
code
stringlengths 2.5k
150k
| kind
stringclasses 1
value |
|---|---|
bluebird Coming from Other Languages Coming from Other Languages
===========================
This page describes parallels of using promises in other languages. Promises as a pattern are very common in other languages and knowing what they map to in other languages might help you with grasping them conceptually
* [C#](#c)
* [Scala](#scala)
* [Python](#python)
* [C++](#c)
* [Haskell](#haskell)
* [Java](#java)
* [Android Java](#android-java)
* [Objective-C](#objective-c)
C#
---
A promise is similar to a C# `Task`. They both represent the result of an operation.
A promise's `then` method is similar to a Task's `ContinueWith` method in that both allow attaching a continuation to the promise. Bluebird's [`Promise.coroutine`](api/promise.coroutine) is analogous to C#'s `async/await` syntax.
A `TaskCompletionSource` is analogous to the promise constructor. Although usually promisification is preferred (see the API reference or working with callbacks section).
`Task.FromResult` is analogous to [`Promise.resolve`](api/promise.resolve).
The difference between a `Task` and a promise are that a task might not be started and might require a `.Start` call where a promise always represents an already started operation.
In addition promises are always unwrapped. A promise implicitly has `Task.Unwrap` called on it - that is, promises perform recursive assimilation of promises within them.
See [this question on StackOverflow](http://stackoverflow.com/questions/26136389/how-can-i-realize-pattern-promise-deffered) for more differences.
Scala
------
A bluebird promise is similar to a Scala `Future`. A scala `Promise` is similar to how the promise constructor can be used (previously, to a bluebird Deferred).
Just like a future, a promise represents a value over time. The value can resolve to either a fulfilled (ok completion) or rejected (error completion) state.
Where blocking on a Future in scala is discouraged, in JavaScript it's downright impossible.
In addition promises are always unwrapped. That is, promises perform recursive assimilation of promises within them. You can't have a `Promise<Promise<T>>` where a `Future[Future[T]]` is valid in Scala.
See [this question on StackOverflow](http://stackoverflow.com/questions/22724883/js-deferred-promise-future-compared-to-functional-languages-like-scala) for more differences.
Python
-------
A promise is similar to a Twisted Deferred object. In fact the first JavaScript implementations of promises were based on it. However, the APIs have diverged since. The mental model is still very similar.
A promise is *not* similar to a Python `concurrent.Future` which does not chain actions.
Asyncio coroutines are similar to bluebird coroutines in what they let you do, however bluebird coroutines also enable functional-style chaining.
C++
----
A bluebird promise is similar to a `std::future` and the promise constructor is similar to an `std::promise` although it should rarely be used in practice (see the promisification section).
However, a bluebird promise is more powerful than the current implementation of `std::future` since while chaining has been discussed it is not yet implemented. Promises can be chained together.
Boost futures expose a `.then` method similar to promises and allow this functionality.
Haskell
--------
A promise is a monadic construct with `.then` filling the role of `>>=` (bind). The major difference is that `.then` performs recursive assimilation which acts like a `flatMap` or a map. The type signature of `then` is quote complicated. If we omit the error argument and not throw - it's similar to:
```
then::Promise a -> (a -> (Either (Promise b) b)) -> Promise b
```
That is, you can return either a promise *or a plain value* from a `then` without wrapping it.
Promises perform a role similar to `IO` in that they allow for easy chaining of asynchronous non-blocking operations. `Promise.coroutine` can be seen as similar to `do` notation although in practice it's not an accurate comparison.
Java
-----
A promise is similar to a guava `Future` with `chain` being similar to `then`.
If your'e familiar with Java 8 lambdas, you can think of a promise as a `Future` you can `map` to another future.
Android Java
-------------
Several popular Android libraries use promises - for example the Parse Java API returns `Task`s which are similar to JavaScript promises.
Objective-C
------------
If you're familiar with PromiseKit, it is based on a same specification bluebird is based on so the API should feel familiar right away.
bluebird Warning Explanations Warning Explanations
====================
> This article is partially or completely unfinished. You are welcome to create [pull requests](https://github.com/petkaantonov/bluebird/edit/master/docs/docs/warning-explanations.md) to help completing this article.
* [Warning: .then() only accepts functions](#warning-then-only-accepts-functions)
* [Warning: a promise was rejected with a non-error](#warning-a-promise-was-rejected-with-a-non-error)
* [Warning: a promise was created in a handler but was not returned from it](#warning-a-promise-was-created-in-a-handler-but-was-not-returned-from-it)
Note - in order to get full stack traces with warnings in Node 6.x+ you need to enable to `--trace-warnings` flag which will give you a full stack trace of where the warning is coming from.
Warning: .then() only accepts functions
----------------------------------------
If you see this warning your code is probably not doing what you expect it to, the most common reason is passing the *result* of calling a function to [`.then()`](api/then) instead of the function *itself*:
```
function processImage(image) {
// Code that processes image
}
getImage().then(processImage());
```
The above calls the function `processImage()` *immediately* and passes the result to [`.then()`](api/then) (which is most likely `undefined` - the default return value when a function doesn't return anything).
To fix it, simply pass the function reference to [`.then()`](api/then) as is:
```
getImage().then(processImage)
```
*If you are wondering why this is a warning and not a simple TypeError it is because the due to historic reasons Promises/A+ specification requires that incorrect usage is silently ignored.*
Warning: a promise was rejected with a non-error
-------------------------------------------------
Due to a historic mistake in JavaScript, the `throw` statement is allowed to be used with any value, not just errors, and Promises/A+ choosing to inherit this mistake, it is possible to reject a promise with a value that is not an error.
An error is an object that is a `instanceof Error`. It will at minimum have the properties `.stack` and `.message`, which are an absolute *must* have for any value that is being used in an automatic propagation mechanism, such as exceptions and rejections. This is because errors are usually handled many levels above where they actually originate - the error object must have sufficient metadata about it so that its ultimate handler (possibly many levels above) will have all the information needed for creating a useful high level error report.
Since all objects support having properties you might still wonder why exactly does it have to be an error object and not just any object. In addition to supporting properties, an equally important feature necessary for values that are automatically propagated is the stack trace property (`.stack`). A stack trace allows you easily find where an error originated from as it gives the code's call stack - along with line numbers for reference in code files.
You should heed this warning because rejecting a promise with a non-error makes debugging extremely hard and costly. Additionally, if you reject with simple primitives such as `undefined` (commonly caused by simply calling `reject()`) you cannot handle errors at all because it's impossible to tell from `undefined` what exactly went wrong. All you can tell the user is that "something went wrong" and lose them forever.
Warning: a promise was created in a handler but was not returned from it
-------------------------------------------------------------------------
This usually means that you simply forgot a `return` statement somewhere, which will cause a runaway promise that is not connected to any promise chain.
For example:
```
getUser().then(function(user) {
getUserData(user);
}).then(function(userData) {
// userData is undefined
});
```
Because the result of `getUserData()` is not returned from the first then handler, it becomes a runaway promise that is not awaited for by the second then. The second [`.then()`](api/then) simply gets immediately called with `undefined` (because `undefined` is the default return value when you don't return anything).
To fix it, you need to `return` the promise:
```
getUser().then(function(user) {
return getUserData(user);
}).then(function(userData) {
// userData is the user's data
});
```
If you know what you're doing and don't want to silence all warnings, you can create runaway promises without causing this warning by returning e.g. `null`:
```
getUser().then(function(user) {
// Perform this in the "background" and don't care about its result at all
saveAnalytics(user);
// return a non-undefined value to signal that we didn't forget to return
return null;
});
```
bluebird Error Explanations Error Explanations
==================
* [Error: Promise.promisify called on an object](#error-promise.promisify-called-on-an-object)
* [Error: the promise constructor requires a resolver function](#error-the-promise-constructor-requires-a-resolver-function)
* [Error: the promise constructor cannot be invoked directly](#error-the-promise-constructor-cannot-be-invoked-directly)
* [Error: expecting an array, a promise or a thenable](#error-expecting-an-array-a-promise-or-a-thenable)
* [Error: generatorFunction must be a function](#error-generatorfunction-must-be-a-function)
* [Error: fn must be a function](#error-fn-must-be-a-function)
* [Error: cannot enable long stack traces after promises have been created](#error-cannot-enable-long-stack-traces-after-promises-have-been-created)
* [Error: cannot get fulfillment value of a non-fulfilled promise](#error-cannot-get-fulfillment-value-of-a-non-fulfilled-promise)
* [Error: cannot get rejection reason of a non-rejected promise](#error-cannot-get-rejection-reason-of-a-non-rejected-promise)
* [Error: the target of promisifyAll must be an object or a function](#error-the-target-of-promisifyall-must-be-an-object-or-a-function)
* [Error: circular promise resolution chain](#error-circular-promise-resolution-chain)
* [Error: cannot await properties of a non-object](#error-cannot-await-properties-of-a-non-object)
* [Error: expecting a positive integer](#error-expecting-a-positive-integer)
* [Error: A value was yielded that could not be treated as a promise](#error-a-value-was-yielded-that-could-not-be-treated-as-a-promise)
* [Error: cannot await properties of a non object](#error-cannot-await-properties-of-a-non-object)
* [Error: Cannot promisify an API that has normal methods](#error-cannot-promisify-an-api-that-has-normal-methods)
* [Error: Catch filter must inherit from Error or be a simple predicate function](#error-catch-filter-must-inherit-from-error-or-be-a-simple-predicate-function)
* [Error: No async scheduler available](#error-no-async-scheduler-available)
Error: Promise.promisify called on an object
---------------------------------------------
You got this this error because you've used `Promise.promisify` on an object, for example:
```
var fs = Promise.promisify(require("fs"));
```
Instead, use [`Promise.promisifyAll`](api/promise.promisifyall) :
```
var fs = Promise.promisifyAll(require("fs"));
```
Error: the promise constructor requires a resolver function
------------------------------------------------------------
You got this error because you used `new Promise()` or `new Promise(something)` without passing a function as the parameter.
If you want to wrap an API with a promise manually, the correct syntax is:
```
function wrapWithPromise(parameter) {
return new Promise(function (resolve, reject) {
doSomethingAsync({
error:reject,
success:resolve
});
});
}
```
Please consider reading about [`new Promise`](api/new-promise) and also consider checking out automatic [`promisification`](api/promisification) as well as [`Promise.method`](api/promise.method)
Error: the promise constructor cannot be invoked directly
----------------------------------------------------------
You can get this error for several reasons:
#### 1. You forgot to use `new` when creating a new promise using `new Promise(resolver)` syntax.
This can happen when you tried to do something like:
```
return Promise(function(resolve,reject){
//...
})
```
You can correct this by doing:
```
return new Promise(function(resolve,reject){
//...
})
```
Please consider reading about [`new Promise`](api/new-promise) and also consider checking out automatic [`promisification`](api/promisification) as well as [`Promise.method`](api/promise.method)
#### 2. You are trying to subclass `Promise`
Bluebird does not support extending promises this way. Instead, see [scoped prototypes](features#scoped-prototypes).
Error: expecting an array, a promise or a thenable
---------------------------------------------------
The function being called expects a Promise, but is given something different. There are two main reasons why this may occur.
**1. Working with collections (like arrays) but pass a single, non-collection element instead**
Example:
```
function returnThree(){ return 3;}
Promise.resolve(5).map(returnThree).then(function(val){
console.log("Hello Value!",val);
});
```
The `map` operation is expecting an array here (or a promise on one) and instead gets the number `5`.
```
function returnThree(){ return 3;}
Promise.resolve([5]).map(returnThree).then(function(val){
console.log("Hello Value!",val);
});
```
`map` is given an array with a single element (see `[5]` instead of `5`), so this statement will work (but is bad practice).
**2.`return` is forgotten in a 'fat' arrow / anonymous function call `=>`:**
When debugging or performing a one-time operation on a variable before passing it to a function, a return variable is forgotten.
Example:
```
function nextFunction(something){ return Promise.resolve(something*3); }
myFunction()
.then(result => nextFunction(result)); // We are implicitly returning a Promise
```
Debugging, we want to see the value of result, so we add a `console.log()` line:
```
function nextFunction(something){ return Promise.resolve(something*3); }
myFunction().then(result => {
console.log("Debug:", result);
nextFunction(result)); // The chain is broken! We don't return anything to the .then() call
});
```
As this is an anonymous function call, we need to **return** something, which is not currently happening.
To fix, simply remember to add `return` in front of your promise-complying function:
```
function nextFunction(something){ return Promise.resolve(something*3); }
myFunction().then(result => {
console.log("Debug:", result);
return nextFunction(result)); // The anonymous function returns the function which returns the promise .then() needs
});
```
Error: generatorFunction must be a function
--------------------------------------------
You are getting this error when trying to use [`Promise.coroutine`](api/promise.coroutine) and not passing it a generator function as a parameter. For example:
```
Promise.coroutine(function* () { // Note the *
var data = yield $.get("http://www.example.com");
var moreUrls = data.split("\n");
var contents = [];
for( var i = 0, len = moreUrls.length; i < len; ++i ) {
contents.push(yield $.get(moreUrls[i]));
}
return contents;
});
```
Please refer to the relevant section in the documentation about [`Generators`](api/generators) in order to get usage instructions:
**Note**: Bluebird used to eagerly check for generators which caused problems with transpilers. Because of this, you might get an error similar to `TypeError: Cannot read property 'next' of undefined` if you pass a function instead of a generator function to Bluebird.
[`Promise.coroutine`](api/promise.coroutine) is built to work with generators to form C# like `async/await`
Error: fn must be a function
-----------------------------
You passed a non-function where a function was expected.
Error: cannot enable long stack traces after promises have been created
------------------------------------------------------------------------
You are getting this error because you are enabling long stack traces after a promise has already been created.
When using `longStackTraces` the first line in your code after requiring Bluebird should be:
```
Promise.config({
longStackTraces: true
});
```
See the API page about [`Promise.longStackTraces`](api/promise.longstacktraces)
Error: cannot get fulfillment value of a non-fulfilled promise
---------------------------------------------------------------
You can get this error when you're trying to call `.value` or `.error` when inspecting a promise where the promise has not been fulfilled or rejected yet.
For example:
```
var p = Promise.delay(1000);
p.inspect().value();
```
Consider using [`.isPending()`](api/ispending) [`.isFulfilled()`](api/isfulfilled) and [`.isRejected()`](api/isrejected) in order to inspect the promise for status.
Please consider reading more about [`synchronous inspection`](api/synchronous-inspection)
Error: cannot get rejection reason of a non-rejected promise
-------------------------------------------------------------
You can get this error when you're trying to call `.value` or `.error` when inspecting a promise where the promise has not been fulfilled or rejected yet.
For example:
```
var p = Promise.delay(1000);
p.inspect().value();
```
Consider using [`.isPending()`](api/ispending) [`.isFulfilled()`](api/isfulfilled) and [`.isRejected()`](api/isrejected) in order to inspect the promise for status.
Please consider reading more about [`synchronous inspection`](api/synchronous-inspection)
Error: the target of promisifyAll must be an object or a function
------------------------------------------------------------------
This can happen when you are calling [`Promise.promisifyAll`](api/promise.promisifyall) on a function and invoking it instead of passing it.
In general, the usage of [`Promise.promisifyAll`](api/promise.promisifyall) is along the lines of `var fs = Promise.promisifyAll(require("fs"))`.
Consider reading the section about [`promisification`](api/promisification)
Error: circular promise resolution chain
-----------------------------------------
This usually happens when you have a promise that resolves or rejects with itself.
For example: `var p = Promise.delay(100).then(function(){ return p});` .
In this case, the promise resolves with itself which was is not intended.
This also happens when implementing live-updating models with a `.then` method that indicates when the model is "ready". A promise is a process, it starts and it ends.
Promises do not aim to solve such live updating problems directly. One option would be to use an intermediate promise - for example a `.loaded` property on the model that fulfills with nothing.
resolving it with itself tells it "it is done when it is done"
Error: cannot await properties of a non-object
-----------------------------------------------
The `.props` method expects to receive an object.
For example:
```
Promise.props({
pictures: getPictures(),
comments: getComments(),
tweets: getTweets()
}).then(function(result){
console.log(result.tweets, result.pictures, result.comments);
});
```
This happens when a non object value or a promise that resolves with something that is not an object is being passed instead.
Error: expecting a positive integer
------------------------------------
This happens when you call `.some` passing it a negative value or a non-integer.
One possible cause is using `.indexOf` which returns `-1` when it doesn't find the value being searched for.
Please consider reading the API docs for [`.some`](api/some)
Error: A value was yielded that could not be treated as a promise
------------------------------------------------------------------
You are getting this error because you have tried to `yield` something in a coroutine without a yield handler, for example:
```
var coroutine = Promise.coroutine(function*(){
var bar = yield "Foo";
console.log(bar);
});
```
The solution is to either convert it to a promise by calling `Promise.resolve` on it or `Promise.promisify` if it's a callback:
```
var coroutine = Promise.coroutine(function*(){
var bar = yield Promise.resolve("Foo");
console.log(bar);
});
```
Or to use [`Promise.coroutine.addYieldHandler``](api/promise.coroutine.addyieldhandler) to teach [`Promise.coroutine`](api/promise.coroutine) to accept these sort of values.
Error: cannot await properties of a non object
-----------------------------------------------
The `.props` method expects to receive an object.
For example:
```
Promise.props({
pictures: getPictures(),
comments: getComments(),
tweets: getTweets()
}).then(function(result){
console.log(result.tweets, result.pictures, result.comments);
});
```
This happens when a non object value or a promise that resolves with something that is not an object is being passed instead.
Error: Cannot promisify an API that has normal methods
-------------------------------------------------------
This error indicates you have tried to call [`Promise.promisifyAll`](api/promise.promisifyall) on an object that already has a property with the `Async` suffix:
```
var myApi = { foo: function(cb){ ... }, fooAsync(cb) { ... }
```
This is because Bluebird adds the `Async` suffix to distinguish the original method from the promisified one, so `fooAsync` would have been overridden. In order to avoid this - either rename `fooAsync` before promisifying the API, or call [`Promise.promisify`](api/promise.promisify) manually on select properties.
You may also use the custom suffix option to choose another suffix that doesn't result in conflicts.
If you find this issue in a common library please [open an issue](https://github.com/petkaantonov/bluebird/issues/new).
Error: Catch filter must inherit from Error or be a simple predicate function
------------------------------------------------------------------------------
Bluebird supports typed and predicate [`.catch()`](api/catch) calls]. However in order to use the typed/predicate catch syntax for error handling you must do one of two things.
Pass it a constructor that inherits from `Error`:
```
}).catch(ReferenceError, function(e) { // this is fine
}).catch(Array, function(e) { // arrays don't capture stack traces
```
This is to enable better stack trace support and to have more consistent and logical code.
Alternatively, if you provide it a predicate be sure it's a simple function:
```
}).catch(function(e){ return false; }, function(e) { // this catches nothing
}).catch(function(e){ return e.someProp = 5; }, function(e) { // this is fine
```
Please see the API docs of [`.catch()`](api/catch) on how to use predicate catches.
Error: No async scheduler available
------------------------------------
Async scheduler is a function that takes a callback function and calls the callback function as soon as possible, but asynchronously. For example `setTimeout`.
By default bluebird only tries a few common async schedulers, such as `setTimeout`, `process.nextTick` and `MutationObserver`. However if your JavaScript runtime environment doesn't expose any of these, you will see this error.
You may use [`Promise.setScheduler`](api/promise.setscheduler) to pass a custom scheduler that your environment supports. For example in DukTape:
```
Promise.setScheduler(function(fn){ // fn is what to execute
var timer = uv.new_timer.call({});
uv.timer_start(timer, 0, 0, fn); // add the function as a callback to the timer
});
```
| programming_docs |
bluebird Working with Callbacks Working with Callbacks
======================
This page explains how to interface your code with existing callback APIs and libraries you're using. We'll see that making bluebird work with callback APIs is not only easy - it's also fast.
We'll cover several subjects. If you want to get the tl;dr what you need is likely the [Working with callback APIs using the Node convention](#working-with-callback-apis-using-the-node-convention) section.
First to make sure we're on the same page:
Promises have state, they start as pending and can settle to:
* **fulfilled** meaning that the computation completed successfully.
* **rejected** meaning that the computation failed.
Promise returning functions *should never throw*, they should always successfully return a promise which is rejected in the case of an error. Throwing from a promise returning function will force you to use both a `} catch {` *and* a `.catch`. People using promisified APIs do not expect promises to throw. If you're not sure how async APIs work in JS - please [see this answer](http://stackoverflow.com/questions/14220321/how-to-return-the-response-from-an-asynchronous-call/16825593#16825593) first.
* [Automatic vs. Manual conversion](#automatic-vs.-manual-conversion)
* [Working with callback APIs using the Node convention](#working-with-callback-apis-using-the-node-convention)
* [Working with one time events.](#working-with-one-time-events)
* [Working with delays](#working-with-delays/setTimeout)
* [Working with browser APIs](#working-with-browser-apis)
* [Working with databases](#working-with-databases)
* [More Common Examples](#more-common-examples)
* [Working with any other APIs](#working-with-any-other-apis)
There is also [this more general StackOverflow question](http://stackoverflow.com/questions/22519784/how-do-i-convert-an-existing-callback-api-to-promises) about conversion of callback APIs to promises. If you find anything missing in this guide however, please do open an issue or pull request.
### Automatic vs. Manual conversion
There are two primary methods of converting callback based APIs into promise based ones. You can either manually map the API calls to promise returning functions or you can let the bluebird do it for you. We **strongly** recommend the latter.
Promises provide a lot of really cool and powerful guarantees like throw safety which are hard to provide when manually converting APIs to use promises. Thus, whenever it is possible to use the `Promise.promisify` and `Promise.promisifyAll` methods - we recommend you use them. Not only are they the safest form of conversion - they also use techniques of dynamic recompilation to introduce very little overhead.
### Working with callback APIs using the Node convention
In Node/io.js most APIs follow a convention of ['error-first, single-parameter'](https://gist.github.com/CrabDude/10907185) as such:
```
function getStuff(data, callback) {
...
}
getStuff("dataParam", function(err, data) {
if (!err) {
}
});
```
This APIs are what most core modules in Node/io use and bluebird comes with a fast and efficient way to convert them to promise based APIs through the `Promise.promisify` and `Promise.promisifyAll` function calls.
* [`Promise.promisify`](api/promise.promisify) - converts a *single* callback taking function into a promise returning function. It does not alter the original function and returns the modified version.
* [`Promise.promisifyAll`](api/promise.promisifyall) - takes an *object* full of functions and *converts each function* into the new one with the `Async` suffix (by default). It does not change the original functions but instead adds new ones.
> **Note** - please check the linked docs for more parameters and usage examples.
>
>
Here's an example of `fs.readFile` with or without promises:
```
// callbacks
var fs = require("fs");
fs.readFile("name", "utf8", function(err, data) {
});
```
Promises:
```
var fs = Promise.promisifyAll(require("fs"));
fs.readFileAsync("name", "utf8").then(function(data) {
});
```
Note the new method is suffixed with `Async`, as in `fs.readFileAsync`. It did not replace the `fs.readFile` function. Single functions can also be promisified for example:
```
var request = Promise.promisify(require("request"));
request("foo.bar").then(function(result) {
});
```
> **Note** `Promise.promisify` and `Promise.promisifyAll` use dynamic recompilation for really fast wrappers and thus calling them should be done only once. [`Promise.fromCallback`](api/promise.fromcallback) exists for cases where this is not possible.
>
>
### Working with one time events
Sometimes we want to find out when a single one time event has finished. For example - a stream is done. For this we can use [`new Promise`](api/new-promise). Note that this option should be considered only if [automatic conversion](#working-with-callback-apis-using-the-node-convention) isn't possible.
Note that promises model a *single value through time*, they only resolve *once* - so while they're a good fit for a single event, they are not recommended for multiple event APIs.
For example, let's say you have a window `onload` event you want to bind to. We can use the promise construction and resolve when the window has loaded as such:
```
// onload example, the promise constructor takes a
// 'resolver' function that tells the promise when
// to resolve and fire off its `then` handlers.
var loaded = new Promise(function(resolve, reject) {
window.addEventListener("load", resolve);
});
loaded.then(function() {
// window is loaded here
});
```
Here is another example with an API that lets us know when a connection is ready. The attempt here is imperfect and we'll describe why soon:
```
function connect() {
var connection = myConnector.getConnection(); // Synchronous.
return new Promise(function(resolve, reject) {
connection.on("ready", function() {
// When a connection has been established
// mark the promise as fulfilled.
resolve(connection);
});
connection.on("error", function(e) {
// If it failed connecting, mark it
// as rejected.
reject(e); // e is preferably an `Error`.
});
});
}
```
The problem with the above is that `getConnection` itself might throw for some reason and if it does we'll get a synchronous rejection. An asynchronous operation should always be asynchronous to prevent double guarding and race conditions so it's best to always put the sync parts inside the promise constructor as such:
```
function connect() {
return new Promise(function(resolve, reject) {
// If getConnection throws here instead of getting
// an exception we're getting a rejection thus
// producing a much more consistent API.
var connection = myConnector.getConnection();
connection.on("ready", function() {
// When a connection has been established
// mark the promise as fulfilled.
resolve(connection);
});
connection.on("error", function(e) {
// If it failed connecting, mark it
// as rejected.
reject(e); // e is preferably an `Error`
});
});
}
```
### Working with delays/setTimeout
There is no need to convert timeouts/delays to a bluebird API, bluebird already ships with the [`Promise.delay`](api/promise.delay) function for this use case. Please consult the [`timers`](api/timers) section of the docs on usage and examples.
### Working with browser APIs
Often browser APIs are nonstandard and automatic promisification will fail for them. If you're running into an API that you can't promisify with [`promisify`](api/promisify) and [`promisifyAll`](api/promisifyall) - please consult the [working with other APIs section](#working-with-any-other-apis)
### Working with databases
For resource management in general and databases in particular, bluebird includes the powerful [`Promise.using`](api/promise.using) and disposers system. This is similar to `with` in Python, `using` in C#, try/resource in Java or RAII in C++ in that it lets you handle resource management in an automatic way.
Several examples of databases follow.
> **Note** for more examples please see the [`Promise.using`](api/promise.using) section.
>
>
#### Mongoose/MongoDB
Mongoose works with persistent connections and the driver takes care of reconnections/disposals. For this reason using `using` with it isn't required - instead connect on server startup and use promisification to expose promises.
Note that Mongoose already ships with promise support but the promises it offers are significantly slower and don't report unhandled rejections so it is recommended to use automatic promisification with it anyway:
```
var Mongoose = Promise.promisifyAll(require("mongoose"));
```
#### Sequelize
Sequelize already uses Bluebird promises internally and has promise returning APIs. Use those.
#### RethinkDB
Rethink already uses Bluebird promises internally and has promise returning APIs. Use those.
#### Bookshelf
Bookshelf already uses Bluebird promises internally and has promise returning APIs. Use those.
#### PostgreSQL
Here is how to create a disposer for the PostgreSQL driver:
```
var pg = require("pg");
// Uncomment if pg has not been properly promisified yet.
//var Promise = require("bluebird");
//Promise.promisifyAll(pg, {
// filter: function(methodName) {
// return methodName === "connect"
// },
// multiArgs: true
//});
// Promisify rest of pg normally.
//Promise.promisifyAll(pg);
function getSqlConnection(connectionString) {
var close;
return pg.connectAsync(connectionString).spread(function(client, done) {
close = done;
return client;
}).disposer(function() {
if (close) close();
});
}
module.exports = getSqlConnection;
```
Which would allow you to use:
```
var using = Promise.using;
using(getSqlConnection(), function(conn) {
// use connection here and _return the promise_
}).then(function(result) {
// connection already disposed here
});
```
It's also possible to use a disposer pattern (but not actual disposers) for transaction management:
```
function withTransaction(fn) {
return Promise.using(pool.acquireConnection(), function(connection) {
var tx = connection.beginTransaction()
return Promise
.try(fn, tx)
.then(function(res) { return connection.commit().thenReturn(res) },
function(err) {
return connection.rollback()
.catch(function(e) {/* maybe add the rollback error to err */})
.thenThrow(err);
});
});
}
exports.withTransaction = withTransaction;
```
Which would let you do:
```
withTransaction(tx => {
return tx.queryAsync(...).then(function() {
return tx.queryAsync(...)
}).then(function() {
return tx.queryAsync(...)
});
});
```
#### MySQL
Here is how to create a disposer for the MySQL driver:
```
var mysql = require("mysql");
// Uncomment if mysql has not been properly promisified yet
// var Promise = require("bluebird");
// Promise.promisifyAll(mysql);
// Promise.promisifyAll(require("mysql/lib/Connection").prototype);
// Promise.promisifyAll(require("mysql/lib/Pool").prototype);
var pool = mysql.createPool({
connectionLimit: 10,
host: 'example.org',
user: 'bob',
password: 'secret'
});
function getSqlConnection() {
return pool.getConnectionAsync().disposer(function(connection) {
connection.release();
});
}
module.exports = getSqlConnection;
```
The usage pattern is similar to the PostgreSQL example above. You can also use a disposer pattern (but not an actual .disposer). See the PostgreSQL example above for instructions.
### More common examples
Some examples of the above practice applied to some popular libraries:
```
// The most popular redis module
var Promise = require("bluebird");
Promise.promisifyAll(require("redis"));
```
```
// The most popular mongodb module
var Promise = require("bluebird");
Promise.promisifyAll(require("mongodb"));
```
```
// The most popular mysql module
var Promise = require("bluebird");
// Note that the library's classes are not properties of the main export
// so we require and promisifyAll them manually
Promise.promisifyAll(require("mysql/lib/Connection").prototype);
Promise.promisifyAll(require("mysql/lib/Pool").prototype);
```
```
// Mongoose
var Promise = require("bluebird");
Promise.promisifyAll(require("mongoose"));
```
```
// Request
var Promise = require("bluebird");
Promise.promisifyAll(require("request"));
// Use request.getAsync(...) not request(..), it will not return a promise
```
```
// mkdir
var Promise = require("bluebird");
Promise.promisifyAll(require("mkdirp"));
// Use mkdirp.mkdirpAsync not mkdirp(..), it will not return a promise
```
```
// winston
var Promise = require("bluebird");
Promise.promisifyAll(require("winston"));
```
```
// rimraf
var Promise = require("bluebird");
// The module isn't promisified but the function returned is
var rimrafAsync = Promise.promisify(require("rimraf"));
```
```
// xml2js
var Promise = require("bluebird");
Promise.promisifyAll(require("xml2js"));
```
```
// jsdom
var Promise = require("bluebird");
Promise.promisifyAll(require("jsdom"));
```
```
// fs-extra
var Promise = require("bluebird");
Promise.promisifyAll(require("fs-extra"));
```
```
// prompt
var Promise = require("bluebird");
Promise.promisifyAll(require("prompt"));
```
```
// Nodemailer
var Promise = require("bluebird");
Promise.promisifyAll(require("nodemailer"));
```
```
// ncp
var Promise = require("bluebird");
Promise.promisifyAll(require("ncp"));
```
```
// pg
var Promise = require("bluebird");
Promise.promisifyAll(require("pg"));
```
In all of the above cases the library made its classes available in one way or another. If this is not the case, you can still promisify by creating a throwaway instance:
```
var ParanoidLib = require("...");
var throwAwayInstance = ParanoidLib.createInstance();
Promise.promisifyAll(Object.getPrototypeOf(throwAwayInstance));
// Like before, from this point on, all new instances + even the throwAwayInstance suddenly support promises
```
### Working with any other APIs
Sometimes you have to work with APIs that are inconsistent and do not follow a common convention.
> **Note** Promise returning function should never throw
>
>
For example, something like:
```
function getUserData(userId, onLoad, onFail) { ...
```
We can use the promise constructor to convert it to a promise returning function:
```
function getUserDataAsync(userId) {
return new Promise(function(resolve, reject) {
// Put all your code here, this section is throw-safe.
getUserData(userId, resolve, reject);
});
}
```
bluebird What About Generators? What About Generators?
======================
There is an [excellent article](https://www.promisejs.org/generators/) on promisejs.org detailing how to combine promises with generators to achieve much cleaner code. Instead of the `async` function the article proposes, you can use [`Promise.coroutine`](api/promise.coroutine).
> This article is partially or completely unfinished. You are welcome to create [pull requests](https://github.com/petkaantonov/bluebird/edit/master/docs/docs/what-about-generators.md) to help completing this article.
bluebird Coming from Other Libraries Coming from Other Libraries
===========================
This page is a reference for migrating to bluebird from other flow control or promise libraries. See [installation](install) on how to use bluebird in your environment.
* [Coming from native promises](#coming-from-native-promises)
* [Coming from jQuery deferreds](#coming-from-jquery-deferreds)
* [Coming from `async` module](#coming-from-async-module)
* [Coming from Q](#coming-from-q)
* [Coming from co/koa](#coming-from-co)
* [Coming from highland, RxJS or BaconJS](#coming-from-highland)
Coming from native promises
----------------------------
Bluebird promises are a drop-in replacement for native promises except for subclassing. Additionally you might want to replace usages of the often incorrectly used [`Promise.race`](api/promise.race) with bluebird's [`Promise.any`](api/promise.any) which does what is usually mistakenly expected from [`Promise.race`](api/promise.race). For maximum compatibility, bluebird does provide [`Promise.race`](api/promise.race) with ES6 semantics.
You can also refactor some looping patterns to a more natural form that would [leak memory when using native promises](https://github.com/promises-aplus/promises-spec/issues/179).
Coming from jQuery deferreds
-----------------------------
Bluebird treats jQuery deferreds and promises interchangeably. Wherever you can take a promise or return a promise, you can take or return a jQuery deferred instead and it works the same.
For instance, there is no need to write something like this:
```
var firstRequest = new Promise(function(resolve, reject) {
$.ajax({...}).done(resolve).fail(reject);
});
var secondRequest = new Promise(function(resolve, reject) {
$.ajax({...}).done(resolve).fail(reject);
});
Promise.all([firstRequest, secondRequest]).then(function() {
// ...
});
```
Since [`Promise.all`](api/promise.all) takes promises, it must also take jQuery deferreds, so the above can be shortened to:
```
var firstRequest = $.ajax({...});
var secondRequest = $.ajax({...});
Promise.all([firstRequest, secondRequest]).then(function() {
// ...
});
```
That said, if you have code written using jQuery deferred methods, such as `.then`, `.done` and so on, you cannot drop-in replace the jQuery deferred with a bluebird promise in that code. Despite having the same names, jQuery deferred methods have different semantics than bluebird promise methods. These differences are due to the completely different goals of the implementations. Bluebird is [an internal DSL](http://en.wikipedia.org/wiki/Domain-specific_language) for the domain of asynchronous control flow while jQuery deferreds are a callback aggregator utility ("glorified event emitters").
If you do have some code using jQuery deferred methods extensively try to see if some of these jQuery deferred patterns and their replacements can be applied:
```
// jQuery
$.when.apply($, someArray).then(...)
// bluebird
Promise.all(someArray).then(...)
```
```
// jQuery
var data = [1,2,3,4];
var processItemsDeferred = [];
for(var i = 0; i < data.length; i++) {
processItemsDeferred.push(processItem(data[i]));
}
$.when.apply($, processItemsDeferred).then(everythingDone);
// bluebird
var data = [1,2,3,4];
Promise.map(data, function(item) {
return processItem(item);
}).then(everythingDone);
```
```
// jQuery
var d = $.Deferred();
d.resolve("value");
// bluebird
var d = Promise.resolve("value");
```
```
// jQuery
var d = $.Deferred();
d.reject(new Error("error"));
// bluebird
var d = Promise.reject(new Error("error"));
```
```
// jQuery
var clicked = $.Deferred();
$("body").one("click", function(e) {
clicked.resolve(e);
});
// bluebird
var clicked = new Promise(function(resolve) {
$("body").one("click", resolve);
});
```
```
// jQuery
.always(removeSpinner);
// bluebird
.finally(removeSpinner);
```
Coming from `async` module
---------------------------
When working with promises the philosophy is basically a complete opposite than when using `async`. Async provides a huge bag of uncomposable helper functions that work at a very low level of abstraction. When using promises you can get the utility otherwise provided by uncountable amount of inflexible helper functions by just combining and composing a few existing functions and concepts.
That means when you have a problem there probably isn't an existing function tailored exactly to that problem but instead you can just combine the existing utilities to arrive at a solution. The upside of this is that you don't need to come up with all these different functions to solve problems that are not that different from each other. The most important thing to do when migrating from async to bluebird is this profound shift in philosophy.
This section lists the most common async module replacements.
### `async.waterfall`
If the waterfall elements are static, you can just replace it with a normal promise chain. For waterfalls with dynamic steps, use [`Promise.each`](api/promise.each). Multiple arguments can be ferried in an array.
Implementing the example from [async homepage](https://github.com/caolan/async#waterfalltasks-callback)
```
async.waterfall([
function(callback) {
callback(null, 'one', 'two');
},
function(arg1, arg2, callback) {
// arg1 now equals 'one' and arg2 now equals 'two'
callback(null, 'three');
},
function(arg1, callback) {
// arg1 now equals 'three'
callback(null, 'done');
}
], function (err, result) {
// result now equals 'done'
});
```
Since the array passed to waterfall is static (always the same 3 functions) a plain old promise chain is used:
```
Promise.resolve(['one', 'two']).spread(function(arg1, arg2) {
// arg1 now equals 'one' and arg2 now equals 'two'
return 'three';
}).then(function(arg1) {
// arg1 now equals 'three'
return 'done';
}).then(function(result) {
// result now equals 'done'
});
```
If destructuring parameters are supported, `.spread(function(arg1, arg2) {})` can be replaced with `.then(function([arg1, arg2]){})`.
### `async.series`
Using [`Promise.mapSeries`](api/promise.mapseries) to implement the example from [async homepage](https://github.com/caolan/async#seriestasks-callback):
```
async.series([
function(callback){
setTimeout(function(){
callback(null, 1);
}, 200);
},
function(callback){
setTimeout(function(){
callback(null, 2);
}, 100);
}
],
// optional callback
function(err, results){
// results is now equal to [1, 2]
});
```
```
Promise.mapSeries([{timeout: 200, value: 1},
{timeout: 100, value: 2}], function(item) {
return Promise.delay(item.timeout, item.value);
}).then(function(results) {
// results is now equal to [1, 2]
});
```
### `async.parallel`
Using [`Promise.all`](api/promise.all) to implement the example from [async homepage](https://github.com/caolan/async#parallel):
```
async.parallel([
function(callback){
setTimeout(function(){
callback(null, 'one');
}, 200);
},
function(callback){
setTimeout(function(){
callback(null, 'two');
}, 100);
}
],
// optional callback
function(err, results){
// the results array will equal ['one','two'] even though
// the second function had a shorter timeout.
});
```
```
Promise.all([Promise.delay(200, 'one'),
Promise.delay(100, 'two')]).then(function(results) {
// the results array will equal ['one','two'] even though
// the second function had a shorter timeout.
});
```
### `async.mapSeries`
Using [`Promise.each`](api/promise.each) to implement the example from [async homepage](https://github.com/caolan/async#maparr-iterator-callback):
```
var fs = require('fs');
async.mapSeries(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
```
```
var fs = Promise.promisifyAll(require('fs'));
Promise.each(['file1','file2','file3'], function(fileName, index, length) {
return fs.statAsync(fileName);
}).then(function(results) {
// results is now an array of stats for each file
});
```
### `async.map`
Using [`Promise.map`](api/promise.map) to implement the example from [async homepage](https://github.com/caolan/async#maparr-iterator-callback):
```
var fs = require('fs');
async.map(['file1','file2','file3'], fs.stat, function(err, results){
// results is now an array of stats for each file
});
```
```
var fs = Promise.promisifyAll(require('fs'));
Promise.map(['file1','file2','file3'], function(fileName, index, length) {
return fs.statAsync(fileName);
}).then(function(results) {
// results is now an array of stats for each file
});
```
### `async.whilst`
Using recursion to implement the example from [async homepage](https://github.com/caolan/async#whilsttest-fn-callback):
```
var count = 0;
async.whilst(
function () { return count < 5; },
function (callback) {
count++;
setTimeout(callback, 1000);
},
function (err) {
// 5 seconds have passed
}
);
```
```
(function loop() {
if (count < 5) {
count++;
return Promise.delay(1000).then(loop);
}
return Promise.resolve();
})().then(function() {
// 5 seconds have passed
});
```
Be warned that the above example implementations are only superficially equivalent. Callbacks, even with the help of async, require too much boilerplate code to provide the same guarantees as promises.
Coming from Q
--------------
Q and bluebird share a lot of common methods that nevertheless have different names:
* `Q(...)` -> [`Promise.resolve()`](api/promise.resolve)
* `.fail()` -> [`.catch()`](api/catch) or `.caught()`
* `.fin()` -> [`.finally()`](api/finally) or `.lastly()`
* `Q.fcall()` -> [`Promise.try`](api/promise.try) or `Promise.attempt()`
* `.thenResolve()` -> [`.return()`](api/return) or `.thenReturn()`
* `.thenReject()` -> [`.throw()`](api/throw) or `thenThrow()`
Coming from co/koa
-------------------
In recent versions generator libraries started abandoning old ideas of special tokens passed to callbacks and started using promises for what's being yielded.
Bluebird's [`Promise.coroutine`](api/promise.coroutine) is a superset of the `co` library, being more extensible as well as supporting cancellation (in environments where [`Generator#return`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Generator/return) is implemented).
Coming from highland, RxJS or BaconJS
--------------------------------------
Stream libraries tend to serve a different purpose than promise libraries. Unlike promise libraries streams can represent multiple values.
Check out the benchmarks section for examples of transitioning an API from Bacon/Rx to promises.
| programming_docs |
bluebird Getting Started Getting Started
===============
> This article is partially or completely unfinished. You are welcome to create [pull requests](https://github.com/petkaantonov/bluebird/edit/master/docs/docs/getting-started.md) to help completing this article.
Node.js
--------
```
npm install bluebird
```
Then:
```
var Promise = require("bluebird");
```
Alternatively in ES6
```
import * as Promise from "bluebird";
```
If that ES6 import [doesn't work](https://github.com/petkaantonov/bluebird/pull/1594)
```
import {Promise} from "bluebird";
```
Browsers
---------
(See also [Installation](install).)
There are many ways to use bluebird in browsers:
* Direct downloads
+ Full build [bluebird.js](https://cdn.jsdelivr.net/bluebird/latest/bluebird.js)
+ Full build minified [bluebird.min.js](https://cdn.jsdelivr.net/bluebird/latest/bluebird.min.js)
+ Core build [bluebird.core.js](https://cdn.jsdelivr.net/bluebird/latest/bluebird.core.js)
+ Core build minified [bluebird.core.min.js](https://cdn.jsdelivr.net/bluebird/latest/bluebird.core.min.js)
* You may use browserify on the main export
* You may use the [bower](http://bower.io) package.
When using script tags the global variables `Promise` and `P` (alias for `Promise`) become available. Bluebird runs on a wide variety of browsers including older versions. We'd like to thank BrowserStack for giving us a free account which helps us test that.
bluebird Beginner's Guide Beginner's Guide
================
> This article is partially or completely unfinished. You are welcome to create [pull requests](https://github.com/petkaantonov/bluebird/edit/master/docs/docs/beginners-guide.md) to help completing this article.
bluebird New in bluebird 3.0 New in bluebird 3.0
===================
Cancellation overhaul
----------------------
Cancellation has been redesigned for bluebird 3.0. Any code that relies on 2.x cancellation semantics won't work in 3.0 or later. See [`Cancellation`](api/cancellation) for more information.
Promisification API changes
----------------------------
Both promisification ([`Promise.promisify`](api/promise.promisify) and [`Promise.promisifyAll`](api/promise.promisifyall)) methods and [`Promise.fromCallback`](api/promise.fromcallback) now by default ignore multiple arguments passed to the callback adapter and instead only the first argument is used to resolve the promise. The behavior in 2.x is to construct an array of the arguments and resolve the promise with it when more than one argument is passed to the callback adapter. The problems with this approach and reasons for the change are discussed in [`#307`](https://github.com/petkaantonov/bluebird/issues/307).
[`Promise.promisify`](api/promise.promisify)'s second argument is now an options object, so any code using the second argument needs to change:
```
// 2.x
Promise.promisify(fn, ctx);
// 3.0
Promise.promisify(fn, {context: ctx});
```
Both promisification ([`Promise.promisify`](api/promise.promisify) and [`Promise.promisifyAll`](api/promise.promisifyall)) methods and [`Promise.fromCallback`](api/promise.fromcallback) all take a new boolean option `multiArgs` which defaults to `false`. Enabling this option will make the adapter callback *always* construct an array of the passed arguments regardless of amount of arguments. This can be used to reliably get access to all arguments rather than just the first one.
Collection method changes
--------------------------
All collection methods now support objects that implement [ES6's *iterable*](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols) protocol along with regular arrays.
[`Promise.props`](api/promise.props) and [`.props`](api/props) now support [ES6 `Map`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) objects along with normal objects. Actual `Map` objects are only considered for their entries in the map instead of both entries and properties.
Warnings
---------
Warnings have been added to report usages which are very likely to be programmer errors. See [`Promise.config`](api/promise.config) for how to enable warnings. See [Warning Explanations](warning-explanations) for list of the warnings and their explanations.
Feature additions
------------------
* [`.catch()`](api/catch) now supports an object predicate as a filter: `.catch({code: 'ENOENT'}, e => ...)`.
* Added [`.suppressUnhandledRejections()`](api/suppressunhandledrejections).
* Added [`.catchThrow()`](api/catchthrow).
* Added [`.catchReturn()`](api/catchreturn).
* Added [`Promise.mapSeries()`](api/promise.mapseries) and [`.mapSeries()`](api/mapseries)
Deprecations
-------------
* `Promise.settle` has been deprecated. Use [`.reflect`](api/reflect) instead.
* `Promise.spawn` has been deprecated. Use [`Promise.coroutine`](api/promise.coroutine) instead.
* [`Promise.try`](api/promise.try)'s `ctx` and `arg` arguments have been deprecated.
* `.nodeify` is now better known as [`.asCallback`](api/ascallback)
* `.fromNode` is now better known as [`Promise.fromCallback`](api/promise.fromcallback)
Summary of breaking changes
----------------------------
* Promisifier APIs.
* Cancellation redesign.
* Promise progression has been completely removed.
* [`.spread`](api/spread)'s second argument has been removed.
* [`.done`](api/done) causes an irrecoverable fatal error in Node.js environments now. See [`#471`](https://github.com/petkaantonov/bluebird/issues/471) for rationale.
* Errors created with [`Promise.reject`](api/promise.reject) or `reject` callback of [`new Promise`](api/new-promise) are no longer marked as [`OperationalError`](api/operationalerror)s.
3.0.1 update
-------------
Note that the 3.0.1 update is strictly speaking backward-incompatible with 3.0.0. Version 3.0.0 changed the previous behavior of the `.each` method and made it work the same as the new `.mapSeries` - 3.0.1 unrolls this change by reverting to the `.tap`-like behavior found in 2.x However, this would only affect users who updated to 3.0.0 during the short time that it wasn't deprecated and started relying on the new `.each` behavior. This seems unlikely, and therefore the major version was not changed.
bluebird Anti-patterns Anti-patterns
=============
This page will contain common promise anti-patterns that are exercised in the wild.
* [The explicit construction anti-pattern](#the-explicit-construction-anti-pattern)
* [The `.then(success, fail)` anti-pattern](#the-.then)
The Explicit Construction Anti-Pattern
---------------------------------------
This is the most common anti-pattern. It is easy to fall into this when you don't really understand promises and think of them as glorified event emitters or callback utility. It's also sometimes called the promise constructor anti-pattern. Let's recap: promises are about making asynchronous code retain most of the lost properties of synchronous code such as flat indentation and one exception channel. This pattern is also called the deferred anti-pattern.
In the explicit construction anti-pattern, promise objects are created for no reason, complicating code.
First example is creating deferred object when you already have a promise or thenable:
```
//Code copyright by Twisternha http://stackoverflow.com/a/19486699/995876 CC BY-SA 2.5
myApp.factory('Configurations', function (Restangular, MotorRestangular, $q) {
var getConfigurations = function () {
var deferred = $q.defer();
MotorRestangular.all('Motors').getList().then(function (Motors) {
//Group by Config
var g = _.groupBy(Motors, 'configuration');
//Map values
var mapped = _.map(g, function (m) {
return {
id: m[0].configuration,
configuration: m[0].configuration,
sizes: _.map(m, function (a) {
return a.sizeMm
})
}
});
deferred.resolve(mapped);
});
return deferred.promise;
};
return {
config: getConfigurations()
}
});
```
This superfluous wrapping is also dangerous, any kind of errors and rejections are swallowed and not propagated to the caller of this function.
Instead of using the Deferred anti-pattern, the code should simply return the promise it already has and propagate values using `return`:
```
myApp.factory('Configurations', function (Restangular, MotorRestangular, $q) {
var getConfigurations = function () {
//Just return the promise we already have!
return MotorRestangular.all('Motors').getList().then(function (Motors) {
//Group by Cofig
var g = _.groupBy(Motors, 'configuration');
//Return the mapped array as the value of this promise
return _.map(g, function (m) {
return {
id: m[0].configuration,
configuration: m[0].configuration,
sizes: _.map(m, function (a) {
return a.sizeMm
})
}
});
});
};
return {
config: getConfigurations()
}
});
```
Not only is the code shorter but more importantly, if there is any error it will propagate properly to the final consumer.
Second example is creating a function that does nothing but manually wrap a callback API and doing a poor job at that:
```
function applicationFunction(arg1) {
return new Promise(function(resolve, reject){ //Or Q.defer() in Q
libraryFunction(arg1, function (err, value) {
if (err) {
reject(err);
} else {
resolve(value);
}
});
}
```
This is reinventing the square wheel because any callback API wrapping can and should be done immediately using the promise library's promisification methods:
```
var applicationFunction = Promise.promisify(libraryFunction);
```
The generic promisification is likely to be faster because it can use internals directly but also handles edge cases like `libraryFunction` throwing synchronously or using multiple success values.
**So when should deferred be used?**
Well simply, when you have to.
You might have to use a deferred object when wrapping a callback API that doesn't follow the standard convention. Like `setTimeout`:
```
//setTimeout that returns a promise
function delay(ms) {
var deferred = Promise.defer(); // warning, defer is deprecated, use the promise constructor
setTimeout(function(){
deferred.fulfill();
}, ms);
return deferred.promise;
}
```
Such wrappers should be rare, if they're common for the reason that the promise library cannot generically promisify them, you should file an issue.
If you cannot do static promisification (promisify and promisifyAll perform too slowly to use at runtime), you may use [`Promise.fromCallback`](api/promise.fromcallback).
Also see [this StackOverflow question](http://stackoverflow.com/questions/23803743/what-is-the-deferred-antipattern-and-how-do-i-avoid-it) for more examples and a debate around it.
The `.then(success, fail)` anti-pattern
----------------------------------------
*Almost* a sure sign of using promises as glorified callbacks. Instead of `doThat(function(err, success))` you do `doThat().then(success, err)` and rationalize to yourself that at least the code is "less coupled" or something.
The `.then` signature is mostly about interop, there is *almost* never a reason to use `.then(success, fail)` in application code. It is even awkward to express it in the sync parallel:
```
var t0;
try {
t0 = doThat();
}
catch(e) {
}
//deal with t0 here and waste the try-catch
var stuff = JSON.parse(t0);
```
It is more likely that you would write this instead in the sync world:
```
try {
var stuff = JSON.parse(doThat());
}
catch(e) {
}
```
So please write the same when using promises too:
```
doThat()
.then(function(v) {
return JSON.parse(v);
})
.catch(function(e) {
});
```
`.catch` is specified for built-in Javascript promises and is "sugar" for `.then(null, function(){})`. Since the way errors work in promises is almost the entire point (and the only thing jQuery never got right, even if it used `.pipe` as a `.then`), I really hope the implementation you are using provides this method for readability.
bluebird Features Features
========
> This article is partially or completely unfinished. You are welcome to create [pull requests](https://github.com/petkaantonov/bluebird/edit/master/docs/docs/features.md) to help completing this article.
* [Synchronous inspection](#synchronous-inspection)
* [Concurrency coordination](#concurrency-coordination)
* [Promisification on steroids](#promisification-on-steroids)
* [Debuggability and error handling](#debuggability-and-error-handling)
* [Resource management](#resource-management)
* [Cancellation and timeouts](#cancellation-and-timeouts)
* [Scoped prototypes](#scoped-prototypes)
* [Promise monitoring](#promise-monitoring)
* [Async/Await](#async-await)
Synchronous inspection
-----------------------
Synchronous inspection allows you to retrieve the fulfillment value of an already fulfilled promise or the rejection reason of an already rejected promise synchronously.
Often it is known in certain code paths that a promise is guaranteed to be fulfilled at that point - it would then be extremely inconvenient to use [`.then`](api/then) to get at the promise's value as the callback is always called asynchronously.
See the API on [`synchronous inspection`](api/synchronous-inspection) for more information.
Concurrency coordination
-------------------------
Through the use of [`.each`](api/each) and [`.map`](api/map) doing things just at the right concurrency level becomes a breeze.
Promisification on steroids
----------------------------
Promisification means converting an existing promise-unaware API to a promise-returning API.
The usual way to use promises in node is to [`Promise.promisifyAll`](api/promise.promisifyall) some API and start exclusively calling promise returning versions of the APIs methods. E.g.
```
var fs = require("fs");
Promise.promisifyAll(fs);
// Now you can use fs as if it was designed to use bluebird promises from the beginning
fs.readFileAsync("file.js", "utf8").then(...)
```
Note that the above is an exceptional case because `fs` is a singleton instance. Most libraries can be promisified by requiring the library's classes (constructor functions) and calling promisifyAll on the `.prototype`. This only needs to be done once in the entire application's lifetime and after that you may use the library's methods exactly as they are documented, except by appending the `"Async"`-suffix to method calls and using the promise interface instead of the callback interface.
As a notable exception in `fs`, `fs.existsAsync` doesn't work as expected, because Node's `fs.exists` doesn't call back with error as first argument. More at [`#418`](https://github.com/petkaantonov/bluebird/issues/418). One possible workaround is using `fs.statAsync`.
Some examples of the above practice applied to some popular libraries:
```
// The most popular redis module
var Promise = require("bluebird");
Promise.promisifyAll(require("redis"));
```
```
// The most popular mongodb module
var Promise = require("bluebird");
Promise.promisifyAll(require("mongodb"));
```
```
// The most popular mysql module
var Promise = require("bluebird");
// Note that the library's classes are not properties of the main export
// so we require and promisifyAll them manually
Promise.promisifyAll(require("mysql/lib/Connection").prototype);
Promise.promisifyAll(require("mysql/lib/Pool").prototype);
```
```
// Mongoose
var Promise = require("bluebird");
Promise.promisifyAll(require("mongoose"));
```
```
// Request
var Promise = require("bluebird");
Promise.promisifyAll(require("request"));
// Use request.getAsync(...) not request(..), it will not return a promise
```
```
// mkdir
var Promise = require("bluebird");
Promise.promisifyAll(require("mkdirp"));
// Use mkdirp.mkdirpAsync not mkdirp(..), it will not return a promise
```
```
// winston
var Promise = require("bluebird");
Promise.promisifyAll(require("winston"));
```
```
// rimraf
var Promise = require("bluebird");
// The module isn't promisified but the function returned is
var rimrafAsync = Promise.promisify(require("rimraf"));
```
```
// xml2js
var Promise = require("bluebird");
Promise.promisifyAll(require("xml2js"));
```
```
// jsdom
var Promise = require("bluebird");
Promise.promisifyAll(require("jsdom"));
```
```
// fs-extra
var Promise = require("bluebird");
Promise.promisifyAll(require("fs-extra"));
```
```
// prompt
var Promise = require("bluebird");
Promise.promisifyAll(require("prompt"));
```
```
// Nodemailer
var Promise = require("bluebird");
Promise.promisifyAll(require("nodemailer"));
```
```
// ncp
var Promise = require("bluebird");
Promise.promisifyAll(require("ncp"));
```
```
// pg
var Promise = require("bluebird");
Promise.promisifyAll(require("pg"));
```
In all of the above cases the library made its classes available in one way or another. If this is not the case, you can still promisify by creating a throwaway instance:
```
var ParanoidLib = require("...");
var throwAwayInstance = ParanoidLib.createInstance();
Promise.promisifyAll(Object.getPrototypeOf(throwAwayInstance));
// Like before, from this point on, all new instances + even the throwAwayInstance suddenly support promises
```
See also [`Promise.promisifyAll`](api/promise.promisifyall).
Debuggability and error handling
---------------------------------
* [Surfacing unhandled errors](#surfacing-unhandled-errors)
* [Long stack traces](#long-stack-traces)
* [Error pattern matching](#error-pattern-matching)
* [Warnings](#warnings)
### Surfacing unhandled errors
The default approach of bluebird is to immediately log the stack trace when there is an unhandled rejection. This is similar to how uncaught exceptions cause the stack trace to be logged so that you have something to work with when something is not working as expected.
However because it is possible to handle a rejected promise at any time in the indeterminate future, some programming patterns will result in false positives. Because such programming patterns are not necessary and can always be refactored to never cause false positives, we recommend doing that to keep debugging as easy as possible . You may however feel differently so bluebird provides hooks to implement more complex failure policies.
Such policies could include:
* Logging after the promise became GCd (requires a native node.js module)
* Showing a live list of rejected promises
* Using no hooks and using [`.done`](api/done) to manually to mark end points where rejections will not be handled
* Swallowing all errors (challenge your debugging skills)
* ...
See [global rejection events](api/error-management-configuration#global-rejection-events) to learn more about the hooks.
### Long stack traces
Normally stack traces don't go beyond asynchronous boundaries so their utility is greatly reduced in asynchronous code:
```
setTimeout(function() {
setTimeout(function() {
setTimeout(function() {
a.b.c;
}, 1);
}, 1)
}, 1)
```
```
ReferenceError: a is not defined
at null._onTimeout file.js:4:13
at Timer.listOnTimeout (timers.js:90:15)
```
Of course you could use hacks like monkey patching or domains but these break down when something can't be monkey patched or new apis are introduced.
Since in bluebird [`promisification`](api/promisification) is made trivial, you can get long stack traces all the time:
```
var Promise = require("bluebird");
Promise.delay(1)
.delay(1)
.delay(1).then(function() {
a.b.c;
});
```
```
Unhandled rejection ReferenceError: a is not defined
at file.js:6:9
at processImmediate [as _immediateCallback] (timers.js:321:17)
From previous event:
at Object.<anonymous> (file.js:5:15)
at Module._compile (module.js:446:26)
at Object.Module._extensions..js (module.js:464:10)
at Module.load (module.js:341:32)
at Function.Module._load (module.js:296:12)
at Function.Module.runMain (module.js:487:10)
at startup (node.js:111:16)
at node.js:799:3
```
And there is more. Bluebird's long stack traces additionally eliminate cycles, don't leak memory, are not limited to a certain amount of asynchronous boundaries and are fast enough for most applications to be used in production. All these are non-trivial problems that haunt straight-forward long stack trace implementations.
See [installation](install) on how to enable long stack traces in your environment.
### Error pattern matching
Perhaps the greatest thing about promises is that it unifies all error handling into one mechanism where errors propagate automatically and have to be explicitly ignored.
### Warnings
Promises can have a steep learning curve and it doesn't help that promise standards go out of their way to make it even harder. Bluebird works around the limitations by providing warnings where the standards disallow throwing errors when incorrect usage is detected. See [Warning Explanations](warning-explanations) for the possible warnings that bluebird covers.
See [installation](install) on how to enable warnings in your environment.
Note - in order to get full stack traces with warnings in Node 6.x+ you need to enable to `--trace-warnings` flag which will give you a full stack trace of where the warning is coming from.
### Promise monitoring
This feature enables subscription to promise lifecycle events via standard global events mechanisms in browsers and Node.js.
The following lifecycle events are available:
* `"promiseCreated"` - Fired when a promise is created through the constructor.
* `"promiseChained"` - Fired when a promise is created through chaining (e.g. [`.then`](api/then)).
* `"promiseFulfilled"` - Fired when a promise is fulfilled.
* `"promiseRejected"` - Fired when a promise is rejected.
* `"promiseResolved"` - Fired when a promise adopts another's state.
* `"promiseCancelled"` - Fired when a promise is cancelled.
This feature has to be explicitly enabled by calling [`Promise.config`](api/promise.config) with `monitoring: true`.
The actual subscription API depends on the environment.
1. In Node.js, use `process.on`:
```
// Note the event name is in camelCase, as per Node.js convention.
process.on("promiseChained", function(promise, child) {
// promise - The parent promise the child was chained from
// child - The created child promise.
});
```
2. In modern browsers use `window.addEventListener` (window context) or `self.addEventListener()` (web worker or window context) method:
```
// Note the event names are in mashedtogetherlowercase, as per DOM convention.
self.addEventListener("promisechained", function(event) {
// event.details.promise - The parent promise the child was chained from
// event.details.child - The created child promise.
});
```
3. In legacy browsers use `window.oneventname = handlerFunction;`.
```
// Note the event names are in mashedtogetherlowercase, as per legacy convention.
window.onpromisechained = function(promise, child) {
// event.details.promise - The parent promise the child was chained from
// event.details.child - The created child promise.
};
```
Resource management
--------------------
Cancellation and timeouts
--------------------------
See [`Cancellation`](api/cancellation) for how to use cancellation.
```
// Enable cancellation
Promise.config({cancellation: true});
var fs = Promise.promisifyAll(require("fs"));
// In 2000ms or less, load & parse a file 'config.json'
var p = Promise.resolve('./config.json')
.timeout(2000)
.catch(console.error.bind(console, 'Failed to load config!'))
.then(fs.readFileAsync)
.then(JSON.parse);
// Listen for exception event to trigger promise cancellation
process.on('unhandledException', function(event) {
// cancel config loading
p.cancel();
});
```
Scoped prototypes
------------------
Building a library that depends on bluebird? You should know about the "scoped prototype" feature.
If your library needs to do something obtrusive like adding or modifying methods on the `Promise` prototype, uses long stack traces or uses a custom unhandled rejection handler then... that's totally ok as long as you don't use `require("bluebird")`. Instead you should create a file that creates an isolated copy. For example, creating a file called `bluebird-extended.js` that contains:
```
//NOTE the function call right after
module.exports = require("bluebird/js/main/promise")();
```
Your library can then use `var Promise = require("bluebird-extended");` and do whatever it wants with it. Then if the application or other library uses their own bluebird promises they will all play well together because of Promises/A+ thenable assimilation magic.
Async/Await
------------
| programming_docs |
bluebird Why Promises? Why Promises?
=============
Promises are a concurrency primitive with a proven track record and language integration in most modern programming languages. They have been extensively studied since the 80s and will make your life much easier.
You should use promises to turn this:
```
fs.readFile("file.json", function (err, val) {
if (err) {
console.error("unable to read file");
}
else {
try {
val = JSON.parse(val);
console.log(val.success);
}
catch (e) {
console.error("invalid json in file");
}
}
});
```
Into this:
```
fs.readFileAsync("file.json").then(JSON.parse).then(function (val) {
console.log(val.success);
})
.catch(SyntaxError, function (e) {
console.error("invalid json in file");
})
.catch(function (e) {
console.error("unable to read file");
});
```
*If you're thinking, "There's no `readFileAsync` method on `fs` that returns a promise!" see [promisification](api/promisification)*
You might notice that the promise approach looks very similar to using synchronous I/O:
```
try {
var val = JSON.parse(fs.readFileSync("file.json"));
console.log(val.success);
}
// Gecko-only syntax; used for illustrative purposes
catch (e if e instanceof SyntaxError) {
console.error("invalid json in file");
}
catch (e) {
console.error("unable to read file");
}
```
This is the point—to have something that works like `return` and `throw` in synchronous code.
You can also use promises to improve code that was written with callbacks:
```
//Copyright Plato http://stackoverflow.com/a/19385911/995876
//CC BY-SA 2.5
mapSeries(URLs, function (URL, done) {
var options = {};
needle.get(URL, options, function (error, response, body) {
if (error) {
return done(error);
}
try {
var ret = JSON.parse(body);
return done(null, ret);
}
catch (e) {
done(e);
}
});
}, function (err, results) {
if (err) {
console.log(err);
} else {
console.log('All Needle requests successful');
// results is a 1 to 1 mapping in order of URLs > needle.body
processAndSaveAllInDB(results, function (err) {
if (err) {
return done(err);
}
console.log('All Needle requests saved');
done(null);
});
}
});
```
This is far more readable when done with promises:
```
Promise.promisifyAll(needle);
var options = {};
var current = Promise.resolve();
Promise.map(URLs, function (URL) {
current = current.then(function () {
return needle.getAsync(URL, options);
});
return current;
}).map(function (responseAndBody) {
return JSON.parse(responseAndBody[1]);
}).then(function (results) {
return processAndSaveAllInDB(results);
}).then(function () {
console.log('All Needle requests saved');
}).catch(function (e) {
console.log(e);
});
```
Also, promises don't just give you correspondences for synchronous features; they can also be used as limited event emitters or callback aggregators.
More reading:
* [Promise nuggets](https://promise-nuggets.github.io/)
* [Why I am switching to promises](http://spion.github.io/posts/why-i-am-switching-to-promises.html)
* [What is the the point of promises](http://domenic.me/2012/10/14/youre-missing-the-point-of-promises/#toc_1)
* [Aren't Promises Just Callbacks?](http://stackoverflow.com/questions/22539815/arent-promises-just-callbacks)
bluebird Benchmarks Benchmarks
==========
Benchmarks have been ran with the following versions of modules.
```
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
├── [email protected]
└── [email protected]
```
### 1. DoxBee sequential
This is Gorki Kosev's benchmark used in the article [Analysis of generators and other async patterns in node](http://spion.github.io/posts/analysis-generators-and-other-async-patterns-node.html). The benchmark emulates a situation where N=10000 requests are being made concurrently to execute some mixed async/sync action with fast I/O response times.
This is a throughput benchmark.
Every implementation runs in a freshly created isolated process which is warmed up to the benchmark code before timing it. The memory column represents the highest snapshotted RSS memory (as reported by `process.memoryUsage().rss`) during processing.
Command: `./bench doxbee` ([needs cloned repository](http://bluebirdjs.com/docs/contribute.html#benchmarking))
The implementations for this benchmark are found in [`benchmark/doxbee-sequential`](https://github.com/petkaantonov/bluebird/tree/master/benchmark/doxbee-sequential) directory.
```
results for 10000 parallel executions, 1 ms per I/O op
file time(ms) memory(MB)
callbacks-baseline.js 116 33.98
callbacks-suguru03-neo-async-waterfall.js 145 43.81
promises-bluebird-generator.js 183 42.35
promises-bluebird.js 214 43.41
promises-cujojs-when.js 312 64.37
promises-then-promise.js 396 74.33
promises-tildeio-rsvp.js 414 84.80
promises-native-async-await.js 422 104.23
promises-ecmascript6-native.js 424 92.12
generators-tj-co.js 444 90.98
promises-lvivski-davy.js 480 114.46
callbacks-caolan-async-waterfall.js 520 109.01
promises-dfilatov-vow.js 612 134.38
promises-obvious-kew.js 725 208.63
promises-calvinmetcalf-lie.js 730 164.96
streamline-generators.js 809 154.36
promises-medikoo-deferred.js 913 178.51
observables-pozadi-kefir.js 991 194.00
streamline-callbacks.js 1127 196.54
observables-Reactive-Extensions-RxJS.js 1906 268.41
observables-caolan-highland.js 6887 662.08
promises-kriskowal-q.js 8533 435.51
observables-baconjs-bacon.js.js 21282 882.61
Platform info:
Linux 4.4.0-79-generic x64
Node.JS 8.6.0
V8 6.0.287.53
Intel(R) Core(TM) i5-6600K CPU @ 3.50GHz × 4
```
### 2. Parallel
This made-up scenario runs 25 shimmed queries in parallel per each request (N=10000) with fast I/O response times.
This is a throughput benchmark.
Every implementation runs in a freshly created isolated process which is warmed up to the benchmark code before timing it. The memory column represents the highest snapshotted RSS memory (as reported by `process.memoryUsage().rss`) during processing.
Command: `./bench parallel` ([needs cloned repository](http://bluebirdjs.com/docs/contribute.html#benchmarking))
The implementations for this benchmark are found in [`benchmark/madeup-parallel`](https://github.com/petkaantonov/bluebird/tree/master/benchmark/madeup-parallel) directory.
```
results for 10000 parallel executions, 1 ms per I/O op
file time(ms) memory(MB)
callbacks-baseline.js 274 75.11
callbacks-suguru03-neo-async-parallel.js 320 88.84
promises-bluebird.js 407 107.25
promises-bluebird-generator.js 432 113.19
callbacks-caolan-async-parallel.js 550 154.27
promises-cujojs-when.js 648 168.65
promises-ecmascript6-native.js 1145 308.87
promises-lvivski-davy.js 1153 257.36
promises-native-async-await.js 1260 323.68
promises-then-promise.js 1372 313.24
promises-tildeio-rsvp.js 1435 398.73
promises-medikoo-deferred.js 1626 306.02
promises-calvinmetcalf-lie.js 1805 351.21
promises-dfilatov-vow.js 2492 558.25
promises-obvious-kew.js 3403 784.61
streamline-generators.js 13068 919.24
streamline-callbacks.js 25509 1141.57
Platform info:
Linux 4.4.0-79-generic x64
Node.JS 8.6.0
V8 6.0.287.53
Intel(R) Core(TM) i5-6600K CPU @ 3.50GHz × 4
```
### 3. Latency benchmarks
For reasonably fast promise implementations latency is going to be fully determined by the scheduler being used and is therefore not interesting to benchmark. [JSPerfs](https://jsperf.com/) that benchmark promises tend to benchmark latency.
bluebird .cancel .cancel
========
```
.cancel() -> undefined
```
Cancel this promise. Will not do anything if this promise is already settled or if the [`Cancellation`](cancellation) feature has not been enabled. See [`Cancellation`](cancellation) for how to use cancellation.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .all .all
=====
```
.all() -> Promise
```
Consume the resolved [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols) and wait for all items to fulfill similar to [`Promise.all()`](promise.all).
[`Promise.resolve(iterable).all()`](promise.resolve) is the same as [`Promise.all(iterable)`](promise.all).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .each .each
======
```
.each(function(any item, int index, int length) iterator) -> Promise
```
Iterate over an array, or a promise of an array, which contains promises (or a mix of promises and values) with the given `iterator` function with the signature `(value, index, length)` where `value` is the resolved value of a respective promise in the input array. Iteration happens serially. If any promise in the input array is rejected the returned promise is rejected as well.
Resolves to the original array unmodified, this method is meant to be used for side effects. If the iterator function returns a promise or a thenable, then the result of the promise is awaited, before continuing with next iteration.
Example where you might want to utilize `.each`:
```
// Source: http://jakearchibald.com/2014/es7-async-functions/
function loadStory() {
return getJSON('story.json')
.then(function(story) {
addHtmlToPage(story.heading);
return story.chapterURLs.map(getJSON);
})
.each(function(chapter) { addHtmlToPage(chapter.html); })
.then(function() { addTextToPage("All done"); })
.catch(function(err) { addTextToPage("Argh, broken: " + err.message); })
.then(function() { document.querySelector('.spinner').style.display = 'none'; });
}
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .throw .throw
=======
```
.throw(any reason) -> Promise
```
```
.thenThrow(any reason) -> Promise
```
Convenience method for:
```
.then(function() {
throw reason;
});
```
Same limitations regarding to the binding time of `reason` to apply as with [`.return`](return).
*For compatibility with earlier ECMAScript version, an alias `.thenThrow` is provided for [`.throw`](throw).*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.some Promise.some
=============
```
Promise.some(
Iterable<any>|Promise<Iterable<any>> input,
int count
) -> Promise
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and return a promise that is fulfilled as soon as `count` promises are fulfilled in the array. The fulfillment value is an array with `count` values in the order they were fulfilled.
This example pings 4 nameservers, and logs the fastest 2 on console:
```
Promise.some([
ping("ns1.example.com"),
ping("ns2.example.com"),
ping("ns3.example.com"),
ping("ns4.example.com")
], 2).spread(function(first, second) {
console.log(first, second);
});
```
If too many promises are rejected so that the promise can never become fulfilled, it will be immediately rejected with an [`AggregateError`](aggregateerror) of the rejection reasons in the order they were thrown in.
You can get a reference to [`AggregateError`](aggregateerror) from `Promise.AggregateError`.
```
Promise.some(...)
.then(...)
.then(...)
.catch(Promise.AggregateError, function(err) {
err.forEach(function(e) {
console.error(e.stack);
});
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .reflect .reflect
=========
```
.reflect() -> Promise<PromiseInspection>
```
The [`.reflect`](reflect) method returns a promise that is always successful when this promise is settled. Its fulfillment value is an object that implements the [`PromiseInspection`](promiseinspection) interface and reflects the resolution of this promise.
Using `.reflect()` to implement `settleAll` (wait until all promises in an array are either rejected or fulfilled) functionality
```
var promises = [getPromise(), getPromise(), getPromise()];
Promise.all(promises.map(function(promise) {
return promise.reflect();
})).each(function(inspection) {
if (inspection.isFulfilled()) {
console.log("A promise in the array was fulfilled with", inspection.value());
} else {
console.error("A promise in the array was rejected with", inspection.reason());
}
});
```
Using `.reflect()` to implement `settleProps` (like settleAll for an object's properties) functionality
```
var object = {
first: getPromise1(),
second: getPromise2()
};
Promise.props(Object.keys(object).reduce(function(newObject, key) {
newObject[key] = object[key].reflect();
return newObject;
}, {})).then(function(object) {
if (object.first.isFulfilled()) {
console.log("first was fulfilled with", object.first.value());
} else {
console.error("first was rejected with", object.first.reason());
}
})
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .catchThrow .catchThrow
============
```
.catchThrow(
[class ErrorClass|function(any error) predicate],
any reason
) -> Promise
```
Convenience method for:
```
.catch(function() {
throw reason;
});
```
You may optionally prepend one predicate function or ErrorClass to pattern match the error (the generic [`.catch`](catch) methods accepts multiple)
Same limitations regarding to the binding time of `reason` to apply as with [`.return`](return).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promisification Promisification
================
Promisification means converting an existing promise-unaware API to a promise-returning API.
The usual way to use promises in node is to [`Promise.promisifyAll`](promise.promisifyall) some API and start exclusively calling promise returning versions of the APIs methods. E.g.
```
var fs = require("fs");
Promise.promisifyAll(fs);
// Now you can use fs as if it was designed to use bluebird promises from the beginning
fs.readFileAsync("file.js", "utf8").then(...)
```
Note that the above is an exceptional case because `fs` is a singleton instance. Most libraries can be promisified by requiring the library's classes (constructor functions) and calling promisifyAll on the `.prototype`. This only needs to be done once in the entire application's lifetime and after that you may use the library's methods exactly as they are documented, except by appending the `"Async"`-suffix to method calls and using the promise interface instead of the callback interface.
As a notable exception in `fs`, `fs.existsAsync` doesn't work as expected, because Node's `fs.exists` doesn't call back with error as first argument. More at [`#418`](https://github.com/petkaantonov/bluebird/issues/418). One possible workaround is using `fs.statAsync`.
Some examples of the above practice applied to some popular libraries:
```
// The most popular redis module
var Promise = require("bluebird");
Promise.promisifyAll(require("redis"));
```
```
// The most popular mongodb module
var Promise = require("bluebird");
Promise.promisifyAll(require("mongodb"));
```
```
// The most popular mysql module
var Promise = require("bluebird");
// Note that the library's classes are not properties of the main export
// so we require and promisifyAll them manually
Promise.promisifyAll(require("mysql/lib/Connection").prototype);
Promise.promisifyAll(require("mysql/lib/Pool").prototype);
```
```
// Mongoose
var Promise = require("bluebird");
Promise.promisifyAll(require("mongoose"));
```
```
// Request
var Promise = require("bluebird");
Promise.promisifyAll(require("request"));
// Use request.getAsync(...) not request(..), it will not return a promise
```
```
// mkdir
var Promise = require("bluebird");
Promise.promisifyAll(require("mkdirp"));
// Use mkdirp.mkdirpAsync not mkdirp(..), it will not return a promise
```
```
// winston
var Promise = require("bluebird");
Promise.promisifyAll(require("winston"));
```
```
// rimraf
var Promise = require("bluebird");
// The module isn't promisified but the function returned is
var rimrafAsync = Promise.promisify(require("rimraf"));
```
```
// xml2js
var Promise = require("bluebird");
Promise.promisifyAll(require("xml2js"));
```
```
// jsdom
var Promise = require("bluebird");
Promise.promisifyAll(require("jsdom"));
```
```
// fs-extra
var Promise = require("bluebird");
Promise.promisifyAll(require("fs-extra"));
```
```
// prompt
var Promise = require("bluebird");
Promise.promisifyAll(require("prompt"));
```
```
// Nodemailer
var Promise = require("bluebird");
Promise.promisifyAll(require("nodemailer"));
```
```
// ncp
var Promise = require("bluebird");
Promise.promisifyAll(require("ncp"));
```
```
// pg
var Promise = require("bluebird");
Promise.promisifyAll(require("pg"));
```
In all of the above cases the library made its classes available in one way or another. If this is not the case, you can still promisify by creating a throwaway instance:
```
var ParanoidLib = require("...");
var throwAwayInstance = ParanoidLib.createInstance();
Promise.promisifyAll(Object.getPrototypeOf(throwAwayInstance));
// Like before, from this point on, all new instances + even the throwAwayInstance suddenly support promises
```
See also [`Promise.promisifyAll`](promise.promisifyall).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .disposer .disposer
==========
```
.disposer(function(any resource, Promise usingOutcomePromise) disposer) -> Disposer
```
A meta method used to specify the disposer method that cleans up a resource when using [`Promise.using`](promise.using).
Returns a Disposer object which encapsulates both the resource as well as the method to clean it up. The user can pass this object to `Promise.using` to get access to the resource when it becomes available, as well as to ensure it's automatically cleaned up.
The second argument passed to a disposer is the result promise of the using block, which you can inspect synchronously.
Example:
```
// This function doesn't return a promise but a Disposer
// so it's very hard to use it wrong (not passing it to `using`)
function getConnection() {
return db.connect().disposer(function(connection, promise) {
connection.close();
});
}
```
In the above example, the connection returned by `getConnection` can only be used via `Promise.using`, like so:
```
function useConnection(query) {
return Promise.using(getConnection(), function(connection) {
return connection.sendQuery(query).then(function(results) {
return process(results);
})
});
}
```
This will ensure that `connection.close()` will be called once the promise returned from the `Promise.using` closure is resolved or if an exception was thrown in the closure body.
Real example:
```
var pg = require("pg");
// Uncomment if pg has not been properly promisified yet
//var Promise = require("bluebird");
//Promise.promisifyAll(pg, {
// filter: function(methodName) {
// return methodName === "connect"
// },
// multiArgs: true
//});
// Promisify rest of pg normally
//Promise.promisifyAll(pg);
function getSqlConnection(connectionString) {
var close;
return pg.connectAsync(connectionString).spread(function(client, done) {
close = done;
return client;
}).disposer(function() {
if (close) close();
});
}
module.exports = getSqlConnection;
```
Real example 2:
```
var mysql = require("mysql");
// Uncomment if mysql has not been properly promisified yet
// var Promise = require("bluebird");
// Promise.promisifyAll(mysql);
// Promise.promisifyAll(require("mysql/lib/Connection").prototype);
// Promise.promisifyAll(require("mysql/lib/Pool").prototype);
var pool = mysql.createPool({
connectionLimit: 10,
host: 'example.org',
user: 'bob',
password: 'secret'
});
function getSqlConnection() {
return pool.getConnectionAsync().disposer(function(connection) {
connection.release();
});
}
module.exports = getSqlConnection;
```
#### Note about disposers in node
If a disposer method throws or returns a rejected promise, it's highly likely that it failed to dispose of the resource. In that case, Bluebird has two options - it can either ignore the error and continue with program execution or throw an exception (crashing the process in node.js).
In bluebird we've chosen to do the latter because resources are typically scarce. For example, if a database connection cannot be disposed of and Bluebird ignores that, the connection pool will be quickly depleted and the process will become unusable (all requests that query the database will wait forever). Since Bluebird doesn't know how to handle that, the only sensible default is to crash the process. That way, rather than getting a useless process that cannot fulfill more requests, we can swap the faulty worker with a new one letting the OS clean up the resources for us.
As a result, if you anticipate thrown errors or promise rejections while disposing of the resource you should use a `try..catch` block (or Promise.try) and write the appropriate catch code to handle the errors. If it's not possible to sensibly handle the error, letting the process crash is the next best option.
This also means that disposers should not contain code that does anything other than resource disposal. For example, you cannot write code inside a disposer to commit or rollback a transaction, because there is no mechanism for the disposer to signal a failure of the commit or rollback action without crashing the process.
For transactions, you can use the following similar pattern instead:
```
function withTransaction(fn) {
return Promise.using(pool.acquireConnection(), function(connection) {
var tx = connection.beginTransaction()
return Promise
.try(fn, tx)
.then(function(res) { return connection.commit().thenReturn(res) },
function(err) {
return connection.rollback()
.catch(function(e) {/* maybe add the rollback error to err */})
.thenThrow(err);
});
});
}
// If the withTransaction block completes successfully, the transaction is automatically committed
// Any error or rejection will automatically roll it back
withTransaction(function(tx) {
return tx.queryAsync(...).then(function() {
return tx.queryAsync(...)
}).then(function() {
return tx.queryAsync(...)
});
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird .any .any
=====
```
.any() -> Promise
```
Same as [`Promise.any(this)`](promise.any).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .map .map
=====
```
.map(
function(any item, int index, int length) mapper,
[Object {concurrency: int=Infinity} options]
) -> Promise
```
Same as [`Promise.map(this, mapper, options)`](promise.map).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Progression migration Progression migration
======================
Progression has been removed as there are composability and chaining issues with APIs that use promise progression handlers. Implementing the common use case of progress bars can be accomplished using a pattern similar to [IProgress](http://blogs.msdn.com/b/dotnet/archive/2012/06/06/async-in-4-5-enabling-progress-and-cancellation-in-async-apis.aspx) in C#.
For old code that still uses it, see [the progression docs in the deprecated API documentation](../deprecated-apis#progression).
Using jQuery before:
```
Promise.resolve($.get(...))
.progressed(function() {
// ...
})
.then(function() {
// ...
})
.catch(function(e) {
// ...
})
```
Using jQuery after:
```
Promise.resolve($.get(...).progress(function() {
// ...
}))
.then(function() {
// ...
})
.catch(function(e) {
// ...
})
```
Implementing general progress interfaces like in C#:
```
function returnsPromiseWithProgress(progressHandler) {
return doFirstAction().tap(function() {
progressHandler(0.33);
}).then(doSecondAction).tap(function() {
progressHandler(0.66);
}).then(doThirdAction).tap(function() {
progressHandler(1.00);
});
}
returnsPromiseWithProgress(function(progress) {
ui.progressbar.setWidth((progress * 200) + "px"); // update width on client side
}).then(function(value) { // action complete
// entire chain is complete.
}).catch(function(e) {
// error
});
```
Another example using `coroutine`:
```
var doNothing = function() {};
var progressSupportingCoroutine = Promise.coroutine(function* (progress) {
progress = typeof progress === "function" ? progress : doNothing;
var first = yield getFirstValue();
// 33% done
progress(0.33);
var second = yield getSecondValue();
progress(0.67);
var third = yield getThirdValue();
progress(1);
return [first, second, third];
});
var progressConsumingCoroutine = Promise.coroutine(function* () {
var allValues = yield progressSupportingCoroutine(function(p) {
ui.progressbar.setWidth((p * 200) + "px");
});
var second = allValues[1];
// ...
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.coroutine Promise.coroutine
==================
```
Promise.coroutine(GeneratorFunction(...arguments) generatorFunction, Object options) -> function
```
Returns a function that can use `yield` to yield promises. Control is returned back to the generator when the yielded promise settles. This can lead to less verbose code when doing lots of sequential async calls with minimal processing in between. Requires node.js 0.12+, io.js 1.0+ or Google Chrome 40+.
```
var Promise = require("bluebird");
function PingPong() {
}
PingPong.prototype.ping = Promise.coroutine(function* (val) {
console.log("Ping?", val);
yield Promise.delay(500);
this.pong(val+1);
});
PingPong.prototype.pong = Promise.coroutine(function* (val) {
console.log("Pong!", val);
yield Promise.delay(500);
this.ping(val+1);
});
var a = new PingPong();
a.ping(0);
```
Running the example:
```
$ node test.js
Ping? 0
Pong! 1
Ping? 2
Pong! 3
Ping? 4
Pong! 5
Ping? 6
Pong! 7
Ping? 8
...
```
When called, the coroutine function will start an instance of the generator and returns a promise for its final value.
Doing `Promise.coroutine` is almost like using the C# `async` keyword to mark the function, with `yield` working as the `await` keyword. Promises are somewhat like `Task`s.
**Tip**
You are able to yield non-promise values by adding your own yield handler using [`Promise.coroutine.addYieldHandler`](promise.coroutine.addyieldhandler) or calling `Promise.coroutine()` with a yield handler function as `options.yieldHandler`.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird ~~Promise.longStackTraces~~ ~~Promise.longStackTraces~~
============================
This method is deprecated. Use [Promise.config](promise.config) instead.
```
Promise.config({
longStackTraces: true
})
```
```
Promise.longStackTraces() -> undefined
```
Call this right after the library is loaded to enable long stack traces. Long stack traces cannot be disabled after being enabled, and cannot be enabled after promises have already been created. Long stack traces imply a substantial performance penalty, around 4-5x for throughput and 0.5x for latency.
Long stack traces are enabled by default in the debug build.
To enable them in all instances of bluebird in node.js, use the environment variable `BLUEBIRD_DEBUG`:
```
BLUEBIRD_DEBUG=1 node server.js
```
Setting the environment variable `NODE_ENV` to `"development"` also automatically enables long stack traces.
You should enabled long stack traces if you want better debugging experience. For example:
```
Promise.longStackTraces();
Promise.resolve().then(function outer() {
return Promise.resolve().then(function inner() {
return Promise.resolve().then(function evenMoreInner() {
a.b.c.d()
}).catch(function catcher(e) {
console.error(e.stack);
});
});
});
```
Gives
```
ReferenceError: a is not defined
at evenMoreInner (<anonymous>:6:13)
From previous event:
at inner (<anonymous>:5:24)
From previous event:
at outer (<anonymous>:4:20)
From previous event:
at <anonymous>:3:9
at Object.InjectedScript._evaluateOn (<anonymous>:581:39)
at Object.InjectedScript._evaluateAndWrap (<anonymous>:540:52)
at Object.InjectedScript.evaluate (<anonymous>:459:21)
```
While with long stack traces disabled, you would get:
```
ReferenceError: a is not defined
at evenMoreInner (<anonymous>:6:13)
at tryCatch1 (<anonymous>:41:19)
at Promise$_resolvePromise [as _resolvePromise] (<anonymous>:1739:13)
at Promise$_resolveLast [as _resolveLast] (<anonymous>:1520:14)
at Async$_consumeFunctionBuffer [as _consumeFunctionBuffer] (<anonymous>:560:33)
at Async$consumeFunctionBuffer (<anonymous>:515:14)
at MutationObserver.Promise$_Deferred (<anonymous>:433:17)
```
On client side, long stack traces currently only work in recent Firefoxes, Chrome and Internet Explorer 10+.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.setScheduler Promise.setScheduler
=====================
```
Promise.setScheduler(function(function fn) scheduler) -> function
```
Scheduler should be a function that asynchronously schedules the calling of the passed in function:
```
// This is just an example of how to use the api, there is no reason to do this
Promise.setScheduler(function(fn) {
setTimeout(fn, 0);
});
```
Setting a custom scheduler could be necessary when you need a faster way to schedule functions than bluebird does by default. It also makes bluebird possible to use in platforms where normal timing constructs like `setTimeout` and `process.nextTick` are not available (like Nashhorn).
You can also use it as a hook:
```
// This will synchronize bluebird promise queue flushing with angulars queue flushing
// Angular is also now responsible for choosing the actual scheduler
Promise.setScheduler(function(fn) {
$rootScope.$evalAsync(fn);
});
```
> **Danger** - in order to keep bluebird promises [Promises/A+](https://promisesaplus.com/) compliant a scheduler that executes the function asynchronously (like the examples in this page) must be used.
>
>
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .finally .finally
=========
```
.finally(function() handler) -> Promise
```
```
.lastly(function() handler) -> Promise
```
Pass a handler that will be called regardless of this promise's fate. Returns a new promise chained from this promise. There are special semantics for [`.finally`](finally) in that the final value cannot be modified from the handler.
*Note: using [`.finally`](finally) for resource management has better alternatives, see [resource management](resource-management)*
Consider the example:
```
function anyway() {
$("#ajax-loader-animation").hide();
}
function ajaxGetAsync(url) {
return new Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest;
xhr.addEventListener("error", reject);
xhr.addEventListener("load", resolve);
xhr.open("GET", url);
xhr.send(null);
}).then(anyway, anyway);
}
```
This example doesn't work as intended because the `then` handler actually swallows the exception and returns `undefined` for any further chainers.
The situation can be fixed with `.finally`:
```
function ajaxGetAsync(url) {
return new Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest;
xhr.addEventListener("error", reject);
xhr.addEventListener("load", resolve);
xhr.open("GET", url);
xhr.send(null);
}).finally(function() {
$("#ajax-loader-animation").hide();
});
}
```
Now the animation is hidden but, unless it throws an exception, the function has no effect on the fulfilled or rejected value of the returned promise. This is similar to how the synchronous `finally` keyword behaves.
If the handler function passed to `.finally` returns a promise, the promise returned by `.finally` will not be settled until the promise returned by the handler is settled. If the handler fulfills its promise, the returned promise will be fulfilled or rejected with the original value. If the handler rejects its promise, the returned promise will be rejected with the handler's value. This is similar to throwing an exception in a synchronous `finally` block, causing the original value or exception to be forgotten. This delay can be useful if the actions performed by the handler are done asynchronously. For example:
```
function ajaxGetAsync(url) {
return new Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest;
xhr.addEventListener("error", reject);
xhr.addEventListener("load", resolve);
xhr.open("GET", url);
xhr.send(null);
}).finally(function() {
return Promise.fromCallback(function(callback) {
$("#ajax-loader-animation").fadeOut(1000, callback);
});
});
}
```
If the fade out completes successfully, the returned promise will be fulfilled or rejected with the value from `xhr`. If `.fadeOut` throws an exception or passes an error to the callback, the returned promise will be rejected with the error from `.fadeOut`.
*For compatibility with earlier ECMAScript version, an alias `.lastly` is provided for [`.finally`](finally).*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird TimeoutError TimeoutError
=============
```
new TimeoutError(String message) -> TimeoutError
```
Signals that an operation has timed out. Used as a custom cancellation reason in [`.timeout`](timeout).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Built-in error types Built-in error types
=====================
Bluebird includes a few built-in error types for common usage. All error types have the same identity across different copies of bluebird module so that pattern matching works in [`.catch`](catch). All error types have a constructor taking a message string as their first argument, with that message becoming the `.message` property of the error object.
By default the error types need to be referenced from the Promise constructor, e.g. to get a reference to [`TimeoutError`](timeouterror), do `var TimeoutError = Promise.TimeoutError`. However, for convenience you will probably want to just make the references global.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.reject Promise.reject
===============
```
Promise.reject(any error) -> Promise
```
Create a promise that is rejected with the given `error`.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.filter Promise.filter
===============
```
Promise.filter(
Iterable<any>|Promise<Iterable<any>> input,
function(any item, int index, int length) filterer,
[Object {concurrency: int=Infinity} options]
) -> Promise
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and [filter the array to another](http://en.wikipedia.org/wiki/Filter_(higher-order_function)) using the given `filterer` function.
It is essentially an efficient shortcut for doing a [`.map`](map) and then [`Array#filter`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/filter):
```
Promise.map(valuesToBeFiltered, function(value, index, length) {
return Promise.all([filterer(value, index, length), value]);
}).then(function(values) {
return values.filter(function(stuff) {
return stuff[0] == true
}).map(function(stuff) {
return stuff[1];
});
});
```
Example for filtering files that are accessible directories in the current directory:
```
var Promise = require("bluebird");
var E = require("core-error-predicates");
var fs = Promise.promisifyAll(require("fs"));
fs.readdirAsync(process.cwd()).filter(function(fileName) {
return fs.statAsync(fileName)
.then(function(stat) {
return stat.isDirectory();
})
.catch(E.FileAccessError, function() {
return false;
});
}).each(function(directoryName) {
console.log(directoryName, " is an accessible directory");
});
```
#### Filter Option: concurrency
See [Map Option: concurrency](#map-option-concurrency)
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .isFulfilled .isFulfilled
=============
```
.isFulfilled() -> boolean
```
See if this promise has been fulfilled.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .props .props
=======
```
.props() -> Promise
```
Same as [`Promise.props(this)`](promise.props).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird CancellationError CancellationError
==================
```
new CancellationError(String message) -> CancellationError
```
Signals that an operation has been aborted or cancelled. The default reason used by [`.cancel`](cancel).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.using Promise.using
==============
```
Promise.using(
Promise|Disposer|any resource,
Promise|Disposer|any resource...,
function(any resources...) handler
) -> Promise
```
```
Promise.using(
Array<Promise|Disposer|Any> resources,
function(Array<any> resources) handler
) -> Promise
```
In conjunction with [`.disposer`](disposer), `using` will make sure that no matter what, the specified disposer will be called when the promise returned by the callback passed to `using` has settled. The disposer is necessary because there is no standard interface in node for disposing resources.
Here is a simple example (where `getConnection()` has been defined to return a proper Disposer object)
```
using(getConnection(), function(connection) {
// Don't leak the `connection` variable anywhere from here
// it is only guaranteed to be open while the promise returned from
// this callback is still pending
return connection.queryAsync("SELECT * FROM TABLE");
// Code that is chained from the promise created in the line above
// still has access to `connection`
}).then(function(rows) {
// The connection has been closed by now
console.log(rows);
});
```
Using multiple resources:
```
using(getConnection(), function(conn1) {
return using(getConnection(), function(conn2) {
// use conn1 and conn 2 here
});
}).then(function() {
// Both connections closed by now
})
```
The above can also be written as (with a caveat, see below)
```
using(getConnection(), getConnection(), function(conn1, conn2) {
// use conn1 and conn2
}).then(function() {
// Both connections closed by now
})
```
However, if the second `getConnection` throws **synchronously**, the first connection is leaked. This will not happen when using APIs through bluebird promisified methods though. You can wrap functions that could throw in [`Promise.method`](promise.method) which will turn synchronous rejections into rejected promises.
Note that you can mix promises and disposers, so that you can acquire all the things you need in parallel instead of sequentially
```
// The files don't need resource management but you should
// still start the process of reading them even before you have the connection
// instead of waiting for the connection
// The connection is always closed, no matter what fails at what point
using(readFile("1.txt"), readFile("2.txt"), getConnection(), function(txt1, txt2, conn) {
// use conn and have access to txt1 and txt2
});
```
You can also pass the resources in an array in the first argument. In this case the handler function will only be called with one argument that is the array containing the resolved resources in respective positions in the array. Example:
```
var connectionPromises = [getConnection(), getConnection()];
using(connectionPromises, function(connections) {
var conn1 = connections[0];
var conn2 = connections[1];
// use conn1 and conn2
}).then(function() {
// Both connections closed by now
})
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.promisifyAll Promise.promisifyAll
=====================
```
Promise.promisifyAll(
Object target,
[Object {
suffix: String="Async",
multiArgs: boolean=false,
filter: boolean function(String name, function func, Object target, boolean passesDefaultFilter),
promisifier: function(function originalFunction, function defaultPromisifier)
} options]
) -> Object
```
Promisifies the entire object by going through the object's properties and creating an async equivalent of each function on the object and its prototype chain. The promisified method name will be the original method name suffixed with `suffix` (default is `"Async"`). Any class properties of the object (which is the case for the main export of many modules) are also promisified, both static and instance methods. Class property is a property with a function value that has a non-empty `.prototype` object. Returns the input object.
Note that the original methods on the object are not overwritten but new methods are created with the `Async`-suffix. For example, if you `promisifyAll` the node.js `fs` object use `fs.statAsync` to call the promisified `stat` method.
Example:
```
Promise.promisifyAll(require("redis"));
//Later on, all redis client instances have promise returning functions:
redisClient.hexistsAsync("myhash", "field").then(function(v) {
}).catch(function(e) {
});
```
It also works on singletons or specific instances:
```
var fs = Promise.promisifyAll(require("fs"));
fs.readFileAsync("myfile.js", "utf8").then(function(contents) {
console.log(contents);
}).catch(function(e) {
console.error(e.stack);
});
```
See [promisification](#promisification) for more examples.
The entire prototype chain of the object is promisified on the object. Only enumerable are considered. If the object already has a promisified version of the method, it will be skipped. The target methods are assumed to conform to node.js callback convention of accepting a callback as last argument and calling that callback with error as the first argument and success value on the second argument. If the node method calls its callback with multiple success values, the fulfillment value will be an array of them.
If a method name already has an `"Async"`-suffix, an exception will be thrown.
#### Option: suffix
Optionally, you can define a custom suffix through the options object:
```
var fs = Promise.promisifyAll(require("fs"), {suffix: "MySuffix"});
fs.readFileMySuffix(...).then(...);
```
All the above limitations apply to custom suffices:
* Choose the suffix carefully, it must not collide with anything
* PascalCase the suffix
* The suffix must be a valid JavaScript identifier using ASCII letters
* Always use the same suffix everywhere in your application, you could create a wrapper to make this easier:
```
module.exports = function myPromisifyAll(target) {
return Promise.promisifyAll(target, {suffix: "MySuffix"});
};
```
#### Option: multiArgs
Setting `multiArgs` to `true` means the resulting promise will always fulfill with an array of the callback's success value(s). This is needed because promises only support a single success value while some callback API's have multiple success value. The default is to ignore all but the first success value of a callback function.
If a module has multiple argument callbacks as an exception rather than the rule, you can filter out the multiple argument methods in first go and then promisify rest of the module in second go:
```
Promise.promisifyAll(something, {
filter: function(name) {
return name === "theMultiArgMethodIwant";
},
multiArgs: true
});
// Rest of the methods
Promise.promisifyAll(something);
```
#### Option: filter
Optionally, you can define a custom filter through the options object:
```
Promise.promisifyAll(..., {
filter: function(name, func, target, passesDefaultFilter) {
// name = the property name to be promisified without suffix
// func = the function
// target = the target object where the promisified func will be put with name + suffix
// passesDefaultFilter = whether the default filter would be passed
// return boolean (return value is coerced, so not returning anything is same as returning false)
return passesDefaultFilter && ...
}
})
```
The default filter function will ignore properties that start with a leading underscore, properties that are not valid JavaScript identifiers and constructor functions (function which have enumerable properties in their `.prototype`).
#### Option: promisifier
Optionally, you can define a custom promisifier, so you could promisifyAll e.g. the chrome APIs used in Chrome extensions.
The promisifier gets a reference to the original method and should return a function which returns a promise.
```
function DOMPromisifier(originalMethod) {
// return a function
return function promisified() {
var args = [].slice.call(arguments);
// Needed so that the original method can be called with the correct receiver
var self = this;
// which returns a promise
return new Promise(function(resolve, reject) {
args.push(resolve, reject);
originalMethod.apply(self, args);
});
};
}
// Promisify e.g. chrome.browserAction
Promise.promisifyAll(chrome.browserAction, {promisifier: DOMPromisifier});
// Later
chrome.browserAction.getTitleAsync({tabId: 1})
.then(function(result) {
});
```
Combining `filter` with `promisifier` for the restler module to promisify event emitter:
```
var Promise = require("bluebird");
var restler = require("restler");
var methodNamesToPromisify = "get post put del head patch json postJson putJson".split(" ");
function EventEmitterPromisifier(originalMethod) {
// return a function
return function promisified() {
var args = [].slice.call(arguments);
// Needed so that the original method can be called with the correct receiver
var self = this;
// which returns a promise
return new Promise(function(resolve, reject) {
// We call the originalMethod here because if it throws,
// it will reject the returned promise with the thrown error
var emitter = originalMethod.apply(self, args);
emitter
.on("success", function(data, response) {
resolve([data, response]);
})
.on("fail", function(data, response) {
// Erroneous response like 400
resolve([data, response]);
})
.on("error", function(err) {
reject(err);
})
.on("abort", function() {
reject(new Promise.CancellationError());
})
.on("timeout", function() {
reject(new Promise.TimeoutError());
});
});
};
};
Promise.promisifyAll(restler, {
filter: function(name) {
return methodNamesToPromisify.indexOf(name) > -1;
},
promisifier: EventEmitterPromisifier
});
// ...
// Later in some other file
var restler = require("restler");
restler.getAsync("http://...", ...,).spread(function(data, response) {
})
```
Using `defaultPromisifier` parameter to add enhancements on top of normal node promisification:
```
var fs = Promise.promisifyAll(require("fs"), {
promisifier: function(originalFunction, defaultPromisifer) {
var promisified = defaultPromisifier(originalFunction);
return function() {
// Enhance normal promisification by supporting promises as
// arguments
var args = [].slice.call(arguments);
var self = this;
return Promise.all(args).then(function(awaitedArgs) {
return promisified.apply(self, awaitedArgs);
});
};
}
});
// All promisified fs functions now await their arguments if they are promises
var version = fs.readFileAsync("package.json", "utf8").then(JSON.parse).get("version");
fs.writeFileAsync("the-version.txt", version, "utf8");
```
#### Promisifying multiple classes in one go
You can promisify multiple classes in one go by constructing an array out of the classes and passing it to `promisifyAll`:
```
var Pool = require("mysql/lib/Pool");
var Connection = require("mysql/lib/Connection");
Promise.promisifyAll([Pool, Connection]);
```
This works because the array acts as a "module" where the indices are the "module"'s properties for classes.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird Promise.resolve Promise.resolve
================
```
Promise.resolve(Promise<any>|any value) -> Promise
```
Create a promise that is resolved with the given value. If `value` is already a trusted `Promise`, it is returned as is. If `value` is not a thenable, a fulfilled Promise is returned with `value` as its fulfillment value. If `value` is a thenable (Promise-like object, like those returned by jQuery's `$.ajax`), returns a trusted Promise that assimilates the state of the thenable.
This can be useful if a function returns a promise (say into a chain) but can optionally return a static value. Say, for a lazy-loaded value. Example:
```
var someCachedValue;
var getValue = function() {
if (someCachedValue) {
return Promise.resolve(someCachedValue);
}
return db.queryAsync().then(function(value) {
someCachedValue = value;
return value;
});
};
```
Another example with handling jQuery castable objects (`$` is jQuery)
```
Promise.resolve($.get("http://www.google.com")).then(function() {
//Returning a thenable from a handler is automatically
//cast to a trusted Promise as per Promises/A+ specification
return $.post("http://www.yahoo.com");
}).then(function() {
}).catch(function(e) {
//jQuery doesn't throw real errors so use catch-all
console.log(e.statusText);
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird OperationalError OperationalError
=================
```
new OperationalError(String message) -> OperationalError
```
Represents an error is an explicit promise rejection as opposed to a thrown error. For example, if an error is errbacked by a callback API promisified through [`Promise.promisify`](promise.promisify) or [`Promise.promisifyAll`](promise.promisifyall) and is not a typed error, it will be converted to a `OperationalError` which has the original error in the `.cause` property.
`OperationalError`s are caught in [`.error`](error) handlers.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Environment variables Environment variables
======================
This section only applies to node.js or io.js.
You can change bluebird behavior globally with various environment variables. These global variables affect all instances of bluebird that are running in your environment, rather than just the one you have `require`d in your application. The effect an environment variable has depends on the bluebird version.
Environment variables supported by 2.x:
* `BLUEBIRD_DEBUG` - Set to any truthy value this will enable long stack traces and warnings
* `NODE_ENV` - If set exactly to `development` it will have the same effect as if the `BLUEBIRD_DEBUG` variable was set.
Environment variables supported by 3.x:
* `BLUEBIRD_DEBUG` - If set this will enable long stack traces and warnings, unless those are explicitly disabled. Setting this to exactly `0` can be used to override `NODE_ENV=development` enabling long stack traces and warnings.
* `NODE_ENV` - If set exactly to `development` it will have the same effect as if the `BLUEBIRD_DEBUG` variable was set.
* `BLUEBIRD_WARNINGS` - if set exactly to `0` it will explicitly disable warnings and this overrides any other setting that might enable warnings. If set to any truthy value, it will explicitly enable warnings.
* `BLUEBIRD_LONG_STACK_TRACES` - if set exactly to `0` it will explicitly disable long stack traces and this overrides any other setting that might enable long stack traces. If set to any truthy value, it will explicitly enable long stack traces.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .catchReturn .catchReturn
=============
```
.catchReturn(
[class ErrorClass|function(any error) predicate],
any value
) -> Promise
```
Convenience method for:
```
.catch(function() {
return value;
});
```
You may optionally prepend one predicate function or ErrorClass to pattern match the error (the generic [`.catch`](catch) methods accepts multiple)
Same limitations regarding to the binding time of `value` to apply as with [`.return`](return).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.any Promise.any
============
```
Promise.any(Iterable<any>|Promise<Iterable<any>> input) -> Promise
```
Like [`Promise.some`](promise.some), with 1 as `count`. However, if the promise fulfills, the fulfillment value is not an array of 1 but the value directly.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.map Promise.map
============
```
Promise.map(
Iterable<any>|Promise<Iterable<any>> input,
function(any item, int index, int length) mapper,
[Object {concurrency: int=Infinity} options]
) -> Promise
```
Given a finite [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and [map the array to another](http://en.wikipedia.org/wiki/Map_(higher-order_function)) using the given `mapper` function.
Promises returned by the `mapper` function are awaited for and the returned promise doesn't fulfill until all mapped promises have fulfilled as well. If any promise in the array is rejected, or any promise returned by the `mapper` function is rejected, the returned promise is rejected as well.
The mapper function for a given item is called as soon as possible, that is, when the promise for that item's index in the input array is fulfilled. This doesn't mean that the result array has items in random order, it means that `.map` can be used for concurrency coordination unlike `.all`.
A common use of `Promise.map` is to replace the `.push`+`Promise.all` boilerplate:
```
var promises = [];
for (var i = 0; i < fileNames.length; ++i) {
promises.push(fs.readFileAsync(fileNames[i]));
}
Promise.all(promises).then(function() {
console.log("done");
});
// Using Promise.map:
Promise.map(fileNames, function(fileName) {
// Promise.map awaits for returned promises as well.
return fs.readFileAsync(fileName);
}).then(function() {
console.log("done");
});
// Using Promise.map and async/await:
await Promise.map(fileNames, function(fileName) {
// Promise.map awaits for returned promises as well.
return fs.readFileAsync(fileName);
});
console.log("done");
```
A more involved example:
```
var Promise = require("bluebird");
var join = Promise.join;
var fs = Promise.promisifyAll(require("fs"));
fs.readdirAsync(".").map(function(fileName) {
var stat = fs.statAsync(fileName);
var contents = fs.readFileAsync(fileName).catch(function ignore() {});
return join(stat, contents, function(stat, contents) {
return {
stat: stat,
fileName: fileName,
contents: contents
}
});
// The return value of .map is a promise that is fulfilled with an array of the mapped values
// That means we only get here after all the files have been statted and their contents read
// into memory. If you need to do more operations per file, they should be chained in the map
// callback for concurrency.
}).call("sort", function(a, b) {
return a.fileName.localeCompare(b.fileName);
}).each(function(file) {
var contentLength = file.stat.isDirectory() ? "(directory)" : file.contents.length + " bytes";
console.log(file.fileName + " last modified " + file.stat.mtime + " " + contentLength)
});
```
#### Map Option: concurrency
You may optionally specify a concurrency limit:
```
...map(..., {concurrency: 3});
```
The concurrency limit applies to Promises returned by the mapper function and it basically limits the number of Promises created. For example, if `concurrency` is `3` and the mapper callback has been called enough so that there are three returned Promises currently pending, no further callbacks are called until one of the pending Promises resolves. So the mapper function will be called three times and it will be called again only after at least one of the Promises resolves.
Playing with the first example with and without limits, and seeing how it affects the duration when reading 20 files:
```
var Promise = require("bluebird");
var join = Promise.join;
var fs = Promise.promisifyAll(require("fs"));
var concurrency = parseFloat(process.argv[2] || "Infinity");
console.time("reading files");
fs.readdirAsync(".").map(function(fileName) {
var stat = fs.statAsync(fileName);
var contents = fs.readFileAsync(fileName).catch(function ignore() {});
return join(stat, contents, function(stat, contents) {
return {
stat: stat,
fileName: fileName,
contents: contents
}
});
// The return value of .map is a promise that is fulfilled with an array of the mapped values
// That means we only get here after all the files have been statted and their contents read
// into memory. If you need to do more operations per file, they should be chained in the map
// callback for concurrency.
}, {concurrency: concurrency}).call("sort", function(a, b) {
return a.fileName.localeCompare(b.fileName);
}).then(function() {
console.timeEnd("reading files");
});
```
```
$ sync && echo 3 > /proc/sys/vm/drop_caches
$ node test.js 1
reading files 35ms
$ sync && echo 3 > /proc/sys/vm/drop_caches
$ node test.js Infinity
reading files: 9ms
```
The order `map` calls the mapper function on the array elements is not specified, there is no guarantee on the order in which it'll execute the `map`er on the elements. For order guarantee in sequential execution - see [`Promise.mapSeries`](promise.mapseries).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .bind .bind
======
```
.bind(any|Promise<any> thisArg) -> BoundPromise
```
Same as calling [`Promise.bind(thisArg, thisPromise)`](promise.bind).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .then .then
======
```
.then(
[function(any value) fulfilledHandler],
[function(any error) rejectedHandler]
) -> Promise
```
[Promises/A+ `.then`](http://promises-aplus.github.io/promises-spec/). If you are new to promises, see the [Beginner's Guide](../beginners-guide).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .delay .delay
=======
```
.delay(int ms) -> Promise
```
Same as calling [`Promise.delay(ms, this)`](promise.delay).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.reduce Promise.reduce
===============
```
Promise.reduce(
Iterable<any>|Promise<Iterable<any>> input,
function(any accumulator, any item, int index, int length) reducer,
[any initialValue]
) -> Promise
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and [reduce the array to a value](http://en.wikipedia.org/wiki/Fold_(higher-order_function)) using the given `reducer` function.
If the reducer function returns a promise, then the result of the promise is awaited, before continuing with next iteration. If any promise in the array is rejected or a promise returned by the reducer function is rejected, the result is rejected as well.
Read given files sequentially while summing their contents as an integer. Each file contains just the text `10`.
```
Promise.reduce(["file1.txt", "file2.txt", "file3.txt"], function(total, fileName) {
return fs.readFileAsync(fileName, "utf8").then(function(contents) {
return total + parseInt(contents, 10);
});
}, 0).then(function(total) {
//Total is 30
});
```
*If `initialValue` is `undefined` (or a promise that resolves to `undefined`) and the iterable contains only 1 item, the callback will not be called and the iterable's single item is returned. If the iterable is empty, the callback will not be called and `initialValue` is returned (which may be `undefined`).*
`Promise.reduce` will start calling the reducer as soon as possible, this is why you might want to use it over `Promise.all` (which awaits for the entire array before you can call [`Array#reduce`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce) on it).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .isRejected .isRejected
============
```
.isRejected() -> boolean
```
See if this promise has been rejected.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.all Promise.all
============
```
Promise.all(Iterable<any>|Promise<Iterable<any>> input) -> Promise<Array<any>>
```
This method is useful for when you want to wait for more than one promise to complete.
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and return a promise that is fulfilled when all the items in the array are fulfilled. The promise's fulfillment value is an array with fulfillment values at respective positions to the original array. If any promise in the array rejects, the returned promise is rejected with the rejection reason.
```
var files = [];
for (var i = 0; i < 100; ++i) {
files.push(fs.writeFileAsync("file-" + i + ".txt", "", "utf-8"));
}
Promise.all(files).then(function() {
console.log("all the files were created");
});
```
This method is compatible with [`Promise.all`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/all) from native promises.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.noConflict Promise.noConflict
===================
```
Promise.noConflict() -> Object
```
This is relevant to browser environments with no module loader.
Release control of the `Promise` namespace to whatever it was before this library was loaded. Returns a reference to the library namespace so you can attach it to something else.
```
<!-- the other promise library must be loaded first -->
<script type="text/javascript" src="/scripts/other_promise.js"></script>
<script type="text/javascript" src="/scripts/bluebird_debug.js"></script>
<script type="text/javascript">
//Release control right after
var Bluebird = Promise.noConflict();
//Cast a promise from some other Promise library using the Promise namespace to Bluebird:
var promise = Bluebird.resolve(new Promise());
</script>
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .suppressUnhandledRejections .suppressUnhandledRejections
=============================
```
.suppressUnhandledRejections() -> undefined
```
Basically sugar for doing:
```
somePromise.catch(function(){});
```
Which is needed in case error handlers are attached asynchronously to the promise later, which would otherwise result in premature unhandled rejection reporting.
Example:
```
var tweets = fetchTweets();
$(document).on("ready", function() {
tweets.then(function() {
// Render tweets
}).catch(function(e) {
alert("failed to fetch tweets because: " + e);
});
});
```
If fetching tweets fails before the document is ready the rejection is reported as unhandled even though it will be eventually handled when the document is ready. This is of course impossible to determine automatically, but you can explicitly do so using `.suppressUnhandledRejections()`:
```
var tweets = fetchTweets();
tweets.suppressUnhandledRejections();
$(document).on("ready", function() {
tweets.then(function() {
// Render tweets
}).catch(function(e) {
alert("failed to fetch tweets because: " + e);
});
});
```
It should be noted that there is no real need to attach the handlers asynchronously. Exactly the same effect can be achieved with:
```
fetchTweets()
.finally(function() {
return $.ready.promise();
})
// DOM guaranteed to be ready after this point
.then(function() {
// Render tweets
})
.catch(function(e) {
alert("failed to fetch tweets because: " + e);
});
```
The advantage of using `.suppressUnhandledRejections()` over `.catch(function(){})` is that it doesn't increment the branch count of the promise. Branch counts matter when using cancellation because a promise will only be cancelled if all of its branches want to cancel it.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .asCallback .asCallback
============
```
.asCallback(
[function(any error, any value) callback],
[Object {spread: boolean=false} options]
) -> this
```
```
.nodeify(
[function(any error, any value) callback],
[Object {spread: boolean=false} options]
) -> this
```
Register a node-style callback on this promise. When this promise is either fulfilled or rejected, the node callback will be called back with the node.js convention where error reason is the first argument and success value is the second argument. The error argument will be `null` in case of success.
Returns back this promise instead of creating a new one. If the `callback` argument is not a function, this method does not do anything.
This can be used to create APIs that both accept node-style callbacks and return promises:
```
function getDataFor(input, callback) {
return dataFromDataBase(input).asCallback(callback);
}
```
The above function can then make everyone happy.
Promises:
```
getDataFor("me").then(function(dataForMe) {
console.log(dataForMe);
});
```
Normal callbacks:
```
getDataFor("me", function(err, dataForMe) {
if( err ) {
console.error( err );
}
console.log(dataForMe);
});
```
Promises can be rejected with falsy values (or no value at all, equal to rejecting with `undefined`), however `.asCallback` will call the callback with an `Error` object if the promise's rejection reason is a falsy value. You can retrieve the original falsy value from the error's `.cause` property.
Example:
```
Promise.reject(null).asCallback(function(err, result) {
// If is executed
if (err) {
// Logs 'null'
console.log(err.cause);
}
});
```
There is no effect on performance if the user doesn't actually pass a node-style callback function.
#### Option: spread
Some nodebacks expect more than 1 success value but there is no mapping for this in the promise world. You may specify the option `spread` to call the nodeback with multiple values when the fulfillment value is an array:
```
Promise.resolve([1,2,3]).asCallback(function(err, result) {
// err == null
// result is the array [1,2,3]
});
Promise.resolve([1,2,3]).asCallback(function(err, a, b, c) {
// err == null
// a == 1
// b == 2
// c == 3
}, {spread: true});
Promise.resolve(123).asCallback(function(err, a, b, c) {
// err == null
// a == 123
// b == undefined
// c == undefined
}, {spread: true});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird .catch .catch
=======
`.catch` is a convenience method for handling errors in promise chains. It comes in two variants - A catch-all variant similar to the synchronous `catch(e) {` block. This variant is compatible with native promises. - A filtered variant (like other non-JS languages typically have) that lets you only handle specific errors. **This variant is usually preferable and is significantly safer**.
### A note on promise exception handling.
Promise exception handling mirrors native exception handling in JavaScript. A synchronous function `throw`ing is similar to a promise rejecting. Here is an example to illustrate it:
```
function getItems(param) {
try {
var items = getItemsSync();
if(!items) throw new InvalidItemsError();
} catch(e) {
// can address the error here, either from getItemsSync returning a falsey value or throwing itself
throw e; // need to re-throw the error unless I want it to be considered handled.
}
return process(items);
}
```
Similarly, with promises:
```
function getItems(param) {
return getItemsAsync().then(items => {
if(!items) throw new InvalidItemsError();
return items;
}).catch(e => {
// can address the error here and recover from it, from getItemsAsync rejects or returns a falsey value
throw e; // Need to rethrow unless we actually recovered, just like in the synchronous version
}).then(process);
}
```
### Catch-all
```
.catch(function(any error) handler) -> Promise
```
```
.caught(function(any error) handler) -> Promise
```
This is a catch-all exception handler, shortcut for calling [`.then(null, handler)`](then) on this promise. Any exception happening in a `.then`-chain will propagate to nearest `.catch` handler.
*For compatibility with earlier ECMAScript versions, an alias `.caught` is provided for [`.catch`](catch).*
### Filtered Catch
```
.catch(
class ErrorClass|function(any error)|Object predicate...,
function(any error) handler
) -> Promise
```
```
.caught(
class ErrorClass|function(any error)|Object predicate...,
function(any error) handler
) -> Promise
```
This is an extension to [`.catch`](catch) to work more like catch-clauses in languages like Java or C#. Instead of manually checking `instanceof` or `.name === "SomeError"`, you may specify a number of error constructors which are eligible for this catch handler. The catch handler that is first met that has eligible constructors specified, is the one that will be called.
Example:
```
somePromise.then(function() {
return a.b.c.d();
}).catch(TypeError, function(e) {
//If it is a TypeError, will end up here because
//it is a type error to reference property of undefined
}).catch(ReferenceError, function(e) {
//Will end up here if a was never declared at all
}).catch(function(e) {
//Generic catch-the rest, error wasn't TypeError nor
//ReferenceError
});
```
You may also add multiple filters for a catch handler:
```
somePromise.then(function() {
return a.b.c.d();
}).catch(TypeError, ReferenceError, function(e) {
//Will end up here on programmer error
}).catch(NetworkError, TimeoutError, function(e) {
//Will end up here on expected everyday network errors
}).catch(function(e) {
//Catch any unexpected errors
});
```
For a parameter to be considered a type of error that you want to filter, you need the constructor to have its `.prototype` property be `instanceof Error`.
Such a constructor can be minimally created like so:
```
function MyCustomError() {}
MyCustomError.prototype = Object.create(Error.prototype);
```
Using it:
```
Promise.resolve().then(function() {
throw new MyCustomError();
}).catch(MyCustomError, function(e) {
//will end up here now
});
```
However if you want stack traces and cleaner string output, then you should do:
*in Node.js and other V8 environments, with support for `Error.captureStackTrace`*
```
function MyCustomError(message) {
this.message = message;
this.name = "MyCustomError";
Error.captureStackTrace(this, MyCustomError);
}
MyCustomError.prototype = Object.create(Error.prototype);
MyCustomError.prototype.constructor = MyCustomError;
```
Using CoffeeScript's `class` for the same:
```
class MyCustomError extends Error
constructor: (@message) ->
@name = "MyCustomError"
Error.captureStackTrace(this, MyCustomError)
```
This method also supports predicate-based filters. If you pass a predicate function instead of an error constructor, the predicate will receive the error as an argument. The return result of the predicate will be used determine whether the error handler should be called.
Predicates should allow for very fine grained control over caught errors: pattern matching, error-type sets with set operations and many other techniques can be implemented on top of them.
Example of using a predicate-based filter:
```
var Promise = require("bluebird");
var request = Promise.promisify(require("request"));
function ClientError(e) {
return e.code >= 400 && e.code < 500;
}
request("http://www.google.com").then(function(contents) {
console.log(contents);
}).catch(ClientError, function(e) {
//A client error like 400 Bad Request happened
});
```
Predicate functions that only check properties have a handy shorthand. In place of a predicate function, you can pass an object, and its properties will be checked against the error object for a match:
```
fs.readFileAsync(...)
.then(...)
.catch({code: 'ENOENT'}, function(e) {
console.log("file not found: " + e.path);
});
```
The object predicate passed to `.catch` in the above code (`{code: 'ENOENT'}`) is shorthand for a predicate function `function predicate(e) { return isObject(e) && e.code == 'ENOENT' }`, I.E. loose equality is used.
*For compatibility with earlier ECMAScript version, an alias `.caught` is provided for [`.catch`](catch).*
By not returning a rejected value or `throw`ing from a catch, you "recover from failure" and continue the chain:
```
Promise.reject(Error('fail!'))
.catch(function(e) {
// fallback with "recover from failure"
return Promise.resolve('success!'); // promise or value
})
.then(function(result) {
console.log(result); // will print "success!"
});
```
This is exactly like the synchronous code:
```
var result;
try {
throw Error('fail');
} catch(e) {
result = 'success!';
}
console.log(result);
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Core Core
=====
Core methods of `Promise` instances and core static methods of the Promise class.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Error management configuration Error management configuration
===============================
The default approach of bluebird is to immediately log the stack trace when there is an unhandled rejection. This is similar to how uncaught exceptions cause the stack trace to be logged so that you have something to work with when something is not working as expected.
However because it is possible to handle a rejected promise at any time in the indeterminate future, some programming patterns will result in false positives. Because such programming patterns are not necessary and can always be refactored to never cause false positives, we recommend doing that to keep debugging as easy as possible . You may however feel differently so bluebird provides hooks to implement more complex failure policies.
Such policies could include:
* Logging after the promise became GCd (requires a native node.js module)
* Showing a live list of rejected promises
* Using no hooks and using [`.done`](done) to manually to mark end points where rejections will not be handled
* Swallowing all errors (challenge your debugging skills)
* ...
### Global rejection events
Starting from 2.7.0 all bluebird instances also fire rejection events globally so that applications can register one universal hook for them.
The global events are:
* `"unhandledRejection"` (corresponds to the local [`Promise.onPossiblyUnhandledRejection`](promise.onpossiblyunhandledrejection))
* `"rejectionHandled"` (corresponds to the local [`Promise.onUnhandledRejectionHandled`](promise.onunhandledrejectionhandled))
Attaching global rejection event handlers in **node.js**:
```
// NOTE: event name is camelCase as per node convention
process.on("unhandledRejection", function(reason, promise) {
// See Promise.onPossiblyUnhandledRejection for parameter documentation
});
// NOTE: event name is camelCase as per node convention
process.on("rejectionHandled", function(promise) {
// See Promise.onUnhandledRejectionHandled for parameter documentation
});
```
Attaching global rejection event handlers in **browsers**:
Using DOM3 `addEventListener` APIs (support starting from IE9+):
```
// NOTE: event name is all lower case as per DOM convention
window.addEventListener("unhandledrejection", function(e) {
// NOTE: e.preventDefault() must be manually called to prevent the default
// action which is currently to log the stack trace to console.warn
e.preventDefault();
// NOTE: parameters are properties of the event detail property
var reason = e.detail.reason;
var promise = e.detail.promise;
// See Promise.onPossiblyUnhandledRejection for parameter documentation
});
// NOTE: event name is all lower case as per DOM convention
window.addEventListener("rejectionhandled", function(e) {
// NOTE: e.preventDefault() must be manually called prevent the default
// action which is currently unset (but might be set to something in the future)
e.preventDefault();
// NOTE: parameters are properties of the event detail property
var promise = e.detail.promise;
// See Promise.onUnhandledRejectionHandled for parameter documentation
});
```
In Web Workers you may use `self.addEventListener`.
Using legacy APIs (support starting from IE6+):
```
// NOTE: event name is all lower case as per legacy convention
window.onunhandledrejection = function(reason, promise) {
// See Promise.onPossiblyUnhandledRejection for parameter documentation
};
// NOTE: event name is all lower case as per legacy convention
window.onrejectionhandled = function(promise) {
// See Promise.onUnhandledRejectionHandled for parameter documentation
};
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Async hooks Promise.config
---------------
```
Promise.config(Object {
warnings: boolean=false,
longStackTraces: boolean=false,
cancellation: boolean=false,
monitoring: boolean=false,
asyncHooks: boolean=false
} options) -> Object;
```
Configure long stack traces, warnings, monitoring, [async hooks](https://nodejs.org/api/async_hooks.html) and cancellation. Note that even though `false` is the default here, a development environment might be detected which automatically enables long stack traces and warnings. For **webpack** and **browserify** *development* environment is *always* enabled. See [installation](../install#browserify-and-webpack) on how to configure webpack and browserify for production.
```
Promise.config({
// Enable warnings
warnings: true,
// Enable long stack traces
longStackTraces: true,
// Enable cancellation
cancellation: true,
// Enable monitoring
monitoring: true,
// Enable async hooks
asyncHooks: true,
});
```
You can configure the warning for checking forgotten return statements with `wForgottenReturn`:
```
Promise.config({
// Enables all warnings except forgotten return statements.
warnings: {
wForgottenReturn: false
}
});
```
`wForgottenReturn` is the only warning type that can be separately configured. The corresponding environmental variable key is `BLUEBIRD_W_FORGOTTEN_RETURN`.
In Node.js you may configure warnings and long stack traces for the entire process using environment variables:
```
BLUEBIRD_LONG_STACK_TRACES=1 BLUEBIRD_WARNINGS=1 node app.js
```
Both features are automatically enabled if the `BLUEBIRD_DEBUG` environment variable has been set or if the `NODE_ENV` environment variable is equal to `"development"`.
Using the value `0` will explicitly disable a feature despite debug environment otherwise activating it:
```
# Warnings are disabled despite being in development environment
NODE_ENV=development BLUEBIRD_WARNINGS=0 node app.js
```
Cancellation is always configured separately per bluebird instance.
Async hooks
============
Bluebird supports [async hooks](https://nodejs.org/api/async_hooks.html) in node versions 9.6.0 and later. After it is enabled promises from the bluebird instance are assigned unique asyncIds:
```
// Async hooks disabled for bluebird
const ah = require('async_hooks');
const Promise = require("bluebird");
Promise.resolve().then(() => {
console.log(`eid ${ah.executionAsyncId()} tid ${ah.triggerAsyncId()}`);
//
});
```
```
// Async hooks enabled for bluebird
const ah = require('async_hooks');
const Promise = require("bluebird");
Promise.config({asyncHooks: true});
Promise.resolve().then(() => {
console.log(`eid ${ah.executionAsyncId()} tid ${ah.triggerAsyncId()}`);
//
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .timeout .timeout
=========
```
.timeout(
int ms,
[String message="operation timed out"]
) -> Promise
```
```
.timeout(
int ms,
[Error error]
) -> Promise
```
Returns a promise that will be fulfilled with this promise's fulfillment value or rejection reason. However, if this promise is not fulfilled or rejected within `ms` milliseconds, the returned promise is rejected with a [`TimeoutError`](timeouterror) or the `error` as the reason.
When using the first signature, you may specify a custom error message with the `message` parameter.
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require('fs'));
fs.readFileAsync("huge-file.txt").timeout(100).then(function(fileContents) {
}).catch(Promise.TimeoutError, function(e) {
console.log("could not read file within 100ms");
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .tapCatch .tapCatch
==========
`.tapCatch` is a convenience method for reacting to errors without handling them with promises - similar to `finally` but only called on rejections. Useful for logging errors.
It comes in two variants. - A tapCatch-all variant similar to [`.catch`](catch) block. This variant is compatible with native promises. - A filtered variant (like other non-JS languages typically have) that lets you only handle specific errors. **This variant is usually preferable**.
### `tapCatch` all
```
.tapCatch(function(any value) handler) -> Promise
```
Like [`.finally`](finally) that is not called for fulfillments.
```
getUser().tapCatch(function(err) {
return logErrorToDatabase(err);
}).then(function(user) {
//user is the user from getUser(), not logErrorToDatabase()
});
```
Common case includes adding logging to an existing promise chain:
#### Rate Limiting
```
Promise.
try(logIn).
then(respondWithSuccess).
tapCatch(countFailuresForRateLimitingPurposes).
catch(respondWithError);
```
#### Circuit Breakers
```
Promise.
try(makeRequest).
then(respondWithSuccess).
tapCatch(adjustCircuitBreakerState).
catch(respondWithError);
```
#### Logging
```
Promise.
try(doAThing).
tapCatch(logErrorsRelatedToThatThing).
then(respondWithSuccess).
catch(respondWithError);
```
*Note: in browsers it is necessary to call `.tapCatch` with `console.log.bind(console)` because console methods can not be called as stand-alone functions.*
### Filtered `tapCatch`
```
.tapCatch(
class ErrorClass|function(any error),
function(any error) handler
) -> Promise
```
```
.tapCatch(
class ErrorClass|function(any error),
function(any error) handler
) -> Promise
```
This is an extension to [`.tapCatch`](tapcatch) to filter exceptions similarly to languages like Java or C#. Instead of manually checking `instanceof` or `.name === "SomeError"`, you may specify a number of error constructors which are eligible for this tapCatch handler. The tapCatch handler that is first met that has eligible constructors specified, is the one that will be called.
Usage examples include:
#### Rate Limiting
```
Promise.
try(logIn).
then(respondWithSuccess).
tapCatch(InvalidCredentialsError, countFailuresForRateLimitingPurposes).
catch(respondWithError);
```
#### Circuit Breakers
```
Promise.
try(makeRequest).
then(respondWithSuccess).
tapCatch(RequestError, adjustCircuitBreakerState).
catch(respondWithError);
```
#### Logging
```
Promise.
try(doAThing).
tapCatch(logErrorsRelatedToThatThing).
then(respondWithSuccess).
catch(respondWithError);
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .done .done
======
```
.done(
[function(any value) fulfilledHandler],
[function(any error) rejectedHandler]
) -> undefined
```
Like [`.then`](then), but any unhandled rejection that ends up here will crash the process (in node) or be thrown as an error (in browsers). The use of this method is heavily discouraged and it only exists for historical reasons.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .call .call
======
```
.call(
String methodName,
[any args...]
)
```
This is a convenience method for doing:
```
promise.then(function(obj) {
return obj[methodName].call(obj, arg...);
});
```
For example ([`some` is a built-in array method](https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/Array/some)):
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
var path = require("path");
var thisPath = process.argv[2] || ".";
var now = Date.now();
fs.readdirAsync(thisPath)
.map(function(fileName) {
return fs.statAsync(path.join(thisPath, fileName));
})
.call("some", function(stat) {
return (now - new Date(stat.mtime)) < 10000;
})
.then(function(someFilesHaveBeenModifiedLessThanTenSecondsAgo) {
console.log(someFilesHaveBeenModifiedLessThanTenSecondsAgo) ;
});
```
Chaining lo-dash or underscore methods (Copy-pasteable example):
```
var Promise = require("bluebird");
var pmap = Promise.map;
var props = Promise.props;
var _ = require("lodash");
var fs = Promise.promisifyAll(require("fs"));
function getTotalSize(paths) {
return pmap(paths, function(path) {
return fs.statAsync(path).get("size");
}).reduce(function(a, b) {
return a + b;
}, 0);
}
fs.readdirAsync(".").then(_)
.call("groupBy", function(fileName) {
return fileName.charAt(0);
})
.call("map", function(fileNames, firstCh) {
return props({
firstCh: firstCh,
count: fileNames.length,
totalSize: getTotalSize(fileNames)
});
})
// Since the currently wrapped array contains promises we need to unwrap it and call .all() before continuing the chain
// If the currently wrapped thing was an object with properties that might be promises, we would call .props() instead
.call("value").all().then(_)
.call("sortBy", "count")
.call("reverse")
.call("map", function(data) {
return data.count + " total files beginning with " + data.firstCh + " with total size of " + data.totalSize + " bytes";
})
.call("join", "\n")
.then(console.log)
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird .tap .tap
=====
```
.tap(function(any value) handler) -> Promise
```
Essentially like `.then()`, except that the value passed in is the value returned.
This means you can insert `.tap()` into a `.then()` chain without affecting what is passed through the chain. (See example below).
Unlike [`.finally`](finally) this is not called for rejections.
```
getUser().tap(function(user) {
//Like in finally, if you return a promise from the handler
//the promise is awaited for before passing the original value through
return recordStatsAsync();
}).then(function(user) {
//user is the user from getUser(), not recordStatsAsync()
});
```
Common case includes adding logging to an existing promise chain:
```
doSomething()
.then(...)
.then(...)
.then(...)
.then(...)
```
```
doSomething()
.then(...)
.then(...)
.tap(console.log)
.then(...)
.then(...)
```
*Note: in browsers it is necessary to call `.tap` with `console.log.bind(console)` because console methods can not be called as stand-alone functions.*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .isPending .isPending
===========
```
.isPending() -> boolean
```
See if this `promise` is pending (not fulfilled or rejected or cancelled).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .reduce .reduce
========
```
.reduce(
function(any accumulator, any item, int index, int length) reducer,
[any initialValue]
) -> Promise
```
Same as [`Promise.reduce(this, reducer, initialValue)`](promise.reduce).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.promisify Promise.promisify
==================
```
Promise.promisify(
function(any arguments..., function callback) nodeFunction,
[Object {
multiArgs: boolean=false,
context: any=this
} options]
) -> function
```
Returns a function that will wrap the given `nodeFunction`. Instead of taking a callback, the returned function will return a promise whose fate is decided by the callback behavior of the given node function. The node function should conform to node.js convention of accepting a callback as last argument and calling that callback with error as the first argument and success value on the second argument.
If the `nodeFunction` calls its callback with multiple success values, the fulfillment value will be the first fulfillment item.
Setting `multiArgs` to `true` means the resulting promise will always fulfill with an array of the callback's success value(s). This is needed because promises only support a single success value while some callback API's have multiple success value. The default is to ignore all but the first success value of a callback function.
If you pass a `context`, the `nodeFunction` will be called as a method on the `context`.
Example of promisifying the asynchronous `readFile` of node.js `fs`-module:
```
var readFile = Promise.promisify(require("fs").readFile);
readFile("myfile.js", "utf8").then(function(contents) {
return eval(contents);
}).then(function(result) {
console.log("The result of evaluating myfile.js", result);
}).catch(SyntaxError, function(e) {
console.log("File had syntax error", e);
//Catch any other error
}).catch(function(e) {
console.log("Error reading file", e);
});
```
Note that if the node function is a method of some object, you can pass the object as the second argument like so:
```
var redisGet = Promise.promisify(redisClient.get, {context: redisClient});
redisGet('foo').then(function() {
//...
});
```
But this will also work:
```
var getAsync = Promise.promisify(redisClient.get);
getAsync.call(redisClient, 'foo').then(function() {
//...
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Cancellation Cancellation
=============
Cancellation has been redesigned for bluebird 3.x, any code that relies on 2.x cancellation semantics won't work in 3.x.
The cancellation feature is **by default turned off**, you can enable it using [`Promise.config`](promise.config).
The new cancellation has "don't care" semantics while the old cancellation had abort semantics. Cancelling a promise simply means that its handler callbacks will not be called.
The advantages of the new cancellation compared to the old cancellation are:
* [`.cancel()`](cancel) is synchronous.
* no setup code required to make cancellation work
* composes with other bluebird features, like [`Promise.all`](promise.all).
* [reasonable semantics for multiple consumer cancellation](#what-about-promises-that-have-multiple-consumers)
As an optimization, the cancellation signal propagates upwards the promise chain so that an ongoing operation e.g. network request can be aborted. However, *not* aborting the network request still doesn't make any operational difference as the callbacks are still not called either way.
You may register an optional cancellation hook at a root promise by using the `onCancel` argument that is passed to the executor function when cancellation is enabled:
```
function makeCancellableRequest(url) {
return new Promise(function(resolve, reject, onCancel) {
var xhr = new XMLHttpRequest();
xhr.on("load", resolve);
xhr.on("error", reject);
xhr.open("GET", url, true);
xhr.send(null);
// Note the onCancel argument only exists if cancellation has been enabled!
onCancel(function() {
xhr.abort();
});
});
}
```
Note that the `onCancel` hook is really an optional disconnected optimization, there is no real requirement to register any cancellation hooks for cancellation to work. As such, any errors that may occur while inside the `onCancel` callback are not caught and turned into rejections.
While `cancel().` is synchronous - `onCancel()` is called asynchronously (in the next turn) just like `then` handlers.
Example:
```
var searchPromise = Promise.resolve(); // Dummy promise to avoid null check.
document.querySelector("#search-input").addEventListener("input", function() {
// The handlers of the previous request must not be called
searchPromise.cancel();
var url = "/search?term=" + encodeURIComponent(this.value.trim());
showSpinner();
searchPromise = makeCancellableRequest(url)
.then(function(results) {
return transformData(results);
})
.then(function(transformedData) {
document.querySelector("#search-results").innerHTML = transformedData;
})
.catch(function(e) {
document.querySelector("#search-results").innerHTML = renderErrorBox(e);
})
.finally(function() {
// This check is necessary because `.finally` handlers are always called.
if (!searchPromise.isCancelled()) {
hideSpinner();
}
});
});
```
As shown in the example the handlers registered with `.finally` are called even if the promise is cancelled. Another such exception is [`.reflect()`](reflect). No other types of handlers will be called in case of cancellation. This means that in `.then(onSuccess, onFailure)` neither `onSuccess` or `onFailure` handler is called. This is similar to how [`Generator#return`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Generator/return) works - only active `finally` blocks are executed and then the generator exits.
### What about promises that have multiple consumers?
It is often said that promises cannot be cancellable because they can have multiple consumers.
For instance:
```
var result = makeCancellableRequest(...);
var firstConsumer = result.then(...);
var secondConsumer = result.then(...);
```
Even though in practice most users of promises will never have any need to take advantage of the fact that you can attach multiple consumers to a promise, it is nevertheless possible. The problem: "what should happen if [`.cancel()`](cancel) is called on `firstConsumer`?" Propagating the cancellation signal (and therefore making it abort the request) would be very bad as the second consumer might still be interested in the result despite the first consumer's disinterest.
What actually happens is that `result` keeps track of how many consumers it has, in this case 2, and only if all the consumers signal cancel will the request be aborted. However, as far as `firstConsumer` can tell, the promise was successfully cancelled and its handlers will not be called.
Note that it is an error to consume an already cancelled promise, doing such a thing will give you a promise that is rejected with `new CancellationError("late cancellation observer")` as the rejection reason.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.fromCallback Promise.fromCallback
=====================
```
Promise.fromCallback(
function(function callback) resolver,
[Object {multiArgs: boolean=false} options]
) -> Promise
```
```
Promise.fromNode(
function(function callback) resolver,
[Object {multiArgs: boolean=false} options]
) -> Promise
```
Returns a promise that is resolved by a node style callback function. This is the most fitting way to do on the fly promisification when libraries don't expose classes for automatic promisification by undefined.
The resolver function is passed a callback that expects to be called back according to error-first node conventions.
Setting `multiArgs` to `true` means the resulting promise will always fulfill with an array of the callback's success value(s). This is needed because promises only support a single success value while some callback API's have multiple success value. The default is to ignore all but the first success value of a callback function.
Using manual resolver:
```
var Promise = require("bluebird");
// "email-templates" doesn't expose prototypes for promisification
var emailTemplates = Promise.promisify(require('email-templates'));
var templatesDir = path.join(__dirname, 'templates');
emailTemplates(templatesDir).then(function(template) {
return Promise.fromCallback(function(callback) {
return template("newsletter", callback);
}, {multiArgs: true}).spread(function(html, text) {
console.log(html, text);
});
});
```
The same can also be written more concisely with `Function.prototype.bind`:
```
var Promise = require("bluebird");
// "email-templates" doesn't expose prototypes for promisification
var emailTemplates = Promise.promisify(require('email-templates'));
var templatesDir = path.join(__dirname, 'templates');
emailTemplates(templatesDir).then(function(template) {
return Promise.fromCallback(template.bind(null, "newsletter"), {multiArgs: true})
.spread(function(html, text) {
console.log(html, text);
});
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Timers Timers
=======
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird new Promise new Promise
============
```
new Promise(function(function resolve, function reject) resolver) -> Promise
```
Create a new promise. The passed in function will receive functions `resolve` and `reject` as its arguments which can be called to seal the fate of the created promise.
*Note: See [explicit construction anti-pattern](../anti-patterns#the-explicit-construction-anti-pattern) before creating promises yourself*
Example:
```
function ajaxGetAsync(url) {
return new Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest;
xhr.addEventListener("error", reject);
xhr.addEventListener("load", resolve);
xhr.open("GET", url);
xhr.send(null);
});
}
```
If you pass a promise object to the `resolve` function, the created promise will follow the state of that promise.
To make sure a function that returns a promise is following the implicit but critically important contract of promises, you can start a function with `new Promise` if you cannot start a chain immediately:
```
function getConnection(urlString) {
return new Promise(function(resolve) {
//Without new Promise, this throwing will throw an actual exception
var params = parse(urlString);
resolve(getAdapter(params).getConnection());
});
}
```
The above ensures `getConnection` fulfills the contract of a promise-returning function of never throwing a synchronous exception. Also see [`Promise.try`](promise.try) and [`Promise.method`](promise.method)
The resolver is called synchronously (the following is for documentation purposes and not idiomatic code):
```
function getPromiseResolveFn() {
var res;
new Promise(function (resolve) {
res = resolve;
});
// res is guaranteed to be set
return res;
}
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.mapSeries Promise.mapSeries
==================
```
Promise.mapSeries(
Iterable<any>|Promise<Iterable<any>> input,
function(any value, int index, int arrayLength) mapper
) -> Promise<Array<any>>
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols) (an array, for example), or a promise of an `Iterable`, iterates serially over all the values in it, executing the given `mapper` on each element. If an element is a promise, the mapper will wait for it before proceeding. The `mapper` function has signature `(value, index, arrayLength)` where `value` is the current element (or its resolved value if it is a promise).
If, at any step:
* The mapper returns a promise or a thenable, it is awaited before continuing to the next iteration.
* The current element of the iteration is a *pending* promise, that promise will be awaited before running the mapper.
* The current element of the iteration is a *rejected* promise, the iteration will stop and be rejected as well (with the same reason).
If all iterations resolve successfully, the `Promise.mapSeries` call resolves to a new array containing the results of each `mapper` execution, in order.
`Promise.mapSeries` is very similar to [`Promise.each`](promise.each). The difference between `Promise.each` and `Promise.mapSeries` is their resolution value. `Promise.mapSeries` resolves with an array as explained above, while `Promise.each` resolves with an array containing the *resolved values of the input elements* (ignoring the outputs of the iteration steps). This way, `Promise.each` is meant to be mainly used for side-effect operations (since the outputs of the iterator are essentially discarded), just like the native `.forEach()` method of arrays, while `Promise.map` is meant to be used as an async version of the native `.map()` method of arrays.
Basic example:
```
// The array to be mapped over can be a mix of values and promises.
var fileNames = ["1.txt", Promise.resolve("2.txt"), "3.txt", Promise.delay(3000, "4.txt"), "5.txt"];
Promise.mapSeries(fileNames, function(fileName, index, arrayLength) {
// The iteration will be performed sequentially, awaiting for any
// promises in the process.
return fs.readFileAsync(fileName).then(function(fileContents) {
// ...
return fileName + "!";
});
}).then(function(result) {
// This will run after the last step is done
console.log("Done!")
console.log(result); // ["1.txt!", "2.txt!", "3.txt!", "4.txt!", "5.txt!"]
});
```
Example with a rejected promise in the array:
```
// If one of the promises in the original array rejects,
// the iteration will stop once it reaches it
var items = ["A", Promise.delay(8000, "B"), Promise.reject("C"), "D"];
Promise.each(items, function(item) {
return Promise.delay(4000).then(function() {
console.log("On mapper: " + item);
});
}).then(function(result) {
// This not run
}).catch(function(rejection) {
console.log("Catch: " + rejection);
});
// The code above outputs the following after 12 seconds (not 16!):
// On mapper: A
// On mapper: B
// Catch: C
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.getNewLibraryCopy Promise.getNewLibraryCopy
==========================
```
Promise.getNewLibraryCopy() -> Object
```
Returns a new independent copy of the Bluebird library.
This method should be used before you use any of the methods which would otherwise alter the global `Bluebird` object - to avoid polluting global state.
A basic example:
```
var Promise = require('bluebird');
var Promise2 = Promise.getNewLibraryCopy();
Promise2.x = 123;
console.log(Promise2 == Promise); // false
console.log(Promise2.x); // 123
console.log(Promise.x); // undefined
```
`Promise2` is independent to `Promise`. Any changes to `Promise2` do not affect the copy of Bluebird returned by `require('bluebird')`.
In practice:
```
var Promise = require('bluebird').getNewLibraryCopy();
Promise.coroutine.addYieldHandler( function() { /* */ } ); // alters behavior of `Promise.coroutine()`
// somewhere in another file or module in same app
var Promise = require('bluebird');
Promise.coroutine(function*() {
// this code is unaffected by the yieldHandler defined above
// because it was defined on an independent copy of Bluebird
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.onPossiblyUnhandledRejection Promise.onPossiblyUnhandledRejection
=====================================
```
Promise.onPossiblyUnhandledRejection(function(any error, Promise promise) handler) -> undefined
```
*Note: this hook is specific to the bluebird instance it's called on, application developers should use [global rejection events](error-management-configuration#global-rejection-events)*
Add `handler` as the handler to call when there is a possibly unhandled rejection. The default handler logs the error stack to stderr or `console.error` in browsers.
```
Promise.onPossiblyUnhandledRejection(function(e, promise) {
throw e;
});
```
Passing no value or a non-function will have the effect of removing any kind of handling for possibly unhandled rejections.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Synchronous inspection Synchronous inspection
=======================
Often it is known in certain code paths that a promise is guaranteed to be fulfilled at that point - it would then be extremely inconvenient to use [`.then`](then) to get at the promise's value as the callback is always called asynchronously.
**Note**: In recent versions of Bluebird a design choice was made to expose [`.reason()`](reason) and [`.value()`](value) as well as other inspection methods on promises directly in order to make the below use case easier to work with. Every promise implements the [`PromiseInspection`](promiseinspection) interface.
For example, if you need to use values of earlier promises in the chain, you could nest:
```
// From Q Docs https://github.com/kriskowal/q/#chaining
// MIT License Copyright 2009–2014 Kristopher Michael Kowal.
function authenticate() {
return getUsername().then(function (username) {
return getUser(username);
// chained because we will not need the user name in the next event
}).then(function (user) {
// nested because we need both user and password next
return getPassword().then(function (password) {
if (user.passwordHash !== hash(password)) {
throw new Error("Can't authenticate");
}
});
});
}
```
Or you could take advantage of the fact that if we reach password validation, then the user promise must be fulfilled:
```
function authenticate() {
var user = getUsername().then(function(username) {
return getUser(username);
});
return user.then(function(user) {
return getPassword();
}).then(function(password) {
// Guaranteed that user promise is fulfilled, so .value() can be called here
if (user.value().passwordHash !== hash(password)) {
throw new Error("Can't authenticate");
}
});
}
```
In the latter the indentation stays flat no matter how many previous variables you need, whereas with the former each additional previous value would require an additional nesting level.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird Promise.try Promise.try
============
```
Promise.try(function() fn) -> Promise
```
```
Promise.attempt(function() fn) -> Promise
```
Start the chain of promises with `Promise.try`. Any synchronous exceptions will be turned into rejections on the returned promise.
```
function getUserById(id) {
return Promise.try(function() {
if (typeof id !== "number") {
throw new Error("id must be a number");
}
return db.getUserById(id);
});
}
```
Now if someone uses this function, they will catch all errors in their Promise `.catch` handlers instead of having to handle both synchronous and asynchronous exception flows.
*For compatibility with earlier ECMAScript version, an alias `Promise.attempt` is provided for [`Promise.try`](promise.try).*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.props Promise.props
==============
```
Promise.props(Object|Map|Promise<Object|Map> input) -> Promise
```
Like [`.all`](all) but for object properties or `Map`s\* entries instead of iterated values. Returns a promise that is fulfilled when all the properties of the object or the `Map`'s' values\*\* are fulfilled. The promise's fulfillment value is an object or a `Map` with fulfillment values at respective keys to the original object or a `Map`. If any promise in the object or `Map` rejects, the returned promise is rejected with the rejection reason.
If `object` is a trusted `Promise`, then it will be treated as a promise for object rather than for its properties. All other objects (except `Map`s) are treated for their properties as is returned by `Object.keys` - the object's own enumerable properties.
*\*Only the native [ECMAScript 6 `Map`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) implementation that is provided by the environment as is is supported*
*\*\*If the map's keys happen to be `Promise`s, they are not awaited for and the resulting `Map` will still have those same `Promise` instances as keys*
```
Promise.props({
pictures: getPictures(),
comments: getComments(),
tweets: getTweets()
}).then(function(result) {
console.log(result.tweets, result.pictures, result.comments);
});
```
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
var _ = require("lodash");
var path = require("path");
var util = require("util");
function directorySizeInfo(root) {
var counts = {dirs: 0, files: 0};
var stats = (function reader(root) {
return fs.readdirAsync(root).map(function(fileName) {
var filePath = path.join(root, fileName);
return fs.statAsync(filePath).then(function(stat) {
stat.filePath = filePath;
if (stat.isDirectory()) {
counts.dirs++;
return reader(filePath)
}
counts.files++;
return stat;
});
}).then(_.flatten);
})(root).then(_.chain);
var smallest = stats.call("min", "size").call("pick", "size", "filePath").call("value");
var largest = stats.call("max", "size").call("pick", "size", "filePath").call("value");
var totalSize = stats.call("pluck", "size").call("reduce", function(a, b) {
return a + b;
}, 0);
return Promise.props({
counts: counts,
smallest: smallest,
largest: largest,
totalSize: totalSize
});
}
directorySizeInfo(process.argv[2] || ".").then(function(sizeInfo) {
console.log(util.format(" \n\
%d directories, %d files \n\
Total size: %d bytes \n\
Smallest file: %s with %d bytes \n\
Largest file: %s with %d bytes \n\
", sizeInfo.counts.dirs, sizeInfo.counts.files, sizeInfo.totalSize,
sizeInfo.smallest.filePath, sizeInfo.smallest.size,
sizeInfo.largest.filePath, sizeInfo.largest.size));
});
```
Note that if you have no use for the result object other than retrieving the properties, it is more convenient to use [`Promise.join`](promise.join):
```
Promise.join(getPictures(), getComments(), getTweets(),
function(pictures, comments, tweets) {
console.log(pictures, comments, tweets);
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .some .some
======
```
.some(int count) -> Promise
```
Same as [`Promise.some(this, count)`](promise.some).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.each Promise.each
=============
```
Promise.each(
Iterable<any>|Promise<Iterable<any>> input,
function(any value, int index, int arrayLength) iterator
) -> Promise<Array<any>>
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols) (an array, for example), or a promise of an `Iterable`, iterates serially over all the values in it, executing the given `iterator` on each element. If an element is a promise, the iterator will wait for it before proceeding. The `iterator` function has signature `(value, index, arrayLength)` where `value` is the current element (or its resolved value if it is a promise).
If, at any step:
* The iterator returns a promise or a thenable, it is awaited before continuing to the next iteration.
* The current element of the iteration is a *pending* promise, that promise will be awaited before running the iterator.
* The current element of the iteration is a *rejected* promise, the iteration will stop and be rejected as well (with the same reason).
If all iterations resolve successfully, the `Promise.each` call resolves to a new array containing the resolved values of the original input elements.
`Promise.each` is very similar to [`Promise.mapSeries`](promise.mapseries). The difference between `Promise.each` and `Promise.mapSeries` is their resolution value. `Promise.each` resolves with an array as explained above, while `Promise.mapSeries` resolves with an array containing the *outputs* of the iterator function on each step. This way, `Promise.each` is meant to be mainly used for side-effect operations (since the outputs of the iterator are essentially discarded), just like the native `.forEach()` method of arrays, while `Promise.map` is meant to be used as an async version of the native `.map()` method of arrays.
Basic example:
```
// The array to be iterated over can be a mix of values and promises.
var fileNames = ["1.txt", Promise.resolve("2.txt"), "3.txt", Promise.delay(3000, "4.txt"), "5.txt"];
Promise.each(fileNames, function(fileName, index, arrayLength) {
// The iteration will be performed sequentially, awaiting for any
// promises in the process.
return fs.readFileAsync(fileName).then(function(fileContents) {
// ...
// The final resolution value of the iterator is is irrelevant,
// since the result of the `Promise.each` has nothing to do with
// the outputs of the iterator.
return "anything"; // Doesn't matter
});
}).then(function(result) {
// This will run after the last step is done
console.log("Done!")
console.log(result); // ["1.txt", "2.txt", "3.txt", "4.txt", "5.txt"]
});
```
Example with a rejected promise in the array:
```
// If one of the promises in the original array rejects,
// the iteration will stop once it reaches it
var items = ["A", Promise.delay(8000, "B"), Promise.reject("C"), "D"];
Promise.each(items, function(item) {
return Promise.delay(4000).then(function() {
console.log("On iterator: " + item);
});
}).then(function(result) {
// This not run
}).catch(function(rejection) {
console.log("Catch: " + rejection);
});
// The code above outputs the following after 12 seconds (not 16!):
// On iterator: A
// On iterator: B
// Catch: C
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.join Promise.join
=============
```
Promise.join(
Promise<any>|any values...,
function handler
) -> Promise
```
For coordinating multiple concurrent discrete promises. While [`.all`](all) is good for handling a dynamically sized list of uniform promises, `Promise.join` is much easier (and more performant) to use when you have a fixed amount of discrete promises that you want to coordinate concurrently. The final parameter, handler function, will be invoked with the result values of all of the fufilled promises. For example:
```
var Promise = require("bluebird");
var join = Promise.join;
join(getPictures(), getComments(), getTweets(),
function(pictures, comments, tweets) {
console.log("in total: " + pictures.length + comments.length + tweets.length);
});
```
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
var pg = require("pg");
Promise.promisifyAll(pg, {
filter: function(methodName) {
return methodName === "connect"
},
multiArgs: true
});
// Promisify rest of pg normally
Promise.promisifyAll(pg);
var join = Promise.join;
var connectionString = "postgres://username:password@localhost/database";
var fContents = fs.readFileAsync("file.txt", "utf8");
var fStat = fs.statAsync("file.txt");
var fSqlClient = pg.connectAsync(connectionString).spread(function(client, done) {
client.close = done;
return client;
});
join(fContents, fStat, fSqlClient, function(contents, stat, sqlClient) {
var query = " \
INSERT INTO files (byteSize, contents) \
VALUES ($1, $2) \
";
return sqlClient.queryAsync(query, [stat.size, contents]).thenReturn(query);
})
.then(function(query) {
console.log("Successfully ran the Query: " + query);
})
.finally(function() {
// This is why you want to use Promise.using for resource management
if (fSqlClient.isFulfilled()) {
fSqlClient.value().close();
}
});
```
*Note: In 1.x and 0.x `Promise.join` used to be a `Promise.all` that took the values in as arguments instead of an array. This behavior has been deprecated but is still supported partially - when the last argument is an immediate function value the new semantics will apply*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .reason .reason
========
```
.reason() -> any
```
Get the rejection reason of this promise. Throws an error if the promise isn't rejected - it is a bug to call this method on an unrejected promise.
You should check if this promise is [`.isRejected()`](isrejected) in code paths where it's guaranteed that this promise is rejected.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Deferred migration Deferred migration
===================
Deferreds are deprecated in favor of the promise constructor. If you need deferreds for some reason, you can create them trivially using the constructor:
```
function defer() {
var resolve, reject;
var promise = new Promise(function() {
resolve = arguments[0];
reject = arguments[1];
});
return {
resolve: resolve,
reject: reject,
promise: promise
};
}
```
For old code that still uses deferred objects, see [the deprecated API docs](../deprecated-apis#promise-resolution) .
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .value .value
=======
```
.value() -> any
```
Get the fulfillment value of this promise. Throws an error if the promise isn't fulfilled - it is a bug to call this method on an unfulfilled promise.
You should check if this promise is [`.isFulfilled()`](isfulfilled) in code paths where it's not guaranteed that this promise is fulfilled.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Utility Utility
========
Functions that could potentially be handy in some situations.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Generators Generators
===========
Using ECMAScript6 generators feature to implement C# 5.0 `async/await` like syntax.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .return .return
========
```
.return(any value) -> Promise
```
```
.thenReturn(any value) -> Promise
```
Convenience method for:
```
.then(function() {
return value;
});
```
in the case where `value` doesn't change its value because its binding time is different than when using a closure.
That means `value` is bound at the time of calling [`.return`](return) so this will not work as expected:
```
function getData() {
var data;
return query().then(function(result) {
data = result;
}).return(data);
}
```
because `data` is `undefined` at the time `.return` is called.
Function that returns the full path of the written file:
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
var baseDir = process.argv[2] || ".";
function writeFile(path, contents) {
var fullpath = require("path").join(baseDir, path);
return fs.writeFileAsync(fullpath, contents).return(fullpath);
}
writeFile("test.txt", "this is text").then(function(fullPath) {
console.log("Successfully file at: " + fullPath);
});
```
*For compatibility with earlier ECMAScript version, an alias `.thenReturn` is provided for [`.return`](return).*
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Collections Collections
============
Methods of `Promise` instances and core static methods of the Promise class to deal with collections of promises or mixed promises and values.
All collection methods have a static equivalent on the Promise object, e.g. `somePromise.map(...)...` is same as `Promise.map(somePromise, ...)...`, `somePromise.all` is same as [`Promise.all`](promise.all) and so on.
None of the collection methods modify the original input. Holes in arrays are treated as if they were defined with the value `undefined`.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .isCancelled .isCancelled
=============
```
.isCancelled() -> boolean
```
See if this `promise` has been cancelled.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird AggregateError AggregateError
===============
```
new AggregateError() extends Array -> AggregateError
```
A collection of errors. `AggregateError` is an array-like object, with numeric indices and a `.length` property. It supports all generic array methods such as `.forEach` directly.
`AggregateError`s are caught in [`.error`](error) handlers, even if the contained errors are not operational.
[`Promise.some`](promise.some) and [`Promise.any`](promise.any) use `AggregateError` as rejection reason when they fail.
Example:
```
//Assumes AggregateError has been made global
var err = new AggregateError();
err.push(new Error("first error"));
err.push(new Error("second error"));
throw err;
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.onUnhandledRejectionHandled Promise.onUnhandledRejectionHandled
====================================
```
Promise.onUnhandledRejectionHandled(function(Promise promise) handler) -> undefined
```
*Note: this hook is specific to the bluebird instance its called on, application developers should use [global rejection events](error-management-configuration#global-rejection-events)*
Add `handler` as the handler to call when a rejected promise that was reported as "possibly unhandled rejection" became handled.
Together with `onPossiblyUnhandledRejection` these hooks can be used to implement a debugger that will show a list of unhandled promise rejections updated in real time as promises become handled.
For example:
```
var unhandledPromises = [];
Promise.onPossiblyUnhandledRejection(function(reason, promise) {
unhandledPromises.push(promise);
//Update some debugger UI
});
Promise.onUnhandledRejectionHandled(function(promise) {
var index = unhandledPromises.indexOf(promise);
unhandledPromises.splice(index, 1);
//Update the debugger UI
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.delay Promise.delay
==============
```
Promise.delay(
int ms,
[any|Promise<any> value=undefined]
) -> Promise
```
Returns a promise that will be resolved with `value` (or `undefined`) after given `ms` milliseconds. If `value` is a promise, the delay will start counting down when it is fulfilled and the returned promise will be fulfilled with the fulfillment value of the `value` promise. If `value` is a rejected promise, the resulting promise will be rejected immediately.
```
Promise.delay(500).then(function() {
console.log("500 ms passed");
return "Hello world";
}).delay(500).then(function(helloWorldString) {
console.log(helloWorldString);
console.log("another 500 ms passed") ;
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Resource management Resource management
====================
Managing resources properly without leaks can be challenging. Simply using `.finally` is not enough as the following example demonstrates:
```
function doStuff() {
return Promise.all([
connectionPool.getConnectionAsync(),
fs.readFileAsync("file.sql", "utf8")
]).spread(function(connection, fileContents) {
return connection.query(fileContents).finally(function() {
connection.close();
});
}).then(function() {
console.log("query successful and connection closed");
});
}
```
It is very subtle but over time this code will exhaust the entire connection pool and the server needs to be restarted. This is because reading the file may fail and then of course `.spread` is not called at all and thus the connection is not closed.
One could solve this by either reading the file first or connecting first, and only proceeding if the first step succeeds. However, this would lose a lot of the benefits of using asynchronity and we might almost as well go back to using simple synchronous code.
We can do better, retaining concurrency and not leaking resources, by using:
* [disposers](disposer), objects that wrap a resource and a method to release that resource, together with
* [`Promise.using`](promise.using), a function to safely use disposers in a way that automatically calls their release method
```
var using = Promise.using;
using(getConnection(),
fs.readFileAsync("file.sql", "utf8"), function(connection, fileContents) {
return connection.query(fileContents);
}).then(function() {
console.log("query successful and connection closed");
});
```
Continue by reading about [disposers](disposer) and [`Promise.using`](promise.using)
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.coroutine.addYieldHandler Promise.coroutine.addYieldHandler
==================================
```
Promise.coroutine.addYieldHandler(function handler) -> undefined
```
By default you can only yield Promises and Thenables inside coroutines. You can use this function to add yielding support for arbitrary types.
For example, if you wanted `yield 500` to be same as `yield Promise.delay`:
```
Promise.coroutine.addYieldHandler(function(value) {
if (typeof value === "number") return Promise.delay(value);
});
```
Yield handlers are called when you yield something that is not supported by default. The first yield handler to return a promise or a thenable will be used. If no yield handler returns a promise or a thenable then an error is raised.
An example of implementing callback support with `addYieldHandler`:
*This is a demonstration of how powerful the feature is and not the recommended usage. For best performance you need to use `promisifyAll` and yield promises directly.*
```
var Promise = require("bluebird");
var fs = require("fs");
var _ = (function() {
var promise = null;
Promise.coroutine.addYieldHandler(function(v) {
if (v === undefined && promise != null) {
return promise;
}
promise = null;
});
return function() {
var def = Promise.defer();
promise = def.promise;
return def.callback;
};
})();
var readFileJSON = Promise.coroutine(function* (fileName) {
var contents = yield fs.readFile(fileName, "utf8", _());
return JSON.parse(contents);
});
```
An example of implementing thunks support with `addYieldHandler`:
*This is a demonstration of how powerful the feature is and not the recommended usage. For best performance you need to use `promisifyAll` and yield promises directly.*
```
var Promise = require("bluebird");
var fs = require("fs");
Promise.coroutine.addYieldHandler(function(v) {
if (typeof v === "function") {
return Promise.fromCallback(function(cb) {
v(cb);
});
}
});
var readFileThunk = function(fileName, encoding) {
return function(cb) {
return fs.readFile(fileName, encoding, cb);
};
};
var readFileJSON = Promise.coroutine(function* (fileName) {
var contents = yield readFileThunk(fileName, "utf8");
return JSON.parse(contents);
});
```
An example of handling promises in parallel by adding an `addYieldHandler` for arrays :
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
Promise.coroutine.addYieldHandler(function(yieldedValue) {
if (Array.isArray(yieldedValue)) return Promise.all(yieldedValue);
});
var readFiles = Promise.coroutine(function* (fileNames) {
return yield fileNames.map(function (fileName) {
return fs.readFileAsync(fileName, "utf8");
});
});
```
A custom yield handler can also be used just for a single call to `Promise.coroutine()`:
```
var Promise = require("bluebird");
var fs = Promise.promisifyAll(require("fs"));
var readFiles = Promise.coroutine(function* (fileNames) {
return yield fileNames.map(function (fileName) {
return fs.readFileAsync(fileName, "utf8");
});
}, {
yieldHandler: function(yieldedValue) {
if (Array.isArray(yieldedValue)) return Promise.all(yieldedValue);
}
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
| programming_docs |
bluebird Promise.method Promise.method
===============
```
Promise.method(function(...arguments) fn) -> function
```
Returns a new function that wraps the given function `fn`. The new function will always return a promise that is fulfilled with the original functions return values or rejected with thrown exceptions from the original function.
This method is convenient when a function can sometimes return synchronously or throw synchronously.
Example without using `Promise.method`:
```
MyClass.prototype.method = function(input) {
if (!this.isValid(input)) {
return Promise.reject(new TypeError("input is not valid"));
}
if (this.cache(input)) {
return Promise.resolve(this.someCachedValue);
}
return db.queryAsync(input).bind(this).then(function(value) {
this.someCachedValue = value;
return value;
});
};
```
Using the same function `Promise.method`, there is no need to manually wrap direct return or throw values into a promise:
```
MyClass.prototype.method = Promise.method(function(input) {
if (!this.isValid(input)) {
throw new TypeError("input is not valid");
}
if (this.cache(input)) {
return this.someCachedValue;
}
return db.queryAsync(input).bind(this).then(function(value) {
this.someCachedValue = value;
return value;
});
});
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.race Promise.race
=============
```
Promise.race(Iterable<any>|Promise<Iterable<any>> input) -> Promise
```
Given an [`Iterable`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Iteration_protocols)(arrays are `Iterable`), or a promise of an `Iterable`, which produces promises (or a mix of promises and values), iterate over all the values in the `Iterable` into an array and return a promise that is fulfilled or rejected as soon as a promise in the array is fulfilled or rejected with the respective rejection reason or fulfillment value.
This method is only implemented because it's in the ES6 standard. If you want to race promises to fulfillment the [`.any`](any) method is more appropriate as it doesn't qualify a rejected promise as the winner. It also has less surprises: `.race` must become infinitely pending if an empty array is passed but passing an empty array to [`.any`](any) is more usefully a `RangeError`
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird Promise.bind Promise.bind
=============
```
Promise.bind(
any|Promise<any> thisArg,
[any|Promise<any> value=undefined]
) -> BoundPromise
```
Create a promise that follows this promise or in the static method is resolved with the given `value`, but is bound to the given `thisArg` value. A bound promise will call its handlers with the bound value set to `this`. Additionally promises derived from a bound promise will also be bound promises with the same `thisArg` binding as the original promise.
If `thisArg` is a promise or thenable, its resolution will be awaited for and the bound value will be the promise's fulfillment value. If `thisArg` rejects then the returned promise is rejected with the `thisArg's` rejection reason. Note that this means you cannot use `this` without checking inside catch handlers for promises that bind to promise because in case of rejection of `thisArg`, `this` will be `undefined`.
Without arrow functions that provide lexical `this`, the correspondence between async and sync code breaks down when writing object-oriented code. [`.bind`](bind) alleviates this.
Consider:
```
MyClass.prototype.method = function() {
try {
var contents = fs.readFileSync(this.file);
var url = urlParse(contents);
var result = this.httpGetSync(url);
var refined = this.refine(result);
return this.writeRefinedSync(refined);
}
catch (e) {
this.error(e.stack);
}
};
```
The above has a direct translation:
```
MyClass.prototype.method = function() {
return fs.readFileAsync(this.file).bind(this)
.then(function(contents) {
var url = urlParse(contents);
return this.httpGetAsync(url);
}).then(function(result) {
var refined = this.refine(result);
return this.writeRefinedAsync(refined);
}).catch(function(e) {
this.error(e.stack);
});
};
```
`.bind` is the most efficient way of utilizing `this` with promises. The handler functions in the above code are not closures and can therefore even be hoisted out if needed. There is literally no overhead when propagating the bound value from one promise to another.
`.bind` also has a useful side purpose - promise handlers don't need to share a function to use shared state:
```
somethingAsync().bind({})
.spread(function (aValue, bValue) {
this.aValue = aValue;
this.bValue = bValue;
return somethingElseAsync(aValue, bValue);
})
.then(function (cValue) {
return this.aValue + this.bValue + cValue;
});
```
The above without [`.bind`](bind) could be achieved with:
```
var scope = {};
somethingAsync()
.spread(function (aValue, bValue) {
scope.aValue = aValue;
scope.bValue = bValue;
return somethingElseAsync(aValue, bValue);
})
.then(function (cValue) {
return scope.aValue + scope.bValue + cValue;
});
```
However, there are many differences when you look closer:
* Requires a statement so cannot be used in an expression context
* If not there already, an additional wrapper function is required to undefined leaking or sharing `scope`
* The handler functions are now closures, thus less efficient and not reusable
Note that bind is only propagated with promise transformation. If you create new promise chains inside a handler, those chains are not bound to the "upper" `this`:
```
something().bind(var1).then(function() {
//`this` is var1 here
return Promise.all(getStuff()).then(function(results) {
//`this` is undefined here
//refine results here etc
});
}).then(function() {
//`this` is var1 here
});
```
However, if you are utilizing the full bluebird API offering, you will *almost never* need to resort to nesting promises in the first place. The above should be written more like:
```
something().bind(var1).then(function() {
//`this` is var1 here
return getStuff();
}).map(function(result) {
//`this` is var1 here
//refine result here
}).then(function() {
//`this` is var1 here
});
```
Also see this [Stackoverflow answer](http://stackoverflow.com/a/24412873/191693) as an additional example.
If you don't want to return a bound promise to the consumers of a promise, you can rebind the chain at the end:
```
MyClass.prototype.method = function() {
return fs.readFileAsync(this.file).bind(this)
.then(function(contents) {
var url = urlParse(contents);
return this.httpGetAsync(url);
}).then(function(result) {
var refined = this.refine(result);
return this.writeRefinedAsync(refined);
}).catch(function(e) {
this.error(e.stack);
}).bind(); //The `thisArg` is implicitly undefined - I.E. the default promise `this` value
};
```
Rebinding can also be abused to do something gratuitous like this:
```
Promise.resolve("my-element")
.bind(document)
.then(document.getElementById)
.bind(console)
.then(console.log);
```
The above does a `console.log` of `my-element`. Doing it this way is necessary because neither of the methods (`getElementById`, `console.log`) can be called as stand-alone methods.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .error .error
=======
```
.error([function(any error) rejectedHandler]) -> Promise
```
Like [`.catch`](catch) but instead of catching all types of exceptions, it only catches operational errors.
*Note, "errors" mean errors, as in objects that are `instanceof Error` - not strings, numbers and so on. See [a string is not an error](http://www.devthought.com/2011/12/22/a-string-is-not-an-error/).*
It is equivalent to the following [`.catch`](catch) pattern:
```
// Assumes OperationalError has been made global
function isOperationalError(e) {
if (e == null) return false;
return (e instanceof OperationalError) || (e.isOperational === true);
}
// Now this bit:
.catch(isOperationalError, function(e) {
// ...
})
// Is equivalent to:
.error(function(e) {
// ...
});
```
For example, if a promisified function errbacks the node-style callback with an error, that could be caught with [`.error`](error). However if the node-style callback **throws** an error, only `.catch` would catch that.
In the following example you might want to handle just the `SyntaxError` from JSON.parse and Filesystem errors from `fs` but let programmer errors bubble as unhandled rejections:
```
var fs = Promise.promisifyAll(require("fs"));
fs.readFileAsync("myfile.json").then(JSON.parse).then(function (json) {
console.log("Successful json")
}).catch(SyntaxError, function (e) {
console.error("file contains invalid json");
}).error(function (e) {
console.error("unable to read file, because: ", e.message);
});
```
Now, because there is no catch-all handler, if you typed `console.lag` (causes an error you don't expect), you will see:
```
Possibly unhandled TypeError: Object #<Console> has no method 'lag'
at application.js:8:13
From previous event:
at Object.<anonymous> (application.js:7:4)
at Module._compile (module.js:449:26)
at Object.Module._extensions..js (module.js:467:10)
at Module.load (module.js:349:32)
at Function.Module._load (module.js:305:12)
at Function.Module.runMain (module.js:490:10)
at startup (node.js:121:16)
at node.js:761:3
```
*( If you don't get the above - you need to enable [long stack traces](promise.config) )*
And if the file contains invalid JSON:
```
file contains invalid json
```
And if the `fs` module causes an error like file not found:
```
unable to read file, because: ENOENT, open 'not_there.txt'
```
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird PromiseInspection PromiseInspection
==================
```
interface PromiseInspection {
any reason()
any value()
boolean isPending()
boolean isRejected()
boolean isFulfilled()
boolean isCancelled()
}
```
This interface is implemented by `Promise` instances as well as the `PromiseInspection` result given by [`.reflect()`](reflect).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .get .get
=====
```
.get(String propertyName|int index) -> Promise
```
This is a convenience method for doing:
```
promise.then(function(obj) {
return obj[propertyName];
});
```
For example:
```
db.query("...")
.get(0)
.then(function(firstRow) {
});
```
If `index` is negative, the indexed load will become `obj.length + index`. So that -1 can be used to read last item in the array, -2 to read the second last and so on. For example:
```
Promise.resolve([1,2,3]).get(-1).then(function(value) {
console.log(value); // 3
});
```
If the `index` is still negative after `obj.length + index`, it will be clamped to 0.
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .spread .spread
========
```
.spread(
[function(any values...) fulfilledHandler]
) -> Promise
```
Like calling `.then`, but the fulfillment value *must be* an array, which is flattened to the formal parameters of the fulfillment handler.
```
Promise.all([
fs.readFileAsync("file1.txt"),
fs.readFileAsync("file2.txt")
]).spread(function(file1text, file2text) {
if (file1text === file2text) {
console.log("files are equal");
}
else {
console.log("files are not equal");
}
});
```
When chaining `.spread`, returning an array of promises also works:
```
Promise.delay(500).then(function() {
return [fs.readFileAsync("file1.txt"),
fs.readFileAsync("file2.txt")] ;
}).spread(function(file1text, file2text) {
if (file1text === file2text) {
console.log("files are equal");
}
else {
console.log("files are not equal");
}
});
```
Note that if using ES6, the above can be replaced with [`.then()`](then) and destructuring:
```
Promise.delay(500).then(function() {
return [fs.readFileAsync("file1.txt"),
fs.readFileAsync("file2.txt")] ;
}).all().then(function([file1text, file2text]) {
if (file1text === file2text) {
console.log("files are equal");
}
else {
console.log("files are not equal");
}
});
```
Note that [`.spread()`](spread) implicitly does [`.all()`](all) but the ES6 destructuring syntax doesn't, hence the manual `.all()` call in the above code.
If you want to coordinate several discrete concurrent promises, use [`Promise.join`](promise.join)
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .mapSeries .mapSeries
===========
```
.mapSeries(function(any item, int index, int length) mapper) -> Promise
```
Same as [`Promise.mapSeries(this, iterator)`](promise.mapseries).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
bluebird .filter .filter
========
```
.filter(
function(any item, int index, int length) filterer,
[Object {concurrency: int=Infinity} options]
) -> Promise
```
Same as [`Promise.filter(this, filterer, options)`](promise.filter).
Please enable JavaScript to view the [comments powered by Disqus.](https://disqus.com/?ref_noscript)
fastapi FastAPI FastAPI
=======
*FastAPI framework, high performance, easy to learn, fast to code, ready for production*
---
**Documentation**: <https://fastapi.tiangolo.com>
**Source Code**: <https://github.com/tiangolo/fastapi>
---
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.7+ based on standard Python type hints.
The key features are:
* **Fast**: Very high performance, on par with **NodeJS** and **Go** (thanks to Starlette and Pydantic). [One of the fastest Python frameworks available](#performance).
* **Fast to code**: Increase the speed to develop features by about 200% to 300%. \*
* **Fewer bugs**: Reduce about 40% of human (developer) induced errors. \*
* **Intuitive**: Great editor support. Completion everywhere. Less time debugging.
* **Easy**: Designed to be easy to use and learn. Less time reading docs.
* **Short**: Minimize code duplication. Multiple features from each parameter declaration. Fewer bugs.
* **Robust**: Get production-ready code. With automatic interactive documentation.
* **Standards-based**: Based on (and fully compatible with) the open standards for APIs: [OpenAPI](https://github.com/OAI/OpenAPI-Specification) (previously known as Swagger) and [JSON Schema](https://json-schema.org/).
\* estimation based on tests on an internal development team, building production applications.
Opinions
--------
Kabir Khan - **Microsoft** [(ref)](https://github.com/tiangolo/fastapi/pull/26)
---
Piero Molino, Yaroslav Dudin, and Sai Sumanth Miryala - **Uber** [(ref)](https://eng.uber.com/ludwig-v0-2/)
---
Kevin Glisson, Marc Vilanova, Forest Monsen - **Netflix** [(ref)](https://netflixtechblog.com/introducing-dispatch-da4b8a2a8072)
---
Brian Okken - **[Python Bytes](https://pythonbytes.fm/episodes/show/123/time-to-right-the-py-wrongs?time_in_sec=855) podcast host** [(ref)](https://twitter.com/brianokken/status/1112220079972728832)
---
Timothy Crosley - **[Hug](https://www.hug.rest/) creator** [(ref)](https://news.ycombinator.com/item?id=19455465)
---
Ines Montani - Matthew Honnibal - **[Explosion AI](https://explosion.ai) founders - [spaCy](https://spacy.io) creators** [(ref)](https://twitter.com/_inesmontani/status/1144173225322143744) - [(ref)](https://twitter.com/honnibal/status/1144031421859655680)
---
Deon Pillsbury - **Cisco** [(ref)](https://www.linkedin.com/posts/deonpillsbury_cisco-cx-python-activity-6963242628536487936-trAp/)
---
**Typer**, the FastAPI of CLIs
-------------------------------
Requirements
------------
* [Starlette](https://www.starlette.io/) for the web parts.
* [Pydantic](https://pydantic-docs.helpmanual.io/) for the data parts.
Installation
------------
```
$ pip install fastapi
---> 100%
```
```
$ pip install "uvicorn[standard]"
---> 100%
```
Example
-------
### Create it
* Create a file `main.py` with:
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
```
Or use `async def`... If your code uses `async` / `await`, use `async def`:
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
```
**Note**:
If you don't know, check the *"In a hurry?"* section about [`async` and `await` in the docs](async/index#in-a-hurry).
### Run it
```
$ uvicorn main:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [28720]
INFO: Started server process [28722]
INFO: Waiting for application startup.
INFO: Application startup complete.
```
About the command `uvicorn main:app --reload`... The command `uvicorn main:app` refers to:
* `main`: the file `main.py` (the Python "module").
* `app`: the object created inside of `main.py` with the line `app = FastAPI()`.
* `--reload`: make the server restart after code changes. Only do this for development.
### Check it
```
{"item_id": 5, "q": "somequery"}
```
* Receives HTTP requests in the *paths* `/` and `/items/{item_id}`.
* Both *paths* take `GET` *operations* (also known as HTTP *methods*).
* The *path* `/items/{item_id}` has a *path parameter* `item_id` that should be an `int`.
* The *path* `/items/{item_id}` has an optional `str` *query parameter* `q`.
### Interactive API docs
### Alternative API docs
Example upgrade
---------------
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: Union[bool, None] = None
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
@app.put("/items/{item_id}")
def update_item(item_id: int, item: Item):
return {"item_name": item.name, "item_id": item_id}
```
### Interactive API docs upgrade
* The interactive API documentation will be automatically updated, including the new body:
* Click on the button "Try it out", it allows you to fill the parameters and directly interact with the API:
* Then click on the "Execute" button, the user interface will communicate with your API, send the parameters, get the results and show them on the screen:
### Alternative API docs upgrade
* The alternative documentation will also reflect the new query parameter and body:
### Recap
```
item_id: int
```
```
item: Item
```
* Editor support, including:
+ Completion.
+ Type checks.
* Validation of data:
+ Automatic and clear errors when the data is invalid.
+ Validation even for deeply nested JSON objects.
* Conversion of input data: coming from the network to Python data and types. Reading from:
+ JSON.
+ Path parameters.
+ Query parameters.
+ Cookies.
+ Headers.
+ Forms.
+ Files.
* Conversion of output data: converting from Python data and types to network data (as JSON):
+ Convert Python types (`str`, `int`, `float`, `bool`, `list`, etc).
+ `datetime` objects.
+ `UUID` objects.
+ Database models.
+ ...and many more.
* Automatic interactive API documentation, including 2 alternative user interfaces:
+ Swagger UI.
+ ReDoc.
---
* Validate that there is an `item_id` in the path for `GET` and `PUT` requests.
* Validate that the `item_id` is of type `int` for `GET` and `PUT` requests.
+ If it is not, the client will see a useful, clear error.
* Check if there is an optional query parameter named `q` (as in `http://127.0.0.1:8000/items/foo?q=somequery`) for `GET` requests.
+ As the `q` parameter is declared with `= None`, it is optional.
+ Without the `None` it would be required (as is the body in the case with `PUT`).
* For `PUT` requests to `/items/{item_id}`, Read the body as JSON:
+ Check that it has a required attribute `name` that should be a `str`.
+ Check that it has a required attribute `price` that has to be a `float`.
+ Check that it has an optional attribute `is_offer`, that should be a `bool`, if present.
+ All this would also work for deeply nested JSON objects.
* Convert from and to JSON automatically.
* Document everything with OpenAPI, that can be used by:
+ Interactive documentation systems.
+ Automatic client code generation systems, for many languages.
* Provide 2 interactive documentation web interfaces directly.
---
```
return {"item_name": item.name, "item_id": item_id}
```
```
... "item_name": item.name ...
```
```
... "item_price": item.price ...
```
* Declaration of **parameters** from other different places as: **headers**, **cookies**, **form fields** and **files**.
* How to set **validation constraints** as `maximum_length` or `regex`.
* A very powerful and easy to use **Dependency Injection** system.
* Security and authentication, including support for **OAuth2** with **JWT tokens** and **HTTP Basic** auth.
* More advanced (but equally easy) techniques for declaring **deeply nested JSON models** (thanks to Pydantic).
* **GraphQL** integration with [Strawberry](https://strawberry.rocks) and other libraries.
* Many extra features (thanks to Starlette) as:
+ **WebSockets**
+ extremely easy tests based on HTTPX and `pytest`
+ **CORS**
+ **Cookie Sessions**
+ ...and more.
Performance
-----------
Optional Dependencies
---------------------
* [`ujson`](https://github.com/esnme/ultrajson) - for faster JSON "parsing".
* [`email_validator`](https://github.com/JoshData/python-email-validator) - for email validation.
* [`httpx`](https://www.python-httpx.org) - Required if you want to use the `TestClient`.
* [`jinja2`](https://jinja.palletsprojects.com) - Required if you want to use the default template configuration.
* [`python-multipart`](https://andrew-d.github.io/python-multipart/) - Required if you want to support form "parsing", with `request.form()`.
* [`itsdangerous`](https://pythonhosted.org/itsdangerous/) - Required for `SessionMiddleware` support.
* [`pyyaml`](https://pyyaml.org/wiki/PyYAMLDocumentation) - Required for Starlette's `SchemaGenerator` support (you probably don't need it with FastAPI).
* [`ujson`](https://github.com/esnme/ultrajson) - Required if you want to use `UJSONResponse`.
* [`uvicorn`](https://www.uvicorn.org) - for the server that loads and serves your application.
* [`orjson`](https://github.com/ijl/orjson) - Required if you want to use `ORJSONResponse`.
License
-------
| programming_docs |
fastapi Advanced User Guide - Intro Advanced User Guide - Intro
===========================
Additional Features
-------------------
The main [Tutorial - User Guide](../tutorial/index) should be enough to give you a tour through all the main features of **FastAPI**.
In the next sections you will see other options, configurations, and additional features.
Tip
The next sections are **not necessarily "advanced"**.
And it's possible that for your use case, the solution is in one of them.
Read the Tutorial first
-----------------------
You could still use most of the features in **FastAPI** with the knowledge from the main [Tutorial - User Guide](../tutorial/index).
And the next sections assume you already read it, and assume that you know those main ideas.
TestDriven.io course
--------------------
If you would like to take an advanced-beginner course to complement this section of the docs, you might want to check: [Test-Driven Development with FastAPI and Docker](https://testdriven.io/courses/tdd-fastapi/) by **TestDriven.io**.
They are currently donating 10% of all profits to the development of **FastAPI**. 🎉 😄
fastapi Generate Clients Generate Clients
================
As **FastAPI** is based on the OpenAPI specification, you get automatic compatibility with many tools, including the automatic API docs (provided by Swagger UI).
One particular advantage that is not necessarily obvious is that you can **generate clients** (sometimes called **SDKs** ) for your API, for many different **programming languages**.
OpenAPI Client Generators
-------------------------
There are many tools to generate clients from **OpenAPI**.
A common tool is [OpenAPI Generator](https://openapi-generator.tech/).
If you are building a **frontend**, a very interesting alternative is [openapi-typescript-codegen](https://github.com/ferdikoomen/openapi-typescript-codegen).
Generate a TypeScript Frontend Client
-------------------------------------
Let's start with a simple FastAPI application:
Python 3.9+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
@app.post("/items/", response_model=ResponseMessage)
async def create_item(item: Item):
return {"message": "item received"}
@app.get("/items/", response_model=list[Item])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
@app.post("/items/", response_model=ResponseMessage)
async def create_item(item: Item):
return {"message": "item received"}
@app.get("/items/", response_model=List[Item])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
```
Notice that the *path operations* define the models they use for request payload and response payload, using the models `Item` and `ResponseMessage`.
### API Docs
If you go to the API docs, you will see that it has the **schemas** for the data to be sent in requests and received in responses:
You can see those schemas because they were declared with the models in the app.
That information is available in the app's **OpenAPI schema**, and then shown in the API docs (by Swagger UI).
And that same information from the models that is included in OpenAPI is what can be used to **generate the client code**.
### Generate a TypeScript Client
Now that we have the app with the models, we can generate the client code for the frontend.
#### Install `openapi-typescript-codegen`
You can install `openapi-typescript-codegen` in your frontend code with:
```
$ npm install openapi-typescript-codegen --save-dev
---> 100%
```
#### Generate Client Code
To generate the client code you can use the command line application `openapi` that would now be installed.
Because it is installed in the local project, you probably wouldn't be able to call that command directly, but you would put it on your `package.json` file.
It could look like this:
```
{
"name": "frontend-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"generate-client": "openapi --input http://localhost:8000/openapi.json --output ./src/client --client axios"
},
"author": "",
"license": "",
"devDependencies": {
"openapi-typescript-codegen": "^0.20.1",
"typescript": "^4.6.2"
}
}
```
After having that NPM `generate-client` script there, you can run it with:
```
$ npm run generate-client
[email protected] generate-client /home/user/code/frontend-app
> openapi --input http://localhost:8000/openapi.json --output ./src/client --client axios
```
That command will generate code in `./src/client` and will use `axios` (the frontend HTTP library) internally.
### Try Out the Client Code
Now you can import and use the client code, it could look like this, notice that you get autocompletion for the methods:
You will also get autocompletion for the payload to send:
Tip
Notice the autocompletion for `name` and `price`, that was defined in the FastAPI application, in the `Item` model.
You will have inline errors for the data that you send:
The response object will also have autocompletion:
FastAPI App with Tags
---------------------
In many cases your FastAPI app will be bigger, and you will probably use tags to separate different groups of *path operations*.
For example, you could have a section for **items** and another section for **users**, and they could be separated by tags:
Python 3.9+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResponseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=list[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResponseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=List[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
```
### Generate a TypeScript Client with Tags
If you generate a client for a FastAPI app using tags, it will normally also separate the client code based on the tags.
This way you will be able to have things ordered and grouped correctly for the client code:
In this case you have:
* `ItemsService`
* `UsersService`
### Client Method Names
Right now the generated method names like `createItemItemsPost` don't look very clean:
```
ItemsService.createItemItemsPost({name: "Plumbus", price: 5})
```
...that's because the client generator uses the OpenAPI internal **operation ID** for each *path operation*.
OpenAPI requires that each operation ID is unique across all the *path operations*, so FastAPI uses the **function name**, the **path**, and the **HTTP method/operation** to generate that operation ID, because that way it can make sure that the operation IDs are unique.
But I'll show you how to improve that next. 🤓
Custom Operation IDs and Better Method Names
--------------------------------------------
You can **modify** the way these operation IDs are **generated** to make them simpler and have **simpler method names** in the clients.
In this case you will have to ensure that each operation ID is **unique** in some other way.
For example, you could make sure that each *path operation* has a tag, and then generate the operation ID based on the **tag** and the *path operation* **name** (the function name).
### Custom Generate Unique ID Function
FastAPI uses a **unique ID** for each *path operation*, it is used for the **operation ID** and also for the names of any needed custom models, for requests or responses.
You can customize that function. It takes an `APIRoute` and outputs a string.
For example, here it is using the first tag (you will probably have only one tag) and the *path operation* name (the function name).
You can then pass that custom function to **FastAPI** as the `generate_unique_id_function` parameter:
Python 3.9+
```
from fastapi import FastAPI
from fastapi.routing import APIRoute
from pydantic import BaseModel
def custom_generate_unique_id(route: APIRoute):
return f"{route.tags[0]}-{route.name}"
app = FastAPI(generate_unique_id_function=custom_generate_unique_id)
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResponseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=list[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI
from fastapi.routing import APIRoute
from pydantic import BaseModel
def custom_generate_unique_id(route: APIRoute):
return f"{route.tags[0]}-{route.name}"
app = FastAPI(generate_unique_id_function=custom_generate_unique_id)
class Item(BaseModel):
name: str
price: float
class ResponseMessage(BaseModel):
message: str
class User(BaseModel):
username: str
email: str
@app.post("/items/", response_model=ResponseMessage, tags=["items"])
async def create_item(item: Item):
return {"message": "Item received"}
@app.get("/items/", response_model=List[Item], tags=["items"])
async def get_items():
return [
{"name": "Plumbus", "price": 3},
{"name": "Portal Gun", "price": 9001},
]
@app.post("/users/", response_model=ResponseMessage, tags=["users"])
async def create_user(user: User):
return {"message": "User received"}
```
### Generate a TypeScript Client with Custom Operation IDs
Now if you generate the client again, you will see that it has the improved method names:
As you see, the method names now have the tag and then the function name, now they don't include information from the URL path and the HTTP operation.
### Preprocess the OpenAPI Specification for the Client Generator
The generated code still has some **duplicated information**.
We already know that this method is related to the **items** because that word is in the `ItemsService` (taken from the tag), but we still have the tag name prefixed in the method name too. 😕
We will probably still want to keep it for OpenAPI in general, as that will ensure that the operation IDs are **unique**.
But for the generated client we could **modify** the OpenAPI operation IDs right before generating the clients, just to make those method names nicer and **cleaner**.
We could download the OpenAPI JSON to a file `openapi.json` and then we could **remove that prefixed tag** with a script like this:
```
import json
from pathlib import Path
file_path = Path("./openapi.json")
openapi_content = json.loads(file_path.read_text())
for path_data in openapi_content["paths"].values():
for operation in path_data.values():
tag = operation["tags"][0]
operation_id = operation["operationId"]
to_remove = f"{tag}-"
new_operation_id = operation_id[len(to_remove) :]
operation["operationId"] = new_operation_id
file_path.write_text(json.dumps(openapi_content))
```
With that, the operation IDs would be renamed from things like `items-get_items` to just `get_items`, that way the client generator can generate simpler method names.
### Generate a TypeScript Client with the Preprocessed OpenAPI
Now as the end result is in a file `openapi.json`, you would modify the `package.json` to use that local file, for example:
```
{
"name": "frontend-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"generate-client": "openapi --input ./openapi.json --output ./src/client --client axios"
},
"author": "",
"license": "",
"devDependencies": {
"openapi-typescript-codegen": "^0.20.1",
"typescript": "^4.6.2"
}
}
```
After generating the new client, you would now have **clean method names**, with all the **autocompletion**, **inline errors**, etc:
Benefits
--------
When using the automatically generated clients you would **autocompletion** for:
* Methods.
* Request payloads in the body, query parameters, etc.
* Response payloads.
You would also have **inline errors** for everything.
And whenever you update the backend code, and **regenerate** the frontend, it would have any new *path operations* available as methods, the old ones removed, and any other change would be reflected on the generated code. 🤓
This also means that if something changed it will be **reflected** on the client code automatically. And if you **build** the client it will error out if you have any **mismatch** in the data used.
So, you would **detect many errors** very early in the development cycle instead of having to wait for the errors to show up to your final users in production and then trying to debug where the problem is. ✨
fastapi Testing WebSockets Testing WebSockets
==================
You can use the same `TestClient` to test WebSockets.
For this, you use the `TestClient` in a `with` statement, connecting to the WebSocket:
```
from fastapi import FastAPI
from fastapi.testclient import TestClient
from fastapi.websockets import WebSocket
app = FastAPI()
@app.get("/")
async def read_main():
return {"msg": "Hello World"}
@app.websocket("/ws")
async def websocket(websocket: WebSocket):
await websocket.accept()
await websocket.send_json({"msg": "Hello WebSocket"})
await websocket.close()
def test_read_main():
client = TestClient(app)
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"msg": "Hello World"}
def test_websocket():
client = TestClient(app)
with client.websocket_connect("/ws") as websocket:
data = websocket.receive_json()
assert data == {"msg": "Hello WebSocket"}
```
Note
For more details, check Starlette's documentation for [testing WebSockets](https://www.starlette.io/testclient/#testing-websocket-sessions).
fastapi Advanced Middleware Advanced Middleware
===================
In the main tutorial you read how to add [Custom Middleware](../../tutorial/middleware/index) to your application.
And then you also read how to handle [CORS with the `CORSMiddleware`](../../tutorial/cors/index).
In this section we'll see how to use other middlewares.
Adding ASGI middlewares
-----------------------
As **FastAPI** is based on Starlette and implements the ASGI specification, you can use any ASGI middleware.
A middleware doesn't have to be made for FastAPI or Starlette to work, as long as it follows the ASGI spec.
In general, ASGI middlewares are classes that expect to receive an ASGI app as the first argument.
So, in the documentation for third-party ASGI middlewares they will probably tell you to do something like:
```
from unicorn import UnicornMiddleware
app = SomeASGIApp()
new_app = UnicornMiddleware(app, some_config="rainbow")
```
But FastAPI (actually Starlette) provides a simpler way to do it that makes sure that the internal middlewares to handle server errors and custom exception handlers work properly.
For that, you use `app.add_middleware()` (as in the example for CORS).
```
from fastapi import FastAPI
from unicorn import UnicornMiddleware
app = FastAPI()
app.add_middleware(UnicornMiddleware, some_config="rainbow")
```
`app.add_middleware()` receives a middleware class as the first argument and any additional arguments to be passed to the middleware.
Integrated middlewares
----------------------
**FastAPI** includes several middlewares for common use cases, we'll see next how to use them.
Technical Details
For the next examples, you could also use `from starlette.middleware.something import SomethingMiddleware`.
**FastAPI** provides several middlewares in `fastapi.middleware` just as a convenience for you, the developer. But most of the available middlewares come directly from Starlette.
`HTTPSRedirectMiddleware`
-------------------------
Enforces that all incoming requests must either be `https` or `wss`.
Any incoming requests to `http` or `ws` will be redirected to the secure scheme instead.
```
from fastapi import FastAPI
from fastapi.middleware.httpsredirect import HTTPSRedirectMiddleware
app = FastAPI()
app.add_middleware(HTTPSRedirectMiddleware)
@app.get("/")
async def main():
return {"message": "Hello World"}
```
`TrustedHostMiddleware`
-----------------------
Enforces that all incoming requests have a correctly set `Host` header, in order to guard against HTTP Host Header attacks.
```
from fastapi import FastAPI
from fastapi.middleware.trustedhost import TrustedHostMiddleware
app = FastAPI()
app.add_middleware(
TrustedHostMiddleware, allowed_hosts=["example.com", "*.example.com"]
)
@app.get("/")
async def main():
return {"message": "Hello World"}
```
The following arguments are supported:
* `allowed_hosts` - A list of domain names that should be allowed as hostnames. Wildcard domains such as `*.example.com` are supported for matching subdomains. To allow any hostname either use `allowed_hosts=["*"]` or omit the middleware.
If an incoming request does not validate correctly then a `400` response will be sent.
`GZipMiddleware`
----------------
Handles GZip responses for any request that includes `"gzip"` in the `Accept-Encoding` header.
The middleware will handle both standard and streaming responses.
```
from fastapi import FastAPI
from fastapi.middleware.gzip import GZipMiddleware
app = FastAPI()
app.add_middleware(GZipMiddleware, minimum_size=1000)
@app.get("/")
async def main():
return "somebigcontent"
```
The following arguments are supported:
* `minimum_size` - Do not GZip responses that are smaller than this minimum size in bytes. Defaults to `500`.
Other middlewares
-----------------
There are many other ASGI middlewares.
For example:
* [Sentry](https://docs.sentry.io/platforms/python/guides/fastapi/)
* [Uvicorn's `ProxyHeadersMiddleware`](https://github.com/encode/uvicorn/blob/master/uvicorn/middleware/proxy_headers.py)
* [MessagePack](https://github.com/florimondmanca/msgpack-asgi)
To see other available middlewares check [Starlette's Middleware docs](https://www.starlette.io/middleware/) and the [ASGI Awesome List](https://github.com/florimondmanca/awesome-asgi).
| programming_docs |
fastapi Settings and Environment Variables Settings and Environment Variables
==================================
In many cases your application could need some external settings or configurations, for example secret keys, database credentials, credentials for email services, etc.
Most of these settings are variable (can change), like database URLs. And many could be sensitive, like secrets.
For this reason it's common to provide them in environment variables that are read by the application.
Environment Variables
---------------------
Tip
If you already know what "environment variables" are and how to use them, feel free to skip to the next section below.
An [environment variable](https://en.wikipedia.org/wiki/Environment_variable) (also known as "env var") is a variable that lives outside of the Python code, in the operating system, and could be read by your Python code (or by other programs as well).
You can create and use environment variables in the shell, without needing Python:
Linux, macOS, Windows Bash
```
// You could create an env var MY_NAME with
$ export MY_NAME="Wade Wilson"
// Then you could use it with other programs, like
$ echo "Hello $MY_NAME"
Hello Wade Wilson
```
Windows PowerShell
```
// Create an env var MY_NAME
$ $Env:MY_NAME = "Wade Wilson"
// Use it with other programs, like
$ echo "Hello $Env:MY_NAME"
Hello Wade Wilson
```
### Read env vars in Python
You could also create environment variables outside of Python, in the terminal (or with any other method), and then read them in Python.
For example you could have a file `main.py` with:
```
import os
name = os.getenv("MY_NAME", "World")
print(f"Hello {name} from Python")
```
Tip
The second argument to [`os.getenv()`](https://docs.python.org/3.8/library/os.html#os.getenv) is the default value to return.
If not provided, it's `None` by default, here we provide `"World"` as the default value to use.
Then you could call that Python program:
```
// Here we don't set the env var yet
$ python main.py
// As we didn't set the env var, we get the default value
Hello World from Python
// But if we create an environment variable first
$ export MY_NAME="Wade Wilson"
// And then call the program again
$ python main.py
// Now it can read the environment variable
Hello Wade Wilson from Python
```
As environment variables can be set outside of the code, but can be read by the code, and don't have to be stored (committed to `git`) with the rest of the files, it's common to use them for configurations or settings.
You can also create an environment variable only for a specific program invocation, that is only available to that program, and only for its duration.
To do that, create it right before the program itself, on the same line:
```
// Create an env var MY_NAME in line for this program call
$ MY_NAME="Wade Wilson" python main.py
// Now it can read the environment variable
Hello Wade Wilson from Python
// The env var no longer exists afterwards
$ python main.py
Hello World from Python
```
Tip
You can read more about it at [The Twelve-Factor App: Config](https://12factor.net/config).
### Types and validation
These environment variables can only handle text strings, as they are external to Python and have to be compatible with other programs and the rest of the system (and even with different operating systems, as Linux, Windows, macOS).
That means that any value read in Python from an environment variable will be a `str`, and any conversion to a different type or validation has to be done in code.
Pydantic `Settings`
-------------------
Fortunately, Pydantic provides a great utility to handle these settings coming from environment variables with [Pydantic: Settings management](https://pydantic-docs.helpmanual.io/usage/settings/).
### Create the `Settings` object
Import `BaseSettings` from Pydantic and create a sub-class, very much like with a Pydantic model.
The same way as with Pydantic models, you declare class attributes with type annotations, and possibly default values.
You can use all the same validation features and tools you use for Pydantic models, like different data types and additional validations with `Field()`.
```
from fastapi import FastAPI
from pydantic import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Tip
If you want something quick to copy and paste, don't use this example, use the last one below.
Then, when you create an instance of that `Settings` class (in this case, in the `settings` object), Pydantic will read the environment variables in a case-insensitive way, so, an upper-case variable `APP_NAME` will still be read for the attribute `app_name`.
Next it will convert and validate the data. So, when you use that `settings` object, you will have data of the types you declared (e.g. `items_per_user` will be an `int`).
### Use the `settings`
Then you can use the new `settings` object in your application:
```
from fastapi import FastAPI
from pydantic import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
### Run the server
Next, you would run the server passing the configurations as environment variables, for example you could set an `ADMIN_EMAIL` and `APP_NAME` with:
```
$ ADMIN_EMAIL="[email protected]" APP_NAME="ChimichangApp" uvicorn main:app
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Tip
To set multiple env vars for a single command just separate them with a space, and put them all before the command.
And then the `admin_email` setting would be set to `"[email protected]"`.
The `app_name` would be `"ChimichangApp"`.
And the `items_per_user` would keep its default value of `50`.
Settings in another module
--------------------------
You could put those settings in another module file as you saw in [Bigger Applications - Multiple Files](../../tutorial/bigger-applications/index).
For example, you could have a file `config.py` with:
```
from pydantic import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
settings = Settings()
```
And then use it in a file `main.py`:
```
from fastapi import FastAPI
from .config import settings
app = FastAPI()
@app.get("/info")
async def info():
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Tip
You would also need a file `__init__.py` as you saw on [Bigger Applications - Multiple Files](../../tutorial/bigger-applications/index).
Settings in a dependency
------------------------
In some occasions it might be useful to provide the settings from a dependency, instead of having a global object with `settings` that is used everywhere.
This could be especially useful during testing, as it's very easy to override a dependency with your own custom settings.
### The config file
Coming from the previous example, your `config.py` file could look like:
```
from pydantic import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
```
Notice that now we don't create a default instance `settings = Settings()`.
### The main app file
Now we create a dependency that returns a new `config.Settings()`.
Python 3.9+
```
from functools import lru_cache
from typing import Annotated
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Settings = Depends(get_settings)):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Tip
We'll discuss the `@lru_cache()` in a bit.
For now you can assume `get_settings()` is a normal function.
And then we can require it from the *path operation function* as a dependency and use it anywhere we need it.
Python 3.9+
```
from functools import lru_cache
from typing import Annotated
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Annotated[Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from .config import Settings
app = FastAPI()
@lru_cache()
def get_settings():
return Settings()
@app.get("/info")
async def info(settings: Settings = Depends(get_settings)):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
### Settings and testing
Then it would be very easy to provide a different settings object during testing by creating a dependency override for `get_settings`:
```
from fastapi.testclient import TestClient
from .config import Settings
from .main import app, get_settings
client = TestClient(app)
def get_settings_override():
return Settings(admin_email="[email protected]")
app.dependency_overrides[get_settings] = get_settings_override
def test_app():
response = client.get("/info")
data = response.json()
assert data == {
"app_name": "Awesome API",
"admin_email": "[email protected]",
"items_per_user": 50,
}
```
In the dependency override we set a new value for the `admin_email` when creating the new `Settings` object, and then we return that new object.
Then we can test that it is used.
Reading a `.env` file
---------------------
If you have many settings that possibly change a lot, maybe in different environments, it might be useful to put them on a file and then read them from it as if they were environment variables.
This practice is common enough that it has a name, these environment variables are commonly placed in a file `.env`, and the file is called a "dotenv".
Tip
A file starting with a dot (`.`) is a hidden file in Unix-like systems, like Linux and macOS.
But a dotenv file doesn't really have to have that exact filename.
Pydantic has support for reading from these types of files using an external library. You can read more at [Pydantic Settings: Dotenv (.env) support](https://pydantic-docs.helpmanual.io/usage/settings/#dotenv-env-support).
Tip
For this to work, you need to `pip install python-dotenv`.
### The `.env` file
You could have a `.env` file with:
```
ADMIN_EMAIL="[email protected]"
APP_NAME="ChimichangApp"
```
### Read settings from `.env`
And then update your `config.py` with:
```
from pydantic import BaseSettings
class Settings(BaseSettings):
app_name: str = "Awesome API"
admin_email: str
items_per_user: int = 50
class Config:
env_file = ".env"
```
Here we create a class `Config` inside of your Pydantic `Settings` class, and set the `env_file` to the filename with the dotenv file we want to use.
Tip
The `Config` class is used just for Pydantic configuration. You can read more at [Pydantic Model Config](https://pydantic-docs.helpmanual.io/usage/model_config/)
### Creating the `Settings` only once with `lru_cache`
Reading a file from disk is normally a costly (slow) operation, so you probably want to do it only once and then re-use the same settings object, instead of reading it for each request.
But every time we do:
```
Settings()
```
a new `Settings` object would be created, and at creation it would read the `.env` file again.
If the dependency function was just like:
```
def get_settings():
return Settings()
```
we would create that object for each request, and we would be reading the `.env` file for each request. ⚠️
But as we are using the `@lru_cache()` decorator on top, the `Settings` object will be created only once, the first time it's called. ✔️
Python 3.9+
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
from . import config
app = FastAPI()
@lru_cache()
def get_settings():
return config.Settings()
@app.get("/info")
async def info(settings: Annotated[config.Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+
```
from functools import lru_cache
from typing import Annotated
from fastapi import Depends, FastAPI
from . import config
app = FastAPI()
@lru_cache()
def get_settings():
return config.Settings()
@app.get("/info")
async def info(settings: Annotated[config.Settings, Depends(get_settings)]):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from functools import lru_cache
from fastapi import Depends, FastAPI
from . import config
app = FastAPI()
@lru_cache()
def get_settings():
return config.Settings()
@app.get("/info")
async def info(settings: config.Settings = Depends(get_settings)):
return {
"app_name": settings.app_name,
"admin_email": settings.admin_email,
"items_per_user": settings.items_per_user,
}
```
Then for any subsequent calls of `get_settings()` in the dependencies for the next requests, instead of executing the internal code of `get_settings()` and creating a new `Settings` object, it will return the same object that was returned on the first call, again and again.
####
`lru_cache` Technical Details
`@lru_cache()` modifies the function it decorates to return the same value that was returned the first time, instead of computing it again, executing the code of the function every time.
So, the function below it will be executed once for each combination of arguments. And then the values returned by each of those combinations of arguments will be used again and again whenever the function is called with exactly the same combination of arguments.
For example, if you have a function:
```
@lru_cache()
def say_hi(name: str, salutation: str = "Ms."):
return f"Hello {salutation} {name}"
```
your program could execute like this:
```
sequenceDiagram
participant code as Code
participant function as say_hi()
participant execute as Execute function
rect rgba(0, 255, 0, .1)
code ->> function: say_hi(name="Camila")
function ->> execute: execute function code
execute ->> code: return the result
end
rect rgba(0, 255, 255, .1)
code ->> function: say_hi(name="Camila")
function ->> code: return stored result
end
rect rgba(0, 255, 0, .1)
code ->> function: say_hi(name="Rick")
function ->> execute: execute function code
execute ->> code: return the result
end
rect rgba(0, 255, 0, .1)
code ->> function: say_hi(name="Rick", salutation="Mr.")
function ->> execute: execute function code
execute ->> code: return the result
end
rect rgba(0, 255, 255, .1)
code ->> function: say_hi(name="Rick")
function ->> code: return stored result
end
rect rgba(0, 255, 255, .1)
code ->> function: say_hi(name="Camila")
function ->> code: return stored result
end
```
In the case of our dependency `get_settings()`, the function doesn't even take any arguments, so it always returns the same value.
That way, it behaves almost as if it was just a global variable. But as it uses a dependency function, then we can override it easily for testing.
`@lru_cache()` is part of `functools` which is part of Python's standard library, you can read more about it in the [Python docs for `@lru_cache()`](https://docs.python.org/3/library/functools.html#functools.lru_cache).
Recap
-----
You can use Pydantic Settings to handle the settings or configurations for your application, with all the power of Pydantic models.
* By using a dependency you can simplify testing.
* You can use `.env` files with it.
* Using `@lru_cache()` lets you avoid reading the dotenv file again and again for each request, while allowing you to override it during testing.
fastapi OpenAPI Callbacks OpenAPI Callbacks
=================
You could create an API with a *path operation* that could trigger a request to an *external API* created by someone else (probably the same developer that would be *using* your API).
The process that happens when your API app calls the *external API* is named a "callback". Because the software that the external developer wrote sends a request to your API and then your API *calls back*, sending a request to an *external API* (that was probably created by the same developer).
In this case, you could want to document how that external API *should* look like. What *path operation* it should have, what body it should expect, what response it should return, etc.
An app with callbacks
---------------------
Let's see all this with an example.
Imagine you develop an app that allows creating invoices.
These invoices will have an `id`, `title` (optional), `customer`, and `total`.
The user of your API (an external developer) will create an invoice in your API with a POST request.
Then your API will (let's imagine):
* Send the invoice to some customer of the external developer.
* Collect the money.
* Send a notification back to the API user (the external developer).
+ This will be done by sending a POST request (from *your API*) to some *external API* provided by that external developer (this is the "callback").
The normal **FastAPI** app
--------------------------
Let's first see how the normal API app would look like before adding the callback.
It will have a *path operation* that will receive an `Invoice` body, and a query parameter `callback_url` that will contain the URL for the callback.
This part is pretty normal, most of the code is probably already familiar to you:
```
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
```
Tip
The `callback_url` query parameter uses a Pydantic [URL](https://pydantic-docs.helpmanual.io/usage/types/#urls) type.
The only new thing is the `callbacks=messages_callback_router.routes` as an argument to the *path operation decorator*. We'll see what that is next.
Documenting the callback
------------------------
The actual callback code will depend heavily on your own API app.
And it will probably vary a lot from one app to the next.
It could be just one or two lines of code, like:
```
callback_url = "https://example.com/api/v1/invoices/events/"
httpx.post(callback_url, json={"description": "Invoice paid", "paid": True})
```
But possibly the most important part of the callback is making sure that your API user (the external developer) implements the *external API* correctly, according to the data that *your API* is going to send in the request body of the callback, etc.
So, what we will do next is add the code to document how that *external API* should look like to receive the callback from *your API*.
That documentation will show up in the Swagger UI at `/docs` in your API, and it will let external developers know how to build the *external API*.
This example doesn't implement the callback itself (that could be just a line of code), only the documentation part.
Tip
The actual callback is just an HTTP request.
When implementing the callback yourself, you could use something like [HTTPX](https://www.python-httpx.org) or [Requests](https://requests.readthedocs.io/).
Write the callback documentation code
-------------------------------------
This code won't be executed in your app, we only need it to *document* how that *external API* should look like.
But, you already know how to easily create automatic documentation for an API with **FastAPI**.
So we are going to use that same knowledge to document how the *external API* should look like... by creating the *path operation(s)* that the external API should implement (the ones your API will call).
Tip
When writing the code to document a callback, it might be useful to imagine that you are that *external developer*. And that you are currently implementing the *external API*, not *your API*.
Temporarily adopting this point of view (of the *external developer*) can help you feel like it's more obvious where to put the parameters, the Pydantic model for the body, for the response, etc. for that *external API*.
### Create a callback `APIRouter`
First create a new `APIRouter` that will contain one or more callbacks.
```
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
```
### Create the callback *path operation*
To create the callback *path operation* use the same `APIRouter` you created above.
It should look just like a normal FastAPI *path operation*:
* It should probably have a declaration of the body it should receive, e.g. `body: InvoiceEvent`.
* And it could also have a declaration of the response it should return, e.g. `response_model=InvoiceEventReceived`.
```
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
```
There are 2 main differences from a normal *path operation*:
* It doesn't need to have any actual code, because your app will never call this code. It's only used to document the *external API*. So, the function could just have `pass`.
* The *path* can contain an [OpenAPI 3 expression](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#key-expression) (see more below) where it can use variables with parameters and parts of the original request sent to *your API*.
### The callback path expression
The callback *path* can have an [OpenAPI 3 expression](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#key-expression) that can contain parts of the original request sent to *your API*.
In this case, it's the `str`:
```
"{$callback_url}/invoices/{$request.body.id}"
```
So, if your API user (the external developer) sends a request to *your API* to:
```
https://yourapi.com/invoices/?callback_url=https://www.external.org/events
```
with a JSON body of:
```
{
"id": "2expen51ve",
"customer": "Mr. Richie Rich",
"total": "9999"
}
```
Then *your API* will process the invoice, and at some point later, send a callback request to the `callback_url` (the *external API*):
```
https://www.external.org/events/invoices/2expen51ve
```
with a JSON body containing something like:
```
{
"description": "Payment celebration",
"paid": true
}
```
and it would expect a response from that *external API* with a JSON body like:
```
{
"ok": true
}
```
Tip
Notice how the callback URL used contains the URL received as a query parameter in `callback_url` (`https://www.external.org/events`) and also the invoice `id` from inside of the JSON body (`2expen51ve`).
### Add the callback router
At this point you have the *callback path operation(s)* needed (the one(s) that the *external developer* should implement in the *external API*) in the callback router you created above.
Now use the parameter `callbacks` in *your API's path operation decorator* to pass the attribute `.routes` (that's actually just a `list` of routes/*path operations*) from that callback router:
```
from typing import Union
from fastapi import APIRouter, FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Invoice(BaseModel):
id: str
title: Union[str, None] = None
customer: str
total: float
class InvoiceEvent(BaseModel):
description: str
paid: bool
class InvoiceEventReceived(BaseModel):
ok: bool
invoices_callback_router = APIRouter()
@invoices_callback_router.post(
"{$callback_url}/invoices/{$request.body.id}", response_model=InvoiceEventReceived
)
def invoice_notification(body: InvoiceEvent):
pass
@app.post("/invoices/", callbacks=invoices_callback_router.routes)
def create_invoice(invoice: Invoice, callback_url: Union[HttpUrl, None] = None):
"""
Create an invoice.
This will (let's imagine) let the API user (some external developer) create an
invoice.
And this path operation will:
* Send the invoice to the client.
* Collect the money from the client.
* Send a notification back to the API user (the external developer), as a callback.
* At this point is that the API will somehow send a POST request to the
external API with the notification of the invoice event
(e.g. "payment successful").
"""
# Send the invoice, collect the money, send the notification (the callback)
return {"msg": "Invoice received"}
```
Tip
Notice that you are not passing the router itself (`invoices_callback_router`) to `callback=`, but the attribute `.routes`, as in `invoices_callback_router.routes`.
### Check the docs
Now you can start your app with Uvicorn and go to <http://127.0.0.1:8000/docs>.
You will see your docs including a "Callback" section for your *path operation* that shows how the *external API* should look like:
| programming_docs |
fastapi Additional Status Codes Additional Status Codes
=======================
By default, **FastAPI** will return the responses using a `JSONResponse`, putting the content you return from your *path operation* inside of that `JSONResponse`.
It will use the default status code or the one you set in your *path operation*.
Additional status codes
-----------------------
If you want to return additional status codes apart from the main one, you can do that by returning a `Response` directly, like a `JSONResponse`, and set the additional status code directly.
For example, let's say that you want to have a *path operation* that allows to update items, and returns HTTP status codes of 200 "OK" when successful.
But you also want it to accept new items. And when the items didn't exist before, it creates them, and returns an HTTP status code of 201 "Created".
To achieve that, import `JSONResponse`, and return your content there directly, setting the `status_code` that you want:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
app = FastAPI()
items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: Annotated[str | None, Body()] = None,
size: Annotated[int | None, Body()] = None,
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
app = FastAPI()
items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: Annotated[Union[str, None], Body()] = None,
size: Annotated[Union[int, None], Body()] = None,
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
from typing_extensions import Annotated
app = FastAPI()
items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: Annotated[Union[str, None], Body()] = None,
size: Annotated[Union[int, None], Body()] = None,
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
app = FastAPI()
items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: str | None = Body(default=None),
size: int | None = Body(default=None),
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI, status
from fastapi.responses import JSONResponse
app = FastAPI()
items = {"foo": {"name": "Fighters", "size": 6}, "bar": {"name": "Tenders", "size": 3}}
@app.put("/items/{item_id}")
async def upsert_item(
item_id: str,
name: Union[str, None] = Body(default=None),
size: Union[int, None] = Body(default=None),
):
if item_id in items:
item = items[item_id]
item["name"] = name
item["size"] = size
return item
else:
item = {"name": name, "size": size}
items[item_id] = item
return JSONResponse(status_code=status.HTTP_201_CREATED, content=item)
```
Warning
When you return a `Response` directly, like in the example above, it will be returned directly.
It won't be serialized with a model, etc.
Make sure it has the data you want it to have, and that the values are valid JSON (if you are using `JSONResponse`).
Technical Details
You could also use `from starlette.responses import JSONResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette. The same with `status`.
OpenAPI and API docs
--------------------
If you return additional status codes and responses directly, they won't be included in the OpenAPI schema (the API docs), because FastAPI doesn't have a way to know beforehand what you are going to return.
But you can document that in your code, using: [Additional Responses](../additional-responses/index).
fastapi Custom Request and APIRoute class Custom Request and APIRoute class
=================================
In some cases, you may want to override the logic used by the `Request` and `APIRoute` classes.
In particular, this may be a good alternative to logic in a middleware.
For example, if you want to read or manipulate the request body before it is processed by your application.
Danger
This is an "advanced" feature.
If you are just starting with **FastAPI** you might want to skip this section.
Use cases
---------
Some use cases include:
* Converting non-JSON request bodies to JSON (e.g. [`msgpack`](https://msgpack.org/index.html)).
* Decompressing gzip-compressed request bodies.
* Automatically logging all request bodies.
Handling custom request body encodings
--------------------------------------
Let's see how to make use of a custom `Request` subclass to decompress gzip requests.
And an `APIRoute` subclass to use that custom request class.
### Create a custom `GzipRequest` class
Tip
This is a toy example to demonstrate how it works, if you need Gzip support, you can use the provided [`GzipMiddleware`](../middleware/index#gzipmiddleware).
First, we create a `GzipRequest` class, which will overwrite the `Request.body()` method to decompress the body in the presence of an appropriate header.
If there's no `gzip` in the header, it will not try to decompress the body.
That way, the same route class can handle gzip compressed or uncompressed requests.
```
import gzip
from typing import Callable, List
from fastapi import Body, FastAPI, Request, Response
from fastapi.routing import APIRoute
class GzipRequest(Request):
async def body(self) -> bytes:
if not hasattr(self, "_body"):
body = await super().body()
if "gzip" in self.headers.getlist("Content-Encoding"):
body = gzip.decompress(body)
self._body = body
return self._body
class GzipRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
request = GzipRequest(request.scope, request.receive)
return await original_route_handler(request)
return custom_route_handler
app = FastAPI()
app.router.route_class = GzipRoute
@app.post("/sum")
async def sum_numbers(numbers: List[int] = Body()):
return {"sum": sum(numbers)}
```
### Create a custom `GzipRoute` class
Next, we create a custom subclass of `fastapi.routing.APIRoute` that will make use of the `GzipRequest`.
This time, it will overwrite the method `APIRoute.get_route_handler()`.
This method returns a function. And that function is what will receive a request and return a response.
Here we use it to create a `GzipRequest` from the original request.
```
import gzip
from typing import Callable, List
from fastapi import Body, FastAPI, Request, Response
from fastapi.routing import APIRoute
class GzipRequest(Request):
async def body(self) -> bytes:
if not hasattr(self, "_body"):
body = await super().body()
if "gzip" in self.headers.getlist("Content-Encoding"):
body = gzip.decompress(body)
self._body = body
return self._body
class GzipRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
request = GzipRequest(request.scope, request.receive)
return await original_route_handler(request)
return custom_route_handler
app = FastAPI()
app.router.route_class = GzipRoute
@app.post("/sum")
async def sum_numbers(numbers: List[int] = Body()):
return {"sum": sum(numbers)}
```
Technical Details
A `Request` has a `request.scope` attribute, that's just a Python `dict` containing the metadata related to the request.
A `Request` also has a `request.receive`, that's a function to "receive" the body of the request.
The `scope` `dict` and `receive` function are both part of the ASGI specification.
And those two things, `scope` and `receive`, are what is needed to create a new `Request` instance.
To learn more about the `Request` check [Starlette's docs about Requests](https://www.starlette.io/requests/).
The only thing the function returned by `GzipRequest.get_route_handler` does differently is convert the `Request` to a `GzipRequest`.
Doing this, our `GzipRequest` will take care of decompressing the data (if necessary) before passing it to our *path operations*.
After that, all of the processing logic is the same.
But because of our changes in `GzipRequest.body`, the request body will be automatically decompressed when it is loaded by **FastAPI** when needed.
Accessing the request body in an exception handler
--------------------------------------------------
Tip
To solve this same problem, it's probably a lot easier to use the `body` in a custom handler for `RequestValidationError` ([Handling Errors](../../tutorial/handling-errors/index#use-the-requestvalidationerror-body)).
But this example is still valid and it shows how to interact with the internal components.
We can also use this same approach to access the request body in an exception handler.
All we need to do is handle the request inside a `try`/`except` block:
```
from typing import Callable, List
from fastapi import Body, FastAPI, HTTPException, Request, Response
from fastapi.exceptions import RequestValidationError
from fastapi.routing import APIRoute
class ValidationErrorLoggingRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
try:
return await original_route_handler(request)
except RequestValidationError as exc:
body = await request.body()
detail = {"errors": exc.errors(), "body": body.decode()}
raise HTTPException(status_code=422, detail=detail)
return custom_route_handler
app = FastAPI()
app.router.route_class = ValidationErrorLoggingRoute
@app.post("/")
async def sum_numbers(numbers: List[int] = Body()):
return sum(numbers)
```
If an exception occurs, the`Request` instance will still be in scope, so we can read and make use of the request body when handling the error:
```
from typing import Callable, List
from fastapi import Body, FastAPI, HTTPException, Request, Response
from fastapi.exceptions import RequestValidationError
from fastapi.routing import APIRoute
class ValidationErrorLoggingRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
try:
return await original_route_handler(request)
except RequestValidationError as exc:
body = await request.body()
detail = {"errors": exc.errors(), "body": body.decode()}
raise HTTPException(status_code=422, detail=detail)
return custom_route_handler
app = FastAPI()
app.router.route_class = ValidationErrorLoggingRoute
@app.post("/")
async def sum_numbers(numbers: List[int] = Body()):
return sum(numbers)
```
Custom `APIRoute` class in a router
-----------------------------------
You can also set the `route_class` parameter of an `APIRouter`:
```
import time
from typing import Callable
from fastapi import APIRouter, FastAPI, Request, Response
from fastapi.routing import APIRoute
class TimedRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
before = time.time()
response: Response = await original_route_handler(request)
duration = time.time() - before
response.headers["X-Response-Time"] = str(duration)
print(f"route duration: {duration}")
print(f"route response: {response}")
print(f"route response headers: {response.headers}")
return response
return custom_route_handler
app = FastAPI()
router = APIRouter(route_class=TimedRoute)
@app.get("/")
async def not_timed():
return {"message": "Not timed"}
@router.get("/timed")
async def timed():
return {"message": "It's the time of my life"}
app.include_router(router)
```
In this example, the *path operations* under the `router` will use the custom `TimedRoute` class, and will have an extra `X-Response-Time` header in the response with the time it took to generate the response:
```
import time
from typing import Callable
from fastapi import APIRouter, FastAPI, Request, Response
from fastapi.routing import APIRoute
class TimedRoute(APIRoute):
def get_route_handler(self) -> Callable:
original_route_handler = super().get_route_handler()
async def custom_route_handler(request: Request) -> Response:
before = time.time()
response: Response = await original_route_handler(request)
duration = time.time() - before
response.headers["X-Response-Time"] = str(duration)
print(f"route duration: {duration}")
print(f"route response: {response}")
print(f"route response headers: {response.headers}")
return response
return custom_route_handler
app = FastAPI()
router = APIRouter(route_class=TimedRoute)
@app.get("/")
async def not_timed():
return {"message": "Not timed"}
@router.get("/timed")
async def timed():
return {"message": "It's the time of my life"}
app.include_router(router)
```
fastapi Testing Events: startup - shutdown Testing Events: startup - shutdown
==================================
When you need your event handlers (`startup` and `shutdown`) to run in your tests, you can use the `TestClient` with a `with` statement:
```
from fastapi import FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
items = {}
@app.on_event("startup")
async def startup_event():
items["foo"] = {"name": "Fighters"}
items["bar"] = {"name": "Tenders"}
@app.get("/items/{item_id}")
async def read_items(item_id: str):
return items[item_id]
def test_read_items():
with TestClient(app) as client:
response = client.get("/items/foo")
assert response.status_code == 200
assert response.json() == {"name": "Fighters"}
```
fastapi Sub Applications - Mounts Sub Applications - Mounts
=========================
If you need to have two independent FastAPI applications, with their own independent OpenAPI and their own docs UIs, you can have a main app and "mount" one (or more) sub-application(s).
Mounting a **FastAPI** application
----------------------------------
"Mounting" means adding a completely "independent" application in a specific path, that then takes care of handling everything under that path, with the *path operations* declared in that sub-application.
### Top-level application
First, create the main, top-level, **FastAPI** application, and its *path operations*:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/app")
def read_main():
return {"message": "Hello World from main app"}
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
app.mount("/subapi", subapi)
```
### Sub-application
Then, create your sub-application, and its *path operations*.
This sub-application is just another standard FastAPI application, but this is the one that will be "mounted":
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/app")
def read_main():
return {"message": "Hello World from main app"}
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
app.mount("/subapi", subapi)
```
### Mount the sub-application
In your top-level application, `app`, mount the sub-application, `subapi`.
In this case, it will be mounted at the path `/subapi`:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/app")
def read_main():
return {"message": "Hello World from main app"}
subapi = FastAPI()
@subapi.get("/sub")
def read_sub():
return {"message": "Hello World from sub API"}
app.mount("/subapi", subapi)
```
### Check the automatic API docs
Now, run `uvicorn` with the main app, if your file is `main.py`, it would be:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And open the docs at <http://127.0.0.1:8000/docs>.
You will see the automatic API docs for the main app, including only its own *path operations*:
And then, open the docs for the sub-application, at <http://127.0.0.1:8000/subapi/docs>.
You will see the automatic API docs for the sub-application, including only its own *path operations*, all under the correct sub-path prefix `/subapi`:
If you try interacting with any of the two user interfaces, they will work correctly, because the browser will be able to talk to each specific app or sub-app.
### Technical Details: `root_path`
When you mount a sub-application as described above, FastAPI will take care of communicating the mount path for the sub-application using a mechanism from the ASGI specification called a `root_path`.
That way, the sub-application will know to use that path prefix for the docs UI.
And the sub-application could also have its own mounted sub-applications and everything would work correctly, because FastAPI handles all these `root_path`s automatically.
You will learn more about the `root_path` and how to use it explicitly in the section about [Behind a Proxy](../behind-a-proxy/index).
fastapi Advanced Security - Intro Advanced Security - Intro
=========================
Additional Features
-------------------
There are some extra features to handle security apart from the ones covered in the [Tutorial - User Guide: Security](../../tutorial/security/index).
Tip
The next sections are **not necessarily "advanced"**.
And it's possible that for your use case, the solution is in one of them.
Read the Tutorial first
-----------------------
The next sections assume you already read the main [Tutorial - User Guide: Security](../../tutorial/security/index).
They are all based on the same concepts, but allow some extra functionalities.
| programming_docs |
fastapi HTTP Basic Auth HTTP Basic Auth
===============
For the simplest cases, you can use HTTP Basic Auth.
In HTTP Basic Auth, the application expects a header that contains a username and a password.
If it doesn't receive it, it returns an HTTP 401 "Unauthorized" error.
And returns a header `WWW-Authenticate` with a value of `Basic`, and an optional `realm` parameter.
That tells the browser to show the integrated prompt for a username and password.
Then, when you type that username and password, the browser sends them in the header automatically.
Simple HTTP Basic Auth
----------------------
* Import `HTTPBasic` and `HTTPBasicCredentials`.
* Create a "`security` scheme" using `HTTPBasic`.
* Use that `security` with a dependency in your *path operation*.
* It returns an object of type `HTTPBasicCredentials`:
+ It contains the `username` and `password` sent.
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
@app.get("/users/me")
def read_current_user(credentials: Annotated[HTTPBasicCredentials, Depends(security)]):
return {"username": credentials.username, "password": credentials.password}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from typing_extensions import Annotated
app = FastAPI()
security = HTTPBasic()
@app.get("/users/me")
def read_current_user(credentials: Annotated[HTTPBasicCredentials, Depends(security)]):
return {"username": credentials.username, "password": credentials.password}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
@app.get("/users/me")
def read_current_user(credentials: HTTPBasicCredentials = Depends(security)):
return {"username": credentials.username, "password": credentials.password}
```
When you try to open the URL for the first time (or click the "Execute" button in the docs) the browser will ask you for your username and password:
Check the username
------------------
Here's a more complete example.
Use a dependency to check if the username and password are correct.
For this, use the Python standard module [`secrets`](https://docs.python.org/3/library/secrets.html) to check the username and password.
`secrets.compare_digest()` needs to take `bytes` or a `str` that only contains ASCII characters (the ones in English), this means it wouldn't work with characters like `á`, as in `Sebastián`.
To handle that, we first convert the `username` and `password` to `bytes` encoding them with UTF-8.
Then we can use `secrets.compare_digest()` to ensure that `credentials.username` is `"stanleyjobson"`, and that `credentials.password` is `"swordfish"`.
Python 3.9+
```
import secrets
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)]
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
```
Python 3.6+
```
import secrets
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from typing_extensions import Annotated
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)]
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
import secrets
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(credentials: HTTPBasicCredentials = Depends(security)):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: str = Depends(get_current_username)):
return {"username": username}
```
This would be similar to:
```
if not (credentials.username == "stanleyjobson") or not (credentials.password == "swordfish"):
# Return some error
...
```
But by using the `secrets.compare_digest()` it will be secure against a type of attacks called "timing attacks".
### Timing Attacks
But what's a "timing attack"?
Let's imagine some attackers are trying to guess the username and password.
And they send a request with a username `johndoe` and a password `love123`.
Then the Python code in your application would be equivalent to something like:
```
if "johndoe" == "stanleyjobson" and "love123" == "swordfish":
...
```
But right at the moment Python compares the first `j` in `johndoe` to the first `s` in `stanleyjobson`, it will return `False`, because it already knows that those two strings are not the same, thinking that "there's no need to waste more computation comparing the rest of the letters". And your application will say "incorrect user or password".
But then the attackers try with username `stanleyjobsox` and password `love123`.
And your application code does something like:
```
if "stanleyjobsox" == "stanleyjobson" and "love123" == "swordfish":
...
```
Python will have to compare the whole `stanleyjobso` in both `stanleyjobsox` and `stanleyjobson` before realizing that both strings are not the same. So it will take some extra microseconds to reply back "incorrect user or password".
#### The time to answer helps the attackers
At that point, by noticing that the server took some microseconds longer to send the "incorrect user or password" response, the attackers will know that they got *something* right, some of the initial letters were right.
And then they can try again knowing that it's probably something more similar to `stanleyjobsox` than to `johndoe`.
#### A "professional" attack
Of course, the attackers would not try all this by hand, they would write a program to do it, possibly with thousands or millions of tests per second. And would get just one extra correct letter at a time.
But doing that, in some minutes or hours the attackers would have guessed the correct username and password, with the "help" of our application, just using the time taken to answer.
#### Fix it with `secrets.compare_digest()`
But in our code we are actually using `secrets.compare_digest()`.
In short, it will take the same time to compare `stanleyjobsox` to `stanleyjobson` than it takes to compare `johndoe` to `stanleyjobson`. And the same for the password.
That way, using `secrets.compare_digest()` in your application code, it will be safe against this whole range of security attacks.
### Return the error
After detecting that the credentials are incorrect, return an `HTTPException` with a status code 401 (the same returned when no credentials are provided) and add the header `WWW-Authenticate` to make the browser show the login prompt again:
Python 3.9+
```
import secrets
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)]
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
```
Python 3.6+
```
import secrets
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from typing_extensions import Annotated
app = FastAPI()
security = HTTPBasic()
def get_current_username(
credentials: Annotated[HTTPBasicCredentials, Depends(security)]
):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: Annotated[str, Depends(get_current_username)]):
return {"username": username}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
import secrets
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import HTTPBasic, HTTPBasicCredentials
app = FastAPI()
security = HTTPBasic()
def get_current_username(credentials: HTTPBasicCredentials = Depends(security)):
current_username_bytes = credentials.username.encode("utf8")
correct_username_bytes = b"stanleyjobson"
is_correct_username = secrets.compare_digest(
current_username_bytes, correct_username_bytes
)
current_password_bytes = credentials.password.encode("utf8")
correct_password_bytes = b"swordfish"
is_correct_password = secrets.compare_digest(
current_password_bytes, correct_password_bytes
)
if not (is_correct_username and is_correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return credentials.username
@app.get("/users/me")
def read_current_user(username: str = Depends(get_current_username)):
return {"username": username}
```
fastapi OAuth2 scopes OAuth2 scopes
=============
You can use OAuth2 scopes directly with **FastAPI**, they are integrated to work seamlessly.
This would allow you to have a more fine-grained permission system, following the OAuth2 standard, integrated into your OpenAPI application (and the API docs).
OAuth2 with scopes is the mechanism used by many big authentication providers, like Facebook, Google, GitHub, Microsoft, Twitter, etc. They use it to provide specific permissions to users and applications.
Every time you "log in with" Facebook, Google, GitHub, Microsoft, Twitter, that application is using OAuth2 with scopes.
In this section you will see how to manage authentication and authorization with the same OAuth2 with scopes in your **FastAPI** application.
Warning
This is a more or less advanced section. If you are just starting, you can skip it.
You don't necessarily need OAuth2 scopes, and you can handle authentication and authorization however you want.
But OAuth2 with scopes can be nicely integrated into your API (with OpenAPI) and your API docs.
Nevertheless, you still enforce those scopes, or any other security/authorization requirement, however you need, in your code.
In many cases, OAuth2 with scopes can be an overkill.
But if you know you need it, or you are curious, keep reading.
OAuth2 scopes and OpenAPI
-------------------------
The OAuth2 specification defines "scopes" as a list of strings separated by spaces.
The content of each of these strings can have any format, but should not contain spaces.
These scopes represent "permissions".
In OpenAPI (e.g. the API docs), you can define "security schemes".
When one of these security schemes uses OAuth2, you can also declare and use scopes.
Each "scope" is just a string (without spaces).
They are normally used to declare specific security permissions, for example:
* `users:read` or `users:write` are common examples.
* `instagram_basic` is used by Facebook / Instagram.
* `https://www.googleapis.com/auth/drive` is used by Google.
Info
In OAuth2 a "scope" is just a string that declares a specific permission required.
It doesn't matter if it has other characters like `:` or if it is a URL.
Those details are implementation specific.
For OAuth2 they are just strings.
Global view
-----------
First, let's quickly see the parts that change from the examples in the main **Tutorial - User Guide** for [OAuth2 with Password (and hashing), Bearer with JWT tokens](../../../tutorial/security/oauth2-jwt/index). Now using OAuth2 scopes:
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Now let's review those changes step by step.
OAuth2 Security scheme
----------------------
The first change is that now we are declaring the OAuth2 security scheme with two available scopes, `me` and `items`.
The `scopes` parameter receives a `dict` with each scope as a key and the description as the value:
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Because we are now declaring those scopes, they will show up in the API docs when you log-in/authorize.
And you will be able to select which scopes you want to give access to: `me` and `items`.
This is the same mechanism used when you give permissions while logging in with Facebook, Google, GitHub, etc:
JWT token with scopes
---------------------
Now, modify the token *path operation* to return the scopes requested.
We are still using the same `OAuth2PasswordRequestForm`. It includes a property `scopes` with a `list` of `str`, with each scope it received in the request.
And we return the scopes as part of the JWT token.
Danger
For simplicity, here we are just adding the scopes received directly to the token.
But in your application, for security, you should make sure you only add the scopes that the user is actually able to have, or the ones you have predefined.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Declare scopes in *path operations* and dependencies
----------------------------------------------------
Now we declare that the *path operation* for `/users/me/items/` requires the scope `items`.
For this, we import and use `Security` from `fastapi`.
You can use `Security` to declare dependencies (just like `Depends`), but `Security` also receives a parameter `scopes` with a list of scopes (strings).
In this case, we pass a dependency function `get_current_active_user` to `Security` (the same way we would do with `Depends`).
But we also pass a `list` of scopes, in this case with just one scope: `items` (it could have more).
And the dependency function `get_current_active_user` can also declare sub-dependencies, not only with `Depends` but also with `Security`. Declaring its own sub-dependency function (`get_current_user`), and more scope requirements.
In this case, it requires the scope `me` (it could require more than one scope).
Note
You don't necessarily need to add different scopes in different places.
We are doing it here to demonstrate how **FastAPI** handles scopes declared at different levels.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Technical Details
`Security` is actually a subclass of `Depends`, and it has just one extra parameter that we'll see later.
But by using `Security` instead of `Depends`, **FastAPI** will know that it can declare security scopes, use them internally, and document the API with OpenAPI.
But when you import `Query`, `Path`, `Depends`, `Security` and others from `fastapi`, those are actually functions that return special classes.
Use `SecurityScopes`
--------------------
Now update the dependency `get_current_user`.
This is the one used by the dependencies above.
Here's were we are using the same OAuth2 scheme we created before, declaring it as a dependency: `oauth2_scheme`.
Because this dependency function doesn't have any scope requirements itself, we can use `Depends` with `oauth2_scheme`, we don't have to use `Security` when we don't need to specify security scopes.
We also declare a special parameter of type `SecurityScopes`, imported from `fastapi.security`.
This `SecurityScopes` class is similar to `Request` (`Request` was used to get the request object directly).
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Use the `scopes`
----------------
The parameter `security_scopes` will be of type `SecurityScopes`.
It will have a property `scopes` with a list containing all the scopes required by itself and all the dependencies that use this as a sub-dependency. That means, all the "dependants"... this might sound confusing, it is explained again later below.
The `security_scopes` object (of class `SecurityScopes`) also provides a `scope_str` attribute with a single string, containing those scopes separated by spaces (we are going to use it).
We create an `HTTPException` that we can re-use (`raise`) later at several points.
In this exception, we include the scopes required (if any) as a string separated by spaces (using `scope_str`). We put that string containing the scopes in the `WWW-Authenticate` header (this is part of the spec).
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Verify the `username` and data shape
------------------------------------
We verify that we get a `username`, and extract the scopes.
And then we validate that data with the Pydantic model (catching the `ValidationError` exception), and if we get an error reading the JWT token or validating the data with Pydantic, we raise the `HTTPException` we created before.
For that, we update the Pydantic model `TokenData` with a new property `scopes`.
By validating the data with Pydantic we can make sure that we have, for example, exactly a `list` of `str` with the scopes and a `str` with the `username`.
Instead of, for example, a `dict`, or something else, as it could break the application at some point later, making it a security risk.
We also verify that we have a user with that username, and if not, we raise that same exception we created before.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Verify the `scopes`
-------------------
We now verify that all the scopes required, by this dependency and all the dependants (including *path operations*), are included in the scopes provided in the token received, otherwise raise an `HTTPException`.
For this, we use `security_scopes.scopes`, that contains a `list` with all these scopes as `str`.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: Annotated[str, Depends(oauth2_scheme)]
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Security(get_current_user, scopes=["me"])]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Security(get_current_active_user, scopes=["items"])]
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: Annotated[User, Depends(get_current_user)]):
return {"status": "ok"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: list[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import List, Union
from fastapi import Depends, FastAPI, HTTPException, Security, status
from fastapi.security import (
OAuth2PasswordBearer,
OAuth2PasswordRequestForm,
SecurityScopes,
)
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel, ValidationError
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Chains",
"email": "[email protected]",
"hashed_password": "$2b$12$gSvqqUPvlXP2tfVFaWK1Be7DlH.PKZbv5H8KnzzVgXXbVxpva.pFm",
"disabled": True,
},
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
scopes: List[str] = []
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(
tokenUrl="token",
scopes={"me": "Read information about the current user.", "items": "Read items."},
)
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(
security_scopes: SecurityScopes, token: str = Depends(oauth2_scheme)
):
if security_scopes.scopes:
authenticate_value = f'Bearer scope="{security_scopes.scope_str}"'
else:
authenticate_value = "Bearer"
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": authenticate_value},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_scopes = payload.get("scopes", [])
token_data = TokenData(scopes=token_scopes, username=username)
except (JWTError, ValidationError):
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
for scope in security_scopes.scopes:
if scope not in token_data.scopes:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Not enough permissions",
headers={"WWW-Authenticate": authenticate_value},
)
return user
async def get_current_active_user(
current_user: User = Security(get_current_user, scopes=["me"])
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(status_code=400, detail="Incorrect username or password")
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username, "scopes": form_data.scopes},
expires_delta=access_token_expires,
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: User = Security(get_current_active_user, scopes=["items"])
):
return [{"item_id": "Foo", "owner": current_user.username}]
@app.get("/status/")
async def read_system_status(current_user: User = Depends(get_current_user)):
return {"status": "ok"}
```
Dependency tree and scopes
--------------------------
Let's review again this dependency tree and the scopes.
As the `get_current_active_user` dependency has as a sub-dependency on `get_current_user`, the scope `"me"` declared at `get_current_active_user` will be included in the list of required scopes in the `security_scopes.scopes` passed to `get_current_user`.
The *path operation* itself also declares a scope, `"items"`, so this will also be in the list of `security_scopes.scopes` passed to `get_current_user`.
Here's how the hierarchy of dependencies and scopes looks like:
* The *path operation* `read_own_items` has:
+ Required scopes `["items"]` with the dependency:
+ `get_current_active_user`:
- The dependency function `get_current_active_user` has:
* Required scopes `["me"]` with the dependency:
* `get_current_user`:
+ The dependency function `get_current_user` has:
- No scopes required by itself.
- A dependency using `oauth2_scheme`.
- A `security_scopes` parameter of type `SecurityScopes`:
* This `security_scopes` parameter has a property `scopes` with a `list` containing all these scopes declared above, so:
+ `security_scopes.scopes` will contain `["me", "items"]` for the *path operation* `read_own_items`.
+ `security_scopes.scopes` will contain `["me"]` for the *path operation* `read_users_me`, because it is declared in the dependency `get_current_active_user`.
+ `security_scopes.scopes` will contain `[]` (nothing) for the *path operation* `read_system_status`, because it didn't declare any `Security` with `scopes`, and its dependency, `get_current_user`, doesn't declare any `scope` either.
Tip
The important and "magic" thing here is that `get_current_user` will have a different list of `scopes` to check for each *path operation*.
All depending on the `scopes` declared in each *path operation* and each dependency in the dependency tree for that specific *path operation*.
More details about `SecurityScopes`
-----------------------------------
You can use `SecurityScopes` at any point, and in multiple places, it doesn't have to be at the "root" dependency.
It will always have the security scopes declared in the current `Security` dependencies and all the dependants for **that specific** *path operation* and **that specific** dependency tree.
Because the `SecurityScopes` will have all the scopes declared by dependants, you can use it to verify that a token has the required scopes in a central dependency function, and then declare different scope requirements in different *path operations*.
They will be checked independently for each *path operation*.
Check it
--------
If you open the API docs, you can authenticate and specify which scopes you want to authorize.
If you don't select any scope, you will be "authenticated", but when you try to access `/users/me/` or `/users/me/items/` you will get an error saying that you don't have enough permissions. You will still be able to access `/status/`.
And if you select the scope `me` but not the scope `items`, you will be able to access `/users/me/` but not `/users/me/items/`.
That's what would happen to a third party application that tried to access one of these *path operations* with a token provided by a user, depending on how many permissions the user gave the application.
About third party integrations
------------------------------
In this example we are using the OAuth2 "password" flow.
This is appropriate when we are logging in to our own application, probably with our own frontend.
Because we can trust it to receive the `username` and `password`, as we control it.
But if you are building an OAuth2 application that others would connect to (i.e., if you are building an authentication provider equivalent to Facebook, Google, GitHub, etc.) you should use one of the other flows.
The most common is the implicit flow.
The most secure is the code flow, but is more complex to implement as it requires more steps. As it is more complex, many providers end up suggesting the implicit flow.
Note
It's common that each authentication provider names their flows in a different way, to make it part of their brand.
But in the end, they are implementing the same OAuth2 standard.
**FastAPI** includes utilities for all these OAuth2 authentication flows in `fastapi.security.oauth2`.
`Security` in decorator `dependencies`
---------------------------------------
The same way you can define a `list` of `Depends` in the decorator's `dependencies` parameter (as explained in [Dependencies in path operation decorators](../../../tutorial/dependencies/dependencies-in-path-operation-decorators/index)), you could also use `Security` with `scopes` there.
| programming_docs |
fastapi Response - Change Status Code Response - Change Status Code
=============================
You probably read before that you can set a default [Response Status Code](../../tutorial/response-status-code/index).
But in some cases you need to return a different status code than the default.
Use case
--------
For example, imagine that you want to return an HTTP status code of "OK" `200` by default.
But if the data didn't exist, you want to create it, and return an HTTP status code of "CREATED" `201`.
But you still want to be able to filter and convert the data you return with a `response_model`.
For those cases, you can use a `Response` parameter.
Use a `Response` parameter
--------------------------
You can declare a parameter of type `Response` in your *path operation function* (as you can do for cookies and headers).
And then you can set the `status_code` in that *temporal* response object.
```
from fastapi import FastAPI, Response, status
app = FastAPI()
tasks = {"foo": "Listen to the Bar Fighters"}
@app.put("/get-or-create-task/{task_id}", status_code=200)
def get_or_create_task(task_id: str, response: Response):
if task_id not in tasks:
tasks[task_id] = "This didn't exist before"
response.status_code = status.HTTP_201_CREATED
return tasks[task_id]
```
And then you can return any object you need, as you normally would (a `dict`, a database model, etc).
And if you declared a `response_model`, it will still be used to filter and convert the object you returned.
**FastAPI** will use that *temporal* response to extract the status code (also cookies and headers), and will put them in the final response that contains the value you returned, filtered by any `response_model`.
You can also declare the `Response` parameter in dependencies, and set the status code in them. But have in mind that the last one to be set will win.
fastapi Testing a Database Testing a Database
==================
You can use the same dependency overrides from [Testing Dependencies with Overrides](../testing-dependencies/index) to alter a database for testing.
You could want to set up a different database for testing, rollback the data after the tests, pre-fill it with some testing data, etc.
The main idea is exactly the same you saw in that previous chapter.
Add tests for the SQL app
-------------------------
Let's update the example from [SQL (Relational) Databases](../../tutorial/sql-databases/index) to use a testing database.
All the app code is the same, you can go back to that chapter check how it was.
The only changes here are in the new testing file.
Your normal dependency `get_db()` would return a database session.
In the test, you could use a dependency override to return your *custom* database session instead of the one that would be used normally.
In this example we'll create a temporary database only for the tests.
File structure
--------------
We create a new file at `sql_app/tests/test_sql_app.py`.
So the new file structure looks like:
```
.
└── sql_app
├── __init__.py
├── crud.py
├── database.py
├── main.py
├── models.py
├── schemas.py
└── tests
├── __init__.py
└── test_sql_app.py
```
Create the new database session
-------------------------------
First, we create a new database session with the new database.
For the tests we'll use a file `test.db` instead of `sql_app.db`.
But the rest of the session code is more or less the same, we just copy it.
```
from fastapi.testclient import TestClient
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from ..database import Base
from ..main import app, get_db
SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
TestingSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base.metadata.create_all(bind=engine)
def override_get_db():
try:
db = TestingSessionLocal()
yield db
finally:
db.close()
app.dependency_overrides[get_db] = override_get_db
client = TestClient(app)
def test_create_user():
response = client.post(
"/users/",
json={"email": "[email protected]", "password": "chimichangas4life"},
)
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert "id" in data
user_id = data["id"]
response = client.get(f"/users/{user_id}")
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert data["id"] == user_id
```
Tip
You could reduce duplication in that code by putting it in a function and using it from both `database.py` and `tests/test_sql_app.py`.
For simplicity and to focus on the specific testing code, we are just copying it.
Create the database
-------------------
Because now we are going to use a new database in a new file, we need to make sure we create the database with:
```
Base.metadata.create_all(bind=engine)
```
That is normally called in `main.py`, but the line in `main.py` uses the database file `sql_app.db`, and we need to make sure we create `test.db` for the tests.
So we add that line here, with the new file.
```
from fastapi.testclient import TestClient
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from ..database import Base
from ..main import app, get_db
SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
TestingSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base.metadata.create_all(bind=engine)
def override_get_db():
try:
db = TestingSessionLocal()
yield db
finally:
db.close()
app.dependency_overrides[get_db] = override_get_db
client = TestClient(app)
def test_create_user():
response = client.post(
"/users/",
json={"email": "[email protected]", "password": "chimichangas4life"},
)
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert "id" in data
user_id = data["id"]
response = client.get(f"/users/{user_id}")
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert data["id"] == user_id
```
Dependency override
-------------------
Now we create the dependency override and add it to the overrides for our app.
```
from fastapi.testclient import TestClient
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from ..database import Base
from ..main import app, get_db
SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
TestingSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base.metadata.create_all(bind=engine)
def override_get_db():
try:
db = TestingSessionLocal()
yield db
finally:
db.close()
app.dependency_overrides[get_db] = override_get_db
client = TestClient(app)
def test_create_user():
response = client.post(
"/users/",
json={"email": "[email protected]", "password": "chimichangas4life"},
)
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert "id" in data
user_id = data["id"]
response = client.get(f"/users/{user_id}")
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert data["id"] == user_id
```
Tip
The code for `override_get_db()` is almost exactly the same as for `get_db()`, but in `override_get_db()` we use the `TestingSessionLocal` for the testing database instead.
Test the app
------------
Then we can just test the app as normally.
```
from fastapi.testclient import TestClient
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from ..database import Base
from ..main import app, get_db
SQLALCHEMY_DATABASE_URL = "sqlite:///./test.db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
TestingSessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base.metadata.create_all(bind=engine)
def override_get_db():
try:
db = TestingSessionLocal()
yield db
finally:
db.close()
app.dependency_overrides[get_db] = override_get_db
client = TestClient(app)
def test_create_user():
response = client.post(
"/users/",
json={"email": "[email protected]", "password": "chimichangas4life"},
)
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert "id" in data
user_id = data["id"]
response = client.get(f"/users/{user_id}")
assert response.status_code == 200, response.text
data = response.json()
assert data["email"] == "[email protected]"
assert data["id"] == user_id
```
And all the modifications we made in the database during the tests will be in the `test.db` database instead of the main `sql_app.db`.
fastapi Including WSGI - Flask, Django, others Including WSGI - Flask, Django, others
======================================
You can mount WSGI applications as you saw with [Sub Applications - Mounts](../sub-applications/index), [Behind a Proxy](../behind-a-proxy/index).
For that, you can use the `WSGIMiddleware` and use it to wrap your WSGI application, for example, Flask, Django, etc.
Using `WSGIMiddleware`
----------------------
You need to import `WSGIMiddleware`.
Then wrap the WSGI (e.g. Flask) app with the middleware.
And then mount that under a path.
```
from fastapi import FastAPI
from fastapi.middleware.wsgi import WSGIMiddleware
from flask import Flask, escape, request
flask_app = Flask(__name__)
@flask_app.route("/")
def flask_main():
name = request.args.get("name", "World")
return f"Hello, {escape(name)} from Flask!"
app = FastAPI()
@app.get("/v2")
def read_main():
return {"message": "Hello World"}
app.mount("/v1", WSGIMiddleware(flask_app))
```
Check it
--------
Now, every request under the path `/v1/` will be handled by the Flask application.
And the rest will be handled by **FastAPI**.
If you run it with Uvicorn and go to <http://localhost:8000/v1/> you will see the response from Flask:
```
Hello, World from Flask!
```
And if you go to <http://localhost:8000/v2> you will see the response from FastAPI:
```
{
"message": "Hello World"
}
```
fastapi Additional Responses in OpenAPI Additional Responses in OpenAPI
===============================
Warning
This is a rather advanced topic.
If you are starting with **FastAPI**, you might not need this.
You can declare additional responses, with additional status codes, media types, descriptions, etc.
Those additional responses will be included in the OpenAPI schema, so they will also appear in the API docs.
But for those additional responses you have to make sure you return a `Response` like `JSONResponse` directly, with your status code and content.
Additional Response with `model`
--------------------------------
You can pass to your *path operation decorators* a parameter `responses`.
It receives a `dict`, the keys are status codes for each response, like `200`, and the values are other `dict`s with the information for each of them.
Each of those response `dict`s can have a key `model`, containing a Pydantic model, just like `response_model`.
**FastAPI** will take that model, generate its JSON Schema and include it in the correct place in OpenAPI.
For example, to declare another response with a status code `404` and a Pydantic model `Message`, you can write:
```
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
class Message(BaseModel):
message: str
app = FastAPI()
@app.get("/items/{item_id}", response_model=Item, responses={404: {"model": Message}})
async def read_item(item_id: str):
if item_id == "foo":
return {"id": "foo", "value": "there goes my hero"}
return JSONResponse(status_code=404, content={"message": "Item not found"})
```
Note
Have in mind that you have to return the `JSONResponse` directly.
Info
The `model` key is not part of OpenAPI.
**FastAPI** will take the Pydantic model from there, generate the `JSON Schema`, and put it in the correct place.
The correct place is:
* In the key `content`, that has as value another JSON object (`dict`) that contains:
+ A key with the media type, e.g. `application/json`, that contains as value another JSON object, that contains:
- A key `schema`, that has as the value the JSON Schema from the model, here's the correct place.
* **FastAPI** adds a reference here to the global JSON Schemas in another place in your OpenAPI instead of including it directly. This way, other applications and clients can use those JSON Schemas directly, provide better code generation tools, etc.
The generated responses in the OpenAPI for this *path operation* will be:
```
{
"responses": {
"404": {
"description": "Additional Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Message"
}
}
}
},
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/Item"
}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
```
The schemas are referenced to another place inside the OpenAPI schema:
```
{
"components": {
"schemas": {
"Message": {
"title": "Message",
"required": [
"message"
],
"type": "object",
"properties": {
"message": {
"title": "Message",
"type": "string"
}
}
},
"Item": {
"title": "Item",
"required": [
"id",
"value"
],
"type": "object",
"properties": {
"id": {
"title": "Id",
"type": "string"
},
"value": {
"title": "Value",
"type": "string"
}
}
},
"ValidationError": {
"title": "ValidationError",
"required": [
"loc",
"msg",
"type"
],
"type": "object",
"properties": {
"loc": {
"title": "Location",
"type": "array",
"items": {
"type": "string"
}
},
"msg": {
"title": "Message",
"type": "string"
},
"type": {
"title": "Error Type",
"type": "string"
}
}
},
"HTTPValidationError": {
"title": "HTTPValidationError",
"type": "object",
"properties": {
"detail": {
"title": "Detail",
"type": "array",
"items": {
"$ref": "#/components/schemas/ValidationError"
}
}
}
}
}
}
}
```
Additional media types for the main response
--------------------------------------------
You can use this same `responses` parameter to add different media types for the same main response.
For example, you can add an additional media type of `image/png`, declaring that your *path operation* can return a JSON object (with media type `application/json`) or a PNG image:
```
from typing import Union
from fastapi import FastAPI
from fastapi.responses import FileResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={
200: {
"content": {"image/png": {}},
"description": "Return the JSON item or an image.",
}
},
)
async def read_item(item_id: str, img: Union[bool, None] = None):
if img:
return FileResponse("image.png", media_type="image/png")
else:
return {"id": "foo", "value": "there goes my hero"}
```
Note
Notice that you have to return the image using a `FileResponse` directly.
Info
Unless you specify a different media type explicitly in your `responses` parameter, FastAPI will assume the response has the same media type as the main response class (default `application/json`).
But if you have specified a custom response class with `None` as its media type, FastAPI will use `application/json` for any additional response that has an associated model.
Combining information
---------------------
You can also combine response information from multiple places, including the `response_model`, `status_code`, and `responses` parameters.
You can declare a `response_model`, using the default status code `200` (or a custom one if you need), and then declare additional information for that same response in `responses`, directly in the OpenAPI schema.
**FastAPI** will keep the additional information from `responses`, and combine it with the JSON Schema from your model.
For example, you can declare a response with a status code `404` that uses a Pydantic model and has a custom `description`.
And a response with a status code `200` that uses your `response_model`, but includes a custom `example`:
```
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
class Message(BaseModel):
message: str
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={
404: {"model": Message, "description": "The item was not found"},
200: {
"description": "Item requested by ID",
"content": {
"application/json": {
"example": {"id": "bar", "value": "The bar tenders"}
}
},
},
},
)
async def read_item(item_id: str):
if item_id == "foo":
return {"id": "foo", "value": "there goes my hero"}
else:
return JSONResponse(status_code=404, content={"message": "Item not found"})
```
It will all be combined and included in your OpenAPI, and shown in the API docs:
Combine predefined responses and custom ones
--------------------------------------------
You might want to have some predefined responses that apply to many *path operations*, but you want to combine them with custom responses needed by each *path operation*.
For those cases, you can use the Python technique of "unpacking" a `dict` with `**dict_to_unpack`:
```
old_dict = {
"old key": "old value",
"second old key": "second old value",
}
new_dict = {**old_dict, "new key": "new value"}
```
Here, `new_dict` will contain all the key-value pairs from `old_dict` plus the new key-value pair:
```
{
"old key": "old value",
"second old key": "second old value",
"new key": "new value",
}
```
You can use that technique to re-use some predefined responses in your *path operations* and combine them with additional custom ones.
For example:
```
from typing import Union
from fastapi import FastAPI
from fastapi.responses import FileResponse
from pydantic import BaseModel
class Item(BaseModel):
id: str
value: str
responses = {
404: {"description": "Item not found"},
302: {"description": "The item was moved"},
403: {"description": "Not enough privileges"},
}
app = FastAPI()
@app.get(
"/items/{item_id}",
response_model=Item,
responses={**responses, 200: {"content": {"image/png": {}}}},
)
async def read_item(item_id: str, img: Union[bool, None] = None):
if img:
return FileResponse("image.png", media_type="image/png")
else:
return {"id": "foo", "value": "there goes my hero"}
```
More information about OpenAPI responses
----------------------------------------
To see what exactly you can include in the responses, you can check these sections in the OpenAPI specification:
* [OpenAPI Responses Object](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#responsesObject), it includes the `Response Object`.
* [OpenAPI Response Object](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md#responseObject), you can include anything from this directly in each response inside your `responses` parameter. Including `description`, `headers`, `content` (inside of this is that you declare different media types and JSON Schemas), and `links`.
| programming_docs |
fastapi Path Operation Advanced Configuration Path Operation Advanced Configuration
=====================================
OpenAPI operationId
-------------------
Warning
If you are not an "expert" in OpenAPI, you probably don't need this.
You can set the OpenAPI `operationId` to be used in your *path operation* with the parameter `operation_id`.
You would have to make sure that it is unique for each operation.
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", operation_id="some_specific_id_you_define")
async def read_items():
return [{"item_id": "Foo"}]
```
### Using the *path operation function* name as the operationId
If you want to use your APIs' function names as `operationId`s, you can iterate over all of them and override each *path operation's* `operation_id` using their `APIRoute.name`.
You should do it after adding all your *path operations*.
```
from fastapi import FastAPI
from fastapi.routing import APIRoute
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"item_id": "Foo"}]
def use_route_names_as_operation_ids(app: FastAPI) -> None:
"""
Simplify operation IDs so that generated API clients have simpler function
names.
Should be called only after all routes have been added.
"""
for route in app.routes:
if isinstance(route, APIRoute):
route.operation_id = route.name # in this case, 'read_items'
use_route_names_as_operation_ids(app)
```
Tip
If you manually call `app.openapi()`, you should update the `operationId`s before that.
Warning
If you do this, you have to make sure each one of your *path operation functions* has a unique name.
Even if they are in different modules (Python files).
Exclude from OpenAPI
--------------------
To exclude a *path operation* from the generated OpenAPI schema (and thus, from the automatic documentation systems), use the parameter `include_in_schema` and set it to `False`:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", include_in_schema=False)
async def read_items():
return [{"item_id": "Foo"}]
```
Advanced description from docstring
-----------------------------------
You can limit the lines used from the docstring of a *path operation function* for OpenAPI.
Adding an `\f` (an escaped "form feed" character) causes **FastAPI** to truncate the output used for OpenAPI at this point.
It won't show up in the documentation, but other tools (such as Sphinx) will be able to use the rest.
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post("/items/", response_model=Item, summary="Create an item")
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
\f
:param item: User input.
"""
return item
```
Additional Responses
--------------------
You probably have seen how to declare the `response_model` and `status_code` for a *path operation*.
That defines the metadata about the main response of a *path operation*.
You can also declare additional responses with their models, status codes, etc.
There's a whole chapter here in the documentation about it, you can read it at [Additional Responses in OpenAPI](../additional-responses/index).
OpenAPI Extra
-------------
When you declare a *path operation* in your application, **FastAPI** automatically generates the relevant metadata about that *path operation* to be included in the OpenAPI schema.
Technical details
In the OpenAPI specification it is called the [Operation Object](https://github.com/OAI/OpenAPI-Specification/blob/main/versions/3.0.3.md#operation-object).
It has all the information about the *path operation* and is used to generate the automatic documentation.
It includes the `tags`, `parameters`, `requestBody`, `responses`, etc.
This *path operation*-specific OpenAPI schema is normally generated automatically by **FastAPI**, but you can also extend it.
Tip
This is a low level extension point.
If you only need to declare additional responses, a more convenient way to do it is with [Additional Responses in OpenAPI](../additional-responses/index).
You can extend the OpenAPI schema for a *path operation* using the parameter `openapi_extra`.
### OpenAPI Extensions
This `openapi_extra` can be helpful, for example, to declare [OpenAPI Extensions](https://github.com/OAI/OpenAPI-Specification/blob/main/versions/3.0.3.md#specificationExtensions):
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", openapi_extra={"x-aperture-labs-portal": "blue"})
async def read_items():
return [{"item_id": "portal-gun"}]
```
If you open the automatic API docs, your extension will show up at the bottom of the specific *path operation*.
And if you see the resulting OpenAPI (at `/openapi.json` in your API), you will see your extension as part of the specific *path operation* too:
```
{
"openapi": "3.0.2",
"info": {
"title": "FastAPI",
"version": "0.1.0"
},
"paths": {
"/items/": {
"get": {
"summary": "Read Items",
"operationId": "read_items_items__get",
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {}
}
}
}
},
"x-aperture-labs-portal": "blue"
}
}
}
}
```
### Custom OpenAPI *path operation* schema
The dictionary in `openapi_extra` will be deeply merged with the automatically generated OpenAPI schema for the *path operation*.
So, you could add additional data to the automatically generated schema.
For example, you could decide to read and validate the request with your own code, without using the automatic features of FastAPI with Pydantic, but you could still want to define the request in the OpenAPI schema.
You could do that with `openapi_extra`:
```
from fastapi import FastAPI, Request
app = FastAPI()
def magic_data_reader(raw_body: bytes):
return {
"size": len(raw_body),
"content": {
"name": "Maaaagic",
"price": 42,
"description": "Just kiddin', no magic here. ✨",
},
}
@app.post(
"/items/",
openapi_extra={
"requestBody": {
"content": {
"application/json": {
"schema": {
"required": ["name", "price"],
"type": "object",
"properties": {
"name": {"type": "string"},
"price": {"type": "number"},
"description": {"type": "string"},
},
}
}
},
"required": True,
},
},
)
async def create_item(request: Request):
raw_body = await request.body()
data = magic_data_reader(raw_body)
return data
```
In this example, we didn't declare any Pydantic model. In fact, the request body is not even parsed as JSON, it is read directly as `bytes`, and the function `magic_data_reader()` would be in charge of parsing it in some way.
Nevertheless, we can declare the expected schema for the request body.
### Custom OpenAPI content type
Using this same trick, you could use a Pydantic model to define the JSON Schema that is then included in the custom OpenAPI schema section for the *path operation*.
And you could do this even if the data type in the request is not JSON.
For example, in this application we don't use FastAPI's integrated functionality to extract the JSON Schema from Pydantic models nor the automatic validation for JSON. In fact, we are declaring the request content type as YAML, not JSON:
```
from typing import List
import yaml
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel, ValidationError
app = FastAPI()
class Item(BaseModel):
name: str
tags: List[str]
@app.post(
"/items/",
openapi_extra={
"requestBody": {
"content": {"application/x-yaml": {"schema": Item.schema()}},
"required": True,
},
},
)
async def create_item(request: Request):
raw_body = await request.body()
try:
data = yaml.safe_load(raw_body)
except yaml.YAMLError:
raise HTTPException(status_code=422, detail="Invalid YAML")
try:
item = Item.parse_obj(data)
except ValidationError as e:
raise HTTPException(status_code=422, detail=e.errors())
return item
```
Nevertheless, although we are not using the default integrated functionality, we are still using a Pydantic model to manually generate the JSON Schema for the data that we want to receive in YAML.
Then we use the request directly, and extract the body as `bytes`. This means that FastAPI won't even try to parse the request payload as JSON.
And then in our code, we parse that YAML content directly, and then we are again using the same Pydantic model to validate the YAML content:
```
from typing import List
import yaml
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel, ValidationError
app = FastAPI()
class Item(BaseModel):
name: str
tags: List[str]
@app.post(
"/items/",
openapi_extra={
"requestBody": {
"content": {"application/x-yaml": {"schema": Item.schema()}},
"required": True,
},
},
)
async def create_item(request: Request):
raw_body = await request.body()
try:
data = yaml.safe_load(raw_body)
except yaml.YAMLError:
raise HTTPException(status_code=422, detail="Invalid YAML")
try:
item = Item.parse_obj(data)
except ValidationError as e:
raise HTTPException(status_code=422, detail=e.errors())
return item
```
Tip
Here we re-use the same Pydantic model.
But the same way, we could have validated it in some other way.
fastapi Behind a Proxy Behind a Proxy
==============
In some situations, you might need to use a **proxy** server like Traefik or Nginx with a configuration that adds an extra path prefix that is not seen by your application.
In these cases you can use `root_path` to configure your application.
The `root_path` is a mechanism provided by the ASGI specification (that FastAPI is built on, through Starlette).
The `root_path` is used to handle these specific cases.
And it's also used internally when mounting sub-applications.
Proxy with a stripped path prefix
---------------------------------
Having a proxy with a stripped path prefix, in this case, means that you could declare a path at `/app` in your code, but then, you add a layer on top (the proxy) that would put your **FastAPI** application under a path like `/api/v1`.
In this case, the original path `/app` would actually be served at `/api/v1/app`.
Even though all your code is written assuming there's just `/app`.
And the proxy would be **"stripping"** the **path prefix** on the fly before transmitting the request to Uvicorn, keep your application convinced that it is serving at `/app`, so that you don't have to update all your code to include the prefix `/api/v1`.
Up to here, everything would work as normally.
But then, when you open the integrated docs UI (the frontend), it would expect to get the OpenAPI schema at `/openapi.json`, instead of `/api/v1/openapi.json`.
So, the frontend (that runs in the browser) would try to reach `/openapi.json` and wouldn't be able to get the OpenAPI schema.
Because we have a proxy with a path prefix of `/api/v1` for our app, the frontend needs to fetch the OpenAPI schema at `/api/v1/openapi.json`.
```
graph LR
browser("Browser")
proxy["Proxy on http://0.0.0.0:9999/api/v1/app"]
server["Server on http://127.0.0.1:8000/app"]
browser --> proxy
proxy --> server
```
Tip
The IP `0.0.0.0` is commonly used to mean that the program listens on all the IPs available in that machine/server.
The docs UI would also need the OpenAPI schema to declare that this API `server` is located at `/api/v1` (behind the proxy). For example:
```
{
"openapi": "3.0.2",
// More stuff here
"servers": [
{
"url": "/api/v1"
}
],
"paths": {
// More stuff here
}
}
```
In this example, the "Proxy" could be something like **Traefik**. And the server would be something like **Uvicorn**, running your FastAPI application.
### Providing the `root_path`
To achieve this, you can use the command line option `--root-path` like:
```
$ uvicorn main:app --root-path /api/v1
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
If you use Hypercorn, it also has the option `--root-path`.
Technical Details
The ASGI specification defines a `root_path` for this use case.
And the `--root-path` command line option provides that `root_path`.
### Checking the current `root_path`
You can get the current `root_path` used by your application for each request, it is part of the `scope` dictionary (that's part of the ASGI spec).
Here we are including it in the message just for demonstration purposes.
```
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
```
Then, if you start Uvicorn with:
```
$ uvicorn main:app --root-path /api/v1
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
The response would be something like:
```
{
"message": "Hello World",
"root_path": "/api/v1"
}
```
### Setting the `root_path` in the FastAPI app
Alternatively, if you don't have a way to provide a command line option like `--root-path` or equivalent, you can set the `root_path` parameter when creating your FastAPI app:
```
from fastapi import FastAPI, Request
app = FastAPI(root_path="/api/v1")
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
```
Passing the `root_path` to `FastAPI` would be the equivalent of passing the `--root-path` command line option to Uvicorn or Hypercorn.
### About `root_path`
Have in mind that the server (Uvicorn) won't use that `root_path` for anything else than passing it to the app.
But if you go with your browser to [http://127.0.0.1:8000/app](http://127.0.0.1:8000) you will see the normal response:
```
{
"message": "Hello World",
"root_path": "/api/v1"
}
```
So, it won't expect to be accessed at `http://127.0.0.1:8000/api/v1/app`.
Uvicorn will expect the proxy to access Uvicorn at `http://127.0.0.1:8000/app`, and then it would be the proxy's responsibility to add the extra `/api/v1` prefix on top.
About proxies with a stripped path prefix
-----------------------------------------
Have in mind that a proxy with stripped path prefix is only one of the ways to configure it.
Probably in many cases the default will be that the proxy doesn't have a stripped path prefix.
In a case like that (without a stripped path prefix), the proxy would listen on something like `https://myawesomeapp.com`, and then if the browser goes to `https://myawesomeapp.com/api/v1/app` and your server (e.g. Uvicorn) listens on `http://127.0.0.1:8000` the proxy (without a stripped path prefix) would access Uvicorn at the same path: `http://127.0.0.1:8000/api/v1/app`.
Testing locally with Traefik
----------------------------
You can easily run the experiment locally with a stripped path prefix using [Traefik](https://docs.traefik.io/).
[Download Traefik](https://github.com/containous/traefik/releases), it's a single binary, you can extract the compressed file and run it directly from the terminal.
Then create a file `traefik.toml` with:
```
[entryPoints]
[entryPoints.http]
address = ":9999"
[providers]
[providers.file]
filename = "routes.toml"
```
This tells Traefik to listen on port 9999 and to use another file `routes.toml`.
Tip
We are using port 9999 instead of the standard HTTP port 80 so that you don't have to run it with admin (`sudo`) privileges.
Now create that other file `routes.toml`:
```
[http]
[http.middlewares]
[http.middlewares.api-stripprefix.stripPrefix]
prefixes = ["/api/v1"]
[http.routers]
[http.routers.app-http]
entryPoints = ["http"]
service = "app"
rule = "PathPrefix(`/api/v1`)"
middlewares = ["api-stripprefix"]
[http.services]
[http.services.app]
[http.services.app.loadBalancer]
[[http.services.app.loadBalancer.servers]]
url = "http://127.0.0.1:8000"
```
This file configures Traefik to use the path prefix `/api/v1`.
And then it will redirect its requests to your Uvicorn running on `http://127.0.0.1:8000`.
Now start Traefik:
```
$ ./traefik --configFile=traefik.toml
INFO[0000] Configuration loaded from file: /home/user/awesomeapi/traefik.toml
```
And now start your app with Uvicorn, using the `--root-path` option:
```
$ uvicorn main:app --root-path /api/v1
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
### Check the responses
Now, if you go to the URL with the port for Uvicorn: <http://127.0.0.1:8000/app>, you will see the normal response:
```
{
"message": "Hello World",
"root_path": "/api/v1"
}
```
Tip
Notice that even though you are accessing it at `http://127.0.0.1:8000/app` it shows the `root_path` of `/api/v1`, taken from the option `--root-path`.
And now open the URL with the port for Traefik, including the path prefix: <http://127.0.0.1:9999/api/v1/app>.
We get the same response:
```
{
"message": "Hello World",
"root_path": "/api/v1"
}
```
but this time at the URL with the prefix path provided by the proxy: `/api/v1`.
Of course, the idea here is that everyone would access the app through the proxy, so the version with the path prefix `/app/v1` is the "correct" one.
And the version without the path prefix (`http://127.0.0.1:8000/app`), provided by Uvicorn directly, would be exclusively for the *proxy* (Traefik) to access it.
That demonstrates how the Proxy (Traefik) uses the path prefix and how the server (Uvicorn) uses the `root_path` from the option `--root-path`.
### Check the docs UI
But here's the fun part. ✨
The "official" way to access the app would be through the proxy with the path prefix that we defined. So, as we would expect, if you try the docs UI served by Uvicorn directly, without the path prefix in the URL, it won't work, because it expects to be accessed through the proxy.
You can check it at <http://127.0.0.1:8000/docs>:
But if we access the docs UI at the "official" URL using the proxy with port `9999`, at `/api/v1/docs`, it works correctly! 🎉
You can check it at <http://127.0.0.1:9999/api/v1/docs>:
Right as we wanted it. ✔️
This is because FastAPI uses this `root_path` to create the default `server` in OpenAPI with the URL provided by `root_path`.
Additional servers
------------------
Warning
This is a more advanced use case. Feel free to skip it.
By default, **FastAPI** will create a `server` in the OpenAPI schema with the URL for the `root_path`.
But you can also provide other alternative `servers`, for example if you want *the same* docs UI to interact with a staging and production environments.
If you pass a custom list of `servers` and there's a `root_path` (because your API lives behind a proxy), **FastAPI** will insert a "server" with this `root_path` at the beginning of the list.
For example:
```
from fastapi import FastAPI, Request
app = FastAPI(
servers=[
{"url": "https://stag.example.com", "description": "Staging environment"},
{"url": "https://prod.example.com", "description": "Production environment"},
],
root_path="/api/v1",
)
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
```
Will generate an OpenAPI schema like:
```
{
"openapi": "3.0.2",
// More stuff here
"servers": [
{
"url": "/api/v1"
},
{
"url": "https://stag.example.com",
"description": "Staging environment"
},
{
"url": "https://prod.example.com",
"description": "Production environment"
}
],
"paths": {
// More stuff here
}
}
```
Tip
Notice the auto-generated server with a `url` value of `/api/v1`, taken from the `root_path`.
In the docs UI at <http://127.0.0.1:9999/api/v1/docs> it would look like:
Tip
The docs UI will interact with the server that you select.
### Disable automatic server from `root_path`
If you don't want **FastAPI** to include an automatic server using the `root_path`, you can use the parameter `root_path_in_servers=False`:
```
from fastapi import FastAPI, Request
app = FastAPI(
servers=[
{"url": "https://stag.example.com", "description": "Staging environment"},
{"url": "https://prod.example.com", "description": "Production environment"},
],
root_path="/api/v1",
root_path_in_servers=False,
)
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
```
and then it won't include it in the OpenAPI schema.
Mounting a sub-application
--------------------------
If you need to mount a sub-application (as described in [Sub Applications - Mounts](../sub-applications/index)) while also using a proxy with `root_path`, you can do it normally, as you would expect.
FastAPI will internally use the `root_path` smartly, so it will just work. ✨
| programming_docs |
fastapi WebSockets WebSockets
==========
You can use [WebSockets](https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API) with **FastAPI**.
Install `WebSockets`
--------------------
First you need to install `WebSockets`:
```
$ pip install websockets
---> 100%
```
WebSockets client
-----------------
### In production
In your production system, you probably have a frontend created with a modern framework like React, Vue.js or Angular.
And to communicate using WebSockets with your backend you would probably use your frontend's utilities.
Or you might have a native mobile application that communicates with your WebSocket backend directly, in native code.
Or you might have any other way to communicate with the WebSocket endpoint.
---
But for this example, we'll use a very simple HTML document with some JavaScript, all inside a long string.
This, of course, is not optimal and you wouldn't use it for production.
In production you would have one of the options above.
But it's the simplest way to focus on the server-side of WebSockets and have a working example:
```
from fastapi import FastAPI, WebSocket
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = new WebSocket("ws://localhost:8000/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
```
Create a `websocket`
--------------------
In your **FastAPI** application, create a `websocket`:
```
from fastapi import FastAPI, WebSocket
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = new WebSocket("ws://localhost:8000/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
```
Technical Details
You could also use `from starlette.websockets import WebSocket`.
**FastAPI** provides the same `WebSocket` directly just as a convenience for you, the developer. But it comes directly from Starlette.
Await for messages and send messages
------------------------------------
In your WebSocket route you can `await` for messages and send messages.
```
from fastapi import FastAPI, WebSocket
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = new WebSocket("ws://localhost:8000/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
```
You can receive and send binary, text, and JSON data.
Try it
------
If your file is named `main.py`, run your application with:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Open your browser at <http://127.0.0.1:8000>.
You will see a simple page like:
You can type messages in the input box, and send them:
And your **FastAPI** application with WebSockets will respond back:
You can send (and receive) many messages:
And all of them will use the same WebSocket connection.
Using `Depends` and others
--------------------------
In WebSocket endpoints you can import from `fastapi` and use:
* `Depends`
* `Security`
* `Cookie`
* `Header`
* `Path`
* `Query`
They work the same way as for other FastAPI endpoints/*path operations*:
Python 3.10+
```
from typing import Annotated
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: Annotated[str | None, Cookie()] = None,
token: Annotated[str | None, Query()] = None,
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
*,
websocket: WebSocket,
item_id: str,
q: int | None = None,
cookie_or_token: Annotated[str, Depends(get_cookie_or_token)],
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: Annotated[Union[str, None], Cookie()] = None,
token: Annotated[Union[str, None], Query()] = None,
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
*,
websocket: WebSocket,
item_id: str,
q: Union[int, None] = None,
cookie_or_token: Annotated[str, Depends(get_cookie_or_token)],
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
Python 3.6+
```
from typing import Union
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
from typing_extensions import Annotated
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: Annotated[Union[str, None], Cookie()] = None,
token: Annotated[Union[str, None], Query()] = None,
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
*,
websocket: WebSocket,
item_id: str,
q: Union[int, None] = None,
cookie_or_token: Annotated[str, Depends(get_cookie_or_token)],
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: str | None = Cookie(default=None),
token: str | None = Query(default=None),
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
item_id: str,
q: int | None = None,
cookie_or_token: str = Depends(get_cookie_or_token),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import (
Cookie,
Depends,
FastAPI,
Query,
WebSocket,
WebSocketException,
status,
)
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
<hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var itemId = document.getElementById("itemId")
var token = document.getElementById("token")
ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_token(
websocket: WebSocket,
session: Union[str, None] = Cookie(default=None),
token: Union[str, None] = Query(default=None),
):
if session is None and token is None:
raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
item_id: str,
q: Union[int, None] = None,
cookie_or_token: str = Depends(get_cookie_or_token),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
Info
As this is a WebSocket it doesn't really make sense to raise an `HTTPException`, instead we raise a `WebSocketException`.
You can use a closing code from the [valid codes defined in the specification](https://tools.ietf.org/html/rfc6455#section-7.4.1).
### Try the WebSockets with dependencies
If your file is named `main.py`, run your application with:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Open your browser at <http://127.0.0.1:8000>.
There you can set:
* The "Item ID", used in the path.
* The "Token" used as a query parameter.
Tip
Notice that the query `token` will be handled by a dependency.
With that you can connect the WebSocket and then send and receive messages:
Handling disconnections and multiple clients
--------------------------------------------
When a WebSocket connection is closed, the `await websocket.receive_text()` will raise a `WebSocketDisconnect` exception, which you can then catch and handle like in this example.
Python 3.9+
```
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<h2>Your ID: <span id="ws-id"></span></h2>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var client_id = Date.now()
document.querySelector("#ws-id").textContent = client_id;
var ws = new WebSocket(`ws://localhost:8000/ws/${client_id}`);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
class ConnectionManager:
def __init__(self):
self.active_connections: list[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
async def broadcast(self, message: str):
for connection in self.active_connections:
await connection.send_text(message)
manager = ConnectionManager()
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws/{client_id}")
async def websocket_endpoint(websocket: WebSocket, client_id: int):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
await manager.send_personal_message(f"You wrote: {data}", websocket)
await manager.broadcast(f"Client #{client_id} says: {data}")
except WebSocketDisconnect:
manager.disconnect(websocket)
await manager.broadcast(f"Client #{client_id} left the chat")
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<h2>Your ID: <span id="ws-id"></span></h2>
<form action="" onsubmit="sendMessage(event)">
<input type="text" id="messageText" autocomplete="off"/>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var client_id = Date.now()
document.querySelector("#ws-id").textContent = client_id;
var ws = new WebSocket(`ws://localhost:8000/ws/${client_id}`);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
class ConnectionManager:
def __init__(self):
self.active_connections: List[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)
async def broadcast(self, message: str):
for connection in self.active_connections:
await connection.send_text(message)
manager = ConnectionManager()
@app.get("/")
async def get():
return HTMLResponse(html)
@app.websocket("/ws/{client_id}")
async def websocket_endpoint(websocket: WebSocket, client_id: int):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
await manager.send_personal_message(f"You wrote: {data}", websocket)
await manager.broadcast(f"Client #{client_id} says: {data}")
except WebSocketDisconnect:
manager.disconnect(websocket)
await manager.broadcast(f"Client #{client_id} left the chat")
```
To try it out:
* Open the app with several browser tabs.
* Write messages from them.
* Then close one of the tabs.
That will raise the `WebSocketDisconnect` exception, and all the other clients will receive a message like:
```
Client #1596980209979 left the chat
```
Tip
The app above is a minimal and simple example to demonstrate how to handle and broadcast messages to several WebSocket connections.
But have in mind that, as everything is handled in memory, in a single list, it will only work while the process is running, and will only work with a single process.
If you need something easy to integrate with FastAPI but that is more robust, supported by Redis, PostgreSQL or others, check [encode/broadcaster](https://github.com/encode/broadcaster).
More info
---------
To learn more about the options, check Starlette's documentation for:
* [The `WebSocket` class](https://www.starlette.io/websockets/).
* [Class-based WebSocket handling](https://www.starlette.io/endpoints/#websocketendpoint).
| programming_docs |
fastapi Return a Response Directly Return a Response Directly
==========================
When you create a **FastAPI** *path operation* you can normally return any data from it: a `dict`, a `list`, a Pydantic model, a database model, etc.
By default, **FastAPI** would automatically convert that return value to JSON using the `jsonable_encoder` explained in [JSON Compatible Encoder](../../tutorial/encoder/index).
Then, behind the scenes, it would put that JSON-compatible data (e.g. a `dict`) inside of a `JSONResponse` that would be used to send the response to the client.
But you can return a `JSONResponse` directly from your *path operations*.
It might be useful, for example, to return custom headers or cookies.
Return a `Response`
-------------------
In fact, you can return any `Response` or any sub-class of it.
Tip
`JSONResponse` itself is a sub-class of `Response`.
And when you return a `Response`, **FastAPI** will pass it directly.
It won't do any data conversion with Pydantic models, it won't convert the contents to any type, etc.
This gives you a lot of flexibility. You can return any data type, override any data declaration or validation, etc.
Using the `jsonable_encoder` in a `Response`
--------------------------------------------
Because **FastAPI** doesn't do any change to a `Response` you return, you have to make sure it's contents are ready for it.
For example, you cannot put a Pydantic model in a `JSONResponse` without first converting it to a `dict` with all the data types (like `datetime`, `UUID`, etc) converted to JSON-compatible types.
For those cases, you can use the `jsonable_encoder` to convert your data before passing it to a response:
```
from datetime import datetime
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from fastapi.responses import JSONResponse
from pydantic import BaseModel
class Item(BaseModel):
title: str
timestamp: datetime
description: Union[str, None] = None
app = FastAPI()
@app.put("/items/{id}")
def update_item(id: str, item: Item):
json_compatible_item_data = jsonable_encoder(item)
return JSONResponse(content=json_compatible_item_data)
```
Technical Details
You could also use `from starlette.responses import JSONResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
Returning a custom `Response`
-----------------------------
The example above shows all the parts you need, but it's not very useful yet, as you could have just returned the `item` directly, and **FastAPI** would put it in a `JSONResponse` for you, converting it to a `dict`, etc. All that by default.
Now, let's see how you could use that to return a custom response.
Let's say that you want to return an [XML](https://en.wikipedia.org/wiki/XML) response.
You could put your XML content in a string, put it in a `Response`, and return it:
```
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/legacy/")
def get_legacy_data():
data = """<?xml version="1.0"?>
<shampoo>
<Header>
Apply shampoo here.
</Header>
<Body>
You'll have to use soap here.
</Body>
</shampoo>
"""
return Response(content=data, media_type="application/xml")
```
Notes
-----
When you return a `Response` directly its data is not validated, converted (serialized), nor documented automatically.
But you can still document it as described in [Additional Responses in OpenAPI](../additional-responses/index).
You can see in later sections how to use/declare these custom `Response`s while still having automatic data conversion, documentation, etc.
fastapi Custom Response - HTML, Stream, File, others Custom Response - HTML, Stream, File, others
============================================
By default, **FastAPI** will return the responses using `JSONResponse`.
You can override it by returning a `Response` directly as seen in [Return a Response directly](../response-directly/index).
But if you return a `Response` directly, the data won't be automatically converted, and the documentation won't be automatically generated (for example, including the specific "media type", in the HTTP header `Content-Type` as part of the generated OpenAPI).
But you can also declare the `Response` that you want to be used, in the *path operation decorator*.
The contents that you return from your *path operation function* will be put inside of that `Response`.
And if that `Response` has a JSON media type (`application/json`), like is the case with the `JSONResponse` and `UJSONResponse`, the data you return will be automatically converted (and filtered) with any Pydantic `response_model` that you declared in the *path operation decorator*.
Note
If you use a response class with no media type, FastAPI will expect your response to have no content, so it will not document the response format in its generated OpenAPI docs.
Use `ORJSONResponse`
--------------------
For example, if you are squeezing performance, you can install and use [`orjson`](https://github.com/ijl/orjson) and set the response to be `ORJSONResponse`.
Import the `Response` class (sub-class) you want to use and declare it in the *path operation decorator*.
For large responses, returning a `Response` directly is much faster than returning a dictionary.
This is because by default, FastAPI will inspect every item inside and make sure it is serializable with JSON, using the same [JSON Compatible Encoder](../../tutorial/encoder/index) explained in the tutorial. This is what allows you to return **arbitrary objects**, for example database models.
But if you are certain that the content that you are returning is **serializable with JSON**, you can pass it directly to the response class and avoid the extra overhead that FastAPI would have by passing your return content through the `jsonable_encoder` before passing it to the response class.
```
from fastapi import FastAPI
from fastapi.responses import ORJSONResponse
app = FastAPI()
@app.get("/items/", response_class=ORJSONResponse)
async def read_items():
return ORJSONResponse([{"item_id": "Foo"}])
```
Info
The parameter `response_class` will also be used to define the "media type" of the response.
In this case, the HTTP header `Content-Type` will be set to `application/json`.
And it will be documented as such in OpenAPI.
Tip
The `ORJSONResponse` is currently only available in FastAPI, not in Starlette.
HTML Response
-------------
To return a response with HTML directly from **FastAPI**, use `HTMLResponse`.
* Import `HTMLResponse`.
* Pass `HTMLResponse` as the parameter `response_class` of your *path operation decorator*.
```
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.get("/items/", response_class=HTMLResponse)
async def read_items():
return """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
```
Info
The parameter `response_class` will also be used to define the "media type" of the response.
In this case, the HTTP header `Content-Type` will be set to `text/html`.
And it will be documented as such in OpenAPI.
### Return a `Response`
As seen in [Return a Response directly](../response-directly/index), you can also override the response directly in your *path operation*, by returning it.
The same example from above, returning an `HTMLResponse`, could look like:
```
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.get("/items/")
async def read_items():
html_content = """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
return HTMLResponse(content=html_content, status_code=200)
```
Warning
A `Response` returned directly by your *path operation function* won't be documented in OpenAPI (for example, the `Content-Type` won't be documented) and won't be visible in the automatic interactive docs.
Info
Of course, the actual `Content-Type` header, status code, etc, will come from the `Response` object your returned.
### Document in OpenAPI and override `Response`
If you want to override the response from inside of the function but at the same time document the "media type" in OpenAPI, you can use the `response_class` parameter AND return a `Response` object.
The `response_class` will then be used only to document the OpenAPI *path operation*, but your `Response` will be used as is.
#### Return an `HTMLResponse` directly
For example, it could be something like:
```
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
app = FastAPI()
def generate_html_response():
html_content = """
<html>
<head>
<title>Some HTML in here</title>
</head>
<body>
<h1>Look ma! HTML!</h1>
</body>
</html>
"""
return HTMLResponse(content=html_content, status_code=200)
@app.get("/items/", response_class=HTMLResponse)
async def read_items():
return generate_html_response()
```
In this example, the function `generate_html_response()` already generates and returns a `Response` instead of returning the HTML in a `str`.
By returning the result of calling `generate_html_response()`, you are already returning a `Response` that will override the default **FastAPI** behavior.
But as you passed the `HTMLResponse` in the `response_class` too, **FastAPI** will know how to document it in OpenAPI and the interactive docs as HTML with `text/html`:
Available responses
-------------------
Here are some of the available responses.
Have in mind that you can use `Response` to return anything else, or even create a custom sub-class.
Technical Details
You could also use `from starlette.responses import HTMLResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
### `Response`
The main `Response` class, all the other responses inherit from it.
You can return it directly.
It accepts the following parameters:
* `content` - A `str` or `bytes`.
* `status_code` - An `int` HTTP status code.
* `headers` - A `dict` of strings.
* `media_type` - A `str` giving the media type. E.g. `"text/html"`.
FastAPI (actually Starlette) will automatically include a Content-Length header. It will also include a Content-Type header, based on the media\_type and appending a charset for text types.
```
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/legacy/")
def get_legacy_data():
data = """<?xml version="1.0"?>
<shampoo>
<Header>
Apply shampoo here.
</Header>
<Body>
You'll have to use soap here.
</Body>
</shampoo>
"""
return Response(content=data, media_type="application/xml")
```
### `HTMLResponse`
Takes some text or bytes and returns an HTML response, as you read above.
### `PlainTextResponse`
Takes some text or bytes and returns an plain text response.
```
from fastapi import FastAPI
from fastapi.responses import PlainTextResponse
app = FastAPI()
@app.get("/", response_class=PlainTextResponse)
async def main():
return "Hello World"
```
### `JSONResponse`
Takes some data and returns an `application/json` encoded response.
This is the default response used in **FastAPI**, as you read above.
### `ORJSONResponse`
A fast alternative JSON response using [`orjson`](https://github.com/ijl/orjson), as you read above.
### `UJSONResponse`
An alternative JSON response using [`ujson`](https://github.com/ultrajson/ultrajson).
Warning
`ujson` is less careful than Python's built-in implementation in how it handles some edge-cases.
```
from fastapi import FastAPI
from fastapi.responses import UJSONResponse
app = FastAPI()
@app.get("/items/", response_class=UJSONResponse)
async def read_items():
return [{"item_id": "Foo"}]
```
Tip
It's possible that `ORJSONResponse` might be a faster alternative.
### `RedirectResponse`
Returns an HTTP redirect. Uses a 307 status code (Temporary Redirect) by default.
You can return a `RedirectResponse` directly:
```
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/typer")
async def redirect_typer():
return RedirectResponse("https://typer.tiangolo.com")
```
---
Or you can use it in the `response_class` parameter:
```
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/fastapi", response_class=RedirectResponse)
async def redirect_fastapi():
return "https://fastapi.tiangolo.com"
```
If you do that, then you can return the URL directly from your *path operation* function.
In this case, the `status_code` used will be the default one for the `RedirectResponse`, which is `307`.
---
You can also use the `status_code` parameter combined with the `response_class` parameter:
```
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/pydantic", response_class=RedirectResponse, status_code=302)
async def redirect_pydantic():
return "https://pydantic-docs.helpmanual.io/"
```
### `StreamingResponse`
Takes an async generator or a normal generator/iterator and streams the response body.
```
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
async def fake_video_streamer():
for i in range(10):
yield b"some fake video bytes"
@app.get("/")
async def main():
return StreamingResponse(fake_video_streamer())
```
#### Using `StreamingResponse` with file-like objects
If you have a file-like object (e.g. the object returned by `open()`), you can create a generator function to iterate over that file-like object.
That way, you don't have to read it all first in memory, and you can pass that generator function to the `StreamingResponse`, and return it.
This includes many libraries to interact with cloud storage, video processing, and others.
```
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
some_file_path = "large-video-file.mp4"
app = FastAPI()
@app.get("/")
def main():
def iterfile(): # (1)
with open(some_file_path, mode="rb") as file_like: # (2)
yield from file_like # (3)
return StreamingResponse(iterfile(), media_type="video/mp4")
```
1. This is the generator function. It's a "generator function" because it contains `yield` statements inside.
2. By using a `with` block, we make sure that the file-like object is closed after the generator function is done. So, after it finishes sending the response.
3. This `yield from` tells the function to iterate over that thing named `file_like`. And then, for each part iterated, yield that part as coming from this generator function.
So, it is a generator function that transfers the "generating" work to something else internally.
By doing it this way, we can put it in a `with` block, and that way, ensure that it is closed after finishing.
Tip
Notice that here as we are using standard `open()` that doesn't support `async` and `await`, we declare the path operation with normal `def`.
### `FileResponse`
Asynchronously streams a file as the response.
Takes a different set of arguments to instantiate than the other response types:
* `path` - The filepath to the file to stream.
* `headers` - Any custom headers to include, as a dictionary.
* `media_type` - A string giving the media type. If unset, the filename or path will be used to infer a media type.
* `filename` - If set, this will be included in the response `Content-Disposition`.
File responses will include appropriate `Content-Length`, `Last-Modified` and `ETag` headers.
```
from fastapi import FastAPI
from fastapi.responses import FileResponse
some_file_path = "large-video-file.mp4"
app = FastAPI()
@app.get("/")
async def main():
return FileResponse(some_file_path)
```
You can also use the `response_class` parameter:
```
from fastapi import FastAPI
from fastapi.responses import FileResponse
some_file_path = "large-video-file.mp4"
app = FastAPI()
@app.get("/", response_class=FileResponse)
async def main():
return some_file_path
```
In this case, you can return the file path directly from your *path operation* function.
Custom response class
---------------------
You can create your own custom response class, inheriting from `Response` and using it.
For example, let's say that you want to use [`orjson`](https://github.com/ijl/orjson), but with some custom settings not used in the included `ORJSONResponse` class.
Let's say you want it to return indented and formatted JSON, so you want to use the orjson option `orjson.OPT_INDENT_2`.
You could create a `CustomORJSONResponse`. The main thing you have to do is create a `Response.render(content)` method that returns the content as `bytes`:
```
from typing import Any
import orjson
from fastapi import FastAPI, Response
app = FastAPI()
class CustomORJSONResponse(Response):
media_type = "application/json"
def render(self, content: Any) -> bytes:
assert orjson is not None, "orjson must be installed"
return orjson.dumps(content, option=orjson.OPT_INDENT_2)
@app.get("/", response_class=CustomORJSONResponse)
async def main():
return {"message": "Hello World"}
```
Now instead of returning:
```
{"message": "Hello World"}
```
...this response will return:
```
{
"message": "Hello World"
}
```
Of course, you will probably find much better ways to take advantage of this than formatting JSON. 😉
Default response class
----------------------
When creating a **FastAPI** class instance or an `APIRouter` you can specify which response class to use by default.
The parameter that defines this is `default_response_class`.
In the example below, **FastAPI** will use `ORJSONResponse` by default, in all *path operations*, instead of `JSONResponse`.
```
from fastapi import FastAPI
from fastapi.responses import ORJSONResponse
app = FastAPI(default_response_class=ORJSONResponse)
@app.get("/items/")
async def read_items():
return [{"item_id": "Foo"}]
```
Tip
You can still override `response_class` in *path operations* as before.
Additional documentation
------------------------
You can also declare the media type and many other details in OpenAPI using `responses`: [Additional Responses in OpenAPI](../additional-responses/index).
fastapi Conditional OpenAPI Conditional OpenAPI
===================
If you needed to, you could use settings and environment variables to configure OpenAPI conditionally depending on the environment, and even disable it entirely.
About security, APIs, and docs
------------------------------
Hiding your documentation user interfaces in production *shouldn't* be the way to protect your API.
That doesn't add any extra security to your API, the *path operations* will still be available where they are.
If there's a security flaw in your code, it will still exist.
Hiding the documentation just makes it more difficult to understand how to interact with your API, and could make it more difficult for you to debug it in production. It could be considered simply a form of [Security through obscurity](https://en.wikipedia.org/wiki/Security_through_obscurity).
If you want to secure your API, there are several better things you can do, for example:
* Make sure you have well defined Pydantic models for your request bodies and responses.
* Configure any required permissions and roles using dependencies.
* Never store plaintext passwords, only password hashes.
* Implement and use well-known cryptographic tools, like Passlib and JWT tokens, etc.
* Add more granular permission controls with OAuth2 scopes where needed.
* ...etc.
Nevertheless, you might have a very specific use case where you really need to disable the API docs for some environment (e.g. for production) or depending on configurations from environment variables.
Conditional OpenAPI from settings and env vars
----------------------------------------------
You can easily use the same Pydantic settings to configure your generated OpenAPI and the docs UIs.
For example:
```
from fastapi import FastAPI
from pydantic import BaseSettings
class Settings(BaseSettings):
openapi_url: str = "/openapi.json"
settings = Settings()
app = FastAPI(openapi_url=settings.openapi_url)
@app.get("/")
def root():
return {"message": "Hello World"}
```
Here we declare the setting `openapi_url` with the same default of `"/openapi.json"`.
And then we use it when creating the `FastAPI` app.
Then you could disable OpenAPI (including the UI docs) by setting the environment variable `OPENAPI_URL` to the empty string, like:
```
$ OPENAPI_URL= uvicorn main:app
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Then if you go to the URLs at `/openapi.json`, `/docs`, or `/redoc` you will just get a `404 Not Found` error like:
```
{
"detail": "Not Found"
}
```
| programming_docs |
fastapi SQL (Relational) Databases with Peewee SQL (Relational) Databases with Peewee
======================================
Warning
If you are just starting, the tutorial [SQL (Relational) Databases](../../tutorial/sql-databases/index) that uses SQLAlchemy should be enough.
Feel free to skip this.
If you are starting a project from scratch, you are probably better off with SQLAlchemy ORM ([SQL (Relational) Databases](../../tutorial/sql-databases/index)), or any other async ORM.
If you already have a code base that uses [Peewee ORM](https://docs.peewee-orm.com/en/latest/), you can check here how to use it with **FastAPI**.
Python 3.7+ required
You will need Python 3.7 or above to safely use Peewee with FastAPI.
Peewee for async
----------------
Peewee was not designed for async frameworks, or with them in mind.
Peewee has some heavy assumptions about its defaults and about how it should be used.
If you are developing an application with an older non-async framework, and can work with all its defaults, **it can be a great tool**.
But if you need to change some of the defaults, support more than one predefined database, work with an async framework (like FastAPI), etc, you will need to add quite some complex extra code to override those defaults.
Nevertheless, it's possible to do it, and here you'll see exactly what code you have to add to be able to use Peewee with FastAPI.
Technical Details
You can read more about Peewee's stand about async in Python [in the docs](https://docs.peewee-orm.com/en/latest/peewee/database.html#async-with-gevent), [an issue](https://github.com/coleifer/peewee/issues/263#issuecomment-517347032), [a PR](https://github.com/coleifer/peewee/pull/2072#issuecomment-563215132).
The same app
------------
We are going to create the same application as in the SQLAlchemy tutorial ([SQL (Relational) Databases](../../tutorial/sql-databases/index)).
Most of the code is actually the same.
So, we are going to focus only on the differences.
File structure
--------------
Let's say you have a directory named `my_super_project` that contains a sub-directory called `sql_app` with a structure like this:
```
.
└── sql_app
├── __init__.py
├── crud.py
├── database.py
├── main.py
└── schemas.py
```
This is almost the same structure as we had for the SQLAlchemy tutorial.
Now let's see what each file/module does.
Create the Peewee parts
-----------------------
Let's refer to the file `sql_app/database.py`.
### The standard Peewee code
Let's first check all the normal Peewee code, create a Peewee database:
```
from contextvars import ContextVar
import peewee
DATABASE_NAME = "test.db"
db_state_default = {"closed": None, "conn": None, "ctx": None, "transactions": None}
db_state = ContextVar("db_state", default=db_state_default.copy())
class PeeweeConnectionState(peewee._ConnectionState):
def __init__(self, **kwargs):
super().__setattr__("_state", db_state)
super().__init__(**kwargs)
def __setattr__(self, name, value):
self._state.get()[name] = value
def __getattr__(self, name):
return self._state.get()[name]
db = peewee.SqliteDatabase(DATABASE_NAME, check_same_thread=False)
db._state = PeeweeConnectionState()
```
Tip
Have in mind that if you wanted to use a different database, like PostgreSQL, you couldn't just change the string. You would need to use a different Peewee database class.
#### Note
The argument:
```
check_same_thread=False
```
is equivalent to the one in the SQLAlchemy tutorial:
```
connect_args={"check_same_thread": False}
```
...it is needed only for `SQLite`.
Technical Details
Exactly the same technical details as in [SQL (Relational) Databases](../../tutorial/sql-databases/index#note) apply.
### Make Peewee async-compatible `PeeweeConnectionState`
The main issue with Peewee and FastAPI is that Peewee relies heavily on [Python's `threading.local`](https://docs.python.org/3/library/threading.html#thread-local-data), and it doesn't have a direct way to override it or let you handle connections/sessions directly (as is done in the SQLAlchemy tutorial).
And `threading.local` is not compatible with the new async features of modern Python.
Technical Details
`threading.local` is used to have a "magic" variable that has a different value for each thread.
This was useful in older frameworks designed to have one single thread per request, no more, no less.
Using this, each request would have its own database connection/session, which is the actual final goal.
But FastAPI, using the new async features, could handle more than one request on the same thread. And at the same time, for a single request, it could run multiple things in different threads (in a threadpool), depending on if you use `async def` or normal `def`. This is what gives all the performance improvements to FastAPI.
But Python 3.7 and above provide a more advanced alternative to `threading.local`, that can also be used in the places where `threading.local` would be used, but is compatible with the new async features.
We are going to use that. It's called [`contextvars`](https://docs.python.org/3/library/contextvars.html).
We are going to override the internal parts of Peewee that use `threading.local` and replace them with `contextvars`, with the corresponding updates.
This might seem a bit complex (and it actually is), you don't really need to completely understand how it works to use it.
We will create a `PeeweeConnectionState`:
```
from contextvars import ContextVar
import peewee
DATABASE_NAME = "test.db"
db_state_default = {"closed": None, "conn": None, "ctx": None, "transactions": None}
db_state = ContextVar("db_state", default=db_state_default.copy())
class PeeweeConnectionState(peewee._ConnectionState):
def __init__(self, **kwargs):
super().__setattr__("_state", db_state)
super().__init__(**kwargs)
def __setattr__(self, name, value):
self._state.get()[name] = value
def __getattr__(self, name):
return self._state.get()[name]
db = peewee.SqliteDatabase(DATABASE_NAME, check_same_thread=False)
db._state = PeeweeConnectionState()
```
This class inherits from a special internal class used by Peewee.
It has all the logic to make Peewee use `contextvars` instead of `threading.local`.
`contextvars` works a bit differently than `threading.local`. But the rest of Peewee's internal code assumes that this class works with `threading.local`.
So, we need to do some extra tricks to make it work as if it was just using `threading.local`. The `__init__`, `__setattr__`, and `__getattr__` implement all the required tricks for this to be used by Peewee without knowing that it is now compatible with FastAPI.
Tip
This will just make Peewee behave correctly when used with FastAPI. Not randomly opening or closing connections that are being used, creating errors, etc.
But it doesn't give Peewee async super-powers. You should still use normal `def` functions and not `async def`.
### Use the custom `PeeweeConnectionState` class
Now, overwrite the `._state` internal attribute in the Peewee database `db` object using the new `PeeweeConnectionState`:
```
from contextvars import ContextVar
import peewee
DATABASE_NAME = "test.db"
db_state_default = {"closed": None, "conn": None, "ctx": None, "transactions": None}
db_state = ContextVar("db_state", default=db_state_default.copy())
class PeeweeConnectionState(peewee._ConnectionState):
def __init__(self, **kwargs):
super().__setattr__("_state", db_state)
super().__init__(**kwargs)
def __setattr__(self, name, value):
self._state.get()[name] = value
def __getattr__(self, name):
return self._state.get()[name]
db = peewee.SqliteDatabase(DATABASE_NAME, check_same_thread=False)
db._state = PeeweeConnectionState()
```
Tip
Make sure you overwrite `db._state` *after* creating `db`.
Tip
You would do the same for any other Peewee database, including `PostgresqlDatabase`, `MySQLDatabase`, etc.
Create the database models
--------------------------
Let's now see the file `sql_app/models.py`.
### Create Peewee models for our data
Now create the Peewee models (classes) for `User` and `Item`.
This is the same you would do if you followed the Peewee tutorial and updated the models to have the same data as in the SQLAlchemy tutorial.
Tip
Peewee also uses the term "**model**" to refer to these classes and instances that interact with the database.
But Pydantic also uses the term "**model**" to refer to something different, the data validation, conversion, and documentation classes and instances.
Import `db` from `database` (the file `database.py` from above) and use it here.
```
import peewee
from .database import db
class User(peewee.Model):
email = peewee.CharField(unique=True, index=True)
hashed_password = peewee.CharField()
is_active = peewee.BooleanField(default=True)
class Meta:
database = db
class Item(peewee.Model):
title = peewee.CharField(index=True)
description = peewee.CharField(index=True)
owner = peewee.ForeignKeyField(User, backref="items")
class Meta:
database = db
```
Tip
Peewee creates several magic attributes.
It will automatically add an `id` attribute as an integer to be the primary key.
It will chose the name of the tables based on the class names.
For the `Item`, it will create an attribute `owner_id` with the integer ID of the `User`. But we don't declare it anywhere.
Create the Pydantic models
--------------------------
Now let's check the file `sql_app/schemas.py`.
Tip
To avoid confusion between the Peewee *models* and the Pydantic *models*, we will have the file `models.py` with the Peewee models, and the file `schemas.py` with the Pydantic models.
These Pydantic models define more or less a "schema" (a valid data shape).
So this will help us avoiding confusion while using both.
### Create the Pydantic *models* / schemas
Create all the same Pydantic models as in the SQLAlchemy tutorial:
```
from typing import Any, List, Union
import peewee
from pydantic import BaseModel
from pydantic.utils import GetterDict
class PeeweeGetterDict(GetterDict):
def get(self, key: Any, default: Any = None):
res = getattr(self._obj, key, default)
if isinstance(res, peewee.ModelSelect):
return list(res)
return res
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
```
Tip
Here we are creating the models with an `id`.
We didn't explicitly specify an `id` attribute in the Peewee models, but Peewee adds one automatically.
We are also adding the magic `owner_id` attribute to `Item`.
### Create a `PeeweeGetterDict` for the Pydantic *models* / schemas
When you access a relationship in a Peewee object, like in `some_user.items`, Peewee doesn't provide a `list` of `Item`.
It provides a special custom object of class `ModelSelect`.
It's possible to create a `list` of its items with `list(some_user.items)`.
But the object itself is not a `list`. And it's also not an actual Python [generator](https://docs.python.org/3/glossary.html#term-generator). Because of this, Pydantic doesn't know by default how to convert it to a `list` of Pydantic *models* / schemas.
But recent versions of Pydantic allow providing a custom class that inherits from `pydantic.utils.GetterDict`, to provide the functionality used when using the `orm_mode = True` to retrieve the values for ORM model attributes.
We are going to create a custom `PeeweeGetterDict` class and use it in all the same Pydantic *models* / schemas that use `orm_mode`:
```
from typing import Any, List, Union
import peewee
from pydantic import BaseModel
from pydantic.utils import GetterDict
class PeeweeGetterDict(GetterDict):
def get(self, key: Any, default: Any = None):
res = getattr(self._obj, key, default)
if isinstance(res, peewee.ModelSelect):
return list(res)
return res
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
```
Here we are checking if the attribute that is being accessed (e.g. `.items` in `some_user.items`) is an instance of `peewee.ModelSelect`.
And if that's the case, just return a `list` with it.
And then we use it in the Pydantic *models* / schemas that use `orm_mode = True`, with the configuration variable `getter_dict = PeeweeGetterDict`.
Tip
We only need to create one `PeeweeGetterDict` class, and we can use it in all the Pydantic *models* / schemas.
CRUD utils
----------
Now let's see the file `sql_app/crud.py`.
### Create all the CRUD utils
Create all the same CRUD utils as in the SQLAlchemy tutorial, all the code is very similar:
```
from . import models, schemas
def get_user(user_id: int):
return models.User.filter(models.User.id == user_id).first()
def get_user_by_email(email: str):
return models.User.filter(models.User.email == email).first()
def get_users(skip: int = 0, limit: int = 100):
return list(models.User.select().offset(skip).limit(limit))
def create_user(user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db_user.save()
return db_user
def get_items(skip: int = 0, limit: int = 100):
return list(models.Item.select().offset(skip).limit(limit))
def create_user_item(item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db_item.save()
return db_item
```
There are some differences with the code for the SQLAlchemy tutorial.
We don't pass a `db` attribute around. Instead we use the models directly. This is because the `db` object is a global object, that includes all the connection logic. That's why we had to do all the `contextvars` updates above.
Aso, when returning several objects, like in `get_users`, we directly call `list`, like in:
```
list(models.User.select())
```
This is for the same reason that we had to create a custom `PeeweeGetterDict`. But by returning something that is already a `list` instead of the `peewee.ModelSelect` the `response_model` in the *path operation* with `List[models.User]` (that we'll see later) will work correctly.
Main **FastAPI** app
--------------------
And now in the file `sql_app/main.py` let's integrate and use all the other parts we created before.
### Create the database tables
In a very simplistic way create the database tables:
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
### Create a dependency
Create a dependency that will connect the database right at the beginning of a request and disconnect it at the end:
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
Here we have an empty `yield` because we are actually not using the database object directly.
It is connecting to the database and storing the connection data in an internal variable that is independent for each request (using the `contextvars` tricks from above).
Because the database connection is potentially I/O blocking, this dependency is created with a normal `def` function.
And then, in each *path operation function* that needs to access the database we add it as a dependency.
But we are not using the value given by this dependency (it actually doesn't give any value, as it has an empty `yield`). So, we don't add it to the *path operation function* but to the *path operation decorator* in the `dependencies` parameter:
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
### Context variable sub-dependency
For all the `contextvars` parts to work, we need to make sure we have an independent value in the `ContextVar` for each request that uses the database, and that value will be used as the database state (connection, transactions, etc) for the whole request.
For that, we need to create another `async` dependency `reset_db_state()` that is used as a sub-dependency in `get_db()`. It will set the value for the context variable (with just a default `dict`) that will be used as the database state for the whole request. And then the dependency `get_db()` will store in it the database state (connection, transactions, etc).
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
For the **next request**, as we will reset that context variable again in the `async` dependency `reset_db_state()` and then create a new connection in the `get_db()` dependency, that new request will have its own database state (connection, transactions, etc).
Tip
As FastAPI is an async framework, one request could start being processed, and before finishing, another request could be received and start processing as well, and it all could be processed in the same thread.
But context variables are aware of these async features, so, a Peewee database state set in the `async` dependency `reset_db_state()` will keep its own data throughout the entire request.
And at the same time, the other concurrent request will have its own database state that will be independent for the whole request.
#### Peewee Proxy
If you are using a [Peewee Proxy](https://docs.peewee-orm.com/en/latest/peewee/database.html#dynamically-defining-a-database), the actual database is at `db.obj`.
So, you would reset it with:
```
async def reset_db_state():
database.db.obj._state._state.set(db_state_default.copy())
database.db.obj._state.reset()
```
### Create your **FastAPI** *path operations*
Now, finally, here's the standard **FastAPI** *path operations* code.
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
### About `def` vs `async def`
The same as with SQLAlchemy, we are not doing something like:
```
user = await models.User.select().first()
```
...but instead we are using:
```
user = models.User.select().first()
```
So, again, we should declare the *path operation functions* and the dependency without `async def`, just with a normal `def`, as:
```
# Something goes here
def read_users(skip: int = 0, limit: int = 100):
# Something goes here
```
Testing Peewee with async
-------------------------
This example includes an extra *path operation* that simulates a long processing request with `time.sleep(sleep_time)`.
It will have the database connection open at the beginning and will just wait some seconds before replying back. And each new request will wait one second less.
This will easily let you test that your app with Peewee and FastAPI is behaving correctly with all the stuff about threads.
If you want to check how Peewee would break your app if used without modification, go the the `sql_app/database.py` file and comment the line:
```
# db._state = PeeweeConnectionState()
```
And in the file `sql_app/main.py` file, comment the body of the `async` dependency `reset_db_state()` and replace it with a `pass`:
```
async def reset_db_state():
# database.db._state._state.set(db_state_default.copy())
# database.db._state.reset()
pass
```
Then run your app with Uvicorn:
```
$ uvicorn sql_app.main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Open your browser at <http://127.0.0.1:8000/docs> and create a couple of users.
Then open 10 tabs at <http://127.0.0.1:8000/docs#/default/read_slow_users_slowusers__get> at the same time.
Go to the *path operation* "Get `/slowusers/`" in all of the tabs. Use the "Try it out" button and execute the request in each tab, one right after the other.
The tabs will wait for a bit and then some of them will show `Internal Server Error`.
### What happens
The first tab will make your app create a connection to the database and wait for some seconds before replying back and closing the database connection.
Then, for the request in the next tab, your app will wait for one second less, and so on.
This means that it will end up finishing some of the last tabs' requests earlier than some of the previous ones.
Then one the last requests that wait less seconds will try to open a database connection, but as one of those previous requests for the other tabs will probably be handled in the same thread as the first one, it will have the same database connection that is already open, and Peewee will throw an error and you will see it in the terminal, and the response will have an `Internal Server Error`.
This will probably happen for more than one of those tabs.
If you had multiple clients talking to your app exactly at the same time, this is what could happen.
And as your app starts to handle more and more clients at the same time, the waiting time in a single request needs to be shorter and shorter to trigger the error.
### Fix Peewee with FastAPI
Now go back to the file `sql_app/database.py`, and uncomment the line:
```
db._state = PeeweeConnectionState()
```
And in the file `sql_app/main.py` file, uncomment the body of the `async` dependency `reset_db_state()`:
```
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
```
Terminate your running app and start it again.
Repeat the same process with the 10 tabs. This time all of them will wait and you will get all the results without errors.
...You fixed it!
Review all the files
--------------------
Remember you should have a directory named `my_super_project` (or however you want) that contains a sub-directory called `sql_app`.
`sql_app` should have the following files:
* `sql_app/__init__.py`: is an empty file.
* `sql_app/database.py`:
```
from contextvars import ContextVar
import peewee
DATABASE_NAME = "test.db"
db_state_default = {"closed": None, "conn": None, "ctx": None, "transactions": None}
db_state = ContextVar("db_state", default=db_state_default.copy())
class PeeweeConnectionState(peewee._ConnectionState):
def __init__(self, **kwargs):
super().__setattr__("_state", db_state)
super().__init__(**kwargs)
def __setattr__(self, name, value):
self._state.get()[name] = value
def __getattr__(self, name):
return self._state.get()[name]
db = peewee.SqliteDatabase(DATABASE_NAME, check_same_thread=False)
db._state = PeeweeConnectionState()
```
* `sql_app/models.py`:
```
import peewee
from .database import db
class User(peewee.Model):
email = peewee.CharField(unique=True, index=True)
hashed_password = peewee.CharField()
is_active = peewee.BooleanField(default=True)
class Meta:
database = db
class Item(peewee.Model):
title = peewee.CharField(index=True)
description = peewee.CharField(index=True)
owner = peewee.ForeignKeyField(User, backref="items")
class Meta:
database = db
```
* `sql_app/schemas.py`:
```
from typing import Any, List, Union
import peewee
from pydantic import BaseModel
from pydantic.utils import GetterDict
class PeeweeGetterDict(GetterDict):
def get(self, key: Any, default: Any = None):
res = getattr(self._obj, key, default)
if isinstance(res, peewee.ModelSelect):
return list(res)
return res
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
getter_dict = PeeweeGetterDict
```
* `sql_app/crud.py`:
```
from . import models, schemas
def get_user(user_id: int):
return models.User.filter(models.User.id == user_id).first()
def get_user_by_email(email: str):
return models.User.filter(models.User.email == email).first()
def get_users(skip: int = 0, limit: int = 100):
return list(models.User.select().offset(skip).limit(limit))
def create_user(user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db_user.save()
return db_user
def get_items(skip: int = 0, limit: int = 100):
return list(models.Item.select().offset(skip).limit(limit))
def create_user_item(item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db_item.save()
return db_item
```
* `sql_app/main.py`:
```
import time
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from . import crud, database, models, schemas
from .database import db_state_default
database.db.connect()
database.db.create_tables([models.User, models.Item])
database.db.close()
app = FastAPI()
sleep_time = 10
async def reset_db_state():
database.db._state._state.set(db_state_default.copy())
database.db._state.reset()
def get_db(db_state=Depends(reset_db_state)):
try:
database.db.connect()
yield
finally:
if not database.db.is_closed():
database.db.close()
@app.post("/users/", response_model=schemas.User, dependencies=[Depends(get_db)])
def create_user(user: schemas.UserCreate):
db_user = crud.get_user_by_email(email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(user=user)
@app.get("/users/", response_model=List[schemas.User], dependencies=[Depends(get_db)])
def read_users(skip: int = 0, limit: int = 100):
users = crud.get_users(skip=skip, limit=limit)
return users
@app.get(
"/users/{user_id}", response_model=schemas.User, dependencies=[Depends(get_db)]
)
def read_user(user_id: int):
db_user = crud.get_user(user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post(
"/users/{user_id}/items/",
response_model=schemas.Item,
dependencies=[Depends(get_db)],
)
def create_item_for_user(user_id: int, item: schemas.ItemCreate):
return crud.create_user_item(item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item], dependencies=[Depends(get_db)])
def read_items(skip: int = 0, limit: int = 100):
items = crud.get_items(skip=skip, limit=limit)
return items
@app.get(
"/slowusers/", response_model=List[schemas.User], dependencies=[Depends(get_db)]
)
def read_slow_users(skip: int = 0, limit: int = 100):
global sleep_time
sleep_time = max(0, sleep_time - 1)
time.sleep(sleep_time) # Fake long processing request
users = crud.get_users(skip=skip, limit=limit)
return users
```
Technical Details
-----------------
Warning
These are very technical details that you probably don't need.
### The problem
Peewee uses [`threading.local`](https://docs.python.org/3/library/threading.html#thread-local-data) by default to store it's database "state" data (connection, transactions, etc).
`threading.local` creates a value exclusive to the current thread, but an async framework would run all the code (e.g. for each request) in the same thread, and possibly not in order.
On top of that, an async framework could run some sync code in a threadpool (using `asyncio.run_in_executor`), but belonging to the same request.
This means that, with Peewee's current implementation, multiple tasks could be using the same `threading.local` variable and end up sharing the same connection and data (that they shouldn't), and at the same time, if they execute sync I/O-blocking code in a threadpool (as with normal `def` functions in FastAPI, in *path operations* and dependencies), that code won't have access to the database state variables, even while it's part of the same request and it should be able to get access to the same database state.
### Context variables
Python 3.7 has [`contextvars`](https://docs.python.org/3/library/contextvars.html) that can create a local variable very similar to `threading.local`, but also supporting these async features.
There are several things to have in mind.
The `ContextVar` has to be created at the top of the module, like:
```
some_var = ContextVar("some_var", default="default value")
```
To set a value used in the current "context" (e.g. for the current request) use:
```
some_var.set("new value")
```
To get a value anywhere inside of the context (e.g. in any part handling the current request) use:
```
some_var.get()
```
### Set context variables in the `async` dependency `reset_db_state()`
If some part of the async code sets the value with `some_var.set("updated in function")` (e.g. like the `async` dependency), the rest of the code in it and the code that goes after (including code inside of `async` functions called with `await`) will see that new value.
So, in our case, if we set the Peewee state variable (with a default `dict`) in the `async` dependency, all the rest of the internal code in our app will see this value and will be able to reuse it for the whole request.
And the context variable would be set again for the next request, even if they are concurrent.
### Set database state in the dependency `get_db()`
As `get_db()` is a normal `def` function, **FastAPI** will make it run in a threadpool, with a *copy* of the "context", holding the same value for the context variable (the `dict` with the reset database state). Then it can add database state to that `dict`, like the connection, etc.
But if the value of the context variable (the default `dict`) was set in that normal `def` function, it would create a new value that would stay only in that thread of the threadpool, and the rest of the code (like the *path operation functions*) wouldn't have access to it. In `get_db()` we can only set values in the `dict`, but not the entire `dict` itself.
So, we need to have the `async` dependency `reset_db_state()` to set the `dict` in the context variable. That way, all the code has access to the same `dict` for the database state for a single request.
### Connect and disconnect in the dependency `get_db()`
Then the next question would be, why not just connect and disconnect the database in the `async` dependency itself, instead of in `get_db()`?
The `async` dependency has to be `async` for the context variable to be preserved for the rest of the request, but creating and closing the database connection is potentially blocking, so it could degrade performance if it was there.
So we also need the normal `def` dependency `get_db()`.
| programming_docs |
fastapi Extending OpenAPI Extending OpenAPI
=================
Warning
This is a rather advanced feature. You probably can skip it.
If you are just following the tutorial - user guide, you can probably skip this section.
If you already know that you need to modify the generated OpenAPI schema, continue reading.
There are some cases where you might need to modify the generated OpenAPI schema.
In this section you will see how.
The normal process
------------------
The normal (default) process, is as follows.
A `FastAPI` application (instance) has an `.openapi()` method that is expected to return the OpenAPI schema.
As part of the application object creation, a *path operation* for `/openapi.json` (or for whatever you set your `openapi_url`) is registered.
It just returns a JSON response with the result of the application's `.openapi()` method.
By default, what the method `.openapi()` does is check the property `.openapi_schema` to see if it has contents and return them.
If it doesn't, it generates them using the utility function at `fastapi.openapi.utils.get_openapi`.
And that function `get_openapi()` receives as parameters:
* `title`: The OpenAPI title, shown in the docs.
* `version`: The version of your API, e.g. `2.5.0`.
* `openapi_version`: The version of the OpenAPI specification used. By default, the latest: `3.0.2`.
* `description`: The description of your API.
* `routes`: A list of routes, these are each of the registered *path operations*. They are taken from `app.routes`.
Overriding the defaults
-----------------------
Using the information above, you can use the same utility function to generate the OpenAPI schema and override each part that you need.
For example, let's add [ReDoc's OpenAPI extension to include a custom logo](https://github.com/Rebilly/ReDoc/blob/master/docs/redoc-vendor-extensions.md#x-logo).
### Normal **FastAPI**
First, write all your **FastAPI** application as normally:
```
from fastapi import FastAPI
from fastapi.openapi.utils import get_openapi
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Custom title",
version="2.5.0",
description="This is a very custom OpenAPI schema",
routes=app.routes,
)
openapi_schema["info"]["x-logo"] = {
"url": "https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png"
}
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapi
```
### Generate the OpenAPI schema
Then, use the same utility function to generate the OpenAPI schema, inside a `custom_openapi()` function:
```
from fastapi import FastAPI
from fastapi.openapi.utils import get_openapi
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Custom title",
version="2.5.0",
description="This is a very custom OpenAPI schema",
routes=app.routes,
)
openapi_schema["info"]["x-logo"] = {
"url": "https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png"
}
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapi
```
### Modify the OpenAPI schema
Now you can add the ReDoc extension, adding a custom `x-logo` to the `info` "object" in the OpenAPI schema:
```
from fastapi import FastAPI
from fastapi.openapi.utils import get_openapi
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Custom title",
version="2.5.0",
description="This is a very custom OpenAPI schema",
routes=app.routes,
)
openapi_schema["info"]["x-logo"] = {
"url": "https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png"
}
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapi
```
### Cache the OpenAPI schema
You can use the property `.openapi_schema` as a "cache", to store your generated schema.
That way, your application won't have to generate the schema every time a user opens your API docs.
It will be generated only once, and then the same cached schema will be used for the next requests.
```
from fastapi import FastAPI
from fastapi.openapi.utils import get_openapi
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Custom title",
version="2.5.0",
description="This is a very custom OpenAPI schema",
routes=app.routes,
)
openapi_schema["info"]["x-logo"] = {
"url": "https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png"
}
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapi
```
### Override the method
Now you can replace the `.openapi()` method with your new function.
```
from fastapi import FastAPI
from fastapi.openapi.utils import get_openapi
app = FastAPI()
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Custom title",
version="2.5.0",
description="This is a very custom OpenAPI schema",
routes=app.routes,
)
openapi_schema["info"]["x-logo"] = {
"url": "https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png"
}
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapi
```
### Check it
Once you go to <http://127.0.0.1:8000/redoc> you will see that you are using your custom logo (in this example, **FastAPI**'s logo):
Self-hosting JavaScript and CSS for docs
----------------------------------------
The API docs use **Swagger UI** and **ReDoc**, and each of those need some JavaScript and CSS files.
By default, those files are served from a CDN.
But it's possible to customize it, you can set a specific CDN, or serve the files yourself.
That's useful, for example, if you need your app to keep working even while offline, without open Internet access, or in a local network.
Here you'll see how to serve those files yourself, in the same FastAPI app, and configure the docs to use them.
### Project file structure
Let's say your project file structure looks like this:
```
.
├── app
│ ├── __init__.py
│ ├── main.py
```
Now create a directory to store those static files.
Your new file structure could look like this:
```
.
├── app
│ ├── __init__.py
│ ├── main.py
└── static/
```
### Download the files
Download the static files needed for the docs and put them on that `static/` directory.
You can probably right-click each link and select an option similar to `Save link as...`.
**Swagger UI** uses the files:
* [`swagger-ui-bundle.js`](https://cdn.jsdelivr.net/npm/swagger-ui-dist@4/swagger-ui-bundle.js)
* [`swagger-ui.css`](https://cdn.jsdelivr.net/npm/swagger-ui-dist@4/swagger-ui.css)
And **ReDoc** uses the file:
* [`redoc.standalone.js`](https://cdn.jsdelivr.net/npm/redoc@next/bundles/redoc.standalone.js)
After that, your file structure could look like:
```
.
├── app
│ ├── __init__.py
│ ├── main.py
└── static
├── redoc.standalone.js
├── swagger-ui-bundle.js
└── swagger-ui.css
```
### Serve the static files
* Import `StaticFiles`.
* "Mount" a `StaticFiles()` instance in a specific path.
```
from fastapi import FastAPI
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
from fastapi.staticfiles import StaticFiles
app = FastAPI(docs_url=None, redoc_url=None)
app.mount("/static", StaticFiles(directory="static"), name="static")
@app.get("/docs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
oauth2_redirect_url=app.swagger_ui_oauth2_redirect_url,
swagger_js_url="/static/swagger-ui-bundle.js",
swagger_css_url="/static/swagger-ui.css",
)
@app.get(app.swagger_ui_oauth2_redirect_url, include_in_schema=False)
async def swagger_ui_redirect():
return get_swagger_ui_oauth2_redirect_html()
@app.get("/redoc", include_in_schema=False)
async def redoc_html():
return get_redoc_html(
openapi_url=app.openapi_url,
title=app.title + " - ReDoc",
redoc_js_url="/static/redoc.standalone.js",
)
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
### Test the static files
Start your application and go to <http://127.0.0.1:8000/static/redoc.standalone.js>.
You should see a very long JavaScript file for **ReDoc**.
It could start with something like:
```
/*!
* ReDoc - OpenAPI/Swagger-generated API Reference Documentation
* -------------------------------------------------------------
* Version: "2.0.0-rc.18"
* Repo: https://github.com/Redocly/redoc
*/
!function(e,t){"object"==typeof exports&&"object"==typeof m
...
```
That confirms that you are being able to serve static files from your app, and that you placed the static files for the docs in the correct place.
Now we can configure the app to use those static files for the docs.
### Disable the automatic docs
The first step is to disable the automatic docs, as those use the CDN by default.
To disable them, set their URLs to `None` when creating your `FastAPI` app:
```
from fastapi import FastAPI
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
from fastapi.staticfiles import StaticFiles
app = FastAPI(docs_url=None, redoc_url=None)
app.mount("/static", StaticFiles(directory="static"), name="static")
@app.get("/docs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
oauth2_redirect_url=app.swagger_ui_oauth2_redirect_url,
swagger_js_url="/static/swagger-ui-bundle.js",
swagger_css_url="/static/swagger-ui.css",
)
@app.get(app.swagger_ui_oauth2_redirect_url, include_in_schema=False)
async def swagger_ui_redirect():
return get_swagger_ui_oauth2_redirect_html()
@app.get("/redoc", include_in_schema=False)
async def redoc_html():
return get_redoc_html(
openapi_url=app.openapi_url,
title=app.title + " - ReDoc",
redoc_js_url="/static/redoc.standalone.js",
)
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
### Include the custom docs
Now you can create the *path operations* for the custom docs.
You can re-use FastAPI's internal functions to create the HTML pages for the docs, and pass them the needed arguments:
* `openapi_url`: the URL where the HTML page for the docs can get the OpenAPI schema for your API. You can use here the attribute `app.openapi_url`.
* `title`: the title of your API.
* `oauth2_redirect_url`: you can use `app.swagger_ui_oauth2_redirect_url` here to use the default.
* `swagger_js_url`: the URL where the HTML for your Swagger UI docs can get the **JavaScript** file. This is the one that your own app is now serving.
* `swagger_css_url`: the URL where the HTML for your Swagger UI docs can get the **CSS** file. This is the one that your own app is now serving.
And similarly for ReDoc...
```
from fastapi import FastAPI
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
from fastapi.staticfiles import StaticFiles
app = FastAPI(docs_url=None, redoc_url=None)
app.mount("/static", StaticFiles(directory="static"), name="static")
@app.get("/docs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
oauth2_redirect_url=app.swagger_ui_oauth2_redirect_url,
swagger_js_url="/static/swagger-ui-bundle.js",
swagger_css_url="/static/swagger-ui.css",
)
@app.get(app.swagger_ui_oauth2_redirect_url, include_in_schema=False)
async def swagger_ui_redirect():
return get_swagger_ui_oauth2_redirect_html()
@app.get("/redoc", include_in_schema=False)
async def redoc_html():
return get_redoc_html(
openapi_url=app.openapi_url,
title=app.title + " - ReDoc",
redoc_js_url="/static/redoc.standalone.js",
)
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
Tip
The *path operation* for `swagger_ui_redirect` is a helper for when you use OAuth2.
If you integrate your API with an OAuth2 provider, you will be able to authenticate and come back to the API docs with the acquired credentials. And interact with it using the real OAuth2 authentication.
Swagger UI will handle it behind the scenes for you, but it needs this "redirect" helper.
### Create a *path operation* to test it
Now, to be able to test that everything works, create a *path operation*:
```
from fastapi import FastAPI
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
from fastapi.staticfiles import StaticFiles
app = FastAPI(docs_url=None, redoc_url=None)
app.mount("/static", StaticFiles(directory="static"), name="static")
@app.get("/docs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
oauth2_redirect_url=app.swagger_ui_oauth2_redirect_url,
swagger_js_url="/static/swagger-ui-bundle.js",
swagger_css_url="/static/swagger-ui.css",
)
@app.get(app.swagger_ui_oauth2_redirect_url, include_in_schema=False)
async def swagger_ui_redirect():
return get_swagger_ui_oauth2_redirect_html()
@app.get("/redoc", include_in_schema=False)
async def redoc_html():
return get_redoc_html(
openapi_url=app.openapi_url,
title=app.title + " - ReDoc",
redoc_js_url="/static/redoc.standalone.js",
)
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
### Test it
Now, you should be able to disconnect your WiFi, go to your docs at <http://127.0.0.1:8000/docs>, and reload the page.
And even without Internet, you would be able to see the docs for your API and interact with it.
Configuring Swagger UI
----------------------
You can configure some extra [Swagger UI parameters](https://swagger.io/docs/open-source-tools/swagger-ui/usage/configuration).
To configure them, pass the `swagger_ui_parameters` argument when creating the `FastAPI()` app object or to the `get_swagger_ui_html()` function.
`swagger_ui_parameters` receives a dictionary with the configurations passed to Swagger UI directly.
FastAPI converts the configurations to **JSON** to make them compatible with JavaScript, as that's what Swagger UI needs.
### Disable Syntax Highlighting
For example, you could disable syntax highlighting in Swagger UI.
Without changing the settings, syntax highlighting is enabled by default:
But you can disable it by setting `syntaxHighlight` to `False`:
```
from fastapi import FastAPI
app = FastAPI(swagger_ui_parameters={"syntaxHighlight": False})
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
...and then Swagger UI won't show the syntax highlighting anymore:
### Change the Theme
The same way you could set the syntax highlighting theme with the key `"syntaxHighlight.theme"` (notice that it has a dot in the middle):
```
from fastapi import FastAPI
app = FastAPI(swagger_ui_parameters={"syntaxHighlight.theme": "obsidian"})
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
That configuration would change the syntax highlighting color theme:
### Change Default Swagger UI Parameters
FastAPI includes some default configuration parameters appropriate for most of the use cases.
It includes these default configurations:
```
swagger_ui_default_parameters = {
"dom_id": "#swagger-ui",
"layout": "BaseLayout",
"deepLinking": True,
"showExtensions": True,
"showCommonExtensions": True,
}
```
You can override any of them by setting a different value in the argument `swagger_ui_parameters`.
For example, to disable `deepLinking` you could pass these settings to `swagger_ui_parameters`:
```
from fastapi import FastAPI
app = FastAPI(swagger_ui_parameters={"deepLinking": False})
@app.get("/users/{username}")
async def read_user(username: str):
return {"message": f"Hello {username}"}
```
### Other Swagger UI Parameters
To see all the other possible configurations you can use, read the official [docs for Swagger UI parameters](https://swagger.io/docs/open-source-tools/swagger-ui/usage/configuration).
### JavaScript-only settings
Swagger UI also allows other configurations to be **JavaScript-only** objects (for example, JavaScript functions).
FastAPI also includes these JavaScript-only `presets` settings:
```
presets: [
SwaggerUIBundle.presets.apis,
SwaggerUIBundle.SwaggerUIStandalonePreset
]
```
These are **JavaScript** objects, not strings, so you can't pass them from Python code directly.
If you need to use JavaScript-only configurations like those, you can use one of the methods above. Override all the Swagger UI *path operation* and manually write any JavaScript you need.
fastapi GraphQL GraphQL
=======
As **FastAPI** is based on the **ASGI** standard, it's very easy to integrate any **GraphQL** library also compatible with ASGI.
You can combine normal FastAPI *path operations* with GraphQL on the same application.
Tip
**GraphQL** solves some very specific use cases.
It has **advantages** and **disadvantages** when compared to common **web APIs**.
Make sure you evaluate if the **benefits** for your use case compensate the **drawbacks**. 🤓
GraphQL Libraries
-----------------
Here are some of the **GraphQL** libraries that have **ASGI** support. You could use them with **FastAPI**:
* [Strawberry](https://strawberry.rocks/) 🍓
+ With [docs for FastAPI](https://strawberry.rocks/docs/integrations/fastapi)
* [Ariadne](https://ariadnegraphql.org/)
+ With [docs for Starlette](https://ariadnegraphql.org/docs/starlette-integration) (that also apply to FastAPI)
* [Tartiflette](https://tartiflette.io/)
+ With [Tartiflette ASGI](https://tartiflette.github.io/tartiflette-asgi/) to provide ASGI integration
* [Graphene](https://graphene-python.org/)
+ With [starlette-graphene3](https://github.com/ciscorn/starlette-graphene3)
GraphQL with Strawberry
-----------------------
If you need or want to work with **GraphQL**, [**Strawberry**](https://strawberry.rocks/) is the **recommended** library as it has the design closest to **FastAPI's** design, it's all based on **type annotations**.
Depending on your use case, you might prefer to use a different library, but if you asked me, I would probably suggest you try **Strawberry**.
Here's a small preview of how you could integrate Strawberry with FastAPI:
```
import strawberry
from fastapi import FastAPI
from strawberry.asgi import GraphQL
@strawberry.type
class User:
name: str
age: int
@strawberry.type
class Query:
@strawberry.field
def user(self) -> User:
return User(name="Patrick", age=100)
schema = strawberry.Schema(query=Query)
graphql_app = GraphQL(schema)
app = FastAPI()
app.add_route("/graphql", graphql_app)
app.add_websocket_route("/graphql", graphql_app)
```
You can learn more about Strawberry in the [Strawberry documentation](https://strawberry.rocks/).
And also the docs about [Strawberry with FastAPI](https://strawberry.rocks/docs/integrations/fastapi).
Older `GraphQLApp` from Starlette
---------------------------------
Previous versions of Starlette included a `GraphQLApp` class to integrate with [Graphene](https://graphene-python.org/).
It was deprecated from Starlette, but if you have code that used it, you can easily **migrate** to [starlette-graphene3](https://github.com/ciscorn/starlette-graphene3), that covers the same use case and has an **almost identical interface**.
Tip
If you need GraphQL, I still would recommend you check out [Strawberry](https://strawberry.rocks/), as it's based on type annotations instead of custom classes and types.
Learn More
----------
You can learn more about **GraphQL** in the [official GraphQL documentation](https://graphql.org/).
You can also read more about each those libraries described above in their links.
| programming_docs |
fastapi Async Tests Async Tests
===========
You have already seen how to test your **FastAPI** applications using the provided `TestClient`. Up to now, you have only seen how to write synchronous tests, without using `async` functions.
Being able to use asynchronous functions in your tests could be useful, for example, when you're querying your database asynchronously. Imagine you want to test sending requests to your FastAPI application and then verify that your backend successfully wrote the correct data in the database, while using an async database library.
Let's look at how we can make that work.
pytest.mark.anyio
-----------------
If we want to call asynchronous functions in our tests, our test functions have to be asynchronous. AnyIO provides a neat plugin for this, that allows us to specify that some test functions are to be called asynchronously.
HTTPX
-----
Even if your **FastAPI** application uses normal `def` functions instead of `async def`, it is still an `async` application underneath.
The `TestClient` does some magic inside to call the asynchronous FastAPI application in your normal `def` test functions, using standard pytest. But that magic doesn't work anymore when we're using it inside asynchronous functions. By running our tests asynchronously, we can no longer use the `TestClient` inside our test functions.
The `TestClient` is based on [HTTPX](https://www.python-httpx.org), and luckily, we can use it directly to test the API.
Example
-------
For a simple example, let's consider a file structure similar to the one described in [Bigger Applications](../../tutorial/bigger-applications/index) and [Testing](../../tutorial/testing/index):
```
.
├── app
│ ├── __init__.py
│ ├── main.py
│ └── test_main.py
```
The file `main.py` would have:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Tomato"}
```
The file `test_main.py` would have the tests for `main.py`, it could look like this now:
```
import pytest
from httpx import AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(app=app, base_url="http://test") as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
```
Run it
------
You can run your tests as usual via:
```
$ pytest
---> 100%
```
In Detail
---------
The marker `@pytest.mark.anyio` tells pytest that this test function should be called asynchronously:
```
import pytest
from httpx import AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(app=app, base_url="http://test") as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
```
Tip
Note that the test function is now `async def` instead of just `def` as before when using the `TestClient`.
Then we can create an `AsyncClient` with the app, and send async requests to it, using `await`.
```
import pytest
from httpx import AsyncClient
from .main import app
@pytest.mark.anyio
async def test_root():
async with AsyncClient(app=app, base_url="http://test") as ac:
response = await ac.get("/")
assert response.status_code == 200
assert response.json() == {"message": "Tomato"}
```
This is the equivalent to:
```
response = client.get('/')
```
...that we used to make our requests with the `TestClient`.
Tip
Note that we're using async/await with the new `AsyncClient` - the request is asynchronous.
Other Asynchronous Function Calls
---------------------------------
As the testing function is now asynchronous, you can now also call (and `await`) other `async` functions apart from sending requests to your FastAPI application in your tests, exactly as you would call them anywhere else in your code.
Tip
If you encounter a `RuntimeError: Task attached to a different loop` when integrating asynchronous function calls in your tests (e.g. when using [MongoDB's MotorClient](https://stackoverflow.com/questions/41584243/runtimeerror-task-attached-to-a-different-loop)) Remember to instantiate objects that need an event loop only within async functions, e.g. an `'@app.on_event("startup")` callback.
fastapi Response Cookies Response Cookies
================
Use a `Response` parameter
--------------------------
You can declare a parameter of type `Response` in your *path operation function*.
And then you can set cookies in that *temporal* response object.
```
from fastapi import FastAPI, Response
app = FastAPI()
@app.post("/cookie-and-object/")
def create_cookie(response: Response):
response.set_cookie(key="fakesession", value="fake-cookie-session-value")
return {"message": "Come to the dark side, we have cookies"}
```
And then you can return any object you need, as you normally would (a `dict`, a database model, etc).
And if you declared a `response_model`, it will still be used to filter and convert the object you returned.
**FastAPI** will use that *temporal* response to extract the cookies (also headers and status code), and will put them in the final response that contains the value you returned, filtered by any `response_model`.
You can also declare the `Response` parameter in dependencies, and set cookies (and headers) in them.
Return a `Response` directly
----------------------------
You can also create cookies when returning a `Response` directly in your code.
To do that, you can create a response as described in [Return a Response Directly](../response-directly/index).
Then set Cookies in it, and then return it:
```
from fastapi import FastAPI
from fastapi.responses import JSONResponse
app = FastAPI()
@app.post("/cookie/")
def create_cookie():
content = {"message": "Come to the dark side, we have cookies"}
response = JSONResponse(content=content)
response.set_cookie(key="fakesession", value="fake-cookie-session-value")
return response
```
Tip
Have in mind that if you return a response directly instead of using the `Response` parameter, FastAPI will return it directly.
So, you will have to make sure your data is of the correct type. E.g. it is compatible with JSON, if you are returning a `JSONResponse`.
And also that you are not sending any data that should have been filtered by a `response_model`.
### More info
Technical Details
You could also use `from starlette.responses import Response` or `from starlette.responses import JSONResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
And as the `Response` can be used frequently to set headers and cookies, **FastAPI** also provides it at `fastapi.Response`.
To see all the available parameters and options, check the [documentation in Starlette](https://www.starlette.io/responses/#set-cookie).
fastapi Using the Request Directly Using the Request Directly
==========================
Up to now, you have been declaring the parts of the request that you need with their types.
Taking data from:
* The path as parameters.
* Headers.
* Cookies.
* etc.
And by doing so, **FastAPI** is validating that data, converting it and generating documentation for your API automatically.
But there are situations where you might need to access the `Request` object directly.
Details about the `Request` object
----------------------------------
As **FastAPI** is actually **Starlette** underneath, with a layer of several tools on top, you can use Starlette's [`Request`](https://www.starlette.io/requests/) object directly when you need to.
It would also mean that if you get data from the `Request` object directly (for example, read the body) it won't be validated, converted or documented (with OpenAPI, for the automatic API user interface) by FastAPI.
Although any other parameter declared normally (for example, the body with a Pydantic model) would still be validated, converted, annotated, etc.
But there are specific cases where it's useful to get the `Request` object.
Use the `Request` object directly
---------------------------------
Let's imagine you want to get the client's IP address/host inside of your *path operation function*.
For that you need to access the request directly.
```
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/items/{item_id}")
def read_root(item_id: str, request: Request):
client_host = request.client.host
return {"client_host": client_host, "item_id": item_id}
```
By declaring a *path operation function* parameter with the type being the `Request` **FastAPI** will know to pass the `Request` in that parameter.
Tip
Note that in this case, we are declaring a path parameter beside the request parameter.
So, the path parameter will be extracted, validated, converted to the specified type and annotated with OpenAPI.
The same way, you can declare any other parameter as normally, and additionally, get the `Request` too.
`Request` documentation
------------------------
You can read more details about the [`Request` object in the official Starlette documentation site](https://www.starlette.io/requests/).
Technical Details
You could also use `from starlette.requests import Request`.
**FastAPI** provides it directly just as a convenience for you, the developer. But it comes directly from Starlette.
fastapi Templates Templates
=========
You can use any template engine you want with **FastAPI**.
A common choice is Jinja2, the same one used by Flask and other tools.
There are utilities to configure it easily that you can use directly in your **FastAPI** application (provided by Starlette).
Install dependencies
--------------------
Install `jinja2`:
```
$ pip install jinja2
---> 100%
```
Using `Jinja2Templates`
-----------------------
* Import `Jinja2Templates`.
* Create a `templates` object that you can re-use later.
* Declare a `Request` parameter in the *path operation* that will return a template.
* Use the `templates` you created to render and return a `TemplateResponse`, passing the `request` as one of the key-value pairs in the Jinja2 "context".
```
from fastapi import FastAPI, Request
from fastapi.responses import HTMLResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
@app.get("/items/{id}", response_class=HTMLResponse)
async def read_item(request: Request, id: str):
return templates.TemplateResponse("item.html", {"request": request, "id": id})
```
Note
Notice that you have to pass the `request` as part of the key-value pairs in the context for Jinja2. So, you also have to declare it in your *path operation*.
Tip
By declaring `response_class=HTMLResponse` the docs UI will be able to know that the response will be HTML.
Technical Details
You could also use `from starlette.templating import Jinja2Templates`.
**FastAPI** provides the same `starlette.templating` as `fastapi.templating` just as a convenience for you, the developer. But most of the available responses come directly from Starlette. The same with `Request` and `StaticFiles`.
Writing templates
-----------------
Then you can write a template at `templates/item.html` with:
```
<html>
<head>
<title>Item Details</title>
<link href="{{ url_for('static', path='/styles.css') }}" rel="stylesheet">
</head>
<body>
<h1>Item ID: {{ id }}</h1>
</body>
</html>
```
It will show the `id` taken from the "context" `dict` you passed:
```
{"request": request, "id": id}
```
Templates and static files
--------------------------
And you can also use `url_for()` inside of the template, and use it, for example, with the `StaticFiles` you mounted.
```
<html>
<head>
<title>Item Details</title>
<link href="{{ url_for('static', path='/styles.css') }}" rel="stylesheet">
</head>
<body>
<h1>Item ID: {{ id }}</h1>
</body>
</html>
```
In this example, it would link to a CSS file at `static/styles.css` with:
```
h1 {
color: green;
}
```
And because you are using `StaticFiles`, that CSS file would be served automatically by your **FastAPI** application at the URL `/static/styles.css`.
More details
------------
For more details, including how to test templates, check [Starlette's docs on templates](https://www.starlette.io/templates/).
fastapi Async SQL (Relational) Databases Async SQL (Relational) Databases
================================
You can also use [`encode/databases`](https://github.com/encode/databases) with **FastAPI** to connect to databases using `async` and `await`.
It is compatible with:
* PostgreSQL
* MySQL
* SQLite
In this example, we'll use **SQLite**, because it uses a single file and Python has integrated support. So, you can copy this example and run it as is.
Later, for your production application, you might want to use a database server like **PostgreSQL**.
Tip
You could adopt ideas from the section about SQLAlchemy ORM ([SQL (Relational) Databases](../../tutorial/sql-databases/index)), like using utility functions to perform operations in the database, independent of your **FastAPI** code.
This section doesn't apply those ideas, to be equivalent to the counterpart in [Starlette](https://www.starlette.io/database/).
Import and set up `SQLAlchemy`
------------------------------
* Import `SQLAlchemy`.
* Create a `metadata` object.
* Create a table `notes` using the `metadata` object.
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Tip
Notice that all this code is pure SQLAlchemy Core.
`databases` is not doing anything here yet.
Import and set up `databases`
-----------------------------
* Import `databases`.
* Create a `DATABASE_URL`.
* Create a `database` object.
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Tip
If you were connecting to a different database (e.g. PostgreSQL), you would need to change the `DATABASE_URL`.
Create the tables
-----------------
In this case, we are creating the tables in the same Python file, but in production, you would probably want to create them with Alembic, integrated with migrations, etc.
Here, this section would run directly, right before starting your **FastAPI** application.
* Create an `engine`.
* Create all the tables from the `metadata` object.
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Create models
-------------
Create Pydantic models for:
* Notes to be created (`NoteIn`).
* Notes to be returned (`Note`).
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
By creating these Pydantic models, the input data will be validated, serialized (converted), and annotated (documented).
So, you will be able to see it all in the interactive API docs.
Connect and disconnect
----------------------
* Create your `FastAPI` application.
* Create event handlers to connect and disconnect from the database.
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Read notes
----------
Create the *path operation function* to read notes:
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Note
Notice that as we communicate with the database using `await`, the *path operation function* is declared with `async`.
### Notice the `response_model=List[Note]`
It uses `typing.List`.
That documents (and validates, serializes, filters) the output data, as a `list` of `Note`s.
Create notes
------------
Create the *path operation function* to create notes:
```
from typing import List
import databases
import sqlalchemy
from fastapi import FastAPI
from pydantic import BaseModel
# SQLAlchemy specific code, as with any other app
DATABASE_URL = "sqlite:///./test.db"
# DATABASE_URL = "postgresql://user:password@postgresserver/db"
database = databases.Database(DATABASE_URL)
metadata = sqlalchemy.MetaData()
notes = sqlalchemy.Table(
"notes",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("text", sqlalchemy.String),
sqlalchemy.Column("completed", sqlalchemy.Boolean),
)
engine = sqlalchemy.create_engine(
DATABASE_URL, connect_args={"check_same_thread": False}
)
metadata.create_all(engine)
class NoteIn(BaseModel):
text: str
completed: bool
class Note(BaseModel):
id: int
text: str
completed: bool
app = FastAPI()
@app.on_event("startup")
async def startup():
await database.connect()
@app.on_event("shutdown")
async def shutdown():
await database.disconnect()
@app.get("/notes/", response_model=List[Note])
async def read_notes():
query = notes.select()
return await database.fetch_all(query)
@app.post("/notes/", response_model=Note)
async def create_note(note: NoteIn):
query = notes.insert().values(text=note.text, completed=note.completed)
last_record_id = await database.execute(query)
return {**note.dict(), "id": last_record_id}
```
Note
Notice that as we communicate with the database using `await`, the *path operation function* is declared with `async`.
### About `{**note.dict(), "id": last_record_id}`
`note` is a Pydantic `Note` object.
`note.dict()` returns a `dict` with its data, something like:
```
{
"text": "Some note",
"completed": False,
}
```
but it doesn't have the `id` field.
So we create a new `dict`, that contains the key-value pairs from `note.dict()` with:
```
{**note.dict()}
```
`**note.dict()` "unpacks" the key value pairs directly, so, `{**note.dict()}` would be, more or less, a copy of `note.dict()`.
And then, we extend that copy `dict`, adding another key-value pair: `"id": last_record_id`:
```
{**note.dict(), "id": last_record_id}
```
So, the final result returned would be something like:
```
{
"id": 1,
"text": "Some note",
"completed": False,
}
```
Check it
--------
You can copy this code as is, and see the docs at <http://127.0.0.1:8000/docs>.
There you can see all your API documented and interact with it:
More info
---------
You can read more about [`encode/databases` at its GitHub page](https://github.com/encode/databases).
| programming_docs |
fastapi Lifespan Events Lifespan Events
===============
You can define logic (code) that should be executed before the application **starts up**. This means that this code will be executed **once**, **before** the application **starts receiving requests**.
The same way, you can define logic (code) that should be executed when the application is **shutting down**. In this case, this code will be executed **once**, **after** having handled possibly **many requests**.
Because this code is executed before the application **starts** taking requests, and right after it **finishes** handling requests, it covers the whole application **lifespan** (the word "lifespan" will be important in a second 😉).
This can be very useful for setting up **resources** that you need to use for the whole app, and that are **shared** among requests, and/or that you need to **clean up** afterwards. For example, a database connection pool, or loading a shared machine learning model.
Use Case
--------
Let's start with an example **use case** and then see how to solve it with this.
Let's imagine that you have some **machine learning models** that you want to use to handle requests. 🤖
The same models are shared among requests, so, it's not one model per request, or one per user or something similar.
Let's imagine that loading the model can **take quite some time**, because it has to read a lot of **data from disk**. So you don't want to do it for every request.
You could load it at the top level of the module/file, but that would also mean that it would **load the model** even if you are just running a simple automated test, then that test would be **slow** because it would have to wait for the model to load before being able to run an independent part of the code.
That's what we'll solve, let's load the model before the requests are handled, but only right before the application starts receiving requests, not while the code is being loaded.
Lifespan
--------
You can define this *startup* and *shutdown* logic using the `lifespan` parameter of the `FastAPI` app, and a "context manager" (I'll show you what that is in a second).
Let's start with an example and then see it in detail.
We create an async function `lifespan()` with `yield` like this:
```
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
```
Here we are simulating the expensive *startup* operation of loading the model by putting the (fake) model function in the dictionary with machine learning models before the `yield`. This code will be executed **before** the application **starts taking requests**, during the *startup*.
And then, right after the `yield`, we unload the model. This code will be executed **after** the application **finishes handling requests**, right before the *shutdown*. This could, for example, release resources like memory or a GPU.
Tip
The `shutdown` would happen when you are **stopping** the application.
Maybe you need to start a new version, or you just got tired of running it. 🤷
### Lifespan function
The first thing to notice, is that we are defining an async function with `yield`. This is very similar to Dependencies with `yield`.
```
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
```
The first part of the function, before the `yield`, will be executed **before** the application starts.
And the part after the `yield` will be executed **after** the application has finished.
### Async Context Manager
If you check, the function is decorated with an `@asynccontextmanager`.
That converts the function into something called an "**async context manager**".
```
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
```
A **context manager** in Python is something that you can use in a `with` statement, for example, `open()` can be used as a context manager:
```
with open("file.txt") as file:
file.read()
```
In recent versions of Python, there's also an **async context manager**. You would use it with `async with`:
```
async with lifespan(app):
await do_stuff()
```
When you create a context manager or an async context manager like above, what it does is that, before entering the `with` block, it will execute the code before the `yield`, and after exiting the `with` block, it will execute the code after the `yield`.
In our code example above, we don't use it directly, but we pass it to FastAPI for it to use it.
The `lifespan` parameter of the `FastAPI` app takes an **async context manager**, so we can pass our new `lifespan` async context manager to it.
```
from contextlib import asynccontextmanager
from fastapi import FastAPI
def fake_answer_to_everything_ml_model(x: float):
return x * 42
ml_models = {}
@asynccontextmanager
async def lifespan(app: FastAPI):
# Load the ML model
ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
yield
# Clean up the ML models and release the resources
ml_models.clear()
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict(x: float):
result = ml_models["answer_to_everything"](x)
return {"result": result}
```
Alternative Events (deprecated)
-------------------------------
Warning
The recommended way to handle the *startup* and *shutdown* is using the `lifespan` parameter of the `FastAPI` app as described above.
You can probably skip this part.
There's an alternative way to define this logic to be executed during *startup* and during *shutdown*.
You can define event handlers (functions) that need to be executed before the application starts up, or when the application is shutting down.
These functions can be declared with `async def` or normal `def`.
###
`startup` event
To add a function that should be run before the application starts, declare it with the event `"startup"`:
```
from fastapi import FastAPI
app = FastAPI()
items = {}
@app.on_event("startup")
async def startup_event():
items["foo"] = {"name": "Fighters"}
items["bar"] = {"name": "Tenders"}
@app.get("/items/{item_id}")
async def read_items(item_id: str):
return items[item_id]
```
In this case, the `startup` event handler function will initialize the items "database" (just a `dict`) with some values.
You can add more than one event handler function.
And your application won't start receiving requests until all the `startup` event handlers have completed.
###
`shutdown` event
To add a function that should be run when the application is shutting down, declare it with the event `"shutdown"`:
```
from fastapi import FastAPI
app = FastAPI()
@app.on_event("shutdown")
def shutdown_event():
with open("log.txt", mode="a") as log:
log.write("Application shutdown")
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
```
Here, the `shutdown` event handler function will write a text line `"Application shutdown"` to a file `log.txt`.
Info
In the `open()` function, the `mode="a"` means "append", so, the line will be added after whatever is on that file, without overwriting the previous contents.
Tip
Notice that in this case we are using a standard Python `open()` function that interacts with a file.
So, it involves I/O (input/output), that requires "waiting" for things to be written to disk.
But `open()` doesn't use `async` and `await`.
So, we declare the event handler function with standard `def` instead of `async def`.
###
`startup` and `shutdown` together
There's a high chance that the logic for your *startup* and *shutdown* is connected, you might want to start something and then finish it, acquire a resource and then release it, etc.
Doing that in separated functions that don't share logic or variables together is more difficult as you would need to store values in global variables or similar tricks.
Because of that, it's now recommended to instead use the `lifespan` as explained above.
Technical Details
-----------------
Just a technical detail for the curious nerds. 🤓
Underneath, in the ASGI technical specification, this is part of the [Lifespan Protocol](https://asgi.readthedocs.io/en/latest/specs/lifespan.html), and it defines events called `startup` and `shutdown`.
Info
You can read more about the Starlette `lifespan` handlers in [Starlette's Lifespan' docs](https://www.starlette.io/lifespan/).
Including how to handle lifespan state that can be used in other areas of your code.
Sub Applications
----------------
🚨 Have in mind that these lifespan events (startup and shutdown) will only be executed for the main application, not for [Sub Applications - Mounts](../sub-applications/index).
fastapi NoSQL (Distributed / Big Data) Databases NoSQL (Distributed / Big Data) Databases
========================================
**FastAPI** can also be integrated with any NoSQL.
Here we'll see an example using **[Couchbase](https://www.couchbase.com/)**, a document based NoSQL database.
You can adapt it to any other NoSQL database like:
* **MongoDB**
* **Cassandra**
* **CouchDB**
* **ArangoDB**
* **ElasticSearch**, etc.
Tip
There is an official project generator with **FastAPI** and **Couchbase**, all based on **Docker**, including a frontend and more tools: <https://github.com/tiangolo/full-stack-fastapi-couchbase>
Import Couchbase components
---------------------------
For now, don't pay attention to the rest, only the imports:
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
Define a constant to use as a "document type"
---------------------------------------------
We will use it later as a fixed field `type` in our documents.
This is not required by Couchbase, but is a good practice that will help you afterwards.
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
Add a function to get a `Bucket`
--------------------------------
In **Couchbase**, a bucket is a set of documents, that can be of different types.
They are generally all related to the same application.
The analogy in the relational database world would be a "database" (a specific database, not the database server).
The analogy in **MongoDB** would be a "collection".
In the code, a `Bucket` represents the main entrypoint of communication with the database.
This utility function will:
* Connect to a **Couchbase** cluster (that might be a single machine).
+ Set defaults for timeouts.
* Authenticate in the cluster.
* Get a `Bucket` instance.
+ Set defaults for timeouts.
* Return it.
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
Create Pydantic models
----------------------
As **Couchbase** "documents" are actually just "JSON objects", we can model them with Pydantic.
###
`User` model
First, let's create a `User` model:
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
We will use this model in our *path operation function*, so, we don't include in it the `hashed_password`.
###
`UserInDB` model
Now, let's create a `UserInDB` model.
This will have the data that is actually stored in the database.
We don't create it as a subclass of Pydantic's `BaseModel` but as a subclass of our own `User`, because it will have all the attributes in `User` plus a couple more:
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
Note
Notice that we have a `hashed_password` and a `type` field that will be stored in the database.
But it is not part of the general `User` model (the one we will return in the *path operation*).
Get the user
------------
Now create a function that will:
* Take a username.
* Generate a document ID from it.
* Get the document with that ID.
* Put the contents of the document in a `UserInDB` model.
By creating a function that is only dedicated to getting your user from a `username` (or any other parameter) independent of your *path operation function*, you can more easily re-use it in multiple parts and also add unit tests for it:
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
### f-strings
If you are not familiar with the `f"userprofile::{username}"`, it is a Python "[f-string](https://docs.python.org/3/glossary.html#term-f-string)".
Any variable that is put inside of `{}` in an f-string will be expanded / injected in the string.
###
`dict` unpacking
If you are not familiar with the `UserInDB(**result.value)`, [it is using `dict` "unpacking"](https://docs.python.org/3/glossary.html#term-argument).
It will take the `dict` at `result.value`, and take each of its keys and values and pass them as key-values to `UserInDB` as keyword arguments.
So, if the `dict` contains:
```
{
"username": "johndoe",
"hashed_password": "some_hash",
}
```
It will be passed to `UserInDB` as:
```
UserInDB(username="johndoe", hashed_password="some_hash")
```
Create your **FastAPI** code
----------------------------
### Create the `FastAPI` app
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
### Create the *path operation function*
As our code is calling Couchbase and we are not using the [experimental Python `await` support](https://docs.couchbase.com/python-sdk/2.5/async-programming.html#asyncio-python-3-5), we should declare our function with normal `def` instead of `async def`.
Also, Couchbase recommends not using a single `Bucket` object in multiple "threads", so, we can just get the bucket directly and pass it to our utility functions:
```
from typing import Union
from couchbase import LOCKMODE_WAIT
from couchbase.bucket import Bucket
from couchbase.cluster import Cluster, PasswordAuthenticator
from fastapi import FastAPI
from pydantic import BaseModel
USERPROFILE_DOC_TYPE = "userprofile"
def get_bucket():
cluster = Cluster(
"couchbase://couchbasehost:8091?fetch_mutation_tokens=1&operation_timeout=30&n1ql_timeout=300"
)
authenticator = PasswordAuthenticator("username", "password")
cluster.authenticate(authenticator)
bucket: Bucket = cluster.open_bucket("bucket_name", lockmode=LOCKMODE_WAIT)
bucket.timeout = 30
bucket.n1ql_timeout = 300
return bucket
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
type: str = USERPROFILE_DOC_TYPE
hashed_password: str
def get_user(bucket: Bucket, username: str):
doc_id = f"userprofile::{username}"
result = bucket.get(doc_id, quiet=True)
if not result.value:
return None
user = UserInDB(**result.value)
return user
# FastAPI specific code
app = FastAPI()
@app.get("/users/{username}", response_model=User)
def read_user(username: str):
bucket = get_bucket()
user = get_user(bucket=bucket, username=username)
return user
```
Recap
-----
You can integrate any third party NoSQL database, just using their standard packages.
The same applies to any other external tool, system or API.
| programming_docs |
fastapi Response Headers Response Headers
================
Use a `Response` parameter
--------------------------
You can declare a parameter of type `Response` in your *path operation function* (as you can do for cookies).
And then you can set headers in that *temporal* response object.
```
from fastapi import FastAPI, Response
app = FastAPI()
@app.get("/headers-and-object/")
def get_headers(response: Response):
response.headers["X-Cat-Dog"] = "alone in the world"
return {"message": "Hello World"}
```
And then you can return any object you need, as you normally would (a `dict`, a database model, etc).
And if you declared a `response_model`, it will still be used to filter and convert the object you returned.
**FastAPI** will use that *temporal* response to extract the headers (also cookies and status code), and will put them in the final response that contains the value you returned, filtered by any `response_model`.
You can also declare the `Response` parameter in dependencies, and set headers (and cookies) in them.
Return a `Response` directly
----------------------------
You can also add headers when you return a `Response` directly.
Create a response as described in [Return a Response Directly](../response-directly/index) and pass the headers as an additional parameter:
```
from fastapi import FastAPI
from fastapi.responses import JSONResponse
app = FastAPI()
@app.get("/headers/")
def get_headers():
content = {"message": "Hello World"}
headers = {"X-Cat-Dog": "alone in the world", "Content-Language": "en-US"}
return JSONResponse(content=content, headers=headers)
```
Technical Details
You could also use `from starlette.responses import Response` or `from starlette.responses import JSONResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
And as the `Response` can be used frequently to set headers and cookies, **FastAPI** also provides it at `fastapi.Response`.
Custom Headers
--------------
Have in mind that custom proprietary headers can be added [using the 'X-' prefix](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers).
But if you have custom headers that you want a client in a browser to be able to see, you need to add them to your CORS configurations (read more in [CORS (Cross-Origin Resource Sharing)](../../tutorial/cors/index)), using the parameter `expose_headers` documented in [Starlette's CORS docs](https://www.starlette.io/middleware/#corsmiddleware).
fastapi Testing Dependencies with Overrides Testing Dependencies with Overrides
===================================
Overriding dependencies during testing
--------------------------------------
There are some scenarios where you might want to override a dependency during testing.
You don't want the original dependency to run (nor any of the sub-dependencies it might have).
Instead, you want to provide a different dependency that will be used only during tests (possibly only some specific tests), and will provide a value that can be used where the value of the original dependency was used.
### Use cases: external service
An example could be that you have an external authentication provider that you need to call.
You send it a token and it returns an authenticated user.
This provider might be charging you per request, and calling it might take some extra time than if you had a fixed mock user for tests.
You probably want to test the external provider once, but not necessarily call it for every test that runs.
In this case, you can override the dependency that calls that provider, and use a custom dependency that returns a mock user, only for your tests.
### Use the `app.dependency_overrides` attribute
For these cases, your **FastAPI** application has an attribute `app.dependency_overrides`, it is a simple `dict`.
To override a dependency for testing, you put as a key the original dependency (a function), and as the value, your dependency override (another function).
And then **FastAPI** will call that override instead of the original dependency.
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: str | None = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit": 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: Union[str, None] = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit": 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: Union[str, None] = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit": 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: str | None = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit": 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return {"message": "Hello Items!", "params": commons}
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return {"message": "Hello Users!", "params": commons}
client = TestClient(app)
async def override_dependency(q: Union[str, None] = None):
return {"q": q, "skip": 5, "limit": 10}
app.dependency_overrides[common_parameters] = override_dependency
def test_override_in_items():
response = client.get("/items/")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": None, "skip": 5, "limit": 10},
}
def test_override_in_items_with_q():
response = client.get("/items/?q=foo")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
def test_override_in_items_with_params():
response = client.get("/items/?q=foo&skip=100&limit=200")
assert response.status_code == 200
assert response.json() == {
"message": "Hello Items!",
"params": {"q": "foo", "skip": 5, "limit": 10},
}
```
Tip
You can set a dependency override for a dependency used anywhere in your **FastAPI** application.
The original dependency could be used in a *path operation function*, a *path operation decorator* (when you don't use the return value), a `.include_router()` call, etc.
FastAPI will still be able to override it.
Then you can reset your overrides (remove them) by setting `app.dependency_overrides` to be an empty `dict`:
```
app.dependency_overrides = {}
```
Tip
If you want to override a dependency only during some tests, you can set the override at the beginning of the test (inside the test function) and reset it at the end (at the end of the test function).
fastapi Advanced Dependencies Advanced Dependencies
=====================
Parameterized dependencies
--------------------------
All the dependencies we have seen are a fixed function or class.
But there could be cases where you want to be able to set parameters on the dependency, without having to declare many different functions or classes.
Let's imagine that we want to have a dependency that checks if the query parameter `q` contains some fixed content.
But we want to be able to parameterize that fixed content.
A "callable" instance
---------------------
In Python there's a way to make an instance of a class a "callable".
Not the class itself (which is already a callable), but an instance of that class.
To do that, we declare a method `__call__`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
```
In this case, this `__call__` is what **FastAPI** will use to check for additional parameters and sub-dependencies, and this is what will be called to pass a value to the parameter in your *path operation function* later.
Parameterize the instance
-------------------------
And now, we can use `__init__` to declare the parameters of the instance that we can use to "parameterize" the dependency:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
```
In this case, **FastAPI** won't ever touch or care about `__init__`, we will use it directly in our code.
Create an instance
------------------
We could create an instance of this class with:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
```
And that way we are able to "parameterize" our dependency, that now has `"bar"` inside of it, as the attribute `checker.fixed_content`.
Use the instance as a dependency
--------------------------------
Then, we could use this `checker` in a `Depends(checker)`, instead of `Depends(FixedContentQueryChecker)`, because the dependency is the instance, `checker`, not the class itself.
And when solving the dependency, **FastAPI** will call this `checker` like:
```
checker(q="somequery")
```
...and pass whatever that returns as the value of the dependency in our *path operation function* as the parameter `fixed_content_included`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: Annotated[bool, Depends(checker)]):
return {"fixed_content_in_query": fixed_content_included}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
class FixedContentQueryChecker:
def __init__(self, fixed_content: str):
self.fixed_content = fixed_content
def __call__(self, q: str = ""):
if q:
return self.fixed_content in q
return False
checker = FixedContentQueryChecker("bar")
@app.get("/query-checker/")
async def read_query_check(fixed_content_included: bool = Depends(checker)):
return {"fixed_content_in_query": fixed_content_included}
```
Tip
All this might seem contrived. And it might not be very clear how is it useful yet.
These examples are intentionally simple, but show how it all works.
In the chapters about security, there are utility functions that are implemented in this same way.
If you understood all this, you already know how those utility tools for security work underneath.
| programming_docs |
fastapi Using Dataclasses Using Dataclasses
=================
FastAPI is built on top of **Pydantic**, and I have been showing you how to use Pydantic models to declare requests and responses.
But FastAPI also supports using [`dataclasses`](https://docs.python.org/3/library/dataclasses.html) the same way:
```
from dataclasses import dataclass
from typing import Union
from fastapi import FastAPI
@dataclass
class Item:
name: str
price: float
description: Union[str, None] = None
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
This is still supported thanks to **Pydantic**, as it has [internal support for `dataclasses`](https://pydantic-docs.helpmanual.io/usage/dataclasses/#use-of-stdlib-dataclasses-with-basemodel).
So, even with the code above that doesn't use Pydantic explicitly, FastAPI is using Pydantic to convert those standard dataclasses to Pydantic's own flavor of dataclasses.
And of course, it supports the same:
* data validation
* data serialization
* data documentation, etc.
This works the same way as with Pydantic models. And it is actually achieved in the same way underneath, using Pydantic.
Info
Have in mind that dataclasses can't do everything Pydantic models can do.
So, you might still need to use Pydantic models.
But if you have a bunch of dataclasses laying around, this is a nice trick to use them to power a web API using FastAPI. 🤓
Dataclasses in `response_model`
-------------------------------
You can also use `dataclasses` in the `response_model` parameter:
```
from dataclasses import dataclass, field
from typing import List, Union
from fastapi import FastAPI
@dataclass
class Item:
name: str
price: float
tags: List[str] = field(default_factory=list)
description: Union[str, None] = None
tax: Union[float, None] = None
app = FastAPI()
@app.get("/items/next", response_model=Item)
async def read_next_item():
return {
"name": "Island In The Moon",
"price": 12.99,
"description": "A place to be be playin' and havin' fun",
"tags": ["breater"],
}
```
The dataclass will be automatically converted to a Pydantic dataclass.
This way, its schema will show up in the API docs user interface:
Dataclasses in Nested Data Structures
-------------------------------------
You can also combine `dataclasses` with other type annotations to make nested data structures.
In some cases, you might still have to use Pydantic's version of `dataclasses`. For example, if you have errors with the automatically generated API documentation.
In that case, you can simply swap the standard `dataclasses` with `pydantic.dataclasses`, which is a drop-in replacement:
```
from dataclasses import field # (1)
from typing import List, Union
from fastapi import FastAPI
from pydantic.dataclasses import dataclass # (2)
@dataclass
class Item:
name: str
description: Union[str, None] = None
@dataclass
class Author:
name: str
items: List[Item] = field(default_factory=list) # (3)
app = FastAPI()
@app.post("/authors/{author_id}/items/", response_model=Author) # (4)
async def create_author_items(author_id: str, items: List[Item]): # (5)
return {"name": author_id, "items": items} # (6)
@app.get("/authors/", response_model=List[Author]) # (7)
def get_authors(): # (8)
return [ # (9)
{
"name": "Breaters",
"items": [
{
"name": "Island In The Moon",
"description": "A place to be be playin' and havin' fun",
},
{"name": "Holy Buddies"},
],
},
{
"name": "System of an Up",
"items": [
{
"name": "Salt",
"description": "The kombucha mushroom people's favorite",
},
{"name": "Pad Thai"},
{
"name": "Lonely Night",
"description": "The mostests lonliest nightiest of allest",
},
],
},
]
```
1. We still import `field` from standard `dataclasses`.
2. `pydantic.dataclasses` is a drop-in replacement for `dataclasses`.
3. The `Author` dataclass includes a list of `Item` dataclasses.
4. The `Author` dataclass is used as the `response_model` parameter.
5. You can use other standard type annotations with dataclasses as the request body.
In this case, it's a list of `Item` dataclasses.
6. Here we are returning a dictionary that contains `items` which is a list of dataclasses.
FastAPI is still capable of serializing the data to JSON.
7. Here the `response_model` is using a type annotation of a list of `Author` dataclasses.
Again, you can combine `dataclasses` with standard type annotations.
8. Notice that this *path operation function* uses regular `def` instead of `async def`.
As always, in FastAPI you can combine `def` and `async def` as needed.
If you need a refresher about when to use which, check out the section *"In a hurry?"* in the docs about [`async` and `await`](../../async/index#in-a-hurry).
9. This *path operation function* is not returning dataclasses (although it could), but a list of dictionaries with internal data.
FastAPI will use the `response_model` parameter (that includes dataclasses) to convert the response.
You can combine `dataclasses` with other type annotations in many different combinations to form complex data structures.
Check the in-code annotation tips above to see more specific details.
Learn More
----------
You can also combine `dataclasses` with other Pydantic models, inherit from them, include them in your own models, etc.
To learn more, check the [Pydantic docs about dataclasses](https://pydantic-docs.helpmanual.io/usage/dataclasses/).
Version
-------
This is available since FastAPI version `0.67.0`. 🔖
fastapi Tutorial - User Guide - Intro Tutorial - User Guide - Intro
=============================
This tutorial shows you how to use **FastAPI** with most of its features, step by step.
Each section gradually builds on the previous ones, but it's structured to separate topics, so that you can go directly to any specific one to solve your specific API needs.
It is also built to work as a future reference.
So you can come back and see exactly what you need.
Run the code
------------
All the code blocks can be copied and used directly (they are actually tested Python files).
To run any of the examples, copy the code to a file `main.py`, and start `uvicorn` with:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
<span style="color: green;">INFO</span>: Started reloader process [28720]
<span style="color: green;">INFO</span>: Started server process [28722]
<span style="color: green;">INFO</span>: Waiting for application startup.
<span style="color: green;">INFO</span>: Application startup complete.
```
It is **HIGHLY encouraged** that you write or copy the code, edit it and run it locally.
Using it in your editor is what really shows you the benefits of FastAPI, seeing how little code you have to write, all the type checks, autocompletion, etc.
---
Install FastAPI
---------------
The first step is to install FastAPI.
For the tutorial, you might want to install it with all the optional dependencies and features:
```
$ pip install "fastapi[all]"
---> 100%
```
...that also includes `uvicorn`, that you can use as the server that runs your code.
Note
You can also install it part by part.
This is what you would probably do once you want to deploy your application to production:
```
pip install fastapi
```
Also install `uvicorn` to work as the server:
```
pip install "uvicorn[standard]"
```
And the same for each of the optional dependencies that you want to use.
Advanced User Guide
-------------------
There is also an **Advanced User Guide** that you can read later after this **Tutorial - User guide**.
The **Advanced User Guide**, builds on this, uses the same concepts, and teaches you some extra features.
But you should first read the **Tutorial - User Guide** (what you are reading right now).
It's designed so that you can build a complete application with just the **Tutorial - User Guide**, and then extend it in different ways, depending on your needs, using some of the additional ideas from the **Advanced User Guide**.
fastapi Middleware Middleware
==========
You can add middleware to **FastAPI** applications.
A "middleware" is a function that works with every **request** before it is processed by any specific *path operation*. And also with every **response** before returning it.
* It takes each **request** that comes to your application.
* It can then do something to that **request** or run any needed code.
* Then it passes the **request** to be processed by the rest of the application (by some *path operation*).
* It then takes the **response** generated by the application (by some *path operation*).
* It can do something to that **response** or run any needed code.
* Then it returns the **response**.
Technical Details
If you have dependencies with `yield`, the exit code will run *after* the middleware.
If there were any background tasks (documented later), they will run *after* all the middleware.
Create a middleware
-------------------
To create a middleware you use the decorator `@app.middleware("http")` on top of a function.
The middleware function receives:
* The `request`.
* A function `call_next` that will receive the `request` as a parameter.
+ This function will pass the `request` to the corresponding *path operation*.
+ Then it returns the `response` generated by the corresponding *path operation*.
* You can then modify further the `response` before returning it.
```
import time
from fastapi import FastAPI, Request
app = FastAPI()
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
response.headers["X-Process-Time"] = str(process_time)
return response
```
Tip
Have in mind that custom proprietary headers can be added [using the 'X-' prefix](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers).
But if you have custom headers that you want a client in a browser to be able to see, you need to add them to your CORS configurations ([CORS (Cross-Origin Resource Sharing)](../cors/index)) using the parameter `expose_headers` documented in [Starlette's CORS docs](https://www.starlette.io/middleware/#corsmiddleware).
Technical Details
You could also use `from starlette.requests import Request`.
**FastAPI** provides it as a convenience for you, the developer. But it comes directly from Starlette.
### Before and after the `response`
You can add code to be run with the `request`, before any *path operation* receives it.
And also after the `response` is generated, before returning it.
For example, you could add a custom header `X-Process-Time` containing the time in seconds that it took to process the request and generate a response:
```
import time
from fastapi import FastAPI, Request
app = FastAPI()
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
response.headers["X-Process-Time"] = str(process_time)
return response
```
Other middlewares
-----------------
You can later read more about other middlewares in the [Advanced User Guide: Advanced Middleware](../../advanced/middleware/index).
You will read about how to handle CORS with a middleware in the next section.
fastapi Bigger Applications - Multiple Files Bigger Applications - Multiple Files
====================================
If you are building an application or a web API, it's rarely the case that you can put everything on a single file.
**FastAPI** provides a convenience tool to structure your application while keeping all the flexibility.
Info
If you come from Flask, this would be the equivalent of Flask's Blueprints.
An example file structure
-------------------------
Let's say you have a file structure like this:
```
.
├── app
│ ├── __init__.py
│ ├── main.py
│ ├── dependencies.py
│ └── routers
│ │ ├── __init__.py
│ │ ├── items.py
│ │ └── users.py
│ └── internal
│ ├── __init__.py
│ └── admin.py
```
Tip
There are several `__init__.py` files: one in each directory or subdirectory.
This is what allows importing code from one file into another.
For example, in `app/main.py` you could have a line like:
```
from app.routers import items
```
* The `app` directory contains everything. And it has an empty file `app/__init__.py`, so it is a "Python package" (a collection of "Python modules"): `app`.
* It contains an `app/main.py` file. As it is inside a Python package (a directory with a file `__init__.py`), it is a "module" of that package: `app.main`.
* There's also an `app/dependencies.py` file, just like `app/main.py`, it is a "module": `app.dependencies`.
* There's a subdirectory `app/routers/` with another file `__init__.py`, so it's a "Python subpackage": `app.routers`.
* The file `app/routers/items.py` is inside a package, `app/routers/`, so, it's a submodule: `app.routers.items`.
* The same with `app/routers/users.py`, it's another submodule: `app.routers.users`.
* There's also a subdirectory `app/internal/` with another file `__init__.py`, so it's another "Python subpackage": `app.internal`.
* And the file `app/internal/admin.py` is another submodule: `app.internal.admin`.
The same file structure with comments:
```
.
├── app # "app" is a Python package
│ ├── __init__.py # this file makes "app" a "Python package"
│ ├── main.py # "main" module, e.g. import app.main
│ ├── dependencies.py # "dependencies" module, e.g. import app.dependencies
│ └── routers # "routers" is a "Python subpackage"
│ │ ├── __init__.py # makes "routers" a "Python subpackage"
│ │ ├── items.py # "items" submodule, e.g. import app.routers.items
│ │ └── users.py # "users" submodule, e.g. import app.routers.users
│ └── internal # "internal" is a "Python subpackage"
│ ├── __init__.py # makes "internal" a "Python subpackage"
│ └── admin.py # "admin" submodule, e.g. import app.internal.admin
```
`APIRouter`
-----------
Let's say the file dedicated to handling just users is the submodule at `/app/routers/users.py`.
You want to have the *path operations* related to your users separated from the rest of the code, to keep it organized.
But it's still part of the same **FastAPI** application/web API (it's part of the same "Python Package").
You can create the *path operations* for that module using `APIRouter`.
### Import `APIRouter`
You import it and create an "instance" the same way you would with the class `FastAPI`:
```
from fastapi import APIRouter
router = APIRouter()
@router.get("/users/", tags=["users"])
async def read_users():
return [{"username": "Rick"}, {"username": "Morty"}]
@router.get("/users/me", tags=["users"])
async def read_user_me():
return {"username": "fakecurrentuser"}
@router.get("/users/{username}", tags=["users"])
async def read_user(username: str):
return {"username": username}
```
###
*Path operations* with `APIRouter`
And then you use it to declare your *path operations*.
Use it the same way you would use the `FastAPI` class:
```
from fastapi import APIRouter
router = APIRouter()
@router.get("/users/", tags=["users"])
async def read_users():
return [{"username": "Rick"}, {"username": "Morty"}]
@router.get("/users/me", tags=["users"])
async def read_user_me():
return {"username": "fakecurrentuser"}
@router.get("/users/{username}", tags=["users"])
async def read_user(username: str):
return {"username": username}
```
You can think of `APIRouter` as a "mini `FastAPI`" class.
All the same options are supported.
All the same `parameters`, `responses`, `dependencies`, `tags`, etc.
Tip
In this example, the variable is called `router`, but you can name it however you want.
We are going to include this `APIRouter` in the main `FastAPI` app, but first, let's check the dependencies and another `APIRouter`.
Dependencies
------------
We see that we are going to need some dependencies used in several places of the application.
So we put them in their own `dependencies` module (`app/dependencies.py`).
We will now use a simple dependency to read a custom `X-Token` header:
Python 3.9+
```
from typing import Annotated
from fastapi import Header, HTTPException
async def get_token_header(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def get_query_token(token: str):
if token != "jessica":
raise HTTPException(status_code=400, detail="No Jessica token provided")
```
Python 3.6+
```
from fastapi import Header, HTTPException
from typing_extensions import Annotated
async def get_token_header(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def get_query_token(token: str):
if token != "jessica":
raise HTTPException(status_code=400, detail="No Jessica token provided")
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Header, HTTPException
async def get_token_header(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def get_query_token(token: str):
if token != "jessica":
raise HTTPException(status_code=400, detail="No Jessica token provided")
```
Tip
We are using an invented header to simplify this example.
But in real cases you will get better results using the integrated [Security utilities](../security/index).
Another module with `APIRouter`
-------------------------------
Let's say you also have the endpoints dedicated to handling "items" from your application in the module at `app/routers/items.py`.
You have *path operations* for:
* `/items/`
* `/items/{item_id}`
It's all the same structure as with `app/routers/users.py`.
But we want to be smarter and simplify the code a bit.
We know all the *path operations* in this module have the same:
* Path `prefix`: `/items`.
* `tags`: (just one tag: `items`).
* Extra `responses`.
* `dependencies`: they all need that `X-Token` dependency we created.
So, instead of adding all that to each *path operation*, we can add it to the `APIRouter`.
```
from fastapi import APIRouter, Depends, HTTPException
from ..dependencies import get_token_header
router = APIRouter(
prefix="/items",
tags=["items"],
dependencies=[Depends(get_token_header)],
responses={404: {"description": "Not found"}},
)
fake_items_db = {"plumbus": {"name": "Plumbus"}, "gun": {"name": "Portal Gun"}}
@router.get("/")
async def read_items():
return fake_items_db
@router.get("/{item_id}")
async def read_item(item_id: str):
if item_id not in fake_items_db:
raise HTTPException(status_code=404, detail="Item not found")
return {"name": fake_items_db[item_id]["name"], "item_id": item_id}
@router.put(
"/{item_id}",
tags=["custom"],
responses={403: {"description": "Operation forbidden"}},
)
async def update_item(item_id: str):
if item_id != "plumbus":
raise HTTPException(
status_code=403, detail="You can only update the item: plumbus"
)
return {"item_id": item_id, "name": "The great Plumbus"}
```
As the path of each *path operation* has to start with `/`, like in:
```
@router.get("/{item_id}")
async def read_item(item_id: str):
...
```
...the prefix must not include a final `/`.
So, the prefix in this case is `/items`.
We can also add a list of `tags` and extra `responses` that will be applied to all the *path operations* included in this router.
And we can add a list of `dependencies` that will be added to all the *path operations* in the router and will be executed/solved for each request made to them.
Tip
Note that, much like [dependencies in *path operation decorators*](../dependencies/dependencies-in-path-operation-decorators/index), no value will be passed to your *path operation function*.
The end result is that the item paths are now:
* `/items/`
* `/items/{item_id}`
...as we intended.
* They will be marked with a list of tags that contain a single string `"items"`.
+ These "tags" are especially useful for the automatic interactive documentation systems (using OpenAPI).
* All of them will include the predefined `responses`.
* All these *path operations* will have the list of `dependencies` evaluated/executed before them.
+ If you also declare dependencies in a specific *path operation*, **they will be executed too**.
+ The router dependencies are executed first, then the [`dependencies` in the decorator](../dependencies/dependencies-in-path-operation-decorators/index), and then the normal parameter dependencies.
+ You can also add [`Security` dependencies with `scopes`](../../advanced/security/oauth2-scopes/index).
Tip
Having `dependencies` in the `APIRouter` can be used, for example, to require authentication for a whole group of *path operations*. Even if the dependencies are not added individually to each one of them.
Check
The `prefix`, `tags`, `responses`, and `dependencies` parameters are (as in many other cases) just a feature from **FastAPI** to help you avoid code duplication.
### Import the dependencies
This code lives in the module `app.routers.items`, the file `app/routers/items.py`.
And we need to get the dependency function from the module `app.dependencies`, the file `app/dependencies.py`.
So we use a relative import with `..` for the dependencies:
```
from fastapi import APIRouter, Depends, HTTPException
from ..dependencies import get_token_header
router = APIRouter(
prefix="/items",
tags=["items"],
dependencies=[Depends(get_token_header)],
responses={404: {"description": "Not found"}},
)
fake_items_db = {"plumbus": {"name": "Plumbus"}, "gun": {"name": "Portal Gun"}}
@router.get("/")
async def read_items():
return fake_items_db
@router.get("/{item_id}")
async def read_item(item_id: str):
if item_id not in fake_items_db:
raise HTTPException(status_code=404, detail="Item not found")
return {"name": fake_items_db[item_id]["name"], "item_id": item_id}
@router.put(
"/{item_id}",
tags=["custom"],
responses={403: {"description": "Operation forbidden"}},
)
async def update_item(item_id: str):
if item_id != "plumbus":
raise HTTPException(
status_code=403, detail="You can only update the item: plumbus"
)
return {"item_id": item_id, "name": "The great Plumbus"}
```
#### How relative imports work
Tip
If you know perfectly how imports work, continue to the next section below.
A single dot `.`, like in:
```
from .dependencies import get_token_header
```
would mean:
* Starting in the same package that this module (the file `app/routers/items.py`) lives in (the directory `app/routers/`)...
* find the module `dependencies` (an imaginary file at `app/routers/dependencies.py`)...
* and from it, import the function `get_token_header`.
But that file doesn't exist, our dependencies are in a file at `app/dependencies.py`.
Remember how our app/file structure looks like:
---
The two dots `..`, like in:
```
from ..dependencies import get_token_header
```
mean:
* Starting in the same package that this module (the file `app/routers/items.py`) lives in (the directory `app/routers/`)...
* go to the parent package (the directory `app/`)...
* and in there, find the module `dependencies` (the file at `app/dependencies.py`)...
* and from it, import the function `get_token_header`.
That works correctly! 🎉
---
The same way, if we had used three dots `...`, like in:
```
from ...dependencies import get_token_header
```
that would mean:
* Starting in the same package that this module (the file `app/routers/items.py`) lives in (the directory `app/routers/`)...
* go to the parent package (the directory `app/`)...
* then go to the parent of that package (there's no parent package, `app` is the top level 😱)...
* and in there, find the module `dependencies` (the file at `app/dependencies.py`)...
* and from it, import the function `get_token_header`.
That would refer to some package above `app/`, with its own file `__init__.py`, etc. But we don't have that. So, that would throw an error in our example. 🚨
But now you know how it works, so you can use relative imports in your own apps no matter how complex they are. 🤓
### Add some custom `tags`, `responses`, and `dependencies`
We are not adding the prefix `/items` nor the `tags=["items"]` to each *path operation* because we added them to the `APIRouter`.
But we can still add *more* `tags` that will be applied to a specific *path operation*, and also some extra `responses` specific to that *path operation*:
```
from fastapi import APIRouter, Depends, HTTPException
from ..dependencies import get_token_header
router = APIRouter(
prefix="/items",
tags=["items"],
dependencies=[Depends(get_token_header)],
responses={404: {"description": "Not found"}},
)
fake_items_db = {"plumbus": {"name": "Plumbus"}, "gun": {"name": "Portal Gun"}}
@router.get("/")
async def read_items():
return fake_items_db
@router.get("/{item_id}")
async def read_item(item_id: str):
if item_id not in fake_items_db:
raise HTTPException(status_code=404, detail="Item not found")
return {"name": fake_items_db[item_id]["name"], "item_id": item_id}
@router.put(
"/{item_id}",
tags=["custom"],
responses={403: {"description": "Operation forbidden"}},
)
async def update_item(item_id: str):
if item_id != "plumbus":
raise HTTPException(
status_code=403, detail="You can only update the item: plumbus"
)
return {"item_id": item_id, "name": "The great Plumbus"}
```
Tip
This last path operation will have the combination of tags: `["items", "custom"]`.
And it will also have both responses in the documentation, one for `404` and one for `403`.
The main `FastAPI`
------------------
Now, let's see the module at `app/main.py`.
Here's where you import and use the class `FastAPI`.
This will be the main file in your application that ties everything together.
And as most of your logic will now live in its own specific module, the main file will be quite simple.
### Import `FastAPI`
You import and create a `FastAPI` class as normally.
And we can even declare [global dependencies](../dependencies/global-dependencies/index) that will be combined with the dependencies for each `APIRouter`:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
### Import the `APIRouter`
Now we import the other submodules that have `APIRouter`s:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
As the files `app/routers/users.py` and `app/routers/items.py` are submodules that are part of the same Python package `app`, we can use a single dot `.` to import them using "relative imports".
### How the importing works
The section:
```
from .routers import items, users
```
Means:
* Starting in the same package that this module (the file `app/main.py`) lives in (the directory `app/`)...
* look for the subpackage `routers` (the directory at `app/routers/`)...
* and from it, import the submodule `items` (the file at `app/routers/items.py`) and `users` (the file at `app/routers/users.py`)...
The module `items` will have a variable `router` (`items.router`). This is the same one we created in the file `app/routers/items.py`, it's an `APIRouter` object.
And then we do the same for the module `users`.
We could also import them like:
```
from app.routers import items, users
```
Info
The first version is a "relative import":
```
from .routers import items, users
```
The second version is an "absolute import":
```
from app.routers import items, users
```
To learn more about Python Packages and Modules, read [the official Python documentation about Modules](https://docs.python.org/3/tutorial/modules.html).
### Avoid name collisions
We are importing the submodule `items` directly, instead of importing just its variable `router`.
This is because we also have another variable named `router` in the submodule `users`.
If we had imported one after the other, like:
```
from .routers.items import router
from .routers.users import router
```
The `router` from `users` would overwrite the one from `items` and we wouldn't be able to use them at the same time.
So, to be able to use both of them in the same file, we import the submodules directly:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
### Include the `APIRouter`s for `users` and `items`
Now, let's include the `router`s from the submodules `users` and `items`:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
Info
`users.router` contains the `APIRouter` inside of the file `app/routers/users.py`.
And `items.router` contains the `APIRouter` inside of the file `app/routers/items.py`.
With `app.include_router()` we can add each `APIRouter` to the main `FastAPI` application.
It will include all the routes from that router as part of it.
Technical Details
It will actually internally create a *path operation* for each *path operation* that was declared in the `APIRouter`.
So, behind the scenes, it will actually work as if everything was the same single app.
Check
You don't have to worry about performance when including routers.
This will take microseconds and will only happen at startup.
So it won't affect performance. ⚡
### Include an `APIRouter` with a custom `prefix`, `tags`, `responses`, and `dependencies`
Now, let's imagine your organization gave you the `app/internal/admin.py` file.
It contains an `APIRouter` with some admin *path operations* that your organization shares between several projects.
For this example it will be super simple. But let's say that because it is shared with other projects in the organization, we cannot modify it and add a `prefix`, `dependencies`, `tags`, etc. directly to the `APIRouter`:
```
from fastapi import APIRouter
router = APIRouter()
@router.post("/")
async def update_admin():
return {"message": "Admin getting schwifty"}
```
But we still want to set a custom `prefix` when including the `APIRouter` so that all its *path operations* start with `/admin`, we want to secure it with the `dependencies` we already have for this project, and we want to include `tags` and `responses`.
We can declare all that without having to modify the original `APIRouter` by passing those parameters to `app.include_router()`:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
That way, the original `APIRouter` will keep unmodified, so we can still share that same `app/internal/admin.py` file with other projects in the organization.
The result is that in our app, each of the *path operations* from the `admin` module will have:
* The prefix `/admin`.
* The tag `admin`.
* The dependency `get_token_header`.
* The response `418`. 🍵
But that will only affect that `APIRouter` in our app, not in any other code that uses it.
So, for example, other projects could use the same `APIRouter` with a different authentication method.
### Include a *path operation*
We can also add *path operations* directly to the `FastAPI` app.
Here we do it... just to show that we can 🤷:
```
from fastapi import Depends, FastAPI
from .dependencies import get_query_token, get_token_header
from .internal import admin
from .routers import items, users
app = FastAPI(dependencies=[Depends(get_query_token)])
app.include_router(users.router)
app.include_router(items.router)
app.include_router(
admin.router,
prefix="/admin",
tags=["admin"],
dependencies=[Depends(get_token_header)],
responses={418: {"description": "I'm a teapot"}},
)
@app.get("/")
async def root():
return {"message": "Hello Bigger Applications!"}
```
and it will work correctly, together with all the other *path operations* added with `app.include_router()`.
Very Technical Details
**Note**: this is a very technical detail that you probably can **just skip**.
---
The `APIRouter`s are not "mounted", they are not isolated from the rest of the application.
This is because we want to include their *path operations* in the OpenAPI schema and the user interfaces.
As we cannot just isolate them and "mount" them independently of the rest, the *path operations* are "cloned" (re-created), not included directly.
Check the automatic API docs
----------------------------
Now, run `uvicorn`, using the module `app.main` and the variable `app`:
```
$ uvicorn app.main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And open the docs at <http://127.0.0.1:8000/docs>.
You will see the automatic API docs, including the paths from all the submodules, using the correct paths (and prefixes) and the correct tags:
Include the same router multiple times with different `prefix`
--------------------------------------------------------------
You can also use `.include_router()` multiple times with the *same* router using different prefixes.
This could be useful, for example, to expose the same API under different prefixes, e.g. `/api/v1` and `/api/latest`.
This is an advanced usage that you might not really need, but it's there in case you do.
Include an `APIRouter` in another
---------------------------------
The same way you can include an `APIRouter` in a `FastAPI` application, you can include an `APIRouter` in another `APIRouter` using:
```
router.include_router(other_router)
```
Make sure you do it before including `router` in the `FastAPI` app, so that the *path operations* from `other_router` are also included.
| programming_docs |
fastapi Background Tasks Background Tasks
================
You can define background tasks to be run *after* returning a response.
This is useful for operations that need to happen after a request, but that the client doesn't really have to be waiting for the operation to complete before receiving the response.
This includes, for example:
* Email notifications sent after performing an action:
+ As connecting to an email server and sending an email tends to be "slow" (several seconds), you can return the response right away and send the email notification in the background.
* Processing data:
+ For example, let's say you receive a file that must go through a slow process, you can return a response of "Accepted" (HTTP 202) and process it in the background.
Using `BackgroundTasks`
-----------------------
First, import `BackgroundTasks` and define a parameter in your *path operation function* with a type declaration of `BackgroundTasks`:
```
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
def write_notification(email: str, message=""):
with open("log.txt", mode="w") as email_file:
content = f"notification for {email}: {message}"
email_file.write(content)
@app.post("/send-notification/{email}")
async def send_notification(email: str, background_tasks: BackgroundTasks):
background_tasks.add_task(write_notification, email, message="some notification")
return {"message": "Notification sent in the background"}
```
**FastAPI** will create the object of type `BackgroundTasks` for you and pass it as that parameter.
Create a task function
----------------------
Create a function to be run as the background task.
It is just a standard function that can receive parameters.
It can be an `async def` or normal `def` function, **FastAPI** will know how to handle it correctly.
In this case, the task function will write to a file (simulating sending an email).
And as the write operation doesn't use `async` and `await`, we define the function with normal `def`:
```
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
def write_notification(email: str, message=""):
with open("log.txt", mode="w") as email_file:
content = f"notification for {email}: {message}"
email_file.write(content)
@app.post("/send-notification/{email}")
async def send_notification(email: str, background_tasks: BackgroundTasks):
background_tasks.add_task(write_notification, email, message="some notification")
return {"message": "Notification sent in the background"}
```
Add the background task
-----------------------
Inside of your *path operation function*, pass your task function to the *background tasks* object with the method `.add_task()`:
```
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
def write_notification(email: str, message=""):
with open("log.txt", mode="w") as email_file:
content = f"notification for {email}: {message}"
email_file.write(content)
@app.post("/send-notification/{email}")
async def send_notification(email: str, background_tasks: BackgroundTasks):
background_tasks.add_task(write_notification, email, message="some notification")
return {"message": "Notification sent in the background"}
```
`.add_task()` receives as arguments:
* A task function to be run in the background (`write_notification`).
* Any sequence of arguments that should be passed to the task function in order (`email`).
* Any keyword arguments that should be passed to the task function (`message="some notification"`).
Dependency Injection
--------------------
Using `BackgroundTasks` also works with the dependency injection system, you can declare a parameter of type `BackgroundTasks` at multiple levels: in a *path operation function*, in a dependency (dependable), in a sub-dependency, etc.
**FastAPI** knows what to do in each case and how to re-use the same object, so that all the background tasks are merged together and are run in the background afterwards:
Python 3.10+
```
from typing import Annotated
from fastapi import BackgroundTasks, Depends, FastAPI
app = FastAPI()
def write_log(message: str):
with open("log.txt", mode="a") as log:
log.write(message)
def get_query(background_tasks: BackgroundTasks, q: str | None = None):
if q:
message = f"found query: {q}\n"
background_tasks.add_task(write_log, message)
return q
@app.post("/send-notification/{email}")
async def send_notification(
email: str, background_tasks: BackgroundTasks, q: Annotated[str, Depends(get_query)]
):
message = f"message to {email}\n"
background_tasks.add_task(write_log, message)
return {"message": "Message sent"}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import BackgroundTasks, Depends, FastAPI
app = FastAPI()
def write_log(message: str):
with open("log.txt", mode="a") as log:
log.write(message)
def get_query(background_tasks: BackgroundTasks, q: Union[str, None] = None):
if q:
message = f"found query: {q}\n"
background_tasks.add_task(write_log, message)
return q
@app.post("/send-notification/{email}")
async def send_notification(
email: str, background_tasks: BackgroundTasks, q: Annotated[str, Depends(get_query)]
):
message = f"message to {email}\n"
background_tasks.add_task(write_log, message)
return {"message": "Message sent"}
```
Python 3.6+
```
from typing import Union
from fastapi import BackgroundTasks, Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
def write_log(message: str):
with open("log.txt", mode="a") as log:
log.write(message)
def get_query(background_tasks: BackgroundTasks, q: Union[str, None] = None):
if q:
message = f"found query: {q}\n"
background_tasks.add_task(write_log, message)
return q
@app.post("/send-notification/{email}")
async def send_notification(
email: str, background_tasks: BackgroundTasks, q: Annotated[str, Depends(get_query)]
):
message = f"message to {email}\n"
background_tasks.add_task(write_log, message)
return {"message": "Message sent"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import BackgroundTasks, Depends, FastAPI
app = FastAPI()
def write_log(message: str):
with open("log.txt", mode="a") as log:
log.write(message)
def get_query(background_tasks: BackgroundTasks, q: str | None = None):
if q:
message = f"found query: {q}\n"
background_tasks.add_task(write_log, message)
return q
@app.post("/send-notification/{email}")
async def send_notification(
email: str, background_tasks: BackgroundTasks, q: str = Depends(get_query)
):
message = f"message to {email}\n"
background_tasks.add_task(write_log, message)
return {"message": "Message sent"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import BackgroundTasks, Depends, FastAPI
app = FastAPI()
def write_log(message: str):
with open("log.txt", mode="a") as log:
log.write(message)
def get_query(background_tasks: BackgroundTasks, q: Union[str, None] = None):
if q:
message = f"found query: {q}\n"
background_tasks.add_task(write_log, message)
return q
@app.post("/send-notification/{email}")
async def send_notification(
email: str, background_tasks: BackgroundTasks, q: str = Depends(get_query)
):
message = f"message to {email}\n"
background_tasks.add_task(write_log, message)
return {"message": "Message sent"}
```
In this example, the messages will be written to the `log.txt` file *after* the response is sent.
If there was a query in the request, it will be written to the log in a background task.
And then another background task generated at the *path operation function* will write a message using the `email` path parameter.
Technical Details
-----------------
The class `BackgroundTasks` comes directly from [`starlette.background`](https://www.starlette.io/background/).
It is imported/included directly into FastAPI so that you can import it from `fastapi` and avoid accidentally importing the alternative `BackgroundTask` (without the `s` at the end) from `starlette.background`.
By only using `BackgroundTasks` (and not `BackgroundTask`), it's then possible to use it as a *path operation function* parameter and have **FastAPI** handle the rest for you, just like when using the `Request` object directly.
It's still possible to use `BackgroundTask` alone in FastAPI, but you have to create the object in your code and return a Starlette `Response` including it.
You can see more details in [Starlette's official docs for Background Tasks](https://www.starlette.io/background/).
Caveat
------
If you need to perform heavy background computation and you don't necessarily need it to be run by the same process (for example, you don't need to share memory, variables, etc), you might benefit from using other bigger tools like [Celery](https://docs.celeryq.dev).
They tend to require more complex configurations, a message/job queue manager, like RabbitMQ or Redis, but they allow you to run background tasks in multiple processes, and especially, in multiple servers.
To see an example, check the [Project Generators](../../project-generation/index), they all include Celery already configured.
But if you need to access variables and objects from the same **FastAPI** app, or you need to perform small background tasks (like sending an email notification), you can simply just use `BackgroundTasks`.
Recap
-----
Import and use `BackgroundTasks` with parameters in *path operation functions* and dependencies to add background tasks.
fastapi Body - Multiple Parameters Body - Multiple Parameters
==========================
Now that we have seen how to use `Path` and `Query`, let's see more advanced uses of request body declarations.
Mix `Path`, `Query` and body parameters
---------------------------------------
First, of course, you can mix `Path`, `Query` and request body parameter declarations freely and **FastAPI** will know what to do.
And you can also declare body parameters as optional, by setting the default to `None`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Path
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
item_id: Annotated[int, Path(title="The ID of the item to get", ge=0, le=1000)],
q: str | None = None,
item: Item | None = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
if item:
results.update({"item": item})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Path
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: Annotated[int, Path(title="The ID of the item to get", ge=0, le=1000)],
q: Union[str, None] = None,
item: Union[Item, None] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
if item:
results.update({"item": item})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Path
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: Annotated[int, Path(title="The ID of the item to get", ge=0, le=1000)],
q: Union[str, None] = None,
item: Union[Item, None] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
if item:
results.update({"item": item})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int = Path(title="The ID of the item to get", ge=0, le=1000),
q: str | None = None,
item: Item | None = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
if item:
results.update({"item": item})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Path
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int = Path(title="The ID of the item to get", ge=0, le=1000),
q: Union[str, None] = None,
item: Union[Item, None] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
if item:
results.update({"item": item})
return results
```
Note
Notice that, in this case, the `item` that would be taken from the body is optional. As it has a `None` default value.
Multiple body parameters
------------------------
In the previous example, the *path operations* would expect a JSON body with the attributes of an `Item`, like:
```
{
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2
}
```
But you can also declare multiple body parameters, e.g. `item` and `user`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class User(BaseModel):
username: str
full_name: str | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item, user: User):
results = {"item_id": item_id, "item": item, "user": user}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item, user: User):
results = {"item_id": item_id, "item": item, "user": user}
return results
```
In this case, **FastAPI** will notice that there are more than one body parameters in the function (two parameters that are Pydantic models).
So, it will then use the parameter names as keys (field names) in the body, and expect a body like:
```
{
"item": {
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2
},
"user": {
"username": "dave",
"full_name": "Dave Grohl"
}
}
```
Note
Notice that even though the `item` was declared the same way as before, it is now expected to be inside of the body with a key `item`.
**FastAPI** will do the automatic conversion from the request, so that the parameter `item` receives it's specific content and the same for `user`.
It will perform the validation of the compound data, and will document it like that for the OpenAPI schema and automatic docs.
Singular values in body
-----------------------
The same way there is a `Query` and `Path` to define extra data for query and path parameters, **FastAPI** provides an equivalent `Body`.
For example, extending the previous model, you could decide that you want to have another key `importance` in the same body, besides the `item` and `user`.
If you declare it as is, because it is a singular value, **FastAPI** will assume that it is a query parameter.
But you can instruct **FastAPI** to treat it as another body key using `Body`:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class User(BaseModel):
username: str
full_name: str | None = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int, item: Item, user: User, importance: Annotated[int, Body()]
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int, item: Item, user: User, importance: Annotated[int, Body()]
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int, item: Item, user: User, importance: Annotated[int, Body()]
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class User(BaseModel):
username: str
full_name: str | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item, user: User, importance: int = Body()):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item, user: User, importance: int = Body()):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
return results
```
In this case, **FastAPI** will expect a body like:
```
{
"item": {
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2
},
"user": {
"username": "dave",
"full_name": "Dave Grohl"
},
"importance": 5
}
```
Again, it will convert the data types, validate, document, etc.
Multiple body params and query
------------------------------
Of course, you can also declare additional query parameters whenever you need, additional to any body parameters.
As, by default, singular values are interpreted as query parameters, you don't have to explicitly add a `Query`, you can just do:
```
q: Union[str, None] = None
```
Or in Python 3.10 and above:
```
q: str | None = None
```
For example:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class User(BaseModel):
username: str
full_name: str | None = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item,
user: User,
importance: Annotated[int, Body(gt=0)],
q: str | None = None,
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item,
user: User,
importance: Annotated[int, Body(gt=0)],
q: Union[str, None] = None,
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item,
user: User,
importance: Annotated[int, Body(gt=0)],
q: Union[str, None] = None,
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class User(BaseModel):
username: str
full_name: str | None = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item,
user: User,
importance: int = Body(gt=0),
q: str | None = None,
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class User(BaseModel):
username: str
full_name: Union[str, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item,
user: User,
importance: int = Body(gt=0),
q: Union[str, None] = None,
):
results = {"item_id": item_id, "item": item, "user": user, "importance": importance}
if q:
results.update({"q": q})
return results
```
Info
`Body` also has all the same extra validation and metadata parameters as `Query`,`Path` and others you will see later.
Embed a single body parameter
-----------------------------
Let's say you only have a single `item` body parameter from a Pydantic model `Item`.
By default, **FastAPI** will then expect its body directly.
But if you want it to expect a JSON with a key `item` and inside of it the model contents, as it does when you declare extra body parameters, you can use the special `Body` parameter `embed`:
```
item: Item = Body(embed=True)
```
as in:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
In this case **FastAPI** will expect a body like:
```
{
"item": {
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2
}
}
```
instead of:
```
{
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2
}
```
Recap
-----
You can add multiple body parameters to your *path operation function*, even though a request can only have a single body.
But **FastAPI** will handle it, give you the correct data in your function, and validate and document the correct schema in the *path operation*.
You can also declare singular values to be received as part of the body.
And you can instruct **FastAPI** to embed the body in a key even when there is only a single parameter declared.
| programming_docs |
fastapi Cookie Parameters Cookie Parameters
=================
You can define Cookie parameters the same way you define `Query` and `Path` parameters.
Import `Cookie`
---------------
First import `Cookie`:
Python 3.10+
```
from typing import Annotated
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[str | None, Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[Union[str, None], Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.6+
```
from typing import Union
from fastapi import Cookie, FastAPI
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[Union[str, None], Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: str | None = Cookie(default=None)):
return {"ads_id": ads_id}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Union[str, None] = Cookie(default=None)):
return {"ads_id": ads_id}
```
Declare `Cookie` parameters
---------------------------
Then declare the cookie parameters using the same structure as with `Path` and `Query`.
The first value is the default value, you can pass all the extra validation or annotation parameters:
Python 3.10+
```
from typing import Annotated
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[str | None, Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[Union[str, None], Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.6+
```
from typing import Union
from fastapi import Cookie, FastAPI
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Annotated[Union[str, None], Cookie()] = None):
return {"ads_id": ads_id}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: str | None = Cookie(default=None)):
return {"ads_id": ads_id}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Cookie, FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(ads_id: Union[str, None] = Cookie(default=None)):
return {"ads_id": ads_id}
```
Technical Details
`Cookie` is a "sister" class of `Path` and `Query`. It also inherits from the same common `Param` class.
But remember that when you import `Query`, `Path`, `Cookie` and others from `fastapi`, those are actually functions that return special classes.
Info
To declare cookies, you need to use `Cookie`, because otherwise the parameters would be interpreted as query parameters.
Recap
-----
Declare cookies with `Cookie`, using the same common pattern as `Query` and `Path`.
fastapi Extra Data Types Extra Data Types
================
Up to now, you have been using common data types, like:
* `int`
* `float`
* `str`
* `bool`
But you can also use more complex data types.
And you will still have the same features as seen up to now:
* Great editor support.
* Data conversion from incoming requests.
* Data conversion for response data.
* Data validation.
* Automatic annotation and documentation.
Other data types
----------------
Here are some of the additional data types you can use:
* `UUID`:
+ A standard "Universally Unique Identifier", common as an ID in many databases and systems.
+ In requests and responses will be represented as a `str`.
* `datetime.datetime`:
+ A Python `datetime.datetime`.
+ In requests and responses will be represented as a `str` in ISO 8601 format, like: `2008-09-15T15:53:00+05:00`.
* `datetime.date`:
+ Python `datetime.date`.
+ In requests and responses will be represented as a `str` in ISO 8601 format, like: `2008-09-15`.
* `datetime.time`:
+ A Python `datetime.time`.
+ In requests and responses will be represented as a `str` in ISO 8601 format, like: `14:23:55.003`.
* `datetime.timedelta`:
+ A Python `datetime.timedelta`.
+ In requests and responses will be represented as a `float` of total seconds.
+ Pydantic also allows representing it as a "ISO 8601 time diff encoding", [see the docs for more info](https://pydantic-docs.helpmanual.io/usage/exporting_models/#json_encoders).
* `frozenset`:
+ In requests and responses, treated the same as a `set`:
- In requests, a list will be read, eliminating duplicates and converting it to a `set`.
- In responses, the `set` will be converted to a `list`.
- The generated schema will specify that the `set` values are unique (using JSON Schema's `uniqueItems`).
* `bytes`:
+ Standard Python `bytes`.
+ In requests and responses will be treated as `str`.
+ The generated schema will specify that it's a `str` with `binary` "format".
* `Decimal`:
+ Standard Python `Decimal`.
+ In requests and responses, handled the same as a `float`.
* You can check all the valid pydantic data types here: [Pydantic data types](https://pydantic-docs.helpmanual.io/usage/types).
Example
-------
Here's an example *path operation* with parameters using some of the above types.
Python 3.10+
```
from datetime import datetime, time, timedelta
from typing import Annotated
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[datetime | None, Body()] = None,
end_datetime: Annotated[datetime | None, Body()] = None,
repeat_at: Annotated[time | None, Body()] = None,
process_after: Annotated[timedelta | None, Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.9+
```
from datetime import datetime, time, timedelta
from typing import Annotated, Union
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[Union[datetime, None], Body()] = None,
end_datetime: Annotated[Union[datetime, None], Body()] = None,
repeat_at: Annotated[Union[time, None], Body()] = None,
process_after: Annotated[Union[timedelta, None], Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.6+
```
from datetime import datetime, time, timedelta
from typing import Union
from uuid import UUID
from fastapi import Body, FastAPI
from typing_extensions import Annotated
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[Union[datetime, None], Body()] = None,
end_datetime: Annotated[Union[datetime, None], Body()] = None,
repeat_at: Annotated[Union[time, None], Body()] = None,
process_after: Annotated[Union[timedelta, None], Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, time, timedelta
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: datetime | None = Body(default=None),
end_datetime: datetime | None = Body(default=None),
repeat_at: time | None = Body(default=None),
process_after: timedelta | None = Body(default=None),
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, time, timedelta
from typing import Union
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Union[datetime, None] = Body(default=None),
end_datetime: Union[datetime, None] = Body(default=None),
repeat_at: Union[time, None] = Body(default=None),
process_after: Union[timedelta, None] = Body(default=None),
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Note that the parameters inside the function have their natural data type, and you can, for example, perform normal date manipulations, like:
Python 3.10+
```
from datetime import datetime, time, timedelta
from typing import Annotated
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[datetime | None, Body()] = None,
end_datetime: Annotated[datetime | None, Body()] = None,
repeat_at: Annotated[time | None, Body()] = None,
process_after: Annotated[timedelta | None, Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.9+
```
from datetime import datetime, time, timedelta
from typing import Annotated, Union
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[Union[datetime, None], Body()] = None,
end_datetime: Annotated[Union[datetime, None], Body()] = None,
repeat_at: Annotated[Union[time, None], Body()] = None,
process_after: Annotated[Union[timedelta, None], Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.6+
```
from datetime import datetime, time, timedelta
from typing import Union
from uuid import UUID
from fastapi import Body, FastAPI
from typing_extensions import Annotated
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Annotated[Union[datetime, None], Body()] = None,
end_datetime: Annotated[Union[datetime, None], Body()] = None,
repeat_at: Annotated[Union[time, None], Body()] = None,
process_after: Annotated[Union[timedelta, None], Body()] = None,
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, time, timedelta
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: datetime | None = Body(default=None),
end_datetime: datetime | None = Body(default=None),
repeat_at: time | None = Body(default=None),
process_after: timedelta | None = Body(default=None),
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, time, timedelta
from typing import Union
from uuid import UUID
from fastapi import Body, FastAPI
app = FastAPI()
@app.put("/items/{item_id}")
async def read_items(
item_id: UUID,
start_datetime: Union[datetime, None] = Body(default=None),
end_datetime: Union[datetime, None] = Body(default=None),
repeat_at: Union[time, None] = Body(default=None),
process_after: Union[timedelta, None] = Body(default=None),
):
start_process = start_datetime + process_after
duration = end_datetime - start_process
return {
"item_id": item_id,
"start_datetime": start_datetime,
"end_datetime": end_datetime,
"repeat_at": repeat_at,
"process_after": process_after,
"start_process": start_process,
"duration": duration,
}
```
fastapi Query Parameters Query Parameters
================
When you declare other function parameters that are not part of the path parameters, they are automatically interpreted as "query" parameters.
```
from fastapi import FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
@app.get("/items/")
async def read_item(skip: int = 0, limit: int = 10):
return fake_items_db[skip : skip + limit]
```
The query is the set of key-value pairs that go after the `?` in a URL, separated by `&` characters.
For example, in the URL:
```
http://127.0.0.1:8000/items/?skip=0&limit=10
```
...the query parameters are:
* `skip`: with a value of `0`
* `limit`: with a value of `10`
As they are part of the URL, they are "naturally" strings.
But when you declare them with Python types (in the example above, as `int`), they are converted to that type and validated against it.
All the same process that applied for path parameters also applies for query parameters:
* Editor support (obviously)
* Data "parsing"
* Data validation
* Automatic documentation
Defaults
--------
As query parameters are not a fixed part of a path, they can be optional and can have default values.
In the example above they have default values of `skip=0` and `limit=10`.
So, going to the URL:
```
http://127.0.0.1:8000/items/
```
would be the same as going to:
```
http://127.0.0.1:8000/items/?skip=0&limit=10
```
But if you go to, for example:
```
http://127.0.0.1:8000/items/?skip=20
```
The parameter values in your function will be:
* `skip=20`: because you set it in the URL
* `limit=10`: because that was the default value
Optional parameters
-------------------
The same way, you can declare optional query parameters, by setting their default to `None`:
Python 3.10+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: str | None = None):
if q:
return {"item_id": item_id, "q": q}
return {"item_id": item_id}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: Union[str, None] = None):
if q:
return {"item_id": item_id, "q": q}
return {"item_id": item_id}
```
In this case, the function parameter `q` will be optional, and will be `None` by default.
Check
Also notice that **FastAPI** is smart enough to notice that the path parameter `item_id` is a path parameter and `q` is not, so, it's a query parameter.
Query parameter type conversion
-------------------------------
You can also declare `bool` types, and they will be converted:
Python 3.10+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: str | None = None, short: bool = False):
item = {"item_id": item_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: str, q: Union[str, None] = None, short: bool = False):
item = {"item_id": item_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
```
In this case, if you go to:
```
http://127.0.0.1:8000/items/foo?short=1
```
or
```
http://127.0.0.1:8000/items/foo?short=True
```
or
```
http://127.0.0.1:8000/items/foo?short=true
```
or
```
http://127.0.0.1:8000/items/foo?short=on
```
or
```
http://127.0.0.1:8000/items/foo?short=yes
```
or any other case variation (uppercase, first letter in uppercase, etc), your function will see the parameter `short` with a `bool` value of `True`. Otherwise as `False`.
Multiple path and query parameters
----------------------------------
You can declare multiple path parameters and query parameters at the same time, **FastAPI** knows which is which.
And you don't have to declare them in any specific order.
They will be detected by name:
Python 3.10+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/users/{user_id}/items/{item_id}")
async def read_user_item(
user_id: int, item_id: str, q: str | None = None, short: bool = False
):
item = {"item_id": item_id, "owner_id": user_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/users/{user_id}/items/{item_id}")
async def read_user_item(
user_id: int, item_id: str, q: Union[str, None] = None, short: bool = False
):
item = {"item_id": item_id, "owner_id": user_id}
if q:
item.update({"q": q})
if not short:
item.update(
{"description": "This is an amazing item that has a long description"}
)
return item
```
Required query parameters
-------------------------
When you declare a default value for non-path parameters (for now, we have only seen query parameters), then it is not required.
If you don't want to add a specific value but just make it optional, set the default as `None`.
But when you want to make a query parameter required, you can just not declare any default value:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_user_item(item_id: str, needy: str):
item = {"item_id": item_id, "needy": needy}
return item
```
Here the query parameter `needy` is a required query parameter of type `str`.
If you open in your browser a URL like:
```
http://127.0.0.1:8000/items/foo-item
```
...without adding the required parameter `needy`, you will see an error like:
```
{
"detail": [
{
"loc": [
"query",
"needy"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
```
As `needy` is a required parameter, you would need to set it in the URL:
```
http://127.0.0.1:8000/items/foo-item?needy=sooooneedy
```
...this would work:
```
{
"item_id": "foo-item",
"needy": "sooooneedy"
}
```
And of course, you can define some parameters as required, some as having a default value, and some entirely optional:
Python 3.10+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_user_item(
item_id: str, needy: str, skip: int = 0, limit: int | None = None
):
item = {"item_id": item_id, "needy": needy, "skip": skip, "limit": limit}
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_user_item(
item_id: str, needy: str, skip: int = 0, limit: Union[int, None] = None
):
item = {"item_id": item_id, "needy": needy, "skip": skip, "limit": limit}
return item
```
In this case, there are 3 query parameters:
* `needy`, a required `str`.
* `skip`, an `int` with a default value of `0`.
* `limit`, an optional `int`.
Tip
You could also use `Enum`s the same way as with [Path Parameters](../path-params/index#predefined-values).
| programming_docs |
fastapi Handling Errors Handling Errors
===============
There are many situations in where you need to notify an error to a client that is using your API.
This client could be a browser with a frontend, a code from someone else, an IoT device, etc.
You could need to tell the client that:
* The client doesn't have enough privileges for that operation.
* The client doesn't have access to that resource.
* The item the client was trying to access doesn't exist.
* etc.
In these cases, you would normally return an **HTTP status code** in the range of **400** (from 400 to 499).
This is similar to the 200 HTTP status codes (from 200 to 299). Those "200" status codes mean that somehow there was a "success" in the request.
The status codes in the 400 range mean that there was an error from the client.
Remember all those **"404 Not Found"** errors (and jokes)?
Use `HTTPException`
-------------------
To return HTTP responses with errors to the client you use `HTTPException`.
### Import `HTTPException`
```
from fastapi import FastAPI, HTTPException
app = FastAPI()
items = {"foo": "The Foo Wrestlers"}
@app.get("/items/{item_id}")
async def read_item(item_id: str):
if item_id not in items:
raise HTTPException(status_code=404, detail="Item not found")
return {"item": items[item_id]}
```
### Raise an `HTTPException` in your code
`HTTPException` is a normal Python exception with additional data relevant for APIs.
Because it's a Python exception, you don't `return` it, you `raise` it.
This also means that if you are inside a utility function that you are calling inside of your *path operation function*, and you raise the `HTTPException` from inside of that utility function, it won't run the rest of the code in the *path operation function*, it will terminate that request right away and send the HTTP error from the `HTTPException` to the client.
The benefit of raising an exception over `return`ing a value will be more evident in the section about Dependencies and Security.
In this example, when the client requests an item by an ID that doesn't exist, raise an exception with a status code of `404`:
```
from fastapi import FastAPI, HTTPException
app = FastAPI()
items = {"foo": "The Foo Wrestlers"}
@app.get("/items/{item_id}")
async def read_item(item_id: str):
if item_id not in items:
raise HTTPException(status_code=404, detail="Item not found")
return {"item": items[item_id]}
```
### The resulting response
If the client requests `http://example.com/items/foo` (an `item_id` `"foo"`), that client will receive an HTTP status code of 200, and a JSON response of:
```
{
"item": "The Foo Wrestlers"
}
```
But if the client requests `http://example.com/items/bar` (a non-existent `item_id` `"bar"`), that client will receive an HTTP status code of 404 (the "not found" error), and a JSON response of:
```
{
"detail": "Item not found"
}
```
Tip
When raising an `HTTPException`, you can pass any value that can be converted to JSON as the parameter `detail`, not only `str`.
You could pass a `dict`, a `list`, etc.
They are handled automatically by **FastAPI** and converted to JSON.
Add custom headers
------------------
There are some situations in where it's useful to be able to add custom headers to the HTTP error. For example, for some types of security.
You probably won't need to use it directly in your code.
But in case you needed it for an advanced scenario, you can add custom headers:
```
from fastapi import FastAPI, HTTPException
app = FastAPI()
items = {"foo": "The Foo Wrestlers"}
@app.get("/items-header/{item_id}")
async def read_item_header(item_id: str):
if item_id not in items:
raise HTTPException(
status_code=404,
detail="Item not found",
headers={"X-Error": "There goes my error"},
)
return {"item": items[item_id]}
```
Install custom exception handlers
---------------------------------
You can add custom exception handlers with [the same exception utilities from Starlette](https://www.starlette.io/exceptions/).
Let's say you have a custom exception `UnicornException` that you (or a library you use) might `raise`.
And you want to handle this exception globally with FastAPI.
You could add a custom exception handler with `@app.exception_handler()`:
```
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
class UnicornException(Exception):
def __init__(self, name: str):
self.name = name
app = FastAPI()
@app.exception_handler(UnicornException)
async def unicorn_exception_handler(request: Request, exc: UnicornException):
return JSONResponse(
status_code=418,
content={"message": f"Oops! {exc.name} did something. There goes a rainbow..."},
)
@app.get("/unicorns/{name}")
async def read_unicorn(name: str):
if name == "yolo":
raise UnicornException(name=name)
return {"unicorn_name": name}
```
Here, if you request `/unicorns/yolo`, the *path operation* will `raise` a `UnicornException`.
But it will be handled by the `unicorn_exception_handler`.
So, you will receive a clean error, with an HTTP status code of `418` and a JSON content of:
```
{"message": "Oops! yolo did something. There goes a rainbow..."}
```
Technical Details
You could also use `from starlette.requests import Request` and `from starlette.responses import JSONResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette. The same with `Request`.
Override the default exception handlers
---------------------------------------
**FastAPI** has some default exception handlers.
These handlers are in charge of returning the default JSON responses when you `raise` an `HTTPException` and when the request has invalid data.
You can override these exception handlers with your own.
### Override request validation exceptions
When a request contains invalid data, **FastAPI** internally raises a `RequestValidationError`.
And it also includes a default exception handler for it.
To override it, import the `RequestValidationError` and use it with `@app.exception_handler(RequestValidationError)` to decorate the exception handler.
The exception handler will receive a `Request` and the exception.
```
from fastapi import FastAPI, HTTPException
from fastapi.exceptions import RequestValidationError
from fastapi.responses import PlainTextResponse
from starlette.exceptions import HTTPException as StarletteHTTPException
app = FastAPI()
@app.exception_handler(StarletteHTTPException)
async def http_exception_handler(request, exc):
return PlainTextResponse(str(exc.detail), status_code=exc.status_code)
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request, exc):
return PlainTextResponse(str(exc), status_code=400)
@app.get("/items/{item_id}")
async def read_item(item_id: int):
if item_id == 3:
raise HTTPException(status_code=418, detail="Nope! I don't like 3.")
return {"item_id": item_id}
```
Now, if you go to `/items/foo`, instead of getting the default JSON error with:
```
{
"detail": [
{
"loc": [
"path",
"item_id"
],
"msg": "value is not a valid integer",
"type": "type_error.integer"
}
]
}
```
you will get a text version, with:
```
1 validation error
path -> item_id
value is not a valid integer (type=type_error.integer)
```
####
`RequestValidationError` vs `ValidationError`
Warning
These are technical details that you might skip if it's not important for you now.
`RequestValidationError` is a sub-class of Pydantic's [`ValidationError`](https://pydantic-docs.helpmanual.io/usage/models/#error-handling).
**FastAPI** uses it so that, if you use a Pydantic model in `response_model`, and your data has an error, you will see the error in your log.
But the client/user will not see it. Instead, the client will receive an "Internal Server Error" with a HTTP status code `500`.
It should be this way because if you have a Pydantic `ValidationError` in your *response* or anywhere in your code (not in the client's *request*), it's actually a bug in your code.
And while you fix it, your clients/users shouldn't have access to internal information about the error, as that could expose a security vulnerability.
### Override the `HTTPException` error handler
The same way, you can override the `HTTPException` handler.
For example, you could want to return a plain text response instead of JSON for these errors:
```
from fastapi import FastAPI, HTTPException
from fastapi.exceptions import RequestValidationError
from fastapi.responses import PlainTextResponse
from starlette.exceptions import HTTPException as StarletteHTTPException
app = FastAPI()
@app.exception_handler(StarletteHTTPException)
async def http_exception_handler(request, exc):
return PlainTextResponse(str(exc.detail), status_code=exc.status_code)
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request, exc):
return PlainTextResponse(str(exc), status_code=400)
@app.get("/items/{item_id}")
async def read_item(item_id: int):
if item_id == 3:
raise HTTPException(status_code=418, detail="Nope! I don't like 3.")
return {"item_id": item_id}
```
Technical Details
You could also use `from starlette.responses import PlainTextResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
### Use the `RequestValidationError` body
The `RequestValidationError` contains the `body` it received with invalid data.
You could use it while developing your app to log the body and debug it, return it to the user, etc.
```
from fastapi import FastAPI, Request, status
from fastapi.encoders import jsonable_encoder
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
from pydantic import BaseModel
app = FastAPI()
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request: Request, exc: RequestValidationError):
return JSONResponse(
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
content=jsonable_encoder({"detail": exc.errors(), "body": exc.body}),
)
class Item(BaseModel):
title: str
size: int
@app.post("/items/")
async def create_item(item: Item):
return item
```
Now try sending an invalid item like:
```
{
"title": "towel",
"size": "XL"
}
```
You will receive a response telling you that the data is invalid containing the received body:
```
{
"detail": [
{
"loc": [
"body",
"size"
],
"msg": "value is not a valid integer",
"type": "type_error.integer"
}
],
"body": {
"title": "towel",
"size": "XL"
}
}
```
#### FastAPI's `HTTPException` vs Starlette's `HTTPException`
**FastAPI** has its own `HTTPException`.
And **FastAPI**'s `HTTPException` error class inherits from Starlette's `HTTPException` error class.
The only difference, is that **FastAPI**'s `HTTPException` allows you to add headers to be included in the response.
This is needed/used internally for OAuth 2.0 and some security utilities.
So, you can keep raising **FastAPI**'s `HTTPException` as normally in your code.
But when you register an exception handler, you should register it for Starlette's `HTTPException`.
This way, if any part of Starlette's internal code, or a Starlette extension or plug-in, raises a Starlette `HTTPException`, your handler will be able to catch and handle it.
In this example, to be able to have both `HTTPException`s in the same code, Starlette's exceptions is renamed to `StarletteHTTPException`:
```
from starlette.exceptions import HTTPException as StarletteHTTPException
```
### Re-use **FastAPI**'s exception handlers
If you want to use the exception along with the same default exception handlers from **FastAPI**, You can import and re-use the default exception handlers from `fastapi.exception_handlers`:
```
from fastapi import FastAPI, HTTPException
from fastapi.exception_handlers import (
http_exception_handler,
request_validation_exception_handler,
)
from fastapi.exceptions import RequestValidationError
from starlette.exceptions import HTTPException as StarletteHTTPException
app = FastAPI()
@app.exception_handler(StarletteHTTPException)
async def custom_http_exception_handler(request, exc):
print(f"OMG! An HTTP error!: {repr(exc)}")
return await http_exception_handler(request, exc)
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request, exc):
print(f"OMG! The client sent invalid data!: {exc}")
return await request_validation_exception_handler(request, exc)
@app.get("/items/{item_id}")
async def read_item(item_id: int):
if item_id == 3:
raise HTTPException(status_code=418, detail="Nope! I don't like 3.")
return {"item_id": item_id}
```
In this example you are just `print`ing the error with a very expressive message, but you get the idea. You can use the exception and then just re-use the default exception handlers.
fastapi Path Parameters and Numeric Validations Path Parameters and Numeric Validations
=======================================
In the same way that you can declare more validations and metadata for query parameters with `Query`, you can declare the same type of validations and metadata for path parameters with `Path`.
Import Path
-----------
First, import `Path` from `fastapi`, and import `Annotated`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[str | None, Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[Union[str, None], Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Path, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[Union[str, None], Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: int = Path(title="The ID of the item to get"),
q: str | None = Query(default=None, alias="item-query"),
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: int = Path(title="The ID of the item to get"),
q: Union[str, None] = Query(default=None, alias="item-query"),
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Declare metadata
----------------
You can declare all the same parameters as for `Query`.
For example, to declare a `title` metadata value for the path parameter `item_id` you can type:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[str | None, Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[Union[str, None], Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Path, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")],
q: Annotated[Union[str, None], Query(alias="item-query")] = None,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: int = Path(title="The ID of the item to get"),
q: str | None = Query(default=None, alias="item-query"),
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: int = Path(title="The ID of the item to get"),
q: Union[str, None] = Query(default=None, alias="item-query"),
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Note
A path parameter is always required as it has to be part of the path.
So, you should declare it with `...` to mark it as required.
Nevertheless, even if you declared it with `None` or set a default value, it would not affect anything, it would still be always required.
Order the parameters as you need
--------------------------------
Tip
This is probably not as important or necessary if you use `Annotated`.
Let's say that you want to declare the query parameter `q` as a required `str`.
And you don't need to declare anything else for that parameter, so you don't really need to use `Query`.
But you still need to use `Path` for the `item_id` path parameter. And you don't want to use `Annotated` for some reason.
Python will complain if you put a value with a "default" before a value that doesn't have a "default".
But you can re-order them, and have the value without a default (the query parameter `q`) first.
It doesn't matter for **FastAPI**. It will detect the parameters by their names, types and default declarations (`Query`, `Path`, etc), it doesn't care about the order.
So, you can declare your function as:
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(q: str, item_id: int = Path(title="The ID of the item to get")):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
But have in mind that if you use `Annotated`, you won't have this problem, it won't matter as you're not using the function parameter default values for `Query()` or `Path()`.
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
q: str, item_id: Annotated[int, Path(title="The ID of the item to get")]
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Path
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
q: str, item_id: Annotated[int, Path(title="The ID of the item to get")]
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Order the parameters as you need, tricks
----------------------------------------
Tip
This is probably not as important or necessary if you use `Annotated`.
Here's a **small trick** that can be handy, but you won't need it often.
If you want to:
* declare the `q` query parameter without a `Query` nor any default value
* declare the path parameter `item_id` using `Path`
* have them in a different order
* not use `Annotated`
...Python has a little special syntax for that.
Pass `*`, as the first parameter of the function.
Python won't do anything with that `*`, but it will know that all the following parameters should be called as keyword arguments (key-value pairs), also known as `kwargs`. Even if they don't have a default value.
```
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(*, item_id: int = Path(title="The ID of the item to get"), q: str):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
### Better with `Annotated`
Have in mind that if you use `Annotated`, as you are not using function parameter default values, you won't have this problem, and yo probably won't need to use `*`.
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")], q: str
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Path
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get")], q: str
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Number validations: greater than or equal
-----------------------------------------
With `Query` and `Path` (and others you'll see later) you can declare number constraints.
Here, with `ge=1`, `item_id` will need to be an integer number "`g`reater than or `e`qual" to `1`.
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get", ge=1)], q: str
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Path
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get", ge=1)], q: str
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
*, item_id: int = Path(title="The ID of the item to get", ge=1), q: str
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Number validations: greater than and less than or equal
-------------------------------------------------------
The same applies for:
* `gt`: `g`reater `t`han
* `le`: `l`ess than or `e`qual
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get", gt=0, le=1000)],
q: str,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Path
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
item_id: Annotated[int, Path(title="The ID of the item to get", gt=0, le=1000)],
q: str,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
*,
item_id: int = Path(title="The ID of the item to get", gt=0, le=1000),
q: str,
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Number validations: floats, greater than and less than
------------------------------------------------------
Number validations also work for `float` values.
Here's where it becomes important to be able to declare `gt` and not just `ge`. As with it you can require, for example, that a value must be greater than `0`, even if it is less than `1`.
So, `0.5` would be a valid value. But `0.0` or `0` would not.
And the same for `lt`.
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
*,
item_id: Annotated[int, Path(title="The ID of the item to get", ge=0, le=1000)],
q: str,
size: Annotated[float, Query(gt=0, lt=10.5)],
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Path, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
*,
item_id: Annotated[int, Path(title="The ID of the item to get", ge=0, le=1000)],
q: str,
size: Annotated[float, Query(gt=0, lt=10.5)],
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Path, Query
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
*,
item_id: int = Path(title="The ID of the item to get", ge=0, le=1000),
q: str,
size: float = Query(gt=0, lt=10.5),
):
results = {"item_id": item_id}
if q:
results.update({"q": q})
return results
```
Recap
-----
With `Query`, `Path` (and others you haven't seen yet) you can declare metadata and string validations in the same ways as with [Query Parameters and String Validations](../query-params-str-validations/index).
And you can also declare numeric validations:
* `gt`: `g`reater `t`han
* `ge`: `g`reater than or `e`qual
* `lt`: `l`ess `t`han
* `le`: `l`ess than or `e`qual
Info
`Query`, `Path`, and other classes you will see later are subclasses of a common `Param` class.
All of them share the same parameters for additional validation and metadata you have seen.
Technical Details
When you import `Query`, `Path` and others from `fastapi`, they are actually functions.
That when called, return instances of classes of the same name.
So, you import `Query`, which is a function. And when you call it, it returns an instance of a class also named `Query`.
These functions are there (instead of just using the classes directly) so that your editor doesn't mark errors about their types.
That way you can use your normal editor and coding tools without having to add custom configurations to disregard those errors.
| programming_docs |
fastapi Body - Updates Body - Updates
==============
Update replacing with `PUT`
---------------------------
To update an item you can use the [HTTP `PUT`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/PUT) operation.
You can use the `jsonable_encoder` to convert the input data to data that can be stored as JSON (e.g. with a NoSQL database). For example, converting `datetime` to `str`.
Python 3.10+
```
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str | None = None
description: str | None = None
price: float | None = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.put("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
update_item_encoded = jsonable_encoder(item)
items[item_id] = update_item_encoded
return update_item_encoded
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.put("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
update_item_encoded = jsonable_encoder(item)
items[item_id] = update_item_encoded
return update_item_encoded
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.put("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
update_item_encoded = jsonable_encoder(item)
items[item_id] = update_item_encoded
return update_item_encoded
```
`PUT` is used to receive data that should replace the existing data.
### Warning about replacing
That means that if you want to update the item `bar` using `PUT` with a body containing:
```
{
"name": "Barz",
"price": 3,
"description": None,
}
```
because it doesn't include the already stored attribute `"tax": 20.2`, the input model would take the default value of `"tax": 10.5`.
And the data would be saved with that "new" `tax` of `10.5`.
Partial updates with `PATCH`
----------------------------
You can also use the [HTTP `PATCH`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/PATCH) operation to *partially* update data.
This means that you can send only the data that you want to update, leaving the rest intact.
Note
`PATCH` is less commonly used and known than `PUT`.
And many teams use only `PUT`, even for partial updates.
You are **free** to use them however you want, **FastAPI** doesn't impose any restrictions.
But this guide shows you, more or less, how they are intended to be used.
### Using Pydantic's `exclude_unset` parameter
If you want to receive partial updates, it's very useful to use the parameter `exclude_unset` in Pydantic's model's `.dict()`.
Like `item.dict(exclude_unset=True)`.
That would generate a `dict` with only the data that was set when creating the `item` model, excluding default values.
Then you can use this to generate a `dict` with only the data that was set (sent in the request), omitting default values:
Python 3.10+
```
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str | None = None
description: str | None = None
price: float | None = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
### Using Pydantic's `update` parameter
Now, you can create a copy of the existing model using `.copy()`, and pass the `update` parameter with a `dict` containing the data to update.
Like `stored_item_model.copy(update=update_data)`:
Python 3.10+
```
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str | None = None
description: str | None = None
price: float | None = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
### Partial updates recap
In summary, to apply partial updates you would:
* (Optionally) use `PATCH` instead of `PUT`.
* Retrieve the stored data.
* Put that data in a Pydantic model.
* Generate a `dict` without default values from the input model (using `exclude_unset`).
+ This way you can update only the values actually set by the user, instead of overriding values already stored with default values in your model.
* Create a copy of the stored model, updating it's attributes with the received partial updates (using the `update` parameter).
* Convert the copied model to something that can be stored in your DB (for example, using the `jsonable_encoder`).
+ This is comparable to using the model's `.dict()` method again, but it makes sure (and converts) the values to data types that can be converted to JSON, for example, `datetime` to `str`.
* Save the data to your DB.
* Return the updated model.
Python 3.10+
```
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str | None = None
description: str | None = None
price: float | None = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: Union[str, None] = None
description: Union[str, None] = None
price: Union[float, None] = None
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item)
async def read_item(item_id: str):
return items[item_id]
@app.patch("/items/{item_id}", response_model=Item)
async def update_item(item_id: str, item: Item):
stored_item_data = items[item_id]
stored_item_model = Item(**stored_item_data)
update_data = item.dict(exclude_unset=True)
updated_item = stored_item_model.copy(update=update_data)
items[item_id] = jsonable_encoder(updated_item)
return updated_item
```
Tip
You can actually use this same technique with an HTTP `PUT` operation.
But the example here uses `PATCH` because it was created for these use cases.
Note
Notice that the input model is still validated.
So, if you want to receive partial updates that can omit all the attributes, you need to have a model with all the attributes marked as optional (with default values or `None`).
To distinguish from the models with all optional values for **updates** and models with required values for **creation**, you can use the ideas described in [Extra Models](../extra-models/index).
fastapi Security Intro Security Intro
==============
There are many ways to handle security, authentication and authorization.
And it normally is a complex and "difficult" topic.
In many frameworks and systems just handling security and authentication takes a big amount of effort and code (in many cases it can be 50% or more of all the code written).
**FastAPI** provides several tools to help you deal with **Security** easily, rapidly, in a standard way, without having to study and learn all the security specifications.
But first, let's check some small concepts.
In a hurry?
-----------
If you don't care about any of these terms and you just need to add security with authentication based on username and password *right now*, skip to the next chapters.
OAuth2
------
OAuth2 is a specification that defines several ways to handle authentication and authorization.
It is quite an extensive specification and covers several complex use cases.
It includes ways to authenticate using a "third party".
That's what all the systems with "login with Facebook, Google, Twitter, GitHub" use underneath.
### OAuth 1
There was an OAuth 1, which is very different from OAuth2, and more complex, as it included directly specifications on how to encrypt the communication.
It is not very popular or used nowadays.
OAuth2 doesn't specify how to encrypt the communication, it expects you to have your application served with HTTPS.
Tip
In the section about **deployment** you will see how to set up HTTPS for free, using Traefik and Let's Encrypt.
OpenID Connect
--------------
OpenID Connect is another specification, based on **OAuth2**.
It just extends OAuth2 specifying some things that are relatively ambiguous in OAuth2, to try to make it more interoperable.
For example, Google login uses OpenID Connect (which underneath uses OAuth2).
But Facebook login doesn't support OpenID Connect. It has its own flavor of OAuth2.
### OpenID (not "OpenID Connect")
There was also an "OpenID" specification. That tried to solve the same thing as **OpenID Connect**, but was not based on OAuth2.
So, it was a complete additional system.
It is not very popular or used nowadays.
OpenAPI
-------
OpenAPI (previously known as Swagger) is the open specification for building APIs (now part of the Linux Foundation).
**FastAPI** is based on **OpenAPI**.
That's what makes it possible to have multiple automatic interactive documentation interfaces, code generation, etc.
OpenAPI has a way to define multiple security "schemes".
By using them, you can take advantage of all these standard-based tools, including these interactive documentation systems.
OpenAPI defines the following security schemes:
* `apiKey`: an application specific key that can come from:
+ A query parameter.
+ A header.
+ A cookie.
* `http`: standard HTTP authentication systems, including:
+ `bearer`: a header `Authorization` with a value of `Bearer` plus a token. This is inherited from OAuth2.
+ HTTP Basic authentication.
+ HTTP Digest, etc.
* `oauth2`: all the OAuth2 ways to handle security (called "flows").
+ Several of these flows are appropriate for building an OAuth 2.0 authentication provider (like Google, Facebook, Twitter, GitHub, etc):
- `implicit`
- `clientCredentials`
- `authorizationCode`
+ But there is one specific "flow" that can be perfectly used for handling authentication in the same application directly:
- `password`: some next chapters will cover examples of this.
* `openIdConnect`: has a way to define how to discover OAuth2 authentication data automatically.
+ This automatic discovery is what is defined in the OpenID Connect specification.
Tip
Integrating other authentication/authorization providers like Google, Facebook, Twitter, GitHub, etc. is also possible and relatively easy.
The most complex problem is building an authentication/authorization provider like those, but **FastAPI** gives you the tools to do it easily, while doing the heavy lifting for you.
**FastAPI** utilities
----------------------
FastAPI provides several tools for each of these security schemes in the `fastapi.security` module that simplify using these security mechanisms.
In the next chapters you will see how to add security to your API using those tools provided by **FastAPI**.
And you will also see how it gets automatically integrated into the interactive documentation system.
| programming_docs |
fastapi OAuth2 with Password (and hashing), Bearer with JWT tokens OAuth2 with Password (and hashing), Bearer with JWT tokens
==========================================================
Now that we have all the security flow, let's make the application actually secure, using JWT tokens and secure password hashing.
This code is something you can actually use in your application, save the password hashes in your database, etc.
We are going to start from where we left in the previous chapter and increment it.
About JWT
---------
JWT means "JSON Web Tokens".
It's a standard to codify a JSON object in a long dense string without spaces. It looks like this:
```
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
```
It is not encrypted, so, anyone could recover the information from the contents.
But it's signed. So, when you receive a token that you emitted, you can verify that you actually emitted it.
That way, you can create a token with an expiration of, let's say, 1 week. And then when the user comes back the next day with the token, you know that user is still logged in to your system.
After a week, the token will be expired and the user will not be authorized and will have to sign in again to get a new token. And if the user (or a third party) tried to modify the token to change the expiration, you would be able to discover it, because the signatures would not match.
If you want to play with JWT tokens and see how they work, check [https://jwt.io](https://jwt.io/).
Install `python-jose`
---------------------
We need to install `python-jose` to generate and verify the JWT tokens in Python:
```
$ pip install "python-jose[cryptography]"
---> 100%
```
[Python-jose](https://github.com/mpdavis/python-jose) requires a cryptographic backend as an extra.
Here we are using the recommended one: [pyca/cryptography](https://cryptography.io/).
Tip
This tutorial previously used [PyJWT](https://pyjwt.readthedocs.io/).
But it was updated to use Python-jose instead as it provides all the features from PyJWT plus some extras that you might need later when building integrations with other tools.
Password hashing
----------------
"Hashing" means converting some content (a password in this case) into a sequence of bytes (just a string) that looks like gibberish.
Whenever you pass exactly the same content (exactly the same password) you get exactly the same gibberish.
But you cannot convert from the gibberish back to the password.
### Why use password hashing
If your database is stolen, the thief won't have your users' plaintext passwords, only the hashes.
So, the thief won't be able to try to use that password in another system (as many users use the same password everywhere, this would be dangerous).
Install `passlib`
-----------------
PassLib is a great Python package to handle password hashes.
It supports many secure hashing algorithms and utilities to work with them.
The recommended algorithm is "Bcrypt".
So, install PassLib with Bcrypt:
```
$ pip install "passlib[bcrypt]"
---> 100%
```
Tip
With `passlib`, you could even configure it to be able to read passwords created by **Django**, a **Flask** security plug-in or many others.
So, you would be able to, for example, share the same data from a Django application in a database with a FastAPI application. Or gradually migrate a Django application using the same database.
And your users would be able to login from your Django app or from your **FastAPI** app, at the same time.
Hash and verify the passwords
-----------------------------
Import the tools we need from `passlib`.
Create a PassLib "context". This is what will be used to hash and verify passwords.
Tip
The PassLib context also has functionality to use different hashing algorithms, including deprecated old ones only to allow verifying them, etc.
For example, you could use it to read and verify passwords generated by another system (like Django) but hash any new passwords with a different algorithm like Bcrypt.
And be compatible with all of them at the same time.
Create a utility function to hash a password coming from the user.
And another utility to verify if a received password matches the hash stored.
And another one to authenticate and return a user.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Note
If you check the new (fake) database `fake_users_db`, you will see how the hashed password looks like now: `"$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW"`.
Handle JWT tokens
-----------------
Import the modules installed.
Create a random secret key that will be used to sign the JWT tokens.
To generate a secure random secret key use the command:
```
$ openssl rand -hex 32
09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7
```
And copy the output to the variable `SECRET_KEY` (don't use the one in the example).
Create a variable `ALGORITHM` with the algorithm used to sign the JWT token and set it to `"HS256"`.
Create a variable for the expiration of the token.
Define a Pydantic Model that will be used in the token endpoint for the response.
Create a utility function to generate a new access token.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Update the dependencies
-----------------------
Update `get_current_user` to receive the same token as before, but this time, using JWT tokens.
Decode the received token, verify it, and return the current user.
If the token is invalid, return an HTTP error right away.
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Update the `/token` *path operation*
------------------------------------
Create a `timedelta` with the expiration time of the token.
Create a real JWT access token and return it
Python 3.10+
```
from datetime import datetime, timedelta
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.9+
```
from datetime import datetime, timedelta
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
from typing_extensions import Annotated
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(
form_data: Annotated[OAuth2PasswordRequestForm, Depends()]
):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
@app.get("/users/me/items/")
async def read_own_items(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: str | None = None
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: timedelta | None = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from datetime import datetime, timedelta
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from jose import JWTError, jwt
from passlib.context import CryptContext
from pydantic import BaseModel
# to get a string like this run:
# openssl rand -hex 32
SECRET_KEY = "09d25e094faa6ca2556c818166b7a9563b93f7099f6f0f4caa6cf63b88e8d3e7"
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 30
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "$2b$12$EixZaYVK1fsbw1ZfbX3OXePaWxn96p36WQoeG6Lruj3vjPGga31lW",
"disabled": False,
}
}
class Token(BaseModel):
access_token: str
token_type: str
class TokenData(BaseModel):
username: Union[str, None] = None
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
app = FastAPI()
def verify_password(plain_password, hashed_password):
return pwd_context.verify(plain_password, hashed_password)
def get_password_hash(password):
return pwd_context.hash(password)
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def authenticate_user(fake_db, username: str, password: str):
user = get_user(fake_db, username)
if not user:
return False
if not verify_password(password, user.hashed_password):
return False
return user
def create_access_token(data: dict, expires_delta: Union[timedelta, None] = None):
to_encode = data.copy()
if expires_delta:
expire = datetime.utcnow() + expires_delta
else:
expire = datetime.utcnow() + timedelta(minutes=15)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
async def get_current_user(token: str = Depends(oauth2_scheme)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
username: str = payload.get("sub")
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError:
raise credentials_exception
user = get_user(fake_users_db, username=token_data.username)
if user is None:
raise credentials_exception
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token", response_model=Token)
async def login_for_access_token(form_data: OAuth2PasswordRequestForm = Depends()):
user = authenticate_user(fake_users_db, form_data.username, form_data.password)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect username or password",
headers={"WWW-Authenticate": "Bearer"},
)
access_token_expires = timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
access_token = create_access_token(
data={"sub": user.username}, expires_delta=access_token_expires
)
return {"access_token": access_token, "token_type": "bearer"}
@app.get("/users/me/", response_model=User)
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
@app.get("/users/me/items/")
async def read_own_items(current_user: User = Depends(get_current_active_user)):
return [{"item_id": "Foo", "owner": current_user.username}]
```
### Technical details about the JWT "subject" `sub`
The JWT specification says that there's a key `sub`, with the subject of the token.
It's optional to use it, but that's where you would put the user's identification, so we are using it here.
JWT might be used for other things apart from identifying a user and allowing them to perform operations directly on your API.
For example, you could identify a "car" or a "blog post".
Then you could add permissions about that entity, like "drive" (for the car) or "edit" (for the blog).
And then, you could give that JWT token to a user (or bot), and they could use it to perform those actions (drive the car, or edit the blog post) without even needing to have an account, just with the JWT token your API generated for that.
Using these ideas, JWT can be used for way more sophisticated scenarios.
In those cases, several of those entities could have the same ID, let's say `foo` (a user `foo`, a car `foo`, and a blog post `foo`).
So, to avoid ID collisions, when creating the JWT token for the user, you could prefix the value of the `sub` key, e.g. with `username:`. So, in this example, the value of `sub` could have been: `username:johndoe`.
The important thing to have in mind is that the `sub` key should have a unique identifier across the entire application, and it should be a string.
Check it
--------
Run the server and go to the docs: <http://127.0.0.1:8000/docs>.
You'll see the user interface like:
Authorize the application the same way as before.
Using the credentials:
Username: `johndoe` Password: `secret`
Check
Notice that nowhere in the code is the plaintext password "`secret`", we only have the hashed version.
Call the endpoint `/users/me/`, you will get the response as:
```
{
"username": "johndoe",
"email": "[email protected]",
"full_name": "John Doe",
"disabled": false
}
```
If you open the developer tools, you could see how the data sent only includes the token, the password is only sent in the first request to authenticate the user and get that access token, but not afterwards:
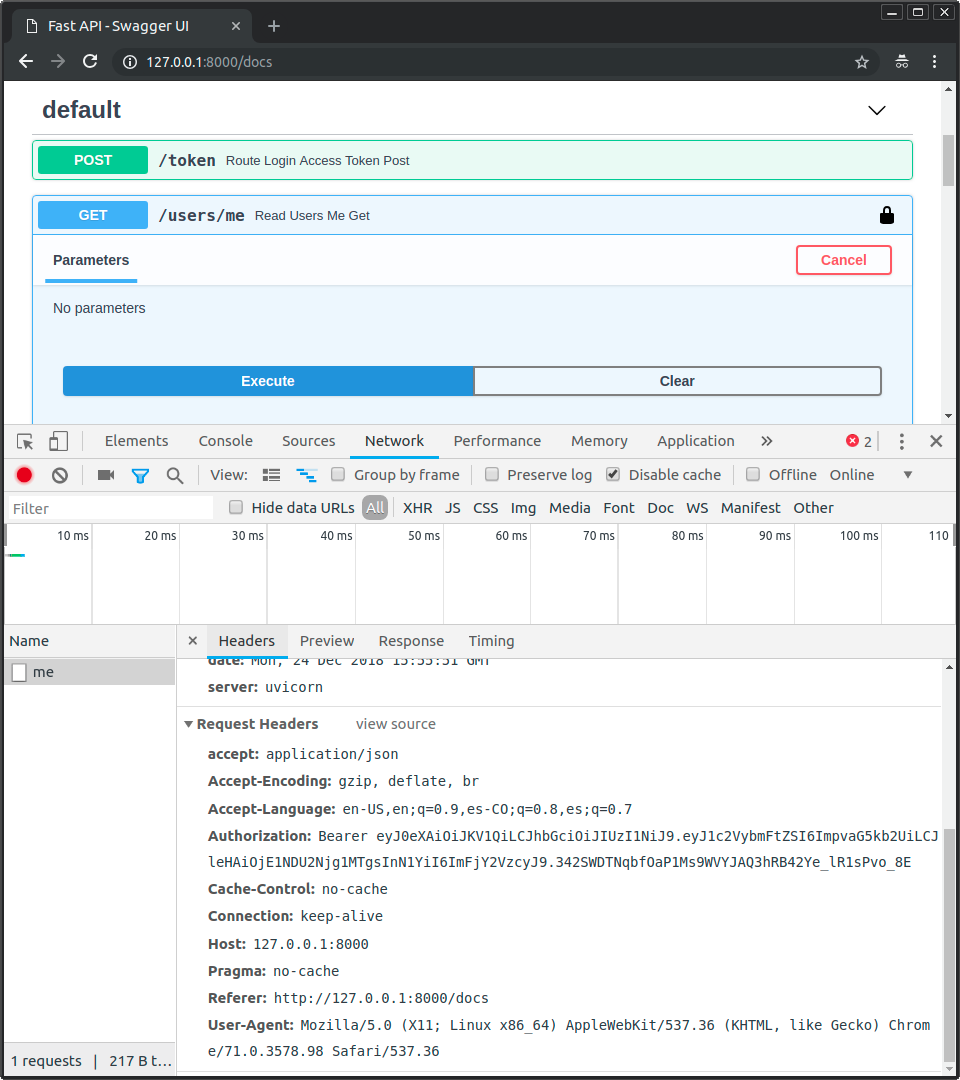
Note
Notice the header `Authorization`, with a value that starts with `Bearer`.
Advanced usage with `scopes`
----------------------------
OAuth2 has the notion of "scopes".
You can use them to add a specific set of permissions to a JWT token.
Then you can give this token to a user directly or a third party, to interact with your API with a set of restrictions.
You can learn how to use them and how they are integrated into **FastAPI** later in the **Advanced User Guide**.
Recap
-----
With what you have seen up to now, you can set up a secure **FastAPI** application using standards like OAuth2 and JWT.
In almost any framework handling the security becomes a rather complex subject quite quickly.
Many packages that simplify it a lot have to make many compromises with the data model, database, and available features. And some of these packages that simplify things too much actually have security flaws underneath.
---
**FastAPI** doesn't make any compromise with any database, data model or tool.
It gives you all the flexibility to choose the ones that fit your project the best.
And you can use directly many well maintained and widely used packages like `passlib` and `python-jose`, because **FastAPI** doesn't require any complex mechanisms to integrate external packages.
But it provides you the tools to simplify the process as much as possible without compromising flexibility, robustness, or security.
And you can use and implement secure, standard protocols, like OAuth2 in a relatively simple way.
You can learn more in the **Advanced User Guide** about how to use OAuth2 "scopes", for a more fine-grained permission system, following these same standards. OAuth2 with scopes is the mechanism used by many big authentication providers, like Facebook, Google, GitHub, Microsoft, Twitter, etc. to authorize third party applications to interact with their APIs on behalf of their users.
| programming_docs |
fastapi Get Current User Get Current User
================
In the previous chapter the security system (which is based on the dependency injection system) was giving the *path operation function* a `token` as a `str`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: str = Depends(oauth2_scheme)):
return {"token": token}
```
But that is still not that useful.
Let's make it give us the current user.
Create a user model
-------------------
First, let's create a Pydantic user model.
The same way we use Pydantic to declare bodies, we can use it anywhere else:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Create a `get_current_user` dependency
--------------------------------------
Let's create a dependency `get_current_user`.
Remember that dependencies can have sub-dependencies?
`get_current_user` will have a dependency with the same `oauth2_scheme` we created before.
The same as we were doing before in the *path operation* directly, our new dependency `get_current_user` will receive a `token` as a `str` from the sub-dependency `oauth2_scheme`:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Get the user
------------
`get_current_user` will use a (fake) utility function we created, that takes a token as a `str` and returns our Pydantic `User` model:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Inject the current user
-----------------------
So now we can use the same `Depends` with our `get_current_user` in the *path operation*:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Notice that we declare the type of `current_user` as the Pydantic model `User`.
This will help us inside of the function with all the completion and type checks.
Tip
You might remember that request bodies are also declared with Pydantic models.
Here **FastAPI** won't get confused because you are using `Depends`.
Check
The way this dependency system is designed allows us to have different dependencies (different "dependables") that all return a `User` model.
We are not restricted to having only one dependency that can return that type of data.
Other models
------------
You can now get the current user directly in the *path operation functions* and deal with the security mechanisms at the **Dependency Injection** level, using `Depends`.
And you can use any model or data for the security requirements (in this case, a Pydantic model `User`).
But you are not restricted to using some specific data model, class or type.
Do you want to have an `id` and `email` and not have any `username` in your model? Sure. You can use these same tools.
Do you want to just have a `str`? Or just a `dict`? Or a database class model instance directly? It all works the same way.
You actually don't have users that log in to your application but robots, bots, or other systems, that have just an access token? Again, it all works the same.
Just use any kind of model, any kind of class, any kind of database that you need for your application. **FastAPI** has you covered with the dependency injection system.
Code size
---------
This example might seem verbose. Have in mind that we are mixing security, data models, utility functions and *path operations* in the same file.
But here's the key point.
The security and dependency injection stuff is written once.
And you can make it as complex as you want. And still, have it written only once, in a single place. With all the flexibility.
But you can have thousands of endpoints (*path operations*) using the same security system.
And all of them (or any portion of them that you want) can take the advantage of re-using these dependencies or any other dependencies you create.
And all these thousands of *path operations* can be as small as 3 lines:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: Annotated[User, Depends(get_current_user)]):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from pydantic import BaseModel
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
def fake_decode_token(token):
return User(
username=token + "fakedecoded", email="[email protected]", full_name="John Doe"
)
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
return user
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_user)):
return current_user
```
Recap
-----
You can now get the current user directly in your *path operation function*.
We are already halfway there.
We just need to add a *path operation* for the user/client to actually send the `username` and `password`.
That comes next.
| programming_docs |
fastapi Security - First Steps Security - First Steps
======================
Let's imagine that you have your **backend** API in some domain.
And you have a **frontend** in another domain or in a different path of the same domain (or in a mobile application).
And you want to have a way for the frontend to authenticate with the backend, using a **username** and **password**.
We can use **OAuth2** to build that with **FastAPI**.
But let's save you the time of reading the full long specification just to find those little pieces of information you need.
Let's use the tools provided by **FastAPI** to handle security.
How it looks
------------
Let's first just use the code and see how it works, and then we'll come back to understand what's happening.
Create `main.py`
----------------
Copy the example in a file `main.py`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: str = Depends(oauth2_scheme)):
return {"token": token}
```
Run it
------
Info
First install [`python-multipart`](https://andrew-d.github.io/python-multipart/).
E.g. `pip install python-multipart`.
This is because **OAuth2** uses "form data" for sending the `username` and `password`.
Run the example with:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
Check it
--------
Go to the interactive docs at: <http://127.0.0.1:8000/docs>.
You will see something like this:
Authorize button!
You already have a shiny new "Authorize" button.
And your *path operation* has a little lock in the top-right corner that you can click.
And if you click it, you have a little authorization form to type a `username` and `password` (and other optional fields):
Note
It doesn't matter what you type in the form, it won't work yet. But we'll get there.
This is of course not the frontend for the final users, but it's a great automatic tool to document interactively all your API.
It can be used by the frontend team (that can also be yourself).
It can be used by third party applications and systems.
And it can also be used by yourself, to debug, check and test the same application.
The `password` flow
-------------------
Now let's go back a bit and understand what is all that.
The `password` "flow" is one of the ways ("flows") defined in OAuth2, to handle security and authentication.
OAuth2 was designed so that the backend or API could be independent of the server that authenticates the user.
But in this case, the same **FastAPI** application will handle the API and the authentication.
So, let's review it from that simplified point of view:
* The user types the `username` and `password` in the frontend, and hits `Enter`.
* The frontend (running in the user's browser) sends that `username` and `password` to a specific URL in our API (declared with `tokenUrl="token"`).
* The API checks that `username` and `password`, and responds with a "token" (we haven't implemented any of this yet).
+ A "token" is just a string with some content that we can use later to verify this user.
+ Normally, a token is set to expire after some time.
- So, the user will have to log in again at some point later.
- And if the token is stolen, the risk is less. It is not like a permanent key that will work forever (in most of the cases).
* The frontend stores that token temporarily somewhere.
* The user clicks in the frontend to go to another section of the frontend web app.
* The frontend needs to fetch some more data from the API.
+ But it needs authentication for that specific endpoint.
+ So, to authenticate with our API, it sends a header `Authorization` with a value of `Bearer` plus the token.
+ If the token contains `foobar`, the content of the `Authorization` header would be: `Bearer foobar`.
**FastAPI**'s `OAuth2PasswordBearer`
-------------------------------------
**FastAPI** provides several tools, at different levels of abstraction, to implement these security features.
In this example we are going to use **OAuth2**, with the **Password** flow, using a **Bearer** token. We do that using the `OAuth2PasswordBearer` class.
Info
A "bearer" token is not the only option.
But it's the best one for our use case.
And it might be the best for most use cases, unless you are an OAuth2 expert and know exactly why there's another option that suits better your needs.
In that case, **FastAPI** also provides you with the tools to build it.
When we create an instance of the `OAuth2PasswordBearer` class we pass in the `tokenUrl` parameter. This parameter contains the URL that the client (the frontend running in the user's browser) will use to send the `username` and `password` in order to get a token.
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: str = Depends(oauth2_scheme)):
return {"token": token}
```
Tip
Here `tokenUrl="token"` refers to a relative URL `token` that we haven't created yet. As it's a relative URL, it's equivalent to `./token`.
Because we are using a relative URL, if your API was located at `https://example.com/`, then it would refer to `https://example.com/token`. But if your API was located at `https://example.com/api/v1/`, then it would refer to `https://example.com/api/v1/token`.
Using a relative URL is important to make sure your application keeps working even in an advanced use case like [Behind a Proxy](../../../advanced/behind-a-proxy/index).
This parameter doesn't create that endpoint / *path operation*, but declares that the URL `/token` will be the one that the client should use to get the token. That information is used in OpenAPI, and then in the interactive API documentation systems.
We will soon also create the actual path operation.
Info
If you are a very strict "Pythonista" you might dislike the style of the parameter name `tokenUrl` instead of `token_url`.
That's because it is using the same name as in the OpenAPI spec. So that if you need to investigate more about any of these security schemes you can just copy and paste it to find more information about it.
The `oauth2_scheme` variable is an instance of `OAuth2PasswordBearer`, but it is also a "callable".
It could be called as:
```
oauth2_scheme(some, parameters)
```
So, it can be used with `Depends`.
### Use it
Now you can pass that `oauth2_scheme` in a dependency with `Depends`.
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
from typing_extensions import Annotated
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: Annotated[str, Depends(oauth2_scheme)]):
return {"token": token}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
from fastapi.security import OAuth2PasswordBearer
app = FastAPI()
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@app.get("/items/")
async def read_items(token: str = Depends(oauth2_scheme)):
return {"token": token}
```
This dependency will provide a `str` that is assigned to the parameter `token` of the *path operation function*.
**FastAPI** will know that it can use this dependency to define a "security scheme" in the OpenAPI schema (and the automatic API docs).
Technical Details
**FastAPI** will know that it can use the class `OAuth2PasswordBearer` (declared in a dependency) to define the security scheme in OpenAPI because it inherits from `fastapi.security.oauth2.OAuth2`, which in turn inherits from `fastapi.security.base.SecurityBase`.
All the security utilities that integrate with OpenAPI (and the automatic API docs) inherit from `SecurityBase`, that's how **FastAPI** can know how to integrate them in OpenAPI.
What it does
------------
It will go and look in the request for that `Authorization` header, check if the value is `Bearer` plus some token, and will return the token as a `str`.
If it doesn't see an `Authorization` header, or the value doesn't have a `Bearer` token, it will respond with a 401 status code error (`UNAUTHORIZED`) directly.
You don't even have to check if the token exists to return an error. You can be sure that if your function is executed, it will have a `str` in that token.
You can try it already in the interactive docs:
We are not verifying the validity of the token yet, but that's a start already.
Recap
-----
So, in just 3 or 4 extra lines, you already have some primitive form of security.
fastapi Simple OAuth2 with Password and Bearer Simple OAuth2 with Password and Bearer
======================================
Now let's build from the previous chapter and add the missing parts to have a complete security flow.
Get the `username` and `password`
---------------------------------
We are going to use **FastAPI** security utilities to get the `username` and `password`.
OAuth2 specifies that when using the "password flow" (that we are using) the client/user must send a `username` and `password` fields as form data.
And the spec says that the fields have to be named like that. So `user-name` or `email` wouldn't work.
But don't worry, you can show it as you wish to your final users in the frontend.
And your database models can use any other names you want.
But for the login *path operation*, we need to use these names to be compatible with the spec (and be able to, for example, use the integrated API documentation system).
The spec also states that the `username` and `password` must be sent as form data (so, no JSON here).
### `scope`
The spec also says that the client can send another form field "`scope`".
The form field name is `scope` (in singular), but it is actually a long string with "scopes" separated by spaces.
Each "scope" is just a string (without spaces).
They are normally used to declare specific security permissions, for example:
* `users:read` or `users:write` are common examples.
* `instagram_basic` is used by Facebook / Instagram.
* `https://www.googleapis.com/auth/drive` is used by Google.
Info
In OAuth2 a "scope" is just a string that declares a specific permission required.
It doesn't matter if it has other characters like `:` or if it is a URL.
Those details are implementation specific.
For OAuth2 they are just strings.
Code to get the `username` and `password`
-----------------------------------------
Now let's use the utilities provided by **FastAPI** to handle this.
### `OAuth2PasswordRequestForm`
First, import `OAuth2PasswordRequestForm`, and use it as a dependency with `Depends` in the *path operation* for `/token`:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
from typing_extensions import Annotated
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
`OAuth2PasswordRequestForm` is a class dependency that declares a form body with:
* The `username`.
* The `password`.
* An optional `scope` field as a big string, composed of strings separated by spaces.
* An optional `grant_type`.
Tip
The OAuth2 spec actually *requires* a field `grant_type` with a fixed value of `password`, but `OAuth2PasswordRequestForm` doesn't enforce it.
If you need to enforce it, use `OAuth2PasswordRequestFormStrict` instead of `OAuth2PasswordRequestForm`.
* An optional `client_id` (we don't need it for our example).
* An optional `client_secret` (we don't need it for our example).
Info
The `OAuth2PasswordRequestForm` is not a special class for **FastAPI** as is `OAuth2PasswordBearer`.
`OAuth2PasswordBearer` makes **FastAPI** know that it is a security scheme. So it is added that way to OpenAPI.
But `OAuth2PasswordRequestForm` is just a class dependency that you could have written yourself, or you could have declared `Form` parameters directly.
But as it's a common use case, it is provided by **FastAPI** directly, just to make it easier.
### Use the form data
Tip
The instance of the dependency class `OAuth2PasswordRequestForm` won't have an attribute `scope` with the long string separated by spaces, instead, it will have a `scopes` attribute with the actual list of strings for each scope sent.
We are not using `scopes` in this example, but the functionality is there if you need it.
Now, get the user data from the (fake) database, using the `username` from the form field.
If there is no such user, we return an error saying "incorrect username or password".
For the error, we use the exception `HTTPException`:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
from typing_extensions import Annotated
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
### Check the password
At this point we have the user data from our database, but we haven't checked the password.
Let's put that data in the Pydantic `UserInDB` model first.
You should never save plaintext passwords, so, we'll use the (fake) password hashing system.
If the passwords don't match, we return the same error.
#### Password hashing
"Hashing" means: converting some content (a password in this case) into a sequence of bytes (just a string) that looks like gibberish.
Whenever you pass exactly the same content (exactly the same password) you get exactly the same gibberish.
But you cannot convert from the gibberish back to the password.
##### Why use password hashing
If your database is stolen, the thief won't have your users' plaintext passwords, only the hashes.
So, the thief won't be able to try to use those same passwords in another system (as many users use the same password everywhere, this would be dangerous).
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
from typing_extensions import Annotated
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
#### About `**user_dict`
`UserInDB(**user_dict)` means:
*Pass the keys and values of the `user_dict` directly as key-value arguments, equivalent to:*
```
UserInDB(
username = user_dict["username"],
email = user_dict["email"],
full_name = user_dict["full_name"],
disabled = user_dict["disabled"],
hashed_password = user_dict["hashed_password"],
)
```
Info
For a more complete explanation of `**user_dict` check back in [the documentation for **Extra Models**](../../extra-models/index#about-user_indict).
Return the token
----------------
The response of the `token` endpoint must be a JSON object.
It should have a `token_type`. In our case, as we are using "Bearer" tokens, the token type should be "`bearer`".
And it should have an `access_token`, with a string containing our access token.
For this simple example, we are going to just be completely insecure and return the same `username` as the token.
Tip
In the next chapter, you will see a real secure implementation, with password hashing and JWT tokens.
But for now, let's focus on the specific details we need.
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
from typing_extensions import Annotated
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Tip
By the spec, you should return a JSON with an `access_token` and a `token_type`, the same as in this example.
This is something that you have to do yourself in your code, and make sure you use those JSON keys.
It's almost the only thing that you have to remember to do correctly yourself, to be compliant with the specifications.
For the rest, **FastAPI** handles it for you.
Update the dependencies
-----------------------
Now we are going to update our dependencies.
We want to get the `current_user` *only* if this user is active.
So, we create an additional dependency `get_current_active_user` that in turn uses `get_current_user` as a dependency.
Both of these dependencies will just return an HTTP error if the user doesn't exist, or if is inactive.
So, in our endpoint, we will only get a user if the user exists, was correctly authenticated, and is active:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
from typing_extensions import Annotated
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: Annotated[str, Depends(oauth2_scheme)]):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(
current_user: Annotated[User, Depends(get_current_user)]
):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: Annotated[OAuth2PasswordRequestForm, Depends()]):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(
current_user: Annotated[User, Depends(get_current_active_user)]
):
return current_user
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: str | None = None
full_name: str | None = None
disabled: bool | None = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI, HTTPException, status
from fastapi.security import OAuth2PasswordBearer, OAuth2PasswordRequestForm
from pydantic import BaseModel
fake_users_db = {
"johndoe": {
"username": "johndoe",
"full_name": "John Doe",
"email": "[email protected]",
"hashed_password": "fakehashedsecret",
"disabled": False,
},
"alice": {
"username": "alice",
"full_name": "Alice Wonderson",
"email": "[email protected]",
"hashed_password": "fakehashedsecret2",
"disabled": True,
},
}
app = FastAPI()
def fake_hash_password(password: str):
return "fakehashed" + password
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
class User(BaseModel):
username: str
email: Union[str, None] = None
full_name: Union[str, None] = None
disabled: Union[bool, None] = None
class UserInDB(User):
hashed_password: str
def get_user(db, username: str):
if username in db:
user_dict = db[username]
return UserInDB(**user_dict)
def fake_decode_token(token):
# This doesn't provide any security at all
# Check the next version
user = get_user(fake_users_db, token)
return user
async def get_current_user(token: str = Depends(oauth2_scheme)):
user = fake_decode_token(token)
if not user:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Invalid authentication credentials",
headers={"WWW-Authenticate": "Bearer"},
)
return user
async def get_current_active_user(current_user: User = Depends(get_current_user)):
if current_user.disabled:
raise HTTPException(status_code=400, detail="Inactive user")
return current_user
@app.post("/token")
async def login(form_data: OAuth2PasswordRequestForm = Depends()):
user_dict = fake_users_db.get(form_data.username)
if not user_dict:
raise HTTPException(status_code=400, detail="Incorrect username or password")
user = UserInDB(**user_dict)
hashed_password = fake_hash_password(form_data.password)
if not hashed_password == user.hashed_password:
raise HTTPException(status_code=400, detail="Incorrect username or password")
return {"access_token": user.username, "token_type": "bearer"}
@app.get("/users/me")
async def read_users_me(current_user: User = Depends(get_current_active_user)):
return current_user
```
Info
The additional header `WWW-Authenticate` with value `Bearer` we are returning here is also part of the spec.
Any HTTP (error) status code 401 "UNAUTHORIZED" is supposed to also return a `WWW-Authenticate` header.
In the case of bearer tokens (our case), the value of that header should be `Bearer`.
You can actually skip that extra header and it would still work.
But it's provided here to be compliant with the specifications.
Also, there might be tools that expect and use it (now or in the future) and that might be useful for you or your users, now or in the future.
That's the benefit of standards...
See it in action
----------------
Open the interactive docs: <http://127.0.0.1:8000/docs>.
### Authenticate
Click the "Authorize" button.
Use the credentials:
User: `johndoe`
Password: `secret`
After authenticating in the system, you will see it like:
### Get your own user data
Now use the operation `GET` with the path `/users/me`.
You will get your user's data, like:
```
{
"username": "johndoe",
"email": "[email protected]",
"full_name": "John Doe",
"disabled": false,
"hashed_password": "fakehashedsecret"
}
```
If you click the lock icon and logout, and then try the same operation again, you will get an HTTP 401 error of:
```
{
"detail": "Not authenticated"
}
```
### Inactive user
Now try with an inactive user, authenticate with:
User: `alice`
Password: `secret2`
And try to use the operation `GET` with the path `/users/me`.
You will get an "inactive user" error, like:
```
{
"detail": "Inactive user"
}
```
Recap
-----
You now have the tools to implement a complete security system based on `username` and `password` for your API.
Using these tools, you can make the security system compatible with any database and with any user or data model.
The only detail missing is that it is not actually "secure" yet.
In the next chapter you'll see how to use a secure password hashing library and JWT tokens.
| programming_docs |
fastapi Request Files Request Files
=============
You can define files to be uploaded by the client using `File`.
Info
To receive uploaded files, first install [`python-multipart`](https://andrew-d.github.io/python-multipart/).
E.g. `pip install python-multipart`.
This is because uploaded files are sent as "form data".
Import `File`
-------------
Import `File` and `UploadFile` from `fastapi`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+
```
from fastapi import FastAPI, File, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: bytes = File()):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Define `File` Parameters
------------------------
Create file parameters the same way you would for `Body` or `Form`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+
```
from fastapi import FastAPI, File, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: bytes = File()):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Info
`File` is a class that inherits directly from `Form`.
But remember that when you import `Query`, `Path`, `File` and others from `fastapi`, those are actually functions that return special classes.
Tip
To declare File bodies, you need to use `File`, because otherwise the parameters would be interpreted as query parameters or body (JSON) parameters.
The files will be uploaded as "form data".
If you declare the type of your *path operation function* parameter as `bytes`, **FastAPI** will read the file for you and you will receive the contents as `bytes`.
Have in mind that this means that the whole contents will be stored in memory. This will work well for small files.
But there are several cases in which you might benefit from using `UploadFile`.
File Parameters with `UploadFile`
---------------------------------
Define a file parameter with a type of `UploadFile`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+
```
from fastapi import FastAPI, File, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File()]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: bytes = File()):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
return {"filename": file.filename}
```
Using `UploadFile` has several advantages over `bytes`:
* You don't have to use `File()` in the default value of the parameter.
* It uses a "spooled" file:
+ A file stored in memory up to a maximum size limit, and after passing this limit it will be stored in disk.
* This means that it will work well for large files like images, videos, large binaries, etc. without consuming all the memory.
* You can get metadata from the uploaded file.
* It has a [file-like](https://docs.python.org/3/glossary.html#term-file-like-object) `async` interface.
* It exposes an actual Python [`SpooledTemporaryFile`](https://docs.python.org/3/library/tempfile.html#tempfile.SpooledTemporaryFile) object that you can pass directly to other libraries that expect a file-like object.
### `UploadFile`
`UploadFile` has the following attributes:
* `filename`: A `str` with the original file name that was uploaded (e.g. `myimage.jpg`).
* `content_type`: A `str` with the content type (MIME type / media type) (e.g. `image/jpeg`).
* `file`: A [`SpooledTemporaryFile`](https://docs.python.org/3/library/tempfile.html#tempfile.SpooledTemporaryFile) (a [file-like](https://docs.python.org/3/glossary.html#term-file-like-object) object). This is the actual Python file that you can pass directly to other functions or libraries that expect a "file-like" object.
`UploadFile` has the following `async` methods. They all call the corresponding file methods underneath (using the internal `SpooledTemporaryFile`).
* `write(data)`: Writes `data` (`str` or `bytes`) to the file.
* `read(size)`: Reads `size` (`int`) bytes/characters of the file.
* `seek(offset)`: Goes to the byte position `offset` (`int`) in the file.
+ E.g., `await myfile.seek(0)` would go to the start of the file.
+ This is especially useful if you run `await myfile.read()` once and then need to read the contents again.
* `close()`: Closes the file.
As all these methods are `async` methods, you need to "await" them.
For example, inside of an `async` *path operation function* you can get the contents with:
```
contents = await myfile.read()
```
If you are inside of a normal `def` *path operation function*, you can access the `UploadFile.file` directly, for example:
```
contents = myfile.file.read()
```
`async` Technical Details
When you use the `async` methods, **FastAPI** runs the file methods in a threadpool and awaits for them.
Starlette Technical Details
**FastAPI**'s `UploadFile` inherits directly from **Starlette**'s `UploadFile`, but adds some necessary parts to make it compatible with **Pydantic** and the other parts of FastAPI.
What is "Form Data"
-------------------
The way HTML forms (`<form></form>`) sends the data to the server normally uses a "special" encoding for that data, it's different from JSON.
**FastAPI** will make sure to read that data from the right place instead of JSON.
Technical Details
Data from forms is normally encoded using the "media type" `application/x-www-form-urlencoded` when it doesn't include files.
But when the form includes files, it is encoded as `multipart/form-data`. If you use `File`, **FastAPI** will know it has to get the files from the correct part of the body.
If you want to read more about these encodings and form fields, head to the [MDN web docs for `POST`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/POST).
Warning
You can declare multiple `File` and `Form` parameters in a *path operation*, but you can't also declare `Body` fields that you expect to receive as JSON, as the request will have the body encoded using `multipart/form-data` instead of `application/json`.
This is not a limitation of **FastAPI**, it's part of the HTTP protocol.
Optional File Upload
--------------------
You can make a file optional by using standard type annotations and setting a default value of `None`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes | None, File()] = None):
if not file:
return {"message": "No file sent"}
else:
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile | None = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[Union[bytes, None], File()] = None):
if not file:
return {"message": "No file sent"}
else:
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: Union[UploadFile, None] = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, File, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[Union[bytes, None], File()] = None):
if not file:
return {"message": "No file sent"}
else:
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: Union[UploadFile, None] = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: bytes | None = File(default=None)):
if not file:
return {"message": "No file sent"}
else:
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile | None = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Union[bytes, None] = File(default=None)):
if not file:
return {"message": "No file sent"}
else:
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(file: Union[UploadFile, None] = None):
if not file:
return {"message": "No upload file sent"}
else:
return {"filename": file.filename}
```
`UploadFile` with Additional Metadata
--------------------------------------
You can also use `File()` with `UploadFile`, for example, to set additional metadata:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File(description="A file read as bytes")]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(
file: Annotated[UploadFile, File(description="A file read as UploadFile")],
):
return {"filename": file.filename}
```
Python 3.6+
```
from fastapi import FastAPI, File, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(file: Annotated[bytes, File(description="A file read as bytes")]):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(
file: Annotated[UploadFile, File(description="A file read as UploadFile")],
):
return {"filename": file.filename}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(file: bytes = File(description="A file read as bytes")):
return {"file_size": len(file)}
@app.post("/uploadfile/")
async def create_upload_file(
file: UploadFile = File(description="A file read as UploadFile"),
):
return {"filename": file.filename}
```
Multiple File Uploads
---------------------
It's possible to upload several files at the same time.
They would be associated to the same "form field" sent using "form data".
To use that, declare a list of `bytes` or `UploadFile`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(files: Annotated[list[bytes], File()]):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(files: list[UploadFile]):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_files(files: Annotated[List[bytes], File()]):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(files: List[UploadFile]):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(files: list[bytes] = File()):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(files: list[UploadFile]):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import List
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(files: List[bytes] = File()):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(files: List[UploadFile]):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
You will receive, as declared, a `list` of `bytes` or `UploadFile`s.
Technical Details
You could also use `from starlette.responses import HTMLResponse`.
**FastAPI** provides the same `starlette.responses` as `fastapi.responses` just as a convenience for you, the developer. But most of the available responses come directly from Starlette.
### Multiple File Uploads with Additional Metadata
And the same way as before, you can use `File()` to set additional parameters, even for `UploadFile`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(
files: Annotated[list[bytes], File(description="Multiple files as bytes")],
):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(
files: Annotated[
list[UploadFile], File(description="Multiple files as UploadFile")
],
):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_files(
files: Annotated[List[bytes], File(description="Multiple files as bytes")],
):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(
files: Annotated[
List[UploadFile], File(description="Multiple files as UploadFile")
],
):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(
files: list[bytes] = File(description="Multiple files as bytes"),
):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(
files: list[UploadFile] = File(description="Multiple files as UploadFile"),
):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import List
from fastapi import FastAPI, File, UploadFile
from fastapi.responses import HTMLResponse
app = FastAPI()
@app.post("/files/")
async def create_files(
files: List[bytes] = File(description="Multiple files as bytes"),
):
return {"file_sizes": [len(file) for file in files]}
@app.post("/uploadfiles/")
async def create_upload_files(
files: List[UploadFile] = File(description="Multiple files as UploadFile"),
):
return {"filenames": [file.filename for file in files]}
@app.get("/")
async def main():
content = """
<body>
<form action="/files/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
<form action="/uploadfiles/" enctype="multipart/form-data" method="post">
<input name="files" type="file" multiple>
<input type="submit">
</form>
</body>
"""
return HTMLResponse(content=content)
```
Recap
-----
Use `File`, `bytes`, and `UploadFile` to declare files to be uploaded in the request, sent as form data.
| programming_docs |
fastapi JSON Compatible Encoder JSON Compatible Encoder
=======================
There are some cases where you might need to convert a data type (like a Pydantic model) to something compatible with JSON (like a `dict`, `list`, etc).
For example, if you need to store it in a database.
For that, **FastAPI** provides a `jsonable_encoder()` function.
Using the `jsonable_encoder`
----------------------------
Let's imagine that you have a database `fake_db` that only receives JSON compatible data.
For example, it doesn't receive `datetime` objects, as those are not compatible with JSON.
So, a `datetime` object would have to be converted to a `str` containing the data in [ISO format](https://en.wikipedia.org/wiki/ISO_8601).
The same way, this database wouldn't receive a Pydantic model (an object with attributes), only a `dict`.
You can use `jsonable_encoder` for that.
It receives an object, like a Pydantic model, and returns a JSON compatible version:
Python 3.10+
```
from datetime import datetime
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
fake_db = {}
class Item(BaseModel):
title: str
timestamp: datetime
description: str | None = None
app = FastAPI()
@app.put("/items/{id}")
def update_item(id: str, item: Item):
json_compatible_item_data = jsonable_encoder(item)
fake_db[id] = json_compatible_item_data
```
Python 3.6+
```
from datetime import datetime
from typing import Union
from fastapi import FastAPI
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel
fake_db = {}
class Item(BaseModel):
title: str
timestamp: datetime
description: Union[str, None] = None
app = FastAPI()
@app.put("/items/{id}")
def update_item(id: str, item: Item):
json_compatible_item_data = jsonable_encoder(item)
fake_db[id] = json_compatible_item_data
```
In this example, it would convert the Pydantic model to a `dict`, and the `datetime` to a `str`.
The result of calling it is something that can be encoded with the Python standard [`json.dumps()`](https://docs.python.org/3/library/json.html#json.dumps).
It doesn't return a large `str` containing the data in JSON format (as a string). It returns a Python standard data structure (e.g. a `dict`) with values and sub-values that are all compatible with JSON.
Note
`jsonable_encoder` is actually used by **FastAPI** internally to convert data. But it is useful in many other scenarios.
fastapi Debugging Debugging
=========
You can connect the debugger in your editor, for example with Visual Studio Code or PyCharm.
Call `uvicorn`
--------------
In your FastAPI application, import and run `uvicorn` directly:
```
import uvicorn
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
a = "a"
b = "b" + a
return {"hello world": b}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
```
### About `__name__ == "__main__"`
The main purpose of the `__name__ == "__main__"` is to have some code that is executed when your file is called with:
```
$ python myapp.py
```
but is not called when another file imports it, like in:
```
from myapp import app
```
#### More details
Let's say your file is named `myapp.py`.
If you run it with:
```
$ python myapp.py
```
then the internal variable `__name__` in your file, created automatically by Python, will have as value the string `"__main__"`.
So, the section:
```
uvicorn.run(app, host="0.0.0.0", port=8000)
```
will run.
---
This won't happen if you import that module (file).
So, if you have another file `importer.py` with:
```
from myapp import app
# Some more code
```
in that case, the automatic variable inside of `myapp.py` will not have the variable `__name__` with a value of `"__main__"`.
So, the line:
```
uvicorn.run(app, host="0.0.0.0", port=8000)
```
will not be executed.
Info
For more information, check [the official Python docs](https://docs.python.org/3/library/__main__.html).
Run your code with your debugger
--------------------------------
Because you are running the Uvicorn server directly from your code, you can call your Python program (your FastAPI application) directly from the debugger.
---
For example, in Visual Studio Code, you can:
* Go to the "Debug" panel.
* "Add configuration...".
* Select "Python"
* Run the debugger with the option "`Python: Current File (Integrated Terminal)`".
It will then start the server with your **FastAPI** code, stop at your breakpoints, etc.
Here's how it might look:
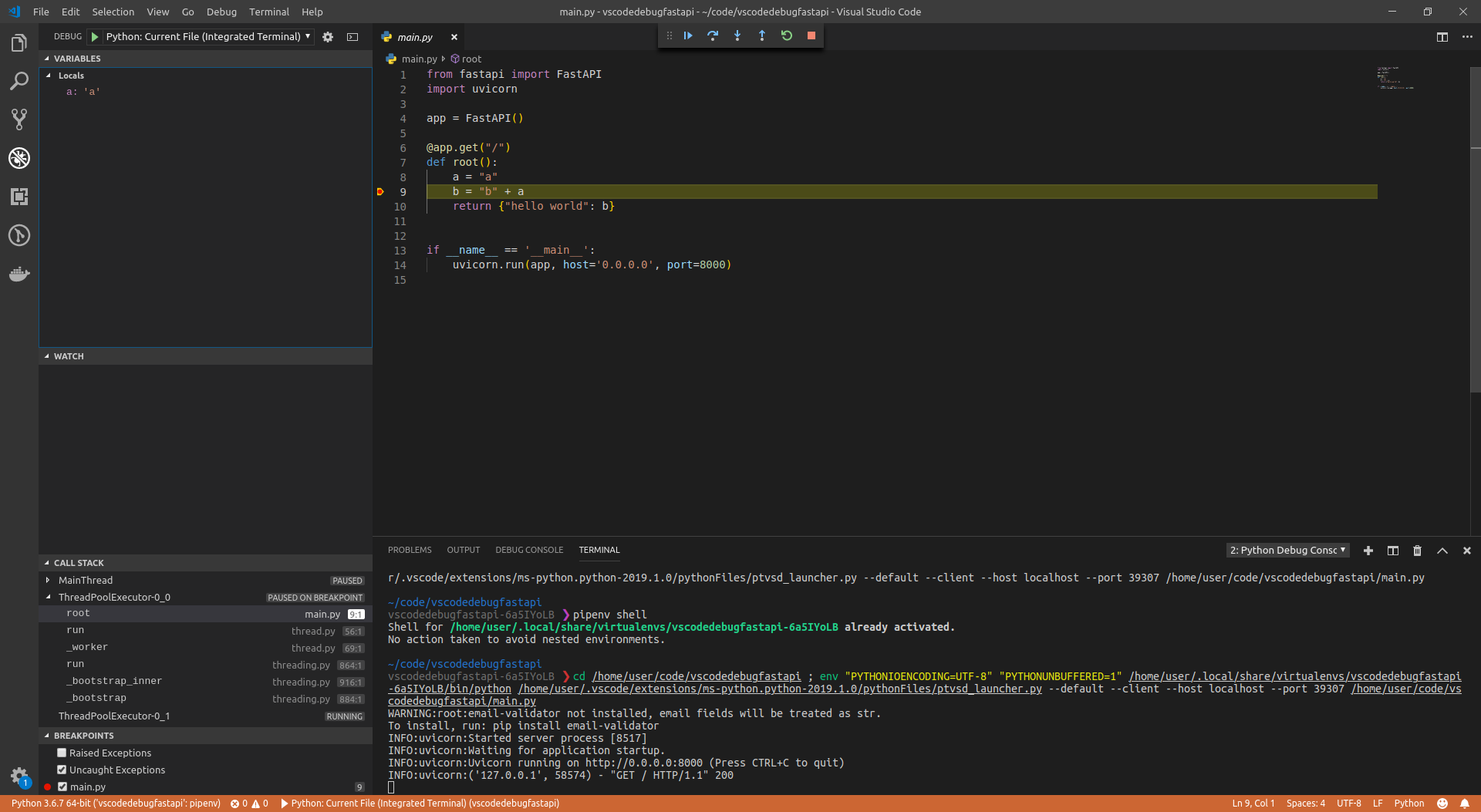
---
If you use Pycharm, you can:
* Open the "Run" menu.
* Select the option "Debug...".
* Then a context menu shows up.
* Select the file to debug (in this case, `main.py`).
It will then start the server with your **FastAPI** code, stop at your breakpoints, etc.
Here's how it might look:
fastapi Request Body Request Body
============
When you need to send data from a client (let's say, a browser) to your API, you send it as a **request body**.
A **request** body is data sent by the client to your API. A **response** body is the data your API sends to the client.
Your API almost always has to send a **response** body. But clients don't necessarily need to send **request** bodies all the time.
To declare a **request** body, you use [Pydantic](https://pydantic-docs.helpmanual.io/) models with all their power and benefits.
Info
To send data, you should use one of: `POST` (the more common), `PUT`, `DELETE` or `PATCH`.
Sending a body with a `GET` request has an undefined behavior in the specifications, nevertheless, it is supported by FastAPI, only for very complex/extreme use cases.
As it is discouraged, the interactive docs with Swagger UI won't show the documentation for the body when using `GET`, and proxies in the middle might not support it.
Import Pydantic's `BaseModel`
-----------------------------
First, you need to import `BaseModel` from `pydantic`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
Create your data model
----------------------
Then you declare your data model as a class that inherits from `BaseModel`.
Use standard Python types for all the attributes:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
The same as when declaring query parameters, when a model attribute has a default value, it is not required. Otherwise, it is required. Use `None` to make it just optional.
For example, this model above declares a JSON "`object`" (or Python `dict`) like:
```
{
"name": "Foo",
"description": "An optional description",
"price": 45.2,
"tax": 3.5
}
```
...as `description` and `tax` are optional (with a default value of `None`), this JSON "`object`" would also be valid:
```
{
"name": "Foo",
"price": 45.2
}
```
Declare it as a parameter
-------------------------
To add it to your *path operation*, declare it the same way you declared path and query parameters:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
return item
```
...and declare its type as the model you created, `Item`.
Results
-------
With just that Python type declaration, **FastAPI** will:
* Read the body of the request as JSON.
* Convert the corresponding types (if needed).
* Validate the data.
+ If the data is invalid, it will return a nice and clear error, indicating exactly where and what was the incorrect data.
* Give you the received data in the parameter `item`.
+ As you declared it in the function to be of type `Item`, you will also have all the editor support (completion, etc) for all of the attributes and their types.
* Generate [JSON Schema](https://json-schema.org) definitions for your model, you can also use them anywhere else you like if it makes sense for your project.
* Those schemas will be part of the generated OpenAPI schema, and used by the automatic documentation UIs.
Automatic docs
--------------
The JSON Schemas of your models will be part of your OpenAPI generated schema, and will be shown in the interactive API docs:
And will be also used in the API docs inside each *path operation* that needs them:
Editor support
--------------
In your editor, inside your function you will get type hints and completion everywhere (this wouldn't happen if you received a `dict` instead of a Pydantic model):
You also get error checks for incorrect type operations:
This is not by chance, the whole framework was built around that design.
And it was thoroughly tested at the design phase, before any implementation, to ensure it would work with all the editors.
There were even some changes to Pydantic itself to support this.
The previous screenshots were taken with [Visual Studio Code](https://code.visualstudio.com).
But you would get the same editor support with [PyCharm](https://www.jetbrains.com/pycharm/) and most of the other Python editors:
Tip
If you use [PyCharm](https://www.jetbrains.com/pycharm/) as your editor, you can use the [Pydantic PyCharm Plugin](https://github.com/koxudaxi/pydantic-pycharm-plugin/).
It improves editor support for Pydantic models, with:
* auto-completion
* type checks
* refactoring
* searching
* inspections
Use the model
-------------
Inside of the function, you can access all the attributes of the model object directly:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
item_dict = item.dict()
if item.tax:
price_with_tax = item.price + item.tax
item_dict.update({"price_with_tax": price_with_tax})
return item_dict
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.post("/items/")
async def create_item(item: Item):
item_dict = item.dict()
if item.tax:
price_with_tax = item.price + item.tax
item_dict.update({"price_with_tax": price_with_tax})
return item_dict
```
Request body + path parameters
------------------------------
You can declare path parameters and request body at the same time.
**FastAPI** will recognize that the function parameters that match path parameters should be **taken from the path**, and that function parameters that are declared to be Pydantic models should be **taken from the request body**.
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.put("/items/{item_id}")
async def create_item(item_id: int, item: Item):
return {"item_id": item_id, **item.dict()}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.put("/items/{item_id}")
async def create_item(item_id: int, item: Item):
return {"item_id": item_id, **item.dict()}
```
Request body + path + query parameters
--------------------------------------
You can also declare **body**, **path** and **query** parameters, all at the same time.
**FastAPI** will recognize each of them and take the data from the correct place.
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
app = FastAPI()
@app.put("/items/{item_id}")
async def create_item(item_id: int, item: Item, q: str | None = None):
result = {"item_id": item_id, **item.dict()}
if q:
result.update({"q": q})
return result
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
app = FastAPI()
@app.put("/items/{item_id}")
async def create_item(item_id: int, item: Item, q: Union[str, None] = None):
result = {"item_id": item_id, **item.dict()}
if q:
result.update({"q": q})
return result
```
The function parameters will be recognized as follows:
* If the parameter is also declared in the **path**, it will be used as a path parameter.
* If the parameter is of a **singular type** (like `int`, `float`, `str`, `bool`, etc) it will be interpreted as a **query** parameter.
* If the parameter is declared to be of the type of a **Pydantic model**, it will be interpreted as a request **body**.
Note
FastAPI will know that the value of `q` is not required because of the default value `= None`.
The `Union` in `Union[str, None]` is not used by FastAPI, but will allow your editor to give you better support and detect errors.
Without Pydantic
----------------
If you don't want to use Pydantic models, you can also use **Body** parameters. See the docs for [Body - Multiple Parameters: Singular values in body](../body-multiple-params/index#singular-values-in-body).
fastapi SQL (Relational) Databases SQL (Relational) Databases
==========================
**FastAPI** doesn't require you to use a SQL (relational) database.
But you can use any relational database that you want.
Here we'll see an example using [SQLAlchemy](https://www.sqlalchemy.org/).
You can easily adapt it to any database supported by SQLAlchemy, like:
* PostgreSQL
* MySQL
* SQLite
* Oracle
* Microsoft SQL Server, etc.
In this example, we'll use **SQLite**, because it uses a single file and Python has integrated support. So, you can copy this example and run it as is.
Later, for your production application, you might want to use a database server like **PostgreSQL**.
Tip
There is an official project generator with **FastAPI** and **PostgreSQL**, all based on **Docker**, including a frontend and more tools: <https://github.com/tiangolo/full-stack-fastapi-postgresql>
Note
Notice that most of the code is the standard `SQLAlchemy` code you would use with any framework.
The **FastAPI** specific code is as small as always.
ORMs
----
**FastAPI** works with any database and any style of library to talk to the database.
A common pattern is to use an "ORM": an "object-relational mapping" library.
An ORM has tools to convert ("*map*") between *objects* in code and database tables ("*relations*").
With an ORM, you normally create a class that represents a table in a SQL database, each attribute of the class represents a column, with a name and a type.
For example a class `Pet` could represent a SQL table `pets`.
And each *instance* object of that class represents a row in the database.
For example an object `orion_cat` (an instance of `Pet`) could have an attribute `orion_cat.type`, for the column `type`. And the value of that attribute could be, e.g. `"cat"`.
These ORMs also have tools to make the connections or relations between tables or entities.
This way, you could also have an attribute `orion_cat.owner` and the owner would contain the data for this pet's owner, taken from the table *owners*.
So, `orion_cat.owner.name` could be the name (from the `name` column in the `owners` table) of this pet's owner.
It could have a value like `"Arquilian"`.
And the ORM will do all the work to get the information from the corresponding table *owners* when you try to access it from your pet object.
Common ORMs are for example: Django-ORM (part of the Django framework), SQLAlchemy ORM (part of SQLAlchemy, independent of framework) and Peewee (independent of framework), among others.
Here we will see how to work with **SQLAlchemy ORM**.
In a similar way you could use any other ORM.
Tip
There's an equivalent article using Peewee here in the docs.
File structure
--------------
For these examples, let's say you have a directory named `my_super_project` that contains a sub-directory called `sql_app` with a structure like this:
```
.
└── sql_app
├── __init__.py
├── crud.py
├── database.py
├── main.py
├── models.py
└── schemas.py
```
The file `__init__.py` is just an empty file, but it tells Python that `sql_app` with all its modules (Python files) is a package.
Now let's see what each file/module does.
Install `SQLAlchemy`
--------------------
First you need to install `SQLAlchemy`:
```
$ pip install sqlalchemy
---> 100%
```
Create the SQLAlchemy parts
---------------------------
Let's refer to the file `sql_app/database.py`.
### Import the SQLAlchemy parts
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
### Create a database URL for SQLAlchemy
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
In this example, we are "connecting" to a SQLite database (opening a file with the SQLite database).
The file will be located at the same directory in the file `sql_app.db`.
That's why the last part is `./sql_app.db`.
If you were using a **PostgreSQL** database instead, you would just have to uncomment the line:
```
SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
```
...and adapt it with your database data and credentials (equivalently for MySQL, MariaDB or any other).
Tip
This is the main line that you would have to modify if you wanted to use a different database.
### Create the SQLAlchemy `engine`
The first step is to create a SQLAlchemy "engine".
We will later use this `engine` in other places.
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
#### Note
The argument:
```
connect_args={"check_same_thread": False}
```
...is needed only for `SQLite`. It's not needed for other databases.
Technical Details
By default SQLite will only allow one thread to communicate with it, assuming that each thread would handle an independent request.
This is to prevent accidentally sharing the same connection for different things (for different requests).
But in FastAPI, using normal functions (`def`) more than one thread could interact with the database for the same request, so we need to make SQLite know that it should allow that with `connect_args={"check_same_thread": False}`.
Also, we will make sure each request gets its own database connection session in a dependency, so there's no need for that default mechanism.
### Create a `SessionLocal` class
Each instance of the `SessionLocal` class will be a database session. The class itself is not a database session yet.
But once we create an instance of the `SessionLocal` class, this instance will be the actual database session.
We name it `SessionLocal` to distinguish it from the `Session` we are importing from SQLAlchemy.
We will use `Session` (the one imported from SQLAlchemy) later.
To create the `SessionLocal` class, use the function `sessionmaker`:
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
### Create a `Base` class
Now we will use the function `declarative_base()` that returns a class.
Later we will inherit from this class to create each of the database models or classes (the ORM models):
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
Create the database models
--------------------------
Let's now see the file `sql_app/models.py`.
### Create SQLAlchemy models from the `Base` class
We will use this `Base` class we created before to create the SQLAlchemy models.
Tip
SQLAlchemy uses the term "**model**" to refer to these classes and instances that interact with the database.
But Pydantic also uses the term "**model**" to refer to something different, the data validation, conversion, and documentation classes and instances.
Import `Base` from `database` (the file `database.py` from above).
Create classes that inherit from it.
These classes are the SQLAlchemy models.
```
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationship
from .database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
items = relationship("Item", back_populates="owner")
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="items")
```
The `__tablename__` attribute tells SQLAlchemy the name of the table to use in the database for each of these models.
### Create model attributes/columns
Now create all the model (class) attributes.
Each of these attributes represents a column in its corresponding database table.
We use `Column` from SQLAlchemy as the default value.
And we pass a SQLAlchemy class "type", as `Integer`, `String`, and `Boolean`, that defines the type in the database, as an argument.
```
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationship
from .database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
items = relationship("Item", back_populates="owner")
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="items")
```
### Create the relationships
Now create the relationships.
For this, we use `relationship` provided by SQLAlchemy ORM.
This will become, more or less, a "magic" attribute that will contain the values from other tables related to this one.
```
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationship
from .database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
items = relationship("Item", back_populates="owner")
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="items")
```
When accessing the attribute `items` in a `User`, as in `my_user.items`, it will have a list of `Item` SQLAlchemy models (from the `items` table) that have a foreign key pointing to this record in the `users` table.
When you access `my_user.items`, SQLAlchemy will actually go and fetch the items from the database in the `items` table and populate them here.
And when accessing the attribute `owner` in an `Item`, it will contain a `User` SQLAlchemy model from the `users` table. It will use the `owner_id` attribute/column with its foreign key to know which record to get from the `users` table.
Create the Pydantic models
--------------------------
Now let's check the file `sql_app/schemas.py`.
Tip
To avoid confusion between the SQLAlchemy *models* and the Pydantic *models*, we will have the file `models.py` with the SQLAlchemy models, and the file `schemas.py` with the Pydantic models.
These Pydantic models define more or less a "schema" (a valid data shape).
So this will help us avoiding confusion while using both.
### Create initial Pydantic *models* / schemas
Create an `ItemBase` and `UserBase` Pydantic *models* (or let's say "schemas") to have common attributes while creating or reading data.
And create an `ItemCreate` and `UserCreate` that inherit from them (so they will have the same attributes), plus any additional data (attributes) needed for creation.
So, the user will also have a `password` when creating it.
But for security, the `password` won't be in other Pydantic *models*, for example, it won't be sent from the API when reading a user.
Python 3.10+
```
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.9+
```
from typing import Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.6+
```
from typing import List, Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
```
#### SQLAlchemy style and Pydantic style
Notice that SQLAlchemy *models* define attributes using `=`, and pass the type as a parameter to `Column`, like in:
```
name = Column(String)
```
while Pydantic *models* declare the types using `:`, the new type annotation syntax/type hints:
```
name: str
```
Have it in mind, so you don't get confused when using `=` and `:` with them.
### Create Pydantic *models* / schemas for reading / returning
Now create Pydantic *models* (schemas) that will be used when reading data, when returning it from the API.
For example, before creating an item, we don't know what will be the ID assigned to it, but when reading it (when returning it from the API) we will already know its ID.
The same way, when reading a user, we can now declare that `items` will contain the items that belong to this user.
Not only the IDs of those items, but all the data that we defined in the Pydantic *model* for reading items: `Item`.
Python 3.10+
```
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.9+
```
from typing import Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.6+
```
from typing import List, Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
```
Tip
Notice that the `User`, the Pydantic *model* that will be used when reading a user (returning it from the API) doesn't include the `password`.
### Use Pydantic's `orm_mode`
Now, in the Pydantic *models* for reading, `Item` and `User`, add an internal `Config` class.
This [`Config`](https://pydantic-docs.helpmanual.io/usage/model_config/) class is used to provide configurations to Pydantic.
In the `Config` class, set the attribute `orm_mode = True`.
Python 3.10+
```
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.9+
```
from typing import Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.6+
```
from typing import List, Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
```
Tip
Notice it's assigning a value with `=`, like:
`orm_mode = True`
It doesn't use `:` as for the type declarations before.
This is setting a config value, not declaring a type.
Pydantic's `orm_mode` will tell the Pydantic *model* to read the data even if it is not a `dict`, but an ORM model (or any other arbitrary object with attributes).
This way, instead of only trying to get the `id` value from a `dict`, as in:
```
id = data["id"]
```
it will also try to get it from an attribute, as in:
```
id = data.id
```
And with this, the Pydantic *model* is compatible with ORMs, and you can just declare it in the `response_model` argument in your *path operations*.
You will be able to return a database model and it will read the data from it.
#### Technical Details about ORM mode
SQLAlchemy and many others are by default "lazy loading".
That means, for example, that they don't fetch the data for relationships from the database unless you try to access the attribute that would contain that data.
For example, accessing the attribute `items`:
```
current_user.items
```
would make SQLAlchemy go to the `items` table and get the items for this user, but not before.
Without `orm_mode`, if you returned a SQLAlchemy model from your *path operation*, it wouldn't include the relationship data.
Even if you declared those relationships in your Pydantic models.
But with ORM mode, as Pydantic itself will try to access the data it needs from attributes (instead of assuming a `dict`), you can declare the specific data you want to return and it will be able to go and get it, even from ORMs.
CRUD utils
----------
Now let's see the file `sql_app/crud.py`.
In this file we will have reusable functions to interact with the data in the database.
**CRUD** comes from: **C**reate, **R**ead, **U**pdate, and **D**elete.
...although in this example we are only creating and reading.
### Read data
Import `Session` from `sqlalchemy.orm`, this will allow you to declare the type of the `db` parameters and have better type checks and completion in your functions.
Import `models` (the SQLAlchemy models) and `schemas` (the Pydantic *models* / schemas).
Create utility functions to:
* Read a single user by ID and by email.
* Read multiple users.
* Read multiple items.
```
from sqlalchemy.orm import Session
from . import models, schemas
def get_user(db: Session, user_id: int):
return db.query(models.User).filter(models.User.id == user_id).first()
def get_user_by_email(db: Session, email: str):
return db.query(models.User).filter(models.User.email == email).first()
def get_users(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.User).offset(skip).limit(limit).all()
def create_user(db: Session, user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
def get_items(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Item).offset(skip).limit(limit).all()
def create_user_item(db: Session, item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db.add(db_item)
db.commit()
db.refresh(db_item)
return db_item
```
Tip
By creating functions that are only dedicated to interacting with the database (get a user or an item) independent of your *path operation function*, you can more easily reuse them in multiple parts and also add unit tests for them.
### Create data
Now create utility functions to create data.
The steps are:
* Create a SQLAlchemy model *instance* with your data.
* `add` that instance object to your database session.
* `commit` the changes to the database (so that they are saved).
* `refresh` your instance (so that it contains any new data from the database, like the generated ID).
```
from sqlalchemy.orm import Session
from . import models, schemas
def get_user(db: Session, user_id: int):
return db.query(models.User).filter(models.User.id == user_id).first()
def get_user_by_email(db: Session, email: str):
return db.query(models.User).filter(models.User.email == email).first()
def get_users(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.User).offset(skip).limit(limit).all()
def create_user(db: Session, user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
def get_items(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Item).offset(skip).limit(limit).all()
def create_user_item(db: Session, item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db.add(db_item)
db.commit()
db.refresh(db_item)
return db_item
```
Tip
The SQLAlchemy model for `User` contains a `hashed_password` that should contain a secure hashed version of the password.
But as what the API client provides is the original password, you need to extract it and generate the hashed password in your application.
And then pass the `hashed_password` argument with the value to save.
Warning
This example is not secure, the password is not hashed.
In a real life application you would need to hash the password and never save them in plaintext.
For more details, go back to the Security section in the tutorial.
Here we are focusing only on the tools and mechanics of databases.
Tip
Instead of passing each of the keyword arguments to `Item` and reading each one of them from the Pydantic *model*, we are generating a `dict` with the Pydantic *model*'s data with:
`item.dict()`
and then we are passing the `dict`'s key-value pairs as the keyword arguments to the SQLAlchemy `Item`, with:
`Item(**item.dict())`
And then we pass the extra keyword argument `owner_id` that is not provided by the Pydantic *model*, with:
`Item(**item.dict(), owner_id=user_id)`
Main **FastAPI** app
--------------------
And now in the file `sql_app/main.py` let's integrate and use all the other parts we created before.
### Create the database tables
In a very simplistic way create the database tables:
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
#### Alembic Note
Normally you would probably initialize your database (create tables, etc) with [Alembic](https://alembic.sqlalchemy.org/en/latest/).
And you would also use Alembic for "migrations" (that's its main job).
A "migration" is the set of steps needed whenever you change the structure of your SQLAlchemy models, add a new attribute, etc. to replicate those changes in the database, add a new column, a new table, etc.
You can find an example of Alembic in a FastAPI project in the templates from [Project Generation - Template](../../project-generation/index). Specifically in [the `alembic` directory in the source code](https://github.com/tiangolo/full-stack-fastapi-postgresql/tree/master/%7B%7Bcookiecutter.project_slug%7D%7D/backend/app/alembic/).
### Create a dependency
Now use the `SessionLocal` class we created in the `sql_app/database.py` file to create a dependency.
We need to have an independent database session/connection (`SessionLocal`) per request, use the same session through all the request and then close it after the request is finished.
And then a new session will be created for the next request.
For that, we will create a new dependency with `yield`, as explained before in the section about [Dependencies with `yield`](../dependencies/dependencies-with-yield/index).
Our dependency will create a new SQLAlchemy `SessionLocal` that will be used in a single request, and then close it once the request is finished.
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Info
We put the creation of the `SessionLocal()` and handling of the requests in a `try` block.
And then we close it in the `finally` block.
This way we make sure the database session is always closed after the request. Even if there was an exception while processing the request.
But you can't raise another exception from the exit code (after `yield`). See more in [Dependencies with `yield` and `HTTPException`](../dependencies/dependencies-with-yield/index#dependencies-with-yield-and-httpexception)
And then, when using the dependency in a *path operation function*, we declare it with the type `Session` we imported directly from SQLAlchemy.
This will then give us better editor support inside the *path operation function*, because the editor will know that the `db` parameter is of type `Session`:
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Technical Details
The parameter `db` is actually of type `SessionLocal`, but this class (created with `sessionmaker()`) is a "proxy" of a SQLAlchemy `Session`, so, the editor doesn't really know what methods are provided.
But by declaring the type as `Session`, the editor now can know the available methods (`.add()`, `.query()`, `.commit()`, etc) and can provide better support (like completion). The type declaration doesn't affect the actual object.
### Create your **FastAPI** *path operations*
Now, finally, here's the standard **FastAPI** *path operations* code.
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
We are creating the database session before each request in the dependency with `yield`, and then closing it afterwards.
And then we can create the required dependency in the *path operation function*, to get that session directly.
With that, we can just call `crud.get_user` directly from inside of the *path operation function* and use that session.
Tip
Notice that the values you return are SQLAlchemy models, or lists of SQLAlchemy models.
But as all the *path operations* have a `response_model` with Pydantic *models* / schemas using `orm_mode`, the data declared in your Pydantic models will be extracted from them and returned to the client, with all the normal filtering and validation.
Tip
Also notice that there are `response_models` that have standard Python types like `List[schemas.Item]`.
But as the content/parameter of that `List` is a Pydantic *model* with `orm_mode`, the data will be retrieved and returned to the client as normally, without problems.
### About `def` vs `async def`
Here we are using SQLAlchemy code inside of the *path operation function* and in the dependency, and, in turn, it will go and communicate with an external database.
That could potentially require some "waiting".
But as SQLAlchemy doesn't have compatibility for using `await` directly, as would be with something like:
```
user = await db.query(User).first()
```
...and instead we are using:
```
user = db.query(User).first()
```
Then we should declare the *path operation functions* and the dependency without `async def`, just with a normal `def`, as:
```
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
...
```
Info
If you need to connect to your relational database asynchronously, see [Async SQL (Relational) Databases](../../advanced/async-sql-databases/index).
Very Technical Details
If you are curious and have a deep technical knowledge, you can check the very technical details of how this `async def` vs `def` is handled in the [Async](../../async/index#very-technical-details) docs.
Migrations
----------
Because we are using SQLAlchemy directly and we don't require any kind of plug-in for it to work with **FastAPI**, we could integrate database migrations with [Alembic](https://alembic.sqlalchemy.org) directly.
And as the code related to SQLAlchemy and the SQLAlchemy models lives in separate independent files, you would even be able to perform the migrations with Alembic without having to install FastAPI, Pydantic, or anything else.
The same way, you would be able to use the same SQLAlchemy models and utilities in other parts of your code that are not related to **FastAPI**.
For example, in a background task worker with [Celery](https://docs.celeryq.dev), [RQ](https://python-rq.org/), or [ARQ](https://arq-docs.helpmanual.io/).
Review all the files
--------------------
Remember you should have a directory named `my_super_project` that contains a sub-directory called `sql_app`.
`sql_app` should have the following files:
* `sql_app/__init__.py`: is an empty file.
* `sql_app/database.py`:
```
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
```
* `sql_app/models.py`:
```
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationship
from .database import Base
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
email = Column(String, unique=True, index=True)
hashed_password = Column(String)
is_active = Column(Boolean, default=True)
items = relationship("Item", back_populates="owner")
class Item(Base):
__tablename__ = "items"
id = Column(Integer, primary_key=True, index=True)
title = Column(String, index=True)
description = Column(String, index=True)
owner_id = Column(Integer, ForeignKey("users.id"))
owner = relationship("User", back_populates="items")
```
* `sql_app/schemas.py`:
Python 3.10+
```
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: str | None = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.9+
```
from typing import Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: list[Item] = []
class Config:
orm_mode = True
```
Python 3.6+
```
from typing import List, Union
from pydantic import BaseModel
class ItemBase(BaseModel):
title: str
description: Union[str, None] = None
class ItemCreate(ItemBase):
pass
class Item(ItemBase):
id: int
owner_id: int
class Config:
orm_mode = True
class UserBase(BaseModel):
email: str
class UserCreate(UserBase):
password: str
class User(UserBase):
id: int
is_active: bool
items: List[Item] = []
class Config:
orm_mode = True
```
* `sql_app/crud.py`:
```
from sqlalchemy.orm import Session
from . import models, schemas
def get_user(db: Session, user_id: int):
return db.query(models.User).filter(models.User.id == user_id).first()
def get_user_by_email(db: Session, email: str):
return db.query(models.User).filter(models.User.email == email).first()
def get_users(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.User).offset(skip).limit(limit).all()
def create_user(db: Session, user: schemas.UserCreate):
fake_hashed_password = user.password + "notreallyhashed"
db_user = models.User(email=user.email, hashed_password=fake_hashed_password)
db.add(db_user)
db.commit()
db.refresh(db_user)
return db_user
def get_items(db: Session, skip: int = 0, limit: int = 100):
return db.query(models.Item).offset(skip).limit(limit).all()
def create_user_item(db: Session, item: schemas.ItemCreate, user_id: int):
db_item = models.Item(**item.dict(), owner_id=user_id)
db.add(db_item)
db.commit()
db.refresh(db_item)
return db_item
```
* `sql_app/main.py`:
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
# Dependency
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Check it
--------
You can copy this code and use it as is.
Info
In fact, the code shown here is part of the tests. As most of the code in these docs.
Then you can run it with Uvicorn:
```
$ uvicorn sql_app.main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And then, you can open your browser at <http://127.0.0.1:8000/docs>.
And you will be able to interact with your **FastAPI** application, reading data from a real database:
Interact with the database directly
-----------------------------------
If you want to explore the SQLite database (file) directly, independently of FastAPI, to debug its contents, add tables, columns, records, modify data, etc. you can use [DB Browser for SQLite](https://sqlitebrowser.org/).
It will look like this:
You can also use an online SQLite browser like [SQLite Viewer](https://inloop.github.io/sqlite-viewer/) or [ExtendsClass](https://extendsclass.com/sqlite-browser.html).
Alternative DB session with middleware
--------------------------------------
If you can't use dependencies with `yield` -- for example, if you are not using **Python 3.7** and can't install the "backports" mentioned above for **Python 3.6** -- you can set up the session in a "middleware" in a similar way.
A "middleware" is basically a function that is always executed for each request, with some code executed before, and some code executed after the endpoint function.
### Create a middleware
The middleware we'll add (just a function) will create a new SQLAlchemy `SessionLocal` for each request, add it to the request and then close it once the request is finished.
Python 3.9+
```
from fastapi import Depends, FastAPI, HTTPException, Request, Response
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
@app.middleware("http")
async def db_session_middleware(request: Request, call_next):
response = Response("Internal server error", status_code=500)
try:
request.state.db = SessionLocal()
response = await call_next(request)
finally:
request.state.db.close()
return response
# Dependency
def get_db(request: Request):
return request.state.db
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Python 3.6+
```
from typing import List
from fastapi import Depends, FastAPI, HTTPException, Request, Response
from sqlalchemy.orm import Session
from . import crud, models, schemas
from .database import SessionLocal, engine
models.Base.metadata.create_all(bind=engine)
app = FastAPI()
@app.middleware("http")
async def db_session_middleware(request: Request, call_next):
response = Response("Internal server error", status_code=500)
try:
request.state.db = SessionLocal()
response = await call_next(request)
finally:
request.state.db.close()
return response
# Dependency
def get_db(request: Request):
return request.state.db
@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):
db_user = crud.get_user_by_email(db, email=user.email)
if db_user:
raise HTTPException(status_code=400, detail="Email already registered")
return crud.create_user(db=db, user=user)
@app.get("/users/", response_model=List[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
users = crud.get_users(db, skip=skip, limit=limit)
return users
@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):
db_user = crud.get_user(db, user_id=user_id)
if db_user is None:
raise HTTPException(status_code=404, detail="User not found")
return db_user
@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(
user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):
return crud.create_user_item(db=db, item=item, user_id=user_id)
@app.get("/items/", response_model=List[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):
items = crud.get_items(db, skip=skip, limit=limit)
return items
```
Info
We put the creation of the `SessionLocal()` and handling of the requests in a `try` block.
And then we close it in the `finally` block.
This way we make sure the database session is always closed after the request. Even if there was an exception while processing the request.
### About `request.state`
`request.state` is a property of each `Request` object. It is there to store arbitrary objects attached to the request itself, like the database session in this case. You can read more about it in [Starlette's docs about `Request` state](https://www.starlette.io/requests/#other-state).
For us in this case, it helps us ensure a single database session is used through all the request, and then closed afterwards (in the middleware).
### Dependencies with `yield` or middleware
Adding a **middleware** here is similar to what a dependency with `yield` does, with some differences:
* It requires more code and is a bit more complex.
* The middleware has to be an `async` function.
+ If there is code in it that has to "wait" for the network, it could "block" your application there and degrade performance a bit.
+ Although it's probably not very problematic here with the way `SQLAlchemy` works.
+ But if you added more code to the middleware that had a lot of I/O waiting, it could then be problematic.
* A middleware is run for *every* request.
+ So, a connection will be created for every request.
+ Even when the *path operation* that handles that request didn't need the DB.
Tip
It's probably better to use dependencies with `yield` when they are enough for the use case.
Info
Dependencies with `yield` were added recently to **FastAPI**.
A previous version of this tutorial only had the examples with a middleware and there are probably several applications using the middleware for database session management.
| programming_docs |
fastapi Body - Fields Body - Fields
=============
The same way you can declare additional validation and metadata in *path operation function* parameters with `Query`, `Path` and `Body`, you can declare validation and metadata inside of Pydantic models using Pydantic's `Field`.
Import `Field`
--------------
First, you have to import it:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
Warning
Notice that `Field` is imported directly from `pydantic`, not from `fastapi` as are all the rest (`Query`, `Path`, `Body`, etc).
Declare model attributes
------------------------
You can then use `Field` with model attributes:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Annotated[Item, Body(embed=True)]):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = Field(
default=None, title="The description of the item", max_length=300
)
price: float = Field(gt=0, description="The price must be greater than zero")
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item = Body(embed=True)):
results = {"item_id": item_id, "item": item}
return results
```
`Field` works the same way as `Query`, `Path` and `Body`, it has all the same parameters, etc.
Technical Details
Actually, `Query`, `Path` and others you'll see next create objects of subclasses of a common `Param` class, which is itself a subclass of Pydantic's `FieldInfo` class.
And Pydantic's `Field` returns an instance of `FieldInfo` as well.
`Body` also returns objects of a subclass of `FieldInfo` directly. And there are others you will see later that are subclasses of the `Body` class.
Remember that when you import `Query`, `Path`, and others from `fastapi`, those are actually functions that return special classes.
Tip
Notice how each model's attribute with a type, default value and `Field` has the same structure as a *path operation function's* parameter, with `Field` instead of `Path`, `Query` and `Body`.
Add extra information
---------------------
You can declare extra information in `Field`, `Query`, `Body`, etc. And it will be included in the generated JSON Schema.
You will learn more about adding extra information later in the docs, when learning to declare examples.
Warning
Extra keys passed to `Field` will also be present in the resulting OpenAPI schema for your application. As these keys may not necessarily be part of the OpenAPI specification, some OpenAPI tools, for example [the OpenAPI validator](https://validator.swagger.io/), may not work with your generated schema.
Recap
-----
You can use Pydantic's `Field` to declare extra validations and metadata for model attributes.
You can also use the extra keyword arguments to pass additional JSON Schema metadata.
fastapi Dependencies - First Steps Dependencies - First Steps
==========================
**FastAPI** has a very powerful but intuitive **Dependency Injection** system.
It is designed to be very simple to use, and to make it very easy for any developer to integrate other components with **FastAPI**.
What is "Dependency Injection"
------------------------------
**"Dependency Injection"** means, in programming, that there is a way for your code (in this case, your *path operation functions*) to declare things that it requires to work and use: "dependencies".
And then, that system (in this case **FastAPI**) will take care of doing whatever is needed to provide your code with those needed dependencies ("inject" the dependencies).
This is very useful when you need to:
* Have shared logic (the same code logic again and again).
* Share database connections.
* Enforce security, authentication, role requirements, etc.
* And many other things...
All these, while minimizing code repetition.
First Steps
-----------
Let's see a very simple example. It will be so simple that it is not very useful, for now.
But this way we can focus on how the **Dependency Injection** system works.
### Create a dependency, or "dependable"
Let's first focus on the dependency.
It is just a function that can take all the same parameters that a *path operation function* can take:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
That's it.
**2 lines**.
And it has the same shape and structure that all your *path operation functions* have.
You can think of it as a *path operation function* without the "decorator" (without the `@app.get("/some-path")`).
And it can return anything you want.
In this case, this dependency expects:
* An optional query parameter `q` that is a `str`.
* An optional query parameter `skip` that is an `int`, and by default is `0`.
* An optional query parameter `limit` that is an `int`, and by default is `100`.
And then it just returns a `dict` containing those values.
### Import `Depends`
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
### Declare the dependency, in the "dependant"
The same way you use `Body`, `Query`, etc. with your *path operation function* parameters, use `Depends` with a new parameter:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Although you use `Depends` in the parameters of your function the same way you use `Body`, `Query`, etc, `Depends` works a bit differently.
You only give `Depends` a single parameter.
This parameter must be something like a function.
You **don't call it** directly (don't add the parenthesis at the end), you just pass it as a parameter to `Depends()`.
And that function takes parameters in the same way that *path operation functions* do.
Tip
You'll see what other "things", apart from functions, can be used as dependencies in the next chapter.
Whenever a new request arrives, **FastAPI** will take care of:
* Calling your dependency ("dependable") function with the correct parameters.
* Get the result from your function.
* Assign that result to the parameter in your *path operation function*.
```
graph TB
common_parameters(["common_parameters"])
read_items["/items/"]
read_users["/users/"]
common_parameters --> read_items
common_parameters --> read_users
```
This way you write shared code once and **FastAPI** takes care of calling it for your *path operations*.
Check
Notice that you don't have to create a special class and pass it somewhere to **FastAPI** to "register" it or anything similar.
You just pass it to `Depends` and **FastAPI** knows how to do the rest.
Share `Annotated` dependencies
------------------------------
In the examples above, you see that there's a tiny bit of **code duplication**.
When you need to use the `common_parameters()` dependency, you have to write the whole parameter with the type annotation and `Depends()`:
```
commons: Annotated[dict, Depends(common_parameters)]
```
But because we are using `Annotated`, we can store that `Annotated` value in a variable and use it in multiple places:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
CommonsDep = Annotated[dict, Depends(common_parameters)]
@app.get("/items/")
async def read_items(commons: CommonsDep):
return commons
@app.get("/users/")
async def read_users(commons: CommonsDep):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
CommonsDep = Annotated[dict, Depends(common_parameters)]
@app.get("/items/")
async def read_items(commons: CommonsDep):
return commons
@app.get("/users/")
async def read_users(commons: CommonsDep):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
CommonsDep = Annotated[dict, Depends(common_parameters)]
@app.get("/items/")
async def read_items(commons: CommonsDep):
return commons
@app.get("/users/")
async def read_users(commons: CommonsDep):
return commons
```
Tip
This is just standard Python, it's called a "type alias", it's actually not specific to **FastAPI**.
But because **FastAPI** is based on the Python standards, including `Annotated`, you can use this trick in your code. 😎
The dependencies will keep working as expected, and the **best part** is that the **type information will be preserved**, which means that your editor will be able to keep providing you with **autocompletion**, **inline errors**, etc. The same for other tools like `mypy`.
This will be especially useful when you use it in a **large code base** where you use **the same dependencies** over and over again in **many *path operations***.
To `async` or not to `async`
----------------------------
As dependencies will also be called by **FastAPI** (the same as your *path operation functions*), the same rules apply while defining your functions.
You can use `async def` or normal `def`.
And you can declare dependencies with `async def` inside of normal `def` *path operation functions*, or `def` dependencies inside of `async def` *path operation functions*, etc.
It doesn't matter. **FastAPI** will know what to do.
Note
If you don't know, check the [Async: *"In a hurry?"*](../../async/index) section about `async` and `await` in the docs.
Integrated with OpenAPI
-----------------------
All the request declarations, validations and requirements of your dependencies (and sub-dependencies) will be integrated in the same OpenAPI schema.
So, the interactive docs will have all the information from these dependencies too:
Simple usage
------------
If you look at it, *path operation functions* are declared to be used whenever a *path* and *operation* matches, and then **FastAPI** takes care of calling the function with the correct parameters, extracting the data from the request.
Actually, all (or most) of the web frameworks work in this same way.
You never call those functions directly. They are called by your framework (in this case, **FastAPI**).
With the Dependency Injection system, you can also tell **FastAPI** that your *path operation function* also "depends" on something else that should be executed before your *path operation function*, and **FastAPI** will take care of executing it and "injecting" the results.
Other common terms for this same idea of "dependency injection" are:
* resources
* providers
* services
* injectables
* components
**FastAPI** plug-ins
---------------------
Integrations and "plug-in"s can be built using the **Dependency Injection** system. But in fact, there is actually **no need to create "plug-ins"**, as by using dependencies it's possible to declare an infinite number of integrations and interactions that become available to your *path operation functions*.
And dependencies can be created in a very simple and intuitive way that allow you to just import the Python packages you need, and integrate them with your API functions in a couple of lines of code, *literally*.
You will see examples of this in the next chapters, about relational and NoSQL databases, security, etc.
**FastAPI** compatibility
--------------------------
The simplicity of the dependency injection system makes **FastAPI** compatible with:
* all the relational databases
* NoSQL databases
* external packages
* external APIs
* authentication and authorization systems
* API usage monitoring systems
* response data injection systems
* etc.
Simple and Powerful
-------------------
Although the hierarchical dependency injection system is very simple to define and use, it's still very powerful.
You can define dependencies that in turn can define dependencies themselves.
In the end, a hierarchical tree of dependencies is built, and the **Dependency Injection** system takes care of solving all these dependencies for you (and their sub-dependencies) and providing (injecting) the results at each step.
For example, let's say you have 4 API endpoints (*path operations*):
* `/items/public/`
* `/items/private/`
* `/users/{user_id}/activate`
* `/items/pro/`
then you could add different permission requirements for each of them just with dependencies and sub-dependencies:
```
graph TB
current_user(["current_user"])
active_user(["active_user"])
admin_user(["admin_user"])
paying_user(["paying_user"])
public["/items/public/"]
private["/items/private/"]
activate_user["/users/{user_id}/activate"]
pro_items["/items/pro/"]
current_user --> active_user
active_user --> admin_user
active_user --> paying_user
current_user --> public
active_user --> private
admin_user --> activate_user
paying_user --> pro_items
```
Integrated with **OpenAPI**
---------------------------
All these dependencies, while declaring their requirements, also add parameters, validations, etc. to your *path operations*.
**FastAPI** will take care of adding it all to the OpenAPI schema, so that it is shown in the interactive documentation systems.
| programming_docs |
fastapi Classes as Dependencies Classes as Dependencies
=======================
Before diving deeper into the **Dependency Injection** system, let's upgrade the previous example.
A `dict` from the previous example
----------------------------------
In the previous example, we were returning a `dict` from our dependency ("dependable"):
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
But then we get a `dict` in the parameter `commons` of the *path operation function*.
And we know that editors can't provide a lot of support (like completion) for `dict`s, because they can't know their keys and value types.
We can do better...
What makes a dependency
-----------------------
Up to now you have seen dependencies declared as functions.
But that's not the only way to declare dependencies (although it would probably be the more common).
The key factor is that a dependency should be a "callable".
A "**callable**" in Python is anything that Python can "call" like a function.
So, if you have an object `something` (that might *not* be a function) and you can "call" it (execute it) like:
```
something()
```
or
```
something(some_argument, some_keyword_argument="foo")
```
then it is a "callable".
Classes as dependencies
-----------------------
You might notice that to create an instance of a Python class, you use that same syntax.
For example:
```
class Cat:
def __init__(self, name: str):
self.name = name
fluffy = Cat(name="Mr Fluffy")
```
In this case, `fluffy` is an instance of the class `Cat`.
And to create `fluffy`, you are "calling" `Cat`.
So, a Python class is also a **callable**.
Then, in **FastAPI**, you could use a Python class as a dependency.
What FastAPI actually checks is that it is a "callable" (function, class or anything else) and the parameters defined.
If you pass a "callable" as a dependency in **FastAPI**, it will analyze the parameters for that "callable", and process them in the same way as the parameters for a *path operation function*. Including sub-dependencies.
That also applies to callables with no parameters at all. The same as it would be for *path operation functions* with no parameters.
Then, we can change the dependency "dependable" `common_parameters` from above to the class `CommonQueryParams`:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Pay attention to the `__init__` method used to create the instance of the class:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
...it has the same parameters as our previous `common_parameters`:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: Annotated[dict, Depends(common_parameters)]):
return commons
@app.get("/users/")
async def read_users(commons: Annotated[dict, Depends(common_parameters)]):
return commons
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(q: str | None = None, skip: int = 0, limit: int = 100):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
async def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
return commons
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
return commons
```
Those parameters are what **FastAPI** will use to "solve" the dependency.
In both cases, it will have:
* An optional `q` query parameter that is a `str`.
* A `skip` query parameter that is an `int`, with a default of `0`.
* A `limit` query parameter that is an `int`, with a default of `100`.
In both cases the data will be converted, validated, documented on the OpenAPI schema, etc.
Use it
------
Now you can declare your dependency using this class.
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
**FastAPI** calls the `CommonQueryParams` class. This creates an "instance" of that class and the instance will be passed as the parameter `commons` to your function.
Type annotation vs `Depends`
----------------------------
Notice how we write `CommonQueryParams` twice in the above code:
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons: CommonQueryParams = Depends(CommonQueryParams)
```
Python 3.6+
```
commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]
```
The last `CommonQueryParams`, in:
```
... Depends(CommonQueryParams)
```
...is what **FastAPI** will actually use to know what is the dependency.
From it is that FastAPI will extract the declared parameters and that is what FastAPI will actually call.
---
In this case, the first `CommonQueryParams`, in:
Python 3.6+
```
commons: Annotated[CommonQueryParams, ...
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons: CommonQueryParams ...
```
...doesn't have any special meaning for **FastAPI**. FastAPI won't use it for data conversion, validation, etc. (as it is using the `Depends(CommonQueryParams)` for that).
You could actually write just:
Python 3.6+
```
commons: Annotated[Any, Depends(CommonQueryParams)]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons = Depends(CommonQueryParams)
```
..as in:
Python 3.10+
```
from typing import Annotated, Any
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[Any, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.9+
```
from typing import Annotated, Any, Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[Any, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+
```
from typing import Any, Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[Any, Depends(CommonQueryParams)]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons=Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons=Depends(CommonQueryParams)):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
But declaring the type is encouraged as that way your editor will know what will be passed as the parameter `commons`, and then it can help you with code completion, type checks, etc:
Shortcut
--------
But you see that we are having some code repetition here, writing `CommonQueryParams` twice:
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons: CommonQueryParams = Depends(CommonQueryParams)
```
Python 3.6+
```
commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]
```
**FastAPI** provides a shortcut for these cases, in where the dependency is *specifically* a class that **FastAPI** will "call" to create an instance of the class itself.
For those specific cases, you can do the following:
Instead of writing:
Python 3.6+
```
commons: Annotated[CommonQueryParams, Depends(CommonQueryParams)]
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons: CommonQueryParams = Depends(CommonQueryParams)
```
...you write:
Python 3.6+
```
commons: Annotated[CommonQueryParams, Depends()]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
commons: CommonQueryParams = Depends()
```
You declare the dependency as the type of the parameter, and you use `Depends()` without any parameter, instead of having to write the full class *again* inside of `Depends(CommonQueryParams)`.
The same example would then look like:
Python 3.10+
```
from typing import Annotated
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends()]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends()]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+
```
from typing import Union
from fastapi import Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: Annotated[CommonQueryParams, Depends()]):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: str | None = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends()):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Depends, FastAPI
app = FastAPI()
fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}]
class CommonQueryParams:
def __init__(self, q: Union[str, None] = None, skip: int = 0, limit: int = 100):
self.q = q
self.skip = skip
self.limit = limit
@app.get("/items/")
async def read_items(commons: CommonQueryParams = Depends()):
response = {}
if commons.q:
response.update({"q": commons.q})
items = fake_items_db[commons.skip : commons.skip + commons.limit]
response.update({"items": items})
return response
```
...and **FastAPI** will know what to do.
Tip
If that seems more confusing than helpful, disregard it, you don't *need* it.
It is just a shortcut. Because **FastAPI** cares about helping you minimize code repetition.
| programming_docs |
fastapi Dependencies in path operation decorators Dependencies in path operation decorators
=========================================
In some cases you don't really need the return value of a dependency inside your *path operation function*.
Or the dependency doesn't return a value.
But you still need it to be executed/solved.
For those cases, instead of declaring a *path operation function* parameter with `Depends`, you can add a `list` of `dependencies` to the *path operation decorator*.
Add `dependencies` to the *path operation decorator*
----------------------------------------------------
The *path operation decorator* receives an optional argument `dependencies`.
It should be a `list` of `Depends()`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: str = Header()):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
These dependencies will be executed/solved the same way normal dependencies. But their value (if they return any) won't be passed to your *path operation function*.
Tip
Some editors check for unused function parameters, and show them as errors.
Using these `dependencies` in the *path operation decorator* you can make sure they are executed while avoiding editor/tooling errors.
It might also help avoid confusion for new developers that see an unused parameter in your code and could think it's unnecessary.
Info
In this example we use invented custom headers `X-Key` and `X-Token`.
But in real cases, when implementing security, you would get more benefits from using the integrated [Security utilities (the next chapter)](../../security/index).
Dependencies errors and return values
-------------------------------------
You can use the same dependency *functions* you use normally.
### Dependency requirements
They can declare request requirements (like headers) or other sub-dependencies:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: str = Header()):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
### Raise exceptions
These dependencies can `raise` exceptions, the same as normal dependencies:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: str = Header()):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
### Return values
And they can return values or not, the values won't be used.
So, you can re-use a normal dependency (that returns a value) you already use somewhere else, and even though the value won't be used, the dependency will be executed:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
app = FastAPI()
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, Header, HTTPException
app = FastAPI()
async def verify_token(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: str = Header()):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
@app.get("/items/", dependencies=[Depends(verify_token), Depends(verify_key)])
async def read_items():
return [{"item": "Foo"}, {"item": "Bar"}]
```
Dependencies for a group of *path operations*
---------------------------------------------
Later, when reading about how to structure bigger applications ([Bigger Applications - Multiple Files](../../bigger-applications/index)), possibly with multiple files, you will learn how to declare a single `dependencies` parameter for a group of *path operations*.
Global Dependencies
-------------------
Next we will see how to add dependencies to the whole `FastAPI` application, so that they apply to each *path operation*.
fastapi Global Dependencies Global Dependencies
===================
For some types of applications you might want to add dependencies to the whole application.
Similar to the way you can [add `dependencies` to the *path operation decorators*](../dependencies-in-path-operation-decorators/index), you can add them to the `FastAPI` application.
In that case, they will be applied to all the *path operations* in the application:
Python 3.9+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
app = FastAPI(dependencies=[Depends(verify_token), Depends(verify_key)])
@app.get("/items/")
async def read_items():
return [{"item": "Portal Gun"}, {"item": "Plumbus"}]
@app.get("/users/")
async def read_users():
return [{"username": "Rick"}, {"username": "Morty"}]
```
Python 3.6+
```
from fastapi import Depends, FastAPI, Header, HTTPException
from typing_extensions import Annotated
async def verify_token(x_token: Annotated[str, Header()]):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: Annotated[str, Header()]):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
app = FastAPI(dependencies=[Depends(verify_token), Depends(verify_key)])
@app.get("/items/")
async def read_items():
return [{"item": "Portal Gun"}, {"item": "Plumbus"}]
@app.get("/users/")
async def read_users():
return [{"username": "Rick"}, {"username": "Morty"}]
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends, FastAPI, Header, HTTPException
async def verify_token(x_token: str = Header()):
if x_token != "fake-super-secret-token":
raise HTTPException(status_code=400, detail="X-Token header invalid")
async def verify_key(x_key: str = Header()):
if x_key != "fake-super-secret-key":
raise HTTPException(status_code=400, detail="X-Key header invalid")
return x_key
app = FastAPI(dependencies=[Depends(verify_token), Depends(verify_key)])
@app.get("/items/")
async def read_items():
return [{"item": "Portal Gun"}, {"item": "Plumbus"}]
@app.get("/users/")
async def read_users():
return [{"username": "Rick"}, {"username": "Morty"}]
```
And all the ideas in the section about [adding `dependencies` to the *path operation decorators*](../dependencies-in-path-operation-decorators/index) still apply, but in this case, to all of the *path operations* in the app.
Dependencies for groups of *path operations*
--------------------------------------------
Later, when reading about how to structure bigger applications ([Bigger Applications - Multiple Files](../../bigger-applications/index)), possibly with multiple files, you will learn how to declare a single `dependencies` parameter for a group of *path operations*.
fastapi Sub-dependencies Sub-dependencies
================
You can create dependencies that have **sub-dependencies**.
They can be as **deep** as you need them to be.
**FastAPI** will take care of solving them.
First dependency "dependable"
-----------------------------
You could create a first dependency ("dependable") like:
Python 3.10+
```
from typing import Annotated
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[str | None, Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.6+
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.10 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor), last_query: str | None = Cookie(default=None)
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor),
last_query: Union[str, None] = Cookie(default=None),
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
It declares an optional query parameter `q` as a `str`, and then it just returns it.
This is quite simple (not very useful), but will help us focus on how the sub-dependencies work.
Second dependency, "dependable" and "dependant"
-----------------------------------------------
Then you can create another dependency function (a "dependable") that at the same time declares a dependency of its own (so it is a "dependant" too):
Python 3.10+
```
from typing import Annotated
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[str | None, Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.6+
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.10 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor), last_query: str | None = Cookie(default=None)
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor),
last_query: Union[str, None] = Cookie(default=None),
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
Let's focus on the parameters declared:
* Even though this function is a dependency ("dependable") itself, it also declares another dependency (it "depends" on something else).
+ It depends on the `query_extractor`, and assigns the value returned by it to the parameter `q`.
* It also declares an optional `last_query` cookie, as a `str`.
+ If the user didn't provide any query `q`, we use the last query used, which we saved to a cookie before.
Use the dependency
------------------
Then we can use the dependency with:
Python 3.10+
```
from typing import Annotated
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[str | None, Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.6+
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
from typing_extensions import Annotated
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: Annotated[str, Depends(query_extractor)],
last_query: Annotated[Union[str, None], Cookie()] = None,
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(
query_or_default: Annotated[str, Depends(query_or_cookie_extractor)]
):
return {"q_or_cookie": query_or_default}
```
Python 3.10 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: str | None = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor), last_query: str | None = Cookie(default=None)
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
Python 3.6 non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Cookie, Depends, FastAPI
app = FastAPI()
def query_extractor(q: Union[str, None] = None):
return q
def query_or_cookie_extractor(
q: str = Depends(query_extractor),
last_query: Union[str, None] = Cookie(default=None),
):
if not q:
return last_query
return q
@app.get("/items/")
async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)):
return {"q_or_cookie": query_or_default}
```
Info
Notice that we are only declaring one dependency in the *path operation function*, the `query_or_cookie_extractor`.
But **FastAPI** will know that it has to solve `query_extractor` first, to pass the results of that to `query_or_cookie_extractor` while calling it.
```
graph TB
query_extractor(["query_extractor"])
query_or_cookie_extractor(["query_or_cookie_extractor"])
read_query["/items/"]
query_extractor --> query_or_cookie_extractor --> read_query
```
Using the same dependency multiple times
----------------------------------------
If one of your dependencies is declared multiple times for the same *path operation*, for example, multiple dependencies have a common sub-dependency, **FastAPI** will know to call that sub-dependency only once per request.
And it will save the returned value in a "cache" and pass it to all the "dependants" that need it in that specific request, instead of calling the dependency multiple times for the same request.
In an advanced scenario where you know you need the dependency to be called at every step (possibly multiple times) in the same request instead of using the "cached" value, you can set the parameter `use_cache=False` when using `Depends`:
Python 3.6+
```
async def needy_dependency(fresh_value: Annotated[str, Depends(get_value, use_cache=False)]):
return {"fresh_value": fresh_value}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
async def needy_dependency(fresh_value: str = Depends(get_value, use_cache=False)):
return {"fresh_value": fresh_value}
```
Recap
-----
Apart from all the fancy words used here, the **Dependency Injection** system is quite simple.
Just functions that look the same as the *path operation functions*.
But still, it is very powerful, and allows you to declare arbitrarily deeply nested dependency "graphs" (trees).
Tip
All this might not seem as useful with these simple examples.
But you will see how useful it is in the chapters about **security**.
And you will also see the amounts of code it will save you.
| programming_docs |
fastapi Dependencies with yield Dependencies with yield
=======================
FastAPI supports dependencies that do some extra steps after finishing.
To do this, use `yield` instead of `return`, and write the extra steps after.
Tip
Make sure to use `yield` one single time.
Technical Details
Any function that is valid to use with:
* [`@contextlib.contextmanager`](https://docs.python.org/3/library/contextlib.html#contextlib.contextmanager) or
* [`@contextlib.asynccontextmanager`](https://docs.python.org/3/library/contextlib.html#contextlib.asynccontextmanager)
would be valid to use as a **FastAPI** dependency.
In fact, FastAPI uses those two decorators internally.
A database dependency with `yield`
----------------------------------
For example, you could use this to create a database session and close it after finishing.
Only the code prior to and including the `yield` statement is executed before sending a response:
```
async def get_db():
db = DBSession()
try:
yield db
finally:
db.close()
```
The yielded value is what is injected into *path operations* and other dependencies:
```
async def get_db():
db = DBSession()
try:
yield db
finally:
db.close()
```
The code following the `yield` statement is executed after the response has been delivered:
```
async def get_db():
db = DBSession()
try:
yield db
finally:
db.close()
```
Tip
You can use `async` or normal functions.
**FastAPI** will do the right thing with each, the same as with normal dependencies.
A dependency with `yield` and `try`
-----------------------------------
If you use a `try` block in a dependency with `yield`, you'll receive any exception that was thrown when using the dependency.
For example, if some code at some point in the middle, in another dependency or in a *path operation*, made a database transaction "rollback" or create any other error, you will receive the exception in your dependency.
So, you can look for that specific exception inside the dependency with `except SomeException`.
In the same way, you can use `finally` to make sure the exit steps are executed, no matter if there was an exception or not.
```
async def get_db():
db = DBSession()
try:
yield db
finally:
db.close()
```
Sub-dependencies with `yield`
-----------------------------
You can have sub-dependencies and "trees" of sub-dependencies of any size and shape, and any or all of them can use `yield`.
**FastAPI** will make sure that the "exit code" in each dependency with `yield` is run in the correct order.
For example, `dependency_c` can have a dependency on `dependency_b`, and `dependency_b` on `dependency_a`:
Python 3.9+
```
from typing import Annotated
from fastapi import Depends
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a: Annotated[DepA, Depends(dependency_a)]):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b: Annotated[DepB, Depends(dependency_b)]):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
Python 3.6+
```
from fastapi import Depends
from typing_extensions import Annotated
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a: Annotated[DepA, Depends(dependency_a)]):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b: Annotated[DepB, Depends(dependency_b)]):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a=Depends(dependency_a)):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b=Depends(dependency_b)):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
And all of them can use `yield`.
In this case `dependency_c`, to execute its exit code, needs the value from `dependency_b` (here named `dep_b`) to still be available.
And, in turn, `dependency_b` needs the value from `dependency_a` (here named `dep_a`) to be available for its exit code.
Python 3.9+
```
from typing import Annotated
from fastapi import Depends
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a: Annotated[DepA, Depends(dependency_a)]):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b: Annotated[DepB, Depends(dependency_b)]):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
Python 3.6+
```
from fastapi import Depends
from typing_extensions import Annotated
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a: Annotated[DepA, Depends(dependency_a)]):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b: Annotated[DepB, Depends(dependency_b)]):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import Depends
async def dependency_a():
dep_a = generate_dep_a()
try:
yield dep_a
finally:
dep_a.close()
async def dependency_b(dep_a=Depends(dependency_a)):
dep_b = generate_dep_b()
try:
yield dep_b
finally:
dep_b.close(dep_a)
async def dependency_c(dep_b=Depends(dependency_b)):
dep_c = generate_dep_c()
try:
yield dep_c
finally:
dep_c.close(dep_b)
```
The same way, you could have dependencies with `yield` and `return` mixed.
And you could have a single dependency that requires several other dependencies with `yield`, etc.
You can have any combinations of dependencies that you want.
**FastAPI** will make sure everything is run in the correct order.
Technical Details
This works thanks to Python's [Context Managers](https://docs.python.org/3/library/contextlib.html).
**FastAPI** uses them internally to achieve this.
Dependencies with `yield` and `HTTPException`
---------------------------------------------
You saw that you can use dependencies with `yield` and have `try` blocks that catch exceptions.
It might be tempting to raise an `HTTPException` or similar in the exit code, after the `yield`. But **it won't work**.
The exit code in dependencies with `yield` is executed *after* the response is sent, so [Exception Handlers](../../handling-errors/index#install-custom-exception-handlers) will have already run. There's nothing catching exceptions thrown by your dependencies in the exit code (after the `yield`).
So, if you raise an `HTTPException` after the `yield`, the default (or any custom) exception handler that catches `HTTPException`s and returns an HTTP 400 response won't be there to catch that exception anymore.
This is what allows anything set in the dependency (e.g. a DB session) to, for example, be used by background tasks.
Background tasks are run *after* the response has been sent. So there's no way to raise an `HTTPException` because there's not even a way to change the response that is *already sent*.
But if a background task creates a DB error, at least you can rollback or cleanly close the session in the dependency with `yield`, and maybe log the error or report it to a remote tracking system.
If you have some code that you know could raise an exception, do the most normal/"Pythonic" thing and add a `try` block in that section of the code.
If you have custom exceptions that you would like to handle *before* returning the response and possibly modifying the response, maybe even raising an `HTTPException`, create a [Custom Exception Handler](../../handling-errors/index#install-custom-exception-handlers).
Tip
You can still raise exceptions including `HTTPException` *before* the `yield`. But not after.
The sequence of execution is more or less like this diagram. Time flows from top to bottom. And each column is one of the parts interacting or executing code.
```
sequenceDiagram
participant client as Client
participant handler as Exception handler
participant dep as Dep with yield
participant operation as Path Operation
participant tasks as Background tasks
Note over client,tasks: Can raise exception for dependency, handled after response is sent
Note over client,operation: Can raise HTTPException and can change the response
client ->> dep: Start request
Note over dep: Run code up to yield
opt raise
dep -->> handler: Raise HTTPException
handler -->> client: HTTP error response
dep -->> dep: Raise other exception
end
dep ->> operation: Run dependency, e.g. DB session
opt raise
operation -->> dep: Raise HTTPException
dep -->> handler: Auto forward exception
handler -->> client: HTTP error response
operation -->> dep: Raise other exception
dep -->> handler: Auto forward exception
end
operation ->> client: Return response to client
Note over client,operation: Response is already sent, can't change it anymore
opt Tasks
operation -->> tasks: Send background tasks
end
opt Raise other exception
tasks -->> dep: Raise other exception
end
Note over dep: After yield
opt Handle other exception
dep -->> dep: Handle exception, can't change response. E.g. close DB session.
end
```
Info
Only **one response** will be sent to the client. It might be one of the error responses or it will be the response from the *path operation*.
After one of those responses is sent, no other response can be sent.
Tip
This diagram shows `HTTPException`, but you could also raise any other exception for which you create a [Custom Exception Handler](../../handling-errors/index#install-custom-exception-handlers).
If you raise any exception, it will be passed to the dependencies with yield, including `HTTPException`, and then **again** to the exception handlers. If there's no exception handler for that exception, it will then be handled by the default internal `ServerErrorMiddleware`, returning a 500 HTTP status code, to let the client know that there was an error in the server.
Context Managers
----------------
### What are "Context Managers"
"Context Managers" are any of those Python objects that you can use in a `with` statement.
For example, [you can use `with` to read a file](https://docs.python.org/3/tutorial/inputoutput.html#reading-and-writing-files):
```
with open("./somefile.txt") as f:
contents = f.read()
print(contents)
```
Underneath, the `open("./somefile.txt")` creates an object that is a called a "Context Manager".
When the `with` block finishes, it makes sure to close the file, even if there were exceptions.
When you create a dependency with `yield`, **FastAPI** will internally convert it to a context manager, and combine it with some other related tools.
### Using context managers in dependencies with `yield`
Warning
This is, more or less, an "advanced" idea.
If you are just starting with **FastAPI** you might want to skip it for now.
In Python, you can create Context Managers by [creating a class with two methods: `__enter__()` and `__exit__()`](https://docs.python.org/3/reference/datamodel.html#context-managers).
You can also use them inside of **FastAPI** dependencies with `yield` by using `with` or `async with` statements inside of the dependency function:
```
class MySuperContextManager:
def __init__(self):
self.db = DBSession()
def __enter__(self):
return self.db
def __exit__(self, exc_type, exc_value, traceback):
self.db.close()
async def get_db():
with MySuperContextManager() as db:
yield db
```
Tip
Another way to create a context manager is with:
* [`@contextlib.contextmanager`](https://docs.python.org/3/library/contextlib.html#contextlib.contextmanager) or
* [`@contextlib.asynccontextmanager`](https://docs.python.org/3/library/contextlib.html#contextlib.asynccontextmanager)
using them to decorate a function with a single `yield`.
That's what **FastAPI** uses internally for dependencies with `yield`.
But you don't have to use the decorators for FastAPI dependencies (and you shouldn't).
FastAPI will do it for you internally.
fastapi Response Model - Return Type Response Model - Return Type
============================
You can declare the type used for the response by annotating the *path operation function* **return type**.
You can use **type annotations** the same way you would for input data in function **parameters**, you can use Pydantic models, lists, dictionaries, scalar values like integers, booleans, etc.
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: list[str] = []
@app.post("/items/")
async def create_item(item: Item) -> Item:
return item
@app.get("/items/")
async def read_items() -> list[Item]:
return [
Item(name="Portal Gun", price=42.0),
Item(name="Plumbus", price=32.0),
]
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: list[str] = []
@app.post("/items/")
async def create_item(item: Item) -> Item:
return item
@app.get("/items/")
async def read_items() -> list[Item]:
return [
Item(name="Portal Gun", price=42.0),
Item(name="Plumbus", price=32.0),
]
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: List[str] = []
@app.post("/items/")
async def create_item(item: Item) -> Item:
return item
@app.get("/items/")
async def read_items() -> List[Item]:
return [
Item(name="Portal Gun", price=42.0),
Item(name="Plumbus", price=32.0),
]
```
FastAPI will use this return type to:
* **Validate** the returned data.
+ If the data is invalid (e.g. you are missing a field), it means that *your* app code is broken, not returning what it should, and it will return a server error instead of returning incorrect data. This way you and your clients can be certain that they will receive the data and the data shape expected.
* Add a **JSON Schema** for the response, in the OpenAPI *path operation*.
+ This will be used by the **automatic docs**.
+ It will also be used by automatic client code generation tools.
But most importantly:
* It will **limit and filter** the output data to what is defined in the return type.
+ This is particularly important for **security**, we'll see more of that below.
`response_model` Parameter
---------------------------
There are some cases where you need or want to return some data that is not exactly what the type declares.
For example, you could want to **return a dictionary** or a database object, but **declare it as a Pydantic model**. This way the Pydantic model would do all the data documentation, validation, etc. for the object that you returned (e.g. a dictionary or database object).
If you added the return type annotation, tools and editors would complain with a (correct) error telling you that your function is returning a type (e.g. a dict) that is different from what you declared (e.g. a Pydantic model).
In those cases, you can use the *path operation decorator* parameter `response_model` instead of the return type.
You can use the `response_model` parameter in any of the *path operations*:
* `@app.get()`
* `@app.post()`
* `@app.put()`
* `@app.delete()`
* etc.
Python 3.10+
```
from typing import Any
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: list[str] = []
@app.post("/items/", response_model=Item)
async def create_item(item: Item) -> Any:
return item
@app.get("/items/", response_model=list[Item])
async def read_items() -> Any:
return [
{"name": "Portal Gun", "price": 42.0},
{"name": "Plumbus", "price": 32.0},
]
```
Python 3.9+
```
from typing import Any, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: list[str] = []
@app.post("/items/", response_model=Item)
async def create_item(item: Item) -> Any:
return item
@app.get("/items/", response_model=list[Item])
async def read_items() -> Any:
return [
{"name": "Portal Gun", "price": 42.0},
{"name": "Plumbus", "price": 32.0},
]
```
Python 3.6+
```
from typing import Any, List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: List[str] = []
@app.post("/items/", response_model=Item)
async def create_item(item: Item) -> Any:
return item
@app.get("/items/", response_model=List[Item])
async def read_items() -> Any:
return [
{"name": "Portal Gun", "price": 42.0},
{"name": "Plumbus", "price": 32.0},
]
```
Note
Notice that `response_model` is a parameter of the "decorator" method (`get`, `post`, etc). Not of your *path operation function*, like all the parameters and body.
`response_model` receives the same type you would declare for a Pydantic model field, so, it can be a Pydantic model, but it can also be, e.g. a `list` of Pydantic models, like `List[Item]`.
FastAPI will use this `response_model` to do all the data documentation, validation, etc. and also to **convert and filter the output data** to its type declaration.
Tip
If you have strict type checks in your editor, mypy, etc, you can declare the function return type as `Any`.
That way you tell the editor that you are intentionally returning anything. But FastAPI will still do the data documentation, validation, filtering, etc. with the `response_model`.
###
`response_model` Priority
If you declare both a return type and a `response_model`, the `response_model` will take priority and be used by FastAPI.
This way you can add correct type annotations to your functions even when you are returning a type different than the response model, to be used by the editor and tools like mypy. And still you can have FastAPI do the data validation, documentation, etc. using the `response_model`.
You can also use `response_model=None` to disable creating a response model for that *path operation*, you might need to do it if you are adding type annotations for things that are not valid Pydantic fields, you will see an example of that in one of the sections below.
Return the same input data
--------------------------
Here we are declaring a `UserIn` model, it will contain a plaintext password:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
# Don't do this in production!
@app.post("/user/")
async def create_user(user: UserIn) -> UserIn:
return user
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
# Don't do this in production!
@app.post("/user/")
async def create_user(user: UserIn) -> UserIn:
return user
```
Info
To use `EmailStr`, first install [`email_validator`](https://github.com/JoshData/python-email-validator).
E.g. `pip install email-validator` or `pip install pydantic[email]`.
And we are using this model to declare our input and the same model to declare our output:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
# Don't do this in production!
@app.post("/user/")
async def create_user(user: UserIn) -> UserIn:
return user
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
# Don't do this in production!
@app.post("/user/")
async def create_user(user: UserIn) -> UserIn:
return user
```
Now, whenever a browser is creating a user with a password, the API will return the same password in the response.
In this case, it might not be a problem, because it's the same user sending the password.
But if we use the same model for another *path operation*, we could be sending our user's passwords to every client.
Danger
Never store the plain password of a user or send it in a response like this, unless you know all the caveats and you know what you are doing.
Add an output model
-------------------
We can instead create an input model with the plaintext password and an output model without it:
Python 3.10+
```
from typing import Any
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
Python 3.6+
```
from typing import Any, Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
Here, even though our *path operation function* is returning the same input user that contains the password:
Python 3.10+
```
from typing import Any
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
Python 3.6+
```
from typing import Any, Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
...we declared the `response_model` to be our model `UserOut`, that doesn't include the password:
Python 3.10+
```
from typing import Any
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
Python 3.6+
```
from typing import Any, Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn) -> Any:
return user
```
So, **FastAPI** will take care of filtering out all the data that is not declared in the output model (using Pydantic).
###
`response_model` or Return Type
In this case, because the two models are different, if we annotated the function return type as `UserOut`, the editor and tools would complain that we are returning an invalid type, as those are different classes.
That's why in this example we have to declare it in the `response_model` parameter.
...but continue reading below to see how to overcome that.
Return Type and Data Filtering
------------------------------
Let's continue from the previous example. We wanted to **annotate the function with one type** but return something that includes **more data**.
We want FastAPI to keep **filtering** the data using the response model.
In the previous example, because the classes were different, we had to use the `response_model` parameter. But that also means that we don't get the support from the editor and tools checking the function return type.
But in most of the cases where we need to do something like this, we want the model just to **filter/remove** some of the data as in this example.
And in those cases, we can use classes and inheritance to take advantage of function **type annotations** to get better support in the editor and tools, and still get the FastAPI **data filtering**.
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class BaseUser(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
class UserIn(BaseUser):
password: str
@app.post("/user/")
async def create_user(user: UserIn) -> BaseUser:
return user
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class BaseUser(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
class UserIn(BaseUser):
password: str
@app.post("/user/")
async def create_user(user: UserIn) -> BaseUser:
return user
```
With this, we get tooling support, from editors and mypy as this code is correct in terms of types, but we also get the data filtering from FastAPI.
How does this work? Let's check that out. 🤓
### Type Annotations and Tooling
First let's see how editors, mypy and other tools would see this.
`BaseUser` has the base fields. Then `UserIn` inherits from `BaseUser` and adds the `password` field, so, it will include all the fields from both models.
We annotate the function return type as `BaseUser`, but we are actually returning a `UserIn` instance.
The editor, mypy, and other tools won't complain about this because, in typing terms, `UserIn` is a subclass of `BaseUser`, which means it's a *valid* type when what is expected is anything that is a `BaseUser`.
### FastAPI Data Filtering
Now, for FastAPI, it will see the return type and make sure that what you return includes **only** the fields that are declared in the type.
FastAPI does several things internally with Pydantic to make sure that those same rules of class inheritance are not used for the returned data filtering, otherwise you could end up returning much more data than what you expected.
This way, you can get the best of both worlds: type annotations with **tooling support** and **data filtering**.
See it in the docs
------------------
When you see the automatic docs, you can check that the input model and output model will both have their own JSON Schema:
And both models will be used for the interactive API documentation:
Other Return Type Annotations
-----------------------------
There might be cases where you return something that is not a valid Pydantic field and you annotate it in the function, only to get the support provided by tooling (the editor, mypy, etc).
### Return a Response Directly
The most common case would be [returning a Response directly as explained later in the advanced docs](../../advanced/response-directly/index).
```
from fastapi import FastAPI, Response
from fastapi.responses import JSONResponse, RedirectResponse
app = FastAPI()
@app.get("/portal")
async def get_portal(teleport: bool = False) -> Response:
if teleport:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
return JSONResponse(content={"message": "Here's your interdimensional portal."})
```
This simple case is handled automatically by FastAPI because the return type annotation is the class (or a subclass) of `Response`.
And tools will also be happy because both `RedirectResponse` and `JSONResponse` are subclasses of `Response`, so the type annotation is correct.
### Annotate a Response Subclass
You can also use a subclass of `Response` in the type annotation:
```
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/teleport")
async def get_teleport() -> RedirectResponse:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
```
This will also work because `RedirectResponse` is a subclass of `Response`, and FastAPI will automatically handle this simple case.
### Invalid Return Type Annotations
But when you return some other arbitrary object that is not a valid Pydantic type (e.g. a database object) and you annotate it like that in the function, FastAPI will try to create a Pydantic response model from that type annotation, and will fail.
The same would happen if you had something like a union between different types where one or more of them are not valid Pydantic types, for example this would fail 💥:
Python 3.10+
```
from fastapi import FastAPI, Response
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/portal")
async def get_portal(teleport: bool = False) -> Response | dict:
if teleport:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
return {"message": "Here's your interdimensional portal."}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Response
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/portal")
async def get_portal(teleport: bool = False) -> Union[Response, dict]:
if teleport:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
return {"message": "Here's your interdimensional portal."}
```
...this fails because the type annotation is not a Pydantic type and is not just a single `Response` class or subclass, it's a union (any of the two) between a `Response` and a `dict`.
### Disable Response Model
Continuing from the example above, you might not want to have the default data validation, documentation, filtering, etc. that is performed by FastAPI.
But you might want to still keep the return type annotation in the function to get the support from tools like editors and type checkers (e.g. mypy).
In this case, you can disable the response model generation by setting `response_model=None`:
Python 3.10+
```
from fastapi import FastAPI, Response
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/portal", response_model=None)
async def get_portal(teleport: bool = False) -> Response | dict:
if teleport:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
return {"message": "Here's your interdimensional portal."}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Response
from fastapi.responses import RedirectResponse
app = FastAPI()
@app.get("/portal", response_model=None)
async def get_portal(teleport: bool = False) -> Union[Response, dict]:
if teleport:
return RedirectResponse(url="https://www.youtube.com/watch?v=dQw4w9WgXcQ")
return {"message": "Here's your interdimensional portal."}
```
This will make FastAPI skip the response model generation and that way you can have any return type annotations you need without it affecting your FastAPI application. 🤓
Response Model encoding parameters
----------------------------------
Your response model could have default values, like:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
* `description: Union[str, None] = None` (or `str | None = None` in Python 3.10) has a default of `None`.
* `tax: float = 10.5` has a default of `10.5`.
* `tags: List[str] = []` as a default of an empty list: `[]`.
but you might want to omit them from the result if they were not actually stored.
For example, if you have models with many optional attributes in a NoSQL database, but you don't want to send very long JSON responses full of default values.
### Use the `response_model_exclude_unset` parameter
You can set the *path operation decorator* parameter `response_model_exclude_unset=True`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
tags: List[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
```
and those default values won't be included in the response, only the values actually set.
So, if you send a request to that *path operation* for the item with ID `foo`, the response (not including default values) will be:
```
{
"name": "Foo",
"price": 50.2
}
```
Info
FastAPI uses Pydantic model's `.dict()` with [its `exclude_unset` parameter](https://pydantic-docs.helpmanual.io/usage/exporting_models/#modeldict) to achieve this.
Info
You can also use:
* `response_model_exclude_defaults=True`
* `response_model_exclude_none=True`
as described in [the Pydantic docs](https://pydantic-docs.helpmanual.io/usage/exporting_models/#modeldict) for `exclude_defaults` and `exclude_none`.
#### Data with values for fields with defaults
But if your data has values for the model's fields with default values, like the item with ID `bar`:
```
{
"name": "Bar",
"description": "The bartenders",
"price": 62,
"tax": 20.2
}
```
they will be included in the response.
#### Data with the same values as the defaults
If the data has the same values as the default ones, like the item with ID `baz`:
```
{
"name": "Baz",
"description": None,
"price": 50.2,
"tax": 10.5,
"tags": []
}
```
FastAPI is smart enough (actually, Pydantic is smart enough) to realize that, even though `description`, `tax`, and `tags` have the same values as the defaults, they were set explicitly (instead of taken from the defaults).
So, they will be included in the JSON response.
Tip
Notice that the default values can be anything, not only `None`.
They can be a list (`[]`), a `float` of `10.5`, etc.
###
`response_model_include` and `response_model_exclude`
You can also use the *path operation decorator* parameters `response_model_include` and `response_model_exclude`.
They take a `set` of `str` with the name of the attributes to include (omitting the rest) or to exclude (including the rest).
This can be used as a quick shortcut if you have only one Pydantic model and want to remove some data from the output.
Tip
But it is still recommended to use the ideas above, using multiple classes, instead of these parameters.
This is because the JSON Schema generated in your app's OpenAPI (and the docs) will still be the one for the complete model, even if you use `response_model_include` or `response_model_exclude` to omit some attributes.
This also applies to `response_model_by_alias` that works similarly.
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float = 10.5
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The Bar fighters", "price": 62, "tax": 20.2},
"baz": {
"name": "Baz",
"description": "There goes my baz",
"price": 50.2,
"tax": 10.5,
},
}
@app.get(
"/items/{item_id}/name",
response_model=Item,
response_model_include={"name", "description"},
)
async def read_item_name(item_id: str):
return items[item_id]
@app.get("/items/{item_id}/public", response_model=Item, response_model_exclude={"tax"})
async def read_item_public_data(item_id: str):
return items[item_id]
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The Bar fighters", "price": 62, "tax": 20.2},
"baz": {
"name": "Baz",
"description": "There goes my baz",
"price": 50.2,
"tax": 10.5,
},
}
@app.get(
"/items/{item_id}/name",
response_model=Item,
response_model_include={"name", "description"},
)
async def read_item_name(item_id: str):
return items[item_id]
@app.get("/items/{item_id}/public", response_model=Item, response_model_exclude={"tax"})
async def read_item_public_data(item_id: str):
return items[item_id]
```
Tip
The syntax `{"name", "description"}` creates a `set` with those two values.
It is equivalent to `set(["name", "description"])`.
#### Using `list`s instead of `set`s
If you forget to use a `set` and use a `list` or `tuple` instead, FastAPI will still convert it to a `set` and it will work correctly:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float = 10.5
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The Bar fighters", "price": 62, "tax": 20.2},
"baz": {
"name": "Baz",
"description": "There goes my baz",
"price": 50.2,
"tax": 10.5,
},
}
@app.get(
"/items/{item_id}/name",
response_model=Item,
response_model_include=["name", "description"],
)
async def read_item_name(item_id: str):
return items[item_id]
@app.get("/items/{item_id}/public", response_model=Item, response_model_exclude=["tax"])
async def read_item_public_data(item_id: str):
return items[item_id]
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: float = 10.5
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The Bar fighters", "price": 62, "tax": 20.2},
"baz": {
"name": "Baz",
"description": "There goes my baz",
"price": 50.2,
"tax": 10.5,
},
}
@app.get(
"/items/{item_id}/name",
response_model=Item,
response_model_include=["name", "description"],
)
async def read_item_name(item_id: str):
return items[item_id]
@app.get("/items/{item_id}/public", response_model=Item, response_model_exclude=["tax"])
async def read_item_public_data(item_id: str):
return items[item_id]
```
Recap
-----
Use the *path operation decorator's* parameter `response_model` to define response models and especially to ensure private data is filtered out.
Use `response_model_exclude_unset` to return only the values explicitly set.
| programming_docs |
fastapi Extra Models Extra Models
============
Continuing with the previous example, it will be common to have more than one related model.
This is especially the case for user models, because:
* The **input model** needs to be able to have a password.
* The **output model** should not have a password.
* The **database model** would probably need to have a hashed password.
Danger
Never store user's plaintext passwords. Always store a "secure hash" that you can then verify.
If you don't know, you will learn what a "password hash" is in the [security chapters](../security/simple-oauth2/index#password-hashing).
Multiple models
---------------
Here's a general idea of how the models could look like with their password fields and the places where they are used:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: str | None = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
class UserInDB(BaseModel):
username: str
hashed_password: str
email: EmailStr
full_name: str | None = None
def fake_password_hasher(raw_password: str):
return "supersecret" + raw_password
def fake_save_user(user_in: UserIn):
hashed_password = fake_password_hasher(user_in.password)
user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password)
print("User saved! ..not really")
return user_in_db
@app.post("/user/", response_model=UserOut)
async def create_user(user_in: UserIn):
user_saved = fake_save_user(user_in)
return user_saved
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserIn(BaseModel):
username: str
password: str
email: EmailStr
full_name: Union[str, None] = None
class UserOut(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
class UserInDB(BaseModel):
username: str
hashed_password: str
email: EmailStr
full_name: Union[str, None] = None
def fake_password_hasher(raw_password: str):
return "supersecret" + raw_password
def fake_save_user(user_in: UserIn):
hashed_password = fake_password_hasher(user_in.password)
user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password)
print("User saved! ..not really")
return user_in_db
@app.post("/user/", response_model=UserOut)
async def create_user(user_in: UserIn):
user_saved = fake_save_user(user_in)
return user_saved
```
### About `**user_in.dict()`
#### Pydantic's `.dict()`
`user_in` is a Pydantic model of class `UserIn`.
Pydantic models have a `.dict()` method that returns a `dict` with the model's data.
So, if we create a Pydantic object `user_in` like:
```
user_in = UserIn(username="john", password="secret", email="[email protected]")
```
and then we call:
```
user_dict = user_in.dict()
```
we now have a `dict` with the data in the variable `user_dict` (it's a `dict` instead of a Pydantic model object).
And if we call:
```
print(user_dict)
```
we would get a Python `dict` with:
```
{
'username': 'john',
'password': 'secret',
'email': '[email protected]',
'full_name': None,
}
```
#### Unwrapping a `dict`
If we take a `dict` like `user_dict` and pass it to a function (or class) with `**user_dict`, Python will "unwrap" it. It will pass the keys and values of the `user_dict` directly as key-value arguments.
So, continuing with the `user_dict` from above, writing:
```
UserInDB(**user_dict)
```
Would result in something equivalent to:
```
UserInDB(
username="john",
password="secret",
email="[email protected]",
full_name=None,
)
```
Or more exactly, using `user_dict` directly, with whatever contents it might have in the future:
```
UserInDB(
username = user_dict["username"],
password = user_dict["password"],
email = user_dict["email"],
full_name = user_dict["full_name"],
)
```
#### A Pydantic model from the contents of another
As in the example above we got `user_dict` from `user_in.dict()`, this code:
```
user_dict = user_in.dict()
UserInDB(**user_dict)
```
would be equivalent to:
```
UserInDB(**user_in.dict())
```
...because `user_in.dict()` is a `dict`, and then we make Python "unwrap" it by passing it to `UserInDB` prepended with `**`.
So, we get a Pydantic model from the data in another Pydantic model.
#### Unwrapping a `dict` and extra keywords
And then adding the extra keyword argument `hashed_password=hashed_password`, like in:
```
UserInDB(**user_in.dict(), hashed_password=hashed_password)
```
...ends up being like:
```
UserInDB(
username = user_dict["username"],
password = user_dict["password"],
email = user_dict["email"],
full_name = user_dict["full_name"],
hashed_password = hashed_password,
)
```
Warning
The supporting additional functions are just to demo a possible flow of the data, but they of course are not providing any real security.
Reduce duplication
------------------
Reducing code duplication is one of the core ideas in **FastAPI**.
As code duplication increments the chances of bugs, security issues, code desynchronization issues (when you update in one place but not in the others), etc.
And these models are all sharing a lot of the data and duplicating attribute names and types.
We could do better.
We can declare a `UserBase` model that serves as a base for our other models. And then we can make subclasses of that model that inherit its attributes (type declarations, validation, etc).
All the data conversion, validation, documentation, etc. will still work as normally.
That way, we can declare just the differences between the models (with plaintext `password`, with `hashed_password` and without password):
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserBase(BaseModel):
username: str
email: EmailStr
full_name: str | None = None
class UserIn(UserBase):
password: str
class UserOut(UserBase):
pass
class UserInDB(UserBase):
hashed_password: str
def fake_password_hasher(raw_password: str):
return "supersecret" + raw_password
def fake_save_user(user_in: UserIn):
hashed_password = fake_password_hasher(user_in.password)
user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password)
print("User saved! ..not really")
return user_in_db
@app.post("/user/", response_model=UserOut)
async def create_user(user_in: UserIn):
user_saved = fake_save_user(user_in)
return user_saved
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class UserBase(BaseModel):
username: str
email: EmailStr
full_name: Union[str, None] = None
class UserIn(UserBase):
password: str
class UserOut(UserBase):
pass
class UserInDB(UserBase):
hashed_password: str
def fake_password_hasher(raw_password: str):
return "supersecret" + raw_password
def fake_save_user(user_in: UserIn):
hashed_password = fake_password_hasher(user_in.password)
user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password)
print("User saved! ..not really")
return user_in_db
@app.post("/user/", response_model=UserOut)
async def create_user(user_in: UserIn):
user_saved = fake_save_user(user_in)
return user_saved
```
`Union` or `anyOf`
-------------------
You can declare a response to be the `Union` of two types, that means, that the response would be any of the two.
It will be defined in OpenAPI with `anyOf`.
To do that, use the standard Python type hint [`typing.Union`](https://docs.python.org/3/library/typing.html#typing.Union):
Note
When defining a [`Union`](https://pydantic-docs.helpmanual.io/usage/types/#unions), include the most specific type first, followed by the less specific type. In the example below, the more specific `PlaneItem` comes before `CarItem` in `Union[PlaneItem, CarItem]`.
Python 3.10+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class BaseItem(BaseModel):
description: str
type: str
class CarItem(BaseItem):
type = "car"
class PlaneItem(BaseItem):
type = "plane"
size: int
items = {
"item1": {"description": "All my friends drive a low rider", "type": "car"},
"item2": {
"description": "Music is my aeroplane, it's my aeroplane",
"type": "plane",
"size": 5,
},
}
@app.get("/items/{item_id}", response_model=Union[PlaneItem, CarItem])
async def read_item(item_id: str):
return items[item_id]
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class BaseItem(BaseModel):
description: str
type: str
class CarItem(BaseItem):
type = "car"
class PlaneItem(BaseItem):
type = "plane"
size: int
items = {
"item1": {"description": "All my friends drive a low rider", "type": "car"},
"item2": {
"description": "Music is my aeroplane, it's my aeroplane",
"type": "plane",
"size": 5,
},
}
@app.get("/items/{item_id}", response_model=Union[PlaneItem, CarItem])
async def read_item(item_id: str):
return items[item_id]
```
###
`Union` in Python 3.10
In this example we pass `Union[PlaneItem, CarItem]` as the value of the argument `response_model`.
Because we are passing it as a **value to an argument** instead of putting it in a **type annotation**, we have to use `Union` even in Python 3.10.
If it was in a type annotation we could have used the vertical bar, as:
```
some_variable: PlaneItem | CarItem
```
But if we put that in `response_model=PlaneItem | CarItem` we would get an error, because Python would try to perform an **invalid operation** between `PlaneItem` and `CarItem` instead of interpreting that as a type annotation.
List of models
--------------
The same way, you can declare responses of lists of objects.
For that, use the standard Python `typing.List` (or just `list` in Python 3.9 and above):
Python 3.9+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str
items = [
{"name": "Foo", "description": "There comes my hero"},
{"name": "Red", "description": "It's my aeroplane"},
]
@app.get("/items/", response_model=list[Item])
async def read_items():
return items
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str
items = [
{"name": "Foo", "description": "There comes my hero"},
{"name": "Red", "description": "It's my aeroplane"},
]
@app.get("/items/", response_model=List[Item])
async def read_items():
return items
```
Response with arbitrary `dict`
------------------------------
You can also declare a response using a plain arbitrary `dict`, declaring just the type of the keys and values, without using a Pydantic model.
This is useful if you don't know the valid field/attribute names (that would be needed for a Pydantic model) beforehand.
In this case, you can use `typing.Dict` (or just `dict` in Python 3.9 and above):
Python 3.9+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/keyword-weights/", response_model=dict[str, float])
async def read_keyword_weights():
return {"foo": 2.3, "bar": 3.4}
```
Python 3.6+
```
from typing import Dict
from fastapi import FastAPI
app = FastAPI()
@app.get("/keyword-weights/", response_model=Dict[str, float])
async def read_keyword_weights():
return {"foo": 2.3, "bar": 3.4}
```
Recap
-----
Use multiple Pydantic models and inherit freely for each case.
You don't need to have a single data model per entity if that entity must be able to have different "states". As the case with the user "entity" with a state including `password`, `password_hash` and no password.
fastapi Testing Testing
=======
Thanks to [Starlette](https://www.starlette.io/testclient/), testing **FastAPI** applications is easy and enjoyable.
It is based on [HTTPX](https://www.python-httpx.org), which in turn is designed based on Requests, so it's very familiar and intuitive.
With it, you can use [pytest](https://docs.pytest.org/) directly with **FastAPI**.
Using `TestClient`
------------------
Info
To use `TestClient`, first install [`httpx`](https://www.python-httpx.org).
E.g. `pip install httpx`.
Import `TestClient`.
Create a `TestClient` by passing your **FastAPI** application to it.
Create functions with a name that starts with `test_` (this is standard `pytest` conventions).
Use the `TestClient` object the same way as you do with `httpx`.
Write simple `assert` statements with the standard Python expressions that you need to check (again, standard `pytest`).
```
from fastapi import FastAPI
from fastapi.testclient import TestClient
app = FastAPI()
@app.get("/")
async def read_main():
return {"msg": "Hello World"}
client = TestClient(app)
def test_read_main():
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"msg": "Hello World"}
```
Tip
Notice that the testing functions are normal `def`, not `async def`.
And the calls to the client are also normal calls, not using `await`.
This allows you to use `pytest` directly without complications.
Technical Details
You could also use `from starlette.testclient import TestClient`.
**FastAPI** provides the same `starlette.testclient` as `fastapi.testclient` just as a convenience for you, the developer. But it comes directly from Starlette.
Tip
If you want to call `async` functions in your tests apart from sending requests to your FastAPI application (e.g. asynchronous database functions), have a look at the [Async Tests](../../advanced/async-tests/index) in the advanced tutorial.
Separating tests
----------------
In a real application, you probably would have your tests in a different file.
And your **FastAPI** application might also be composed of several files/modules, etc.
###
**FastAPI** app file
Let's say you have a file structure as described in [Bigger Applications](../bigger-applications/index):
```
.
├── app
│ ├── __init__.py
│ └── main.py
```
In the file `main.py` you have your **FastAPI** app:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_main():
return {"msg": "Hello World"}
```
### Testing file
Then you could have a file `test_main.py` with your tests. It could live on the same Python package (the same directory with a `__init__.py` file):
```
.
├── app
│ ├── __init__.py
│ ├── main.py
│ └── test_main.py
```
Because this file is in the same package, you can use relative imports to import the object `app` from the `main` module (`main.py`):
```
from fastapi.testclient import TestClient
from .main import app
client = TestClient(app)
def test_read_main():
response = client.get("/")
assert response.status_code == 200
assert response.json() == {"msg": "Hello World"}
```
...and have the code for the tests just like before.
Testing: extended example
-------------------------
Now let's extend this example and add more details to see how to test different parts.
### Extended **FastAPI** app file
Let's continue with the same file structure as before:
```
.
├── app
│ ├── __init__.py
│ ├── main.py
│ └── test_main.py
```
Let's say that now the file `main.py` with your **FastAPI** app has some other **path operations**.
It has a `GET` operation that could return an error.
It has a `POST` operation that could return several errors.
Both *path operations* require an `X-Token` header.
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
fake_secret_token = "coneofsilence"
fake_db = {
"foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"},
"bar": {"id": "bar", "title": "Bar", "description": "The bartenders"},
}
app = FastAPI()
class Item(BaseModel):
id: str
title: str
description: str | None = None
@app.get("/items/{item_id}", response_model=Item)
async def read_main(item_id: str, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item_id not in fake_db:
raise HTTPException(status_code=404, detail="Item not found")
return fake_db[item_id]
@app.post("/items/", response_model=Item)
async def create_item(item: Item, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item.id in fake_db:
raise HTTPException(status_code=400, detail="Item already exists")
fake_db[item.id] = item
return item
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
fake_secret_token = "coneofsilence"
fake_db = {
"foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"},
"bar": {"id": "bar", "title": "Bar", "description": "The bartenders"},
}
app = FastAPI()
class Item(BaseModel):
id: str
title: str
description: Union[str, None] = None
@app.get("/items/{item_id}", response_model=Item)
async def read_main(item_id: str, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item_id not in fake_db:
raise HTTPException(status_code=404, detail="Item not found")
return fake_db[item_id]
@app.post("/items/", response_model=Item)
async def create_item(item: Item, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item.id in fake_db:
raise HTTPException(status_code=400, detail="Item already exists")
fake_db[item.id] = item
return item
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
from typing_extensions import Annotated
fake_secret_token = "coneofsilence"
fake_db = {
"foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"},
"bar": {"id": "bar", "title": "Bar", "description": "The bartenders"},
}
app = FastAPI()
class Item(BaseModel):
id: str
title: str
description: Union[str, None] = None
@app.get("/items/{item_id}", response_model=Item)
async def read_main(item_id: str, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item_id not in fake_db:
raise HTTPException(status_code=404, detail="Item not found")
return fake_db[item_id]
@app.post("/items/", response_model=Item)
async def create_item(item: Item, x_token: Annotated[str, Header()]):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item.id in fake_db:
raise HTTPException(status_code=400, detail="Item already exists")
fake_db[item.id] = item
return item
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
fake_secret_token = "coneofsilence"
fake_db = {
"foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"},
"bar": {"id": "bar", "title": "Bar", "description": "The bartenders"},
}
app = FastAPI()
class Item(BaseModel):
id: str
title: str
description: str | None = None
@app.get("/items/{item_id}", response_model=Item)
async def read_main(item_id: str, x_token: str = Header()):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item_id not in fake_db:
raise HTTPException(status_code=404, detail="Item not found")
return fake_db[item_id]
@app.post("/items/", response_model=Item)
async def create_item(item: Item, x_token: str = Header()):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item.id in fake_db:
raise HTTPException(status_code=400, detail="Item already exists")
fake_db[item.id] = item
return item
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
fake_secret_token = "coneofsilence"
fake_db = {
"foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"},
"bar": {"id": "bar", "title": "Bar", "description": "The bartenders"},
}
app = FastAPI()
class Item(BaseModel):
id: str
title: str
description: Union[str, None] = None
@app.get("/items/{item_id}", response_model=Item)
async def read_main(item_id: str, x_token: str = Header()):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item_id not in fake_db:
raise HTTPException(status_code=404, detail="Item not found")
return fake_db[item_id]
@app.post("/items/", response_model=Item)
async def create_item(item: Item, x_token: str = Header()):
if x_token != fake_secret_token:
raise HTTPException(status_code=400, detail="Invalid X-Token header")
if item.id in fake_db:
raise HTTPException(status_code=400, detail="Item already exists")
fake_db[item.id] = item
return item
```
### Extended testing file
You could then update `test_main.py` with the extended tests:
```
from fastapi.testclient import TestClient
from .main import app
client = TestClient(app)
def test_read_item():
response = client.get("/items/foo", headers={"X-Token": "coneofsilence"})
assert response.status_code == 200
assert response.json() == {
"id": "foo",
"title": "Foo",
"description": "There goes my hero",
}
def test_read_item_bad_token():
response = client.get("/items/foo", headers={"X-Token": "hailhydra"})
assert response.status_code == 400
assert response.json() == {"detail": "Invalid X-Token header"}
def test_read_inexistent_item():
response = client.get("/items/baz", headers={"X-Token": "coneofsilence"})
assert response.status_code == 404
assert response.json() == {"detail": "Item not found"}
def test_create_item():
response = client.post(
"/items/",
headers={"X-Token": "coneofsilence"},
json={"id": "foobar", "title": "Foo Bar", "description": "The Foo Barters"},
)
assert response.status_code == 200
assert response.json() == {
"id": "foobar",
"title": "Foo Bar",
"description": "The Foo Barters",
}
def test_create_item_bad_token():
response = client.post(
"/items/",
headers={"X-Token": "hailhydra"},
json={"id": "bazz", "title": "Bazz", "description": "Drop the bazz"},
)
assert response.status_code == 400
assert response.json() == {"detail": "Invalid X-Token header"}
def test_create_existing_item():
response = client.post(
"/items/",
headers={"X-Token": "coneofsilence"},
json={
"id": "foo",
"title": "The Foo ID Stealers",
"description": "There goes my stealer",
},
)
assert response.status_code == 400
assert response.json() == {"detail": "Item already exists"}
```
Whenever you need the client to pass information in the request and you don't know how to, you can search (Google) how to do it in `httpx`, or even how to do it with `requests`, as HTTPX's design is based on Requests' design.
Then you just do the same in your tests.
E.g.:
* To pass a *path* or *query* parameter, add it to the URL itself.
* To pass a JSON body, pass a Python object (e.g. a `dict`) to the parameter `json`.
* If you need to send *Form Data* instead of JSON, use the `data` parameter instead.
* To pass *headers*, use a `dict` in the `headers` parameter.
* For *cookies*, a `dict` in the `cookies` parameter.
For more information about how to pass data to the backend (using `httpx` or the `TestClient`) check the [HTTPX documentation](https://www.python-httpx.org).
Info
Note that the `TestClient` receives data that can be converted to JSON, not Pydantic models.
If you have a Pydantic model in your test and you want to send its data to the application during testing, you can use the `jsonable_encoder` described in [JSON Compatible Encoder](../encoder/index).
Run it
------
After that, you just need to install `pytest`:
```
$ pip install pytest
---> 100%
```
It will detect the files and tests automatically, execute them, and report the results back to you.
Run the tests with:
```
$ pytest
================ test session starts ================
platform linux -- Python 3.6.9, pytest-5.3.5, py-1.8.1, pluggy-0.13.1
rootdir: /home/user/code/superawesome-cli/app
plugins: forked-1.1.3, xdist-1.31.0, cov-2.8.1
collected 6 items
---> 100%
test_main.py <span style="color: green; white-space: pre;">...... [100%]</span>
<span style="color: green;">================= 1 passed in 0.03s =================</span>
```
| programming_docs |
fastapi Path Operation Configuration Path Operation Configuration
============================
There are several parameters that you can pass to your *path operation decorator* to configure it.
Warning
Notice that these parameters are passed directly to the *path operation decorator*, not to your *path operation function*.
Response Status Code
--------------------
You can define the (HTTP) `status_code` to be used in the response of your *path operation*.
You can pass directly the `int` code, like `404`.
But if you don't remember what each number code is for, you can use the shortcut constants in `status`:
Python 3.10+
```
from fastapi import FastAPI, status
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, status_code=status.HTTP_201_CREATED)
async def create_item(item: Item):
return item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI, status
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, status_code=status.HTTP_201_CREATED)
async def create_item(item: Item):
return item
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI, status
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post("/items/", response_model=Item, status_code=status.HTTP_201_CREATED)
async def create_item(item: Item):
return item
```
That status code will be used in the response and will be added to the OpenAPI schema.
Technical Details
You could also use `from starlette import status`.
**FastAPI** provides the same `starlette.status` as `fastapi.status` just as a convenience for you, the developer. But it comes directly from Starlette.
Tags
----
You can add tags to your *path operation*, pass the parameter `tags` with a `list` of `str` (commonly just one `str`):
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, tags=["items"])
async def create_item(item: Item):
return item
@app.get("/items/", tags=["items"])
async def read_items():
return [{"name": "Foo", "price": 42}]
@app.get("/users/", tags=["users"])
async def read_users():
return [{"username": "johndoe"}]
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, tags=["items"])
async def create_item(item: Item):
return item
@app.get("/items/", tags=["items"])
async def read_items():
return [{"name": "Foo", "price": 42}]
@app.get("/users/", tags=["users"])
async def read_users():
return [{"username": "johndoe"}]
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post("/items/", response_model=Item, tags=["items"])
async def create_item(item: Item):
return item
@app.get("/items/", tags=["items"])
async def read_items():
return [{"name": "Foo", "price": 42}]
@app.get("/users/", tags=["users"])
async def read_users():
return [{"username": "johndoe"}]
```
They will be added to the OpenAPI schema and used by the automatic documentation interfaces:
### Tags with Enums
If you have a big application, you might end up accumulating **several tags**, and you would want to make sure you always use the **same tag** for related *path operations*.
In these cases, it could make sense to store the tags in an `Enum`.
**FastAPI** supports that the same way as with plain strings:
```
from enum import Enum
from fastapi import FastAPI
app = FastAPI()
class Tags(Enum):
items = "items"
users = "users"
@app.get("/items/", tags=[Tags.items])
async def get_items():
return ["Portal gun", "Plumbus"]
@app.get("/users/", tags=[Tags.users])
async def read_users():
return ["Rick", "Morty"]
```
Summary and description
-----------------------
You can add a `summary` and `description`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
description="Create an item with all the information, name, description, price, tax and a set of unique tags",
)
async def create_item(item: Item):
return item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
description="Create an item with all the information, name, description, price, tax and a set of unique tags",
)
async def create_item(item: Item):
return item
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
description="Create an item with all the information, name, description, price, tax and a set of unique tags",
)
async def create_item(item: Item):
return item
```
Description from docstring
--------------------------
As descriptions tend to be long and cover multiple lines, you can declare the *path operation* description in the function docstring and **FastAPI** will read it from there.
You can write [Markdown](https://en.wikipedia.org/wiki/Markdown) in the docstring, it will be interpreted and displayed correctly (taking into account docstring indentation).
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, summary="Create an item")
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.post("/items/", response_model=Item, summary="Create an item")
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post("/items/", response_model=Item, summary="Create an item")
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
It will be used in the interactive docs:
Response description
--------------------
You can specify the response description with the parameter `response_description`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
response_description="The created item",
)
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
response_description="The created item",
)
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.post(
"/items/",
response_model=Item,
summary="Create an item",
response_description="The created item",
)
async def create_item(item: Item):
"""
Create an item with all the information:
- **name**: each item must have a name
- **description**: a long description
- **price**: required
- **tax**: if the item doesn't have tax, you can omit this
- **tags**: a set of unique tag strings for this item
"""
return item
```
Info
Notice that `response_description` refers specifically to the response, the `description` refers to the *path operation* in general.
Check
OpenAPI specifies that each *path operation* requires a response description.
So, if you don't provide one, **FastAPI** will automatically generate one of "Successful response".
Deprecate a *path operation*
----------------------------
If you need to mark a *path operation* as deprecated, but without removing it, pass the parameter `deprecated`:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/", tags=["items"])
async def read_items():
return [{"name": "Foo", "price": 42}]
@app.get("/users/", tags=["users"])
async def read_users():
return [{"username": "johndoe"}]
@app.get("/elements/", tags=["items"], deprecated=True)
async def read_elements():
return [{"item_id": "Foo"}]
```
It will be clearly marked as deprecated in the interactive docs:
Check how deprecated and non-deprecated *path operations* look like:
Recap
-----
You can configure and add metadata for your *path operations* easily by passing parameters to the *path operation decorators*.
fastapi First Steps First Steps
===========
The simplest FastAPI file could look like this:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
Copy that to a file `main.py`.
Run the live server:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
<span style="color: green;">INFO</span>: Started reloader process [28720]
<span style="color: green;">INFO</span>: Started server process [28722]
<span style="color: green;">INFO</span>: Waiting for application startup.
<span style="color: green;">INFO</span>: Application startup complete.
```
Note
The command `uvicorn main:app` refers to:
* `main`: the file `main.py` (the Python "module").
* `app`: the object created inside of `main.py` with the line `app = FastAPI()`.
* `--reload`: make the server restart after code changes. Only use for development.
In the output, there's a line with something like:
```
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
That line shows the URL where your app is being served, in your local machine.
### Check it
Open your browser at <http://127.0.0.1:8000>.
You will see the JSON response as:
```
{"message": "Hello World"}
```
### Interactive API docs
Now go to <http://127.0.0.1:8000/docs>.
You will see the automatic interactive API documentation (provided by [Swagger UI](https://github.com/swagger-api/swagger-ui)):
### Alternative API docs
And now, go to <http://127.0.0.1:8000/redoc>.
You will see the alternative automatic documentation (provided by [ReDoc](https://github.com/Rebilly/ReDoc)):
### OpenAPI
**FastAPI** generates a "schema" with all your API using the **OpenAPI** standard for defining APIs.
#### "Schema"
A "schema" is a definition or description of something. Not the code that implements it, but just an abstract description.
#### API "schema"
In this case, [OpenAPI](https://github.com/OAI/OpenAPI-Specification) is a specification that dictates how to define a schema of your API.
This schema definition includes your API paths, the possible parameters they take, etc.
#### Data "schema"
The term "schema" might also refer to the shape of some data, like a JSON content.
In that case, it would mean the JSON attributes, and data types they have, etc.
#### OpenAPI and JSON Schema
OpenAPI defines an API schema for your API. And that schema includes definitions (or "schemas") of the data sent and received by your API using **JSON Schema**, the standard for JSON data schemas.
#### Check the `openapi.json`
If you are curious about how the raw OpenAPI schema looks like, FastAPI automatically generates a JSON (schema) with the descriptions of all your API.
You can see it directly at: <http://127.0.0.1:8000/openapi.json>.
It will show a JSON starting with something like:
```
{
"openapi": "3.0.2",
"info": {
"title": "FastAPI",
"version": "0.1.0"
},
"paths": {
"/items/": {
"get": {
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
...
```
#### What is OpenAPI for
The OpenAPI schema is what powers the two interactive documentation systems included.
And there are dozens of alternatives, all based on OpenAPI. You could easily add any of those alternatives to your application built with **FastAPI**.
You could also use it to generate code automatically, for clients that communicate with your API. For example, frontend, mobile or IoT applications.
Recap, step by step
-------------------
### Step 1: import `FastAPI`
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
`FastAPI` is a Python class that provides all the functionality for your API.
Technical Details
`FastAPI` is a class that inherits directly from `Starlette`.
You can use all the [Starlette](https://www.starlette.io/) functionality with `FastAPI` too.
### Step 2: create a `FastAPI` "instance"
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
Here the `app` variable will be an "instance" of the class `FastAPI`.
This will be the main point of interaction to create all your API.
This `app` is the same one referred by `uvicorn` in the command:
```
$ uvicorn main:app --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
If you create your app like:
```
from fastapi import FastAPI
my_awesome_api = FastAPI()
@my_awesome_api.get("/")
async def root():
return {"message": "Hello World"}
```
And put it in a file `main.py`, then you would call `uvicorn` like:
```
$ uvicorn main:my_awesome_api --reload
<span style="color: green;">INFO</span>: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
### Step 3: create a *path operation*
#### Path
"Path" here refers to the last part of the URL starting from the first `/`.
So, in a URL like:
```
https://example.com/items/foo
```
...the path would be:
```
/items/foo
```
Info
A "path" is also commonly called an "endpoint" or a "route".
While building an API, the "path" is the main way to separate "concerns" and "resources".
#### Operation
"Operation" here refers to one of the HTTP "methods".
One of:
* `POST`
* `GET`
* `PUT`
* `DELETE`
...and the more exotic ones:
* `OPTIONS`
* `HEAD`
* `PATCH`
* `TRACE`
In the HTTP protocol, you can communicate to each path using one (or more) of these "methods".
---
When building APIs, you normally use these specific HTTP methods to perform a specific action.
Normally you use:
* `POST`: to create data.
* `GET`: to read data.
* `PUT`: to update data.
* `DELETE`: to delete data.
So, in OpenAPI, each of the HTTP methods is called an "operation".
We are going to call them "**operations**" too.
#### Define a *path operation decorator*
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
The `@app.get("/")` tells **FastAPI** that the function right below is in charge of handling requests that go to:
* the path `/`
* using a `get` operation
`@decorator` Info
That `@something` syntax in Python is called a "decorator".
You put it on top of a function. Like a pretty decorative hat (I guess that's where the term came from).
A "decorator" takes the function below and does something with it.
In our case, this decorator tells **FastAPI** that the function below corresponds to the **path** `/` with an **operation** `get`.
It is the "**path operation decorator**".
You can also use the other operations:
* `@app.post()`
* `@app.put()`
* `@app.delete()`
And the more exotic ones:
* `@app.options()`
* `@app.head()`
* `@app.patch()`
* `@app.trace()`
Tip
You are free to use each operation (HTTP method) as you wish.
**FastAPI** doesn't enforce any specific meaning.
The information here is presented as a guideline, not a requirement.
For example, when using GraphQL you normally perform all the actions using only `POST` operations.
### Step 4: define the **path operation function**
This is our "**path operation function**":
* **path**: is `/`.
* **operation**: is `get`.
* **function**: is the function below the "decorator" (below `@app.get("/")`).
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
This is a Python function.
It will be called by **FastAPI** whenever it receives a request to the URL "`/`" using a `GET` operation.
In this case, it is an `async` function.
---
You could also define it as a normal function instead of `async def`:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
return {"message": "Hello World"}
```
Note
If you don't know the difference, check the [Async: *"In a hurry?"*](../../async/index#in-a-hurry).
### Step 5: return the content
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
```
You can return a `dict`, `list`, singular values as `str`, `int`, etc.
You can also return Pydantic models (you'll see more about that later).
There are many other objects and models that will be automatically converted to JSON (including ORMs, etc). Try using your favorite ones, it's highly probable that they are already supported.
Recap
-----
* Import `FastAPI`.
* Create an `app` instance.
* Write a **path operation decorator** (like `@app.get("/")`).
* Write a **path operation function** (like `def root(): ...` above).
* Run the development server (like `uvicorn main:app --reload`).
| programming_docs |
fastapi Body - Nested Models Body - Nested Models
====================
With **FastAPI**, you can define, validate, document, and use arbitrarily deeply nested models (thanks to Pydantic).
List fields
-----------
You can define an attribute to be a subtype. For example, a Python `list`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: list = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: list = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
This will make `tags` be a list, although it doesn't declare the type of the elements of the list.
List fields with type parameter
-------------------------------
But Python has a specific way to declare lists with internal types, or "type parameters":
### Import typing's `List`
In Python 3.9 and above you can use the standard `list` to declare these type annotations as we'll see below. 💡
But in Python versions before 3.9 (3.6 and above), you first need to import `List` from standard Python's `typing` module:
```
from typing import List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: List[str] = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
### Declare a `list` with a type parameter
To declare types that have type parameters (internal types), like `list`, `dict`, `tuple`:
* If you are in a Python version lower than 3.9, import their equivalent version from the `typing` module
* Pass the internal type(s) as "type parameters" using square brackets: `[` and `]`
In Python 3.9 it would be:
```
my_list: list[str]
```
In versions of Python before 3.9, it would be:
```
from typing import List
my_list: List[str]
```
That's all standard Python syntax for type declarations.
Use that same standard syntax for model attributes with internal types.
So, in our example, we can make `tags` be specifically a "list of strings":
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: list[str] = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: list[str] = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: List[str] = []
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Set types
---------
But then we think about it, and realize that tags shouldn't repeat, they would probably be unique strings.
And Python has a special data type for sets of unique items, the `set`.
Then we can declare `tags` as a set of strings:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
With this, even if you receive a request with duplicate data, it will be converted to a set of unique items.
And whenever you output that data, even if the source had duplicates, it will be output as a set of unique items.
And it will be annotated / documented accordingly too.
Nested Models
-------------
Each attribute of a Pydantic model has a type.
But that type can itself be another Pydantic model.
So, you can declare deeply nested JSON "objects" with specific attribute names, types and validations.
All that, arbitrarily nested.
### Define a submodel
For example, we can define an `Image` model:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
image: Image | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
### Use the submodel as a type
And then we can use it as the type of an attribute:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
image: Image | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Image(BaseModel):
url: str
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
This would mean that **FastAPI** would expect a body similar to:
```
{
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2,
"tags": ["rock", "metal", "bar"],
"image": {
"url": "http://example.com/baz.jpg",
"name": "The Foo live"
}
}
```
Again, doing just that declaration, with **FastAPI** you get:
* Editor support (completion, etc), even for nested models
* Data conversion
* Data validation
* Automatic documentation
Special types and validation
----------------------------
Apart from normal singular types like `str`, `int`, `float`, etc. You can use more complex singular types that inherit from `str`.
To see all the options you have, checkout the docs for [Pydantic's exotic types](https://pydantic-docs.helpmanual.io/usage/types/). You will see some examples in the next chapter.
For example, as in the `Image` model we have a `url` field, we can declare it to be instead of a `str`, a Pydantic's `HttpUrl`:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
image: Image | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Set, Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
image: Union[Image, None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
The string will be checked to be a valid URL, and documented in JSON Schema / OpenAPI as such.
Attributes with lists of submodels
----------------------------------
You can also use Pydantic models as subtypes of `list`, `set`, etc:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
images: list[Image] | None = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
images: Union[list[Image], None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import List, Set, Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
images: Union[List[Image], None] = None
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
This will expect (convert, validate, document, etc) a JSON body like:
```
{
"name": "Foo",
"description": "The pretender",
"price": 42.0,
"tax": 3.2,
"tags": [
"rock",
"metal",
"bar"
],
"images": [
{
"url": "http://example.com/baz.jpg",
"name": "The Foo live"
},
{
"url": "http://example.com/dave.jpg",
"name": "The Baz"
}
]
}
```
Info
Notice how the `images` key now has a list of image objects.
Deeply nested models
--------------------
You can define arbitrarily deeply nested models:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
tags: set[str] = set()
images: list[Image] | None = None
class Offer(BaseModel):
name: str
description: str | None = None
price: float
items: list[Item]
@app.post("/offers/")
async def create_offer(offer: Offer):
return offer
```
Python 3.9+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: set[str] = set()
images: Union[list[Image], None] = None
class Offer(BaseModel):
name: str
description: Union[str, None] = None
price: float
items: list[Item]
@app.post("/offers/")
async def create_offer(offer: Offer):
return offer
```
Python 3.6+
```
from typing import List, Set, Union
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
tags: Set[str] = set()
images: Union[List[Image], None] = None
class Offer(BaseModel):
name: str
description: Union[str, None] = None
price: float
items: List[Item]
@app.post("/offers/")
async def create_offer(offer: Offer):
return offer
```
Info
Notice how `Offer` has a list of `Item`s, which in turn have an optional list of `Image`s
Bodies of pure lists
--------------------
If the top level value of the JSON body you expect is a JSON `array` (a Python `list`), you can declare the type in the parameter of the function, the same as in Pydantic models:
```
images: List[Image]
```
or in Python 3.9 and above:
```
images: list[Image]
```
as in:
Python 3.9+
```
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
@app.post("/images/multiple/")
async def create_multiple_images(images: list[Image]):
return images
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI
from pydantic import BaseModel, HttpUrl
app = FastAPI()
class Image(BaseModel):
url: HttpUrl
name: str
@app.post("/images/multiple/")
async def create_multiple_images(images: List[Image]):
return images
```
Editor support everywhere
-------------------------
And you get editor support everywhere.
Even for items inside of lists:
You couldn't get this kind of editor support if you were working directly with `dict` instead of Pydantic models.
But you don't have to worry about them either, incoming dicts are converted automatically and your output is converted automatically to JSON too.
Bodies of arbitrary `dict`s
---------------------------
You can also declare a body as a `dict` with keys of some type and values of other type.
Without having to know beforehand what are the valid field/attribute names (as would be the case with Pydantic models).
This would be useful if you want to receive keys that you don't already know.
---
Other useful case is when you want to have keys of other type, e.g. `int`.
That's what we are going to see here.
In this case, you would accept any `dict` as long as it has `int` keys with `float` values:
Python 3.9+
```
from fastapi import FastAPI
app = FastAPI()
@app.post("/index-weights/")
async def create_index_weights(weights: dict[int, float]):
return weights
```
Python 3.6+
```
from typing import Dict
from fastapi import FastAPI
app = FastAPI()
@app.post("/index-weights/")
async def create_index_weights(weights: Dict[int, float]):
return weights
```
Tip
Have in mind that JSON only supports `str` as keys.
But Pydantic has automatic data conversion.
This means that, even though your API clients can only send strings as keys, as long as those strings contain pure integers, Pydantic will convert them and validate them.
And the `dict` you receive as `weights` will actually have `int` keys and `float` values.
Recap
-----
With **FastAPI** you have the maximum flexibility provided by Pydantic models, while keeping your code simple, short and elegant.
But with all the benefits:
* Editor support (completion everywhere!)
* Data conversion (a.k.a. parsing / serialization)
* Data validation
* Schema documentation
* Automatic docs
fastapi CORS (Cross-Origin Resource Sharing) CORS (Cross-Origin Resource Sharing)
====================================
[CORS or "Cross-Origin Resource Sharing"](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS) refers to the situations when a frontend running in a browser has JavaScript code that communicates with a backend, and the backend is in a different "origin" than the frontend.
Origin
------
An origin is the combination of protocol (`http`, `https`), domain (`myapp.com`, `localhost`, `localhost.tiangolo.com`), and port (`80`, `443`, `8080`).
So, all these are different origins:
* `http://localhost`
* `https://localhost`
* `http://localhost:8080`
Even if they are all in `localhost`, they use different protocols or ports, so, they are different "origins".
Steps
-----
So, let's say you have a frontend running in your browser at `http://localhost:8080`, and its JavaScript is trying to communicate with a backend running at `http://localhost` (because we don't specify a port, the browser will assume the default port `80`).
Then, the browser will send an HTTP `OPTIONS` request to the backend, and if the backend sends the appropriate headers authorizing the communication from this different origin (`http://localhost:8080`) then the browser will let the JavaScript in the frontend send its request to the backend.
To achieve this, the backend must have a list of "allowed origins".
In this case, it would have to include `http://localhost:8080` for the frontend to work correctly.
Wildcards
---------
It's also possible to declare the list as `"*"` (a "wildcard") to say that all are allowed.
But that will only allow certain types of communication, excluding everything that involves credentials: Cookies, Authorization headers like those used with Bearer Tokens, etc.
So, for everything to work correctly, it's better to specify explicitly the allowed origins.
Use `CORSMiddleware`
--------------------
You can configure it in your **FastAPI** application using the `CORSMiddleware`.
* Import `CORSMiddleware`.
* Create a list of allowed origins (as strings).
* Add it as a "middleware" to your **FastAPI** application.
You can also specify if your backend allows:
* Credentials (Authorization headers, Cookies, etc).
* Specific HTTP methods (`POST`, `PUT`) or all of them with the wildcard `"*"`.
* Specific HTTP headers or all of them with the wildcard `"*"`.
```
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
origins = [
"http://localhost.tiangolo.com",
"https://localhost.tiangolo.com",
"http://localhost",
"http://localhost:8080",
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/")
async def main():
return {"message": "Hello World"}
```
The default parameters used by the `CORSMiddleware` implementation are restrictive by default, so you'll need to explicitly enable particular origins, methods, or headers, in order for browsers to be permitted to use them in a Cross-Domain context.
The following arguments are supported:
* `allow_origins` - A list of origins that should be permitted to make cross-origin requests. E.g. `['https://example.org', 'https://www.example.org']`. You can use `['*']` to allow any origin.
* `allow_origin_regex` - A regex string to match against origins that should be permitted to make cross-origin requests. e.g. `'https://.*\.example\.org'`.
* `allow_methods` - A list of HTTP methods that should be allowed for cross-origin requests. Defaults to `['GET']`. You can use `['*']` to allow all standard methods.
* `allow_headers` - A list of HTTP request headers that should be supported for cross-origin requests. Defaults to `[]`. You can use `['*']` to allow all headers. The `Accept`, `Accept-Language`, `Content-Language` and `Content-Type` headers are always allowed for [simple CORS requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#simple_requests).
* `allow_credentials` - Indicate that cookies should be supported for cross-origin requests. Defaults to `False`. Also, `allow_origins` cannot be set to `['*']` for credentials to be allowed, origins must be specified.
* `expose_headers` - Indicate any response headers that should be made accessible to the browser. Defaults to `[]`.
* `max_age` - Sets a maximum time in seconds for browsers to cache CORS responses. Defaults to `600`.
The middleware responds to two particular types of HTTP request...
### CORS preflight requests
These are any `OPTIONS` request with `Origin` and `Access-Control-Request-Method` headers.
In this case the middleware will intercept the incoming request and respond with appropriate CORS headers, and either a `200` or `400` response for informational purposes.
### Simple requests
Any request with an `Origin` header. In this case the middleware will pass the request through as normal, but will include appropriate CORS headers on the response.
More info
---------
For more info about CORS, check the [Mozilla CORS documentation](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS).
Technical Details
You could also use `from starlette.middleware.cors import CORSMiddleware`.
**FastAPI** provides several middlewares in `fastapi.middleware` just as a convenience for you, the developer. But most of the available middlewares come directly from Starlette.
| programming_docs |
fastapi Response Status Code Response Status Code
====================
The same way you can specify a response model, you can also declare the HTTP status code used for the response with the parameter `status_code` in any of the *path operations*:
* `@app.get()`
* `@app.post()`
* `@app.put()`
* `@app.delete()`
* etc.
```
from fastapi import FastAPI
app = FastAPI()
@app.post("/items/", status_code=201)
async def create_item(name: str):
return {"name": name}
```
Note
Notice that `status_code` is a parameter of the "decorator" method (`get`, `post`, etc). Not of your *path operation function*, like all the parameters and body.
The `status_code` parameter receives a number with the HTTP status code.
Info
`status_code` can alternatively also receive an `IntEnum`, such as Python's [`http.HTTPStatus`](https://docs.python.org/3/library/http.html#http.HTTPStatus).
It will:
* Return that status code in the response.
* Document it as such in the OpenAPI schema (and so, in the user interfaces):
Note
Some response codes (see the next section) indicate that the response does not have a body.
FastAPI knows this, and will produce OpenAPI docs that state there is no response body.
About HTTP status codes
-----------------------
Note
If you already know what HTTP status codes are, skip to the next section.
In HTTP, you send a numeric status code of 3 digits as part of the response.
These status codes have a name associated to recognize them, but the important part is the number.
In short:
* `100` and above are for "Information". You rarely use them directly. Responses with these status codes cannot have a body.
* **`200`** and above are for "Successful" responses. These are the ones you would use the most.
+ `200` is the default status code, which means everything was "OK".
+ Another example would be `201`, "Created". It is commonly used after creating a new record in the database.
+ A special case is `204`, "No Content". This response is used when there is no content to return to the client, and so the response must not have a body.
* **`300`** and above are for "Redirection". Responses with these status codes may or may not have a body, except for `304`, "Not Modified", which must not have one.
* **`400`** and above are for "Client error" responses. These are the second type you would probably use the most.
+ An example is `404`, for a "Not Found" response.
+ For generic errors from the client, you can just use `400`.
* `500` and above are for server errors. You almost never use them directly. When something goes wrong at some part in your application code, or server, it will automatically return one of these status codes.
Tip
To know more about each status code and which code is for what, check the [MDN documentation about HTTP status codes](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status).
Shortcut to remember the names
------------------------------
Let's see the previous example again:
```
from fastapi import FastAPI
app = FastAPI()
@app.post("/items/", status_code=201)
async def create_item(name: str):
return {"name": name}
```
`201` is the status code for "Created".
But you don't have to memorize what each of these codes mean.
You can use the convenience variables from `fastapi.status`.
```
from fastapi import FastAPI, status
app = FastAPI()
@app.post("/items/", status_code=status.HTTP_201_CREATED)
async def create_item(name: str):
return {"name": name}
```
They are just a convenience, they hold the same number, but that way you can use the editor's autocomplete to find them:
Technical Details
You could also use `from starlette import status`.
**FastAPI** provides the same `starlette.status` as `fastapi.status` just as a convenience for you, the developer. But it comes directly from Starlette.
Changing the default
--------------------
Later, in the [Advanced User Guide](../../advanced/response-change-status-code/index), you will see how to return a different status code than the default you are declaring here.
fastapi Query Parameters and String Validations Query Parameters and String Validations
=======================================
**FastAPI** allows you to declare additional information and validation for your parameters.
Let's take this application as example:
Python 3.10+
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(q: str | None = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[str, None] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
The query parameter `q` is of type `Union[str, None]` (or `str | None` in Python 3.10), that means that it's of type `str` but could also be `None`, and indeed, the default value is `None`, so FastAPI will know it's not required.
Note
FastAPI will know that the value of `q` is not required because of the default value `= None`.
The `Union` in `Union[str, None]` will allow your editor to give you better support and detect errors.
Additional validation
---------------------
We are going to enforce that even though `q` is optional, whenever it is provided, **its length doesn't exceed 50 characters**.
### Import `Query` and `Annotated`
To achieve that, first import:
* `Query` from `fastapi`
* `Annotated` from `typing` (or from `typing_extensions` in Python below 3.9)
Python 3.10+ In Python 3.9 or above, `Annotated` is part of the standard library, so you can import it from `typing`.
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str | None, Query(max_length=50)] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ In versions of Python below Python 3.9 you import `Annotation` from `typing_extensions`.
It will already be installed with FastAPI.
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(max_length=50)] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Use `Annotated` in the type for the `q` parameter
-------------------------------------------------
Remember I told you before that `Annotated` can be used to add metadata to your parameters in the [Python Types Intro](../../python-types/index#type-hints-with-metadata-annotations)?
Now it's the time to use it with FastAPI. 🚀
We had this type annotation:
Python 3.10+
```
q: str | None = None
```
Python 3.6+
```
q: Union[str, None] = None
```
What we will do is wrap that with `Annotated`, so it becomes:
Python 3.10+
```
q: Annotated[str | None] = None
```
Python 3.6+
```
q: Annotated[Union[str, None]] = None
```
Both of those versions mean the same thing, `q` is a parameter that can be a `str` or `None`, and by default, it is `None`.
Now let's jump to the fun stuff. 🎉
Add `Query` to `Annotated` in the `q` parameter
-----------------------------------------------
Now that we have this `Annotated` where we can put more metadata, add `Query` to it, and set the parameter `max_length` to 50:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str | None, Query(max_length=50)] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(max_length=50)] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Notice that the default value is still `None`, so the parameter is still optional.
But now, having `Query(max_length=50)` inside of `Annotated`, we are telling FastAPI that we want it to extract this value from the query parameters (this would have been the default anyway 🤷) and that we want to have **additional validation** for this value (that's why we do this, to get the additional validation). 😎
FastAPI wll now:
* **Validate** the data making sure that the max length is 50 characters
* Show a **clear error** for the client when the data is not valid
* **Document** the parameter in the OpenAPI schema *path operation* (so it will show up in the **automatic docs UI**)
Alternative (old) `Query` as the default value
----------------------------------------------
Previous versions of FastAPI (before 0.95.0) required you to use `Query` as the default value of your parameter, instead of putting it in `Annotated`, there's a high chance that you will see code using it around, so I'll explain it to you.
Tip
For new code and whenever possible, use `Annotated` as explained above. There are multiple advantages (explained below) and no disadvantages. 🍰
This is how you would use `Query()` as the default value of your function parameter, setting the parameter `max_length` to 50:
Python 3.10+
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str | None = Query(default=None, max_length=50)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[str, None] = Query(default=None, max_length=50)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
As in this case (without using `Annotated`) we have to replace the default value `None` in the function with `Query()`, we now need to set the default value with the parameter `Query(default=None)`, it serves the same purpose of defining that default value (at least for FastAPI).
So:
```
q: Union[str, None] = Query(default=None)
```
...makes the parameter optional, with a default value of `None`, the same as:
```
q: Union[str, None] = None
```
And in Python 3.10 and above:
```
q: str | None = Query(default=None)
```
...makes the parameter optional, with a default value of `None`, the same as:
```
q: str | None = None
```
But it declares it explicitly as being a query parameter.
Info
Have in mind that the most important part to make a parameter optional is the part:
```
= None
```
or the:
```
= Query(default=None)
```
as it will use that `None` as the default value, and that way make the parameter **not required**.
The `Union[str, None]` part allows your editor to provide better support, but it is not what tells FastAPI that this parameter is not required.
Then, we can pass more parameters to `Query`. In this case, the `max_length` parameter that applies to strings:
```
q: Union[str, None] = Query(default=None, max_length=50)
```
This will validate the data, show a clear error when the data is not valid, and document the parameter in the OpenAPI schema *path operation*.
###
`Query` as the default value or in `Annotated`
Have in mind that when using `Query` inside of `Annotated` you cannot use the `default` parameter for `Query`.
Instead use the actual default value of the function parameter. Otherwise, it would be inconsistent.
For example, this is not allowed:
```
q: Annotated[str Query(default="rick")] = "morty"
```
...because it's not clear if the default value should be `"rick"` or `"morty"`.
So, you would use (preferably):
```
q: Annotated[str, Query()] = "rick"
```
...or in older code bases you will find:
```
q: str = Query(default="rick")
```
### Advantages of `Annotated`
**Using `Annotated` is recommended** instead of the default value in function parameters, it is **better** for multiple reasons. 🤓
The **default** value of the **function parameter** is the **actual default** value, that's more intuitive with Python in general. 😌
You could **call** that same function in **other places** without FastAPI, and it would **work as expected**. If there's a **required** parameter (without a default value), your **editor** will let you know with an error, **Python** will also complain if you run it without passing the required parameter.
When you don't use `Annotated` and instead use the **(old) default value style**, if you call that function without FastAPI in **other place**, you have to **remember** to pass the arguments to the function for it to work correctly, otherwise the values will be different from what you expect (e.g. `QueryInfo` or something similar instead of `str`). And your editor won't complain, and Python won't complain running that function, only when the operations inside error out.
Because `Annotated` can have more than one metadata annotation, you could now even use the same function with other tools, like [Typer](https://typer.tiangolo.com/). 🚀
Add more validations
--------------------
You can also add a parameter `min_length`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[str | None, Query(min_length=3, max_length=50)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[Union[str, None], Query(min_length=3, max_length=50)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[Union[str, None], Query(min_length=3, max_length=50)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str | None = Query(default=None, min_length=3, max_length=50)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Union[str, None] = Query(default=None, min_length=3, max_length=50)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Add regular expressions
-----------------------
You can define a regular expression that the parameter should match:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
str | None, Query(min_length=3, max_length=50, regex="^fixedquery$")
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None], Query(min_length=3, max_length=50, regex="^fixedquery$")
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None], Query(min_length=3, max_length=50, regex="^fixedquery$")
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: str
| None = Query(default=None, min_length=3, max_length=50, regex="^fixedquery$")
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Union[str, None] = Query(
default=None, min_length=3, max_length=50, regex="^fixedquery$"
)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
This specific regular expression checks that the received parameter value:
* `^`: starts with the following characters, doesn't have characters before.
* `fixedquery`: has the exact value `fixedquery`.
* `$`: ends there, doesn't have any more characters after `fixedquery`.
If you feel lost with all these **"regular expression"** ideas, don't worry. They are a hard topic for many people. You can still do a lot of stuff without needing regular expressions yet.
But whenever you need them and go and learn them, know that you can already use them directly in **FastAPI**.
Default values
--------------
You can, of course, use default values other than `None`.
Let's say that you want to declare the `q` query parameter to have a `min_length` of `3`, and to have a default value of `"fixedquery"`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = "fixedquery"):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = "fixedquery"):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str = Query(default="fixedquery", min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Note
Having a default value of any type, including `None`, makes the parameter optional (not required).
Make it required
----------------
When we don't need to declare more validations or metadata, we can make the `q` query parameter required just by not declaring a default value, like:
```
q: str
```
instead of:
```
q: Union[str, None] = None
```
But we are now declaring it with `Query`, for example like:
Annotated
```
q: Annotated[Union[str, None], Query(min_length=3)] = None
```
non-Annotated
```
q: Union[str, None] = Query(default=None, min_length=3)
```
So, when you need to declare a value as required while using `Query`, you can simply not declare a default value:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)]):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)]):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str = Query(min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Tip
Notice that, even though in this case the `Query()` is used as the function parameter default value, we don't pass the `default=None` to `Query()`.
Still, probably better to use the `Annotated` version. 😉
### Required with Ellipsis (`...`)
There's an alternative way to explicitly declare that a value is required. You can set the default to the literal value `...`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = ...):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = ...):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str = Query(default=..., min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Info
If you hadn't seen that `...` before: it is a special single value, it is [part of Python and is called "Ellipsis"](https://docs.python.org/3/library/constants.html#Ellipsis).
It is used by Pydantic and FastAPI to explicitly declare that a value is required.
This will let **FastAPI** know that this parameter is required.
### Required with `None`
You can declare that a parameter can accept `None`, but that it's still required. This would force clients to send a value, even if the value is `None`.
To do that, you can declare that `None` is a valid type but still use `...` as the default:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str | None, Query(min_length=3)] = ...):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(min_length=3)] = ...):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(min_length=3)] = ...):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str | None = Query(default=..., min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[str, None] = Query(default=..., min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Tip
Pydantic, which is what powers all the data validation and serialization in FastAPI, has a special behavior when you use `Optional` or `Union[Something, None]` without a default value, you can read more about it in the Pydantic docs about [Required Optional fields](https://pydantic-docs.helpmanual.io/usage/models/#required-optional-fields).
### Use Pydantic's `Required` instead of Ellipsis (`...`)
If you feel uncomfortable using `...`, you can also import and use `Required` from Pydantic:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
from pydantic import Required
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = Required):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from fastapi import FastAPI, Query
from pydantic import Required
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str, Query(min_length=3)] = Required):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
from pydantic import Required
app = FastAPI()
@app.get("/items/")
async def read_items(q: str = Query(default=Required, min_length=3)):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Tip
Remember that in most of the cases, when something is required, you can simply omit the default, so you normally don't have to use `...` nor `Required`.
Query parameter list / multiple values
--------------------------------------
When you define a query parameter explicitly with `Query` you can also declare it to receive a list of values, or said in other way, to receive multiple values.
For example, to declare a query parameter `q` that can appear multiple times in the URL, you can write:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[list[str] | None, Query()] = None):
query_items = {"q": q}
return query_items
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[list[str], None], Query()] = None):
query_items = {"q": q}
return query_items
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[List[str], None], Query()] = None):
query_items = {"q": q}
return query_items
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: list[str] | None = Query(default=None)):
query_items = {"q": q}
return query_items
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[list[str], None] = Query(default=None)):
query_items = {"q": q}
return query_items
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import List, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[List[str], None] = Query(default=None)):
query_items = {"q": q}
return query_items
```
Then, with a URL like:
```
http://localhost:8000/items/?q=foo&q=bar
```
you would receive the multiple `q` *query parameters'* values (`foo` and `bar`) in a Python `list` inside your *path operation function*, in the *function parameter* `q`.
So, the response to that URL would be:
```
{
"q": [
"foo",
"bar"
]
}
```
Tip
To declare a query parameter with a type of `list`, like in the example above, you need to explicitly use `Query`, otherwise it would be interpreted as a request body.
The interactive API docs will update accordingly, to allow multiple values:
### Query parameter list / multiple values with defaults
And you can also define a default `list` of values if none are provided:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[list[str], Query()] = ["foo", "bar"]):
query_items = {"q": q}
return query_items
```
Python 3.6+
```
from typing import List
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[List[str], Query()] = ["foo", "bar"]):
query_items = {"q": q}
return query_items
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: list[str] = Query(default=["foo", "bar"])):
query_items = {"q": q}
return query_items
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import List
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: List[str] = Query(default=["foo", "bar"])):
query_items = {"q": q}
return query_items
```
If you go to:
```
http://localhost:8000/items/
```
the default of `q` will be: `["foo", "bar"]` and your response will be:
```
{
"q": [
"foo",
"bar"
]
}
```
#### Using `list`
You can also use `list` directly instead of `List[str]` (or `list[str]` in Python 3.9+):
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[list, Query()] = []):
query_items = {"q": q}
return query_items
```
Python 3.6+
```
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[list, Query()] = []):
query_items = {"q": q}
return query_items
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: list = Query(default=[])):
query_items = {"q": q}
return query_items
```
Note
Have in mind that in this case, FastAPI won't check the contents of the list.
For example, `List[int]` would check (and document) that the contents of the list are integers. But `list` alone wouldn't.
Declare more metadata
---------------------
You can add more information about the parameter.
That information will be included in the generated OpenAPI and used by the documentation user interfaces and external tools.
Note
Have in mind that different tools might have different levels of OpenAPI support.
Some of them might not show all the extra information declared yet, although in most of the cases, the missing feature is already planned for development.
You can add a `title`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[str | None, Query(title="Query string", min_length=3)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[Union[str, None], Query(title="Query string", min_length=3)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[Union[str, None], Query(title="Query string", min_length=3)] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: str | None = Query(default=None, title="Query string", min_length=3)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Union[str, None] = Query(default=None, title="Query string", min_length=3)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
And a `description`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
str | None,
Query(
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None],
Query(
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None],
Query(
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: str
| None = Query(
default=None,
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Union[str, None] = Query(
default=None,
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Alias parameters
----------------
Imagine that you want the parameter to be `item-query`.
Like in:
```
http://127.0.0.1:8000/items/?item-query=foobaritems
```
But `item-query` is not a valid Python variable name.
The closest would be `item_query`.
But you still need it to be exactly `item-query`...
Then you can declare an `alias`, and that alias is what will be used to find the parameter value:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[str | None, Query(alias="item-query")] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(alias="item-query")] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(q: Annotated[Union[str, None], Query(alias="item-query")] = None):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: str | None = Query(default=None, alias="item-query")):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(q: Union[str, None] = Query(default=None, alias="item-query")):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Deprecating parameters
----------------------
Now let's say you don't like this parameter anymore.
You have to leave it there a while because there are clients using it, but you want the docs to clearly show it as deprecated.
Then pass the parameter `deprecated=True` to `Query`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
str | None,
Query(
alias="item-query",
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
max_length=50,
regex="^fixedquery$",
deprecated=True,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None],
Query(
alias="item-query",
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
max_length=50,
regex="^fixedquery$",
deprecated=True,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Annotated[
Union[str, None],
Query(
alias="item-query",
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
max_length=50,
regex="^fixedquery$",
deprecated=True,
),
] = None
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: str
| None = Query(
default=None,
alias="item-query",
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
max_length=50,
regex="^fixedquery$",
deprecated=True,
)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
q: Union[str, None] = Query(
default=None,
alias="item-query",
title="Query string",
description="Query string for the items to search in the database that have a good match",
min_length=3,
max_length=50,
regex="^fixedquery$",
deprecated=True,
)
):
results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]}
if q:
results.update({"q": q})
return results
```
The docs will show it like this:
Exclude from OpenAPI
--------------------
To exclude a query parameter from the generated OpenAPI schema (and thus, from the automatic documentation systems), set the parameter `include_in_schema` of `Query` to `False`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
hidden_query: Annotated[str | None, Query(include_in_schema=False)] = None
):
if hidden_query:
return {"hidden_query": hidden_query}
else:
return {"hidden_query": "Not found"}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
hidden_query: Annotated[Union[str, None], Query(include_in_schema=False)] = None
):
if hidden_query:
return {"hidden_query": hidden_query}
else:
return {"hidden_query": "Not found"}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Query
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
hidden_query: Annotated[Union[str, None], Query(include_in_schema=False)] = None
):
if hidden_query:
return {"hidden_query": hidden_query}
else:
return {"hidden_query": "Not found"}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
hidden_query: str | None = Query(default=None, include_in_schema=False)
):
if hidden_query:
return {"hidden_query": hidden_query}
else:
return {"hidden_query": "Not found"}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Query
app = FastAPI()
@app.get("/items/")
async def read_items(
hidden_query: Union[str, None] = Query(default=None, include_in_schema=False)
):
if hidden_query:
return {"hidden_query": hidden_query}
else:
return {"hidden_query": "Not found"}
```
Recap
-----
You can declare additional validations and metadata for your parameters.
Generic validations and metadata:
* `alias`
* `title`
* `description`
* `deprecated`
Validations specific for strings:
* `min_length`
* `max_length`
* `regex`
In these examples you saw how to declare validations for `str` values.
See the next chapters to see how to declare validations for other types, like numbers.
| programming_docs |
fastapi Static Files Static Files
============
You can serve static files automatically from a directory using `StaticFiles`.
Use `StaticFiles`
-----------------
* Import `StaticFiles`.
* "Mount" a `StaticFiles()` instance in a specific path.
```
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
```
Technical Details
You could also use `from starlette.staticfiles import StaticFiles`.
**FastAPI** provides the same `starlette.staticfiles` as `fastapi.staticfiles` just as a convenience for you, the developer. But it actually comes directly from Starlette.
### What is "Mounting"
"Mounting" means adding a complete "independent" application in a specific path, that then takes care of handling all the sub-paths.
This is different from using an `APIRouter` as a mounted application is completely independent. The OpenAPI and docs from your main application won't include anything from the mounted application, etc.
You can read more about this in the **Advanced User Guide**.
Details
-------
The first `"/static"` refers to the sub-path this "sub-application" will be "mounted" on. So, any path that starts with `"/static"` will be handled by it.
The `directory="static"` refers to the name of the directory that contains your static files.
The `name="static"` gives it a name that can be used internally by **FastAPI**.
All these parameters can be different than "`static`", adjust them with the needs and specific details of your own application.
More info
---------
For more details and options check [Starlette's docs about Static Files](https://www.starlette.io/staticfiles/).
fastapi Path Parameters Path Parameters
===============
You can declare path "parameters" or "variables" with the same syntax used by Python format strings:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id):
return {"item_id": item_id}
```
The value of the path parameter `item_id` will be passed to your function as the argument `item_id`.
So, if you run this example and go to <http://127.0.0.1:8000/items/foo>, you will see a response of:
```
{"item_id":"foo"}
```
Path parameters with types
--------------------------
You can declare the type of a path parameter in the function, using standard Python type annotations:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
```
In this case, `item_id` is declared to be an `int`.
Check
This will give you editor support inside of your function, with error checks, completion, etc.
Data conversion
---------------
If you run this example and open your browser at <http://127.0.0.1:8000/items/3>, you will see a response of:
```
{"item_id":3}
```
Check
Notice that the value your function received (and returned) is `3`, as a Python `int`, not a string `"3"`.
So, with that type declaration, **FastAPI** gives you automatic request "parsing".
Data validation
---------------
But if you go to the browser at <http://127.0.0.1:8000/items/foo>, you will see a nice HTTP error of:
```
{
"detail": [
{
"loc": [
"path",
"item_id"
],
"msg": "value is not a valid integer",
"type": "type_error.integer"
}
]
}
```
because the path parameter `item_id` had a value of `"foo"`, which is not an `int`.
The same error would appear if you provided a `float` instead of an `int`, as in: <http://127.0.0.1:8000/items/4.2>
Check
So, with the same Python type declaration, **FastAPI** gives you data validation.
Notice that the error also clearly states exactly the point where the validation didn't pass.
This is incredibly helpful while developing and debugging code that interacts with your API.
Documentation
-------------
And when you open your browser at <http://127.0.0.1:8000/docs>, you will see an automatic, interactive, API documentation like:
Check
Again, just with that same Python type declaration, **FastAPI** gives you automatic, interactive documentation (integrating Swagger UI).
Notice that the path parameter is declared to be an integer.
Standards-based benefits, alternative documentation
---------------------------------------------------
And because the generated schema is from the [OpenAPI](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md) standard, there are many compatible tools.
Because of this, **FastAPI** itself provides an alternative API documentation (using ReDoc), which you can access at <http://127.0.0.1:8000/redoc>:
The same way, there are many compatible tools. Including code generation tools for many languages.
Pydantic
--------
All the data validation is performed under the hood by [Pydantic](https://pydantic-docs.helpmanual.io/), so you get all the benefits from it. And you know you are in good hands.
You can use the same type declarations with `str`, `float`, `bool` and many other complex data types.
Several of these are explored in the next chapters of the tutorial.
Order matters
-------------
When creating *path operations*, you can find situations where you have a fixed path.
Like `/users/me`, let's say that it's to get data about the current user.
And then you can also have a path `/users/{user_id}` to get data about a specific user by some user ID.
Because *path operations* are evaluated in order, you need to make sure that the path for `/users/me` is declared before the one for `/users/{user_id}`:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/users/me")
async def read_user_me():
return {"user_id": "the current user"}
@app.get("/users/{user_id}")
async def read_user(user_id: str):
return {"user_id": user_id}
```
Otherwise, the path for `/users/{user_id}` would match also for `/users/me`, "thinking" that it's receiving a parameter `user_id` with a value of `"me"`.
Similarly, you cannot redefine a path operation:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/users")
async def read_users():
return ["Rick", "Morty"]
@app.get("/users")
async def read_users2():
return ["Bean", "Elfo"]
```
The first one will always be used since the path matches first.
Predefined values
-----------------
If you have a *path operation* that receives a *path parameter*, but you want the possible valid *path parameter* values to be predefined, you can use a standard Python `Enum`.
### Create an `Enum` class
Import `Enum` and create a sub-class that inherits from `str` and from `Enum`.
By inheriting from `str` the API docs will be able to know that the values must be of type `string` and will be able to render correctly.
Then create class attributes with fixed values, which will be the available valid values:
```
from enum import Enum
from fastapi import FastAPI
class ModelName(str, Enum):
alexnet = "alexnet"
resnet = "resnet"
lenet = "lenet"
app = FastAPI()
@app.get("/models/{model_name}")
async def get_model(model_name: ModelName):
if model_name is ModelName.alexnet:
return {"model_name": model_name, "message": "Deep Learning FTW!"}
if model_name.value == "lenet":
return {"model_name": model_name, "message": "LeCNN all the images"}
return {"model_name": model_name, "message": "Have some residuals"}
```
Info
[Enumerations (or enums) are available in Python](https://docs.python.org/3/library/enum.html) since version 3.4.
Tip
If you are wondering, "AlexNet", "ResNet", and "LeNet" are just names of Machine Learning models.
### Declare a *path parameter*
Then create a *path parameter* with a type annotation using the enum class you created (`ModelName`):
```
from enum import Enum
from fastapi import FastAPI
class ModelName(str, Enum):
alexnet = "alexnet"
resnet = "resnet"
lenet = "lenet"
app = FastAPI()
@app.get("/models/{model_name}")
async def get_model(model_name: ModelName):
if model_name is ModelName.alexnet:
return {"model_name": model_name, "message": "Deep Learning FTW!"}
if model_name.value == "lenet":
return {"model_name": model_name, "message": "LeCNN all the images"}
return {"model_name": model_name, "message": "Have some residuals"}
```
### Check the docs
Because the available values for the *path parameter* are predefined, the interactive docs can show them nicely:
### Working with Python *enumerations*
The value of the *path parameter* will be an *enumeration member*.
#### Compare *enumeration members*
You can compare it with the *enumeration member* in your created enum `ModelName`:
```
from enum import Enum
from fastapi import FastAPI
class ModelName(str, Enum):
alexnet = "alexnet"
resnet = "resnet"
lenet = "lenet"
app = FastAPI()
@app.get("/models/{model_name}")
async def get_model(model_name: ModelName):
if model_name is ModelName.alexnet:
return {"model_name": model_name, "message": "Deep Learning FTW!"}
if model_name.value == "lenet":
return {"model_name": model_name, "message": "LeCNN all the images"}
return {"model_name": model_name, "message": "Have some residuals"}
```
#### Get the *enumeration value*
You can get the actual value (a `str` in this case) using `model_name.value`, or in general, `your_enum_member.value`:
```
from enum import Enum
from fastapi import FastAPI
class ModelName(str, Enum):
alexnet = "alexnet"
resnet = "resnet"
lenet = "lenet"
app = FastAPI()
@app.get("/models/{model_name}")
async def get_model(model_name: ModelName):
if model_name is ModelName.alexnet:
return {"model_name": model_name, "message": "Deep Learning FTW!"}
if model_name.value == "lenet":
return {"model_name": model_name, "message": "LeCNN all the images"}
return {"model_name": model_name, "message": "Have some residuals"}
```
Tip
You could also access the value `"lenet"` with `ModelName.lenet.value`.
#### Return *enumeration members*
You can return *enum members* from your *path operation*, even nested in a JSON body (e.g. a `dict`).
They will be converted to their corresponding values (strings in this case) before returning them to the client:
```
from enum import Enum
from fastapi import FastAPI
class ModelName(str, Enum):
alexnet = "alexnet"
resnet = "resnet"
lenet = "lenet"
app = FastAPI()
@app.get("/models/{model_name}")
async def get_model(model_name: ModelName):
if model_name is ModelName.alexnet:
return {"model_name": model_name, "message": "Deep Learning FTW!"}
if model_name.value == "lenet":
return {"model_name": model_name, "message": "LeCNN all the images"}
return {"model_name": model_name, "message": "Have some residuals"}
```
In your client you will get a JSON response like:
```
{
"model_name": "alexnet",
"message": "Deep Learning FTW!"
}
```
Path parameters containing paths
--------------------------------
Let's say you have a *path operation* with a path `/files/{file_path}`.
But you need `file_path` itself to contain a *path*, like `home/johndoe/myfile.txt`.
So, the URL for that file would be something like: `/files/home/johndoe/myfile.txt`.
### OpenAPI support
OpenAPI doesn't support a way to declare a *path parameter* to contain a *path* inside, as that could lead to scenarios that are difficult to test and define.
Nevertheless, you can still do it in **FastAPI**, using one of the internal tools from Starlette.
And the docs would still work, although not adding any documentation telling that the parameter should contain a path.
### Path convertor
Using an option directly from Starlette you can declare a *path parameter* containing a *path* using a URL like:
```
/files/{file_path:path}
```
In this case, the name of the parameter is `file_path`, and the last part, `:path`, tells it that the parameter should match any *path*.
So, you can use it with:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/files/{file_path:path}")
async def read_file(file_path: str):
return {"file_path": file_path}
```
Tip
You could need the parameter to contain `/home/johndoe/myfile.txt`, with a leading slash (`/`).
In that case, the URL would be: `/files//home/johndoe/myfile.txt`, with a double slash (`//`) between `files` and `home`.
Recap
-----
With **FastAPI**, by using short, intuitive and standard Python type declarations, you get:
* Editor support: error checks, autocompletion, etc.
* Data "parsing"
* Data validation
* API annotation and automatic documentation
And you only have to declare them once.
That's probably the main visible advantage of **FastAPI** compared to alternative frameworks (apart from the raw performance).
fastapi Form Data Form Data
=========
When you need to receive form fields instead of JSON, you can use `Form`.
Info
To use forms, first install [`python-multipart`](https://andrew-d.github.io/python-multipart/).
E.g. `pip install python-multipart`.
Import `Form`
-------------
Import `Form` from `fastapi`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login/")
async def login(username: Annotated[str, Form()], password: Annotated[str, Form()]):
return {"username": username}
```
Python 3.6+
```
from fastapi import FastAPI, Form
from typing_extensions import Annotated
app = FastAPI()
@app.post("/login/")
async def login(username: Annotated[str, Form()], password: Annotated[str, Form()]):
return {"username": username}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login/")
async def login(username: str = Form(), password: str = Form()):
return {"username": username}
```
Define `Form` parameters
------------------------
Create form parameters the same way you would for `Body` or `Query`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login/")
async def login(username: Annotated[str, Form()], password: Annotated[str, Form()]):
return {"username": username}
```
Python 3.6+
```
from fastapi import FastAPI, Form
from typing_extensions import Annotated
app = FastAPI()
@app.post("/login/")
async def login(username: Annotated[str, Form()], password: Annotated[str, Form()]):
return {"username": username}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Form
app = FastAPI()
@app.post("/login/")
async def login(username: str = Form(), password: str = Form()):
return {"username": username}
```
For example, in one of the ways the OAuth2 specification can be used (called "password flow") it is required to send a `username` and `password` as form fields.
The spec requires the fields to be exactly named `username` and `password`, and to be sent as form fields, not JSON.
With `Form` you can declare the same configurations as with `Body` (and `Query`, `Path`, `Cookie`), including validation, examples, an alias (e.g. `user-name` instead of `username`), etc.
Info
`Form` is a class that inherits directly from `Body`.
Tip
To declare form bodies, you need to use `Form` explicitly, because without it the parameters would be interpreted as query parameters or body (JSON) parameters.
About "Form Fields"
-------------------
The way HTML forms (`<form></form>`) sends the data to the server normally uses a "special" encoding for that data, it's different from JSON.
**FastAPI** will make sure to read that data from the right place instead of JSON.
Technical Details
Data from forms is normally encoded using the "media type" `application/x-www-form-urlencoded`.
But when the form includes files, it is encoded as `multipart/form-data`. You'll read about handling files in the next chapter.
If you want to read more about these encodings and form fields, head to the [MDN web docs for `POST`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/POST).
Warning
You can declare multiple `Form` parameters in a *path operation*, but you can't also declare `Body` fields that you expect to receive as JSON, as the request will have the body encoded using `application/x-www-form-urlencoded` instead of `application/json`.
This is not a limitation of **FastAPI**, it's part of the HTTP protocol.
Recap
-----
Use `Form` to declare form data input parameters.
fastapi Metadata and Docs URLs Metadata and Docs URLs
======================
You can customize several metadata configurations in your **FastAPI** application.
Metadata for API
----------------
You can set the following fields that are used in the OpenAPI specification and the automatic API docs UIs:
| Parameter | Type | Description |
| --- | --- | --- |
| `title` | `str` | The title of the API. |
| `description` | `str` | A short description of the API. It can use Markdown. |
| `version` | `string` | The version of the API. This is the version of your own application, not of OpenAPI. For example `2.5.0`. |
| `terms_of_service` | `str` | A URL to the Terms of Service for the API. If provided, this has to be a URL. |
| `contact` | `dict` | The contact information for the exposed API. It can contain several fields. `contact` fields
| Parameter | Type | Description |
| --- | --- | --- |
| `name` | `str` | The identifying name of the contact person/organization. |
| `url` | `str` | The URL pointing to the contact information. MUST be in the format of a URL. |
| `email` | `str` | The email address of the contact person/organization. MUST be in the format of an email address. |
|
| `license_info` | `dict` | The license information for the exposed API. It can contain several fields. `license_info` fields
| Parameter | Type | Description |
| --- | --- | --- |
| `name` | `str` | **REQUIRED** (if a `license_info` is set). The license name used for the API. |
| `url` | `str` | A URL to the license used for the API. MUST be in the format of a URL. |
|
You can set them as follows:
```
from fastapi import FastAPI
description = """
ChimichangApp API helps you do awesome stuff. 🚀
## Items
You can **read items**.
## Users
You will be able to:
* **Create users** (_not implemented_).
* **Read users** (_not implemented_).
"""
app = FastAPI(
title="ChimichangApp",
description=description,
version="0.0.1",
terms_of_service="http://example.com/terms/",
contact={
"name": "Deadpoolio the Amazing",
"url": "http://x-force.example.com/contact/",
"email": "[email protected]",
},
license_info={
"name": "Apache 2.0",
"url": "https://www.apache.org/licenses/LICENSE-2.0.html",
},
)
@app.get("/items/")
async def read_items():
return [{"name": "Katana"}]
```
Tip
You can write Markdown in the `description` field and it will be rendered in the output.
With this configuration, the automatic API docs would look like:
Metadata for tags
-----------------
You can also add additional metadata for the different tags used to group your path operations with the parameter `openapi_tags`.
It takes a list containing one dictionary for each tag.
Each dictionary can contain:
* `name` (**required**): a `str` with the same tag name you use in the `tags` parameter in your *path operations* and `APIRouter`s.
* `description`: a `str` with a short description for the tag. It can have Markdown and will be shown in the docs UI.
* `externalDocs`: a `dict` describing external documentation with:
+ `description`: a `str` with a short description for the external docs.
+ `url` (**required**): a `str` with the URL for the external documentation.
### Create metadata for tags
Let's try that in an example with tags for `users` and `items`.
Create metadata for your tags and pass it to the `openapi_tags` parameter:
```
from fastapi import FastAPI
tags_metadata = [
{
"name": "users",
"description": "Operations with users. The **login** logic is also here.",
},
{
"name": "items",
"description": "Manage items. So _fancy_ they have their own docs.",
"externalDocs": {
"description": "Items external docs",
"url": "https://fastapi.tiangolo.com/",
},
},
]
app = FastAPI(openapi_tags=tags_metadata)
@app.get("/users/", tags=["users"])
async def get_users():
return [{"name": "Harry"}, {"name": "Ron"}]
@app.get("/items/", tags=["items"])
async def get_items():
return [{"name": "wand"}, {"name": "flying broom"}]
```
Notice that you can use Markdown inside of the descriptions, for example "login" will be shown in bold (**login**) and "fancy" will be shown in italics (*fancy*).
Tip
You don't have to add metadata for all the tags that you use.
### Use your tags
Use the `tags` parameter with your *path operations* (and `APIRouter`s) to assign them to different tags:
```
from fastapi import FastAPI
tags_metadata = [
{
"name": "users",
"description": "Operations with users. The **login** logic is also here.",
},
{
"name": "items",
"description": "Manage items. So _fancy_ they have their own docs.",
"externalDocs": {
"description": "Items external docs",
"url": "https://fastapi.tiangolo.com/",
},
},
]
app = FastAPI(openapi_tags=tags_metadata)
@app.get("/users/", tags=["users"])
async def get_users():
return [{"name": "Harry"}, {"name": "Ron"}]
@app.get("/items/", tags=["items"])
async def get_items():
return [{"name": "wand"}, {"name": "flying broom"}]
```
Info
Read more about tags in [Path Operation Configuration](../path-operation-configuration/index#tags).
### Check the docs
Now, if you check the docs, they will show all the additional metadata:
### Order of tags
The order of each tag metadata dictionary also defines the order shown in the docs UI.
For example, even though `users` would go after `items` in alphabetical order, it is shown before them, because we added their metadata as the first dictionary in the list.
OpenAPI URL
-----------
By default, the OpenAPI schema is served at `/openapi.json`.
But you can configure it with the parameter `openapi_url`.
For example, to set it to be served at `/api/v1/openapi.json`:
```
from fastapi import FastAPI
app = FastAPI(openapi_url="/api/v1/openapi.json")
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
```
If you want to disable the OpenAPI schema completely you can set `openapi_url=None`, that will also disable the documentation user interfaces that use it.
Docs URLs
---------
You can configure the two documentation user interfaces included:
* **Swagger UI**: served at `/docs`.
+ You can set its URL with the parameter `docs_url`.
+ You can disable it by setting `docs_url=None`.
* **ReDoc**: served at `/redoc`.
+ You can set its URL with the parameter `redoc_url`.
+ You can disable it by setting `redoc_url=None`.
For example, to set Swagger UI to be served at `/documentation` and disable ReDoc:
```
from fastapi import FastAPI
app = FastAPI(docs_url="/documentation", redoc_url=None)
@app.get("/items/")
async def read_items():
return [{"name": "Foo"}]
```
| programming_docs |
fastapi Header Parameters Header Parameters
=================
You can define Header parameters the same way you define `Query`, `Path` and `Cookie` parameters.
Import `Header`
---------------
First import `Header`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[str | None, Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[Union[str, None], Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Header
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[Union[str, None], Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: str | None = Header(default=None)):
return {"User-Agent": user_agent}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Union[str, None] = Header(default=None)):
return {"User-Agent": user_agent}
```
Declare `Header` parameters
---------------------------
Then declare the header parameters using the same structure as with `Path`, `Query` and `Cookie`.
The first value is the default value, you can pass all the extra validation or annotation parameters:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[str | None, Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[Union[str, None], Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Header
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Annotated[Union[str, None], Header()] = None):
return {"User-Agent": user_agent}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: str | None = Header(default=None)):
return {"User-Agent": user_agent}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(user_agent: Union[str, None] = Header(default=None)):
return {"User-Agent": user_agent}
```
Technical Details
`Header` is a "sister" class of `Path`, `Query` and `Cookie`. It also inherits from the same common `Param` class.
But remember that when you import `Query`, `Path`, `Header`, and others from `fastapi`, those are actually functions that return special classes.
Info
To declare headers, you need to use `Header`, because otherwise the parameters would be interpreted as query parameters.
Automatic conversion
--------------------
`Header` has a little extra functionality on top of what `Path`, `Query` and `Cookie` provide.
Most of the standard headers are separated by a "hyphen" character, also known as the "minus symbol" (`-`).
But a variable like `user-agent` is invalid in Python.
So, by default, `Header` will convert the parameter names characters from underscore (`_`) to hyphen (`-`) to extract and document the headers.
Also, HTTP headers are case-insensitive, so, you can declare them with standard Python style (also known as "snake\_case").
So, you can use `user_agent` as you normally would in Python code, instead of needing to capitalize the first letters as `User_Agent` or something similar.
If for some reason you need to disable automatic conversion of underscores to hyphens, set the parameter `convert_underscores` of `Header` to `False`:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(
strange_header: Annotated[str | None, Header(convert_underscores=False)] = None
):
return {"strange_header": strange_header}
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(
strange_header: Annotated[
Union[str, None], Header(convert_underscores=False)
] = None
):
return {"strange_header": strange_header}
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI, Header
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(
strange_header: Annotated[
Union[str, None], Header(convert_underscores=False)
] = None
):
return {"strange_header": strange_header}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(
strange_header: str | None = Header(default=None, convert_underscores=False)
):
return {"strange_header": strange_header}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(
strange_header: Union[str, None] = Header(default=None, convert_underscores=False)
):
return {"strange_header": strange_header}
```
Warning
Before setting `convert_underscores` to `False`, bear in mind that some HTTP proxies and servers disallow the usage of headers with underscores.
Duplicate headers
-----------------
It is possible to receive duplicate headers. That means, the same header with multiple values.
You can define those cases using a list in the type declaration.
You will receive all the values from the duplicate header as a Python `list`.
For example, to declare a header of `X-Token` that can appear more than once, you can write:
Python 3.10+
```
from typing import Annotated
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: Annotated[list[str] | None, Header()] = None):
return {"X-Token values": x_token}
```
Python 3.9+
```
from typing import Annotated, List, Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: Annotated[Union[List[str], None], Header()] = None):
return {"X-Token values": x_token}
```
Python 3.6+
```
from typing import List, Union
from fastapi import FastAPI, Header
from typing_extensions import Annotated
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: Annotated[Union[List[str], None], Header()] = None):
return {"X-Token values": x_token}
```
Python 3.10+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: list[str] | None = Header(default=None)):
return {"X-Token values": x_token}
```
Python 3.9+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: Union[list[str], None] = Header(default=None)):
return {"X-Token values": x_token}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import List, Union
from fastapi import FastAPI, Header
app = FastAPI()
@app.get("/items/")
async def read_items(x_token: Union[List[str], None] = Header(default=None)):
return {"X-Token values": x_token}
```
If you communicate with that *path operation* sending two HTTP headers like:
```
X-Token: foo
X-Token: bar
```
The response would be like:
```
{
"X-Token values": [
"bar",
"foo"
]
}
```
Recap
-----
Declare headers with `Header`, using the same common pattern as `Query`, `Path` and `Cookie`.
And don't worry about underscores in your variables, **FastAPI** will take care of converting them.
fastapi Declare Request Example Data Declare Request Example Data
============================
You can declare examples of the data your app can receive.
Here are several ways to do it.
Pydantic `schema_extra`
-----------------------
You can declare an `example` for a Pydantic model using `Config` and `schema_extra`, as described in [Pydantic's docs: Schema customization](https://pydantic-docs.helpmanual.io/usage/schema/#schema-customization):
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
class Config:
schema_extra = {
"example": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
}
}
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
class Config:
schema_extra = {
"example": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
}
}
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
That extra info will be added as-is to the output **JSON Schema** for that model, and it will be used in the API docs.
Tip
You could use the same technique to extend the JSON Schema and add your own custom extra info.
For example you could use it to add metadata for a frontend user interface, etc.
`Field` additional arguments
-----------------------------
When using `Field()` with Pydantic models, you can also declare extra info for the **JSON Schema** by passing any other arbitrary arguments to the function.
You can use this to add `example` for each field:
Python 3.10+
```
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str = Field(example="Foo")
description: str | None = Field(default=None, example="A very nice Item")
price: float = Field(example=35.4)
tax: float | None = Field(default=None, example=3.2)
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
class Item(BaseModel):
name: str = Field(example="Foo")
description: Union[str, None] = Field(default=None, example="A very nice Item")
price: float = Field(example=35.4)
tax: Union[float, None] = Field(default=None, example=3.2)
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: Item):
results = {"item_id": item_id, "item": item}
return results
```
Warning
Keep in mind that those extra arguments passed won't add any validation, only extra information, for documentation purposes.
`example` and `examples` in OpenAPI
------------------------------------
When using any of:
* `Path()`
* `Query()`
* `Header()`
* `Cookie()`
* `Body()`
* `Form()`
* `File()`
you can also declare a data `example` or a group of `examples` with additional information that will be added to **OpenAPI**.
###
`Body` with `example`
Here we pass an `example` of the data expected in `Body()`:
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int,
item: Annotated[
Item,
Body(
example={
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int,
item: Annotated[
Item,
Body(
example={
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int,
item: Annotated[
Item,
Body(
example={
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.10+ non-Annotated
```
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int,
item: Item = Body(
example={
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
),
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
item_id: int,
item: Item = Body(
example={
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
),
):
results = {"item_id": item_id, "item": item}
return results
```
### Example in the docs UI
With any of the methods above it would look like this in the `/docs`:
###
`Body` with multiple `examples`
Alternatively to the single `example`, you can pass `examples` using a `dict` with **multiple examples**, each with extra information that will be added to **OpenAPI** too.
The keys of the `dict` identify each example, and each value is another `dict`.
Each specific example `dict` in the `examples` can contain:
* `summary`: Short description for the example.
* `description`: A long description that can contain Markdown text.
* `value`: This is the actual example shown, e.g. a `dict`.
* `externalValue`: alternative to `value`, a URL pointing to the example. Although this might not be supported by as many tools as `value`.
Python 3.10+
```
from typing import Annotated
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Annotated[
Item,
Body(
examples={
"normal": {
"summary": "A normal example",
"description": "A **normal** item works correctly.",
"value": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
},
"converted": {
"summary": "An example with converted data",
"description": "FastAPI can convert price `strings` to actual `numbers` automatically",
"value": {
"name": "Bar",
"price": "35.4",
},
},
"invalid": {
"summary": "Invalid data is rejected with an error",
"value": {
"name": "Baz",
"price": "thirty five point four",
},
},
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.9+
```
from typing import Annotated, Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Annotated[
Item,
Body(
examples={
"normal": {
"summary": "A normal example",
"description": "A **normal** item works correctly.",
"value": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
},
"converted": {
"summary": "An example with converted data",
"description": "FastAPI can convert price `strings` to actual `numbers` automatically",
"value": {
"name": "Bar",
"price": "35.4",
},
},
"invalid": {
"summary": "Invalid data is rejected with an error",
"value": {
"name": "Baz",
"price": "thirty five point four",
},
},
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
from typing_extensions import Annotated
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Annotated[
Item,
Body(
examples={
"normal": {
"summary": "A normal example",
"description": "A **normal** item works correctly.",
"value": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
},
"converted": {
"summary": "An example with converted data",
"description": "FastAPI can convert price `strings` to actual `numbers` automatically",
"value": {
"name": "Bar",
"price": "35.4",
},
},
"invalid": {
"summary": "Invalid data is rejected with an error",
"value": {
"name": "Baz",
"price": "thirty five point four",
},
},
},
),
],
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.10+ non-Annotated
```
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float | None = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item = Body(
examples={
"normal": {
"summary": "A normal example",
"description": "A **normal** item works correctly.",
"value": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
},
"converted": {
"summary": "An example with converted data",
"description": "FastAPI can convert price `strings` to actual `numbers` automatically",
"value": {
"name": "Bar",
"price": "35.4",
},
},
"invalid": {
"summary": "Invalid data is rejected with an error",
"value": {
"name": "Baz",
"price": "thirty five point four",
},
},
},
),
):
results = {"item_id": item_id, "item": item}
return results
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from typing import Union
from fastapi import Body, FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: Union[str, None] = None
price: float
tax: Union[float, None] = None
@app.put("/items/{item_id}")
async def update_item(
*,
item_id: int,
item: Item = Body(
examples={
"normal": {
"summary": "A normal example",
"description": "A **normal** item works correctly.",
"value": {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2,
},
},
"converted": {
"summary": "An example with converted data",
"description": "FastAPI can convert price `strings` to actual `numbers` automatically",
"value": {
"name": "Bar",
"price": "35.4",
},
},
"invalid": {
"summary": "Invalid data is rejected with an error",
"value": {
"name": "Baz",
"price": "thirty five point four",
},
},
},
),
):
results = {"item_id": item_id, "item": item}
return results
```
### Examples in the docs UI
With `examples` added to `Body()` the `/docs` would look like:
Technical Details
-----------------
Warning
These are very technical details about the standards **JSON Schema** and **OpenAPI**.
If the ideas above already work for you, that might be enough, and you probably don't need these details, feel free to skip them.
When you add an example inside of a Pydantic model, using `schema_extra` or `Field(example="something")` that example is added to the **JSON Schema** for that Pydantic model.
And that **JSON Schema** of the Pydantic model is included in the **OpenAPI** of your API, and then it's used in the docs UI.
**JSON Schema** doesn't really have a field `example` in the standards. Recent versions of JSON Schema define a field [`examples`](https://json-schema.org/draft/2019-09/json-schema-validation.html#rfc.section.9.5), but OpenAPI 3.0.3 is based on an older version of JSON Schema that didn't have `examples`.
So, OpenAPI 3.0.3 defined its own [`example`](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md#fixed-fields-20) for the modified version of **JSON Schema** it uses, for the same purpose (but it's a single `example`, not `examples`), and that's what is used by the API docs UI (using Swagger UI).
So, although `example` is not part of JSON Schema, it is part of OpenAPI's custom version of JSON Schema, and that's what will be used by the docs UI.
But when you use `example` or `examples` with any of the other utilities (`Query()`, `Body()`, etc.) those examples are not added to the JSON Schema that describes that data (not even to OpenAPI's own version of JSON Schema), they are added directly to the *path operation* declaration in OpenAPI (outside the parts of OpenAPI that use JSON Schema).
For `Path()`, `Query()`, `Header()`, and `Cookie()`, the `example` or `examples` are added to the [OpenAPI definition, to the `Parameter Object` (in the specification)](https://github.com/OAI/OpenAPI-Specification/blob/main/versions/3.0.3.md#parameter-object).
And for `Body()`, `File()`, and `Form()`, the `example` or `examples` are equivalently added to the [OpenAPI definition, to the `Request Body Object`, in the field `content`, on the `Media Type Object` (in the specification)](https://github.com/OAI/OpenAPI-Specification/blob/main/versions/3.0.3.md#mediaTypeObject).
On the other hand, there's a newer version of OpenAPI: **3.1.0**, recently released. It is based on the latest JSON Schema and most of the modifications from OpenAPI's custom version of JSON Schema are removed, in exchange of the features from the recent versions of JSON Schema, so all these small differences are reduced. Nevertheless, Swagger UI currently doesn't support OpenAPI 3.1.0, so, for now, it's better to continue using the ideas above.
| programming_docs |
fastapi Request Forms and Files Request Forms and Files
=======================
You can define files and form fields at the same time using `File` and `Form`.
Info
To receive uploaded files and/or form data, first install [`python-multipart`](https://andrew-d.github.io/python-multipart/).
E.g. `pip install python-multipart`.
Import `File` and `Form`
------------------------
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, Form, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(
file: Annotated[bytes, File()],
fileb: Annotated[UploadFile, File()],
token: Annotated[str, Form()],
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
Python 3.6+
```
from fastapi import FastAPI, File, Form, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(
file: Annotated[bytes, File()],
fileb: Annotated[UploadFile, File()],
token: Annotated[str, Form()],
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, Form, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(
file: bytes = File(), fileb: UploadFile = File(), token: str = Form()
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
Define `File` and `Form` parameters
-----------------------------------
Create file and form parameters the same way you would for `Body` or `Query`:
Python 3.9+
```
from typing import Annotated
from fastapi import FastAPI, File, Form, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(
file: Annotated[bytes, File()],
fileb: Annotated[UploadFile, File()],
token: Annotated[str, Form()],
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
Python 3.6+
```
from fastapi import FastAPI, File, Form, UploadFile
from typing_extensions import Annotated
app = FastAPI()
@app.post("/files/")
async def create_file(
file: Annotated[bytes, File()],
fileb: Annotated[UploadFile, File()],
token: Annotated[str, Form()],
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
Python 3.6+ non-Annotated Tip
Prefer to use the `Annotated` version if possible.
```
from fastapi import FastAPI, File, Form, UploadFile
app = FastAPI()
@app.post("/files/")
async def create_file(
file: bytes = File(), fileb: UploadFile = File(), token: str = Form()
):
return {
"file_size": len(file),
"token": token,
"fileb_content_type": fileb.content_type,
}
```
The files and form fields will be uploaded as form data and you will receive the files and form fields.
And you can declare some of the files as `bytes` and some as `UploadFile`.
Warning
You can declare multiple `File` and `Form` parameters in a *path operation*, but you can't also declare `Body` fields that you expect to receive as JSON, as the request will have the body encoded using `multipart/form-data` instead of `application/json`.
This is not a limitation of **FastAPI**, it's part of the HTTP protocol.
Recap
-----
Use `File` and `Form` together when you need to receive data and files in the same request.
fastapi Concurrency and async / await Concurrency and async / await
=============================
Details about the `async def` syntax for *path operation functions* and some background about asynchronous code, concurrency, and parallelism.
In a hurry?
-----------
**TL;DR:**
If you are using third party libraries that tell you to call them with `await`, like:
```
results = await some_library()
```
Then, declare your *path operation functions* with `async def` like:
```
@app.get('/')
async def read_results():
results = await some_library()
return results
```
Note
You can only use `await` inside of functions created with `async def`.
---
If you are using a third party library that communicates with something (a database, an API, the file system, etc.) and doesn't have support for using `await`, (this is currently the case for most database libraries), then declare your *path operation functions* as normally, with just `def`, like:
```
@app.get('/')
def results():
results = some_library()
return results
```
---
If your application (somehow) doesn't have to communicate with anything else and wait for it to respond, use `async def`.
---
If you just don't know, use normal `def`.
---
**Note**: You can mix `def` and `async def` in your *path operation functions* as much as you need and define each one using the best option for you. FastAPI will do the right thing with them.
Anyway, in any of the cases above, FastAPI will still work asynchronously and be extremely fast.
But by following the steps above, it will be able to do some performance optimizations.
Technical Details
-----------------
Modern versions of Python have support for **"asynchronous code"** using something called **"coroutines"**, with **`async` and `await`** syntax.
Let's see that phrase by parts in the sections below:
* **Asynchronous Code**
* **`async` and `await`**
* **Coroutines**
Asynchronous Code
-----------------
Asynchronous code just means that the language 💬 has a way to tell the computer / program 🤖 that at some point in the code, it 🤖 will have to wait for *something else* to finish somewhere else. Let's say that *something else* is called "slow-file" 📝.
So, during that time, the computer can go and do some other work, while "slow-file" 📝 finishes.
Then the computer / program 🤖 will come back every time it has a chance because it's waiting again, or whenever it 🤖 finished all the work it had at that point. And it 🤖 will see if any of the tasks it was waiting for have already finished, doing whatever it had to do.
Next, it 🤖 takes the first task to finish (let's say, our "slow-file" 📝) and continues whatever it had to do with it.
That "wait for something else" normally refers to I/O operations that are relatively "slow" (compared to the speed of the processor and the RAM memory), like waiting for:
* the data from the client to be sent through the network
* the data sent by your program to be received by the client through the network
* the contents of a file in the disk to be read by the system and given to your program
* the contents your program gave to the system to be written to disk
* a remote API operation
* a database operation to finish
* a database query to return the results
* etc.
As the execution time is consumed mostly by waiting for I/O operations, they call them "I/O bound" operations.
It's called "asynchronous" because the computer / program doesn't have to be "synchronized" with the slow task, waiting for the exact moment that the task finishes, while doing nothing, to be able to take the task result and continue the work.
Instead of that, by being an "asynchronous" system, once finished, the task can wait in line a little bit (some microseconds) for the computer / program to finish whatever it went to do, and then come back to take the results and continue working with them.
For "synchronous" (contrary to "asynchronous") they commonly also use the term "sequential", because the computer / program follows all the steps in sequence before switching to a different task, even if those steps involve waiting.
### Concurrency and Burgers
This idea of **asynchronous** code described above is also sometimes called **"concurrency"**. It is different from **"parallelism"**.
**Concurrency** and **parallelism** both relate to "different things happening more or less at the same time".
But the details between *concurrency* and *parallelism* are quite different.
To see the difference, imagine the following story about burgers:
### Concurrent Burgers
You go with your crush to get fast food, you stand in line while the cashier takes the orders from the people in front of you. 😍

Then it's your turn, you place your order of 2 very fancy burgers for your crush and you. 🍔🍔

The cashier says something to the cook in the kitchen so they know they have to prepare your burgers (even though they are currently preparing the ones for the previous clients).

You pay. 💸
The cashier gives you the number of your turn.

While you are waiting, you go with your crush and pick a table, you sit and talk with your crush for a long time (as your burgers are very fancy and take some time to prepare).
As you are sitting at the table with your crush, while you wait for the burgers, you can spend that time admiring how awesome, cute and smart your crush is ✨😍✨.

While waiting and talking to your crush, from time to time, you check the number displayed on the counter to see if it's your turn already.
Then at some point, it finally is your turn. You go to the counter, get your burgers and come back to the table.

You and your crush eat the burgers and have a nice time. ✨

Info
Beautiful illustrations by [Ketrina Thompson](https://www.instagram.com/ketrinadrawsalot). 🎨
---
Imagine you are the computer / program 🤖 in that story.
While you are at the line, you are just idle 😴, waiting for your turn, not doing anything very "productive". But the line is fast because the cashier is only taking the orders (not preparing them), so that's fine.
Then, when it's your turn, you do actual "productive" work, you process the menu, decide what you want, get your crush's choice, pay, check that you give the correct bill or card, check that you are charged correctly, check that the order has the correct items, etc.
But then, even though you still don't have your burgers, your work with the cashier is "on pause" ⏸, because you have to wait 🕙 for your burgers to be ready.
But as you go away from the counter and sit at the table with a number for your turn, you can switch 🔀 your attention to your crush, and "work" ⏯ 🤓 on that. Then you are again doing something very "productive" as is flirting with your crush 😍.
Then the cashier 💁 says "I'm finished with doing the burgers" by putting your number on the counter's display, but you don't jump like crazy immediately when the displayed number changes to your turn number. You know no one will steal your burgers because you have the number of your turn, and they have theirs.
So you wait for your crush to finish the story (finish the current work ⏯ / task being processed 🤓), smile gently and say that you are going for the burgers ⏸.
Then you go to the counter 🔀, to the initial task that is now finished ⏯, pick the burgers, say thanks and take them to the table. That finishes that step / task of interaction with the counter ⏹. That in turn, creates a new task, of "eating burgers" 🔀 ⏯, but the previous one of "getting burgers" is finished ⏹.
### Parallel Burgers
Now let's imagine these aren't "Concurrent Burgers", but "Parallel Burgers".
You go with your crush to get parallel fast food.
You stand in line while several (let's say 8) cashiers that at the same time are cooks take the orders from the people in front of you.
Everyone before you is waiting for their burgers to be ready before leaving the counter because each of the 8 cashiers goes and prepares the burger right away before getting the next order.

Then it's finally your turn, you place your order of 2 very fancy burgers for your crush and you.
You pay 💸.

The cashier goes to the kitchen.
You wait, standing in front of the counter 🕙, so that no one else takes your burgers before you do, as there are no numbers for turns.

As you and your crush are busy not letting anyone get in front of you and take your burgers whenever they arrive, you cannot pay attention to your crush. 😞
This is "synchronous" work, you are "synchronized" with the cashier/cook 👨🍳. You have to wait 🕙 and be there at the exact moment that the cashier/cook 👨🍳 finishes the burgers and gives them to you, or otherwise, someone else might take them.

Then your cashier/cook 👨🍳 finally comes back with your burgers, after a long time waiting 🕙 there in front of the counter.

You take your burgers and go to the table with your crush.
You just eat them, and you are done. ⏹

There was not much talk or flirting as most of the time was spent waiting 🕙 in front of the counter. 😞
Info
Beautiful illustrations by [Ketrina Thompson](https://www.instagram.com/ketrinadrawsalot). 🎨
---
In this scenario of the parallel burgers, you are a computer / program 🤖 with two processors (you and your crush), both waiting 🕙 and dedicating their attention ⏯ to be "waiting on the counter" 🕙 for a long time.
The fast food store has 8 processors (cashiers/cooks). While the concurrent burgers store might have had only 2 (one cashier and one cook).
But still, the final experience is not the best. 😞
---
This would be the parallel equivalent story for burgers. 🍔
For a more "real life" example of this, imagine a bank.
Up to recently, most of the banks had multiple cashiers 👨💼👨💼👨💼👨💼 and a big line 🕙🕙🕙🕙🕙🕙🕙🕙.
All of the cashiers doing all the work with one client after the other 👨💼⏯.
And you have to wait 🕙 in the line for a long time or you lose your turn.
You probably wouldn't want to take your crush 😍 with you to do errands at the bank 🏦.
### Burger Conclusion
In this scenario of "fast food burgers with your crush", as there is a lot of waiting 🕙, it makes a lot more sense to have a concurrent system ⏸🔀⏯.
This is the case for most of the web applications.
Many, many users, but your server is waiting 🕙 for their not-so-good connection to send their requests.
And then waiting 🕙 again for the responses to come back.
This "waiting" 🕙 is measured in microseconds, but still, summing it all, it's a lot of waiting in the end.
That's why it makes a lot of sense to use asynchronous ⏸🔀⏯ code for web APIs.
This kind of asynchronicity is what made NodeJS popular (even though NodeJS is not parallel) and that's the strength of Go as a programming language.
And that's the same level of performance you get with **FastAPI**.
And as you can have parallelism and asynchronicity at the same time, you get higher performance than most of the tested NodeJS frameworks and on par with Go, which is a compiled language closer to C [(all thanks to Starlette)](https://www.techempower.com/benchmarks/#section=data-r17&hw=ph&test=query&l=zijmkf-1).
### Is concurrency better than parallelism?
Nope! That's not the moral of the story.
Concurrency is different than parallelism. And it is better on **specific** scenarios that involve a lot of waiting. Because of that, it generally is a lot better than parallelism for web application development. But not for everything.
So, to balance that out, imagine the following short story:
> You have to clean a big, dirty house.
>
>
*Yep, that's the whole story*.
---
There's no waiting 🕙 anywhere, just a lot of work to be done, on multiple places of the house.
You could have turns as in the burgers example, first the living room, then the kitchen, but as you are not waiting 🕙 for anything, just cleaning and cleaning, the turns wouldn't affect anything.
It would take the same amount of time to finish with or without turns (concurrency) and you would have done the same amount of work.
But in this case, if you could bring the 8 ex-cashier/cooks/now-cleaners, and each one of them (plus you) could take a zone of the house to clean it, you could do all the work in **parallel**, with the extra help, and finish much sooner.
In this scenario, each one of the cleaners (including you) would be a processor, doing their part of the job.
And as most of the execution time is taken by actual work (instead of waiting), and the work in a computer is done by a CPU, they call these problems "CPU bound".
---
Common examples of CPU bound operations are things that require complex math processing.
For example:
* **Audio** or **image processing**.
* **Computer vision**: an image is composed of millions of pixels, each pixel has 3 values / colors, processing that normally requires computing something on those pixels, all at the same time.
* **Machine Learning**: it normally requires lots of "matrix" and "vector" multiplications. Think of a huge spreadsheet with numbers and multiplying all of them together at the same time.
* **Deep Learning**: this is a sub-field of Machine Learning, so, the same applies. It's just that there is not a single spreadsheet of numbers to multiply, but a huge set of them, and in many cases, you use a special processor to build and / or use those models.
### Concurrency + Parallelism: Web + Machine Learning
With **FastAPI** you can take the advantage of concurrency that is very common for web development (the same main attraction of NodeJS).
But you can also exploit the benefits of parallelism and multiprocessing (having multiple processes running in parallel) for **CPU bound** workloads like those in Machine Learning systems.
That, plus the simple fact that Python is the main language for **Data Science**, Machine Learning and especially Deep Learning, make FastAPI a very good match for Data Science / Machine Learning web APIs and applications (among many others).
To see how to achieve this parallelism in production see the section about [Deployment](../deployment/index).
`async` and `await`
--------------------
Modern versions of Python have a very intuitive way to define asynchronous code. This makes it look just like normal "sequential" code and do the "awaiting" for you at the right moments.
When there is an operation that will require waiting before giving the results and has support for these new Python features, you can code it like:
```
burgers = await get_burgers(2)
```
The key here is the `await`. It tells Python that it has to wait ⏸ for `get_burgers(2)` to finish doing its thing 🕙 before storing the results in `burgers`. With that, Python will know that it can go and do something else 🔀 ⏯ in the meanwhile (like receiving another request).
For `await` to work, it has to be inside a function that supports this asynchronicity. To do that, you just declare it with `async def`:
```
async def get_burgers(number: int):
# Do some asynchronous stuff to create the burgers
return burgers
```
...instead of `def`:
```
# This is not asynchronous
def get_sequential_burgers(number: int):
# Do some sequential stuff to create the burgers
return burgers
```
With `async def`, Python knows that, inside that function, it has to be aware of `await` expressions, and that it can "pause" ⏸ the execution of that function and go do something else 🔀 before coming back.
When you want to call an `async def` function, you have to "await" it. So, this won't work:
```
# This won't work, because get_burgers was defined with: async def
burgers = get_burgers(2)
```
---
So, if you are using a library that tells you that you can call it with `await`, you need to create the *path operation functions* that uses it with `async def`, like in:
```
@app.get('/burgers')
async def read_burgers():
burgers = await get_burgers(2)
return burgers
```
### More technical details
You might have noticed that `await` can only be used inside of functions defined with `async def`.
But at the same time, functions defined with `async def` have to be "awaited". So, functions with `async def` can only be called inside of functions defined with `async def` too.
So, about the egg and the chicken, how do you call the first `async` function?
If you are working with **FastAPI** you don't have to worry about that, because that "first" function will be your *path operation function*, and FastAPI will know how to do the right thing.
But if you want to use `async` / `await` without FastAPI, you can do it as well.
### Write your own async code
Starlette (and **FastAPI**) are based on [AnyIO](https://anyio.readthedocs.io/en/stable/), which makes it compatible with both Python's standard library [asyncio](https://docs.python.org/3/library/asyncio-task.html) and [Trio](https://trio.readthedocs.io/en/stable/).
In particular, you can directly use [AnyIO](https://anyio.readthedocs.io/en/stable/) for your advanced concurrency use cases that require more advanced patterns in your own code.
And even if you were not using FastAPI, you could also write your own async applications with [AnyIO](https://anyio.readthedocs.io/en/stable/) to be highly compatible and get its benefits (e.g. *structured concurrency*).
### Other forms of asynchronous code
This style of using `async` and `await` is relatively new in the language.
But it makes working with asynchronous code a lot easier.
This same syntax (or almost identical) was also included recently in modern versions of JavaScript (in Browser and NodeJS).
But before that, handling asynchronous code was quite more complex and difficult.
In previous versions of Python, you could have used threads or [Gevent](https://www.gevent.org/). But the code is way more complex to understand, debug, and think about.
In previous versions of NodeJS / Browser JavaScript, you would have used "callbacks". Which leads to [callback hell](http://callbackhell.com/).
Coroutines
----------
**Coroutine** is just the very fancy term for the thing returned by an `async def` function. Python knows that it is something like a function that it can start and that it will end at some point, but that it might be paused ⏸ internally too, whenever there is an `await` inside of it.
But all this functionality of using asynchronous code with `async` and `await` is many times summarized as using "coroutines". It is comparable to the main key feature of Go, the "Goroutines".
Conclusion
----------
Let's see the same phrase from above:
> Modern versions of Python have support for **"asynchronous code"** using something called **"coroutines"**, with **`async` and `await`** syntax.
>
>
That should make more sense now. ✨
All that is what powers FastAPI (through Starlette) and what makes it have such an impressive performance.
Very Technical Details
----------------------
Warning
You can probably skip this.
These are very technical details of how **FastAPI** works underneath.
If you have quite some technical knowledge (co-routines, threads, blocking, etc.) and are curious about how FastAPI handles `async def` vs normal `def`, go ahead.
### Path operation functions
When you declare a *path operation function* with normal `def` instead of `async def`, it is run in an external threadpool that is then awaited, instead of being called directly (as it would block the server).
If you are coming from another async framework that does not work in the way described above and you are used to defining trivial compute-only *path operation functions* with plain `def` for a tiny performance gain (about 100 nanoseconds), please note that in **FastAPI** the effect would be quite opposite. In these cases, it's better to use `async def` unless your *path operation functions* use code that performs blocking I/O.
Still, in both situations, chances are that **FastAPI** will [still be faster](../index#performance) than (or at least comparable to) your previous framework.
### Dependencies
The same applies for [dependencies](../tutorial/dependencies/index.md). If a dependency is a standard `def` function instead of `async def`, it is run in the external threadpool.
### Sub-dependencies
You can have multiple dependencies and [sub-dependencies](../tutorial/dependencies/sub-dependencies.md) requiring each other (as parameters of the function definitions), some of them might be created with `async def` and some with normal `def`. It would still work, and the ones created with normal `def` would be called on an external thread (from the threadpool) instead of being "awaited".
### Other utility functions
Any other utility function that you call directly can be created with normal `def` or `async def` and FastAPI won't affect the way you call it.
This is in contrast to the functions that FastAPI calls for you: *path operation functions* and dependencies.
If your utility function is a normal function with `def`, it will be called directly (as you write it in your code), not in a threadpool, if the function is created with `async def` then you should `await` for that function when you call it in your code.
---
Again, these are very technical details that would probably be useful if you came searching for them.
Otherwise, you should be good with the guidelines from the section above: [In a hurry?](#in-a-hurry).
| programming_docs |
fastapi Features Features
========
FastAPI features
----------------
**FastAPI** gives you the following:
### Based on open standards
* [**OpenAPI**](https://github.com/OAI/OpenAPI-Specification) for API creation, including declarations of path operations, parameters, body requests, security, etc.
* Automatic data model documentation with [**JSON Schema**](https://json-schema.org/) (as OpenAPI itself is based on JSON Schema).
* Designed around these standards, after a meticulous study. Instead of an afterthought layer on top.
* This also allows using automatic **client code generation** in many languages.
### Automatic docs
Interactive API documentation and exploration web user interfaces. As the framework is based on OpenAPI, there are multiple options, 2 included by default.
* [**Swagger UI**](https://github.com/swagger-api/swagger-ui), with interactive exploration, call and test your API directly from the browser.
* Alternative API documentation with [**ReDoc**](https://github.com/Rebilly/ReDoc).
### Just Modern Python
It's all based on standard **Python 3.6 type** declarations (thanks to Pydantic). No new syntax to learn. Just standard modern Python.
If you need a 2 minute refresher of how to use Python types (even if you don't use FastAPI), check the short tutorial: [Python Types](../python-types/index).
You write standard Python with types:
```
from datetime import date
from pydantic import BaseModel
# Declare a variable as a str
# and get editor support inside the function
def main(user_id: str):
return user_id
# A Pydantic model
class User(BaseModel):
id: int
name: str
joined: date
```
That can then be used like:
```
my_user: User = User(id=3, name="John Doe", joined="2018-07-19")
second_user_data = {
"id": 4,
"name": "Mary",
"joined": "2018-11-30",
}
my_second_user: User = User(**second_user_data)
```
Info
`**second_user_data` means:
Pass the keys and values of the `second_user_data` dict directly as key-value arguments, equivalent to: `User(id=4, name="Mary", joined="2018-11-30")`
### Editor support
All the framework was designed to be easy and intuitive to use, all the decisions were tested on multiple editors even before starting development, to ensure the best development experience.
In the last Python developer survey it was clear [that the most used feature is "autocompletion"](https://www.jetbrains.com/research/python-developers-survey-2017/#tools-and-features).
The whole **FastAPI** framework is based to satisfy that. Autocompletion works everywhere.
You will rarely need to come back to the docs.
Here's how your editor might help you:
* in [Visual Studio Code](https://code.visualstudio.com/):
* in [PyCharm](https://www.jetbrains.com/pycharm/):
You will get completion in code you might even consider impossible before. As for example, the `price` key inside a JSON body (that could have been nested) that comes from a request.
No more typing the wrong key names, coming back and forth between docs, or scrolling up and down to find if you finally used `username` or `user_name`.
### Short
It has sensible **defaults** for everything, with optional configurations everywhere. All the parameters can be fine-tuned to do what you need and to define the API you need.
But by default, it all **"just works"**.
### Validation
* Validation for most (or all?) Python **data types**, including:
+ JSON objects (`dict`).
+ JSON array (`list`) defining item types.
+ String (`str`) fields, defining min and max lengths.
+ Numbers (`int`, `float`) with min and max values, etc.
* Validation for more exotic types, like:
+ URL.
+ Email.
+ UUID.
+ ...and others.
All the validation is handled by the well-established and robust **Pydantic**.
### Security and authentication
Security and authentication integrated. Without any compromise with databases or data models.
All the security schemes defined in OpenAPI, including:
* HTTP Basic.
* **OAuth2** (also with **JWT tokens**). Check the tutorial on [OAuth2 with JWT](../tutorial/security/oauth2-jwt/index).
* API keys in:
+ Headers.
+ Query parameters.
+ Cookies, etc.
Plus all the security features from Starlette (including **session cookies**).
All built as reusable tools and components that are easy to integrate with your systems, data stores, relational and NoSQL databases, etc.
### Dependency Injection
FastAPI includes an extremely easy to use, but extremely powerful **Dependency Injection** system.
* Even dependencies can have dependencies, creating a hierarchy or **"graph" of dependencies**.
* All **automatically handled** by the framework.
* All the dependencies can require data from requests and **augment the path operation** constraints and automatic documentation.
* **Automatic validation** even for *path operation* parameters defined in dependencies.
* Support for complex user authentication systems, **database connections**, etc.
* **No compromise** with databases, frontends, etc. But easy integration with all of them.
### Unlimited "plug-ins"
Or in other way, no need for them, import and use the code you need.
Any integration is designed to be so simple to use (with dependencies) that you can create a "plug-in" for your application in 2 lines of code using the same structure and syntax used for your *path operations*.
### Tested
* 100% test coverage.
* 100% type annotated code base.
* Used in production applications.
Starlette features
------------------
**FastAPI** is fully compatible with (and based on) [**Starlette**](https://www.starlette.io/). So, any additional Starlette code you have, will also work.
`FastAPI` is actually a sub-class of `Starlette`. So, if you already know or use Starlette, most of the functionality will work the same way.
With **FastAPI** you get all of **Starlette**'s features (as FastAPI is just Starlette on steroids):
* Seriously impressive performance. It is [one of the fastest Python frameworks available, on par with **NodeJS** and **Go**](https://github.com/encode/starlette#performance).
* **WebSocket** support.
* In-process background tasks.
* Startup and shutdown events.
* Test client built on HTTPX.
* **CORS**, GZip, Static Files, Streaming responses.
* **Session and Cookie** support.
* 100% test coverage.
* 100% type annotated codebase.
Pydantic features
-----------------
**FastAPI** is fully compatible with (and based on) [**Pydantic**](https://pydantic-docs.helpmanual.io). So, any additional Pydantic code you have, will also work.
Including external libraries also based on Pydantic, as ORMs, ODMs for databases.
This also means that in many cases you can pass the same object you get from a request **directly to the database**, as everything is validated automatically.
The same applies the other way around, in many cases you can just pass the object you get from the database **directly to the client**.
With **FastAPI** you get all of **Pydantic**'s features (as FastAPI is based on Pydantic for all the data handling):
* **No brainfuck**:
+ No new schema definition micro-language to learn.
+ If you know Python types you know how to use Pydantic.
* Plays nicely with your **IDE/linter/brain**:
+ Because pydantic data structures are just instances of classes you define; auto-completion, linting, mypy and your intuition should all work properly with your validated data.
* **Fast**:
+ in [benchmarks](https://pydantic-docs.helpmanual.io/benchmarks/) Pydantic is faster than all other tested libraries.
* Validate **complex structures**:
+ Use of hierarchical Pydantic models, Python `typing`’s `List` and `Dict`, etc.
+ And validators allow complex data schemas to be clearly and easily defined, checked and documented as JSON Schema.
+ You can have deeply **nested JSON** objects and have them all validated and annotated.
* **Extensible**:
+ Pydantic allows custom data types to be defined or you can extend validation with methods on a model decorated with the validator decorator.
* 100% test coverage.
fastapi Python Types Intro Python Types Intro
==================
Python has support for optional "type hints" (also called "type annotations").
These **"type hints"** or annotations are a special syntax that allow declaring the type of a variable.
By declaring types for your variables, editors and tools can give you better support.
This is just a **quick tutorial / refresher** about Python type hints. It covers only the minimum necessary to use them with **FastAPI**... which is actually very little.
**FastAPI** is all based on these type hints, they give it many advantages and benefits.
But even if you never use **FastAPI**, you would benefit from learning a bit about them.
Note
If you are a Python expert, and you already know everything about type hints, skip to the next chapter.
Motivation
----------
Let's start with a simple example:
```
def get_full_name(first_name, last_name):
full_name = first_name.title() + " " + last_name.title()
return full_name
print(get_full_name("john", "doe"))
```
Calling this program outputs:
```
John Doe
```
The function does the following:
* Takes a `first_name` and `last_name`.
* Converts the first letter of each one to upper case with `title()`.
* Concatenates them with a space in the middle.
```
def get_full_name(first_name, last_name):
full_name = first_name.title() + " " + last_name.title()
return full_name
print(get_full_name("john", "doe"))
```
### Edit it
It's a very simple program.
But now imagine that you were writing it from scratch.
At some point you would have started the definition of the function, you had the parameters ready...
But then you have to call "that method that converts the first letter to upper case".
Was it `upper`? Was it `uppercase`? `first_uppercase`? `capitalize`?
Then, you try with the old programmer's friend, editor autocompletion.
You type the first parameter of the function, `first_name`, then a dot (`.`) and then hit `Ctrl+Space` to trigger the completion.
But, sadly, you get nothing useful:
### Add types
Let's modify a single line from the previous version.
We will change exactly this fragment, the parameters of the function, from:
```
first_name, last_name
```
to:
```
first_name: str, last_name: str
```
That's it.
Those are the "type hints":
```
def get_full_name(first_name: str, last_name: str):
full_name = first_name.title() + " " + last_name.title()
return full_name
print(get_full_name("john", "doe"))
```
That is not the same as declaring default values like would be with:
```
first_name="john", last_name="doe"
```
It's a different thing.
We are using colons (`:`), not equals (`=`).
And adding type hints normally doesn't change what happens from what would happen without them.
But now, imagine you are again in the middle of creating that function, but with type hints.
At the same point, you try to trigger the autocomplete with `Ctrl+Space` and you see:
With that, you can scroll, seeing the options, until you find the one that "rings a bell":
More motivation
---------------
Check this function, it already has type hints:
```
def get_name_with_age(name: str, age: int):
name_with_age = name + " is this old: " + age
return name_with_age
```
Because the editor knows the types of the variables, you don't only get completion, you also get error checks:
Now you know that you have to fix it, convert `age` to a string with `str(age)`:
```
def get_name_with_age(name: str, age: int):
name_with_age = name + " is this old: " + str(age)
return name_with_age
```
Declaring types
---------------
You just saw the main place to declare type hints. As function parameters.
This is also the main place you would use them with **FastAPI**.
### Simple types
You can declare all the standard Python types, not only `str`.
You can use, for example:
* `int`
* `float`
* `bool`
* `bytes`
```
def get_items(item_a: str, item_b: int, item_c: float, item_d: bool, item_e: bytes):
return item_a, item_b, item_c, item_d, item_d, item_e
```
### Generic types with type parameters
There are some data structures that can contain other values, like `dict`, `list`, `set` and `tuple`. And the internal values can have their own type too.
These types that have internal types are called "**generic**" types. And it's possible to declare them, even with their internal types.
To declare those types and the internal types, you can use the standard Python module `typing`. It exists specifically to support these type hints.
#### Newer versions of Python
The syntax using `typing` is **compatible** with all versions, from Python 3.6 to the latest ones, including Python 3.9, Python 3.10, etc.
As Python advances, **newer versions** come with improved support for these type annotations and in many cases you won't even need to import and use the `typing` module to declare the type annotations.
If you can choose a more recent version of Python for your project, you will be able to take advantage of that extra simplicity.
In all the docs there are examples compatible with each version of Python (when there's a difference).
For example "**Python 3.6+**" means it's compatible with Python 3.6 or above (including 3.7, 3.8, 3.9, 3.10, etc). And "**Python 3.9+**" means it's compatible with Python 3.9 or above (including 3.10, etc).
If you can use the **latest versions of Python**, use the examples for the latest version, those will have the **best and simplest syntax**, for example, "**Python 3.10+**".
#### List
For example, let's define a variable to be a `list` of `str`.
Python 3.9+ Declare the variable, with the same colon (`:`) syntax.
As the type, put `list`.
As the list is a type that contains some internal types, you put them in square brackets:
```
def process_items(items: list[str]):
for item in items:
print(item)
```
Python 3.6+ From `typing`, import `List` (with a capital `L`):
```
from typing import List
def process_items(items: List[str]):
for item in items:
print(item)
```
Declare the variable, with the same colon (`:`) syntax.
As the type, put the `List` that you imported from `typing`.
As the list is a type that contains some internal types, you put them in square brackets:
```
from typing import List
def process_items(items: List[str]):
for item in items:
print(item)
```
Info
Those internal types in the square brackets are called "type parameters".
In this case, `str` is the type parameter passed to `List` (or `list` in Python 3.9 and above).
That means: "the variable `items` is a `list`, and each of the items in this list is a `str`".
Tip
If you use Python 3.9 or above, you don't have to import `List` from `typing`, you can use the same regular `list` type instead.
By doing that, your editor can provide support even while processing items from the list:
Without types, that's almost impossible to achieve.
Notice that the variable `item` is one of the elements in the list `items`.
And still, the editor knows it is a `str`, and provides support for that.
#### Tuple and Set
You would do the same to declare `tuple`s and `set`s:
Python 3.9+
```
def process_items(items_t: tuple[int, int, str], items_s: set[bytes]):
return items_t, items_s
```
Python 3.6+
```
from typing import Set, Tuple
def process_items(items_t: Tuple[int, int, str], items_s: Set[bytes]):
return items_t, items_s
```
This means:
* The variable `items_t` is a `tuple` with 3 items, an `int`, another `int`, and a `str`.
* The variable `items_s` is a `set`, and each of its items is of type `bytes`.
#### Dict
To define a `dict`, you pass 2 type parameters, separated by commas.
The first type parameter is for the keys of the `dict`.
The second type parameter is for the values of the `dict`:
Python 3.9+
```
def process_items(prices: dict[str, float]):
for item_name, item_price in prices.items():
print(item_name)
print(item_price)
```
Python 3.6+
```
from typing import Dict
def process_items(prices: Dict[str, float]):
for item_name, item_price in prices.items():
print(item_name)
print(item_price)
```
This means:
* The variable `prices` is a `dict`:
+ The keys of this `dict` are of type `str` (let's say, the name of each item).
+ The values of this `dict` are of type `float` (let's say, the price of each item).
#### Union
You can declare that a variable can be any of **several types**, for example, an `int` or a `str`.
In Python 3.6 and above (including Python 3.10) you can use the `Union` type from `typing` and put inside the square brackets the possible types to accept.
In Python 3.10 there's also a **new syntax** where you can put the possible types separated by a vertical bar (`|`).
Python 3.10+
```
def process_item(item: int | str):
print(item)
```
Python 3.6+
```
from typing import Union
def process_item(item: Union[int, str]):
print(item)
```
In both cases this means that `item` could be an `int` or a `str`.
#### Possibly `None`
You can declare that a value could have a type, like `str`, but that it could also be `None`.
In Python 3.6 and above (including Python 3.10) you can declare it by importing and using `Optional` from the `typing` module.
```
from typing import Optional
def say_hi(name: Optional[str] = None):
if name is not None:
print(f"Hey {name}!")
else:
print("Hello World")
```
Using `Optional[str]` instead of just `str` will let the editor help you detecting errors where you could be assuming that a value is always a `str`, when it could actually be `None` too.
`Optional[Something]` is actually a shortcut for `Union[Something, None]`, they are equivalent.
This also means that in Python 3.10, you can use `Something | None`:
Python 3.10+
```
def say_hi(name: str | None = None):
if name is not None:
print(f"Hey {name}!")
else:
print("Hello World")
```
Python 3.6+
```
from typing import Optional
def say_hi(name: Optional[str] = None):
if name is not None:
print(f"Hey {name}!")
else:
print("Hello World")
```
Python 3.6+ alternative
```
from typing import Union
def say_hi(name: Union[str, None] = None):
if name is not None:
print(f"Hey {name}!")
else:
print("Hello World")
```
#### Using `Union` or `Optional`
If you are using a Python version below 3.10, here's a tip from my very **subjective** point of view:
* 🚨 Avoid using `Optional[SomeType]`
* Instead ✨ **use `Union[SomeType, None]`** ✨.
Both are equivalent and underneath they are the same, but I would recommend `Union` instead of `Optional` because the word "**optional**" would seem to imply that the value is optional, and it actually means "it can be `None`", even if it's not optional and is still required.
I think `Union[SomeType, None]` is more explicit about what it means.
It's just about the words and names. But those words can affect how you and your teammates think about the code.
As an example, let's take this function:
```
from typing import Optional
def say_hi(name: Optional[str]):
print(f"Hey {name}!")
```
The parameter `name` is defined as `Optional[str]`, but it is **not optional**, you cannot call the function without the parameter:
```
say_hi() # Oh, no, this throws an error! 😱
```
The `name` parameter is **still required** (not *optional*) because it doesn't have a default value. Still, `name` accepts `None` as the value:
```
say_hi(name=None) # This works, None is valid 🎉
```
The good news is, once you are on Python 3.10 you won't have to worry about that, as you will be able to simply use `|` to define unions of types:
```
def say_hi(name: str | None):
print(f"Hey {name}!")
```
And then you won't have to worry about names like `Optional` and `Union`. 😎
#### Generic types
These types that take type parameters in square brackets are called **Generic types** or **Generics**, for example:
Python 3.10+ You can use the same builtin types as generics (with square brackets and types inside):
* `list`
* `tuple`
* `set`
* `dict`
And the same as with Python 3.6, from the `typing` module:
* `Union`
* `Optional` (the same as with Python 3.6)
* ...and others.
In Python 3.10, as an alternative to using the generics `Union` and `Optional`, you can use the vertical bar (`|`) to declare unions of types, that's a lot better and simpler.
Python 3.9+ You can use the same builtin types as generics (with square brackets and types inside):
* `list`
* `tuple`
* `set`
* `dict`
And the same as with Python 3.6, from the `typing` module:
* `Union`
* `Optional`
* ...and others.
Python 3.6+ * `List`
* `Tuple`
* `Set`
* `Dict`
* `Union`
* `Optional`
* ...and others.
### Classes as types
You can also declare a class as the type of a variable.
Let's say you have a class `Person`, with a name:
```
class Person:
def __init__(self, name: str):
self.name = name
def get_person_name(one_person: Person):
return one_person.name
```
Then you can declare a variable to be of type `Person`:
```
class Person:
def __init__(self, name: str):
self.name = name
def get_person_name(one_person: Person):
return one_person.name
```
And then, again, you get all the editor support:
Notice that this means "`one_person` is an **instance** of the class `Person`".
It doesn't mean "`one_person` is the **class** called `Person`".
Pydantic models
---------------
[Pydantic](https://pydantic-docs.helpmanual.io/) is a Python library to perform data validation.
You declare the "shape" of the data as classes with attributes.
And each attribute has a type.
Then you create an instance of that class with some values and it will validate the values, convert them to the appropriate type (if that's the case) and give you an object with all the data.
And you get all the editor support with that resulting object.
An example from the official Pydantic docs:
Python 3.10+
```
from datetime import datetime
from pydantic import BaseModel
class User(BaseModel):
id: int
name = "John Doe"
signup_ts: datetime | None = None
friends: list[int] = []
external_data = {
"id": "123",
"signup_ts": "2017-06-01 12:22",
"friends": [1, "2", b"3"],
}
user = User(**external_data)
print(user)
# > User id=123 name='John Doe' signup_ts=datetime.datetime(2017, 6, 1, 12, 22) friends=[1, 2, 3]
print(user.id)
# > 123
```
Python 3.9+
```
from datetime import datetime
from typing import Union
from pydantic import BaseModel
class User(BaseModel):
id: int
name = "John Doe"
signup_ts: Union[datetime, None] = None
friends: list[int] = []
external_data = {
"id": "123",
"signup_ts": "2017-06-01 12:22",
"friends": [1, "2", b"3"],
}
user = User(**external_data)
print(user)
# > User id=123 name='John Doe' signup_ts=datetime.datetime(2017, 6, 1, 12, 22) friends=[1, 2, 3]
print(user.id)
# > 123
```
Python 3.6+
```
from datetime import datetime
from typing import List, Union
from pydantic import BaseModel
class User(BaseModel):
id: int
name = "John Doe"
signup_ts: Union[datetime, None] = None
friends: List[int] = []
external_data = {
"id": "123",
"signup_ts": "2017-06-01 12:22",
"friends": [1, "2", b"3"],
}
user = User(**external_data)
print(user)
# > User id=123 name='John Doe' signup_ts=datetime.datetime(2017, 6, 1, 12, 22) friends=[1, 2, 3]
print(user.id)
# > 123
```
Info
To learn more about [Pydantic, check its docs](https://pydantic-docs.helpmanual.io/).
**FastAPI** is all based on Pydantic.
You will see a lot more of all this in practice in the [Tutorial - User Guide](../tutorial/index).
Tip
Pydantic has a special behavior when you use `Optional` or `Union[Something, None]` without a default value, you can read more about it in the Pydantic docs about [Required Optional fields](https://pydantic-docs.helpmanual.io/usage/models/#required-optional-fields).
Type Hints with Metadata Annotations
------------------------------------
Python also has a feature that allows putting **additional metadata** in these type hints using `Annotated`.
Python 3.9+ In Python 3.9, `Annotated` is part of the standard library, so you can import it from `typing`.
```
from typing import Annotated
def say_hello(name: Annotated[str, "this is just metadata"]) -> str:
return f"Hello {name}"
```
Python 3.6+ In versions below Python 3.9, you import `Annotated` from `typing_extensions`.
It will already be installed with **FastAPI**.
```
from typing_extensions import Annotated
def say_hello(name: Annotated[str, "this is just metadata"]) -> str:
return f"Hello {name}"
```
Python itself doesn't do anything with this `Annotated`. And for editors and other tools, the type is still `str`.
But you can use this space in `Annotated` to provide **FastAPI** with additional metadata about how you want your application to behave.
The important thing to remember is that **the first *type parameter*** you pass to `Annotated` is the **actual type**. The rest, is just metadata for other tools.
For now, you just need to know that `Annotated` exists, and that it's standard Python. 😎
Later you will see how **powerful** it can be.
Tip
The fact that this is **standard Python** means that you will still get the **best possible developer experience** in your editor, with the tools you use to analyze and refactor your code, etc. ✨
And also that your code will be very compatible with many other Python tools and libraries. 🚀
Type hints in **FastAPI**
-------------------------
**FastAPI** takes advantage of these type hints to do several things.
With **FastAPI** you declare parameters with type hints and you get:
* **Editor support**.
* **Type checks**.
...and **FastAPI** uses the same declarations to:
* **Define requirements**: from request path parameters, query parameters, headers, bodies, dependencies, etc.
* **Convert data**: from the request to the required type.
* **Validate data**: coming from each request:
+ Generating **automatic errors** returned to the client when the data is invalid.
* **Document** the API using OpenAPI:
+ which is then used by the automatic interactive documentation user interfaces.
This might all sound abstract. Don't worry. You'll see all this in action in the [Tutorial - User Guide](../tutorial/index).
The important thing is that by using standard Python types, in a single place (instead of adding more classes, decorators, etc), **FastAPI** will do a lot of the work for you.
Info
If you already went through all the tutorial and came back to see more about types, a good resource is [the "cheat sheet" from `mypy`](https://mypy.readthedocs.io/en/latest/cheat_sheet_py3.html).
| programming_docs |
fastapi Deployment - Intro Deployment - Intro
==================
Deploying a **FastAPI** application is relatively easy.
What Does Deployment Mean
-------------------------
To **deploy** an application means to perform the necessary steps to make it **available to the users**.
For a **web API**, it normally involves putting it in a **remote machine**, with a **server program** that provides good performance, stability, etc, so that your **users** can **access** the application efficiently and without interruptions or problems.
This is in contrast to the **development** stages, where you are constantly changing the code, breaking it and fixing it, stopping and restarting the development server, etc.
Deployment Strategies
---------------------
There are several ways to do it depending on your specific use case and the tools that you use.
You could **deploy a server** yourself using a combination of tools, you could use a **cloud service** that does part of the work for you, or other possible options.
I will show you some of the main concepts you should probably have in mind when deploying a **FastAPI** application (although most of it applies to any other type of web application).
You will see more details to have in mind and some of the techniques to do it in the next sections. ✨
fastapi About HTTPS About HTTPS
===========
It is easy to assume that HTTPS is something that is just "enabled" or not.
But it is way more complex than that.
Tip
If you are in a hurry or don't care, continue with the next sections for step by step instructions to set everything up with different techniques.
To **learn the basics of HTTPS**, from a consumer perspective, check <https://howhttps.works/>.
Now, from a **developer's perspective**, here are several things to have in mind while thinking about HTTPS:
* For HTTPS, **the server** needs to **have "certificates"** generated by a **third party**.
+ Those certificates are actually **acquired** from the third party, not "generated".
* Certificates have a **lifetime**.
+ They **expire**.
+ And then they need to be **renewed**, **acquired again** from the third party.
* The encryption of the connection happens at the **TCP level**.
+ That's one layer **below HTTP**.
+ So, the **certificate and encryption** handling is done **before HTTP**.
* **TCP doesn't know about "domains"**. Only about IP addresses.
+ The information about the **specific domain** requested goes in the **HTTP data**.
* The **HTTPS certificates** "certify" a **certain domain**, but the protocol and encryption happen at the TCP level, **before knowing** which domain is being dealt with.
* **By default**, that would mean that you can only have **one HTTPS certificate per IP address**.
+ No matter how big your server is or how small each application you have on it might be.
+ There is a **solution** to this, however.
* There's an **extension** to the **TLS** protocol (the one handling the encryption at the TCP level, before HTTP) called **[SNI](https://en.wikipedia.org/wiki/Server_Name_Indication)**.
+ This SNI extension allows one single server (with a **single IP address**) to have **several HTTPS certificates** and serve **multiple HTTPS domains/applications**.
+ For this to work, a **single** component (program) running on the server, listening on the **public IP address**, must have **all the HTTPS certificates** in the server.
* **After** obtaining a secure connection, the communication protocol is **still HTTP**.
+ The contents are **encrypted**, even though they are being sent with the **HTTP protocol**.
It is a common practice to have **one program/HTTP server** running on the server (the machine, host, etc.) and **managing all the HTTPS parts**: receiving the **encrypted HTTPS requests**, sending the **decrypted HTTP requests** to the actual HTTP application running in the same server (the **FastAPI** application, in this case), take the **HTTP response** from the application, **encrypt it** using the appropriate **HTTPS certificate** and sending it back to the client using **HTTPS**. This server is often called a **[TLS Termination Proxy](https://en.wikipedia.org/wiki/TLS_termination_proxy)**.
Some of the options you could use as a TLS Termination Proxy are:
* Traefik (that can also handle certificate renewals)
* Caddy (that can also handle certificate renewals)
* Nginx
* HAProxy
Let's Encrypt
-------------
Before Let's Encrypt, these **HTTPS certificates** were sold by trusted third parties.
The process to acquire one of these certificates used to be cumbersome, require quite some paperwork and the certificates were quite expensive.
But then **[Let's Encrypt](https://letsencrypt.org/)** was created.
It is a project from the Linux Foundation. It provides **HTTPS certificates for free**, in an automated way. These certificates use all the standard cryptographic security, and are short-lived (about 3 months), so the **security is actually better** because of their reduced lifespan.
The domains are securely verified and the certificates are generated automatically. This also allows automating the renewal of these certificates.
The idea is to automate the acquisition and renewal of these certificates so that you can have **secure HTTPS, for free, forever**.
HTTPS for Developers
--------------------
Here's an example of how an HTTPS API could look like, step by step, paying attention mainly to the ideas important for developers.
### Domain Name
It would probably all start by you **acquiring** some **domain name**. Then, you would configure it in a DNS server (possibly your same cloud provider).
You would probably get a cloud server (a virtual machine) or something similar, and it would have a fixed **public IP address**.
In the DNS server(s) you would configure a record (an "`A record`") to point **your domain** to the public **IP address of your server**.
You would probably do this just once, the first time, when setting everything up.
Tip
This Domain Name part is way before HTTPS, but as everything depends on the domain and the IP address, it's worth mentioning it here.
### DNS
Now let's focus on all the actual HTTPS parts.
First, the browser would check with the **DNS servers** what is the **IP for the domain**, in this case, `someapp.example.com`.
The DNS servers would tell the browser to use some specific **IP address**. That would be the public IP address used by your server, that you configured in the DNS servers.
### TLS Handshake Start
The browser would then communicate with that IP address on **port 443** (the HTTPS port).
The first part of the communication is just to establish the connection between the client and the server and to decide the cryptographic keys they will use, etc.
This interaction between the client and the server to establish the TLS connection is called the **TLS handshake**.
### TLS with SNI Extension
**Only one process** in the server can be listening on a specific **port** in a specific **IP address**. There could be other processes listening on other ports in the same IP address, but only one for each combination of IP address and port.
TLS (HTTPS) uses the specific port `443` by default. So that's the port we would need.
As only one process can be listening on this port, the process that would do it would be the **TLS Termination Proxy**.
The TLS Termination Proxy would have access to one or more **TLS certificates** (HTTPS certificates).
Using the **SNI extension** discussed above, the TLS Termination Proxy would check which of the TLS (HTTPS) certificates available it should use for this connection, using the one that matches the domain expected by the client.
In this case, it would use the certificate for `someapp.example.com`.
The client already **trusts** the entity that generated that TLS certificate (in this case Let's Encrypt, but we'll see about that later), so it can **verify** that the certificate is valid.
Then, using the certificate, the client and the TLS Termination Proxy **decide how to encrypt** the rest of the **TCP communication**. This completes the **TLS Handshake** part.
After this, the client and the server have an **encrypted TCP connection**, this is what TLS provides. And then they can use that connection to start the actual **HTTP communication**.
And that's what **HTTPS** is, it's just plain **HTTP** inside a **secure TLS connection** instead of a pure (unencrypted) TCP connection.
Tip
Notice that the encryption of the communication happens at the **TCP level**, not at the HTTP level.
### HTTPS Request
Now that the client and server (specifically the browser and the TLS Termination Proxy) have an **encrypted TCP connection**, they can start the **HTTP communication**.
So, the client sends an **HTTPS request**. This is just an HTTP request through an encrypted TLS connection.
### Decrypt the Request
The TLS Termination Proxy would use the encryption agreed to **decrypt the request**, and would transmit the **plain (decrypted) HTTP request** to the process running the application (for example a process with Uvicorn running the FastAPI application).
### HTTP Response
The application would process the request and send a **plain (unencrypted) HTTP response** to the TLS Termination Proxy.
### HTTPS Response
The TLS Termination Proxy would then **encrypt the response** using the cryptography agreed before (that started with the certificate for `someapp.example.com`), and send it back to the browser.
Next, the browser would verify that the response is valid and encrypted with the right cryptographic key, etc. It would then **decrypt the response** and process it.
The client (browser) will know that the response comes from the correct server because it is using the cryptography they agreed using the **HTTPS certificate** before.
### Multiple Applications
In the same server (or servers), there could be **multiple applications**, for example, other API programs or a database.
Only one process can be handling the specific IP and port (the TLS Termination Proxy in our example) but the other applications/processes can be running on the server(s) too, as long as they don't try to use the same **combination of public IP and port**.
That way, the TLS Termination Proxy could handle HTTPS and certificates for **multiple domains**, for multiple applications, and then transmit the requests to the right application in each case.
### Certificate Renewal
At some point in the future, each certificate would **expire** (about 3 months after acquiring it).
And then, there would be another program (in some cases it's another program, in some cases it could be the same TLS Termination Proxy) that would talk to Let's Encrypt, and renew the certificate(s).
The **TLS certificates** are **associated with a domain name**, not with an IP address.
So, to renew the certificates, the renewal program needs to **prove** to the authority (Let's Encrypt) that it indeed **"owns" and controls that domain**.
To do that, and to accommodate different application needs, there are several ways it can do it. Some popular ways are:
* **Modify some DNS records**.
+ For this, the renewal program needs to support the APIs of the DNS provider, so, depending on the DNS provider you are using, this might or might not be an option.
* **Run as a server** (at least during the certificate acquisition process) on the public IP address associated with the domain.
+ As we said above, only one process can be listening on a specific IP and port.
+ This is one of the reasons why it's very useful when the same TLS Termination Proxy also takes care of the certificate renewal process.
+ Otherwise, you might have to stop the TLS Termination Proxy momentarily, start the renewal program to acquire the certificates, then configure them with the TLS Termination Proxy, and then restart the TLS Termination Proxy. This is not ideal, as your app(s) will not be available during the time that the TLS Termination Proxy is off.
All this renewal process, while still serving the app, is one of the main reasons why you would want to have a **separate system to handle HTTPS** with a TLS Termination Proxy instead of just using the TLS certificates with the application server directly (e.g. Uvicorn).
Recap
-----
Having **HTTPS** is very important, and quite **critical** in most cases. Most of the effort you as a developer have to put around HTTPS is just about **understanding these concepts** and how they work.
But once you know the basic information of **HTTPS for developers** you can easily combine and configure different tools to help you manage everything in a simple way.
In some of the next chapters, I'll show you several concrete examples of how to set up **HTTPS** for **FastAPI** applications. 🔒
fastapi FastAPI in Containers - Docker FastAPI in Containers - Docker
==============================
When deploying FastAPI applications a common approach is to build a **Linux container image**. It's normally done using [**Docker**](https://www.docker.com/). You can then deploy that container image in one of a few possible ways.
Using Linux containers has several advantages including **security**, **replicability**, **simplicity**, and others.
Tip
In a hurry and already know this stuff? Jump to the [`Dockerfile` below 👇](#build-a-docker-image-for-fastapi).
Dockerfile Preview 👀
```
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./app /code/app
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
# If running behind a proxy like Nginx or Traefik add --proxy-headers
# CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80", "--proxy-headers"]
```
What is a Container
-------------------
Containers (mainly Linux containers) are a very **lightweight** way to package applications including all their dependencies and necessary files while keeping them isolated from other containers (other applications or components) in the same system.
Linux containers run using the same Linux kernel of the host (machine, virtual machine, cloud server, etc). This just means that they are very lightweight (compared to full virtual machines emulating an entire operating system).
This way, containers consume **little resources**, an amount comparable to running the processes directly (a virtual machine would consume much more).
Containers also have their own **isolated** running processes (commonly just one process), file system, and network, simplifying deployment, security, development, etc.
What is a Container Image
-------------------------
A **container** is run from a **container image**.
A container image is a **static** version of all the files, environment variables, and the default command/program that should be present in a container. **Static** here means that the container **image** is not running, it's not being executed, it's only the packaged files and metadata.
In contrast to a "**container image**" that is the stored static contents, a "**container**" normally refers to the running instance, the thing that is being **executed**.
When the **container** is started and running (started from a **container image**) it could create or change files, environment variables, etc. Those changes will exist only in that container, but would not persist in the underlying container image (would not be saved to disk).
A container image is comparable to the **program** file and contents, e.g. `python` and some file `main.py`.
And the **container** itself (in contrast to the **container image**) is the actual running instance of the image, comparable to a **process**. In fact, a container is running only when it has a **process running** (and normally it's only a single process). The container stops when there's no process running in it.
Container Images
----------------
Docker has been one of the main tools to create and manage **container images** and **containers**.
And there's a public [Docker Hub](https://hub.docker.com/) with pre-made **official container images** for many tools, environments, databases, and applications.
For example, there's an official [Python Image](https://hub.docker.com/_/python).
And there are many other images for different things like databases, for example for:
* [PostgreSQL](https://hub.docker.com/_/postgres)
* [MySQL](https://hub.docker.com/_/mysql)
* [MongoDB](https://hub.docker.com/_/mongo)
* [Redis](https://hub.docker.com/_/redis), etc.
By using a pre-made container image it's very easy to **combine** and use different tools. For example, to try out a new database. In most cases, you can use the **official images**, and just configure them with environment variables.
That way, in many cases you can learn about containers and Docker and re-use that knowledge with many different tools and components.
So, you would run **multiple containers** with different things, like a database, a Python application, a web server with a React frontend application, and connect them together via their internal network.
All the container management systems (like Docker or Kubernetes) have these networking features integrated into them.
Containers and Processes
------------------------
A **container image** normally includes in its metadata the default program or command that should be run when the **container** is started and the parameters to be passed to that program. Very similar to what would be if it was in the command line.
When a **container** is started, it will run that command/program (although you can override it and make it run a different command/program).
A container is running as long as the **main process** (command or program) is running.
A container normally has a **single process**, but it's also possible to start subprocesses from the main process, and that way you will have **multiple processes** in the same container.
But it's not possible to have a running container without **at least one running process**. If the main process stops, the container stops.
Build a Docker Image for FastAPI
--------------------------------
Okay, let's build something now! 🚀
I'll show you how to build a **Docker image** for FastAPI **from scratch**, based on the **official Python** image.
This is what you would want to do in **most cases**, for example:
* Using **Kubernetes** or similar tools
* When running on a **Raspberry Pi**
* Using a cloud service that would run a container image for you, etc.
### Package Requirements
You would normally have the **package requirements** for your application in some file.
It would depend mainly on the tool you use to **install** those requirements.
The most common way to do it is to have a file `requirements.txt` with the package names and their versions, one per line.
You would of course use the same ideas you read in [About FastAPI versions](../versions/index) to set the ranges of versions.
For example, your `requirements.txt` could look like:
```
fastapi>=0.68.0,<0.69.0
pydantic>=1.8.0,<2.0.0
uvicorn>=0.15.0,<0.16.0
```
And you would normally install those package dependencies with `pip`, for example:
```
$ pip install -r requirements.txt
---> 100%
Successfully installed fastapi pydantic uvicorn
```
Info
There are other formats and tools to define and install package dependencies.
I'll show you an example using Poetry later in a section below. 👇
### Create the **FastAPI** Code
* Create an `app` directory and enter it.
* Create an empty file `__init__.py`.
* Create a `main.py` file with:
```
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
```
### Dockerfile
Now in the same project directory create a file `Dockerfile` with:
```
# (1)
FROM python:3.9
# (2)
WORKDIR /code
# (3)
COPY ./requirements.txt /code/requirements.txt
# (4)
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (5)
COPY ./app /code/app
# (6)
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
```
1. Start from the official Python base image.
2. Set the current working directory to `/code`.
This is where we'll put the `requirements.txt` file and the `app` directory.
3. Copy the file with the requirements to the `/code` directory.
Copy **only** the file with the requirements first, not the rest of the code.
As this file **doesn't change often**, Docker will detect it and use the **cache** for this step, enabling the cache for the next step too.
4. Install the package dependencies in the requirements file.
The `--no-cache-dir` option tells `pip` to not save the downloaded packages locally, as that is only if `pip` was going to be run again to install the same packages, but that's not the case when working with containers.
Note
The `--no-cache-dir` is only related to `pip`, it has nothing to do with Docker or containers.
The `--upgrade` option tells `pip` to upgrade the packages if they are already installed.
Because the previous step copying the file could be detected by the **Docker cache**, this step will also **use the Docker cache** when available.
Using the cache in this step will **save** you a lot of **time** when building the image again and again during development, instead of **downloading and installing** all the dependencies **every time**.
5. Copy the `./app` directory inside the `/code` directory.
As this has all the code which is what **changes most frequently** the Docker **cache** won't be used for this or any **following steps** easily.
So, it's important to put this **near the end** of the `Dockerfile`, to optimize the container image build times.
6. Set the **command** to run the `uvicorn` server.
`CMD` takes a list of strings, each of these strings is what you would type in the command line separated by spaces.
This command will be run from the **current working directory**, the same `/code` directory you set above with `WORKDIR /code`.
Because the program will be started at `/code` and inside of it is the directory `./app` with your code, **Uvicorn** will be able to see and **import** `app` from `app.main`.
Tip
Review what each line does by clicking each number bubble in the code. 👆
You should now have a directory structure like:
```
.
├── app
│ ├── __init__.py
│ └── main.py
├── Dockerfile
└── requirements.txt
```
#### Behind a TLS Termination Proxy
If you are running your container behind a TLS Termination Proxy (load balancer) like Nginx or Traefik, add the option `--proxy-headers`, this will tell Uvicorn to trust the headers sent by that proxy telling it that the application is running behind HTTPS, etc.
```
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]
```
#### Docker Cache
There's an important trick in this `Dockerfile`, we first copy the **file with the dependencies alone**, not the rest of the code. Let me tell you why is that.
```
COPY ./requirements.txt /code/requirements.txt
```
Docker and other tools **build** these container images **incrementally**, adding **one layer on top of the other**, starting from the top of the `Dockerfile` and adding any files created by each of the instructions of the `Dockerfile`.
Docker and similar tools also use an **internal cache** when building the image, if a file hasn't changed since the last time building the container image, then it will **re-use the same layer** created the last time, instead of copying the file again and creating a new layer from scratch.
Just avoiding the copy of files doesn't necessarily improve things too much, but because it used the cache for that step, it can **use the cache for the next step**. For example, it could use the cache for the instruction that installs dependencies with:
```
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
```
The file with the package requirements **won't change frequently**. So, by copying only that file, Docker will be able to **use the cache** for that step.
And then, Docker will be able to **use the cache for the next step** that downloads and install those dependencies. And here's where we **save a lot of time**. ✨ ...and avoid boredom waiting. 😪😆
Downloading and installing the package dependencies **could take minutes**, but using the **cache** would **take seconds** at most.
And as you would be building the container image again and again during development to check that your code changes are working, there's a lot of accumulated time this would save.
Then, near the end of the `Dockerfile`, we copy all the code. As this is what **changes most frequently**, we put it near the end, because almost always, anything after this step will not be able to use the cache.
```
COPY ./app /code/app
```
### Build the Docker Image
Now that all the files are in place, let's build the container image.
* Go to the project directory (in where your `Dockerfile` is, containing your `app` directory).
* Build your FastAPI image:
```
$ docker build -t myimage .
---> 100%
```
Tip
Notice the `.` at the end, it's equivalent to `./`, it tells Docker the directory to use to build the container image.
In this case, it's the same current directory (`.`).
### Start the Docker Container
* Run a container based on your image:
```
$ docker run -d --name mycontainer -p 80:80 myimage
```
Check it
--------
You should be able to check it in your Docker container's URL, for example: <http://192.168.99.100/items/5?q=somequery> or <http://127.0.0.1/items/5?q=somequery> (or equivalent, using your Docker host).
You will see something like:
```
{"item_id": 5, "q": "somequery"}
```
Interactive API docs
--------------------
Now you can go to <http://192.168.99.100/docs> or <http://127.0.0.1/docs> (or equivalent, using your Docker host).
You will see the automatic interactive API documentation (provided by [Swagger UI](https://github.com/swagger-api/swagger-ui)):
Alternative API docs
--------------------
And you can also go to <http://192.168.99.100/redoc> or <http://127.0.0.1/redoc> (or equivalent, using your Docker host).
You will see the alternative automatic documentation (provided by [ReDoc](https://github.com/Rebilly/ReDoc)):
Build a Docker Image with a Single-File FastAPI
-----------------------------------------------
If your FastAPI is a single file, for example, `main.py` without an `./app` directory, your file structure could look like this:
```
.
├── Dockerfile
├── main.py
└── requirements.txt
```
Then you would just have to change the corresponding paths to copy the file inside the `Dockerfile`:
```
FROM python:3.9
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (1)
COPY ./main.py /code/
# (2)
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "80"]
```
1. Copy the `main.py` file to the `/code` directory directly (without any `./app` directory).
2. Run Uvicorn and tell it to import the `app` object from `main` (instead of importing from `app.main`).
Then adjust the Uvicorn command to use the new module `main` instead of `app.main` to import the FastAPI object `app`.
Deployment Concepts
-------------------
Let's talk again about some of the same [Deployment Concepts](../concepts/index) in terms of containers.
Containers are mainly a tool to simplify the process of **building and deploying** an application, but they don't enforce a particular approach to handle these **deployment concepts**, and there are several possible strategies.
The **good news** is that with each different strategy there's a way to cover all of the deployment concepts. 🎉
Let's review these **deployment concepts** in terms of containers:
* HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
HTTPS
-----
If we focus just on the **container image** for a FastAPI application (and later the running **container**), HTTPS normally would be handled **externally** by another tool.
It could be another container, for example with [Traefik](https://traefik.io/), handling **HTTPS** and **automatic** acquisition of **certificates**.
Tip
Traefik has integrations with Docker, Kubernetes, and others, so it's very easy to set up and configure HTTPS for your containers with it.
Alternatively, HTTPS could be handled by a cloud provider as one of their services (while still running the application in a container).
Running on Startup and Restarts
-------------------------------
There is normally another tool in charge of **starting and running** your container.
It could be **Docker** directly, **Docker Compose**, **Kubernetes**, a **cloud service**, etc.
In most (or all) cases, there's a simple option to enable running the container on startup and enabling restarts on failures. For example, in Docker, it's the command line option `--restart`.
Without using containers, making applications run on startup and with restarts can be cumbersome and difficult. But when **working with containers** in most cases that functionality is included by default. ✨
Replication - Number of Processes
---------------------------------
If you have a cluster of machines with **Kubernetes**, Docker Swarm Mode, Nomad, or another similar complex system to manage distributed containers on multiple machines, then you will probably want to **handle replication** at the **cluster level** instead of using a **process manager** (like Gunicorn with workers) in each container.
One of those distributed container management systems like Kubernetes normally has some integrated way of handling **replication of containers** while still supporting **load balancing** for the incoming requests. All at the **cluster level**.
In those cases, you would probably want to build a **Docker image from scratch** as [explained above](#dockerfile), installing your dependencies, and running **a single Uvicorn process** instead of running something like Gunicorn with Uvicorn workers.
### Load Balancer
When using containers, you would normally have some component **listening on the main port**. It could possibly be another container that is also a **TLS Termination Proxy** to handle **HTTPS** or some similar tool.
As this component would take the **load** of requests and distribute that among the workers in a (hopefully) **balanced** way, it is also commonly called a **Load Balancer**.
Tip
The same **TLS Termination Proxy** component used for HTTPS would probably also be a **Load Balancer**.
And when working with containers, the same system you use to start and manage them would already have internal tools to transmit the **network communication** (e.g. HTTP requests) from that **load balancer** (that could also be a **TLS Termination Proxy**) to the container(s) with your app.
### One Load Balancer - Multiple Worker Containers
When working with **Kubernetes** or similar distributed container management systems, using their internal networking mechanisms would allow the single **load balancer** that is listening on the main **port** to transmit communication (requests) to possibly **multiple containers** running your app.
Each of these containers running your app would normally have **just one process** (e.g. a Uvicorn process running your FastAPI application). They would all be **identical containers**, running the same thing, but each with its own process, memory, etc. That way you would take advantage of **parallelization** in **different cores** of the CPU, or even in **different machines**.
And the distributed container system with the **load balancer** would **distribute the requests** to each one of the containers with your app **in turns**. So, each request could be handled by one of the multiple **replicated containers** running your app.
And normally this **load balancer** would be able to handle requests that go to *other* apps in your cluster (e.g. to a different domain, or under a different URL path prefix), and would transmit that communication to the right containers for *that other* application running in your cluster.
### One Process per Container
In this type of scenario, you probably would want to have **a single (Uvicorn) process per container**, as you would already be handling replication at the cluster level.
So, in this case, you **would not** want to have a process manager like Gunicorn with Uvicorn workers, or Uvicorn using its own Uvicorn workers. You would want to have just a **single Uvicorn process** per container (but probably multiple containers).
Having another process manager inside the container (as would be with Gunicorn or Uvicorn managing Uvicorn workers) would only add **unnecessary complexity** that you are most probably already taking care of with your cluster system.
### Containers with Multiple Processes and Special Cases
Of course, there are **special cases** where you could want to have **a container** with a **Gunicorn process manager** starting several **Uvicorn worker processes** inside.
In those cases, you can use the **official Docker image** that includes **Gunicorn** as a process manager running multiple **Uvicorn worker processes**, and some default settings to adjust the number of workers based on the current CPU cores automatically. I'll tell you more about it below in [Official Docker Image with Gunicorn - Uvicorn](#official-docker-image-with-gunicorn-uvicorn).
Here are some examples of when that could make sense:
#### A Simple App
You could want a process manager in the container if your application is **simple enough** that you don't need (at least not yet) to fine-tune the number of processes too much, and you can just use an automated default (with the official Docker image), and you are running it on a **single server**, not a cluster.
#### Docker Compose
You could be deploying to a **single server** (not a cluster) with **Docker Compose**, so you wouldn't have an easy way to manage replication of containers (with Docker Compose) while preserving the shared network and **load balancing**.
Then you could want to have **a single container** with a **process manager** starting **several worker processes** inside.
#### Prometheus and Other Reasons
You could also have **other reasons** that would make it easier to have a **single container** with **multiple processes** instead of having **multiple containers** with **a single process** in each of them.
For example (depending on your setup) you could have some tool like a Prometheus exporter in the same container that should have access to **each of the requests** that come.
In this case, if you had **multiple containers**, by default, when Prometheus came to **read the metrics**, it would get the ones for **a single container each time** (for the container that handled that particular request), instead of getting the **accumulated metrics** for all the replicated containers.
Then, in that case, it could be simpler to have **one container** with **multiple processes**, and a local tool (e.g. a Prometheus exporter) on the same container collecting Prometheus metrics for all the internal processes and exposing those metrics on that single container.
---
The main point is, **none** of these are **rules written in stone** that you have to blindly follow. You can use these ideas to **evaluate your own use case** and decide what is the best approach for your system, checking out how to manage the concepts of:
* Security - HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
Memory
------
If you run **a single process per container** you will have a more or less well-defined, stable, and limited amount of memory consumed by each of those containers (more than one if they are replicated).
And then you can set those same memory limits and requirements in your configurations for your container management system (for example in **Kubernetes**). That way it will be able to **replicate the containers** in the **available machines** taking into account the amount of memory needed by them, and the amount available in the machines in the cluster.
If your application is **simple**, this will probably **not be a problem**, and you might not need to specify hard memory limits. But if you are **using a lot of memory** (for example with **machine learning** models), you should check how much memory you are consuming and adjust the **number of containers** that runs in **each machine** (and maybe add more machines to your cluster).
If you run **multiple processes per container** (for example with the official Docker image) you will have to make sure that the number of processes started doesn't **consume more memory** than what is available.
Previous Steps Before Starting and Containers
---------------------------------------------
If you are using containers (e.g. Docker, Kubernetes), then there are two main approaches you can use.
### Multiple Containers
If you have **multiple containers**, probably each one running a **single process** (for example, in a **Kubernetes** cluster), then you would probably want to have a **separate container** doing the work of the **previous steps** in a single container, running a single process, **before** running the replicated worker containers.
Info
If you are using Kubernetes, this would probably be an [Init Container](https://kubernetes.io/docs/concepts/workloads/pods/init-containers/).
If in your use case there's no problem in running those previous steps **multiple times in parallel** (for example if you are not running database migrations, but just checking if the database is ready yet), then you could also just put them in each container right before starting the main process.
### Single Container
If you have a simple setup, with a **single container** that then starts multiple **worker processes** (or also just one process), then you could run those previous steps in the same container, right before starting the process with the app. The official Docker image supports this internally.
Official Docker Image with Gunicorn - Uvicorn
---------------------------------------------
There is an official Docker image that includes Gunicorn running with Uvicorn workers, as detailed in a previous chapter: [Server Workers - Gunicorn with Uvicorn](../server-workers/index).
This image would be useful mainly in the situations described above in: [Containers with Multiple Processes and Special Cases](#containers-with-multiple-processes-and-special-cases).
* [tiangolo/uvicorn-gunicorn-fastapi](https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker).
Warning
There's a high chance that you **don't** need this base image or any other similar one, and would be better off by building the image from scratch as [described above in: Build a Docker Image for FastAPI](#build-a-docker-image-for-fastapi).
This image has an **auto-tuning** mechanism included to set the **number of worker processes** based on the CPU cores available.
It has **sensible defaults**, but you can still change and update all the configurations with **environment variables** or configuration files.
It also supports running [**previous steps before starting**](https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker#pre_start_path) with a script.
Tip
To see all the configurations and options, go to the Docker image page: [tiangolo/uvicorn-gunicorn-fastapi](https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker).
### Number of Processes on the Official Docker Image
The **number of processes** on this image is **computed automatically** from the CPU **cores** available.
This means that it will try to **squeeze** as much **performance** from the CPU as possible.
You can also adjust it with the configurations using **environment variables**, etc.
But it also means that as the number of processes depends on the CPU the container is running, the **amount of memory consumed** will also depend on that.
So, if your application consumes a lot of memory (for example with machine learning models), and your server has a lot of CPU cores **but little memory**, then your container could end up trying to use more memory than what is available, and degrading performance a lot (or even crashing). 🚨
### Create a `Dockerfile`
Here's how you would create a `Dockerfile` based on this image:
```
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app
```
### Bigger Applications
If you followed the section about creating [Bigger Applications with Multiple Files](../../tutorial/bigger-applications/index), your `Dockerfile` might instead look like:
```
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.9
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
COPY ./app /app/app
```
### When to Use
You should probably **not** use this official base image (or any other similar one) if you are using **Kubernetes** (or others) and you are already setting **replication** at the cluster level, with multiple **containers**. In those cases, you are better off **building an image from scratch** as described above: [Build a Docker Image for FastAPI](#build-a-docker-image-for-fastapi).
This image would be useful mainly in the special cases described above in [Containers with Multiple Processes and Special Cases](#containers-with-multiple-processes-and-special-cases). For example, if your application is **simple enough** that setting a default number of processes based on the CPU works well, you don't want to bother with manually configuring the replication at the cluster level, and you are not running more than one container with your app. Or if you are deploying with **Docker Compose**, running on a single server, etc.
Deploy the Container Image
--------------------------
After having a Container (Docker) Image there are several ways to deploy it.
For example:
* With **Docker Compose** in a single server
* With a **Kubernetes** cluster
* With a Docker Swarm Mode cluster
* With another tool like Nomad
* With a cloud service that takes your container image and deploys it
Docker Image with Poetry
------------------------
If you use [Poetry](https://python-poetry.org/) to manage your project's dependencies, you could use Docker multi-stage building:
```
# (1)
FROM python:3.9 as requirements-stage
# (2)
WORKDIR /tmp
# (3)
RUN pip install poetry
# (4)
COPY ./pyproject.toml ./poetry.lock* /tmp/
# (5)
RUN poetry export -f requirements.txt --output requirements.txt --without-hashes
# (6)
FROM python:3.9
# (7)
WORKDIR /code
# (8)
COPY --from=requirements-stage /tmp/requirements.txt /code/requirements.txt
# (9)
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
# (10)
COPY ./app /code/app
# (11)
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "80"]
```
1. This is the first stage, it is named `requirements-stage`.
2. Set `/tmp` as the current working directory.
Here's where we will generate the file `requirements.txt`
3. Install Poetry in this Docker stage.
4. Copy the `pyproject.toml` and `poetry.lock` files to the `/tmp` directory.
Because it uses `./poetry.lock*` (ending with a `*`), it won't crash if that file is not available yet.
5. Generate the `requirements.txt` file.
6. This is the final stage, anything here will be preserved in the final container image.
7. Set the current working directory to `/code`.
8. Copy the `requirements.txt` file to the `/code` directory.
This file only lives in the previous Docker stage, that's why we use `--from-requirements-stage` to copy it.
9. Install the package dependencies in the generated `requirements.txt` file.
10. Copy the `app` directory to the `/code` directory.
11. Run the `uvicorn` command, telling it to use the `app` object imported from `app.main`.
Tip
Click the bubble numbers to see what each line does.
A **Docker stage** is a part of a `Dockerfile` that works as a **temporary container image** that is only used to generate some files to be used later.
The first stage will only be used to **install Poetry** and to **generate the `requirements.txt`** with your project dependencies from Poetry's `pyproject.toml` file.
This `requirements.txt` file will be used with `pip` later in the **next stage**.
In the final container image **only the final stage** is preserved. The previous stage(s) will be discarded.
When using Poetry, it would make sense to use **Docker multi-stage builds** because you don't really need to have Poetry and its dependencies installed in the final container image, you **only need** to have the generated `requirements.txt` file to install your project dependencies.
Then in the next (and final) stage you would build the image more or less in the same way as described before.
### Behind a TLS Termination Proxy - Poetry
Again, if you are running your container behind a TLS Termination Proxy (load balancer) like Nginx or Traefik, add the option `--proxy-headers` to the command:
```
CMD ["uvicorn", "app.main:app", "--proxy-headers", "--host", "0.0.0.0", "--port", "80"]
```
Recap
-----
Using container systems (e.g. with **Docker** and **Kubernetes**) it becomes fairly straightforward to handle all the **deployment concepts**:
* HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
In most cases, you probably won't want to use any base image, and instead **build a container image from scratch** one based on the official Python Docker image.
Taking care of the **order** of instructions in the `Dockerfile` and the **Docker cache** you can **minimize build times**, to maximize your productivity (and avoid boredom). 😎
In certain special cases, you might want to use the official Docker image for FastAPI. 🤓
| programming_docs |
fastapi About FastAPI versions About FastAPI versions
======================
**FastAPI** is already being used in production in many applications and systems. And the test coverage is kept at 100%. But its development is still moving quickly.
New features are added frequently, bugs are fixed regularly, and the code is still continuously improving.
That's why the current versions are still `0.x.x`, this reflects that each version could potentially have breaking changes. This follows the [Semantic Versioning](https://semver.org/) conventions.
You can create production applications with **FastAPI** right now (and you have probably been doing it for some time), you just have to make sure that you use a version that works correctly with the rest of your code.
Pin your `fastapi` version
--------------------------
The first thing you should do is to "pin" the version of **FastAPI** you are using to the specific latest version that you know works correctly for your application.
For example, let's say you are using version `0.45.0` in your app.
If you use a `requirements.txt` file you could specify the version with:
```
fastapi==0.45.0
```
that would mean that you would use exactly the version `0.45.0`.
Or you could also pin it with:
```
fastapi>=0.45.0,<0.46.0
```
that would mean that you would use the versions `0.45.0` or above, but less than `0.46.0`, for example, a version `0.45.2` would still be accepted.
If you use any other tool to manage your installations, like Poetry, Pipenv, or others, they all have a way that you can use to define specific versions for your packages.
Available versions
------------------
You can see the available versions (e.g. to check what is the current latest) in the [Release Notes](https://fastapi.tiangolo.com/release-notes/).
About versions
--------------
Following the Semantic Versioning conventions, any version below `1.0.0` could potentially add breaking changes.
FastAPI also follows the convention that any "PATCH" version change is for bug fixes and non-breaking changes.
Tip
The "PATCH" is the last number, for example, in `0.2.3`, the PATCH version is `3`.
So, you should be able to pin to a version like:
```
fastapi>=0.45.0,<0.46.0
```
Breaking changes and new features are added in "MINOR" versions.
Tip
The "MINOR" is the number in the middle, for example, in `0.2.3`, the MINOR version is `2`.
Upgrading the FastAPI versions
------------------------------
You should add tests for your app.
With **FastAPI** it's very easy (thanks to Starlette), check the docs: [Testing](../../tutorial/testing/index)
After you have tests, then you can upgrade the **FastAPI** version to a more recent one, and make sure that all your code is working correctly by running your tests.
If everything is working, or after you make the necessary changes, and all your tests are passing, then you can pin your `fastapi` to that new recent version.
About Starlette
---------------
You shouldn't pin the version of `starlette`.
Different versions of **FastAPI** will use a specific newer version of Starlette.
So, you can just let **FastAPI** use the correct Starlette version.
About Pydantic
--------------
Pydantic includes the tests for **FastAPI** with its own tests, so new versions of Pydantic (above `1.0.0`) are always compatible with FastAPI.
You can pin Pydantic to any version above `1.0.0` that works for you and below `2.0.0`.
For example:
```
pydantic>=1.2.0,<2.0.0
```
fastapi Server Workers - Gunicorn with Uvicorn Server Workers - Gunicorn with Uvicorn
======================================
Let's check back those deployment concepts from before:
* Security - HTTPS
* Running on startup
* Restarts
* **Replication (the number of processes running)**
* Memory
* Previous steps before starting
Up to this point, with all the tutorials in the docs, you have probably been running a **server program** like Uvicorn, running a **single process**.
When deploying applications you will probably want to have some **replication of processes** to take advantage of **multiple cores** and to be able to handle more requests.
As you saw in the previous chapter about [Deployment Concepts](../concepts/index), there are multiple strategies you can use.
Here I'll show you how to use [**Gunicorn**](https://gunicorn.org/) with **Uvicorn worker processes**.
Info
If you are using containers, for example with Docker or Kubernetes, I'll tell you more about that in the next chapter: [FastAPI in Containers - Docker](../docker/index).
In particular, when running on **Kubernetes** you will probably **not** want to use Gunicorn and instead run **a single Uvicorn process per container**, but I'll tell you about it later in that chapter.
Gunicorn with Uvicorn Workers
-----------------------------
**Gunicorn** is mainly an application server using the **WSGI standard**. That means that Gunicorn can serve applications like Flask and Django. Gunicorn by itself is not compatible with **FastAPI**, as FastAPI uses the newest **[ASGI standard](https://asgi.readthedocs.io/en/latest/)**.
But Gunicorn supports working as a **process manager** and allowing users to tell it which specific **worker process class** to use. Then Gunicorn would start one or more **worker processes** using that class.
And **Uvicorn** has a **Gunicorn-compatible worker class**.
Using that combination, Gunicorn would act as a **process manager**, listening on the **port** and the **IP**. And it would **transmit** the communication to the worker processes running the **Uvicorn class**.
And then the Gunicorn-compatible **Uvicorn worker** class would be in charge of converting the data sent by Gunicorn to the ASGI standard for FastAPI to use it.
Install Gunicorn and Uvicorn
----------------------------
```
$ pip install "uvicorn[standard]" gunicorn
---> 100%
```
That will install both Uvicorn with the `standard` extra packages (to get high performance) and Gunicorn.
Run Gunicorn with Uvicorn Workers
---------------------------------
Then you can run Gunicorn with:
```
$ gunicorn main:app --workers 4 --worker-class uvicorn.workers.UvicornWorker --bind 0.0.0.0:80
[19499] [INFO] Starting gunicorn 20.1.0
[19499] [INFO] Listening at: http://0.0.0.0:80 (19499)
[19499] [INFO] Using worker: uvicorn.workers.UvicornWorker
[19511] [INFO] Booting worker with pid: 19511
[19513] [INFO] Booting worker with pid: 19513
[19514] [INFO] Booting worker with pid: 19514
[19515] [INFO] Booting worker with pid: 19515
[19511] [INFO] Started server process [19511]
[19511] [INFO] Waiting for application startup.
[19511] [INFO] Application startup complete.
[19513] [INFO] Started server process [19513]
[19513] [INFO] Waiting for application startup.
[19513] [INFO] Application startup complete.
[19514] [INFO] Started server process [19514]
[19514] [INFO] Waiting for application startup.
[19514] [INFO] Application startup complete.
[19515] [INFO] Started server process [19515]
[19515] [INFO] Waiting for application startup.
[19515] [INFO] Application startup complete.
```
Let's see what each of those options mean:
* `main:app`: This is the same syntax used by Uvicorn, `main` means the Python module named "`main`", so, a file `main.py`. And `app` is the name of the variable that is the **FastAPI** application.
+ You can imagine that `main:app` is equivalent to a Python `import` statement like:
```
from main import app
```
+ So, the colon in `main:app` would be equivalent to the Python `import` part in `from main import app`.
+ `--workers`: The number of worker processes to use, each will run a Uvicorn worker, in this case, 4 workers.
+ `--worker-class`: The Gunicorn-compatible worker class to use in the worker processes.
+ Here we pass the class that Gunicorn can import and use with:
```
import uvicorn.workers.UvicornWorker
```
* `--bind`: This tells Gunicorn the IP and the port to listen to, using a colon (`:`) to separate the IP and the port.
+ If you were running Uvicorn directly, instead of `--bind 0.0.0.0:80` (the Gunicorn option) you would use `--host 0.0.0.0` and `--port 80`.
In the output, you can see that it shows the **PID** (process ID) of each process (it's just a number).
You can see that:
* The Gunicorn **process manager** starts with PID `19499` (in your case it will be a different number).
* Then it starts `Listening at: http://0.0.0.0:80`.
* Then it detects that it has to use the worker class at `uvicorn.workers.UvicornWorker`.
* And then it starts **4 workers**, each with its own PID: `19511`, `19513`, `19514`, and `19515`.
Gunicorn would also take care of managing **dead processes** and **restarting** new ones if needed to keep the number of workers. So that helps in part with the **restart** concept from the list above.
Nevertheless, you would probably also want to have something outside making sure to **restart Gunicorn** if necessary, and also to **run it on startup**, etc.
Uvicorn with Workers
--------------------
Uvicorn also has an option to start and run several **worker processes**.
Nevertheless, as of now, Uvicorn's capabilities for handling worker processes are more limited than Gunicorn's. So, if you want to have a process manager at this level (at the Python level), then it might be better to try with Gunicorn as the process manager.
In any case, you would run it like this:
```
$ uvicorn main:app --host 0.0.0.0 --port 8080 --workers 4
<font color="#A6E22E">INFO</font>: Uvicorn running on <b>http://0.0.0.0:8080</b> (Press CTRL+C to quit)
<font color="#A6E22E">INFO</font>: Started parent process [<font color="#A1EFE4"><b>27365</b></font>]
<font color="#A6E22E">INFO</font>: Started server process [<font color="#A1EFE4">27368</font>]
<font color="#A6E22E">INFO</font>: Waiting for application startup.
<font color="#A6E22E">INFO</font>: Application startup complete.
<font color="#A6E22E">INFO</font>: Started server process [<font color="#A1EFE4">27369</font>]
<font color="#A6E22E">INFO</font>: Waiting for application startup.
<font color="#A6E22E">INFO</font>: Application startup complete.
<font color="#A6E22E">INFO</font>: Started server process [<font color="#A1EFE4">27370</font>]
<font color="#A6E22E">INFO</font>: Waiting for application startup.
<font color="#A6E22E">INFO</font>: Application startup complete.
<font color="#A6E22E">INFO</font>: Started server process [<font color="#A1EFE4">27367</font>]
<font color="#A6E22E">INFO</font>: Waiting for application startup.
<font color="#A6E22E">INFO</font>: Application startup complete.
```
The only new option here is `--workers` telling Uvicorn to start 4 worker processes.
You can also see that it shows the **PID** of each process, `27365` for the parent process (this is the **process manager**) and one for each worker process: `27368`, `27369`, `27370`, and `27367`.
Deployment Concepts
-------------------
Here you saw how to use **Gunicorn** (or Uvicorn) managing **Uvicorn worker processes** to **parallelize** the execution of the application, take advantage of **multiple cores** in the CPU, and be able to serve **more requests**.
From the list of deployment concepts from above, using workers would mainly help with the **replication** part, and a little bit with the **restarts**, but you still need to take care of the others:
* **Security - HTTPS**
* **Running on startup**
* ***Restarts***
* Replication (the number of processes running)
* **Memory**
* **Previous steps before starting**
Containers and Docker
---------------------
In the next chapter about [FastAPI in Containers - Docker](../docker/index) I'll tell some strategies you could use to handle the other **deployment concepts**.
I'll also show you the **official Docker image** that includes **Gunicorn with Uvicorn workers** and some default configurations that can be useful for simple cases.
There I'll also show you how to **build your own image from scratch** to run a single Uvicorn process (without Gunicorn). It is a simple process and is probably what you would want to do when using a distributed container management system like **Kubernetes**.
Recap
-----
You can use **Gunicorn** (or also Uvicorn) as a process manager with Uvicorn workers to take advantage of **multi-core CPUs**, to run **multiple processes in parallel**.
You could use these tools and ideas if you are setting up **your own deployment system** while taking care of the other deployment concepts yourself.
Check out the next chapter to learn about **FastAPI** with containers (e.g. Docker and Kubernetes). You will see that those tools have simple ways to solve the other **deployment concepts** as well. ✨
fastapi Deployments Concepts Deployments Concepts
====================
When deploying a **FastAPI** application, or actually, any type of web API, there are several concepts that you probably care about, and using them you can find the **most appropriate** way to **deploy your application**.
Some of the important concepts are:
* Security - HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
We'll see how they would affect **deployments**.
In the end, the ultimate objective is to be able to **serve your API clients** in a way that is **secure**, to **avoid disruptions**, and to use the **compute resources** (for example remote servers/virtual machines) as efficiently as possible. 🚀
I'll tell you a bit more about these **concepts** here, and that would hopefully give you the **intuition** you would need to decide how to deploy your API in very different environments, possibly even in **future** ones that don't exist yet.
By considering these concepts, you will be able to **evaluate and design** the best way to deploy **your own APIs**.
In the next chapters, I'll give you more **concrete recipes** to deploy FastAPI applications.
But for now, let's check these important **conceptual ideas**. These concepts also apply to any other type of web API. 💡
Security - HTTPS
----------------
In the [previous chapter about HTTPS](../https/index) we learned about how HTTPS provides encryption for your API.
We also saw that HTTPS is normally provided by a component **external** to your application server, a **TLS Termination Proxy**.
And there has to be something in charge of **renewing the HTTPS certificates**, it could be the same component or it could be something different.
### Example Tools for HTTPS
Some of the tools you could use as a TLS Termination Proxy are:
* Traefik
+ Automatically handles certificates renewals ✨
* Caddy
+ Automatically handles certificates renewals ✨
* Nginx
+ With an external component like Certbot for certificate renewals
* HAProxy
+ With an external component like Certbot for certificate renewals
* Kubernetes with an Ingress Controller like Nginx
+ With an external component like cert-manager for certificate renewals
* Handled internally by a cloud provider as part of their services (read below 👇)
Another option is that you could use a **cloud service** that does more of the work including setting up HTTPS. It could have some restrictions or charge you more, etc. But in that case, you wouldn't have to set up a TLS Termination Proxy yourself.
I'll show you some concrete examples in the next chapters.
---
Then the next concepts to consider are all about the program running your actual API (e.g. Uvicorn).
Program and Process
-------------------
We will talk a lot about the running "**process**", so it's useful to have clarity about what it means, and what's the difference with the word "**program**".
### What is a Program
The word **program** is commonly used to describe many things:
* The **code** that you write, the **Python files**.
* The **file** that can be **executed** by the operating system, for example: `python`, `python.exe` or `uvicorn`.
* A particular program while it is **running** on the operating system, using the CPU, and storing things on memory. This is also called a **process**.
### What is a Process
The word **process** is normally used in a more specific way, only referring to the thing that is running in the operating system (like in the last point above):
* A particular program while it is **running** on the operating system.
+ This doesn't refer to the file, nor to the code, it refers **specifically** to the thing that is being **executed** and managed by the operating system.
* Any program, any code, **can only do things** when it is being **executed**. So, when there's a **process running**.
* The process can be **terminated** (or "killed") by you, or by the operating system. At that point, it stops running/being executed, and it can **no longer do things**.
* Each application that you have running on your computer has some process behind it, each running program, each window, etc. And there are normally many processes running **at the same time** while a computer is on.
* There can be **multiple processes** of the **same program** running at the same time.
If you check out the "task manager" or "system monitor" (or similar tools) in your operating system, you will be able to see many of those processes running.
And, for example, you will probably see that there are multiple processes running the same browser program (Firefox, Chrome, Edge, etc). They normally run one process per tab, plus some other extra processes.
---
Now that we know the difference between the terms **process** and **program**, let's continue talking about deployments.
Running on Startup
------------------
In most cases, when you create a web API, you want it to be **always running**, uninterrupted, so that your clients can always access it. This is of course, unless you have a specific reason why you want it to run only in certain situations, but most of the time you want it constantly running and **available**.
### In a Remote Server
When you set up a remote server (a cloud server, a virtual machine, etc.) the simplest thing you can do is to run Uvicorn (or similar) manually, the same way you do when developing locally.
And it will work and will be useful **during development**.
But if your connection to the server is lost, the **running process** will probably die.
And if the server is restarted (for example after updates, or migrations from the cloud provider) you probably **won't notice it**. And because of that, you won't even know that you have to restart the process manually. So, your API will just stay dead. 😱
### Run Automatically on Startup
In general, you will probably want the server program (e.g. Uvicorn) to be started automatically on server startup, and without needing any **human intervention**, to have a process always running with your API (e.g. Uvicorn running your FastAPI app).
### Separate Program
To achieve this, you will normally have a **separate program** that would make sure your application is run on startup. And in many cases, it would also make sure other components or applications are also run, for example, a database.
### Example Tools to Run at Startup
Some examples of the tools that can do this job are:
* Docker
* Kubernetes
* Docker Compose
* Docker in Swarm Mode
* Systemd
* Supervisor
* Handled internally by a cloud provider as part of their services
* Others...
I'll give you more concrete examples in the next chapters.
Restarts
--------
Similar to making sure your application is run on startup, you probably also want to make sure it is **restarted** after failures.
### We Make Mistakes
We, as humans, make **mistakes**, all the time. Software almost *always* has **bugs** hidden in different places. 🐛
And we as developers keep improving the code as we find those bugs and as we implement new features (possibly adding new bugs too 😅).
### Small Errors Automatically Handled
When building web APIs with FastAPI, if there's an error in our code, FastAPI will normally contain it to the single request that triggered the error. 🛡
The client will get a **500 Internal Server Error** for that request, but the application will continue working for the next requests instead of just crashing completely.
### Bigger Errors - Crashes
Nevertheless, there might be cases where we write some code that **crashes the entire application** making Uvicorn and Python crash. 💥
And still, you would probably not want the application to stay dead because there was an error in one place, you probably want it to **continue running** at least for the *path operations* that are not broken.
### Restart After Crash
But in those cases with really bad errors that crash the running **process**, you would want an external component that is in charge of **restarting** the process, at least a couple of times...
Tip
...Although if the whole application is just **crashing immediately** it probably doesn't make sense to keep restarting it forever. But in those cases, you will probably notice it during development, or at least right after deployment.
So let's focus on the main cases, where it could crash entirely in some particular cases **in the future**, and it still makes sense to restart it.
You would probably want to have the thing in charge of restarting your application as an **external component**, because by that point, the same application with Uvicorn and Python already crashed, so there's nothing in the same code of the same app that could do anything about it.
### Example Tools to Restart Automatically
In most cases, the same tool that is used to **run the program on startup** is also used to handle automatic **restarts**.
For example, this could be handled by:
* Docker
* Kubernetes
* Docker Compose
* Docker in Swarm Mode
* Systemd
* Supervisor
* Handled internally by a cloud provider as part of their services
* Others...
Replication - Processes and Memory
----------------------------------
With a FastAPI application, using a server program like Uvicorn, running it once in **one process** can serve multiple clients concurrently.
But in many cases, you will want to run several worker processes at the same time.
### Multiple Processes - Workers
If you have more clients than what a single process can handle (for example if the virtual machine is not too big) and you have **multiple cores** in the server's CPU, then you could have **multiple processes** running with the same application at the same time, and distribute all the requests among them.
When you run **multiple processes** of the same API program, they are commonly called **workers**.
### Worker Processes and Ports
Remember from the docs [About HTTPS](../https/index) that only one process can be listening on one combination of port and IP address in a server?
This is still true.
So, to be able to have **multiple processes** at the same time, there has to be a **single process listening on a port** that then transmits the communication to each worker process in some way.
### Memory per Process
Now, when the program loads things in memory, for example, a machine learning model in a variable, or the contents of a large file in a variable, all that **consumes a bit of the memory (RAM)** of the server.
And multiple processes normally **don't share any memory**. This means that each running process has its own things, variables, and memory. And if you are consuming a large amount of memory in your code, **each process** will consume an equivalent amount of memory.
### Server Memory
For example, if your code loads a Machine Learning model with **1 GB in size**, when you run one process with your API, it will consume at least 1 GB of RAM. And if you start **4 processes** (4 workers), each will consume 1 GB of RAM. So in total, your API will consume **4 GB of RAM**.
And if your remote server or virtual machine only has 3 GB of RAM, trying to load more than 4 GB of RAM will cause problems. 🚨
### Multiple Processes - An Example
In this example, there's a **Manager Process** that starts and controls two **Worker Processes**.
This Manager Process would probably be the one listening on the **port** in the IP. And it would transmit all the communication to the worker processes.
Those worker processes would be the ones running your application, they would perform the main computations to receive a **request** and return a **response**, and they would load anything you put in variables in RAM.
And of course, the same machine would probably have **other processes** running as well, apart from your application.
An interesting detail is that the percentage of the **CPU used** by each process can **vary** a lot over time, but the **memory (RAM)** normally stays more or less **stable**.
If you have an API that does a comparable amount of computations every time and you have a lot of clients, then the **CPU utilization** will probably *also be stable* (instead of constantly going up and down quickly).
### Examples of Replication Tools and Strategies
There can be several approaches to achieve this, and I'll tell you more about specific strategies in the next chapters, for example when talking about Docker and containers.
The main constraint to consider is that there has to be a **single** component handling the **port** in the **public IP**. And then it has to have a way to **transmit** the communication to the replicated **processes/workers**.
Here are some possible combinations and strategies:
* **Gunicorn** managing **Uvicorn workers**
+ Gunicorn would be the **process manager** listening on the **IP** and **port**, the replication would be by having **multiple Uvicorn worker processes**
* **Uvicorn** managing **Uvicorn workers**
+ One Uvicorn **process manager** would listen on the **IP** and **port**, and it would start **multiple Uvicorn worker processes**
* **Kubernetes** and other distributed **container systems**
+ Something in the **Kubernetes** layer would listen on the **IP** and **port**. The replication would be by having **multiple containers**, each with **one Uvicorn process** running
* **Cloud services** that handle this for you
+ The cloud service will probably **handle replication for you**. It would possibly let you define **a process to run**, or a **container image** to use, in any case, it would most probably be **a single Uvicorn process**, and the cloud service would be in charge of replicating it.
Tip
Don't worry if some of these items about **containers**, Docker, or Kubernetes don't make a lot of sense yet.
I'll tell you more about container images, Docker, Kubernetes, etc. in a future chapter: [FastAPI in Containers - Docker](../docker/index).
Previous Steps Before Starting
------------------------------
There are many cases where you want to perform some steps **before starting** your application.
For example, you might want to run **database migrations**.
But in most cases, you will want to perform these steps only **once**.
So, you will want to have a **single process** to perform those **previous steps**, before starting the application.
And you will have to make sure that it's a single process running those previous steps *even* if afterwards, you start **multiple processes** (multiple workers) for the application itself. If those steps were run by **multiple processes**, they would **duplicate** the work by running it on **parallel**, and if the steps were something delicate like a database migration, they could cause conflicts with each other.
Of course, there are some cases where there's no problem in running the previous steps multiple times, in that case, it's a lot easier to handle.
Tip
Also, have in mind that depending on your setup, in some cases you **might not even need any previous steps** before starting your application.
In that case, you wouldn't have to worry about any of this. 🤷
### Examples of Previous Steps Strategies
This will **depend heavily** on the way you **deploy your system**, and it would probably be connected to the way you start programs, handling restarts, etc.
Here are some possible ideas:
* An "Init Container" in Kubernetes that runs before your app container
* A bash script that runs the previous steps and then starts your application
+ You would still need a way to start/restart *that* bash script, detect errors, etc.
Tip
I'll give you more concrete examples for doing this with containers in a future chapter: [FastAPI in Containers - Docker](../docker/index).
Resource Utilization
--------------------
Your server(s) is (are) a **resource**, you can consume or **utilize**, with your programs, the computation time on the CPUs, and the RAM memory available.
How much of the system resources do you want to be consuming/utilizing? It might be easy to think "not much", but in reality, you will probably want to consume **as much as possible without crashing**.
If you are paying for 3 servers but you are using only a little bit of their RAM and CPU, you are probably **wasting money** 💸, and probably **wasting server electric power** 🌎, etc.
In that case, it could be better to have only 2 servers and use a higher percentage of their resources (CPU, memory, disk, network bandwidth, etc).
On the other hand, if you have 2 servers and you are using **100% of their CPU and RAM**, at some point one process will ask for more memory, and the server will have to use the disk as "memory" (which can be thousands of times slower), or even **crash**. Or one process might need to do some computation and would have to wait until the CPU is free again.
In this case, it would be better to get **one extra server** and run some processes on it so that they all have **enough RAM and CPU time**.
There's also the chance that for some reason you have a **spike** of usage of your API. Maybe it went viral, or maybe some other services or bots start using it. And you might want to have extra resources to be safe in those cases.
You could put an **arbitrary number** to target, for example, something **between 50% to 90%** of resource utilization. The point is that those are probably the main things you will want to measure and use to tweak your deployments.
You can use simple tools like `htop` to see the CPU and RAM used in your server or the amount used by each process. Or you can use more complex monitoring tools, which may be distributed across servers, etc.
Recap
-----
You have been reading here some of the main concepts that you would probably need to have in mind when deciding how to deploy your application:
* Security - HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
Understanding these ideas and how to apply them should give you the intuition necessary to take any decisions when configuring and tweaking your deployments. 🤓
In the next sections, I'll give you more concrete examples of possible strategies you can follow. 🚀
| programming_docs |
fastapi Deploy FastAPI on Deta Deploy FastAPI on Deta
======================
In this section you will learn how to easily deploy a **FastAPI** application on [Deta](https://www.deta.sh/?ref=fastapi) using the free plan. 🎁
It will take you about **10 minutes**.
Info
[Deta](https://www.deta.sh/?ref=fastapi) is a **FastAPI** sponsor. 🎉
A basic **FastAPI** app
-----------------------
* Create a directory for your app, for example, `./fastapideta/` and enter into it.
### FastAPI code
* Create a `main.py` file with:
```
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int):
return {"item_id": item_id}
```
### Requirements
Now, in the same directory create a file `requirements.txt` with:
```
fastapi
```
Tip
You don't need to install Uvicorn to deploy on Deta, although you would probably want to install it locally to test your app.
### Directory structure
You will now have one directory `./fastapideta/` with two files:
```
.
└── main.py
└── requirements.txt
```
Create a free Deta account
--------------------------
Now create a [free account on Deta](https://www.deta.sh/?ref=fastapi), you just need an email and password.
You don't even need a credit card.
Install the CLI
---------------
Once you have your account, install the Deta CLI:
Linux, macOS
```
$ curl -fsSL https://get.deta.dev/cli.sh | sh
```
Windows PowerShell
```
$ iwr https://get.deta.dev/cli.ps1 -useb | iex
```
After installing it, open a new terminal so that the installed CLI is detected.
In a new terminal, confirm that it was correctly installed with:
```
$ deta --help
Deta command line interface for managing deta micros.
Complete documentation available at https://docs.deta.sh
Usage:
deta [flags]
deta [command]
Available Commands:
auth Change auth settings for a deta micro
...
```
Tip
If you have problems installing the CLI, check the [official Deta docs](https://docs.deta.sh/docs/micros/getting_started?ref=fastapi).
Login with the CLI
------------------
Now login to Deta from the CLI with:
```
$ deta login
Please, log in from the web page. Waiting..
Logged in successfully.
```
This will open a web browser and authenticate automatically.
Deploy with Deta
----------------
Next, deploy your application with the Deta CLI:
```
$ deta new
Successfully created a new micro
// Notice the "endpoint" 🔍
{
"name": "fastapideta",
"runtime": "python3.7",
"endpoint": "https://qltnci.deta.dev",
"visor": "enabled",
"http_auth": "enabled"
}
Adding dependencies...
---> 100%
Successfully installed fastapi-0.61.1 pydantic-1.7.2 starlette-0.13.6
```
You will see a JSON message similar to:
```
{
"name": "fastapideta",
"runtime": "python3.7",
"endpoint": "https://qltnci.deta.dev",
"visor": "enabled",
"http_auth": "enabled"
}
```
Tip
Your deployment will have a different `"endpoint"` URL.
Check it
--------
Now open your browser in your `endpoint` URL. In the example above it was `https://qltnci.deta.dev`, but yours will be different.
You will see the JSON response from your FastAPI app:
```
{
"Hello": "World"
}
```
And now go to the `/docs` for your API, in the example above it would be `https://qltnci.deta.dev/docs`.
It will show your docs like:
Enable public access
--------------------
By default, Deta will handle authentication using cookies for your account.
But once you are ready, you can make it public with:
```
$ deta auth disable
Successfully disabled http auth
```
Now you can share that URL with anyone and they will be able to access your API. 🚀
HTTPS
-----
Congrats! You deployed your FastAPI app to Deta! 🎉 🍰
Also, notice that Deta correctly handles HTTPS for you, so you don't have to take care of that and can be sure that your clients will have a secure encrypted connection. ✅ 🔒
Check the Visor
---------------
From your docs UI (they will be in a URL like `https://qltnci.deta.dev/docs`) send a request to your *path operation* `/items/{item_id}`.
For example with ID `5`.
Now go to [https://web.deta.sh](https://web.deta.sh/).
You will see there's a section to the left called "Micros" with each of your apps.
You will see a tab with "Details", and also a tab "Visor", go to the tab "Visor".
In there you can inspect the recent requests sent to your app.
You can also edit them and re-play them.
Learn more
----------
At some point, you will probably want to store some data for your app in a way that persists through time. For that you can use [Deta Base](https://docs.deta.sh/docs/base/py_tutorial?ref=fastapi), it also has a generous **free tier**.
You can also read more in the [Deta Docs](https://docs.deta.sh?ref=fastapi).
Deployment Concepts
-------------------
Coming back to the concepts we discussed in [Deployments Concepts](../concepts/index), here's how each of them would be handled with Deta:
* **HTTPS**: Handled by Deta, they will give you a subdomain and handle HTTPS automatically.
* **Running on startup**: Handled by Deta, as part of their service.
* **Restarts**: Handled by Deta, as part of their service.
* **Replication**: Handled by Deta, as part of their service.
* **Memory**: Limit predefined by Deta, you could contact them to increase it.
* **Previous steps before starting**: Not directly supported, you could make it work with their Cron system or additional scripts.
Note
Deta is designed to make it easy (and free) to deploy simple applications quickly.
It can simplify several use cases, but at the same time, it doesn't support others, like using external databases (apart from Deta's own NoSQL database system), custom virtual machines, etc.
You can read more details in the [Deta docs](https://docs.deta.sh/docs/micros/about/) to see if it's the right choice for you.
fastapi Run a Server Manually - Uvicorn Run a Server Manually - Uvicorn
===============================
The main thing you need to run a **FastAPI** application in a remote server machine is an ASGI server program like **Uvicorn**.
There are 3 main alternatives:
* [Uvicorn](https://www.uvicorn.org/): a high performance ASGI server.
* [Hypercorn](https://pgjones.gitlab.io/hypercorn/): an ASGI server compatible with HTTP/2 and Trio among other features.
* [Daphne](https://github.com/django/daphne): the ASGI server built for Django Channels.
Server Machine and Server Program
---------------------------------
There's a small detail about names to have in mind. 💡
The word "**server**" is commonly used to refer to both the remote/cloud computer (the physical or virtual machine) and also the program that is running on that machine (e.g. Uvicorn).
Just have that in mind when you read "server" in general, it could refer to one of those two things.
When referring to the remote machine, it's common to call it **server**, but also **machine**, **VM** (virtual machine), **node**. Those all refer to some type of remote machine, normally running Linux, where you run programs.
Install the Server Program
--------------------------
You can install an ASGI compatible server with:
Uvicorn * [Uvicorn](https://www.uvicorn.org/), a lightning-fast ASGI server, built on uvloop and httptools.
```
$ pip install "uvicorn[standard]"
---> 100%
```
Tip
By adding the `standard`, Uvicorn will install and use some recommended extra dependencies.
That including `uvloop`, the high-performance drop-in replacement for `asyncio`, that provides the big concurrency performance boost.
Hypercorn * [Hypercorn](https://gitlab.com/pgjones/hypercorn), an ASGI server also compatible with HTTP/2.
```
$ pip install hypercorn
---> 100%
```
...or any other ASGI server.
Run the Server Program
----------------------
You can then run your application the same way you have done in the tutorials, but without the `--reload` option, e.g.:
Uvicorn
```
$ uvicorn main:app --host 0.0.0.0 --port 80
<span style="color: green;">INFO</span>: Uvicorn running on http://0.0.0.0:80 (Press CTRL+C to quit)
```
Hypercorn
```
$ hypercorn main:app --bind 0.0.0.0:80
Running on 0.0.0.0:8080 over http (CTRL + C to quit)
```
Warning
Remember to remove the `--reload` option if you were using it.
The `--reload` option consumes much more resources, is more unstable, etc.
It helps a lot during **development**, but you **shouldn't** use it in **production**.
Hypercorn with Trio
-------------------
Starlette and **FastAPI** are based on [AnyIO](https://anyio.readthedocs.io/en/stable/), which makes them compatible with both Python's standard library [asyncio](https://docs.python.org/3/library/asyncio-task.html) and [Trio](https://trio.readthedocs.io/en/stable/).
Nevertheless, Uvicorn is currently only compatible with asyncio, and it normally uses [`uvloop`](https://github.com/MagicStack/uvloop), the high-performance drop-in replacement for `asyncio`.
But if you want to directly use **Trio**, then you can use **Hypercorn** as it supports it. ✨
### Install Hypercorn with Trio
First you need to install Hypercorn with Trio support:
```
$ pip install "hypercorn[trio]"
---> 100%
```
### Run with Trio
Then you can pass the command line option `--worker-class` with the value `trio`:
```
$ hypercorn main:app --worker-class trio
```
And that will start Hypercorn with your app using Trio as the backend.
Now you can use Trio internally in your app. Or even better, you can use AnyIO, to keep your code compatible with both Trio and asyncio. 🎉
Deployment Concepts
-------------------
These examples run the server program (e.g Uvicorn), starting **a single process**, listening on all the IPs (`0.0.0.0`) on a predefined port (e.g. `80`).
This is the basic idea. But you will probably want to take care of some additional things, like:
* Security - HTTPS
* Running on startup
* Restarts
* Replication (the number of processes running)
* Memory
* Previous steps before starting
I'll tell you more about each of these concepts, how to think about them, and some concrete examples with strategies to handle them in the next chapters. 🚀
fastapi Project Generation - Template Project Generation - Template
=============================
You can use a project generator to get started, as it includes a lot of the initial set up, security, database and some API endpoints already done for you.
A project generator will always have a very opinionated setup that you should update and adapt for your own needs, but it might be a good starting point for your project.
Full Stack FastAPI PostgreSQL
-----------------------------
GitHub: <https://github.com/tiangolo/full-stack-fastapi-postgresql>
### Full Stack FastAPI PostgreSQL - Features
* Full **Docker** integration (Docker based).
* Docker Swarm Mode deployment.
* **Docker Compose** integration and optimization for local development.
* **Production ready** Python web server using Uvicorn and Gunicorn.
* Python [**FastAPI**](https://github.com/tiangolo/fastapi) backend:
+ **Fast**: Very high performance, on par with **NodeJS** and **Go** (thanks to Starlette and Pydantic).
+ **Intuitive**: Great editor support. Completion everywhere. Less time debugging.
+ **Easy**: Designed to be easy to use and learn. Less time reading docs.
+ **Short**: Minimize code duplication. Multiple features from each parameter declaration.
+ **Robust**: Get production-ready code. With automatic interactive documentation.
+ **Standards-based**: Based on (and fully compatible with) the open standards for APIs: [OpenAPI](https://github.com/OAI/OpenAPI-Specification) and [JSON Schema](https://json-schema.org/).
+ [**Many other features**](../features/index) including automatic validation, serialization, interactive documentation, authentication with OAuth2 JWT tokens, etc.
* **Secure password** hashing by default.
* **JWT token** authentication.
* **SQLAlchemy** models (independent of Flask extensions, so they can be used with Celery workers directly).
* Basic starting models for users (modify and remove as you need).
* **Alembic** migrations.
* **CORS** (Cross Origin Resource Sharing).
* **Celery** worker that can import and use models and code from the rest of the backend selectively.
* REST backend tests based on **Pytest**, integrated with Docker, so you can test the full API interaction, independent on the database. As it runs in Docker, it can build a new data store from scratch each time (so you can use ElasticSearch, MongoDB, CouchDB, or whatever you want, and just test that the API works).
* Easy Python integration with **Jupyter Kernels** for remote or in-Docker development with extensions like Atom Hydrogen or Visual Studio Code Jupyter.
* **Vue** frontend:
+ Generated with Vue CLI.
+ **JWT Authentication** handling.
+ Login view.
+ After login, main dashboard view.
+ Main dashboard with user creation and edition.
+ Self user edition.
+ **Vuex**.
+ **Vue-router**.
+ **Vuetify** for beautiful material design components.
+ **TypeScript**.
+ Docker server based on **Nginx** (configured to play nicely with Vue-router).
+ Docker multi-stage building, so you don't need to save or commit compiled code.
+ Frontend tests ran at build time (can be disabled too).
+ Made as modular as possible, so it works out of the box, but you can re-generate with Vue CLI or create it as you need, and re-use what you want.
* **PGAdmin** for PostgreSQL database, you can modify it to use PHPMyAdmin and MySQL easily.
* **Flower** for Celery jobs monitoring.
* Load balancing between frontend and backend with **Traefik**, so you can have both under the same domain, separated by path, but served by different containers.
* Traefik integration, including Let's Encrypt **HTTPS** certificates automatic generation.
* GitLab **CI** (continuous integration), including frontend and backend testing.
Full Stack FastAPI Couchbase
----------------------------
GitHub: <https://github.com/tiangolo/full-stack-fastapi-couchbase>
⚠️ **WARNING** ⚠️
If you are starting a new project from scratch, check the alternatives here.
For example, the project generator [Full Stack FastAPI PostgreSQL](https://github.com/tiangolo/full-stack-fastapi-postgresql) might be a better alternative, as it is actively maintained and used. And it includes all the new features and improvements.
You are still free to use the Couchbase-based generator if you want to, it should probably still work fine, and if you already have a project generated with it that's fine as well (and you probably already updated it to suit your needs).
You can read more about it in the docs for the repo.
Full Stack FastAPI MongoDB
--------------------------
...might come later, depending on my time availability and other factors. 😅 🎉
Machine Learning models with spaCy and FastAPI
----------------------------------------------
GitHub: <https://github.com/microsoft/cookiecutter-spacy-fastapi>
### Machine Learning models with spaCy and FastAPI - Features
* **spaCy** NER model integration.
* **Azure Cognitive Search** request format built in.
* **Production ready** Python web server using Uvicorn and Gunicorn.
* **Azure DevOps** Kubernetes (AKS) CI/CD deployment built in.
* **Multilingual** Easily choose one of spaCy's built in languages during project setup.
* **Easily extensible** to other model frameworks (Pytorch, Tensorflow), not just spaCy.
tensorflow tf.sort tf.sort
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/sort_ops.py#L29-L83) |
Sorts a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.sort`](https://www.tensorflow.org/api_docs/python/tf/sort)
```
tf.sort(
values, axis=-1, direction='ASCENDING', name=None
)
```
#### Usage:
```
a = [1, 10, 26.9, 2.8, 166.32, 62.3]
tf.sort(a).numpy()
array([ 1. , 2.8 , 10. , 26.9 , 62.3 , 166.32], dtype=float32)
```
```
tf.sort(a, direction='DESCENDING').numpy()
array([166.32, 62.3 , 26.9 , 10. , 2.8 , 1. ], dtype=float32)
```
For multidimensional inputs you can control which axis the sort is applied along. The default `axis=-1` sorts the innermost axis.
```
mat = [[3,2,1],
[2,1,3],
[1,3,2]]
tf.sort(mat, axis=-1).numpy()
array([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]], dtype=int32)
tf.sort(mat, axis=0).numpy()
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]], dtype=int32)
```
#### See also:
* [`tf.argsort`](argsort): Like sort, but it returns the sort indices.
* [`tf.math.top_k`](math/top_k): A partial sort that returns a fixed number of top values and corresponding indices.
| Args |
| `values` | 1-D or higher **numeric** `Tensor`. |
| `axis` | The axis along which to sort. The default is -1, which sorts the last axis. |
| `direction` | The direction in which to sort the values (`'ASCENDING'` or `'DESCENDING'`). |
| `name` | Optional name for the operation. |
| Returns |
| A `Tensor` with the same dtype and shape as `values`, with the elements sorted along the given `axis`. |
| Raises |
| [`tf.errors.InvalidArgumentError`](https://www.tensorflow.org/api_docs/python/tf/errors/InvalidArgumentError) | If the `values.dtype` is not a `float` or `int` type. |
| `ValueError` | If axis is not a constant scalar, or the direction is invalid. |
tensorflow tf.identity_n tf.identity\_n
==============
Returns a list of tensors with the same shapes and contents as the input
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.identity_n`](https://www.tensorflow.org/api_docs/python/tf/identity_n)
```
tf.identity_n(
input, name=None
)
```
tensors.
This op can be used to override the gradient for complicated functions. For example, suppose y = f(x) and we wish to apply a custom function g for backprop such that dx = g(dy). In Python,
```
with tf.get_default_graph().gradient_override_map(
{'IdentityN': 'OverrideGradientWithG'}):
y, _ = identity_n([f(x), x])
@tf.RegisterGradient('OverrideGradientWithG')
def ApplyG(op, dy, _):
return [None, g(dy)] # Do not backprop to f(x).
```
| Args |
| `input` | A list of `Tensor` objects. |
| `name` | A name for the operation (optional). |
| Returns |
| A list of `Tensor` objects. Has the same type as `input`. |
tensorflow tf.dynamic_partition tf.dynamic\_partition
=====================
Partitions `data` into `num_partitions` tensors using indices from `partitions`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.dynamic_partition`](https://www.tensorflow.org/api_docs/python/tf/dynamic_partition)
```
tf.dynamic_partition(
data, partitions, num_partitions, name=None
)
```
For each index tuple `js` of size `partitions.ndim`, the slice `data[js, ...]` becomes part of `outputs[partitions[js]]`. The slices with `partitions[js] = i` are placed in `outputs[i]` in lexicographic order of `js`, and the first dimension of `outputs[i]` is the number of entries in `partitions` equal to `i`. In detail,
```
outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:]
outputs[i] = pack([data[js, ...] for js if partitions[js] == i])
```
`data.shape` must start with `partitions.shape`.
#### For example:
```
# Scalar partitions.
partitions = 1
num_partitions = 2
data = [10, 20]
outputs[0] = [] # Empty with shape [0, 2]
outputs[1] = [[10, 20]]
# Vector partitions.
partitions = [0, 0, 1, 1, 0]
num_partitions = 2
data = [10, 20, 30, 40, 50]
outputs[0] = [10, 20, 50]
outputs[1] = [30, 40]
```
See `dynamic_stitch` for an example on how to merge partitions back.
| Args |
| `data` | A `Tensor`. |
| `partitions` | A `Tensor` of type `int32`. Any shape. Indices in the range `[0, num_partitions)`. |
| `num_partitions` | An `int` that is `>= 1`. The number of partitions to output. |
| `name` | A name for the operation (optional). |
| Returns |
| A list of `num_partitions` `Tensor` objects with the same type as `data`. |
| programming_docs |
tensorflow tf.TensorArraySpec tf.TensorArraySpec
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1340-L1466) |
Type specification for a [`tf.TensorArray`](tensorarray).
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.TensorArraySpec`](https://www.tensorflow.org/api_docs/python/tf/TensorArraySpec)
```
tf.TensorArraySpec(
element_shape=None,
dtype=tf.dtypes.float32,
dynamic_size=False,
infer_shape=True
)
```
| Args |
| `element_shape` | The shape of each element in the `TensorArray`. |
| `dtype` | Data type of the `TensorArray`. |
| `dynamic_size` | Whether the `TensorArray` can grow past its initial size. |
| `infer_shape` | Whether shape inference is enabled. |
| Attributes |
| `value_type` | |
Methods
-------
### `from_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1445-L1455)
```
@staticmethod
from_value(
value
)
```
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1400-L1409)
```
is_compatible_with(
other
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1365-L1369)
```
is_subtype_of(
other
)
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1371-L1398)
```
most_specific_common_supertype(
others
)
```
Returns the most specific supertype of `self` and `others`.
| Args |
| `others` | A Sequence of `TypeSpec`. |
Returns `None` if a supertype does not exist.
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
tensorflow tf.parallel_stack tf.parallel\_stack
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1357-L1416) |
Stacks a list of rank-`R` tensors into one rank-`(R+1)` tensor in parallel.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.parallel_stack`](https://www.tensorflow.org/api_docs/python/tf/parallel_stack)
```
tf.parallel_stack(
values, name='parallel_stack'
)
```
Requires that the shape of inputs be known at graph construction time.
Packs the list of tensors in `values` into a tensor with rank one higher than each tensor in `values`, by packing them along the first dimension. Given a list of length `N` of tensors of shape `(A, B, C)`; the `output` tensor will have the shape `(N, A, B, C)`.
#### For example:
```
x = tf.constant([1, 4])
y = tf.constant([2, 5])
z = tf.constant([3, 6])
tf.parallel_stack([x, y, z]) # [[1, 4], [2, 5], [3, 6]]
```
The difference between `stack` and `parallel_stack` is that `stack` requires all the inputs be computed before the operation will begin but doesn't require that the input shapes be known during graph construction.
`parallel_stack` will copy pieces of the input into the output as they become available, in some situations this can provide a performance benefit.
Unlike `stack`, `parallel_stack` does NOT support backpropagation.
This is the opposite of unstack. The numpy equivalent is
```
tf.parallel_stack([x, y, z]) = np.asarray([x, y, z])
```
| Args |
| `values` | A list of `Tensor` objects with the same shape and type. |
| `name` | A name for this operation (optional). |
| Returns |
| `output` | A stacked `Tensor` with the same type as `values`. |
| Raises |
| `RuntimeError` | if executed in eager mode. |
eager compatibility
-------------------
parallel\_stack is not compatible with eager execution.
tensorflow tf.IndexedSlicesSpec tf.IndexedSlicesSpec
====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/indexed_slices.py#L201-L264) |
Type specification for a [`tf.IndexedSlices`](indexedslices).
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.IndexedSlicesSpec`](https://www.tensorflow.org/api_docs/python/tf/IndexedSlicesSpec)
```
tf.IndexedSlicesSpec(
shape=None,
dtype=tf.dtypes.float32,
indices_dtype=tf.dtypes.int64,
dense_shape_dtype=None,
indices_shape=None
)
```
| Args |
| `shape` | The dense shape of the `IndexedSlices`, or `None` to allow any dense shape. |
| `dtype` | [`tf.DType`](dtypes/dtype) of values in the `IndexedSlices`. |
| `indices_dtype` | [`tf.DType`](dtypes/dtype) of the `indices` in the `IndexedSlices`. One of [`tf.int32`](../tf#int32) or [`tf.int64`](../tf#int64). |
| `dense_shape_dtype` | [`tf.DType`](dtypes/dtype) of the `dense_shape` in the `IndexedSlices`. One of [`tf.int32`](../tf#int32), [`tf.int64`](../tf#int64), or `None` (if the `IndexedSlices` has no `dense_shape` tensor). |
| `indices_shape` | The shape of the `indices` component, which indicates how many slices are in the `IndexedSlices`. |
| Attributes |
| `value_type` | |
Methods
-------
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L193-L214)
```
is_compatible_with(
spec_or_value
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
tensorflow tf.case tf.case
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L3341-L3443) |
Create a case operation.
```
tf.case(
pred_fn_pairs,
default=None,
exclusive=False,
strict=False,
name='case'
)
```
See also [`tf.switch_case`](switch_case).
The `pred_fn_pairs` parameter is a list of pairs of size N. Each pair contains a boolean scalar tensor and a python callable that creates the tensors to be returned if the boolean evaluates to True. `default` is a callable generating a list of tensors. All the callables in `pred_fn_pairs` as well as `default` (if provided) should return the same number and types of tensors.
If `exclusive==True`, all predicates are evaluated, and an exception is thrown if more than one of the predicates evaluates to `True`. If `exclusive==False`, execution stops at the first predicate which evaluates to True, and the tensors generated by the corresponding function are returned immediately. If none of the predicates evaluate to True, this operation returns the tensors generated by `default`.
[`tf.case`](case) supports nested structures as implemented in [`tf.nest`](nest). All of the callables must return the same (possibly nested) value structure of lists, tuples, and/or named tuples. Singleton lists and tuples form the only exceptions to this: when returned by a callable, they are implicitly unpacked to single values. This behavior is disabled by passing `strict=True`.
**Example 1:**
#### Pseudocode:
```
if (x < y) return 17;
else return 23;
```
#### Expressions:
```
f1 = lambda: tf.constant(17)
f2 = lambda: tf.constant(23)
r = tf.case([(tf.less(x, y), f1)], default=f2)
```
**Example 2:**
#### Pseudocode:
```
if (x < y && x > z) raise OpError("Only one predicate may evaluate to True");
if (x < y) return 17;
else if (x > z) return 23;
else return -1;
```
#### Expressions:
```
def f1(): return tf.constant(17)
def f2(): return tf.constant(23)
def f3(): return tf.constant(-1)
r = tf.case([(tf.less(x, y), f1), (tf.greater(x, z), f2)],
default=f3, exclusive=True)
```
| Args |
| `pred_fn_pairs` | List of pairs of a boolean scalar tensor and a callable which returns a list of tensors. |
| `default` | Optional callable that returns a list of tensors. |
| `exclusive` | True iff at most one predicate is allowed to evaluate to `True`. |
| `strict` | A boolean that enables/disables 'strict' mode; see above. |
| `name` | A name for this operation (optional). |
| Returns |
| The tensors returned by the first pair whose predicate evaluated to True, or those returned by `default` if none does. |
| Raises |
| `TypeError` | If `pred_fn_pairs` is not a list/tuple. |
| `TypeError` | If `pred_fn_pairs` is a list but does not contain 2-tuples. |
| `TypeError` | If `fns[i]` is not callable for any i, or `default` is not callable. |
v2 compatibility
----------------
`pred_fn_pairs` could be a dictionary in v1. However, tf.Tensor and tf.Variable are no longer hashable in v2, so cannot be used as a key for a dictionary. Please use a list or a tuple instead.
tensorflow tf.space_to_batch tf.space\_to\_batch
===================
SpaceToBatch for N-D tensors of type T.
#### View aliases
**Main aliases**
[`tf.nn.space_to_batch`](https://www.tensorflow.org/api_docs/python/tf/space_to_batch)
```
tf.space_to_batch(
input, block_shape, paddings, name=None
)
```
This operation divides "spatial" dimensions `[1, ..., M]` of the input into a grid of blocks of shape `block_shape`, and interleaves these blocks with the "batch" dimension (0) such that in the output, the spatial dimensions `[1, ..., M]` correspond to the position within the grid, and the batch dimension combines both the position within a spatial block and the original batch position. Prior to division into blocks, the spatial dimensions of the input are optionally zero padded according to `paddings`. See below for a precise description.
This operation is equivalent to the following steps:
1. Zero-pad the start and end of dimensions `[1, ..., M]` of the input according to `paddings` to produce `padded` of shape `padded_shape`.
2. Reshape `padded` to `reshaped_padded` of shape:
[batch] + [padded\_shape[1] / block\_shape[0], block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1], block\_shape[M-1]] + remaining\_shape
3. Permute dimensions of `reshaped_padded` to produce `permuted_reshaped_padded` of shape:
block\_shape + [batch] + [padded\_shape[1] / block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1]] + remaining\_shape
4. Reshape `permuted_reshaped_padded` to flatten `block_shape` into the batch dimension, producing an output tensor of shape:
[batch \* prod(block\_shape)] + [padded\_shape[1] / block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1]] + remaining\_shape
#### Some examples:
(1) For the following input of shape `[1, 2, 2, 1]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1], [2]], [[3], [4]]]]
```
The output tensor has shape `[4, 1, 1, 1]` and value:
```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
(2) For the following input of shape `[1, 2, 2, 3]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
```
[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]]
```
(3) For the following input of shape `[1, 4, 4, 1]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
[[13], [14], [15], [16]]]]
```
The output tensor has shape `[4, 2, 2, 1]` and value:
```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
[[[6], [8]], [[14], [16]]]]
```
(4) For the following input of shape `[2, 2, 4, 1]`, block\_shape = `[2, 2]`, and paddings = `[[0, 0], [2, 0]]`:
```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]],
[[[9], [10], [11], [12]],
[[13], [14], [15], [16]]]]
```
The output tensor has shape `[8, 1, 3, 1]` and value:
```
x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]],
[[[0], [5], [7]]], [[[0], [13], [15]]],
[[[0], [6], [8]]], [[[0], [14], [16]]]]
```
Among others, this operation is useful for reducing atrous convolution into regular convolution.
| Args |
| `input` | A `Tensor`. N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`, where spatial\_shape has `M` dimensions. |
| `block_shape` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 1-D with shape `[M]`, all values must be >= 1. |
| `paddings` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 2-D with shape `[M, 2]`, all values must be >= 0. `paddings[i] = [pad_start, pad_end]` specifies the padding for input dimension `i + 1`, which corresponds to spatial dimension `i`. It is required that `block_shape[i]` divides `input_shape[i + 1] + pad_start + pad_end`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.type_spec_from_value tf.type\_spec\_from\_value
==========================
Returns a [`tf.TypeSpec`](typespec) that represents the given `value`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.type_spec_from_value`](https://www.tensorflow.org/api_docs/python/tf/type_spec_from_value)
```
tf.type_spec_from_value(
value
) -> tf.TypeSpec
```
#### Examples:
```
tf.type_spec_from_value(tf.constant([1, 2, 3]))
TensorSpec(shape=(3,), dtype=tf.int32, name=None)
tf.type_spec_from_value(np.array([4.0, 5.0], np.float64))
TensorSpec(shape=(2,), dtype=tf.float64, name=None)
tf.type_spec_from_value(tf.ragged.constant([[1, 2], [3, 4, 5]]))
RaggedTensorSpec(TensorShape([2, None]), tf.int32, 1, tf.int64)
```
```
example_input = tf.ragged.constant([[1, 2], [3]])
@tf.function(input_signature=[tf.type_spec_from_value(example_input)])
def f(x):
return tf.reduce_sum(x, axis=1)
```
| Args |
| `value` | A value that can be accepted or returned by TensorFlow APIs. Accepted types for `value` include [`tf.Tensor`](tensor), any value that can be converted to [`tf.Tensor`](tensor) using [`tf.convert_to_tensor`](convert_to_tensor), and any subclass of `CompositeTensor` (such as [`tf.RaggedTensor`](raggedtensor)). |
| Returns |
| A `TypeSpec` that is compatible with `value`. |
| Raises |
| `TypeError` | If a TypeSpec cannot be built for `value`, because its type is not supported. |
tensorflow tf.size tf.size
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L721-L752) |
Returns the size of a tensor.
```
tf.size(
input,
out_type=tf.dtypes.int32,
name=None
)
```
See also [`tf.shape`](shape).
Returns a 0-D `Tensor` representing the number of elements in `input` of type `out_type`. Defaults to tf.int32.
#### For example:
```
t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])
tf.size(t)
<tf.Tensor: shape=(), dtype=int32, numpy=12>
```
| Args |
| `input` | A `Tensor` or `SparseTensor`. |
| `name` | A name for the operation (optional). |
| `out_type` | (Optional) The specified non-quantized numeric output type of the operation. Defaults to [`tf.int32`](../tf#int32). |
| Returns |
| A `Tensor` of type `out_type`. Defaults to [`tf.int32`](../tf#int32). |
numpy compatibility
-------------------
Equivalent to np.size()
tensorflow tf.IndexedSlices tf.IndexedSlices
================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/indexed_slices.py#L57-L193) |
A sparse representation of a set of tensor slices at given indices.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.IndexedSlices`](https://www.tensorflow.org/api_docs/python/tf/IndexedSlices)
```
tf.IndexedSlices(
values, indices, dense_shape=None
)
```
This class is a simple wrapper for a pair of `Tensor` objects:
* `values`: A `Tensor` of any dtype with shape `[D0, D1, ..., Dn]`.
* `indices`: A 1-D integer `Tensor` with shape `[D0]`.
An `IndexedSlices` is typically used to represent a subset of a larger tensor `dense` of shape `[LARGE0, D1, .. , DN]` where `LARGE0 >> D0`. The values in `indices` are the indices in the first dimension of the slices that have been extracted from the larger tensor.
The dense tensor `dense` represented by an `IndexedSlices` `slices` has
```
dense[slices.indices[i], :, :, :, ...] = slices.values[i, :, :, :, ...]
```
The `IndexedSlices` class is used principally in the definition of gradients for operations that have sparse gradients (e.g. [`tf.gather`](gather)).
```
v = tf.Variable([[0.,1, 2], [2, 3, 4], [4, 5, 6], [6, 7, 8]])
with tf.GradientTape() as tape:
r = tf.gather(v, [1,3])
index_slices = tape.gradient(r,v)
index_slices
<...IndexedSlices object ...>
index_slices.indices.numpy()
array([1, 3], dtype=int32)
index_slices.values.numpy()
array([[1., 1., 1.],
[1., 1., 1.]], dtype=float32)
```
Contrast this representation with [`tf.sparse.SparseTensor`](sparse/sparsetensor), which uses multi-dimensional indices and scalar values.
| Attributes |
| `dense_shape` | A 1-D `Tensor` containing the shape of the corresponding dense tensor. |
| `device` | The name of the device on which `values` will be produced, or `None`. |
| `dtype` | The `DType` of elements in this tensor. |
| `graph` | The `Graph` that contains the values, indices, and shape tensors. |
| `indices` | A 1-D `Tensor` containing the indices of the slices. |
| `name` | The name of this `IndexedSlices`. |
| `op` | The `Operation` that produces `values` as an output. |
| `shape` | Gets the [`tf.TensorShape`](tensorshape) representing the shape of the dense tensor. |
| `values` | A `Tensor` containing the values of the slices. |
Methods
-------
### `consumers`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/indexed_slices.py#L192-L193)
```
consumers()
```
### `__neg__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/indexed_slices.py#L161-L162)
```
__neg__()
```
| programming_docs |
tensorflow tf.fill tf.fill
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L207-L248) |
Creates a tensor filled with a scalar value.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.fill`](https://www.tensorflow.org/api_docs/python/tf/fill)
```
tf.fill(
dims, value, name=None
)
```
See also [`tf.ones`](ones), [`tf.zeros`](zeros), [`tf.one_hot`](one_hot), [`tf.eye`](eye).
This operation creates a tensor of shape `dims` and fills it with `value`.
#### For example:
```
tf.fill([2, 3], 9)
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[9, 9, 9],
[9, 9, 9]], dtype=int32)>
```
[`tf.fill`](fill) evaluates at graph runtime and supports dynamic shapes based on other runtime `tf.Tensors`, unlike [`tf.constant(value, shape=dims)`](constant), which embeds the value as a `Const` node.
| Args |
| `dims` | A 1-D sequence of non-negative numbers. Represents the shape of the output [`tf.Tensor`](tensor). Entries should be of type: `int32`, `int64`. |
| `value` | A value to fill the returned [`tf.Tensor`](tensor). |
| `name` | Optional string. The name of the output [`tf.Tensor`](tensor). |
| Returns |
| A [`tf.Tensor`](tensor) with shape `dims` and the same dtype as `value`. |
| Raises |
| `InvalidArgumentError` | `dims` contains negative entries. |
| `NotFoundError` | `dims` contains non-integer entries. |
numpy compatibility
-------------------
Similar to `np.full`. In `numpy`, more parameters are supported. Passing a number argument as the shape (`np.full(5, value)`) is valid in `numpy` for specifying a 1-D shaped result, while TensorFlow does not support this syntax.
tensorflow tf.make_tensor_proto tf.make\_tensor\_proto
======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_util.py#L357-L561) |
Create a TensorProto.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.make_tensor_proto`](https://www.tensorflow.org/api_docs/python/tf/make_tensor_proto)
```
tf.make_tensor_proto(
values, dtype=None, shape=None, verify_shape=False, allow_broadcast=False
)
```
In TensorFlow 2.0, representing tensors as protos should no longer be a common workflow. That said, this utility function is still useful for generating TF Serving request protos:
```
request = tensorflow_serving.apis.predict_pb2.PredictRequest()
request.model_spec.name = "my_model"
request.model_spec.signature_name = "serving_default"
request.inputs["images"].CopyFrom(tf.make_tensor_proto(X_new))
```
`make_tensor_proto` accepts "values" of a python scalar, a python list, a numpy ndarray, or a numpy scalar.
If "values" is a python scalar or a python list, make\_tensor\_proto first convert it to numpy ndarray. If dtype is None, the conversion tries its best to infer the right numpy data type. Otherwise, the resulting numpy array has a compatible data type with the given dtype.
In either case above, the numpy ndarray (either the caller provided or the auto-converted) must have the compatible type with dtype.
`make_tensor_proto` then converts the numpy array to a tensor proto.
If "shape" is None, the resulting tensor proto represents the numpy array precisely.
Otherwise, "shape" specifies the tensor's shape and the numpy array can not have more elements than what "shape" specifies.
| Args |
| `values` | Values to put in the TensorProto. |
| `dtype` | Optional tensor\_pb2 DataType value. |
| `shape` | List of integers representing the dimensions of tensor. |
| `verify_shape` | Boolean that enables verification of a shape of values. |
| `allow_broadcast` | Boolean that enables allowing scalars and 1 length vector broadcasting. Cannot be true when verify\_shape is true. |
| Returns |
| A `TensorProto`. Depending on the type, it may contain data in the "tensor\_content" attribute, which is not directly useful to Python programs. To access the values you should convert the proto back to a numpy ndarray with [`tf.make_ndarray(proto)`](make_ndarray). If `values` is a `TensorProto`, it is immediately returned; `dtype` and `shape` are ignored. |
| Raises |
| `TypeError` | if unsupported types are provided. |
| `ValueError` | if arguments have inappropriate values or if verify\_shape is True and shape of values is not equals to a shape from the argument. |
tensorflow tf.get_static_value tf.get\_static\_value
=====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_util.py#L808-L883) |
Returns the constant value of the given tensor, if efficiently calculable.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.get_static_value`](https://www.tensorflow.org/api_docs/python/tf/get_static_value)
```
tf.get_static_value(
tensor, partial=False
)
```
This function attempts to partially evaluate the given tensor, and returns its value as a numpy ndarray if this succeeds.
#### Example usage:
```
a = tf.constant(10)
tf.get_static_value(a)
10
b = tf.constant(20)
tf.get_static_value(tf.add(a, b))
30
```
```
# `tf.Variable` is not supported.
c = tf.Variable(30)
print(tf.get_static_value(c))
None
```
Using `partial` option is most relevant when calling `get_static_value` inside a [`tf.function`](function). Setting it to `True` will return the results but for the values that cannot be evaluated will be `None`. For example:
```
class Foo(object):
def __init__(self):
self.a = tf.Variable(1)
self.b = tf.constant(2)
@tf.function
def bar(self, partial):
packed = tf.raw_ops.Pack(values=[self.a, self.b])
static_val = tf.get_static_value(packed, partial=partial)
tf.print(static_val)
f = Foo()
f.bar(partial=True) # `array([None, array(2, dtype=int32)], dtype=object)`
f.bar(partial=False) # `None`
```
Compatibility(V1): If `constant_value(tensor)` returns a non-`None` result, it will no longer be possible to feed a different value for `tensor`. This allows the result of this function to influence the graph that is constructed, and permits static shape optimizations.
| Args |
| `tensor` | The Tensor to be evaluated. |
| `partial` | If True, the returned numpy array is allowed to have partially evaluated values. Values that can't be evaluated will be None. |
| Returns |
| A numpy ndarray containing the constant value of the given `tensor`, or None if it cannot be calculated. |
| Raises |
| `TypeError` | if tensor is not an ops.Tensor. |
tensorflow tf.VariableAggregation tf.VariableAggregation
======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L98-L129) |
Indicates how a distributed variable will be aggregated.
[`tf.distribute.Strategy`](distribute/strategy) distributes a model by making multiple copies (called "replicas") acting data-parallel on different elements of the input batch. When performing some variable-update operation, say `var.assign_add(x)`, in a model, we need to resolve how to combine the different values for `x` computed in the different replicas.
* `NONE`: This is the default, giving an error if you use a variable-update operation with multiple replicas.
* `SUM`: Add the updates across replicas.
* `MEAN`: Take the arithmetic mean ("average") of the updates across replicas.
* `ONLY_FIRST_REPLICA`: This is for when every replica is performing the same update, but we only want to perform the update once. Used, e.g., for the global step counter.
| Class Variables |
| MEAN | `<VariableAggregationV2.MEAN: 2>` |
| NONE | `<VariableAggregationV2.NONE: 0>` |
| ONLY\_FIRST\_REPLICA | `<VariableAggregationV2.ONLY_FIRST_REPLICA: 3>` |
| SUM | `<VariableAggregationV2.SUM: 1>` |
tensorflow tf.executing_eagerly tf.executing\_eagerly
=====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/context.py#L2161-L2219) |
Checks whether the current thread has eager execution enabled.
```
tf.executing_eagerly()
```
Eager execution is enabled by default and this API returns `True` in most of cases. However, this API might return `False` in the following use cases.
* Executing inside [`tf.function`](function), unless under [`tf.init_scope`](init_scope) or [`tf.config.run_functions_eagerly(True)`](config/run_functions_eagerly) is previously called.
* Executing inside a transformation function for `tf.dataset`.
* [`tf.compat.v1.disable_eager_execution()`](compat/v1/disable_eager_execution) is called.
#### General case:
```
print(tf.executing_eagerly())
True
```
Inside [`tf.function`](function):
```
@tf.function
def fn():
with tf.init_scope():
print(tf.executing_eagerly())
print(tf.executing_eagerly())
fn()
True
False
```
Inside [`tf.function`](function) after [`tf.config.run_functions_eagerly(True)`](config/run_functions_eagerly) is called:
```
tf.config.run_functions_eagerly(True)
@tf.function
def fn():
with tf.init_scope():
print(tf.executing_eagerly())
print(tf.executing_eagerly())
fn()
True
True
tf.config.run_functions_eagerly(False)
```
Inside a transformation function for `tf.dataset`:
```
def data_fn(x):
print(tf.executing_eagerly())
return x
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(data_fn)
False
```
| Returns |
| `True` if the current thread has eager execution enabled. |
tensorflow tf.is_tensor tf.is\_tensor
=============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_util.py#L1030-L1060) |
Checks whether `x` is a TF-native type that can be passed to many TF ops.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.is_tensor`](https://www.tensorflow.org/api_docs/python/tf/is_tensor)
```
tf.is_tensor(
x
)
```
Use `is_tensor` to differentiate types that can ingested by TensorFlow ops without any conversion (e.g., [`tf.Tensor`](tensor), [`tf.SparseTensor`](sparse/sparsetensor), and [`tf.RaggedTensor`](raggedtensor)) from types that need to be converted into tensors before they are ingested (e.g., numpy `ndarray` and Python scalars).
For example, in the following code block:
```
if not tf.is_tensor(t):
t = tf.convert_to_tensor(t)
return t.shape, t.dtype
```
we check to make sure that `t` is a tensor (and convert it if not) before accessing its `shape` and `dtype`. (But note that not all TensorFlow native types have shapes or dtypes; [`tf.data.Dataset`](data/dataset) is an example of a TensorFlow native type that has neither shape nor dtype.)
| Args |
| `x` | A python object to check. |
| Returns |
| `True` if `x` is a TensorFlow-native type. |
tensorflow Module: tf.sets Module: tf.sets
===============
Tensorflow set operations.
Functions
---------
[`difference(...)`](sets/difference): Compute set difference of elements in last dimension of `a` and `b`.
[`intersection(...)`](sets/intersection): Compute set intersection of elements in last dimension of `a` and `b`.
[`size(...)`](sets/size): Compute number of unique elements along last dimension of `a`.
[`union(...)`](sets/union): Compute set union of elements in last dimension of `a` and `b`.
tensorflow tf.stop_gradient tf.stop\_gradient
=================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L6966-L6993) |
Stops gradient computation.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.stop_gradient`](https://www.tensorflow.org/api_docs/python/tf/stop_gradient)
```
tf.stop_gradient(
input, name=None
)
```
When executed in a graph, this op outputs its input tensor as-is.
When building ops to compute gradients, this op prevents the contribution of its inputs to be taken into account. Normally, the gradient generator adds ops to a graph to compute the derivatives of a specified 'loss' by recursively finding out inputs that contributed to its computation. If you insert this op in the graph it inputs are masked from the gradient generator. They are not taken into account for computing gradients.
This is useful any time you want to compute a value with TensorFlow but need to pretend that the value was a constant. For example, the softmax function for a vector x can be written as
```
def softmax(x):
numerator = tf.exp(x)
denominator = tf.reduce_sum(numerator)
return numerator / denominator
```
This however is susceptible to overflow if the values in x are large. An alternative more stable way is to subtract the maximum of x from each of the values.
```
def stable_softmax(x):
z = x - tf.reduce_max(x)
numerator = tf.exp(z)
denominator = tf.reduce_sum(numerator)
return numerator / denominator
```
However, when we backprop through the softmax to x, we dont want to backprop through the [`tf.reduce_max(x)`](math/reduce_max) (if the max values are not unique then the gradient could flow to the wrong input) calculation and treat that as a constant. Therefore, we should write this out as
```
def stable_softmax(x):
z = x - tf.stop_gradient(tf.reduce_max(x))
numerator = tf.exp(z)
denominator = tf.reduce_sum(numerator)
return numerator / denominator
```
Some other examples include:
* The *EM* algorithm where the *M-step* should not involve backpropagation through the output of the *E-step*.
* Contrastive divergence training of Boltzmann machines where, when differentiating the energy function, the training must not backpropagate through the graph that generated the samples from the model.
* Adversarial training, where no backprop should happen through the adversarial example generation process.
| Args |
| `input` | A `Tensor`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.ones tf.ones
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3238-L3291) |
Creates a tensor with all elements set to one (1).
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.ones`](https://www.tensorflow.org/api_docs/python/tf/ones)
```
tf.ones(
shape,
dtype=tf.dtypes.float32,
name=None
)
```
See also [`tf.ones_like`](ones_like), [`tf.zeros`](zeros), [`tf.fill`](fill), [`tf.eye`](eye).
This operation returns a tensor of type `dtype` with shape `shape` and all elements set to one.
```
tf.ones([3, 4], tf.int32)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]], dtype=int32)>
```
| Args |
| `shape` | A `list` of integers, a `tuple` of integers, or a 1-D `Tensor` of type `int32`. |
| `dtype` | Optional DType of an element in the resulting `Tensor`. Default is [`tf.float32`](../tf#float32). |
| `name` | Optional string. A name for the operation. |
| Returns |
| A `Tensor` with all elements set to one (1). |
tensorflow tf.linspace tf.linspace
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L114-L224) |
Generates evenly-spaced values in an interval along a given axis.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.lin_space`](https://www.tensorflow.org/api_docs/python/tf/linspace), [`tf.compat.v1.linspace`](https://www.tensorflow.org/api_docs/python/tf/linspace)
```
tf.linspace(
start, stop, num, name=None, axis=0
)
```
A sequence of `num` evenly-spaced values are generated beginning at `start` along a given `axis`. If `num > 1`, the values in the sequence increase by `(stop - start) / (num - 1)`, so that the last one is exactly `stop`. If `num <= 0`, `ValueError` is raised.
Matches [np.linspace](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html)'s behaviour except when `num == 0`.
#### For example:
```
tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]
```
`Start` and `stop` can be tensors of arbitrary size:
```
tf.linspace([0., 5.], [10., 40.], 5, axis=0)
<tf.Tensor: shape=(5, 2), dtype=float32, numpy=
array([[ 0. , 5. ],
[ 2.5 , 13.75],
[ 5. , 22.5 ],
[ 7.5 , 31.25],
[10. , 40. ]], dtype=float32)>
```
`Axis` is where the values will be generated (the dimension in the returned tensor which corresponds to the axis will be equal to `num`)
```
tf.linspace([0., 5.], [10., 40.], 5, axis=-1)
<tf.Tensor: shape=(2, 5), dtype=float32, numpy=
array([[ 0. , 2.5 , 5. , 7.5 , 10. ],
[ 5. , 13.75, 22.5 , 31.25, 40. ]], dtype=float32)>
```
| Args |
| `start` | A `Tensor`. Must be one of the following types: `bfloat16`, `float32`, `float64`. N-D tensor. First entry in the range. |
| `stop` | A `Tensor`. Must have the same type and shape as `start`. N-D tensor. Last entry in the range. |
| `num` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 0-D tensor. Number of values to generate. |
| `name` | A name for the operation (optional). |
| `axis` | Axis along which the operation is performed (used only when N-D tensors are provided). |
| Returns |
| A `Tensor`. Has the same type as `start`. |
tensorflow Module: tf.autodiff Module: tf.autodiff
===================
Public API for tf.autodiff namespace.
Classes
-------
[`class ForwardAccumulator`](autodiff/forwardaccumulator): Computes Jacobian-vector products ("JVP"s) using forward-mode autodiff.
[`class GradientTape`](gradienttape): Record operations for automatic differentiation.
tensorflow Module: tf.image Module: tf.image
================
Image ops.
The [`tf.image`](image) module contains various functions for image processing and decoding-encoding Ops.
Many of the encoding/decoding functions are also available in the core [`tf.io`](io) module.
Image processing
----------------
### Resizing
The resizing Ops accept input images as tensors of several types. They always output resized images as float32 tensors.
The convenience function [`tf.image.resize`](image/resize) supports both 4-D and 3-D tensors as input and output. 4-D tensors are for batches of images, 3-D tensors for individual images.
Resized images will be distorted if their original aspect ratio is not the same as size. To avoid distortions see tf.image.resize\_with\_pad.
* [`tf.image.resize`](image/resize)
* [`tf.image.resize_with_pad`](image/resize_with_pad)
* [`tf.image.resize_with_crop_or_pad`](image/resize_with_crop_or_pad)
The Class [`tf.image.ResizeMethod`](image/resizemethod) provides various resize methods like `bilinear`, `nearest_neighbor`.
### Converting Between Colorspaces
Image ops work either on individual images or on batches of images, depending on the shape of their input Tensor.
If 3-D, the shape is `[height, width, channels]`, and the Tensor represents one image. If 4-D, the shape is `[batch_size, height, width, channels]`, and the Tensor represents `batch_size` images.
Currently, `channels` can usefully be 1, 2, 3, or 4. Single-channel images are grayscale, images with 3 channels are encoded as either RGB or HSV. Images with 2 or 4 channels include an alpha channel, which has to be stripped from the image before passing the image to most image processing functions (and can be re-attached later).
Internally, images are either stored in as one `float32` per channel per pixel (implicitly, values are assumed to lie in `[0,1)`) or one `uint8` per channel per pixel (values are assumed to lie in `[0,255]`).
TensorFlow can convert between images in RGB or HSV or YIQ.
* [`tf.image.rgb_to_grayscale`](image/rgb_to_grayscale), [`tf.image.grayscale_to_rgb`](image/grayscale_to_rgb)
* [`tf.image.rgb_to_hsv`](image/rgb_to_hsv), [`tf.image.hsv_to_rgb`](image/hsv_to_rgb)
* [`tf.image.rgb_to_yiq`](image/rgb_to_yiq), [`tf.image.yiq_to_rgb`](image/yiq_to_rgb)
* [`tf.image.rgb_to_yuv`](image/rgb_to_yuv), [`tf.image.yuv_to_rgb`](image/yuv_to_rgb)
* [`tf.image.image_gradients`](image/image_gradients)
* [`tf.image.convert_image_dtype`](image/convert_image_dtype)
### Image Adjustments
TensorFlow provides functions to adjust images in various ways: brightness, contrast, hue, and saturation. Each adjustment can be done with predefined parameters or with random parameters picked from predefined intervals. Random adjustments are often useful to expand a training set and reduce overfitting.
If several adjustments are chained it is advisable to minimize the number of redundant conversions by first converting the images to the most natural data type and representation.
* [`tf.image.adjust_brightness`](image/adjust_brightness)
* [`tf.image.adjust_contrast`](image/adjust_contrast)
* [`tf.image.adjust_gamma`](image/adjust_gamma)
* [`tf.image.adjust_hue`](image/adjust_hue)
* [`tf.image.adjust_jpeg_quality`](image/adjust_jpeg_quality)
* [`tf.image.adjust_saturation`](image/adjust_saturation)
* [`tf.image.random_brightness`](image/random_brightness)
* [`tf.image.random_contrast`](image/random_contrast)
* [`tf.image.random_hue`](image/random_hue)
* [`tf.image.random_saturation`](image/random_saturation)
* [`tf.image.per_image_standardization`](image/per_image_standardization)
### Working with Bounding Boxes
* [`tf.image.draw_bounding_boxes`](image/draw_bounding_boxes)
* [`tf.image.combined_non_max_suppression`](image/combined_non_max_suppression)
* [`tf.image.generate_bounding_box_proposals`](image/generate_bounding_box_proposals)
* [`tf.image.non_max_suppression`](image/non_max_suppression)
* [`tf.image.non_max_suppression_overlaps`](image/non_max_suppression_overlaps)
* [`tf.image.non_max_suppression_padded`](image/non_max_suppression_padded)
* [`tf.image.non_max_suppression_with_scores`](image/non_max_suppression_with_scores)
* [`tf.image.pad_to_bounding_box`](image/pad_to_bounding_box)
* [`tf.image.sample_distorted_bounding_box`](image/sample_distorted_bounding_box)
### Cropping
* [`tf.image.central_crop`](image/central_crop)
* [`tf.image.crop_and_resize`](image/crop_and_resize)
* [`tf.image.crop_to_bounding_box`](image/crop_to_bounding_box)
* [`tf.io.decode_and_crop_jpeg`](io/decode_and_crop_jpeg)
* [`tf.image.extract_glimpse`](image/extract_glimpse)
* [`tf.image.random_crop`](image/random_crop)
* [`tf.image.resize_with_crop_or_pad`](image/resize_with_crop_or_pad)
### Flipping, Rotating and Transposing
* [`tf.image.flip_left_right`](image/flip_left_right)
* [`tf.image.flip_up_down`](image/flip_up_down)
* [`tf.image.random_flip_left_right`](image/random_flip_left_right)
* [`tf.image.random_flip_up_down`](image/random_flip_up_down)
* [`tf.image.rot90`](image/rot90)
* [`tf.image.transpose`](image/transpose)
Image decoding and encoding
---------------------------
TensorFlow provides Ops to decode and encode JPEG and PNG formats. Encoded images are represented by scalar string Tensors, decoded images by 3-D uint8 tensors of shape `[height, width, channels]`. (PNG also supports uint16.)
>
> **Note:** `decode_gif` returns a 4-D array `[num_frames, height, width, 3]`
>
The encode and decode Ops apply to one image at a time. Their input and output are all of variable size. If you need fixed size images, pass the output of the decode Ops to one of the cropping and resizing Ops.
* [`tf.io.decode_bmp`](io/decode_bmp)
* [`tf.io.decode_gif`](io/decode_gif)
* [`tf.io.decode_image`](io/decode_image)
* [`tf.io.decode_jpeg`](io/decode_jpeg)
* [`tf.io.decode_and_crop_jpeg`](io/decode_and_crop_jpeg)
* [`tf.io.decode_png`](io/decode_png)
* [`tf.io.encode_jpeg`](io/encode_jpeg)
* [`tf.io.encode_png`](io/encode_png)
Classes
-------
[`class ResizeMethod`](image/resizemethod): See [`tf.image.resize`](image/resize) for details.
Functions
---------
[`adjust_brightness(...)`](image/adjust_brightness): Adjust the brightness of RGB or Grayscale images.
[`adjust_contrast(...)`](image/adjust_contrast): Adjust contrast of RGB or grayscale images.
[`adjust_gamma(...)`](image/adjust_gamma): Performs [Gamma Correction](http://en.wikipedia.org/wiki/Gamma_correction).
[`adjust_hue(...)`](image/adjust_hue): Adjust hue of RGB images.
[`adjust_jpeg_quality(...)`](image/adjust_jpeg_quality): Adjust jpeg encoding quality of an image.
[`adjust_saturation(...)`](image/adjust_saturation): Adjust saturation of RGB images.
[`central_crop(...)`](image/central_crop): Crop the central region of the image(s).
[`combined_non_max_suppression(...)`](image/combined_non_max_suppression): Greedily selects a subset of bounding boxes in descending order of score.
[`convert_image_dtype(...)`](image/convert_image_dtype): Convert `image` to `dtype`, scaling its values if needed.
[`crop_and_resize(...)`](image/crop_and_resize): Extracts crops from the input image tensor and resizes them.
[`crop_to_bounding_box(...)`](image/crop_to_bounding_box): Crops an `image` to a specified bounding box.
[`decode_and_crop_jpeg(...)`](io/decode_and_crop_jpeg): Decode and Crop a JPEG-encoded image to a uint8 tensor.
[`decode_bmp(...)`](io/decode_bmp): Decode the first frame of a BMP-encoded image to a uint8 tensor.
[`decode_gif(...)`](io/decode_gif): Decode the frame(s) of a GIF-encoded image to a uint8 tensor.
[`decode_image(...)`](io/decode_image): Function for `decode_bmp`, `decode_gif`, `decode_jpeg`, and `decode_png`.
[`decode_jpeg(...)`](io/decode_jpeg): Decode a JPEG-encoded image to a uint8 tensor.
[`decode_png(...)`](io/decode_png): Decode a PNG-encoded image to a uint8 or uint16 tensor.
[`draw_bounding_boxes(...)`](image/draw_bounding_boxes): Draw bounding boxes on a batch of images.
[`encode_jpeg(...)`](io/encode_jpeg): JPEG-encode an image.
[`encode_png(...)`](io/encode_png): PNG-encode an image.
[`extract_glimpse(...)`](image/extract_glimpse): Extracts a glimpse from the input tensor.
[`extract_jpeg_shape(...)`](io/extract_jpeg_shape): Extract the shape information of a JPEG-encoded image.
[`extract_patches(...)`](image/extract_patches): Extract `patches` from `images`.
[`flip_left_right(...)`](image/flip_left_right): Flip an image horizontally (left to right).
[`flip_up_down(...)`](image/flip_up_down): Flip an image vertically (upside down).
[`generate_bounding_box_proposals(...)`](image/generate_bounding_box_proposals): Generate bounding box proposals from encoded bounding boxes.
[`grayscale_to_rgb(...)`](image/grayscale_to_rgb): Converts one or more images from Grayscale to RGB.
[`hsv_to_rgb(...)`](image/hsv_to_rgb): Convert one or more images from HSV to RGB.
[`image_gradients(...)`](image/image_gradients): Returns image gradients (dy, dx) for each color channel.
[`is_jpeg(...)`](io/is_jpeg): Convenience function to check if the 'contents' encodes a JPEG image.
[`non_max_suppression(...)`](image/non_max_suppression): Greedily selects a subset of bounding boxes in descending order of score.
[`non_max_suppression_overlaps(...)`](image/non_max_suppression_overlaps): Greedily selects a subset of bounding boxes in descending order of score.
[`non_max_suppression_padded(...)`](image/non_max_suppression_padded): Greedily selects a subset of bounding boxes in descending order of score.
[`non_max_suppression_with_scores(...)`](image/non_max_suppression_with_scores): Greedily selects a subset of bounding boxes in descending order of score.
[`pad_to_bounding_box(...)`](image/pad_to_bounding_box): Pad `image` with zeros to the specified `height` and `width`.
[`per_image_standardization(...)`](image/per_image_standardization): Linearly scales each image in `image` to have mean 0 and variance 1.
[`psnr(...)`](image/psnr): Returns the Peak Signal-to-Noise Ratio between a and b.
[`random_brightness(...)`](image/random_brightness): Adjust the brightness of images by a random factor.
[`random_contrast(...)`](image/random_contrast): Adjust the contrast of an image or images by a random factor.
[`random_crop(...)`](image/random_crop): Randomly crops a tensor to a given size.
[`random_flip_left_right(...)`](image/random_flip_left_right): Randomly flip an image horizontally (left to right).
[`random_flip_up_down(...)`](image/random_flip_up_down): Randomly flips an image vertically (upside down).
[`random_hue(...)`](image/random_hue): Adjust the hue of RGB images by a random factor.
[`random_jpeg_quality(...)`](image/random_jpeg_quality): Randomly changes jpeg encoding quality for inducing jpeg noise.
[`random_saturation(...)`](image/random_saturation): Adjust the saturation of RGB images by a random factor.
[`resize(...)`](image/resize): Resize `images` to `size` using the specified `method`.
[`resize_with_crop_or_pad(...)`](image/resize_with_crop_or_pad): Crops and/or pads an image to a target width and height.
[`resize_with_pad(...)`](image/resize_with_pad): Resizes and pads an image to a target width and height.
[`rgb_to_grayscale(...)`](image/rgb_to_grayscale): Converts one or more images from RGB to Grayscale.
[`rgb_to_hsv(...)`](image/rgb_to_hsv): Converts one or more images from RGB to HSV.
[`rgb_to_yiq(...)`](image/rgb_to_yiq): Converts one or more images from RGB to YIQ.
[`rgb_to_yuv(...)`](image/rgb_to_yuv): Converts one or more images from RGB to YUV.
[`rot90(...)`](image/rot90): Rotate image(s) counter-clockwise by 90 degrees.
[`sample_distorted_bounding_box(...)`](image/sample_distorted_bounding_box): Generate a single randomly distorted bounding box for an image.
[`sobel_edges(...)`](image/sobel_edges): Returns a tensor holding Sobel edge maps.
[`ssim(...)`](image/ssim): Computes SSIM index between img1 and img2.
[`ssim_multiscale(...)`](image/ssim_multiscale): Computes the MS-SSIM between img1 and img2.
[`stateless_random_brightness(...)`](image/stateless_random_brightness): Adjust the brightness of images by a random factor deterministically.
[`stateless_random_contrast(...)`](image/stateless_random_contrast): Adjust the contrast of images by a random factor deterministically.
[`stateless_random_crop(...)`](image/stateless_random_crop): Randomly crops a tensor to a given size in a deterministic manner.
[`stateless_random_flip_left_right(...)`](image/stateless_random_flip_left_right): Randomly flip an image horizontally (left to right) deterministically.
[`stateless_random_flip_up_down(...)`](image/stateless_random_flip_up_down): Randomly flip an image vertically (upside down) deterministically.
[`stateless_random_hue(...)`](image/stateless_random_hue): Adjust the hue of RGB images by a random factor deterministically.
[`stateless_random_jpeg_quality(...)`](image/stateless_random_jpeg_quality): Deterministically radomize jpeg encoding quality for inducing jpeg noise.
[`stateless_random_saturation(...)`](image/stateless_random_saturation): Adjust the saturation of RGB images by a random factor deterministically.
[`stateless_sample_distorted_bounding_box(...)`](image/stateless_sample_distorted_bounding_box): Generate a randomly distorted bounding box for an image deterministically.
[`total_variation(...)`](image/total_variation): Calculate and return the total variation for one or more images.
[`transpose(...)`](image/transpose): Transpose image(s) by swapping the height and width dimension.
[`yiq_to_rgb(...)`](image/yiq_to_rgb): Converts one or more images from YIQ to RGB.
[`yuv_to_rgb(...)`](image/yuv_to_rgb): Converts one or more images from YUV to RGB.
| programming_docs |
tensorflow tf.tensor_scatter_nd_add tf.tensor\_scatter\_nd\_add
===========================
Adds sparse `updates` to an existing tensor according to `indices`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.tensor_scatter_add`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_add), [`tf.compat.v1.tensor_scatter_nd_add`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_add)
```
tf.tensor_scatter_nd_add(
tensor, indices, updates, name=None
)
```
This operation creates a new tensor by adding sparse `updates` to the passed in `tensor`. This operation is very similar to [`tf.compat.v1.scatter_nd_add`](compat/v1/scatter_nd_add), except that the updates are added onto an existing tensor (as opposed to a variable). If the memory for the existing tensor cannot be re-used, a copy is made and updated.
`indices` is an integer tensor containing indices into a new tensor of shape `tensor.shape`. The last dimension of `indices` can be at most the rank of `tensor.shape`:
```
indices.shape[-1] <= tensor.shape.rank
```
The last dimension of `indices` corresponds to indices into elements (if `indices.shape[-1] = tensor.shape.rank`) or slices (if `indices.shape[-1] < tensor.shape.rank`) along dimension `indices.shape[-1]` of `tensor.shape`. `updates` is a tensor with shape
```
indices.shape[:-1] + tensor.shape[indices.shape[-1]:]
```
The simplest form of `tensor_scatter_nd_add` is to add individual elements to a tensor by index. For example, say we want to add 4 elements in a rank-1 tensor with 8 elements.
In Python, this scatter add operation would look like this:
```
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
tensor = tf.ones([8], dtype=tf.int32)
updated = tf.tensor_scatter_nd_add(tensor, indices, updates)
updated
<tf.Tensor: shape=(8,), dtype=int32,
numpy=array([ 1, 12, 1, 11, 10, 1, 1, 13], dtype=int32)>
```
We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter add operation would look like this:
```
indices = tf.constant([[0], [2]])
updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]],
[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]]])
tensor = tf.ones([4, 4, 4],dtype=tf.int32)
updated = tf.tensor_scatter_nd_add(tensor, indices, updates)
updated
<tf.Tensor: shape=(4, 4, 4), dtype=int32,
numpy=array([[[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]],
[[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]],
[[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]],
[[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]], dtype=int32)>
```
>
> **Note:** on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
>
| Args |
| `tensor` | A `Tensor`. Tensor to copy/update. |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `updates` | A `Tensor`. Must have the same type as `tensor`. Updates to scatter into output. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
tensorflow tf.boolean_mask tf.boolean\_mask
================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1921-L1978) |
Apply boolean mask to tensor.
```
tf.boolean_mask(
tensor, mask, axis=None, name='boolean_mask'
)
```
Numpy equivalent is `tensor[mask]`.
In general, `0 < dim(mask) = K <= dim(tensor)`, and `mask`'s shape must match the first K dimensions of `tensor`'s shape. We then have: `boolean_mask(tensor, mask)[i, j1,...,jd] = tensor[i1,...,iK,j1,...,jd]` where `(i1,...,iK)` is the ith `True` entry of `mask` (row-major order). The `axis` could be used with `mask` to indicate the axis to mask from. In that case, `axis + dim(mask) <= dim(tensor)` and `mask`'s shape must match the first `axis + dim(mask)` dimensions of `tensor`'s shape.
See also: [`tf.ragged.boolean_mask`](ragged/boolean_mask), which can be applied to both dense and ragged tensors, and can be used if you need to preserve the masked dimensions of `tensor` (rather than flattening them, as [`tf.boolean_mask`](boolean_mask) does).
#### Examples:
```
tensor = [0, 1, 2, 3] # 1-D example
mask = np.array([True, False, True, False])
tf.boolean_mask(tensor, mask)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([0, 2], dtype=int32)>
```
```
tensor = [[1, 2], [3, 4], [5, 6]] # 2-D example
mask = np.array([True, False, True])
tf.boolean_mask(tensor, mask)
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[1, 2],
[5, 6]], dtype=int32)>
```
| Args |
| `tensor` | N-D Tensor. |
| `mask` | K-D boolean Tensor, K <= N and K must be known statically. |
| `axis` | A 0-D int Tensor representing the axis in `tensor` to mask from. By default, axis is 0 which will mask from the first dimension. Otherwise K + axis <= N. |
| `name` | A name for this operation (optional). |
| Returns |
| (N-K+1)-dimensional tensor populated by entries in `tensor` corresponding to `True` values in `mask`. |
| Raises |
| `ValueError` | If shapes do not conform. |
#### Examples:
```
# 2-D example
tensor = [[1, 2], [3, 4], [5, 6]]
mask = np.array([True, False, True])
boolean_mask(tensor, mask) # [[1, 2], [5, 6]]
```
tensorflow Module: tf.nn Module: tf.nn
=============
Primitive Neural Net (NN) Operations.
Notes on padding
----------------
Several neural network operations, such as [`tf.nn.conv2d`](nn/conv2d) and [`tf.nn.max_pool2d`](nn/max_pool2d), take a `padding` parameter, which controls how the input is padded before running the operation. The input is padded by inserting values (typically zeros) before and after the tensor in each spatial dimension. The `padding` parameter can either be the string `'VALID'`, which means use no padding, or `'SAME'` which adds padding according to a formula which is described below. Certain ops also allow the amount of padding per dimension to be explicitly specified by passing a list to `padding`.
In the case of convolutions, the input is padded with zeros. In case of pools, the padded input values are ignored. For example, in a max pool, the sliding window ignores padded values, which is equivalent to the padded values being `-infinity`.
###
`'VALID'` padding
Passing `padding='VALID'` to an op causes no padding to be used. This causes the output size to typically be smaller than the input size, even when the stride is one. In the 2D case, the output size is computed as:
```
out_height = ceil((in_height - filter_height + 1) / stride_height)
out_width = ceil((in_width - filter_width + 1) / stride_width)
```
The 1D and 3D cases are similar. Note `filter_height` and `filter_width` refer to the filter size after dilations (if any) for convolutions, and refer to the window size for pools.
###
`'SAME'` padding
With `'SAME'` padding, padding is applied to each spatial dimension. When the strides are 1, the input is padded such that the output size is the same as the input size. In the 2D case, the output size is computed as:
```
out_height = ceil(in_height / stride_height)
out_width = ceil(in_width / stride_width)
```
The amount of padding used is the smallest amount that results in the output size. The formula for the total amount of padding per dimension is:
```
if (in_height % strides[1] == 0):
pad_along_height = max(filter_height - stride_height, 0)
else:
pad_along_height = max(filter_height - (in_height % stride_height), 0)
if (in_width % strides[2] == 0):
pad_along_width = max(filter_width - stride_width, 0)
else:
pad_along_width = max(filter_width - (in_width % stride_width), 0)
```
Finally, the padding on the top, bottom, left and right are:
```
pad_top = pad_along_height // 2
pad_bottom = pad_along_height - pad_top
pad_left = pad_along_width // 2
pad_right = pad_along_width - pad_left
```
Note that the division by 2 means that there might be cases when the padding on both sides (top vs bottom, right vs left) are off by one. In this case, the bottom and right sides always get the one additional padded pixel. For example, when pad\_along\_height is 5, we pad 2 pixels at the top and 3 pixels at the bottom. Note that this is different from existing libraries such as PyTorch and Caffe, which explicitly specify the number of padded pixels and always pad the same number of pixels on both sides.
Here is an example of `'SAME'` padding:
```
in_height = 5
filter_height = 3
stride_height = 2
in_width = 2
filter_width = 2
stride_width = 1
inp = tf.ones((2, in_height, in_width, 2))
filter = tf.ones((filter_height, filter_width, 2, 2))
strides = [stride_height, stride_width]
output = tf.nn.conv2d(inp, filter, strides, padding='SAME')
output.shape[1] # output_height: ceil(5 / 2)
3
output.shape[2] # output_width: ceil(2 / 1)
2
```
### Explicit padding
Certain ops, like [`tf.nn.conv2d`](nn/conv2d), also allow a list of explicit padding amounts to be passed to the `padding` parameter. This list is in the same format as what is passed to [`tf.pad`](pad), except the padding must be a nested list, not a tensor. For example, in the 2D case, the list is in the format `[[0, 0], [pad_top, pad_bottom], [pad_left, pad_right], [0, 0]]` when `data_format` is its default value of `'NHWC'`. The two `[0, 0]` pairs indicate the batch and channel dimensions have no padding, which is required, as only spatial dimensions can have padding.
#### For example:
```
inp = tf.ones((1, 3, 3, 1))
filter = tf.ones((2, 2, 1, 1))
strides = [1, 1]
padding = [[0, 0], [1, 2], [0, 1], [0, 0]]
output = tf.nn.conv2d(inp, filter, strides, padding=padding)
tuple(output.shape)
(1, 5, 3, 1)
# Equivalently, tf.pad can be used, since convolutions pad with zeros.
inp = tf.pad(inp, padding)
# 'VALID' means to use no padding in conv2d (we already padded inp)
output2 = tf.nn.conv2d(inp, filter, strides, padding='VALID')
tf.debugging.assert_equal(output, output2)
```
Modules
-------
[`experimental`](nn/experimental) module: Public API for tf.nn.experimental namespace.
Classes
-------
[`class RNNCellDeviceWrapper`](nn/rnncelldevicewrapper): Operator that ensures an RNNCell runs on a particular device.
[`class RNNCellDropoutWrapper`](nn/rnncelldropoutwrapper): Operator adding dropout to inputs and outputs of the given cell.
[`class RNNCellResidualWrapper`](nn/rnncellresidualwrapper): RNNCell wrapper that ensures cell inputs are added to the outputs.
Functions
---------
[`all_candidate_sampler(...)`](random/all_candidate_sampler): Generate the set of all classes.
[`atrous_conv2d(...)`](nn/atrous_conv2d): Atrous convolution (a.k.a. convolution with holes or dilated convolution).
[`atrous_conv2d_transpose(...)`](nn/atrous_conv2d_transpose): The transpose of `atrous_conv2d`.
[`avg_pool(...)`](nn/avg_pool): Performs the avg pooling on the input.
[`avg_pool1d(...)`](nn/avg_pool1d): Performs the average pooling on the input.
[`avg_pool2d(...)`](nn/avg_pool2d): Performs the average pooling on the input.
[`avg_pool3d(...)`](nn/avg_pool3d): Performs the average pooling on the input.
[`batch_norm_with_global_normalization(...)`](nn/batch_norm_with_global_normalization): Batch normalization.
[`batch_normalization(...)`](nn/batch_normalization): Batch normalization.
[`bias_add(...)`](nn/bias_add): Adds `bias` to `value`.
[`collapse_repeated(...)`](nn/collapse_repeated): Merge repeated labels into single labels.
[`compute_accidental_hits(...)`](nn/compute_accidental_hits): Compute the position ids in `sampled_candidates` matching `true_classes`.
[`compute_average_loss(...)`](nn/compute_average_loss): Scales per-example losses with sample\_weights and computes their average.
[`conv1d(...)`](nn/conv1d): Computes a 1-D convolution given 3-D input and filter tensors.
[`conv1d_transpose(...)`](nn/conv1d_transpose): The transpose of `conv1d`.
[`conv2d(...)`](nn/conv2d): Computes a 2-D convolution given `input` and 4-D `filters` tensors.
[`conv2d_transpose(...)`](nn/conv2d_transpose): The transpose of `conv2d`.
[`conv3d(...)`](nn/conv3d): Computes a 3-D convolution given 5-D `input` and `filters` tensors.
[`conv3d_transpose(...)`](nn/conv3d_transpose): The transpose of `conv3d`.
[`conv_transpose(...)`](nn/conv_transpose): The transpose of `convolution`.
[`convolution(...)`](nn/convolution): Computes sums of N-D convolutions (actually cross-correlation).
[`crelu(...)`](nn/crelu): Computes Concatenated ReLU.
[`ctc_beam_search_decoder(...)`](nn/ctc_beam_search_decoder): Performs beam search decoding on the logits given in input.
[`ctc_greedy_decoder(...)`](nn/ctc_greedy_decoder): Performs greedy decoding on the logits given in input (best path).
[`ctc_loss(...)`](nn/ctc_loss): Computes CTC (Connectionist Temporal Classification) loss.
[`ctc_unique_labels(...)`](nn/ctc_unique_labels): Get unique labels and indices for batched labels for [`tf.nn.ctc_loss`](nn/ctc_loss).
[`depth_to_space(...)`](nn/depth_to_space): DepthToSpace for tensors of type T.
[`depthwise_conv2d(...)`](nn/depthwise_conv2d): Depthwise 2-D convolution.
[`depthwise_conv2d_backprop_filter(...)`](nn/depthwise_conv2d_backprop_filter): Computes the gradients of depthwise convolution with respect to the filter.
[`depthwise_conv2d_backprop_input(...)`](nn/depthwise_conv2d_backprop_input): Computes the gradients of depthwise convolution with respect to the input.
[`dilation2d(...)`](nn/dilation2d): Computes the grayscale dilation of 4-D `input` and 3-D `filters` tensors.
[`dropout(...)`](nn/dropout): Computes dropout: randomly sets elements to zero to prevent overfitting.
[`elu(...)`](nn/elu): Computes the exponential linear function.
[`embedding_lookup(...)`](nn/embedding_lookup): Looks up embeddings for the given `ids` from a list of tensors.
[`embedding_lookup_sparse(...)`](nn/embedding_lookup_sparse): Looks up embeddings for the given ids and weights from a list of tensors.
[`erosion2d(...)`](nn/erosion2d): Computes the grayscale erosion of 4-D `value` and 3-D `filters` tensors.
[`fixed_unigram_candidate_sampler(...)`](random/fixed_unigram_candidate_sampler): Samples a set of classes using the provided (fixed) base distribution.
[`fractional_avg_pool(...)`](nn/fractional_avg_pool): Performs fractional average pooling on the input.
[`fractional_max_pool(...)`](nn/fractional_max_pool): Performs fractional max pooling on the input.
[`gelu(...)`](nn/gelu): Compute the Gaussian Error Linear Unit (GELU) activation function.
[`in_top_k(...)`](math/in_top_k): Says whether the targets are in the top `K` predictions.
[`isotonic_regression(...)`](nn/isotonic_regression): Solves isotonic regression problems along the given axis.
[`l2_loss(...)`](nn/l2_loss): L2 Loss.
[`l2_normalize(...)`](math/l2_normalize): Normalizes along dimension `axis` using an L2 norm. (deprecated arguments)
[`leaky_relu(...)`](nn/leaky_relu): Compute the Leaky ReLU activation function.
[`learned_unigram_candidate_sampler(...)`](random/learned_unigram_candidate_sampler): Samples a set of classes from a distribution learned during training.
[`local_response_normalization(...)`](nn/local_response_normalization): Local Response Normalization.
[`log_poisson_loss(...)`](nn/log_poisson_loss): Computes log Poisson loss given `log_input`.
[`log_softmax(...)`](nn/log_softmax): Computes log softmax activations.
[`lrn(...)`](nn/local_response_normalization): Local Response Normalization.
[`max_pool(...)`](nn/max_pool): Performs max pooling on the input.
[`max_pool1d(...)`](nn/max_pool1d): Performs the max pooling on the input.
[`max_pool2d(...)`](nn/max_pool2d): Performs max pooling on 2D spatial data such as images.
[`max_pool3d(...)`](nn/max_pool3d): Performs the max pooling on the input.
[`max_pool_with_argmax(...)`](nn/max_pool_with_argmax): Performs max pooling on the input and outputs both max values and indices.
[`moments(...)`](nn/moments): Calculates the mean and variance of `x`.
[`nce_loss(...)`](nn/nce_loss): Computes and returns the noise-contrastive estimation training loss.
[`normalize_moments(...)`](nn/normalize_moments): Calculate the mean and variance of based on the sufficient statistics.
[`pool(...)`](nn/pool): Performs an N-D pooling operation.
[`relu(...)`](nn/relu): Computes rectified linear: `max(features, 0)`.
[`relu6(...)`](nn/relu6): Computes Rectified Linear 6: `min(max(features, 0), 6)`.
[`safe_embedding_lookup_sparse(...)`](nn/safe_embedding_lookup_sparse): Lookup embedding results, accounting for invalid IDs and empty features.
[`sampled_softmax_loss(...)`](nn/sampled_softmax_loss): Computes and returns the sampled softmax training loss.
[`scale_regularization_loss(...)`](nn/scale_regularization_loss): Scales the sum of the given regularization losses by number of replicas.
[`selu(...)`](nn/selu): Computes scaled exponential linear: `scale * alpha * (exp(features) - 1)`
[`separable_conv2d(...)`](nn/separable_conv2d): 2-D convolution with separable filters.
[`sigmoid(...)`](math/sigmoid): Computes sigmoid of `x` element-wise.
[`sigmoid_cross_entropy_with_logits(...)`](nn/sigmoid_cross_entropy_with_logits): Computes sigmoid cross entropy given `logits`.
[`silu(...)`](nn/silu): Computes the SiLU or Swish activation function: `x * sigmoid(beta * x)`.
[`softmax(...)`](nn/softmax): Computes softmax activations.
[`softmax_cross_entropy_with_logits(...)`](nn/softmax_cross_entropy_with_logits): Computes softmax cross entropy between `logits` and `labels`.
[`softplus(...)`](math/softplus): Computes elementwise softplus: `softplus(x) = log(exp(x) + 1)`.
[`softsign(...)`](nn/softsign): Computes softsign: `features / (abs(features) + 1)`.
[`space_to_batch(...)`](space_to_batch): SpaceToBatch for N-D tensors of type T.
[`space_to_depth(...)`](nn/space_to_depth): SpaceToDepth for tensors of type T.
[`sparse_softmax_cross_entropy_with_logits(...)`](nn/sparse_softmax_cross_entropy_with_logits): Computes sparse softmax cross entropy between `logits` and `labels`.
[`sufficient_statistics(...)`](nn/sufficient_statistics): Calculate the sufficient statistics for the mean and variance of `x`.
[`swish(...)`](nn/silu): Computes the SiLU or Swish activation function: `x * sigmoid(beta * x)`.
[`tanh(...)`](math/tanh): Computes hyperbolic tangent of `x` element-wise.
[`top_k(...)`](math/top_k): Finds values and indices of the `k` largest entries for the last dimension.
[`weighted_cross_entropy_with_logits(...)`](nn/weighted_cross_entropy_with_logits): Computes a weighted cross entropy.
[`weighted_moments(...)`](nn/weighted_moments): Returns the frequency-weighted mean and variance of `x`.
[`with_space_to_batch(...)`](nn/with_space_to_batch): Performs `op` on the space-to-batch representation of `input`.
[`zero_fraction(...)`](math/zero_fraction): Returns the fraction of zeros in `value`.
tensorflow tf.RaggedTensorSpec tf.RaggedTensorSpec
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2309-L2634) |
Type specification for a [`tf.RaggedTensor`](raggedtensor).
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.RaggedTensorSpec`](https://www.tensorflow.org/api_docs/python/tf/RaggedTensorSpec)
```
tf.RaggedTensorSpec(
shape=None,
dtype=tf.dtypes.float32,
ragged_rank=None,
row_splits_dtype=tf.dtypes.int64,
flat_values_spec=None
)
```
| Args |
| `shape` | The shape of the RaggedTensor, or `None` to allow any shape. If a shape is specified, then all ragged dimensions must have size `None`. |
| `dtype` | [`tf.DType`](dtypes/dtype) of values in the RaggedTensor. |
| `ragged_rank` | Python integer, the number of times the RaggedTensor's flat\_values is partitioned. Defaults to `shape.ndims - 1`. |
| `row_splits_dtype` | `dtype` for the RaggedTensor's `row_splits` tensor. One of [`tf.int32`](../tf#int32) or [`tf.int64`](../tf#int64). |
| `flat_values_spec` | TypeSpec for flat\_value of the RaggedTensor. It shall be provided when the flat\_values is a CompositeTensor rather then Tensor. If both `dtype` and `flat_values_spec` and are provided, `dtype` must be the same as `flat_values_spec.dtype`. (experimental) |
| Attributes |
| `dtype` | The [`tf.dtypes.DType`](dtypes/dtype) specified by this type for the RaggedTensor.
```
rt = tf.ragged.constant([["a"], ["b", "c"]], dtype=tf.string)
tf.type_spec_from_value(rt).dtype
tf.string
```
|
| `flat_values_spec` | The `TypeSpec` of the flat\_values of RaggedTensor. |
| `ragged_rank` | The number of times the RaggedTensor's flat\_values is partitioned. Defaults to `shape.ndims - 1`.
```
values = tf.ragged.constant([[1, 2, 3], [4], [5, 6], [7, 8, 9, 10]])
tf.type_spec_from_value(values).ragged_rank
1
```
```
rt1 = tf.RaggedTensor.from_uniform_row_length(values, 2)
tf.type_spec_from_value(rt1).ragged_rank
2
```
|
| `row_splits_dtype` | The [`tf.dtypes.DType`](dtypes/dtype) of the RaggedTensor's `row_splits`.
```
rt = tf.ragged.constant([[1, 2, 3], [4]], row_splits_dtype=tf.int64)
tf.type_spec_from_value(rt).row_splits_dtype
tf.int64
```
|
| `shape` | The statically known shape of the RaggedTensor.
```
rt = tf.ragged.constant([[0], [1, 2]])
tf.type_spec_from_value(rt).shape
TensorShape([2, None])
```
```
rt = tf.ragged.constant([[[0, 1]], [[1, 2], [3, 4]]], ragged_rank=1)
tf.type_spec_from_value(rt).shape
TensorShape([2, None, 2])
```
|
| `value_type` | The Python type for values that are compatible with this TypeSpec. In particular, all values that are compatible with this TypeSpec must be an instance of this type. |
Methods
-------
### `from_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2619-L2634)
```
@classmethod
from_value(
value
)
```
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2455-L2464)
```
is_compatible_with(
spec_or_value
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
| programming_docs |
tensorflow tf.cond tf.cond
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L1319-L1391) |
Return `true_fn()` if the predicate `pred` is true else `false_fn()`.
```
tf.cond(
pred, true_fn=None, false_fn=None, name=None
)
```
`true_fn` and `false_fn` both return lists of output tensors. `true_fn` and `false_fn` must have the same non-zero number and type of outputs.
Although this behavior is consistent with the dataflow model of TensorFlow, it has frequently surprised users who expected a lazier semantics. Consider the following simple program:
```
z = tf.multiply(a, b)
result = tf.cond(x < y, lambda: tf.add(x, z), lambda: tf.square(y))
```
If `x < y`, the `tf.add` operation will be executed and `tf.square` operation will not be executed. Since `z` is needed for at least one branch of the `cond`, the [`tf.multiply`](math/multiply) operation is always executed, unconditionally.
Note that `cond` calls `true_fn` and `false_fn` *exactly once* (inside the call to `cond`, and not at all during `Session.run()`). `cond` stitches together the graph fragments created during the `true_fn` and `false_fn` calls with some additional graph nodes to ensure that the right branch gets executed depending on the value of `pred`.
[`tf.cond`](cond) supports nested structures as implemented in `tensorflow.python.util.nest`. Both `true_fn` and `false_fn` must return the same (possibly nested) value structure of lists, tuples, and/or named tuples. Singleton lists and tuples form the only exceptions to this: when returned by `true_fn` and/or `false_fn`, they are implicitly unpacked to single values.
>
> **Note:** It is illegal to "directly" use tensors created inside a cond branch outside it, e.g. by storing a reference to a branch tensor in the python state. If you need to use a tensor created in a branch function you should return it as an output of the branch function and use the output from [`tf.cond`](cond) instead.
>
| Args |
| `pred` | A scalar determining whether to return the result of `true_fn` or `false_fn`. |
| `true_fn` | The callable to be performed if pred is true. |
| `false_fn` | The callable to be performed if pred is false. |
| `name` | Optional name prefix for the returned tensors. |
| Returns |
| Tensors returned by the call to either `true_fn` or `false_fn`. If the callables return a singleton list, the element is extracted from the list. |
| Raises |
| `TypeError` | if `true_fn` or `false_fn` is not callable. |
| `ValueError` | if `true_fn` and `false_fn` do not return the same number of tensors, or return tensors of different types. |
#### Example:
```
x = tf.constant(2)
y = tf.constant(5)
def f1(): return tf.multiply(x, 17)
def f2(): return tf.add(y, 23)
r = tf.cond(tf.less(x, y), f1, f2)
# r is set to f1().
# Operations in f2 (e.g., tf.add) are not executed.
```
tensorflow Module: tf Module: tf
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/__init__.py) |
TensorFlow
----------
```
pip install tensorflow
```
Modules
-------
[`audio`](audio) module: Public API for tf.audio namespace.
[`autodiff`](autodiff) module: Public API for tf.autodiff namespace.
[`autograph`](autograph) module: Conversion of eager-style Python into TensorFlow graph code.
[`bitwise`](bitwise) module: Operations for manipulating the binary representations of integers.
[`compat`](compat) module: Compatibility functions.
[`config`](config) module: Public API for tf.config namespace.
[`data`](data) module: [`tf.data.Dataset`](data/dataset) API for input pipelines.
[`debugging`](debugging) module: Public API for tf.debugging namespace.
[`distribute`](distribute) module: Library for running a computation across multiple devices.
[`dtypes`](dtypes) module: Public API for tf.dtypes namespace.
[`errors`](errors) module: Exception types for TensorFlow errors.
[`estimator`](estimator) module: Estimator: High level tools for working with models.
[`experimental`](experimental) module: Public API for tf.experimental namespace.
[`feature_column`](feature_column) module: Public API for tf.feature\_column namespace.
[`graph_util`](graph_util) module: Helpers to manipulate a tensor graph in python.
[`image`](image) module: Image ops.
[`io`](io) module: Public API for tf.io namespace.
[`keras`](keras) module: Implementation of the Keras API, the high-level API of TensorFlow.
[`linalg`](linalg) module: Operations for linear algebra.
[`lite`](lite) module: Public API for tf.lite namespace.
[`lookup`](lookup) module: Public API for tf.lookup namespace.
[`math`](math) module: Math Operations.
[`mlir`](mlir) module: Public API for tf.mlir namespace.
[`nest`](nest) module: Functions that work with structures.
[`nn`](nn) module: Primitive Neural Net (NN) Operations.
[`profiler`](profiler) module: Public API for tf.profiler namespace.
[`quantization`](quantization) module: Public API for tf.quantization namespace.
[`queue`](queue) module: Public API for tf.queue namespace.
[`ragged`](ragged) module: Ragged Tensors.
[`random`](random) module: Public API for tf.random namespace.
[`raw_ops`](raw_ops) module: Public API for tf.raw\_ops namespace.
[`saved_model`](saved_model) module: Public API for tf.saved\_model namespace.
[`sets`](sets) module: Tensorflow set operations.
[`signal`](signal) module: Signal processing operations.
[`sparse`](sparse) module: Sparse Tensor Representation.
[`strings`](strings) module: Operations for working with string Tensors.
[`summary`](summary) module: Operations for writing summary data, for use in analysis and visualization.
[`sysconfig`](sysconfig) module: System configuration library.
[`test`](test) module: Testing.
[`tpu`](tpu) module: Ops related to Tensor Processing Units.
[`train`](train) module: Support for training models.
[`types`](types) module: Public TensorFlow type definitions.
[`version`](version) module: Public API for tf.version namespace.
[`xla`](xla) module: Public API for tf.xla namespace.
Classes
-------
[`class AggregationMethod`](aggregationmethod): A class listing aggregation methods used to combine gradients.
[`class CriticalSection`](criticalsection): Critical section.
[`class DType`](dtypes/dtype): Represents the type of the elements in a `Tensor`.
[`class DeviceSpec`](devicespec): Represents a (possibly partial) specification for a TensorFlow device.
[`class GradientTape`](gradienttape): Record operations for automatic differentiation.
[`class Graph`](graph): A TensorFlow computation, represented as a dataflow graph.
[`class IndexedSlices`](indexedslices): A sparse representation of a set of tensor slices at given indices.
[`class IndexedSlicesSpec`](indexedslicesspec): Type specification for a [`tf.IndexedSlices`](indexedslices).
[`class Module`](module): Base neural network module class.
[`class Operation`](operation): Represents a graph node that performs computation on tensors.
[`class OptionalSpec`](optionalspec): Type specification for [`tf.experimental.Optional`](experimental/optional).
[`class RaggedTensor`](raggedtensor): Represents a ragged tensor.
[`class RaggedTensorSpec`](raggedtensorspec): Type specification for a [`tf.RaggedTensor`](raggedtensor).
[`class RegisterGradient`](registergradient): A decorator for registering the gradient function for an op type.
[`class SparseTensor`](sparse/sparsetensor): Represents a sparse tensor.
[`class SparseTensorSpec`](sparsetensorspec): Type specification for a [`tf.sparse.SparseTensor`](sparse/sparsetensor).
[`class Tensor`](tensor): A [`tf.Tensor`](tensor) represents a multidimensional array of elements.
[`class TensorArray`](tensorarray): Class wrapping dynamic-sized, per-time-step, write-once Tensor arrays.
[`class TensorArraySpec`](tensorarrayspec): Type specification for a [`tf.TensorArray`](tensorarray).
[`class TensorShape`](tensorshape): Represents the shape of a `Tensor`.
[`class TensorSpec`](tensorspec): Describes a tf.Tensor.
[`class TypeSpec`](typespec): Specifies a TensorFlow value type.
[`class UnconnectedGradients`](unconnectedgradients): Controls how gradient computation behaves when y does not depend on x.
[`class Variable`](variable): See the [variable guide](https://tensorflow.org/guide/variable).
[`class VariableAggregation`](variableaggregation): Indicates how a distributed variable will be aggregated.
[`class VariableSynchronization`](variablesynchronization): Indicates when a distributed variable will be synced.
[`class constant_initializer`](constant_initializer): Initializer that generates tensors with constant values.
[`class name_scope`](name_scope): A context manager for use when defining a Python op.
[`class ones_initializer`](ones_initializer): Initializer that generates tensors initialized to 1.
[`class random_normal_initializer`](random_normal_initializer): Initializer that generates tensors with a normal distribution.
[`class random_uniform_initializer`](random_uniform_initializer): Initializer that generates tensors with a uniform distribution.
[`class zeros_initializer`](zeros_initializer): Initializer that generates tensors initialized to 0.
Functions
---------
[`Assert(...)`](debugging/assert): Asserts that the given condition is true.
[`abs(...)`](math/abs): Computes the absolute value of a tensor.
[`acos(...)`](math/acos): Computes acos of x element-wise.
[`acosh(...)`](math/acosh): Computes inverse hyperbolic cosine of x element-wise.
[`add(...)`](math/add): Returns x + y element-wise.
[`add_n(...)`](math/add_n): Adds all input tensors element-wise.
[`argmax(...)`](math/argmax): Returns the index with the largest value across axes of a tensor.
[`argmin(...)`](math/argmin): Returns the index with the smallest value across axes of a tensor.
[`argsort(...)`](argsort): Returns the indices of a tensor that give its sorted order along an axis.
[`as_dtype(...)`](dtypes/as_dtype): Converts the given `type_value` to a `DType`.
[`as_string(...)`](strings/as_string): Converts each entry in the given tensor to strings.
[`asin(...)`](math/asin): Computes the trignometric inverse sine of x element-wise.
[`asinh(...)`](math/asinh): Computes inverse hyperbolic sine of x element-wise.
[`assert_equal(...)`](debugging/assert_equal): Assert the condition `x == y` holds element-wise.
[`assert_greater(...)`](debugging/assert_greater): Assert the condition `x > y` holds element-wise.
[`assert_less(...)`](debugging/assert_less): Assert the condition `x < y` holds element-wise.
[`assert_rank(...)`](debugging/assert_rank): Assert that `x` has rank equal to `rank`.
[`atan(...)`](math/atan): Computes the trignometric inverse tangent of x element-wise.
[`atan2(...)`](math/atan2): Computes arctangent of `y/x` element-wise, respecting signs of the arguments.
[`atanh(...)`](math/atanh): Computes inverse hyperbolic tangent of x element-wise.
[`batch_to_space(...)`](batch_to_space): BatchToSpace for N-D tensors of type T.
[`bitcast(...)`](bitcast): Bitcasts a tensor from one type to another without copying data.
[`boolean_mask(...)`](boolean_mask): Apply boolean mask to tensor.
[`broadcast_dynamic_shape(...)`](broadcast_dynamic_shape): Computes the shape of a broadcast given symbolic shapes.
[`broadcast_static_shape(...)`](broadcast_static_shape): Computes the shape of a broadcast given known shapes.
[`broadcast_to(...)`](broadcast_to): Broadcast an array for a compatible shape.
[`case(...)`](case): Create a case operation.
[`cast(...)`](cast): Casts a tensor to a new type.
[`clip_by_global_norm(...)`](clip_by_global_norm): Clips values of multiple tensors by the ratio of the sum of their norms.
[`clip_by_norm(...)`](clip_by_norm): Clips tensor values to a maximum L2-norm.
[`clip_by_value(...)`](clip_by_value): Clips tensor values to a specified min and max.
[`complex(...)`](dtypes/complex): Converts two real numbers to a complex number.
[`concat(...)`](concat): Concatenates tensors along one dimension.
[`cond(...)`](cond): Return `true_fn()` if the predicate `pred` is true else `false_fn()`.
[`constant(...)`](constant): Creates a constant tensor from a tensor-like object.
[`control_dependencies(...)`](control_dependencies): Wrapper for [`Graph.control_dependencies()`](graph#control_dependencies) using the default graph.
[`convert_to_tensor(...)`](convert_to_tensor): Converts the given `value` to a `Tensor`.
[`cos(...)`](math/cos): Computes cos of x element-wise.
[`cosh(...)`](math/cosh): Computes hyperbolic cosine of x element-wise.
[`cumsum(...)`](math/cumsum): Compute the cumulative sum of the tensor `x` along `axis`.
[`custom_gradient(...)`](custom_gradient): Decorator to define a function with a custom gradient.
[`device(...)`](device): Specifies the device for ops created/executed in this context.
[`divide(...)`](math/divide): Computes Python style division of `x` by `y`.
[`dynamic_partition(...)`](dynamic_partition): Partitions `data` into `num_partitions` tensors using indices from `partitions`.
[`dynamic_stitch(...)`](dynamic_stitch): Interleave the values from the `data` tensors into a single tensor.
[`edit_distance(...)`](edit_distance): Computes the Levenshtein distance between sequences.
[`eig(...)`](linalg/eig): Computes the eigen decomposition of a batch of matrices.
[`eigvals(...)`](linalg/eigvals): Computes the eigenvalues of one or more matrices.
[`einsum(...)`](einsum): Tensor contraction over specified indices and outer product.
[`ensure_shape(...)`](ensure_shape): Updates the shape of a tensor and checks at runtime that the shape holds.
[`equal(...)`](math/equal): Returns the truth value of (x == y) element-wise.
[`executing_eagerly(...)`](executing_eagerly): Checks whether the current thread has eager execution enabled.
[`exp(...)`](math/exp): Computes exponential of x element-wise. \(y = e^x\).
[`expand_dims(...)`](expand_dims): Returns a tensor with a length 1 axis inserted at index `axis`.
[`extract_volume_patches(...)`](extract_volume_patches): Extract `patches` from `input` and put them in the `"depth"` output dimension. 3D extension of `extract_image_patches`.
[`eye(...)`](eye): Construct an identity matrix, or a batch of matrices.
[`fill(...)`](fill): Creates a tensor filled with a scalar value.
[`fingerprint(...)`](fingerprint): Generates fingerprint values.
[`floor(...)`](math/floor): Returns element-wise largest integer not greater than x.
[`foldl(...)`](foldl): foldl on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
[`foldr(...)`](foldr): foldr on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
[`function(...)`](function): Compiles a function into a callable TensorFlow graph. (deprecated arguments) (deprecated arguments)
[`gather(...)`](gather): Gather slices from params axis `axis` according to indices. (deprecated arguments)
[`gather_nd(...)`](gather_nd): Gather slices from `params` into a Tensor with shape specified by `indices`.
[`get_current_name_scope(...)`](get_current_name_scope): Returns current full name scope specified by [`tf.name_scope(...)`](name_scope)s.
[`get_logger(...)`](get_logger): Return TF logger instance.
[`get_static_value(...)`](get_static_value): Returns the constant value of the given tensor, if efficiently calculable.
[`grad_pass_through(...)`](grad_pass_through): Creates a grad-pass-through op with the forward behavior provided in f.
[`gradients(...)`](gradients): Constructs symbolic derivatives of sum of `ys` w.r.t. x in `xs`.
[`greater(...)`](math/greater): Returns the truth value of (x > y) element-wise.
[`greater_equal(...)`](math/greater_equal): Returns the truth value of (x >= y) element-wise.
[`group(...)`](group): Create an op that groups multiple operations.
[`guarantee_const(...)`](guarantee_const): Promise to the TF runtime that the input tensor is a constant. (deprecated)
[`hessians(...)`](hessians): Constructs the Hessian of sum of `ys` with respect to `x` in `xs`.
[`histogram_fixed_width(...)`](histogram_fixed_width): Return histogram of values.
[`histogram_fixed_width_bins(...)`](histogram_fixed_width_bins): Bins the given values for use in a histogram.
[`identity(...)`](identity): Return a Tensor with the same shape and contents as input.
[`identity_n(...)`](identity_n): Returns a list of tensors with the same shapes and contents as the input
[`import_graph_def(...)`](graph_util/import_graph_def): Imports the graph from `graph_def` into the current default `Graph`. (deprecated arguments)
[`init_scope(...)`](init_scope): A context manager that lifts ops out of control-flow scopes and function-building graphs.
[`inside_function(...)`](inside_function): Indicates whether the caller code is executing inside a [`tf.function`](function).
[`is_tensor(...)`](is_tensor): Checks whether `x` is a TF-native type that can be passed to many TF ops.
[`less(...)`](math/less): Returns the truth value of (x < y) element-wise.
[`less_equal(...)`](math/less_equal): Returns the truth value of (x <= y) element-wise.
[`linspace(...)`](linspace): Generates evenly-spaced values in an interval along a given axis.
[`load_library(...)`](load_library): Loads a TensorFlow plugin.
[`load_op_library(...)`](load_op_library): Loads a TensorFlow plugin, containing custom ops and kernels.
[`logical_and(...)`](math/logical_and): Returns the truth value of x AND y element-wise.
[`logical_not(...)`](math/logical_not): Returns the truth value of `NOT x` element-wise.
[`logical_or(...)`](math/logical_or): Returns the truth value of x OR y element-wise.
[`make_ndarray(...)`](make_ndarray): Create a numpy ndarray from a tensor.
[`make_tensor_proto(...)`](make_tensor_proto): Create a TensorProto.
[`map_fn(...)`](map_fn): Transforms `elems` by applying `fn` to each element unstacked on axis 0. (deprecated arguments)
[`matmul(...)`](linalg/matmul): Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
[`matrix_square_root(...)`](linalg/sqrtm): Computes the matrix square root of one or more square matrices:
[`maximum(...)`](math/maximum): Returns the max of x and y (i.e. x > y ? x : y) element-wise.
[`meshgrid(...)`](meshgrid): Broadcasts parameters for evaluation on an N-D grid.
[`minimum(...)`](math/minimum): Returns the min of x and y (i.e. x < y ? x : y) element-wise.
[`multiply(...)`](math/multiply): Returns an element-wise x \* y.
[`negative(...)`](math/negative): Computes numerical negative value element-wise.
[`no_gradient(...)`](no_gradient): Specifies that ops of type `op_type` is not differentiable.
[`no_op(...)`](no_op): Does nothing. Only useful as a placeholder for control edges.
[`nondifferentiable_batch_function(...)`](nondifferentiable_batch_function): Batches the computation done by the decorated function.
[`norm(...)`](norm): Computes the norm of vectors, matrices, and tensors.
[`not_equal(...)`](math/not_equal): Returns the truth value of (x != y) element-wise.
[`numpy_function(...)`](numpy_function): Wraps a python function and uses it as a TensorFlow op.
[`one_hot(...)`](one_hot): Returns a one-hot tensor.
[`ones(...)`](ones): Creates a tensor with all elements set to one (1).
[`ones_like(...)`](ones_like): Creates a tensor of all ones that has the same shape as the input.
[`pad(...)`](pad): Pads a tensor.
[`parallel_stack(...)`](parallel_stack): Stacks a list of rank-`R` tensors into one rank-`(R+1)` tensor in parallel.
[`pow(...)`](math/pow): Computes the power of one value to another.
[`print(...)`](print): Print the specified inputs.
[`py_function(...)`](py_function): Wraps a python function into a TensorFlow op that executes it eagerly.
[`random_index_shuffle(...)`](random_index_shuffle): Outputs the position of `value` in a permutation of [0, ..., max\_index].
[`range(...)`](range): Creates a sequence of numbers.
[`rank(...)`](rank): Returns the rank of a tensor.
[`realdiv(...)`](realdiv): Returns x / y element-wise for real types.
[`recompute_grad(...)`](recompute_grad): Defines a function as a recompute-checkpoint for the tape auto-diff.
[`reduce_all(...)`](math/reduce_all): Computes [`tf.math.logical_and`](math/logical_and) of elements across dimensions of a tensor.
[`reduce_any(...)`](math/reduce_any): Computes [`tf.math.logical_or`](math/logical_or) of elements across dimensions of a tensor.
[`reduce_logsumexp(...)`](math/reduce_logsumexp): Computes log(sum(exp(elements across dimensions of a tensor))).
[`reduce_max(...)`](math/reduce_max): Computes [`tf.math.maximum`](math/maximum) of elements across dimensions of a tensor.
[`reduce_mean(...)`](math/reduce_mean): Computes the mean of elements across dimensions of a tensor.
[`reduce_min(...)`](math/reduce_min): Computes the [`tf.math.minimum`](math/minimum) of elements across dimensions of a tensor.
[`reduce_prod(...)`](math/reduce_prod): Computes [`tf.math.multiply`](math/multiply) of elements across dimensions of a tensor.
[`reduce_sum(...)`](math/reduce_sum): Computes the sum of elements across dimensions of a tensor.
[`register_tensor_conversion_function(...)`](register_tensor_conversion_function): Registers a function for converting objects of `base_type` to `Tensor`.
[`repeat(...)`](repeat): Repeat elements of `input`.
[`required_space_to_batch_paddings(...)`](required_space_to_batch_paddings): Calculate padding required to make block\_shape divide input\_shape.
[`reshape(...)`](reshape): Reshapes a tensor.
[`reverse(...)`](reverse): Reverses specific dimensions of a tensor.
[`reverse_sequence(...)`](reverse_sequence): Reverses variable length slices.
[`roll(...)`](roll): Rolls the elements of a tensor along an axis.
[`round(...)`](math/round): Rounds the values of a tensor to the nearest integer, element-wise.
[`saturate_cast(...)`](dtypes/saturate_cast): Performs a safe saturating cast of `value` to `dtype`.
[`scalar_mul(...)`](math/scalar_mul): Multiplies a scalar times a `Tensor` or `IndexedSlices` object.
[`scan(...)`](scan): scan on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
[`scatter_nd(...)`](scatter_nd): Scatters `updates` into a tensor of shape `shape` according to `indices`.
[`searchsorted(...)`](searchsorted): Searches for where a value would go in a sorted sequence.
[`sequence_mask(...)`](sequence_mask): Returns a mask tensor representing the first N positions of each cell.
[`shape(...)`](shape): Returns a tensor containing the shape of the input tensor.
[`shape_n(...)`](shape_n): Returns shape of tensors.
[`sigmoid(...)`](math/sigmoid): Computes sigmoid of `x` element-wise.
[`sign(...)`](math/sign): Returns an element-wise indication of the sign of a number.
[`sin(...)`](math/sin): Computes sine of x element-wise.
[`sinh(...)`](math/sinh): Computes hyperbolic sine of x element-wise.
[`size(...)`](size): Returns the size of a tensor.
[`slice(...)`](slice): Extracts a slice from a tensor.
[`sort(...)`](sort): Sorts a tensor.
[`space_to_batch(...)`](space_to_batch): SpaceToBatch for N-D tensors of type T.
[`space_to_batch_nd(...)`](space_to_batch_nd): SpaceToBatch for N-D tensors of type T.
[`split(...)`](split): Splits a tensor `value` into a list of sub tensors.
[`sqrt(...)`](math/sqrt): Computes element-wise square root of the input tensor.
[`square(...)`](math/square): Computes square of x element-wise.
[`squeeze(...)`](squeeze): Removes dimensions of size 1 from the shape of a tensor.
[`stack(...)`](stack): Stacks a list of rank-`R` tensors into one rank-`(R+1)` tensor.
[`stop_gradient(...)`](stop_gradient): Stops gradient computation.
[`strided_slice(...)`](strided_slice): Extracts a strided slice of a tensor (generalized Python array indexing).
[`subtract(...)`](math/subtract): Returns x - y element-wise.
[`switch_case(...)`](switch_case): Create a switch/case operation, i.e. an integer-indexed conditional.
[`tan(...)`](math/tan): Computes tan of x element-wise.
[`tanh(...)`](math/tanh): Computes hyperbolic tangent of `x` element-wise.
[`tensor_scatter_nd_add(...)`](tensor_scatter_nd_add): Adds sparse `updates` to an existing tensor according to `indices`.
[`tensor_scatter_nd_max(...)`](tensor_scatter_nd_max): Apply a sparse update to a tensor taking the element-wise maximum.
[`tensor_scatter_nd_min(...)`](tensor_scatter_nd_min)
[`tensor_scatter_nd_sub(...)`](tensor_scatter_nd_sub): Subtracts sparse `updates` from an existing tensor according to `indices`.
[`tensor_scatter_nd_update(...)`](tensor_scatter_nd_update): Scatter `updates` into an existing tensor according to `indices`.
[`tensordot(...)`](tensordot): Tensor contraction of a and b along specified axes and outer product.
[`tile(...)`](tile): Constructs a tensor by tiling a given tensor.
[`timestamp(...)`](timestamp): Provides the time since epoch in seconds.
[`transpose(...)`](transpose): Transposes `a`, where `a` is a Tensor.
[`truediv(...)`](math/truediv): Divides x / y elementwise (using Python 3 division operator semantics).
[`truncatediv(...)`](truncatediv): Returns x / y element-wise for integer types.
[`truncatemod(...)`](truncatemod): Returns element-wise remainder of division. This emulates C semantics in that
[`tuple(...)`](tuple): Groups tensors together.
[`type_spec_from_value(...)`](type_spec_from_value): Returns a [`tf.TypeSpec`](typespec) that represents the given `value`.
[`unique(...)`](unique): Finds unique elements in a 1-D tensor.
[`unique_with_counts(...)`](unique_with_counts): Finds unique elements in a 1-D tensor.
[`unravel_index(...)`](unravel_index): Converts an array of flat indices into a tuple of coordinate arrays.
[`unstack(...)`](unstack): Unpacks the given dimension of a rank-`R` tensor into rank-`(R-1)` tensors.
[`variable_creator_scope(...)`](variable_creator_scope): Scope which defines a variable creation function to be used by variable().
[`vectorized_map(...)`](vectorized_map): Parallel map on the list of tensors unpacked from `elems` on dimension 0.
[`where(...)`](where): Returns the indices of non-zero elements, or multiplexes `x` and `y`.
[`while_loop(...)`](while_loop): Repeat `body` while the condition `cond` is true. (deprecated argument values)
[`zeros(...)`](zeros): Creates a tensor with all elements set to zero.
[`zeros_like(...)`](zeros_like): Creates a tensor with all elements set to zero.
| Other Members |
| **version** | `'2.9.0'` |
| bfloat16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit bfloat (brain floating point). |
| bool | Instance of [`tf.dtypes.DType`](dtypes/dtype) Boolean. |
| complex128 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 128-bit complex. |
| complex64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit complex. |
| double | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit (double precision) floating-point. |
| float16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit (half precision) floating-point. |
| float32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 32-bit (single precision) floating-point. |
| float64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit (double precision) floating-point. |
| half | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit (half precision) floating-point. |
| int16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 16-bit integer. |
| int32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 32-bit integer. |
| int64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 64-bit integer. |
| int8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 8-bit integer. |
| newaxis | `None` |
| qint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed quantized 16-bit integer. |
| qint32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) signed quantized 32-bit integer. |
| qint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed quantized 8-bit integer. |
| quint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned quantized 16-bit integer. |
| quint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned quantized 8-bit integer. |
| resource | Instance of [`tf.dtypes.DType`](dtypes/dtype) Handle to a mutable, dynamically allocated resource. |
| string | Instance of [`tf.dtypes.DType`](dtypes/dtype) Variable-length string, represented as byte array. |
| uint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 16-bit (word) integer. |
| uint32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 32-bit (dword) integer. |
| uint64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 64-bit (qword) integer. |
| uint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 8-bit (byte) integer. |
| variant | Instance of [`tf.dtypes.DType`](dtypes/dtype) Data of arbitrary type (known at runtime). |
| programming_docs |
tensorflow Module: tf.nest Module: tf.nest
===============
Functions that work with structures.
#### A structure is either:
* one of the recognized Python collections, holding *nested structures*;
* a value of any other type, typically a TensorFlow data type like Tensor, Variable, or of compatible types such as int, float, ndarray, etc. these are commonly referred to as *atoms* of the structure.
A structure of type `T` is a structure whose atomic items are of type `T`. For example, a structure of [`tf.Tensor`](tensor) only contains [`tf.Tensor`](tensor) as its atoms.
Historically a *nested structure* was called a *nested sequence* in TensorFlow. A nested structure is sometimes called a *nest* or a *tree*, but the formal name *nested structure* is preferred.
Refer to [Nesting Data Structures](https://en.wikipedia.org/wiki/Nesting_(computing)#Data_structures).
The following collection types are recognized by [`tf.nest`](nest) as nested structures:
* `collections.abc.Sequence` (except `string` and `bytes`). This includes `list`, `tuple`, and `namedtuple`.
* `collections.abc.Mapping` (with sortable keys). This includes `dict` and `collections.OrderedDict`.
* `collections.abc.MappingView` (with sortable keys).
* [`attr.s` classes](https://www.attrs.org/).
Any other values are considered **atoms**. Not all collection types are considered nested structures. For example, the following types are considered atoms:
* `set`; `{"a", "b"}` is an atom, while `["a", "b"]` is a nested structure.
* [`dataclass` classes](https://docs.python.org/library/dataclasses.html)
* [`tf.Tensor`](tensor)
* `numpy.array`
[`tf.nest.is_nested`](nest/is_nested) checks whether an object is a nested structure or an atom. For example:
```
tf.nest.is_nested("1234")
False
tf.nest.is_nested([1, 3, [4, 5]])
True
tf.nest.is_nested(((7, 8), (5, 6)))
True
tf.nest.is_nested([])
True
tf.nest.is_nested({"a": 1, "b": 2})
True
tf.nest.is_nested({"a": 1, "b": 2}.keys())
True
tf.nest.is_nested({"a": 1, "b": 2}.values())
True
tf.nest.is_nested({"a": 1, "b": 2}.items())
True
tf.nest.is_nested(set([1, 2]))
False
ones = tf.ones([2, 3])
tf.nest.is_nested(ones)
False
```
>
> **Note:** A proper structure shall form a tree. The user shall ensure there is no cyclic references within the items in the structure, i.e., no references in the structure of the input of these functions should be recursive. The behavior is undefined if there is a cycle.
>
Functions
---------
[`assert_same_structure(...)`](nest/assert_same_structure): Asserts that two structures are nested in the same way.
[`flatten(...)`](nest/flatten): Returns a flat list from a given structure.
[`is_nested(...)`](nest/is_nested): Returns true if its input is a nested structure.
[`map_structure(...)`](nest/map_structure): Creates a new structure by applying `func` to each atom in `structure`.
[`pack_sequence_as(...)`](nest/pack_sequence_as): Returns a given flattened sequence packed into a given structure.
tensorflow tf.make_ndarray tf.make\_ndarray
================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_util.py#L565-L649) |
Create a numpy ndarray from a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.make_ndarray`](https://www.tensorflow.org/api_docs/python/tf/make_ndarray)
```
tf.make_ndarray(
tensor
)
```
Create a numpy ndarray with the same shape and data as the tensor.
#### For example:
```
# Tensor a has shape (2,3)
a = tf.constant([[1,2,3],[4,5,6]])
proto_tensor = tf.make_tensor_proto(a) # convert `tensor a` to a proto tensor
tf.make_ndarray(proto_tensor) # output: array([[1, 2, 3],
# [4, 5, 6]], dtype=int32)
# output has shape (2,3)
```
| Args |
| `tensor` | A TensorProto. |
| Returns |
| A numpy array with the tensor contents. |
| Raises |
| `TypeError` | if tensor has unsupported type. |
tensorflow tf.ones_initializer tf.ones\_initializer
====================
Initializer that generates tensors initialized to 1.
Initializers allow you to pre-specify an initialization strategy, encoded in the Initializer object, without knowing the shape and dtype of the variable being initialized.
#### Examples:
```
def make_variables(k, initializer):
return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
v1, v2 = make_variables(3, tf.ones_initializer())
v1
<tf.Variable ... shape=(3,) ... numpy=array([1., 1., 1.], dtype=float32)>
v2
<tf.Variable ... shape=(3, 3) ... numpy=
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=float32)>
make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
(<tf.Variable...shape=(4,) dtype=float32...>, <tf.Variable...shape=(4, 4) ...
```
Methods
-------
### `from_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L76-L96)
```
@classmethod
from_config(
config
)
```
Instantiates an initializer from a configuration dictionary.
#### Example:
```
initializer = RandomUniform(-1, 1)
config = initializer.get_config()
initializer = RandomUniform.from_config(config)
```
| Args |
| `config` | A Python dictionary. It will typically be the output of `get_config`. |
| Returns |
| An Initializer instance. |
### `get_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L68-L74)
```
get_config()
```
Returns the configuration of the initializer as a JSON-serializable dict.
| Returns |
| A JSON-serializable Python dict. |
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L182-L201)
```
__call__(
shape,
dtype=tf.dtypes.float32,
**kwargs
)
```
Returns a tensor object initialized as specified by the initializer.
| Args |
| `shape` | Shape of the tensor. |
| `dtype` | Optional dtype of the tensor. Only numeric or boolean dtypes are supported. |
| `**kwargs` | Additional keyword arguments. |
| Raises |
| `ValuesError` | If the dtype is not numeric or boolean. |
tensorflow tf.scan tf.scan
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/functional_ops.py#L693-L814) |
scan on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
```
tf.scan(
fn,
elems,
initializer=None,
parallel_iterations=10,
back_prop=True,
swap_memory=False,
infer_shape=True,
reverse=False,
name=None
)
```
The simplest version of `scan` repeatedly applies the callable `fn` to a sequence of elements from first to last. The elements are made of the tensors unpacked from `elems` on dimension 0. The callable fn takes two tensors as arguments. The first argument is the accumulated value computed from the preceding invocation of fn, and the second is the value at the current position of `elems`. If `initializer` is None, `elems` must contain at least one element, and its first element is used as the initializer.
Suppose that `elems` is unpacked into `values`, a list of tensors. The shape of the result tensor is `[len(values)] + fn(initializer, values[0]).shape`. If reverse=True, it's fn(initializer, values[-1]).shape.
This method also allows multi-arity `elems` and accumulator. If `elems` is a (possibly nested) list or tuple of tensors, then each of these tensors must have a matching first (unpack) dimension. The second argument of `fn` must match the structure of `elems`.
If no `initializer` is provided, the output structure and dtypes of `fn` are assumed to be the same as its input; and in this case, the first argument of `fn` must match the structure of `elems`.
If an `initializer` is provided, then the output of `fn` must have the same structure as `initializer`; and the first argument of `fn` must match this structure.
For example, if `elems` is `(t1, [t2, t3])` and `initializer` is `[i1, i2]` then an appropriate signature for `fn` in `python2` is: `fn = lambda (acc_p1, acc_p2), (t1, [t2, t3]):` and `fn` must return a list, `[acc_n1, acc_n2]`. An alternative correct signature for `fn`, and the one that works in `python3`, is: `fn = lambda a, t:`, where `a` and `t` correspond to the input tuples.
| Args |
| `fn` | The callable to be performed. It accepts two arguments. The first will have the same structure as `initializer` if one is provided, otherwise it will have the same structure as `elems`. The second will have the same (possibly nested) structure as `elems`. Its output must have the same structure as `initializer` if one is provided, otherwise it must have the same structure as `elems`. |
| `elems` | A tensor or (possibly nested) sequence of tensors, each of which will be unpacked along their first dimension. The nested sequence of the resulting slices will be the first argument to `fn`. |
| `initializer` | (optional) A tensor or (possibly nested) sequence of tensors, initial value for the accumulator, and the expected output type of `fn`. |
| `parallel_iterations` | (optional) The number of iterations allowed to run in parallel. |
| `back_prop` | (optional) Deprecated. False disables support for back propagation. Prefer using [`tf.stop_gradient`](stop_gradient) instead. |
| `swap_memory` | (optional) True enables GPU-CPU memory swapping. |
| `infer_shape` | (optional) False disables tests for consistent output shapes. |
| `reverse` | (optional) True scans the tensor last to first (instead of first to last). |
| `name` | (optional) Name prefix for the returned tensors. |
| Returns |
| A tensor or (possibly nested) sequence of tensors. Each tensor packs the results of applying `fn` to tensors unpacked from `elems` along the first dimension, and the previous accumulator value(s), from first to last (or last to first, if `reverse=True`). |
| Raises |
| `TypeError` | if `fn` is not callable or the structure of the output of `fn` and `initializer` do not match. |
| `ValueError` | if the lengths of the output of `fn` and `initializer` do not match. |
#### Examples:
```
elems = np.array([1, 2, 3, 4, 5, 6])
sum = scan(lambda a, x: a + x, elems)
# sum == [1, 3, 6, 10, 15, 21]
sum = scan(lambda a, x: a + x, elems, reverse=True)
# sum == [21, 20, 18, 15, 11, 6]
```
```
elems = np.array([1, 2, 3, 4, 5, 6])
initializer = np.array(0)
sum_one = scan(
lambda a, x: x[0] - x[1] + a, (elems + 1, elems), initializer)
# sum_one == [1, 2, 3, 4, 5, 6]
```
```
elems = np.array([1, 0, 0, 0, 0, 0])
initializer = (np.array(0), np.array(1))
fibonaccis = scan(lambda a, _: (a[1], a[0] + a[1]), elems, initializer)
# fibonaccis == ([1, 1, 2, 3, 5, 8], [1, 2, 3, 5, 8, 13])
```
tensorflow Module: tf.distribute Module: tf.distribute
=====================
Library for running a computation across multiple devices.
The intent of this library is that you can write an algorithm in a stylized way and it will be usable with a variety of different [`tf.distribute.Strategy`](distribute/strategy) implementations. Each descendant will implement a different strategy for distributing the algorithm across multiple devices/machines. Furthermore, these changes can be hidden inside the specific layers and other library classes that need special treatment to run in a distributed setting, so that most users' model definition code can run unchanged. The [`tf.distribute.Strategy`](distribute/strategy) API works the same way with eager and graph execution.
*Guides*
* [TensorFlow v2.x](https://www.tensorflow.org/guide/distributed_training)
* [TensorFlow v1.x](https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/distribute_strategy.ipynb)
*Tutorials*
* [Distributed Training Tutorials](https://www.tensorflow.org/tutorials/distribute/)
The tutorials cover how to use [`tf.distribute.Strategy`](distribute/strategy) to do distributed training with native Keras APIs, custom training loops, and Estimator APIs. They also cover how to save/load model when using [`tf.distribute.Strategy`](distribute/strategy).
*Glossary*
* *Data parallelism* is where we run multiple copies of the model on different slices of the input data. This is in contrast to *model parallelism* where we divide up a single copy of a model across multiple devices. Note: we only support data parallelism for now, but hope to add support for model parallelism in the future.
* A *device* is a CPU or accelerator (e.g. GPUs, TPUs) on some machine that TensorFlow can run operations on (see e.g. [`tf.device`](device)). You may have multiple devices on a single machine, or be connected to devices on multiple machines. Devices used to run computations are called *worker devices*. Devices used to store variables are *parameter devices*. For some strategies, such as [`tf.distribute.MirroredStrategy`](distribute/mirroredstrategy), the worker and parameter devices will be the same (see mirrored variables below). For others they will be different. For example, [`tf.distribute.experimental.CentralStorageStrategy`](distribute/experimental/centralstoragestrategy) puts the variables on a single device (which may be a worker device or may be the CPU), and [`tf.distribute.experimental.ParameterServerStrategy`](distribute/experimental/parameterserverstrategy) puts the variables on separate machines called *parameter servers* (see below).
* A *replica* is one copy of the model, running on one slice of the input data. Right now each replica is executed on its own worker device, but once we add support for model parallelism a replica may span multiple worker devices.
* A *host* is the CPU device on a machine with worker devices, typically used for running input pipelines.
* A *worker* is defined to be the physical machine(s) containing the physical devices (e.g. GPUs, TPUs) on which the replicated computation is executed. A worker may contain one or more replicas, but contains at least one replica. Typically one worker will correspond to one machine, but in the case of very large models with model parallelism, one worker may span multiple machines. We typically run one input pipeline per worker, feeding all the replicas on that worker.
* *Synchronous*, or more commonly *sync*, training is where the updates from each replica are aggregated together before updating the model variables. This is in contrast to *asynchronous*, or *async* training, where each replica updates the model variables independently. You may also have replicas partitioned into groups which are in sync within each group but async between groups.
* *Parameter servers*: These are machines that hold a single copy of parameters/variables, used by some strategies (right now just [`tf.distribute.experimental.ParameterServerStrategy`](distribute/experimental/parameterserverstrategy)). All replicas that want to operate on a variable retrieve it at the beginning of a step and send an update to be applied at the end of the step. These can in principle support either sync or async training, but right now we only have support for async training with parameter servers. Compare to [`tf.distribute.experimental.CentralStorageStrategy`](distribute/experimental/centralstoragestrategy), which puts all variables on a single device on the same machine (and does sync training), and [`tf.distribute.MirroredStrategy`](distribute/mirroredstrategy), which mirrors variables to multiple devices (see below).
* *Replica context* vs. *Cross-replica context* vs *Update context*
A *replica context* applies when you execute the computation function that was called with `strategy.run`. Conceptually, you're in replica context when executing the computation function that is being replicated.
An *update context* is entered in a [`tf.distribute.StrategyExtended.update`](distribute/strategyextended#update) call.
An *cross-replica context* is entered when you enter a `strategy.scope`. This is useful for calling [`tf.distribute.Strategy`](distribute/strategy) methods which operate across the replicas (like `reduce_to()`). By default you start in a *replica context* (the "default single *replica context*") and then some methods can switch you back and forth.
* *Distributed value*: Distributed value is represented by the base class [`tf.distribute.DistributedValues`](distribute/distributedvalues). [`tf.distribute.DistributedValues`](distribute/distributedvalues) is useful to represent values on multiple devices, and it contains a map from replica id to values. Two representative kinds of [`tf.distribute.DistributedValues`](distribute/distributedvalues) are "PerReplica" and "Mirrored" values.
"PerReplica" values exist on the worker devices, with a different value for each replica. They are produced by iterating through a distributed dataset returned by [`tf.distribute.Strategy.experimental_distribute_dataset`](distribute/strategy#experimental_distribute_dataset) and [`tf.distribute.Strategy.distribute_datasets_from_function`](distribute/strategy#distribute_datasets_from_function). They are also the typical result returned by [`tf.distribute.Strategy.run`](distribute/strategy#run).
"Mirrored" values are like "PerReplica" values, except we know that the value on all replicas are the same. We can safely read a "Mirrored" value in a cross-replica context by using the value on any replica.
* *Unwrapping* and *merging*: Consider calling a function `fn` on multiple replicas, like `strategy.run(fn, args=[w])` with an argument `w` that is a [`tf.distribute.DistributedValues`](distribute/distributedvalues). This means `w` will have a map taking replica id `0` to `w0`, replica id `1` to `w1`, etc. `strategy.run()` unwraps `w` before calling `fn`, so it calls `fn(w0)` on device `d0`, `fn(w1)` on device `d1`, etc. It then merges the return values from `fn()`, which leads to one common object if the returned values are the same object from every replica, or a `DistributedValues` object otherwise.
* *Reductions* and *all-reduce*: A *reduction* is a method of aggregating multiple values into one value, like "sum" or "mean". If a strategy is doing sync training, we will perform a reduction on the gradients to a parameter from all replicas before applying the update. *All-reduce* is an algorithm for performing a reduction on values from multiple devices and making the result available on all of those devices.
* *Mirrored variables*: These are variables that are created on multiple devices, where we keep the variables in sync by applying the same updates to every copy. Mirrored variables are created with [`tf.Variable(...synchronization=tf.VariableSynchronization.ON_WRITE...)`](variable). Normally they are only used in synchronous training.
* *SyncOnRead variables*
*SyncOnRead variables* are created by [`tf.Variable(...synchronization=tf.VariableSynchronization.ON_READ...)`](variable), and they are created on multiple devices. In replica context, each component variable on the local replica can perform reads and writes without synchronization with each other. When the *SyncOnRead variable* is read in cross-replica context, the values from component variables are aggregated and returned.
*SyncOnRead variables* bring a lot of custom configuration difficulty to the underlying logic, so we do not encourage users to instantiate and use *SyncOnRead variable* on their own. We have mainly used *SyncOnRead variables* for use cases such as batch norm and metrics. For performance reasons, we often don't need to keep these statistics in sync every step and they can be accumulated on each replica independently. The only time we want to sync them is reporting or checkpointing, which typically happens in cross-replica context. *SyncOnRead variables* are also often used by advanced users who want to control when variable values are aggregated. For example, users sometimes want to maintain gradients independently on each replica for a couple of steps without aggregation.
* *Distribute-aware layers*
Layers are generally called in a replica context, except when defining a Keras functional model. [`tf.distribute.in_cross_replica_context`](distribute/in_cross_replica_context) will let you determine which case you are in. If in a replica context, the [`tf.distribute.get_replica_context`](distribute/get_replica_context) function will return the default replica context outside a strategy scope, `None` within a strategy scope, and a [`tf.distribute.ReplicaContext`](distribute/replicacontext) object inside a strategy scope and within a [`tf.distribute.Strategy.run`](distribute/strategy#run) function. The `ReplicaContext` object has an `all_reduce` method for aggregating across all replicas.
Note that we provide a default version of [`tf.distribute.Strategy`](distribute/strategy) that is used when no other strategy is in scope, that provides the same API with reasonable default behavior.
Modules
-------
[`cluster_resolver`](distribute/cluster_resolver) module: Library imports for ClusterResolvers.
[`coordinator`](distribute/coordinator) module: Public API for tf.distribute.coordinator namespace.
[`experimental`](distribute/experimental) module: Experimental Distribution Strategy library.
Classes
-------
[`class CrossDeviceOps`](distribute/crossdeviceops): Base class for cross-device reduction and broadcasting algorithms.
[`class DistributedDataset`](distribute/distributeddataset): Represents a dataset distributed among devices and machines.
[`class DistributedIterator`](distribute/distributediterator): An iterator over [`tf.distribute.DistributedDataset`](distribute/distributeddataset).
[`class DistributedValues`](distribute/distributedvalues): Base class for representing distributed values.
[`class HierarchicalCopyAllReduce`](distribute/hierarchicalcopyallreduce): Hierarchical copy all-reduce implementation of CrossDeviceOps.
[`class InputContext`](distribute/inputcontext): A class wrapping information needed by an input function.
[`class InputOptions`](distribute/inputoptions): Run options for `experimental_distribute_dataset(s_from_function)`.
[`class InputReplicationMode`](distribute/inputreplicationmode): Replication mode for input function.
[`class MirroredStrategy`](distribute/mirroredstrategy): Synchronous training across multiple replicas on one machine.
[`class MultiWorkerMirroredStrategy`](distribute/multiworkermirroredstrategy): A distribution strategy for synchronous training on multiple workers.
[`class NcclAllReduce`](distribute/ncclallreduce): NCCL all-reduce implementation of CrossDeviceOps.
[`class OneDeviceStrategy`](distribute/onedevicestrategy): A distribution strategy for running on a single device.
[`class ParameterServerStrategy`](distribute/experimental/parameterserverstrategy): An multi-worker tf.distribute strategy with parameter servers.
[`class ReduceOp`](distribute/reduceop): Indicates how a set of values should be reduced.
[`class ReductionToOneDevice`](distribute/reductiontoonedevice): A CrossDeviceOps implementation that copies values to one device to reduce.
[`class ReplicaContext`](distribute/replicacontext): A class with a collection of APIs that can be called in a replica context.
[`class RunOptions`](distribute/runoptions): Run options for `strategy.run`.
[`class Server`](distribute/server): An in-process TensorFlow server, for use in distributed training.
[`class Strategy`](distribute/strategy): A state & compute distribution policy on a list of devices.
[`class StrategyExtended`](distribute/strategyextended): Additional APIs for algorithms that need to be distribution-aware.
[`class TPUStrategy`](distribute/tpustrategy): Synchronous training on TPUs and TPU Pods.
Functions
---------
[`experimental_set_strategy(...)`](distribute/experimental_set_strategy): Set a [`tf.distribute.Strategy`](distribute/strategy) as current without `with strategy.scope()`.
[`get_replica_context(...)`](distribute/get_replica_context): Returns the current [`tf.distribute.ReplicaContext`](distribute/replicacontext) or `None`.
[`get_strategy(...)`](distribute/get_strategy): Returns the current [`tf.distribute.Strategy`](distribute/strategy) object.
[`has_strategy(...)`](distribute/has_strategy): Return if there is a current non-default [`tf.distribute.Strategy`](distribute/strategy).
[`in_cross_replica_context(...)`](distribute/in_cross_replica_context): Returns `True` if in a cross-replica context.
| programming_docs |
tensorflow tf.switch_case tf.switch\_case
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L3555-L3628) |
Create a switch/case operation, i.e. an integer-indexed conditional.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.switch_case`](https://www.tensorflow.org/api_docs/python/tf/switch_case)
```
tf.switch_case(
branch_index, branch_fns, default=None, name='switch_case'
)
```
See also [`tf.case`](case).
This op can be substantially more efficient than [`tf.case`](case) when exactly one branch will be selected. [`tf.switch_case`](switch_case) is more like a C++ switch/case statement than [`tf.case`](case), which is more like an if/elif/elif/else chain.
The `branch_fns` parameter is either a dict from `int` to callables, or list of (`int`, callable) pairs, or simply a list of callables (in which case the index is implicitly the key). The `branch_index` `Tensor` is used to select an element in `branch_fns` with matching `int` key, falling back to `default` if none match, or `max(keys)` if no `default` is provided. The keys must form a contiguous set from `0` to `len(branch_fns) - 1`.
[`tf.switch_case`](switch_case) supports nested structures as implemented in [`tf.nest`](nest). All callables must return the same (possibly nested) value structure of lists, tuples, and/or named tuples.
**Example:**
#### Pseudocode:
```
switch (branch_index) { // c-style switch
case 0: return 17;
case 1: return 31;
default: return -1;
}
```
or
```
branches = {0: lambda: 17, 1: lambda: 31}
branches.get(branch_index, lambda: -1)()
```
#### Expressions:
```
def f1(): return tf.constant(17)
def f2(): return tf.constant(31)
def f3(): return tf.constant(-1)
r = tf.switch_case(branch_index, branch_fns={0: f1, 1: f2}, default=f3)
# Equivalent: tf.switch_case(branch_index, branch_fns={0: f1, 1: f2, 2: f3})
```
| Args |
| `branch_index` | An int Tensor specifying which of `branch_fns` should be executed. |
| `branch_fns` | A `dict` mapping `int`s to callables, or a `list` of (`int`, callable) pairs, or simply a list of callables (in which case the index serves as the key). Each callable must return a matching structure of tensors. |
| `default` | Optional callable that returns a structure of tensors. |
| `name` | A name for this operation (optional). |
| Returns |
| The tensors returned by the callable identified by `branch_index`, or those returned by `default` if no key matches and `default` was provided, or those returned by the max-keyed `branch_fn` if no `default` is provided. |
| Raises |
| `TypeError` | If `branch_fns` is not a list/dictionary. |
| `TypeError` | If `branch_fns` is a list but does not contain 2-tuples or callables. |
| `TypeError` | If `fns[i]` is not callable for any i, or `default` is not callable. |
tensorflow tf.batch_to_space tf.batch\_to\_space
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L4152-L4287) |
BatchToSpace for N-D tensors of type T.
```
tf.batch_to_space(
input, block_shape, crops, name=None
)
```
This operation reshapes the "batch" dimension 0 into `M + 1` dimensions of shape `block_shape + [batch]`, interleaves these blocks back into the grid defined by the spatial dimensions `[1, ..., M]`, to obtain a result with the same rank as the input. The spatial dimensions of this intermediate result are then optionally cropped according to `crops` to produce the output. This is the reverse of SpaceToBatch (see [`tf.space_to_batch`](space_to_batch)).
| Args |
| `input` | A N-D `Tensor` with shape `input_shape = [batch] + spatial_shape + remaining_shape`, where `spatial_shape` has M dimensions. |
| `block_shape` | A 1-D `Tensor` with shape [M]. Must be one of the following types: `int32`, `int64`. All values must be >= 1. For backwards compatibility with TF 1.0, this parameter may be an int, in which case it is converted to `numpy.array([block_shape, block_shape], dtype=numpy.int64)`. |
| `crops` | A 2-D `Tensor` with shape `[M, 2]`. Must be one of the following types: `int32`, `int64`. All values must be >= 0. `crops[i] = [crop_start, crop_end]` specifies the amount to crop from input dimension `i + 1`, which corresponds to spatial dimension `i`. It is required that `crop_start[i] + crop_end[i] <= block_shape[i] * input_shape[i + 1]`. This operation is equivalent to the following steps: 1. Reshape `input` to `reshaped` of shape: [block\_shape[0], ..., block\_shape[M-1], batch / prod(block\_shape), input\_shape[1], ..., input\_shape[N-1]]
2. Permute dimensions of `reshaped` to produce `permuted` of shape [batch / prod(block\_shape), input\_shape[1], block\_shape[0], ..., input\_shape[M], block\_shape[M-1], input\_shape[M+1], ..., input\_shape[N-1]]
3. Reshape `permuted` to produce `reshaped_permuted` of shape [batch / prod(block\_shape), input\_shape[1] \* block\_shape[0], ..., input\_shape[M] \* block\_shape[M-1], input\_shape[M+1], ..., input\_shape[N-1]]
4. Crop the start and end of dimensions `[1, ..., M]` of `reshaped_permuted` according to `crops` to produce the output of shape: [batch / prod(block\_shape), input\_shape[1] \* block\_shape[0] - crops[0,0] - crops[0,1], ..., input\_shape[M] \* block\_shape[M-1] - crops[M-1,0] - crops[M-1,1], input\_shape[M+1], ..., input\_shape[N-1]]
|
| `name` | A name for the operation (optional). |
#### Examples:
1. For the following input of shape `[4, 1, 1, 1]`, `block_shape = [2, 2]`, and `crops = [[0, 0], [0, 0]]`:
```
[[[[1]]],
[[[2]]],
[[[3]]],
[[[4]]]]
```
The output tensor has shape `[1, 2, 2, 1]` and value:
```
x = [[[[1], [2]],
[[3], [4]]]]
```
2. For the following input of shape `[4, 1, 1, 3]`, `block_shape = [2, 2]`, and `crops = [[0, 0], [0, 0]]`:
```
[[[1, 2, 3]],
[[4, 5, 6]],
[[7, 8, 9]],
[[10, 11, 12]]]
```
The output tensor has shape `[1, 2, 2, 3]` and value:
```
x = [[[[1, 2, 3], [4, 5, 6 ]],
[[7, 8, 9], [10, 11, 12]]]]
```
3. For the following input of shape `[4, 2, 2, 1]`, `block_shape = [2, 2]`, and `crops = [[0, 0], [0, 0]]`:
```
x = [[[[1], [3]], [[ 9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
[[[6], [8]], [[14], [16]]]]
```
The output tensor has shape `[1, 4, 4, 1]` and value:
```
x = [[[1], [2], [ 3], [ 4]],
[[5], [6], [ 7], [ 8]],
[[9], [10], [11], [12]],
[[13], [14], [15], [16]]]
```
4. For the following input of shape `[8, 1, 3, 1]`, `block_shape = [2, 2]`, and `crops = [[0, 0], [2, 0]]`:
```
x = [[[[0], [ 1], [ 3]]],
[[[0], [ 9], [11]]],
[[[0], [ 2], [ 4]]],
[[[0], [10], [12]]],
[[[0], [ 5], [ 7]]],
[[[0], [13], [15]]],
[[[0], [ 6], [ 8]]],
[[[0], [14], [16]]]]
```
The output tensor has shape `[2, 2, 4, 1]` and value:
```
x = [[[[ 1], [ 2], [ 3], [ 4]],
[[ 5], [ 6], [ 7], [ 8]]],
[[[ 9], [10], [11], [12]],
[[13], [14], [15], [16]]]]
```
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.timestamp tf.timestamp
============
Provides the time since epoch in seconds.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.timestamp`](https://www.tensorflow.org/api_docs/python/tf/timestamp)
```
tf.timestamp(
name=None
)
```
Returns the timestamp as a `float64` for seconds since the Unix epoch.
>
> **Note:** the timestamp is computed when the op is executed, not when it is added to the graph.
>
| Args |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `float64`. |
tensorflow tf.register_tensor_conversion_function tf.register\_tensor\_conversion\_function
=========================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_conversion_registry.py#L52-L109) |
Registers a function for converting objects of `base_type` to `Tensor`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.register_tensor_conversion_function`](https://www.tensorflow.org/api_docs/python/tf/register_tensor_conversion_function)
```
tf.register_tensor_conversion_function(
base_type, conversion_func, priority=100
)
```
The conversion function must have the following signature:
```
def conversion_func(value, dtype=None, name=None, as_ref=False):
# ...
```
It must return a `Tensor` with the given `dtype` if specified. If the conversion function creates a new `Tensor`, it should use the given `name` if specified. All exceptions will be propagated to the caller.
The conversion function may return `NotImplemented` for some inputs. In this case, the conversion process will continue to try subsequent conversion functions.
If `as_ref` is true, the function must return a `Tensor` reference, such as a `Variable`.
>
> **Note:** The conversion functions will execute in order of priority, followed by order of registration. To ensure that a conversion function `F` runs before another conversion function `G`, ensure that `F` is registered with a smaller priority than `G`.
>
| Args |
| `base_type` | The base type or tuple of base types for all objects that `conversion_func` accepts. |
| `conversion_func` | A function that converts instances of `base_type` to `Tensor`. |
| `priority` | Optional integer that indicates the priority for applying this conversion function. Conversion functions with smaller priority values run earlier than conversion functions with larger priority values. Defaults to 100. |
| Raises |
| `TypeError` | If the arguments do not have the appropriate type. |
tensorflow tf.zeros_like tf.zeros\_like
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3078-L3121) |
Creates a tensor with all elements set to zero.
```
tf.zeros_like(
input, dtype=None, name=None
)
```
See also [`tf.zeros`](zeros).
Given a single tensor or array-like object (`input`), this operation returns a tensor of the same type and shape as `input` with all elements set to zero. Optionally, you can use `dtype` to specify a new type for the returned tensor.
#### Examples:
```
tensor = tf.constant([[1, 2, 3], [4, 5, 6]])
tf.zeros_like(tensor)
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 0, 0],
[0, 0, 0]], dtype=int32)>
```
```
tf.zeros_like(tensor, dtype=tf.float32)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0., 0., 0.],
[0., 0., 0.]], dtype=float32)>
```
```
tf.zeros_like([[1, 2, 3], [4, 5, 6]])
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 0, 0],
[0, 0, 0]], dtype=int32)>
```
| Args |
| `input` | A `Tensor` or array-like object. |
| `dtype` | A type for the returned `Tensor`. Must be `float16`, `float32`, `float64`, `int8`, `uint8`, `int16`, `uint16`, `int32`, `int64`, `complex64`, `complex128`, `bool` or `string` (optional). |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` with all elements set to zero. |
tensorflow Module: tf.audio Module: tf.audio
================
Public API for tf.audio namespace.
Functions
---------
[`decode_wav(...)`](audio/decode_wav): Decode a 16-bit PCM WAV file to a float tensor.
[`encode_wav(...)`](audio/encode_wav): Encode audio data using the WAV file format.
tensorflow tf.map_fn tf.map\_fn
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/map_fn.py#L614-L645) |
Transforms `elems` by applying `fn` to each element unstacked on axis 0. (deprecated arguments)
```
tf.map_fn(
fn,
elems,
dtype=None,
parallel_iterations=None,
back_prop=True,
swap_memory=False,
infer_shape=True,
name=None,
fn_output_signature=None
)
```
See also [`tf.scan`](scan).
`map_fn` unstacks `elems` on axis 0 to obtain a sequence of elements; calls `fn` to transform each element; and then stacks the transformed values back together.
#### Mapping functions with single-Tensor inputs and outputs
If `elems` is a single tensor and `fn`'s signature is `tf.Tensor->tf.Tensor`, then `map_fn(fn, elems)` is equivalent to `tf.stack([fn(elem) for elem in tf.unstack(elems)])`. E.g.:
```
tf.map_fn(fn=lambda t: tf.range(t, t + 3), elems=tf.constant([3, 5, 2]))
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[3, 4, 5],
[5, 6, 7],
[2, 3, 4]], dtype=int32)>
```
`map_fn(fn, elems).shape = [elems.shape[0]] + fn(elems[0]).shape`.
#### Mapping functions with multi-arity inputs and outputs
`map_fn` also supports functions with multi-arity inputs and outputs:
* If `elems` is a tuple (or nested structure) of tensors, then those tensors must all have the same outer-dimension size (`num_elems`); and `fn` is used to transform each tuple (or structure) of corresponding slices from `elems`. E.g., if `elems` is a tuple `(t1, t2, t3)`, then `fn` is used to transform each tuple of slices `(t1[i], t2[i], t3[i])` (where `0 <= i < num_elems`).
* If `fn` returns a tuple (or nested structure) of tensors, then the result is formed by stacking corresponding elements from those structures.
#### Specifying `fn`'s output signature
If `fn`'s input and output signatures are different, then the output signature must be specified using `fn_output_signature`. (The input and output signatures are differ if their structures, dtypes, or tensor types do not match). E.g.:
```
tf.map_fn(fn=tf.strings.length, # input & output have different dtypes
elems=tf.constant(["hello", "moon"]),
fn_output_signature=tf.int32)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([5, 4], dtype=int32)>
tf.map_fn(fn=tf.strings.join, # input & output have different structures
elems=[tf.constant(['The', 'A']), tf.constant(['Dog', 'Cat'])],
fn_output_signature=tf.string)
<tf.Tensor: shape=(2,), dtype=string,
numpy=array([b'TheDog', b'ACat'], dtype=object)>
```
`fn_output_signature` can be specified using any of the following:
* A [`tf.DType`](dtypes/dtype) or [`tf.TensorSpec`](tensorspec) (to describe a [`tf.Tensor`](tensor))
* A [`tf.RaggedTensorSpec`](raggedtensorspec) (to describe a [`tf.RaggedTensor`](raggedtensor))
* A [`tf.SparseTensorSpec`](sparsetensorspec) (to describe a [`tf.sparse.SparseTensor`](sparse/sparsetensor))
* A (possibly nested) tuple, list, or dict containing the above types.
#### RaggedTensors
`map_fn` supports [`tf.RaggedTensor`](raggedtensor) inputs and outputs. In particular:
* If `elems` is a `RaggedTensor`, then `fn` will be called with each row of that ragged tensor.
+ If `elems` has only one ragged dimension, then the values passed to `fn` will be [`tf.Tensor`](tensor)s.
+ If `elems` has multiple ragged dimensions, then the values passed to `fn` will be [`tf.RaggedTensor`](raggedtensor)s with one fewer ragged dimension.
* If the result of `map_fn` should be a `RaggedTensor`, then use a [`tf.RaggedTensorSpec`](raggedtensorspec) to specify `fn_output_signature`.
+ If `fn` returns [`tf.Tensor`](tensor)s with varying sizes, then use a [`tf.RaggedTensorSpec`](raggedtensorspec) with `ragged_rank=0` to combine them into a single ragged tensor (which will have ragged\_rank=1).
+ If `fn` returns [`tf.RaggedTensor`](raggedtensor)s, then use a [`tf.RaggedTensorSpec`](raggedtensorspec) with the same `ragged_rank`.
```
# Example: RaggedTensor input
rt = tf.ragged.constant([[1, 2, 3], [], [4, 5], [6]])
tf.map_fn(tf.reduce_sum, rt, fn_output_signature=tf.int32)
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([6, 0, 9, 6], dtype=int32)>
```
```
# Example: RaggedTensor output
elems = tf.constant([3, 5, 0, 2])
tf.map_fn(tf.range, elems,
fn_output_signature=tf.RaggedTensorSpec(shape=[None],
dtype=tf.int32))
<tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [], [0, 1]]>
```
>
> **Note:** `map_fn` should only be used if you need to map a function over the *rows* of a `RaggedTensor`. If you wish to map a function over the individual values, then you should use:
>
* [`tf.ragged.map_flat_values(fn, rt)`](ragged/map_flat_values) (if fn is expressible as TensorFlow ops)
* `rt.with_flat_values(map_fn(fn, rt.flat_values))` (otherwise)
E.g.:
```
rt = tf.ragged.constant([[1, 2, 3], [], [4, 5], [6]])
tf.ragged.map_flat_values(lambda x: x + 2, rt)
<tf.RaggedTensor [[3, 4, 5], [], [6, 7], [8]]>
```
#### SparseTensors
`map_fn` supports [`tf.sparse.SparseTensor`](sparse/sparsetensor) inputs and outputs. In particular:
* If `elems` is a `SparseTensor`, then `fn` will be called with each row of that sparse tensor. In particular, the value passed to `fn` will be a [`tf.sparse.SparseTensor`](sparse/sparsetensor) with one fewer dimension than `elems`.
* If the result of `map_fn` should be a `SparseTensor`, then use a [`tf.SparseTensorSpec`](sparsetensorspec) to specify `fn_output_signature`. The individual `SparseTensor`s returned by `fn` will be stacked into a single `SparseTensor` with one more dimension.
```
# Example: SparseTensor input
st = tf.sparse.SparseTensor([[0, 0], [2, 0], [2, 1]], [2, 3, 4], [4, 4])
tf.map_fn(tf.sparse.reduce_sum, st, fn_output_signature=tf.int32)
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([2, 0, 7, 0], dtype=int32)>
```
```
# Example: SparseTensor output
tf.sparse.to_dense(
tf.map_fn(tf.sparse.eye, tf.constant([2, 3]),
fn_output_signature=tf.SparseTensorSpec(None, tf.float32)))
<tf.Tensor: shape=(2, 3, 3), dtype=float32, numpy=
array([[[1., 0., 0.],
[0., 1., 0.],
[0., 0., 0.]],
[[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]]], dtype=float32)>
```
>
> **Note:** `map_fn` should only be used if you need to map a function over the *rows* of a `SparseTensor`. If you wish to map a function over the nonzero values, then you should use:
>
* If the function is expressible as TensorFlow ops, use:
```
tf.sparse.SparseTensor(st.indices, fn(st.values), st.dense_shape)
```
* Otherwise, use:
```
tf.sparse.SparseTensor(st.indices, tf.map_fn(fn, st.values),
st.dense_shape)
```
####
`map_fn` vs. vectorized operations
`map_fn` will apply the operations used by `fn` to each element of `elems`, resulting in `O(elems.shape[0])` total operations. This is somewhat mitigated by the fact that `map_fn` can process elements in parallel. However, a transform expressed using `map_fn` is still typically less efficient than an equivalent transform expressed using vectorized operations.
`map_fn` should typically only be used if one of the following is true:
* It is difficult or expensive to express the desired transform with vectorized operations.
* `fn` creates large intermediate values, so an equivalent vectorized transform would take too much memory.
* Processing elements in parallel is more efficient than an equivalent vectorized transform.
* Efficiency of the transform is not critical, and using `map_fn` is more readable.
E.g., the example given above that maps `fn=lambda t: tf.range(t, t + 3)` across `elems` could be rewritten more efficiently using vectorized ops:
```
elems = tf.constant([3, 5, 2])
tf.range(3) + tf.expand_dims(elems, 1)
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[3, 4, 5],
[5, 6, 7],
[2, 3, 4]], dtype=int32)>
```
In some cases, [`tf.vectorized_map`](vectorized_map) can be used to automatically convert a function to a vectorized equivalent.
#### Eager execution
When executing eagerly, `map_fn` does not execute in parallel even if `parallel_iterations` is set to a value > 1. You can still get the performance benefits of running a function in parallel by using the [`tf.function`](function) decorator:
```
fn=lambda t: tf.range(t, t + 3)
@tf.function
def func(elems):
return tf.map_fn(fn, elems, parallel_iterations=3)
func(tf.constant([3, 5, 2]))
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[3, 4, 5],
[5, 6, 7],
[2, 3, 4]], dtype=int32)>
```
>
> **Note:** if you use the [`tf.function`](function) decorator, any non-TensorFlow Python code that you may have written in your function won't get executed. See [`tf.function`](function) for more details. The recommendation would be to debug without [`tf.function`](function) but switch to it to get performance benefits of running `map_fn` in parallel.
>
| Args |
| `fn` | The callable to be performed. It accepts one argument, which will have the same (possibly nested) structure as `elems`. Its output must have the same structure as `fn_output_signature` if one is provided; otherwise it must have the same structure as `elems`. |
| `elems` | A tensor or (possibly nested) sequence of tensors, each of which will be unstacked along their first dimension. `fn` will be applied to the nested sequence of the resulting slices. `elems` may include ragged and sparse tensors. `elems` must consist of at least one tensor. |
| `dtype` | Deprecated: Equivalent to `fn_output_signature`. |
| `parallel_iterations` | (optional) The number of iterations allowed to run in parallel. When graph building, the default value is 10. While executing eagerly, the default value is set to 1. |
| `back_prop` | (optional) Deprecated: prefer using [`tf.stop_gradient`](stop_gradient) instead. False disables support for back propagation. |
| `swap_memory` | (optional) True enables GPU-CPU memory swapping. |
| `infer_shape` | (optional) False disables tests for consistent output shapes. |
| `name` | (optional) Name prefix for the returned tensors. |
| `fn_output_signature` | The output signature of `fn`. Must be specified if `fn`'s input and output signatures are different (i.e., if their structures, dtypes, or tensor types do not match). `fn_output_signature` can be specified using any of the following: * A [`tf.DType`](dtypes/dtype) or [`tf.TensorSpec`](tensorspec) (to describe a [`tf.Tensor`](tensor))
* A [`tf.RaggedTensorSpec`](raggedtensorspec) (to describe a [`tf.RaggedTensor`](raggedtensor))
* A [`tf.SparseTensorSpec`](sparsetensorspec) (to describe a [`tf.sparse.SparseTensor`](sparse/sparsetensor))
* A (possibly nested) tuple, list, or dict containing the above types.
|
| Returns |
| A tensor or (possibly nested) sequence of tensors. Each tensor stacks the results of applying `fn` to tensors unstacked from `elems` along the first dimension, from first to last. The result may include ragged and sparse tensors. |
| Raises |
| `TypeError` | if `fn` is not callable or the structure of the output of `fn` and `fn_output_signature` do not match. |
| `ValueError` | if the lengths of the output of `fn` and `fn_output_signature` do not match, or if the `elems` does not contain any tensor. |
#### Examples:
```
elems = np.array([1, 2, 3, 4, 5, 6])
tf.map_fn(lambda x: x * x, elems)
<tf.Tensor: shape=(6,), dtype=int64, numpy=array([ 1, 4, 9, 16, 25, 36])>
```
```
elems = (np.array([1, 2, 3]), np.array([-1, 1, -1]))
tf.map_fn(lambda x: x[0] * x[1], elems, fn_output_signature=tf.int64)
<tf.Tensor: shape=(3,), dtype=int64, numpy=array([-1, 2, -3])>
```
```
elems = np.array([1, 2, 3])
tf.map_fn(lambda x: (x, -x), elems,
fn_output_signature=(tf.int64, tf.int64))
(<tf.Tensor: shape=(3,), dtype=int64, numpy=array([1, 2, 3])>,
<tf.Tensor: shape=(3,), dtype=int64, numpy=array([-1, -2, -3])>)
```
| programming_docs |
tensorflow Module: tf.lookup Module: tf.lookup
=================
Public API for tf.lookup namespace.
Modules
-------
[`experimental`](lookup/experimental) module: Public API for tf.lookup.experimental namespace.
Classes
-------
[`class KeyValueTensorInitializer`](lookup/keyvaluetensorinitializer): Table initializers given `keys` and `values` tensors.
[`class StaticHashTable`](lookup/statichashtable): A generic hash table that is immutable once initialized.
[`class StaticVocabularyTable`](lookup/staticvocabularytable): String to Id table that assigns out-of-vocabulary keys to hash buckets.
[`class TextFileIndex`](lookup/textfileindex): The key and value content to get from each line.
[`class TextFileInitializer`](lookup/textfileinitializer): Table initializers from a text file.
tensorflow tf.truncatemod tf.truncatemod
==============
Returns element-wise remainder of division. This emulates C semantics in that
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.truncatemod`](https://www.tensorflow.org/api_docs/python/tf/truncatemod)
```
tf.truncatemod(
x, y, name=None
)
```
the result here is consistent with a truncating divide. E.g. `truncate(x / y) * y + truncate_mod(x, y) = x`.
>
> **Note:** `truncatemod` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int32`, `int64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
tensorflow tf.group tf.group
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L2882-L2958) |
Create an op that groups multiple operations.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.group`](https://www.tensorflow.org/api_docs/python/tf/group)
```
tf.group(
*inputs, **kwargs
)
```
When this op finishes, all ops in `inputs` have finished. This op has no output.
>
> **Note:** *In TensorFlow 2 with eager and/or Autograph, you should not require this method, as ops execute in the expected order thanks to automatic control dependencies.* Only use [`tf.group`](group) when working with v1 [`tf.Graph`](graph) code.
>
When operating in a v1-style graph context, ops are not executed in the same order as specified in the code; TensorFlow will attempt to execute ops in parallel or in an order convenient to the result it is computing. [`tf.group`](group) allows you to request that one or more results finish before execution continues.
[`tf.group`](group) creates a single op (of type `NoOp`), and then adds appropriate control dependencies. Thus, `c = tf.group(a, b)` will compute the same graph as this:
```
with tf.control_dependencies([a, b]):
c = tf.no_op()
```
See also [`tf.tuple`](tuple) and [`tf.control_dependencies`](control_dependencies).
| Args |
| `*inputs` | Zero or more tensors to group. |
| `name` | A name for this operation (optional). |
| Returns |
| An Operation that executes all its inputs. |
| Raises |
| `ValueError` | If an unknown keyword argument is provided. |
tensorflow tf.sequence_mask tf.sequence\_mask
=================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L4468-L4532) |
Returns a mask tensor representing the first N positions of each cell.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.sequence_mask`](https://www.tensorflow.org/api_docs/python/tf/sequence_mask)
```
tf.sequence_mask(
lengths,
maxlen=None,
dtype=tf.dtypes.bool,
name=None
)
```
If `lengths` has shape `[d_1, d_2, ..., d_n]` the resulting tensor `mask` has dtype `dtype` and shape `[d_1, d_2, ..., d_n, maxlen]`, with
```
mask[i_1, i_2, ..., i_n, j] = (j < lengths[i_1, i_2, ..., i_n])
```
#### Examples:
```
tf.sequence_mask([1, 3, 2], 5) # [[True, False, False, False, False],
# [True, True, True, False, False],
# [True, True, False, False, False]]
tf.sequence_mask([[1, 3],[2,0]]) # [[[True, False, False],
# [True, True, True]],
# [[True, True, False],
# [False, False, False]]]
```
| Args |
| `lengths` | integer tensor, all its values <= maxlen. |
| `maxlen` | scalar integer tensor, size of last dimension of returned tensor. Default is the maximum value in `lengths`. |
| `dtype` | output type of the resulting tensor. |
| `name` | name of the op. |
| Returns |
| A mask tensor of shape `lengths.shape + (maxlen,)`, cast to specified dtype. |
| Raises |
| `ValueError` | if `maxlen` is not a scalar. |
tensorflow tf.squeeze tf.squeeze
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L4590-L4639) |
Removes dimensions of size 1 from the shape of a tensor.
```
tf.squeeze(
input, axis=None, name=None
)
```
Given a tensor `input`, this operation returns a tensor of the same type with all dimensions of size 1 removed. If you don't want to remove all size 1 dimensions, you can remove specific size 1 dimensions by specifying `axis`.
#### For example:
```
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1]
tf.shape(tf.squeeze(t)) # [2, 3]
```
Or, to remove specific size 1 dimensions:
```
# 't' is a tensor of shape [1, 2, 1, 3, 1, 1]
tf.shape(tf.squeeze(t, [2, 4])) # [1, 2, 3, 1]
```
Unlike the older op [`tf.compat.v1.squeeze`](compat/v1/squeeze), this op does not accept a deprecated `squeeze_dims` argument.
>
> **Note:** if `input` is a [`tf.RaggedTensor`](raggedtensor), then this operation takes `O(N)` time, where `N` is the number of elements in the squeezed dimensions.
>
| Args |
| `input` | A `Tensor`. The `input` to squeeze. |
| `axis` | An optional list of `ints`. Defaults to `[]`. If specified, only squeezes the dimensions listed. The dimension index starts at 0. It is an error to squeeze a dimension that is not 1. Must be in the range `[-rank(input), rank(input))`. Must be specified if `input` is a `RaggedTensor`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. Contains the same data as `input`, but has one or more dimensions of size 1 removed. |
| Raises |
| `ValueError` | The input cannot be converted to a tensor, or the specified axis cannot be squeezed. |
tensorflow tf.name_scope tf.name\_scope
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L6877-L6966) |
A context manager for use when defining a Python op.
```
tf.name_scope(
name
)
```
This context manager pushes a name scope, which will make the name of all operations added within it have a prefix.
For example, to define a new Python op called `my_op`:
```
def my_op(a, b, c, name=None):
with tf.name_scope("MyOp") as scope:
a = tf.convert_to_tensor(a, name="a")
b = tf.convert_to_tensor(b, name="b")
c = tf.convert_to_tensor(c, name="c")
# Define some computation that uses `a`, `b`, and `c`.
return foo_op(..., name=scope)
```
When executed, the Tensors `a`, `b`, `c`, will have names `MyOp/a`, `MyOp/b`, and `MyOp/c`.
Inside a [`tf.function`](function), if the scope name already exists, the name will be made unique by appending `_n`. For example, calling `my_op` the second time will generate `MyOp_1/a`, etc.
| Args |
| `name` | The prefix to use on all names created within the name scope. |
| Raises |
| `ValueError` | If name is not a string. |
| Attributes |
| `name` | |
Methods
-------
### `__enter__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L6923-L6955)
```
__enter__()
```
Start the scope block.
| Returns |
| The scope name. |
### `__exit__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L6957-L6959)
```
__exit__(
type_arg, value_arg, traceback_arg
)
```
tensorflow tf.tuple tf.tuple
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L2961-L2989) |
Groups tensors together.
```
tf.tuple(
tensors, control_inputs=None, name=None
)
```
The returned tensors have the same value as the input tensors, but they are computed only after all the input tensors have been computed.
>
> **Note:** *In TensorFlow 2 with eager and/or Autograph, you should not require this method, as ops execute in the expected order thanks to automatic control dependencies.* Only use [`tf.tuple`](tuple) when working with v1 [`tf.Graph`](graph) code.
>
See also [`tf.group`](group) and [`tf.control_dependencies`](control_dependencies).
| Args |
| `tensors` | A list of `Tensor`s or `IndexedSlices`, some entries can be `None`. |
| `control_inputs` | List of additional ops to finish before returning. |
| `name` | (optional) A name to use as a `name_scope` for the operation. |
| Returns |
| Same as `tensors`. |
| Raises |
| `ValueError` | If `tensors` does not contain any `Tensor` or `IndexedSlices`. |
| `TypeError` | If `control_inputs` is not a list of `Operation` or `Tensor` objects. |
tensorflow tf.tile tf.tile
=======
Constructs a tensor by tiling a given tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.tile`](https://www.tensorflow.org/api_docs/python/tf/tile), [`tf.compat.v1.tile`](https://www.tensorflow.org/api_docs/python/tf/tile)
```
tf.tile(
input, multiples, name=None
)
```
This operation creates a new tensor by replicating `input` `multiples` times. The output tensor's i'th dimension has `input.dims(i) * multiples[i]` elements, and the values of `input` are replicated `multiples[i]` times along the 'i'th dimension. For example, tiling `[a b c d]` by `[2]` produces `[a b c d a b c d]`.
```
a = tf.constant([[1,2,3],[4,5,6]], tf.int32)
b = tf.constant([1,2], tf.int32)
tf.tile(a, b)
<tf.Tensor: shape=(2, 6), dtype=int32, numpy=
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]], dtype=int32)>
c = tf.constant([2,1], tf.int32)
tf.tile(a, c)
<tf.Tensor: shape=(4, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6],
[1, 2, 3],
[4, 5, 6]], dtype=int32)>
d = tf.constant([2,2], tf.int32)
tf.tile(a, d)
<tf.Tensor: shape=(4, 6), dtype=int32, numpy=
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6],
[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]], dtype=int32)>
```
| Args |
| `input` | A `Tensor`. 1-D or higher. |
| `multiples` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 1-D. Length must be the same as the number of dimensions in `input` |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.numpy_function tf.numpy\_function
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/script_ops.py#L686-L770) |
Wraps a python function and uses it as a TensorFlow op.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.numpy_function`](https://www.tensorflow.org/api_docs/python/tf/numpy_function)
```
tf.numpy_function(
func, inp, Tout, stateful=True, name=None
)
```
Given a python function `func` wrap this function as an operation in a TensorFlow function. `func` must take numpy arrays as its arguments and return numpy arrays as its outputs.
The following example creates a TensorFlow graph with `np.sinh()` as an operation in the graph:
```
def my_numpy_func(x):
# x will be a numpy array with the contents of the input to the
# tf.function
return np.sinh(x)
@tf.function(input_signature=[tf.TensorSpec(None, tf.float32)])
def tf_function(input):
y = tf.numpy_function(my_numpy_func, [input], tf.float32)
return y * y
tf_function(tf.constant(1.))
<tf.Tensor: shape=(), dtype=float32, numpy=1.3810978>
```
Comparison to [`tf.py_function`](py_function): [`tf.py_function`](py_function) and [`tf.numpy_function`](numpy_function) are very similar, except that [`tf.numpy_function`](numpy_function) takes numpy arrays, and not [`tf.Tensor`](tensor)s. If you want the function to contain `tf.Tensors`, and have any TensorFlow operations executed in the function be differentiable, please use [`tf.py_function`](py_function).
>
> **Note:** We recommend to avoid using [`tf.numpy_function`](numpy_function) outside of prototyping and experimentation due to the following known limitations:
>
* Calling [`tf.numpy_function`](numpy_function) will acquire the Python Global Interpreter Lock (GIL) that allows only one thread to run at any point in time. This will preclude efficient parallelization and distribution of the execution of the program. Therefore, you are discouraged to use [`tf.numpy_function`](numpy_function) outside of prototyping and experimentation.
* The body of the function (i.e. `func`) will not be serialized in a `tf.SavedModel`. Therefore, you should not use this function if you need to serialize your model and restore it in a different environment.
* The operation must run in the same address space as the Python program that calls [`tf.numpy_function()`](numpy_function). If you are using distributed TensorFlow, you must run a [`tf.distribute.Server`](distribute/server) in the same process as the program that calls [`tf.numpy_function`](numpy_function) you must pin the created operation to a device in that server (e.g. using `with tf.device():`).
* Currently [`tf.numpy_function`](numpy_function) is not compatible with XLA. Calling [`tf.numpy_function`](numpy_function) inside [`tf.function(jit_comiple=True)`](function) will raise an error.
* Since the function takes numpy arrays, you cannot take gradients through a numpy\_function. If you require something that is differentiable, please consider using tf.py\_function.
| Args |
| `func` | A Python function, which accepts `numpy.ndarray` objects as arguments and returns a list of `numpy.ndarray` objects (or a single `numpy.ndarray`). This function must accept as many arguments as there are tensors in `inp`, and these argument types will match the corresponding [`tf.Tensor`](tensor) objects in `inp`. The returns `numpy.ndarray`s must match the number and types defined `Tout`. Important Note: Input and output `numpy.ndarray`s of `func` are not guaranteed to be copies. In some cases their underlying memory will be shared with the corresponding TensorFlow tensors. In-place modification or storing `func` input or return values in python datastructures without explicit (np.)copy can have non-deterministic consequences. |
| `inp` | A list of [`tf.Tensor`](tensor) objects. |
| `Tout` | A list or tuple of tensorflow data types or a single tensorflow data type if there is only one, indicating what `func` returns. |
| `stateful` | (Boolean.) Setting this argument to False tells the runtime to treat the function as stateless, which enables certain optimizations. A function is stateless when given the same input it will return the same output and have no side effects; its only purpose is to have a return value. The behavior for a stateful function with the `stateful` argument False is undefined. In particular, caution should be taken when mutating the input arguments as this is a stateful operation. |
| `name` | (Optional) A name for the operation. |
| Returns |
| Single or list of [`tf.Tensor`](tensor) which `func` computes. |
tensorflow tf.split tf.split
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L2126-L2205) |
Splits a tensor `value` into a list of sub tensors.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.split`](https://www.tensorflow.org/api_docs/python/tf/split)
```
tf.split(
value, num_or_size_splits, axis=0, num=None, name='split'
)
```
See also [`tf.unstack`](unstack).
If `num_or_size_splits` is an `int`, then it splits `value` along the dimension `axis` into `num_or_size_splits` smaller tensors. This requires that `value.shape[axis]` is divisible by `num_or_size_splits`.
If `num_or_size_splits` is a 1-D Tensor (or list), then `value` is split into `len(num_or_size_splits)` elements. The shape of the `i`-th element has the same size as the `value` except along dimension `axis` where the size is `num_or_size_splits[i]`.
#### For example:
```
x = tf.Variable(tf.random.uniform([5, 30], -1, 1))
# Split `x` into 3 tensors along dimension 1
s0, s1, s2 = tf.split(x, num_or_size_splits=3, axis=1)
tf.shape(s0).numpy()
array([ 5, 10], dtype=int32)
# Split `x` into 3 tensors with sizes [4, 15, 11] along dimension 1
split0, split1, split2 = tf.split(x, [4, 15, 11], 1)
tf.shape(split0).numpy()
array([5, 4], dtype=int32)
tf.shape(split1).numpy()
array([ 5, 15], dtype=int32)
tf.shape(split2).numpy()
array([ 5, 11], dtype=int32)
```
| Args |
| `value` | The `Tensor` to split. |
| `num_or_size_splits` | Either an `int` indicating the number of splits along `axis` or a 1-D integer `Tensor` or Python list containing the sizes of each output tensor along `axis`. If an `int`, then it must evenly divide `value.shape[axis]`; otherwise the sum of sizes along the split axis must match that of the `value`. |
| `axis` | An `int` or scalar `int32` `Tensor`. The dimension along which to split. Must be in the range `[-rank(value), rank(value))`. Defaults to 0. |
| `num` | Optional, an `int`, used to specify the number of outputs when it cannot be inferred from the shape of `size_splits`. |
| `name` | A name for the operation (optional). |
| Returns |
| if `num_or_size_splits` is an `int` returns a list of `num_or_size_splits` `Tensor` objects; if `num_or_size_splits` is a 1-D list or 1-D `Tensor` returns `num_or_size_splits.get_shape[0]` `Tensor` objects resulting from splitting `value`. |
| Raises |
| `ValueError` | If `num` is unspecified and cannot be inferred. |
| `ValueError` | If `num_or_size_splits` is a scalar `Tensor`. |
tensorflow tf.norm tf.norm
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/linalg_ops.py#L556-L624) |
Computes the norm of vectors, matrices, and tensors.
#### View aliases
**Main aliases**
[`tf.linalg.norm`](https://www.tensorflow.org/api_docs/python/tf/norm)
```
tf.norm(
tensor, ord='euclidean', axis=None, keepdims=None, name=None
)
```
This function can compute several different vector norms (the 1-norm, the Euclidean or 2-norm, the inf-norm, and in general the p-norm for p > 0) and matrix norms (Frobenius, 1-norm, 2-norm and inf-norm).
| Args |
| `tensor` | `Tensor` of types `float32`, `float64`, `complex64`, `complex128` |
| `ord` | Order of the norm. Supported values are `'fro'`, `'euclidean'`, `1`, `2`, `np.inf` and any positive real number yielding the corresponding p-norm. Default is `'euclidean'` which is equivalent to Frobenius norm if `tensor` is a matrix and equivalent to 2-norm for vectors. Some restrictions apply: a) The Frobenius norm `'fro'` is not defined for vectors, b) If axis is a 2-tuple (matrix norm), only `'euclidean'`, '`fro'`, `1`, `2`, `np.inf` are supported. See the description of `axis` on how to compute norms for a batch of vectors or matrices stored in a tensor. |
| `axis` | If `axis` is `None` (the default), the input is considered a vector and a single vector norm is computed over the entire set of values in the tensor, i.e. `norm(tensor, ord=ord)` is equivalent to `norm(reshape(tensor, [-1]), ord=ord)`. If `axis` is a Python integer, the input is considered a batch of vectors, and `axis` determines the axis in `tensor` over which to compute vector norms. If `axis` is a 2-tuple of Python integers it is considered a batch of matrices and `axis` determines the axes in `tensor` over which to compute a matrix norm. Negative indices are supported. Example: If you are passing a tensor that can be either a matrix or a batch of matrices at runtime, pass `axis=[-2,-1]` instead of `axis=None` to make sure that matrix norms are computed. |
| `keepdims` | If True, the axis indicated in `axis` are kept with size 1. Otherwise, the dimensions in `axis` are removed from the output shape. |
| `name` | The name of the op. |
| Returns |
| `output` | A `Tensor` of the same type as tensor, containing the vector or matrix norms. If `keepdims` is True then the rank of output is equal to the rank of `tensor`. Otherwise, if `axis` is none the output is a scalar, if `axis` is an integer, the rank of `output` is one less than the rank of `tensor`, if `axis` is a 2-tuple the rank of `output` is two less than the rank of `tensor`. |
| Raises |
| `ValueError` | If `ord` or `axis` is invalid. |
numpy compatibility
-------------------
Mostly equivalent to numpy.linalg.norm. Not supported: ord <= 0, 2-norm for matrices, nuclear norm. Other differences: a) If axis is `None`, treats the flattened `tensor` as a vector regardless of rank. b) Explicitly supports 'euclidean' norm as the default, including for higher order tensors.
| programming_docs |
tensorflow tf.eye tf.eye
======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/linalg_ops.py#L192-L237) |
Construct an identity matrix, or a batch of matrices.
#### View aliases
**Main aliases**
[`tf.linalg.eye`](https://www.tensorflow.org/api_docs/python/tf/eye)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.eye`](https://www.tensorflow.org/api_docs/python/tf/eye), [`tf.compat.v1.linalg.eye`](https://www.tensorflow.org/api_docs/python/tf/eye)
```
tf.eye(
num_rows,
num_columns=None,
batch_shape=None,
dtype=tf.dtypes.float32,
name=None
)
```
See also [`tf.ones`](ones), [`tf.zeros`](zeros), [`tf.fill`](fill), [`tf.one_hot`](one_hot).
```
# Construct one identity matrix.
tf.eye(2)
==> [[1., 0.],
[0., 1.]]
# Construct a batch of 3 identity matrices, each 2 x 2.
# batch_identity[i, :, :] is a 2 x 2 identity matrix, i = 0, 1, 2.
batch_identity = tf.eye(2, batch_shape=[3])
# Construct one 2 x 3 "identity" matrix
tf.eye(2, num_columns=3)
==> [[ 1., 0., 0.],
[ 0., 1., 0.]]
```
| Args |
| `num_rows` | Non-negative `int32` scalar `Tensor` giving the number of rows in each batch matrix. |
| `num_columns` | Optional non-negative `int32` scalar `Tensor` giving the number of columns in each batch matrix. Defaults to `num_rows`. |
| `batch_shape` | A list or tuple of Python integers or a 1-D `int32` `Tensor`. If provided, the returned `Tensor` will have leading batch dimensions of this shape. |
| `dtype` | The type of an element in the resulting `Tensor` |
| `name` | A name for this `Op`. Defaults to "eye". |
| Returns |
| A `Tensor` of shape `batch_shape + [num_rows, num_columns]` |
tensorflow tf.rank tf.rank
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L825-L858) |
Returns the rank of a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.rank`](https://www.tensorflow.org/api_docs/python/tf/rank)
```
tf.rank(
input, name=None
)
```
See also [`tf.shape`](shape).
Returns a 0-D `int32` `Tensor` representing the rank of `input`.
#### For example:
```
# shape of tensor 't' is [2, 2, 3]
t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])
tf.rank(t) # 3
```
>
> **Note:** The rank of a tensor is not the same as the rank of a matrix. The rank of a tensor is the number of indices required to uniquely select each element of the tensor. Rank is also known as "order", "degree", or "ndims."
>
| Args |
| `input` | A `Tensor` or `SparseTensor`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `int32`. |
numpy compatibility
-------------------
Equivalent to np.ndim
tensorflow tf.shape_n tf.shape\_n
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L701-L718) |
Returns shape of tensors.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.shape_n`](https://www.tensorflow.org/api_docs/python/tf/shape_n)
```
tf.shape_n(
input,
out_type=tf.dtypes.int32,
name=None
)
```
| Args |
| `input` | A list of at least 1 `Tensor` object with the same type. |
| `out_type` | The specified output type of the operation (`int32` or `int64`). Defaults to [`tf.int32`](../tf#int32)(optional). |
| `name` | A name for the operation (optional). |
| Returns |
| A list with the same length as `input` of `Tensor` objects with type `out_type`. |
tensorflow tf.init_scope tf.init\_scope
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5874-L5976) |
A context manager that lifts ops out of control-flow scopes and function-building graphs.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.init_scope`](https://www.tensorflow.org/api_docs/python/tf/init_scope)
```
@tf_contextlib.contextmanager
tf.init_scope()
```
There is often a need to lift variable initialization ops out of control-flow scopes, function-building graphs, and gradient tapes. Entering an `init_scope` is a mechanism for satisfying these desiderata. In particular, entering an `init_scope` has three effects:
(1) All control dependencies are cleared the moment the scope is entered; this is equivalent to entering the context manager returned from `control_dependencies(None)`, which has the side-effect of exiting control-flow scopes like [`tf.cond`](cond) and [`tf.while_loop`](while_loop).
(2) All operations that are created while the scope is active are lifted into the lowest context on the `context_stack` that is not building a graph function. Here, a context is defined as either a graph or an eager context. Every context switch, i.e., every installation of a graph as the default graph and every switch into eager mode, is logged in a thread-local stack called `context_switches`; the log entry for a context switch is popped from the stack when the context is exited. Entering an `init_scope` is equivalent to crawling up `context_switches`, finding the first context that is not building a graph function, and entering it. A caveat is that if graph mode is enabled but the default graph stack is empty, then entering an `init_scope` will simply install a fresh graph as the default one.
(3) The gradient tape is paused while the scope is active.
When eager execution is enabled, code inside an init\_scope block runs with eager execution enabled even when tracing a [`tf.function`](function). For example:
```
tf.compat.v1.enable_eager_execution()
@tf.function
def func():
# A function constructs TensorFlow graphs,
# it does not execute eagerly.
assert not tf.executing_eagerly()
with tf.init_scope():
# Initialization runs with eager execution enabled
assert tf.executing_eagerly()
```
| Raises |
| `RuntimeError` | if graph state is incompatible with this initialization. |
tensorflow Module: tf.compat Module: tf.compat
=================
Compatibility functions.
The [`tf.compat`](compat) module contains two sets of compatibility functions.
Tensorflow 1.x and 2.x APIs
---------------------------
The [`compat.v1`](compat/v1) and `compat.v2` submodules provide a complete copy of both the [`v1`](compat/v1) and `v2` APIs for backwards and forwards compatibility across TensorFlow versions 1.x and 2.x. See the [migration guide](https://www.tensorflow.org/guide/migrate) for details.
Utilities for writing compatible code
-------------------------------------
Aside from the [`compat.v1`](compat/v1) and `compat.v2` submodules, [`tf.compat`](compat) also contains a set of helper functions for writing code that works in both:
* TensorFlow 1.x and 2.x
* Python 2 and 3
Type collections
----------------
The compatibility module also provides the following aliases for common sets of python types:
* `bytes_or_text_types`
* `complex_types`
* `integral_types`
* `real_types`
Modules
-------
[`v1`](compat/v1) module: Bring in all of the public TensorFlow interface into this module.
Functions
---------
[`as_bytes(...)`](compat/as_bytes): Converts `bytearray`, `bytes`, or unicode python input types to `bytes`.
[`as_str(...)`](compat/as_str)
[`as_str_any(...)`](compat/as_str_any): Converts input to `str` type.
[`as_text(...)`](compat/as_text): Converts any string-like python input types to unicode.
[`dimension_at_index(...)`](compat/dimension_at_index): Compatibility utility required to allow for both V1 and V2 behavior in TF.
[`dimension_value(...)`](compat/dimension_value): Compatibility utility required to allow for both V1 and V2 behavior in TF.
[`forward_compatibility_horizon(...)`](compat/forward_compatibility_horizon): Context manager for testing forward compatibility of generated graphs.
[`forward_compatible(...)`](compat/forward_compatible): Return true if the forward compatibility window has expired.
[`path_to_str(...)`](compat/path_to_str): Converts input which is a `PathLike` object to `str` type.
| Other Members |
| bytes\_or\_text\_types | `(<class 'bytes'>, <class 'str'>)` |
| complex\_types | `(<class 'numbers.Complex'>, <class 'numpy.number'>)` |
| integral\_types | `(<class 'numbers.Integral'>, <class 'numpy.integer'>)` |
| real\_types | `(<class 'numbers.Real'>, <class 'numpy.integer'>, <class 'numpy.floating'>)` |
tensorflow tf.Operation tf.Operation
============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L1969-L2731) |
Represents a graph node that performs computation on tensors.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.Operation`](https://www.tensorflow.org/api_docs/python/tf/Operation)
```
tf.Operation(
node_def,
g,
inputs=None,
output_types=None,
control_inputs=None,
input_types=None,
original_op=None,
op_def=None
)
```
An `Operation` is a node in a [`tf.Graph`](graph) that takes zero or more `Tensor` objects as input, and produces zero or more `Tensor` objects as output. Objects of type `Operation` are created by calling a Python op constructor (such as [`tf.matmul`](linalg/matmul)) within a [`tf.function`](function) or under a [`tf.Graph.as_default`](graph#as_default) context manager.
For example, within a [`tf.function`](function), `c = tf.matmul(a, b)` creates an `Operation` of type "MatMul" that takes tensors `a` and `b` as input, and produces `c` as output.
If a [`tf.compat.v1.Session`](compat/v1/session) is used, an `Operation` of a [`tf.Graph`](graph) can be executed by passing it to `tf.Session.run`. `op.run()` is a shortcut for calling `tf.compat.v1.get_default_session().run(op)`.
| Args |
| `node_def` | `node_def_pb2.NodeDef`. `NodeDef` for the `Operation`. Used for attributes of `node_def_pb2.NodeDef`, typically `name`, `op`, and `device`. The `input` attribute is irrelevant here as it will be computed when generating the model. |
| `g` | `Graph`. The parent graph. |
| `inputs` | list of `Tensor` objects. The inputs to this `Operation`. |
| `output_types` | list of `DType` objects. List of the types of the `Tensors` computed by this operation. The length of this list indicates the number of output endpoints of the `Operation`. |
| `control_inputs` | list of operations or tensors from which to have a control dependency. |
| `input_types` | List of `DType` objects representing the types of the tensors accepted by the `Operation`. By default uses `[x.dtype.base_dtype for x in inputs]`. Operations that expect reference-typed inputs must specify these explicitly. |
| `original_op` | Optional. Used to associate the new `Operation` with an existing `Operation` (for example, a replica with the op that was replicated). |
| `op_def` | Optional. The `op_def_pb2.OpDef` proto that describes the op type that this `Operation` represents. |
| Raises |
| `TypeError` | if control inputs are not Operations or Tensors, or if `node_def` is not a `NodeDef`, or if `g` is not a `Graph`, or if `inputs` are not tensors, or if `inputs` and `input_types` are incompatible. |
| `ValueError` | if the `node_def` name is not valid. |
| Attributes |
| `control_inputs` | The `Operation` objects on which this op has a control dependency. Before this op is executed, TensorFlow will ensure that the operations in `self.control_inputs` have finished executing. This mechanism can be used to run ops sequentially for performance reasons, or to ensure that the side effects of an op are observed in the correct order. |
| `device` | The name of the device to which this op has been assigned, if any. |
| `graph` | The `Graph` that contains this operation. |
| `inputs` | The sequence of `Tensor` objects representing the data inputs of this op. |
| `name` | The full name of this operation. |
| `node_def` | Returns the `NodeDef` representation of this operation. |
| `op_def` | Returns the `OpDef` proto that represents the type of this op. |
| `outputs` | The list of `Tensor` objects representing the outputs of this op. |
| `traceback` | Returns the call stack from when this operation was constructed. |
| `type` | The type of the op (e.g. `"MatMul"`). |
Methods
-------
### `colocation_groups`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2171-L2188)
```
colocation_groups()
```
Returns the list of colocation groups of the op.
### `experimental_set_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2697-L2713)
```
experimental_set_type(
type_proto
)
```
Sets the corresponding node's `experimental_type` field.
See the description of `NodeDef.experimental_type` for more info.
| Args |
| `type_proto` | A FullTypeDef proto message. The root type\_if of this object must be `TFT_PRODUCT`, even for ops which only have a singlre return value. |
### `get_attr`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2633-L2670)
```
get_attr(
name
)
```
Returns the value of the attr of this op with the given `name`.
| Args |
| `name` | The name of the attr to fetch. |
| Returns |
| The value of the attr, as a Python object. |
| Raises |
| `ValueError` | If this op does not have an attr with the given `name`. |
### `run`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2715-L2731)
```
run(
feed_dict=None, session=None
)
```
Runs this operation in a `Session`.
Calling this method will execute all preceding operations that produce the inputs needed for this operation.
>
> **Note:** Before invoking [`Operation.run()`](operation#run), its graph must have been launched in a session, and either a default session must be available, or `session` must be specified explicitly.
>
| Args |
| `feed_dict` | A dictionary that maps `Tensor` objects to feed values. See `tf.Session.run` for a description of the valid feed values. |
| `session` | (Optional.) The `Session` to be used to run to this operation. If none, the default session will be used. |
### `values`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2190-L2192)
```
values()
```
tensorflow tf.nondifferentiable_batch_function tf.nondifferentiable\_batch\_function
=====================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/batch_ops.py#L28-L121) |
Batches the computation done by the decorated function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.nondifferentiable_batch_function`](https://www.tensorflow.org/api_docs/python/tf/nondifferentiable_batch_function)
```
tf.nondifferentiable_batch_function(
num_batch_threads,
max_batch_size,
batch_timeout_micros,
allowed_batch_sizes=None,
max_enqueued_batches=10,
autograph=True,
enable_large_batch_splitting=True
)
```
So, for example, in the following code
```
@batch_function(1, 2, 3)
def layer(a):
return tf.matmul(a, a)
b = layer(w)
```
if more than one session.run call is simultaneously trying to compute `b` the values of `w` will be gathered, non-deterministically concatenated along the first axis, and only one thread will run the computation. See the documentation of the `Batch` op for more details.
Assumes that all arguments of the decorated function are Tensors which will be batched along their first dimension.
SparseTensor is not supported. The return value of the decorated function must be a Tensor or a list/tuple of Tensors.
| Args |
| `num_batch_threads` | Number of scheduling threads for processing batches of work. Determines the number of batches processed in parallel. |
| `max_batch_size` | Batch sizes will never be bigger than this. |
| `batch_timeout_micros` | Maximum number of microseconds to wait before outputting an incomplete batch. |
| `allowed_batch_sizes` | Optional list of allowed batch sizes. If left empty, does nothing. Otherwise, supplies a list of batch sizes, causing the op to pad batches up to one of those sizes. The entries must increase monotonically, and the final entry must equal max\_batch\_size. |
| `max_enqueued_batches` | The maximum depth of the batch queue. Defaults to 10. |
| `autograph` | Whether to use autograph to compile python and eager style code for efficient graph-mode execution. |
| `enable_large_batch_splitting` | The value of this option doesn't affect processing output given the same input; it affects implementation details as stated below: 1. Improve batching efficiency by eliminating unnecessary adding. 2.`max_batch_size` specifies the limit of input and `allowed_batch_sizes` specifies the limit of a task to be processed. API user can give an input of size 128 when 'max\_execution\_batch\_size' is 32 -> implementation can split input of 128 into 4 x 32, schedule concurrent processing, and then return concatenated results corresponding to 128. |
| Returns |
| The decorated function will return the unbatched computation output Tensors. |
tensorflow tf.convert_to_tensor tf.convert\_to\_tensor
======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L1430-L1495) |
Converts the given `value` to a `Tensor`.
```
tf.convert_to_tensor(
value, dtype=None, dtype_hint=None, name=None
)
```
This function converts Python objects of various types to `Tensor` objects. It accepts `Tensor` objects, numpy arrays, Python lists, and Python scalars.
#### For example:
```
import numpy as np
def my_func(arg):
arg = tf.convert_to_tensor(arg, dtype=tf.float32)
return arg
```
```
# The following calls are equivalent.
value_1 = my_func(tf.constant([[1.0, 2.0], [3.0, 4.0]]))
print(value_1)
tf.Tensor(
[[1. 2.]
[3. 4.]], shape=(2, 2), dtype=float32)
value_2 = my_func([[1.0, 2.0], [3.0, 4.0]])
print(value_2)
tf.Tensor(
[[1. 2.]
[3. 4.]], shape=(2, 2), dtype=float32)
value_3 = my_func(np.array([[1.0, 2.0], [3.0, 4.0]], dtype=np.float32))
print(value_3)
tf.Tensor(
[[1. 2.]
[3. 4.]], shape=(2, 2), dtype=float32)
```
This function can be useful when composing a new operation in Python (such as `my_func` in the example above). All standard Python op constructors apply this function to each of their Tensor-valued inputs, which allows those ops to accept numpy arrays, Python lists, and scalars in addition to `Tensor` objects.
>
> **Note:** This function diverges from default Numpy behavior for `float` and `string` types when `None` is present in a Python list or scalar. Rather than silently converting `None` values, an error will be thrown.
>
| Args |
| `value` | An object whose type has a registered `Tensor` conversion function. |
| `dtype` | Optional element type for the returned tensor. If missing, the type is inferred from the type of `value`. |
| `dtype_hint` | Optional element type for the returned tensor, used when dtype is None. In some cases, a caller may not have a dtype in mind when converting to a tensor, so dtype\_hint can be used as a soft preference. If the conversion to `dtype_hint` is not possible, this argument has no effect. |
| `name` | Optional name to use if a new `Tensor` is created. |
| Returns |
| A `Tensor` based on `value`. |
| Raises |
| `TypeError` | If no conversion function is registered for `value` to `dtype`. |
| `RuntimeError` | If a registered conversion function returns an invalid value. |
| `ValueError` | If the `value` is a tensor not of given `dtype` in graph mode. |
| programming_docs |
tensorflow tf.strided_slice tf.strided\_slice
=================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1168-L1305) |
Extracts a strided slice of a tensor (generalized Python array indexing).
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.strided_slice`](https://www.tensorflow.org/api_docs/python/tf/strided_slice)
```
tf.strided_slice(
input_,
begin,
end,
strides=None,
begin_mask=0,
end_mask=0,
ellipsis_mask=0,
new_axis_mask=0,
shrink_axis_mask=0,
var=None,
name=None
)
```
See also [`tf.slice`](slice).
**Instead of calling this op directly most users will want to use the NumPy-style slicing syntax (e.g. `tensor[..., 3:4:-1, tf.newaxis, 3]`), which is supported via [`tf.Tensor.**getitem**`](tensor#__getitem__) and [`tf.Variable.**getitem**`](variable#__getitem__).** The interface of this op is a low-level encoding of the slicing syntax.
Roughly speaking, this op extracts a slice of size `(end-begin)/stride` from the given `input_` tensor. Starting at the location specified by `begin` the slice continues by adding `stride` to the index until all dimensions are not less than `end`. Note that a stride can be negative, which causes a reverse slice.
Given a Python slice `input[spec0, spec1, ..., specn]`, this function will be called as follows.
`begin`, `end`, and `strides` will be vectors of length n. n in general is not equal to the rank of the `input_` tensor.
In each mask field (`begin_mask`, `end_mask`, `ellipsis_mask`, `new_axis_mask`, `shrink_axis_mask`) the ith bit will correspond to the ith spec.
If the ith bit of `begin_mask` is set, `begin[i]` is ignored and the fullest possible range in that dimension is used instead. `end_mask` works analogously, except with the end range.
`foo[5:,:,:3]` on a 7x8x9 tensor is equivalent to `foo[5:7,0:8,0:3]`. `foo[::-1]` reverses a tensor with shape 8.
If the ith bit of `ellipsis_mask` is set, as many unspecified dimensions as needed will be inserted between other dimensions. Only one non-zero bit is allowed in `ellipsis_mask`.
For example `foo[3:5,...,4:5]` on a shape 10x3x3x10 tensor is equivalent to `foo[3:5,:,:,4:5]` and `foo[3:5,...]` is equivalent to `foo[3:5,:,:,:]`.
If the ith bit of `new_axis_mask` is set, then `begin`, `end`, and `stride` are ignored and a new length 1 dimension is added at this point in the output tensor.
For example, `foo[:4, tf.newaxis, :2]` would produce a shape `(4, 1, 2)` tensor.
If the ith bit of `shrink_axis_mask` is set, it implies that the ith specification shrinks the dimensionality by 1, taking on the value at index `begin[i]`. `end[i]` and `strides[i]` are ignored in this case. For example in Python one might do `foo[:, 3, :]` which would result in `shrink_axis_mask` equal to 2.
>
> **Note:** `begin` and `end` are zero-indexed. `strides` entries must be non-zero.
>
```
t = tf.constant([[[1, 1, 1], [2, 2, 2]],
[[3, 3, 3], [4, 4, 4]],
[[5, 5, 5], [6, 6, 6]]])
tf.strided_slice(t, [1, 0, 0], [2, 1, 3], [1, 1, 1]) # [[[3, 3, 3]]]
tf.strided_slice(t, [1, 0, 0], [2, 2, 3], [1, 1, 1]) # [[[3, 3, 3],
# [4, 4, 4]]]
tf.strided_slice(t, [1, -1, 0], [2, -3, 3], [1, -1, 1]) # [[[4, 4, 4],
# [3, 3, 3]]]
```
| Args |
| `input_` | A `Tensor`. |
| `begin` | An `int32` or `int64` `Tensor`. |
| `end` | An `int32` or `int64` `Tensor`. |
| `strides` | An `int32` or `int64` `Tensor`. |
| `begin_mask` | An `int32` mask. |
| `end_mask` | An `int32` mask. |
| `ellipsis_mask` | An `int32` mask. |
| `new_axis_mask` | An `int32` mask. |
| `shrink_axis_mask` | An `int32` mask. |
| `var` | The variable corresponding to `input_` or None |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` the same type as `input`. |
tensorflow tf.Module tf.Module
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/module/module.py#L31-L313) |
Base neural network module class.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.Module`](https://www.tensorflow.org/api_docs/python/tf/Module)
```
tf.Module(
name=None
)
```
A module is a named container for [`tf.Variable`](variable)s, other [`tf.Module`](module)s and functions which apply to user input. For example a dense layer in a neural network might be implemented as a [`tf.Module`](module):
```
class Dense(tf.Module):
def __init__(self, input_dim, output_size, name=None):
super(Dense, self).__init__(name=name)
self.w = tf.Variable(
tf.random.normal([input_dim, output_size]), name='w')
self.b = tf.Variable(tf.zeros([output_size]), name='b')
def __call__(self, x):
y = tf.matmul(x, self.w) + self.b
return tf.nn.relu(y)
```
You can use the Dense layer as you would expect:
```
d = Dense(input_dim=3, output_size=2)
d(tf.ones([1, 3]))
<tf.Tensor: shape=(1, 2), dtype=float32, numpy=..., dtype=float32)>
```
By subclassing [`tf.Module`](module) instead of `object` any [`tf.Variable`](variable) or [`tf.Module`](module) instances assigned to object properties can be collected using the `variables`, `trainable_variables` or `submodules` property:
```
d.variables
(<tf.Variable 'b:0' shape=(2,) dtype=float32, numpy=...,
dtype=float32)>,
<tf.Variable 'w:0' shape=(3, 2) dtype=float32, numpy=..., dtype=float32)>)
```
Subclasses of [`tf.Module`](module) can also take advantage of the `_flatten` method which can be used to implement tracking of any other types.
All [`tf.Module`](module) classes have an associated [`tf.name_scope`](name_scope) which can be used to group operations in TensorBoard and create hierarchies for variable names which can help with debugging. We suggest using the name scope when creating nested submodules/parameters or for forward methods whose graph you might want to inspect in TensorBoard. You can enter the name scope explicitly using `with self.name_scope:` or you can annotate methods (apart from `__init__`) with [`@tf.Module.with_name_scope`](module#with_name_scope).
```
class MLP(tf.Module):
def __init__(self, input_size, sizes, name=None):
super(MLP, self).__init__(name=name)
self.layers = []
with self.name_scope:
for size in sizes:
self.layers.append(Dense(input_dim=input_size, output_size=size))
input_size = size
@tf.Module.with_name_scope
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
```
```
module = MLP(input_size=5, sizes=[5, 5])
module.variables
(<tf.Variable 'mlp/b:0' shape=(5,) dtype=float32, numpy=..., dtype=float32)>,
<tf.Variable 'mlp/w:0' shape=(5, 5) dtype=float32, numpy=...,
dtype=float32)>,
<tf.Variable 'mlp/b:0' shape=(5,) dtype=float32, numpy=..., dtype=float32)>,
<tf.Variable 'mlp/w:0' shape=(5, 5) dtype=float32, numpy=...,
dtype=float32)>)
```
| Attributes |
| `name` | Returns the name of this module as passed or determined in the ctor.
**Note:** This is not the same as the `self.name_scope.name` which includes parent module names.
|
| `name_scope` | Returns a [`tf.name_scope`](name_scope) instance for this class. |
| `non_trainable_variables` | Sequence of non-trainable variables owned by this module and its submodules.
**Note:** this method uses reflection to find variables on the current instance and submodules. For performance reasons you may wish to cache the result of calling this method if you don't expect the return value to change.
|
| `submodules` | Sequence of all sub-modules. Submodules are modules which are properties of this module, or found as properties of modules which are properties of this module (and so on).
```
a = tf.Module()
b = tf.Module()
c = tf.Module()
a.b = b
b.c = c
list(a.submodules) == [b, c]
True
list(b.submodules) == [c]
True
list(c.submodules) == []
True
```
|
| `trainable_variables` | Sequence of trainable variables owned by this module and its submodules.
**Note:** this method uses reflection to find variables on the current instance and submodules. For performance reasons you may wish to cache the result of calling this method if you don't expect the return value to change.
|
| `variables` | Sequence of variables owned by this module and its submodules.
**Note:** this method uses reflection to find variables on the current instance and submodules. For performance reasons you may wish to cache the result of calling this method if you don't expect the return value to change.
|
Methods
-------
### `with_name_scope`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/module/module.py#L282-L313)
```
@classmethod
with_name_scope(
method
)
```
Decorator to automatically enter the module name scope.
```
class MyModule(tf.Module):
@tf.Module.with_name_scope
def __call__(self, x):
if not hasattr(self, 'w'):
self.w = tf.Variable(tf.random.normal([x.shape[1], 3]))
return tf.matmul(x, self.w)
```
Using the above module would produce [`tf.Variable`](variable)s and [`tf.Tensor`](tensor)s whose names included the module name:
```
mod = MyModule()
mod(tf.ones([1, 2]))
<tf.Tensor: shape=(1, 3), dtype=float32, numpy=..., dtype=float32)>
mod.w
<tf.Variable 'my_module/Variable:0' shape=(2, 3) dtype=float32,
numpy=..., dtype=float32)>
```
| Args |
| `method` | The method to wrap. |
| Returns |
| The original method wrapped such that it enters the module's name scope. |
tensorflow tf.no_gradient tf.no\_gradient
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2785-L2817) |
Specifies that ops of type `op_type` is not differentiable.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.NoGradient`](https://www.tensorflow.org/api_docs/python/tf/no_gradient), [`tf.compat.v1.NotDifferentiable`](https://www.tensorflow.org/api_docs/python/tf/no_gradient), [`tf.compat.v1.no_gradient`](https://www.tensorflow.org/api_docs/python/tf/no_gradient)
```
tf.no_gradient(
op_type
)
```
This function should *not* be used for operations that have a well-defined gradient that is not yet implemented.
This function is only used when defining a new op type. It may be used for ops such as [`tf.size()`](size) that are not differentiable. For example:
```
tf.no_gradient("Size")
```
The gradient computed for 'op\_type' will then propagate zeros.
For ops that have a well-defined gradient but are not yet implemented, no declaration should be made, and an error *must* be thrown if an attempt to request its gradient is made.
| Args |
| `op_type` | The string type of an operation. This corresponds to the `OpDef.name` field for the proto that defines the operation. |
| Raises |
| `TypeError` | If `op_type` is not a string. |
tensorflow tf.py_function tf.py\_function
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/script_ops.py#L422-L523) |
Wraps a python function into a TensorFlow op that executes it eagerly.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.py_function`](https://www.tensorflow.org/api_docs/python/tf/py_function)
```
tf.py_function(
func, inp, Tout, name=None
)
```
This function allows expressing computations in a TensorFlow graph as Python functions. In particular, it wraps a Python function `func` in a once-differentiable TensorFlow operation that executes it with eager execution enabled. As a consequence, [`tf.py_function`](py_function) makes it possible to express control flow using Python constructs (`if`, `while`, `for`, etc.), instead of TensorFlow control flow constructs ([`tf.cond`](cond), [`tf.while_loop`](while_loop)). For example, you might use [`tf.py_function`](py_function) to implement the log huber function:
```
def log_huber(x, m):
if tf.abs(x) <= m:
return x**2
else:
return m**2 * (1 - 2 * tf.math.log(m) + tf.math.log(x**2))
x = tf.constant(1.0)
m = tf.constant(2.0)
with tf.GradientTape() as t:
t.watch([x, m])
y = tf.py_function(func=log_huber, inp=[x, m], Tout=tf.float32)
dy_dx = t.gradient(y, x)
assert dy_dx.numpy() == 2.0
```
You can also use [`tf.py_function`](py_function) to debug your models at runtime using Python tools, i.e., you can isolate portions of your code that you want to debug, wrap them in Python functions and insert `pdb` tracepoints or print statements as desired, and wrap those functions in [`tf.py_function`](py_function).
For more information on eager execution, see the [Eager guide](https://tensorflow.org/guide/eager).
[`tf.py_function`](py_function) is similar in spirit to [`tf.compat.v1.py_func`](compat/v1/py_func), but unlike the latter, the former lets you use TensorFlow operations in the wrapped Python function. In particular, while [`tf.compat.v1.py_func`](compat/v1/py_func) only runs on CPUs and wraps functions that take NumPy arrays as inputs and return NumPy arrays as outputs, [`tf.py_function`](py_function) can be placed on GPUs and wraps functions that take Tensors as inputs, execute TensorFlow operations in their bodies, and return Tensors as outputs.
>
> **Note:** We recommend to avoid using [`tf.py_function`](py_function) outside of prototyping and experimentation due to the following known limitations:
>
* Calling [`tf.py_function`](py_function) will acquire the Python Global Interpreter Lock (GIL) that allows only one thread to run at any point in time. This will preclude efficient parallelization and distribution of the execution of the program.
* The body of the function (i.e. `func`) will not be serialized in a `GraphDef`. Therefore, you should not use this function if you need to serialize your model and restore it in a different environment.
* The operation must run in the same address space as the Python program that calls [`tf.py_function()`](py_function). If you are using distributed TensorFlow, you must run a [`tf.distribute.Server`](distribute/server) in the same process as the program that calls [`tf.py_function()`](py_function) and you must pin the created operation to a device in that server (e.g. using `with tf.device():`).
* Currently [`tf.py_function`](py_function) is not compatible with XLA. Calling [`tf.py_function`](py_function) inside [`tf.function(jit_comiple=True)`](function) will raise an error.
| Args |
| `func` | A Python function that accepts `inp` as arguments, and returns a value (or list of values) whose type is described by `Tout`. |
| `inp` | Input arguments for `func`. A list whose elements are `Tensor`s or `CompositeTensors` (such as [`tf.RaggedTensor`](raggedtensor)); or a single `Tensor` or `CompositeTensor`. |
| `Tout` | The type(s) of the value(s) returned by `func`. One of the following. * If `func` returns a `Tensor` (or a value that can be converted to a Tensor): the [`tf.DType`](dtypes/dtype) for that value.
* If `func` returns a `CompositeTensor`: The [`tf.TypeSpec`](typespec) for that value.
* If `func` returns `None`: the empty list (`[]`).
* If `func` returns a list of `Tensor` and `CompositeTensor` values: a corresponding list of [`tf.DType`](dtypes/dtype)s and [`tf.TypeSpec`](typespec)s for each value.
|
| `name` | A name for the operation (optional). |
| Returns |
| The value(s) computed by `func`: a `Tensor`, `CompositeTensor`, or list of `Tensor` and `CompositeTensor`; or an empty list if `func` returns `None`. |
tensorflow tf.Graph tf.Graph
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L3012-L5431) |
A TensorFlow computation, represented as a dataflow graph.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.Graph`](https://www.tensorflow.org/api_docs/python/tf/Graph)
```
tf.Graph()
```
Graphs are used by [`tf.function`](function)s to represent the function's computations. Each graph contains a set of [`tf.Operation`](operation) objects, which represent units of computation; and [`tf.Tensor`](tensor) objects, which represent the units of data that flow between operations.
### Using graphs directly (deprecated)
A [`tf.Graph`](graph) can be constructed and used directly without a [`tf.function`](function), as was required in TensorFlow 1, but this is deprecated and it is recommended to use a [`tf.function`](function) instead. If a graph is directly used, other deprecated TensorFlow 1 classes are also required to execute the graph, such as a [`tf.compat.v1.Session`](compat/v1/session).
A default graph can be registered with the [`tf.Graph.as_default`](graph#as_default) context manager. Then, operations will be added to the graph instead of being executed eagerly. For example:
```
g = tf.Graph()
with g.as_default():
# Define operations and tensors in `g`.
c = tf.constant(30.0)
assert c.graph is g
```
[`tf.compat.v1.get_default_graph()`](compat/v1/get_default_graph) can be used to obtain the default graph.
Important note: This class *is not* thread-safe for graph construction. All operations should be created from a single thread, or external synchronization must be provided. Unless otherwise specified, all methods are not thread-safe.
A `Graph` instance supports an arbitrary number of "collections" that are identified by name. For convenience when building a large graph, collections can store groups of related objects: for example, the [`tf.Variable`](variable) uses a collection (named `tf.GraphKeys.GLOBAL_VARIABLES`) for all variables that are created during the construction of a graph. The caller may define additional collections by specifying a new name.
| Attributes |
| `building_function` | Returns True iff this graph represents a function. |
| `collections` | Returns the names of the collections known to this graph. |
| `finalized` | True if this graph has been finalized. |
| `graph_def_versions` | The GraphDef version information of this graph. For details on the meaning of each version, see [`GraphDef`](https://www.tensorflow.org/code/tensorflow/core/framework/graph.proto). |
| `seed` | The graph-level random seed of this graph. |
| `version` | Returns a version number that increases as ops are added to the graph. Note that this is unrelated to the [`tf.Graph.graph_def_versions`](graph#graph_def_versions). |
Methods
-------
### `add_to_collection`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4215-L4231)
```
add_to_collection(
name, value
)
```
Stores `value` in the collection with the given `name`.
Note that collections are not sets, so it is possible to add a value to a collection several times.
| Args |
| `name` | The key for the collection. The `GraphKeys` class contains many standard names for collections. |
| `value` | The value to add to the collection. |
### `add_to_collections`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4233-L4252)
```
add_to_collections(
names, value
)
```
Stores `value` in the collections given by `names`.
Note that collections are not sets, so it is possible to add a value to a collection several times. This function makes sure that duplicates in `names` are ignored, but it will not check for pre-existing membership of `value` in any of the collections in `names`.
`names` can be any iterable, but if `names` is a string, it is treated as a single collection name.
| Args |
| `names` | The keys for the collections to add to. The `GraphKeys` class contains many standard names for collections. |
| `value` | The value to add to the collections. |
### `as_default`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4168-L4208)
```
as_default()
```
Returns a context manager that makes this `Graph` the default graph.
This method should be used if you want to create multiple graphs in the same process. For convenience, a global default graph is provided, and all ops will be added to this graph if you do not create a new graph explicitly.
Use this method with the `with` keyword to specify that ops created within the scope of a block should be added to this graph. In this case, once the scope of the `with` is exited, the previous default graph is set again as default. There is a stack, so it's ok to have multiple nested levels of `as_default` calls.
The default graph is a property of the current thread. If you create a new thread, and wish to use the default graph in that thread, you must explicitly add a `with g.as_default():` in that thread's function.
The following code examples are equivalent:
```
# 1. Using Graph.as_default():
g = tf.Graph()
with g.as_default():
c = tf.constant(5.0)
assert c.graph is g
# 2. Constructing and making default:
with tf.Graph().as_default() as g:
c = tf.constant(5.0)
assert c.graph is g
```
If eager execution is enabled ops created under this context manager will be added to the graph instead of executed eagerly.
| Returns |
| A context manager for using this graph as the default graph. |
### `as_graph_def`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L3542-L3569)
```
as_graph_def(
from_version=None, add_shapes=False
)
```
Returns a serialized `GraphDef` representation of this graph.
The serialized `GraphDef` can be imported into another `Graph` (using [`tf.import_graph_def`](graph_util/import_graph_def)) or used with the [C++ Session API](https://www.tensorflow.org/versions/r2.9/api_docs/api_docs/cc/index).
This method is thread-safe.
| Args |
| `from_version` | Optional. If this is set, returns a `GraphDef` containing only the nodes that were added to this graph since its `version` property had the given value. |
| `add_shapes` | If true, adds an "\_output\_shapes" list attr to each node with the inferred shapes of each of its outputs. |
| Returns |
| A [`GraphDef`](https://www.tensorflow.org/code/tensorflow/core/framework/graph.proto) protocol buffer. |
| Raises |
| `ValueError` | If the `graph_def` would be too large. |
### `as_graph_element`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L3918-L3952)
```
as_graph_element(
obj, allow_tensor=True, allow_operation=True
)
```
Returns the object referred to by `obj`, as an `Operation` or `Tensor`.
This function validates that `obj` represents an element of this graph, and gives an informative error message if it is not.
This function is the canonical way to get/validate an object of one of the allowed types from an external argument reference in the Session API.
This method may be called concurrently from multiple threads.
| Args |
| `obj` | A `Tensor`, an `Operation`, or the name of a tensor or operation. Can also be any object with an `_as_graph_element()` method that returns a value of one of these types. Note: `_as_graph_element` will be called inside the graph's lock and so may not modify the graph. |
| `allow_tensor` | If true, `obj` may refer to a `Tensor`. |
| `allow_operation` | If true, `obj` may refer to an `Operation`. |
| Returns |
| The `Tensor` or `Operation` in the Graph corresponding to `obj`. |
| Raises |
| `TypeError` | If `obj` is not a type we support attempting to convert to types. |
| `ValueError` | If `obj` is of an appropriate type but invalid. For example, an invalid string. |
| `KeyError` | If `obj` is not an object in the graph. |
### `clear_collection`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4324-L4334)
```
clear_collection(
name
)
```
Clears all values in a collection.
| Args |
| `name` | The key for the collection. The `GraphKeys` class contains many standard names for collections. |
### `colocate_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4581-L4658)
```
@tf_contextlib.contextmanager
colocate_with(
op, ignore_existing=False
)
```
Returns a context manager that specifies an op to colocate with.
>
> **Note:** this function is not for public use, only for internal libraries.
>
#### For example:
```
a = tf.Variable([1.0])
with g.colocate_with(a):
b = tf.constant(1.0)
c = tf.add(a, b)
```
`b` and `c` will always be colocated with `a`, no matter where `a` is eventually placed.
>
> **Note:** Using a colocation scope resets any existing device constraints.
>
If `op` is `None` then `ignore_existing` must be `True` and the new scope resets all colocation and device constraints.
| Args |
| `op` | The op to colocate all created ops with, or `None`. |
| `ignore_existing` | If true, only applies colocation of this op within the context, rather than applying all colocation properties on the stack. If `op` is `None`, this value must be `True`. |
| Raises |
| `ValueError` | if op is None but ignore\_existing is False. |
| Yields |
| A context manager that specifies the op with which to colocate newly created ops. |
### `container`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4764-L4814)
```
@tf_contextlib.contextmanager
container(
container_name
)
```
Returns a context manager that specifies the resource container to use.
Stateful operations, such as variables and queues, can maintain their states on devices so that they can be shared by multiple processes. A resource container is a string name under which these stateful operations are tracked. These resources can be released or cleared with `tf.Session.reset()`.
#### For example:
```
with g.container('experiment0'):
# All stateful Operations constructed in this context will be placed
# in resource container "experiment0".
v1 = tf.Variable([1.0])
v2 = tf.Variable([2.0])
with g.container("experiment1"):
# All stateful Operations constructed in this context will be
# placed in resource container "experiment1".
v3 = tf.Variable([3.0])
q1 = tf.queue.FIFOQueue(10, tf.float32)
# All stateful Operations constructed in this context will be
# be created in the "experiment0".
v4 = tf.Variable([4.0])
q1 = tf.queue.FIFOQueue(20, tf.float32)
with g.container(""):
# All stateful Operations constructed in this context will be
# be placed in the default resource container.
v5 = tf.Variable([5.0])
q3 = tf.queue.FIFOQueue(30, tf.float32)
# Resets container "experiment0", after which the state of v1, v2, v4, q1
# will become undefined (such as uninitialized).
tf.Session.reset(target, ["experiment0"])
```
| Args |
| `container_name` | container name string. |
| Returns |
| A context manager for defining resource containers for stateful ops, yields the container name. |
### `control_dependencies`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4945-L5056)
```
control_dependencies(
control_inputs
)
```
Returns a context manager that specifies control dependencies.
Use with the `with` keyword to specify that all operations constructed within the context should have control dependencies on `control_inputs`. For example:
```
with g.control_dependencies([a, b, c]):
# `d` and `e` will only run after `a`, `b`, and `c` have executed.
d = ...
e = ...
```
Multiple calls to `control_dependencies()` can be nested, and in that case a new `Operation` will have control dependencies on the union of `control_inputs` from all active contexts.
```
with g.control_dependencies([a, b]):
# Ops constructed here run after `a` and `b`.
with g.control_dependencies([c, d]):
# Ops constructed here run after `a`, `b`, `c`, and `d`.
```
You can pass None to clear the control dependencies:
```
with g.control_dependencies([a, b]):
# Ops constructed here run after `a` and `b`.
with g.control_dependencies(None):
# Ops constructed here run normally, not waiting for either `a` or `b`.
with g.control_dependencies([c, d]):
# Ops constructed here run after `c` and `d`, also not waiting
# for either `a` or `b`.
```
>
> **Note:** The control dependencies context applies *only* to ops that are constructed within the context. Merely using an op or tensor in the context does not add a control dependency. The following example illustrates this point:
>
```
# WRONG
def my_func(pred, tensor):
t = tf.matmul(tensor, tensor)
with tf.control_dependencies([pred]):
# The matmul op is created outside the context, so no control
# dependency will be added.
return t
# RIGHT
def my_func(pred, tensor):
with tf.control_dependencies([pred]):
# The matmul op is created in the context, so a control dependency
# will be added.
return tf.matmul(tensor, tensor)
```
Also note that though execution of ops created under this scope will trigger execution of the dependencies, the ops created under this scope might still be pruned from a normal tensorflow graph. For example, in the following snippet of code the dependencies are never executed:
```
loss = model.loss()
with tf.control_dependencies(dependencies):
loss = loss + tf.constant(1) # note: dependencies ignored in the
# backward pass
return tf.gradients(loss, model.variables)
```
This is because evaluating the gradient graph does not require evaluating the constant(1) op created in the forward pass.
| Args |
| `control_inputs` | A list of `Operation` or `Tensor` objects which must be executed or computed before running the operations defined in the context. Can also be `None` to clear the control dependencies. |
| Returns |
| A context manager that specifies control dependencies for all operations constructed within the context. |
| Raises |
| `TypeError` | If `control_inputs` is not a list of `Operation` or `Tensor` objects. |
### `create_op`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L3636-L3693)
```
create_op(
op_type,
inputs,
dtypes=None,
input_types=None,
name=None,
attrs=None,
op_def=None,
compute_shapes=True,
compute_device=True
)
```
Creates an `Operation` in this graph. (deprecated arguments)
This is a low-level interface for creating an `Operation`. Most programs will not call this method directly, and instead use the Python op constructors, such as [`tf.constant()`](constant), which add ops to the default graph.
| Args |
| `op_type` | The `Operation` type to create. This corresponds to the `OpDef.name` field for the proto that defines the operation. |
| `inputs` | A list of `Tensor` objects that will be inputs to the `Operation`. |
| `dtypes` | (Optional) A list of `DType` objects that will be the types of the tensors that the operation produces. |
| `input_types` | (Optional.) A list of `DType`s that will be the types of the tensors that the operation consumes. By default, uses the base `DType` of each input in `inputs`. Operations that expect reference-typed inputs must specify `input_types` explicitly. |
| `name` | (Optional.) A string name for the operation. If not specified, a name is generated based on `op_type`. |
| `attrs` | (Optional.) A dictionary where the key is the attribute name (a string) and the value is the respective `attr` attribute of the `NodeDef` proto that will represent the operation (an `AttrValue` proto). |
| `op_def` | (Optional.) The `OpDef` proto that describes the `op_type` that the operation will have. |
| `compute_shapes` | (Optional.) Deprecated. Has no effect (shapes are always computed). |
| `compute_device` | (Optional.) If True, device functions will be executed to compute the device property of the Operation. |
| Raises |
| `TypeError` | if any of the inputs is not a `Tensor`. |
| `ValueError` | if colocation conflicts with existing device assignment. |
| Returns |
| An `Operation` object. |
### `device`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4667-L4736)
```
@tf_contextlib.contextmanager
device(
device_name_or_function
)
```
Returns a context manager that specifies the default device to use.
The `device_name_or_function` argument may either be a device name string, a device function, or None:
* If it is a device name string, all operations constructed in this context will be assigned to the device with that name, unless overridden by a nested `device()` context.
* If it is a function, it will be treated as a function from Operation objects to device name strings, and invoked each time a new Operation is created. The Operation will be assigned to the device with the returned name.
* If it is None, all `device()` invocations from the enclosing context will be ignored.
For information about the valid syntax of device name strings, see the documentation in [`DeviceNameUtils`](https://www.tensorflow.org/code/tensorflow/core/util/device_name_utils.h).
#### For example:
```
with g.device('/device:GPU:0'):
# All operations constructed in this context will be placed
# on GPU 0.
with g.device(None):
# All operations constructed in this context will have no
# assigned device.
# Defines a function from `Operation` to device string.
def matmul_on_gpu(n):
if n.type == "MatMul":
return "/device:GPU:0"
else:
return "/cpu:0"
with g.device(matmul_on_gpu):
# All operations of type "MatMul" constructed in this context
# will be placed on GPU 0; all other operations will be placed
# on CPU 0.
```
>
> **Note:** The device scope may be overridden by op wrappers or other library code. For example, a variable assignment op `v.assign()` must be colocated with the [`tf.Variable`](variable) `v`, and incompatible device scopes will be ignored.
>
| Args |
| `device_name_or_function` | The device name or function to use in the context. |
| Yields |
| A context manager that specifies the default device to use for newly created ops. |
| Raises |
| `RuntimeError` | If device scopes are not properly nested. |
### `finalize`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L3397-L3405)
```
finalize()
```
Finalizes this graph, making it read-only.
After calling `g.finalize()`, no new operations can be added to `g`. This method is used to ensure that no operations are added to a graph when it is shared between multiple threads, for example when using a [`tf.compat.v1.train.QueueRunner`](compat/v1/train/queuerunner).
### `get_all_collection_keys`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4319-L4322)
```
get_all_collection_keys()
```
Returns a list of collections used in this graph.
### `get_collection`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4279-L4317)
```
get_collection(
name, scope=None
)
```
Returns a list of values in the collection with the given `name`.
This is different from `get_collection_ref()` which always returns the actual collection list if it exists in that it returns a new list each time it is called.
| Args |
| `name` | The key for the collection. For example, the `GraphKeys` class contains many standard names for collections. |
| `scope` | (Optional.) A string. If supplied, the resulting list is filtered to include only items whose `name` attribute matches `scope` using `re.match`. Items without a `name` attribute are never returned if a scope is supplied. The choice of `re.match` means that a `scope` without special tokens filters by prefix. |
| Returns |
| The list of values in the collection with the given `name`, or an empty list if no value has been added to that collection. The list contains the values in the order under which they were collected. |
### `get_collection_ref`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4254-L4277)
```
get_collection_ref(
name
)
```
Returns a list of values in the collection with the given `name`.
If the collection exists, this returns the list itself, which can be modified in place to change the collection. If the collection does not exist, it is created as an empty list and the list is returned.
This is different from `get_collection()` which always returns a copy of the collection list if it exists and never creates an empty collection.
| Args |
| `name` | The key for the collection. For example, the `GraphKeys` class contains many standard names for collections. |
| Returns |
| The list of values in the collection with the given `name`, or an empty list if no value has been added to that collection. |
### `get_name_scope`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4547-L4562)
```
get_name_scope()
```
Returns the current name scope.
#### For example:
```
with tf.name_scope('scope1'):
with tf.name_scope('scope2'):
print(tf.compat.v1.get_default_graph().get_name_scope())
```
would print the string `scope1/scope2`.
| Returns |
| A string representing the current name scope. |
### `get_operation_by_name`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4061-L4080)
```
get_operation_by_name(
name
)
```
Returns the `Operation` with the given `name`.
This method may be called concurrently from multiple threads.
| Args |
| `name` | The name of the `Operation` to return. |
| Returns |
| The `Operation` with the given `name`. |
| Raises |
| `TypeError` | If `name` is not a string. |
| `KeyError` | If `name` does not correspond to an operation in this graph. |
### `get_operations`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4043-L4059)
```
get_operations()
```
Return the list of operations in the graph.
You can modify the operations in place, but modifications to the list such as inserts/delete have no effect on the list of operations known to the graph.
This method may be called concurrently from multiple threads.
| Returns |
| A list of Operations. |
### `get_tensor_by_name`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4109-L4128)
```
get_tensor_by_name(
name
)
```
Returns the `Tensor` with the given `name`.
This method may be called concurrently from multiple threads.
| Args |
| `name` | The name of the `Tensor` to return. |
| Returns |
| The `Tensor` with the given `name`. |
| Raises |
| `TypeError` | If `name` is not a string. |
| `KeyError` | If `name` does not correspond to a tensor in this graph. |
### `gradient_override_map`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5201-L5260)
```
@tf_contextlib.contextmanager
gradient_override_map(
op_type_map
)
```
EXPERIMENTAL: A context manager for overriding gradient functions.
This context manager can be used to override the gradient function that will be used for ops within the scope of the context.
#### For example:
```
@tf.RegisterGradient("CustomSquare")
def _custom_square_grad(op, grad):
# ...
with tf.Graph().as_default() as g:
c = tf.constant(5.0)
s_1 = tf.square(c) # Uses the default gradient for tf.square.
with g.gradient_override_map({"Square": "CustomSquare"}):
s_2 = tf.square(s_2) # Uses _custom_square_grad to compute the
# gradient of s_2.
```
| Args |
| `op_type_map` | A dictionary mapping op type strings to alternative op type strings. |
| Returns |
| A context manager that sets the alternative op type to be used for one or more ops created in that context. |
| Raises |
| `TypeError` | If `op_type_map` is not a dictionary mapping strings to strings. |
### `is_feedable`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5268-L5270)
```
is_feedable(
tensor
)
```
Returns `True` if and only if `tensor` is feedable.
### `is_fetchable`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5276-L5281)
```
is_fetchable(
tensor_or_op
)
```
Returns `True` if and only if `tensor_or_op` is fetchable.
### `name_scope`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4373-L4491)
```
@tf_contextlib.contextmanager
name_scope(
name
)
```
Returns a context manager that creates hierarchical names for operations.
A graph maintains a stack of name scopes. A `with name_scope(...):` statement pushes a new name onto the stack for the lifetime of the context.
The `name` argument will be interpreted as follows:
* A string (not ending with '/') will create a new name scope, in which `name` is appended to the prefix of all operations created in the context. If `name` has been used before, it will be made unique by calling `self.unique_name(name)`.
* A scope previously captured from a `with g.name_scope(...) as scope:` statement will be treated as an "absolute" name scope, which makes it possible to re-enter existing scopes.
* A value of `None` or the empty string will reset the current name scope to the top-level (empty) name scope.
#### For example:
```
with tf.Graph().as_default() as g:
c = tf.constant(5.0, name="c")
assert c.op.name == "c"
c_1 = tf.constant(6.0, name="c")
assert c_1.op.name == "c_1"
# Creates a scope called "nested"
with g.name_scope("nested") as scope:
nested_c = tf.constant(10.0, name="c")
assert nested_c.op.name == "nested/c"
# Creates a nested scope called "inner".
with g.name_scope("inner"):
nested_inner_c = tf.constant(20.0, name="c")
assert nested_inner_c.op.name == "nested/inner/c"
# Create a nested scope called "inner_1".
with g.name_scope("inner"):
nested_inner_1_c = tf.constant(30.0, name="c")
assert nested_inner_1_c.op.name == "nested/inner_1/c"
# Treats `scope` as an absolute name scope, and
# switches to the "nested/" scope.
with g.name_scope(scope):
nested_d = tf.constant(40.0, name="d")
assert nested_d.op.name == "nested/d"
with g.name_scope(""):
e = tf.constant(50.0, name="e")
assert e.op.name == "e"
```
The name of the scope itself can be captured by `with g.name_scope(...) as scope:`, which stores the name of the scope in the variable `scope`. This value can be used to name an operation that represents the overall result of executing the ops in a scope. For example:
```
inputs = tf.constant(...)
with g.name_scope('my_layer') as scope:
weights = tf.Variable(..., name="weights")
biases = tf.Variable(..., name="biases")
affine = tf.matmul(inputs, weights) + biases
output = tf.nn.relu(affine, name=scope)
```
>
> **Note:** This constructor validates the given `name`. Valid scope names match one of the following regular expressions:
>
```
[A-Za-z0-9.][A-Za-z0-9_.\-/]* (for scopes at the root)
[A-Za-z0-9_.\-/]* (for other scopes)
```
| Args |
| `name` | A name for the scope. |
| Returns |
| A context manager that installs `name` as a new name scope. |
| Raises |
| `ValueError` | If `name` is not a valid scope name, according to the rules above. |
### `prevent_feeding`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5264-L5266)
```
prevent_feeding(
tensor
)
```
Marks the given `tensor` as unfeedable in this graph.
### `prevent_fetching`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5272-L5274)
```
prevent_fetching(
op
)
```
Marks the given `op` as unfetchable in this graph.
### `switch_to_thread_local`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5283-L5298)
```
switch_to_thread_local()
```
Make device, colocation and dependencies stacks thread-local.
Device, colocation and dependencies stacks are not thread-local be default. If multiple threads access them, then the state is shared. This means that one thread may affect the behavior of another thread.
After this method is called, the stacks become thread-local. If multiple threads access them, then the state is not shared. Each thread uses its own value; a thread doesn't affect other threads by mutating such a stack.
The initial value for every thread's stack is set to the current value of the stack when `switch_to_thread_local()` was first called.
### `unique_name`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L4495-L4545)
```
unique_name(
name, mark_as_used=True
)
```
Return a unique operation name for `name`.
>
> **Note:** You rarely need to call `unique_name()` directly. Most of the time you just need to create `with g.name_scope()` blocks to generate structured names.
>
`unique_name` is used to generate structured names, separated by `"/"`, to help identify operations when debugging a graph. Operation names are displayed in error messages reported by the TensorFlow runtime, and in various visualization tools such as TensorBoard.
If `mark_as_used` is set to `True`, which is the default, a new unique name is created and marked as in use. If it's set to `False`, the unique name is returned without actually being marked as used. This is useful when the caller simply wants to know what the name to be created will be.
| Args |
| `name` | The name for an operation. |
| `mark_as_used` | Whether to mark this name as being used. |
| Returns |
| A string to be passed to `create_op()` that will be used to name the operation being created. |
| programming_docs |
tensorflow Module: tf.debugging Module: tf.debugging
====================
Public API for tf.debugging namespace.
Modules
-------
[`experimental`](debugging/experimental) module: Public API for tf.debugging.experimental namespace.
Functions
---------
[`Assert(...)`](debugging/assert): Asserts that the given condition is true.
[`assert_all_finite(...)`](debugging/assert_all_finite): Assert that the tensor does not contain any NaN's or Inf's.
[`assert_equal(...)`](debugging/assert_equal): Assert the condition `x == y` holds element-wise.
[`assert_greater(...)`](debugging/assert_greater): Assert the condition `x > y` holds element-wise.
[`assert_greater_equal(...)`](debugging/assert_greater_equal): Assert the condition `x >= y` holds element-wise.
[`assert_integer(...)`](debugging/assert_integer): Assert that `x` is of integer dtype.
[`assert_less(...)`](debugging/assert_less): Assert the condition `x < y` holds element-wise.
[`assert_less_equal(...)`](debugging/assert_less_equal): Assert the condition `x <= y` holds element-wise.
[`assert_near(...)`](debugging/assert_near): Assert the condition `x` and `y` are close element-wise.
[`assert_negative(...)`](debugging/assert_negative): Assert the condition `x < 0` holds element-wise.
[`assert_non_negative(...)`](debugging/assert_non_negative): Assert the condition `x >= 0` holds element-wise.
[`assert_non_positive(...)`](debugging/assert_non_positive): Assert the condition `x <= 0` holds element-wise.
[`assert_none_equal(...)`](debugging/assert_none_equal): Assert the condition `x != y` holds for all elements.
[`assert_positive(...)`](debugging/assert_positive): Assert the condition `x > 0` holds element-wise.
[`assert_proper_iterable(...)`](debugging/assert_proper_iterable): Static assert that values is a "proper" iterable.
[`assert_rank(...)`](debugging/assert_rank): Assert that `x` has rank equal to `rank`.
[`assert_rank_at_least(...)`](debugging/assert_rank_at_least): Assert that `x` has rank of at least `rank`.
[`assert_rank_in(...)`](debugging/assert_rank_in): Assert that `x` has a rank in `ranks`.
[`assert_same_float_dtype(...)`](debugging/assert_same_float_dtype): Validate and return float type based on `tensors` and `dtype`.
[`assert_scalar(...)`](debugging/assert_scalar): Asserts that the given `tensor` is a scalar.
[`assert_shapes(...)`](debugging/assert_shapes): Assert tensor shapes and dimension size relationships between tensors.
[`assert_type(...)`](debugging/assert_type): Asserts that the given `Tensor` is of the specified type.
[`check_numerics(...)`](debugging/check_numerics): Checks a tensor for NaN and Inf values.
[`disable_check_numerics(...)`](debugging/disable_check_numerics): Disable the eager/graph unified numerics checking mechanism.
[`disable_traceback_filtering(...)`](debugging/disable_traceback_filtering): Disable filtering out TensorFlow-internal frames in exception stack traces.
[`enable_check_numerics(...)`](debugging/enable_check_numerics): Enable tensor numerics checking in an eager/graph unified fashion.
[`enable_traceback_filtering(...)`](debugging/enable_traceback_filtering): Enable filtering out TensorFlow-internal frames in exception stack traces.
[`get_log_device_placement(...)`](debugging/get_log_device_placement): Get if device placements are logged.
[`is_numeric_tensor(...)`](debugging/is_numeric_tensor): Returns `True` if the elements of `tensor` are numbers.
[`is_traceback_filtering_enabled(...)`](debugging/is_traceback_filtering_enabled): Check whether traceback filtering is currently enabled.
[`set_log_device_placement(...)`](debugging/set_log_device_placement): Turns logging for device placement decisions on or off.
tensorflow Module: tf.train Module: tf.train
================
Support for training models.
See the [Training](https://tensorflow.org/api_guides/python/train) guide.
Modules
-------
[`experimental`](train/experimental) module: Public API for tf.train.experimental namespace.
Classes
-------
[`class BytesList`](train/byteslist): Used in [`tf.train.Example`](train/example) protos. Holds a list of byte-strings.
[`class Checkpoint`](train/checkpoint): Manages saving/restoring trackable values to disk.
[`class CheckpointManager`](train/checkpointmanager): Manages multiple checkpoints by keeping some and deleting unneeded ones.
[`class CheckpointOptions`](train/checkpointoptions): Options for constructing a Checkpoint.
[`class ClusterDef`](train/clusterdef): A ProtocolMessage
[`class ClusterSpec`](train/clusterspec): Represents a cluster as a set of "tasks", organized into "jobs".
[`class Coordinator`](train/coordinator): A coordinator for threads.
[`class Example`](train/example): An `Example` is a standard proto storing data for training and inference.
[`class ExponentialMovingAverage`](train/exponentialmovingaverage): Maintains moving averages of variables by employing an exponential decay.
[`class Feature`](train/feature): Used in [`tf.train.Example`](train/example) protos. Contains a list of values.
[`class FeatureList`](train/featurelist): Mainly used as part of a [`tf.train.SequenceExample`](train/sequenceexample).
[`class FeatureLists`](train/featurelists): Mainly used as part of a [`tf.train.SequenceExample`](train/sequenceexample).
[`class Features`](train/features): Used in [`tf.train.Example`](train/example) protos. Contains the mapping from keys to `Feature`.
[`class FloatList`](train/floatlist): Used in [`tf.train.Example`](train/example) protos. Holds a list of floats.
[`class Int64List`](train/int64list): Used in [`tf.train.Example`](train/example) protos. Holds a list of Int64s.
[`class JobDef`](train/jobdef): A ProtocolMessage
[`class SequenceExample`](train/sequenceexample): A `SequenceExample` is a format a sequences and some context.
[`class ServerDef`](train/serverdef): A ProtocolMessage
Functions
---------
[`checkpoints_iterator(...)`](train/checkpoints_iterator): Continuously yield new checkpoint files as they appear.
[`get_checkpoint_state(...)`](train/get_checkpoint_state): Returns CheckpointState proto from the "checkpoint" file.
[`latest_checkpoint(...)`](train/latest_checkpoint): Finds the filename of latest saved checkpoint file.
[`list_variables(...)`](train/list_variables): Lists the checkpoint keys and shapes of variables in a checkpoint.
[`load_checkpoint(...)`](train/load_checkpoint): Returns `CheckpointReader` for checkpoint found in `ckpt_dir_or_file`.
[`load_variable(...)`](train/load_variable): Returns the tensor value of the given variable in the checkpoint.
tensorflow tf.meshgrid tf.meshgrid
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3681-L3759) |
Broadcasts parameters for evaluation on an N-D grid.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.meshgrid`](https://www.tensorflow.org/api_docs/python/tf/meshgrid)
```
tf.meshgrid(
*args, **kwargs
)
```
Given N one-dimensional coordinate arrays `*args`, returns a list `outputs` of N-D coordinate arrays for evaluating expressions on an N-D grid.
#### Notes:
`meshgrid` supports cartesian ('xy') and matrix ('ij') indexing conventions. When the `indexing` argument is set to 'xy' (the default), the broadcasting instructions for the first two dimensions are swapped.
#### Examples:
Calling `X, Y = meshgrid(x, y)` with the tensors
```
x = [1, 2, 3]
y = [4, 5, 6]
X, Y = tf.meshgrid(x, y)
# X = [[1, 2, 3],
# [1, 2, 3],
# [1, 2, 3]]
# Y = [[4, 4, 4],
# [5, 5, 5],
# [6, 6, 6]]
```
| Args |
| `*args` | `Tensor`s with rank 1. |
| `**kwargs` | * indexing: Either 'xy' or 'ij' (optional, default: 'xy').
* name: A name for the operation (optional).
|
| Returns |
| `outputs` | A list of N `Tensor`s with rank N. |
| Raises |
| `TypeError` | When no keyword arguments (kwargs) are passed. |
| `ValueError` | When indexing keyword argument is not one of `xy` or `ij`. |
tensorflow tf.expand_dims tf.expand\_dims
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L376-L443) |
Returns a tensor with a length 1 axis inserted at index `axis`.
```
tf.expand_dims(
input, axis, name=None
)
```
Given a tensor `input`, this operation inserts a dimension of length 1 at the dimension index `axis` of `input`'s shape. The dimension index follows Python indexing rules: It's zero-based, a negative index it is counted backward from the end.
This operation is useful to:
* Add an outer "batch" dimension to a single element.
* Align axes for broadcasting.
* To add an inner vector length axis to a tensor of scalars.
#### For example:
If you have a single image of shape `[height, width, channels]`:
```
image = tf.zeros([10,10,3])
```
You can add an outer `batch` axis by passing `axis=0`:
```
tf.expand_dims(image, axis=0).shape.as_list()
[1, 10, 10, 3]
```
The new axis location matches Python `list.insert(axis, 1)`:
```
tf.expand_dims(image, axis=1).shape.as_list()
[10, 1, 10, 3]
```
Following standard Python indexing rules, a negative `axis` counts from the end so `axis=-1` adds an inner most dimension:
```
tf.expand_dims(image, -1).shape.as_list()
[10, 10, 3, 1]
```
This operation requires that `axis` is a valid index for `input.shape`, following Python indexing rules:
```
-1-tf.rank(input) <= axis <= tf.rank(input)
```
This operation is related to:
* [`tf.squeeze`](squeeze), which removes dimensions of size 1.
* [`tf.reshape`](reshape), which provides more flexible reshaping capability.
* [`tf.sparse.expand_dims`](sparse/expand_dims), which provides this functionality for [`tf.SparseTensor`](sparse/sparsetensor)
| Args |
| `input` | A `Tensor`. |
| `axis` | Integer specifying the dimension index at which to expand the shape of `input`. Given an input of D dimensions, `axis` must be in range `[-(D+1), D]` (inclusive). |
| `name` | Optional string. The name of the output `Tensor`. |
| Returns |
| A tensor with the same data as `input`, with an additional dimension inserted at the index specified by `axis`. |
| Raises |
| `TypeError` | If `axis` is not specified. |
| `InvalidArgumentError` | If `axis` is out of range `[-(D+1), D]`. |
tensorflow Module: tf.sysconfig Module: tf.sysconfig
====================
System configuration library.
Functions
---------
[`get_build_info(...)`](sysconfig/get_build_info): Get a dictionary describing TensorFlow's build environment.
[`get_compile_flags(...)`](sysconfig/get_compile_flags): Get the compilation flags for custom operators.
[`get_include(...)`](sysconfig/get_include): Get the directory containing the TensorFlow C++ header files.
[`get_lib(...)`](sysconfig/get_lib): Get the directory containing the TensorFlow framework library.
[`get_link_flags(...)`](sysconfig/get_link_flags): Get the link flags for custom operators.
| Other Members |
| CXX11\_ABI\_FLAG | `1` |
| MONOLITHIC\_BUILD | `0` |
tensorflow Module: tf.sparse Module: tf.sparse
=================
Sparse Tensor Representation.
See also [`tf.sparse.SparseTensor`](sparse/sparsetensor).
Classes
-------
[`class SparseTensor`](sparse/sparsetensor): Represents a sparse tensor.
Functions
---------
[`add(...)`](sparse/add): Adds two tensors, at least one of each is a `SparseTensor`.
[`bincount(...)`](sparse/bincount): Count the number of times an integer value appears in a tensor.
[`concat(...)`](sparse/concat): Concatenates a list of `SparseTensor` along the specified dimension. (deprecated arguments)
[`cross(...)`](sparse/cross): Generates sparse cross from a list of sparse and dense tensors.
[`cross_hashed(...)`](sparse/cross_hashed): Generates hashed sparse cross from a list of sparse and dense tensors.
[`expand_dims(...)`](sparse/expand_dims): Returns a tensor with an length 1 axis inserted at index `axis`.
[`eye(...)`](sparse/eye): Creates a two-dimensional sparse tensor with ones along the diagonal.
[`fill_empty_rows(...)`](sparse/fill_empty_rows): Fills empty rows in the input 2-D `SparseTensor` with a default value.
[`from_dense(...)`](sparse/from_dense): Converts a dense tensor into a sparse tensor.
[`map_values(...)`](sparse/map_values): Applies `op` to the `.values` tensor of one or more `SparseTensor`s.
[`mask(...)`](sparse/mask): Masks elements of `IndexedSlices`.
[`maximum(...)`](sparse/maximum): Returns the element-wise max of two SparseTensors.
[`minimum(...)`](sparse/minimum): Returns the element-wise min of two SparseTensors.
[`reduce_max(...)`](sparse/reduce_max): Computes [`tf.sparse.maximum`](sparse/maximum) of elements across dimensions of a SparseTensor.
[`reduce_sum(...)`](sparse/reduce_sum): Computes [`tf.sparse.add`](sparse/add) of elements across dimensions of a SparseTensor.
[`reorder(...)`](sparse/reorder): Reorders a `SparseTensor` into the canonical, row-major ordering.
[`reset_shape(...)`](sparse/reset_shape): Resets the shape of a `SparseTensor` with indices and values unchanged.
[`reshape(...)`](sparse/reshape): Reshapes a `SparseTensor` to represent values in a new dense shape.
[`retain(...)`](sparse/retain): Retains specified non-empty values within a `SparseTensor`.
[`segment_mean(...)`](sparse/segment_mean): Computes the mean along sparse segments of a tensor.
[`segment_sqrt_n(...)`](sparse/segment_sqrt_n): Computes the sum along sparse segments of a tensor divided by the sqrt(N).
[`segment_sum(...)`](sparse/segment_sum): Computes the sum along sparse segments of a tensor.
[`slice(...)`](sparse/slice): Slice a `SparseTensor` based on the `start` and `size`.
[`softmax(...)`](sparse/softmax): Applies softmax to a batched N-D `SparseTensor`.
[`sparse_dense_matmul(...)`](sparse/sparse_dense_matmul): Multiply SparseTensor (or dense Matrix) (of rank 2) "A" by dense matrix
[`split(...)`](sparse/split): Split a `SparseTensor` into `num_split` tensors along `axis`.
[`to_dense(...)`](sparse/to_dense): Converts a `SparseTensor` into a dense tensor.
[`to_indicator(...)`](sparse/to_indicator): Converts a `SparseTensor` of ids into a dense bool indicator tensor.
[`transpose(...)`](sparse/transpose): Transposes a `SparseTensor`
tensorflow tf.repeat tf.repeat
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L6893-L6944) |
Repeat elements of `input`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.repeat`](https://www.tensorflow.org/api_docs/python/tf/repeat)
```
tf.repeat(
input, repeats, axis=None, name=None
)
```
See also [`tf.concat`](concat), [`tf.stack`](stack), [`tf.tile`](tile).
| Args |
| `input` | An `N`-dimensional Tensor. |
| `repeats` | An 1-D `int` Tensor. The number of repetitions for each element. repeats is broadcasted to fit the shape of the given axis. `len(repeats)` must equal `input.shape[axis]` if axis is not None. |
| `axis` | An int. The axis along which to repeat values. By default (axis=None), use the flattened input array, and return a flat output array. |
| `name` | A name for the operation. |
| Returns |
| A Tensor which has the same shape as `input`, except along the given axis. If axis is None then the output array is flattened to match the flattened input array. |
#### Example usage:
```
repeat(['a', 'b', 'c'], repeats=[3, 0, 2], axis=0)
<tf.Tensor: shape=(5,), dtype=string,
numpy=array([b'a', b'a', b'a', b'c', b'c'], dtype=object)>
```
```
repeat([[1, 2], [3, 4]], repeats=[2, 3], axis=0)
<tf.Tensor: shape=(5, 2), dtype=int32, numpy=
array([[1, 2],
[1, 2],
[3, 4],
[3, 4],
[3, 4]], dtype=int32)>
```
```
repeat([[1, 2], [3, 4]], repeats=[2, 3], axis=1)
<tf.Tensor: shape=(2, 5), dtype=int32, numpy=
array([[1, 1, 2, 2, 2],
[3, 3, 4, 4, 4]], dtype=int32)>
```
```
repeat(3, repeats=4)
<tf.Tensor: shape=(4,), dtype=int32, numpy=array([3, 3, 3, 3], dtype=int32)>
```
```
repeat([[1,2], [3,4]], repeats=2)
<tf.Tensor: shape=(8,), dtype=int32,
numpy=array([1, 1, 2, 2, 3, 3, 4, 4], dtype=int32)>
```
tensorflow Module: tf.strings Module: tf.strings
==================
Operations for working with string Tensors.
Functions
---------
[`as_string(...)`](strings/as_string): Converts each entry in the given tensor to strings.
[`bytes_split(...)`](strings/bytes_split): Split string elements of `input` into bytes.
[`format(...)`](strings/format): Formats a string template using a list of tensors.
[`join(...)`](strings/join): Perform element-wise concatenation of a list of string tensors.
[`length(...)`](strings/length): String lengths of `input`.
[`lower(...)`](strings/lower): Converts all uppercase characters into their respective lowercase replacements.
[`ngrams(...)`](strings/ngrams): Create a tensor of n-grams based on `data`.
[`reduce_join(...)`](strings/reduce_join): Joins all strings into a single string, or joins along an axis.
[`regex_full_match(...)`](strings/regex_full_match): Check if the input matches the regex pattern.
[`regex_replace(...)`](strings/regex_replace): Replace elements of `input` matching regex `pattern` with `rewrite`.
[`split(...)`](strings/split): Split elements of `input` based on `sep` into a `RaggedTensor`.
[`strip(...)`](strings/strip): Strip leading and trailing whitespaces from the Tensor.
[`substr(...)`](strings/substr): Return substrings from `Tensor` of strings.
[`to_hash_bucket(...)`](strings/to_hash_bucket): Converts each string in the input Tensor to its hash mod by a number of buckets.
[`to_hash_bucket_fast(...)`](strings/to_hash_bucket_fast): Converts each string in the input Tensor to its hash mod by a number of buckets.
[`to_hash_bucket_strong(...)`](strings/to_hash_bucket_strong): Converts each string in the input Tensor to its hash mod by a number of buckets.
[`to_number(...)`](strings/to_number): Converts each string in the input Tensor to the specified numeric type.
[`unicode_decode(...)`](strings/unicode_decode): Decodes each string in `input` into a sequence of Unicode code points.
[`unicode_decode_with_offsets(...)`](strings/unicode_decode_with_offsets): Decodes each string into a sequence of code points with start offsets.
[`unicode_encode(...)`](strings/unicode_encode): Encodes each sequence of Unicode code points in `input` into a string.
[`unicode_script(...)`](strings/unicode_script): Determine the script codes of a given tensor of Unicode integer code points.
[`unicode_split(...)`](strings/unicode_split): Splits each string in `input` into a sequence of Unicode code points.
[`unicode_split_with_offsets(...)`](strings/unicode_split_with_offsets): Splits each string into a sequence of code points with start offsets.
[`unicode_transcode(...)`](strings/unicode_transcode): Transcode the input text from a source encoding to a destination encoding.
[`unsorted_segment_join(...)`](strings/unsorted_segment_join): Joins the elements of `inputs` based on `segment_ids`.
[`upper(...)`](strings/upper): Converts all lowercase characters into their respective uppercase replacements.
tensorflow tf.edit_distance tf.edit\_distance
=================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3826-L3928) |
Computes the Levenshtein distance between sequences.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.edit_distance`](https://www.tensorflow.org/api_docs/python/tf/edit_distance)
```
tf.edit_distance(
hypothesis, truth, normalize=True, name='edit_distance'
)
```
This operation takes variable-length sequences (`hypothesis` and `truth`), each provided as a `SparseTensor`, and computes the Levenshtein distance. You can normalize the edit distance by length of `truth` by setting `normalize` to true.
#### For example:
Given the following input,
* `hypothesis` is a [`tf.SparseTensor`](sparse/sparsetensor) of shape `[2, 1, 1]`
* `truth` is a [`tf.SparseTensor`](sparse/sparsetensor) of shape `[2, 2, 2]`
```
hypothesis = tf.SparseTensor(
[[0, 0, 0],
[1, 0, 0]],
["a", "b"],
(2, 1, 1))
truth = tf.SparseTensor(
[[0, 1, 0],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0]],
["a", "b", "c", "a"],
(2, 2, 2))
tf.edit_distance(hypothesis, truth, normalize=True)
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[inf, 1. ],
[0.5, 1. ]], dtype=float32)>
```
The operation returns a dense Tensor of shape `[2, 2]` with edit distances normalized by `truth` lengths.
>
> **Note:** It is possible to calculate edit distance between two sparse tensors with variable-length values. However, attempting to create them while eager execution is enabled will result in a `ValueError`.
>
For the following inputs,
```
# 'hypothesis' is a tensor of shape `[2, 1]` with variable-length values:
# (0,0) = ["a"]
# (1,0) = ["b"]
hypothesis = tf.sparse.SparseTensor(
[[0, 0, 0],
[1, 0, 0]],
["a", "b"],
(2, 1, 1))
# 'truth' is a tensor of shape `[2, 2]` with variable-length values:
# (0,0) = []
# (0,1) = ["a"]
# (1,0) = ["b", "c"]
# (1,1) = ["a"]
truth = tf.sparse.SparseTensor(
[[0, 1, 0],
[1, 0, 0],
[1, 0, 1],
[1, 1, 0]],
["a", "b", "c", "a"],
(2, 2, 2))
normalize = True
# The output would be a dense Tensor of shape `(2,)`, with edit distances
normalized by 'truth' lengths.
# output => array([0., 0.5], dtype=float32)
```
| Args |
| `hypothesis` | A `SparseTensor` containing hypothesis sequences. |
| `truth` | A `SparseTensor` containing truth sequences. |
| `normalize` | A `bool`. If `True`, normalizes the Levenshtein distance by length of `truth.` |
| `name` | A name for the operation (optional). |
| Returns |
| A dense `Tensor` with rank `R - 1`, where R is the rank of the `SparseTensor` inputs `hypothesis` and `truth`. |
| Raises |
| `TypeError` | If either `hypothesis` or `truth` are not a `SparseTensor`. |
| programming_docs |
tensorflow Module: tf.io Module: tf.io
=============
Public API for tf.io namespace.
Modules
-------
[`gfile`](io/gfile) module: Public API for tf.io.gfile namespace.
Classes
-------
[`class FixedLenFeature`](io/fixedlenfeature): Configuration for parsing a fixed-length input feature.
[`class FixedLenSequenceFeature`](io/fixedlensequencefeature): Configuration for parsing a variable-length input feature into a `Tensor`.
[`class RaggedFeature`](io/raggedfeature): Configuration for passing a RaggedTensor input feature.
[`class SparseFeature`](io/sparsefeature): Configuration for parsing a sparse input feature from an `Example`.
[`class TFRecordOptions`](io/tfrecordoptions): Options used for manipulating TFRecord files.
[`class TFRecordWriter`](io/tfrecordwriter): A class to write records to a TFRecords file.
[`class VarLenFeature`](io/varlenfeature): Configuration for parsing a variable-length input feature.
Functions
---------
[`decode_and_crop_jpeg(...)`](io/decode_and_crop_jpeg): Decode and Crop a JPEG-encoded image to a uint8 tensor.
[`decode_base64(...)`](io/decode_base64): Decode web-safe base64-encoded strings.
[`decode_bmp(...)`](io/decode_bmp): Decode the first frame of a BMP-encoded image to a uint8 tensor.
[`decode_compressed(...)`](io/decode_compressed): Decompress strings.
[`decode_csv(...)`](io/decode_csv): Convert CSV records to tensors. Each column maps to one tensor.
[`decode_gif(...)`](io/decode_gif): Decode the frame(s) of a GIF-encoded image to a uint8 tensor.
[`decode_image(...)`](io/decode_image): Function for `decode_bmp`, `decode_gif`, `decode_jpeg`, and `decode_png`.
[`decode_jpeg(...)`](io/decode_jpeg): Decode a JPEG-encoded image to a uint8 tensor.
[`decode_json_example(...)`](io/decode_json_example): Convert JSON-encoded Example records to binary protocol buffer strings.
[`decode_png(...)`](io/decode_png): Decode a PNG-encoded image to a uint8 or uint16 tensor.
[`decode_proto(...)`](io/decode_proto): The op extracts fields from a serialized protocol buffers message into tensors.
[`decode_raw(...)`](io/decode_raw): Convert raw bytes from input tensor into numeric tensors.
[`deserialize_many_sparse(...)`](io/deserialize_many_sparse): Deserialize and concatenate `SparseTensors` from a serialized minibatch.
[`encode_base64(...)`](io/encode_base64): Encode strings into web-safe base64 format.
[`encode_jpeg(...)`](io/encode_jpeg): JPEG-encode an image.
[`encode_png(...)`](io/encode_png): PNG-encode an image.
[`encode_proto(...)`](io/encode_proto): The op serializes protobuf messages provided in the input tensors.
[`extract_jpeg_shape(...)`](io/extract_jpeg_shape): Extract the shape information of a JPEG-encoded image.
[`is_jpeg(...)`](io/is_jpeg): Convenience function to check if the 'contents' encodes a JPEG image.
[`match_filenames_once(...)`](io/match_filenames_once): Save the list of files matching pattern, so it is only computed once.
[`matching_files(...)`](io/matching_files): Returns the set of files matching one or more glob patterns.
[`parse_example(...)`](io/parse_example): Parses `Example` protos into a `dict` of tensors.
[`parse_sequence_example(...)`](io/parse_sequence_example): Parses a batch of `SequenceExample` protos.
[`parse_single_example(...)`](io/parse_single_example): Parses a single `Example` proto.
[`parse_single_sequence_example(...)`](io/parse_single_sequence_example): Parses a single `SequenceExample` proto.
[`parse_tensor(...)`](io/parse_tensor): Transforms a serialized tensorflow.TensorProto proto into a Tensor.
[`read_file(...)`](io/read_file): Reads the contents of file.
[`serialize_many_sparse(...)`](io/serialize_many_sparse): Serialize `N`-minibatch `SparseTensor` into an `[N, 3]` `Tensor`.
[`serialize_sparse(...)`](io/serialize_sparse): Serialize a `SparseTensor` into a 3-vector (1-D `Tensor`) object.
[`serialize_tensor(...)`](io/serialize_tensor): Transforms a Tensor into a serialized TensorProto proto.
[`write_file(...)`](io/write_file): Writes `contents` to the file at input `filename`.
[`write_graph(...)`](io/write_graph): Writes a graph proto to a file.
tensorflow tf.control_dependencies tf.control\_dependencies
========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5561-L5594) |
Wrapper for [`Graph.control_dependencies()`](graph#control_dependencies) using the default graph.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.control_dependencies`](https://www.tensorflow.org/api_docs/python/tf/control_dependencies)
```
tf.control_dependencies(
control_inputs
)
```
See [`tf.Graph.control_dependencies`](graph#control_dependencies) for more details.
>
> **Note:** *In TensorFlow 2 with eager and/or Autograph, you should not require this method, as ops execute in the expected order thanks to automatic control dependencies.* Only use [`tf.control_dependencies`](control_dependencies) when working with v1 [`tf.Graph`](graph) code.
>
When eager execution is enabled, any callable object in the `control_inputs` list will be called.
| Args |
| `control_inputs` | A list of `Operation` or `Tensor` objects which must be executed or computed before running the operations defined in the context. Can also be `None` to clear the control dependencies. If eager execution is enabled, any callable object in the `control_inputs` list will be called. |
| Returns |
| A context manager that specifies control dependencies for all operations constructed within the context. |
tensorflow tf.reverse_sequence tf.reverse\_sequence
====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L5002-L5054) |
Reverses variable length slices.
```
tf.reverse_sequence(
input, seq_lengths, seq_axis=None, batch_axis=None, name=None
)
```
This op first slices `input` along the dimension `batch_axis`, and for each slice `i`, reverses the first `seq_lengths[i]` elements along the dimension `seq_axis`.
The elements of `seq_lengths` must obey `seq_lengths[i] <= input.dims[seq_axis]`, and `seq_lengths` must be a vector of length `input.dims[batch_axis]`.
The output slice `i` along dimension `batch_axis` is then given by input slice `i`, with the first `seq_lengths[i]` slices along dimension `seq_axis` reversed.
#### Example usage:
```
seq_lengths = [7, 2, 3, 5]
input = [[1, 2, 3, 4, 5, 0, 0, 0], [1, 2, 0, 0, 0, 0, 0, 0],
[1, 2, 3, 4, 0, 0, 0, 0], [1, 2, 3, 4, 5, 6, 7, 8]]
output = tf.reverse_sequence(input, seq_lengths, seq_axis=1, batch_axis=0)
output
<tf.Tensor: shape=(4, 8), dtype=int32, numpy=
array([[0, 0, 5, 4, 3, 2, 1, 0],
[2, 1, 0, 0, 0, 0, 0, 0],
[3, 2, 1, 4, 0, 0, 0, 0],
[5, 4, 3, 2, 1, 6, 7, 8]], dtype=int32)>
```
| Args |
| `input` | A `Tensor`. The input to reverse. |
| `seq_lengths` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 1-D with length `input.dims(batch_axis)` and `max(seq_lengths) <= input.dims(seq_axis)` |
| `seq_axis` | An `int`. The dimension which is partially reversed. |
| `batch_axis` | An optional `int`. Defaults to `0`. The dimension along which reversal is performed. |
| `name` | A name for the operation (optional). |
| Returns |
| A Tensor. Has the same type as input. |
tensorflow tf.reverse tf.reverse
==========
Reverses specific dimensions of a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.reverse`](https://www.tensorflow.org/api_docs/python/tf/reverse), [`tf.compat.v1.reverse`](https://www.tensorflow.org/api_docs/python/tf/reverse), [`tf.compat.v1.reverse_v2`](https://www.tensorflow.org/api_docs/python/tf/reverse)
```
tf.reverse(
tensor, axis, name=None
)
```
Given a `tensor`, and a `int32` tensor `axis` representing the set of dimensions of `tensor` to reverse. This operation reverses each dimension `i` for which there exists `j` s.t. `axis[j] == i`.
`tensor` can have up to 8 dimensions. The number of dimensions specified in `axis` may be 0 or more entries. If an index is specified more than once, a InvalidArgument error is raised.
#### For example:
```
# tensor 't' is [[[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]]]
# tensor 't' shape is [1, 2, 3, 4]
# 'dims' is [3] or 'dims' is [-1]
reverse(t, dims) ==> [[[[ 3, 2, 1, 0],
[ 7, 6, 5, 4],
[ 11, 10, 9, 8]],
[[15, 14, 13, 12],
[19, 18, 17, 16],
[23, 22, 21, 20]]]]
# 'dims' is '[1]' (or 'dims' is '[-3]')
reverse(t, dims) ==> [[[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]
[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]]]
# 'dims' is '[2]' (or 'dims' is '[-2]')
reverse(t, dims) ==> [[[[8, 9, 10, 11],
[4, 5, 6, 7],
[0, 1, 2, 3]]
[[20, 21, 22, 23],
[16, 17, 18, 19],
[12, 13, 14, 15]]]]
```
| Args |
| `tensor` | A `Tensor`. Must be one of the following types: `uint8`, `int8`, `uint16`, `int16`, `int32`, `uint32`, `int64`, `uint64`, `bool`, `bfloat16`, `half`, `float32`, `float64`, `complex64`, `complex128`, `string`. Up to 8-D. |
| `axis` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 1-D. The indices of the dimensions to reverse. Must be in the range `[-rank(tensor), rank(tensor))`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
tensorflow tf.where tf.where
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L4723-L4932) |
Returns the indices of non-zero elements, or multiplexes `x` and `y`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.where_v2`](https://www.tensorflow.org/api_docs/python/tf/where)
```
tf.where(
condition, x=None, y=None, name=None
)
```
This operation has two modes:
1. **Return the indices of non-zero elements** - When only `condition` is provided the result is an `int64` tensor where each row is the index of a non-zero element of `condition`. The result's shape is `[tf.math.count_nonzero(condition), tf.rank(condition)]`.
2. **Multiplex `x` and `y`** - When both `x` and `y` are provided the result has the shape of `x`, `y`, and `condition` broadcast together. The result is taken from `x` where `condition` is non-zero or `y` where `condition` is zero.
#### 1. Return the indices of non-zero elements
>
> **Note:** In this mode `condition` can have a dtype of `bool` or any numeric dtype.
>
If `x` and `y` are not provided (both are None):
[`tf.where`](where) will return the indices of `condition` that are non-zero, in the form of a 2-D tensor with shape `[n, d]`, where `n` is the number of non-zero elements in `condition` (`tf.count_nonzero(condition)`), and `d` is the number of axes of `condition` ([`tf.rank(condition)`](rank)).
Indices are output in row-major order. The `condition` can have a `dtype` of [`tf.bool`](../tf#bool), or any numeric `dtype`.
Here `condition` is a 1-axis `bool` tensor with 2 `True` values. The result has a shape of `[2,1]`
```
tf.where([True, False, False, True]).numpy()
array([[0],
[3]])
```
Here `condition` is a 2-axis integer tensor, with 3 non-zero values. The result has a shape of `[3, 2]`.
```
tf.where([[1, 0, 0], [1, 0, 1]]).numpy()
array([[0, 0],
[1, 0],
[1, 2]])
```
Here `condition` is a 3-axis float tensor, with 5 non-zero values. The output shape is `[5, 3]`.
```
float_tensor = [[[0.1, 0], [0, 2.2], [3.5, 1e6]],
[[0, 0], [0, 0], [99, 0]]]
tf.where(float_tensor).numpy()
array([[0, 0, 0],
[0, 1, 1],
[0, 2, 0],
[0, 2, 1],
[1, 2, 0]])
```
These indices are the same that [`tf.sparse.SparseTensor`](sparse/sparsetensor) would use to represent the condition tensor:
```
sparse = tf.sparse.from_dense(float_tensor)
sparse.indices.numpy()
array([[0, 0, 0],
[0, 1, 1],
[0, 2, 0],
[0, 2, 1],
[1, 2, 0]])
```
A complex number is considered non-zero if either the real or imaginary component is non-zero:
```
tf.where([complex(0.), complex(1.), 0+1j, 1+1j]).numpy()
array([[1],
[2],
[3]])
```
#### 2. Multiplex `x` and `y`
>
> **Note:** In this mode `condition` must have a dtype of `bool`.
>
If `x` and `y` are also provided (both have non-None values) the `condition` tensor acts as a mask that chooses whether the corresponding element / row in the output should be taken from `x` (if the element in `condition` is `True`) or `y` (if it is `False`).
The shape of the result is formed by [broadcasting](https://docs.scipy.org/doc/numpy/reference/ufuncs.html) together the shapes of `condition`, `x`, and `y`.
When all three inputs have the same size, each is handled element-wise.
```
tf.where([True, False, False, True],
[1, 2, 3, 4],
[100, 200, 300, 400]).numpy()
array([ 1, 200, 300, 4], dtype=int32)
```
There are two main rules for broadcasting:
1. If a tensor has fewer axes than the others, length-1 axes are added to the left of the shape.
2. Axes with length-1 are streched to match the coresponding axes of the other tensors.
A length-1 vector is streched to match the other vectors:
```
tf.where([True, False, False, True], [1, 2, 3, 4], [100]).numpy()
array([ 1, 100, 100, 4], dtype=int32)
```
A scalar is expanded to match the other arguments:
```
tf.where([[True, False], [False, True]], [[1, 2], [3, 4]], 100).numpy()
array([[ 1, 100], [100, 4]], dtype=int32)
tf.where([[True, False], [False, True]], 1, 100).numpy()
array([[ 1, 100], [100, 1]], dtype=int32)
```
A scalar `condition` returns the complete `x` or `y` tensor, with broadcasting applied.
```
tf.where(True, [1, 2, 3, 4], 100).numpy()
array([1, 2, 3, 4], dtype=int32)
tf.where(False, [1, 2, 3, 4], 100).numpy()
array([100, 100, 100, 100], dtype=int32)
```
For a non-trivial example of broadcasting, here `condition` has a shape of `[3]`, `x` has a shape of `[3,3]`, and `y` has a shape of `[3,1]`. Broadcasting first expands the shape of `condition` to `[1,3]`. The final broadcast shape is `[3,3]`. `condition` will select columns from `x` and `y`. Since `y` only has one column, all columns from `y` will be identical.
```
tf.where([True, False, True],
x=[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
y=[[100],
[200],
[300]]
).numpy()
array([[ 1, 100, 3],
[ 4, 200, 6],
[ 7, 300, 9]], dtype=int32)
```
Note that if the gradient of either branch of the [`tf.where`](where) generates a `NaN`, then the gradient of the entire [`tf.where`](where) will be `NaN`. This is because the gradient calculation for [`tf.where`](where) combines the two branches, for performance reasons.
A workaround is to use an inner [`tf.where`](where) to ensure the function has no asymptote, and to avoid computing a value whose gradient is `NaN` by replacing dangerous inputs with safe inputs.
Instead of this,
```
x = tf.constant(0., dtype=tf.float32)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.where(x < 1., 0., 1. / x)
print(tape.gradient(y, x))
tf.Tensor(nan, shape=(), dtype=float32)
```
Although, the `1. / x` values are never used, its gradient is a `NaN` when `x = 0`. Instead, we should guard that with another [`tf.where`](where)
```
x = tf.constant(0., dtype=tf.float32)
with tf.GradientTape() as tape:
tape.watch(x)
safe_x = tf.where(tf.equal(x, 0.), 1., x)
y = tf.where(x < 1., 0., 1. / safe_x)
print(tape.gradient(y, x))
tf.Tensor(0.0, shape=(), dtype=float32)
```
#### See also:
* [`tf.sparse`](sparse) - The indices returned by the first form of [`tf.where`](where) can be useful in [`tf.sparse.SparseTensor`](sparse/sparsetensor) objects.
* [`tf.gather_nd`](gather_nd), [`tf.scatter_nd`](scatter_nd), and related ops - Given the list of indices returned from [`tf.where`](where) the `scatter` and `gather` family of ops can be used fetch values or insert values at those indices.
* [`tf.strings.length`](strings/length) - [`tf.string`](../tf#string) is not an allowed dtype for the `condition`. Use the string length instead.
| Args |
| `condition` | A [`tf.Tensor`](tensor) of dtype bool, or any numeric dtype. `condition` must have dtype `bool` when `x` and `y` are provided. |
| `x` | If provided, a Tensor which is of the same type as `y`, and has a shape broadcastable with `condition` and `y`. |
| `y` | If provided, a Tensor which is of the same type as `x`, and has a shape broadcastable with `condition` and `x`. |
| `name` | A name of the operation (optional). |
| Returns |
| If `x` and `y` are provided: A `Tensor` with the same type as `x` and `y`, and shape that is broadcast from `condition`, `x`, and `y`. Otherwise, a `Tensor` with shape `[tf.math.count_nonzero(condition), tf.rank(condition)]`. |
| Raises |
| `ValueError` | When exactly one of `x` or `y` is non-None, or the shapes are not all broadcastable. |
tensorflow tf.guarantee_const tf.guarantee\_const
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L6947-L6963) |
Promise to the TF runtime that the input tensor is a constant. (deprecated)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.guarantee_const`](https://www.tensorflow.org/api_docs/python/tf/guarantee_const)
```
tf.guarantee_const(
input, name=None
)
```
The runtime is then free to make optimizations based on this.
Returns the input tensor without modification.
| Args |
| `input` | A `Tensor`. |
| `name` | A name for this operation. |
| Returns |
| A `Tensor`. Has the same dtype as `input`. |
tensorflow tf.GradientTape tf.GradientTape
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L739-L1384) |
Record operations for automatic differentiation.
#### View aliases
**Main aliases**
[`tf.autodiff.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.GradientTape`](https://www.tensorflow.org/api_docs/python/tf/GradientTape)
```
tf.GradientTape(
persistent=False, watch_accessed_variables=True
)
```
Operations are recorded if they are executed within this context manager and at least one of their inputs is being "watched".
Trainable variables (created by [`tf.Variable`](variable) or [`tf.compat.v1.get_variable`](compat/v1/get_variable), where `trainable=True` is default in both cases) are automatically watched. Tensors can be manually watched by invoking the `watch` method on this context manager.
For example, consider the function `y = x * x`. The gradient at `x = 3.0` can be computed as:
```
x = tf.constant(3.0)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
dy_dx = g.gradient(y, x)
print(dy_dx)
tf.Tensor(6.0, shape=(), dtype=float32)
```
GradientTapes can be nested to compute higher-order derivatives. For example,
```
x = tf.constant(5.0)
with tf.GradientTape() as g:
g.watch(x)
with tf.GradientTape() as gg:
gg.watch(x)
y = x * x
dy_dx = gg.gradient(y, x) # dy_dx = 2 * x
d2y_dx2 = g.gradient(dy_dx, x) # d2y_dx2 = 2
print(dy_dx)
tf.Tensor(10.0, shape=(), dtype=float32)
print(d2y_dx2)
tf.Tensor(2.0, shape=(), dtype=float32)
```
By default, the resources held by a GradientTape are released as soon as GradientTape.gradient() method is called. To compute multiple gradients over the same computation, create a persistent gradient tape. This allows multiple calls to the gradient() method as resources are released when the tape object is garbage collected. For example:
```
x = tf.constant(3.0)
with tf.GradientTape(persistent=True) as g:
g.watch(x)
y = x * x
z = y * y
dz_dx = g.gradient(z, x) # (4*x^3 at x = 3)
print(dz_dx)
tf.Tensor(108.0, shape=(), dtype=float32)
dy_dx = g.gradient(y, x)
print(dy_dx)
tf.Tensor(6.0, shape=(), dtype=float32)
```
By default GradientTape will automatically watch any trainable variables that are accessed inside the context. If you want fine grained control over which variables are watched you can disable automatic tracking by passing `watch_accessed_variables=False` to the tape constructor:
```
x = tf.Variable(2.0)
w = tf.Variable(5.0)
with tf.GradientTape(
watch_accessed_variables=False, persistent=True) as tape:
tape.watch(x)
y = x ** 2 # Gradients will be available for `x`.
z = w ** 3 # No gradients will be available as `w` isn't being watched.
dy_dx = tape.gradient(y, x)
print(dy_dx)
tf.Tensor(4.0, shape=(), dtype=float32)
# No gradients will be available as `w` isn't being watched.
dz_dw = tape.gradient(z, w)
print(dz_dw)
None
```
Note that when using models you should ensure that your variables exist when using `watch_accessed_variables=False`. Otherwise it's quite easy to make your first iteration not have any gradients:
```
a = tf.keras.layers.Dense(32)
b = tf.keras.layers.Dense(32)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(a.variables) # Since `a.build` has not been called at this point
# `a.variables` will return an empty list and the
# tape will not be watching anything.
result = b(a(inputs))
tape.gradient(result, a.variables) # The result of this computation will be
# a list of `None`s since a's variables
# are not being watched.
```
Note that only tensors with real or complex dtypes are differentiable.
| Args |
| `persistent` | Boolean controlling whether a persistent gradient tape is created. False by default, which means at most one call can be made to the gradient() method on this object. |
| `watch_accessed_variables` | Boolean controlling whether the tape will automatically `watch` any (trainable) variables accessed while the tape is active. Defaults to True meaning gradients can be requested from any result computed in the tape derived from reading a trainable `Variable`. If False users must explicitly `watch` any `Variable`s they want to request gradients from. |
Methods
-------
### `batch_jacobian`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L1234-L1384)
```
batch_jacobian(
target,
source,
unconnected_gradients=tf.UnconnectedGradients.NONE,
parallel_iterations=None,
experimental_use_pfor=True
)
```
Computes and stacks per-example jacobians.
See [wikipedia article](http://en.wikipedia.org/wiki/jacobian_matrix_and_determinant) for the definition of a Jacobian. This function is essentially an efficient implementation of the following:
`tf.stack([self.jacobian(y[i], x[i]) for i in range(x.shape[0])])`.
Note that compared to [`GradientTape.jacobian`](gradienttape#jacobian) which computes gradient of each output value w.r.t each input value, this function is useful when `target[i,...]` is independent of `source[j,...]` for `j != i`. This assumption allows more efficient computation as compared to [`GradientTape.jacobian`](gradienttape#jacobian). The output, as well as intermediate activations, are lower dimensional and avoid a bunch of redundant zeros which would result in the jacobian computation given the independence assumption.
>
> **Note:** Unless you set `persistent=True` a GradientTape can only be used to compute one set of gradients (or jacobians).
>
>
> **Note:** By default the batch\_jacobian implementation uses parallel for (pfor), which creates a tf.function under the hood for each batch\_jacobian call. For better performance, and to avoid recompilation and vectorization rewrites on each call, enclose GradientTape code in @tf.function.
>
#### Example usage:
```
with tf.GradientTape() as g:
x = tf.constant([[1., 2.], [3., 4.]], dtype=tf.float32)
g.watch(x)
y = x * x
batch_jacobian = g.batch_jacobian(y, x)
# batch_jacobian is [[[2, 0], [0, 4]], [[6, 0], [0, 8]]]
```
| Args |
| `target` | A tensor with rank 2 or higher and with shape [b, y1, ..., y\_n]. `target[i,...]` should only depend on `source[i,...]`. |
| `source` | A tensor with rank 2 or higher and with shape [b, x1, ..., x\_m]. |
| `unconnected_gradients` | a value which can either hold 'none' or 'zero' and alters the value which will be returned if the target and sources are unconnected. The possible values and effects are detailed in 'UnconnectedGradients' and it defaults to 'none'. |
| `parallel_iterations` | A knob to control how many iterations are dispatched in parallel. This knob can be used to control the total memory usage. |
| `experimental_use_pfor` | If true, uses pfor for computing the Jacobian. Else uses a tf.while\_loop. |
| Returns |
| A tensor `t` with shape [b, y\_1, ..., y\_n, x1, ..., x\_m] where `t[i, ...]` is the jacobian of `target[i, ...]` w.r.t. `source[i, ...]`, i.e. stacked per-example jacobians. |
| Raises |
| `RuntimeError` | If called on a used, non-persistent tape. |
| `RuntimeError` | If called on a non-persistent tape with eager execution enabled and without enabling experimental\_use\_pfor. |
| `ValueError` | If vectorization of jacobian computation fails or if first dimension of `target` and `source` do not match. |
### `gradient`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L995-L1116)
```
gradient(
target,
sources,
output_gradients=None,
unconnected_gradients=tf.UnconnectedGradients.NONE
)
```
Computes the gradient using operations recorded in context of this tape.
>
> **Note:** Unless you set `persistent=True` a GradientTape can only be used to compute one set of gradients (or jacobians).
>
In addition to Tensors, gradient also supports RaggedTensors. For example,
```
x = tf.ragged.constant([[1.0, 2.0], [3.0]])
with tf.GradientTape() as g:
g.watch(x)
y = x * x
g.gradient(y, x)
<tf.RaggedTensor [[2.0, 4.0], [6.0]]>
```
| Args |
| `target` | a list or nested structure of Tensors or Variables or CompositeTensors to be differentiated. |
| `sources` | a list or nested structure of Tensors or Variables or CompositeTensors. `target` will be differentiated against elements in `sources`. |
| `output_gradients` | a list of gradients, one for each differentiable element of target. Defaults to None. |
| `unconnected_gradients` | a value which can either hold 'none' or 'zero' and alters the value which will be returned if the target and sources are unconnected. The possible values and effects are detailed in 'UnconnectedGradients' and it defaults to 'none'. |
| Returns |
| a list or nested structure of Tensors (or IndexedSlices, or None, or CompositeTensor), one for each element in `sources`. Returned structure is the same as the structure of `sources`. |
| Raises |
| `RuntimeError` | If called on a used, non-persistent tape. |
| `RuntimeError` | If called inside the context of the tape. |
| `TypeError` | If the target is a None object. |
| `ValueError` | If the target is a variable or if unconnected gradients is called with an unknown value. |
### `jacobian`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L1118-L1232)
```
jacobian(
target,
sources,
unconnected_gradients=tf.UnconnectedGradients.NONE,
parallel_iterations=None,
experimental_use_pfor=True
)
```
Computes the jacobian using operations recorded in context of this tape.
>
> **Note:** Unless you set `persistent=True` a GradientTape can only be used to compute one set of gradients (or jacobians).
>
>
> **Note:** By default the jacobian implementation uses parallel for (pfor), which creates a tf.function under the hood for each jacobian call. For better performance, and to avoid recompilation and vectorization rewrites on each call, enclose GradientTape code in @tf.function.
>
See[wikipedia article](http://en.wikipedia.org/wiki/jacobian_matrix_and_determinant) for the definition of a Jacobian.
#### Example usage:
```
with tf.GradientTape() as g:
x = tf.constant([1.0, 2.0])
g.watch(x)
y = x * x
jacobian = g.jacobian(y, x)
# jacobian value is [[2., 0.], [0., 4.]]
```
| Args |
| `target` | Tensor to be differentiated. |
| `sources` | a list or nested structure of Tensors or Variables. `target` will be differentiated against elements in `sources`. |
| `unconnected_gradients` | a value which can either hold 'none' or 'zero' and alters the value which will be returned if the target and sources are unconnected. The possible values and effects are detailed in 'UnconnectedGradients' and it defaults to 'none'. |
| `parallel_iterations` | A knob to control how many iterations are dispatched in parallel. This knob can be used to control the total memory usage. |
| `experimental_use_pfor` | If true, vectorizes the jacobian computation. Else falls back to a sequential while\_loop. Vectorization can sometimes fail or lead to excessive memory usage. This option can be used to disable vectorization in such cases. |
| Returns |
| A list or nested structure of Tensors (or None), one for each element in `sources`. Returned structure is the same as the structure of `sources`. Note if any gradient is sparse (IndexedSlices), jacobian function currently makes it dense and returns a Tensor instead. This may change in the future. |
| Raises |
| `RuntimeError` | If called on a used, non-persistent tape. |
| `RuntimeError` | If called on a non-persistent tape with eager execution enabled and without enabling experimental\_use\_pfor. |
| `ValueError` | If vectorization of jacobian computation fails. |
### `reset`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L953-L987)
```
reset()
```
Clears all information stored in this tape.
Equivalent to exiting and reentering the tape context manager with a new tape. For example, the two following code blocks are equivalent:
```
with tf.GradientTape() as t:
loss = loss_fn()
with tf.GradientTape() as t:
loss += other_loss_fn()
t.gradient(loss, ...) # Only differentiates other_loss_fn, not loss_fn
# The following is equivalent to the above
with tf.GradientTape() as t:
loss = loss_fn()
t.reset()
loss += other_loss_fn()
t.gradient(loss, ...) # Only differentiates other_loss_fn, not loss_fn
```
This is useful if you don't want to exit the context manager for the tape, or can't because the desired reset point is inside a control flow construct:
```
with tf.GradientTape() as t:
loss = ...
if loss > k:
t.reset()
```
### `stop_recording`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L921-L951)
```
@tf_contextlib.contextmanager
stop_recording()
```
Temporarily stops recording operations on this tape.
Operations executed while this context manager is active will not be recorded on the tape. This is useful for reducing the memory used by tracing all computations.
#### For example:
```
x = tf.constant(4.0)
with tf.GradientTape() as tape:
with tape.stop_recording():
y = x ** 2
dy_dx = tape.gradient(y, x)
print(dy_dx)
None
```
| Yields |
| None |
| Raises |
| `RuntimeError` | if the tape is not currently recording. |
### `watch`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L896-L919)
```
watch(
tensor
)
```
Ensures that `tensor` is being traced by this tape.
| Args |
| `tensor` | a Tensor or list of Tensors. |
| Raises |
| `ValueError` | if it encounters something that is not a tensor. |
### `watched_variables`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L989-L993)
```
watched_variables()
```
Returns variables watched by this tape in order of construction.
### `__enter__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L855-L858)
```
__enter__()
```
Enters a context inside which operations are recorded on this tape.
### `__exit__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/backprop.py#L860-L863)
```
__exit__(
typ, value, traceback
)
```
Exits the recording context, no further operations are traced.
| programming_docs |
tensorflow tf.histogram_fixed_width_bins tf.histogram\_fixed\_width\_bins
================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/histogram_ops.py#L30-L99) |
Bins the given values for use in a histogram.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.histogram_fixed_width_bins`](https://www.tensorflow.org/api_docs/python/tf/histogram_fixed_width_bins)
```
tf.histogram_fixed_width_bins(
values,
value_range,
nbins=100,
dtype=tf.dtypes.int32,
name=None
)
```
Given the tensor `values`, this operation returns a rank 1 `Tensor` representing the indices of a histogram into which each element of `values` would be binned. The bins are equal width and determined by the arguments `value_range` and `nbins`.
| Args |
| `values` | Numeric `Tensor`. |
| `value_range` | Shape [2] `Tensor` of same `dtype` as `values`. values <= value\_range[0] will be mapped to hist[0], values >= value\_range[1] will be mapped to hist[-1]. |
| `nbins` | Scalar `int32 Tensor`. Number of histogram bins. |
| `dtype` | dtype for returned histogram. |
| `name` | A name for this operation (defaults to 'histogram\_fixed\_width'). |
| Returns |
| A `Tensor` holding the indices of the binned values whose shape matches `values`. |
| Raises |
| `TypeError` | If any unsupported dtype is provided. |
| [`tf.errors.InvalidArgumentError`](https://www.tensorflow.org/api_docs/python/tf/errors/InvalidArgumentError) | If value\_range does not satisfy value\_range[0] < value\_range[1]. |
#### Examples:
```
# Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf)
nbins = 5
value_range = [0.0, 5.0]
new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]
indices = tf.histogram_fixed_width_bins(new_values, value_range, nbins=5)
indices.numpy()
array([0, 0, 1, 2, 4, 4], dtype=int32)
```
tensorflow tf.ones_like tf.ones\_like
=============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3189-L3222) |
Creates a tensor of all ones that has the same shape as the input.
```
tf.ones_like(
input, dtype=None, name=None
)
```
See also [`tf.ones`](ones).
Given a single tensor (`tensor`), this operation returns a tensor of the same type and shape as `tensor` with all elements set to 1. Optionally, you can use `dtype` to specify a new type for the returned tensor.
#### For example:
```
tensor = tf.constant([[1, 2, 3], [4, 5, 6]])
tf.ones_like(tensor)
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 1, 1],
[1, 1, 1]], dtype=int32)>
```
| Args |
| `input` | A `Tensor`. |
| `dtype` | A type for the returned `Tensor`. Must be `float16`, `float32`, `float64`, `int8`, `uint8`, `int16`, `uint16`, `int32`, `int64`, `complex64`, `complex128`, `bool` or `string`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` with all elements set to one. |
tensorflow tf.einsum tf.einsum
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/special_math_ops.py#L617-L762) |
Tensor contraction over specified indices and outer product.
#### View aliases
**Main aliases**
[`tf.linalg.einsum`](https://www.tensorflow.org/api_docs/python/tf/einsum)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.einsum`](https://www.tensorflow.org/api_docs/python/tf/einsum), [`tf.compat.v1.linalg.einsum`](https://www.tensorflow.org/api_docs/python/tf/einsum)
```
tf.einsum(
equation, *inputs, **kwargs
)
```
Einsum allows defining Tensors by defining their element-wise computation. This computation is defined by `equation`, a shorthand form based on Einstein summation. As an example, consider multiplying two matrices A and B to form a matrix C. The elements of C are given by:
\[ C\_{i,k} = \sum\_j A\_{i,j} B\_{j,k} \]
or
```
C[i,k] = sum_j A[i,j] * B[j,k]
```
The corresponding einsum `equation` is:
```
ij,jk->ik
```
In general, to convert the element-wise equation into the `equation` string, use the following procedure (intermediate strings for matrix multiplication example provided in parentheses):
1. remove variable names, brackets, and commas, (`ik = sum_j ij * jk`)
2. replace "\*" with ",", (`ik = sum_j ij , jk`)
3. drop summation signs, and (`ik = ij, jk`)
4. move the output to the right, while replacing "=" with "->". (`ij,jk->ik`)
>
> **Note:** If the output indices are not specified repeated indices are summed. So `ij,jk->ik` can be simplified to `ij,jk`.
>
Many common operations can be expressed in this way. For example:
**Matrix multiplication**
```
m0 = tf.random.normal(shape=[2, 3])
m1 = tf.random.normal(shape=[3, 5])
e = tf.einsum('ij,jk->ik', m0, m1)
# output[i,k] = sum_j m0[i,j] * m1[j, k]
print(e.shape)
(2, 5)
```
Repeated indices are summed if the output indices are not specified.
```
e = tf.einsum('ij,jk', m0, m1) # output[i,k] = sum_j m0[i,j] * m1[j, k]
print(e.shape)
(2, 5)
```
**Dot product**
```
u = tf.random.normal(shape=[5])
v = tf.random.normal(shape=[5])
e = tf.einsum('i,i->', u, v) # output = sum_i u[i]*v[i]
print(e.shape)
()
```
**Outer product**
```
u = tf.random.normal(shape=[3])
v = tf.random.normal(shape=[5])
e = tf.einsum('i,j->ij', u, v) # output[i,j] = u[i]*v[j]
print(e.shape)
(3, 5)
```
**Transpose**
```
m = tf.ones(2,3)
e = tf.einsum('ij->ji', m0) # output[j,i] = m0[i,j]
print(e.shape)
(3, 2)
```
**Diag**
```
m = tf.reshape(tf.range(9), [3,3])
diag = tf.einsum('ii->i', m)
print(diag.shape)
(3,)
```
**Trace**
```
# Repeated indices are summed.
trace = tf.einsum('ii', m) # output[j,i] = trace(m) = sum_i m[i, i]
assert trace == sum(diag)
print(trace.shape)
()
```
**Batch matrix multiplication**
```
s = tf.random.normal(shape=[7,5,3])
t = tf.random.normal(shape=[7,3,2])
e = tf.einsum('bij,bjk->bik', s, t)
# output[a,i,k] = sum_j s[a,i,j] * t[a, j, k]
print(e.shape)
(7, 5, 2)
```
This method does not support broadcasting on named-axes. All axes with matching labels should have the same length. If you have length-1 axes, use [`tf.squeeze`](squeeze) or [`tf.reshape`](reshape) to eliminate them.
To write code that is agnostic to the number of indices in the input use an ellipsis. The ellipsis is a placeholder for "whatever other indices fit here".
For example, to perform a NumPy-style broadcasting-batch-matrix multiplication where the matrix multiply acts on the last two axes of the input, use:
```
s = tf.random.normal(shape=[11, 7, 5, 3])
t = tf.random.normal(shape=[11, 7, 3, 2])
e = tf.einsum('...ij,...jk->...ik', s, t)
print(e.shape)
(11, 7, 5, 2)
```
Einsum **will** broadcast over axes covered by the ellipsis.
```
s = tf.random.normal(shape=[11, 1, 5, 3])
t = tf.random.normal(shape=[1, 7, 3, 2])
e = tf.einsum('...ij,...jk->...ik', s, t)
print(e.shape)
(11, 7, 5, 2)
```
| Args |
| `equation` | a `str` describing the contraction, in the same format as `numpy.einsum`. |
| `*inputs` | the inputs to contract (each one a `Tensor`), whose shapes should be consistent with `equation`. |
| `**kwargs` | * optimize: Optimization strategy to use to find contraction path using opt\_einsum. Must be 'greedy', 'optimal', 'branch-2', 'branch-all' or 'auto'. (optional, default: 'greedy').
* name: A name for the operation (optional).
|
| Returns |
| The contracted `Tensor`, with shape determined by `equation`. |
| Raises |
| `ValueError` | If * the format of `equation` is incorrect,
* number of inputs or their shapes are inconsistent with `equation`.
|
tensorflow tf.get_current_name_scope tf.get\_current\_name\_scope
============================
Returns current full name scope specified by [`tf.name_scope(...)`](name_scope)s.
```
tf.get_current_name_scope()
```
For example,
```
with tf.name_scope("outer"):
tf.get_current_name_scope() # "outer"
with tf.name_scope("inner"):
tf.get_current_name_scope() # "outer/inner"
```
In other words, [`tf.get_current_name_scope()`](get_current_name_scope) returns the op name prefix that will be prepended to, if an op is created at that place.
Note that [`@tf.function`](function) resets the name scope stack as shown below.
```
with tf.name_scope("outer"):
@tf.function
def foo(x):
with tf.name_scope("inner"):
return tf.add(x * x) # Op name is "inner/Add", not "outer/inner/Add"
```
tensorflow tf.RaggedTensor tf.RaggedTensor
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L60-L2248) |
Represents a ragged tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.RaggedTensor`](https://www.tensorflow.org/api_docs/python/tf/RaggedTensor)
A `RaggedTensor` is a tensor with one or more *ragged dimensions*, which are dimensions whose slices may have different lengths. For example, the inner (column) dimension of `rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]` is ragged, since the column slices (`rt[0, :]`, ..., `rt[4, :]`) have different lengths. Dimensions whose slices all have the same length are called *uniform dimensions*. The outermost dimension of a `RaggedTensor` is always uniform, since it consists of a single slice (and so there is no possibility for differing slice lengths).
The total number of dimensions in a `RaggedTensor` is called its *rank*, and the number of ragged dimensions in a `RaggedTensor` is called its *ragged-rank*. A `RaggedTensor`'s ragged-rank is fixed at graph creation time: it can't depend on the runtime values of `Tensor`s, and can't vary dynamically for different session runs.
Note that the `__init__` constructor is private. Please use one of the following methods to construct a `RaggedTensor`:
* [`tf.RaggedTensor.from_row_lengths`](raggedtensor#from_row_lengths)
* [`tf.RaggedTensor.from_value_rowids`](raggedtensor#from_value_rowids)
* [`tf.RaggedTensor.from_row_splits`](raggedtensor#from_row_splits)
* [`tf.RaggedTensor.from_row_starts`](raggedtensor#from_row_starts)
* [`tf.RaggedTensor.from_row_limits`](raggedtensor#from_row_limits)
* [`tf.RaggedTensor.from_nested_row_splits`](raggedtensor#from_nested_row_splits)
* [`tf.RaggedTensor.from_nested_row_lengths`](raggedtensor#from_nested_row_lengths)
* [`tf.RaggedTensor.from_nested_value_rowids`](raggedtensor#from_nested_value_rowids)
### Potentially Ragged Tensors
Many ops support both `Tensor`s and `RaggedTensor`s (see [tf.ragged](https://www.tensorflow.org/api_docs/python/tf/ragged) for a full listing). The term "potentially ragged tensor" may be used to refer to a tensor that might be either a `Tensor` or a `RaggedTensor`. The ragged-rank of a `Tensor` is zero.
### Documenting RaggedTensor Shapes
When documenting the shape of a RaggedTensor, ragged dimensions can be indicated by enclosing them in parentheses. For example, the shape of a 3-D `RaggedTensor` that stores the fixed-size word embedding for each word in a sentence, for each sentence in a batch, could be written as `[num_sentences, (num_words), embedding_size]`. The parentheses around `(num_words)` indicate that dimension is ragged, and that the length of each element list in that dimension may vary for each item.
### Component Tensors
Internally, a `RaggedTensor` consists of a concatenated list of values that are partitioned into variable-length rows. In particular, each `RaggedTensor` consists of:
* A `values` tensor, which concatenates the variable-length rows into a flattened list. For example, the `values` tensor for `[[3, 1, 4, 1], [], [5, 9, 2], [6], []]` is `[3, 1, 4, 1, 5, 9, 2, 6]`.
* A `row_splits` vector, which indicates how those flattened values are divided into rows. In particular, the values for row `rt[i]` are stored in the slice `rt.values[rt.row_splits[i]:rt.row_splits[i+1]]`.
#### Example:
```
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2, 6],
row_splits=[0, 4, 4, 7, 8, 8]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### Alternative Row-Partitioning Schemes
In addition to `row_splits`, ragged tensors provide support for five other row-partitioning schemes:
* `row_lengths`: a vector with shape `[nrows]`, which specifies the length of each row.
* `value_rowids` and `nrows`: `value_rowids` is a vector with shape `[nvals]`, corresponding one-to-one with `values`, which specifies each value's row index. In particular, the row `rt[row]` consists of the values `rt.values[j]` where `value_rowids[j]==row`. `nrows` is an integer scalar that specifies the number of rows in the `RaggedTensor`. (`nrows` is used to indicate trailing empty rows.)
* `row_starts`: a vector with shape `[nrows]`, which specifies the start offset of each row. Equivalent to `row_splits[:-1]`.
* `row_limits`: a vector with shape `[nrows]`, which specifies the stop offset of each row. Equivalent to `row_splits[1:]`.
* `uniform_row_length`: A scalar tensor, specifying the length of every row. This row-partitioning scheme may only be used if all rows have the same length.
Example: The following ragged tensors are equivalent, and all represent the nested list `[[3, 1, 4, 1], [], [5, 9, 2], [6], []]`.
```
values = [3, 1, 4, 1, 5, 9, 2, 6]
RaggedTensor.from_row_splits(values, row_splits=[0, 4, 4, 7, 8, 8])
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
RaggedTensor.from_row_lengths(values, row_lengths=[4, 0, 3, 1, 0])
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
RaggedTensor.from_value_rowids(
values, value_rowids=[0, 0, 0, 0, 2, 2, 2, 3], nrows=5)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
RaggedTensor.from_row_starts(values, row_starts=[0, 4, 4, 7, 8])
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
RaggedTensor.from_row_limits(values, row_limits=[4, 4, 7, 8, 8])
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
RaggedTensor.from_uniform_row_length(values, uniform_row_length=2)
<tf.RaggedTensor [[3, 1], [4, 1], [5, 9], [2, 6]]>
```
### Multiple Ragged Dimensions
`RaggedTensor`s with multiple ragged dimensions can be defined by using a nested `RaggedTensor` for the `values` tensor. Each nested `RaggedTensor` adds a single ragged dimension.
```
inner_rt = RaggedTensor.from_row_splits( # =rt1 from above
values=[3, 1, 4, 1, 5, 9, 2, 6], row_splits=[0, 4, 4, 7, 8, 8])
outer_rt = RaggedTensor.from_row_splits(
values=inner_rt, row_splits=[0, 3, 3, 5])
print(outer_rt.to_list())
[[[3, 1, 4, 1], [], [5, 9, 2]], [], [[6], []]]
print(outer_rt.ragged_rank)
2
```
The factory function [`RaggedTensor.from_nested_row_splits`](raggedtensor#from_nested_row_splits) may be used to construct a `RaggedTensor` with multiple ragged dimensions directly, by providing a list of `row_splits` tensors:
```
RaggedTensor.from_nested_row_splits(
flat_values=[3, 1, 4, 1, 5, 9, 2, 6],
nested_row_splits=([0, 3, 3, 5], [0, 4, 4, 7, 8, 8])).to_list()
[[[3, 1, 4, 1], [], [5, 9, 2]], [], [[6], []]]
```
### Uniform Inner Dimensions
`RaggedTensor`s with uniform inner dimensions can be defined by using a multidimensional `Tensor` for `values`.
```
rt = RaggedTensor.from_row_splits(values=tf.ones([5, 3], tf.int32),
row_splits=[0, 2, 5])
print(rt.to_list())
[[[1, 1, 1], [1, 1, 1]],
[[1, 1, 1], [1, 1, 1], [1, 1, 1]]]
print(rt.shape)
(2, None, 3)
```
### Uniform Outer Dimensions
`RaggedTensor`s with uniform outer dimensions can be defined by using one or more `RaggedTensor` with a `uniform_row_length` row-partitioning tensor. For example, a `RaggedTensor` with shape `[2, 2, None]` can be constructed with this method from a `RaggedTensor` values with shape `[4, None]`:
```
values = tf.ragged.constant([[1, 2, 3], [4], [5, 6], [7, 8, 9, 10]])
print(values.shape)
(4, None)
rt6 = tf.RaggedTensor.from_uniform_row_length(values, 2)
print(rt6)
<tf.RaggedTensor [[[1, 2, 3], [4]], [[5, 6], [7, 8, 9, 10]]]>
print(rt6.shape)
(2, 2, None)
```
Note that `rt6` only contains one ragged dimension (the innermost dimension). In contrast, if `from_row_splits` is used to construct a similar `RaggedTensor`, then that `RaggedTensor` will have two ragged dimensions:
```
rt7 = tf.RaggedTensor.from_row_splits(values, [0, 2, 4])
print(rt7.shape)
(2, None, None)
```
Uniform and ragged outer dimensions may be interleaved, meaning that a tensor with any combination of ragged and uniform dimensions may be created. For example, a RaggedTensor `t4` with shape `[3, None, 4, 8, None, 2]` could be constructed as follows:
```
t0 = tf.zeros([1000, 2]) # Shape: [1000, 2]
t1 = RaggedTensor.from_row_lengths(t0, [...]) # [160, None, 2]
t2 = RaggedTensor.from_uniform_row_length(t1, 8) # [20, 8, None, 2]
t3 = RaggedTensor.from_uniform_row_length(t2, 4) # [5, 4, 8, None, 2]
t4 = RaggedTensor.from_row_lengths(t3, [...]) # [3, None, 4, 8, None, 2]
```
| Attributes |
| `dtype` | The `DType` of values in this tensor. |
| `flat_values` | The innermost `values` tensor for this ragged tensor. Concretely, if `rt.values` is a `Tensor`, then `rt.flat_values` is `rt.values`; otherwise, `rt.flat_values` is `rt.values.flat_values`. Conceptually, `flat_values` is the tensor formed by flattening the outermost dimension and all of the ragged dimensions into a single dimension. `rt.flat_values.shape = [nvals] + rt.shape[rt.ragged_rank + 1:]` (where `nvals` is the number of items in the flattened dimensions). Example:
```
rt = tf.ragged.constant([[[3, 1, 4, 1], [], [5, 9, 2]], [], [[6], []]])
print(rt.flat_values)
tf.Tensor([3 1 4 1 5 9 2 6], shape=(8,), dtype=int32)
```
|
| `nested_row_splits` | A tuple containing the row\_splits for all ragged dimensions. `rt.nested_row_splits` is a tuple containing the `row_splits` tensors for all ragged dimensions in `rt`, ordered from outermost to innermost. In particular, `rt.nested_row_splits = (rt.row_splits,) + value_splits` where:
```
* `value_splits = ()` if `rt.values` is a `Tensor`.
* `value_splits = rt.values.nested_row_splits` otherwise.
```
Example:
```
rt = tf.ragged.constant(
[[[[3, 1, 4, 1], [], [5, 9, 2]], [], [[6], []]]])
for i, splits in enumerate(rt.nested_row_splits):
print('Splits for dimension %d: %s' % (i+1, splits.numpy()))
Splits for dimension 1: [0 3]
Splits for dimension 2: [0 3 3 5]
Splits for dimension 3: [0 4 4 7 8 8]
```
|
| `ragged_rank` | The number of times the RaggedTensor's flat\_values is partitioned.
```
values = tf.ragged.constant([[1, 2, 3], [4], [5, 6], [7, 8, 9, 10]])
values.ragged_rank
1
```
```
rt = tf.RaggedTensor.from_uniform_row_length(values, 2)
rt.ragged_rank
2
```
|
| `row_splits` | The row-split indices for this ragged tensor's `values`. `rt.row_splits` specifies where the values for each row begin and end in `rt.values`. In particular, the values for row `rt[i]` are stored in the slice `rt.values[rt.row_splits[i]:rt.row_splits[i+1]]`. Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.row_splits) # indices of row splits in rt.values
tf.Tensor([0 4 4 7 8 8], shape=(6,), dtype=int64)
```
|
| `shape` | The statically known shape of this ragged tensor.
```
tf.ragged.constant([[0], [1, 2]]).shape
TensorShape([2, None])
```
```
tf.ragged.constant([[[0, 1]], [[1, 2], [3, 4]]], ragged_rank=1).shape
TensorShape([2, None, 2])
```
|
| `uniform_row_length` | The length of each row in this ragged tensor, or None if rows are ragged.
```
rt1 = tf.ragged.constant([[1, 2, 3], [4], [5, 6], [7, 8, 9, 10]])
print(rt1.uniform_row_length) # rows are ragged.
None
```
```
rt2 = tf.RaggedTensor.from_uniform_row_length(
values=rt1, uniform_row_length=2)
print(rt2)
<tf.RaggedTensor [[[1, 2, 3], [4]], [[5, 6], [7, 8, 9, 10]]]>
print(rt2.uniform_row_length) # rows are not ragged (all have size 2).
tf.Tensor(2, shape=(), dtype=int64)
```
A RaggedTensor's rows are only considered to be uniform (i.e. non-ragged) if it can be determined statically (at graph construction time) that the rows all have the same length. |
| `values` | The concatenated rows for this ragged tensor. `rt.values` is a potentially ragged tensor formed by flattening the two outermost dimensions of `rt` into a single dimension. `rt.values.shape = [nvals] + rt.shape[2:]` (where `nvals` is the number of items in the outer two dimensions of `rt`). `rt.ragged_rank = self.ragged_rank - 1` Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.values)
tf.Tensor([3 1 4 1 5 9 2 6], shape=(8,), dtype=int32)
```
|
Methods
-------
### `bounding_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1318-L1376)
```
bounding_shape(
axis=None, name=None, out_type=None
)
```
Returns the tight bounding box shape for this `RaggedTensor`.
| Args |
| `axis` | An integer scalar or vector indicating which axes to return the bounding box for. If not specified, then the full bounding box is returned. |
| `name` | A name prefix for the returned tensor (optional). |
| `out_type` | `dtype` for the returned tensor. Defaults to `self.row_splits.dtype`. |
| Returns |
| An integer `Tensor` (`dtype=self.row_splits.dtype`). If `axis` is not specified, then `output` is a vector with `output.shape=[self.shape.ndims]`. If `axis` is a scalar, then the `output` is a scalar. If `axis` is a vector, then `output` is a vector, where `output[i]` is the bounding size for dimension `axis[i]`. |
#### Example:
```
rt = tf.ragged.constant([[1, 2, 3, 4], [5], [], [6, 7, 8, 9], [10]])
rt.bounding_shape().numpy()
array([5, 4])
```
### `consumers`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2244-L2245)
```
consumers()
```
### `from_nested_row_lengths`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L764-L804)
```
@classmethod
from_nested_row_lengths(
flat_values, nested_row_lengths, name=None, validate=True
)
```
Creates a `RaggedTensor` from a nested list of `row_lengths` tensors.
#### Equivalent to:
```
result = flat_values
for row_lengths in reversed(nested_row_lengths):
result = from_row_lengths(result, row_lengths)
```
| Args |
| `flat_values` | A potentially ragged tensor. |
| `nested_row_lengths` | A list of 1-D integer tensors. The `i`th tensor is used as the `row_lengths` for the `i`th ragged dimension. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor` (or `flat_values` if `nested_row_lengths` is empty). |
### `from_nested_row_splits`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L722-L762)
```
@classmethod
from_nested_row_splits(
flat_values, nested_row_splits, name=None, validate=True
)
```
Creates a `RaggedTensor` from a nested list of `row_splits` tensors.
#### Equivalent to:
```
result = flat_values
for row_splits in reversed(nested_row_splits):
result = from_row_splits(result, row_splits)
```
| Args |
| `flat_values` | A potentially ragged tensor. |
| `nested_row_splits` | A list of 1-D integer tensors. The `i`th tensor is used as the `row_splits` for the `i`th ragged dimension. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor` (or `flat_values` if `nested_row_splits` is empty). |
### `from_nested_value_rowids`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L659-L720)
```
@classmethod
from_nested_value_rowids(
flat_values,
nested_value_rowids,
nested_nrows=None,
name=None,
validate=True
)
```
Creates a `RaggedTensor` from a nested list of `value_rowids` tensors.
#### Equivalent to:
```
result = flat_values
for (rowids, nrows) in reversed(zip(nested_value_rowids, nested_nrows)):
result = from_value_rowids(result, rowids, nrows)
```
| Args |
| `flat_values` | A potentially ragged tensor. |
| `nested_value_rowids` | A list of 1-D integer tensors. The `i`th tensor is used as the `value_rowids` for the `i`th ragged dimension. |
| `nested_nrows` | A list of integer scalars. The `i`th scalar is used as the `nrows` for the `i`th ragged dimension. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor` (or `flat_values` if `nested_value_rowids` is empty). |
| Raises |
| `ValueError` | If `len(nested_values_rowids) != len(nested_nrows)`. |
### `from_row_lengths`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L459-L501)
```
@classmethod
from_row_lengths(
values, row_lengths, name=None, validate=True
)
```
Creates a `RaggedTensor` with rows partitioned by `row_lengths`.
The returned `RaggedTensor` corresponds with the python list defined by:
```
result = [[values.pop(0) for i in range(length)]
for length in row_lengths]
```
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `row_lengths` | A 1-D integer tensor with shape `[nrows]`. Must be nonnegative. `sum(row_lengths)` must be `nvals`. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor`. `result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
#### Example:
```
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2, 6],
row_lengths=[4, 0, 3, 1, 0]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### `from_row_limits`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L544-L581)
```
@classmethod
from_row_limits(
values, row_limits, name=None, validate=True
)
```
Creates a `RaggedTensor` with rows partitioned by `row_limits`.
Equivalent to: `from_row_splits(values, concat([0, row_limits]))`.
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `row_limits` | A 1-D integer tensor with shape `[nrows]`. Must be sorted in ascending order. If `nrows>0`, then `row_limits[-1]` must be `nvals`. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor`. `result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
#### Example:
```
print(tf.RaggedTensor.from_row_limits(
values=[3, 1, 4, 1, 5, 9, 2, 6],
row_limits=[4, 4, 7, 8, 8]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### `from_row_splits`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L411-L457)
```
@classmethod
from_row_splits(
values, row_splits, name=None, validate=True
)
```
Creates a `RaggedTensor` with rows partitioned by `row_splits`.
The returned `RaggedTensor` corresponds with the python list defined by:
```
result = [values[row_splits[i]:row_splits[i + 1]]
for i in range(len(row_splits) - 1)]
```
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `row_splits` | A 1-D integer tensor with shape `[nrows+1]`. Must not be empty, and must be sorted in ascending order. `row_splits[0]` must be zero and `row_splits[-1]` must be `nvals`. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor`. `result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
| Raises |
| `ValueError` | If `row_splits` is an empty list. |
#### Example:
```
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2, 6],
row_splits=[0, 4, 4, 7, 8, 8]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### `from_row_starts`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L503-L542)
```
@classmethod
from_row_starts(
values, row_starts, name=None, validate=True
)
```
Creates a `RaggedTensor` with rows partitioned by `row_starts`.
Equivalent to: `from_row_splits(values, concat([row_starts, nvals]))`.
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `row_starts` | A 1-D integer tensor with shape `[nrows]`. Must be nonnegative and sorted in ascending order. If `nrows>0`, then `row_starts[0]` must be zero. |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor`. `result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
#### Example:
```
print(tf.RaggedTensor.from_row_starts(
values=[3, 1, 4, 1, 5, 9, 2, 6],
row_starts=[0, 4, 4, 7, 8]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### `from_sparse`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1862-L1925)
```
@classmethod
from_sparse(
st_input,
name=None,
row_splits_dtype=tf.dtypes.int64
)
```
Converts a 2D [`tf.sparse.SparseTensor`](sparse/sparsetensor) to a `RaggedTensor`.
Each row of the `output` `RaggedTensor` will contain the explicit values from the same row in `st_input`. `st_input` must be ragged-right. If not it is not ragged-right, then an error will be generated.
#### Example:
```
indices = [[0, 0], [0, 1], [0, 2], [1, 0], [3, 0]]
st = tf.sparse.SparseTensor(indices=indices,
values=[1, 2, 3, 4, 5],
dense_shape=[4, 3])
tf.RaggedTensor.from_sparse(st).to_list()
[[1, 2, 3], [4], [], [5]]
```
Currently, only two-dimensional `SparseTensors` are supported.
| Args |
| `st_input` | The sparse tensor to convert. Must have rank 2. |
| `name` | A name prefix for the returned tensors (optional). |
| `row_splits_dtype` | `dtype` for the returned `RaggedTensor`'s `row_splits` tensor. One of [`tf.int32`](../tf#int32) or [`tf.int64`](../tf#int64). |
| Returns |
| A `RaggedTensor` with the same values as `st_input`. `output.ragged_rank = rank(st_input) - 1`. `output.shape = [st_input.dense_shape[0], None]`. |
| Raises |
| `ValueError` | If the number of dimensions in `st_input` is not known statically, or is not two. |
### `from_tensor`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1573-L1787)
```
@classmethod
from_tensor(
tensor,
lengths=None,
padding=None,
ragged_rank=1,
name=None,
row_splits_dtype=tf.dtypes.int64
)
```
Converts a [`tf.Tensor`](tensor) into a `RaggedTensor`.
The set of absent/default values may be specified using a vector of lengths or a padding value (but not both). If `lengths` is specified, then the output tensor will satisfy `output[row] = tensor[row][:lengths[row]]`. If 'lengths' is a list of lists or tuple of lists, those lists will be used as nested row lengths. If `padding` is specified, then any row *suffix* consisting entirely of `padding` will be excluded from the returned `RaggedTensor`. If neither `lengths` nor `padding` is specified, then the returned `RaggedTensor` will have no absent/default values.
#### Examples:
```
dt = tf.constant([[5, 7, 0], [0, 3, 0], [6, 0, 0]])
tf.RaggedTensor.from_tensor(dt)
<tf.RaggedTensor [[5, 7, 0], [0, 3, 0], [6, 0, 0]]>
tf.RaggedTensor.from_tensor(dt, lengths=[1, 0, 3])
<tf.RaggedTensor [[5], [], [6, 0, 0]]>
```
```
tf.RaggedTensor.from_tensor(dt, padding=0)
<tf.RaggedTensor [[5, 7], [0, 3], [6]]>
```
```
dt = tf.constant([[[5, 0], [7, 0], [0, 0]],
[[0, 0], [3, 0], [0, 0]],
[[6, 0], [0, 0], [0, 0]]])
tf.RaggedTensor.from_tensor(dt, lengths=([2, 0, 3], [1, 1, 2, 0, 1]))
<tf.RaggedTensor [[[5], [7]], [], [[6, 0], [], [0]]]>
```
| Args |
| `tensor` | The `Tensor` to convert. Must have rank `ragged_rank + 1` or higher. |
| `lengths` | An optional set of row lengths, specified using a 1-D integer `Tensor` whose length is equal to `tensor.shape[0]` (the number of rows in `tensor`). If specified, then `output[row]` will contain `tensor[row][:lengths[row]]`. Negative lengths are treated as zero. You may optionally pass a list or tuple of lengths to this argument, which will be used as nested row lengths to construct a ragged tensor with multiple ragged dimensions. |
| `padding` | An optional padding value. If specified, then any row suffix consisting entirely of `padding` will be excluded from the returned RaggedTensor. `padding` is a `Tensor` with the same dtype as `tensor` and with `shape=tensor.shape[ragged_rank + 1:]`. |
| `ragged_rank` | Integer specifying the ragged rank for the returned `RaggedTensor`. Must be greater than zero. |
| `name` | A name prefix for the returned tensors (optional). |
| `row_splits_dtype` | `dtype` for the returned `RaggedTensor`'s `row_splits` tensor. One of [`tf.int32`](../tf#int32) or [`tf.int64`](../tf#int64). |
| Returns |
| A `RaggedTensor` with the specified `ragged_rank`. The shape of the returned ragged tensor is compatible with the shape of `tensor`. |
| Raises |
| `ValueError` | If both `lengths` and `padding` are specified. |
| `ValueError` | If the rank of `tensor` is 0 or 1. |
### `from_uniform_row_length`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L583-L657)
```
@classmethod
from_uniform_row_length(
values, uniform_row_length, nrows=None, validate=True, name=None
)
```
Creates a `RaggedTensor` with rows partitioned by `uniform_row_length`.
This method can be used to create `RaggedTensor`s with multiple uniform outer dimensions. For example, a `RaggedTensor` with shape `[2, 2, None]` can be constructed with this method from a `RaggedTensor` values with shape `[4, None]`:
```
values = tf.ragged.constant([[1, 2, 3], [4], [5, 6], [7, 8, 9, 10]])
print(values.shape)
(4, None)
rt1 = tf.RaggedTensor.from_uniform_row_length(values, 2)
print(rt1)
<tf.RaggedTensor [[[1, 2, 3], [4]], [[5, 6], [7, 8, 9, 10]]]>
print(rt1.shape)
(2, 2, None)
```
Note that `rt1` only contains one ragged dimension (the innermost dimension). In contrast, if `from_row_splits` is used to construct a similar `RaggedTensor`, then that `RaggedTensor` will have two ragged dimensions:
```
rt2 = tf.RaggedTensor.from_row_splits(values, [0, 2, 4])
print(rt2.shape)
(2, None, None)
```
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `uniform_row_length` | A scalar integer tensor. Must be nonnegative. The size of the outer axis of `values` must be evenly divisible by `uniform_row_length`. |
| `nrows` | The number of rows in the constructed RaggedTensor. If not specified, then it defaults to `nvals/uniform_row_length` (or `0` if `uniform_row_length==0`). `nrows` only needs to be specified if `uniform_row_length` might be zero. `uniform_row_length*nrows` must be `nvals`. |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| `name` | A name prefix for the RaggedTensor (optional). |
| Returns |
| A `RaggedTensor` that corresponds with the python list defined by:
```
result = [[values.pop(0) for i in range(uniform_row_length)]
for _ in range(nrows)]
```
`result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
### `from_value_rowids`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L351-L409)
```
@classmethod
from_value_rowids(
values, value_rowids, nrows=None, name=None, validate=True
)
```
Creates a `RaggedTensor` with rows partitioned by `value_rowids`.
The returned `RaggedTensor` corresponds with the python list defined by:
```
result = [[values[i] for i in range(len(values)) if value_rowids[i] == row]
for row in range(nrows)]
```
| Args |
| `values` | A potentially ragged tensor with shape `[nvals, ...]`. |
| `value_rowids` | A 1-D integer tensor with shape `[nvals]`, which corresponds one-to-one with `values`, and specifies each value's row index. Must be nonnegative, and must be sorted in ascending order. |
| `nrows` | An integer scalar specifying the number of rows. This should be specified if the `RaggedTensor` may containing empty training rows. Must be greater than `value_rowids[-1]` (or zero if `value_rowids` is empty). Defaults to `value_rowids[-1] + 1` (or zero if `value_rowids` is empty). |
| `name` | A name prefix for the RaggedTensor (optional). |
| `validate` | If true, then use assertions to check that the arguments form a valid `RaggedTensor`. Note: these assertions incur a runtime cost, since they must be checked for each tensor value. |
| Returns |
| A `RaggedTensor`. `result.rank = values.rank + 1`. `result.ragged_rank = values.ragged_rank + 1`. |
| Raises |
| `ValueError` | If `nrows` is incompatible with `value_rowids`. |
#### Example:
```
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2, 6],
value_rowids=[0, 0, 0, 0, 2, 2, 2, 3],
nrows=5))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
```
### `get_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L920-L939)
```
get_shape()
```
The statically known shape of this ragged tensor.
| Returns |
| A `TensorShape` containing the statically known shape of this ragged tensor. Ragged dimensions have a size of `None`. |
Alias for `shape` property.
#### Examples:
```
tf.ragged.constant([[0], [1, 2]]).get_shape()
TensorShape([2, None])
```
```
tf.ragged.constant(
[[[0, 1]], [[1, 2], [3, 4]]], ragged_rank=1).get_shape()
TensorShape([2, None, 2])
```
### `merge_dims`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1464-L1510)
```
merge_dims(
outer_axis, inner_axis
)
```
Merges outer\_axis...inner\_axis into a single dimension.
Returns a copy of this RaggedTensor with the specified range of dimensions flattened into a single dimension, with elements in row-major order.
#### Examples:
```
rt = tf.ragged.constant([[[1, 2], [3]], [[4, 5, 6]]])
print(rt.merge_dims(0, 1))
<tf.RaggedTensor [[1, 2], [3], [4, 5, 6]]>
print(rt.merge_dims(1, 2))
<tf.RaggedTensor [[1, 2, 3], [4, 5, 6]]>
print(rt.merge_dims(0, 2))
tf.Tensor([1 2 3 4 5 6], shape=(6,), dtype=int32)
```
To mimic the behavior of `np.flatten` (which flattens all dimensions), use `rt.merge_dims(0, -1). To mimic the behavior of`tf.layers.Flatten`(which flattens all dimensions except the outermost batch dimension), use`rt.merge\_dims(1, -1)`.
| Args |
| `outer_axis` | `int`: The first dimension in the range of dimensions to merge. May be negative if `self.shape.rank` is statically known. |
| `inner_axis` | `int`: The last dimension in the range of dimensions to merge. May be negative if `self.shape.rank` is statically known. |
| Returns |
| A copy of this tensor, with the specified dimensions merged into a single dimension. The shape of the returned tensor will be `self.shape[:outer_axis] + [N] + self.shape[inner_axis + 1:]`, where `N` is the total number of slices in the merged dimensions. |
### `nested_row_lengths`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1297-L1316)
```
nested_row_lengths(
name=None
)
```
Returns a tuple containing the row\_lengths for all ragged dimensions.
`rt.nested_row_lengths()` is a tuple containing the `row_lengths` tensors for all ragged dimensions in `rt`, ordered from outermost to innermost.
| Args |
| `name` | A name prefix for the returned tensors (optional). |
| Returns |
| A `tuple` of 1-D integer `Tensors`. The length of the tuple is equal to `self.ragged_rank`. |
### `nested_value_rowids`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1135-L1170)
```
nested_value_rowids(
name=None
)
```
Returns a tuple containing the value\_rowids for all ragged dimensions.
`rt.nested_value_rowids` is a tuple containing the `value_rowids` tensors for all ragged dimensions in `rt`, ordered from outermost to innermost. In particular, `rt.nested_value_rowids = (rt.value_rowids(),) + value_ids` where:
* `value_ids = ()` if `rt.values` is a `Tensor`.
* `value_ids = rt.values.nested_value_rowids` otherwise.
| Args |
| `name` | A name prefix for the returned tensors (optional). |
| Returns |
| A `tuple` of 1-D integer `Tensor`s. |
#### Example:
```
rt = tf.ragged.constant(
[[[[3, 1, 4, 1], [], [5, 9, 2]], [], [[6], []]]])
for i, ids in enumerate(rt.nested_value_rowids()):
print('row ids for dimension %d: %s' % (i+1, ids.numpy()))
row ids for dimension 1: [0 0 0]
row ids for dimension 2: [0 0 0 2 2]
row ids for dimension 3: [0 0 0 0 2 2 2 3]
```
### `nrows`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1172-L1196)
```
nrows(
out_type=None, name=None
)
```
Returns the number of rows in this ragged tensor.
I.e., the size of the outermost dimension of the tensor.
| Args |
| `out_type` | `dtype` for the returned tensor. Defaults to `self.row_splits.dtype`. |
| `name` | A name prefix for the returned tensor (optional). |
| Returns |
| A scalar `Tensor` with dtype `out_type`. |
#### Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.nrows()) # rt has 5 rows.
tf.Tensor(5, shape=(), dtype=int64)
```
### `numpy`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2077-L2119)
```
numpy()
```
Returns a numpy `array` with the values for this `RaggedTensor`.
Requires that this `RaggedTensor` was constructed in eager execution mode.
Ragged dimensions are encoded using numpy `arrays` with `dtype=object` and `rank=1`, where each element is a single row.
#### Examples
In the following example, the value returned by [`RaggedTensor.numpy()`](raggedtensor#numpy) contains three numpy `array` objects: one for each row (with `rank=1` and `dtype=int64`), and one to combine them (with `rank=1` and `dtype=object`):
```
tf.ragged.constant([[1, 2, 3], [4, 5]], dtype=tf.int64).numpy()
array([array([1, 2, 3]), array([4, 5])], dtype=object)
```
Uniform dimensions are encoded using multidimensional numpy `array`s. In the following example, the value returned by [`RaggedTensor.numpy()`](raggedtensor#numpy) contains a single numpy `array` object, with `rank=2` and `dtype=int64`:
```
tf.ragged.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.int64).numpy()
array([[1, 2, 3], [4, 5, 6]])
```
| Returns |
| A numpy `array`. |
### `row_lengths`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1248-L1295)
```
row_lengths(
axis=1, name=None
)
```
Returns the lengths of the rows in this ragged tensor.
`rt.row_lengths()[i]` indicates the number of values in the `i`th row of `rt`.
| Args |
| `axis` | An integer constant indicating the axis whose row lengths should be returned. |
| `name` | A name prefix for the returned tensor (optional). |
| Returns |
| A potentially ragged integer Tensor with shape `self.shape[:axis]`. |
| Raises |
| `ValueError` | If `axis` is out of bounds. |
#### Example:
```
rt = tf.ragged.constant(
[[[3, 1, 4], [1]], [], [[5, 9], [2]], [[6]], []])
print(rt.row_lengths()) # lengths of rows in rt
tf.Tensor([2 0 2 1 0], shape=(5,), dtype=int64)
print(rt.row_lengths(axis=2)) # lengths of axis=2 rows.
<tf.RaggedTensor [[3, 1], [], [2, 1], [1], []]>
```
### `row_limits`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1223-L1246)
```
row_limits(
name=None
)
```
Returns the limit indices for rows in this ragged tensor.
These indices specify where the values for each row end in `self.values`. `rt.row_limits(self)` is equal to `rt.row_splits[:-1]`.
| Args |
| `name` | A name prefix for the returned tensor (optional). |
| Returns |
| A 1-D integer Tensor with shape `[nrows]`. The returned tensor is nonnegative, and is sorted in ascending order. |
#### Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.values)
tf.Tensor([3 1 4 1 5 9 2 6], shape=(8,), dtype=int32)
print(rt.row_limits()) # indices of row limits in rt.values
tf.Tensor([4 4 7 8 8], shape=(5,), dtype=int64)
```
### `row_starts`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1198-L1221)
```
row_starts(
name=None
)
```
Returns the start indices for rows in this ragged tensor.
These indices specify where the values for each row begin in `self.values`. `rt.row_starts()` is equal to `rt.row_splits[:-1]`.
| Args |
| `name` | A name prefix for the returned tensor (optional). |
| Returns |
| A 1-D integer Tensor with shape `[nrows]`. The returned tensor is nonnegative, and is sorted in ascending order. |
#### Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.values)
tf.Tensor([3 1 4 1 5 9 2 6], shape=(8,), dtype=int32)
print(rt.row_starts()) # indices of row starts in rt.values
tf.Tensor([0 4 4 7 8], shape=(5,), dtype=int64)
```
### `to_list`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L2121-L2151)
```
to_list()
```
Returns a nested Python `list` with the values for this `RaggedTensor`.
Requires that `rt` was constructed in eager execution mode.
| Returns |
| A nested Python `list`. |
### `to_sparse`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1927-L1951)
```
to_sparse(
name=None
)
```
Converts this `RaggedTensor` into a [`tf.sparse.SparseTensor`](sparse/sparsetensor).
#### Example:
```
rt = tf.ragged.constant([[1, 2, 3], [4], [], [5, 6]])
print(rt.to_sparse())
SparseTensor(indices=tf.Tensor(
[[0 0] [0 1] [0 2] [1 0] [3 0] [3 1]],
shape=(6, 2), dtype=int64),
values=tf.Tensor([1 2 3 4 5 6], shape=(6,), dtype=int32),
dense_shape=tf.Tensor([4 3], shape=(2,), dtype=int64))
```
| Args |
| `name` | A name prefix for the returned tensors (optional). |
| Returns |
| A SparseTensor with the same values as `self`. |
### `to_tensor`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1789-L1860)
```
to_tensor(
default_value=None, name=None, shape=None
)
```
Converts this `RaggedTensor` into a [`tf.Tensor`](tensor).
If `shape` is specified, then the result is padded and/or truncated to the specified shape.
#### Examples:
```
rt = tf.ragged.constant([[9, 8, 7], [], [6, 5], [4]])
print(rt.to_tensor())
tf.Tensor(
[[9 8 7] [0 0 0] [6 5 0] [4 0 0]], shape=(4, 3), dtype=int32)
print(rt.to_tensor(shape=[5, 2]))
tf.Tensor(
[[9 8] [0 0] [6 5] [4 0] [0 0]], shape=(5, 2), dtype=int32)
```
| Args |
| `default_value` | Value to set for indices not specified in `self`. Defaults to zero. `default_value` must be broadcastable to `self.shape[self.ragged_rank + 1:]`. |
| `name` | A name prefix for the returned tensors (optional). |
| `shape` | The shape of the resulting dense tensor. In particular, `result.shape[i]` is `shape[i]` (if `shape[i]` is not None), or `self.bounding_shape(i)` (otherwise).`shape.rank` must be `None` or equal to `self.rank`. |
| Returns |
| A `Tensor` with shape `ragged.bounding_shape(self)` and the values specified by the non-empty values in `self`. Empty values are assigned `default_value`. |
### `value_rowids`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1108-L1133)
```
value_rowids(
name=None
)
```
Returns the row indices for the `values` in this ragged tensor.
`rt.value_rowids()` corresponds one-to-one with the outermost dimension of `rt.values`, and specifies the row containing each value. In particular, the row `rt[row]` consists of the values `rt.values[j]` where `rt.value_rowids()[j] == row`.
| Args |
| `name` | A name prefix for the returned tensor (optional). |
| Returns |
| A 1-D integer `Tensor` with shape `self.values.shape[:1]`. The returned tensor is nonnegative, and is sorted in ascending order. |
#### Example:
```
rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
print(rt.values)
tf.Tensor([3 1 4 1 5 9 2 6], shape=(8,), dtype=int32)
print(rt.value_rowids()) # corresponds 1:1 with rt.values
tf.Tensor([0 0 0 0 2 2 2 3], shape=(8,), dtype=int64)
```
### `with_flat_values`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1411-L1431)
```
with_flat_values(
new_values
)
```
Returns a copy of `self` with `flat_values` replaced by `new_value`.
Preserves cached row-partitioning tensors such as `self.cached_nrows` and `self.cached_value_rowids` if they have values.
| Args |
| `new_values` | Potentially ragged tensor that should replace `self.flat_values`. Must have `rank > 0`, and must have the same number of rows as `self.flat_values`. |
| Returns |
| A `RaggedTensor`. `result.rank = self.ragged_rank + new_values.rank`. `result.ragged_rank = self.ragged_rank + new_values.ragged_rank`. |
### `with_row_splits_dtype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1433-L1462)
```
with_row_splits_dtype(
dtype
)
```
Returns a copy of this RaggedTensor with the given `row_splits` dtype.
For RaggedTensors with multiple ragged dimensions, the `row_splits` for all nested `RaggedTensor` objects are cast to the given dtype.
| Args |
| `dtype` | The dtype for `row_splits`. One of [`tf.int32`](../tf#int32) or [`tf.int64`](../tf#int64). |
| Returns |
| A copy of this RaggedTensor, with the `row_splits` cast to the given type. |
### `with_values`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_tensor.py#L1382-L1409)
```
with_values(
new_values
)
```
Returns a copy of `self` with `values` replaced by `new_value`.
Preserves cached row-partitioning tensors such as `self.cached_nrows` and `self.cached_value_rowids` if they have values.
| Args |
| `new_values` | Potentially ragged tensor to use as the `values` for the returned `RaggedTensor`. Must have `rank > 0`, and must have the same number of rows as `self.values`. |
| Returns |
| A `RaggedTensor`. `result.rank = 1 + new_values.rank`. `result.ragged_rank = 1 + new_values.ragged_rank` |
### `__abs__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L364-L408)
```
__abs__(
name=None
)
```
Computes the absolute value of a tensor.
Given a tensor of integer or floating-point values, this operation returns a tensor of the same type, where each element contains the absolute value of the corresponding element in the input.
Given a tensor `x` of complex numbers, this operation returns a tensor of type `float32` or `float64` that is the absolute value of each element in `x`. For a complex number \(a + bj\), its absolute value is computed as \(\sqrt{a^2 + b^2}\).
#### For example:
```
# real number
x = tf.constant([-2.25, 3.25])
tf.abs(x)
<tf.Tensor: shape=(2,), dtype=float32,
numpy=array([2.25, 3.25], dtype=float32)>
```
```
# complex number
x = tf.constant([[-2.25 + 4.75j], [-3.25 + 5.75j]])
tf.abs(x)
<tf.Tensor: shape=(2, 1), dtype=float64, numpy=
array([[5.25594901],
[6.60492241]])>
```
| Args |
| `x` | A `Tensor` or `SparseTensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64` or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` or `SparseTensor` of the same size, type and sparsity as `x`, with absolute values. Note, for `complex64` or `complex128` input, the returned `Tensor` will be of type `float32` or `float64`, respectively. If `x` is a `SparseTensor`, returns `SparseTensor(x.indices, tf.math.abs(x.values, ...), x.dense_shape)` |
### `__add__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L3925-L4003)
```
__add__(
y, name=None
)
```
Returns x + y element-wise.
Example usages below.
Add a scalar and a list:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.add(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([2, 3, 4, 5, 6],
dtype=int32)>
```
Note that binary `+` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x + y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([2, 3, 4, 5, 6],
dtype=int32)>
```
Add a tensor and a list of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([1, 2, 3, 4, 5])
tf.add(x, y)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 2, 4, 6, 8, 10], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**7 + 1, 2**7 + 2]
tf.add(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([-126, -124], dtype=int8)>
```
When adding two input values of different shapes, `Add` follows NumPy broadcasting rules. The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(1, 2, 1, 3)
y = np.ones(6).reshape(2, 1, 3, 1)
tf.add(x, y).shape.as_list()
[2, 2, 3, 3]
```
Another example with two arrays of different dimension.
```
x = np.ones([1, 2, 1, 4])
y = np.ones([3, 4])
tf.add(x, y).shape.as_list()
[1, 2, 3, 4]
```
The reduction version of this elementwise operation is [`tf.math.reduce_sum`](math/reduce_sum)
| Args |
| `x` | A [`tf.Tensor`](tensor). Must be one of the following types: bfloat16, half, float32, float64, uint8, int8, int16, int32, int64, complex64, complex128, string. |
| `y` | A [`tf.Tensor`](tensor). Must have the same type as x. |
| `name` | A name for the operation (optional) |
### `__and__`
```
__and__(
y, name=None
)
```
Returns the truth value of x AND y element-wise.
Logical AND function.
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`.
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical AND with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical AND of the two input tensors.
You can also use the `&` operator instead.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_and(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([False])>
a & b
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([False])>
```
```
c = tf.constant([True])
x = tf.constant([False, True, True, False])
tf.math.logical_and(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
c & x
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_and(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, False, False, True])>
y & z
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, False, False, True])>
```
This op also supports broadcasting
```
tf.logical_and([[True, False]], [[True], [False]])
<tf.Tensor: shape=(2, 2), dtype=bool, numpy=
array([[ True, False],
[False, False]])>
```
The reduction version of this elementwise operation is [`tf.math.reduce_all`](math/reduce_all).
| Args |
| `x` | A [`tf.Tensor`](tensor) of type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the shape that `x` and `y` broadcast to. |
| Args |
| `x` | A `Tensor` of type `bool`. |
| `y` | A `Tensor` of type `bool`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__bool__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_operators.py#L85-L87)
```
__bool__()
```
Dummy method to prevent a RaggedTensor from being used as a Python bool.
### `__div__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1592-L1621)
```
__div__(
y, name=None
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1962-L1998)
```
__eq__(
other
)
```
The operation invoked by the [`Tensor.**eq**`](raggedtensor#__eq__) operator.
Compares two tensors element-wise for equality if they are broadcast-compatible; or returns False if they are not broadcast-compatible. (Note that this behavior differs from [`tf.math.equal`](math/equal), which raises an exception if the two tensors are not broadcast-compatible.)
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**eq**`](raggedtensor#__eq__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `self` | The left-hand side of the `==` operator. |
| `other` | The right-hand side of the `==` operator. |
| Returns |
| The result of the elementwise `==` operation, or `False` if the arguments are not broadcast-compatible. |
### `__floordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1691-L1718)
```
__floordiv__(
y, name=None
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__ge__`
```
__ge__(
y, name=None
)
```
Returns the truth value of (x >= y) element-wise.
>
> **Note:** [`math.greater_equal`](math/greater_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5, 2, 5, 10])
tf.math.greater_equal(x, y) ==> [True, True, True, False]
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5])
tf.math.greater_equal(x, y) ==> [True, False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__getitem__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_getitem.py#L33-L105)
```
__getitem__(
key
)
```
Returns the specified piece of this RaggedTensor.
Supports multidimensional indexing and slicing, with one restriction: indexing into a ragged inner dimension is not allowed. This case is problematic because the indicated value may exist in some rows but not others. In such cases, it's not obvious whether we should (1) report an IndexError; (2) use a default value; or (3) skip that value and return a tensor with fewer rows than we started with. Following the guiding principles of Python ("In the face of ambiguity, refuse the temptation to guess"), we simply disallow this operation.
| Args |
| `rt_input` | The RaggedTensor to slice. |
| `key` | Indicates which piece of the RaggedTensor to return, using standard Python semantics (e.g., negative values index from the end). `key` may have any of the following types: * `int` constant
* Scalar integer `Tensor`
* `slice` containing integer constants and/or scalar integer `Tensor`s
* `Ellipsis`
* [`tf.newaxis`](../tf#newaxis)
* `tuple` containing any of the above (for multidimensional indexing)
|
| Returns |
| A `Tensor` or `RaggedTensor` object. Values that include at least one ragged dimension are returned as `RaggedTensor`. Values that include no ragged dimensions are returned as `Tensor`. See above for examples of expressions that return `Tensor`s vs `RaggedTensor`s. |
| Raises |
| `ValueError` | If `key` is out of bounds. |
| `ValueError` | If `key` is not supported. |
| `TypeError` | If the indices in `key` have an unsupported type. |
#### Examples:
```
# A 2-D ragged tensor with 1 ragged dimension.
rt = tf.ragged.constant([['a', 'b', 'c'], ['d', 'e'], ['f'], ['g']])
rt[0].numpy() # First row (1-D `Tensor`)
array([b'a', b'b', b'c'], dtype=object)
rt[:3].to_list() # First three rows (2-D RaggedTensor)
[[b'a', b'b', b'c'], [b'd', b'e'], [b'f']]
rt[3, 0].numpy() # 1st element of 4th row (scalar)
b'g'
```
```
# A 3-D ragged tensor with 2 ragged dimensions.
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
rt[1].to_list() # Second row (2-D RaggedTensor)
[[5], [], [6]]
rt[3, 0].numpy() # First element of fourth row (1-D Tensor)
array([8, 9], dtype=int32)
rt[:, 1:3].to_list() # Items 1-3 of each row (3-D RaggedTensor)
[[[4]], [[], [6]], [], [[10]]]
rt[:, -1:].to_list() # Last item of each row (3-D RaggedTensor)
[[[4]], [[6]], [[7]], [[10]]]
```
### `__gt__`
```
__gt__(
y, name=None
)
```
Returns the truth value of (x > y) element-wise.
>
> **Note:** [`math.greater`](math/greater) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5, 2, 5])
tf.math.greater(x, y) ==> [False, True, True]
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.greater(x, y) ==> [False, False, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__invert__`
```
__invert__(
name=None
)
```
Returns the truth value of `NOT x` element-wise.
#### Example:
```
tf.math.logical_not(tf.constant([True, False]))
<tf.Tensor: shape=(2,), dtype=bool, numpy=array([False, True])>
```
| Args |
| `x` | A `Tensor` of type `bool`. A `Tensor` of type `bool`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__le__`
```
__le__(
y, name=None
)
```
Returns the truth value of (x <= y) element-wise.
>
> **Note:** [`math.less_equal`](math/less_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less_equal(x, y) ==> [True, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 6])
tf.math.less_equal(x, y) ==> [True, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__lt__`
```
__lt__(
y, name=None
)
```
Returns the truth value of (x < y) element-wise.
>
> **Note:** [`math.less`](math/less) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less(x, y) ==> [False, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 7])
tf.math.less(x, y) ==> [False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__mod__`
```
__mod__(
y, name=None
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__mul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L480-L529)
```
__mul__(
y, name=None
)
```
Returns an element-wise x \* y.
#### For example:
```
x = tf.constant(([1, 2, 3, 4]))
tf.math.multiply(x, x)
<tf.Tensor: shape=(4,), dtype=..., numpy=array([ 1, 4, 9, 16], dtype=int32)>
```
Since [`tf.math.multiply`](math/multiply) will convert its arguments to `Tensor`s, you can also pass in non-`Tensor` arguments:
```
tf.math.multiply(7,6)
<tf.Tensor: shape=(), dtype=int32, numpy=42>
```
If `x.shape` is not the same as `y.shape`, they will be broadcast to a compatible shape. (More about broadcasting [here](https://docs.scipy.org/doc/numpy/user/basics.broadcasting.html).)
#### For example:
```
x = tf.ones([1, 2]);
y = tf.ones([2, 1]);
x * y # Taking advantage of operator overriding
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[1., 1.],
[1., 1.]], dtype=float32)>
```
The reduction version of this elementwise operation is [`tf.math.reduce_prod`](math/reduce_prod)
| Args |
| `x` | A Tensor. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
A `Tensor`. Has the same type as `x`.
| Raises |
| * InvalidArgumentError: When `x` and `y` have incompatible shapes or types.
|
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L2001-L2035)
```
__ne__(
other
)
```
The operation invoked by the [`Tensor.**ne**`](raggedtensor#__ne__) operator.
Compares two tensors element-wise for inequality if they are broadcast-compatible; or returns True if they are not broadcast-compatible. (Note that this behavior differs from [`tf.math.not_equal`](math/not_equal), which raises an exception if the two tensors are not broadcast-compatible.)
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**ne**`](raggedtensor#__ne__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `self` | The left-hand side of the `!=` operator. |
| `other` | The right-hand side of the `!=` operator. |
| Returns |
| The result of the elementwise `!=` operation, or `True` if the arguments are not broadcast-compatible. |
### `__neg__`
```
__neg__(
name=None
)
```
Computes numerical negative value element-wise.
I.e., \(y = -x\).
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `int8`, `int16`, `int32`, `int64`, `complex64`, `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. If `x` is a `SparseTensor`, returns `SparseTensor(x.indices, tf.math.negative(x.values, ...), x.dense_shape)` |
### `__nonzero__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/ragged/ragged_operators.py#L85-L87)
```
__nonzero__()
```
Dummy method to prevent a RaggedTensor from being used as a Python bool.
### `__or__`
```
__or__(
y, name=None
)
```
Returns the truth value of x OR y element-wise.
Logical OR function.
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`.
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical OR with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical OR of the two input tensors.
You can also use the `|` operator instead.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_or(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
a | b
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
```
```
c = tf.constant([False])
x = tf.constant([False, True, True, False])
tf.math.logical_or(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
c | x
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_or(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>
y | z
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>
```
This op also supports broadcasting
```
tf.logical_or([[True, False]], [[True], [False]])
<tf.Tensor: shape=(2, 2), dtype=bool, numpy=
array([[ True, True],
[ True, False]])>
```
The reduction version of this elementwise operation is [`tf.math.reduce_any`](math/reduce_any).
| Args |
| `x` | A [`tf.Tensor`](tensor) of type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the shape that `x` and `y` broadcast to. |
| Args |
| `x` | A `Tensor` of type `bool`. |
| `y` | A `Tensor` of type `bool`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__pow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L668-L694)
```
__pow__(
y, name=None
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__radd__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L3925-L4003)
```
__radd__(
y, name=None
)
```
Returns x + y element-wise.
Example usages below.
Add a scalar and a list:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.add(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([2, 3, 4, 5, 6],
dtype=int32)>
```
Note that binary `+` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x + y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([2, 3, 4, 5, 6],
dtype=int32)>
```
Add a tensor and a list of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([1, 2, 3, 4, 5])
tf.add(x, y)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 2, 4, 6, 8, 10], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**7 + 1, 2**7 + 2]
tf.add(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([-126, -124], dtype=int8)>
```
When adding two input values of different shapes, `Add` follows NumPy broadcasting rules. The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(1, 2, 1, 3)
y = np.ones(6).reshape(2, 1, 3, 1)
tf.add(x, y).shape.as_list()
[2, 2, 3, 3]
```
Another example with two arrays of different dimension.
```
x = np.ones([1, 2, 1, 4])
y = np.ones([3, 4])
tf.add(x, y).shape.as_list()
[1, 2, 3, 4]
```
The reduction version of this elementwise operation is [`tf.math.reduce_sum`](math/reduce_sum)
| Args |
| `x` | A [`tf.Tensor`](tensor). Must be one of the following types: bfloat16, half, float32, float64, uint8, int8, int16, int32, int64, complex64, complex128, string. |
| `y` | A [`tf.Tensor`](tensor). Must have the same type as x. |
| `name` | A name for the operation (optional) |
### `__rand__`
```
__rand__(
y, name=None
)
```
Returns the truth value of x AND y element-wise.
Logical AND function.
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`.
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical AND with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical AND of the two input tensors.
You can also use the `&` operator instead.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_and(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([False])>
a & b
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([False])>
```
```
c = tf.constant([True])
x = tf.constant([False, True, True, False])
tf.math.logical_and(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
c & x
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_and(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, False, False, True])>
y & z
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, False, False, True])>
```
This op also supports broadcasting
```
tf.logical_and([[True, False]], [[True], [False]])
<tf.Tensor: shape=(2, 2), dtype=bool, numpy=
array([[ True, False],
[False, False]])>
```
The reduction version of this elementwise operation is [`tf.math.reduce_all`](math/reduce_all).
| Args |
| `x` | A [`tf.Tensor`](tensor) of type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the shape that `x` and `y` broadcast to. |
| Args |
| `x` | A `Tensor` of type `bool`. |
| `y` | A `Tensor` of type `bool`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__rdiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1592-L1621)
```
__rdiv__(
y, name=None
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__rfloordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1691-L1718)
```
__rfloordiv__(
y, name=None
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__rmod__`
```
__rmod__(
y, name=None
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L480-L529)
```
__rmul__(
y, name=None
)
```
Returns an element-wise x \* y.
#### For example:
```
x = tf.constant(([1, 2, 3, 4]))
tf.math.multiply(x, x)
<tf.Tensor: shape=(4,), dtype=..., numpy=array([ 1, 4, 9, 16], dtype=int32)>
```
Since [`tf.math.multiply`](math/multiply) will convert its arguments to `Tensor`s, you can also pass in non-`Tensor` arguments:
```
tf.math.multiply(7,6)
<tf.Tensor: shape=(), dtype=int32, numpy=42>
```
If `x.shape` is not the same as `y.shape`, they will be broadcast to a compatible shape. (More about broadcasting [here](https://docs.scipy.org/doc/numpy/user/basics.broadcasting.html).)
#### For example:
```
x = tf.ones([1, 2]);
y = tf.ones([2, 1]);
x * y # Taking advantage of operator overriding
<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[1., 1.],
[1., 1.]], dtype=float32)>
```
The reduction version of this elementwise operation is [`tf.math.reduce_prod`](math/reduce_prod)
| Args |
| `x` | A Tensor. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
A `Tensor`. Has the same type as `x`.
| Raises |
| * InvalidArgumentError: When `x` and `y` have incompatible shapes or types.
|
### `__ror__`
```
__ror__(
y, name=None
)
```
Returns the truth value of x OR y element-wise.
Logical OR function.
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`.
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical OR with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical OR of the two input tensors.
You can also use the `|` operator instead.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_or(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
a | b
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
```
```
c = tf.constant([False])
x = tf.constant([False, True, True, False])
tf.math.logical_or(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
c | x
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_or(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>
y | z
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>
```
This op also supports broadcasting
```
tf.logical_or([[True, False]], [[True], [False]])
<tf.Tensor: shape=(2, 2), dtype=bool, numpy=
array([[ True, True],
[ True, False]])>
```
The reduction version of this elementwise operation is [`tf.math.reduce_any`](math/reduce_any).
| Args |
| `x` | A [`tf.Tensor`](tensor) of type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the shape that `x` and `y` broadcast to. |
| Args |
| `x` | A `Tensor` of type `bool`. |
| `y` | A `Tensor` of type `bool`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__rpow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L668-L694)
```
__rpow__(
y, name=None
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__rsub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L544-L548)
```
__rsub__(
y, name=None
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rtruediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1558-L1589)
```
__rtruediv__(
y, name=None
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__rxor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1789-L1838)
```
__rxor__(
y, name='LogicalXor'
)
```
Logical XOR function.
x ^ y = (x | y) & ~(x & y)
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical XOR with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical XOR of the two input tensors.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_xor(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
```
```
c = tf.constant([True])
x = tf.constant([False, True, True, False])
tf.math.logical_xor(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([ True, False, False, True])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_xor(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
| Args |
| `x` | A [`tf.Tensor`](tensor) type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the same size as that of x or y. |
### `__sub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L544-L548)
```
__sub__(
y, name=None
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__truediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1558-L1589)
```
__truediv__(
y, name=None
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__xor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1789-L1838)
```
__xor__(
y, name='LogicalXor'
)
```
Logical XOR function.
x ^ y = (x | y) & ~(x & y)
Requires that `x` and `y` have the same shape or have [broadcast-compatible](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html) shapes. For example, `x` and `y` can be:
* Two single elements of type `bool`
* One [`tf.Tensor`](tensor) of type `bool` and one single `bool`, where the result will be calculated by applying logical XOR with the single element to each element in the larger Tensor.
* Two [`tf.Tensor`](tensor) objects of type `bool` of the same shape. In this case, the result will be the element-wise logical XOR of the two input tensors.
#### Usage:
```
a = tf.constant([True])
b = tf.constant([False])
tf.math.logical_xor(a, b)
<tf.Tensor: shape=(1,), dtype=bool, numpy=array([ True])>
```
```
c = tf.constant([True])
x = tf.constant([False, True, True, False])
tf.math.logical_xor(c, x)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([ True, False, False, True])>
```
```
y = tf.constant([False, False, True, True])
z = tf.constant([False, True, False, True])
tf.math.logical_xor(y, z)
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, False])>
```
| Args |
| `x` | A [`tf.Tensor`](tensor) type bool. |
| `y` | A [`tf.Tensor`](tensor) of type bool. |
| `name` | A name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of type bool with the same size as that of x or y. |
| programming_docs |
tensorflow tf.argsort tf.argsort
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/sort_ops.py#L86-L150) |
Returns the indices of a tensor that give its sorted order along an axis.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.argsort`](https://www.tensorflow.org/api_docs/python/tf/argsort)
```
tf.argsort(
values, axis=-1, direction='ASCENDING', stable=False, name=None
)
```
```
values = [1, 10, 26.9, 2.8, 166.32, 62.3]
sort_order = tf.argsort(values)
sort_order.numpy()
array([0, 3, 1, 2, 5, 4], dtype=int32)
```
#### For a 1D tensor:
```
sorted = tf.gather(values, sort_order)
assert tf.reduce_all(sorted == tf.sort(values))
```
For higher dimensions, the output has the same shape as `values`, but along the given axis, values represent the index of the sorted element in that slice of the tensor at the given position.
```
mat = [[30,20,10],
[20,10,30],
[10,30,20]]
indices = tf.argsort(mat)
indices.numpy()
array([[2, 1, 0],
[1, 0, 2],
[0, 2, 1]], dtype=int32)
```
If `axis=-1` these indices can be used to apply a sort using `tf.gather`:
```
tf.gather(mat, indices, batch_dims=-1).numpy()
array([[10, 20, 30],
[10, 20, 30],
[10, 20, 30]], dtype=int32)
```
#### See also:
* [`tf.sort`](sort): Sort along an axis.
* [`tf.math.top_k`](math/top_k): A partial sort that returns a fixed number of top values and corresponding indices.
| Args |
| `values` | 1-D or higher **numeric** `Tensor`. |
| `axis` | The axis along which to sort. The default is -1, which sorts the last axis. |
| `direction` | The direction in which to sort the values (`'ASCENDING'` or `'DESCENDING'`). |
| `stable` | If True, equal elements in the original tensor will not be re-ordered in the returned order. Unstable sort is not yet implemented, but will eventually be the default for performance reasons. If you require a stable order, pass `stable=True` for forwards compatibility. |
| `name` | Optional name for the operation. |
| Returns |
| An int32 `Tensor` with the same shape as `values`. The indices that would sort each slice of the given `values` along the given `axis`. |
| Raises |
| `ValueError` | If axis is not a constant scalar, or the direction is invalid. |
| [`tf.errors.InvalidArgumentError`](https://www.tensorflow.org/api_docs/python/tf/errors/InvalidArgumentError) | If the `values.dtype` is not a `float` or `int` type. |
tensorflow tf.extract_volume_patches tf.extract\_volume\_patches
===========================
Extract `patches` from `input` and put them in the `"depth"` output dimension. 3D extension of `extract_image_patches`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.extract_volume_patches`](https://www.tensorflow.org/api_docs/python/tf/extract_volume_patches)
```
tf.extract_volume_patches(
input, ksizes, strides, padding, name=None
)
```
| Args |
| `input` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. 5-D Tensor with shape `[batch, in_planes, in_rows, in_cols, depth]`. |
| `ksizes` | A list of `ints` that has length `>= 5`. The size of the sliding window for each dimension of `input`. |
| `strides` | A list of `ints` that has length `>= 5`. 1-D of length 5. How far the centers of two consecutive patches are in `input`. Must be: `[1, stride_planes, stride_rows, stride_cols, 1]`. |
| `padding` | A `string` from: `"SAME", "VALID"`. The type of padding algorithm to use. The size-related attributes are specified as follows:
```
ksizes = [1, ksize_planes, ksize_rows, ksize_cols, 1]
strides = [1, stride_planes, strides_rows, strides_cols, 1]
```
|
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.constant_initializer tf.constant\_initializer
========================
Initializer that generates tensors with constant values.
```
tf.constant_initializer(
value=0
)
```
Initializers allow you to pre-specify an initialization strategy, encoded in the Initializer object, without knowing the shape and dtype of the variable being initialized.
[`tf.constant_initializer`](constant_initializer) returns an object which when called returns a tensor populated with the `value` specified in the constructor. This `value` must be convertible to the requested `dtype`.
The argument `value` can be a scalar constant value, or a list of values. Scalars broadcast to whichever shape is requested from the initializer.
If `value` is a list, then the length of the list must be equal to the number of elements implied by the desired shape of the tensor. If the total number of elements in `value` is not equal to the number of elements required by the tensor shape, the initializer will raise a `TypeError`.
#### Examples:
```
def make_variables(k, initializer):
return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
v1, v2 = make_variables(3, tf.constant_initializer(2.))
v1
<tf.Variable ... shape=(3,) ... numpy=array([2., 2., 2.], dtype=float32)>
v2
<tf.Variable ... shape=(3, 3) ... numpy=
array([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]], dtype=float32)>
make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
(<tf.Variable...shape=(4,) dtype=float32...>, <tf.Variable...shape=(4, 4) ...
```
```
value = [0, 1, 2, 3, 4, 5, 6, 7]
init = tf.constant_initializer(value)
# Fitting shape
tf.Variable(init(shape=[2, 4], dtype=tf.float32))
<tf.Variable ...
array([[0., 1., 2., 3.],
[4., 5., 6., 7.]], dtype=float32)>
# Larger shape
tf.Variable(init(shape=[3, 4], dtype=tf.float32))
Traceback (most recent call last):
TypeError: ...value has 8 elements, shape is (3, 4) with 12 elements...
# Smaller shape
tf.Variable(init(shape=[2, 3], dtype=tf.float32))
Traceback (most recent call last):
TypeError: ...value has 8 elements, shape is (2, 3) with 6 elements...
```
| Args |
| `value` | A Python scalar, list or tuple of values, or a N-dimensional numpy array. All elements of the initialized variable will be set to the corresponding value in the `value` argument. |
| Raises |
| `TypeError` | If the input `value` is not one of the expected types. |
Methods
-------
### `from_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L76-L96)
```
@classmethod
from_config(
config
)
```
Instantiates an initializer from a configuration dictionary.
#### Example:
```
initializer = RandomUniform(-1, 1)
config = initializer.get_config()
initializer = RandomUniform.from_config(config)
```
| Args |
| `config` | A Python dictionary. It will typically be the output of `get_config`. |
| Returns |
| An Initializer instance. |
### `get_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L293-L294)
```
get_config()
```
Returns the configuration of the initializer as a JSON-serializable dict.
| Returns |
| A JSON-serializable Python dict. |
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L275-L291)
```
__call__(
shape, dtype=None, **kwargs
)
```
Returns a tensor object initialized as specified by the initializer.
| Args |
| `shape` | Shape of the tensor. |
| `dtype` | Optional dtype of the tensor. If not provided the dtype of the tensor created will be the type of the inital value. |
| `**kwargs` | Additional keyword arguments. |
| Raises |
| `TypeError` | If the initializer cannot create a tensor of the requested dtype. |
tensorflow Module: tf.ragged Module: tf.ragged
=================
Ragged Tensors.
This package defines ops for manipulating ragged tensors ([`tf.RaggedTensor`](raggedtensor)), which are tensors with non-uniform shapes. In particular, each `RaggedTensor` has one or more *ragged dimensions*, which are dimensions whose slices may have different lengths. For example, the inner (column) dimension of `rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]` is ragged, since the column slices (`rt[0, :]`, ..., `rt[4, :]`) have different lengths. For a more detailed description of ragged tensors, see the [`tf.RaggedTensor`](raggedtensor) class documentation and the [Ragged Tensor Guide](https://www.tensorflow.org/guide/ragged_tensor).
### Additional ops that support `RaggedTensor`
Arguments that accept `RaggedTensor`s are marked in **bold**.
* `tf.__operators__.eq`(**self**, **other**)
* `tf.__operators__.ne`(**self**, **other**)
* [`tf.bitcast`](bitcast)(**input**, type, name=`None`)
* [`tf.bitwise.bitwise_and`](bitwise/bitwise_and)(**x**, **y**, name=`None`)
* [`tf.bitwise.bitwise_or`](bitwise/bitwise_or)(**x**, **y**, name=`None`)
* [`tf.bitwise.bitwise_xor`](bitwise/bitwise_xor)(**x**, **y**, name=`None`)
* [`tf.bitwise.invert`](bitwise/invert)(**x**, name=`None`)
* [`tf.bitwise.left_shift`](bitwise/left_shift)(**x**, **y**, name=`None`)
* [`tf.bitwise.right_shift`](bitwise/right_shift)(**x**, **y**, name=`None`)
* [`tf.broadcast_to`](broadcast_to)(**input**, **shape**, name=`None`)
* [`tf.cast`](cast)(**x**, dtype, name=`None`)
* [`tf.clip_by_value`](clip_by_value)(**t**, clip\_value\_min, clip\_value\_max, name=`None`)
* [`tf.concat`](concat)(**values**, axis, name=`'concat'`)
* [`tf.debugging.check_numerics`](debugging/check_numerics)(**tensor**, message, name=`None`)
* [`tf.dtypes.complex`](dtypes/complex)(**real**, **imag**, name=`None`)
* [`tf.dtypes.saturate_cast`](dtypes/saturate_cast)(**value**, dtype, name=`None`)
* [`tf.dynamic_partition`](dynamic_partition)(**data**, **partitions**, num\_partitions, name=`None`)
* [`tf.expand_dims`](expand_dims)(**input**, axis, name=`None`)
* [`tf.gather_nd`](gather_nd)(**params**, **indices**, batch\_dims=`0`, name=`None`)
* [`tf.gather`](gather)(**params**, **indices**, validate\_indices=`None`, axis=`None`, batch\_dims=`0`, name=`None`)
* [`tf.image.adjust_brightness`](image/adjust_brightness)(**image**, delta)
* [`tf.image.adjust_gamma`](image/adjust_gamma)(**image**, gamma=`1`, gain=`1`)
* [`tf.image.convert_image_dtype`](image/convert_image_dtype)(**image**, dtype, saturate=`False`, name=`None`)
* [`tf.image.random_brightness`](image/random_brightness)(**image**, max\_delta, seed=`None`)
* [`tf.image.resize`](image/resize)(**images**, size, method=`'bilinear'`, preserve\_aspect\_ratio=`False`, antialias=`False`, name=`None`)
* [`tf.image.stateless_random_brightness`](image/stateless_random_brightness)(**image**, max\_delta, seed)
* [`tf.io.decode_base64`](io/decode_base64)(**input**, name=`None`)
* [`tf.io.decode_compressed`](io/decode_compressed)(**bytes**, compression\_type=`''`, name=`None`)
* [`tf.io.encode_base64`](io/encode_base64)(**input**, pad=`False`, name=`None`)
* [`tf.linalg.matmul`](linalg/matmul)(**a**, **b**, transpose\_a=`False`, transpose\_b=`False`, adjoint\_a=`False`, adjoint\_b=`False`, a\_is\_sparse=`False`, b\_is\_sparse=`False`, output\_type=`None`, name=`None`)
* [`tf.math.abs`](math/abs)(**x**, name=`None`)
* [`tf.math.acos`](math/acos)(**x**, name=`None`)
* [`tf.math.acosh`](math/acosh)(**x**, name=`None`)
* [`tf.math.add_n`](math/add_n)(**inputs**, name=`None`)
* [`tf.math.add`](math/add)(**x**, **y**, name=`None`)
* [`tf.math.angle`](math/angle)(**input**, name=`None`)
* [`tf.math.asin`](math/asin)(**x**, name=`None`)
* [`tf.math.asinh`](math/asinh)(**x**, name=`None`)
* [`tf.math.atan2`](math/atan2)(**y**, **x**, name=`None`)
* [`tf.math.atan`](math/atan)(**x**, name=`None`)
* [`tf.math.atanh`](math/atanh)(**x**, name=`None`)
* [`tf.math.bessel_i0`](math/bessel_i0)(**x**, name=`None`)
* [`tf.math.bessel_i0e`](math/bessel_i0e)(**x**, name=`None`)
* [`tf.math.bessel_i1`](math/bessel_i1)(**x**, name=`None`)
* [`tf.math.bessel_i1e`](math/bessel_i1e)(**x**, name=`None`)
* [`tf.math.ceil`](math/ceil)(**x**, name=`None`)
* [`tf.math.conj`](math/conj)(**x**, name=`None`)
* [`tf.math.cos`](math/cos)(**x**, name=`None`)
* [`tf.math.cosh`](math/cosh)(**x**, name=`None`)
* [`tf.math.digamma`](math/digamma)(**x**, name=`None`)
* [`tf.math.divide_no_nan`](math/divide_no_nan)(**x**, **y**, name=`None`)
* [`tf.math.divide`](math/divide)(**x**, **y**, name=`None`)
* [`tf.math.equal`](math/equal)(**x**, **y**, name=`None`)
* [`tf.math.erf`](math/erf)(**x**, name=`None`)
* [`tf.math.erfc`](math/erfc)(**x**, name=`None`)
* [`tf.math.erfcinv`](math/erfcinv)(**x**, name=`None`)
* [`tf.math.erfinv`](math/erfinv)(**x**, name=`None`)
* [`tf.math.exp`](math/exp)(**x**, name=`None`)
* [`tf.math.expm1`](math/expm1)(**x**, name=`None`)
* [`tf.math.floor`](math/floor)(**x**, name=`None`)
* [`tf.math.floordiv`](math/floordiv)(**x**, **y**, name=`None`)
* [`tf.math.floormod`](math/floormod)(**x**, **y**, name=`None`)
* [`tf.math.greater_equal`](math/greater_equal)(**x**, **y**, name=`None`)
* [`tf.math.greater`](math/greater)(**x**, **y**, name=`None`)
* [`tf.math.imag`](math/imag)(**input**, name=`None`)
* [`tf.math.is_finite`](math/is_finite)(**x**, name=`None`)
* [`tf.math.is_inf`](math/is_inf)(**x**, name=`None`)
* [`tf.math.is_nan`](math/is_nan)(**x**, name=`None`)
* [`tf.math.less_equal`](math/less_equal)(**x**, **y**, name=`None`)
* [`tf.math.less`](math/less)(**x**, **y**, name=`None`)
* [`tf.math.lgamma`](math/lgamma)(**x**, name=`None`)
* [`tf.math.log1p`](math/log1p)(**x**, name=`None`)
* [`tf.math.log_sigmoid`](math/log_sigmoid)(**x**, name=`None`)
* [`tf.math.log`](math/log)(**x**, name=`None`)
* [`tf.math.logical_and`](math/logical_and)(**x**, **y**, name=`None`)
* [`tf.math.logical_not`](math/logical_not)(**x**, name=`None`)
* [`tf.math.logical_or`](math/logical_or)(**x**, **y**, name=`None`)
* [`tf.math.logical_xor`](math/logical_xor)(**x**, **y**, name=`'LogicalXor'`)
* [`tf.math.maximum`](math/maximum)(**x**, **y**, name=`None`)
* [`tf.math.minimum`](math/minimum)(**x**, **y**, name=`None`)
* [`tf.math.multiply_no_nan`](math/multiply_no_nan)(**x**, **y**, name=`None`)
* [`tf.math.multiply`](math/multiply)(**x**, **y**, name=`None`)
* [`tf.math.ndtri`](math/ndtri)(**x**, name=`None`)
* [`tf.math.negative`](math/negative)(**x**, name=`None`)
* [`tf.math.nextafter`](math/nextafter)(**x1**, x2, name=`None`)
* [`tf.math.not_equal`](math/not_equal)(**x**, **y**, name=`None`)
* [`tf.math.pow`](math/pow)(**x**, **y**, name=`None`)
* [`tf.math.real`](math/real)(**input**, name=`None`)
* [`tf.math.reciprocal_no_nan`](math/reciprocal_no_nan)(**x**, name=`None`)
* [`tf.math.reciprocal`](math/reciprocal)(**x**, name=`None`)
* [`tf.math.reduce_all`](math/reduce_all)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_any`](math/reduce_any)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_max`](math/reduce_max)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_mean`](math/reduce_mean)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_min`](math/reduce_min)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_prod`](math/reduce_prod)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_std`](math/reduce_std)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_sum`](math/reduce_sum)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.reduce_variance`](math/reduce_variance)(**input\_tensor**, axis=`None`, keepdims=`False`, name=`None`)
* [`tf.math.rint`](math/rint)(**x**, name=`None`)
* [`tf.math.round`](math/round)(**x**, name=`None`)
* [`tf.math.rsqrt`](math/rsqrt)(**x**, name=`None`)
* [`tf.math.scalar_mul`](math/scalar_mul)(**scalar**, **x**, name=`None`)
* [`tf.math.sigmoid`](math/sigmoid)(**x**, name=`None`)
* [`tf.math.sign`](math/sign)(**x**, name=`None`)
* [`tf.math.sin`](math/sin)(**x**, name=`None`)
* [`tf.math.sinh`](math/sinh)(**x**, name=`None`)
* [`tf.math.softplus`](math/softplus)(**features**, name=`None`)
* [`tf.math.special.bessel_j0`](math/special/bessel_j0)(**x**, name=`None`)
* [`tf.math.special.bessel_j1`](math/special/bessel_j1)(**x**, name=`None`)
* [`tf.math.special.bessel_k0`](math/special/bessel_k0)(**x**, name=`None`)
* [`tf.math.special.bessel_k0e`](math/special/bessel_k0e)(**x**, name=`None`)
* [`tf.math.special.bessel_k1`](math/special/bessel_k1)(**x**, name=`None`)
* [`tf.math.special.bessel_k1e`](math/special/bessel_k1e)(**x**, name=`None`)
* [`tf.math.special.bessel_y0`](math/special/bessel_y0)(**x**, name=`None`)
* [`tf.math.special.bessel_y1`](math/special/bessel_y1)(**x**, name=`None`)
* [`tf.math.special.dawsn`](math/special/dawsn)(**x**, name=`None`)
* [`tf.math.special.expint`](math/special/expint)(**x**, name=`None`)
* [`tf.math.special.fresnel_cos`](math/special/fresnel_cos)(**x**, name=`None`)
* [`tf.math.special.fresnel_sin`](math/special/fresnel_sin)(**x**, name=`None`)
* [`tf.math.special.spence`](math/special/spence)(**x**, name=`None`)
* [`tf.math.sqrt`](math/sqrt)(**x**, name=`None`)
* [`tf.math.square`](math/square)(**x**, name=`None`)
* [`tf.math.squared_difference`](math/squared_difference)(**x**, **y**, name=`None`)
* [`tf.math.subtract`](math/subtract)(**x**, **y**, name=`None`)
* [`tf.math.tan`](math/tan)(**x**, name=`None`)
* [`tf.math.tanh`](math/tanh)(**x**, name=`None`)
* [`tf.math.truediv`](math/truediv)(**x**, **y**, name=`None`)
* [`tf.math.unsorted_segment_max`](math/unsorted_segment_max)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.unsorted_segment_mean`](math/unsorted_segment_mean)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.unsorted_segment_min`](math/unsorted_segment_min)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.unsorted_segment_prod`](math/unsorted_segment_prod)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.unsorted_segment_sqrt_n`](math/unsorted_segment_sqrt_n)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.unsorted_segment_sum`](math/unsorted_segment_sum)(**data**, **segment\_ids**, num\_segments, name=`None`)
* [`tf.math.xdivy`](math/xdivy)(**x**, **y**, name=`None`)
* [`tf.math.xlog1py`](math/xlog1py)(**x**, **y**, name=`None`)
* [`tf.math.xlogy`](math/xlogy)(**x**, **y**, name=`None`)
* [`tf.math.zeta`](math/zeta)(**x**, **q**, name=`None`)
* [`tf.nn.dropout`](nn/dropout)(**x**, rate, noise\_shape=`None`, seed=`None`, name=`None`)
* [`tf.nn.elu`](nn/elu)(**features**, name=`None`)
* [`tf.nn.gelu`](nn/gelu)(**features**, approximate=`False`, name=`None`)
* [`tf.nn.leaky_relu`](nn/leaky_relu)(**features**, alpha=`0.2`, name=`None`)
* [`tf.nn.relu6`](nn/relu6)(**features**, name=`None`)
* [`tf.nn.relu`](nn/relu)(**features**, name=`None`)
* [`tf.nn.selu`](nn/selu)(**features**, name=`None`)
* [`tf.nn.sigmoid_cross_entropy_with_logits`](nn/sigmoid_cross_entropy_with_logits)(**labels**=`None`, **logits**=`None`, name=`None`)
* [`tf.nn.silu`](nn/silu)(**features**, beta=`1.0`)
* [`tf.nn.softmax`](nn/softmax)(**logits**, axis=`None`, name=`None`)
* [`tf.nn.softsign`](nn/softsign)(**features**, name=`None`)
* [`tf.one_hot`](one_hot)(**indices**, depth, on\_value=`None`, off\_value=`None`, axis=`None`, dtype=`None`, name=`None`)
* [`tf.ones_like`](ones_like)(**input**, dtype=`None`, name=`None`)
* [`tf.print`](print)(\***inputs**, \*\*kwargs)
* [`tf.rank`](rank)(**input**, name=`None`)
* [`tf.realdiv`](realdiv)(**x**, **y**, name=`None`)
* [`tf.reshape`](reshape)(**tensor**, **shape**, name=`None`)
* [`tf.reverse`](reverse)(**tensor**, axis, name=`None`)
* [`tf.size`](size)(**input**, out\_type=[`tf.int32`](../tf#int32), name=`None`)
* [`tf.split`](split)(**value**, num\_or\_size\_splits, axis=`0`, num=`None`, name=`'split'`)
* [`tf.squeeze`](squeeze)(**input**, axis=`None`, name=`None`)
* [`tf.stack`](stack)(**values**, axis=`0`, name=`'stack'`)
* [`tf.strings.as_string`](strings/as_string)(**input**, precision=`-1`, scientific=`False`, shortest=`False`, width=`-1`, fill=`''`, name=`None`)
* [`tf.strings.format`](strings/format)(**template**, **inputs**, placeholder=`'{}'`, summarize=`3`, name=`None`)
* [`tf.strings.join`](strings/join)(**inputs**, separator=`''`, name=`None`)
* [`tf.strings.length`](strings/length)(**input**, unit=`'BYTE'`, name=`None`)
* [`tf.strings.lower`](strings/lower)(**input**, encoding=`''`, name=`None`)
* [`tf.strings.reduce_join`](strings/reduce_join)(**inputs**, axis=`None`, keepdims=`False`, separator=`''`, name=`None`)
* [`tf.strings.regex_full_match`](strings/regex_full_match)(**input**, pattern, name=`None`)
* [`tf.strings.regex_replace`](strings/regex_replace)(**input**, pattern, rewrite, replace\_global=`True`, name=`None`)
* [`tf.strings.strip`](strings/strip)(**input**, name=`None`)
* [`tf.strings.substr`](strings/substr)(**input**, pos, len, unit=`'BYTE'`, name=`None`)
* [`tf.strings.to_hash_bucket_fast`](strings/to_hash_bucket_fast)(**input**, num\_buckets, name=`None`)
* [`tf.strings.to_hash_bucket_strong`](strings/to_hash_bucket_strong)(**input**, num\_buckets, key, name=`None`)
* [`tf.strings.to_hash_bucket`](strings/to_hash_bucket)(**input**, num\_buckets, name=`None`)
* [`tf.strings.to_number`](strings/to_number)(**input**, out\_type=[`tf.float32`](../tf#float32), name=`None`)
* [`tf.strings.unicode_script`](strings/unicode_script)(**input**, name=`None`)
* [`tf.strings.unicode_transcode`](strings/unicode_transcode)(**input**, input\_encoding, output\_encoding, errors=`'replace'`, replacement\_char=`65533`, replace\_control\_characters=`False`, name=`None`)
* [`tf.strings.upper`](strings/upper)(**input**, encoding=`''`, name=`None`)
* [`tf.tile`](tile)(**input**, multiples, name=`None`)
* [`tf.truncatediv`](truncatediv)(**x**, **y**, name=`None`)
* [`tf.truncatemod`](truncatemod)(**x**, **y**, name=`None`)
* [`tf.where`](where)(**condition**, **x**=`None`, **y**=`None`, name=`None`)
* [`tf.zeros_like`](zeros_like)(**input**, dtype=`None`, name=`None`)n
Functions
---------
[`boolean_mask(...)`](ragged/boolean_mask): Applies a boolean mask to `data` without flattening the mask dimensions.
[`constant(...)`](ragged/constant): Constructs a constant RaggedTensor from a nested Python list.
[`cross(...)`](ragged/cross): Generates feature cross from a list of tensors.
[`cross_hashed(...)`](ragged/cross_hashed): Generates hashed feature cross from a list of tensors.
[`map_flat_values(...)`](ragged/map_flat_values): Applies `op` to the `flat_values` of one or more RaggedTensors.
[`range(...)`](ragged/range): Returns a `RaggedTensor` containing the specified sequences of numbers.
[`row_splits_to_segment_ids(...)`](ragged/row_splits_to_segment_ids): Generates the segmentation corresponding to a RaggedTensor `row_splits`.
[`segment_ids_to_row_splits(...)`](ragged/segment_ids_to_row_splits): Generates the RaggedTensor `row_splits` corresponding to a segmentation.
[`stack(...)`](ragged/stack): Stacks a list of rank-`R` tensors into one rank-`(R+1)` `RaggedTensor`.
[`stack_dynamic_partitions(...)`](ragged/stack_dynamic_partitions): Stacks dynamic partitions of a Tensor or RaggedTensor.
| programming_docs |
tensorflow tf.one_hot tf.one\_hot
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L4290-L4450) |
Returns a one-hot tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.one_hot`](https://www.tensorflow.org/api_docs/python/tf/one_hot)
```
tf.one_hot(
indices,
depth,
on_value=None,
off_value=None,
axis=None,
dtype=None,
name=None
)
```
See also [`tf.fill`](fill), [`tf.eye`](eye).
The locations represented by indices in `indices` take value `on_value`, while all other locations take value `off_value`.
`on_value` and `off_value` must have matching data types. If `dtype` is also provided, they must be the same data type as specified by `dtype`.
If `on_value` is not provided, it will default to the value `1` with type `dtype`
If `off_value` is not provided, it will default to the value `0` with type `dtype`
If the input `indices` is rank `N`, the output will have rank `N+1`. The new axis is created at dimension `axis` (default: the new axis is appended at the end).
If `indices` is a scalar the output shape will be a vector of length `depth`
If `indices` is a vector of length `features`, the output shape will be:
```
features x depth if axis == -1
depth x features if axis == 0
```
If `indices` is a matrix (batch) with shape `[batch, features]`, the output shape will be:
```
batch x features x depth if axis == -1
batch x depth x features if axis == 1
depth x batch x features if axis == 0
```
If `indices` is a RaggedTensor, the 'axis' argument must be positive and refer to a non-ragged axis. The output will be equivalent to applying 'one\_hot' on the values of the RaggedTensor, and creating a new RaggedTensor from the result.
If `dtype` is not provided, it will attempt to assume the data type of `on_value` or `off_value`, if one or both are passed in. If none of `on_value`, `off_value`, or `dtype` are provided, `dtype` will default to the value [`tf.float32`](../tf#float32).
>
> **Note:** If a non-numeric data type output is desired ([`tf.string`](../tf#string), [`tf.bool`](../tf#bool), etc.), both `on_value` and `off_value` *must* be provided to `one_hot`.
>
#### For example:
```
indices = [0, 1, 2]
depth = 3
tf.one_hot(indices, depth) # output: [3 x 3]
# [[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]]
indices = [0, 2, -1, 1]
depth = 3
tf.one_hot(indices, depth,
on_value=5.0, off_value=0.0,
axis=-1) # output: [4 x 3]
# [[5.0, 0.0, 0.0], # one_hot(0)
# [0.0, 0.0, 5.0], # one_hot(2)
# [0.0, 0.0, 0.0], # one_hot(-1)
# [0.0, 5.0, 0.0]] # one_hot(1)
indices = [[0, 2], [1, -1]]
depth = 3
tf.one_hot(indices, depth,
on_value=1.0, off_value=0.0,
axis=-1) # output: [2 x 2 x 3]
# [[[1.0, 0.0, 0.0], # one_hot(0)
# [0.0, 0.0, 1.0]], # one_hot(2)
# [[0.0, 1.0, 0.0], # one_hot(1)
# [0.0, 0.0, 0.0]]] # one_hot(-1)
indices = tf.ragged.constant([[0, 1], [2]])
depth = 3
tf.one_hot(indices, depth) # output: [2 x None x 3]
# [[[1., 0., 0.],
# [0., 1., 0.]],
# [[0., 0., 1.]]]
```
| Args |
| `indices` | A `Tensor` of indices. |
| `depth` | A scalar defining the depth of the one hot dimension. |
| `on_value` | A scalar defining the value to fill in output when `indices[j] = i`. (default: 1) |
| `off_value` | A scalar defining the value to fill in output when `indices[j] != i`. (default: 0) |
| `axis` | The axis to fill (default: -1, a new inner-most axis). |
| `dtype` | The data type of the output tensor. |
| `name` | A name for the operation (optional). |
| Returns |
| `output` | The one-hot tensor. |
| Raises |
| `TypeError` | If dtype of either `on_value` or `off_value` don't match `dtype` |
| `TypeError` | If dtype of `on_value` and `off_value` don't match one another |
tensorflow Module: tf.queue Module: tf.queue
================
Public API for tf.queue namespace.
Classes
-------
[`class FIFOQueue`](queue/fifoqueue): A queue implementation that dequeues elements in first-in first-out order.
[`class PaddingFIFOQueue`](queue/paddingfifoqueue): A FIFOQueue that supports batching variable-sized tensors by padding.
[`class PriorityQueue`](queue/priorityqueue): A queue implementation that dequeues elements in prioritized order.
[`class QueueBase`](queue/queuebase): Base class for queue implementations.
[`class RandomShuffleQueue`](queue/randomshufflequeue): A queue implementation that dequeues elements in a random order.
tensorflow tf.custom_gradient tf.custom\_gradient
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/custom_gradient.py#L43-L297) |
Decorator to define a function with a custom gradient.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.custom_gradient`](https://www.tensorflow.org/api_docs/python/tf/custom_gradient)
```
tf.custom_gradient(
f=None
)
```
This decorator allows fine grained control over the gradients of a sequence for operations. This may be useful for multiple reasons, including providing a more efficient or numerically stable gradient for a sequence of operations.
For example, consider the following function that commonly occurs in the computation of cross entropy and log likelihoods:
```
def log1pexp(x):
return tf.math.log(1 + tf.exp(x))
```
Due to numerical instability, the gradient of this function evaluated at x=100 is NaN. For example:
```
x = tf.constant(100.)
y = log1pexp(x)
dy_dx = tf.gradients(y, x) # Will be NaN when evaluated.
```
The gradient expression can be analytically simplified to provide numerical stability:
```
@tf.custom_gradient
def log1pexp(x):
e = tf.exp(x)
def grad(upstream):
return upstream * (1 - 1 / (1 + e))
return tf.math.log(1 + e), grad
```
With this definition, the gradient `dy_dx` at `x = 100` will be correctly evaluated as 1.0.
The variable `upstream` is defined as the upstream gradient. i.e. the gradient from all the layers or functions originating from this layer. The above example has no upstream functions, therefore `upstream = dy/dy = 1.0`.
Assume that `x_i` is `log1pexp` in the forward pass `x_1 = x_1(x_0)`, `x_2 = x_2(x_1)`, ..., `x_i = x_i(x_i-1)`, ..., `x_n = x_n(x_n-1)`. By chain rule we know that `dx_n/dx_0 = dx_n/dx_n-1 * dx_n-1/dx_n-2 * ... * dx_i/dx_i-1 * ... * dx_1/dx_0`.
In this case the gradient of our current function defined as `dx_i/dx_i-1 = (1 - 1 / (1 + e))`. The upstream gradient `upstream` would be `dx_n/dx_n-1 * dx_n-1/dx_n-2 * ... * dx_i+1/dx_i`. The upstream gradient multiplied by the current gradient is then passed downstream.
In case the function takes multiple variables as input, the `grad` function must also return the same number of variables. We take the function `z = x * y` as an example.
```
@tf.custom_gradient
def bar(x, y):
def grad(upstream):
dz_dx = y
dz_dy = x
return upstream * dz_dx, upstream * dz_dy
z = x * y
return z, grad
x = tf.constant(2.0, dtype=tf.float32)
y = tf.constant(3.0, dtype=tf.float32)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
tape.watch(y)
z = bar(x, y)
z
<tf.Tensor: shape=(), dtype=float32, numpy=6.0>
tape.gradient(z, x)
<tf.Tensor: shape=(), dtype=float32, numpy=3.0>
tape.gradient(z, y)
<tf.Tensor: shape=(), dtype=float32, numpy=2.0>
```
Nesting custom gradients can lead to unintuitive results. The default behavior does not correspond to n-th order derivatives. For example
```
@tf.custom_gradient
def op(x):
y = op1(x)
@tf.custom_gradient
def grad_fn(dy):
gdy = op2(x, y, dy)
def grad_grad_fn(ddy): # Not the 2nd order gradient of op w.r.t. x.
return op3(x, y, dy, ddy)
return gdy, grad_grad_fn
return y, grad_fn
```
The function `grad_grad_fn` will be calculating the first order gradient of `grad_fn` with respect to `dy`, which is used to generate forward-mode gradient graphs from backward-mode gradient graphs, but is not the same as the second order gradient of `op` with respect to `x`.
Instead, wrap nested `@tf.custom_gradients` in another function:
```
@tf.custom_gradient
def op_with_fused_backprop(x):
y, x_grad = fused_op(x)
def first_order_gradient(dy):
@tf.custom_gradient
def first_order_custom(unused_x):
def second_order_and_transpose(ddy):
return second_order_for_x(...), gradient_wrt_dy(...)
return x_grad, second_order_and_transpose
return dy * first_order_custom(x)
return y, first_order_gradient
```
Additional arguments to the inner [`@tf.custom_gradient`](custom_gradient)-decorated function control the expected return values of the innermost function.
The examples above illustrate how to specify custom gradients for functions which do not read from variables. The following example uses variables, which require special handling because they are effectively inputs of the forward function.
```
weights = tf.Variable(tf.ones([2])) # Trainable variable weights
@tf.custom_gradient
def linear_poly(x):
# Creating polynomial
poly = weights[1] * x + weights[0]
def grad_fn(dpoly, variables):
# dy/dx = weights[1] and we need to left multiply dpoly
grad_xs = dpoly * weights[1] # Scalar gradient
grad_vars = [] # To store gradients of passed variables
assert variables is not None
assert len(variables) == 1
assert variables[0] is weights
# Manually computing dy/dweights
dy_dw = dpoly * tf.stack([x ** 1, x ** 0])
grad_vars.append(
tf.reduce_sum(tf.reshape(dy_dw, [2, -1]), axis=1)
)
return grad_xs, grad_vars
return poly, grad_fn
x = tf.constant([1., 2., 3.])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
poly = linear_poly(x)
poly # poly = x + 1
<tf.Tensor: shape=(3,),
dtype=float32,
numpy=array([2., 3., 4.], dtype=float32)>
tape.gradient(poly, x) # conventional scalar gradient dy/dx
<tf.Tensor: shape=(3,),
dtype=float32,
numpy=array([1., 1., 1.], dtype=float32)>
tape.gradient(poly, weights)
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([6., 3.], dtype=float32)>
```
Above example illustrates usage of trainable variable `weights`. In the example, the inner `grad_fn` accepts an extra `variables` input parameter and also returns an extra `grad_vars` output. That extra argument is passed if the forward function reads any variables. You need to compute the gradient w.r.t. each of those `variables` and output it as a list of `grad_vars`. Note here that default value of `variables` is set to `None` when no variables are used in the forward function.
It should be noted [`tf.GradientTape`](gradienttape) is still watching the forward pass of a [`tf.custom_gradient`](custom_gradient), and will use the ops it watches. As a consequence, calling [`tf.function`](function) while the tape is still watching leads to a gradient graph being built. If an op is used in [`tf.function`](function) without registered gradient, a `LookupError` will be raised.
Users can insert [`tf.stop_gradient`](stop_gradient) to customize this behavior. This is demonstrated in the example below. [`tf.random.shuffle`](random/shuffle) does not have a registered gradient. As a result [`tf.stop_gradient`](stop_gradient) is used to avoid the `LookupError`.
```
x = tf.constant([0.3, 0.5], dtype=tf.float32)
@tf.custom_gradient
def test_func_with_stop_grad(x):
@tf.function
def _inner_func():
# Avoid exception during the forward pass
return tf.stop_gradient(tf.random.shuffle(x))
# return tf.random.shuffle(x) # This will raise
res = _inner_func()
def grad(upstream):
return upstream # Arbitrarily defined custom gradient
return res, grad
with tf.GradientTape() as g:
g.watch(x)
res = test_func_with_stop_grad(x)
g.gradient(res, x)
```
See also [`tf.RegisterGradient`](registergradient) which registers a gradient function for a primitive TensorFlow operation. [`tf.custom_gradient`](custom_gradient) on the other hand allows for fine grained control over the gradient computation of a sequence of operations.
Note that if the decorated function uses `Variable`s, the enclosing variable scope must be using `ResourceVariable`s.
| Args |
| `f` | function `f(*x)` that returns a tuple `(y, grad_fn)` where: * `x` is a sequence of (nested structures of) `Tensor` inputs to the function.
* `y` is a (nested structure of) `Tensor` outputs of applying TensorFlow operations in `f` to `x`.
* `grad_fn` is a function with the signature `g(*grad_ys)` which returns a list of `Tensor`s the same size as (flattened) `x` - the derivatives of `Tensor`s in `y` with respect to the `Tensor`s in `x`. `grad_ys` is a sequence of `Tensor`s the same size as (flattened) `y` holding the initial value gradients for each `Tensor` in `y`. In a pure mathematical sense, a vector-argument vector-valued function `f`'s derivatives should be its Jacobian matrix `J`. Here we are expressing the Jacobian `J` as a function `grad_fn` which defines how `J` will transform a vector `grad_ys` when left-multiplied with it (`grad_ys * J`, the vector-Jacobian product, or VJP). This functional representation of a matrix is convenient to use for chain-rule calculation (in e.g. the back-propagation algorithm). If `f` uses `Variable`s (that are not part of the inputs), i.e. through `get_variable`, then `grad_fn` should have signature `g(*grad_ys, variables=None)`, where `variables` is a list of the `Variable`s, and return a 2-tuple `(grad_xs, grad_vars)`, where `grad_xs` is the same as above, and `grad_vars` is a `list<Tensor>` with the derivatives of `Tensor`s in `y` with respect to the variables (that is, grad\_vars has one Tensor per variable in variables).
|
| Returns |
| A function `h(x)` which returns the same value as `f(x)[0]` and whose gradient (as calculated by [`tf.gradients`](gradients)) is determined by `f(x)[1]`. |
tensorflow tf.gradients tf.gradients
============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/gradients_impl.py#L172-L314) |
Constructs symbolic derivatives of sum of `ys` w.r.t. x in `xs`.
```
tf.gradients(
ys,
xs,
grad_ys=None,
name='gradients',
gate_gradients=False,
aggregation_method=None,
stop_gradients=None,
unconnected_gradients=tf.UnconnectedGradients.NONE
)
```
[`tf.gradients`](gradients) is only valid in a graph context. In particular, it is valid in the context of a [`tf.function`](function) wrapper, where code is executing as a graph.
`ys` and `xs` are each a `Tensor` or a list of tensors. `grad_ys` is a list of `Tensor`, holding the gradients received by the `ys`. The list must be the same length as `ys`.
`gradients()` adds ops to the graph to output the derivatives of `ys` with respect to `xs`. It returns a list of `Tensor` of length `len(xs)` where each tensor is the `sum(dy/dx)` for y in `ys` and for x in `xs`.
`grad_ys` is a list of tensors of the same length as `ys` that holds the initial gradients for each y in `ys`. When `grad_ys` is None, we fill in a tensor of '1's of the shape of y for each y in `ys`. A user can provide their own initial `grad_ys` to compute the derivatives using a different initial gradient for each y (e.g., if one wanted to weight the gradient differently for each value in each y).
`stop_gradients` is a `Tensor` or a list of tensors to be considered constant with respect to all `xs`. These tensors will not be backpropagated through, as though they had been explicitly disconnected using `stop_gradient`. Among other things, this allows computation of partial derivatives as opposed to total derivatives. For example:
```
@tf.function
def example():
a = tf.constant(0.)
b = 2 * a
return tf.gradients(a + b, [a, b], stop_gradients=[a, b])
example()
[<tf.Tensor: shape=(), dtype=float32, numpy=1.0>,
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>]
```
Here the partial derivatives `g` evaluate to `[1.0, 1.0]`, compared to the total derivatives `tf.gradients(a + b, [a, b])`, which take into account the influence of `a` on `b` and evaluate to `[3.0, 1.0]`. Note that the above is equivalent to:
```
@tf.function
def example():
a = tf.stop_gradient(tf.constant(0.))
b = tf.stop_gradient(2 * a)
return tf.gradients(a + b, [a, b])
example()
[<tf.Tensor: shape=(), dtype=float32, numpy=1.0>,
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>]
```
`stop_gradients` provides a way of stopping gradient after the graph has already been constructed, as compared to [`tf.stop_gradient`](stop_gradient) which is used during graph construction. When the two approaches are combined, backpropagation stops at both [`tf.stop_gradient`](stop_gradient) nodes and nodes in `stop_gradients`, whichever is encountered first.
All integer tensors are considered constant with respect to all `xs`, as if they were included in `stop_gradients`.
`unconnected_gradients` determines the value returned for each x in xs if it is unconnected in the graph to ys. By default this is None to safeguard against errors. Mathematically these gradients are zero which can be requested using the `'zero'` option. `tf.UnconnectedGradients` provides the following options and behaviors:
```
@tf.function
def example(use_zero):
a = tf.ones([1, 2])
b = tf.ones([3, 1])
if use_zero:
return tf.gradients([b], [a], unconnected_gradients='zero')
else:
return tf.gradients([b], [a], unconnected_gradients='none')
example(False)
[None]
example(True)
[<tf.Tensor: shape=(1, 2), dtype=float32, numpy=array([[0., 0.]], ...)>]
```
Let us take one practical example which comes during the back propogation phase. This function is used to evaluate the derivatives of the cost function with respect to Weights `Ws` and Biases `bs`. Below sample implementation provides the exaplantion of what it is actually used for :
```
@tf.function
def example():
Ws = tf.constant(0.)
bs = 2 * Ws
cost = Ws + bs # This is just an example. Please ignore the formulas.
g = tf.gradients(cost, [Ws, bs])
dCost_dW, dCost_db = g
return dCost_dW, dCost_db
example()
(<tf.Tensor: shape=(), dtype=float32, numpy=3.0>,
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>)
```
| Args |
| `ys` | A `Tensor` or list of tensors to be differentiated. |
| `xs` | A `Tensor` or list of tensors to be used for differentiation. |
| `grad_ys` | Optional. A `Tensor` or list of tensors the same size as `ys` and holding the gradients computed for each y in `ys`. |
| `name` | Optional name to use for grouping all the gradient ops together. defaults to 'gradients'. |
| `gate_gradients` | If True, add a tuple around the gradients returned for an operations. This avoids some race conditions. |
| `aggregation_method` | Specifies the method used to combine gradient terms. Accepted values are constants defined in the class `AggregationMethod`. |
| `stop_gradients` | Optional. A `Tensor` or list of tensors not to differentiate through. |
| `unconnected_gradients` | Optional. Specifies the gradient value returned when the given input tensors are unconnected. Accepted values are constants defined in the class [`tf.UnconnectedGradients`](unconnectedgradients) and the default value is `none`. |
| Returns |
| A list of `Tensor` of length `len(xs)` where each tensor is the `sum(dy/dx)` for y in `ys` and for x in `xs`. |
| Raises |
| `LookupError` | if one of the operations between `x` and `y` does not have a registered gradient function. |
| `ValueError` | if the arguments are invalid. |
| `RuntimeError` | if called in Eager mode. |
tensorflow tf.TypeSpec tf.TypeSpec
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L47-L572) |
Specifies a TensorFlow value type.
Inherits From: [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.TypeSpec`](https://www.tensorflow.org/api_docs/python/tf/TypeSpec), [`tf.compat.v1.data.experimental.Structure`](https://www.tensorflow.org/api_docs/python/tf/TypeSpec)
A [`tf.TypeSpec`](typespec) provides metadata describing an object accepted or returned by TensorFlow APIs. Concrete subclasses, such as [`tf.TensorSpec`](tensorspec) and [`tf.RaggedTensorSpec`](raggedtensorspec), are used to describe different value types.
For example, [`tf.function`](function)'s `input_signature` argument accepts a list (or nested structure) of `TypeSpec`s.
Creating new subclasses of `TypeSpec` (outside of TensorFlow core) is not currently supported. In particular, we may make breaking changes to the private methods and properties defined by this base class.
#### Example:
```
spec = tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)
@tf.function(input_signature=[spec])
def double(x):
return x * 2
print(double(tf.ragged.constant([[1, 2], [3]])))
<tf.RaggedTensor [[2, 4], [6]]>
```
| Attributes |
| `value_type` | The Python type for values that are compatible with this TypeSpec. In particular, all values that are compatible with this TypeSpec must be an instance of this type. |
Methods
-------
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L193-L214)
```
is_compatible_with(
spec_or_value
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
| programming_docs |
tensorflow tf.hessians tf.hessians
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/gradients_impl.py#L439-L475) |
Constructs the Hessian of sum of `ys` with respect to `x` in `xs`.
```
tf.hessians(
ys,
xs,
gate_gradients=False,
aggregation_method=None,
name='hessians'
)
```
`hessians()` adds ops to the graph to output the Hessian matrix of `ys` with respect to `xs`. It returns a list of `Tensor` of length `len(xs)` where each tensor is the Hessian of `sum(ys)`.
The Hessian is a matrix of second-order partial derivatives of a scalar tensor (see <https://en.wikipedia.org/wiki/Hessian_matrix> for more details).
| Args |
| `ys` | A `Tensor` or list of tensors to be differentiated. |
| `xs` | A `Tensor` or list of tensors to be used for differentiation. |
| `gate_gradients` | See `gradients()` documentation for details. |
| `aggregation_method` | See `gradients()` documentation for details. |
| `name` | Optional name to use for grouping all the gradient ops together. defaults to 'hessians'. |
| Returns |
| A list of Hessian matrices of `sum(ys)` for each `x` in `xs`. |
| Raises |
| `LookupError` | if one of the operations between `xs` and `ys` does not have a registered gradient function. |
tensorflow tf.ensure_shape tf.ensure\_shape
================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/check_ops.py#L2300-L2441) |
Updates the shape of a tensor and checks at runtime that the shape holds.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.ensure_shape`](https://www.tensorflow.org/api_docs/python/tf/ensure_shape)
```
tf.ensure_shape(
x, shape, name=None
)
```
When executed, this operation asserts that the input tensor `x`'s shape is compatible with the `shape` argument. See [`tf.TensorShape.is_compatible_with`](tensorshape#is_compatible_with) for details.
```
x = tf.constant([[1, 2, 3],
[4, 5, 6]])
x = tf.ensure_shape(x, [2, 3])
```
Use `None` for unknown dimensions:
```
x = tf.ensure_shape(x, [None, 3])
x = tf.ensure_shape(x, [2, None])
```
If the tensor's shape is not compatible with the `shape` argument, an error is raised:
```
x = tf.ensure_shape(x, [5])
Traceback (most recent call last):
tf.errors.InvalidArgumentError: Shape of tensor dummy_input [3] is not
compatible with expected shape [5]. [Op:EnsureShape]
```
During graph construction (typically tracing a [`tf.function`](function)), [`tf.ensure_shape`](ensure_shape) updates the static-shape of the **result** tensor by merging the two shapes. See [`tf.TensorShape.merge_with`](tensorshape#merge_with) for details.
This is most useful when **you** know a shape that can't be determined statically by TensorFlow.
The following trivial [`tf.function`](function) prints the input tensor's static-shape before and after `ensure_shape` is applied.
```
@tf.function
def f(tensor):
print("Static-shape before:", tensor.shape)
tensor = tf.ensure_shape(tensor, [None, 3])
print("Static-shape after:", tensor.shape)
return tensor
```
This lets you see the effect of [`tf.ensure_shape`](ensure_shape) when the function is traced:
```
>>> cf = f.get_concrete_function(tf.TensorSpec([None, None]))
Static-shape before: (None, None)
Static-shape after: (None, 3)
```
```
cf(tf.zeros([3, 3])) # Passes
cf(tf.constant([1, 2, 3])) # fails
Traceback (most recent call last):
InvalidArgumentError: Shape of tensor x [3] is not compatible with expected shape [3,3].
```
The above example raises [`tf.errors.InvalidArgumentError`](errors/invalidargumenterror), because `x`'s shape, `(3,)`, is not compatible with the `shape` argument, `(None, 3)`
Inside a [`tf.function`](function) or [`v1.Graph`](graph) context it checks both the buildtime and runtime shapes. This is stricter than [`tf.Tensor.set_shape`](tensor#set_shape) which only checks the buildtime shape.
>
> **Note:** This differs from [`tf.Tensor.set_shape`](tensor#set_shape) in that it sets the static shape of the resulting tensor and enforces it at runtime, raising an error if the tensor's runtime shape is incompatible with the specified shape. [`tf.Tensor.set_shape`](tensor#set_shape) sets the static shape of the tensor without enforcing it at runtime, which may result in inconsistencies between the statically-known shape of tensors and the runtime value of tensors.
>
For example, of loading images of a known size:
```
@tf.function
def decode_image(png):
image = tf.image.decode_png(png, channels=3)
# the `print` executes during tracing.
print("Initial shape: ", image.shape)
image = tf.ensure_shape(image,[28, 28, 3])
print("Final shape: ", image.shape)
return image
```
When tracing a function, no ops are being executed, shapes may be unknown. See the [Concrete Functions Guide](https://www.tensorflow.org/guide/concrete_function) for details.
```
concrete_decode = decode_image.get_concrete_function(
tf.TensorSpec([], dtype=tf.string))
Initial shape: (None, None, 3)
Final shape: (28, 28, 3)
```
```
image = tf.random.uniform(maxval=255, shape=[28, 28, 3], dtype=tf.int32)
image = tf.cast(image,tf.uint8)
png = tf.image.encode_png(image)
image2 = concrete_decode(png)
print(image2.shape)
(28, 28, 3)
```
```
image = tf.concat([image,image], axis=0)
print(image.shape)
(56, 28, 3)
png = tf.image.encode_png(image)
image2 = concrete_decode(png)
Traceback (most recent call last):
tf.errors.InvalidArgumentError: Shape of tensor DecodePng [56,28,3] is not
compatible with expected shape [28,28,3].
```
```
@tf.function
def bad_decode_image(png):
image = tf.image.decode_png(png, channels=3)
# the `print` executes during tracing.
print("Initial shape: ", image.shape)
# BAD: forgot to use the returned tensor.
tf.ensure_shape(image,[28, 28, 3])
print("Final shape: ", image.shape)
return image
```
```
image = bad_decode_image(png)
Initial shape: (None, None, 3)
Final shape: (None, None, 3)
print(image.shape)
(56, 28, 3)
```
| Args |
| `x` | A `Tensor`. |
| `shape` | A `TensorShape` representing the shape of this tensor, a `TensorShapeProto`, a list, a tuple, or None. |
| `name` | A name for this operation (optional). Defaults to "EnsureShape". |
| Returns |
| A `Tensor`. Has the same type and contents as `x`. |
| Raises |
| [`tf.errors.InvalidArgumentError`](https://www.tensorflow.org/api_docs/python/tf/errors/InvalidArgumentError) | If `shape` is incompatible with the shape of `x`. |
tensorflow tf.constant tf.constant
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/constant_op.py#L170-L268) |
Creates a constant tensor from a tensor-like object.
```
tf.constant(
value, dtype=None, shape=None, name='Const'
)
```
>
> **Note:** All eager [`tf.Tensor`](tensor) values are immutable (in contrast to [`tf.Variable`](variable)). There is nothing especially *constant* about the value returned from [`tf.constant`](constant). This function is not fundamentally different from [`tf.convert_to_tensor`](convert_to_tensor). The name [`tf.constant`](constant) comes from the `value` being embedded in a `Const` node in the [`tf.Graph`](graph). [`tf.constant`](constant) is useful for asserting that the value can be embedded that way.
>
If the argument `dtype` is not specified, then the type is inferred from the type of `value`.
```
# Constant 1-D Tensor from a python list.
tf.constant([1, 2, 3, 4, 5, 6])
<tf.Tensor: shape=(6,), dtype=int32,
numpy=array([1, 2, 3, 4, 5, 6], dtype=int32)>
# Or a numpy array
a = np.array([[1, 2, 3], [4, 5, 6]])
tf.constant(a)
<tf.Tensor: shape=(2, 3), dtype=int64, numpy=
array([[1, 2, 3],
[4, 5, 6]])>
```
If `dtype` is specified, the resulting tensor values are cast to the requested `dtype`.
```
tf.constant([1, 2, 3, 4, 5, 6], dtype=tf.float64)
<tf.Tensor: shape=(6,), dtype=float64,
numpy=array([1., 2., 3., 4., 5., 6.])>
```
If `shape` is set, the `value` is reshaped to match. Scalars are expanded to fill the `shape`:
```
tf.constant(0, shape=(2, 3))
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 0, 0],
[0, 0, 0]], dtype=int32)>
tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
```
[`tf.constant`](constant) has no effect if an eager Tensor is passed as the `value`, it even transmits gradients:
```
v = tf.Variable([0.0])
with tf.GradientTape() as g:
loss = tf.constant(v + v)
g.gradient(loss, v).numpy()
array([2.], dtype=float32)
```
But, since [`tf.constant`](constant) embeds the value in the [`tf.Graph`](graph) this fails for symbolic tensors:
```
with tf.compat.v1.Graph().as_default():
i = tf.compat.v1.placeholder(shape=[None, None], dtype=tf.float32)
t = tf.constant(i)
Traceback (most recent call last):
TypeError: ...
```
[`tf.constant`](constant) will create tensors on the current device. Inputs which are already tensors maintain their placements unchanged.
#### Related Ops:
* [`tf.convert_to_tensor`](convert_to_tensor) is similar but:
+ It has no `shape` argument.
+ Symbolic tensors are allowed to pass through.
```
with tf.compat.v1.Graph().as_default():
i = tf.compat.v1.placeholder(shape=[None, None], dtype=tf.float32)
t = tf.convert_to_tensor(i)
```
* [`tf.fill`](fill): differs in a few ways:
+ [`tf.constant`](constant) supports arbitrary constants, not just uniform scalar Tensors like [`tf.fill`](fill).
+ [`tf.fill`](fill) creates an Op in the graph that is expanded at runtime, so it can efficiently represent large tensors.
+ Since [`tf.fill`](fill) does not embed the value, it can produce dynamically sized outputs.
| Args |
| `value` | A constant value (or list) of output type `dtype`. |
| `dtype` | The type of the elements of the resulting tensor. |
| `shape` | Optional dimensions of resulting tensor. |
| `name` | Optional name for the tensor. |
| Returns |
| A Constant Tensor. |
| Raises |
| `TypeError` | if shape is incorrectly specified or unsupported. |
| `ValueError` | if called on a symbolic tensor. |
tensorflow tf.identity tf.identity
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L251-L299) |
Return a Tensor with the same shape and contents as input.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.identity`](https://www.tensorflow.org/api_docs/python/tf/identity)
```
tf.identity(
input, name=None
)
```
The return value is not the same Tensor as the original, but contains the same values. This operation is fast when used on the same device.
#### For example:
```
a = tf.constant([0.78])
a_identity = tf.identity(a)
a.numpy()
array([0.78], dtype=float32)
a_identity.numpy()
array([0.78], dtype=float32)
```
Calling [`tf.identity`](identity) on a variable will make a Tensor that represents the value of that variable at the time it is called. This is equivalent to calling `<variable>.read_value()`.
```
a = tf.Variable(5)
a_identity = tf.identity(a)
a.assign_add(1)
<tf.Variable ... shape=() dtype=int32, numpy=6>
a.numpy()
6
a_identity.numpy()
5
```
| Args |
| `input` | A `Tensor`, a `Variable`, a `CompositeTensor` or anything that can be converted to a tensor using [`tf.convert_to_tensor`](convert_to_tensor). |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` or CompositeTensor. Has the same type and contents as `input`. |
tensorflow tf.tensordot tf.tensordot
============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L4960-L5139) |
Tensor contraction of a and b along specified axes and outer product.
#### View aliases
**Main aliases**
[`tf.linalg.tensordot`](https://www.tensorflow.org/api_docs/python/tf/tensordot)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.linalg.tensordot`](https://www.tensorflow.org/api_docs/python/tf/tensordot), [`tf.compat.v1.tensordot`](https://www.tensorflow.org/api_docs/python/tf/tensordot)
```
tf.tensordot(
a, b, axes, name=None
)
```
Tensordot (also known as tensor contraction) sums the product of elements from `a` and `b` over the indices specified by `axes`.
This operation corresponds to `numpy.tensordot(a, b, axes)`.
Example 1: When `a` and `b` are matrices (order 2), the case `axes=1` is equivalent to matrix multiplication.
Example 2: When `a` and `b` are matrices (order 2), the case `axes = [[1], [0]]` is equivalent to matrix multiplication.
Example 3: When `a` and `b` are matrices (order 2), the case `axes=0` gives the outer product, a tensor of order 4.
Example 4: Suppose that \(a\_{ijk}\) and \(b\_{lmn}\) represent two tensors of order 3. Then, `contract(a, b, [[0], [2]])` is the order 4 tensor \(c\_{jklm}\) whose entry corresponding to the indices \((j,k,l,m)\) is given by:
\( c\_{jklm} = \sum\_i a\_{ijk} b\_{lmi} \).
In general, `order(c) = order(a) + order(b) - 2*len(axes[0])`.
| Args |
| `a` | `Tensor` of type `float32` or `float64`. |
| `b` | `Tensor` with the same type as `a`. |
| `axes` | Either a scalar `N`, or a list or an `int32` `Tensor` of shape [2, k]. If axes is a scalar, sum over the last N axes of a and the first N axes of b in order. If axes is a list or `Tensor` the first and second row contain the set of unique integers specifying axes along which the contraction is computed, for `a` and `b`, respectively. The number of axes for `a` and `b` must be equal. If `axes=0`, computes the outer product between `a` and `b`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` with the same type as `a`. |
| Raises |
| `ValueError` | If the shapes of `a`, `b`, and `axes` are incompatible. |
| `IndexError` | If the values in axes exceed the rank of the corresponding tensor. |
tensorflow tf.random_normal_initializer tf.random\_normal\_initializer
==============================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L367-L429) |
Initializer that generates tensors with a normal distribution.
```
tf.random_normal_initializer(
mean=0.0, stddev=0.05, seed=None
)
```
Initializers allow you to pre-specify an initialization strategy, encoded in the Initializer object, without knowing the shape and dtype of the variable being initialized.
#### Examples:
```
def make_variables(k, initializer):
return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
v1, v2 = make_variables(3,
tf.random_normal_initializer(mean=1., stddev=2.))
v1
<tf.Variable ... shape=(3,) ... numpy=array([...], dtype=float32)>
v2
<tf.Variable ... shape=(3, 3) ... numpy=
make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
(<tf.Variable...shape=(4,) dtype=float32...>, <tf.Variable...shape=(4, 4) ...
```
| Args |
| `mean` | a python scalar or a scalar tensor. Mean of the random values to generate. |
| `stddev` | a python scalar or a scalar tensor. Standard deviation of the random values to generate. |
| `seed` | A Python integer. Used to create random seeds. See [`tf.random.set_seed`](random/set_seed) for behavior. |
Methods
-------
### `from_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L76-L96)
```
@classmethod
from_config(
config
)
```
Instantiates an initializer from a configuration dictionary.
#### Example:
```
initializer = RandomUniform(-1, 1)
config = initializer.get_config()
initializer = RandomUniform.from_config(config)
```
| Args |
| `config` | A Python dictionary. It will typically be the output of `get_config`. |
| Returns |
| An Initializer instance. |
### `get_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L424-L429)
```
get_config()
```
Returns the configuration of the initializer as a JSON-serializable dict.
| Returns |
| A JSON-serializable Python dict. |
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L405-L422)
```
__call__(
shape,
dtype=tf.dtypes.float32,
**kwargs
)
```
Returns a tensor object initialized as specified by the initializer.
| Args |
| `shape` | Shape of the tensor. |
| `dtype` | Optional dtype of the tensor. Only floating point types are supported. |
| `**kwargs` | Additional keyword arguments. |
| Raises |
| `ValueError` | If the dtype is not floating point |
tensorflow tf.print tf.print
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/logging_ops.py#L144-L392) |
Print the specified inputs.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.print`](https://www.tensorflow.org/api_docs/python/tf/print)
```
tf.print(
*inputs, **kwargs
)
```
A TensorFlow operator that prints the specified inputs to a desired output stream or logging level. The inputs may be dense or sparse Tensors, primitive python objects, data structures that contain tensors, and printable Python objects. Printed tensors will recursively show the first and last elements of each dimension to summarize.
#### Example:
Single-input usage:
```
tensor = tf.range(10)
tf.print(tensor, output_stream=sys.stderr)
```
(This prints "[0 1 2 ... 7 8 9]" to sys.stderr)
Multi-input usage:
```
tensor = tf.range(10)
tf.print("tensors:", tensor, {2: tensor * 2}, output_stream=sys.stdout)
```
(This prints "tensors: [0 1 2 ... 7 8 9] {2: [0 2 4 ... 14 16 18]}" to sys.stdout)
Changing the input separator:
```
tensor_a = tf.range(2)
tensor_b = tensor_a * 2
tf.print(tensor_a, tensor_b, output_stream=sys.stderr, sep=',')
```
(This prints "[0 1],[0 2]" to sys.stderr)
Usage in a [`tf.function`](function):
```
@tf.function
def f():
tensor = tf.range(10)
tf.print(tensor, output_stream=sys.stderr)
return tensor
range_tensor = f()
```
(This prints "[0 1 2 ... 7 8 9]" to sys.stderr)
*Compatibility usage in TF 1.x graphs*:
In graphs manually created outside of [`tf.function`](function), this method returns the created TF operator that prints the data. To make sure the operator runs, users need to pass the produced op to [`tf.compat.v1.Session`](compat/v1/session)'s run method, or to use the op as a control dependency for executed ops by specifying `with tf.compat.v1.control_dependencies([print_op])`.
```
tf.compat.v1.disable_v2_behavior() # for TF1 compatibility only
sess = tf.compat.v1.Session()
with sess.as_default():
tensor = tf.range(10)
print_op = tf.print("tensors:", tensor, {2: tensor * 2},
output_stream=sys.stdout)
with tf.control_dependencies([print_op]):
tripled_tensor = tensor * 3
sess.run(tripled_tensor)
```
(This prints "tensors: [0 1 2 ... 7 8 9] {2: [0 2 4 ... 14 16 18]}" to sys.stdout)
>
> **Note:** In Jupyter notebooks and colabs, [`tf.print`](print) prints to the notebook cell outputs. It will not write to the notebook kernel's console logs.
>
| Args |
| `*inputs` | Positional arguments that are the inputs to print. Inputs in the printed output will be separated by spaces. Inputs may be python primitives, tensors, data structures such as dicts and lists that may contain tensors (with the data structures possibly nested in arbitrary ways), and printable python objects. |
| `output_stream` | The output stream, logging level, or file to print to. Defaults to sys.stderr, but sys.stdout, tf.compat.v1.logging.info, tf.compat.v1.logging.warning, tf.compat.v1.logging.error, absl.logging.info, absl.logging.warning and absl.logging.error are also supported. To print to a file, pass a string started with "file://" followed by the file path, e.g., "file:///tmp/foo.out". |
| `summarize` | The first and last `summarize` elements within each dimension are recursively printed per Tensor. If None, then the first 3 and last 3 elements of each dimension are printed for each tensor. If set to -1, it will print all elements of every tensor. |
| `sep` | The string to use to separate the inputs. Defaults to " ". |
| `end` | End character that is appended at the end the printed string. Defaults to the newline character. |
| `name` | A name for the operation (optional). |
| Returns |
| None when executing eagerly. During graph tracing this returns a TF operator that prints the specified inputs in the specified output stream or logging level. This operator will be automatically executed except inside of [`tf.compat.v1`](compat/v1) graphs and sessions. |
| Raises |
| `ValueError` | If an unsupported output stream is specified. |
| programming_docs |
tensorflow tf.tensor_scatter_nd_update tf.tensor\_scatter\_nd\_update
==============================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L5781-L6065) |
Scatter `updates` into an existing tensor according to `indices`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.tensor_scatter_nd_update`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_update), [`tf.compat.v1.tensor_scatter_update`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_update)
```
tf.tensor_scatter_nd_update(
tensor, indices, updates, name=None
)
```
This operation creates a new tensor by applying sparse `updates` to the input `tensor`. This is similar to an index assignment.
```
# Not implemented: tensors cannot be updated inplace.
tensor[indices] = updates
```
If an out of bound index is found on CPU, an error is returned.
> * If an out of bound index is found, the index is ignored.
> * The order in which updates are applied is nondeterministic, so the output will be nondeterministic if `indices` contains duplicates.
>
>
This operation is very similar to [`tf.scatter_nd`](scatter_nd), except that the updates are scattered onto an existing tensor (as opposed to a zero-tensor). If the memory for the existing tensor cannot be re-used, a copy is made and updated.
#### In general:
* `indices` is an integer tensor - the indices to update in `tensor`.
* `indices` has **at least two** axes, the last axis is the depth of the index vectors.
* For each index vector in `indices` there is a corresponding entry in `updates`.
* If the length of the index vectors matches the rank of the `tensor`, then the index vectors each point to scalars in `tensor` and each update is a scalar.
* If the length of the index vectors is less than the rank of `tensor`, then the index vectors each point to slices of `tensor` and shape of the updates must match that slice.
Overall this leads to the following shape constraints:
```
assert tf.rank(indices) >= 2
index_depth = indices.shape[-1]
batch_shape = indices.shape[:-1]
assert index_depth <= tf.rank(tensor)
outer_shape = tensor.shape[:index_depth]
inner_shape = tensor.shape[index_depth:]
assert updates.shape == batch_shape + inner_shape
```
Typical usage is often much simpler than this general form, and it can be better understood starting with simple examples:
### Scalar updates
The simplest usage inserts scalar elements into a tensor by index. In this case, the `index_depth` must equal the rank of the input `tensor`, slice each column of `indices` is an index into an axis of the input `tensor`.
In this simplest case the shape constraints are:
```
num_updates, index_depth = indices.shape.as_list()
assert updates.shape == [num_updates]
assert index_depth == tf.rank(tensor)`
```
For example, to insert 4 scattered elements in a rank-1 tensor with 8 elements.
This scatter operation would look like this:
```
tensor = [0, 0, 0, 0, 0, 0, 0, 0] # tf.rank(tensor) == 1
indices = [[1], [3], [4], [7]] # num_updates == 4, index_depth == 1
updates = [9, 10, 11, 12] # num_updates == 4
print(tf.tensor_scatter_nd_update(tensor, indices, updates))
tf.Tensor([ 0 9 0 10 11 0 0 12], shape=(8,), dtype=int32)
```
The length (first axis) of `updates` must equal the length of the `indices`: `num_updates`. This is the number of updates being inserted. Each scalar update is inserted into `tensor` at the indexed location.
For a higher rank input `tensor` scalar updates can be inserted by using an `index_depth` that matches [`tf.rank(tensor)`](rank):
```
tensor = [[1, 1], [1, 1], [1, 1]] # tf.rank(tensor) == 2
indices = [[0, 1], [2, 0]] # num_updates == 2, index_depth == 2
updates = [5, 10] # num_updates == 2
print(tf.tensor_scatter_nd_update(tensor, indices, updates))
tf.Tensor(
[[ 1 5]
[ 1 1]
[10 1]], shape=(3, 2), dtype=int32)
```
### Slice updates
When the input `tensor` has more than one axis scatter can be used to update entire slices.
In this case it's helpful to think of the input `tensor` as being a two level array-of-arrays. The shape of this two level array is split into the `outer_shape` and the `inner_shape`.
`indices` indexes into the outer level of the input tensor (`outer_shape`). and replaces the sub-array at that location with the corresponding item from the `updates` list. The shape of each update is `inner_shape`.
When updating a list of slices the shape constraints are:
```
num_updates, index_depth = indices.shape.as_list()
inner_shape = tensor.shape[:index_depth]
outer_shape = tensor.shape[index_depth:]
assert updates.shape == [num_updates, inner_shape]
```
For example, to update rows of a `(6, 3)` `tensor`:
```
tensor = tf.zeros([6, 3], dtype=tf.int32)
```
Use an index depth of one.
```
indices = tf.constant([[2], [4]]) # num_updates == 2, index_depth == 1
num_updates, index_depth = indices.shape.as_list()
```
The `outer_shape` is `6`, the inner shape is `3`:
```
outer_shape = tensor.shape[:index_depth]
inner_shape = tensor.shape[index_depth:]
```
2 rows are being indexed so 2 `updates` must be supplied. Each update must be shaped to match the `inner_shape`.
```
# num_updates == 2, inner_shape==3
updates = tf.constant([[1, 2, 3],
[4, 5, 6]])
```
#### Altogether this gives:
```
tf.tensor_scatter_nd_update(tensor, indices, updates).numpy()
array([[0, 0, 0],
[0, 0, 0],
[1, 2, 3],
[0, 0, 0],
[4, 5, 6],
[0, 0, 0]], dtype=int32)
```
#### More slice update examples
A tensor representing a batch of uniformly sized video clips naturally has 5 axes: `[batch_size, time, width, height, channels]`.
#### For example:
```
batch_size, time, width, height, channels = 13,11,7,5,3
video_batch = tf.zeros([batch_size, time, width, height, channels])
```
To replace a selection of video clips:
* Use an `index_depth` of 1 (indexing the `outer_shape`: `[batch_size]`)
* Provide updates each with a shape matching the `inner_shape`: `[time, width, height, channels]`.
To replace the first two clips with ones:
```
indices = [[0],[1]]
new_clips = tf.ones([2, time, width, height, channels])
tf.tensor_scatter_nd_update(video_batch, indices, new_clips)
```
To replace a selection of frames in the videos:
* `indices` must have an `index_depth` of 2 for the `outer_shape`: `[batch_size, time]`.
* `updates` must be shaped like a list of images. Each update must have a shape, matching the `inner_shape`: `[width, height, channels]`.
To replace the first frame of the first three video clips:
```
indices = [[0, 0], [1, 0], [2, 0]] # num_updates=3, index_depth=2
new_images = tf.ones([
# num_updates=3, inner_shape=(width, height, channels)
3, width, height, channels])
tf.tensor_scatter_nd_update(video_batch, indices, new_images)
```
### Folded indices
In simple cases it's convenient to think of `indices` and `updates` as lists, but this is not a strict requirement. Instead of a flat `num_updates`, the `indices` and `updates` can be folded into a `batch_shape`. This `batch_shape` is all axes of the `indices`, except for the innermost `index_depth` axis.
```
index_depth = indices.shape[-1]
batch_shape = indices.shape[:-1]
```
>
> **Note:** The one exception is that the `batch_shape` cannot be `[]`. You can't update a single index by passing indices with shape `[index_depth]`.
>
`updates` must have a matching `batch_shape` (the axes before `inner_shape`).
```
assert updates.shape == batch_shape + inner_shape
```
>
> **Note:** The result is equivalent to flattening the `batch_shape` axes of `indices` and `updates`. This generalization just avoids the need for reshapes when it is more natural to construct "folded" indices and updates.
>
With this generalization the full shape constraints are:
```
assert tf.rank(indices) >= 2
index_depth = indices.shape[-1]
batch_shape = indices.shape[:-1]
assert index_depth <= tf.rank(tensor)
outer_shape = tensor.shape[:index_depth]
inner_shape = tensor.shape[index_depth:]
assert updates.shape == batch_shape + inner_shape
```
For example, to draw an `X` on a `(5,5)` matrix start with these indices:
```
tensor = tf.zeros([5,5])
indices = tf.constant([
[[0,0],
[1,1],
[2,2],
[3,3],
[4,4]],
[[0,4],
[1,3],
[2,2],
[3,1],
[4,0]],
])
indices.shape.as_list() # batch_shape == [2, 5], index_depth == 2
[2, 5, 2]
```
Here the `indices` do not have a shape of `[num_updates, index_depth]`, but a shape of `batch_shape+[index_depth]`.
Since the `index_depth` is equal to the rank of `tensor`:
* `outer_shape` is `(5,5)`
* `inner_shape` is `()` - each update is scalar
* `updates.shape` is `batch_shape + inner_shape == (5,2) + ()`
```
updates = [
[1,1,1,1,1],
[1,1,1,1,1],
]
```
Putting this together gives:
```
tf.tensor_scatter_nd_update(tensor, indices, updates).numpy()
array([[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 0., 1.]], dtype=float32)
```
| Args |
| `tensor` | Tensor to copy/update. |
| `indices` | Indices to update. |
| `updates` | Updates to apply at the indices. |
| `name` | Optional name for the operation. |
| Returns |
| A new tensor with the given shape and updates applied according to the indices. |
tensorflow Module: tf.data Module: tf.data
===============
[`tf.data.Dataset`](data/dataset) API for input pipelines.
See [Importing Data](https://tensorflow.org/guide/data) for an overview.
Modules
-------
[`experimental`](data/experimental) module: Experimental API for building input pipelines.
Classes
-------
[`class Dataset`](data/dataset): Represents a potentially large set of elements.
[`class DatasetSpec`](data/datasetspec): Type specification for [`tf.data.Dataset`](data/dataset).
[`class FixedLengthRecordDataset`](data/fixedlengthrecorddataset): A `Dataset` of fixed-length records from one or more binary files.
[`class Iterator`](data/iterator): Represents an iterator of a [`tf.data.Dataset`](data/dataset).
[`class IteratorSpec`](data/iteratorspec): Type specification for [`tf.data.Iterator`](data/iterator).
[`class Options`](data/options): Represents options for [`tf.data.Dataset`](data/dataset).
[`class TFRecordDataset`](data/tfrecorddataset): A `Dataset` comprising records from one or more TFRecord files.
[`class TextLineDataset`](data/textlinedataset): Creates a `Dataset` comprising lines from one or more text files.
[`class ThreadingOptions`](data/threadingoptions): Represents options for dataset threading.
| Other Members |
| AUTOTUNE | `-1` |
| INFINITE\_CARDINALITY | `-1` |
| UNKNOWN\_CARDINALITY | `-2` |
tensorflow tf.roll tf.roll
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/manip_ops.py#L24-L28) |
Rolls the elements of a tensor along an axis.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.roll`](https://www.tensorflow.org/api_docs/python/tf/roll), [`tf.compat.v1.roll`](https://www.tensorflow.org/api_docs/python/tf/roll)
```
tf.roll(
input, shift, axis, name=None
)
```
The elements are shifted positively (towards larger indices) by the offset of `shift` along the dimension of `axis`. Negative `shift` values will shift elements in the opposite direction. Elements that roll passed the last position will wrap around to the first and vice versa. Multiple shifts along multiple axes may be specified.
#### For example:
```
# 't' is [0, 1, 2, 3, 4]
roll(t, shift=2, axis=0) ==> [3, 4, 0, 1, 2]
# shifting along multiple dimensions
# 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
roll(t, shift=[1, -2], axis=[0, 1]) ==> [[7, 8, 9, 5, 6], [2, 3, 4, 0, 1]]
# shifting along the same axis multiple times
# 't' is [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
roll(t, shift=[2, -3], axis=[1, 1]) ==> [[1, 2, 3, 4, 0], [6, 7, 8, 9, 5]]
```
| Args |
| `input` | A `Tensor`. |
| `shift` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Dimension must be 0-D or 1-D. `shift[i]` specifies the number of places by which elements are shifted positively (towards larger indices) along the dimension specified by `axis[i]`. Negative shifts will roll the elements in the opposite direction. |
| `axis` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Dimension must be 0-D or 1-D. `axis[i]` specifies the dimension that the shift `shift[i]` should occur. If the same axis is referenced more than once, the total shift for that axis will be the sum of all the shifts that belong to that axis. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow Module: tf.bitwise Module: tf.bitwise
==================
Operations for manipulating the binary representations of integers.
Functions
---------
[`bitwise_and(...)`](bitwise/bitwise_and): Elementwise computes the bitwise AND of `x` and `y`.
[`bitwise_or(...)`](bitwise/bitwise_or): Elementwise computes the bitwise OR of `x` and `y`.
[`bitwise_xor(...)`](bitwise/bitwise_xor): Elementwise computes the bitwise XOR of `x` and `y`.
[`invert(...)`](bitwise/invert): Invert (flip) each bit of supported types; for example, type `uint8` value 01010101 becomes 10101010.
[`left_shift(...)`](bitwise/left_shift): Elementwise computes the bitwise left-shift of `x` and `y`.
[`right_shift(...)`](bitwise/right_shift): Elementwise computes the bitwise right-shift of `x` and `y`.
tensorflow tf.histogram_fixed_width tf.histogram\_fixed\_width
==========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/histogram_ops.py#L102-L147) |
Return histogram of values.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.histogram_fixed_width`](https://www.tensorflow.org/api_docs/python/tf/histogram_fixed_width)
```
tf.histogram_fixed_width(
values,
value_range,
nbins=100,
dtype=tf.dtypes.int32,
name=None
)
```
Given the tensor `values`, this operation returns a rank 1 histogram counting the number of entries in `values` that fell into every bin. The bins are equal width and determined by the arguments `value_range` and `nbins`.
| Args |
| `values` | Numeric `Tensor`. |
| `value_range` | Shape [2] `Tensor` of same `dtype` as `values`. values <= value\_range[0] will be mapped to hist[0], values >= value\_range[1] will be mapped to hist[-1]. |
| `nbins` | Scalar `int32 Tensor`. Number of histogram bins. |
| `dtype` | dtype for returned histogram. |
| `name` | A name for this operation (defaults to 'histogram\_fixed\_width'). |
| Returns |
| A 1-D `Tensor` holding histogram of values. |
| Raises |
| `TypeError` | If any unsupported dtype is provided. |
| [`tf.errors.InvalidArgumentError`](https://www.tensorflow.org/api_docs/python/tf/errors/InvalidArgumentError) | If value\_range does not satisfy value\_range[0] < value\_range[1]. |
#### Examples:
```
# Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf)
nbins = 5
value_range = [0.0, 5.0]
new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]
hist = tf.histogram_fixed_width(new_values, value_range, nbins=5)
hist.numpy()
array([2, 1, 1, 0, 2], dtype=int32)
```
tensorflow tf.truncatediv tf.truncatediv
==============
Returns x / y element-wise for integer types.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.truncatediv`](https://www.tensorflow.org/api_docs/python/tf/truncatediv)
```
tf.truncatediv(
x, y, name=None
)
```
Truncation designates that negative numbers will round fractional quantities toward zero. I.e. -7 / 5 = -1. This matches C semantics but it is different than Python semantics. See `FloorDiv` for a division function that matches Python Semantics.
>
> **Note:** `truncatediv` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `uint32`, `uint64`, `int64`, `complex64`, `complex128`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
tensorflow tf.zeros tf.zeros
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L2979-L3035) |
Creates a tensor with all elements set to zero.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.zeros`](https://www.tensorflow.org/api_docs/python/tf/zeros)
```
tf.zeros(
shape,
dtype=tf.dtypes.float32,
name=None
)
```
See also [`tf.zeros_like`](zeros_like), [`tf.ones`](ones), [`tf.fill`](fill), [`tf.eye`](eye).
This operation returns a tensor of type `dtype` with shape `shape` and all elements set to zero.
```
tf.zeros([3, 4], tf.int32)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int32)>
```
| Args |
| `shape` | A `list` of integers, a `tuple` of integers, or a 1-D `Tensor` of type `int32`. |
| `dtype` | The DType of an element in the resulting `Tensor`. |
| `name` | Optional string. A name for the operation. |
| Returns |
| A `Tensor` with all elements set to zero. |
tensorflow tf.Variable tf.Variable
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L273-L1329) |
See the [variable guide](https://tensorflow.org/guide/variable).
```
tf.Variable(
initial_value=None,
trainable=None,
validate_shape=True,
caching_device=None,
name=None,
variable_def=None,
dtype=None,
import_scope=None,
constraint=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.compat.v1.VariableAggregation.NONE,
shape=None
)
```
A variable maintains shared, persistent state manipulated by a program.
The `Variable()` constructor requires an initial value for the variable, which can be a `Tensor` of any type and shape. This initial value defines the type and shape of the variable. After construction, the type and shape of the variable are fixed. The value can be changed using one of the assign methods.
```
v = tf.Variable(1.)
v.assign(2.)
<tf.Variable ... shape=() dtype=float32, numpy=2.0>
v.assign_add(0.5)
<tf.Variable ... shape=() dtype=float32, numpy=2.5>
```
The `shape` argument to `Variable`'s constructor allows you to construct a variable with a less defined shape than its `initial_value`:
```
v = tf.Variable(1., shape=tf.TensorShape(None))
v.assign([[1.]])
<tf.Variable ... shape=<unknown> dtype=float32, numpy=array([[1.]], ...)>
```
Just like any `Tensor`, variables created with `Variable()` can be used as inputs to operations. Additionally, all the operators overloaded for the `Tensor` class are carried over to variables.
```
w = tf.Variable([[1.], [2.]])
x = tf.constant([[3., 4.]])
tf.matmul(w, x)
<tf.Tensor:... shape=(2, 2), ... numpy=
array([[3., 4.],
[6., 8.]], dtype=float32)>
tf.sigmoid(w + x)
<tf.Tensor:... shape=(2, 2), ...>
```
When building a machine learning model it is often convenient to distinguish between variables holding trainable model parameters and other variables such as a `step` variable used to count training steps. To make this easier, the variable constructor supports a `trainable=<bool>` parameter. [`tf.GradientTape`](gradienttape) watches trainable variables by default:
```
with tf.GradientTape(persistent=True) as tape:
trainable = tf.Variable(1.)
non_trainable = tf.Variable(2., trainable=False)
x1 = trainable * 2.
x2 = non_trainable * 3.
tape.gradient(x1, trainable)
<tf.Tensor:... shape=(), dtype=float32, numpy=2.0>
assert tape.gradient(x2, non_trainable) is None # Unwatched
```
Variables are automatically tracked when assigned to attributes of types inheriting from [`tf.Module`](module).
```
m = tf.Module()
m.v = tf.Variable([1.])
m.trainable_variables
(<tf.Variable ... shape=(1,) ... numpy=array([1.], dtype=float32)>,)
```
This tracking then allows saving variable values to [training checkpoints](https://www.tensorflow.org/guide/checkpoint), or to [SavedModels](https://www.tensorflow.org/guide/saved_model) which include serialized TensorFlow graphs.
Variables are often captured and manipulated by [`tf.function`](function)s. This works the same way the un-decorated function would have:
```
v = tf.Variable(0.)
read_and_decrement = tf.function(lambda: v.assign_sub(0.1))
read_and_decrement()
<tf.Tensor: shape=(), dtype=float32, numpy=-0.1>
read_and_decrement()
<tf.Tensor: shape=(), dtype=float32, numpy=-0.2>
```
Variables created inside a [`tf.function`](function) must be owned outside the function and be created only once:
```
class M(tf.Module):
@tf.function
def __call__(self, x):
if not hasattr(self, "v"): # Or set self.v to None in __init__
self.v = tf.Variable(x)
return self.v * x
m = M()
m(2.)
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
m(3.)
<tf.Tensor: shape=(), dtype=float32, numpy=6.0>
m.v
<tf.Variable ... shape=() dtype=float32, numpy=2.0>
```
See the [`tf.function`](function) documentation for details.
| Args |
| `initial_value` | A `Tensor`, or Python object convertible to a `Tensor`, which is the initial value for the Variable. The initial value must have a shape specified unless `validate_shape` is set to False. Can also be a callable with no argument that returns the initial value when called. In that case, `dtype` must be specified. (Note that initializer functions from init\_ops.py must first be bound to a shape before being used here.) |
| `trainable` | If `True`, GradientTapes automatically watch uses of this variable. Defaults to `True`, unless `synchronization` is set to `ON_READ`, in which case it defaults to `False`. |
| `validate_shape` | If `False`, allows the variable to be initialized with a value of unknown shape. If `True`, the default, the shape of `initial_value` must be known. |
| `caching_device` | Note: This argument is only valid when using a v1-style `Session`. Optional device string describing where the Variable should be cached for reading. Defaults to the Variable's device. If not `None`, caches on another device. Typical use is to cache on the device where the Ops using the Variable reside, to deduplicate copying through `Switch` and other conditional statements. |
| `name` | Optional name for the variable. Defaults to `'Variable'` and gets uniquified automatically. |
| `variable_def` | `VariableDef` protocol buffer. If not `None`, recreates the Variable object with its contents, referencing the variable's nodes in the graph, which must already exist. The graph is not changed. `variable_def` and the other arguments are mutually exclusive. |
| `dtype` | If set, initial\_value will be converted to the given type. If `None`, either the datatype will be kept (if `initial_value` is a Tensor), or `convert_to_tensor` will decide. |
| `import_scope` | Optional `string`. Name scope to add to the `Variable.` Only used when initializing from protocol buffer. |
| `constraint` | An optional projection function to be applied to the variable after being updated by an `Optimizer` (e.g. used to implement norm constraints or value constraints for layer weights). The function must take as input the unprojected Tensor representing the value of the variable and return the Tensor for the projected value (which must have the same shape). Constraints are not safe to use when doing asynchronous distributed training. |
| `synchronization` | Indicates when a distributed a variable will be aggregated. Accepted values are constants defined in the class [`tf.VariableSynchronization`](variablesynchronization). By default the synchronization is set to `AUTO` and the current `DistributionStrategy` chooses when to synchronize. |
| `aggregation` | Indicates how a distributed variable will be aggregated. Accepted values are constants defined in the class [`tf.VariableAggregation`](variableaggregation). |
| `shape` | (optional) The shape of this variable. If None, the shape of `initial_value` will be used. When setting this argument to [`tf.TensorShape(None)`](tensorshape) (representing an unspecified shape), the variable can be assigned with values of different shapes. |
| Raises |
| `ValueError` | If both `variable_def` and initial\_value are specified. |
| `ValueError` | If the initial value is not specified, or does not have a shape and `validate_shape` is `True`. |
| Attributes |
| `aggregation` | |
| `constraint` | Returns the constraint function associated with this variable. |
| `device` | The device of this variable. |
| `dtype` | The `DType` of this variable. |
| `graph` | The `Graph` of this variable. |
| `initial_value` | Returns the Tensor used as the initial value for the variable. Note that this is different from `initialized_value()` which runs the op that initializes the variable before returning its value. This method returns the tensor that is used by the op that initializes the variable. |
| `initializer` | The initializer operation for this variable. |
| `name` | The name of this variable. |
| `op` | The `Operation` of this variable. |
| `shape` | The `TensorShape` of this variable. |
| `synchronization` | |
| `trainable` | |
Child Classes
-------------
[`class SaveSliceInfo`](variable/savesliceinfo)
Methods
-------
### `assign`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L579-L595)
```
assign(
value, use_locking=False, name=None, read_value=True
)
```
Assigns a new value to the variable.
This is essentially a shortcut for `assign(self, value)`.
| Args |
| `value` | A `Tensor`. The new value for this variable. |
| `use_locking` | If `True`, use locking during the assignment. |
| `name` | The name of the operation to be created |
| `read_value` | if True, will return something which evaluates to the new value of the variable; if False will return the assign op. |
| Returns |
| The updated variable. If `read_value` is false, instead returns None in Eager mode and the assign op in graph mode. |
### `assign_add`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L597-L613)
```
assign_add(
delta, use_locking=False, name=None, read_value=True
)
```
Adds a value to this variable.
This is essentially a shortcut for `assign_add(self, delta)`.
| Args |
| `delta` | A `Tensor`. The value to add to this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | The name of the operation to be created |
| `read_value` | if True, will return something which evaluates to the new value of the variable; if False will return the assign op. |
| Returns |
| The updated variable. If `read_value` is false, instead returns None in Eager mode and the assign op in graph mode. |
### `assign_sub`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L615-L631)
```
assign_sub(
delta, use_locking=False, name=None, read_value=True
)
```
Subtracts a value from this variable.
This is essentially a shortcut for `assign_sub(self, delta)`.
| Args |
| `delta` | A `Tensor`. The value to subtract from this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | The name of the operation to be created |
| `read_value` | if True, will return something which evaluates to the new value of the variable; if False will return the assign op. |
| Returns |
| The updated variable. If `read_value` is false, instead returns None in Eager mode and the assign op in graph mode. |
### `batch_scatter_update`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L747-L791)
```
batch_scatter_update(
sparse_delta, use_locking=False, name=None
)
```
Assigns [`tf.IndexedSlices`](indexedslices) to this variable batch-wise.
Analogous to `batch_gather`. This assumes that this variable and the sparse\_delta IndexedSlices have a series of leading dimensions that are the same for all of them, and the updates are performed on the last dimension of indices. In other words, the dimensions should be the following:
`num_prefix_dims = sparse_delta.indices.ndims - 1` `batch_dim = num_prefix_dims + 1` `sparse_delta.updates.shape = sparse_delta.indices.shape + var.shape[ batch_dim:]`
where
`sparse_delta.updates.shape[:num_prefix_dims]` `== sparse_delta.indices.shape[:num_prefix_dims]` `== var.shape[:num_prefix_dims]`
And the operation performed can be expressed as:
`var[i_1, ..., i_n, sparse_delta.indices[i_1, ..., i_n, j]] = sparse_delta.updates[ i_1, ..., i_n, j]`
When sparse\_delta.indices is a 1D tensor, this operation is equivalent to `scatter_update`.
To avoid this operation one can looping over the first `ndims` of the variable and using `scatter_update` on the subtensors that result of slicing the first dimension. This is a valid option for `ndims = 1`, but less efficient than this implementation.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to be assigned to this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `count_up_to`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L962-L983)
```
count_up_to(
limit
)
```
Increments this variable until it reaches `limit`. (deprecated)
When that Op is run it tries to increment the variable by `1`. If incrementing the variable would bring it above `limit` then the Op raises the exception `OutOfRangeError`.
If no error is raised, the Op outputs the value of the variable before the increment.
This is essentially a shortcut for `count_up_to(self, limit)`.
| Args |
| `limit` | value at which incrementing the variable raises an error. |
| Returns |
| A `Tensor` that will hold the variable value before the increment. If no other Op modifies this variable, the values produced will all be distinct. |
### `eval`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L496-L526)
```
eval(
session=None
)
```
In a session, computes and returns the value of this variable.
This is not a graph construction method, it does not add ops to the graph.
This convenience method requires a session where the graph containing this variable has been launched. If no session is passed, the default session is used. See [`tf.compat.v1.Session`](compat/v1/session) for more information on launching a graph and on sessions.
```
v = tf.Variable([1, 2])
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
# Usage passing the session explicitly.
print(v.eval(sess))
# Usage with the default session. The 'with' block
# above makes 'sess' the default session.
print(v.eval())
```
| Args |
| `session` | The session to use to evaluate this variable. If none, the default session is used. |
| Returns |
| A numpy `ndarray` with a copy of the value of this variable. |
### `experimental_ref`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1205-L1207)
```
experimental_ref()
```
DEPRECATED FUNCTION
### `from_proto`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1189-L1192)
```
@staticmethod
from_proto(
variable_def, import_scope=None
)
```
Returns a `Variable` object created from `variable_def`.
### `gather_nd`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L947-L960)
```
gather_nd(
indices, name=None
)
```
Gather slices from `params` into a Tensor with shape specified by `indices`.
See tf.gather\_nd for details.
| Args |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `params`. |
### `get_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1169-L1171)
```
get_shape()
```
Alias of [`Variable.shape`](variable#shape).
### `initialized_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L528-L553)
```
initialized_value()
```
Returns the value of the initialized variable. (deprecated)
You should use this instead of the variable itself to initialize another variable with a value that depends on the value of this variable.
```
# Initialize 'v' with a random tensor.
v = tf.Variable(tf.random.truncated_normal([10, 40]))
# Use `initialized_value` to guarantee that `v` has been
# initialized before its value is used to initialize `w`.
# The random values are picked only once.
w = tf.Variable(v.initialized_value() * 2.0)
```
| Returns |
| A `Tensor` holding the value of this variable after its initializer has run. |
### `load`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L985-L1028)
```
load(
value, session=None
)
```
Load new value into this variable. (deprecated)
Writes new value to variable's memory. Doesn't add ops to the graph.
This convenience method requires a session where the graph containing this variable has been launched. If no session is passed, the default session is used. See [`tf.compat.v1.Session`](compat/v1/session) for more information on launching a graph and on sessions.
```
v = tf.Variable([1, 2])
init = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)
# Usage passing the session explicitly.
v.load([2, 3], sess)
print(v.eval(sess)) # prints [2 3]
# Usage with the default session. The 'with' block
# above makes 'sess' the default session.
v.load([3, 4], sess)
print(v.eval()) # prints [3 4]
```
| Args |
| `value` | New variable value |
| `session` | The session to use to evaluate this variable. If none, the default session is used. |
| Raises |
| `ValueError` | Session is not passed and no default session |
### `read_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L465-L474)
```
read_value()
```
Returns the value of this variable, read in the current context.
Can be different from value() if it's on another device, with control dependencies, etc.
| Returns |
| A `Tensor` containing the value of the variable. |
### `ref`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1209-L1248)
```
ref()
```
Returns a hashable reference object to this Variable.
The primary use case for this API is to put variables in a set/dictionary. We can't put variables in a set/dictionary as `variable.__hash__()` is no longer available starting Tensorflow 2.0.
The following will raise an exception starting 2.0
```
x = tf.Variable(5)
y = tf.Variable(10)
z = tf.Variable(10)
variable_set = {x, y, z}
Traceback (most recent call last):
TypeError: Variable is unhashable. Instead, use tensor.ref() as the key.
variable_dict = {x: 'five', y: 'ten'}
Traceback (most recent call last):
TypeError: Variable is unhashable. Instead, use tensor.ref() as the key.
```
Instead, we can use `variable.ref()`.
```
variable_set = {x.ref(), y.ref(), z.ref()}
x.ref() in variable_set
True
variable_dict = {x.ref(): 'five', y.ref(): 'ten', z.ref(): 'ten'}
variable_dict[y.ref()]
'ten'
```
Also, the reference object provides `.deref()` function that returns the original Variable.
```
x = tf.Variable(5)
x.ref().deref()
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=5>
```
### `scatter_add`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L649-L663)
```
scatter_add(
sparse_delta, use_locking=False, name=None
)
```
Adds [`tf.IndexedSlices`](indexedslices) to this variable.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to be added to this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_div`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L715-L729)
```
scatter_div(
sparse_delta, use_locking=False, name=None
)
```
Divide this variable by [`tf.IndexedSlices`](indexedslices).
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to divide this variable by. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_max`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L665-L680)
```
scatter_max(
sparse_delta, use_locking=False, name=None
)
```
Updates this variable with the max of [`tf.IndexedSlices`](indexedslices) and itself.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to use as an argument of max with this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_min`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L682-L697)
```
scatter_min(
sparse_delta, use_locking=False, name=None
)
```
Updates this variable with the min of [`tf.IndexedSlices`](indexedslices) and itself.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to use as an argument of min with this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_mul`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L699-L713)
```
scatter_mul(
sparse_delta, use_locking=False, name=None
)
```
Multiply this variable by [`tf.IndexedSlices`](indexedslices).
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to multiply this variable by. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_nd_add`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L839-L883)
```
scatter_nd_add(
indices, updates, name=None
)
```
Applies sparse addition to individual values or slices in a Variable.
The Variable has rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into self. It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th dimension of self.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, self.shape[K], ..., self.shape[P-1]].
```
For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that update would look like this:
```
v = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1] ,[7]])
updates = tf.constant([9, 10, 11, 12])
v.scatter_nd_add(indices, updates)
print(v)
```
The resulting update to v would look like this:
```
[1, 13, 3, 14, 14, 6, 7, 20]
```
See [`tf.scatter_nd`](scatter_nd) for more details about how to make updates to slices.
| Args |
| `indices` | The indices to be used in the operation. |
| `updates` | The values to be used in the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
### `scatter_nd_sub`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L793-L837)
```
scatter_nd_sub(
indices, updates, name=None
)
```
Applies sparse subtraction to individual values or slices in a Variable.
Assuming the variable has rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into self. It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th dimension of self.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, self.shape[K], ..., self.shape[P-1]].
```
For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that update would look like this:
```
v = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1] ,[7]])
updates = tf.constant([9, 10, 11, 12])
v.scatter_nd_sub(indices, updates)
print(v)
```
After the update `v` would look like this:
```
[1, -9, 3, -6, -4, 6, 7, -4]
```
See [`tf.scatter_nd`](scatter_nd) for more details about how to make updates to slices.
| Args |
| `indices` | The indices to be used in the operation. |
| `updates` | The values to be used in the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
### `scatter_nd_update`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L885-L929)
```
scatter_nd_update(
indices, updates, name=None
)
```
Applies sparse assignment to individual values or slices in a Variable.
The Variable has rank `P` and `indices` is a `Tensor` of rank `Q`.
`indices` must be integer tensor, containing indices into self. It must be shape `[d_0, ..., d_{Q-2}, K]` where `0 < K <= P`.
The innermost dimension of `indices` (with length `K`) corresponds to indices into elements (if `K = P`) or slices (if `K < P`) along the `K`th dimension of self.
`updates` is `Tensor` of rank `Q-1+P-K` with shape:
```
[d_0, ..., d_{Q-2}, self.shape[K], ..., self.shape[P-1]].
```
For example, say we want to add 4 scattered elements to a rank-1 tensor to 8 elements. In Python, that update would look like this:
```
v = tf.Variable([1, 2, 3, 4, 5, 6, 7, 8])
indices = tf.constant([[4], [3], [1] ,[7]])
updates = tf.constant([9, 10, 11, 12])
v.scatter_nd_update(indices, updates)
print(v)
```
The resulting update to v would look like this:
```
[1, 11, 3, 10, 9, 6, 7, 12]
```
See [`tf.scatter_nd`](scatter_nd) for more details about how to make updates to slices.
| Args |
| `indices` | The indices to be used in the operation. |
| `updates` | The values to be used in the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
### `scatter_sub`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L633-L647)
```
scatter_sub(
sparse_delta, use_locking=False, name=None
)
```
Subtracts [`tf.IndexedSlices`](indexedslices) from this variable.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to be subtracted from this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `scatter_update`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L731-L745)
```
scatter_update(
sparse_delta, use_locking=False, name=None
)
```
Assigns [`tf.IndexedSlices`](indexedslices) to this variable.
| Args |
| `sparse_delta` | [`tf.IndexedSlices`](indexedslices) to be assigned to this variable. |
| `use_locking` | If `True`, use locking during the operation. |
| `name` | the name of the operation. |
| Returns |
| The updated variable. |
| Raises |
| `TypeError` | if `sparse_delta` is not an `IndexedSlices`. |
### `set_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L476-L482)
```
set_shape(
shape
)
```
Overrides the shape for this variable.
| Args |
| `shape` | the `TensorShape` representing the overridden shape. |
### `sparse_read`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L931-L945)
```
sparse_read(
indices, name=None
)
```
Gather slices from params axis axis according to indices.
This function supports a subset of tf.gather, see tf.gather for details on usage.
| Args |
| `indices` | The index `Tensor`. Must be one of the following types: `int32`, `int64`. Must be in range `[0, params.shape[axis])`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `params`. |
### `to_proto`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1177-L1187)
```
to_proto(
export_scope=None
)
```
Converts a `Variable` to a `VariableDef` protocol buffer.
| Args |
| `export_scope` | Optional `string`. Name scope to remove. |
| Returns |
| A `VariableDef` protocol buffer, or `None` if the `Variable` is not in the specified name scope. |
### `value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L446-L463)
```
value()
```
Returns the last snapshot of this variable.
You usually do not need to call this method as all ops that need the value of the variable call it automatically through a `convert_to_tensor()` call.
Returns a `Tensor` which holds the value of the variable. You can not assign a new value to this tensor as it is not a reference to the variable.
To avoid copies, if the consumer of the returned value is on the same device as the variable, this actually returns the live value of the variable, not a copy. Updates to the variable are seen by the consumer. If the consumer is on a different device it will get a copy of the variable.
| Returns |
| A `Tensor` containing the value of the variable. |
### `__abs__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L364-L408)
```
__abs__(
name=None
)
```
Computes the absolute value of a tensor.
Given a tensor of integer or floating-point values, this operation returns a tensor of the same type, where each element contains the absolute value of the corresponding element in the input.
Given a tensor `x` of complex numbers, this operation returns a tensor of type `float32` or `float64` that is the absolute value of each element in `x`. For a complex number \(a + bj\), its absolute value is computed as \(\sqrt{a^2 + b^2}\).
#### For example:
```
# real number
x = tf.constant([-2.25, 3.25])
tf.abs(x)
<tf.Tensor: shape=(2,), dtype=float32,
numpy=array([2.25, 3.25], dtype=float32)>
```
```
# complex number
x = tf.constant([[-2.25 + 4.75j], [-3.25 + 5.75j]])
tf.abs(x)
<tf.Tensor: shape=(2, 1), dtype=float64, numpy=
array([[5.25594901],
[6.60492241]])>
```
| Args |
| `x` | A `Tensor` or `SparseTensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64` or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` or `SparseTensor` of the same size, type and sparsity as `x`, with absolute values. Note, for `complex64` or `complex128` input, the returned `Tensor` will be of type `float32` or `float64`, respectively. |
### `__add__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__add__(
y
)
```
The operation invoked by the [`Tensor.**add**`](tensor#__add__) operator.
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**add**`](tensor#__add__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `x` | The left-hand side of the `+` operator. |
| `y` | The right-hand side of the `+` operator. |
| `name` | an optional name for the operation. |
| Returns |
| The result of the elementwise `+` operation. |
### `__and__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__and__(
y
)
```
### `__div__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__div__(
y
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1088-L1094)
```
__eq__(
other
)
```
Compares two variables element-wise for equality.
### `__floordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__floordiv__(
y
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__ge__`
```
__ge__(
y, name=None
)
```
Returns the truth value of (x >= y) element-wise.
>
> **Note:** [`math.greater_equal`](math/greater_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5, 2, 5, 10])
tf.math.greater_equal(x, y) ==> [True, True, True, False]
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5])
tf.math.greater_equal(x, y) ==> [True, False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__getitem__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1308-L1351)
```
__getitem__(
slice_spec
)
```
Creates a slice helper object given a variable.
This allows creating a sub-tensor from part of the current contents of a variable. See [`tf.Tensor.**getitem**`](tensor#__getitem__) for detailed examples of slicing.
This function in addition also allows assignment to a sliced range. This is similar to `__setitem__` functionality in Python. However, the syntax is different so that the user can capture the assignment operation for grouping or passing to `sess.run()`. For example,
```
import tensorflow as tf
A = tf.Variable([[1,2,3], [4,5,6], [7,8,9]], dtype=tf.float32)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
print(sess.run(A[:2, :2])) # => [[1,2], [4,5]]
op = A[:2,:2].assign(22. * tf.ones((2, 2)))
print(sess.run(op)) # => [[22, 22, 3], [22, 22, 6], [7,8,9]]
```
Note that assignments currently do not support NumPy broadcasting semantics.
| Args |
| `var` | An `ops.Variable` object. |
| `slice_spec` | The arguments to [`Tensor.**getitem**`](tensor#__getitem__). |
| Returns |
| The appropriate slice of "tensor", based on "slice\_spec". As an operator. The operator also has a `assign()` method that can be used to generate an assignment operator. |
| Raises |
| `ValueError` | If a slice range is negative size. |
| `TypeError` | TypeError: If the slice indices aren't int, slice, ellipsis, tf.newaxis or int32/int64 tensors. |
### `__gt__`
```
__gt__(
y, name=None
)
```
Returns the truth value of (x > y) element-wise.
>
> **Note:** [`math.greater`](math/greater) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5, 2, 5])
tf.math.greater(x, y) ==> [False, True, True]
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.greater(x, y) ==> [False, False, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__invert__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1859-L1862)
```
__invert__(
name=None
)
```
### `__iter__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1105-L1107)
```
__iter__()
```
When executing eagerly, iterates over the value of the variable.
### `__le__`
```
__le__(
y, name=None
)
```
Returns the truth value of (x <= y) element-wise.
>
> **Note:** [`math.less_equal`](math/less_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less_equal(x, y) ==> [True, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 6])
tf.math.less_equal(x, y) ==> [True, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__lt__`
```
__lt__(
y, name=None
)
```
Returns the truth value of (x < y) element-wise.
>
> **Note:** [`math.less`](math/less) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less(x, y) ==> [False, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 7])
tf.math.less(x, y) ==> [False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__matmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__matmul__(
y
)
```
Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
The inputs must, following any transpositions, be tensors of rank >= 2 where the inner 2 dimensions specify valid matrix multiplication dimensions, and any further outer dimensions specify matching batch size.
Both matrices must be of the same type. The supported types are: `bfloat16`, `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, `complex128`.
Either matrix can be transposed or adjointed (conjugated and transposed) on the fly by setting one of the corresponding flag to `True`. These are `False` by default.
If one or both of the matrices contain a lot of zeros, a more efficient multiplication algorithm can be used by setting the corresponding `a_is_sparse` or `b_is_sparse` flag to `True`. These are `False` by default. This optimization is only available for plain matrices (rank-2 tensors) with datatypes `bfloat16` or `float32`.
A simple 2-D tensor matrix multiplication:
```
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
a # 2-D tensor
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2])
b # 2-D tensor
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[ 7, 8],
[ 9, 10],
[11, 12]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[ 58, 64],
[139, 154]], dtype=int32)>
```
A batch matrix multiplication with batch shape [2]:
```
a = tf.constant(np.arange(1, 13, dtype=np.int32), shape=[2, 2, 3])
a # 3-D tensor
<tf.Tensor: shape=(2, 2, 3), dtype=int32, numpy=
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]], dtype=int32)>
b = tf.constant(np.arange(13, 25, dtype=np.int32), shape=[2, 3, 2])
b # 3-D tensor
<tf.Tensor: shape=(2, 3, 2), dtype=int32, numpy=
array([[[13, 14],
[15, 16],
[17, 18]],
[[19, 20],
[21, 22],
[23, 24]]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy=
array([[[ 94, 100],
[229, 244]],
[[508, 532],
[697, 730]]], dtype=int32)>
```
Since python >= 3.5 the @ operator is supported (see [PEP 465](https://www.python.org/dev/peps/pep-0465/)). In TensorFlow, it simply calls the [`tf.matmul()`](linalg/matmul) function, so the following lines are equivalent:
```
d = a @ b @ [[10], [11]]
d = tf.matmul(tf.matmul(a, b), [[10], [11]])
```
| Args |
| `a` | [`tf.Tensor`](tensor) of type `float16`, `float32`, `float64`, `int32`, `complex64`, `complex128` and rank > 1. |
| `b` | [`tf.Tensor`](tensor) with same type and rank as `a`. |
| `transpose_a` | If `True`, `a` is transposed before multiplication. |
| `transpose_b` | If `True`, `b` is transposed before multiplication. |
| `adjoint_a` | If `True`, `a` is conjugated and transposed before multiplication. |
| `adjoint_b` | If `True`, `b` is conjugated and transposed before multiplication. |
| `a_is_sparse` | If `True`, `a` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `b_is_sparse` | If `True`, `b` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `output_type` | The output datatype if needed. Defaults to None in which case the output\_type is the same as input type. Currently only works when input tensors are type (u)int8 and output\_type can be int32. |
| `name` | Name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of the same type as `a` and `b` where each inner-most matrix is the product of the corresponding matrices in `a` and `b`, e.g. if all transpose or adjoint attributes are `False`: `output[..., i, j] = sum_k (a[..., i, k] * b[..., k, j])`, for all indices `i`, `j`. |
| `Note` | This is matrix product, not element-wise product. |
| Raises |
| `ValueError` | If `transpose_a` and `adjoint_a`, or `transpose_b` and `adjoint_b` are both set to `True`. |
| `TypeError` | If output\_type is specified but the types of `a`, `b` and `output_type` is not (u)int8, (u)int8 and int32. |
### `__mod__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__mod__(
y
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__mul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__mul__(
y
)
```
Dispatches cwise mul for "Dense*Dense" and "Dense*Sparse".
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L1097-L1103)
```
__ne__(
other
)
```
Compares two variables element-wise for equality.
### `__neg__`
```
__neg__(
name=None
)
```
Computes numerical negative value element-wise.
I.e., \(y = -x\).
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `int8`, `int16`, `int32`, `int64`, `complex64`, `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__or__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__or__(
y
)
```
### `__pow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__pow__(
y
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__radd__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__radd__(
x
)
```
The operation invoked by the [`Tensor.**add**`](tensor#__add__) operator.
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**add**`](tensor#__add__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `x` | The left-hand side of the `+` operator. |
| `y` | The right-hand side of the `+` operator. |
| `name` | an optional name for the operation. |
| Returns |
| The result of the elementwise `+` operation. |
### `__rand__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rand__(
x
)
```
### `__rdiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rdiv__(
x
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__rfloordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rfloordiv__(
x
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__rmatmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmatmul__(
x
)
```
Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
The inputs must, following any transpositions, be tensors of rank >= 2 where the inner 2 dimensions specify valid matrix multiplication dimensions, and any further outer dimensions specify matching batch size.
Both matrices must be of the same type. The supported types are: `bfloat16`, `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, `complex128`.
Either matrix can be transposed or adjointed (conjugated and transposed) on the fly by setting one of the corresponding flag to `True`. These are `False` by default.
If one or both of the matrices contain a lot of zeros, a more efficient multiplication algorithm can be used by setting the corresponding `a_is_sparse` or `b_is_sparse` flag to `True`. These are `False` by default. This optimization is only available for plain matrices (rank-2 tensors) with datatypes `bfloat16` or `float32`.
A simple 2-D tensor matrix multiplication:
```
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
a # 2-D tensor
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2])
b # 2-D tensor
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[ 7, 8],
[ 9, 10],
[11, 12]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[ 58, 64],
[139, 154]], dtype=int32)>
```
A batch matrix multiplication with batch shape [2]:
```
a = tf.constant(np.arange(1, 13, dtype=np.int32), shape=[2, 2, 3])
a # 3-D tensor
<tf.Tensor: shape=(2, 2, 3), dtype=int32, numpy=
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]], dtype=int32)>
b = tf.constant(np.arange(13, 25, dtype=np.int32), shape=[2, 3, 2])
b # 3-D tensor
<tf.Tensor: shape=(2, 3, 2), dtype=int32, numpy=
array([[[13, 14],
[15, 16],
[17, 18]],
[[19, 20],
[21, 22],
[23, 24]]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy=
array([[[ 94, 100],
[229, 244]],
[[508, 532],
[697, 730]]], dtype=int32)>
```
Since python >= 3.5 the @ operator is supported (see [PEP 465](https://www.python.org/dev/peps/pep-0465/)). In TensorFlow, it simply calls the [`tf.matmul()`](linalg/matmul) function, so the following lines are equivalent:
```
d = a @ b @ [[10], [11]]
d = tf.matmul(tf.matmul(a, b), [[10], [11]])
```
| Args |
| `a` | [`tf.Tensor`](tensor) of type `float16`, `float32`, `float64`, `int32`, `complex64`, `complex128` and rank > 1. |
| `b` | [`tf.Tensor`](tensor) with same type and rank as `a`. |
| `transpose_a` | If `True`, `a` is transposed before multiplication. |
| `transpose_b` | If `True`, `b` is transposed before multiplication. |
| `adjoint_a` | If `True`, `a` is conjugated and transposed before multiplication. |
| `adjoint_b` | If `True`, `b` is conjugated and transposed before multiplication. |
| `a_is_sparse` | If `True`, `a` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `b_is_sparse` | If `True`, `b` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `output_type` | The output datatype if needed. Defaults to None in which case the output\_type is the same as input type. Currently only works when input tensors are type (u)int8 and output\_type can be int32. |
| `name` | Name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of the same type as `a` and `b` where each inner-most matrix is the product of the corresponding matrices in `a` and `b`, e.g. if all transpose or adjoint attributes are `False`: `output[..., i, j] = sum_k (a[..., i, k] * b[..., k, j])`, for all indices `i`, `j`. |
| `Note` | This is matrix product, not element-wise product. |
| Raises |
| `ValueError` | If `transpose_a` and `adjoint_a`, or `transpose_b` and `adjoint_b` are both set to `True`. |
| `TypeError` | If output\_type is specified but the types of `a`, `b` and `output_type` is not (u)int8, (u)int8 and int32. |
### `__rmod__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmod__(
x
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmul__(
x
)
```
Dispatches cwise mul for "Dense*Dense" and "Dense*Sparse".
### `__ror__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__ror__(
x
)
```
### `__rpow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rpow__(
x
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__rsub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rsub__(
x
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rtruediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rtruediv__(
x
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__rxor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rxor__(
x
)
```
### `__sub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__sub__(
y
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__truediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__truediv__(
y
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__xor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__xor__(
y
)
```
| programming_docs |
tensorflow tf.random_uniform_initializer tf.random\_uniform\_initializer
===============================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L298-L363) |
Initializer that generates tensors with a uniform distribution.
```
tf.random_uniform_initializer(
minval=-0.05, maxval=0.05, seed=None
)
```
Initializers allow you to pre-specify an initialization strategy, encoded in the Initializer object, without knowing the shape and dtype of the variable being initialized.
#### Examples:
```
def make_variables(k, initializer):
return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
v1, v2 = make_variables(3, tf.ones_initializer())
v1
<tf.Variable ... shape=(3,) ... numpy=array([1., 1., 1.], dtype=float32)>
v2
<tf.Variable ... shape=(3, 3) ... numpy=
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=float32)>
make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
(<tf.Variable...shape=(4,) dtype=float32...>, <tf.Variable...shape=(4, 4) ...
```
| Args |
| `minval` | A python scalar or a scalar tensor. Lower bound of the range of random values to generate (inclusive). |
| `maxval` | A python scalar or a scalar tensor. Upper bound of the range of random values to generate (exclusive). |
| `seed` | A Python integer. Used to create random seeds. See [`tf.random.set_seed`](random/set_seed) for behavior. |
Methods
-------
### `from_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L76-L96)
```
@classmethod
from_config(
config
)
```
Instantiates an initializer from a configuration dictionary.
#### Example:
```
initializer = RandomUniform(-1, 1)
config = initializer.get_config()
initializer = RandomUniform.from_config(config)
```
| Args |
| `config` | A Python dictionary. It will typically be the output of `get_config`. |
| Returns |
| An Initializer instance. |
### `get_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L358-L363)
```
get_config()
```
Returns the configuration of the initializer as a JSON-serializable dict.
| Returns |
| A JSON-serializable Python dict. |
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L336-L356)
```
__call__(
shape,
dtype=tf.dtypes.float32,
**kwargs
)
```
Returns a tensor object initialized as specified by the initializer.
| Args |
| `shape` | Shape of the tensor. |
| `dtype` | Optional dtype of the tensor. Only floating point and integer types are supported. |
| `**kwargs` | Additional keyword arguments. |
| Raises |
| `ValueError` | If the dtype is not numeric. |
tensorflow tf.zeros_initializer tf.zeros\_initializer
=====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L111-L154) |
Initializer that generates tensors initialized to 0.
Initializers allow you to pre-specify an initialization strategy, encoded in the Initializer object, without knowing the shape and dtype of the variable being initialized.
#### Examples:
```
def make_variables(k, initializer):
return (tf.Variable(initializer(shape=[k], dtype=tf.float32)),
tf.Variable(initializer(shape=[k, k], dtype=tf.float32)))
v1, v2 = make_variables(3, tf.zeros_initializer())
v1
<tf.Variable ... shape=(3,) ... numpy=array([0., 0., 0.], dtype=float32)>
v2
<tf.Variable ... shape=(3, 3) ... numpy=
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]], dtype=float32)>
make_variables(4, tf.random_uniform_initializer(minval=-1., maxval=1.))
(<tf.Variable...shape=(4,) dtype=float32...>, <tf.Variable...shape=(4, 4) ...
```
Methods
-------
### `from_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L76-L96)
```
@classmethod
from_config(
config
)
```
Instantiates an initializer from a configuration dictionary.
#### Example:
```
initializer = RandomUniform(-1, 1)
config = initializer.get_config()
initializer = RandomUniform.from_config(config)
```
| Args |
| `config` | A Python dictionary. It will typically be the output of `get_config`. |
| Returns |
| An Initializer instance. |
### `get_config`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L68-L74)
```
get_config()
```
Returns the configuration of the initializer as a JSON-serializable dict.
| Returns |
| A JSON-serializable Python dict. |
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/init_ops_v2.py#L135-L154)
```
__call__(
shape,
dtype=tf.dtypes.float32,
**kwargs
)
```
Returns a tensor object initialized as specified by the initializer.
| Args |
| `shape` | Shape of the tensor. |
| `dtype` | Optional dtype of the tensor. Only numeric or boolean dtypes are supported. |
| `**kwargs` | Additional keyword arguments. |
| Raises |
| `ValuesError` | If the dtype is not numeric or boolean. |
tensorflow tf.vectorized_map tf.vectorized\_map
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/parallel_for/control_flow_ops.py#L426-L550) |
Parallel map on the list of tensors unpacked from `elems` on dimension 0.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.vectorized_map`](https://www.tensorflow.org/api_docs/python/tf/vectorized_map)
```
tf.vectorized_map(
fn, elems, fallback_to_while_loop=True
)
```
This method works similar to [`tf.map_fn`](map_fn) but is optimized to run much faster, possibly with a much larger memory footprint. The speedups are obtained by vectorization (see [Auto-Vectorizing TensorFlow Graphs: Jacobians, Auto-Batching and Beyond](https://arxiv.org/pdf/1903.04243.pdf)). The idea behind vectorization is to semantically launch all the invocations of `fn` in parallel and fuse corresponding operations across all these invocations. This fusion is done statically at graph generation time and the generated code is often similar in performance to a manually fused version.
Because [`tf.vectorized_map`](vectorized_map) fully parallelizes the batch, this method will generally be significantly faster than using [`tf.map_fn`](map_fn), especially in eager mode. However this is an experimental feature and currently has a lot of limitations:
* There should be no data dependency between the different semantic invocations of `fn`, i.e. it should be safe to map the elements of the inputs in any order.
* Stateful kernels may mostly not be supported since these often imply a data dependency. We do support a limited set of such stateful kernels though (like RandomFoo, Variable operations like reads, etc).
* `fn` has limited support for control flow operations.
* `fn` should return nested structure of Tensors or Operations. However if an Operation is returned, it should have zero outputs.
* The shape and dtype of any intermediate or output tensors in the computation of `fn` should not depend on the input to `fn`.
#### Examples:
```
def outer_product(a):
return tf.tensordot(a, a, 0)
batch_size = 100
a = tf.ones((batch_size, 32, 32))
c = tf.vectorized_map(outer_product, a)
assert c.shape == (batch_size, 32, 32, 32, 32)
```
```
# Computing per-example gradients
batch_size = 10
num_features = 32
layer = tf.keras.layers.Dense(1)
def model_fn(arg):
with tf.GradientTape() as g:
inp, label = arg
inp = tf.expand_dims(inp, 0)
label = tf.expand_dims(label, 0)
prediction = layer(inp)
loss = tf.nn.l2_loss(label - prediction)
return g.gradient(loss, (layer.kernel, layer.bias))
inputs = tf.random.uniform([batch_size, num_features])
labels = tf.random.uniform([batch_size, 1])
per_example_gradients = tf.vectorized_map(model_fn, (inputs, labels))
assert per_example_gradients[0].shape == (batch_size, num_features, 1)
assert per_example_gradients[1].shape == (batch_size, 1)
```
| Args |
| `fn` | The callable to be performed. It accepts one argument, which will have the same (possibly nested) structure as `elems`, and returns a possibly nested structure of Tensors and Operations, which may be different than the structure of `elems`. |
| `elems` | A tensor or (possibly nested) sequence of tensors, each of which will be unpacked along their first dimension. The nested sequence of the resulting slices will be mapped over by `fn`. The first dimensions of all elements must broadcast to a consistent value; equivalently, each element tensor must have first dimension of either `B` or `1`, for some common batch size `B >= 1`. |
| `fallback_to_while_loop` | If true, on failing to vectorize an operation, the unsupported op is wrapped in a tf.while\_loop to execute the map iterations. Note that this fallback only happens for unsupported ops and other parts of `fn` are still vectorized. If false, on encountering an unsupported op, a ValueError is thrown. Note that the fallbacks can result in slowdowns since vectorization often yields speedup of one to two orders of magnitude. |
| Returns |
| A tensor or (possibly nested) sequence of tensors. Each tensor packs the results of applying fn to tensors unpacked from elems along the first dimension, from first to last. Although they are less common as user-visible inputs and outputs, note that tensors of type [`tf.variant`](../tf#variant) which represent tensor lists (for example from [`tf.raw_ops.TensorListFromTensor`](raw_ops/tensorlistfromtensor)) are vectorized by stacking the list contents rather than the variant itself, and so the container tensor will have a scalar shape when returned rather than the usual stacked shape. This improves the performance of control flow gradient vectorization. |
| Raises |
| `ValueError` | If vectorization fails and fallback\_to\_while\_loop is False. |
tensorflow tf.space_to_batch_nd tf.space\_to\_batch\_nd
=======================
SpaceToBatch for N-D tensors of type T.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.space_to_batch_nd`](https://www.tensorflow.org/api_docs/python/tf/space_to_batch_nd), [`tf.compat.v1.space_to_batch_nd`](https://www.tensorflow.org/api_docs/python/tf/space_to_batch_nd)
```
tf.space_to_batch_nd(
input, block_shape, paddings, name=None
)
```
This operation divides "spatial" dimensions `[1, ..., M]` of the input into a grid of blocks of shape `block_shape`, and interleaves these blocks with the "batch" dimension (0) such that in the output, the spatial dimensions `[1, ..., M]` correspond to the position within the grid, and the batch dimension combines both the position within a spatial block and the original batch position. Prior to division into blocks, the spatial dimensions of the input are optionally zero padded according to `paddings`. See below for a precise description.
This operation is equivalent to the following steps:
1. Zero-pad the start and end of dimensions `[1, ..., M]` of the input according to `paddings` to produce `padded` of shape `padded_shape`.
2. Reshape `padded` to `reshaped_padded` of shape:
[batch] + [padded\_shape[1] / block\_shape[0], block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1], block\_shape[M-1]] + remaining\_shape
3. Permute dimensions of `reshaped_padded` to produce `permuted_reshaped_padded` of shape:
block\_shape + [batch] + [padded\_shape[1] / block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1]] + remaining\_shape
4. Reshape `permuted_reshaped_padded` to flatten `block_shape` into the batch dimension, producing an output tensor of shape:
[batch \* prod(block\_shape)] + [padded\_shape[1] / block\_shape[0], ..., padded\_shape[M] / block\_shape[M-1]] + remaining\_shape
#### Some examples:
(1) For the following input of shape `[1, 2, 2, 1]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1], [2]], [[3], [4]]]]
```
The output tensor has shape `[4, 1, 1, 1]` and value:
```
[[[[1]]], [[[2]]], [[[3]]], [[[4]]]]
```
(2) For the following input of shape `[1, 2, 2, 3]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1, 2, 3], [4, 5, 6]],
[[7, 8, 9], [10, 11, 12]]]]
```
The output tensor has shape `[4, 1, 1, 3]` and value:
```
[[[[1, 2, 3]]], [[[4, 5, 6]]], [[[7, 8, 9]]], [[[10, 11, 12]]]]
```
(3) For the following input of shape `[1, 4, 4, 1]`, `block_shape = [2, 2]`, and `paddings = [[0, 0], [0, 0]]`:
```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]],
[[9], [10], [11], [12]],
[[13], [14], [15], [16]]]]
```
The output tensor has shape `[4, 2, 2, 1]` and value:
```
x = [[[[1], [3]], [[9], [11]]],
[[[2], [4]], [[10], [12]]],
[[[5], [7]], [[13], [15]]],
[[[6], [8]], [[14], [16]]]]
```
(4) For the following input of shape `[2, 2, 4, 1]`, block\_shape = `[2, 2]`, and paddings = `[[0, 0], [2, 0]]`:
```
x = [[[[1], [2], [3], [4]],
[[5], [6], [7], [8]]],
[[[9], [10], [11], [12]],
[[13], [14], [15], [16]]]]
```
The output tensor has shape `[8, 1, 3, 1]` and value:
```
x = [[[[0], [1], [3]]], [[[0], [9], [11]]],
[[[0], [2], [4]]], [[[0], [10], [12]]],
[[[0], [5], [7]]], [[[0], [13], [15]]],
[[[0], [6], [8]]], [[[0], [14], [16]]]]
```
Among others, this operation is useful for reducing atrous convolution into regular convolution.
| Args |
| `input` | A `Tensor`. N-D with shape `input_shape = [batch] + spatial_shape + remaining_shape`, where spatial\_shape has `M` dimensions. |
| `block_shape` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 1-D with shape `[M]`, all values must be >= 1. |
| `paddings` | A `Tensor`. Must be one of the following types: `int32`, `int64`. 2-D with shape `[M, 2]`, all values must be >= 0. `paddings[i] = [pad_start, pad_end]` specifies the padding for input dimension `i + 1`, which corresponds to spatial dimension `i`. It is required that `block_shape[i]` divides `input_shape[i + 1] + pad_start + pad_end`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow Module: tf.mlir Module: tf.mlir
===============
Public API for tf.mlir namespace.
Modules
-------
[`experimental`](mlir/experimental) module: Public API for tf.mlir.experimental namespace.
tensorflow tf.broadcast_dynamic_shape tf.broadcast\_dynamic\_shape
============================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L511-L542) |
Computes the shape of a broadcast given symbolic shapes.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.broadcast_dynamic_shape`](https://www.tensorflow.org/api_docs/python/tf/broadcast_dynamic_shape)
```
tf.broadcast_dynamic_shape(
shape_x, shape_y
)
```
When `shape_x` and `shape_y` are Tensors representing shapes (i.e. the result of calling tf.shape on another Tensor) this computes a Tensor which is the shape of the result of a broadcasting op applied in tensors of shapes `shape_x` and `shape_y`.
This is useful when validating the result of a broadcasting operation when the tensors do not have statically known shapes.
#### Example:
```
shape_x = (1, 2, 3)
shape_y = (5, 1, 3)
tf.broadcast_dynamic_shape(shape_x, shape_y)
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([5, 2, 3], ...>
```
| Args |
| `shape_x` | A rank 1 integer `Tensor`, representing the shape of x. |
| `shape_y` | A rank 1 integer `Tensor`, representing the shape of y. |
| Returns |
| A rank 1 integer `Tensor` representing the broadcasted shape. |
| Raises |
| `InvalidArgumentError` | If the two shapes are incompatible for broadcasting. |
tensorflow tf.inside_function tf.inside\_function
===================
Indicates whether the caller code is executing inside a [`tf.function`](function).
```
tf.inside_function()
```
| Returns |
| Boolean, True if the caller code is executing inside a [`tf.function`](function) rather than eagerly. |
#### Example:
```
tf.inside_function()
False
@tf.function
def f():
print(tf.inside_function())
f()
True
```
tensorflow tf.dynamic_stitch tf.dynamic\_stitch
==================
Interleave the values from the `data` tensors into a single tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.dynamic_stitch`](https://www.tensorflow.org/api_docs/python/tf/dynamic_stitch)
```
tf.dynamic_stitch(
indices, data, name=None
)
```
Builds a merged tensor such that
```
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
```
For example, if each `indices[m]` is scalar or vector, we have
```
# Scalar indices:
merged[indices[m], ...] = data[m][...]
# Vector indices:
merged[indices[m][i], ...] = data[m][i, ...]
```
Each `data[i].shape` must start with the corresponding `indices[i].shape`, and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we must have `data[i].shape = indices[i].shape + constant`. In terms of this `constant`, the output shape is
```
merged.shape = [max(indices)] + constant
```
Values are merged in order, so if an index appears in both `indices[m][i]` and `indices[n][j]` for `(m,i) < (n,j)` the slice `data[n][j]` will appear in the merged result. If you do not need this guarantee, ParallelDynamicStitch might perform better on some devices.
#### For example:
```
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
```
This method can be used to merge partitions created by `dynamic_partition` as illustrated on the following example:
```
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
```
| Args |
| `indices` | A list of at least 1 `Tensor` objects with type `int32`. |
| `data` | A list with the same length as `indices` of `Tensor` objects with the same type. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `data`. |
tensorflow Module: tf.random Module: tf.random
=================
Public API for tf.random namespace.
Modules
-------
[`experimental`](random/experimental) module: Public API for tf.random.experimental namespace.
Classes
-------
[`class Algorithm`](random/algorithm): An enumeration.
[`class Generator`](random/generator): Random-number generator.
Functions
---------
[`all_candidate_sampler(...)`](random/all_candidate_sampler): Generate the set of all classes.
[`categorical(...)`](random/categorical): Draws samples from a categorical distribution.
[`create_rng_state(...)`](random/create_rng_state): Creates a RNG state from an integer or a vector.
[`fixed_unigram_candidate_sampler(...)`](random/fixed_unigram_candidate_sampler): Samples a set of classes using the provided (fixed) base distribution.
[`gamma(...)`](random/gamma): Draws `shape` samples from each of the given Gamma distribution(s).
[`get_global_generator(...)`](random/get_global_generator): Retrieves the global generator.
[`learned_unigram_candidate_sampler(...)`](random/learned_unigram_candidate_sampler): Samples a set of classes from a distribution learned during training.
[`log_uniform_candidate_sampler(...)`](random/log_uniform_candidate_sampler): Samples a set of classes using a log-uniform (Zipfian) base distribution.
[`normal(...)`](random/normal): Outputs random values from a normal distribution.
[`poisson(...)`](random/poisson): Draws `shape` samples from each of the given Poisson distribution(s).
[`set_global_generator(...)`](random/set_global_generator): Replaces the global generator with another `Generator` object.
[`set_seed(...)`](random/set_seed): Sets the global random seed.
[`shuffle(...)`](random/shuffle): Randomly shuffles a tensor along its first dimension.
[`stateless_binomial(...)`](random/stateless_binomial): Outputs deterministic pseudorandom values from a binomial distribution.
[`stateless_categorical(...)`](random/stateless_categorical): Draws deterministic pseudorandom samples from a categorical distribution.
[`stateless_gamma(...)`](random/stateless_gamma): Outputs deterministic pseudorandom values from a gamma distribution.
[`stateless_normal(...)`](random/stateless_normal): Outputs deterministic pseudorandom values from a normal distribution.
[`stateless_parameterized_truncated_normal(...)`](random/stateless_parameterized_truncated_normal): Outputs random values from a truncated normal distribution.
[`stateless_poisson(...)`](random/stateless_poisson): Outputs deterministic pseudorandom values from a Poisson distribution.
[`stateless_truncated_normal(...)`](random/stateless_truncated_normal): Outputs deterministic pseudorandom values, truncated normally distributed.
[`stateless_uniform(...)`](random/stateless_uniform): Outputs deterministic pseudorandom values from a uniform distribution.
[`truncated_normal(...)`](random/truncated_normal): Outputs random values from a truncated normal distribution.
[`uniform(...)`](random/uniform): Outputs random values from a uniform distribution.
[`uniform_candidate_sampler(...)`](random/uniform_candidate_sampler): Samples a set of classes using a uniform base distribution.
| programming_docs |
tensorflow tf.recompute_grad tf.recompute\_grad
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/custom_gradient.py#L580-L750) |
Defines a function as a recompute-checkpoint for the tape auto-diff.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.recompute_grad`](https://www.tensorflow.org/api_docs/python/tf/recompute_grad)
```
tf.recompute_grad(
f
)
```
Tape checkpointing is a technique to reduce the memory consumption of the auto-diff tape:
* Without tape checkpointing operations and intermediate values are recorded to the tape for use in the backward pass.
* With tape checkpointing, only the function call and its inputs are recorded. During back-propagation the `recompute_grad` custom gradient ([`tf.custom_gradient`](custom_gradient)) recomputes the function under a localized Tape object. This recomputation of the function during backpropagation performs redundant calculation, but reduces the overall memory usage of the Tape.
```
y = tf.Variable(1.0)
```
```
def my_function(x):
tf.print('running')
z = x*y
return z
```
```
my_function_recompute = tf.recompute_grad(my_function)
```
```
with tf.GradientTape() as tape:
r = tf.constant(1.0)
for i in range(4):
r = my_function_recompute(r)
running
running
running
running
```
```
grad = tape.gradient(r, [y])
running
running
running
running
```
Without `recompute_grad`, the tape contains all intermitate steps, and no recomputation is performed.
```
with tf.GradientTape() as tape:
r = tf.constant(1.0)
for i in range(4):
r = my_function(r)
running
running
running
running
```
```
grad = tape.gradient(r, [y])
```
If `f` was a [`tf.keras`](keras) `Model` or `Layer` object, methods and attributes such as `f.variables` are not available on the returned function `g`. Either keep a reference of `f` , or use `g.__wrapped__` for accessing these variables and methods.
```
def print_running_and_return(x):
tf.print("running")
return x
```
```
model = tf.keras.Sequential([
tf.keras.layers.Lambda(print_running_and_return),
tf.keras.layers.Dense(2)
])
```
```
model_recompute = tf.recompute_grad(model)
```
```
with tf.GradientTape(persistent=True) as tape:
r = tf.constant([[1,2]])
for i in range(4):
r = model_recompute(r)
running
running
running
running
```
```
grad = tape.gradient(r, model.variables)
running
running
running
running
```
Alternatively, use the `__wrapped__` attribute to access the original model object.
```
grad = tape.gradient(r, model_recompute.__wrapped__.variables)
running
running
running
running
```
| Args |
| `f` | function `f(*x)` that returns a `Tensor` or sequence of `Tensor` outputs. |
| Returns |
| A function `g` wrapping `f` that defines a custom gradient, which recomputes `f` on the backwards pass of a gradient call. |
tensorflow tf.slice tf.slice
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1112-L1164) |
Extracts a slice from a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.slice`](https://www.tensorflow.org/api_docs/python/tf/slice)
```
tf.slice(
input_, begin, size, name=None
)
```
See also [`tf.strided_slice`](strided_slice).
This operation extracts a slice of size `size` from a tensor `input_` starting at the location specified by `begin`. The slice `size` is represented as a tensor shape, where `size[i]` is the number of elements of the 'i'th dimension of `input_` that you want to slice. The starting location (`begin`) for the slice is represented as an offset in each dimension of `input_`. In other words, `begin[i]` is the offset into the i'th dimension of `input_` that you want to slice from.
Note that [`tf.Tensor.**getitem**`](tensor#__getitem__) is typically a more pythonic way to perform slices, as it allows you to write `foo[3:7, :-2]` instead of `tf.slice(foo, [3, 0], [4, foo.get_shape()[1]-2])`.
`begin` is zero-based; `size` is one-based. If `size[i]` is -1, all remaining elements in dimension i are included in the slice. In other words, this is equivalent to setting:
`size[i] = input_.dim_size(i) - begin[i]`
This operation requires that:
`0 <= begin[i] <= begin[i] + size[i] <= Di for i in [0, n]`
#### For example:
```
t = tf.constant([[[1, 1, 1], [2, 2, 2]],
[[3, 3, 3], [4, 4, 4]],
[[5, 5, 5], [6, 6, 6]]])
tf.slice(t, [1, 0, 0], [1, 1, 3]) # [[[3, 3, 3]]]
tf.slice(t, [1, 0, 0], [1, 2, 3]) # [[[3, 3, 3],
# [4, 4, 4]]]
tf.slice(t, [1, 0, 0], [2, 1, 3]) # [[[3, 3, 3]],
# [[5, 5, 5]]]
```
| Args |
| `input_` | A `Tensor`. |
| `begin` | An `int32` or `int64` `Tensor`. |
| `size` | An `int32` or `int64` `Tensor`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` the same type as `input_`. |
tensorflow tf.fingerprint tf.fingerprint
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L6612-L6659) |
Generates fingerprint values.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.fingerprint`](https://www.tensorflow.org/api_docs/python/tf/fingerprint)
```
tf.fingerprint(
data, method='farmhash64', name=None
)
```
Generates fingerprint values of `data`.
Fingerprint op considers the first dimension of `data` as the batch dimension, and `output[i]` contains the fingerprint value generated from contents in `data[i, ...]` for all `i`.
Fingerprint op writes fingerprint values as byte arrays. For example, the default method `farmhash64` generates a 64-bit fingerprint value at a time. This 8-byte value is written out as an [`tf.uint8`](../tf#uint8) array of size 8, in little-endian order.
For example, suppose that `data` has data type [`tf.int32`](../tf#int32) and shape (2, 3, 4), and that the fingerprint method is `farmhash64`. In this case, the output shape is (2, 8), where 2 is the batch dimension size of `data`, and 8 is the size of each fingerprint value in bytes. `output[0, :]` is generated from 12 integers in `data[0, :, :]` and similarly `output[1, :]` is generated from other 12 integers in `data[1, :, :]`.
Note that this op fingerprints the raw underlying buffer, and it does not fingerprint Tensor's metadata such as data type and/or shape. For example, the fingerprint values are invariant under reshapes and bitcasts as long as the batch dimension remain the same:
```
tf.fingerprint(data) == tf.fingerprint(tf.reshape(data, ...))
tf.fingerprint(data) == tf.fingerprint(tf.bitcast(data, ...))
```
For string data, one should expect `tf.fingerprint(data) != tf.fingerprint(tf.string.reduce_join(data))` in general.
| Args |
| `data` | A `Tensor`. Must have rank 1 or higher. |
| `method` | A `Tensor` of type [`tf.string`](../tf#string). Fingerprint method used by this op. Currently available method is `farmhash64`. |
| `name` | A name for the operation (optional). |
| Returns |
| A two-dimensional `Tensor` of type [`tf.uint8`](../tf#uint8). The first dimension equals to `data`'s first dimension, and the second dimension size depends on the fingerprint algorithm. |
tensorflow tf.TensorArray tf.TensorArray
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L957-L1292) |
Class wrapping dynamic-sized, per-time-step, write-once Tensor arrays.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.TensorArray`](https://www.tensorflow.org/api_docs/python/tf/TensorArray)
```
tf.TensorArray(
dtype,
size=None,
dynamic_size=None,
clear_after_read=None,
tensor_array_name=None,
handle=None,
flow=None,
infer_shape=True,
element_shape=None,
colocate_with_first_write_call=True,
name=None
)
```
This class is meant to be used with dynamic iteration primitives such as `while_loop` and `map_fn`. It supports gradient back-propagation via special "flow" control flow dependencies.
Example 1: Plain reading and writing.
```
ta = tf.TensorArray(tf.float32, size=0, dynamic_size=True, clear_after_read=False)
ta = ta.write(0, 10)
ta = ta.write(1, 20)
ta = ta.write(2, 30)
ta.read(0)
<tf.Tensor: shape=(), dtype=float32, numpy=10.0>
ta.read(1)
<tf.Tensor: shape=(), dtype=float32, numpy=20.0>
ta.read(2)
<tf.Tensor: shape=(), dtype=float32, numpy=30.0>
ta.stack()
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([10., 20., 30.],
dtype=float32)>
```
Example 2: Fibonacci sequence algorithm that writes in a loop then returns.
```
@tf.function
def fibonacci(n):
ta = tf.TensorArray(tf.float32, size=0, dynamic_size=True)
ta = ta.unstack([0., 1.])
for i in range(2, n):
ta = ta.write(i, ta.read(i - 1) + ta.read(i - 2))
return ta.stack()
fibonacci(7)
<tf.Tensor: shape=(7,), dtype=float32,
numpy=array([0., 1., 1., 2., 3., 5., 8.], dtype=float32)>
```
Example 3: A simple loop interacting with a [`tf.Variable`](variable).
```
v = tf.Variable(1)
@tf.function
def f(x):
ta = tf.TensorArray(tf.int32, size=0, dynamic_size=True)
for i in tf.range(x):
v.assign_add(i)
ta = ta.write(i, v)
return ta.stack()
f(5)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([ 1, 2, 4, 7, 11],
dtype=int32)>
```
| Args |
| `dtype` | (required) data type of the TensorArray. |
| `size` | (optional) int32 scalar `Tensor`: the size of the TensorArray. Required if handle is not provided. |
| `dynamic_size` | (optional) Python bool: If true, writes to the TensorArray can grow the TensorArray past its initial size. Default: False. |
| `clear_after_read` | Boolean (optional, default: True). If True, clear TensorArray values after reading them. This disables read-many semantics, but allows early release of memory. |
| `tensor_array_name` | (optional) Python string: the name of the TensorArray. This is used when creating the TensorArray handle. If this value is set, handle should be None. |
| `handle` | (optional) A `Tensor` handle to an existing TensorArray. If this is set, tensor\_array\_name should be None. Only supported in graph mode. |
| `flow` | (optional) A float `Tensor` scalar coming from an existing [`TensorArray.flow`](tensorarray#flow). Only supported in graph mode. |
| `infer_shape` | (optional, default: True) If True, shape inference is enabled. In this case, all elements must have the same shape. |
| `element_shape` | (optional, default: None) A `TensorShape` object specifying the shape constraints of each of the elements of the TensorArray. Need not be fully defined. |
| `colocate_with_first_write_call` | If `True`, the TensorArray will be colocated on the same device as the Tensor used on its first write (write operations include `write`, `unstack`, and `split`). If `False`, the TensorArray will be placed on the device determined by the device context available during its initialization. |
| `name` | A name for the operation (optional). |
| Raises |
| `ValueError` | if both handle and tensor\_array\_name are provided. |
| `TypeError` | if handle is provided but is not a Tensor. |
| Attributes |
| `dtype` | The data type of this TensorArray. |
| `dynamic_size` | Python bool; if `True` the TensorArray can grow dynamically. |
| `element_shape` | The [`tf.TensorShape`](tensorshape) of elements in this TensorArray. |
| `flow` | The flow `Tensor` forcing ops leading to this TensorArray state. |
| `handle` | The reference to the TensorArray. |
Methods
-------
### `close`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1289-L1292)
```
close(
name=None
)
```
Close the current TensorArray.
>
> **Note:** The output of this function should be used. If it is not, a warning will be logged or an error may be raised. To mark the output as used, call its .mark\_used() method.
>
### `concat`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1213-L1225)
```
concat(
name=None
)
```
Return the values in the TensorArray as a concatenated `Tensor`.
All of the values must have been written, their ranks must match, and and their shapes must all match for all dimensions except the first.
| Args |
| `name` | A name for the operation (optional). |
| Returns |
| All the tensors in the TensorArray concatenated into one tensor. |
### `gather`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1196-L1211)
```
gather(
indices, name=None
)
```
Return selected values in the TensorArray as a packed `Tensor`.
All of selected values must have been written and their shapes must all match.
| Args |
| `indices` | A `1-D` `Tensor` taking values in `[0, max_value)`. If the `TensorArray` is not dynamic, `max_value=size()`. |
| `name` | A name for the operation (optional). |
| Returns |
| The tensors in the `TensorArray` selected by `indices`, packed into one tensor. |
### `grad`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1135-L1136)
```
grad(
source, flow=None, name=None
)
```
### `identity`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1125-L1133)
```
identity()
```
Returns a TensorArray with the same content and properties.
| Returns |
| A new TensorArray object with flow that ensures the control dependencies from the contexts will become control dependencies for writes, reads, etc. Use this object for all subsequent operations. |
### `read`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1138-L1148)
```
read(
index, name=None
)
```
Read the value at location `index` in the TensorArray.
| Args |
| `index` | 0-D. int32 tensor with the index to read from. |
| `name` | A name for the operation (optional). |
| Returns |
| The tensor at index `index`. |
### `scatter`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1247-L1264)
```
scatter(
indices, value, name=None
)
```
Scatter the values of a `Tensor` in specific indices of a `TensorArray`.
| Args |
| `indices` | A `1-D` `Tensor` taking values in `[0, max_value)`. If the `TensorArray` is not dynamic, `max_value=size()`. |
| `value` | (N+1)-D. Tensor of type `dtype`. The Tensor to unpack. |
| `name` | A name for the operation (optional). |
| Returns |
| A new TensorArray object with flow that ensures the scatter occurs. Use this object for all subsequent operations. |
| Raises |
| `ValueError` | if the shape inference fails. |
>
> **Note:** The output of this function should be used. If it is not, a warning will be logged or an error may be raised. To mark the output as used, call its .mark\_used() method.
>
### `size`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1285-L1287)
```
size(
name=None
)
```
Return the size of the TensorArray.
### `split`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1266-L1283)
```
split(
value, lengths, name=None
)
```
Split the values of a `Tensor` into the TensorArray.
| Args |
| `value` | (N+1)-D. Tensor of type `dtype`. The Tensor to split. |
| `lengths` | 1-D. int32 vector with the lengths to use when splitting `value` along its first dimension. |
| `name` | A name for the operation (optional). |
| Returns |
| A new TensorArray object with flow that ensures the split occurs. Use this object for all subsequent operations. |
| Raises |
| `ValueError` | if the shape inference fails. |
>
> **Note:** The output of this function should be used. If it is not, a warning will be logged or an error may be raised. To mark the output as used, call its .mark\_used() method.
>
### `stack`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1168-L1194)
```
stack(
name=None
)
```
Return the values in the TensorArray as a stacked `Tensor`.
All of the values must have been written and their shapes must all match. If input shapes have rank-`R`, then output shape will have rank-`(R+1)`.
#### For example:
```
ta = tf.TensorArray(tf.int32, size=3)
ta.write(0, tf.constant([1, 2]))
ta.write(1, tf.constant([3, 4]))
ta.write(2, tf.constant([5, 6]))
ta.stack()
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)>
```
| Args |
| `name` | A name for the operation (optional). |
| Returns |
| All the tensors in the TensorArray stacked into one tensor. |
### `unstack`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1227-L1245)
```
unstack(
value, name=None
)
```
Unstack the values of a `Tensor` in the TensorArray.
If input value shapes have rank-`R`, then the output TensorArray will contain elements whose shapes are rank-`(R-1)`.
| Args |
| `value` | (N+1)-D. Tensor of type `dtype`. The Tensor to unstack. |
| `name` | A name for the operation (optional). |
| Returns |
| A new TensorArray object with flow that ensures the unstack occurs. Use this object for all subsequent operations. |
| Raises |
| `ValueError` | if the shape inference fails. |
>
> **Note:** The output of this function should be used. If it is not, a warning will be logged or an error may be raised. To mark the output as used, call its .mark\_used() method.
>
### `write`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/tensor_array_ops.py#L1150-L1166)
```
write(
index, value, name=None
)
```
Write `value` into index `index` of the TensorArray.
| Args |
| `index` | 0-D. int32 scalar with the index to write to. |
| `value` | N-D. Tensor of type `dtype`. The Tensor to write to this index. |
| `name` | A name for the operation (optional). |
| Returns |
| A new TensorArray object with flow that ensures the write occurs. Use this object for all subsequent operations. |
| Raises |
| `ValueError` | if there are more writers than specified. |
>
> **Note:** The output of this function should be used. If it is not, a warning will be logged or an error may be raised. To mark the output as used, call its .mark\_used() method.
>
tensorflow Module: tf.test Module: tf.test
===============
Testing.
Classes
-------
[`class Benchmark`](test/benchmark): Abstract class that provides helpers for TensorFlow benchmarks.
[`class TestCase`](test/testcase): Base class for tests that need to test TensorFlow.
Functions
---------
[`assert_equal_graph_def(...)`](test/assert_equal_graph_def): Asserts that two `GraphDef`s are (mostly) the same.
[`benchmark_config(...)`](test/benchmark_config): Returns a tf.compat.v1.ConfigProto for disabling the dependency optimizer.
[`compute_gradient(...)`](test/compute_gradient): Computes the theoretical and numeric Jacobian of `f`.
[`create_local_cluster(...)`](test/create_local_cluster): Create and start local servers and return the associated `Server` objects.
[`disable_with_predicate(...)`](test/disable_with_predicate): Disables the test if pred is true.
[`gpu_device_name(...)`](test/gpu_device_name): Returns the name of a GPU device if available or a empty string.
[`is_built_with_cuda(...)`](test/is_built_with_cuda): Returns whether TensorFlow was built with CUDA (GPU) support.
[`is_built_with_gpu_support(...)`](test/is_built_with_gpu_support): Returns whether TensorFlow was built with GPU (CUDA or ROCm) support.
[`is_built_with_rocm(...)`](test/is_built_with_rocm): Returns whether TensorFlow was built with ROCm (GPU) support.
[`is_built_with_xla(...)`](test/is_built_with_xla): Returns whether TensorFlow was built with XLA support.
[`is_gpu_available(...)`](test/is_gpu_available): Returns whether TensorFlow can access a GPU. (deprecated)
[`main(...)`](test/main): Runs all unit tests.
[`with_eager_op_as_function(...)`](test/with_eager_op_as_function): Adds methods that call original methods with eager\_op\_as\_function enabled.
| programming_docs |
tensorflow tf.unstack tf.unstack
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1603-L1729) |
Unpacks the given dimension of a rank-`R` tensor into rank-`(R-1)` tensors.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.unstack`](https://www.tensorflow.org/api_docs/python/tf/unstack)
```
tf.unstack(
value, num=None, axis=0, name='unstack'
)
```
Unpacks tensors from `value` by chipping it along the `axis` dimension.
```
x = tf.reshape(tf.range(12), (3,4))
p, q, r = tf.unstack(x)
p.shape.as_list()
[4]
```
```
i, j, k, l = tf.unstack(x, axis=1)
i.shape.as_list()
[3]
```
This is the opposite of stack.
```
x = tf.stack([i, j, k, l], axis=1)
```
More generally if you have a tensor of shape `(A, B, C, D)`:
```
A, B, C, D = [2, 3, 4, 5]
t = tf.random.normal(shape=[A, B, C, D])
```
The number of tensor returned is equal to the length of the target `axis`:
```
axis = 2
items = tf.unstack(t, axis=axis)
len(items) == t.shape[axis]
True
```
The shape of each result tensor is equal to the shape of the input tensor, with the target `axis` removed.
```
items[0].shape.as_list() # [A, B, D]
[2, 3, 5]
```
The value of each tensor `items[i]` is equal to the slice of `input` across `axis` at index `i`:
```
for i in range(len(items)):
slice = t[:,:,i,:]
assert tf.reduce_all(slice == items[i])
```
#### Python iterable unpacking
With eager execution you *can* unstack the 0th axis of a tensor using python's iterable unpacking:
```
t = tf.constant([1,2,3])
a,b,c = t
```
`unstack` is still necessary because Iterable unpacking doesn't work in a [`@tf.function`](function): Symbolic tensors are not iterable.
You need to use [`tf.unstack`](unstack) here:
```
@tf.function
def bad(t):
a,b,c = t
return a
bad(t)
Traceback (most recent call last):
OperatorNotAllowedInGraphError: ...
```
```
@tf.function
def good(t):
a,b,c = tf.unstack(t)
return a
good(t).numpy()
1
```
#### Unknown shapes
Eager tensors have concrete values, so their shape is always known. Inside a [`tf.function`](function) the symbolic tensors may have unknown shapes. If the length of `axis` is unknown [`tf.unstack`](unstack) will fail because it cannot handle an unknown number of tensors:
```
@tf.function(input_signature=[tf.TensorSpec([None], tf.float32)])
def bad(t):
tensors = tf.unstack(t)
return tensors[0]
bad(tf.constant([1,2,3]))
Traceback (most recent call last):
ValueError: Cannot infer argument `num` from shape (None,)
```
If you know the `axis` length you can pass it as the `num` argument. But this must be a constant value.
If you actually need a variable number of tensors in a single [`tf.function`](function) trace, you will need to use exlicit loops and a [`tf.TensorArray`](tensorarray) instead.
| Args |
| `value` | A rank `R > 0` `Tensor` to be unstacked. |
| `num` | An `int`. The length of the dimension `axis`. Automatically inferred if `None` (the default). |
| `axis` | An `int`. The axis to unstack along. Defaults to the first dimension. Negative values wrap around, so the valid range is `[-R, R)`. |
| `name` | A name for the operation (optional). |
| Returns |
| The list of `Tensor` objects unstacked from `value`. |
| Raises |
| `ValueError` | If `axis` is out of the range `[-R, R)`. |
| `ValueError` | If `num` is unspecified and cannot be inferred. |
| `InvalidArgumentError` | If `num` does not match the shape of `value`. |
tensorflow tf.TensorSpec tf.TensorSpec
=============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L103-L225) |
Describes a tf.Tensor.
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.TensorSpec`](https://www.tensorflow.org/api_docs/python/tf/TensorSpec)
```
tf.TensorSpec(
shape,
dtype=tf.dtypes.float32,
name=None
)
```
Metadata for describing the [`tf.Tensor`](tensor) objects accepted or returned by some TensorFlow APIs.
| Args |
| `shape` | Value convertible to [`tf.TensorShape`](tensorshape). The shape of the tensor. |
| `dtype` | Value convertible to [`tf.DType`](dtypes/dtype). The type of the tensor values. |
| `name` | Optional name for the Tensor. |
| Raises |
| `TypeError` | If shape is not convertible to a [`tf.TensorShape`](tensorshape), or dtype is not convertible to a [`tf.DType`](dtypes/dtype). |
| Attributes |
| `dtype` | Returns the `dtype` of elements in the tensor. |
| `name` | Returns the (optionally provided) name of the described tensor. |
| `shape` | Returns the `TensorShape` that represents the shape of the tensor. |
| `value_type` | The Python type for values that are compatible with this TypeSpec. |
Methods
-------
### `from_spec`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L126-L138)
```
@classmethod
from_spec(
spec, name=None
)
```
Returns a `TensorSpec` with the same shape and dtype as `spec`.
```
spec = tf.TensorSpec(shape=[8, 3], dtype=tf.int32, name="OriginalName")
tf.TensorSpec.from_spec(spec, "NewName")
TensorSpec(shape=(8, 3), dtype=tf.int32, name='NewName')
```
| Args |
| `spec` | The `TypeSpec` used to create the new `TensorSpec`. |
| `name` | The name for the new `TensorSpec`. Defaults to `spec.name`. |
### `from_tensor`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L140-L160)
```
@classmethod
from_tensor(
tensor, name=None
)
```
Returns a `TensorSpec` that describes `tensor`.
```
tf.TensorSpec.from_tensor(tf.constant([1, 2, 3]))
TensorSpec(shape=(3,), dtype=tf.int32, name=None)
```
| Args |
| `tensor` | The [`tf.Tensor`](tensor) that should be described. |
| `name` | A name for the `TensorSpec`. Defaults to `tensor.op.name`. |
| Returns |
| A `TensorSpec` that describes `tensor`. |
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L112-L124)
```
is_compatible_with(
spec_or_tensor
)
```
Returns True if spec\_or\_tensor is compatible with this TensorSpec.
Two tensors are considered compatible if they have the same dtype and their shapes are compatible (see [`tf.TensorShape.is_compatible_with`](tensorshape#is_compatible_with)).
| Args |
| `spec_or_tensor` | A tf.TensorSpec or a tf.Tensor |
| Returns |
| True if spec\_or\_tensor is compatible with self. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L78-L83)
```
__eq__(
other
)
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_spec.py#L85-L86)
```
__ne__(
other
)
```
Return self!=value.
tensorflow tf.cast tf.cast
=======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L936-L1005) |
Casts a tensor to a new type.
#### View aliases
**Main aliases**
[`tf.dtypes.cast`](https://www.tensorflow.org/api_docs/python/tf/cast)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.cast`](https://www.tensorflow.org/api_docs/python/tf/cast), [`tf.compat.v1.dtypes.cast`](https://www.tensorflow.org/api_docs/python/tf/cast)
```
tf.cast(
x, dtype, name=None
)
```
The operation casts `x` (in case of `Tensor`) or `x.values` (in case of `SparseTensor` or `IndexedSlices`) to `dtype`.
#### For example:
```
x = tf.constant([1.8, 2.2], dtype=tf.float32)
tf.cast(x, tf.int32)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 2], dtype=int32)>
```
Notice [`tf.cast`](cast) has an alias [`tf.dtypes.cast`](cast):
```
x = tf.constant([1.8, 2.2], dtype=tf.float32)
tf.dtypes.cast(x, tf.int32)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 2], dtype=int32)>
```
The operation supports data types (for `x` and `dtype`) of `uint8`, `uint16`, `uint32`, `uint64`, `int8`, `int16`, `int32`, `int64`, `float16`, `float32`, `float64`, `complex64`, `complex128`, `bfloat16`. In case of casting from complex types (`complex64`, `complex128`) to real types, only the real part of `x` is returned. In case of casting from real types to complex types (`complex64`, `complex128`), the imaginary part of the returned value is set to `0`. The handling of complex types here matches the behavior of numpy.
Note casting nan and inf values to integral types has undefined behavior.
| Args |
| `x` | A `Tensor` or `SparseTensor` or `IndexedSlices` of numeric type. It could be `uint8`, `uint16`, `uint32`, `uint64`, `int8`, `int16`, `int32`, `int64`, `float16`, `float32`, `float64`, `complex64`, `complex128`, `bfloat16`. |
| `dtype` | The destination type. The list of supported dtypes is the same as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` or `SparseTensor` or `IndexedSlices` with same shape as `x` and same type as `dtype`. |
| Raises |
| `TypeError` | If `x` cannot be cast to the `dtype`. |
tensorflow Module: tf.keras Module: tf.keras
================
Implementation of the Keras API, the high-level API of TensorFlow.
Detailed documentation and user guides are available at [keras.io](https://keras.io).
Modules
-------
[`activations`](keras/activations) module: Built-in activation functions.
[`applications`](keras/applications) module: Keras Applications are premade architectures with pre-trained weights.
[`backend`](keras/backend) module: Keras backend API.
[`callbacks`](keras/callbacks) module: Callbacks: utilities called at certain points during model training.
[`constraints`](keras/constraints) module: Constraints: functions that impose constraints on weight values.
[`datasets`](keras/datasets) module: Small NumPy datasets for debugging/testing.
[`dtensor`](keras/dtensor) module: Keras' DTensor library.
[`estimator`](keras/estimator) module: Keras estimator API.
[`experimental`](keras/experimental) module: Public API for tf.keras.experimental namespace.
[`initializers`](keras/initializers) module: Keras initializer serialization / deserialization.
[`layers`](keras/layers) module: Keras layers API.
[`losses`](keras/losses) module: Built-in loss functions.
[`metrics`](keras/metrics) module: All Keras metrics.
[`mixed_precision`](keras/mixed_precision) module: Keras mixed precision API.
[`models`](keras/models) module: Keras models API.
[`optimizers`](keras/optimizers) module: Built-in optimizer classes.
[`preprocessing`](keras/preprocessing) module: Utilities to preprocess data before training.
[`regularizers`](keras/regularizers) module: Built-in regularizers.
[`utils`](keras/utils) module: Public Keras utilities.
[`wrappers`](keras/wrappers) module: Public API for tf.keras.wrappers namespace.
Classes
-------
[`class Model`](keras/model): `Model` groups layers into an object with training and inference features.
[`class Sequential`](keras/sequential): `Sequential` groups a linear stack of layers into a [`tf.keras.Model`](keras/model).
Functions
---------
[`Input(...)`](keras/input): `Input()` is used to instantiate a Keras tensor.
| Other Members |
| **version** | `'2.9.0'` |
tensorflow tf.Tensor tf.Tensor
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L293-L1044) |
A [`tf.Tensor`](tensor) represents a multidimensional array of elements.
#### View aliases
**Main aliases**
[`tf.experimental.numpy.ndarray`](https://www.tensorflow.org/api_docs/python/tf/Tensor)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.Tensor`](https://www.tensorflow.org/api_docs/python/tf/Tensor)
```
tf.Tensor(
op, value_index, dtype
)
```
All elements are of a single known data type.
When writing a TensorFlow program, the main object that is manipulated and passed around is the [`tf.Tensor`](tensor).
A [`tf.Tensor`](tensor) has the following properties:
* a single data type (float32, int32, or string, for example)
* a shape
TensorFlow supports eager execution and graph execution. In eager execution, operations are evaluated immediately. In graph execution, a computational graph is constructed for later evaluation.
TensorFlow defaults to eager execution. In the example below, the matrix multiplication results are calculated immediately.
```
# Compute some values using a Tensor
c = tf.constant([[1.0, 2.0], [3.0, 4.0]])
d = tf.constant([[1.0, 1.0], [0.0, 1.0]])
e = tf.matmul(c, d)
print(e)
tf.Tensor(
[[1. 3.]
[3. 7.]], shape=(2, 2), dtype=float32)
```
Note that during eager execution, you may discover your `Tensors` are actually of type `EagerTensor`. This is an internal detail, but it does give you access to a useful function, `numpy`:
```
type(e)
<class '...ops.EagerTensor'>
print(e.numpy())
[[1. 3.]
[3. 7.]]
```
In TensorFlow, [`tf.function`](function)s are a common way to define graph execution.
A Tensor's shape (that is, the rank of the Tensor and the size of each dimension) may not always be fully known. In [`tf.function`](function) definitions, the shape may only be partially known.
Most operations produce tensors of fully-known shapes if the shapes of their inputs are also fully known, but in some cases it's only possible to find the shape of a tensor at execution time.
A number of specialized tensors are available: see [`tf.Variable`](variable), [`tf.constant`](constant), `tf.placeholder`, [`tf.sparse.SparseTensor`](sparse/sparsetensor), and [`tf.RaggedTensor`](raggedtensor).
```
a = np.array([1, 2, 3])
b = tf.constant(a)
a[0] = 4
print(b) # tf.Tensor([4 2 3], shape=(3,), dtype=int64)
```
>
> **Note:** this is an implementation detail that is subject to change and users should not rely on this behaviour.
>
For more on Tensors, see the [guide](https://tensorflow.org/guide/tensor).
| Args |
| `op` | An `Operation`. `Operation` that computes this tensor. |
| `value_index` | An `int`. Index of the operation's endpoint that produces this tensor. |
| `dtype` | A `DType`. Type of elements stored in this tensor. |
| Raises |
| `TypeError` | If the op is not an `Operation`. |
| Attributes |
| `device` | The name of the device on which this tensor will be produced, or None. |
| `dtype` | The `DType` of elements in this tensor. |
| `graph` | The `Graph` that contains this tensor. |
| `name` | The string name of this tensor. |
| `op` | The `Operation` that produces this tensor as an output. |
| `shape` | Returns a [`tf.TensorShape`](tensorshape) that represents the shape of this tensor.
```
t = tf.constant([1,2,3,4,5])
t.shape
TensorShape([5])
```
[`tf.Tensor.shape`](tensor#shape) is equivalent to [`tf.Tensor.get_shape()`](tensor#get_shape). In a [`tf.function`](function) or when building a model using [`tf.keras.Input`](keras/input), they return the build-time shape of the tensor, which may be partially unknown. A [`tf.TensorShape`](tensorshape) is not a tensor. Use [`tf.shape(t)`](shape) to get a tensor containing the shape, calculated at runtime. See [`tf.Tensor.get_shape()`](tensor#get_shape), and [`tf.TensorShape`](tensorshape) for details and examples. |
| `value_index` | The index of this tensor in the outputs of its `Operation`. |
Methods
-------
### `consumers`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L843-L855)
```
consumers()
```
Returns a list of `Operation`s that consume this tensor.
| Returns |
| A list of `Operation`s. |
### `eval`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L971-L995)
```
eval(
feed_dict=None, session=None
)
```
Evaluates this tensor in a `Session`.
>
> **Note:** If you are not using [`compat.v1`](compat/v1) libraries, you should not need this, (or `feed_dict` or `Session`). In eager execution (or within [`tf.function`](function)) you do not need to call `eval`.
>
Calling this method will execute all preceding operations that produce the inputs needed for the operation that produces this tensor.
>
> **Note:** Before invoking [`Tensor.eval()`](tensor#eval), its graph must have been launched in a session, and either a default session must be available, or `session` must be specified explicitly.
>
| Args |
| `feed_dict` | A dictionary that maps `Tensor` objects to feed values. See `tf.Session.run` for a description of the valid feed values. |
| `session` | (Optional.) The `Session` to be used to evaluate this tensor. If none, the default session will be used. |
| Returns |
| A numpy array corresponding to the value of this tensor. |
### `experimental_ref`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L997-L999)
```
experimental_ref()
```
DEPRECATED FUNCTION
### `get_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L611-L690)
```
get_shape()
```
Returns a [`tf.TensorShape`](tensorshape) that represents the shape of this tensor.
In eager execution the shape is always fully-known.
```
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
print(a.shape)
(2, 3)
```
[`tf.Tensor.get_shape()`](tensor#get_shape) is equivalent to [`tf.Tensor.shape`](tensor#shape).
When executing in a [`tf.function`](function) or building a model using [`tf.keras.Input`](keras/input), [`Tensor.shape`](tensor#shape) may return a partial shape (including `None` for unknown dimensions). See [`tf.TensorShape`](tensorshape) for more details.
```
inputs = tf.keras.Input(shape = [10])
# Unknown batch size
print(inputs.shape)
(None, 10)
```
The shape is computed using shape inference functions that are registered for each [`tf.Operation`](operation).
The returned [`tf.TensorShape`](tensorshape) is determined at *build* time, without executing the underlying kernel. It is not a [`tf.Tensor`](tensor). If you need a shape *tensor*, either convert the [`tf.TensorShape`](tensorshape) to a [`tf.constant`](constant), or use the [`tf.shape(tensor)`](shape) function, which returns the tensor's shape at *execution* time.
This is useful for debugging and providing early errors. For example, when tracing a [`tf.function`](function), no ops are being executed, shapes may be unknown (See the [Concrete Functions Guide](https://www.tensorflow.org/guide/concrete_function) for details).
```
@tf.function
def my_matmul(a, b):
result = a@b
# the `print` executes during tracing.
print("Result shape: ", result.shape)
return result
```
The shape inference functions propagate shapes to the extent possible:
```
f = my_matmul.get_concrete_function(
tf.TensorSpec([None,3]),
tf.TensorSpec([3,5]))
Result shape: (None, 5)
```
Tracing may fail if a shape missmatch can be detected:
```
cf = my_matmul.get_concrete_function(
tf.TensorSpec([None,3]),
tf.TensorSpec([4,5]))
Traceback (most recent call last):
ValueError: Dimensions must be equal, but are 3 and 4 for 'matmul' (op:
'MatMul') with input shapes: [?,3], [4,5].
```
In some cases, the inferred shape may have unknown dimensions. If the caller has additional information about the values of these dimensions, [`tf.ensure_shape`](ensure_shape) or [`Tensor.set_shape()`](tensor#set_shape) can be used to augment the inferred shape.
```
@tf.function
def my_fun(a):
a = tf.ensure_shape(a, [5, 5])
# the `print` executes during tracing.
print("Result shape: ", a.shape)
return a
```
```
cf = my_fun.get_concrete_function(
tf.TensorSpec([None, None]))
Result shape: (5, 5)
```
| Returns |
| A [`tf.TensorShape`](tensorshape) representing the shape of this tensor. |
### `ref`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L1001-L1040)
```
ref()
```
Returns a hashable reference object to this Tensor.
The primary use case for this API is to put tensors in a set/dictionary. We can't put tensors in a set/dictionary as `tensor.__hash__()` is no longer available starting Tensorflow 2.0.
The following will raise an exception starting 2.0
```
x = tf.constant(5)
y = tf.constant(10)
z = tf.constant(10)
tensor_set = {x, y, z}
Traceback (most recent call last):
TypeError: Tensor is unhashable. Instead, use tensor.ref() as the key.
tensor_dict = {x: 'five', y: 'ten'}
Traceback (most recent call last):
TypeError: Tensor is unhashable. Instead, use tensor.ref() as the key.
```
Instead, we can use `tensor.ref()`.
```
tensor_set = {x.ref(), y.ref(), z.ref()}
x.ref() in tensor_set
True
tensor_dict = {x.ref(): 'five', y.ref(): 'ten', z.ref(): 'ten'}
tensor_dict[y.ref()]
'ten'
```
Also, the reference object provides `.deref()` function that returns the original Tensor.
```
x = tf.constant(5)
x.ref().deref()
<tf.Tensor: shape=(), dtype=int32, numpy=5>
```
### `set_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L692-L836)
```
set_shape(
shape
)
```
Updates the shape of this tensor.
>
> **Note:** It is recommended to use [`tf.ensure_shape`](ensure_shape) instead of [`Tensor.set_shape`](tensor#set_shape), because [`tf.ensure_shape`](ensure_shape) provides better checking for programming errors and can create guarantees for compiler optimization.
>
With eager execution this operates as a shape assertion. Here the shapes match:
```
t = tf.constant([[1,2,3]])
t.set_shape([1, 3])
```
Passing a `None` in the new shape allows any value for that axis:
```
t.set_shape([1,None])
```
An error is raised if an incompatible shape is passed.
```
t.set_shape([1,5])
Traceback (most recent call last):
ValueError: Tensor's shape (1, 3) is not compatible with supplied
shape [1, 5]
```
When executing in a [`tf.function`](function), or building a model using [`tf.keras.Input`](keras/input), [`Tensor.set_shape`](tensor#set_shape) will *merge* the given `shape` with the current shape of this tensor, and set the tensor's shape to the merged value (see [`tf.TensorShape.merge_with`](tensorshape#merge_with) for details):
```
t = tf.keras.Input(shape=[None, None, 3])
print(t.shape)
(None, None, None, 3)
```
Dimensions set to `None` are not updated:
```
t.set_shape([None, 224, 224, None])
print(t.shape)
(None, 224, 224, 3)
```
The main use case for this is to provide additional shape information that cannot be inferred from the graph alone.
For example if you know all the images in a dataset have shape [28,28,3] you can set it with `tf.set_shape`:
```
@tf.function
def load_image(filename):
raw = tf.io.read_file(filename)
image = tf.image.decode_png(raw, channels=3)
# the `print` executes during tracing.
print("Initial shape: ", image.shape)
image.set_shape([28, 28, 3])
print("Final shape: ", image.shape)
return image
```
Trace the function, see the [Concrete Functions Guide](https://www.tensorflow.org/guide/concrete_function) for details.
```
cf = load_image.get_concrete_function(
tf.TensorSpec([], dtype=tf.string))
Initial shape: (None, None, 3)
Final shape: (28, 28, 3)
```
Similarly the [`tf.io.parse_tensor`](io/parse_tensor) function could return a tensor with any shape, even the [`tf.rank`](rank) is unknown. If you know that all your serialized tensors will be 2d, set it with `set_shape`:
```
@tf.function
def my_parse(string_tensor):
result = tf.io.parse_tensor(string_tensor, out_type=tf.float32)
# the `print` executes during tracing.
print("Initial shape: ", result.shape)
result.set_shape([None, None])
print("Final shape: ", result.shape)
return result
```
Trace the function
```
concrete_parse = my_parse.get_concrete_function(
tf.TensorSpec([], dtype=tf.string))
Initial shape: <unknown>
Final shape: (None, None)
```
#### Make sure it works:
```
t = tf.ones([5,3], dtype=tf.float32)
serialized = tf.io.serialize_tensor(t)
print(serialized.dtype)
<dtype: 'string'>
print(serialized.shape)
()
t2 = concrete_parse(serialized)
print(t2.shape)
(5, 3)
```
```
# Serialize a rank-3 tensor
t = tf.ones([5,5,5], dtype=tf.float32)
serialized = tf.io.serialize_tensor(t)
# The function still runs, even though it `set_shape([None,None])`
t2 = concrete_parse(serialized)
print(t2.shape)
(5, 5, 5)
```
| Args |
| `shape` | A `TensorShape` representing the shape of this tensor, a `TensorShapeProto`, a list, a tuple, or None. |
| Raises |
| `ValueError` | If `shape` is not compatible with the current shape of this tensor. |
### `__abs__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L364-L408)
```
__abs__(
name=None
)
```
Computes the absolute value of a tensor.
Given a tensor of integer or floating-point values, this operation returns a tensor of the same type, where each element contains the absolute value of the corresponding element in the input.
Given a tensor `x` of complex numbers, this operation returns a tensor of type `float32` or `float64` that is the absolute value of each element in `x`. For a complex number \(a + bj\), its absolute value is computed as \(\sqrt{a^2 + b^2}\).
#### For example:
```
# real number
x = tf.constant([-2.25, 3.25])
tf.abs(x)
<tf.Tensor: shape=(2,), dtype=float32,
numpy=array([2.25, 3.25], dtype=float32)>
```
```
# complex number
x = tf.constant([[-2.25 + 4.75j], [-3.25 + 5.75j]])
tf.abs(x)
<tf.Tensor: shape=(2, 1), dtype=float64, numpy=
array([[5.25594901],
[6.60492241]])>
```
| Args |
| `x` | A `Tensor` or `SparseTensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64` or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` or `SparseTensor` of the same size, type and sparsity as `x`, with absolute values. Note, for `complex64` or `complex128` input, the returned `Tensor` will be of type `float32` or `float64`, respectively. If `x` is a `SparseTensor`, returns `SparseTensor(x.indices, tf.math.abs(x.values, ...), x.dense_shape)` |
### `__add__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__add__(
y
)
```
The operation invoked by the [`Tensor.**add**`](tensor#__add__) operator.
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**add**`](tensor#__add__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `x` | The left-hand side of the `+` operator. |
| `y` | The right-hand side of the `+` operator. |
| `name` | an optional name for the operation. |
| Returns |
| The result of the elementwise `+` operation. |
### `__and__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__and__(
y
)
```
### `__array__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L924-L929)
```
__array__(
dtype=None
)
```
### `__bool__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L941-L959)
```
__bool__()
```
Dummy method to prevent a tensor from being used as a Python `bool`.
This overload raises a `TypeError` when the user inadvertently treats a `Tensor` as a boolean (most commonly in an `if` or `while` statement), in code that was not converted by AutoGraph. For example:
```
if tf.constant(True): # Will raise.
# ...
if tf.constant(5) < tf.constant(7): # Will raise.
# ...
```
| Raises |
| `TypeError`. |
### `__div__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__div__(
y
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1962-L1998)
```
__eq__(
other
)
```
The operation invoked by the [`Tensor.**eq**`](raggedtensor#__eq__) operator.
Compares two tensors element-wise for equality if they are broadcast-compatible; or returns False if they are not broadcast-compatible. (Note that this behavior differs from [`tf.math.equal`](math/equal), which raises an exception if the two tensors are not broadcast-compatible.)
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**eq**`](raggedtensor#__eq__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `self` | The left-hand side of the `==` operator. |
| `other` | The right-hand side of the `==` operator. |
| Returns |
| The result of the elementwise `==` operation, or `False` if the arguments are not broadcast-compatible. |
### `__floordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__floordiv__(
y
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__ge__`
```
__ge__(
y, name=None
)
```
Returns the truth value of (x >= y) element-wise.
>
> **Note:** [`math.greater_equal`](math/greater_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5, 2, 5, 10])
tf.math.greater_equal(x, y) ==> [True, True, True, False]
x = tf.constant([5, 4, 6, 7])
y = tf.constant([5])
tf.math.greater_equal(x, y) ==> [True, False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__getitem__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L914-L1108)
```
__getitem__(
slice_spec, var=None
)
```
Overload for Tensor.**getitem**.
This operation extracts the specified region from the tensor. The notation is similar to NumPy with the restriction that currently only support basic indexing. That means that using a non-scalar tensor as input is not currently allowed.
#### Some useful examples:
```
# Strip leading and trailing 2 elements
foo = tf.constant([1,2,3,4,5,6])
print(foo[2:-2].eval()) # => [3,4]
# Skip every other row and reverse the order of the columns
foo = tf.constant([[1,2,3], [4,5,6], [7,8,9]])
print(foo[::2,::-1].eval()) # => [[3,2,1], [9,8,7]]
# Use scalar tensors as indices on both dimensions
print(foo[tf.constant(0), tf.constant(2)].eval()) # => 3
# Insert another dimension
foo = tf.constant([[1,2,3], [4,5,6], [7,8,9]])
print(foo[tf.newaxis, :, :].eval()) # => [[[1,2,3], [4,5,6], [7,8,9]]]
print(foo[:, tf.newaxis, :].eval()) # => [[[1,2,3]], [[4,5,6]], [[7,8,9]]]
print(foo[:, :, tf.newaxis].eval()) # => [[[1],[2],[3]], [[4],[5],[6]],
[[7],[8],[9]]]
# Ellipses (3 equivalent operations)
foo = tf.constant([[1,2,3], [4,5,6], [7,8,9]])
print(foo[tf.newaxis, :, :].eval()) # => [[[1,2,3], [4,5,6], [7,8,9]]]
print(foo[tf.newaxis, ...].eval()) # => [[[1,2,3], [4,5,6], [7,8,9]]]
print(foo[tf.newaxis].eval()) # => [[[1,2,3], [4,5,6], [7,8,9]]]
# Masks
foo = tf.constant([[1,2,3], [4,5,6], [7,8,9]])
print(foo[foo > 2].eval()) # => [3, 4, 5, 6, 7, 8, 9]
```
#### Notes:
* [`tf.newaxis`](../tf#newaxis) is `None` as in NumPy.
* An implicit ellipsis is placed at the end of the `slice_spec`
* NumPy advanced indexing is currently not supported.
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**getitem**`](tensor#__getitem__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `tensor` | An ops.Tensor object. |
| `slice_spec` | The arguments to Tensor.**getitem**. |
| `var` | In the case of variable slice assignment, the Variable object to slice (i.e. tensor is the read-only view of this variable). |
| Returns |
| The appropriate slice of "tensor", based on "slice\_spec". |
| Raises |
| `ValueError` | If a slice range is negative size. |
| `TypeError` | If the slice indices aren't int, slice, ellipsis, tf.newaxis or scalar int32/int64 tensors. |
### `__gt__`
```
__gt__(
y, name=None
)
```
Returns the truth value of (x > y) element-wise.
>
> **Note:** [`math.greater`](math/greater) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5, 2, 5])
tf.math.greater(x, y) ==> [False, True, True]
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.greater(x, y) ==> [False, False, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__invert__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1859-L1862)
```
__invert__(
name=None
)
```
### `__iter__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L577-L589)
```
__iter__()
```
### `__le__`
```
__le__(
y, name=None
)
```
Returns the truth value of (x <= y) element-wise.
>
> **Note:** [`math.less_equal`](math/less_equal) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less_equal(x, y) ==> [True, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 6])
tf.math.less_equal(x, y) ==> [True, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__len__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L931-L934)
```
__len__()
```
### `__lt__`
```
__lt__(
y, name=None
)
```
Returns the truth value of (x < y) element-wise.
>
> **Note:** [`math.less`](math/less) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
#### Example:
```
x = tf.constant([5, 4, 6])
y = tf.constant([5])
tf.math.less(x, y) ==> [False, True, False]
x = tf.constant([5, 4, 6])
y = tf.constant([5, 6, 7])
tf.math.less(x, y) ==> [False, True, True]
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `float32`, `float64`, `int32`, `uint8`, `int16`, `int8`, `int64`, `bfloat16`, `uint16`, `half`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `bool`. |
### `__matmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__matmul__(
y
)
```
Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
The inputs must, following any transpositions, be tensors of rank >= 2 where the inner 2 dimensions specify valid matrix multiplication dimensions, and any further outer dimensions specify matching batch size.
Both matrices must be of the same type. The supported types are: `bfloat16`, `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, `complex128`.
Either matrix can be transposed or adjointed (conjugated and transposed) on the fly by setting one of the corresponding flag to `True`. These are `False` by default.
If one or both of the matrices contain a lot of zeros, a more efficient multiplication algorithm can be used by setting the corresponding `a_is_sparse` or `b_is_sparse` flag to `True`. These are `False` by default. This optimization is only available for plain matrices (rank-2 tensors) with datatypes `bfloat16` or `float32`.
A simple 2-D tensor matrix multiplication:
```
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
a # 2-D tensor
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2])
b # 2-D tensor
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[ 7, 8],
[ 9, 10],
[11, 12]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[ 58, 64],
[139, 154]], dtype=int32)>
```
A batch matrix multiplication with batch shape [2]:
```
a = tf.constant(np.arange(1, 13, dtype=np.int32), shape=[2, 2, 3])
a # 3-D tensor
<tf.Tensor: shape=(2, 2, 3), dtype=int32, numpy=
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]], dtype=int32)>
b = tf.constant(np.arange(13, 25, dtype=np.int32), shape=[2, 3, 2])
b # 3-D tensor
<tf.Tensor: shape=(2, 3, 2), dtype=int32, numpy=
array([[[13, 14],
[15, 16],
[17, 18]],
[[19, 20],
[21, 22],
[23, 24]]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy=
array([[[ 94, 100],
[229, 244]],
[[508, 532],
[697, 730]]], dtype=int32)>
```
Since python >= 3.5 the @ operator is supported (see [PEP 465](https://www.python.org/dev/peps/pep-0465/)). In TensorFlow, it simply calls the [`tf.matmul()`](linalg/matmul) function, so the following lines are equivalent:
```
d = a @ b @ [[10], [11]]
d = tf.matmul(tf.matmul(a, b), [[10], [11]])
```
| Args |
| `a` | [`tf.Tensor`](tensor) of type `float16`, `float32`, `float64`, `int32`, `complex64`, `complex128` and rank > 1. |
| `b` | [`tf.Tensor`](tensor) with same type and rank as `a`. |
| `transpose_a` | If `True`, `a` is transposed before multiplication. |
| `transpose_b` | If `True`, `b` is transposed before multiplication. |
| `adjoint_a` | If `True`, `a` is conjugated and transposed before multiplication. |
| `adjoint_b` | If `True`, `b` is conjugated and transposed before multiplication. |
| `a_is_sparse` | If `True`, `a` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `b_is_sparse` | If `True`, `b` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `output_type` | The output datatype if needed. Defaults to None in which case the output\_type is the same as input type. Currently only works when input tensors are type (u)int8 and output\_type can be int32. |
| `name` | Name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of the same type as `a` and `b` where each inner-most matrix is the product of the corresponding matrices in `a` and `b`, e.g. if all transpose or adjoint attributes are `False`: `output[..., i, j] = sum_k (a[..., i, k] * b[..., k, j])`, for all indices `i`, `j`. |
| `Note` | This is matrix product, not element-wise product. |
| Raises |
| `ValueError` | If `transpose_a` and `adjoint_a`, or `transpose_b` and `adjoint_b` are both set to `True`. |
| `TypeError` | If output\_type is specified but the types of `a`, `b` and `output_type` is not (u)int8, (u)int8 and int32. |
### `__mod__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__mod__(
y
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__mul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__mul__(
y
)
```
Dispatches cwise mul for "Dense*Dense" and "Dense*Sparse".
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L2001-L2035)
```
__ne__(
other
)
```
The operation invoked by the [`Tensor.**ne**`](raggedtensor#__ne__) operator.
Compares two tensors element-wise for inequality if they are broadcast-compatible; or returns True if they are not broadcast-compatible. (Note that this behavior differs from [`tf.math.not_equal`](math/not_equal), which raises an exception if the two tensors are not broadcast-compatible.)
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**ne**`](raggedtensor#__ne__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `self` | The left-hand side of the `!=` operator. |
| `other` | The right-hand side of the `!=` operator. |
| Returns |
| The result of the elementwise `!=` operation, or `True` if the arguments are not broadcast-compatible. |
### `__neg__`
```
__neg__(
name=None
)
```
Computes numerical negative value element-wise.
I.e., \(y = -x\).
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `int8`, `int16`, `int32`, `int64`, `complex64`, `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. If `x` is a `SparseTensor`, returns `SparseTensor(x.indices, tf.math.negative(x.values, ...), x.dense_shape)` |
### `__nonzero__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L961-L969)
```
__nonzero__()
```
Dummy method to prevent a tensor from being used as a Python `bool`.
This is the Python 2.x counterpart to `__bool__()` above.
| Raises |
| `TypeError`. |
### `__or__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__or__(
y
)
```
### `__pow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__pow__(
y
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__radd__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__radd__(
x
)
```
The operation invoked by the [`Tensor.**add**`](tensor#__add__) operator.
#### Purpose in the API:
This method is exposed in TensorFlow's API so that library developers can register dispatching for [`Tensor.**add**`](tensor#__add__) to allow it to handle custom composite tensors & other custom objects.
The API symbol is not intended to be called by users directly and does appear in TensorFlow's generated documentation.
| Args |
| `x` | The left-hand side of the `+` operator. |
| `y` | The right-hand side of the `+` operator. |
| `name` | an optional name for the operation. |
| Returns |
| The result of the elementwise `+` operation. |
### `__rand__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rand__(
x
)
```
### `__rdiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rdiv__(
x
)
```
Divides x / y elementwise (using Python 2 division operator semantics). (deprecated)
This function divides `x` and `y`, forcing Python 2 semantics. That is, if `x` and `y` are both integers then the result will be an integer. This is in contrast to Python 3, where division with `/` is always a float while division with `//` is always an integer.
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` returns the quotient of x and y. |
#### Migrate to TF2
This function is deprecated in TF2. Prefer using the Tensor division operator, [`tf.divide`](math/divide), or [`tf.math.divide`](math/divide), which obey the Python 3 division operator semantics.
### `__rfloordiv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rfloordiv__(
x
)
```
Divides `x / y` elementwise, rounding toward the most negative integer.
Mathematically, this is equivalent to floor(x / y). For example: floor(8.4 / 4.0) = floor(2.1) = 2.0 floor(-8.4 / 4.0) = floor(-2.1) = -3.0 This is equivalent to the '//' operator in Python 3.0 and above.
>
> **Note:** `x` and `y` must have the same type, and the result will have the same type as well.
>
| Args |
| `x` | `Tensor` numerator of real numeric type. |
| `y` | `Tensor` denominator of real numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` rounded toward -infinity. |
| Raises |
| `TypeError` | If the inputs are complex. |
### `__rmatmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmatmul__(
x
)
```
Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
The inputs must, following any transpositions, be tensors of rank >= 2 where the inner 2 dimensions specify valid matrix multiplication dimensions, and any further outer dimensions specify matching batch size.
Both matrices must be of the same type. The supported types are: `bfloat16`, `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, `complex128`.
Either matrix can be transposed or adjointed (conjugated and transposed) on the fly by setting one of the corresponding flag to `True`. These are `False` by default.
If one or both of the matrices contain a lot of zeros, a more efficient multiplication algorithm can be used by setting the corresponding `a_is_sparse` or `b_is_sparse` flag to `True`. These are `False` by default. This optimization is only available for plain matrices (rank-2 tensors) with datatypes `bfloat16` or `float32`.
A simple 2-D tensor matrix multiplication:
```
a = tf.constant([1, 2, 3, 4, 5, 6], shape=[2, 3])
a # 2-D tensor
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
b = tf.constant([7, 8, 9, 10, 11, 12], shape=[3, 2])
b # 2-D tensor
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[ 7, 8],
[ 9, 10],
[11, 12]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[ 58, 64],
[139, 154]], dtype=int32)>
```
A batch matrix multiplication with batch shape [2]:
```
a = tf.constant(np.arange(1, 13, dtype=np.int32), shape=[2, 2, 3])
a # 3-D tensor
<tf.Tensor: shape=(2, 2, 3), dtype=int32, numpy=
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]], dtype=int32)>
b = tf.constant(np.arange(13, 25, dtype=np.int32), shape=[2, 3, 2])
b # 3-D tensor
<tf.Tensor: shape=(2, 3, 2), dtype=int32, numpy=
array([[[13, 14],
[15, 16],
[17, 18]],
[[19, 20],
[21, 22],
[23, 24]]], dtype=int32)>
c = tf.matmul(a, b)
c # `a` * `b`
<tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy=
array([[[ 94, 100],
[229, 244]],
[[508, 532],
[697, 730]]], dtype=int32)>
```
Since python >= 3.5 the @ operator is supported (see [PEP 465](https://www.python.org/dev/peps/pep-0465/)). In TensorFlow, it simply calls the [`tf.matmul()`](linalg/matmul) function, so the following lines are equivalent:
```
d = a @ b @ [[10], [11]]
d = tf.matmul(tf.matmul(a, b), [[10], [11]])
```
| Args |
| `a` | [`tf.Tensor`](tensor) of type `float16`, `float32`, `float64`, `int32`, `complex64`, `complex128` and rank > 1. |
| `b` | [`tf.Tensor`](tensor) with same type and rank as `a`. |
| `transpose_a` | If `True`, `a` is transposed before multiplication. |
| `transpose_b` | If `True`, `b` is transposed before multiplication. |
| `adjoint_a` | If `True`, `a` is conjugated and transposed before multiplication. |
| `adjoint_b` | If `True`, `b` is conjugated and transposed before multiplication. |
| `a_is_sparse` | If `True`, `a` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `b_is_sparse` | If `True`, `b` is treated as a sparse matrix. Notice, this **does not support [`tf.sparse.SparseTensor`](sparse/sparsetensor)**, it just makes optimizations that assume most values in `a` are zero. See [`tf.sparse.sparse_dense_matmul`](sparse/sparse_dense_matmul) for some support for [`tf.sparse.SparseTensor`](sparse/sparsetensor) multiplication. |
| `output_type` | The output datatype if needed. Defaults to None in which case the output\_type is the same as input type. Currently only works when input tensors are type (u)int8 and output\_type can be int32. |
| `name` | Name for the operation (optional). |
| Returns |
| A [`tf.Tensor`](tensor) of the same type as `a` and `b` where each inner-most matrix is the product of the corresponding matrices in `a` and `b`, e.g. if all transpose or adjoint attributes are `False`: `output[..., i, j] = sum_k (a[..., i, k] * b[..., k, j])`, for all indices `i`, `j`. |
| `Note` | This is matrix product, not element-wise product. |
| Raises |
| `ValueError` | If `transpose_a` and `adjoint_a`, or `transpose_b` and `adjoint_b` are both set to `True`. |
| `TypeError` | If output\_type is specified but the types of `a`, `b` and `output_type` is not (u)int8, (u)int8 and int32. |
### `__rmod__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmod__(
x
)
```
Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
true, this follows Python semantics in that the result here is consistent with a flooring divide. E.g. `floor(x / y) * y + mod(x, y) = x`.
>
> **Note:** [`math.floormod`](math/floormod) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `int8`, `int16`, `int32`, `int64`, `uint8`, `uint16`, `uint32`, `uint64`, `bfloat16`, `half`, `float32`, `float64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rmul__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rmul__(
x
)
```
Dispatches cwise mul for "Dense*Dense" and "Dense*Sparse".
### `__ror__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__ror__(
x
)
```
### `__rpow__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rpow__(
x
)
```
Computes the power of one value to another.
Given a tensor `x` and a tensor `y`, this operation computes \(x^y\) for corresponding elements in `x` and `y`. For example:
```
x = tf.constant([[2, 2], [3, 3]])
y = tf.constant([[8, 16], [2, 3]])
tf.pow(x, y) # [[256, 65536], [9, 27]]
```
| Args |
| `x` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `y` | A `Tensor` of type `float16`, `float32`, `float64`, `int32`, `int64`, `complex64`, or `complex128`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. |
### `__rsub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rsub__(
x
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__rtruediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rtruediv__(
x
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__rxor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1435-L1441)
```
__rxor__(
x
)
```
### `__sub__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__sub__(
y
)
```
Returns x - y element-wise.
>
> **Note:** [`tf.subtract`](math/subtract) supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
Both input and output have a range `(-inf, inf)`.
Example usages below.
Subtract operation between an array and a scalar:
```
x = [1, 2, 3, 4, 5]
y = 1
tf.subtract(x, y)
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 0, -1, -2, -3, -4], dtype=int32)>
```
Note that binary `-` operator can be used instead:
```
x = tf.convert_to_tensor([1, 2, 3, 4, 5])
y = tf.convert_to_tensor(1)
x - y
<tf.Tensor: shape=(5,), dtype=int32, numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
Subtract operation between an array and a tensor of same shape:
```
x = [1, 2, 3, 4, 5]
y = tf.constant([5, 4, 3, 2, 1])
tf.subtract(y, x)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 4, 2, 0, -2, -4], dtype=int32)>
```
For example,
```
x = tf.constant([1, 2], dtype=tf.int8)
y = [2**8 + 1, 2**8 + 2]
tf.subtract(x, y)
<tf.Tensor: shape=(2,), dtype=int8, numpy=array([0, 0], dtype=int8)>
```
When subtracting two input values of different shapes, [`tf.subtract`](math/subtract) follows the [general broadcasting rules](https://numpy.org/doc/stable/user/basics.broadcasting.html#general-broadcasting-rules) . The two input array shapes are compared element-wise. Starting with the trailing dimensions, the two dimensions either have to be equal or one of them needs to be `1`.
For example,
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(2, 1, 3)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 3), dtype=float64, numpy=
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])>
```
Example with inputs of different dimensions:
```
x = np.ones(6).reshape(2, 3, 1)
y = np.ones(6).reshape(1, 6)
tf.subtract(x, y)
<tf.Tensor: shape=(2, 3, 6), dtype=float64, numpy=
array([[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]]])>
```
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `int64`, `complex64`, `complex128`, `uint32`, `uint64`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
### `__truediv__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__truediv__(
y
)
```
Divides x / y elementwise (using Python 3 division operator semantics).
>
> **Note:** Prefer using the Tensor operator or tf.divide which obey Python division operator semantics.
>
This function forces Python 3 division operator semantics where all integer arguments are cast to floating types first. This op is generated by normal `x / y` division in Python 3 and in Python 2.7 with `from __future__ import division`. If you want integer division that rounds down, use `x // y` or `tf.math.floordiv`.
`x` and `y` must have the same numeric type. If the inputs are floating point, the output will have the same type. If the inputs are integral, the inputs are cast to `float32` for `int8` and `int16` and `float64` for `int32` and `int64` (matching the behavior of Numpy).
| Args |
| `x` | `Tensor` numerator of numeric type. |
| `y` | `Tensor` denominator of numeric type. |
| `name` | A name for the operation (optional). |
| Returns |
| `x / y` evaluated in floating point. |
| Raises |
| `TypeError` | If `x` and `y` have different dtypes. |
### `__xor__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L1398-L1424)
```
__xor__(
y
)
```
| Class Variables |
| OVERLOADABLE\_OPERATORS |
```
{
'__abs__',
'__add__',
'__and__',
'__div__',
'__eq__',
'__floordiv__',
'__ge__',
'__getitem__',
'__gt__',
'__invert__',
'__le__',
'__lt__',
'__matmul__',
'__mod__',
'__mul__',
'__ne__',
'__neg__',
'__or__',
'__pow__',
'__radd__',
'__rand__',
'__rdiv__',
'__rfloordiv__',
'__rmatmul__',
'__rmod__',
'__rmul__',
'__ror__',
'__rpow__',
'__rsub__',
'__rtruediv__',
'__rxor__',
'__sub__',
'__truediv__',
'__xor__'
}
```
|
| programming_docs |
tensorflow Module: tf.experimental Module: tf.experimental
=======================
Public API for tf.experimental namespace.
Modules
-------
[`dlpack`](experimental/dlpack) module: Public API for tf.experimental.dlpack namespace.
[`dtensor`](experimental/dtensor) module: Public API for tf.experimental.dtensor namespace.
[`numpy`](experimental/numpy) module: # tf.experimental.numpy: NumPy API on TensorFlow.
[`tensorrt`](experimental/tensorrt) module: Public API for tf.experimental.tensorrt namespace.
Classes
-------
[`class BatchableExtensionType`](experimental/batchableextensiontype): An ExtensionType that can be batched and unbatched.
[`class DynamicRaggedShape`](experimental/dynamicraggedshape): The shape of a ragged or dense tensor.
[`class ExtensionType`](experimental/extensiontype): Base class for TensorFlow `ExtensionType` classes.
[`class ExtensionTypeBatchEncoder`](experimental/extensiontypebatchencoder): Class used to encode and decode extension type values for batching.
[`class Optional`](experimental/optional): Represents a value that may or may not be present.
[`class RowPartition`](experimental/rowpartition): Partitioning of a sequence of values into contiguous subsequences ("rows").
Functions
---------
[`async_clear_error(...)`](experimental/async_clear_error): Clear pending operations and error statuses in async execution.
[`async_scope(...)`](experimental/async_scope): Context manager for grouping async operations.
[`dispatch_for_api(...)`](experimental/dispatch_for_api): Decorator that overrides the default implementation for a TensorFlow API.
[`dispatch_for_binary_elementwise_apis(...)`](experimental/dispatch_for_binary_elementwise_apis): Decorator to override default implementation for binary elementwise APIs.
[`dispatch_for_unary_elementwise_apis(...)`](experimental/dispatch_for_unary_elementwise_apis): Decorator to override default implementation for unary elementwise APIs.
[`function_executor_type(...)`](experimental/function_executor_type): Context manager for setting the executor of eager defined functions.
[`register_filesystem_plugin(...)`](experimental/register_filesystem_plugin): Loads a TensorFlow FileSystem plugin.
[`unregister_dispatch_for(...)`](experimental/unregister_dispatch_for): Unregisters a function that was registered with `@dispatch_for_*`.
tensorflow Module: tf.autograph Module: tf.autograph
====================
Conversion of eager-style Python into TensorFlow graph code.
>
> **Note:** In TensorFlow 2.0, AutoGraph is automatically applied when using [`tf.function`](function). This module contains lower-level APIs for advanced use.
>
AutoGraph transforms a subset of Python which operates on TensorFlow objects into equivalent TensorFlow graph code. When executing the graph, it has the same effect as if you ran the original code in eager mode. Python code which doesn't operate on TensorFlow objects remains functionally unchanged, but keep in mind that [`tf.function`](function) only executes such code at trace time, and generally will not be consistent with eager execution.
For more information, see the [AutoGraph reference documentation](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/index.md), and the [tf.function guide](https://www.tensorflow.org/guide/function#autograph_transformations).
Modules
-------
[`experimental`](autograph/experimental) module: Public API for tf.autograph.experimental namespace.
Functions
---------
[`set_verbosity(...)`](autograph/set_verbosity): Sets the AutoGraph verbosity level.
[`to_code(...)`](autograph/to_code): Returns the source code generated by AutoGraph, as a string.
[`to_graph(...)`](autograph/to_graph): Converts a Python entity into a TensorFlow graph.
[`trace(...)`](autograph/trace): Traces argument information at compilation time.
tensorflow tf.grad_pass_through tf.grad\_pass\_through
======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/custom_gradient.py#L753-L803) |
Creates a grad-pass-through op with the forward behavior provided in f.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.grad_pass_through`](https://www.tensorflow.org/api_docs/python/tf/grad_pass_through)
```
tf.grad_pass_through(
f
)
```
Use this function to wrap any op, maintaining its behavior in the forward pass, but replacing the original op in the backward graph with an identity. For example:
```
x = tf.Variable(1.0, name="x")
z = tf.Variable(3.0, name="z")
with tf.GradientTape() as tape:
# y will evaluate to 9.0
y = tf.grad_pass_through(x.assign)(z**2)
# grads will evaluate to 6.0
grads = tape.gradient(y, z)
```
Another example is a 'differentiable' moving average approximation, where gradients are allowed to flow into the last value fed to the moving average, but the moving average is still used for the forward pass:
```
x = ... # Some scalar value
# A moving average object, we don't need to know how this is implemented
moving_average = MovingAverage()
with backprop.GradientTape() as tape:
# mavg_x will evaluate to the current running average value
mavg_x = tf.grad_pass_through(moving_average)(x)
grads = tape.gradient(mavg_x, x) # grads will evaluate to 1.0
```
| Args |
| `f` | function `f(*x)` that returns a `Tensor` or nested structure of `Tensor` outputs. |
| Returns |
| A function `h(x)` which returns the same values as `f(x)` and whose gradients are the same as those of an identity function. |
tensorflow Module: tf.dtypes Module: tf.dtypes
=================
Public API for tf.dtypes namespace.
Classes
-------
[`class DType`](dtypes/dtype): Represents the type of the elements in a `Tensor`.
Functions
---------
[`as_dtype(...)`](dtypes/as_dtype): Converts the given `type_value` to a `DType`.
[`cast(...)`](cast): Casts a tensor to a new type.
[`complex(...)`](dtypes/complex): Converts two real numbers to a complex number.
[`saturate_cast(...)`](dtypes/saturate_cast): Performs a safe saturating cast of `value` to `dtype`.
| Other Members |
| QUANTIZED\_DTYPES |
```
{
tf.qint16,
tf.qint16_ref,
tf.qint32,
tf.qint32_ref,
tf.qint8,
tf.qint8_ref,
tf.quint16,
tf.quint16_ref,
tf.quint8,
tf.quint8_ref
}
```
|
| bfloat16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit bfloat (brain floating point). |
| bool | Instance of [`tf.dtypes.DType`](dtypes/dtype) Boolean. |
| complex128 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 128-bit complex. |
| complex64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit complex. |
| double | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit (double precision) floating-point. |
| float16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit (half precision) floating-point. |
| float32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 32-bit (single precision) floating-point. |
| float64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) 64-bit (double precision) floating-point. |
| half | Instance of [`tf.dtypes.DType`](dtypes/dtype) 16-bit (half precision) floating-point. |
| int16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 16-bit integer. |
| int32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 32-bit integer. |
| int64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 64-bit integer. |
| int8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed 8-bit integer. |
| qint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed quantized 16-bit integer. |
| qint32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) signed quantized 32-bit integer. |
| qint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Signed quantized 8-bit integer. |
| quint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned quantized 16-bit integer. |
| quint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned quantized 8-bit integer. |
| resource | Instance of [`tf.dtypes.DType`](dtypes/dtype) Handle to a mutable, dynamically allocated resource. |
| string | Instance of [`tf.dtypes.DType`](dtypes/dtype) Variable-length string, represented as byte array. |
| uint16 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 16-bit (word) integer. |
| uint32 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 32-bit (dword) integer. |
| uint64 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 64-bit (qword) integer. |
| uint8 | Instance of [`tf.dtypes.DType`](dtypes/dtype) Unsigned 8-bit (byte) integer. |
| variant | Instance of [`tf.dtypes.DType`](dtypes/dtype) Data of arbitrary type (known at runtime). |
tensorflow tf.transpose tf.transpose
============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L2208-L2286) |
Transposes `a`, where `a` is a Tensor.
```
tf.transpose(
a, perm=None, conjugate=False, name='transpose'
)
```
Permutes the dimensions according to the value of `perm`.
The returned tensor's dimension `i` will correspond to the input dimension `perm[i]`. If `perm` is not given, it is set to (n-1...0), where n is the rank of the input tensor. Hence by default, this operation performs a regular matrix transpose on 2-D input Tensors.
If conjugate is `True` and `a.dtype` is either `complex64` or `complex128` then the values of `a` are conjugated and transposed.
#### For example:
```
x = tf.constant([[1, 2, 3], [4, 5, 6]])
tf.transpose(x)
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 4],
[2, 5],
[3, 6]], dtype=int32)>
```
Equivalently, you could call `tf.transpose(x, perm=[1, 0])`.
If `x` is complex, setting conjugate=True gives the conjugate transpose:
```
x = tf.constant([[1 + 1j, 2 + 2j, 3 + 3j],
[4 + 4j, 5 + 5j, 6 + 6j]])
tf.transpose(x, conjugate=True)
<tf.Tensor: shape=(3, 2), dtype=complex128, numpy=
array([[1.-1.j, 4.-4.j],
[2.-2.j, 5.-5.j],
[3.-3.j, 6.-6.j]])>
```
'perm' is more useful for n-dimensional tensors where n > 2:
```
x = tf.constant([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
```
As above, simply calling [`tf.transpose`](transpose) will default to `perm=[2,1,0]`.
To take the transpose of the matrices in dimension-0 (such as when you are transposing matrices where 0 is the batch dimension), you would set `perm=[0,2,1]`.
```
tf.transpose(x, perm=[0, 2, 1])
<tf.Tensor: shape=(2, 3, 2), dtype=int32, numpy=
array([[[ 1, 4],
[ 2, 5],
[ 3, 6]],
[[ 7, 10],
[ 8, 11],
[ 9, 12]]], dtype=int32)>
```
>
> **Note:** This has a shorthand [`linalg.matrix_transpose`](linalg/matrix_transpose)):
>
| Args |
| `a` | A `Tensor`. |
| `perm` | A permutation of the dimensions of `a`. This should be a vector. |
| `conjugate` | Optional bool. Setting it to `True` is mathematically equivalent to tf.math.conj(tf.transpose(input)). |
| `name` | A name for the operation (optional). |
| Returns |
| A transposed `Tensor`. |
numpy compatibility
-------------------
In `numpy` transposes are memory-efficient constant time operations as they simply return a new view of the same data with adjusted `strides`.
TensorFlow does not support strides, so `transpose` returns a new tensor with the items permuted.
tensorflow tf.clip_by_norm tf.clip\_by\_norm
=================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/clip_ops.py#L151-L233) |
Clips tensor values to a maximum L2-norm.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.clip_by_norm`](https://www.tensorflow.org/api_docs/python/tf/clip_by_norm)
```
tf.clip_by_norm(
t, clip_norm, axes=None, name=None
)
```
Given a tensor `t`, and a maximum clip value `clip_norm`, this operation normalizes `t` so that its L2-norm is less than or equal to `clip_norm`, along the dimensions given in `axes`. Specifically, in the default case where all dimensions are used for calculation, if the L2-norm of `t` is already less than or equal to `clip_norm`, then `t` is not modified. If the L2-norm is greater than `clip_norm`, then this operation returns a tensor of the same type and shape as `t` with its values set to:
`t * clip_norm / l2norm(t)`
In this case, the L2-norm of the output tensor is `clip_norm`.
As another example, if `t` is a matrix and `axes == [1]`, then each row of the output will have L2-norm less than or equal to `clip_norm`. If `axes == [0]` instead, each column of the output will be clipped.
#### Code example:
```
some_nums = tf.constant([[1, 2, 3, 4, 5]], dtype=tf.float32)
tf.clip_by_norm(some_nums, 2.0).numpy()
array([[0.26967996, 0.5393599 , 0.80903983, 1.0787199 , 1.3483998 ]],
dtype=float32)
```
This operation is typically used to clip gradients before applying them with an optimizer. Most gradient data is a collection of different shaped tensors for different parts of the model. Thus, this is a common usage:
```
# Get your gradients after training
loss_value, grads = grad(model, features, labels)
# Apply some clipping
grads = [tf.clip_by_norm(g, norm)
for g in grads]
# Continue on with training
optimizer.apply_gradients(grads)
```
| Args |
| `t` | A `Tensor` or `IndexedSlices`. This must be a floating point type. |
| `clip_norm` | A 0-D (scalar) `Tensor` > 0. A maximum clipping value, also floating point |
| `axes` | A 1-D (vector) `Tensor` of type int32 containing the dimensions to use for computing the L2-norm. If `None` (the default), uses all dimensions. |
| `name` | A name for the operation (optional). |
| Returns |
| A clipped `Tensor` or `IndexedSlices`. |
| Raises |
| `ValueError` | If the clip\_norm tensor is not a 0-D scalar tensor. |
| `TypeError` | If dtype of the input is not a floating point or complex type. |
tensorflow tf.unravel_index tf.unravel\_index
=================
Converts an array of flat indices into a tuple of coordinate arrays.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.unravel_index`](https://www.tensorflow.org/api_docs/python/tf/unravel_index)
```
tf.unravel_index(
indices, dims, name=None
)
```
#### Example:
```
y = tf.unravel_index(indices=[2, 5, 7], dims=[3, 3])
# 'dims' represent a hypothetical (3, 3) tensor of indices:
# [[0, 1, *2*],
# [3, 4, *5*],
# [6, *7*, 8]]
# For each entry from 'indices', this operation returns
# its coordinates (marked with '*'), such as
# 2 ==> (0, 2)
# 5 ==> (1, 2)
# 7 ==> (2, 1)
y ==> [[0, 1, 2], [2, 2, 1]]
```
| Args |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. An 0-D or 1-D `int` Tensor whose elements are indices into the flattened version of an array of dimensions dims. |
| `dims` | A `Tensor`. Must have the same type as `indices`. An 1-D `int` Tensor. The shape of the array to use for unraveling indices. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `indices`. |
numpy compatibility
-------------------
Equivalent to np.unravel\_index
tensorflow tf.gather tf.gather
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L5275-L5289) |
Gather slices from params axis `axis` according to indices. (deprecated arguments)
```
tf.gather(
params, indices, validate_indices=None, axis=None, batch_dims=0, name=None
)
```
Gather slices from `params` axis `axis` according to `indices`. `indices` must be an integer tensor of any dimension (often 1-D).
[`Tensor.**getitem**`](tensor#__getitem__) works for scalars, [`tf.newaxis`](../tf#newaxis), and [python slices](https://numpy.org/doc/stable/reference/arrays.indexing.html#basic-slicing-and-indexing)
[`tf.gather`](gather) extends indexing to handle tensors of indices.
In the simplest case it's identical to scalar indexing:
```
params = tf.constant(['p0', 'p1', 'p2', 'p3', 'p4', 'p5'])
params[3].numpy()
b'p3'
tf.gather(params, 3).numpy()
b'p3'
```
The most common case is to pass a single axis tensor of indices (this can't be expressed as a python slice because the indices are not sequential):
```
indices = [2, 0, 2, 5]
tf.gather(params, indices).numpy()
array([b'p2', b'p0', b'p2', b'p5'], dtype=object)
```
The indices can have any shape. When the `params` has 1 axis, the output shape is equal to the input shape:
```
tf.gather(params, [[2, 0], [2, 5]]).numpy()
array([[b'p2', b'p0'],
[b'p2', b'p5']], dtype=object)
```
The `params` may also have any shape. `gather` can select slices across any axis depending on the `axis` argument (which defaults to 0). Below it is used to gather first rows, then columns from a matrix:
```
params = tf.constant([[0, 1.0, 2.0],
[10.0, 11.0, 12.0],
[20.0, 21.0, 22.0],
[30.0, 31.0, 32.0]])
tf.gather(params, indices=[3,1]).numpy()
array([[30., 31., 32.],
[10., 11., 12.]], dtype=float32)
tf.gather(params, indices=[2,1], axis=1).numpy()
array([[ 2., 1.],
[12., 11.],
[22., 21.],
[32., 31.]], dtype=float32)
```
More generally: The output shape has the same shape as the input, with the indexed-axis replaced by the shape of the indices.
```
def result_shape(p_shape, i_shape, axis=0):
return p_shape[:axis] + i_shape + p_shape[axis+1:]
result_shape([1, 2, 3], [], axis=1)
[1, 3]
result_shape([1, 2, 3], [7], axis=1)
[1, 7, 3]
result_shape([1, 2, 3], [7, 5], axis=1)
[1, 7, 5, 3]
```
Here are some examples:
```
params.shape.as_list()
[4, 3]
indices = tf.constant([[0, 2]])
tf.gather(params, indices=indices, axis=0).shape.as_list()
[1, 2, 3]
tf.gather(params, indices=indices, axis=1).shape.as_list()
[4, 1, 2]
```
```
params = tf.random.normal(shape=(5, 6, 7, 8))
indices = tf.random.uniform(shape=(10, 11), maxval=7, dtype=tf.int32)
result = tf.gather(params, indices, axis=2)
result.shape.as_list()
[5, 6, 10, 11, 8]
```
This is because each index takes a slice from `params`, and places it at the corresponding location in the output. For the above example
```
# For any location in indices
a, b = 0, 1
tf.reduce_all(
# the corresponding slice of the result
result[:, :, a, b, :] ==
# is equal to the slice of `params` along `axis` at the index.
params[:, :, indices[a, b], :]
).numpy()
True
```
### Batching:
The `batch_dims` argument lets you gather different items from each element of a batch.
Using `batch_dims=1` is equivalent to having an outer loop over the first axis of `params` and `indices`:
```
params = tf.constant([
[0, 0, 1, 0, 2],
[3, 0, 0, 0, 4],
[0, 5, 0, 6, 0]])
indices = tf.constant([
[2, 4],
[0, 4],
[1, 3]])
```
```
tf.gather(params, indices, axis=1, batch_dims=1).numpy()
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)
```
#### This is equivalent to:
```
def manually_batched_gather(params, indices, axis):
batch_dims=1
result = []
for p,i in zip(params, indices):
r = tf.gather(p, i, axis=axis-batch_dims)
result.append(r)
return tf.stack(result)
manually_batched_gather(params, indices, axis=1).numpy()
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)
```
Higher values of `batch_dims` are equivalent to multiple nested loops over the outer axes of `params` and `indices`. So the overall shape function is
```
def batched_result_shape(p_shape, i_shape, axis=0, batch_dims=0):
return p_shape[:axis] + i_shape[batch_dims:] + p_shape[axis+1:]
batched_result_shape(
p_shape=params.shape.as_list(),
i_shape=indices.shape.as_list(),
axis=1,
batch_dims=1)
[3, 2]
```
```
tf.gather(params, indices, axis=1, batch_dims=1).shape.as_list()
[3, 2]
```
This comes up naturally if you need to use the indices of an operation like [`tf.argsort`](argsort), or [`tf.math.top_k`](math/top_k) where the last dimension of the indices indexes into the last dimension of input, at the corresponding location. In this case you can use `tf.gather(values, indices, batch_dims=-1)`.
#### See also:
* [`tf.Tensor.**getitem**`](tensor#__getitem__): The direct tensor index operation (`t[]`), handles scalars and python-slices `tensor[..., 7, 1:-1]`
* `tf.scatter`: A collection of operations similar to `__setitem__` (`t[i] = x`)
* [`tf.gather_nd`](gather_nd): An operation similar to [`tf.gather`](gather) but gathers across multiple axis at once (it can gather elements of a matrix instead of rows or columns)
* [`tf.boolean_mask`](boolean_mask), [`tf.where`](where): Binary indexing.
* [`tf.slice`](slice) and [`tf.strided_slice`](strided_slice): For lower level access to the implementation of `__getitem__`'s python-slice handling (`t[1:-1:2]`)
| Args |
| `params` | The `Tensor` from which to gather values. Must be at least rank `axis + 1`. |
| `indices` | The index `Tensor`. Must be one of the following types: `int32`, `int64`. The values must be in range `[0, params.shape[axis])`. |
| `validate_indices` | Deprecated, does nothing. Indices are always validated on CPU, never validated on GPU.
|
| `axis` | A `Tensor`. Must be one of the following types: `int32`, `int64`. The `axis` in `params` to gather `indices` from. Must be greater than or equal to `batch_dims`. Defaults to the first non-batch dimension. Supports negative indexes. |
| `batch_dims` | An `integer`. The number of batch dimensions. Must be less than or equal to `rank(indices)`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `params`. |
| programming_docs |
tensorflow Module: tf.lite Module: tf.lite
===============
Public API for tf.lite namespace.
Modules
-------
[`experimental`](lite/experimental) module: Public API for tf.lite.experimental namespace.
Classes
-------
[`class Interpreter`](lite/interpreter): Interpreter interface for running TensorFlow Lite models.
[`class OpsSet`](lite/opsset): Enum class defining the sets of ops available to generate TFLite models.
[`class Optimize`](lite/optimize): Enum defining the optimizations to apply when generating a tflite model.
[`class RepresentativeDataset`](lite/representativedataset): Representative dataset used to optimize the model.
[`class TFLiteConverter`](lite/tfliteconverter): Converts a TensorFlow model into TensorFlow Lite model.
[`class TargetSpec`](lite/targetspec): Specification of target device used to optimize the model.
tensorflow tf.searchsorted tf.searchsorted
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L6355-L6435) |
Searches for where a value would go in a sorted sequence.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.searchsorted`](https://www.tensorflow.org/api_docs/python/tf/searchsorted)
```
tf.searchsorted(
sorted_sequence,
values,
side='left',
out_type=tf.dtypes.int32,
name=None
)
```
This is not a method for checking containment (like python `in`).
The typical use case for this operation is "binning", "bucketing", or "discretizing". The `values` are assigned to bucket-indices based on the **edges** listed in `sorted_sequence`. This operation returns the bucket-index for each value.
```
edges = [-1, 3.3, 9.1, 10.0]
values = [0.0, 4.1, 12.0]
tf.searchsorted(edges, values).numpy()
array([1, 2, 4], dtype=int32)
```
The `side` argument controls which index is returned if a value lands exactly on an edge:
```
seq = [0, 3, 9, 10, 10]
values = [0, 4, 10]
tf.searchsorted(seq, values).numpy()
array([0, 2, 3], dtype=int32)
tf.searchsorted(seq, values, side="right").numpy()
array([1, 2, 5], dtype=int32)
```
The `axis` is not settable for this operation. It always operates on the innermost dimension (`axis=-1`). The operation will accept any number of outer dimensions. Here it is applied to the rows of a matrix:
```
sorted_sequence = [[0., 3., 8., 9., 10.],
[1., 2., 3., 4., 5.]]
values = [[9.8, 2.1, 4.3],
[0.1, 6.6, 4.5, ]]
tf.searchsorted(sorted_sequence, values).numpy()
array([[4, 1, 2],
[0, 5, 4]], dtype=int32)
```
>
> **Note:** This operation assumes that `sorted_sequence` **is sorted** along the innermost axis, maybe using `tf.sort(..., axis=-1)`. **If the sequence is not sorted no error is raised** and the content of the returned tensor is not well defined.
>
| Args |
| `sorted_sequence` | N-D `Tensor` containing a sorted sequence. |
| `values` | N-D `Tensor` containing the search values. |
| `side` | 'left' or 'right'; 'left' corresponds to lower\_bound and 'right' to upper\_bound. |
| `out_type` | The output type (`int32` or `int64`). Default is [`tf.int32`](../tf#int32). |
| `name` | Optional name for the operation. |
| Returns |
| An N-D `Tensor` the size of `values` containing the result of applying either lower\_bound or upper\_bound (depending on side) to each value. The result is not a global index to the entire `Tensor`, but the index in the last dimension. |
| Raises |
| `ValueError` | If the last dimension of `sorted_sequence >= 2^31-1` elements. If the total size of `values` exceeds `2^31 - 1` elements. If the first `N-1` dimensions of the two tensors don't match. |
tensorflow Module: tf.profiler Module: tf.profiler
===================
Public API for tf.profiler namespace.
Modules
-------
[`experimental`](profiler/experimental) module: Public API for tf.profiler.experimental namespace.
tensorflow Module: tf.quantization Module: tf.quantization
=======================
Public API for tf.quantization namespace.
Functions
---------
[`dequantize(...)`](quantization/dequantize): Dequantize the 'input' tensor into a float or bfloat16 Tensor.
[`fake_quant_with_min_max_args(...)`](quantization/fake_quant_with_min_max_args): Fake-quantize the 'inputs' tensor, type float to 'outputs' tensor of same type.
[`fake_quant_with_min_max_args_gradient(...)`](quantization/fake_quant_with_min_max_args_gradient): Compute gradients for a FakeQuantWithMinMaxArgs operation.
[`fake_quant_with_min_max_vars(...)`](quantization/fake_quant_with_min_max_vars): Fake-quantize the 'inputs' tensor of type float via global float scalars
[`fake_quant_with_min_max_vars_gradient(...)`](quantization/fake_quant_with_min_max_vars_gradient): Compute gradients for a FakeQuantWithMinMaxVars operation.
[`fake_quant_with_min_max_vars_per_channel(...)`](quantization/fake_quant_with_min_max_vars_per_channel): Fake-quantize the 'inputs' tensor of type float via per-channel floats
[`fake_quant_with_min_max_vars_per_channel_gradient(...)`](quantization/fake_quant_with_min_max_vars_per_channel_gradient): Compute gradients for a FakeQuantWithMinMaxVarsPerChannel operation.
[`quantize(...)`](quantization/quantize): Quantize the 'input' tensor of type float to 'output' tensor of type 'T'.
[`quantize_and_dequantize(...)`](quantization/quantize_and_dequantize): Quantizes then dequantizes a tensor. (deprecated)
[`quantize_and_dequantize_v2(...)`](quantization/quantize_and_dequantize_v2): Quantizes then dequantizes a tensor.
[`quantized_concat(...)`](quantization/quantized_concat): Concatenates quantized tensors along one dimension.
tensorflow tf.device tf.device
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L5474-L5510) |
Specifies the device for ops created/executed in this context.
```
tf.device(
device_name
)
```
This function specifies the device to be used for ops created/executed in a particular context. Nested contexts will inherit and also create/execute their ops on the specified device. If a specific device is not required, consider not using this function so that a device can be automatically assigned. In general the use of this function is optional. `device_name` can be fully specified, as in "/job:worker/task:1/device:cpu:0", or partially specified, containing only a subset of the "/"-separated fields. Any fields which are specified will override device annotations from outer scopes.
#### For example:
```
with tf.device('/job:foo'):
# ops created here have devices with /job:foo
with tf.device('/job:bar/task:0/device:gpu:2'):
# ops created here have the fully specified device above
with tf.device('/device:gpu:1'):
# ops created here have the device '/job:foo/device:gpu:1'
```
| Args |
| `device_name` | The device name to use in the context. |
| Returns |
| A context manager that specifies the default device to use for newly created ops. |
| Raises |
| `RuntimeError` | If a function is passed in. |
tensorflow tf.foldr tf.foldr
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/functional_ops.py#L360-L434) |
foldr on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
```
tf.foldr(
fn,
elems,
initializer=None,
parallel_iterations=10,
back_prop=True,
swap_memory=False,
name=None
)
```
This foldr operator repeatedly applies the callable `fn` to a sequence of elements from last to first. The elements are made of the tensors unpacked from `elems`. The callable fn takes two tensors as arguments. The first argument is the accumulated value computed from the preceding invocation of fn, and the second is the value at the current position of `elems`. If `initializer` is None, `elems` must contain at least one element, and its first element is used as the initializer.
Suppose that `elems` is unpacked into `values`, a list of tensors. The shape of the result tensor is `fn(initializer, values[0]).shape`.
This method also allows multi-arity `elems` and output of `fn`. If `elems` is a (possibly nested) list or tuple of tensors, then each of these tensors must have a matching first (unpack) dimension. The signature of `fn` may match the structure of `elems`. That is, if `elems` is `(t1, [t2, t3, [t4, t5]])`, then an appropriate signature for `fn` is: `fn = lambda (t1, [t2, t3, [t4, t5]]):`.
| Args |
| `fn` | The callable to be performed. |
| `elems` | A tensor or (possibly nested) sequence of tensors, each of which will be unpacked along their first dimension. The nested sequence of the resulting slices will be the first argument to `fn`. |
| `initializer` | (optional) A tensor or (possibly nested) sequence of tensors, as the initial value for the accumulator. |
| `parallel_iterations` | (optional) The number of iterations allowed to run in parallel. |
| `back_prop` | (optional) Deprecated. False disables support for back propagation. Prefer using [`tf.stop_gradient`](stop_gradient) instead. |
| `swap_memory` | (optional) True enables GPU-CPU memory swapping. |
| `name` | (optional) Name prefix for the returned tensors. |
| Returns |
| A tensor or (possibly nested) sequence of tensors, resulting from applying `fn` consecutively to the list of tensors unpacked from `elems`, from last to first. |
| Raises |
| `TypeError` | if `fn` is not callable. |
#### Example:
```
elems = [1, 2, 3, 4, 5, 6]
sum = foldr(lambda a, x: a + x, elems)
# sum == 21
```
tensorflow tf.bitcast tf.bitcast
==========
Bitcasts a tensor from one type to another without copying data.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.bitcast`](https://www.tensorflow.org/api_docs/python/tf/bitcast)
```
tf.bitcast(
input, type, name=None
)
```
Given a tensor `input`, this operation returns a tensor that has the same buffer data as `input` with datatype `type`.
If the input datatype `T` is larger than the output datatype `type` then the shape changes from [...] to [..., sizeof(`T`)/sizeof(`type`)].
If `T` is smaller than `type`, the operator requires that the rightmost dimension be equal to sizeof(`type`)/sizeof(`T`). The shape then goes from [..., sizeof(`type`)/sizeof(`T`)] to [...].
tf.bitcast() and tf.cast() work differently when real dtype is casted as a complex dtype (e.g. tf.complex64 or tf.complex128) as tf.cast() make imaginary part 0 while tf.bitcast() gives module error. For example,
#### Example 1:
```
a = [1., 2., 3.]
equality_bitcast = tf.bitcast(a, tf.complex128)
Traceback (most recent call last):
InvalidArgumentError: Cannot bitcast from 1 to 18 [Op:Bitcast]
equality_cast = tf.cast(a, tf.complex128)
print(equality_cast)
tf.Tensor([1.+0.j 2.+0.j 3.+0.j], shape=(3,), dtype=complex128)
```
#### Example 2:
```
tf.bitcast(tf.constant(0xffffffff, dtype=tf.uint32), tf.uint8)
<tf.Tensor: shape=(4,), dtype=uint8, numpy=array([255, 255, 255, 255], dtype=uint8)>
```
#### Example 3:
```
x = [1., 2., 3.]
y = [0., 2., 3.]
equality= tf.equal(x,y)
equality_cast = tf.cast(equality,tf.float32)
equality_bitcast = tf.bitcast(equality_cast,tf.uint8)
print(equality)
tf.Tensor([False True True], shape=(3,), dtype=bool)
print(equality_cast)
tf.Tensor([0. 1. 1.], shape=(3,), dtype=float32)
print(equality_bitcast)
tf.Tensor(
[[ 0 0 0 0]
[ 0 0 128 63]
[ 0 0 128 63]], shape=(3, 4), dtype=uint8)
```
>
> **Note:** Bitcast is implemented as a low-level cast, so machines with different endian orderings will give different results.
>
| Args |
| `input` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `int64`, `int32`, `uint8`, `uint16`, `uint32`, `uint64`, `int8`, `int16`, `complex64`, `complex128`, `qint8`, `quint8`, `qint16`, `quint16`, `qint32`. |
| `type` | A [`tf.DType`](dtypes/dtype) from: `tf.bfloat16, tf.half, tf.float32, tf.float64, tf.int64, tf.int32, tf.uint8, tf.uint16, tf.uint32, tf.uint64, tf.int8, tf.int16, tf.complex64, tf.complex128, tf.qint8, tf.quint8, tf.qint16, tf.quint16, tf.qint32`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `type`. |
tensorflow tf.variable_creator_scope tf.variable\_creator\_scope
===========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variable_scope.py#L2860-L2926) |
Scope which defines a variable creation function to be used by variable().
```
@tf_contextlib.contextmanager
tf.variable_creator_scope(
variable_creator
)
```
variable\_creator is expected to be a function with the following signature:
```
def variable_creator(next_creator, **kwargs)
```
The creator is supposed to eventually call the next\_creator to create a variable if it does want to create a variable and not call Variable or ResourceVariable directly. This helps make creators composable. A creator may choose to create multiple variables, return already existing variables, or simply register that a variable was created and defer to the next creators in line. Creators can also modify the keyword arguments seen by the next creators.
Custom getters in the variable scope will eventually resolve down to these custom creators when they do create variables.
The valid keyword arguments in kwds are:
* initial\_value: A `Tensor`, or Python object convertible to a `Tensor`, which is the initial value for the Variable. The initial value must have a shape specified unless `validate_shape` is set to False. Can also be a callable with no argument that returns the initial value when called. In that case, `dtype` must be specified. (Note that initializer functions from init\_ops.py must first be bound to a shape before being used here.)
* trainable: If `True`, the default, GradientTapes automatically watch uses of this Variable.
* validate\_shape: If `False`, allows the variable to be initialized with a value of unknown shape. If `True`, the default, the shape of `initial_value` must be known.
* caching\_device: Optional device string describing where the Variable should be cached for reading. Defaults to the Variable's device. If not `None`, caches on another device. Typical use is to cache on the device where the Ops using the Variable reside, to deduplicate copying through `Switch` and other conditional statements.
* name: Optional name for the variable. Defaults to `'Variable'` and gets uniquified automatically. dtype: If set, initial\_value will be converted to the given type. If `None`, either the datatype will be kept (if `initial_value` is a Tensor), or `convert_to_tensor` will decide.
* constraint: A constraint function to be applied to the variable after updates by some algorithms.
* synchronization: Indicates when a distributed a variable will be aggregated. Accepted values are constants defined in the class [`tf.VariableSynchronization`](variablesynchronization). By default the synchronization is set to `AUTO` and the current `DistributionStrategy` chooses when to synchronize.
* aggregation: Indicates how a distributed variable will be aggregated. Accepted values are constants defined in the class [`tf.VariableAggregation`](variableaggregation).
This set may grow over time, so it's important the signature of creators is as mentioned above.
| Args |
| `variable_creator` | the passed creator |
| Yields |
| A scope in which the creator is active |
tensorflow Module: tf.config Module: tf.config
=================
Public API for tf.config namespace.
Modules
-------
[`experimental`](config/experimental) module: Public API for tf.config.experimental namespace.
[`optimizer`](config/optimizer) module: Public API for tf.config.optimizer namespace.
[`threading`](config/threading) module: Public API for tf.config.threading namespace.
Classes
-------
[`class LogicalDevice`](config/logicaldevice): Abstraction for a logical device initialized by the runtime.
[`class LogicalDeviceConfiguration`](config/logicaldeviceconfiguration): Configuration class for a logical devices.
[`class PhysicalDevice`](config/physicaldevice): Abstraction for a locally visible physical device.
Functions
---------
[`experimental_connect_to_cluster(...)`](config/experimental_connect_to_cluster): Connects to the given cluster.
[`experimental_connect_to_host(...)`](config/experimental_connect_to_host): Connects to a single machine to enable remote execution on it.
[`experimental_functions_run_eagerly(...)`](config/experimental_functions_run_eagerly): Returns the value of the `experimental_run_functions_eagerly` setting. (deprecated)
[`experimental_run_functions_eagerly(...)`](config/experimental_run_functions_eagerly): Enables / disables eager execution of [`tf.function`](function)s. (deprecated)
[`functions_run_eagerly(...)`](config/functions_run_eagerly): Returns the value of the `run_functions_eagerly` setting.
[`get_logical_device_configuration(...)`](config/get_logical_device_configuration): Get the virtual device configuration for a [`tf.config.PhysicalDevice`](config/physicaldevice).
[`get_soft_device_placement(...)`](config/get_soft_device_placement): Return status of soft device placement flag.
[`get_visible_devices(...)`](config/get_visible_devices): Get the list of visible physical devices.
[`list_logical_devices(...)`](config/list_logical_devices): Return a list of logical devices created by runtime.
[`list_physical_devices(...)`](config/list_physical_devices): Return a list of physical devices visible to the host runtime.
[`run_functions_eagerly(...)`](config/run_functions_eagerly): Enables / disables eager execution of [`tf.function`](function)s.
[`set_logical_device_configuration(...)`](config/set_logical_device_configuration): Set the logical device configuration for a [`tf.config.PhysicalDevice`](config/physicaldevice).
[`set_soft_device_placement(...)`](config/set_soft_device_placement): Enable or disable soft device placement.
[`set_visible_devices(...)`](config/set_visible_devices): Set the list of visible devices.
tensorflow tf.range tf.range
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/math_ops.py#L2042-L2123) |
Creates a sequence of numbers.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.range`](https://www.tensorflow.org/api_docs/python/tf/range)
```
tf.range(limit, delta=1, dtype=None, name='range')
tf.range(start, limit, delta=1, dtype=None, name='range')
```
Creates a sequence of numbers that begins at `start` and extends by increments of `delta` up to but not including `limit`.
The dtype of the resulting tensor is inferred from the inputs unless it is provided explicitly.
Like the Python builtin `range`, `start` defaults to 0, so that `range(n) = range(0, n)`.
#### For example:
```
start = 3
limit = 18
delta = 3
tf.range(start, limit, delta)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([ 3, 6, 9, 12, 15], dtype=int32)>
```
```
start = 3
limit = 1
delta = -0.5
tf.range(start, limit, delta)
<tf.Tensor: shape=(4,), dtype=float32,
numpy=array([3. , 2.5, 2. , 1.5], dtype=float32)>
```
```
limit = 5
tf.range(limit)
<tf.Tensor: shape=(5,), dtype=int32,
numpy=array([0, 1, 2, 3, 4], dtype=int32)>
```
| Args |
| `start` | A 0-D `Tensor` (scalar). Acts as first entry in the range if `limit` is not None; otherwise, acts as range limit and first entry defaults to 0. |
| `limit` | A 0-D `Tensor` (scalar). Upper limit of sequence, exclusive. If None, defaults to the value of `start` while the first entry of the range defaults to 0. |
| `delta` | A 0-D `Tensor` (scalar). Number that increments `start`. Defaults to 1. |
| `dtype` | The type of the elements of the resulting tensor. |
| `name` | A name for the operation. Defaults to "range". |
| Returns |
| An 1-D `Tensor` of type `dtype`. |
numpy compatibility
-------------------
Equivalent to np.arange
| programming_docs |
tensorflow Module: tf.types Module: tf.types
================
Public TensorFlow type definitions.
For details, see <https://github.com/tensorflow/community/blob/master/rfcs/20200211-tf-types.md>
Modules
-------
[`experimental`](types/experimental) module: Public API for tf.types.experimental namespace.
tensorflow Module: tf.xla Module: tf.xla
==============
Public API for tf.xla namespace.
Modules
-------
[`experimental`](xla/experimental) module: Public API for tf.xla.experimental namespace.
tensorflow tf.CriticalSection tf.CriticalSection
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/critical_section_ops.py#L122-L419) |
Critical section.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.CriticalSection`](https://www.tensorflow.org/api_docs/python/tf/CriticalSection)
```
tf.CriticalSection(
name=None, shared_name=None, critical_section_def=None, import_scope=None
)
```
A `CriticalSection` object is a resource in the graph which executes subgraphs in **serial** order. A common example of a subgraph one may wish to run exclusively is the one given by the following function:
```
v = resource_variable_ops.ResourceVariable(0.0, name="v")
def count():
value = v.read_value()
with tf.control_dependencies([value]):
with tf.control_dependencies([v.assign_add(1)]):
return tf.identity(value)
```
Here, a snapshot of `v` is captured in `value`; and then `v` is updated. The snapshot value is returned.
If multiple workers or threads all execute `count` in parallel, there is no guarantee that access to the variable `v` is atomic at any point within any thread's calculation of `count`. In fact, even implementing an atomic counter that guarantees that the user will see each value `0, 1, ...,` is currently impossible.
The solution is to ensure any access to the underlying resource `v` is only processed through a critical section:
```
cs = CriticalSection()
f1 = cs.execute(count)
f2 = cs.execute(count)
output = f1 + f2
session.run(output)
```
The functions `f1` and `f2` will be executed serially, and updates to `v` will be atomic.
**NOTES**
All resource objects, including the critical section and any captured variables of functions executed on that critical section, will be colocated to the same device (host and cpu/gpu).
When using multiple critical sections on the same resources, there is no guarantee of exclusive access to those resources. This behavior is disallowed by default (but see the kwarg `exclusive_resource_access`).
For example, running the same function in two separate critical sections will not ensure serial execution:
```
v = tf.compat.v1.get_variable("v", initializer=0.0, use_resource=True)
def accumulate(up):
x = v.read_value()
with tf.control_dependencies([x]):
with tf.control_dependencies([v.assign_add(up)]):
return tf.identity(x)
ex1 = CriticalSection().execute(
accumulate, 1.0, exclusive_resource_access=False)
ex2 = CriticalSection().execute(
accumulate, 1.0, exclusive_resource_access=False)
bad_sum = ex1 + ex2
sess.run(v.initializer)
sess.run(bad_sum) # May return 0.0
```
| Attributes |
| `name` | |
Methods
-------
### `execute`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/critical_section_ops.py#L231-L335)
```
execute(
fn, exclusive_resource_access=True, name=None
)
```
Execute function `fn()` inside the critical section.
`fn` should not accept any arguments. To add extra arguments to when calling `fn` in the critical section, create a lambda:
```
critical_section.execute(lambda: fn(*my_args, **my_kwargs))
```
| Args |
| `fn` | The function to execute. Must return at least one tensor. |
| `exclusive_resource_access` | Whether the resources required by `fn` should be exclusive to this `CriticalSection`. Default: `True`. You may want to set this to `False` if you will be accessing a resource in read-only mode in two different CriticalSections. |
| `name` | The name to use when creating the execute operation. |
| Returns |
| The tensors returned from `fn()`. |
| Raises |
| `ValueError` | If `fn` attempts to lock this `CriticalSection` in any nested or lazy way that may cause a deadlock. |
| `ValueError` | If `exclusive_resource_access == True` and another `CriticalSection` has an execution requesting the same resources as `fn``. Note, even if`exclusive\_resource\_access`is`True`, if another execution in another`CriticalSection`was created without`exclusive\_resource\_access=True`, a`ValueError` will be raised. |
tensorflow tf.load_op_library tf.load\_op\_library
====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/load_library.py#L31-L74) |
Loads a TensorFlow plugin, containing custom ops and kernels.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.load_op_library`](https://www.tensorflow.org/api_docs/python/tf/load_op_library)
```
tf.load_op_library(
library_filename
)
```
Pass "library\_filename" to a platform-specific mechanism for dynamically loading a library. The rules for determining the exact location of the library are platform-specific and are not documented here. When the library is loaded, ops and kernels registered in the library via the `REGISTER_*` macros are made available in the TensorFlow process. Note that ops with the same name as an existing op are rejected and not registered with the process.
| Args |
| `library_filename` | Path to the plugin. Relative or absolute filesystem path to a dynamic library file. |
| Returns |
| A python module containing the Python wrappers for Ops defined in the plugin. |
| Raises |
| `RuntimeError` | when unable to load the library or get the python wrappers. |
tensorflow Module: tf.errors Module: tf.errors
=================
Exception types for TensorFlow errors.
Classes
-------
[`class AbortedError`](errors/abortederror): The operation was aborted, typically due to a concurrent action.
[`class AlreadyExistsError`](errors/alreadyexistserror): Raised when an entity that we attempted to create already exists.
[`class CancelledError`](errors/cancellederror): Raised when an operation or step is cancelled.
[`class DataLossError`](errors/datalosserror): Raised when unrecoverable data loss or corruption is encountered.
[`class DeadlineExceededError`](errors/deadlineexceedederror): Raised when a deadline expires before an operation could complete.
[`class FailedPreconditionError`](errors/failedpreconditionerror): Operation was rejected because the system is not in a state to execute it.
[`class InternalError`](errors/internalerror): Raised when the system experiences an internal error.
[`class InvalidArgumentError`](errors/invalidargumenterror): Raised when an operation receives an invalid argument.
[`class NotFoundError`](errors/notfounderror): Raised when a requested entity (e.g., a file or directory) was not found.
[`class OpError`](errors/operror): The base class for TensorFlow exceptions.
[`class OperatorNotAllowedInGraphError`](errors/operatornotallowedingrapherror): An error is raised for unsupported operator in Graph execution.
[`class OutOfRangeError`](errors/outofrangeerror): Raised when an operation iterates past the valid input range.
[`class PermissionDeniedError`](errors/permissiondeniederror): Raised when the caller does not have permission to run an operation.
[`class ResourceExhaustedError`](errors/resourceexhaustederror): Some resource has been exhausted.
[`class UnauthenticatedError`](errors/unauthenticatederror): The request does not have valid authentication credentials.
[`class UnavailableError`](errors/unavailableerror): Raised when the runtime is currently unavailable.
[`class UnimplementedError`](errors/unimplementederror): Raised when an operation has not been implemented.
[`class UnknownError`](errors/unknownerror): Unknown error.
| Other Members |
| ABORTED | `10` |
| ALREADY\_EXISTS | `6` |
| CANCELLED | `1` |
| DATA\_LOSS | `15` |
| DEADLINE\_EXCEEDED | `4` |
| FAILED\_PRECONDITION | `9` |
| INTERNAL | `13` |
| INVALID\_ARGUMENT | `3` |
| NOT\_FOUND | `5` |
| OK | `0` |
| OUT\_OF\_RANGE | `11` |
| PERMISSION\_DENIED | `7` |
| RESOURCE\_EXHAUSTED | `8` |
| UNAUTHENTICATED | `16` |
| UNAVAILABLE | `14` |
| UNIMPLEMENTED | `12` |
| UNKNOWN | `2` |
tensorflow Module: tf.feature_column Module: tf.feature\_column
==========================
Public API for tf.feature\_column namespace.
Functions
---------
[`bucketized_column(...)`](feature_column/bucketized_column): Represents discretized dense input bucketed by `boundaries`.
[`categorical_column_with_hash_bucket(...)`](feature_column/categorical_column_with_hash_bucket): Represents sparse feature where ids are set by hashing.
[`categorical_column_with_identity(...)`](feature_column/categorical_column_with_identity): A `CategoricalColumn` that returns identity values.
[`categorical_column_with_vocabulary_file(...)`](feature_column/categorical_column_with_vocabulary_file): A `CategoricalColumn` with a vocabulary file.
[`categorical_column_with_vocabulary_list(...)`](feature_column/categorical_column_with_vocabulary_list): A `CategoricalColumn` with in-memory vocabulary.
[`crossed_column(...)`](feature_column/crossed_column): Returns a column for performing crosses of categorical features.
[`embedding_column(...)`](feature_column/embedding_column): `DenseColumn` that converts from sparse, categorical input.
[`indicator_column(...)`](feature_column/indicator_column): Represents multi-hot representation of given categorical column.
[`make_parse_example_spec(...)`](feature_column/make_parse_example_spec): Creates parsing spec dictionary from input feature\_columns.
[`numeric_column(...)`](feature_column/numeric_column): Represents real valued or numerical features.
[`sequence_categorical_column_with_hash_bucket(...)`](feature_column/sequence_categorical_column_with_hash_bucket): A sequence of categorical terms where ids are set by hashing.
[`sequence_categorical_column_with_identity(...)`](feature_column/sequence_categorical_column_with_identity): Returns a feature column that represents sequences of integers.
[`sequence_categorical_column_with_vocabulary_file(...)`](feature_column/sequence_categorical_column_with_vocabulary_file): A sequence of categorical terms where ids use a vocabulary file.
[`sequence_categorical_column_with_vocabulary_list(...)`](feature_column/sequence_categorical_column_with_vocabulary_list): A sequence of categorical terms where ids use an in-memory list.
[`sequence_numeric_column(...)`](feature_column/sequence_numeric_column): Returns a feature column that represents sequences of numeric data.
[`shared_embeddings(...)`](feature_column/shared_embeddings): List of dense columns that convert from sparse, categorical input.
[`weighted_categorical_column(...)`](feature_column/weighted_categorical_column): Applies weight values to a `CategoricalColumn`.
tensorflow tf.clip_by_global_norm tf.clip\_by\_global\_norm
=========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/clip_ops.py#L288-L379) |
Clips values of multiple tensors by the ratio of the sum of their norms.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.clip_by_global_norm`](https://www.tensorflow.org/api_docs/python/tf/clip_by_global_norm)
```
tf.clip_by_global_norm(
t_list, clip_norm, use_norm=None, name=None
)
```
Given a tuple or list of tensors `t_list`, and a clipping ratio `clip_norm`, this operation returns a list of clipped tensors `list_clipped` and the global norm (`global_norm`) of all tensors in `t_list`. Optionally, if you've already computed the global norm for `t_list`, you can specify the global norm with `use_norm`.
To perform the clipping, the values `t_list[i]` are set to:
```
t_list[i] * clip_norm / max(global_norm, clip_norm)
```
where:
```
global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))
```
If `clip_norm > global_norm` then the entries in `t_list` remain as they are, otherwise they're all shrunk by the global ratio.
If `global_norm == infinity` then the entries in `t_list` are all set to `NaN` to signal that an error occurred.
Any of the entries of `t_list` that are of type `None` are ignored.
This is the correct way to perform gradient clipping (Pascanu et al., 2012).
However, it is slower than `clip_by_norm()` because all the parameters must be ready before the clipping operation can be performed.
| Args |
| `t_list` | A tuple or list of mixed `Tensors`, `IndexedSlices`, or None. |
| `clip_norm` | A 0-D (scalar) `Tensor` > 0. The clipping ratio. |
| `use_norm` | A 0-D (scalar) `Tensor` of type `float` (optional). The global norm to use. If not provided, `global_norm()` is used to compute the norm. |
| `name` | A name for the operation (optional). |
| Returns |
| `list_clipped` | A list of `Tensors` of the same type as `list_t`. |
| `global_norm` | A 0-D (scalar) `Tensor` representing the global norm. |
| Raises |
| `TypeError` | If `t_list` is not a sequence. |
#### References:
On the difficulty of training Recurrent Neural Networks: [Pascanu et al., 2012](http://proceedings.mlr.press/v28/pascanu13.html) ([pdf](http://proceedings.mlr.press/v28/pascanu13.pdf))
tensorflow tf.tensor_scatter_nd_sub tf.tensor\_scatter\_nd\_sub
===========================
Subtracts sparse `updates` from an existing tensor according to `indices`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.tensor_scatter_nd_sub`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_sub), [`tf.compat.v1.tensor_scatter_sub`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_sub)
```
tf.tensor_scatter_nd_sub(
tensor, indices, updates, name=None
)
```
This operation creates a new tensor by subtracting sparse `updates` from the passed in `tensor`. This operation is very similar to `tf.scatter_nd_sub`, except that the updates are subtracted from an existing tensor (as opposed to a variable). If the memory for the existing tensor cannot be re-used, a copy is made and updated.
`indices` is an integer tensor containing indices into a new tensor of shape `shape`. The last dimension of `indices` can be at most the rank of `shape`:
```
indices.shape[-1] <= shape.rank
```
The last dimension of `indices` corresponds to indices into elements (if `indices.shape[-1] = shape.rank`) or slices (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of `shape`. `updates` is a tensor with shape
```
indices.shape[:-1] + shape[indices.shape[-1]:]
```
The simplest form of tensor\_scatter\_sub is to subtract individual elements from a tensor by index. For example, say we want to insert 4 scattered elements in a rank-1 tensor with 8 elements.
In Python, this scatter subtract operation would look like this:
```
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
tensor = tf.ones([8], dtype=tf.int32)
updated = tf.tensor_scatter_nd_sub(tensor, indices, updates)
print(updated)
```
The resulting tensor would look like this:
```
[1, -10, 1, -9, -8, 1, 1, -11]
```
We can also, insert entire slices of a higher rank tensor all at once. For example, if we wanted to insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter add operation would look like this:
```
indices = tf.constant([[0], [2]])
updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]],
[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]]])
tensor = tf.ones([4, 4, 4],dtype=tf.int32)
updated = tf.tensor_scatter_nd_sub(tensor, indices, updates)
print(updated)
```
The resulting tensor would look like this:
```
[[[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]],
[[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]],
[[-4, -4, -4, -4], [-5, -5, -5, -5], [-6, -6, -6, -6], [-7, -7, -7, -7]],
[[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]]
```
Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
| Args |
| `tensor` | A `Tensor`. Tensor to copy/update. |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `updates` | A `Tensor`. Must have the same type as `tensor`. Updates to scatter into output. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
tensorflow tf.unique_with_counts tf.unique\_with\_counts
=======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L2073-L2120) |
Finds unique elements in a 1-D tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.unique_with_counts`](https://www.tensorflow.org/api_docs/python/tf/unique_with_counts)
```
tf.unique_with_counts(
x,
out_idx=tf.dtypes.int32,
name=None
)
```
This operation returns a tensor `y` containing all of the unique elements of `x` sorted in the same order that they occur in `x`. This operation also returns a tensor `idx` the same size as `x` that contains the index of each value of `x` in the unique output `y`. Finally, it returns a third tensor `count` that contains the count of each element of `y` in `x`. In other words:
`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`
#### For example:
```
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]
y, idx, count = unique_with_counts(x)
y ==> [1, 2, 4, 7, 8]
idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]
count ==> [2, 1, 3, 1, 2]
```
| Args |
| `x` | A `Tensor`. 1-D. |
| `out_idx` | An optional [`tf.DType`](dtypes/dtype) from: `tf.int32, tf.int64`. Defaults to [`tf.int32`](../tf#int32). |
| `name` | A name for the operation (optional). |
| Returns |
| A tuple of `Tensor` objects (y, idx, count). |
| `y` | A `Tensor`. Has the same type as `x`. |
| `idx` | A `Tensor` of type `out_idx`. |
| `count` | A `Tensor` of type `out_idx`. |
tensorflow tf.clip_by_value tf.clip\_by\_value
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/clip_ops.py#L31-L119) |
Clips tensor values to a specified min and max.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.clip_by_value`](https://www.tensorflow.org/api_docs/python/tf/clip_by_value)
```
tf.clip_by_value(
t, clip_value_min, clip_value_max, name=None
)
```
Given a tensor `t`, this operation returns a tensor of the same type and shape as `t` with its values clipped to `clip_value_min` and `clip_value_max`. Any values less than `clip_value_min` are set to `clip_value_min`. Any values greater than `clip_value_max` are set to `clip_value_max`.
>
> **Note:** `clip_value_min` needs to be smaller or equal to `clip_value_max` for correct results.
>
#### For example:
Basic usage passes a scalar as the min and max value.
```
t = tf.constant([[-10., -1., 0.], [0., 2., 10.]])
t2 = tf.clip_by_value(t, clip_value_min=-1, clip_value_max=1)
t2.numpy()
array([[-1., -1., 0.],
[ 0., 1., 1.]], dtype=float32)
```
The min and max can be the same size as `t`, or broadcastable to that size.
```
t = tf.constant([[-1, 0., 10.], [-1, 0, 10]])
clip_min = [[2],[1]]
t3 = tf.clip_by_value(t, clip_value_min=clip_min, clip_value_max=100)
t3.numpy()
array([[ 2., 2., 10.],
[ 1., 1., 10.]], dtype=float32)
```
Broadcasting fails, intentionally, if you would expand the dimensions of `t`
```
t = tf.constant([[-1, 0., 10.], [-1, 0, 10]])
clip_min = [[[2, 1]]] # Has a third axis
t4 = tf.clip_by_value(t, clip_value_min=clip_min, clip_value_max=100)
Traceback (most recent call last):
InvalidArgumentError: Incompatible shapes: [2,3] vs. [1,1,2]
```
It throws a `TypeError` if you try to clip an `int` to a `float` value ([`tf.cast`](cast) the input to `float` first).
```
t = tf.constant([[1, 2], [3, 4]], dtype=tf.int32)
t5 = tf.clip_by_value(t, clip_value_min=-3.1, clip_value_max=3.1)
Traceback (most recent call last):
TypeError: Cannot convert ...
```
| Args |
| `t` | A `Tensor` or `IndexedSlices`. |
| `clip_value_min` | The minimum value to clip to. A scalar `Tensor` or one that is broadcastable to the shape of `t`. |
| `clip_value_max` | The maximum value to clip to. A scalar `Tensor` or one that is broadcastable to the shape of `t`. |
| `name` | A name for the operation (optional). |
| Returns |
| A clipped `Tensor` or `IndexedSlices`. |
| Raises |
| [`tf.errors.InvalidArgumentError`](errors/invalidargumenterror): If the clip tensors would trigger array broadcasting that would make the returned tensor larger than the input. |
| `TypeError` | If dtype of the input is `int32` and dtype of the `clip_value_min` or `clip_value_max` is `float32` |
| programming_docs |
tensorflow tf.DeviceSpec tf.DeviceSpec
=============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L47-L412) |
Represents a (possibly partial) specification for a TensorFlow device.
```
tf.DeviceSpec(
job=None, replica=None, task=None, device_type=None, device_index=None
)
```
`DeviceSpec`s are used throughout TensorFlow to describe where state is stored and computations occur. Using `DeviceSpec` allows you to parse device spec strings to verify their validity, merge them or compose them programmatically.
#### Example:
```
# Place the operations on device "GPU:0" in the "ps" job.
device_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
with tf.device(device_spec.to_string()):
# Both my_var and squared_var will be placed on /job:ps/device:GPU:0.
my_var = tf.Variable(..., name="my_variable")
squared_var = tf.square(my_var)
```
With eager execution disabled (by default in TensorFlow 1.x and by calling disable\_eager\_execution() in TensorFlow 2.x), the following syntax can be used:
```
tf.compat.v1.disable_eager_execution()
# Same as previous
device_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
# No need of .to_string() method.
with tf.device(device_spec):
my_var = tf.Variable(..., name="my_variable")
squared_var = tf.square(my_var)
```
If a `DeviceSpec` is partially specified, it will be merged with other `DeviceSpec`s according to the scope in which it is defined. `DeviceSpec` components defined in inner scopes take precedence over those defined in outer scopes.
```
gpu0_spec = DeviceSpec(job="ps", device_type="GPU", device_index=0)
with tf.device(DeviceSpec(job="train").to_string()):
with tf.device(gpu0_spec.to_string()):
# Nodes created here will be assigned to /job:ps/device:GPU:0.
with tf.device(DeviceSpec(device_type="GPU", device_index=1).to_string()):
# Nodes created here will be assigned to /job:train/device:GPU:1.
```
A `DeviceSpec` consists of 5 components -- each of which is optionally specified:
* Job: The job name.
* Replica: The replica index.
* Task: The task index.
* Device type: The device type string (e.g. "CPU" or "GPU").
* Device index: The device index.
| Args |
| `job` | string. Optional job name. |
| `replica` | int. Optional replica index. |
| `task` | int. Optional task index. |
| `device_type` | Optional device type string (e.g. "CPU" or "GPU") |
| `device_index` | int. Optional device index. If left unspecified, device represents 'any' device\_index. |
| Attributes |
| `device_index` | |
| `device_type` | |
| `job` | |
| `replica` | |
| `task` | |
Methods
-------
### `from_string`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L145-L158)
```
@classmethod
from_string(
spec
)
```
Construct a `DeviceSpec` from a string.
| Args |
| `spec` | a string of the form /job:/replica:/task:/device:CPU: or /job:/replica:/task:/device:GPU: as cpu and gpu are mutually exclusive. All entries are optional. |
| Returns |
| A DeviceSpec. |
### `make_merged_spec`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L215-L237)
```
make_merged_spec(
dev
)
```
Returns a new DeviceSpec which incorporates `dev`.
When combining specs, `dev` will take precedence over the current spec. So for instance:
```
first_spec = tf.DeviceSpec(job=0, device_type="CPU")
second_spec = tf.DeviceSpec(device_type="GPU")
combined_spec = first_spec.make_merged_spec(second_spec)
```
is equivalent to:
```
combined_spec = tf.DeviceSpec(job=0, device_type="GPU")
```
| Args |
| `dev` | a `DeviceSpec` |
| Returns |
| A new `DeviceSpec` which combines `self` and `dev` |
### `parse_from_string`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L160-L213)
```
parse_from_string(
spec
)
```
Parse a `DeviceSpec` name into its components.
**2.x behavior change**:
In TensorFlow 1.x, this function mutates its own state and returns itself. In 2.x, DeviceSpecs are immutable, and this function will return a DeviceSpec which contains the spec.
* Recommended:
```
# my_spec and my_updated_spec are unrelated.
my_spec = tf.DeviceSpec.from_string("/CPU:0")
my_updated_spec = tf.DeviceSpec.from_string("/GPU:0")
with tf.device(my_updated_spec):
...
```
* Will work in 1.x and 2.x (though deprecated in 2.x):
```
my_spec = tf.DeviceSpec.from_string("/CPU:0")
my_updated_spec = my_spec.parse_from_string("/GPU:0")
with tf.device(my_updated_spec):
...
```
* Will NOT work in 2.x:
```
my_spec = tf.DeviceSpec.from_string("/CPU:0")
my_spec.parse_from_string("/GPU:0") # <== Will not update my_spec
with tf.device(my_spec):
...
```
In general, [`DeviceSpec.from_string`](devicespec#from_string) should completely replace [`DeviceSpec.parse_from_string`](devicespec#parse_from_string), and [`DeviceSpec.replace`](devicespec#replace) should completely replace setting attributes directly.
| Args |
| `spec` | an optional string of the form /job:/replica:/task:/device:CPU: or /job:/replica:/task:/device:GPU: as cpu and gpu are mutually exclusive. All entries are optional. |
| Returns |
| The `DeviceSpec`. |
| Raises |
| `ValueError` | if the spec was not valid. |
### `replace`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L239-L264)
```
replace(
**kwargs
)
```
Convenience method for making a new DeviceSpec by overriding fields.
#### For instance:
```
my_spec = DeviceSpec=(job="my_job", device="CPU")
my_updated_spec = my_spec.replace(device="GPU")
my_other_spec = my_spec.replace(device=None)
```
| Args |
| `**kwargs` | This method takes the same args as the DeviceSpec constructor |
| Returns |
| A DeviceSpec with the fields specified in kwargs overridden. |
### `to_string`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L136-L143)
```
to_string()
```
Return a string representation of this `DeviceSpec`.
| Returns |
| a string of the form /job:/replica:/task:/device::. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/device_spec.py#L395-L409)
```
__eq__(
other
)
```
Checks if the `other` DeviceSpec is same as the current instance, eg have
same value for all the internal fields.
| Args |
| `other` | Another DeviceSpec |
| Returns |
| Return `True` if `other` is also a DeviceSpec instance and has same value as the current instance. Return `False` otherwise. |
tensorflow tf.SparseTensorSpec tf.SparseTensorSpec
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/sparse_tensor.py#L293-L427) |
Type specification for a [`tf.sparse.SparseTensor`](sparse/sparsetensor).
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.SparseTensorSpec`](https://www.tensorflow.org/api_docs/python/tf/SparseTensorSpec)
```
tf.SparseTensorSpec(
shape=None,
dtype=tf.dtypes.float32
)
```
| Args |
| `shape` | The dense shape of the `SparseTensor`, or `None` to allow any dense shape. |
| `dtype` | [`tf.DType`](dtypes/dtype) of values in the `SparseTensor`. |
| Attributes |
| `dtype` | The [`tf.dtypes.DType`](dtypes/dtype) specified by this type for the SparseTensor. |
| `shape` | The [`tf.TensorShape`](tensorshape) specified by this type for the SparseTensor. |
| `value_type` | |
Methods
-------
### `from_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/sparse_tensor.py#L416-L427)
```
@classmethod
from_value(
value
)
```
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L193-L214)
```
is_compatible_with(
spec_or_value
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
tensorflow tf.TensorShape tf.TensorShape
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L743-L1422) |
Represents the shape of a `Tensor`.
Inherits From: [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.TensorShape`](https://www.tensorflow.org/api_docs/python/tf/TensorShape)
```
tf.TensorShape(
dims
)
```
A `TensorShape` represents a possibly-partial shape specification for a `Tensor`. It may be one of the following:
* *Fully-known shape:* has a known number of dimensions and a known size for each dimension. e.g. `TensorShape([16, 256])`
* *Partially-known shape:* has a known number of dimensions, and an unknown size for one or more dimension. e.g. `TensorShape([None, 256])`
* *Unknown shape:* has an unknown number of dimensions, and an unknown size in all dimensions. e.g. `TensorShape(None)`
If a tensor is produced by an operation of type `"Foo"`, its shape may be inferred if there is a registered shape function for `"Foo"`. See [Shape functions](https://www.tensorflow.org/guide/create_op#shape_functions_in_c) for details of shape functions and how to register them. Alternatively, you may set the shape explicitly using [`tf.Tensor.set_shape`](tensor#set_shape).
| Args |
| `dims` | A list of Dimensions, or None if the shape is unspecified. |
| Raises |
| `TypeError` | If dims cannot be converted to a list of dimensions. |
| Attributes |
| `dims` | Deprecated. Returns list of dimensions for this shape. Suggest [`TensorShape.as_list`](tensorshape#as_list) instead. |
| `ndims` | Deprecated accessor for `rank`. |
| `rank` | Returns the rank of this shape, or None if it is unspecified. |
Methods
-------
### `as_list`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1337-L1348)
```
as_list()
```
Returns a list of integers or `None` for each dimension.
| Returns |
| A list of integers or `None` for each dimension. |
| Raises |
| `ValueError` | If `self` is an unknown shape with an unknown rank. |
### `as_proto`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1350-L1358)
```
as_proto()
```
Returns this shape as a `TensorShapeProto`.
### `assert_has_rank`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1044-L1054)
```
assert_has_rank(
rank
)
```
Raises an exception if `self` is not compatible with the given `rank`.
| Args |
| `rank` | An integer. |
| Raises |
| `ValueError` | If `self` does not represent a shape with the given `rank`. |
### `assert_is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1278-L1291)
```
assert_is_compatible_with(
other
)
```
Raises exception if `self` and `other` do not represent the same shape.
This method can be used to assert that there exists a shape that both `self` and `other` represent.
| Args |
| `other` | Another TensorShape. |
| Raises |
| `ValueError` | If `self` and `other` do not represent the same shape. |
### `assert_is_fully_defined`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1328-L1335)
```
assert_is_fully_defined()
```
Raises an exception if `self` is not fully defined in every dimension.
| Raises |
| `ValueError` | If `self` does not have a known value for every dimension. |
### `assert_same_rank`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1028-L1042)
```
assert_same_rank(
other
)
```
Raises an exception if `self` and `other` do not have compatible ranks.
| Args |
| `other` | Another `TensorShape`. |
| Raises |
| `ValueError` | If `self` and `other` do not represent shapes with the same rank. |
### `concatenate`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1005-L1026)
```
concatenate(
other
)
```
Returns the concatenation of the dimension in `self` and `other`.
>
> **Note:** If either `self` or `other` is completely unknown, concatenation will discard information about the other shape. In future, we might support concatenation that preserves this information for use with slicing.
>
| Args |
| `other` | Another `TensorShape`. |
| Returns |
| A `TensorShape` whose dimensions are the concatenation of the dimensions in `self` and `other`. |
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1231-L1276)
```
is_compatible_with(
other
)
```
Returns True iff `self` is compatible with `other`.
Two possibly-partially-defined shapes are compatible if there exists a fully-defined shape that both shapes can represent. Thus, compatibility allows the shape inference code to reason about partially-defined shapes. For example:
* TensorShape(None) is compatible with all shapes.
* TensorShape([None, None]) is compatible with all two-dimensional shapes, such as TensorShape([32, 784]), and also TensorShape(None). It is not compatible with, for example, TensorShape([None]) or TensorShape([None, None, None]).
* TensorShape([32, None]) is compatible with all two-dimensional shapes with size 32 in the 0th dimension, and also TensorShape([None, None]) and TensorShape(None). It is not compatible with, for example, TensorShape([32]), TensorShape([32, None, 1]) or TensorShape([64, None]).
* TensorShape([32, 784]) is compatible with itself, and also TensorShape([32, None]), TensorShape([None, 784]), TensorShape([None, None]) and TensorShape(None). It is not compatible with, for example, TensorShape([32, 1, 784]) or TensorShape([None]).
The compatibility relation is reflexive and symmetric, but not transitive. For example, TensorShape([32, 784]) is compatible with TensorShape(None), and TensorShape(None) is compatible with TensorShape([4, 4]), but TensorShape([32, 784]) is not compatible with TensorShape([4, 4]).
| Args |
| `other` | Another TensorShape. |
| Returns |
| True iff `self` is compatible with `other`. |
### `is_fully_defined`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1323-L1326)
```
is_fully_defined()
```
Returns True iff `self` is fully defined in every dimension.
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1114-L1172)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True iff `self` is subtype of `other`.
Shape A is a subtype of shape B if shape B can successfully represent it:
* A `TensorShape` of any rank is a subtype of `TensorShape(None)`.
* TensorShapes of equal ranks are covariant, i.e. `TensorShape([A1, A2, ..])` is a subtype of `TensorShape([B1, B2, ..])` iff An is a subtype of Bn.
An is subtype of Bn iff An == Bn or Bn is None.
* TensorShapes of different defined ranks have no subtyping relation.
The subtyping relation is reflexive and transitive, but not symmetric.
#### Some examples:
* `TensorShape([32, 784])` is a subtype of `TensorShape(None)`, and `TensorShape([4, 4])` is also a subtype of `TensorShape(None)` but `TensorShape([32, 784])` and `TensorShape([4, 4])` are not subtypes of each other.
* All two-dimensional shapes are subtypes of `TensorShape([None, None])`, such as `TensorShape([32, 784])`. There is no subtype relationship with, for example, `TensorShape([None])` or `TensorShape([None, None, None])`.
* `TensorShape([32, None])` is also a subtype of `TensorShape([None, None])` and `TensorShape(None)`. It is not a subtype of, for example, `TensorShape([32])`, `TensorShape([32, None, 1])`, `TensorShape([64, None])` or `TensorShape([None, 32])`.
* `TensorShape([32, 784])` is a subtype of itself, and also `TensorShape([32, None])`, `TensorShape([None, 784])`, `TensorShape([None, None])` and `TensorShape(None)`. It has no subtype relation with, for example, `TensorShape([32, 1, 784])` or `TensorShape([None])`.
| Args |
| `other` | Another `TensorShape`. |
| Returns |
| True iff `self` is subtype of `other`. |
### `merge_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L945-L995)
```
merge_with(
other
)
```
Returns a `TensorShape` combining the information in `self` and `other`.
The dimensions in `self` and `other` are merged element-wise, according to the rules below:
```
Dimension(n).merge_with(Dimension(None)) == Dimension(n)
Dimension(None).merge_with(Dimension(n)) == Dimension(n)
Dimension(None).merge_with(Dimension(None)) == Dimension(None)
# raises ValueError for n != m
Dimension(n).merge_with(Dimension(m))
```
> ts = tf.TensorShape([1,2]) ot1 = tf.TensorShape([1,2]) ts.merge\_with(ot).as\_list() [1,2]
>
>
> ot2 = tf.TensorShape([1,None]) ts.merge\_with(ot2).as\_list() [1,2]
>
>
> ot3 = tf.TensorShape([None, None]) ot3.merge\_with(ot2).as\_list() [1, None]
>
>
| Args |
| `other` | Another `TensorShape`. |
| Returns |
| A `TensorShape` containing the combined information of `self` and `other`. |
| Raises |
| `ValueError` | If `self` and `other` are not compatible. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1174-L1228)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TensorShape']
```
Returns the most specific supertype `TensorShape` of self and others.
* `TensorShape([None, 1])` is the most specific `TensorShape` supertyping both `TensorShape([2, 1])` and `TensorShape([5, 1])`. Note that `TensorShape(None)` is also a supertype but it is not "most specific".
* `TensorShape([1, 2, 3])` is the most specific `TensorShape` supertyping both `TensorShape([1, 2, 3])` and `TensorShape([1, 2, 3]`). There are other less specific TensorShapes that supertype above mentioned TensorShapes, e.g. `TensorShape([1, 2, None])`, `TensorShape(None)`.
+ `TensorShape([None, None])` is the most specific `TensorShape` supertyping both `TensorShape([2, None])` and `TensorShape([None, 3])`. As always, `TensorShape(None)` is also a supertype but not the most specific one.
+ `TensorShape(None`) is the only `TensorShape` supertyping both `TensorShape([1, 2, 3])` and `TensorShape([1, 2])`. In general, any two shapes that have different ranks will only have `TensorShape(None)` as a common supertype.
+ `TensorShape(None)` is the only `TensorShape` supertyping both `TensorShape([1, 2, 3])` and `TensorShape(None)`. In general, the common supertype of any shape with `TensorShape(None)` is `TensorShape(None)`.
| Args |
| `others` | Sequence of `TensorShape`. |
| Returns |
| A `TensorShape` which is the most specific supertype shape of `self` and `others`. None if it does not exist. |
### `most_specific_compatible_shape`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1293-L1321)
```
most_specific_compatible_shape(
other
)
```
Returns the most specific TensorShape compatible with `self` and `other`.
* TensorShape([None, 1]) is the most specific TensorShape compatible with both TensorShape([2, 1]) and TensorShape([5, 1]). Note that TensorShape(None) is also compatible with above mentioned TensorShapes.
* TensorShape([1, 2, 3]) is the most specific TensorShape compatible with both TensorShape([1, 2, 3]) and TensorShape([1, 2, 3]). There are more less specific TensorShapes compatible with above mentioned TensorShapes, e.g. TensorShape([1, 2, None]), TensorShape(None).
| Args |
| `other` | Another `TensorShape`. |
| Returns |
| A `TensorShape` which is the most specific compatible shape of `self` and `other`. |
### `num_elements`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L938-L943)
```
num_elements()
```
Returns the total number of elements, or none for incomplete shapes.
### `with_rank`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1056-L1074)
```
with_rank(
rank
)
```
Returns a shape based on `self` with the given rank.
This method promotes a completely unknown shape to one with a known rank.
| Args |
| `rank` | An integer. |
| Returns |
| A shape that is at least as specific as `self` with the given rank. |
| Raises |
| `ValueError` | If `self` does not represent a shape with the given `rank`. |
### `with_rank_at_least`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1076-L1093)
```
with_rank_at_least(
rank
)
```
Returns a shape based on `self` with at least the given rank.
| Args |
| `rank` | An integer. |
| Returns |
| A shape that is at least as specific as `self` with at least the given rank. |
| Raises |
| `ValueError` | If `self` does not represent a shape with at least the given `rank`. |
### `with_rank_at_most`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1095-L1112)
```
with_rank_at_most(
rank
)
```
Returns a shape based on `self` with at most the given rank.
| Args |
| `rank` | An integer. |
| Returns |
| A shape that is at least as specific as `self` with at most the given rank. |
| Raises |
| `ValueError` | If `self` does not represent a shape with at most the given `rank`. |
### `__add__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L997-L998)
```
__add__(
other
)
```
### `__bool__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L871-L873)
```
__bool__()
```
Returns True if this shape contains non-zero information.
### `__concat__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1421-L1422)
```
__concat__(
other
)
```
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1360-L1413)
```
__eq__(
other
)
```
Returns True if `self` is equivalent to `other`.
It first tries to convert `other` to `TensorShape`. `TypeError` is thrown when the conversion fails. Otherwise, it compares each element in the TensorShape dimensions.
* Two *Fully known* shapes, return True iff each element is equal.
```
>>> t_a = tf.TensorShape([1,2])
>>> a = [1, 2]
>>> t_b = tf.TensorShape([1,2])
>>> t_c = tf.TensorShape([1,2,3])
>>> t_a.__eq__(a)
True
>>> t_a.__eq__(t_b)
True
>>> t_a.__eq__(t_c)
False
```
* Two *Partially-known* shapes, return True iff each element is equal.
```
>>> p_a = tf.TensorShape([1,None])
>>> p_b = tf.TensorShape([1,None])
>>> p_c = tf.TensorShape([2,None])
>>> p_a.__eq__(p_b)
True
>>> t_a.__eq__(p_a)
False
>>> p_a.__eq__(p_c)
False
```
* Two *Unknown shape*, return True.
```
>>> unk_a = tf.TensorShape(None)
>>> unk_b = tf.TensorShape(None)
>>> unk_a.__eq__(unk_b)
True
>>> unk_a.__eq__(t_a)
False
```
| Args |
| `other` | A `TensorShape` or type that can be converted to `TensorShape`. |
| Returns |
| True if the dimensions are all equal. |
| Raises |
| TypeError if `other` can not be converted to `TensorShape`. |
### `__getitem__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L888-L936)
```
__getitem__(
key
)
```
Returns the value of a dimension or a shape, depending on the key.
| Args |
| `key` | If `key` is an integer, returns the dimension at that index; otherwise if `key` is a slice, returns a TensorShape whose dimensions are those selected by the slice from `self`. |
| Returns |
| An integer if `key` is an integer, or a `TensorShape` if `key` is a slice. |
| Raises |
| `ValueError` | If `key` is a slice and `self` is completely unknown and the step is set. |
### `__iter__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L878-L886)
```
__iter__()
```
Returns `self.dims` if the rank is known, otherwise raises ValueError.
### `__len__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L865-L869)
```
__len__()
```
Returns the rank of this shape, or raises ValueError if unspecified.
### `__nonzero__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L871-L873)
```
__nonzero__()
```
Returns True if this shape contains non-zero information.
### `__radd__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/tensor_shape.py#L1000-L1003)
```
__radd__(
other
)
```
| programming_docs |
tensorflow tf.while_loop tf.while\_loop
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/control_flow_ops.py#L2331-L2517) |
Repeat `body` while the condition `cond` is true. (deprecated argument values)
```
tf.while_loop(
cond,
body,
loop_vars,
shape_invariants=None,
parallel_iterations=10,
back_prop=True,
swap_memory=False,
maximum_iterations=None,
name=None
)
```
`cond` is a callable returning a boolean scalar tensor. `body` is a callable returning a (possibly nested) tuple, namedtuple or list of tensors of the same arity (length and structure) and types as `loop_vars`. `loop_vars` is a (possibly nested) tuple, namedtuple or list of tensors that is passed to both `cond` and `body`. `cond` and `body` both take as many arguments as there are `loop_vars`.
In addition to regular Tensors or IndexedSlices, the body may accept and return TensorArray objects. The flows of the TensorArray objects will be appropriately forwarded between loops and during gradient calculations.
Note that `while_loop` calls `cond` and `body` *exactly once* (inside the call to `while_loop`, and not at all during `Session.run()`). `while_loop` stitches together the graph fragments created during the `cond` and `body` calls with some additional graph nodes to create the graph flow that repeats `body` until `cond` returns false.
For correctness, [`tf.while_loop()`](while_loop) strictly enforces shape invariants for the loop variables. A shape invariant is a (possibly partial) shape that is unchanged across the iterations of the loop. An error will be raised if the shape of a loop variable after an iteration is determined to be more general than or incompatible with its shape invariant. For example, a shape of [11, None] is more general than a shape of [11, 17], and [11, 21] is not compatible with [11, 17]. By default (if the argument `shape_invariants` is not specified), it is assumed that the initial shape of each tensor in `loop_vars` is the same in every iteration. The `shape_invariants` argument allows the caller to specify a less specific shape invariant for each loop variable, which is needed if the shape varies between iterations. The [`tf.Tensor.set_shape`](tensor#set_shape) function may also be used in the `body` function to indicate that the output loop variable has a particular shape. The shape invariant for SparseTensor and IndexedSlices are treated specially as follows:
a) If a loop variable is a SparseTensor, the shape invariant must be TensorShape([r]) where r is the rank of the dense tensor represented by the sparse tensor. It means the shapes of the three tensors of the SparseTensor are ([None], [None, r], [r]). NOTE: The shape invariant here is the shape of the SparseTensor.dense\_shape property. It must be the shape of a vector.
b) If a loop variable is an IndexedSlices, the shape invariant must be a shape invariant of the values tensor of the IndexedSlices. It means the shapes of the three tensors of the IndexedSlices are (shape, [shape[0]], [shape.ndims]).
`while_loop` implements non-strict semantics, enabling multiple iterations to run in parallel. The maximum number of parallel iterations can be controlled by `parallel_iterations`, which gives users some control over memory consumption and execution order. For correct programs, `while_loop` should return the same result for any parallel\_iterations > 0.
For training, TensorFlow stores the tensors that are produced in the forward inference and are needed in back propagation. These tensors are a main source of memory consumption and often cause OOM errors when training on GPUs. When the flag swap\_memory is true, we swap out these tensors from GPU to CPU. This for example allows us to train RNN models with very long sequences and large batches.
| Args |
| `cond` | A callable that represents the termination condition of the loop. |
| `body` | A callable that represents the loop body. |
| `loop_vars` | A (possibly nested) tuple, namedtuple or list of numpy array, `Tensor`, and `TensorArray` objects. |
| `shape_invariants` | The shape invariants for the loop variables. |
| `parallel_iterations` | The number of iterations allowed to run in parallel. It must be a positive integer. |
| `back_prop` | (optional) Deprecated. False disables support for back propagation. Prefer using [`tf.stop_gradient`](stop_gradient) instead. |
| `swap_memory` | Whether GPU-CPU memory swap is enabled for this loop. |
| `maximum_iterations` | Optional maximum number of iterations of the while loop to run. If provided, the `cond` output is AND-ed with an additional condition ensuring the number of iterations executed is no greater than `maximum_iterations`. |
| `name` | Optional name prefix for the returned tensors. |
| Returns |
| The output tensors for the loop variables after the loop. The return value has the same structure as `loop_vars`. |
| Raises |
| `TypeError` | if `cond` or `body` is not callable. |
| `ValueError` | if `loop_vars` is empty. |
#### Example:
```
i = tf.constant(0)
c = lambda i: tf.less(i, 10)
b = lambda i: (tf.add(i, 1), )
r = tf.while_loop(c, b, [i])
```
Example with nesting and a namedtuple:
```
import collections
Pair = collections.namedtuple('Pair', 'j, k')
ijk_0 = (tf.constant(0), Pair(tf.constant(1), tf.constant(2)))
c = lambda i, p: i < 10
b = lambda i, p: (i + 1, Pair((p.j + p.k), (p.j - p.k)))
ijk_final = tf.while_loop(c, b, ijk_0)
```
Example using shape\_invariants:
```
i0 = tf.constant(0)
m0 = tf.ones([2, 2])
c = lambda i, m: i < 10
b = lambda i, m: [i+1, tf.concat([m, m], axis=0)]
tf.while_loop(
c, b, loop_vars=[i0, m0],
shape_invariants=[i0.get_shape(), tf.TensorShape([None, 2])])
```
Example which demonstrates non-strict semantics: In the following example, the final value of the counter `i` does not depend on `x`. So the `while_loop` can increment the counter parallel to updates of `x`. However, because the loop counter at one loop iteration depends on the value at the previous iteration, the loop counter itself cannot be incremented in parallel. Hence if we just want the final value of the counter (which we print on the line `print(sess.run(i))`), then `x` will never be incremented, but the counter will be updated on a single thread. Conversely, if we want the value of the output (which we print on the line `print(sess.run(out).shape)`), then the counter may be incremented on its own thread, while `x` can be incremented in parallel on a separate thread. In the extreme case, it is conceivable that the thread incrementing the counter runs until completion before `x` is incremented even a single time. The only thing that can never happen is that the thread updating `x` can never get ahead of the counter thread because the thread incrementing `x` depends on the value of the counter.
```
import tensorflow as tf
n = 10000
x = tf.constant(list(range(n)))
c = lambda i, x: i < n
b = lambda i, x: (tf.compat.v1.Print(i + 1, [i]), tf.compat.v1.Print(x + 1,
[i], "x:"))
i, out = tf.while_loop(c, b, (0, x))
with tf.compat.v1.Session() as sess:
print(sess.run(i)) # prints [0] ... [9999]
# The following line may increment the counter and x in parallel.
# The counter thread may get ahead of the other thread, but not the
# other way around. So you may see things like
# [9996] x:[9987]
# meaning that the counter thread is on iteration 9996,
# while the other thread is on iteration 9987
print(sess.run(out).shape)
```
tensorflow tf.AggregationMethod tf.AggregationMethod
====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/gradients_util.py#L905-L934) |
A class listing aggregation methods used to combine gradients.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.AggregationMethod`](https://www.tensorflow.org/api_docs/python/tf/AggregationMethod)
Computing partial derivatives can require aggregating gradient contributions. This class lists the various methods that can be used to combine gradients in the graph.
The following aggregation methods are part of the stable API for aggregating gradients:
* `ADD_N`: All of the gradient terms are summed as part of one operation using the "AddN" op (see [`tf.add_n`](math/add_n)). This method has the property that all gradients must be ready and buffered separately in memory before any aggregation is performed.
* `DEFAULT`: The system-chosen default aggregation method.
The following aggregation methods are experimental and may not be supported in future releases:
* `EXPERIMENTAL_TREE`: Gradient terms are summed in pairs using the "AddN" op. This method of summing gradients may reduce performance, but it can improve memory utilization because the gradients can be released earlier.
| Class Variables |
| ADD\_N | `0` |
| DEFAULT | `0` |
| EXPERIMENTAL\_ACCUMULATE\_N | `2` |
| EXPERIMENTAL\_TREE | `1` |
tensorflow tf.tensor_scatter_nd_max tf.tensor\_scatter\_nd\_max
===========================
Apply a sparse update to a tensor taking the element-wise maximum.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.tensor_scatter_nd_max`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_max)
```
tf.tensor_scatter_nd_max(
tensor, indices, updates, name=None
)
```
Returns a new tensor copied from `tensor` whose values are element-wise maximum between tensor and updates according to the indices.
```
tensor = [0, 0, 0, 0, 0, 0, 0, 0]
indices = [[1], [4], [5]]
updates = [1, -1, 1]
tf.tensor_scatter_nd_max(tensor, indices, updates).numpy()
array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int32)
```
Refer to [`tf.tensor_scatter_nd_update`](tensor_scatter_nd_update) for more details.
| Args |
| `tensor` | A `Tensor`. Tensor to update. |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `updates` | A `Tensor`. Must have the same type as `tensor`. Updates to scatter into output. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
tensorflow tf.required_space_to_batch_paddings tf.required\_space\_to\_batch\_paddings
=======================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3984-L4060) |
Calculate padding required to make block\_shape divide input\_shape.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.required_space_to_batch_paddings`](https://www.tensorflow.org/api_docs/python/tf/required_space_to_batch_paddings)
```
tf.required_space_to_batch_paddings(
input_shape, block_shape, base_paddings=None, name=None
)
```
This function can be used to calculate a suitable paddings argument for use with space\_to\_batch\_nd and batch\_to\_space\_nd.
| Args |
| `input_shape` | int32 Tensor of shape [N]. |
| `block_shape` | int32 Tensor of shape [N]. |
| `base_paddings` | Optional int32 Tensor of shape [N, 2]. Specifies the minimum amount of padding to use. All elements must be >= 0. If not specified, defaults to 0. |
| `name` | string. Optional name prefix. |
| Returns |
| (paddings, crops), where: `paddings` and `crops` are int32 Tensors of rank 2 and shape [N, 2] |
| `satisfying` | paddings[i, 0] = base\_paddings[i, 0]. 0 <= paddings[i, 1] - base\_paddings[i, 1] < block\_shape[i](input_shape%5bi%5d%20+%20paddings%5bi,%200%5d%20+%20paddings%5bi,%201%5d) % block\_shape[i] == 0 crops[i, 0] = 0 crops[i, 1] = paddings[i, 1] - base\_paddings[i, 1] |
Raises: ValueError if called with incompatible shapes.
tensorflow tf.get_logger tf.get\_logger
==============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/platform/tf_logging.py#L89-L139) |
Return TF logger instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.get_logger`](https://www.tensorflow.org/api_docs/python/tf/get_logger)
```
tf.get_logger()
```
tensorflow tf.broadcast_static_shape tf.broadcast\_static\_shape
===========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L545-L578) |
Computes the shape of a broadcast given known shapes.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.broadcast_static_shape`](https://www.tensorflow.org/api_docs/python/tf/broadcast_static_shape)
```
tf.broadcast_static_shape(
shape_x, shape_y
)
```
When `shape_x` and `shape_y` are fully known `TensorShape`s this computes a `TensorShape` which is the shape of the result of a broadcasting op applied in tensors of shapes `shape_x` and `shape_y`.
For example, if shape\_x is `TensorShape([1, 2, 3])` and shape\_y is `TensorShape([5, 1, 3])`, the result is a TensorShape whose value is `TensorShape([5, 2, 3])`.
This is useful when validating the result of a broadcasting operation when the tensors have statically known shapes.
#### Example:
```
shape_x = tf.TensorShape([1, 2, 3])
shape_y = tf.TensorShape([5, 1 ,3])
tf.broadcast_static_shape(shape_x, shape_y)
TensorShape([5, 2, 3])
```
| Args |
| `shape_x` | A `TensorShape` |
| `shape_y` | A `TensorShape` |
| Returns |
| A `TensorShape` representing the broadcasted shape. |
| Raises |
| `ValueError` | If the two shapes can not be broadcasted. |
tensorflow tf.broadcast_to tf.broadcast\_to
================
Broadcast an array for a compatible shape.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.broadcast_to`](https://www.tensorflow.org/api_docs/python/tf/broadcast_to)
```
tf.broadcast_to(
input, shape, name=None
)
```
Broadcasting is the process of making arrays to have compatible shapes for arithmetic operations. Two shapes are compatible if for each dimension pair they are either equal or one of them is one. When trying to broadcast a Tensor to a shape, it starts with the trailing dimensions, and works its way forward.
For example,
```
x = tf.constant([1, 2, 3])
y = tf.broadcast_to(x, [3, 3])
print(y)
tf.Tensor(
[[1 2 3]
[1 2 3]
[1 2 3]], shape=(3, 3), dtype=int32)
```
In the above example, the input Tensor with the shape of `[1, 3]` is broadcasted to output Tensor with shape of `[3, 3]`.
When doing broadcasted operations such as multiplying a tensor by a scalar, broadcasting (usually) confers some time or space benefit, as the broadcasted tensor is never materialized.
However, `broadcast_to` does not carry with it any such benefits. The newly-created tensor takes the full memory of the broadcasted shape. (In a graph context, `broadcast_to` might be fused to subsequent operation and then be optimized away, however.)
| Args |
| `input` | A `Tensor`. A Tensor to broadcast. |
| `shape` | A `Tensor`. Must be one of the following types: `int32`, `int64`. An 1-D `int` Tensor. The shape of the desired output. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `input`. |
tensorflow tf.reshape tf.reshape
==========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L66-L204) |
Reshapes a tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.reshape`](https://www.tensorflow.org/api_docs/python/tf/reshape), [`tf.compat.v1.reshape`](https://www.tensorflow.org/api_docs/python/tf/reshape)
```
tf.reshape(
tensor, shape, name=None
)
```
Given `tensor`, this operation returns a new [`tf.Tensor`](tensor) that has the same values as `tensor` in the same order, except with a new shape given by `shape`.
```
t1 = [[1, 2, 3],
[4, 5, 6]]
print(tf.shape(t1).numpy())
[2 3]
t2 = tf.reshape(t1, [6])
t2
<tf.Tensor: shape=(6,), dtype=int32,
numpy=array([1, 2, 3, 4, 5, 6], dtype=int32)>
tf.reshape(t2, [3, 2])
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)>
```
The [`tf.reshape`](reshape) does not change the order of or the total number of elements in the tensor, and so it can reuse the underlying data buffer. This makes it a fast operation independent of how big of a tensor it is operating on.
```
tf.reshape([1, 2, 3], [2, 2])
Traceback (most recent call last):
InvalidArgumentError: Input to reshape is a tensor with 3 values, but the
requested shape has 4
```
To instead reorder the data to rearrange the dimensions of a tensor, see [`tf.transpose`](transpose).
```
t = [[1, 2, 3],
[4, 5, 6]]
tf.reshape(t, [3, 2]).numpy()
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)
tf.transpose(t, perm=[1, 0]).numpy()
array([[1, 4],
[2, 5],
[3, 6]], dtype=int32)
```
If one component of `shape` is the special value -1, the size of that dimension is computed so that the total size remains constant. In particular, a `shape` of `[-1]` flattens into 1-D. At most one component of `shape` can be -1.
```
t = [[1, 2, 3],
[4, 5, 6]]
tf.reshape(t, [-1])
<tf.Tensor: shape=(6,), dtype=int32,
numpy=array([1, 2, 3, 4, 5, 6], dtype=int32)>
tf.reshape(t, [3, -1])
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)>
tf.reshape(t, [-1, 2])
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4],
[5, 6]], dtype=int32)>
```
`tf.reshape(t, [])` reshapes a tensor `t` with one element to a scalar.
```
tf.reshape([7], []).numpy()
7
```
#### More examples:
```
t = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(tf.shape(t).numpy())
[9]
tf.reshape(t, [3, 3])
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]], dtype=int32)>
```
```
t = [[[1, 1], [2, 2]],
[[3, 3], [4, 4]]]
print(tf.shape(t).numpy())
[2 2 2]
tf.reshape(t, [2, 4])
<tf.Tensor: shape=(2, 4), dtype=int32, numpy=
array([[1, 1, 2, 2],
[3, 3, 4, 4]], dtype=int32)>
```
```
t = [[[1, 1, 1],
[2, 2, 2]],
[[3, 3, 3],
[4, 4, 4]],
[[5, 5, 5],
[6, 6, 6]]]
print(tf.shape(t).numpy())
[3 2 3]
# Pass '[-1]' to flatten 't'.
tf.reshape(t, [-1])
<tf.Tensor: shape=(18,), dtype=int32,
numpy=array([1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6],
dtype=int32)>
# -- Using -1 to infer the shape --
# Here -1 is inferred to be 9:
tf.reshape(t, [2, -1])
<tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 2, 2, 2, 3, 3, 3],
[4, 4, 4, 5, 5, 5, 6, 6, 6]], dtype=int32)>
# -1 is inferred to be 2:
tf.reshape(t, [-1, 9])
<tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 2, 2, 2, 3, 3, 3],
[4, 4, 4, 5, 5, 5, 6, 6, 6]], dtype=int32)>
# -1 is inferred to be 3:
tf.reshape(t, [ 2, -1, 3])
<tf.Tensor: shape=(2, 3, 3), dtype=int32, numpy=
array([[[1, 1, 1],
[2, 2, 2],
[3, 3, 3]],
[[4, 4, 4],
[5, 5, 5],
[6, 6, 6]]], dtype=int32)>
```
| Args |
| `tensor` | A `Tensor`. |
| `shape` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Defines the shape of the output tensor. |
| `name` | Optional string. A name for the operation. |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
| programming_docs |
tensorflow tf.load_library tf.load\_library
================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/load_library.py#L120-L157) |
Loads a TensorFlow plugin.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.load_library`](https://www.tensorflow.org/api_docs/python/tf/load_library)
```
tf.load_library(
library_location
)
```
"library\_location" can be a path to a specific shared object, or a folder. If it is a folder, all shared objects that are named "libtfkernel\*" will be loaded. When the library is loaded, kernels registered in the library via the `REGISTER_*` macros are made available in the TensorFlow process.
| Args |
| `library_location` | Path to the plugin or the folder of plugins. Relative or absolute filesystem path to a dynamic library file or folder. |
| Returns |
| None |
| Raises |
| `OSError` | When the file to be loaded is not found. |
| `RuntimeError` | when unable to load the library. |
tensorflow tf.RegisterGradient tf.RegisterGradient
===================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2738-L2782) |
A decorator for registering the gradient function for an op type.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.RegisterGradient`](https://www.tensorflow.org/api_docs/python/tf/RegisterGradient)
```
tf.RegisterGradient(
op_type
)
```
This decorator is only used when defining a new op type. For an op with `m` inputs and `n` outputs, the gradient function is a function that takes the original `Operation` and `n` `Tensor` objects (representing the gradients with respect to each output of the op), and returns `m` `Tensor` objects (representing the partial gradients with respect to each input of the op).
For example, assuming that operations of type `"Sub"` take two inputs `x` and `y`, and return a single output `x - y`, the following gradient function would be registered:
```
@tf.RegisterGradient("Sub")
def _sub_grad(unused_op, grad):
return grad, tf.negative(grad)
```
The decorator argument `op_type` is the string type of an operation. This corresponds to the `OpDef.name` field for the proto that defines the operation.
| Args |
| `op_type` | The string type of an operation. This corresponds to the `OpDef.name` field for the proto that defines the operation. |
| Raises |
| `TypeError` | If `op_type` is not string. |
Methods
-------
### `__call__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/ops.py#L2779-L2782)
```
__call__(
f
)
```
Registers the function `f` as gradient function for `op_type`.
tensorflow tf.pad tf.pad
======
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L3502-L3558) |
Pads a tensor.
```
tf.pad(
tensor, paddings, mode='CONSTANT', constant_values=0, name=None
)
```
This operation pads a `tensor` according to the `paddings` you specify. `paddings` is an integer tensor with shape `[n, 2]`, where n is the rank of `tensor`. For each dimension D of `input`, `paddings[D, 0]` indicates how many values to add before the contents of `tensor` in that dimension, and `paddings[D, 1]` indicates how many values to add after the contents of `tensor` in that dimension. If `mode` is "REFLECT" then both `paddings[D, 0]` and `paddings[D, 1]` must be no greater than `tensor.dim_size(D) - 1`. If `mode` is "SYMMETRIC" then both `paddings[D, 0]` and `paddings[D, 1]` must be no greater than `tensor.dim_size(D)`.
The padded size of each dimension D of the output is:
`paddings[D, 0] + tensor.dim_size(D) + paddings[D, 1]`
#### For example:
```
t = tf.constant([[1, 2, 3], [4, 5, 6]])
paddings = tf.constant([[1, 1,], [2, 2]])
# 'constant_values' is 0.
# rank of 't' is 2.
tf.pad(t, paddings, "CONSTANT") # [[0, 0, 0, 0, 0, 0, 0],
# [0, 0, 1, 2, 3, 0, 0],
# [0, 0, 4, 5, 6, 0, 0],
# [0, 0, 0, 0, 0, 0, 0]]
tf.pad(t, paddings, "REFLECT") # [[6, 5, 4, 5, 6, 5, 4],
# [3, 2, 1, 2, 3, 2, 1],
# [6, 5, 4, 5, 6, 5, 4],
# [3, 2, 1, 2, 3, 2, 1]]
tf.pad(t, paddings, "SYMMETRIC") # [[2, 1, 1, 2, 3, 3, 2],
# [2, 1, 1, 2, 3, 3, 2],
# [5, 4, 4, 5, 6, 6, 5],
# [5, 4, 4, 5, 6, 6, 5]]
```
| Args |
| `tensor` | A `Tensor`. |
| `paddings` | A `Tensor` of type `int32`. |
| `mode` | One of "CONSTANT", "REFLECT", or "SYMMETRIC" (case-insensitive) |
| `constant_values` | In "CONSTANT" mode, the scalar pad value to use. Must be same type as `tensor`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
| Raises |
| `ValueError` | When mode is not one of "CONSTANT", "REFLECT", or "SYMMETRIC". |
tensorflow Module: tf.saved_model Module: tf.saved\_model
=======================
Public API for tf.saved\_model namespace.
Modules
-------
[`experimental`](saved_model/experimental) module: Public API for tf.saved\_model.experimental namespace.
Classes
-------
[`class Asset`](saved_model/asset): Represents a file asset to hermetically include in a SavedModel.
[`class LoadOptions`](saved_model/loadoptions): Options for loading a SavedModel.
[`class SaveOptions`](saved_model/saveoptions): Options for saving to SavedModel.
Functions
---------
[`contains_saved_model(...)`](saved_model/contains_saved_model): Checks whether the provided export directory could contain a SavedModel.
[`load(...)`](saved_model/load): Load a SavedModel from `export_dir`.
[`save(...)`](saved_model/save): Exports a [tf.Module](https://www.tensorflow.org/api_docs/python/tf/Module) (and subclasses) `obj` to [SavedModel format](https://www.tensorflow.org/guide/saved_model#the_savedmodel_format_on_disk).
| Other Members |
| ASSETS\_DIRECTORY | `'assets'` |
| ASSETS\_KEY | `'saved_model_assets'` |
| CLASSIFY\_INPUTS | `'inputs'` |
| CLASSIFY\_METHOD\_NAME | `'tensorflow/serving/classify'` |
| CLASSIFY\_OUTPUT\_CLASSES | `'classes'` |
| CLASSIFY\_OUTPUT\_SCORES | `'scores'` |
| DEBUG\_DIRECTORY | `'debug'` |
| DEBUG\_INFO\_FILENAME\_PB | `'saved_model_debug_info.pb'` |
| DEFAULT\_SERVING\_SIGNATURE\_DEF\_KEY | `'serving_default'` |
| GPU | `'gpu'` |
| PREDICT\_INPUTS | `'inputs'` |
| PREDICT\_METHOD\_NAME | `'tensorflow/serving/predict'` |
| PREDICT\_OUTPUTS | `'outputs'` |
| REGRESS\_INPUTS | `'inputs'` |
| REGRESS\_METHOD\_NAME | `'tensorflow/serving/regress'` |
| REGRESS\_OUTPUTS | `'outputs'` |
| SAVED\_MODEL\_FILENAME\_PB | `'saved_model.pb'` |
| SAVED\_MODEL\_FILENAME\_PBTXT | `'saved_model.pbtxt'` |
| SAVED\_MODEL\_SCHEMA\_VERSION | `1` |
| SERVING | `'serve'` |
| TPU | `'tpu'` |
| TRAINING | `'train'` |
| VARIABLES\_DIRECTORY | `'variables'` |
| VARIABLES\_FILENAME | `'variables'` |
tensorflow Module: tf.math Module: tf.math
===============
Math Operations.
>
> **Note:** Functions taking `Tensor` arguments can also take anything accepted by [`tf.convert_to_tensor`](convert_to_tensor).
>
>
> **Note:** Elementwise binary operations in TensorFlow follow [numpy-style broadcasting](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html).
>
TensorFlow provides a variety of math functions including:
* Basic arithmetic operators and trigonometric functions.
* Special math functions (like: [`tf.math.igamma`](math/igamma) and [`tf.math.zeta`](math/zeta))
* Complex number functions (like: [`tf.math.imag`](math/imag) and [`tf.math.angle`](math/angle))
* Reductions and scans (like: [`tf.math.reduce_mean`](math/reduce_mean) and [`tf.math.cumsum`](math/cumsum))
* Segment functions (like: [`tf.math.segment_sum`](math/segment_sum))
See: [`tf.linalg`](linalg) for matrix and tensor functions.
About Segmentation
------------------
TensorFlow provides several operations that you can use to perform common math computations on tensor segments. Here a segmentation is a partitioning of a tensor along the first dimension, i.e. it defines a mapping from the first dimension onto `segment_ids`. The `segment_ids` tensor should be the size of the first dimension, `d0`, with consecutive IDs in the range `0` to `k`, where `k<d0`. In particular, a segmentation of a matrix tensor is a mapping of rows to segments.
#### For example:
```
c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]])
tf.math.segment_sum(c, tf.constant([0, 0, 1]))
# ==> [[0 0 0 0]
# [5 6 7 8]]
```
The standard `segment_*` functions assert that the segment indices are sorted. If you have unsorted indices use the equivalent `unsorted_segment_` function. These functions take an additional argument `num_segments` so that the output tensor can be efficiently allocated.
```
c = tf.constant([[1,2,3,4], [-1,-2,-3,-4], [5,6,7,8]])
tf.math.unsorted_segment_sum(c, tf.constant([0, 1, 0]), num_segments=2)
# ==> [[ 6, 8, 10, 12],
# [-1, -2, -3, -4]]
```
Modules
-------
[`special`](math/special) module: Public API for tf.math.special namespace.
Functions
---------
[`abs(...)`](math/abs): Computes the absolute value of a tensor.
[`accumulate_n(...)`](math/accumulate_n): Returns the element-wise sum of a list of tensors.
[`acos(...)`](math/acos): Computes acos of x element-wise.
[`acosh(...)`](math/acosh): Computes inverse hyperbolic cosine of x element-wise.
[`add(...)`](math/add): Returns x + y element-wise.
[`add_n(...)`](math/add_n): Adds all input tensors element-wise.
[`angle(...)`](math/angle): Returns the element-wise argument of a complex (or real) tensor.
[`argmax(...)`](math/argmax): Returns the index with the largest value across axes of a tensor.
[`argmin(...)`](math/argmin): Returns the index with the smallest value across axes of a tensor.
[`asin(...)`](math/asin): Computes the trignometric inverse sine of x element-wise.
[`asinh(...)`](math/asinh): Computes inverse hyperbolic sine of x element-wise.
[`atan(...)`](math/atan): Computes the trignometric inverse tangent of x element-wise.
[`atan2(...)`](math/atan2): Computes arctangent of `y/x` element-wise, respecting signs of the arguments.
[`atanh(...)`](math/atanh): Computes inverse hyperbolic tangent of x element-wise.
[`bessel_i0(...)`](math/bessel_i0): Computes the Bessel i0 function of `x` element-wise.
[`bessel_i0e(...)`](math/bessel_i0e): Computes the Bessel i0e function of `x` element-wise.
[`bessel_i1(...)`](math/bessel_i1): Computes the Bessel i1 function of `x` element-wise.
[`bessel_i1e(...)`](math/bessel_i1e): Computes the Bessel i1e function of `x` element-wise.
[`betainc(...)`](math/betainc): Compute the regularized incomplete beta integral \(I\_x(a, b)\).
[`bincount(...)`](math/bincount): Counts the number of occurrences of each value in an integer array.
[`ceil(...)`](math/ceil): Return the ceiling of the input, element-wise.
[`confusion_matrix(...)`](math/confusion_matrix): Computes the confusion matrix from predictions and labels.
[`conj(...)`](math/conj): Returns the complex conjugate of a complex number.
[`cos(...)`](math/cos): Computes cos of x element-wise.
[`cosh(...)`](math/cosh): Computes hyperbolic cosine of x element-wise.
[`count_nonzero(...)`](math/count_nonzero): Computes number of nonzero elements across dimensions of a tensor.
[`cumprod(...)`](math/cumprod): Compute the cumulative product of the tensor `x` along `axis`.
[`cumsum(...)`](math/cumsum): Compute the cumulative sum of the tensor `x` along `axis`.
[`cumulative_logsumexp(...)`](math/cumulative_logsumexp): Compute the cumulative log-sum-exp of the tensor `x` along `axis`.
[`digamma(...)`](math/digamma): Computes Psi, the derivative of Lgamma (the log of the absolute value of
[`divide(...)`](math/divide): Computes Python style division of `x` by `y`.
[`divide_no_nan(...)`](math/divide_no_nan): Computes a safe divide which returns 0 if `y` (denominator) is zero.
[`equal(...)`](math/equal): Returns the truth value of (x == y) element-wise.
[`erf(...)`](math/erf): Computes the [Gauss error function](https://en.wikipedia.org/wiki/Error_function) of `x` element-wise. In statistics, for non-negative values of \(x\), the error function has the following interpretation: for a random variable \(Y\) that is normally distributed with mean 0 and variance \(1/\sqrt{2}\), \(erf(x)\) is the probability that \(Y\) falls in the range \([−x, x]\).
[`erfc(...)`](math/erfc): Computes the complementary error function of `x` element-wise.
[`erfcinv(...)`](math/erfcinv): Computes the inverse of complementary error function.
[`erfinv(...)`](math/erfinv): Compute inverse error function.
[`exp(...)`](math/exp): Computes exponential of x element-wise. \(y = e^x\).
[`expm1(...)`](math/expm1): Computes `exp(x) - 1` element-wise.
[`floor(...)`](math/floor): Returns element-wise largest integer not greater than x.
[`floordiv(...)`](math/floordiv): Divides `x / y` elementwise, rounding toward the most negative integer.
[`floormod(...)`](math/floormod): Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
[`greater(...)`](math/greater): Returns the truth value of (x > y) element-wise.
[`greater_equal(...)`](math/greater_equal): Returns the truth value of (x >= y) element-wise.
[`igamma(...)`](math/igamma): Compute the lower regularized incomplete Gamma function `P(a, x)`.
[`igammac(...)`](math/igammac): Compute the upper regularized incomplete Gamma function `Q(a, x)`.
[`imag(...)`](math/imag): Returns the imaginary part of a complex (or real) tensor.
[`in_top_k(...)`](math/in_top_k): Says whether the targets are in the top `K` predictions.
[`invert_permutation(...)`](math/invert_permutation): Computes the inverse permutation of a tensor.
[`is_finite(...)`](math/is_finite): Returns which elements of x are finite.
[`is_inf(...)`](math/is_inf): Returns which elements of x are Inf.
[`is_nan(...)`](math/is_nan): Returns which elements of x are NaN.
[`is_non_decreasing(...)`](math/is_non_decreasing): Returns `True` if `x` is non-decreasing.
[`is_strictly_increasing(...)`](math/is_strictly_increasing): Returns `True` if `x` is strictly increasing.
[`l2_normalize(...)`](math/l2_normalize): Normalizes along dimension `axis` using an L2 norm. (deprecated arguments)
[`lbeta(...)`](math/lbeta): Computes \(ln(|Beta(x)|)\), reducing along the last dimension.
[`less(...)`](math/less): Returns the truth value of (x < y) element-wise.
[`less_equal(...)`](math/less_equal): Returns the truth value of (x <= y) element-wise.
[`lgamma(...)`](math/lgamma): Computes the log of the absolute value of `Gamma(x)` element-wise.
[`log(...)`](math/log): Computes natural logarithm of x element-wise.
[`log1p(...)`](math/log1p): Computes natural logarithm of (1 + x) element-wise.
[`log_sigmoid(...)`](math/log_sigmoid): Computes log sigmoid of `x` element-wise.
[`log_softmax(...)`](nn/log_softmax): Computes log softmax activations.
[`logical_and(...)`](math/logical_and): Returns the truth value of x AND y element-wise.
[`logical_not(...)`](math/logical_not): Returns the truth value of `NOT x` element-wise.
[`logical_or(...)`](math/logical_or): Returns the truth value of x OR y element-wise.
[`logical_xor(...)`](math/logical_xor): Logical XOR function.
[`maximum(...)`](math/maximum): Returns the max of x and y (i.e. x > y ? x : y) element-wise.
[`minimum(...)`](math/minimum): Returns the min of x and y (i.e. x < y ? x : y) element-wise.
[`mod(...)`](math/floormod): Returns element-wise remainder of division. When `x < 0` xor `y < 0` is
[`multiply(...)`](math/multiply): Returns an element-wise x \* y.
[`multiply_no_nan(...)`](math/multiply_no_nan): Computes the product of x and y and returns 0 if the y is zero, even if x is NaN or infinite.
[`ndtri(...)`](math/ndtri): Compute quantile of Standard Normal.
[`negative(...)`](math/negative): Computes numerical negative value element-wise.
[`nextafter(...)`](math/nextafter): Returns the next representable value of `x1` in the direction of `x2`, element-wise.
[`not_equal(...)`](math/not_equal): Returns the truth value of (x != y) element-wise.
[`polygamma(...)`](math/polygamma): Compute the polygamma function \(\psi^{(n)}(x)\).
[`polyval(...)`](math/polyval): Computes the elementwise value of a polynomial.
[`pow(...)`](math/pow): Computes the power of one value to another.
[`real(...)`](math/real): Returns the real part of a complex (or real) tensor.
[`reciprocal(...)`](math/reciprocal): Computes the reciprocal of x element-wise.
[`reciprocal_no_nan(...)`](math/reciprocal_no_nan): Performs a safe reciprocal operation, element wise.
[`reduce_all(...)`](math/reduce_all): Computes [`tf.math.logical_and`](math/logical_and) of elements across dimensions of a tensor.
[`reduce_any(...)`](math/reduce_any): Computes [`tf.math.logical_or`](math/logical_or) of elements across dimensions of a tensor.
[`reduce_euclidean_norm(...)`](math/reduce_euclidean_norm): Computes the Euclidean norm of elements across dimensions of a tensor.
[`reduce_logsumexp(...)`](math/reduce_logsumexp): Computes log(sum(exp(elements across dimensions of a tensor))).
[`reduce_max(...)`](math/reduce_max): Computes [`tf.math.maximum`](math/maximum) of elements across dimensions of a tensor.
[`reduce_mean(...)`](math/reduce_mean): Computes the mean of elements across dimensions of a tensor.
[`reduce_min(...)`](math/reduce_min): Computes the [`tf.math.minimum`](math/minimum) of elements across dimensions of a tensor.
[`reduce_prod(...)`](math/reduce_prod): Computes [`tf.math.multiply`](math/multiply) of elements across dimensions of a tensor.
[`reduce_std(...)`](math/reduce_std): Computes the standard deviation of elements across dimensions of a tensor.
[`reduce_sum(...)`](math/reduce_sum): Computes the sum of elements across dimensions of a tensor.
[`reduce_variance(...)`](math/reduce_variance): Computes the variance of elements across dimensions of a tensor.
[`rint(...)`](math/rint): Returns element-wise integer closest to x.
[`round(...)`](math/round): Rounds the values of a tensor to the nearest integer, element-wise.
[`rsqrt(...)`](math/rsqrt): Computes reciprocal of square root of x element-wise.
[`scalar_mul(...)`](math/scalar_mul): Multiplies a scalar times a `Tensor` or `IndexedSlices` object.
[`segment_max(...)`](math/segment_max): Computes the maximum along segments of a tensor.
[`segment_mean(...)`](math/segment_mean): Computes the mean along segments of a tensor.
[`segment_min(...)`](math/segment_min): Computes the minimum along segments of a tensor.
[`segment_prod(...)`](math/segment_prod): Computes the product along segments of a tensor.
[`segment_sum(...)`](math/segment_sum): Computes the sum along segments of a tensor.
[`sigmoid(...)`](math/sigmoid): Computes sigmoid of `x` element-wise.
[`sign(...)`](math/sign): Returns an element-wise indication of the sign of a number.
[`sin(...)`](math/sin): Computes sine of x element-wise.
[`sinh(...)`](math/sinh): Computes hyperbolic sine of x element-wise.
[`sobol_sample(...)`](math/sobol_sample): Generates points from the Sobol sequence.
[`softmax(...)`](nn/softmax): Computes softmax activations.
[`softplus(...)`](math/softplus): Computes elementwise softplus: `softplus(x) = log(exp(x) + 1)`.
[`softsign(...)`](nn/softsign): Computes softsign: `features / (abs(features) + 1)`.
[`sqrt(...)`](math/sqrt): Computes element-wise square root of the input tensor.
[`square(...)`](math/square): Computes square of x element-wise.
[`squared_difference(...)`](math/squared_difference): Returns conj(x - y)(x - y) element-wise.
[`subtract(...)`](math/subtract): Returns x - y element-wise.
[`tan(...)`](math/tan): Computes tan of x element-wise.
[`tanh(...)`](math/tanh): Computes hyperbolic tangent of `x` element-wise.
[`top_k(...)`](math/top_k): Finds values and indices of the `k` largest entries for the last dimension.
[`truediv(...)`](math/truediv): Divides x / y elementwise (using Python 3 division operator semantics).
[`unsorted_segment_max(...)`](math/unsorted_segment_max): Computes the maximum along segments of a tensor.
[`unsorted_segment_mean(...)`](math/unsorted_segment_mean): Computes the mean along segments of a tensor.
[`unsorted_segment_min(...)`](math/unsorted_segment_min): Computes the minimum along segments of a tensor.
[`unsorted_segment_prod(...)`](math/unsorted_segment_prod): Computes the product along segments of a tensor.
[`unsorted_segment_sqrt_n(...)`](math/unsorted_segment_sqrt_n): Computes the sum along segments of a tensor divided by the sqrt(N).
[`unsorted_segment_sum(...)`](math/unsorted_segment_sum): Computes the sum along segments of a tensor.
[`xdivy(...)`](math/xdivy): Returns 0 if x == 0, and x / y otherwise, elementwise.
[`xlog1py(...)`](math/xlog1py): Compute x \* log1p(y).
[`xlogy(...)`](math/xlogy): Returns 0 if x == 0, and x \* log(y) otherwise, elementwise.
[`zero_fraction(...)`](math/zero_fraction): Returns the fraction of zeros in `value`.
[`zeta(...)`](math/zeta): Compute the Hurwitz zeta function \(\zeta(x, q)\).
| programming_docs |
tensorflow tf.UnconnectedGradients tf.UnconnectedGradients
=======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/unconnected_gradients.py#L23-L39) |
Controls how gradient computation behaves when y does not depend on x.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.UnconnectedGradients`](https://www.tensorflow.org/api_docs/python/tf/UnconnectedGradients)
The gradient of y with respect to x can be zero in two different ways: there could be no differentiable path in the graph connecting x to y (and so we can statically prove that the gradient is zero) or it could be that runtime values of tensors in a particular execution lead to a gradient of zero (say, if a relu unit happens to not be activated). To allow you to distinguish between these two cases you can choose what value gets returned for the gradient when there is no path in the graph from x to y:
* `NONE`: Indicates that [None] will be returned if there is no path from x to y
* `ZERO`: Indicates that a zero tensor will be returned in the shape of x.
| Class Variables |
| NONE | `<UnconnectedGradients.NONE: 'none'>` |
| ZERO | `<UnconnectedGradients.ZERO: 'zero'>` |
tensorflow tf.foldl tf.foldl
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/functional_ops.py#L163-L237) |
foldl on the list of tensors unpacked from `elems` on dimension 0. (deprecated argument values)
```
tf.foldl(
fn,
elems,
initializer=None,
parallel_iterations=10,
back_prop=True,
swap_memory=False,
name=None
)
```
This foldl operator repeatedly applies the callable `fn` to a sequence of elements from first to last. The elements are made of the tensors unpacked from `elems` on dimension 0. The callable fn takes two tensors as arguments. The first argument is the accumulated value computed from the preceding invocation of fn, and the second is the value at the current position of `elems`. If `initializer` is None, `elems` must contain at least one element, and its first element is used as the initializer.
Suppose that `elems` is unpacked into `values`, a list of tensors. The shape of the result tensor is fn(initializer, values[0]).shape`.
This method also allows multi-arity `elems` and output of `fn`. If `elems` is a (possibly nested) list or tuple of tensors, then each of these tensors must have a matching first (unpack) dimension. The signature of `fn` may match the structure of `elems`. That is, if `elems` is `(t1, [t2, t3, [t4, t5]])`, then an appropriate signature for `fn` is: `fn = lambda (t1, [t2, t3, [t4, t5]]):`.
| Args |
| `fn` | The callable to be performed. |
| `elems` | A tensor or (possibly nested) sequence of tensors, each of which will be unpacked along their first dimension. The nested sequence of the resulting slices will be the first argument to `fn`. |
| `initializer` | (optional) A tensor or (possibly nested) sequence of tensors, as the initial value for the accumulator. |
| `parallel_iterations` | (optional) The number of iterations allowed to run in parallel. |
| `back_prop` | (optional) Deprecated. False disables support for back propagation. Prefer using [`tf.stop_gradient`](stop_gradient) instead. |
| `swap_memory` | (optional) True enables GPU-CPU memory swapping. |
| `name` | (optional) Name prefix for the returned tensors. |
| Returns |
| A tensor or (possibly nested) sequence of tensors, resulting from applying `fn` consecutively to the list of tensors unpacked from `elems`, from first to last. |
| Raises |
| `TypeError` | if `fn` is not callable. |
#### Example:
```
elems = tf.constant([1, 2, 3, 4, 5, 6])
sum = foldl(lambda a, x: a + x, elems)
# sum == 21
```
tensorflow tf.concat tf.concat
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1732-L1824) |
Concatenates tensors along one dimension.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.concat`](https://www.tensorflow.org/api_docs/python/tf/concat)
```
tf.concat(
values, axis, name='concat'
)
```
See also [`tf.tile`](tile), [`tf.stack`](stack), [`tf.repeat`](repeat).
Concatenates the list of tensors `values` along dimension `axis`. If `values[i].shape = [D0, D1, ... Daxis(i), ...Dn]`, the concatenated result has shape
```
[D0, D1, ... Raxis, ...Dn]
```
where
```
Raxis = sum(Daxis(i))
```
That is, the data from the input tensors is joined along the `axis` dimension.
The number of dimensions of the input tensors must match, and all dimensions except `axis` must be equal.
#### For example:
```
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0)
<tf.Tensor: shape=(4, 3), dtype=int32, numpy=
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]], dtype=int32)>
```
```
tf.concat([t1, t2], 1)
<tf.Tensor: shape=(2, 6), dtype=int32, numpy=
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]], dtype=int32)>
```
As in Python, the `axis` could also be negative numbers. Negative `axis` are interpreted as counting from the end of the rank, i.e., `axis + rank(values)`-th dimension.
#### For example:
```
t1 = [[[1, 2], [2, 3]], [[4, 4], [5, 3]]]
t2 = [[[7, 4], [8, 4]], [[2, 10], [15, 11]]]
tf.concat([t1, t2], -1)
<tf.Tensor: shape=(2, 2, 4), dtype=int32, numpy=
array([[[ 1, 2, 7, 4],
[ 2, 3, 8, 4]],
[[ 4, 4, 2, 10],
[ 5, 3, 15, 11]]], dtype=int32)>
```
>
> **Note:** If you are concatenating along a new axis consider using stack. E.g.
>
```
tf.concat([tf.expand_dims(t, axis) for t in tensors], axis)
```
can be rewritten as
```
tf.stack(tensors, axis=axis)
```
| Args |
| `values` | A list of `Tensor` objects or a single `Tensor`. |
| `axis` | 0-D `int32` `Tensor`. Dimension along which to concatenate. Must be in the range `[-rank(values), rank(values))`. As in Python, indexing for axis is 0-based. Positive axis in the rage of `[0, rank(values))` refers to `axis`-th dimension. And negative axis refers to `axis + rank(values)`-th dimension. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` resulting from concatenation of the input tensors. |
tensorflow tf.gather_nd tf.gather\_nd
=============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L5693-L5696) |
Gather slices from `params` into a Tensor with shape specified by `indices`.
```
tf.gather_nd(
params, indices, batch_dims=0, name=None
)
```
`indices` is a `Tensor` of indices into `params`. The index vectors are arranged along the last axis of `indices`.
This is similar to [`tf.gather`](gather), in which `indices` defines slices into the first dimension of `params`. In [`tf.gather_nd`](gather_nd), `indices` defines slices into the first `N` dimensions of `params`, where `N = indices.shape[-1]`.
Gathering scalars
-----------------
In the simplest case the vectors in `indices` index the full rank of `params`:
```
tf.gather_nd(
indices=[[0, 0],
[1, 1]],
params = [['a', 'b'],
['c', 'd']]).numpy()
array([b'a', b'd'], dtype=object)
```
In this case the result has 1-axis fewer than `indices`, and each index vector is replaced by the scalar indexed from `params`.
In this case the shape relationship is:
```
index_depth = indices.shape[-1]
assert index_depth == params.shape.rank
result_shape = indices.shape[:-1]
```
If `indices` has a rank of `K`, it is helpful to think `indices` as a (K-1)-dimensional tensor of indices into `params`.
Gathering slices
----------------
If the index vectors do not index the full rank of `params` then each location in the result contains a slice of params. This example collects rows from a matrix:
```
tf.gather_nd(
indices = [[1],
[0]],
params = [['a', 'b', 'c'],
['d', 'e', 'f']]).numpy()
array([[b'd', b'e', b'f'],
[b'a', b'b', b'c']], dtype=object)
```
Here `indices` contains `[2]` index vectors, each with a length of `1`. The index vectors each refer to rows of the `params` matrix. Each row has a shape of `[3]` so the output shape is `[2, 3]`.
In this case, the relationship between the shapes is:
```
index_depth = indices.shape[-1]
outer_shape = indices.shape[:-1]
assert index_depth <= params.shape.rank
inner_shape = params.shape[index_depth:]
output_shape = outer_shape + inner_shape
```
It is helpful to think of the results in this case as tensors-of-tensors. The shape of the outer tensor is set by the leading dimensions of `indices`. While the shape of the inner tensors is the shape of a single slice.
Batches
-------
Additionally both `params` and `indices` can have `M` leading batch dimensions that exactly match. In this case `batch_dims` must be set to `M`.
For example, to collect one row from each of a batch of matrices you could set the leading elements of the index vectors to be their location in the batch:
```
tf.gather_nd(
indices = [[0, 1],
[1, 0],
[2, 4],
[3, 2],
[4, 1]],
params=tf.zeros([5, 7, 3])).shape.as_list()
[5, 3]
```
The `batch_dims` argument lets you omit those leading location dimensions from the index:
```
tf.gather_nd(
batch_dims=1,
indices = [[1],
[0],
[4],
[2],
[1]],
params=tf.zeros([5, 7, 3])).shape.as_list()
[5, 3]
```
This is equivalent to caling a separate `gather_nd` for each location in the batch dimensions.
```
params=tf.zeros([5, 7, 3])
indices=tf.zeros([5, 1])
batch_dims = 1
index_depth = indices.shape[-1]
batch_shape = indices.shape[:batch_dims]
assert params.shape[:batch_dims] == batch_shape
outer_shape = indices.shape[batch_dims:-1]
assert index_depth <= params.shape.rank
inner_shape = params.shape[batch_dims + index_depth:]
output_shape = batch_shape + outer_shape + inner_shape
output_shape.as_list()
[5, 3]
```
### More examples
Indexing into a 3-tensor:
```
tf.gather_nd(
indices = [[1]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[[b'a1', b'b1'],
[b'c1', b'd1']]], dtype=object)
```
```
tf.gather_nd(
indices = [[0, 1], [1, 0]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[b'c0', b'd0'],
[b'a1', b'b1']], dtype=object)
```
```
tf.gather_nd(
indices = [[0, 0, 1], [1, 0, 1]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([b'b0', b'b1'], dtype=object)
```
The examples below are for the case when only indices have leading extra dimensions. If both 'params' and 'indices' have leading batch dimensions, use the 'batch\_dims' parameter to run gather\_nd in batch mode.
Batched indexing into a matrix:
```
tf.gather_nd(
indices = [[[0, 0]], [[0, 1]]],
params = [['a', 'b'], ['c', 'd']]).numpy()
array([[b'a'],
[b'b']], dtype=object)
```
Batched slice indexing into a matrix:
```
tf.gather_nd(
indices = [[[1]], [[0]]],
params = [['a', 'b'], ['c', 'd']]).numpy()
array([[[b'c', b'd']],
[[b'a', b'b']]], dtype=object)
```
Batched indexing into a 3-tensor:
```
tf.gather_nd(
indices = [[[1]], [[0]]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[[[b'a1', b'b1'],
[b'c1', b'd1']]],
[[[b'a0', b'b0'],
[b'c0', b'd0']]]], dtype=object)
```
```
tf.gather_nd(
indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[[b'c0', b'd0'],
[b'a1', b'b1']],
[[b'a0', b'b0'],
[b'c1', b'd1']]], dtype=object)
```
```
tf.gather_nd(
indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[b'b0', b'b1'],
[b'd0', b'c1']], dtype=object)
```
Examples with batched 'params' and 'indices':
```
tf.gather_nd(
batch_dims = 1,
indices = [[1],
[0]],
params = [[['a0', 'b0'],
['c0', 'd0']],
[['a1', 'b1'],
['c1', 'd1']]]).numpy()
array([[b'c0', b'd0'],
[b'a1', b'b1']], dtype=object)
```
```
tf.gather_nd(
batch_dims = 1,
indices = [[[1]], [[0]]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[[b'c0', b'd0']],
[[b'a1', b'b1']]], dtype=object)
```
```
tf.gather_nd(
batch_dims = 1,
indices = [[[1, 0]], [[0, 1]]],
params = [[['a0', 'b0'], ['c0', 'd0']],
[['a1', 'b1'], ['c1', 'd1']]]).numpy()
array([[b'c0'],
[b'b1']], dtype=object)
```
See also [`tf.gather`](gather).
| Args |
| `params` | A `Tensor`. The tensor from which to gather values. |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `name` | A name for the operation (optional). |
| `batch_dims` | An integer or a scalar 'Tensor'. The number of batch dimensions. |
| Returns |
| A `Tensor`. Has the same type as `params`. |
tensorflow Module: tf.linalg Module: tf.linalg
=================
Operations for linear algebra.
Modules
-------
[`experimental`](linalg/experimental) module: Public API for tf.linalg.experimental namespace.
Classes
-------
[`class LinearOperator`](linalg/linearoperator): Base class defining a [batch of] linear operator[s].
[`class LinearOperatorAdjoint`](linalg/linearoperatoradjoint): `LinearOperator` representing the adjoint of another operator.
[`class LinearOperatorBlockDiag`](linalg/linearoperatorblockdiag): Combines one or more `LinearOperators` in to a Block Diagonal matrix.
[`class LinearOperatorBlockLowerTriangular`](linalg/linearoperatorblocklowertriangular): Combines `LinearOperators` into a blockwise lower-triangular matrix.
[`class LinearOperatorCirculant`](linalg/linearoperatorcirculant): `LinearOperator` acting like a circulant matrix.
[`class LinearOperatorCirculant2D`](linalg/linearoperatorcirculant2d): `LinearOperator` acting like a block circulant matrix.
[`class LinearOperatorCirculant3D`](linalg/linearoperatorcirculant3d): `LinearOperator` acting like a nested block circulant matrix.
[`class LinearOperatorComposition`](linalg/linearoperatorcomposition): Composes one or more `LinearOperators`.
[`class LinearOperatorDiag`](linalg/linearoperatordiag): `LinearOperator` acting like a [batch] square diagonal matrix.
[`class LinearOperatorFullMatrix`](linalg/linearoperatorfullmatrix): `LinearOperator` that wraps a [batch] matrix.
[`class LinearOperatorHouseholder`](linalg/linearoperatorhouseholder): `LinearOperator` acting like a [batch] of Householder transformations.
[`class LinearOperatorIdentity`](linalg/linearoperatoridentity): `LinearOperator` acting like a [batch] square identity matrix.
[`class LinearOperatorInversion`](linalg/linearoperatorinversion): `LinearOperator` representing the inverse of another operator.
[`class LinearOperatorKronecker`](linalg/linearoperatorkronecker): Kronecker product between two `LinearOperators`.
[`class LinearOperatorLowRankUpdate`](linalg/linearoperatorlowrankupdate): Perturb a `LinearOperator` with a rank `K` update.
[`class LinearOperatorLowerTriangular`](linalg/linearoperatorlowertriangular): `LinearOperator` acting like a [batch] square lower triangular matrix.
[`class LinearOperatorPermutation`](linalg/linearoperatorpermutation): `LinearOperator` acting like a [batch] of permutation matrices.
[`class LinearOperatorScaledIdentity`](linalg/linearoperatorscaledidentity): `LinearOperator` acting like a scaled [batch] identity matrix `A = c I`.
[`class LinearOperatorToeplitz`](linalg/linearoperatortoeplitz): `LinearOperator` acting like a [batch] of toeplitz matrices.
[`class LinearOperatorTridiag`](linalg/linearoperatortridiag): `LinearOperator` acting like a [batch] square tridiagonal matrix.
[`class LinearOperatorZeros`](linalg/linearoperatorzeros): `LinearOperator` acting like a [batch] zero matrix.
Functions
---------
[`adjoint(...)`](linalg/adjoint): Transposes the last two dimensions of and conjugates tensor `matrix`.
[`band_part(...)`](linalg/band_part): Copy a tensor setting everything outside a central band in each innermost matrix to zero.
[`banded_triangular_solve(...)`](linalg/banded_triangular_solve): Solve triangular systems of equations with a banded solver.
[`cholesky(...)`](linalg/cholesky): Computes the Cholesky decomposition of one or more square matrices.
[`cholesky_solve(...)`](linalg/cholesky_solve): Solves systems of linear eqns `A X = RHS`, given Cholesky factorizations.
[`cross(...)`](linalg/cross): Compute the pairwise cross product.
[`det(...)`](linalg/det): Computes the determinant of one or more square matrices.
[`diag(...)`](linalg/diag): Returns a batched diagonal tensor with given batched diagonal values.
[`diag_part(...)`](linalg/diag_part): Returns the batched diagonal part of a batched tensor.
[`eig(...)`](linalg/eig): Computes the eigen decomposition of a batch of matrices.
[`eigh(...)`](linalg/eigh): Computes the eigen decomposition of a batch of self-adjoint matrices.
[`eigh_tridiagonal(...)`](linalg/eigh_tridiagonal): Computes the eigenvalues of a Hermitian tridiagonal matrix.
[`eigvals(...)`](linalg/eigvals): Computes the eigenvalues of one or more matrices.
[`eigvalsh(...)`](linalg/eigvalsh): Computes the eigenvalues of one or more self-adjoint matrices.
[`einsum(...)`](einsum): Tensor contraction over specified indices and outer product.
[`expm(...)`](linalg/expm): Computes the matrix exponential of one or more square matrices.
[`eye(...)`](eye): Construct an identity matrix, or a batch of matrices.
[`global_norm(...)`](linalg/global_norm): Computes the global norm of multiple tensors.
[`inv(...)`](linalg/inv): Computes the inverse of one or more square invertible matrices or their adjoints (conjugate transposes).
[`l2_normalize(...)`](math/l2_normalize): Normalizes along dimension `axis` using an L2 norm. (deprecated arguments)
[`logdet(...)`](linalg/logdet): Computes log of the determinant of a hermitian positive definite matrix.
[`logm(...)`](linalg/logm): Computes the matrix logarithm of one or more square matrices:
[`lstsq(...)`](linalg/lstsq): Solves one or more linear least-squares problems.
[`lu(...)`](linalg/lu): Computes the LU decomposition of one or more square matrices.
[`lu_matrix_inverse(...)`](linalg/lu_matrix_inverse): Computes the inverse given the LU decomposition(s) of one or more matrices.
[`lu_reconstruct(...)`](linalg/lu_reconstruct): The reconstruct one or more matrices from their LU decomposition(s).
[`lu_solve(...)`](linalg/lu_solve): Solves systems of linear eqns `A X = RHS`, given LU factorizations.
[`matmul(...)`](linalg/matmul): Multiplies matrix `a` by matrix `b`, producing `a` \* `b`.
[`matrix_rank(...)`](linalg/matrix_rank): Compute the matrix rank of one or more matrices.
[`matrix_transpose(...)`](linalg/matrix_transpose): Transposes last two dimensions of tensor `a`.
[`matvec(...)`](linalg/matvec): Multiplies matrix `a` by vector `b`, producing `a` \* `b`.
[`norm(...)`](norm): Computes the norm of vectors, matrices, and tensors.
[`normalize(...)`](linalg/normalize): Normalizes `tensor` along dimension `axis` using specified norm.
[`pinv(...)`](linalg/pinv): Compute the Moore-Penrose pseudo-inverse of one or more matrices.
[`qr(...)`](linalg/qr): Computes the QR decompositions of one or more matrices.
[`set_diag(...)`](linalg/set_diag): Returns a batched matrix tensor with new batched diagonal values.
[`slogdet(...)`](linalg/slogdet): Computes the sign and the log of the absolute value of the determinant of
[`solve(...)`](linalg/solve): Solves systems of linear equations.
[`sqrtm(...)`](linalg/sqrtm): Computes the matrix square root of one or more square matrices:
[`svd(...)`](linalg/svd): Computes the singular value decompositions of one or more matrices.
[`tensor_diag(...)`](linalg/tensor_diag): Returns a diagonal tensor with a given diagonal values.
[`tensor_diag_part(...)`](linalg/tensor_diag_part): Returns the diagonal part of the tensor.
[`tensordot(...)`](tensordot): Tensor contraction of a and b along specified axes and outer product.
[`trace(...)`](linalg/trace): Compute the trace of a tensor `x`.
[`triangular_solve(...)`](linalg/triangular_solve): Solve systems of linear equations with upper or lower triangular matrices.
[`tridiagonal_matmul(...)`](linalg/tridiagonal_matmul): Multiplies tridiagonal matrix by matrix.
[`tridiagonal_solve(...)`](linalg/tridiagonal_solve): Solves tridiagonal systems of equations.
| programming_docs |
tensorflow Module: tf.graph_util Module: tf.graph\_util
======================
Helpers to manipulate a tensor graph in python.
Functions
---------
[`import_graph_def(...)`](graph_util/import_graph_def): Imports the graph from `graph_def` into the current default `Graph`. (deprecated arguments)
tensorflow Module: tf.version Module: tf.version
==================
Public API for tf.version namespace.
| Other Members |
| COMPILER\_VERSION | `'9.3.1 20200408'` |
| GIT\_VERSION | `'v2.9.0-rc2-42-g8a20d54a3c1'` |
| GRAPH\_DEF\_VERSION | `1087` |
| GRAPH\_DEF\_VERSION\_MIN\_CONSUMER | `0` |
| GRAPH\_DEF\_VERSION\_MIN\_PRODUCER | `0` |
| VERSION | `'2.9.0'` |
tensorflow tf.realdiv tf.realdiv
==========
Returns x / y element-wise for real types.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.realdiv`](https://www.tensorflow.org/api_docs/python/tf/realdiv)
```
tf.realdiv(
x, y, name=None
)
```
If `x` and `y` are reals, this will return the floating-point division.
>
> **Note:** `Div` supports broadcasting. More about broadcasting [here](http://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)
>
| Args |
| `x` | A `Tensor`. Must be one of the following types: `bfloat16`, `half`, `float32`, `float64`, `uint8`, `int8`, `uint16`, `int16`, `int32`, `uint32`, `uint64`, `int64`, `complex64`, `complex128`. |
| `y` | A `Tensor`. Must have the same type as `x`. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `x`. |
tensorflow tf.scatter_nd tf.scatter\_nd
==============
Scatters `updates` into a tensor of shape `shape` according to `indices`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.manip.scatter_nd`](https://www.tensorflow.org/api_docs/python/tf/scatter_nd), [`tf.compat.v1.scatter_nd`](https://www.tensorflow.org/api_docs/python/tf/scatter_nd)
```
tf.scatter_nd(
indices, updates, shape, name=None
)
```
Update the input tensor by scattering sparse `updates` according to individual values at the specified `indices`. This op returns an `output` tensor with the `shape` you specify. This op is the inverse of the [`tf.gather_nd`](gather_nd) operator which extracts values or slices from a given tensor.
This operation is similar to [`tf.tensor_scatter_nd_add`](tensor_scatter_nd_add), except that the tensor is zero-initialized. Calling [`tf.scatter_nd(indices, values, shape)`](scatter_nd) is identical to calling `tf.tensor_scatter_nd_add(tf.zeros(shape, values.dtype), indices, values)`
If `indices` contains duplicates, the duplicate `values` are accumulated (summed).
`indices` is an integer tensor of shape `shape`. The last dimension of `indices` can be at most the rank of `shape`:
```
indices.shape[-1] <= shape.rank
```
The last dimension of `indices` corresponds to indices of elements (if `indices.shape[-1] = shape.rank`) or slices (if `indices.shape[-1] < shape.rank`) along dimension `indices.shape[-1]` of `shape`.
`updates` is a tensor with shape:
```
indices.shape[:-1] + shape[indices.shape[-1]:]
```
The simplest form of the scatter op is to insert individual elements in a tensor by index. Consider an example where you want to insert 4 scattered elements in a rank-1 tensor with 8 elements.
In Python, this scatter operation would look like this:
```
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
scatter = tf.scatter_nd(indices, updates, shape)
print(scatter)
```
The resulting tensor would look like this:
```
[0, 11, 0, 10, 9, 0, 0, 12]
```
You can also insert entire slices of a higher rank tensor all at once. For example, you can insert two slices in the first dimension of a rank-3 tensor with two matrices of new values.
In Python, this scatter operation would look like this:
```
indices = tf.constant([[0], [2]])
updates = tf.constant([[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]],
[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]]])
shape = tf.constant([4, 4, 4])
scatter = tf.scatter_nd(indices, updates, shape)
print(scatter)
```
The resulting tensor would look like this:
```
[[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]],
[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]
```
Note that on CPU, if an out of bound index is found, an error is returned. On GPU, if an out of bound index is found, the index is ignored.
| Args |
| `indices` | A `Tensor`. Must be one of the following types: `int16`, `int32`, `int64`. Tensor of indices. |
| `updates` | A `Tensor`. Values to scatter into the output tensor. |
| `shape` | A `Tensor`. Must have the same type as `indices`. 1-D. The shape of the output tensor. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `updates`. |
tensorflow tf.function tf.function
===========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/eager/def_function.py#L1285-L1694) |
Compiles a function into a callable TensorFlow graph. (deprecated arguments) (deprecated arguments)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.function`](https://www.tensorflow.org/api_docs/python/tf/function)
```
tf.function(
func=None,
input_signature=None,
autograph=True,
jit_compile=None,
reduce_retracing=False,
experimental_implements=None,
experimental_autograph_options=None,
experimental_relax_shapes=None,
experimental_compile=None,
experimental_follow_type_hints=None
) -> tf.types.experimental.GenericFunction
```
[`tf.function`](function) constructs a [`tf.types.experimental.GenericFunction`](types/experimental/genericfunction) that executes a TensorFlow graph ([`tf.Graph`](graph)) created by trace-compiling the TensorFlow operations in `func`. More information on the topic can be found in [Introduction to Graphs and tf.function](https://www.tensorflow.org/guide/intro_to_graphs).
See [Better Performance with tf.function](https://www.tensorflow.org/guide/function) for tips on performance and known limitations.
#### Example usage:
```
@tf.function
def f(x, y):
return x ** 2 + y
x = tf.constant([2, 3])
y = tf.constant([3, -2])
f(x, y)
<tf.Tensor: ... numpy=array([7, 7], ...)>
```
The trace-compilation allows non-TensorFlow operations to execute, but under special conditions. In general, only TensorFlow operations are guaranteed to run and create fresh results whenever the `GenericFunction` is called.
Features
--------
`func` may use data-dependent Python control flow statements, including `if`, `for`, `while` `break`, `continue` and `return`:
```
@tf.function
def f(x):
if tf.reduce_sum(x) > 0:
return x * x
else:
return -x // 2
f(tf.constant(-2))
<tf.Tensor: ... numpy=1>
```
`func`'s closure may include [`tf.Tensor`](tensor) and [`tf.Variable`](variable) objects:
```
@tf.function
def f():
return x ** 2 + y
x = tf.constant([-2, -3])
y = tf.Variable([3, -2])
f()
<tf.Tensor: ... numpy=array([7, 7], ...)>
```
`func` may also use ops with side effects, such as [`tf.print`](print), [`tf.Variable`](variable) and others:
```
v = tf.Variable(1)
@tf.function
def f(x):
for i in tf.range(x):
v.assign_add(i)
f(3)
v
<tf.Variable ... numpy=4>
```
```
l = []
@tf.function
def f(x):
for i in x:
l.append(i + 1) # Caution! Will only happen once when tracing
f(tf.constant([1, 2, 3]))
l
[<tf.Tensor ...>]
```
Instead, use TensorFlow collections like [`tf.TensorArray`](tensorarray):
```
@tf.function
def f(x):
ta = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
for i in range(len(x)):
ta = ta.write(i, x[i] + 1)
return ta.stack()
f(tf.constant([1, 2, 3]))
<tf.Tensor: ..., numpy=array([2, 3, 4], ...)>
```
[`tf.function`](function) creates polymorphic callables
--------------------------------------------------------
Internally, [`tf.types.experimental.GenericFunction`](types/experimental/genericfunction) may contain multiple [`tf.types.experimental.ConcreteFunction`](types/experimental/concretefunction)s, each specialized to arguments with different data types or shapes, since TensorFlow can perform more optimizations on graphs of specific shapes, dtypes and values of constant arguments. [`tf.function`](function) treats any pure Python values as opaque objects (best thought of as compile-time constants), and builds a separate [`tf.Graph`](graph) for each set of Python arguments that it encounters. For more information, see the [tf.function guide](https://www.tensorflow.org/guide/function#rules_of_tracing)
Executing a `GenericFunction` will select and execute the appropriate `ConcreteFunction` based on the argument types and values.
To obtain an individual `ConcreteFunction`, use the [`GenericFunction.get_concrete_function`](types/experimental/genericfunction#get_concrete_function) method. It can be called with the same arguments as `func` and returns a [`tf.types.experimental.ConcreteFunction`](types/experimental/concretefunction). `ConcreteFunction`s are backed by a single [`tf.Graph`](graph):
```
@tf.function
def f(x):
return x + 1
isinstance(f.get_concrete_function(1).graph, tf.Graph)
True
```
`ConcreteFunction`s can be executed just like `GenericFunction`s, but their input is resticted to the types to which they're specialized.
Retracing
---------
`ConcreteFunctions` are built (traced) on the fly, as the `GenericFunction` is called with new TensorFlow types or shapes, or with new Python values as arguments. When `GenericFunction` builds a new trace, it is said that `func` is retraced. Retracing is a frequent performance concern for [`tf.function`](function) as it can be considerably slower than executing a graph that's already been traced. It is ideal to minimize the amount of retracing in your code.
```
@tf.function
def f(x):
return tf.abs(x)
f1 = f.get_concrete_function(1)
f2 = f.get_concrete_function(2) # Slow - compiles new graph
f1 is f2
False
f1 = f.get_concrete_function(tf.constant(1))
f2 = f.get_concrete_function(tf.constant(2)) # Fast - reuses f1
f1 is f2
True
```
Python numerical arguments should only be used when they take few distinct values, such as hyperparameters like the number of layers in a neural network.
Input signatures
----------------
For Tensor arguments, `GenericFunction`creates a new `ConcreteFunction` for every unique set of input shapes and datatypes. The example below creates two separate `ConcreteFunction`s, each specialized to a different shape:
```
@tf.function
def f(x):
return x + 1
vector = tf.constant([1.0, 1.0])
matrix = tf.constant([[3.0]])
f.get_concrete_function(vector) is f.get_concrete_function(matrix)
False
```
An "input signature" can be optionally provided to [`tf.function`](function) to control this process. The input signature specifies the shape and type of each Tensor argument to the function using a [`tf.TensorSpec`](tensorspec) object. More general shapes can be used. This ensures only one `ConcreteFunction` is created, and restricts the `GenericFunction` to the specified shapes and types. It is an effective way to limit retracing when Tensors have dynamic shapes.
```
@tf.function(
input_signature=[tf.TensorSpec(shape=None, dtype=tf.float32)])
def f(x):
return x + 1
vector = tf.constant([1.0, 1.0])
matrix = tf.constant([[3.0]])
f.get_concrete_function(vector) is f.get_concrete_function(matrix)
True
```
Variables may only be created once
----------------------------------
[`tf.function`](function) only allows creating new [`tf.Variable`](variable) objects when it is called for the first time:
```
class MyModule(tf.Module):
def __init__(self):
self.v = None
@tf.function
def __call__(self, x):
if self.v is None:
self.v = tf.Variable(tf.ones_like(x))
return self.v * x
```
In general, it is recommended to create [`tf.Variable`](variable)s outside of [`tf.function`](function). In simple cases, persisting state across [`tf.function`](function) boundaries may be implemented using a pure functional style in which state is represented by [`tf.Tensor`](tensor)s passed as arguments and returned as return values.
Contrast the two styles below:
```
state = tf.Variable(1)
@tf.function
def f(x):
state.assign_add(x)
f(tf.constant(2)) # Non-pure functional style
state
<tf.Variable ... numpy=3>
```
```
state = tf.constant(1)
@tf.function
def f(state, x):
state += x
return state
state = f(state, tf.constant(2)) # Pure functional style
state
<tf.Tensor: ... numpy=3>
```
Python operations execute only once per trace
---------------------------------------------
`func` may contain TensorFlow operations mixed with pure Python operations. However, when the function is executed, only the TensorFlow operations will run. The Python operations run only once, at trace time. If TensorFlow operations depend on results from Pyhton operations, those results will be frozen into the graph.
```
@tf.function
def f(a, b):
print('this runs at trace time; a is', a, 'and b is', b)
return b
f(1, tf.constant(1))
this runs at trace time; a is 1 and b is Tensor("...", shape=(), dtype=int32)
<tf.Tensor: shape=(), dtype=int32, numpy=1>
```
```
f(1, tf.constant(2))
<tf.Tensor: shape=(), dtype=int32, numpy=2>
```
```
f(2, tf.constant(1))
this runs at trace time; a is 2 and b is Tensor("...", shape=(), dtype=int32)
<tf.Tensor: shape=(), dtype=int32, numpy=1>
```
```
f(2, tf.constant(2))
<tf.Tensor: shape=(), dtype=int32, numpy=2>
```
Using type annotations to improve performance
---------------------------------------------
'experimental\_follow\_type\_hints` can be used along with type annotations to reduce retracing by automatically casting any Python values to [`tf.Tensor`](tensor) (something that is not done by default, unless you use input signatures).
```
@tf.function(experimental_follow_type_hints=True)
def f_with_hints(x: tf.Tensor):
print('Tracing')
return x
@tf.function(experimental_follow_type_hints=False)
def f_no_hints(x: tf.Tensor):
print('Tracing')
return x
f_no_hints(1)
Tracing
<tf.Tensor: shape=(), dtype=int32, numpy=1>
f_no_hints(2)
Tracing
<tf.Tensor: shape=(), dtype=int32, numpy=2>
f_with_hints(1)
Tracing
<tf.Tensor: shape=(), dtype=int32, numpy=1>
f_with_hints(2)
<tf.Tensor: shape=(), dtype=int32, numpy=2>
```
| Args |
| `func` | the function to be compiled. If `func` is None, [`tf.function`](function) returns a decorator that can be invoked with a single argument - `func`. In other words, `tf.function(input_signature=...)(func)` is equivalent to [`tf.function(func, input_signature=...)`](function). The former can be used as decorator. |
| `input_signature` | A possibly nested sequence of [`tf.TensorSpec`](tensorspec) objects specifying the shapes and dtypes of the Tensors that will be supplied to this function. If `None`, a separate function is instantiated for each inferred input signature. If input\_signature is specified, every input to `func` must be a `Tensor`, and `func` cannot accept `**kwargs`. |
| `autograph` | Whether autograph should be applied on `func` before tracing a graph. Data-dependent Python control flow statements require `autograph=True`. For more information, see the [tf.function and AutoGraph guide](https://www.tensorflow.org/guide/function#autograph_transformations). |
| `jit_compile` | If `True`, compiles the function using [XLA](https://tensorflow.org/xla). XLA performs compiler optimizations, such as fusion, and attempts to emit more efficient code. This may drastically improve the performance. If set to `True`, the whole function needs to be compilable by XLA, or an [`errors.InvalidArgumentError`](errors/invalidargumenterror) is thrown. If `None` (default), compiles the function with XLA when running on TPU and goes through the regular function execution path when running on other devices. If `False`, executes the function without XLA compilation. Set this value to `False` when directly running a multi-device function on TPUs (e.g. two TPU cores, one TPU core and its host CPU). Not all functions are compilable, see a list of [sharp corners](https://tensorflow.org/xla/known_issues). |
| `reduce_retracing` | When True, [`tf.function`](function) attempts to reduce the amount of retracing, for example by using more generic shapes. This can be controlled for user objects by customizing their associated [`tf.types.experimental.TraceType`](types/experimental/tracetype). |
| `experimental_implements` | If provided, contains a name of a "known" function this implements. For example "mycompany.my\_recurrent\_cell". This is stored as an attribute in inference function, which can then be detected when processing serialized function. See [standardizing composite ops](https://github.com/tensorflow/community/blob/master/rfcs/20190610-standardizing-composite_ops.md) for details. For an example of utilizing this attribute see this [example](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/lite/transforms/prepare_composite_functions_tf.cc) The code above automatically detects and substitutes function that implements "embedded\_matmul" and allows TFLite to substitute its own implementations. For instance, a tensorflow user can use this attribute to mark that their function also implements `embedded_matmul` (perhaps more efficiently!) by specifying it using this parameter: `@tf.function(experimental_implements="embedded_matmul")` This can either be specified as just the string name of the function or a NameAttrList corresponding to a list of key-value attributes associated with the function name. The name of the function will be in the 'name' field of the NameAttrList. To define a formal TF op for this function implements, try the experimental [composite TF](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/tfr) project. |
| `experimental_autograph_options` | Optional tuple of [`tf.autograph.experimental.Feature`](autograph/experimental/feature) values. |
| `experimental_relax_shapes` | Deprecated. Use `reduce_retracing` instead. |
| `experimental_compile` | Deprecated alias to 'jit\_compile'. |
| `experimental_follow_type_hints` | When True, the function may use type annotations from `func` to optimize the tracing performance. For example, arguments annotated with [`tf.Tensor`](tensor) will automatically be converted to a Tensor. |
| Returns |
| If `func` is not None, returns a [`tf.types.experimental.GenericFunction`](types/experimental/genericfunction). If `func` is None, returns a decorator that, when invoked with a single `func` argument, returns a [`tf.types.experimental.GenericFunction`](types/experimental/genericfunction). |
| Raises |
| `ValueError` when attempting to use `jit_compile=True`, but XLA support is not available. |
tensorflow tf.OptionalSpec tf.OptionalSpec
===============
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/data/ops/optional_ops.py#L203-L259) |
Type specification for [`tf.experimental.Optional`](experimental/optional).
Inherits From: [`TypeSpec`](typespec), [`TraceType`](types/experimental/tracetype)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.OptionalSpec`](https://www.tensorflow.org/api_docs/python/tf/OptionalSpec), [`tf.compat.v1.data.experimental.OptionalStructure`](https://www.tensorflow.org/api_docs/python/tf/OptionalSpec)
```
tf.OptionalSpec(
element_spec
)
```
For instance, [`tf.OptionalSpec`](optionalspec) can be used to define a tf.function that takes [`tf.experimental.Optional`](experimental/optional) as an input argument:
```
@tf.function(input_signature=[tf.OptionalSpec(
tf.TensorSpec(shape=(), dtype=tf.int32, name=None))])
def maybe_square(optional):
if optional.has_value():
x = optional.get_value()
return x * x
return -1
optional = tf.experimental.Optional.from_value(5)
print(maybe_square(optional))
tf.Tensor(25, shape=(), dtype=int32)
```
| Attributes |
| `element_spec` | A (nested) structure of `TypeSpec` objects that represents the type specification of the optional element. |
| `value_type` | The Python type for values that are compatible with this TypeSpec. In particular, all values that are compatible with this TypeSpec must be an instance of this type. |
Methods
-------
### `from_value`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/data/ops/optional_ops.py#L248-L250)
```
@staticmethod
from_value(
value
)
```
### `is_compatible_with`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L193-L214)
```
is_compatible_with(
spec_or_value
)
```
Returns true if `spec_or_value` is compatible with this TypeSpec.
Prefer using "is\_subtype\_of" and "most\_specific\_common\_supertype" wherever possible.
| Args |
| `spec_or_value` | A TypeSpec or TypeSpec associated value to compare against. |
### `is_subtype_of`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L100-L137)
```
is_subtype_of(
other: tf.types.experimental.TraceType
) -> bool
```
Returns True if `self` is a subtype of `other`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `other` | A TraceType object. |
### `most_specific_common_supertype`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L139-L185)
```
most_specific_common_supertype(
others: Sequence[tf.types.experimental.TraceType]
) -> Optional['TypeSpec']
```
Returns the most specific supertype TypeSpec of `self` and `others`.
Implements the tf.types.experimental.func.TraceType interface.
If not overridden by a subclass, the default behavior is to assume the TypeSpec is covariant upon attributes that implement TraceType and invariant upon rest of the attributes as well as the structure and type of the TypeSpec.
| Args |
| `others` | A sequence of TraceTypes. |
### `most_specific_compatible_type`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L216-L234)
```
most_specific_compatible_type(
other: 'TypeSpec'
) -> 'TypeSpec'
```
Returns the most specific TypeSpec compatible with `self` and `other`. (deprecated)
Deprecated. Please use `most_specific_common_supertype` instead. Do not override this function.
| Args |
| `other` | A `TypeSpec`. |
| Raises |
| `ValueError` | If there is no TypeSpec that is compatible with both `self` and `other`. |
### `__eq__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L438-L441)
```
__eq__(
other
) -> bool
```
Return self==value.
### `__ne__`
[View source](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/framework/type_spec.py#L443-L444)
```
__ne__(
other
) -> bool
```
Return self!=value.
| programming_docs |
tensorflow Module: tf.summary Module: tf.summary
==================
[View source on GitHub](https://github.com/tensorflow/tensorboard/tree/2.9.0/tensorboard/summary/_tf/summary/__init__.py) |
Operations for writing summary data, for use in analysis and visualization.
The [`tf.summary`](summary) module provides APIs for writing summary data. This data can be visualized in TensorBoard, the visualization toolkit that comes with TensorFlow. See the [TensorBoard website](https://www.tensorflow.org/tensorboard) for more detailed tutorials about how to use these APIs, or some quick examples below.
Example usage with eager execution, the default in TF 2.0:
```
writer = tf.summary.create_file_writer("/tmp/mylogs")
with writer.as_default():
for step in range(100):
# other model code would go here
tf.summary.scalar("my_metric", 0.5, step=step)
writer.flush()
```
Example usage with [`tf.function`](function) graph execution:
```
writer = tf.summary.create_file_writer("/tmp/mylogs")
@tf.function
def my_func(step):
# other model code would go here
with writer.as_default():
tf.summary.scalar("my_metric", 0.5, step=step)
for step in range(100):
my_func(step)
writer.flush()
```
Example usage with legacy TF 1.x graph execution:
```
with tf.compat.v1.Graph().as_default():
step = tf.Variable(0, dtype=tf.int64)
step_update = step.assign_add(1)
writer = tf.summary.create_file_writer("/tmp/mylogs")
with writer.as_default():
tf.summary.scalar("my_metric", 0.5, step=step)
all_summary_ops = tf.compat.v1.summary.all_v2_summary_ops()
writer_flush = writer.flush()
sess = tf.compat.v1.Session()
sess.run([writer.init(), step.initializer])
for i in range(100):
sess.run(all_summary_ops)
sess.run(step_update)
sess.run(writer_flush)
```
Classes
-------
[`class SummaryWriter`](summary/summarywriter): Interface representing a stateful summary writer object.
Functions
---------
[`audio(...)`](summary/audio): Write an audio summary.
[`create_file_writer(...)`](summary/create_file_writer): Creates a summary file writer for the given log directory.
[`create_noop_writer(...)`](summary/create_noop_writer): Returns a summary writer that does nothing.
[`flush(...)`](summary/flush): Forces summary writer to send any buffered data to storage.
[`graph(...)`](summary/graph): Writes a TensorFlow graph summary.
[`histogram(...)`](summary/histogram): Write a histogram summary.
[`image(...)`](summary/image): Write an image summary.
[`record_if(...)`](summary/record_if): Sets summary recording on or off per the provided boolean value.
[`scalar(...)`](summary/scalar): Write a scalar summary.
[`should_record_summaries(...)`](summary/should_record_summaries): Returns boolean Tensor which is True if summaries will be recorded.
[`text(...)`](summary/text): Write a text summary.
[`trace_export(...)`](summary/trace_export): Stops and exports the active trace as a Summary and/or profile file.
[`trace_off(...)`](summary/trace_off): Stops the current trace and discards any collected information.
[`trace_on(...)`](summary/trace_on): Starts a trace to record computation graphs and profiling information.
[`write(...)`](summary/write): Writes a generic summary to the default SummaryWriter if one exists.
tensorflow tf.unique tf.unique
=========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L2025-L2067) |
Finds unique elements in a 1-D tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.unique`](https://www.tensorflow.org/api_docs/python/tf/unique)
```
tf.unique(
x,
out_idx=tf.dtypes.int32,
name=None
)
```
This operation returns a tensor `y` containing all of the unique elements of `x` sorted in the same order that they occur in `x`; `x` does not need to be sorted. This operation also returns a tensor `idx` the same size as `x` that contains the index of each value of `x` in the unique output `y`. In other words:
`y[idx[i]] = x[i] for i in [0, 1,...,rank(x) - 1]`
#### Examples:
```
# tensor 'x' is [1, 1, 2, 4, 4, 4, 7, 8, 8]
y, idx = unique(x)
y ==> [1, 2, 4, 7, 8]
idx ==> [0, 0, 1, 2, 2, 2, 3, 4, 4]
```
```
# tensor 'x' is [4, 5, 1, 2, 3, 3, 4, 5]
y, idx = unique(x)
y ==> [4, 5, 1, 2, 3]
idx ==> [0, 1, 2, 3, 4, 4, 0, 1]
```
| Args |
| `x` | A `Tensor`. 1-D. |
| `out_idx` | An optional [`tf.DType`](dtypes/dtype) from: `tf.int32, tf.int64`. Defaults to [`tf.int32`](../tf#int32). |
| `name` | A name for the operation (optional). |
| Returns |
| A tuple of `Tensor` objects (y, idx). |
| `y` | A `Tensor`. Has the same type as `x`. |
| `idx` | A `Tensor` of type `out_idx`. |
tensorflow tf.VariableSynchronization tf.VariableSynchronization
==========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/variables.py#L70-L93) |
Indicates when a distributed variable will be synced.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.VariableSynchronization`](https://www.tensorflow.org/api_docs/python/tf/VariableSynchronization)
* `AUTO`: Indicates that the synchronization will be determined by the current `DistributionStrategy` (eg. With `MirroredStrategy` this would be `ON_WRITE`).
* `NONE`: Indicates that there will only be one copy of the variable, so there is no need to sync.
* `ON_WRITE`: Indicates that the variable will be updated across devices every time it is written.
* `ON_READ`: Indicates that the variable will be aggregated across devices when it is read (eg. when checkpointing or when evaluating an op that uses the variable).
Example:
```
>>> temp_grad=[tf.Variable([0.], trainable=False,
... synchronization=tf.VariableSynchronization.ON_READ,
... aggregation=tf.VariableAggregation.MEAN
... )]
```
| Class Variables |
| AUTO | `<VariableSynchronization.AUTO: 0>` |
| NONE | `<VariableSynchronization.NONE: 1>` |
| ON\_READ | `<VariableSynchronization.ON_READ: 3>` |
| ON\_WRITE | `<VariableSynchronization.ON_WRITE: 2>` |
tensorflow tf.tensor_scatter_nd_min tf.tensor\_scatter\_nd\_min
===========================
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.tensor_scatter_nd_min`](https://www.tensorflow.org/api_docs/python/tf/tensor_scatter_nd_min)
```
tf.tensor_scatter_nd_min(
tensor, indices, updates, name=None
)
```
| Args |
| `tensor` | A `Tensor`. Tensor to update. |
| `indices` | A `Tensor`. Must be one of the following types: `int32`, `int64`. Index tensor. |
| `updates` | A `Tensor`. Must have the same type as `tensor`. Updates to scatter into output. |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `tensor`. |
tensorflow tf.shape tf.shape
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L581-L630) |
Returns a tensor containing the shape of the input tensor.
```
tf.shape(
input,
out_type=tf.dtypes.int32,
name=None
)
```
See also [`tf.size`](size), [`tf.rank`](rank).
[`tf.shape`](shape) returns a 1-D integer tensor representing the shape of `input`. For a scalar input, the tensor returned has a shape of (0,) and its value is the empty vector (i.e. []).
#### For example:
```
tf.shape(1.)
<tf.Tensor: shape=(0,), dtype=int32, numpy=array([], dtype=int32)>
```
```
t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])
tf.shape(t)
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 2, 3], dtype=int32)>
```
>
> **Note:** When using symbolic tensors, such as when using the Keras API, tf.shape() will return the shape of the symbolic tensor.
>
```
a = tf.keras.layers.Input((None, 10))
tf.shape(a)
<... shape=(3,) dtype=int32...>
```
In these cases, using [`tf.Tensor.shape`](tensor#shape) will return more informative results.
```
a.shape
TensorShape([None, None, 10])
```
(The first `None` represents the as yet unknown batch size.)
[`tf.shape`](shape) and [`Tensor.shape`](tensor#shape) should be identical in eager mode. Within [`tf.function`](function) or within a [`compat.v1`](compat/v1) context, not all dimensions may be known until execution time. Hence when defining custom layers and models for graph mode, prefer the dynamic [`tf.shape(x)`](shape) over the static `x.shape`.
| Args |
| `input` | A `Tensor` or `SparseTensor`. |
| `out_type` | (Optional) The specified output type of the operation (`int32` or `int64`). Defaults to [`tf.int32`](../tf#int32). |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor` of type `out_type`. |
tensorflow Module: tf.estimator Module: tf.estimator
====================
Estimator: High level tools for working with models.
Modules
-------
[`experimental`](estimator/experimental) module: Public API for tf.estimator.experimental namespace.
[`export`](estimator/export) module: All public utility methods for exporting Estimator to SavedModel.
Classes
-------
[`class BaselineClassifier`](estimator/baselineclassifier): A classifier that can establish a simple baseline.
[`class BaselineEstimator`](estimator/baselineestimator): An estimator that can establish a simple baseline.
[`class BaselineRegressor`](estimator/baselineregressor): A regressor that can establish a simple baseline.
[`class BestExporter`](estimator/bestexporter): This class exports the serving graph and checkpoints of the best models.
[`class BinaryClassHead`](estimator/binaryclasshead): Creates a `Head` for single label binary classification.
[`class CheckpointSaverHook`](estimator/checkpointsaverhook): Saves checkpoints every N steps or seconds.
[`class CheckpointSaverListener`](estimator/checkpointsaverlistener): Interface for listeners that take action before or after checkpoint save.
[`class DNNClassifier`](estimator/dnnclassifier): A classifier for TensorFlow DNN models.
[`class DNNEstimator`](estimator/dnnestimator): An estimator for TensorFlow DNN models with user-specified head.
[`class DNNLinearCombinedClassifier`](estimator/dnnlinearcombinedclassifier): An estimator for TensorFlow Linear and DNN joined classification models.
[`class DNNLinearCombinedEstimator`](estimator/dnnlinearcombinedestimator): An estimator for TensorFlow Linear and DNN joined models with custom head.
[`class DNNLinearCombinedRegressor`](estimator/dnnlinearcombinedregressor): An estimator for TensorFlow Linear and DNN joined models for regression.
[`class DNNRegressor`](estimator/dnnregressor): A regressor for TensorFlow DNN models.
[`class Estimator`](estimator/estimator): Estimator class to train and evaluate TensorFlow models.
[`class EstimatorSpec`](estimator/estimatorspec): Ops and objects returned from a `model_fn` and passed to an `Estimator`.
[`class EvalSpec`](estimator/evalspec): Configuration for the "eval" part for the `train_and_evaluate` call.
[`class Exporter`](estimator/exporter): A class representing a type of model export.
[`class FeedFnHook`](estimator/feedfnhook): Runs `feed_fn` and sets the `feed_dict` accordingly.
[`class FinalExporter`](estimator/finalexporter): This class exports the serving graph and checkpoints at the end.
[`class FinalOpsHook`](estimator/finalopshook): A hook which evaluates `Tensors` at the end of a session.
[`class GlobalStepWaiterHook`](estimator/globalstepwaiterhook): Delays execution until global step reaches `wait_until_step`.
[`class Head`](estimator/head): Interface for the head/top of a model.
[`class LatestExporter`](estimator/latestexporter): This class regularly exports the serving graph and checkpoints.
[`class LinearClassifier`](estimator/linearclassifier): Linear classifier model.
[`class LinearEstimator`](estimator/linearestimator): An estimator for TensorFlow linear models with user-specified head.
[`class LinearRegressor`](estimator/linearregressor): An estimator for TensorFlow Linear regression problems.
[`class LoggingTensorHook`](estimator/loggingtensorhook): Prints the given tensors every N local steps, every N seconds, or at end.
[`class LogisticRegressionHead`](estimator/logisticregressionhead): Creates a `Head` for logistic regression.
[`class ModeKeys`](estimator/modekeys): Standard names for Estimator model modes.
[`class MultiClassHead`](estimator/multiclasshead): Creates a `Head` for multi class classification.
[`class MultiHead`](estimator/multihead): Creates a `Head` for multi-objective learning.
[`class MultiLabelHead`](estimator/multilabelhead): Creates a `Head` for multi-label classification.
[`class NanLossDuringTrainingError`](estimator/nanlossduringtrainingerror): Unspecified run-time error.
[`class NanTensorHook`](estimator/nantensorhook): Monitors the loss tensor and stops training if loss is NaN.
[`class PoissonRegressionHead`](estimator/poissonregressionhead): Creates a `Head` for poisson regression using [`tf.nn.log_poisson_loss`](nn/log_poisson_loss).
[`class ProfilerHook`](estimator/profilerhook): Captures CPU/GPU profiling information every N steps or seconds.
[`class RegressionHead`](estimator/regressionhead): Creates a `Head` for regression using the `mean_squared_error` loss.
[`class RunConfig`](estimator/runconfig): This class specifies the configurations for an `Estimator` run.
[`class SecondOrStepTimer`](estimator/secondorsteptimer): Timer that triggers at most once every N seconds or once every N steps.
[`class SessionRunArgs`](estimator/sessionrunargs): Represents arguments to be added to a `Session.run()` call.
[`class SessionRunContext`](estimator/sessionruncontext): Provides information about the `session.run()` call being made.
[`class SessionRunHook`](estimator/sessionrunhook): Hook to extend calls to MonitoredSession.run().
[`class SessionRunValues`](estimator/sessionrunvalues): Contains the results of `Session.run()`.
[`class StepCounterHook`](estimator/stepcounterhook): Hook that counts steps per second.
[`class StopAtStepHook`](estimator/stopatstephook): Hook that requests stop at a specified step.
[`class SummarySaverHook`](estimator/summarysaverhook): Saves summaries every N steps.
[`class TrainSpec`](estimator/trainspec): Configuration for the "train" part for the `train_and_evaluate` call.
[`class VocabInfo`](estimator/vocabinfo): Vocabulary information for warm-starting.
[`class WarmStartSettings`](estimator/warmstartsettings): Settings for warm-starting in `tf.estimator.Estimators`.
Functions
---------
[`add_metrics(...)`](estimator/add_metrics): Creates a new [`tf.estimator.Estimator`](estimator/estimator) which has given metrics.
[`classifier_parse_example_spec(...)`](estimator/classifier_parse_example_spec): Generates parsing spec for tf.parse\_example to be used with classifiers.
[`regressor_parse_example_spec(...)`](estimator/regressor_parse_example_spec): Generates parsing spec for tf.parse\_example to be used with regressors.
[`train_and_evaluate(...)`](estimator/train_and_evaluate): Train and evaluate the `estimator`.
tensorflow tf.random_index_shuffle tf.random\_index\_shuffle
=========================
Outputs the position of `value` in a permutation of [0, ..., max\_index].
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.random_index_shuffle`](https://www.tensorflow.org/api_docs/python/tf/random_index_shuffle)
```
tf.random_index_shuffle(
index, seed, max_index, name=None
)
```
Output values are a bijection of the `index` for any combination and `seed` and `max_index`.
If multiple inputs are vectors (matrix in case of seed) then the size of the first dimension must match.
The outputs are deterministic.
| Args |
| `index` | A `Tensor`. Must be one of the following types: `int32`, `uint32`, `int64`, `uint64`. A scalar tensor or a vector of dtype `dtype`. The index (or indices) to be shuffled. Must be within [0, max\_index]. |
| `seed` | A `Tensor`. Must be one of the following types: `int32`, `uint32`, `int64`, `uint64`. A tensor of dtype `Tseed` and shape [3] or [n, 3]. The random seed. |
| `max_index` | A `Tensor`. Must have the same type as `index`. A scalar tensor or vector of dtype `dtype`. The upper bound(s) of the interval (inclusive). |
| `name` | A name for the operation (optional). |
| Returns |
| A `Tensor`. Has the same type as `index`. |
tensorflow Module: tf.signal Module: tf.signal
=================
Signal processing operations.
See the [tf.signal](https://tensorflow.org/api_guides/python/contrib.signal) guide.
Functions
---------
[`dct(...)`](signal/dct): Computes the 1D [Discrete Cosine Transform (DCT)][dct] of `input`.
[`fft(...)`](signal/fft): Fast Fourier transform.
[`fft2d(...)`](signal/fft2d): 2D fast Fourier transform.
[`fft3d(...)`](signal/fft3d): 3D fast Fourier transform.
[`fftshift(...)`](signal/fftshift): Shift the zero-frequency component to the center of the spectrum.
[`frame(...)`](signal/frame): Expands `signal`'s `axis` dimension into frames of `frame_length`.
[`hamming_window(...)`](signal/hamming_window): Generate a [Hamming](https://en.wikipedia.org/wiki/Window_function#Hamming_window) window.
[`hann_window(...)`](signal/hann_window): Generate a [Hann window](https://en.wikipedia.org/wiki/Window_function#Hann_window).
[`idct(...)`](signal/idct): Computes the 1D [Inverse Discrete Cosine Transform (DCT)][idct] of `input`.
[`ifft(...)`](signal/ifft): Inverse fast Fourier transform.
[`ifft2d(...)`](signal/ifft2d): Inverse 2D fast Fourier transform.
[`ifft3d(...)`](signal/ifft3d): Inverse 3D fast Fourier transform.
[`ifftshift(...)`](signal/ifftshift): The inverse of fftshift.
[`inverse_mdct(...)`](signal/inverse_mdct): Computes the inverse modified DCT of `mdcts`.
[`inverse_stft(...)`](signal/inverse_stft): Computes the inverse [Short-time Fourier Transform](https://en.wikipedia.org/wiki/Short-time_Fourier_transform) of `stfts`.
[`inverse_stft_window_fn(...)`](signal/inverse_stft_window_fn): Generates a window function that can be used in `inverse_stft`.
[`irfft(...)`](signal/irfft): Inverse real-valued fast Fourier transform.
[`irfft2d(...)`](signal/irfft2d): Inverse 2D real-valued fast Fourier transform.
[`irfft3d(...)`](signal/irfft3d): Inverse 3D real-valued fast Fourier transform.
[`kaiser_bessel_derived_window(...)`](signal/kaiser_bessel_derived_window): Generate a [Kaiser Bessel derived window][kbd].
[`kaiser_window(...)`](signal/kaiser_window): Generate a [Kaiser window][kaiser].
[`linear_to_mel_weight_matrix(...)`](signal/linear_to_mel_weight_matrix): Returns a matrix to warp linear scale spectrograms to the [mel scale](https://en.wikipedia.org/wiki/Mel_scale).
[`mdct(...)`](signal/mdct): Computes the [Modified Discrete Cosine Transform][mdct] of `signals`.
[`mfccs_from_log_mel_spectrograms(...)`](signal/mfccs_from_log_mel_spectrograms): Computes [MFCCs](https://en.wikipedia.org/wiki/Mel-frequency_cepstrum) of `log_mel_spectrograms`.
[`overlap_and_add(...)`](signal/overlap_and_add): Reconstructs a signal from a framed representation.
[`rfft(...)`](signal/rfft): Real-valued fast Fourier transform.
[`rfft2d(...)`](signal/rfft2d): 2D real-valued fast Fourier transform.
[`rfft3d(...)`](signal/rfft3d): 3D real-valued fast Fourier transform.
[`stft(...)`](signal/stft): Computes the [Short-time Fourier Transform](https://en.wikipedia.org/wiki/Short-time_Fourier_transform) of `signals`.
[`vorbis_window(...)`](signal/vorbis_window): Generate a [Vorbis power complementary window][vorbis].
| programming_docs |
tensorflow tf.no_op tf.no\_op
=========
Does nothing. Only useful as a placeholder for control edges.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.no_op`](https://www.tensorflow.org/api_docs/python/tf/no_op)
```
tf.no_op(
name=None
)
```
| Args |
| `name` | A name for the operation (optional). |
| Returns |
| The created Operation. |
tensorflow tf.stack tf.stack
========
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/ops/array_ops.py#L1419-L1480) |
Stacks a list of rank-`R` tensors into one rank-`(R+1)` tensor.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.stack`](https://www.tensorflow.org/api_docs/python/tf/stack)
```
tf.stack(
values, axis=0, name='stack'
)
```
See also [`tf.concat`](concat), [`tf.tile`](tile), [`tf.repeat`](repeat).
Packs the list of tensors in `values` into a tensor with rank one higher than each tensor in `values`, by packing them along the `axis` dimension. Given a list of length `N` of tensors of shape `(A, B, C)`;
if `axis == 0` then the `output` tensor will have the shape `(N, A, B, C)`. if `axis == 1` then the `output` tensor will have the shape `(A, N, B, C)`. Etc.
#### For example:
```
x = tf.constant([1, 4])
y = tf.constant([2, 5])
z = tf.constant([3, 6])
tf.stack([x, y, z])
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 4],
[2, 5],
[3, 6]], dtype=int32)>
tf.stack([x, y, z], axis=1)
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],
[4, 5, 6]], dtype=int32)>
```
This is the opposite of unstack. The numpy equivalent is `np.stack`
```
np.array_equal(np.stack([x, y, z]), tf.stack([x, y, z]))
True
```
| Args |
| `values` | A list of `Tensor` objects with the same shape and type. |
| `axis` | An `int`. The axis to stack along. Defaults to the first dimension. Negative values wrap around, so the valid range is `[-(R+1), R+1)`. |
| `name` | A name for this operation (optional). |
| Returns |
| `output` | A stacked `Tensor` with the same type as `values`. |
| Raises |
| `ValueError` | If `axis` is out of the range [-(R+1), R+1). |
tensorflow tf.raw_ops tf.raw\_ops
===========
Public API for tf.raw\_ops namespace.
>
> **Note:** [`tf.raw_ops`](https://www.tensorflow.org/api_docs/python/tf/raw_ops) provides direct/low level access to all TensorFlow ops. See [the RFC](https://github.com/tensorflow/community/blob/master/rfcs/20181225-tf-raw-ops.md) for details. Unless you are library writer, you likely do not need to use these ops directly.
>
| Op Name | Has Gradient |
| --- | --- |
| [Abort](raw_ops/abort) | ❌ |
| [Abs](raw_ops/abs) | ✔️ |
| [AccumulateNV2](raw_ops/accumulatenv2) | ✔️ |
| [AccumulatorApplyGradient](raw_ops/accumulatorapplygradient) | ❌ |
| [AccumulatorNumAccumulated](raw_ops/accumulatornumaccumulated) | ❌ |
| [AccumulatorSetGlobalStep](raw_ops/accumulatorsetglobalstep) | ❌ |
| [AccumulatorTakeGradient](raw_ops/accumulatortakegradient) | ❌ |
| [Acos](raw_ops/acos) | ✔️ |
| [Acosh](raw_ops/acosh) | ✔️ |
| [Add](raw_ops/add) | ✔️ |
| [AddManySparseToTensorsMap](raw_ops/addmanysparsetotensorsmap) | ❌ |
| [AddN](raw_ops/addn) | ✔️ |
| [AddSparseToTensorsMap](raw_ops/addsparsetotensorsmap) | ❌ |
| [AddV2](raw_ops/addv2) | ✔️ |
| [AdjustContrast](raw_ops/adjustcontrast) | ❌ |
| [AdjustContrastv2](raw_ops/adjustcontrastv2) | ❌ |
| [AdjustHue](raw_ops/adjusthue) | ❌ |
| [AdjustSaturation](raw_ops/adjustsaturation) | ❌ |
| [All](raw_ops/all) | ❌ |
| [AllCandidateSampler](raw_ops/allcandidatesampler) | ❌ |
| [AllToAll](raw_ops/alltoall) | ✔️ |
| [Angle](raw_ops/angle) | ✔️ |
| [AnonymousHashTable](raw_ops/anonymoushashtable) | ❌ |
| [AnonymousIterator](raw_ops/anonymousiterator) | ❌ |
| [AnonymousIteratorV2](raw_ops/anonymousiteratorv2) | ❌ |
| [AnonymousIteratorV3](raw_ops/anonymousiteratorv3) | ❌ |
| [AnonymousMemoryCache](raw_ops/anonymousmemorycache) | ❌ |
| [AnonymousMultiDeviceIterator](raw_ops/anonymousmultideviceiterator) | ❌ |
| [AnonymousMultiDeviceIteratorV3](raw_ops/anonymousmultideviceiteratorv3) | ❌ |
| [AnonymousMutableDenseHashTable](raw_ops/anonymousmutabledensehashtable) | ❌ |
| [AnonymousMutableHashTable](raw_ops/anonymousmutablehashtable) | ❌ |
| [AnonymousMutableHashTableOfTensors](raw_ops/anonymousmutablehashtableoftensors) | ❌ |
| [AnonymousRandomSeedGenerator](raw_ops/anonymousrandomseedgenerator) | ❌ |
| [AnonymousSeedGenerator](raw_ops/anonymousseedgenerator) | ❌ |
| [Any](raw_ops/any) | ❌ |
| [ApplyAdaMax](raw_ops/applyadamax) | ❌ |
| [ApplyAdadelta](raw_ops/applyadadelta) | ❌ |
| [ApplyAdagrad](raw_ops/applyadagrad) | ❌ |
| [ApplyAdagradDA](raw_ops/applyadagradda) | ❌ |
| [ApplyAdagradV2](raw_ops/applyadagradv2) | ❌ |
| [ApplyAdam](raw_ops/applyadam) | ❌ |
| [ApplyAddSign](raw_ops/applyaddsign) | ❌ |
| [ApplyCenteredRMSProp](raw_ops/applycenteredrmsprop) | ❌ |
| [ApplyFtrl](raw_ops/applyftrl) | ❌ |
| [ApplyFtrlV2](raw_ops/applyftrlv2) | ❌ |
| [ApplyGradientDescent](raw_ops/applygradientdescent) | ❌ |
| [ApplyMomentum](raw_ops/applymomentum) | ❌ |
| [ApplyPowerSign](raw_ops/applypowersign) | ❌ |
| [ApplyProximalAdagrad](raw_ops/applyproximaladagrad) | ❌ |
| [ApplyProximalGradientDescent](raw_ops/applyproximalgradientdescent) | ❌ |
| [ApplyRMSProp](raw_ops/applyrmsprop) | ❌ |
| [ApproximateEqual](raw_ops/approximateequal) | ✔️ |
| [ArgMax](raw_ops/argmax) | ✔️ |
| [ArgMin](raw_ops/argmin) | ✔️ |
| [AsString](raw_ops/asstring) | ✔️ |
| [Asin](raw_ops/asin) | ✔️ |
| [Asinh](raw_ops/asinh) | ✔️ |
| [Assert](raw_ops/assert) | ✔️ |
| [AssertCardinalityDataset](raw_ops/assertcardinalitydataset) | ❌ |
| [AssertNextDataset](raw_ops/assertnextdataset) | ❌ |
| [AssertPrevDataset](raw_ops/assertprevdataset) | ❌ |
| [Assign](raw_ops/assign) | ✔️ |
| [AssignAdd](raw_ops/assignadd) | ✔️ |
| [AssignAddVariableOp](raw_ops/assignaddvariableop) | ❌ |
| [AssignSub](raw_ops/assignsub) | ✔️ |
| [AssignSubVariableOp](raw_ops/assignsubvariableop) | ❌ |
| [AssignVariableOp](raw_ops/assignvariableop) | ❌ |
| [AssignVariableXlaConcatND](raw_ops/assignvariablexlaconcatnd) | ❌ |
| [Atan](raw_ops/atan) | ✔️ |
| [Atan2](raw_ops/atan2) | ✔️ |
| [Atanh](raw_ops/atanh) | ✔️ |
| [AudioSpectrogram](raw_ops/audiospectrogram) | ❌ |
| [AudioSummary](raw_ops/audiosummary) | ✔️ |
| [AudioSummaryV2](raw_ops/audiosummaryv2) | ✔️ |
| [AutoShardDataset](raw_ops/autosharddataset) | ❌ |
| [AvgPool](raw_ops/avgpool) | ✔️ |
| [AvgPool3D](raw_ops/avgpool3d) | ✔️ |
| [AvgPool3DGrad](raw_ops/avgpool3dgrad) | ✔️ |
| [AvgPoolGrad](raw_ops/avgpoolgrad) | ✔️ |
| [BandedTriangularSolve](raw_ops/bandedtriangularsolve) | ✔️ |
| [Barrier](raw_ops/barrier) | ❌ |
| [BarrierClose](raw_ops/barrierclose) | ❌ |
| [BarrierIncompleteSize](raw_ops/barrierincompletesize) | ❌ |
| [BarrierInsertMany](raw_ops/barrierinsertmany) | ❌ |
| [BarrierReadySize](raw_ops/barrierreadysize) | ❌ |
| [BarrierTakeMany](raw_ops/barriertakemany) | ❌ |
| [Batch](raw_ops/batch) | ❌ |
| [BatchCholesky](raw_ops/batchcholesky) | ❌ |
| [BatchCholeskyGrad](raw_ops/batchcholeskygrad) | ❌ |
| [BatchDataset](raw_ops/batchdataset) | ❌ |
| [BatchDatasetV2](raw_ops/batchdatasetv2) | ❌ |
| [BatchFFT](raw_ops/batchfft) | ❌ |
| [BatchFFT2D](raw_ops/batchfft2d) | ❌ |
| [BatchFFT3D](raw_ops/batchfft3d) | ❌ |
| [BatchFunction](raw_ops/batchfunction) | ❌ |
| [BatchIFFT](raw_ops/batchifft) | ❌ |
| [BatchIFFT2D](raw_ops/batchifft2d) | ❌ |
| [BatchIFFT3D](raw_ops/batchifft3d) | ❌ |
| [BatchMatMul](raw_ops/batchmatmul) | ✔️ |
| [BatchMatMulV2](raw_ops/batchmatmulv2) | ✔️ |
| [BatchMatMulV3](raw_ops/batchmatmulv3) | ✔️ |
| [BatchMatrixBandPart](raw_ops/batchmatrixbandpart) | ❌ |
| [BatchMatrixDeterminant](raw_ops/batchmatrixdeterminant) | ❌ |
| [BatchMatrixDiag](raw_ops/batchmatrixdiag) | ❌ |
| [BatchMatrixDiagPart](raw_ops/batchmatrixdiagpart) | ❌ |
| [BatchMatrixInverse](raw_ops/batchmatrixinverse) | ❌ |
| [BatchMatrixSetDiag](raw_ops/batchmatrixsetdiag) | ❌ |
| [BatchMatrixSolve](raw_ops/batchmatrixsolve) | ❌ |
| [BatchMatrixSolveLs](raw_ops/batchmatrixsolvels) | ❌ |
| [BatchMatrixTriangularSolve](raw_ops/batchmatrixtriangularsolve) | ❌ |
| [BatchNormWithGlobalNormalization](raw_ops/batchnormwithglobalnormalization) | ✔️ |
| [BatchNormWithGlobalNormalizationGrad](raw_ops/batchnormwithglobalnormalizationgrad) | ❌ |
| [BatchSelfAdjointEig](raw_ops/batchselfadjointeig) | ❌ |
| [BatchSelfAdjointEigV2](raw_ops/batchselfadjointeigv2) | ❌ |
| [BatchSvd](raw_ops/batchsvd) | ❌ |
| [BatchToSpace](raw_ops/batchtospace) | ✔️ |
| [BatchToSpaceND](raw_ops/batchtospacend) | ✔️ |
| [BesselI0](raw_ops/besseli0) | ✔️ |
| [BesselI0e](raw_ops/besseli0e) | ✔️ |
| [BesselI1](raw_ops/besseli1) | ✔️ |
| [BesselI1e](raw_ops/besseli1e) | ✔️ |
| [BesselJ0](raw_ops/besselj0) | ✔️ |
| [BesselJ1](raw_ops/besselj1) | ✔️ |
| [BesselK0](raw_ops/besselk0) | ✔️ |
| [BesselK0e](raw_ops/besselk0e) | ✔️ |
| [BesselK1](raw_ops/besselk1) | ✔️ |
| [BesselK1e](raw_ops/besselk1e) | ✔️ |
| [BesselY0](raw_ops/bessely0) | ✔️ |
| [BesselY1](raw_ops/bessely1) | ✔️ |
| [Betainc](raw_ops/betainc) | ✔️ |
| [BiasAdd](raw_ops/biasadd) | ✔️ |
| [BiasAddGrad](raw_ops/biasaddgrad) | ✔️ |
| [BiasAddV1](raw_ops/biasaddv1) | ✔️ |
| [Bincount](raw_ops/bincount) | ❌ |
| [Bitcast](raw_ops/bitcast) | ❌ |
| [BitwiseAnd](raw_ops/bitwiseand) | ✔️ |
| [BitwiseOr](raw_ops/bitwiseor) | ✔️ |
| [BitwiseXor](raw_ops/bitwisexor) | ✔️ |
| [BlockLSTM](raw_ops/blocklstm) | ✔️ |
| [BlockLSTMGrad](raw_ops/blocklstmgrad) | ❌ |
| [BlockLSTMGradV2](raw_ops/blocklstmgradv2) | ❌ |
| [BlockLSTMV2](raw_ops/blocklstmv2) | ✔️ |
| [BoostedTreesAggregateStats](raw_ops/boostedtreesaggregatestats) | ❌ |
| [BoostedTreesBucketize](raw_ops/boostedtreesbucketize) | ❌ |
| [BoostedTreesCalculateBestFeatureSplit](raw_ops/boostedtreescalculatebestfeaturesplit) | ❌ |
| [BoostedTreesCalculateBestFeatureSplitV2](raw_ops/boostedtreescalculatebestfeaturesplitv2) | ❌ |
| [BoostedTreesCalculateBestGainsPerFeature](raw_ops/boostedtreescalculatebestgainsperfeature) | ❌ |
| [BoostedTreesCenterBias](raw_ops/boostedtreescenterbias) | ❌ |
| [BoostedTreesCreateEnsemble](raw_ops/boostedtreescreateensemble) | ❌ |
| [BoostedTreesCreateQuantileStreamResource](raw_ops/boostedtreescreatequantilestreamresource) | ❌ |
| [BoostedTreesDeserializeEnsemble](raw_ops/boostedtreesdeserializeensemble) | ❌ |
| [BoostedTreesEnsembleResourceHandleOp](raw_ops/boostedtreesensembleresourcehandleop) | ❌ |
| [BoostedTreesExampleDebugOutputs](raw_ops/boostedtreesexampledebugoutputs) | ❌ |
| [BoostedTreesFlushQuantileSummaries](raw_ops/boostedtreesflushquantilesummaries) | ❌ |
| [BoostedTreesGetEnsembleStates](raw_ops/boostedtreesgetensemblestates) | ❌ |
| [BoostedTreesMakeQuantileSummaries](raw_ops/boostedtreesmakequantilesummaries) | ❌ |
| [BoostedTreesMakeStatsSummary](raw_ops/boostedtreesmakestatssummary) | ❌ |
| [BoostedTreesPredict](raw_ops/boostedtreespredict) | ❌ |
| [BoostedTreesQuantileStreamResourceAddSummaries](raw_ops/boostedtreesquantilestreamresourceaddsummaries) | ❌ |
| [BoostedTreesQuantileStreamResourceDeserialize](raw_ops/boostedtreesquantilestreamresourcedeserialize) | ❌ |
| [BoostedTreesQuantileStreamResourceFlush](raw_ops/boostedtreesquantilestreamresourceflush) | ❌ |
| [BoostedTreesQuantileStreamResourceGetBucketBoundaries](raw_ops/boostedtreesquantilestreamresourcegetbucketboundaries) | ❌ |
| [BoostedTreesQuantileStreamResourceHandleOp](raw_ops/boostedtreesquantilestreamresourcehandleop) | ❌ |
| [BoostedTreesSerializeEnsemble](raw_ops/boostedtreesserializeensemble) | ❌ |
| [BoostedTreesSparseAggregateStats](raw_ops/boostedtreessparseaggregatestats) | ❌ |
| [BoostedTreesSparseCalculateBestFeatureSplit](raw_ops/boostedtreessparsecalculatebestfeaturesplit) | ❌ |
| [BoostedTreesTrainingPredict](raw_ops/boostedtreestrainingpredict) | ❌ |
| [BoostedTreesUpdateEnsemble](raw_ops/boostedtreesupdateensemble) | ❌ |
| [BoostedTreesUpdateEnsembleV2](raw_ops/boostedtreesupdateensemblev2) | ❌ |
| [BroadcastArgs](raw_ops/broadcastargs) | ❌ |
| [BroadcastGradientArgs](raw_ops/broadcastgradientargs) | ✔️ |
| [BroadcastTo](raw_ops/broadcastto) | ✔️ |
| [Bucketize](raw_ops/bucketize) | ❌ |
| [BytesProducedStatsDataset](raw_ops/bytesproducedstatsdataset) | ❌ |
| [CSRSparseMatrixComponents](raw_ops/csrsparsematrixcomponents) | ❌ |
| [CSRSparseMatrixToDense](raw_ops/csrsparsematrixtodense) | ✔️ |
| [CSRSparseMatrixToSparseTensor](raw_ops/csrsparsematrixtosparsetensor) | ✔️ |
| [CSVDataset](raw_ops/csvdataset) | ❌ |
| [CSVDatasetV2](raw_ops/csvdatasetv2) | ❌ |
| [CTCBeamSearchDecoder](raw_ops/ctcbeamsearchdecoder) | ✔️ |
| [CTCGreedyDecoder](raw_ops/ctcgreedydecoder) | ✔️ |
| [CTCLoss](raw_ops/ctcloss) | ✔️ |
| [CTCLossV2](raw_ops/ctclossv2) | ✔️ |
| [CacheDataset](raw_ops/cachedataset) | ❌ |
| [CacheDatasetV2](raw_ops/cachedatasetv2) | ❌ |
| [Case](raw_ops/case) | ✔️ |
| [Cast](raw_ops/cast) | ✔️ |
| [Ceil](raw_ops/ceil) | ✔️ |
| [CheckNumerics](raw_ops/checknumerics) | ✔️ |
| [CheckNumericsV2](raw_ops/checknumericsv2) | ✔️ |
| [Cholesky](raw_ops/cholesky) | ✔️ |
| [CholeskyGrad](raw_ops/choleskygrad) | ❌ |
| [ChooseFastestBranchDataset](raw_ops/choosefastestbranchdataset) | ❌ |
| [ChooseFastestDataset](raw_ops/choosefastestdataset) | ❌ |
| [ClipByValue](raw_ops/clipbyvalue) | ❌ |
| [CloseSummaryWriter](raw_ops/closesummarywriter) | ❌ |
| [CollectiveAllToAllV3](raw_ops/collectivealltoallv3) | ❌ |
| [CollectiveAssignGroupV2](raw_ops/collectiveassigngroupv2) | ❌ |
| [CollectiveBcastRecv](raw_ops/collectivebcastrecv) | ❌ |
| [CollectiveBcastRecvV2](raw_ops/collectivebcastrecvv2) | ❌ |
| [CollectiveBcastSend](raw_ops/collectivebcastsend) | ❌ |
| [CollectiveBcastSendV2](raw_ops/collectivebcastsendv2) | ❌ |
| [CollectiveGather](raw_ops/collectivegather) | ❌ |
| [CollectiveGatherV2](raw_ops/collectivegatherv2) | ❌ |
| [CollectiveInitializeCommunicator](raw_ops/collectiveinitializecommunicator) | ❌ |
| [CollectivePermute](raw_ops/collectivepermute) | ✔️ |
| [CollectiveReduce](raw_ops/collectivereduce) | ❌ |
| [CollectiveReduceV2](raw_ops/collectivereducev2) | ❌ |
| [CollectiveReduceV3](raw_ops/collectivereducev3) | ❌ |
| [CombinedNonMaxSuppression](raw_ops/combinednonmaxsuppression) | ❌ |
| [Complex](raw_ops/complex) | ✔️ |
| [ComplexAbs](raw_ops/complexabs) | ✔️ |
| [CompositeTensorVariantFromComponents](raw_ops/compositetensorvariantfromcomponents) | ✔️ |
| [CompositeTensorVariantToComponents](raw_ops/compositetensorvarianttocomponents) | ✔️ |
| [CompressElement](raw_ops/compresselement) | ❌ |
| [ComputeAccidentalHits](raw_ops/computeaccidentalhits) | ❌ |
| [ComputeBatchSize](raw_ops/computebatchsize) | ❌ |
| [Concat](raw_ops/concat) | ✔️ |
| [ConcatOffset](raw_ops/concatoffset) | ✔️ |
| [ConcatV2](raw_ops/concatv2) | ✔️ |
| [ConcatenateDataset](raw_ops/concatenatedataset) | ❌ |
| [ConditionalAccumulator](raw_ops/conditionalaccumulator) | ❌ |
| [ConfigureDistributedTPU](raw_ops/configuredistributedtpu) | ❌ |
| [ConfigureTPUEmbedding](raw_ops/configuretpuembedding) | ❌ |
| [Conj](raw_ops/conj) | ✔️ |
| [ConjugateTranspose](raw_ops/conjugatetranspose) | ✔️ |
| [Const](raw_ops/const) | ✔️ |
| [ConsumeMutexLock](raw_ops/consumemutexlock) | ❌ |
| [ControlTrigger](raw_ops/controltrigger) | ❌ |
| [Conv2D](raw_ops/conv2d) | ✔️ |
| [Conv2DBackpropFilter](raw_ops/conv2dbackpropfilter) | ✔️ |
| [Conv2DBackpropInput](raw_ops/conv2dbackpropinput) | ✔️ |
| [Conv3D](raw_ops/conv3d) | ✔️ |
| [Conv3DBackpropFilter](raw_ops/conv3dbackpropfilter) | ❌ |
| [Conv3DBackpropFilterV2](raw_ops/conv3dbackpropfilterv2) | ✔️ |
| [Conv3DBackpropInput](raw_ops/conv3dbackpropinput) | ❌ |
| [Conv3DBackpropInputV2](raw_ops/conv3dbackpropinputv2) | ✔️ |
| [Copy](raw_ops/copy) | ❌ |
| [CopyHost](raw_ops/copyhost) | ❌ |
| [Cos](raw_ops/cos) | ✔️ |
| [Cosh](raw_ops/cosh) | ✔️ |
| [CountUpTo](raw_ops/countupto) | ❌ |
| [CreateSummaryDbWriter](raw_ops/createsummarydbwriter) | ❌ |
| [CreateSummaryFileWriter](raw_ops/createsummaryfilewriter) | ❌ |
| [CropAndResize](raw_ops/cropandresize) | ✔️ |
| [CropAndResizeGradBoxes](raw_ops/cropandresizegradboxes) | ❌ |
| [CropAndResizeGradImage](raw_ops/cropandresizegradimage) | ❌ |
| [Cross](raw_ops/cross) | ✔️ |
| [CrossReplicaSum](raw_ops/crossreplicasum) | ✔️ |
| [CudnnRNN](raw_ops/cudnnrnn) | ✔️ |
| [CudnnRNNBackprop](raw_ops/cudnnrnnbackprop) | ❌ |
| [CudnnRNNBackpropV2](raw_ops/cudnnrnnbackpropv2) | ❌ |
| [CudnnRNNBackpropV3](raw_ops/cudnnrnnbackpropv3) | ❌ |
| [CudnnRNNCanonicalToParams](raw_ops/cudnnrnncanonicaltoparams) | ❌ |
| [CudnnRNNCanonicalToParamsV2](raw_ops/cudnnrnncanonicaltoparamsv2) | ❌ |
| [CudnnRNNParamsSize](raw_ops/cudnnrnnparamssize) | ❌ |
| [CudnnRNNParamsToCanonical](raw_ops/cudnnrnnparamstocanonical) | ❌ |
| [CudnnRNNParamsToCanonicalV2](raw_ops/cudnnrnnparamstocanonicalv2) | ❌ |
| [CudnnRNNV2](raw_ops/cudnnrnnv2) | ✔️ |
| [CudnnRNNV3](raw_ops/cudnnrnnv3) | ✔️ |
| [Cumprod](raw_ops/cumprod) | ✔️ |
| [Cumsum](raw_ops/cumsum) | ✔️ |
| [CumulativeLogsumexp](raw_ops/cumulativelogsumexp) | ✔️ |
| [DataFormatDimMap](raw_ops/dataformatdimmap) | ❌ |
| [DataFormatVecPermute](raw_ops/dataformatvecpermute) | ❌ |
| [DataServiceDataset](raw_ops/dataservicedataset) | ❌ |
| [DataServiceDatasetV2](raw_ops/dataservicedatasetv2) | ❌ |
| [DataServiceDatasetV3](raw_ops/dataservicedatasetv3) | ❌ |
| [DatasetCardinality](raw_ops/datasetcardinality) | ❌ |
| [DatasetFromGraph](raw_ops/datasetfromgraph) | ❌ |
| [DatasetToGraph](raw_ops/datasettograph) | ❌ |
| [DatasetToGraphV2](raw_ops/datasettographv2) | ❌ |
| [DatasetToSingleElement](raw_ops/datasettosingleelement) | ❌ |
| [DatasetToTFRecord](raw_ops/datasettotfrecord) | ❌ |
| [Dawsn](raw_ops/dawsn) | ✔️ |
| [DebugGradientIdentity](raw_ops/debuggradientidentity) | ✔️ |
| [DebugGradientRefIdentity](raw_ops/debuggradientrefidentity) | ✔️ |
| [DebugIdentity](raw_ops/debugidentity) | ❌ |
| [DebugIdentityV2](raw_ops/debugidentityv2) | ✔️ |
| [DebugNanCount](raw_ops/debugnancount) | ❌ |
| [DebugNumericSummary](raw_ops/debugnumericsummary) | ❌ |
| [DebugNumericSummaryV2](raw_ops/debugnumericsummaryv2) | ❌ |
| [DecodeAndCropJpeg](raw_ops/decodeandcropjpeg) | ❌ |
| [DecodeBase64](raw_ops/decodebase64) | ✔️ |
| [DecodeBmp](raw_ops/decodebmp) | ❌ |
| [DecodeCSV](raw_ops/decodecsv) | ❌ |
| [DecodeCompressed](raw_ops/decodecompressed) | ❌ |
| [DecodeGif](raw_ops/decodegif) | ❌ |
| [DecodeImage](raw_ops/decodeimage) | ❌ |
| [DecodeJSONExample](raw_ops/decodejsonexample) | ❌ |
| [DecodeJpeg](raw_ops/decodejpeg) | ❌ |
| [DecodePaddedRaw](raw_ops/decodepaddedraw) | ✔️ |
| [DecodePng](raw_ops/decodepng) | ❌ |
| [DecodeProtoV2](raw_ops/decodeprotov2) | ✔️ |
| [DecodeRaw](raw_ops/decoderaw) | ✔️ |
| [DecodeWav](raw_ops/decodewav) | ❌ |
| [DeepCopy](raw_ops/deepcopy) | ❌ |
| [DeleteIterator](raw_ops/deleteiterator) | ❌ |
| [DeleteMemoryCache](raw_ops/deletememorycache) | ❌ |
| [DeleteMultiDeviceIterator](raw_ops/deletemultideviceiterator) | ❌ |
| [DeleteRandomSeedGenerator](raw_ops/deleterandomseedgenerator) | ❌ |
| [DeleteSeedGenerator](raw_ops/deleteseedgenerator) | ❌ |
| [DeleteSessionTensor](raw_ops/deletesessiontensor) | ✔️ |
| [DenseBincount](raw_ops/densebincount) | ❌ |
| [DenseCountSparseOutput](raw_ops/densecountsparseoutput) | ❌ |
| [DenseToCSRSparseMatrix](raw_ops/densetocsrsparsematrix) | ✔️ |
| [DenseToDenseSetOperation](raw_ops/densetodensesetoperation) | ✔️ |
| [DenseToSparseBatchDataset](raw_ops/densetosparsebatchdataset) | ❌ |
| [DenseToSparseSetOperation](raw_ops/densetosparsesetoperation) | ✔️ |
| [DepthToSpace](raw_ops/depthtospace) | ✔️ |
| [DepthwiseConv2dNative](raw_ops/depthwiseconv2dnative) | ✔️ |
| [DepthwiseConv2dNativeBackpropFilter](raw_ops/depthwiseconv2dnativebackpropfilter) | ✔️ |
| [DepthwiseConv2dNativeBackpropInput](raw_ops/depthwiseconv2dnativebackpropinput) | ✔️ |
| [Dequantize](raw_ops/dequantize) | ❌ |
| [DeserializeIterator](raw_ops/deserializeiterator) | ❌ |
| [DeserializeManySparse](raw_ops/deserializemanysparse) | ❌ |
| [DeserializeSparse](raw_ops/deserializesparse) | ❌ |
| [DestroyResourceOp](raw_ops/destroyresourceop) | ❌ |
| [DestroyTemporaryVariable](raw_ops/destroytemporaryvariable) | ❌ |
| [DeviceIndex](raw_ops/deviceindex) | ❌ |
| [Diag](raw_ops/diag) | ✔️ |
| [DiagPart](raw_ops/diagpart) | ✔️ |
| [Digamma](raw_ops/digamma) | ✔️ |
| [Dilation2D](raw_ops/dilation2d) | ✔️ |
| [Dilation2DBackpropFilter](raw_ops/dilation2dbackpropfilter) | ❌ |
| [Dilation2DBackpropInput](raw_ops/dilation2dbackpropinput) | ❌ |
| [DirectedInterleaveDataset](raw_ops/directedinterleavedataset) | ❌ |
| [Div](raw_ops/div) | ✔️ |
| [DivNoNan](raw_ops/divnonan) | ✔️ |
| [DrawBoundingBoxes](raw_ops/drawboundingboxes) | ✔️ |
| [DrawBoundingBoxesV2](raw_ops/drawboundingboxesv2) | ❌ |
| [DummyIterationCounter](raw_ops/dummyiterationcounter) | ❌ |
| [DummyMemoryCache](raw_ops/dummymemorycache) | ❌ |
| [DummySeedGenerator](raw_ops/dummyseedgenerator) | ❌ |
| [DynamicEnqueueTPUEmbeddingArbitraryTensorBatch](raw_ops/dynamicenqueuetpuembeddingarbitrarytensorbatch) | ❌ |
| [DynamicPartition](raw_ops/dynamicpartition) | ✔️ |
| [DynamicStitch](raw_ops/dynamicstitch) | ✔️ |
| [EagerPyFunc](raw_ops/eagerpyfunc) | ✔️ |
| [EditDistance](raw_ops/editdistance) | ✔️ |
| [Eig](raw_ops/eig) | ✔️ |
| [Einsum](raw_ops/einsum) | ✔️ |
| [Elu](raw_ops/elu) | ✔️ |
| [EluGrad](raw_ops/elugrad) | ✔️ |
| [Empty](raw_ops/empty) | ❌ |
| [EmptyTensorList](raw_ops/emptytensorlist) | ❌ |
| [EncodeBase64](raw_ops/encodebase64) | ✔️ |
| [EncodeJpeg](raw_ops/encodejpeg) | ❌ |
| [EncodeJpegVariableQuality](raw_ops/encodejpegvariablequality) | ❌ |
| [EncodePng](raw_ops/encodepng) | ❌ |
| [EncodeProto](raw_ops/encodeproto) | ✔️ |
| [EncodeWav](raw_ops/encodewav) | ❌ |
| [EnqueueTPUEmbeddingArbitraryTensorBatch](raw_ops/enqueuetpuembeddingarbitrarytensorbatch) | ❌ |
| [EnqueueTPUEmbeddingIntegerBatch](raw_ops/enqueuetpuembeddingintegerbatch) | ❌ |
| [EnqueueTPUEmbeddingRaggedTensorBatch](raw_ops/enqueuetpuembeddingraggedtensorbatch) | ❌ |
| [EnqueueTPUEmbeddingSparseBatch](raw_ops/enqueuetpuembeddingsparsebatch) | ❌ |
| [EnqueueTPUEmbeddingSparseTensorBatch](raw_ops/enqueuetpuembeddingsparsetensorbatch) | ❌ |
| [EnsureShape](raw_ops/ensureshape) | ✔️ |
| [Enter](raw_ops/enter) | ✔️ |
| [Equal](raw_ops/equal) | ✔️ |
| [Erf](raw_ops/erf) | ✔️ |
| [Erfc](raw_ops/erfc) | ✔️ |
| [Erfinv](raw_ops/erfinv) | ✔️ |
| [EuclideanNorm](raw_ops/euclideannorm) | ✔️ |
| [Exit](raw_ops/exit) | ✔️ |
| [Exp](raw_ops/exp) | ✔️ |
| [ExpandDims](raw_ops/expanddims) | ✔️ |
| [ExperimentalAssertNextDataset](raw_ops/experimentalassertnextdataset) | ❌ |
| [ExperimentalAutoShardDataset](raw_ops/experimentalautosharddataset) | ❌ |
| [ExperimentalBytesProducedStatsDataset](raw_ops/experimentalbytesproducedstatsdataset) | ❌ |
| [ExperimentalCSVDataset](raw_ops/experimentalcsvdataset) | ❌ |
| [ExperimentalChooseFastestDataset](raw_ops/experimentalchoosefastestdataset) | ❌ |
| [ExperimentalDatasetCardinality](raw_ops/experimentaldatasetcardinality) | ❌ |
| [ExperimentalDatasetToTFRecord](raw_ops/experimentaldatasettotfrecord) | ❌ |
| [ExperimentalDenseToSparseBatchDataset](raw_ops/experimentaldensetosparsebatchdataset) | ❌ |
| [ExperimentalDirectedInterleaveDataset](raw_ops/experimentaldirectedinterleavedataset) | ❌ |
| [ExperimentalGroupByReducerDataset](raw_ops/experimentalgroupbyreducerdataset) | ❌ |
| [ExperimentalGroupByWindowDataset](raw_ops/experimentalgroupbywindowdataset) | ❌ |
| [ExperimentalIgnoreErrorsDataset](raw_ops/experimentalignoreerrorsdataset) | ❌ |
| [ExperimentalIteratorGetDevice](raw_ops/experimentaliteratorgetdevice) | ❌ |
| [ExperimentalLMDBDataset](raw_ops/experimentallmdbdataset) | ❌ |
| [ExperimentalLatencyStatsDataset](raw_ops/experimentallatencystatsdataset) | ❌ |
| [ExperimentalMapAndBatchDataset](raw_ops/experimentalmapandbatchdataset) | ❌ |
| [ExperimentalMapDataset](raw_ops/experimentalmapdataset) | ❌ |
| [ExperimentalMatchingFilesDataset](raw_ops/experimentalmatchingfilesdataset) | ❌ |
| [ExperimentalMaxIntraOpParallelismDataset](raw_ops/experimentalmaxintraopparallelismdataset) | ❌ |
| [ExperimentalNonSerializableDataset](raw_ops/experimentalnonserializabledataset) | ❌ |
| [ExperimentalParallelInterleaveDataset](raw_ops/experimentalparallelinterleavedataset) | ❌ |
| [ExperimentalParseExampleDataset](raw_ops/experimentalparseexampledataset) | ❌ |
| [ExperimentalPrivateThreadPoolDataset](raw_ops/experimentalprivatethreadpooldataset) | ❌ |
| [ExperimentalRandomDataset](raw_ops/experimentalrandomdataset) | ❌ |
| [ExperimentalRebatchDataset](raw_ops/experimentalrebatchdataset) | ❌ |
| [ExperimentalScanDataset](raw_ops/experimentalscandataset) | ❌ |
| [ExperimentalSetStatsAggregatorDataset](raw_ops/experimentalsetstatsaggregatordataset) | ❌ |
| [ExperimentalSleepDataset](raw_ops/experimentalsleepdataset) | ❌ |
| [ExperimentalSlidingWindowDataset](raw_ops/experimentalslidingwindowdataset) | ❌ |
| [ExperimentalSqlDataset](raw_ops/experimentalsqldataset) | ❌ |
| [ExperimentalStatsAggregatorHandle](raw_ops/experimentalstatsaggregatorhandle) | ❌ |
| [ExperimentalStatsAggregatorSummary](raw_ops/experimentalstatsaggregatorsummary) | ❌ |
| [ExperimentalTakeWhileDataset](raw_ops/experimentaltakewhiledataset) | ❌ |
| [ExperimentalThreadPoolDataset](raw_ops/experimentalthreadpooldataset) | ❌ |
| [ExperimentalThreadPoolHandle](raw_ops/experimentalthreadpoolhandle) | ❌ |
| [ExperimentalUnbatchDataset](raw_ops/experimentalunbatchdataset) | ❌ |
| [ExperimentalUniqueDataset](raw_ops/experimentaluniquedataset) | ❌ |
| [Expint](raw_ops/expint) | ✔️ |
| [Expm1](raw_ops/expm1) | ✔️ |
| [ExtractGlimpse](raw_ops/extractglimpse) | ✔️ |
| [ExtractGlimpseV2](raw_ops/extractglimpsev2) | ❌ |
| [ExtractImagePatches](raw_ops/extractimagepatches) | ✔️ |
| [ExtractJpegShape](raw_ops/extractjpegshape) | ❌ |
| [ExtractVolumePatches](raw_ops/extractvolumepatches) | ✔️ |
| [FFT](raw_ops/fft) | ✔️ |
| [FFT2D](raw_ops/fft2d) | ✔️ |
| [FFT3D](raw_ops/fft3d) | ✔️ |
| [FIFOQueue](raw_ops/fifoqueue) | ❌ |
| [FIFOQueueV2](raw_ops/fifoqueuev2) | ❌ |
| [Fact](raw_ops/fact) | ❌ |
| [FakeParam](raw_ops/fakeparam) | ❌ |
| [FakeQuantWithMinMaxArgs](raw_ops/fakequantwithminmaxargs) | ✔️ |
| [FakeQuantWithMinMaxArgsGradient](raw_ops/fakequantwithminmaxargsgradient) | ❌ |
| [FakeQuantWithMinMaxVars](raw_ops/fakequantwithminmaxvars) | ✔️ |
| [FakeQuantWithMinMaxVarsGradient](raw_ops/fakequantwithminmaxvarsgradient) | ❌ |
| [FakeQuantWithMinMaxVarsPerChannel](raw_ops/fakequantwithminmaxvarsperchannel) | ✔️ |
| [FakeQuantWithMinMaxVarsPerChannelGradient](raw_ops/fakequantwithminmaxvarsperchannelgradient) | ❌ |
| [FakeQueue](raw_ops/fakequeue) | ❌ |
| [Fill](raw_ops/fill) | ✔️ |
| [FilterByLastComponentDataset](raw_ops/filterbylastcomponentdataset) | ❌ |
| [FilterDataset](raw_ops/filterdataset) | ❌ |
| [FinalizeDataset](raw_ops/finalizedataset) | ❌ |
| [Fingerprint](raw_ops/fingerprint) | ❌ |
| [FixedLengthRecordDataset](raw_ops/fixedlengthrecorddataset) | ❌ |
| [FixedLengthRecordDatasetV2](raw_ops/fixedlengthrecorddatasetv2) | ❌ |
| [FixedLengthRecordReader](raw_ops/fixedlengthrecordreader) | ✔️ |
| [FixedLengthRecordReaderV2](raw_ops/fixedlengthrecordreaderv2) | ❌ |
| [FixedUnigramCandidateSampler](raw_ops/fixedunigramcandidatesampler) | ❌ |
| [FlatMapDataset](raw_ops/flatmapdataset) | ❌ |
| [Floor](raw_ops/floor) | ✔️ |
| [FloorDiv](raw_ops/floordiv) | ✔️ |
| [FloorMod](raw_ops/floormod) | ✔️ |
| [FlushSummaryWriter](raw_ops/flushsummarywriter) | ❌ |
| [For](raw_ops/for) | ❌ |
| [FractionalAvgPool](raw_ops/fractionalavgpool) | ✔️ |
| [FractionalAvgPoolGrad](raw_ops/fractionalavgpoolgrad) | ❌ |
| [FractionalMaxPool](raw_ops/fractionalmaxpool) | ✔️ |
| [FractionalMaxPoolGrad](raw_ops/fractionalmaxpoolgrad) | ❌ |
| [FresnelCos](raw_ops/fresnelcos) | ✔️ |
| [FresnelSin](raw_ops/fresnelsin) | ✔️ |
| [FusedBatchNorm](raw_ops/fusedbatchnorm) | ✔️ |
| [FusedBatchNormGrad](raw_ops/fusedbatchnormgrad) | ✔️ |
| [FusedBatchNormGradV2](raw_ops/fusedbatchnormgradv2) | ✔️ |
| [FusedBatchNormGradV3](raw_ops/fusedbatchnormgradv3) | ✔️ |
| [FusedBatchNormV2](raw_ops/fusedbatchnormv2) | ✔️ |
| [FusedBatchNormV3](raw_ops/fusedbatchnormv3) | ✔️ |
| [FusedPadConv2D](raw_ops/fusedpadconv2d) | ❌ |
| [FusedResizeAndPadConv2D](raw_ops/fusedresizeandpadconv2d) | ❌ |
| [GRUBlockCell](raw_ops/grublockcell) | ❌ |
| [GRUBlockCellGrad](raw_ops/grublockcellgrad) | ❌ |
| [Gather](raw_ops/gather) | ✔️ |
| [GatherNd](raw_ops/gathernd) | ✔️ |
| [GatherV2](raw_ops/gatherv2) | ✔️ |
| [GenerateBoundingBoxProposals](raw_ops/generateboundingboxproposals) | ✔️ |
| [GenerateVocabRemapping](raw_ops/generatevocabremapping) | ✔️ |
| [GeneratorDataset](raw_ops/generatordataset) | ❌ |
| [GetElementAtIndex](raw_ops/getelementatindex) | ❌ |
| [GetOptions](raw_ops/getoptions) | ❌ |
| [GetSessionHandle](raw_ops/getsessionhandle) | ✔️ |
| [GetSessionHandleV2](raw_ops/getsessionhandlev2) | ✔️ |
| [GetSessionTensor](raw_ops/getsessiontensor) | ✔️ |
| [Greater](raw_ops/greater) | ✔️ |
| [GreaterEqual](raw_ops/greaterequal) | ✔️ |
| [GroupByReducerDataset](raw_ops/groupbyreducerdataset) | ❌ |
| [GroupByWindowDataset](raw_ops/groupbywindowdataset) | ❌ |
| [GuaranteeConst](raw_ops/guaranteeconst) | ❌ |
| [HSVToRGB](raw_ops/hsvtorgb) | ✔️ |
| [HashTable](raw_ops/hashtable) | ✔️ |
| [HashTableV2](raw_ops/hashtablev2) | ✔️ |
| [HistogramFixedWidth](raw_ops/histogramfixedwidth) | ❌ |
| [HistogramSummary](raw_ops/histogramsummary) | ✔️ |
| [IFFT](raw_ops/ifft) | ✔️ |
| [IFFT2D](raw_ops/ifft2d) | ✔️ |
| [IFFT3D](raw_ops/ifft3d) | ✔️ |
| [IRFFT](raw_ops/irfft) | ✔️ |
| [IRFFT2D](raw_ops/irfft2d) | ✔️ |
| [IRFFT3D](raw_ops/irfft3d) | ❌ |
| [Identity](raw_ops/identity) | ✔️ |
| [IdentityN](raw_ops/identityn) | ✔️ |
| [IdentityReader](raw_ops/identityreader) | ✔️ |
| [IdentityReaderV2](raw_ops/identityreaderv2) | ❌ |
| [If](raw_ops/if) | ✔️ |
| [Igamma](raw_ops/igamma) | ✔️ |
| [IgammaGradA](raw_ops/igammagrada) | ❌ |
| [Igammac](raw_ops/igammac) | ✔️ |
| [IgnoreErrorsDataset](raw_ops/ignoreerrorsdataset) | ❌ |
| [Imag](raw_ops/imag) | ✔️ |
| [ImageProjectiveTransformV2](raw_ops/imageprojectivetransformv2) | ✔️ |
| [ImageProjectiveTransformV3](raw_ops/imageprojectivetransformv3) | ✔️ |
| [ImageSummary](raw_ops/imagesummary) | ✔️ |
| [ImmutableConst](raw_ops/immutableconst) | ❌ |
| [ImportEvent](raw_ops/importevent) | ❌ |
| [InTopK](raw_ops/intopk) | ❌ |
| [InTopKV2](raw_ops/intopkv2) | ❌ |
| [InfeedDequeue](raw_ops/infeeddequeue) | ❌ |
| [InfeedDequeueTuple](raw_ops/infeeddequeuetuple) | ❌ |
| [InfeedEnqueue](raw_ops/infeedenqueue) | ❌ |
| [InfeedEnqueuePrelinearizedBuffer](raw_ops/infeedenqueueprelinearizedbuffer) | ❌ |
| [InfeedEnqueueTuple](raw_ops/infeedenqueuetuple) | ❌ |
| [InitializeTable](raw_ops/initializetable) | ✔️ |
| [InitializeTableFromDataset](raw_ops/initializetablefromdataset) | ❌ |
| [InitializeTableFromTextFile](raw_ops/initializetablefromtextfile) | ✔️ |
| [InitializeTableFromTextFileV2](raw_ops/initializetablefromtextfilev2) | ✔️ |
| [InitializeTableV2](raw_ops/initializetablev2) | ✔️ |
| [InplaceAdd](raw_ops/inplaceadd) | ❌ |
| [InplaceSub](raw_ops/inplacesub) | ❌ |
| [InplaceUpdate](raw_ops/inplaceupdate) | ❌ |
| [InterleaveDataset](raw_ops/interleavedataset) | ❌ |
| [Inv](raw_ops/inv) | ✔️ |
| [InvGrad](raw_ops/invgrad) | ✔️ |
| [Invert](raw_ops/invert) | ✔️ |
| [InvertPermutation](raw_ops/invertpermutation) | ✔️ |
| [IsBoostedTreesEnsembleInitialized](raw_ops/isboostedtreesensembleinitialized) | ❌ |
| [IsBoostedTreesQuantileStreamResourceInitialized](raw_ops/isboostedtreesquantilestreamresourceinitialized) | ❌ |
| [IsFinite](raw_ops/isfinite) | ❌ |
| [IsInf](raw_ops/isinf) | ❌ |
| [IsNan](raw_ops/isnan) | ❌ |
| [IsTPUEmbeddingInitialized](raw_ops/istpuembeddinginitialized) | ❌ |
| [IsVariableInitialized](raw_ops/isvariableinitialized) | ❌ |
| [IsotonicRegression](raw_ops/isotonicregression) | ✔️ |
| [Iterator](raw_ops/iterator) | ❌ |
| [IteratorFromStringHandle](raw_ops/iteratorfromstringhandle) | ❌ |
| [IteratorFromStringHandleV2](raw_ops/iteratorfromstringhandlev2) | ❌ |
| [IteratorGetDevice](raw_ops/iteratorgetdevice) | ❌ |
| [IteratorGetNext](raw_ops/iteratorgetnext) | ❌ |
| [IteratorGetNextAsOptional](raw_ops/iteratorgetnextasoptional) | ❌ |
| [IteratorGetNextSync](raw_ops/iteratorgetnextsync) | ❌ |
| [IteratorToStringHandle](raw_ops/iteratortostringhandle) | ❌ |
| [IteratorV2](raw_ops/iteratorv2) | ❌ |
| [L2Loss](raw_ops/l2loss) | ✔️ |
| [LMDBDataset](raw_ops/lmdbdataset) | ❌ |
| [LMDBReader](raw_ops/lmdbreader) | ✔️ |
| [LRN](raw_ops/lrn) | ✔️ |
| [LRNGrad](raw_ops/lrngrad) | ❌ |
| [LSTMBlockCell](raw_ops/lstmblockcell) | ❌ |
| [LSTMBlockCellGrad](raw_ops/lstmblockcellgrad) | ❌ |
| [LatencyStatsDataset](raw_ops/latencystatsdataset) | ❌ |
| [LeakyRelu](raw_ops/leakyrelu) | ✔️ |
| [LeakyReluGrad](raw_ops/leakyrelugrad) | ✔️ |
| [LearnedUnigramCandidateSampler](raw_ops/learnedunigramcandidatesampler) | ❌ |
| [LeftShift](raw_ops/leftshift) | ✔️ |
| [LegacyParallelInterleaveDatasetV2](raw_ops/legacyparallelinterleavedatasetv2) | ❌ |
| [Less](raw_ops/less) | ✔️ |
| [LessEqual](raw_ops/lessequal) | ✔️ |
| [Lgamma](raw_ops/lgamma) | ✔️ |
| [LinSpace](raw_ops/linspace) | ✔️ |
| [ListDiff](raw_ops/listdiff) | ❌ |
| [LoadAndRemapMatrix](raw_ops/loadandremapmatrix) | ✔️ |
| [LoadDataset](raw_ops/loaddataset) | ❌ |
| [LoadTPUEmbeddingADAMParameters](raw_ops/loadtpuembeddingadamparameters) | ❌ |
| [LoadTPUEmbeddingAdadeltaParameters](raw_ops/loadtpuembeddingadadeltaparameters) | ❌ |
| [LoadTPUEmbeddingAdagradMomentumParameters](raw_ops/loadtpuembeddingadagradmomentumparameters) | ❌ |
| [LoadTPUEmbeddingAdagradParameters](raw_ops/loadtpuembeddingadagradparameters) | ❌ |
| [LoadTPUEmbeddingCenteredRMSPropParameters](raw_ops/loadtpuembeddingcenteredrmspropparameters) | ❌ |
| [LoadTPUEmbeddingFTRLParameters](raw_ops/loadtpuembeddingftrlparameters) | ❌ |
| [LoadTPUEmbeddingFrequencyEstimatorParameters](raw_ops/loadtpuembeddingfrequencyestimatorparameters) | ❌ |
| [LoadTPUEmbeddingMDLAdagradLightParameters](raw_ops/loadtpuembeddingmdladagradlightparameters) | ❌ |
| [LoadTPUEmbeddingMomentumParameters](raw_ops/loadtpuembeddingmomentumparameters) | ❌ |
| [LoadTPUEmbeddingProximalAdagradParameters](raw_ops/loadtpuembeddingproximaladagradparameters) | ❌ |
| [LoadTPUEmbeddingProximalYogiParameters](raw_ops/loadtpuembeddingproximalyogiparameters) | ❌ |
| [LoadTPUEmbeddingRMSPropParameters](raw_ops/loadtpuembeddingrmspropparameters) | ❌ |
| [LoadTPUEmbeddingStochasticGradientDescentParameters](raw_ops/loadtpuembeddingstochasticgradientdescentparameters) | ❌ |
| [Log](raw_ops/log) | ✔️ |
| [Log1p](raw_ops/log1p) | ✔️ |
| [LogMatrixDeterminant](raw_ops/logmatrixdeterminant) | ✔️ |
| [LogSoftmax](raw_ops/logsoftmax) | ✔️ |
| [LogUniformCandidateSampler](raw_ops/loguniformcandidatesampler) | ❌ |
| [LogicalAnd](raw_ops/logicaland) | ✔️ |
| [LogicalNot](raw_ops/logicalnot) | ✔️ |
| [LogicalOr](raw_ops/logicalor) | ✔️ |
| [LookupTableExport](raw_ops/lookuptableexport) | ❌ |
| [LookupTableExportV2](raw_ops/lookuptableexportv2) | ❌ |
| [LookupTableFind](raw_ops/lookuptablefind) | ✔️ |
| [LookupTableFindV2](raw_ops/lookuptablefindv2) | ✔️ |
| [LookupTableImport](raw_ops/lookuptableimport) | ❌ |
| [LookupTableImportV2](raw_ops/lookuptableimportv2) | ❌ |
| [LookupTableInsert](raw_ops/lookuptableinsert) | ✔️ |
| [LookupTableInsertV2](raw_ops/lookuptableinsertv2) | ✔️ |
| [LookupTableRemoveV2](raw_ops/lookuptableremovev2) | ❌ |
| [LookupTableSize](raw_ops/lookuptablesize) | ✔️ |
| [LookupTableSizeV2](raw_ops/lookuptablesizev2) | ✔️ |
| [LoopCond](raw_ops/loopcond) | ✔️ |
| [LowerBound](raw_ops/lowerbound) | ❌ |
| [Lu](raw_ops/lu) | ❌ |
| [MakeIterator](raw_ops/makeiterator) | ❌ |
| [MapAndBatchDataset](raw_ops/mapandbatchdataset) | ❌ |
| [MapClear](raw_ops/mapclear) | ❌ |
| [MapDataset](raw_ops/mapdataset) | ❌ |
| [MapDefun](raw_ops/mapdefun) | ❌ |
| [MapIncompleteSize](raw_ops/mapincompletesize) | ❌ |
| [MapPeek](raw_ops/mappeek) | ❌ |
| [MapSize](raw_ops/mapsize) | ❌ |
| [MapStage](raw_ops/mapstage) | ❌ |
| [MapUnstage](raw_ops/mapunstage) | ❌ |
| [MapUnstageNoKey](raw_ops/mapunstagenokey) | ❌ |
| [MatMul](raw_ops/matmul) | ✔️ |
| [MatchingFiles](raw_ops/matchingfiles) | ❌ |
| [MatchingFilesDataset](raw_ops/matchingfilesdataset) | ❌ |
| [MatrixBandPart](raw_ops/matrixbandpart) | ✔️ |
| [MatrixDeterminant](raw_ops/matrixdeterminant) | ✔️ |
| [MatrixDiag](raw_ops/matrixdiag) | ✔️ |
| [MatrixDiagPart](raw_ops/matrixdiagpart) | ✔️ |
| [MatrixDiagPartV2](raw_ops/matrixdiagpartv2) | ✔️ |
| [MatrixDiagPartV3](raw_ops/matrixdiagpartv3) | ✔️ |
| [MatrixDiagV2](raw_ops/matrixdiagv2) | ✔️ |
| [MatrixDiagV3](raw_ops/matrixdiagv3) | ✔️ |
| [MatrixExponential](raw_ops/matrixexponential) | ❌ |
| [MatrixInverse](raw_ops/matrixinverse) | ✔️ |
| [MatrixLogarithm](raw_ops/matrixlogarithm) | ❌ |
| [MatrixSetDiag](raw_ops/matrixsetdiag) | ✔️ |
| [MatrixSetDiagV2](raw_ops/matrixsetdiagv2) | ✔️ |
| [MatrixSetDiagV3](raw_ops/matrixsetdiagv3) | ✔️ |
| [MatrixSolve](raw_ops/matrixsolve) | ✔️ |
| [MatrixSolveLs](raw_ops/matrixsolvels) | ✔️ |
| [MatrixSquareRoot](raw_ops/matrixsquareroot) | ✔️ |
| [MatrixTriangularSolve](raw_ops/matrixtriangularsolve) | ✔️ |
| [Max](raw_ops/max) | ✔️ |
| [MaxIntraOpParallelismDataset](raw_ops/maxintraopparallelismdataset) | ❌ |
| [MaxPool](raw_ops/maxpool) | ✔️ |
| [MaxPool3D](raw_ops/maxpool3d) | ✔️ |
| [MaxPool3DGrad](raw_ops/maxpool3dgrad) | ✔️ |
| [MaxPool3DGradGrad](raw_ops/maxpool3dgradgrad) | ✔️ |
| [MaxPoolGrad](raw_ops/maxpoolgrad) | ✔️ |
| [MaxPoolGradGrad](raw_ops/maxpoolgradgrad) | ✔️ |
| [MaxPoolGradGradV2](raw_ops/maxpoolgradgradv2) | ❌ |
| [MaxPoolGradGradWithArgmax](raw_ops/maxpoolgradgradwithargmax) | ❌ |
| [MaxPoolGradV2](raw_ops/maxpoolgradv2) | ✔️ |
| [MaxPoolGradWithArgmax](raw_ops/maxpoolgradwithargmax) | ❌ |
| [MaxPoolV2](raw_ops/maxpoolv2) | ✔️ |
| [MaxPoolWithArgmax](raw_ops/maxpoolwithargmax) | ✔️ |
| [Maximum](raw_ops/maximum) | ✔️ |
| [Mean](raw_ops/mean) | ✔️ |
| [Merge](raw_ops/merge) | ✔️ |
| [MergeSummary](raw_ops/mergesummary) | ✔️ |
| [MergeV2Checkpoints](raw_ops/mergev2checkpoints) | ❌ |
| [Mfcc](raw_ops/mfcc) | ❌ |
| [Min](raw_ops/min) | ✔️ |
| [Minimum](raw_ops/minimum) | ✔️ |
| [MirrorPad](raw_ops/mirrorpad) | ✔️ |
| [MirrorPadGrad](raw_ops/mirrorpadgrad) | ✔️ |
| [Mod](raw_ops/mod) | ❌ |
| [ModelDataset](raw_ops/modeldataset) | ❌ |
| [Mul](raw_ops/mul) | ✔️ |
| [MulNoNan](raw_ops/mulnonan) | ✔️ |
| [MultiDeviceIterator](raw_ops/multideviceiterator) | ❌ |
| [MultiDeviceIteratorFromStringHandle](raw_ops/multideviceiteratorfromstringhandle) | ❌ |
| [MultiDeviceIteratorGetNextFromShard](raw_ops/multideviceiteratorgetnextfromshard) | ❌ |
| [MultiDeviceIteratorInit](raw_ops/multideviceiteratorinit) | ❌ |
| [MultiDeviceIteratorToStringHandle](raw_ops/multideviceiteratortostringhandle) | ❌ |
| [Multinomial](raw_ops/multinomial) | ✔️ |
| [MutableDenseHashTable](raw_ops/mutabledensehashtable) | ✔️ |
| [MutableDenseHashTableV2](raw_ops/mutabledensehashtablev2) | ✔️ |
| [MutableHashTable](raw_ops/mutablehashtable) | ✔️ |
| [MutableHashTableOfTensors](raw_ops/mutablehashtableoftensors) | ✔️ |
| [MutableHashTableOfTensorsV2](raw_ops/mutablehashtableoftensorsv2) | ✔️ |
| [MutableHashTableV2](raw_ops/mutablehashtablev2) | ✔️ |
| [MutexLock](raw_ops/mutexlock) | ❌ |
| [MutexV2](raw_ops/mutexv2) | ❌ |
| [NcclAllReduce](raw_ops/ncclallreduce) | ✔️ |
| [NcclBroadcast](raw_ops/ncclbroadcast) | ✔️ |
| [NcclReduce](raw_ops/ncclreduce) | ✔️ |
| [Ndtri](raw_ops/ndtri) | ✔️ |
| [Neg](raw_ops/neg) | ✔️ |
| [NextAfter](raw_ops/nextafter) | ✔️ |
| [NextIteration](raw_ops/nextiteration) | ✔️ |
| [NoOp](raw_ops/noop) | ❌ |
| [NonDeterministicInts](raw_ops/nondeterministicints) | ❌ |
| [NonMaxSuppression](raw_ops/nonmaxsuppression) | ✔️ |
| [NonMaxSuppressionV2](raw_ops/nonmaxsuppressionv2) | ✔️ |
| [NonMaxSuppressionV3](raw_ops/nonmaxsuppressionv3) | ❌ |
| [NonMaxSuppressionV4](raw_ops/nonmaxsuppressionv4) | ❌ |
| [NonMaxSuppressionV5](raw_ops/nonmaxsuppressionv5) | ❌ |
| [NonMaxSuppressionWithOverlaps](raw_ops/nonmaxsuppressionwithoverlaps) | ✔️ |
| [NonSerializableDataset](raw_ops/nonserializabledataset) | ❌ |
| [NotEqual](raw_ops/notequal) | ✔️ |
| [NthElement](raw_ops/nthelement) | ✔️ |
| [OneHot](raw_ops/onehot) | ✔️ |
| [OneShotIterator](raw_ops/oneshotiterator) | ❌ |
| [OnesLike](raw_ops/oneslike) | ✔️ |
| [OptimizeDataset](raw_ops/optimizedataset) | ❌ |
| [OptimizeDatasetV2](raw_ops/optimizedatasetv2) | ❌ |
| [OptionalFromValue](raw_ops/optionalfromvalue) | ✔️ |
| [OptionalGetValue](raw_ops/optionalgetvalue) | ✔️ |
| [OptionalHasValue](raw_ops/optionalhasvalue) | ❌ |
| [OptionalNone](raw_ops/optionalnone) | ❌ |
| [OptionsDataset](raw_ops/optionsdataset) | ❌ |
| [OrderedMapClear](raw_ops/orderedmapclear) | ❌ |
| [OrderedMapIncompleteSize](raw_ops/orderedmapincompletesize) | ❌ |
| [OrderedMapPeek](raw_ops/orderedmappeek) | ❌ |
| [OrderedMapSize](raw_ops/orderedmapsize) | ❌ |
| [OrderedMapStage](raw_ops/orderedmapstage) | ❌ |
| [OrderedMapUnstage](raw_ops/orderedmapunstage) | ❌ |
| [OrderedMapUnstageNoKey](raw_ops/orderedmapunstagenokey) | ❌ |
| [OutfeedDequeue](raw_ops/outfeeddequeue) | ❌ |
| [OutfeedDequeueTuple](raw_ops/outfeeddequeuetuple) | ❌ |
| [OutfeedDequeueTupleV2](raw_ops/outfeeddequeuetuplev2) | ❌ |
| [OutfeedDequeueV2](raw_ops/outfeeddequeuev2) | ❌ |
| [OutfeedEnqueue](raw_ops/outfeedenqueue) | ❌ |
| [OutfeedEnqueueTuple](raw_ops/outfeedenqueuetuple) | ❌ |
| [Pack](raw_ops/pack) | ✔️ |
| [Pad](raw_ops/pad) | ✔️ |
| [PadV2](raw_ops/padv2) | ✔️ |
| [PaddedBatchDataset](raw_ops/paddedbatchdataset) | ❌ |
| [PaddedBatchDatasetV2](raw_ops/paddedbatchdatasetv2) | ❌ |
| [PaddingFIFOQueue](raw_ops/paddingfifoqueue) | ❌ |
| [PaddingFIFOQueueV2](raw_ops/paddingfifoqueuev2) | ❌ |
| [ParallelBatchDataset](raw_ops/parallelbatchdataset) | ❌ |
| [ParallelConcat](raw_ops/parallelconcat) | ❌ |
| [ParallelDynamicStitch](raw_ops/paralleldynamicstitch) | ✔️ |
| [ParallelFilterDataset](raw_ops/parallelfilterdataset) | ❌ |
| [ParallelInterleaveDataset](raw_ops/parallelinterleavedataset) | ❌ |
| [ParallelInterleaveDatasetV2](raw_ops/parallelinterleavedatasetv2) | ❌ |
| [ParallelInterleaveDatasetV3](raw_ops/parallelinterleavedatasetv3) | ❌ |
| [ParallelInterleaveDatasetV4](raw_ops/parallelinterleavedatasetv4) | ❌ |
| [ParallelMapDataset](raw_ops/parallelmapdataset) | ❌ |
| [ParallelMapDatasetV2](raw_ops/parallelmapdatasetv2) | ❌ |
| [ParameterizedTruncatedNormal](raw_ops/parameterizedtruncatednormal) | ✔️ |
| [ParseExample](raw_ops/parseexample) | ❌ |
| [ParseExampleDataset](raw_ops/parseexampledataset) | ❌ |
| [ParseExampleDatasetV2](raw_ops/parseexampledatasetv2) | ❌ |
| [ParseExampleV2](raw_ops/parseexamplev2) | ❌ |
| [ParseSequenceExample](raw_ops/parsesequenceexample) | ❌ |
| [ParseSequenceExampleV2](raw_ops/parsesequenceexamplev2) | ❌ |
| [ParseSingleExample](raw_ops/parsesingleexample) | ❌ |
| [ParseSingleSequenceExample](raw_ops/parsesinglesequenceexample) | ❌ |
| [ParseTensor](raw_ops/parsetensor) | ✔️ |
| [PartitionedCall](raw_ops/partitionedcall) | ❌ |
| [Placeholder](raw_ops/placeholder) | ❌ |
| [PlaceholderV2](raw_ops/placeholderv2) | ❌ |
| [PlaceholderWithDefault](raw_ops/placeholderwithdefault) | ✔️ |
| [Polygamma](raw_ops/polygamma) | ✔️ |
| [PopulationCount](raw_ops/populationcount) | ✔️ |
| [Pow](raw_ops/pow) | ✔️ |
| [PrefetchDataset](raw_ops/prefetchdataset) | ❌ |
| [Prelinearize](raw_ops/prelinearize) | ❌ |
| [PrelinearizeTuple](raw_ops/prelinearizetuple) | ❌ |
| [PreventGradient](raw_ops/preventgradient) | ✔️ |
| [Print](raw_ops/print) | ✔️ |
| [PrintV2](raw_ops/printv2) | ❌ |
| [PriorityQueue](raw_ops/priorityqueue) | ❌ |
| [PriorityQueueV2](raw_ops/priorityqueuev2) | ❌ |
| [PrivateThreadPoolDataset](raw_ops/privatethreadpooldataset) | ❌ |
| [Prod](raw_ops/prod) | ✔️ |
| [PyFunc](raw_ops/pyfunc) | ✔️ |
| [PyFuncStateless](raw_ops/pyfuncstateless) | ✔️ |
| [Qr](raw_ops/qr) | ✔️ |
| [QuantizeAndDequantize](raw_ops/quantizeanddequantize) | ✔️ |
| [QuantizeAndDequantizeV2](raw_ops/quantizeanddequantizev2) | ✔️ |
| [QuantizeAndDequantizeV3](raw_ops/quantizeanddequantizev3) | ✔️ |
| [QuantizeAndDequantizeV4](raw_ops/quantizeanddequantizev4) | ✔️ |
| [QuantizeAndDequantizeV4Grad](raw_ops/quantizeanddequantizev4grad) | ✔️ |
| [QuantizeDownAndShrinkRange](raw_ops/quantizedownandshrinkrange) | ❌ |
| [QuantizeV2](raw_ops/quantizev2) | ❌ |
| [QuantizedAdd](raw_ops/quantizedadd) | ❌ |
| [QuantizedAvgPool](raw_ops/quantizedavgpool) | ❌ |
| [QuantizedBatchNormWithGlobalNormalization](raw_ops/quantizedbatchnormwithglobalnormalization) | ❌ |
| [QuantizedBiasAdd](raw_ops/quantizedbiasadd) | ❌ |
| [QuantizedConcat](raw_ops/quantizedconcat) | ❌ |
| [QuantizedConv2D](raw_ops/quantizedconv2d) | ❌ |
| [QuantizedConv2DAndRelu](raw_ops/quantizedconv2dandrelu) | ❌ |
| [QuantizedConv2DAndReluAndRequantize](raw_ops/quantizedconv2dandreluandrequantize) | ❌ |
| [QuantizedConv2DAndRequantize](raw_ops/quantizedconv2dandrequantize) | ❌ |
| [QuantizedConv2DPerChannel](raw_ops/quantizedconv2dperchannel) | ❌ |
| [QuantizedConv2DWithBias](raw_ops/quantizedconv2dwithbias) | ❌ |
| [QuantizedConv2DWithBiasAndRelu](raw_ops/quantizedconv2dwithbiasandrelu) | ❌ |
| [QuantizedConv2DWithBiasAndReluAndRequantize](raw_ops/quantizedconv2dwithbiasandreluandrequantize) | ❌ |
| [QuantizedConv2DWithBiasAndRequantize](raw_ops/quantizedconv2dwithbiasandrequantize) | ❌ |
| [QuantizedConv2DWithBiasSignedSumAndReluAndRequantize](raw_ops/quantizedconv2dwithbiassignedsumandreluandrequantize) | ❌ |
| [QuantizedConv2DWithBiasSumAndRelu](raw_ops/quantizedconv2dwithbiassumandrelu) | ❌ |
| [QuantizedConv2DWithBiasSumAndReluAndRequantize](raw_ops/quantizedconv2dwithbiassumandreluandrequantize) | ❌ |
| [QuantizedDepthwiseConv2D](raw_ops/quantizeddepthwiseconv2d) | ❌ |
| [QuantizedDepthwiseConv2DWithBias](raw_ops/quantizeddepthwiseconv2dwithbias) | ❌ |
| [QuantizedDepthwiseConv2DWithBiasAndRelu](raw_ops/quantizeddepthwiseconv2dwithbiasandrelu) | ❌ |
| [QuantizedDepthwiseConv2DWithBiasAndReluAndRequantize](raw_ops/quantizeddepthwiseconv2dwithbiasandreluandrequantize) | ❌ |
| [QuantizedInstanceNorm](raw_ops/quantizedinstancenorm) | ❌ |
| [QuantizedMatMul](raw_ops/quantizedmatmul) | ❌ |
| [QuantizedMatMulWithBias](raw_ops/quantizedmatmulwithbias) | ❌ |
| [QuantizedMatMulWithBiasAndDequantize](raw_ops/quantizedmatmulwithbiasanddequantize) | ❌ |
| [QuantizedMatMulWithBiasAndRelu](raw_ops/quantizedmatmulwithbiasandrelu) | ❌ |
| [QuantizedMatMulWithBiasAndReluAndRequantize](raw_ops/quantizedmatmulwithbiasandreluandrequantize) | ❌ |
| [QuantizedMatMulWithBiasAndRequantize](raw_ops/quantizedmatmulwithbiasandrequantize) | ❌ |
| [QuantizedMaxPool](raw_ops/quantizedmaxpool) | ❌ |
| [QuantizedMul](raw_ops/quantizedmul) | ❌ |
| [QuantizedRelu](raw_ops/quantizedrelu) | ❌ |
| [QuantizedRelu6](raw_ops/quantizedrelu6) | ❌ |
| [QuantizedReluX](raw_ops/quantizedrelux) | ❌ |
| [QuantizedReshape](raw_ops/quantizedreshape) | ❌ |
| [QuantizedResizeBilinear](raw_ops/quantizedresizebilinear) | ❌ |
| [QueueClose](raw_ops/queueclose) | ✔️ |
| [QueueCloseV2](raw_ops/queueclosev2) | ❌ |
| [QueueDequeue](raw_ops/queuedequeue) | ✔️ |
| [QueueDequeueMany](raw_ops/queuedequeuemany) | ✔️ |
| [QueueDequeueManyV2](raw_ops/queuedequeuemanyv2) | ❌ |
| [QueueDequeueUpTo](raw_ops/queuedequeueupto) | ✔️ |
| [QueueDequeueUpToV2](raw_ops/queuedequeueuptov2) | ❌ |
| [QueueDequeueV2](raw_ops/queuedequeuev2) | ❌ |
| [QueueEnqueue](raw_ops/queueenqueue) | ✔️ |
| [QueueEnqueueMany](raw_ops/queueenqueuemany) | ✔️ |
| [QueueEnqueueManyV2](raw_ops/queueenqueuemanyv2) | ❌ |
| [QueueEnqueueV2](raw_ops/queueenqueuev2) | ❌ |
| [QueueIsClosed](raw_ops/queueisclosed) | ❌ |
| [QueueIsClosedV2](raw_ops/queueisclosedv2) | ❌ |
| [QueueSize](raw_ops/queuesize) | ✔️ |
| [QueueSizeV2](raw_ops/queuesizev2) | ❌ |
| [RFFT](raw_ops/rfft) | ✔️ |
| [RFFT2D](raw_ops/rfft2d) | ✔️ |
| [RFFT3D](raw_ops/rfft3d) | ❌ |
| [RGBToHSV](raw_ops/rgbtohsv) | ✔️ |
| [RaggedBincount](raw_ops/raggedbincount) | ❌ |
| [RaggedCountSparseOutput](raw_ops/raggedcountsparseoutput) | ❌ |
| [RaggedCross](raw_ops/raggedcross) | ❌ |
| [RaggedGather](raw_ops/raggedgather) | ✔️ |
| [RaggedRange](raw_ops/raggedrange) | ✔️ |
| [RaggedTensorFromVariant](raw_ops/raggedtensorfromvariant) | ✔️ |
| [RaggedTensorToSparse](raw_ops/raggedtensortosparse) | ✔️ |
| [RaggedTensorToTensor](raw_ops/raggedtensortotensor) | ✔️ |
| [RaggedTensorToVariant](raw_ops/raggedtensortovariant) | ✔️ |
| [RaggedTensorToVariantGradient](raw_ops/raggedtensortovariantgradient) | ❌ |
| [RandomCrop](raw_ops/randomcrop) | ✔️ |
| [RandomDataset](raw_ops/randomdataset) | ❌ |
| [RandomGamma](raw_ops/randomgamma) | ✔️ |
| [RandomGammaGrad](raw_ops/randomgammagrad) | ❌ |
| [RandomIndexShuffle](raw_ops/randomindexshuffle) | ✔️ |
| [RandomPoisson](raw_ops/randompoisson) | ❌ |
| [RandomPoissonV2](raw_ops/randompoissonv2) | ❌ |
| [RandomShuffle](raw_ops/randomshuffle) | ❌ |
| [RandomShuffleQueue](raw_ops/randomshufflequeue) | ❌ |
| [RandomShuffleQueueV2](raw_ops/randomshufflequeuev2) | ❌ |
| [RandomStandardNormal](raw_ops/randomstandardnormal) | ✔️ |
| [RandomUniform](raw_ops/randomuniform) | ✔️ |
| [RandomUniformInt](raw_ops/randomuniformint) | ❌ |
| [Range](raw_ops/range) | ✔️ |
| [RangeDataset](raw_ops/rangedataset) | ❌ |
| [Rank](raw_ops/rank) | ✔️ |
| [ReadFile](raw_ops/readfile) | ❌ |
| [ReadVariableOp](raw_ops/readvariableop) | ✔️ |
| [ReadVariableXlaSplitND](raw_ops/readvariablexlasplitnd) | ❌ |
| [ReaderNumRecordsProduced](raw_ops/readernumrecordsproduced) | ✔️ |
| [ReaderNumRecordsProducedV2](raw_ops/readernumrecordsproducedv2) | ❌ |
| [ReaderNumWorkUnitsCompleted](raw_ops/readernumworkunitscompleted) | ✔️ |
| [ReaderNumWorkUnitsCompletedV2](raw_ops/readernumworkunitscompletedv2) | ❌ |
| [ReaderRead](raw_ops/readerread) | ✔️ |
| [ReaderReadUpTo](raw_ops/readerreadupto) | ✔️ |
| [ReaderReadUpToV2](raw_ops/readerreaduptov2) | ❌ |
| [ReaderReadV2](raw_ops/readerreadv2) | ❌ |
| [ReaderReset](raw_ops/readerreset) | ✔️ |
| [ReaderResetV2](raw_ops/readerresetv2) | ❌ |
| [ReaderRestoreState](raw_ops/readerrestorestate) | ✔️ |
| [ReaderRestoreStateV2](raw_ops/readerrestorestatev2) | ❌ |
| [ReaderSerializeState](raw_ops/readerserializestate) | ✔️ |
| [ReaderSerializeStateV2](raw_ops/readerserializestatev2) | ❌ |
| [Real](raw_ops/real) | ✔️ |
| [RealDiv](raw_ops/realdiv) | ✔️ |
| [RebatchDataset](raw_ops/rebatchdataset) | ❌ |
| [RebatchDatasetV2](raw_ops/rebatchdatasetv2) | ❌ |
| [Reciprocal](raw_ops/reciprocal) | ✔️ |
| [ReciprocalGrad](raw_ops/reciprocalgrad) | ✔️ |
| [RecordInput](raw_ops/recordinput) | ❌ |
| [Recv](raw_ops/recv) | ❌ |
| [RecvTPUEmbeddingActivations](raw_ops/recvtpuembeddingactivations) | ❌ |
| [ReduceDataset](raw_ops/reducedataset) | ✔️ |
| [ReduceJoin](raw_ops/reducejoin) | ✔️ |
| [RefEnter](raw_ops/refenter) | ✔️ |
| [RefExit](raw_ops/refexit) | ✔️ |
| [RefIdentity](raw_ops/refidentity) | ✔️ |
| [RefMerge](raw_ops/refmerge) | ✔️ |
| [RefNextIteration](raw_ops/refnextiteration) | ✔️ |
| [RefSelect](raw_ops/refselect) | ❌ |
| [RefSwitch](raw_ops/refswitch) | ✔️ |
| [RegexFullMatch](raw_ops/regexfullmatch) | ❌ |
| [RegexReplace](raw_ops/regexreplace) | ✔️ |
| [RegisterDataset](raw_ops/registerdataset) | ❌ |
| [Relu](raw_ops/relu) | ✔️ |
| [Relu6](raw_ops/relu6) | ✔️ |
| [Relu6Grad](raw_ops/relu6grad) | ✔️ |
| [ReluGrad](raw_ops/relugrad) | ✔️ |
| [RemoteCall](raw_ops/remotecall) | ❌ |
| [RepeatDataset](raw_ops/repeatdataset) | ❌ |
| [RequantizationRange](raw_ops/requantizationrange) | ❌ |
| [RequantizationRangePerChannel](raw_ops/requantizationrangeperchannel) | ❌ |
| [Requantize](raw_ops/requantize) | ❌ |
| [RequantizePerChannel](raw_ops/requantizeperchannel) | ❌ |
| [Reshape](raw_ops/reshape) | ✔️ |
| [ResizeArea](raw_ops/resizearea) | ❌ |
| [ResizeBicubic](raw_ops/resizebicubic) | ✔️ |
| [ResizeBicubicGrad](raw_ops/resizebicubicgrad) | ❌ |
| [ResizeBilinear](raw_ops/resizebilinear) | ✔️ |
| [ResizeBilinearGrad](raw_ops/resizebilineargrad) | ❌ |
| [ResizeNearestNeighbor](raw_ops/resizenearestneighbor) | ✔️ |
| [ResizeNearestNeighborGrad](raw_ops/resizenearestneighborgrad) | ❌ |
| [ResourceAccumulatorApplyGradient](raw_ops/resourceaccumulatorapplygradient) | ❌ |
| [ResourceAccumulatorNumAccumulated](raw_ops/resourceaccumulatornumaccumulated) | ❌ |
| [ResourceAccumulatorSetGlobalStep](raw_ops/resourceaccumulatorsetglobalstep) | ❌ |
| [ResourceAccumulatorTakeGradient](raw_ops/resourceaccumulatortakegradient) | ❌ |
| [ResourceApplyAdaMax](raw_ops/resourceapplyadamax) | ❌ |
| [ResourceApplyAdadelta](raw_ops/resourceapplyadadelta) | ❌ |
| [ResourceApplyAdagrad](raw_ops/resourceapplyadagrad) | ❌ |
| [ResourceApplyAdagradDA](raw_ops/resourceapplyadagradda) | ❌ |
| [ResourceApplyAdagradV2](raw_ops/resourceapplyadagradv2) | ❌ |
| [ResourceApplyAdam](raw_ops/resourceapplyadam) | ❌ |
| [ResourceApplyAdamWithAmsgrad](raw_ops/resourceapplyadamwithamsgrad) | ❌ |
| [ResourceApplyAddSign](raw_ops/resourceapplyaddsign) | ❌ |
| [ResourceApplyCenteredRMSProp](raw_ops/resourceapplycenteredrmsprop) | ❌ |
| [ResourceApplyFtrl](raw_ops/resourceapplyftrl) | ❌ |
| [ResourceApplyFtrlV2](raw_ops/resourceapplyftrlv2) | ❌ |
| [ResourceApplyGradientDescent](raw_ops/resourceapplygradientdescent) | ❌ |
| [ResourceApplyKerasMomentum](raw_ops/resourceapplykerasmomentum) | ❌ |
| [ResourceApplyMomentum](raw_ops/resourceapplymomentum) | ❌ |
| [ResourceApplyPowerSign](raw_ops/resourceapplypowersign) | ❌ |
| [ResourceApplyProximalAdagrad](raw_ops/resourceapplyproximaladagrad) | ❌ |
| [ResourceApplyProximalGradientDescent](raw_ops/resourceapplyproximalgradientdescent) | ❌ |
| [ResourceApplyRMSProp](raw_ops/resourceapplyrmsprop) | ❌ |
| [ResourceConditionalAccumulator](raw_ops/resourceconditionalaccumulator) | ❌ |
| [ResourceCountUpTo](raw_ops/resourcecountupto) | ❌ |
| [ResourceGather](raw_ops/resourcegather) | ✔️ |
| [ResourceGatherNd](raw_ops/resourcegathernd) | ✔️ |
| [ResourceScatterAdd](raw_ops/resourcescatteradd) | ❌ |
| [ResourceScatterDiv](raw_ops/resourcescatterdiv) | ❌ |
| [ResourceScatterMax](raw_ops/resourcescattermax) | ❌ |
| [ResourceScatterMin](raw_ops/resourcescattermin) | ❌ |
| [ResourceScatterMul](raw_ops/resourcescattermul) | ❌ |
| [ResourceScatterNdAdd](raw_ops/resourcescatterndadd) | ❌ |
| [ResourceScatterNdMax](raw_ops/resourcescatterndmax) | ❌ |
| [ResourceScatterNdMin](raw_ops/resourcescatterndmin) | ❌ |
| [ResourceScatterNdSub](raw_ops/resourcescatterndsub) | ❌ |
| [ResourceScatterNdUpdate](raw_ops/resourcescatterndupdate) | ❌ |
| [ResourceScatterSub](raw_ops/resourcescattersub) | ❌ |
| [ResourceScatterUpdate](raw_ops/resourcescatterupdate) | ❌ |
| [ResourceSparseApplyAdadelta](raw_ops/resourcesparseapplyadadelta) | ❌ |
| [ResourceSparseApplyAdagrad](raw_ops/resourcesparseapplyadagrad) | ❌ |
| [ResourceSparseApplyAdagradDA](raw_ops/resourcesparseapplyadagradda) | ❌ |
| [ResourceSparseApplyAdagradV2](raw_ops/resourcesparseapplyadagradv2) | ❌ |
| [ResourceSparseApplyCenteredRMSProp](raw_ops/resourcesparseapplycenteredrmsprop) | ❌ |
| [ResourceSparseApplyFtrl](raw_ops/resourcesparseapplyftrl) | ❌ |
| [ResourceSparseApplyFtrlV2](raw_ops/resourcesparseapplyftrlv2) | ❌ |
| [ResourceSparseApplyKerasMomentum](raw_ops/resourcesparseapplykerasmomentum) | ❌ |
| [ResourceSparseApplyMomentum](raw_ops/resourcesparseapplymomentum) | ❌ |
| [ResourceSparseApplyProximalAdagrad](raw_ops/resourcesparseapplyproximaladagrad) | ❌ |
| [ResourceSparseApplyProximalGradientDescent](raw_ops/resourcesparseapplyproximalgradientdescent) | ❌ |
| [ResourceSparseApplyRMSProp](raw_ops/resourcesparseapplyrmsprop) | ❌ |
| [ResourceStridedSliceAssign](raw_ops/resourcestridedsliceassign) | ❌ |
| [Restore](raw_ops/restore) | ❌ |
| [RestoreSlice](raw_ops/restoreslice) | ❌ |
| [RestoreV2](raw_ops/restorev2) | ❌ |
| [RetrieveTPUEmbeddingADAMParameters](raw_ops/retrievetpuembeddingadamparameters) | ❌ |
| [RetrieveTPUEmbeddingAdadeltaParameters](raw_ops/retrievetpuembeddingadadeltaparameters) | ❌ |
| [RetrieveTPUEmbeddingAdagradMomentumParameters](raw_ops/retrievetpuembeddingadagradmomentumparameters) | ❌ |
| [RetrieveTPUEmbeddingAdagradParameters](raw_ops/retrievetpuembeddingadagradparameters) | ❌ |
| [RetrieveTPUEmbeddingCenteredRMSPropParameters](raw_ops/retrievetpuembeddingcenteredrmspropparameters) | ❌ |
| [RetrieveTPUEmbeddingFTRLParameters](raw_ops/retrievetpuembeddingftrlparameters) | ❌ |
| [RetrieveTPUEmbeddingFrequencyEstimatorParameters](raw_ops/retrievetpuembeddingfrequencyestimatorparameters) | ❌ |
| [RetrieveTPUEmbeddingMDLAdagradLightParameters](raw_ops/retrievetpuembeddingmdladagradlightparameters) | ❌ |
| [RetrieveTPUEmbeddingMomentumParameters](raw_ops/retrievetpuembeddingmomentumparameters) | ❌ |
| [RetrieveTPUEmbeddingProximalAdagradParameters](raw_ops/retrievetpuembeddingproximaladagradparameters) | ❌ |
| [RetrieveTPUEmbeddingProximalYogiParameters](raw_ops/retrievetpuembeddingproximalyogiparameters) | ❌ |
| [RetrieveTPUEmbeddingRMSPropParameters](raw_ops/retrievetpuembeddingrmspropparameters) | ❌ |
| [RetrieveTPUEmbeddingStochasticGradientDescentParameters](raw_ops/retrievetpuembeddingstochasticgradientdescentparameters) | ❌ |
| [Reverse](raw_ops/reverse) | ✔️ |
| [ReverseSequence](raw_ops/reversesequence) | ✔️ |
| [ReverseV2](raw_ops/reversev2) | ✔️ |
| [RightShift](raw_ops/rightshift) | ✔️ |
| [Rint](raw_ops/rint) | ✔️ |
| [RngReadAndSkip](raw_ops/rngreadandskip) | ❌ |
| [RngSkip](raw_ops/rngskip) | ❌ |
| [Roll](raw_ops/roll) | ✔️ |
| [Round](raw_ops/round) | ✔️ |
| [Rsqrt](raw_ops/rsqrt) | ✔️ |
| [RsqrtGrad](raw_ops/rsqrtgrad) | ✔️ |
| [SampleDistortedBoundingBox](raw_ops/sampledistortedboundingbox) | ✔️ |
| [SampleDistortedBoundingBoxV2](raw_ops/sampledistortedboundingboxv2) | ✔️ |
| [SamplingDataset](raw_ops/samplingdataset) | ❌ |
| [Save](raw_ops/save) | ❌ |
| [SaveDataset](raw_ops/savedataset) | ❌ |
| [SaveDatasetV2](raw_ops/savedatasetv2) | ❌ |
| [SaveSlices](raw_ops/saveslices) | ❌ |
| [SaveV2](raw_ops/savev2) | ❌ |
| [ScalarSummary](raw_ops/scalarsummary) | ✔️ |
| [ScaleAndTranslate](raw_ops/scaleandtranslate) | ✔️ |
| [ScaleAndTranslateGrad](raw_ops/scaleandtranslategrad) | ❌ |
| [ScanDataset](raw_ops/scandataset) | ❌ |
| [ScatterAdd](raw_ops/scatteradd) | ✔️ |
| [ScatterDiv](raw_ops/scatterdiv) | ✔️ |
| [ScatterMax](raw_ops/scattermax) | ❌ |
| [ScatterMin](raw_ops/scattermin) | ❌ |
| [ScatterMul](raw_ops/scattermul) | ✔️ |
| [ScatterNd](raw_ops/scatternd) | ✔️ |
| [ScatterNdAdd](raw_ops/scatterndadd) | ✔️ |
| [ScatterNdMax](raw_ops/scatterndmax) | ❌ |
| [ScatterNdMin](raw_ops/scatterndmin) | ❌ |
| [ScatterNdNonAliasingAdd](raw_ops/scatterndnonaliasingadd) | ✔️ |
| [ScatterNdSub](raw_ops/scatterndsub) | ✔️ |
| [ScatterNdUpdate](raw_ops/scatterndupdate) | ✔️ |
| [ScatterSub](raw_ops/scattersub) | ✔️ |
| [ScatterUpdate](raw_ops/scatterupdate) | ❌ |
| [SdcaFprint](raw_ops/sdcafprint) | ✔️ |
| [SdcaOptimizer](raw_ops/sdcaoptimizer) | ✔️ |
| [SdcaOptimizerV2](raw_ops/sdcaoptimizerv2) | ✔️ |
| [SdcaShrinkL1](raw_ops/sdcashrinkl1) | ✔️ |
| [SegmentMax](raw_ops/segmentmax) | ✔️ |
| [SegmentMean](raw_ops/segmentmean) | ✔️ |
| [SegmentMin](raw_ops/segmentmin) | ✔️ |
| [SegmentProd](raw_ops/segmentprod) | ✔️ |
| [SegmentSum](raw_ops/segmentsum) | ✔️ |
| [Select](raw_ops/select) | ✔️ |
| [SelectV2](raw_ops/selectv2) | ✔️ |
| [SelfAdjointEig](raw_ops/selfadjointeig) | ❌ |
| [SelfAdjointEigV2](raw_ops/selfadjointeigv2) | ✔️ |
| [Selu](raw_ops/selu) | ✔️ |
| [SeluGrad](raw_ops/selugrad) | ✔️ |
| [Send](raw_ops/send) | ❌ |
| [SendTPUEmbeddingGradients](raw_ops/sendtpuembeddinggradients) | ❌ |
| [SerializeIterator](raw_ops/serializeiterator) | ❌ |
| [SerializeManySparse](raw_ops/serializemanysparse) | ❌ |
| [SerializeSparse](raw_ops/serializesparse) | ❌ |
| [SerializeTensor](raw_ops/serializetensor) | ✔️ |
| [SetSize](raw_ops/setsize) | ✔️ |
| [SetStatsAggregatorDataset](raw_ops/setstatsaggregatordataset) | ❌ |
| [Shape](raw_ops/shape) | ✔️ |
| [ShapeN](raw_ops/shapen) | ✔️ |
| [ShardDataset](raw_ops/sharddataset) | ❌ |
| [ShardedFilename](raw_ops/shardedfilename) | ❌ |
| [ShardedFilespec](raw_ops/shardedfilespec) | ❌ |
| [ShuffleAndRepeatDataset](raw_ops/shuffleandrepeatdataset) | ❌ |
| [ShuffleAndRepeatDatasetV2](raw_ops/shuffleandrepeatdatasetv2) | ❌ |
| [ShuffleDataset](raw_ops/shuffledataset) | ❌ |
| [ShuffleDatasetV2](raw_ops/shuffledatasetv2) | ❌ |
| [ShuffleDatasetV3](raw_ops/shuffledatasetv3) | ❌ |
| [ShutdownDistributedTPU](raw_ops/shutdowndistributedtpu) | ❌ |
| [Sigmoid](raw_ops/sigmoid) | ✔️ |
| [SigmoidGrad](raw_ops/sigmoidgrad) | ✔️ |
| [Sign](raw_ops/sign) | ✔️ |
| [Sin](raw_ops/sin) | ✔️ |
| [Sinh](raw_ops/sinh) | ✔️ |
| [Size](raw_ops/size) | ✔️ |
| [SkipDataset](raw_ops/skipdataset) | ❌ |
| [SleepDataset](raw_ops/sleepdataset) | ❌ |
| [Slice](raw_ops/slice) | ✔️ |
| [SlidingWindowDataset](raw_ops/slidingwindowdataset) | ❌ |
| [Snapshot](raw_ops/snapshot) | ❌ |
| [SnapshotDataset](raw_ops/snapshotdataset) | ❌ |
| [SnapshotDatasetReader](raw_ops/snapshotdatasetreader) | ❌ |
| [SnapshotDatasetV2](raw_ops/snapshotdatasetv2) | ❌ |
| [SnapshotNestedDatasetReader](raw_ops/snapshotnesteddatasetreader) | ❌ |
| [SobolSample](raw_ops/sobolsample) | ❌ |
| [Softmax](raw_ops/softmax) | ✔️ |
| [SoftmaxCrossEntropyWithLogits](raw_ops/softmaxcrossentropywithlogits) | ✔️ |
| [Softplus](raw_ops/softplus) | ✔️ |
| [SoftplusGrad](raw_ops/softplusgrad) | ✔️ |
| [Softsign](raw_ops/softsign) | ✔️ |
| [SoftsignGrad](raw_ops/softsigngrad) | ❌ |
| [SpaceToBatch](raw_ops/spacetobatch) | ✔️ |
| [SpaceToBatchND](raw_ops/spacetobatchnd) | ✔️ |
| [SpaceToDepth](raw_ops/spacetodepth) | ✔️ |
| [SparseAccumulatorApplyGradient](raw_ops/sparseaccumulatorapplygradient) | ❌ |
| [SparseAccumulatorTakeGradient](raw_ops/sparseaccumulatortakegradient) | ❌ |
| [SparseAdd](raw_ops/sparseadd) | ✔️ |
| [SparseAddGrad](raw_ops/sparseaddgrad) | ✔️ |
| [SparseApplyAdadelta](raw_ops/sparseapplyadadelta) | ❌ |
| [SparseApplyAdagrad](raw_ops/sparseapplyadagrad) | ❌ |
| [SparseApplyAdagradDA](raw_ops/sparseapplyadagradda) | ❌ |
| [SparseApplyAdagradV2](raw_ops/sparseapplyadagradv2) | ❌ |
| [SparseApplyCenteredRMSProp](raw_ops/sparseapplycenteredrmsprop) | ❌ |
| [SparseApplyFtrl](raw_ops/sparseapplyftrl) | ❌ |
| [SparseApplyFtrlV2](raw_ops/sparseapplyftrlv2) | ❌ |
| [SparseApplyMomentum](raw_ops/sparseapplymomentum) | ❌ |
| [SparseApplyProximalAdagrad](raw_ops/sparseapplyproximaladagrad) | ❌ |
| [SparseApplyProximalGradientDescent](raw_ops/sparseapplyproximalgradientdescent) | ❌ |
| [SparseApplyRMSProp](raw_ops/sparseapplyrmsprop) | ❌ |
| [SparseBincount](raw_ops/sparsebincount) | ❌ |
| [SparseConcat](raw_ops/sparseconcat) | ✔️ |
| [SparseConditionalAccumulator](raw_ops/sparseconditionalaccumulator) | ❌ |
| [SparseCountSparseOutput](raw_ops/sparsecountsparseoutput) | ❌ |
| [SparseCross](raw_ops/sparsecross) | ❌ |
| [SparseCrossHashed](raw_ops/sparsecrosshashed) | ❌ |
| [SparseCrossV2](raw_ops/sparsecrossv2) | ❌ |
| [SparseDenseCwiseAdd](raw_ops/sparsedensecwiseadd) | ✔️ |
| [SparseDenseCwiseDiv](raw_ops/sparsedensecwisediv) | ✔️ |
| [SparseDenseCwiseMul](raw_ops/sparsedensecwisemul) | ✔️ |
| [SparseFillEmptyRows](raw_ops/sparsefillemptyrows) | ✔️ |
| [SparseFillEmptyRowsGrad](raw_ops/sparsefillemptyrowsgrad) | ❌ |
| [SparseMatMul](raw_ops/sparsematmul) | ✔️ |
| [SparseMatrixAdd](raw_ops/sparsematrixadd) | ✔️ |
| [SparseMatrixMatMul](raw_ops/sparsematrixmatmul) | ✔️ |
| [SparseMatrixMul](raw_ops/sparsematrixmul) | ✔️ |
| [SparseMatrixNNZ](raw_ops/sparsematrixnnz) | ✔️ |
| [SparseMatrixOrderingAMD](raw_ops/sparsematrixorderingamd) | ❌ |
| [SparseMatrixSoftmax](raw_ops/sparsematrixsoftmax) | ✔️ |
| [SparseMatrixSoftmaxGrad](raw_ops/sparsematrixsoftmaxgrad) | ❌ |
| [SparseMatrixSparseCholesky](raw_ops/sparsematrixsparsecholesky) | ❌ |
| [SparseMatrixSparseMatMul](raw_ops/sparsematrixsparsematmul) | ✔️ |
| [SparseMatrixTranspose](raw_ops/sparsematrixtranspose) | ✔️ |
| [SparseMatrixZeros](raw_ops/sparsematrixzeros) | ✔️ |
| [SparseReduceMax](raw_ops/sparsereducemax) | ❌ |
| [SparseReduceMaxSparse](raw_ops/sparsereducemaxsparse) | ❌ |
| [SparseReduceSum](raw_ops/sparsereducesum) | ✔️ |
| [SparseReduceSumSparse](raw_ops/sparsereducesumsparse) | ❌ |
| [SparseReorder](raw_ops/sparsereorder) | ✔️ |
| [SparseReshape](raw_ops/sparsereshape) | ❌ |
| [SparseSegmentMean](raw_ops/sparsesegmentmean) | ✔️ |
| [SparseSegmentMeanGrad](raw_ops/sparsesegmentmeangrad) | ❌ |
| [SparseSegmentMeanWithNumSegments](raw_ops/sparsesegmentmeanwithnumsegments) | ✔️ |
| [SparseSegmentSqrtN](raw_ops/sparsesegmentsqrtn) | ✔️ |
| [SparseSegmentSqrtNGrad](raw_ops/sparsesegmentsqrtngrad) | ❌ |
| [SparseSegmentSqrtNWithNumSegments](raw_ops/sparsesegmentsqrtnwithnumsegments) | ✔️ |
| [SparseSegmentSum](raw_ops/sparsesegmentsum) | ✔️ |
| [SparseSegmentSumGrad](raw_ops/sparsesegmentsumgrad) | ❌ |
| [SparseSegmentSumWithNumSegments](raw_ops/sparsesegmentsumwithnumsegments) | ✔️ |
| [SparseSlice](raw_ops/sparseslice) | ✔️ |
| [SparseSliceGrad](raw_ops/sparseslicegrad) | ❌ |
| [SparseSoftmax](raw_ops/sparsesoftmax) | ✔️ |
| [SparseSoftmaxCrossEntropyWithLogits](raw_ops/sparsesoftmaxcrossentropywithlogits) | ✔️ |
| [SparseSparseMaximum](raw_ops/sparsesparsemaximum) | ✔️ |
| [SparseSparseMinimum](raw_ops/sparsesparseminimum) | ✔️ |
| [SparseSplit](raw_ops/sparsesplit) | ❌ |
| [SparseTensorDenseAdd](raw_ops/sparsetensordenseadd) | ✔️ |
| [SparseTensorDenseMatMul](raw_ops/sparsetensordensematmul) | ✔️ |
| [SparseTensorSliceDataset](raw_ops/sparsetensorslicedataset) | ❌ |
| [SparseTensorToCSRSparseMatrix](raw_ops/sparsetensortocsrsparsematrix) | ✔️ |
| [SparseToDense](raw_ops/sparsetodense) | ✔️ |
| [SparseToSparseSetOperation](raw_ops/sparsetosparsesetoperation) | ✔️ |
| [Spence](raw_ops/spence) | ✔️ |
| [Split](raw_ops/split) | ✔️ |
| [SplitV](raw_ops/splitv) | ✔️ |
| [SqlDataset](raw_ops/sqldataset) | ❌ |
| [Sqrt](raw_ops/sqrt) | ✔️ |
| [SqrtGrad](raw_ops/sqrtgrad) | ✔️ |
| [Square](raw_ops/square) | ✔️ |
| [SquaredDifference](raw_ops/squareddifference) | ✔️ |
| [Squeeze](raw_ops/squeeze) | ✔️ |
| [Stack](raw_ops/stack) | ✔️ |
| [StackClose](raw_ops/stackclose) | ✔️ |
| [StackCloseV2](raw_ops/stackclosev2) | ❌ |
| [StackPop](raw_ops/stackpop) | ✔️ |
| [StackPopV2](raw_ops/stackpopv2) | ❌ |
| [StackPush](raw_ops/stackpush) | ✔️ |
| [StackPushV2](raw_ops/stackpushv2) | ❌ |
| [StackV2](raw_ops/stackv2) | ❌ |
| [Stage](raw_ops/stage) | ❌ |
| [StageClear](raw_ops/stageclear) | ❌ |
| [StagePeek](raw_ops/stagepeek) | ❌ |
| [StageSize](raw_ops/stagesize) | ❌ |
| [StatefulPartitionedCall](raw_ops/statefulpartitionedcall) | ❌ |
| [StatefulRandomBinomial](raw_ops/statefulrandombinomial) | ❌ |
| [StatefulStandardNormal](raw_ops/statefulstandardnormal) | ❌ |
| [StatefulStandardNormalV2](raw_ops/statefulstandardnormalv2) | ❌ |
| [StatefulTruncatedNormal](raw_ops/statefultruncatednormal) | ❌ |
| [StatefulUniform](raw_ops/statefuluniform) | ❌ |
| [StatefulUniformFullInt](raw_ops/statefuluniformfullint) | ❌ |
| [StatefulUniformInt](raw_ops/statefuluniformint) | ❌ |
| [StatelessCase](raw_ops/statelesscase) | ✔️ |
| [StatelessIf](raw_ops/statelessif) | ✔️ |
| [StatelessMultinomial](raw_ops/statelessmultinomial) | ✔️ |
| [StatelessParameterizedTruncatedNormal](raw_ops/statelessparameterizedtruncatednormal) | ✔️ |
| [StatelessRandomBinomial](raw_ops/statelessrandombinomial) | ✔️ |
| [StatelessRandomGammaV2](raw_ops/statelessrandomgammav2) | ✔️ |
| [StatelessRandomGetAlg](raw_ops/statelessrandomgetalg) | ❌ |
| [StatelessRandomGetKeyCounter](raw_ops/statelessrandomgetkeycounter) | ❌ |
| [StatelessRandomGetKeyCounterAlg](raw_ops/statelessrandomgetkeycounteralg) | ❌ |
| [StatelessRandomNormal](raw_ops/statelessrandomnormal) | ✔️ |
| [StatelessRandomNormalV2](raw_ops/statelessrandomnormalv2) | ✔️ |
| [StatelessRandomPoisson](raw_ops/statelessrandompoisson) | ✔️ |
| [StatelessRandomUniform](raw_ops/statelessrandomuniform) | ✔️ |
| [StatelessRandomUniformFullInt](raw_ops/statelessrandomuniformfullint) | ✔️ |
| [StatelessRandomUniformFullIntV2](raw_ops/statelessrandomuniformfullintv2) | ✔️ |
| [StatelessRandomUniformInt](raw_ops/statelessrandomuniformint) | ✔️ |
| [StatelessRandomUniformIntV2](raw_ops/statelessrandomuniformintv2) | ✔️ |
| [StatelessRandomUniformV2](raw_ops/statelessrandomuniformv2) | ✔️ |
| [StatelessSampleDistortedBoundingBox](raw_ops/statelesssampledistortedboundingbox) | ❌ |
| [StatelessTruncatedNormal](raw_ops/statelesstruncatednormal) | ✔️ |
| [StatelessTruncatedNormalV2](raw_ops/statelesstruncatednormalv2) | ✔️ |
| [StatelessWhile](raw_ops/statelesswhile) | ✔️ |
| [StaticRegexFullMatch](raw_ops/staticregexfullmatch) | ❌ |
| [StaticRegexReplace](raw_ops/staticregexreplace) | ❌ |
| [StatsAggregatorHandle](raw_ops/statsaggregatorhandle) | ❌ |
| [StatsAggregatorHandleV2](raw_ops/statsaggregatorhandlev2) | ❌ |
| [StatsAggregatorSetSummaryWriter](raw_ops/statsaggregatorsetsummarywriter) | ❌ |
| [StatsAggregatorSummary](raw_ops/statsaggregatorsummary) | ❌ |
| [StopGradient](raw_ops/stopgradient) | ✔️ |
| [StridedSlice](raw_ops/stridedslice) | ✔️ |
| [StridedSliceAssign](raw_ops/stridedsliceassign) | ❌ |
| [StridedSliceGrad](raw_ops/stridedslicegrad) | ✔️ |
| [StringFormat](raw_ops/stringformat) | ❌ |
| [StringJoin](raw_ops/stringjoin) | ✔️ |
| [StringLength](raw_ops/stringlength) | ❌ |
| [StringLower](raw_ops/stringlower) | ❌ |
| [StringNGrams](raw_ops/stringngrams) | ❌ |
| [StringSplit](raw_ops/stringsplit) | ✔️ |
| [StringSplitV2](raw_ops/stringsplitv2) | ❌ |
| [StringStrip](raw_ops/stringstrip) | ❌ |
| [StringToHashBucket](raw_ops/stringtohashbucket) | ✔️ |
| [StringToHashBucketFast](raw_ops/stringtohashbucketfast) | ✔️ |
| [StringToHashBucketStrong](raw_ops/stringtohashbucketstrong) | ✔️ |
| [StringToNumber](raw_ops/stringtonumber) | ✔️ |
| [StringUpper](raw_ops/stringupper) | ❌ |
| [Sub](raw_ops/sub) | ✔️ |
| [Substr](raw_ops/substr) | ❌ |
| [Sum](raw_ops/sum) | ✔️ |
| [SummaryWriter](raw_ops/summarywriter) | ❌ |
| [Svd](raw_ops/svd) | ✔️ |
| [Switch](raw_ops/switch) | ✔️ |
| [SymbolicGradient](raw_ops/symbolicgradient) | ❌ |
| [TFRecordDataset](raw_ops/tfrecorddataset) | ❌ |
| [TFRecordReader](raw_ops/tfrecordreader) | ✔️ |
| [TFRecordReaderV2](raw_ops/tfrecordreaderv2) | ❌ |
| [TPUCompilationResult](raw_ops/tpucompilationresult) | ❌ |
| [TPUEmbeddingActivations](raw_ops/tpuembeddingactivations) | ✔️ |
| [TPUOrdinalSelector](raw_ops/tpuordinalselector) | ❌ |
| [TPUPartitionedCall](raw_ops/tpupartitionedcall) | ❌ |
| [TPUPartitionedInput](raw_ops/tpupartitionedinput) | ❌ |
| [TPUPartitionedOutput](raw_ops/tpupartitionedoutput) | ❌ |
| [TPUReplicateMetadata](raw_ops/tpureplicatemetadata) | ❌ |
| [TPUReplicatedInput](raw_ops/tpureplicatedinput) | ✔️ |
| [TPUReplicatedOutput](raw_ops/tpureplicatedoutput) | ❌ |
| [TakeDataset](raw_ops/takedataset) | ❌ |
| [TakeManySparseFromTensorsMap](raw_ops/takemanysparsefromtensorsmap) | ❌ |
| [TakeWhileDataset](raw_ops/takewhiledataset) | ❌ |
| [Tan](raw_ops/tan) | ✔️ |
| [Tanh](raw_ops/tanh) | ✔️ |
| [TanhGrad](raw_ops/tanhgrad) | ✔️ |
| [TemporaryVariable](raw_ops/temporaryvariable) | ❌ |
| [TensorArray](raw_ops/tensorarray) | ✔️ |
| [TensorArrayClose](raw_ops/tensorarrayclose) | ✔️ |
| [TensorArrayCloseV2](raw_ops/tensorarrayclosev2) | ✔️ |
| [TensorArrayCloseV3](raw_ops/tensorarrayclosev3) | ✔️ |
| [TensorArrayConcat](raw_ops/tensorarrayconcat) | ✔️ |
| [TensorArrayConcatV2](raw_ops/tensorarrayconcatv2) | ✔️ |
| [TensorArrayConcatV3](raw_ops/tensorarrayconcatv3) | ✔️ |
| [TensorArrayGather](raw_ops/tensorarraygather) | ✔️ |
| [TensorArrayGatherV2](raw_ops/tensorarraygatherv2) | ✔️ |
| [TensorArrayGatherV3](raw_ops/tensorarraygatherv3) | ✔️ |
| [TensorArrayGrad](raw_ops/tensorarraygrad) | ✔️ |
| [TensorArrayGradV2](raw_ops/tensorarraygradv2) | ✔️ |
| [TensorArrayGradV3](raw_ops/tensorarraygradv3) | ✔️ |
| [TensorArrayGradWithShape](raw_ops/tensorarraygradwithshape) | ✔️ |
| [TensorArrayPack](raw_ops/tensorarraypack) | ❌ |
| [TensorArrayRead](raw_ops/tensorarrayread) | ✔️ |
| [TensorArrayReadV2](raw_ops/tensorarrayreadv2) | ✔️ |
| [TensorArrayReadV3](raw_ops/tensorarrayreadv3) | ✔️ |
| [TensorArrayScatter](raw_ops/tensorarrayscatter) | ✔️ |
| [TensorArrayScatterV2](raw_ops/tensorarrayscatterv2) | ✔️ |
| [TensorArrayScatterV3](raw_ops/tensorarrayscatterv3) | ✔️ |
| [TensorArraySize](raw_ops/tensorarraysize) | ✔️ |
| [TensorArraySizeV2](raw_ops/tensorarraysizev2) | ✔️ |
| [TensorArraySizeV3](raw_ops/tensorarraysizev3) | ✔️ |
| [TensorArraySplit](raw_ops/tensorarraysplit) | ✔️ |
| [TensorArraySplitV2](raw_ops/tensorarraysplitv2) | ✔️ |
| [TensorArraySplitV3](raw_ops/tensorarraysplitv3) | ✔️ |
| [TensorArrayUnpack](raw_ops/tensorarrayunpack) | ❌ |
| [TensorArrayV2](raw_ops/tensorarrayv2) | ✔️ |
| [TensorArrayV3](raw_ops/tensorarrayv3) | ✔️ |
| [TensorArrayWrite](raw_ops/tensorarraywrite) | ✔️ |
| [TensorArrayWriteV2](raw_ops/tensorarraywritev2) | ✔️ |
| [TensorArrayWriteV3](raw_ops/tensorarraywritev3) | ✔️ |
| [TensorDataset](raw_ops/tensordataset) | ❌ |
| [TensorListConcat](raw_ops/tensorlistconcat) | ✔️ |
| [TensorListConcatLists](raw_ops/tensorlistconcatlists) | ✔️ |
| [TensorListConcatV2](raw_ops/tensorlistconcatv2) | ✔️ |
| [TensorListElementShape](raw_ops/tensorlistelementshape) | ✔️ |
| [TensorListFromTensor](raw_ops/tensorlistfromtensor) | ✔️ |
| [TensorListGather](raw_ops/tensorlistgather) | ✔️ |
| [TensorListGetItem](raw_ops/tensorlistgetitem) | ✔️ |
| [TensorListLength](raw_ops/tensorlistlength) | ✔️ |
| [TensorListPopBack](raw_ops/tensorlistpopback) | ✔️ |
| [TensorListPushBack](raw_ops/tensorlistpushback) | ✔️ |
| [TensorListPushBackBatch](raw_ops/tensorlistpushbackbatch) | ✔️ |
| [TensorListReserve](raw_ops/tensorlistreserve) | ❌ |
| [TensorListResize](raw_ops/tensorlistresize) | ✔️ |
| [TensorListScatter](raw_ops/tensorlistscatter) | ✔️ |
| [TensorListScatterIntoExistingList](raw_ops/tensorlistscatterintoexistinglist) | ✔️ |
| [TensorListScatterV2](raw_ops/tensorlistscatterv2) | ✔️ |
| [TensorListSetItem](raw_ops/tensorlistsetitem) | ✔️ |
| [TensorListSplit](raw_ops/tensorlistsplit) | ✔️ |
| [TensorListStack](raw_ops/tensorliststack) | ✔️ |
| [TensorScatterAdd](raw_ops/tensorscatteradd) | ✔️ |
| [TensorScatterMax](raw_ops/tensorscattermax) | ✔️ |
| [TensorScatterMin](raw_ops/tensorscattermin) | ✔️ |
| [TensorScatterSub](raw_ops/tensorscattersub) | ✔️ |
| [TensorScatterUpdate](raw_ops/tensorscatterupdate) | ✔️ |
| [TensorSliceDataset](raw_ops/tensorslicedataset) | ❌ |
| [TensorStridedSliceUpdate](raw_ops/tensorstridedsliceupdate) | ✔️ |
| [TensorSummary](raw_ops/tensorsummary) | ✔️ |
| [TensorSummaryV2](raw_ops/tensorsummaryv2) | ✔️ |
| [TextLineDataset](raw_ops/textlinedataset) | ❌ |
| [TextLineReader](raw_ops/textlinereader) | ✔️ |
| [TextLineReaderV2](raw_ops/textlinereaderv2) | ❌ |
| [ThreadPoolDataset](raw_ops/threadpooldataset) | ❌ |
| [ThreadPoolHandle](raw_ops/threadpoolhandle) | ❌ |
| [ThreadUnsafeUnigramCandidateSampler](raw_ops/threadunsafeunigramcandidatesampler) | ❌ |
| [Tile](raw_ops/tile) | ✔️ |
| [TileGrad](raw_ops/tilegrad) | ❌ |
| [Timestamp](raw_ops/timestamp) | ✔️ |
| [ToBool](raw_ops/tobool) | ❌ |
| [TopK](raw_ops/topk) | ✔️ |
| [TopKV2](raw_ops/topkv2) | ✔️ |
| [Transpose](raw_ops/transpose) | ✔️ |
| [TridiagonalMatMul](raw_ops/tridiagonalmatmul) | ✔️ |
| [TridiagonalSolve](raw_ops/tridiagonalsolve) | ✔️ |
| [TruncateDiv](raw_ops/truncatediv) | ✔️ |
| [TruncateMod](raw_ops/truncatemod) | ❌ |
| [TruncatedNormal](raw_ops/truncatednormal) | ✔️ |
| [Unbatch](raw_ops/unbatch) | ❌ |
| [UnbatchDataset](raw_ops/unbatchdataset) | ❌ |
| [UnbatchGrad](raw_ops/unbatchgrad) | ❌ |
| [UncompressElement](raw_ops/uncompresselement) | ❌ |
| [UnicodeDecode](raw_ops/unicodedecode) | ❌ |
| [UnicodeDecodeWithOffsets](raw_ops/unicodedecodewithoffsets) | ❌ |
| [UnicodeEncode](raw_ops/unicodeencode) | ❌ |
| [UnicodeScript](raw_ops/unicodescript) | ❌ |
| [UnicodeTranscode](raw_ops/unicodetranscode) | ❌ |
| [UniformCandidateSampler](raw_ops/uniformcandidatesampler) | ❌ |
| [Unique](raw_ops/unique) | ❌ |
| [UniqueDataset](raw_ops/uniquedataset) | ❌ |
| [UniqueV2](raw_ops/uniquev2) | ❌ |
| [UniqueWithCounts](raw_ops/uniquewithcounts) | ❌ |
| [UniqueWithCountsV2](raw_ops/uniquewithcountsv2) | ❌ |
| [Unpack](raw_ops/unpack) | ✔️ |
| [UnravelIndex](raw_ops/unravelindex) | ❌ |
| [UnsortedSegmentJoin](raw_ops/unsortedsegmentjoin) | ❌ |
| [UnsortedSegmentMax](raw_ops/unsortedsegmentmax) | ✔️ |
| [UnsortedSegmentMin](raw_ops/unsortedsegmentmin) | ✔️ |
| [UnsortedSegmentProd](raw_ops/unsortedsegmentprod) | ✔️ |
| [UnsortedSegmentSum](raw_ops/unsortedsegmentsum) | ✔️ |
| [Unstage](raw_ops/unstage) | ❌ |
| [UnwrapDatasetVariant](raw_ops/unwrapdatasetvariant) | ❌ |
| [UpperBound](raw_ops/upperbound) | ❌ |
| [VarHandleOp](raw_ops/varhandleop) | ❌ |
| [VarIsInitializedOp](raw_ops/varisinitializedop) | ✔️ |
| [Variable](raw_ops/variable) | ❌ |
| [VariableShape](raw_ops/variableshape) | ✔️ |
| [VariableV2](raw_ops/variablev2) | ❌ |
| [Where](raw_ops/where) | ❌ |
| [While](raw_ops/while) | ✔️ |
| [WholeFileReader](raw_ops/wholefilereader) | ✔️ |
| [WholeFileReaderV2](raw_ops/wholefilereaderv2) | ❌ |
| [WindowDataset](raw_ops/windowdataset) | ❌ |
| [WindowOp](raw_ops/windowop) | ❌ |
| [WorkerHeartbeat](raw_ops/workerheartbeat) | ❌ |
| [WrapDatasetVariant](raw_ops/wrapdatasetvariant) | ❌ |
| [WriteAudioSummary](raw_ops/writeaudiosummary) | ❌ |
| [WriteFile](raw_ops/writefile) | ❌ |
| [WriteGraphSummary](raw_ops/writegraphsummary) | ❌ |
| [WriteHistogramSummary](raw_ops/writehistogramsummary) | ❌ |
| [WriteImageSummary](raw_ops/writeimagesummary) | ❌ |
| [WriteRawProtoSummary](raw_ops/writerawprotosummary) | ❌ |
| [WriteScalarSummary](raw_ops/writescalarsummary) | ❌ |
| [WriteSummary](raw_ops/writesummary) | ❌ |
| [Xdivy](raw_ops/xdivy) | ✔️ |
| [XlaConcatND](raw_ops/xlaconcatnd) | ❌ |
| [XlaSplitND](raw_ops/xlasplitnd) | ❌ |
| [Xlog1py](raw_ops/xlog1py) | ✔️ |
| [Xlogy](raw_ops/xlogy) | ✔️ |
| [ZerosLike](raw_ops/zeroslike) | ✔️ |
| [Zeta](raw_ops/zeta) | ✔️ |
| [ZipDataset](raw_ops/zipdataset) | ❌ |
| programming_docs |
tensorflow Module: tf.tpu Module: tf.tpu
==============
Ops related to Tensor Processing Units.
Modules
-------
[`experimental`](tpu/experimental) module: Public API for tf.tpu.experimental namespace.
Classes
-------
[`class XLAOptions`](tpu/xlaoptions): XLA compilation options.
tensorflow Module: tf.autograph.experimental Module: tf.autograph.experimental
=================================
Public API for tf.autograph.experimental namespace.
Classes
-------
[`class Feature`](experimental/feature): This enumeration represents optional conversion options.
Functions
---------
[`do_not_convert(...)`](experimental/do_not_convert): Decorator that suppresses the conversion of a function.
[`set_loop_options(...)`](experimental/set_loop_options): Specifies additional arguments to be passed to the enclosing while\_loop.
tensorflow tf.autograph.to_code tf.autograph.to\_code
=====================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/impl/api.py#L903-L945) |
Returns the source code generated by AutoGraph, as a string.
```
tf.autograph.to_code(
entity, recursive=True, experimental_optional_features=None
)
```
#### Example usage:
```
def f(x):
if x < 0:
x = -x
return x
tf.autograph.to_code(f)
"...def tf__f(x):..."
```
Also see: [`tf.autograph.to_graph`](to_graph).
>
> **Note:** If a function has been decorated with [`tf.function`](../function), pass its underlying Python function, rather than the callable that `tf.function creates:
>
```
@tf.function
def f(x):
if x < 0:
x = -x
return x
tf.autograph.to_code(f.python_function)
"...def tf__f(x):..."
```
| Args |
| `entity` | Python callable or class to convert. |
| `recursive` | Whether to recursively convert any functions that the converted function may call. |
| `experimental_optional_features` | `None`, a tuple of, or a single [`tf.autograph.experimental.Feature`](experimental/feature) value. |
| Returns |
| The converted code as string. |
tensorflow tf.autograph.set_verbosity tf.autograph.set\_verbosity
===========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/utils/ag_logging.py#L36-L84) |
Sets the AutoGraph verbosity level.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.autograph.set_verbosity`](https://www.tensorflow.org/api_docs/python/tf/autograph/set_verbosity)
```
tf.autograph.set_verbosity(
level, alsologtostdout=False
)
```
*Debug logging in AutoGraph*
More verbose logging is useful to enable when filing bug reports or doing more in-depth debugging.
There are two means to control the logging verbosity:
* The `set_verbosity` function
* The `AUTOGRAPH_VERBOSITY` environment variable
`set_verbosity` takes precedence over the environment variable.
#### For example:
```
import os
import tensorflow as tf
os.environ['AUTOGRAPH_VERBOSITY'] = '5'
# Verbosity is now 5
tf.autograph.set_verbosity(0)
# Verbosity is now 0
os.environ['AUTOGRAPH_VERBOSITY'] = '1'
# No effect, because set_verbosity was already called.
```
Logs entries are output to [absl](https://abseil.io)'s [default output](https://abseil.io/docs/python/guides/logging), with `INFO` level. Logs can be mirrored to stdout by using the `alsologtostdout` argument. Mirroring is enabled by default when Python runs in interactive mode.
| Args |
| `level` | int, the verbosity level; larger values specify increased verbosity; 0 means no logging. When reporting bugs, it is recommended to set this value to a larger number, like 10. |
| `alsologtostdout` | bool, whether to also output log messages to `sys.stdout`. |
tensorflow tf.autograph.to_graph tf.autograph.to\_graph
======================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/impl/api.py#L706-L775) |
Converts a Python entity into a TensorFlow graph.
```
tf.autograph.to_graph(
entity, recursive=True, experimental_optional_features=None
)
```
Also see: [`tf.autograph.to_code`](to_code), [`tf.function`](../function).
Unlike [`tf.function`](../function), `to_graph` is a low-level transpiler that converts Python code to TensorFlow graph code. It does not implement any caching, variable management or create any actual ops, and is best used where greater control over the generated TensorFlow graph is desired. Another difference from [`tf.function`](../function) is that `to_graph` will not wrap the graph into a TensorFlow function or a Python callable. Internally, [`tf.function`](../function) uses `to_graph`.
#### Example usage:
```
def f(x):
if x > 0:
y = x * x
else:
y = -x
return y
converted_f = to_graph(f)
x = tf.constant(2)
converted_f(x) # converted_foo is like a TensorFlow Op.
<tf.Tensor: shape=(), dtype=int32, numpy=4>
```
Supported Python entities include:
* functions
* classes
* object methods
Functions are converted into new functions with converted code.
Classes are converted by generating a new class whose methods use converted code.
Methods are converted into unbound function that have an additional first argument called `self`.
For a tutorial, see the [tf.function and AutoGraph guide](https://www.tensorflow.org/guide/function). For more detailed information, see the [AutoGraph reference documentation](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/autograph/g3doc/reference/index.md).
| Args |
| `entity` | Python callable or class to convert. |
| `recursive` | Whether to recursively convert any functions that the converted function may call. |
| `experimental_optional_features` | `None`, a tuple of, or a single [`tf.autograph.experimental.Feature`](experimental/feature) value. |
| Returns |
| Same as `entity`, the converted Python function or class. |
| Raises |
| `ValueError` | If the entity could not be converted. |
tensorflow tf.autograph.trace tf.autograph.trace
==================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/utils/ag_logging.py#L87-L107) |
Traces argument information at compilation time.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.autograph.trace`](https://www.tensorflow.org/api_docs/python/tf/autograph/trace)
```
tf.autograph.trace(
*args
)
```
`trace` is useful when debugging, and it always executes during the tracing phase, that is, when the TF graph is constructed.
*Example usage*
```
import tensorflow as tf
for i in tf.range(10):
tf.autograph.trace(i)
# Output: <Tensor ...>
```
| Args |
| `*args` | Arguments to print to `sys.stdout`. |
tensorflow tf.autograph.experimental.set_loop_options tf.autograph.experimental.set\_loop\_options
============================================
Specifies additional arguments to be passed to the enclosing while\_loop.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.autograph.experimental.set_loop_options`](https://www.tensorflow.org/api_docs/python/tf/autograph/experimental/set_loop_options)
```
tf.autograph.experimental.set_loop_options(
parallel_iterations=UNSPECIFIED,
swap_memory=UNSPECIFIED,
maximum_iterations=UNSPECIFIED,
shape_invariants=UNSPECIFIED
)
```
The parameters apply to and only to the immediately enclosing loop. It only has effect if the loop is staged as a TF while\_loop; otherwise the parameters have no effect.
#### Usage:
```
@tf.function(autograph=True)
def f():
n = 0
for i in tf.range(10):
tf.autograph.experimental.set_loop_options(maximum_iterations=3)
n += 1
return n
```
```
@tf.function(autograph=True)
def f():
v = tf.constant((0,))
for i in tf.range(3):
tf.autograph.experimental.set_loop_options(
shape_invariants=[(v, tf.TensorShape([None]))]
)
v = tf.concat((v, [i]), 0)
return v
```
Also see tf.while\_loop.
| Args |
| `parallel_iterations` | The maximum number of iterations allowed to run in parallel at any given time. Note that this does not guarantee parallel execution. |
| `swap_memory` | Whether to store intermediate values needed for gradients on the CPU instead of GPU. |
| `maximum_iterations` | Allows limiting the total number of iterations executed by the loop. |
| `shape_invariants` | Allows controlling the argument with the same name passed to tf.while\_loop. Unlike tf.while\_loop, this is a list of `(tensor, shape)` pairs. |
tensorflow tf.autograph.experimental.do_not_convert tf.autograph.experimental.do\_not\_convert
==========================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/impl/api.py#L623-L647) |
Decorator that suppresses the conversion of a function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.autograph.experimental.do_not_convert`](https://www.tensorflow.org/api_docs/python/tf/autograph/experimental/do_not_convert)
```
tf.autograph.experimental.do_not_convert(
func=None
)
```
| Args |
| `func` | function to decorate. |
| Returns |
| If `func` is not None, returns a `Callable` which is equivalent to `func`, but is not converted by AutoGraph. If `func` is None, returns a decorator that, when invoked with a single `func` argument, returns a `Callable` equivalent to the above case. |
tensorflow tf.autograph.experimental.Feature tf.autograph.experimental.Feature
=================================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/autograph/core/converter.py#L79-L128) |
This enumeration represents optional conversion options.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.autograph.experimental.Feature`](https://www.tensorflow.org/api_docs/python/tf/autograph/experimental/Feature)
These conversion options are experimental. They are subject to change without notice and offer no guarantees.
*Example Usage*
```
optionals= tf.autograph.experimental.Feature.EQUALITY_OPERATORS
@tf.function(experimental_autograph_options=optionals)
def f(i):
if i == 0: # EQUALITY_OPERATORS allows the use of == here.
tf.print('i is zero')
```
| Attributes |
| `ALL` | Enable all features. |
| `AUTO_CONTROL_DEPS` | Insert of control dependencies in the generated code. |
| `ASSERT_STATEMENTS` | Convert Tensor-dependent assert statements to tf.Assert. |
| `BUILTIN_FUNCTIONS` | Convert builtin functions applied to Tensors to their TF counterparts. |
| `EQUALITY_OPERATORS` | Whether to convert the comparison operators, like equality. This is soon to be deprecated as support is being added to the Tensor class. |
| `LISTS` | Convert list idioms, like initializers, slices, append, etc. |
| `NAME_SCOPES` | Insert name scopes that name ops according to context, like the function they were defined in. |
| Class Variables |
| ALL | `<Feature.ALL: 'ALL'>` |
| ASSERT\_STATEMENTS | `<Feature.ASSERT_STATEMENTS: 'ASSERT_STATEMENTS'>` |
| AUTO\_CONTROL\_DEPS | `<Feature.AUTO_CONTROL_DEPS: 'AUTO_CONTROL_DEPS'>` |
| BUILTIN\_FUNCTIONS | `<Feature.BUILTIN_FUNCTIONS: 'BUILTIN_FUNCTIONS'>` |
| EQUALITY\_OPERATORS | `<Feature.EQUALITY_OPERATORS: 'EQUALITY_OPERATORS'>` |
| LISTS | `<Feature.LISTS: 'LISTS'>` |
| NAME\_SCOPES | `<Feature.NAME_SCOPES: 'NAME_SCOPES'>` |
tensorflow Module: tf.xla.experimental Module: tf.xla.experimental
===========================
Public API for tf.xla.experimental namespace.
Functions
---------
[`compile(...)`](experimental/compile): Builds an operator that compiles and runs `computation` with XLA. (deprecated)
[`jit_scope(...)`](experimental/jit_scope): Enable or disable JIT compilation of operators within the scope.
tensorflow tf.xla.experimental.compile tf.xla.experimental.compile
===========================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/compiler/xla/xla.py#L62-L122) |
Builds an operator that compiles and runs `computation` with XLA. (deprecated)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.xla.experimental.compile`](https://www.tensorflow.org/api_docs/python/tf/xla/experimental/compile)
```
tf.xla.experimental.compile(
computation, inputs=None
)
```
>
> **Note:** In eager mode, `computation` will have [`@tf.function`](../../function) semantics.
>
| Args |
| `computation` | A Python function that builds a computation to apply to the input. If the function takes n inputs, 'inputs' should be a list of n tensors. `computation` may return a list of operations and tensors. Tensors must come before operations in the returned list. The return value of `compile` is a list of tensors corresponding to the tensors from the output of `computation`. All `Operation`s returned from `computation` will be executed when evaluating any of the returned output tensors. |
| `inputs` | A list of inputs or `None` (equivalent to an empty list). Each input can be a nested structure containing values that are convertible to tensors. Note that passing an N-dimension list of compatible values will result in a N-dimension list of scalar tensors rather than a single Rank-N tensors. If you need different behavior, convert part of inputs to tensors with [`tf.convert_to_tensor`](../../convert_to_tensor). |
| Returns |
| Same data structure as if computation(\*inputs) is called directly with some exceptions for correctness. Exceptions include: 1) None output: a NoOp would be returned which control-depends on computation. 2) Single value output: A tuple containing the value would be returned. 3) Operation-only outputs: a NoOp would be returned which control-depends on computation. |
| Raises |
| `RuntimeError` | if called when eager execution is enabled. |
#### Known issues:
When a tf.random operation is built with XLA, the implementation doesn't pass the user provided seed to the XLA compiler. As such, the XLA compiler generates a random number and uses it as a seed when compiling the operation. This implementation causes a violation of the Tensorflow defined semantics in two aspects. First, changing the value of the user defined seed doesn't change the numbers generated by the operation. Second, when a seed is not specified, running the program multiple times will generate the same numbers.
tensorflow tf.xla.experimental.jit_scope tf.xla.experimental.jit\_scope
==============================
[View source on GitHub](https://github.com/tensorflow/tensorflow/blob/v2.9.0/tensorflow/python/compiler/xla/jit.py#L36-L156) |
Enable or disable JIT compilation of operators within the scope.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.xla.experimental.jit_scope`](https://www.tensorflow.org/api_docs/python/tf/xla/experimental/jit_scope)
```
@contextlib.contextmanager
tf.xla.experimental.jit_scope(
compile_ops=True, separate_compiled_gradients=False
)
```
>
> **Note:** This is an experimental feature.
>
The compilation is a hint and only supported on a best-effort basis.
#### Example usage:
```
with tf.xla.experimental.jit_scope():
c = tf.matmul(a, b) # compiled
with tf.xla.experimental.jit_scope(compile_ops=False):
d = tf.matmul(a, c) # not compiled
with tf.xla.experimental.jit_scope(
compile_ops=lambda node_def: 'matmul' in node_def.op.lower()):
e = tf.matmul(a, b) + d # matmul is compiled, the addition is not.
```
Example of `separate_compiled_gradients`:
```
# In the example below, the computations for f, g and h will all be compiled
# in separate scopes.
with tf.xla.experimental.jit_scope(
separate_compiled_gradients=True):
f = tf.matmul(a, b)
g = tf.gradients([f], [a, b], name='mygrads1')
h = tf.gradients([f], [a, b], name='mygrads2')
```
Ops that are not in the scope may be clustered and compiled with ops in the scope with `compile_ops=True`, while the ops in the scope with `compile_ops=False` will never be compiled.
#### For example:
```
# In the example below, x and loss may be clustered and compiled together,
# while y will not be compiled.
with tf.xla.experimental.jit_scope():
x = tf.matmul(a, b)
with tf.xla.experimental.jit_scope(compile_ops=False):
y = tf.matmul(c, d)
loss = x + y
```
If you want to only compile the ops in the scope with `compile_ops=True`, consider adding an outer `jit_scope(compile_ops=False)`:
```
# In the example below, only x will be compiled.
with tf.xla.experimental.jit_scope(compile_ops=False):
with tf.xla.experimental.jit_scope():
x = tf.matmul(a, b)
y = tf.matmul(c, d)
loss = x + y
```
| Args |
| `compile_ops` | Whether to enable or disable compilation in the scope. Either a Python bool, or a callable that accepts the parameter `node_def` and returns a python bool. |
| `separate_compiled_gradients` | If true put each gradient subgraph into a separate compilation scope. This gives fine-grained control over which portions of the graph will be compiled as a single unit. Compiling gradients separately may yield better performance for some graphs. The scope is named based on the scope of the forward computation as well as the name of the gradients. As a result, the gradients will be compiled in a scope that is separate from both the forward computation, and from other gradients. |
| Raises |
| `RuntimeError` | if called when eager execution is enabled. |
| Yields |
| The current scope, enabling or disabling compilation. |
tensorflow Module: tf.keras.regularizers Module: tf.keras.regularizers
=============================
Built-in regularizers.
Classes
-------
[`class L1`](regularizers/l1): A regularizer that applies a L1 regularization penalty.
[`class L1L2`](regularizers/l1l2): A regularizer that applies both L1 and L2 regularization penalties.
[`class L2`](regularizers/l2): A regularizer that applies a L2 regularization penalty.
[`class OrthogonalRegularizer`](regularizers/orthogonalregularizer): A regularizer that encourages input vectors to be orthogonal to each other.
[`class Regularizer`](regularizers/regularizer): Regularizer base class.
[`class l1`](regularizers/l1): A regularizer that applies a L1 regularization penalty.
[`class l2`](regularizers/l2): A regularizer that applies a L2 regularization penalty.
[`class orthogonal_regularizer`](regularizers/orthogonalregularizer): A regularizer that encourages input vectors to be orthogonal to each other.
Functions
---------
[`deserialize(...)`](regularizers/deserialize)
[`get(...)`](regularizers/get): Retrieve a regularizer instance from a config or identifier.
[`l1_l2(...)`](regularizers/l1_l2): Create a regularizer that applies both L1 and L2 penalties.
[`serialize(...)`](regularizers/serialize)
tensorflow Module: tf.keras.layers Module: tf.keras.layers
=======================
Keras layers API.
Modules
-------
[`experimental`](layers/experimental) module: Public API for tf.keras.layers.experimental namespace.
Classes
-------
[`class AbstractRNNCell`](layers/abstractrnncell): Abstract object representing an RNN cell.
[`class Activation`](layers/activation): Applies an activation function to an output.
[`class ActivityRegularization`](layers/activityregularization): Layer that applies an update to the cost function based input activity.
[`class Add`](layers/add): Layer that adds a list of inputs.
[`class AdditiveAttention`](layers/additiveattention): Additive attention layer, a.k.a. Bahdanau-style attention.
[`class AlphaDropout`](layers/alphadropout): Applies Alpha Dropout to the input.
[`class Attention`](layers/attention): Dot-product attention layer, a.k.a. Luong-style attention.
[`class Average`](layers/average): Layer that averages a list of inputs element-wise.
[`class AveragePooling1D`](layers/averagepooling1d): Average pooling for temporal data.
[`class AveragePooling2D`](layers/averagepooling2d): Average pooling operation for spatial data.
[`class AveragePooling3D`](layers/averagepooling3d): Average pooling operation for 3D data (spatial or spatio-temporal).
[`class AvgPool1D`](layers/averagepooling1d): Average pooling for temporal data.
[`class AvgPool2D`](layers/averagepooling2d): Average pooling operation for spatial data.
[`class AvgPool3D`](layers/averagepooling3d): Average pooling operation for 3D data (spatial or spatio-temporal).
[`class BatchNormalization`](layers/batchnormalization): Layer that normalizes its inputs.
[`class Bidirectional`](layers/bidirectional): Bidirectional wrapper for RNNs.
[`class CategoryEncoding`](layers/categoryencoding): A preprocessing layer which encodes integer features.
[`class CenterCrop`](layers/centercrop): A preprocessing layer which crops images.
[`class Concatenate`](layers/concatenate): Layer that concatenates a list of inputs.
[`class Conv1D`](layers/conv1d): 1D convolution layer (e.g. temporal convolution).
[`class Conv1DTranspose`](layers/conv1dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class Conv2D`](layers/conv2d): 2D convolution layer (e.g. spatial convolution over images).
[`class Conv2DTranspose`](layers/conv2dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class Conv3D`](layers/conv3d): 3D convolution layer (e.g. spatial convolution over volumes).
[`class Conv3DTranspose`](layers/conv3dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class ConvLSTM1D`](layers/convlstm1d): 1D Convolutional LSTM.
[`class ConvLSTM2D`](layers/convlstm2d): 2D Convolutional LSTM.
[`class ConvLSTM3D`](layers/convlstm3d): 3D Convolutional LSTM.
[`class Convolution1D`](layers/conv1d): 1D convolution layer (e.g. temporal convolution).
[`class Convolution1DTranspose`](layers/conv1dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class Convolution2D`](layers/conv2d): 2D convolution layer (e.g. spatial convolution over images).
[`class Convolution2DTranspose`](layers/conv2dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class Convolution3D`](layers/conv3d): 3D convolution layer (e.g. spatial convolution over volumes).
[`class Convolution3DTranspose`](layers/conv3dtranspose): Transposed convolution layer (sometimes called Deconvolution).
[`class Cropping1D`](layers/cropping1d): Cropping layer for 1D input (e.g. temporal sequence).
[`class Cropping2D`](layers/cropping2d): Cropping layer for 2D input (e.g. picture).
[`class Cropping3D`](layers/cropping3d): Cropping layer for 3D data (e.g. spatial or spatio-temporal).
[`class Dense`](layers/dense): Just your regular densely-connected NN layer.
[`class DenseFeatures`](layers/densefeatures): A layer that produces a dense `Tensor` based on given `feature_columns`.
[`class DepthwiseConv1D`](layers/depthwiseconv1d): Depthwise 1D convolution.
[`class DepthwiseConv2D`](layers/depthwiseconv2d): Depthwise 2D convolution.
[`class Discretization`](layers/discretization): A preprocessing layer which buckets continuous features by ranges.
[`class Dot`](layers/dot): Layer that computes a dot product between samples in two tensors.
[`class Dropout`](layers/dropout): Applies Dropout to the input.
[`class ELU`](layers/elu): Exponential Linear Unit.
[`class Embedding`](layers/embedding): Turns positive integers (indexes) into dense vectors of fixed size.
[`class Flatten`](layers/flatten): Flattens the input. Does not affect the batch size.
[`class GRU`](layers/gru): Gated Recurrent Unit - Cho et al. 2014.
[`class GRUCell`](layers/grucell): Cell class for the GRU layer.
[`class GaussianDropout`](layers/gaussiandropout): Apply multiplicative 1-centered Gaussian noise.
[`class GaussianNoise`](layers/gaussiannoise): Apply additive zero-centered Gaussian noise.
[`class GlobalAveragePooling1D`](layers/globalaveragepooling1d): Global average pooling operation for temporal data.
[`class GlobalAveragePooling2D`](layers/globalaveragepooling2d): Global average pooling operation for spatial data.
[`class GlobalAveragePooling3D`](layers/globalaveragepooling3d): Global Average pooling operation for 3D data.
[`class GlobalAvgPool1D`](layers/globalaveragepooling1d): Global average pooling operation for temporal data.
[`class GlobalAvgPool2D`](layers/globalaveragepooling2d): Global average pooling operation for spatial data.
[`class GlobalAvgPool3D`](layers/globalaveragepooling3d): Global Average pooling operation for 3D data.
[`class GlobalMaxPool1D`](layers/globalmaxpool1d): Global max pooling operation for 1D temporal data.
[`class GlobalMaxPool2D`](layers/globalmaxpool2d): Global max pooling operation for spatial data.
[`class GlobalMaxPool3D`](layers/globalmaxpool3d): Global Max pooling operation for 3D data.
[`class GlobalMaxPooling1D`](layers/globalmaxpool1d): Global max pooling operation for 1D temporal data.
[`class GlobalMaxPooling2D`](layers/globalmaxpool2d): Global max pooling operation for spatial data.
[`class GlobalMaxPooling3D`](layers/globalmaxpool3d): Global Max pooling operation for 3D data.
[`class Hashing`](layers/hashing): A preprocessing layer which hashes and bins categorical features.
[`class InputLayer`](layers/inputlayer): Layer to be used as an entry point into a Network (a graph of layers).
[`class InputSpec`](layers/inputspec): Specifies the rank, dtype and shape of every input to a layer.
[`class IntegerLookup`](layers/integerlookup): A preprocessing layer which maps integer features to contiguous ranges.
[`class LSTM`](layers/lstm): Long Short-Term Memory layer - Hochreiter 1997.
[`class LSTMCell`](layers/lstmcell): Cell class for the LSTM layer.
[`class Lambda`](layers/lambda): Wraps arbitrary expressions as a `Layer` object.
[`class Layer`](layers/layer): This is the class from which all layers inherit.
[`class LayerNormalization`](layers/layernormalization): Layer normalization layer (Ba et al., 2016).
[`class LeakyReLU`](layers/leakyrelu): Leaky version of a Rectified Linear Unit.
[`class LocallyConnected1D`](layers/locallyconnected1d): Locally-connected layer for 1D inputs.
[`class LocallyConnected2D`](layers/locallyconnected2d): Locally-connected layer for 2D inputs.
[`class Masking`](layers/masking): Masks a sequence by using a mask value to skip timesteps.
[`class MaxPool1D`](layers/maxpool1d): Max pooling operation for 1D temporal data.
[`class MaxPool2D`](layers/maxpool2d): Max pooling operation for 2D spatial data.
[`class MaxPool3D`](layers/maxpool3d): Max pooling operation for 3D data (spatial or spatio-temporal).
[`class MaxPooling1D`](layers/maxpool1d): Max pooling operation for 1D temporal data.
[`class MaxPooling2D`](layers/maxpool2d): Max pooling operation for 2D spatial data.
[`class MaxPooling3D`](layers/maxpool3d): Max pooling operation for 3D data (spatial or spatio-temporal).
[`class Maximum`](layers/maximum): Layer that computes the maximum (element-wise) a list of inputs.
[`class Minimum`](layers/minimum): Layer that computes the minimum (element-wise) a list of inputs.
[`class MultiHeadAttention`](layers/multiheadattention): MultiHeadAttention layer.
[`class Multiply`](layers/multiply): Layer that multiplies (element-wise) a list of inputs.
[`class Normalization`](layers/normalization): A preprocessing layer which normalizes continuous features.
[`class PReLU`](layers/prelu): Parametric Rectified Linear Unit.
[`class Permute`](layers/permute): Permutes the dimensions of the input according to a given pattern.
[`class RNN`](layers/rnn): Base class for recurrent layers.
[`class RandomBrightness`](layers/randombrightness): A preprocessing layer which randomly adjusts brightness during training.
[`class RandomContrast`](layers/randomcontrast): A preprocessing layer which randomly adjusts contrast during training.
[`class RandomCrop`](layers/randomcrop): A preprocessing layer which randomly crops images during training.
[`class RandomFlip`](layers/randomflip): A preprocessing layer which randomly flips images during training.
[`class RandomHeight`](layers/randomheight): A preprocessing layer which randomly varies image height during training.
[`class RandomRotation`](layers/randomrotation): A preprocessing layer which randomly rotates images during training.
[`class RandomTranslation`](layers/randomtranslation): A preprocessing layer which randomly translates images during training.
[`class RandomWidth`](layers/randomwidth): A preprocessing layer which randomly varies image width during training.
[`class RandomZoom`](layers/randomzoom): A preprocessing layer which randomly zooms images during training.
[`class ReLU`](layers/relu): Rectified Linear Unit activation function.
[`class RepeatVector`](layers/repeatvector): Repeats the input n times.
[`class Rescaling`](layers/rescaling): A preprocessing layer which rescales input values to a new range.
[`class Reshape`](layers/reshape): Layer that reshapes inputs into the given shape.
[`class Resizing`](layers/resizing): A preprocessing layer which resizes images.
[`class SeparableConv1D`](layers/separableconv1d): Depthwise separable 1D convolution.
[`class SeparableConv2D`](layers/separableconv2d): Depthwise separable 2D convolution.
[`class SeparableConvolution1D`](layers/separableconv1d): Depthwise separable 1D convolution.
[`class SeparableConvolution2D`](layers/separableconv2d): Depthwise separable 2D convolution.
[`class SimpleRNN`](layers/simplernn): Fully-connected RNN where the output is to be fed back to input.
[`class SimpleRNNCell`](layers/simplernncell): Cell class for SimpleRNN.
[`class Softmax`](layers/softmax): Softmax activation function.
[`class SpatialDropout1D`](layers/spatialdropout1d): Spatial 1D version of Dropout.
[`class SpatialDropout2D`](layers/spatialdropout2d): Spatial 2D version of Dropout.
[`class SpatialDropout3D`](layers/spatialdropout3d): Spatial 3D version of Dropout.
[`class StackedRNNCells`](layers/stackedrnncells): Wrapper allowing a stack of RNN cells to behave as a single cell.
[`class StringLookup`](layers/stringlookup): A preprocessing layer which maps string features to integer indices.
[`class Subtract`](layers/subtract): Layer that subtracts two inputs.
[`class TextVectorization`](layers/textvectorization): A preprocessing layer which maps text features to integer sequences.
[`class ThresholdedReLU`](layers/thresholdedrelu): Thresholded Rectified Linear Unit.
[`class TimeDistributed`](layers/timedistributed): This wrapper allows to apply a layer to every temporal slice of an input.
[`class UnitNormalization`](layers/unitnormalization): Unit normalization layer.
[`class UpSampling1D`](layers/upsampling1d): Upsampling layer for 1D inputs.
[`class UpSampling2D`](layers/upsampling2d): Upsampling layer for 2D inputs.
[`class UpSampling3D`](layers/upsampling3d): Upsampling layer for 3D inputs.
[`class Wrapper`](layers/wrapper): Abstract wrapper base class.
[`class ZeroPadding1D`](layers/zeropadding1d): Zero-padding layer for 1D input (e.g. temporal sequence).
[`class ZeroPadding2D`](layers/zeropadding2d): Zero-padding layer for 2D input (e.g. picture).
[`class ZeroPadding3D`](layers/zeropadding3d): Zero-padding layer for 3D data (spatial or spatio-temporal).
Functions
---------
[`Input(...)`](input): `Input()` is used to instantiate a Keras tensor.
[`add(...)`](layers/add): Functional interface to the [`tf.keras.layers.Add`](layers/add) layer.
[`average(...)`](layers/average): Functional interface to the [`tf.keras.layers.Average`](layers/average) layer.
[`concatenate(...)`](layers/concatenate): Functional interface to the `Concatenate` layer.
[`deserialize(...)`](layers/deserialize): Instantiates a layer from a config dictionary.
[`dot(...)`](layers/dot): Functional interface to the `Dot` layer.
[`maximum(...)`](layers/maximum): Functional interface to compute maximum (element-wise) list of `inputs`.
[`minimum(...)`](layers/minimum): Functional interface to the `Minimum` layer.
[`multiply(...)`](layers/multiply): Functional interface to the `Multiply` layer.
[`serialize(...)`](layers/serialize): Serializes a `Layer` object into a JSON-compatible representation.
[`subtract(...)`](layers/subtract): Functional interface to the `Subtract` layer.
| programming_docs |
tensorflow Module: tf.keras.backend Module: tf.keras.backend
========================
Keras backend API.
Modules
-------
[`experimental`](backend/experimental) module: Public API for tf.keras.backend.experimental namespace.
Functions
---------
[`clear_session(...)`](backend/clear_session): Resets all state generated by Keras.
[`epsilon(...)`](backend/epsilon): Returns the value of the fuzz factor used in numeric expressions.
[`floatx(...)`](backend/floatx): Returns the default float type, as a string.
[`get_uid(...)`](backend/get_uid): Associates a string prefix with an integer counter in a TensorFlow graph.
[`image_data_format(...)`](backend/image_data_format): Returns the default image data format convention.
[`is_keras_tensor(...)`](backend/is_keras_tensor): Returns whether `x` is a Keras tensor.
[`reset_uids(...)`](backend/reset_uids): Resets graph identifiers.
[`rnn(...)`](backend/rnn): Iterates over the time dimension of a tensor.
[`set_epsilon(...)`](backend/set_epsilon): Sets the value of the fuzz factor used in numeric expressions.
[`set_floatx(...)`](backend/set_floatx): Sets the default float type.
[`set_image_data_format(...)`](backend/set_image_data_format): Sets the value of the image data format convention.
tensorflow Module: tf.keras.preprocessing Module: tf.keras.preprocessing
==============================
Utilities to preprocess data before training.
Modules
-------
[`image`](preprocessing/image) module: Utilies for image preprocessing and augmentation.
[`sequence`](preprocessing/sequence) module: Utilities for preprocessing sequence data.
[`text`](preprocessing/text) module: Utilities for text input preprocessing.
Functions
---------
[`image_dataset_from_directory(...)`](utils/image_dataset_from_directory): Generates a [`tf.data.Dataset`](../data/dataset) from image files in a directory.
[`text_dataset_from_directory(...)`](utils/text_dataset_from_directory): Generates a [`tf.data.Dataset`](../data/dataset) from text files in a directory.
[`timeseries_dataset_from_array(...)`](utils/timeseries_dataset_from_array): Creates a dataset of sliding windows over a timeseries provided as array.
tensorflow Module: tf.keras.callbacks Module: tf.keras.callbacks
==========================
Callbacks: utilities called at certain points during model training.
Modules
-------
[`experimental`](callbacks/experimental) module: Public API for tf.keras.callbacks.experimental namespace.
Classes
-------
[`class BackupAndRestore`](callbacks/backupandrestore): Callback to back up and restore the training state.
[`class BaseLogger`](callbacks/baselogger): Callback that accumulates epoch averages of metrics.
[`class CSVLogger`](callbacks/csvlogger): Callback that streams epoch results to a CSV file.
[`class Callback`](callbacks/callback): Abstract base class used to build new callbacks.
[`class CallbackList`](callbacks/callbacklist): Container abstracting a list of callbacks.
[`class EarlyStopping`](callbacks/earlystopping): Stop training when a monitored metric has stopped improving.
[`class History`](callbacks/history): Callback that records events into a `History` object.
[`class LambdaCallback`](callbacks/lambdacallback): Callback for creating simple, custom callbacks on-the-fly.
[`class LearningRateScheduler`](callbacks/learningratescheduler): Learning rate scheduler.
[`class ModelCheckpoint`](callbacks/modelcheckpoint): Callback to save the Keras model or model weights at some frequency.
[`class ProgbarLogger`](callbacks/progbarlogger): Callback that prints metrics to stdout.
[`class ReduceLROnPlateau`](callbacks/reducelronplateau): Reduce learning rate when a metric has stopped improving.
[`class RemoteMonitor`](callbacks/remotemonitor): Callback used to stream events to a server.
[`class TensorBoard`](callbacks/tensorboard): Enable visualizations for TensorBoard.
[`class TerminateOnNaN`](callbacks/terminateonnan): Callback that terminates training when a NaN loss is encountered.
tensorflow Module: tf.keras.constraints Module: tf.keras.constraints
============================
Constraints: functions that impose constraints on weight values.
Classes
-------
[`class Constraint`](constraints/constraint): Base class for weight constraints.
[`class MaxNorm`](constraints/maxnorm): MaxNorm weight constraint.
[`class MinMaxNorm`](constraints/minmaxnorm): MinMaxNorm weight constraint.
[`class NonNeg`](constraints/nonneg): Constrains the weights to be non-negative.
[`class RadialConstraint`](constraints/radialconstraint): Constrains `Conv2D` kernel weights to be the same for each radius.
[`class UnitNorm`](constraints/unitnorm): Constrains the weights incident to each hidden unit to have unit norm.
[`class max_norm`](constraints/maxnorm): MaxNorm weight constraint.
[`class min_max_norm`](constraints/minmaxnorm): MinMaxNorm weight constraint.
[`class non_neg`](constraints/nonneg): Constrains the weights to be non-negative.
[`class radial_constraint`](constraints/radialconstraint): Constrains `Conv2D` kernel weights to be the same for each radius.
[`class unit_norm`](constraints/unitnorm): Constrains the weights incident to each hidden unit to have unit norm.
Functions
---------
[`deserialize(...)`](constraints/deserialize)
[`get(...)`](constraints/get): Retrieves a Keras constraint function.
[`serialize(...)`](constraints/serialize)
tensorflow Module: tf.keras.mixed_precision Module: tf.keras.mixed\_precision
=================================
Keras mixed precision API.
See [the mixed precision guide](https://www.tensorflow.org/guide/keras/mixed_precision) to learn how to use the API.
Classes
-------
[`class LossScaleOptimizer`](mixed_precision/lossscaleoptimizer): An optimizer that applies loss scaling to prevent numeric underflow.
[`class Policy`](mixed_precision/policy): A dtype policy for a Keras layer.
Functions
---------
[`global_policy(...)`](mixed_precision/global_policy): Returns the global dtype policy.
[`set_global_policy(...)`](mixed_precision/set_global_policy): Sets the global dtype policy.
tensorflow Module: tf.keras.applications Module: tf.keras.applications
=============================
Keras Applications are premade architectures with pre-trained weights.
Modules
-------
[`densenet`](applications/densenet) module: DenseNet models for Keras.
[`efficientnet`](applications/efficientnet) module: EfficientNet models for Keras.
[`efficientnet_v2`](applications/efficientnet_v2) module: EfficientNet V2 models for Keras.
[`imagenet_utils`](applications/imagenet_utils) module: Utilities for ImageNet data preprocessing & prediction decoding.
[`inception_resnet_v2`](applications/inception_resnet_v2) module: Inception-ResNet V2 model for Keras.
[`inception_v3`](applications/inception_v3) module: Inception V3 model for Keras.
[`mobilenet`](applications/mobilenet) module: MobileNet v1 models for Keras.
[`mobilenet_v2`](applications/mobilenet_v2) module: MobileNet v2 models for Keras.
[`mobilenet_v3`](applications/mobilenet_v3) module: MobileNet v3 models for Keras.
[`nasnet`](applications/nasnet) module: NASNet-A models for Keras.
[`regnet`](applications/regnet) module: RegNet models for Keras.
[`resnet`](applications/resnet) module: ResNet models for Keras.
[`resnet50`](applications/resnet50) module: Public API for tf.keras.applications.resnet50 namespace.
[`resnet_rs`](applications/resnet_rs) module: ResNet-RS models for Keras.
[`resnet_v2`](applications/resnet_v2) module: ResNet v2 models for Keras.
[`vgg16`](applications/vgg16) module: VGG16 model for Keras.
[`vgg19`](applications/vgg19) module: VGG19 model for Keras.
[`xception`](applications/xception) module: Xception V1 model for Keras.
Functions
---------
[`DenseNet121(...)`](applications/densenet/densenet121): Instantiates the Densenet121 architecture.
[`DenseNet169(...)`](applications/densenet/densenet169): Instantiates the Densenet169 architecture.
[`DenseNet201(...)`](applications/densenet/densenet201): Instantiates the Densenet201 architecture.
[`EfficientNetB0(...)`](applications/efficientnet/efficientnetb0): Instantiates the EfficientNetB0 architecture.
[`EfficientNetB1(...)`](applications/efficientnet/efficientnetb1): Instantiates the EfficientNetB1 architecture.
[`EfficientNetB2(...)`](applications/efficientnet/efficientnetb2): Instantiates the EfficientNetB2 architecture.
[`EfficientNetB3(...)`](applications/efficientnet/efficientnetb3): Instantiates the EfficientNetB3 architecture.
[`EfficientNetB4(...)`](applications/efficientnet/efficientnetb4): Instantiates the EfficientNetB4 architecture.
[`EfficientNetB5(...)`](applications/efficientnet/efficientnetb5): Instantiates the EfficientNetB5 architecture.
[`EfficientNetB6(...)`](applications/efficientnet/efficientnetb6): Instantiates the EfficientNetB6 architecture.
[`EfficientNetB7(...)`](applications/efficientnet/efficientnetb7): Instantiates the EfficientNetB7 architecture.
[`EfficientNetV2B0(...)`](applications/efficientnet_v2/efficientnetv2b0): Instantiates the EfficientNetV2B0 architecture.
[`EfficientNetV2B1(...)`](applications/efficientnet_v2/efficientnetv2b1): Instantiates the EfficientNetV2B1 architecture.
[`EfficientNetV2B2(...)`](applications/efficientnet_v2/efficientnetv2b2): Instantiates the EfficientNetV2B2 architecture.
[`EfficientNetV2B3(...)`](applications/efficientnet_v2/efficientnetv2b3): Instantiates the EfficientNetV2B3 architecture.
[`EfficientNetV2L(...)`](applications/efficientnet_v2/efficientnetv2l): Instantiates the EfficientNetV2L architecture.
[`EfficientNetV2M(...)`](applications/efficientnet_v2/efficientnetv2m): Instantiates the EfficientNetV2M architecture.
[`EfficientNetV2S(...)`](applications/efficientnet_v2/efficientnetv2s): Instantiates the EfficientNetV2S architecture.
[`InceptionResNetV2(...)`](applications/inception_resnet_v2/inceptionresnetv2): Instantiates the Inception-ResNet v2 architecture.
[`InceptionV3(...)`](applications/inception_v3/inceptionv3): Instantiates the Inception v3 architecture.
[`MobileNet(...)`](applications/mobilenet/mobilenet): Instantiates the MobileNet architecture.
[`MobileNetV2(...)`](applications/mobilenet_v2/mobilenetv2): Instantiates the MobileNetV2 architecture.
[`MobileNetV3Large(...)`](applications/mobilenetv3large): Instantiates the MobileNetV3Large architecture.
[`MobileNetV3Small(...)`](applications/mobilenetv3small): Instantiates the MobileNetV3Small architecture.
[`NASNetLarge(...)`](applications/nasnet/nasnetlarge): Instantiates a NASNet model in ImageNet mode.
[`NASNetMobile(...)`](applications/nasnet/nasnetmobile): Instantiates a Mobile NASNet model in ImageNet mode.
[`RegNetX002(...)`](applications/regnet/regnetx002): Instantiates the RegNetX002 architecture.
[`RegNetX004(...)`](applications/regnet/regnetx004): Instantiates the RegNetX004 architecture.
[`RegNetX006(...)`](applications/regnet/regnetx006): Instantiates the RegNetX006 architecture.
[`RegNetX008(...)`](applications/regnet/regnetx008): Instantiates the RegNetX008 architecture.
[`RegNetX016(...)`](applications/regnet/regnetx016): Instantiates the RegNetX016 architecture.
[`RegNetX032(...)`](applications/regnet/regnetx032): Instantiates the RegNetX032 architecture.
[`RegNetX040(...)`](applications/regnet/regnetx040): Instantiates the RegNetX040 architecture.
[`RegNetX064(...)`](applications/regnet/regnetx064): Instantiates the RegNetX064 architecture.
[`RegNetX080(...)`](applications/regnet/regnetx080): Instantiates the RegNetX080 architecture.
[`RegNetX120(...)`](applications/regnet/regnetx120): Instantiates the RegNetX120 architecture.
[`RegNetX160(...)`](applications/regnet/regnetx160): Instantiates the RegNetX160 architecture.
[`RegNetX320(...)`](applications/regnet/regnetx320): Instantiates the RegNetX320 architecture.
[`RegNetY002(...)`](applications/regnet/regnety002): Instantiates the RegNetY002 architecture.
[`RegNetY004(...)`](applications/regnet/regnety004): Instantiates the RegNetY004 architecture.
[`RegNetY006(...)`](applications/regnet/regnety006): Instantiates the RegNetY006 architecture.
[`RegNetY008(...)`](applications/regnet/regnety008): Instantiates the RegNetY008 architecture.
[`RegNetY016(...)`](applications/regnet/regnety016): Instantiates the RegNetY016 architecture.
[`RegNetY032(...)`](applications/regnet/regnety032): Instantiates the RegNetY032 architecture.
[`RegNetY040(...)`](applications/regnet/regnety040): Instantiates the RegNetY040 architecture.
[`RegNetY064(...)`](applications/regnet/regnety064): Instantiates the RegNetY064 architecture.
[`RegNetY080(...)`](applications/regnet/regnety080): Instantiates the RegNetY080 architecture.
[`RegNetY120(...)`](applications/regnet/regnety120): Instantiates the RegNetY120 architecture.
[`RegNetY160(...)`](applications/regnet/regnety160): Instantiates the RegNetY160 architecture.
[`RegNetY320(...)`](applications/regnet/regnety320): Instantiates the RegNetY320 architecture.
[`ResNet101(...)`](applications/resnet/resnet101): Instantiates the ResNet101 architecture.
[`ResNet101V2(...)`](applications/resnet_v2/resnet101v2): Instantiates the ResNet101V2 architecture.
[`ResNet152(...)`](applications/resnet/resnet152): Instantiates the ResNet152 architecture.
[`ResNet152V2(...)`](applications/resnet_v2/resnet152v2): Instantiates the ResNet152V2 architecture.
[`ResNet50(...)`](applications/resnet50/resnet50): Instantiates the ResNet50 architecture.
[`ResNet50V2(...)`](applications/resnet_v2/resnet50v2): Instantiates the ResNet50V2 architecture.
[`ResNetRS101(...)`](applications/resnet_rs/resnetrs101): Build ResNet-RS101 model.
[`ResNetRS152(...)`](applications/resnet_rs/resnetrs152): Instantiates the ResNetRS152 architecture.
[`ResNetRS200(...)`](applications/resnet_rs/resnetrs200): Instantiates the ResNetRS200 architecture.
[`ResNetRS270(...)`](applications/resnet_rs/resnetrs270): Instantiates the ResNetRS270 architecture.
[`ResNetRS350(...)`](applications/resnet_rs/resnetrs350): Instantiates the ResNetRS350 architecture.
[`ResNetRS420(...)`](applications/resnet_rs/resnetrs420): Instantiates the ResNetRS420 architecture.
[`ResNetRS50(...)`](applications/resnet_rs/resnetrs50): Instantiates the ResNetRS50 architecture.
[`VGG16(...)`](applications/vgg16/vgg16): Instantiates the VGG16 model.
[`VGG19(...)`](applications/vgg19/vgg19): Instantiates the VGG19 architecture.
[`Xception(...)`](applications/xception/xception): Instantiates the Xception architecture.
tensorflow Module: tf.keras.losses Module: tf.keras.losses
=======================
Built-in loss functions.
Classes
-------
[`class BinaryCrossentropy`](losses/binarycrossentropy): Computes the cross-entropy loss between true labels and predicted labels.
[`class BinaryFocalCrossentropy`](losses/binaryfocalcrossentropy): Computes the focal cross-entropy loss between true labels and predictions.
[`class CategoricalCrossentropy`](losses/categoricalcrossentropy): Computes the crossentropy loss between the labels and predictions.
[`class CategoricalHinge`](losses/categoricalhinge): Computes the categorical hinge loss between `y_true` and `y_pred`.
[`class CosineSimilarity`](losses/cosinesimilarity): Computes the cosine similarity between labels and predictions.
[`class Hinge`](losses/hinge): Computes the hinge loss between `y_true` and `y_pred`.
[`class Huber`](losses/huber): Computes the Huber loss between `y_true` and `y_pred`.
[`class KLDivergence`](losses/kldivergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`class LogCosh`](losses/logcosh): Computes the logarithm of the hyperbolic cosine of the prediction error.
[`class Loss`](losses/loss): Loss base class.
[`class MeanAbsoluteError`](losses/meanabsoluteerror): Computes the mean of absolute difference between labels and predictions.
[`class MeanAbsolutePercentageError`](losses/meanabsolutepercentageerror): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`class MeanSquaredError`](losses/meansquarederror): Computes the mean of squares of errors between labels and predictions.
[`class MeanSquaredLogarithmicError`](losses/meansquaredlogarithmicerror): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`class Poisson`](losses/poisson): Computes the Poisson loss between `y_true` and `y_pred`.
[`class Reduction`](losses/reduction): Types of loss reduction.
[`class SparseCategoricalCrossentropy`](losses/sparsecategoricalcrossentropy): Computes the crossentropy loss between the labels and predictions.
[`class SquaredHinge`](losses/squaredhinge): Computes the squared hinge loss between `y_true` and `y_pred`.
Functions
---------
[`KLD(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`MAE(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`MAPE(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`MSE(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`MSLE(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`binary_crossentropy(...)`](metrics/binary_crossentropy): Computes the binary crossentropy loss.
[`binary_focal_crossentropy(...)`](metrics/binary_focal_crossentropy): Computes the binary focal crossentropy loss.
[`categorical_crossentropy(...)`](metrics/categorical_crossentropy): Computes the categorical crossentropy loss.
[`categorical_hinge(...)`](losses/categorical_hinge): Computes the categorical hinge loss between `y_true` and `y_pred`.
[`cosine_similarity(...)`](losses/cosine_similarity): Computes the cosine similarity between labels and predictions.
[`deserialize(...)`](losses/deserialize): Deserializes a serialized loss class/function instance.
[`get(...)`](losses/get): Retrieves a Keras loss as a `function`/`Loss` class instance.
[`hinge(...)`](metrics/hinge): Computes the hinge loss between `y_true` and `y_pred`.
[`huber(...)`](losses/huber): Computes Huber loss value.
[`kl_divergence(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`kld(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`kullback_leibler_divergence(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`log_cosh(...)`](losses/log_cosh): Logarithm of the hyperbolic cosine of the prediction error.
[`logcosh(...)`](losses/log_cosh): Logarithm of the hyperbolic cosine of the prediction error.
[`mae(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`mape(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`mean_absolute_error(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`mean_absolute_percentage_error(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`mean_squared_error(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`mean_squared_logarithmic_error(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`mse(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`msle(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`poisson(...)`](metrics/poisson): Computes the Poisson loss between y\_true and y\_pred.
[`serialize(...)`](losses/serialize): Serializes loss function or `Loss` instance.
[`sparse_categorical_crossentropy(...)`](metrics/sparse_categorical_crossentropy): Computes the sparse categorical crossentropy loss.
[`squared_hinge(...)`](metrics/squared_hinge): Computes the squared hinge loss between `y_true` and `y_pred`.
| programming_docs |
tensorflow tf.keras.Sequential tf.keras.Sequential
===================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/sequential.py#L42-L472) |
`Sequential` groups a linear stack of layers into a [`tf.keras.Model`](model).
Inherits From: [`Model`](model), [`Layer`](layers/layer), [`Module`](../module)
#### View aliases
**Main aliases**
[`tf.keras.models.Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/Sequential)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/Sequential), [`tf.compat.v1.keras.models.Sequential`](https://www.tensorflow.org/api_docs/python/tf/keras/Sequential)
```
tf.keras.Sequential(
layers=None, name=None
)
```
`Sequential` provides training and inference features on this model.
#### Examples:
```
# Optionally, the first layer can receive an `input_shape` argument:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8, input_shape=(16,)))
# Afterwards, we do automatic shape inference:
model.add(tf.keras.layers.Dense(4))
# This is identical to the following:
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=(16,)))
model.add(tf.keras.layers.Dense(8))
# Note that you can also omit the `input_shape` argument.
# In that case the model doesn't have any weights until the first call
# to a training/evaluation method (since it isn't yet built):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8))
model.add(tf.keras.layers.Dense(4))
# model.weights not created yet
# Whereas if you specify the input shape, the model gets built
# continuously as you are adding layers:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8, input_shape=(16,)))
model.add(tf.keras.layers.Dense(4))
len(model.weights)
# Returns "4"
# When using the delayed-build pattern (no input shape specified), you can
# choose to manually build your model by calling
# `build(batch_input_shape)`:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8))
model.add(tf.keras.layers.Dense(4))
model.build((None, 16))
len(model.weights)
# Returns "4"
# Note that when using the delayed-build pattern (no input shape specified),
# the model gets built the first time you call `fit`, `eval`, or `predict`,
# or the first time you call the model on some input data.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(8))
model.add(tf.keras.layers.Dense(1))
model.compile(optimizer='sgd', loss='mse')
# This builds the model for the first time:
model.fit(x, y, batch_size=32, epochs=10)
```
| Args |
| `layers` | Optional list of layers to add to the model. |
| `name` | Optional name for the model. |
| Attributes |
| `distribute_strategy` | The [`tf.distribute.Strategy`](../distribute/strategy) this model was created under. |
| `layers` | |
| `metrics_names` | Returns the model's display labels for all outputs.
**Note:** `metrics_names` are available only after a [`keras.Model`](model) has been trained/evaluated on actual data.
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
model.metrics_names
[]
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
model.fit(x, y)
model.metrics_names
['loss', 'mae']
```
```
inputs = tf.keras.layers.Input(shape=(3,))
d = tf.keras.layers.Dense(2, name='out')
output_1 = d(inputs)
output_2 = d(inputs)
model = tf.keras.models.Model(
inputs=inputs, outputs=[output_1, output_2])
model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
model.fit(x, (y, y))
model.metrics_names
['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
'out_1_acc']
```
|
| `run_eagerly` | Settable attribute indicating whether the model should run eagerly. Running eagerly means that your model will be run step by step, like Python code. Your model might run slower, but it should become easier for you to debug it by stepping into individual layer calls. By default, we will attempt to compile your model to a static graph to deliver the best execution performance. |
Methods
-------
### `add`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/sequential.py#L150-L233)
```
add(
layer
)
```
Adds a layer instance on top of the layer stack.
| Args |
| `layer` | layer instance. |
| Raises |
| `TypeError` | If `layer` is not a layer instance. |
| `ValueError` | In case the `layer` argument does not know its input shape. |
| `ValueError` | In case the `layer` argument has multiple output tensors, or is already connected somewhere else (forbidden in `Sequential` models). |
### `compile`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L523-L659)
```
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
```
Configures the model for training.
#### Example:
```
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.FalseNegatives()])
```
| Args |
| `optimizer` | String (name of optimizer) or optimizer instance. See [`tf.keras.optimizers`](optimizers). |
| `loss` | Loss function. May be a string (name of loss function), or a [`tf.keras.losses.Loss`](losses/loss) instance. See [`tf.keras.losses`](losses). A loss function is any callable with the signature `loss = fn(y_true, y_pred)`, where `y_true` are the ground truth values, and `y_pred` are the model's predictions. `y_true` should have shape `(batch_size, d0, .. dN)` (except in the case of sparse loss functions such as sparse categorical crossentropy which expects integer arrays of shape `(batch_size, d0, .. dN-1)`). `y_pred` should have shape `(batch_size, d0, .. dN)`. The loss function should return a float tensor. If a custom `Loss` instance is used and reduction is set to `None`, return value has shape `(batch_size, d0, .. dN-1)` i.e. per-sample or per-timestep loss values; otherwise, it is a scalar. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses, unless `loss_weights` is specified. |
| `metrics` | List of metrics to be evaluated by the model during training and testing. Each of this can be a string (name of a built-in function), function or a [`tf.keras.metrics.Metric`](metrics/metric) instance. See [`tf.keras.metrics`](metrics). Typically you will use `metrics=['accuracy']`. A function is any callable with the signature `result = fn(y_true, y_pred)`. To specify different metrics for different outputs of a multi-output model, you could also pass a dictionary, such as `metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}`. You can also pass a list to specify a metric or a list of metrics for each output, such as `metrics=[['accuracy'], ['accuracy', 'mse']]` or `metrics=['accuracy', ['accuracy', 'mse']]`. When you pass the strings 'accuracy' or 'acc', we convert this to one of [`tf.keras.metrics.BinaryAccuracy`](metrics/binaryaccuracy), [`tf.keras.metrics.CategoricalAccuracy`](metrics/categoricalaccuracy), [`tf.keras.metrics.SparseCategoricalAccuracy`](metrics/sparsecategoricalaccuracy) based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well. |
| `loss_weights` | Optional list or dictionary specifying scalar coefficients (Python floats) to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the *weighted sum* of all individual losses, weighted by the `loss_weights` coefficients. If a list, it is expected to have a 1:1 mapping to the model's outputs. If a dict, it is expected to map output names (strings) to scalar coefficients. |
| `weighted_metrics` | List of metrics to be evaluated and weighted by `sample_weight` or `class_weight` during training and testing. |
| `run_eagerly` | Bool. Defaults to `False`. If `True`, this `Model`'s logic will not be wrapped in a [`tf.function`](../function). Recommended to leave this as `None` unless your `Model` cannot be run inside a [`tf.function`](../function). `run_eagerly=True` is not supported when using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy). |
| `steps_per_execution` | Int. Defaults to 1. The number of batches to run during each [`tf.function`](../function) call. Running multiple batches inside a single [`tf.function`](../function) call can greatly improve performance on TPUs or small models with a large Python overhead. At most, one full epoch will be run each execution. If a number larger than the size of the epoch is passed, the execution will be truncated to the size of the epoch. Note that if `steps_per_execution` is set to `N`, [`Callback.on_batch_begin`](callbacks/callback#on_batch_begin) and [`Callback.on_batch_end`](callbacks/callback#on_batch_end) methods will only be called every `N` batches (i.e. before/after each [`tf.function`](../function) execution). |
| `jit_compile` | If `True`, compile the model training step with XLA. [XLA](https://www.tensorflow.org/xla) is an optimizing compiler for machine learning. `jit_compile` is not enabled for by default. This option cannot be enabled with `run_eagerly=True`. Note that `jit_compile=True` is may not necessarily work for all models. For more information on supported operations please refer to the [XLA documentation](https://www.tensorflow.org/xla). Also refer to [known XLA issues](https://www.tensorflow.org/xla/known_issues) for more details. |
| `**kwargs` | Arguments supported for backwards compatibility only. |
### `compute_loss`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L896-L949)
```
compute_loss(
x=None, y=None, y_pred=None, sample_weight=None
)
```
Compute the total loss, validate it, and return it.
Subclasses can optionally override this method to provide custom loss computation logic.
#### Example:
```
class MyModel(tf.keras.Model):
def __init__(self, *args, **kwargs):
super(MyModel, self).__init__(*args, **kwargs)
self.loss_tracker = tf.keras.metrics.Mean(name='loss')
def compute_loss(self, x, y, y_pred, sample_weight):
loss = tf.reduce_mean(tf.math.squared_difference(y_pred, y))
loss += tf.add_n(self.losses)
self.loss_tracker.update_state(loss)
return loss
def reset_metrics(self):
self.loss_tracker.reset_states()
@property
def metrics(self):
return [self.loss_tracker]
tensors = tf.random.uniform((10, 10)), tf.random.uniform((10,))
dataset = tf.data.Dataset.from_tensor_slices(tensors).repeat().batch(1)
inputs = tf.keras.layers.Input(shape=(10,), name='my_input')
outputs = tf.keras.layers.Dense(10)(inputs)
model = MyModel(inputs, outputs)
model.add_loss(tf.reduce_sum(outputs))
optimizer = tf.keras.optimizers.SGD()
model.compile(optimizer, loss='mse', steps_per_execution=10)
model.fit(dataset, epochs=2, steps_per_epoch=10)
print('My custom loss: ', model.loss_tracker.result().numpy())
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| The total loss as a [`tf.Tensor`](../tensor), or `None` if no loss results (which is the case when called by [`Model.test_step`](model#test_step)). |
### `compute_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L951-L996)
```
compute_metrics(
x, y, y_pred, sample_weight
)
```
Update metric states and collect all metrics to be returned.
Subclasses can optionally override this method to provide custom metric updating and collection logic.
#### Example:
```
class MyModel(tf.keras.Sequential):
def compute_metrics(self, x, y, y_pred, sample_weight):
# This super call updates `self.compiled_metrics` and returns results
# for all metrics listed in `self.metrics`.
metric_results = super(MyModel, self).compute_metrics(
x, y, y_pred, sample_weight)
# Note that `self.custom_metric` is not listed in `self.metrics`.
self.custom_metric.update_state(x, y, y_pred, sample_weight)
metric_results['custom_metric_name'] = self.custom_metric.result()
return metric_results
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model.call(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end()`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the metrics listed in `self.metrics` are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
### `evaluate`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1602-L1768)
```
evaluate(
x=None,
y=None,
batch_size=None,
verbose='auto',
sample_weight=None,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
return_dict=False,
**kwargs
)
```
Returns the loss value & metrics values for the model in test mode.
Computation is done in batches (see the `batch_size` arg.)
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator or [`keras.utils.Sequence`](utils/sequence) instance, `y` should not be specified (since targets will be obtained from the iterator/dataset). |
| `batch_size` | Integer or `None`. Number of samples per batch of computation. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of a dataset, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `sample_weight` | Optional Numpy array of weights for the test samples, used for weighting the loss function. You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, instead pass sample weights as the third element of `x`. |
| `steps` | Integer or `None`. Total number of steps (batches of samples) before declaring the evaluation round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../data) dataset and `steps` is None, 'evaluate' will run until the dataset is exhausted. This argument is not supported with array inputs. |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during evaluation. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| `**kwargs` | Unused at this time. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](model#fit).
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.evaluate` is wrapped in a [`tf.function`](../function). |
### `fit`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1099-L1472)
```
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose='auto',
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Trains the model for a fixed number of epochs (iterations on a dataset).
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A [`tf.keras.utils.experimental.DatasetCreator`](utils/experimental/datasetcreator), which wraps a callable that takes a single argument of type [`tf.distribute.InputContext`](../distribute/inputcontext), and returns a [`tf.data.Dataset`](../data/dataset). `DatasetCreator` should be used when users prefer to specify the per-replica batching and sharding logic for the `Dataset`. See [`tf.keras.utils.experimental.DatasetCreator`](utils/experimental/datasetcreator) doc for more information. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given below. If using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy), only `DatasetCreator` type is supported for `x`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator, or [`keras.utils.Sequence`](utils/sequence) instance, `y` should not be specified (since targets will be obtained from `x`). |
| `batch_size` | Integer or `None`. Number of samples per gradient update. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `epochs` | Integer. Number of epochs to train the model. An epoch is an iteration over the entire `x` and `y` data provided (unless the `steps_per_epoch` flag is set to something other than None). Note that in conjunction with `initial_epoch`, `epochs` is to be understood as "final epoch". The model is not trained for a number of iterations given by `epochs`, but merely until the epoch of index `epochs` is reached. |
| `verbose` | 'auto', 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch. 'auto' defaults to 1 for most cases, but 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so verbose=2 is recommended when not running interactively (eg, in a production environment). |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during training. See [`tf.keras.callbacks`](callbacks). Note [`tf.keras.callbacks.ProgbarLogger`](callbacks/progbarlogger) and [`tf.keras.callbacks.History`](callbacks/history) callbacks are created automatically and need not be passed into `model.fit`. [`tf.keras.callbacks.ProgbarLogger`](callbacks/progbarlogger) is created or not based on `verbose` argument to `model.fit`. Callbacks with batch-level calls are currently unsupported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy), and users are advised to implement epoch-level calls instead with an appropriate `steps_per_epoch` value. |
| `validation_split` | Float between 0 and 1. Fraction of the training data to be used as validation data. The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch. The validation data is selected from the last samples in the `x` and `y` data provided, before shuffling. This argument is not supported when `x` is a dataset, generator or [`keras.utils.Sequence`](utils/sequence) instance. If both `validation_data` and `validation_split` are provided, `validation_data` will override `validation_split`. `validation_split` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy). |
| `validation_data` | Data on which to evaluate the loss and any model metrics at the end of each epoch. The model will not be trained on this data. Thus, note the fact that the validation loss of data provided using `validation_split` or `validation_data` is not affected by regularization layers like noise and dropout. `validation_data` will override `validation_split`. `validation_data` could be: * A tuple `(x_val, y_val)` of Numpy arrays or tensors.
* A tuple `(x_val, y_val, val_sample_weights)` of NumPy arrays.
* A [`tf.data.Dataset`](../data/dataset).
* A Python generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. `validation_data` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy).
|
| `shuffle` | Boolean (whether to shuffle the training data before each epoch) or str (for 'batch'). This argument is ignored when `x` is a generator or an object of tf.data.Dataset. 'batch' is a special option for dealing with the limitations of HDF5 data; it shuffles in batch-sized chunks. Has no effect when `steps_per_epoch` is not `None`. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function (during training only). This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `sample_weight` | Optional Numpy array of weights for the training samples, used for weighting the loss function (during training only). You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, generator, or [`keras.utils.Sequence`](utils/sequence) instance, instead provide the sample\_weights as the third element of `x`. |
| `initial_epoch` | Integer. Epoch at which to start training (useful for resuming a previous training run). |
| `steps_per_epoch` | Integer or `None`. Total number of steps (batches of samples) before declaring one epoch finished and starting the next epoch. When training with input tensors such as TensorFlow data tensors, the default `None` is equal to the number of samples in your dataset divided by the batch size, or 1 if that cannot be determined. If x is a [`tf.data`](../data) dataset, and 'steps\_per\_epoch' is None, the epoch will run until the input dataset is exhausted. When passing an infinitely repeating dataset, you must specify the `steps_per_epoch` argument. If `steps_per_epoch=-1` the training will run indefinitely with an infinitely repeating dataset. This argument is not supported with array inputs. When using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy): - `steps_per_epoch=None` is not supported.
|
| `validation_steps` | Only relevant if `validation_data` is provided and is a [`tf.data`](../data) dataset. Total number of steps (batches of samples) to draw before stopping when performing validation at the end of every epoch. If 'validation\_steps' is None, validation will run until the `validation_data` dataset is exhausted. In the case of an infinitely repeated dataset, it will run into an infinite loop. If 'validation\_steps' is specified and only part of the dataset will be consumed, the evaluation will start from the beginning of the dataset at each epoch. This ensures that the same validation samples are used every time. |
| `validation_batch_size` | Integer or `None`. Number of samples per validation batch. If unspecified, will default to `batch_size`. Do not specify the `validation_batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `validation_freq` | Only relevant if validation data is provided. Integer or `collections.abc.Container` instance (e.g. list, tuple, etc.). If an integer, specifies how many training epochs to run before a new validation run is performed, e.g. `validation_freq=2` runs validation every 2 epochs. If a Container, specifies the epochs on which to run validation, e.g. `validation_freq=[1, 2, 10]` runs validation at the end of the 1st, 2nd, and 10th epochs. |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
Unpacking behavior for iterator-like inputs: A common pattern is to pass a tf.data.Dataset, generator, or tf.keras.utils.Sequence to the `x` argument of fit, which will in fact yield not only features (x) but optionally targets (y) and sample weights. Keras requires that the output of such iterator-likes be unambiguous. The iterator should return a tuple of length 1, 2, or 3, where the optional second and third elements will be used for y and sample\_weight respectively. Any other type provided will be wrapped in a length one tuple, effectively treating everything as 'x'. When yielding dicts, they should still adhere to the top-level tuple structure. e.g. `({"x0": x0, "x1": x1}, y)`. Keras will not attempt to separate features, targets, and weights from the keys of a single dict. A notable unsupported data type is the namedtuple. The reason is that it behaves like both an ordered datatype (tuple) and a mapping datatype (dict). So given a namedtuple of the form: `namedtuple("example_tuple", ["y", "x"])` it is ambiguous whether to reverse the order of the elements when interpreting the value. Even worse is a tuple of the form: `namedtuple("other_tuple", ["x", "y", "z"])` where it is unclear if the tuple was intended to be unpacked into x, y, and sample\_weight or passed through as a single element to `x`. As a result the data processing code will simply raise a ValueError if it encounters a namedtuple. (Along with instructions to remedy the issue.)
| Returns |
| A `History` object. Its `History.history` attribute is a record of training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). |
| Raises |
| `RuntimeError` | 1. If the model was never compiled or,
2. If `model.fit` is wrapped in [`tf.function`](../function).
|
| `ValueError` | In case of mismatch between the provided input data and what the model expects or when the input data is empty. |
### `get_layer`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2891-L2925)
```
get_layer(
name=None, index=None
)
```
Retrieves a layer based on either its name (unique) or index.
If `name` and `index` are both provided, `index` will take precedence. Indices are based on order of horizontal graph traversal (bottom-up).
| Args |
| `name` | String, name of layer. |
| `index` | Integer, index of layer. |
| Returns |
| A layer instance. |
### `load_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2556-L2661)
```
load_weights(
filepath, by_name=False, skip_mismatch=False, options=None
)
```
Loads all layer weights, either from a TensorFlow or an HDF5 weight file.
If `by_name` is False weights are loaded based on the network's topology. This means the architecture should be the same as when the weights were saved. Note that layers that don't have weights are not taken into account in the topological ordering, so adding or removing layers is fine as long as they don't have weights.
If `by_name` is True, weights are loaded into layers only if they share the same name. This is useful for fine-tuning or transfer-learning models where some of the layers have changed.
Only topological loading (`by_name=False`) is supported when loading weights from the TensorFlow format. Note that topological loading differs slightly between TensorFlow and HDF5 formats for user-defined classes inheriting from [`tf.keras.Model`](model): HDF5 loads based on a flattened list of weights, while the TensorFlow format loads based on the object-local names of attributes to which layers are assigned in the `Model`'s constructor.
| Args |
| `filepath` | String, path to the weights file to load. For weight files in TensorFlow format, this is the file prefix (the same as was passed to `save_weights`). This can also be a path to a SavedModel saved from `model.save`. |
| `by_name` | Boolean, whether to load weights by name or by topological order. Only topological loading is supported for weight files in TensorFlow format. |
| `skip_mismatch` | Boolean, whether to skip loading of layers where there is a mismatch in the number of weights, or a mismatch in the shape of the weight (only valid when `by_name=True`). |
| `options` | Optional [`tf.train.CheckpointOptions`](../train/checkpointoptions) object that specifies options for loading weights. |
| Returns |
| When loading a weight file in TensorFlow format, returns the same status object as [`tf.train.Checkpoint.restore`](../train/checkpoint#restore). When graph building, restore ops are run automatically as soon as the network is built (on first call for user-defined classes inheriting from `Model`, immediately if it is already built). When loading weights in HDF5 format, returns `None`. |
| Raises |
| `ImportError` | If `h5py` is not available and the weight file is in HDF5 format. |
| `ValueError` | If `skip_mismatch` is set to `True` when `by_name` is `False`. |
### `make_predict_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1793-L1867)
```
make_predict_function(
force=False
)
```
Creates a function that executes one step of inference.
This method can be overridden to support custom inference logic. This method is called by [`Model.predict`](model#predict) and [`Model.predict_on_batch`](model#predict_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.predict_step`](model#predict_step).
This function is cached the first time [`Model.predict`](model#predict) or [`Model.predict_on_batch`](model#predict_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the predict function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return the outputs of the `Model`. |
### `make_test_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1504-L1600)
```
make_test_function(
force=False
)
```
Creates a function that executes one step of evaluation.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.evaluate`](model#evaluate) and [`Model.test_on_batch`](model#test_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.test_step`](model#test_step).
This function is cached the first time [`Model.evaluate`](model#evaluate) or [`Model.test_on_batch`](model#test_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the test function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_test_batch_end`. |
### `make_train_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L998-L1097)
```
make_train_function(
force=False
)
```
Creates a function that executes one step of training.
This method can be overridden to support custom training logic. This method is called by [`Model.fit`](model#fit) and [`Model.train_on_batch`](model#train_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual training logic to [`Model.train_step`](model#train_step).
This function is cached the first time [`Model.fit`](model#fit) or [`Model.train_on_batch`](model#train_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the train function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_train_batch_end`, such as `{'loss': 0.2, 'accuracy': 0.7}`. |
### `pop`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/sequential.py#L235-L259)
```
pop()
```
Removes the last layer in the model.
| Raises |
| `TypeError` | if there are no layers in the model. |
### `predict`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1869-L2064)
```
predict(
x,
batch_size=None,
verbose='auto',
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Generates output predictions for the input samples.
Computation is done in batches. This method is designed for batch processing of large numbers of inputs. It is not intended for use inside of loops that iterate over your data and process small numbers of inputs at a time.
For small numbers of inputs that fit in one batch, directly use `__call__()` for faster execution, e.g., `model(x)`, or `model(x, training=False)` if you have layers such as [`tf.keras.layers.BatchNormalization`](layers/batchnormalization) that behave differently during inference. You may pair the individual model call with a [`tf.function`](../function) for additional performance inside your inner loop. If you need access to numpy array values instead of tensors after your model call, you can use `tensor.numpy()` to get the numpy array value of an eager tensor.
Also, note the fact that test loss is not affected by regularization layers like noise and dropout.
>
> **Note:** See [this FAQ entry](https://keras.io/getting_started/faq/#whats-the-difference-between-model-methods-predict-and-call) for more details about the difference between `Model` methods `predict()` and `__call__()`.
>
| Args |
| `x` | Input samples. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A [`tf.data`](../data) dataset.
* A generator or [`keras.utils.Sequence`](utils/sequence) instance. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `batch_size` | Integer or `None`. Number of samples per batch. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of dataset, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `steps` | Total number of steps (batches of samples) before declaring the prediction round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../data) dataset and `steps` is None, `predict()` will run until the input dataset is exhausted. |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during prediction. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](model#fit). Note that Model.predict uses the same interpretation rules as [`Model.fit`](model#fit) and [`Model.evaluate`](model#evaluate), so inputs must be unambiguous for all three methods.
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict` is wrapped in a [`tf.function`](../function). |
| `ValueError` | In case of mismatch between the provided input data and the model's expectations, or in case a stateful model receives a number of samples that is not a multiple of the batch size. |
### `predict_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2209-L2231)
```
predict_on_batch(
x
)
```
Returns predictions for a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
|
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict_on_batch` is wrapped in a [`tf.function`](../function). |
### `predict_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1770-L1791)
```
predict_step(
data
)
```
The logic for one inference step.
This method can be overridden to support custom inference logic. This method is called by [`Model.make_predict_function`](model#make_predict_function).
This method should contain the mathematical logic for one step of inference. This typically includes the forward pass.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_predict_function`](model#make_predict_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| The result of one inference step, typically the output of calling the `Model` on data. |
### `reset_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2066-L2086)
```
reset_metrics()
```
Resets the state of all the metrics in the model.
#### Examples:
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
_ = model.fit(x, y, verbose=0)
assert all(float(m.result()) for m in model.metrics)
```
```
model.reset_metrics()
assert all(float(m.result()) == 0 for m in model.metrics)
```
### `reset_states`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2788-L2791)
```
reset_states()
```
### `save`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2383-L2436)
```
save(
filepath,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None,
save_traces=True
)
```
Saves the model to Tensorflow SavedModel or a single HDF5 file.
Please see [`tf.keras.models.save_model`](models/save_model) or the [Serialization and Saving guide](https://keras.io/guides/serialization_and_saving/) for details.
| Args |
| `filepath` | String, PathLike, path to SavedModel or H5 file to save the model. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `include_optimizer` | If True, save optimizer's state together. |
| `save_format` | Either `'tf'` or `'h5'`, indicating whether to save the model to Tensorflow SavedModel or HDF5. Defaults to 'tf' in TF 2.X, and 'h5' in TF 1.X. |
| `signatures` | Signatures to save with the SavedModel. Applicable to the 'tf' format only. Please see the `signatures` argument in [`tf.saved_model.save`](../saved_model/save) for details. |
| `options` | (only applies to SavedModel format) [`tf.saved_model.SaveOptions`](../saved_model/saveoptions) object that specifies options for saving to SavedModel. |
| `save_traces` | (only applies to SavedModel format) When enabled, the SavedModel will store the function traces for each layer. This can be disabled, so that only the configs of each layer are stored. Defaults to `True`. Disabling this will decrease serialization time and reduce file size, but it requires that all custom layers/models implement a `get_config()` method. |
#### Example:
```
from keras.models import load_model
model.save('my_model.h5') # creates a HDF5 file 'my_model.h5'
del model # deletes the existing model
# returns a compiled model
# identical to the previous one
model = load_model('my_model.h5')
```
### `save_spec`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2965-L3002)
```
save_spec(
dynamic_batch=True
)
```
Returns the [`tf.TensorSpec`](../tensorspec) of call inputs as a tuple `(args, kwargs)`.
This value is automatically defined after calling the model for the first time. Afterwards, you can use it when exporting the model for serving:
```
model = tf.keras.Model(...)
@tf.function
def serve(*args, **kwargs):
outputs = model(*args, **kwargs)
# Apply postprocessing steps, or add additional outputs.
...
return outputs
# arg_specs is `[tf.TensorSpec(...), ...]`. kwarg_specs, in this example, is
# an empty dict since functional models do not use keyword arguments.
arg_specs, kwarg_specs = model.save_spec()
model.save(path, signatures={
'serving_default': serve.get_concrete_function(*arg_specs, **kwarg_specs)
})
```
| Args |
| `dynamic_batch` | Whether to set the batch sizes of all the returned [`tf.TensorSpec`](../tensorspec) to `None`. (Note that when defining functional or Sequential models with `tf.keras.Input([...], batch_size=X)`, the batch size will always be preserved). Defaults to `True`. |
| Returns |
| If the model inputs are defined, returns a tuple `(args, kwargs)`. All elements in `args` and `kwargs` are [`tf.TensorSpec`](../tensorspec). If the model inputs are not defined, returns `None`. The model inputs are automatically set when calling the model, `model.fit`, `model.evaluate` or `model.predict`. |
### `save_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2438-L2554)
```
save_weights(
filepath, overwrite=True, save_format=None, options=None
)
```
Saves all layer weights.
Either saves in HDF5 or in TensorFlow format based on the `save_format` argument.
When saving in HDF5 format, the weight file has:
* `layer_names` (attribute), a list of strings (ordered names of model layers).
* For every layer, a `group` named `layer.name`
+ For every such layer group, a group attribute `weight_names`, a list of strings (ordered names of weights tensor of the layer).
+ For every weight in the layer, a dataset storing the weight value, named after the weight tensor.
When saving in TensorFlow format, all objects referenced by the network are saved in the same format as [`tf.train.Checkpoint`](../train/checkpoint), including any `Layer` instances or `Optimizer` instances assigned to object attributes. For networks constructed from inputs and outputs using `tf.keras.Model(inputs, outputs)`, `Layer` instances used by the network are tracked/saved automatically. For user-defined classes which inherit from [`tf.keras.Model`](model), `Layer` instances must be assigned to object attributes, typically in the constructor. See the documentation of [`tf.train.Checkpoint`](../train/checkpoint) and [`tf.keras.Model`](model) for details.
While the formats are the same, do not mix `save_weights` and [`tf.train.Checkpoint`](../train/checkpoint). Checkpoints saved by [`Model.save_weights`](model#save_weights) should be loaded using [`Model.load_weights`](model#load_weights). Checkpoints saved using [`tf.train.Checkpoint.save`](../train/checkpoint#save) should be restored using the corresponding [`tf.train.Checkpoint.restore`](../train/checkpoint#restore). Prefer [`tf.train.Checkpoint`](../train/checkpoint) over `save_weights` for training checkpoints.
The TensorFlow format matches objects and variables by starting at a root object, `self` for `save_weights`, and greedily matching attribute names. For [`Model.save`](model#save) this is the `Model`, and for [`Checkpoint.save`](../train/checkpoint#save) this is the `Checkpoint` even if the `Checkpoint` has a model attached. This means saving a [`tf.keras.Model`](model) using `save_weights` and loading into a [`tf.train.Checkpoint`](../train/checkpoint) with a `Model` attached (or vice versa) will not match the `Model`'s variables. See the [guide to training checkpoints](https://www.tensorflow.org/guide/checkpoint) for details on the TensorFlow format.
| Args |
| `filepath` | String or PathLike, path to the file to save the weights to. When saving in TensorFlow format, this is the prefix used for checkpoint files (multiple files are generated). Note that the '.h5' suffix causes weights to be saved in HDF5 format. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `save_format` | Either 'tf' or 'h5'. A `filepath` ending in '.h5' or '.keras' will default to HDF5 if `save_format` is `None`. Otherwise `None` defaults to 'tf'. |
| `options` | Optional [`tf.train.CheckpointOptions`](../train/checkpointoptions) object that specifies options for saving weights. |
| Raises |
| `ImportError` | If `h5py` is not available when attempting to save in HDF5 format. |
### `summary`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2841-L2879)
```
summary(
line_length=None,
positions=None,
print_fn=None,
expand_nested=False,
show_trainable=False
)
```
Prints a string summary of the network.
| Args |
| `line_length` | Total length of printed lines (e.g. set this to adapt the display to different terminal window sizes). |
| `positions` | Relative or absolute positions of log elements in each line. If not provided, defaults to `[.33, .55, .67, 1.]`. |
| `print_fn` | Print function to use. Defaults to `print`. It will be called on each line of the summary. You can set it to a custom function in order to capture the string summary. |
| `expand_nested` | Whether to expand the nested models. If not provided, defaults to `False`. |
| `show_trainable` | Whether to show if a layer is trainable. If not provided, defaults to `False`. |
| Raises |
| `ValueError` | if `summary()` is called before the model is built. |
### `test_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2152-L2207)
```
test_on_batch(
x, y=None, sample_weight=None, reset_metrics=True, return_dict=False
)
```
Test the model on a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.test_on_batch` is wrapped in a [`tf.function`](../function). |
### `test_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1474-L1502)
```
test_step(
data
)
```
The logic for one evaluation step.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.make_test_function`](model#make_test_function).
This function should contain the mathematical logic for one step of evaluation. This typically includes the forward pass, loss calculation, and metrics updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_test_function`](model#make_test_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. |
### `to_json`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2743-L2758)
```
to_json(
**kwargs
)
```
Returns a JSON string containing the network configuration.
To load a network from a JSON save file, use [`keras.models.model_from_json(json_string, custom_objects={})`](models/model_from_json).
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `json.dumps()`. |
| Returns |
| A JSON string. |
### `to_yaml`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2760-L2786)
```
to_yaml(
**kwargs
)
```
Returns a yaml string containing the network configuration.
>
> **Note:** Since TF 2.6, this method is no longer supported and will raise a RuntimeError.
>
To load a network from a yaml save file, use [`keras.models.model_from_yaml(yaml_string, custom_objects={})`](models/model_from_yaml).
`custom_objects` should be a dictionary mapping the names of custom losses / layers / etc to the corresponding functions / classes.
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `yaml.dump()`. |
| Returns |
| A YAML string. |
| Raises |
| `RuntimeError` | announces that the method poses a security risk |
### `train_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2088-L2150)
```
train_on_batch(
x,
y=None,
sample_weight=None,
class_weight=None,
reset_metrics=True,
return_dict=False
)
```
Runs a single gradient update on a single batch of data.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) to apply to the model's loss for the samples from this class during training. This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar training loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.train_on_batch` is wrapped in a [`tf.function`](../function). |
### `train_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L861-L894)
```
train_step(
data
)
```
The logic for one training step.
This method can be overridden to support custom training logic. For concrete examples of how to override this method see [Customizing what happends in fit](https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit). This method is called by [`Model.make_train_function`](model#make_train_function).
This method should contain the mathematical logic for one step of training. This typically includes the forward pass, loss calculation, backpropagation, and metric updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_train_function`](model#make_train_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
| programming_docs |
tensorflow Module: tf.keras.utils Module: tf.keras.utils
======================
Public Keras utilities.
Modules
-------
[`experimental`](utils/experimental) module: Public API for tf.keras.utils.experimental namespace.
Classes
-------
[`class CustomObjectScope`](utils/custom_object_scope): Exposes custom classes/functions to Keras deserialization internals.
[`class GeneratorEnqueuer`](utils/generatorenqueuer): Builds a queue out of a data generator.
[`class OrderedEnqueuer`](utils/orderedenqueuer): Builds a Enqueuer from a Sequence.
[`class Progbar`](utils/progbar): Displays a progress bar.
[`class Sequence`](utils/sequence): Base object for fitting to a sequence of data, such as a dataset.
[`class SequenceEnqueuer`](utils/sequenceenqueuer): Base class to enqueue inputs.
[`class SidecarEvaluator`](utils/sidecarevaluator): A class designed for a dedicated evaluator task.
[`class custom_object_scope`](utils/custom_object_scope): Exposes custom classes/functions to Keras deserialization internals.
Functions
---------
[`array_to_img(...)`](utils/array_to_img): Converts a 3D Numpy array to a PIL Image instance.
[`deserialize_keras_object(...)`](utils/deserialize_keras_object): Turns the serialized form of a Keras object back into an actual object.
[`disable_interactive_logging(...)`](utils/disable_interactive_logging): Turn off interactive logging.
[`enable_interactive_logging(...)`](utils/enable_interactive_logging): Turn on interactive logging.
[`get_custom_objects(...)`](utils/get_custom_objects): Retrieves a live reference to the global dictionary of custom objects.
[`get_file(...)`](utils/get_file): Downloads a file from a URL if it not already in the cache.
[`get_registered_name(...)`](utils/get_registered_name): Returns the name registered to an object within the Keras framework.
[`get_registered_object(...)`](utils/get_registered_object): Returns the class associated with `name` if it is registered with Keras.
[`get_source_inputs(...)`](utils/get_source_inputs): Returns the list of input tensors necessary to compute `tensor`.
[`image_dataset_from_directory(...)`](utils/image_dataset_from_directory): Generates a [`tf.data.Dataset`](../data/dataset) from image files in a directory.
[`img_to_array(...)`](utils/img_to_array): Converts a PIL Image instance to a Numpy array.
[`is_interactive_logging_enabled(...)`](utils/is_interactive_logging_enabled): Check if interactive logging is enabled.
[`load_img(...)`](utils/load_img): Loads an image into PIL format.
[`model_to_dot(...)`](utils/model_to_dot): Convert a Keras model to dot format.
[`normalize(...)`](utils/normalize): Normalizes a Numpy array.
[`pack_x_y_sample_weight(...)`](utils/pack_x_y_sample_weight): Packs user-provided data into a tuple.
[`pad_sequences(...)`](utils/pad_sequences): Pads sequences to the same length.
[`plot_model(...)`](utils/plot_model): Converts a Keras model to dot format and save to a file.
[`register_keras_serializable(...)`](utils/register_keras_serializable): Registers an object with the Keras serialization framework.
[`save_img(...)`](utils/save_img): Saves an image stored as a Numpy array to a path or file object.
[`serialize_keras_object(...)`](utils/serialize_keras_object): Serialize a Keras object into a JSON-compatible representation.
[`set_random_seed(...)`](utils/set_random_seed): Sets all random seeds for the program (Python, NumPy, and TensorFlow).
[`text_dataset_from_directory(...)`](utils/text_dataset_from_directory): Generates a [`tf.data.Dataset`](../data/dataset) from text files in a directory.
[`timeseries_dataset_from_array(...)`](utils/timeseries_dataset_from_array): Creates a dataset of sliding windows over a timeseries provided as array.
[`to_categorical(...)`](utils/to_categorical): Converts a class vector (integers) to binary class matrix.
[`unpack_x_y_sample_weight(...)`](utils/unpack_x_y_sample_weight): Unpacks user-provided data tuple.
tensorflow Module: tf.keras.initializers Module: tf.keras.initializers
=============================
Keras initializer serialization / deserialization.
Classes
-------
[`class Constant`](initializers/constant): Initializer that generates tensors with constant values.
[`class GlorotNormal`](initializers/glorotnormal): The Glorot normal initializer, also called Xavier normal initializer.
[`class GlorotUniform`](initializers/glorotuniform): The Glorot uniform initializer, also called Xavier uniform initializer.
[`class HeNormal`](initializers/henormal): He normal initializer.
[`class HeUniform`](initializers/heuniform): He uniform variance scaling initializer.
[`class Identity`](initializers/identity): Initializer that generates the identity matrix.
[`class Initializer`](initializers/initializer): Initializer base class: all Keras initializers inherit from this class.
[`class LecunNormal`](initializers/lecunnormal): Lecun normal initializer.
[`class LecunUniform`](initializers/lecununiform): Lecun uniform initializer.
[`class Ones`](initializers/ones): Initializer that generates tensors initialized to 1.
[`class Orthogonal`](initializers/orthogonal): Initializer that generates an orthogonal matrix.
[`class RandomNormal`](initializers/randomnormal): Initializer that generates tensors with a normal distribution.
[`class RandomUniform`](initializers/randomuniform): Initializer that generates tensors with a uniform distribution.
[`class TruncatedNormal`](initializers/truncatednormal): Initializer that generates a truncated normal distribution.
[`class VarianceScaling`](initializers/variancescaling): Initializer capable of adapting its scale to the shape of weights tensors.
[`class Zeros`](initializers/zeros): Initializer that generates tensors initialized to 0.
[`class constant`](initializers/constant): Initializer that generates tensors with constant values.
[`class glorot_normal`](initializers/glorotnormal): The Glorot normal initializer, also called Xavier normal initializer.
[`class glorot_uniform`](initializers/glorotuniform): The Glorot uniform initializer, also called Xavier uniform initializer.
[`class he_normal`](initializers/henormal): He normal initializer.
[`class he_uniform`](initializers/heuniform): He uniform variance scaling initializer.
[`class identity`](initializers/identity): Initializer that generates the identity matrix.
[`class lecun_normal`](initializers/lecunnormal): Lecun normal initializer.
[`class lecun_uniform`](initializers/lecununiform): Lecun uniform initializer.
[`class ones`](initializers/ones): Initializer that generates tensors initialized to 1.
[`class orthogonal`](initializers/orthogonal): Initializer that generates an orthogonal matrix.
[`class random_normal`](initializers/randomnormal): Initializer that generates tensors with a normal distribution.
[`class random_uniform`](initializers/randomuniform): Initializer that generates tensors with a uniform distribution.
[`class truncated_normal`](initializers/truncatednormal): Initializer that generates a truncated normal distribution.
[`class variance_scaling`](initializers/variancescaling): Initializer capable of adapting its scale to the shape of weights tensors.
[`class zeros`](initializers/zeros): Initializer that generates tensors initialized to 0.
Functions
---------
[`deserialize(...)`](initializers/deserialize): Return an `Initializer` object from its config.
[`get(...)`](initializers/get): Retrieve a Keras initializer by the identifier.
[`serialize(...)`](initializers/serialize)
tensorflow Module: tf.keras.datasets Module: tf.keras.datasets
=========================
Small NumPy datasets for debugging/testing.
Modules
-------
[`boston_housing`](datasets/boston_housing) module: Boston housing price regression dataset.
[`cifar10`](datasets/cifar10) module: CIFAR10 small images classification dataset.
[`cifar100`](datasets/cifar100) module: CIFAR100 small images classification dataset.
[`fashion_mnist`](datasets/fashion_mnist) module: Fashion-MNIST dataset.
[`imdb`](datasets/imdb) module: IMDB sentiment classification dataset.
[`mnist`](datasets/mnist) module: MNIST handwritten digits dataset.
[`reuters`](datasets/reuters) module: Reuters topic classification dataset.
tensorflow Module: tf.keras.optimizers Module: tf.keras.optimizers
===========================
Built-in optimizer classes.
For more examples see the base class [`tf.keras.optimizers.Optimizer`](optimizers/optimizer).
Modules
-------
[`experimental`](optimizers/experimental) module: Public API for tf.keras.optimizers.experimental namespace.
[`legacy`](optimizers/legacy) module: Public API for tf.keras.optimizers.legacy namespace.
[`schedules`](optimizers/schedules) module: Public API for tf.keras.optimizers.schedules namespace.
Classes
-------
[`class Adadelta`](optimizers/adadelta): Optimizer that implements the Adadelta algorithm.
[`class Adagrad`](optimizers/adagrad): Optimizer that implements the Adagrad algorithm.
[`class Adam`](optimizers/adam): Optimizer that implements the Adam algorithm.
[`class Adamax`](optimizers/adamax): Optimizer that implements the Adamax algorithm.
[`class Ftrl`](optimizers/ftrl): Optimizer that implements the FTRL algorithm.
[`class Nadam`](optimizers/nadam): Optimizer that implements the NAdam algorithm.
[`class Optimizer`](optimizers/optimizer): Base class for Keras optimizers.
[`class RMSprop`](optimizers/rmsprop): Optimizer that implements the RMSprop algorithm.
[`class SGD`](optimizers/sgd): Gradient descent (with momentum) optimizer.
Functions
---------
[`deserialize(...)`](optimizers/deserialize): Inverse of the `serialize` function.
[`get(...)`](optimizers/get): Retrieves a Keras Optimizer instance.
[`serialize(...)`](optimizers/serialize): Serialize the optimizer configuration to JSON compatible python dict.
tensorflow Module: tf.keras.experimental Module: tf.keras.experimental
=============================
Public API for tf.keras.experimental namespace.
Classes
-------
[`class CosineDecay`](optimizers/schedules/cosinedecay): A LearningRateSchedule that uses a cosine decay schedule.
[`class CosineDecayRestarts`](optimizers/schedules/cosinedecayrestarts): A LearningRateSchedule that uses a cosine decay schedule with restarts.
[`class LinearModel`](experimental/linearmodel): Linear Model for regression and classification problems.
[`class SequenceFeatures`](experimental/sequencefeatures): A layer for sequence input.
[`class SidecarEvaluator`](experimental/sidecarevaluator): Deprecated. Please use [`tf.keras.utils.SidecarEvaluator`](utils/sidecarevaluator) instead.
[`class WideDeepModel`](experimental/widedeepmodel): Wide & Deep Model for regression and classification problems.
tensorflow tf.keras.Input tf.keras.Input
==============
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/input_layer.py#L258-L396) |
`Input()` is used to instantiate a Keras tensor.
#### View aliases
**Main aliases**
[`tf.keras.layers.Input`](https://www.tensorflow.org/api_docs/python/tf/keras/Input)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.Input`](https://www.tensorflow.org/api_docs/python/tf/keras/Input), [`tf.compat.v1.keras.layers.Input`](https://www.tensorflow.org/api_docs/python/tf/keras/Input)
```
tf.keras.Input(
shape=None,
batch_size=None,
name=None,
dtype=None,
sparse=None,
tensor=None,
ragged=None,
type_spec=None,
**kwargs
)
```
A Keras tensor is a symbolic tensor-like object, which we augment with certain attributes that allow us to build a Keras model just by knowing the inputs and outputs of the model.
For instance, if `a`, `b` and `c` are Keras tensors, it becomes possible to do: `model = Model(input=[a, b], output=c)`
| Args |
| `shape` | A shape tuple (integers), not including the batch size. For instance, `shape=(32,)` indicates that the expected input will be batches of 32-dimensional vectors. Elements of this tuple can be None; 'None' elements represent dimensions where the shape is not known. |
| `batch_size` | optional static batch size (integer). |
| `name` | An optional name string for the layer. Should be unique in a model (do not reuse the same name twice). It will be autogenerated if it isn't provided. |
| `dtype` | The data type expected by the input, as a string (`float32`, `float64`, `int32`...) |
| `sparse` | A boolean specifying whether the placeholder to be created is sparse. Only one of 'ragged' and 'sparse' can be True. Note that, if `sparse` is False, sparse tensors can still be passed into the input - they will be densified with a default value of 0. |
| `tensor` | Optional existing tensor to wrap into the `Input` layer. If set, the layer will use the [`tf.TypeSpec`](../typespec) of this tensor rather than creating a new placeholder tensor. |
| `ragged` | A boolean specifying whether the placeholder to be created is ragged. Only one of 'ragged' and 'sparse' can be True. In this case, values of 'None' in the 'shape' argument represent ragged dimensions. For more information about RaggedTensors, see [this guide](https://www.tensorflow.org/guide/ragged_tensors). |
| `type_spec` | A [`tf.TypeSpec`](../typespec) object to create the input placeholder from. When provided, all other args except name must be None. |
| `**kwargs` | deprecated arguments support. Supports `batch_shape` and `batch_input_shape`. |
| Returns |
| A `tensor`. |
#### Example:
```
# this is a logistic regression in Keras
x = Input(shape=(32,))
y = Dense(16, activation='softmax')(x)
model = Model(x, y)
```
Note that even if eager execution is enabled, `Input` produces a symbolic tensor-like object (i.e. a placeholder). This symbolic tensor-like object can be used with lower-level TensorFlow ops that take tensors as inputs, as such:
```
x = Input(shape=(32,))
y = tf.square(x) # This op will be treated like a layer
model = Model(x, y)
```
(This behavior does not work for higher-order TensorFlow APIs such as control flow and being directly watched by a [`tf.GradientTape`](../gradienttape)).
However, the resulting model will not track any variables that were used as inputs to TensorFlow ops. All variable usages must happen within Keras layers to make sure they will be tracked by the model's weights.
The Keras Input can also create a placeholder from an arbitrary [`tf.TypeSpec`](../typespec), e.g:
```
x = Input(type_spec=tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32, ragged_rank=1))
y = x.values
model = Model(x, y)
```
When passing an arbitrary [`tf.TypeSpec`](../typespec), it must represent the signature of an entire batch instead of just one example.
| Raises |
| `ValueError` | If both `sparse` and `ragged` are provided. |
| `ValueError` | If both `shape` and (`batch_input_shape` or `batch_shape`) are provided. |
| `ValueError` | If `shape`, `tensor` and `type_spec` are None. |
| `ValueError` | If arguments besides `type_spec` are non-None while `type_spec` is passed. |
| `ValueError` | if any unrecognized parameters are provided. |
tensorflow Module: tf.keras.activations Module: tf.keras.activations
============================
Built-in activation functions.
Functions
---------
[`deserialize(...)`](activations/deserialize): Returns activation function given a string identifier.
[`elu(...)`](activations/elu): Exponential Linear Unit.
[`exponential(...)`](activations/exponential): Exponential activation function.
[`gelu(...)`](activations/gelu): Applies the Gaussian error linear unit (GELU) activation function.
[`get(...)`](activations/get): Returns function.
[`hard_sigmoid(...)`](activations/hard_sigmoid): Hard sigmoid activation function.
[`linear(...)`](activations/linear): Linear activation function (pass-through).
[`relu(...)`](activations/relu): Applies the rectified linear unit activation function.
[`selu(...)`](activations/selu): Scaled Exponential Linear Unit (SELU).
[`serialize(...)`](activations/serialize): Returns the string identifier of an activation function.
[`sigmoid(...)`](activations/sigmoid): Sigmoid activation function, `sigmoid(x) = 1 / (1 + exp(-x))`.
[`softmax(...)`](activations/softmax): Softmax converts a vector of values to a probability distribution.
[`softplus(...)`](activations/softplus): Softplus activation function, `softplus(x) = log(exp(x) + 1)`.
[`softsign(...)`](activations/softsign): Softsign activation function, `softsign(x) = x / (abs(x) + 1)`.
[`swish(...)`](activations/swish): Swish activation function, `swish(x) = x * sigmoid(x)`.
[`tanh(...)`](activations/tanh): Hyperbolic tangent activation function.
tensorflow Module: tf.keras.dtensor Module: tf.keras.dtensor
========================
Keras' DTensor library.
Modules
-------
[`experimental`](dtensor/experimental) module: Public API for tf.keras.dtensor.experimental namespace.
tensorflow Module: tf.keras.wrappers Module: tf.keras.wrappers
=========================
Public API for tf.keras.wrappers namespace.
Modules
-------
[`scikit_learn`](wrappers/scikit_learn) module: Wrapper for using the Scikit-Learn API with Keras models.
tensorflow Module: tf.keras.models Module: tf.keras.models
=======================
Keras models API.
Classes
-------
[`class Model`](model): `Model` groups layers into an object with training and inference features.
[`class Sequential`](sequential): `Sequential` groups a linear stack of layers into a [`tf.keras.Model`](model).
Functions
---------
[`clone_model(...)`](models/clone_model): Clone a Functional or Sequential `Model` instance.
[`load_model(...)`](models/load_model): Loads a model saved via `model.save()`.
[`model_from_config(...)`](models/model_from_config): Instantiates a Keras model from its config.
[`model_from_json(...)`](models/model_from_json): Parses a JSON model configuration string and returns a model instance.
[`model_from_yaml(...)`](models/model_from_yaml): Parses a yaml model configuration file and returns a model instance.
[`save_model(...)`](models/save_model): Saves a model as a TensorFlow SavedModel or HDF5 file.
tensorflow tf.keras.Model tf.keras.Model
==============
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L68-L3266) |
`Model` groups layers into an object with training and inference features.
Inherits From: [`Layer`](layers/layer), [`Module`](../module)
#### View aliases
**Main aliases**
[`tf.keras.models.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model), [`tf.compat.v1.keras.models.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)
```
tf.keras.Model(
*args, **kwargs
)
```
| Args |
| `inputs` | The input(s) of the model: a [`keras.Input`](input) object or list of [`keras.Input`](input) objects. |
| `outputs` | The output(s) of the model. See Functional API example below. |
| `name` | String, the name of the model. |
There are two ways to instantiate a `Model`:
1 - With the "Functional API", where you start from `Input`, you chain layer calls to specify the model's forward pass, and finally you create your model from inputs and outputs:
```
import tensorflow as tf
inputs = tf.keras.Input(shape=(3,))
x = tf.keras.layers.Dense(4, activation=tf.nn.relu)(inputs)
outputs = tf.keras.layers.Dense(5, activation=tf.nn.softmax)(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
```
>
> **Note:** Only dicts, lists, and tuples of input tensors are supported. Nested inputs are not supported (e.g. lists of list or dicts of dict).
>
A new Functional API model can also be created by using the intermediate tensors. This enables you to quickly extract sub-components of the model.
#### Example:
```
inputs = keras.Input(shape=(None, None, 3))
processed = keras.layers.RandomCrop(width=32, height=32)(inputs)
conv = keras.layers.Conv2D(filters=2, kernel_size=3)(processed)
pooling = keras.layers.GlobalAveragePooling2D()(conv)
feature = keras.layers.Dense(10)(pooling)
full_model = keras.Model(inputs, feature)
backbone = keras.Model(processed, conv)
activations = keras.Model(conv, feature)
```
Note that the `backbone` and `activations` models are not created with [`keras.Input`](input) objects, but with the tensors that are originated from `keras.Inputs` objects. Under the hood, the layers and weights will be shared across these models, so that user can train the `full_model`, and use `backbone` or `activations` to do feature extraction. The inputs and outputs of the model can be nested structures of tensors as well, and the created models are standard Functional API models that support all the existing APIs.
2 - By subclassing the `Model` class: in that case, you should define your layers in `__init__()` and you should implement the model's forward pass in `call()`.
```
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
def call(self, inputs):
x = self.dense1(inputs)
return self.dense2(x)
model = MyModel()
```
If you subclass `Model`, you can optionally have a `training` argument (boolean) in `call()`, which you can use to specify a different behavior in training and inference:
```
import tensorflow as tf
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax)
self.dropout = tf.keras.layers.Dropout(0.5)
def call(self, inputs, training=False):
x = self.dense1(inputs)
if training:
x = self.dropout(x, training=training)
return self.dense2(x)
model = MyModel()
```
Once the model is created, you can config the model with losses and metrics with `model.compile()`, train the model with `model.fit()`, or use the model to do prediction with `model.predict()`.
| Attributes |
| `distribute_strategy` | The [`tf.distribute.Strategy`](../distribute/strategy) this model was created under. |
| `layers` | |
| `metrics_names` | Returns the model's display labels for all outputs.
**Note:** `metrics_names` are available only after a [`keras.Model`](model) has been trained/evaluated on actual data.
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
model.metrics_names
[]
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
model.fit(x, y)
model.metrics_names
['loss', 'mae']
```
```
inputs = tf.keras.layers.Input(shape=(3,))
d = tf.keras.layers.Dense(2, name='out')
output_1 = d(inputs)
output_2 = d(inputs)
model = tf.keras.models.Model(
inputs=inputs, outputs=[output_1, output_2])
model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
model.fit(x, (y, y))
model.metrics_names
['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
'out_1_acc']
```
|
| `run_eagerly` | Settable attribute indicating whether the model should run eagerly. Running eagerly means that your model will be run step by step, like Python code. Your model might run slower, but it should become easier for you to debug it by stepping into individual layer calls. By default, we will attempt to compile your model to a static graph to deliver the best execution performance. |
Methods
-------
### `call`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L492-L521)
```
call(
inputs, training=None, mask=None
)
```
Calls the model on new inputs and returns the outputs as tensors.
In this case `call()` just reapplies all ops in the graph to the new inputs (e.g. build a new computational graph from the provided inputs).
>
> **Note:** This method should not be called directly. It is only meant to be overridden when subclassing [`tf.keras.Model`](model). To call a model on an input, always use the `__call__()` method, i.e. `model(inputs)`, which relies on the underlying `call()` method.
>
| Args |
| `inputs` | Input tensor, or dict/list/tuple of input tensors. |
| `training` | Boolean or boolean scalar tensor, indicating whether to run the `Network` in training mode or inference mode. |
| `mask` | A mask or list of masks. A mask can be either a boolean tensor or None (no mask). For more details, check the guide [here](https://www.tensorflow.org/guide/keras/masking_and_padding). |
| Returns |
| A tensor if there is a single output, or a list of tensors if there are more than one outputs. |
### `compile`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L523-L659)
```
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
```
Configures the model for training.
#### Example:
```
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.FalseNegatives()])
```
| Args |
| `optimizer` | String (name of optimizer) or optimizer instance. See [`tf.keras.optimizers`](optimizers). |
| `loss` | Loss function. May be a string (name of loss function), or a [`tf.keras.losses.Loss`](losses/loss) instance. See [`tf.keras.losses`](losses). A loss function is any callable with the signature `loss = fn(y_true, y_pred)`, where `y_true` are the ground truth values, and `y_pred` are the model's predictions. `y_true` should have shape `(batch_size, d0, .. dN)` (except in the case of sparse loss functions such as sparse categorical crossentropy which expects integer arrays of shape `(batch_size, d0, .. dN-1)`). `y_pred` should have shape `(batch_size, d0, .. dN)`. The loss function should return a float tensor. If a custom `Loss` instance is used and reduction is set to `None`, return value has shape `(batch_size, d0, .. dN-1)` i.e. per-sample or per-timestep loss values; otherwise, it is a scalar. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses, unless `loss_weights` is specified. |
| `metrics` | List of metrics to be evaluated by the model during training and testing. Each of this can be a string (name of a built-in function), function or a [`tf.keras.metrics.Metric`](metrics/metric) instance. See [`tf.keras.metrics`](metrics). Typically you will use `metrics=['accuracy']`. A function is any callable with the signature `result = fn(y_true, y_pred)`. To specify different metrics for different outputs of a multi-output model, you could also pass a dictionary, such as `metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}`. You can also pass a list to specify a metric or a list of metrics for each output, such as `metrics=[['accuracy'], ['accuracy', 'mse']]` or `metrics=['accuracy', ['accuracy', 'mse']]`. When you pass the strings 'accuracy' or 'acc', we convert this to one of [`tf.keras.metrics.BinaryAccuracy`](metrics/binaryaccuracy), [`tf.keras.metrics.CategoricalAccuracy`](metrics/categoricalaccuracy), [`tf.keras.metrics.SparseCategoricalAccuracy`](metrics/sparsecategoricalaccuracy) based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well. |
| `loss_weights` | Optional list or dictionary specifying scalar coefficients (Python floats) to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the *weighted sum* of all individual losses, weighted by the `loss_weights` coefficients. If a list, it is expected to have a 1:1 mapping to the model's outputs. If a dict, it is expected to map output names (strings) to scalar coefficients. |
| `weighted_metrics` | List of metrics to be evaluated and weighted by `sample_weight` or `class_weight` during training and testing. |
| `run_eagerly` | Bool. Defaults to `False`. If `True`, this `Model`'s logic will not be wrapped in a [`tf.function`](../function). Recommended to leave this as `None` unless your `Model` cannot be run inside a [`tf.function`](../function). `run_eagerly=True` is not supported when using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy). |
| `steps_per_execution` | Int. Defaults to 1. The number of batches to run during each [`tf.function`](../function) call. Running multiple batches inside a single [`tf.function`](../function) call can greatly improve performance on TPUs or small models with a large Python overhead. At most, one full epoch will be run each execution. If a number larger than the size of the epoch is passed, the execution will be truncated to the size of the epoch. Note that if `steps_per_execution` is set to `N`, [`Callback.on_batch_begin`](callbacks/callback#on_batch_begin) and [`Callback.on_batch_end`](callbacks/callback#on_batch_end) methods will only be called every `N` batches (i.e. before/after each [`tf.function`](../function) execution). |
| `jit_compile` | If `True`, compile the model training step with XLA. [XLA](https://www.tensorflow.org/xla) is an optimizing compiler for machine learning. `jit_compile` is not enabled for by default. This option cannot be enabled with `run_eagerly=True`. Note that `jit_compile=True` is may not necessarily work for all models. For more information on supported operations please refer to the [XLA documentation](https://www.tensorflow.org/xla). Also refer to [known XLA issues](https://www.tensorflow.org/xla/known_issues) for more details. |
| `**kwargs` | Arguments supported for backwards compatibility only. |
### `compute_loss`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L896-L949)
```
compute_loss(
x=None, y=None, y_pred=None, sample_weight=None
)
```
Compute the total loss, validate it, and return it.
Subclasses can optionally override this method to provide custom loss computation logic.
#### Example:
```
class MyModel(tf.keras.Model):
def __init__(self, *args, **kwargs):
super(MyModel, self).__init__(*args, **kwargs)
self.loss_tracker = tf.keras.metrics.Mean(name='loss')
def compute_loss(self, x, y, y_pred, sample_weight):
loss = tf.reduce_mean(tf.math.squared_difference(y_pred, y))
loss += tf.add_n(self.losses)
self.loss_tracker.update_state(loss)
return loss
def reset_metrics(self):
self.loss_tracker.reset_states()
@property
def metrics(self):
return [self.loss_tracker]
tensors = tf.random.uniform((10, 10)), tf.random.uniform((10,))
dataset = tf.data.Dataset.from_tensor_slices(tensors).repeat().batch(1)
inputs = tf.keras.layers.Input(shape=(10,), name='my_input')
outputs = tf.keras.layers.Dense(10)(inputs)
model = MyModel(inputs, outputs)
model.add_loss(tf.reduce_sum(outputs))
optimizer = tf.keras.optimizers.SGD()
model.compile(optimizer, loss='mse', steps_per_execution=10)
model.fit(dataset, epochs=2, steps_per_epoch=10)
print('My custom loss: ', model.loss_tracker.result().numpy())
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| The total loss as a [`tf.Tensor`](../tensor), or `None` if no loss results (which is the case when called by [`Model.test_step`](model#test_step)). |
### `compute_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L951-L996)
```
compute_metrics(
x, y, y_pred, sample_weight
)
```
Update metric states and collect all metrics to be returned.
Subclasses can optionally override this method to provide custom metric updating and collection logic.
#### Example:
```
class MyModel(tf.keras.Sequential):
def compute_metrics(self, x, y, y_pred, sample_weight):
# This super call updates `self.compiled_metrics` and returns results
# for all metrics listed in `self.metrics`.
metric_results = super(MyModel, self).compute_metrics(
x, y, y_pred, sample_weight)
# Note that `self.custom_metric` is not listed in `self.metrics`.
self.custom_metric.update_state(x, y, y_pred, sample_weight)
metric_results['custom_metric_name'] = self.custom_metric.result()
return metric_results
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model.call(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end()`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the metrics listed in `self.metrics` are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
### `evaluate`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1602-L1768)
```
evaluate(
x=None,
y=None,
batch_size=None,
verbose='auto',
sample_weight=None,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
return_dict=False,
**kwargs
)
```
Returns the loss value & metrics values for the model in test mode.
Computation is done in batches (see the `batch_size` arg.)
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator or [`keras.utils.Sequence`](utils/sequence) instance, `y` should not be specified (since targets will be obtained from the iterator/dataset). |
| `batch_size` | Integer or `None`. Number of samples per batch of computation. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of a dataset, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `sample_weight` | Optional Numpy array of weights for the test samples, used for weighting the loss function. You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, instead pass sample weights as the third element of `x`. |
| `steps` | Integer or `None`. Total number of steps (batches of samples) before declaring the evaluation round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../data) dataset and `steps` is None, 'evaluate' will run until the dataset is exhausted. This argument is not supported with array inputs. |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during evaluation. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| `**kwargs` | Unused at this time. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](model#fit).
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.evaluate` is wrapped in a [`tf.function`](../function). |
### `fit`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1099-L1472)
```
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose='auto',
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Trains the model for a fixed number of epochs (iterations on a dataset).
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A [`tf.keras.utils.experimental.DatasetCreator`](utils/experimental/datasetcreator), which wraps a callable that takes a single argument of type [`tf.distribute.InputContext`](../distribute/inputcontext), and returns a [`tf.data.Dataset`](../data/dataset). `DatasetCreator` should be used when users prefer to specify the per-replica batching and sharding logic for the `Dataset`. See [`tf.keras.utils.experimental.DatasetCreator`](utils/experimental/datasetcreator) doc for more information. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given below. If using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy), only `DatasetCreator` type is supported for `x`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator, or [`keras.utils.Sequence`](utils/sequence) instance, `y` should not be specified (since targets will be obtained from `x`). |
| `batch_size` | Integer or `None`. Number of samples per gradient update. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `epochs` | Integer. Number of epochs to train the model. An epoch is an iteration over the entire `x` and `y` data provided (unless the `steps_per_epoch` flag is set to something other than None). Note that in conjunction with `initial_epoch`, `epochs` is to be understood as "final epoch". The model is not trained for a number of iterations given by `epochs`, but merely until the epoch of index `epochs` is reached. |
| `verbose` | 'auto', 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch. 'auto' defaults to 1 for most cases, but 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so verbose=2 is recommended when not running interactively (eg, in a production environment). |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during training. See [`tf.keras.callbacks`](callbacks). Note [`tf.keras.callbacks.ProgbarLogger`](callbacks/progbarlogger) and [`tf.keras.callbacks.History`](callbacks/history) callbacks are created automatically and need not be passed into `model.fit`. [`tf.keras.callbacks.ProgbarLogger`](callbacks/progbarlogger) is created or not based on `verbose` argument to `model.fit`. Callbacks with batch-level calls are currently unsupported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy), and users are advised to implement epoch-level calls instead with an appropriate `steps_per_epoch` value. |
| `validation_split` | Float between 0 and 1. Fraction of the training data to be used as validation data. The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch. The validation data is selected from the last samples in the `x` and `y` data provided, before shuffling. This argument is not supported when `x` is a dataset, generator or [`keras.utils.Sequence`](utils/sequence) instance. If both `validation_data` and `validation_split` are provided, `validation_data` will override `validation_split`. `validation_split` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy). |
| `validation_data` | Data on which to evaluate the loss and any model metrics at the end of each epoch. The model will not be trained on this data. Thus, note the fact that the validation loss of data provided using `validation_split` or `validation_data` is not affected by regularization layers like noise and dropout. `validation_data` will override `validation_split`. `validation_data` could be: * A tuple `(x_val, y_val)` of Numpy arrays or tensors.
* A tuple `(x_val, y_val, val_sample_weights)` of NumPy arrays.
* A [`tf.data.Dataset`](../data/dataset).
* A Python generator or [`keras.utils.Sequence`](utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. `validation_data` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy).
|
| `shuffle` | Boolean (whether to shuffle the training data before each epoch) or str (for 'batch'). This argument is ignored when `x` is a generator or an object of tf.data.Dataset. 'batch' is a special option for dealing with the limitations of HDF5 data; it shuffles in batch-sized chunks. Has no effect when `steps_per_epoch` is not `None`. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function (during training only). This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `sample_weight` | Optional Numpy array of weights for the training samples, used for weighting the loss function (during training only). You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, generator, or [`keras.utils.Sequence`](utils/sequence) instance, instead provide the sample\_weights as the third element of `x`. |
| `initial_epoch` | Integer. Epoch at which to start training (useful for resuming a previous training run). |
| `steps_per_epoch` | Integer or `None`. Total number of steps (batches of samples) before declaring one epoch finished and starting the next epoch. When training with input tensors such as TensorFlow data tensors, the default `None` is equal to the number of samples in your dataset divided by the batch size, or 1 if that cannot be determined. If x is a [`tf.data`](../data) dataset, and 'steps\_per\_epoch' is None, the epoch will run until the input dataset is exhausted. When passing an infinitely repeating dataset, you must specify the `steps_per_epoch` argument. If `steps_per_epoch=-1` the training will run indefinitely with an infinitely repeating dataset. This argument is not supported with array inputs. When using [`tf.distribute.experimental.ParameterServerStrategy`](../distribute/experimental/parameterserverstrategy): - `steps_per_epoch=None` is not supported.
|
| `validation_steps` | Only relevant if `validation_data` is provided and is a [`tf.data`](../data) dataset. Total number of steps (batches of samples) to draw before stopping when performing validation at the end of every epoch. If 'validation\_steps' is None, validation will run until the `validation_data` dataset is exhausted. In the case of an infinitely repeated dataset, it will run into an infinite loop. If 'validation\_steps' is specified and only part of the dataset will be consumed, the evaluation will start from the beginning of the dataset at each epoch. This ensures that the same validation samples are used every time. |
| `validation_batch_size` | Integer or `None`. Number of samples per validation batch. If unspecified, will default to `batch_size`. Do not specify the `validation_batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `validation_freq` | Only relevant if validation data is provided. Integer or `collections.abc.Container` instance (e.g. list, tuple, etc.). If an integer, specifies how many training epochs to run before a new validation run is performed, e.g. `validation_freq=2` runs validation every 2 epochs. If a Container, specifies the epochs on which to run validation, e.g. `validation_freq=[1, 2, 10]` runs validation at the end of the 1st, 2nd, and 10th epochs. |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
Unpacking behavior for iterator-like inputs: A common pattern is to pass a tf.data.Dataset, generator, or tf.keras.utils.Sequence to the `x` argument of fit, which will in fact yield not only features (x) but optionally targets (y) and sample weights. Keras requires that the output of such iterator-likes be unambiguous. The iterator should return a tuple of length 1, 2, or 3, where the optional second and third elements will be used for y and sample\_weight respectively. Any other type provided will be wrapped in a length one tuple, effectively treating everything as 'x'. When yielding dicts, they should still adhere to the top-level tuple structure. e.g. `({"x0": x0, "x1": x1}, y)`. Keras will not attempt to separate features, targets, and weights from the keys of a single dict. A notable unsupported data type is the namedtuple. The reason is that it behaves like both an ordered datatype (tuple) and a mapping datatype (dict). So given a namedtuple of the form: `namedtuple("example_tuple", ["y", "x"])` it is ambiguous whether to reverse the order of the elements when interpreting the value. Even worse is a tuple of the form: `namedtuple("other_tuple", ["x", "y", "z"])` where it is unclear if the tuple was intended to be unpacked into x, y, and sample\_weight or passed through as a single element to `x`. As a result the data processing code will simply raise a ValueError if it encounters a namedtuple. (Along with instructions to remedy the issue.)
| Returns |
| A `History` object. Its `History.history` attribute is a record of training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). |
| Raises |
| `RuntimeError` | 1. If the model was never compiled or,
2. If `model.fit` is wrapped in [`tf.function`](../function).
|
| `ValueError` | In case of mismatch between the provided input data and what the model expects or when the input data is empty. |
### `get_layer`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2891-L2925)
```
get_layer(
name=None, index=None
)
```
Retrieves a layer based on either its name (unique) or index.
If `name` and `index` are both provided, `index` will take precedence. Indices are based on order of horizontal graph traversal (bottom-up).
| Args |
| `name` | String, name of layer. |
| `index` | Integer, index of layer. |
| Returns |
| A layer instance. |
### `load_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2556-L2661)
```
load_weights(
filepath, by_name=False, skip_mismatch=False, options=None
)
```
Loads all layer weights, either from a TensorFlow or an HDF5 weight file.
If `by_name` is False weights are loaded based on the network's topology. This means the architecture should be the same as when the weights were saved. Note that layers that don't have weights are not taken into account in the topological ordering, so adding or removing layers is fine as long as they don't have weights.
If `by_name` is True, weights are loaded into layers only if they share the same name. This is useful for fine-tuning or transfer-learning models where some of the layers have changed.
Only topological loading (`by_name=False`) is supported when loading weights from the TensorFlow format. Note that topological loading differs slightly between TensorFlow and HDF5 formats for user-defined classes inheriting from [`tf.keras.Model`](model): HDF5 loads based on a flattened list of weights, while the TensorFlow format loads based on the object-local names of attributes to which layers are assigned in the `Model`'s constructor.
| Args |
| `filepath` | String, path to the weights file to load. For weight files in TensorFlow format, this is the file prefix (the same as was passed to `save_weights`). This can also be a path to a SavedModel saved from `model.save`. |
| `by_name` | Boolean, whether to load weights by name or by topological order. Only topological loading is supported for weight files in TensorFlow format. |
| `skip_mismatch` | Boolean, whether to skip loading of layers where there is a mismatch in the number of weights, or a mismatch in the shape of the weight (only valid when `by_name=True`). |
| `options` | Optional [`tf.train.CheckpointOptions`](../train/checkpointoptions) object that specifies options for loading weights. |
| Returns |
| When loading a weight file in TensorFlow format, returns the same status object as [`tf.train.Checkpoint.restore`](../train/checkpoint#restore). When graph building, restore ops are run automatically as soon as the network is built (on first call for user-defined classes inheriting from `Model`, immediately if it is already built). When loading weights in HDF5 format, returns `None`. |
| Raises |
| `ImportError` | If `h5py` is not available and the weight file is in HDF5 format. |
| `ValueError` | If `skip_mismatch` is set to `True` when `by_name` is `False`. |
### `make_predict_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1793-L1867)
```
make_predict_function(
force=False
)
```
Creates a function that executes one step of inference.
This method can be overridden to support custom inference logic. This method is called by [`Model.predict`](model#predict) and [`Model.predict_on_batch`](model#predict_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.predict_step`](model#predict_step).
This function is cached the first time [`Model.predict`](model#predict) or [`Model.predict_on_batch`](model#predict_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the predict function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return the outputs of the `Model`. |
### `make_test_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1504-L1600)
```
make_test_function(
force=False
)
```
Creates a function that executes one step of evaluation.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.evaluate`](model#evaluate) and [`Model.test_on_batch`](model#test_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.test_step`](model#test_step).
This function is cached the first time [`Model.evaluate`](model#evaluate) or [`Model.test_on_batch`](model#test_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the test function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_test_batch_end`. |
### `make_train_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L998-L1097)
```
make_train_function(
force=False
)
```
Creates a function that executes one step of training.
This method can be overridden to support custom training logic. This method is called by [`Model.fit`](model#fit) and [`Model.train_on_batch`](model#train_on_batch).
Typically, this method directly controls [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings, and delegates the actual training logic to [`Model.train_step`](model#train_step).
This function is cached the first time [`Model.fit`](model#fit) or [`Model.train_on_batch`](model#train_on_batch) is called. The cache is cleared whenever [`Model.compile`](model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the train function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_train_batch_end`, such as `{'loss': 0.2, 'accuracy': 0.7}`. |
### `predict`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1869-L2064)
```
predict(
x,
batch_size=None,
verbose='auto',
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Generates output predictions for the input samples.
Computation is done in batches. This method is designed for batch processing of large numbers of inputs. It is not intended for use inside of loops that iterate over your data and process small numbers of inputs at a time.
For small numbers of inputs that fit in one batch, directly use `__call__()` for faster execution, e.g., `model(x)`, or `model(x, training=False)` if you have layers such as [`tf.keras.layers.BatchNormalization`](layers/batchnormalization) that behave differently during inference. You may pair the individual model call with a [`tf.function`](../function) for additional performance inside your inner loop. If you need access to numpy array values instead of tensors after your model call, you can use `tensor.numpy()` to get the numpy array value of an eager tensor.
Also, note the fact that test loss is not affected by regularization layers like noise and dropout.
>
> **Note:** See [this FAQ entry](https://keras.io/getting_started/faq/#whats-the-difference-between-model-methods-predict-and-call) for more details about the difference between `Model` methods `predict()` and `__call__()`.
>
| Args |
| `x` | Input samples. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A [`tf.data`](../data) dataset.
* A generator or [`keras.utils.Sequence`](utils/sequence) instance. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `batch_size` | Integer or `None`. Number of samples per batch. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of dataset, generators, or [`keras.utils.Sequence`](utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `steps` | Total number of steps (batches of samples) before declaring the prediction round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../data) dataset and `steps` is None, `predict()` will run until the input dataset is exhausted. |
| `callbacks` | List of [`keras.callbacks.Callback`](callbacks/callback) instances. List of callbacks to apply during prediction. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](model#fit). Note that Model.predict uses the same interpretation rules as [`Model.fit`](model#fit) and [`Model.evaluate`](model#evaluate), so inputs must be unambiguous for all three methods.
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict` is wrapped in a [`tf.function`](../function). |
| `ValueError` | In case of mismatch between the provided input data and the model's expectations, or in case a stateful model receives a number of samples that is not a multiple of the batch size. |
### `predict_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2209-L2231)
```
predict_on_batch(
x
)
```
Returns predictions for a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
|
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict_on_batch` is wrapped in a [`tf.function`](../function). |
### `predict_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1770-L1791)
```
predict_step(
data
)
```
The logic for one inference step.
This method can be overridden to support custom inference logic. This method is called by [`Model.make_predict_function`](model#make_predict_function).
This method should contain the mathematical logic for one step of inference. This typically includes the forward pass.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_predict_function`](model#make_predict_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| The result of one inference step, typically the output of calling the `Model` on data. |
### `reset_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2066-L2086)
```
reset_metrics()
```
Resets the state of all the metrics in the model.
#### Examples:
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
_ = model.fit(x, y, verbose=0)
assert all(float(m.result()) for m in model.metrics)
```
```
model.reset_metrics()
assert all(float(m.result()) == 0 for m in model.metrics)
```
### `reset_states`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2788-L2791)
```
reset_states()
```
### `save`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2383-L2436)
```
save(
filepath,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None,
save_traces=True
)
```
Saves the model to Tensorflow SavedModel or a single HDF5 file.
Please see [`tf.keras.models.save_model`](models/save_model) or the [Serialization and Saving guide](https://keras.io/guides/serialization_and_saving/) for details.
| Args |
| `filepath` | String, PathLike, path to SavedModel or H5 file to save the model. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `include_optimizer` | If True, save optimizer's state together. |
| `save_format` | Either `'tf'` or `'h5'`, indicating whether to save the model to Tensorflow SavedModel or HDF5. Defaults to 'tf' in TF 2.X, and 'h5' in TF 1.X. |
| `signatures` | Signatures to save with the SavedModel. Applicable to the 'tf' format only. Please see the `signatures` argument in [`tf.saved_model.save`](../saved_model/save) for details. |
| `options` | (only applies to SavedModel format) [`tf.saved_model.SaveOptions`](../saved_model/saveoptions) object that specifies options for saving to SavedModel. |
| `save_traces` | (only applies to SavedModel format) When enabled, the SavedModel will store the function traces for each layer. This can be disabled, so that only the configs of each layer are stored. Defaults to `True`. Disabling this will decrease serialization time and reduce file size, but it requires that all custom layers/models implement a `get_config()` method. |
#### Example:
```
from keras.models import load_model
model.save('my_model.h5') # creates a HDF5 file 'my_model.h5'
del model # deletes the existing model
# returns a compiled model
# identical to the previous one
model = load_model('my_model.h5')
```
### `save_spec`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2965-L3002)
```
save_spec(
dynamic_batch=True
)
```
Returns the [`tf.TensorSpec`](../tensorspec) of call inputs as a tuple `(args, kwargs)`.
This value is automatically defined after calling the model for the first time. Afterwards, you can use it when exporting the model for serving:
```
model = tf.keras.Model(...)
@tf.function
def serve(*args, **kwargs):
outputs = model(*args, **kwargs)
# Apply postprocessing steps, or add additional outputs.
...
return outputs
# arg_specs is `[tf.TensorSpec(...), ...]`. kwarg_specs, in this example, is
# an empty dict since functional models do not use keyword arguments.
arg_specs, kwarg_specs = model.save_spec()
model.save(path, signatures={
'serving_default': serve.get_concrete_function(*arg_specs, **kwarg_specs)
})
```
| Args |
| `dynamic_batch` | Whether to set the batch sizes of all the returned [`tf.TensorSpec`](../tensorspec) to `None`. (Note that when defining functional or Sequential models with `tf.keras.Input([...], batch_size=X)`, the batch size will always be preserved). Defaults to `True`. |
| Returns |
| If the model inputs are defined, returns a tuple `(args, kwargs)`. All elements in `args` and `kwargs` are [`tf.TensorSpec`](../tensorspec). If the model inputs are not defined, returns `None`. The model inputs are automatically set when calling the model, `model.fit`, `model.evaluate` or `model.predict`. |
### `save_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2438-L2554)
```
save_weights(
filepath, overwrite=True, save_format=None, options=None
)
```
Saves all layer weights.
Either saves in HDF5 or in TensorFlow format based on the `save_format` argument.
When saving in HDF5 format, the weight file has:
* `layer_names` (attribute), a list of strings (ordered names of model layers).
* For every layer, a `group` named `layer.name`
+ For every such layer group, a group attribute `weight_names`, a list of strings (ordered names of weights tensor of the layer).
+ For every weight in the layer, a dataset storing the weight value, named after the weight tensor.
When saving in TensorFlow format, all objects referenced by the network are saved in the same format as [`tf.train.Checkpoint`](../train/checkpoint), including any `Layer` instances or `Optimizer` instances assigned to object attributes. For networks constructed from inputs and outputs using `tf.keras.Model(inputs, outputs)`, `Layer` instances used by the network are tracked/saved automatically. For user-defined classes which inherit from [`tf.keras.Model`](model), `Layer` instances must be assigned to object attributes, typically in the constructor. See the documentation of [`tf.train.Checkpoint`](../train/checkpoint) and [`tf.keras.Model`](model) for details.
While the formats are the same, do not mix `save_weights` and [`tf.train.Checkpoint`](../train/checkpoint). Checkpoints saved by [`Model.save_weights`](model#save_weights) should be loaded using [`Model.load_weights`](model#load_weights). Checkpoints saved using [`tf.train.Checkpoint.save`](../train/checkpoint#save) should be restored using the corresponding [`tf.train.Checkpoint.restore`](../train/checkpoint#restore). Prefer [`tf.train.Checkpoint`](../train/checkpoint) over `save_weights` for training checkpoints.
The TensorFlow format matches objects and variables by starting at a root object, `self` for `save_weights`, and greedily matching attribute names. For [`Model.save`](model#save) this is the `Model`, and for [`Checkpoint.save`](../train/checkpoint#save) this is the `Checkpoint` even if the `Checkpoint` has a model attached. This means saving a [`tf.keras.Model`](model) using `save_weights` and loading into a [`tf.train.Checkpoint`](../train/checkpoint) with a `Model` attached (or vice versa) will not match the `Model`'s variables. See the [guide to training checkpoints](https://www.tensorflow.org/guide/checkpoint) for details on the TensorFlow format.
| Args |
| `filepath` | String or PathLike, path to the file to save the weights to. When saving in TensorFlow format, this is the prefix used for checkpoint files (multiple files are generated). Note that the '.h5' suffix causes weights to be saved in HDF5 format. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `save_format` | Either 'tf' or 'h5'. A `filepath` ending in '.h5' or '.keras' will default to HDF5 if `save_format` is `None`. Otherwise `None` defaults to 'tf'. |
| `options` | Optional [`tf.train.CheckpointOptions`](../train/checkpointoptions) object that specifies options for saving weights. |
| Raises |
| `ImportError` | If `h5py` is not available when attempting to save in HDF5 format. |
### `summary`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2841-L2879)
```
summary(
line_length=None,
positions=None,
print_fn=None,
expand_nested=False,
show_trainable=False
)
```
Prints a string summary of the network.
| Args |
| `line_length` | Total length of printed lines (e.g. set this to adapt the display to different terminal window sizes). |
| `positions` | Relative or absolute positions of log elements in each line. If not provided, defaults to `[.33, .55, .67, 1.]`. |
| `print_fn` | Print function to use. Defaults to `print`. It will be called on each line of the summary. You can set it to a custom function in order to capture the string summary. |
| `expand_nested` | Whether to expand the nested models. If not provided, defaults to `False`. |
| `show_trainable` | Whether to show if a layer is trainable. If not provided, defaults to `False`. |
| Raises |
| `ValueError` | if `summary()` is called before the model is built. |
### `test_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2152-L2207)
```
test_on_batch(
x, y=None, sample_weight=None, reset_metrics=True, return_dict=False
)
```
Test the model on a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.test_on_batch` is wrapped in a [`tf.function`](../function). |
### `test_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1474-L1502)
```
test_step(
data
)
```
The logic for one evaluation step.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.make_test_function`](model#make_test_function).
This function should contain the mathematical logic for one step of evaluation. This typically includes the forward pass, loss calculation, and metrics updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_test_function`](model#make_test_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. |
### `to_json`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2743-L2758)
```
to_json(
**kwargs
)
```
Returns a JSON string containing the network configuration.
To load a network from a JSON save file, use [`keras.models.model_from_json(json_string, custom_objects={})`](models/model_from_json).
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `json.dumps()`. |
| Returns |
| A JSON string. |
### `to_yaml`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2760-L2786)
```
to_yaml(
**kwargs
)
```
Returns a yaml string containing the network configuration.
>
> **Note:** Since TF 2.6, this method is no longer supported and will raise a RuntimeError.
>
To load a network from a yaml save file, use [`keras.models.model_from_yaml(yaml_string, custom_objects={})`](models/model_from_yaml).
`custom_objects` should be a dictionary mapping the names of custom losses / layers / etc to the corresponding functions / classes.
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `yaml.dump()`. |
| Returns |
| A YAML string. |
| Raises |
| `RuntimeError` | announces that the method poses a security risk |
### `train_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2088-L2150)
```
train_on_batch(
x,
y=None,
sample_weight=None,
class_weight=None,
reset_metrics=True,
return_dict=False
)
```
Runs a single gradient update on a single batch of data.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) to apply to the model's loss for the samples from this class during training. This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar training loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.train_on_batch` is wrapped in a [`tf.function`](../function). |
### `train_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L861-L894)
```
train_step(
data
)
```
The logic for one training step.
This method can be overridden to support custom training logic. For concrete examples of how to override this method see [Customizing what happends in fit](https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit). This method is called by [`Model.make_train_function`](model#make_train_function).
This method should contain the mathematical logic for one step of training. This typically includes the forward pass, loss calculation, backpropagation, and metric updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../function) and [`tf.distribute.Strategy`](../distribute/strategy) settings), should be left to [`Model.make_train_function`](model#make_train_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
| programming_docs |
tensorflow Module: tf.keras.estimator Module: tf.keras.estimator
==========================
Keras estimator API.
Functions
---------
[`model_to_estimator(...)`](estimator/model_to_estimator): Constructs an `Estimator` instance from given keras model.
tensorflow Module: tf.keras.metrics Module: tf.keras.metrics
========================
All Keras metrics.
Classes
-------
[`class AUC`](metrics/auc): Approximates the AUC (Area under the curve) of the ROC or PR curves.
[`class Accuracy`](metrics/accuracy): Calculates how often predictions equal labels.
[`class BinaryAccuracy`](metrics/binaryaccuracy): Calculates how often predictions match binary labels.
[`class BinaryCrossentropy`](metrics/binarycrossentropy): Computes the crossentropy metric between the labels and predictions.
[`class BinaryIoU`](metrics/binaryiou): Computes the Intersection-Over-Union metric for class 0 and/or 1.
[`class CategoricalAccuracy`](metrics/categoricalaccuracy): Calculates how often predictions match one-hot labels.
[`class CategoricalCrossentropy`](metrics/categoricalcrossentropy): Computes the crossentropy metric between the labels and predictions.
[`class CategoricalHinge`](metrics/categoricalhinge): Computes the categorical hinge metric between `y_true` and `y_pred`.
[`class CosineSimilarity`](metrics/cosinesimilarity): Computes the cosine similarity between the labels and predictions.
[`class FalseNegatives`](metrics/falsenegatives): Calculates the number of false negatives.
[`class FalsePositives`](metrics/falsepositives): Calculates the number of false positives.
[`class Hinge`](metrics/hinge): Computes the hinge metric between `y_true` and `y_pred`.
[`class IoU`](metrics/iou): Computes the Intersection-Over-Union metric for specific target classes.
[`class KLDivergence`](metrics/kldivergence): Computes Kullback-Leibler divergence metric between `y_true` and `y_pred`.
[`class LogCoshError`](metrics/logcosherror): Computes the logarithm of the hyperbolic cosine of the prediction error.
[`class Mean`](metrics/mean): Computes the (weighted) mean of the given values.
[`class MeanAbsoluteError`](metrics/meanabsoluteerror): Computes the mean absolute error between the labels and predictions.
[`class MeanAbsolutePercentageError`](metrics/meanabsolutepercentageerror): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`class MeanIoU`](metrics/meaniou): Computes the mean Intersection-Over-Union metric.
[`class MeanMetricWrapper`](metrics/meanmetricwrapper): Wraps a stateless metric function with the Mean metric.
[`class MeanRelativeError`](metrics/meanrelativeerror): Computes the mean relative error by normalizing with the given values.
[`class MeanSquaredError`](metrics/meansquarederror): Computes the mean squared error between `y_true` and `y_pred`.
[`class MeanSquaredLogarithmicError`](metrics/meansquaredlogarithmicerror): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`class MeanTensor`](metrics/meantensor): Computes the element-wise (weighted) mean of the given tensors.
[`class Metric`](metrics/metric): Encapsulates metric logic and state.
[`class OneHotIoU`](metrics/onehotiou): Computes the Intersection-Over-Union metric for one-hot encoded labels.
[`class OneHotMeanIoU`](metrics/onehotmeaniou): Computes mean Intersection-Over-Union metric for one-hot encoded labels.
[`class Poisson`](metrics/poisson): Computes the Poisson metric between `y_true` and `y_pred`.
[`class Precision`](metrics/precision): Computes the precision of the predictions with respect to the labels.
[`class PrecisionAtRecall`](metrics/precisionatrecall): Computes best precision where recall is >= specified value.
[`class Recall`](metrics/recall): Computes the recall of the predictions with respect to the labels.
[`class RecallAtPrecision`](metrics/recallatprecision): Computes best recall where precision is >= specified value.
[`class RootMeanSquaredError`](metrics/rootmeansquarederror): Computes root mean squared error metric between `y_true` and `y_pred`.
[`class SensitivityAtSpecificity`](metrics/sensitivityatspecificity): Computes best sensitivity where specificity is >= specified value.
[`class SparseCategoricalAccuracy`](metrics/sparsecategoricalaccuracy): Calculates how often predictions match integer labels.
[`class SparseCategoricalCrossentropy`](metrics/sparsecategoricalcrossentropy): Computes the crossentropy metric between the labels and predictions.
[`class SparseTopKCategoricalAccuracy`](metrics/sparsetopkcategoricalaccuracy): Computes how often integer targets are in the top `K` predictions.
[`class SpecificityAtSensitivity`](metrics/specificityatsensitivity): Computes best specificity where sensitivity is >= specified value.
[`class SquaredHinge`](metrics/squaredhinge): Computes the squared hinge metric between `y_true` and `y_pred`.
[`class Sum`](metrics/sum): Computes the (weighted) sum of the given values.
[`class TopKCategoricalAccuracy`](metrics/topkcategoricalaccuracy): Computes how often targets are in the top `K` predictions.
[`class TrueNegatives`](metrics/truenegatives): Calculates the number of true negatives.
[`class TruePositives`](metrics/truepositives): Calculates the number of true positives.
Functions
---------
[`KLD(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`MAE(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`MAPE(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`MSE(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`MSLE(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`binary_accuracy(...)`](metrics/binary_accuracy): Calculates how often predictions match binary labels.
[`binary_crossentropy(...)`](metrics/binary_crossentropy): Computes the binary crossentropy loss.
[`binary_focal_crossentropy(...)`](metrics/binary_focal_crossentropy): Computes the binary focal crossentropy loss.
[`categorical_accuracy(...)`](metrics/categorical_accuracy): Calculates how often predictions match one-hot labels.
[`categorical_crossentropy(...)`](metrics/categorical_crossentropy): Computes the categorical crossentropy loss.
[`deserialize(...)`](metrics/deserialize): Deserializes a serialized metric class/function instance.
[`get(...)`](metrics/get): Retrieves a Keras metric as a `function`/`Metric` class instance.
[`hinge(...)`](metrics/hinge): Computes the hinge loss between `y_true` and `y_pred`.
[`kl_divergence(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`kld(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`kullback_leibler_divergence(...)`](metrics/kl_divergence): Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
[`log_cosh(...)`](losses/log_cosh): Logarithm of the hyperbolic cosine of the prediction error.
[`logcosh(...)`](losses/log_cosh): Logarithm of the hyperbolic cosine of the prediction error.
[`mae(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`mape(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`mean_absolute_error(...)`](metrics/mean_absolute_error): Computes the mean absolute error between labels and predictions.
[`mean_absolute_percentage_error(...)`](metrics/mean_absolute_percentage_error): Computes the mean absolute percentage error between `y_true` and `y_pred`.
[`mean_squared_error(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`mean_squared_logarithmic_error(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`mse(...)`](metrics/mean_squared_error): Computes the mean squared error between labels and predictions.
[`msle(...)`](metrics/mean_squared_logarithmic_error): Computes the mean squared logarithmic error between `y_true` and `y_pred`.
[`poisson(...)`](metrics/poisson): Computes the Poisson loss between y\_true and y\_pred.
[`serialize(...)`](metrics/serialize): Serializes metric function or `Metric` instance.
[`sparse_categorical_accuracy(...)`](metrics/sparse_categorical_accuracy): Calculates how often predictions match integer labels.
[`sparse_categorical_crossentropy(...)`](metrics/sparse_categorical_crossentropy): Computes the sparse categorical crossentropy loss.
[`sparse_top_k_categorical_accuracy(...)`](metrics/sparse_top_k_categorical_accuracy): Computes how often integer targets are in the top `K` predictions.
[`squared_hinge(...)`](metrics/squared_hinge): Computes the squared hinge loss between `y_true` and `y_pred`.
[`top_k_categorical_accuracy(...)`](metrics/top_k_categorical_accuracy): Computes how often targets are in the top `K` predictions.
tensorflow tf.keras.activations.selu tf.keras.activations.selu
=========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L145-L196) |
Scaled Exponential Linear Unit (SELU).
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.selu`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/selu)
```
tf.keras.activations.selu(
x
)
```
The Scaled Exponential Linear Unit (SELU) activation function is defined as:
* `if x > 0: return scale * x`
* `if x < 0: return scale * alpha * (exp(x) - 1)`
where `alpha` and `scale` are pre-defined constants (`alpha=1.67326324` and `scale=1.05070098`).
Basically, the SELU activation function multiplies `scale` (> 1) with the output of the [`tf.keras.activations.elu`](elu) function to ensure a slope larger than one for positive inputs.
The values of `alpha` and `scale` are chosen so that the mean and variance of the inputs are preserved between two consecutive layers as long as the weights are initialized correctly (see [`tf.keras.initializers.LecunNormal`](../initializers/lecunnormal) initializer) and the number of input units is "large enough" (see reference paper for more information).
#### Example Usage:
```
num_classes = 10 # 10-class problem
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(64, kernel_initializer='lecun_normal',
activation='selu'))
model.add(tf.keras.layers.Dense(32, kernel_initializer='lecun_normal',
activation='selu'))
model.add(tf.keras.layers.Dense(16, kernel_initializer='lecun_normal',
activation='selu'))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
```
| Args |
| `x` | A tensor or variable to compute the activation function for. |
| Returns |
| The scaled exponential unit activation: `scale * elu(x, alpha)`. |
#### Notes:
* To be used together with the [`tf.keras.initializers.LecunNormal`](../initializers/lecunnormal) initializer.
* To be used together with the dropout variant [`tf.keras.layers.AlphaDropout`](../layers/alphadropout) (not regular dropout).
#### References:
* [Klambauer et al., 2017](https://arxiv.org/abs/1706.02515)
tensorflow tf.keras.activations.exponential tf.keras.activations.exponential
================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L409-L427) |
Exponential activation function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.exponential`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/exponential)
```
tf.keras.activations.exponential(
x
)
```
#### For example:
```
a = tf.constant([-3.0,-1.0, 0.0,1.0,3.0], dtype = tf.float32)
b = tf.keras.activations.exponential(a)
b.numpy()
array([0.04978707, 0.36787945, 1., 2.7182817 , 20.085537], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| Tensor with exponential activation: `exp(x)`. |
tensorflow tf.keras.activations.softsign tf.keras.activations.softsign
=============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L221-L239) |
Softsign activation function, `softsign(x) = x / (abs(x) + 1)`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.softsign`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/softsign)
```
tf.keras.activations.softsign(
x
)
```
#### Example Usage:
```
a = tf.constant([-1.0, 0.0, 1.0], dtype = tf.float32)
b = tf.keras.activations.softsign(a)
b.numpy()
array([-0.5, 0. , 0.5], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| The softsign activation: `x / (abs(x) + 1)`. |
tensorflow tf.keras.activations.hard_sigmoid tf.keras.activations.hard\_sigmoid
==================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L430-L456) |
Hard sigmoid activation function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.hard_sigmoid`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/hard_sigmoid)
```
tf.keras.activations.hard_sigmoid(
x
)
```
A faster approximation of the sigmoid activation. Piecewise linear approximation of the sigmoid function. Ref: 'https://en.wikipedia.org/wiki/Hard\_sigmoid'
#### For example:
```
a = tf.constant([-3.0,-1.0, 0.0,1.0,3.0], dtype = tf.float32)
b = tf.keras.activations.hard_sigmoid(a)
b.numpy()
array([0. , 0.3, 0.5, 0.7, 1. ], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| The hard sigmoid activation, defined as: * `if x < -2.5: return 0`
* `if x > 2.5: return 1`
* `if -2.5 <= x <= 2.5: return 0.2 * x + 0.5`
|
tensorflow tf.keras.activations.linear tf.keras.activations.linear
===========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L459-L477) |
Linear activation function (pass-through).
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.linear`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/linear)
```
tf.keras.activations.linear(
x
)
```
#### For example:
```
a = tf.constant([-3.0,-1.0, 0.0,1.0,3.0], dtype = tf.float32)
b = tf.keras.activations.linear(a)
b.numpy()
array([-3., -1., 0., 1., 3.], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| The input, unmodified. |
tensorflow tf.keras.activations.gelu tf.keras.activations.gelu
=========================
Applies the Gaussian error linear unit (GELU) activation function.
```
tf.keras.activations.gelu(
x, approximate=False
)
```
Gaussian error linear unit (GELU) computes `x * P(X <= x)`, where `P(X) ~ N(0, 1)`. The (GELU) nonlinearity weights inputs by their value, rather than gates inputs by their sign as in ReLU.
#### For example:
```
x = tf.constant([-3.0, -1.0, 0.0, 1.0, 3.0], dtype=tf.float32)
y = tf.keras.activations.gelu(x)
y.numpy()
array([-0.00404951, -0.15865529, 0. , 0.8413447 , 2.9959507 ],
dtype=float32)
y = tf.keras.activations.gelu(x, approximate=True)
y.numpy()
array([-0.00363752, -0.15880796, 0. , 0.841192 , 2.9963627 ],
dtype=float32)
```
| Args |
| `x` | Input tensor. |
| `approximate` | A `bool`, whether to enable approximation. |
| Returns |
| The gaussian error linear activation: `0.5 * x * (1 + tanh(sqrt(2 / pi) * (x + 0.044715 * x^3)))` if `approximate` is `True` or `x * P(X <= x) = 0.5 * x * (1 + erf(x / sqrt(2)))`, where `P(X) ~ N(0, 1)`, if `approximate` is `False`. |
#### Reference:
* [Gaussian Error Linear Units (GELUs)](https://arxiv.org/abs/1606.08415)
tensorflow tf.keras.activations.relu tf.keras.activations.relu
=========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L273-L311) |
Applies the rectified linear unit activation function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.relu`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/relu)
```
tf.keras.activations.relu(
x, alpha=0.0, max_value=None, threshold=0.0
)
```
With default values, this returns the standard ReLU activation: `max(x, 0)`, the element-wise maximum of 0 and the input tensor.
Modifying default parameters allows you to use non-zero thresholds, change the max value of the activation, and to use a non-zero multiple of the input for values below the threshold.
#### For example:
```
foo = tf.constant([-10, -5, 0.0, 5, 10], dtype = tf.float32)
tf.keras.activations.relu(foo).numpy()
array([ 0., 0., 0., 5., 10.], dtype=float32)
tf.keras.activations.relu(foo, alpha=0.5).numpy()
array([-5. , -2.5, 0. , 5. , 10. ], dtype=float32)
tf.keras.activations.relu(foo, max_value=5.).numpy()
array([0., 0., 0., 5., 5.], dtype=float32)
tf.keras.activations.relu(foo, threshold=5.).numpy()
array([-0., -0., 0., 0., 10.], dtype=float32)
```
| Args |
| `x` | Input `tensor` or `variable`. |
| `alpha` | A `float` that governs the slope for values lower than the threshold. |
| `max_value` | A `float` that sets the saturation threshold (the largest value the function will return). |
| `threshold` | A `float` giving the threshold value of the activation function below which values will be damped or set to zero. |
| Returns |
| A `Tensor` representing the input tensor, transformed by the relu activation function. Tensor will be of the same shape and dtype of input `x`. |
tensorflow tf.keras.activations.tanh tf.keras.activations.tanh
=========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L354-L373) |
Hyperbolic tangent activation function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.tanh`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/tanh)
```
tf.keras.activations.tanh(
x
)
```
#### For example:
```
a = tf.constant([-3.0,-1.0, 0.0,1.0,3.0], dtype = tf.float32)
b = tf.keras.activations.tanh(a)
b.numpy()
array([-0.9950547, -0.7615942, 0., 0.7615942, 0.9950547], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| Tensor of same shape and dtype of input `x`, with tanh activation: `tanh(x) = sinh(x)/cosh(x) = ((exp(x) - exp(-x))/(exp(x) + exp(-x)))`. |
tensorflow tf.keras.activations.softmax tf.keras.activations.softmax
============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L38-L92) |
Softmax converts a vector of values to a probability distribution.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.softmax`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/softmax)
```
tf.keras.activations.softmax(
x, axis=-1
)
```
The elements of the output vector are in range (0, 1) and sum to 1.
Each vector is handled independently. The `axis` argument sets which axis of the input the function is applied along.
Softmax is often used as the activation for the last layer of a classification network because the result could be interpreted as a probability distribution.
The softmax of each vector x is computed as `exp(x) / tf.reduce_sum(exp(x))`.
The input values in are the log-odds of the resulting probability.
| Args |
| `x` | Input tensor. |
| `axis` | Integer, axis along which the softmax normalization is applied. |
| Returns |
| Tensor, output of softmax transformation (all values are non-negative and sum to 1). |
#### Examples:
**Example 1: standalone usage**
```
inputs = tf.random.normal(shape=(32, 10))
outputs = tf.keras.activations.softmax(inputs)
tf.reduce_sum(outputs[0, :]) # Each sample in the batch now sums to 1
<tf.Tensor: shape=(), dtype=float32, numpy=1.0000001>
```
**Example 2: usage in a `Dense` layer**
```
layer = tf.keras.layers.Dense(32, activation=tf.keras.activations.softmax)
```
| programming_docs |
tensorflow tf.keras.activations.elu tf.keras.activations.elu
========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L95-L142) |
Exponential Linear Unit.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.elu`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/elu)
```
tf.keras.activations.elu(
x, alpha=1.0
)
```
The exponential linear unit (ELU) with `alpha > 0` is: `x` if `x > 0` and `alpha * (exp(x) - 1)` if `x < 0` The ELU hyperparameter `alpha` controls the value to which an ELU saturates for negative net inputs. ELUs diminish the vanishing gradient effect.
ELUs have negative values which pushes the mean of the activations closer to zero. Mean activations that are closer to zero enable faster learning as they bring the gradient closer to the natural gradient. ELUs saturate to a negative value when the argument gets smaller. Saturation means a small derivative which decreases the variation and the information that is propagated to the next layer.
#### Example Usage:
```
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='elu',
input_shape=(28, 28, 1)))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='elu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='elu'))
```
| Args |
| `x` | Input tensor. |
| `alpha` | A scalar, slope of negative section. `alpha` controls the value to which an ELU saturates for negative net inputs. |
| Returns |
| The exponential linear unit (ELU) activation function: `x` if `x > 0` and `alpha * (exp(x) - 1)` if `x < 0`. |
#### Reference:
[Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) (Clevert et al, 2016)](https://arxiv.org/abs/1511.07289)
tensorflow tf.keras.activations.deserialize tf.keras.activations.deserialize
================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L519-L559) |
Returns activation function given a string identifier.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.deserialize`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/deserialize)
```
tf.keras.activations.deserialize(
name, custom_objects=None
)
```
| Args |
| `name` | The name of the activation function. |
| `custom_objects` | Optional `{function_name: function_obj}` dictionary listing user-provided activation functions. |
| Returns |
| Corresponding activation function. |
#### For example:
```
tf.keras.activations.deserialize('linear')
<function linear at 0x1239596a8>
tf.keras.activations.deserialize('sigmoid')
<function sigmoid at 0x123959510>
tf.keras.activations.deserialize('abcd')
Traceback (most recent call last):
ValueError: Unknown activation function:abcd
```
| Raises |
| `ValueError` | `Unknown activation function` if the input string does not denote any defined Tensorflow activation function. |
tensorflow tf.keras.activations.softplus tf.keras.activations.softplus
=============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L199-L218) |
Softplus activation function, `softplus(x) = log(exp(x) + 1)`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.softplus`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/softplus)
```
tf.keras.activations.softplus(
x
)
```
#### Example Usage:
```
a = tf.constant([-20, -1.0, 0.0, 1.0, 20], dtype = tf.float32)
b = tf.keras.activations.softplus(a)
b.numpy()
array([2.0611537e-09, 3.1326166e-01, 6.9314718e-01, 1.3132616e+00,
2.0000000e+01], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| The softplus activation: `log(exp(x) + 1)`. |
tensorflow tf.keras.activations.swish tf.keras.activations.swish
==========================
Swish activation function, `swish(x) = x * sigmoid(x)`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.swish`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/swish)
```
tf.keras.activations.swish(
x
)
```
Swish activation function which returns `x*sigmoid(x)`. It is a smooth, non-monotonic function that consistently matches or outperforms ReLU on deep networks, it is unbounded above and bounded below.
#### Example Usage:
```
a = tf.constant([-20, -1.0, 0.0, 1.0, 20], dtype = tf.float32)
b = tf.keras.activations.swish(a)
b.numpy()
array([-4.1223075e-08, -2.6894143e-01, 0.0000000e+00, 7.3105860e-01,
2.0000000e+01], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| The swish activation applied to `x` (see reference paper for details). |
#### Reference:
* [Ramachandran et al., 2017](https://arxiv.org/abs/1710.05941)
tensorflow tf.keras.activations.serialize tf.keras.activations.serialize
==============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L480-L508) |
Returns the string identifier of an activation function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.serialize`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/serialize)
```
tf.keras.activations.serialize(
activation
)
```
| Args |
| `activation` | Function object. |
| Returns |
| String denoting the name attribute of the input function |
#### For example:
```
tf.keras.activations.serialize(tf.keras.activations.tanh)
'tanh'
tf.keras.activations.serialize(tf.keras.activations.sigmoid)
'sigmoid'
tf.keras.activations.serialize('abcd')
Traceback (most recent call last):
ValueError: ('Cannot serialize', 'abcd')
```
| Raises |
| `ValueError` | The input function is not a valid one. |
tensorflow tf.keras.activations.get tf.keras.activations.get
========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L562-L600) |
Returns function.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.get`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/get)
```
tf.keras.activations.get(
identifier
)
```
| Args |
| `identifier` | Function or string |
| Returns |
| Function corresponding to the input string or input function. |
#### For example:
```
tf.keras.activations.get('softmax')
<function softmax at 0x1222a3d90>
tf.keras.activations.get(tf.keras.activations.softmax)
<function softmax at 0x1222a3d90>
tf.keras.activations.get(None)
<function linear at 0x1239596a8>
tf.keras.activations.get(abs)
<built-in function abs>
tf.keras.activations.get('abcd')
Traceback (most recent call last):
ValueError: Unknown activation function:abcd
```
| Raises |
| `ValueError` | Input is an unknown function or string, i.e., the input does not denote any defined function. |
tensorflow tf.keras.activations.sigmoid tf.keras.activations.sigmoid
============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/activations.py#L376-L406) |
Sigmoid activation function, `sigmoid(x) = 1 / (1 + exp(-x))`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.activations.sigmoid`](https://www.tensorflow.org/api_docs/python/tf/keras/activations/sigmoid)
```
tf.keras.activations.sigmoid(
x
)
```
Applies the sigmoid activation function. For small values (<-5), `sigmoid` returns a value close to zero, and for large values (>5) the result of the function gets close to 1.
Sigmoid is equivalent to a 2-element Softmax, where the second element is assumed to be zero. The sigmoid function always returns a value between 0 and 1.
#### For example:
```
a = tf.constant([-20, -1.0, 0.0, 1.0, 20], dtype = tf.float32)
b = tf.keras.activations.sigmoid(a)
b.numpy()
array([2.0611537e-09, 2.6894143e-01, 5.0000000e-01, 7.3105860e-01,
1.0000000e+00], dtype=float32)
```
| Args |
| `x` | Input tensor. |
| Returns |
| Tensor with the sigmoid activation: `1 / (1 + exp(-x))`. |
tensorflow tf.keras.metrics.Precision tf.keras.metrics.Precision
==========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L710-L850) |
Computes the precision of the predictions with respect to the labels.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Precision`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Precision)
```
tf.keras.metrics.Precision(
thresholds=None, top_k=None, class_id=None, name=None, dtype=None
)
```
The metric creates two local variables, `true_positives` and `false_positives` that are used to compute the precision. This value is ultimately returned as `precision`, an idempotent operation that simply divides `true_positives` by the sum of `true_positives` and `false_positives`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `top_k` is set, we'll calculate precision as how often on average a class among the top-k classes with the highest predicted values of a batch entry is correct and can be found in the label for that entry.
If `class_id` is specified, we calculate precision by considering only the entries in the batch for which `class_id` is above the threshold and/or in the top-k highest predictions, and computing the fraction of them for which `class_id` is indeed a correct label.
| Args |
| `thresholds` | (Optional) A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. If neither thresholds nor top\_k are set, the default is to calculate precision with `thresholds=0.5`. |
| `top_k` | (Optional) Unset by default. An int value specifying the top-k predictions to consider when calculating precision. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Precision()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1])
m.result().numpy()
0.6666667
```
```
m.reset_state()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
```
# With top_k=2, it will calculate precision over y_true[:2] and y_pred[:2]
m = tf.keras.metrics.Precision(top_k=2)
m.update_state([0, 0, 1, 1], [1, 1, 1, 1])
m.result().numpy()
0.0
```
```
# With top_k=4, it will calculate precision over y_true[:4] and y_pred[:4]
m = tf.keras.metrics.Precision(top_k=4)
m.update_state([0, 0, 1, 1], [1, 1, 1, 1])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.Precision()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L837-L841)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L831-L835)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L804-L829)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates true positive and false positive statistics.
| Args |
| `y_true` | The ground truth values, with the same dimensions as `y_pred`. Will be cast to `bool`. |
| `y_pred` | The predicted values. Each element must be in the range `[0, 1]`. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.Recall tf.keras.metrics.Recall
=======================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L854-L981) |
Computes the recall of the predictions with respect to the labels.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Recall`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Recall)
```
tf.keras.metrics.Recall(
thresholds=None, top_k=None, class_id=None, name=None, dtype=None
)
```
This metric creates two local variables, `true_positives` and `false_negatives`, that are used to compute the recall. This value is ultimately returned as `recall`, an idempotent operation that simply divides `true_positives` by the sum of `true_positives` and `false_negatives`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `top_k` is set, recall will be computed as how often on average a class among the labels of a batch entry is in the top-k predictions.
If `class_id` is specified, we calculate recall by considering only the entries in the batch for which `class_id` is in the label, and computing the fraction of them for which `class_id` is above the threshold and/or in the top-k predictions.
| Args |
| `thresholds` | (Optional) A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. If neither thresholds nor top\_k are set, the default is to calculate recall with `thresholds=0.5`. |
| `top_k` | (Optional) Unset by default. An int value specifying the top-k predictions to consider when calculating recall. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Recall()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1])
m.result().numpy()
0.6666667
```
```
m.reset_state()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.Recall()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L968-L972)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L962-L966)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L935-L960)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates true positive and false negative statistics.
| Args |
| `y_true` | The ground truth values, with the same dimensions as `y_pred`. Will be cast to `bool`. |
| `y_pred` | The predicted values. Each element must be in the range `[0, 1]`. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.Mean tf.keras.metrics.Mean
=====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L540-L579) |
Computes the (weighted) mean of the given values.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Mean`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Mean)
```
tf.keras.metrics.Mean(
name='mean', dtype=None
)
```
For example, if values is [1, 3, 5, 7] then the mean is 4. If the weights were specified as [1, 1, 0, 0] then the mean would be 2.
This metric creates two variables, `total` and `count` that are used to compute the average of `values`. This average is ultimately returned as `mean` which is an idempotent operation that simply divides `total` by `count`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Mean()
m.update_state([1, 3, 5, 7])
m.result().numpy()
4.0
m.reset_state()
m.update_state([1, 3, 5, 7], sample_weight=[1, 1, 0, 0])
m.result().numpy()
2.0
```
Usage with `compile()` API:
```
model.add_metric(tf.keras.metrics.Mean(name='mean_1')(outputs))
model.compile(optimizer='sgd', loss='mse')
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L420-L485)
```
update_state(
values, sample_weight=None
)
```
Accumulates statistics for computing the metric.
| Args |
| `values` | Per-example value. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.MeanMetricWrapper tf.keras.metrics.MeanMetricWrapper
==================================
Wraps a stateless metric function with the Mean metric.
Inherits From: [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanMetricWrapper`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanMetricWrapper)
```
tf.keras.metrics.MeanMetricWrapper(
fn, name=None, dtype=None, **kwargs
)
```
You could use this class to quickly build a mean metric from a function. The function needs to have the signature `fn(y_true, y_pred)` and return a per-sample loss array. [`MeanMetricWrapper.result()`](accuracy#result) will return the average metric value across all samples seen so far.
#### For example:
```
def accuracy(y_true, y_pred):
return tf.cast(tf.math.equal(y_true, y_pred), tf.float32)
accuracy_metric = tf.keras.metrics.MeanMetricWrapper(fn=accuracy)
keras_model.compile(..., metrics=accuracy_metric)
```
| Args |
| `fn` | The metric function to wrap, with signature `fn(y_true, y_pred, **kwargs)`. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `**kwargs` | Keyword arguments to pass on to `fn`. |
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.MeanTensor tf.keras.metrics.MeanTensor
===========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L675-L798) |
Computes the element-wise (weighted) mean of the given tensors.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanTensor`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanTensor)
```
tf.keras.metrics.MeanTensor(
name='mean_tensor', dtype=None, shape=None
)
```
`MeanTensor` returns a tensor with the same shape of the input tensors. The mean value is updated by keeping local variables `total` and `count`. The `total` tracks the sum of the weighted values, and `count` stores the sum of the weighted counts.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `shape` | (Optional) A list of integers, a tuple of integers, or a 1-D Tensor of type int32. If not specified, the shape is inferred from the values at the first call of update\_state. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanTensor()
m.update_state([0, 1, 2, 3])
m.update_state([4, 5, 6, 7])
m.result().numpy()
array([2., 3., 4., 5.], dtype=float32)
```
```
m.update_state([12, 10, 8, 6], sample_weight= [0, 0.2, 0.5, 1])
m.result().numpy()
array([2. , 3.6363635, 4.8 , 5.3333335], dtype=float32)
```
```
m = tf.keras.metrics.MeanTensor(dtype=tf.float64, shape=(1, 4))
m.result().numpy()
array([[0., 0., 0., 0.]])
m.update_state([[0, 1, 2, 3]])
m.update_state([[4, 5, 6, 7]])
m.result().numpy()
array([[2., 3., 4., 5.]])
```
| Attributes |
| `count` | |
| `total` | |
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L794-L798)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L786-L792)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L742-L784)
```
update_state(
values, sample_weight=None
)
```
Accumulates statistics for computing the element-wise mean.
| Args |
| `values` | Per-example value. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.SpecificityAtSensitivity tf.keras.metrics.SpecificityAtSensitivity
=========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1193-L1286) |
Computes best specificity where sensitivity is >= specified value.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SpecificityAtSensitivity`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SpecificityAtSensitivity)
```
tf.keras.metrics.SpecificityAtSensitivity(
sensitivity, num_thresholds=200, class_id=None, name=None, dtype=None
)
```
`Sensitivity` measures the proportion of actual positives that are correctly identified as such (tp / (tp + fn)). `Specificity` measures the proportion of actual negatives that are correctly identified as such (tn / (tn + fp)).
This metric creates four local variables, `true_positives`, `true_negatives`, `false_positives` and `false_negatives` that are used to compute the specificity at the given sensitivity. The threshold for the given sensitivity value is computed and used to evaluate the corresponding specificity.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `class_id` is specified, we calculate precision by considering only the entries in the batch for which `class_id` is above the threshold predictions, and computing the fraction of them for which `class_id` is indeed a correct label.
For additional information about specificity and sensitivity, see [the following](https://en.wikipedia.org/wiki/Sensitivity_and_specificity).
| Args |
| `sensitivity` | A scalar value in range `[0, 1]`. |
| `num_thresholds` | (Optional) Defaults to 200. The number of thresholds to use for matching the given sensitivity. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.SpecificityAtSensitivity(0.5)
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8])
m.result().numpy()
0.66666667
```
```
m.reset_state()
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8],
sample_weight=[1, 1, 2, 2, 2])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SpecificityAtSensitivity()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1058-L1064)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1270-L1278)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1031-L1056)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.categorical_crossentropy tf.keras.metrics.categorical\_crossentropy
==========================================
Computes the categorical crossentropy loss.
#### View aliases
**Main aliases**
[`tf.keras.losses.categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/categorical_crossentropy)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/categorical_crossentropy), [`tf.compat.v1.keras.metrics.categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/categorical_crossentropy)
```
tf.keras.metrics.categorical_crossentropy(
y_true, y_pred, from_logits=False, label_smoothing=0.0, axis=-1
)
```
#### Standalone usage:
```
y_true = [[0, 1, 0], [0, 0, 1]]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred)
assert loss.shape == (2,)
loss.numpy()
array([0.0513, 2.303], dtype=float32)
```
| Args |
| `y_true` | Tensor of one-hot true targets. |
| `y_pred` | Tensor of predicted targets. |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `label_smoothing` | Float in [0, 1]. If > `0` then smooth the labels. For example, if `0.1`, use `0.1 / num_classes` for non-target labels and `0.9 + 0.1 / num_classes` for target labels. |
| `axis` | Defaults to -1. The dimension along which the entropy is computed. |
| Returns |
| Categorical crossentropy loss value. |
tensorflow tf.keras.metrics.FalsePositives tf.keras.metrics.FalsePositives
===============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L510-L556) |
Calculates the number of false positives.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.FalsePositives`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/FalsePositives)
```
tf.keras.metrics.FalsePositives(
thresholds=None, name=None, dtype=None
)
```
If `sample_weight` is given, calculates the sum of the weights of false positives. This metric creates one local variable, `accumulator` that is used to keep track of the number of false positives.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `thresholds` | (Optional) Defaults to 0.5. A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.FalsePositives()
m.update_state([0, 1, 0, 0], [0, 0, 1, 1])
m.result().numpy()
2.0
```
```
m.reset_state()
m.update_state([0, 1, 0, 0], [0, 0, 1, 1], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.FalsePositives()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L498-L501)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L491-L496)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L470-L489)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the metric statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.PrecisionAtRecall tf.keras.metrics.PrecisionAtRecall
==================================
Computes best precision where recall is >= specified value.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.PrecisionAtRecall`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/PrecisionAtRecall)
```
tf.keras.metrics.PrecisionAtRecall(
recall, num_thresholds=200, class_id=None, name=None, dtype=None
)
```
This metric creates four local variables, `true_positives`, `true_negatives`, `false_positives` and `false_negatives` that are used to compute the precision at the given recall. The threshold for the given recall value is computed and used to evaluate the corresponding precision.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `class_id` is specified, we calculate precision by considering only the entries in the batch for which `class_id` is above the threshold predictions, and computing the fraction of them for which `class_id` is indeed a correct label.
| Args |
| `recall` | A scalar value in range `[0, 1]`. |
| `num_thresholds` | (Optional) Defaults to 200. The number of thresholds to use for matching the given recall. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.PrecisionAtRecall(0.5)
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8],
sample_weight=[2, 2, 2, 1, 1])
m.result().numpy()
0.33333333
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.PrecisionAtRecall(recall=0.8)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1058-L1064)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1359-L1367)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1031-L1056)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.IoU tf.keras.metrics.IoU
====================
Computes the Intersection-Over-Union metric for specific target classes.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.IoU`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/IoU)
```
tf.keras.metrics.IoU(
num_classes: int,
target_class_ids: Union[List[int], Tuple[int, ...]],
name=None,
dtype=None
)
```
General definition and computation:
Intersection-Over-Union is a common evaluation metric for semantic image segmentation.
For an individual class, the IoU metric is defined as follows:
```
iou = true_positives / (true_positives + false_positives + false_negatives)
```
To compute IoUs, the predictions are accumulated in a confusion matrix, weighted by `sample_weight` and the metric is then calculated from it.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
Note, this class first computes IoUs for all individual classes, then returns the mean of IoUs for the classes that are specified by `target_class_ids`. If `target_class_ids` has only one id value, the IoU of that specific class is returned.
| Args |
| `num_classes` | The possible number of labels the prediction task can have. A confusion matrix of dimension = [num\_classes, num\_classes] will be allocated to accumulate predictions from which the metric is calculated. |
| `target_class_ids` | A tuple or list of target class ids for which the metric is returned. To compute IoU for a specific class, a list (or tuple) of a single id value should be provided. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
# cm = [[1, 1],
# [1, 1]]
# sum_row = [2, 2], sum_col = [2, 2], true_positives = [1, 1]
# iou = true_positives / (sum_row + sum_col - true_positives))
# iou = [0.33, 0.33]
m = tf.keras.metrics.IoU(num_classes=2, target_class_ids=[0])
m.update_state([0, 0, 1, 1], [0, 1, 0, 1])
m.result().numpy()
0.33333334
```
```
m.reset_state()
m.update_state([0, 0, 1, 1], [0, 1, 0, 1],
sample_weight=[0.3, 0.3, 0.3, 0.1])
# cm = [[0.3, 0.3],
# [0.3, 0.1]]
# sum_row = [0.6, 0.4], sum_col = [0.6, 0.4], true_positives = [0.3, 0.1]
# iou = [0.33, 0.14]
m.result().numpy()
0.33333334
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.IoU(num_classes=2, target_class_ids=[0])])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2502-L2504)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2594-L2618)
```
result()
```
Compute the intersection-over-union via the confusion matrix.
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2464-L2500)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.mean_squared_logarithmic_error tf.keras.metrics.mean\_squared\_logarithmic\_error
==================================================
Computes the mean squared logarithmic error between `y_true` and `y_pred`.
#### View aliases
**Main aliases**
[`tf.keras.losses.MSLE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.keras.losses.mean_squared_logarithmic_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.keras.losses.msle`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.keras.metrics.MSLE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.keras.metrics.msle`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MSLE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.compat.v1.keras.losses.mean_squared_logarithmic_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.compat.v1.keras.losses.msle`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.compat.v1.keras.metrics.MSLE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.compat.v1.keras.metrics.mean_squared_logarithmic_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error), [`tf.compat.v1.keras.metrics.msle`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_logarithmic_error)
```
tf.keras.metrics.mean_squared_logarithmic_error(
y_true, y_pred
)
```
`loss = mean(square(log(y_true + 1) - log(y_pred + 1)), axis=-1)`
#### Standalone usage:
```
y_true = np.random.randint(0, 2, size=(2, 3))
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.mean_squared_logarithmic_error(y_true, y_pred)
assert loss.shape == (2,)
y_true = np.maximum(y_true, 1e-7)
y_pred = np.maximum(y_pred, 1e-7)
assert np.allclose(
loss.numpy(),
np.mean(
np.square(np.log(y_true + 1.) - np.log(y_pred + 1.)), axis=-1))
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Mean squared logarithmic error values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.Accuracy tf.keras.metrics.Accuracy
=========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L131-L170) |
Calculates how often predictions equal labels.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Accuracy)
```
tf.keras.metrics.Accuracy(
name='accuracy', dtype=None
)
```
This metric creates two local variables, `total` and `count` that are used to compute the frequency with which `y_pred` matches `y_true`. This frequency is ultimately returned as `binary accuracy`: an idempotent operation that simply divides `total` by `count`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Accuracy()
m.update_state([[1], [2], [3], [4]], [[0], [2], [3], [4]])
m.result().numpy()
0.75
```
```
m.reset_state()
m.update_state([[1], [2], [3], [4]], [[0], [2], [3], [4]],
sample_weight=[1, 1, 0, 0])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.Accuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.RootMeanSquaredError tf.keras.metrics.RootMeanSquaredError
=====================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2258-L2310) |
Computes root mean squared error metric between `y_true` and `y_pred`.
Inherits From: [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.RootMeanSquaredError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/RootMeanSquaredError)
```
tf.keras.metrics.RootMeanSquaredError(
name='root_mean_squared_error', dtype=None
)
```
#### Standalone usage:
```
m = tf.keras.metrics.RootMeanSquaredError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.70710677
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2309-L2310)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2288-L2307)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates root mean squared error statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.squared_hinge tf.keras.metrics.squared\_hinge
===============================
Computes the squared hinge loss between `y_true` and `y_pred`.
#### View aliases
**Main aliases**
[`tf.keras.losses.squared_hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/squared_hinge)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.squared_hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/squared_hinge), [`tf.compat.v1.keras.metrics.squared_hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/squared_hinge)
```
tf.keras.metrics.squared_hinge(
y_true, y_pred
)
```
`loss = mean(square(maximum(1 - y_true * y_pred, 0)), axis=-1)`
#### Standalone usage:
```
y_true = np.random.choice([-1, 1], size=(2, 3))
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.squared_hinge(y_true, y_pred)
assert loss.shape == (2,)
assert np.array_equal(
loss.numpy(),
np.mean(np.square(np.maximum(1. - y_true * y_pred, 0.)), axis=-1))
```
| Args |
| `y_true` | The ground truth values. `y_true` values are expected to be -1 or 1. If binary (0 or 1) labels are provided we will convert them to -1 or 1. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Squared hinge loss values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.Metric tf.keras.metrics.Metric
=======================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L43-L398) |
Encapsulates metric logic and state.
Inherits From: [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Metric`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Metric)
```
tf.keras.metrics.Metric(
name=None, dtype=None, **kwargs
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `**kwargs` | Additional layer keywords arguments. |
#### Standalone usage:
```
m = SomeMetric(...)
for input in ...:
m.update_state(input)
print('Final result: ', m.result().numpy())
```
Usage with `compile()` API:
```
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.01),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=[tf.keras.metrics.CategoricalAccuracy()])
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
model.fit(dataset, epochs=10)
```
To be implemented by subclasses:
* `__init__()`: All state variables should be created in this method by calling `self.add_weight()` like: `self.var = self.add_weight(...)`
* `update_state()`: Has all updates to the state variables like: self.var.assign\_add(...).
* `result()`: Computes and returns a scalar value or a dict of scalar values for the metric from the state variables.
Example subclass implementation:
```
class BinaryTruePositives(tf.keras.metrics.Metric):
def __init__(self, name='binary_true_positives', **kwargs):
super(BinaryTruePositives, self).__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name='tp', initializer='zeros')
def update_state(self, y_true, y_pred, sample_weight=None):
y_true = tf.cast(y_true, tf.bool)
y_pred = tf.cast(y_pred, tf.bool)
values = tf.logical_and(tf.equal(y_true, True), tf.equal(y_pred, True))
values = tf.cast(values, self.dtype)
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, self.dtype)
sample_weight = tf.broadcast_to(sample_weight, values.shape)
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L311-L321)
```
@abc.abstractmethod
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L255-L273)
```
@abc.abstractmethod
update_state(
*args, **kwargs
)
```
Accumulates statistics for the metric.
>
> **Note:** This function is executed as a graph function in graph mode. This means: a) Operations on the same resource are executed in textual order. This should make it easier to do things like add the updated value of a variable to another, for example. b) You don't need to worry about collecting the update ops to execute. All update ops added to the graph by this function will be executed. As a result, code should generally work the same way with graph or eager execution.
>
| Args |
| `*args` | |
| `**kwargs` | A mini-batch of inputs to the Metric. |
tensorflow tf.keras.metrics.sparse_top_k_categorical_accuracy tf.keras.metrics.sparse\_top\_k\_categorical\_accuracy
======================================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3366-L3394) |
Computes how often integer targets are in the top `K` predictions.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.sparse_top_k_categorical_accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_top_k_categorical_accuracy)
```
tf.keras.metrics.sparse_top_k_categorical_accuracy(
y_true, y_pred, k=5
)
```
#### Standalone usage:
```
y_true = [2, 1]
y_pred = [[0.1, 0.9, 0.8], [0.05, 0.95, 0]]
m = tf.keras.metrics.sparse_top_k_categorical_accuracy(
y_true, y_pred, k=3)
assert m.shape == (2,)
m.numpy()
array([1., 1.], dtype=float32)
```
| Args |
| `y_true` | tensor of true targets. |
| `y_pred` | tensor of predicted targets. |
| `k` | (Optional) Number of top elements to look at for computing accuracy. Defaults to 5. |
| Returns |
| Sparse top K categorical accuracy value. |
tensorflow tf.keras.metrics.sparse_categorical_crossentropy tf.keras.metrics.sparse\_categorical\_crossentropy
==================================================
Computes the sparse categorical crossentropy loss.
#### View aliases
**Main aliases**
[`tf.keras.losses.sparse_categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.sparse_categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy), [`tf.compat.v1.keras.metrics.sparse_categorical_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_crossentropy)
```
tf.keras.metrics.sparse_categorical_crossentropy(
y_true, y_pred, from_logits=False, axis=-1
)
```
#### Standalone usage:
```
y_true = [1, 2]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred)
assert loss.shape == (2,)
loss.numpy()
array([0.0513, 2.303], dtype=float32)
```
| Args |
| `y_true` | Ground truth values. |
| `y_pred` | The predicted values. |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `axis` | Defaults to -1. The dimension along which the entropy is computed. |
| Returns |
| Sparse categorical crossentropy loss value. |
tensorflow tf.keras.metrics.BinaryCrossentropy tf.keras.metrics.BinaryCrossentropy
===================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3035-L3085) |
Computes the crossentropy metric between the labels and predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.BinaryCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/BinaryCrossentropy)
```
tf.keras.metrics.BinaryCrossentropy(
name='binary_crossentropy',
dtype=None,
from_logits=False,
label_smoothing=0
)
```
This is the crossentropy metric class to be used when there are only two label classes (0 and 1).
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `from_logits` | (Optional )Whether output is expected to be a logits tensor. By default, we consider that output encodes a probability distribution. |
| `label_smoothing` | (Optional) Float in [0, 1]. When > 0, label values are smoothed, meaning the confidence on label values are relaxed. e.g. `label_smoothing=0.2` means that we will use a value of `0.1` for label `0` and `0.9` for label `1`". |
#### Standalone usage:
```
m = tf.keras.metrics.BinaryCrossentropy()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]])
m.result().numpy()
0.81492424
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]],
sample_weight=[1, 0])
m.result().numpy()
0.9162905
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.BinaryCrossentropy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.SquaredHinge tf.keras.metrics.SquaredHinge
=============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2183-L2218) |
Computes the squared hinge metric between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SquaredHinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SquaredHinge)
```
tf.keras.metrics.SquaredHinge(
name='squared_hinge', dtype=None
)
```
`y_true` values are expected to be -1 or 1. If binary (0 or 1) labels are provided we will convert them to -1 or 1.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.SquaredHinge()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]])
m.result().numpy()
1.86
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]],
sample_weight=[1, 0])
m.result().numpy()
1.46
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SquaredHinge()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.top_k_categorical_accuracy tf.keras.metrics.top\_k\_categorical\_accuracy
==============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3336-L3363) |
Computes how often targets are in the top `K` predictions.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.top_k_categorical_accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/top_k_categorical_accuracy)
```
tf.keras.metrics.top_k_categorical_accuracy(
y_true, y_pred, k=5
)
```
#### Standalone usage:
```
y_true = [[0, 0, 1], [0, 1, 0]]
y_pred = [[0.1, 0.9, 0.8], [0.05, 0.95, 0]]
m = tf.keras.metrics.top_k_categorical_accuracy(y_true, y_pred, k=3)
assert m.shape == (2,)
m.numpy()
array([1., 1.], dtype=float32)
```
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The prediction values. |
| `k` | (Optional) Number of top elements to look at for computing accuracy. Defaults to 5. |
| Returns |
| Top K categorical accuracy value. |
| programming_docs |
tensorflow tf.keras.metrics.MeanIoU tf.keras.metrics.MeanIoU
========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2747-L2820) |
Computes the mean Intersection-Over-Union metric.
Inherits From: [`IoU`](iou), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanIoU`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanIoU)
```
tf.keras.metrics.MeanIoU(
num_classes, name=None, dtype=None
)
```
General definition and computation:
Intersection-Over-Union is a common evaluation metric for semantic image segmentation.
For an individual class, the IoU metric is defined as follows:
```
iou = true_positives / (true_positives + false_positives + false_negatives)
```
To compute IoUs, the predictions are accumulated in a confusion matrix, weighted by `sample_weight` and the metric is then calculated from it.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
Note that this class first computes IoUs for all individual classes, then returns the mean of these values.
| Args |
| `num_classes` | The possible number of labels the prediction task can have. This value must be provided, since a confusion matrix of dimension = [num\_classes, num\_classes] will be allocated. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
# cm = [[1, 1],
# [1, 1]]
# sum_row = [2, 2], sum_col = [2, 2], true_positives = [1, 1]
# iou = true_positives / (sum_row + sum_col - true_positives))
# result = (1 / (2 + 2 - 1) + 1 / (2 + 2 - 1)) / 2 = 0.33
m = tf.keras.metrics.MeanIoU(num_classes=2)
m.update_state([0, 0, 1, 1], [0, 1, 0, 1])
m.result().numpy()
0.33333334
```
```
m.reset_state()
m.update_state([0, 0, 1, 1], [0, 1, 0, 1],
sample_weight=[0.3, 0.3, 0.3, 0.1])
m.result().numpy()
0.23809525
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanIoU(num_classes=2)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2502-L2504)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2594-L2618)
```
result()
```
Compute the intersection-over-union via the confusion matrix.
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2464-L2500)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.Sum tf.keras.metrics.Sum
====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L502-L536) |
Computes the (weighted) sum of the given values.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Sum`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Sum)
```
tf.keras.metrics.Sum(
name='sum', dtype=None
)
```
For example, if values is [1, 3, 5, 7] then the sum is 16. If the weights were specified as [1, 1, 0, 0] then the sum would be 4.
This metric creates one variable, `total`, that is used to compute the sum of `values`. This is ultimately returned as `sum`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Sum()
m.update_state([1, 3, 5, 7])
m.result().numpy()
16.0
```
Usage with `compile()` API:
```
model.add_metric(tf.keras.metrics.Sum(name='sum_1')(outputs))
model.compile(optimizer='sgd', loss='mse')
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L420-L485)
```
update_state(
values, sample_weight=None
)
```
Accumulates statistics for computing the metric.
| Args |
| `values` | Per-example value. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.OneHotIoU tf.keras.metrics.OneHotIoU
==========================
Computes the Intersection-Over-Union metric for one-hot encoded labels.
Inherits From: [`IoU`](iou), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.OneHotIoU`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/OneHotIoU)
```
tf.keras.metrics.OneHotIoU(
num_classes: int,
target_class_ids: Union[List[int], Tuple[int, ...]],
name=None,
dtype=None
)
```
General definition and computation:
Intersection-Over-Union is a common evaluation metric for semantic image segmentation.
For an individual class, the IoU metric is defined as follows:
```
iou = true_positives / (true_positives + false_positives + false_negatives)
```
To compute IoUs, the predictions are accumulated in a confusion matrix, weighted by `sample_weight` and the metric is then calculated from it.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
This class can be used to compute IoU for multi-class classification tasks where the labels are one-hot encoded (the last axis should have one dimension per class). Note that the predictions should also have the same shape. To compute the IoU, first the labels and predictions are converted back into integer format by taking the argmax over the class axis. Then the same computation steps as for the base `IoU` class apply.
Note, if there is only one channel in the labels and predictions, this class is the same as class `IoU`. In this case, use `IoU` instead.
Also, make sure that `num_classes` is equal to the number of classes in the data, to avoid a "labels out of bound" error when the confusion matrix is computed.
| Args |
| `num_classes` | The possible number of labels the prediction task can have. A confusion matrix of shape `(num_classes, num_classes)` will be allocated to accumulate predictions from which the metric is calculated. |
| `target_class_ids` | A tuple or list of target class ids for which the metric is returned. To compute IoU for a specific class, a list (or tuple) of a single id value should be provided. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
y_true = tf.constant([[0, 0, 1], [1, 0, 0], [0, 1, 0], [1, 0, 0]])
y_pred = tf.constant([[0.2, 0.3, 0.5], [0.1, 0.2, 0.7], [0.5, 0.3, 0.1],
[0.1, 0.4, 0.5]])
sample_weight = [0.1, 0.2, 0.3, 0.4]
m = tf.keras.metrics.OneHotIoU(num_classes=3, target_class_ids=[0, 2])
m.update_state(y_true=y_true, y_pred=y_pred, sample_weight=sample_weight)
# cm = [[0, 0, 0.2+0.4],
# [0.3, 0, 0],
# [0, 0, 0.1]]
# sum_row = [0.3, 0, 0.7], sum_col = [0.6, 0.3, 0.1]
# true_positives = [0, 0, 0.1]
# single_iou = true_positives / (sum_row + sum_col - true_positives))
# mean_iou = (0 / (0.3 + 0.6 - 0) + 0.1 / (0.7 + 0.1 - 0.1)) / 2
m.result().numpy()
0.071
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.OneHotIoU(num_classes=3, target_class_id=[1])])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2502-L2504)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2594-L2618)
```
result()
```
Compute the intersection-over-union via the confusion matrix.
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2911-L2928)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.CategoricalAccuracy tf.keras.metrics.CategoricalAccuracy
====================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L220-L272) |
Calculates how often predictions match one-hot labels.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.CategoricalAccuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/CategoricalAccuracy)
```
tf.keras.metrics.CategoricalAccuracy(
name='categorical_accuracy', dtype=None
)
```
You can provide logits of classes as `y_pred`, since argmax of logits and probabilities are same.
This metric creates two local variables, `total` and `count` that are used to compute the frequency with which `y_pred` matches `y_true`. This frequency is ultimately returned as `categorical accuracy`: an idempotent operation that simply divides `total` by `count`.
`y_pred` and `y_true` should be passed in as vectors of probabilities, rather than as labels. If necessary, use [`tf.one_hot`](../../one_hot) to expand `y_true` as a vector.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.CategoricalAccuracy()
m.update_state([[0, 0, 1], [0, 1, 0]], [[0.1, 0.9, 0.8],
[0.05, 0.95, 0]])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([[0, 0, 1], [0, 1, 0]], [[0.1, 0.9, 0.8],
[0.05, 0.95, 0]],
sample_weight=[0.7, 0.3])
m.result().numpy()
0.3
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.CategoricalAccuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.binary_focal_crossentropy tf.keras.metrics.binary\_focal\_crossentropy
============================================
Computes the binary focal crossentropy loss.
#### View aliases
**Main aliases**
[`tf.keras.losses.binary_focal_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_focal_crossentropy)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.binary_focal_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_focal_crossentropy), [`tf.compat.v1.keras.metrics.binary_focal_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_focal_crossentropy)
```
tf.keras.metrics.binary_focal_crossentropy(
y_true, y_pred, gamma=2.0, from_logits=False, label_smoothing=0.0, axis=-1
)
```
According to [Lin et al., 2018](https://arxiv.org/pdf/1708.02002.pdf), it helps to apply a focal factor to down-weight easy examples and focus more on hard examples. By default, the focal tensor is computed as follows:
`focal_factor = (1 - output)**gamma` for class 1 `focal_factor = output**gamma` for class 0 where `gamma` is a focusing parameter. When `gamma` = 0, this function is equivalent to the binary crossentropy loss.
#### Standalone usage:
```
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
loss = tf.keras.losses.binary_focal_crossentropy(y_true, y_pred, gamma=2)
assert loss.shape == (2,)
loss.numpy()
array([0.330, 0.206], dtype=float32)
```
| Args |
| `y_true` | Ground truth values, of shape `(batch_size, d0, .. dN)`. |
| `y_pred` | The predicted values, of shape `(batch_size, d0, .. dN)`. |
| `gamma` | A focusing parameter, default is `2.0` as mentioned in the reference. |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `label_smoothing` | Float in `[0, 1]`. If higher than 0 then smooth the labels by squeezing them towards `0.5`, i.e., using `1. - 0.5 * label_smoothing` for the target class and `0.5 * label_smoothing` for the non-target class. |
| `axis` | The axis along which the mean is computed. Defaults to `-1`. |
| Returns |
| Binary focal crossentropy loss value. shape = `[batch_size, d0, .. dN-1]`. |
| programming_docs |
tensorflow tf.keras.metrics.TruePositives tf.keras.metrics.TruePositives
==============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L660-L706) |
Calculates the number of true positives.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.TruePositives`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/TruePositives)
```
tf.keras.metrics.TruePositives(
thresholds=None, name=None, dtype=None
)
```
If `sample_weight` is given, calculates the sum of the weights of true positives. This metric creates one local variable, `true_positives` that is used to keep track of the number of true positives.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `thresholds` | (Optional) Defaults to 0.5. A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.TruePositives()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1])
m.result().numpy()
2.0
```
```
m.reset_state()
m.update_state([0, 1, 1, 1], [1, 0, 1, 1], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.TruePositives()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L498-L501)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L491-L496)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L470-L489)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the metric statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.binary_accuracy tf.keras.metrics.binary\_accuracy
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3238-L3265) |
Calculates how often predictions match binary labels.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.binary_accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_accuracy)
```
tf.keras.metrics.binary_accuracy(
y_true, y_pred, threshold=0.5
)
```
#### Standalone usage:
```
y_true = [[1], [1], [0], [0]]
y_pred = [[1], [1], [0], [0]]
m = tf.keras.metrics.binary_accuracy(y_true, y_pred)
assert m.shape == (4,)
m.numpy()
array([1., 1., 1., 1.], dtype=float32)
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| `threshold` | (Optional) Float representing the threshold for deciding whether prediction values are 1 or 0. |
| Returns |
| Binary accuracy values. shape = `[batch_size, d0, .. dN-1]` |
tensorflow tf.keras.metrics.Hinge tf.keras.metrics.Hinge
======================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2147-L2179) |
Computes the hinge metric between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Hinge)
```
tf.keras.metrics.Hinge(
name='hinge', dtype=None
)
```
`y_true` values are expected to be -1 or 1. If binary (0 or 1) labels are provided we will convert them to -1 or 1.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Hinge()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]])
m.result().numpy()
1.3
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]],
sample_weight=[1, 0])
m.result().numpy()
1.1
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd', loss='mse', metrics=[tf.keras.metrics.Hinge()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.mean_squared_error tf.keras.metrics.mean\_squared\_error
=====================================
Computes the mean squared error between labels and predictions.
#### View aliases
**Main aliases**
[`tf.keras.losses.MSE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.keras.losses.mean_squared_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.keras.losses.mse`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.keras.metrics.MSE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.keras.metrics.mse`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MSE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.compat.v1.keras.losses.mean_squared_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.compat.v1.keras.losses.mse`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.compat.v1.keras.metrics.MSE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.compat.v1.keras.metrics.mean_squared_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error), [`tf.compat.v1.keras.metrics.mse`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error)
```
tf.keras.metrics.mean_squared_error(
y_true, y_pred
)
```
After computing the squared distance between the inputs, the mean value over the last dimension is returned.
`loss = mean(square(y_true - y_pred), axis=-1)`
#### Standalone usage:
```
y_true = np.random.randint(0, 2, size=(2, 3))
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.mean_squared_error(y_true, y_pred)
assert loss.shape == (2,)
assert np.array_equal(
loss.numpy(), np.mean(np.square(y_true - y_pred), axis=-1))
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Mean squared error values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.deserialize tf.keras.metrics.deserialize
============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/__init__.py#L126-L142) |
Deserializes a serialized metric class/function instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.deserialize`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/deserialize)
```
tf.keras.metrics.deserialize(
config, custom_objects=None
)
```
| Args |
| `config` | Metric configuration. |
| `custom_objects` | Optional dictionary mapping names (strings) to custom objects (classes and functions) to be considered during deserialization. |
| Returns |
| A Keras `Metric` instance or a metric function. |
tensorflow tf.keras.metrics.BinaryAccuracy tf.keras.metrics.BinaryAccuracy
===============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L174-L216) |
Calculates how often predictions match binary labels.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.BinaryAccuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/BinaryAccuracy)
```
tf.keras.metrics.BinaryAccuracy(
name='binary_accuracy', dtype=None, threshold=0.5
)
```
This metric creates two local variables, `total` and `count` that are used to compute the frequency with which `y_pred` matches `y_true`. This frequency is ultimately returned as `binary accuracy`: an idempotent operation that simply divides `total` by `count`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `threshold` | (Optional) Float representing the threshold for deciding whether prediction values are 1 or 0. |
#### Standalone usage:
```
m = tf.keras.metrics.BinaryAccuracy()
m.update_state([[1], [1], [0], [0]], [[0.98], [1], [0], [0.6]])
m.result().numpy()
0.75
```
```
m.reset_state()
m.update_state([[1], [1], [0], [0]], [[0.98], [1], [0], [0.6]],
sample_weight=[1, 0, 0, 1])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.BinaryAccuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.MeanRelativeError tf.keras.metrics.MeanRelativeError
==================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L50-L127) |
Computes the mean relative error by normalizing with the given values.
Inherits From: [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanRelativeError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanRelativeError)
```
tf.keras.metrics.MeanRelativeError(
normalizer, name=None, dtype=None
)
```
This metric creates two local variables, `total` and `count` that are used to compute the mean relative error. This is weighted by `sample_weight`, and it is ultimately returned as `mean_relative_error`: an idempotent operation that simply divides `total` by `count`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `normalizer` | The normalizer values with same shape as predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanRelativeError(normalizer=[1, 3, 2, 3])
m.update_state([1, 3, 2, 3], [2, 4, 6, 8])
```
```
# metric = mean(|y_pred - y_true| / normalizer)
# = mean([1, 1, 4, 5] / [1, 3, 2, 3]) = mean([1, 1/3, 2, 5/3])
# = 5/4 = 1.25
m.result().numpy()
1.25
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanRelativeError(normalizer=[1, 3])])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L93-L121)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.binary_crossentropy tf.keras.metrics.binary\_crossentropy
=====================================
Computes the binary crossentropy loss.
#### View aliases
**Main aliases**
[`tf.keras.losses.binary_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_crossentropy)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.binary_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_crossentropy), [`tf.compat.v1.keras.metrics.binary_crossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/binary_crossentropy)
```
tf.keras.metrics.binary_crossentropy(
y_true, y_pred, from_logits=False, label_smoothing=0.0, axis=-1
)
```
#### Standalone usage:
```
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
loss = tf.keras.losses.binary_crossentropy(y_true, y_pred)
assert loss.shape == (2,)
loss.numpy()
array([0.916 , 0.714], dtype=float32)
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `label_smoothing` | Float in [0, 1]. If > `0` then smooth the labels by squeezing them towards 0.5 That is, using `1. - 0.5 * label_smoothing` for the target class and `0.5 * label_smoothing` for the non-target class. |
| `axis` | The axis along which the mean is computed. Defaults to -1. |
| Returns |
| Binary crossentropy loss value. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.Poisson tf.keras.metrics.Poisson
========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2351-L2384) |
Computes the Poisson metric between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.Poisson`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/Poisson)
```
tf.keras.metrics.Poisson(
name='poisson', dtype=None
)
```
`metric = y_pred - y_true * log(y_pred)`
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.Poisson()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.49999997
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.99999994
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.Poisson()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.sparse_categorical_accuracy tf.keras.metrics.sparse\_categorical\_accuracy
==============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3299-L3333) |
Calculates how often predictions match integer labels.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.sparse_categorical_accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/sparse_categorical_accuracy)
```
tf.keras.metrics.sparse_categorical_accuracy(
y_true, y_pred
)
```
#### Standalone usage:
```
y_true = [2, 1]
y_pred = [[0.1, 0.9, 0.8], [0.05, 0.95, 0]]
m = tf.keras.metrics.sparse_categorical_accuracy(y_true, y_pred)
assert m.shape == (2,)
m.numpy()
array([0., 1.], dtype=float32)
```
You can provide logits of classes as `y_pred`, since argmax of logits and probabilities are same.
| Args |
| `y_true` | Integer ground truth values. |
| `y_pred` | The prediction values. |
| Returns |
| Sparse categorical accuracy values. |
tensorflow tf.keras.metrics.MeanSquaredLogarithmicError tf.keras.metrics.MeanSquaredLogarithmicError
============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2110-L2143) |
Computes the mean squared logarithmic error between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanSquaredLogarithmicError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanSquaredLogarithmicError)
```
tf.keras.metrics.MeanSquaredLogarithmicError(
name='mean_squared_logarithmic_error', dtype=None
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanSquaredLogarithmicError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.12011322
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.24022643
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanSquaredLogarithmicError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.MeanAbsoluteError tf.keras.metrics.MeanAbsoluteError
==================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1999-L2032) |
Computes the mean absolute error between the labels and predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanAbsoluteError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanAbsoluteError)
```
tf.keras.metrics.MeanAbsoluteError(
name='mean_absolute_error', dtype=None
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanAbsoluteError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.25
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanAbsoluteError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.CategoricalCrossentropy tf.keras.metrics.CategoricalCrossentropy
========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3089-L3150) |
Computes the crossentropy metric between the labels and predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.CategoricalCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/CategoricalCrossentropy)
```
tf.keras.metrics.CategoricalCrossentropy(
name='categorical_crossentropy',
dtype=None,
from_logits=False,
label_smoothing=0
)
```
This is the crossentropy metric class to be used when there are multiple label classes (2 or more). Here we assume that labels are given as a `one_hot` representation. eg., When labels values are [2, 0, 1], `y_true` = [[0, 0, 1], [1, 0, 0], [0, 1, 0]].
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `from_logits` | (Optional) Whether output is expected to be a logits tensor. By default, we consider that output encodes a probability distribution. |
| `label_smoothing` | (Optional) Float in [0, 1]. When > 0, label values are smoothed, meaning the confidence on label values are relaxed. e.g. `label_smoothing=0.2` means that we will use a value of `0.1` for label `0` and `0.9` for label `1`" |
#### Standalone usage:
```
# EPSILON = 1e-7, y = y_true, y` = y_pred
# y` = clip_ops.clip_by_value(output, EPSILON, 1. - EPSILON)
# y` = [[0.05, 0.95, EPSILON], [0.1, 0.8, 0.1]]
# xent = -sum(y * log(y'), axis = -1)
# = -((log 0.95), (log 0.1))
# = [0.051, 2.302]
# Reduced xent = (0.051 + 2.302) / 2
m = tf.keras.metrics.CategoricalCrossentropy()
m.update_state([[0, 1, 0], [0, 0, 1]],
[[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
m.result().numpy()
1.1769392
```
```
m.reset_state()
m.update_state([[0, 1, 0], [0, 0, 1]],
[[0.05, 0.95, 0], [0.1, 0.8, 0.1]],
sample_weight=tf.constant([0.3, 0.7]))
m.result().numpy()
1.6271976
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.CategoricalCrossentropy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.SparseTopKCategoricalAccuracy tf.keras.metrics.SparseTopKCategoricalAccuracy
==============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L398-L433) |
Computes how often integer targets are in the top `K` predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SparseTopKCategoricalAccuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SparseTopKCategoricalAccuracy)
```
tf.keras.metrics.SparseTopKCategoricalAccuracy(
k=5, name='sparse_top_k_categorical_accuracy', dtype=None
)
```
| Args |
| `k` | (Optional) Number of top elements to look at for computing accuracy. Defaults to 5. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.SparseTopKCategoricalAccuracy(k=1)
m.update_state([2, 1], [[0.1, 0.9, 0.8], [0.05, 0.95, 0]])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([2, 1], [[0.1, 0.9, 0.8], [0.05, 0.95, 0]],
sample_weight=[0.7, 0.3])
m.result().numpy()
0.3
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SparseTopKCategoricalAccuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.KLDivergence tf.keras.metrics.KLDivergence
=============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2388-L2422) |
Computes Kullback-Leibler divergence metric between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.KLDivergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/KLDivergence)
```
tf.keras.metrics.KLDivergence(
name='kullback_leibler_divergence', dtype=None
)
```
`metric = y_true * log(y_true / y_pred)`
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.KLDivergence()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]])
m.result().numpy()
0.45814306
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]],
sample_weight=[1, 0])
m.result().numpy()
0.9162892
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.KLDivergence()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.mean_absolute_error tf.keras.metrics.mean\_absolute\_error
======================================
Computes the mean absolute error between labels and predictions.
#### View aliases
**Main aliases**
[`tf.keras.losses.MAE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.keras.losses.mae`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.keras.losses.mean_absolute_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.keras.metrics.MAE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.keras.metrics.mae`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MAE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.compat.v1.keras.losses.mae`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.compat.v1.keras.losses.mean_absolute_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.compat.v1.keras.metrics.MAE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.compat.v1.keras.metrics.mae`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error), [`tf.compat.v1.keras.metrics.mean_absolute_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_error)
```
tf.keras.metrics.mean_absolute_error(
y_true, y_pred
)
```
`loss = mean(abs(y_true - y_pred), axis=-1)`
#### Standalone usage:
```
y_true = np.random.randint(0, 2, size=(2, 3))
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.mean_absolute_error(y_true, y_pred)
assert loss.shape == (2,)
assert np.array_equal(
loss.numpy(), np.mean(np.abs(y_true - y_pred), axis=-1))
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Mean absolute error values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.MeanAbsolutePercentageError tf.keras.metrics.MeanAbsolutePercentageError
============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2036-L2069) |
Computes the mean absolute percentage error between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanAbsolutePercentageError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanAbsolutePercentageError)
```
tf.keras.metrics.MeanAbsolutePercentageError(
name='mean_absolute_percentage_error', dtype=None
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanAbsolutePercentageError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
250000000.0
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
500000000.0
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanAbsolutePercentageError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.SensitivityAtSpecificity tf.keras.metrics.SensitivityAtSpecificity
=========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1094-L1189) |
Computes best sensitivity where specificity is >= specified value.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SensitivityAtSpecificity`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SensitivityAtSpecificity)
```
tf.keras.metrics.SensitivityAtSpecificity(
specificity, num_thresholds=200, class_id=None, name=None, dtype=None
)
```
the sensitivity at a given specificity.
`Sensitivity` measures the proportion of actual positives that are correctly identified as such (tp / (tp + fn)). `Specificity` measures the proportion of actual negatives that are correctly identified as such (tn / (tn + fp)).
This metric creates four local variables, `true_positives`, `true_negatives`, `false_positives` and `false_negatives` that are used to compute the sensitivity at the given specificity. The threshold for the given specificity value is computed and used to evaluate the corresponding sensitivity.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `class_id` is specified, we calculate precision by considering only the entries in the batch for which `class_id` is above the threshold predictions, and computing the fraction of them for which `class_id` is indeed a correct label.
For additional information about specificity and sensitivity, see [the following](https://en.wikipedia.org/wiki/Sensitivity_and_specificity).
| Args |
| `specificity` | A scalar value in range `[0, 1]`. |
| `num_thresholds` | (Optional) Defaults to 200. The number of thresholds to use for matching the given specificity. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.SensitivityAtSpecificity(0.5)
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([0, 0, 0, 1, 1], [0, 0.3, 0.8, 0.3, 0.8],
sample_weight=[1, 1, 2, 2, 1])
m.result().numpy()
0.333333
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SensitivityAtSpecificity()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1058-L1064)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1173-L1181)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1031-L1056)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.TrueNegatives tf.keras.metrics.TrueNegatives
==============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L610-L656) |
Calculates the number of true negatives.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.TrueNegatives`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/TrueNegatives)
```
tf.keras.metrics.TrueNegatives(
thresholds=None, name=None, dtype=None
)
```
If `sample_weight` is given, calculates the sum of the weights of true negatives. This metric creates one local variable, `accumulator` that is used to keep track of the number of true negatives.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `thresholds` | (Optional) Defaults to 0.5. A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.TrueNegatives()
m.update_state([0, 1, 0, 0], [1, 1, 0, 0])
m.result().numpy()
2.0
```
```
m.reset_state()
m.update_state([0, 1, 0, 0], [1, 1, 0, 0], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.TrueNegatives()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L498-L501)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L491-L496)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L470-L489)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the metric statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.categorical_accuracy tf.keras.metrics.categorical\_accuracy
======================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3268-L3296) |
Calculates how often predictions match one-hot labels.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.categorical_accuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/categorical_accuracy)
```
tf.keras.metrics.categorical_accuracy(
y_true, y_pred
)
```
#### Standalone usage:
```
y_true = [[0, 0, 1], [0, 1, 0]]
y_pred = [[0.1, 0.9, 0.8], [0.05, 0.95, 0]]
m = tf.keras.metrics.categorical_accuracy(y_true, y_pred)
assert m.shape == (2,)
m.numpy()
array([0., 1.], dtype=float32)
```
You can provide logits of classes as `y_pred`, since argmax of logits and probabilities are same.
| Args |
| `y_true` | One-hot ground truth values. |
| `y_pred` | The prediction values. |
| Returns |
| Categorical accuracy values. |
tensorflow tf.keras.metrics.SparseCategoricalAccuracy tf.keras.metrics.SparseCategoricalAccuracy
==========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L276-L324) |
Calculates how often predictions match integer labels.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SparseCategoricalAccuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SparseCategoricalAccuracy)
```
tf.keras.metrics.SparseCategoricalAccuracy(
name='sparse_categorical_accuracy', dtype=None
)
```
```
acc = np.dot(sample_weight, np.equal(y_true, np.argmax(y_pred, axis=1))
```
You can provide logits of classes as `y_pred`, since argmax of logits and probabilities are same.
This metric creates two local variables, `total` and `count` that are used to compute the frequency with which `y_pred` matches `y_true`. This frequency is ultimately returned as `sparse categorical accuracy`: an idempotent operation that simply divides `total` by `count`.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.SparseCategoricalAccuracy()
m.update_state([[2], [1]], [[0.1, 0.6, 0.3], [0.05, 0.95, 0]])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([[2], [1]], [[0.1, 0.6, 0.3], [0.05, 0.95, 0]],
sample_weight=[0.7, 0.3])
m.result().numpy()
0.3
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.OneHotMeanIoU tf.keras.metrics.OneHotMeanIoU
==============================
Computes mean Intersection-Over-Union metric for one-hot encoded labels.
Inherits From: [`MeanIoU`](meaniou), [`IoU`](iou), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.OneHotMeanIoU`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/OneHotMeanIoU)
```
tf.keras.metrics.OneHotMeanIoU(
num_classes: int, name=None, dtype=None
)
```
General definition and computation:
Intersection-Over-Union is a common evaluation metric for semantic image segmentation.
For an individual class, the IoU metric is defined as follows:
```
iou = true_positives / (true_positives + false_positives + false_negatives)
```
To compute IoUs, the predictions are accumulated in a confusion matrix, weighted by `sample_weight` and the metric is then calculated from it.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
This class can be used to compute the mean IoU for multi-class classification tasks where the labels are one-hot encoded (the last axis should have one dimension per class). Note that the predictions should also have the same shape. To compute the mean IoU, first the labels and predictions are converted back into integer format by taking the argmax over the class axis. Then the same computation steps as for the base `MeanIoU` class apply.
Note, if there is only one channel in the labels and predictions, this class is the same as class `MeanIoU`. In this case, use `MeanIoU` instead.
Also, make sure that `num_classes` is equal to the number of classes in the data, to avoid a "labels out of bound" error when the confusion matrix is computed.
| Args |
| `num_classes` | The possible number of labels the prediction task can have. A confusion matrix of shape `(num_classes, num_classes)` will be allocated to accumulate predictions from which the metric is calculated. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
y_true = tf.constant([[0, 0, 1], [1, 0, 0], [0, 1, 0], [1, 0, 0]])
y_pred = tf.constant([[0.2, 0.3, 0.5], [0.1, 0.2, 0.7], [0.5, 0.3, 0.1],
[0.1, 0.4, 0.5]])
sample_weight = [0.1, 0.2, 0.3, 0.4]
m = tf.keras.metrics.OneHotMeanIoU(num_classes=3)
m.update_state(y_true=y_true, y_pred=y_pred, sample_weight=sample_weight)
# cm = [[0, 0, 0.2+0.4],
# [0.3, 0, 0],
# [0, 0, 0.1]]
# sum_row = [0.3, 0, 0.7], sum_col = [0.6, 0.3, 0.1]
# true_positives = [0, 0, 0.1]
# single_iou = true_positives / (sum_row + sum_col - true_positives))
# mean_iou = (0 + 0 + 0.1 / (0.7 + 0.1 - 0.1)) / 3
m.result().numpy()
0.048
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.OneHotMeanIoU(num_classes=3)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2502-L2504)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2594-L2618)
```
result()
```
Compute the intersection-over-union via the confusion matrix.
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3014-L3031)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.MeanSquaredError tf.keras.metrics.MeanSquaredError
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2073-L2106) |
Computes the mean squared error between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.MeanSquaredError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/MeanSquaredError)
```
tf.keras.metrics.MeanSquaredError(
name='mean_squared_error', dtype=None
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.MeanSquaredError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.25
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.5
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.MeanSquaredError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.kl_divergence tf.keras.metrics.kl\_divergence
===============================
Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
#### View aliases
**Main aliases**
[`tf.keras.losses.KLD`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.losses.kl_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.losses.kld`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.losses.kullback_leibler_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.metrics.KLD`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.metrics.kld`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.keras.metrics.kullback_leibler_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.KLD`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.losses.kl_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.losses.kld`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.losses.kullback_leibler_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.metrics.KLD`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.metrics.kl_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.metrics.kld`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence), [`tf.compat.v1.keras.metrics.kullback_leibler_divergence`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/kl_divergence)
```
tf.keras.metrics.kl_divergence(
y_true, y_pred
)
```
`loss = y_true * log(y_true / y_pred)`
See: <https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence>
#### Standalone usage:
```
y_true = np.random.randint(0, 2, size=(2, 3)).astype(np.float64)
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.kullback_leibler_divergence(y_true, y_pred)
assert loss.shape == (2,)
y_true = tf.keras.backend.clip(y_true, 1e-7, 1)
y_pred = tf.keras.backend.clip(y_pred, 1e-7, 1)
assert np.array_equal(
loss.numpy(), np.sum(y_true * np.log(y_true / y_pred), axis=-1))
```
| Args |
| `y_true` | Tensor of true targets. |
| `y_pred` | Tensor of predicted targets. |
| Returns |
| A `Tensor` with loss. |
| Raises |
| `TypeError` | If `y_true` cannot be cast to the `y_pred.dtype`. |
tensorflow tf.keras.metrics.BinaryIoU tf.keras.metrics.BinaryIoU
==========================
Computes the Intersection-Over-Union metric for class 0 and/or 1.
Inherits From: [`IoU`](iou), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.BinaryIoU`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/BinaryIoU)
```
tf.keras.metrics.BinaryIoU(
target_class_ids: Union[List[int], Tuple[int, ...]] = (0, 1),
threshold=0.5,
name=None,
dtype=None
)
```
General definition and computation:
Intersection-Over-Union is a common evaluation metric for semantic image segmentation.
For an individual class, the IoU metric is defined as follows:
```
iou = true_positives / (true_positives + false_positives + false_negatives)
```
To compute IoUs, the predictions are accumulated in a confusion matrix, weighted by `sample_weight` and the metric is then calculated from it.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
This class can be used to compute IoUs for a binary classification task where the predictions are provided as logits. First a `threshold` is applied to the predicted values such that those that are below the `threshold` are converted to class 0 and those that are above the `threshold` are converted to class 1.
IoUs for classes 0 and 1 are then computed, the mean of IoUs for the classes that are specified by `target_class_ids` is returned.
>
> **Note:** with `threshold=0`, this metric has the same behavior as `IoU`.
>
| Args |
| `target_class_ids` | A tuple or list of target class ids for which the metric is returned. Options are `[0]`, `[1]`, or `[0, 1]`. With `[0]` (or `[1]`), the IoU metric for class 0 (or class 1, respectively) is returned. With `[0, 1]`, the mean of IoUs for the two classes is returned. |
| `threshold` | A threshold that applies to the prediction logits to convert them to either predicted class 0 if the logit is below `threshold` or predicted class 1 if the logit is above `threshold`. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.BinaryIoU(target_class_ids=[0, 1], threshold=0.3)
m.update_state([0, 1, 0, 1], [0.1, 0.2, 0.4, 0.7])
m.result().numpy()
0.33333334
```
```
m.reset_state()
m.update_state([0, 1, 0, 1], [0.1, 0.2, 0.4, 0.7],
sample_weight=[0.2, 0.3, 0.4, 0.1])
# cm = [[0.2, 0.4],
# [0.3, 0.1]]
# sum_row = [0.6, 0.4], sum_col = [0.5, 0.5], true_positives = [0.2, 0.1]
# iou = [0.222, 0.125]
m.result().numpy()
0.17361112
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.BinaryIoU(target_class_ids=[0], threshold=0.5)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2502-L2504)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2594-L2618)
```
result()
```
Compute the intersection-over-union via the confusion matrix.
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2715-L2735)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the confusion matrix statistics.
Before the confusion matrix is updated, the predicted values are thresholded to be: 0 for values that are smaller than the `threshold` 1 for values that are larger or equal to the `threshold`
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.SparseCategoricalCrossentropy tf.keras.metrics.SparseCategoricalCrossentropy
==============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L3154-L3222) |
Computes the crossentropy metric between the labels and predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.SparseCategoricalCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SparseCategoricalCrossentropy)
```
tf.keras.metrics.SparseCategoricalCrossentropy(
name='sparse_categorical_crossentropy',
dtype=None,
from_logits=False,
axis=-1
)
```
Use this crossentropy metric when there are two or more label classes. We expect labels to be provided as integers. If you want to provide labels using `one-hot` representation, please use `CategoricalCrossentropy` metric. There should be `# classes` floating point values per feature for `y_pred` and a single floating point value per feature for `y_true`.
In the snippet below, there is a single floating point value per example for `y_true` and `# classes` floating pointing values per example for `y_pred`. The shape of `y_true` is `[batch_size]` and the shape of `y_pred` is `[batch_size, num_classes]`.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `from_logits` | (Optional) Whether output is expected to be a logits tensor. By default, we consider that output encodes a probability distribution. |
| `axis` | (Optional) Defaults to -1. The dimension along which the metric is computed. |
#### Standalone usage:
```
# y_true = one_hot(y_true) = [[0, 1, 0], [0, 0, 1]]
# logits = log(y_pred)
# softmax = exp(logits) / sum(exp(logits), axis=-1)
# softmax = [[0.05, 0.95, EPSILON], [0.1, 0.8, 0.1]]
# xent = -sum(y * log(softmax), 1)
# log(softmax) = [[-2.9957, -0.0513, -16.1181],
# [-2.3026, -0.2231, -2.3026]]
# y_true * log(softmax) = [[0, -0.0513, 0], [0, 0, -2.3026]]
# xent = [0.0513, 2.3026]
# Reduced xent = (0.0513 + 2.3026) / 2
m = tf.keras.metrics.SparseCategoricalCrossentropy()
m.update_state([1, 2],
[[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
m.result().numpy()
1.1769392
```
```
m.reset_state()
m.update_state([1, 2],
[[0.05, 0.95, 0], [0.1, 0.8, 0.1]],
sample_weight=tf.constant([0.3, 0.7]))
m.result().numpy()
1.6271976
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.SparseCategoricalCrossentropy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.LogCoshError tf.keras.metrics.LogCoshError
=============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2314-L2347) |
Computes the logarithm of the hyperbolic cosine of the prediction error.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.LogCoshError`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/LogCoshError)
```
tf.keras.metrics.LogCoshError(
name='logcosh', dtype=None
)
```
`logcosh = log((exp(x) + exp(-x))/2)`, where x is the error (y\_pred - y\_true)
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.LogCoshError()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]])
m.result().numpy()
0.10844523
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[1, 1], [0, 0]],
sample_weight=[1, 0])
m.result().numpy()
0.21689045
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.LogCoshError()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.serialize tf.keras.metrics.serialize
==========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/__init__.py#L113-L123) |
Serializes metric function or `Metric` instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.serialize`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/serialize)
```
tf.keras.metrics.serialize(
metric
)
```
| Args |
| `metric` | A Keras `Metric` instance or a metric function. |
| Returns |
| Metric configuration dictionary. |
tensorflow tf.keras.metrics.FalseNegatives tf.keras.metrics.FalseNegatives
===============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L560-L606) |
Calculates the number of false negatives.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.FalseNegatives`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/FalseNegatives)
```
tf.keras.metrics.FalseNegatives(
thresholds=None, name=None, dtype=None
)
```
If `sample_weight` is given, calculates the sum of the weights of false negatives. This metric creates one local variable, `accumulator` that is used to keep track of the number of false negatives.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `thresholds` | (Optional) Defaults to 0.5. A float value or a python list/tuple of float threshold values in [0, 1]. A threshold is compared with prediction values to determine the truth value of predictions (i.e., above the threshold is `true`, below is `false`). One metric value is generated for each threshold value. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.FalseNegatives()
m.update_state([0, 1, 1, 1], [0, 1, 0, 0])
m.result().numpy()
2.0
```
```
m.reset_state()
m.update_state([0, 1, 1, 1], [0, 1, 0, 0], sample_weight=[0, 0, 1, 0])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.FalseNegatives()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L498-L501)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L491-L496)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L470-L489)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates the metric statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.CategoricalHinge tf.keras.metrics.CategoricalHinge
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L2222-L2254) |
Computes the categorical hinge metric between `y_true` and `y_pred`.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.CategoricalHinge`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/CategoricalHinge)
```
tf.keras.metrics.CategoricalHinge(
name='categorical_hinge', dtype=None
)
```
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.CategoricalHinge()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]])
m.result().numpy()
1.4000001
```
```
m.reset_state()
m.update_state([[0, 1], [0, 0]], [[0.6, 0.4], [0.4, 0.6]],
sample_weight=[1, 0])
m.result().numpy()
1.2
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.CategoricalHinge()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.get tf.keras.metrics.get
====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/__init__.py#L145-L187) |
Retrieves a Keras metric as a `function`/`Metric` class instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.get`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/get)
```
tf.keras.metrics.get(
identifier
)
```
The `identifier` may be the string name of a metric function or class.
```
metric = tf.keras.metrics.get("categorical_crossentropy")
type(metric)
<class 'function'>
metric = tf.keras.metrics.get("CategoricalCrossentropy")
type(metric)
<class '...metrics.CategoricalCrossentropy'>
```
You can also specify `config` of the metric to this function by passing dict containing `class_name` and `config` as an identifier. Also note that the `class_name` must map to a `Metric` class
```
identifier = {"class_name": "CategoricalCrossentropy",
"config": {"from_logits": True} }
metric = tf.keras.metrics.get(identifier)
type(metric)
<class '...metrics.CategoricalCrossentropy'>
```
| Args |
| `identifier` | A metric identifier. One of None or string name of a metric function/class or metric configuration dictionary or a metric function or a metric class instance |
| Returns |
| A Keras metric as a `function`/ `Metric` class instance. |
| Raises |
| `ValueError` | If `identifier` cannot be interpreted. |
tensorflow tf.keras.metrics.RecallAtPrecision tf.keras.metrics.RecallAtPrecision
==================================
Computes best recall where precision is >= specified value.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.RecallAtPrecision`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/RecallAtPrecision)
```
tf.keras.metrics.RecallAtPrecision(
precision, num_thresholds=200, class_id=None, name=None, dtype=None
)
```
For a given score-label-distribution the required precision might not be achievable, in this case 0.0 is returned as recall.
This metric creates four local variables, `true_positives`, `true_negatives`, `false_positives` and `false_negatives` that are used to compute the recall at the given precision. The threshold for the given precision value is computed and used to evaluate the corresponding recall.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
If `class_id` is specified, we calculate precision by considering only the entries in the batch for which `class_id` is above the threshold predictions, and computing the fraction of them for which `class_id` is indeed a correct label.
| Args |
| `precision` | A scalar value in range `[0, 1]`. |
| `num_thresholds` | (Optional) Defaults to 200. The number of thresholds to use for matching the given precision. |
| `class_id` | (Optional) Integer class ID for which we want binary metrics. This must be in the half-open interval `[0, num_classes)`, where `num_classes` is the last dimension of predictions. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.RecallAtPrecision(0.8)
m.update_state([0, 0, 1, 1], [0, 0.5, 0.3, 0.9])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([0, 0, 1, 1], [0, 0.5, 0.3, 0.9],
sample_weight=[1, 0, 0, 1])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.RecallAtPrecision(precision=0.8)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1058-L1064)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1448-L1456)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1031-L1056)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.TopKCategoricalAccuracy tf.keras.metrics.TopKCategoricalAccuracy
========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L354-L394) |
Computes how often targets are in the top `K` predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.TopKCategoricalAccuracy`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/TopKCategoricalAccuracy)
```
tf.keras.metrics.TopKCategoricalAccuracy(
k=5, name='top_k_categorical_accuracy', dtype=None
)
```
| Args |
| `k` | (Optional) Number of top elements to look at for computing accuracy. Defaults to 5. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
#### Standalone usage:
```
m = tf.keras.metrics.TopKCategoricalAccuracy(k=1)
m.update_state([[0, 0, 1], [0, 1, 0]],
[[0.1, 0.9, 0.8], [0.05, 0.95, 0]])
m.result().numpy()
0.5
```
```
m.reset_state()
m.update_state([[0, 0, 1], [0, 1, 0]],
[[0.1, 0.9, 0.8], [0.05, 0.95, 0]],
sample_weight=[0.7, 0.3])
m.result().numpy()
0.3
```
Usage with `compile()` API:
```
model.compile(optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.TopKCategoricalAccuracy()])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
tensorflow tf.keras.metrics.mean_absolute_percentage_error tf.keras.metrics.mean\_absolute\_percentage\_error
==================================================
Computes the mean absolute percentage error between `y_true` and `y_pred`.
#### View aliases
**Main aliases**
[`tf.keras.losses.MAPE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.keras.losses.mape`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.keras.losses.mean_absolute_percentage_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.keras.metrics.MAPE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.keras.metrics.mape`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MAPE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.compat.v1.keras.losses.mape`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.compat.v1.keras.losses.mean_absolute_percentage_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.compat.v1.keras.metrics.MAPE`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.compat.v1.keras.metrics.mape`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error), [`tf.compat.v1.keras.metrics.mean_absolute_percentage_error`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_absolute_percentage_error)
```
tf.keras.metrics.mean_absolute_percentage_error(
y_true, y_pred
)
```
`loss = 100 * mean(abs((y_true - y_pred) / y_true), axis=-1)`
#### Standalone usage:
```
y_true = np.random.random(size=(2, 3))
y_true = np.maximum(y_true, 1e-7) # Prevent division by zero
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.mean_absolute_percentage_error(y_true, y_pred)
assert loss.shape == (2,)
assert np.array_equal(
loss.numpy(),
100. * np.mean(np.abs((y_true - y_pred) / y_true), axis=-1))
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Mean absolute percentage error values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.metrics.CosineSimilarity tf.keras.metrics.CosineSimilarity
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1948-L1995) |
Computes the cosine similarity between the labels and predictions.
Inherits From: [`MeanMetricWrapper`](meanmetricwrapper), [`Mean`](mean), [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.CosineSimilarity`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/CosineSimilarity)
```
tf.keras.metrics.CosineSimilarity(
name='cosine_similarity', dtype=None, axis=-1
)
```
`cosine similarity = (a . b) / ||a|| ||b||`
See: [Cosine Similarity](https://en.wikipedia.org/wiki/Cosine_similarity).
This metric keeps the average cosine similarity between `predictions` and `labels` over a stream of data.
| Args |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `axis` | (Optional) Defaults to -1. The dimension along which the cosine similarity is computed. |
#### Standalone usage:
```
# l2_norm(y_true) = [[0., 1.], [1./1.414, 1./1.414]]
# l2_norm(y_pred) = [[1., 0.], [1./1.414, 1./1.414]]
# l2_norm(y_true) . l2_norm(y_pred) = [[0., 0.], [0.5, 0.5]]
# result = mean(sum(l2_norm(y_true) . l2_norm(y_pred), axis=1))
# = ((0. + 0.) + (0.5 + 0.5)) / 2
m = tf.keras.metrics.CosineSimilarity(axis=1)
m.update_state([[0., 1.], [1., 1.]], [[1., 0.], [1., 1.]])
m.result().numpy()
0.49999997
```
```
m.reset_state()
m.update_state([[0., 1.], [1., 1.]], [[1., 0.], [1., 1.]],
sample_weight=[0.3, 0.7])
m.result().numpy()
0.6999999
```
Usage with `compile()` API:
```
model.compile(
optimizer='sgd',
loss='mse',
metrics=[tf.keras.metrics.CosineSimilarity(axis=1)])
```
Methods
-------
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L238-L253)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L487-L498)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L616-L648)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates metric statistics.
For sparse categorical metrics, the shapes of `y_true` and `y_pred` are different.
| Args |
| `y_true` | Ground truth label values. shape = `[batch_size, d0, .. dN-1]` or shape = `[batch_size, d0, .. dN-1, 1]`. |
| `y_pred` | The predicted probability values. shape = `[batch_size, d0, .. dN]`. |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the metric. If a scalar is provided, then the metric is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the metric for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each metric element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on `dN-1`: all metric functions reduce by 1 dimension, usually the last axis (-1)). |
| Returns |
| Update op. |
| programming_docs |
tensorflow tf.keras.metrics.AUC tf.keras.metrics.AUC
====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1466-L1944) |
Approximates the AUC (Area under the curve) of the ROC or PR curves.
Inherits From: [`Metric`](metric), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.metrics.AUC`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/AUC)
```
tf.keras.metrics.AUC(
num_thresholds=200,
curve='ROC',
summation_method='interpolation',
name=None,
dtype=None,
thresholds=None,
multi_label=False,
num_labels=None,
label_weights=None,
from_logits=False
)
```
The AUC (Area under the curve) of the ROC (Receiver operating characteristic; default) or PR (Precision Recall) curves are quality measures of binary classifiers. Unlike the accuracy, and like cross-entropy losses, ROC-AUC and PR-AUC evaluate all the operational points of a model.
This class approximates AUCs using a Riemann sum. During the metric accumulation phrase, predictions are accumulated within predefined buckets by value. The AUC is then computed by interpolating per-bucket averages. These buckets define the evaluated operational points.
This metric creates four local variables, `true_positives`, `true_negatives`, `false_positives` and `false_negatives` that are used to compute the AUC. To discretize the AUC curve, a linearly spaced set of thresholds is used to compute pairs of recall and precision values. The area under the ROC-curve is therefore computed using the height of the recall values by the false positive rate, while the area under the PR-curve is the computed using the height of the precision values by the recall.
This value is ultimately returned as `auc`, an idempotent operation that computes the area under a discretized curve of precision versus recall values (computed using the aforementioned variables). The `num_thresholds` variable controls the degree of discretization with larger numbers of thresholds more closely approximating the true AUC. The quality of the approximation may vary dramatically depending on `num_thresholds`. The `thresholds` parameter can be used to manually specify thresholds which split the predictions more evenly.
For a best approximation of the real AUC, `predictions` should be distributed approximately uniformly in the range [0, 1](if%20%60from_logits=false%60). The quality of the AUC approximation may be poor if this is not the case. Setting `summation_method` to 'minoring' or 'majoring' can help quantify the error in the approximation by providing lower or upper bound estimate of the AUC.
If `sample_weight` is `None`, weights default to 1. Use `sample_weight` of 0 to mask values.
| Args |
| `num_thresholds` | (Optional) Defaults to 200. The number of thresholds to use when discretizing the roc curve. Values must be > 1. |
| `curve` | (Optional) Specifies the name of the curve to be computed, 'ROC' [default] or 'PR' for the Precision-Recall-curve. |
| `summation_method` | (Optional) Specifies the [Riemann summation method](https://en.wikipedia.org/wiki/Riemann_sum) used. 'interpolation' (default) applies mid-point summation scheme for `ROC`. For PR-AUC, interpolates (true/false) positives but not the ratio that is precision (see Davis & Goadrich 2006 for details); 'minoring' applies left summation for increasing intervals and right summation for decreasing intervals; 'majoring' does the opposite. |
| `name` | (Optional) string name of the metric instance. |
| `dtype` | (Optional) data type of the metric result. |
| `thresholds` | (Optional) A list of floating point values to use as the thresholds for discretizing the curve. If set, the `num_thresholds` parameter is ignored. Values should be in [0, 1]. Endpoint thresholds equal to {-epsilon, 1+epsilon} for a small positive epsilon value will be automatically included with these to correctly handle predictions equal to exactly 0 or 1. |
| `multi_label` | boolean indicating whether multilabel data should be treated as such, wherein AUC is computed separately for each label and then averaged across labels, or (when False) if the data should be flattened into a single label before AUC computation. In the latter case, when multilabel data is passed to AUC, each label-prediction pair is treated as an individual data point. Should be set to False for multi-class data. |
| `num_labels` | (Optional) The number of labels, used when `multi_label` is True. If `num_labels` is not specified, then state variables get created on the first call to `update_state`. |
| `label_weights` | (Optional) list, array, or tensor of non-negative weights used to compute AUCs for multilabel data. When `multi_label` is True, the weights are applied to the individual label AUCs when they are averaged to produce the multi-label AUC. When it's False, they are used to weight the individual label predictions in computing the confusion matrix on the flattened data. Note that this is unlike class\_weights in that class\_weights weights the example depending on the value of its label, whereas label\_weights depends only on the index of that label before flattening; therefore `label_weights` should not be used for multi-class data. |
| `from_logits` | boolean indicating whether the predictions (`y_pred` in `update_state`) are probabilities or sigmoid logits. As a rule of thumb, when using a keras loss, the `from_logits` constructor argument of the loss should match the AUC `from_logits` constructor argument. |
#### Standalone usage:
```
m = tf.keras.metrics.AUC(num_thresholds=3)
m.update_state([0, 0, 1, 1], [0, 0.5, 0.3, 0.9])
# threshold values are [0 - 1e-7, 0.5, 1 + 1e-7]
# tp = [2, 1, 0], fp = [2, 0, 0], fn = [0, 1, 2], tn = [0, 2, 2]
# tp_rate = recall = [1, 0.5, 0], fp_rate = [1, 0, 0]
# auc = ((((1+0.5)/2)*(1-0)) + (((0.5+0)/2)*(0-0))) = 0.75
m.result().numpy()
0.75
```
```
m.reset_state()
m.update_state([0, 0, 1, 1], [0, 0.5, 0.3, 0.9],
sample_weight=[1, 0, 0, 1])
m.result().numpy()
1.0
```
Usage with `compile()` API:
```
# Reports the AUC of a model outputting a probability.
model.compile(optimizer='sgd',
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.AUC()])
# Reports the AUC of a model outputting a logit.
model.compile(optimizer='sgd',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.AUC(from_logits=True)])
```
| Attributes |
| `thresholds` | The thresholds used for evaluating AUC. |
Methods
-------
### `interpolate_pr_auc`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1778-L1857)
```
interpolate_pr_auc()
```
Interpolation formula inspired by section 4 of Davis & Goadrich 2006.
<https://www.biostat.wisc.edu/~page/rocpr.pdf>
Note here we derive & use a closed formula not present in the paper as follows:
Precision = TP / (TP + FP) = TP / P
Modeling all of TP (true positive), FP (false positive) and their sum P = TP + FP (predicted positive) as varying linearly within each interval [A, B] between successive thresholds, we get
Precision slope = dTP / dP = (TP\_B - TP\_A) / (P\_B - P\_A) = (TP - TP\_A) / (P - P\_A) Precision = (TP\_A + slope \* (P - P\_A)) / P
The area within the interval is (slope / total\_pos\_weight) times
int\_A^B{Precision.dP} = int\_A^B{(TP\_A + slope \* (P - P\_A)) \* dP / P} int\_A^B{Precision.dP} = int\_A^B{slope \* dP + intercept \* dP / P}
where intercept = TP\_A - slope \* P\_A = TP\_B - slope \* P\_B, resulting in
int\_A^B{Precision.dP} = TP\_B - TP\_A + intercept \* log(P\_B / P\_A)
Bringing back the factor (slope / total\_pos\_weight) we'd put aside, we get
slope \* [dTP + intercept \* log(P\_B / P\_A)] / total\_pos\_weight
where dTP == TP\_B - TP\_A.
Note that when P\_A == 0 the above calculation simplifies into
int\_A^B{Precision.dTP} = int\_A^B{slope \* dTP} = slope \* (TP\_B - TP\_A)
which is really equivalent to imputing constant precision throughout the first bucket having >0 true positives.
| Returns |
| `pr_auc` | an approximation of the area under the P-R curve. |
### `merge_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/base_metric.py#L275-L309)
```
merge_state(
metrics
)
```
Merges the state from one or more metrics.
This method can be used by distributed systems to merge the state computed by different metric instances. Typically the state will be stored in the form of the metric's weights. For example, a tf.keras.metrics.Mean metric contains a list of two weight values: a total and a count. If there were two instances of a tf.keras.metrics.Accuracy that each independently aggregated partial state for an overall accuracy calculation, these two metric's states could be combined as follows:
```
m1 = tf.keras.metrics.Accuracy()
_ = m1.update_state([[1], [2]], [[0], [2]])
```
```
m2 = tf.keras.metrics.Accuracy()
_ = m2.update_state([[3], [4]], [[3], [4]])
```
```
m2.merge_state([m1])
m2.result().numpy()
0.75
```
| Args |
| `metrics` | an iterable of metrics. The metrics must have compatible state. |
| Raises |
| `ValueError` | If the provided iterable does not contain metrics matching the metric's required specifications. |
### `reset_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1913-L1923)
```
reset_state()
```
Resets all of the metric state variables.
This function is called between epochs/steps, when a metric is evaluated during training.
### `result`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1859-L1911)
```
result()
```
Computes and returns the scalar metric value tensor or a dict of scalars.
Result computation is an idempotent operation that simply calculates the metric value using the state variables.
| Returns |
| A scalar tensor, or a dictionary of scalar tensors. |
### `update_state`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/metrics/metrics.py#L1717-L1776)
```
update_state(
y_true, y_pred, sample_weight=None
)
```
Accumulates confusion matrix statistics.
| Args |
| `y_true` | The ground truth values. |
| `y_pred` | The predicted values. |
| `sample_weight` | Optional weighting of each example. Defaults to 1. Can be a `Tensor` whose rank is either 0, or the same rank as `y_true`, and must be broadcastable to `y_true`. |
| Returns |
| Update op. |
tensorflow tf.keras.losses.BinaryFocalCrossentropy tf.keras.losses.BinaryFocalCrossentropy
=======================================
Computes the focal cross-entropy loss between true labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.BinaryFocalCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/BinaryFocalCrossentropy)
```
tf.keras.losses.BinaryFocalCrossentropy(
gamma=2.0,
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='binary_focal_crossentropy'
)
```
Binary cross-entropy loss is often used for binary (0 or 1) classification tasks. The loss function requires the following inputs:
* `y_true` (true label): This is either 0 or 1.
* `y_pred` (predicted value): This is the model's prediction, i.e, a single floating-point value which either represents a [logit](https://en.wikipedia.org/wiki/Logit), (i.e, value in [-inf, inf] when `from_logits=True`) or a probability (i.e, value in `[0., 1.]` when `from_logits=False`).
According to [Lin et al., 2018](https://arxiv.org/pdf/1708.02002.pdf), it helps to apply a "focal factor" to down-weight easy examples and focus more on hard examples. By default, the focal tensor is computed as follows:
`focal_factor = (1 - output) ** gamma` for class 1 `focal_factor = output ** gamma` for class 0 where `gamma` is a focusing parameter. When `gamma=0`, this function is equivalent to the binary crossentropy loss.
With the `compile()` API:
```
model.compile(
loss=tf.keras.losses.BinaryFocalCrossentropy(gamma=2.0, from_logits=True),
....
)
```
As a standalone function:
```
# Example 1: (batch_size = 1, number of samples = 4)
y_true = [0, 1, 0, 0]
y_pred = [-18.6, 0.51, 2.94, -12.8]
loss = tf.keras.losses.BinaryFocalCrossentropy(gamma=2, from_logits=True)
loss(y_true, y_pred).numpy()
0.691
```
```
# Example 2: (batch_size = 2, number of samples = 4)
y_true = [[0, 1], [0, 0]]
y_pred = [[-18.6, 0.51], [2.94, -12.8]]
# Using default 'auto'/'sum_over_batch_size' reduction type.
loss = tf.keras.losses.BinaryFocalCrossentropy(gamma=3, from_logits=True)
loss(y_true, y_pred).numpy()
0.647
```
```
# Using 'sample_weight' attribute
loss(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
0.133
```
```
# Using 'sum' reduction` type.
loss = tf.keras.losses.BinaryFocalCrossentropy(gamma=4, from_logits=True,
reduction=tf.keras.losses.Reduction.SUM)
loss(y_true, y_pred).numpy()
1.222
```
```
# Using 'none' reduction type.
loss = tf.keras.losses.BinaryFocalCrossentropy(gamma=5, from_logits=True,
reduction=tf.keras.losses.Reduction.NONE)
loss(y_true, y_pred).numpy()
array([0.0017 1.1561], dtype=float32)
```
| Args |
| `gamma` | A focusing parameter used to compute the focal factor, default is `2.0` as mentioned in the reference [Lin et al., 2018](https://arxiv.org/pdf/1708.02002.pdf). |
| `from_logits` | Whether to interpret `y_pred` as a tensor of [logit](https://en.wikipedia.org/wiki/Logit) values. By default, we assume that `y_pred` are probabilities (i.e., values in `[0, 1]`). |
| `label_smoothing` | Float in `[0, 1]`. When `0`, no smoothing occurs. When > `0`, we compute the loss between the predicted labels and a smoothed version of the true labels, where the smoothing squeezes the labels towards `0.5`. Larger values of `label_smoothing` correspond to heavier smoothing. |
| `axis` | The axis along which to compute crossentropy (the features axis). Defaults to `-1`. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras), `compile()` and `fit()`, using `SUM_OVER_BATCH_SIZE` or `AUTO` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Name for the op. Defaults to 'binary\_focal\_crossentropy'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L711-L716)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.BinaryCrossentropy tf.keras.losses.BinaryCrossentropy
==================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L497-L596) |
Computes the cross-entropy loss between true labels and predicted labels.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.BinaryCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/BinaryCrossentropy)
```
tf.keras.losses.BinaryCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='binary_crossentropy'
)
```
Use this cross-entropy loss for binary (0 or 1) classification applications. The loss function requires the following inputs:
* `y_true` (true label): This is either 0 or 1.
* `y_pred` (predicted value): This is the model's prediction, i.e, a single floating-point value which either represents a [logit](https://en.wikipedia.org/wiki/Logit), (i.e, value in [-inf, inf] when `from_logits=True`) or a probability (i.e, value in [0., 1.] when `from_logits=False`).
**Recommended Usage:** (set `from_logits=True`)
With [`tf.keras`](../../keras) API:
```
model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
....
)
```
As a standalone function:
```
# Example 1: (batch_size = 1, number of samples = 4)
y_true = [0, 1, 0, 0]
y_pred = [-18.6, 0.51, 2.94, -12.8]
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True)
bce(y_true, y_pred).numpy()
0.865
```
```
# Example 2: (batch_size = 2, number of samples = 4)
y_true = [[0, 1], [0, 0]]
y_pred = [[-18.6, 0.51], [2.94, -12.8]]
# Using default 'auto'/'sum_over_batch_size' reduction type.
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True)
bce(y_true, y_pred).numpy()
0.865
# Using 'sample_weight' attribute
bce(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
0.243
# Using 'sum' reduction` type.
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True,
reduction=tf.keras.losses.Reduction.SUM)
bce(y_true, y_pred).numpy()
1.730
# Using 'none' reduction type.
bce = tf.keras.losses.BinaryCrossentropy(from_logits=True,
reduction=tf.keras.losses.Reduction.NONE)
bce(y_true, y_pred).numpy()
array([0.235, 1.496], dtype=float32)
```
**Default Usage:** (set `from_logits=False`)
```
# Make the following updates to the above "Recommended Usage" section
# 1. Set `from_logits=False`
tf.keras.losses.BinaryCrossentropy() # OR ...('from_logits=False')
# 2. Update `y_pred` to use probabilities instead of logits
y_pred = [0.6, 0.3, 0.2, 0.8] # OR [[0.6, 0.3], [0.2, 0.8]]
```
| Args |
| `from_logits` | Whether to interpret `y_pred` as a tensor of [logit](https://en.wikipedia.org/wiki/Logit) values. By default, we assume that `y_pred` contains probabilities (i.e., values in [0, 1]). |
| `label_smoothing` | Float in [0, 1]. When 0, no smoothing occurs. When > 0, we compute the loss between the predicted labels and a smoothed version of the true labels, where the smoothing squeezes the labels towards 0.5. Larger values of `label_smoothing` correspond to heavier smoothing. |
| `axis` | The axis along which to compute crossentropy (the features axis). Defaults to -1. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Name for the op. Defaults to 'binary\_crossentropy'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
| programming_docs |
tensorflow tf.keras.losses.SquaredHinge tf.keras.losses.SquaredHinge
============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L938-L995) |
Computes the squared hinge loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.SquaredHinge`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/SquaredHinge)
```
tf.keras.losses.SquaredHinge(
reduction=losses_utils.ReductionV2.AUTO, name='squared_hinge'
)
```
`loss = square(maximum(1 - y_true * y_pred, 0))`
`y_true` values are expected to be -1 or 1. If binary (0 or 1) labels are provided we will convert them to -1 or 1.
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# Using 'auto'/'sum_over_batch_size' reduction type.
h = tf.keras.losses.SquaredHinge()
h(y_true, y_pred).numpy()
1.86
```
```
# Calling with 'sample_weight'.
h(y_true, y_pred, sample_weight=[1, 0]).numpy()
0.73
```
```
# Using 'sum' reduction type.
h = tf.keras.losses.SquaredHinge(
reduction=tf.keras.losses.Reduction.SUM)
h(y_true, y_pred).numpy()
3.72
```
```
# Using 'none' reduction type.
h = tf.keras.losses.SquaredHinge(
reduction=tf.keras.losses.Reduction.NONE)
h(y_true, y_pred).numpy()
array([1.46, 2.26], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.SquaredHinge())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'squared\_hinge'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.log_cosh tf.keras.losses.log\_cosh
=========================
Logarithm of the hyperbolic cosine of the prediction error.
#### View aliases
**Main aliases**
[`tf.keras.losses.logcosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh), [`tf.keras.metrics.log_cosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh), [`tf.keras.metrics.logcosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh)
**Compat aliases for migration** See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.log_cosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh), [`tf.compat.v1.keras.losses.logcosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh), [`tf.compat.v1.keras.metrics.log_cosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh), [`tf.compat.v1.keras.metrics.logcosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/log_cosh)
```
tf.keras.losses.log_cosh(
y_true, y_pred
)
```
`log(cosh(x))` is approximately equal to `(x ** 2) / 2` for small `x` and to `abs(x) - log(2)` for large `x`. This means that 'logcosh' works mostly like the mean squared error, but will not be so strongly affected by the occasional wildly incorrect prediction.
#### Standalone usage:
```
y_true = np.random.random(size=(2, 3))
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.logcosh(y_true, y_pred)
assert loss.shape == (2,)
x = y_pred - y_true
assert np.allclose(
loss.numpy(),
np.mean(x + np.log(np.exp(-2. * x) + 1.) - tf.math.log(2.), axis=-1),
atol=1e-5)
```
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`. |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]`. |
| Returns |
| Logcosh error values. shape = `[batch_size, d0, .. dN-1]`. |
tensorflow tf.keras.losses.Hinge tf.keras.losses.Hinge
=====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L879-L934) |
Computes the hinge loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.Hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/Hinge)
```
tf.keras.losses.Hinge(
reduction=losses_utils.ReductionV2.AUTO, name='hinge'
)
```
`loss = maximum(1 - y_true * y_pred, 0)`
`y_true` values are expected to be -1 or 1. If binary (0 or 1) labels are provided we will convert them to -1 or 1.
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# Using 'auto'/'sum_over_batch_size' reduction type.
h = tf.keras.losses.Hinge()
h(y_true, y_pred).numpy()
1.3
```
```
# Calling with 'sample_weight'.
h(y_true, y_pred, sample_weight=[1, 0]).numpy()
0.55
```
```
# Using 'sum' reduction type.
h = tf.keras.losses.Hinge(
reduction=tf.keras.losses.Reduction.SUM)
h(y_true, y_pred).numpy()
2.6
```
```
# Using 'none' reduction type.
h = tf.keras.losses.Hinge(
reduction=tf.keras.losses.Reduction.NONE)
h(y_true, y_pred).numpy()
array([1.1, 1.5], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.Hinge())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'hinge'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.Loss tf.keras.losses.Loss
====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L35-L197) |
Loss base class.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.Loss`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/Loss)
```
tf.keras.losses.Loss(
reduction=losses_utils.ReductionV2.AUTO, name=None
)
```
To be implemented by subclasses:
* `call()`: Contains the logic for loss calculation using `y_true`, `y_pred`.
Example subclass implementation:
```
class MeanSquaredError(Loss):
def call(self, y_true, y_pred):
return tf.reduce_mean(tf.math.square(y_pred - y_true), axis=-1)
```
When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, please use 'SUM' or 'NONE' reduction types, and reduce losses explicitly in your training loop. Using 'AUTO' or 'SUM\_OVER\_BATCH\_SIZE' will raise an error.
Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details on this.
You can implement 'SUM\_OVER\_BATCH\_SIZE' using global batch size like:
```
with strategy.scope():
loss_obj = tf.keras.losses.CategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.NONE)
....
loss = (tf.reduce_sum(loss_obj(labels, predictions)) *
(1. / global_batch_size))
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. |
Methods
-------
### `call`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L159-L173)
```
@abc.abstractmethod
call(
y_true, y_pred
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| Returns |
| Loss values with the shape `[batch_size, d0, .. dN-1]`. |
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L155-L157)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.categorical_hinge tf.keras.losses.categorical\_hinge
==================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L1634-L1666) |
Computes the categorical hinge loss between `y_true` and `y_pred`.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.categorical_hinge`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/categorical_hinge)
```
tf.keras.losses.categorical_hinge(
y_true, y_pred
)
```
`loss = maximum(neg - pos + 1, 0)` where `neg=maximum((1-y_true)*y_pred) and pos=sum(y_true*y_pred)`
#### Standalone usage:
```
y_true = np.random.randint(0, 3, size=(2,))
y_true = tf.keras.utils.to_categorical(y_true, num_classes=3)
y_pred = np.random.random(size=(2, 3))
loss = tf.keras.losses.categorical_hinge(y_true, y_pred)
assert loss.shape == (2,)
pos = np.sum(y_true * y_pred, axis=-1)
neg = np.amax((1. - y_true) * y_pred, axis=-1)
assert np.array_equal(loss.numpy(), np.maximum(0., neg - pos + 1.))
```
| Args |
| `y_true` | The ground truth values. `y_true` values are expected to be either `{-1, +1}` or `{0, 1}` (i.e. a one-hot-encoded tensor). |
| `y_pred` | The predicted values. |
| Returns |
| Categorical hinge loss values. |
tensorflow tf.keras.losses.deserialize tf.keras.losses.deserialize
===========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L2310-L2326) |
Deserializes a serialized loss class/function instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.deserialize`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/deserialize)
```
tf.keras.losses.deserialize(
name, custom_objects=None
)
```
| Args |
| `name` | Loss configuration. |
| `custom_objects` | Optional dictionary mapping names (strings) to custom objects (classes and functions) to be considered during deserialization. |
| Returns |
| A Keras `Loss` instance or a loss function. |
tensorflow tf.keras.losses.Poisson tf.keras.losses.Poisson
=======================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L1058-L1110) |
Computes the Poisson loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.Poisson`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/Poisson)
```
tf.keras.losses.Poisson(
reduction=losses_utils.ReductionV2.AUTO, name='poisson'
)
```
`loss = y_pred - y_true * log(y_pred)`
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [0., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
p = tf.keras.losses.Poisson()
p(y_true, y_pred).numpy()
0.5
```
```
# Calling with 'sample_weight'.
p(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
0.4
```
```
# Using 'sum' reduction type.
p = tf.keras.losses.Poisson(
reduction=tf.keras.losses.Reduction.SUM)
p(y_true, y_pred).numpy()
0.999
```
```
# Using 'none' reduction type.
p = tf.keras.losses.Poisson(
reduction=tf.keras.losses.Reduction.NONE)
p(y_true, y_pred).numpy()
array([0.999, 0.], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.Poisson())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'poisson'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
| programming_docs |
tensorflow tf.keras.losses.MeanSquaredLogarithmicError tf.keras.losses.MeanSquaredLogarithmicError
===========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L436-L493) |
Computes the mean squared logarithmic error between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MeanSquaredLogarithmicError`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/MeanSquaredLogarithmicError)
```
tf.keras.losses.MeanSquaredLogarithmicError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_squared_logarithmic_error'
)
```
`loss = square(log(y_true + 1.) - log(y_pred + 1.))`
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
msle = tf.keras.losses.MeanSquaredLogarithmicError()
msle(y_true, y_pred).numpy()
0.240
```
```
# Calling with 'sample_weight'.
msle(y_true, y_pred, sample_weight=[0.7, 0.3]).numpy()
0.120
```
```
# Using 'sum' reduction type.
msle = tf.keras.losses.MeanSquaredLogarithmicError(
reduction=tf.keras.losses.Reduction.SUM)
msle(y_true, y_pred).numpy()
0.480
```
```
# Using 'none' reduction type.
msle = tf.keras.losses.MeanSquaredLogarithmicError(
reduction=tf.keras.losses.Reduction.NONE)
msle(y_true, y_pred).numpy()
array([0.240, 0.240], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd',
loss=tf.keras.losses.MeanSquaredLogarithmicError())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'mean\_squared\_logarithmic\_error'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.LogCosh tf.keras.losses.LogCosh
=======================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L1114-L1167) |
Computes the logarithm of the hyperbolic cosine of the prediction error.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.LogCosh`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/LogCosh)
```
tf.keras.losses.LogCosh(
reduction=losses_utils.ReductionV2.AUTO, name='log_cosh'
)
```
`logcosh = log((exp(x) + exp(-x))/2)`, where x is the error `y_pred - y_true`.
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [0., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
l = tf.keras.losses.LogCosh()
l(y_true, y_pred).numpy()
0.108
```
```
# Calling with 'sample_weight'.
l(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
0.087
```
```
# Using 'sum' reduction type.
l = tf.keras.losses.LogCosh(
reduction=tf.keras.losses.Reduction.SUM)
l(y_true, y_pred).numpy()
0.217
```
```
# Using 'none' reduction type.
l = tf.keras.losses.LogCosh(
reduction=tf.keras.losses.Reduction.NONE)
l(y_true, y_pred).numpy()
array([0.217, 0.], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.LogCosh())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'log\_cosh'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.MeanAbsoluteError tf.keras.losses.MeanAbsoluteError
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L312-L366) |
Computes the mean of absolute difference between labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MeanAbsoluteError`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/MeanAbsoluteError)
```
tf.keras.losses.MeanAbsoluteError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_absolute_error'
)
```
`loss = abs(y_true - y_pred)`
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
mae = tf.keras.losses.MeanAbsoluteError()
mae(y_true, y_pred).numpy()
0.5
```
```
# Calling with 'sample_weight'.
mae(y_true, y_pred, sample_weight=[0.7, 0.3]).numpy()
0.25
```
```
# Using 'sum' reduction type.
mae = tf.keras.losses.MeanAbsoluteError(
reduction=tf.keras.losses.Reduction.SUM)
mae(y_true, y_pred).numpy()
1.0
```
```
# Using 'none' reduction type.
mae = tf.keras.losses.MeanAbsoluteError(
reduction=tf.keras.losses.Reduction.NONE)
mae(y_true, y_pred).numpy()
array([0.5, 0.5], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.MeanAbsoluteError())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'mean\_absolute\_error'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.CategoricalCrossentropy tf.keras.losses.CategoricalCrossentropy
=======================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L720-L799) |
Computes the crossentropy loss between the labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.CategoricalCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/CategoricalCrossentropy)
```
tf.keras.losses.CategoricalCrossentropy(
from_logits=False,
label_smoothing=0.0,
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='categorical_crossentropy'
)
```
Use this crossentropy loss function when there are two or more label classes. We expect labels to be provided in a `one_hot` representation. If you want to provide labels as integers, please use `SparseCategoricalCrossentropy` loss. There should be `# classes` floating point values per feature.
In the snippet below, there is `# classes` floating pointing values per example. The shape of both `y_pred` and `y_true` are `[batch_size, num_classes]`.
#### Standalone usage:
```
y_true = [[0, 1, 0], [0, 0, 1]]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
# Using 'auto'/'sum_over_batch_size' reduction type.
cce = tf.keras.losses.CategoricalCrossentropy()
cce(y_true, y_pred).numpy()
1.177
```
```
# Calling with 'sample_weight'.
cce(y_true, y_pred, sample_weight=tf.constant([0.3, 0.7])).numpy()
0.814
```
```
# Using 'sum' reduction type.
cce = tf.keras.losses.CategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.SUM)
cce(y_true, y_pred).numpy()
2.354
```
```
# Using 'none' reduction type.
cce = tf.keras.losses.CategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.NONE)
cce(y_true, y_pred).numpy()
array([0.0513, 2.303], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.CategoricalCrossentropy())
```
| Args |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `label_smoothing` | Float in [0, 1]. When > 0, label values are smoothed, meaning the confidence on label values are relaxed. For example, if `0.1`, use `0.1 / num_classes` for non-target labels and `0.9 + 0.1 / num_classes` for target labels. |
| `axis` | The axis along which to compute crossentropy (the features axis). Defaults to -1. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'categorical\_crossentropy'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.KLDivergence tf.keras.losses.KLDivergence
============================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L1171-L1227) |
Computes Kullback-Leibler divergence loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.KLDivergence`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/KLDivergence)
```
tf.keras.losses.KLDivergence(
reduction=losses_utils.ReductionV2.AUTO, name='kl_divergence'
)
```
`loss = y_true * log(y_true / y_pred)`
See: <https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence>
#### Standalone usage:
```
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# Using 'auto'/'sum_over_batch_size' reduction type.
kl = tf.keras.losses.KLDivergence()
kl(y_true, y_pred).numpy()
0.458
```
```
# Calling with 'sample_weight'.
kl(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
0.366
```
```
# Using 'sum' reduction type.
kl = tf.keras.losses.KLDivergence(
reduction=tf.keras.losses.Reduction.SUM)
kl(y_true, y_pred).numpy()
0.916
```
```
# Using 'none' reduction type.
kl = tf.keras.losses.KLDivergence(
reduction=tf.keras.losses.Reduction.NONE)
kl(y_true, y_pred).numpy()
array([0.916, -3.08e-06], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.KLDivergence())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'kl\_divergence'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
| programming_docs |
tensorflow tf.keras.losses.Reduction tf.keras.losses.Reduction
=========================
Types of loss reduction.
Contains the following values:
* `AUTO`: Indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, we expect reduction value to be `SUM` or `NONE`. Using `AUTO` in that case will raise an error.
* `NONE`: No **additional** reduction is applied to the output of the wrapped loss function. When non-scalar losses are returned to Keras functions like `fit`/`evaluate`, the unreduced vector loss is passed to the optimizer but the reported loss will be a scalar value.
* `SUM`: Scalar sum of weighted losses.
* `SUM_OVER_BATCH_SIZE`: Scalar `SUM` divided by number of elements in losses. This reduction type is not supported when used with [`tf.distribute.Strategy`](../../distribute/strategy) outside of built-in training loops like [`tf.keras`](../../keras) `compile`/`fit`.
You can implement 'SUM\_OVER\_BATCH\_SIZE' using global batch size like:
```
with strategy.scope():
loss_obj = tf.keras.losses.CategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.NONE)
....
loss = tf.reduce_sum(loss_obj(labels, predictions)) *
(1. / global_batch_size)
```
Please see the [custom training guide](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details on this.
Methods
-------
### `all`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/utils/losses_utils.py#L77-L79)
```
@classmethod
all()
```
### `validate`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/utils/losses_utils.py#L81-L85)
```
@classmethod
validate(
key
)
```
| Class Variables |
| AUTO | `'auto'` |
| NONE | `'none'` |
| SUM | `'sum'` |
| SUM\_OVER\_BATCH\_SIZE | `'sum_over_batch_size'` |
tensorflow tf.keras.losses.MeanAbsolutePercentageError tf.keras.losses.MeanAbsolutePercentageError
===========================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L370-L432) |
Computes the mean absolute percentage error between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MeanAbsolutePercentageError`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/MeanAbsolutePercentageError)
```
tf.keras.losses.MeanAbsolutePercentageError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_absolute_percentage_error'
)
```
#### Formula:
`loss = 100 * abs((y_true - y_pred) / y_true)`
Note that to avoid dividing by zero, a small epsilon value is added to the denominator.
#### Standalone usage:
```
y_true = [[2., 1.], [2., 3.]]
y_pred = [[1., 1.], [1., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
mape = tf.keras.losses.MeanAbsolutePercentageError()
mape(y_true, y_pred).numpy()
50.
```
```
# Calling with 'sample_weight'.
mape(y_true, y_pred, sample_weight=[0.7, 0.3]).numpy()
20.
```
```
# Using 'sum' reduction type.
mape = tf.keras.losses.MeanAbsolutePercentageError(
reduction=tf.keras.losses.Reduction.SUM)
mape(y_true, y_pred).numpy()
100.
```
```
# Using 'none' reduction type.
mape = tf.keras.losses.MeanAbsolutePercentageError(
reduction=tf.keras.losses.Reduction.NONE)
mape(y_true, y_pred).numpy()
array([25., 75.], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd',
loss=tf.keras.losses.MeanAbsolutePercentageError())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'mean\_absolute\_percentage\_error'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.cosine_similarity tf.keras.losses.cosine\_similarity
==================================
Computes the cosine similarity between labels and predictions.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.cosine`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/cosine_similarity), [`tf.compat.v1.keras.losses.cosine_proximity`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/cosine_similarity), [`tf.compat.v1.keras.losses.cosine_similarity`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/cosine_similarity), [`tf.compat.v1.keras.metrics.cosine`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/cosine_similarity), [`tf.compat.v1.keras.metrics.cosine_proximity`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/cosine_similarity)
```
tf.keras.losses.cosine_similarity(
y_true, y_pred, axis=-1
)
```
Note that it is a number between -1 and 1. When it is a negative number between -1 and 0, 0 indicates orthogonality and values closer to -1 indicate greater similarity. The values closer to 1 indicate greater dissimilarity. This makes it usable as a loss function in a setting where you try to maximize the proximity between predictions and targets. If either `y_true` or `y_pred` is a zero vector, cosine similarity will be 0 regardless of the proximity between predictions and targets.
`loss = -sum(l2_norm(y_true) * l2_norm(y_pred))`
#### Standalone usage:
```
y_true = [[0., 1.], [1., 1.], [1., 1.]]
y_pred = [[1., 0.], [1., 1.], [-1., -1.]]
loss = tf.keras.losses.cosine_similarity(y_true, y_pred, axis=1)
loss.numpy()
array([-0., -0.999, 0.999], dtype=float32)
```
| Args |
| `y_true` | Tensor of true targets. |
| `y_pred` | Tensor of predicted targets. |
| `axis` | Axis along which to determine similarity. |
| Returns |
| Cosine similarity tensor. |
tensorflow tf.keras.losses.Huber tf.keras.losses.Huber
=====================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L1231-L1294) |
Computes the Huber loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.Huber`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/Huber)
```
tf.keras.losses.Huber(
delta=1.0,
reduction=losses_utils.ReductionV2.AUTO,
name='huber_loss'
)
```
For each value x in `error = y_true - y_pred`:
```
loss = 0.5 * x^2 if |x| <= d
loss = 0.5 * d^2 + d * (|x| - d) if |x| > d
```
where d is `delta`. See: <https://en.wikipedia.org/wiki/Huber_loss>
#### Standalone usage:
```
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# Using 'auto'/'sum_over_batch_size' reduction type.
h = tf.keras.losses.Huber()
h(y_true, y_pred).numpy()
0.155
```
```
# Calling with 'sample_weight'.
h(y_true, y_pred, sample_weight=[1, 0]).numpy()
0.09
```
```
# Using 'sum' reduction type.
h = tf.keras.losses.Huber(
reduction=tf.keras.losses.Reduction.SUM)
h(y_true, y_pred).numpy()
0.31
```
```
# Using 'none' reduction type.
h = tf.keras.losses.Huber(
reduction=tf.keras.losses.Reduction.NONE)
h(y_true, y_pred).numpy()
array([0.18, 0.13], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.Huber())
```
| Args |
| `delta` | A float, the point where the Huber loss function changes from a quadratic to linear. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'huber\_loss'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.MeanSquaredError tf.keras.losses.MeanSquaredError
================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L254-L308) |
Computes the mean of squares of errors between labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.MeanSquaredError`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/MeanSquaredError)
```
tf.keras.losses.MeanSquaredError(
reduction=losses_utils.ReductionV2.AUTO,
name='mean_squared_error'
)
```
`loss = square(y_true - y_pred)`
#### Standalone usage:
```
y_true = [[0., 1.], [0., 0.]]
y_pred = [[1., 1.], [1., 0.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
mse = tf.keras.losses.MeanSquaredError()
mse(y_true, y_pred).numpy()
0.5
```
```
# Calling with 'sample_weight'.
mse(y_true, y_pred, sample_weight=[0.7, 0.3]).numpy()
0.25
```
```
# Using 'sum' reduction type.
mse = tf.keras.losses.MeanSquaredError(
reduction=tf.keras.losses.Reduction.SUM)
mse(y_true, y_pred).numpy()
1.0
```
```
# Using 'none' reduction type.
mse = tf.keras.losses.MeanSquaredError(
reduction=tf.keras.losses.Reduction.NONE)
mse(y_true, y_pred).numpy()
array([0.5, 0.5], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.MeanSquaredError())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'mean\_squared\_error'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.SparseCategoricalCrossentropy tf.keras.losses.SparseCategoricalCrossentropy
=============================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L803-L875) |
Computes the crossentropy loss between the labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.SparseCategoricalCrossentropy`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy)
```
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False,
reduction=losses_utils.ReductionV2.AUTO,
name='sparse_categorical_crossentropy'
)
```
Use this crossentropy loss function when there are two or more label classes. We expect labels to be provided as integers. If you want to provide labels using `one-hot` representation, please use `CategoricalCrossentropy` loss. There should be `# classes` floating point values per feature for `y_pred` and a single floating point value per feature for `y_true`.
In the snippet below, there is a single floating point value per example for `y_true` and `# classes` floating pointing values per example for `y_pred`. The shape of `y_true` is `[batch_size]` and the shape of `y_pred` is `[batch_size, num_classes]`.
#### Standalone usage:
```
y_true = [1, 2]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
# Using 'auto'/'sum_over_batch_size' reduction type.
scce = tf.keras.losses.SparseCategoricalCrossentropy()
scce(y_true, y_pred).numpy()
1.177
```
```
# Calling with 'sample_weight'.
scce(y_true, y_pred, sample_weight=tf.constant([0.3, 0.7])).numpy()
0.814
```
```
# Using 'sum' reduction type.
scce = tf.keras.losses.SparseCategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.SUM)
scce(y_true, y_pred).numpy()
2.354
```
```
# Using 'none' reduction type.
scce = tf.keras.losses.SparseCategoricalCrossentropy(
reduction=tf.keras.losses.Reduction.NONE)
scce(y_true, y_pred).numpy()
array([0.0513, 2.303], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd',
loss=tf.keras.losses.SparseCategoricalCrossentropy())
```
| Args |
| `from_logits` | Whether `y_pred` is expected to be a logits tensor. By default, we assume that `y_pred` encodes a probability distribution. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'sparse\_categorical\_crossentropy'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
| programming_docs |
tensorflow tf.keras.losses.serialize tf.keras.losses.serialize
=========================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L2297-L2307) |
Serializes loss function or `Loss` instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.serialize`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/serialize)
```
tf.keras.losses.serialize(
loss
)
```
| Args |
| `loss` | A Keras `Loss` instance or a loss function. |
| Returns |
| Loss configuration dictionary. |
tensorflow tf.keras.losses.CategoricalHinge tf.keras.losses.CategoricalHinge
================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L999-L1054) |
Computes the categorical hinge loss between `y_true` and `y_pred`.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.CategoricalHinge`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/CategoricalHinge)
```
tf.keras.losses.CategoricalHinge(
reduction=losses_utils.ReductionV2.AUTO, name='categorical_hinge'
)
```
`loss = maximum(neg - pos + 1, 0)` where `neg=maximum((1-y_true)*y_pred) and pos=sum(y_true*y_pred)`
#### Standalone usage:
```
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# Using 'auto'/'sum_over_batch_size' reduction type.
h = tf.keras.losses.CategoricalHinge()
h(y_true, y_pred).numpy()
1.4
```
```
# Calling with 'sample_weight'.
h(y_true, y_pred, sample_weight=[1, 0]).numpy()
0.6
```
```
# Using 'sum' reduction type.
h = tf.keras.losses.CategoricalHinge(
reduction=tf.keras.losses.Reduction.SUM)
h(y_true, y_pred).numpy()
2.8
```
```
# Using 'none' reduction type.
h = tf.keras.losses.CategoricalHinge(
reduction=tf.keras.losses.Reduction.NONE)
h(y_true, y_pred).numpy()
array([1.2, 1.6], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.CategoricalHinge())
```
| Args |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. Defaults to 'categorical\_hinge'. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow tf.keras.losses.get tf.keras.losses.get
===================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L2329-L2373) |
Retrieves a Keras loss as a `function`/`Loss` class instance.
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.get`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/get)
```
tf.keras.losses.get(
identifier
)
```
The `identifier` may be the string name of a loss function or `Loss` class.
```
loss = tf.keras.losses.get("categorical_crossentropy")
type(loss)
<class 'function'>
loss = tf.keras.losses.get("CategoricalCrossentropy")
type(loss)
<class '...keras.losses.CategoricalCrossentropy'>
```
You can also specify `config` of the loss to this function by passing dict containing `class_name` and `config` as an identifier. Also note that the `class_name` must map to a `Loss` class
```
identifier = {"class_name": "CategoricalCrossentropy",
"config": {"from_logits": True} }
loss = tf.keras.losses.get(identifier)
type(loss)
<class '...keras.losses.CategoricalCrossentropy'>
```
| Args |
| `identifier` | A loss identifier. One of None or string name of a loss function/class or loss configuration dictionary or a loss function or a loss class instance. |
| Returns |
| A Keras loss as a `function`/ `Loss` class instance. |
| Raises |
| `ValueError` | If `identifier` cannot be interpreted. |
tensorflow tf.keras.losses.CosineSimilarity tf.keras.losses.CosineSimilarity
================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L2203-L2272) |
Computes the cosine similarity between labels and predictions.
Inherits From: [`Loss`](loss)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.losses.CosineSimilarity`](https://www.tensorflow.org/api_docs/python/tf/keras/losses/CosineSimilarity)
```
tf.keras.losses.CosineSimilarity(
axis=-1,
reduction=losses_utils.ReductionV2.AUTO,
name='cosine_similarity'
)
```
Note that it is a number between -1 and 1. When it is a negative number between -1 and 0, 0 indicates orthogonality and values closer to -1 indicate greater similarity. The values closer to 1 indicate greater dissimilarity. This makes it usable as a loss function in a setting where you try to maximize the proximity between predictions and targets. If either `y_true` or `y_pred` is a zero vector, cosine similarity will be 0 regardless of the proximity between predictions and targets.
`loss = -sum(l2_norm(y_true) * l2_norm(y_pred))`
#### Standalone usage:
```
y_true = [[0., 1.], [1., 1.]]
y_pred = [[1., 0.], [1., 1.]]
# Using 'auto'/'sum_over_batch_size' reduction type.
cosine_loss = tf.keras.losses.CosineSimilarity(axis=1)
# l2_norm(y_true) = [[0., 1.], [1./1.414, 1./1.414]]
# l2_norm(y_pred) = [[1., 0.], [1./1.414, 1./1.414]]
# l2_norm(y_true) . l2_norm(y_pred) = [[0., 0.], [0.5, 0.5]]
# loss = mean(sum(l2_norm(y_true) . l2_norm(y_pred), axis=1))
# = -((0. + 0.) + (0.5 + 0.5)) / 2
cosine_loss(y_true, y_pred).numpy()
-0.5
```
```
# Calling with 'sample_weight'.
cosine_loss(y_true, y_pred, sample_weight=[0.8, 0.2]).numpy()
-0.0999
```
```
# Using 'sum' reduction type.
cosine_loss = tf.keras.losses.CosineSimilarity(axis=1,
reduction=tf.keras.losses.Reduction.SUM)
cosine_loss(y_true, y_pred).numpy()
-0.999
```
```
# Using 'none' reduction type.
cosine_loss = tf.keras.losses.CosineSimilarity(axis=1,
reduction=tf.keras.losses.Reduction.NONE)
cosine_loss(y_true, y_pred).numpy()
array([-0., -0.999], dtype=float32)
```
Usage with the `compile()` API:
```
model.compile(optimizer='sgd', loss=tf.keras.losses.CosineSimilarity(axis=1))
```
| Args |
| `axis` | The axis along which the cosine similarity is computed (the features axis). Defaults to -1. |
| `reduction` | Type of [`tf.keras.losses.Reduction`](reduction) to apply to loss. Default value is `AUTO`. `AUTO` indicates that the reduction option will be determined by the usage context. For almost all cases this defaults to `SUM_OVER_BATCH_SIZE`. When used with [`tf.distribute.Strategy`](../../distribute/strategy), outside of built-in training loops such as [`tf.keras`](../../keras) `compile` and `fit`, using `AUTO` or `SUM_OVER_BATCH_SIZE` will raise an error. Please see this custom training [tutorial](https://www.tensorflow.org/tutorials/distribute/custom_training) for more details. |
| `name` | Optional name for the instance. |
Methods
-------
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L143-L153)
```
@classmethod
from_config(
config
)
```
Instantiates a `Loss` from its config (output of `get_config()`).
| Args |
| `config` | Output of `get_config()`. |
| Returns |
| A `Loss` instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L245-L250)
```
get_config()
```
Returns the config dictionary for a `Loss` instance.
### `__call__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/losses.py#L104-L141)
```
__call__(
y_true, y_pred, sample_weight=None
)
```
Invokes the `Loss` instance.
| Args |
| `y_true` | Ground truth values. shape = `[batch_size, d0, .. dN]`, except sparse loss functions such as sparse categorical crossentropy where shape = `[batch_size, d0, .. dN-1]` |
| `y_pred` | The predicted values. shape = `[batch_size, d0, .. dN]` |
| `sample_weight` | Optional `sample_weight` acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value. If `sample_weight` is a tensor of size `[batch_size]`, then the total loss for each sample of the batch is rescaled by the corresponding element in the `sample_weight` vector. If the shape of `sample_weight` is `[batch_size, d0, .. dN-1]` (or can be broadcasted to this shape), then each loss element of `y_pred` is scaled by the corresponding value of `sample_weight`. (Note on`dN-1`: all loss functions reduce by 1 dimension, usually axis=-1.) |
| Returns |
| Weighted loss float `Tensor`. If `reduction` is `NONE`, this has shape `[batch_size, d0, .. dN-1]`; otherwise, it is scalar. (Note `dN-1` because all loss functions reduce by 1 dimension, usually axis=-1.) |
| Raises |
| `ValueError` | If the shape of `sample_weight` is invalid. |
tensorflow Module: tf.keras.wrappers.scikit_learn Module: tf.keras.wrappers.scikit\_learn
=======================================
Wrapper for using the Scikit-Learn API with Keras models.
tensorflow tf.keras.experimental.SidecarEvaluator tf.keras.experimental.SidecarEvaluator
======================================
Deprecated. Please use [`tf.keras.utils.SidecarEvaluator`](../utils/sidecarevaluator) instead.
Inherits From: [`SidecarEvaluator`](../utils/sidecarevaluator)
```
tf.keras.experimental.SidecarEvaluator(
*args, **kwargs
)
```
| Args |
| `model` | Model to use for evaluation. The model object used here should be a [`tf.keras.Model`](../model), and should be the same as the one that is used in training, where [`tf.keras.Model`](../model)s are checkpointed. The model should have one or more metrics compiled before using `SidecarEvaluator`. |
| `data` | The input data for evaluation. `SidecarEvaluator` supports all data types that Keras `model.evaluate` supports as the input data `x`, such as a [`tf.data.Dataset`](../../data/dataset). |
| `checkpoint_dir` | Directory where checkpoint files are saved. |
| `steps` | Number of steps to perform evaluation for, when evaluating a single checkpoint file. If `None`, evaluation continues until the dataset is exhausted. For repeated evaluation dataset, user must specify `steps` to avoid infinite evaluation loop. |
| `max_evaluations` | Maximum number of the checkpoint file to be evaluated, for `SidecarEvaluator` to know when to stop. The evaluator will stop after it evaluates a checkpoint filepath ending with '-'. If using [`tf.train.CheckpointManager.save`](../../train/checkpointmanager#save) for saving checkpoints, the kth saved checkpoint has the filepath suffix '-' (k=1 for the first saved), and if checkpoints are saved every epoch after training, the filepath saved at the kth epoch would end with '-. Thus, if training runs for n epochs, and the evaluator should end after the training finishes, use n for this parameter. Note that this is not necessarily equal to the number of total evaluations, since some checkpoints may be skipped if evaluation is slower than checkpoint creation. If `None`, `SidecarEvaluator` will evaluate indefinitely, and the user must terminate evaluator program themselves. |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances to apply during evaluation. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
Methods
-------
### `start`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/distribute/sidecar_evaluator.py#L189-L261)
```
start()
```
Starts the evaluation loop.
tensorflow tf.keras.experimental.LinearModel tf.keras.experimental.LinearModel
=================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/premade_models/linear.py#L33-L200) |
Linear Model for regression and classification problems.
Inherits From: [`Model`](../model), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.experimental.LinearModel`](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/LinearModel), [`tf.compat.v1.keras.models.LinearModel`](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/LinearModel)
```
tf.keras.experimental.LinearModel(
units=1,
activation=None,
use_bias=True,
kernel_initializer='zeros',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
**kwargs
)
```
This model approximates the following function:
\[y = \beta + \sum\_{i=1}^{N} w\_{i} \* x\_{i}\]
where \(\beta\) is the bias and \(w\_{i}\) is the weight for each feature.
#### Example:
```
model = LinearModel()
model.compile(optimizer='sgd', loss='mse')
model.fit(x, y, epochs=epochs)
```
This model accepts sparse float inputs as well:
#### Example:
```
model = LinearModel()
opt = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.MeanSquaredError()
with tf.GradientTape() as tape:
output = model(sparse_input)
loss = tf.reduce_mean(loss_fn(target, output))
grads = tape.gradient(loss, model.weights)
opt.apply_gradients(zip(grads, model.weights))
```
| Args |
| `units` | Positive integer, output dimension without the batch size. |
| `activation` | Activation function to use. If you don't specify anything, no activation is applied. |
| `use_bias` | whether to calculate the bias/intercept for this model. If set to False, no bias/intercept will be used in calculations, e.g., the data is already centered. |
| `kernel_initializer` | Initializer for the `kernel` weights matrices. |
| `bias_initializer` | Initializer for the bias vector. |
| `kernel_regularizer` | regularizer for kernel vectors. |
| `bias_regularizer` | regularizer for bias vector. |
| `**kwargs` | The keyword arguments that are passed on to BaseLayer.**init**. |
| Attributes |
| `distribute_strategy` | The [`tf.distribute.Strategy`](../../distribute/strategy) this model was created under. |
| `layers` | |
| `metrics_names` | Returns the model's display labels for all outputs.
**Note:** `metrics_names` are available only after a [`keras.Model`](../model) has been trained/evaluated on actual data.
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
model.metrics_names
[]
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
model.fit(x, y)
model.metrics_names
['loss', 'mae']
```
```
inputs = tf.keras.layers.Input(shape=(3,))
d = tf.keras.layers.Dense(2, name='out')
output_1 = d(inputs)
output_2 = d(inputs)
model = tf.keras.models.Model(
inputs=inputs, outputs=[output_1, output_2])
model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
model.fit(x, (y, y))
model.metrics_names
['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
'out_1_acc']
```
|
| `run_eagerly` | Settable attribute indicating whether the model should run eagerly. Running eagerly means that your model will be run step by step, like Python code. Your model might run slower, but it should become easier for you to debug it by stepping into individual layer calls. By default, we will attempt to compile your model to a static graph to deliver the best execution performance. |
Methods
-------
### `call`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/premade_models/linear.py#L149-L182)
```
call(
inputs
)
```
Calls the model on new inputs and returns the outputs as tensors.
In this case `call()` just reapplies all ops in the graph to the new inputs (e.g. build a new computational graph from the provided inputs).
>
> **Note:** This method should not be called directly. It is only meant to be overridden when subclassing [`tf.keras.Model`](../model). To call a model on an input, always use the `__call__()` method, i.e. `model(inputs)`, which relies on the underlying `call()` method.
>
| Args |
| `inputs` | Input tensor, or dict/list/tuple of input tensors. |
| `training` | Boolean or boolean scalar tensor, indicating whether to run the `Network` in training mode or inference mode. |
| `mask` | A mask or list of masks. A mask can be either a boolean tensor or None (no mask). For more details, check the guide [here](https://www.tensorflow.org/guide/keras/masking_and_padding). |
| Returns |
| A tensor if there is a single output, or a list of tensors if there are more than one outputs. |
### `compile`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L523-L659)
```
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
```
Configures the model for training.
#### Example:
```
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.FalseNegatives()])
```
| Args |
| `optimizer` | String (name of optimizer) or optimizer instance. See [`tf.keras.optimizers`](../optimizers). |
| `loss` | Loss function. May be a string (name of loss function), or a [`tf.keras.losses.Loss`](../losses/loss) instance. See [`tf.keras.losses`](../losses). A loss function is any callable with the signature `loss = fn(y_true, y_pred)`, where `y_true` are the ground truth values, and `y_pred` are the model's predictions. `y_true` should have shape `(batch_size, d0, .. dN)` (except in the case of sparse loss functions such as sparse categorical crossentropy which expects integer arrays of shape `(batch_size, d0, .. dN-1)`). `y_pred` should have shape `(batch_size, d0, .. dN)`. The loss function should return a float tensor. If a custom `Loss` instance is used and reduction is set to `None`, return value has shape `(batch_size, d0, .. dN-1)` i.e. per-sample or per-timestep loss values; otherwise, it is a scalar. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses, unless `loss_weights` is specified. |
| `metrics` | List of metrics to be evaluated by the model during training and testing. Each of this can be a string (name of a built-in function), function or a [`tf.keras.metrics.Metric`](../metrics/metric) instance. See [`tf.keras.metrics`](../metrics). Typically you will use `metrics=['accuracy']`. A function is any callable with the signature `result = fn(y_true, y_pred)`. To specify different metrics for different outputs of a multi-output model, you could also pass a dictionary, such as `metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}`. You can also pass a list to specify a metric or a list of metrics for each output, such as `metrics=[['accuracy'], ['accuracy', 'mse']]` or `metrics=['accuracy', ['accuracy', 'mse']]`. When you pass the strings 'accuracy' or 'acc', we convert this to one of [`tf.keras.metrics.BinaryAccuracy`](../metrics/binaryaccuracy), [`tf.keras.metrics.CategoricalAccuracy`](../metrics/categoricalaccuracy), [`tf.keras.metrics.SparseCategoricalAccuracy`](../metrics/sparsecategoricalaccuracy) based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well. |
| `loss_weights` | Optional list or dictionary specifying scalar coefficients (Python floats) to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the *weighted sum* of all individual losses, weighted by the `loss_weights` coefficients. If a list, it is expected to have a 1:1 mapping to the model's outputs. If a dict, it is expected to map output names (strings) to scalar coefficients. |
| `weighted_metrics` | List of metrics to be evaluated and weighted by `sample_weight` or `class_weight` during training and testing. |
| `run_eagerly` | Bool. Defaults to `False`. If `True`, this `Model`'s logic will not be wrapped in a [`tf.function`](../../function). Recommended to leave this as `None` unless your `Model` cannot be run inside a [`tf.function`](../../function). `run_eagerly=True` is not supported when using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy). |
| `steps_per_execution` | Int. Defaults to 1. The number of batches to run during each [`tf.function`](../../function) call. Running multiple batches inside a single [`tf.function`](../../function) call can greatly improve performance on TPUs or small models with a large Python overhead. At most, one full epoch will be run each execution. If a number larger than the size of the epoch is passed, the execution will be truncated to the size of the epoch. Note that if `steps_per_execution` is set to `N`, [`Callback.on_batch_begin`](../callbacks/callback#on_batch_begin) and [`Callback.on_batch_end`](../callbacks/callback#on_batch_end) methods will only be called every `N` batches (i.e. before/after each [`tf.function`](../../function) execution). |
| `jit_compile` | If `True`, compile the model training step with XLA. [XLA](https://www.tensorflow.org/xla) is an optimizing compiler for machine learning. `jit_compile` is not enabled for by default. This option cannot be enabled with `run_eagerly=True`. Note that `jit_compile=True` is may not necessarily work for all models. For more information on supported operations please refer to the [XLA documentation](https://www.tensorflow.org/xla). Also refer to [known XLA issues](https://www.tensorflow.org/xla/known_issues) for more details. |
| `**kwargs` | Arguments supported for backwards compatibility only. |
### `compute_loss`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L896-L949)
```
compute_loss(
x=None, y=None, y_pred=None, sample_weight=None
)
```
Compute the total loss, validate it, and return it.
Subclasses can optionally override this method to provide custom loss computation logic.
#### Example:
```
class MyModel(tf.keras.Model):
def __init__(self, *args, **kwargs):
super(MyModel, self).__init__(*args, **kwargs)
self.loss_tracker = tf.keras.metrics.Mean(name='loss')
def compute_loss(self, x, y, y_pred, sample_weight):
loss = tf.reduce_mean(tf.math.squared_difference(y_pred, y))
loss += tf.add_n(self.losses)
self.loss_tracker.update_state(loss)
return loss
def reset_metrics(self):
self.loss_tracker.reset_states()
@property
def metrics(self):
return [self.loss_tracker]
tensors = tf.random.uniform((10, 10)), tf.random.uniform((10,))
dataset = tf.data.Dataset.from_tensor_slices(tensors).repeat().batch(1)
inputs = tf.keras.layers.Input(shape=(10,), name='my_input')
outputs = tf.keras.layers.Dense(10)(inputs)
model = MyModel(inputs, outputs)
model.add_loss(tf.reduce_sum(outputs))
optimizer = tf.keras.optimizers.SGD()
model.compile(optimizer, loss='mse', steps_per_execution=10)
model.fit(dataset, epochs=2, steps_per_epoch=10)
print('My custom loss: ', model.loss_tracker.result().numpy())
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| The total loss as a [`tf.Tensor`](../../tensor), or `None` if no loss results (which is the case when called by [`Model.test_step`](../model#test_step)). |
### `compute_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L951-L996)
```
compute_metrics(
x, y, y_pred, sample_weight
)
```
Update metric states and collect all metrics to be returned.
Subclasses can optionally override this method to provide custom metric updating and collection logic.
#### Example:
```
class MyModel(tf.keras.Sequential):
def compute_metrics(self, x, y, y_pred, sample_weight):
# This super call updates `self.compiled_metrics` and returns results
# for all metrics listed in `self.metrics`.
metric_results = super(MyModel, self).compute_metrics(
x, y, y_pred, sample_weight)
# Note that `self.custom_metric` is not listed in `self.metrics`.
self.custom_metric.update_state(x, y, y_pred, sample_weight)
metric_results['custom_metric_name'] = self.custom_metric.result()
return metric_results
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model.call(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end()`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the metrics listed in `self.metrics` are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
### `evaluate`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1602-L1768)
```
evaluate(
x=None,
y=None,
batch_size=None,
verbose='auto',
sample_weight=None,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
return_dict=False,
**kwargs
)
```
Returns the loss value & metrics values for the model in test mode.
Computation is done in batches (see the `batch_size` arg.)
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator or [`keras.utils.Sequence`](../utils/sequence) instance, `y` should not be specified (since targets will be obtained from the iterator/dataset). |
| `batch_size` | Integer or `None`. Number of samples per batch of computation. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of a dataset, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `sample_weight` | Optional Numpy array of weights for the test samples, used for weighting the loss function. You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, instead pass sample weights as the third element of `x`. |
| `steps` | Integer or `None`. Total number of steps (batches of samples) before declaring the evaluation round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../../data) dataset and `steps` is None, 'evaluate' will run until the dataset is exhausted. This argument is not supported with array inputs. |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during evaluation. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| `**kwargs` | Unused at this time. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](../model#fit).
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.evaluate` is wrapped in a [`tf.function`](../../function). |
### `fit`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1099-L1472)
```
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose='auto',
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Trains the model for a fixed number of epochs (iterations on a dataset).
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A [`tf.keras.utils.experimental.DatasetCreator`](../utils/experimental/datasetcreator), which wraps a callable that takes a single argument of type [`tf.distribute.InputContext`](../../distribute/inputcontext), and returns a [`tf.data.Dataset`](../../data/dataset). `DatasetCreator` should be used when users prefer to specify the per-replica batching and sharding logic for the `Dataset`. See [`tf.keras.utils.experimental.DatasetCreator`](../utils/experimental/datasetcreator) doc for more information. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given below. If using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy), only `DatasetCreator` type is supported for `x`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator, or [`keras.utils.Sequence`](../utils/sequence) instance, `y` should not be specified (since targets will be obtained from `x`). |
| `batch_size` | Integer or `None`. Number of samples per gradient update. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `epochs` | Integer. Number of epochs to train the model. An epoch is an iteration over the entire `x` and `y` data provided (unless the `steps_per_epoch` flag is set to something other than None). Note that in conjunction with `initial_epoch`, `epochs` is to be understood as "final epoch". The model is not trained for a number of iterations given by `epochs`, but merely until the epoch of index `epochs` is reached. |
| `verbose` | 'auto', 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch. 'auto' defaults to 1 for most cases, but 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so verbose=2 is recommended when not running interactively (eg, in a production environment). |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during training. See [`tf.keras.callbacks`](../callbacks). Note [`tf.keras.callbacks.ProgbarLogger`](../callbacks/progbarlogger) and [`tf.keras.callbacks.History`](../callbacks/history) callbacks are created automatically and need not be passed into `model.fit`. [`tf.keras.callbacks.ProgbarLogger`](../callbacks/progbarlogger) is created or not based on `verbose` argument to `model.fit`. Callbacks with batch-level calls are currently unsupported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy), and users are advised to implement epoch-level calls instead with an appropriate `steps_per_epoch` value. |
| `validation_split` | Float between 0 and 1. Fraction of the training data to be used as validation data. The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch. The validation data is selected from the last samples in the `x` and `y` data provided, before shuffling. This argument is not supported when `x` is a dataset, generator or [`keras.utils.Sequence`](../utils/sequence) instance. If both `validation_data` and `validation_split` are provided, `validation_data` will override `validation_split`. `validation_split` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy). |
| `validation_data` | Data on which to evaluate the loss and any model metrics at the end of each epoch. The model will not be trained on this data. Thus, note the fact that the validation loss of data provided using `validation_split` or `validation_data` is not affected by regularization layers like noise and dropout. `validation_data` will override `validation_split`. `validation_data` could be: * A tuple `(x_val, y_val)` of Numpy arrays or tensors.
* A tuple `(x_val, y_val, val_sample_weights)` of NumPy arrays.
* A [`tf.data.Dataset`](../../data/dataset).
* A Python generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. `validation_data` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy).
|
| `shuffle` | Boolean (whether to shuffle the training data before each epoch) or str (for 'batch'). This argument is ignored when `x` is a generator or an object of tf.data.Dataset. 'batch' is a special option for dealing with the limitations of HDF5 data; it shuffles in batch-sized chunks. Has no effect when `steps_per_epoch` is not `None`. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function (during training only). This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `sample_weight` | Optional Numpy array of weights for the training samples, used for weighting the loss function (during training only). You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, generator, or [`keras.utils.Sequence`](../utils/sequence) instance, instead provide the sample\_weights as the third element of `x`. |
| `initial_epoch` | Integer. Epoch at which to start training (useful for resuming a previous training run). |
| `steps_per_epoch` | Integer or `None`. Total number of steps (batches of samples) before declaring one epoch finished and starting the next epoch. When training with input tensors such as TensorFlow data tensors, the default `None` is equal to the number of samples in your dataset divided by the batch size, or 1 if that cannot be determined. If x is a [`tf.data`](../../data) dataset, and 'steps\_per\_epoch' is None, the epoch will run until the input dataset is exhausted. When passing an infinitely repeating dataset, you must specify the `steps_per_epoch` argument. If `steps_per_epoch=-1` the training will run indefinitely with an infinitely repeating dataset. This argument is not supported with array inputs. When using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy): - `steps_per_epoch=None` is not supported.
|
| `validation_steps` | Only relevant if `validation_data` is provided and is a [`tf.data`](../../data) dataset. Total number of steps (batches of samples) to draw before stopping when performing validation at the end of every epoch. If 'validation\_steps' is None, validation will run until the `validation_data` dataset is exhausted. In the case of an infinitely repeated dataset, it will run into an infinite loop. If 'validation\_steps' is specified and only part of the dataset will be consumed, the evaluation will start from the beginning of the dataset at each epoch. This ensures that the same validation samples are used every time. |
| `validation_batch_size` | Integer or `None`. Number of samples per validation batch. If unspecified, will default to `batch_size`. Do not specify the `validation_batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `validation_freq` | Only relevant if validation data is provided. Integer or `collections.abc.Container` instance (e.g. list, tuple, etc.). If an integer, specifies how many training epochs to run before a new validation run is performed, e.g. `validation_freq=2` runs validation every 2 epochs. If a Container, specifies the epochs on which to run validation, e.g. `validation_freq=[1, 2, 10]` runs validation at the end of the 1st, 2nd, and 10th epochs. |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
Unpacking behavior for iterator-like inputs: A common pattern is to pass a tf.data.Dataset, generator, or tf.keras.utils.Sequence to the `x` argument of fit, which will in fact yield not only features (x) but optionally targets (y) and sample weights. Keras requires that the output of such iterator-likes be unambiguous. The iterator should return a tuple of length 1, 2, or 3, where the optional second and third elements will be used for y and sample\_weight respectively. Any other type provided will be wrapped in a length one tuple, effectively treating everything as 'x'. When yielding dicts, they should still adhere to the top-level tuple structure. e.g. `({"x0": x0, "x1": x1}, y)`. Keras will not attempt to separate features, targets, and weights from the keys of a single dict. A notable unsupported data type is the namedtuple. The reason is that it behaves like both an ordered datatype (tuple) and a mapping datatype (dict). So given a namedtuple of the form: `namedtuple("example_tuple", ["y", "x"])` it is ambiguous whether to reverse the order of the elements when interpreting the value. Even worse is a tuple of the form: `namedtuple("other_tuple", ["x", "y", "z"])` where it is unclear if the tuple was intended to be unpacked into x, y, and sample\_weight or passed through as a single element to `x`. As a result the data processing code will simply raise a ValueError if it encounters a namedtuple. (Along with instructions to remedy the issue.)
| Returns |
| A `History` object. Its `History.history` attribute is a record of training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). |
| Raises |
| `RuntimeError` | 1. If the model was never compiled or,
2. If `model.fit` is wrapped in [`tf.function`](../../function).
|
| `ValueError` | In case of mismatch between the provided input data and what the model expects or when the input data is empty. |
### `get_layer`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2891-L2925)
```
get_layer(
name=None, index=None
)
```
Retrieves a layer based on either its name (unique) or index.
If `name` and `index` are both provided, `index` will take precedence. Indices are based on order of horizontal graph traversal (bottom-up).
| Args |
| `name` | String, name of layer. |
| `index` | Integer, index of layer. |
| Returns |
| A layer instance. |
### `load_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2556-L2661)
```
load_weights(
filepath, by_name=False, skip_mismatch=False, options=None
)
```
Loads all layer weights, either from a TensorFlow or an HDF5 weight file.
If `by_name` is False weights are loaded based on the network's topology. This means the architecture should be the same as when the weights were saved. Note that layers that don't have weights are not taken into account in the topological ordering, so adding or removing layers is fine as long as they don't have weights.
If `by_name` is True, weights are loaded into layers only if they share the same name. This is useful for fine-tuning or transfer-learning models where some of the layers have changed.
Only topological loading (`by_name=False`) is supported when loading weights from the TensorFlow format. Note that topological loading differs slightly between TensorFlow and HDF5 formats for user-defined classes inheriting from [`tf.keras.Model`](../model): HDF5 loads based on a flattened list of weights, while the TensorFlow format loads based on the object-local names of attributes to which layers are assigned in the `Model`'s constructor.
| Args |
| `filepath` | String, path to the weights file to load. For weight files in TensorFlow format, this is the file prefix (the same as was passed to `save_weights`). This can also be a path to a SavedModel saved from `model.save`. |
| `by_name` | Boolean, whether to load weights by name or by topological order. Only topological loading is supported for weight files in TensorFlow format. |
| `skip_mismatch` | Boolean, whether to skip loading of layers where there is a mismatch in the number of weights, or a mismatch in the shape of the weight (only valid when `by_name=True`). |
| `options` | Optional [`tf.train.CheckpointOptions`](../../train/checkpointoptions) object that specifies options for loading weights. |
| Returns |
| When loading a weight file in TensorFlow format, returns the same status object as [`tf.train.Checkpoint.restore`](../../train/checkpoint#restore). When graph building, restore ops are run automatically as soon as the network is built (on first call for user-defined classes inheriting from `Model`, immediately if it is already built). When loading weights in HDF5 format, returns `None`. |
| Raises |
| `ImportError` | If `h5py` is not available and the weight file is in HDF5 format. |
| `ValueError` | If `skip_mismatch` is set to `True` when `by_name` is `False`. |
### `make_predict_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1793-L1867)
```
make_predict_function(
force=False
)
```
Creates a function that executes one step of inference.
This method can be overridden to support custom inference logic. This method is called by [`Model.predict`](../model#predict) and [`Model.predict_on_batch`](../model#predict_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.predict_step`](../model#predict_step).
This function is cached the first time [`Model.predict`](../model#predict) or [`Model.predict_on_batch`](../model#predict_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the predict function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return the outputs of the `Model`. |
### `make_test_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1504-L1600)
```
make_test_function(
force=False
)
```
Creates a function that executes one step of evaluation.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.evaluate`](../model#evaluate) and [`Model.test_on_batch`](../model#test_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.test_step`](../model#test_step).
This function is cached the first time [`Model.evaluate`](../model#evaluate) or [`Model.test_on_batch`](../model#test_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the test function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_test_batch_end`. |
### `make_train_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L998-L1097)
```
make_train_function(
force=False
)
```
Creates a function that executes one step of training.
This method can be overridden to support custom training logic. This method is called by [`Model.fit`](../model#fit) and [`Model.train_on_batch`](../model#train_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual training logic to [`Model.train_step`](../model#train_step).
This function is cached the first time [`Model.fit`](../model#fit) or [`Model.train_on_batch`](../model#train_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the train function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_train_batch_end`, such as `{'loss': 0.2, 'accuracy': 0.7}`. |
### `predict`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1869-L2064)
```
predict(
x,
batch_size=None,
verbose='auto',
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Generates output predictions for the input samples.
Computation is done in batches. This method is designed for batch processing of large numbers of inputs. It is not intended for use inside of loops that iterate over your data and process small numbers of inputs at a time.
For small numbers of inputs that fit in one batch, directly use `__call__()` for faster execution, e.g., `model(x)`, or `model(x, training=False)` if you have layers such as [`tf.keras.layers.BatchNormalization`](../layers/batchnormalization) that behave differently during inference. You may pair the individual model call with a [`tf.function`](../../function) for additional performance inside your inner loop. If you need access to numpy array values instead of tensors after your model call, you can use `tensor.numpy()` to get the numpy array value of an eager tensor.
Also, note the fact that test loss is not affected by regularization layers like noise and dropout.
>
> **Note:** See [this FAQ entry](https://keras.io/getting_started/faq/#whats-the-difference-between-model-methods-predict-and-call) for more details about the difference between `Model` methods `predict()` and `__call__()`.
>
| Args |
| `x` | Input samples. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A [`tf.data`](../../data) dataset.
* A generator or [`keras.utils.Sequence`](../utils/sequence) instance. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `batch_size` | Integer or `None`. Number of samples per batch. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of dataset, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `steps` | Total number of steps (batches of samples) before declaring the prediction round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../../data) dataset and `steps` is None, `predict()` will run until the input dataset is exhausted. |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during prediction. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](../model#fit). Note that Model.predict uses the same interpretation rules as [`Model.fit`](../model#fit) and [`Model.evaluate`](../model#evaluate), so inputs must be unambiguous for all three methods.
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict` is wrapped in a [`tf.function`](../../function). |
| `ValueError` | In case of mismatch between the provided input data and the model's expectations, or in case a stateful model receives a number of samples that is not a multiple of the batch size. |
### `predict_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2209-L2231)
```
predict_on_batch(
x
)
```
Returns predictions for a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
|
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict_on_batch` is wrapped in a [`tf.function`](../../function). |
### `predict_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1770-L1791)
```
predict_step(
data
)
```
The logic for one inference step.
This method can be overridden to support custom inference logic. This method is called by [`Model.make_predict_function`](../model#make_predict_function).
This method should contain the mathematical logic for one step of inference. This typically includes the forward pass.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_predict_function`](../model#make_predict_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| The result of one inference step, typically the output of calling the `Model` on data. |
### `reset_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2066-L2086)
```
reset_metrics()
```
Resets the state of all the metrics in the model.
#### Examples:
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
_ = model.fit(x, y, verbose=0)
assert all(float(m.result()) for m in model.metrics)
```
```
model.reset_metrics()
assert all(float(m.result()) == 0 for m in model.metrics)
```
### `reset_states`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2788-L2791)
```
reset_states()
```
### `save`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2383-L2436)
```
save(
filepath,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None,
save_traces=True
)
```
Saves the model to Tensorflow SavedModel or a single HDF5 file.
Please see [`tf.keras.models.save_model`](../models/save_model) or the [Serialization and Saving guide](https://keras.io/guides/serialization_and_saving/) for details.
| Args |
| `filepath` | String, PathLike, path to SavedModel or H5 file to save the model. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `include_optimizer` | If True, save optimizer's state together. |
| `save_format` | Either `'tf'` or `'h5'`, indicating whether to save the model to Tensorflow SavedModel or HDF5. Defaults to 'tf' in TF 2.X, and 'h5' in TF 1.X. |
| `signatures` | Signatures to save with the SavedModel. Applicable to the 'tf' format only. Please see the `signatures` argument in [`tf.saved_model.save`](../../saved_model/save) for details. |
| `options` | (only applies to SavedModel format) [`tf.saved_model.SaveOptions`](../../saved_model/saveoptions) object that specifies options for saving to SavedModel. |
| `save_traces` | (only applies to SavedModel format) When enabled, the SavedModel will store the function traces for each layer. This can be disabled, so that only the configs of each layer are stored. Defaults to `True`. Disabling this will decrease serialization time and reduce file size, but it requires that all custom layers/models implement a `get_config()` method. |
#### Example:
```
from keras.models import load_model
model.save('my_model.h5') # creates a HDF5 file 'my_model.h5'
del model # deletes the existing model
# returns a compiled model
# identical to the previous one
model = load_model('my_model.h5')
```
### `save_spec`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2965-L3002)
```
save_spec(
dynamic_batch=True
)
```
Returns the [`tf.TensorSpec`](../../tensorspec) of call inputs as a tuple `(args, kwargs)`.
This value is automatically defined after calling the model for the first time. Afterwards, you can use it when exporting the model for serving:
```
model = tf.keras.Model(...)
@tf.function
def serve(*args, **kwargs):
outputs = model(*args, **kwargs)
# Apply postprocessing steps, or add additional outputs.
...
return outputs
# arg_specs is `[tf.TensorSpec(...), ...]`. kwarg_specs, in this example, is
# an empty dict since functional models do not use keyword arguments.
arg_specs, kwarg_specs = model.save_spec()
model.save(path, signatures={
'serving_default': serve.get_concrete_function(*arg_specs, **kwarg_specs)
})
```
| Args |
| `dynamic_batch` | Whether to set the batch sizes of all the returned [`tf.TensorSpec`](../../tensorspec) to `None`. (Note that when defining functional or Sequential models with `tf.keras.Input([...], batch_size=X)`, the batch size will always be preserved). Defaults to `True`. |
| Returns |
| If the model inputs are defined, returns a tuple `(args, kwargs)`. All elements in `args` and `kwargs` are [`tf.TensorSpec`](../../tensorspec). If the model inputs are not defined, returns `None`. The model inputs are automatically set when calling the model, `model.fit`, `model.evaluate` or `model.predict`. |
### `save_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2438-L2554)
```
save_weights(
filepath, overwrite=True, save_format=None, options=None
)
```
Saves all layer weights.
Either saves in HDF5 or in TensorFlow format based on the `save_format` argument.
When saving in HDF5 format, the weight file has:
* `layer_names` (attribute), a list of strings (ordered names of model layers).
* For every layer, a `group` named `layer.name`
+ For every such layer group, a group attribute `weight_names`, a list of strings (ordered names of weights tensor of the layer).
+ For every weight in the layer, a dataset storing the weight value, named after the weight tensor.
When saving in TensorFlow format, all objects referenced by the network are saved in the same format as [`tf.train.Checkpoint`](../../train/checkpoint), including any `Layer` instances or `Optimizer` instances assigned to object attributes. For networks constructed from inputs and outputs using `tf.keras.Model(inputs, outputs)`, `Layer` instances used by the network are tracked/saved automatically. For user-defined classes which inherit from [`tf.keras.Model`](../model), `Layer` instances must be assigned to object attributes, typically in the constructor. See the documentation of [`tf.train.Checkpoint`](../../train/checkpoint) and [`tf.keras.Model`](../model) for details.
While the formats are the same, do not mix `save_weights` and [`tf.train.Checkpoint`](../../train/checkpoint). Checkpoints saved by [`Model.save_weights`](../model#save_weights) should be loaded using [`Model.load_weights`](../model#load_weights). Checkpoints saved using [`tf.train.Checkpoint.save`](../../train/checkpoint#save) should be restored using the corresponding [`tf.train.Checkpoint.restore`](../../train/checkpoint#restore). Prefer [`tf.train.Checkpoint`](../../train/checkpoint) over `save_weights` for training checkpoints.
The TensorFlow format matches objects and variables by starting at a root object, `self` for `save_weights`, and greedily matching attribute names. For [`Model.save`](../model#save) this is the `Model`, and for [`Checkpoint.save`](../../train/checkpoint#save) this is the `Checkpoint` even if the `Checkpoint` has a model attached. This means saving a [`tf.keras.Model`](../model) using `save_weights` and loading into a [`tf.train.Checkpoint`](../../train/checkpoint) with a `Model` attached (or vice versa) will not match the `Model`'s variables. See the [guide to training checkpoints](https://www.tensorflow.org/guide/checkpoint) for details on the TensorFlow format.
| Args |
| `filepath` | String or PathLike, path to the file to save the weights to. When saving in TensorFlow format, this is the prefix used for checkpoint files (multiple files are generated). Note that the '.h5' suffix causes weights to be saved in HDF5 format. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `save_format` | Either 'tf' or 'h5'. A `filepath` ending in '.h5' or '.keras' will default to HDF5 if `save_format` is `None`. Otherwise `None` defaults to 'tf'. |
| `options` | Optional [`tf.train.CheckpointOptions`](../../train/checkpointoptions) object that specifies options for saving weights. |
| Raises |
| `ImportError` | If `h5py` is not available when attempting to save in HDF5 format. |
### `summary`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2841-L2879)
```
summary(
line_length=None,
positions=None,
print_fn=None,
expand_nested=False,
show_trainable=False
)
```
Prints a string summary of the network.
| Args |
| `line_length` | Total length of printed lines (e.g. set this to adapt the display to different terminal window sizes). |
| `positions` | Relative or absolute positions of log elements in each line. If not provided, defaults to `[.33, .55, .67, 1.]`. |
| `print_fn` | Print function to use. Defaults to `print`. It will be called on each line of the summary. You can set it to a custom function in order to capture the string summary. |
| `expand_nested` | Whether to expand the nested models. If not provided, defaults to `False`. |
| `show_trainable` | Whether to show if a layer is trainable. If not provided, defaults to `False`. |
| Raises |
| `ValueError` | if `summary()` is called before the model is built. |
### `test_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2152-L2207)
```
test_on_batch(
x, y=None, sample_weight=None, reset_metrics=True, return_dict=False
)
```
Test the model on a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.test_on_batch` is wrapped in a [`tf.function`](../../function). |
### `test_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1474-L1502)
```
test_step(
data
)
```
The logic for one evaluation step.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.make_test_function`](../model#make_test_function).
This function should contain the mathematical logic for one step of evaluation. This typically includes the forward pass, loss calculation, and metrics updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_test_function`](../model#make_test_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. |
### `to_json`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2743-L2758)
```
to_json(
**kwargs
)
```
Returns a JSON string containing the network configuration.
To load a network from a JSON save file, use [`keras.models.model_from_json(json_string, custom_objects={})`](../models/model_from_json).
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `json.dumps()`. |
| Returns |
| A JSON string. |
### `to_yaml`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2760-L2786)
```
to_yaml(
**kwargs
)
```
Returns a yaml string containing the network configuration.
>
> **Note:** Since TF 2.6, this method is no longer supported and will raise a RuntimeError.
>
To load a network from a yaml save file, use [`keras.models.model_from_yaml(yaml_string, custom_objects={})`](../models/model_from_yaml).
`custom_objects` should be a dictionary mapping the names of custom losses / layers / etc to the corresponding functions / classes.
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `yaml.dump()`. |
| Returns |
| A YAML string. |
| Raises |
| `RuntimeError` | announces that the method poses a security risk |
### `train_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2088-L2150)
```
train_on_batch(
x,
y=None,
sample_weight=None,
class_weight=None,
reset_metrics=True,
return_dict=False
)
```
Runs a single gradient update on a single batch of data.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) to apply to the model's loss for the samples from this class during training. This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar training loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.train_on_batch` is wrapped in a [`tf.function`](../../function). |
### `train_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L861-L894)
```
train_step(
data
)
```
The logic for one training step.
This method can be overridden to support custom training logic. For concrete examples of how to override this method see [Customizing what happends in fit](https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit). This method is called by [`Model.make_train_function`](../model#make_train_function).
This method should contain the mathematical logic for one step of training. This typically includes the forward pass, loss calculation, backpropagation, and metric updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_train_function`](../model#make_train_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
| programming_docs |
tensorflow tf.keras.experimental.SequenceFeatures tf.keras.experimental.SequenceFeatures
======================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/feature_column/sequence_feature_column.py#L33-L167) |
A layer for sequence input.
Inherits From: [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.experimental.SequenceFeatures`](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/SequenceFeatures)
```
tf.keras.experimental.SequenceFeatures(
feature_columns, trainable=True, name=None, **kwargs
)
```
All `feature_columns` must be sequence dense columns with the same `sequence_length`. The output of this method can be fed into sequence networks, such as RNN.
The output of this method is a 3D `Tensor` of shape `[batch_size, T, D]`. `T` is the maximum sequence length for this batch, which could differ from batch to batch.
If multiple `feature_columns` are given with `Di` `num_elements` each, their outputs are concatenated. So, the final `Tensor` has shape `[batch_size, T, D0 + D1 + ... + Dn]`.
#### Example:
```
import tensorflow as tf
# Behavior of some cells or feature columns may depend on whether we are in
# training or inference mode, e.g. applying dropout.
training = True
rating = tf.feature_column.sequence_numeric_column('rating')
watches = tf.feature_column.sequence_categorical_column_with_identity(
'watches', num_buckets=1000)
watches_embedding = tf.feature_column.embedding_column(watches,
dimension=10)
columns = [rating, watches_embedding]
features = {
'rating': tf.sparse.from_dense([[1.0,1.1, 0, 0, 0],
[2.0,2.1,2.2, 2.3, 2.5]]),
'watches': tf.sparse.from_dense([[2, 85, 0, 0, 0],[33,78, 2, 73, 1]])
}
sequence_input_layer = tf.keras.experimental.SequenceFeatures(columns)
sequence_input, sequence_length = sequence_input_layer(
features, training=training)
sequence_length_mask = tf.sequence_mask(sequence_length)
hidden_size = 32
rnn_cell = tf.keras.layers.SimpleRNNCell(hidden_size)
rnn_layer = tf.keras.layers.RNN(rnn_cell)
outputs, state = rnn_layer(sequence_input, mask=sequence_length_mask)
```
| Args |
| `feature_columns` | An iterable of dense sequence columns. Valid columns are * `embedding_column` that wraps a `sequence_categorical_column_with_*`
* `sequence_numeric_column`.
|
| `trainable` | Boolean, whether the layer's variables will be updated via gradient descent during training. |
| `name` | Name to give to the SequenceFeatures. |
| `**kwargs` | Keyword arguments to construct a layer. |
| Raises |
| `ValueError` | If any of the `feature_columns` is not a `SequenceDenseColumn`. |
tensorflow tf.keras.experimental.WideDeepModel tf.keras.experimental.WideDeepModel
===================================
[View source on GitHub](https://github.com/keras-team/keras/tree/v2.9.0/keras/premade_models/wide_deep.py#L33-L217) |
Wide & Deep Model for regression and classification problems.
Inherits From: [`Model`](../model), [`Layer`](../layers/layer), [`Module`](../../module)
#### View aliases
**Compat aliases for migration**
See [Migration guide](https://www.tensorflow.org/guide/migrate) for more details.
[`tf.compat.v1.keras.experimental.WideDeepModel`](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/WideDeepModel), [`tf.compat.v1.keras.models.WideDeepModel`](https://www.tensorflow.org/api_docs/python/tf/keras/experimental/WideDeepModel)
```
tf.keras.experimental.WideDeepModel(
linear_model, dnn_model, activation=None, **kwargs
)
```
This model jointly train a linear and a dnn model.
#### Example:
```
linear_model = LinearModel()
dnn_model = keras.Sequential([keras.layers.Dense(units=64),
keras.layers.Dense(units=1)])
combined_model = WideDeepModel(linear_model, dnn_model)
combined_model.compile(optimizer=['sgd', 'adam'], 'mse', ['mse'])
# define dnn_inputs and linear_inputs as separate numpy arrays or
# a single numpy array if dnn_inputs is same as linear_inputs.
combined_model.fit([linear_inputs, dnn_inputs], y, epochs)
# or define a single `tf.data.Dataset` that contains a single tensor or
# separate tensors for dnn_inputs and linear_inputs.
dataset = tf.data.Dataset.from_tensors(([linear_inputs, dnn_inputs], y))
combined_model.fit(dataset, epochs)
```
Both linear and dnn model can be pre-compiled and trained separately before jointly training:
#### Example:
```
linear_model = LinearModel()
linear_model.compile('adagrad', 'mse')
linear_model.fit(linear_inputs, y, epochs)
dnn_model = keras.Sequential([keras.layers.Dense(units=1)])
dnn_model.compile('rmsprop', 'mse')
dnn_model.fit(dnn_inputs, y, epochs)
combined_model = WideDeepModel(linear_model, dnn_model)
combined_model.compile(optimizer=['sgd', 'adam'], 'mse', ['mse'])
combined_model.fit([linear_inputs, dnn_inputs], y, epochs)
```
| Args |
| `linear_model` | a premade LinearModel, its output must match the output of the dnn model. |
| `dnn_model` | a [`tf.keras.Model`](../model), its output must match the output of the linear model. |
| `activation` | Activation function. Set it to None to maintain a linear activation. |
| `**kwargs` | The keyword arguments that are passed on to BaseLayer.**init**. Allowed keyword arguments include `name`. |
| Attributes |
| `distribute_strategy` | The [`tf.distribute.Strategy`](../../distribute/strategy) this model was created under. |
| `layers` | |
| `metrics_names` | Returns the model's display labels for all outputs.
**Note:** `metrics_names` are available only after a [`keras.Model`](../model) has been trained/evaluated on actual data.
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
model.metrics_names
[]
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
model.fit(x, y)
model.metrics_names
['loss', 'mae']
```
```
inputs = tf.keras.layers.Input(shape=(3,))
d = tf.keras.layers.Dense(2, name='out')
output_1 = d(inputs)
output_2 = d(inputs)
model = tf.keras.models.Model(
inputs=inputs, outputs=[output_1, output_2])
model.compile(optimizer="Adam", loss="mse", metrics=["mae", "acc"])
model.fit(x, (y, y))
model.metrics_names
['loss', 'out_loss', 'out_1_loss', 'out_mae', 'out_acc', 'out_1_mae',
'out_1_acc']
```
|
| `run_eagerly` | Settable attribute indicating whether the model should run eagerly. Running eagerly means that your model will be run step by step, like Python code. Your model might run slower, but it should become easier for you to debug it by stepping into individual layer calls. By default, we will attempt to compile your model to a static graph to deliver the best execution performance. |
Methods
-------
### `call`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/premade_models/wide_deep.py#L92-L109)
```
call(
inputs, training=None
)
```
Calls the model on new inputs and returns the outputs as tensors.
In this case `call()` just reapplies all ops in the graph to the new inputs (e.g. build a new computational graph from the provided inputs).
>
> **Note:** This method should not be called directly. It is only meant to be overridden when subclassing [`tf.keras.Model`](../model). To call a model on an input, always use the `__call__()` method, i.e. `model(inputs)`, which relies on the underlying `call()` method.
>
| Args |
| `inputs` | Input tensor, or dict/list/tuple of input tensors. |
| `training` | Boolean or boolean scalar tensor, indicating whether to run the `Network` in training mode or inference mode. |
| `mask` | A mask or list of masks. A mask can be either a boolean tensor or None (no mask). For more details, check the guide [here](https://www.tensorflow.org/guide/keras/masking_and_padding). |
| Returns |
| A tensor if there is a single output, or a list of tensors if there are more than one outputs. |
### `compile`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L523-L659)
```
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
```
Configures the model for training.
#### Example:
```
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.FalseNegatives()])
```
| Args |
| `optimizer` | String (name of optimizer) or optimizer instance. See [`tf.keras.optimizers`](../optimizers). |
| `loss` | Loss function. May be a string (name of loss function), or a [`tf.keras.losses.Loss`](../losses/loss) instance. See [`tf.keras.losses`](../losses). A loss function is any callable with the signature `loss = fn(y_true, y_pred)`, where `y_true` are the ground truth values, and `y_pred` are the model's predictions. `y_true` should have shape `(batch_size, d0, .. dN)` (except in the case of sparse loss functions such as sparse categorical crossentropy which expects integer arrays of shape `(batch_size, d0, .. dN-1)`). `y_pred` should have shape `(batch_size, d0, .. dN)`. The loss function should return a float tensor. If a custom `Loss` instance is used and reduction is set to `None`, return value has shape `(batch_size, d0, .. dN-1)` i.e. per-sample or per-timestep loss values; otherwise, it is a scalar. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses, unless `loss_weights` is specified. |
| `metrics` | List of metrics to be evaluated by the model during training and testing. Each of this can be a string (name of a built-in function), function or a [`tf.keras.metrics.Metric`](../metrics/metric) instance. See [`tf.keras.metrics`](../metrics). Typically you will use `metrics=['accuracy']`. A function is any callable with the signature `result = fn(y_true, y_pred)`. To specify different metrics for different outputs of a multi-output model, you could also pass a dictionary, such as `metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}`. You can also pass a list to specify a metric or a list of metrics for each output, such as `metrics=[['accuracy'], ['accuracy', 'mse']]` or `metrics=['accuracy', ['accuracy', 'mse']]`. When you pass the strings 'accuracy' or 'acc', we convert this to one of [`tf.keras.metrics.BinaryAccuracy`](../metrics/binaryaccuracy), [`tf.keras.metrics.CategoricalAccuracy`](../metrics/categoricalaccuracy), [`tf.keras.metrics.SparseCategoricalAccuracy`](../metrics/sparsecategoricalaccuracy) based on the loss function used and the model output shape. We do a similar conversion for the strings 'crossentropy' and 'ce' as well. |
| `loss_weights` | Optional list or dictionary specifying scalar coefficients (Python floats) to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the *weighted sum* of all individual losses, weighted by the `loss_weights` coefficients. If a list, it is expected to have a 1:1 mapping to the model's outputs. If a dict, it is expected to map output names (strings) to scalar coefficients. |
| `weighted_metrics` | List of metrics to be evaluated and weighted by `sample_weight` or `class_weight` during training and testing. |
| `run_eagerly` | Bool. Defaults to `False`. If `True`, this `Model`'s logic will not be wrapped in a [`tf.function`](../../function). Recommended to leave this as `None` unless your `Model` cannot be run inside a [`tf.function`](../../function). `run_eagerly=True` is not supported when using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy). |
| `steps_per_execution` | Int. Defaults to 1. The number of batches to run during each [`tf.function`](../../function) call. Running multiple batches inside a single [`tf.function`](../../function) call can greatly improve performance on TPUs or small models with a large Python overhead. At most, one full epoch will be run each execution. If a number larger than the size of the epoch is passed, the execution will be truncated to the size of the epoch. Note that if `steps_per_execution` is set to `N`, [`Callback.on_batch_begin`](../callbacks/callback#on_batch_begin) and [`Callback.on_batch_end`](../callbacks/callback#on_batch_end) methods will only be called every `N` batches (i.e. before/after each [`tf.function`](../../function) execution). |
| `jit_compile` | If `True`, compile the model training step with XLA. [XLA](https://www.tensorflow.org/xla) is an optimizing compiler for machine learning. `jit_compile` is not enabled for by default. This option cannot be enabled with `run_eagerly=True`. Note that `jit_compile=True` is may not necessarily work for all models. For more information on supported operations please refer to the [XLA documentation](https://www.tensorflow.org/xla). Also refer to [known XLA issues](https://www.tensorflow.org/xla/known_issues) for more details. |
| `**kwargs` | Arguments supported for backwards compatibility only. |
### `compute_loss`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L896-L949)
```
compute_loss(
x=None, y=None, y_pred=None, sample_weight=None
)
```
Compute the total loss, validate it, and return it.
Subclasses can optionally override this method to provide custom loss computation logic.
#### Example:
```
class MyModel(tf.keras.Model):
def __init__(self, *args, **kwargs):
super(MyModel, self).__init__(*args, **kwargs)
self.loss_tracker = tf.keras.metrics.Mean(name='loss')
def compute_loss(self, x, y, y_pred, sample_weight):
loss = tf.reduce_mean(tf.math.squared_difference(y_pred, y))
loss += tf.add_n(self.losses)
self.loss_tracker.update_state(loss)
return loss
def reset_metrics(self):
self.loss_tracker.reset_states()
@property
def metrics(self):
return [self.loss_tracker]
tensors = tf.random.uniform((10, 10)), tf.random.uniform((10,))
dataset = tf.data.Dataset.from_tensor_slices(tensors).repeat().batch(1)
inputs = tf.keras.layers.Input(shape=(10,), name='my_input')
outputs = tf.keras.layers.Dense(10)(inputs)
model = MyModel(inputs, outputs)
model.add_loss(tf.reduce_sum(outputs))
optimizer = tf.keras.optimizers.SGD()
model.compile(optimizer, loss='mse', steps_per_execution=10)
model.fit(dataset, epochs=2, steps_per_epoch=10)
print('My custom loss: ', model.loss_tracker.result().numpy())
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| The total loss as a [`tf.Tensor`](../../tensor), or `None` if no loss results (which is the case when called by [`Model.test_step`](../model#test_step)). |
### `compute_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L951-L996)
```
compute_metrics(
x, y, y_pred, sample_weight
)
```
Update metric states and collect all metrics to be returned.
Subclasses can optionally override this method to provide custom metric updating and collection logic.
#### Example:
```
class MyModel(tf.keras.Sequential):
def compute_metrics(self, x, y, y_pred, sample_weight):
# This super call updates `self.compiled_metrics` and returns results
# for all metrics listed in `self.metrics`.
metric_results = super(MyModel, self).compute_metrics(
x, y, y_pred, sample_weight)
# Note that `self.custom_metric` is not listed in `self.metrics`.
self.custom_metric.update_state(x, y, y_pred, sample_weight)
metric_results['custom_metric_name'] = self.custom_metric.result()
return metric_results
```
| Args |
| `x` | Input data. |
| `y` | Target data. |
| `y_pred` | Predictions returned by the model (output of `model.call(x)`) |
| `sample_weight` | Sample weights for weighting the loss function. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end()`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the metrics listed in `self.metrics` are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
### `evaluate`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1602-L1768)
```
evaluate(
x=None,
y=None,
batch_size=None,
verbose='auto',
sample_weight=None,
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False,
return_dict=False,
**kwargs
)
```
Returns the loss value & metrics values for the model in test mode.
Computation is done in batches (see the `batch_size` arg.)
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator or [`keras.utils.Sequence`](../utils/sequence) instance, `y` should not be specified (since targets will be obtained from the iterator/dataset). |
| `batch_size` | Integer or `None`. Number of samples per batch of computation. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of a dataset, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `sample_weight` | Optional Numpy array of weights for the test samples, used for weighting the loss function. You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, instead pass sample weights as the third element of `x`. |
| `steps` | Integer or `None`. Total number of steps (batches of samples) before declaring the evaluation round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../../data) dataset and `steps` is None, 'evaluate' will run until the dataset is exhausted. This argument is not supported with array inputs. |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during evaluation. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| `**kwargs` | Unused at this time. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](../model#fit).
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.evaluate` is wrapped in a [`tf.function`](../../function). |
### `fit`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1099-L1472)
```
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose='auto',
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Trains the model for a fixed number of epochs (iterations on a dataset).
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
* A [`tf.data`](../../data) dataset. Should return a tuple of either `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`.
* A [`tf.keras.utils.experimental.DatasetCreator`](../utils/experimental/datasetcreator), which wraps a callable that takes a single argument of type [`tf.distribute.InputContext`](../../distribute/inputcontext), and returns a [`tf.data.Dataset`](../../data/dataset). `DatasetCreator` should be used when users prefer to specify the per-replica batching and sharding logic for the `Dataset`. See [`tf.keras.utils.experimental.DatasetCreator`](../utils/experimental/datasetcreator) doc for more information. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given below. If using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy), only `DatasetCreator` type is supported for `x`.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). If `x` is a dataset, generator, or [`keras.utils.Sequence`](../utils/sequence) instance, `y` should not be specified (since targets will be obtained from `x`). |
| `batch_size` | Integer or `None`. Number of samples per gradient update. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `epochs` | Integer. Number of epochs to train the model. An epoch is an iteration over the entire `x` and `y` data provided (unless the `steps_per_epoch` flag is set to something other than None). Note that in conjunction with `initial_epoch`, `epochs` is to be understood as "final epoch". The model is not trained for a number of iterations given by `epochs`, but merely until the epoch of index `epochs` is reached. |
| `verbose` | 'auto', 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch. 'auto' defaults to 1 for most cases, but 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so verbose=2 is recommended when not running interactively (eg, in a production environment). |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during training. See [`tf.keras.callbacks`](../callbacks). Note [`tf.keras.callbacks.ProgbarLogger`](../callbacks/progbarlogger) and [`tf.keras.callbacks.History`](../callbacks/history) callbacks are created automatically and need not be passed into `model.fit`. [`tf.keras.callbacks.ProgbarLogger`](../callbacks/progbarlogger) is created or not based on `verbose` argument to `model.fit`. Callbacks with batch-level calls are currently unsupported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy), and users are advised to implement epoch-level calls instead with an appropriate `steps_per_epoch` value. |
| `validation_split` | Float between 0 and 1. Fraction of the training data to be used as validation data. The model will set apart this fraction of the training data, will not train on it, and will evaluate the loss and any model metrics on this data at the end of each epoch. The validation data is selected from the last samples in the `x` and `y` data provided, before shuffling. This argument is not supported when `x` is a dataset, generator or [`keras.utils.Sequence`](../utils/sequence) instance. If both `validation_data` and `validation_split` are provided, `validation_data` will override `validation_split`. `validation_split` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy). |
| `validation_data` | Data on which to evaluate the loss and any model metrics at the end of each epoch. The model will not be trained on this data. Thus, note the fact that the validation loss of data provided using `validation_split` or `validation_data` is not affected by regularization layers like noise and dropout. `validation_data` will override `validation_split`. `validation_data` could be: * A tuple `(x_val, y_val)` of Numpy arrays or tensors.
* A tuple `(x_val, y_val, val_sample_weights)` of NumPy arrays.
* A [`tf.data.Dataset`](../../data/dataset).
* A Python generator or [`keras.utils.Sequence`](../utils/sequence) returning `(inputs, targets)` or `(inputs, targets, sample_weights)`. `validation_data` is not yet supported with [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy).
|
| `shuffle` | Boolean (whether to shuffle the training data before each epoch) or str (for 'batch'). This argument is ignored when `x` is a generator or an object of tf.data.Dataset. 'batch' is a special option for dealing with the limitations of HDF5 data; it shuffles in batch-sized chunks. Has no effect when `steps_per_epoch` is not `None`. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function (during training only). This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `sample_weight` | Optional Numpy array of weights for the training samples, used for weighting the loss function (during training only). You can either pass a flat (1D) Numpy array with the same length as the input samples (1:1 mapping between weights and samples), or in the case of temporal data, you can pass a 2D array with shape `(samples, sequence_length)`, to apply a different weight to every timestep of every sample. This argument is not supported when `x` is a dataset, generator, or [`keras.utils.Sequence`](../utils/sequence) instance, instead provide the sample\_weights as the third element of `x`. |
| `initial_epoch` | Integer. Epoch at which to start training (useful for resuming a previous training run). |
| `steps_per_epoch` | Integer or `None`. Total number of steps (batches of samples) before declaring one epoch finished and starting the next epoch. When training with input tensors such as TensorFlow data tensors, the default `None` is equal to the number of samples in your dataset divided by the batch size, or 1 if that cannot be determined. If x is a [`tf.data`](../../data) dataset, and 'steps\_per\_epoch' is None, the epoch will run until the input dataset is exhausted. When passing an infinitely repeating dataset, you must specify the `steps_per_epoch` argument. If `steps_per_epoch=-1` the training will run indefinitely with an infinitely repeating dataset. This argument is not supported with array inputs. When using [`tf.distribute.experimental.ParameterServerStrategy`](../../distribute/experimental/parameterserverstrategy): - `steps_per_epoch=None` is not supported.
|
| `validation_steps` | Only relevant if `validation_data` is provided and is a [`tf.data`](../../data) dataset. Total number of steps (batches of samples) to draw before stopping when performing validation at the end of every epoch. If 'validation\_steps' is None, validation will run until the `validation_data` dataset is exhausted. In the case of an infinitely repeated dataset, it will run into an infinite loop. If 'validation\_steps' is specified and only part of the dataset will be consumed, the evaluation will start from the beginning of the dataset at each epoch. This ensures that the same validation samples are used every time. |
| `validation_batch_size` | Integer or `None`. Number of samples per validation batch. If unspecified, will default to `batch_size`. Do not specify the `validation_batch_size` if your data is in the form of datasets, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `validation_freq` | Only relevant if validation data is provided. Integer or `collections.abc.Container` instance (e.g. list, tuple, etc.). If an integer, specifies how many training epochs to run before a new validation run is performed, e.g. `validation_freq=2` runs validation every 2 epochs. If a Container, specifies the epochs on which to run validation, e.g. `validation_freq=[1, 2, 10]` runs validation at the end of the 1st, 2nd, and 10th epochs. |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
Unpacking behavior for iterator-like inputs: A common pattern is to pass a tf.data.Dataset, generator, or tf.keras.utils.Sequence to the `x` argument of fit, which will in fact yield not only features (x) but optionally targets (y) and sample weights. Keras requires that the output of such iterator-likes be unambiguous. The iterator should return a tuple of length 1, 2, or 3, where the optional second and third elements will be used for y and sample\_weight respectively. Any other type provided will be wrapped in a length one tuple, effectively treating everything as 'x'. When yielding dicts, they should still adhere to the top-level tuple structure. e.g. `({"x0": x0, "x1": x1}, y)`. Keras will not attempt to separate features, targets, and weights from the keys of a single dict. A notable unsupported data type is the namedtuple. The reason is that it behaves like both an ordered datatype (tuple) and a mapping datatype (dict). So given a namedtuple of the form: `namedtuple("example_tuple", ["y", "x"])` it is ambiguous whether to reverse the order of the elements when interpreting the value. Even worse is a tuple of the form: `namedtuple("other_tuple", ["x", "y", "z"])` where it is unclear if the tuple was intended to be unpacked into x, y, and sample\_weight or passed through as a single element to `x`. As a result the data processing code will simply raise a ValueError if it encounters a namedtuple. (Along with instructions to remedy the issue.)
| Returns |
| A `History` object. Its `History.history` attribute is a record of training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). |
| Raises |
| `RuntimeError` | 1. If the model was never compiled or,
2. If `model.fit` is wrapped in [`tf.function`](../../function).
|
| `ValueError` | In case of mismatch between the provided input data and what the model expects or when the input data is empty. |
### `get_layer`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2891-L2925)
```
get_layer(
name=None, index=None
)
```
Retrieves a layer based on either its name (unique) or index.
If `name` and `index` are both provided, `index` will take precedence. Indices are based on order of horizontal graph traversal (bottom-up).
| Args |
| `name` | String, name of layer. |
| `index` | Integer, index of layer. |
| Returns |
| A layer instance. |
### `load_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2556-L2661)
```
load_weights(
filepath, by_name=False, skip_mismatch=False, options=None
)
```
Loads all layer weights, either from a TensorFlow or an HDF5 weight file.
If `by_name` is False weights are loaded based on the network's topology. This means the architecture should be the same as when the weights were saved. Note that layers that don't have weights are not taken into account in the topological ordering, so adding or removing layers is fine as long as they don't have weights.
If `by_name` is True, weights are loaded into layers only if they share the same name. This is useful for fine-tuning or transfer-learning models where some of the layers have changed.
Only topological loading (`by_name=False`) is supported when loading weights from the TensorFlow format. Note that topological loading differs slightly between TensorFlow and HDF5 formats for user-defined classes inheriting from [`tf.keras.Model`](../model): HDF5 loads based on a flattened list of weights, while the TensorFlow format loads based on the object-local names of attributes to which layers are assigned in the `Model`'s constructor.
| Args |
| `filepath` | String, path to the weights file to load. For weight files in TensorFlow format, this is the file prefix (the same as was passed to `save_weights`). This can also be a path to a SavedModel saved from `model.save`. |
| `by_name` | Boolean, whether to load weights by name or by topological order. Only topological loading is supported for weight files in TensorFlow format. |
| `skip_mismatch` | Boolean, whether to skip loading of layers where there is a mismatch in the number of weights, or a mismatch in the shape of the weight (only valid when `by_name=True`). |
| `options` | Optional [`tf.train.CheckpointOptions`](../../train/checkpointoptions) object that specifies options for loading weights. |
| Returns |
| When loading a weight file in TensorFlow format, returns the same status object as [`tf.train.Checkpoint.restore`](../../train/checkpoint#restore). When graph building, restore ops are run automatically as soon as the network is built (on first call for user-defined classes inheriting from `Model`, immediately if it is already built). When loading weights in HDF5 format, returns `None`. |
| Raises |
| `ImportError` | If `h5py` is not available and the weight file is in HDF5 format. |
| `ValueError` | If `skip_mismatch` is set to `True` when `by_name` is `False`. |
### `make_predict_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1793-L1867)
```
make_predict_function(
force=False
)
```
Creates a function that executes one step of inference.
This method can be overridden to support custom inference logic. This method is called by [`Model.predict`](../model#predict) and [`Model.predict_on_batch`](../model#predict_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.predict_step`](../model#predict_step).
This function is cached the first time [`Model.predict`](../model#predict) or [`Model.predict_on_batch`](../model#predict_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the predict function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return the outputs of the `Model`. |
### `make_test_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1504-L1600)
```
make_test_function(
force=False
)
```
Creates a function that executes one step of evaluation.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.evaluate`](../model#evaluate) and [`Model.test_on_batch`](../model#test_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual evaluation logic to [`Model.test_step`](../model#test_step).
This function is cached the first time [`Model.evaluate`](../model#evaluate) or [`Model.test_on_batch`](../model#test_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the test function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_test_batch_end`. |
### `make_train_function`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L998-L1097)
```
make_train_function(
force=False
)
```
Creates a function that executes one step of training.
This method can be overridden to support custom training logic. This method is called by [`Model.fit`](../model#fit) and [`Model.train_on_batch`](../model#train_on_batch).
Typically, this method directly controls [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings, and delegates the actual training logic to [`Model.train_step`](../model#train_step).
This function is cached the first time [`Model.fit`](../model#fit) or [`Model.train_on_batch`](../model#train_on_batch) is called. The cache is cleared whenever [`Model.compile`](../model#compile) is called. You can skip the cache and generate again the function with `force=True`.
| Args |
| `force` | Whether to regenerate the train function and skip the cached function if available. |
| Returns |
| Function. The function created by this method should accept a [`tf.data.Iterator`](../../data/iterator), and return a `dict` containing values that will be passed to `tf.keras.Callbacks.on_train_batch_end`, such as `{'loss': 0.2, 'accuracy': 0.7}`. |
### `predict`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1869-L2064)
```
predict(
x,
batch_size=None,
verbose='auto',
steps=None,
callbacks=None,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
```
Generates output predictions for the input samples.
Computation is done in batches. This method is designed for batch processing of large numbers of inputs. It is not intended for use inside of loops that iterate over your data and process small numbers of inputs at a time.
For small numbers of inputs that fit in one batch, directly use `__call__()` for faster execution, e.g., `model(x)`, or `model(x, training=False)` if you have layers such as [`tf.keras.layers.BatchNormalization`](../layers/batchnormalization) that behave differently during inference. You may pair the individual model call with a [`tf.function`](../../function) for additional performance inside your inner loop. If you need access to numpy array values instead of tensors after your model call, you can use `tensor.numpy()` to get the numpy array value of an eager tensor.
Also, note the fact that test loss is not affected by regularization layers like noise and dropout.
>
> **Note:** See [this FAQ entry](https://keras.io/getting_started/faq/#whats-the-difference-between-model-methods-predict-and-call) for more details about the difference between `Model` methods `predict()` and `__call__()`.
>
| Args |
| `x` | Input samples. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A [`tf.data`](../../data) dataset.
* A generator or [`keras.utils.Sequence`](../utils/sequence) instance. A more detailed description of unpacking behavior for iterator types (Dataset, generator, Sequence) is given in the `Unpacking behavior for iterator-like inputs` section of `Model.fit`.
|
| `batch_size` | Integer or `None`. Number of samples per batch. If unspecified, `batch_size` will default to 32. Do not specify the `batch_size` if your data is in the form of dataset, generators, or [`keras.utils.Sequence`](../utils/sequence) instances (since they generate batches). |
| `verbose` | `"auto"`, 0, 1, or 2. Verbosity mode. 0 = silent, 1 = progress bar, 2 = single line. `"auto"` defaults to 1 for most cases, and to 2 when used with `ParameterServerStrategy`. Note that the progress bar is not particularly useful when logged to a file, so `verbose=2` is recommended when not running interactively (e.g. in a production environment). |
| `steps` | Total number of steps (batches of samples) before declaring the prediction round finished. Ignored with the default value of `None`. If x is a [`tf.data`](../../data) dataset and `steps` is None, `predict()` will run until the input dataset is exhausted. |
| `callbacks` | List of [`keras.callbacks.Callback`](../callbacks/callback) instances. List of callbacks to apply during prediction. See [callbacks](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks). |
| `max_queue_size` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum size for the generator queue. If unspecified, `max_queue_size` will default to 10. |
| `workers` | Integer. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. Maximum number of processes to spin up when using process-based threading. If unspecified, `workers` will default to 1. |
| `use_multiprocessing` | Boolean. Used for generator or [`keras.utils.Sequence`](../utils/sequence) input only. If `True`, use process-based threading. If unspecified, `use_multiprocessing` will default to `False`. Note that because this implementation relies on multiprocessing, you should not pass non-picklable arguments to the generator as they can't be passed easily to children processes. |
See the discussion of `Unpacking behavior for iterator-like inputs` for [`Model.fit`](../model#fit). Note that Model.predict uses the same interpretation rules as [`Model.fit`](../model#fit) and [`Model.evaluate`](../model#evaluate), so inputs must be unambiguous for all three methods.
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict` is wrapped in a [`tf.function`](../../function). |
| `ValueError` | In case of mismatch between the provided input data and the model's expectations, or in case a stateful model receives a number of samples that is not a multiple of the batch size. |
### `predict_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2209-L2231)
```
predict_on_batch(
x
)
```
Returns predictions for a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
|
| Returns |
| Numpy array(s) of predictions. |
| Raises |
| `RuntimeError` | If `model.predict_on_batch` is wrapped in a [`tf.function`](../../function). |
### `predict_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1770-L1791)
```
predict_step(
data
)
```
The logic for one inference step.
This method can be overridden to support custom inference logic. This method is called by [`Model.make_predict_function`](../model#make_predict_function).
This method should contain the mathematical logic for one step of inference. This typically includes the forward pass.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_predict_function`](../model#make_predict_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| The result of one inference step, typically the output of calling the `Model` on data. |
### `reset_metrics`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2066-L2086)
```
reset_metrics()
```
Resets the state of all the metrics in the model.
#### Examples:
```
inputs = tf.keras.layers.Input(shape=(3,))
outputs = tf.keras.layers.Dense(2)(inputs)
model = tf.keras.models.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer="Adam", loss="mse", metrics=["mae"])
```
```
x = np.random.random((2, 3))
y = np.random.randint(0, 2, (2, 2))
_ = model.fit(x, y, verbose=0)
assert all(float(m.result()) for m in model.metrics)
```
```
model.reset_metrics()
assert all(float(m.result()) == 0 for m in model.metrics)
```
### `reset_states`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2788-L2791)
```
reset_states()
```
### `save`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2383-L2436)
```
save(
filepath,
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None,
save_traces=True
)
```
Saves the model to Tensorflow SavedModel or a single HDF5 file.
Please see [`tf.keras.models.save_model`](../models/save_model) or the [Serialization and Saving guide](https://keras.io/guides/serialization_and_saving/) for details.
| Args |
| `filepath` | String, PathLike, path to SavedModel or H5 file to save the model. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `include_optimizer` | If True, save optimizer's state together. |
| `save_format` | Either `'tf'` or `'h5'`, indicating whether to save the model to Tensorflow SavedModel or HDF5. Defaults to 'tf' in TF 2.X, and 'h5' in TF 1.X. |
| `signatures` | Signatures to save with the SavedModel. Applicable to the 'tf' format only. Please see the `signatures` argument in [`tf.saved_model.save`](../../saved_model/save) for details. |
| `options` | (only applies to SavedModel format) [`tf.saved_model.SaveOptions`](../../saved_model/saveoptions) object that specifies options for saving to SavedModel. |
| `save_traces` | (only applies to SavedModel format) When enabled, the SavedModel will store the function traces for each layer. This can be disabled, so that only the configs of each layer are stored. Defaults to `True`. Disabling this will decrease serialization time and reduce file size, but it requires that all custom layers/models implement a `get_config()` method. |
#### Example:
```
from keras.models import load_model
model.save('my_model.h5') # creates a HDF5 file 'my_model.h5'
del model # deletes the existing model
# returns a compiled model
# identical to the previous one
model = load_model('my_model.h5')
```
### `save_spec`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2965-L3002)
```
save_spec(
dynamic_batch=True
)
```
Returns the [`tf.TensorSpec`](../../tensorspec) of call inputs as a tuple `(args, kwargs)`.
This value is automatically defined after calling the model for the first time. Afterwards, you can use it when exporting the model for serving:
```
model = tf.keras.Model(...)
@tf.function
def serve(*args, **kwargs):
outputs = model(*args, **kwargs)
# Apply postprocessing steps, or add additional outputs.
...
return outputs
# arg_specs is `[tf.TensorSpec(...), ...]`. kwarg_specs, in this example, is
# an empty dict since functional models do not use keyword arguments.
arg_specs, kwarg_specs = model.save_spec()
model.save(path, signatures={
'serving_default': serve.get_concrete_function(*arg_specs, **kwarg_specs)
})
```
| Args |
| `dynamic_batch` | Whether to set the batch sizes of all the returned [`tf.TensorSpec`](../../tensorspec) to `None`. (Note that when defining functional or Sequential models with `tf.keras.Input([...], batch_size=X)`, the batch size will always be preserved). Defaults to `True`. |
| Returns |
| If the model inputs are defined, returns a tuple `(args, kwargs)`. All elements in `args` and `kwargs` are [`tf.TensorSpec`](../../tensorspec). If the model inputs are not defined, returns `None`. The model inputs are automatically set when calling the model, `model.fit`, `model.evaluate` or `model.predict`. |
### `save_weights`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2438-L2554)
```
save_weights(
filepath, overwrite=True, save_format=None, options=None
)
```
Saves all layer weights.
Either saves in HDF5 or in TensorFlow format based on the `save_format` argument.
When saving in HDF5 format, the weight file has:
* `layer_names` (attribute), a list of strings (ordered names of model layers).
* For every layer, a `group` named `layer.name`
+ For every such layer group, a group attribute `weight_names`, a list of strings (ordered names of weights tensor of the layer).
+ For every weight in the layer, a dataset storing the weight value, named after the weight tensor.
When saving in TensorFlow format, all objects referenced by the network are saved in the same format as [`tf.train.Checkpoint`](../../train/checkpoint), including any `Layer` instances or `Optimizer` instances assigned to object attributes. For networks constructed from inputs and outputs using `tf.keras.Model(inputs, outputs)`, `Layer` instances used by the network are tracked/saved automatically. For user-defined classes which inherit from [`tf.keras.Model`](../model), `Layer` instances must be assigned to object attributes, typically in the constructor. See the documentation of [`tf.train.Checkpoint`](../../train/checkpoint) and [`tf.keras.Model`](../model) for details.
While the formats are the same, do not mix `save_weights` and [`tf.train.Checkpoint`](../../train/checkpoint). Checkpoints saved by [`Model.save_weights`](../model#save_weights) should be loaded using [`Model.load_weights`](../model#load_weights). Checkpoints saved using [`tf.train.Checkpoint.save`](../../train/checkpoint#save) should be restored using the corresponding [`tf.train.Checkpoint.restore`](../../train/checkpoint#restore). Prefer [`tf.train.Checkpoint`](../../train/checkpoint) over `save_weights` for training checkpoints.
The TensorFlow format matches objects and variables by starting at a root object, `self` for `save_weights`, and greedily matching attribute names. For [`Model.save`](../model#save) this is the `Model`, and for [`Checkpoint.save`](../../train/checkpoint#save) this is the `Checkpoint` even if the `Checkpoint` has a model attached. This means saving a [`tf.keras.Model`](../model) using `save_weights` and loading into a [`tf.train.Checkpoint`](../../train/checkpoint) with a `Model` attached (or vice versa) will not match the `Model`'s variables. See the [guide to training checkpoints](https://www.tensorflow.org/guide/checkpoint) for details on the TensorFlow format.
| Args |
| `filepath` | String or PathLike, path to the file to save the weights to. When saving in TensorFlow format, this is the prefix used for checkpoint files (multiple files are generated). Note that the '.h5' suffix causes weights to be saved in HDF5 format. |
| `overwrite` | Whether to silently overwrite any existing file at the target location, or provide the user with a manual prompt. |
| `save_format` | Either 'tf' or 'h5'. A `filepath` ending in '.h5' or '.keras' will default to HDF5 if `save_format` is `None`. Otherwise `None` defaults to 'tf'. |
| `options` | Optional [`tf.train.CheckpointOptions`](../../train/checkpointoptions) object that specifies options for saving weights. |
| Raises |
| `ImportError` | If `h5py` is not available when attempting to save in HDF5 format. |
### `summary`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2841-L2879)
```
summary(
line_length=None,
positions=None,
print_fn=None,
expand_nested=False,
show_trainable=False
)
```
Prints a string summary of the network.
| Args |
| `line_length` | Total length of printed lines (e.g. set this to adapt the display to different terminal window sizes). |
| `positions` | Relative or absolute positions of log elements in each line. If not provided, defaults to `[.33, .55, .67, 1.]`. |
| `print_fn` | Print function to use. Defaults to `print`. It will be called on each line of the summary. You can set it to a custom function in order to capture the string summary. |
| `expand_nested` | Whether to expand the nested models. If not provided, defaults to `False`. |
| `show_trainable` | Whether to show if a layer is trainable. If not provided, defaults to `False`. |
| Raises |
| `ValueError` | if `summary()` is called before the model is built. |
### `test_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2152-L2207)
```
test_on_batch(
x, y=None, sample_weight=None, reset_metrics=True, return_dict=False
)
```
Test the model on a single batch of samples.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). It should be consistent with `x` (you cannot have Numpy inputs and tensor targets, or inversely). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar test loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.test_on_batch` is wrapped in a [`tf.function`](../../function). |
### `test_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L1474-L1502)
```
test_step(
data
)
```
The logic for one evaluation step.
This method can be overridden to support custom evaluation logic. This method is called by [`Model.make_test_function`](../model#make_test_function).
This function should contain the mathematical logic for one step of evaluation. This typically includes the forward pass, loss calculation, and metrics updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_test_function`](../model#make_test_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. |
### `to_json`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2743-L2758)
```
to_json(
**kwargs
)
```
Returns a JSON string containing the network configuration.
To load a network from a JSON save file, use [`keras.models.model_from_json(json_string, custom_objects={})`](../models/model_from_json).
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `json.dumps()`. |
| Returns |
| A JSON string. |
### `to_yaml`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2760-L2786)
```
to_yaml(
**kwargs
)
```
Returns a yaml string containing the network configuration.
>
> **Note:** Since TF 2.6, this method is no longer supported and will raise a RuntimeError.
>
To load a network from a yaml save file, use [`keras.models.model_from_yaml(yaml_string, custom_objects={})`](../models/model_from_yaml).
`custom_objects` should be a dictionary mapping the names of custom losses / layers / etc to the corresponding functions / classes.
| Args |
| `**kwargs` | Additional keyword arguments to be passed to `yaml.dump()`. |
| Returns |
| A YAML string. |
| Raises |
| `RuntimeError` | announces that the method poses a security risk |
### `train_on_batch`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/engine/training.py#L2088-L2150)
```
train_on_batch(
x,
y=None,
sample_weight=None,
class_weight=None,
reset_metrics=True,
return_dict=False
)
```
Runs a single gradient update on a single batch of data.
| Args |
| `x` | Input data. It could be: * A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
* A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
* A dict mapping input names to the corresponding array/tensors, if the model has named inputs.
|
| `y` | Target data. Like the input data `x`, it could be either Numpy array(s) or TensorFlow tensor(s). |
| `sample_weight` | Optional array of the same length as x, containing weights to apply to the model's loss for each sample. In the case of temporal data, you can pass a 2D array with shape (samples, sequence\_length), to apply a different weight to every timestep of every sample. |
| `class_weight` | Optional dictionary mapping class indices (integers) to a weight (float) to apply to the model's loss for the samples from this class during training. This can be useful to tell the model to "pay more attention" to samples from an under-represented class. |
| `reset_metrics` | If `True`, the metrics returned will be only for this batch. If `False`, the metrics will be statefully accumulated across batches. |
| `return_dict` | If `True`, loss and metric results are returned as a dict, with each key being the name of the metric. If `False`, they are returned as a list. |
| Returns |
| Scalar training loss (if the model has a single output and no metrics) or list of scalars (if the model has multiple outputs and/or metrics). The attribute `model.metrics_names` will give you the display labels for the scalar outputs. |
| Raises |
| `RuntimeError` | If `model.train_on_batch` is wrapped in a [`tf.function`](../../function). |
### `train_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/premade_models/wide_deep.py#L112-L134)
```
train_step(
data
)
```
The logic for one training step.
This method can be overridden to support custom training logic. For concrete examples of how to override this method see [Customizing what happends in fit](https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit). This method is called by [`Model.make_train_function`](../model#make_train_function).
This method should contain the mathematical logic for one step of training. This typically includes the forward pass, loss calculation, backpropagation, and metric updates.
Configuration details for *how* this logic is run (e.g. [`tf.function`](../../function) and [`tf.distribute.Strategy`](../../distribute/strategy) settings), should be left to [`Model.make_train_function`](../model#make_train_function), which can also be overridden.
| Args |
| `data` | A nested structure of `Tensor`s. |
| Returns |
| A `dict` containing values that will be passed to [`tf.keras.callbacks.CallbackList.on_train_batch_end`](../callbacks/callbacklist#on_train_batch_end). Typically, the values of the `Model`'s metrics are returned. Example: `{'loss': 0.2, 'accuracy': 0.7}`. |
| programming_docs |
tensorflow Module: tf.keras.dtensor.experimental Module: tf.keras.dtensor.experimental
=====================================
Public API for tf.keras.dtensor.experimental namespace.
Modules
-------
[`optimizers`](experimental/optimizers) module: Public API for tf.keras.dtensor.experimental.optimizers namespace.
Classes
-------
[`class LayoutMap`](experimental/layoutmap): A dict-like object that maps string to `Layout` instances.
Functions
---------
[`layout_map_scope(...)`](experimental/layout_map_scope): Apply the layout to all the tf.Variables created under the scope.
tensorflow tf.keras.dtensor.experimental.LayoutMap tf.keras.dtensor.experimental.LayoutMap
=======================================
A dict-like object that maps string to `Layout` instances.
```
tf.keras.dtensor.experimental.LayoutMap(
mesh=None
)
```
`LayoutMap` uses a string as key and a `Layout` as value. There is a behavior difference between a normal Python dict and this class. The string key will be treated as a regex when retrieving the value. See the docstring of `get` for more details.
See below for a usage example. You can define the naming schema of the `Layout`, and then retrieve the corresponding `Layout` instance.
To use the `LayoutMap` with a `Model`, please see the docstring of [`tf.keras.dtensor.experimental.layout_map_scope`](layout_map_scope).
```
map = LayoutMap(mesh=None)
map['.*dense.*kernel'] = layout_2d
map['.*dense.*bias'] = layout_1d
map['.*conv2d.*kernel'] = layout_4d
map['.*conv2d.*bias'] = layout_1d
layout_1 = map['dense_1.kernel'] # layout_1 == layout_2d
layout_2 = map['dense_1.bias'] # layout_2 == layout_1d
layout_3 = map['dense_2.kernel'] # layout_3 == layout_2d
layout_4 = map['dense_2.bias'] # layout_4 == layout_1d
layout_5 = map['my_model/conv2d_123/kernel'] # layout_5 == layout_4d
layout_6 = map['my_model/conv2d_123/bias'] # layout_6 == layout_1d
```
| Args |
| `mesh` | An optional `Mesh` that can be used to create all replicated layout as default when there isn't a layout found based on the input string query. |
Methods
-------
### `clear`
```
clear()
```
D.clear() -> None. Remove all items from D.
### `get`
```
get(
key, default=None
)
```
Retrieve the corresponding layout by the string key.
When there isn't an exact match, all the existing keys in the layout map will be treated as a regex and map against the input key again. The first match will be returned, based on the key insertion order. Return None if there isn't any match found.
| Args |
| `key` | the string key as the query for the layout. |
| Returns |
| Corresponding layout based on the query. |
### `get_default_mesh`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/layout_map.py#L130-L136)
```
get_default_mesh()
```
Return the default `Mesh` set at instance creation.
The `Mesh` can be used to create default replicated `Layout` when there isn't a match of the input string query.
### `items`
```
items()
```
D.items() -> a set-like object providing a view on D's items
### `keys`
```
keys()
```
D.keys() -> a set-like object providing a view on D's keys
### `pop`
```
pop(
key, default=__marker
)
```
D.pop(k[,d]) -> v, remove specified key and return the corresponding value. If key is not found, d is returned if given, otherwise KeyError is raised.
### `popitem`
```
popitem()
```
D.popitem() -> (k, v), remove and return some (key, value) pair as a 2-tuple; but raise KeyError if D is empty.
### `setdefault`
```
setdefault(
key, default=None
)
```
D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
### `update`
```
update(
*args, **kwds
)
```
D.update([E, ]\*\*F) -> None. Update D from mapping/iterable E and F. If E present and has a .keys() method, does: for k in E: D[k] = E[k] If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v In either case, this is followed by: for k, v in F.items(): D[k] = v
### `values`
```
values()
```
D.values() -> an object providing a view on D's values
### `__contains__`
```
__contains__(
key
)
```
### `__eq__`
```
__eq__(
other
)
```
Return self==value.
### `__getitem__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/layout_map.py#L87-L107)
```
__getitem__(
key
)
```
Retrieve the corresponding layout by the string key.
When there isn't an exact match, all the existing keys in the layout map will be treated as a regex and map against the input key again. The first match will be returned, based on the key insertion order. Return None if there isn't any match found.
| Args |
| `key` | the string key as the query for the layout. |
| Returns |
| Corresponding layout based on the query. |
### `__iter__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/layout_map.py#L127-L128)
```
__iter__()
```
### `__len__`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/layout_map.py#L124-L125)
```
__len__()
```
tensorflow tf.keras.dtensor.experimental.layout_map_scope tf.keras.dtensor.experimental.layout\_map\_scope
================================================
Apply the layout to all the tf.Variables created under the scope.
```
@contextlib.contextmanager
tf.keras.dtensor.experimental.layout_map_scope(
layout_map
)
```
Create a scope that all the tf.Variable created under this scope will be lazily inited, and initialized later on with proper layout when the object path in the model is stable/finalized.
Note that the layout mapping will use the object/attribute names as the key to map the variable against the layout.
For subclassed models, the full object/attribute name is used as the key. For Functional/Sequential models, since the layers within the model do not get assigned to a meaningful attribute, we use `layer.name` as the key for the layer, followed by the attribute name. Keras ensures name uniqueness among the layers in all Functional/Sequential models.
See the following examples that show the variable object names for different Keras model types:
```
layout_map = layout_map_lib.LayoutMap(mesh=self.mesh)
layout_map['d1.kernel'] = layout_1
layout_map['d1.bias'] = layout_2
layout_map['d2.kernel'] = layout_3
layout_map['d2.bias'] = layout_4
## Subclassed model
class SubclassModel(tf.keras.Model):
def __init__(self, name=None):
super().__init__(name=name)
self.d1 = tf.keras.layers.Dense(1000)
self.d2 = tf.keras.layers.Dense(1000)
def call(self, inputs):
x = self.d1(inputs)
return self.d2(x)
with layout_map_scope(layout_map):
model = SubclassModel()
# Triggering the creation of weights within or outside of the scope works
inputs = tf.zeros((10, 10))
results = model(inputs)
model.d1.kernel.layout == layout_1
model.d1.bias.layout == layout_2
model.d2.kernel.layout == layout_3
model.d2.bias.layout == layout_4
## Functional model
with layout_map_scope(layout_map):
inputs = tf.keras.Input((10,), batch_size=10)
x = tf.keras.layers.Dense(20, name='d1')(inputs)
output = tf.keras.layers.Dense(30, name='d2')(x)
model = tf.keras.Model(inputs, output)
d1 = model.layers[1]
d2 = model.layers[2]
d1.kernel.layout == layout_1
d1.bias.layout == layout_2
d1.kernel.layout == layout_3
d1.bias.layout == layout_4
## Sequential model
with layout_map_scope(layout_map):
model = tf.keras.Sequential([
tf.keras.layers.Dense(20, name='d1', input_shape=(10,)),
tf.keras.layers.Dense(30, name='d2')
])
d1 = model.layers[0]
d2 = model.layers[1]
d1.kernel.layout == layout_1
d1.bias.layout == layout_2
d1.kernel.layout == layout_3
d1.bias.layout == layout_4
```
| Args |
| `layout_map` | a LayoutMap which contains the variable\_object\_path (string) -> Layout. When a layout is not found for the variable, a default all replicated layout will be created for the variable. |
| Yields |
| A context that will lazily initialize all [`tf.Variable`](../../../variable) objects within the model, with their attributed layouts. |
tensorflow Module: tf.keras.dtensor.experimental.optimizers Module: tf.keras.dtensor.experimental.optimizers
================================================
Public API for tf.keras.dtensor.experimental.optimizers namespace.
Classes
-------
[`class Adadelta`](optimizers/adadelta): DTensor specific optimizers.
[`class Adagrad`](optimizers/adagrad): DTensor specific optimizers.
[`class Adam`](optimizers/adam): DTensor specific optimizers.
[`class RMSprop`](optimizers/rmsprop): DTensor specific optimizers.
[`class SGD`](optimizers/sgd): DTensor specific optimizers.
tensorflow tf.keras.dtensor.experimental.optimizers.RMSprop tf.keras.dtensor.experimental.optimizers.RMSprop
================================================
DTensor specific optimizers.
Inherits From: [`RMSprop`](../../../optimizers/experimental/rmsprop), [`Optimizer`](../../../optimizers/experimental/optimizer), [`Module`](../../../../module)
```
tf.keras.dtensor.experimental.optimizers.RMSprop(
learning_rate=0.001,
rho=0.9,
momentum=0.0,
epsilon=1e-07,
centered=False,
gradients_clip_option=None,
ema_option=None,
jit_compile=False,
name='RMSprop',
mesh=None
)
```
The major changes for this class is that all the variable init logic will be mesh/layout aware.
Optimizer that implements the RMSprop algorithm.
The gist of RMSprop is to:
* Maintain a moving (discounted) average of the square of gradients
* Divide the gradient by the root of this average
This implementation of RMSprop uses plain momentum, not Nesterov momentum.
The centered version additionally maintains a moving average of the gradients, and uses that average to estimate the variance.
| Args |
| `learning_rate` | Initial value for the learning rate: either a floating point value, or a [`tf.keras.optimizers.schedules.LearningRateSchedule`](../../../optimizers/schedules/learningrateschedule) instance. Defaults to 0.001. |
| `rho` | float, defaults to 0.9. Discounting factor for the old gradients. |
| `momentum` | float, defaults to 0.0. If not 0.0., the optimizer tracks the momentum value, with a decay rate equals to `1 - momentum`. |
| `epsilon` | A small constant for numerical stability. This epsilon is "epsilon hat" in the Kingma and Ba paper (in the formula just before Section 2.1), not the epsilon in Algorithm 1 of the paper. Defaults to 1e-7. |
| `centered` | Boolean. If `True`, gradients are normalized by the estimated variance of the gradient; if False, by the uncentered second moment. Setting this to `True` may help with training, but is slightly more expensive in terms of computation and memory. Defaults to `False`. |
| `name` | String. The name to use for momentum accumulator weights created by the optimizer. |
| `clipnorm` | Float. If set, the gradient of each weight is individually clipped so that its norm is no higher than this value. |
| `clipvalue` | Float. If set, the gradient of each weight is clipped to be no higher than this value. |
| `global_clipnorm` | Float. If set, the gradient of all weights is clipped so that their global norm is no higher than this value. |
| `use_ema` | Boolean, defaults to False. If True, exponential moving average (EMA) is applied. EMA consists of computing an exponential moving average of the weights of the model (as the weight values change after each training batch), and periodically overwriting the weights with their moving average. |
| `ema_momentum` | Float, defaults to 0.99. Only used if `use_ema=True`. This is the momentum to use when computing the EMA of the model's weights: `new_average = ema_momentum * old_average + (1 - ema_momentum) * current_variable_value`. |
| `ema_overwrite_frequency` | Int or None, defaults to None. Only used if `use_ema=True`. Every `ema_overwrite_frequency` steps of iterations, we overwrite the model variable by its moving average. If None, the optimizer does not overwrite model variables in the middle of training, and you need to explicitly overwrite the variables at the end of training by calling `optimizer.finalize_variable_values()` (which updates the model variables in-place). When using the built-in `fit()` training loop, this happens automatically after the last epoch, and you don't need to do anything. |
| `jit_compile` | Boolean, defaults to True. If True, the optimizer will use XLA compilation. `jit_compile` cannot be True when training with [`tf.distribute.experimental.ParameterServerStrategy`](../../../../distribute/experimental/parameterserverstrategy). Additionally, if no GPU device is found, this flag will be ignored. |
| `**kwargs` | keyword arguments only used for backward compatibility. |
#### Usage:
```
opt = tf.keras.optimizers.RMSprop(learning_rate=0.1)
var1 = tf.Variable(10.0)
loss = lambda: (var1 ** 2) / 2.0 # d(loss) / d(var1) = var1
step_count = opt.minimize(loss, [var1]).numpy()
var1.numpy()
9.683772
```
#### Reference:
* [Hinton, 2012](http://www.cs.toronto.edu/%7Etijmen/csc321/slides/lecture_slides_lec6.pdf)
| Attributes |
| `iterations` | The number of training steps this `optimizer` has run. By default, iterations would be incremented by one every time `apply_gradients()` is called. |
| `learning_rate` | |
Methods
-------
### `add_variable`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L319-L341)
```
add_variable(
shape, dtype=None, initializer='zeros', name=None
)
```
Create an optimizer variable.
| Args |
| `shape` | A list of integers, a tuple of integers, or a 1-D Tensor of type int32. Defaults to scalar if unspecified. |
| `dtype` | The DType of the optimizer variable to be created. Defaults to [`tf.keras.backend.floatx`](../../../backend/floatx) if unspecified. |
| `initializer` | string or callable. Initializer instance. |
| `name` | The name of the optimizer variable to be created. |
| Returns |
| An optimizer variable, in the format of tf.Variable. |
### `add_variable_from_reference`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/optimizers.py#L71-L105)
```
add_variable_from_reference(
model_variable, variable_name, initial_value=None
)
```
Create an optimizer variable from model variable.
Create an optimizer variable based on the information of model variable. For example, in SGD optimizer momemtum, for each model variable, a corresponding momemtum variable is created of the same shape and dtype.
| Args |
| `model_variable` | The corresponding model variable to the optimizer variable to be created. |
| `variable_name` | The name prefix of the optimizer variable to be created. The create variables name will follow the pattern `{variable_name}/{model_variable.name}`, e.g., `momemtum/dense_1`. |
| `initial_value` | The initial value of the optimizer variable, if None, the value will be default to 0. |
| Returns |
| An optimizer variable. |
### `apply_gradients`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/optimizers.py#L117-L131)
```
apply_gradients(
grads_and_vars
)
```
Apply gradients to variables.
| Args |
| `grads_and_vars` | List of (gradient, variable) pairs. |
| Returns |
| None |
| Raises |
| `TypeError` | If `grads_and_vars` is malformed. |
### `build`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/rmsprop.py#L104-L125)
```
build(
var_list
)
```
Initialize the optimizer's variables, such as momemtum variables.
This function has to be implemented by subclass optimizers, and subclass optimizers need to call `super().build(var_list)`.
| Args |
| `var_list` | List of model variables to build optimizers on. For example, SGD optimizer with momentum will store one momentum variable corresponding to each model variable. |
### `compute_gradients`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L152-L177)
```
compute_gradients(
loss, var_list, tape=None
)
```
Compute gradients of loss on trainable variables.
| Args |
| `loss` | `Tensor` or callable. If a callable, `loss` should take no arguments and return the value to minimize. |
| `var_list` | list or tuple of `Variable` objects to update to minimize `loss`. |
| `tape` | (Optional) [`tf.GradientTape`](../../../../gradienttape). If `loss` is provided as a `Tensor`, the tape that computed the `loss` must be provided. |
| Returns |
| A list of (gradient, variable) pairs. Variable is always present, but gradient can be `None`. |
### `finalize_variable_values`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L469-L481)
```
finalize_variable_values(
var_list
)
```
Set the final value of model's trainable variables.
Sometimes there are some extra steps before ending the variable updates, such as overriding the model variables with its average value.
| Args |
| `var_list` | list of model variables. |
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L518-L535)
```
@classmethod
from_config(
config
)
```
Creates an optimizer from its config.
This method is the reverse of `get_config`, capable of instantiating the same optimizer from the config dictionary.
| Args |
| `config` | A Python dictionary, typically the output of get\_config. |
| Returns |
| An optimizer instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/rmsprop.py#L180-L190)
```
get_config()
```
Returns the config of the optimizer.
An optimizer config is a Python dictionary (serializable) containing the configuration of an optimizer. The same optimizer can be reinstantiated later (without any saved state) from this configuration.
Subclass optimizer should override this method to include other hyperparameters.
| Returns |
| Python dictionary. |
### `minimize`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L382-L401)
```
minimize(
loss, var_list, tape=None
)
```
Minimize `loss` by updating `var_list`.
This method simply computes gradient using [`tf.GradientTape`](../../../../gradienttape) and calls `apply_gradients()`. If you want to process the gradient before applying then call [`tf.GradientTape`](../../../../gradienttape) and `apply_gradients()` explicitly instead of using this function.
| Args |
| `loss` | `Tensor` or callable. If a callable, `loss` should take no arguments and return the value to minimize. |
| `var_list` | list or tuple of `Variable` objects to update to minimize `loss`. |
| `tape` | (Optional) [`tf.GradientTape`](../../../../gradienttape). |
| Returns |
| None |
### `update_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/rmsprop.py#L127-L178)
```
update_step(
gradient, variable
)
```
Update step given gradient and the associated model variable.
tensorflow tf.keras.dtensor.experimental.optimizers.SGD tf.keras.dtensor.experimental.optimizers.SGD
============================================
DTensor specific optimizers.
Inherits From: [`SGD`](../../../optimizers/experimental/sgd), [`Optimizer`](../../../optimizers/experimental/optimizer), [`Module`](../../../../module)
```
tf.keras.dtensor.experimental.optimizers.SGD(
learning_rate=0.01,
momentum=0.0,
nesterov=False,
amsgrad=False,
gradients_clip_option=None,
ema_option=None,
jit_compile=False,
name='SGD',
mesh=None
)
```
The major changes for this class is that all the variable init logic will be mesh/layout aware.
Gradient descent (with momentum) optimizer.
Update rule for parameter `w` with gradient `g` when `momentum` is 0:
```
w = w - learning_rate * g
```
Update rule when `momentum` is larger than 0:
```
velocity = momentum * velocity - learning_rate * g
w = w + velocity
```
When `nesterov=True`, this rule becomes:
```
velocity = momentum * velocity - learning_rate * g
w = w + momentum * velocity - learning_rate * g
```
| Args |
| `learning_rate` | A `Tensor`, floating point value, or a schedule that is a [`tf.keras.optimizers.schedules.LearningRateSchedule`](../../../optimizers/schedules/learningrateschedule), or a callable that takes no arguments and returns the actual value to use. The learning rate. Defaults to 0.001. |
| `momentum` | float hyperparameter >= 0 that accelerates gradient descent in the relevant direction and dampens oscillations. Defaults to 0, i.e., vanilla gradient descent. |
| `nesterov` | boolean. Whether to apply Nesterov momentum. Defaults to `False`. |
| `name` | String. The name to use for momentum accumulator weights created by the optimizer. |
| `clipnorm` | Float. If set, the gradient of each weight is individually clipped so that its norm is no higher than this value. |
| `clipvalue` | Float. If set, the gradient of each weight is clipped to be no higher than this value. |
| `global_clipnorm` | Float. If set, the gradient of all weights is clipped so that their global norm is no higher than this value. |
| `use_ema` | Boolean, defaults to False. If True, exponential moving average (EMA) is applied. EMA consists of computing an exponential moving average of the weights of the model (as the weight values change after each training batch), and periodically overwriting the weights with their moving average. |
| `ema_momentum` | Float, defaults to 0.99. Only used if `use_ema=True`. This is the momentum to use when computing the EMA of the model's weights: `new_average = ema_momentum * old_average + (1 - ema_momentum) * current_variable_value`. |
| `ema_overwrite_frequency` | Int or None, defaults to None. Only used if `use_ema=True`. Every `ema_overwrite_frequency` steps of iterations, we overwrite the model variable by its moving average. If None, the optimizer does not overwrite model variables in the middle of training, and you need to explicitly overwrite the variables at the end of training by calling `optimizer.finalize_variable_values()` (which updates the model variables in-place). When using the built-in `fit()` training loop, this happens automatically after the last epoch, and you don't need to do anything. |
| `jit_compile` | Boolean, defaults to True. If True, the optimizer will use XLA compilation. `jit_compile` cannot be True when training with [`tf.distribute.experimental.ParameterServerStrategy`](../../../../distribute/experimental/parameterserverstrategy). Additionally, if no GPU device is found, this flag will be ignored. |
| `**kwargs` | keyword arguments only used for backward compatibility. |
#### Usage:
```
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
var = tf.Variable(1.0)
loss = lambda: (var ** 2)/2.0 # d(loss)/d(var1) = var1
step_count = opt.minimize(loss, [var]).numpy()
# Step is `- learning_rate * grad`
var.numpy()
0.9
```
```
opt = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9)
var = tf.Variable(1.0)
val0 = var.value()
loss = lambda: (var ** 2)/2.0 # d(loss)/d(var1) = var1
# First step is `- learning_rate * grad`
step_count = opt.minimize(loss, [var]).numpy()
val1 = var.value()
(val0 - val1).numpy()
0.1
# On later steps, step-size increases because of momentum
step_count = opt.minimize(loss, [var]).numpy()
val2 = var.value()
(val1 - val2).numpy()
0.18
```
#### Reference:
* For `nesterov=True`, See [Sutskever et al., 2013](http://jmlr.org/proceedings/papers/v28/sutskever13.pdf).
| Attributes |
| `iterations` | The number of training steps this `optimizer` has run. By default, iterations would be incremented by one every time `apply_gradients()` is called. |
| `learning_rate` | |
Methods
-------
### `add_variable`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L319-L341)
```
add_variable(
shape, dtype=None, initializer='zeros', name=None
)
```
Create an optimizer variable.
| Args |
| `shape` | A list of integers, a tuple of integers, or a 1-D Tensor of type int32. Defaults to scalar if unspecified. |
| `dtype` | The DType of the optimizer variable to be created. Defaults to [`tf.keras.backend.floatx`](../../../backend/floatx) if unspecified. |
| `initializer` | string or callable. Initializer instance. |
| `name` | The name of the optimizer variable to be created. |
| Returns |
| An optimizer variable, in the format of tf.Variable. |
### `add_variable_from_reference`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/optimizers.py#L71-L105)
```
add_variable_from_reference(
model_variable, variable_name, initial_value=None
)
```
Create an optimizer variable from model variable.
Create an optimizer variable based on the information of model variable. For example, in SGD optimizer momemtum, for each model variable, a corresponding momemtum variable is created of the same shape and dtype.
| Args |
| `model_variable` | The corresponding model variable to the optimizer variable to be created. |
| `variable_name` | The name prefix of the optimizer variable to be created. The create variables name will follow the pattern `{variable_name}/{model_variable.name}`, e.g., `momemtum/dense_1`. |
| `initial_value` | The initial value of the optimizer variable, if None, the value will be default to 0. |
| Returns |
| An optimizer variable. |
### `apply_gradients`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/dtensor/optimizers.py#L117-L131)
```
apply_gradients(
grads_and_vars
)
```
Apply gradients to variables.
| Args |
| `grads_and_vars` | List of (gradient, variable) pairs. |
| Returns |
| None |
| Raises |
| `TypeError` | If `grads_and_vars` is malformed. |
### `build`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/sgd.py#L123-L141)
```
build(
var_list
)
```
Initialize optimizer variables.
SGD optimizer has one variable `momentums`, only set if `self.momentum` is not 0.
| Args |
| `var_list` | list of model variables to build SGD variables on. |
### `compute_gradients`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L152-L177)
```
compute_gradients(
loss, var_list, tape=None
)
```
Compute gradients of loss on trainable variables.
| Args |
| `loss` | `Tensor` or callable. If a callable, `loss` should take no arguments and return the value to minimize. |
| `var_list` | list or tuple of `Variable` objects to update to minimize `loss`. |
| `tape` | (Optional) [`tf.GradientTape`](../../../../gradienttape). If `loss` is provided as a `Tensor`, the tape that computed the `loss` must be provided. |
| Returns |
| A list of (gradient, variable) pairs. Variable is always present, but gradient can be `None`. |
### `finalize_variable_values`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L469-L481)
```
finalize_variable_values(
var_list
)
```
Set the final value of model's trainable variables.
Sometimes there are some extra steps before ending the variable updates, such as overriding the model variables with its average value.
| Args |
| `var_list` | list of model variables. |
### `from_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L518-L535)
```
@classmethod
from_config(
config
)
```
Creates an optimizer from its config.
This method is the reverse of `get_config`, capable of instantiating the same optimizer from the config dictionary.
| Args |
| `config` | A Python dictionary, typically the output of get\_config. |
| Returns |
| An optimizer instance. |
### `get_config`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/sgd.py#L177-L185)
```
get_config()
```
Returns the config of the optimizer.
An optimizer config is a Python dictionary (serializable) containing the configuration of an optimizer. The same optimizer can be reinstantiated later (without any saved state) from this configuration.
Subclass optimizer should override this method to include other hyperparameters.
| Returns |
| Python dictionary. |
### `minimize`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/optimizer.py#L382-L401)
```
minimize(
loss, var_list, tape=None
)
```
Minimize `loss` by updating `var_list`.
This method simply computes gradient using [`tf.GradientTape`](../../../../gradienttape) and calls `apply_gradients()`. If you want to process the gradient before applying then call [`tf.GradientTape`](../../../../gradienttape) and `apply_gradients()` explicitly instead of using this function.
| Args |
| `loss` | `Tensor` or callable. If a callable, `loss` should take no arguments and return the value to minimize. |
| `var_list` | list or tuple of `Variable` objects to update to minimize `loss`. |
| `tape` | (Optional) [`tf.GradientTape`](../../../../gradienttape). |
| Returns |
| None |
### `update_step`
[View source](https://github.com/keras-team/keras/tree/v2.9.0/keras/optimizers/optimizer_experimental/sgd.py#L143-L175)
```
update_step(
gradient, variable
)
```
Update step given gradient and the associated model variable.
| programming_docs |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.