, fig.axes):
ax.imshow(X_train[s].reshape(8, 8), cmap='gray_r')
ax.set_title(f"Prototype of class {y_train[s]}")
Z = X_train[s].reshape(8, 8)
levels = [0.1, 0.2, 0.4]
norm = cm.colors.Normalize(vmax=abs(Z).max(), vmin=-abs(Z).max())
cmap = cm.PRGn
cset2 = ax.contour(Z, levels, colors='y')
for c in cset2.collections:
c.set_linestyle('solid')
plt.tight_layout()
plt.show()
it_explainer = ITExpr_explainer(
itexpr=final_itexpr,
tfuncs=tfuncs
).fit(X_train, y_train)
fig, axs = plt.subplots(2, 5, figsize=(12,5))
for s, ax in zip(S, fig.axes):
importances = it_explainer.average_partial_effects(X_train[s, :].reshape(1, -1))[y_train[s]]
ax.imshow(importances.reshape(8, 8), cmap='gray_r')
ax.set_title(f"Feature importance\nprototype of class {y_train[s]}")
Z = X_train[s].reshape(8, 8)
levels = [0.1, 0.2, 0.4]
norm = cm.colors.Normalize(vmax=abs(Z).max(), vmin=-abs(Z).max())
cmap = cm.PRGn
cset2 = ax.contour(Z, levels, colors='y')
for c in cset2.collections:
c.set_linestyle('solid')
plt.tight_layout()
plt.show()
shap_explainer = shap.KernelExplainer(
final_itexpr.predict,
shap.sample(pd.DataFrame(X_train, columns=labels), 100)
)
fig, axs = plt.subplots(2, 5, figsize=(12,5))
for s, ax in zip(S, fig.axes):
importances = np.abs(shap_explainer.shap_values(
X_train[s, :].reshape(1, -1), silent=True, l1_reg='num_features(10)'))
ax.imshow(importances.reshape(8, 8), cmap='gray_r')
ax.set_title(f"Feature importance\nprototype of class {y_train[s]}")
Z = X_train[s].reshape(8, 8)
levels = [0.1, 0.2, 0.4]
norm = cm.colors.Normalize(vmax=abs(Z).max(), vmin=-abs(Z).max())
cmap = cm.PRGn
cset2 = ax.contour(Z, levels, colors='y')
for c in cset2.collections:
c.set_linestyle('solid')
plt.tight_layout()
plt.show()
it_explainer = ITExpr_explainer(
itexpr=final_itexpr,
tfuncs=tfuncs
).fit(X_train, y_train)
fig, axs = plt.subplots(2, 5, figsize=(12,5))
for c, ax in zip(final_itexpr.classes_, fig.axes):
c_idx = np.array([i for i in range(len(y_train)) if y_train[i]==c])
importances = it_explainer.average_partial_effects(X_train[c_idx, :])[c]
ax.imshow(importances.reshape(8, 8), cmap='gray_r')
ax.set_title(f"Feature importance\nprototype of class {c}")
Z = X_train[c_idx, :].mean(axis=0).reshape(8, 8)
levels = [0.1, 0.2, 0.4]
norm = cm.colors.Normalize(vmax=abs(Z).max(), vmin=-abs(Z).max())
cmap = cm.PRGn
cset2 = ax.contour(Z, levels, colors='y')
for c in cset2.collections:
c.set_linestyle('solid')
plt.tight_layout()
plt.show()
```
| github_jupyter |
<h2> 6. Bayes Classification </h2>
This notebook has the code for the charts in Chapter 6
### Install BigQuery module
You don't need this on AI Platform, but you need this on plain-old JupyterLab
```
!pip install google-cloud-bigquery
%load_ext google.cloud.bigquery
```
### Setup
```
import os
PROJECT = 'data-science-on-gcp-180606' # REPLACE WITH YOUR PROJECT ID
BUCKET = 'data-science-on-gcp' # REPLACE WITH YOUR BUCKET NAME
REGION = 'us-central1' # REPLACE WITH YOUR BUCKET REGION e.g. us-central1
os.environ['BUCKET'] = BUCKET
```
<h3> Exploration using BigQuery </h3>
```
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import google.cloud.bigquery as bigquery
bq = bigquery.Client()
sql = """
SELECT DISTANCE, DEP_DELAY
FROM `flights.tzcorr`
WHERE RAND() < 0.001 AND dep_delay > -20 AND dep_delay < 30 AND distance < 2000
"""
df = bq.query(sql).to_dataframe()
sns.set_style("whitegrid")
g = sns.jointplot(df['DISTANCE'], df['DEP_DELAY'], kind="hex", size=10, joint_kws={'gridsize':20})
```
<h3> Set up views in Spark SQL </h3>
Start a Spark Session if necessary and get a handle to it.
```
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Bayes classification using Spark") \
.getOrCreate()
print(spark)
```
Set up the schema to read in the CSV files on GCS
```
from pyspark.sql.types import StringType, FloatType, StructType, StructField
header = 'FL_DATE,UNIQUE_CARRIER,AIRLINE_ID,CARRIER,FL_NUM,ORIGIN_AIRPORT_ID,ORIGIN_AIRPORT_SEQ_ID,ORIGIN_CITY_MARKET_ID,ORIGIN,DEST_AIRPORT_ID,DEST_AIRPORT_SEQ_ID,DEST_CITY_MARKET_ID,DEST,CRS_DEP_TIME,DEP_TIME,DEP_DELAY,TAXI_OUT,WHEELS_OFF,WHEELS_ON,TAXI_IN,CRS_ARR_TIME,ARR_TIME,ARR_DELAY,CANCELLED,CANCELLATION_CODE,DIVERTED,DISTANCE,DEP_AIRPORT_LAT,DEP_AIRPORT_LON,DEP_AIRPORT_TZOFFSET,ARR_AIRPORT_LAT,ARR_AIRPORT_LON,ARR_AIRPORT_TZOFFSET,EVENT,NOTIFY_TIME'
def get_structfield(colname):
if colname in ['ARR_DELAY', 'DEP_DELAY', 'DISTANCE']:
return StructField(colname, FloatType(), True)
else:
return StructField(colname, StringType(), True)
schema = StructType([get_structfield(colname) for colname in header.split(',')])
print(schema)
```
Create a table definition (this is done lazily; the files won't be read until we issue a query):
```
inputs = 'gs://{}/flights/tzcorr/all_flights-00000-*'.format(BUCKET) # 1/30th
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
flights = spark.read\
.schema(schema)\
.csv(inputs)
# this view can now be queried ...
flights.createOrReplaceTempView('flights')
```
Example query over the view (this will take a while; it's Spark SQL, not BigQuery):
```
results = spark.sql('SELECT COUNT(*) FROM flights WHERE dep_delay > -20 AND distance < 2000')
results.show()
```
<h2> Restrict to train days </h2>
Let's create a CSV file of the training days
```
sql = """
SELECT *
FROM `flights.trainday`
"""
df = bq.query(sql).to_dataframe()
df.to_csv('trainday.csv', index=False)
!head -3 trainday.csv
%%bash
gsutil cp trainday.csv gs://${BUCKET}/flights/trainday.csv
```
Create dataframe of traindays, but this time because the file has a header, and is a small file, we can have Spark infer the schema
```
traindays = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.csv('gs://{}/flights/trainday.csv'.format(BUCKET))
traindays.createOrReplaceTempView('traindays')
results = spark.sql('SELECT * FROM traindays')
results.head(5)
statement = """
SELECT
f.FL_DATE AS date,
distance,
dep_delay
FROM flights f
JOIN traindays t
ON f.FL_DATE == t.FL_DATE
WHERE
t.is_train_day AND
f.dep_delay IS NOT NULL
ORDER BY
f.dep_delay DESC
"""
flights = spark.sql(statement)
```
<h3> Hexbin plot </h3>
Create a hexbin plot using Spark (repeat of what we did in BigQuery, except that we are now restricting to train days only).
```
df = flights[(flights['distance'] < 2000) & (flights['dep_delay'] > -20) & (flights['dep_delay'] < 30)]
df.describe().show()
```
Sample the dataframe so that it fits into memory (not a problem in development, but will be on full dataset); then plot it.
```
pdf = df.sample(False, 0.02, 20).toPandas() # to 100,000 rows approx on complete dataset
g = sns.jointplot(pdf['distance'], pdf['dep_delay'], kind="hex", size=10, joint_kws={'gridsize':20})
```
<h3> Quantization </h3>
Now find the quantiles
```
distthresh = flights.approxQuantile('distance', list(np.arange(0, 1.0, 0.1)), 0.02)
distthresh
delaythresh = flights.approxQuantile('dep_delay', list(np.arange(0, 1.0, 0.1)), 0.05)
delaythresh
results = spark.sql('SELECT COUNT(*) FROM flights WHERE dep_delay >= 3 AND dep_delay < 8 AND distance >= 447 AND distance < 557')
results.show()
```
<h2> Repeat, but on full dataset </h2>
You can launch the above processing on the full dataset from within JupyterLab if you want the statistics and graphs updated. I didn't, though, because this is not what I would have really done. Instead,
I would have created a standalone Python script and submitted it to the cluster -- there is no need to put JupyterLab in the middle of a production process. We'll submit a standalone Pig program to the cluster in the next section.
Steps:
<ol>
<li> Change the input variable to process all-flights-* </li>
<li> Increase cluster size (bash increase_cluster.sh from CloudShell) </li>
<li> Clear all cells from this notebook </li>
<li> Run all cells </li>
<li> Decrease cluster size (bash decrease_cluster.sh from CloudShell) </li>
</ol>
Copyright 2019 Google Inc. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
| github_jupyter |
```
import pandas as pd
from datetime import timedelta, date
import matplotlib.pyplot as plt
def append_it(date, amount,treasury,Agency,MBS, duration):
append_data = {'Date':[date], 'Amount':[amount], 'Duration':[duration],'Treasury':[treasury],'Agency':[Agency], 'MBS':[MBS]}
append_df = pd.DataFrame(append_data)
return append_df
print(repos)
data = {'Date':[date(2019, 9, 17)], 'Amount':[53.15], 'Treasury':[40.85], 'Agency':[0.6], 'MBS':[11.7], 'Duration':[1]}
repos = pd.DataFrame(data)
repos = repos.append(append_it(date(2019, 9, 18),75,51.55,0.7,22.75,1))
repos = repos.append(append_it(date(2019, 9, 19),75,55.843,0,19.157,1))
repos = repos.append(append_it(date(2019, 9, 20),75,59.6,0.5,15.350,3))
repos = repos.append(append_it(date(2019, 9, 23),67.75,49.7,0.6,15.45,1))
repos = repos.append(append_it(date(2019, 9, 24),30,22.732,0,7.268,14))
repos = repos.append(append_it(date(2019, 9, 24),75,58.75,.36,15.49,1))
repos = repos.append(append_it(date(2019, 9, 25),75,44.35,1,29.65,1))
repos = repos.append(append_it(date(2019, 9, 26),60,35.75,0,24.25,14))
repos = repos.append(append_it(date(2019, 9, 26),50.1,34.55,0,15.55,1))
repos = repos.append(append_it(date(2019, 9, 27),49,34.55,0,14.45,14))
repos = repos.append(append_it(date(2019, 9, 27),22.7,14.45,0,8.25,3))
repos = repos.append(append_it(date(2019, 9, 30),63.5,49.75,0,13.75,1))
repos = repos.append(append_it(date(2019, 10, 1),54.85,50.0,0.1,4.75,1))
repos = repos.append(append_it(date(2019, 10, 2),42.05,35.0,0,7.05,1))
repos = repos.append(append_it(date(2019, 10, 3),33.55,28.0,0,5.55,1))
repos = repos.append(append_it(date(2019, 10, 4),38.55,29.5,0,9.05,3))
repos = repos.append(append_it(date(2019, 10, 7),38.85,36.0,0,11.05,1))
repos = repos.append(append_it(date(2019, 10, 8),38.85,29.3,0,9.55,14))
repos = repos.append(append_it(date(2019, 10, 8),37.5,31.75,0,5.75,1))
repos = repos.append(append_it(date(2019, 10, 9),30.8,26.25,0,4.55,1))
repos = repos.append(append_it(date(2019, 10, 10),42.6,30.7,0,11.9,14))
repos = repos.append(append_it(date(2019, 10, 10),45.5,37.6,0.5,7.4,1))
repos = repos.append(append_it(date(2019, 10, 11),21.15,13.15,0,8.0,6))
repos = repos.append(append_it(date(2019, 10, 11),61.55,58.35,0,3.2,4))
repos = repos.append(append_it(date(2019, 10, 15),20.1,10.6,0,9.5,14))
repos = repos.append(append_it(date(2019, 10, 15),67.6,59.95,0,7.65,1))
repos = repos.append(append_it(date(2019, 10, 16),75,72.592,0,2.408,1))
repos = repos.append(append_it(date(2019, 10, 17),30.65,18.15,0,12.5,15))
repos = repos.append(append_it(date(2019, 10, 17),73.5,67.7,0.1,5.7,1))
repos = repos.append(append_it(date(2019, 10, 18),56.65,47.95,0.5,8.2,3))
repos = repos.append(append_it(date(2019, 10, 21),58.15,50.95,0.5,6.7,1))
repos = repos.append(append_it(date(2019, 10, 22),35,31.141,0,3.859,14))
repos = repos.append(append_it(date(2019, 10, 22),64.904,54.404,0,9.5,1))
repos = repos.reset_index(drop=True)
repos.tail(10)
def daterange(start_date, end_date):
for n in range(int ((end_date - start_date).days)):
yield start_date + timedelta(n)
#repos_amount = pd.DataFrame(columns=['foo', 'bar'])
repos_amount = pd.DataFrame(columns=['Date', 'Amount','Treasury','Agency', 'MBS'])
start_date = date(2019, 9, 17)
# ***** Make it one higher than you need *****
# ***** Make it one higher than you need *****
# ***** Make it one higher than you need *****
end_date = date(2019, 10, 22+1)
for single_date in daterange(start_date, end_date):
append_data = {'Date':[single_date], 'Amount': 0,'Treasury':0,'Agency':0, 'MBS':0}
append_df = pd.DataFrame(append_data)
#print("Append:")
#print(append_df)
#print(repos_amount)
repos_amount = repos_amount.append(append_df)
repos_amount.set_index('Date', inplace=True)
print(repos_amount)
def update_row(row, df):
the_date = row['Date']
the_amount = row['Amount']
the_duration = row['Duration']
the_treasury = row['Treasury']
the_agency = row['Agency']
the_MBS = row['MBS']
end_date = the_date + timedelta(the_duration)
the_date = date(the_date.year, the_date.month, the_date.day)
#the_date =
end_date = date(end_date.year, end_date.month, end_date.day)
for date_var in daterange(the_date, end_date):
date_lookup = date(date_var.year, date_var.month, date_var.day)
last_date = df.tail(1).index[0]
if last_date >= date_lookup:
#current_amount = df.loc[date_lookup]['Amount']
#new_amount = df.loc[date_lookup]['Amount'] + the_amount
df.loc[date_lookup]['Amount'] = df.loc[date_lookup]['Amount'] + the_amount
df.loc[date_lookup]['Treasury'] = df.loc[date_lookup]['Treasury'] + the_treasury
df.loc[date_lookup]['Agency'] = df.loc[date_lookup]['Agency'] + the_agency
df.loc[date_lookup]['MBS'] = df.loc[date_lookup]['MBS'] + the_MBS
#current_treasury = df.loc[date_lookup]['Treasury']
#new_treasury = current_treasury + the_treasury
#df.loc[date_lookup]['Treasury'] = new_treasury
#current_agency = df.loc[date_lookup]['Agency']
#new_agency = current_agency + the_amount
#df.loc[date_lookup]['Agency'] = new_agency
#current_amount = df.loc[date_lookup]['Amount']
#new_amount = current_amount + the_amount
#df.loc[date_lookup]['Amount'] = new_amount
return df
for index, a_row in repos.iterrows():
repos_amount = update_row(a_row, repos_amount)
#print(repos_amount)
#repos_amount.plot(kind='bar',y='Amount',color='red')
colors = ["Green", "Red","Blue"]
repos_amount[['Agency','MBS','Treasury']].plot.bar(stacked=True, color=colors, figsize=(12,7))
plt.title('Total Outstanding Fed Repos', fontsize=16)
plt.ylabel('$ Billions', fontsize=12)
plt.show()
print(repos_amount)
print(repos_amount.loc[date(2019, 10, 11)])
repos_amount.set_index('Date', inplace=True)
repos_amount.info()
#print(repos_amount.iloc[1, :]['Amount'])
amount = repos_amount.loc[date(2019, 10, 11)]['Amount']
amount = amount + 10
repos_amount.set_value(date(2019, 10, 11), 'Amount', amount)
print(repos_amount)
```
| github_jupyter |
# Time series analysis (Pandas)
Nikolay Koldunov
[email protected]
================
Here I am going to show just some basic [pandas](http://pandas.pydata.org/) stuff for time series analysis, as I think for the Earth Scientists it's the most interesting topic. If you find this small tutorial useful, I encourage you to watch [this video](http://pyvideo.org/video/1198/time-series-data-analysis-with-pandas), where Wes McKinney give extensive introduction to the time series data analysis with pandas.
On the official website you can find explanation of what problems pandas solve in general, but I can tell you what problem pandas solve for me. It makes analysis and visualisation of 1D data, especially time series, MUCH faster. Before pandas working with time series in python was a pain for me, now it's fun. Ease of use stimulate in-depth exploration of the data: why wouldn't you make some additional analysis if it's just one line of code? Hope you will also find this great tool helpful and useful. So, let's begin.
As an example we are going to use time series of [Arctic Oscillation (AO)](http://en.wikipedia.org/wiki/Arctic_oscillation) and [North Atlantic Oscillation (NAO)](http://en.wikipedia.org/wiki/North_Atlantic_oscillation) data sets.
## Module import
First we have to import necessary modules:
```
import pandas as pd
import numpy as np
%matplotlib inline
pd.set_option('max_rows',15) # this limit maximum numbers of rows
np.set_printoptions(precision=3 , suppress= True) # this is just to make the output look better
pd.__version__
```
## Loading data
Now, when we are done with preparations, let's get some data.
Pandas has very good IO capabilities, but we not going to use them in this tutorial in order to keep things simple. For now we open the file simply with numpy loadtxt:
```
temp = np.loadtxt('../Week03/Ham_3column.txt')
```
Every line in the file consist of three elements: year, month, value:
```
temp[-1]
```
And here is the shape of our array (note that shape of the file might differ in your case, since data updated monthly):
```
temp.shape
```
## Time Series
We would like to convert this data in to time series, that can be manipulated naturally and easily. First step, that we have to do is to create the range of dates for our time series. From the file it is clear, that record starts at January 1891 and ends at August 2014 (at the time I am writing this, of course). Frequency of the data is one day (freq='D').
```
dates = pd.date_range('1891-01-01', '2014-08-31', freq='D')
```
As you see syntax is quite simple, and this is one of the reasons why I love Pandas so much :) You can check if the range of dates is properly generated:
```
dates
```
Now we are ready to create our first time series. Dates from the *dates* variable will be our index, and `temp` values will be our, hm... values:
```
ham = pd.Series(temp[:,3]/10., index=dates)
ham
```
Now we can plot complete time series:
```
ham.plot()
```
or its part:
```
ham['1980':'1990'].plot()
```
or even smaller part:
```
ham['1980-05-02':'1981-03-17'].plot()
```
Reference to the time periods is done in a very natural way. You, of course, can also get individual values. By number:
```
ham[120]
```
or by index (date in our case):
```
ham['1960-01']
```
And what if we choose only one year?
```
ham['1960']
```
Isn't that great? :)
##Exercise
What was temperature in Hampurg at your burthsday?
## One bonus example :)
```
ham[ham > 0]['1990':'2000'].plot(style='r*')
ham[ham < 0]['1990':'2000'].plot(style='b*')
```
##Exercise
- plot all positive temperatures (red stars) and negative temperatires (blue stars)
- limit this plot by 1990-2000 period
## Data Frame
Now let's make live a bit more interesting and get more data. This will be TMIN time series.
We use pandas function `read_csv` to parse dates and create Data Frame
```
hamm = pd.read_csv('Ham_tmin.txt', parse_dates=True, index_col=0, names=['Time','tmin'])
hamm
type(hamm)
```
Time period is the same:
```
hamm.index
```
Now we create Data Frame, that will contain both TMAX and TMIN data. It is sort of an Excel table where the first row contain headers for the columns and firs column is an index:
```
tmp = pd.DataFrame({'TMAX':ham, 'TMIN':hamm.tmin/10})
tmp
```
One can plot the data straight away:
```
tmp.plot()
```
Or have a look at the first several rows:
```
tmp.head()
```
We can reference each column by its name:
```
tmp['TMIN']
```
or as method of the Data Frame variable (if name of the variable is a valid python name):
```
tmp.TMIN
```
We can simply add column to the Data Frame:
```
tmp['Diff'] = tmp['TMAX'] - tmp['TMIN']
tmp.head()
```
##Exercise
Find and plot all differences that are larger than 20
```
tmp['Diff'][tmp['Diff']>20].plot(style='r*')
```
And delete it:
```
del tmp['Diff']
tmp.tail()
```
Slicing will also work:
```
tmp['1981-03'].plot()
```
## Statistics
Back to simple stuff. We can obtain statistical information over elements of the Data Frame. Default is column wise:
```
tmp.mean()
tmp.max()
tmp.min()
```
You can also do it row-wise:
```
tmp.mean(1)
```
Or get everything at once:
```
tmp.describe()
```
By the way getting correlation coefficients for members of the Data Frame is as simple as:
```
tmp.corr()
```
##Exercise
Find mean of all temperatures larger than 5
```
tmp[tmp>5].mean()
```
## Resampling
Pandas provide easy way to resample data to different time frequency. Two main parameters for resampling is time period you resemple to and the method that you use. By default the method is mean. Following example calculates monthly ('M'):
```
tmp_mm = tmp.resample("M")
tmp_mm['2000':].plot()
```
median:
```
tmp_mm = tmp.resample("M", how='median')
tmp_mm['2000':].plot()
```
You can use your methods for resampling, for example np.max (in this case we change resampling frequency to 3 years):
```
tmp_mm = tmp.resample("3M", how=np.max)
tmp_mm['2000':].plot()
```
You can specify several functions at once as a list:
```
tmp_mm = tmp.resample("M", how=['mean', np.min, np.max])
tmp_mm['1900':'2020'].plot(subplots=True, figsize=(10,10))
tmp_mm['2000':].plot(figsize=(10,10))
```
##Exercise
Define function that will find difference between maximum and minimum values of the time series, and resample our `tmp` variable with this function.
```
def satardays(x):
xmin = x.min()
xmax = x.max()
diff = xmin - xmax
return diff
tmp_mm = tmp.resample("A", how=satardays)
tmp_mm['2000':].plot()
tmp_mm
```
That's it. I hope you at least get a rough impression of what pandas can do for you. Comments are very welcome (below). If you have intresting examples of pandas usage in Earth Science, we would be happy to put them on [EarthPy](http://earthpy.org).
## Links
[Time Series Data Analysis with pandas (Video)](http://www.youtube.com/watch?v=0unf-C-pBYE)
[Data analysis in Python with pandas (Video)](http://www.youtube.com/watch?v=w26x-z-BdWQ)
[Python for Data Analysis](http://shop.oreilly.com/product/0636920023784.do)
| github_jupyter |
<i>Copyright (c) Microsoft Corporation.</i>
<i>Licensed under the MIT License.</i>
# LightGBM: A Highly Efficient Gradient Boosting Decision Tree
This notebook gives an example of how to perform multiple rounds of training and testing of LightGBM models to generate point forecasts of product sales in retail. We will train the LightGBM models based on the Orange Juice dataset.
[LightGBM](https://github.com/Microsoft/LightGBM) is a gradient boosting framework that uses tree-based learning algorithms. [Gradient boosting](https://en.wikipedia.org/wiki/Gradient_boosting) is an ensemble technique in which models are added to the ensemble sequentially and at each iteration a new model is trained with respect to the error of the whole ensemble learned so far. More detailed information about gradient boosting can be found in this [tutorial paper](https://www.frontiersin.org/articles/10.3389/fnbot.2013.00021/full). Using this technique, LightGBM achieves great accuracy in many applications. Apart from this, it is designed to be distributed and efficient with the following advantages:
* Fast training speed and high efficiency.
* Low memory usage.
* Support of parallel and GPU learning.
* Capable of handling large-scale data.
Due to these advantages, LightGBM has been widely-used in a lot of [winning solutions](https://github.com/microsoft/LightGBM/blob/master/examples/README.md#machine-learning-challenge-winning-solutions) of machine learning competitions.
## Global Settings and Imports
```
%load_ext autoreload
%autoreload 2
%matplotlib inline
import os
import sys
import math
import datetime
import warnings
import numpy as np
import pandas as pd
import lightgbm as lgb
from fclib.models.lightgbm import predict
from fclib.evaluation.evaluation_utils import MAPE
from fclib.common.plot import plot_predictions_with_history
from fclib.dataset.ojdata import split_train_test, FIRST_WEEK_START
from fclib.feature_engineering.feature_utils import (
week_of_month,
df_from_cartesian_product,
combine_features,
)
warnings.filterwarnings("ignore")
print("System version: {}".format(sys.version))
print("LightGBM version: {}".format(lgb.__version__))
```
## Parameter Settings
In what follows, we define global settings related to the model and feature engineering. LightGBM supports both classification models and regression models. In our case, we set the objective function to `mape` which stands for mean-absolute-percentage-error (MAPE) since we will build a regression model to predict product sales and evaluate the accuracy of the model using MAPE.
Generally, we can adjust the number of leaves (`num_leaves`), the minimum number of data in each leaf (`min_data_in_leaf`), maximum number of boosting rounds (`num_rounds`), the learning rate of trees (`learning_rate`) and `early_stopping_rounds` (to avoid overfitting) in the model to get better performance. Besides, we can also adjust other supported parameters to optimize the results. [In this link](https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst), a list of all the parameters is given. In addition, advice on how to tune these parameters can be found [in this url](https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters-Tuning.rst).
We will use historical weekly sales, date time information, and product information as input features to train the model. Prior sales are used as lag features and `lags` contains the lags where each number indicates the number of time steps (i.e., weeks) that we shift the data backwards to get the historical sales. We also use the average sales within a certain time window in the past as a moving average feature. `window_size` controls the size of the moving window. Apart from these parameters, we use `use_columns` and `categ_fea` to denote all other features that we leverage in the model and the categorical features, respectively.
```
# Data directory
DATA_DIR = os.path.join("ojdata")
# Parameters of LightGBM model
params = {
"objective": "mape",
"num_leaves": 124,
"min_data_in_leaf": 340,
"learning_rate": 0.1,
"feature_fraction": 0.65,
"bagging_fraction": 0.87,
"bagging_freq": 19,
"num_rounds": 940,
"early_stopping_rounds": 125,
"num_threads": 16,
"seed": 1,
}
# Lags, window size, and feature column names
lags = np.arange(2, 20)
window_size = 40
used_columns = [
"store",
"brand",
"week",
"week_of_month",
"month",
"deal",
"feat",
"move",
"price",
"price_ratio",
]
categ_fea = ["store", "brand", "deal"]
# Forecasting settings
N_SPLITS = 10
HORIZON = 2
GAP = 2
FIRST_WEEK = 40
LAST_WEEK = 156
```
## Feature Engineering
Next we create a function to extract a number of features from the data for training the forecasting model. These features include
* datetime features including week, week of the month, and month
* historical weekly sales of each orange juice in recent weeks
* average sales of each orange juice during recent weeks
* other features including `store`, `brand`, `deal`, `feat` columns and price features
Note that the logarithm of the unit sales is stored in a column named `logmove` both for `train_df` and `test_df`. We compute the unit sales `move` based on this quantity.
```
def create_features(pred_round, train_dir, lags, window_size, used_columns):
"""Create input features for model training and testing.
Args:
pred_round (int): Prediction round (1, 2, ...)
train_dir (str): Path of the training data directory
lags (np.array): Numpy array including all the lags
window_size (int): Maximum step for computing the moving average
used_columns (list[str]): A list of names of columns used in model training (including target variable)
Returns:
pd.Dataframe: Dataframe including all the input features and target variable
int: Last week of the training data
"""
# Load training data
train_df = pd.read_csv(os.path.join(train_dir, "train_" + str(pred_round) + ".csv"))
train_df["move"] = train_df["logmove"].apply(lambda x: round(math.exp(x)))
train_df = train_df[["store", "brand", "week", "move"]]
# Create a dataframe to hold all necessary data
store_list = train_df["store"].unique()
brand_list = train_df["brand"].unique()
train_end_week = train_df["week"].max()
week_list = range(FIRST_WEEK, train_end_week + GAP + HORIZON)
d = {"store": store_list, "brand": brand_list, "week": week_list}
data_grid = df_from_cartesian_product(d)
data_filled = pd.merge(data_grid, train_df, how="left", on=["store", "brand", "week"])
# Get future price, deal, and advertisement info
aux_df = pd.read_csv(os.path.join(train_dir, "auxi_" + str(pred_round) + ".csv"))
data_filled = pd.merge(data_filled, aux_df, how="left", on=["store", "brand", "week"])
# Create relative price feature
price_cols = [
"price1",
"price2",
"price3",
"price4",
"price5",
"price6",
"price7",
"price8",
"price9",
"price10",
"price11",
]
data_filled["price"] = data_filled.apply(lambda x: x.loc["price" + str(int(x.loc["brand"]))], axis=1)
data_filled["avg_price"] = data_filled[price_cols].sum(axis=1).apply(lambda x: x / len(price_cols))
data_filled["price_ratio"] = data_filled["price"] / data_filled["avg_price"]
data_filled.drop(price_cols, axis=1, inplace=True)
# Fill missing values
data_filled = data_filled.groupby(["store", "brand"]).apply(
lambda x: x.fillna(method="ffill").fillna(method="bfill")
)
# Create datetime features
data_filled["week_start"] = data_filled["week"].apply(
lambda x: FIRST_WEEK_START + datetime.timedelta(days=(x - 1) * 7)
)
data_filled["year"] = data_filled["week_start"].apply(lambda x: x.year)
data_filled["month"] = data_filled["week_start"].apply(lambda x: x.month)
data_filled["week_of_month"] = data_filled["week_start"].apply(lambda x: week_of_month(x))
data_filled["day"] = data_filled["week_start"].apply(lambda x: x.day)
data_filled.drop("week_start", axis=1, inplace=True)
# Create other features (lagged features, moving averages, etc.)
features = data_filled.groupby(["store", "brand"]).apply(
lambda x: combine_features(x, ["move"], lags, window_size, used_columns)
)
# Drop rows with NaN values
features.dropna(inplace=True)
return features, train_end_week
```
## Model Training
We then perform a multi-round training by fitting a LightGBM model using the training data in each forecast round. After the models are trained, we apply them to generate forecasts for the target weeks. The paradigm of model training and testing is illustrated in the following diagram
<img src="https://user-images.githubusercontent.com/20047467/77784194-84faee00-7030-11ea-83ee-6e2c33eb2434.png">
```
# Train and predict for all forecast rounds
pred_all = []
metric_all = []
train_dir = os.path.join(DATA_DIR, "train")
for r in range(1, N_SPLITS + 1):
print("---------- Round " + str(r) + " ----------")
features, train_end_week = create_features(r, train_dir, lags, window_size, used_columns)
train_fea = features[features.week <= train_end_week].reset_index(drop=True)
print("Maximum training week number is {}".format(max(train_fea["week"])))
# Create training set
dtrain = lgb.Dataset(train_fea.drop("move", axis=1, inplace=False), label=train_fea["move"])
# Train GBM model
print("Training LightGBM model started.")
bst = lgb.train(params, dtrain, valid_sets=[dtrain], categorical_feature=categ_fea, verbose_eval=False,)
print("Training LightGBM model finished.")
# Generate forecasts
test_fea = features[features.week >= train_end_week + GAP].reset_index(drop=True)
idx_cols = ["store", "brand", "week"]
pred = predict(test_fea, bst, target_col="move", idx_cols=idx_cols).sort_values(by=idx_cols).reset_index(drop=True)
print("Prediction results:")
print(pred.head())
print("")
# Keep the predictions
pred["round"] = r
pred_all.append(pred)
pred_all = pd.concat(pred_all, axis=0)
pred_all.rename(columns={"move": "prediction"}, inplace=True)
pred_all = pred_all[["round", "week", "store", "brand", "prediction"]]
```
## Model Evaluation
To evaluate the model performance, we compute MAPE of the forecasts from all the forecast rounds below.
```
# Evaluate prediction accuracy
test_all = []
test_dir = os.path.join(DATA_DIR, "test")
for r in range(1, N_SPLITS + 1):
test_df = pd.read_csv(os.path.join(test_dir, "test_" + str(r) + ".csv"))
test_all.append(test_df)
test_all = pd.concat(test_all, axis=0).reset_index(drop=True)
test_all["actual"] = test_all["logmove"].apply(lambda x: round(math.exp(x)))
test_all.drop("logmove", axis=1, inplace=True)
combined = pd.merge(pred_all, test_all, on=["store", "brand", "week"], how="left")
metric_value = MAPE(combined["prediction"], combined["actual"]) * 100
print("MAPE of the predictions is {}".format(metric_value))
```
## Result Visualization
Finally, we plot out the forecast results of a few sample store-brand combinations to visually check the forecasts. Note that there could be gaps in the curve of actual sales due to missing sales data.
```
results = combined[["week", "store", "brand", "prediction"]]
results.rename(columns={"prediction": "move"}, inplace=True)
actual = combined[["week", "store", "brand", "actual"]]
actual.rename(columns={"actual": "move"}, inplace=True)
store_list = combined["store"].unique()
brand_list = combined["brand"].unique()
plot_predictions_with_history(
results,
actual,
store_list,
brand_list,
"week",
"move",
grain1_name="store",
grain2_name="brand",
min_timestep=137,
num_samples=6,
predict_at_timestep=135,
line_at_predict_time=False,
title="Prediction results for a few sample time series",
x_label="time step",
y_label="target value",
random_seed=6,
)
```
## Additional Reading
\[1\] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems. 3146–3154.<br>
\[2\] Alexey Natekin and Alois Knoll. 2013. Gradient boosting machines, a tutorial. Frontiers in neurorobotics, 7 (21). <br>
\[3\] The parameters of LightGBM: https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst <br>
\[4\] Anna Veronika Dorogush, Vasily Ershov, and Andrey Gulin. 2018. CatBoost: gradient boosting with categorical features support. arXiv preprint arXiv:1810.11363 (2018).<br>
| github_jupyter |
# External Validation of SWAST Forecasting Model
## Overall results summary.
This notebook generates the overall results summary for the MASE, and prediction intervals for LAS, YAS and WAST.
```
print('******************Summary of External validation results*****************\n\n')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from os import listdir
from os.path import isfile, join
from scipy.stats import norm, t
sns.set(style="whitegrid")
cwd = os.getcwd()
cwd
if cwd[-7:] != "results":
mypath = './results/external_validation/'
TABLE_PATH = './paper/tables/'
FIGURE_PATH = './paper/figures/'
APPENDIX_PATH = './paper/appendix/'
else:
mypath = './external_validation/'
TABLE_PATH = '../paper/tables/'
FIGURE_PATH = '../paper/figures/'
APPENDIX_PATH = '../paper/appendix/'
result_files = [os.path.join(dp, f) for dp, dn, filenames in os.walk(mypath)
for f in filenames if os.path.splitext(f)[1] == '.csv']
results_mean = pd.DataFrame()
results_med = pd.DataFrame()
results_mean_std = pd.DataFrame()
results_all = pd.DataFrame()
```
## Point Estimate Results
```
error_measures = ['smape', 'rmse', 'mase', 'coverage_80', 'coverage_95']
mypath
#start = len('/external_validation/')
start = len(mypath) - 1
for metric in error_measures:
to_read = [filename for filename in result_files if metric in filename]
model_names = ['.' + name[start:name.index('_', start)] for name in to_read]
for filename, model_name in zip(to_read, model_names):
df = pd.read_csv(filename, index_col=0)
if 'snaive' not in model_name:
prefix = model_name + '_' + metric
results_mean[prefix + '_mean'] = df.mean()
results_mean[prefix + '_std'] = df.std()
results_med[prefix + '_med'] = df.median()
results_med[prefix + '_iqr'] = df.quantile(0.75) - df.quantile(0.25)
results_mean_std[prefix] = results_mean[prefix + '_mean'].map('{:,.2f}'.format) \
+ ' (' + results_mean[prefix + '_std'].map('{:,.2f}'.format) + ')'
if 'mase' in filename:
results_all[prefix] = df.to_numpy().flatten()
```
## Seperate dataframes for prediction intervals
```
summary_fa = results_mean.filter(
like="coverage_95").filter(like="fbp-arima").filter(like='mean')
summary_fa2 = results_mean.filter(
like="coverage_80").filter(like="fbp-arima").filter(like='mean')
```
# Overall statistics
## Mean absolute scaled error
```
alpha = 0.05
#overall MASE
summary_fa = results_mean.filter(
like="mase").filter(like="fbp-arima").filter(like='mean')
mean = summary_fa.to_numpy().flatten().mean()
print(f'\nOverall External Evaluation Statistics for MASE')
#sample std
std = summary_fa.to_numpy().flatten().std(ddof=1)
n = summary_fa.to_numpy().flatten().shape[0]
#Confidence interval calculation
se = std / np.sqrt(n)
z = np.abs(t.ppf(alpha / 2, n - 1))
hw = z * se
lower = mean - hw
upper = mean + hw
#lower and upper 95% CI
print(f'mean: {mean:.4f} 95% CI ({lower:.4f}-{upper:.4f})')
#median
med = np.percentile(summary_fa.to_numpy().flatten(), 50)
lq = np.percentile(summary_fa.to_numpy().flatten(), 25)
uq = np.percentile(summary_fa.to_numpy().flatten(), 75)
print(f'median: {med:.3f}, IQR {uq - lq:.3f}')
#middle 90% of data lies between
fifth = np.percentile(summary_fa.to_numpy().flatten(), 5)
ninetyfifth = np.percentile(summary_fa.to_numpy().flatten(), 95)
print(f'middle 90%: {fifth:.3f} - {ninetyfifth:.3f}')
plt.hist(summary_fa.to_numpy().flatten());
```
## 80% Prediction interval coverage
```
alpha = 0.05
#overall 80% PI coverage
mean = summary_fa2.to_numpy().flatten().mean()
print(f'\nOverall External Evaluation Statistics for 80% PI coverage')
#sample std
std = summary_fa2.to_numpy().flatten().std(ddof=1)
n = summary_fa2.to_numpy().flatten().shape[0]
#Confidence interval calculation
se = std / np.sqrt(n)
z = np.abs(t.ppf(alpha / 2, n - 1))
hw = z * se
lower = mean - hw
upper = mean + hw
#lower and upper 95% CI
print(f'mean: {mean:.4f} 95% CI ({lower:.4f}-{upper:.4f})')
#median
med = np.percentile(summary_fa2.to_numpy().flatten(), 50)
lq = np.percentile(summary_fa2.to_numpy().flatten(), 25)
uq = np.percentile(summary_fa2.to_numpy().flatten(), 75)
print(f'median: {med:.3f}, IQR {uq - lq:.3f}')
#middle 90% of data lies between
fifth = np.percentile(summary_fa2.to_numpy().flatten(), 5)
ninetyfifth = np.percentile(summary_fa2.to_numpy().flatten(), 95)
print(f'middle 90%: {fifth:.3f} - {ninetyfifth:.3f}')
plt.hist(summary_fa.to_numpy().flatten());
```
## 95% prediction interval coverage
```
summary_fa = results_mean.filter(
like="coverage_95").filter(like="fbp-arima").filter(like='mean')
mean = summary_fa.to_numpy().flatten().mean()
print(f'\nOverall External Evaluation Statistics for 95% PI Coverage')
#sample std
std = summary_fa.to_numpy().flatten().std(ddof=1)
n = summary_fa.to_numpy().flatten().shape[0]
#Confidence interval calculation
se = std / np.sqrt(n)
z = np.abs(t.ppf(alpha / 2, n - 1))
hw = z * se
lower = mean - hw
upper = mean + hw
#lower and upper 95% CI
print(f'mean: {mean:.4f} 95% CI ({lower:.4f}-{upper:.4f})')
#median
med = np.percentile(summary_fa.to_numpy().flatten(), 50)
lq = np.percentile(summary_fa.to_numpy().flatten(), 25)
uq = np.percentile(summary_fa.to_numpy().flatten(), 75)
print(f'median: {med:.3f}, IQR {uq - lq:.3f}')
#middle 90% of data lies between
fifth = np.percentile(summary_fa.to_numpy().flatten(), 5)
ninetyfifth = np.percentile(summary_fa.to_numpy().flatten(), 95)
print(f'middle 90%: {fifth:.3f} - {ninetyfifth:.3f}')
plt.hist(summary_fa.to_numpy().flatten());
```
## Overall Results Summary Table
```
#filter for mase - mean results
region_means = results_mean.filter(
like="mase").filter(like='mean').filter(like='fbp-arima').mean().sort_index()
#filter for mase stdev
region_std = results_mean.filter(
like="mase").filter(like='std').filter(like='fbp-arima').mean().sort_index()
#coverage mean
region_95_mean = results_mean.filter(like="coverage_95").filter(like='mean').filter(like='fbp-arima').mean().sort_index()
region_80_mean = results_mean.filter(like="coverage_80").filter(like='mean').filter(like='fbp-arima').mean().sort_index()
#coverage stdev
region_95_std = results_mean.filter(like="coverage_95").filter(like='std').filter(like='fbp-arima').mean().sort_index()
region_80_std = results_mean.filter(like="coverage_80").filter(like='std').filter(like='fbp-arima').mean().sort_index()
#create index of dataframe
comparisons = list(region_means.index)
idx = [i.replace('_mase_mean', '') for i in comparisons]
#construct table
df_regions = pd.DataFrame(region_means.to_numpy(), columns=['mean'])
df_regions['std'] = region_std.to_numpy()
df_regions['mean_80'] = region_80_mean.to_numpy()
df_regions['std_80'] = region_80_std.to_numpy()
df_regions['mean_95'] = region_95_mean.to_numpy()
df_regions['std_95'] = region_95_std.to_numpy()
df_regions['MASE'] = df_regions['mean'].map('{:,.2f}'.format) \
+ ' (' + df_regions['std'].map('{:,.2f}'.format) + ')'
df_regions['Coverage 80'] = df_regions['mean_80'].map('{:,.2f}'.format) \
+ ' (' + df_regions['std_80'].map('{:,.2f}'.format) + ')'
df_regions['Coverage 95'] = df_regions['mean_95'].map('{:,.2f}'.format) \
+ ' (' + df_regions['std_95'].map('{:,.2f}'.format) + ')'
df_regions.index = idx
df_regions = df_regions.drop(['mean', 'std', 'mean_80', 'std_80',
'mean_95', 'std_95'], axis=1)
df_regions.shape
#trim out trust and region intro seperate columns
df_regions['trust'] = [i[2:i.find('/', 2)] for i in list(df_regions.index)]
df_regions['region'] = [i[i.find('/', 2)+1:] for i in list(df_regions.index)]
#summary frame of results
print("**Table 5: External validation: Point forecast and coverage performance by region.")
df_regions['region'] = [str(i).replace('-fbp-arima', '')
for i in list(df_regions.region)]
df_regions.index = pd.MultiIndex.from_frame(df_regions[['trust', 'region']])
df_regions.drop(['trust'], axis=1, inplace=True)
df_regions.drop(['region'], axis=1, inplace=True)
df_regions.drop(('york','Trust'), axis=0, inplace=True)
df_regions.drop(('wales','Trust'), axis=0, inplace=True)
df_regions
df_regions.sort_index().to_latex(f'{TABLE_PATH}Table5.tex')
print(df_regions)
```
# End
| github_jupyter |
# Bayesian Regression - Inference Algorithms (Part 2)
In [Part I](bayesian_regression.ipynb), we looked at how to perform inference on a simple Bayesian linear regression model using SVI. In this tutorial, we'll explore more expressive guides as well as exact inference techniques. We'll use the same dataset as before.
```
%reset -sf
import logging
import os
import torch
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from torch.distributions import constraints
import pyro
import pyro.distributions as dist
import pyro.optim as optim
pyro.set_rng_seed(1)
assert pyro.__version__.startswith('1.5.0')
%matplotlib inline
plt.style.use('default')
logging.basicConfig(format='%(message)s', level=logging.INFO)
# Enable validation checks
pyro.enable_validation(True)
smoke_test = ('CI' in os.environ)
pyro.set_rng_seed(1)
DATA_URL = "https://d2hg8soec8ck9v.cloudfront.net/datasets/rugged_data.csv"
rugged_data = pd.read_csv(DATA_URL, encoding="ISO-8859-1")
```
## Bayesian Linear Regression
Our goal is once again to predict log GDP per capita of a nation as a function of two features from the dataset - whether the nation is in Africa, and its Terrain Ruggedness Index, but we will explore more expressive guides.
## Model + Guide
We will write out the model again, similar to that in [Part I](bayesian_regression.ipynb), but explicitly without the use of `PyroModule`. We will write out each term in the regression, using the same priors. `bA` and `bR` are regression coefficients corresponding to `is_cont_africa` and `ruggedness`, `a` is the intercept, and `bAR` is the correlating factor between the two features.
Writing down a guide will proceed in close analogy to the construction of our model, with the key difference that the guide parameters need to be trainable. To do this we register the guide parameters in the ParamStore using `pyro.param()`. Note the positive constraints on scale parameters.
```
def model(is_cont_africa, ruggedness, log_gdp):
a = pyro.sample("a", dist.Normal(0., 10.))
b_a = pyro.sample("bA", dist.Normal(0., 1.))
b_r = pyro.sample("bR", dist.Normal(0., 1.))
b_ar = pyro.sample("bAR", dist.Normal(0., 1.))
sigma = pyro.sample("sigma", dist.Uniform(0., 10.))
mean = a + b_a * is_cont_africa + b_r * ruggedness + b_ar * is_cont_africa * ruggedness
with pyro.plate("data", len(ruggedness)):
pyro.sample("obs", dist.Normal(mean, sigma), obs=log_gdp)
def guide(is_cont_africa, ruggedness, log_gdp):
a_loc = pyro.param('a_loc', torch.tensor(0.))
a_scale = pyro.param('a_scale', torch.tensor(1.),
constraint=constraints.positive)
sigma_loc = pyro.param('sigma_loc', torch.tensor(1.),
constraint=constraints.positive)
weights_loc = pyro.param('weights_loc', torch.randn(3))
weights_scale = pyro.param('weights_scale', torch.ones(3),
constraint=constraints.positive)
a = pyro.sample("a", dist.Normal(a_loc, a_scale))
b_a = pyro.sample("bA", dist.Normal(weights_loc[0], weights_scale[0]))
b_r = pyro.sample("bR", dist.Normal(weights_loc[1], weights_scale[1]))
b_ar = pyro.sample("bAR", dist.Normal(weights_loc[2], weights_scale[2]))
sigma = pyro.sample("sigma", dist.Normal(sigma_loc, torch.tensor(0.05)))
mean = a + b_a * is_cont_africa + b_r * ruggedness + b_ar * is_cont_africa * ruggedness
# Utility function to print latent sites' quantile information.
def summary(samples):
site_stats = {}
for site_name, values in samples.items():
marginal_site = pd.DataFrame(values)
describe = marginal_site.describe(percentiles=[.05, 0.25, 0.5, 0.75, 0.95]).transpose()
site_stats[site_name] = describe[["mean", "std", "5%", "25%", "50%", "75%", "95%"]]
return site_stats
# Prepare training data
df = rugged_data[["cont_africa", "rugged", "rgdppc_2000"]]
df = df[np.isfinite(df.rgdppc_2000)]
df["rgdppc_2000"] = np.log(df["rgdppc_2000"])
train = torch.tensor(df.values, dtype=torch.float)
```
## SVI
As before, we will use SVI to perform inference.
```
from pyro.infer import SVI, Trace_ELBO
svi = SVI(model,
guide,
optim.Adam({"lr": .05}),
loss=Trace_ELBO())
is_cont_africa, ruggedness, log_gdp = train[:, 0], train[:, 1], train[:, 2]
pyro.clear_param_store()
num_iters = 5000 if not smoke_test else 2
for i in range(num_iters):
elbo = svi.step(is_cont_africa, ruggedness, log_gdp)
if i % 500 == 0:
logging.info("Elbo loss: {}".format(elbo))
from pyro.infer import Predictive
num_samples = 1000
predictive = Predictive(model, guide=guide, num_samples=num_samples)
svi_samples = {k: v.reshape(num_samples).detach().cpu().numpy()
for k, v in predictive(log_gdp, is_cont_africa, ruggedness).items()
if k != "obs"}
```
Let us observe the posterior distribution over the different latent variables in the model.
```
for site, values in summary(svi_samples).items():
print("Site: {}".format(site))
print(values, "\n")
```
## HMC
In contrast to using variational inference which gives us an approximate posterior over our latent variables, we can also do exact inference using [Markov Chain Monte Carlo](http://docs.pyro.ai/en/dev/mcmc.html) (MCMC), a class of algorithms that in the limit, allow us to draw unbiased samples from the true posterior. The algorithm that we will be using is called the No-U Turn Sampler (NUTS) \[1\], which provides an efficient and automated way of running Hamiltonian Monte Carlo. It is slightly slower than variational inference, but provides an exact estimate.
```
from pyro.infer import MCMC, NUTS
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=1000, warmup_steps=200)
mcmc.run(is_cont_africa, ruggedness, log_gdp)
hmc_samples = {k: v.detach().cpu().numpy() for k, v in mcmc.get_samples().items()}
for site, values in summary(hmc_samples).items():
print("Site: {}".format(site))
print(values, "\n")
```
## Comparing Posterior Distributions
Let us compare the posterior distribution of the latent variables that we obtained from variational inference with those from Hamiltonian Monte Carlo. As can be seen below, for Variational Inference, the marginal distribution of the different regression coefficients is under-dispersed w.r.t. the true posterior (from HMC). This is an artifact of the *KL(q||p)* loss (the KL divergence of the true posterior from the approximate posterior) that is minimized by Variational Inference.
This can be better seen when we plot different cross sections from the joint posterior distribution overlaid with the approximate posterior from variational inference. Note that since our variational family has diagonal covariance, we cannot model any correlation between the latents and the resulting approximation is overconfident (under-dispersed)
```
sites = ["a", "bA", "bR", "bAR", "sigma"]
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
fig.suptitle("Marginal Posterior density - Regression Coefficients", fontsize=16)
for i, ax in enumerate(axs.reshape(-1)):
site = sites[i]
sns.distplot(svi_samples[site], ax=ax, label="SVI (DiagNormal)")
sns.distplot(hmc_samples[site], ax=ax, label="HMC")
ax.set_title(site)
handles, labels = ax.get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right');
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
fig.suptitle("Cross-section of the Posterior Distribution", fontsize=16)
sns.kdeplot(hmc_samples["bA"], hmc_samples["bR"], ax=axs[0], shade=True, label="HMC")
sns.kdeplot(svi_samples["bA"], svi_samples["bR"], ax=axs[0], label="SVI (DiagNormal)")
axs[0].set(xlabel="bA", ylabel="bR", xlim=(-2.5, -1.2), ylim=(-0.5, 0.1))
sns.kdeplot(hmc_samples["bR"], hmc_samples["bAR"], ax=axs[1], shade=True, label="HMC")
sns.kdeplot(svi_samples["bR"], svi_samples["bAR"], ax=axs[1], label="SVI (DiagNormal)")
axs[1].set(xlabel="bR", ylabel="bAR", xlim=(-0.45, 0.05), ylim=(-0.15, 0.8))
handles, labels = axs[1].get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right');
```
## MultivariateNormal Guide
As comparison to the previously obtained results from Diagonal Normal guide, we will now use a guide that generates samples from a Cholesky factorization of a multivariate normal distribution. This allows us to capture the correlations between the latent variables via a covariance matrix. If we wrote this manually, we would need to combine all the latent variables so we could sample a Multivarite Normal jointly.
```
from pyro.infer.autoguide import AutoMultivariateNormal, init_to_mean
guide = AutoMultivariateNormal(model, init_loc_fn=init_to_mean)
svi = SVI(model,
guide,
optim.Adam({"lr": .01}),
loss=Trace_ELBO())
is_cont_africa, ruggedness, log_gdp = train[:, 0], train[:, 1], train[:, 2]
pyro.clear_param_store()
for i in range(num_iters):
elbo = svi.step(is_cont_africa, ruggedness, log_gdp)
if i % 500 == 0:
logging.info("Elbo loss: {}".format(elbo))
```
Let's look at the shape of the posteriors again. You can see the multivariate guide is able to capture more of the true posterior.
```
predictive = Predictive(model, guide=guide, num_samples=num_samples)
svi_mvn_samples = {k: v.reshape(num_samples).detach().cpu().numpy()
for k, v in predictive(log_gdp, is_cont_africa, ruggedness).items()
if k != "obs"}
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
fig.suptitle("Marginal Posterior density - Regression Coefficients", fontsize=16)
for i, ax in enumerate(axs.reshape(-1)):
site = sites[i]
sns.distplot(svi_mvn_samples[site], ax=ax, label="SVI (Multivariate Normal)")
sns.distplot(hmc_samples[site], ax=ax, label="HMC")
ax.set_title(site)
handles, labels = ax.get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right');
```
Now let's compare the posterior computed by the Diagonal Normal guide vs the Multivariate Normal guide. Note that the multivariate distribution is more dispresed than the Diagonal Normal.
```
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
fig.suptitle("Cross-sections of the Posterior Distribution", fontsize=16)
sns.kdeplot(svi_samples["bA"], svi_samples["bR"], ax=axs[0], label="SVI (Diagonal Normal)")
sns.kdeplot(svi_mvn_samples["bA"], svi_mvn_samples["bR"], ax=axs[0], shade=True, label="SVI (Multivariate Normal)")
axs[0].set(xlabel="bA", ylabel="bR", xlim=(-2.5, -1.2), ylim=(-0.5, 0.1))
sns.kdeplot(svi_samples["bR"], svi_samples["bAR"], ax=axs[1], label="SVI (Diagonal Normal)")
sns.kdeplot(svi_mvn_samples["bR"], svi_mvn_samples["bAR"], ax=axs[1], shade=True, label="SVI (Multivariate Normal)")
axs[1].set(xlabel="bR", ylabel="bAR", xlim=(-0.45, 0.05), ylim=(-0.15, 0.8))
handles, labels = axs[1].get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right');
```
and the Multivariate guide with the posterior computed by HMC. Note that the Multivariate guide better captures the true posterior.
```
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
fig.suptitle("Cross-sections of the Posterior Distribution", fontsize=16)
sns.kdeplot(hmc_samples["bA"], hmc_samples["bR"], ax=axs[0], shade=True, label="HMC")
sns.kdeplot(svi_mvn_samples["bA"], svi_mvn_samples["bR"], ax=axs[0], label="SVI (Multivariate Normal)")
axs[0].set(xlabel="bA", ylabel="bR", xlim=(-2.5, -1.2), ylim=(-0.5, 0.1))
sns.kdeplot(hmc_samples["bR"], hmc_samples["bAR"], ax=axs[1], shade=True, label="HMC")
sns.kdeplot(svi_mvn_samples["bR"], svi_mvn_samples["bAR"], ax=axs[1], label="SVI (Multivariate Normal)")
axs[1].set(xlabel="bR", ylabel="bAR", xlim=(-0.45, 0.05), ylim=(-0.15, 0.8))
handles, labels = axs[1].get_legend_handles_labels()
fig.legend(handles, labels, loc='upper right');
```
## References
[1] Hoffman, Matthew D., and Andrew Gelman. "The No-U-turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo." Journal of Machine Learning Research 15.1 (2014): 1593-1623. https://arxiv.org/abs/1111.4246.
| github_jupyter |
## 1. Google Play Store apps and reviews
<p>Mobile apps are everywhere. They are easy to create and can be lucrative. Because of these two factors, more and more apps are being developed. In this notebook, we will do a comprehensive analysis of the Android app market by comparing over ten thousand apps in Google Play across different categories. We'll look for insights in the data to devise strategies to drive growth and retention.</p>
<p><img src="https://assets.datacamp.com/production/project_619/img/google_play_store.png" alt="Google Play logo"></p>
<p>Let's take a look at the data, which consists of two files:</p>
<ul>
<li><code>apps.csv</code>: contains all the details of the applications on Google Play. There are 13 features that describe a given app.</li>
<li><code>user_reviews.csv</code>: contains 100 reviews for each app, <a href="https://www.androidpolice.com/2019/01/21/google-play-stores-redesigned-ratings-and-reviews-section-lets-you-easily-filter-by-star-rating/">most helpful first</a>. The text in each review has been pre-processed and attributed with three new features: Sentiment (Positive, Negative or Neutral), Sentiment Polarity and Sentiment Subjectivity.</li>
</ul>
```
# Read in dataset
import pandas as pd
apps_with_duplicates = pd.read_csv('datasets/apps.csv')
# Drop duplicates
apps = apps_with_duplicates.drop_duplicates()
# Print the total number of apps
print('Total number of apps in the dataset = ', len(apps['App']))
# Have a look at a random sample of 5 rows
n = 5
apps.sample(n)
```
## 2. Data cleaning
<p>The four features that we will be working with most frequently henceforth are <code>Installs</code>, <code>Size</code>, <code>Rating</code> and <code>Price</code>. The <code>info()</code> function (from the previous task) told us that <code>Installs</code> and <code>Price</code> columns are of type <code>object</code> and not <code>int64</code> or <code>float64</code> as we would expect. This is because the column contains some characters more than just [0,9] digits. Ideally, we would want these columns to be numeric as their name suggests. <br>
Hence, we now proceed to data cleaning and prepare our data to be consumed in our analyis later. Specifically, the presence of special characters (<code>, $ +</code>) in the <code>Installs</code> and <code>Price</code> columns make their conversion to a numerical data type difficult.</p>
```
# List of characters to remove
chars_to_remove = ['+' , ',' , '$']
# List of column names to clean
cols_to_clean = ['Installs' , 'Price']
# Loop for each column
for col in cols_to_clean:
# Replace each character with an empty string
for char in chars_to_remove:
apps[col] = apps[col].str.replace(char, '')
# Convert col to numeric
apps[col] = pd.to_numeric(apps[col])
```
## 3. Exploring app categories
<p>With more than 1 billion active users in 190 countries around the world, Google Play continues to be an important distribution platform to build a global audience. For businesses to get their apps in front of users, it's important to make them more quickly and easily discoverable on Google Play. To improve the overall search experience, Google has introduced the concept of grouping apps into categories.</p>
<p>This brings us to the following questions:</p>
<ul>
<li>Which category has the highest share of (active) apps in the market? </li>
<li>Is any specific category dominating the market?</li>
<li>Which categories have the fewest number of apps?</li>
</ul>
<p>We will see that there are <code>33</code> unique app categories present in our dataset. <em>Family</em> and <em>Game</em> apps have the highest market prevalence. Interestingly, <em>Tools</em>, <em>Business</em> and <em>Medical</em> apps are also at the top.</p>
```
import plotly
plotly.offline.init_notebook_mode(connected=True)
import plotly.graph_objs as go
# Print the total number of unique categories
num_categories = len(apps["Category"].unique())
print('Number of categories = ', num_categories)
# Count the number of apps in each 'Category' and sort them in descending order
num_apps_in_category = apps["Category"].value_counts().sort_values(ascending = False)
data = [go.Bar(
x = num_apps_in_category.index, # index = category name
y = num_apps_in_category.values, # value = count
)]
plotly.offline.iplot(data)
```
## 4. Distribution of app ratings
<p>After having witnessed the market share for each category of apps, let's see how all these apps perform on an average. App ratings (on a scale of 1 to 5) impact the discoverability, conversion of apps as well as the company's overall brand image. Ratings are a key performance indicator of an app.</p>
<p>From our research, we found that the average volume of ratings across all app categories is <code>4.17</code>. The histogram plot is skewed to the right indicating that the majority of the apps are highly rated with only a few exceptions in the low-rated apps.</p>
```
# Average rating of apps
avg_app_rating = apps['Rating'].mean()
print('Average app rating = ', avg_app_rating)
# Distribution of apps according to their ratings
data = [go.Histogram(
x = apps['Rating']
)]
# Vertical dashed line to indicate the average app rating
layout = {'shapes': [{
'type' :'line',
'x0': avg_app_rating,
'y0': 0,
'x1': avg_app_rating,
'y1': 1000,
'line': { 'dash': 'dashdot'}
}]
}
plotly.offline.iplot({'data': data, 'layout': layout})
```
## 5. Size and price of an app
<p>Let's now examine app size and app price. For size, if the mobile app is too large, it may be difficult and/or expensive for users to download. Lengthy download times could turn users off before they even experience your mobile app. Plus, each user's device has a finite amount of disk space. For price, some users expect their apps to be free or inexpensive. These problems compound if the developing world is part of your target market; especially due to internet speeds, earning power and exchange rates.</p>
<p>How can we effectively come up with strategies to size and price our app?</p>
<ul>
<li>Does the size of an app affect its rating? </li>
<li>Do users really care about system-heavy apps or do they prefer light-weighted apps? </li>
<li>Does the price of an app affect its rating? </li>
<li>Do users always prefer free apps over paid apps?</li>
</ul>
<p>We find that the majority of top rated apps (rating over 4) range from 2 MB to 20 MB. We also find that the vast majority of apps price themselves under \$10.</p>
```
%matplotlib inline
import seaborn as sns
sns.set_style("darkgrid")
apps_with_size_and_rating_present = apps[(apps['Rating'].notnull()) & (apps["Size"].notnull())]
# Subset for categories with at least 250 apps
large_categories = apps_with_size_and_rating_present.groupby('Category').filter(lambda x: len(x) >= 250).reset_index()
# Plot size vs. rating
plt1 = sns.jointplot(x = large_categories['Size'] , y = large_categories['Rating'] , kind = 'hex')
# Subset out apps whose type is 'Paid'
paid_apps = apps_with_size_and_rating_present[apps_with_size_and_rating_present['Type'] == 'Paid']
# Plot price vs. rating
plt2 = sns.jointplot(x = paid_apps['Price'] , y = paid_apps['Rating'] )
```
## 6. Relation between app category and app price
<p>So now comes the hard part. How are companies and developers supposed to make ends meet? What monetization strategies can companies use to maximize profit? The costs of apps are largely based on features, complexity, and platform.</p>
<p>There are many factors to consider when selecting the right pricing strategy for your mobile app. It is important to consider the willingness of your customer to pay for your app. A wrong price could break the deal before the download even happens. Potential customers could be turned off by what they perceive to be a shocking cost, or they might delete an app they’ve downloaded after receiving too many ads or simply not getting their money's worth.</p>
<p>Different categories demand different price ranges. Some apps that are simple and used daily, like the calculator app, should probably be kept free. However, it would make sense to charge for a highly-specialized medical app that diagnoses diabetic patients. Below, we see that <em>Medical and Family</em> apps are the most expensive. Some medical apps extend even up to \$80! All game apps are reasonably priced below \$20.</p>
```
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
fig.set_size_inches(15, 8)
# Select a few popular app categories
popular_app_cats = apps[apps.Category.isin(['GAME', 'FAMILY', 'PHOTOGRAPHY',
'MEDICAL', 'TOOLS', 'FINANCE',
'LIFESTYLE','BUSINESS'])]
# Examine the price trend by plotting Price vs Category
ax = sns.stripplot(x = popular_app_cats['Price'], y = popular_app_cats['Category'], jitter=True, linewidth=1)
ax.set_title('App pricing trend across categories')
# Apps whose Price is greater than 200
apps_above_200 = popular_app_cats[['Category', 'App', 'Price']][popular_app_cats['Price'] > 200]
apps_above_200
```
## 7. Filter out "junk" apps
<p>It looks like a bunch of the really expensive apps are "junk" apps. That is, apps that don't really have a purpose. Some app developer may create an app called <em>I Am Rich Premium</em> or <em>most expensive app (H)</em> just for a joke or to test their app development skills. Some developers even do this with malicious intent and try to make money by hoping people accidentally click purchase on their app in the store.</p>
<p>Let's filter out these junk apps and re-do our visualization. The distribution of apps under \$20 becomes clearer.</p>
```
# Select apps priced below $100
apps_under_100 = popular_app_cats[popular_app_cats['Price'] < 100]
fig, ax = plt.subplots()
fig.set_size_inches(15, 8)
# Examine price vs category with the authentic apps
ax = sns.stripplot(x=apps_under_100['Price'], y=apps_under_100['Category'], data=apps_under_100,
jitter=True, linewidth=1)
ax.set_title('App pricing trend across categories after filtering for junk apps')
```
## 8. Popularity of paid apps vs free apps
<p>For apps in the Play Store today, there are five types of pricing strategies: free, freemium, paid, paymium, and subscription. Let's focus on free and paid apps only. Some characteristics of free apps are:</p>
<ul>
<li>Free to download.</li>
<li>Main source of income often comes from advertisements.</li>
<li>Often created by companies that have other products and the app serves as an extension of those products.</li>
<li>Can serve as a tool for customer retention, communication, and customer service.</li>
</ul>
<p>Some characteristics of paid apps are:</p>
<ul>
<li>Users are asked to pay once for the app to download and use it.</li>
<li>The user can't really get a feel for the app before buying it.</li>
</ul>
<p>Are paid apps installed as much as free apps? It turns out that paid apps have a relatively lower number of installs than free apps, though the difference is not as stark as I would have expected!</p>
```
trace0 = go.Box(
# Data for paid apps
y=apps[apps['Type'] == 'Paid']['Installs'],
name = 'Paid'
)
trace1 = go.Box(
# Data for free apps
y=apps[apps['Type'] == 'Free']['Installs'],
name = 'Free'
)
layout = go.Layout(
title = "Number of downloads of paid apps vs. free apps",
yaxis = dict(
type = 'log',
autorange = True
)
)
# Add trace0 and trace1 to a list for plotting
data = [trace0 , trace1]
plotly.offline.iplot({'data': data, 'layout': layout})
```
## 9. Sentiment analysis of user reviews
<p>Mining user review data to determine how people feel about your product, brand, or service can be done using a technique called sentiment analysis. User reviews for apps can be analyzed to identify if the mood is positive, negative or neutral about that app. For example, positive words in an app review might include words such as 'amazing', 'friendly', 'good', 'great', and 'love'. Negative words might be words like 'malware', 'hate', 'problem', 'refund', and 'incompetent'.</p>
<p>By plotting sentiment polarity scores of user reviews for paid and free apps, we observe that free apps receive a lot of harsh comments, as indicated by the outliers on the negative y-axis. Reviews for paid apps appear never to be extremely negative. This may indicate something about app quality, i.e., paid apps being of higher quality than free apps on average. The median polarity score for paid apps is a little higher than free apps, thereby syncing with our previous observation.</p>
<p>In this notebook, we analyzed over ten thousand apps from the Google Play Store. We can use our findings to inform our decisions should we ever wish to create an app ourselves.</p>
```
# Load user_reviews.csv
reviews_df = pd.read_csv('datasets/user_reviews.csv')
# Join and merge the two dataframe
merged_df = pd.merge(apps, reviews_df, on = 'App', how = "inner")
# Drop NA values from Sentiment and Translated_Review columns
merged_df = merged_df.dropna(subset=['Sentiment', 'Translated_Review'])
sns.set_style('ticks')
fig, ax = plt.subplots()
fig.set_size_inches(11, 8)
# User review sentiment polarity for paid vs. free apps
ax = sns.boxplot(x = merged_df['Type'], y = merged_df['Sentiment_Polarity'], data = merged_df)
ax.set_title('Sentiment Polarity Distribution')
```
| github_jupyter |
<a href="https://colab.research.google.com/github/ksetdekov/HSE_DS/blob/master/07%20NLP/kaggle%20hw/solution.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# !pip3 install kaggle
from google.colab import files
files.upload()
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle competitions download -c toxic-comments-classification-apdl-2021
!ls
import pandas as pd
import numpy as np
from sklearn.metrics import *
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
train = pd.read_csv('train_data.csv.zip', compression='zip')
test = pd.read_csv('test_data.csv.zip', compression='zip')
train.toxic.describe()
train.sample(5)
test.sample(5)
x_train, x_test, y_train, y_test = train_test_split(train.comment, train.toxic, random_state=0, stratify=train.toxic)
y_train.describe()
y_test.describe()
```
## Bag of words
```
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
from nltk import ngrams
vec = CountVectorizer(ngram_range=(1, 2)) # строим BoW для слов
bow = vec.fit_transform(x_train)
vec2 = CountVectorizer(ngram_range=(1, 2)) # строим BoW для слов
bow2 = vec2.fit_transform(train.comment)
list(vec2.vocabulary_.items())[:10]
bow.mean()
clf = LogisticRegression(random_state=0, max_iter=500, class_weight='balanced')
clf.fit(bow, y_train)
clf2 = LogisticRegression(random_state=0, max_iter=500, class_weight='balanced')
clf2.fit(bow2, train.toxic)
pred = clf.predict(vec.transform(x_test))
print(classification_report(pred, y_test))
test
bow_test_pred = test.copy()
bow_test_pred['toxic'] = clf.predict(vec.transform(test.comment))
bow_test_pred['toxic'] = bow_test_pred['toxic'].astype(int)
bow_test_pred.drop('comment', axis=1, inplace=True)
bow_test_pred
bow_test_pred2 = test.copy()
bow_test_pred2['toxic'] = clf2.predict(vec2.transform(test.comment))
bow_test_pred2['toxic'] = bow_test_pred2['toxic'].astype(int)
bow_test_pred2.drop('comment', axis=1, inplace=True)
bow_test_pred2
bow_test_pred.to_csv('bow_v1.csv', index=False)
bow_test_pred2.to_csv('bow_v2.csv', index=False)
confusion_matrix(bow_test_pred.toxic, bow_test_pred2.toxic)
# !kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f bow_v2.csv -m "kirill_setdekov first bow v2 submission all data"
```
## TF-IDF
```
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(ngram_range=(1, 1))
bow = vec.fit_transform(x_train)
clf2 = LogisticRegression(random_state=1, max_iter = 500)
clf2.fit(bow, y_train)
pred = clf2.predict(vec.transform(x_test))
print(classification_report(pred, y_test))
tf_idf = test.copy()
tf_idf['toxic'] = clf2.predict(vec.transform(test.comment))
tf_idf['toxic'] = tf_idf['toxic'].astype(int)
tf_idf.drop('comment', axis=1, inplace=True)
tf_idf
tf_idf.to_csv('tf_idf_v1.csv', index=False)
# !kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f tf_idf_v1.csv -m "kirill_setdekov tfidf v1 submission"
```
## Symbol n-Grams
```
vec = CountVectorizer(analyzer='char', ngram_range=(1, 5))
bowsimb = vec.fit_transform(x_train)
from sklearn.preprocessing import MaxAbsScaler
scaler = MaxAbsScaler()
scaler.fit(bowsimb)
bowsimb = scaler.transform(bowsimb)
clf3 = LogisticRegression(random_state=0, max_iter=1000)
clf3.fit(bowsimb, y_train)
pred = clf3.predict(scaler.transform(vec.transform(x_test)))
print(classification_report(pred, y_test))
importances = list(zip(vec.vocabulary_, clf.coef_[0]))
importances[0]
sorted_importances = sorted(importances, key = lambda x: -abs(x[1]))
sorted_importances[:20]
symbol_ngrams = test.copy()
symbol_ngrams['toxic'] = clf3.predict(scaler.
transform(vec.transform(test.comment)))
symbol_ngrams['toxic'] = tf_idf['toxic'].astype(int)
symbol_ngrams.drop('comment', axis=1, inplace=True)
symbol_ngrams
symbol_ngrams.to_csv('symbol_ngrams_v1.csv', index=False)
from sklearn.metrics import confusion_matrix
confusion_matrix(symbol_ngrams.toxic, tf_idf.toxic)
# !kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f symbol_ngrams_v1.csv -m "kirill_setdekov symbol_ngrams_v1 v1 submission"
```
#FastText
```
!pip3 install fasttext
import fasttext
with open('ft_train_data.txt', 'w') as f:
for pair in list(zip(x_train, y_train)):
text, label = pair
f.write(f'__label__{int(label)} {text.lower()}\n')
with open('ft_test_data.txt', 'w') as f:
for pair in list(zip(x_test, y_test)):
text, label = pair
f.write(f'__label__{int(label)} {text.lower()}\n')
with open('ft_all.txt', 'w') as f:
for pair in list(zip(train.comment, train.toxic)):
text, label = pair
f.write(f'__label__{int(label)} {text.lower()}\n')
classifier = fasttext.train_supervised('ft_train_data.txt')#, 'model')
result = classifier.test('ft_test_data.txt')
print('P@1:', result[1])#.precision)
print('R@1:', result[2])#.recall)
print('Number of examples:', result[0])#.nexamples)
classifier2 = fasttext.train_supervised('ft_all.txt')#, 'model')
k = 0
for item in [i.lower() for i in test.comment]:
item = item.replace("\n"," ")
k +=1
k
prediction = []
for item in [i.lower() for i in test.comment]:
item = item.replace("\n"," ")
prediction.append(classifier.predict(item))
prediction2 = []
for item in [i.lower() for i in test.comment]:
item = item.replace("\n"," ")
prediction2.append(classifier2.predict(item))
pred = [int(label[0][0].split('__')[2][0]) for label in prediction]
pred2 = [int(label[0][0].split('__')[2][0]) for label in prediction2]
fasttext_pred = test.copy()
fasttext_pred['toxic'] = pred
fasttext_pred.drop('comment', axis=1, inplace=True)
fasttext_pred
fasttext_pred2 = test.copy()
fasttext_pred2['toxic'] = pred2
fasttext_pred2.drop('comment', axis=1, inplace=True)
fasttext_pred2
confusion_matrix(symbol_ngrams.toxic, fasttext_pred.toxic)
confusion_matrix(fasttext_pred2.toxic, fasttext_pred.toxic)
fasttext_pred.to_csv('fasttext_pred_v1.csv', index=False)
fasttext_pred2.to_csv('fasttext_pred_v2.csv', index=False)
!kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f fasttext_pred_v2.csv -m "kirill_setdekov fasttext_pred v2 submission"
```
## CNN
```
from torchtext.legacy import data
pd.read_csv('train_data.csv.zip', compression='zip')
!unzip train_data.csv.zip
!unzip test_data.csv.zip
# классы Field и LabelField отвечают за то, как данные будут храниться и обрабатываться при считывании
TEXT = data.Field(tokenize='spacy') # spacy -- значит, токенизацию будет делать модуль
LABEL = data.LabelField()
ds = data.TabularDataset(
path='train_data.csv', format='csv',
skip_header=True,
fields=[('comment', TEXT),
('toxic', LABEL)]
)
pd.read_csv('test_data.csv')
test = data.TabularDataset(
path='test_data.csv', format='csv',
skip_header=True,
fields=[('id', TEXT), ('comment', TEXT)]
)
next(ds.comment)
next(ds.toxic)
TEXT.build_vocab(ds, max_size=25000, vectors="glove.6B.100d")
LABEL.build_vocab(ds)
TEXT.vocab.itos[:20]
len(TEXT.vocab.itos)
train, val = ds.split(split_ratio=0.9, stratified=True, strata_field='toxic') # дефолтное соотношение 0.7
print(len(train))
print(len(val))
print(len(test))
BATCH_SIZE = 64
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train, val, test),
batch_size=BATCH_SIZE,
sort=True,
sort_key=lambda x: len(x.comment), # сорируем тексты по длине, чтобы рядом оказывались предложения с одинаковой длиной и добавлялось меньше паддинга
repeat=False)
for i, batch in enumerate(valid_iterator):
print(batch.batch_size)
# pass
batch.fields
batch.batch_size
batch.comment
batch.toxic
len(batch.toxic)
import torch.nn as nn
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout_proba):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.conv_0 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[2], embedding_dim))
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout_proba)
def forward(self, x):
#x = [sent len, batch size]
# print(x.shape)
x = x.permute(1, 0)
#x = [batch size, sent len]
embedded = self.embedding(x)
#print(embedded.shape)
#embedded = [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1)
#embedded = [batch size, 1, sent len, emb dim]
conv_0 = self.conv_0(embedded)
#print(conv_0.shape)
conv_0 = conv_0.squeeze(3)
#print(conv_0.shape)
conved_0 = F.relu(conv_0)
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
#conv_n = [batch size, n_filters, sent len - filter_sizes[n]]
# print(conved_0.shape)
pool_0 = F.max_pool1d(conved_0, conved_0.shape[2])
# print(pool_0.shape)
pooled_0 = pool_0.squeeze(2)
# print(pooled_0.shape)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim=1))
#cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
import torch.nn.functional as F
def binary_accuracy(preds, y):
rounded_preds = torch.round(F.sigmoid(preds))
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
def train_func(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.comment.cuda()).squeeze(1)
loss = criterion(predictions.float(), batch.toxic.float().cuda())
acc = binary_accuracy(predictions.float(), batch.toxic.float().cuda())
loss.backward()
optimizer.step()
epoch_loss += loss
epoch_acc += acc
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate_func(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.comment.cuda()).squeeze(1)
loss = criterion(predictions.float(), batch.toxic.float().cuda())
acc = binary_accuracy(predictions.float(), batch.toxic.float().cuda())
epoch_loss += loss
epoch_acc += acc
return epoch_loss / len(iterator), epoch_acc / len(iterator)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [2,3,4]
OUTPUT_DIM = 1
DROPOUT_PROBA = 0.5
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT_PROBA)
INPUT_DIM
model
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
import torch.optim as optim
optimizer = optim.Adam(model.parameters()) # мы подали оптимизатору все параметры -- значит, эмбеддиги тоже будут дообучаться
criterion = nn.BCEWithLogitsLoss() # бинарная кросс-энтропия с логитами
model = model.cuda() # будем учить на gpu! =)
model.embedding
from torchsummary import summary
# summary(model, (14))
import torch
N_EPOCHS = 8
for epoch in range(N_EPOCHS):
train_loss, train_acc = train_func(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate_func(model, valid_iterator, criterion)
print(f'Epoch: {epoch+1:02}, Train Loss: {train_loss:.3f}, Train Acc: {train_acc*100:.2f}%, Val. Loss: {valid_loss:.3f}, Val. Acc: {valid_acc*100:.2f}%')
test.examples
model.eval()
cnn_res = []
with torch.no_grad():
for batch in test_iterator:
predictions = model(batch.comment.cuda())
cnn_res.append(predictions)
testout = pd.read_csv('test_data.csv.zip', compression='zip')
cnnpred = testout.copy()
cnnpred['toxic'] = [float(item) for sublist in cnn_res for item in sublist]
cnnpred.drop('comment', axis=1, inplace=True)
cnnpred
cnnpred['toxic'] = (cnnpred['toxic'] > 0).astype(int)
cnnpred
cnnpred.to_csv('cnnpred_v4.csv', index=False)
!kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f cnnpred_v4.csv -m "kirill_setdekov cnn v4 with threshold 0"
```
# word2vec
> not done, skip this model
```
! wget https://nlp.stanford.edu/data/glove.6B.zip
with open("alice.txt", 'r', encoding='utf-8') as f:
text = f.read()
text = re.sub('\n', ' ', text)
sents = sent_tokenize(text)
punct = '!"#$%&()*+,-./:;<=>?@[\]^_`{|}~„“«»†*—/\-‘’'
clean_sents = []
for sent in sents:
s = [w.lower().strip(punct) for w in sent.split()]
clean_sents.append(s)
print(clean_sents[:2])
model_path = "movie_reviews.model"
print("Saving model...")
model_en.save(model_path)
model = word2vec.Word2Vec.load(model_path)
model.build_vocab(clean_sents, update=True)
model.train(clean_sents, total_examples=model.corpus_count, epochs=5)
```
# bow on random forest

```
! pip install pymystem3
! pip install --force-reinstall pymorphy2
!pip install pymorphy2-dicts-ru
import pymorphy2
import re
morph = pymorphy2.MorphAnalyzer()
# убираем все небуквенные символы
regex = re.compile("[А-Яа-яA-z]+")
def words_only(text, regex=regex):
try:
return regex.findall(text.lower())
except:
return []
for i in train.comment[10].split():
lemmas = morph.parse(i)
print(lemmas[0])
from functools import lru_cache
@lru_cache(maxsize=128)
def lemmatize_word(token, pymorphy=morph):
return pymorphy.parse(token)[0].normal_form
def lemmatize_text(text):
return [lemmatize_word(w) for w in text]
tokens = words_only(train.comment[10])
print(lemmatize_text(tokens))
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
mystopwords = stopwords.words('russian')
def remove_stopwords(lemmas, stopwords = mystopwords):
return [w for w in lemmas if not w in stopwords]
lemmas = lemmatize_text(tokens)
print(*remove_stopwords(lemmas))
def remove_stopwords(lemmas, stopwords = mystopwords):
return [w for w in lemmas if not w in stopwords and len(w) > 3]
print(*remove_stopwords(lemmas))
def clean_text(text):
tokens = words_only(text)
lemmas = lemmatize_text(tokens)
return remove_stopwords(lemmas)
for i in range(20):
print(* clean_text(train.comment[i]))
from tqdm.auto import trange
new_comments = []
for i in trange(len(train.comment), desc='loop'):
new_comments.append(" ".join(clean_text(train.comment[i])))
new_comments[:10]
vec3 = CountVectorizer(ngram_range=(1, 2)) # строим BoW для слов
bow3 = vec3.fit_transform(new_comments)
list(vec3.vocabulary_.items())[100:120]
bow3
clf3 = LogisticRegression(random_state=0, max_iter=500, class_weight='balanced')
clf3.fit(bow3, train.toxic)
pred = clf3.predict(bow3)
print(classification_report(pred, train.toxic))
test
new_commentstest = []
for i in trange(len(test.comment), desc='loop'):
new_commentstest.append(" ".join(clean_text(test.comment[i])))
bow_test_pred3 = test.copy()
bow_test_pred3['newcomment'] = new_commentstest
bow_test_pred3.tail()
bow_test_pred3['toxic'] = clf3.predict(vec3.transform(bow_test_pred3.newcomment))
bow_test_pred3['toxic'] = bow_test_pred3['toxic'].astype(int)
bow_test_pred3.drop('comment', axis=1, inplace=True)
bow_test_pred3.drop('newcomment', axis=1, inplace=True)
bow_test_pred3
confusion_matrix(bow_test_pred2.toxic, bow_test_pred3.toxic)
bow_test_pred3.to_csv('bow_v3.csv', index=False)
# !kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f bow_v3.csv -m "kirill_setdekov bow3 with preprocessing"
!pip install scikit-learn==0.24
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingGridSearchCV
```
nor run -too slow
```
# rnd_reg = RandomForestClassifier( )
# # hyper-parameter space
# param_grid_RF = {
# 'n_estimators' : [10,20,50,100,200,500,1000],
# 'max_features' : [0.6,0.8,"auto","sqrt"],
# }
# search_two = HalvingGridSearchCV(rnd_reg, param_grid_RF, factor=5, scoring='accuracy',
# n_jobs=-1, random_state=0, verbose=2).fit(bow3, train.toxic)
# search_two.best_params_
rnd_reg_2 = RandomForestClassifier(n_estimators=1000, verbose=5, n_jobs=-1)
search_no = rnd_reg_2.fit(bow3, train.toxic)
bow_test_pred4 = test.copy()
bow_test_pred4['newcomment'] = new_commentstest
bow_test_pred4.tail()
bow_test_pred4['toxic'] = search_no.predict(vec3.transform(bow_test_pred4.newcomment))
bow_test_pred4['toxic'] = bow_test_pred4['toxic'].astype(int)
bow_test_pred4.drop('comment', axis=1, inplace=True)
bow_test_pred4.drop('newcomment', axis=1, inplace=True)
bow_test_pred4
confusion_matrix(bow_test_pred4.toxic, bow_test_pred3.toxic)
bow_test_pred4.to_csv('bow_v4.csv', index=False)
!kaggle competitions submit -c toxic-comments-classification-apdl-2021 -f bow_v4.csv -m "kirill_setdekov bow4 with preprocessing and RF"
```
| github_jupyter |
# Satellite sea surface temperatures along the West Coast of the United States
# during the 2014–2016 northeast Pacific marine heat wave
In 2016 we published a [paper](https://agupubs.onlinelibrary.wiley.com/doi/10.1002/2016GL071039) on the heat wave in the ocean off the California coast
This analysis was the last time I used Matlab to process scientific data. To make Figure 1, here are the following steps:
- Download 4 TB of data from NASA PO.DAAC data archive via FTP
- Go through each day of data and subset to the West Coast Region to reduce size and save each subsetted day
- Go through 2002-2012 and create a daily climatology and save all 365 days of the climatology
- Go through each day of data and calculate the anomaly and save each day's anomaly
This whole process took about 1 month. Once the anomalies were calculated, then I could start to do analyses and explore the data.
Below we will do this using MUR SST data on AWS Open Data Program in a few minutes using Python.
```
import warnings
import numpy as np
import pandas as pd
import xarray as xr
import fsspec
import matplotlib.pyplot as plt
warnings.simplefilter('ignore') # filter some warning messages
xr.set_options(display_style="html") #display dataset nicely
dir_out = './../../data/zarr_testing/'
file_aws = 'https://mur-sst.s3.us-west-2.amazonaws.com/zarr-v1'
file_aws_time = 'https://mur-sst.s3.us-west-2.amazonaws.com/zarr'
%%time
ds_sst = xr.open_zarr(file_aws,consolidated=True)
ds_sst
#region for figure 1
xlat1,xlat2 = 33,48
xlon1,xlon2 = -132, -118,
date1,date2 = '2002-01-01','2013-01-01'
subset = ds_sst.sel(lat=slice(xlat1,xlat2),lon=slice(xlon1,xlon2))
subset
```
# Just plot a random day to make sure it looks correct
```
subset.analysed_sst[0,:,:].plot()
```
# How big is this dataset?
- Because xarray uses lazy loading, we have access to this entire dataset but it only loads what it needs to for calculations
```
print('GB data = ',subset.nbytes/(1024 * 1024 * 1024))
```
# Caluculate the Monthly Sea Surface Temperature Anomalies
```
sst_monthly = subset.resample(time='1MS').mean('time',keep_attrs=True,skipna=False)
climatology_mean_monthly = sst_monthly.sel(time=slice(date1,date2)).groupby('time.month').mean('time',keep_attrs=True,skipna=False)
sst_anomaly_monthly = sst_monthly.groupby('time.month')-climatology_mean_monthly #take out annual mean to remove trends
sst_anomaly_monthly
sst_anomaly_monthly.analysed_sst[0,:,:].plot(vmin=-3,vmax=3,cmap='RdYlBu_r')
sst_anomaly_monthly.analysed_sst.sel(time='2015-03').plot(vmin=-3,vmax=3,cmap='RdYlBu_r')
#plt.pcolormesh(tem.lon,tem.lat,tem.analysed_sst,transform=ccrs.PlateCarree(),cmap=vik_map,vmin=-2,vmax=2)
#ax.coastlines(resolution='50m', color='black', linewidth=1)
#ax.add_feature(cfeature.LAND)
#ax.add_feature(cfeature.STATES.with_scale('10m'))
#ax.set_extent([-132.27,-117,32,48])
#plt.colorbar(ax=ax,label='SST Anomaly (K)')
#tt=plt.text(-122,47,tstr,fontsize=16)
```
# Let's try and re-do figure 2 which uses 5-day average SST anomalies
```
sst_5day = subset.resample(time='5D').mean('time',keep_attrs=True,skipna=False)
climatology_mean_5day = sst_5day.sel(time=slice(date1,date2)).groupby('time.day').mean('time',keep_attrs=True,skipna=False)
sst_anomaly_5day = sst_5day.groupby('time.day')-climatology_mean_5day #take out annual mean to remove trends
sst_anomaly_5day
%%time
max_5day = sst_anomaly_5day.analysed_sst.sel(time=slice('2012','2016')).max("time")
max_5day
#running out of memory right now. maybe need to breakdown into yearly bits or something. could try using time arranged zarr file store
#max_5day.plot(vmin=0,vmax=5,cmap='jet')
```
# Switch to same data, but it is chunked differently
- it is optimized for timeseries rather than spatial analysis
```
ds_sst = xr.open_zarr(file_aws_time,consolidated=True)
ds_sst
%%time
sst_newport_nearshore = ds_sst.analysed_sst.sel(lat=44.6,lon=-124.11,method='nearest').rolling(time=30, center=True).mean().load()
sst_newport_offshore = ds_sst.analysed_sst.sel(lat=44.6,lon=-134.11,method='nearest').rolling(time=30, center=True).mean().load()
plt.plot(sst_newport_nearshore.time.dt.dayofyear,sst_newport_nearshore)
```
| github_jupyter |
# Minimal end-to-end causal analysis with ```cause2e```
This notebook shows a minimal example of how ```cause2e``` can be used as a standalone package for end-to-end causal analysis. It illustrates how we can proceed in stringing together many causal techniques that have previously required fitting together various algorithms from separate sources with unclear interfaces. Additionally, the numerous techniques have been packed into only two easy-to-use functions for causal discovery and causal estimation. Hopefully, you will find this notebook helpful in guiding you through the process of setting up your own causal analyses for custom problems. The overall structure should always be the same regardless of the application domain. For more advanced features, check out the other notebooks.
### Imports
By the end of this notebook, you will probably be pleasantly surprised by the fact that we did not have to import lots of different packages to perform a full causal analysis consisting of different subtasks.
```
import os
from cause2e import path_mgr, knowledge, discovery
```
## Set up paths to data and output directories
This step is conveniently handled by the ```PathManager``` class, which avoids having to wrestle with paths throughout the multistep causal analysis. If we want to perform the analysis in a directory ```'dirname'``` that contains ```'dirname/data'``` and ```'dirname/output'``` as subdirectories, we can also use ```PathManagerQuick``` for an even easier setup. The ```experiment_name``` argument is used for generating output files with meaningful names, in case we want to study multiple scenarios (e.g. with varying model parameters).
For this analysis, we use the sprinkler dataset. Unfortunately, there are still some problems to be sorted out with categorical data in the estimation step, but continuous and discrete data work fine. Therefore, we use a version of the dataset where only the seasons ```'Spring'``` and ```'Summer'``` are present, such that we can replace these values by 0 and 1.
```
cwd = os.getcwd()
wd = os.path.dirname(cwd)
paths = path_mgr.PathManagerQuick(experiment_name='sprinkler',
data_name='sprinkler.csv',
directory=wd
)
```
## Learn the causal graph from data and domain knowledge
Model-based causal inference leverages qualitative knowledge about pairwise causal connections to obtain unbiased estimates of quantitative causal effects. The qualitative knowledge is encoded in the causal graph, so we must recover this graph before we can start actually estimating the desired effects. For learning the graph from data and domain knowledge, we use the ```StructureLearner``` class.
```
learner = discovery.StructureLearner(paths)
```
### Read the data
The ```StructureLearner``` has reading methods for csv and parquet files.
```
learner.read_csv(index_col=0)
```
The first step in the analysis should be an assessment of which variables we are dealing with. In the sprinkler dataset, each sample tells us
- the current season
- whether it is raining
- whether our lawn sprinkler is activated
- whether our lawn is slippery
- whether our lawn is wet.
```
learner.variables
```
### Preprocess the data
As mentioned above, currently there are problems in the estimation step with categorical data, so we use this occasion to showcase ```cause2e```'s built-in preprocessing functionalities. We define a function that replaces instances of ```'Summer'``` by 1, and instances of ```'Spring'``` by 0. Afterwards we apply it to our data and throw out the categorical ```'Season'``` column. For more preprocessing options, check out the pertaining notebook.
```
def is_summer(data, col_name):
return (data[col_name] == 'Summer').apply(int)
learner.combine_variables(name='Season_binary', func=is_summer, input_cols=['Season'], keep_old=False)
```
It necessary to communicate to the ```StructureLearner``` if the variables are discrete, continuous, or both. We check how many unique values each variable takes on in our sample and deduce that all variables are discrete.
```
learner.data.nunique()
```
This information is passed to the ```StructureLearner``` by indicating the exact sets of discrete and continuous variables.
```
learner.discrete = learner.variables
learner.continuous = set()
```
### Provide domain knowledge
Humans can often infer parts of the causal graph from domain knowledge. The nodes are always just the variables in the data, so the problem of finding the right graph comes down to selecting the right edges between them.
As a reminder: The correct causal graph has an edge from variable A to variable B if and only if variable A directly influences variable B (changing the value of variable A changes the value of variable B if we keep all other variables fixed).
There are three ways of passing domain knowledge for the graph search:
- Indicate which edges must be present in the causal graph.
- Indicate which edges must not be present in the causal graph.
- Indicate a temporal order in which the variables have been created. This is then used to generate forbidden edges, since the future can never influence the past.
In this example, we use the ```knowledge.EdgeCreator``` to prescribe that
- no variables are direct causes of the season,
- the lawn being slippery is not a direct cause of any other variable
- turning the sprinkler on or off directly affects the wetness of the lawn,
- turning the sprinkler on or off does not directly affect the weather.
```
edge_creator = knowledge.EdgeCreator()
edge_creator.forbid_edges_from_groups({'Season_binary'}, incoming=learner.variables)
edge_creator.forbid_edges_from_groups({'Slippery'}, outgoing=learner.variables)
edge_creator.require_edge('Sprinkler', 'Wet')
edge_creator.forbid_edge('Sprinkler', 'Rain')
```
There is a fourth way of passing knowledge which is not used in learning the graph, but in validating the quantitative estimates resulting from our end-to-end causal analysis. We often know beforehand what some of the quantitative effects should look like, e.g.
- turning the sprinkler on should have a positive overall effect (-> average treatment effect; read below if you are not familiar with types of causal effects) on the lawn being wet and
- making the lawn wet should have a positive overall effect on the lawn being slippery.
Instead of checking manually at the end if our expectations have been met, we can automate this validation by using the ```knowledge.ValidationCreator```. For instructiveness, we also add two more validations that should fail:
- the sprinkler has a negative natural direct effect on the weather and
- the natural indirect effect of the lawn being slippery on the season is between 0.2 and 0.4 (remember to normalize your data before such a validation if they are not measured on the same scale).
```
validation_creator = knowledge.ValidationCreator()
validation_creator.add_expected_effect(('Sprinkler', 'Wet', 'nonparametric-ate'), ('greater', 0))
validation_creator.add_expected_effect(('Wet', 'Slippery', 'nonparametric-ate'), ('greater', 0))
validation_creator.add_expected_effect(('Sprinkler', 'Rain', 'nonparametric-nde'), ('less', 0))
validation_creator.add_expected_effect(('Slippery', 'Season_binary', 'nonparametric-nie'), ('between', 0.2, 0.4))
```
We pass the knowledge to the ```StructureLearner``` and check if it has been correctly received.
```
learner.set_knowledge(edge_creator=edge_creator, validation_creator=validation_creator)
```
### Apply a structure learning algorithm
Now that the ```StructureLearner``` has received the data and the domain knowledge, we can try to recover the original graph using causal discovery methods provided by the internally called ```py-causal``` package. There are many parameters that can be tuned (choice of algorithm, search score, independence test, hyperparameters, ...) and we can get an overview by calling some informative methods of the learner. Reasonable default arguments are provided (FGES with CG-BIC score for possibly mixed datatypes and respecting domain knowledge), so we use these for our minimal example.
```
learner.run_quick_search()
```
The output of the search is a proposed causal graph. We can ignore the warning about stopping the Java Virtual Machine (needed by ```py-causal``` which is a wrapper around the ```TETRAD``` software that is written in Java) if we do not run into any problems. If the algorithm cannot orient all edges, we need to do this manually. Therefore, the output includes a list of all undirected edges, so we do not miss them in complicated graphs with many variables and edges. In our case, all the edges are already oriented.
The result seems reasonable:
- The weather depends on the season.
- The sprinkler use also depends on the season.
- The lawn will be wet if it rains or if the sprinkler is activated.
- The lawn will be slippery if it is wet.
### Saving the graph
```Cause2e``` allows us to save the result of our search to different file formats with the ```StructureLearner.save_graphs``` method. The name of the file is determined by the ```experiment_name``` parameter from the ```PathManager```. If the result of the graph search is already a directed acyclic graph that respects our domain knowledge, the graph is automatically saved, as we can see from the above output. Check out the graph postprocessing notebook for information on how to proceed when the result of the search needs further adjustments.
## Estimate causal effects from the graph and the data
After we have successfully recovered the causal graph from data and domain knowledge, we can use it to estimate quantitative causal effects between the variables in the graph. It is pleasant that we can use the same graph and data to estimate multiple causal effects, e.g. the one that the Sprinkler has on the lawn being slippery, as well as the one that the season has on the rain probability, without having to repeat the previous steps. Once we have managed to qualitatively model the data generating process, we are already in a very good position. The remaining challenges can be tackled with the core functionality from the ```DoWhy``` package, which we have wrapped into a single easy-to-use convenience method. Usually, all estimation topics are handled by the ```estimator.Estimator```, but the ```StructureLearner``` has the possibility to run a quick analysis of all causal effects with preset parameters. For more detailed analyses, check out the other notebooks that describe the causal identification and estimation process step by step.
```
learner.run_all_quick_analyses()
```
The output consists of a detailed analysis of the causal effects in our system.
### Heatmaps
The first three images are heatmaps, where the (i, j)-entry shows the causal effect of variable i on variable j. The three heatmaps differ in the type of causal effect that they are describing:
- **Average Treatment Effect (ATE)**: Shows how the outcome variable varies if we vary the treatment variable. This comprises direct and indirect effects. The sprinkler influences the lawn being slippery, even if this does not happen directly, but via its influence on the lawn being wet.
- **Natural Direct Effect (NDE)**: Shows how the outcome variable varies if we vary the treatment variable and keep all other variables fixed. This comprises only direct effects. The sprinkler does not directly influence the lawn being slippery, as we can read off from the heatmap.
- **Natural Indirect Effect (NIE)**: Shows the difference between ATE and NDE. By definition, this comprises only indirect effects. The sprinkler has a strong indirect influence on the lawn being slippery, as we can read off from the heatmap.
In our example, we can easily identify from the graph if an effect is direct or indirect, but in examples where a variable simultaneously has a direct and an indirect influence on another variable, it is very challenging to separate the effects without resorting to the algebraic methods that ```cause2e``` uses internally.
### Validations
The next output shows if our model has passed each of the validations, based on the expected causal effects that we have communicated before running the causal end-to-end analysis. If we are interested in a specific effect, say, the effect of the sprinkler on the lawn being slippery, the estimation of this effect by our learnt causal model can be trusted more if the estimation for other effects match our expectations. We see that the results of the validations turned out exactly as described above (in practice we would not want validations to fail, this was only for demonstrative purposes).
### Numeric tables
The three numeric tables show the same information as the three previous heatmaps, only in quantitative instead of visual form.
### PDF report
```Cause2e``` automatically generates a pdf report that contains
- the causal graph indicating all qualitative relationships,
- the three heatmaps visualizing all quantitative causal effects,
- the results of the validations,
- the three numeric tables reporting all quantitative causal effects.
This is helpful if we want to communicate our findings to other people, or if we want to modify the analysis at a later time and compare the outcome for both methods.
## Discussion of the results
The heatmaps show the effects that we would expect given our causal graph:
- There is less rain in summer than in spring.
- Sprinklers are more often turned on in summer than in spring.
- Rain increases the wetness of the lawn.
- Turning the sprinkler on also increases the wetness of the lawn.
- Wetting the lawn causes it to be slippery.
It is interesting to see that the first two effects roughly cancel each other out, resulting in a small ATE of 0.1 that ```'Season_binary'``` has on ```'Slippery'``` and ```'Wet'```. In general, it is a good strategy to look at the heatmaps for discovering the qualitative nature of the different causal effects and then inspect the numeric tables for the exact numbers if needed.
Another noteworthy entry is the overall effect of ```'Sprinkler'``` on ```'Wet'```. The result is 0.638, so turning on the sprinkler makes it more likely for the lawn to be wet, as it should be. However, we might ask ourselves: "Why is the effect not 1? Whenever we turn on the sprinkler, the lawn will be wet!" This can be explained by looking at the definition of our chosen effect type, the nonparametric average treatment effect (ATE): The ATE tells us how much (on average) we change the outcome by changing the treatment. In our case, we can distinguish between two possible scenarios:
If it is raining, then the lawn is wet anyway, so turning the sprinkler on does not change the outcome at all. Only if it is not raining, the lawn state is changed to wet by turning on the sprinkler.
We can convince ourselves that this is the correct explanation by looking at the proportion of samples where it is not raining.
```
1 - sum(learner.data['Rain']) / len(learner.data)
```
We recover the same number of 0.638. Additionally, we can change our data to consist only of the instances where it is not raining. If we now repeat the causal analysis, the effect is indeed 1 (skip after the warnings that are caused by the now degenerate dataset). This procedure can be generalized to analyzing other conditional causal effects.
```
learner.data = learner.data[learner.data['Rain']==0]
learner.run_all_quick_analyses()
```
| github_jupyter |
The data and the description:
https://archive.ics.uci.edu/ml/datasets/APS+Failure+at+Scania+Trucks
Abstract: The datasets' positive class consists of component failures for a specific component of the APS system. The negative class consists of trucks with failures for components not related to the APS.
```
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import LabelEncoder
pd.options.display.max_columns = None
import warnings
warnings.filterwarnings('ignore')
df_original = pd.read_csv('../Data/aps_failure_training_set.csv', dtype = 'str')
df_original = df_original.replace(r'na', np.nan, regex=True)
df_original.head()
#encode labels to 0 and 1
le = LabelEncoder()
df_original['class'] = le.fit_transform(df_original['class'])
df = df_original.copy()
df.head()
```
The set is very unbalanced with one label (0) being more frequent than the other (1). The algorithm needs to adjust for that.
It is done using 'class_weight' hyperparameter which is the ratio of number of 0s to 1s in the label.
```
df = df_original.copy()
from sklearn.model_selection import train_test_split
X, y = df.iloc[:,1:], df.iloc[:,0]
X_tr, X_t, y_tr, y_t = train_test_split(X, y, test_size = 0.2, random_state = 0)
weight = sum(y_tr == 0)/sum(y_tr == 1)
lr_full = LogisticRegression(C = 1, class_weight={1:weight}, random_state = 0)
lr_full.fit(X_tr, y_tr)
y_pred = lr_full.predict(X_t)
#calculate the score using confusion matrix values
def score(cm):
cm_score = cm[0][1] * 10 + cm[1][0] * 500
cm_score = int(cm_score * 1.33) #1.33 is because the actual test set is 33% larger than this test set
return cm_score
#calculate confusion matrix
cm = confusion_matrix(y_t, y_pred)
score(cm)
```
13632 is our basic score. We'll use it as a reference for further optimizations.
The data seemed to be scaled but let's apply scaling to the data just in case.
```
#testing scaling
df = df_original.copy()
from sklearn.preprocessing import MinMaxScaler
scaler_minmax = MinMaxScaler()
X, y = df.iloc[:,1:], df.iloc[:,0]
X_scaled = scaler_minmax.fit_transform(X.values)
X_tr, X_t, y_tr, y_t = train_test_split(X_scaled, y, test_size = 0.2, random_state = 0)
weight = sum(y_tr == 0)/sum(y_tr == 1)
lr_full = LogisticRegression(C = 1, class_weight={1:weight}, random_state = 0)
lr_full.fit(X_tr, y_tr)
y_pred = lr_full.predict(X_t)
#calculate confusion matrix
cm = confusion_matrix(y_t, y_pred)
score(cm)
```
MinMaxScaler slightly improved the result.
Let's tune the 'C', a hyperparameter (parameter) of the Logistic Regression algorithm.
```
#tuning hyperparameters for Logistic Regression
df = df_original.copy()
X, y = df.iloc[:,1:], df.iloc[:,0]
X_tr, X_t, y_tr, y_t = train_test_split(X, y, test_size = 0.2, random_state = 0)
Cs = list(np.arange(0.1, 0.5, 0.1))
weight = sum(y_tr == 0)/sum(y_tr == 1)
for C_ in Cs:
lr_full = LogisticRegression(C = C_, class_weight={1:weight}, random_state = 0)
lr_full.fit(X_tr, y_tr)
y_pred = lr_full.predict(X_t)
#calculate confusion matrix
cm = confusion_matrix(y_t, y_pred)
score(cm)
print("C is {0}. Score is: {1}".format(C_, score(cm)))
```
C = 0.1 gives the best score.
Let's try another algorithm. Maybe Random Forest will perfom better.
```
#check algorithm with all NAs replaced with mean column values (none rows/columns dropped)
df = df_original.copy()
X, y = df.iloc[:,1:], df.iloc[:,0]
#split into train and test
from sklearn.model_selection import train_test_split
X_tr, X_t, y_tr, y_t = train_test_split(X, y, test_size = 0.2, random_state = 0)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators = 200, oob_score = True, class_weight={1:weight}, random_state = 0, bootstrap = True)
rf.fit(X_tr, y_tr)
y_pred = rf.predict(X_t)
cm = confusion_matrix(y_t, y_pred)
score(cm)
```
61938 is significanlty worse.
It seems Logistic Regression gives us the best score.
We need to train it on the full training data set and fit the actual test set to get the final score.
```
df = df_original.copy()
X_train, y_train = df.iloc[:,1:], df.iloc[:,0]
X_train_scaled = scaler_minmax.fit_transform(X_train.values)
#calculation of the score for the actual test set
weight = sum(y_train == 0)/sum(y_train == 1)
log_reg = LogisticRegression(class_weight = {1:weight}, C = 0.2, random_state=1)
log_reg.fit(X_train_scaled, y_train)
#process the test data set
df_test = pd.read_csv('../input/aps_failure_test_set_processed_8bit.csv', dtype = 'str')
df_test = df_test.replace(r'na', np.nan, regex=True)
le = LabelEncoder()
df_test['class'] = le.fit_transform(df_test['class'])
X_test, y_test = df_test.iloc[:,1:], df_test.iloc[:,0]
X_test_scaled = scaler_minmax.transform(X_test.values)
#predict the class for the test set
y_test_pred = log_reg.predict(X_test_scaled)
cm = confusion_matrix(y_test, y_test_pred)
def score(cm):
cm_score = cm[0][1] * 10 + cm[1][0] * 500
cm_score = int(cm_score)
return cm_score
score(cm)
```
The final score is 14520. It is not the best score, but a good one. Scheduling repairs according to the algorithm's predictions will significantly reduce the cost of truck repairs.
| github_jupyter |
## stripplot() and swarmplot()
Many datasets have categorical data and Seaborn supports several useful plot types for this data. In this example, we will continue to look at the 2010 School Improvement data and segment the data by the types of school improvement models used.
As a refresher, here is the KDE distribution of the Award Amounts:
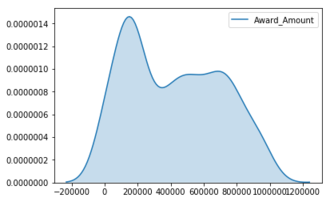
While this plot is useful, there is a lot more we can learn by looking at the individual `Award_Amounts` and how they are distributed among the 4 categories.
Instructions
1. Create a `stripplot` of the `Award_Amount` with the `Model Selected` on the y axis with `jitter` enabled.
2. Create a `swarmplot()` of the same data, but also include the `hue` by `Region`.
```
# Import packages
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Import dataset
df = pd.read_csv('grant_file.csv')
# Create the stripplot
sns.stripplot(data=df,
x='Award_Amount',
y='Model Selected',
jitter=True)
plt.show()
# Create and display a swarmplot with hue set to the Region
sns.swarmplot(data=df,
x='Award_Amount',
y='Model Selected',
hue='Region')
plt.show()
```
## boxplots, violinplots and lvplots
Seaborn's categorical plots also support several abstract representations of data. The API for each of these is the same so it is very convenient to try each plot and see if the data lends itself to one over the other.
In this exercise, we will use the color palette options presented in Chapter 2 to show how colors can easily be included in the plots.
Instructions
1. Create and display a `boxplot` of the data with `Award_Amount` on the x axis and `Model Selected` on the y axis.
2. Create and display a similar `violinplot` of the data, but use the `husl` palette for colors.
3. Create and display an `lvplot` using the `Paired` palette and the `Region` column as the `hue`.
_NOTE: lvplot function has been renamed to boxenplot._
```
# Create a boxplot
sns.boxplot(data=df,
x='Award_Amount',
y='Model Selected')
plt.show()
plt.clf()
# Create a violinplot with the husl palette
sns.violinplot(data=df,
x='Award_Amount',
y='Model Selected',
palette='husl')
plt.show()
plt.clf()
# Create a lvplot with the Paired palette and the Region column as the hue
sns.boxenplot(data=df,
x='Award_Amount',
y='Model Selected',
palette='Paired',
hue='Region')
plt.show()
plt.clf()
```
## barplots, pointplots and countplots
The final group of categorical plots are `barplots`, `pointplots` and `countplot` which create statistical summaries of the data. The plots follow a similar API as the other plots and allow further customization for the specific problem at hand.
Instructions
1. Create a `countplot` with the `df` dataframe and `Model Selected` on the y axis and the color varying by `Region`.
2. Create a `pointplot` with the `df` dataframe and `Model Selected` on the x-axis and `Award_Amount` on the y-axis.
3. Use a `capsize` in the `pointplot` in order to add caps to the error bars.
4. Create a `barplot` with the same data on the x and y axis and change the color of each bar based on the `Region` column.
```
# Show a countplot with the number of models used with each region a different color
sns.countplot(data=df,
y='Model Selected',
hue='Region')
plt.show()
plt.clf()
# Create a pointplot and include the capsize in order to show caps on the error bars
sns.pointplot(data=df,
x='Model Selected',
y='Award_Amount',
capsize=.1)
plt.show()
plt.clf()
# Create a barplot with each Region shown as a different color
sns.barplot(data=df,
x='Model Selected',
y='Award_Amount',
hue='Region')
plt.show()
plt.clf()
```
## Regression and residual plots
Linear regression is a useful tool for understanding the relationship between numerical variables. Seaborn has simple but powerful tools for examining these relationships.
For these exercises, we will look at some details from the US Department of Education on 4 year college tuition information and see if there are any interesting insights into which variables might help predict tuition costs.
For these exercises, all data is loaded in the `college` variable.
Instructions
1. Plot a regression plot comparing `Tuition` and average SAT scores (`SAT_AVG_ALL`).
2. Make sure the values are shown as green triangles.
3. Use a residual plot to determine if the relationship looks linear.
```
# Import dataset
college = pd.read_csv('college_datav3.csv')
# Display a regression plot for Tuition
sns.regplot(data=college,
y='Tuition',
x='SAT_AVG_ALL',
marker='^',
color='g')
plt.show()
plt.clf()
# Display the residual plot
sns.residplot(data=college,
y='Tuition',
x="SAT_AVG_ALL",
color='g')
plt.show()
plt.clf()
```
## Regression plot parameters
Seaborn's regression plot supports several parameters that can be used to configure the plots and drive more insight into the data.
For the next exercise, we can look at the relationship between tuition and the percent of students that receive Pell grants. A Pell grant is based on student financial need and subsidized by the US Government. In this data set, each University has some percentage of students that receive these grants. Since this data is continuous, using `x_bins` can be useful to break the percentages into categories in order to summarize and understand the data.
Instructions
1. Plot a regression plot of `Tuition` and `PCTPELL`.
2. Create another plot that breaks the `PCTPELL` column into 5 different bins.
3. Create a final regression plot that includes a 2nd `order` polynomial regression line.
```
# Plot a regression plot of Tuition and the Percentage of Pell Grants
sns.regplot(data=college,
y='Tuition',
x='PCTPELL')
plt.show()
plt.clf()
# Create another plot that estimates the tuition by PCTPELL
sns.regplot(data=college,
y='Tuition',
x='PCTPELL',
x_bins=5)
plt.show()
plt.clf()
# The final plot should include a line using a 2nd order polynomial
sns.regplot(data=college,
y='Tuition',
x='PCTPELL',
x_bins=5,
order=2)
plt.show()
plt.clf()
```
## Binning data
When the data on the x axis is a continuous value, it can be useful to break it into different bins in order to get a better visualization of the changes in the data.
For this exercise, we will look at the relationship between tuition and the Undergraduate population abbreviated as `UG` in this data. We will start by looking at a scatter plot of the data and examining the impact of different bin sizes on the visualization.
Instructions
1. Create a `regplot` of `Tuition` and `UG` and set the `fit_reg` parameter to `False` to disable the regression line.
2. Create another plot with the `UG` data divided into 5 bins.
3. Create a `regplot()` with the data divided into 8 bins.
```
# Create a scatter plot by disabling the regression line
sns.regplot(data=college,
y='Tuition',
x='UG',
fit_reg=False)
plt.show()
plt.clf()
# Create a scatter plot and bin the data into 5 bins
sns.regplot(data=college,
y='Tuition',
x='UG',
x_bins=5)
plt.show()
plt.clf()
# Create a regplot and bin the data into 8 bins
sns.regplot(data=college,
y='Tuition',
x='UG',
x_bins=8)
plt.show()
plt.clf()
```
## Creating heatmaps
A heatmap is a common matrix plot that can be used to graphically summarize the relationship between two variables. For this exercise, we will start by looking at guests of the Daily Show from 1999 - 2015 and see how the occupations of the guests have changed over time.
The data includes the date of each guest appearance as well as their occupation. For the first exercise, we need to get the data into the right format for Seaborn's `heatmap` function to correctly plot the data. All of the data has already been read into the `df` variable.
Instructions
1. Use pandas' `crosstab()` function to build a table of visits by `Group` and `Year`.
2. Print the `pd_crosstab` DataFrame.
3. Plot the data using Seaborn's `heatmap()`.
```
# Import dataset
daily_show = pd.read_csv('daily_show_guests_cleaned.csv')
# Create a crosstab table of the data
pd_crosstab = pd.crosstab(daily_show['Group'], daily_show['YEAR'])
pd_crosstab
# Plot a heatmap of the table
sns.heatmap(pd_crosstab)
# Rotate tick marks for visibility
plt.yticks(rotation=0)
plt.xticks(rotation=90)
plt.show()
```
## Customizing heatmaps
Seaborn supports several types of additional customizations to improve the output of a heatmap. For this exercise, we will continue to use the Daily Show data that is stored in the `daily_show` variable but we will customize the output.
Instructions
1. Create a crosstab table of `Group` and `YEAR`.
2. Create a heatmap of the data using the `BuGn` palette.
3. Disable the `cbar` and increase the linewidth to `0.3`.
```
# Create the crosstab DataFrame
pd_crosstab = pd.crosstab(daily_show['Group'], daily_show['YEAR'])
# Plot a heatmap of the table with no color bar and using the BuGn palette
sns.heatmap(pd_crosstab, cbar=False, cmap='BuGn', linewidths=0.3)
# Rotate tick marks for visibility
plt.yticks(rotation=0)
plt.xticks(rotation=90)
#Show the plot
plt.show()
plt.clf()
```
| github_jupyter |
<a href="https://colab.research.google.com/github/elcoreano/DS-Unit-1-Sprint-1-Dealing-With-Data/blob/master/module1-afirstlookatdata/LS_DSPT3_111_A_First_Look_at_Data.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# Lambda School Data Science - A First Look at Data
## Lecture - let's explore Python DS libraries and examples!
The Python Data Science ecosystem is huge. You've seen some of the big pieces - pandas, scikit-learn, matplotlib. What parts do you want to see more of?
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
```
## Assignment - now it's your turn
Pick at least one Python DS library, and using documentation/examples reproduce in this notebook something cool. It's OK if you don't fully understand it or get it 100% working, but do put in effort and look things up.
```
# TODO - your code here
# Use what we did live in lecture as an example
np.random.randint(0, 10, size=10)
np.random.randint(0, 10, size=10)
x = [9, 4, 9, 9, 6, 2, 2, 5, 0, 3]
y = [0, 5, 8, 8, 5, 2, 1, 0, 7, 9]
df = pd.DataFrame ({'set 1': x, "set 2": y})
df
df['set 1']
df.shape
df['set 3'] = df['set 1'] + 2*df['set 2']
df
df.shape
```
### Assignment questions
After you've worked on some code, answer the following questions in this text block:
1. Describe in a paragraph of text what you did and why, as if you were writing an email to somebody interested but nontechnical.
*# I tinkered with three of the most used libraries for python. A library is a group of tools that makes life easier for a user of any coding program.*
2. What was the most challenging part of what you did?
*# The precourse helped in familiarizing me with the libraries and their hidden super powers, so, that wasn't too challenging. What was challenging was the lecture and getting used to Alex's teaching style, the Zoom/Slack environment, and using GitHub.*
3. What was the most interesting thing you learned?
*# GitHub is pretty damn powerful.*
4. What area would you like to explore with more time?
*# Everything covered in this lecture. However, with time, I'll become more fluent with all tools. Just a bit excited.*
## Stretch goals and resources
Following are *optional* things for you to take a look at. Focus on the above assignment first, and make sure to commit and push your changes to GitHub (and since this is the first assignment of the sprint, open a PR as well).
- [pandas documentation](https://pandas.pydata.org/pandas-docs/stable/)
- [scikit-learn documentation](http://scikit-learn.org/stable/documentation.html)
- [matplotlib documentation](https://matplotlib.org/contents.html)
- [Awesome Data Science](https://github.com/bulutyazilim/awesome-datascience) - a list of many types of DS resources
Stretch goals:
- Find and read blogs, walkthroughs, and other examples of people working through cool things with data science - and share with your classmates!
- Write a blog post (Medium is a popular place to publish) introducing yourself as somebody learning data science, and talking about what you've learned already and what you're excited to learn more about.
| github_jupyter |
# Training Keyword Spotting
This notebook builds on the Colab in which we used the pre-trained [micro_speech](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/micro_speech) example as well as the HarvardX [3_5_18_TrainingKeywordSpotting.ipynb](https://github.com/tinyMLx/colabs) and [4_5_16_KWS_PretrainedModel](https://github.com/tinyMLx/colabs) from the [TinyML Specialization on edX](https://www.edx.org/professional-certificate/harvardx-tiny-machine-learning).
# Setup
<font color='red'>**This Notebook only works on Tensorflow 1.15 and was tested with Tensorflow 1.15.5**</font>
### Prerequisites
Clone the TensorFlow Github Repository with the relevant base code.
```
%%bash
rm -rf tensorflow log v2.4.1.zip logs models train dataset extract_loudest_section
apt-get update -qq && apt-get install -y wget unzip
wget https://github.com/tensorflow/tensorflow/archive/v2.4.1.zip
unzip v2.4.1.zip &> log
mv tensorflow-2.4.1/ tensorflow/
rm -rf v2.4.1.zip log
```
### Import Packages
Import standard packages as well as the additional packages from the cloned Github Repo.
```
import tensorflow as tf
import sys
# We add this path so we can import the speech processing modules.
sys.path.append("./tensorflow/tensorflow/examples/speech_commands/")
import input_data
import models
import numpy as np
import pickle
import shutil
import os
```
### Check GPU availability
The code will also work without GPU acceleration, but it will be significantly slower.
```
tf.test.is_gpu_available(cuda_only=True, min_cuda_compute_capability=None)
```
### Configure Your Model!
Select your keywords and model settings with which to train!
**This is where you need to make choices and input data!**
```WANTED_WORDS``` = A comma-delimited string of the words you want to train for (e.g., "yes,no"). All the other words you do not select will be used to train an "unknown" label so that the model does not just recognize speech but your specific words. Audio data with no spoken words will be used to train a "silence" label. We suggest picking 2-4 words for best results.
Options for target words are (PICK FROM THIS LIST FOR BEST RESULTS): "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "yes", "no", "up", "down", "left", "right", "on", "off", "stop", "go", “backward”, “forward”, “follow”, “learn”,
Additional words that will be used to help train the "unkown" label are: "bed", "bird", "cat", "dog", "happy", "house", "marvin", "sheila", "tree", "wow"
```
WANTED_WORDS = "stop,go"
```
The number of training steps and learning rates can be specified as comma-separated strings to define the amount/rate at each stage. For example, ```TRAINING_STEPS="12000,3000"``` and ```LEARNING_RATE="0.001,0.0001"``` will run 12,000 training steps with a rate of 0.001 followed by 3,000 final steps with a learning rate of 0.0001. These are good default values to work off of when you choose your values as the course staff has gotten this to work well with those values in the past!
```
TRAINING_STEPS = "12000,3000"
LEARNING_RATE = "0.001,0.0001"
```
We suggest you leave the ```MODEL_ARCHITECTURE``` as tiny_conv the first time but if you would like to do this again and explore additional models some options are: ```single_fc, conv, low_latency_conv, low_latency_svdf, tiny_embedding_conv```
```
MODEL_ARCHITECTURE = 'tiny_conv'
# Calculate the total number of steps, which is used to identify the checkpoint
# file name.
TOTAL_STEPS = str(sum(map(lambda string: int(string), TRAINING_STEPS.split(","))))
# Print the configuration to confirm it
print("Training these words: %s" % WANTED_WORDS)
print("Training steps in each stage: %s" % TRAINING_STEPS)
print("Learning rate in each stage: %s" % LEARNING_RATE)
print("Total number of training steps: %s" % TOTAL_STEPS)
```
**DO NOT MODIFY** the following constants as they include filepaths used in this notebook and data that is shared during training and inference.
```
# Calculate the percentage of 'silence' and 'unknown' training samples required
# to ensure that we have equal number of samples for each label.
number_of_labels = WANTED_WORDS.count(',') + 1
number_of_total_labels = number_of_labels + 2 # for 'silence' and 'unknown' label
equal_percentage_of_training_samples = int(100.0/(number_of_total_labels))
SILENT_PERCENTAGE = equal_percentage_of_training_samples
UNKNOWN_PERCENTAGE = equal_percentage_of_training_samples
# Constants which are shared during training and inference
PREPROCESS = 'micro'
WINDOW_STRIDE = 20
# Constants used during training only
VERBOSITY = 'DEBUG'
EVAL_STEP_INTERVAL = '1000'
SAVE_STEP_INTERVAL = '1000'
# Constants for training directories and filepaths
DATASET_DIR = 'dataset/'
LOGS_DIR = 'logs/'
TRAIN_DIR = 'train/' # for training checkpoints and other files.
# Constants for inference directories and filepaths
import os
MODELS_DIR = 'models'
if not os.path.exists(MODELS_DIR):
os.mkdir(MODELS_DIR)
MODEL_TF = os.path.join(MODELS_DIR, 'model.pb')
MODEL_TFLITE = os.path.join(MODELS_DIR, 'model.tflite')
FLOAT_MODEL_TFLITE = os.path.join(MODELS_DIR, 'float_model.tflite')
MODEL_TFLITE_MICRO = os.path.join(MODELS_DIR, 'model.cc')
SAVED_MODEL = os.path.join(MODELS_DIR, 'saved_model')
# Constants for Quantization
QUANT_INPUT_MIN = 0.0
QUANT_INPUT_MAX = 26.0
QUANT_INPUT_RANGE = QUANT_INPUT_MAX - QUANT_INPUT_MIN
# Constants for audio process during Quantization and Evaluation
SAMPLE_RATE = 16000
CLIP_DURATION_MS = 1000
WINDOW_SIZE_MS = 30.0
FEATURE_BIN_COUNT = 40
BACKGROUND_FREQUENCY = 0.8
BACKGROUND_VOLUME_RANGE = 0.1
TIME_SHIFT_MS = 100.0
# URL for the dataset and train/val/test split
DATA_URL = 'https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.02.tar.gz'
VALIDATION_PERCENTAGE = 10
TESTING_PERCENTAGE = 10
# Calculate the correct flattened input data shape for later use in model conversion
# since the model takes a flattened version of the spectrogram. The shape is number of
# overlapping windows times the number of frequency bins. For the default settings we have
# 40 bins (as set above) times 49 windows (as calculated below) so the shape is (1,1960)
def window_counter(total_samples, window_size, stride):
'''helper function to count the number of full-length overlapping windows'''
window_count = 0
sample_index = 0
while True:
window = range(sample_index,sample_index+stride)
if window.stop < total_samples:
window_count += 1
else:
break
sample_index += stride
return window_count
OVERLAPPING_WINDOWS = window_counter(CLIP_DURATION_MS, int(WINDOW_SIZE_MS), WINDOW_STRIDE)
FLATTENED_SPECTROGRAM_SHAPE = (1, OVERLAPPING_WINDOWS * FEATURE_BIN_COUNT)
```
# Train the model
### Load in TensorBoard to visulaize the training process.
As training progresses you should see the training status show up in the Tensorboard area. If this works it is very helpful for analyzing your training progress. Unfortunately, the staff has found that it sometimes doesn't start showing data for a while (~15 minutes) and sometimes doesn't show data until training completes (and instead shows ```No dashboards are active for the current data set```.). If it is working and then stops updating look to the top of the cell and click reconnect.
```
%load_ext tensorboard
logs_base_dir='./logs/'
os.makedirs(logs_base_dir, exist_ok=True)
%tensorboard --logdir {logs_base_dir} --host 0.0.0.0 --port 6006
```
### Launch Training
If you would like to get more information on the training script you can find the source code for the script [here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/speech_commands/train.py). In short it sets up the optimizer and preprocessor based on all of the flags we pass in!
Finally, by setting the ```VERBOSITY = 'DEBUG'``` above be aware that the training cell will print A LOT of information. Specifically you will get the accuracy and loss at each step as well as a confusion matrix every 1000 steps. We hope that is helpful in case TensorBoard fails to work. If you would like to run with less printouts you can change the setting to ```WARN``` or ```FATAL```. You will find this in the "Configure Your Model!" section.
```
!python tensorflow/tensorflow/examples/speech_commands/train.py \
--data_dir={DATASET_DIR} \
--wanted_words={WANTED_WORDS} \
--silence_percentage={SILENT_PERCENTAGE} \
--unknown_percentage={UNKNOWN_PERCENTAGE} \
--preprocess={PREPROCESS} \
--window_stride={WINDOW_STRIDE} \
--model_architecture={MODEL_ARCHITECTURE} \
--how_many_training_steps={TRAINING_STEPS} \
--learning_rate={LEARNING_RATE} \
--train_dir={TRAIN_DIR} \
--summaries_dir={LOGS_DIR} \
--verbosity={VERBOSITY} \
--eval_step_interval={EVAL_STEP_INTERVAL} \
--save_step_interval={SAVE_STEP_INTERVAL}
```
# Generating your Model
Just like with the pre-trained model we will now take the final checkpoint and convert it into a quantized TensorFlow Lite model.
### Generate a TensorFlow Model for Inference
Combine relevant training results (graph, weights, etc) into a single file for inference. This process is known as freezing a model and the resulting model is known as a frozen model/graph, as it cannot be further re-trained after this process.
```
!rm -rf {SAVED_MODEL}
!python tensorflow/tensorflow/examples/speech_commands/freeze.py \
--wanted_words=$WANTED_WORDS \
--window_stride_ms=$WINDOW_STRIDE \
--preprocess=$PREPROCESS \
--model_architecture=$MODEL_ARCHITECTURE \
--start_checkpoint=$TRAIN_DIR$MODEL_ARCHITECTURE'.ckpt-'{TOTAL_STEPS} \
--save_format=saved_model \
--output_file={SAVED_MODEL}
```
### Generate a TensorFlow Lite Model
Convert the frozen graph into a TensorFlow Lite model, which is fully quantized for use with embedded devices.
The following cell will also print the model size, which will be under 20 kilobytes.
We download the dataset to use as a representative dataset for more thoughtful post training quantization.
```
model_settings = models.prepare_model_settings(
len(input_data.prepare_words_list(WANTED_WORDS.split(','))),
SAMPLE_RATE, CLIP_DURATION_MS, WINDOW_SIZE_MS,
WINDOW_STRIDE, FEATURE_BIN_COUNT, PREPROCESS)
audio_processor = input_data.AudioProcessor(
DATA_URL, DATASET_DIR,
SILENT_PERCENTAGE, UNKNOWN_PERCENTAGE,
WANTED_WORDS.split(','), VALIDATION_PERCENTAGE,
TESTING_PERCENTAGE, model_settings, LOGS_DIR)
with tf.Session() as sess:
float_converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL)
float_tflite_model = float_converter.convert()
float_tflite_model_size = open(FLOAT_MODEL_TFLITE, "wb").write(float_tflite_model)
print("Float model is %d bytes" % float_tflite_model_size)
converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.lite.constants.INT8
converter.inference_output_type = tf.lite.constants.INT8
def representative_dataset_gen():
for i in range(100):
data, _ = audio_processor.get_data(1, i*1, model_settings,
BACKGROUND_FREQUENCY,
BACKGROUND_VOLUME_RANGE,
TIME_SHIFT_MS,
'testing',
sess)
flattened_data = np.array(data.flatten(), dtype=np.float32).reshape(FLATTENED_SPECTROGRAM_SHAPE)
yield [flattened_data]
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
tflite_model_size = open(MODEL_TFLITE, "wb").write(tflite_model)
print("Quantized model is %d bytes" % tflite_model_size)
```
### Testing the accuracy after Quantization
Verify that the model we've exported is still accurate, using the TF Lite Python API and our test set.
```
# Helper function to run inference
def run_tflite_inference_testSet(tflite_model_path, model_type="Float"):
#
# Load test data
#
np.random.seed(0) # set random seed for reproducible test results.
with tf.Session() as sess:
test_data, test_labels = audio_processor.get_data(
-1, 0, model_settings, BACKGROUND_FREQUENCY, BACKGROUND_VOLUME_RANGE,
TIME_SHIFT_MS, 'testing', sess)
test_data = np.expand_dims(test_data, axis=1).astype(np.float32)
#
# Initialize the interpreter
#
interpreter = tf.lite.Interpreter(tflite_model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()[0]
output_details = interpreter.get_output_details()[0]
#
# For quantized models, manually quantize the input data from float to integer
#
if model_type == "Quantized":
input_scale, input_zero_point = input_details["quantization"]
test_data = test_data / input_scale + input_zero_point
test_data = test_data.astype(input_details["dtype"])
#
# Evaluate the predictions
#
correct_predictions = 0
for i in range(len(test_data)):
interpreter.set_tensor(input_details["index"], test_data[i])
interpreter.invoke()
output = interpreter.get_tensor(output_details["index"])[0]
top_prediction = output.argmax()
correct_predictions += (top_prediction == test_labels[i])
print('%s model accuracy is %f%% (Number of test samples=%d)' % (
model_type, (correct_predictions * 100) / len(test_data), len(test_data)))
# Compute float model accuracy
run_tflite_inference_testSet(FLOAT_MODEL_TFLITE)
# Compute quantized model accuracy
run_tflite_inference_testSet(MODEL_TFLITE, model_type='Quantized')
```
# Testing the model with your own data!
Now comes the fun part. It's time to test your model with your own realworld data. We'll proceed in the same way we tested the pre-trained model. Have fun!
### Importing packages
```
!apt-get update -qqq && apt-get -y -qqq install apt-utils gcc libpq-dev libsndfile-dev git
!python3 -m pip install --upgrade --no-cache-dir --quiet pip ffmpeg-python scipy librosa google-colab
from IPython.display import HTML, Audio
from google.colab.output import eval_js
from base64 import b64decode
import numpy as np
from scipy.io.wavfile import read as wav_read
import io
import ffmpeg
#!pip install librosa
import librosa
import scipy.io.wavfile
!git clone https://github.com/petewarden/extract_loudest_section.git
!make -C extract_loudest_section/
print("Packages Imported, Extract_Loudest_Section Built")
```
### Define the helper function to run inference
```
# Helper function to run inference (on a single input this time)
# Note: this also includes additional manual pre-processing
TF_SESS = tf.compat.v1.InteractiveSession()
def run_tflite_inference_singleFile(tflite_model_path, custom_audio, sr_custom_audio, model_type="Float"):
#
# Preprocess the sample to get the features we pass to the model
#
# First re-sample to the needed rate (and convert to mono if needed)
custom_audio_resampled = librosa.resample(librosa.to_mono(np.float64(custom_audio)), sr_custom_audio, SAMPLE_RATE)
# Then extract the loudest one second
scipy.io.wavfile.write('custom_audio.wav', SAMPLE_RATE, np.int16(custom_audio_resampled))
!/tmp/extract_loudest_section/gen/bin/extract_loudest_section custom_audio.wav ./trimmed
# Finally pass it through the TFLiteMicro preprocessor to produce the
# spectrogram/MFCC input that the model expects
custom_model_settings = models.prepare_model_settings(
0, SAMPLE_RATE, CLIP_DURATION_MS, WINDOW_SIZE_MS,
WINDOW_STRIDE, FEATURE_BIN_COUNT, PREPROCESS)
custom_audio_processor = input_data.AudioProcessor(None, None, 0, 0, '', 0, 0,
model_settings, None)
custom_audio_preprocessed = custom_audio_processor.get_features_for_wav(
'trimmed/custom_audio.wav', model_settings, TF_SESS)
# Reshape the output into a 1,1960 matrix as that is what the model expects
custom_audio_input = custom_audio_preprocessed[0].flatten()
test_data = np.reshape(custom_audio_input,(1,len(custom_audio_input)))
#
# Initialize the interpreter
#
interpreter = tf.lite.Interpreter(tflite_model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()[0]
output_details = interpreter.get_output_details()[0]
#
# For quantized models, manually quantize the input data from float to integer
#
if model_type == "Quantized":
input_scale, input_zero_point = input_details["quantization"]
test_data = test_data / input_scale + input_zero_point
test_data = test_data.astype(input_details["dtype"])
#
# Run the interpreter
#
interpreter.set_tensor(input_details["index"], test_data)
interpreter.invoke()
output = interpreter.get_tensor(output_details["index"])[0]
top_prediction = output.argmax()
#
# Translate the output
#
top_prediction_str = ''
if top_prediction >= 2:
top_prediction_str = WANTED_WORDS.split(',')[top_prediction-2]
elif top_prediction == 0:
top_prediction_str = 'silence'
else:
top_prediction_str = 'unknown'
print('%s model guessed the value to be %s' % (model_type, top_prediction_str))
```
### Define the audio importing function
Adapted from: https://ricardodeazambuja.com/deep_learning/2019/03/09/audio_and_video_google_colab/ and https://colab.research.google.com/drive/1Z6VIRZ_sX314hyev3Gm5gBqvm1wQVo-a#scrollTo=RtMcXr3o6gxN
```
def get_audio():
"""Records audio from your local microphone inside a colab notebook
Returns
-------
tuple
audio (numpy.ndarray), sample rate (int)
Obs:
To write this piece of code I took inspiration/code from a lot of places.
It was late night, so I'm not sure how much I created or just copied o.O
Here are some of the possible references:
https://blog.addpipe.com/recording-audio-in-the-browser-using-pure-html5-and-minimal-javascript/
https://stackoverflow.com/a/18650249
https://hacks.mozilla.org/2014/06/easy-audio-capture-with-the-mediarecorder-api/
https://air.ghost.io/recording-to-an-audio-file-using-html5-and-js/
https://stackoverflow.com/a/49019356
"""
AUDIO_HTML = """
<script>
var my_div = document.createElement("DIV");
var my_p = document.createElement("P");
var my_btn = document.createElement("BUTTON");
var t = document.createTextNode("Press to start recording");
my_btn.appendChild(t);
//my_p.appendChild(my_btn);
my_div.appendChild(my_btn);
document.body.appendChild(my_div);
var base64data = 0;
var reader;
var recorder, gumStream;
var recordButton = my_btn;
var handleSuccess = function(stream) {
gumStream = stream;
var options = {
//bitsPerSecond: 8000, //chrome seems to ignore, always 48k
mimeType : 'audio/webm;codecs=opus'
//mimeType : 'audio/webm;codecs=pcm'
};
//recorder = new MediaRecorder(stream, options);
recorder = new MediaRecorder(stream);
recorder.ondataavailable = function(e) {
var url = URL.createObjectURL(e.data);
var preview = document.createElement('audio');
preview.controls = true;
preview.src = url;
document.body.appendChild(preview);
reader = new FileReader();
reader.readAsDataURL(e.data);
reader.onloadend = function() {
base64data = reader.result;
//console.log("Inside FileReader:" + base64data);
}
};
recorder.start();
};
recordButton.innerText = "Recording... press to stop";
navigator.mediaDevices.getUserMedia({audio: true}).then(handleSuccess);
function toggleRecording() {
if (recorder && recorder.state == "recording") {
recorder.stop();
gumStream.getAudioTracks()[0].stop();
recordButton.innerText = "Saving the recording... pls wait!"
}
}
// https://stackoverflow.com/a/951057
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
var data = new Promise(resolve=>{
//recordButton.addEventListener("click", toggleRecording);
recordButton.onclick = ()=>{
toggleRecording()
sleep(2000).then(() => {
// wait 2000ms for the data to be available...
// ideally this should use something like await...
//console.log("Inside data:" + base64data)
resolve(base64data.toString())
});
}
});
</script>
"""
display(HTML(AUDIO_HTML))
data = eval_js("data")
binary = b64decode(data.split(',')[1])
process = (ffmpeg
.input('pipe:0')
.output('pipe:1', format='wav')
.run_async(pipe_stdin=True, pipe_stdout=True, pipe_stderr=True, quiet=True, overwrite_output=True)
)
output, err = process.communicate(input=binary)
riff_chunk_size = len(output) - 8
# Break up the chunk size into four bytes, held in b.
q = riff_chunk_size
b = []
for i in range(4):
q, r = divmod(q, 256)
b.append(r)
# Replace bytes 4:8 in proc.stdout with the actual size of the RIFF chunk.
riff = output[:4] + bytes(b) + output[8:]
sr, audio = wav_read(BytesIO(riff))
return audio, sr
```
### Record your own audio and test the model!
After you run the record cell wait for the stop button to appear then start recording and then press the button to stop the recording once you have said the word!
```
custom_audio, sr_custom_audio = get_audio()
print("DONE")
# Then test the model
run_tflite_inference_singleFile(MODEL_TFLITE, custom_audio, sr_custom_audio, model_type="Quantized")
```
### Generate a TensorFlow Lite for Microcontrollers Model
To convert the TensorFlow Lite quantized model into a C source file that can be loaded by TensorFlow Lite for Microcontrollers on Arduino we simply need to use the ```xxd``` tool to convert the ```.tflite``` file into a ```.cc``` file.
```
!apt-get update -qqq && apt-get -qqq install xxd
MODEL_TFLITE = './models/model.tflite'
MODEL_TFLITE_MICRO = './models/model.cc'
!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}
REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')
!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}
```
The generated Tensorflow Lite for Microcontroller model can now be used in the Arduino IDE. There are **two options** to do this:
1. Copy the screen output directly from the Jupyter Notebook into the **micro_features_model.cpp** file (in the Arduino IDE)
2. Download the **model.cc** file for later use to copy its content into the **micro_features_model.cpp** file (in the Arduino IDE)
### Option 1: Copy Output directly
```
!cat {MODEL_TFLITE_MICRO}
```
### Option 2: Download Model File
```
from IPython.display import FileLink
local_file = FileLink('./models/model.cc', result_html_prefix="Click here to download: ")
display(local_file)
```
| github_jupyter |
```
!pip install scikit-optimize
```
Based on this:
* https://scikit-optimize.github.io/stable/auto_examples/bayesian-optimization.html#sphx-glr-auto-examples-bayesian-optimization-py
```
import numpy as np
np.random.seed(1234)
import matplotlib.pyplot as plt
from skopt.plots import plot_gaussian_process
from skopt import Optimizer
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from skopt import gp_minimize
import numpy as np
%matplotlib inline
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import Matern
noise_level = 0.1
# Our 1D toy problem, this is the function we are trying to
# minimize
def objective(x, noise_level=noise_level):
return np.sin(5 * x[0]) * (1 - np.tanh(x[0] ** 2))\
+ np.random.randn() * noise_level
def objective_wo_noise(x):
return objective(x, noise_level=0)
opt_gp = Optimizer([(-2.0, 2.0)], base_estimator="GP", n_initial_points=5,
acq_optimizer="sampling", random_state=42)
# let's do this by hand first...
X = np.linspace(-2, 2, 100)
y = np.vectorize(lambda x: objective_wo_noise([x]))(X)
plt.plot(X, y)
# Generate data and fit GP
rng = np.random.RandomState(4)
kernel = Matern(length_scale=1.0, nu=2.5)
gp = GaussianProcessRegressor(kernel=kernel, alpha=0.0)
# take 5 points...
X = rng.uniform(-2, 2, 5)
X = np.sort(X)
y = np.vectorize(lambda x: objective_wo_noise([x]))(X)
gp.fit(X.reshape(-1, 1), y)
# how should we approach this? One curve?
X_ = np.linspace(-2, 2, 100)
y_mean, y_std = gp.predict(X_.reshape(-1, 1), return_std=True)
y_samples = gp.sample_y(X_.reshape(-1, 1), 1)
plt.plot(X_, y_samples, 'r')
plt.plot(X_, np.vectorize(lambda x: objective_wo_noise([x]))(X_))
plt.plot(X, y, 'ro')
# if we add some noise...
X_ = np.linspace(-2, 2, 100)
y_mean, y_std = gp.predict(X_.reshape(-1, 1), return_std=True)
y_samples = gp.sample_y(X_.reshape(-1, 1), 100)
plt.plot(X_, y_samples)
# plt.plot(X_, np.vectorize(lambda x: objective_wo_noise([x]))(X_))
plt.plot(X, y, 'ro')
```
How do we pick the next point to evaluate?
From here there are several way to pick the next point. Two common approaches are around:
* Upper confidence bound (exploration vs exploitation)
* Expected improvement
```
plt.plot(X_, y_mean, 'r', X, y, 'ro')
plt.grid(True)
plt.fill_between(X_, y_mean - y_std, y_mean + y_std,
alpha=0.5, color='k')
# for example, let's just consider the lower bound
# kappa controls the exploration/exploitation.
kappa = 0.5
plt.plot(X_, y_mean, 'r', X, y, 'ro', X_, y_mean - y_std, 'b', X_, y_mean - kappa*y_std, 'k')
plt.grid(True)
# expected improvement
from scipy.stats import norm
best_y = np.min(y)
z = (y_mean - best_y + X_)/y_std
ei = (y_mean - best_y+X_)*norm.cdf(z) + y_std*norm.pdf(z)
plt.plot(X_, y_mean, 'r', X, y, 'ro', X_, y_mean - y_std, 'b', X_, ei, 'k')
plt.grid(True)
```
Let's use scikit optimise instead...
```
res = gp_minimize(objective_wo_noise, # the function to minimize
[(-2.0, 2.0)], # the bounds on each dimension of x
acq_func="EI", # the acquisition function
n_calls=10, # the number of evaluations of f
n_random_starts=1, # the number of random initialization points
x0 = [[x] for x in X],
random_state=1234) # the random seed
from skopt.plots import plot_convergence
plot_convergence(res);
plot_gaussian_process(res, n_calls=0,
objective=objective_wo_noise,
show_title=False)
plot_gaussian_process(res, n_calls=0,
show_legend=True, show_title=False,
show_mu=False, show_acq_func=True,
show_observations=False,
show_next_point=True)
plot_gaussian_process(res, n_calls=1,
objective=objective_wo_noise,
show_title=False)
plot_gaussian_process(res, n_calls=1,
show_legend=True, show_title=False,
show_mu=False, show_acq_func=True,
show_observations=False,
show_next_point=True)
plt.figure
plt.figure(figsize=(20,20))
for n_iter in range(5):
# Plot true function.
plt.subplot(5, 2, 2*n_iter+1)
if n_iter == 0:
show_legend = True
else:
show_legend = False
ax = plot_gaussian_process(res, n_calls=n_iter,
objective=objective_wo_noise,
noise_level=noise_level,
show_legend=show_legend, show_title=False,
show_next_point=False, show_acq_func=False)
ax.set_ylabel("")
ax.set_xlabel("")
# Plot EI(x)
plt.subplot(5, 2, 2*n_iter+2)
ax = plot_gaussian_process(res, n_calls=n_iter,
show_legend=show_legend, show_title=False,
show_mu=False, show_acq_func=True,
show_observations=False,
show_next_point=True)
ax.set_ylabel("")
ax.set_xlabel("")
plt.show()
```
| github_jupyter |
```
import pandas as pd
import numpy as np
import seaborn as sns
%matplotlib inline
cc = pd.read_csv('./posts_ccompare_raw.csv', index_col=0, encoding='utf-8')
cc['Timestamp'] = pd.to_datetime(cc['Timestamp'])
```
# Reaction features
```
features_reactions = pd.DataFrame(index=cc.index)
features_reactions['n_up'] = cc['Actions.Agree.Total']
features_reactions['n_down'] = cc['Actions.Disagree.Total']
features_reactions['n_reply'] = cc['Actions.Comment.Total']
sns.pairplot(features_reactions)
```
# Post date features
```
features_date = pd.DataFrame(index=cc.index)
features_date['t_week'] = cc.Timestamp.dt.week
features_date['t_dow'] = cc.Timestamp.dt.dayofweek
features_date['t_hour'] = cc.Timestamp.dt.hour
features_date['t_day'] = cc.Timestamp.dt.day
sns.pairplot(features_date)
```
# Spacy NLP ...
```
import spacy # See "Installing spaCy"
nlp = spacy.load('en') # You are here.
spacy_docs = pd.DataFrame(index=cc.index)
docs = cc.Body.apply(nlp)
vec = docs.apply(lambda x: x.vector)
feature_word_vec = pd.DataFrame(vec.tolist(), columns=['spacy_%s'%i for i in range(300)])
feature_word_vec['spacy_sent'] = docs.apply(lambda x: x.sentiment)
# tfidf
'''
Author: Giovanni Kastanja
Python: 3.6.0
Date: 24/6/2017
'''
import pandas as pd
import numpy as np
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
from scipy.sparse import csr_matrix
text = cc['Body']
# create a stopset (words that occur to many times)
stopset = set(stopwords.words('english'))
vectorizer = TfidfVectorizer(use_idf=True, lowercase=True, strip_accents='ascii', stop_words=stopset)
features_tfidf = pd.DataFrame(vectorizer.fit_transform(text).toarray())
```
# Target
```
targets = pd.read_csv('./btc-ind.csv')
targets['date'] = pd.to_datetime(targets['Date'])
targets = targets.set_index('date')
del targets['Date']
targets.tail()
join_by_date = pd.DataFrame(index=cc.index)
join_by_date['date'] = cc.Timestamp.dt.round(freq="d")
Y_all = join_by_date.join(targets, on='date').dropna()
groups = Y_all['date']
del Y_all['date']
cols = Y_all.columns
index = Y_all.index
#Y_all = pd.DataFrame(normalize(Y_all, axis=1, norm='l2'), columns=cols, index=index)
Y_all = Y_all - Y_all.mean()
Y_all = Y_all/Y_all.std()
#Y_all.plot()
```
# Combine features
```
#features = pd.concat([features_date, features_tfidf, features_reactions, feature_word_vec], axis=1)
features = pd.concat([features_date, features_reactions, feature_word_vec], axis=1)
X_all = features.ix[Y_all.index]
X_all.shape
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import normalize
from xgboost.sklearn import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso
rf = RandomForestRegressor(n_estimators=10, max_depth=3, criterion='mse')
xgb = XGBRegressor(n_estimators=10)
regressors = [rf, Lasso()]
target_scores = {}
for indicator in targets.columns:
Y =Y_all[indicator]
for reg in regressors:
tag = indicator+':'+str(reg)[:15]
scores = cross_val_score(reg, X_all, Y, cv=4, groups=groups, scoring='neg_mean_squared_error')
print np.mean(scores), tag
target_scores[tag] = scores
cv_score = pd.DataFrame(target_scores)
ms = cv_score.mean(axis=0)
ms.sort_values(ascending=False)
indicator = 'BTC_cbrt_dv_T1:Lasso(alpha=1.0'
indicator = indicator.split(":")[0]
Y = Y_all[indicator]
reg = XGBRegressor(n_estimators=100)
reg.fit(X_all, Y)
Y_t = reg.predict(X_all)
error = abs(Y - Y_t)
error.hist()
# DROP THE BULL$HIT
itruth = error < error.quantile(0.3)
X = X_all[itruth]
Y = Y_all[indicator][itruth]
G = groups[itruth]
reg = XGBRegressor(n_estimators=100, max_depth=8)
scores = cross_val_score(reg, X, Y, cv=4, groups=G, scoring='neg_mean_squared_error')
print sorted(scores)
ax = groups.hist(figsize=(12,5))
G.hist(ax=ax)
reg = XGBRegressor(n_estimators=100, max_depth=8)
reg.fit(X,Y)
Y_ = reg.predict(X)
truth_df = pd.DataFrame({'date': G, 'Y': Y_})
def get_stats(group):
return {'min': group.min(), 'max': group.max(), 'count': group.count(), 'mean': group.mean()}
ax = targets.BTC_cbrt_dv_T1.plot()
truth.plot(ax=ax)
truth
def drop_bs(indicator, q=0.3):
Y = Y_all[indicator]
reg = XGBRegressor(n_estimators=100)
reg.fit(X_all, Y)
Y_t = reg.predict(X_all)
error = abs(Y - Y_t)
error.hist()
itruth = error < error.quantile(q)
X = X_all[itruth]
Y = Y_all[indicator][itruth]
G = groups[itruth]
reg = XGBRegressor(n_estimators=30, max_depth=5)
scores = cross_val_score(reg, X, Y, cv=4, groups=G, scoring='neg_mean_squared_error')
print sorted(scores)
print "MEAN CV SCORE: ", np.mean(scores)
reg = XGBRegressor(n_estimators=100, max_depth=8)
reg.fit(X,Y)
Y_ = reg.predict(X)
agg = pd.Series(Y_).groupby(G)
truthscore = agg.mean()
impact_count = agg.count()
truth_max = agg.max()
return pd.DataFrame(dict(truthscore=truthscore, impact_count=impact_count, truth_max=truth_max, date=truthscore.index))
dv = drop_bs('BTC_cbrt_dv_T1', 0.4)
import json
def to_json(df, path):
a = []
for i,d in list(df.iterrows()):
d = d.to_dict()
d['date'] = str(d['date'])
a.append(d)
with open(path, 'w') as f:
json.dump(a, f)
to_json(dv, '../bitcoin-daily-bars/out-truth-volume.json')
impactfull = cc.ix[itruth.index][itruth]
impactfull.head()
f = 'Cryptopian.Name'
a = impactfull.groupby(f).size()
b = cc.groupby(f).size()
c = pd.DataFrame(dict(a=a,b=b))
c = c[c.a>1]
c['impact'] = c.a/c.b
c.sort_values('impact', ascending=False)
dv.truthscore.plot()
target_sc
```
| github_jupyter |
```
import os
import json
import pandas as pd
from tqdm import tqdm_notebook
df_larval = pd.read_csv(os.path.join('..', 'data', 'breeding-sites', 'larval-survey-en.csv'))
df_larval.head()
```
## Shapefile
```
with open(os.path.join('..', 'data','shapefiles','Nakhon-Si-Thammarat.geojson')) as f:
data = json.load(f)
for i, feature in enumerate(data['features']):
prop = feature['properties']
province = prop['PV_TN']
district = prop['AP_TN']
subdist = prop['TB_TN']
df_tmp = df_larval.loc[(df_larval['province'] == province) &
(df_larval['district'] == district)]
province_en, district_en = df_tmp[['province_en','district_en']].values[0]
prop['PV_EN'] = province_en
prop['AP_EN'] = district_en
data['features'][2]['properties']
with open(os.path.join('..', 'data', 'shapefiles', 'Nakhon-Si-Thammarat-en.geojson'), 'w') as FILE:
json.dump(data, FILE, indent=4, ensure_ascii=False, sort_keys=True)
```
## Dictonary file
```
province_entry = []
for feature in data['features']:
prop = feature['properties']
province_entry.append([
prop['PV_TN'],
prop['AP_TN'],
prop['TB_TN'],
prop['PV_EN'],
prop['AP_EN'],
prop['TB_EN'],
])
province_entry = pd.DataFrame.from_records(province_entry, columns=['province_th', 'district_th', 'subdist_th',
'province_en', 'district_en', 'subdist_en'])
province_entry.to_csv(os.path.join('..', 'data', 'shapefiles', 'Nakhon-Si-Thammarat-dictionary.csv'))
province_entry.head()
```
## Detection file
```
with open(os.path.join('..', 'data','breeding-sites','detection.geojson')) as f:
detection = json.load(f)
for feature in tqdm_notebook(detection['features']):
prop = feature['properties']
province = prop['province']
district = prop['district']
subdist = prop['subdist']
df_tmp = province_entry.loc[
(province_entry['province_th'] == province) &
(province_entry['district_th'] == district) &
(province_entry['subdist_th'] == subdist)
]
province_en, district_en, subdist_en = df_tmp[['province_en','district_en', 'subdist_en']].values[0]
prop['province_en'] = province_en
prop['district_en'] = district_en
prop['subdist_en'] = subdist_en
with open(os.path.join('..', 'data','breeding-sites','detection-en.geojson'), 'w') as FILE:
json.dump(detection, FILE, indent=4, ensure_ascii=False, sort_keys=True)
```
| github_jupyter |
```
# Les imports pour l'exercice
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import string
import random
from collections import deque
```
## Partie 1 : Code de César
### Implementation
Le code suivant contient deux fonctions principales : `encryptMessage` et `decryptMessage`.
Ces fonctions permet d'encoder et de decoder un string donnée.
L'encryption se fait de facon classique par decalage d'alphabet. La clé donnée est le nombre de decalage.
La fonction `convertAlphabets` permet de convertir un texte entre deux alphabets.
La fonction `shiftAlphabet` permet de décaler les éléments d'une matrice en faisant une rotation. C'est l'équivalent de decaler la roue interne du code de César.
```
alphabet_string = string.printable
alphabetListOrdered = list(alphabet_string)
numberListOrdered = list(map(ord, alphabetListOrdered))
def convertAlphabets(messageCharNumList, numList, numListToConvert, encrypt = True) :
index = 0
newList = []
for val in messageCharNumList:
indexOfLetter = numListToConvert.index(val)
newList.append(numList[indexOfLetter])
index += 1
if encrypt :
return ' '.join(map(chr,newList))
else :
return ''.join(map(chr,newList))
def shiftAlphabet(listToShift, keyShift):
keyShift = keyShift % len(listToShift)
return listToShift[keyShift:] + listToShift[:keyShift]
```
Pour la fonction d'encryption, on utilisera l'alphabet de tout les caracteres imprimable en ascii donnée par `string.printable`.
```
string.printable
def encryptMessage(m, shiftKey):
alphabet_string = string.printable
alphabetListOrdered = list(alphabet_string)
numberListOrdered = list(map(ord, alphabetListOrdered))
alphabetListShuffled = shiftAlphabet(list(alphabetListOrdered), shiftKey)
numberListShuffled = list(map(ord, alphabetListShuffled))
return convertAlphabets(list(map(ord, list(m))), numberListShuffled, numberListOrdered)
def decryptMessage(m, shiftKey):
m = m.replace(' ', '')
alphabet_string = string.printable
alphabetListOrdered = list(alphabet_string)
numberListOrdered = list(map(ord, alphabetListOrdered))
alphabetListShuffled = list(alphabetListOrdered)
alphabetListShuffled = shiftAlphabet(list(alphabetListOrdered), shiftKey)
numberListShuffled = list(map(ord, alphabetListShuffled))
return convertAlphabets(list(map(ord, list(m))), numberListOrdered, numberListShuffled, False)
```
En dessous est un exemple d'encryption et de decryption.
```
m = "Vous savez, moi je ne crois pas qu'il y ait de bonne ou de mauvaise situation. Moi, si je devais resumer ma vie aujourd'hui avec vous, je dirais que c'est d'abord des rencontres. Des gens qui m'ont tendu la main, peut-etre a un moment ou je ne pouvais pas, ou j'etais seul chez moi"
m
```
On encrypte le texte plus haut au moins d'une clé de valeur `4051`
```
e = encryptMessage(m, 4501)
e
```
On verifie que la decryption marche bien quand on remet la clé.
```
d = decryptMessage(e, 4501)
d
```
### Exercice : Cracker un cypher par décalage avec l'analyse de fréquence
Voici un cypher généré avec l'algorithme d'encryption de cypher encryptMessage.
Le but est d'arriver a decrypter le message grace a l'analyse de frequence des caracteres du message.
Le message code est en anglais, donc un morceau de texte anglais vous est donne pour que vous puissez comparer les frequences.
```
# Ceci est le message codé à cracker.
# Des espaces sont laissés expres pour permettre de bien reconnaitre les caracteres
# Attention aux caracteres speciaux d'ascii. E.g. `\r` est bien compté comme 1 caractere de lalphabet.
cypher = "Z C D M P C i W M S i B G Q A S Q Q i R F C i P C Q M J S R G M L \r i J C R i K C i N J y A C i z C D M P C i W M S i M L C i M P i R U M i R F G L E Q \r i ' i U y L R i W M S i R M i S L B C P Q R y L B i R U M i R F G L E Q i T C P W i A J C y P J W i y L B i R M i A M L Q G B C P i R F C K i D P M K i R F C i Q y K C i N M G L R i M D i T G C U i D P M K i U F G A F i ' i y K i N J y A G L E i R F C K i z C D M P C i W M S \x0c i ' i y Q I i W M S i R M i A M L Q G B C P i G R i D P M K i K W i N M G L R i M D i T G C U \r i z C A y S Q C i G D i W M S i y N N P M T C i M D i G R \r i W M S i U G J J i z C i C L H M G L C B i R M i A y P P W i M S R i y J J i ' i Q y W \x0c i ' R i U G J J i z C i y i E P C y R i P C Q N M L Q G z G J G R W \x0c i < F C P C i y P C i N C M N J C i U F M i y Q I i K C i U F C R F C P i ' i y K i R F C i Q y K C i K y L i R F y R i ' i U y Q i G L i p x q o \r i M P i U F C R F C P i R F C P C i F y Q i z C C L i y L W i A F y L E C i G L i K C \x0c i [ M S i y P C i P G E F R i G L i y Q I G L E i R F y R i O S C Q R G M L \x0c i * C R i K C \r i F M U C T C P \r i F y Q R C L i R M i y Q Q S P C i R F y R i ' i y K i R F C i Q y K C i % y L B F G i y Q i ' i U y Q i G L i p x q o \x0c i ' i F y T C i L M R i A F y L E C B i G L i y L W i D S L B y K C L R y J i P C Q N C A R \x0c i ' i y R R y A F i R F C i Q y K C i G K N M P R y L A C i R M i L M L T G M J C L A C i R F y R i ' i B G B i R F C L \x0c i ' D i y R i y J J \r i K W i C K N F y Q G Q i M L i G R i F y Q i E P M U L i Q R P M L E C P \x0c i < F C P C i G Q i L M i P C y J i A M L R P y B G A R G M L i z C R U C C L i R F C i N P C Q C L R i P C Q M J S R G M L i y L B i K W i N P C T G M S Q i U P G R G L E Q i y L B i S R R C P y L A C Q \x0c i - A A y Q G M L Q i J G I C i R F C i N P C Q C L R i B M i L M R i M A A S P i G L i C T C P W z M B W } Q i y L B i z S R i P y P C J W i G L i y L W z M B W } Q i J G D C \x0c i ' i U y L R i W M S i R M i I L M U i y L B i D C C J i R F y R i R F C P C i G Q i L M R F G L E i z S R i N S P C Q R i Y F G K Q y i G L i y J J i R F y R i ' i y K i Q y W G L E i y L B i B M G L E i R M B y W \x0c i < F C i B P y D R i P C Q M J S R G M L i M D i R F C i ? M P I G L E i ! M K K G R R C C i G Q i z y Q C B i M L i Y F G K Q y \r i R F C i A M L R C K N J y R C B i Q R P S E E J C i Q G K G J y P J W i F y Q i G R Q i P M M R Q i G L i Y F G K Q y \x0c i ' D \r i R F C P C D M P C \r i R F C P C i G Q i y L W i y K M L E i W M S i U F M i F y Q i J M Q R i D y G R F i G L i Y F G K Q y i M P i G Q i U C y P G C B i M D i G R \r i J C R i F G K i L M R i T M R C i D M P i R F G Q i P C Q M J S R G M L \x0c`"
# Le code ici permet de transformer le cypher en tableau, enlevant au passage tout les espaces entre chaque caracteres
cypherList = list(cypher)[0::2]
cypherList
```
Pour vous aider, voici un morceau de discours en anglais sur lequel vous pouvez faire une premiere analyse de frequences de caracteres.
Le texte est assez long pour etre representatif d'une distribution classique de la langue anglaise.
Votre histogramme devrait ressembler a celui sur la page web suivante :
https://www3.nd.edu/~busiforc/handouts/cryptography/letterfrequencies.html
```
englishText = "I am the First Accused.I hold a Bachelor's Degree in Arts and practised as an attorney in Johannesburg for a number of years in partnership with Oliver Tambo. I am a convicted prisoner serving five years for leaving the country without a permit and for inciting people to go on strike at the end of May 1961. At the outset, I want to say that the suggestion made by the State in its opening that the struggle in South Africa is under the influence of foreigners or communists is wholly incorrect. I have done whatever I did, both as an individual and as a leader of my people, because of my experience in South Africa and my own proudly felt African background, and not because of what any outsider might have said. In my youth in the Transkei I listened to the elders of my tribe telling stories of the old days. Amongst the tales they related to me were those of wars fought by our ancestors in defence of the fatherland. The names of Dingane and Bambata, Hintsa and Makana, Squngthi and Dalasile, Moshoeshoe and Sekhukhuni, were praised as the glory of the entire African nation. I hoped then that life might offer me the opportunity to serve my people and make my own humble contribution to their freedom struggle. This is what has motivated me in all that I have done in relation to the charges made against me in this case. Having said this, I must deal immediately and at some length with the question of violence. Some of the things so far told to the Court are true and some are untrue. I do not, however, deny that I planned sabotage. I did not plan it in a spirit of recklessness, nor because I have any love of violence. I planned it as a result of a calm and sober assessment of the political situation that had arisen after many years of tyranny, exploitation, and oppression of my people by the Whites."
```
**Consigne** :
Comparer la frequence d'apparition des caracteres du cypher et du discours.
Par simplicité, triez les tableaux dans l'ordre alphabetique.
Il faut ensuite que vous decaliez l'alphabet du cypher jusqu'a que les deux distributions se superposent.
Vous pouvez utiliser la fonction `shiftAlphabet` donnée plus haut.
Ce décalage sera donc la clé d'encryption et de decryption!
```
# Zone a coder en dessous
```
## Partie 2 : Code de César Aléatoire
## Implementation
Voici une legere modification des fonctions d'encryptions du debut de l'exercice.
La seule difference etant qu'au lieu de mélanger par décalage, la position de chaque lettre est aléatoire
```
def convertAlphabetsRand(messageCharNumList, numList, numListToConvert, encrypt = True) :
index = 0
newList = []
for val in messageCharNumList:
indexOfLetter = numListToConvert.index(val)
newList.append(numList[indexOfLetter])
index += 1
if encrypt :
return ' '.join(map(chr,newList))
else :
return ''.join(map(chr,newList))
def encryptMessageRand(m, seedKey):
alphabet_string = string.printable
alphabetListOrdered = list(alphabet_string)
numberListOrdered = list(map(ord, alphabetListOrdered))
alphabetListShuffled = list(alphabetListOrdered)
def seed():
return seedKey
random.shuffle(alphabetListShuffled, seed)
numberListShuffled = list(map(ord, alphabetListShuffled))
return convertAlphabetsRand(list(map(ord, list(m))), numberListShuffled, numberListOrdered)
def decryptMessageRand(m, seedKey):
m = m.replace(' ', '')
alphabet_string = string.printable
alphabetListOrdered = list(alphabet_string)
numberListOrdered = list(map(ord, alphabetListOrdered))
alphabetListShuffled = list(alphabetListOrdered)
def seed():
return seedKey
random.shuffle(alphabetListShuffled, seed)
numberListShuffled = list(map(ord, alphabetListShuffled))
return convertAlphabets(list(map(ord, list(m))), numberListOrdered, numberListShuffled, False)
m = "Vous savez, moi je ne crois pas qu'il y ait de bonne ou de mauvaise situation. Moi, si je devais resumer ma vie aujourd'hui avec vous, je dirais que c'est d'abord des rencontres. Des gens qui m'ont tendu la main, peut-etre a un moment ou je ne pouvais pas, ou j'etais seul chez moi"
m
e = encryptMessageRand(m, 0.42)
e
d = decryptMessageRand(e, 0.42)
d
```
## Cracking a Random Cypher
Voici un cypher généré avec l'algorithme d'encryption de cypher encryptMessageRand.
Le but est d'arriver a decrypter le message grace a l'analyse de frequence des caracteres du message.
Le message code est en anglais, donc un morceau de texte anglais vous est donne pour que vous puissez comparer les frequences.
```
random_cypher = 'J \t _ n \t i _ q q z \t u p \t k p j 2 \t x j u i \t z p v \t u p e _ z \t j 2 \t x i _ u \t x j m m \t h p \t e p x 2 \t j 2 \t i j t u p s z \t _ t \t u i f \t h s f _ u f t u \t e f n p 2 t u s _ u j p 2 \t 1 p s \t 1 s f f e p n \t j 2 \t u i f \t i j t u p s z \t p 1 \t p v s \t 2 _ u j p 2 / \t G j 3 f \t t d p s f \t z f _ s t \t _ h p - \t _ \t h s f _ u \t B n f s j d _ 2 - \t j 2 \t x i p t f \t t z n \n p m j d \t t i _ e p x \t x f \t t u _ 2 e \t u p e _ z - \t t j h 2 f e \t u i f \t F n _ 2 d j q _ u j p 2 \t Q s p d m _ n _ u j p 2 / \t 6 i j t \t n p n f 2 u p v t \t e f d s f f \t d _ n f \t _ t \t _ \t h s f _ u \t \n f _ d p 2 \t m j h i u \t p 1 \t i p q f \t u p \t n j m m j p 2 t \t p 1 \t O f h s p \t t m _ 3 f t \t x i p \t i _ e \t \n f f 2 \t t f _ s f e \t j 2 \t u i f \t 1 m _ n f t \t p 1 \t x j u i f s j 2 h \t j 2 k v t u j d f / \t J u \t d _ n f \t _ t \t _ \t k p z p v t \t e _ z \n s f _ l \t u p \t f 2 e \t u i f \t m p 2 h \t 2 j h i u \t p 1 \t u i f j s \t d _ q u j 3 j u z / \t C v u \t p 2 f \t i v 2 e s f e \t z f _ s t \t m _ u f s - \t u i f \t O f h s p \t t u j m m \t j t \t 2 p u \t 1 s f f / \t P 2 f \t i v 2 e s f e \t z f _ s t \t m _ u f s - \t u i f \t m j 1 f \t p 1 \t u i f \t O f h s p \t j t \t t u j m m \t t _ e m z \t d s j q q m f e \t \n z \t u i f \t n _ 2 _ d m f t \t p 1 \t t f h s f h _ u j p 2 \t _ 2 e \t u i f \t d i _ j 2 t \t p 1 \t e j t d s j n j 2 _ u j p 2 / \t P 2 f \t i v 2 e s f e \t z f _ s t \t m _ u f s - \t u i f \t O f h s p \t m j 3 f t \t p 2 \t _ \t m p 2 f m z \t j t m _ 2 e \t p 1 \t q p 3 f s u z \t j 2 \t u i f \t n j e t u \t p 1 \t _ \t 3 _ t u \t p d f _ 2 \t p 1 \t n _ u f s j _ m \t q s p t q f s j u z / \t P 2 f \t i v 2 e s f e \t z f _ s t \t m _ u f s - \t u i f \t O f h s p \t j t \t t u j m m \t m _ 2 h v j t i f e \t j 2 \t u i f \t d p s 2 f s t \t p 1 \t B n f s j d _ 2 \t t p d j f u z \t _ 2 e \t 1 j 2 e t \t i j n t f m 1 \t _ 2 \t f y j m f \t j 2 \t i j t \t p x 2 \t m _ 2 e / \t B 2 e \t t p \t x f ( 3 f \t d p n f \t i f s f \t u p e _ z \t u p \t e s _ n _ u j A f \t _ \t t i _ n f 1 v m \t d p 2 e j u j p 2 /'
random_cypherList = list(random_cypher)[0::2]
random_cypherList
englishText = "I am the First Accused.I hold a Bachelor's Degree in Arts and practised as an attorney in Johannesburg for a number of years in partnership with Oliver Tambo. I am a convicted prisoner serving five years for leaving the country without a permit and for inciting people to go on strike at the end of May 1961. At the outset, I want to say that the suggestion made by the State in its opening that the struggle in South Africa is under the influence of foreigners or communists is wholly incorrect. I have done whatever I did, both as an individual and as a leader of my people, because of my experience in South Africa and my own proudly felt African background, and not because of what any outsider might have said. In my youth in the Transkei I listened to the elders of my tribe telling stories of the old days. Amongst the tales they related to me were those of wars fought by our ancestors in defence of the fatherland. The names of Dingane and Bambata, Hintsa and Makana, Squngthi and Dalasile, Moshoeshoe and Sekhukhuni, were praised as the glory of the entire African nation. I hoped then that life might offer me the opportunity to serve my people and make my own humble contribution to their freedom struggle. This is what has motivated me in all that I have done in relation to the charges made against me in this case. Having said this, I must deal immediately and at some length with the question of violence. Some of the things so far told to the Court are true and some are untrue. I do not, however, deny that I planned sabotage. I did not plan it in a spirit of recklessness, nor because I have any love of violence. I planned it as a result of a calm and sober assessment of the political situation that had arisen after many years of tyranny, exploitation, and oppression of my people by the Whites."
```
| github_jupyter |
```
# Run in python console
import nltk; nltk.download('stopwords')
```
Import Packages
```
import re
import numpy as np
import pandas as pd
from pprint import pprint
# Gensim
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
from gensim.models import CoherenceModel
# spacy for lemmatization
import spacy
# Plotting tools
import pyLDAvis
import pyLDAvis.gensim # don't skip this
import matplotlib.pyplot as plt
%matplotlib inline
# Enable logging for gensim - optional
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.ERROR)
import warnings
warnings.filterwarnings("ignore",category=DeprecationWarning)
# NLTK Stop words
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
stop_words.extend(['from', 'subject', 're', 'edu', 'use'])
```
Importing Lyrics data
```
# Import Dataset
df = pd.read_csv('')
df1.head()
# df = df1.head(10)
print(df.genre.unique())
print(df.artist.unique())
print(df.year.unique())
```
Remove newline characters
```
# Convert to list
# data = df.lyrics.values.tolist()
# data = [re.sub('[^a-zA-Z ]' ,'', str(sent)) for sent in data]
# pprint(data[:1])
# def sent_to_words(sentences):
# for sentence in sentences:
# yield(gensim.utils.simple_preprocess(str(sentence), deacc=True)) # deacc=True removes punctuations
# data_words = list(sent_to_words(data))
# print(data_words[:1])
```
### Creating Bigram and Trigram Models
Bigrams are two words frequently occurring together in the document. Trigrams are 3 words frequently occurring.
Some examples in our example are: ‘front_bumper’, ‘oil_leak’, ‘maryland_college_park’ etc.
Gensim’s Phrases model can build and implement the bigrams, trigrams, quadgrams and more. The two important arguments to Phrases are min_count and threshold. The higher the values of these param, the harder it is for words to be combined to bigrams.
```
# Build the bigram and trigram models
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100) # higher threshold fewer phrases.
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
# Faster way to get a sentence clubbed as a trigram/bigram
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
# See trigram example
print(bigram_mod[data_words[0]])
```
### Remove Stopwords, Make Bigrams and Lemmatize
The bigrams model is ready. Let’s define the functions to remove the stopwords, make bigrams and lemmatization and call them sequentially.
```
# Define functions for stopwords, bigrams, trigrams and lemmatization
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc)) if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
"""https://spacy.io/api/annotation"""
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
```
Let’s call the functions in order.
```
# Remove Stop Words
data_words_nostops = remove_stopwords(data_words)
# Form Bigrams
data_words_bigrams = make_bigrams(data_words_nostops)
# Initialize spacy 'en' model, keeping only tagger component (for efficiency)
# python3 -m spacy download en
nlp = spacy.load('en', disable=['parser', 'ner'])
# Do lemmatization keeping only noun, adj, vb, adv
data_lemmatized = lemmatization(data_words_bigrams, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV'])
print(data_lemmatized[:1])
```
### Create the Dictionary and Corpus needed for Topic Modeling
The two main inputs to the LDA topic model are the dictionary(id2word) and the corpus. Let’s create them.
```
# Create Dictionary
id2word = corpora.Dictionary(data_lemmatized)
# Create Corpus
texts = data_lemmatized
# Term Document Frequency
corpus = [id2word.doc2bow(text) for text in texts]
# View
print(corpus[:1])
```
Gensim creates a unique id for each word in the document. The produced corpus shown above is a mapping of (word_id, word_frequency).
For example, (0, 1) above implies, word id 0 occurs once in the first document. Likewise, word id 1 occurs twice and so on.
This is used as the input by the LDA model.
If you want to see what word a given id corresponds to, pass the id as a key to the dictionary.
```
id2word[10]
# Human readable format of corpus (term-frequency)
[[(id2word[id], freq) for id, freq in cp] for cp in corpus[:1]]
```
### Building the Topic Model
We have everything required to train the LDA model. In addition to the corpus and dictionary, you need to provide the number of topics as well.
Apart from that, alpha and eta are hyperparameters that affect sparsity of the topics. According to the Gensim docs, both defaults to 1.0/num_topics prior.
chunksize is the number of documents to be used in each training chunk. update_every determines how often the model parameters should be updated and passes is the total number of training passes.
```
# Build LDA model
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=20,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
# Print the Keyword in the 10 topics
pprint(lda_model.print_topics())
doc_lda = lda_model[corpus]
# Compute Perplexity
print('\nPerplexity: ', lda_model.log_perplexity(corpus)) # a measure of how good the model is. lower the better.
# Compute Coherence Score
coherence_model_lda = CoherenceModel(model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)
# Visualize the topics
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)
vis
mallet_path = '/Users/neha/Downloads/mallet-2.0.8/bin/mallet' # update this path
ldamallet = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=20, id2word=id2word)
# Show Topics
pprint(ldamallet.show_topics(formatted=False))
# Compute Coherence Score
coherence_model_ldamallet = CoherenceModel(model=ldamallet, texts=data_lemmatized, dictionary=id2word, coherence='c_v')
coherence_ldamallet = coherence_model_ldamallet.get_coherence()
print('\nCoherence Score: ', coherence_ldamallet)
```
```
def compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3):
"""
Compute c_v coherence for various number of topics
Parameters:
----------
dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
limit : Max num of topics
Returns:
-------
model_list : List of LDA topic models
coherence_values : Coherence values corresponding to the LDA model with respective number of topics
"""
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus, num_topics=num_topics, id2word=id2word)
model_list.append(model)
coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
# Can take a long time to run.
model_list, coherence_values = compute_coherence_values(dictionary=id2word, corpus=corpus, texts=data_lemmatized, start=2, limit=40, step=6)
# Show graph
limit=40; start=2; step=6;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()
# Print the coherence scores
for m, cv in zip(x, coherence_values):
print("Num Topics =", m, " has Coherence Value of", round(cv, 4))
# Select the model and print the topics
optimal_model = model_list[3]
model_topics = optimal_model.show_topics(formatted=False)
pprint(optimal_model.print_topics(num_words=10))
def format_topics_sentences(ldamodel=lda_model, corpus=corpus, texts=data):
# Init output
sent_topics_df = pd.DataFrame()
# Get main topic in each document
for i, row in enumerate(ldamodel[corpus]):
row = sorted(row, key=lambda x: (x[1]), reverse=True)
# Get the Dominant topic, Perc Contribution and Keywords for each document
for j, (topic_num, prop_topic) in enumerate(row):
if j == 0: # => dominant topic
wp = ldamodel.show_topic(topic_num)
topic_keywords = ", ".join([word for word, prop in wp])
sent_topics_df = sent_topics_df.append(pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True)
else:
break
sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']
# Add original text to the end of the output
contents = pd.Series(texts)
sent_topics_df = pd.concat([sent_topics_df, contents], axis=1)
return(sent_topics_df)
df_topic_sents_keywords = format_topics_sentences(ldamodel=optimal_model, corpus=corpus, texts=data)
# Format
df_dominant_topic = df_topic_sents_keywords.reset_index()
df_dominant_topic.columns = ['Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text']
# Show
df_dominant_topic.head(10)
```
```
# Group top 5 sentences under each topic
sent_topics_sorteddf_mallet = pd.DataFrame()
sent_topics_outdf_grpd = df_topic_sents_keywords.groupby('Dominant_Topic')
for i, grp in sent_topics_outdf_grpd:
sent_topics_sorteddf_mallet = pd.concat([sent_topics_sorteddf_mallet,
grp.sort_values(['Perc_Contribution'], ascending=[0]).head(1)],
axis=0)
# Reset Index
sent_topics_sorteddf_mallet.reset_index(drop=True, inplace=True)
# Format
sent_topics_sorteddf_mallet.columns = ['Topic_Num', "Topic_Perc_Contrib", "Keywords", "Text"]
# Show
sent_topics_sorteddf_mallet.head()
```
| github_jupyter |
# Evaluate AminoAcids Prediction
```
%matplotlib inline
import pylab
pylab.rcParams['figure.figsize'] = (15.0, 12.0)
import os
import sys
import numpy as np
from shutil import copyfile
from src.python.aa_predict import *
import src.python.aa_predict as AA
checkpoint_path = "../../data/trained/aapred_cnn_latest.tar"
emb_dim = 5
win_size = 10
model = GoodOldCNN(emb_dim, win_size)
if os.path.exists(checkpoint_path):
print("=> loading checkpoint '%s'" % checkpoint_path)
checkpoint = torch.load(checkpoint_path, map_location=lambda storage, loc: storage)
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '%s' (epoch %s)" %
(checkpoint_path, checkpoint['epoch'] + 1))
else:
print("=> no checkpoint found at '%s'" % checkpoint_path)
```
### Define Evaluation Function(s)
```
import torch
import torch.nn as nn
from torch.autograd import Variable
from pymongo import MongoClient
```
### 1 2 3 Predict...
```
class_names = sorted(dictionary.keys(), key=lambda aa: dictionary[aa])
client = MongoClient("mongodb://127.0.0.1:27017")
db = client['prot2vec']
global collection_test, size_test, verbose
AA.collection_test = db['sprot']
AA.size_test = 100
AA.verbose = True
AA.use_cuda = False
batch_size = 32
loader = WindowBatchLoader(win_size, batch_size, False)
y_test, y_pred, _ = predict(model, loader)
# data = []
# for i, (x, y) in enumerate(loader):
# data.append((np.random.permutation(x), np.random.permutation(y)))
# y_test, y_pred, _ = predict(model, data)
```
### Evaluate
```
import itertools
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
# print(cm)
# print(cm.shape)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test, y_pred, labels=list(range(25)))
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
# Plot normalized confusion matrix
# plt.figure()
# plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True,
# title='Normalized confusion matrix')
plt.show()
```
### Plot Accuracy
```
###https://matplotlib.org/examples/api/barchart_demo.html
def plot_accuracy(title, scores):
N = len(scores)
acc = list(scores.values())
ind = np.arange(N) # the x locations for the groups
width = 0.2 # the width of the bars
fig, ax = plt.subplots()
rects1 = ax.bar(ind, acc, width, color='b')
# add some text for labels, title and axes ticks
ax.set_ylabel('Scores')
ax.set_title(title)
ax.set_xticks(ind)
ax.set_xticklabels(list(scores.keys()))
ax.legend((rects1,), ('acc',))
autolabel(rects1, ax)
def autolabel(rects, ax):
"""
Attach a text label above each bar displaying its height
"""
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2., 1.05*height,
'%.2f' % height,
ha='center', va='bottom')
indx = [i for i, row in enumerate(cnf_matrix) if row[i] > 0]
acc_scores = {reverse_dictionary[i]:cnf_matrix[i, i]/np.sum(row)
for i, row in enumerate(cnf_matrix) if i in indx}
plot_accuracy("AA Prediction Accuracy", acc_scores)
plt.show()
import pandas as pd
aa_feat = pd.read_csv('Data/aa_feat.csv')
x = aa_feat["Occurrence.in.Bacteria.proteins....."][indx]
y = list(acc_scores.values())
labels = [reverse_dictionary[i] for i in indx]
def plot(x, y, labels, title):
xy = list(zip(x, y))
for i, label in enumerate(labels):
x, y = xy[i]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right', va='bottom')
plt.title(title)
plot(x, y, labels, "Prediction acc vs. % Occurrence in Data")
m, b = np.polyfit(x, y, 1)
plt.plot(x, m*x + b, '-')
```
| github_jupyter |
```
import os
import numpy as np
import torch
torch.manual_seed(29)
from torch import nn
import torch.backends.cudnn as cudnn
import torch.nn.parallel
cudnn.benchmark = True
import torch.nn.functional as F
from PIL import Image, ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
from glob import glob
from PIL.PngImagePlugin import PngImageFile, PngInfo
from tqdm import tqdm
def bpg_enc(I, out_f, enc_cmd, w, h):
# out_f = out_f
I.save("test_en.png")
os.system(enc_cmd + ' -m 9 -f 444 -q 29 test_en.png -o ' + '"'+out_f + '"')
if not os.path.exists(out_f): print(out_f)
os.setxattr(out_f, 'user.h', bytes(str(h), 'utf-8'))
os.setxattr(out_f, 'user.w', bytes(str(w), 'utf-8'))
os.remove("test_en.png")
def bpg_dec(bpg_enc_file, dec_cmd):
# bpg_enc_file = bpg_enc_file.replace(" ", "\ ")
os.system(dec_cmd + ' "' + bpg_enc_file + '" -o test_de.png')
h = int(os.getxattr(bpg_enc_file, 'user.h'))
w = int(os.getxattr(bpg_enc_file, 'user.w'))
I = Image.open("test_de.png")
return I, w, h
class quantclip(torch.autograd.Function):
"""
We can implement our own custom autograd Functions by subclassing
torch.autograd.Function and implementing the forward and backward passes
which operate on Tensors.
"""
@staticmethod
def forward(self, input, quant):
"""
In the forward pass we receive a Tensor containing the input and return a
Tensor containing the output. You can cache arbitrary Tensors for use in the
backward pass using the save_for_backward method.
"""
self.save_for_backward(input)
c = (input.clamp(min=-1, max =1)+1)/2.0 * quant
c = 2 * (c.round()/quant) - 1
return c
@staticmethod
def backward(self, grad_output):
"""
In the backward pass we receive a Tensor containing the gradient of the loss
with respect to the output, and we need to compute the gradient of the loss
with respect to the input.
"""
input, = self.saved_tensors
grad_input = grad_output.clone()
grad_input[input < -1] = 0
grad_input[input > 1] = 0
return grad_input, None
class QuantCLIP(torch.nn.Module):
def __init__(self, num_bits, dtype = torch.cuda.FloatTensor):
super(QuantCLIP, self).__init__()
self.quant = 2 ** num_bits - 1
self.quantclip = quantclip
def forward(self, input):
return self.quantclip.apply(input, self.quant)
def getHAARFilters(num_filters):
LL = np.asarray([[0.5, 0.5], [0.5, 0.5]])
LH = np.asarray([[-0.5, -0.5], [0.5, 0.5]])
HL = np.asarray([[-0.5, 0.5], [-0.5, 0.5]])
HH = np.asarray([[0.5, -0.5], [-0.5, 0.5]])
DWT = np.concatenate((LL[np.newaxis, ...],
LH[np.newaxis, ...],
HL[np.newaxis, ...],
HH[np.newaxis, ...]))[:, np.newaxis, ...]
DWT = np.float32(DWT)
DWT = torch.from_numpy(DWT)
return DWT.repeat(num_filters, 1, 1, 1)
class HaarDWT(torch.nn.Module):
def __init__(self, in_ch = 1):
super(HaarDWT, self).__init__()
weights = getHAARFilters(in_ch)
self.conv = nn.Conv2d(in_ch, in_ch * 4, 2, stride=2, bias=False, groups = in_ch)
self.conv.weight.data = weights
self.conv.weight.requires_grad = False
def forward(self, input):
return self.conv(input)
class HaarIDWT(torch.nn.Module):
def __init__(self, out_ch = 1):
super(HaarIDWT, self).__init__()
weights = getHAARFilters(out_ch)
self.conv = nn.ConvTranspose2d(out_ch * 4, out_ch, 2, stride=2, bias=False, groups = out_ch)
self.conv.weight.data = weights
self.conv.weight.requires_grad = False
def forward(self, input):
return self.conv(input)
"""
Single CONV blocks:
"""
class BLOCK_3x3(nn.Module):
def __init__(
self, in_ch, out_ch, ker, stride = 1
):
super(BLOCK_3x3, self).__init__()
self.feat = nn.Sequential(
nn.ReflectionPad2d(ker//2),
nn.Conv2d(in_ch, out_ch, ker, stride = stride, bias = True)
)
def forward(self, x):
x = self.feat(x)
return x
"""
Residual CONV blocks:
"""
class RES_3x3_BLOCK1(nn.Module):
"""
Residual Block:
[INPUT] -> 2*[CONV 3x3] -> [OUTPUT] + [INPUT]
"""
def __init__(
self, in_ch, out_ch, ker, squeeze = 2, res_scale = 0.25
):
super(RES_3x3_BLOCK1, self).__init__()
self.skip = in_ch == out_ch
self.rs = res_scale
self.feat = nn.Sequential(
nn.BatchNorm2d(in_ch),
nn.ReLU(inplace=True),
BLOCK_3x3(in_ch, out_ch//squeeze, ker),
nn.BatchNorm2d(out_ch//squeeze),
nn.ReLU(inplace=True),
BLOCK_3x3(out_ch//squeeze, out_ch, ker),
)
def forward(self, x):
out = self.feat(x)
if self.skip: out = self.rs * out + x
return out
"""
Enocder:
"""
class Encoder(nn.Module):
def __init__(
self,
):
super(Encoder, self).__init__()
self.E = nn.Sequential(
HaarDWT(3),HaarDWT(12),
BLOCK_3x3(in_ch = 48, out_ch = 128, ker = 3, stride = 1),
RES_3x3_BLOCK1(in_ch = 128, out_ch = 128, ker = 3, squeeze = 4, res_scale = 1.0),
RES_3x3_BLOCK1(in_ch = 128, out_ch = 128, ker = 3, squeeze = 4, res_scale = 1.0),
nn.Conv2d(128, 3, 1),
QuantCLIP(8)
)
def forward(self, x):
x = self.E(x)
return x
"""
Deocder:
"""
class Decoder(nn.Module):
def __init__(
self,
):
super(Decoder, self).__init__()
self.D = nn.Sequential(
BLOCK_3x3(in_ch = 3, out_ch = 256, ker = 3, stride = 1),
RES_3x3_BLOCK1(in_ch = 256, out_ch = 256, ker = 3, squeeze = 4, res_scale = 1.0),
RES_3x3_BLOCK1(in_ch = 256, out_ch = 256, ker = 3, squeeze = 4, res_scale = 1.0),
RES_3x3_BLOCK1(in_ch = 256, out_ch = 256, ker = 3, squeeze = 4, res_scale = 1.0),
RES_3x3_BLOCK1(in_ch = 256, out_ch = 256, ker = 3, squeeze = 4, res_scale = 1.0),
nn.Conv2d(256, 48, 1),
HaarIDWT(12),HaarIDWT(3),
nn.ReLU(),
)
self.S = nn.Sequential(nn.ReflectionPad2d(1),
nn.AvgPool2d(3, stride=1, padding=0))
def forward(self, x):
x = self.D(x)
# x = self.S(x)
return x
de_model = Decoder()
check_point_file = "/home/cibitaw1/local/1WeStar/weights/submission_weights/decode.pth"
checkpoint = torch.load(check_point_file)
de_model.load_state_dict(checkpoint, strict = False)
de_model.cuda()
print('.')
en_model = Encoder()
check_point_file = "/home/cibitaw1/local/1WeStar/weights/submission_weights/encode.pth"
checkpoint = torch.load(check_point_file)
en_model.load_state_dict(checkpoint, strict = False)
en_model.cuda()
print('.')
de_model = Decoder()
check_point_file = "/media/cibitaw1/DATA/SP2020/compressACT/weights/"+\
"QuantACTShuffleV6_exp01/checkpoint.pth.tar"
checkpoint = torch.load(check_point_file)
de_model.load_state_dict(checkpoint['state_dict'], strict = False)
de_model.cuda()
print('.')
en_model = Encoder()
check_point_file = "/media/cibitaw1/DATA/SP2020/compressACT/weights/"+\
"QuantACTShuffleV6_exp01/checkpoint.pth.tar"
checkpoint = torch.load(check_point_file)
en_model.load_state_dict(checkpoint['state_dict'], strict = False)
en_model.cuda()
print('.')
torch.save(de_model.state_dict(), "/home/cibitaw1/local/1WeStar/weights/submission_weights/decode.pth")
torch.save(de_model.state_dict(), "/home/cibitaw1/local/1WeStar/submission_package/decode.pth")
torch.save(en_model.state_dict(), "/home/cibitaw1/local/1WeStar/weights/submission_weights/encode.pth")
def compress(I_org, model):
e_ = 512
c_ = 4
d_ = e_ // c_
pad_ = 4
w, h = I_org.size
comp_w_new = np.ceil(w/c_)
comp_h_new = np.ceil(h/c_)
new_w = int(e_ * np.ceil(w/e_))
new_h = int(e_ * np.ceil(h/e_))
com_w = new_w // c_
com_h = new_h // c_
I = np.uint8(I_org).copy()
I = np.pad(I, ((0, int(new_h - h)),
(0, int(new_w - w)),
(0, 0)), mode = "reflect")
I = Image.fromarray(I)
I1 = np.float32(I)/255.0
I1 = np.transpose(I1, [2, 0, 1])
Enout = np.zeros((3, com_h, com_w))
Enout_w = np.zeros((3, com_h, com_w))
for i in list(np.arange(0, new_h, e_)):
for j in list(np.arange(0, new_w, e_)):
if i == 0:
x1 = int(i)
x2 = int((i + e_) + (pad_*2*c_))
else:
x1 = int(i - (pad_*c_))
x2 = int((i + e_) + (pad_*c_))
if j == 0:
y1 = int(j)
y2 = int((j + e_) + (pad_*2*c_))
else:
y1 = int(j - (pad_*c_))
y2 = int((j + e_) + (pad_*c_))
It = torch.from_numpy(np.expand_dims(I1[:, x1:x2, y1:y2], 0))
Xe = model(It.cuda())
Xe = (Xe + 1.0)/2.0
Enout[:, x1//c_:x2//c_, y1//c_:y2//c_] += Xe.data.squeeze().cpu().numpy()
Enout_w[:, x1//c_:x2//c_, y1//c_:y2//c_] += 1.0
Enout = Enout/Enout_w
Enout = np.uint8(255 * Enout.transpose([1, 2, 0]))
Enout = Image.fromarray(Enout).crop((0, 0, comp_w_new, comp_h_new))
return Enout
def decompress(EnIn, model, w, h):
e_ = 256
c_ = 4
d_ = e_ // c_
pad_ = 4
# w, h = int(EnIn.text['w']), int(EnIn.text['h'])
comp_w_new = np.ceil(w/c_)
comp_h_new = np.ceil(h/c_)
new_w = int(e_ * np.ceil(w/e_))
new_h = int(e_ * np.ceil(h/e_))
com_w = new_w // c_
com_h = new_h // c_
Iout = np.zeros((3,new_h,new_w), dtype = np.float32)
Iout_w = np.zeros((3,new_h,new_w), dtype = np.float32)
EnIn = np.uint8(EnIn).copy()
EnIn = np.pad(EnIn, ((0, int(com_h - EnIn.shape[0])),
(0, int(com_w - EnIn.shape[1])),
(0, 0)), mode = "reflect")
EnIn = np.float32(EnIn)/255.0
EnIn = np.transpose(EnIn, [2, 0, 1])
for i in list(np.arange(0, com_h, d_)):
for j in list(np.arange(0, com_w, d_)):
if i == 0:
x1 = int(i)
x2 = int((i + d_) + pad_*2)
else:
x1 = int(i - pad_)
x2 = int((i + d_) + pad_)
if j == 0:
y1 = int(j)
y2 = int((j + d_) + pad_*2)
else:
y1 = int(j - pad_)
y2 = int((j + d_) + pad_)
It = torch.from_numpy(np.expand_dims(EnIn[:, x1:x2, y1:y2], 0))
It = It * 2.0 - 1.0
Xe = model(It.cuda()).data.squeeze().cpu()
Iout[:, x1*c_:x2*c_, y1*c_:y2*c_] += np.clip(Xe.numpy(), 0, 1)
Iout_w[:, x1*c_:x2*c_, y1*c_:y2*c_] += 1.0
Iout = Iout/Iout_w
Iout = np.uint8(255 * Iout.transpose([1, 2, 0]))
Iout = Image.fromarray(Iout).crop((0, 0, w, h))
return Iout
img_file = "/media/cibitaw1/DATA/super_rez/professional_valid/valid/alberto-montalesi-176097.png"
I = Image.open(img_file).convert("RGB")
Enout = compress(I, en_model)
bpg_enc(Enout, "test_en.bpg", "bpgenc", I.size[0], I.size[1])
Enout, w, h = bpg_dec("test_en.bpg", "bpgdec")
Iout = decompress(Enout, de_model, w, h)
src_fldr = "/media/cibitaw1/DATA/super_rez/professional_valid/valid"
imgs = glob(src_fldr + os.sep + "*.png")
src_fldr = "/media/cibitaw1/DATA/super_rez/mobile_valid/valid"
imgs += glob(src_fldr + os.sep + "*.png")
dst_fldr = "/media/cibitaw1/DATA/super_rez/comp_test/compressed"
for img in tqdm(imgs):
I = Image.open(img).convert("RGB")
Enout = compress(I, en_model)
img_name = os.path.join(dst_fldr, img.split(os.sep)[-1]).replace(".png", ".bpg")
bpg_enc(Enout, img_name, "bpgenc", I.size[0], I.size[1])
for img in tqdm(imgs):
I = Image.open(img).convert("RGB")
img_name = os.path.join(dst_fldr, img.split(os.sep)[-1]).replace(".png", ".bpg")
new_img_name = img_name + '__w_' + str(I.size[0]) + '__h_' + str(I.size[1])
os.rename(img_name, new_img_name)
def bpg_dec(bpg_enc_file, dec_cmd):
# bpg_enc_file = bpg_enc_file.replace(" ", "\ ")
x = bpg_enc_file.split('__')
bpg_enc_file = x[0]
w = int(x[1].replace("w_", ""))
h = int(x[2].replace("h_", ""))
os.system(dec_cmd + ' "' + bpg_enc_file + '" -o test_de.png')
# h = int(os.getxattr(bpg_enc_file, 'user.h'))
# w = int(os.getxattr(bpg_enc_file, 'user.w'))
I = Image.open("test_de.png")
os.remove("test_de.png")
return I, w, h, bpg_enc_file
X = bpg_dec("/media/cibitaw1/DATA/super_rez/comp_test/images/IMG_20170725_123034.bpg__w_2024__h_1518", "bpgdec")
X
X1.split('__')
```
| github_jupyter |
# Create a Learner for inference
```
from fastai import *
from fastai.gen_doc.nbdoc import *
```
In this tutorial, we'll see how the same API allows you to create an empty [`DataBunch`](/basic_data.html#DataBunch) for a [`Learner`](/basic_train.html#Learner) at inference time (once you have trained your model) and how to call the `predict` method to get the predictions on a single item.
```
jekyll_note("""As usual, this page is generated from a notebook that you can find in the docs_srs folder of the
[fastai repo](https://github.com/fastai/fastai). We use the saved models from [this tutorial](/tutorial.data.html) to
have this notebook run fast.
""")
```
## Vision
To quickly get acces to all the vision functions inside fastai, we use the usual import statements.
```
from fastai import *
from fastai.vision import *
```
### A classification problem
Let's begin with our sample of the MNIST dataset.
```
mnist = untar_data(URLs.MNIST_TINY)
tfms = get_transforms(do_flip=False)
```
It's set up with an imagenet structure so we use it to split our training and validation set, then labelling.
```
data = (ImageItemList.from_folder(mnist)
.split_by_folder()
.label_from_folder()
.transform(tfms, size=32)
.databunch()
.normalize(imagenet_stats))
```
Now that our data has been properly set up, we can train a model. Once the time comes to deploy it for inference, we'll need to save the information this [`DataBunch`](/basic_data.html#DataBunch) contains (classes for instance), to do this, we call `data.export()`. This will create an 'export.pkl' file that you'll need to copy with your model file if you want do deploy pn another device.
```
data.export()
```
To create the [`DataBunch`](/basic_data.html#DataBunch) for inference, you'll need to use the `load_empty` method. Note that for now, transforms and normalization aren't saved inside the export file. This is going to be integrated in a future version of the library. For now, we pass the transforms we applied on the validation set, along with all relevant kwargs, and we normalize with the same statistics as during training.
Then, we use it to create a [`Learner`](/basic_train.html#Learner) and load the model we trained before.
```
empty_data = ImageDataBunch.load_empty(mnist, tfms=tfms[1],size=32).normalize(imagenet_stats)
learn = create_cnn(empty_data, models.resnet18)
learn.load('mini_train');
```
You can now get the predictions on any image via `learn.predict`.
```
img = data.train_ds[0][0]
learn.predict(img)
```
It returns a tuple of three things: the object predicted (with the class in this instance), the underlying data (here the corresponding index) and the raw probabilities.
### A multilabel problem
Now let's try these on the planet dataset, which is a little bit different in the sense that each image can have multiple tags (and not jsut one label).
```
planet = untar_data(URLs.PLANET_TINY)
planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)
```
Here each images is labelled in a file named 'labels.csv'. We have to add 'train' as a prefix to the filenames, '.jpg' as a suffix and he labels are separated by spaces.
```
data = (ImageItemList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg')
.random_split_by_pct()
.label_from_df(sep=' ')
.transform(planet_tfms, size=128)
.databunch()
.normalize(imagenet_stats))
```
Again, we call `data.export()` to export our data object properties.
```
data.export()
```
We can then create the [`DataBunch`](/basic_data.html#DataBunch) for inference, by using the `load_empty` method as before.
```
empty_data = ImageDataBunch.load_empty(planet, tfms=tfms[1],size=32).normalize(imagenet_stats)
learn = create_cnn(empty_data, models.resnet18)
learn.load('mini_train');
```
And we get the predictions on any image via `learn.predict`.
```
img = data.train_ds[0][0]
learn.predict(img)
```
Here we can specify a particular theshold to consider the predictions are a hit or not. The default is 0.5 but we can change it.
```
learn.predict(img, thresh=0.3)
```
### A regression example
For the next example, we are going to use the [BIWI head pose](https://data.vision.ee.ethz.ch/cvl/gfanelli/head_pose/head_forest.html#db) dataset. On pictures of persons, we have to find the center of their face. For the fastai docs, we have built a small subsample of the dataset (200 images) and prepared a dictionary for the correspondance fielname to center.
```
biwi = untar_data(URLs.BIWI_SAMPLE)
fn2ctr = pickle.load(open(biwi/'centers.pkl', 'rb'))
```
To grab our data, we use this dictionary to label our items. We also use the [`PointsItemList`](/vision.data.html#PointsItemList) class to have the targets be of type [`ImagePoints`](/vision.image.html#ImagePoints) (which will make sure the data augmentation is properly applied to them). When calling [`transform`](/tabular.transform.html#tabular.transform) we make sure to set `tfm_y=True`.
```
data = (ImageItemList.from_folder(biwi)
.random_split_by_pct()
.label_from_func(lambda o:fn2ctr[o.name], label_cls=PointsItemList)
.transform(get_transforms(), tfm_y=True, size=(120,160))
.databunch()
.normalize(imagenet_stats))
```
As before, the road to inference is pretty straightforward: export the data, then load an empty [`DataBunch`](/basic_data.html#DataBunch).
```
data.export()
empty_data = ImageDataBunch.load_empty(biwi, tfms=get_transforms()[1], tfm_y=True, size=(120,60)).normalize(imagenet_stats)
learn = create_cnn(empty_data, models.resnet18)
learn.load('mini_train');
```
And now we can a prediction on an image.
```
img = data.train_ds[0][0]
learn.predict(img)
```
To visualize the predictions, we can use the [`Image.show`](/vision.image.html#Image.show) method.
```
img.show(y=learn.predict(img)[0])
```
### A segmentation example
Now we are going to look at the [camvid dataset](http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/) (at least a small sample of it), where we have to predict the class of each pixel in an image. Each image in the 'images' subfolder as an equivalent in 'labels' that is its segmentations mask.
```
camvid = untar_data(URLs.CAMVID_TINY)
path_lbl = camvid/'labels'
path_img = camvid/'images'
```
We read the classes in 'codes.txt' and the function maps each image filename with its corresponding mask filename.
```
codes = np.loadtxt(camvid/'codes.txt', dtype=str)
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
```
The data block API allows us to uickly get everything in a [`DataBunch`](/basic_data.html#DataBunch) and then we can have a look with `show_batch`.
```
data = (SegmentationItemList.from_folder(path_img)
.random_split_by_pct()
.label_from_func(get_y_fn, classes=codes)
.transform(get_transforms(), tfm_y=True, size=128)
.databunch(bs=16, path=camvid)
.normalize(imagenet_stats))
```
As before, we export the data then create an empty [`DataBunch`](/basic_data.html#DataBunch) that we pass to a [`Learner`](/basic_train.html#Learner).
```
data.export()
empty_data = ImageDataBunch.load_empty(camvid, tfms=get_transforms()[1], tfm_y=True, size=128).normalize(imagenet_stats)
learn = Learner.create_unet(empty_data, models.resnet18)
learn.load('mini_train');
```
And now we can a prediction on an image.
```
img = data.train_ds[0][0]
learn.predict(img)
```
To visualize the predictions, we can use the [`Image.show`](/vision.image.html#Image.show) method.
```
img.show(y=learn.predict(img)[0])
```
## Text
Next application is text, so let's start by importing everything we'll need.
```
from fastai import *
from fastai.text import *
```
### Language modelling
First let's look a how to get a language model ready for inference. Since we'll load the model trained in the [visualize data tutorial](/tutorial.data.html), we load the vocabulary used there.
```
imdb = untar_data(URLs.IMDB_SAMPLE)
vocab = Vocab(pickle.load(open(imdb/'tmp'/'itos.pkl', 'rb')))
data_lm = (TextList.from_csv(imdb, 'texts.csv', cols='text', vocab=vocab)
.random_split_by_pct()
.label_for_lm()
.databunch())
```
Like in vision, we just have to type `data_lm.export()` to save all the information inside the [`DataBunch`](/basic_data.html#DataBunch) we'll need. In this case, this includes all the vocabulary we created.
```
data_lm.export()
```
Now let's define a language model learner from an empty data object.
```
empty_data = TextLMDataBunch.load_empty(imdb)
learn = language_model_learner(empty_data)
learn.load('mini_train_lm');
```
Then we can predict with the usual method, here we can specify how many words we want the model to predict.
```
learn.predict('This is a simple test of', n_words=20)
```
### Classification
Now let's see a classification example. We have to use the same vocabulary as for the language model if we want to be able to use the encoder we saved.
```
data_clas = (TextList.from_csv(imdb, 'texts.csv', cols='text', vocab=vocab)
.split_from_df(col='is_valid')
.label_from_df(cols='label')
.databunch(bs=42))
```
Again we export the data.
```
data_clas.export()
```
Now let's define a text classifier from an empty data object.
```
empty_data = TextClasDataBunch.load_empty(imdb)
learn = text_classifier_learner(empty_data)
learn.load('mini_train_clas');
```
Then we can predict with the usual method.
```
learn.predict('I really loved that movie!')
```
# Tabular
Last application brings us to tabular data. First let's import everything we'll need.
```
from fastai import *
from fastai.tabular import *
```
We'll use a sample of the [adult dataset](https://archive.ics.uci.edu/ml/datasets/adult) here. Once we read the csv file, we'll need to specify the dependant variable, the categorical variables, the continuous variables and the processors we want to use.
```
adult = untar_data(URLs.ADULT_SAMPLE)
df = pd.read_csv(adult/'adult.csv')
dep_var = '>=50k'
cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country']
cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain']
procs = [FillMissing, Categorify, Normalize]
```
Then we can use the data block API to grab everything together before using `data.show_batch()`
```
data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx=range(800,1000))
.label_from_df(cols=dep_var)
.databunch())
```
We define a [`Learner`](/basic_train.html#Learner) object that we fit and then save the model.
```
learn = tabular_learner(data, layers=[200,100], metrics=accuracy)
learn.fit(1, 1e-2)
learn.save('mini_train')
```
As in the other applications, we just have to type `data.export()` to save everything we'll need for inference (here the inner state of each processor).
```
data.export()
```
Then we create an empty data object and a learner from it like before.
```
data = TabularDataBunch.load_empty(adult)
learn = tabular_learner(data, layers=[200,100])
learn.load('mini_train');
```
And we can predict on a row of dataframe that has the right `cat_names` and `cont_names`.
```
learn.predict(df.iloc[0])
```
| github_jupyter |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.