
text
stringlengths 2.5k
6.39M
| kind
stringclasses 3
values |
|---|---|
```
#import all the dependencies
import os
import csv
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#read the csv files to view the data
google_apps = pd.read_csv("googleplaystore.csv")
google_apps.shape
```
# Data Cleaning
```
#Check for number of apps in total
no_apps = google_apps["App"].nunique()
print(f"Total number of unique apps: {no_apps}")
#dropping all the duplicate apps from the dataframe
google_apps.drop_duplicates(subset = "App", inplace = True)
google_apps
#size of the apps are not consistent so convert all to same measure and replace any other values with nan and ""
google_apps["Size"] = google_apps["Size"].apply(lambda x: str(x).replace(",", "") if "," in str(x) else x)
google_apps["Size"] = google_apps["Size"].apply(lambda x: str(x).replace('M', '') if 'M' in str(x) else x)
google_apps["Size"] = google_apps["Size"].apply(lambda x: str(x).replace("Varies with device", "NAN") if "Varies with device" in str(x) else x)
google_apps["Size"] = google_apps["Size"].apply(lambda x: float(str(x).replace('k', '')) / 1000 if 'k' in str(x) else x)
#convert all the sizes to float
# google_apps = google_apps.drop([10472])
google_apps["Size"] = google_apps["Size"].apply(lambda x:float(x))
#Install column has '+' sign so removing that will help easy computation
google_apps["Installs"] = google_apps["Installs"].apply(lambda x:x.replace("+","")if "+" in str(x) else x)
google_apps["Installs"] = google_apps["Installs"].apply(lambda x: x.replace(",","") if "," in str(x) else x)
google_apps["Installs"] = google_apps["Installs"].apply(lambda x:float(x))
#Make the price column consistent by removing the '$' symbol and replacing "Free" with 0
google_apps["Price"] = google_apps["Price"].apply(lambda x: x.replace("Free",0) if "Free" in str(x) else x)
google_apps["Price"] = google_apps["Price"].apply(lambda x:x.replace("$","") if "$" in str(x)else x)
google_apps["Price"] = google_apps["Price"].apply(lambda x: float(x))
google_apps["Price"].dtype
```
# Exploratory Analysis
```
#Basic pie chart to view distribution of apps across various categories
fig, ax = plt.subplots(figsize=(10, 10), subplot_kw=dict(aspect="equal"))
number_of_apps = google_apps["Category"].value_counts()
labels = number_of_apps.index
sizes = number_of_apps.values
ax.pie(sizes,labeldistance=2,autopct='%1.1f%%')
ax.legend(labels=labels,loc="right",bbox_to_anchor=(0.9, 0, 0.5, 1))
ax.axis("equal")
plt.show()
#looking at the number of installs in the top 5 categories and their geners
no_of_apps_category = google_apps["Category"].value_counts()
no_of_apps_category[0:5]
number_of_installs = google_apps["Installs"].groupby(google_apps["Category"]).sum()
print(f"Number of installs in family: {number_of_installs.loc['FAMILY']}")
print(f"Number of installs in Game: {number_of_installs.loc['GAME']}")
print(f"Number of installs in Tools: {number_of_installs.loc['TOOLS']}")
#Plotting a simple bar graph to represent the number of installs in each category
plt.figure(figsize=(10,8))
sns.barplot(x="Category", y="Installs", data=google_apps,
label="Total Installs", color="b")
plt.xticks(rotation=90)
plt.show()
print("Top 3 categories in terms of number of installations are: Communication,Video Players and Entertainment")
#Let's look at why family even though has lot of apps does not have the highest number of installs. Price could be one of the factors
paid_apps = google_apps[google_apps["Price"] != 0.0]
paid_family_apps = paid_apps[paid_apps["Category"]=="FAMILY"]
paid_family_apps.count()
paid_communications_apps = paid_apps[paid_apps["Category"]=="COMMUNICATION"]
paid_communications_apps.count()
#Let's visualize this in the form of a simple bar graph
plt.figure(figsize=(10,8))
sns.barplot(x="Category", y="Price", data=paid_apps,
label="Total Paid Apps in Each Category")
plt.xticks(rotation=90)
plt.show()
#Ratings of the apps over various categories
avg_rating = google_apps["Rating"].mean()
print(avg_rating)
plt.figure(figsize=(10,8))
sns.boxplot('Category','Rating',data=google_apps)
plt.title("Distribution of Categorywise Ratings")
plt.ylabel("Rating")
plt.xlabel("Category")
plt.xticks(rotation=90)
# plt.savefig('data_images/plot3a_income.png',bbox_inches='tight')
plt.show();
#Paid Vs free and the number of installs
installs_greater_1000 = google_apps[google_apps["Installs"]>1000]
installs_greater_1000 = installs_greater_1000.sort_values(['Price'])
plt.figure(figsize=(20,20))
sns.catplot(x="Installs", y="Price",data=installs_greater_1000);
plt.xticks(rotation=90)
# plt.ytick.direction('out')
plt.show()
#take a deeper look at the apps priced more than $100
expensive_apps = google_apps[google_apps["Price"]>100]
expensive_apps["Installs"].groupby(expensive_apps["App"]).sum()
#number of installs Vs price Vs Category
sns.relplot(x="Installs", y="Price", hue="Category", size="Rating",
sizes=(200, 400), alpha=1,
height=5, data=expensive_apps)
plt.show()
```
# Conclusions
```
print(f"The Top three category of Apps based on the number of Apps are")
print(f" - Family")
print(f" - Game")
print(f" - Tool")
print(f"The bottom three category of Apps based on the number of Apps are")
print(f" - Parenting")
print(f" - Comics")
print(f" - Beauty")
print(f"This is not the case when we look at the number of intalls. Based on number of installs, Communication,Video players and entertainment are the top 3 categories")
print(f"To find out why, I looked at the price of paid apps in each category and clearly, communication was priced less than the family apps. This could be one of the reasons")
print(f"-----------------------------------------------------------------------------------------------------------------------------")
print(f"The Average rating of the apps across all the categories is 4.17")
print(f"-----------------------------------------------------------------------------------------------------------------------------")
print(f"Users tend to download more free apps compared to paid apps. This being said, there are people who are willing to pay more than $100 for an app")
print(f"-----------------------------------------------------------------------------------------------------------------------------")
print(f"Based on the data, Users tend to buy apps which are priced $1 - $30 compared to other expensive apps")
print(f"-----------------------------------------------------------------------------------------------------------------------------")
print(f"There are 20 apps which cost above $100. Finance, Lifestyle and family being the top 3 categories.")
print(f"-----------------------------------------------------------------------------------------------------------------------------")
print(f"Among the most expensive apps, 'I am Rich' is the most popular app with the most number of installs")
```
|
github_jupyter
|
###### ECE 283: Homework 2
###### Topics: Classification using neural networks
###### Due: Monday April 30
- Neural networks; Tensorflow
- 2D synthetic gaussian mixture data for binary classification
### Report
----------------------------------------
##### 1. Tensorflow based neural network
- 2D Gaussian mixture is synthesized based on the provided mean, covariances for class 0 and 1.
- Training, validation and test sample counts are 70, 20, and 10 respectively
##### (a) One hidden layer: Implementation code below In[7] : oneHiddenNeuralNetwork()
Below are the parameters that are used to run training for this network.
The validation data is used to compute loss/accuracy in order to tune the hyper parameters.
```
Hyper Parameters
learning_rate = 0.001
num_steps = 1000
batch_size = 1000
display_step = 100
reg_const_lambda = 0.01
Network Parameters
n_hidden_1 = 9 # 1st layer number of neurons
num_input = 2 # data input (shape: 2 * 70)
num_classes = 1 # total classes (0 or 1 based on the value)
```
###### Execution:
1. Without input preprocessing: Single Layer Network
> Log
> - Trn Step 1, Minibatch Loss= 2.3662, Accuracy= 49.500
> - Val Step 1, Minibatch Loss= 2.4016, Accuracy= 48.800
> - Trn Step 100, Minibatch Loss= 1.8325, Accuracy= 58.437
> - Val Step 100, Minibatch Loss= 1.8935, Accuracy= 57.050
> - Trn Step 1000, Minibatch Loss= 0.6166, Accuracy= 79.854
> - Val Step 1000, Minibatch Loss= 0.6331, Accuracy= 79.000
> - Test Accuracy: 80.800
> - Diff Error: 192/1000
2. With input preprocessing: Single Layer Network
> Log
> - Trn Step 1, Minibatch Loss= 1.3303, Accuracy= 30.100
> - Val Step 1, Minibatch Loss= 1.6977, Accuracy= 33.150
> - Trn Step 100, Minibatch Loss= 1.0398, Accuracy= 36.600
> - Val Step 100, Minibatch Loss= 1.2065, Accuracy= 37.400
> - Trn Step 1000, Minibatch Loss= 0.5143, Accuracy= 80.700
> - Val Step 1000, Minibatch Loss= 0.5572, Accuracy= 76.700
> - Test Accuracy: 77.100
> - Diff Error: 229/1000
###### Observations: Q 1,2,3,4
1. The number of neurons here are 10 which provided more accuracy over single neuron. Upon changing the number of neurons from 1 to 10 we see a jump of accuracy from 50% to 75%. However growing neurons beyond 10 does not provide much benefit/accuracy change on the validation data. Which says that training further may be overfitting to the training dataset.
2. Training samples are 70% and validation samples are 20%. When we run for 1000 steps/epoch with batch size 1000 on a learning rate of 0.001. We see that training loss converges towards 0.5572, while training accuracy converges from 30% to 80%. The validation values appear to be peaks at 77%. Training was stopped when we saw consistent convergence and similar accuracy on the validation and the test dataset.
> - Upon changing the learning rate to a higher value like 1 we see that convergence is an issue. This was observed since the data kept alternating between two values consistently, irrespective of the iterations ran. When learning rate is of the order 10**(-3) then we see the convergence in the data.
> - The L2 regularization constant will penalize the square value of the weights and it is set to 0.01 here. When we changed the value to say 10 it will allow for a higher order coefficient to affect and may cause over fitting. However, it does not seem to affect the results here and it may be due to the fact that the higher order coefficient do not affect this data.
> - Final Test Accuracy: 77.1%
3. Input pre-processing and Weight Initialization
> Normalization/input-preprocessing is achieved by subracting the mean and scaling with standard deviation.
> - The function getNextTrainBatch() was without normalization and gave the results in sections 1 and 2 above. Upon using normalized batch training data using getNextNormalizedTrainBatch() function we have the following observations,
> - The convergence was relatively faster than before (1 Step)
> - The batch loss reduced to ~0.5572 while the accuracy on test was around 77%
> Weight initialization has a major impact since these multipliers lead to vanishing or exploding gradients issue.
> - In the current scenario we have used random_normal distribution for initialization. In the currnt scenario since the convergence is fast and data is separable we do not see any difference by using uniform initialization. However there are datasets that demonstrate the empirical benefit of using a uniform distribution for initializing weights.
4. Comparing the performance of neural network from HW1 (MAP, Kernelized Logistic Regression and Logistic Regression with feature engg)
> - We observed a probability of error around 23% here.
> - Misclassification rate in MAP was around 16% for class0 and 47% for class1
> - Misclassification in Kernelized Logistic regression was slightly better than the MAP
> - Misclassification for Logistic regression by feature engineering was around 56% for class0 and 10% for class1
However if we see the overall misclassification error rate we get a great accuracy of about 77%-81% using the neural network technique here. We can be sure that upon learning more data this technique will provide a better accuracy.
##### (b) Two hidden layer: Implementation code below In[11] : twoHiddenNeuralNetwork()
Below are the parameters that are used to run training for this network
```
Hyper Parameters
learning_rate = 0.001
num_steps = 1000
batch_size = 1000
display_step = 100
reg_const_lambda = 0.01
Network Parameters
n_hidden_1 = 4 # 1st layer number of neurons
n_hidden_2 = 4 # 2nd layer number of neurons
num_input = 2 # data input (shape: 2 * 70)
num_classes = 1 # total classes (0 or 1 based on the value)
```
###### Execution:
1. Without input preprocessing: Two Layer Network
> Log
> - Trn Step 1, Minibatch Loss= 1.8265, Accuracy= 67.295
> - Val Step 1, Minibatch Loss= 1.9003, Accuracy= 66.800
> - Trn Step 100, Minibatch Loss= 1.2101, Accuracy= 80.126
> - Val Step 100, Minibatch Loss= 1.2648, Accuracy= 80.550
> - Trn Step 1000, Minibatch Loss= 1.0394, Accuracy= 83.812
> - Val Step 1000, Minibatch Loss= 1.0760, Accuracy= 83.750
> - Test Accuracy: 83.600
> - Diff Error: 164/1000
2. With input preprocessing: Two Layer Network
> Log
> - Trn Step 1, Minibatch Loss= 2.0676, Accuracy= 30.800
> - Val Step 1, Minibatch Loss= 2.1635, Accuracy= 27.600
> - Trn Step 100, Minibatch Loss= 0.8971, Accuracy= 51.700
> - Val Step 100, Minibatch Loss= 1.0530, Accuracy= 51.000
> - Trn Step 1000, Minibatch Loss= 0.6649, Accuracy= 80.600
> - Val Step 1000, Minibatch Loss= 0.6496, Accuracy= 83.100
> - Test Accuracy: 81.900
> - Diff Error: 181/1000
###### Observations: Additional observations for two layer network only
1. In this case we see a better result when compared to the single network but that may not always the case. Upon increasing the number of layers to two we add more capacity. By doing this we allow for complex fitting of the weights which leads to good results on the training data and I.I.D. test data.
2. On increasing the learning rate we see that the convergence is quick around the loss value of 0.6496
> - Final Test Accuracy: 81.900
> - All the same observations as described for a single layer network as above. However here we see that due to higher capacity a better linear accuracy is observed at every neuron count.
3. The number of neurons here are 4 each and provides a peak accuracy at that value. An overfitting may be occurring beyond that.
> - The test accuracy is 82% but we also see that the training and validation accuracy are 81% and 83% respectively. This is data specific and can be improved by increasing the size of the training data. 10000 test samples is not a great sample to compute a general accuracy for the entire dataset.

# Code Section
```
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
from math import *
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from scipy.stats import norm
from IPython.display import Image, display, Math, Latex
# Params
n_inpoints = 10000
def generateClass0():
theta0 = 0
lmb01 = 2
lmb02 = 1
m0 = (0, 0)
# computing u * u.T and later multiplying with lambda
cov01 = [[(cos(theta0))**2, cos(theta0)*sin(theta0)],
[(sin(theta0))*cos(theta0), (sin(theta0))**2]]
cov02 = [[(sin(theta0))**2, -(cos(theta0)*sin(theta0))],
[-(cos(theta0)*sin(theta0)), (cos(theta0))**2]]
cov0 = lmb01*np.matrix(cov01) + lmb02*np.matrix(cov02)
cov0_det = np.linalg.det(cov0)
x0, y0 = np.random.multivariate_normal(m0, cov0, int(n_inpoints/2)).T
return x0,y0
x0, y0 = generateClass0()
plt.scatter(x0, y0, color = 'r',marker='x', label = 'Cl 0')
plt.legend()
plt.title('Distribution of Class 0')
plt.show()
def generateClass1():
# Mixture A
theta1a = -3*pi/4
lmb1a1 = 2
lmb1a2 = 1/4
m1a = (-2, 1)
cov1a = [[(cos(theta1a))**2, cos(theta1a)*sin(theta1a)],
[(sin(theta1a))*cos(theta1a), (sin(theta1a))**2]]
cov2a = [[(sin(theta1a))**2, -(cos(theta1a)*sin(theta1a))],
[-(cos(theta1a)*sin(theta1a)), (cos(theta1a))**2]]
cov1a = lmb1a1*np.matrix(cov1a) + lmb1a2*np.matrix(cov2a)
cov1a_det = np.linalg.det(cov1a)
x1a, y1a = np.random.multivariate_normal(m1a, cov1a, int(n_inpoints/2)).T
#print('Shape: ',x1a.shape,', ',y1a.shape,', ',cov1a)
# Mixture B
theta1b = pi/4
lmb1b1 = 3
lmb1b2 = 1
m1b = (3, 2)
cov1b = [[(cos(theta1b))**2, cos(theta1b)*sin(theta1b)],
[(sin(theta1b))*cos(theta1b), (sin(theta1b))**2]]
cov2b = [[(sin(theta1b))**2, -(cos(theta1b)*sin(theta1b))],
[-(cos(theta1b)*sin(theta1b)), (cos(theta1b))**2]]
cov1b = lmb1b1*np.matrix(cov1b) + lmb1b2*np.matrix(cov2b)
cov1b_det = np.linalg.det(cov1b)
x1b, y1b = np.random.multivariate_normal(m1b, cov1b, int(n_inpoints/2)).T
#print('Shape: ',x1b.shape,', ',y1b.shape,', ',cov1b)
# Class 1 (A * 0.33 +B * 0.66)
y1 = np.array(y1a)* (1 / 3)+np.array(y1b)* (2 / 3)
x1 = np.array(x1a)* (1 / 3)+np.array(x1b)* (2 / 3)
return x1,y1
x1, y1 = generateClass1()
plt.scatter(x1, y1, color = 'b',marker='^', label = 'Cl 1')
plt.title('Distribution of Class 1')
plt.legend()
plt.show()
x = np.concatenate((x0, x1))
y = np.concatenate((y0, y1))
print('Shape; X:',x.shape,', Y:',y.shape)
plt.scatter(x0, y0, color = 'r',marker='x', label = 'Cl 0')
plt.scatter(x1, y1, color = 'b',marker='^', label = 'Cl 1')
plt.legend()
plt.show()
c0 = np.vstack((x0, y0)).T
c1 = np.vstack((x1, y1)).T
# ----------------------------------------
# Set up the [xi, yi] training data vector
# ----------------------------------------
X = np.concatenate((c0,c1), axis = 0)
Y = np.array([0]*int(n_inpoints/2) + [1]*int(n_inpoints/2)).reshape(n_inpoints,1)
```
### Training, test and validation sets (70:20:10)
##### Without Normalization
```
# Divide the data into Train Valid, Test
tot_count = n_inpoints
trn_count = int(0.7 * tot_count)
val_count = int(0.2 * tot_count)
tst_count = int(0.1 * tot_count)
# Shuffle X & Y values
sfl_idx = np.arange(0,tot_count)
np.random.shuffle(sfl_idx)
Xc0 = X[:,0]
Xc1 = X[:,1]
Xc0 = Xc0.reshape(tot_count,1)
Xc1 = Xc1.reshape(tot_count,1)
print(Xc1.shape)
train_X0 = Xc0[sfl_idx[np.arange(0,trn_count)]]
train_X1 = Xc1[sfl_idx[np.arange(0,trn_count)]]
train_Y = Y[sfl_idx[np.arange(0,trn_count)]]
n_samples = train_X1.shape[0]
valid_X0 = Xc0[sfl_idx[np.arange(trn_count,trn_count+val_count)]]
valid_X1 = Xc1[sfl_idx[np.arange(trn_count,trn_count+val_count)]]
valid_X = np.vstack((valid_X0.T, valid_X1.T))
valid_Y = Y[sfl_idx[np.arange(trn_count,trn_count+val_count)]]
tests_X0 = Xc0[sfl_idx[np.arange(trn_count+val_count, tot_count)]]
tests_X1 = Xc1[sfl_idx[np.arange(trn_count+val_count, tot_count)]]
tests_X = np.vstack((tests_X0.T, tests_X1.T))
tests_Y = Y[sfl_idx[np.arange(trn_count+val_count, tot_count)]]
batchIndex = 0
def getNextTrainBatch(size):
global batchIndex
if((batchIndex + size) >= trn_count):
size = trn_count-1
batchIndex = 0 # recycle the batches from start
#trn_sfl_idx = np.arange(0,trn_count)
#np.random.shuffle(trn_sfl_idx)
trn_X0_r1 = train_X0[np.arange(batchIndex, batchIndex + size)]
trn_X1_r1 = train_X1[np.arange(batchIndex, batchIndex + size)]
trn_Y_r1 = train_Y[np.arange(batchIndex, batchIndex + size)]
#print(trn_X0_r1.shape)
trn_X = np.vstack((trn_X0_r1.T, trn_X1_r1.T))
#print((trn_X.T).shape)
batchIndex = batchIndex + size
return trn_X.T, trn_Y_r1
print('Train: ',train_X0.shape, train_Y.shape)
print('Valid: ',valid_X.shape, valid_Y.shape)
print('Tests: ',tests_X.shape, tests_Y.shape)
```
##### With Normalization
```
# -------------------
# Normalize the data
# -------------------
# Mean
train_X0_mean = np.mean(train_X0)
train_X1_mean = np.mean(train_X1)
# Standard deviation
train_X0_stddev = np.std(train_X0)
train_X1_stddev = np.std(train_X1)
# Normalization by scaling using standard deviation
train_X0_nrm = (train_X0 - train_X0_mean)/train_X0_stddev
train_X1_nrm = (train_X1 - train_X1_mean)/train_X1_stddev
print(train_X0_nrm.shape)
print(train_X1_nrm.shape)
train_X_nrm = np.vstack((train_X0_nrm.T, train_X1_nrm.T))
def getNextNormalizedTrainBatch(size):
global batchIndex
batchIndex = 0
if((batchIndex + size) >= trn_count):
size = trn_count-1
batchIndex = 0 # recycle the batches from start
# Shuffle the dataset each time
trn_sfl_idx = np.arange(batchIndex, batchIndex + size)
np.random.shuffle(trn_sfl_idx)
trn_X0_r1 = train_X0_nrm[trn_sfl_idx[np.arange(batchIndex, batchIndex + size)]]
trn_X1_r1 = train_X1_nrm[trn_sfl_idx[np.arange(batchIndex, batchIndex + size)]]
trn_Y_r1 = train_Y[trn_sfl_idx[np.arange(batchIndex, batchIndex + size)]]
#print(trn_X0_r1.shape)
trn_X = np.vstack((trn_X0_r1.T, trn_X1_r1.T))
#print((trn_X.T).shape)
batchIndex = batchIndex + size
return trn_X.T, trn_Y_r1
print('Train: ',train_X_nrm.shape, train_Y.shape)
#print('Valid: ',valid_X.shape, valid_Y.T)
#print('Tests: ',tests_X.shape, tests_Y.T)
def linearRegression():
# Parameters
learning_rate = 0.01
training_epochs = 500
display_step = 50
rng = np.random
# tf Graph Input
Xtf = tf.placeholder(tf.float32, [None, 1])
Ytf = tf.placeholder(tf.float32, [None, 1])
# Set model weights
# figure tf.rand
# tf.keras.initializer
Wtf = tf.Variable(np.zeros([1,1]), dtype=tf.float32, name="weight")
btf = tf.Variable(np.zeros([1,1]), dtype=tf.float32, name="bias")
# Construct a linear model
predtf = tf.add(tf.matmul(Xtf, Wtf), btf)
# Mean squared error
costtf = tf.reduce_sum(tf.pow(predtf-Ytf, 2))/(2*n_samples)
# Gradient descent
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(costtf)
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
sess.run(optimizer, feed_dict={Xtf: train_X1, Ytf: train_Y})
#Display logs per epoch step
if (epoch+1) % display_step == 0:
c = sess.run(costtf, feed_dict={Xtf: train_X1, Ytf:train_Y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(Wtf), "b=", sess.run(btf))
print("Optimization Finished!")
training_cost = sess.run(costtf, feed_dict={Xtf: train_X1, Ytf: train_Y})
print("Training cost=", training_cost, "W=", sess.run(Wtf), "b=", sess.run(btf), '\n')
#Graphic display plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.scatter(x0, y0, color = 'r',marker='x', label = 'Cl 0')
plt.scatter(x1, y1, color = 'b',marker='^', label = 'Cl 1')
plt.plot(train_X1, sess.run(Wtf) * train_X1 + sess.run(btf), label='Fitted line')
plt.legend()
plt.show()
sess.close()
# Run Linear Regression
linearRegression()
```
### Neural Network implementation
- 1.(a) One hidden layer
```
def oneHiddenNeuralNetwork():
# Parameters
learning_rate = 0.001
num_steps = 1000
batch_size = 1000
display_step = 100
reg_const_lambda = 0.01
# Network Parameters
n_hidden_1 = 9 # 1st layer number of neurons
num_input = 2 # data input (shape: 2 * 70)
num_classes = 1 # total classes (0 or 1 based on the value)
# tf Graph input
X = tf.placeholder("float", [None, num_input])
Y = tf.placeholder("float", [None, num_classes])
# Store layers weight & bias (initializing using random nromal)
weights = {
'h1': tf.Variable(tf.random_normal([num_input, n_hidden_1])),
'out': tf.Variable(tf.random_normal([n_hidden_1, num_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'out': tf.Variable(tf.random_normal([num_classes]))
}
# Create model
def one_neural_net(x):
# Hidden fully connected layer, a1
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
#layer_1 = tf.nn.relu(layer_1)
# Output fully connected layer with a neuron for each class
out_layer = tf.matmul(layer_1, weights['out']) + biases['out']
return out_layer
# Construct model
logits = one_neural_net(X)
output = tf.sigmoid(logits) # Convert output to a probability
# Define loss and optimizer
cel_loss_op = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=Y))
reg_loss = tf.nn.l2_loss(weights['h1']) + tf.nn.l2_loss(weights['out']) # L2 regularization
loss_op = tf.reduce_mean(cel_loss_op + reg_const_lambda*reg_loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
# keep in mind boolean to float32 tensor output
#correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(Y, 1))
correct_pred = tf.cast(tf.greater(output, 0.5), tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(correct_pred, Y), tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
batchIndex = 0
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = getNextNormalizedTrainBatch(batch_size)
# Run optimization op (backprop)
# print(batch_x)
# print(batch_y)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Training batch loss and accuracy
loss, acc, pred = sess.run([loss_op, accuracy, correct_pred], feed_dict={X: batch_x,
Y: batch_y})
print("Trn Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Accuracy= " + \
"{:.3f}".format(100*acc))
#print("actuals:", batch_y.T)
#print("predict:", pred.T)
print("differr:", (pred.T != batch_y.T).sum())
# Validation accuracy
loss_v, acc_v, pred_v = sess.run([loss_op, accuracy, correct_pred], feed_dict={X: valid_X.T,
Y: valid_Y})
print("Val Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss_v) + ", Accuracy= " + \
"{:.3f}".format(100*acc_v))
#print("actuals:", valid_Y.T)
#print("predict:", pred_v.T)
print("differr:", (pred_v.T != valid_Y.T).sum())
print("Optimization Finished!")
# Calculate accuracy for test data
acc_t, pred_t = sess.run([accuracy,correct_pred], feed_dict={X: tests_X.T, Y: tests_Y})
print("Test Accuracy:", "{:.3f}".format(100*acc_t))
print("actuals:", tests_Y.shape)
print("predict:", pred_t.shape)
print("differr:", (pred_t.T != tests_Y.T).sum())
sess.close()
# Execute
oneHiddenNeuralNetwork()
```
- 1.(b) Two hidden layer
```
def twoHiddenNeuralNetwork():
# Parameters
learning_rate = 0.01
num_steps = 1000
batch_size = 1000
display_step = 100
reg_const_lambda = 0.01
# Network Parameters
n_hidden_1 = 4 # 1st layer number of neurons
n_hidden_2 = 4 # 2nd layer number of neurons
num_input = 2 # data input (shape: 2 * 70)
num_classes = 1 # total classes (0 or 1 based on the value)
# tf Graph input
X = tf.placeholder("float", [None, num_input])
Y = tf.placeholder("float", [None, num_classes])
# Store layers weight & bias (initializing using random nromal)
weights = {
'h1': tf.Variable(tf.random_normal([num_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, num_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([num_classes]))
}
# Create model
def two_neural_net(x):
# Hidden fully connected layer, a1
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output fully connected layer with a neuron for each class
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# Construct model
logits = two_neural_net(X)
output = tf.sigmoid(logits) # Convert output to a probability
# Define loss and optimizer
cel_loss_op = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=Y))
reg_loss = tf.nn.l2_loss(weights['h1']) + tf.nn.l2_loss(weights['h2']) + tf.nn.l2_loss(weights['out']) # L2 regularization
loss_op = tf.reduce_mean(cel_loss_op + reg_const_lambda*reg_loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
# keep in mind boolean to float32 tensor output
#correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(Y, 1))
correct_pred = tf.cast(tf.greater(output, 0.5), tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(correct_pred, Y), tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
batchIndex = 0
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, num_steps+1):
batch_x, batch_y = getNextNormalizedTrainBatch(batch_size)
# Run optimization op (backprop)
# print(batch_x)
# print(batch_y)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# Training batch loss and accuracy
loss, acc, pred = sess.run([loss_op, accuracy, correct_pred], feed_dict={X: batch_x,
Y: batch_y})
print("Trn Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Accuracy= " + \
"{:.3f}".format(100*acc))
#print("actuals:", batch_y.T)
#print("predict:", pred.T)
print("differr:", (pred.T != batch_y.T).sum())
# Validation accuracy
loss_v, acc_v, pred_v = sess.run([loss_op, accuracy, correct_pred], feed_dict={X: valid_X.T,
Y: valid_Y})
print("Val Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss_v) + ", Accuracy= " + \
"{:.3f}".format(100*acc_v))
#print("actuals:", valid_Y.T)
#print("predict:", pred_v.T)
print("differr:", (pred_v.T != valid_Y.T).sum())
print("Optimization Finished!")
# Calculate accuracy for test data
acc_t, pred_t = sess.run([accuracy,correct_pred], feed_dict={X: tests_X.T, Y: tests_Y})
print("Test Accuracy:", "{:.3f}".format(100*acc_t))
print("actuals:", tests_Y.shape)
print("predict:", pred_t.shape)
print("differr:", (pred_t.T != tests_Y.T).sum())
sess.close()
# Execute
twoHiddenNeuralNetwork()
```
### Results
```
num_neurons = np.arange(0, 15)
accuracy_1_net = [50,66,57,72,75,72,74,69,77,75,74,70,70,74,75]
accuracy_2_net = [74,67,78,82,73,78,79,75,78,79,80,80,80,78,80]
plt.plot(num_neurons, accuracy_2_net, c = 'red' , label = 'Two Layer Network')
plt.plot(num_neurons, accuracy_1_net, c = 'blue' , label = 'One Layer Network')
plt.legend()
plt.title("Number of Neurons vs Accuracy")
plt.show()
```
|
github_jupyter
|
```
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KDTree
from sklearn.decomposition import PCA
#### Visulization imports
import pandas_profiling
import plotly.express as px
import seaborn as sns
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
df_april_19 = pd.read_csv('../data/SpotifyAudioFeaturesApril2019.csv')
df_nov_18 = pd.read_csv('../data/SpotifyAudioFeaturesNov2018.csv')
df = pd.concat([df_april_19, df_nov_18], ignore_index=True)
print(df.shape)
assert df.shape[0] == (df_april_19.shape[0] + df_nov_18.shape[0])
df = df.drop_duplicates(subset = 'track_id', keep='first')
print(df.shape)
# number_of_songs = 200
# remove categoricals
df_numerics = df.drop(columns=['track_id', 'track_name', 'artist_name'])
# Scale Data To Cluster More Accurately, and fit clustering model
df_scaled = StandardScaler().fit_transform(df_numerics)
df_modeled = KDTree(df_scaled)
# Querying the model for the 15 Nearest Neighbors
dist, ind = df_modeled.query(df_scaled, k=(number_of_songs+1))
# Putting the Results into a Dataframe
dist_df = pd.DataFrame(dist)
# Calculating the Distances
scores = (1 - ((dist - dist.min()) / (dist.max() - dist.min()))) * 100
# Creating A New Dataframe for the Distances
columns = ['Searched_Song']
for i in range(number_of_songs):
columns.append(f'Nearest_Song{i}')
dist_score = pd.DataFrame(scores.tolist(), columns = columns)
# An Array of all indices of the nearest neighbors
ind[:(number_of_songs+1)]
# Making an array of the Track IDs
song_ids = np.array(df.track_id)
# A function that creates list of the each song with its nearest neighbors
def find_similars(song_ids, ind):
similars = []
for row in ind:
ids = [song_ids[i] for i in row]
similars.append(ids)
return similars
# using the above function
nearest_neighbors = find_similars(song_ids, ind)
# putting the results into a dataframe
nearest_neighbors_df = pd.DataFrame(nearest_neighbors, columns=columns)
```
## 3D Representation of a Random Sample From Dataset, Visualized Spacially
```
fig = px.scatter_3d(df.sample(n=5000, random_state=69), x='acousticness', y='liveness', z='tempo', color='loudness', size='popularity',
opacity=.7, hover_name='track_name', color_discrete_sequence=px.colors.sequential.Plasma[-2::-1],
template="plotly_dark")
fig.show()
```
# A variety of Song Selections along with 200 Song recommendations
## Notice how they generally follow the same trajectory along the path across the features
This helping to Visually convey how Songs are recommended based on songs nearest to in terms of quantifable Audio Features such as accoustiness, danceability, energy etc.
```
id_numbers = ''' 16UKw34UY9w40Vc7TOkPpA 7LYb6OuJcmMsBXnBHacrZE 0Lpsmg0pmlm1h1SJyWPGN2 6T8CFjCR5G83Ew3EILL60q 5ba3vTyegTVbMoLDniANWy 6VK3ZdppJW3Q6I1plyADxX 47nZUjQa9NZb7Nheg8gSj0 5P42OvFcCn5hZm8lzXqNJZ 77RsQL1RDECVnB3LL7zhTF 2vqZnmBn0REOMmNp5pMTJz 1dLHaoG70esepC2eC0ykV4 4SUQbrebZgvSX8i3aYHMB6 4D0Xgaln0O8K8LK2gjwpr8 5ipjhrirlnBV7BMY7QV3H5 2lvkak4Ik64c4vlAQyek12 0t4JgAUj8ZCbWOwSU9h4nt 1RjYRvWpZeh9vMjjKzpH3w 0YELRuijk4XsKWvyoWY7jI 3Xn791JUhuITZdLsIuKuQQ 1Y2wWhbLCHW0WfTczmuA2X 65CE7YGQzGY4p1MqnfWYZt 6a6zG2o8geJvBVJkDkFCHQ 4Vcqv8zsfoNpxr7dWEJi48 2sfcE3uPqDObs5COsvk7QJ 2gz8HI5hZew7abJ9gcLY7J 2UFpXorq5JOIctCwcmDyZ5 7pNNFcYN2N1T0lOKMHL8u9 7deuaj4pjJqxWVky0jcFrd 2eCdpRpnYLp4fj0iMNra3p 5WyXaXmMpo1fJds5pzmS4c 2HLNwAHYH7Ejs2rZLLyrmj 0wXjzthQdMd7SZu2kNwsVC 3EnzqTwdFWe68x0OTxR9T5 50rPhDfxSL2kmEovmXqTNf 3VY3JjW7T0f49JqdFlvqIV 458Cn793jgrNc6miDUSAiK 40XOJ16Zc7pqgqYq9o7wjS 0QuuDvOB9fZ49pZ2cIdEdw 1f5aQjgYy4mKjA7EgJJvLY 1QJjIWHLf05mUQPq3N2hxZ 0wrhAauh8QSw2DFDi6ZHFV 2K55wT0q49n54mZmA3hqS8 6glST22VPJZRTKvxecHSp6 0lvEyZrkTDg0vK9luhcjZg 5YaV62mxj62GSlXvwzgG3J 6yC44aQAf9AALUyJPimZ11 1frCKo4D3lktaPHfkyEuHo 3hXsGl1WdOuKye1aHo6pF7 40NAjxDw25daUXVt1b0A0D 0bkPHOwWOIG6ffwJISGNUr 6w3401sQAMkeKdQ3z3RPXt 56UwCbkvU1p3vHTnlbv3kS 04MkdoV7vxprPhtYA0Cx5y 7AesCHBrKOy4Npkxt907mG 5B7w6neMDX6BYPJdb6ikRE 4AowP9TvejSnEpxxJigpyn 4M9onsaj8IxHJEFVezMRoA 2DRNLTuiZr3MdFNfEHzWfz 4Wo5LyWddbPCogBIBrkhlt 0UJmSMFB05CyY3dTps6g2c 7nZR4x2aHeIyzAtrMi4Wua 6UZVW9DjfRKrcIVco5uwc1 2O1FwU85kgG0SJGJhszkB0 4OK4tHSUnCXpBfIusCOdAo 0MfWpTp3GrJ51bNxLanyy1 5DVsV3ZetLbmDUak9z0d1E 3ki056t9qL4g9GHWkPFJYe 4WCNiW7DJFE6h94q5NPZmZ 3N0Q5ce0Q3v6MmcNwaGG2p 7rQFDOKqUEaXE6X6Of4HTw 0wi0Hn8puUPmYdZ0JvpG2H 5wMD46niyehV3y5HfeQpNf 1nTn4pZhcgfRPobs43xrvL 0NxPZvt6UYWLgTbvjCJd2n 7fdHvtur1uLx5crFzAfWJ2 5AZt6HoqpUdHyhia36Khtc 1exbNAnvvYLYsEFESsCjDO 27ZfYwqic7RnwuitxJZiE9 2iPvO3ctXFGlkzOsx6iWyn 2w8g5LJzKqez8mENuk2pbL 3aBmFnfx9QfLB3knrKr1Mo 4UUA76EBTJzcICr2nNyhnV 4aV1txuotqBFGLB2jwiogo 7ASmnEp32JgxgH76TAaWwo 344WuUSk6SRQd9849fkAct 7aXH7YjPAixvHIPxCKxwIo 1CakWoqY0bPK9Ov8UocFTR 2B9VQlYlq6CUH0VXdQqB4y 3gCPlZpymjidx564rWcPHX 691J2jGivJasVLkWU11dpU 0ulEzQTIdtZGvYH3mkK84G 2XpxTgvloEbIIVfEt4XUKt 4dqcedp9451K9DvxYugrTt 2Y6IAs1aCdb4rzFfGjONUo 7LDtRLCz9D5DOR31jQZ65m 0oliuZWC43aafuxqNlGuxy 0Ks2NJH2PCxyWAFPlI4p9B 7oLqoswT2hfCG90crbiToe 11wZ39zESerUTPXKWhx7QE 4HWfA0iD0gXuL6gVreNYTL 5EFw2MVleUknhnPzfrCrTq 2drp4ajf2V2xUvV79EmzMw 6KL8uR3Y3JjFpzzLQFBzQa 0SYo2aRh2MYfBoJAFOYtNs 6Iq5a3BvMSx6X7auul0yDE 6TZUjNnW4qHI9wPrO54L5o 4v3s1AdtPSBxFK93PNMFSg 7FM6VwHNF3EWQTyiloogTV 3FNbf1Qt2ycepS4fasCuOm 2qK9xZkbBrTRiDw2dnJul8 5ozbdCZw5MZmJryCOyDYO1 0M82DdRxHFedS7fg7Gk2qB 6k1Epe9JbePsbdq0EZCc4i 63TMt7zR9YLpNBpzRYLG5I 6tbdFaJWas52BT8DZH76Xj 4V7gH33fKlEhX4d1uk2xYB 6jY7PeOZ4P6ww8XuzCyGfO 3m4nvQbC1n3dm6SbYIDbDR 6J5ArwJqeLHFKNfHcDP6OG 4RlzULwFEYBjTJNhc7frWm 1kZ0mav2lhlhXf4fWjw5Nc 0gJBsp5q8Ro6zXxKzT4DiQ 0CWuF6SrEXmfM0EDIERBS1 0ogRPfqHhhZuaeeVt02L0Z 4AEJ6dqjb3uo7K9R2xKGJ0 0b4akisi6edx4RkU3VO1XW 2xLzmImDWvk0jw92tTsnHk 2PFvERcsENO2mSXV2abmMW 57miVDdQOiOx7ZNaEjGaFC 0LdkVfBGmZUOKf8sway0tM 5GtQkJTQ01zxZ9xRuIBRyY 1LX7SGrc4FIE6LnzV498Ow 2l3OlYqGIiJrPByZNx8Ll6 1yCb0FSeO48efDRg80Turo 3r5OR32RDkcp3eIQ2ylF5o 3grKLoUX87NaEkvouW0vmz 7ts8ZBKNCtJvd0ijGxTgCw 6LSlTgBUF1T8rBrTKtzbWB 0VCTFk3PtHHTbCdiI2SNf6 5flKCotkqTK0SRHyu9ywOE 7FNVvZKIFb5VIwyY4tCMXt 1mc6PrRRhSipTHKSLRuv5B 1s7X6ZKOMhP2luohWVXNNP 5WPjMN7nxk2HqcPfewseyz 2rX3PbfV6OrObng2YL9Osd 6ahWJqh8GQag4OWmyRbcnE 3ZYN2cfyCFn4NuWxEW9tuh 3DchJOgF4JUzQJyoAVePa7 1fhnlsDdCLs1Oi5X3oVCTD 3T0UOBcMTeytq7RmFDZMbu 14gtLymOStY8niLakJlbf8 677SnHIc0M92Nb6XUnaSCT 1t2hs48AduLr9wik6nF0pw 3QavdjzqIxMUPeSXgoA4Di 4LK5o7buDJB9A3aL86y5dR 1JAGP2PPls6WXahoN9IM14 0uteQpEpt2XpZ99ZT7m0eA 0zm5v1li5HwBcFJZzXz2Iq 7epZd4ZUwXGq5CTOwW9EO7 1R8ihhEOnbscF8kheDNC0H 5gYUBAE3o6k5yBv2Ni7KwQ 4EuW6g3eq56jUDqdNbUryM 727FY7suhFAVmwP3tsg6uG 2j9tX4ubo2WISo9GIJLySx 3QUtbFgjjnAHTtLup31xVa 6viaOSezCxDApUQlIc8mhA 3J0ZbecfqYszqlQJKYswVV 10aAr61dsWKA9RRdAmk2CM 7gE8QvR9Pxl7G2ey8XFtwa 6RF6zRVTz1FUYzBhop3jen 2stJA4LcpvwPHIRa1Gxp2P 0yrFVbIvtPU6bb4YMD2Vcr 68Hwxn8KEb3cXjv3w3eHtV 6aTdoiCwo5eYrl6ik4jRYH 3FWU0Aq3QHHkslDWD5sXvJ 3ckyP4jOXNBskOGeM1E4WY 137Lgw0gey9uw6hDKI6Los 4FrbvIGxud4J9DeWC5OYrd 0d29ZVNUaxWOtUFzElL3B9 7AvTgaX6gs7L0f1O0qSlDf 3C3pZzGJJR8wwuh6npPvHv 3YcmUK7BiWMBJoRWC5p0vi 3gBPhTsYDm9xtuOt4iFjMW 6QotxMJ0VE8eh1rvm2alsC 1fh5YKCSpo4OvC6usURns4 11bs6ROtD5D1VfDcCje9Sy 2DLcXvfFrQRm9D1GzMbgMg 1HqOKMf8bNLaEPvd8NXx3c 3tN1favTAEXAadxfygjNmG 7F8ip8rt5cfD18wUTgE7us 08pFqsZZZYeFbiTGPQj1J8 512JyhHrndIxZ81JmYZLmP 5Df1IuQ5AqKIrK1Rplsr9p 52MsPDozAb8oy9IjsndB6v 4tYja8TMtjBAejK7pzP2y4 3s9BUjzYDIesX8PXqcWno3 4jAbuuhObXbHrJP5ShVOZ8 7ezSDJfiOAmSt5nYe00VaQ 1p6BhKjxF03jOd00W6io6O 56b6kZuturLKiFl9v29tEp 3YGG0dmOCgA60bQts3J0C2 '''.split(' ')
to_be_parallel_coordinated = df.query('track_id == @id_numbers')
len(to_be_parallel_coordinated)
px.parallel_coordinates(to_be_parallel_coordinated, template="plotly_dark")
id_numbers = ''' 3Rx1zM3nDFQzAOYg9Hd0D4 67AHtK2jFq8dlOLSSSbQ7T 2ystp6xiBASPJkFR16gJON 5VNGj3qgKC1n28B9etIoJv 6OarwT6HBT8jW6MsnVwn58 61VbbeUd8bXxzyZYrg4djH 21rvKibsH3WmojUZh5H3Gm 11wxWExHmqBNKIo6zK9NEn 5ZGXAHp0YPYFUMbyMqDQH9 4BMPGmOzi4H3S31B2Ckx0u 1VcVGJ4sqRv2Iruxc8CfYf 1xOoqWTv2wLhUeLtXZTm9q 4SV8h3RlcuQc9jE9MUQfFF 5c1Hz72Bc8VMbghi4MJQus 0iZOviuGDLFc8vSrB4RI2T 7JRV17HtiiXksxDdTdpYTy 7apGuGr4Zf6t9JkATkolAI 0Mw9dLno600aQgA0Gf9Usr 6jUXJaXtxOhBLeWbpR2kN5 1nASmYf1d9HiiIgEOPhYQR 5LAe0lSl7rMle11o6Et9WI 5LZu2syDoQNaA0NptU1YIs 0lz57CGwAyuYdMk7BO72XI 3MDnGMGGC00nbpkLP1r6cN 4QZpmKzjC5t1OxEKCvL7Ft 15sVDXzpwJLfHM99VeP7mR 3Yeb5nDeWTvXfJ4TdlTtIP 56Tuc3GqQrByXDZu82TfN2 2jyrDZbZoScSdiTxVRlzb3 5RHZg80sV4QFq3alySZABa 3IYkFudbmV1sgbz4riV73P 0xtEwGTNW1fjQVJM6PZ3U2 5zllzp3gvXWq2cmyBZReij 43hjTh4WF2cICX1JhwfE9x 7BCPy7FIt6MIZwIYjgwHUc 3HRLlKWdmzXfAmbcrOkevH 5zTE3LjI0vXoNs5sXe1wBd 5ijr9nCHXMTb9qYvn3taSg 0R9HIKNmfmn44AYsSux8Qs 4AtiPcMHA5VPbNlO4EdB4T 0Ica23299eon0SQ5GMcJYc 2xkcKjB8CYW1wXiZ4haZfu 1kcNoS77udN6sSUWq9mI60 2kWUZwAhXDQmEvxv6zAxsx 6a5vpD5O3gMZH7G8xwOv5X 2mg15L7RUwpaymfobUFHOM 6HMKAeNDeWkPaHVEwvf6OJ 6zZeZcCSnugaVt5mCiCCP0 58xiGZhGtgJGCBDlXwCTbe 5O4MkYjbKpC3UH7oE7YRQa 6NBheB7uq3KuwjrriafhSy 6Tdyv7xZrcnHmO9iQoysKS 6GJh9XXO7e9D16Eyw0RIuz 3ayOojGZYT6wNtFC0NDQTm 79wTeGSVlONiNfZTdyGUNq 43w1mfDBN6MHueSkUjN7D8 4HqgpQdgUT12xACerT4yS6 3XRfdbb65XE1bfrAwlRu28 3Cv56grsf8F5iWn4BHtZx8 3YG5WGhUOj8Qzj4q9hF4TE 2MpCXZtBR02QWKP6xwRqy8 1WmKw3lMhA5YU869ilylyn 0vOSZ7hAUxocDU7qPh0VCo 3rnjAdt1duHuVV5AjavYk2 3uUzHjzRxKewzg1bE4TJwq 7M3e3QMHiGgWaGqwaRS0oH 6JtZVLdOzT6GeTgPzSoGAA 5u7UqEwOyaEIoA1TLLFpz9 0TWdTb7si8hunDhLmynRsr 0fzEYa7EiGDTU9wz976bAX 1HybrAhpKs9bm4ol6UR8bZ 4dp22919ccLK9SpvAEfTbA 4dhR3lLe5XLiR1TDNuGJ25 2Ovrl3OYjw4Ys4UJJQZaVT 0KU1n705y9CXC2F6fBOWej 4sPQHt3Tk3zz2TxBv6iSwu 1IdFop8kheQ8DF0rFhHiqa 4Ex2Fk2vc5JOsYptDUBtJA 1slZlNfFpMAfNiqtf9uYto 5ykg5P1kKcYCVqF5cHXjYu 6IGRNK7vC8fuhncF7YXXg9 1gZRSXSFGgZ2FfTClxI2A9 46BanJsjr1hqamrvLBYkng 5IwncSTQf2nC5aTktUNJFQ 58iaGunPax6nehU5K3AlCO 5vEwDx78onSExtBl8Q44Qf 65fd6IOZZjFYkuApCdbGxR 0G69NybuKLFtOulxwW348d 1z0b8KGrWldcZLakynC9Hc 2iaJ69ql68l3uCFtP6Rz0w 525g3ZvALoI6eTwOnE0dvh 54Amn3maW5gDB20vIkOzMK 3ZSj7F0vNEUmr0pJX3ROcD 0DbubpYjXBCGCrbcVl6YCY 6gdYVynIAdcSMWIaK3x7lW 23NI7LEZNcNgqMQ4MtNZPf 3sVNfmjOawrMVBxZ5HR992 4CCFVqakDhrAqEBbIeebgw 4VRoNouo8soGhl3GaFLmdr 5Mtb2rpcBkZEbNqLx06qfp 2m2Si8RtoOGPfbIjDx9Ug7 64SrUvSXvi2DCqwnScNQ87 7boSAJxzyyCJbP3LcDzssT 0SgncrTJSvH5xrvkllBZWj 23ptyiin2PKgaHZW6F0mMa 6gpomTTKog3SU0if4XT8E3 71jN5pqWqS1Gq2UXg8IabB 0yItuTAWCQ4JRvo9a081uD 0TSzNyWeCGVz9VdwFLWc2k 4gq34v5gzCtdaL4o8drPBx 3IR6Za6YHTAeikVF8w1DvK 2pkluglrMGfygP1yVADsX6 6sQyFRXaDU3MmLORr6EdNv 4QtS332yh4ex5KFgcMA40E 5t6GgWRjcigpk0pXpcwzSO 1bHaP4ZOPgtpoZ3CN6bIML 2zT9xdBcvSo1CO8RZ8Tcqj 0GgFwGjaAdqVga8j3ZKCtl 7m5LVVSaWzik4h332VqvbN 1P3RGzIqmcHKvH68e5nkBW 6uIYA3RVNgr1btPAtr1XXy 79pqKla5Q9IiAQfK4jalAO 3KDZxrjgFLKWs7ds2rvVcW 3yiT9hyDinSAvubb3XZ8S5 4byppJf1BVIEYj0FV48uN7 1PihJ1fLjU2wkTatRudSyE 1rVYJMGey3MZapQwCx6xXn 3X1MK1cg0in1bV5s8BvI4O 6xDEZCZm0Ehbzgj1HAqLIe 5fDXSKPlZQlaq1jC3izCkd 3JOdpt3Msi1e20Nxmor4o5 7gLSX6HlNso7WkoWPCGNGr 0PswjCzT2lZY8EDjVRPrPc 3XXbyMFA9F4adfcnEjMKHM 5jM3bDFV7UuyhHA5264QAs 1KRiMLHjthCAhWqDunAJOV 79ojwy5zomoWoQNuaOWbKh 7qbUjczokcnGFIwx68aBqV 5IKtH5C078QBjDSniwdTXj 2LfM9NwbQkBFV8XKAwhuTo 7A2lPmhXhtlZlsRMz0ShNs 3nSvqC1W3IEhdubx1538g6 5pFoVXWo5sCBfC5pLZu1Gg 1XCccHjyDRUdOVrEOpLzoH 6LeiYw9DsrS6fTGG329tK4 7md22n0LputBo41lYOG7tA 6YPafAdayjyjcoPoKIxn6y 5Tpbw8WbGEwI2pzjxXrGvm 6ummA8cVxCDnjT9382Ui8G 3m9yfMVIpEYvNLQZl2f8YF 37S7watyULcdUTc7z8Opha 2uOPEftUSMDJK4UpsUjGPO 2Xv0TmNKxLIV0cVRwM2HFz 246dN8gCiMv5nHi5wR2Anr 6i05cmZT3PHtSriKFWxTPn 06M77pQeFWvFiVn1Be6XsI 6WW4VgC1CHJjrWxYOtvayZ 06qD1C1Tcd0mYdRBBmYuTx 02ZFCSXPFgFPEahuN88kOQ 06QqCHpEStp7fwJYK4qoB1 3XuQifZguMGzjZJ7zHw7O8 7bXHynjjhieyUVyq8PfjHg 5WGOhaEiVJzjeUbjgPK2ww 4FXamUtTru5LlMNoCjlBRH 5oi0T9CsacaGLVECLBKWq5 5ulm5IhULY27ehqTSrQeLB 4L0RXCGs4SP8CkrBbZxsfS 5jYACoLz1e0r07W9G7oqOi 5PbIFyF34gCASgnG7yi0AG 0iZU8XzmveXaRiWBpE1ZTI 4pvwyXkwtXdrKIXpOc0keI 4wILZuKMKmJZIQxW30u960 3DrjcLyxLSG3aOh3MvXnUF 6Zm6DJFgghFMnMw7xBIwyn 02MMgyaLCvnIBw4skXmZ9V 1kVyvQzqxOZz4BgAWOY8ps 6U3j5OkhwwHlVeVgZlyl7n 6wdOphejlm1hNfFhXmzT0l 5rNFuymSOcCW8nTfd3vYJn 7kfZsjQgEApwNuceCzJIp8 4AhUSi91kDdC4G51qwvDlD 5Oi4T8e7vZK1xfJgBEWDdd 5Q5POfYGAdWGSSYLtkVQ4T 1KgOw1rCe9YWTFbFJYuYjD 2Z40xmLbAGbv1vQno1YMvJ 4PgpYEtlH6VfWmds9jVDoT 0ERjKxvwU91tthphZGgLFn 45b5fAvIFHBWmEcBGytul1 5biNqsTCkccqUfmzRFVIPO 1fdwOBuqrsjf95i8rAMUCC 0Sm76b6hQobYvHebmCa49H 73A5MOZ2MJyKw5sigQe64R 56rBa1McCcF8Q6cyPOAWji 76B1zH5bbarUGH4CYLfvbS 1bUQorCYDuyQhIyDYWzNyz 0eOAeqbD5sxU77qdHSYLOY 26VXbBYVzPXvl0wAAEppnr 5DK7vMKUkq3ejNQK1SP2I0 1E3e15pztQETb3hysHnuDy 6yl56wrtGJVrnhFJjQvIVS 1xWDs7mhV3YbENkbEkmvH8 '''.split(' ')
to_be_parallel_coordinated = df.query('track_id == @id_numbers')
len(to_be_parallel_coordinated)
px.parallel_coordinates(to_be_parallel_coordinated, template="plotly_dark")
id_numbers = ''' 6bwTuNxmVEOQw0dXdmgLjC 4rTVdzMKkbRtcJtbHCtTKm 09m4moKIXDyQNZDkoDqjNk 74VJWMSZHMcvkHQhyFmsXk 6CE0gR4USBQnxKj9vWiotk 3REJFRU6OZmqWk5neOLPXd 1jEH3K14qOijd64Sa052fn 5Z5YYYAFiSsfwOm3EMmWJY 58bs4VQUlgyZcMKJVjpZ6o 78EsU5Njik3K2b1Os6zwLV 0BdUgqNA6b63BXGDu4PeKN 4PdEXwNLZrPK0BxuJwr0nJ 4kKREED4rj50B72mZFuIip 14houuG4FrK5ZHlzVccj3I 5gH7dn57qXFVoeY2IKULtY 2bJs4cwj40fPxm3m94ORe7 0KE6mugI11bbF8kBYC41R3 2PWUpPMK2GeLxLm6boZjto 60bhcR1KCbE3KXx0zDv0XY 1zl1cnISd42IeaGjcnQNAD 07jABQKHpIpXKCOcqWtDpV 1kdgim6R7kqUAOOakjyWGq 5NiqIB4BwRpoU1V6U195OU 1oNvNkTsX2YtpPpYQHL9Zv 038Cff0ZD16m5byH6ohfVM 0dgHfb4WaQAzBdS7n4SPmN 2Us0EFBMreM3VlE8AS9srv 6K3E77Wxm5oH9kEI7Qb6rv 2IAvDrAdvPDiz7Z9ABphO5 2m0pE0vX5h4NahhFsPMwnr 2jaKU9jN3X2auwOGjukuE3 5MtAIjUBeWqQ4ZUsb66vEZ 4CvRCtSjUTYksvMiHsT0CV 537UFrFPasLdnwe4Rk0ROO 2UBg1GC3tMTnw0VzwmLelz 4dVWz5zq7XXigjOfrAfI19 3Ek6sWpamhmmtk032Uhg2V 7oYH3VjR13Kmtj7o7xLEZr 5wZxmzrLNDTcw2JNyaKHS1 7EsGSHSaobePkf3Lsqre6s 1pe3AGBuipdklcKbJKDP9u 4IDNf4oDocAj6dufznifao 0rjX0ul1dfUmtNDAUXIPup 46Pk9K4Ta26lFiUs5thsU0 2OP7W1lsZkSWGBPdnO3mgk 3jrcoA3eEMZGKzF11VzxO2 1XbzwdyDW4YohbntjCdso4 78XVcxI67oXSzfV6YAODtr 3BWTnYtojgn68TZSkGeaZw 6pVGYwDiMSfrEAMdIVSoLt 0S3f2G3nuCWHmmSbck4i9C 58yF5Yqokn4NxABBmpK8Yi 0cEL1Cg68zorMS2hFq0JJI 536PcP6LHChvhsH64QVBhq 4gRH3vcS741pSZW66LQK4P 6ULiCxVUaWBG0Gw2UAg8Dz 5QkHEhAJcVrsTKSZFJDzwX 5bQygUkLEUYEWSk6rA59QU 4XdhTfbWbD11U3fTW4EHcj 1rS24VudoY628mdFumzVcI 32iYiowgoEfTsWQkcwTRlX 7HcbJJxIaZbbPIRb1CyZ3m 27do8NxmUa0D1O9Mfi7qJN 4MpCSQSpk2yLnfrOSHsZxq 0PkKfT55z3nNSVhII0tZdN 20QnKWlncgqaX5NYOybhgy 5gFjlxAUKTqM1GUlFNKw0S 0CkMQnSzNWzx30BaLnllr9 30ZIabSNa8EbZT49b6HdFO 0hrdCoV5LPC0ni1ahSbAID 3FfWjwjwjVDZWlddoQ7jP9 1RDif5mDdaGro37AxOVYoJ 5rfLztZGbpbF2qC2sU0LZq 6bcIIzSu0niVuplUk7t7LB 4khYVmGHZz4JWpFlOMXanb 3xXqlPnnVXRsxfz7UGVi71 5a26fblCJE2O4kEJSJxU5h 3up1JsYa4JNZBakiWP41s0 3WOFMQnYvfcGFxA13J1e55 6On8OnESrMsfScviCLu0ac 2vVVMFMLolbasmvpkyEF8K 2GgiRBztrAUC3SHmBxAgdB 0aCwjJMzkOdxUZfAjKtmuY 5k3DQ5XZGBc5a0Rwbwc8hW 3DOm109bpm8LVlGrPj8601 6uSQ61RK297rMcatNDbUqW 4kcM8vye44jgsRMus1UjER 3umDgMGgONpKVH6KzpCcho 6CqEVY16aBgIMzKmHOBLAy 3x2Xk59n3Ey2703JJX8ss7 0ajlXtd6JWlrEGt1Cb2gRH 5YE0jwzEgR55ngUvtAzEG3 31Z3tkTDOaYAIJt37DG7lW 0v5tTD8cCbNsuSPdZq4ppU 62tQ11UnK9za7j0dyqT7Hs 5h53e771faNluczmIdNTqd 2lhWPS4vdx7F0kkwfLmAwG 7oLLKRFfOyE6FnIbbpXsyR 16Hf2J1HuPbNPWFvNZzYPs 6i1fuTteHcDcO64tGAnGeh 0URolWwoi4SSkoNHXDrTpO 6KiZqNhZtkdB219BIJkxNJ 1XKMWyhXlzu54mHfQuLUlf 064OyTlK7wUeK3D0OcCNcp 53APvcivoxGrAmK2b0Givf 2qKCyrQ61bmJqoV0cCl6eW 2mpINSrBUHvmP5oYSZ1ZFV 5K7gKm344eKOkDPHQPKAzd 0utSnGPZthEAuKH2kUfTcj 1FC2CEy48qcygiudnhS11x 2uGcDgpKyKBIIOfGwTd6bu 3CgPWIPgiLM0fuYQSPV3Vb 3cQCiT1PvddSKI8pRk4ygK 7rPm8nyaZMDzrt7HDFC1IA 6FS6mOlzpyIWMz9o7pZoWo 5bOGB5m6V5yWR0tGhbBhX6 6HnJLuczohJYWkDGgYmm0u 1BZe0OJ0eEjJloBAvg6aJJ 5avuMjb46hBDucxFvxn0zo 2Z0q1138jfn6aSMB7O8o4w 1sVtiUcsOJTWYjucbPoVnN 1QSdwCcfv00YVFjlMFzlo9 4IRGT4KQBDfevJfYgUuZvP 3zM11n3Po3s6eBH9QAqcNr 5w6y38iH5HdSNk0EtjAdW9 5BZNTeEo1t1HXVucObfYSp 66bWbHHVd9Zi5xNAKQjTmS 4NlYgUpDS3K7m7mw4lsTM0 1NBksoTuYxMACF2v9OVDMB 4jomQr6ARl89f4ZguNlIQm 3lQ1IPdzulBHfTrqLYH4vX 7gsd2pg4vXfmAnMuXRxTEE 56Sz3MTf0cGyjYwTJOZVRY 7aw7h5j6BK5KvzSPNpKNRj 3woUcMUIeew0PfIlEAGUcH 3j1jNAZIgr4vhBfI6sgfxC 7zhc7NI9JHyPmcOaDcHCVn 6lGe38gKVRfF6cKeXmhidF 0XUZDGgOioOehdcstP1hU6 4aILeLn5yHT6AsB1W7bEHG 6DdGyHy8hlqylxfaDRpVcK 2Kt3W0rl0PjPCOjAsf9mjX 0sAuFhtMq2SKZ3jZeU59Yn 6ldSXWJYVt1Qig7mDm3fXv 2YlIQsylMAOcqI7aLas6zj 4G96MmIt9XmoVPn9XzgtSy 4gPw3HZ18KN0UOniw4UEm3 5n0mpjpvR5iWWkiQL4kgRX 2pX3YMabAIjH2yQxb56n9l 4p3zss13iYj3TcxUgjmrKM 3QuoES16r0kfiewaKeYYnJ 6Cz0v9MHjAdviUGTtzO3Dq 0DdCjDmCzioT6W6nIhMOgA 4ZNj2L44lvkGZ58SaSql7O 04ENoZKEACEkrcc7v9EjnY 3xYgJpdnAuKPBSA0LHtg4I 4Xds70hJW0HNo0K7OKJbl7 1AIYotQAJnVXpyfAznXK8y 1Ez2SpFr05CspgDgHSja91 0si5v3WiNFDgQUcbkgRp3o 0HRQMiz9Ua969JXOPVLlcB 51XnpBsO8S8utaHscyhOnP 5myMjEVTHoBQrvatNM0kyy 58b7PzFbREarz0Os8GRBZK 4sX6evSOdSL04HR40EcEN1 4fubn0dRFW1WMa7yiYIZSs 1OKVJpL9RPeLjFGJUzeXv6 33gjPr3rzp1dylPMPgvLYV 2qeEyuDUaucAe63BoqJqoS 5v44Md1bcJYN0rL5kpWfd7 6PSyaM5jEbwLXm1RsKZyWE 0hLPDVYwODPeJfkHSol5aI 4OPPSKaowfmIiUEVNyh0l2 682gIKe9M4YJeDbw0Uqimn 5aGZpag8gyQf8bYu1RhYZe 42o454bTsMf9g1A0cwGxke 40vqauqc0VQpvTGYYH8ad1 6oxVrlxeTwhmOroYJkrAad 3AVBA0GTpnMFh1Rv6Xqymu 1VZmjJ3WV1nc3ojykNVxFa 4Nclo8xnQeuX54AGKOybbM 7Dba82QckMfi9xvgeePc72 6PFiq41950kSI58ILz7uGO 2jJUHXFaFdvtxCOVW7q8bd 2lEmjaR8rQqsQqe6CLXtdz 3lPO5WuqFNY12UGkZzZ4Xf 1o1tRS1Vzt9RZDJSDJUzSC 5D7erlQmTndO42J9VuvBW0 1kjxPdNwFKldrMVxlO7lio 3l7DVkePu6bBxBXTl8cIDc 6pTMJuynSqNQXuGar4Skno 7oGEP1UfFPnJOFeE38Erjr 6tIXXMXvOi3XNHdRTwYFOl 5lYAexg45DfNm7LfJNYMva 2wgL4gIm8InPw4IPaOBp8h 1CzXfJbCKcHb33F28SyGv2 4nHMoGnvsDsCMHmwfSVWop 2R3ifU5sK0FygVOZpk1yJW 7yeO78qI0fxnz6gjTZEp7i 68SS7wcjzSTXcifbplZztH 6fbTH5few6yjRaQuD0tqfA '''.split(' ')
to_be_parallel_coordinated = df.query('track_id == @id_numbers')
len(to_be_parallel_coordinated)
px.parallel_coordinates(to_be_parallel_coordinated, template="plotly_dark")
id_numbers = ''' 16VsMwJDmhKf8rzvIHB1lJ 4DdgOzDiK3VocRlOpgyZvI 5smmdqbHwTdVJI1VlnBizP 6lyFgQE2nJwT34DYJO0gr9 6C7oT5ZSNyy7ljnkgwRH6E 4YSO3y5EkzXDiBW2JSsXyk 2PktIwDOLDNRntJHjghIZj 2OKbnAB4LIw93b8IXJr34m 6drCDhqlK6cZ7LKDi3SB18 0ZsWvJXGaHqKUHrvBjZxSy 4hnq2TnTGgiLG1qFAFQtQG 40OCjuNPJQUTjSnTqFc9u5 2J3vblLOe0NKOJvHXxmvuu 2NGl2ljBxtvl5duT5U0Rgc 07iwjTrXQsfQRJ65rEConJ 4Mjn1iv3fhTtDt1ZRnUvn7 77MM047j6loQsPsUFntTiC 1oTmjppGp1ITPZCKsYNqs9 1DJUNsDTNuMWGrxfJmNGnm 5ZTiNyy1YtvyBEwDWoVOsa 20iBwNgEMH8b63MZ7wmN2F 6HgNAjt5zvGy3YQfib9hbC 4zG58gSipyazhsiVdS84lM 4NDw0ExQPFKQNkkFKvPh32 5ghFFUCCEspRulW23d3Awc 6FCl5VIhI3c6StmRgieLKu 1IeEYWlLBatGhtSTVRdOgJ 5MzQStKKOo666peyPoltxh 6D2KvMGxjFMk47D6CbCEaT 0DVnlsmBltpcWafM3TScIu 6jwmlu44QMMDesyUIFLQS9 4lUz3IxMsXYpsrbV6SVQAM 01y9jiO8FHCzv9iLmYpw4F 5XIkSMJ9sODfZoHUJYoi1g 7atUBpdQv34PNmYix84wzR 6vhOg0jBNyCzQo7nlotVeH 0m0ndzeNd7bTNWpgeGoQcP 1NBBs5Ym76El2gojyE4EvP 0R5S8PHmsl3TzHdMUx1oiM 1b35m5XbZpyNAx9atEDaDH 3aCIbAoc0CTE46enUrDmuu 2Y88xiM3oe4DFYX0jLLSON 7DcVWzeud5tqtNTZKQWvhz 6DdG99q2hNKrSHZ7hL6pBt 7ESz0yGdmhiWp85j5z09Ub 3xmwsqwkhI9gbvmapDO9S0 2N9LsBQMtLyMZL0LeydiLW 1sGGodtsPFq1JC2w3vXZLv 150NZIcOF5CtN93dp72A6g 1COgmyz8tnpvBoZvqqZqCL 314QsKiXd2SgDXPYNsKu0N 57p3QcWwIjVwvAcQpu4hkr 5IYNm9xiOZkLjGJYH0kqsR 6z2Rtx1CjQGaEEC1xzqtIT 247ye33xXOEhnjN2rCdj8I 32ccjDeiYYtombISVtse9U 5eEZLIu17HRBwt0Beldd0j 30DnQCN64v8xBpGZpLgb6l 0PrPfp5FbP87rTk39MUKcc 14EblrVdzyjpAWaedKO7x8 1l5CriNdYpEL3NoJxKA9uA 45ZTQl9GbmdM418qgLZvQZ 3dgf8JT9Ya3QAfWaJTNuI6 6ga6wioJAkB7MtOwremcSe 3HUsmE6j4afm7zWM3bprkW 7Jcf74UJvImsHrGOqSS0tG 7he1eOKQBxz1JK66afUzzD 2jtaAeW1k3qgbpQxT8Y4lm 3C9ZhZSSd2ki6Ko4Zj4sOo 3KuP7KttXAKmsjCLx9gKeM 6I5FyefGR36b9OF8rFkxVK 6YNIvsHK5fdy0ROHDuFpm4 0M7ZzCZ75sAUBq6Rkwpu09 5soDoRuEEmx9BriBtoWbr4 0zjLqMGvY7j7TuBkh2MIVd 4YfWZTRKOt0Lp1x1TkgsJz 3xhxhvEYDY0Txl8jUqbH0p 05FSDW170E4Brk3Et2Tsn9 64sixBk8xj9Eaz1VmdbenU 2KcO2wBpD9kfEUq7K5L8NU 5lpIW3pxLBGZ47LhXmHuH7 3aayFmSl21VgL3vybq2EAe 1nhZ34zdByR7TKRNLi6jXH 1WU3fG5GlEsQSsxj4SlGn2 6mAMDridbMDlW2ovdyPDUy 4yKqq31wiiTYlzsTspc9bF 5BgjDdJGaa7iB3kQfj6QMh 0AYTA3nevKu9S6LpeJwG7B 2q1mQzjkmrUINRWiyvctSi 2OIGt6nkvpYyTCsgqgosut 4nHpPnnYddn9KhXWKcVcPS 1aeKIPo431ykCa62MFpVxO 6J0LsDeQEMbXNCJCsPEnPx 4U4UKccQf96YM2pVVehbDd 0iInUMrkWaGGUkPwIY1Ntk 5kM4TGc7A3VyX1AmnIznGx 5ByZw9BY1See6eYgqUiB1x 1odwlrTdOkOVUoJhlE25Dx 4zsYOCkDiS14hdCc7gJX1Q 3XnpqyDY1Jo53Tgod58Mxf 5w3peXuUoDQIRWJbtK4kYi 1LWhjl461aekeNdmQk2JuJ 18zmtkXBaSHd7G3xobWIEJ 45vdRv1YwLbpbVeJ8BO2pR 1K6WHHqLXlqyGxX2lUMQr3 7gIS4JjropHYqNq3UzjHNB 2wklaFrsGnIfvLggxQhwQB 68WhMF4gKml7wKQcpILei6 2NVoGLBsrbQrH9c8bRDQu7 5gxxz91fYTlkR2cqmDkPWP 0tewjlNbotxqF2obibsg36 55hoUnXPjk2xma2eYSbltW 2iGTayx2t62y1J0XOInyfX 6ScbJrUjGIWS76VXsK8UEp 6M1W8DojBHXnjenYcn7H7M 4VyvzQoIfG49xiNuYVYBiv 1dMabx7tqxUpeDYQAu8c7S 2bQN2bSNXxpGTnVKpKXl2R 1FCueyFK8jtU0zmxQZyVtJ 0sMph7dbpLD4DlzEEfJlpX 5rW3anmLNKDA81nVJvW50H 0w71NjrPNzBsa6yO0of2CZ 76hmKWewz3vGnKLbY2nPRh 3BIyzKK2U5O4Ij19G9z51J 5OLQw1i9uk8Je39V0SJ2GR 6FAPlqbXTuXOPM1UmJj1X3 1kAJBuEhXnXHNA64DDO0Bq 2H5cbxbGjC00Zqe8IqKHm7 6wd1MrcFIjgblPkTvm0veJ 2BfTod61ST4H3K9jxPg9mp 4Uq8jQxsADt7piVcuwYgVJ 3z8VNabIASkrBxq94cP3TL 4c86vSmmzcIO4x21LuD7XM 6gqoJC9MUub1AbISMFCuWr 7s4SSLsUwBjEJzNVODbV8z 1zXA806qSJVWnHpGWQ3UUC 57E1gf3WclWxUuLcwYYyU4 33azw14HJcaClFGZ5kW6Nn 1izLAQzCTkTCTpu3l9TFzB 754UYs1LuDtaEKKfaDkx7Y 6sNMSl0MAqzvlGEt4Y072v 4aAZVfU1M4cm7XqTnzhCnr 28Val6Yko2x2iJQ9YlG789 4RwLQseJrBm0Pjl6vQcY5D 4TZvXowrJenK3OCEbmJzUT 1I3iCPuCId7Vkg5rlqYDrp 7hWa53fOj9Fh0X790Bl32B 1JMkYhhLa7KPDd8i3sPGOL 355ezvqbe2QtgMf70xXBE6 0KlGGlCwuBw9cPcjq7xjgf 5kwDBRZrCvDtN27XtT2wzA 7oMJTXLhm8TAkk6K3j8u1E 0ELWm49HJEJqIvqzTdZK3n 6VziOL8abdt5gchEEBCMRg 0XUHYxHOOctkSXReILAaJV 3wMVhcD7YbfOFqhgYiN9hp 30VCkYXm8pkZ1rOg5yC4LL 1NE1ljBeJzmk6wZZ4uUdRT 6FWhcFQApH24r8AgaOLrFw 5z4mf1xZt0z0u89ntbWN5z 05Tz6QuSWq66WaqpHGK6iw 6xq7BAoiGiXC27rW6RH3ww 47AJA4geNelnpulvvfZjdn 0BOhco72YhbPpJIqDEZNmA 1ciJCLzKzezhHbBtii28UD 63IkPNf3Z4xHLASIyhxS1R 0BNWj55u3tfVB3hozoC5lY 55FD4r3EgXRMKP79hDbt5y 3SatXFFuUyX2IlV9JbaWp2 0L4u2qg18ieitQkA2HBXgq 5OmUVlZP8zQ5zGCX9wsD3p 38ueylzenb5JK5JHDGnWuO 7FLUgR5esAR2m8kl6CSQ32 7KOOHzDAxzl87i8VYk1iO2 47jAQrNH7CLIcYu1lqE7pZ 7ve96Lk22N2ZGVqVq8EJOf 6F6MrtUbHqf7AASOXDMlMp 78E3QFSTlLijRUrukdbXK8 5wMlr2ncg0SoPOKEs0Pc85 0rfSwqjq0k20rVZLzATVwP 0PYPlbP5Vdz5ivIfC0jAmf 4UWkS1obHdt123rtx5v9cx 5RpMFAJcf116DGFBcK5Ny8 6i4o7jn033PDiNab3Yc3jY 6FCWOKBTjzHsHpa0cF0br6 2b3Xo30P9KFEqBvsTRQTM6 1b903k5gadxEFXhbGHAoWD 5tA3oQh58iYSdJWhSw0yJV 4f01YssEopYUrYIO6YZmjZ 3960gvUO5yuDJtI6VtPqYS 7fc3kOECAsJoCbsV2p64rt 3CboU4vdisSItbjfbx6SqO 745VS3h8id3zcLh7Gd6gGa 5JQlQR9REVJmP34AqI7Tpc 5K4LPGFKqKO7YSbUdSQAZH 18vjAkuAMaSxfAf2EAcjP5 7is6wEBQ4zPEcjust2rB7u 1PxJV79Px9gFHPLvFO9ZOS 7cgt4TZJH3HDdmHQhfVmzx 3bl6n1sBma0Lp7etqjx5j6 76rLK2XhT6waumcLkLNTID '''.split(' ')
to_be_parallel_coordinated = df.query('track_id == @id_numbers')
len(to_be_parallel_coordinated)
px.parallel_coordinates(to_be_parallel_coordinated, template="plotly_dark")
id_numbers = ''' 6eZ4ivJPxbK7I6QToXVPTU 6V37apVtCiUpEKcAUyUjoA 5SxlhL1idBgsfYBfR1KEcR 0C0XJ2JYr9jEGAt89JyZqJ 1XsqZ0mMrIRMAktdnEuFF8 5SUMNsXNVtR4ujz84sWEWe 1xfTdLDg10CJfhcR4Yis0z 5zHgA4J4CrOaUvQ9UD219j 1XO9zgpDMkwhmAijuYBCxb 1U6vwXAvc7VvbhqNyedGEG 2T9ZyRnW6omzsVDLo4I72l 0UBDke5y1kqTgTkgmyHiwj 23tftAc7uJnxEfy5AGS9lr 0n2gtAOGT6Pxu5cEeaugym 0nqRtO4jdv4K6AJ7hYmDW6 2wsVeO1Hqx6IqM48UXGWSO 7mmqxoKWTFZB8tHXfQpmk4 336ihMIODpi6nlL1ytSEm6 4w2lb0V0qHGwj1GR2f52c5 7cKSdtwLEayFd8MuLdZR85 44q1XQgawoP50HHMiMMWCq 4iPaNKCg8kY3rwUK3CnUw3 5EvsUz8wsUh0dP7HaixMh8 6A1prRyHlB113go9En4cX7 7iylYXaOUTO3BixPecSjhP 52pvmjSRaV7k0TCqJK5sKn 5ATIMj2gOKsj06UvoTkFxe 6Isu6pTUwBa3ftiyOpKf7s 6lajHnTKM9Fiv10kzUpD90 37VDfyF70jTo1HqGQOsrRR 3RYMOo7YF9gCkVZomhOPrK 1ZIQ5girZEdA70xIkevkrt 76C7vN5uEcuF1BXvUJMvjk 3v8Zu57HCIauve733J6PjR 0KfjaQSlDL0r7dLaXNDMv5 7sRTfvTV5EUhDY4e4LjlVS 5wI6LhywYSgmHNMVERAJpe 4K0hPQgmWzx4jGM2Q4tNQN 0WmyLH7XemypvsAHuIOCp7 2YbZbmqqxrCysQDc4AkIIX 1UegIYDIgDicEBuHhWY026 3gdHLVZqeU2mHNggC6Tzwr 1uYAog8LWWeVnqNWItZaHc 4LpsUDYp9D7VvzU0iRTCq3 2akKNicOhUSp1QHQEQDTbC 4zHo8J0WbUDDiHTAURs6kO 32Q6wqR85WhBeoqZwMRwnV 5iofFSJRoRDyiKD4kWTpf9 7owI1qTHoXGBVznJod7yuh 6rbiT8DV9h50NBjPxkDygF 5twkCu1ET6objhnLfQtgJQ 7gGLo0dwMbJhRy0JVJP00p 2ZWv2tklegv3gwKeLD35o9 7sLsIr2vhjYeR6rniJj5dj 5IOozjD7gJOOhTV1lDXrXl 2cC2PIXKFjnY8sbuS8spzw 4PHM9PG5J6IQ8fumsJuSYJ 0WcGdMWl75v33B27KafycK 6K4pZ32MorbsHeqtAwaWHW 0h0jNccol3eyMQ2mIcNcBp 2MfFjRh4gv4lU0vtYH0GaZ 3uEFKAtU1hdfcgFC60yt84 0slfqpTh3q10bNfAYb73RS 7dg0pRcn7R5VVekBryq583 082bDyzPxizG0gIqArJoQ7 73OC95krAM3n1u2LcKraBX 3qpm5w0qS99qUN0q8MzvlL 1NywSw2TUrdnpnNtGu8KL8 1zSqLFmuL6mDCVbZNj7hTR 7kPsDSN7eFLbzNF0xEchjc 2qw3xeuKWfsV8GynO2peHr 6tEeqhvdmOVU2iQqnLk2zg 5K7VRObcsBDfKnyVbVhwTx 78WeKIDpoVu6r0TziQwl3y 4ZYir67KzcmiNKTmFVqNf8 22BJjJeknJ7ff8vGGzPB98 0b81xIMQLSdUpeGv1oStXH 4u00iLhEPkbLlclQDYuIHV 1p8QusGejMBctlhsZ3jtSF 2FzI0rp4FsSvx7N1GFs4HB 1XKqzLGxhIcpEXv8SoA8tu 6T3yaivZB0v5AODCyaR67G 4WOPKEtVmSAZvWXtyApl3h 3xvtJJiFdTR6d5N8PaFb8f 4ZAjZHxvrzKZMXdHmg0DFz 3ekvh2GPv2ebjPHYKhuIXG 0bv1k0dLjgp9f9rj5dBScM 1MQio3srmAmDC0c32Xh56A 0BZ7rkI4prRAbfkO3jo2OB 5Vu5DPFMNAJc0eoq7i8skM 1zE9o1WK0Vpocnf1H5nssQ 3zdIn3IbbJAddtf9Qo6i0D 3huj9hX9ECvhipWIGNObFl 1rFMpIUb6Hs66ypS32MOOb 1Qmb5p0mK08hxMjWJvCfBw 3C6fiBrM14YAynsEeRZXWv 4t8WpwzDLTYwMulJBavljv 7vqMKsg985FFLyK5DN9uq1 5yqoXxgDIQ9fPOcSAQUjUq 2D0FmjFP7dxrin4XanSnbo 4Yuux4zVxXI0KVHil24U9L 5MzGtEojUtMsLueJ55hRn3 2RDFWx08YULhklhS0DyVtj 4yEdofTvNsL7PnBJNDN1Sf 4n9SsVwbc7Y4tn5UfPTNn4 29ldunhjkUfuB5k1gXlqFS 6VFAILGN7uOz24elIyt4vB 2361cLjSnEpolPC3Mb0yv1 0T19N334CPKgpMpxh36KiE 3RjuP7n7x8DaOVN62TXFke 3V5LrENP5AgplQwvGeTIIU 4SNbrw7KNj3rupRnXzV31d 5XdtGPF22knBwy1fAzjSCK 3GE6KLTgmCxsNzhp0nI3Zf 75iGW6GTfBU7j6ldQNAvu4 1FvxqWCDg1xYdg0eXOr9FU 3NmVag0g3N0B4nDT0ypVk4 07jMNENLpJ60ej30L1BFPD 4KVybsvg26UiPJEVynN3qE 4k304lkj8Ga9Kp0p82cii2 1HVwhAQMU71rg7GVlQVxNz 6nYTfmQEE9ZYYFzdLRWP8Z 5QdTBAXXaFZDhsBqPT0GBI 3QElxQCbZjCqAG8yLRwLsm 5yvF3kvaX2ufVt3VvWbGP2 52uwpMhSoReK5wQ3Yxr2eC 1awdo11NQFC6THLXQAaDjV 6n6Wrf6HRSgTXwyWugKDwf 5MXF8IhBY1z63VZVRvFZUK 6NjMv3rcXwyQg4Dtr3WpoE 0JsAUsmagEqYQo8FZUkpBE 36Kumm8Qj49ABflKCvltIH 078Sr3upDQIPRIAc2IpSxy 2wJdo21bsx5HfTnwPJ3p92 0WWk0UiErQiR8EAnSjll1o 1Fs2986kJPeJR94vCqRGha 5eImJYwPyrdhUqZ4gTO6Qs 6bXr647nkFkrphCoA3L2KK 1counClRuzpBxsb8gkTCmO 7yCtrkXdQEVJQyk7pFxGyq 4sGN5db8sJsecYNWoxLPky 4EbVxLV394SADIDf5zFTHY 0tZvlW8YxwnPS7Ui7pzF9q 69LAIJUcPbsw6G8F1vCv1y 4wzeevLrnqs87z6FrcFNKu 2fKvOnZPwh4gz24MjM5hWp 3Hbl4FnRkj8TK88Jg37Omt 2mSHfW689yTYIZCu0k1Frb 00MLppbVubwv4Rbf46CCfg 1MvhXhNkwRJDH94ZloFU4c 7oM8U222NuBLUun8aFjhKu 2veD2T9UElKuePBt6FW4nO 4Bulfi18OkBRXehhVg1SzI 6M9bTZutc2QtXWl2p5TQ1I 4fM8cupzQbc6qNeDK9FXu3 7xktbw9wyJyJbwS3y4LZFg 63PP8XGwgRI7gIruMO7IG3 3C0Kxh2lnOTmlSCD1rB15W 0YFoUawskWM6iKHSyQgeNZ 1HEzYfexDpgfwyceOWvNz8 2zKB5hjGfqoYZUi7B3LAK0 3mEnnPSXvKoVouByyUqhUX 0dC2glrlKpld5xY5BAX9lK 0XXvMZGbrz60taMwPbVGgK 2y2xE0gB5lVIGbdAnHNUIz 6Ech2zanuCQ2ihfXDOLtID 6rEcPr1jbReCGcT7LD2cB1 0gn77iNwUHN2pScHbqttN8 5NH0w0LSvcjiMjWnTwhm2u 19HDqVwakevUkynlB1Ztut 0g5kny7FqZlnS1bGMPQFWR 02PBxJsA9YIhdbiXMNN9Cd 0tpRok1p8ooccX7DQqy1BZ 1P5uhYSYMDxXpcYgpMYnkg 3UTt7dSBf9MG6833z9gNUV 0Si0HsULu8gFAtYm0BwqXI 4sO0deplZf1WJnXwrEVNUt 1fTuKuiLtYmckVKwtoT812 0hMOYGKQK3m2ipKTZKUbrI 6nsyzCRGHluwU3QIDSQr6d 5y3HyzqdypXCRFz2V8OpOF 0mPvAhvAA0IyrcbUh9KEQv 3n5N1ECcHzZDvAzHLpJULT 5Wo8dHK8N9pMyDdXI4WWsZ 7KvGuebu3RAtH0FSY8RG6l 6XEfmMikJLYbYZ3ZL4l7yK 5ijg8Z5M9WNI2VLXDaxrAz 0FGiZTL9LSSzdO05Vtgg9U 1tYLrptJ56VWore4o9Mj50 4EI3t79hsPIQJLdHitvB2A 0uwIsRVkvzZTzxqCQHlgiz 4dM9Vju1O76L2V79EebLsj 20XscF3HtxEGo8ghFhOgCx 0QPSeBG4P39z9KOihZARLf 7wbsdw0VnVe421V68sNwDk 75nO71NiNoIaGVIqYTqSvN 6Jk8VFFPoUyr7zCXIGcUQS 1UdTsJcI4MwzKIxCP5HHXG 53oWCQ8bcFSFzcQd0Xggl8 4iFYF17QReVxN6bQoKE4NM 4uAg8KXLiGu0kIvICmdUR0 '''.split(' ')
to_be_parallel_coordinated = df.query('track_id == @id_numbers')
len(to_be_parallel_coordinated)
px.parallel_coordinates(to_be_parallel_coordinated, template="plotly_dark")
fig = px.line_polar(df.sample(n=1000, random_state=42), theta = 'tempo',
color_discrete_sequence=px.colors.sequential.Plasma[-2::-1],
template="plotly_dark")
fig.show()
# Make a PCA like the one I did on the Iris, but make it 2d and 3d because that's cool
pd.set_option('display.max_columns', None)
nearest_neighbors_df.iloc[[69000]]
```
|
github_jupyter
|
# Measuring PROV Provenance on the Web of Data
* Authors:
* [Paul Groth](http://pgroth.com), [Elsevier Labs](http://labs.elsevier.com)
* [Wouter Beek](http://www.wouterbeek.com), Vrije Universiteit Amsterdam
* Date: May 11, 2016
One of the motivations behind the original charter for the [W3C Provenance Incubator group](https://www.w3.org/2005/Incubator/prov/charter) was the need for provenance information for Semantic Web and Linked Data applications. Thus, a question to ask, three years after the introduction of the [W3C PROV family of documents](https://www.w3.org/TR/prov-overview/), is what is the adoption of PROV by the Semantic Web community.
A proxy for this adoption is measuring how often PROV is used within Linked Data. In this work, we begin to do such a measurement. Our analytics are based on the [LOD Laundromat](http://lodlaundromat.org/) (Beek et al. 2014). The LOD Laudromat crawls and cleans over 650 thousand linked data documents representing over 38 billion triples. LOD Laudromat has been used in the past to do large scale analysis of linked data (Rietveld et al. 2015).
Here, we focus on core statistics based around what [PROV-DM](http://www.w3.org/TR/prov-dm/) refers to as core structures. We only look at directly asserted information about resources in the dataset (i.e. no inference was performed before calculating these statistics).
```
from IPython.display import HTML
display(HTML('''<script>
code_show=true;
function code_toggle() {
if (code_show){
$('div.input').hide();
} else {
$('div.input').show();
}
code_show = !code_show
}
$( document ).ready(code_toggle);
</script>
We note that the code for our analysis is embeded within this document but is by default hidden for easier reading.
To toggle on/off the raw code, click <a href="javascript:code_toggle()">here</a>.'''))
```
Additionally, all code is available [online](https://github.com/pgroth/prov-wod-analysis)
```
import requests
nsr = requests.get("http://index.lodlaundromat.org/ns2d/", params={"uri":"http://www.w3.org/ns/prov#"})
total_prov_docs = nsr.json()["totalResults"]
nsr = requests.get("http://index.lodlaundromat.org/ns2d/", params={"uri":"http://www.w3.org/ns/prov#","limit":total_prov_docs} )
import io
from rdflib.namespace import RDFS, RDF
from rdflib.namespace import Namespace
from rdflib import Graph
from rdflib import URIRef
PROV = Namespace('http://www.w3.org/ns/prov#')
entitySubclasses = []
activitySubclasses = []
agentSubclasses = []
totalNumberOfEntities = 0
totalNumberOfActivities = 0
totalNumberOfAgents = 0
numWasDerivedFrom = 0
numUsed = 0
numWGB = 0
numWAW = 0
numWasAttributedTo = 0
for doc in nsr.json()["results"]:
#print(doc)
headers = {'Accept': 'text/turtle'}
x = requests.get("http://ldf.lodlaundromat.org/" + doc, headers=headers)
txt_res = x.text
tmpGraph = Graph()
tmpGraph.parse(io.StringIO(txt_res), format="turtle")
#print(doc + " " + str(len(tmpGraph)))
for entityClass in tmpGraph.subjects(RDFS.subClassOf, PROV.Entity):
#print(entityClass)
entitySubclasses.append(entityClass)
for entity in tmpGraph.subjects(RDF.type, PROV.Entity):
totalNumberOfEntities = totalNumberOfEntities + 1
for activityClass in tmpGraph.subjects(RDFS.subClassOf, PROV.Activity):
#print(activityClass)
activitySubclasses.append(activityClass)
for activity in tmpGraph.subjects(RDF.type, PROV.Activity):
totalNumberOfActivities = totalNumberOfActivities + 1
for agentClass in tmpGraph.subjects(RDFS.subClassOf, PROV.Agent):
#print(agentClass)
agentSubclasses.append(agentClass)
for agent in tmpGraph.subjects(RDF.type, PROV.Agent):
totalNumberOfAgents = totalNumberOfAgents + 1
##look at relations
for s,p,o in tmpGraph.triples( (None, PROV.wasDerivedFrom, None )):
numWasDerivedFrom = numWasDerivedFrom + 1
for s,p,o in tmpGraph.triples( (None, PROV.used, None )):
numUsed = numUsed + 1
for s,p,o in tmpGraph.triples( (None, PROV.wasGeneratedBy, None )):
numWGB = numWGB + 1
for s,p,o in tmpGraph.triples( (None, PROV.wasAssociatedWith, None )):
numWAW = numWAW + 1
for s,p,o in tmpGraph.triples( (None, PROV.wasAttributedTo, None) ):
numWasAttributedTo = numWasAttributedTo + 1
from IPython.display import display, Markdown
output = "### Statistics \n"
output += "We first look at how many times both the namespace is declared and how many resources are of a given core type.\n"
output += "* The PROV namespace occurs in " + str(total_prov_docs) + " documents.\n"
output += "* Number of Entites: " + str(totalNumberOfEntities) + "\n"
output += "* Number of Activities: " + str(totalNumberOfActivities) + "\n"
output += "* Number of Agents: " + str(totalNumberOfAgents) + "\n\n"
output += "We also looked at the number of PROV edges that were used with the various documents.\n"
output += "* Number of wasDerivedFrom edges: " + str(numWasDerivedFrom) + "\n"
output += "* Number of used edges: " + str(numUsed) + "\n"
output += "* Number of wasGeneratedBy edges: " + str(numWGB) + "\n"
output += "* Number of wasAssociatedWith edges: " + str(numWAW) + "\n"
output += "* Number of wasAttributedTo edges: " + str(numWasAttributedTo) + "\n\n"
display(Markdown(output))
```
We also note that PROV has been extended by 8 other ontologies as calculated by manual inspection of the extensions of the various core classes as listed in the appendix.
### Conclusion
This initial analysis shows some uptake within the Semantic Web community. However, while PROV is widely referenced within the community's literature, it appears, that direct usage of the standard could be improved (at least within the dataset represented by the LOD Laudromat). It should be noted that our analysis is preliminary and there is a much room for further work. In particular, we aim to look at the indirect usage of PROV through usage by ontologies that extend it (e.g. The Provenance Vocabulary) or that map to it such as Dublin Core or [PAV](http://pav-ontology.github.io/pav/). Understanding such indirect usage will help us better understand the true state of provenance interoperability within Linked Data. Likewise, it would be interesting to perform network analysis to understand the role that PROV plays within the Linked Data network.
### References
* Beek, W. & Rietveld, L & Bazoobandi, H.R. & Wielemaker, J. & Schlobach, S.: LOD Laundromat: A Uniform Way of Publishing Other People's Dirty Data. Proceedings of the International Semantic Web Conference (2014).
* Rietveld, L. & Beek, W. & Schlobach, S.: LOD Lab: Experiments at LOD Scale. Proceedings of the International Semantic Web Conference (2015).
### Appendix: Classes that subclass a PROV core class
```
print("Subclasses of Entity")
for i in entitySubclasses:
print(i)
print("Subclasses of Activity")
for i in activitySubclasses:
print(i)
print("Subclasses of Agent")
for i in agentSubclasses:
print(i)
```
|
github_jupyter
|
```
# Import required modules
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, BaggingClassifier, RandomForestClassifier, VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVC
import xgboost as xgb
import lightgbm as lgb
from sklearn import metrics
from catboost import CatBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
# Import original train set and Principal Components (PCs) obtained from PCA done in other notebook
df = pd.read_csv('train.csv')
pca_train = pd.read_csv('pca_train.csv')
pca_train.head()
# Convert the Categorical Y/N target variable 'Loan_Status' for binary 1/0 classification
df['Loan_Status'] = df['Loan_Status'].map(lambda x: 1 if x == 'Y' else 0)
# Set X and y for ML model training do train-test split using sklearn module
X = pca_train.values
y = df['Loan_Status']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=1)
y_test.shape
X_train.shape
# Initiate a new Adaptive Classifier, an ensemble boosting algorithm
ada = AdaBoostClassifier()
# Create a dictionary of all values we want to test for selected model parameters of the respective algorithm
params_ada = {'n_estimators': np.arange(1, 10)}
# Use GridSearchCV to test all values for selected model parameters
ada_gs = GridSearchCV(ada, params_ada, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
# Fit model to training data
ada_gs.fit(X_train, y_train)
# Save the best model
ada_best = ada_gs.best_estimator_
# Check the value of the best selected model parameter(s)
print(ada_gs.best_params_)
# Print the accuracy score on the test data using best model
print('ada: {}'.format(ada_best.score(X_test, y_test)))
# Initiate a new Gradient Boosting Classifier, an ensemble boosting algorithm
gbc = GradientBoostingClassifier(learning_rate=0.005,warm_start=True)
# Create a dictionary of all values we want to test for selected model parameters of the respective algorithm
params_gbc = {'n_estimators': np.arange(1, 200)}
# Use GridSearchCV to test all values for selected model parameters
gbc_gs = GridSearchCV(gbc, params_gbc, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
# Fit model to training data
gbc_gs.fit(X_train, y_train)
# Save the best model
gbc_best = gbc_gs.best_estimator_
# Check the value of the best selected model parameter(s)
print(gbc_gs.best_params_)
# Print the accuracy score on the test data using best model
print('gbc: {}'.format(gbc_best.score(X_test, y_test)))
# Initiate a new Bagging Classifier, an ensemble bagging algorithm
bcdt = BaggingClassifier(DecisionTreeClassifier(random_state=1))
# Create a dictionary of all values we want to test for selected model parameters of the respective algorithm
params_bcdt = {'n_estimators': np.arange(1, 100)}
# Use GridSearchCV to test all values for selected model parameters
bcdt_gs = GridSearchCV(bcdt, params_bcdt, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
# Fit model to training data
bcdt_gs.fit(X_train, y_train)
# Save the best model
bcdt_best = bcdt_gs.best_estimator_
# Check the value of the best selected model parameter(s)
print(bcdt_gs.best_params_)
# Print the accuracy score on the test data using best model
print('bcdt: {}'.format(bcdt_best.score(X_test, y_test)))
# Initiate a new Decision Tree Classifier and follow the similar process as mentioned in comments above
dt = DecisionTreeClassifier(random_state=1)
params_dt = {}
dt_gs = GridSearchCV(dt, params_dt, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
dt_gs.fit(X_train, y_train)
# Save the best model and check best model parameters
dt_best = dt_gs.best_estimator_
print(dt_gs.best_params_)
# Print the accuracy score on the test data using best model
print('dt: {}'.format(dt_best.score(X_test, y_test)))
# Initiate a new Support Vector Classifier and follow the similar process as mentioned in comments above
svc = LinearSVC(random_state=1)
params_svc = {}
svc_gs = GridSearchCV(svc, params_svc, cv=10,verbose=1,n_jobs=-1,pre_dispatch='128*n_jobs')
svc_gs.fit(X_train, y_train)
# Save the best model and check best model parameters
svc_best = svc_gs.best_estimator_
print(svc_gs.best_params_)
# Print the accuracy score on the test data using best model
print('svc: {}'.format(svc_best.score(X_test, y_test)))
# Initiate a new XG Boost Classifier, an ensemble boosting algorithm and follow the similar process as mentioned in comments above
xg = xgb.XGBClassifier(random_state=1,learning_rate=0.005)
params_xg = {'max_depth': np.arange(2,5), 'n_estimators': np.arange(1, 100)}
xg_gs = GridSearchCV(xg, params_xg, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
xg_gs.fit(X_train, y_train)
# Save the best model and check best model parameters
xg_best = xg_gs.best_estimator_
print(xg_gs.best_params_)
# Print the accuracy score on the test data using best model
print('xg: {}'.format(xg_best.score(X_test, y_test)))
# Initiate a new Light Gradient Boosted Machine, an ensemble boosting algorithm
# Set the train data and initiate ML training
train_data = lgb.Dataset(X_train,label=y_train)
params = {'learning_rate':0.01}
lgbm = lgb.train(params, train_data, 100)
y_pred = lgbm.predict(X_test)
for i in range(0,y_test.shape[0]):
if y_pred[i]>=0.5:
y_pred[i]=1
else:
y_pred[i]=0
# Print the overall accuracy
print(metrics.accuracy_score(y_test,y_pred))
# Initiate a new Cat Boost Classifier, an ensemble boosting algorithm and fit on train data
cbc = CatBoostClassifier(random_state=1, iterations=100)
cbc.fit(X_train, y_train)
# Print the overall accuracy
print('cbc: {}'.format(cbc.score(X_test, y_test)))
# Initiate a new KNeighbors Classifier and follow the similar process as mentioned in previous comments
knn = KNeighborsClassifier()
params_knn = {'n_neighbors': np.arange(1, 25)}
knn_gs = GridSearchCV(knn, params_knn, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
knn_gs.fit(X_train, y_train)
# Save the best model and check best model parameters
knn_best = knn_gs.best_estimator_
print(knn_gs.best_params_)
# Print the overall accuracy
print('knn: {}'.format(knn_best.score(X_test, y_test)))
# Initiate a new Random Forest Classifier, an ensemble bagging algorithm and follow the similar process as mentioned in previous comments
rf = RandomForestClassifier()
params_rf = {'n_estimators': [100, 150, 200, 250, 300, 350, 400, 450, 500]}
rf_gs = GridSearchCV(rf, params_rf, cv=10, verbose=1, n_jobs=-1, pre_dispatch='128*n_jobs')
rf_gs.fit(X_train, y_train)
# Save the best model and check best model parameters
rf_best = rf_gs.best_estimator_
print(rf_gs.best_params_)
# Print the overall accuracy
print('rf: {}'.format(rf_best.score(X_test, y_test)))
# Create a new Logistic Regression model and fit on train data
log_reg = LogisticRegression(solver='lbfgs')
log_reg.fit(X_train, y_train)
# Print the overall accuracy
print('log_reg: {}'.format(log_reg.score(X_test, y_test)))
# Print the overall accuracy score for all the 11 best classification models trained earlier
print('Overall Accuracy of best selected models on X_test dataset\n')
print('knn: {}'.format(knn_best.score(X_test, y_test)))
print('rf: {}'.format(rf_best.score(X_test, y_test)))
print('log_reg: {}'.format(log_reg.score(X_test, y_test)))
print('ada: {}'.format(ada_best.score(X_test, y_test)))
print('gbc: {}'.format(gbc_best.score(X_test, y_test)))
print('bcdt: {}'.format(bcdt_best.score(X_test, y_test)))
print('dt: {}'.format(dt_best.score(X_test, y_test)))
print('svc: {}'.format(svc_best.score(X_test, y_test)))
print('xg: {}'.format(xg_best.score(X_test, y_test)))
print('lgbm: {}'.format(metrics.accuracy_score(y_test,y_pred)))
print('cbc: {}'.format(cbc.score(X_test, y_test)))
# Create a dictionary of our models
estimators=[('knn', knn_best), ('rf', rf_best), ('log_reg', log_reg), ('ada', ada_best), ('gbc', gbc_best), ('bcdt', bcdt_best), ('dt', dt_best), ('xg', xg_best), ('cbc', cbc)]
# Create a voting classifier, input the dictionary of our models as estimators for the ensemble
ensemble = VotingClassifier(estimators, voting='soft', n_jobs=-1, flatten_transform=True, weights=[1/9,1/9,1/9,1/9,1/9,1/9,1/9,1/9,1/9])
# Fit the Final Ensemble Model on train data
ensemble.fit(X_train, y_train)
# Test our final model on the test data and print our final accuracy score for the Ensemble made using Bagging and Boosting techniques
ensemble.score(X_test, y_test)
# Import the PCs of test data for final predictions
dft = pd.read_csv('pca_test.csv')
dft.head()
# Assign the PCs dft to test_X
test_X = dft.values
print(len(test_X))
# Make final predictions on the test data
test_predictions = ensemble.predict(test_X)
test_predictions
# Import original test file for Loan_IDs and assign the test_predictions to a new column 'Loan_Status'
dft2 = pd.read_csv('test.csv')
dft2['Loan_Status'] = test_predictions
# Drop unnecessary columns
dft2 = dft2.drop(['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome','CoapplicantIncome','LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'],axis=1)
dft2.head()
# Convert binary 1/0 targets back to Categorical Y/N alphabets
dft2['Loan_Status'] = dft2['Loan_Status'].map(lambda x: 'Y' if x == 1 else 'N')
dft2.head()
# Save the predictions from the final Ensemble on local disk
dft2.to_csv('Ensemble.csv', index=False)
```
|
github_jupyter
|
# Predicting movie ratings
One of the most common uses of big data is to predict what users want. This allows Google to show you relevant ads, Amazon to recommend relevant products, and Netflix to recommend movies that you might like. This lab will demonstrate how we can use Apache Spark to recommend movies to a user. We will start with some basic techniques, and then use the mllib library's Alternating Least Squares method to make more sophisticated predictions.
## 1. Data Setup
Before starting with the recommendation systems, we need to download the dataset and we need to do a little bit of pre-processing.
### 1.1 Download
Let's begin with downloading the dataset. If you have already a copy of the dataset you can skip this part. For this lab, we will use [movielens 25M stable benchmark rating dataset](https://files.grouplens.org/datasets/movielens/ml-25m.zip).
```
# let's start by downloading the dataset.
import wget
wget.download(url = "https://files.grouplens.org/datasets/movielens/ml-25m.zip", out = "dataset.zip")
# let's unzip the dataset
import zipfile
with zipfile.ZipFile("dataset.zip", "r") as zfile:
zfile.extractall()
```
### 1.2 Dataset Format
The following table highlights some data from `ratings.csv` (with comma-separated elements):
| UserID | MovieID | Rating | Timestamp |
|--------|---------|--------|------------|
|...|...|...|...|
|3022|152836|5.0|1461788770|
|3023|169|5.0|1302559971|
|3023|262|5.0|1302559918|
|...|...|...|...|
The following table highlights some data from `movies.csv` (with comma-separated elements):
| MovieID | Title | Genres |
|---------|---------|--------|
|...|...|...|
| 209133 |The Riot and the Dance (2018) | (no genres listed) |
| 209135 |Jane B. by Agnès V. (1988) | Documentary\|Fantasy |
|...|...|...|
The `Genres` field has the format
`Genres1|Genres2|Genres3|...` or `(no generes listed)`
The format of these files is uniform and simple, so we can easily parse them using python:
- For each line in the rating dataset, we create a tuple of (UserID, MovieID, Rating). We drop
the timestamp because we do not need it for this exercise.
- For each line in the movies dataset, we create a tuple of (MovieID, Title). We drop the Genres
because we do not need them for this exercise.
### 1.3 Preprocessing
We can begin to preprocess our data. This step includes:
1) We should drop the timestamp, we do not need it.
2) We should drop the genres, we do not need them.
3) We should parse data according to their intended type. For example, the elements of rating should be floats.
4) Each line should encode data in an easily processable format, like a tuple.
5) We should filter the first line of both datasets (the header).
```
# let's intialize the spark session
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Python Spark SQL basic example") \
.getOrCreate()
spark
```
#### 1.3.1 Load The Data
We can start by loading the dataset formatted as raw text.
```
from pprint import pprint
ratings_rdd = spark.sparkContext.textFile(name = "ml-25m/ratings.csv", minPartitions = 2)
movies_rdd = spark.sparkContext.textFile(name = "ml-25m/movies.csv" , minPartitions = 2)
# let's have a peek a our dataset
print("ratings --->")
pprint(ratings_rdd.take(5))
print("\nmovies --->")
pprint(movies_rdd.take(5))
```
#### 1.3.2 SubSampling
Since we have limited resources in terms of computation, sometimes, it is useful to work with only a fraction of the whole dataset.
```
ratings_rdd = ratings_rdd.sample(withReplacement=False, fraction=1/25, seed=14).cache()
movies_rdd = movies_rdd .sample(withReplacement=False, fraction=1, seed=14).cache()
print(f"ratings_rdd: {ratings_rdd.count()}, movies_rdd {movies_rdd.count()}")
```
#### 1.3.2 Parsing
Here, we do the real preprocessing: dropping columns, parsing elements, and filtering the heading.
```
def string2rating(line):
""" Parse a line in the ratings dataset.
Args:
line (str): a line in the ratings dataset in the form of UserID,MovieID,Rating,Timestamp
Returns:
tuple[int,int,float]: (UserID, MovieID, Rating)
"""
userID, movieID, rating, *others = line.split(",")
try: return int(userID), int(movieID), float(rating),
except ValueError: return None
def string2movie(line):
""" Parse a line in the movies dataset.
Args:
line (str): a line in the movies dataset in the form of MovieID,Title,Genres.
Genres in the form of Genre1|Genre2|...
Returns:
tuple[int,str,list[str]]: (MovieID, Title, Genres)
"""
movieID, title, *others = line.split(",")
try: return int(movieID), title
except ValueError: return None
ratings_rdd = ratings_rdd.map(string2rating).filter(lambda x:x!=None).cache()
movies_rdd = movies_rdd .map(string2movie ).filter(lambda x:x!=None).cache()
print(f"There are {ratings_rdd.count()} ratings and {movies_rdd.count()} movies in the datasets")
print(f"Ratings: ---> \n{ratings_rdd.take(3)}")
print(f"Movies: ---> \n{movies_rdd.take(3)}")
```
## 2. Basic Raccomandations
### 2.1 Highest Average Rating.
One way to recommend movies is to always recommend the movies with the highest average rating. In this section, we will use Spark to find the name, number of ratings, and the average rating of the 20 movies with the highest average rating and more than 500 reviews. We want to filter our movies with high ratings but fewer than or equal to 500 reviews because movies with few reviews may not have broad appeal to everyone.
```
def averageRating(ratings):
""" Computes the average rating.
Args:
tuple[int, list[float]]: a MovieID with its list of ratings
Returns:
tuple[int, float]: returns the the MovieID with its average rating.
"""
return (ratings[0], sum(ratings[1]) / len(ratings[1]))
rdd = ratings_rdd.map(lambda x:(x[0], x[2])).groupByKey() # group by MovieID
rdd = rdd.filter(lambda x:len(x[1])>500) # filter movies with less than 500 reviews
rdd = rdd.map(averageRating) # computes the average Rating
rdd = rdd.sortBy(lambda x:x[1], ascending=False)
rdd.take(5)
```
Ok, now we have the best (according to the average) popular (according to the number of reviews) movies. However, we can only see their MovieID. Let's convert the IDs into titles.
```
rdd.join(movies_rdd)\
.map(lambda x:(x[1][1],x[1][0]))\
.sortBy(lambda x:x[1], ascending=False)\
.take(20)
```
### 2.2 Collaborative Filtering
We are going to use a technique called collaborative filtering. Collaborative filtering is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating). The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B's opinion on a different issue x than to have the opinion on x of a person chosen randomly.
At first, people rate different items (like videos, images, games). After that, the system is making predictions about a user's rating for an item, which the user has not rated yet. These predictions are built upon the existing ratings of other users, who have similar ratings with the active user.
#### 2.2.1 Creating a Training Set
Before we jump into using machine learning, we need to break up the `ratings_rdd` dataset into three pieces:
* a training set (RDD), which we will use to train models,
* a validation set (RDD), which we will use to choose the best model,
* a test set (RDD), which we will use for estimating the predictive power of the recommender system.
To randomly split the dataset into multiple groups, we can use the pyspark [randomSplit] transformation, which takes a list of splits with a seed and returns multiple RDDs.
[randomSplit]:https://spark.apache.org/docs/3.1.1/api/python/reference/api/pyspark.RDD.randomSplit.html?highlight=randomsplit#pyspark.RDD.randomSplit
```
training_rdd, validation_rdd, test_rdd = ratings_rdd.randomSplit([6, 2, 2], seed=14)
print(f"Training: {training_rdd.count()}, validation: {validation_rdd.count()}, test: {test_rdd .count()}")
print("training samples: ", training_rdd .take(3))
print("validation samples: ", validation_rdd.take(3))
print("test samples: ", test_rdd .take(3))
```
#### 2.2.2 Alternating Least Square Errors
For movie recommendations, we start with a matrix whose entries are movie ratings by users. Each column represents a user and each row represents a particular movie.
Since not all users have rated all movies, we do not know all of the entries in this matrix, which is precisely why we need collaborative filtering. For each user, we have ratings for only a subset of the movies. With collaborative filtering, the idea is to approximate the rating matrix by factorizing it as the product of two matrices: one that describes properties of each user, and one that describes properties of each movie.
We want to select these two matrices such that the error for the users/movie pairs where we know the correct ratings is minimized. The *Alternating Least Squares* algorithm does this by first randomly filling the user matrix with values and then optimizing the value of the movies such that the error is minimized. Then, it holds the movies matrix constant and optimizes the value of the user's matrix. This alternation between which matrix to optimize is the reason for the "alternating" in the name.
```
from pyspark.mllib.recommendation import ALS
# thanks to modern libraries training an ALS model is as easy as
model = ALS.train(training_rdd, rank = 4, seed = 14, iterations = 5, lambda_ = 0.1)
# let's have a peek to few predictions
model.predictAll(validation_rdd.map(lambda x:(x[0],x[1]))).take(5)
```
#### 2.2.3 Root Mean Square Error (RMSE)
Next, we need to evaluate our model: is it good or is it bad?
To score the model, we will use RMSE (often called also Root Mean Square Deviation (RMSD)). You can think of RMSE as a distance function that measures the distance between the predictions and the ground truths. It is computed as follows:
$$ RMSE(f, \mathcal{D}) = \sqrt{\frac{\sum_{(x,y) \in \mathcal{D}} (f(x) - y)^2}{|\mathcal{D}|}}$$
Where:
* $\mathcal{D}$ is our dataset it contains samples alongside their predictions. Formally, $\mathcal{D} \subseteq \mathcal{X} \times \mathcal{Y}$. Where:
* $\mathcal{X}$ is the set of all input samples.
* $\mathcal{Y}$ is the set of all possible predictions.
* $f : \mathcal{X} \rightarrow \mathcal{Y}$ is the model we wish to evaluate. Given an input $x$ (from $\mathcal{X}$, the set of possible inputs) it returns a value $f(x)$ (from $\mathcal{Y}$, the set of possible outputs).
* $x$ represents an input.
* $f(x)$ represents the prediction of $x$.
* $y$ represents the ground truth.
As you can imagine $f(x)$ and $y$ can be different, i.e our model is wrong. With $RMSE(f, \mathcal{D})$, we want to measure the degree to which our model, $f$, is wrong on the dataset $\mathcal{D}$. The higher is $RMSE(f, \mathcal{D})$ the higher is the degree to which $f$ is wrong. The smaller is $RMSE(f, \mathcal{D})$ the more accurate $f$ is.
To better understand the RMSE consider the following facts:
* When $f(x)$ is close to $y$ our model is accurate. In the same case $(f(x) - y)^2$ is small.
* When $f(x)$ is far from $y$ our model is inaccurate. In the same case $(f(x) - y)^2$ is high.
* If our model is accurate, it will be often accurate in $\mathcal{D}$. Therefore, it will make often small errors which will amount to a small RMSE.
* If our model is inaccurate, it will be often inaccurate in $\mathcal{D}$. Therefore, it will make often big errors which will amount to a large RMSE.
Let's make a function to compute the RMSE so that we can use it multiple times easily.
```
def RMSE(predictions_rdd, truths_rdd):
""" Compute the root mean squared error between predicted and actual
Args:
predictions_rdd: predicted ratings for each movie and each user where each entry is in the form (UserID, MovieID, Rating).
truths_rdd: actual ratings where each entry is in the form (UserID, MovieID, Rating).
Returns:
RSME (float): computed RSME value
"""
# Transform predictions and truths into the tuples of the form ((UserID, MovieID), Rating)
predictions = predictions_rdd.map(lambda i: ((i[0], i[1]), i[2]))
truths = truths_rdd .map(lambda i: ((i[0], i[1]), i[2]))
# Compute the squared error for each matching entry (i.e., the same (User ID, Movie ID) in each
# RDD) in the reformatted RDDs using RDD transformtions - do not use collect()
squared_errors = predictions.join(truths)\
.map(lambda i: (i[1][0] - i[1][1])**2)
total_squared_error = squared_errors.sum()
total_ratings = squared_errors.count()
mean_squared_error = total_squared_error / total_ratings
root_mean_squared_error = mean_squared_error ** (1/2)
return root_mean_squared_error
# let's evaluate the trained models
RMSE(predictions_rdd = model.predictAll(validation_rdd.map(lambda x:(x[0],x[1]))),
truths_rdd = validation_rdd)
```
#### 2.2.4 HyperParameters Tuning
Can we do better?
When training the ALS model there were few parameters to set. However, we do not know which is the best configuration. On these occasions, we want to try a few combinations to obtain even better results. In this section, we will search a few parameters. We will perform a so-called **grid search**. We will proceed as follows:
1) We decide the parameters to tune.
2) We train with all possible configurations.
3) We evaluate a trained model with all possible configurations on the validation set.
4) We evaluate the best model on the test set.
```
HyperParameters = {
"rank" : [4, 8, 12],
"seed" : [14],
"iterations" : [5, 10],
"lambda" : [0.05, 0.1, 0.25]
}
best_model = None
best_error = float("inf")
best_conf = dict()
# how many training are we doing ?
for rank in HyperParameters["rank"]: #
for seed in HyperParameters["seed"]: # I consider these nested for-loops an anti-pattern.
for iterations in HyperParameters["iterations"]: # However, We can leave as it is for sake of simplicity.
for lambda_ in HyperParameters["lambda"]: #
model = ALS.train(training_rdd, rank = rank, seed = seed, iterations = iterations, lambda_ = lambda_)
validation_error = RMSE(predictions_rdd = model.predictAll(validation_rdd.map(lambda x:(x[0],x[1]))),
truths_rdd = validation_rdd)
if validation_error < best_error:
best_model, best_error = model, validation_error
best_conf = {"rank":rank, "seed":seed, "iterations":iterations, "lambda":lambda_}
print(f"current best validation error {best_error} with configuration {best_conf}")
test_error = RMSE(predictions_rdd = model.predictAll(test_rdd.map(lambda x:(x[0],x[1]))), truths_rdd = test_rdd)
print(f"test error {test_error} with configuration {best_conf}")
```
|
github_jupyter
|
# Regresión con Redes Neuronales
Empleando diferentes *funciones de pérdida* y *funciones de activación* las **redes neuronales** pueden resolver
efectivamente problemas de **regresión.**
En esta libreta se estudia el ejemplo de [California Housing](http://www.spatial-statistics.com/pace_manuscripts/spletters_ms_dir/statistics_prob_lets/html/ms_sp_lets1.html)
donde el propósito es predecir el valor medio de una casa según 8 atributos.
## Descripción general del conjunto de datos
El conjunto de datos `California Housing` está hecho de 9 variables numéricas, donde 8 son las *características* y 1 es la variable objetivo.
Este conjunto de datos fue creado en 1990 basándose en el censo poblacional realizado por el gobierno de EUA. La estructura del conjunto de datos
es simple: cada línea en el archivo de datos cuenta por un **bloque** poblacional que consta de entre 600 y 3000 personas. Por cada *bloque*
se tienen 8 características de cada casa y su costo medio.
Empleando *redes neuronales* se pretende predecir el costo de las casas por bloque.
## Atributos del conjunto de datos
Este conjunto de datos cuenta con 8 *atributos*, descritos a continuación, con la etiqueta como viene en el conjunto de datos de `scikit-learn`:
- **MedInc**, *Ingresos promedio por bloque*
- **HouseAge**, *Antigüedad promedio por casa en el bloque*
- **AveRooms**, *Número promedio de cuartos por casa en el bloque*
- **AveBedrms**, *Número promedio de recámaras por casa en el bloque*
- **Population**, *Población total del bloque*
- **AveOccup**, *Ocupancia promedio por casa en el bloque*
- **Latitude**, *Latitud del bloque*
- **Longitude**, *Longitud del bloque*
Y la *variable respuesta* es:
- **MedValue**, *Costo promedio por casa en el distrito*
```
import tensorflow as tf
from sklearn import datasets, metrics, model_selection, preprocessing
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# Importar el conjunto de datos California Housing
cali_data = datasets.fetch_california_housing()
```
## Visualización de datos
```
# Realizar una visualización general de la relación entre atributos del conjunto de datos
sns.pairplot(pd.DataFrame(cali_data.data, columns=cali_data.feature_names))
plt.show()
```
Con estas figuras se pueden observar algunas características interesantes:
- *Primero*, todas las variables importan en el modelo. Esto significa que el modelo de regresión viene pesado por todas las
características y se requiere que el modelo sea *robusto* ante esta situación.
- *Segundo*, hay algunas características que tienen relación *lineal* entre ellas, como lo es **AveRooms** y **AveBedrms**.
Esto puede ayudar a discriminar ciertas características que no tienen mucho peso sobre el modelo y solamente utilizar
aquellas que influyen mucho más. A esta parte del *procesamiento de datos* se le conoce como **selección de características**
y es una rama específica de la *inteligencia computacional.*
- *Tercero*, la línea diagonal muestra la relación *distribución* de cada una de las características. Esto es algo importante
de estudiar dado que algunas características muestran *distribuciones* conocidas y este hecho se puede utilizar para
emplear técnicas estadísticas más avanzadas en el **análisis de regresión.**
Sin embargo, en toda esta libreta se dejarán las 8 características para que sean pesadas en el modelo final.
```
# Separar todos los datos y estandarizarlos
X = cali_data.data
y = cali_data.target
# Crear el transformador para estandarización
std = preprocessing.StandardScaler()
X = std.fit_transform(X)
X = np.array(X).astype(np.float32)
y = std.fit_transform(y.reshape(-1, 1))
y = np.array(y).astype(np.float32)
```
Dado que los datos vienen en diferentes unidades y escalas, siempre se debe estandarizar los datos de alguna forma. En particular
en esta libreta se emplea la normalización de los datos, haciendo que tengan *media* $\mu = 0$ y *desviación estándar* $\sigma = 1$.
```
# Separar en conjunto de entrenamiento y prueba
x_train, x_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.2, random_state=49
)
# Definir parámetros generales de la Red Neuronal
pasos_entrenamiento = 1000
tam_lote = 30
ratio_aprendizaje = 0.01
```
## Estructura o *topología* de la red neuronal
Para esta regresión se pretende utilizar una *red neuronal* de **dos capas ocultas**, con *funciones de activación* **ReLU**,
la **primera** capa oculta cuenta con 25 neuronas mientras que la **segunda** cuenta con 50.
La **capa de salida** *no* tiene función de activación, por lo que el modelo lineal queda de la siguiente forma
$$ \hat{y}(x) = \sum_{i=1}^{8} \alpha_i \cdot x_i + \beta_i$$
donde $\alpha_i$ son los *pesos* de la *capa de salida*, mientras que $\beta_i$ son los *sesgos*.
```
# Parámetros para la estructura general de la red
# Número de neuronas por capa
n_capa_oculta_1 = 25
n_capa_oculta_2 = 50
n_entrada = X.shape[1]
n_salida = 1
# Definir las entradas de la red neuronal
x_entrada = tf.placeholder(tf.float32, shape=[None, n_entrada])
y_entrada = tf.placeholder(tf.float32, shape=[None, n_salida])
# Diccionario de pesos
pesos = {
"o1": tf.Variable(tf.random_normal([n_entrada, n_capa_oculta_1])),
"o2": tf.Variable(tf.random_normal([n_capa_oculta_1, n_capa_oculta_2])),
"salida": tf.Variable(tf.random_normal([n_capa_oculta_2, n_salida])),
}
# Diccionario de sesgos
sesgos = {
"b1": tf.Variable(tf.random_normal([n_capa_oculta_1])),
"b2": tf.Variable(tf.random_normal([n_capa_oculta_2])),
"salida": tf.Variable(tf.random_normal([n_salida])),
}
def propagacion_adelante(x):
# Capa oculta 1
# Esto es la mismo que Ax + b, un modelo lineal
capa_1 = tf.add(tf.matmul(x, pesos["o1"]), sesgos["b1"])
# ReLU como función de activación
capa_1 = tf.nn.relu(capa_1)
# Capa oculta 1
# Esto es la mismo que Ax + b, un modelo lineal
capa_2 = tf.add(tf.matmul(capa_1, pesos["o2"]), sesgos["b2"])
# ReLU como función de activación
capa_2 = tf.nn.relu(capa_2)
# Capa de salida
# Nuevamente, un modelo lineal
capa_salida = tf.add(tf.matmul(capa_2, pesos["salida"]), sesgos["salida"])
return capa_salida
# Implementar el modelo y sus capas
y_prediccion = propagacion_adelante(x_entrada)
```
## Función de pérdida
Para la función de pérdida se emplea la [función de Huber](https://en.wikipedia.org/wiki/Huber_loss) definida como
\begin{equation}
L_{\delta} \left( y, f(x) \right) =
\begin{cases}
\frac{1}{2} \left( y - f(x) \right)^2 & \text{para} \vert y - f(x) \vert \leq \delta, \\
\delta \vert y - f(x) \vert - \frac{1}{2} \delta^2 & \text{en cualquier otro caso.}
\end{cases}
\end{equation}
Esta función es [robusta](https://en.wikipedia.org/wiki/Robust_regression) lo cual está hecha para erradicar el peso de posibles
valores atípicos y puede encontrar la verdadera relación entre las características sin tener que recurrir a metodologías paramétricas
y no paramétricas.
## Nota
Es importante mencionar que el valor de $\delta$ en la función de Huber es un **hiperparámetro** que debe de ser ajustado mediante *validación cruzada*
pero no es realiza en esta libreta por limitaciones de equipo y rendimiento en la ejecución de esta libreta.
```
# Definir la función de costo
f_costo = tf.reduce_mean(tf.losses.huber_loss(y_entrada, y_prediccion, delta=2.0))
# f_costo = tf.reduce_mean(tf.square(y_entrada - y_prediccion))
optimizador = tf.train.AdamOptimizer(learning_rate=ratio_aprendizaje).minimize(f_costo)
# Primero, inicializar las variables
init = tf.global_variables_initializer()
# Función para evaluar la precisión de clasificación
def precision(prediccion, real):
return tf.sqrt(tf.losses.mean_squared_error(real, prediccion))
```
## Precisión del modelo
Para evaluar la precisión del modelo se emplea la función [RMSE](https://en.wikipedia.org/wiki/Root-mean-square_deviation) (Root Mean Squared Error)
definida por la siguiente función:
$$ RMSE = \sqrt{\frac{\sum_{i=1}^{N} \left( \hat{y}_i - y_i \right)^2}{N}} $$
Para crear un mejor estimado, se empleará validación cruzada de 5 pliegues.
```
# Crear el plegador para el conjunto de datos
kf = model_selection.KFold(n_splits=5)
kf_val_score_train = []
kf_val_score_test = []
# Crear un grafo de computación
with tf.Session() as sess:
# Inicializar las variables
sess.run(init)
for tr_idx, ts_idx in kf.split(x_train):
# Comenzar los pasos de entrenamiento
# solamente con el conjunto de datos de entrenamiento
for p in range(pasos_entrenamiento):
# Minimizar la función de costo
minimizacion = sess.run(
optimizador,
feed_dict={x_entrada: x_train[tr_idx], y_entrada: y_train[tr_idx]},
)
# Cada tamaño de lote, calcular la precisión del modelo
if p % tam_lote == 0:
prec_entrenamiento = sess.run(
precision(y_prediccion, y_entrada),
feed_dict={x_entrada: x_train[tr_idx], y_entrada: y_train[tr_idx]},
)
kf_val_score_train.append(prec_entrenamiento)
prec_prueba = sess.run(
precision(y_prediccion, y_entrada),
feed_dict={x_entrada: x_train[ts_idx], y_entrada: y_train[ts_idx]},
)
kf_val_score_test.append(prec_prueba)
# Prediccion final, una vez entrenado el modelo
pred_final = sess.run(
precision(y_prediccion, y_entrada),
feed_dict={x_entrada: x_test, y_entrada: y_test},
)
pred_report = sess.run(y_prediccion, feed_dict={x_entrada: x_test})
print("Precisión final: {0}".format(pred_final))
print("Precisión RMSE para entrenamiento: {0}".format(np.mean(kf_val_score_train)))
print("Precisión RMSE para entrenamiento: {0}".format(np.mean(kf_val_score_test)))
```
Aquí se muestra el valor de *RMSE* final para cada parte, entrenamiento y prueba. Se puede observar que hay muy poco sobreajuste,
y si se quisiera corregir se puede realizar aumentando el número de neuronas, de capas, cambiando las funciones de activación,
entre muchas otras cosas.
|
github_jupyter
|
```
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data_path = '../results/results.csv'
df = pd.read_csv(data_path, delimiter='\t')
ray = df['Ray_et_al'].to_numpy()
matrixreduce = df['MatrixREDUCE'].to_numpy()
rnacontext = df['RNAcontext'].to_numpy()
deepbind = df['DeepBind'].to_numpy()
dlprb = df['DLPRB'].to_numpy()
rck = df['RCK'].to_numpy()
cdeepbind = df['cDeepbind'].to_numpy()
thermonet = df['ThermoNet'].to_numpy()
residualbind = df['ResidualBind'].to_numpy()
```
# Plot box-violin plot
```
names = ['Ray et al.', 'MatrixREDUCE', 'RNAcontext', 'DeepBind', 'DLPRB', 'RCK', 'cDeepbind', 'ThermoNet', 'ResidualBind']
data = [ray, matrixreduce, rnacontext, deepbind, rck, dlprb, cdeepbind, thermonet, residualbind]
fig = plt.figure(figsize=(12,5))
vplot = plt.violinplot(data,
showextrema=False);
data = [ray, matrixreduce, rnacontext, deepbind, rck, dlprb, cdeepbind, thermonet, residualbind]
import matplotlib.cm as cm
cmap = cm.ScalarMappable(cmap='tab10')
test_mean = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
for patch, color in zip(vplot['bodies'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
medianprops = dict(color="red",linewidth=2)
bplot = plt.boxplot(data,
notch=True, patch_artist=True,
widths=0.2,
medianprops=medianprops);
for patch, color in zip(bplot['boxes'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
#patch.set(color=colors[i])
plt.xticks(range(1,len(names)+1), names, rotation=40, fontsize=14, ha='right');
ax = plt.gca();
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Pearson correlation', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
```
# plot comparison between ResidualBind and ThermoNet
```
fig = plt.figure(figsize=(3,3))
ax = plt.subplot(111)
plt.hist(residualbind-thermonet, bins=20);
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Counts', fontsize=14);
plt.setp(ax.get_xticklabels(),fontsize=14)
plt.xlabel('$\Delta$ Pearson r', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_hist.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
from scipy import stats
stats.wilcoxon(residualbind, thermonet)
```
# Compare performance based on binding score normalization and different input features
```
data_path = '../results/rnacompete_2013/clip_norm_seq_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
clip_norm_seq = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2013/clip_norm_pu_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
clip_norm_pu = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2013/clip_norm_struct_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
clip_norm_struct = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2013/log_norm_seq_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
log_norm_seq = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2013/log_norm_pu_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
log_norm_pu = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2013/log_norm_struct_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
log_norm_struct = df['Pearson score'].to_numpy()
names = ['Clip-norm', 'Log-norm']
data = [clip_norm_seq, log_norm_seq]
fig = plt.figure(figsize=(3,3))
vplot = plt.violinplot(data,
showextrema=False);
import matplotlib.cm as cm
cmap = cm.ScalarMappable(cmap='viridis')
test_mean = [0.1, 0.5, 0.9]
for patch, color in zip(vplot['bodies'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
medianprops = dict(color="red",linewidth=2)
bplot = plt.boxplot(data,
notch=True, patch_artist=True,
widths=0.2,
medianprops=medianprops);
for patch, color in zip(bplot['boxes'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
#patch.set(color=colors[i])
plt.xticks(range(1,len(names)+1), names, rotation=40, fontsize=14, ha='right');
ax = plt.gca();
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Pearson correlation', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_clip_vs_log.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
names = ['Sequence', 'Sequence + PU', 'Sequence + PHIME']
data = [clip_norm_seq, clip_norm_pu, clip_norm_struct]
fig = plt.figure(figsize=(5,5))
vplot = plt.violinplot(data,
showextrema=False);
import matplotlib.cm as cm
cmap = cm.ScalarMappable(cmap='viridis')
test_mean = [0.1, 0.5, 0.9]
for patch, color in zip(vplot['bodies'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
medianprops = dict(color="red",linewidth=2)
bplot = plt.boxplot(data,
notch=True, patch_artist=True,
widths=0.2,
medianprops=medianprops);
for patch, color in zip(bplot['boxes'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
#patch.set(color=colors[i])
plt.xticks(range(1,len(names)+1), names, rotation=40, fontsize=14, ha='right');
ax = plt.gca();
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Pearson correlation', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_clip_structure.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
names = ['Sequence', 'Sequence + PU', 'Sequence + PHIME']
data = [log_norm_seq, log_norm_pu, log_norm_struct]
fig = plt.figure(figsize=(5,3))
vplot = plt.violinplot(data,
showextrema=False);
import matplotlib.cm as cm
cmap = cm.ScalarMappable(cmap='viridis')
test_mean = [0.1, 0.5, 0.9]
for patch, color in zip(vplot['bodies'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
medianprops = dict(color="red",linewidth=2)
bplot = plt.boxplot(data,
notch=True, patch_artist=True,
widths=0.2,
medianprops=medianprops);
for patch, color in zip(bplot['boxes'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
#patch.set(color=colors[i])
plt.xticks(range(1,len(names)+1), names, rotation=40, fontsize=14, ha='right');
ax = plt.gca();
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Pearson correlation', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_log_structure.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
data = [clip_norm_seq, clip_norm_pu, clip_norm_struct, log_norm_seq, log_norm_pu, log_norm_struct]
name = ['clip_norm_seq', 'clip_norm_pu', 'clip_norm_struct', 'log_norm_seq', 'log_norm_pu', 'log_norm_struct']
for n,x in zip(name, data):
print(n, np.mean(x), np.std(x))
```
# compare PHIME vs seq only
```
fig = plt.figure(figsize=(3,3))
ax = plt.subplot(111)
plt.hist(clip_norm_seq-clip_norm_struct, bins=15)
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Counts', fontsize=14);
plt.setp(ax.get_xticklabels(),fontsize=14)
plt.xlabel('$\Delta$ Pearson r', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_hist_seq_vs_struct.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
```
# 2009 RNAcompete analysis
```
data_path = '../results/rnacompete_2009/log_norm_seq_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
log_norm_seq = df['Pearson score'].to_numpy()
data_path = '../results/rnacompete_2009/log_norm_pu_performance.tsv'
df = pd.read_csv(data_path, delimiter='\t')
log_norm_pu = df['Pearson score'].to_numpy()
names = ['Sequence', 'Sequence + PU']
data = [log_norm_seq, log_norm_pu]
fig = plt.figure(figsize=(5,5))
vplot = plt.violinplot(data,
showextrema=False);
import matplotlib.cm as cm
cmap = cm.ScalarMappable(cmap='viridis')
test_mean = [0.1, 0.5, 0.9]
for patch, color in zip(vplot['bodies'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
medianprops = dict(color="red",linewidth=2)
bplot = plt.boxplot(data,
notch=True, patch_artist=True,
widths=0.2,
medianprops=medianprops);
for patch, color in zip(bplot['boxes'], cmap.to_rgba(test_mean)):
patch.set_facecolor(color)
patch.set_edgecolor('black')
#patch.set(color=colors[i])
plt.xticks(range(1,len(names)+1), names, rotation=40, fontsize=14, ha='right');
ax = plt.gca();
plt.setp(ax.get_yticklabels(),fontsize=14)
plt.ylabel('Pearson correlation', fontsize=14);
plot_path = '../results/rnacompete_2013/'
outfile = os.path.join(plot_path, 'Performance_comparison_log_structure_2009.pdf')
fig.savefig(outfile, format='pdf', dpi=200, bbox_inches='tight')
```
# Compare log vs clip as a scatter plot
```
data_path = '../data/RNAcompete_2013/rnacompete2013.h5'
results_path = helper.make_directory('../results', 'rnacompete_2013')
experiment = 'RNCMPT00169'
rbp_index = helper.find_experiment_index(data_path, experiment)
normalization = 'clip_norm' # 'log_norm' or 'clip_norm'
ss_type = 'seq' # 'seq', 'pu', or 'struct'
save_path = helper.make_directory(results_path, normalization+'_'+ss_type)
# load rbp dataset
train, valid, test = helper.load_rnacompete_data(data_path,
ss_type=ss_type,
normalization=normalization,
rbp_index=rbp_index)
# load residualbind model
input_shape = list(train['inputs'].shape)[1:]
weights_path = os.path.join(save_path, experiment + '_weights.hdf5')
model = ResidualBind(input_shape, weights_path)
# load pretrained weights
model.load_weights()
# get predictions for test sequences
predictions_clip = model.predict(test['inputs'])
y = test['targets']
fig = plt.figure(figsize=(3,3))
plt.scatter(predictions_clip, y, alpha=0.5, rasterized=True)
plt.plot([-2,9],[-2,9],'--k')
plt.xlabel('Predicted binding scores', fontsize=14)
plt.ylabel('Experimental binding scores', fontsize=14)
plt.xticks([-2, 0, 2, 4, 6, 8], fontsize=14)
plt.yticks([-2, 0, 2, 4, 6, 8], fontsize=14)
outfile = os.path.join(results_path, experiment+'_scatter_clip.pdf')
fig.savefig(outfile, format='pdf', dpi=600, bbox_inches='tight')
normalization = 'log_norm' # 'log_norm' or 'clip_norm'
ss_type = 'seq' # 'seq', 'pu', or 'struct'
save_path = helper.make_directory(results_path, normalization+'_'+ss_type)
# load rbp dataset
train, valid, test = helper.load_rnacompete_data(data_path,
ss_type=ss_type,
normalization=normalization,
rbp_index=rbp_index)
# load residualbind model
input_shape = list(train['inputs'].shape)[1:]
weights_path = os.path.join(save_path, experiment + '_weights.hdf5')
model = ResidualBind(input_shape, weights_path)
# load pretrained weights
model.load_weights()
# get predictions for test sequences
predictions_log = model.predict(test['inputs'])
y2 = test['targets']
fig = plt.figure(figsize=(3,3))
plt.scatter(predictions_log, y2, alpha=0.5, rasterized=True)
plt.plot([-2,9],[-2,9],'--k')
plt.xlabel('Predicted binding scores', fontsize=14)
plt.ylabel('Experimental binding scores', fontsize=14)
plt.xticks([-2, 0, 2, 4, 6, 8,], fontsize=14)
plt.yticks([-2, 0, 2, 4, 6, 8], fontsize=14)
outfile = os.path.join(results_path, experiment+'_scatter_log.pdf')
fig.savefig(outfile, format='pdf', dpi=600, bbox_inches='tight')
```
|
github_jupyter
|
## Fish classification
In this notebook the fish classification is done. We are going to classify in four classes: Tuna fish (TUNA), LAG, DOL and SHARK. The detector will save the cropped image of a fish. Here we will take this image and we will use a CNN to classify it.
In the original Kaggle competition there are six classes of fish: ALB, BET, YFT, DOL, LAG and SHARK. We started trying to classify them all, but three of them are vey similar: ALB, BET and YFT. In fact, they are all different tuna species, while the other fishes come from different families. Therefore, the classification of those species was difficult and the results were not too good. We will make a small comparison of both on the presentation, but here we will only upload the clsifier with four classes.
```
from PIL import Image
import tensorflow as tf
import numpy as np
import scipy
import os
import cv2
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import log_loss
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import Convolution2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras import backend as K
import matplotlib.pyplot as plt
#Define some values and constants
fish_classes = ['TUNA','DOL','SHARK','LAG']
fish_classes_test = fish_classes
number_classes = len(fish_classes)
main_path_train = '../train_cut_oversample'
main_path_test = '../test'
channels = 3
ROWS_RESIZE = 100
COLS_RESIZE = 100
```
Now we read the data from the file where the fish detection part has stored the images.
We also preprocess slightly the images to convert them to the same size (100x100). The aspect ratio of the images is important, so instead of just resizing the image, we have created the function resize(im). This function takes an image and resizes its longest side to 100, keeping the aspect ratio. In other words, the short side of the image will be smaller than 100 poixels. This image is pasted onto the middle of a white layer that is 100x100. So, our image will have white pixels on two of its sides. This is not optimum, but it is still better than changing the aspect ratio. We have also tried with other colors, but the best results were achieved with white.
```
# Get data and preproccess it
def resize(image):
rows = image.shape[0]
cols = image.shape[1]
dominant = max(rows,cols)
ratio = ROWS_RESIZE/float(dominant)
im_res = scipy.misc.imresize(image,ratio)
rows = im_res.shape[0]
cols = im_res.shape[1]
im_res = Image.fromarray(im_res)
layer = Image.new('RGB',[ROWS_RESIZE,COLS_RESIZE],(255,255,255))
if rows > cols:
layer.paste(im_res,(COLS_RESIZE/2-cols/2,0))
if cols > rows:
layer.paste(im_res,(0,ROWS_RESIZE/2-rows/2))
if rows == cols:
layer.paste(im_res,(0,0))
return np.array(layer)
X_train = []
y_labels = []
for classes in fish_classes:
path_class = os.path.join(main_path_train,classes)
y_class = np.tile(classes,len(os.listdir(path_class)))
y_labels.extend(y_class)
for image in os.listdir(path_class):
path = os.path.join(path_class,image)
im = scipy.misc.imread(path)
im = resize(im)
X_train.append(np.array(im))
X_train = np.array(X_train)
# Convert labels into one hot vectors
y_labels = LabelEncoder().fit_transform(y_labels)
y_train = np_utils.to_categorical(y_labels)
X_test = []
y_test = []
for classes in fish_classes_test:
path_class = os.path.join(main_path_test,classes)
y_class = np.tile(classes,len(os.listdir(path_class)))
y_test.extend(y_class)
for image in os.listdir(path_class):
path = os.path.join(path_class,image)
im = scipy.misc.imread(path)
im = resize(im)
X_test.append(np.array(im))
X_test = np.array(X_test)
# Convert labels into one hot vectors
y_test = LabelEncoder().fit_transform(y_test)
y_test = np_utils.to_categorical(y_test)
X_train = np.reshape(X_train,(X_train.shape[0],ROWS_RESIZE,COLS_RESIZE,channels))
X_test = np.reshape(X_test,(X_test.shape[0],ROWS_RESIZE,COLS_RESIZE,channels))
print('X_train shape: ',X_train.shape)
print('y_train shape: ',y_train.shape)
print('X_test shape: ',X_test.shape)
print('y_test shape: ',y_test.shape)
```
The data is now organized in the following way:
-The training has been done with 23581 images of size 100x100x3 (rgb).
-There are 4 possible classes: LAG, SHARK, DOL and TUNA.
-The test has been done with 400 images of the same size, 100 per class.
We are now ready to build and train the classifier. Th CNN has 7 convolutional layers, 4 pooling layers and three fully connected layers at the end. Dropout has been used in the fully connected layers to avoid overfitting. The loss function used is multi class logloss because is the one used by Kaggle in the competition. The optimizeer is gradient descent.
```
def center_normalize(x):
return (x-K.mean(x))/K.std(x)
# Convolutional net
model = Sequential()
model.add(Activation(activation=center_normalize,input_shape=(ROWS_RESIZE,COLS_RESIZE,channels)))
model.add(Convolution2D(6,20,20,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(MaxPooling2D(pool_size=(2,2),dim_ordering='tf'))
model.add(Convolution2D(12,10,10,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(Convolution2D(12,10,10,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(MaxPooling2D(pool_size=(2,2),dim_ordering='tf'))
model.add(Convolution2D(24,5,5,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(Convolution2D(24,5,5,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(MaxPooling2D(pool_size=(2,2),dim_ordering='tf'))
model.add(Convolution2D(24,5,5,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(Convolution2D(24,5,5,border_mode='same',activation='relu',dim_ordering='tf'))
model.add(MaxPooling2D(pool_size=(2,2),dim_ordering='tf'))
model.add(Flatten())
model.add(Dense(4092,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1024,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(number_classes))
model.add(Activation('softmax'))
print(model.summary())
model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(X_train,y_train,nb_epoch=1,verbose=1)
```
Since there are a lot of images the training takes around one hour. Once it is done we can pass the test set to the classifier and measure its accuracy.
```
(loss,accuracy) = model.evaluate(X_test,y_test,verbose=1)
print('accuracy',accuracy)
```
|
github_jupyter
|
# Uptake of carbon, heat, and oxygen
Plotting a global map of carbon, heat, and oxygen uptake
```
from dask.distributed import Client
client = Client("tcp://10.32.15.112:32829")
client
%matplotlib inline
import xarray as xr
import intake
import numpy as np
from cmip6_preprocessing.preprocessing import read_data
from cmip6_preprocessing.parse_static_metrics import parse_static_thkcello
from cmip6_preprocessing.preprocessing import rename_cmip6
import warnings
import matplotlib.pyplot as plt
# util.py is in the local directory
# it contains code that is common across project notebooks
# or routines that are too extensive and might otherwise clutter
# the notebook design
import util
def _compute_slope(y):
"""
Private function to compute slopes at each grid cell using
polyfit.
"""
x = np.arange(len(y))
return np.polyfit(x, y, 1)[0] # return only the slope
def compute_slope(da):
"""
Computes linear slope (m) at each grid cell.
Args:
da: xarray DataArray to compute slopes for
Returns:
xarray DataArray with slopes computed at each grid cell.
"""
# apply_ufunc can apply a raw numpy function to a grid.
#
# vectorize is only needed for functions that aren't already
# vectorized. You don't need it for polyfit in theory, but it's
# good to use when using things like np.cov.
#
# dask='parallelized' parallelizes this across dask chunks. It requires
# an output_dtypes of the numpy array datatype coming out.
#
# input_core_dims should pass the dimension that is being *reduced* by this operation,
# if one is being reduced.
slopes = xr.apply_ufunc(_compute_slope,
da,
vectorize=True,
dask='parallelized',
input_core_dims=[['time']],
output_dtypes=[float],
)
return slopes
if util.is_ncar_host():
col = intake.open_esm_datastore("../catalogs/glade-cmip6.json")
else:
col = intake.open_esm_datastore("../catalogs/pangeo-cmip6_update_2019_10_18.json")
cat = col.search(experiment_id=['historical'], table_id='Omon', variable_id=['dissic'], grid_label='gr')
import pprint
uni_dict = col.unique(['source_id', 'experiment_id', 'table_id'])
#pprint.pprint(uni_dict, compact=True)
models = set(uni_dict['source_id']['values']) # all the models
for experiment_id in ['historical']:
query = dict(experiment_id=experiment_id, table_id=['Omon','Ofx'],
variable_id=['dissic'], grid_label=['gn','gr'])
cat = col.search(**query)
models = models.intersection({model for model in cat.df.source_id.unique().tolist()})
# for oxygen, ensure the CESM2 models are not included (oxygen was erroneously submitted to the archive)
# UKESM has an issue with the attributes
models = models - {'UKESM1-0-LL','GISS-E2-1-G-CC','GISS-E2-1-G','MCM-UA-1-0'}
models = list(models)
models
# read all data with thickness and DIC for DIC storage
with warnings.catch_warnings(): # these lines just make sure that the warnings dont clutter your notebook
warnings.simplefilter("ignore")
data_dict_thk = read_data(col,
experiment_id=['historical'],
grid_label='gn',
variable_id=['thkcello','dissic'],
table_id = ['Omon'],
source_id = models,
#member_id = 'r1i1p1f1', # so that this runs faster for testing
required_variable_id = ['thkcello','dissic']
)
#data_dict_thk['IPSL-CM6A-LR'] = data_dict_thk['IPSL-CM6A-LR'].rename({'olevel':'lev'})
# read all data with volume and oxygen
with warnings.catch_warnings(): # these lines just make sure that the warnings dont clutter your notebook
warnings.simplefilter("ignore")
data_dict_dic = read_data(col,
experiment_id=['historical'],
grid_label='gn',
variable_id=['dissic'],
table_id = ['Omon'],
source_id = models,
#member_id = 'r1i1p1f1', # so that this runs faster for testing
required_variable_id = ['dissic']
)
data_dict_dic['IPSL-CM6A-LR'] = data_dict_dic['IPSL-CM6A-LR'].rename({'olevel_bounds':'lev_bounds'})
#data_dict_dic['IPSL-CM6A-LR'] = data_dict_dic['IPSL-CM6A-LR'].rename({'olevel_bounds':'lev_bounds'})
data_dict_dic['MIROC-ES2L'] = data_dict_dic['MIROC-ES2L'].rename({'zlev_bnds':'lev_bounds'})
data_dict_dic_thk = {k: parse_static_thkcello(ds) for k, ds in data_dict_dic.items()}
```
### Loading data
`intake-esm` enables loading data directly into an [xarray.Dataset](http://xarray.pydata.org/en/stable/api.html#dataset).
Note that data on the cloud are in
[zarr](https://zarr.readthedocs.io/en/stable/) format and data on
[glade](https://www2.cisl.ucar.edu/resources/storage-and-file-systems/glade-file-spaces) are stored as
[netCDF](https://www.unidata.ucar.edu/software/netcdf/) files. This is opaque to the user.
`intake-esm` has rules for aggegating datasets; these rules are defined in the collection-specification file.
```
#cat = col.search(experiment_id=['historical'], table_id='Omon',
# variable_id=['dissic'], grid_label='gn', source_id=models)
#dset_dict_dic_gn = cat.to_dataset_dict(zarr_kwargs={'consolidated': True, 'decode_times': False},
# cdf_kwargs={'chunks': {'time' : 20}, 'decode_times': False})
```
### Plotting DIC storage
```
data_dict_dic.keys()
fig, ax = plt.subplots(ncols=3, nrows=2,figsize=[15, 10])
A = 0
for model_key in data_dict_dic.keys():
dsC = data_dict_dic[model_key]
ds = dsC['dissic'].isel(lev = 0).chunk({'time': -1, 'x': 110, 'y': 110, 'member_id': 10})
#dz = dsC['thkcello'].isel(member_id=0)
#DICstore_slope = (ds.isel(time=-np.arange(10*12)).mean('time')*dz-ds.isel(time=np.arange(10*12)).mean('time')*dz).sum('lev')
slope = compute_slope(ds)
slope = slope.compute()
slope = slope.mean('member_id')*12 # in mol/m^3/year
A1 = int(np.floor(A/3))
A2 = np.mod(A,3)
slope.plot(ax = ax[A1][A2],vmax = 0.001)
ax[A1][A2].title.set_text(model_key)
A += 1
fig.tight_layout()
fig.savefig('rate_of_change_DIC_surface_historical.png')
fig, ax = plt.subplots(ncols=3, nrows=2,figsize=[15, 10])
A = 0
for model_key in data_dict_thk.keys():
dsC = data_dict_thk[model_key]
ds = dsC['dissic']
dz = dsC['thkcello']
DICstore = (ds*dz).sum('lev').chunk({'time': -1, 'x': 110, 'y': 110, 'member_id': 10})
slope = compute_slope(DICstore)
slope = slope.compute()
slope = slope.mean('member_id')*12 # in mol/m^3/year
A1 = int(np.floor(A/3))
A2 = np.mod(A,3)
slope.plot(ax = ax[A1][A2],vmax = 0.8)
ax[A1][A2].title.set_text(model_key)
A += 1
fig.tight_layout()
fig.savefig('rate_of_change_DIC_content_historical.png')
```
# Load heat content
```
cat = col.search(experiment_id=['historical'], table_id='Omon', variable_id=['thetao','thkcello'], grid_label='gn')
import pprint
uni_dict = col.unique(['source_id', 'experiment_id', 'table_id'])
#pprint.pprint(uni_dict, compact=True)
models = set(uni_dict['source_id']['values']) # all the models
for experiment_id in ['historical']:
query = dict(experiment_id=experiment_id, table_id=['Omon','Ofx'],
variable_id=['thetao','thkcello'], grid_label='gn')
cat = col.search(**query)
models = models.intersection({model for model in cat.df.source_id.unique().tolist()})
# for oxygen, ensure the CESM2 models are not included (oxygen was erroneously submitted to the archive)
# UKESM has an issue with the attributes
models = models - {'HadGEM3-GC31-LL','UKESM1-0-LL'}
#{'UKESM1-0-LL','GISS-E2-1-G-CC','GISS-E2-1-G','MCM-UA-1-0'}
models = list(models)
models
# read all data with thickness and DIC for DIC storage
with warnings.catch_warnings(): # these lines just make sure that the warnings dont clutter your notebook
warnings.simplefilter("ignore")
data_dict_heat_thk = read_data(col,
experiment_id=['historical'],
grid_label='gn',
variable_id=['thkcello','thetao'],
table_id = ['Omon'],
source_id = models,
#member_id = 'r1i1p1f1', # so that this runs faster for testing
required_variable_id = ['thkcello','thetao']
)
#data_dict_heat_thk['IPSL-CM6A-LR'] = data_dict_heat_thk['IPSL-CM6A-LR'].rename({'olevel':'lev'})
```
# Plot heat content
```
data_dict_heat_thk.keys()
fig, ax = plt.subplots(ncols=3, nrows=2,figsize=[15, 10])
A = 0
for model_key in data_dict_heat_thk.keys():
dsC = data_dict_heat_thk[model_key]
ds = (dsC['thetao']+273.15)*4.15*1e6/1025 # heat content (assume constant density and heat capacity)
dz = dsC['thkcello'].isel(member_id=0)
DICstore = (ds*dz).sum('lev').chunk({'time': -1, 'x': 110, 'y': 110, 'member_id': 10})
slope = compute_slope(DICstore)
slope = slope.compute()
slope = slope.mean('member_id')*12 # in mol/m^3/year
A1 = int(np.floor(A/3))
A2 = np.mod(A,3)
slope.plot(ax = ax[A1][A2],vmax = 80000)
ax[A1][A2].title.set_text(model_key)
A += 1
fig.tight_layout()
fig.savefig('rate_of_change_heat_content_historical.png')
```
# Load oxygen content
```
cat = col.search(experiment_id=['piControl'], table_id='Omon', variable_id=['o2','thkcello'], grid_label='gn')
import pprint
uni_dict = col.unique(['source_id', 'experiment_id', 'table_id'])
#pprint.pprint(uni_dict, compact=True)
models = set(uni_dict['source_id']['values']) # all the models
for experiment_id in ['historical']:
query = dict(experiment_id=experiment_id, table_id=['Omon','Ofx'],
variable_id=['o2','thkcello'], grid_label='gn')
cat = col.search(**query)
models = models.intersection({model for model in cat.df.source_id.unique().tolist()})
# for oxygen, ensure the CESM2 models are not included (oxygen was erroneously submitted to the archive)
# UKESM has an issue with the attributes
models = models - {'UKESM1-0-LL'}
#{'UKESM1-0-LL','GISS-E2-1-G-CC','GISS-E2-1-G','MCM-UA-1-0'}
models = list(models)
models
# read all data with thickness and o2 for o2 content
with warnings.catch_warnings(): # these lines just make sure that the warnings dont clutter your notebook
warnings.simplefilter("ignore")
data_dict_o2_thk = read_data(col,
experiment_id=['historical'],
grid_label='gn',
variable_id=['thkcello','o2'],
table_id = ['Omon'],
source_id = models,
#member_id = 'r1i1p1f1', # so that this runs faster for testing
required_variable_id = ['thkcello','o2']
)
#data_dict_o2_thk['IPSL-CM6A-LR'] = data_dict_o2_thk['IPSL-CM6A-LR'].rename({'olevel':'lev'})
```
# Plot O2 content
```
data_dict_o2_thk.keys()
fig, ax = plt.subplots(ncols=2, nrows=1,figsize=[10, 5])
A = 0
for model_key in data_dict_o2_thk.keys():
dsC = data_dict_o2_thk[model_key]
ds = dsC['o2']
dz = dsC['thkcello'].isel(member_id=0)
DICstore = (ds*dz).sum('lev').chunk({'time': -1, 'x': 110, 'y': 110, 'member_id': 10})
slope = compute_slope(DICstore)
slope = slope.compute()
slope = slope.mean('member_id')*12 # in mol/m^3/year
slope.plot(ax = ax[A],vmax = 0.8)
ax[A].title.set_text(model_key)
A += 1
fig.tight_layout()
fig.savefig('rate_of_change_o2_content_historical.png')
```
|
github_jupyter
|
### Halo check
Plot halos to see if halofinders work well
```
#import os
#base = os.path.abspath('/home/hoseung/Work/data/05427/')
#base = base + '/'
# basic parameters
# Directory, file names, snapshots, scale, npix
base = '/home/hoseung/Work/data/05427/'
cluster_name = base.split('/')[-2]
frefine= 'refine_params.txt'
fnml = input("type namelist file name (enter = cosmo_200.nml):")
if fnml =="":
fnml = 'cosmo_200.nml'
nout_ini=int(input("Starting nout?"))
nout_fi=int(input("ending nout?"))
nouts = range(nout_ini,nout_fi+1)
scale = input("Scale?: ")
if scale=="":
scale = 0.3
scale = float(scale)
npix = input("npix (enter = 400)")
if npix == "":
npix = 400
npix = int(npix)
# data loading parameters
ptype=["star pos mass"]
refine_params = True
dmo=False
draw=True
draw_halos=True
draw_part = True
draw_hydro = False
if draw_hydro:
lmax=input("maximum level")
if lmax=="":
lmax=19
lmax = int(lmax)
import load
import utils.sampling as smp
import utils.match as mtc
import draw
import pickle
for nout in nouts:
snout = str(nout).zfill(3)
if refine_params:
# instead of calculating zoomin region, just load it from the refine_params.txt file.
# region = s.part.search_zoomin(scale=0.5, load=True)
rr = load.info.RefineParam()
rr.loadRegion(base + frefine)
nn = load.info.Nml(fname=base + fnml)
aexp = nn.aout[nout-1]
i_aexp = mtc.closest(aexp, rr.aexp)
x_refine = rr.x_refine[i_aexp]
y_refine = rr.y_refine[i_aexp]
z_refine = rr.z_refine[i_aexp]
r_refine = rr.r_refine[i_aexp] * 0.5
region = smp.set_region(xc = x_refine, yc = y_refine, zc = z_refine,
radius = r_refine * scale)
else:
region = smp.set_region(xc=0.5, yc=0.5, zc=0.5, radius=0.1)
s = load.sim.Sim(nout, base, dmo=dmo, ranges=region["ranges"], setup=True)
imgs = draw.img_obj.MapSet(info=s.info, region=region)
imgp = draw.img_obj.MapImg(info=s.info, proj='z', npix=npix, ptype=ptype)
imgp.set_region(region)
#%%
if draw_part:
s.add_part(ptype)
s.part.load()
part = getattr(s.part, s.part.pt[0])
x = part['x']
y = part['y']
z = part['y']
m = part['m'] * s.info.msun # part must be normalized already!
#imgp.set_data(draw.pp.den2d(x, y, z, m, npix, s.info, cic=True, norm_integer=True))
imgp.set_data(draw.pp.den2d(x, y, z, m, npix, region, cic=True, norm_integer=True))
imgs.ptden2d = imgp
# imgp.show_data()
#%%
if draw_hydro:
s.add_hydro()
s.hydro.amr2cell(lmax=lmax)
field = draw.pp.pp_cell(s.hydro.cell, npix, s.info, verbose=True)
ptype = 'gas_den'
imgh = draw.img_obj.MapImg(info=s.info, proj='z', npix=npix, ptype=ptype)
imgh.set_data(field)
imgh.set_region(region)
# imgh.show_data()
imgs.hydro = imgh
#%%
fdump = base + snout + 'map.pickle'
with open(fdump, 'wb') as f:
pickle.dump(imgs, f)
if draw:
if draw_part:
imgs.ptden2d.plot_2d_den(save= base + cluster_name + snout +'star.png', dpi=400, show=False)
if draw_hydro:
imgs.hydro.plot_2d_den(save= base + cluster_name +snout + 'hydro.png',vmax=15,vmin=10, show=False,
dpi=400)
import matplotlib.pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(111)
snout = str(nout).zfill(3)
fin = base + snout + 'map.pickle'
with open(fin, 'rb') as f:
img = pickle.load(f)
ptimg = img.ptden2d
fout = base + snout + "dmmap_" + ptimg.proj + ".png"
img.ptden2d.plot_2d_den(save=False, show=False, vmin=1e13, vmax=1e20, dpi=400, axes=ax1)
import tree
import numpy as np
#s = load.sim.Sim(nout, base_dir)
info = load.info.Info(nout=nout, base=base, load=True)
hall = tree.halomodule.Halo(nout=nout, base=base, halofinder="HM", info=info, load=True)
i_center = np.where(hall.data['np'] == max(hall.data['np']))
h = tree.halomodule.Halo()
h.derive_from(hall, [i_center])
#region = smp.set_region(xc=h.data.x, yc=h.data.y, zc=h.data.z, radius = h.data.rvir * 2)
#%%
from draw import pp
ind = np.where(hall.data.mvir > 5e10)
h_sub = tree.halomodule.Halo()
h_sub.derive_from(hall, ind)
#x = hall.data.x#[ind]
#y = hall.data.y#[ind]
#r = hall.data.rvir#[ind]
#pp.circle_scatter(ax1, x*npix, y*npix, r*30, facecolor='none', edgecolor='b', label='555')
#ax1.set_xlim(right=npix).
#ax1.set_ylim(top=npix)
pp.pp_halo(h_sub, npix, region=img.ptden2d.region, axes=ax1, rscale=3, name=True)
plt.show()
```
##### Load halofinder result
##### get position and virial radius
##### load particles data (star or DM) and draw density map
##### plot halos on top of particle density map
|
github_jupyter
|
# WGAN with MNIST (or Fashion MNIST)
* `Wasserstein GAN`, [arXiv:1701.07875](https://arxiv.org/abs/1701.07875)
* Martin Arjovsky, Soumith Chintala, and L ́eon Bottou
* This code is available to tensorflow version 2.0
* Implemented by [`tf.keras.layers`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/layers) [`tf.losses`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/losses)
* Use `transposed_conv2d` and `conv2d` for Generator and Discriminator, respectively.
* I do not use `dense` layer for model architecture consistency. (So my architecture is different from original dcgan structure)
* based on DCGAN model
## Import modules
```
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import os
import sys
import time
import glob
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import PIL
import imageio
from IPython import display
import tensorflow as tf
from tensorflow.keras import layers
sys.path.append(os.path.dirname(os.path.abspath('.')))
from utils.image_utils import *
from utils.ops import *
os.environ["CUDA_VISIBLE_DEVICES"]="0"
```
## Setting hyperparameters
```
# Training Flags (hyperparameter configuration)
model_name = 'wgan'
train_dir = os.path.join('train', model_name, 'exp1')
dataset_name = 'mnist'
assert dataset_name in ['mnist', 'fashion_mnist']
max_epochs = 100
save_model_epochs = 10
print_steps = 200
save_images_epochs = 1
batch_size = 64
learning_rate_D = 5e-5
learning_rate_G = 5e-5
k = 5 # the number of step of learning D before learning G (Not used in this code)
num_examples_to_generate = 25
noise_dim = 100
clip_value = 0.01 # cliping value for D weights in order to implement `1-Lipshitz function`
```
## Load the MNIST dataset
```
# Load training and eval data from tf.keras
if dataset_name == 'mnist':
(train_images, train_labels), _ = \
tf.keras.datasets.mnist.load_data()
else:
(train_images, train_labels), _ = \
tf.keras.datasets.fashion_mnist.load_data()
train_images = train_images.reshape(-1, MNIST_SIZE, MNIST_SIZE, 1).astype('float32')
#train_images = train_images / 255. # Normalize the images to [0, 1]
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
```
## Set up dataset with `tf.data`
### create input pipeline with `tf.data.Dataset`
```
#tf.random.set_seed(219)
# for train
N = len(train_images)
train_dataset = tf.data.Dataset.from_tensor_slices(train_images)
train_dataset = train_dataset.shuffle(buffer_size=N)
train_dataset = train_dataset.batch(batch_size=batch_size, drop_remainder=True)
print(train_dataset)
```
## Create the generator and discriminator models
```
class Generator(tf.keras.Model):
"""Build a generator that maps latent space to real space.
G(z): z -> x
"""
def __init__(self):
super(Generator, self).__init__()
self.conv1 = ConvTranspose(256, 3, padding='valid')
self.conv2 = ConvTranspose(128, 3, padding='valid')
self.conv3 = ConvTranspose(64, 4)
self.conv4 = ConvTranspose(1, 4, apply_batchnorm=False, activation='tanh')
def call(self, inputs, training=True):
"""Run the model."""
# inputs: [1, 1, 100]
conv1 = self.conv1(inputs, training=training) # conv1: [3, 3, 256]
conv2 = self.conv2(conv1, training=training) # conv2: [7, 7, 128]
conv3 = self.conv3(conv2, training=training) # conv3: [14, 14, 64]
generated_images = self.conv4(conv3, training=training) # generated_images: [28, 28, 1]
return generated_images
class Discriminator(tf.keras.Model):
"""Build a discriminator that discriminate real image x whether real or fake.
D(x): x -> [0, 1]
"""
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = Conv(64, 4, 2, apply_batchnorm=False, activation='leaky_relu')
self.conv2 = Conv(128, 4, 2, activation='leaky_relu')
self.conv3 = Conv(256, 3, 2, padding='valid', activation='leaky_relu')
self.conv4 = Conv(1, 3, 1, padding='valid', apply_batchnorm=False, activation='none')
def call(self, inputs, training=True):
"""Run the model."""
# inputs: [28, 28, 1]
conv1 = self.conv1(inputs) # conv1: [14, 14, 64]
conv2 = self.conv2(conv1) # conv2: [7, 7, 128]
conv3 = self.conv3(conv2) # conv3: [3, 3, 256]
conv4 = self.conv4(conv3) # conv4: [1, 1, 1]
discriminator_logits = tf.squeeze(conv4, axis=[1, 2]) # discriminator_logits: [1,]
return discriminator_logits
generator = Generator()
discriminator = Discriminator()
```
### Plot generated image via generator network
```
noise = tf.random.normal([1, 1, 1, noise_dim])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
```
### Test discriminator network
* **CAUTION**: the outputs of discriminator is **logits** (unnormalized probability) NOT probabilites
```
decision = discriminator(generated_image)
print(decision)
```
## Define the loss functions and the optimizer
```
# use logits for consistency with previous code I made
# `tf.losses` and `tf.keras.losses` are the same API (alias)
bce = tf.losses.BinaryCrossentropy(from_logits=True)
mse = tf.losses.MeanSquaredError()
def WGANLoss(logits, is_real=True):
"""Computes Wasserstain GAN loss
Args:
logits (`2-rank Tensor`): logits
is_real (`bool`): boolean, Treu means `-` sign, False means `+` sign.
Returns:
loss (`0-rank Tensor`): the WGAN loss value.
"""
loss = tf.reduce_mean(logits)
if is_real:
loss = -loss
return loss
def GANLoss(logits, is_real=True, use_lsgan=True):
"""Computes standard GAN or LSGAN loss between `logits` and `labels`.
Args:
logits (`2-rank Tensor`): logits.
is_real (`bool`): True means `1` labeling, False means `0` labeling.
use_lsgan (`bool`): True means LSGAN loss, False means standard GAN loss.
Returns:
loss (`0-rank Tensor`): the standard GAN or LSGAN loss value. (binary_cross_entropy or mean_squared_error)
"""
if is_real:
labels = tf.ones_like(logits)
else:
labels = tf.zeros_like(logits)
if use_lsgan:
loss = mse(labels, tf.nn.sigmoid(logits))
else:
loss = bce(labels, logits)
return loss
def discriminator_loss(real_logits, fake_logits):
# losses of real with label "1"
real_loss = WGANLoss(logits=real_logits, is_real=True)
# losses of fake with label "0"
fake_loss = WGANLoss(logits=fake_logits, is_real=False)
return real_loss + fake_loss
def generator_loss(fake_logits):
# losses of Generator with label "1" that used to fool the Discriminator
return WGANLoss(logits=fake_logits, is_real=True)
discriminator_optimizer = tf.keras.optimizers.RMSprop(learning_rate_D)
generator_optimizer = tf.keras.optimizers.RMSprop(learning_rate_G)
```
## Checkpoints (Object-based saving)
```
checkpoint_dir = train_dir
if not tf.io.gfile.exists(checkpoint_dir):
tf.io.gfile.makedirs(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
```
## Training
```
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement of the gan.
# To visualize progress in the animated GIF
const_random_vector_for_saving = tf.random.uniform([num_examples_to_generate, 1, 1, noise_dim],
minval=-1.0, maxval=1.0)
```
### Define training one step function
```
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def discriminator_train_step(images):
# generating noise from a uniform distribution
noise = tf.random.uniform([batch_size, 1, 1, noise_dim], minval=-1.0, maxval=1.0)
with tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_logits = discriminator(images, training=True)
fake_logits = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_logits)
disc_loss = discriminator_loss(real_logits, fake_logits)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# clip the weights for discriminator to implement 1-Lipshitz function
for var in discriminator.trainable_variables:
var.assign(tf.clip_by_value(var, -clip_value, clip_value))
return gen_loss, disc_loss
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def generator_train_step():
# generating noise from a uniform distribution
noise = tf.random.uniform([batch_size, 1, 1, noise_dim], minval=-1.0, maxval=1.0)
with tf.GradientTape() as gen_tape:
generated_images = generator(noise, training=True)
fake_logits = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_logits)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
```
### Train full steps
```
print('Start Training.')
num_batches_per_epoch = int(N / batch_size)
global_step = tf.Variable(0, trainable=False)
num_learning_critic = 0
for epoch in range(max_epochs):
for step, images in enumerate(train_dataset):
start_time = time.time()
if num_learning_critic < k:
gen_loss, disc_loss = discriminator_train_step(images)
num_learning_critic += 1
global_step.assign_add(1)
else:
generator_train_step()
num_learning_critic = 0
if global_step.numpy() % print_steps == 0:
epochs = epoch + step / float(num_batches_per_epoch)
duration = time.time() - start_time
examples_per_sec = batch_size / float(duration)
display.clear_output(wait=True)
print("Epochs: {:.2f} global_step: {} Wasserstein distance: {:.3g} loss_G: {:.3g} ({:.2f} examples/sec; {:.3f} sec/batch)".format(
epochs, global_step.numpy(), -disc_loss, gen_loss, examples_per_sec, duration))
random_vector_for_sampling = tf.random.uniform([num_examples_to_generate, 1, 1, noise_dim],
minval=-1.0, maxval=1.0)
sample_images = generator(random_vector_for_sampling, training=False)
print_or_save_sample_images(sample_images.numpy(), num_examples_to_generate)
if (epoch + 1) % save_images_epochs == 0:
display.clear_output(wait=True)
print("This images are saved at {} epoch".format(epoch+1))
sample_images = generator(const_random_vector_for_saving, training=False)
print_or_save_sample_images(sample_images.numpy(), num_examples_to_generate,
is_square=True, is_save=True, epoch=epoch+1,
checkpoint_dir=checkpoint_dir)
# saving (checkpoint) the model every save_epochs
if (epoch + 1) % save_model_epochs == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print('Training Done.')
# generating after the final epoch
display.clear_output(wait=True)
sample_images = generator(const_random_vector_for_saving, training=False)
print_or_save_sample_images(sample_images.numpy(), num_examples_to_generate,
is_square=True, is_save=True, epoch=epoch+1,
checkpoint_dir=checkpoint_dir)
```
## Restore the latest checkpoint
```
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
```
## Display an image using the epoch number
```
display_image(max_epochs, checkpoint_dir=checkpoint_dir)
```
## Generate a GIF of all the saved images.
```
filename = model_name + '_' + dataset_name + '.gif'
generate_gif(filename, checkpoint_dir)
display.Image(filename=filename + '.png')
```
|
github_jupyter
|
```
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import TensorBoard
from keras.layers import *
import numpy
from sklearn.model_selection import train_test_split
#ignoring the first row (header)
# and the first column (unique experiment id, which I'm not using here)
dataset = numpy.loadtxt("/results/shadow_robot_dataset.csv", skiprows=1, usecols=range(1,30), delimiter=",")
```
# Loading the data
Each row of my dataset contains the following:
|0 | 1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24|25|26|27|28|29|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
| experiment_number | robustness| H1_F1J2_pos | H1_F1J2_vel | H1_F1J2_effort | H1_F1J3_pos | H1_F1J3_vel | H1_F1J3_effort | H1_F1J1_pos | H1_F1J1_vel | H1_F1J1_effort | H1_F3J1_pos | H1_F3J1_vel | H1_F3J1_effort | H1_F3J2_pos | H1_F3J2_vel | H1_F3J2_effort | H1_F3J3_pos | H1_F3J3_vel | H1_F3J3_effort | H1_F2J1_pos | H1_F2J1_vel | H1_F2J1_effort | H1_F2J3_pos | H1_F2J3_vel | H1_F2J3_effort | H1_F2J2_pos | H1_F2J2_vel | H1_F2J2_effort | measurement_number|
My input vector contains the velocity and effort for each joint. I'm creating the vector `X` containing those below:
```
# Getting the header
header = ""
with open('/results/shadow_robot_dataset.csv', 'r') as f:
header = f.readline()
header = header.strip("\n").split(',')
header = [i.strip(" ") for i in header]
# only use velocity and effort, not position
saved_cols = []
for index,col in enumerate(header[1:]):
if ("vel" in col) or ("eff" in col):
saved_cols.append(index)
new_X = []
for x in dataset:
new_X.append([x[i] for i in saved_cols])
X = numpy.array(new_X)
```
My output vector is the predicted grasp robustness.
```
Y = dataset[:,0]
```
We are also splitting the dataset into a training set and a test set.
This gives us 4 sets:
* `X_train` associated to its `Y_train`
* `X_test` associated to its `Y_test`
We also discretize the output: 1 is a stable grasp and 0 is unstable. A grasp is considered stable if the robustness value is more than 100.
```
# fix random seed for reproducibility
# and splitting the dataset
seed = 7
numpy.random.seed(seed)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20, random_state=seed)
# this is a sensible grasp threshold for stability
GOOD_GRASP_THRESHOLD = 50
# we're also storing the best and worst grasps of the test set to do some sanity checks on them
itemindex = numpy.where(Y_test>1.05*GOOD_GRASP_THRESHOLD)
best_grasps = X_test[itemindex[0]]
itemindex = numpy.where(Y_test<=0.95*GOOD_GRASP_THRESHOLD)
bad_grasps = X_test[itemindex[0]]
# discretizing the grasp quality for stable or unstable grasps
Y_train = numpy.array([int(i>GOOD_GRASP_THRESHOLD) for i in Y_train])
Y_train = numpy.reshape(Y_train, (Y_train.shape[0],))
Y_test = numpy.array([int(i>GOOD_GRASP_THRESHOLD) for i in Y_test])
Y_test = numpy.reshape(Y_test, (Y_test.shape[0],))
```
# Creating the model
I'm now creating a model to train. It's a very simple topology. Feel free to play with it and experiment with different model shapes.
```
# create model
model = Sequential()
model.add(Dense(20*len(X[0]), use_bias=True, input_dim=len(X[0]), activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
```
# Training the model
The model training should be relatively quick. To speed it up you can use a GPU :)
I'm using 80% of the data for training and 20% for validation.
```
model.fit(X_train, Y_train, validation_split=0.20, epochs=50,
batch_size=500000)
```
Now that the model is trained I'm saving it to be able to load it easily later on.
```
import h5py
model.save("./model.h5")
```
# Evaluating the model
First let's see how this model performs on the test set - which hasn't been used during the training phase.
```
scores = model.evaluate(X_test, Y_test)
print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
```
Now let's take a quick look at the good grasps we stored earlier. Are they correctly predicted as stable?
```
predictions = model.predict(best_grasps)
%matplotlib inline
import matplotlib.pyplot as plt
plt.hist(predictions,
color='#77D651',
alpha=0.5,
label='Good Grasps',
bins=np.arange(0.0, 1.0, 0.03))
plt.title('Histogram of grasp prediction')
plt.ylabel('Number of grasps')
plt.xlabel('Grasp quality prediction')
plt.legend(loc='upper right')
plt.show()
```
Most of the grasps are correctly predicted as stable (the grasp quality prediction is more than 0.5)! Looking good.
What about the unstable grasps?
```
predictions_bad_grasp = model.predict(bad_grasps)
# Plot a histogram of defender size
plt.hist(predictions_bad_grasp,
color='#D66751',
alpha=0.3,
label='Bad Grasps',
bins=np.arange(0.0, 1.0, 0.03))
plt.title('Histogram of grasp prediction')
plt.ylabel('Number of grasps')
plt.xlabel('Grasp quality prediction')
plt.legend(loc='upper right')
plt.show()
```
Most of the grasps are considered unstable - below 0.5 - with a few bad classification.
|
github_jupyter
|
<table class="ee-notebook-buttons" align="left">
<td><a target="_blank" href="https://github.com/giswqs/earthengine-py-notebooks/tree/master/Image/canny_edge_detector.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_blank" href="https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/Image/canny_edge_detector.ipynb"><img width=26px src="https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png" />Notebook Viewer</a></td>
<td><a target="_blank" href="https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/Image/canny_edge_detector.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" /> Run in Google Colab</a></td>
</table>
## Install Earth Engine API and geemap
Install the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://geemap.org). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.
The following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.
```
# Installs geemap package
import subprocess
try:
import geemap
except ImportError:
print('Installing geemap ...')
subprocess.check_call(["python", '-m', 'pip', 'install', 'geemap'])
import ee
import geemap
```
## Create an interactive map
The default basemap is `Google Maps`. [Additional basemaps](https://github.com/giswqs/geemap/blob/master/geemap/basemaps.py) can be added using the `Map.add_basemap()` function.
```
Map = geemap.Map(center=[40,-100], zoom=4)
Map
```
## Add Earth Engine Python script
```
# Add Earth Engine dataset
# Canny Edge Detector example.
# Load an image and compute NDVI from it.
image = ee.Image('LANDSAT/LT05/C01/T1_TOA/LT05_031034_20110619')
ndvi = image.normalizedDifference(['B4','B3'])
# Detect edges in the composite.
canny = ee.Algorithms.CannyEdgeDetector(ndvi, 0.7)
# Mask the image with itself to get rid of areas with no edges.
canny = canny.updateMask(canny)
Map.setCenter(-101.05259, 37.93418, 13)
Map.addLayer(ndvi, {'min': 0, 'max': 1}, 'Landsat NDVI')
Map.addLayer(canny, {'min': 0, 'max': 1, 'palette': 'FF0000'}, 'Canny Edges')
```
## Display Earth Engine data layers
```
Map.addLayerControl() # This line is not needed for ipyleaflet-based Map.
Map
```
|
github_jupyter
|
# Gaussian Mixture Model
```
!pip install tqdm torchvision tensorboardX
from __future__ import print_function
import torch
import torch.utils.data
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
seed = 0
torch.manual_seed(seed)
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
```
### toy dataset
```
# https://angusturner.github.io/generative_models/2017/11/03/pytorch-gaussian-mixture-model.html
def sample(mu, var, nb_samples=500):
"""
Return a tensor of (nb_samples, features), sampled
from the parameterized gaussian.
:param mu: torch.Tensor of the means
:param var: torch.Tensor of variances (NOTE: zero covars.)
"""
out = []
for i in range(nb_samples):
out += [
torch.normal(mu, var.sqrt())
]
return torch.stack(out, dim=0)
# generate some clusters
cluster1 = sample(
torch.Tensor([1.5, 2.5]),
torch.Tensor([1.2, .8]),
nb_samples=150
)
cluster2 = sample(
torch.Tensor([7.5, 7.5]),
torch.Tensor([.75, .5]),
nb_samples=50
)
cluster3 = sample(
torch.Tensor([8, 1.5]),
torch.Tensor([.6, .8]),
nb_samples=100
)
def plot_2d_sample(sample_dict):
x = sample_dict["x"][:,0].data.numpy()
y = sample_dict["x"][:,1].data.numpy()
plt.plot(x, y, 'gx')
plt.show()
# create the dummy dataset, by combining the clusters.
samples = torch.cat([cluster1, cluster2, cluster3])
samples = (samples-samples.mean(dim=0)) / samples.std(dim=0)
samples_dict = {"x": samples}
plot_2d_sample(samples_dict)
```
## GMM
```
from pixyz.distributions import Normal, Categorical
from pixyz.distributions.mixture_distributions import MixtureModel
from pixyz.utils import print_latex
z_dim = 3 # the number of mixture
x_dim = 2
distributions = []
for i in range(z_dim):
loc = torch.randn(x_dim)
scale = torch.empty(x_dim).fill_(0.6)
distributions.append(Normal(loc=loc, scale=scale, var=["x"], name="p_%d" %i))
probs = torch.empty(z_dim).fill_(1. / z_dim)
prior = Categorical(probs=probs, var=["z"], name="p_{prior}")
p = MixtureModel(distributions=distributions, prior=prior)
print(p)
print_latex(p)
post = p.posterior()
print(post)
print_latex(post)
def get_density(N=200, x_range=(-5, 5), y_range=(-5, 5)):
x = np.linspace(*x_range, N)
y = np.linspace(*y_range, N)
x, y = np.meshgrid(x, y)
# get the design matrix
points = np.concatenate([x.reshape(-1, 1), y.reshape(-1, 1)], axis=1)
points = torch.from_numpy(points).float()
pdf = p.prob().eval({"x": points}).data.numpy().reshape([N, N])
return x, y, pdf
def plot_density_3d(x, y, loglike):
fig = plt.figure(figsize=(10, 10))
ax = fig.gca(projection='3d')
ax.plot_surface(x, y, loglike, rstride=3, cstride=3, linewidth=1, antialiased=True,
cmap=cm.inferno)
cset = ax.contourf(x, y, loglike, zdir='z', offset=-0.15, cmap=cm.inferno)
# adjust the limits, ticks and view angle
ax.set_zlim(-0.15,0.2)
ax.set_zticks(np.linspace(0,0.2,5))
ax.view_init(27, -21)
plt.show()
def plot_density_2d(x, y, pdf):
fig = plt.figure(figsize=(5, 5))
plt.plot(samples_dict["x"][:,0].data.numpy(), samples_dict["x"][:,1].data.numpy(), 'gx')
for d in distributions:
plt.scatter(d.loc[0,0], d.loc[0,1], c='r', marker='o')
cs = plt.contour(x, y, pdf, 10, colors='k', linewidths=2)
plt.show()
eps = 1e-6
min_scale = 1e-6
# plot_density_3d(*get_density())
plot_density_2d(*get_density())
print("Epoch: {}, log-likelihood: {}".format(0, p.log_prob().mean().eval(samples_dict)))
for epoch in range(20):
# E-step
posterior = post.prob().eval(samples_dict)
# M-step
N_k = posterior.sum(dim=1) # (n_mix,)
# update probs
probs = N_k / N_k.sum() # (n_mix,)
prior.probs[0] = probs
# update loc & scale
loc = (posterior[:, None] @ samples[None]).squeeze(1) # (n_mix, n_dim)
loc /= (N_k[:, None] + eps)
cov = (samples[None, :, :] - loc[:, None, :]) ** 2 # Covariances are set to 0.
var = (posterior[:, None, :] @ cov).squeeze(1) # (n_mix, n_dim)
var /= (N_k[:, None] + eps)
scale = var.sqrt()
for i, d in enumerate(distributions):
d.loc[0] = loc[i]
d.scale[0] = scale[i]
# plot_density_3d(*get_density())
plot_density_2d(*get_density())
print("Epoch: {}, log-likelihood: {}".format(epoch+1, p.log_prob().mean().eval({"x": samples}).mean()))
psudo_sample_dict = p.sample(batch_n=200)
plot_2d_sample(samples_dict)
```
|
github_jupyter
|
# Import libraries
```
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
%matplotlib inline
```
# Read csv
```
data = pd.read_csv('Data/ml.csv')
#Check the columns
data.columns
#Number of rows and columns
data.shape
#Transform categorical variables to object
data['is_banked'] = data['is_banked'].apply(str)
data['code_module'] = data['code_module'].apply(str)
data['code_presentation'] = data['code_presentation'].apply(str)
#Dummies
to_dummies = ['is_banked','code_module', 'code_presentation', 'gender', 'region',
'highest_education', 'imd_band', 'age_band', 'disability', 'final_result',]
data = pd.get_dummies(data, columns=to_dummies)
#Check columns
data.columns
#Separate target from the rest of columns
data_data = data[['date_submitted', 'num_of_prev_attempts', 'studied_credits',
'module_presentation_length', 'is_banked_0', 'is_banked_1',
'code_module_AAA', 'code_module_BBB', 'code_module_CCC',
'code_module_DDD', 'code_module_EEE', 'code_module_FFF',
'code_module_GGG', 'code_presentation_2013B', 'code_presentation_2013J',
'code_presentation_2014B', 'code_presentation_2014J', 'gender_F',
'gender_M', 'region_East Anglian Region', 'region_East Midlands Region',
'region_Ireland', 'region_London Region', 'region_North Region',
'region_North Western Region', 'region_Scotland',
'region_South East Region', 'region_South Region',
'region_South West Region', 'region_Wales',
'region_West Midlands Region', 'region_Yorkshire Region',
'highest_education_A Level or Equivalent',
'highest_education_HE Qualification',
'highest_education_Lower Than A Level',
'highest_education_No Formal quals',
'highest_education_Post Graduate Qualification', 'imd_band_0-10%',
'imd_band_10-20', 'imd_band_20-30%', 'imd_band_30-40%',
'imd_band_40-50%', 'imd_band_50-60%', 'imd_band_60-70%',
'imd_band_70-80%', 'imd_band_80-90%', 'imd_band_90-100%', 'imd_band_?',
'age_band_0-35', 'age_band_35-55', 'age_band_55<=', 'disability_N',
'disability_Y', 'final_result_Distinction', 'final_result_Fail',
'final_result_Pass', 'final_result_Withdrawn']]
data_target = data_ml["score"]
# Split Train and Test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(data_data, data_target, test_size=0.3, random_state=42)
#Grid search for parameter selection for a Random Forest Regressor model
param_grid = {
'n_estimators': [100, 1000],
'max_features': ['auto','sqrt','log2'],
'max_depth': [25, 15]
}
RFR = RandomForestRegressor(n_jobs=-1)
GS = GridSearchCV(RFR, param_grid, cv=5, verbose = 3)
GS.fit(X_train, y_train)
GS.best_params_
RFR = RandomForestRegressor(max_depth = 25, max_features='sqrt', n_estimators=1000)
RFR.fit(X_train, y_train)
y_train_pred = RFR.predict(X_train)
y_pred = RFR.predict(X_test)
r2 = r2_score(y_train, y_train_pred)
mae = mean_absolute_error(y_train, y_train_pred)
print ('TRAIN MODEL METRICS:')
print('The R2 score is: ' + str(r2))
print('The MAE score is: ' + str(mae))
plt.scatter(y_train, y_train_pred)
plt.plot([0,100], [0,100], color='red')
plt.show()
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
print ('TEST MODEL METRICS:')
print('The R2 score is: ' + str(r2))
print('The MAE score is: ' + str(mae))
plt.scatter(y_test, y_pred)
plt.plot([0,100], [0,100], color='red')
plt.show()
data_ml.head()
data_ml.info()
```
|
github_jupyter
|
<a href="https://colab.research.google.com/github/gdg-ml-team/ioExtended/blob/master/Lab_2.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
!pip install -q tensorflow_hub
from __future__ import absolute_import, division, print_function
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
tf.VERSION
data_root = tf.keras.utils.get_file(
'flower_photos','https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)
image_data = image_generator.flow_from_directory(str(data_root))
for image_batch,label_batch in image_data:
print("Image batch shape: ", image_batch.shape)
print("Labe batch shape: ", label_batch.shape)
break
classifier_url = "https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/classification/2" #@param {type:"string"}
def classifier(x):
classifier_module = hub.Module(classifier_url)
return classifier_module(x)
IMAGE_SIZE = hub.get_expected_image_size(hub.Module(classifier_url))
classifier_layer = layers.Lambda(classifier, input_shape = IMAGE_SIZE+[3])
classifier_model = tf.keras.Sequential([classifier_layer])
classifier_model.summary()
image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SIZE)
for image_batch,label_batch in image_data:
print("Image batch shape: ", image_batch.shape)
print("Labe batch shape: ", label_batch.shape)
break
import tensorflow.keras.backend as K
sess = K.get_session()
init = tf.global_variables_initializer()
sess.run(init)
import numpy as np
import PIL.Image as Image
grace_hopper = tf.keras.utils.get_file('image.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg')
grace_hopper = Image.open(grace_hopper).resize(IMAGE_SIZE)
grace_hopper
grace_hopper = np.array(grace_hopper)/255.0
grace_hopper.shape
result = classifier_model.predict(grace_hopper[np.newaxis, ...])
result.shape
predicted_class = np.argmax(result[0], axis=-1)
predicted_class
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
plt.imshow(grace_hopper)
plt.axis('off')
predicted_class_name = imagenet_labels[predicted_class]
_ = plt.title("Prediction: " + predicted_class_name)
```
|
github_jupyter
|
<a href="https://practicalai.me"><img src="https://raw.githubusercontent.com/practicalAI/images/master/images/rounded_logo.png" width="100" align="left" hspace="20px" vspace="20px"></a>
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/numpy.png" width="200" vspace="30px" align="right">
<div align="left">
<h1>NumPy</h1>
In this lesson we will learn the basics of numerical analysis using the NumPy package.
</div>
<table align="center">
<td>
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/rounded_logo.png" width="25"><a target="_blank" href="https://practicalai.me"> View on practicalAI</a>
</td>
<td>
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/colab_logo.png" width="25"><a target="_blank" href="https://colab.research.google.com/github/practicalAI/practicalAI/blob/master/notebooks/02_NumPy.ipynb"> Run in Google Colab</a>
</td>
<td>
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/github_logo.png" width="22"><a target="_blank" href="https://github.com/practicalAI/practicalAI/blob/master/notebooks/02_NumPy.ipynb"> View code on GitHub</a>
</td>
</table>
# Set up
```
import numpy as np
# Set seed for reproducibility
np.random.seed(seed=1234)
```
# Basics
Let's take a took at how to create tensors with NumPy.
* **Tensor**: collection of values
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/tensors.png" width="650">
</div>
```
# Scalar
x = np.array(6) # scalar
print ("x: ", x)
# Number of dimensions
print ("x ndim: ", x.ndim)
# Dimensions
print ("x shape:", x.shape)
# Size of elements
print ("x size: ", x.size)
# Data type
print ("x dtype: ", x.dtype)
# Vector
x = np.array([1.3 , 2.2 , 1.7])
print ("x: ", x)
print ("x ndim: ", x.ndim)
print ("x shape:", x.shape)
print ("x size: ", x.size)
print ("x dtype: ", x.dtype) # notice the float datatype
# Matrix
x = np.array([[1,2], [3,4]])
print ("x:\n", x)
print ("x ndim: ", x.ndim)
print ("x shape:", x.shape)
print ("x size: ", x.size)
print ("x dtype: ", x.dtype)
# 3-D Tensor
x = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])
print ("x:\n", x)
print ("x ndim: ", x.ndim)
print ("x shape:", x.shape)
print ("x size: ", x.size)
print ("x dtype: ", x.dtype)
```
NumPy also comes with several functions that allow us to create tensors quickly.
```
# Functions
print ("np.zeros((2,2)):\n", np.zeros((2,2)))
print ("np.ones((2,2)):\n", np.ones((2,2)))
print ("np.eye((2)):\n", np.eye((2))) # identity matrix
print ("np.random.random((2,2)):\n", np.random.random((2,2)))
```
# Indexing
Keep in mind that when indexing the row and column, indices start at 0. And like indexing with lists, we can use negative indices as well (where -1 is the last item).
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/indexing.png" width="300">
</div>
```
# Indexing
x = np.array([1, 2, 3])
print ("x: ", x)
print ("x[0]: ", x[0])
x[0] = 0
print ("x: ", x)
# Slicing
x = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print (x)
print ("x column 1: ", x[:, 1])
print ("x row 0: ", x[0, :])
print ("x rows 0,1 & cols 1,2: \n", x[0:2, 1:3])
# Integer array indexing
print (x)
rows_to_get = np.array([0, 1, 2])
print ("rows_to_get: ", rows_to_get)
cols_to_get = np.array([0, 2, 1])
print ("cols_to_get: ", cols_to_get)
# Combine sequences above to get values to get
print ("indexed values: ", x[rows_to_get, cols_to_get]) # (0, 0), (1, 2), (2, 1)
# Boolean array indexing
x = np.array([[1, 2], [3, 4], [5, 6]])
print ("x:\n", x)
print ("x > 2:\n", x > 2)
print ("x[x > 2]:\n", x[x > 2])
```
# Arithmetic
```
# Basic math
x = np.array([[1,2], [3,4]], dtype=np.float64)
y = np.array([[1,2], [3,4]], dtype=np.float64)
print ("x + y:\n", np.add(x, y)) # or x + y
print ("x - y:\n", np.subtract(x, y)) # or x - y
print ("x * y:\n", np.multiply(x, y)) # or x * y
```
### Dot product
One of the most common NumPy operations we’ll use in machine learning is matrix multiplication using the dot product. We take the rows of our first matrix (2) and the columns of our second matrix (2) to determine the dot product, giving us an output of `[2 X 2]`. The only requirement is that the inside dimensions match, in this case the frist matrix has 3 columns and the second matrix has 3 rows.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/dot.gif" width="450">
</div>
```
# Dot product
a = np.array([[1,2,3], [4,5,6]], dtype=np.float64) # we can specify dtype
b = np.array([[7,8], [9,10], [11, 12]], dtype=np.float64)
c = a.dot(b)
print (f"{a.shape} · {b.shape} = {c.shape}")
print (c)
```
### Axis operations
We can also do operations across a specific axis.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/axis.gif" width="450">
</div>
```
# Sum across a dimension
x = np.array([[1,2],[3,4]])
print (x)
print ("sum all: ", np.sum(x)) # adds all elements
print ("sum axis=0: ", np.sum(x, axis=0)) # sum across rows
print ("sum axis=1: ", np.sum(x, axis=1)) # sum across columns
# Min/max
x = np.array([[1,2,3], [4,5,6]])
print ("min: ", x.min())
print ("max: ", x.max())
print ("min axis=0: ", x.min(axis=0))
print ("min axis=1: ", x.min(axis=1))
```
### Broadcasting
Here, we’re adding a vector with a scalar. Their dimensions aren’t compatible as is but how does NumPy still gives us the right result? This is where broadcasting comes in. The scalar is *broadcast* across the vector so that they have compatible shapes.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/broadcasting.png" width="300">
</div>
```
# Broadcasting
x = np.array([1,2]) # vector
y = np.array(3) # scalar
z = x + y
print ("z:\n", z)
```
# Advanced
### Transposing
We often need to change the dimensions of our tensors for operations like the dot product. If we need to switch two dimensions, we can transpose
the tensor.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/transpose.png" width="400">
</div>
```
# Transposing
x = np.array([[1,2,3], [4,5,6]])
print ("x:\n", x)
print ("x.shape: ", x.shape)
y = np.transpose(x, (1,0)) # flip dimensions at index 0 and 1
print ("y:\n", y)
print ("y.shape: ", y.shape)
```
### Reshaping
Sometimes, we'll need to alter the dimensions of the matrix. Reshaping allows us to transform a tensor into different permissible shapes -- our reshaped tensor has the same amount of values in the tensor. (1X6 = 2X3). We can also use `-1` on a dimension and NumPy will infer the dimension based on our input tensor.
The way reshape works is by looking at each dimension of the new tensor and separating our original tensor into that many units. So here the dimension at index 0 of the new tensor is 2 so we divide our original tensor into 2 units, and each of those has 3 values.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape.png" width="450">
</div>
```
# Reshaping
x = np.array([[1,2,3,4,5,6]])
print (x)
print ("x.shape: ", x.shape)
y = np.reshape(x, (2, 3))
print ("y: \n", y)
print ("y.shape: ", y.shape)
z = np.reshape(x, (2, -1))
print ("z: \n", z)
print ("z.shape: ", z.shape)
```
### Unintended reshaping
Though reshaping is very convenient to manipulate tensors, we must be careful of their pitfalls as well. Let's look at the example below. Suppose we have `x`, which has the shape `[2 X 3 X 4]`.
```
[[[ 1 1 1 1]
[ 2 2 2 2]
[ 3 3 3 3]]
[[10 10 10 10]
[20 20 20 20]
[30 30 30 30]]]
```
We want to reshape x so that it has shape `[3 X 8]` which we'll get by moving the dimension at index 0 to become the dimension at index 1 and then combining the last two dimensions. But when we do this, we want our output
to look like:
✅
```
[[ 1 1 1 1 10 10 10 10]
[ 2 2 2 2 20 20 20 20]
[ 3 3 3 3 30 30 30 30]]
```
and not like:
❌
```
[[ 1 1 1 1 2 2 2 2]
[ 3 3 3 3 10 10 10 10]
[20 20 20 20 30 30 30 30]]
```
even though they both have the same shape `[3X8]`.
```
x = np.array([[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],
[[10, 10, 10, 10], [20, 20, 20, 20], [30, 30, 30, 30]]])
print ("x:\n", x)
print ("x.shape: ", x.shape)
```
When we naively do a reshape, we get the right shape but the values are not what we're looking for.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape_wrong.png" width="600">
</div>
```
# Unintended reshaping
z_incorrect = np.reshape(x, (x.shape[1], -1))
print ("z_incorrect:\n", z_incorrect)
print ("z_incorrect.shape: ", z_incorrect.shape)
```
Instead, if we transpose the tensor and then do a reshape, we get our desired tensor. Transpose allows us to put our two vectors that we want to combine together and then we use reshape to join them together.
Always create a dummy example like this when you’re unsure about reshaping. Blindly going by the tensor shape can lead to lots of issues downstream.
<div align="left">
<img src="https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape_right.png" width="600">
</div>
```
# Intended reshaping
y = np.transpose(x, (1,0,2))
print ("y:\n", y)
print ("y.shape: ", y.shape)
z_correct = np.reshape(y, (y.shape[0], -1))
print ("z_correct:\n", z_correct)
print ("z_correct.shape: ", z_correct.shape)
```
### Adding/removing dimensions
We can also easily add and remove dimensions to our tensors and we'll want to do this to make tensors compatible for certain operations.
```
# Adding dimensions
x = np.array([[1,2,3],[4,5,6]])
print ("x:\n", x)
print ("x.shape: ", x.shape)
y = np.expand_dims(x, 1) # expand dim 1
print ("y: \n", y)
print ("y.shape: ", y.shape) # notice extra set of brackets are added
# Removing dimensions
x = np.array([[[1,2,3]],[[4,5,6]]])
print ("x:\n", x)
print ("x.shape: ", x.shape)
y = np.squeeze(x, 1) # squeeze dim 1
print ("y: \n", y)
print ("y.shape: ", y.shape) # notice extra set of brackets are gone
```
# Additional resources
* **NumPy reference manual**: We don't have to memorize anything here and we will be taking a closer look at NumPy in the later lessons. If you want to learn more checkout the [NumPy reference manual](https://docs.scipy.org/doc/numpy-1.15.1/reference/).
---
<div align="center">
Subscribe to our <a href="https://practicalai.me/#newsletter">newsletter</a> and follow us on social media to get the latest updates!
<a class="ai-header-badge" target="_blank" href="https://github.com/practicalAI/practicalAI">
<img src="https://img.shields.io/github/stars/practicalAI/practicalAI.svg?style=social&label=Star"></a>
<a class="ai-header-badge" target="_blank" href="https://www.linkedin.com/company/practicalai-me">
<img src="https://img.shields.io/badge/style--5eba00.svg?label=LinkedIn&logo=linkedin&style=social"></a>
<a class="ai-header-badge" target="_blank" href="https://twitter.com/practicalAIme">
<img src="https://img.shields.io/twitter/follow/practicalAIme.svg?label=Follow&style=social">
</a>
</div>
</div>
|
github_jupyter
|
**This notebook is an exercise in the [Introduction to Machine Learning](https://www.kaggle.com/learn/intro-to-machine-learning) course. You can reference the tutorial at [this link](https://www.kaggle.com/dansbecker/underfitting-and-overfitting).**
---
## Recap
You've built your first model, and now it's time to optimize the size of the tree to make better predictions. Run this cell to set up your coding environment where the previous step left off.
```
# Code you have previously used to load data
import pandas as pd
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
# Path of the file to read
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
home_data = pd.read_csv(iowa_file_path)
# Create target object and call it y
y = home_data.SalePrice
# Create X
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[features]
# Split into validation and training data
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
# Specify Model
iowa_model = DecisionTreeRegressor(random_state=1)
# Fit Model
iowa_model.fit(train_X, train_y)
# Make validation predictions and calculate mean absolute error
val_predictions = iowa_model.predict(val_X)
val_mae = mean_absolute_error(val_predictions, val_y)
print("Validation MAE: {:,.0f}".format(val_mae))
# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex5 import *
print("\nSetup complete")
```
# Exercises
You could write the function `get_mae` yourself. For now, we'll supply it. This is the same function you read about in the previous lesson. Just run the cell below.
```
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
```
## Step 1: Compare Different Tree Sizes
Write a loop that tries the following values for *max_leaf_nodes* from a set of possible values.
Call the *get_mae* function on each value of max_leaf_nodes. Store the output in some way that allows you to select the value of `max_leaf_nodes` that gives the most accurate model on your data.
```
candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# Write loop to find the ideal tree size from candidate_max_leaf_nodes
for max_leaf_nodes in candidate_max_leaf_nodes:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
# Store the best value of max_leaf_nodes (it will be either 5, 25, 50, 100, 250 or 500)
best_tree_size = 100
# Check your answer
step_1.check()
# The lines below will show you a hint or the solution.
# step_1.hint()
# step_1.solution()
```
## Step 2: Fit Model Using All Data
You know the best tree size. If you were going to deploy this model in practice, you would make it even more accurate by using all of the data and keeping that tree size. That is, you don't need to hold out the validation data now that you've made all your modeling decisions.
```
# Fill in argument to make optimal size and uncomment
final_model = DecisionTreeRegressor(max_leaf_nodes=100, random_state=0)
# fit the final model and uncomment the next two lines
final_model.fit(X, y)
# Check your answer
step_2.check()
# step_2.hint()
# step_2.solution()
```
You've tuned this model and improved your results. But we are still using Decision Tree models, which are not very sophisticated by modern machine learning standards. In the next step you will learn to use Random Forests to improve your models even more.
# Keep Going
You are ready for **[Random Forests](https://www.kaggle.com/dansbecker/random-forests).**
---
*Have questions or comments? Visit the [Learn Discussion forum](https://www.kaggle.com/learn-forum/161285) to chat with other Learners.*
|
github_jupyter
|
```
import pandas as pd
import numpy as np
import emoji
import pickle
import cv2
import matplotlib.pyplot as plt
import os
sentiment_data = pd.read_csv("../../resource/Emoji_Sentiment_Ranking/Emoji_Sentiment_Data_v1.0.csv")
sentiment_data.head()
def clean(x):
x = x.replace(" ", "-").lower()
return str(x)
sentiment_data['Unicode name'] = sentiment_data['Unicode name'].apply(clean)
sentiment_data.head()
score_dict = {}
for i in range(len(sentiment_data)) :
score_dict[sentiment_data.loc[i, "Unicode name"]] = [sentiment_data.loc[i, "Negative"]/sentiment_data.loc[i, "Occurrences"],
sentiment_data.loc[i, "Neutral"]/sentiment_data.loc[i, "Occurrences"],
sentiment_data.loc[i, "Positive"]/sentiment_data.loc[i, "Occurrences"]]
score_dict['angry-face']
```
### Dumping name_2_score as pickle file
```
with open('../../lib/score_dict.pickle', 'wb') as handle:
pickle.dump(score_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('../../lib/score_dict.pickle', 'rb') as handle:
score_dict = pickle.load(handle)
```
### First transform the screenshot to process-able image
#### for that we need to import the module `ss_to_image` first
```
import os,sys,inspect
currentdir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0,parentdir)
print(currentdir)
print(parentdir)
sys.path
from utils.ss_to_image import final_crop
cropped_image = final_crop('../../resource/screenshots/Rohan.jpeg')
img = cropped_image
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
```
### Image pre-processing
```
img.shape
```
#### Resizing image : dim = (560, 280) / ALREADY DONE THO..
```
dim = (560,280)
resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
plt.imshow(cv2.cvtColor(resized, cv2.COLOR_BGR2RGB))
plt.show()
resized.shape
n_col = resized.shape[1]//2
img_left = resized[:, :n_col]
print("img_left",img_left.shape)
img_right = resized[:, n_col:]
print("img_right",img_right.shape)
plt.imshow(cv2.cvtColor(img_left, cv2.COLOR_BGR2RGB))
plt.show()
plt.imshow(cv2.cvtColor(img_right, cv2.COLOR_BGR2RGB))
plt.show()
i = 1
j = 0
temp = img_right[i*70:(i+1)*70,j*70:(j+1)*70]
plt.imshow(cv2.cvtColor(temp, cv2.COLOR_BGR2RGB))
plt.show()
```
### Final code for image processing
```
# takes input the image outputs the extracted emojis as np-arrays
def image_2_emoji(file_path):
def to_half(image):
n_col = image.shape[1]//2
img_left = image[:, :n_col]
img_right = image[:, n_col:]
return (img_left, img_right)
def extract_from_half(image):
emoji_list = []
for i in range(4):
for j in range(4):
temp = image[i*70:(i+1)*70,j*70:(j+1)*70]
emoji_list.append(temp)
return emoji_list
img = cv2.imread(file_path)
dim = (560,280)
resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA)
halfed = to_half(resized)
output = extract_from_half(halfed[0])
output += extract_from_half(halfed[1])
return output
template = cv2.imread('../../resource/emoji_database/smiling-face-with-sunglasses_1f60e.png')
dim = (50,50)
template = cv2.resize(template, dim, interpolation = cv2.INTER_AREA)
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.show()
```
### Each emoji after extraction has shape (70 $\times$ 70)
### Each template has size shape (50 $\times$ 50)
```
# Takes file_path of the screenshot as input and outputs the predicted list of names of the emojis
def emoji_2_name(file_path, method = 'cv2.TM_SQDIFF_NORMED'):
'''
available methods : 'cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED'
'''
methods = eval(method)
emoji_list = image_2_emoji(file_path)
emoji_name_list = [0]*len(emoji_list)
output = [0]*len(emoji_list)
for i in os.listdir('../resource/emoji_database'):
template = cv2.imread('../resource/emoji_database/' + str(i))
dim = (50,50)
template = cv2.resize(template, dim, interpolation = cv2.INTER_AREA)
for j in range(len(emoji_list)):
res = cv2.matchTemplate(emoji_list[j][:, :, 0] ,template[:, :, 0],methods)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
try:
if emoji_name_list[j][0]>min_val:
emoji_name_list[j] = (min_val, i)
except TypeError:
emoji_name_list[j] = (min_val, i)
output[j] = emoji_name_list[j][1].split('_')[0]
#return emoji_name_list
return output
```
#### Function to compute the sentiment score from the screenshots
```
# takes the creenshot as input and returns the score
def name_2_score(file_path):
output = None
emoji_name_list = image_2_name(file_path)
for i in emoji_name_list:
try:
output = np.add(output,np.array(score_dict[i]))
except TypeError:
output = np.array(score_dict[i])
except KeyError:
pass
return output/np.sum(output)
```
## ROUGH
```
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('../../resource/screenshots/Arka.jpeg',0)
#img = im2_right[:, :, 2]
img2 = img.copy()
template = cv2.imread('../../resource/emoji_database/face-savouring-delicious-food_1f60b.png',0)
#template = template[:, :, 2]
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
res.shape
from PIL import Image
from matplotlib import pyplot
cv2.imshow(res, map = 'gray')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
plt.imshow(cv2.cvtColor(res, cv2.COLOR_BGR2RGB))
plt.show()
img
for i in template:
for j in range(len(i)):
if i[j]==0:
i[j]=26
template
min_val, max_val, min_loc, max_loc
```
|
github_jupyter
|
# Computing the Bayesian Hilbert Transform-DRT
In this tutorial example, we will show how the developed BHT-DRT method works using a simple ZARC model. The equivalent circuit consists one ZARC model, *i.e*., a resistor in parallel with a CPE element.
```
# import the libraries
import numpy as np
from math import pi, log10
import matplotlib.pyplot as plt
import seaborn as sns
# core library
import Bayes_HT
import importlib
importlib.reload(Bayes_HT)
# plot standards
plt.rc('font', family='serif', size=15)
plt.rc('text', usetex=True)
plt.rc('xtick', labelsize=15)
plt.rc('ytick', labelsize=15)
```
## 1) Define the synthetic impedance experiment $Z_{\rm exp}(\omega)$
### 1.1) Define the frequency range
```
N_freqs = 81
freq_min = 10**-4 # Hz
freq_max = 10**4 # Hz
freq_vec = np.logspace(log10(freq_min), log10(freq_max), num=N_freqs, endpoint=True)
tau_vec = np.logspace(-log10(freq_max), -log10(freq_min), num=N_freqs, endpoint=True)
omega_vec = 2.*pi*freq_vec
```
### 1.2) Define the circuit parameters for the two ZARCs
```
R_ct = 50 # Ohm
R_inf = 10. # Ohm
phi = 0.8
tau_0 = 1. # sec
```
### 1.3) Generate exact impedance $Z_{\rm exact}(\omega)$ as well as the stochastic experiment $Z_{\rm exp}(\omega)$, here $Z_{\rm exp}(\omega)=Z_{\rm exact}(\omega)+\sigma_n(\varepsilon_{\rm re}+i\varepsilon_{\rm im})$
```
# generate exact
T = tau_0**phi/R_ct
Z_exact = R_inf + 1./(1./R_ct+T*(1j*2.*pi*freq_vec)**phi)
# random
rng = np.random.seed(121295)
sigma_n_exp = 0.8 # Ohm
Z_exp = Z_exact + sigma_n_exp*(np.random.normal(0, 1, N_freqs)+1j*np.random.normal(0, 1, N_freqs))
```
### 1.4) show the impedance in Nyquist plot
```
fig, ax = plt.subplots()
plt.plot(Z_exact.real, -Z_exact.imag, linewidth=4, color='black', label='exact')
plt.plot(np.real(Z_exp), -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')
plt.plot(np.real(Z_exp[0:70:20]), -np.imag(Z_exp[0:70:20]), 's', markersize=8, color="black")
plt.plot(np.real(Z_exp[30]), -np.imag(Z_exp[30]), 's', markersize=8, color="black")
plt.annotate(r'$10^{-4}$', xy=(np.real(Z_exp[0]), -np.imag(Z_exp[0])),
xytext=(np.real(Z_exp[0])-15, -np.imag(Z_exp[0])),
arrowprops=dict(arrowstyle='-',connectionstyle='arc'))
plt.annotate(r'$10^{-1}$', xy=(np.real(Z_exp[20]), -np.imag(Z_exp[20])),
xytext=(np.real(Z_exp[20])-5, 10-np.imag(Z_exp[20])),
arrowprops=dict(arrowstyle='-',connectionstyle='arc'))
plt.annotate(r'$1$', xy=(np.real(Z_exp[30]), -np.imag(Z_exp[30])),
xytext=(np.real(Z_exp[30]), 8-np.imag(Z_exp[30])),
arrowprops=dict(arrowstyle='-',connectionstyle='arc'))
plt.annotate(r'$10$', xy=(np.real(Z_exp[40]), -np.imag(Z_exp[40])),
xytext=(np.real(Z_exp[40]), 8-np.imag(Z_exp[40])),
arrowprops=dict(arrowstyle='-',connectionstyle='arc'))
plt.annotate(r'$10^2$', xy=(np.real(Z_exp[60]), -np.imag(Z_exp[60])),
xytext=(np.real(Z_exp[60])+5, -np.imag(Z_exp[60])),
arrowprops=dict(arrowstyle='-',connectionstyle='arc'))
plt.legend(frameon=False, fontsize = 15)
plt.axis('scaled')
plt.xlim(5, 70)
plt.ylim(-2, 32)
plt.xticks(range(5, 70, 10))
plt.yticks(range(0, 40, 10))
plt.xlabel(r'$Z_{\rm re}/\Omega$', fontsize = 20)
plt.ylabel(r'$-Z_{\rm im}/\Omega$', fontsize = 20)
plt.show()
```
## 2) Calculate the DRT impedance $Z_{\rm DRT}(\omega)$ and the Hilbert transformed impedance $Z_{\rm H}(\omega)$
### 2.1) optimize the hyperparamters
```
# set the intial parameters
sigma_n = 1
sigma_beta = 20
sigma_lambda = 100
theta_0 = np.array([sigma_n, sigma_beta, sigma_lambda])
data_real, data_imag, scores = Bayes_HT.HT_est(theta_0, Z_exp, freq_vec, tau_vec)
```
### 2.2) Calculate the real part of the $Z_{\rm DRT}(\omega)$ and the imaginary part of the $Z_{\rm H}(\omega)$
#### 2.2.1) Bayesian regression to obtain the real part of impedance for both mean and covariance
```
mu_Z_re = data_real.get('mu_Z')
cov_Z_re = np.diag(data_real.get('Sigma_Z'))
# the mean and covariance of $R_\infty$
mu_R_inf = data_real.get('mu_gamma')[0]
cov_R_inf = np.diag(data_real.get('Sigma_gamma'))[0]
```
#### 2.2.2) Calculate the real part of DRT impedance for both mean and covariance
```
mu_Z_DRT_re = data_real.get('mu_Z_DRT')
cov_Z_DRT_re = np.diag(data_real.get('Sigma_Z_DRT'))
```
#### 2.2.3) Calculate the imaginary part of HT impedance for both mean and covariance
```
mu_Z_H_im = data_real.get('mu_Z_H')
cov_Z_H_im = np.diag(data_real.get('Sigma_Z_H'))
```
#### 2.2.4) Estimate the $\sigma_n$
```
sigma_n_re = data_real.get('theta')[0]
```
### 2.3) Calculate the imaginary part of the $Z_{\rm DRT}(\omega)$ and the real part of the $Z_{\rm H}(\omega)$
```
# 2.3.1 Bayesian regression
mu_Z_im = data_imag.get('mu_Z')
cov_Z_im = np.diag(data_imag.get('Sigma_Z'))
# the mean and covariance of the inductance $L_0$
mu_L_0 = data_imag.get('mu_gamma')[0]
cov_L_0 = np.diag(data_imag.get('Sigma_gamma'))[0]
# 2.3.2 DRT part
mu_Z_DRT_im = data_imag.get('mu_Z_DRT')
cov_Z_DRT_im = np.diag(data_imag.get('Sigma_Z_DRT'))
# 2.3.3 HT prediction
mu_Z_H_re = data_imag.get('mu_Z_H')
cov_Z_H_re = np.diag(data_imag.get('Sigma_Z_H'))
# 2.3.4 estimated sigma_n
sigma_n_im = data_imag.get('theta')[0]
```
## 3) Plot the BHT_DRT
### 3.1) plot the real parts of impedance for both Bayesian regression and the synthetic experiment
```
band = np.sqrt(cov_Z_re)
plt.fill_between(freq_vec, mu_Z_re-3*band, mu_Z_re+3*band, facecolor='lightgrey')
plt.semilogx(freq_vec, mu_Z_re, linewidth=4, color='black', label='mean')
plt.semilogx(freq_vec, Z_exp.real, 'o', markersize=8, color='red', label='synth exp')
plt.xlim(1E-4, 1E4)
plt.ylim(5, 65)
plt.xscale('log')
plt.yticks(range(5, 70, 10))
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$Z_{\rm re}/\Omega$', fontsize=20)
plt.legend(frameon=False, fontsize = 15)
plt.show()
```
### 3.2 plot the imaginary parts of impedance for both Bayesian regression and the synthetic experiment
```
band = np.sqrt(cov_Z_im)
plt.fill_between(freq_vec, -mu_Z_im-3*band, -mu_Z_im+3*band, facecolor='lightgrey')
plt.semilogx(freq_vec, -mu_Z_im, linewidth=4, color='black', label='mean')
plt.semilogx(freq_vec, -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')
plt.xlim(1E-4, 1E4)
plt.ylim(-3, 30)
plt.xscale('log')
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$-Z_{\rm im}/\Omega$', fontsize=20)
plt.legend(frameon=False, fontsize = 15)
plt.show()
```
### 3.3) plot the real parts of impedance for both Hilbert transform and the synthetic experiment
```
mu_Z_H_re_agm = mu_R_inf + mu_Z_H_re
band_agm = np.sqrt(cov_R_inf + cov_Z_H_re + sigma_n_im**2)
plt.fill_between(freq_vec, mu_Z_H_re_agm-3*band_agm, mu_Z_H_re_agm+3*band_agm, facecolor='lightgrey')
plt.semilogx(freq_vec, mu_Z_H_re_agm, linewidth=4, color='black', label='mean')
plt.semilogx(freq_vec, Z_exp.real, 'o', markersize=8, color='red', label='synth exp')
plt.xlim(1E-4, 1E4)
plt.ylim(-3, 70)
plt.xscale('log')
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$\left(R_\infty + Z_{\rm H, re}\right)/\Omega$', fontsize=20)
plt.legend(frameon=False, fontsize = 15)
plt.show()
```
### 3.4) plot the imaginary parts of impedance for both Hilbert transform and the synthetic experiment
```
mu_Z_H_im_agm = omega_vec*mu_L_0 + mu_Z_H_im
band_agm = np.sqrt((omega_vec**2)*cov_L_0 + cov_Z_H_im + sigma_n_re**2)
plt.fill_between(freq_vec, -mu_Z_H_im_agm-3*band_agm, -mu_Z_H_im_agm+3*band_agm, facecolor='lightgrey')
plt.semilogx(freq_vec, -mu_Z_H_im_agm, linewidth=4, color='black', label='mean')
plt.semilogx(freq_vec, -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')
plt.xlim(1E-4, 1E4)
plt.ylim(-3, 30)
plt.xscale('log')
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$-\left(\omega L_0 + Z_{\rm H, im}\right)/\Omega$', fontsize=20)
plt.legend(frameon=False, fontsize = 15)
plt.show()
```
### 3.5) plot the difference between real parts of impedance for Hilbert transform and the synthetic experiment
```
difference_re = mu_R_inf + mu_Z_H_re - Z_exp.real
band = np.sqrt(cov_R_inf + cov_Z_H_re + sigma_n_im**2)
plt.fill_between(freq_vec, -3*band, 3*band, facecolor='lightgrey')
plt.plot(freq_vec, difference_re, 'o', markersize=8, color='red')
plt.xlim(1E-4, 1E4)
plt.ylim(-10, 10)
plt.xscale('log')
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$\left(R_\infty + Z_{\rm H, re} - Z_{\rm exp, re}\right)/\Omega$', fontsize=20)
plt.show()
```
### 3.6) plot the density distribution of residuals for the real part
```
fig = plt.figure(1)
a = sns.kdeplot(difference_re, shade=True, color='grey')
a = sns.rugplot(difference_re, color='black')
a.set_xlabel(r'$\left(R_\infty + Z_{\rm H, re} - Z_{\rm exp, re}\right)/\Omega$',fontsize=20)
a.set_ylabel(r'pdf',fontsize=20)
a.tick_params(labelsize=15)
plt.xlim(-5, 5)
plt.ylim(0, 0.5)
plt.show()
```
### 3.7) plot the difference between imaginary parts of impedance for Hilbert transform and the synthetic experiment
```
difference_im = omega_vec*mu_L_0 + mu_Z_H_im - Z_exp.imag
band = np.sqrt((omega_vec**2)*cov_L_0 + cov_Z_H_im + sigma_n_re**2)
plt.fill_between(freq_vec, -3*band, 3*band, facecolor='lightgrey')
plt.plot(freq_vec, difference_im, 'o', markersize=8, color='red')
plt.xlim(1E-4, 1E4)
plt.ylim(-10, 10)
plt.xscale('log')
plt.xlabel(r'$f/{\rm Hz}$', fontsize=20)
plt.ylabel(r'$\left(\omega L_0 + Z_{\rm H, im} - Z_{\rm exp, im}\right)/\Omega$', fontsize=20)
plt.show()
```
### 3.8) plot the density distribution of residuals for the imaginary part
```
fig = plt.figure(2)
a = sns.kdeplot(difference_im, shade=True, color='grey')
a = sns.rugplot(difference_im, color='black')
a.set_xlabel(r'$\left(\omega L_0 + Z_{\rm H, im} - Z_{\rm exp, im}\right)/\Omega$',fontsize=20)
a.set_ylabel(r'pdf',fontsize=20)
a.tick_params(labelsize=15)
plt.xlim(-5, 5)
plt.ylim(0, 0.5)
plt.show()
```
|
github_jupyter
|
```
from functools import reduce
import numpy as np
import pandas as pd
from pandas.tseries.offsets import DateOffset
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from xgboost import XGBRegressor
from ta import add_all_ta_features
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
np.seterr(divide="ignore", invalid="ignore");
```
## Model without Rebalace
```
def build_momentum(df):
df["mom_6m"] = np.log(df.close)-np.log(df.close.shift(6))
df["mom_1m"] = np.log(df.close)-np.log(df.close.shift(1))
df["log_return"] = np.log(df.close.shift(-3)) - np.log(df.close)
return df.loc[df.prccd > 5, ["mcap", "mom_6m", "mom_1m", "log_return"]].dropna()
def be_extreme(df):
"""Retain the 20% values that are the smallest and the 20% that are the largest."""
top = df.log_return.quantile(0.8)
low = df.log_return.quantile(0.2)
return df[(df.log_return < low) | (df.log_return > top)]
df = pd.read_parquet("../data/merged_data_alpha.6.parquet")
df_basic = df[["mcap", "prccd", "close"]]
df_mom = df_basic.groupby("gvkey").apply(build_momentum)
df_train = df_mom.xs(slice("2002-01-01", "2012-01-01"), level="date", drop_level=False).groupby("date").apply(be_extreme)
df_test = df_mom.xs(slice("2012-01-01", "2016-01-01"), level="date", drop_level=False)
X_train = df_train.drop("log_return", axis=1).to_numpy()
y_train = df_train["log_return"].to_numpy()
X_test = df_test.drop("log_return", axis=1).to_numpy()
y_test = df_test["log_return"].to_numpy()
xgb_reg = XGBRegressor(n_estimators=100, max_depth=5, n_jobs=-1)
xgb_fit = xgb_reg.fit(X_train, y_train)
print(xgb_reg.score(X_train, y_train))
print(xgb_reg.score(X_test, y_test))
xgb_clf = XGBClassifier(n_estimators=100, max_depth=3, n_jobs=-1)
xgb_fit = xgb_clf.fit(X_train, np.sign(y_train))
print(xgb_clf.score(X_train, np.sign(y_train)))
print(xgb_clf.score(X_test, np.sign(y_test)))
```
## Model with Rebalance
```
def be_extreme(df):
"""Retain the 20% values that are the smallest and the 20% that are the largest."""
top = df.y.quantile(0.8)
low = df.y.quantile(0.2)
return df[(df.y < low) | (df.y > top)]
def be_balance(df):
"""Returns minus a cross-sectional median"""
median = df.log_return.quantile(0.5)
df["y"] = df.log_return - median
return df
df_train = df_mom.xs(slice("2002-01-01", "2012-01-01"), level="date", drop_level=False).groupby("date").apply(be_balance).groupby("date").apply(be_extreme)
df_test = df_mom.xs(slice("2012-01-01", "2016-01-01"), level="date", drop_level=False).groupby("date").apply(be_balance)
X_train = df_train.drop(["log_return", "y"], axis=1).to_numpy()
y_train = df_train["y"].to_numpy()
X_test = df_test.drop(["log_return", "y"], axis=1).to_numpy()
y_test = df_test["y"].to_numpy()
df_train.plot.scatter(x="mom_6m", y="y")
df_train.plot.scatter(x="mcap", y="y")
xgb_reg = XGBRegressor(n_estimators=100, max_depth=3, n_jobs=-1)
xgb_fit = xgb_reg.fit(X_train, y_train)
print(xgb_reg.score(X_train, y_train))
print(xgb_reg.score(X_test, y_test))
xgb_clf = XGBClassifier(n_estimators=100, max_depth=3, n_jobs=-1)
xgb_fit = xgb_clf.fit(X_train, np.sign(y_train))
print(xgb_clf.score(X_train, np.sign(y_train)))
print(xgb_clf.score(X_test, np.sign(y_test)))
```
The algorithm improves after rebalancing.
|
github_jupyter
|
# Python Data Science
> Dataframe Wrangling with Pandas
Kuo, Yao-Jen from [DATAINPOINT](https://www.datainpoint.com/)
```
import requests
import json
from datetime import date
from datetime import timedelta
```
## TL; DR
> In this lecture, we will talk about essential data wrangling skills in `pandas`.
## Essential Data Wrangling Skills in `pandas`
## What is `pandas`?
> Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more.
Source: <https://github.com/pandas-dev/pandas>
## Why `pandas`?
Python used to have a weak spot in its analysis capability due to it did not have an appropriate structure handling the common tabular datasets. Pythonists had to switch to a more data-centric language like R or Matlab during the analysis stage until the presence of `pandas`.
## Import Pandas with `import` command
Pandas is officially aliased as `pd`.
```
import pandas as pd
```
## If Pandas is not installed, we will encounter a `ModuleNotFoundError`
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'pandas'
```
## Use `pip install` at Terminal to install pandas
```bash
pip install pandas
```
## Check version and its installation file path
- `__version__` attribute
- `__file__` attribute
```
print(pd.__version__)
print(pd.__file__)
```
## What does `pandas` mean?

Source: <https://giphy.com/>
## Turns out its naming has nothing to do with panda the animal, it refers to three primary class customed by its author [Wes McKinney](https://wesmckinney.com/)
- **Pan**el(Deprecated since version 0.20.0)
- **Da**taFrame
- **S**eries
## In order to master `pandas`, it is vital to understand the relationships between `Index`, `ndarray`, `Series`, and `DataFrame`
- An `Index` and a `ndarray` assembles a `Series`
- A couple of `Series` that sharing the same `Index` can then form a `DataFrame`
## `Index` from Pandas
The simpliest way to create an `Index` is using `pd.Index()`.
```
prime_indices = pd.Index([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])
print(type(prime_indices))
```
## An `Index` is like a combination of `tuple` and `set`
- It is immutable.
- It has the characteristics of a set.
```
# It is immutable
prime_indices = pd.Index([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])
#prime_indices[-1] = 31
# It has the characteristics of a set
odd_indices = pd.Index(range(1, 30, 2))
print(prime_indices.intersection(odd_indices)) # prime_indices & odd_indices
print(prime_indices.union(odd_indices)) # prime_indices | odd_indices
print(prime_indices.symmetric_difference(odd_indices)) # prime_indices ^ odd_indices
print(prime_indices.difference(odd_indices))
print(odd_indices.difference(prime_indices))
```
## `Series` from Pandas
The simpliest way to create an `Series` is using `pd.Series()`.
```
prime_series = pd.Series([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])
print(type(prime_series))
```
## A `Series` is a combination of `Index` and `ndarray`
```
print(type(prime_series.index))
print(type(prime_series.values))
```
## `DataFrame` from Pandas
The simpliest way to create an `DataFrame` is using `pd.DataFrame()`.
```
movie_df = pd.DataFrame()
movie_df["title"] = ["The Shawshank Redemption", "The Dark Knight", "Schindler's List", "Forrest Gump", "Inception"]
movie_df["imdb_rating"] = [9.3, 9.0, 8.9, 8.8, 8.7]
print(type(movie_df))
```
## A `DataFrame` is a combination of multiple `Series` sharing the same `Index`
```
print(type(movie_df.index))
print(type(movie_df["title"]))
print(type(movie_df["imdb_rating"]))
```
## Review of the definition of modern data science
> Modern data science is a huge field, it invovles applications and tools like importing, tidying, transformation, visualization, modeling, and communication. Surrounding all these is programming.

Source: [R for Data Science](https://r4ds.had.co.nz/)
## Key functionalities analysts rely on `pandas` are
- Importing
- Tidying
- Transforming
## Tidying and transforming together is also known as WRANGLING
Source: <https://giphy.com/>
## Importing
## `pandas` has massive functions importing tabular data
- Flat text file
- Database table
- Spreadsheet
- Array of JSONs
- HTML `<table></table>` tags
- ...etc.
Source: <https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html>
## Using `read_csv` function for flat text files
```
from datetime import date
from datetime import timedelta
def get_covid19_latest_daily_report():
"""
Get latest daily report(world) from:
https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports
"""
data_date = date.today()
data_date_delta = timedelta(days=1)
daily_report_url_no_date = "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/{}.csv"
while True:
data_date_str = date.strftime(data_date, '%m-%d-%Y')
daily_report_url = daily_report_url_no_date.format(data_date_str)
try:
print("嘗試載入{}的每日報告".format(data_date_str))
daily_report = pd.read_csv(daily_report_url)
print("檔案存在,擷取了{}的每日報告".format(data_date_str))
break
except:
print("{}的檔案還沒有上傳".format(data_date_str))
data_date -= data_date_delta # data_date = data_date - data_date_delta
return daily_report
daily_report = get_covid19_latest_daily_report()
```
## Using `read_sql` function for database tables
```python
import sqlite3
conn = sqlite3.connect('YOUR_DATABASE.db')
sql_query = """
SELECT *
FROM YOUR_TABLE
LIMIT 100;
"""
pd.read_sql(sql_query, conn)
```
## Using `read_excel` function for spreadsheets
```python
excel_file_path = "PATH/TO/YOUR/EXCEL/FILE"
pd.read_excel(excel_file_path)
```
## Using `read_json` function for array of JSONs
```python
json_file_path = "PATH/TO/YOUR/JSON/FILE"
pd.read_json(json_file_path)
```
## What is JSON?
> JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
Source: <https://www.json.org/json-en.html>
## Using `read_html` function for HTML `<table></table>` tags
> The `<table>` tag defines an HTML table. An HTML table consists of one `<table>` element and one or more `<tr>`, `<th>`, and `<td>` elements. The `<tr>` element defines a table row, the `<th>` element defines a table header, and the `<td>` element defines a table cell.
Source: <https://www.w3schools.com/default.asp>
```
request_url = "https://www.imdb.com/chart/top"
html_tables = pd.read_html(request_url)
print(type(html_tables))
print(len(html_tables))
html_tables[0]
```
## Basic attributes and methods
## Basic attributes of a `DataFrame` object
- `shape`
- `dtypes`
- `index`
- `columns`
```
print(daily_report.shape)
print(daily_report.dtypes)
print(daily_report.index)
print(daily_report.columns)
```
## Basic methods of a `DataFrame` object
- `head(n)`
- `tail(n)`
- `describe`
- `info`
- `set_index`
- `reset_index`
## `head(n)` returns the top n observations with header
```
daily_report.head() # n is default to 5
```
## `tail(n)` returns the bottom n observations with header
```
daily_report.tail(3)
```
## `describe` returns the descriptive summary for numeric columns
```
daily_report.describe()
```
## `info` returns the concise information of the dataframe
```
daily_report.info()
```
## `set_index` replaces current `Index` with a specific variable
```
daily_report.set_index('Combined_Key')
```
## `reset_index` resets current `Index` with default `RangeIndex`
```
daily_report.set_index('Combined_Key').reset_index()
```
## Basic Dataframe Wrangling
## Basic wrangling is like writing SQL queries
- Selecting: `SELECT FROM`
- Filtering: `WHERE`
- Subsetting: `SELECT FROM WHERE`
- Indexing
- Sorting: `ORDER BY`
- Deriving
- Summarizing
- Summarizing and Grouping: `GROUP BY`
## Selecting a column as `Series`
```
print(daily_report['Country_Region'])
print(type(daily_report['Country_Region']))
```
## Selecting a column as `DataFrame`
```
print(type(daily_report[['Country_Region']]))
daily_report[['Country_Region']]
```
## Selecting multiple columns as `DataFrame`, for sure
```
cols = ['Country_Region', 'Province_State']
daily_report[cols]
```
## Filtering rows with conditional statements
```
is_taiwan = daily_report['Country_Region'] == 'Taiwan*'
daily_report[is_taiwan]
```
## Subsetting columns and rows simultaneously
```
cols_to_select = ['Country_Region', 'Confirmed']
rows_to_filter = daily_report['Country_Region'] == 'Taiwan*'
daily_report[rows_to_filter][cols_to_select]
```
## Indexing `DataFrame` with
- `loc[]`
- `iloc[]`
## `loc[]` is indexing `DataFrame` with `Index`
```
print(daily_report.loc[3388, ['Country_Region', 'Confirmed']]) # as Series
daily_report.loc[[3388], ['Country_Region', 'Confirmed']] # as DataFrame
```
## `iloc[]` is indexing `DataFrame` with absolute position
```
print(daily_report.iloc[3388, [3, 7]]) # as Series
daily_report.iloc[[3388], [3, 7]] # as DataFrame
```
## Sorting `DataFrame` with
- `sort_values`
- `sort_index`
## `sort_values` sorts `DataFrame` with specific columns
```
daily_report.sort_values(['Country_Region', 'Confirmed'])
```
## `sort_index` sorts `DataFrame` with the `Index` of `DataFrame`
```
daily_report.sort_index(ascending=False)
```
## Deriving new variables from `DataFrame`
- Simple operations
- `pd.cut`
- `map` with a `dict`
- `map` with a function(or a lambda expression)
## Deriving new variable with simple operations
```
active = daily_report['Confirmed'] - daily_report['Deaths'] - daily_report['Recovered']
print(active)
```
## Deriving categorical from numerical with `pd.cut`
```
import numpy as np
cut_bins = [0, 1000, 10000, 100000, np.Inf]
cut_labels = ['Less than 1000', 'Between 1000 and 10000', 'Between 10000 and 100000', 'Above 100000']
confirmed_categorical = pd.cut(daily_report['Confirmed'], bins=cut_bins, labels=cut_labels, right=False)
print(confirmed_categorical)
```
## Deriving categorical from categorical with `map`
- Passing a `dict`
- Passing a function(or lambda expression)
```
# Passing a dict
country_name = {
'Taiwan*': 'Taiwan'
}
daily_report_tw = daily_report[is_taiwan]
daily_report_tw['Country_Region'].map(country_name)
# Passing a function
def is_us(x):
if x == 'US':
return 'US'
else:
return 'Not US'
daily_report['Country_Region'].map(is_us)
# Passing a lambda expression)
daily_report['Country_Region'].map(lambda x: 'US' if x == 'US' else 'Not US')
```
## Summarizing `DataFrame` with aggregate methods
```
daily_report['Confirmed'].sum()
```
## Summarizing and grouping `DataFrame` with aggregate methods
```
daily_report.groupby('Country_Region')['Confirmed'].sum()
```
## More Dataframe Wrangling Operations
## Other common `Dataframe` wranglings including
- Dealing with missing values
- Dealing with text values
- Reshaping dataframes
- Merging and joining dataframes
## Dealing with missing values
- Using `isnull` or `notnull` to check if `np.NaN` exists
- Using `dropna` to drop rows with `np.NaN`
- Using `fillna` to fill `np.NaN` with specific values
```
print(daily_report['Province_State'].size)
print(daily_report['Province_State'].isnull().sum())
print(daily_report['Province_State'].notnull().sum())
print(daily_report.dropna().shape)
print(daily_report['FIPS'].fillna(0))
```
## Splitting strings with `str.split` as a `Series`
```
split_pattern = ', '
daily_report['Combined_Key'].str.split(split_pattern)
```
## Splitting strings with `str.split` as a `DataFrame`
```
split_pattern = ', '
daily_report['Combined_Key'].str.split(split_pattern, expand=True)
```
## Replacing strings with `str.replace`
```
daily_report['Combined_Key'].str.replace(", ", ';')
```
## Testing for strings that match or contain a pattern with `str.contains`
```
print(daily_report['Country_Region'].str.contains('land').sum())
daily_report[daily_report['Country_Region'].str.contains('land')]
```
## Reshaping dataframes from wide to long format with `pd.melt`
A common problem is that a dataset where some of the column names are not names of variables, but values of a variable.
```
ts_confirmed_global_url = "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv"
ts_confirmed_global = pd.read_csv(ts_confirmed_global_url)
ts_confirmed_global
```
## We can pivot the columns into a new pair of variables
To describe that operation we need four parameters:
- The set of columns whose names are not values
- The set of columns whose names are values
- The name of the variable to move the column names to
- The name of the variable to move the column values to
## In this example, the four parameters are
- `id_vars`: `['Province/State', 'Country/Region', 'Lat', 'Long']`
- `value_vars`: The columns from `1/22/20` to the last column
- `var_name`: Let's name it `Date`
- `value_name`: Let's name it `Confirmed`
```
idVars = ['Province/State', 'Country/Region', 'Lat', 'Long']
ts_confirmed_global_long = pd.melt(ts_confirmed_global,
id_vars=idVars,
var_name='Date',
value_name='Confirmed')
ts_confirmed_global_long
```
## Merging and joining dataframes
- `merge` on column names
- `join` on index
## Using `merge` function to join dataframes on columns
```
left_df = daily_report[daily_report['Country_Region'].isin(['Taiwan*', 'Japan'])]
right_df = ts_confirmed_global_long[ts_confirmed_global_long['Country/Region'].isin(['Taiwan*', 'Korea, South'])]
# default: inner join
pd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region')
# left join
pd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region', how='left')
# right join
pd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region', how='right')
```
## Using `join` method to join dataframes on index
```
left_df = daily_report[daily_report['Country_Region'].isin(['Taiwan*', 'Japan'])]
right_df = ts_confirmed_global_long[ts_confirmed_global_long['Country/Region'].isin(['Taiwan*', 'Korea, South'])]
left_df = left_df.set_index('Country_Region')
right_df = right_df.set_index('Country/Region')
# default: left join
left_df.join(right_df, lsuffix='_x', rsuffix='_y')
# inner join
left_df.join(right_df, lsuffix='_x', rsuffix='_y', how='inner')
# inner join
left_df.join(right_df, lsuffix='_x', rsuffix='_y', how='inner')
# right join
left_df.join(right_df, lsuffix='_x', rsuffix='_y', how='right')
```
|
github_jupyter
|
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
# Part 1: Training Tensorflow 2.0 Model on Azure Machine Learning Service
## Overview of the part 1
This notebook is Part 1 (Preparing Data and Model Training) of a two part workshop that demonstrates an end-to-end workflow using Tensorflow 2.0 on Azure Machine Learning service. The different components of the workshop are as follows:
- Part 1: [Model Training](https://github.com/microsoft/bert-stack-overflow/blob/master/1-Training/AzureServiceClassifier_Training.ipynb)
- Part 2: [Inferencing and Deploying a Model](https://github.com/microsoft/bert-stack-overflow/blob/master/2-Inferencing/AzureServiceClassifier_Inferencing.ipynb)
**This notebook will cover the following topics:**
- Stackoverflow question tagging problem
- Introduction to Transformer and BERT deep learning models
- Registering cleaned up training data as a Dataset
- Training the model on GPU cluster
- Monitoring training progress with built-in Tensorboard dashboard
- Automated search of best hyper-parameters of the model
- Registering the trained model for future deployment
## Prerequisites
This notebook is designed to be run in Azure ML Notebook VM. See [readme](https://github.com/microsoft/bert-stack-overflow/blob/master/README.md) file for instructions on how to create Notebook VM and open this notebook in it.
### Check Azure Machine Learning Python SDK version
This tutorial requires version 1.0.69 or higher. Let's check the version of the SDK:
```
import azureml.core
print("Azure Machine Learning Python SDK version:", azureml.core.VERSION)
```
## Stackoverflow Question Tagging Problem
In this workshop we will use powerful language understanding model to automatically route Stackoverflow questions to the appropriate support team on the example of Azure services.
One of the key tasks to ensuring long term success of any Azure service is actively responding to related posts in online forums such as Stackoverflow. In order to keep track of these posts, Microsoft relies on the associated tags to direct questions to the appropriate support team. While Stackoverflow has different tags for each Azure service (azure-web-app-service, azure-virtual-machine-service, etc), people often use the generic **azure** tag. This makes it hard for specific teams to track down issues related to their product and as a result, many questions get left unanswered.
**In order to solve this problem, we will build a model to classify posts on Stackoverflow with the appropriate Azure service tag.**
We will be using a BERT (Bidirectional Encoder Representations from Transformers) model which was published by researchers at Google AI Reasearch. Unlike prior language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of natural language processing (NLP) tasks without substantial architecture modifications.
## Why use BERT model?
[Introduction of BERT model](https://arxiv.org/pdf/1810.04805.pdf) changed the world of NLP. Many NLP problems that before relied on specialized models to achive state of the art performance are now solved with BERT better and with more generic approach.
If we look at the leaderboards on such popular NLP problems as GLUE and SQUAD, most of the top models are based on BERT:
* [GLUE Benchmark Leaderboard](https://gluebenchmark.com/leaderboard/)
* [SQuAD Benchmark Leaderboard](https://rajpurkar.github.io/SQuAD-explorer/)
Recently, Allen Institue for AI announced new language understanding system called Aristo [https://allenai.org/aristo/](https://allenai.org/aristo/). The system has been developed for 20 years, but it's performance was stuck at 60% on 8th grade science test. The result jumped to 90% once researchers adopted BERT as core language understanding component. With BERT Aristo now solves the test with A grade.
## Quick Overview of How BERT model works
The foundation of BERT model is Transformer model, which was introduced in [Attention Is All You Need paper](https://arxiv.org/abs/1706.03762). Before that event the dominant way of processing language was Recurrent Neural Networks (RNNs). Let's start our overview with RNNs.
## RNNs
RNNs were powerful way of processing language due to their ability to memorize its previous state and perform sophisticated inference based on that.
<img src="https://miro.medium.com/max/400/1*L38xfe59H5tAgvuIjKoWPg.png" alt="Drawing" style="width: 100px;"/>
_Taken from [1](https://towardsdatascience.com/transformers-141e32e69591)_
Applied to language translation task, the processing dynamics looked like this.
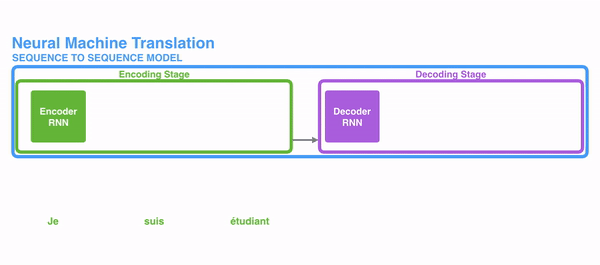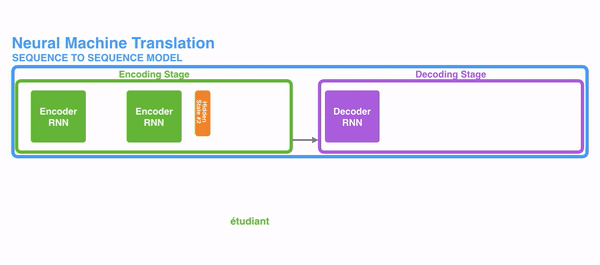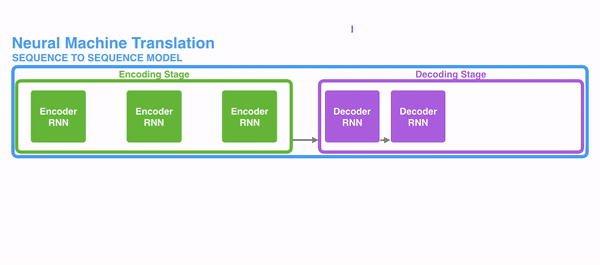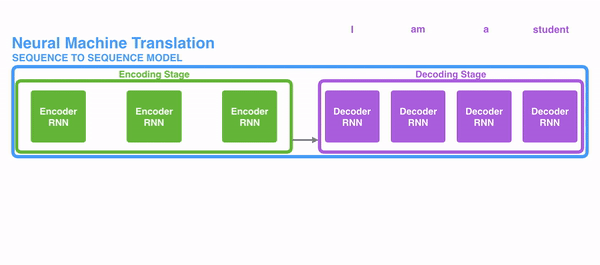
_Taken from [2](https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/)_
But RNNs suffered from 2 disadvantes:
1. Sequential computation put a limit on parallelization, which limited effectiveness of larger models.
2. Long term relationships between words were harder to detect.
## Transformers
Transformers were designed to address these two limitations of RNNs.
<img src="https://miro.medium.com/max/2436/1*V2435M1u0tiSOz4nRBfl4g.png" alt="Drawing" style="width: 500px;"/>
_Taken from [3](http://jalammar.github.io/illustrated-transformer/)_
In each Encoder layer Transformer performs Self-Attention operation which detects relationships between all word embeddings in one matrix multiplication operation.
<img src="https://miro.medium.com/max/2176/1*fL8arkEFVKA3_A7VBgapKA.gif" alt="Drawing" style="width: 500px;"/>
_Taken from [4](https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1)_
## BERT Model
BERT is a very large network with multiple layers of Transformers (12 for BERT-base, and 24 for BERT-large). The model is first pre-trained on large corpus of text data (WikiPedia + books) using un-superwised training (predicting masked words in a sentence). During pre-training the model absorbs significant level of language understanding.
<img src="http://jalammar.github.io/images/bert-output-vector.png" alt="Drawing" style="width: 700px;"/>
_Taken from [5](http://jalammar.github.io/illustrated-bert/)_
Pre-trained network then can easily be fine-tuned to solve specific language task, like answering questions, or categorizing spam emails.
<img src="http://jalammar.github.io/images/bert-classifier.png" alt="Drawing" style="width: 700px;"/>
_Taken from [5](http://jalammar.github.io/illustrated-bert/)_
The end-to-end training process of the stackoverflow question tagging model looks like this:

## What is Azure Machine Learning Service?
Azure Machine Learning service is a cloud service that you can use to develop and deploy machine learning models. Using Azure Machine Learning service, you can track your models as you build, train, deploy, and manage them, all at the broad scale that the cloud provides.

#### How can we use it for training machine learning models?
Training machine learning models, particularly deep neural networks, is often a time- and compute-intensive task. Once you've finished writing your training script and running on a small subset of data on your local machine, you will likely want to scale up your workload.
To facilitate training, the Azure Machine Learning Python SDK provides a high-level abstraction, the estimator class, which allows users to easily train their models in the Azure ecosystem. You can create and use an Estimator object to submit any training code you want to run on remote compute, whether it's a single-node run or distributed training across a GPU cluster.
## Connect To Workspace
The [workspace](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.workspace(class)?view=azure-ml-py) is the top-level resource for Azure Machine Learning, providing a centralized place to work with all the artifacts you create when you use Azure Machine Learning. The workspace holds all your experiments, compute targets, models, datastores, etc.
You can [open ml.azure.com](https://ml.azure.com) to access your workspace resources through a graphical user interface of **Azure Machine Learning studio**.

**You will be asked to login in the next step. Use your Microsoft AAD credentials.**
```
from azureml.core import Workspace
workspace = Workspace.from_config()
print('Workspace name: ' + workspace.name,
'Azure region: ' + workspace.location,
'Subscription id: ' + workspace.subscription_id,
'Resource group: ' + workspace.resource_group, sep = '\n')
```
## Create Compute Target
A [compute target](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.computetarget?view=azure-ml-py) is a designated compute resource/environment where you run your training script or host your service deployment. This location may be your local machine or a cloud-based compute resource. Compute targets can be reused across the workspace for different runs and experiments.
For this tutorial, we will create an auto-scaling [Azure Machine Learning Compute](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute?view=azure-ml-py) cluster, which is a managed-compute infrastructure that allows the user to easily create a single or multi-node compute. To create the cluster, we need to specify the following parameters:
- `vm_size`: The is the type of GPUs that we want to use in our cluster. For this tutorial, we will use **Standard_NC12s_v2 (NVIDIA P100) GPU Machines** .
- `idle_seconds_before_scaledown`: This is the number of seconds before a node will scale down in our auto-scaling cluster. We will set this to **6000** seconds.
- `min_nodes`: This is the minimum numbers of nodes that the cluster will have. To avoid paying for compute while they are not being used, we will set this to **0** nodes.
- `max_modes`: This is the maximum number of nodes that the cluster will scale up to. Will will set this to **2** nodes.
**When jobs are submitted to the cluster it takes approximately 5 minutes to allocate new nodes**
```
from azureml.core.compute import AmlCompute, ComputeTarget
cluster_name = 'p100cluster'
compute_config = AmlCompute.provisioning_configuration(vm_size='Standard_NC12s_v2',
idle_seconds_before_scaledown=6000,
min_nodes=0,
max_nodes=2)
compute_target = ComputeTarget.create(workspace, cluster_name, compute_config)
compute_target.wait_for_completion(show_output=True)
```
To ensure our compute target was created successfully, we can check it's status.
```
compute_target.get_status().serialize()
```
#### If the compute target has already been created, then you (and other users in your workspace) can directly run this cell.
```
compute_target = workspace.compute_targets['p100cluster']
```
## Prepare Data Using Apache Spark
To train our model, we used the Stackoverflow data dump from [Stack exchange archive](https://archive.org/download/stackexchange). Since the Stackoverflow _posts_ dataset is 12GB, we prepared the data using [Apache Spark](https://spark.apache.org/) framework on a scalable Spark compute cluster in [Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/).
For the purpose of this tutorial, we have processed the data ahead of time and uploaded it to an [Azure Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/) container. The full data processing notebook can be found in the _spark_ folder.
* **ACTION**: Open and explore [data preparation notebook](spark/stackoverflow-data-prep.ipynb).
## Register Datastore
A [Datastore](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py) is used to store connection information to a central data storage. This allows you to access your storage without having to hard code this (potentially confidential) information into your scripts.
In this tutorial, the data was been previously prepped and uploaded into a central [Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/) container. We will register this container into our workspace as a datastore using a [shared access signature (SAS) token](https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview).
```
from azureml.core import Datastore, Dataset
datastore_name = 'tfworld'
container_name = 'azureml-blobstore-7c6bdd88-21fa-453a-9c80-16998f02935f'
account_name = 'tfworld6818510241'
sas_token = '?sv=2019-02-02&ss=bfqt&srt=sco&sp=rl&se=2021-01-01T06:07:44Z&st=2020-01-11T22:00:44Z&spr=https&sig=geV1mc46gEv9yLBsWjnlJwij%2Blg4qN53KFyyK84tn3Q%3D'
datastore = Datastore.register_azure_blob_container(workspace=workspace,
datastore_name=datastore_name,
container_name=container_name,
account_name=account_name,
sas_token=sas_token)
```
#### If the datastore has already been registered, then you (and other users in your workspace) can directly run this cell.
```
datastore = workspace.datastores['tfworld']
```
#### What if my data wasn't already hosted remotely?
All workspaces also come with a blob container which is registered as a default datastore. This allows you to easily upload your own data to a remote storage location. You can access this datastore and upload files as follows:
```
datastore = workspace.get_default_datastore()
ds.upload(src_dir='<LOCAL-PATH>', target_path='<REMOTE-PATH>')
```
## Register Dataset
Azure Machine Learning service supports first class notion of a Dataset. A [Dataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.dataset.dataset?view=azure-ml-py) is a resource for exploring, transforming and managing data in Azure Machine Learning. The following Dataset types are supported:
* [TabularDataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.tabulardataset?view=azure-ml-py) represents data in a tabular format created by parsing the provided file or list of files.
* [FileDataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.filedataset?view=azure-ml-py) references single or multiple files in datastores or from public URLs.
We can use visual tools in Azure ML studio to register and explore dataset. In this workshop we will skip this step to save time. After the workshop please explore visual way of creating dataset as your homework. Use the guide below as guiding steps.
* **Homework**: After workshop follow [create-dataset](images/create-dataset.ipynb) guide to create Tabular Dataset from our training data using visual tools in studio.
#### Use created dataset in code
```
from azureml.core import Dataset
# Get a dataset by name
tabular_ds = Dataset.get_by_name(workspace=workspace, name='Stackoverflow dataset')
# Load a TabularDataset into pandas DataFrame
df = tabular_ds.to_pandas_dataframe()
df.head(10)
```
## Register Dataset using SDK
In addition to UI we can register datasets using SDK. In this workshop we will register second type of Datasets using code - File Dataset. File Dataset allows specific folder in our datastore that contains our data files to be registered as a Dataset.
There is a folder within our datastore called **azure-service-data** that contains all our training and testing data. We will register this as a dataset.
```
azure_dataset = Dataset.File.from_files(path=(datastore, 'azure-service-classifier/data'))
azure_dataset = azure_dataset.register(workspace=workspace,
name='Azure Services Dataset',
description='Dataset containing azure related posts on Stackoverflow')
```
#### If the dataset has already been registered, then you (and other users in your workspace) can directly run this cell.
```
azure_dataset = workspace.datasets['Azure Services Dataset']
```
## Explore Training Code
In this workshop the training code is provided in [train.py](./train.py) and [model.py](./model.py) files. The model is based on popular [huggingface/transformers](https://github.com/huggingface/transformers) libary. Transformers library provides performant implementation of BERT model with high level and easy to use APIs based on Tensorflow 2.0.

* **ACTION**: Explore _train.py_ and _model.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)
* NOTE: You can also explore the files using Jupyter or Jupyter Lab UI.
## Test Locally
Let's try running the script locally to make sure it works before scaling up to use our compute cluster. To do so, you will need to install the transformers libary.
```
%pip install transformers==2.0.0
```
We have taken a small partition of the dataset and included it in this repository. Let's take a quick look at the format of the data.
```
data_dir = './data'
import os
import pandas as pd
data = pd.read_csv(os.path.join(data_dir, 'train.csv'), header=None)
data.head(5)
```
Now we know what the data looks like, let's test out our script!
```
import sys
!{sys.executable} train.py --data_dir {data_dir} --max_seq_length 128 --batch_size 16 --learning_rate 3e-5 --steps_per_epoch 5 --num_epochs 1 --export_dir ../outputs/model
```
## Homework: Debugging in TensorFlow 2.0 Eager Mode
Eager mode is new feature in TensorFlow 2.0 which makes understanding and debugging models easy. You can use VS Code Remote feature to connect to Notebook VM and perform debugging in the cloud environment.
#### More info: Configuring VS Code Remote connection to Notebook VM
* Homework: Install [Microsoft VS Code](https://code.visualstudio.com/) on your local machine.
* Homework: Follow this [configuration guide](https://github.com/danielsc/azureml-debug-training/blob/master/Setting%20up%20VSCode%20Remote%20on%20an%20AzureML%20Notebook%20VM.md) to setup VS Code Remote connection to Notebook VM.
On a CPU machine training on a full dataset will take approximatly 1.5 hours. Although it's a small dataset, it still takes a long time. Let's see how we can speed up the training by using latest NVidia V100 GPUs in the Azure cloud.
## Perform Experiment
Now that we have our compute target, dataset, and training script working locally, it is time to scale up so that the script can run faster. We will start by creating an [experiment](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.experiment.experiment?view=azure-ml-py). An experiment is a grouping of many runs from a specified script. All runs in this tutorial will be performed under the same experiment.
```
from azureml.core import Experiment
experiment_name = 'azure-service-classifier'
experiment = Experiment(workspace, name=experiment_name)
```
#### Create TensorFlow Estimator
The Azure Machine Learning Python SDK Estimator classes allow you to easily construct run configurations for your experiments. They allow you too define parameters such as the training script to run, the compute target to run it on, framework versions, additional package requirements, etc.
You can also use a generic [Estimator](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.estimator.estimator?view=azure-ml-py) to submit training scripts that use any learning framework you choose.
For popular libaries like PyTorch and Tensorflow you can use their framework specific estimators. We will use the [TensorFlow Estimator](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.dnn.tensorflow?view=azure-ml-py) for our experiment.
```
from azureml.train.dnn import TensorFlow
estimator1 = TensorFlow(source_directory='.',
entry_script='train_logging.py',
compute_target=compute_target,
script_params = {
'--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),
'--max_seq_length': 128,
'--batch_size': 32,
'--learning_rate': 3e-5,
'--steps_per_epoch': 150,
'--num_epochs': 3,
'--export_dir':'./outputs/model'
},
framework_version='2.0',
use_gpu=True,
pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])
```
A quick description for each of the parameters we have just defined:
- `source_directory`: This specifies the root directory of our source code.
- `entry_script`: This specifies the training script to run. It should be relative to the source_directory.
- `compute_target`: This specifies to compute target to run the job on. We will use the one created earlier.
- `script_params`: This specifies the input parameters to the training script. Please note:
1) *azure_dataset.as_named_input('azureservicedata').as_mount()* mounts the dataset to the remote compute and provides the path to the dataset on our datastore.
2) All outputs from the training script must be outputted to an './outputs' directory as this is the only directory that will be saved to the run.
- `framework_version`: This specifies the version of TensorFlow to use. Use Tensorflow.get_supported_verions() to see all supported versions.
- `use_gpu`: This will use the GPU on the compute target for training if set to True.
- `pip_packages`: This allows you to define any additional libraries to install before training.
#### 1) Submit a Run
We can now train our model by submitting the estimator object as a [run](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.run.run?view=azure-ml-py).
```
run1 = experiment.submit(estimator1)
```
We can view the current status of the run and stream the logs from within the notebook.
```
from azureml.widgets import RunDetails
RunDetails(run1).show()
```
You cancel a run at anytime which will stop the run and scale down the nodes in the compute target.
```
run1.cancel()
```
While we wait for the run to complete, let's go over how a Run is executed in Azure Machine Learning.

#### 2) Monitoring metrics with Azure ML SDK
To monitor performance of our model we log those metrics using a few lines of code in our training script:
```python
# 1) Import SDK Run object
from azureml.core.run import Run
# 2) Get current service context
run = Run.get_context()
# 3) Log the metrics that we want
run.log('val_accuracy', float(logs.get('val_accuracy')))
run.log('accuracy', float(logs.get('accuracy')))
```
#### 3) Monitoring metrics with Tensorboard
Tensorboard is a popular Deep Learning Training visualization tool and it's built-in into TensorFlow framework. We can easily add tracking of the metrics in Tensorboard format by adding Tensorboard callback to the **fit** function call.
```python
# Add callback to record Tensorboard events
model.fit(train_dataset, epochs=FLAGS.num_epochs,
steps_per_epoch=FLAGS.steps_per_epoch, validation_data=valid_dataset,
callbacks=[
AmlLogger(),
tf.keras.callbacks.TensorBoard(update_freq='batch')]
)
```
* **ACTION**: Explore _train_logging.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)
#### Launch Tensorboard
Azure ML service provides built-in integration with Tensorboard through **tensorboard** package.
While the run is in progress (or after it has completed), we can start Tensorboard with the run as its target, and it will begin streaming logs.
```
from azureml.tensorboard import Tensorboard
# The Tensorboard constructor takes an array of runs, so be sure and pass it in as a single-element array here
tb = Tensorboard([run1])
# If successful, start() returns a string with the URI of the instance.
tb.start()
```
#### Stop Tensorboard
When you're done, make sure to call the stop() method of the Tensorboard object, or it will stay running even after your job completes.
```
tb.stop()
```
## Check the model performance
Last training run produced model of decent accuracy. Let's test it out and see what it does. First, let's check what files our latest training run produced and download the model files.
#### Download model files
```
run1.get_file_names()
run1.download_files(prefix='outputs/model')
# If you haven't finished training the model then just download pre-made model from datastore
datastore.download('./',prefix="azure-service-classifier/model")
```
#### Instantiate the model
Next step is to import our model class and instantiate fine-tuned model from the model file.
```
from model import TFBertForMultiClassification
from transformers import BertTokenizer
import tensorflow as tf
def encode_example(text, max_seq_length):
# Encode inputs using tokenizer
inputs = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_seq_length
)
input_ids, token_type_ids = inputs["input_ids"], inputs["token_type_ids"]
# The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.
attention_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_length - len(input_ids)
input_ids = input_ids + ([0] * padding_length)
attention_mask = attention_mask + ([0] * padding_length)
token_type_ids = token_type_ids + ([0] * padding_length)
return input_ids, attention_mask, token_type_ids
labels = ['azure-web-app-service', 'azure-storage', 'azure-devops', 'azure-virtual-machine', 'azure-functions']
# Load model and tokenizer
loaded_model = TFBertForMultiClassification.from_pretrained('azure-service-classifier/model', num_labels=len(labels))
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
print("Model loaded from disk.")
```
#### Define prediction function
Using the model object we can interpret new questions and predict what Azure service they talk about. To do that conveniently we'll define **predict** function.
```
# Prediction function
def predict(question):
input_ids, attention_mask, token_type_ids = encode_example(question, 128)
predictions = loaded_model.predict({
'input_ids': tf.convert_to_tensor([input_ids], dtype=tf.int32),
'attention_mask': tf.convert_to_tensor([attention_mask], dtype=tf.int32),
'token_type_ids': tf.convert_to_tensor([token_type_ids], dtype=tf.int32)
})
prediction = labels[predictions[0].argmax().item()]
probability = predictions[0].max()
result = {
'prediction': str(labels[predictions[0].argmax().item()]),
'probability': str(predictions[0].max())
}
print('Prediction: {}'.format(prediction))
print('Probability: {}'.format(probability))
```
#### Experiment with our new model
Now we can easily test responses of the model to new inputs.
* **ACTION**: Invent your own input for one of the 5 services our model understands: 'azure-web-app-service', 'azure-storage', 'azure-devops', 'azure-virtual-machine', 'azure-functions'.
```
# Route question
predict("How can I specify Service Principal in devops pipeline when deploying virtual machine")
# Now more tricky case - the opposite
predict("How can virtual machine trigger devops pipeline")
```
## Distributed Training Across Multiple GPUs
Distributed training allows us to train across multiple nodes if your cluster allows it. Azure Machine Learning service helps manage the infrastructure for training distributed jobs. All we have to do is add the following parameters to our estimator object in order to enable this:
- `node_count`: The number of nodes to run this job across. Our cluster has a maximum node limit of 2, so we can set this number up to 2.
- `process_count_per_node`: The number of processes to enable per node. The nodes in our cluster have 2 GPUs each. We will set this value to 2 which will allow us to distribute the load on both GPUs. Using multi-GPUs nodes is benefitial as communication channel bandwidth on local machine is higher.
- `distributed_training`: The backend to use for our distributed job. We will be using an MPI (Message Passing Interface) backend which is used by Horovod framework.
We use [Horovod](https://github.com/horovod/horovod), which is a framework that allows us to easily modifying our existing training script to be run across multiple nodes/GPUs. The distributed training script is saved as *train_horovod.py*.
* **ACTION**: Explore _train_horovod.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)
We can submit this run in the same way that we did with the others, but with the additional parameters.
```
from azureml.train.dnn import Mpi
estimator3 = TensorFlow(source_directory='./',
entry_script='train_horovod.py',compute_target=compute_target,
script_params = {
'--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),
'--max_seq_length': 128,
'--batch_size': 32,
'--learning_rate': 3e-5,
'--steps_per_epoch': 150,
'--num_epochs': 3,
'--export_dir':'./outputs/model'
},
framework_version='2.0',
node_count=1,
distributed_training=Mpi(process_count_per_node=2),
use_gpu=True,
pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])
run3 = experiment.submit(estimator3)
```
Once again, we can view the current details of the run.
```
from azureml.widgets import RunDetails
RunDetails(run3).show()
```
Once the run completes note the time it took. It should be around 5 minutes. As you can see, by moving to the cloud GPUs and using distibuted training we managed to reduce training time of our model from more than an hour to 5 minutes. This greatly improves speed of experimentation and innovation.
## Tune Hyperparameters Using Hyperdrive
So far we have been putting in default hyperparameter values, but in practice we would need tune these values to optimize the performance. Azure Machine Learning service provides many methods for tuning hyperparameters using different strategies.
The first step is to choose the parameter space that we want to search. We have a few choices to make here :
- **Parameter Sampling Method**: This is how we select the combinations of parameters to sample. Azure Machine Learning service offers [RandomParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.randomparametersampling?view=azure-ml-py), [GridParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.gridparametersampling?view=azure-ml-py), and [BayesianParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.bayesianparametersampling?view=azure-ml-py). We will use the `GridParameterSampling` method.
- **Parameters To Search**: We will be searching for optimal combinations of `learning_rate` and `num_epochs`.
- **Parameter Expressions**: This defines the [functions that can be used to describe a hyperparameter search space](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.parameter_expressions?view=azure-ml-py), which can be discrete or continuous. We will be using a `discrete set of choices`.
The following code allows us to define these options.
```
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive.parameter_expressions import choice
param_sampling = GridParameterSampling( {
'--learning_rate': choice(3e-5, 3e-4),
'--num_epochs': choice(3, 4)
}
)
```
The next step is to a define how we want to measure our performance. We do so by specifying two classes:
- **[PrimaryMetricGoal](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.primarymetricgoal?view=azure-ml-py)**: We want to `MAXIMIZE` the `val_accuracy` that is logged in our training script.
- **[BanditPolicy](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.banditpolicy?view=azure-ml-py)**: A policy for early termination so that jobs which don't show promising results will stop automatically.
```
from azureml.train.hyperdrive import BanditPolicy
from azureml.train.hyperdrive import PrimaryMetricGoal
primary_metric_name='val_accuracy'
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=2)
```
We define an estimator as usual, but this time without the script parameters that we are planning to search.
```
estimator4 = TensorFlow(source_directory='./',
entry_script='train_logging.py',
compute_target=compute_target,
script_params = {
'--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),
'--max_seq_length': 128,
'--batch_size': 32,
'--steps_per_epoch': 150,
'--export_dir':'./outputs/model',
},
framework_version='2.0',
use_gpu=True,
pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])
```
Finally, we add all our parameters in a [HyperDriveConfig](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.hyperdriveconfig?view=azure-ml-py) class and submit it as a run.
```
from azureml.train.hyperdrive import HyperDriveConfig
hyperdrive_run_config = HyperDriveConfig(estimator=estimator4,
hyperparameter_sampling=param_sampling,
policy=early_termination_policy,
primary_metric_name=primary_metric_name,
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,
max_total_runs=10,
max_concurrent_runs=2)
run4 = experiment.submit(hyperdrive_run_config)
```
When we view the details of our run this time, we will see information and metrics for every run in our hyperparameter tuning.
```
from azureml.widgets import RunDetails
RunDetails(run4).show()
```
We can retrieve the best run based on our defined metric.
```
best_run = run4.get_best_run_by_primary_metric()
```
## Register Model
A registered [model](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.model(class)?view=azure-ml-py) is a reference to the directory or file that make up your model. After registering a model, you and other people in your workspace can easily gain access to and deploy your model without having to run the training script again.
We need to define the following parameters to register a model:
- `model_name`: The name for your model. If the model name already exists in the workspace, it will create a new version for the model.
- `model_path`: The path to where the model is stored. In our case, this was the *export_dir* defined in our estimators.
- `description`: A description for the model.
Let's register the best run from our hyperparameter tuning.
```
model = best_run.register_model(model_name='azure-service-classifier',
model_path='./outputs/model',
datasets=[('train, test, validation data', azure_dataset)],
description='BERT model for classifying azure services on stackoverflow posts.')
```
We have registered the model with Dataset reference.
* **ACTION**: Check dataset to model link in **Azure ML studio > Datasets tab > Azure Service Dataset**.
In the [next tutorial](), we will perform inferencing on this model and deploy it to a web service.
|
github_jupyter
|
# Introduction
© Harishankar Manikantan, maintained on GitHub at [hmanikantan/ECH60](https://github.com/hmanikantan/ECH60) and published under an [MIT license](https://github.com/hmanikantan/ECH60/blob/master/LICENSE).
Return to [Course Home Page](https://hmanikantan.github.io/ECH60/)
**[Context and Scope](#scope) <br>**
**[Getting used to Python](#install)**
* [Installing and Using Python](#start)
* [Useful tips](#tips)
<a id='scope'></a>
## Context and Scope
This set of tutorials are written at an introductory level for an engineering or physical sciences major. It is ideal for someone who has completed college level courses in linear algebra, calculus and differential equations. While prior experience with programming is a certain advantage, it is not expected. At UC Davis, this is aimed at sophomore level Chemical and Biochemical Engineers and Materials Scientists: examples and the language used here might reflect this. At the same time, this is not meant to be an exhaustive course in Python or in numerical methods.
The objective of the module is to get the reader to appreciate and apply Python to basic scientific calculations. While computational efficiency and succinct programming are certainly factors that become important to advanced coders, the focus here is on learning the methods. Brevity will often be forsaken for clarity in what follows. The goal is to flatten the learning curve as much as possible for a beginner.
In the same vein, most of the 'application' chapters (fitting, root finding, calculus and differential equations) introduces classic numerical methods built from first principles but then also provides the inbuilt Python routine to do the same. These 'black-box' approaches are often more efficient because they are written by experts in the most efficient and optimal manner. The hope is that the reader learns and appreciates the methods and the algorithms behind these approaches, while also learning to use the easiest and most efficient tools to get the job done.
These are casual notes based on a course taught at UC Davis and are certainly not free of errors. Typos and coding gaffes are sure to have escaped my attention, and I take full responsibility for errors. For those comfortable with GitHub, I welcome pull requests for modifications. Or just send me an [email](mailto:[email protected]) with any mistakes you spot, and I will be greateful. Outside of technical accuracy, I have taken an approach that favors a pedagogic development of topics, one that I hoped would least intimidate an engineer in training with no prior experience in coding. Criticism and feedback on stylistic changes in this spirit are also welcome.
I recommend the following wonderful books that have guided aspects of the course that I teach with these notes.
* [A Student's Guide to Python for Physical Modeling, Jesse M. Kinder & Philip Nelson, Princeton University Press](https://press.princeton.edu/books/hardcover/9780691180564/a-students-guide-to-python-for-physical-modeling)
* [Numerical Methods for Engineers and Scientists, Amos Gilat & Vish Subramaniam, Wiley](https://www.wiley.com/en-us/Numerical+Methods+for+Engineers+and+Scientists%2C+3rd+Edition-p-9781118554937)
* [Numerical Methods in Engineering with Python 3, Jaan Kiusalaas, Cambridge University Press](https://doi.org/10.1017/CBO9781139523899)
While any of these books provide a fantastic introduction to the topic, I believe that interactive tutorials using the Jupyter framework provide an engaging complement to learning numerical methods. Yet I was unable to find a set of pedagogic and interactive code notebooks that covered the range of topics suitable for this level of instruction. I have hoped to fill this gap. If you are new to coding, the best way to learn is to download these notebooks from the GitHub repository (linked at the course [home page](https://hmanikantan.github.io/ECH60/)), and edit and execute every code cell in these chapters as you read through them. Details on installing and using Python are below.
My ECH 60 students beta tested these tutorials, and their learning styles, feedback and comments crafted the structure of this series. And finally, the world of Python is a fantastic testament to the power of open-source science and learning. I thank the countless selfless nameless strangers whose stackoverflow comments have informed me, and whose coding styles have inadvertently creeped in to my interpretation of the code and style in what follows. And I thank the generous online notes of [John Kitchin](https://kitchingroup.cheme.cmu.edu/pycse/pycse.html), [Patrick Walls](https://www.math.ubc.ca/~pwalls/math-python/), [Vivi Andasari](http://people.bu.edu/andasari/courses/numericalpython/python.html), [Charles Jekel](https://github.com/cjekel/Introduction-to-Python-Numerical-Analysis-for-Engineers-and-Scientist), and [Jeffrey Kantor](https://github.com/jckantor) whose works directly or indirectly inspired and influenced what follows. I am happy to contribute to this collective knowledge base, free for anyone to adapt, build on, and make it their own.
<a id='install'></a>
## Getting Used to Python
Python is a popular, powerful and free prgramming language that is rapidly becoming one of [the most widely used computational tools](https://stackoverflow.blog/2017/09/06/incredible-growth-python/) in science and engineering. Python is notable for its minimalist syntax, clear and logical flow of code, efficient organization, readily and freely available 'plug and play' modules for every kind of advanced scientific computation, and the massive online community of support. This makes Python easy to learn for beginners, and extremely convenient to adapt for those transitioning from other languages.
<a id='start'></a>
### Installing and Using Python
Python is free to download and use. The [Anaconda distribution](https://www.anaconda.com) is a user-friendly way to get Python on your computer. Anaconda is free and easy to install on all platforms. It installs the Python language, and related useful packages like Jupyter and Spyder.
#### Jupyter
The Jupyter environment allows interactive computations and runs on any browser. This file you are reading is written using Jupyter, and each such file is saved with a `.ipynb` extension. To open an ipynb file, first open Jupyter from the Anaconda launch screen. Once you have Jupyter up and runnning, navigate to the folder where you saved the file and double click to open. Alternatively, you can launch Jupyter by typing `jupyter notebook` in your terminal prompt. Note that you can only open files after you launch Jupyter and navigate to the folder containing your ipynb file. You cannot simply double click, or use a 'right click and open with' option.
Jupyter allows us to write and edit plain text (like the one you are reading) and code. This paragraph and the ones above are 'mark down' text: meaning, Jupyter treats them as plain text. From within Jupyter, double click anywhere on the text to go into 'edit' mode. When you are done changing anything, hit `shift+enter` to exit to the 'view' mode.
You can toggle between markdown and code using the drop down in the menu above. Code cells look like the following
```
print('Hello')
```
Single click on a code cell to select it, edit it, and hit `shift+enter` to execute that bit of code. For example, the following code cell evaluates the sum of two numbers when you execute it. Try it, type in any two numbers, see what happens.
```
# add two numbers
2+40
```
The `#` sign is useful to write comments in Python, and are not executed.
Play around with all editable code cells in these tutorials so you get comfortable. The more you practice, the faster you will get comfortable with coding and Python.
Jupyter allows LaTeX as well in the markdown cells: so you can write things like $\alpha+i \sqrt{\beta}=e^{i\theta}$. You can also play around with fonts, colors, sizes, hyperlinks, and text organization. This makes Jupyter a great environment for teaching, learning, tutorials, assignments, and academic reports. This entire course is written and tested in the Jupyter environment.
#### Spyder
An integrated development environment (IDE) like Spyder is more apt for longer projects. Spyder has features like variable explorer, script editor, live debugging, history log, and more. For those comfortable with Matlab or R, adapting to Spyder is an easy learning curve. The ipynb files will not open in a usable manner in Spyder (or any other Python IDE) as it contains markdown text in addition to code. However, every bit of code that we will learn in what follows works in Spyder or a similar IDE. When using Spyder, save the code as 'script' files with a `.py` extension. This is the traditional or standard Python format: just code, no markdown.
Another big advantage with `.py` files is modularity: bit of code written in one file can be easily accessed in another. This makes the traditional `.py` Python format more suitable for large-scale and collaborative projects. Nevertheless, for pedagogic reasons, we will continue with Jupyter notebooks and the `.ipynb` files for this course: as you learn Python, you are heavily encouraged to get comfortable with and port all the code you develop into Spyder.
#### Python, more generally
Of course, Anaconda (and it's inbuilt environments like Jupyter and Spyder) are not the only ways to interact with Python. You can install just the Python language directly from [Python.org](https://www.python.org/downloads/), write a bit of Python code in any text editor, save it as a `.py` file, and run it on your terminal using `python filename.py`. Python is an _interpreted_ language, meaning you do not need to compile it to execute it (unlike C, C++, Fortran etc) and you can run the scripts directly.
<a id='tips'></a>
### Useful Tips
Whether you are a beginner to coding or a seasoned coder transitioning from another language, the following (non-exhaustive) tips are useful to bear in mind as you learn Python:
* Blocks of code in Python are identified by indentation. We will see this when we start with loops and conditional and functions in Chapter 1: indents (and a preliminary colon) identify lines of code that go together. As you learn to go through and Python code, it is good practice to ensure an 'indentation discipline'. That's the only way Python knows which bits of code belong together.
* All but the most basic Python operations will need imported _modules_. Modules are collections of code written in an efficient manner, and are easily 'loaded' into your code by using the `import` statement. For example, a common module that you will find yourself using in pretty much every engineering code is `numpy` (Chapter 1), which you would import using the line `import numpy`. This doesn't have to be in the beginning of the code, as long as it is executed before you use something that belongs to `numpy`.
* Individual code cells in Jupyter are executed independent of the rest of the notebook. So, make sure to execute the `import` line for necessary modules before you execute a code cell that needs that module or you will see an error.
* If you need to import a data file or an image, Python looks for that file in the current folder unless you provide a full path. The same goes when you save an image or export a data file: the exported file is saved in the current directly unless explicitly stated.
* Notebook files with an `.ipynb` extension can only be opened, edited or renamed from within the Jupyter framework. Opening these files in a text editor or another application, even when possible, does not display the markdown or code in a comprehensible manner.
|
github_jupyter
|
# Softmax exercise
*Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the [assignments page](http://vision.stanford.edu/teaching/cs231n/assignments.html) on the course website.*
This exercise is analogous to the SVM exercise. You will:
- implement a fully-vectorized **loss function** for the Softmax classifier
- implement the fully-vectorized expression for its **analytic gradient**
- **check your implementation** with numerical gradient
- use a validation set to **tune the learning rate and regularization** strength
- **optimize** the loss function with **SGD**
- **visualize** the final learned weights
```
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
from __future__ import print_function
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading extenrnal modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000, num_dev=500):
"""
Load the CIFAR-10 dataset from disk and perform preprocessing to prepare
it for the linear classifier. These are the same steps as we used for the
SVM, but condensed to a single function.
"""
# Load the raw CIFAR-10 data
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# subsample the data
mask = list(range(num_training, num_training + num_validation))
X_val = X_train[mask]
y_val = y_train[mask]
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
mask = np.random.choice(num_training, num_dev, replace=False)
X_dev = X_train[mask]
y_dev = y_train[mask]
# Preprocessing: reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_val = np.reshape(X_val, (X_val.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
X_dev = np.reshape(X_dev, (X_dev.shape[0], -1))
# Normalize the data: subtract the mean image
mean_image = np.mean(X_train, axis = 0)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
X_dev -= mean_image
# add bias dimension and transform into columns
X_train = np.hstack([X_train, np.ones((X_train.shape[0], 1))])
X_val = np.hstack([X_val, np.ones((X_val.shape[0], 1))])
X_test = np.hstack([X_test, np.ones((X_test.shape[0], 1))])
X_dev = np.hstack([X_dev, np.ones((X_dev.shape[0], 1))])
return X_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev
# Invoke the above function to get our data.
X_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev = get_CIFAR10_data()
print('Train data shape: ', X_train.shape)
print('Train labels shape: ', y_train.shape)
print('Validation data shape: ', X_val.shape)
print('Validation labels shape: ', y_val.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
print('dev data shape: ', X_dev.shape)
print('dev labels shape: ', y_dev.shape)
```
## Softmax Classifier
Your code for this section will all be written inside **cs231n/classifiers/softmax.py**.
```
# First implement the naive softmax loss function with nested loops.
# Open the file cs231n/classifiers/softmax.py and implement the
# softmax_loss_naive function.
from cs231n.classifiers.softmax import softmax_loss_naive
import time
# Generate a random softmax weight matrix and use it to compute the loss.
W = np.random.randn(3073, 10) * 0.0001
loss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)
# As a rough sanity check, our loss should be something close to -log(0.1).
print('loss: %f' % loss)
print('sanity check: %f' % (-np.log(0.1)))
```
## Inline Question 1:
Why do we expect our loss to be close to -log(0.1)? Explain briefly.**
**Your answer:** *Fill this in*
```
# Complete the implementation of softmax_loss_naive and implement a (naive)
# version of the gradient that uses nested loops.
loss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)
# As we did for the SVM, use numeric gradient checking as a debugging tool.
# The numeric gradient should be close to the analytic gradient.
from cs231n.gradient_check import grad_check_sparse
f = lambda w: softmax_loss_naive(w, X_dev, y_dev, 0.0)[0]
grad_numerical = grad_check_sparse(f, W, grad, 10)
# similar to SVM case, do another gradient check with regularization
loss, grad = softmax_loss_naive(W, X_dev, y_dev, 5e1)
f = lambda w: softmax_loss_naive(w, X_dev, y_dev, 5e1)[0]
grad_numerical = grad_check_sparse(f, W, grad, 10)
# Now that we have a naive implementation of the softmax loss function and its gradient,
# implement a vectorized version in softmax_loss_vectorized.
# The two versions should compute the same results, but the vectorized version should be
# much faster.
tic = time.time()
loss_naive, grad_naive = softmax_loss_naive(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('naive loss: %e computed in %fs' % (loss_naive, toc - tic))
from cs231n.classifiers.softmax import softmax_loss_vectorized
tic = time.time()
loss_vectorized, grad_vectorized = softmax_loss_vectorized(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))
# As we did for the SVM, we use the Frobenius norm to compare the two versions
# of the gradient.
grad_difference = np.linalg.norm(grad_naive - grad_vectorized, ord='fro')
print('Loss difference: %f' % np.abs(loss_naive - loss_vectorized))
print('Gradient difference: %f' % grad_difference)
# Use the validation set to tune hyperparameters (regularization strength and
# learning rate). You should experiment with different ranges for the learning
# rates and regularization strengths; if you are careful you should be able to
# get a classification accuracy of over 0.35 on the validation set.
from cs231n.classifiers import Softmax
results = {}
best_val = -1
best_softmax = None
learning_rates = [1e-7, 5e-7]
regularization_strengths = [2.5e4, 5e4]
################################################################################
# TODO: #
# Use the validation set to set the learning rate and regularization strength. #
# This should be identical to the validation that you did for the SVM; save #
# the best trained softmax classifer in best_softmax. #
################################################################################
#pass
for lr in learning_rates:
for reg in regularization_strengths:
softmax = Softmax()
softmax.train(X_train, y_train, lr, reg, num_iters=1500)
y_train_pred = softmax.predict(X_train)
train_acc = np.mean(y_train == y_train_pred)
y_val_pred = softmax.predict(X_val)
val_acc = np.mean(y_val == y_val_pred)
if val_acc > best_val:
best_val = val_acc
best_softmax = softmax
results[(lr, reg)] = train_acc, val_acc
################################################################################
# END OF YOUR CODE #
################################################################################
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (
lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
# evaluate on test set
# Evaluate the best softmax on test set
y_test_pred = best_softmax.predict(X_test)
test_accuracy = np.mean(y_test == y_test_pred)
print('softmax on raw pixels final test set accuracy: %f' % (test_accuracy, ))
# Visualize the learned weights for each class
w = best_softmax.W[:-1,:] # strip out the bias
w = w.reshape(32, 32, 3, 10)
w_min, w_max = np.min(w), np.max(w)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(10):
plt.subplot(2, 5, i + 1)
# Rescale the weights to be between 0 and 255
wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)
plt.imshow(wimg.astype('uint8'))
plt.axis('off')
plt.title(classes[i])
```
|
github_jupyter
|
## Week 2-2 - Visualizing General Social Survey data
Your mission is to analyze a data set of social attitudes by turning it into vectors, then visualizing the result.
### 1. Choose a topic and get your data
We're going to be working with data from the General Social Survey, which asks Americans thousands of questions ever year, over decades. This is an enormous data set and there have been very many stories written from its data. The first thing you need to do is decide which questions and which years you are going to try to analyze.
Use their [data explorer](https://gssdataexplorer.norc.org/) to see what's available, and ultimately download an Excel file with the data.
- Click the `Search Varibles` button.
- You will need at least a dozen or two related variables. Try selecting some using their `Filter by Module / Subject` interface.
- When you've made your selection, click the `+ All` button to add all listed variables, then choose `Extract Data` under the `Actions` menu.
- Then you have a multi-step process. Step 1 is just naming your extract
- Step 2: select variables *again!* Click `Add All` in the upper right of the "Variable Cart" in the "Choose Variables" step.
- Step 3: Skip it. You could use this to filter the data in various ways.
- Step 4: Click `Select certain years` to pick one year of data, then check `Excel Workbook (data + metadata)` as the output format.
- Click `Create Extract` and wait a minute or two on the "Extracts" page until the spinner stops and turns into a download link.
You'll end up with an compressed file in tar.gz format, which you should be able to decompressed by double-clicking on it. Inside is an Excel file. Open it in Excel (or your favorite spreadsheet program) and resave it as a CSV.
```
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import math
# load your data set here
gss = pd.read_csv(...)
```
### 3. Turn people into vectors
I know, it sounds cruel. We're trying to group people, but computers can only group vectors, so there we are.
Translating the spreadsheet you downloaded from GSS Explorer into vectors is a multistep process. Generally, each row of the spreadsheet is one person, and each column is one qeustion.
- First, we need to throw away any extra rows and columns: headers, questions with no data, etc.
- Many GSS questions already have numerical answers. These usually don't require any work.
- But you'll need to turn categorical variables into numbers.
Basically, you have to remove or convert every value that isn't a number. Because this is survey data, we can turn most questions into an integer scale. The cleanup might use functions like this:
```
# drop the last two rows, which are just notes and do not contain data
gss = gss.iloc[0:-2,:]
# Here's a bunch of cleanup code. It probably won't be quite right for your data.
# The goal is to convert all values to small integers, to make them easy to plot with colors below.
# First, replace all of the "Not Applicable" values with None
gss = gss.replace({'Not applicable' : None,
'No answer' : None,
'Don\'t know' : None,
'Dont know' : None})
# Manually code likert scales
gss = gss.replace({'Strongly disagree':-2, 'Disagree':-1, 'Neither agree nor disagree':0, 'Agree':1, 'Strongly agree':2})
# yes/no -> 1/-1
gss = gss.replace({'Yes':1, 'No':-1})
# Some frequency scales should have numeric coding too
gss = gss.replace({'Not at all in the past year' : 0,
'Once in the past year' : 1,
'At least 2 or 3 times in the past year' : 2,
'Once a month' : 3,
'Once a week' : 4,
'More than once a week':5})
gss = gss.replace({ 'Never or almost never' : 0,
'Once in a while' : 1,
'Some days' : 2,
'Most days' : 3,
'Every day' : 4,
'Many times a day' : 5})
# Drop some columns that don't contain useful information
gss = gss.drop(['Respondent id number',
'Ballot used for interview',
'Gss year for this respondent'], axis=1)
# Turn invalid numeric entries into zeros
gss = gss.replace({np.nan:0.0})
```
### 4. Plot those vectors!
For this assignment, we'll use the PCA projection algorithm to make 2D (or 3D!) pictures of the set of vectors. Once you have the vectors, it should be easy to make a PCA plot using the steps we followed in class.
```
# make a PCA plot here
```
### 5. Add color to help interpretation
Congratulations, you have a picture of a blob of dots. Hopefully, that blob has some structure representing clusters of similar people. To understand what the plot is telling us, it really helps to take one of the original variables and use it to assign colors to the points.
So: pick one of the questions that you think will separate people into natural groups. Use it to set the color of the dots in your scatterplot. By repeating this with different questions, or combining questions (like two binary questions giving rise to a four color scheme) you should be able to figure out what the structure of the clusters represents.
```
# map integer columns to colors
def col2colors(colvals):
# gray for zero, then a rainbow.
# This is set up so yes = 1 = red and no = -1 = indigo
my_colors = ['gray', 'red','orange','yellow','lightgreen','cyan','blue','indigo']
# We may have integers higher than len(my_colors) or less than zero
# So use the mod operator (%) to make values "wrap around" when they go off the end of the list
column_ints = colvals.astype(int) % len(my_colors)
# map each index to the corresponding color
return column_ints.apply(lambda x: my_colors[x])
# Make a plot using colors from a particular column
# Make another plot using colors from another column
# ... repeat and see if you can figure out what each axis means
```
### 6. Tell us what it means?
What did you learn from this exercise? Did you find the standard left-right divide? Or urban-rural? Early adopters vs. luddites? People with vs. without children?
What did you learn? What could end up in a story?
|
github_jupyter
|
```
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.metrics import precision_score, recall_score
import matplotlib.pyplot as plt
#reading train.csv
data = pd.read_csv('train.csv')
# show the actaul data
data
# show the first few rows
data.head(10)
# count the null values
null_values = data.isnull().sum()
null_values
plt.plot(null_values)
plt.show()
```
## Data Processing
```
def handle_non_numerical_data(df):
columns = df.columns.values
for column in columns:
text_digit_vals = {}
def convert_to_int(val):
return text_digit_vals[val]
#print(column,df[column].dtype)
if df[column].dtype != np.int64 and df[column].dtype != np.float64:
column_contents = df[column].values.tolist()
#finding just the uniques
unique_elements = set(column_contents)
# great, found them.
x = 0
for unique in unique_elements:
if unique not in text_digit_vals:
text_digit_vals[unique] = x
x+=1
df[column] = list(map(convert_to_int,df[column]))
return df
y_target = data['Survived']
# Y_target.reshape(len(Y_target),1)
x_train = data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare','Embarked', 'Ticket']]
x_train = handle_non_numerical_data(x_train)
x_train.head()
fare = pd.DataFrame(x_train['Fare'])
# Normalizing
min_max_scaler = preprocessing.MinMaxScaler()
newfare = min_max_scaler.fit_transform(fare)
x_train['Fare'] = newfare
x_train
null_values = x_train.isnull().sum()
null_values
plt.plot(null_values)
plt.show()
# Fill the NAN values with the median values in the datasets
x_train['Age'] = x_train['Age'].fillna(x_train['Age'].mean())
print("Number of NULL values" , x_train['Age'].isnull().sum())
print(x_train.head(3))
x_train['Sex'] = x_train['Sex'].replace('male', 0)
x_train['Sex'] = x_train['Sex'].replace('female', 1)
# print(type(x_train))
corr = x_train.corr()
corr.style.background_gradient()
def plot_corr(df,size=10):
corr = df.corr()
fig, ax = plt.subplots(figsize=(size, size))
ax.matshow(corr)
plt.xticks(range(len(corr.columns)), corr.columns);
plt.yticks(range(len(corr.columns)), corr.columns);
# plot_corr(x_train)
x_train.corr()
corr.style.background_gradient()
# Dividing the data into train and test data set
X_train, X_test, Y_train, Y_test = train_test_split(x_train, y_target, test_size = 0.4, random_state = 40)
clf = RandomForestClassifier()
clf.fit(X_train, Y_train)
print(clf.predict(X_test))
print("Accuracy: ",clf.score(X_test, Y_test))
## Testing the model.
test_data = pd.read_csv('test.csv')
test_data.head(3)
# test_data.isnull().sum()
### Preprocessing on the test data
test_data = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare', 'Ticket', 'Embarked']]
test_data = handle_non_numerical_data(test_data)
fare = pd.DataFrame(test_data['Fare'])
min_max_scaler = preprocessing.MinMaxScaler()
newfare = min_max_scaler.fit_transform(fare)
test_data['Fare'] = newfare
test_data['Fare'] = test_data['Fare'].fillna(test_data['Fare'].median())
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())
test_data['Sex'] = test_data['Sex'].replace('male', 0)
test_data['Sex'] = test_data['Sex'].replace('female', 1)
print(test_data.head())
print(clf.predict(test_data))
from sklearn.model_selection import cross_val_predict
predictions = cross_val_predict(clf, X_train, Y_train, cv=3)
print("Precision:", precision_score(Y_train, predictions))
print("Recall:",recall_score(Y_train, predictions))
from sklearn.metrics import precision_recall_curve
# getting the probabilities of our predictions
y_scores = clf.predict_proba(X_train)
y_scores = y_scores[:,1]
precision, recall, threshold = precision_recall_curve(Y_train, y_scores)
def plot_precision_and_recall(precision, recall, threshold):
plt.plot(threshold, precision[:-1], "r-", label="precision", linewidth=5)
plt.plot(threshold, recall[:-1], "b", label="recall", linewidth=5)
plt.xlabel("threshold", fontsize=19)
plt.legend(loc="upper right", fontsize=19)
plt.ylim([0, 1])
plt.figure(figsize=(14, 7))
plot_precision_and_recall(precision, recall, threshold)
plt.axis([0.3,0.8,0.8,1])
plt.show()
def plot_precision_vs_recall(precision, recall):
plt.plot(recall, precision, "g--", linewidth=2.5)
plt.ylabel("recall", fontsize=19)
plt.xlabel("precision", fontsize=19)
plt.axis([0, 1.5, 0, 1.5])
plt.figure(figsize=(14, 7))
plot_precision_vs_recall(precision, recall)
plt.show()
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
predictions = cross_val_predict(clf, X_train, Y_train, cv=3)
confusion_matrix(Y_train, predictions)
```
True positive: 293 (We predicted a positive result and it was positive)
True negative: 143 (We predicted a negative result and it was negative)
False positive: 34 (We predicted a positive result and it was negative)
False negative: 64 (We predicted a negative result and it was positive)
### data v
```
import seaborn as sns
survived = 'survived'
not_survived = 'not survived'
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(10, 4))
women = data[data['Sex']=='female']
men = data[data['Sex']=='male']
ax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[0], kde =False)
ax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[0], kde =False)
ax.legend()
ax.set_title('Female')
ax = sns.distplot(men[men['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[1], kde = False)
ax = sns.distplot(men[men['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[1], kde = False)
ax.legend()
_ = ax.set_title('Male')
FacetGrid = sns.FacetGrid(data, row='Embarked', size=4.5, aspect=1.6)
FacetGrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette=None, order=None, hue_order=None )
FacetGrid.add_legend()
```
#### Embarked seems to be correlated with survival, depending on the gender.
Women on port Q and on port S have a higher chance of survival. The inverse is true, if they are at port C. Men have a high survival probability if they are on port C, but a low probability if they are on port Q or S.
```
sns.barplot('Pclass', 'Survived', data=data, color="darkturquoise")
plt.show()
sns.barplot('Embarked', 'Survived', data=data, color="teal")
plt.show()
sns.barplot('Sex', 'Survived', data=data, color="aquamarine")
plt.show()
print(clf.predict(X_test))
print("Accuracy: ",clf.score(X_test, Y_test))
data
```
|
github_jupyter
|
# Extracting training data from the ODC <img align="right" src="../../Supplementary_data/dea_logo.jpg">
* [**Sign up to the DEA Sandbox**](https://docs.dea.ga.gov.au/setup/sandbox.html) to run this notebook interactively from a browser
* **Compatibility:** Notebook currently compatible with the `DEA Sandbox` environment
* **Products used:**
[ls8_nbart_geomedian_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_geomedian_annual/extents),
[ls8_nbart_tmad_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_tmad_annual/extents),
[fc_percentile_albers_annual](https://explorer.sandbox.dea.ga.gov.au/products/fc_percentile_albers_annual/extents)
## Background
**Training data** is the most important part of any supervised machine learning workflow. The quality of the training data has a greater impact on the classification than the algorithm used. Large and accurate training data sets are preferable: increasing the training sample size results in increased classification accuracy ([Maxell et al 2018](https://www.tandfonline.com/doi/full/10.1080/01431161.2018.1433343)). A review of training data methods in the context of Earth Observation is available [here](https://www.mdpi.com/2072-4292/12/6/1034)
When creating training labels, be sure to capture the **spectral variability** of the class, and to use imagery from the time period you want to classify (rather than relying on basemap composites). Another common problem with training data is **class imbalance**. This can occur when one of your classes is relatively rare and therefore the rare class will comprise a smaller proportion of the training set. When imbalanced data is used, it is common that the final classification will under-predict less abundant classes relative to their true proportion.
There are many platforms to use for gathering training labels, the best one to use depends on your application. GIS platforms are great for collection training data as they are highly flexible and mature platforms; [Geo-Wiki](https://www.geo-wiki.org/) and [Collect Earth Online](https://collect.earth/home) are two open-source websites that may also be useful depending on the reference data strategy employed. Alternatively, there are many pre-existing training datasets on the web that may be useful, e.g. [Radiant Earth](https://www.radiant.earth/) manages a growing number of reference datasets for use by anyone.
## Description
This notebook will extract training data (feature layers, in machine learning parlance) from the `open-data-cube` using labelled geometries within a geojson. The default example will use the crop/non-crop labels within the `'data/crop_training_WA.geojson'` file. This reference data was acquired and pre-processed from the USGS's Global Food Security Analysis Data portal [here](https://croplands.org/app/data/search?page=1&page_size=200) and [here](https://e4ftl01.cr.usgs.gov/MEASURES/GFSAD30VAL.001/2008.01.01/).
To do this, we rely on a custom `dea-notebooks` function called `collect_training_data`, contained within the [dea_tools.classification](../../Tools/dea_tools/classification.py) script. The principal goal of this notebook is to familarise users with this function so they can extract the appropriate data for their use-case. The default example also highlights extracting a set of useful feature layers for generating a cropland mask forWA.
1. Preview the polygons in our training data by plotting them on a basemap
2. Extract training data from the datacube using `collect_training_data`'s inbuilt feature layer parameters
3. Extract training data from the datacube using a **custom defined feature layer function** that we can pass to `collect_training_data`
4. Export the training data to disk for use in subsequent scripts
***
## Getting started
To run this analysis, run all the cells in the notebook, starting with the "Load packages" cell.
### Load packages
```
%matplotlib inline
import os
import sys
import datacube
import numpy as np
import xarray as xr
import subprocess as sp
import geopandas as gpd
from odc.io.cgroups import get_cpu_quota
from datacube.utils.geometry import assign_crs
sys.path.append('../../Scripts')
from dea_plotting import map_shapefile
from dea_bandindices import calculate_indices
from dea_classificationtools import collect_training_data
import warnings
warnings.filterwarnings("ignore")
```
## Analysis parameters
* `path`: The path to the input vector file from which we will extract training data. A default geojson is provided.
* `field`: This is the name of column in your shapefile attribute table that contains the class labels. **The class labels must be integers**
```
path = 'data/crop_training_WA.geojson'
field = 'class'
```
### Find the number of CPUs
```
ncpus = round(get_cpu_quota())
print('ncpus = ' + str(ncpus))
```
## Preview input data
We can load and preview our input data shapefile using `geopandas`. The shapefile should contain a column with class labels (e.g. 'class'). These labels will be used to train our model.
> Remember, the class labels **must** be represented by `integers`.
```
# Load input data shapefile
input_data = gpd.read_file(path)
# Plot first five rows
input_data.head()
# Plot training data in an interactive map
map_shapefile(input_data, attribute=field)
```
## Extracting training data
The function `collect_training_data` takes our geojson containing class labels and extracts training data (features) from the datacube over the locations specified by the input geometries. The function will also pre-process our training data by stacking the arrays into a useful format and removing any `NaN` or `inf` values.
`Collect_training_data` has the ability to generate many different types of **feature layers**. Relatively simple layers can be calculated using pre-defined parameters within the function, while more complex layers can be computed by passing in a `custom_func`. To begin with, let's try generating feature layers using the pre-defined methods.
The in-built feature layer parameters are described below:
* `product`: The name of the product to extract from the datacube. In this example we use a Landsat 8 geomedian composite from 2019, `'ls8_nbart_geomedian_annual'`
* `time`: The time range from which to extract data
* `calc_indices`: This parameter provides a method for calculating a number of remote sensing indices (e.g. `['NDWI', 'NDVI']`). Any of the indices found in the [dea_tools.bandindices](../../Tools/dea_tools/bandindices.py) script can be used here
* `drop`: If this variable is set to `True`, and 'calc_indices' are supplied, the spectral bands will be dropped from the dataset leaving only the band indices as data variables in the dataset.
* `reduce_func`: The classification models we're applying here require our training data to be in two dimensions (ie. `x` & `y`). If our data has a time-dimension (e.g. if we load in an annual time-series of satellite images) then we need to collapse the time dimension. `reduce_func` is simply the summary statistic used to collapse the temporal dimension. Options are 'mean', 'median', 'std', 'max', 'min', and 'geomedian'. In the default example we are loading a geomedian composite, so there is no time dimension to reduce.
* `zonal_stats`: An optional string giving the names of zonal statistics to calculate across each polygon. Default is `None` (all pixel values are returned). Supported values are 'mean', 'median', 'max', and 'min'.
* `return_coords` : If `True`, then the training data will contain two extra columns 'x_coord' and 'y_coord' corresponding to the x,y coordinate of each sample. This variable can be useful for handling spatial autocorrelation between samples later on in the ML workflow when we conduct k-fold cross validation.
> Note: `collect_training_data` also has a number of additional parameters for handling ODC I/O read failures, where polygons that return an excessive number of null values can be resubmitted to the multiprocessing queue. Check out the [docs](https://github.com/GeoscienceAustralia/dea-notebooks/blob/68d3526f73779f3316c5e28001c69f556c0d39ae/Tools/dea_tools/classification.py#L661) to learn more.
In addition to the parameters required for `collect_training_data`, we also need to set up a few parameters for the Open Data Cube query, such as `measurements` (the bands to load from the satellite), the `resolution` (the cell size), and the `output_crs` (the output projection).
```
# Set up our inputs to collect_training_data
products = ['ls8_nbart_geomedian_annual']
time = ('2014')
reduce_func = None
calc_indices = ['NDVI', 'MNDWI']
drop = False
zonal_stats = 'median'
return_coords = True
# Set up the inputs for the ODC query
measurements = ['blue', 'green', 'red', 'nir', 'swir1', 'swir2']
resolution = (-30, 30)
output_crs = 'epsg:3577'
```
Generate a datacube query object from the parameters above:
```
query = {
'time': time,
'measurements': measurements,
'resolution': resolution,
'output_crs': output_crs,
'group_by': 'solar_day',
}
```
Now let's run the `collect_training_data` function. We will limit this run to only a subset of all samples (first 100) as here we are only demonstrating the use of the function. Futher on in the notebook we will rerun this function but with all the polygons in the training data.
> **Note**: With supervised classification, its common to have many, many labelled geometries in the training data. `collect_training_data` can parallelize across the geometries in order to speed up the extracting of training data. Setting `ncpus>1` will automatically trigger the parallelization. However, its best to set `ncpus=1` to begin with to assist with debugging before triggering the parallelization. You can also limit the number of polygons to run when checking code. For example, passing in `gdf=input_data[0:5]` will only run the code over the first 5 polygons.
```
column_names, model_input = collect_training_data(gdf=input_data[0:100],
products=products,
dc_query=query,
ncpus=ncpus,
return_coords=return_coords,
field=field,
calc_indices=calc_indices,
reduce_func=reduce_func,
drop=drop,
zonal_stats=zonal_stats)
```
The function returns two numpy arrays, the first (`column_names`) contains a list of the names of the feature layers we've computed:
```
print(column_names)
```
The second array (`model_input`) contains the data from our labelled geometries. The first item in the array is the class integer (e.g. in the default example 1. 'crop', or 0. 'noncrop'), the second set of items are the values for each feature layer we computed:
```
print(np.array_str(model_input, precision=2, suppress_small=True))
```
## Custom feature layers
The feature layers that are most relevant for discriminating the classes of your classification problem may be more complicated than those provided in the `collect_training_data` function. In this case, we can pass a custom feature layer function through the `custom_func` parameter. Below, we will use a custom function to recollect training data (overwriting the previous example above).
* `custom_func`: A custom function for generating feature layers. If this parameter is set, all other options (excluding 'zonal_stats'), will be ignored. The result of the 'custom_func' must be a single xarray dataset containing 2D coordinates (i.e x and y with no time dimension). The custom function has access to the datacube dataset extracted using the `dc_query` params. To load other datasets, you can use the `like=ds.geobox` parameter in `dc.load`
First, lets define a custom feature layer function. This function is fairly basic and replicates some of what the `collect_training_data` function can do, but you can build these custom functions as complex as you like. We will calculate some band indices on the Landsat 8 geomedian, append the ternary median aboslute deviation dataset from the same year: [ls8_nbart_tmad_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_tmad_annual/extents), and append fractional cover percentiles for the photosynthetic vegetation band, also from the same year: [fc_percentile_albers_annual](https://explorer.sandbox.dea.ga.gov.au/products/fc_percentile_albers_annual/extents).
```
def custom_reduce_function(ds):
# Calculate some band indices
da = calculate_indices(ds,
index=['NDVI', 'LAI', 'MNDWI'],
drop=False,
collection='ga_ls_2')
# Connect to datacube to add TMADs product
dc = datacube.Datacube(app='custom_feature_layers')
# Add TMADs dataset
tmad = dc.load(product='ls8_nbart_tmad_annual',
measurements=['sdev','edev','bcdev'],
like=ds.geobox, #will match geomedian extent
time='2014' #same as geomedian
)
# Add Fractional cover percentiles
fc = dc.load(product='fc_percentile_albers_annual',
measurements=['PV_PC_10','PV_PC_50','PV_PC_90'], #only the PV band
like=ds.geobox, #will match geomedian extent
time='2014' #same as geomedian
)
# Merge results into single dataset
result = xr.merge([da, tmad, fc],compat='override')
return result.squeeze()
```
Now, we can pass this function to `collect_training_data`. We will redefine our intial parameters to align with the new custom function. Remember, passing in a `custom_func` to `collect_training_data` means many of the other feature layer parameters are ignored.
```
# Set up our inputs to collect_training_data
products = ['ls8_nbart_geomedian_annual']
time = ('2014')
zonal_stats = 'median'
return_coords = True
# Set up the inputs for the ODC query
measurements = ['blue', 'green', 'red', 'nir', 'swir1', 'swir2']
resolution = (-30, 30)
output_crs = 'epsg:3577'
# Generate a new datacube query object
query = {
'time': time,
'measurements': measurements,
'resolution': resolution,
'output_crs': output_crs,
'group_by': 'solar_day',
}
```
Below we collect training data from the datacube using the custom function. This will take around 5-6 minutes to run all 430 samples on the default sandbox as it only has two cpus.
```
%%time
column_names, model_input = collect_training_data(
gdf=input_data,
products=products,
dc_query=query,
ncpus=ncpus,
return_coords=return_coords,
field=field,
zonal_stats=zonal_stats,
custom_func=custom_reduce_function)
print(column_names)
print('')
print(np.array_str(model_input, precision=2, suppress_small=True))
```
## Separate coordinate data
By setting `return_coords=True` in the `collect_training_data` function, our training data now has two extra columns called `x_coord` and `y_coord`. We need to separate these from our training dataset as they will not be used to train the machine learning model. Instead, these variables will be used to help conduct Spatial K-fold Cross validation (SKVC) in the notebook `3_Evaluate_optimize_fit_classifier`. For more information on why this is important, see this [article](https://www.tandfonline.com/doi/abs/10.1080/13658816.2017.1346255?journalCode=tgis20).
```
# Select the variables we want to use to train our model
coord_variables = ['x_coord', 'y_coord']
# Extract relevant indices from the processed shapefile
model_col_indices = [column_names.index(var_name) for var_name in coord_variables]
# Export to coordinates to file
np.savetxt("results/training_data_coordinates.txt", model_input[:, model_col_indices])
```
## Export training data
Once we've collected all the training data we require, we can write the data to disk. This will allow us to import the data in the next step(s) of the workflow.
```
# Set the name and location of the output file
output_file = "results/test_training_data.txt"
# Grab all columns except the x-y coords
model_col_indices = [column_names.index(var_name) for var_name in column_names[0:-2]]
# Export files to disk
np.savetxt(output_file, model_input[:, model_col_indices], header=" ".join(column_names[0:-2]), fmt="%4f")
```
## Recommended next steps
To continue working through the notebooks in this `Scalable Machine Learning on the ODC` workflow, go to the next notebook `2_Inspect_training_data.ipynb`.
1. **Extracting training data from the ODC (this notebook)**
2. [Inspecting training data](2_Inspect_training_data.ipynb)
3. [Evaluate, optimize, and fit a classifier](3_Evaluate_optimize_fit_classifier.ipynb)
4. [Classifying satellite data](4_Classify_satellite_data.ipynb)
5. [Object-based filtering of pixel classifications](5_Object-based_filtering.ipynb)
***
## Additional information
**License:** The code in this notebook is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
Digital Earth Australia data is licensed under the [Creative Commons by Attribution 4.0](https://creativecommons.org/licenses/by/4.0/) license.
**Contact:** If you need assistance, please post a question on the [Open Data Cube Slack channel](http://slack.opendatacube.org/) or on the [GIS Stack Exchange](https://gis.stackexchange.com/questions/ask?tags=open-data-cube) using the `open-data-cube` tag (you can view previously asked questions [here](https://gis.stackexchange.com/questions/tagged/open-data-cube)).
If you would like to report an issue with this notebook, you can file one on [Github](https://github.com/GeoscienceAustralia/dea-notebooks).
**Last modified:** March 2021
**Compatible datacube version:**
```
print(datacube.__version__)
```
## Tags
Browse all available tags on the DEA User Guide's [Tags Index](https://docs.dea.ga.gov.au/genindex.html)
|
github_jupyter
|
```
import numpy as np
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
%matplotlib inline
```
## Read in the data
*I'm using pandas*
```
data = pd.read_csv('bar.csv')
data
```
## Here is the default bar chart from python
```
f,ax = plt.subplots()
ind = np.arange(len(data)) # the x locations for the bars
width = 0.5 # the width of the bars
rects = ax.bar(ind, data['Value'], width)
```
## Add some labels
```
f,ax = plt.subplots()
ind = np.arange(len(data)) # the x locations for the bars
width = 0.5 # the width of the bars
rects = ax.bar(ind, data['Value'], width)
# add some text for labels, title and axes ticks
ax.set_ylabel('Percent')
ax.set_title('Percentage of Poor Usage')
ax.set_xticks(ind)
ax.set_xticklabels(data['Label'])
```
## Rotate the plot and add gridlines
```
f,ax = plt.subplots()
ind = np.arange(len(data)) # the x locations for the bars
width = 0.5 # the width of the bars
rects = ax.barh(ind, data['Value'], width, zorder=2)
# add some text for labels, title and axes ticks
ax.set_xlabel('Percent')
ax.set_title('Percentage of Poor Usage')
ax.set_yticks(ind)
ax.set_yticklabels(data['Label'])
#add a grid behind the plot
ax.grid(color='gray', linestyle='-', linewidth=1, zorder = 1)
```
## Sort the data, and add the percentage values to each bar
```
f,ax = plt.subplots()
#sort the data (nice aspect of pandas dataFrames)
data.sort_values('Value', inplace=True)
ind = np.arange(len(data)) # the x locations for the bars
width = 0.5 # the width of the bars
rects = ax.barh(ind, data['Value'], width, zorder=2)
# add some text for labels, title and axes ticks
ax.set_xlabel('Percent')
ax.set_title('Percentage of Poor Usage')
ax.set_yticks(ind)
ax.set_yticklabels(data['Label'])
#add a grid behind the plot
ax.grid(color='gray', linestyle='-', linewidth=1, zorder = 1)
#I grabbed this from here : https://matplotlib.org/examples/api/barchart_demo.html
#and tweaked it slightly
for r in rects:
h = r.get_height()
w = r.get_width()
y = r.get_y()
if (w > 1):
x = w - 0.5
else:
x = w + 0.5
ax.text(x, y ,'%.1f%%' % w, ha='center', va='bottom', zorder = 3)
```
## Clean this up a bit
* I don't want the grid lines anymore
* Make the font larger
* Let's change the colors, and highlight one of them
* Save the plot
```
#this will change the font globally, but you could also change the fontsize for each label independently
font = {'size' : 20}
matplotlib.rc('font', **font)
f,ax = plt.subplots(figsize=(10,8))
#sort the data (nice aspect of pandas dataFrames)
data.sort_values('Value', inplace=True)
ind = np.arange(len(data)) # the x locations for the bars
width = 0.5 # the width of the bars
rects = ax.barh(ind, data['Value'], width, zorder=2)
# add some text for labels, title and axes ticks
ax.set_title('Percentage of Poor Usage', fontsize = 30)
ax.set_yticks(ind)
ax.set_yticklabels(data['Label'])
#remove all the axes, ticks and lower x label
aoff = ['right', 'left', 'top', 'bottom']
for x in aoff:
ax.spines[x].set_visible(False)
ax.tick_params(length=0)
ax.set_xticklabels([' ']*len(data))
#I grabbed this from here : https://matplotlib.org/examples/api/barchart_demo.html
#and tweaked it slightly
highlight = [4]
for i, r in enumerate(rects):
h = r.get_height()
w = r.get_width()
y = r.get_y()
if (w >= 10):
x = w - 0.75
elif (w > 1):
x = w - 0.6
else:
x = w + 0.5
r.set_color('gray')
if (i in highlight):
r.set_color('orange')
ax.text(x, y ,'%.1f%%' % w, ha='center', va='bottom', zorder = 3)
f.savefig('bar.pdf',format='pdf', bbox_inches = 'tight')
```
|
github_jupyter
|
```
import sys
sys.path.append('../src')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
pd.set_option('display.max_rows', None)
import datetime
from plotly.subplots import make_subplots
from covid19.config import covid_19_data
data = covid_19_data
data[["Confirmed","Deaths","Recovered"]] =data[["Confirmed","Deaths","Recovered"]].astype(int)
data['Active_case'] = data['Confirmed'] - data['Deaths'] - data['Recovered']
Data_India = data [(data['Country/Region'] == 'India') ].reset_index(drop=True)
Data_India_op= Data_India.groupby(["ObservationDate","Country/Region"])[["Confirmed","Deaths","Recovered","Active_case"]].sum().reset_index().reset_index(drop=True)
fig = go.Figure()
fig.add_trace(go.Scatter(x=Data_India_op["ObservationDate"], y=Data_India_op['Confirmed'],
mode="lines+text",
name='Confirmed cases',
marker_color='orange',
))
fig.add_annotation(
x="03/24/2020",
y=Data_India_op['Confirmed'].max(),
text="COVID-19 pandemic lockdown in India",
font=dict(
family="Courier New, monospace",
size=16,
color="red"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="03/24/2020",
y0=Data_India_op['Confirmed'].max(),
x1="03/24/2020",
line=dict(
color="red",
width=3
)
))
fig.add_annotation(
x="04/24/2020",
y=Data_India_op['Confirmed'].max()-30000,
text="Month after lockdown",
font=dict(
family="Courier New, monospace",
size=16,
color="#00FE58"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="04/24/2020",
y0=Data_India_op['Confirmed'].max(),
x1="04/24/2020",
line=dict(
color="#00FE58",
width=3
)
))
fig
fig.update_layout(
title='Evolution of Confirmed cases over time in India',
template='plotly_dark'
)
fig.show()
fig = go.Figure()
fig.add_trace(go.Scatter(x=Data_India_op["ObservationDate"], y=Data_India_op['Active_case'],
mode="lines+text",
name='Active cases',
marker_color='#00FE58',
))
fig.add_annotation(
x="03/24/2020",
y=Data_India_op['Active_case'].max(),
text="COVID-19 pandemic lockdown in India",
font=dict(
family="Courier New, monospace",
size=16,
color="red"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="03/24/2020",
y0=Data_India_op['Active_case'].max(),
x1="03/24/2020",
line=dict(
color="red",
width=3
)
))
fig.add_annotation(
x="04/24/2020",
y=Data_India_op['Active_case'].max()-20000,
text="Month after lockdown",
font=dict(
family="Courier New, monospace",
size=16,
color="rgb(255,217,47)"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="04/24/2020",
y0=Data_India_op['Active_case'].max(),
x1="04/24/2020",
line=dict(
color="rgb(255,217,47)",
width=3
)
))
fig.update_layout(
title='Evolution of Active cases over time in India',
template='plotly_dark'
)
fig.show()
fig = go.Figure()
fig.add_trace(go.Scatter(x=Data_India_op["ObservationDate"], y=Data_India_op['Recovered'],
mode="lines+text",
name='Recovered cases',
marker_color='rgb(229,151,232)',
))
fig.add_annotation(
x="03/24/2020",
y=Data_India_op['Recovered'].max(),
text="COVID-19 pandemic lockdown in India",
font=dict(
family="Courier New, monospace",
size=16,
color="red"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="03/24/2020",
y0=Data_India_op['Recovered'].max(),
x1="03/24/2020",
line=dict(
color="red",
width=3
)
))
fig.add_annotation(
x="04/24/2020",
y=Data_India_op['Recovered'].max()-20000,
text="Month after lockdown",
font=dict(
family="Courier New, monospace",
size=16,
color="rgb(103,219,165)"
),
)
fig.add_shape(
# Line Vertical
dict(
type="line",
x0="04/24/2020",
y0=Data_India_op['Recovered'].max(),
x1="04/24/2020",
line=dict(
color="rgb(103,219,165)",
width=3
)
))
fig.update_layout(
title='Evolution of Recovered cases over time in India',
template='plotly_dark'
)
fig.show()
```
|
github_jupyter
|
# Introduction to Band Ratios & Spectral Features
The BandRatios project explore properties of band ratio measures.
Band ratio measures are an analysis measure in which the ratio of power between frequency bands is calculated.
By 'spectral features' we mean features we can measure from the power spectra, such as periodic components (oscillations), that we can describe with their center frequency, power and bandwidth, and the aperiodic component, which we can describe with their exponent and offset value. These parameters will be further explored and explained later on.
In this introductory notebook, we walk through how band ratio measures and spectral features are calculated.
```
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context('poster')
from fooof import FOOOF
from fooof.sim import gen_power_spectrum
from fooof.analysis import get_band_peak_fm
from fooof.plts import plot_spectrum, plot_spectrum_shading
# Import custom project code
import sys
sys.path.append('../bratios')
from ratios import *
from paths import FIGS_PATHS as fp
from paths import DATA_PATHS as dp
# Settings
SAVE_FIG = False
```
## What is a Band Ratio
This project explores frequency band ratios, a metric used in spectral analysis since at least the 1960's to characterize cognitive functions such as vigilance, aging, memory among other. In clinical work, band ratios have also been used as a biomarker for diagnosing and monitoring of ADHD, diseases of consciousness, and nervous system disorders such as Parkinson's disease.
Given a power spectrum, a band ratio is the ratio of average power within a band between two frequency ranges.
Typically, band ratio measures are calculated as:
$ \frac{avg(low\ band\ power)}{avg(high\ band\ power} $
The following cell generates a power spectrum and highlights the frequency ranges used to calculate a theta/beta band ratio.
```
# Settings
theta_band = [4, 8]
beta_band = [20, 30]
freq_range = [1, 35]
# Define default simulation values
ap_def = [0, 1]
theta_def = [6, 0.25, 1]
alpha_def = [10, 0.4, 0.75]
beta_def = [25, 0.2, 1.5]
# Plot Settings
line_color = 'black'
shade_colors = ['#057D2E', '#0365C0']
# Generate a simulated power spectrum
fs, ps = gen_power_spectrum(freq_range, ap_def,
[theta_def, alpha_def, beta_def])
# Plot the power spectrum, shading the frequency bands used for the ratio
plot_spectrum_shading(fs, ps, [theta_band, beta_band],
color=line_color, shade_colors=shade_colors,
log_powers=True, linewidth=3.5)
# Plot aesthetics
ax = plt.gca()
for it in [ax.xaxis.label, ax.yaxis.label]:
it.set_fontsize(26)
ax.set_xlim([0, 35])
ax.set_ylim([-1.6, 0])
if SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'Ratio-example', 'pdf'))
```
# Calculate theta/beta ratios
### Average Power Ratio
The typical way of calculating band ratios is to take average power in the low-band and divide it by the average power from the high-band.
Average power is calculated as the sum of all discrete power values divided by number on power values in that band.
```
# Calculate the theta / beta ratio for our simulated power spectrum
ratio = calc_band_ratio(fs, ps, theta_band, beta_band)
print('Theta-beta ratio is: {:1.4f}'.format(ratio))
```
And there you have it - our first computed frequency band ratio!
# The FOOOF Model
To measure spectral features from power spectra, which we can then compare to ratio measures, we will use the [FOOOF](https://github.com/fooof-tools/fooof) library.
Briefly, the FOOOF algorithm parameterizes neural power spectra, measuring both periodic (oscillatory) and aperiodic features.
Each identified oscillation is parameterized as a peak, fit as a gaussian, which provides us with a measures of the center frequency, power and bandwidth of peak.
The aperiodic component is measured by a function of the form $ 1/f^\chi $, in which this $ \chi $ value is referred to as the aperiodic exponent.
This exponent is equivalent the the negative slope of the power spectrum, when plotted in log-log.
More details on FOOOF can be found in the associated [paper](https://doi.org/10.1101/299859) and/or on the documentation [site](https://fooof-tools.github.io/fooof/).
```
# Load power spectra from an example subject
psd = np.load(dp.make_file_path(dp.eeg_psds, 'A00051886_ec_psds', 'npz'))
# Unpack the loaded power spectra, and select a spectrum to fit
freqs = psd['arr_0']
powers = psd['arr_1'][0][50]
# Initialize a FOOOF object
fm = FOOOF(verbose=False)
# Fit the FOOOF model
fm.fit(freqs, powers)
# Plot the power spectrum, with the FOOOF model
fm.plot()
# Plot aesthetic updates
ax = plt.gca()
ax.set_ylabel('log(Power)', {'fontsize':35})
ax.set_xlabel('Frequency', {'fontsize':35})
plt.legend(prop={'size': 24})
for line, width in zip(ax.get_lines(), [3, 5, 5]):
line.set_linewidth(width)
ax.set_xlim([0, 35]);
if SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'FOOOF-example', 'pdf'))
```
In the plot above, the the FOOOF model fit, in red, is plotted over the original data, in black.
The blue dashed line is the fit of the aperiodic component of the data. The aperiodic exponent describes the steepness of this line.
For all future notebooks, the aperiodic exponent reflects values that are simulated and/or measured with the FOOOF model, reflecting the blue line.
Periodic spectral features are simulation values and/or model fit values from the FOOOF model that measure oscillatory peaks over and above the blue dashed line.
#### Helper settings & functions for the next section
```
# Settings
f_theta = 6
f_beta = 25
# Functions
def style_plot(ax):
"""Helper function to style plots."""
ax.get_legend().remove()
ax.grid(False)
for line in ax.get_lines():
line.set_linewidth(3.5)
ax.set_xticks([])
ax.set_yticks([])
def add_lines(ax, fs, ps, f_val):
"""Helper function to add vertical lines to power spectra plots."""
y_lims = ax.get_ylim()
ax.plot([f_val, f_val], [y_lims[0], np.log10(ps[fs==f_val][0])],
'g--', markersize=12, alpha=0.75)
ax.set_ylim(y_lims)
```
### Comparing Ratios With and Without Periodic Activity
In the next section, we will explore power spectra with and without periodic activity within specified bands.
We will use simulations to explore how ratio measures relate to the presence or absence or periodic activity, and how this relates to the analyses we will be performing, comparing ratio measures to spectral features.
```
# Generate simulated power spectrum, with and without a theta & beta oscillations
fs, ps0 = gen_power_spectrum(freq_range, ap_def,
[theta_def, alpha_def, beta_def])
fs, ps1 = gen_power_spectrum(freq_range, ap_def,
[alpha_def, beta_def])
fs, ps2 = gen_power_spectrum(freq_range, ap_def,
[theta_def, alpha_def])
fs, ps3 = gen_power_spectrum(freq_range, ap_def,
[alpha_def])
# Initialize some FOOOF models
fm0 = FOOOF(verbose=False)
fm1 = FOOOF(verbose=False)
fm2 = FOOOF(verbose=False)
fm3 = FOOOF(verbose=False)
# Fit FOOOF models
fm0.fit(fs, ps0)
fm1.fit(fs, ps1)
fm2.fit(fs, ps2)
fm3.fit(fs, ps3)
# Create a plot with the spectra
fig, axes = plt.subplots(1, 4, figsize=(18, 4))
titles = ['Theta & Beta', 'Beta Only', 'Theta Only', 'Neither']
for cur_fm, cur_ps, cur_title, cur_ax in zip(
[fm0, fm1, fm2, fm3], [ps0, ps1, ps2, ps3], titles, axes):
# Create the
cur_fm.plot(ax=cur_ax)
cur_ax.set_title(cur_title)
style_plot(cur_ax)
add_lines(cur_ax, fs, cur_ps, f_theta)
add_lines(cur_ax, fs, cur_ps, f_beta)
# Save out the FOOOF figure
if SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'PeakComparisons', 'pdf'))
```
Note that in the plots above, we have plotted the power spectra, with the aperiodic component parameterized in blue, and the potential location of peaks is indicated in green.
Keep in mind that under the FOOOF model idea, there is only evidence for an oscillation if there is band specific power over and above the aperiodic activity.
In the first power spectrum, for example, we see clear peaks in both theta and beta. However, in subsequent power spectra, we have created spectra without theta, without theta, and without either (or, alternatively put, spectra in which the FOOOF model would say there is no evidence of peaks in these bands).
We can actually check our model parameterizations, to see if and when theta and beta peaks were detected, over and above the aperiodic, was measured.
```
# Check if there are extracted thetas in the model parameterizations
print('Detected Theta Values:')
print('\tTheta & Beta: \t', get_band_peak_fm(fm0, theta_band))
print('\tBeta Only: \t', get_band_peak_fm(fm1, theta_band))
print('\tTheta Only: \t', get_band_peak_fm(fm2, theta_band))
print('\tNeither: \t', get_band_peak_fm(fm3, theta_band))
```
Now, just because there is no evidence of, for example, theta activity specifically, does not mean there is no power in the 4-8 Hz range.
We can see this in the power spectra, as the aperiodic component also contributes power across all frequencies.
This means that, due to the way that band ratio measures are calculated, the theta-beta ratio in power spectra without any actual theta activity (or beta) will still measure a value.
```
print('Theta / Beta Ratio of Theta & Beta: \t{:1.4f}'.format(
calc_band_ratio(fm0.freqs, fm0.power_spectrum, theta_band, beta_band)))
print('Theta / Beta Ratio of Beta Only: \t{:1.4f}'.format(
calc_band_ratio(fm1.freqs, fm1.power_spectrum, theta_band, beta_band)))
print('Theta / Beta Ratio of Theta Only: \t{:1.4f}'.format(
calc_band_ratio(fm2.freqs, fm2.power_spectrum, theta_band, beta_band)))
print('Theta / Beta Ratio of Neither: \t{:1.4f}'.format(
calc_band_ratio(fm3.freqs, fm3.power_spectrum, theta_band, beta_band)))
```
As we can see above, as compared to the 'Theta & Beta' PSD, the theta / beta ratio of the 'Beta Only' PSD is higher (which we might interpret as reflecting less theta or more beta activity), and the theta / beta ratio of the 'Theta Only' PSD is lower (which we might interpret as reflecting more theta or less beta activity).
However, we know that these are not really the best interpretations, in so far as we would like to say that these differences reflect the lack of theta and beta, and not merely a change in their power.
In the extreme case, with no theta or beta peaks at all, we still measure a (quite high) value for the theta / beta ratio, though in this case it entirely reflects aperiodic activity. It is important to note that the measure is not zero (or undefined) as we might expect or want in cases in which there is no oscillatory activity, over and above the aperiodic component.
### Summary
In this notebook, we have explored band ratio measures, and spectral features, using the FOOOF model.
One thing to keep in mind, for the upcoming analyses in this project is that when we compare a ratio value to periodic power, we do so to the isolated periodic power - periodic power over and above the aperiodic power - and we can only calculate this when there is actually power over and above the aperiodic component.
That is to say, revisiting the plots above, the periodic activity we are interested in is not the green line, which is total power, but rather is section of the green line above the blue line (the aperiodic adjusted power measured by FOOOF). This means that to compare ratio values to periodic power, we can only calculate this, and only do so, when we measure periodic power within the specified band.
|
github_jupyter
|
# Bayesian Curve Fitting
### Overview
The predictive distribution resulting from a Baysian treatment of polynominal curve fittting using an $M = 9$ polynominal, with the fixed parameters $\alpha = 5×10^{-3}$ and $\beta = 11.1$ (Corresponding to known noise variance), in which the red curve denotes the mean of the predictive distribution and the red region corresponds to $±1$ standard deviation around the mean.
### Procedure
1. The predictive distribution tis written in the form
\begin{equation*}
p(t| x, {\bf x}, {\bf t}) = N(t| m(x), s^2(x)) (1.69).
\end{equation*}
2. The basis function is defined as $\phi_i(x) = x^i$ for $i = 0,...M$.
3. The mean and variance are given by
\begin{equation*}m(x) = \beta\phi(x)^{\bf T}{\bf S} \sum_{n=1}^N \phi(x_n)t_n(1.70)\end{equation*}
\begin{equation*} s^2(x) = \beta^{-1} + \phi(x)^{\bf T} {\bf S} \phi(x)(1.71)\end{equation*}
\begin{equation*}{\bf S}^{-1} = \alpha {\bf I} + \beta \sum_{n=1}^N \phi(x_n)\phi(x_n)^{\bf T}(1.72)\end{equation*}
4. Inprement these equation and visualize the predictive distribution in the raneg of $0.0<x<1.0$.
```
import numpy as np
from numpy.linalg import inv
import pandas as pd
from pylab import *
import matplotlib.pyplot as plt
%matplotlib inline
#From p31 the authors define phi as following
def phi(x):
return np.array([x ** i for i in range(M + 1)]).reshape((M + 1, 1))
#(1.70) Mean of predictive distribution
def mean(x, x_train, y_train, S): #m
sum = np.array(zeros((M+1, 1)))
for n in range(len(x_train)):
sum += np.dot(phi(x_train[n]), y_train[n])
return Beta * phi(x).T.dot(S).dot(sum)
#(1.71) Variance of predictive distribution
def var(x, S): #s2
return 1.0/Beta + phi(x).T.dot(S).dot(phi(x))
#(1.72)
def S(x_train, y_train):
I = np.identity(M + 1)
Sigma = np.zeros((M + 1, M + 1))
for n in range(len(x_train)):
Sigma += np.dot(phi(x_train[n]), phi(x_train[n]).T)
S_inv = alpha * I + Beta * Sigma
return inv(S_inv)
alpha = 0.005
Beta = 11.1
M = 9
#Sine curve
x_real = np.arange(0, 1, 0.01)
y_real = np.sin(2*np.pi*x_real)
##Training Data
N=10
x_train = np.linspace(0, 1, 10)
#Set "small level of random noise having a Gaussian distribution"
loc = 0
scale = 0.3
y_train = np.sin(2* np.pi * x_train) + np.random.normal(loc, scale, N)
result = S(x_train, y_train)
#Seek predictive distribution corespponding to entire x
mu = [mean(x, x_train, y_train, result)[0,0] for x in x_real]
variance = [var(x, result)[0,0] for x in x_real]
SD = np.sqrt(variance)
upper = mu + SD
lower = mu - SD
plt.figure(figsize=(10, 7))
plot(x_train, y_train, 'bo')
plot(x_real, y_real, 'g-')
plot(x_real, mu, 'r-')
fill_between(x_real, upper, lower, color='pink')
xlim(0.0, 1.0)
ylim(-2, 2)
title("Figure 1.17")
```
|
github_jupyter
|
```
''' setting before run. every notebook should include this code. '''
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import sys
_r = os.getcwd().split('/')
_p = '/'.join(_r[:_r.index('gate-decorator-pruning')+1])
print('Change dir from %s to %s' % (os.getcwd(), _p))
os.chdir(_p)
sys.path.append(_p)
from config import parse_from_dict
parse_from_dict({
"base": {
"task_name": "resnet56_cifar10_ticktock",
"cuda": True,
"seed": 0,
"checkpoint_path": "",
"epoch": 0,
"multi_gpus": True,
"fp16": False
},
"model": {
"name": "cifar.resnet56",
"num_class": 10,
"pretrained": False
},
"train": {
"trainer": "normal",
"max_epoch": 160,
"optim": "sgd",
"steplr": [
[80, 0.1],
[120, 0.01],
[160, 0.001]
],
"weight_decay": 5e-4,
"momentum": 0.9,
"nesterov": False
},
"data": {
"type": "cifar10",
"shuffle": True,
"batch_size": 128,
"test_batch_size": 128,
"num_workers": 4
},
"loss": {
"criterion": "softmax"
},
"gbn": {
"sparse_lambda": 1e-3,
"flops_eta": 0,
"lr_min": 1e-3,
"lr_max": 1e-2,
"tock_epoch": 10,
"T": 10,
"p": 0.002
}
})
from config import cfg
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from logger import logger
from main import set_seeds, recover_pack, adjust_learning_rate, _step_lr, _sgdr
from models import get_model
from utils import dotdict
from prune.universal import Meltable, GatedBatchNorm2d, Conv2dObserver, IterRecoverFramework, FinalLinearObserver
from prune.utils import analyse_model, finetune
set_seeds()
pack = recover_pack()
model_dict = torch.load('./ckps/resnet56_cifair10_baseline.ckp', map_location='cpu' if not cfg.base.cuda else 'cuda')
pack.net.module.load_state_dict(model_dict)
GBNs = GatedBatchNorm2d.transform(pack.net)
for gbn in GBNs:
gbn.extract_from_bn()
pack.optimizer = optim.SGD(
pack.net.parameters() ,
lr=2e-3,
momentum=cfg.train.momentum,
weight_decay=cfg.train.weight_decay,
nesterov=cfg.train.nesterov
)
```
----
```
import uuid
def bottleneck_set_group(net):
layers = [
net.module.layer1,
net.module.layer2,
net.module.layer3
]
for m in layers:
masks = []
if m == net.module.layer1:
masks.append(pack.net.module.bn1)
for mm in m.modules():
if mm.__class__.__name__ == 'BasicBlock':
if len(mm.shortcut._modules) > 0:
masks.append(mm.shortcut._modules['1'])
masks.append(mm.bn2)
group_id = uuid.uuid1()
for mk in masks:
mk.set_groupid(group_id)
bottleneck_set_group(pack.net)
def clone_model(net):
model = get_model()
gbns = GatedBatchNorm2d.transform(model.module)
model.load_state_dict(net.state_dict())
return model, gbns
cloned, _ = clone_model(pack.net)
BASE_FLOPS, BASE_PARAM = analyse_model(cloned.module, torch.randn(1, 3, 32, 32).cuda())
print('%.3f MFLOPS' % (BASE_FLOPS / 1e6))
print('%.3f M' % (BASE_PARAM / 1e6))
del cloned
def eval_prune(pack):
cloned, _ = clone_model(pack.net)
_ = Conv2dObserver.transform(cloned.module)
cloned.module.linear = FinalLinearObserver(cloned.module.linear)
cloned_pack = dotdict(pack.copy())
cloned_pack.net = cloned
Meltable.observe(cloned_pack, 0.001)
Meltable.melt_all(cloned_pack.net)
flops, params = analyse_model(cloned_pack.net.module, torch.randn(1, 3, 32, 32).cuda())
del cloned
del cloned_pack
return flops, params
```
----
```
pack.trainer.test(pack)
pack.tick_trainset = pack.train_loader
prune_agent = IterRecoverFramework(pack, GBNs, sparse_lambda = cfg.gbn.sparse_lambda, flops_eta = cfg.gbn.flops_eta, minium_filter = 3)
LOGS = []
flops_save_points = set([40, 38, 35, 32, 30])
iter_idx = 0
prune_agent.tock(lr_min=cfg.gbn.lr_min, lr_max=cfg.gbn.lr_max, tock_epoch=cfg.gbn.tock_epoch)
while True:
left_filter = prune_agent.total_filters - prune_agent.pruned_filters
num_to_prune = int(left_filter * cfg.gbn.p)
info = prune_agent.prune(num_to_prune, tick=True, lr=cfg.gbn.lr_min)
flops, params = eval_prune(pack)
info.update({
'flops': '[%.2f%%] %.3f MFLOPS' % (flops/BASE_FLOPS * 100, flops / 1e6),
'param': '[%.2f%%] %.3f M' % (params/BASE_PARAM * 100, params / 1e6)
})
LOGS.append(info)
print('Iter: %d,\t FLOPS: %s,\t Param: %s,\t Left: %d,\t Pruned Ratio: %.2f %%,\t Train Loss: %.4f,\t Test Acc: %.2f' %
(iter_idx, info['flops'], info['param'], info['left'], info['total_pruned_ratio'] * 100, info['train_loss'], info['after_prune_test_acc']))
iter_idx += 1
if iter_idx % cfg.gbn.T == 0:
print('Tocking:')
prune_agent.tock(lr_min=cfg.gbn.lr_min, lr_max=cfg.gbn.lr_max, tock_epoch=cfg.gbn.tock_epoch)
flops_ratio = flops/BASE_FLOPS * 100
for point in [i for i in list(flops_save_points)]:
if flops_ratio <= point:
torch.save(pack.net.module.state_dict(), './logs/resnet56_cifar10_ticktock/%s.ckp' % str(point))
flops_save_points.remove(point)
if len(flops_save_points) == 0:
break
```
### You can see how to fine-tune and get the pruned network in the finetune.ipynb
|
github_jupyter
|
# Cavity flow with Navier-Stokes
The final two steps will both solve the Navier–Stokes equations in two dimensions, but with different boundary conditions.
The momentum equation in vector form for a velocity field v⃗
is:
$$ \frac{\partial \overrightarrow{v}}{\partial t} + (\overrightarrow{v} \cdot \nabla ) \overrightarrow{v} = -\frac{1}{\rho}\nabla p + \nu \nabla^2 \overrightarrow{v}$$
This represents three scalar equations, one for each velocity component (u,v,w). But we will solve it in two dimensions, so there will be two scalar equations.
Remember the continuity equation? This is where the Poisson equation for pressure comes in!
Here is the system of differential equations: two equations for the velocity components u,v and one equation for pressure:
$$ \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} + v \frac{\partial u}{\partial y}= -\frac{1}{\rho}\frac{\partial p}{\partial x} + \nu \left[ \frac{\partial^2 u}{\partial x^2} +\frac{\partial^2 u}{\partial y^2} \right] $$
$$ \frac{\partial v}{\partial t} + u \frac{\partial v}{\partial x} + v \frac{\partial v}{\partial y}= -\frac{1}{\rho}\frac{\partial p}{\partial y} + \nu \left[ \frac{\partial^2 v}{\partial x^2} +\frac{\partial^2 v}{\partial y^2} \right] $$
$$
\frac{\partial^2 p}{\partial x^2} +\frac{\partial^2 p}{\partial y^2} =
\rho \left[\frac{\partial}{\partial t} \left(\frac{\partial u}{\partial x} + \frac{\partial v}{\partial y} \right) - \left(\frac{\partial u}{\partial x}\frac{\partial u}{\partial x}+2\frac{\partial u}{\partial y}\frac{\partial v}{\partial x}+\frac{\partial v}{\partial y}\frac{\partial v}{\partial y} \right) \right]
$$
From the previous steps, we already know how to discretize all these terms. Only the last equation is a little unfamiliar. But with a little patience, it will not be hard!
Our stencils look like this:
First the momentum equation in the u direction
$$
\begin{split}
u_{i,j}^{n+1} = u_{i,j}^{n} & - u_{i,j}^{n} \frac{\Delta t}{\Delta x} \left(u_{i,j}^{n}-u_{i-1,j}^{n}\right) - v_{i,j}^{n} \frac{\Delta t}{\Delta y} \left(u_{i,j}^{n}-u_{i,j-1}^{n}\right) \\
& - \frac{\Delta t}{\rho 2\Delta x} \left(p_{i+1,j}^{n}-p_{i-1,j}^{n}\right) \\
& + \nu \left(\frac{\Delta t}{\Delta x^2} \left(u_{i+1,j}^{n}-2u_{i,j}^{n}+u_{i-1,j}^{n}\right) + \frac{\Delta t}{\Delta y^2} \left(u_{i,j+1}^{n}-2u_{i,j}^{n}+u_{i,j-1}^{n}\right)\right)
\end{split}
$$
Second the momentum equation in the v direction
$$
\begin{split}
v_{i,j}^{n+1} = v_{i,j}^{n} & - u_{i,j}^{n} \frac{\Delta t}{\Delta x} \left(v_{i,j}^{n}-v_{i-1,j}^{n}\right) - v_{i,j}^{n} \frac{\Delta t}{\Delta y} \left(v_{i,j}^{n}-v_{i,j-1}^{n})\right) \\
& - \frac{\Delta t}{\rho 2\Delta y} \left(p_{i,j+1}^{n}-p_{i,j-1}^{n}\right) \\
& + \nu \left(\frac{\Delta t}{\Delta x^2} \left(v_{i+1,j}^{n}-2v_{i,j}^{n}+v_{i-1,j}^{n}\right) + \frac{\Delta t}{\Delta y^2} \left(v_{i,j+1}^{n}-2v_{i,j}^{n}+v_{i,j-1}^{n}\right)\right)
\end{split}
$$
Finally the pressure-Poisson equation
$$\begin{split}
p_{i,j}^{n} = & \frac{\left(p_{i+1,j}^{n}+p_{i-1,j}^{n}\right) \Delta y^2 + \left(p_{i,j+1}^{n}+p_{i,j-1}^{n}\right) \Delta x^2}{2\left(\Delta x^2+\Delta y^2\right)} \\
& -\frac{\rho\Delta x^2\Delta y^2}{2\left(\Delta x^2+\Delta y^2\right)} \\
& \times \left[\frac{1}{\Delta t}\left(\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}+\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\right)-\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}\frac{u_{i+1,j}-u_{i-1,j}}{2\Delta x}\right. \\
& \left. -2\frac{u_{i,j+1}-u_{i,j-1}}{2\Delta y}\frac{v_{i+1,j}-v_{i-1,j}}{2\Delta x}-\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y}\frac{v_{i,j+1}-v_{i,j-1}}{2\Delta y} \right]
\end{split}
$$
The initial condition is $u,v,p=0$
everywhere, and the boundary conditions are:
$u=1$ at $y=1$ (the "lid");
$u,v=0$ on the other boundaries;
$\frac{\partial p}{\partial y}=0$ at $y=0,1$;
$\frac{\partial p}{\partial x}=0$ at $x=0,1$
$p=0$ at $(0,0)$
Interestingly these boundary conditions describe a well known problem in the Computational Fluid Dynamics realm, where it is known as the lid driven square cavity flow problem.
## Numpy Implementation
```
import numpy as np
from matplotlib import pyplot, cm
%matplotlib inline
nx = 41
ny = 41
nt = 1000
nit = 50
c = 1
dx = 1. / (nx - 1)
dy = 1. / (ny - 1)
x = np.linspace(0, 1, nx)
y = np.linspace(0, 1, ny)
Y, X = np.meshgrid(x, y)
rho = 1
nu = .1
dt = .001
u = np.zeros((nx, ny))
v = np.zeros((nx, ny))
p = np.zeros((nx, ny))
```
The pressure Poisson equation that's written above can be hard to write out without typos. The function `build_up_b` below represents the contents of the square brackets, so that the entirety of the Poisson pressure equation is slightly more manageable.
```
def build_up_b(b, rho, dt, u, v, dx, dy):
b[1:-1, 1:-1] = (rho * (1 / dt *
((u[2:, 1:-1] - u[0:-2, 1:-1]) /
(2 * dx) + (v[1:-1, 2:] - v[1:-1, 0:-2]) / (2 * dy)) -
((u[2:, 1:-1] - u[0:-2, 1:-1]) / (2 * dx))**2 -
2 * ((u[1:-1, 2:] - u[1:-1, 0:-2]) / (2 * dy) *
(v[2:, 1:-1] - v[0:-2, 1:-1]) / (2 * dx))-
((v[1:-1, 2:] - v[1:-1, 0:-2]) / (2 * dy))**2))
return b
```
The function `pressure_poisson` is also defined to help segregate the different rounds of calculations. Note the presence of the pseudo-time variable nit. This sub-iteration in the Poisson calculation helps ensure a divergence-free field.
```
def pressure_poisson(p, dx, dy, b):
pn = np.empty_like(p)
pn = p.copy()
for q in range(nit):
pn = p.copy()
p[1:-1, 1:-1] = (((pn[2:, 1:-1] + pn[0:-2, 1:-1]) * dy**2 +
(pn[1:-1, 2:] + pn[1:-1, 0:-2]) * dx**2) /
(2 * (dx**2 + dy**2)) -
dx**2 * dy**2 / (2 * (dx**2 + dy**2)) *
b[1:-1,1:-1])
p[-1, :] = p[-2, :] # dp/dx = 0 at x = 2
p[:, 0] = p[:, 1] # dp/dy = 0 at y = 0
p[0, :] = p[1, :] # dp/dx = 0 at x = 0
p[:, -1] = p[:, -2] # p = 0 at y = 2
p[0, 0] = 0
return p, pn
```
Finally, the rest of the cavity flow equations are wrapped inside the function `cavity_flow`, allowing us to easily plot the results of the cavity flow solver for different lengths of time.
```
def cavity_flow(nt, u, v, dt, dx, dy, p, rho, nu):
un = np.empty_like(u)
vn = np.empty_like(v)
b = np.zeros((nx, ny))
for n in range(0,nt):
un = u.copy()
vn = v.copy()
b = build_up_b(b, rho, dt, u, v, dx, dy)
p = pressure_poisson(p, dx, dy, b)[0]
pn = pressure_poisson(p, dx, dy, b)[1]
u[1:-1, 1:-1] = (un[1:-1, 1:-1]-
un[1:-1, 1:-1] * dt / dx *
(un[1:-1, 1:-1] - un[0:-2, 1:-1]) -
vn[1:-1, 1:-1] * dt / dy *
(un[1:-1, 1:-1] - un[1:-1, 0:-2]) -
dt / (2 * rho * dx) * (p[2:, 1:-1] - p[0:-2, 1:-1]) +
nu * (dt / dx**2 *
(un[2:, 1:-1] - 2 * un[1:-1, 1:-1] + un[0:-2, 1:-1]) +
dt / dy**2 *
(un[1:-1, 2:] - 2 * un[1:-1, 1:-1] + un[1:-1, 0:-2])))
v[1:-1,1:-1] = (vn[1:-1, 1:-1] -
un[1:-1, 1:-1] * dt / dx *
(vn[1:-1, 1:-1] - vn[0:-2, 1:-1]) -
vn[1:-1, 1:-1] * dt / dy *
(vn[1:-1, 1:-1] - vn[1:-1, 0:-2]) -
dt / (2 * rho * dy) * (p[1:-1, 2:] - p[1:-1, 0:-2]) +
nu * (dt / dx**2 *
(vn[2:, 1:-1] - 2 * vn[1:-1, 1:-1] + vn[0:-2, 1:-1]) +
dt / dy**2 *
(vn[1:-1, 2:] - 2 * vn[1:-1, 1:-1] + vn[1:-1, 0:-2])))
u[:, 0] = 0
u[0, :] = 0
u[-1, :] = 0
u[:, -1] = 1 # Set velocity on cavity lid equal to 1
v[:, 0] = 0
v[:, -1] = 0
v[0, :] = 0
v[-1, :] = 0
return u, v, p, pn
#NBVAL_IGNORE_OUTPUT
u = np.zeros((nx, ny))
v = np.zeros((nx, ny))
p = np.zeros((nx, ny))
b = np.zeros((nx, ny))
nt = 1000
# Store the output velocity and pressure fields in the variables a, b and c.
# This is so they do not clash with the devito outputs below.
a, b, c, d = cavity_flow(nt, u, v, dt, dx, dy, p, rho, nu)
fig = pyplot.figure(figsize=(11, 7), dpi=100)
pyplot.contourf(X, Y, c, alpha=0.5, cmap=cm.viridis)
pyplot.colorbar()
pyplot.contour(X, Y, c, cmap=cm.viridis)
pyplot.quiver(X[::2, ::2], Y[::2, ::2], a[::2, ::2], b[::2, ::2])
pyplot.xlabel('X')
pyplot.ylabel('Y');
```
### Validation
Marchi et al (2009)$^1$ compared numerical implementations of the lid driven cavity problem with their solution on a 1024 x 1024 nodes grid. We will compare a solution using both NumPy and Devito with the results of their paper below.
1. https://www.scielo.br/scielo.php?pid=S1678-58782009000300004&script=sci_arttext
```
# Import u values at x=L/2 (table 6, column 2 rows 12-26) in Marchi et al.
Marchi_Re10_u = np.array([[0.0625, -3.85425800e-2],
[0.125, -6.96238561e-2],
[0.1875, -9.6983962e-2],
[0.25, -1.22721979e-1],
[0.3125, -1.47636199e-1],
[0.375, -1.71260757e-1],
[0.4375, -1.91677043e-1],
[0.5, -2.05164738e-1],
[0.5625, -2.05770198e-1],
[0.625, -1.84928116e-1],
[0.6875, -1.313892353e-1],
[0.75, -3.1879308e-2],
[0.8125, 1.26912095e-1],
[0.875, 3.54430364e-1],
[0.9375, 6.50529292e-1]])
# Import v values at y=L/2 (table 6, column 2 rows 27-41) in Marchi et al.
Marchi_Re10_v = np.array([[0.0625, 9.2970121e-2],
[0.125, 1.52547843e-1],
[0.1875, 1.78781456e-1],
[0.25, 1.76415100e-1],
[0.3125, 1.52055820e-1],
[0.375, 1.121477612e-1],
[0.4375, 6.21048147e-2],
[0.5, 6.3603620e-3],
[0.5625,-5.10417285e-2],
[0.625, -1.056157259e-1],
[0.6875,-1.51622101e-1],
[0.75, -1.81633561e-1],
[0.8125,-1.87021651e-1],
[0.875, -1.59898186e-1],
[0.9375,-9.6409942e-2]])
#NBVAL_IGNORE_OUTPUT
# Check results with Marchi et al 2009.
npgrid=[nx,ny]
x_coord = np.linspace(0, 1, npgrid[0])
y_coord = np.linspace(0, 1, npgrid[1])
fig = pyplot.figure(figsize=(12, 6))
ax1 = fig.add_subplot(121)
ax1.plot(a[int(npgrid[0]/2),:],y_coord[:])
ax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')
ax1.set_xlabel('$u$')
ax1.set_ylabel('$y$')
ax1 = fig.add_subplot(122)
ax1.plot(x_coord[:],b[:,int(npgrid[1]/2)])
ax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')
ax1.set_xlabel('$x$')
ax1.set_ylabel('$v$')
pyplot.show()
```
## Devito Implementation
```
from devito import Grid
grid = Grid(shape=(nx, ny), extent=(1., 1.))
x, y = grid.dimensions
t = grid.stepping_dim
```
Reminder: here are our equations
$$ \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} + v \frac{\partial u}{\partial y}= -\frac{1}{\rho}\frac{\partial p}{\partial x} + \nu \left[ \frac{\partial^2 u}{\partial x^2} +\frac{\partial^2 u}{\partial y^2} \right] $$
$$ \frac{\partial v}{\partial t} + u \frac{\partial v}{\partial x} + v \frac{\partial v}{\partial y}= -\frac{1}{\rho}\frac{\partial p}{\partial y} + \nu \left[ \frac{\partial^2 v}{\partial x^2} +\frac{\partial^2 v}{\partial y^2} \right] $$
$$
\frac{\partial^2 p}{\partial x^2} +\frac{\partial^2 p}{\partial y^2} =
\rho \left[\frac{\partial}{\partial t} \left(\frac{\partial u}{\partial x} + \frac{\partial v}{\partial y} \right) - \left(\frac{\partial u}{\partial x}\frac{\partial u}{\partial x}+2\frac{\partial u}{\partial y}\frac{\partial v}{\partial x}+\frac{\partial v}{\partial y}\frac{\partial v}{\partial y} \right) \right]
$$
Note that p has no time dependence, so we are going to solve for p in pseudotime then move to the next time step and solve for u and v. This will require two operators, one for p (using p and pn) in pseudotime and one for u and v in time.
As shown in the Poisson equation tutorial, a TimeFunction can be used despite the lack of a time-dependence. This will cause Devito to allocate two grid buffers, which we can addressed directly via the terms pn and pn.forward. The internal time loop can be controlled by supplying the number of pseudotime steps (iterations) as a time argument to the operator.
The time steps are advanced through a Python loop where a separator operator calculates u and v.
Also note that we need to use first order spatial derivatives for the velocites and these derivatives are not the maximum spatial derivative order (2nd order) in these equations. This is the first time we have seen this in this tutorial series (previously we have only used a single spatial derivate order).
To use a first order derivative of a devito function, we use the syntax `function.dxc` or `function.dyc` for the x and y derivatives respectively.
```
from devito import TimeFunction, Function, \
Eq, solve, Operator, configuration
# Build Required Functions and derivatives:
# --------------------------------------
# |Variable | Required Derivatives |
# --------------------------------------
# | u | dt, dx, dy, dx**2, dy**2 |
# | v | dt, dx, dy, dx**2, dy**2 |
# | p | dx, dy, dx**2, dy**2 |
# | pn | dx, dy, dx**2, dy**2 |
# --------------------------------------
u = TimeFunction(name='u', grid=grid, space_order=2)
v = TimeFunction(name='v', grid=grid, space_order=2)
p = TimeFunction(name='p', grid=grid, space_order=2)
#Variables are automatically initalized at 0.
# First order derivatives will be handled with p.dxc
eq_u =Eq(u.dt + u*u.dx + v*u.dy, -1./rho * p.dxc + nu*(u.laplace), subdomain=grid.interior)
eq_v =Eq(v.dt + u*v.dx + v*v.dy, -1./rho * p.dyc + nu*(v.laplace), subdomain=grid.interior)
eq_p =Eq(p.laplace,rho*(1./dt*(u.dxc+v.dyc)-(u.dxc*u.dxc)+2*(u.dyc*v.dxc)+(v.dyc*v.dyc)), subdomain=grid.interior)
# NOTE: Pressure has no time dependence so we solve for the other pressure buffer.
stencil_u =solve(eq_u , u.forward)
stencil_v =solve(eq_v , v.forward)
stencil_p=solve(eq_p, p)
update_u =Eq(u.forward, stencil_u)
update_v =Eq(v.forward, stencil_v)
update_p =Eq(p.forward, stencil_p)
# Boundary Conds. u=v=0 for all sides
bc_u = [Eq(u[t+1, 0, y], 0)]
bc_u += [Eq(u[t+1, nx-1, y], 0)]
bc_u += [Eq(u[t+1, x, 0], 0)]
bc_u += [Eq(u[t+1, x, ny-1], 1)] # except u=1 for y=2
bc_v = [Eq(v[t+1, 0, y], 0)]
bc_v += [Eq(v[t+1, nx-1, y], 0)]
bc_v += [Eq(v[t+1, x, ny-1], 0)]
bc_v += [Eq(v[t+1, x, 0], 0)]
bc_p = [Eq(p[t+1, 0, y],p[t+1, 1,y])] # dpn/dx = 0 for x=0.
bc_p += [Eq(p[t+1,nx-1, y],p[t+1,nx-2, y])] # dpn/dx = 0 for x=2.
bc_p += [Eq(p[t+1, x, 0],p[t+1,x ,1])] # dpn/dy = 0 at y=0
bc_p += [Eq(p[t+1, x, ny-1],p[t+1, x, ny-2])] # pn=0 for y=2
bc_p += [Eq(p[t+1, 0, 0], 0)]
bc=bc_u+bc_v
optime=Operator([update_u, update_v]+bc_u+bc_v)
oppres=Operator([update_p]+bc_p)
# Silence non-essential outputs from the solver.
configuration['log-level'] = 'ERROR'
# This is the time loop.
for step in range(0,nt):
if step>0:
oppres(time_M = nit)
optime(time_m=step, time_M=step, dt=dt)
#NBVAL_IGNORE_OUTPUT
fig = pyplot.figure(figsize=(11,7), dpi=100)
# Plotting the pressure field as a contour.
pyplot.contourf(X, Y, p.data[0], alpha=0.5, cmap=cm.viridis)
pyplot.colorbar()
# Plotting the pressure field outlines.
pyplot.contour(X, Y, p.data[0], cmap=cm.viridis)
# Plotting velocity field.
pyplot.quiver(X[::2,::2], Y[::2,::2], u.data[0,::2,::2], v.data[0,::2,::2])
pyplot.xlabel('X')
pyplot.ylabel('Y');
```
### Validation
```
#NBVAL_IGNORE_OUTPUT
# Again, check results with Marchi et al 2009.
fig = pyplot.figure(figsize=(12, 6))
ax1 = fig.add_subplot(121)
ax1.plot(u.data[0,int(grid.shape[0]/2),:],y_coord[:])
ax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')
ax1.set_xlabel('$u$')
ax1.set_ylabel('$y$')
ax1 = fig.add_subplot(122)
ax1.plot(x_coord[:],v.data[0,:,int(grid.shape[0]/2)])
ax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')
ax1.set_xlabel('$x$')
ax1.set_ylabel('$v$')
pyplot.show()
```
The Devito implementation produces results consistent with the benchmark solution. There is a small disparity in a few of the velocity values, but this is expected as the Devito 41 x 41 node grid is much coarser than the benchmark on a 1024 x 1024 node grid.
## Comparison
```
#NBVAL_IGNORE_OUTPUT
fig = pyplot.figure(figsize=(12, 6))
ax1 = fig.add_subplot(121)
ax1.plot(a[int(npgrid[0]/2),:],y_coord[:])
ax1.plot(u.data[0,int(grid.shape[0]/2),:],y_coord[:],'--')
ax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')
ax1.set_xlabel('$u$')
ax1.set_ylabel('$y$')
ax1 = fig.add_subplot(122)
ax1.plot(x_coord[:],b[:,int(npgrid[1]/2)])
ax1.plot(x_coord[:],v.data[0,:,int(grid.shape[0]/2)],'--')
ax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')
ax1.set_xlabel('$x$')
ax1.set_ylabel('$v$')
ax1.legend(['numpy','devito','Marchi (2009)'])
pyplot.show()
#Pressure norm check
tol = 1e-3
assert np.sum((c[:,:]-d[:,:])**2/ np.maximum(d[:,:]**2,1e-10)) < tol
assert np.sum((p.data[0]-p.data[1])**2/np.maximum(p.data[0]**2,1e-10)) < tol
```
Overlaying all the graphs together shows how the Devito, NumPy and Marchi et al (2009)$^1$
solutions compare with each other. A final accuracy check is done which is to test whether the pressure norm has exceeded a specified tolerance.
|
github_jupyter
|
```
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
from TutorML.decomposition import LFM
def load_movielens(train_path, test_path, basedir=None):
if basedir:
train_path = os.path.join(basedir,train_path)
test_path = os.path.join(basedir,test_path)
col_names = ['user_id','item_id','score','timestamp']
use_cols = ['user_id','item_id','score']
df_train = pd.read_csv(train_path,sep='\t',header=None,
names=col_names,usecols=use_cols)
df_test = pd.read_csv(test_path,sep='\t',header=None,
names=col_names,usecols=use_cols)
df_train.user_id -= 1
df_train.item_id -= 1
df_test.user_id -= 1
df_test.item_id -=1
return df_train, df_test
df_train, df_test = load_movielens(train_path='u1.base',test_path='u1.test',
basedir='ml-100k/')
data = pd.concat([df_train,df_test]).reset_index().drop('index',axis=1)
n_users = data.user_id.nunique()
n_items = data.item_id.nunique()
train_idx = np.ravel_multi_index(df_train[['user_id','item_id']].values.T,
dims=(n_users,n_items))
test_idx = np.ravel_multi_index(df_test[['user_id','item_id']].values.T,
dims=(n_users,n_items))
X = np.zeros(shape=(n_users*n_items,))
mask = np.zeros(shape=(n_users*n_items))
X[train_idx] = df_train['score']
mask[train_idx] = 1
y_test = df_test.score.values.ravel()
X = X.reshape((n_users,n_items))
mask = mask.reshape((n_users, n_items))
"""
if you want to increace number of factors,
you should lower the learning rate too. otherwise nan or inf may appear
"""
lfm = LFM(n_factors=5,max_iter=1000,early_stopping=50,reg_lambda=2,
learning_rate=1e-3,print_every=20)
lfm.fit(X,mask,test_data=(test_idx,y_test))
rounded_prediction_mse = lfm.mse_history
lfm = LFM(n_factors=2,max_iter=1000,early_stopping=50,reg_lambda=1,
round_prediction=False, learning_rate=1e-3,print_every=20)
lfm.fit(X,mask,test_data=(test_idx,y_test))
mse = lfm.mse_history
def plot(xy, start_it, title):
n_iters = xy.shape[0]
plt.plot(range(start_it,n_iters), xy[start_it:,0],label='train mse')
plt.plot(range(start_it,n_iters), xy[start_it:,1],label='test mse')
plt.title(title)
plt.legend()
plt.xlabel('iter')
plt.figure(figsize=(12,4))
plt.subplot(121)
plot(rounded_prediction_mse, 20, 'Mse with prediction rounded')
plt.subplot(122)
plot(mse, 20, 'Mse with prediction unrounded')
plt.show()
```
|
github_jupyter
|
# Setup
```
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model, load_model, clone_model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Activation
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, accuracy_score, confusion_matrix
import itertools
from random import randint
from skimage.segmentation import slic, mark_boundaries, felzenszwalb, quickshift
from matplotlib.colors import LinearSegmentedColormap
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import os
import time
import cv2
import numpy as np
import shap
from alibi.explainers import AnchorImage
import lime
from lime import lime_image
from lime.wrappers.scikit_image import SegmentationAlgorithm
import vis
from vis.visualization import visualize_saliency
from exmatchina import *
num_classes = 10
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship','truck']
class_dict = {
'airplane': 0,
'automobile':1,
'bird':2,
'cat':3,
'deer':4,
'dog':5,
'frog':6,
'horse':7,
'ship':8,
'truck':9
}
inv_class_dict = {v: k for k, v in class_dict.items()}
## These are the randomly generated indices that were used in our survey
# all_idx = np.array([23, 26, 390, 429, 570, 649, 732, 739, 1081, 1163, 1175, 1289, 1310, 1323
# , 1487, 1623, 1715, 1733, 1825, 1881, 1951, 2102, 2246, 2300, 2546, 2702, 2994, 3095
# , 3308, 3488, 3727, 3862, 4190, 4299, 4370, 4417, 4448, 4526, 4537, 4559, 4604, 4672
# , 4857, 5050, 5138, 5281, 5332, 5471, 5495, 5694, 5699, 5754, 5802, 5900, 6039, 6042
# , 6046, 6127, 6285, 6478, 6649, 6678, 6795, 7023, 7087, 7254, 7295, 7301, 7471, 7524
# , 7544, 7567, 7670, 7885, 7914, 7998, 8197, 8220, 8236, 8291, 8311, 8355, 8430, 8437
# , 8510, 8646, 8662, 8755, 8875, 8896, 8990, 9106, 9134, 9169, 9436, 9603, 9739, 9772
# , 9852, 9998])
all_idx = [23, 26, 390, 429, 570] #Considering just 5 samples
x_train = np.load('../data/image/X_train.npy')
y_train = np.load('../data/image/y_train.npy')
x_test = np.load('../data/image/X_test.npy')
y_test = np.load('../data/image/y_test.npy')
print(f'Number of Training samples: {x_train.shape[0]}')
print(f'Number of Test samples: {x_test.shape[0]}')
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
y_train = to_categorical(y_train,num_classes)
y_test = to_categorical(y_test,num_classes)
model = load_model('../trained_models/image.hdf5')
model.summary()
def calculate_metrics(model, X_test, y_test_binary):
y_pred = np.argmax(model.predict(X_test), axis=1)
y_true = np.argmax(y_test_binary, axis=1)
mismatch = np.where(y_true != y_pred)
cf_matrix = confusion_matrix(y_true, y_pred)
accuracy = accuracy_score(y_true, y_pred)
#micro_f1 = f1_score(y_true, y_pred, average='micro')
macro_f1 = f1_score(y_true, y_pred, average='macro')
return cf_matrix, accuracy, macro_f1, mismatch, y_pred
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
# print(cm)
else:
print('Confusion matrix, without normalization')
# print(cm)
plt.figure(figsize = (10,7))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, fontsize = 15)
plt.yticks(tick_marks, classes, fontsize = 15)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt), fontsize = 15,
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label', fontsize = 12)
plt.xlabel('Predicted label', fontsize = 12)
cf_matrix, accuracy, macro_f1, mismatch, y_pred = calculate_metrics(model, x_test, y_test)
print('Accuracy : {}'.format(accuracy))
print('F1-score : {}'.format(macro_f1))
plot_confusion_matrix(cf_matrix, classes,
normalize=True,
title='Confusion matrix',
cmap=plt.cm.Blues)
```
# LIME
```
explainer = lime_image.LimeImageExplainer()
segmentation_fn = SegmentationAlgorithm('felzenszwalb', scale=10,
sigma=0.4, min_size=20)
for i in all_idx:
image = x_test[i]
to_explain = np.expand_dims(image,axis=0)
class_idx = np.argmax(model.predict(to_explain))
print(inv_class_dict[class_idx])
# Hide color is the color for a superpixel turned OFF.
# Alternatively, if it is NONE, the superpixel will be replaced by the average of its pixels
explanation = explainer.explain_instance(image, model.predict,segmentation_fn = segmentation_fn,
top_labels=5, hide_color=0, num_samples=1000)
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0],
positive_only=True, num_features=5, hide_rest=True)
#Plotting
fig, axes1 = plt.subplots(1,2, figsize=(10,10))
# fig.suptitle(inv_class_dict[y_test[i]])
axes1[0].set_axis_off()
axes1[1].set_axis_off()
axes1[0].imshow(x_test[i], interpolation='nearest')
axes1[1].imshow(mark_boundaries(temp, mask), interpolation='nearest')
# plt.savefig(f'./image/image-{i}-lime',bbox_inches = 'tight', pad_inches = 0.5)
plt.show()
```
# Anchor Explanations
```
# Define a Prediction Function
predict_fn = lambda x: model.predict(x)
image_shape = (32,32,3)
segmentation_fn = 'felzenszwalb'
slic_kwargs = {'n_segments': 100, 'compactness': 1, 'sigma': .5, 'max_iter': 50}
felzenszwalb_kwargs = {'scale': 10, 'sigma': 0.4, 'min_size': 50}
explainer = AnchorImage(predict_fn, image_shape, segmentation_fn=segmentation_fn,
segmentation_kwargs=felzenszwalb_kwargs, images_background=None)
for i in all_idx:
image = x_test[i]
to_explain = np.expand_dims(image,axis=0)
class_idx = np.argmax(model.predict(to_explain))
print(inv_class_dict[class_idx])
explanation = explainer.explain(image, threshold=.99, p_sample=0.5, tau=0.15)
## Plotting
fig, axes1 = plt.subplots(1,2, figsize=(10,10))
# fig.suptitle(inv_class_dict[y_test[i]])
axes1[0].set_axis_off()
axes1[1].set_axis_off()
axes1[0].imshow(x_test[i], interpolation='nearest')
axes1[1].imshow(explanation['anchor'], interpolation='nearest')
# plt.savefig(f'./image-{i}-anchor', bbox_inches = 'tight', pad_inches = 0.5)
plt.show()
```
# SHAP
```
background = x_train[np.random.choice(x_train.shape[0], 1000, replace=False)]
# map input to specified layer
def map2layer(x, layer):
feed_dict = dict(zip([model.layers[0].input], x.reshape((1,) + x.shape)))
return K.get_session().run(model.layers[layer].input, feed_dict)
def get_shap_full(idx):
layer = 14
to_explain = np.expand_dims(x_test[idx],axis=0)
class_idx = np.argmax(model.predict(to_explain))
print(inv_class_dict[class_idx])
# get shap values
e = shap.GradientExplainer((model.layers[layer].input, model.layers[-1].output), map2layer(background, layer))
shap_values,indexes = e.shap_values(map2layer(to_explain, layer), ranked_outputs=1)
# use SHAP plot
shap.image_plot(shap_values, to_explain, show=False)
# plt.savefig('./image/image-' + str(idx) + '-shap.png', bbox_inches='tight')
for i in all_idx:
get_shap_full(i)
```
# Saliency Map
```
# Replace activation with linear
new_model = clone_model(model)
new_model.pop()
new_model.add(Activation('linear', name="linear_p"))
new_model.summary()
def plot_map(img_index, class_idx, grads):
print(inv_class_dict[class_idx])
fig, axes = plt.subplots(ncols=2,figsize=(8,6))
axes[0].imshow(x_test[img_index])
axes[0].axis('off')
axes[1].imshow(x_test[img_index])
axes[1].axis('off')
i = axes[1].imshow(grads,cmap="jet",alpha=0.6)
fig.subplots_adjust(right=0.9)
cbar_ax = fig.add_axes([1, 0.2, 0.04, 0.59])
fig.colorbar(i, cax=cbar_ax)
# plt.savefig('./image/image-' + str(img_index) + '-saliencymap.png', bbox_inches='tight', pad_inches=0.3)
# plt.close(fig)
plt.show()
def getSaliencyMap(img_index):
to_explain = x_test[img_index].reshape(1,32,32,3)
class_idx = np.argmax(model.predict(to_explain))
grads = visualize_saliency(new_model,
14,
filter_indices = None,
seed_input = x_test[img_index])
plot_map(img_index, class_idx , grads)
for i in all_idx:
getSaliencyMap(i)
```
# Grad-Cam++
```
def get_gradcampp(idx):
img = x_test[idx]
cls_true = np.argmax(y_test[idx])
x = np.expand_dims(img, axis=0)
# get cam
cls_pred, cam = grad_cam_plus_plus(model=model, x=x, layer_name="Conv_6")
print(inv_class_dict[cls_pred])
# resize to to size of image
heatmap = cv2.resize(cam, (img.shape[1], img.shape[0]))
fig, axes = plt.subplots(ncols=2,figsize=(8,6))
axes[0].imshow(img)
axes[0].axis('off')
axes[1].imshow(img)
axes[1].axis('off')
i = axes[1].imshow(heatmap,cmap="jet",alpha=0.6)
fig.subplots_adjust(right=0.9)
cbar_ax = fig.add_axes([1, 0.2, 0.04, 0.60])
fig.colorbar(i, cax=cbar_ax)
# plt.savefig('./image/image-' + str(idx) + '-gradcampp.png', bbox_inches='tight', pad_inches=0.3)
# plt.close(fig)
plt.show()
def grad_cam_plus_plus(model, x, layer_name):
cls = np.argmax(model.predict(x))
y_c = model.output[0, cls]
conv_output = model.get_layer(layer_name).output
grads = K.gradients(y_c, conv_output)[0]
first = K.exp(y_c) * grads
second = K.exp(y_c) * grads * grads
third = K.exp(y_c) * grads * grads * grads
gradient_function = K.function([model.input], [y_c, first, second, third, conv_output, grads])
y_c, conv_first_grad, conv_second_grad, conv_third_grad, conv_output, grads_val = gradient_function([x])
global_sum = np.sum(conv_output[0].reshape((-1,conv_first_grad[0].shape[2])), axis=0)
alpha_num = conv_second_grad[0]
alpha_denom = conv_second_grad[0] * 2.0 + conv_third_grad[0] * global_sum.reshape((1, 1, conv_first_grad[0].shape[2]))
alpha_denom = np.where(alpha_denom != 0.0, alpha_denom, np.ones(alpha_denom.shape))
alphas = alpha_num / alpha_denom
weights = np.maximum(conv_first_grad[0], 0.0)
alpha_normalization_constant = np.sum(np.sum(alphas, axis=0), axis=0) # 0
alphas /= alpha_normalization_constant.reshape((1, 1, conv_first_grad[0].shape[2])) # NAN
deep_linearization_weights = np.sum((weights * alphas).reshape((-1, conv_first_grad[0].shape[2])), axis=0)
cam = np.sum(deep_linearization_weights * conv_output[0], axis=2)
cam = np.maximum(cam, 0)
cam /= np.max(cam)
return cls, cam
for i in all_idx:
get_gradcampp(i)
```
# ExMatchina
```
def plot_images(test, examples, label):
# =======GENERATE STUDY EXAMPLES=========
fig = plt.figure(figsize=(10,3))
num_display = 4
fig.add_subplot(1, num_display, 1).title.set_text(inv_class_dict[label])
plt.imshow(test, interpolation='nearest')
plt.axis('off')
line = fig.add_subplot(1, 1, 1)
line.plot([2.39,2.39],[0,1],'--')
line.set_xlim(0,10)
line.axis('off')
for k in range(num_display-1):
if k >= len(examples):
continue
fig.add_subplot(1,num_display,k+2).title.set_text(inv_class_dict[label])
fig.add_subplot(1,num_display,k+2).title.set_color('#0067FF')
plt.imshow(examples[k], interpolation='nearest')
plt.axis('off')
fig.tight_layout()
plt.tight_layout()
plt.show()
# plt.savefig('./image-' + str(i) + '-example.png', bbox_inches='tight')
selected_layer = 'Flatten_1'
exm = ExMatchina(model=model, layer=selected_layer, examples=x_train)
for test_idx in all_idx:
test_input = x_test[test_idx]
label = exm.get_label_for(test_input)
(examples, indices) = exm.return_nearest_examples(test_input)
plot_images(test_input, examples, label)
```
|
github_jupyter
|
Here is a simple example of file IO:
```
#Write a file
out_file = open("test.txt", "w")
out_file.write("This Text is going to out file\nLook at it and see\n")
out_file.close()
#Read a file
in_file = open("test.txt", "r")
text = in_file.read()
in_file.close()
print(text)
```
The output and the contents of the file test.txt are:
Notice that it wrote a file called test.txt in the directory that you ran the program from. The `\n` in the string tells Python to put a **n**ewline where it is.
A overview of file IO is:
1. Get a file object with the `open` function.
2. Read or write to the file object (depending on if you open it with a "r" or "w")
3. Close it
The first step is to get a file object. The way to do this is to use the `open` function. The format is `file_object = open(filename, mode)` where `file_object` is the variable to put the file object, `filename` is a string with the filename, and `mode` is either `"r"` to **r**ead a file or `"w"` to **w**rite a file. Next the file object's functions can be called. The two most common functions are `read` and `write`. The `write` function adds a string to the end of the file. The `read` function reads the next thing in the file and returns it as a string. If no argument is given it will return the whole file (as done in the example).
Now here is a new version of the phone numbers program that we made earlier:
```
def print_numbers(numbers):
print("Telephone Numbers:")
for x in numbers:
print("Name: ", x, " \tNumber: ", numbers[x])
print()
def add_number(numbers, name, number):
numbers[name] = number
def lookup_number(numbers, name):
if name in numbers:
return "The number is "+numbers[name]
else:
return name+" was not found"
def remove_number(numbers, name):
if name in numbers:
del numbers[name]
else:
print(name, " was not found")
def load_numbers(numbers, filename):
in_file = open(filename, "r")
while True:
in_line = in_file.readline()
if in_line == "":
break
in_line = in_line[:-1]
[name, number] = in_line.split(",")
numbers[name] = number
in_file.close()
def save_numbers(numbers, filename):
out_file = open(filename, "w")
for x in numbers:
out_file.write(x+","+numbers[x]+"\n")
out_file.close()
def print_menu():
print('1. Print Phone Numbers')
print('2. Add a Phone Number')
print('3. Remove a Phone Number')
print('4. Lookup a Phone Number')
print('5. Load numbers')
print('6. Save numbers')
print('7. Quit')
print()
phone_list = {}
menu_choice = 0
print_menu()
while menu_choice != 7:
menu_choice = int(input("Type in a number (1-7):"))
if menu_choice == 1:
print_numbers(phone_list)
elif menu_choice == 2:
print("Add Name and Number")
name = input("Name:")
phone = input("Number:")
add_number(phone_list, name, phone)
elif menu_choice == 3:
print("Remove Name and Number")
name = input("Name:")
remove_number(phone_list, name)
elif menu_choice == 4:
print("Lookup Number")
name = input("Name:")
print(lookup_number(phone_list, name))
elif menu_choice == 5:
filename = input("Filename to load:")
load_numbers(phone_list, filename)
elif menu_choice == 6:
filename = input("Filename to save:")
save_numbers(phone_list, filename)
elif menu_choice == 7:
pass
else:
print_menu()
print("Goodbye")
```
Notice that it now includes saving and loading files. Here is some output of my running it twice:
The new portions of this program are:
First we will look at the save portion of the program. First, it creates a file object with the command open(filename, "w"). Next, it goes through and creates a line for each of the phone numbers with the command `out_file.write(x+","+numbers[x]+"\n")`. This writes out a line that contains the name, a comma, the number and follows it by a newline.
The loading portion is a little more complicated. It starts by getting a file object. Then, it uses a while True: loop to keep looping until a `break` statement is encountered. Next, it gets a line with the line in\_line = in\_file.readline(). The `readline` function will return a empty string (len(string) == 0) when the end of the file is reached. The `if` statement checks for this and `break`s out of the `while` loop when that happens. Of course if the `readline` function did not return the newline at the end of the line there would be no way to tell if an empty string was an empty line or the end of the file so the newline is left in what `readline` returns. Hence we have to get rid of the newline. The line `in_line = in_line[:-1]` does this for us by dropping the last character. Next the line `[name, number] = string.split(in_line, ",")` splits the line at the comma into a name and a number. This is then added to the `numbers` dictionary.
Exercises
=========
Now modify the grades program from notebook 10 (copied below) so that it uses file
IO to keep a record of the students.
```
max_points = [25, 25, 50, 25, 100]
assignments = ['hw ch 1', 'hw ch 2', 'quiz ', 'hw ch 3', 'test']
students = {'#Max':max_points}
def print_menu():
print("1. Add student")
print("2. Remove student")
print("3. Print grades")
print("4. Record grade")
print("5. Print Menu")
print("6. Exit")
def print_all_grades():
print('\t', end=' ')
for i in range(len(assignments)):
print(assignments[i], '\t', end=' ')
print()
keys = list(students.keys())
keys.sort()
for x in keys:
print(x, '\t', end=' ')
grades = students[x]
print_grades(grades)
def print_grades(grades):
for i in range(len(grades)):
print(grades[i], '\t\t', end=' ')
print()
print_menu()
menu_choice = 0
while menu_choice != 6:
print()
menu_choice = int(input("Menu Choice (1-6):"))
if menu_choice == 1:
name = input("Student to add:")
students[name] = [0]*len(max_points)
elif menu_choice == 2:
name = input("Student to remove:")
if name in students:
del students[name]
else:
print("Student: ", name, " not found")
elif menu_choice == 3:
print_all_grades()
elif menu_choice == 4:
print("Record Grade")
name = input("Student:")
if name in students:
grades = students[name]
print("Type in the number of the grade to record")
print("Type a 0 (zero) to exit")
for i in range(len(assignments)):
print(i+1, ' ', assignments[i], '\t', end=' ')
print()
print_grades(grades)
which = 1234
while which != -1:
which = int(input("Change which Grade:"))
which = which-1
if 0 <= which < len(grades):
grade = int(input("Grade:"))
grades[which] = grade
elif which != -1:
print("Invalid Grade Number")
else:
print("Student not found")
elif menu_choice != 6:
print_menu()
```
|
github_jupyter
|
```
# accessing documentation with ?
# We can use help function to understand the documentation
print(help(len))
# or we can use the ? operator
len?
# The notation works for objects also
L = [1,2,4,5]
L.append?
L?
# This will also work for functions that we create ourselves, the ? returns the doc string in the function
def square(n):
'''return the square of the number'''
return n**2
square?
# Accessing the source code with ??
square??
# Sometimes it might not return the source code because it might be written in an other language
from collections import deque as d
d??
# Wild Card matching
# We can use the wild card * and type the known part to retrieve the unknown command
# Example for looking at different type of warnings
*Warning?
# We can use this in functions also
d.app*?
# Shortcuts in Ipython notebook
''' Navigation shortcuts
Ctrl-a Move cursor to the beginning of the line
Ctrl-e Move cursor to the end of the line
Ctrl-b or the left arrow key Move cursor back one character
Ctrl-f or the right arrow key Move cursor forward one character
Text Entry shortcuts
Backspace key Delete previous character in line
Ctrl-d Delete next character in line
Ctrl-k Cut text from cursor to end of line
Ctrl-u Cut text from beginning of line to cursor
Ctrl-y Yank (i.e. paste) text that was previously cut
Ctrl-t Transpose (i.e., switch) previous two characters
Command History Shortcuts
Ctrl-p (or the up arrow key) Access previous command in history
Ctrl-n (or the down arrow key) Access next command in history
Ctrl-r Reverse-search through command history
Keystroke Action
Ctrl-l Clear terminal screen
Ctrl-c Interrupt current Python command
Ctrl-d Exit IPython session '''
# MAGIC COMMANDS
# We can use %run to execute python (.py) file in notebook, any functions defined in the script can be used by the notebook
# We can use %timeit to check the execution time for a single iteration or line command, for finding multiline command time execution we can use %%timeit
%%timeit
L = []
for i in range(10000):
L.append(i**2)
%timeit L = [n ** 2 for n in range(1000)] # Checking time for executing list comprehensions, we can see list comprehension execution is very efficient
# Input/ Output history commands
# We can use In/ Out objects to print the Input and output objects in history, lets say we start the below session
import math
math.sin(2)
math.cos(2)
# print(In), will print all the commands inputted in the current notebook
print(In) # returns a list of all the commands executed so far.
# Similarly we can use 'OUT' to print the output of these functions
print(Out) # Returns a dictonary with input and output
# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function
math.sin(2) + math.cos(2); # We usually use this ';' symbol especially if in case of matplolib
# For accesing previous batch of inputs we can use %history command
#%history?
%history -n 1-4
# Shell Commands
# We can use '!' for executing os commands
# Shell is a direct way to interact textually with computer
!ls
!pwd
!echo "printing from the shell"
contents = !ls
print(contents)
# Errors and debugging
# Controlling Exceptions: %xmode
# Using %xmode we can control the length of content of error message
%xmode Plain
def func2(x):
a = x
b = 0
return a/b
func2(4)
# We can use '%xmode verbose' to have additional information reported regarding the error
%xmode verbose
func2(90)
# We can apply the default mode to take things normal
#%xmode Default
# Debugging
# The standard tool for reading traceback is pdb(python debugger), ipdb(ipython version)
# We can also use the %debug magic command, in case of an exception it will automatically open an interactive debugging shell
# The ipdb prompt lets you explore the current state of the stack, explore the available variables, and even run Python commands!
%debug
# Other debugging commands in the shell
'''list Show the current location in the file
h(elp) Show a list of commands, or find help on a specific command
q(uit) Quit the debugger and the program
c(ontinue) Quit the debugger, continue in the program
n(ext) Go to the next step of the program
<enter> Repeat the previous command
p(rint) Print variables
s(tep) Step into a subroutine
r(eturn) Return out of a subroutine '''
# We can use these commands to figureout the execution time for various snnipets and code
'''%time: Time the execution of a single statement
%timeit: Time repeated execution of a single statement for more accuracy
%prun: Run code with the profiler
%lprun: Run code with the line-by-line profiler
%memit: Measure the memory use of a single statement
%mprun: Run code with the line-by-line memory profiler'''
# Data Structures and Processing for Machine Learing
import numpy as np
np.__version__
# Data types in python
# As we know python is dynamically typed language, but inside it is just complex 'c' lang structure disguised in python
'''struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
ob_refcnt, a reference count that helps Python silently handle memory allocation and deallocation
ob_type, which encodes the type of the variable
ob_size, which specifies the size of the following data members
ob_digit, which contains the actual integer value that we expect the Python variable to represent. '''
# usually all this additional information comes at a cost of memory and computation
# A list if also a complex structure that can accomodate multiple data types, So we make use of a numpy array for manipulating integer data
# Although a list might be flexible, but a numpy array is very efficient to store and manipulate data
# We can make use of 'array' data structure make computationally effective manipulations
import array
L = list(range(10))
arr = array.array('i',L) # 'i' is a type code indicating the elements of the array as integer
arr
import numpy as np
# Creating array
np.array([1,2,3,4,5]) # Unlike list, numpy array need to have same data type
np.array([1, 2, 3, 4], dtype='float32') # We can explicitly declare the type using 'dtype' attribute
# nested lists result in multi-dimensional arrays
np.array([range(i, i + 3) for i in [2, 4, 6]])
# Create a length-10 integer array filled with zeros
np.zeros(10, dtype=int)
# Create a 3x5 floating-point array filled with ones
np.ones((3, 5), dtype=float)
# Create a 3x5 array filled with 3.14
np.full((3, 5), 3.14)
# Create an array filled with a linear sequence
# Starting at 0, ending at 20, stepping by 2
# (this is similar to the built-in range() function)
np.arange(0, 20, 2).reshape(5,2) # We can use reshape() to convert the shape as we want to
# Create an array of five values evenly spaced between 0 and 1
np.linspace(0, 1, 25)
# Create a 3x3 array of uniformly distributed
# random values between 0 and 1
np.random.random((3, 3))
# Create a 3x3 array of normally distributed random values
# with mean 0 and standard deviation 1
np.random.normal(0, 1, (3, 3))
# Create a 3x3 array of random integers in the interval [0, 10)
np.random.randint(0, 10000, (3, 3))
# Create a 3x3 identity matrix
np.eye(3)
# Create an uninitialized array of three integers
# The values will be whatever happens to already exist at that memory location
np.empty(3)
# Numpy built in data types, numpy is built in 'C'.
'''
bool_ Boolean (True or False) stored as a byte
int_ Default integer type (same as C long; normally either int64 or int32)
intc Identical to C int (normally int32 or int64)
intp Integer used for indexing (same as C ssize_t; normally either int32 or int64)
int8 Byte (-128 to 127)
int16 Integer (-32768 to 32767)
int32 Integer (-2147483648 to 2147483647)
int64 Integer (-9223372036854775808 to 9223372036854775807)
uint8 Unsigned integer (0 to 255)
uint16 Unsigned integer (0 to 65535)
uint32 Unsigned integer (0 to 4294967295)
uint64 Unsigned integer (0 to 18446744073709551615)
float_ Shorthand for float64.
float16 Half precision float: sign bit, 5 bits exponent, 10 bits mantissa
float32 Single precision float: sign bit, 8 bits exponent, 23 bits mantissa
float64 Double precision float: sign bit, 11 bits exponent, 52 bits mantissa
complex_ Shorthand for complex128.
complex64 Complex number, represented by two 32-bit floats
complex128 Complex number, represented by two 64-bit floats'''
# Numpy Array Attributes
np.random.seed(0) # seed for reproducibility
# 3 array's with random integers and different dimensions
x1 = np.random.randint(10, size=6) # One-dimensional array
x2 = np.random.randint(10, size=(3, 4)) # Two-dimensional array
x3 = np.random.randint(10, size=(3, 4, 5)) # Three-dimensional array
print("x3 ndim: ", x3.ndim) # number of dimensions
print("x3 shape:", x3.shape) # size of dimension
print("x3 size: ", x3.size) # total size of array
print("dtype:", x3.dtype) # Data type stored in numpy array
print("itemsize:", x3.itemsize, "bytes") # itemsize of single item in bytes
print("nbytes:", x3.nbytes, "bytes") # total array itemsize ,nbyted = itemsize*size
# Accesing elements (Single)
print(x1)
print(x1[0]) # prints the first element
print(x1[4]) # prints the fifth element
print(x1[-1]) # To index array from end (prints last element)
print(x1[-2]) # prints second last element
# Multidimentional array can be accessed using a comma seperated tuple of indices
print(x2)
print(x2[0,0]) # array_name(row,column)
print(x2[2,0]) # 3rd row element(0,1,2), first column
print(x2[2,-1]) # 3rd row element, last column
x2[0,0] = 90 # values can also be modified at any index
# but if we change 'x1[0] = 9.9', it gets trucated and converted to 3 as 'x1' is declared as int32
# Accessing elements via slicing
#x[start:stop:step]
print(x1)
print(x1[0:2]) # returns first 2 elements
print(x1[1:]) # returns all elements from 2nd position
print(x1[0:3:2]) # returns all elements from 0 to 2 position with step '2' (so 5,3)
print(x1[::2]) # every other element
print(x1[1::2]) # every other element, starting at index 1
# If step is negative then it returns in reverse order, internally start and stop are swapped
print(x1[::-1]) # all elements, reversed
print(x1[3::-1]) # reversed from index 3 to starting, this includes 3
print(x1[4:1:-1]) # revered from index 4 up to 2nd element.
# Multidimentional array
print(x2)
print(x2[:2,:3]) # returns array from start row up to 3rd row, and up to 4th column
print('\n')
print(x2[:3, ::2]) # all rows, every other column as step value is 2
print(x2[::-1, ::-1]) # sub array dimensions can also be reveresed
# Accesing array rows and columns
print(x2)
print(x2[:, 0]) # first column of x2
print(x2[0, :]) # first row of x2
print(x2[0]) # equivalent to x2[0, :], first row
# When we copy sub array, to another array (internally it does not make copies it just returns a view, so on changing the subarray will make change in original array)
# In order to actually create a copy we can use the 'copy()' method
x2_sub_copy = x2[:2, :2].copy()
print(x2_sub_copy)
# Reshaping array
grid = np.arange(1, 10).reshape((3, 3))
print(grid) # for this to work, the initial array needs to have the same shape
# Array Concatenation and Spliting
# We can use np.concatenate, np.hstack, np.vstack
x = np.array([1, 2, 3])
y = np.array([3, 2, 1])
np.concatenate([x, y])
# We can also concatenate more than one array at once
z = [99, 99, 99]
print(np.concatenate([x, y, z]))
# Concatenating 2d array
grid = np.array([[1, 2, 3],
[4, 5, 6]])
grids = np.concatenate([grid,grid])
print(grids)
# concatenate along the axis (zero-indexed)
print(np.concatenate([grid, grid], axis=1))
# Using vstack and hstack
x = np.array([1, 2, 3])
grid = np.array([[9, 8, 7],
[6, 5, 4]])
# vertically stack the arrays
print(np.vstack([x, grid])) # We simply stack vertically
print(np.hstack([grids,grids])) # We concatenate them horizontally sideways
# Similarly we can use np.dstack to concatenate along the 3rd axis
# Spliting is opposite to concatenation. We use np.vsplit, np.hsplit and np.split to split the array
x = [1, 2, 3, 99, 99, 3, 2, 1]
x1, x2, x3 = np.split(x, [3, 5]) # these are points where to split for 'n' points we get 'n+1' sub arrays
print(x1, x2, x3)
# using np.vsplit
grid = np.arange(16).reshape((4, 4))
print('\n')
print(grid)
upper, lower = np.vsplit(grid, [2]) # its like a horizontal plane spliting at a point
print(upper)
print(lower)
# using np.hsplit
left, right = np.hsplit(grid, [2])
print(left)
print(right)
# Similarly we can use np.dsplit to split along the 3rd axis
# numpy for computation
# Numpy is very fast when we use it for vectorised operations, generally implemented through "Numpy Universal Functions"
# It makes repeated calculations on numpy very efficient
# Slowness of python loops, the loops mostly implemented via cpython are slow due to dynamic and interpreted nature
# Sometimes it is absurdly slow, especially while running loops
# So for many types of operations numpy is quite efficient especially as it is statically typed and complied routine. (called vectorized operations)
# vectorized operation is simple applying the operation on the array which is then applied on each element
#Vectorized operations in NumPy are implemented via ufuncs, whose main purpose is to quickly execute repeated operations.
#On values in NumPy arrays. Ufuncs are extremely flexible – before we saw an operation between a scalar and an array,
# but we can also operate between two arrays
print(np.arange(5) / np.arange(1, 6))
# Multi dimentional array
x = np.arange(9).reshape((3, 3))
2 ** x
#Array arithmetic
#NumPy's ufuncs feel very natural to use because they make use of Python's native arithmetic operators.
#The standard addition, subtraction, multiplication, and division can all be used
x = np.arange(4)
print("x =", x)
print("x + 5 =", x + 5)
print("x - 5 =", x - 5)
print("x * 2 =", x * 2)
print("x / 2 =", x / 2)
print("x // 2 =", x // 2) # floor division
print("-x = ", -x)
print("x ** 2 = ", x ** 2)
print("x % 2 = ", x % 2)
print(-(0.5*x + 1) ** 2) # These can be strung together as you wish
# We can also call functions instead
'''
+ np.add Addition (e.g., 1 + 1 = 2)
- np.subtract Subtraction (e.g., 3 - 2 = 1)
- np.negative Unary negation (e.g., -2)
* np.multiply Multiplication (e.g., 2 * 3 = 6)
/ np.divide Division (e.g., 3 / 2 = 1.5)
// np.floor_divide Floor division (e.g., 3 // 2 = 1)
** np.power Exponentiation (e.g., 2 ** 3 = 8)
% np.mod Modulus/remainder (e.g., 9 % 4 = 1) '''
x = np.array([-2, -1, 0, 1, 2])
print(abs(x))
# Array trignometry
theta = np.linspace(0, np.pi, 3)
print("theta = ", theta)
print("sin(theta) = ", np.sin(theta))
print("cos(theta) = ", np.cos(theta))
print("tan(theta) = ", np.tan(theta))
x = [-1, 0, 1]
print("x = ", x)
print("arcsin(x) = ", np.arcsin(x))
print("arccos(x) = ", np.arccos(x))
print("arctan(x) = ", np.arctan(x))
# Exponents and logrithms
x = [1, 2, 3]
print("x =", x)
print("e^x =", np.exp(x))
print("2^x =", np.exp2(x))
print("3^x =", np.power(3, x))
x = [1, 2, 4, 10]
print("x =", x)
print("ln(x) =", np.log(x))
print("log2(x) =", np.log2(x))
print("log10(x) =", np.log10(x))
# Special functions
from scipy import special
# Gamma functions (generalized factorials) and related functions
x = [1, 5, 10]
print("gamma(x) =", special.gamma(x))
print("ln|gamma(x)| =", special.gammaln(x))
print("beta(x, 2) =", special.beta(x, 2))
# Error function (integral of Gaussian)
# its complement, and its inverse
x = np.array([0, 0.3, 0.7, 1.0])
print("erf(x) =", special.erf(x))
print("erfc(x) =", special.erfc(x))
print("erfinv(x) =", special.erfinv(x))
# Aggregation min/max
import numpy as np
L = np.random.random(100)
sum(L)
# Using np.sum()
print(np.sum(L))
# The reason numpy is fast is because it executes the operations as compiled code
big_array = np.random.rand(1000000)
%timeit sum(big_array)
%timeit np.sum(big_array) # The difference between time of execution is in square order.
# Max and Min in big_array
min(big_array), max(big_array)
np.min(big_array), np.max(big_array)
%timeit min(big_array)
%timeit np.min(big_array)
# Multidimentional Array Aggregation
M = np.random.random((3, 4))
print(M)
# By default each aggregation the function will aggregate on the entire np.array
M.sum()
#Aggregation functions take an additional argument specifying the axis along which the aggregate is computed.
#For example, we can find the minimum value within each column by specifying axis=0:
M.min(axis=0)
# Additional List of aggregation functions in python
'''
Function Name NaN-safe Version Description
np.sum np.nansum Compute sum of elements
np.prod np.nanprod Compute product of elements
np.mean np.nanmean Compute mean of elements
np.std np.nanstd Compute standard deviation
np.var np.nanvar Compute variance
np.min np.nanmin Find minimum value
np.max np.nanmax Find maximum value
np.argmin np.nanargmin Find index of minimum value
np.argmax np.nanargmax Find index of maximum value
np.median np.nanmedian Compute median of elements
np.percentile np.nanpercentile Compute rank-based statistics of elements
np.any N/A Evaluate whether any elements are true
np.all N/A Evaluate whether all elements are true '''
# Broadcasting for Computation in numpy arrays
# For same size, binary operations are performed element by element wise
a = np.array([0, 1, 2])
b = np.array([5, 5, 5])
print(a + b)
print(a+5)
# Adding 1 dimentional array to 2 dimentional array.
M = np.ones((3, 3))
print(M+a) # The 'a' is stretched, or broadcast across the second dimension in order to match the shape of M.
# Masking in Numpy array's, we use masking for extracting, modifying, counting the values in an array based on a criteria
# Ex: Counting all values greater than a certain value.
# Comparision Operators as ufuncs
x = np.array([1, 2, 3, 4, 5])
print(x < 3) # less than
print((2 * x) == (x ** 2))
'''
Operator Equivalent ufunc Operator Equivalent ufunc
== np.equal != np.not_equal
< np.less <= np.less_equal
> np.greater >= np.greater_equal '''
# how many values less than 3?
print(np.count_nonzero(x < 3))
# Fancy Indexing
rand = np.random.RandomState(42)
x = rand.randint(100, size=10)
print(x)
# Accesing different elements
print([x[3], x[7], x[2]])
# Alternatively we can also access the elements as
ind = [3, 7, 4]
print(x[ind])
# Sorting Array's
x = np.array([2, 1, 4, 3, 5])
print(np.sort(x)) # Using builtin sort function we can sort the values of an array
# Using argsort we can return the indices of these elements after sorting
x = np.array([2, 1, 4, 3, 5])
i = np.argsort(x)
print(i)
# Soring elements row wise or column wise
rand = np.random.RandomState(42)
X = rand.randint(0, 10, (4, 6))
print(X)
# sort each column of X
print(np.sort(X, axis=0))
# Handling Missing Data
data = pd.Series([1, np.nan, 'hello', None])
data.isnull() # Using to detect missing values in a pandas data frame
data.dropna() # Drops the null values present in a data frame
# We can drop null values along different axis
# df.dropna(axis='columns')
# df.dropna(axis='columns', how='all')
# df.dropna(axis='rows', thresh=3) 'thresh' parameter specifies the minimum number of not null values to be kept
data = pd.Series([1, np.nan, 2, None, 3], index=list('abcde'))
data.fillna(0) # Fills null values with zero
# forward-fill
data.fillna(method='ffill') # Fills the previous value in the series
# back-fill
data.fillna(method='bfill')
#data.fillna(method='ffill', axis=1) We can also specify the axis to fill
# Pivot tables in Pandas
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.pivot_table('survived', index='sex', columns='class')
# Date and time tools for handling time series data
from datetime import datetime
datetime(year=2015, month=7, day=4)
# Using date util module we can parse date in string format
from dateutil import parser
date = parser.parse("4th of July, 2015")
date
# Dates which are consecutive using arange
date = np.array('2015-07-04', dtype=np.datetime64)
print(date)
print(date + np.arange(12))
# Datetime in pandas
import pandas as pd
date = pd.to_datetime("4th of July, 2015")
print(date)
print(date.strftime('%A'))
# Vectorized operations on the same object
print(date + pd.to_timedelta(np.arange(12), 'D'))
# Visualizations
# Simple Line plots
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
fig = plt.figure()
ax = plt.axes()
x = np.linspace(0, 10, 1000)
ax.plot(x, np.sin(x));
plt.plot(x, np.cos(x));
plt.plot(x, np.sin(x - 0), color='blue') # specify color by name
plt.plot(x, np.sin(x - 1), color='g') # short color code (rgbcmyk)
plt.plot(x, np.sin(x - 2), color='0.75') # Grayscale between 0 and 1
plt.plot(x, np.sin(x - 3), color='#FFDD44') # Hex code (RRGGBB from 00 to FF)
plt.plot(x, np.sin(x - 4), color=(1.0,0.2,0.3)) # RGB tuple, values 0 to 1
plt.plot(x, np.sin(x - 5), color='chartreuse'); # all HTML color names supported
plt.plot(x, x + 0, linestyle='solid')
plt.plot(x, x + 1, linestyle='dashed')
plt.plot(x, x + 2, linestyle='dashdot')
plt.plot(x, x + 3, linestyle='dotted');
# For short, you can use the following codes:
plt.plot(x, x + 4, linestyle='-') # solid
plt.plot(x, x + 5, linestyle='--') # dashed
plt.plot(x, x + 6, linestyle='-.') # dashdot
plt.plot(x, x + 7, linestyle=':'); # dotted
plt.plot(x, x + 0, '-g') # solid green
plt.plot(x, x + 1, '--c') # dashed cyan
plt.plot(x, x + 2, '-.k') # dashdot black
plt.plot(x, x + 3, ':r'); # dotted red
plt.plot(x, np.sin(x))
plt.xlim(-1, 11)
plt.ylim(-1.5, 1.5);
x = np.linspace(0, 10, 30)
y = np.sin(x)
plt.plot(x, y, 'o', color='black');
rng = np.random.RandomState(0)
for marker in ['o', '.', ',', 'x', '+', 'v', '^', '<', '>', 's', 'd']:
plt.plot(rng.rand(5), rng.rand(5), marker,
label="marker='{0}'".format(marker))
plt.legend(numpoints=1)
plt.xlim(0, 1.8);
plt.plot(x, y, '-p', color='gray',
markersize=15, linewidth=4,
markerfacecolor='white',
markeredgecolor='gray',
markeredgewidth=2)
plt.ylim(-1.2, 1.2);
rng = np.random.RandomState(0)
x = rng.randn(100)
y = rng.randn(100)
colors = rng.rand(100)
sizes = 1000 * rng.rand(100)
plt.scatter(x, y, c=colors, s=sizes, alpha=0.3,
cmap='viridis')
plt.colorbar(); # show color scale
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data.T
plt.scatter(features[0], features[1], alpha=0.2,
s=100*features[3], c=iris.target, cmap='viridis')
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1]);
# Contour Plots
def f(x, y):
return np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)
x = np.linspace(0, 5, 50)
y = np.linspace(0, 5, 40)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
plt.contour(X, Y, Z, colors='black');
plt.contour(X, Y, Z, 20, cmap='RdGy');
```
|
github_jupyter
|
# Imports
```
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from pymongo import MongoClient
import csv
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import spacy
import tweepy
```
# Help-Functions
```
def open_csv(csv_address):
'''Loading CSV document with token bearer for conection with Twitter API'''
with open(csv_address, 'r', encoding = 'utf8') as file:
reader = csv.reader(file)
data = list(reader)
file.close()
return data[0][1]
def conection_twitter(bearer_token):
''' Connecting with Twitter API'''
# Access key
client = tweepy.Client(bearer_token=bearer_token)
return client
def mongo_connection(database_name):
'''Connecting with Mongo DB and creating Database'''
client = MongoClient('localhost', 27017)
# Creating database or connecting
db = client[database_name]
return db
def load_tweet(candidate_dict:dict, client_twitter, data_base, maximum_results: int = 100):
'''Using tweetpy API for loading tweets'''
# Accessing a dictionary that contains name as key and id as value
for key, value in candidate_dict.items():
# Creating a collection in MongoDB using key in dictionary as name
collection = data_base[key]
# Collecting tweets ussing method .get_users_id from tweepy
tweets = client_twitter.get_users_tweets(id= value,
tweet_fields = ['created_at',
'lang',
'public_metrics',
'reply_settings',
'entities',
'referenced_tweets',
'in_reply_to_user_id'],
expansions='referenced_tweets.id.author_id',
max_results=maximum_results)
# Using iteration to create variables that will receive data in each tweet, to insert a tweet into the MongoDB collection.
for tweet in tweets.data:
tweet_id = tweet.id
user_id = value
texto = tweet.text
data = tweet.created_at
likes = tweet.public_metrics['like_count']
retweet_count = tweet.public_metrics['retweet_count']
reply_count = tweet.public_metrics['reply_count']
quote_count = tweet.public_metrics['quote_count']
retweet_origen_id = tweet.referenced_tweets
try:
link = tweet.entities['urls'][0]['expanded_url']
except:
link = ('Null')
# Error handling for Tweet Id already added, because mongo db does not accept repeated Ids
try:
collection.insert_one({
'_id': tweet_id,
'user_id':user_id,
'texto': texto,
'data': data,
'likes': likes,
'retweet_count':retweet_count,
'reply_count': reply_count,
'quote_count': quote_count,
'retweet_origen_id': retweet_origen_id,
'link': link
})
except:
pass
def extract_words(data):
'''Extracting stopwords for text in tweets using spacy'''
stop_words = stopwords.words('portuguese')
texto = data['texto'].to_list()
# Removing stopwords
striped_phrase = []
for element in texto:
words = word_tokenize(element)
for word in words:
if word not in stop_words:
word = word.strip(',:.#')
word = word.replace('https', '')
if len(word) >=3:
striped_phrase.append(word)
'Removing whitespaces in a list'
str_list = list(filter(None, striped_phrase))
return str_list
def create_label(word_list):
'''Using trained pipelines for Portuguese linguage fron spacy library to create label on each word in the list'''
nlp_lg = spacy.load("pt_core_news_lg")
#To instantiate the object it is necessary that it is in a string in text format
str1 = ", "
#Adds an empty space to each word of the comma
stem2 = str1.join(word_list)
#Instance text as spacy object
stem2 = nlp_lg(stem2)
#Using a Comprehension list to create a selected list of text and label '''
label_lg = [(X.text, X.label_) for X in stem2.ents]
return label_lg
def create_df(word_label, term: str, max_rows: int):
'''Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.'''
upper = term.upper()
df = pd.DataFrame(word_label, columns = ['Word','Entity'])
#Entity filtering
df_org = df.where(df['Entity'] == upper)
#Creates a repeated word count
df_org_count = df_org['Word'].value_counts()
#Selecting the most commonly used words
df = df_org_count[:max_rows]
return df
def create_plot(df, title: str, size: tuple ):
'''Creating a barplot'''
title_save = title.replace(' ', '-').lower()
path = 'images'
plt.figure(figsize= size)
sns.barplot(df.values, df.index, alpha=0.8)
plt.title(title)
plt.ylabel('Word from Tweet', fontsize=12)
plt.xlabel('Count of Words', fontsize=12)
plt.savefig(path + '/' + title_save + '.png', dpi = 300, transparent = True, bbox_inches='tight')
plt.show()
```
# Dictionary with candidates
```
# Dict where key = User, Value = Id User
candidate_dict = {
'Bolsonaro':'128372940',
'Ciro': '33374761',
'Lula': '2670726740',
'Sergio_Moro': '1113094855281008641'
}
```
# Creating connection to Twitter API
```
# Load a token from csv
token = open_csv('C:/Users/Diego/OneDrive/Cursos e codigos/Codigos/twitter/bearertoken.csv')
# Connecting with Twitter API
client_twitter = conection_twitter(token)
```
# Creating connection to MongoDB Database
```
# Creating connection to MongoDB Database
db = mongo_connection('data_twitter')
```
# Load tweets and insert then inside MongoDB Collections
```
# Load tweets and insert then inside MongoDB Collections
load_tweet(candidate_dict = candidate_dict,
client_twitter = client_twitter,
data_base = db,
maximum_results = 5)
```
# Connecting with Collections and Loading DataFrames from MongoDB
```
# Connecting with collections from MongoDb
collection_Bolsonaro = db.Bolsonaro
collection_Ciro = db.Ciro
collection_Lula = db.Lula
collection_SergioMoro = db.Sergio_Moro
# Loading DataFrames from MongoDB
df_bol = pd.DataFrame(collection_Bolsonaro.find())
df_cir = pd.DataFrame(collection_Ciro.find())
df_lul = pd.DataFrame(collection_Lula.find())
df_ser = pd.DataFrame(collection_SergioMoro.find())
```
# Operations in DataFrame
```
# Extracting words fron DataFrame and remove stopwords
bol_words = extract_words(df_bol)
cir_words = extract_words(df_cir)
lul_words = extract_words(df_lul)
ser_words = extract_words(df_ser)
# Creating labels from the list, uning spacy
bol_label = create_label(bol_words)
cir_label = create_label(cir_words)
lul_label = create_label(lul_words)
ser_label = create_label(ser_words)
# Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.
bol_df_loc = create_df(bol_label, 'LOC', 30)
cir_df_loc = create_df(cir_label, 'LOC', 30)
lul_df_loc = create_df(lul_label, 'LOC', 30)
ser_df_loc = create_df(ser_label, 'LOC', 30)
```
# Views of the top location mentioned by each candidate
```
# Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.
bol_df_loc = create_df(bol_label, 'LOC', 30)
cir_df_loc = create_df(cir_label, 'LOC', 30)
lul_df_loc = create_df(lul_label, 'LOC', 30)
ser_df_loc = create_df(ser_label, 'LOC', 30)
# Creating plots from DataFrames
bol_plot = create_plot(bol_df_loc, 'Top Location Mentioned By Bolsonaro', (20,10))
cir_plot = create_plot(cir_df_loc, 'Top Location Mentioned By Ciro Gomes', (20,10))
lul_plot = create_plot(lul_df_loc, 'Top Location Mentioned By Luiz Inácio Lula da Silva', (20,10))
ser_plot = create_plot(ser_df_loc, 'Top Location Mentioned By Sergio Moro', (20,10))
```
# Views of the top persons mentioned by each candidate
```
bol_df_loc = create_df(bol_label, 'PER', 30)
cir_df_loc = create_df(cir_label, 'PER', 30)
lul_df_loc = create_df(lul_label, 'PER', 30)
ser_df_loc = create_df(ser_label, 'PER', 30)
bol_plot = create_plot(bol_df_loc, 'Top Persons Mentioned By Bolsonaro', (20,10))
cir_plot = create_plot(cir_df_loc, 'Top Persons Mentioned By Ciro Gomes', (20,10))
lul_plot = create_plot(lul_df_loc, 'Top Persons Mentioned By Luiz Inácio Lula da Silva', (20,10))
ser_plot = create_plot(ser_df_loc, 'Top Persons Mentioned By Sergio Moro', (20,10))
```
# Views of the top organizations mentioned by each candidate
```
bol_df_loc = create_df(bol_label, 'ORG', 30)
cir_df_loc = create_df(cir_label, 'ORG', 30)
lul_df_loc = create_df(lul_label, 'ORG', 30)
ser_df_loc = create_df(ser_label, 'ORG', 30)
bol_plot = create_plot(bol_df_loc, 'Top Organization Mentioned By Bolsonaro', (20,10))
cir_plot = create_plot(cir_df_loc, 'Top Organization Mentioned By Ciro Gomes', (20,10))
lul_plot = create_plot(lul_df_loc, 'Top Organization Mentioned By Luiz Inácio Lula da Silva', (20,10))
ser_plot = create_plot(ser_df_loc, 'Top Organization Mentioned By Sergio Moro', (20,10))
```
|
github_jupyter
|
# Data Prep of Chicago Food Inspections Data
This notebook reads in the food inspections dataset containing records of food inspections in Chicago since 2010. This dataset is freely available through healthdata.gov, but must be provided with the odbl license linked below and provided within this repository. This notebook prepares the data for statistical analysis and modeling by creating features from categorical variables and enforcing a prevalence threshold for these categories. Note that in this way, rare features are not analyzed or used to create a model (to encourage generalizability), though the code is designed so that it would be easy to change or eliminate the prevalence threshold to run downstream analysis with a different feature set.
### References
- Data Source: https://healthdata.gov/dataset/food-inspections
- License: http://opendefinition.org/licenses/odc-odbl/
### Set Global Seed
```
SEED = 666
```
### Imports
```
import pandas as pd
```
### Read Chicago Food Inspections Data
Count records and columns.
```
food_inspections_df = pd.read_csv('../data/Food_Inspections.gz', compression='gzip')
food_inspections_df.shape
```
### Rename Columns
```
food_inspections_df.columns.tolist()
columns = ['inspection_id', 'dba_name', 'aka_name', 'license_number', 'facility_type',
'risk', 'address', 'city', 'state', 'zip', 'inspection_date', 'inspection_type',
'result', 'violation', 'latitude', 'longitude', 'location']
food_inspections_df.columns = columns
```
### Convert Zip Code to String
And take only the first five digits, chopping off the decimal from reading the column as a float.
```
food_inspections_df['zip'] = food_inspections_df['zip'].astype(str).apply(lambda x: x.split('.')[0])
```
### Normalize Casing of Chicago
Accept only proper spellings of the word Chicago with mixed casing accepted.
```
food_inspections_df['city'] = food_inspections_df['city'].apply(lambda x: 'CHICAGO'
if str(x).upper() == 'CHICAGO'
else x)
```
### Filter for Facilities in Chicago Illinois
```
loc_condition = (food_inspections_df['city'] == 'CHICAGO') & (food_inspections_df['state'] == 'IL')
```
### Drop Redundant Information
- Only Chicago is considered
- Only Illinois is considered
- Location is encoded as separate latitute and longitude columns
```
food_inspections_df = food_inspections_df[loc_condition].drop(['city', 'state', 'location'], 1)
food_inspections_df.shape
```
### Create Codes Corresponding to Each Violation Type by Parsing Violation Text
```
def create_violation_code(violation_text):
if violation_text != violation_text:
return -1
else:
return int(violation_text.split('.')[0])
food_inspections_df['violation_code'] = food_inspections_df['violation'].apply(create_violation_code)
```
### Create Attribute Dataframes with the Unique Inspection ID for Lookups if Needed
- Names
- Licenses
- Locations
- Violations
- Dates
```
names = ['inspection_id', 'dba_name', 'aka_name']
names_df = food_inspections_df[names]
licenses = ['inspection_id', 'license_number']
licenses_df = food_inspections_df[licenses]
locations = ['inspection_id', 'address', 'latitude', 'longitude']
locations_df = food_inspections_df[locations]
violations = ['inspection_id', 'violation', 'violation_code']
violations_df = food_inspections_df[violations]
dates = ['inspection_id', 'inspection_date']
dates_df = food_inspections_df[dates]
```
### Drop Features Not Used in Statistical Analysis
Features such as:
- `DBA Name`
- `AKA Name`
- `License #`
- `Address`
- `Violations`
- `Inspection Date`
May be examined following statistical analysis by joining on `Inspection ID`. **Note:** future iterations of this work may wish to consider:
- Text from the the facility name
- Street level information from the facility address
- Prior inspections of the same facility by performing a temporal analysis of the data using `Inspection Date`
```
not_considered = ['dba_name', 'aka_name', 'license_number', 'address', 'violation', 'inspection_date']
food_inspections_df = food_inspections_df.drop(not_considered, 1)
```
### Create Dataframes of Count and Prevalence for Categorical Features
- Facility types
- Violation codes
- Zip codes
- Inspection types
```
facilities = food_inspections_df['facility_type'].value_counts()
facilities_df = pd.DataFrame({'facility_type':facilities.index, 'count':facilities.values})
facilities_df['prevalence'] = facilities_df['count'] / food_inspections_df.shape[0]
facilities_df.nlargest(10, 'count')
facilities_df.nsmallest(10, 'count')
violations = food_inspections_df['violation_code'].value_counts()
violations_df = pd.DataFrame({'violation_code':violations.index, 'count':violations.values})
violations_df['prevalence'] = violations_df['count'] / food_inspections_df.shape[0]
violations_df.nlargest(10, 'count')
violations_df.nsmallest(10, 'count')
zips = food_inspections_df['zip'].value_counts()
zips_df = pd.DataFrame({'zip':zips.index, 'count':zips.values})
zips_df['prevalence'] = zips_df['count'] / food_inspections_df.shape[0]
zips_df.nlargest(10, 'count')
zips_df.nsmallest(10, 'count')
inspections = food_inspections_df['inspection_type'].value_counts()
inspections_df = pd.DataFrame({'inspection_type':inspections.index, 'count':inspections.values})
inspections_df['prevalence'] = inspections_df['count'] / food_inspections_df.shape[0]
inspections_df.nlargest(10, 'count')
inspections_df.nsmallest(10, 'count')
results = food_inspections_df['result'].value_counts()
results_df = pd.DataFrame({'result':results.index, 'count':results.values})
results_df['prevalence'] = results_df['count'] / food_inspections_df.shape[0]
results_df.nlargest(10, 'count')
```
### Drop Violation Code for Now
We can join back using the Inspection ID to learn about types of violations, but we don't want to use any information about the violation itself to predict if a food inspection will pass or fail.
```
food_inspections_df = food_inspections_df.drop('violation_code', 1)
```
### Create Risk Group Feature
If the feature cannot be found in the middle of the text string as a value 1-3, return -1.
```
def create_risk_groups(risk_text):
try:
risk = int(risk_text.split(' ')[1])
return risk
except:
return -1
food_inspections_df['risk'] = food_inspections_df['risk'].apply(create_risk_groups)
```
### Format Result
- Encode Pass and Pass w/ Conditions as 0
- Encode Fail as 1
- Encode all others as -1 and filter out these results
```
def format_results(result):
if result == 'Pass':
return 0
elif result == 'Pass w/ Conditions':
return 0
elif result == 'Fail':
return 1
else:
return -1
food_inspections_df['result'] = food_inspections_df['result'].apply(format_results)
food_inspections_df = food_inspections_df[food_inspections_df['result'] != -1]
food_inspections_df.shape
```
### Filter for Categorical Features that Pass some Prevalence Threshold
This way we only consider fairly common attributes of historical food establishments and inspections so that our analysis will generalize to new establishments and inspections. **Note:** the prevalence threshold is set to **0.1%**.
```
categorical_features = ['facility_type', 'zip', 'inspection_type']
def prev_filter(df, feature, prevalence='prevalence', prevalence_threshold=0.001):
return df[df[prevalence] > prevalence_threshold][feature].tolist()
feature_dict = dict(zip(categorical_features, [prev_filter(facilities_df, 'facility_type'),
prev_filter(zips_df, 'zip'),
prev_filter(inspections_df, 'inspection_type')]))
```
### Encode Rare Features with the 'DROP' String, to be Removed Later
Note that by mapping all rare features to the 'DROP' attribute, we avoid having to one-hot-encode all rare features and then drop them after the fact. That would create an unnecessarily large feature matrix. Instead we one-hot encode features passing the prevalence threshold and then drop all rare features that were tagged with the 'DROP' string.
```
for feature in categorical_features:
food_inspections_df[feature] = food_inspections_df[feature].apply(lambda x:
x if x in feature_dict[feature]
else 'DROP')
feature_df = pd.get_dummies(food_inspections_df,
prefix=['{}'.format(feature) for feature in categorical_features],
columns=categorical_features)
feature_df = feature_df[[col for col in feature_df.columns if 'DROP' not in col]]
feature_df.shape
```
### Drop Features with:
- Risk level not recorded as 1, 2, or 3
- Result not recorded as Pass, Pass w/ Conditions, or Fail
- NA values (Some latitudes and longitudes are NA)
```
feature_df = feature_df[feature_df['risk'] != -1]
feature_df = feature_df[feature_df['result'] != -1]
feature_df = feature_df.dropna()
feature_df.shape
```
### Write the Feature Set to a Compressed CSV File to Load for Modeling and Analysis
```
feature_df.to_csv('../data/Food_Inspection_Features.gz', compression='gzip', index=False)
```
### Write off Zip Codes to Join with Census Data
```
zips_df.to_csv('../data/Zips.csv', index=False)
```
|
github_jupyter
|
##### Copyright 2019 The TensorFlow Authors.
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#@title MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.
```
# Transfer learning and fine-tuning
<table class="tfo-notebook-buttons" align="left">
<td>
<a target="_blank" href="https://www.tensorflow.org/tutorials/images/transfer_learning"><img src="https://www.tensorflow.org/images/tf_logo_32px.png" />View on TensorFlow.org</a>
</td>
<td>
<a target="_blank" href="https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/images/transfer_learning.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
</td>
<td>
<a target="_blank" href="https://github.com/tensorflow/docs/blob/master/site/en/tutorials/images/transfer_learning.ipynb"><img src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" />View source on GitHub</a>
</td>
<td>
<a href="https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/images/transfer_learning.ipynb"><img src="https://www.tensorflow.org/images/download_logo_32px.png" />Download notebook</a>
</td>
</table>
In this tutorial, you will learn how to classify images of cats and dogs by using transfer learning from a pre-trained network.
A pre-trained model is a saved network that was previously trained on a large dataset, typically on a large-scale image-classification task. You either use the pretrained model as is or use transfer learning to customize this model to a given task.
The intuition behind transfer learning for image classification is that if a model is trained on a large and general enough dataset, this model will effectively serve as a generic model of the visual world. You can then take advantage of these learned feature maps without having to start from scratch by training a large model on a large dataset.
In this notebook, you will try two ways to customize a pretrained model:
1. Feature Extraction: Use the representations learned by a previous network to extract meaningful features from new samples. You simply add a new classifier, which will be trained from scratch, on top of the pretrained model so that you can repurpose the feature maps learned previously for the dataset.
You do not need to (re)train the entire model. The base convolutional network already contains features that are generically useful for classifying pictures. However, the final, classification part of the pretrained model is specific to the original classification task, and subsequently specific to the set of classes on which the model was trained.
1. Fine-Tuning: Unfreeze a few of the top layers of a frozen model base and jointly train both the newly-added classifier layers and the last layers of the base model. This allows us to "fine-tune" the higher-order feature representations in the base model in order to make them more relevant for the specific task.
You will follow the general machine learning workflow.
1. Examine and understand the data
1. Build an input pipeline, in this case using Keras ImageDataGenerator
1. Compose the model
* Load in the pretrained base model (and pretrained weights)
* Stack the classification layers on top
1. Train the model
1. Evaluate model
```
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
```
## Data preprocessing
### Data download
In this tutorial, you will use a dataset containing several thousand images of cats and dogs. Download and extract a zip file containing the images, then create a `tf.data.Dataset` for training and validation using the `tf.keras.utils.image_dataset_from_directory` utility. You can learn more about loading images in this [tutorial](https://www.tensorflow.org/tutorials/load_data/images).
```
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
```
Show the first nine images and labels from the training set:
```
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
```
As the original dataset doesn't contain a test set, you will create one. To do so, determine how many batches of data are available in the validation set using `tf.data.experimental.cardinality`, then move 20% of them to a test set.
```
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
```
### Configure the dataset for performance
Use buffered prefetching to load images from disk without having I/O become blocking. To learn more about this method see the [data performance](https://www.tensorflow.org/guide/data_performance) guide.
```
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
```
### Use data augmentation
When you don't have a large image dataset, it's a good practice to artificially introduce sample diversity by applying random, yet realistic, transformations to the training images, such as rotation and horizontal flipping. This helps expose the model to different aspects of the training data and reduce [overfitting](https://www.tensorflow.org/tutorials/keras/overfit_and_underfit). You can learn more about data augmentation in this [tutorial](https://www.tensorflow.org/tutorials/images/data_augmentation).
```
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
```
Note: These layers are active only during training, when you call `Model.fit`. They are inactive when the model is used in inference mode in `Model.evaluate` or `Model.fit`.
Let's repeatedly apply these layers to the same image and see the result.
```
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')
```
### Rescale pixel values
In a moment, you will download `tf.keras.applications.MobileNetV2` for use as your base model. This model expects pixel values in `[-1, 1]`, but at this point, the pixel values in your images are in `[0, 255]`. To rescale them, use the preprocessing method included with the model.
```
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
```
Note: Alternatively, you could rescale pixel values from `[0, 255]` to `[-1, 1]` using `tf.keras.layers.Rescaling`.
```
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
```
Note: If using other `tf.keras.applications`, be sure to check the API doc to determine if they expect pixels in `[-1, 1]` or `[0, 1]`, or use the included `preprocess_input` function.
## Create the base model from the pre-trained convnets
You will create the base model from the **MobileNet V2** model developed at Google. This is pre-trained on the ImageNet dataset, a large dataset consisting of 1.4M images and 1000 classes. ImageNet is a research training dataset with a wide variety of categories like `jackfruit` and `syringe`. This base of knowledge will help us classify cats and dogs from our specific dataset.
First, you need to pick which layer of MobileNet V2 you will use for feature extraction. The very last classification layer (on "top", as most diagrams of machine learning models go from bottom to top) is not very useful. Instead, you will follow the common practice to depend on the very last layer before the flatten operation. This layer is called the "bottleneck layer". The bottleneck layer features retain more generality as compared to the final/top layer.
First, instantiate a MobileNet V2 model pre-loaded with weights trained on ImageNet. By specifying the **include_top=False** argument, you load a network that doesn't include the classification layers at the top, which is ideal for feature extraction.
```
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
```
This feature extractor converts each `160x160x3` image into a `5x5x1280` block of features. Let's see what it does to an example batch of images:
```
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
```
## Feature extraction
In this step, you will freeze the convolutional base created from the previous step and to use as a feature extractor. Additionally, you add a classifier on top of it and train the top-level classifier.
### Freeze the convolutional base
It is important to freeze the convolutional base before you compile and train the model. Freezing (by setting layer.trainable = False) prevents the weights in a given layer from being updated during training. MobileNet V2 has many layers, so setting the entire model's `trainable` flag to False will freeze all of them.
```
base_model.trainable = False
```
### Important note about BatchNormalization layers
Many models contain `tf.keras.layers.BatchNormalization` layers. This layer is a special case and precautions should be taken in the context of fine-tuning, as shown later in this tutorial.
When you set `layer.trainable = False`, the `BatchNormalization` layer will run in inference mode, and will not update its mean and variance statistics.
When you unfreeze a model that contains BatchNormalization layers in order to do fine-tuning, you should keep the BatchNormalization layers in inference mode by passing `training = False` when calling the base model. Otherwise, the updates applied to the non-trainable weights will destroy what the model has learned.
For more details, see the [Transfer learning guide](https://www.tensorflow.org/guide/keras/transfer_learning).
```
# Let's take a look at the base model architecture
base_model.summary()
```
### Add a classification head
To generate predictions from the block of features, average over the spatial `5x5` spatial locations, using a `tf.keras.layers.GlobalAveragePooling2D` layer to convert the features to a single 1280-element vector per image.
```
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
```
Apply a `tf.keras.layers.Dense` layer to convert these features into a single prediction per image. You don't need an activation function here because this prediction will be treated as a `logit`, or a raw prediction value. Positive numbers predict class 1, negative numbers predict class 0.
```
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
```
Build a model by chaining together the data augmentation, rescaling, `base_model` and feature extractor layers using the [Keras Functional API](https://www.tensorflow.org/guide/keras/functional). As previously mentioned, use `training=False` as our model contains a `BatchNormalization` layer.
```
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
```
### Compile the model
Compile the model before training it. Since there are two classes, use the `tf.keras.losses.BinaryCrossentropy` loss with `from_logits=True` since the model provides a linear output.
```
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
```
The 2.5 million parameters in MobileNet are frozen, but there are 1.2 thousand _trainable_ parameters in the Dense layer. These are divided between two `tf.Variable` objects, the weights and biases.
```
len(model.trainable_variables)
```
### Train the model
After training for 10 epochs, you should see ~94% accuracy on the validation set.
```
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
```
### Learning curves
Let's take a look at the learning curves of the training and validation accuracy/loss when using the MobileNetV2 base model as a fixed feature extractor.
```
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
```
Note: If you are wondering why the validation metrics are clearly better than the training metrics, the main factor is because layers like `tf.keras.layers.BatchNormalization` and `tf.keras.layers.Dropout` affect accuracy during training. They are turned off when calculating validation loss.
To a lesser extent, it is also because training metrics report the average for an epoch, while validation metrics are evaluated after the epoch, so validation metrics see a model that has trained slightly longer.
## Fine tuning
In the feature extraction experiment, you were only training a few layers on top of an MobileNetV2 base model. The weights of the pre-trained network were **not** updated during training.
One way to increase performance even further is to train (or "fine-tune") the weights of the top layers of the pre-trained model alongside the training of the classifier you added. The training process will force the weights to be tuned from generic feature maps to features associated specifically with the dataset.
Note: This should only be attempted after you have trained the top-level classifier with the pre-trained model set to non-trainable. If you add a randomly initialized classifier on top of a pre-trained model and attempt to train all layers jointly, the magnitude of the gradient updates will be too large (due to the random weights from the classifier) and your pre-trained model will forget what it has learned.
Also, you should try to fine-tune a small number of top layers rather than the whole MobileNet model. In most convolutional networks, the higher up a layer is, the more specialized it is. The first few layers learn very simple and generic features that generalize to almost all types of images. As you go higher up, the features are increasingly more specific to the dataset on which the model was trained. The goal of fine-tuning is to adapt these specialized features to work with the new dataset, rather than overwrite the generic learning.
### Un-freeze the top layers of the model
All you need to do is unfreeze the `base_model` and set the bottom layers to be un-trainable. Then, you should recompile the model (necessary for these changes to take effect), and resume training.
```
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
```
### Compile the model
As you are training a much larger model and want to readapt the pretrained weights, it is important to use a lower learning rate at this stage. Otherwise, your model could overfit very quickly.
```
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
len(model.trainable_variables)
```
### Continue training the model
If you trained to convergence earlier, this step will improve your accuracy by a few percentage points.
```
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
```
Let's take a look at the learning curves of the training and validation accuracy/loss when fine-tuning the last few layers of the MobileNetV2 base model and training the classifier on top of it. The validation loss is much higher than the training loss, so you may get some overfitting.
You may also get some overfitting as the new training set is relatively small and similar to the original MobileNetV2 datasets.
After fine tuning the model nearly reaches 98% accuracy on the validation set.
```
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
```
### Evaluation and prediction
Finaly you can verify the performance of the model on new data using test set.
```
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
```
And now you are all set to use this model to predict if your pet is a cat or dog.
```
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
```
## Summary
* **Using a pre-trained model for feature extraction**: When working with a small dataset, it is a common practice to take advantage of features learned by a model trained on a larger dataset in the same domain. This is done by instantiating the pre-trained model and adding a fully-connected classifier on top. The pre-trained model is "frozen" and only the weights of the classifier get updated during training.
In this case, the convolutional base extracted all the features associated with each image and you just trained a classifier that determines the image class given that set of extracted features.
* **Fine-tuning a pre-trained model**: To further improve performance, one might want to repurpose the top-level layers of the pre-trained models to the new dataset via fine-tuning.
In this case, you tuned your weights such that your model learned high-level features specific to the dataset. This technique is usually recommended when the training dataset is large and very similar to the original dataset that the pre-trained model was trained on.
To learn more, visit the [Transfer learning guide](https://www.tensorflow.org/guide/keras/transfer_learning).
|
github_jupyter
|
# Markov Decision Process (MDP)
# Discounted Future Return
$$R_t = \sum^{T}_{k=0}\gamma^{t}r_{t+k+1}$$
$$R_0 = \gamma^{0} * r_{1} + \gamma^{1} * r_{2} = r_{1} + \gamma^{1} * r_{2}\ (while\ T\ =\ 1) $$
$$R_1 = \gamma^{1} * r_{2} =\ (while\ T\ =\ 1) $$
$$so,\ R_0 = r_{1} + R_1$$
Higher $\gamma$ stands for lower discounted value, and lower $\gamma$ stands for higher discounted value (in normal, $\gamma$ value is between 0.97 and 0.99).
```
def discount_rewards(rewards, gamma=0.98):
discounted_returns = [0 for _ in rewards]
discounted_returns[-1] = rewards[-1]
for t in range(len(rewards)-2, -1, -1):
discounted_returns[t] = rewards[t] + discounted_returns[t+1]*gamma
return discounted_returns
```
If returns get higher when the time passes by, the Discounted Future Return method is not suggested.
```
print(discount_rewards([1,2,4]))
```
If returns are the same or lesser when the time passes by, the Discounted Future Return method is suggested.
```
# about 2.94 fold
# examples are like succeeding or failing
print(discount_rewards([1,1,1]))
# about 3.31 fold
# examples are like relating to the time-consuming
print(discount_rewards([1,0.9,0.8]))
```
# Explore and Exploit
## $\epsilon$-Greedy strategy
Each time the agent decides to take an action, it will consider one of which, the recommended one (exploit) or the random one (explore). The value $\epsilon$ standing for the probability of taking random actions.
```
import random
import numpy as np
def epsilon_greedy_action(action_distribution, epsilon=1e-1):
if random.random() < epsilon:
return np.argmax(np.random.random(action_distribution.shape))
else:
return np.argmax(action_distribution)
```
here we assume there are 10 actions as well as their probabilities (fixed probabilities on each step making us easier to monitor the result) for the agent to take
```
action_distribution = np.random.random((1, 10))
print(action_distribution)
print(epsilon_greedy_action(action_distribution))
```
## Annealing $\epsilon$-Greedy strategy
At the beginning of training reinforcement learning, the agent knows nothing about the environment and the state or the feedback while taking an action as well. Thus we hope the agent takes more random actions (exploring) at the beginning of training.
After a long training period, the agent knows the environment more and learns more the feedback given an action. Thus, we hope the agent takes an action based on its own experience (exploiting).
We provide a new idea to anneal (or decay) the $\epsilon$ parameter in each time the agent takes an action. The classic annealing strategy is decaying $\epsilon$ value from 0.99 to 0.01 in around 10000 steps.
```
def epsilon_greedy_annealed(action_distribution, training_percentage, epsilon_start=1.0, epsilon_end=1e-2):
annealed_epsilon = epsilon_start * (1-training_percentage) + epsilon_end * training_percentage
if random.random() < annealed_epsilon:
# take random action
return np.argmax(np.random.random(action_distribution.shape))
else:
# take the recommended action
return np.argmax(action_distribution)
```
here we assume there are 10 actions as well as their probabilities (fixed probabilities on each step making us easier to monitor the result) for the agent to take
```
action_distribution = np.random.random((1, 10))
print(action_distribution)
for i in range(1, 99, 10):
percentage = i / 100.0
action = epsilon_greedy_annealed(action_distribution, percentage)
print("percentage : {} and action is {}".format(percentage, action))
```
# Learning to Earn Max Returns
## Policy Learning
Policy learning is the policy the agent learning to earn the maximum returns. For instance, if we ride a bicycle, when the bicycle is tilt to the left we try to give more power to the right side. The above strategy is called policy learning.
### Gradient Descent in Policy Learning
$$arg\ min_\theta\ -\sum_{i}\ R_{i}\ log{p(y_{i}|x_{i}, \theta)}$$
$R_{i}$ is the discounted future return, $y_{i}$ is the action taken at time $i$.
## Value Learning
Value learning is the agent learns the value from the state while taking an action. That is, value learning is to learn the value from a pair [state, action]. For example, if we ride a bicycle, we give higher or lower values to any combinations of [state, action], such a strategy is called value learning.
```
```
|
github_jupyter
|
<img src="../figures/HeaDS_logo_large_withTitle.png" width="300">
<img src="../figures/tsunami_logo.PNG" width="600">
[](https://colab.research.google.com/github/Center-for-Health-Data-Science/PythonTsunami/blob/intro/Numbers_and_operators/Numbers_and_operators.ipynb)
# Numerical Operators
*Prepared by [Katarina Nastou](https://www.cpr.ku.dk/staff/?pure=en/persons/672471)*
## Objectives
- understand differences between `int`s and `float`s
- work with simple math operators
- add comments to your code
## Numbers
Two main types of numbers:
- Integers: `56, 3, -90`
- Floating Points: `5.666, 0.0, -8.9`
## Operators
- addition: `+`
- subtraction: `-`
- multiplication: `*`
- division: `/`
- exponentiation, power: `**`
- modulo: `%`
- integer division: `//` (what does it return?)
```
# playground
```
### Qestions: Ints and Floats
- Question 1: Which of the following numbers is NOT a float?
(a) 0
(b) 2.3
(c) 23.0
(d) -23.0
(e) 0.0
- Question 2: What type does the following expression result in?
```python
3.0 + 5
```
### Operators 1
- Question 3: How can we add parenthesis to the following expression to make it equal 100?
```python
1 + 9 * 10
```
- Question 4: What is the result of the following expression?
```python
3 + 14 * 2 + 4 * 5
```
- Question 5: What is the result of the following expression
```python
5 * 9 / 4 ** 3 - 6 * 7
```
```
```
### Comments
- Question 6: What is the result of running this code?
```python
15 / 3 * 2 # + 1
```
```
```
### Questions: Operators 2
- Question 7: Which of the following result in integers in Python?
(a) 8 / 2
(b) 3 // 2
(c) 4.5 * 2
- Question 8: What is the result of `18 // 3` ?
- Question 9: What is the result of `121 % 7` ?
## Exercise
Ask the user for a number using the function [input()](https://www.askpython.com/python/examples/python-user-input) and then multiply that number by 2 and print out the value. Remember to store the input value into a variable, so that you can use it afterwards in the multiplication.
Modfify your previous calculator and ask for the second number (instead of x * 2 --> x * y).
Now get the square of the number that the user inputs
### Note
Check out also the [math library](https://docs.python.org/3/library/math.html) in Python. You can use this library for more complex operations with numbers. Just import the library and try it out:
```python
import math
print(math.sqrt(25))
print(math.log10(10))
```
|
github_jupyter
|
```
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
import sklearn
sklearn.set_config(print_changed_only=True)
```
## Automatic Feature Selection
### Univariate statistics
```
from sklearn.datasets import load_breast_cancer
from sklearn.feature_selection import SelectPercentile
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
# get deterministic random numbers
rng = np.random.RandomState(42)
noise = rng.normal(size=(len(cancer.data), 50))
# add noise features to the data
# the first 30 features are from the dataset, the next 50 are noise
X_w_noise = np.hstack([cancer.data, noise])
X_train, X_test, y_train, y_test = train_test_split(
X_w_noise, cancer.target, random_state=0, test_size=.5)
# use f_classif (the default) and SelectPercentile to select 10% of features:
select = SelectPercentile(percentile=50)
select.fit(X_train, y_train)
# transform training set:
X_train_selected = select.transform(X_train)
print(X_train.shape)
print(X_train_selected.shape)
from sklearn.feature_selection import f_classif, f_regression, chi2
F, p = f_classif(X_train, y_train)
plt.figure()
plt.semilogy(p, 'o')
mask = select.get_support()
print(mask)
# visualize the mask. black is True, white is False
plt.matshow(mask.reshape(1, -1), cmap='gray_r')
from sklearn.linear_model import LogisticRegression
# transform test data:
X_test_selected = select.transform(X_test)
lr = LogisticRegression()
lr.fit(X_train, y_train)
print("Score with all features: %f" % lr.score(X_test, y_test))
lr.fit(X_train_selected, y_train)
print("Score with only selected features: %f" % lr.score(X_test_selected, y_test))
```
### Model-based Feature Selection
```
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
select = SelectFromModel(RandomForestClassifier(n_estimators=100, random_state=42),
threshold="median")
select.fit(X_train, y_train)
X_train_rf = select.transform(X_train)
print(X_train.shape)
print(X_train_rf.shape)
mask = select.get_support()
# visualize the mask. black is True, white is False
plt.matshow(mask.reshape(1, -1), cmap='gray_r')
X_test_rf = select.transform(X_test)
LogisticRegression().fit(X_train_rf, y_train).score(X_test_rf, y_test)
```
### Recursive Feature Elimination
```
from sklearn.feature_selection import RFE
select = RFE(RandomForestClassifier(n_estimators=100, random_state=42),
n_features_to_select=40)
select.fit(X_train, y_train)
# visualize the selected features:
mask = select.get_support()
plt.matshow(mask.reshape(1, -1), cmap='gray_r')
X_train_rfe = select.transform(X_train)
X_test_rfe = select.transform(X_test)
LogisticRegression().fit(X_train_rfe, y_train).score(X_test_rfe, y_test)
select.score(X_test, y_test)
```
### Sequential Feature Selection
```
from mlxtend.feature_selection import SequentialFeatureSelector
sfs = SequentialFeatureSelector(LogisticRegression(), k_features=40,
forward=False, scoring='accuracy',cv=5)
sfs = sfs.fit(X_train, y_train)
mask = np.zeros(80, dtype='bool')
mask[np.array(sfs.k_feature_idx_)] = True
plt.matshow(mask.reshape(1, -1), cmap='gray_r')
LogisticRegression().fit(sfs.transform(X_train), y_train).score(
sfs.transform(X_test), y_test)
```
# Exercises
Choose either the Boston housing dataset or the adult dataset from above. Compare a linear model with interaction features against one without interaction features.
Use feature selection to determine which interaction features were most important.
```
# %load solutions/feature_importance.py
```
|
github_jupyter
|
### EXP: Pilote2 QC rating
- **Aim:** Test reliability of quality control (QC) of brain registration ratings between two experts raters (PB: Pierre Bellec, YB: Yassine Benahajali) based on the first drafted qc protocol on the zooniverse platform ( ref: https://www.zooniverse.org/projects/simexp/brain-match ).
- **Exp:**
- We choose 50 anatomical brain images (16 OK, 17 Maybe and 17 Fail) preprocced with NIAK pipelines from ADHD200 datsets.
- Each rater (PB and YB) rated (OK, Maybe or Fail) Zooniverse platform interface.
```
import os
import pandas as pd
import numpy as np
import json
import itertools
import seaborn as sns
from sklearn import metrics
from matplotlib import gridspec as gs
import matplotlib.pyplot as plt
from functools import reduce
%matplotlib inline
%load_ext rpy2.ipython
sns.set(style="white")
def CustomParser(data):
j1 = json.loads(data)
return j1
# Read raw table
classifications = pd.read_csv('../data/rating/brain-match-classifications-12-10-2018.csv',
converters={'metadata':CustomParser,
'annotations':CustomParser,
'subject_data':CustomParser},
header=0)
# Filter out only specific workflow
ratings = classifications.loc[classifications['workflow_name'].isin(['anat_internal_rating_pierre',
'anat_internal_rating_yassine'])]
ratings.count()
# extract tagging count
ratings.loc[:,"n_tagging"] = [ len(q[1]['value']) for q in ratings.annotations]
# extract rating count
ratings.loc[:,"rating"] = [ q[0]['value'] for q in ratings.annotations]
# extract subjects id
ratings.loc[:,"ID"] = [ row.subject_data[str(ratings.subject_ids[ind])]['subject_ID'] for ind,row in ratings.iterrows()]
# extract files name
ratings.loc[:,"imgnm"] = [ row.subject_data[str(ratings.subject_ids[ind])]['images'] for ind,row in ratings.iterrows()]
# How many rating per user
user_count = ratings.user_name.value_counts()
user_count
# drop duplicated rating
inc = 0
sum_dup = 0
for ind,user in enumerate(ratings.user_name.unique()):
user_select_df = ratings[ratings.user_name.isin([user])]
mask=~user_select_df.ID.duplicated()
dup = len([m for m in mask if m == False])
sum_dup = sum_dup+ dup
if dup > 0 :
print('{} have {} duplicated ratings'.format(user,dup))
if ind == 0 and inc == 0:
classi_unique= user_select_df[mask]
inc+=1
else:
classi_unique = classi_unique.append(user_select_df[~user_select_df.ID.duplicated()])
inc+=1
print('Total number of duplicated ratings = {}'.format(sum_dup))
# Get the final rating numbers per subject
user_count = classi_unique.user_name.value_counts()
user_count
#Create Users rating dataframe
list_user = user_count.index
concat_rating = [classi_unique[classi_unique.user_name == user][['ID','rating']].rename(columns={'rating': user})
for user in list_user]
df_ratings = reduce(lambda left,right: pd.merge(left,right,how='outer',on='ID'), concat_rating)
df_ratings.rename(columns={'simexp':'PB','Yassinebha':'YB'},inplace=True)
df_ratings.head()
# Import rating from Pilot1
ratings_p1 = pd.read_csv('../data/rating/Pilot_QC_Pierre_Yassine-12-10-2018.csv').rename(index=str, columns={"status_Athena": "PB_Athena", "status_NIAK": "PB_NIAK",
"status_Athena.1": "YB_Athena", "status_NIAK.1": "YB_NIAK"})
ratings_p1 = ratings_p1[['id_subject','PB_NIAK','YB_NIAK']].rename(columns={'id_subject':'ID','PB_NIAK':'PB_P1','YB_NIAK':'YB_P1'})
ratings_p1.head()
# Merge Pilot1 and 2
ratings_p1p2= pd.merge(df_ratings,ratings_p1,how='inner',on='ID').rename(columns={"PB": "PB_P2", "YB": "YB_P2"}).apply(lambda x: x.str.strip() if x.dtype == "object" else x)
ratings_p1p2.head()
# Save a copy on the disk
df_ratings.to_csv('../data/rating/Pilot2_internal_rating-PB_YB.csv',index=False)
ratings_p1p2.to_csv('../data/rating/Pilot1-2_internal_rating-PB_YB.csv',index=False)
```
### Kappa for Pilote 2 only
```
# Add matching column between the raters
df_ratings.loc[:,"rating_match"] = df_ratings.loc[:,['PB','YB']].apply(lambda x: len(set(x)) == 1, axis=1)
df_ratings.head()
# Replace OK with 1 , Maybe with 2 and Fail with 3
df_ratings.replace({'OK':1,'Maybe':2, 'Fail':3}, inplace=True)
df_ratings.head()
# calculate the percentage of agreement between raters
agreem_ = (df_ratings.rating_match.sum()/df_ratings.ID.count())*100
print("The percentage of agreement is: {:.2f}".format(agreem_))
%%R
suppressPackageStartupMessages(library(dplyr))
#install.packages("irr")
library(irr)
# Percenteage of agrrement between raters with R package IRR
agree_ = df_ratings[['PB','YB']]
%Rpush agree_
agree_n = %R agree(agree_)
print(agree_n)
# FDR correction
from statsmodels.sandbox.stats import multicomp as smi
def fdr_transf(mat,log10 = False):
'''compute fdr of a given matrix'''
row = mat.shape[0]
col = mat.shape[1]
flatt = mat.flatten()
fdr_2d = smi.multipletests(flatt, alpha=0.05, method='fdr_bh')[1]
if log10 == True:
fdr_2d = [-np.log10(ii) if ii != 0 else 50 for ii in fdr_2d ]
fdr_3d = np.reshape(fdr_2d,(row,col))
return fdr_3d
# Kappa calculation
def kappa_score(k_df,log10 = False):
'''compute Kappa between diferent raters organized in dataframe'''
k_store = np.zeros((len(k_df.columns), len(k_df.columns)))
p_store = np.zeros((len(k_df.columns), len(k_df.columns)))
%Rpush k_df
for user1_id, user1 in enumerate(k_df.columns):
for user2_id, user2 in enumerate(k_df.columns):
weight = np.unique(kappa_df[[user1,user2]])
%Rpush user1_id user1 user2_id user2 weight
kappaR = %R kappa2(k_df[,c(user1,user2)],weight)
# store the kappa
k_store[user1_id, user2_id] = [kappaR[x][0] for x in range(np.shape(kappaR)[0])][4]
p_store[user1_id, user2_id] = [kappaR[x][0] for x in range(np.shape(kappaR)[0])][-1]
# FDR Correction
p_store = fdr_transf(p_store,log10)
return k_store, p_store
# Get Kappa score out of all different combination of ratings
kappa_df = df_ratings[['PB','YB']]
kappa_store, Pval_store = kappa_score(kappa_df)
mean_kap = np.mean(kappa_store[np.triu_indices(len(kappa_store),k=1)])
std_kap = np.std(kappa_store[np.triu_indices(len(kappa_store),k=1)])
print('Mean Kappa : {0:.2f} , std : {1:.2f}\n'.format(mean_kap, std_kap))
#calculte the over all kappa values of all ratings
%Rpush kappa_df
fleiss_kappa = %R kappam.fleiss(kappa_df,c(0,1,2))
print(fleiss_kappa)
# Plot kappa matrix
kappa_out = pd.DataFrame(kappa_store,
index=kappa_df.columns.get_values(),
columns=kappa_df.columns.get_values())
# Set up the matplotlib figure
f, axes = plt.subplots(figsize = (7,5))
f.subplots_adjust(hspace= .8)
f.suptitle('Pilot2 QC',x=0.49,y=1.05, fontsize=14, fontweight='bold')
# Draw kappa heat map
sns.heatmap(kappa_out,vmin=0,vmax=1,cmap="YlGnBu",
square=True,
annot=True,
linewidths=.5,
cbar_kws={"shrink": .9,"label": "Cohen's Kappa"},
ax=axes)
axes.set_yticks([x+0.5 for x in range(len(kappa_df.columns))])
axes.set_yticklabels(kappa_df.columns,rotation=0)
axes.set_title("Cohen's Kappa matrix for 2 raters and {} images".format(len(df_ratings)),pad=20,fontsize=12)
# Caption
pval = np.unique(Pval_store)[-1]
txt = '''
Fig1: Kappa matrix for 2 raters PB & YB - Substantial
agreement beteween raters. Kappa's P-values
is {:.2g} '''.format(pval)
f.text(.1,-0.08,txt,fontsize=12)
# Save figure
f.savefig('../reports/figures/pilot2_qc.svg')
from IPython.display import Image
Image(url= "https://i.stack.imgur.com/kYNd6.png" ,width=600, height=600)
```
### Kappa between pilot 1 and 2
```
# Add matching column between the raters
ratings_p1p2.loc[:,"rating_match"] = ratings_p1p2.loc[:,['PB_P1','YB_P1','PB_P2','YB_P2']].apply(lambda x: len(set(x)) == 1, axis=1)
ratings_p1p2.head()
# Replace OK with 1 , Maybe with 2 and Fail with 3
ratings_p1p2.replace({'OK':1,'Maybe':2, 'Fail':3}, inplace=True)
ratings_p1p2.head()
# calculate the percentage of agreement between raters
agreem_ = (ratings_p1p2.rating_match.sum()/ratings_p1p2.ID.count())*100
print("The percentage of agreement is: {:.2f}".format(agreem_))
%%R
suppressPackageStartupMessages(library(dplyr))
#install.packages("irr")
library(irr)
# Percenteage of agrrement between raters with R package IRR
agree_ = ratings_p1p2[['PB_P2','YB_P2','PB_P1','YB_P1']]
%Rpush agree_
agree_n = %R agree(agree_)
print(agree_n)
# Get Kappa score out of all different combination of ratings
kappa_df = ratings_p1p2[['PB_P2','YB_P2','PB_P1','YB_P1']]
kappa_store, Pval_store = kappa_score(kappa_df)
mean_kap = np.mean(kappa_store[np.triu_indices(len(kappa_store),k=1)])
std_kap = np.std(kappa_store[np.triu_indices(len(kappa_store),k=1)])
print('Mean Kappa : {0:.2f} , std : {1:.2f}\n'.format(mean_kap, std_kap))
#calculte the over all kappa values of all ratings
%Rpush kappa_df
fleiss_kappa = %R kappam.fleiss(kappa_df,c(0,1,2))
print(fleiss_kappa)
# Plot kappa matrix
kappa_out = pd.DataFrame(kappa_store,
index=kappa_df.columns.get_values(),
columns=kappa_df.columns.get_values())
# Set up the matplotlib figure
f, axes = plt.subplots(figsize = (7,5))
f.subplots_adjust(hspace= .8)
f.suptitle('Pilot1 & Pilot2 QC',x=0.49,y=1.05, fontsize=14, fontweight='bold')
# Draw kappa heat map
sns.heatmap(kappa_out,vmin=0,vmax=1,cmap="YlGnBu",
square=True,
annot=True,
linewidths=.5,
cbar_kws={"shrink": .9,"label": "Cohen's Kappa"},
ax=axes)
axes.set_yticks([x+0.5 for x in range(len(kappa_df.columns))])
axes.set_yticklabels(kappa_df.columns,rotation=0)
axes.set_title("Cohen's Kappa matrix for 2 raters {} images".format(len(ratings_p1p2)),pad=20,fontsize=12)
# Caption
pval = np.unique(Pval_store)[-1]
txt = '''
Fig1: Kappa matrix for 2 raters PB & YB from two pilots
projects- {} Images are rated twice,once from
pilot1 and secondfrom pilot2. Substantial agreement
beteween raters and pilots. Kappa's P-values FDR
corrected range from {:.2g}to {:.2g} '''.format(len(ratings_p1p2),Pval_store.min(), Pval_store.max())
f.text(.1,-0.17,txt,fontsize=12)
# Save figure
f.savefig('../reports/figures/pilot2_qc.svg')
```
### Report tagging
```
# output markings from classifications
clist=[]
for index, c in classi_unique.iterrows():
if c['n_tagging'] > 0:
for q in c.annotations[1]['value']:
clist.append({'ID':c.ID, 'workflow_name':c.workflow_name,'user_name':c.user_name, 'rating':c.rating,'imgnm':c.imgnm,
'x':q['x'], 'y':np.round(q['y']).astype(int), 'r':'1.5','n_tagging':c.n_tagging ,'frame':q['frame']})
else:
clist.append({'ID':c.ID, 'workflow_name':c.workflow_name, 'user_name':c.user_name,'rating':c.rating,'imgnm':c.imgnm,
'x':float('nan'), 'y':float('nan'), 'r':float('nan'),'n_tagging':c.n_tagging ,'frame':'1'})
col_order=['ID','workflow_name','user_name','rating','x','y','r','n_tagging','imgnm','frame']
out_tag = pd.DataFrame(clist)[col_order]
out_tag.user_name.replace({'simexp':'PB','Yassinebha':'YB'},inplace=True)
out_tag.head()
# Extract unique IDs for each image
ids_imgnm = np.reshape([out_tag.ID.unique(),out_tag.imgnm.unique()],(2,np.shape(out_tag.ID.unique())[0]))
df_ids_imgnm = pd.DataFrame(np.sort(ids_imgnm.T, axis=0),columns=['ID', 'imgnm'])
df_ids_imgnm.head()
# Create custom color map
from matplotlib.colors import LinearSegmentedColormap , ListedColormap
from PIL import Image
def _cmap_from_image_path(img_path):
img = Image.open(img_path)
img = img.resize((256, img.height))
colours = (img.getpixel((x, 0)) for x in range(256))
colours = [(r/255, g/255, b/255, a/255) for (r, g, b, a) in colours]
return colours,LinearSegmentedColormap.from_list('from_image', colours)
coll,a=_cmap_from_image_path('../data/Misc/custom_ColBar.png')
#invert color map
coll_r = ListedColormap(coll[::-1])
# set color different for each rater
list_tagger = out_tag.user_name.unique()
colors_tagger = sns.color_palette("Set2", len(list_tagger))
colors_tagger
```
### Plot tagging per rater
```
from matplotlib.collections import PatchCollection
from matplotlib.patches import Circle, Arrow
#Set Template image as background
fig = plt.figure(figsize=(10,14))
ax = fig.add_subplot(111)
im = plt.imread('../data/Misc/template_stereotaxic_v1.png')
ax.set_title('All taggings')
ax.imshow(im)
fig.suptitle('Pilot2 QC',x=0.51,y=.87, fontsize=14, fontweight='bold')
# Plot tags
for ind, row in df_ids_imgnm.iterrows():
out_tmp = out_tag[out_tag['ID'] == row.ID]
patches = []
labels = []
for ind,row in out_tmp.iterrows():
for idx,tagger in enumerate(list_tagger):
out_tagger = out_tmp[out_tmp['user_name'] == tagger]
c = [Circle((rowtag.x,rowtag.y), 7)
for itag,rowtag in out_tagger.iterrows()]
p = PatchCollection(c,facecolor='none',
edgecolor=colors_tagger[idx],
alpha=0.4,
linewidth=2,
linestyle='dashed')
ax.add_collection(p)
#Set figure Tags labels
tag_ = np.zeros((len(df_ids_imgnm),len(list_tagger)))
l = list()
labels = list()
for ind, row in df_ids_imgnm.iterrows():
out_tmp = out_tag[out_tag['ID'] == row.ID]
patches = []
labels = []
tag_[ind,:]= [sum(out_tmp[out_tmp['user_name'] == rater].n_tagging.unique())
for rater in list_tagger]
for rater_id, rater in enumerate(list_tagger):
l.append(Circle((None,None), facecolor=colors_tagger[rater_id], alpha=0.7))
labels.append('{} : {:g} Tags'.format(rater,tag_.sum(axis=0)[rater_id]))
ax.legend(handles=l,labels=labels,
bbox_to_anchor=(0., 1.02, 1., .2),
mode='expand', ncol=1, loc="lower right")
ax.set_xticklabels([])
ax.set_yticklabels([])
fig.savefig('../reports/figures/pilot2_qc_tags.svg')
```
### Plot heat map for all tagging
```
from heatmappy import Heatmapper
from PIL import Image
patches=list()
for ind, row in df_ids_imgnm.iterrows():
out_tmp = out_tag[out_tag['ID'] == row.ID]
patches.append([(row.x,row.y) for ind,row in out_tmp.iterrows()])
patches = [x for x in sum(patches,[]) if str(x[0]) != 'nan']
# plot heat map on the template
f, axes = plt.subplots(1, 1,figsize = (10,14))
f.subplots_adjust(hspace= .8)
f.suptitle('Pilot2 QC',x=0.49,y=.83, fontsize=14, fontweight='bold')
img = Image.open('../data/Misc/template_stereotaxic_v1.png')
axes.set_title('Tagging from PB & YB raters')
heatmapper = Heatmapper(opacity=0.5,
point_diameter=20,
point_strength = 0.5,
colours=a)
heatmap= heatmapper.heatmap_on_img(patches, img)
im = axes.imshow(heatmap,cmap=coll_r)
axes.set_yticklabels([])
axes.set_xticklabels([])
cbar = plt.colorbar(im, orientation='vertical', ticks=[0, 125, 255],fraction=0.046, pad=0.04,ax=axes)
cbar.ax.set_yticklabels(['0', '1', '> 2'])
img.close()
heatmap.close()
f.savefig('../reports/figures/pilot2_qc_heatmap_tags.svg')
```
|
github_jupyter
|
<a href="https://colab.research.google.com/github/mrdbourke/tensorflow-deep-learning/blob/main/05_transfer_learning_in_tensorflow_part_2_fine_tuning.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# 05. Transfer Learning with TensorFlow Part 2: Fine-tuning
In the previous section, we saw how we could leverage feature extraction transfer learning to get far better results on our Food Vision project than building our own models (even with less data).
Now we're going to cover another type of transfer learning: fine-tuning.
In **fine-tuning transfer learning** the pre-trained model weights from another model are unfrozen and tweaked during to better suit your own data.
For feature extraction transfer learning, you may only train the top 1-3 layers of a pre-trained model with your own data, in fine-tuning transfer learning, you might train 1-3+ layers of a pre-trained model (where the '+' indicates that many or all of the layers could be trained).
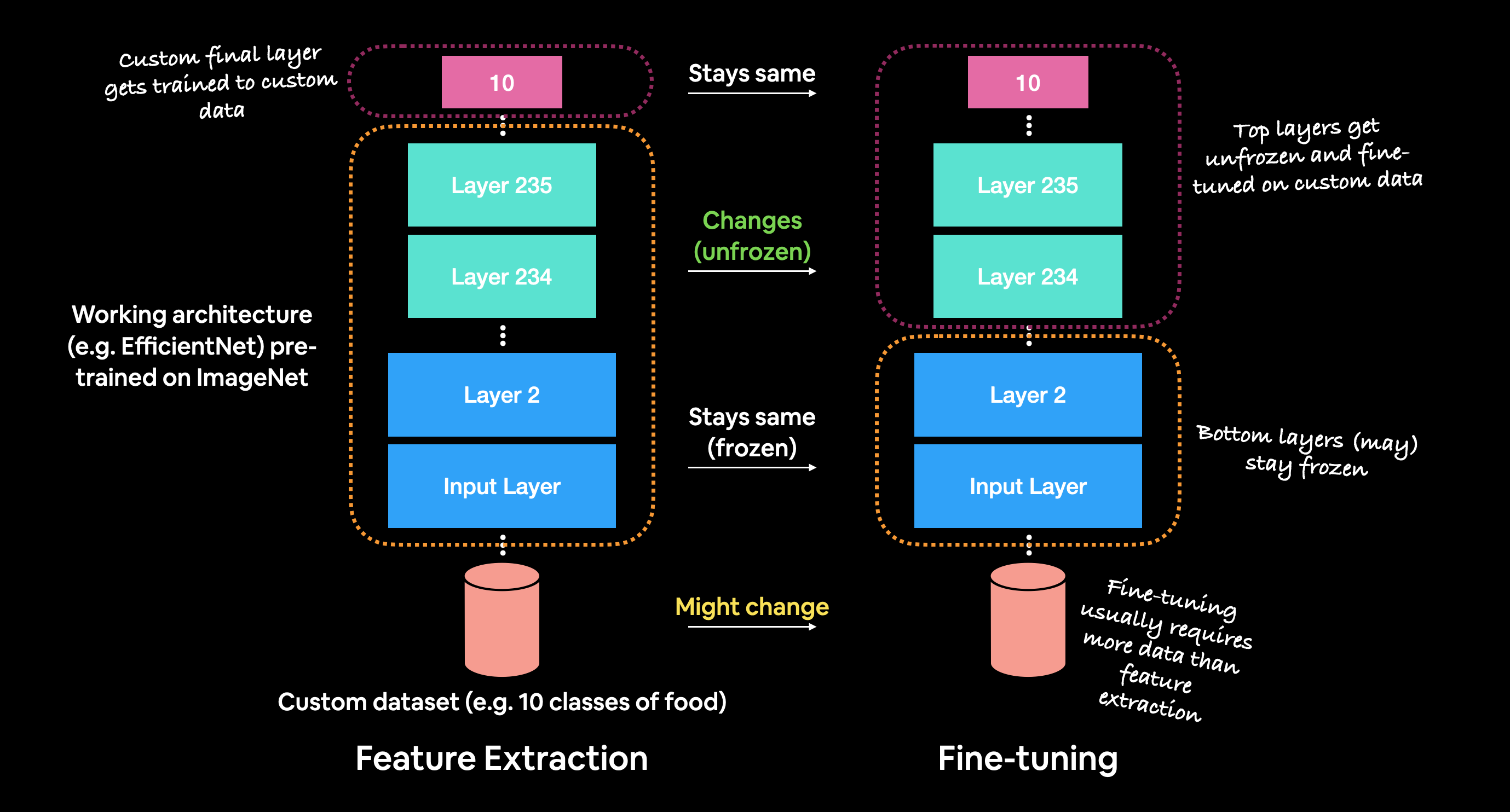
*Feature extraction transfer learning vs. fine-tuning transfer learning. The main difference between the two is that in fine-tuning, more layers of the pre-trained model get unfrozen and tuned on custom data. This fine-tuning usually takes more data than feature extraction to be effective.*
## What we're going to cover
We're going to go through the follow with TensorFlow:
- Introduce fine-tuning, a type of transfer learning to modify a pre-trained model to be more suited to your data
- Using the Keras Functional API (a differnt way to build models in Keras)
- Using a smaller dataset to experiment faster (e.g. 1-10% of training samples of 10 classes of food)
- Data augmentation (how to make your training dataset more diverse without adding more data)
- Running a series of modelling experiments on our Food Vision data
- Model 0: a transfer learning model using the Keras Functional API
- Model 1: a feature extraction transfer learning model on 1% of the data with data augmentation
- Model 2: a feature extraction transfer learning model on 10% of the data with data augmentation
- Model 3: a fine-tuned transfer learning model on 10% of the data
- Model 4: a fine-tuned transfer learning model on 100% of the data
- Introduce the ModelCheckpoint callback to save intermediate training results
- Compare model experiments results using TensorBoard
## How you can use this notebook
You can read through the descriptions and the code (it should all run, except for the cells which error on purpose), but there's a better option.
Write all of the code yourself.
Yes. I'm serious. Create a new notebook, and rewrite each line by yourself. Investigate it, see if you can break it, why does it break?
You don't have to write the text descriptions but writing the code yourself is a great way to get hands-on experience.
Don't worry if you make mistakes, we all do. The way to get better and make less mistakes is to **write more code**.
```
# Are we using a GPU? (if not & you're using Google Colab, go to Runtime -> Change Runtime Type -> Harware Accelerator: GPU )
!nvidia-smi
```
## Creating helper functions
Throughout your machine learning experiments, you'll likely come across snippets of code you want to use over and over again.
For example, a plotting function which plots a model's `history` object (see `plot_loss_curves()` below).
You could recreate these functions over and over again.
But as you might've guessed, rewritting the same functions becomes tedious.
One of the solutions is to store them in a helper script such as [`helper_functions.py`](https://github.com/mrdbourke/tensorflow-deep-learning/blob/main/extras/helper_functions.py). And then import the necesary functionality when you need it.
For example, you might write:
```
from helper_functions import plot_loss_curves
...
plot_loss_curves(history)
```
Let's see what this looks like.
```
# Get helper_functions.py script from course GitHub
!wget https://raw.githubusercontent.com/mrdbourke/tensorflow-deep-learning/main/extras/helper_functions.py
# Import helper functions we're going to use
from helper_functions import create_tensorboard_callback, plot_loss_curves, unzip_data, walk_through_dir
```
Wonderful, now we've got a bunch of helper functions we can use throughout the notebook without having to rewrite them from scratch each time.
> 🔑 **Note:** If you're running this notebook in Google Colab, when it times out Colab will delete the `helper_functions.py` file. So to use the functions imported above, you'll have to rerun the cell.
## 10 Food Classes: Working with less data
We saw in the [previous notebook](https://github.com/mrdbourke/tensorflow-deep-learning/blob/main/04_transfer_learning_in_tensorflow_part_1_feature_extraction.ipynb) that we could get great results with only 10% of the training data using transfer learning with TensorFlow Hub.
In this notebook, we're going to continue to work with smaller subsets of the data, except this time we'll have a look at how we can use the in-built pretrained models within the `tf.keras.applications` module as well as how to fine-tune them to our own custom dataset.
We'll also practice using a new but similar dataloader function to what we've used before, [`image_dataset_from_directory()`](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image_dataset_from_directory) which is part of the [`tf.keras.preprocessing`](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing) module.
Finally, we'll also be practicing using the [Keras Functional API](https://keras.io/guides/functional_api/) for building deep learning models. The Functional API is a more flexible way to create models than the tf.keras.Sequential API.
We'll explore each of these in more detail as we go.
Let's start by downloading some data.
```
# Get 10% of the data of the 10 classes
!wget https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_10_percent.zip
unzip_data("10_food_classes_10_percent.zip")
```
The dataset we're downloading is the 10 food classes dataset (from Food 101) with 10% of the training images we used in the previous notebook.
> 🔑 **Note:** You can see how this dataset was created in the [image data modification notebook](https://github.com/mrdbourke/tensorflow-deep-learning/blob/main/extras/image_data_modification.ipynb).
```
# Walk through 10 percent data directory and list number of files
walk_through_dir("10_food_classes_10_percent")
```
We can see that each of the training directories contain 75 images and each of the testing directories contain 250 images.
Let's define our training and test filepaths.
```
# Create training and test directories
train_dir = "10_food_classes_10_percent/train/"
test_dir = "10_food_classes_10_percent/test/"
```
Now we've got some image data, we need a way of loading it into a TensorFlow compatible format.
Previously, we've used the [`ImageDataGenerator`](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/ImageDataGenerator) class. And while this works well and is still very commonly used, this time we're going to use the `image_data_from_directory` function.
It works much the same way as `ImageDataGenerator`'s `flow_from_directory` method meaning your images need to be in the following file format:
```
Example of file structure
10_food_classes_10_percent <- top level folder
└───train <- training images
│ └───pizza
│ │ │ 1008104.jpg
│ │ │ 1638227.jpg
│ │ │ ...
│ └───steak
│ │ 1000205.jpg
│ │ 1647351.jpg
│ │ ...
│
└───test <- testing images
│ └───pizza
│ │ │ 1001116.jpg
│ │ │ 1507019.jpg
│ │ │ ...
│ └───steak
│ │ 100274.jpg
│ │ 1653815.jpg
│ │ ...
```
One of the main benefits of using [`tf.keras.prepreprocessing.image_dataset_from_directory()`](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image_dataset_from_directory) rather than `ImageDataGenerator` is that it creates a [`tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) object rather than a generator. The main advantage of this is the `tf.data.Dataset` API is much more efficient (faster) than the `ImageDataGenerator` API which is paramount for larger datasets.
Let's see it in action.
```
# Create data inputs
import tensorflow as tf
IMG_SIZE = (224, 224) # define image size
train_data_10_percent = tf.keras.preprocessing.image_dataset_from_directory(directory=train_dir,
image_size=IMG_SIZE,
label_mode="categorical", # what type are the labels?
batch_size=32) # batch_size is 32 by default, this is generally a good number
test_data_10_percent = tf.keras.preprocessing.image_dataset_from_directory(directory=test_dir,
image_size=IMG_SIZE,
label_mode="categorical")
```
Wonderful! Looks like our dataloaders have found the correct number of images for each dataset.
For now, the main parameters we're concerned about in the `image_dataset_from_directory()` funtion are:
* `directory` - the filepath of the target directory we're loading images in from.
* `image_size` - the target size of the images we're going to load in (height, width).
* `batch_size` - the batch size of the images we're going to load in. For example if the `batch_size` is 32 (the default), batches of 32 images and labels at a time will be passed to the model.
There are more we could play around with if we needed to [in the `tf.keras.preprocessing` documentation](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image_dataset_from_directory).
If we check the training data datatype we should see it as a `BatchDataset` with shapes relating to our data.
```
# Check the training data datatype
train_data_10_percent
```
In the above output:
* `(None, 224, 224, 3)` refers to the tensor shape of our images where `None` is the batch size, `224` is the height (and width) and `3` is the color channels (red, green, blue).
* `(None, 10)` refers to the tensor shape of the labels where `None` is the batch size and `10` is the number of possible labels (the 10 different food classes).
* Both image tensors and labels are of the datatype `tf.float32`.
The `batch_size` is `None` due to it only being used during model training. You can think of `None` as a placeholder waiting to be filled with the `batch_size` parameter from `image_dataset_from_directory()`.
Another benefit of using the `tf.data.Dataset` API are the assosciated methods which come with it.
For example, if we want to find the name of the classes we were working with, we could use the `class_names` attribute.
```
# Check out the class names of our dataset
train_data_10_percent.class_names
```
Or if we wanted to see an example batch of data, we could use the `take()` method.
```
# See an example batch of data
for images, labels in train_data_10_percent.take(1):
print(images, labels)
```
Notice how the image arrays come out as tensors of pixel values where as the labels come out as one-hot encodings (e.g. `[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]` for `hamburger`).
### Model 0: Building a transfer learning model using the Keras Functional API
Alright, our data is tensor-ified, let's build a model.
To do so we're going to be using the [`tf.keras.applications`](https://www.tensorflow.org/api_docs/python/tf/keras/applications) module as it contains a series of already trained (on ImageNet) computer vision models as well as the Keras Functional API to construct our model.
We're going to go through the following steps:
1. Instantiate a pre-trained base model object by choosing a target model such as [`EfficientNetB0`](https://www.tensorflow.org/api_docs/python/tf/keras/applications/EfficientNetB0) from `tf.keras.applications`, setting the `include_top` parameter to `False` (we do this because we're going to create our own top, which are the output layers for the model).
2. Set the base model's `trainable` attribute to `False` to freeze all of the weights in the pre-trained model.
3. Define an input layer for our model, for example, what shape of data should our model expect?
4. [Optional] Normalize the inputs to our model if it requires. Some computer vision models such as `ResNetV250` require their inputs to be between 0 & 1.
> 🤔 **Note:** As of writing, the `EfficientNet` models in the `tf.keras.applications` module do not require images to be normalized (pixel values between 0 and 1) on input, where as many of the other models do. I posted [an issue to the TensorFlow GitHub](https://github.com/tensorflow/tensorflow/issues/42506) about this and they confirmed this.
5. Pass the inputs to the base model.
6. Pool the outputs of the base model into a shape compatible with the output activation layer (turn base model output tensors into same shape as label tensors). This can be done using [`tf.keras.layers.GlobalAveragePooling2D()`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalAveragePooling2D) or [`tf.keras.layers.GlobalMaxPooling2D()`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalMaxPool2D?hl=en) though the former is more common in practice.
7. Create an output activation layer using `tf.keras.layers.Dense()` with the appropriate activation function and number of neurons.
8. Combine the inputs and outputs layer into a model using [`tf.keras.Model()`](https://www.tensorflow.org/api_docs/python/tf/keras/Model).
9. Compile the model using the appropriate loss function and choose of optimizer.
10. Fit the model for desired number of epochs and with necessary callbacks (in our case, we'll start off with the TensorBoard callback).
Woah... that sounds like a lot. Before we get ahead of ourselves, let's see it in practice.
```
# 1. Create base model with tf.keras.applications
base_model = tf.keras.applications.EfficientNetB0(include_top=False)
# 2. Freeze the base model (so the pre-learned patterns remain)
base_model.trainable = False
# 3. Create inputs into the base model
inputs = tf.keras.layers.Input(shape=(224, 224, 3), name="input_layer")
# 4. If using ResNet50V2, add this to speed up convergence, remove for EfficientNet
# x = tf.keras.layers.experimental.preprocessing.Rescaling(1./255)(inputs)
# 5. Pass the inputs to the base_model (note: using tf.keras.applications, EfficientNet inputs don't have to be normalized)
x = base_model(inputs)
# Check data shape after passing it to base_model
print(f"Shape after base_model: {x.shape}")
# 6. Average pool the outputs of the base model (aggregate all the most important information, reduce number of computations)
x = tf.keras.layers.GlobalAveragePooling2D(name="global_average_pooling_layer")(x)
print(f"After GlobalAveragePooling2D(): {x.shape}")
# 7. Create the output activation layer
outputs = tf.keras.layers.Dense(10, activation="softmax", name="output_layer")(x)
# 8. Combine the inputs with the outputs into a model
model_0 = tf.keras.Model(inputs, outputs)
# 9. Compile the model
model_0.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# 10. Fit the model (we use less steps for validation so it's faster)
history_10_percent = model_0.fit(train_data_10_percent,
epochs=5,
steps_per_epoch=len(train_data_10_percent),
validation_data=test_data_10_percent,
# Go through less of the validation data so epochs are faster (we want faster experiments!)
validation_steps=int(0.25 * len(test_data_10_percent)),
# Track our model's training logs for visualization later
callbacks=[create_tensorboard_callback("transfer_learning", "10_percent_feature_extract")])
```
Nice! After a minute or so of training our model performs incredibly well on both the training (87%+ accuracy) and test sets (~83% accuracy).
This is incredible. All thanks to the power of transfer learning.
It's important to note the kind of transfer learning we used here is called feature extraction transfer learning, similar to what we did with the TensorFlow Hub models.
In other words, we passed our custom data to an already pre-trained model (`EfficientNetB0`), asked it "what patterns do you see?" and then put our own output layer on top to make sure the outputs were tailored to our desired number of classes.
We also used the Keras Functional API to build our model rather than the Sequential API. For now, the benefits of this main not seem clear but when you start to build more sophisticated models, you'll probably want to use the Functional API. So it's important to have exposure to this way of building models.
> 📖 **Resource:** To see the benefits and use cases of the Functional API versus the Sequential API, check out the [TensorFlow Functional API documentation](https://www.tensorflow.org/guide/keras/functional).
Let's inspect the layers in our model, we'll start with the base.
```
# Check layers in our base model
for layer_number, layer in enumerate(base_model.layers):
print(layer_number, layer.name)
```
Wow, that's a lot of layers... to handcode all of those would've taken a fairly long time to do, yet we can still take advatange of them thanks to the power of transfer learning.
How about a summary of the base model?
```
base_model.summary()
```
You can see how each of the different layers have a certain number of parameters each. Since we are using a pre-trained model, you can think of all of these parameters are patterns the base model has learned on another dataset. And because we set `base_model.trainable = False`, these patterns remain as they are during training (they're frozen and don't get updated).
Alright that was the base model, let's see the summary of our overall model.
```
# Check summary of model constructed with Functional API
model_0.summary()
```
Our overall model has five layers but really, one of those layers (`efficientnetb0`) has 236 layers.
You can see how the output shape started out as `(None, 224, 224, 3)` for the input layer (the shape of our images) but was transformed to be `(None, 10)` by the output layer (the shape of our labels), where `None` is the placeholder for the batch size.
Notice too, the only trainable parameters in the model are those in the output layer.
How do our model's training curves look?
```
# Check out our model's training curves
plot_loss_curves(history_10_percent)
```
## Getting a feature vector from a trained model
> 🤔 **Question:** What happens with the `tf.keras.layers.GlobalAveragePooling2D()` layer? I haven't seen it before.
The [`tf.keras.layers.GlobalAveragePooling2D()`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalAveragePooling2D) layer transforms a 4D tensor into a 2D tensor by averaging the values across the inner-axes.
The previous sentence is a bit of a mouthful, so let's see an example.
```
# Define input tensor shape (same number of dimensions as the output of efficientnetb0)
input_shape = (1, 4, 4, 3)
# Create a random tensor
tf.random.set_seed(42)
input_tensor = tf.random.normal(input_shape)
print(f"Random input tensor:\n {input_tensor}\n")
# Pass the random tensor through a global average pooling 2D layer
global_average_pooled_tensor = tf.keras.layers.GlobalAveragePooling2D()(input_tensor)
print(f"2D global average pooled random tensor:\n {global_average_pooled_tensor}\n")
# Check the shapes of the different tensors
print(f"Shape of input tensor: {input_tensor.shape}")
print(f"Shape of 2D global averaged pooled input tensor: {global_average_pooled_tensor.shape}")
```
You can see the `tf.keras.layers.GlobalAveragePooling2D()` layer condensed the input tensor from shape `(1, 4, 4, 3)` to `(1, 3)`. It did so by averaging the `input_tensor` across the middle two axes.
We can replicate this operation using the `tf.reduce_mean()` operation and specifying the appropriate axes.
```
# This is the same as GlobalAveragePooling2D()
tf.reduce_mean(input_tensor, axis=[1, 2]) # average across the middle axes
```
Doing this not only makes the output of the base model compatible with the input shape requirement of our output layer (`tf.keras.layers.Dense()`), it also condenses the information found by the base model into a lower dimension **feature vector**.
> 🔑 **Note:** One of the reasons feature extraction transfer learning is named how it is is because what often happens is a pretrained model outputs a **feature vector** (a long tensor of numbers, in our case, this is the output of the [`tf.keras.layers.GlobalAveragePooling2D()`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalAveragePooling2D) layer) which can then be used to extract patterns out of.
> 🛠 **Practice:** Do the same as the above cell but for [`tf.keras.layers.GlobalMaxPool2D()`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GlobalMaxPool2D).
## Running a series of transfer learning experiments
We've seen the incredible results of transfer learning on 10% of the training data, what about 1% of the training data?
What kind of results do you think we can get using 100x less data than the original CNN models we built ourselves?
Why don't we answer that question while running the following modelling experiments:
1. `model_1`: Use feature extraction transfer learning on 1% of the training data with data augmentation.
2. `model_2`: Use feature extraction transfer learning on 10% of the training data with data augmentation.
3. `model_3`: Use fine-tuning transfer learning on 10% of the training data with data augmentation.
4. `model_4`: Use fine-tuning transfer learning on 100% of the training data with data augmentation.
While all of the experiments will be run on different versions of the training data, they will all be evaluated on the same test dataset, this ensures the results of each experiment are as comparable as possible.
All experiments will be done using the `EfficientNetB0` model within the `tf.keras.applications` module.
To make sure we're keeping track of our experiments, we'll use our `create_tensorboard_callback()` function to log all of the model training logs.
We'll construct each model using the Keras Functional API and instead of implementing data augmentation in the `ImageDataGenerator` class as we have previously, we're going to build it right into the model using the [`tf.keras.layers.experimental.preprocessing`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing) module.
Let's begin by downloading the data for experiment 1, using feature extraction transfer learning on 1% of the training data with data augmentation.
```
# Download and unzip data
!wget https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_1_percent.zip
unzip_data("10_food_classes_1_percent.zip")
# Create training and test dirs
train_dir_1_percent = "10_food_classes_1_percent/train/"
test_dir = "10_food_classes_1_percent/test/"
```
How many images are we working with?
```
# Walk through 1 percent data directory and list number of files
walk_through_dir("10_food_classes_1_percent")
```
Alright, looks like we've only got seven images of each class, this should be a bit of a challenge for our model.
> 🔑 **Note:** As with the 10% of data subset, the 1% of images were chosen at random from the original full training dataset. The test images are the same as the ones which have previously been used. If you want to see how this data was preprocessed, check out the [Food Vision Image Preprocessing notebook](https://github.com/mrdbourke/tensorflow-deep-learning/blob/main/extras/image_data_modification.ipynb).
Time to load our images in as `tf.data.Dataset` objects, to do so, we'll use the [`image_dataset_from_directory()`](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image_dataset_from_directory) method.
```
import tensorflow as tf
IMG_SIZE = (224, 224)
train_data_1_percent = tf.keras.preprocessing.image_dataset_from_directory(train_dir_1_percent,
label_mode="categorical",
batch_size=32, # default
image_size=IMG_SIZE)
test_data = tf.keras.preprocessing.image_dataset_from_directory(test_dir,
label_mode="categorical",
image_size=IMG_SIZE)
```
Data loaded. Time to augment it.
### Adding data augmentation right into the model
Previously we've used the different parameters of the `ImageDataGenerator` class to augment our training images, this time we're going to build data augmentation right into the model.
How?
Using the [`tf.keras.layers.experimental.preprocessing`](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing) module and creating a dedicated data augmentation layer.
This a relatively new feature added to TensorFlow 2.2+ but it's very powerful. Adding a data augmentation layer to the model has the following benefits:
* Preprocessing of the images (augmenting them) happens on the GPU rather than on the CPU (much faster).
* Images are best preprocessed on the GPU where as text and structured data are more suited to be preprocessed on the CPU.
* Image data augmentation only happens during training so we can still export our whole model and use it elsewhere. And if someone else wanted to train the same model as us, including the same kind of data augmentation, they could.

*Example of using data augmentation as the first layer within a model (EfficientNetB0).*
> 🤔 **Note:** At the time of writing, the preprocessing layers we're using for data augmentation are in *experimental* status within the in TensorFlow library. This means although the layers should be considered stable, the code may change slightly in a future version of TensorFlow. For more information on the other preprocessing layers avaiable and the different methods of data augmentation, check out the [Keras preprocessing layers guide](https://keras.io/guides/preprocessing_layers/) and the [TensorFlow data augmentation guide](https://www.tensorflow.org/tutorials/images/data_augmentation).
To use data augmentation right within our model we'll create a Keras Sequential model consisting of only data preprocessing layers, we can then use this Sequential model within another Functional model.
If that sounds confusing, it'll make sense once we create it in code.
The data augmentation transformations we're going to use are:
* [RandomFlip](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/RandomFlip) - flips image on horizontal or vertical axis.
* [RandomRotation](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/RandomRotation) - randomly rotates image by a specified amount.
* [RandomZoom](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/RandomZoom) - randomly zooms into an image by specified amount.
* [RandomHeight](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/RandomHeight) - randomly shifts image height by a specified amount.
* [RandomWidth](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/RandomWidth) - randomly shifts image width by a specified amount.
* [Rescaling](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/Rescaling) - normalizes the image pixel values to be between 0 and 1, this is worth mentioning because it is required for some image models but since we're using the `tf.keras.applications` implementation of `EfficientNetB0`, it's not required.
There are more option but these will do for now.
```
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
# Create a data augmentation stage with horizontal flipping, rotations, zooms
data_augmentation = keras.Sequential([
preprocessing.RandomFlip("horizontal"),
preprocessing.RandomRotation(0.2),
preprocessing.RandomZoom(0.2),
preprocessing.RandomHeight(0.2),
preprocessing.RandomWidth(0.2),
# preprocessing.Rescaling(1./255) # keep for ResNet50V2, remove for EfficientNetB0
], name ="data_augmentation")
```
And that's it! Our data augmentation Sequential model is ready to go. As you'll see shortly, we'll be able to slot this "model" as a layer into our transfer learning model later on.
But before we do that, let's test it out by passing random images through it.
```
# View a random image
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import os
import random
target_class = random.choice(train_data_1_percent.class_names) # choose a random class
target_dir = "10_food_classes_1_percent/train/" + target_class # create the target directory
random_image = random.choice(os.listdir(target_dir)) # choose a random image from target directory
random_image_path = target_dir + "/" + random_image # create the choosen random image path
img = mpimg.imread(random_image_path) # read in the chosen target image
plt.imshow(img) # plot the target image
plt.title(f"Original random image from class: {target_class}")
plt.axis(False); # turn off the axes
# Augment the image
augmented_img = data_augmentation(tf.expand_dims(img, axis=0)) # data augmentation model requires shape (None, height, width, 3)
plt.figure()
plt.imshow(tf.squeeze(augmented_img)/255.) # requires normalization after augmentation
plt.title(f"Augmented random image from class: {target_class}")
plt.axis(False);
```
Run the cell above a few times and you can see the different random augmentations on different classes of images. Because we're going to add the data augmentation model as a layer in our upcoming transfer learning model, it'll apply these kind of random augmentations to each of the training images which passes through it.
Doing this will make our training dataset a little more varied. You can think of it as if you were taking a photo of food in real-life, not all of the images are going to be perfect, some of them are going to be orientated in strange ways. These are the kind of images we want our model to be able to handle.
Speaking of model, let's build one with the Functional API. We'll run through all of the same steps as before except for one difference, we'll add our data augmentation Sequential model as a layer immediately after the input layer.
## Model 1: Feature extraction transfer learning on 1% of the data with data augmentation
```
# Setup input shape and base model, freezing the base model layers
input_shape = (224, 224, 3)
base_model = tf.keras.applications.EfficientNetB0(include_top=False)
base_model.trainable = False
# Create input layer
inputs = layers.Input(shape=input_shape, name="input_layer")
# Add in data augmentation Sequential model as a layer
x = data_augmentation(inputs)
# Give base_model inputs (after augmentation) and don't train it
x = base_model(x, training=False)
# Pool output features of base model
x = layers.GlobalAveragePooling2D(name="global_average_pooling_layer")(x)
# Put a dense layer on as the output
outputs = layers.Dense(10, activation="softmax", name="output_layer")(x)
# Make a model with inputs and outputs
model_1 = keras.Model(inputs, outputs)
# Compile the model
model_1.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Fit the model
history_1_percent = model_1.fit(train_data_1_percent,
epochs=5,
steps_per_epoch=len(train_data_1_percent),
validation_data=test_data,
validation_steps=int(0.25* len(test_data)), # validate for less steps
# Track model training logs
callbacks=[create_tensorboard_callback("transfer_learning", "1_percent_data_aug")])
```
Wow! How cool is that? Using only 7 training images per class, using transfer learning our model was able to get ~40% accuracy on the validation set. This result is pretty amazing since the [original Food-101 paper](https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/static/bossard_eccv14_food-101.pdf) achieved 50.67% accuracy with all the data, namely, 750 training images per class (**note:** this metric was across 101 classes, not 10, we'll get to 101 classes soon).
If we check out a summary of our model, we should see the data augmentation layer just after the input layer.
```
# Check out model summary
model_1.summary()
```
There it is. We've now got data augmentation built right into the our model. This means if we saved it and reloaded it somewhere else, the data augmentation layers would come with it.
The important thing to remember is **data augmentation only runs during training**. So if we were to evaluate or use our model for inference (predicting the class of an image) the data augmentation layers will be automatically turned off.
To see this in action, let's evaluate our model on the test data.
```
# Evaluate on the test data
results_1_percent_data_aug = model_1.evaluate(test_data)
results_1_percent_data_aug
```
The results here may be slightly better/worse than the log outputs of our model during training because during training we only evaluate our model on 25% of the test data using the line `validation_steps=int(0.25 * len(test_data))`. Doing this speeds up our epochs but still gives us enough of an idea of how our model is going.
Let's stay consistent and check out our model's loss curves.
```
# How does the model go with a data augmentation layer with 1% of data
plot_loss_curves(history_1_percent)
```
It looks like the metrics on both datasets would improve if we kept training for more epochs. But we'll leave that for now, we've got more experiments to do!
## Model 2: Feature extraction transfer learning with 10% of data and data augmentation
Alright, we've tested 1% of the training data with data augmentation, how about we try 10% of the data with data augmentation?
But wait...
> 🤔 **Question:** How do you know what experiments to run?
Great question.
The truth here is you often won't. Machine learning is still a very experimental practice. It's only after trying a fair few things that you'll start to develop an intuition of what to try.
My advice is to follow your curiosity as tenaciously as possible. If you feel like you want to try something, write the code for it and run it. See how it goes. The worst thing that'll happen is you'll figure out what doesn't work, the most valuable kind of knowledge.
From a practical standpoint, as we've talked about before, you'll want to reduce the amount of time between your initial experiments as much as possible. In other words, run a plethora of smaller experiments, using less data and less training iterations before you find something promising and then scale it up.
In the theme of scale, let's scale our 1% training data augmentation experiment up to 10% training data augmentation. That sentence doesn't really make sense but you get what I mean.
We're going to run through the exact same steps as the previous model, the only difference being using 10% of the training data instead of 1%.
```
# Get 10% of the data of the 10 classes (uncomment if you haven't gotten "10_food_classes_10_percent.zip" already)
# !wget https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_10_percent.zip
# unzip_data("10_food_classes_10_percent.zip")
train_dir_10_percent = "10_food_classes_10_percent/train/"
test_dir = "10_food_classes_10_percent/test/"
```
Data downloaded. Let's create the dataloaders.
```
# Setup data inputs
import tensorflow as tf
IMG_SIZE = (224, 224)
train_data_10_percent = tf.keras.preprocessing.image_dataset_from_directory(train_dir_10_percent,
label_mode="categorical",
image_size=IMG_SIZE)
# Note: the test data is the same as the previous experiment, we could
# skip creating this, but we'll leave this here to practice.
test_data = tf.keras.preprocessing.image_dataset_from_directory(test_dir,
label_mode="categorical",
image_size=IMG_SIZE)
```
Awesome! We've got 10x more images to work with, 75 per class instead of 7 per class.
Let's build a model with data augmentation built in. We could reuse the data augmentation Sequential model we created before but we'll recreate it to practice.
```
# Create a functional model with data augmentation
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
from tensorflow.keras.models import Sequential
# Build data augmentation layer
data_augmentation = Sequential([
preprocessing.RandomFlip('horizontal'),
preprocessing.RandomHeight(0.2),
preprocessing.RandomWidth(0.2),
preprocessing.RandomZoom(0.2),
preprocessing.RandomRotation(0.2),
# preprocessing.Rescaling(1./255) # keep for ResNet50V2, remove for EfficientNet
], name="data_augmentation")
# Setup the input shape to our model
input_shape = (224, 224, 3)
# Create a frozen base model
base_model = tf.keras.applications.EfficientNetB0(include_top=False)
base_model.trainable = False
# Create input and output layers
inputs = layers.Input(shape=input_shape, name="input_layer") # create input layer
x = data_augmentation(inputs) # augment our training images
x = base_model(x, training=False) # pass augmented images to base model but keep it in inference mode, so batchnorm layers don't get updated: https://keras.io/guides/transfer_learning/#build-a-model
x = layers.GlobalAveragePooling2D(name="global_average_pooling_layer")(x)
outputs = layers.Dense(10, activation="softmax", name="output_layer")(x)
model_2 = tf.keras.Model(inputs, outputs)
# Compile
model_2.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(lr=0.001), # use Adam optimizer with base learning rate
metrics=["accuracy"])
```
### Creating a ModelCheckpoint callback
Our model is compiled and ready to be fit, so why haven't we fit it yet?
Well, for this experiment we're going to introduce a new callback, the `ModelCheckpoint` callback.
The [`ModelCheckpoint`](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ModelCheckpoint) callback gives you the ability to save your model, as a whole in the [`SavedModel`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) format or the [weights (patterns) only](https://www.tensorflow.org/tutorials/keras/save_and_load#manually_save_weights) to a specified directory as it trains.
This is helpful if you think your model is going to be training for a long time and you want to make backups of it as it trains. It also means if you think your model could benefit from being trained for longer, you can reload it from a specific checkpoint and continue training from there.
For example, say you fit a feature extraction transfer learning model for 5 epochs and you check the training curves and see it was still improving and you want to see if fine-tuning for another 5 epochs could help, you can load the checkpoint, unfreeze some (or all) of the base model layers and then continue training.
In fact, that's exactly what we're going to do.
But first, let's create a `ModelCheckpoint` callback. To do so, we have to specifcy a directory we'd like to save to.
```
# Setup checkpoint path
checkpoint_path = "ten_percent_model_checkpoints_weights/checkpoint.ckpt" # note: remember saving directly to Colab is temporary
# Create a ModelCheckpoint callback that saves the model's weights only
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True, # set to False to save the entire model
save_best_only=False, # set to True to save only the best model instead of a model every epoch
save_freq="epoch", # save every epoch
verbose=1)
```
> 🤔 **Question:** What's the difference between saving the entire model (SavedModel format) and saving the weights only?
The [`SavedModel`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) format saves a model's architecture, weights and training configuration all in one folder. It makes it very easy to reload your model exactly how it is elsewhere. However, if you do not want to share all of these details with others, you may want to save and share the weights only (these will just be large tensors of non-human interpretable numbers). If disk space is an issue, saving the weights only is faster and takes up less space than saving the whole model.
Time to fit the model.
Because we're going to be fine-tuning it later, we'll create a variable `initial_epochs` and set it to 5 to use later.
We'll also add in our `checkpoint_callback` in our list of `callbacks`.
```
# Fit the model saving checkpoints every epoch
initial_epochs = 5
history_10_percent_data_aug = model_2.fit(train_data_10_percent,
epochs=initial_epochs,
validation_data=test_data,
validation_steps=int(0.25 * len(test_data)), # do less steps per validation (quicker)
callbacks=[create_tensorboard_callback("transfer_learning", "10_percent_data_aug"),
checkpoint_callback])
```
Would you look at that! Looks like our `ModelCheckpoint` callback worked and our model saved its weights every epoch without too much overhead (saving the whole model takes longer than just the weights).
Let's evaluate our model and check its loss curves.
```
# Evaluate on the test data
results_10_percent_data_aug = model_2.evaluate(test_data)
results_10_percent_data_aug
# Plot model loss curves
plot_loss_curves(history_10_percent_data_aug)
```
Looking at these, our model's performance with 10% of the data and data augmentation isn't as good as the model with 10% of the data without data augmentation (see `model_0` results above), however the curves are trending in the right direction, meaning if we decided to train for longer, its metrics would likely improve.
Since we checkpointed (is that a word?) our model's weights, we might as well see what it's like to load it back in. We'll be able to test if it saved correctly by evaluting it on the test data.
To load saved model weights you can use the the [`load_weights()`](https://www.tensorflow.org/tutorials/keras/save_and_load#checkpoint_callback_options) method, passing it the path where your saved weights are stored.
```
# Load in saved model weights and evaluate model
model_2.load_weights(checkpoint_path)
loaded_weights_model_results = model_2.evaluate(test_data)
```
Now let's compare the results of our previously trained model and the loaded model. These results should very close if not exactly the same. The reason for minor differences comes down to the precision level of numbers calculated.
```
# If the results from our native model and the loaded weights are the same, this should output True
results_10_percent_data_aug == loaded_weights_model_results
```
If the above cell doesn't output `True`, it's because the numbers are close but not the *exact* same (due to how computers store numbers with degrees of precision).
However, they should be *very* close...
```
import numpy as np
# Check to see if loaded model results are very close to native model results (should output True)
np.isclose(np.array(results_10_percent_data_aug), np.array(loaded_weights_model_results))
# Check the difference between the two results
print(np.array(results_10_percent_data_aug) - np.array(loaded_weights_model_results))
```
## Model 3: Fine-tuning an existing model on 10% of the data
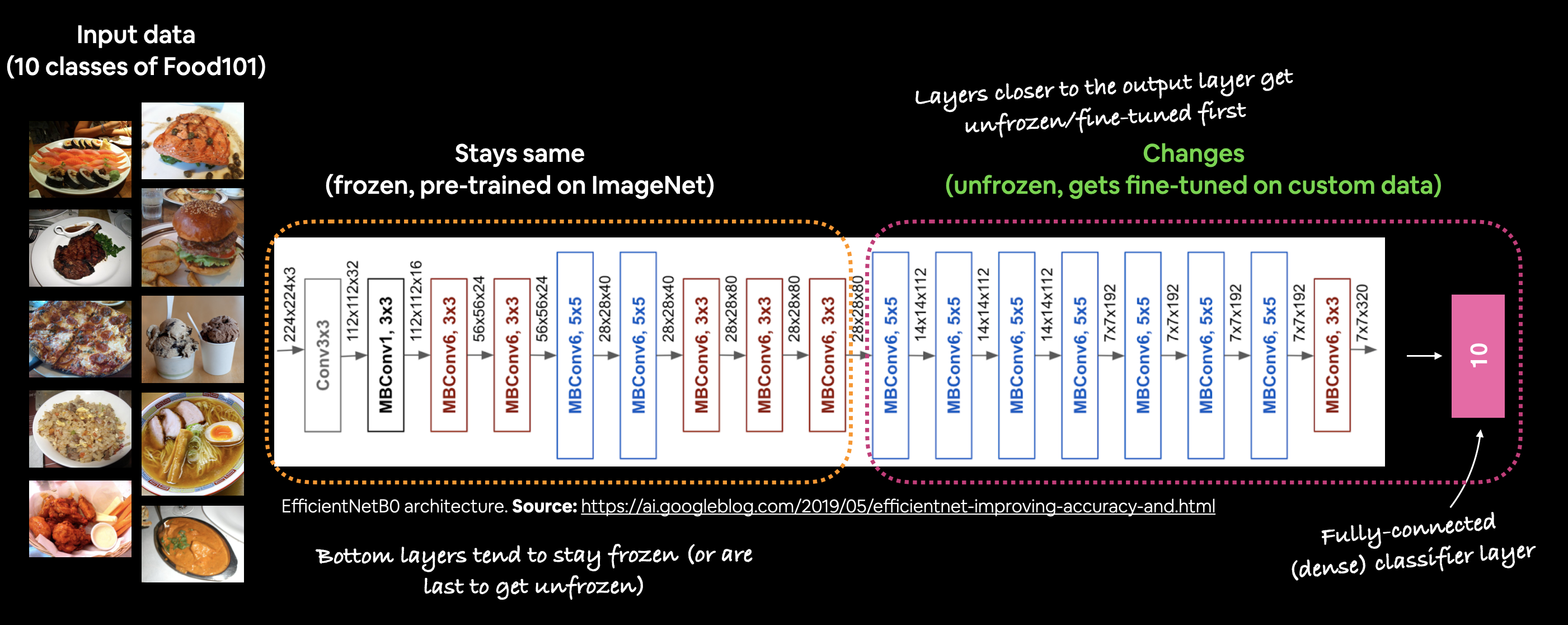
*High-level example of fine-tuning an EfficientNet model. Bottom layers (layers closer to the input data) stay frozen where as top layers (layers closer to the output data) are updated during training.*
So far our saved model has been trained using feature extraction transfer learning for 5 epochs on 10% of the training data and data augmentation.
This means all of the layers in the base model (EfficientNetB0) were frozen during training.
For our next experiment we're going to switch to fine-tuning transfer learning. This means we'll be using the same base model except we'll be unfreezing some of its layers (ones closest to the top) and running the model for a few more epochs.
The idea with fine-tuning is to start customizing the pre-trained model more to our own data.
> 🔑 **Note:** Fine-tuning usually works best *after* training a feature extraction model for a few epochs and with large amounts of data. For more on this, check out [Keras' guide on Transfer learning & fine-tuning](https://keras.io/guides/transfer_learning/).
We've verified our loaded model's performance, let's check out its layers.
```
# Layers in loaded model
model_2.layers
for layer in model_2.layers:
print(layer.trainable)
```
Looking good. We've got an input layer, a Sequential layer (the data augmentation model), a Functional layer (EfficientNetB0), a pooling layer and a Dense layer (the output layer).
How about a summary?
```
model_2.summary()
```
Alright, it looks like all of the layers in the `efficientnetb0` layer are frozen. We can confirm this using the `trainable_variables` attribute.
```
# How many layers are trainable in our base model?
print(len(model_2.layers[2].trainable_variables)) # layer at index 2 is the EfficientNetB0 layer (the base model)
```
This is the same as our base model.
```
print(len(base_model.trainable_variables))
```
We can even check layer by layer to see if the they're trainable.
```
# Check which layers are tuneable (trainable)
for layer_number, layer in enumerate(base_model.layers):
print(layer_number, layer.name, layer.trainable)
```
Beautiful. This is exactly what we're after.
Now to fine-tune the base model to our own data, we're going to unfreeze the top 10 layers and continue training our model for another 5 epochs.
This means all of the base model's layers except for the last 10 will remain frozen and untrainable. And the weights in the remaining unfrozen layers will be updated during training.
Ideally, we should see the model's performance improve.
> 🤔 **Question:** How many layers should you unfreeze when training?
There's no set rule for this. You could unfreeze every layer in the pretrained model or you could try unfreezing one layer at a time. Best to experiment with different amounts of unfreezing and fine-tuning to see what happens. Generally, the less data you have, the less layers you want to unfreeze and the more gradually you want to fine-tune.
> 📖 **Resource:** The [ULMFiT (Universal Language Model Fine-tuning for Text Classification) paper](https://arxiv.org/abs/1801.06146) has a great series of experiments on fine-tuning models.
To begin fine-tuning, we'll unfreeze the entire base model by setting its `trainable` attribute to `True`. Then we'll refreeze every layer in the base model except for the last 10 by looping through them and setting their `trainable` attribute to `False`. Finally, we'll recompile the model.
```
base_model.trainable = True
# Freeze all layers except for the
for layer in base_model.layers[:-10]:
layer.trainable = False
# Recompile the model (always recompile after any adjustments to a model)
model_2.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(lr=0.0001), # lr is 10x lower than before for fine-tuning
metrics=["accuracy"])
```
Wonderful, now let's check which layers of the pretrained model are trainable.
```
# Check which layers are tuneable (trainable)
for layer_number, layer in enumerate(base_model.layers):
print(layer_number, layer.name, layer.trainable)
```
Nice! It seems all layers except for the last 10 are frozen and untrainable. This means only the last 10 layers of the base model along with the output layer will have their weights updated during training.
> 🤔 **Question:** Why did we recompile the model?
Every time you make a change to your models, you need to recompile them.
In our case, we're using the exact same loss, optimizer and metrics as before, except this time the learning rate for our optimizer will be 10x smaller than before (0.0001 instead of Adam's default of 0.001).
We do this so the model doesn't try to overwrite the existing weights in the pretrained model too fast. In other words, we want learning to be more gradual.
> 🔑 **Note:** There's no set standard for setting the learning rate during fine-tuning, though reductions of [2.6x-10x+ seem to work well in practice](https://arxiv.org/abs/1801.06146).
How many trainable variables do we have now?
```
print(len(model_2.trainable_variables))
```
Wonderful, it looks like our model has a total of 10 trainable variables, the last 10 layers of the base model and the weight and bias parameters of the Dense output layer.
Time to fine-tune!
We're going to continue training on from where our previous model finished. Since it trained for 5 epochs, our fine-tuning will begin on the epoch 5 and continue for another 5 epochs.
To do this, we can use the `initial_epoch` parameter of the [`fit()`](https://keras.rstudio.com/reference/fit.html) method. We'll pass it the last epoch of the previous model's training history (`history_10_percent_data_aug.epoch[-1]`).
```
# Fine tune for another 5 epochs
fine_tune_epochs = initial_epochs + 5
# Refit the model (same as model_2 except with more trainable layers)
history_fine_10_percent_data_aug = model_2.fit(train_data_10_percent,
epochs=fine_tune_epochs,
validation_data=test_data,
initial_epoch=history_10_percent_data_aug.epoch[-1], # start from previous last epoch
validation_steps=int(0.25 * len(test_data)),
callbacks=[create_tensorboard_callback("transfer_learning", "10_percent_fine_tune_last_10")]) # name experiment appropriately
```
> 🔑 **Note:** Fine-tuning usually takes far longer per epoch than feature extraction (due to updating more weights throughout a network).
Ho ho, looks like our model has gained a few percentage points of accuracy! Let's evalaute it.
```
# Evaluate the model on the test data
results_fine_tune_10_percent = model_2.evaluate(test_data)
```
Remember, the results from evaluating the model might be slightly different to the outputs from training since during training we only evaluate on 25% of the test data.
Alright, we need a way to evaluate our model's performance before and after fine-tuning. How about we write a function to compare the before and after?
```
def compare_historys(original_history, new_history, initial_epochs=5):
"""
Compares two model history objects.
"""
# Get original history measurements
acc = original_history.history["accuracy"]
loss = original_history.history["loss"]
print(len(acc))
val_acc = original_history.history["val_accuracy"]
val_loss = original_history.history["val_loss"]
# Combine original history with new history
total_acc = acc + new_history.history["accuracy"]
total_loss = loss + new_history.history["loss"]
total_val_acc = val_acc + new_history.history["val_accuracy"]
total_val_loss = val_loss + new_history.history["val_loss"]
print(len(total_acc))
print(total_acc)
# Make plots
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(total_acc, label='Training Accuracy')
plt.plot(total_val_acc, label='Validation Accuracy')
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning') # reshift plot around epochs
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(total_loss, label='Training Loss')
plt.plot(total_val_loss, label='Validation Loss')
plt.plot([initial_epochs-1, initial_epochs-1],
plt.ylim(), label='Start Fine Tuning') # reshift plot around epochs
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
```
This is where saving the history variables of our model training comes in handy. Let's see what happened after fine-tuning the last 10 layers of our model.
```
compare_historys(original_history=history_10_percent_data_aug,
new_history=history_fine_10_percent_data_aug,
initial_epochs=5)
```
Alright, alright, seems like the curves are heading in the right direction after fine-tuning. But remember, it should be noted that fine-tuning usually works best with larger amounts of data.
## Model 4: Fine-tuning an existing model all of the data
Enough talk about how fine-tuning a model usually works with more data, let's try it out.
We'll start by downloading the full version of our 10 food classes dataset.
```
# Download and unzip 10 classes of data with all images
!wget https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_all_data.zip
unzip_data("10_food_classes_all_data.zip")
# Setup data directories
train_dir = "10_food_classes_all_data/train/"
test_dir = "10_food_classes_all_data/test/"
# How many images are we working with now?
walk_through_dir("10_food_classes_all_data")
```
And now we'll turn the images into tensors datasets.
```
# Setup data inputs
import tensorflow as tf
IMG_SIZE = (224, 224)
train_data_10_classes_full = tf.keras.preprocessing.image_dataset_from_directory(train_dir,
label_mode="categorical",
image_size=IMG_SIZE)
# Note: this is the same test dataset we've been using for the previous modelling experiments
test_data = tf.keras.preprocessing.image_dataset_from_directory(test_dir,
label_mode="categorical",
image_size=IMG_SIZE)
```
Oh this is looking good. We've got 10x more images in of the training classes to work with.
The **test dataset is the same** we've been using for our previous experiments.
As it is now, our `model_2` has been fine-tuned on 10 percent of the data, so to begin fine-tuning on all of the data and keep our experiments consistent, we need to revert it back to the weights we checkpointed after 5 epochs of feature-extraction.
To demonstrate this, we'll first evaluate the current `model_2`.
```
# Evaluate model (this is the fine-tuned 10 percent of data version)
model_2.evaluate(test_data)
```
These are the same values as `results_fine_tune_10_percent`.
```
results_fine_tune_10_percent
```
Now we'll revert the model back to the saved weights.
```
# Load model from checkpoint, that way we can fine-tune from the same stage the 10 percent data model was fine-tuned from
model_2.load_weights(checkpoint_path) # revert model back to saved weights
```
And the results should be the same as `results_10_percent_data_aug`.
```
# After loading the weights, this should have gone down (no fine-tuning)
model_2.evaluate(test_data)
# Check to see if the above two results are the same (they should be)
results_10_percent_data_aug
```
Alright, the previous steps might seem quite confusing but all we've done is:
1. Trained a feature extraction transfer learning model for 5 epochs on 10% of the data (with all base model layers frozen) and saved the model's weights using `ModelCheckpoint`.
2. Fine-tuned the same model on the same 10% of the data for a further 5 epochs with the top 10 layers of the base model unfrozen.
3. Saved the results and training logs each time.
4. Reloaded the model from 1 to do the same steps as 2 but with all of the data.
The same steps as 2?
Yeah, we're going to fine-tune the last 10 layers of the base model with the full dataset for another 5 epochs but first let's remind ourselves which layers are trainable.
```
# Check which layers are tuneable in the whole model
for layer_number, layer in enumerate(model_2.layers):
print(layer_number, layer.name, layer.trainable)
```
Can we get a little more specific?
```
# Check which layers are tuneable in the base model
for layer_number, layer in enumerate(base_model.layers):
print(layer_number, layer.name, layer.trainable)
```
Looking good! The last 10 layers are trainable (unfrozen).
We've got one more step to do before we can begin fine-tuning.
Do you remember what it is?
I'll give you a hint. We just reloaded the weights to our model and what do we need to do every time we make a change to our models?
Recompile them!
This will be just as before.
```
# Compile
model_2.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(lr=0.0001), # divide learning rate by 10 for fine-tuning
metrics=["accuracy"])
```
Alright, time to fine-tune on all of the data!
```
# Continue to train and fine-tune the model to our data
fine_tune_epochs = initial_epochs + 5
history_fine_10_classes_full = model_2.fit(train_data_10_classes_full,
epochs=fine_tune_epochs,
initial_epoch=history_10_percent_data_aug.epoch[-1],
validation_data=test_data,
validation_steps=int(0.25 * len(test_data)),
callbacks=[create_tensorboard_callback("transfer_learning", "full_10_classes_fine_tune_last_10")])
```
> 🔑 **Note:** Training took longer per epoch, but that makes sense because we're using 10x more training data than before.
Let's evaluate on all of the test data.
```
results_fine_tune_full_data = model_2.evaluate(test_data)
results_fine_tune_full_data
```
Nice! It looks like fine-tuning with all of the data has given our model a boost, how do the training curves look?
```
# How did fine-tuning go with more data?
compare_historys(original_history=history_10_percent_data_aug,
new_history=history_fine_10_classes_full,
initial_epochs=5)
```
Looks like that extra data helped! Those curves are looking great. And if we trained for longer, they might even keep improving.
## Viewing our experiment data on TensorBoard
Right now our experimental results are scattered all throughout our notebook. If we want to share them with someone, they'd be getting a bunch of different graphs and metrics... not a fun time.
But guess what?
Thanks to the TensorBoard callback we made with our helper function `create_tensorflow_callback()`, we've been tracking our modelling experiments the whole time.
How about we upload them to TensorBoard.dev and check them out?
We can do with the `tensorboard dev upload` command and passing it the directory where our experiments have been logged.
> 🔑 **Note:** Remember, whatever you upload to TensorBoard.dev becomes public. If there are training logs you don't want to share, don't upload them.
```
# View tensorboard logs of transfer learning modelling experiments (should be 4 models)
# Upload TensorBoard dev records
!tensorboard dev upload --logdir ./transfer_learning \
--name "Transfer learning experiments" \
--description "A series of different transfer learning experiments with varying amounts of data and fine-tuning" \
--one_shot # exits the uploader when upload has finished
```
Once we've uploaded the results to TensorBoard.dev we get a shareable link we can use to view and compare our experiments and share our results with others if needed.
You can view the original versions of the experiments we ran in this notebook here: https://tensorboard.dev/experiment/2O76kw3PQbKl0lByfg5B4w/
> 🤔 **Question:** Which model performed the best? Why do you think this is? How did fine-tuning go?
To find all of your previous TensorBoard.dev experiments using the command `tensorboard dev list`.
```
# View previous experiments
!tensorboard dev list
```
And if you want to remove a previous experiment (and delete it from public viewing) you can use the command:
```
tensorboard dev delete --experiment_id [INSERT_EXPERIMENT_ID_TO_DELETE]```
```
# Remove previous experiments
# !tensorboard dev delete --experiment_id OUbW0O3pRqqQgAphVBxi8Q
```
## 🛠 Exercises
1. Write a function to visualize an image from any dataset (train or test file) and any class (e.g. "steak", "pizza"... etc), visualize it and make a prediction on it using a trained model.
2. Use feature-extraction to train a transfer learning model on 10% of the Food Vision data for 10 epochs using [`tf.keras.applications.EfficientNetB0`](https://www.tensorflow.org/api_docs/python/tf/keras/applications/EfficientNetB0) as the base model. Use the [`ModelCheckpoint`](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/ModelCheckpoint) callback to save the weights to file.
3. Fine-tune the last 20 layers of the base model you trained in 2 for another 10 epochs. How did it go?
4. Fine-tune the last 30 layers of the base model you trained in 2 for another 10 epochs. How did it go?
## 📖 Extra-curriculum
* Read the [documentation on data augmentation](https://www.tensorflow.org/tutorials/images/data_augmentation) in TensorFlow.
* Read the [ULMFit paper](https://arxiv.org/abs/1801.06146) (technical) for an introduction to the concept of freezing and unfreezing different layers.
* Read up on learning rate scheduling (there's a [TensorFlow callback](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/LearningRateScheduler) for this), how could this influence our model training?
* If you're training for longer, you probably want to reduce the learning rate as you go... the closer you get to the bottom of the hill, the smaller steps you want to take. Imagine it like finding a coin at the bottom of your couch. In the beginning your arm movements are going to be large and the closer you get, the smaller your movements become.
|
github_jupyter
|
```
# This notebook demonstrates using bankroll to load positions across brokers
# and highlights some basic portfolio rebalancing opportunities based on a set of desired allocations.
#
# The default portfolio allocation is described (with comments) in notebooks/Rebalance.example.ini.
# Copy this to Rebalance.ini in the top level folder, then edit accordingly, to provide your own
# desired allocation.
%cd ..
import pandas as pd
from bankroll.interface import *
from configparser import ConfigParser
from decimal import Decimal
from functools import reduce
from ib_insync import IB, util
from itertools import *
from math import *
import logging
import operator
import re
util.startLoop()
accounts = AccountAggregator.fromSettings(AccountAggregator.allSettings(loadConfig()), lenient=False)
stockPositions = [p for p in accounts.positions() if isinstance(p.instrument, Stock)]
stockPositions.sort(key=lambda p: p.instrument)
values = liveValuesForPositions(stockPositions, marketDataProvider(accounts))
config = ConfigParser(interpolation=None)
try:
config.read_file(open('Rebalance.ini'))
except OSError:
config.read_file(open('notebooks/Rebalance.example.ini'))
def parsePercentage(str):
match = re.match(r'([0-9\.]+)%', str)
if match:
return float(match[1]) / 100
else:
return float(str)
settings = config['Settings']
ignoredSecurities = {s.strip() for s in settings['ignored securities'].split(',')}
maximumDeviation = parsePercentage(settings['maximum deviation'])
baseCurrency = Currency[settings['base currency']]
categoryAllocations = {category: parsePercentage(allocation) for category, allocation in config['Portfolio'].items()}
totalAllocation = sum(categoryAllocations.values())
assert abs(totalAllocation - 1) < 0.0001, f'Category allocations do not total 100%, got {totalAllocation:.2%}'
securityAllocations = {}
for category, categoryAllocation in categoryAllocations.items():
securities = {security.upper(): parsePercentage(allocation) for security, allocation in config[category].items()}
totalAllocation = sum(securities.values())
assert abs(totalAllocation - 1) < 0.0001, f'Allocations in category {category} do not total 100%, got {totalAllocation:.2%}'
securityAllocations.update({security: allocation * categoryAllocation for security, allocation in securities.items()})
cashBalance = accounts.balance()
portfolioBalance = reduce(operator.add, (value for p, value in values.items() if p.instrument.symbol not in ignoredSecurities), cashBalance)
portfolioValue = convertCashToCurrency(baseCurrency, portfolioBalance.cash.values(), marketDataProvider(accounts))
def color_deviations(val):
color = 'black'
if abs(val) > maximumDeviation:
if val > 0:
color = 'green'
else:
color = 'red'
return f'color: {color}'
def positionPctOfPortfolio(position) -> float:
if position not in values:
return nan
value = values[position]
if value.currency != baseCurrency:
# TODO: Cache this somehow?
value = convertCashToCurrency(baseCurrency, [value], marketDataProvider(accounts))
return float(value.quantity) / float(portfolioValue.quantity)
rows = {p.instrument.symbol: [
p.quantity,
values.get(p, nan),
positionPctOfPortfolio(p),
Decimal(securityAllocations.get(p.instrument.symbol)) * portfolioValue if securityAllocations.get(p.instrument.symbol) else None,
securityAllocations.get(p.instrument.symbol),
positionPctOfPortfolio(p) - securityAllocations.get(p.instrument.symbol, 0),
] for p in stockPositions if p.instrument.symbol not in ignoredSecurities}
missing = {symbol: [
nan,
nan,
nan,
allocation,
nan,
] for symbol, allocation in securityAllocations.items() if symbol not in rows}
df = pd.DataFrame.from_dict(data=dict(chain(rows.items(), missing.items())), orient='index', columns=[
'Quantity',
'Market value',
'% of portfolio',
'Desired value',
'Desired %',
'Deviation'
]).sort_index()
df.style.format({
'Quantity': '{:.2f}',
'% of portfolio': '{:.2%}',
'Desired %': '{:.2%}',
'Deviation': '{:.2%}'
}).applymap(color_deviations, 'Deviation').highlight_null()
print(cashBalance)
print()
print('Total portfolio value:', portfolioValue)
```
|
github_jupyter
|
# 1. Event approach
## Reading the full stats file
```
import numpy
import pandas
full_stats_file = '/Users/irv033/Downloads/data/stats_example.csv'
df = pandas.read_csv(full_stats_file)
def date_only(x):
"""Chop a datetime64 down to date only"""
x = numpy.datetime64(x)
return numpy.datetime64(numpy.datetime_as_string(x, timezone='local')[:10])
#df.time = df.time.apply(lambda x: numpy.datetime64(x))
df.time = df.time.apply(date_only)
#print pandas.to_datetime(df['time'].values)
#df_times = df.time.apply(lambda x: x.date())
df = df.set_index('time')
```
## Read xarray data frame
```
import xray
data_file = '/Users/irv033/Downloads/data/va_ERAInterim_500hPa_2006-030day-runmean_native.nc'
dset_in = xray.open_dataset(data_file)
print dset_in
darray = dset_in['va']
print darray
times = darray.time.values
date_only(times[5])
darray_times = map(date_only, list(times))
print darray_times[0:5]
```
## Merge
### Re-index the event data
```
event_numbers = df['event_number']
event_numbers = event_numbers.reindex(darray_times)
```
### Broadcast the shape
```
print darray
print darray.shape
print type(darray)
print type(event_numbers.values)
type(darray.data)
event_data = numpy.zeros((365, 241, 480))
for i in range(0,365):
event_data[i,:,:] = event_numbers.values[i]
```
### Cobmine
```
d = {}
d['time'] = darray['time']
d['latitude'] = darray['latitude']
d['longitude'] = darray['longitude']
d['va'] = (['time', 'latitude', 'longitude'], darray.data)
d['event'] = (['time'], event_numbers.values)
ds = xray.Dataset(d)
print ds
```
## Get event averages
```
event_averages = ds.groupby('event').mean('time')
print event_averages
```
# 2. Standard autocorrelation approach
### Read data
```
tas_file = '/Users/irv033/Downloads/data/tas_ERAInterim_surface_030day-runmean-anom-wrt-all-2005-2006_native.nc'
tas_dset = xray.open_dataset(tas_file)
tas_darray = tas_dset['tas']
print tas_darray
tas_data = tas_darray[dict(longitude=130, latitude=-40)].values
print tas_data.shape
```
### Plot autocorrelation with Pandas
```
%matplotlib inline
from pandas.tools.plotting import autocorrelation_plot
pandas_test_data = pandas.Series(tas_data)
autocorrelation_plot(pandas_test_data)
```
### Calculate autocorrelation with statsmodels
```
import statsmodels
from statsmodels.tsa.stattools import acf
n = len(tas_data)
statsmodels_test_data = acf(tas_data, nlags=n-2)
import matplotlib.pyplot as plt
k = numpy.arange(1, n - 1)
plt.plot(k, statsmodels_test_data[1:])
plt.plot(k[0:40], statsmodels_test_data[1:41])
# Formula from Zieba2010, equation 12
r_k_sum = ((n - k) / float(n)) * statsmodels_test_data[1:]
n_eff = float(n) / (1 + 2 * numpy.sum(r_k_sum))
print n_eff
print numpy.sum(r_k_sum)
```
So an initial sample size of 730 has an effective sample size of 90.
### Get the p value
```
from scipy import stats
var_x = tas_data.var() / n_eff
tval = tas_data.mean() / numpy.sqrt(var_x)
pval = stats.t.sf(numpy.abs(tval), n - 1) * 2 # two-sided pvalue = Prob(abs(t)>tt)
print 't-statistic = %6.3f pvalue = %6.4f' % (tval, pval)
```
## Implementation
```
def calc_significance(data_subset, data_all, standard_name):
"""Perform significance test.
Once sample t-test, with sample size adjusted for autocorrelation.
Reference:
Zięba, A. (2010). Metrology and Measurement Systems, XVII(1), 3–16
doi:10.2478/v10178-010-0001-0
"""
# Data must be three dimensional, with time first
assert len(data_subset.shape) == 3, "Input data must be 3 dimensional"
# Define autocorrelation function
n = data_subset.shape[0]
autocorr_func = numpy.apply_along_axis(acf, 0, data_subset, nlags=n - 2)
# Calculate effective sample size (formula from Zieba2010, eq 12)
k = numpy.arange(1, n - 1)
r_k_sum = ((n - k[:, None, None]) / float(n)) * autocorr_func[1:]
n_eff = float(n) / (1 + 2 * numpy.sum(r_k_sum))
# Calculate significance
var_x = data_subset.var(axis=0) / n_eff
tvals = (data_subset.mean(axis=0) - data_all.mean(axis=0)) / numpy.sqrt(var_x)
pvals = stats.t.sf(numpy.abs(tvals), n - 1) * 2 # two-sided pvalue = Prob(abs(t)>tt)
notes = "One sample t-test, with sample size adjusted for autocorrelation (Zieba2010, eq 12)"
pval_atts = {'standard_name': standard_name,
'long_name': standard_name,
'units': ' ',
'notes': notes,}
return pvals, pval_atts
min_lon, max_lon = (130, 135)
min_lat, max_lat = (-40, -37)
subset_dict = {'time': slice('2005-03-01', '2005-05-31'),
'latitude': slice(min_lat, max_lat),
'longitude': slice(min_lon, max_lon)}
all_dict = {'latitude': slice(min_lat, max_lat),
'longitude': slice(min_lon, max_lon)}
subset_data = tas_darray.sel(**subset_dict).values
all_data = tas_darray.sel(**all_dict).values
print all_data.shape
print subset_data.shape
p, atts = calc_significance(subset_data, all_data, 'p_mam')
p.shape
print atts
```
|
github_jupyter
|
# The effect of steel casing in AEM data
Figures 4, 5, 6 in Kang et al. (2020) are generated using this
```
# core python packages
import numpy as np
import scipy.sparse as sp
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
from scipy.constants import mu_0, inch, foot
import ipywidgets
import properties
import time
from scipy.interpolate import interp1d
from simpegEM1D.Waveforms import piecewise_pulse_fast
# SimPEG and discretize
import discretize
from discretize import utils
from SimPEG.EM import TDEM
from SimPEG import Utils, Maps
from SimPEG.Utils import Zero
from pymatsolver import Pardiso
# casing utilities
import casingSimulations as casingSim
%matplotlib inline
```
## Model Parameters
We will two classes of examples
- permeable wells, one example is run for each $\mu_r$ in `casing_mur`. The conductivity of this well is `sigma_permeable_casing`
- conductive wells ($\mu_r$=1), one example is run for each $\sigma$ value in `sigma_casing`
To add model runs to the simulation, just add to the list
```
# permeabilities to model
casing_mur = [100]
sigma_permeable_casing = 1.45*1e6
1./1.45*1e6
# background parameters
sigma_air = 1e-6
sigma_back = 1./340.
casing_t = 10e-3 # 10mm thick casing
casing_d = 300e-3 # 30cm diameter
casing_l = 200
def get_model(mur, sigc):
model = casingSim.model.CasingInHalfspace(
directory = simDir,
sigma_air = sigma_air,
sigma_casing = sigc, # conductivity of the casing (S/m)
sigma_back = sigma_back, # conductivity of the background (S/m)
sigma_inside = sigma_back, # fluid inside the well has same conductivity as the background
casing_d = casing_d-casing_t, # 135mm is outer casing diameter
casing_l = casing_l,
casing_t = casing_t,
mur_casing = mur,
src_a = np.r_[0., 0., 30.],
src_b = np.r_[0., 0., 30.]
)
return model
```
## store the different models
```
simDir = "./"
model_names_permeable = ["casing_{}".format(mur) for mur in casing_mur]
model_dict_permeable = {
key: get_model(mur, sigma_permeable_casing) for key, mur in zip(model_names_permeable, casing_mur)
}
model_names = model_names_permeable
model_dict = {}
model_dict.update(model_dict_permeable)
model_dict["baseline"] = model_dict[model_names[0]].copy()
model_dict["baseline"].sigma_casing = model_dict["baseline"].sigma_back
model_names = ["baseline"] + model_names
model_names
```
## Create a mesh
```
# parameters defining the core region of the mesh
csx2 = 2.5 # cell size in the x-direction in the second uniform region of the mesh (where we measure data)
csz = 2.5 # cell size in the z-direction
domainx2 = 100 # go out 500m from the well
# padding parameters
npadx, npadz = 19, 17 # number of padding cells
pfx2 = 1.4 # expansion factor for the padding to infinity in the x-direction
pfz = 1.4
# set up a mesh generator which will build a mesh based on the provided parameters
# and casing geometry
def get_mesh(mod):
return casingSim.CasingMeshGenerator(
directory=simDir, # directory where we can save things
modelParameters=mod, # casing parameters
npadx=npadx, # number of padding cells in the x-direction
npadz=npadz, # number of padding cells in the z-direction
domain_x=domainx2, # extent of the second uniform region of the mesh
# hy=hy, # cell spacings in the
csx1=mod.casing_t/4., # use at least 4 cells per across the thickness of the casing
csx2=csx2, # second core cell size
csz=csz, # cell size in the z-direction
pfx2=pfx2, # padding factor to "infinity"
pfz=pfz # padding factor to "infinity" for the z-direction
)
mesh_generator = get_mesh(model_dict[model_names[0]])
mesh_generator.mesh.hx.sum()
mesh_generator.mesh.hx.min() * 1e3
mesh_generator.mesh.hz.sum()
# diffusion_distance(1e-2, 1./340.) * 2
```
## Physical Properties
```
# Assign physical properties on the mesh
physprops = {
name: casingSim.model.PhysicalProperties(mesh_generator, mod)
for name, mod in model_dict.items()
}
from matplotlib.colors import LogNorm
import matplotlib
matplotlib.rcParams['font.size'] = 14
pp = physprops['casing_100']
sigma = pp.sigma
fig, ax = plt.subplots()
out = mesh_generator.mesh.plotImage(
1./sigma, grid=True,
gridOpts={'alpha':0.2, 'color':'w'},
pcolorOpts={'norm':LogNorm(), 'cmap':'jet'},
mirror=True, ax=ax
)
cb= plt.colorbar(out[0], ax=ax)
cb.set_label("Resistivity ($\Omega$m)")
ax.set_xlabel("x (m)")
ax.set_ylabel("z (m)")
ax.set_xlim(-0.3, 0.3)
ax.set_ylim(-30, 30)
ax.set_aspect(0.008)
plt.tight_layout()
fig.savefig("./figures/figure-4", dpi=200)
from simpegEM1D import diffusion_distance
mesh_generator.mesh.plotGrid()
```
## Set up the time domain EM problem
We run a time domain EM simulation with SkyTEM geometry
```
data_dir = "./data/"
waveform_hm = np.loadtxt(data_dir+"HM_butte_312.txt")
time_gates_hm = np.loadtxt(data_dir+"HM_butte_312_gates")[7:,:] * 1e-6
waveform_lm = np.loadtxt(data_dir+"LM_butte_312.txt")
time_gates_lm = np.loadtxt(data_dir+"LM_butte_312_gates")[8:,:] * 1e-6
time_input_currents_HM = waveform_hm[:,0]
input_currents_HM = waveform_hm[:,1]
time_input_currents_LM = waveform_lm[:,0]
input_currents_LM = waveform_lm[:,1]
time_LM = time_gates_lm[:,3] - waveform_lm[:,0].max()
time_HM = time_gates_hm[:,3] - waveform_hm[:,0].max()
base_frequency_HM = 30.
base_frequency_LM = 210.
radius = 13.25
source_area = np.pi * radius**2
pico = 1e12
def run_simulation(sigma, mu, z_src):
mesh = mesh_generator.mesh
dts = np.diff(np.logspace(-6, -1, 50))
timeSteps = []
for dt in dts:
timeSteps.append((dt, 1))
prb = TDEM.Problem3D_e(
mesh=mesh, timeSteps=timeSteps,
Solver=Pardiso
)
x_rx = 0.
z_offset = 0.
rxloc = np.array([x_rx, 0., z_src+z_offset])
srcloc = np.array([0., 0., z_src])
times = np.logspace(np.log10(1e-5), np.log10(1e-2), 31)
rx = TDEM.Rx.Point_dbdt(locs=np.array([x_rx, 0., z_src+z_offset]), times=times, orientation="z")
src = TDEM.Src.CircularLoop(
[rx],
loc=np.r_[0., 0., z_src], orientation="z", radius=13.25
)
area = np.pi * src.radius**2
def bdf2(sigma):
# Operators
C = mesh.edgeCurl
Mfmui = mesh.getFaceInnerProduct(1./mu_0)
MeSigma = mesh.getEdgeInnerProduct(sigma)
n_steps = prb.timeSteps.size
Fz = mesh.getInterpolationMat(rx.locs, locType='Fz')
eps = 1e-10
def getA(dt, factor=1.):
return C.T*Mfmui*C + factor/dt * MeSigma
dt_0 = 0.
data_test = np.zeros(prb.timeSteps.size)
sol_n0 = np.zeros(mesh.nE)
sol_n1 = np.zeros(mesh.nE)
sol_n2 = np.zeros(mesh.nE)
for ii in range(n_steps):
dt = prb.timeSteps[ii]
#Factor for BDF2
factor=3/2.
if abs(dt_0-dt) > eps:
if ii != 0:
Ainv.clean()
# print (ii, factor)
A = getA(dt, factor=factor)
Ainv = prb.Solver(A)
if ii==0:
b0 = src.bInitial(prb)
s_e = C.T*Mfmui*b0
rhs = factor/dt*s_e
elif ii==1:
rhs = -factor/dt*(MeSigma*(-4/3.*sol_n1+1/3.*sol_n0) + 1./3.*s_e)
else:
rhs = -factor/dt*(MeSigma*(-4/3.*sol_n1+1/3.*sol_n0))
sol_n2 = Ainv*rhs
data_test[ii] = Fz*(-C*sol_n2)
dt_0 = dt
sol_n0 = sol_n1.copy()
sol_n1 = sol_n2.copy()
step_response = -data_test.copy()
step_func = interp1d(
np.log10(prb.times[1:]), step_response
)
period_HM = 1./base_frequency_HM
period_LM = 1./base_frequency_LM
data_hm = piecewise_pulse_fast(
step_func, time_HM,
time_input_currents_HM, input_currents_HM,
period_HM, n_pulse=1
)
data_lm = piecewise_pulse_fast(
step_func, time_LM,
time_input_currents_LM, input_currents_LM,
period_LM, n_pulse=1
)
return np.r_[data_hm, data_lm] / area * pico
return bdf2(sigma)
```
## Run the simulation
- for each permeability model we run the simulation for 2 conductivity models (casing = $10^6$S/m and $10^{-4}$S/m
- each simulation takes 15s-20s on my machine: the next cell takes ~ 4min to run
```
pp = physprops['baseline']
sigma_base = pp.sigma
pp = physprops['casing_100']
sigma = pp.sigma
mu = pp.mu
inds_half_space = sigma_base != sigma_air
inds_air = ~inds_half_space
inds_casing = sigma == sigma_permeable_casing
print (pp.mesh.hx.sum())
print (pp.mesh.hz.sum())
sigma_backgrounds = np.r_[1./1, 1./20, 1./100, 1./200, 1./340]
# start = timeit.timeit()
data_base = {}
data_casing = {}
for sigma_background in sigma_backgrounds:
sigma_base = np.ones(pp.mesh.nC) * sigma_air
sigma_base[inds_half_space] = sigma_background
sigma = np.ones(pp.mesh.nC) * sigma_air
sigma[inds_half_space] = sigma_background
sigma[inds_casing] = sigma_permeable_casing
for height in [20, 30, 40, 60, 80]:
rho = 1/sigma_background
name = str(int(rho)) + str(height)
data_base[name] = run_simulation(sigma_base, mu_0, height)
data_casing[name] = run_simulation(sigma, mu, height)
# end = timeit.timeit()
# print(("Elapsed time is %1.f")%(end - start))
rerr_max = []
for sigma_background in sigma_backgrounds:
rerr_tmp = np.zeros(5)
for ii, height in enumerate([20, 30, 40, 60, 80]):
rho = 1/sigma_background
name = str(int(rho)) + str(height)
data_casing_tmp = data_casing[name]
data_base_tmp = data_base[name]
rerr_hm = abs(data_casing_tmp[:time_HM.size]-data_base_tmp[:time_HM.size]) / abs(data_base_tmp[:time_HM.size])
rerr_lm = abs(data_casing_tmp[time_HM.size:]-data_base_tmp[time_HM.size:]) / abs(data_base_tmp[time_HM.size:])
# rerr_tmp[ii] = np.r_[rerr_hm, rerr_lm].max()
rerr_tmp[ii] = np.sqrt(((np.r_[rerr_hm, rerr_lm])**2).sum() / np.r_[rerr_hm, rerr_lm].size)
rerr_max.append(rerr_tmp)
import matplotlib
matplotlib.rcParams['font.size'] = 14
fig_dir = "./figures/"
times = np.logspace(np.log10(1e-5), np.log10(1e-2), 31)
colors = ['k', 'b', 'g', 'r']
name='2040'
fig, axs = plt.subplots(1,2, figsize=(10, 5))
axs[0].loglog(time_gates_hm[:,3]*1e3, data_base[name][:time_HM.size], 'k--')
axs[0].loglog(time_gates_lm[:,3]*1e3, data_base[name][time_HM.size:], 'b--')
axs[0].loglog(time_gates_hm[:,3]*1e3, data_casing[name][:time_HM.size], 'k-')
axs[0].loglog(time_gates_lm[:,3]*1e3, data_casing[name][time_HM.size:], 'b-')
rerr_hm = abs(data_casing[name][:time_HM.size]-data_base[name][:time_HM.size]) / abs(data_base[name][:time_HM.size])
rerr_lm = abs(data_casing[name][time_HM.size:]-data_base[name][time_HM.size:]) / abs(data_base[name][time_HM.size:])
axs[1].loglog(time_gates_hm[:,3]*1e3, rerr_hm * 100, 'k-')
axs[1].loglog(time_gates_lm[:,3]*1e3, rerr_lm * 100, 'b-')
axs[1].set_ylim(0, 100)
axs[0].legend(('HM-background', 'LM-background', 'HM-casing', 'LM-casing'))
for ax in axs:
ax.set_xlabel("Time (ms)")
ax.grid(True)
axs[0].set_title('(a) AEM response')
axs[1].set_title('(b) Percentage casing effect')
axs[0].set_ylabel("Voltage (pV/A-m$^4$)")
axs[1].set_ylabel("Percentage casing effect (%)")
ax_1 = axs[1].twinx()
xlim = axs[1].get_xlim()
ax_1.loglog(xlim, (3,3), '-', color='grey', alpha=0.8)
axs[1].set_ylim((1e-4, 100))
ax_1.set_ylim((1e-4, 100))
axs[1].set_xlim(xlim)
ax_1.set_xlim(xlim)
ax_1.set_yticks([3])
ax_1.set_yticklabels(["3%"])
plt.tight_layout()
fig.savefig("./figures/figure-5", dpi=200)
fig = plt.figure(figsize = (10,5))
ax = plt.gca()
ax_1 = ax.twinx()
markers = ['k--', 'b--', 'g--', 'r--', 'y--']
for ii, rerr in enumerate(rerr_max[::-1]):
ax.plot([20, 30, 40, 60, 80], rerr*100, markers[ii], ms=10)
ax.set_xlabel("Transmitter height (m)")
ax.set_ylabel("Total percentage casing effect (%)")
ax.legend(("340 $\Omega$m", "200 $\Omega$m", "100 $\Omega$m", "20 $\Omega$m", "1 $\Omega$m",), bbox_to_anchor=(1.4,1))
ax.set_yscale('log')
ax_1.set_yscale('log')
xlim = ax.get_xlim()
ylim = ax.get_ylim()
ax_1.plot(xlim, (3,3), '-', color='grey', alpha=0.8)
ax.set_ylim(ylim)
ax_1.set_ylim(ylim)
ax.set_xlim(xlim)
ax_1.set_yticks([3])
ax_1.set_yticklabels(["3%"])
plt.tight_layout()
fig.savefig("./figures/figure-6", dpi=200)
```
|
github_jupyter
|
```
import numpy as np
import pandas as pd
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from matplotlib import pyplot as plt
%matplotlib inline
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
train_data = np.load("train_blob_data.npy",allow_pickle=True)
test_data = np.load("test_blob_data.npy",allow_pickle=True)
mosaic_list_of_images = train_data[0]["mosaic_list"]
mosaic_label = train_data[0]["mosaic_label"]
fore_idx = train_data[0]["fore_idx"]
test_mosaic_list_of_images = test_data[0]["mosaic_list"]
test_mosaic_label = test_data[0]["mosaic_label"]
test_fore_idx = test_data[0]["fore_idx"]
class MosaicDataset1(Dataset):
"""MosaicDataset dataset."""
def __init__(self, mosaic_list, mosaic_label,fore_idx):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.mosaic = mosaic_list
self.label = mosaic_label
self.fore_idx = fore_idx
def __len__(self):
return len(self.label)
def __getitem__(self, idx):
return self.mosaic[idx] , self.label[idx] , self.fore_idx[idx]
batch = 250
train_dataset = MosaicDataset1(mosaic_list_of_images, mosaic_label, fore_idx)
train_loader = DataLoader( train_dataset,batch_size= batch ,shuffle=False)
test_dataset = MosaicDataset1(test_mosaic_list_of_images, test_mosaic_label, test_fore_idx)
test_loader = DataLoader(test_dataset,batch_size= batch ,shuffle=False)
bg = []
for i in range(12):
torch.manual_seed(i)
betag = torch.randn(250,9)#torch.ones((250,9))/9
bg.append( betag.requires_grad_() )
bg
class Module2(nn.Module):
def __init__(self):
super(Module2, self).__init__()
self.linear1 = nn.Linear(5,100)
self.linear2 = nn.Linear(100,3)
def forward(self,x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
torch.manual_seed(1234)
what_net = Module2().double()
#what_net.load_state_dict(torch.load("type4_what_net.pt"))
what_net = what_net.to("cuda")
def attn_avg(x,beta):
y = torch.zeros([batch,5], dtype=torch.float64)
y = y.to("cuda")
alpha = F.softmax(beta,dim=1) # alphas
#print(alpha[0],x[0,:])
for i in range(9):
alpha1 = alpha[:,i]
y = y + torch.mul(alpha1[:,None],x[:,i])
return y,alpha
def calculate_attn_loss(dataloader,what,criter):
what.eval()
r_loss = 0
alphas = []
lbls = []
pred = []
fidices = []
correct = 0
tot = 0
with torch.no_grad():
for i, data in enumerate(dataloader, 0):
inputs, labels,fidx= data
lbls.append(labels)
fidices.append(fidx)
inputs = inputs.double()
beta = bg[i] # beta for ith batch
inputs, labels,beta = inputs.to("cuda"),labels.to("cuda"),beta.to("cuda")
avg,alpha = attn_avg(inputs,beta)
alpha = alpha.to("cuda")
outputs = what(avg)
_, predicted = torch.max(outputs.data, 1)
correct += sum(predicted == labels)
tot += len(predicted)
pred.append(predicted.cpu().numpy())
alphas.append(alpha.cpu().numpy())
loss = criter(outputs, labels)
r_loss += loss.item()
alphas = np.concatenate(alphas,axis=0)
pred = np.concatenate(pred,axis=0)
lbls = np.concatenate(lbls,axis=0)
fidices = np.concatenate(fidices,axis=0)
#print(alphas.shape,pred.shape,lbls.shape,fidices.shape)
analysis = analyse_data(alphas,lbls,pred,fidices)
return r_loss/i,analysis,correct.item(),tot,correct.item()/tot
# for param in what_net.parameters():
# param.requires_grad = False
def analyse_data(alphas,lbls,predicted,f_idx):
'''
analysis data is created here
'''
batch = len(predicted)
amth,alth,ftpt,ffpt,ftpf,ffpf = 0,0,0,0,0,0
for j in range (batch):
focus = np.argmax(alphas[j])
if(alphas[j][focus] >= 0.5):
amth +=1
else:
alth +=1
if(focus == f_idx[j] and predicted[j] == lbls[j]):
ftpt += 1
elif(focus != f_idx[j] and predicted[j] == lbls[j]):
ffpt +=1
elif(focus == f_idx[j] and predicted[j] != lbls[j]):
ftpf +=1
elif(focus != f_idx[j] and predicted[j] != lbls[j]):
ffpf +=1
#print(sum(predicted==lbls),ftpt+ffpt)
return [ftpt,ffpt,ftpf,ffpf,amth,alth]
optim1 = []
for i in range(12):
optim1.append(optim.RMSprop([bg[i]], lr=0.1))
# instantiate optimizer
optimizer_what = optim.RMSprop(what_net.parameters(), lr=0.001)#, momentum=0.9)#,nesterov=True)
criterion = nn.CrossEntropyLoss()
acti = []
analysis_data_tr = []
analysis_data_tst = []
loss_curi_tr = []
loss_curi_tst = []
epochs = 200
# calculate zeroth epoch loss and FTPT values
running_loss,anlys_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,criterion)
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(0,running_loss,correct,total,accuracy))
loss_curi_tr.append(running_loss)
analysis_data_tr.append(anlys_data)
# training starts
for epoch in range(epochs): # loop over the dataset multiple times
ep_lossi = []
running_loss = 0.0
what_net.train()
for i, data in enumerate(train_loader, 0):
# get the inputs
inputs, labels,_ = data
inputs = inputs.double()
beta = bg[i] # alpha for ith batch
#print(labels)
inputs, labels,beta = inputs.to("cuda"),labels.to("cuda"),beta.to("cuda")
# zero the parameter gradients
optimizer_what.zero_grad()
optim1[i].zero_grad()
# forward + backward + optimize
avg,alpha = attn_avg(inputs,beta)
outputs = what_net(avg)
loss = criterion(outputs, labels)
# print statistics
running_loss += loss.item()
#alpha.retain_grad()
loss.backward(retain_graph=False)
optimizer_what.step()
optim1[i].step()
running_loss_tr,anls_data,correct,total,accuracy = calculate_attn_loss(train_loader,what_net,criterion)
analysis_data_tr.append(anls_data)
loss_curi_tr.append(running_loss_tr) #loss per epoch
print('training epoch: [%d ] loss: %.3f correct: %.3f, total: %.3f, accuracy: %.3f' %(epoch+1,running_loss_tr,correct,total,accuracy))
if running_loss_tr<=0.08:
break
print('Finished Training run ')
analysis_data_tr = np.array(analysis_data_tr)
columns = ["epochs", "argmax > 0.5" ,"argmax < 0.5", "focus_true_pred_true", "focus_false_pred_true", "focus_true_pred_false", "focus_false_pred_false" ]
df_train = pd.DataFrame()
df_test = pd.DataFrame()
df_train[columns[0]] = np.arange(0,epoch+2)
df_train[columns[1]] = analysis_data_tr[:,-2]
df_train[columns[2]] = analysis_data_tr[:,-1]
df_train[columns[3]] = analysis_data_tr[:,0]
df_train[columns[4]] = analysis_data_tr[:,1]
df_train[columns[5]] = analysis_data_tr[:,2]
df_train[columns[6]] = analysis_data_tr[:,3]
df_train
fig= plt.figure(figsize=(6,6))
plt.plot(df_train[columns[0]],df_train[columns[3]]/30, label ="focus_true_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[4]]/30, label ="focus_false_pred_true ")
plt.plot(df_train[columns[0]],df_train[columns[5]]/30, label ="focus_true_pred_false ")
plt.plot(df_train[columns[0]],df_train[columns[6]]/30, label ="focus_false_pred_false ")
plt.title("On Train set")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel("epochs")
plt.ylabel("percentage of data")
plt.xticks([0,5,10,15])
#plt.vlines(vline_list,min(min(df_train[columns[3]]/300),min(df_train[columns[4]]/300),min(df_train[columns[5]]/300),min(df_train[columns[6]]/300)), max(max(df_train[columns[3]]/300),max(df_train[columns[4]]/300),max(df_train[columns[5]]/300),max(df_train[columns[6]]/300)),linestyles='dotted')
plt.show()
fig.savefig("train_analysis.pdf")
fig.savefig("train_analysis.png")
aph = []
for i in bg:
aph.append(F.softmax(i,dim=1).detach().numpy())
aph = np.concatenate(aph,axis=0)
torch.save({
'epoch': 500,
'model_state_dict': what_net.state_dict(),
#'optimizer_state_dict': optimizer_what.state_dict(),
"optimizer_alpha":optim1,
"FTPT_analysis":analysis_data_tr,
"alpha":aph
}, "type4_what_net_500.pt")
aph[0]
```
|
github_jupyter
|
## 2-3. 量子フーリエ変換
この節では、量子アルゴリズムの中でも最も重要なアルゴリズムの一つである量子フーリエ変換について学ぶ。
量子フーリエ変換はその名の通りフーリエ変換を行う量子アルゴリズムであり、様々な量子アルゴリズムのサブルーチンとしても用いられることが多い。
(参照:Nielsen-Chuang 5.1 `The quantum Fourier transform`)
※なお、最後のコラムでも多少述べるが、回路が少し複雑である・入力状態を用意することが難しいといった理由から、いわゆるNISQデバイスでの量子フーリエ変換の実行は難しいと考えられている。
### 定義
まず、$2^n$成分の配列 $\{x_j\}$ に対して$(j=0,\cdots,2^n-1)$、その[離散フーリエ変換](https://ja.wikipedia.org/wiki/離散フーリエ変換)である配列$\{ y_k \}$を
$$
y_k = \frac{1}{\sqrt{2^n}} \sum_{j=0}^{2^n-1} x_j e^{i\frac{2\pi kj}{2^n}} \tag{1}
$$
で定義する$(k=0, \cdots 2^n-1)$。配列 $\{x_j\}$ は$\sum_{j=0}^{2^n-1} |x_j|^2 = 1$ と規格化されているものとする。
量子フーリエ変換アルゴリズムは、入力の量子状態
$$
|x\rangle := \sum_{j=0}^{2^n-1} x_j |j\rangle
$$
を、
$$
|y \rangle := \sum_{k=0}^{2^n-1} y_k |k\rangle \tag{2}
$$
となるように変換する量子アルゴリズムである。ここで、$|i \rangle$は、整数$i$の二進数での表示$i_1 \cdots i_n$ ($i_m = 0,1$)に対応する量子状態$|i_1 \cdots i_n \rangle$の略記である。(例えば、$|2 \rangle = |0\cdots0 10 \rangle, |7 \rangle = |0\cdots0111 \rangle$となる)
ここで、式(1)を(2)に代入してみると、
$$
|y \rangle = \frac{1}{\sqrt{2^n}} \sum_{k=0}^{2^n-1} \sum_{j=0}^{2^n-1} x_j e^{i\frac{2\pi kj}{2^n}} |k\rangle
= \sum_{j=0}^{2^n-1} x_j \left( \frac{1}{\sqrt{2^n}} \sum_{k=0}^{2^n-1} e^{i\frac{2\pi kj}{2^n}} |k\rangle \right)
$$
となる。よって、量子フーリエ変換では、
$$
|j\rangle \to \frac{1}{\sqrt{2^n}} \sum_{k=0}^{2^n-1} e^{i\frac{2\pi kj}{2^n}} |k\rangle
$$
を行う量子回路(変換)$U$を見つければ良いことになる。(余裕のある読者は、これがユニタリ変換であることを実際に計算して確かめてみよう)
この式はさらに式変形できて(やや複雑なので最後の結果だけ見てもよい)
$$
\begin{eqnarray}
\sum_{k=0}^{2^n-1} e^{i\frac{2\pi kj}{2^n}} |k\rangle
&=& \sum_{k_1=0}^1 \cdots \sum_{k_n=0}^1 e^{i\frac{2\pi (k_1 2^{n-1} + \cdots k_n 2^0 )\cdot j}{2^n}} |k_1 \cdots k_n\rangle \:\:\:\: \text{(kの和を2進数表示で書き直した)} \\
&=& \sum_{k_1=0}^1 \cdots \sum_{k_n=0}^1 e^{i 2\pi j (k_1 2^{-1} + \cdots k_n 2^{-n})} |k_1 \cdots k_n\rangle \\
&=& \left( \sum_{k_1=0}^1 e^{i 2\pi j k_1 2^{-1}} |k_1 \rangle \right) \otimes \cdots \otimes \left( \sum_{k_n=0}^1 e^{i 2\pi j k_n 2^{-n}} |k_n \rangle \right) \:\:\:\: \text{("因数分解"をして、全体をテンソル積で書き直した)} \\
&=& \left( |0\rangle + e^{i 2\pi 0.j_n} |1 \rangle \right) \otimes \left( |0\rangle + e^{i 2\pi 0.j_{n-1}j_n} |1 \rangle \right) \otimes \cdots \otimes \left( |0\rangle + e^{i 2\pi 0.j_1j_2\cdots j_n} |1 \rangle \right) \:\:\:\: \text{(カッコの中の和を計算した)}
\end{eqnarray}
$$
となる。ここで、
$$
0.j_l\cdots j_n = \frac{j_l}{2} + \frac{j_{l-1}}{2^2} + \cdots + \frac{j_n}{2^{n-l+1}}
$$
は2進小数であり、$e^{i 2\pi j/2^{-l} } = e^{i 2\pi j_1 \cdots j_l . j_{l-1}\cdots j_n }
= e^{i 2\pi 0. j_{l-1}\cdots j_n }$となることを用いた。($e^{i2\pi}=1$なので、整数部分は関係ない)
まとめると、量子フーリエ変換では、
$$
|j\rangle = |j_1 \cdots j_n \rangle \to \frac{ \left( |0\rangle + e^{i 2\pi 0.j_n} |1 \rangle \right) \otimes \left( |0\rangle + e^{i 2\pi 0.j_{n-1}j_n} |1 \rangle \right) \otimes \cdots \otimes \left( |0\rangle + e^{i 2\pi 0.j_1j_2\cdots j_n} |1 \rangle \right) }{\sqrt{2^n}}
\tag{*}
$$
という変換ができればよい。
### 回路の構成
それでは、量子フーリエ変換を実行する回路を実際にどのように構成するかを見ていこう。
そのために、次のアダマールゲート$H$についての等式(計算すると合っていることが分かる)
$$
H |m \rangle = \frac{|0\rangle + e^{i 2\pi 0.m}|1\rangle }{\sqrt{2}} \:\:\: (m=0,1)
$$
と、角度 $2\pi/2^l$ の一般位相ゲート
$$
R_l =
\begin{pmatrix} 1 & 0\\ 0 & e^{i \frac{2\pi}{2^l} } \end{pmatrix}
$$
を多用する。
1. まず、状態$\left( |0\rangle + e^{i 2\pi 0.j_1j_2\cdots j_n} |1\rangle \right)$の部分をつくる。1番目の量子ビット$|j_1\rangle$にアダマールゲートをかけると
$$
|j_1 \cdots j_n \rangle \to \frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1} |1\rangle \right) |j_2 \cdots j_n \rangle
$$
となるが、ここで、2番目のビット$|j_2\rangle$を制御ビットとする一般位相ゲート$R_2$を1番目の量子ビットにかけると、$j_2=0$の時は何もせず、$j_2=1$の時のみ1番目の量子ビットの$|1\rangle$部分に位相 $2\pi/2^2 = 0.01$(二進小数)がつくから、
$$
\frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1} |1\rangle \right) |j_2 \cdots j_n \rangle
\to \frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1j_2} |1\rangle \right) |j_2 \cdots j_n \rangle
$$
となる。以下、$l$番目の量子ビット$|j_l\rangle$を制御ビットとする一般位相ゲート$R_l$をかければ($l=3,\cdots n$)、最終的に
$$
\frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1\cdots j_n} |1\rangle \right) |j_2 \cdots j_n \rangle
$$
が得られる。
2. 次に、状態$\left( |0\rangle + e^{i2\pi 0.j_2\cdots j_n} |1\rangle\right)$の部分をつくる。先ほどと同様に、2番目のビット$|j_2\rangle$にアダマールゲートをかければ
$$
\frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1\cdots j_n}|1\rangle \right) \frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_2} |1\rangle \right) |j_3 \cdots j_n \rangle
$$
ができる。再び、3番目の量子ビットを制御ビット$|j_3\rangle$とする位相ゲート$R_2$をかければ
$$
\frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1\cdots j_n}|1\rangle \right) \frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_2j_3}|1\rangle \right) |j_3 \cdots j_n \rangle
$$
となり、これを繰り返して
$$
\frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_1\cdots j_n}|1\rangle \right) \frac{1}{\sqrt{2}} \left( |0\rangle + e^{i2\pi 0.j_2\cdots j_n}|1\rangle \right) |j_3 \cdots j_n \rangle
$$
を得る。
3. 1,2と同様の手順で、$l$番目の量子ビット$|j_l\rangle$にアダマールゲート・制御位相ゲート$R_l, R_{l+1},\cdots$をかけていく($l=3,\cdots,n$)。すると最終的に
$$
|j_1 \cdots j_n \rangle \to \left( \frac{|0\rangle + e^{i 2\pi 0.j_1\cdots j_n} |1 \rangle}{\sqrt{2}} \right) \otimes
\left( \frac{|0\rangle + e^{i 2\pi 0.j_2\cdots j_n} |1 \rangle}{\sqrt{2}} \right) \otimes \cdots \otimes
\left( \frac{|0\rangle + e^{i 2\pi 0.j_n} |1 \rangle}{\sqrt{2}} \right)
$$
が得られるので、最後にビットの順番をSWAPゲートで反転させてあげれば、量子フーリエ変換を実行する回路が構成できたことになる(式($*$)とはビットの順番が逆になっていることに注意)。
SWAPを除いた部分を回路図で書くと以下のようである。

### SymPyを用いた実装
量子フーリエ変換への理解を深めるために、SymPyを用いて$n=3$の場合の回路を実装してみよう。
```
from sympy import *
from sympy.physics.quantum import *
from sympy.physics.quantum.qubit import Qubit,QubitBra
init_printing() # ベクトルや行列を綺麗に表示するため
from sympy.physics.quantum.gate import X,Y,Z,H,S,T,CNOT,SWAP,CPHASE,CGateS
# Google Colaboratory上でのみ実行してください
from IPython.display import HTML
def setup_mathjax():
display(HTML('''
<script>
if (!window.MathJax && window.google && window.google.colab) {
window.MathJax = {
'tex2jax': {
'inlineMath': [['$', '$'], ['\\(', '\\)']],
'displayMath': [['$$', '$$'], ['\\[', '\\]']],
'processEscapes': true,
'processEnvironments': true,
'skipTags': ['script', 'noscript', 'style', 'textarea', 'code'],
'displayAlign': 'center',
},
'HTML-CSS': {
'styles': {'.MathJax_Display': {'margin': 0}},
'linebreaks': {'automatic': true},
// Disable to prevent OTF font loading, which aren't part of our
// distribution.
'imageFont': null,
},
'messageStyle': 'none'
};
var script = document.createElement("script");
script.src = "https://colab.research.google.com/static/mathjax/MathJax.js?config=TeX-AMS_HTML-full,Safe";
document.head.appendChild(script);
}
</script>
'''))
get_ipython().events.register('pre_run_cell', setup_mathjax)
```
まず、フーリエ変換される入力$|x\rangle$として、
$$
|x\rangle = \sum_{j=0}^7 \frac{1}{\sqrt{8}} |j\rangle
$$
という全ての状態の重ね合わせ状態を考える($x_0 = \cdots = x_7 = 1/\sqrt{8}$)。
```
input = 1/sqrt(8) *( Qubit("000")+Qubit("001")+Qubit("010")+Qubit("011")+Qubit("100")+Qubit("101")+Qubit("110")+Qubit("111"))
input
```
この状態に対応する配列をnumpyでフーリエ変換すると
```
import numpy as np
input_np_array = 1/np.sqrt(8)*np.ones(8)
print( input_np_array ) ## 入力
print( np.fft.ifft(input_np_array) * np.sqrt(8) ) ## 出力. ここでのフーリエ変換の定義とnumpyのifftの定義を合わせるため、sqrt(2^3)をかける
```
となり、フーリエ変換すると $y_0=1,y_1=\cdots=y_7=0$ という簡単な配列になることが分かる。これを量子フーリエ変換で確かめてみよう。
まず、$R_1, R_2, R_3$ゲートはそれぞれ$Z, S, T$ゲートに等しいことに注意する($e^{i\pi}=-1, e^{i\pi/2}=i$)。
```
represent(Z(0),nqubits=1), represent(S(0),nqubits=1), represent(T(0),nqubits=1)
```
量子フーリエ変換(Quantum Fourier TransformなのでQFTと略す)を実行回路を構成していく。
最初に、1番目(SymPyは右から0,1,2とビットを数えるので、SymPyでは2番目)の量子ビットにアダマール演算子をかけ、2番目・3番目のビットを制御ビットとする$R_2, R_3$ゲートをかける。
```
QFT_gate = H(2)
QFT_gate = CGateS(1, S(2)) * QFT_gate
QFT_gate = CGateS(0, T(2)) * QFT_gate
```
2番目(SymPyでは1番目)の量子ビットにもアダマールゲートと制御$R_2$演算を施す。
```
QFT_gate = H(1) * QFT_gate
QFT_gate = CGateS(0, S(1)) * QFT_gate
```
3番目(SymPyでは0番目)の量子ビットにはアダマールゲートのみをかければ良い。
```
QFT_gate = H(0) * QFT_gate
```
最後に、ビットの順番を合わせるためにSWAPゲートをかける。
```
QFT_gate = SWAP(0, 2) * QFT_gate
```
これで$n=3$の時の量子フーリエ変換の回路を構成できた。回路自体はやや複雑である。
```
QFT_gate
```
入力ベクトル$|x\rangle$ にこの回路を作用させると、以下のようになり、正しくフーリエ変換された状態が出力されていることが分かる。($y_0=1,y_1=\cdots=y_7=0$)
```
simplify( qapply( QFT_gate * input) )
```
読者は是非、入力を様々に変えてこの回路を実行し、フーリエ変換が正しく行われていることを確認してみてほしい。
---
### コラム:計算量について
「量子コンピュータは計算を高速に行える」とは、どういうことだろうか。本節で学んだ量子フーリエ変換を例にとって考えてみる。
量子フーリエ変換を行うために必要なゲート操作の回数は、1番目の量子ビットに$n$回、2番目の量子ビットに$n-1$回、...、$n$番目の量子ビットに1回で合計$n(n-1)/2$回、そして最後のSWAP操作が約$n/2$回であるから、全て合わせると$\mathcal{O}(n^2)$回である($\mathcal{O}$記法について詳しく知りたい人は、下記セクションを参照)。
一方、古典コンピュータでフーリエ変換を行う[高速フーリエ変換](https://ja.wikipedia.org/wiki/高速フーリエ変換)は、同じ計算を行うのに$\mathcal{O}(n2^n)$の計算量を必要とする。この意味で、量子フーリエ変換は、古典コンピュータで行う高速フーリエ変換に比べて「高速」と言える。
これは一見喜ばしいことに見えるが、落とし穴がある。フーリエ変換した結果$\{y_k\}$は量子フーリエ変換後の状態$|y\rangle$の確率振幅として埋め込まれているが、この振幅を素直に読み出そうとすると、結局は**指数関数的な回数の観測を繰り返さなくてはならない**。さらに、そもそも入力$|x\rangle$を用意する方法も簡単ではない(素直にやると、やはり指数関数的な時間がかかってしまう)。
このように、量子コンピュータや量子アルゴリズムを「実用」するのは簡単ではなく、さまざまな工夫・技術発展がまだまだ求められている。
一体どのような問題で量子コンピュータが高速だと思われているのか、理論的にはどのように扱われているのかなど、詳しく学びたい方はQmediaの記事[「量子計算機が古典計算機より優れている」とはどういうことか](https://www.qmedia.jp/computational-complexity-and-quantum-computer/)(竹嵜智之)を参照されたい。
#### オーダー記法$\mathcal{O}$についての註
そもそも、アルゴリズムの性能はどのように定量評価できるのだろうか。ここでは、アルゴリズムの実行に必要な資源、主に時間をその基準として考える。とくに問題のサイズを$n$としたとき、計算ステップ数(時間)や消費メモリなど、必要な計算資源が$n$の関数としてどう振る舞うかを考える。(問題のサイズとは、例えばソートするデータの件数、あるいは素因数分解したい数の二進数表現の桁数などである。)
例えば、問題のサイズ$n$に対し、アルゴリズムの要求する計算資源が次の$f(n)$で与えられるとする。
$$ f(n) = 2n^2 + 5n + 8 $$
$n$が十分大きいとき(例えば$n=10^{10}$)、$2n^2$に比べて$5n$や$6$は十分に小さい。したがって、このアルゴリズムの評価という観点では$5n+8$という因子は重要ではない。また、$n^2$の係数が$2$であるという情報も、$n$が十分大きいときの振る舞いには影響を与えない。こうして、計算時間$f(n)$の一番**「強い」**項の情報が重要であると考えることができる。このような考え方を漸近的評価といい、計算量のオーダー記法では次の式で表す。
$$f(n) = \mathcal{O}(n^2)$$
一般に$f(n) = \mathcal{O}(g(n))$とは、ある正の数$n_0, c$が存在して、任意の$n > n_0$に対して
$$|f(n)| \leq c |g(n)|$$
が成り立つことである。上の例では、$n_0=7, c=3$とすればこの定義の通りである(グラフを描画してみよ)。練習として、$f(n) = 6n^3 +5n$のオーダー記法$f(n) = \mathcal{O}(n^3)$を与える$n_0, c$の組を考えてみよ。
アルゴリズムの性能評価では、その入力のサイズを$n$としたときに必要な計算資源を$n$の関数として表す。特にオーダー記法による漸近評価は、入力のサイズが大きくなったときの振る舞いを把握するときに便利である。そして、こうした漸近評価に基づいた計算量理論というものを用いて、様々なアルゴリズムの分類が行われている。詳細は上記のQmedia記事を参照されたい。
|
github_jupyter
|
# Lab 2: cleaning operations practice with the Adult dataset
In this lab, we will practice what we learned in the clearning operations lab, but now we use a larger dataset, __Adult__, which we already used in the previous lab . We start by loading the data as we have done before, as well as the necessary libraries. We will look at how to generate train/validation/test partitions, as well as how to do some cleaning of outliers on those, or balancing of training sets. We will also look at how to assess the problem of missing values and how to impute those by a couple of techniques.
## Loading the data
Now we begin by loading the data as we have done before and printing the `.head()` and `.tail()` to inspect the data. Also produce a `countplot` of the target variable _income_ to observe the distribution of classes. Load the data as the _Adult_data_ data frame. We will use that through the lab.
As in the previous lab, we specify the columns which are: "age", "workclass", "fnlwgt", "education", "educational-num", "marital-status", "occupation", "relationship", "race", "gender", "capital-gain", "capital-loss", "hours-per-week", "native-country".
We will also specify two lists, one which contains the __categorical columns__, and one which contains the __numeric columns__ of interest. The categorical columns of interest are: "workclass", "education", "marital-status", "occupation","relationship", "race", "gender", "native-country". The numeric columns are: "age", "education-num", "capital-gain", "capital-loss", "hours-per-week". We will exclude _fnlwgt_ as it is not a particularly useful variable and we will see this soon.
We can start by creating a `boxplot` of the `adult_data` (which will include the numeric variables only in it by default. What can we see in it? Is there any problematic variables?
We can now designate our X or input variables. Once assigned look at the `.head()` of X.
Now designate the outcome or target variable as _y_ and look at the `.head() to see what we get.
## Sampling (train/validation/test)
First, let us divide the Adult dataset into train/validation/test partitions. We first designated 20% for a test partition, call it _test_X_. The remainder we can call _part1_X_ as a first partition to be later subdivided. We then subdivide the partition _part1_X_ into train/validate. For the second partition we will make we also designate 20% as the validation set. We will not use the test set until the final stage of testing the model, but we can use the validation set to test any intermediary decision as we later build models for classification.
So we start by sampling and dividing the original X,y into the part1_X/test_X and part1_y/test_y with the `train_test_split` method and looking at each with the `describe()` method.
Now we sample by dividing the _part1_X_ partition into a Train/Validation partition and we also inspect it with `.describe()`. We can compare _train_X, val_X and test_X_, the three sets we have obtained.
## Outlier detection
We start now looking at outliers. For the purpose of looking at outliers, let us consider the continous columns we have already defined only so X can be equal to the CONTINUOUS_COLUMNS of the data frame. We can create a new train_X wich we can call train_OL_X with the CONTINUOUS_COLUMNS only.
We now try to detect outliers, first with the DBSCAN algorithm. Since this file is rather large we do not print the objects with their allocation (outliers designated as -1, or not outliers) but we can print the total number of outliers found. We can also alter the parameters `min_samples` and `eps` to see the effect on the outliers detected. Once you have the code working, experiment with the algorithm parameters to get a not too large number of outliers. We can apply this on the train data only, but to the one with continous columns, i.e. train_OL_X.
We can now create a mask or filter to ensure only those rows that are not outliers are retained in a new data frame that we can later use for classification. Let us create a new output variable _y1_ and input set of variables _X1_ which contain a filtered version of the original data frame. For this, we can create a mask which takes the value of `clusters!= -1`. This will be a boolean array which we can then use to filter _y_ into a new version _y1_, and similarly _X_ into a new version _X1_. Check the shape of the new X and y with `.shape` to see the size of each. The amount of rows should be equal to the rows in the original data frame minus the rows that were designated as outliers. Note that we need to filter the data frame that contains all the columns (_train_X, train_y_), and not just the numeric ones, as all columns will be needed for the classification algorithms.
Let us now do similarly but using the `IsolationForest` algorithm. Again, investigate the parameters to understand how many outliers are found as we change those paramaters.
Again, we can create a mask or filter to ensure only those rows that are not outliers are retained in a new data frame that we can later use for classification. Let us create a new output variable _y2_ and input set of variables _X2_ which contain a filtered version of the original data frame, this time with the isolation algorithm filter. For this, we can create a mask which takes the value of `preds!= -1`. This will be a boolean array which we can then use to filter _train_y_ into a new version _y2_, and similarly _Train_X_ into a new version _X2_. Again check the shape of the new X and y with `.shape` to see the size of each.
Finally, we can try to run the `LocalOutlierFactor` algorithm on the Adult data. Once this is done, if you wish to visualise the outliers, you could produce a graph similar to the one produced in the _CleaningExamples_ lab, but this time plot for example _age_ versus _educational_num_ (columns 0 and 1). You may not need to use limits on the x and y axis for this plot, or you will need to adapt them to the right values.
Again, we filter to ensure only those rows that are not outliers are retained in a new data frame that we can later use for classification. Let us create a new output variable _y3_ and input set of variables _X3_ which contain a filtered version of the original data frame, this time with the LOF algorithm filter, similar to the previous to cells.
If you wish to save any of the dataframes you have created to load them elsewhere you can do that with the `.to_csv()` method. You can pass inside as parameters the path and file name and `index = False` if you don't wish to save the index. Alternatively, you can repeat the code above to get the data frame in a later lab.
## Balancing of the data
Now we will practice balancing the data. We can apply balancing operations to the original training data, or we could apply it to any of the versions with outliers removed if we later decided that removing the outliers may be beneficial. Let us use the original training data ignoring outlier removal for the time being. We can start by producing a count of how many rows are there for each label using the `value_counts()` method on the _train_y_ series.
Now we will try to produce a balanced sample but instead of doing it from the whole file, as we do not want to balance the test data, we wil do it from the training data only, the _train_X_ data frame. First we need to concatanate the X and y part of the training data to apply balancing. We can separate again later. We can start by trying to upsample the minority class so they both have an equal number of samples. We can look at the statistics of the upsampled data, together with the new value counts.
We may now want to produce another `countplot` to compare the class imbalance.
Additionally, we may produce a `stripplot` to understand how the data was distributed for the two classes in the original data frame, _Adult_data_ and then another one for how it is distributed in the new upsampled data for comparison.
Now, we do similarly, but this time we downsample the majority class to produce a reduced balanced dataset. We look at value counts and after we can produce a `countplot` to look at the distribution of values in the classes.
Again a `stripplot` can show the distribution of points within the classes in the downsampled data frame.
Now you could chose to use either your dowsampled or upsampled training data as the data to classify. For this you will need to divide the _X_ part (decision variables) from the _y_ part (target variable), before feeding to any classification algorithms. Attempt that for the upsampled data.
## Missing data
Now we will get to deal with missing data. First thing is to understand how missing data, if there is any, is represented in the dataset we are looking at. The distribution graphs we did in the previous lab for the Adult data frame showed that _occupation_, _workclass_ and _native_country_ appeared to have missing values represented as '?'. We can start by replacing all values of _'?'_ in the data frame with _nan_, the representation of missing data in _numpy_. For this the `.replace()` method can be used with the first parameter being what we want to replace, i.e. '?' and the second being what we want to replace it with, i.e. _nan_. We need to make missing data consistently represented in the whole dataset so we apply this to the _Adult_data_ data frame.
Now, we can count how many missing (i.e. nan) numbers there are in the data frame as a whole. Then how many there are in each column or variable.
We now start by removing all rows that contain a missing value. How many rows are left?
And finally, we look at how to impute the data with the `KNNImputer` from sklearn. We can then use `.describe()` on the new data frame to underestand what the imputed data may look like.
Note that we could have used imputation only on the training part of the data frame, although if the classification algorithm we are going to use does not accept missing data, then we may need to apply the imputation on the whole dataset as we just did.
Now that is all for this lab!!! We have created a number of data frames we may use in later labs for classification so make sure you save your work ready for re-use later.
|
github_jupyter
|
# CA Coronavirus Cases and Deaths Trends
CA's [Blueprint for a Safer Economy](https://www.cdph.ca.gov/Programs/CID/DCDC/Pages/COVID-19/COVID19CountyMonitoringOverview.aspx) assigns each county [to a tier](https://www.cdph.ca.gov/Programs/CID/DCDC/Pages/COVID-19/COVID19CountyMonitoringOverview.aspx) based on case rate and test positivity rate. What's opened / closed [under each tier](https://www.cdph.ca.gov/Programs/CID/DCDC/CDPH%20Document%20Library/COVID-19/Dimmer-Framework-September_2020.pdf).
Tiers, from most severe to least severe, categorizes coronavirus spread as <strong><span style='color:#6B1F84'>widespread; </span></strong>
<strong><span style='color:#F3324C'>substantial; </span></strong><strong><span style='color:#F7AE1D'>moderate; </span></strong><strong><span style = 'color:#D0E700'>or minimal.</span></strong>
**Counties must stay in the current tier for 3 consecutive weeks and metrics from the last 2 consecutive weeks must fall into less restrictive tier before moving into a less restrictive tier.**
We show *only* case charts labeled with each county's population-adjusted tier cut-offs.
**Related daily reports:**
1. **[US counties report on cases and deaths for select major cities](https://cityoflosangeles.github.io/covid19-indicators/us-county-trends.html)**
1. **[Los Angeles County, detailed indicators](https://cityoflosangeles.github.io/covid19-indicators/coronavirus-stats.html)**
1. **[Los Angeles County neighborhoods report on cases and deaths](https://cityoflosangeles.github.io/covid19-indicators/la-neighborhoods-trends.html)**
Code available in GitHub: [https://github.com/CityOfLosAngeles/covid19-indicators](https://github.com/CityOfLosAngeles/covid19-indicators)
<br>
Get informed with [public health research](https://github.com/CityOfLosAngeles/covid19-indicators/blob/master/reopening-sources.md)
```
import altair as alt
import altair_saver
import geopandas as gpd
import os
import pandas as pd
from processing_utils import default_parameters
from processing_utils import make_charts
from processing_utils import make_maps
from processing_utils import neighborhood_utils
from processing_utils import us_county_utils
from processing_utils import utils
from datetime import date, datetime, timedelta
from IPython.display import display_html, Markdown, HTML, Image
# For map
import branca.colormap
import ipywidgets
# There's a warning that comes up about projects, suppress
import warnings
warnings.filterwarnings("ignore")
# Default parameters
time_zone = default_parameters.time_zone
start_date = datetime(2021, 3, 1).date()
today_date = default_parameters.today_date
fulldate_format = default_parameters.fulldate_format
#alt.renderers.enable('html')
STATE = "CA"
jhu = us_county_utils.clean_jhu(start_date)
jhu = jhu[jhu.state_abbrev==STATE]
hospitalizations = us_county_utils.clean_hospitalizations(start_date)
vaccinations = utils.clean_vaccines_by_county()
vaccinations_demog = utils.clean_vaccines_by_demographics()
ca_counties = list(jhu[jhu.state_abbrev==STATE].county.unique())
# Put LA county first
ca_counties.remove("Los Angeles")
ca_counties = ["Los Angeles"] + ca_counties
data_through = jhu.date.max()
display(Markdown(
f"Report updated: {default_parameters.today_date.strftime(fulldate_format)}; "
f"data available through {data_through.strftime(fulldate_format)}."
)
)
title_font_size = 9
def plot_charts(cases_df, hospital_df, vaccine_df, vaccine_demog_df, county_name):
cases_df = cases_df[cases_df.county==county_name]
hospital_df = hospital_df[hospital_df.county==county_name]
vaccine_df = vaccine_df[vaccine_df.county==county_name]
vaccine_df2 = vaccine_demog_df[vaccine_demog_df.county==county_name]
name = cases_df.county.iloc[0]
cases_chart, deaths_chart = make_charts.setup_cases_deaths_chart(cases_df, "county", name)
hospitalizations_chart = make_charts.setup_county_covid_hospital_chart(
hospital_df.drop(columns = "date"), county_name)
vaccines_type_chart = make_charts.setup_county_vaccination_doses_chart(vaccine_df, county_name)
vaccines_pop_chart = make_charts.setup_county_vaccinated_population_chart(vaccine_df, county_name)
vaccines_age_chart = make_charts.setup_county_vaccinated_category(vaccine_df2, county_name, category="Age Group")
outbreak_chart = (alt.hconcat(
cases_chart,
deaths_chart,
make_charts.add_tooltip(hospitalizations_chart, "hospitalizations")
).configure_concat(spacing=50)
)
#https://stackoverflow.com/questions/60328943/how-to-display-two-different-legends-in-hconcat-chart-using-altair
vaccines_chart = (alt.hconcat(
make_charts.add_tooltip(vaccines_type_chart, "vaccines_type"),
make_charts.add_tooltip(vaccines_pop_chart, "vaccines_pop"),
make_charts.add_tooltip(vaccines_age_chart, "vaccines_age"),
).resolve_scale(color="independent")
.configure_view(stroke=None)
.configure_concat(spacing=0)
)
outbreak_chart = (make_charts.configure_chart(outbreak_chart)
.configure_title(fontSize=title_font_size)
)
vaccines_chart = (make_charts.configure_chart(vaccines_chart)
.configure_title(fontSize=title_font_size)
)
county_state_name = county_name + f", {STATE}"
display(Markdown(f"#### {county_state_name}"))
try:
us_county_utils.county_caption(cases_df, county_name)
except:
pass
us_county_utils.ca_hospitalizations_caption(hospital_df, county_name)
us_county_utils.ca_vaccinations_caption(vaccine_df, county_name)
make_charts.show_svg(outbreak_chart)
make_charts.show_svg(vaccines_chart)
display(Markdown("<strong>Cases chart, explained</strong>"))
Image("../notebooks/chart_parts_explained.png", width=700)
```
<a id='counties_by_region'></a>
## Counties by Region
<strong>Superior California Region: </strong> [Butte](#Butte), Colusa,
[El Dorado](#El-Dorado),
Glenn,
[Lassen](#Lassen), Modoc,
[Nevada](#Nevada),
[Placer](#Placer), Plumas,
[Sacramento](#Sacramento),
[Shasta](#Shasta), Sierra, Siskiyou,
[Sutter](#Sutter),
[Tehama](#Tehama),
[Yolo](#Yolo),
[Yuba](#Yuba)
<br>
<strong>North Coast:</strong> [Del Norte](#Del-Norte),
[Humboldt](#Humboldt),
[Lake](#Lake),
[Mendocino](#Mendocino),
[Napa](#Napa),
[Sonoma](#Sonoma), Trinity
<br>
<strong>San Francisco Bay Area:</strong> [Alameda](#Alameda),
[Contra Costa](#Contra-Costa),
[Marin](#Marin),
[San Francisco](#San-Francisco),
[San Mateo](#San-Mateo),
[Santa Clara](#Santa-Clara),
[Solano](#Solano)
<br>
<strong>Northern San Joaquin Valley:</strong> Alpine, Amador, Calaveras,
[Madera](#Madera), Mariposa,
[Merced](#Merced),
Mono,
[San Joaquin](#San-Joaquin),
[Stanislaus](#Stanislaus),
[Tuolumne](#Tuolumne)
<br>
<strong>Central Coast:</strong> [Monterey](#Monterey),
[San Benito](#San-Benito),
[San Luis Obispo](#San-Luis-Obispo),
[Santa Barbara](#Santa-Barbara),
[Santa Cruz](#Santa-Cruz),
[Ventura](#Ventura)
<br>
<strong>Southern San Joaquin Valley:</strong> [Fresno](#Fresno),
Inyo,
[Kern](#Kern),
[Kings](#Kings),
[Tulare](#Tulare)
<br>
<strong>Southern California:</strong> [Los Angeles](#Los-Angeles),
[Orange](#Orange),
[Riverside](#Riverside),
[San Bernardino](#San-Bernardino)
<br>
<strong>San Diego-Imperial:</strong> [Imperial](#Imperial),
[San Diego](#San-Diego)
<br>
<br>
[**Summary of CA County Severity Map**](#summary)
<br>
[**Vaccinations by Zip Code**](#vax_map)
Note for <i>small values</i>: If the 7-day rolling average of new cases or new deaths is under 10, the 7-day rolling average is listed for the past week, rather than a percent change. Given that it is a rolling average, decimals are possible, and are rounded to 1 decimal place. Similarly for hospitalizations.
```
for c in ca_counties:
id_anchor = c.replace(" - ", "-").replace(" ", "-")
display(HTML(f"<a id={id_anchor}></a>"))
plot_charts(jhu, hospitalizations, vaccinations, vaccinations_demog, c)
display(HTML(
"<br>"
"<a href=#counties_by_region>Return to top</a><br>"
))
```
<a id=summary></a>
## Summary of CA Counties
```
ca_boundary = gpd.read_file(f"{default_parameters.S3_FILE_PATH}ca_counties_boundary.geojson")
def grab_map_stats(df):
# Let's grab the last available date for each county
df = (df.sort_values(["county", "fips", "date2"],
ascending = [True, True, False])
.drop_duplicates(subset = ["county", "fips"], keep = "first")
.reset_index(drop=True)
)
# Calculate its severity metric
df = df.assign(
severity = (df.cases_avg7 / df.tier3_case_cutoff).round(1)
)
# Make gdf
gdf = pd.merge(ca_boundary, df,
on = ["fips", "county"], how = "left", validate = "1:1")
gdf = gdf.assign(
cases_avg7 = gdf.cases_avg7.round(1),
deaths_avg7 = gdf.deaths_avg7.round(1),
)
return gdf
gdf = grab_map_stats(jhu)
```
#### Severity by County
Severity measured as proportion relative to Tier 1 (minimal) threshold.
<br>*1 = at Tier 1 threshold*
<br>*2 = 2x higher than Tier 1 threshold*
```
MAX_SEVERITY = gdf.severity.max()
light_gray = make_charts.light_gray
#https://stackoverflow.com/questions/47846744/create-an-asymmetric-colormap
"""
Against Tier 4 cut-off
If severity = 1 when case_rate = 7 per 100k
If severity = x when case_rate = 4 per 100k
If severity = y when case_rate = 1 per 100k
x = 4/7; y = 1/7
Against Tier 1 cut-off
If severity = 1 when case_rate = 1 per 100k
If severity = x when case_rate = 4 per 100k
If severity = y when case_rate = 7 per 100k
x = 4; y = 7
"""
tier_4_colormap_cutoff = [
(1/7), (4/7), 1, 2.5, 5
]
tier_1_colormap_cutoff = [
1, 4, 7, 10, 15
]
# Note: CA reopening guidelines have diff thresholds based on how many vaccines are administered...
# We don't have vaccine info, so ignore, use original cut-offs
colormap_cutoff = tier_4_colormap_cutoff
colorscale = branca.colormap.StepColormap(
colors=["#D0E700", "#F7AE1D", "#F77889",
"#D59CE8", "#B249D4", "#6B1F84", # purples
],
index=colormap_cutoff,
vmin=0, vmax=MAX_SEVERITY,
)
popup_dict = {
"county": "County",
"severity": "Severity",
}
tooltip_dict = {
"county": "County: ",
"severity": "Severity: ",
"new_cases": "New Cases Yesterday: ",
"cases_avg7": "New Cases (7-day rolling avg): ",
"new_deaths": "New Deaths Yesterday: ",
"deaths_avg7": "New Deaths (7-day rolling avg): ",
"cases": "Cumulative Cases",
"deaths": "Cumulative Deaths",
}
fig = make_maps.make_choropleth_map(gdf.drop(columns = ["date", "date2"]),
plot_col = "severity",
popup_dict = popup_dict,
tooltip_dict = tooltip_dict,
colorscale = colorscale,
fig_width = 570, fig_height = 700,
zoom=6, centroid = [36.2, -119.1])
display(Markdown("Severity Scale"))
display(colorscale)
fig
table = (gdf[gdf.severity.notna()]
[["county", "severity"]]
.sort_values("severity", ascending = False)
.reset_index(drop=True)
)
df1_styler = (table.iloc[:14].style.format({'severity': "{:.1f}"})
.set_table_attributes("style='display:inline'")
#.set_caption('Caption table 1')
.hide_index()
)
df2_styler = (table.iloc[15:29].style.format({'severity': "{:.1f}"})
.set_table_attributes("style='display:inline'")
#.set_caption('Caption table 2')
.hide_index()
)
df3_styler = (table.iloc[30:].style.format({'severity': "{:.1f}"})
.set_table_attributes("style='display:inline'")
#.set_caption('Caption table 2')
.hide_index()
)
display(Markdown("#### Counties (in order of decreasing severity)"))
display_html(df1_styler._repr_html_() +
df2_styler._repr_html_() +
df3_styler._repr_html_(), raw=True)
```
[Return to top](#counties_by_region)
```
# Vaccination data by zip code
def select_latest_date(df):
df = (df[df.date == df.date.max()]
.sort_values(["county", "zipcode"])
.reset_index(drop=True)
)
return df
vax_by_zipcode = neighborhood_utils.clean_zipcode_vax_data()
vax_by_zipcode = select_latest_date(vax_by_zipcode)
popup_dict = {
"county": "County",
"zipcode": "Zip Code",
"fully_vaccinated_percent": "% Fully Vax"
}
tooltip_dict = {
"county": "County: ",
"zipcode": "Zip Code",
"at_least_one_dose_percent": "% 1+ dose",
"fully_vaccinated_percent": "% fully vax"
}
colormap_cutoff = [
0, 0.2, 0.4, 0.6, 0.8, 1
]
colorscale = branca.colormap.StepColormap(
colors=["#CDEAF8", "#97BFD6", "#5F84A9",
"#315174", "#17375E",
],
index=colormap_cutoff,
vmin=0, vmax=1,
)
fig = make_maps.make_choropleth_map(vax_by_zipcode.drop(columns = "date"),
plot_col = "fully_vaccinated_percent",
popup_dict = popup_dict,
tooltip_dict = tooltip_dict,
colorscale = colorscale,
fig_width = 570, fig_height = 700,
zoom=6, centroid = [36.2, -119.1])
```
<a id=vax_map></a>
#### Full Vaccination Rates by Zip Code
```
display(Markdown("% Fully Vaccinated by Zip Code"))
display(colorscale)
fig
zipcode_dropdown = ipywidgets.Dropdown(description="Zip Code",
options=sorted(vax_by_zipcode.zipcode.unique()),
value=90012)
def make_map_show_table(x):
plot_col = "fully_vaccinated_percent"
popup_dict = {
"county": "County",
"zipcode": "Zip Code",
"fully_vaccinated_percent": "% Fully Vax"
}
tooltip_dict = {
"county": "County: ",
"zipcode": "Zip Code",
"at_least_one_dose_percent": "% 1+ dose",
"fully_vaccinated_percent": "% fully vax"
}
colormap_cutoff = [
0, 0.2, 0.4, 0.6, 0.8, 1
]
colorscale = branca.colormap.StepColormap(
colors=["#CDEAF8", "#97BFD6", "#5F84A9",
"#315174", "#17375E",
],
index=colormap_cutoff,
vmin=0, vmax=1,
)
fig_width = 300
fig_height = 300
zoom = 12
df = vax_by_zipcode.copy()
subset_df = (df[df.zipcode==x]
.assign(
# When calculating centroids, use EPSG:2229, but when mapping, put it back into EPSG:4326
# https://gis.stackexchange.com/questions/372564/userwarning-when-trying-to-get-centroid-from-a-polygon-geopandas
lon = df.geometry.centroid.x,
lat = df.geometry.centroid.y,
county_partial_vax_avg = neighborhood_utils.calculate_county_avg(df,
group_by="county",
output_col = "at_least_one_dose_percent"),
county_full_vax_avg = neighborhood_utils.calculate_county_avg(df,
group_by = "county",
output_col = "fully_vaccinated_percent"),
at_least_one_dose_percent = round(df.apply(lambda x: x.at_least_one_dose_percent * 100, axis=1), 0),
fully_vaccinated_percent = round(df.apply(lambda x: x.fully_vaccinated_percent * 100, axis=1), 0),
).drop(columns = "date")
)
display_cols = ["county", "zipcode", "population",
"% 1+ dose", "% fully vax",
"county_partial_vax_avg", "county_full_vax_avg",
]
table = (subset_df.rename(columns = {
"at_least_one_dose_percent": "% 1+ dose",
"fully_vaccinated_percent": "% fully vax",})
[display_cols].style.format({
'% 1+ dose': "{:.0f}%",
'% fully vax': "{:.0f}%",
'date': '{:%-m-%d-%y}',
'population': '{:,.0f}',
'county_partial_vax_avg': '{:.0f}%',
'county_full_vax_avg': '{:.0f}%',
}).set_table_attributes("style='display:inline'")
.hide_index()
)
display_html(table)
center = [subset_df.lat, subset_df.lon]
fig = make_maps.make_choropleth_map(subset_df,
plot_col, popup_dict, tooltip_dict,
colorscale, fig_width, fig_height, zoom, center)
display(fig)
ipywidgets.interact(make_map_show_table, x=zipcode_dropdown)
```
[Return to top](#counties_by_region)
|
github_jupyter
|
```
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import tensorflow as tf
sess_config = tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True))
np.random.seed(219)
tf.set_random_seed(219)
# Load training and eval data from tf.keras
(train_data, train_labels), (test_data, test_labels) = \
tf.keras.datasets.mnist.load_data()
train_data = train_data[:50]
train_labels = train_labels[:50]
train_data = train_data / 255.
train_labels = np.asarray(train_labels, dtype=np.int32)
test_data = test_data[:50]
test_labels = test_labels[:50]
test_data = test_data / 255.
test_labels = np.asarray(test_labels, dtype=np.int32)
batch_size = 16
# for train
train_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
#train_dataset = train_dataset.shuffle(buffer_size=10000)
train_dataset = train_dataset.shuffle(buffer_size=10000, seed=None, reshuffle_each_iteration=False)
train_dataset = train_dataset.repeat(count=2)
train_dataset = train_dataset.batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_data, test_labels))
test_dataset = test_dataset.shuffle(buffer_size = 10000)
test_dataset = test_dataset.repeat(count=2)
test_dataset = test_dataset.batch(batch_size = batch_size)
print(test_dataset)
```
## 1. `from_string_handle`
```python
@staticmethod
from_string_handle(
string_handle,
output_types,
output_shapes=None,
output_classes=None
)
```
Creates a new, uninitialized Iterator based on the given handle.
### 1.1 `make_one_shot_iterator()`
Creates an Iterator for enumerating the elements of this dataset.
* Note: The returned iterator will be initialized automatically. A "one-shot" iterator does not currently support re-initialization.
```
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle, train_iterator.output_types)
x, y = iterator.get_next()
x = tf.cast(x, dtype = tf.float32)
y = tf.cast(y, dtype = tf.int32)
sess = tf.Session(config=sess_config)
train_iterator_handle = sess.run(train_iterator.string_handle())
test_iterator_handle = sess.run(test_iterator.string_handle())
# Train
max_epochs = 2
step = 0
for epoch in range(max_epochs):
#sess.run(iterator.initializer) 할 필요 없음
try:
while True:
train_labels_ = sess.run(y, feed_dict={handle: train_iterator_handle})
test_labels_ = sess.run(y, feed_dict={handle: test_iterator_handle})
print("step: %d labels:" % step)
print(train_labels_)
print(test_labels_)
step += 1
except tf.errors.OutOfRangeError:
print("End of dataset") # ==> "End of dataset"
```
### 1.2 `make_initializable_iterator()`
```python
make_initializable_iterator(shared_name=None)
```
Creates an Iterator for enumerating the elements of this dataset.
사용법
```python
dataset = ...
iterator = dataset.make_initializable_iterator()
# ...
sess.run(iterator.initializer)
```
```
train_iterator = train_dataset.make_initializable_iterator()
test_iterator = test_dataset.make_initializable_iterator()
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle, train_iterator.output_types, train_iterator.output_shapes)
x, y = iterator.get_next()
x = tf.cast(x, dtype = tf.float32)
y = tf.cast(y, dtype = tf.int32)
sess = tf.Session(config=sess_config)
train_iterator_handle = sess.run(train_iterator.string_handle())
test_iterator_handle = sess.run(test_iterator.string_handle())
train_initializer = iterator.make_initializer(train_dataset)
test_initializer = iterator.make_initializer(test_dataset)
# Train
max_epochs = 2
step = 0
for epoch in range(max_epochs):
sess.run(train_iterator.initializer)
sess.run(test_iterator.initializer)
try:
while True:
train_labels_ = sess.run(y, feed_dict={handle: train_iterator_handle})
test_labels_ = sess.run(y, feed_dict={handle: test_iterator_handle})
print("step: %d labels:" % step)
print(train_labels_)
print(test_labels_)
step += 1
except tf.errors.OutOfRangeError:
print("End of dataset") # ==> "End of dataset"
```
## 2. `from_structure`
```python
@staticmethod
from_structure(
output_types,
output_shapes=None,
shared_name=None,
output_classes=None
)
```
Creates a new, uninitialized Iterator with the given structure.
### 2.1 `make_one_shot_iterator()`
Creates an Iterator for enumerating the elements of this dataset.
* Note: The returned iterator will be initialized automatically. A "one-shot" iterator does not currently support re-initialization.
```
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
iterator = tf.data.Iterator.from_structure(train_iterator.output_types)
train_initializer = iterator.make_initializer(train_dataset)
test_initializer = iterator.make_initializer(test_dataset)
x, y = iterator.get_next()
sess = tf.Session(config=sess_config)
# Train for `num_epochs`, where for each epoch, we first iterate over
# dataset_range, and then iterate over dataset_evens.
for _ in range(2):
# Initialize the iterator to `dataset_range`
print('train')
sess.run(train_initializer)
while True:
try:
y_ = sess.run(y)
print(y_)
except tf.errors.OutOfRangeError:
break
print('test')
sess.run(test_initializer)
while True:
try:
y_ = sess.run(y)
print(y_)
except tf.errors.OutOfRangeError:
break
```
### 2.2 `make_initializable_iterator()`
```python
make_initializable_iterator(shared_name=None)
```
Creates an Iterator for enumerating the elements of this dataset.
사용법
```python
dataset = ...
iterator = dataset.make_initializable_iterator()
# ...
sess.run(iterator.initializer)
```
```
train_iterator = train_dataset.make_initializable_iterator()
test_iterator = test_dataset.make_initializable_iterator()
iterator = tf.data.Iterator.from_structure(train_iterator.output_types)
train_initializer = iterator.make_initializer(train_dataset)
test_initializer = iterator.make_initializer(test_dataset)
x, y = iterator.get_next()
sess = tf.Session(config=sess_config)
# Train for `num_epochs`, where for each epoch, we first iterate over
# dataset_range, and then iterate over dataset_evens.
for _ in range(2):
# Initialize the iterator to `dataset_range`
print('train')
sess.run(train_initializer)
while True:
try:
y_ = sess.run(y)
print(y_)
except tf.errors.OutOfRangeError:
break
print('test')
sess.run(test_initializer)
while True:
try:
y_ = sess.run(y)
print(y_)
except tf.errors.OutOfRangeError:
break
```
|
github_jupyter
|
# Simulators
## Introduction
This notebook shows how to import the *Qiskit Aer* simulator backend and use it to run ideal (noise free) Qiskit Terra circuits.
```
import numpy as np
# Import Qiskit
from qiskit import QuantumCircuit
from qiskit import Aer, transpile
from qiskit.tools.visualization import plot_histogram, plot_state_city
import qiskit.quantum_info as qi
```
## The Aer Provider
The `Aer` provider contains a variety of high performance simulator backends for a variety of simulation methods. The available backends on the current system can be viwed using `Aer.backends`
```
Aer.backends()
```
## The Aer Simulator
The main simulator backend of the Aer provider is the `AerSimulator` backend. A new simulator backend can be created using `Aer.get_backend('aer_simulator')`.
```
simulator = Aer.get_backend('aer_simulator')
```
The default behavior of teh `AerSimulator` backend is to mimic the execution of an actual device. If a `QuantumCircuit` containing measurements is run it will return a count dictionary containing the final values of any classical registers in the circuit. The circuit may contain gates, measurements, resets, conditionals, and other custom simulator instructions that will be discussed in another notebook.
### Simulating a quantum circuit
The basic operation runs a quantum circuit and returns a counts dictionary of measurement outcomes. Here we run a simple circuit that prepares a 2-qubit Bell-state $\left|\psi\right\rangle = \frac{1}{2}\left(\left|0,0\right\rangle + \left|1,1 \right\rangle\right)$ and measures both qubits.
```
# Create circuit
circ = QuantumCircuit(2)
circ.h(0)
circ.cx(0, 1)
circ.measure_all()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get counts
result = simulator.run(circ).result()
counts = result.get_counts(circ)
plot_histogram(counts, title='Bell-State counts')
```
### Returning measurement outcomes for each shot
The `QasmSimulator` also supports returning a list of measurement outcomes for each individual shot. This is enabled by setting the keyword argument `memory=True` in the `run`.
```
# Run and get memory
result = simulator.run(circ, shots=10, memory=True).result()
memory = result.get_memory(circ)
print(memory)
```
## Aer Simulator Options
The `AerSimulator` backend supports a variety of configurable options which can be updated using the `set_options` method. See the `AerSimulator` API documentation for additional details.
### Simulation Method
The `AerSimulator` supports a variety of simulation methods, each of which supports a different set of instructions. The method can be set manually using `simulator.set_option(method=value)` option, or a simulator backend with a preconfigured method can be obtained directly from the `Aer` provider using `Aer.get_backend`.
When simulating ideal circuits, changing the method between the exact simulation methods `stabilizer`, `statevector`, `density_matrix` and `matrix_product_state` should not change the simulation result (other than usual variations from sampling probabilities for measurement outcomes)
```
# Increase shots to reduce sampling variance
shots = 10000
# Stabilizer simulation method
sim_stabilizer = Aer.get_backend('aer_simulator_stabilizer')
job_stabilizer = sim_stabilizer.run(circ, shots=shots)
counts_stabilizer = job_stabilizer.result().get_counts(0)
# Statevector simulation method
sim_statevector = Aer.get_backend('aer_simulator_statevector')
job_statevector = sim_statevector.run(circ, shots=shots)
counts_statevector = job_statevector.result().get_counts(0)
# Density Matrix simulation method
sim_density = Aer.get_backend('aer_simulator_density_matrix')
job_density = sim_density.run(circ, shots=shots)
counts_density = job_density.result().get_counts(0)
# Matrix Product State simulation method
sim_mps = Aer.get_backend('aer_simulator_matrix_product_state')
job_mps = sim_mps.run(circ, shots=shots)
counts_mps = job_mps.result().get_counts(0)
plot_histogram([counts_stabilizer, counts_statevector, counts_density, counts_mps],
title='Counts for different simulation methods',
legend=['stabilizer', 'statevector',
'density_matrix', 'matrix_product_state'])
```
#### Automatic Simulation Method
The default simulation method is `automatic` which will automatically select a one of the other simulation methods for each circuit based on the instructions in those circuits. A fixed simualtion method can be specified by by adding the method name when getting the backend, or by setting the `method` option on the backend.
### GPU Simulation
The `statevector`, `density_matrix` and `unitary` simulators support running on a NVidia GPUs. For these methods the simulation device can also be manually set to CPU or GPU using `simulator.set_options(device='GPU')` backend option. If a GPU device is not available setting this option will raise an exception.
```
from qiskit.providers.aer import AerError
# Initialize a GPU backend
# Note that the cloud instance for tutorials does not have a GPU
# so this will raise an exception.
try:
simulator_gpu = Aer.get_backend('aer_simulator')
simulator_gpu.set_options(device='GPU')
except AerError as e:
print(e)
```
The `Aer` provider will also contain preconfigured GPU simulator backends if Qiskit Aer was installed with GPU support on a complatible system:
* `aer_simulator_statevector_gpu`
* `aer_simulator_density_matrix_gpu`
* `aer_simulator_unitary_gpu`
*Note: The GPU version of Aer can be installed using `pip install qiskit-aer-gpu`.*
### Simulation Precision
One of the available simulator options allows setting the float precision for the `statevector`, `density_matrix` `unitary` and `superop` methods. This is done using the `set_precision="single"` or `precision="double"` (default) option:
```
# Configure a single-precision statevector simulator backend
simulator = Aer.get_backend('aer_simulator_statevector')
simulator.set_options(precision='single')
# Run and get counts
result = simulator.run(circ).result()
counts = result.get_counts(circ)
print(counts)
```
Setting the simulation precesion applies to both CPU and GPU simulation devices. Single precision will halve the requried memeory and may provide performance improvements on certain systems.
## Custom Simulator Instructions
### Saving the simulator state
The state of the simulator can be saved in a variety of formats using custom simulator instructions.
| Circuit method | Description |Supported Methods |
|----------------|-------------|------------------|
| `save_state` | Save the simulator state in the native format for the simulation method | All |
| `save_statevector` | Save the simulator state as a statevector | `"automatic"`, `"statevector"`, `"matrix_product_state"`, `"extended_stabilizer"`|
| `save_stabilizer` | Save the simulator state as a Clifford stabilizer | `"automatic"`, `"stabilizer"`|
| `save_density_matrix` | Save the simulator state as a density matrix | `"automatic"`, `"statevector"`, `"matrix_product_state"`, `"density_matrix"` |
| `save_matrix_product_state` | Save the simulator state as a a matrix product state tensor | `"automatic"`, `"matrix_product_state"`|
| `save_unitary` | Save the simulator state as unitary matrix of the run circuit | `"automatic"`, `"unitary"`|
| `save_superop` | Save the simulator state as superoperator matrix of the run circuit | `"automatic"`, `"superop"`|
Note that these instructions are only supported by the Aer simulator and will result in an error if a circuit containing them is run on a non-simulator backend such as an IBM Quantum device.
#### Saving the final statevector
To save the final statevector of the simulation we can append the circuit with the `save_statevector` instruction. Note that this instruction should be applied *before* any measurements if we do not want to save the collapsed post-measurement state
```
# Construct quantum circuit without measure
circ = QuantumCircuit(2)
circ.h(0)
circ.cx(0, 1)
circ.save_statevector()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get statevector
result = simulator.run(circ).result()
statevector = result.get_statevector(circ)
plot_state_city(statevector, title='Bell state')
```
#### Saving the circuit unitary
To save the unitary matrix for a `QuantumCircuit` we can append the circuit with the `save_unitary` instruction. Note that this circuit cannot contain any measurements or resets since these instructions are not suppored on for the `"unitary"` simulation method
```
# Construct quantum circuit without measure
circ = QuantumCircuit(2)
circ.h(0)
circ.cx(0, 1)
circ.save_unitary()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get unitary
result = simulator.run(circ).result()
unitary = result.get_unitary(circ)
print("Circuit unitary:\n", unitary.round(5))
```
#### Saving multiple states
We can also apply save instructions at multiple locations in a circuit. Note that when doing this we must provide a unique label for each instruction to retrieve them from the results
```
# Construct quantum circuit without measure
steps = 5
circ = QuantumCircuit(1)
for i in range(steps):
circ.save_statevector(label=f'psi_{i}')
circ.rx(i * np.pi / steps, 0)
circ.save_statevector(label=f'psi_{steps}')
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get saved data
result = simulator.run(circ).result()
data = result.data(0)
data
```
### Setting the simulator to a custom state
The `AerSimulator` allows setting a custom simulator state for several of its simulation methods using custom simulator instructions
| Circuit method | Description |Supported Methods |
|----------------|-------------|------------------|
| `set_statevector` | Set the simulator state to the specified statevector | `"automatic"`, `"statevector"`, `"density_matrix"`|
| `set_stabilizer` | Set the simulator state to the specified Clifford stabilizer | `"automatic"`, `"stabilizer"`|
| `set_density_matrix` | Set the simulator state to the specified density matrix | `"automatic"`, `"density_matrix"` |
| `set_unitary` | Set the simulator state to the specified unitary matrix | `"automatic"`, `"unitary"`, `"superop"`|
| `set_superop` | Set the simulator state to the specified superoperator matrix | `"automatic"`, `"superop"`|
**Notes:**
* These instructions must be applied to all qubits in a circuit, otherwise an exception will be raised.
* The input state must also be a valid state (statevector, denisty matrix, unitary etc) otherwise an exception will be raised.
* These instructions can be applied at any location in a circuit and will override the current state with the specified one. Any classical register values (eg from preceeding measurements) will be unaffected
* Set state instructions are only supported by the Aer simulator and will result in an error if a circuit containing them is run on a non-simulator backend such as an IBM Quantum device.
#### Setting a custom statevector
The `set_statevector` instruction can be used to set a custom `Statevector` state. The input statevector must be valid ($|\langle\psi|\psi\rangle|=1$)
```
# Generate a random statevector
num_qubits = 2
psi = qi.random_statevector(2 ** num_qubits, seed=100)
# Set initial state to generated statevector
circ = QuantumCircuit(num_qubits)
circ.set_statevector(psi)
circ.save_state()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get saved data
result = simulator.run(circ).result()
result.data(0)
```
#### Using the initialize instruction
It is also possible to initialize the simulator to a custom statevector using the `initialize` instruction. Unlike the `set_statevector` instruction this instruction is also supported on real device backends by unrolling to reset and standard gate instructions.
```
# Use initilize instruction to set initial state
circ = QuantumCircuit(num_qubits)
circ.initialize(psi, range(num_qubits))
circ.save_state()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get result data
result = simulator.run(circ).result()
result.data(0)
```
#### Setting a custom density matrix
The `set_density_matrix` instruction can be used to set a custom `DensityMatrix` state. The input density matrix must be valid ($Tr[\rho]=1, \rho \ge 0$)
```
num_qubits = 2
rho = qi.random_density_matrix(2 ** num_qubits, seed=100)
circ = QuantumCircuit(num_qubits)
circ.set_density_matrix(rho)
circ.save_state()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get saved data
result = simulator.run(circ).result()
result.data(0)
```
#### Setting a custom stabilizer state
The `set_stabilizer` instruction can be used to set a custom `Clifford` stabilizer state. The input stabilizer must be a valid `Clifford`.
```
# Generate a random Clifford C
num_qubits = 2
stab = qi.random_clifford(num_qubits, seed=100)
# Set initial state to stabilizer state C|0>
circ = QuantumCircuit(num_qubits)
circ.set_stabilizer(stab)
circ.save_state()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get saved data
result = simulator.run(circ).result()
result.data(0)
```
#### Setting a custom unitary
The `set_unitary` instruction can be used to set a custom unitary `Operator` state. The input unitary matrix must be valid ($U^\dagger U=\mathbb{1}$)
```
# Generate a random unitary
num_qubits = 2
unitary = qi.random_unitary(2 ** num_qubits, seed=100)
# Set initial state to unitary
circ = QuantumCircuit(num_qubits)
circ.set_unitary(unitary)
circ.save_state()
# Transpile for simulator
simulator = Aer.get_backend('aer_simulator')
circ = transpile(circ, simulator)
# Run and get saved data
result = simulator.run(circ).result()
result.data(0)
import qiskit.tools.jupyter
%qiskit_version_table
%qiskit_copyright
```
|
github_jupyter
|
```
repo_directory = '/Users/iaincarmichael/Dropbox/Research/law/law-net/'
data_dir = '/Users/iaincarmichael/Documents/courtlistener/data/'
import numpy as np
import sys
import matplotlib.pyplot as plt
from scipy.stats import rankdata
from collections import Counter
# graph package
import igraph as ig
# our code
sys.path.append(repo_directory + 'code/')
from setup_data_dir import setup_data_dir, make_subnetwork_directory
from pipeline.download_data import download_bulk_resource, download_master_edgelist, download_scdb
from helpful_functions import case_info
sys.path.append(repo_directory + 'vertex_metrics_experiment/code/')
from rankscore_experiment_sort import *
from rankscore_experiment_LR import *
from rankscore_experiment_search import *
from make_tr_edge_df import *
# which network to download data for
network_name = 'scotus' # 'federal', 'ca1', etc
# some sub directories that get used
raw_dir = data_dir + 'raw/'
subnet_dir = data_dir + network_name + '/'
text_dir = subnet_dir + 'textfiles/'
# jupyter notebook settings
%load_ext autoreload
%autoreload 2
%matplotlib inline
# load scotes
G = ig.Graph.Read_GraphML(subnet_dir + network_name +'_network.graphml')
# get a small sugraph to work wit
np.random.seed(234)
v = G.vs[np.random.choice(range(len(G.vs)))]
subset_ids = G.neighborhood(v.index, order=2)
g = G.subgraph(subset_ids)
# get adjacency matrix
A = np.array(g.get_adjacency().data)
```
# helper functions
```
def get_leading_evector(M, normalized=True):
evals, evecs = np.linalg.eig(M)
# there really has to be a more elegant way to do this
return np.real(evecs[:, np.argmax(evals)].reshape(-1))
```
# parameters
```
n = len(g.vs)
case_years = np.array(g.vs['year']).astype(int)
Y = case_years - min(case_years) # zero index the years
m = max(Y) + 1
cases_per_year = [0] * m
cases_per_year_counter = Counter(Y)
for k in cases_per_year_counter.keys():
cases_per_year[k] = cases_per_year_counter[k]
p = .85
qtv = .8
qvt = .2
```
# PageRank transition matrix
```
# set up the page rank transition matrix
D = np.diag([0 if d == 0 else 1.0/d for d in g.outdegree()])
z = [1.0/n if d == 0 else (1.0 - p) / n for d in g.outdegree()]
PR = p * np.dot(A.T, D) + np.outer([1] * n, z)
np.allclose(PR.sum(axis=0), [1]*n)
pr = get_leading_evector(PR)
pr = pr/sum(pr) # scale to probability
# check again igraph's page rank value
# TODO: still a little off
pr_ig = np.array(g.pagerank(damping = p))
print "sum square diff: %f " % sum(np.square(pr_ig - pr))
print "mean: %f" % np.mean(pr)
plt.figure(figsize=[8, 4])
plt.subplot(1,2,1)
plt.scatter(range(n), pr_ig, color='blue', label='igraph')
plt.scatter(range(n), pr, color='red', label='iain')
plt.xlim([0, n])
plt.ylim([0, 1.2 * max(max(pr_ig), max(pr))])
plt.legend(loc='upper right')
plt.subplot(1,2,2)
diff = pr_ig - pr
plt.scatter(range(n), diff, color='green')
plt.ylabel('diff')
plt.xlim([0, n])
plt.ylim(min(diff), max(diff))
plt.axhline(0, color='black')
```
# time-time transition matrix
ones on line below diagonal
```
TT = np.zeros((m, m))
TT[1:m, :m-1] = np.diag([1] * (m - 1))
```
# vertex - time transition matrix
the i-th column is the Y[i]th basis vector
```
VT = np.zeros((m, n))
# for basis vectors
identity_m = np.eye(m)
for i in range(n):
VT[:, i] = identity_m[:, Y[i]]
np.allclose(VT.sum(axis=0), [1]*n)
```
# time - vertex transition matrix
VT transpose but entries are scaled by number of cases in the year
```
TV = np.zeros((n, m))
n_inv = [0 if cases_per_year[i] == 0 else 1.0/cases_per_year[i] for i in range(m)]
for i in range(n):
TV[i, :] = identity_m[Y[i], :] * n_inv[Y[i]]
qtv_diag = [0 if cases_per_year[i] == 0 else qtv for i in range(m)]
qtv_diag[-1] = 1
Qtv = np.diag(qtv_diag)
```
# Make overall transition matrix
```
print sum(PR[:, 0])
print sum(VT[0, :])
print sum(TT[0, :])
print sum(TV[0, :])
P = np.zeros((n + m, n + m))
# upper left
P[:n, :n] = (1 - qvt) * PR
# upper right
P[:n, -m:] = np.dot(TV, Qtv)
# lower left
P[n:, :-m] = qvt * VT
# lower right
P[-m:, -m:] = np.dot(TT, np.eye(m) - Qtv)
np.allclose(P.sum(axis=0), [1]*(n + m))
ta_pr = get_leading_evector(P)
ta_pr = ta_pr/sum(ta_pr)
```
# time aware page rank function
```
def time_aware_pagerank(A, years, p, qtv, qvt):
"""
Computes the time aware PageRank defined by the following random walk
Create bi-partide graph time graph F whose vertices are the original vertices
of G and the vertex years.
- F contains a copy of G
- edge from each vetex to AND from its year
- edges go from year to the following year
When the random walk is at a vertex of G
- probability qvt transitions to the time node
- probability 1 - qvt does a PageRank move
When the random walk is at a time node
- probability qtv transitions to a vertex in G (of the corresponding year)
- probability 1 - qtv moves to the next year
Parameters
----------
A: adjacency matrix of original matrix where Aij = 1 iff there is an edge from i to j
Y: the years assigned to each node
p: PageRank parameter
qtv: probability of transitioning from time to vertex in original graph
qvt: probability of transitioning from vertx to time
Output
------
"""
# number of vertices in the graph
n = A.shape[0]
outdegrees = A.sum(axis=1)
# zero index the years
Y = np.array(years) - min(years)
# number of years in graph
m = max(Y) + 1
# PageRank transition matrix
# (see murphy 17.37)
D = np.diag([0 if d == 0 else 1.0/d for d in outdegrees])
z = [1.0/n if d == 0 else (1.0 - p) / n for d in outdegrees]
PR = p * np.dot(A.T, D) + np.outer([1] * n, z)
# Time-Time transition matrix
# ones below diagonal
TT = np.zeros((m, m))
TT[1:m, :m-1] = np.diag([1] * (m - 1))
# Vertex-Time transition matrix
# i-th column is the Y[i]th basis vector
VT = np.zeros((m, n))
identity_m = np.eye(m) # for basis vectors
for i in range(n):
VT[:, i] = identity_m[:, Y[i]]
# Time-Vertex transition matrix
# VT transpose but entries are scaled by number of cases in the year
TV = np.zeros((n, m))
# 1 over number of cases per year
n_inv = [0 if cases_per_year[i] == 0 else 1.0/cases_per_year[i] for i in range(m)]
for i in range(n):
TV[i, :] = identity_m[Y[i], :] * n_inv[Y[i]]
# normalization matrix for TV
qtv_diag = [0 if cases_per_year[i] == 0 else qtv for i in range(m)]
qtv_diag[-1] = 1 # last column of TT is zeros
Qtv = np.diag(qtv_diag)
# overall transition matrix
P = np.zeros((n + m, n + m))
# upper left
P[:n, :n] = (1 - qvt) * PR
# upper right
P[:n, -m:] = np.dot(TV, Qtv)
# lower left
P[n:, :-m] = qvt * VT
# lower right
P[-m:, -m:] = np.dot(TT, np.eye(m) - Qtv)
# get PageRank values
leading_eig = get_leading_evector(P)
ta_pr = leading_eig[:n]
pr_years = leading_eig[-m:]
return ta_pr/sum(ta_pr), pr_years/sum(pr_years)
```
# test
```
p = .85
qtv = .8
qvt = .2
%%time
A = np.array(G.get_adjacency().data)
years = np.array(G.vs['year']).astype(int)
%%time
ta_pr, pr_years = time_aware_pagerank(A, years, p, qtv, qvt)
plt.figure(figsize=[10, 5])
# plot pr and ta_pr
plt.subplot(1,2,1)
plt.scatter(range(n), pr, color='blue', label='pr')
plt.scatter(range(n), ta_pr[:n], color='red', label='ta pr')
plt.xlim([0, n])
plt.ylim([0, 1.2 * max(max(ta_pr), max(pr))])
plt.legend(loc='upper right')
plt.xlabel('vertex')
plt.ylabel('pr value')
# plot time
plt.subplot(1,2,2)
plt.scatter(range(min(years), max(years) + 1), ta_pr[-m:])
plt.xlim([min(years), max(years) ])
plt.ylim([0, 1.2 * max(ta_pr[-m:])])
plt.ylabel('pr value')
plt.xlabel('year')
```
|
github_jupyter
|
# Distance Based Statistical Method for Planar Point Patterns
**Authors: Serge Rey <[email protected]> and Wei Kang <[email protected]>**
## Introduction
Distance based methods for point patterns are of three types:
* [Mean Nearest Neighbor Distance Statistics](#Mean-Nearest-Neighbor-Distance-Statistics)
* [Nearest Neighbor Distance Functions](#Nearest-Neighbor-Distance-Functions)
* [Interevent Distance Functions](#Interevent-Distance-Functions)
In addition, we are going to introduce a computational technique [Simulation Envelopes](#Simulation-Envelopes) to aid in making inferences about the data generating process. An [example](#CSR-Example) is used to demonstrate how to use and interpret simulation envelopes.
```
import scipy.spatial
import pysal.lib as ps
import numpy as np
from pysal.explore.pointpats import PointPattern, PoissonPointProcess, as_window, G, F, J, K, L, Genv, Fenv, Jenv, Kenv, Lenv
%matplotlib inline
import matplotlib.pyplot as plt
```
## Mean Nearest Neighbor Distance Statistics
The nearest neighbor(s) for a point $u$ is the point(s) $N(u)$ which meet the condition
$$d_{u,N(u)} \leq d_{u,j} \forall j \in S - u$$
The distance between the nearest neighbor(s) $N(u)$ and the point $u$ is nearest neighbor distance for $u$. After searching for nearest neighbor(s) for all the points and calculating the corresponding distances, we are able to calculate mean nearest neighbor distance by averaging these distances.
It was demonstrated by Clark and Evans(1954) that mean nearest neighbor distance statistics distribution is a normal distribution under null hypothesis (underlying spatial process is CSR). We can utilize the test statistics to determine whether the point pattern is the outcome of CSR. If not, is it the outcome of cluster or regular
spatial process?
Mean nearest neighbor distance statistic
$$\bar{d}_{min}=\frac{1}{n} \sum_{i=1}^n d_{min}(s_i)$$
```
points = [[66.22, 32.54], [22.52, 22.39], [31.01, 81.21],
[9.47, 31.02], [30.78, 60.10], [75.21, 58.93],
[79.26, 7.68], [8.23, 39.93], [98.73, 77.17],
[89.78, 42.53], [65.19, 92.08], [54.46, 8.48]]
pp = PointPattern(points)
pp.summary()
```
We may call the method **knn** in PointPattern class to find $k$ nearest neighbors for each point in the point pattern *pp*.
```
# one nearest neighbor (default)
pp.knn()
```
The first array is the ids of the most nearest neighbor for each point, the second array is the distance between each point and its most nearest neighbor.
```
# two nearest neighbors
pp.knn(2)
pp.max_nnd # Maximum nearest neighbor distance
pp.min_nnd # Minimum nearest neighbor distance
pp.mean_nnd # mean nearest neighbor distance
pp.nnd # Nearest neighbor distances
pp.nnd.sum()/pp.n # same as pp.mean_nnd
pp.plot()
```
## Nearest Neighbor Distance Functions
Nearest neighbour distance distribution functions (including the nearest “event-to-event” and “point-event” distance distribution functions) of a point process are cumulative distribution functions of several kinds -- $G, F, J$. By comparing the distance function of the observed point pattern with that of the point pattern from a CSR process, we are able to infer whether the underlying spatial process of the observed point pattern is CSR or not for a given confidence level.
#### $G$ function - event-to-event
The $G$ function is defined as follows: for a given distance $d$, $G(d)$ is the proportion of nearest neighbor distances that are less than $d$.
$$G(d) = \sum_{i=1}^n \frac{ \phi_i^d}{n}$$
$$
\phi_i^d =
\begin{cases}
1 & \quad \text{if } d_{min}(s_i)<d \\
0 & \quad \text{otherwise } \\
\end{cases}
$$
If the underlying point process is a CSR process, $G$ function has an expectation of:
$$
G(d) = 1-e(-\lambda \pi d^2)
$$
However, if the $G$ function plot is above the expectation this reflects clustering, while departures below expectation reflect dispersion.
```
gp1 = G(pp, intervals=20)
gp1.plot()
```
A slightly different visualization of the empirical function is the quantile-quantile plot:
```
gp1.plot(qq=True)
```
in the q-q plot the csr function is now a diagonal line which serves to make accessment of departures from csr visually easier.
It is obvious that the above $G$ increases very slowly at small distances and the line is below the expected value for a CSR process (green line). We might think that the underlying spatial process is regular point process. However, this visual inspection is not enough for a final conclusion. In [Simulation Envelopes](#Simulation-Envelopes), we are going to demonstrate how to simulate data under CSR many times and construct the $95\%$ simulation envelope for $G$.
```
gp1.d # distance domain sequence (corresponding to the x-axis)
gp1.G #cumulative nearest neighbor distance distribution over d (corresponding to the y-axis))
```
#### $F$ function - "point-event"
When the number of events in a point pattern is small, $G$ function is rough (see the $G$ function plot for the 12 size point pattern above). One way to get around this is to turn to $F$ function where a given number of randomly distributed points are generated in the domain and the nearest event neighbor distance is calculated for each point. The cumulative distribution of all nearest event neighbor distances is called $F$ function.
```
fp1 = F(pp, intervals=20) # The default is to randomly generate 100 points.
fp1.plot()
fp1.plot(qq=True)
```
We can increase the number of intervals to make $F$ more smooth.
```
fp1 = F(pp, intervals=50)
fp1.plot()
fp1.plot(qq=True)
```
$F$ function is more smooth than $G$ function.
#### $J$ function - a combination of "event-event" and "point-event"
$J$ function is defined as follows:
$$J(d) = \frac{1-G(d)}{1-F(d)}$$
If $J(d)<1$, the underlying point process is a cluster point process; if $J(d)=1$, the underlying point process is a random point process; otherwise, it is a regular point process.
```
jp1 = J(pp, intervals=20)
jp1.plot()
```
From the above figure, we can observe that $J$ function is obviously above the $J(d)=1$ horizontal line. It is approaching infinity with nearest neighbor distance increasing. We might tend to conclude that the underlying point process is a regular one.
## Interevent Distance Functions
Nearest neighbor distance functions consider only the nearest neighbor distances, "event-event", "point-event" or the combination. Thus, distances to higher order neighbors are ignored, which might reveal important information regarding the point process. Interevent distance functions, including $K$ and $L$ functions, are proposed to consider distances between all pairs of event points. Similar to $G$, $F$ and $J$ functions, $K$ and $L$ functions are also cumulative distribution function.
#### $K$ function - "interevent"
Given distance $d$, $K(d)$ is defined as:
$$K(d) = \frac{\sum_{i=1}^n \sum_{j=1}^n \psi_{ij}(d)}{n \hat{\lambda}}$$
where
$$
\psi_{ij}(d) =
\begin{cases}
1 & \quad \text{if } d_{ij}<d \\
0 & \quad \text{otherwise } \\
\end{cases}
$$
$\sum_{j=1}^n \psi_{ij}(d)$ is the number of events within a circle of radius $d$ centered on event $s_i$ .
Still, we use CSR as the benchmark (null hypothesis) and see how the $K$ function estimated from the observed point pattern deviate from that under CSR, which is $K(d)=\pi d^2$. $K(d)<\pi d^2$ indicates that the underlying point process is a regular point process. $K(d)>\pi d^2$ indicates that the underlying point process is a cluster point process.
```
kp1 = K(pp)
kp1.plot()
```
#### $L$ function - "interevent"
$L$ function is a scaled version of $K$ function, defined as:
$$L(d) = \sqrt{\frac{K(d)}{\pi}}-d$$
```
lp1 = L(pp)
lp1.plot()
```
## Simulation Envelopes
A [Simulation envelope](http://www.esajournals.org/doi/pdf/10.1890/13-2042.1) is a computer intensive technique for inferring whether an observed pattern significantly deviates from what would be expected under a specific process. Here, we always use CSR as the benchmark. In order to construct a simulation envelope for a given function, we need to simulate CSR a lot of times, say $1000$ times. Then, we can calculate the function for each simulated point pattern. For every distance $d$, we sort the function values of the $1000$ simulated point patterns. Given a confidence level, say $95\%$, we can acquire the $25$th and $975$th value for every distance $d$. Thus, a simulation envelope is constructed.
#### Simulation Envelope for G function
**Genv** class in pysal.
```
realizations = PoissonPointProcess(pp.window, pp.n, 100, asPP=True) # simulate CSR 100 times
genv = Genv(pp, intervals=20, realizations=realizations) # call Genv to generate simulation envelope
genv
genv.observed
genv.plot()
```
In the above figure, **LB** and **UB** comprise the simulation envelope. **CSR** is the mean function calculated from the simulated data. **G** is the function estimated from the observed point pattern. It is well below the simulation envelope. We can infer that the underlying point process is a regular one.
#### Simulation Envelope for F function
**Fenv** class in pysal.
```
fenv = Fenv(pp, intervals=20, realizations=realizations)
fenv.plot()
```
#### Simulation Envelope for J function
**Jenv** class in pysal.
```
jenv = Jenv(pp, intervals=20, realizations=realizations)
jenv.plot()
```
#### Simulation Envelope for K function
**Kenv** class in pysal.
```
kenv = Kenv(pp, intervals=20, realizations=realizations)
kenv.plot()
```
#### Simulation Envelope for L function
**Lenv** class in pysal.
```
lenv = Lenv(pp, intervals=20, realizations=realizations)
lenv.plot()
```
## CSR Example
In this example, we are going to generate a point pattern as the "observed" point pattern. The data generating process is CSR. Then, we will simulate CSR in the same domain for 100 times and construct a simulation envelope for each function.
```
from pysal.lib.cg import shapely_ext
from pysal.explore.pointpats import Window
import pysal.lib as ps
va = ps.io.open(ps.examples.get_path("vautm17n.shp"))
polys = [shp for shp in va]
state = shapely_ext.cascaded_union(polys)
```
Generate the point pattern **pp** (size 100) from CSR as the "observed" point pattern.
```
a = [[1],[1,2]]
np.asarray(a)
n = 100
samples = 1
pp = PoissonPointProcess(Window(state.parts), n, samples, asPP=True)
pp.realizations[0]
pp.n
```
Simulate CSR in the same domain for 100 times which would be used for constructing simulation envelope under the null hypothesis of CSR.
```
csrs = PoissonPointProcess(pp.window, 100, 100, asPP=True)
csrs
```
Construct the simulation envelope for $G$ function.
```
genv = Genv(pp.realizations[0], realizations=csrs)
genv.plot()
```
Since the "observed" $G$ is well contained by the simulation envelope, we infer that the underlying point process is a random process.
```
genv.low # lower bound of the simulation envelope for G
genv.high # higher bound of the simulation envelope for G
```
Construct the simulation envelope for $F$ function.
```
fenv = Fenv(pp.realizations[0], realizations=csrs)
fenv.plot()
```
Construct the simulation envelope for $J$ function.
```
jenv = Jenv(pp.realizations[0], realizations=csrs)
jenv.plot()
```
Construct the simulation envelope for $K$ function.
```
kenv = Kenv(pp.realizations[0], realizations=csrs)
kenv.plot()
```
Construct the simulation envelope for $L$ function.
```
lenv = Lenv(pp.realizations[0], realizations=csrs)
lenv.plot()
```
|
github_jupyter
|
```
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.per_process_gpu_memory_fraction = 0.3
tf.Session(config=config)
import keras
from keras.models import *
from keras.layers import *
from keras import optimizers
from keras.applications.resnet50 import ResNet50
from keras.applications.vgg16 import VGG16
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
from keras.backend import tf as ktf
from keras.callbacks import EarlyStopping
from tqdm import tqdm
import numpy as np
import pandas as pd
import sys
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from utils import *
%matplotlib inline
from jupyterthemes import jtplot
jtplot.style()
```
### Data pipeline
```
%%time
X_train = np.load('data/processed/X_train.npy')
print(X_train.shape)
Y_train = np.load('data/processed/Y_train.npy')
print(Y_train.shape)
X_test = np.load('data/processed/X_test.npy')
print(X_test.shape)
# train_data = np.load('models/bottleneck_features_train.npy')
# validation_data = np.load('models/bottleneck_features_validation.npy')
# test_data = np.load('models/bottleneck_features_test.npy')
# X_train, X_dev, Y_train, Y_dev = train_test_split(X_train, Y_train, test_size=0.25, random_state=0)
train_datagen = ImageDataGenerator(
rotation_range = 10,
horizontal_flip = True,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range=0.2,
zoom_range = 0.2,
fill_mode='nearest')
dev_datagen = ImageDataGenerator(rescale=1./255)
def aug_data(X_train, Y_train, batch_count):
X, Y = [], []
count = 0
for bx, by in train_datagen.flow(X_train, Y_train, batch_size=64):
for x, y in zip(bx, by):
X.append(x)
Y.append(y)
count+=1
print(count, end='\r')
if count>batch_count:
break
X = np.asarray(X)
Y = np.asarray(Y)
return X, Y
# X, Y = aug_data(X_train, Y_train, 500)
# X = np.load('data/preprocess/X_aug.npy')
# Y = np.load('data/preprocess/Y_aug.npy')
def top_model(input_shape):
input_img = Input(input_shape)
X = GlobalAveragePooling2D()(input_img)
# X = Flatten(input_shape=input_shape)(input_img)
X = Dropout(0.2)(X)
X = Dense(1024, activation='relu')(X)
X = Dropout(0.5)(X)
X = Dense(1024, activation='relu')(X)
X = Dropout(0.5)(X)
X = Dense(120, activation='softmax')(X)
model = Model(inputs=input_img, outputs=X)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
```
### VGG
```
vgg_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3), classes=1)
type(vgg_model)
vgg_model.ad
# vgg_train_bf = vgg_model.predict(X_train, verbose=1)
# vgg_test_bf = vgg_model.predict(X_test, verbose=1)
# np.save('data/processed/vgg_test_bf.npy', vgg_test_bf)
# np.save('data/processed/vgg_train_bf.npy', vgg_train_bf)
vgg_train_bf = np.load('data/processed/vgg_train_bf.npy')
vgg_test_bf = np.load('data/processed/vgg_test_bf.npy')
vggtop_model = top_model(vgg_train_bf.shape[1:])
vggtop_history = vggtop_model.fit(vgg_train_bf, Y_train, batch_size=100, epochs=30, validation_split=0.2,
callbacks=[EarlyStopping(monitor='val_acc', patience=3, verbose=1)])
plot_training(vggtop_history)
```
## ResNet
```
# base_model = ResNet50(input_tensor=Input((224, 224, 3)), weights='imagenet', include_top=False)
# train_bf = base_model.predict(X_train, verbose=1)
# test_bf = base_model.predict(X_test, verbose=1)
# np.save('data/processed/res_test_bf.npy', test_bf)
# np.save('data/processed/res_train_bf.npy', train_bf)
res_train_bf = np.load('data/processed/res_train_bf.npy')
res_test_bf = np.load('data/processed/res_test_bf.npy')
restop_model = top_model(res_train_bf.shape[1:])
restop_history = restop_model.fit(res_train_bf, Y_train, batch_size=100, epochs=30, validation_split=0.2,
callbacks=[EarlyStopping(monitor='val_acc', patience=3, verbose=1)])
plot_training(restop_history)
```
## InceptionV3
```
# inception_model = InceptionV3(input_tensor=Input((224, 224, 3)), weights='imagenet', include_top=False)
# inc_train_bf = inception_model.predict(X, verbose=1)
# inc_test_bf = inception_model.predict(X_test, verbose=1)
# np.save('data/processed/inc_test_bf.npy', inc_test_bf)
# np.save('data/processed/inc_train_bf.npy', inc_train_bf)
%%time
inc_train_bf = np.load('data/processed/inc_train_bf.npy')
Y = np.load('data/processed/Y_aug.npy')
inc_test_bf = np.load('data/processed/inc_test_bf.npy')
inctop_model = top_model(inc_train_bf.shape[1:])
inc_history = inctop_model.fit(inc_train_bf, Y, batch_size=100, epochs=25, validation_split=0.2,
callbacks=[EarlyStopping(monitor='val_acc', patience=3, verbose=1)])
plot_training(inc_history)
inctop_model.save_weights('models/weights/inctop1.h5')
inctop_model.load_weights('models/weights/inctop1.h5')
inctop_model.optimizer.lr = 0.1
inc_history = inctop_model.fit(inc_train_bf, Y, batch_size=100, epochs=20, validation_split=0.2,
callbacks=[EarlyStopping(monitor='val_acc', patience=3, verbose=1)])
plot_training(inc_history)
inctop_model.save_weights('models/weights/inctop2.h5')
inctop_model.load_weights('models/weights/inctop2.h5')
inctop_model.optimizer.lr = 0.01
inc_history = inctop_model.fit(inc_train_bf, Y, batch_size=100, epochs=5, validation_split=0.2)
plot_training(inc_history)
inctop_model.save_weights('models/weights/inctop3.h5')
inctop_model.optimizer.lr = 0.001
inc_history = inctop_model.fit(inc_train_bf, Y, batch_size=100, epochs=5, validation_split=0.2)
plot_training(inc_history)
inctop_model.load_weights('models/weights/inctop4.h5')
inctop_model.evaluate(inc_train_bf, Y)
```
## Fine tuning
```
def ft_model(base_model, top_model_weights_path):
top = top_model(base_model.output_shape[1:])
top.load_weights(top_model_weights_path)
# x = base_model.predict(X_train)
# print(top.evaluate(x, Y_train))
ft_model = Model(inputs=base_model.inputs, outputs=top(base_model.output))
ft_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
return ft_model
inception_model = InceptionV3(input_tensor=Input((224, 224, 3)), weights='imagenet', include_top=False)
for layer in inception_model.layers[:299]:
layer.trainable = False
# inc_train_bf = inception_model.predict(X_train, verbose=1)
inc_ft_model = ft_model(inception_model, 'models/inctop_model.h5')
# inc_ft_model.evaluate(X_train, Y_train)
# inc_ft_model.summary()
inc_ft_history = inc_ft_model.fit(X_train, Y_train, batch_size=50, epochs=20, validation_split=0.2,
callbacks=[EarlyStopping(monitor='val_acc', patience=3, verbose=1)])
plot_training(inc_ft_history)
inc_ft_model2 = ft_model(inception_model, 'models/inctop_model.h5')
inc_ft_model2.fit_generator(
train_generator,
steps_per_epoch=X_train.shape[0] // batch_size,
epochs=20,
verbose=1)
```
## Prediction
```
preds = inctop_model.predict(inc_test_bf, verbose=1, batch_size=16)
df_train = pd.read_csv('labels.csv')
df_test = pd.read_csv('sample_submission.csv')
one_hot = pd.get_dummies(df_train['breed'], sparse = True)
sub = pd.DataFrame(preds)
sub.columns = one_hot.columns.values
sub.insert(0, 'id', df_test['id'])
sub.to_csv('sub.csv', index=False)
```
|
github_jupyter
|
# Loss and Regularization
```
%load_ext autoreload
%autoreload 2
import numpy as np
from numpy import linalg as nplin
from cs771 import plotData as pd
from cs771 import optLib as opt
from sklearn import linear_model
from matplotlib import pyplot as plt
from matplotlib.ticker import MaxNLocator
import random
```
**Loading Benchmark Datasets using _sklearn_**: the _sklearn_ library, along with providing methods for various ML problems like classification, regression and clustering, also gives the facility to download various datasets. We will use the _Boston Housing_ dataset that requires us to predict house prices in the city of Boston using 13 features such as crime rates, pollution levels, education facilities etc. Check this [[link]](https://scikit-learn.org/stable/datasets/index.html#boston-dataset) to learn more.
**Caution**: when executing the dataset download statement for the first time, sklearn will attempt to download this dataset from an internet source. Make sure you have a working internet connection at this point otherwise the statement will fail. Once you have downloaded the dataset once, it will be cached and you would not have to download it again and again.
```
from sklearn.datasets import load_boston
(X, y) = load_boston( return_X_y=True )
(n, d) = X.shape
print( "This dataset has %d data points and %d features" % (n,d) )
print( "The mean value of the (real-valued) labels is %.2f" % np.mean(y) )
```
**Experiments with Ridge Regression**: we first use rigde regression (that uses the least squares loss and $L_2$ regularization) to try and solve this problem. We will try out a variety of regularization parameters ranging across 15 orders of magnitude from $10^{-4}$ all the way to $10^{11}$. Note that as the regularization parameter increases, the model norm drops significantly so that at extremely high levels of regularization, the learnt model is almost a zero vector. Naturally, such a trivial model offers poor prediction hence, beyond a point, increasing the regularization parameter decreases prediction performance. We measure prediction performance in term of _mean absolute error_ (shortened to MAE).
**Regularization Path**: the concept of a regularization path traces the values different coordinates of the model take when the problem is solved using various values of the regularization parameter. Note that initially, when there is very feeble regularization (say $\alpha = 10^{-4}$), model coordinates take large magnitude values, some positive, others negative. However, as regularization increases, all model coordinate values _shrink_ towards zero.
```
alphaVals = np.concatenate( [np.linspace( 1e-4 * 10**i, 1e-4 * 10**(i+1), num = 5 )[:-1] for i in range(15)] )
MAEVals = np.zeros_like( alphaVals )
modelNorms = np.zeros_like( alphaVals )
models = np.zeros( (X.shape[1], len(alphaVals)) )
for i in range( len(alphaVals) ):
reg = linear_model.Ridge( alpha = alphaVals[i] )
reg.fit( X, y )
w = reg.coef_
b = reg.intercept_
MAEVals[i] = np.mean( np.abs( X.dot(w) + b - y ) )
modelNorms[i] = nplin.norm( w, 2 )
models[:,i] = w
bestRRMAENoCorr = min( MAEVals )
fig = pd.getFigure( 7, 7 )
ax = plt.gca()
ax.set_title( "The effect of the strength of L2 regularization on performance" )
ax.set_xlabel( "L2 Regularization Parameter Value" )
ax.set_ylabel( "Mean Absolute Error", color = "r" )
ax.semilogx( alphaVals, MAEVals, color = 'r', linestyle = '-' )
ax2 = ax.twinx()
ax2.set_ylabel( "Model Complexity (L2 Norm)", color = "b" )
ax2.semilogx( alphaVals, modelNorms, color = 'b', linestyle = '-' )
fig2 = pd.getFigure( 7, 7 )
plt.figure( fig2.number )
plt.title( "The Regularization Path for L2 regularization" )
plt.xlabel( "L2 Regularization Parameter Value" )
plt.ylabel( "Value of Various Coordinates of Models" )
for i in range(d):
plt.semilogx( alphaVals, models[i,:] )
```
**Robust Regression**: we will now investigate how to deal with cases when the data is corrupted. We will randomly choose 25% of the data points and significantly change their labels (i.e. $y$ values). We will note that ridge regression fails to offer a decent solution no matter what value of the regression parameter we choose. The best MAE offered by ridge regression in this case is 8.1 whereas it was around 3.2 when data was not corrupted. Clearly $L_2$ regularization is not a good option when data is maliciously or adversarially corrupted.
```
# How many points do we want to corrupt?
k = int( 0.25 * n )
corr = np.zeros_like( y )
idx_corr = np.random.permutation( n )[:k]
# What diff do we want to introduce in the labels of the corrupted data points?
corr[idx_corr] = 30
y_corr = y + corr
MAEVals = np.zeros_like( alphaVals )
modelNorms = np.zeros_like( alphaVals )
for i in range( len(alphaVals) ):
reg = linear_model.Ridge( alpha = alphaVals[i] )
reg.fit( X, y_corr )
w = reg.coef_
b = reg.intercept_
MAEVals[i] = np.mean( np.abs( X.dot(w) + b - y ) )
modelNorms[i] = nplin.norm( w, 2 )
bestRRMAE = min( MAEVals )
fig3 = pd.getFigure( 7, 7 )
ax = plt.gca()
ax.set_title( "L2 regularization on Corrupted Data" )
ax.set_xlabel( "L2 Regularization Parameter Value" )
ax.set_ylabel( "Mean Absolute Error", color = "r" )
ax.semilogx( alphaVals, MAEVals, color = 'r', linestyle = '-' )
ax2 = ax.twinx()
ax2.set_ylabel( "Model Complexity (L2 Norm)", color = "b" )
ax2.semilogx( alphaVals, modelNorms, color = 'b', linestyle = '-' )
```
**Alternating Minimization for Robust Regression**: a simple heuristic that works well in such corrupted data settings is to learn the model and try to identify the subset of the data that is corrupted simultaneously. A variant of this heuristic, as presented in the _TORRENT_ algorithm is implemented below. At each time step, this method takes an existing model and postulates that data points with high residuals with respect to this model may be corrupted and sets them aside. Ridge regression is then carried out with the rest of the data points to update the model.
The results show that this simple heuristic not only offers a much better MAE (of around 3.2, the same that ridge regression offered when executed with clean data) but that the method is able to identify most of the data points that were corrupted. The method converges in only a couple of iterations.
**Reference**\
Kush Bhatia, Prateek Jain and P.K., _Robust Regression via Hard Thresholding_ , Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), 2015.
```
# How many iterations do we wish to run the algorithm
horizon = 10
MAEVals = np.zeros( (horizon,) )
suppErrVals = np.zeros( (horizon,) )
# Initialization
w = np.zeros( (d,) )
b = 0
reg = linear_model.Ridge( alpha = 0.005 )
# Find out how many of the corrupted data points were correctly identified by the algorithm
def getSupportIden( idx, idxAst ):
return len( set(idxAst).intersection( set(idx) ) )
# Implement the TORRENT algorithm
for t in range( horizon ):
MAEVals[t] = np.mean( np.abs( X.dot(w) + b - y ) )
# Find out the data points with largest residual -- these maybe the corrupted points
res = np.abs( X.dot(w) + b - y_corr )
idx_sorted = np.argsort( res )
idx_clean_hat = idx_sorted[0:n-k]
idx_corr_hat = idx_sorted[-k:]
suppErrVals[t] = getSupportIden( idx_corr, idx_corr_hat )
# The points with low residuals are used to update the model
XClean = X[idx_clean_hat,:]
yClean = y_corr[idx_clean_hat]
reg.fit( XClean, yClean )
w = reg.coef_
b = reg.intercept_
fig4 = pd.getFigure( 7, 7 )
plt.plot( np.arange( horizon ), bestRRMAE * np.ones_like(suppErrVals), color = 'r', linestyle = ':', label = "Best MAE achieved by Ridge Regression on Corrupted Data" )
plt.plot( np.arange( horizon ), bestRRMAENoCorr * np.ones_like(suppErrVals), color = 'g', linestyle = ':', label = "Best MAE achieved by Ridge Regression on Clean Data" )
plt.legend()
ax = plt.gca()
ax.set_title( "Alternating Minimization on Corrupted Data" )
ax.set_xlabel( "Number of Iterations" )
ax.set_ylabel( "Mean Absolute Error", color = "r" )
ax.plot( np.arange( horizon ), MAEVals, color = 'r', linestyle = '-' )
plt.ylim( np.floor(min(MAEVals)), np.ceil(bestRRMAE) )
ax2 = ax.twinx()
ax2.set_ylabel( "Number of Corrupted Indices (out of %d) Identified Correctly" % k, color = "b" )
ax2.yaxis.set_major_locator( MaxNLocator( integer = True ) )
ax2.plot( np.arange( horizon ), suppErrVals, color = 'b', linestyle = '-' )
plt.ylim( min(suppErrVals)-1, k )
```
**Spurious Features present a Sparse Recovery Problem**: in this experiment we add 500 new features to the dataset (with the new features containing nothing but pure random white noise), taking the total number of features to 513 which is greater than the total number of data points which is 506. Upon executing ridge regression on this dataset, we find something very surprising. We find that at low levels of regularization, the method offers almost zero MAE!
The above may seem paradoxical since the new features were white noise and had nothing informative to say about the problem. What happened was that these new features increased the power of the linear model and since there was not enough data, ridge regression used these new features to artificially reduce the error. This is clear from the regularization path plot.
Such a model is actually not very useful since it would not perform very well on test data. To do well on test data, the only way is to identify the truly informative features (of which there are only 13). Note that in the error plot, the blue curve demonstrates the amount of weight the model puts on the spurious features. Only when there is heavy regularization (around $\alpha = 10^4$ does the model stop placing large weights on the spurious features and error levels climb to around 3.2, where they were when spurious features were not present. Thus, L2 regularization may not be the best option when there are several irrelevant features.
```
X_spurious = np.random.normal( 0, 1, (n, 500) )
X_extend = np.hstack( (X, X_spurious) )
(n,d) = X_extend.shape
MAEVals = np.zeros_like( alphaVals )
spuriousModelNorms = np.zeros_like( alphaVals )
models = np.zeros( (d, len(alphaVals)) )
for i in range( len(alphaVals) ):
reg = linear_model.Ridge( alpha = alphaVals[i] )
reg.fit( X_extend, y )
w = reg.coef_
b = reg.intercept_
MAEVals[i] = np.mean( np.abs( X_extend.dot(w) + b - y ) )
spuriousModelNorms[i] = nplin.norm( w[13:], 2 )
models[:,i] = w
fig5 = pd.getFigure( 7, 7 )
plt.plot( alphaVals, bestRRMAENoCorr * np.ones_like(alphaVals), color = 'g', linestyle = ':', label = "Best MAE achieved by Ridge Regression on Original Data" )
plt.legend()
ax = plt.gca()
ax.set_title( "Effect of L2 regularization with Spurious Features" )
ax.set_xlabel( "L2 Regularization Parameter Value" )
ax.set_ylabel( "Mean Absolute Error", color = "r" )
ax.semilogx( alphaVals, MAEVals, color = 'r', linestyle = '-' )
ax2 = ax.twinx()
ax2.set_ylabel( "Weight on Spurious Features", color = "b" )
ax2.semilogx( alphaVals, spuriousModelNorms, color = 'b', linestyle = '-' )
fig6 = pd.getFigure( 7, 7 )
plt.figure( fig6.number )
plt.title( "The Regularization Path for L2 regularization with Spurious Features" )
plt.xlabel( "L2 Regularization Parameter Value" )
plt.ylabel( "Value of Various Coordinates of Models" )
for i in range(d):
plt.semilogx( alphaVals, models[i,:] )
```
**LASSO for Sparse Recovery**: the LASSO (Least Absolute Shrinkage and Selection Operator) performs regression using the least squares loss and the $L_1$ regularizer instead. The error plot and the regularization path plots show that LASSO offers a far quicker identification of the spurious features. LASSO is indeed a very popular technique to deal with sparse recovery when we have very less data and suspect that there may be irrelevant features.
```
MAEVals = np.zeros_like( alphaVals )
spuriousModelNorms = np.zeros_like( alphaVals )
models = np.zeros( (X_extend.shape[1], len(alphaVals)) )
for i in range( len(alphaVals) ):
reg = linear_model.Lasso( alpha = alphaVals[i] )
reg.fit( X_extend, y )
w = reg.coef_
b = reg.intercept_
MAEVals[i] = np.mean( np.abs( X_extend.dot(w) + b - y ) )
spuriousModelNorms[i] = nplin.norm( w[13:], 2 )
models[:,i] = w
fig5 = pd.getFigure( 7, 7 )
plt.plot( alphaVals, bestRRMAENoCorr * np.ones_like(alphaVals), color = 'g', linestyle = ':', label = "Best MAE achieved by Ridge Regression on Original Data" )
plt.legend()
ax = plt.gca()
ax.set_title( "Examining the effect of the strength of L1 regularization" )
ax.set_xlabel( "L1 Regularization Parameter Value" )
ax.set_ylabel( "Mean Absolute Error", color = "r" )
ax.semilogx( alphaVals, MAEVals, color = 'r', linestyle = '-' )
ax2 = ax.twinx()
ax2.set_ylabel( "Weight on Spurious Features", color = "b" )
ax2.semilogx( alphaVals, spuriousModelNorms, color = 'b', linestyle = '-' )
fig6 = pd.getFigure( 7, 7 )
plt.figure( fig6.number )
plt.title( "Plotting the Regularization Path for L1 regularization" )
plt.xlabel( "L2 Regularization Parameter Value" )
plt.ylabel( "Value of Various Coordinates of Models" )
for i in range(X_extend.shape[1]):
plt.semilogx( alphaVals, models[i,:] )
```
**Proximal Gradient Descent to solve LASSO**: we will now implement the proximal gradient descent method to minimize the LASSO objective. The _ProxGD_ method performs a usual gradient step and then applies the _prox operator_ corresponding to the regularizer. For the $L_1$ regularizer $\lambda\cdot\|\cdot\|_1$, the prox operator $\text{prox}_{\lambda\cdot\|\cdot\|_1}$ is simply the so-called _soft-thresholding_ operator described below. If $\mathbf z = \text{prox}_{\lambda\cdot\|\cdot\|_1}(\mathbf x)$, then for all $i \in [d]$, we have
$$
\mathbf z_i = \begin{cases} \mathbf x_i - \lambda & \mathbf x_i > \lambda \\ 0 & |\mathbf x_i| \leq \lambda \\ \mathbf x_i + \lambda & \mathbf x_i < -\lambda \end{cases}
$$
Applying ProxGD to the LASSO problem is often called _ISTA_ (Iterative Soft Thresholding Algorithm) for this reason. Note that at time $t$, if the step length used for the gradient step is $\eta_t$, then the prox operator corresponding to $\text{prox}_{\lambda_t\cdot\|\cdot\|_1}$ is used where $\lambda_t = \eta_t\cdot\lambda$ and $\lambda$ is the regularization parameter in the LASSO problem we are trying to solve. Thus, ISTA requires shrinkage to be smaller if we are also using small step sizes.
To speed up convergence, _acceleration_ techniques (e.g. NAG, Adam) are helpful. We will use a very straightforward acceleration technique which simply sets
$$
\mathbf w^t = \mathbf w^t + \frac {t}{t+1}\cdot(\mathbf w^t - \mathbf w^{t-1})
$$
In particular, the application of Nesterov's acceleartion i.e. NAG to ISTA gives us the so-called _FISTA_ (Fast ISTA).
```
# Get the MAE and LASSO objective
def getLASSOObj( model ):
w = model[:-1]
b = model[-1]
res = X_extend.dot(w) + b - y
objVal = alpha * nplin.norm( w, 1 ) + 1/(2*n) * ( nplin.norm( res ) ** 2 )
MAEVal = np.mean( np.abs( res ) )
return (objVal, MAEVal)
# Apply the prox operator and also apply acceleration
def doSoftThresholding( model, t ):
global modelPrev
w = model[:-1]
b = model[-1]
# Shrink all model coordinates by the effective value of alpha
idx = w < 0
alphaEff = alpha * stepFunc(t)
w = np.abs(w) - alphaEff
w[w < 0] = 0
w[idx] = w[idx] * -1
model = np.append( w, b )
# Acceleration step improves convergence rate
model = model + (t/(t+1)) * (model - modelPrev)
modelPrev = model
return model
# Get the gradient to the loss function in LASSO (just the least squares part)
# Note that gradients w.r.t the regularizer are not required in proximal gradient
# This is one reason why they are useful with non-differentiable regularizers
def getLASSOGrad( model, t ):
w = model[:-1]
b = model[-1]
samples = random.sample( range(0, n), B )
X_ = X_extend[samples,:]
y_ = y[samples]
res = X_.dot(w) + b - y_
grad = np.append( X_.T.dot(res), np.sum(res) )
return grad/B
# Set hyperparameters and initialize the model
alpha = 1
B = 10
eta = 2e-6
init = np.zeros( (d+1,) )
modelPrev = np.zeros( (d+1,) )
# A constant step length seems to work well here
stepFunc = opt.stepLengthGenerator( "constant", eta )
(modelProxGD, objProxGD, timeProxGD) = opt.doGD( getLASSOGrad, stepFunc, getLASSOObj, init, horizon = 50000, doModelAveraging = True, postGradFunc = doSoftThresholding )
objVals = [objProxGD[i][0] for i in range(len(objProxGD))]
MAEVals = [objProxGD[i][1] for i in range(len(objProxGD))]
fig7 = pd.getFigure( 7, 7 )
ax = plt.gca()
ax.set_title( "An Accelerated ProxGD Solver for LASSO" )
ax.set_xlabel( "Elapsed time (sec)" )
ax.set_ylabel( "Objective Value for LASSO", color = "r" )
ax.plot( timeProxGD, objVals, color = 'r', linestyle = ':' )
ax2 = ax.twinx()
ax2.set_ylabel( "MAE Value for LASSO", color = "b" )
ax2.plot( timeProxGD, MAEVals, color = 'b', linestyle = '--' )
plt.ylim( 2, 10 )
```
**Improving the Performance of ProxGD**: there are several steps one can adopt to get better performance
1. Use a line search method to tune the step length instead of using a fixed step length or a regular schedule
1. Perform a better implementation of the acceleration step (which may require additional hyperparameters)
1. The Boston housing problem is what is called _ill-conditioned_ (this was true even before spurious features were added). Advanced methods like conjugate gradient descent (beyond the scope of CS771) perform better for ill-conditioned problems.
1. Use better solvers -- coordinate descent solvers for the Lagrangian dual of the LASSO are known to offer superior performance.
**Data Normalization to Improve Data Conditioning**: in some cases (and fortunately, this happens to be one of them), the data conditioning can be improved somewhat by normalizing the data features. This does not change the problem (we will see below how) but it definitely makes life easier for the solvers. Professional solvers such as those used within libraries such as sklearn often attempt to normalize data themselves.
The two most common data normalization steps are
1. _Mean centering_ : we calculate the mean/average feature vector from the data set $\mathbf \mu \in \mathbb R^d$ and subtract it from each feature vector to get centered feature vectors. This has an effect of bringing the dataset feature vectors closer to the origin.
1. _Variance normalization_ : we calculate the standard deviation along each feature as a vector $\mathbf \sigma \in \mathbb R^d$ and divide each centered feature vector by this vector (in an element-wise manner). This has an effect of limiting how wildly any feature can vary.
If you are not familiar with concepts such as mean and variance, please refer to the Statistics Refresher material in the course or else consult some other external source of your liking.
Thus, we transform each feature vector as follows (let $\Sigma \in \mathbb R^{d \times d}$ denote a diagonal matrix with entries of the vector $\mathbf \sigma$ along its diagonal):
$$
\tilde{\mathbf x}^i = \Sigma^{-1}(\mathbf x^i - \mathbf \mu)
$$
We then learn our linear model, say $(\tilde{\mathbf w}, \tilde b)$ over the centered data. We will see that our solvers will thank us for normalizing our data. However, it is very easy to transform this linear model to one that works over the original data (we may want to do this since our test data would not be normalized and normalizing test data may take precious time which we may wish to save).
To transform the model to one that works over the original data features, simply notice that we have
$$
\tilde{\mathbf w}^\top\tilde{\mathbf x}^i + \tilde b = \tilde{\mathbf w}^\top\Sigma^{-1}(\mathbf x^i - \mathbf \mu) + \tilde b = \mathbf w^\top\mathbf x^i + b,
$$
where $\mathbf w = \Sigma^{-1}\tilde{\mathbf w}$ and $b = \tilde b - \tilde{\mathbf w}^\top\Sigma^{-1}\mathbf \mu$ (we exploited the fact that $\Sigma$ being a diagonal matrix, is a symmetric matrix)
```
# Normalize data
mu = np.mean( X_extend, axis = 0 )
sg = np.std( X_extend, axis = 0 )
XNorm = (X_extend - mu)/sg
# The original dataset is still recoverable from the centered data
if np.allclose( X_extend, XNorm * sg + mu, atol = 1e-7 ):
print( "Successfully recovered the original data from the normalized data" )
```
**Running ProxGD on Normalized Data**: we will have to make two simple changes. Firstly, we will need to change the gradient calculator method to perform gradient computations with normalized data. Secondly, we will change the method that calculates the objective values since we want evaluation to be still done on unnormalized data (to demonstrate that the model can be translated to work with unnormalized data).
```
# Get the MAE and LASSO objective on original data by translating the model
def getLASSOObjNorm( model ):
w = model[:-1]
b = model[-1]
# Translate the model to work with original data features
b = b - w.dot(mu / sg)
w = w / sg
res = X_extend.dot(w) + b - y
objVal = alpha * nplin.norm( w, 1 ) + 1/(2*n) * ( nplin.norm( res ) ** 2 )
MAEVal = np.mean( np.abs( res ) )
return (objVal, MAEVal)
# Get the gradient to the loss function in LASSO for normalized data
def getLASSOGradNorm( model, t ):
w = model[:-1]
b = model[-1]
samples = random.sample( range(0, n), B )
X_ = XNorm[samples,:]
y_ = y[samples]
res = X_.dot(w) + b - y_
grad = np.append( X_.T.dot(res), np.sum(res) )
return grad/B
# Set hyperparameters and initialize the model as before
# Since our normalized data is better conditioned, we are able to use a much
# bigger value of the step length parameter which leads to faster progress
alpha = 1
B = 10
eta = 1e-2
init = np.zeros( (d+1,) )
modelPrev = np.zeros( (d+1,) )
# A constant step length seems to work well here
stepFunc = opt.stepLengthGenerator( "constant", eta )
# Notice that we are running the ProxGD method for far fewer iterations (1000)
# than we did (50000) when we had badly conditioned data
(modelProxGD, objProxGD, timeProxGD) = opt.doGD( getLASSOGradNorm, stepFunc, getLASSOObjNorm, init, horizon = 1000, doModelAveraging = True, postGradFunc = doSoftThresholding )
objVals = [objProxGD[i][0] for i in range(len(objProxGD))]
MAEVals = [objProxGD[i][1] for i in range(len(objProxGD))]
fig8 = pd.getFigure( 7, 7 )
ax = plt.gca()
ax.set_title( "The Accelerated ProxGD Solver on Normalized Data" )
ax.set_xlabel( "Elapsed time (sec)" )
ax.set_ylabel( "Objective Value for LASSO", color = "r" )
ax.plot( timeProxGD, objVals, color = 'r', linestyle = ':' )
ax2 = ax.twinx()
ax2.set_ylabel( "MAE Value for LASSO", color = "b" )
ax2.plot( timeProxGD, MAEVals, color = 'b', linestyle = '--' )
plt.ylim( 2, 10 )
```
**Support Recovery**: we note that our accelerated ProxGD is able to offer good support recovery. If we look at the top 13 coordinates of the model learnt by ProxGD in terms of magnitude, we find that several of them are actually the non-spurious features. We should note that one of the features of the original data, namely the fourth coordinate called CHAS (Charles River dummy variable) is, as its name suggests, known to be a dummy variable itself (see [[link]](https://scikit-learn.org/stable/datasets/index.html#boston-dataset) to learn more) with nothing to do with the regression problem!
```
idxTop = np.argsort( np.abs(modelProxGD) )[::-1][:13]
print( "The top 13 coordinates in terms of magnitude are \n ", idxTop )
print( "These contain %d of the non-spurious coordinates" % len( set(idxTop).intersection( set(np.arange(13)) ) ) )
```
|
github_jupyter
|
# Import statements
```
from google.colab import drive
drive.mount('/content/drive')
from my_ml_lib import MetricTools, PlotTools
import os
import numpy as np
import matplotlib.pyplot as plt
import pickle
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import json
import datetime
import copy
from PIL import Image as im
import joblib
from sklearn.model_selection import train_test_split
# import math as Math
import random
import torch.optim
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import torchvision
import cv2
```
# Saving and Loading code
```
# Saving and Loading models using joblib
def save(filename, obj):
with open(filename, 'wb') as handle:
joblib.dump(obj, handle, protocol=pickle.HIGHEST_PROTOCOL)
def load(filename):
with open(filename, 'rb') as handle:
return joblib.load(filename)
```
# Importing Dataset
```
p = "/content/drive/MyDrive/A3/"
data_path = p + "dataset/train.pkl"
x = load(data_path)
# save_path = "/content/drive/MyDrive/SEM-2/05-DL /Assignments/A3/dataset/"
# # saving the images and labels array
# save(save_path + "data_image.pkl",data_image)
# save(save_path + "data_label.pkl",data_label)
# # dict values where labels key and image arrays as vlaues in form of list
# save(save_path + "my_dict.pkl",my_dict)
save_path = p+ "dataset/"
# saving the images and labels array
data_image = load(save_path + "data_image.pkl")
data_label = load(save_path + "data_label.pkl")
# dict values where labels key and image arrays as vlaues in form of list
my_dict = load(save_path + "my_dict.pkl")
len(data_image) , len(data_label), my_dict.keys()
```
# Data Class and Data Loaders and Data transforms
```
len(x['names']) ,x['names'][4999] , data_image[0].shape
```
## Splitting the data into train and val
```
X_train, X_test, y_train, y_test = train_test_split(data_image, data_label, test_size=0.10, random_state=42,stratify=data_label )
len(X_train) , len(y_train) , len(X_test) ,len(y_test)
pd.DataFrame(y_test).value_counts()
```
## Data Class
```
class myDataClass(Dataset):
"""Custom dataset class"""
def __init__(self, images, labels , transform=None):
"""
Args:
images : Array of all the images
labels : Correspoing labels of all the images
"""
self.images = images
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# converts image value between 0 and 1 and returns a tensor C,H,W
img = torchvision.transforms.functional.to_tensor(self.images[idx])
target = self.labels[idx]
if self.transform:
img = self.transform(img)
return img,target
```
## Data Loaders
```
batch = 64
train_dataset = myDataClass(X_train, y_train)
test_dataset = myDataClass(X_test, y_test)
train_dataloader = DataLoader(train_dataset, batch_size= batch, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size= batch, shuffle=True)
# next(iter(train_dataloader))[0].shape
len(train_dataloader) , len(test_dataloader)
```
# Train and Test functions
```
def load_best(all_models,model_test):
FILE = all_models[-1]
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_test.parameters(), lr=0)
checkpoint = torch.load(FILE)
model_test.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['optim_state'])
epoch = checkpoint['epoch']
model_test.eval()
return model_test
def train(save_path,epochs,train_dataloader,model,test_dataloader,optimizer,criterion,basic_name):
model_no = 1
c = 1
all_models = []
valid_loss_min = np.Inf
train_losses = []
val_losses = []
for e in range(epochs):
train_loss = 0.0
valid_loss = 0.0
model.train()
for idx, (images,labels) in enumerate(train_dataloader):
images, labels = images.to(device) , labels.to(device)
optimizer.zero_grad()
log_ps= model(images)
loss = criterion(log_ps, labels)
loss.backward()
optimizer.step()
train_loss += ((1 / (idx + 1)) * (loss.data - train_loss))
else:
accuracy = 0
correct = 0
model.eval()
with torch.no_grad():
for idx, (images,labels) in enumerate(test_dataloader):
images, labels = images.to(device) , labels.to(device)
log_ps = model(images)
_, predicted = torch.max(log_ps.data, 1)
loss = criterion(log_ps, labels)
# correct += (predicted == labels).sum().item()
equals = predicted == labels.view(*predicted.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor))
valid_loss += ((1 / (idx + 1)) * (loss.data - valid_loss))
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
e+1,
train_loss,
valid_loss
), "Test Accuracy: {:.3f}".format(accuracy/len(test_dataloader)))
train_losses.append(train_loss)
val_losses.append(valid_loss)
if valid_loss < valid_loss_min:
print('Saving model..' + str(model_no))
valid_loss_min = valid_loss
checkpoint = {
"epoch": e+1,
"model_state": model.state_dict(),
"optim_state": optimizer.state_dict(),
"train_losses": train_losses,
"test_losses": val_losses,
}
FILE = save_path + basic_name +"_epoch_" + str(e+1) + "_model_" + str(model_no)
all_models.append(FILE)
torch.save(checkpoint, FILE)
model_no = model_no + 1
save(save_path + basic_name + "_all_models.pkl", all_models)
return model, train_losses, val_losses, all_models
def plot(train_losses,val_losses,title='Training Validation Loss with CNN'):
plt.plot(train_losses, label='Training loss')
plt.plot(val_losses, label='Validation loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
_ = plt.ylim()
plt.title(title)
# plt.savefig('plots/Training Validation Loss with CNN from scratch.png')
plt.show()
def test(loader, model, criterion, device, name):
test_loss = 0.
correct = 0.
total = 0.
y = None
y_hat = None
model.eval()
for batch_idx, (images, labels) in enumerate(loader):
# move to GPU or CPU
images, labels = images.to(device) , labels.to(device)
target = labels
# forward pass: compute predicted outputs by passing inputs to the model
output = model(images)
# calculate the loss
loss = criterion(output,labels)
# update average test loss
test_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data - test_loss))
# convert output probabilities to predicted class
pred = output.data.max(1, keepdim=True)[1]
if y is None:
y = target.cpu().numpy()
y_hat = pred.data.cpu().view_as(target).numpy()
else:
y = np.append(y, target.cpu().numpy())
y_hat = np.append(y_hat, pred.data.cpu().view_as(target).numpy())
correct += np.sum(pred.view_as(labels).cpu().numpy() == labels.cpu().numpy())
total = total + images.size(0)
# if batch_idx % 20 == 0:
# print("done till batch" , batch_idx+1)
print(name + ' Loss: {:.6f}\n'.format(test_loss))
print(name + ' Accuracy: %2d%% (%2d/%2d)' % (
100. * correct / total, correct, total))
return y, y_hat
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# def train(save_path,epochs,train_dataloader,model,test_dataloader,optimizer,criterion,basic_name)
# def plot(train_losses,val_losses,title='Training Validation Loss with CNN')
# def test(loader, model, criterion, device)
```
# Relu [ X=2 Y=3 Z=1 ]
## CNN-Block-123
### model
```
cfg3 = {
'B123': [16,16,'M',32,32,32,'M',64,'M'],
}
def make_layers3(cfg, batch_norm=True):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'M1':
layers += [nn.MaxPool2d(kernel_size=4, stride=3)]
elif v == 'D':
layers += [nn.Dropout(p=0.5)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
class Model_B123(nn.Module):
'''
Model
'''
def __init__(self, features):
super(Model_B123, self).__init__()
self.features = features
self.classifier = nn.Sequential(
# nn.Linear(1600, 512),
# nn.ReLU(True),
# nn.Linear(512, 256),
# nn.ReLU(True),
# nn.Linear(256, 64),
# nn.ReLU(True),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.features(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# m = Model_B123(make_layers3(cfg3['B123']))
# for i,l in train_dataloader:
# o = m(i)
model3 = Model_B123(make_layers3(cfg3['B123'])).to(device)
learning_rate = 0.01
criterion3 = nn.CrossEntropyLoss()
optimizer3 = optim.Adam(model3.parameters(), lr=learning_rate)
print(model3)
```
### train
```
# !rm '/content/drive/MyDrive/SEM-2/05-DL /Assignments/A3/models_saved_Q1/1_3/bw_blocks/Dropout(0.5)/cnn_block123/'*
# !ls '/content/drive/MyDrive/SEM-2/05-DL /Assignments/A3/models_saved_Q1/1_3/bw_blocks/Dropout(0.5)/cnn_block123/'
save_path3 = p + "models_saved_Q1/1_4/colab_notebooks /Batchnorm_and_pooling/models/"
m, train_losses, val_losses,m_all_models = train(save_path3,30,train_dataloader,model3,test_dataloader,optimizer3,criterion3,"cnn_b123_x2_y3_z1")
```
### Tests and Plots
```
plot(train_losses,val_losses,'Training Validation Loss with CNN-block1')
all_models3 = load(save_path3 + "cnn_b123_x2_y3_z1_all_models.pkl")
FILE = all_models3[-1]
m3 = Model_B123(make_layers3(cfg3['B123'])).to(device)
m3 = load_best(all_models3,m3)
train_y, train_y_hat = test(train_dataloader, m3, criterion3, device, "TRAIN")
cm = MetricTools.confusion_matrix(train_y, train_y_hat, nclasses=10)
PlotTools.confusion_matrix(cm, [i for i in range(10)], title='',
filename='Confusion Matrix with CNN', figsize=(6,6))
test_y, test_y_hat = test(test_dataloader, m3, criterion3, device,"TEST")
cm = MetricTools.confusion_matrix(test_y, test_y_hat, nclasses=10)
PlotTools.confusion_matrix(cm, [i for i in range(10)], title='',
filename='Confusion Matrix with CNN', figsize=(6,6))
```
|
github_jupyter
|
#### From Quarks to Cosmos with AI: Tutorial Day 4
---
# Field-level cosmological inference with IMNN + DELFI
by Lucas Makinen [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/Orcid-ID.png" alt="drawing" width="20"/>](https://orcid.org/0000-0002-3795-6933 "") [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/twitter-graphic.png" alt="drawing" width="20" style="background-color: transparent"/>](https://twitter.com/lucasmakinen?lang=en ""), Tom Charnock [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/Orcid-ID.png" alt="drawing" width="20"/>](https://orcid.org/0000-0002-7416-3107 "Redirect to orcid") [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/twitter-graphic.png" alt="drawing" width="20" style="background-color: transparent"/>](https://twitter.com/t_charnock?lang=en "")), Justin Alsing [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/Orcid-ID.png" alt="drawing" width="20"/>](https://scholar.google.com/citations?user=ICPFL8AAAAAJ&hl=en "Redirect to orcid"), and Ben Wandelt [<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/twitter-graphic.png" alt="drawing" width="20" style="background-color: transparent"/>](https://twitter.com/bwandelt?lang=en "")
>read the paper: [on arXiv tomorrow !]
>get the code: [https://github.com/tlmakinen/FieldIMNNs](https://github.com/tlmakinen/FieldIMNNs)
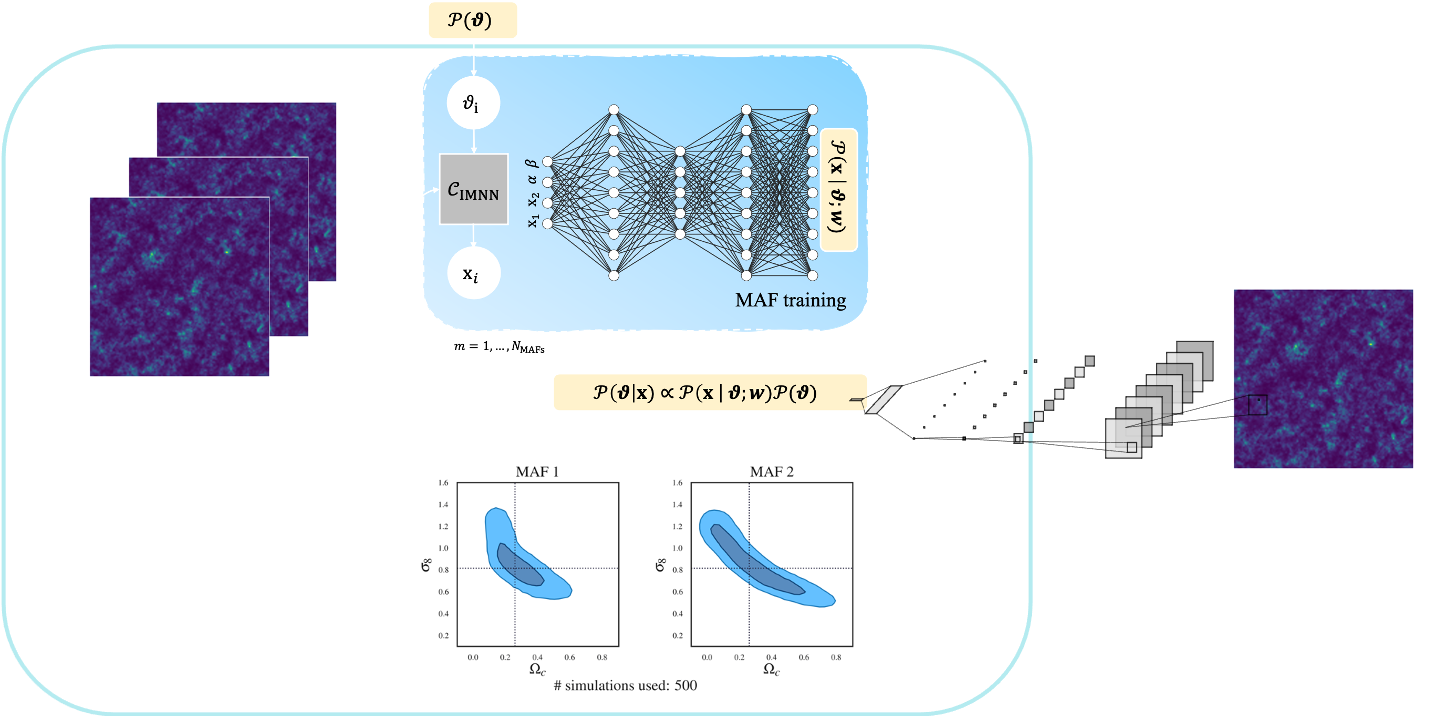
$\quad$
In this tutorial we will demonstrate Implicit Likelihood Inference (IFI) using Density Estimation Likelihood Free Inference (DELFI) with optimal nonlinear summaries obtained from an Information Maximising Neural Network (IMNN). The goal of the exercise will be to build posterior distributions for the cosmological parameters $\Omega_c$ and $\sigma_8$ *directly* from overdensity field simulations.
First we'll install the relevant libraries and walk through the simulation implementation. Then we'll build a neural IMNN compressor to generate two optimal summaries for our simulations. Finally, we'll use these summaries to build and train a Conditional Masked Autoregressive Flow, from which we'll construct our parameter posterior distributions.
### Q: Wait a second -- how do we know this works ?
If you're not convinced by our method by the end of this tutorial, we invite you to take a look at our [benchmarking tutorial with Gaussian fields from power spectra](https://www.aquila-consortium.org/doc/imnn/pages/examples/2d_field_inference/2d_field_inference.html), which is also runnable in-browser on [this Colab notebook](https://colab.research.google.com/drive/1_y_Rgn3vrb2rlk9YUDUtfwDv9hx774ZF#scrollTo=EW4H-R8I0q6n).
---
# HOW TO USE THIS NOTEBOOK
You will (most likely) be running this code using a free version of Google Colab. The code runs just like a Jupyter notebook (`shift` + `enter` or click the play button to run cells). There are some cells with lengthy infrastructure code that you need to run to proceed. These are clearly marked with <font color='lightgreen'>[run me]</font>. When you get to the challenge exercises, you are welcome to code some functions yourself. However, if you want to run the notebook end-to-end, solution code is presented in hidden cells below (again with the marker <font color='lightgreen'>[run me]</font>).
Some cells are not meant to be run here as a part of Quarks to Cosmos, but can be run (with a Colab Pro account) on your own.
---
# step 1: loading packages and setting up environment
1. check that Colab is set to run on a GPU ! Go to `Runtime`>`change runtime type` and select `GPU` from the dropdown menu. Next, enable dark mode by going to `settings`>`Theme` and selecting `dark` (protect your eyes !)
2. install packages. The current code relies on several libraries, namely `jax` and `tensorflow_probability`. However, we require both plain `tensorflow_probability` (`tfp`) and the experimental `tensorflow_probability.substrates.jax` (`tfpj`) packages for different parts of our inference
3. for some Colab sessions, you may need to run the second cell so that `!pip install jax-cosmo` gets the package imported properly.
```
#@title set up environment <font color='lightgreen'>[RUN ME FIRST]</font>
%tensorflow_version 2.x
import tensorflow as tf
print('tf version', tf.__version__)
!pip install -q jax==0.2.11
!pip install -q tensorflow-probability
import tensorflow_probability as tfp
print('tfp version:', tfp.__version__)
tfd = tfp.distributions
tfb = tfp.bijectors
!pip install -q imnn
!python -m pip install -q jax-cosmo
```
note: if the cell below fails for installing jax-cosmo, just run it again: Colab will rearrange the headings needed.
```
# now import all the required libraries
import jax.numpy as np
from jax import grad, jit, vmap
from jax import random
import jax
print('jax version:', jax.__version__)
# for nn model stuff
import jax.experimental.optimizers as optimizers
import jax.experimental.stax as stax
# tensorflow-prob VANILLA
tfd = tfp.distributions
tfb = tfp.bijectors
# tensorflow-prob-JAX
import tensorflow_probability.substrates.jax as tfpj
tfdj = tfpj.distributions
tfbj = tfpj.bijectors
# for imnn
import imnn
import imnn.lfi
print('IMNN version:', imnn.__version__)
# jax-cosmo module
!python -m pip install -q jax-cosmo
import jax_cosmo as jc
print('jax-cosmo version:', jc.__version__)
# matplotlib stuff
import matplotlib.pyplot as plt
from scipy.linalg import toeplitz
import seaborn as sns
sns.set()
rng = random.PRNGKey(2)
from jax.config import config
config.update('jax_enable_x64', True)
```
make sure we're using 64-bit precision and running on a GPU !
```
from jax.lib import xla_bridge
print(xla_bridge.get_backend().platform)
```
# Cosmological Fields from the Eisenstein-Hu linear matter power spectrum
We're interested in extracting the cosmological parameters $\Omega_c$ and $\sigma_8$ *directly* from cosmological field pixels. To generate our simulations we'll need to install the library `jax-cosmo` to generate our differentiable model power spectra.
## choose fiducial model
To train our neural compression, we first need to choose a fiducial model to train the IMNN.
For example lets say that our fiducial cosmology has $\Omega_c=0.40$ and $\sigma_8=0.60$. This is *deliberately* far from, say, Planck parameters -- we want to investigate how our compression behaves if we don't know our universe's true parameters.
```
cosmo_params = jc.Planck15(Omega_c=0.40, sigma8=0.60)
θ_fid = np.array(
[cosmo_params.Omega_c,
cosmo_params.sigma8],
dtype=np.float32)
n_params = θ_fid.shape[0]
```
Our power spectrum $P_{\rm LN}(k)$ is the linear matter power spectrum defined as
```
def P(k, A=0.40, B=0.60):
cosmo_params = jc.Planck15(Omega_c=A, sigma8=B)
return jc.power.linear_matter_power(cosmo_params, k)
```
and we can visualize it in $k$-space (small $k$ <=> big $r$, big $k$ <=> small $r$) :
```
#@title plot the Eisenstein-Hu $P(k)$ <font color='lightgreen'>[run me]</font>
sns.set()
L = 250.
N = 128.
#kmax = 1.0
#kmin = 0.5 / (N)
kmax = N / L
kmin = 1. / L
kbin = np.linspace(kmin, kmax, num=100)
power_spec = P(kbin, A=cosmo_params.Omega_c, B=cosmo_params.sigma8)
plt.style.use('dark_background')
plt.grid(b=None)
plt.plot(kbin, power_spec, linewidth=2)
plt.xlabel(r'$k\ \rm [h\ Mpc^{-1}]$', fontsize=14)
plt.ylabel(r'$P(k)\ \rm$', fontsize=14)
plt.ylim((1e2, 1e4))
plt.xscale('log')
plt.yscale('log')
```
____
## Lognormal Fields from Power Spectra: how much information is embedded in the field ?
Cosmologists often use lognormal fields as "the poor man's large scale structure" since they're analytically interrogable and easy to obtain from Gaussian fields. We'll walk through how to obtain the *theoretical* information content of such fields using the Fisher formalism.
The likelihood for an $N_{\rm pix}\times N_{\rm pix}$ Gaussian field, $\boldsymbol{\delta}$, can be explicitly written down for the Fourier transformed data, $\boldsymbol{\Delta}$ as
$$\mathcal{L}(\boldsymbol{\Delta}|\boldsymbol{\theta}) = \frac{1}{(2\pi)^{N_{\rm pix}^2 / 2} |P_{\rm G}({\bf k}, \boldsymbol{\theta})|^{1/2}}\exp{\left(-\frac{1}{2}\boldsymbol{\Delta}\left(P_{\rm G}({\bf k}, \boldsymbol{\theta})\right)^{-1}\boldsymbol{\Delta}\right)}$$
Since the Fisher information can be calculated from the expectation value of the second derivative of the score, i.e. the log likelihood
$${\bf F}_{\alpha\beta} = - \left.\left\langle\frac{\partial^2\ln\mathcal{L}(\Delta|\boldsymbol{\theta})}{\partial\theta_\alpha\partial\theta_\beta}\right\rangle\right|_{\boldsymbol{\theta}=\boldsymbol{\theta}^\textrm{fid}}$$
then we know that analytically the Fisher information must be
$${\bf F}_{\alpha\beta} = \frac{1}{2} {\rm Tr} \left(\frac{\partial P_{\rm G}({\bf k}, \boldsymbol{\theta})}{\partial\theta_\alpha}\left(P_{\rm G}({\bf k}, \boldsymbol{\theta})\right)^{-1}\frac{\partial P_{\rm G}({\bf k}, \boldsymbol{\theta})}{\partial\theta_\beta}\left(P_{\rm G}({\bf k}, \boldsymbol{\theta})\right)^{-1}\right)$$
where $\alpha$ and $\beta$ label the parameters (for instance $ \Omega_c, \sigma_8$) in the power spectrum. As each $k$-mode is uncoupled for this power law form we require the derivatives
$$\begin{align}
\left(\frac{\partial P_{\rm G}({\bf k}, \boldsymbol{\theta})}{\partial \Omega_c},\
\frac{\partial P_{\rm G}({\bf k}, \boldsymbol{\theta})}{\partial \sigma_8}\right) \\
\end{align}$$
We can set up these derivative functions *so long as our code for $P(k)$ is differentiable*.
For *lognormal* fields, this likelihood changes somewhat. Formally, if a random variable $Y$ has a normal distribution, then the exponential function of $Y$, $X = \exp(Y)$, has a log-normal distribution. We will generate our log-normal fields with a power spectrum such that the *lognormal field has the specified $P_{\rm LN}(k)$*. This means that we need to employ the *backwards conversion formula* , presented by [M. Greiner? and T.A. Enßlin](https://arxiv.org/pdf/1312.1354.pdf), to obtain the correct form for $P_{\rm G}(k)$ needed for the above Fisher evaluation:
$$ P_{\rm G} = \int d^u x e^{i \textbf{k} \cdot \textbf{x}} \ln \left( \int \frac{d^u q}{(2\pi)^u} e^{i \textbf{q} \cdot \textbf{x}} P_{\rm LN}(\textbf{q}) \right) $$
which we can do numerically (and differentiably !) in `Jax`. If you're curious about the computation, check out [this notebook](https://colab.research.google.com/drive/1beknmt3CwjEDFFnZjXRClzig1sf54aMR?usp=sharing). We performed the computation using a Colab Pro account with increased GPU resources to accomodate such large fields. When the smoke clears, our fields have a fiducial theoretical Fisher information content, $|\textbf{F}|_{(0.4, 0.6)}$ of
det_F = 656705.6827
this can be equivalently expressed in terms of the Shannon information (up to a constant, in nats !) of a Gaussian with covariance matrix $\textbf{F}^{-1}$:
shannon info = 0.5 * np.log(det_F) = 6.6975 # nats
When testing our neural IMNN compressor, we used these metrics to verify that we indeed capture the maximal (or close to it) amount of information from our field simulations.
____
# Simulating the universe with power spectra
We can now set the simulator arguments, i.e. the $k$-modes to evaluate, the length of the side of a box, the shape of the box and whether to normalise via the volume and squeeze the output dimensions
## choose $k$-modes (the size of our universe-in-a-box)
Next, we're going to set our $N$-side to 128 (the size of our data vector), $k$-vector, as well as the $L$-side (the physical dimensions of the universe-in-a-box:
```
N = 128
shape = (N, N)
k = np.sqrt(
np.sum(
np.array(
np.meshgrid(
*((np.hstack(
(np.arange(0, _shape // 2 + 1),
np.arange(-_shape // 2 + 1, 0)))
* 2 * np.pi / _shape)**2.
for _shape in shape))),
axis=0))
simulator_args = dict(
k=k, # k-vector (grid units)
L=250, # in Mpc h^-1
shape=shape,
vol_norm=True, # whether to normalise P(k) by volume
N_scale=False, # scale field values up or down
squeeze=True,
log_normal=True)
```
___
## Next, we provide you our universe simulator in `jax`. This is how it works:
### 2D random field simulator in jax
To create a 2D lognormal random field we can follow these steps:
1. Generate a $(N_\textrm{pix}\times N_\textrm{pix})$ white noise field $\varphi$ such that $\langle \varphi_k \varphi_{-k} \rangle' = 1$
2. Fourier Transform $\varphi$ to real space: $R_{\rm white}({\bf x}) \rightarrow R_{\rm white}({\bf k})$
Note that NumPy's DFT Fourier convention is:
$$\phi_{ab}^{\bf k} = \sum_{c,d = 0}^{N-1} \exp{(-i x_c k_a - i x_d k_b) \phi^{\bf x}_{cd}}$$
$$\phi_{ab}^{\bf x} = \frac{1}{N^2}\sum_{c,d = 0}^{N-1} \exp{(-i x_c k_a - i x_d k_b) \phi^{\bf k}_{cd}}$$
3. Evaluate the chosen power spectrum over a field of $k$ values and do the lognormal transformation:
$$P_{\rm LN}(k) \gets \ln(1 + P(k)) $$
Here we need to ensure that this array of amplitudes are Hermitian, e.g. $\phi^{* {\bf k}}_{a(N/2 + b)} = \phi^{{\bf k}}_{a(N/2 - b)}$. This is accomplished by choosing indices $k_a = k_b = \frac{2\pi}{N} (0, \dots, N/2, -N/2+1, \dots, -1)$ (as above) and then evaluating the square root of the outer product of the meshgrid between the two: $k = \sqrt{k^2_a + k^2_b}$. We can then evaluate $P_{\rm LN}^{1/2}(k)$.
4. Scale white noise $R_{\rm white}({\bf k})$ by the power spectrum:
$$R_P({\bf k}) = P_{\rm LN}^{1/2}(k) R_{\rm white}({\bf k}) $$
5. Fourier Transform $R_{P}({\bf k})$ to real space: $R_P({\bf x}) = \int d^d \tilde{k} e^{i{\bf k} \cdot {\bf x}} R_p({\bf k})$
$$R_{ab}^{\bf x} = \frac{1}{N^2}\sum_{c,d = 0}^{N-1} \exp{(-i x_c k_a - i x_d k_b) R^{\bf k}_{cd}}$$
We are going to use a broadcastable jax simultor which takes in a variety of different shaped parameter arrays and vmaps them until a single parameter pair are passed. This is very efficient for generating many simulations at once, for Approximate Bayesian Computation for example.
```
#@title simulator code <font color='lightgreen'>[RUN ME]</font>
def simulator(rng, θ, simulator_args, foregrounds=None):
def fn(rng, A, B):
dim = len(simulator_args["shape"])
L = simulator_args["L"]
if np.isscalar(L):
L = [L] * int(dim)
Lk = ()
shape = ()
for i, _shape in enumerate(simulator_args["shape"]):
Lk += (_shape / L[i],)
if _shape % 2 == 0:
shape += (_shape + 1,)
else:
shape += (_shape,)
k = simulator_args["k"]
k_shape = k.shape
k = k.flatten()[1:]
tpl = ()
for _d in range(dim):
tpl += (_d,)
V = np.prod(np.array(L))
scale = V**(1. / dim)
fft_norm = np.prod(np.array(Lk))
rng, key = jax.random.split(rng)
mag = jax.random.normal(
key, shape=shape)
pha = 2. * np.pi * jax.random.uniform(
key, shape=shape)
# now make hermitian field (reality condition)
revidx = (slice(None, None, -1),) * dim
mag = (mag + mag[revidx]) / np.sqrt(2)
pha = (pha - pha[revidx]) / 2 + np.pi
dk = mag * (np.cos(pha) + 1j * np.sin(pha))
cutidx = (slice(None, -1),) * dim
dk = dk[cutidx]
powers = np.concatenate(
(np.zeros(1),
np.sqrt(P(k, A=A, B=B)))).reshape(k_shape)
if simulator_args['vol_norm']:
powers /= V
if simulator_args["log_normal"]:
powers = np.real(
np.fft.ifftshift(
np.fft.ifftn(
powers)
* fft_norm) * V)
powers = np.log(1. + powers)
powers = np.abs(np.fft.fftn(powers))
fourier_field = powers * dk
fourier_field = jax.ops.index_update(
fourier_field,
np.zeros(dim, dtype=int),
np.zeros((1,)))
if simulator_args["log_normal"]:
field = np.real(np.fft.ifftn(fourier_field)) * fft_norm * np.sqrt(V)
sg = np.var(field)
field = np.exp(field - sg / 2.) - 1.
else:
field = np.real(np.fft.ifftn(fourier_field) * fft_norm * np.sqrt(V)**2)
if simulator_args["N_scale"]:
field *= scale
if foregrounds is not None:
rng, key = jax.random.split(key)
foreground = foregrounds[
jax.random.randint(
key,
minval=0,
maxval=foregrounds.shape[0],
shape=())]
field = np.expand_dims(field + foreground, (0,))
if not simulator_args["squeeze"]:
field = np.expand_dims(field, (0, -1))
return np.array(field, dtype='float32')
if isinstance(θ, tuple):
A, B = θ
else:
A = np.take(θ, 0, axis=-1)
B = np.take(θ, 1, axis=-1)
if A.shape == B.shape:
if len(A.shape) == 0:
return fn(rng, A, B)
else:
keys = jax.random.split(rng, num=A.shape[0] + 1)
rng = keys[0]
keys = keys[1:]
return jax.vmap(
lambda key, A, B: simulator(
key, (A, B), simulator_args=simulator_args))(
keys, A, B)
else:
if len(A.shape) > 0:
keys = jax.random.split(rng, num=A.shape[0] + 1)
rng = keys[0]
keys = keys[1:]
return jax.vmap(
lambda key, A: simulator(
key, (A, B), simulator_args=simulator_args))(
keys, A)
elif len(B.shape) > 0:
keys = jax.random.split(rng, num=B.shape[0])
return jax.vmap(
lambda key, B: simulator(
key, (A, B), simulator_args=simulator_args))(
keys, B)
```
By constructing our random field simulator *and* cosmological power spectrum in `Jax`, we have access to *exact numerical derivatives*, meaning we can simulate a *differentiable* universe. Let's visualize what our universe and derivatives look like at our fiducial model below:
```
#@title visualize a fiducial universe and gradients <font color='lightgreen'>[run me]</font>
from imnn.utils import value_and_jacrev, value_and_jacfwd
def simulator_gradient(rng, θ, simulator_args=simulator_args):
return value_and_jacrev(simulator, argnums=1, allow_int=True, holomorphic=True)(rng, θ, simulator_args=simulator_args)
simulation, simulation_gradient = value_and_jacfwd(simulator, argnums=1)(rng, θ_fid,
simulator_args=simulator_args)
cmap = 'viridis'
from mpl_toolkits.axes_grid1 import make_axes_locatable
fig,ax = plt.subplots(nrows=1, ncols=3, figsize=(12,15))
im1 = ax[0].imshow(np.squeeze(simulation),
extent=(0,1,0,1), cmap=cmap)
ax[0].title.set_text(r'example fiducial $\rm d$')
divider = make_axes_locatable(ax[0])
cax = divider.append_axes('right', size='5%', pad=0.05)
fig.colorbar(im1, cax=cax, orientation='vertical')
im1 = ax[1].imshow(np.squeeze(simulation_gradient).T[0].T,
extent=(0,1,0,1), cmap=cmap)
ax[1].title.set_text(r'$\nabla_{\Omega_m} \rm d$')
divider = make_axes_locatable(ax[1])
cax = divider.append_axes('right', size='5%', pad=0.05)
fig.colorbar(im1, cax=cax, orientation='vertical')
im1 = ax[2].imshow(np.squeeze(simulation_gradient).T[1].T,
extent=(0,1,0,1), cmap=cmap)
ax[2].title.set_text(r'$\nabla_{\sigma_8} \rm d$')
divider = make_axes_locatable(ax[2])
cax = divider.append_axes('right', size='5%', pad=0.05)
fig.colorbar(im1, cax=cax, orientation='vertical')
for a in ax:
a.set_xticks([])
a.set_yticks([])
plt.show()
```
Nice ! Since we can differentiate our universe and power spectrum, we can easily compute gradients of a neural network's outputs with respect to simulation parameters. This will come in handy for compression training.
---
## Training an IMNN
<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/imnn-scheme-white.png" alt="drawing" width="700"/>
The details behind the IMNN algorithm [can be found here on arxiv](https://arxiv.org/abs/1802.03537), but we'll summarize the gist briefly:
1. We want to maximise the Fisher information, $\textbf{F}$, of compressed summaries to satisfy the Cramer-Rao bound:
$$ \langle (\vartheta_\alpha - \langle \vartheta_\alpha \rangle ) (\vartheta_\beta - \langle \vartheta_\beta
\rangle) \rangle \geq \textbf{F}^{-1}_{\alpha \beta} $$ which means saturating the Fisher information minimizes the average variance of the parameter estimates.
2. To do this, and without loss of generality (proof coming soon!) we compute a Gaussian likelihood form to compute our Fisher information:
$$ -2 \ln \mathcal{L}(\textbf{x} | \textbf{d}) = (\textbf{x} - \boldsymbol{\mu}_f(\vartheta))^T \textbf{C}_f^{-1}(\textbf{x} - \boldsymbol{\mu}_f(\vartheta)) $$ where $\boldsymbol{\mu}_f$ and $\textbf{C}$ are the mean and covariance of the network output (summaries). The Fisher is then $$ \textbf{F}_{\alpha \beta} = {\rm tr} [\boldsymbol{\mu}_{f,\alpha}^T C^{-1}_f \boldsymbol{\mu}_{f, \beta}] $$
Since we can differentiate through our neural network *and* simulated universe, we have the exact derivatives with respect to the pipeline we need to compute the Fisher matrix of compressed summaries on-the-fly during compression training.
___
### Q: wait -- what if my simulator isn't differentiable ?
We don't *need* to have the exact derivatives for IMNN training ! Having the gradients accessible just means that we don't have to optimize finite-differencing for estimating derivatives by hand, however (as is done in the original IMNN paper).
___
Let's use an IMNN trained on cosmological fields to see how much information we can extract an what sort of constraints we can get. We will use 2000 simulations to estimate the covariance and use all of their derivatives and we'll summarise the whole cosmological field using 2 summaries.
```
n_s = 200 # number of simulations used to estimate covariance of network outputs
n_d = n_s # number of simulations used to estimate the numerical derivative of
# the mean of the network outputs
n_summaries = 2
```
We're going to use a fully convolutional inception network built using stax with some custom designed blocks. The inception block itself is implemented in the following block:
```
#@title nn model stuff <font color='lightgreen'>[RUN ME]</font>
def InceptBlock(filters, strides, do_5x5=True, do_3x3=True):
"""InceptNet convolutional striding block.
filters: tuple: (f1,f2,f3)
filters1: for conv1x1
filters2: for conv1x1,conv3x3
filters3L for conv1x1,conv5x5"""
filters1, filters2, filters3 = filters
conv1x1 = stax.serial(stax.Conv(filters1, (1, 1), strides, padding="SAME"))
filters4 = filters2
conv3x3 = stax.serial(stax.Conv(filters2, (1, 1), strides=None, padding="SAME"),
stax.Conv(filters4, (3, 3), strides, padding="SAME"))
filters5 = filters3
conv5x5 = stax.serial(stax.Conv(filters3, (1, 1), strides=None, padding="SAME"),
stax.Conv(filters5, (5, 5), strides, padding="SAME"))
maxpool = stax.serial(stax.MaxPool((3, 3), padding="SAME"),
stax.Conv(filters4, (1, 1), strides, padding="SAME"))
if do_3x3:
if do_5x5:
return stax.serial(
stax.FanOut(4),
stax.parallel(conv1x1, conv3x3, conv5x5, maxpool),
stax.FanInConcat(),
stax.LeakyRelu)
else:
return stax.serial(
stax.FanOut(3),
stax.parallel(conv1x1, conv3x3, maxpool),
stax.FanInConcat(),
stax.LeakyRelu)
else:
return stax.serial(
stax.FanOut(2),
stax.parallel(conv1x1, maxpool),
stax.FanInConcat(),
stax.LeakyRelu)
```
We'll also want to make sure that the output of the network is the correct shape, for which we'll introduce a Reshaping layer
```
def Reshape(shape):
"""Layer function for a reshape layer."""
init_fun = lambda rng, input_shape: (shape,())
apply_fun = lambda params, inputs, **kwargs: np.reshape(inputs, shape)
return init_fun, apply_fun
```
Now we can build the network, with 55 filters and strides of 4 in each direction in each layer
```
fs = 55
layers = [
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(2, 2), do_5x5=False, do_3x3=False),
stax.Conv(n_summaries, (1, 1), strides=(1, 1), padding="SAME"),
stax.Flatten,
Reshape((n_summaries,))
]
model = stax.serial(*layers)
```
We'll also introduce a function to check our model output:
```
def print_model(layers, input_shape, rng):
print('input_shape: ', input_shape)
for l in range(len(layers)):
_m = stax.serial(*layers[:l+1])
print('layer %d shape: '%(l+1), _m[0](rng, input_shape)[0])
# print model specs
key,rng = jax.random.split(rng)
input_shape = (1,) + shape + (1,)
print_model(layers, input_shape, rng)
```
We'll also grab an adam optimiser from jax.experimental.optimizers
```
optimiser = optimizers.adam(step_size=1e-3)
```
Note that due to the form of the network we'll want to have simulations that have a "channel" dimension, which we can set up by not allowing for squeezing in the simulator.
### Load an IMNN
Finally we can load a pre-trained IMNN and compare its compression efficiency to the theoretical Fisher. We will pull the weights and state from the parent repository and calculate the compressor statistics.
We've used a SimulatorIMNN trained on new simulations on-the-fly, eliminating the need for a validation dataset. If you're interested in the IMNN training, see the [benchmarking Colab notebook](https://colab.research.google.com/drive/1_y_Rgn3vrb2rlk9YUDUtfwDv9hx774ZF#scrollTo=EW4H-R8I0q6n) or the Bonus challenge at the end of this tutorial.
We're not training an IMNN here because this model takes $\approx 50$ minutes and requires elevated Colab Pro resources.
```
!git clone https://github.com/tlmakinen/FieldIMNNs.git
# load IMNN state
import cloudpickle as pickle
import os
def unpickle_me(path):
file = open(path, 'rb')
return pickle.load(file)
folder_name = './FieldIMNNs/tutorial/IMNN-aspects/'
loadstate = unpickle_me(os.path.join(folder_name, 'IMNN_state'))
state = jax.experimental.optimizers.pack_optimizer_state(loadstate)
startup_key = np.load(os.path.join(folder_name, 'IMNN_startup_key.npy'), allow_pickle=True)
# load weights to set the IMNN
best_weights = np.load(os.path.join(folder_name, 'best_w.npy'), allow_pickle=True)
# initialize IMNN with pre-trained state
rng, key = jax.random.split(rng)
IMNN = imnn.IMNN(
n_s=n_s,
n_d=n_d,
n_params=n_params,
n_summaries=n_summaries,
input_shape=(1,) + shape + (1,),
θ_fid=θ_fid,
model=model,
optimiser=optimiser,
key_or_state=state, # <---- initialize with state
simulator=lambda rng, θ: simulator(
rng, θ, simulator_args={
**simulator_args,
**{"squeeze": False}}))
# now set weights using the best training weights and startup key (this can take a moment)
IMNN.set_F_statistics(w=best_weights, key=startup_key)
print('det F from IMNN:', np.linalg.det(IMNN.F))
print('% Fisher information captured by IMNN compared to theory: ', np.linalg.det(IMNN.F) / 656705.6827)
```
### if you want to check out how to train an IMNN, see the end of the tutorial !
---
# Inference on a target cosmological field
Now that we have a trained compression function (albeit at a somewhat arbitrary fiducial model), we can now perform simulation-based inference with the optimal summaries.
We'll now pretend to "observe" a cosmological density field at some target parameters, $\theta_{\rm target}$. We'll select $\Omega_c=0.25$ and $\sigma_8=0.81$ (measured 2015 Planck parameters). To get started with this tutorial, we'll load a pre-generated field from the GitHub ("field 2" from our paper !), but you can always generate a new realization with the simulator code.
```
θ_target = np.array([jc.Planck15().Omega_c, jc.Planck15().sigma8,])
δ_target = np.load('./FieldIMNNs/tutorial/target_field_planck.npy')
sns.set() # set up plot settings
cmap='viridis'
plt.imshow(δ_target, cmap=cmap)
plt.colorbar()
plt.title('target cosmological field')
plt.show()
```
Now we're going to **forget we ever knew our choice of target parameters** and do inference on this target data as if it were a real observation (minus measurement noise for now, of course !)
## Inference
We can now attempt to do inference of some target data using the IMNN.
First we're going to compress our target field down to parameter estimates using the IMNN method `IMNN.get_estimate(d)`. What this code does is returns the score estimator for the parameters, obtained via the transformation
$$ \hat{\theta}_{\alpha} = \theta^{\rm fid}_\alpha + \textbf{F}^{-1}_{\alpha \beta} \frac{\partial \mu_i}{\partial \theta_\beta} \textbf{C}^{-1}_{ij} \textbf({x}(\textbf{w}, \textbf{d}) - {\mu})_j $$
where ${x}(\textbf{w}, \textbf{d})$ are the network summaries.
```
estimates = IMNN.get_estimate(np.expand_dims(δ_target, (0, 1, -1)))
print('IMNN parameter estimates:', estimates)
```
The cool thing about training an IMNN is that it *automatically* gives you a simple uncertainty estimate on the parameters of interest via the optimal Fisher matrix. We can make a Gaussian approximation to the likelihood using the inverse of the matrix.
Note that to demonstrate robustness, the fiducial parameter values are deliberately far from the target parameters that this estimate of the Fisher information as the covariance will likely be misleading.
We'll need to select a prior distribution first. We'll do this in `tfpj`, selecting wide uniform priors for both $\Omega_c$ and $\sigma_8$.
```
prior = tfpj.distributions.Blockwise(
[tfpj.distributions.Uniform(low=low, high=high)
for low, high in zip([0.01, 0.2], [1.0, 1.3])])
prior.low = np.array([0.01, 0.])
prior.high = np.array([1.0, 1.3])
```
Then we can use the IMNN's built-in Gaussian approximation code:
```
sns.set()
GA = imnn.lfi.GaussianApproximation(
parameter_estimates=estimates,
invF=np.expand_dims(np.linalg.inv(IMNN.F), 0),
prior=prior,
gridsize=100)
ax = GA.marginal_plot(
known=θ_target,
label="Gaussian approximation",
axis_labels=[r"$\Omega_c$", r"$\sigma_8$"],
colours="C1");
```
Even though our fiducial model was trained far away $(\Omega_c, \sigma_8) = (0.4, 0.6)$, our score esimates (center of our ellipse) are very close to the target Planck (crosshairs).
we now have a compression and informative summaries of our target data. We'll next proceed to setting up density estimation to construct our posteriors !
___
# Posterior Construction with DELFI
Density Estimation Likelihood-Free Inference (DELFI) is presented formally [here on arxiv](https://arxiv.org/abs/1903.00007), but we'll give you the TLDR here:
Now that we have nonlinear IMNN summaries, $\textbf{x}$, to describe our cosmological fields, we can perform density estimation to model the *summary data likelihood*, $p(\textbf{x} | \boldsymbol{\theta})$. Once we have this, we can obtain the posterior distribution for $\boldsymbol{\theta}$ via Bayes' rule:
$$ p(\boldsymbol{\theta} | \textbf{x}) \propto p(\textbf{x} | \boldsymbol{\theta}) p(\boldsymbol{\theta}) $$.
## What are CMAFs ?
DELFI provides Conditional Masked Autoregressive Flows (CMAFs) are stacks of neural autoencoders carefully masked to parameterize the summary-parameter likelihood. To start, note that any probability density can be factored as a product of one-dimensional conditional distributions via the chain rule of probability:
\begin{equation}
p(\textbf{x} | \boldsymbol{\theta}) = \prod_{i=1}^{\dim(\textbf{x})} p({\rm x}_i | \textbf{x}_{1:i-1}, \boldsymbol{\theta})
\end{equation}
Masked Autoencoders for density estimation (MADE) model each of these one-dimensional conditionals as Gaussians with mean and variance parameters parameterized by neural network weights, $\textbf{w}$. The neural network layers are masked in such a way that the autoregressive property is preserved, e.g. the output nodes for the density $p({\rm x}_i | \textbf{x}_{1:i-1}, \boldsymbol{\theta})$ *only* depend on $\textbf{x}_{1:i-1}$ and $\boldsymbol{\theta}$, satisfying the chain rule.
We can then stack a bunch of MADEs to form a neural flow for our posterior !
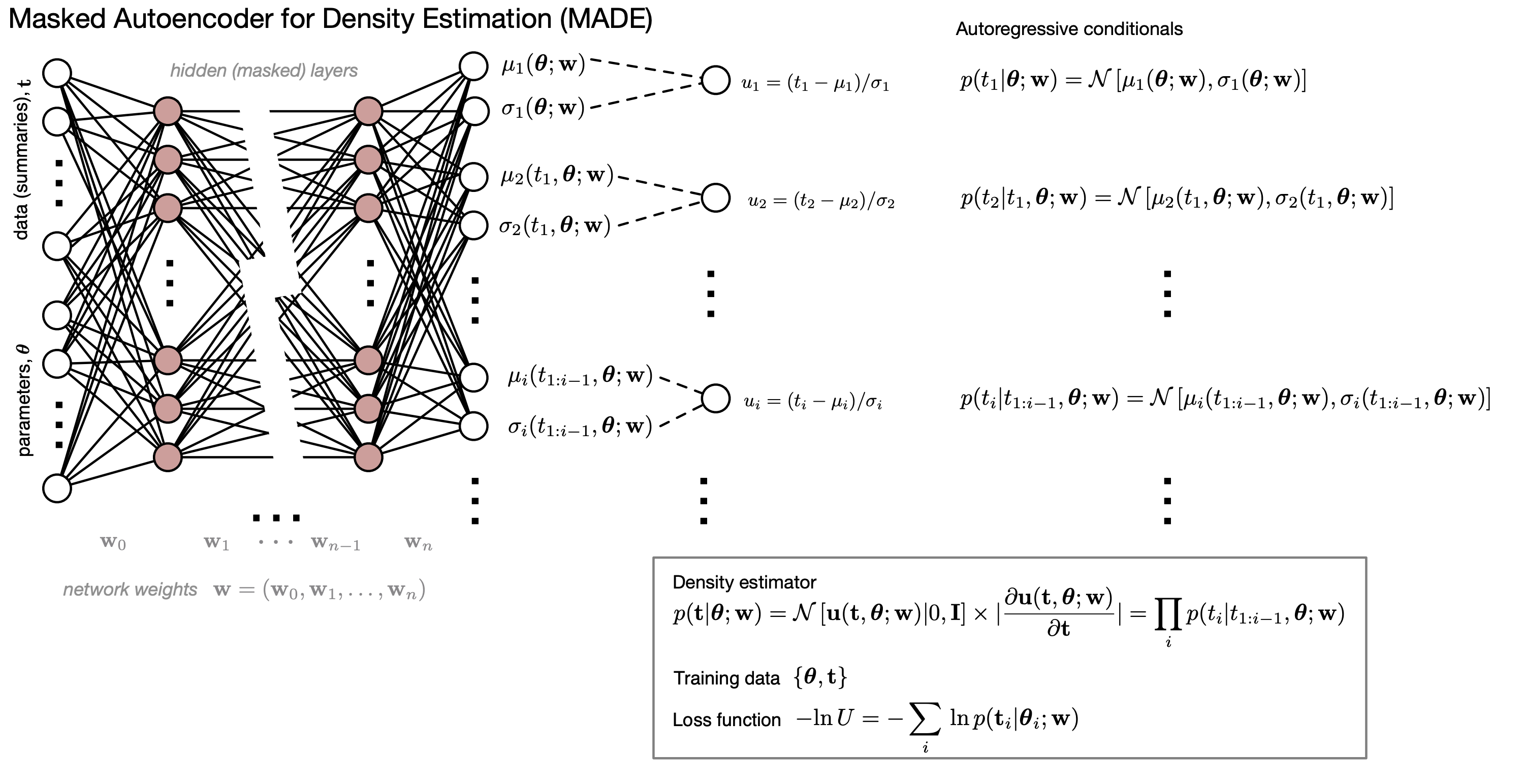
What we're going to do is
1. Train a Conditional Masked Autoregressive Flow to parameterize $p(\textbf{x} | \boldsymbol{\theta})$ to minimize the log-probability, $-\ln U$.
2. Use an affine MCMC sampler to draw from the posterior at the target summaries, $\textbf{x}^{\rm target}$
3. Append training data from the posterior and re-train MAFs.
```
!pip install -q getdist
!pip install -q corner
!pip install -q chainconsumer
import keras
import tensorflow.keras.backend as K
import time
from tqdm import tqdm
from chainconsumer import ChainConsumer
```
(ignore the red error message)
We'll set up the same prior as before, this time in regular `tensorflow-probability`. This means that our CMAFs can talk to our prior draws in the form of tensorflow tensors.
```
# set up prior in non-jax tfp
samp_prior = tfp.distributions.Blockwise(
[tfp.distributions.Uniform(low=low, high=high)
for low, high in zip([0.01, 0.2], [1.0, 1.3])])
samp_prior.low = np.array([0.01, 0.])
samp_prior.high = np.array([1.0, 1.3])
#@title set up the CMAF code <font color='lightgreen'>[RUN ME]</font>
class ConditionalMaskedAutoregressiveFlow(tf.Module):
def __init__(self, n_dimensions=None, n_conditionals=None, n_mades=1, n_hidden=[50,50], input_order="random",
activation=keras.layers.LeakyReLU(0.01),
all_layers=True,
kernel_initializer=keras.initializers.RandomNormal(mean=0.0, stddev=1e-5, seed=None),
bias_initializer=keras.initializers.RandomNormal(mean=0.0, stddev=1e-5, seed=None),
kernel_regularizer=None, bias_regularizer=None, kernel_constraint=None,
bias_constraint=None):
super(ConditionalMaskedAutoregressiveFlow, self).__init__('hi')
# extract init parameters
self.n_dimensions = n_dimensions
self.n_conditionals = n_conditionals
self.n_mades = n_mades
# construct the base (normal) distribution
self.base_distribution = tfd.MultivariateNormalDiag(loc=tf.zeros(self.n_dimensions), scale_diag=tf.ones(self.n_dimensions))
# put the conditional inputs to all layers, or just the first layer?
if all_layers == True:
all_layers = "all_layers"
else:
all_layers = "first_layer"
# construct stack of conditional MADEs
self.MADEs = [tfb.AutoregressiveNetwork(
params=2,
hidden_units=n_hidden,
activation=activation,
event_shape=[n_dimensions],
conditional=True,
conditional_event_shape=[n_conditionals],
conditional_input_layers=all_layers,
input_order=input_order,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
kernel_constraint=kernel_constraint,
bias_constraint=bias_constraint,
) for i in range(n_mades)
]
# bijector for x | y (chain the conditional MADEs together)
def bijector(self, y):
# start with an empty bijector
MAF = tfb.Identity()
# pass through the MADE layers (passing conditional inputs each time)
for i in range(self.n_mades):
MAF = tfb.MaskedAutoregressiveFlow(shift_and_log_scale_fn=lambda x: self.MADEs[i](x, conditional_input=y))(MAF)
return MAF
# construct distribution P(x | y)
def __call__(self, y):
return tfd.TransformedDistribution(
self.base_distribution,
bijector=self.bijector(y))
# log probability ln P(x | y)
def log_prob(self, x, y):
return self.__call__(y).log_prob(x)
# sample n samples from P(x | y)
def sample(self, n, y):
# base samples
base_samples = self.base_distribution.sample(n)
# biject the samples
return self.bijector(y).forward(base_samples)
```
If you're curious about how the MCMC sampler and CMAF code work, feel free to double-click the hidden cells above. We'll walk through the gist of how each module works though:
The `ConditionalMaskedAutoregressiveFlow` API functions similarly to other `tfp` distributions. To set up a model we need to choose a few aspects of the flow. We first need to choose how many MADEs we want to stack to form our flow, `n_mades`. To set up a model with three MADEs, two parameters (`n_dimensions`) and two conditionals (`n_conditionals`), and two hidden layers of 50 neurons per MADE, we'd call:
my_CMAF = ConditionalMaskedAutoregressiveFlow(n_dimensions=2, n_conditionals=2, n_mades=3, n_hidden=[50,50])
What's cool is that this module works just like a `tfp.distributions` function, which means that we can call a log-probability, $p(x | y)$ *conditional* on some $y$-value:
key,rng = jax.random.split(rng)
n_samples = 1
x = prior.sample(sample_shape=(n_samples,), seed=key)
y = np.array([0.3, 0.4])
logU = my_CMAF.log_prob(x, y)
We're going to work with this basic syntax to set up useful DELFI dictionaries to store useful aspects.
___
# Exercise 0: initialize models for target data
Now we're going to initialize several CMAF models for our piece of target data. Using multiple (and varied) deep learning architectures for the same problem is called the "deep ensemble" technique ([see this paper for an overview](https://papers.nips.cc/paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf)).
When setting up DELFI, it's important to remember that each ensemble of CMAFs ought to be generated *per piece of target data*, since we're interested in observing the "slice" of parameter space that gives us each datum's posterior. Since these models are written in Tensorflow, we don't have to worry about specifying a random key or initialization for the model like we do in `Jax`.
1. Declare a `DELFI` dictionary to store the following aspects:
- a list of CMAF models
- a list of optimizers
- a training dataset
- a validation dataset
- the IMNN estimates
2. Initialize `num_models=2` models, each with `n_mades=3` MADEs. Try one set of MADEs with two layers of 50 neurons, and another with three layers. See if you can set up their respective optimizers (we'll use `tf.keras.optimizers.Adam()` with a learning rate of $10^-3$.
## note: remove all `pass` arguments to functions to make them runnable !
```
DELFI = {
}
#@title Ex. 0 solution <font color='lightgreen'>[run me to proceed]</font>
num_targets = 1
# set up list of dictionaries for the target datum
DELFI = {
'MAFs': None, # list of CAMF models
'opts': [], # list of optimizers
'posts':[], # list of MAF posteriors
'train_data': None, # training dataset
'val_data': None, # validation dataset
'train_losses' : [], # losses
'val_losses' : [],
'estimates': estimates,
'target_data' : δ_target,
'F_IMNN': IMNN.F,
'θ_target': θ_target,
}
# number of CMAFs per DELFI ensemble
num_models = 2
n_hiddens = [[50,50], [50,50]] # try different architectures
DELFI['MAFs'] = [ConditionalMaskedAutoregressiveFlow(n_dimensions=2, n_mades=3,
n_conditionals=2, n_hidden=n_hiddens[i]) for i in range(num_models)]
DELFI['opts'] = [tf.keras.optimizers.Adam(learning_rate=1e-3) for i in range(num_models)]
```
___
# Exercise 1: define train and validation steps
Here we want to define tensorflow function training and validation steps that we'll later call in a loop to train each CMAF model in the DELFI ensemble.
1. set up the log posterior loss: $-\ln U = -\ln p(x | y) - \ln p(y)$ where $y=\theta$ are our parameters.
*hint*: try the `samp_prior.log_prob()` call on a few data
2. obtain gradients, `grads` with respect to the scalar loss
3. update each optimizer with the call `optimizer.apply_gradients(zip(grads, model.trainable_variables)`
```
# define loss function -ln U
def logloss(x, y, model, prior):
pass
#@title Ex. 1 solution <font color='lightgreen'>[run me to proceed]</font>
# define loss function
def logloss(x, y, model):
return - model.log_prob(x,y) - samp_prior.log_prob(y)
```
Now that we have our loss defined, we can use it to train our CMAFs via backpropagation:
```
@tf.function
def train_step(x, y, ensemble, opts):
losses = []
# loop over models in ensemble
for m in range(len(ensemble)):
with tf.GradientTape() as tape:
# get loss across batch using our log-loss function
loss = K.mean(logloss(x, y, ensemble[m]))
losses.append(loss)
grads = tape.gradient(loss, ensemble[m].trainable_variables)
opts[m].apply_gradients(zip(grads, ensemble[m].trainable_variables))
return losses
@tf.function
def val_step(x, y, ensemble):
val_l = []
for m in range(len(ensemble)):
loss = K.mean(logloss(x, y, ensemble[m]))
val_l.append(loss)
return val_l
```
___
# Exercise 2: create some dataset functions
Here we want to create the dataset of $(\textbf{x}, \boldsymbol{\theta})$ pairs to train our CMAFs on. Write a function that:
1. generate simulations (with random keys) from sampled parameter pairs, $\theta$. We've set up the key-splitting and simulator code for you.
2. feed simulations through `IMNN.get_estimate()` to get summaries, $\textbf{x}$
3. try to use `jax.vmap()` the above to do this efficiently !
```
#@title hints for vmapping:
# for a function `my_fn(a, x)`, you can vmap, "vector map" over a set of array values as follows:
def my_fn(x, a, b):
return a*x**3 - x + b
# define a slope and intercept
a = 0.5
b = 1.0
# define our x-values
x = np.linspace(-10,10, num=100)
# define a mini function that only depends on x
mini_fn = lambda x: my_fn(x, a=a, b=b)
y = jax.vmap(mini_fn)(x)
plt.plot(x, y)
plt.xlabel('$x$')
plt.ylabel('$y$')
def get_params_summaries(key, θ_samp, simulator=simulator):
"""
function for generating (x,θ) pairs from IMNN compression
over the prior range
θ_samp: array of sampled parameters over prior range
simulator: function for simulating data to be compressed
"""
n_samples = θ_samp.shape[0]
# we'll split up the keys for you
keys = np.array(jax.random.split(key, num=n_samples))
# next define a simulator that takes a key as argument
my_simulator = lambda rng, θ: simulator(
rng, θ, simulator_args={
**simulator_args,
**{"squeeze": False}})
# generate data, vmapping over the random keys and parameters:
# d =
# generate summaries
# x =
# return paired training data
pass
#@title Ex. 2 solution <font color='lightgreen'>[run me to proceed]</font>
def get_params_summaries(key, n_samples, θ_samp, simulator=simulator):
keys = np.array(jax.random.split(key, num=n_samples))
sim = lambda rng, θ: simulator(
rng, θ, simulator_args={
**simulator_args,
**{"squeeze": False}})
# generate a bunch of fields over the prior ranges
d = jax.vmap(sim)(keys, θ_samp)
# compress fields to summaries
x = IMNN.get_estimate(d)
return x, θ_samp
def get_dataset(data, batch_size=20, buffer_size=1000, split=0.75):
"""
helper function for creating tensorflow dataset for CMAF training.
data: pair of vectors (x, θ) = (x, y)
batch_size: how many data pairs per gradient descent
buffer_size: what chunk of the dataset to shuffle (default: random)
split: train-validation split
"""
x,y = data
idx = int(len(x)*split)
x_train = x[:idx]
y_train = y[:idx]
x_val = x[idx:]
y_val = y[idx:]
# Prepare the training dataset.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=buffer_size).batch(batch_size)
# Prepare the validation dataset.
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(batch_size)
return train_dataset, val_dataset
```
# Visualize compressed summaries at fiducial model and over the prior
Now that we a function that can take in parameter vectors, generates simulations, and then compresses them into summaries, we can visualize how the IMNN compresses the fields in summary space. We will visualize:
1. compressed simulations run at the fiducial model ($\Omega_c, \sigma_8)$ = (0.4, 0.6)
2. compressed simulations at the target model ($\Omega_c, \sigma_8)$ = (0.2589, 0.8159)
3. compressed simulations run across the full (uniform) prior range
```
n_samples = 1000
buffer_size = n_samples
key1,key2 = jax.random.split(rng)
# params over the prior range
θ_samp = prior.sample(sample_shape=(n_samples,), seed=key1)
xs, θ_samp = get_params_summaries(key2, n_samples, θ_samp)
# fiducial params
key,rng = jax.random.split(key1)
_θfids = np.repeat(np.expand_dims(θ_fid, 1), 1000, axis=1).T
xs_fid, _ = get_params_summaries(key, n_samples, _θfids)
# target params
_θtargets = np.repeat(np.expand_dims(θ_target, 1), 1000, axis=1).T
xs_target, _ = get_params_summaries(key, n_samples, _θtargets)
plt.scatter(xs.T[0], xs.T[1], label='prior', s=5, alpha=0.7)
plt.scatter(xs_fid.T[0], xs_fid.T[1], label='fiducial', s=5, marker='*', alpha=0.7)
plt.scatter(xs_target.T[0], xs_target.T[1], label='target', s=5, marker='+', alpha=0.7)
plt.title('summary scatter')
plt.xlabel(r'$x_1$')
plt.ylabel(r'$x_2$')
plt.xlim(-1.0, 2.0)
plt.legend()
plt.show()
```
### Q: Wait, why is our prior in summary space not uniform (rectangular) ?
Remember, we've passed our parameters through our simulator, and our simulations through the IMNN compressor, meaning our summaries are nonlinear (weirdly-shaped). These score estimates obtained from the IMNN is are quick and convenient, but can be biased and suboptimal if the fiducial model is far from the truth.
Even then, these IMNN score summaries can be used for likelihood-free inference to give consistent posterior estimates, albeit with some information loss (since we haven't compressed near the target).
---
## Now, onto the good bit--CMAF training !
### Generate our training dataset
We're going to call our dataset functions to create a dataset of $(\textbf{x}, \boldsymbol{\theta})$ of shape $((1000, 2), (1000, 2))$.
```
n_samples = 1000
batch_size = 100
buffer_size = n_samples
key1,key2 = jax.random.split(rng)
# sample from the tfpj prior so that we can specify the key
# and stay in jax.numpy:
θ_samp = prior.sample(sample_shape=(n_samples,), seed=key1)
# generate sims and compress to summaries
ts, θ_samp = get_params_summaries(key2, n_samples, θ_samp)
data = (ts, θ_samp)
# use the dataset function
train_dataset, val_dataset = get_dataset(data, batch_size=batch_size, buffer_size=buffer_size)
DELFI['train_dataset'] = train_dataset
DELFI['val_dataset'] = val_dataset
```
Next let's define a training loop for a set number of epochs, calling our training and validation step functions.
___
# Exercise 3: define training loop
We're going to use the `train_step` functions to train our CMAF models for a set number of epochs.
```
def training_loop(delfi, epochs=2000):
"""training loop function that updates optimizers and
stores training history"""
# unpack our dictionary's attributes
ensemble = delfi['MAFs']
opts = delfi['opts']
train_dataset = delfi['train_dataset']
val_dataset = delfi['val_dataset']
for epoch in tqdm(range(epochs)):
# shuffle training data anew every 50th epoch (done for you)
if epoch % 50 == 0:
train_dataset = train_dataset.shuffle(buffer_size=buffer_size)
# Iterate over the batches of the dataset.
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# 1) call train step and capture loss value
pass
# 2) store loss value
# Run a validation loop at the end of each epoch.
for x_batch_val, y_batch_val in val_dataset:
# 3) call val step and capture loss value
pass
# 4) store validation loss value
pass
#@title Ex. 3 solution <font color='lightgreen'>[run me to proceed]</font>
def training_loop(delfi, epochs=2000):
"""training loop function that updates optimizers and
stores training history"""
# unpack our dictionary's attributes
ensemble = delfi['MAFs']
opts = delfi['opts']
train_dataset = delfi['train_dataset']
val_dataset = delfi['val_dataset']
for epoch in tqdm(range(epochs)):
# shuffle training data anew every 50th epoch
if epoch % 50 == 0:
train_dataset = train_dataset.shuffle(buffer_size=buffer_size)
# Iterate over the batches of the dataset.
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# call train step and capture loss value
loss_values = train_step(x_batch_train, y_batch_train, ensemble, opts)
# store loss value
delfi['train_losses'].append(loss_values)
# Run a validation loop at the end of each epoch.
for x_batch_val, y_batch_val in val_dataset:
# call val step and capture loss value
val_loss = val_step(x_batch_val, y_batch_val, ensemble)
# store validation loss value
delfi['val_losses'].append(val_loss)
#@title define some useful plotting functions <font color='lightgreen'>[run me]</font>
# visualize training trajectories
def plot_trajectories(delfis, num_models=4, num_targets=4):
"""code for plotting training trajectories. note that num_targets should be
equal to len(delfis)"""
if num_targets > 1:
fig,axs = plt.subplots(ncols=num_models, nrows=num_targets, figsize=(8,8))
for i,d in enumerate(delfis):
for j in range(num_models):
axs[i,j].plot(np.array(d['train_losses']).T[j], label='train')
axs[i,j].plot(np.array(d['val_losses']).T[j], label='val')
if j == 0:
axs[i,j].set_ylabel(r'$p(t\ |\ \vartheta; w)$')
if i == num_models-1:
axs[i,j].set_xlabel(r'num epochs')
else:
fig,axs = plt.subplots(ncols=num_models, nrows=num_targets, figsize=(7,3))
d = delfis
for j in range(num_models):
axs[j].plot(np.array(d['train_losses']).T[j], label='train')
axs[j].plot(np.array(d['val_losses']).T[j], label='val')
if j == 0:
#axs[j].set_ylabel(r'$p(t\ |\ \vartheta; w)$')
axs[j].set_ylabel(r'$-\ln U$')
axs[j].set_xlabel(r'num epochs')
axs[j].set_title('CMAF model %d'%(j + 1))
# if i == num_models-1:
# axs[j].set_xlabel(r'\# epochs')
plt.legend()
plt.tight_layout()
plt.show()
# then visualize all posteriors
def plot_posts(delfis, params, num_models=4, num_targets=4,
Fisher=None, estimates=estimates, truth=None):
fig,ax = plt.subplots(ncols=num_models, nrows=num_targets, figsize=(7,4))
params = [r'$\Omega_c$', r'$\sigma_8$']
if num_targets > 1:
for i,delfi in enumerate(delfis):
for j in range(num_models):
cs = ChainConsumer()
cs.add_chain(delfi['posts'][j], parameters=params, name='DELFI + IMNN') #, color=corner_colors[0])
#cs.add_covariance(θ_target, -Finv_analytic, parameters=params, name="Analytic Fisher", color=corner_colors[2])
cs.configure(linestyles=["-", "-", "-"], linewidths=[1.0, 1.0, 1.0], usetex=False,
shade=[True, True, False], shade_alpha=[0.7, 0.6, 0.], tick_font_size=8)
cs.plotter.plot_contour(ax[i, j], r"$\Omega_c$", r"$\sigma_8$")
ax[i, j].axvline(θ_target[0], linestyle=':', linewidth=1)
ax[i, j].axhline(θ_target[1], linestyle=':', linewidth=1)
ax[i,j].set_ylim([prior.low[1], prior.high[1]])
ax[i,j].set_xlim([prior.low[0], prior.high[0]])
else:
delfi = delfis
for j in range(num_models):
cs = ChainConsumer()
cs.add_chain(delfi['posts'][j], parameters=params, name='DELFI + IMNN')
if Fisher is not None:
cs.add_covariance(np.squeeze(estimates), np.linalg.inv(Fisher),
parameters=params, name="Fisher", color='k')
cs.configure(linestyles=["-", "-", "-"], linewidths=[1.0, 1.0, 1.0], usetex=False,
shade=[True, False, False], shade_alpha=[0.7, 0.6, 0.], tick_font_size=8)
cs.plotter.plot_contour(ax[j], r"$\Omega_c$", r"$\sigma_8$")
if truth is not None:
ax[j].axvline(truth[0], linestyle=':', linewidth=1, color='k')
ax[j].axhline(truth[1], linestyle=':', linewidth=1, color='k')
ax[j].set_ylim([prior.low[1], prior.high[1]])
ax[j].set_xlim([prior.low[0], prior.high[0]])
ax[j].set_xlabel(params[0])
ax[j].set_ylabel(params[1])
ax[j].set_title('CMAF model %d'%(j+1))
plt.legend()
plt.tight_layout()
plt.show()
return ax
```
### train our CMAF models !
```
# train both models with the training loop
epochs = 2000
training_loop(DELFI, epochs=epochs)
# visualize training trajectories
import seaborn as sns
%matplotlib inline
sns.set_theme()
plot_trajectories(DELFI, num_models=2, num_targets=1)
```
# Exercise 4: using the affine MCMC sampler
Now that we have trained CMAF models with which to compute $p(x | \theta)$, we now need to set up an efficient MCMC sampler to draw from the posterior, $p(x | \theta) \times p(\theta)$. We can do this using the `affine_sample()` sampler, included in `pydelfi` package. This code is written in Tensorflow, adapted from the [`emcee` package](https://arxiv.org/abs/1202.3665), and can be called with only a few lines of code:
# initialize walkers...
walkers1 = tf.random.normal([n_walkers, 2], (a, b), sigma)
walkers2 = tf.random.normal([n_walkers, 2], (a, b), sigma)
# sample using affine
chains = affine_sample(log_prob, n_params, n_walkers, n_steps, walkers1, walkers2)
1. First we'll need to set up our log-probability for the posterior. Write a function `log_posterior()` that returns a probability given $x$ and a conditional $y$:
```
#@title set up the affine MCMC sampler <font color='lightgreen'>[run me]</font>
from tqdm import trange
import numpy as onp
def affine_sample(log_prob, n_params, n_walkers, n_steps, walkers1, walkers2):
# initialize current state
current_state1 = tf.Variable(walkers1)
current_state2 = tf.Variable(walkers2)
# initial target log prob for the walkers (and set any nans to -inf)...
logp_current1 = log_prob(current_state1)
logp_current2 = log_prob(current_state2)
logp_current1 = tf.where(tf.math.is_nan(logp_current1), tf.ones_like(logp_current1)*tf.math.log(0.), logp_current1)
logp_current2 = tf.where(tf.math.is_nan(logp_current2), tf.ones_like(logp_current2)*tf.math.log(0.), logp_current2)
# holder for the whole chain
chain = [tf.concat([current_state1, current_state2], axis=0)]
# MCMC loop
with trange(1, n_steps) as t:
for epoch in t:
# first set of walkers:
# proposals
partners1 = tf.gather(current_state2, onp.random.randint(0, n_walkers, n_walkers))
z1 = 0.5*(tf.random.uniform([n_walkers], minval=0, maxval=1)+1)**2
proposed_state1 = partners1 + tf.transpose(z1*tf.transpose(current_state1 - partners1))
# target log prob at proposed points
logp_proposed1 = log_prob(proposed_state1)
logp_proposed1 = tf.where(tf.math.is_nan(logp_proposed1), tf.ones_like(logp_proposed1)*tf.math.log(0.), logp_proposed1)
# acceptance probability
p_accept1 = tf.math.minimum(tf.ones(n_walkers), z1**(n_params-1)*tf.exp(logp_proposed1 - logp_current1) )
# accept or not
accept1_ = (tf.random.uniform([n_walkers], minval=0, maxval=1) <= p_accept1)
accept1 = tf.cast(accept1_, tf.float32)
# update the state
current_state1 = tf.transpose( tf.transpose(current_state1)*(1-accept1) + tf.transpose(proposed_state1)*accept1)
logp_current1 = tf.where(accept1_, logp_proposed1, logp_current1)
# second set of walkers:
# proposals
partners2 = tf.gather(current_state1, onp.random.randint(0, n_walkers, n_walkers))
z2 = 0.5*(tf.random.uniform([n_walkers], minval=0, maxval=1)+1)**2
proposed_state2 = partners2 + tf.transpose(z2*tf.transpose(current_state2 - partners2))
# target log prob at proposed points
logp_proposed2 = log_prob(proposed_state2)
logp_proposed2 = tf.where(tf.math.is_nan(logp_proposed2), tf.ones_like(logp_proposed2)*tf.math.log(0.), logp_proposed2)
# acceptance probability
p_accept2 = tf.math.minimum(tf.ones(n_walkers), z2**(n_params-1)*tf.exp(logp_proposed2 - logp_current2) )
# accept or not
accept2_ = (tf.random.uniform([n_walkers], minval=0, maxval=1) <= p_accept2)
accept2 = tf.cast(accept2_, tf.float32)
# update the state
current_state2 = tf.transpose( tf.transpose(current_state2)*(1-accept2) + tf.transpose(proposed_state2)*accept2)
logp_current2 = tf.where(accept2_, logp_proposed2, logp_current2)
# append to chain
chain.append(tf.concat([current_state1, current_state2], axis=0))
# stack up the chain
chain = tf.stack(chain, axis=0)
return chain
@tf.function
def log_posterior(x, y, cmaf):
# define likelihood p(x|y) with CMAF
# compute prior probability p(y)
# return the log-posterior
pass
#@title Ex. 4.1 solution <font color='lightgreen'>[run me to proceed]</font>
@tf.function
def log_posterior(x, y, cmaf):
# define likelihood p(x|y) with CMAF
like = cmaf.log_prob(x,y)
# compute prior probability p(y)
_prior = samp_prior.log_prob(y)
return like + _prior # the log-posterior
```
2. Now we're going to use the sampler and write a function to obtain our posteriors. To call the sampler, we need to call our log-posterior function, as well as specify the number of walkers in parameter space:
```
# define function for getting posteriors
def get_posteriors(delfi, n_params, n_steps=2000, n_walkers=500, burnin_steps=1800, skip=4):
delfi['posts'] = [] # reset posteriors (can save if you want to keep a record)
# center affine sampler walkers on the IMNN estimates
a,b = np.squeeze(delfi['estimates'])
# choose width of proposal distribution
# sigma =
# loop over models in the ensemble
for m,cmaf in enumerate(delfi['MAFs']):
print('getting posterior for target data with model %d'%(m+1))
# wrapper for log_posterior function: freeze at target summary slice, x_target
@tf.function
def my_log_prob(y, x=delfi['estimates']):
return log_posterior(x, y, cmaf)
# initialize walkers...
# walkers1 =
# walkers2 =
# sample using affine. note that this returns a tensorflow tensor
# chain = affine_sample()
# convert chain to numpy and append to dictionary
delfi['posts'].append(np.stack([chain.numpy()[burnin_steps::skip,:,0].flatten(),
chain.numpy()[burnin_steps::skip,:,1].flatten()], axis=-1))
pass
#@title Ex. 4.2 solution <font color='lightgreen'>[run me to proceed]</font>
# define function for getting posteriors
def get_posteriors(delfi, n_params, n_steps=2000, n_walkers=500, burnin_steps=1800, skip=4):
delfi['posts'] = [] # reset posteriors (can save if you want to keep a record)
# center affine sampler walkers on the IMNN estimates
a,b = np.squeeze(delfi['estimates'])
# choose width of proposal distribution
sigma = 0.5
# loop over models in the ensemble
for m,cmaf in enumerate(delfi['MAFs']):
print('getting posterior for target data with model %d'%(m+1))
# wrapper for log_posterior function: freeze at target summary slice
@tf.function
def my_log_prob(y, x=delfi['estimates']):
return log_posterior(x, y, cmaf)
# initialize walkers...
walkers1 = tf.random.normal([n_walkers, 2], (a, b), sigma)
walkers2 = tf.random.normal([n_walkers, 2], (a, b), sigma)
# sample using affine
chain = affine_sample(my_log_prob, n_params, n_walkers, n_steps, walkers1, walkers2)
delfi['posts'].append(np.stack([chain.numpy()[burnin_steps::skip,:,0].flatten(),
chain.numpy()[burnin_steps::skip,:,1].flatten()], axis=-1))
# get all intermediate posteriors --> this should be really fast !
get_posteriors(DELFI, n_params)
```
We're going to use our plotting client to visualize our posteriors for each model. We'll also plot the IMNN's Fisher Gaussian Approximation in black, centered on our estimates. Finally, we'll display the true Planck parameters using crosshairs:
```
params = [r'$\Omega_c$', r'$\sigma_8$']
plot_posts(DELFI, params, num_models=num_models, num_targets=1,
Fisher=IMNN.F, estimates=np.squeeze(estimates), truth=θ_target)
```
___
# Exercise 5: append new posterior training data to hone in on the truth (repeat several times)
Finally, we're going to draw parameters from the posterior, re-simulate cosmological fields, compress, append the new ($x$, $\theta$) pairs to the dataset, and keep training our DELFI ensemble. Within a few iterations, this should shrink our posteriors considerably.
Since we've coded all of our training functions modularly, we can just run them in a loop (once we've drawn and simulated from the prior). First we'll give you a piece of code to draw from the posterior chains:
concat_data(DELFI, key, n_samples=500)
Here, remember to re-set your random key for new samples !
Next, write a loop that:
1. draws `n_samples` summary-parameter pairs from *each* existing CMAF model's posteriors
2. continues training the DELFI ensemble members
3. re-samples the posterior
**bonus**: Can you develop a scheme that requires fewer `n_samples` draws each iteration ? What about optimizer stability ? (hint: try a decaying learning rate)
___
```
#@title `concat_data` function to draw from each posterior and concatenate dataset <font color='lightgreen'>[run me to proceed]</font>
import pandas as pd
def drop_samples(samples, prior=prior):
"""
helper function for dropping posterior draws outside
the specified prior range
"""
mydf = pd.DataFrame(samples)
mydf = mydf.drop(mydf[mydf[0] < prior.low[0]].index)
mydf = mydf.drop(mydf[mydf[1] < prior.low[1]].index)
mydf = mydf.drop(mydf[mydf[0] > prior.high[0]].index)
mydf = mydf.drop(mydf[mydf[1] > prior.high[1]].index)
return np.array(mydf.values, dtype='float32')
def concat_data(delfi, key, n_samples=500, prior=prior):
"""
helper code for concatenating data for each DELFI CMAF model.
delfi: DELFI dictionary object with 'train_dataset'
and 'val_dataset' attributes
key: jax.PRNGkey
n_samples: number of samples to draw from EACH DELFI ensemble model
"""
# take 500 samples from each posterior for each training data
key,rng = jax.random.split(key)
idx = np.arange(len(delfi['posts'][0]))
ϑ_samp = []
for m,_post in enumerate(delfi['posts']):
ϑ_samp.append(_post[45000:][onp.random.choice(idx, size=n_samples)])
ϑ_samp = np.concatenate(ϑ_samp, axis=0)
print(ϑ_samp.shape)
ϑ_samp = drop_samples(ϑ_samp, prior=prior)
dropped = n_samples*len(delfi['posts']) - ϑ_samp.shape[0]
print('I dropped {} parameter pairs that were outside the prior'.format(dropped))
_n_samples = len(ϑ_samp)
ts, ϑ_samp = get_params_summaries(key2, _n_samples, ϑ_samp)
new_data = (ts, ϑ_samp)
print("I've drawn %d new summary-parameter pairs"%(ts.shape[0]))
# this should shuffle the dataset
new_train_dataset, new_val_dataset = get_dataset(new_data, batch_size=batch_size, buffer_size=len(new_data[0]))
# concatenate datasets
delfi['train_dataset'] = delfi['train_dataset'].concatenate(new_train_dataset)
delfi['val_dataset'] = delfi['val_dataset'].concatenate(new_val_dataset)
#@title Ex. 5 solution <font color='lightgreen'>[run me to proceed]</font>
for repeat in range(1):
key,rng = jax.random.split(rng)
print('doing retraining iteration %d'%(repeat))
concat_data(DELFI, key, n_samples=500)
print('retraining on augmented dataset')
epochs = 500
training_loop(DELFI, epochs=epochs)
plot_trajectories(DELFI, num_models=2, num_targets=1)
get_posteriors(DELFI, n_params)
plot_posts(DELFI, params, num_models=num_models, num_targets=1,
Fisher=IMNN.F, estimates=np.squeeze(estimates), truth=θ_target)
```
___
# Exercise 6: create ensemble posterior
Once we're happy with the DELFI training, we can proceed to reporting our ensemble's combined posterior. Using the [`ChainConsumer` API](https://samreay.github.io/ChainConsumer/index.html), concatenate the posterior chains and report a nice corner plot:
```
#@title Exercise 6 solution <font color='lightgreen'>[run me to proceed]</font>
def drop_samples(samples, prior=prior):
"""
helper function for dropping posterior draws outside
the specified prior range
"""
mydf = pd.DataFrame(samples)
mydf = mydf.drop(mydf[mydf[0] < prior.low[0]].index)
mydf = mydf.drop(mydf[mydf[1] < prior.low[1]].index)
mydf = mydf.drop(mydf[mydf[0] > prior.high[0]].index)
mydf = mydf.drop(mydf[mydf[1] > prior.high[1]].index)
return np.array(mydf.values, dtype='float32')
super_post = np.concatenate(DELFI['posts'], axis=0)
# assign new dict entry after dropping samples outside the prior
DELFI['super_post'] = drop_samples(super_post)
params = [r"$\Omega_c$", r"$\sigma_8$"]
corner_colors = [None, None, 'k']
c = ChainConsumer()
c.add_chain(DELFI['super_post'][::10], parameters=params, name='DELFI + IMNN', color=corner_colors[0])
c.add_covariance(np.squeeze(estimates), IMNN.invF, parameters=params, name="IMNN F @estimates", color=corner_colors[2])
c.configure(linestyles=["-", "-", "--"], linewidths=[1.0, 1.0, 1.0,],
shade=[True, False, False], shade_alpha=[0.7, 0.6, 0.],
tick_font_size=8, usetex=False,
legend_kwargs={"loc": "upper left", "fontsize": 8},
legend_color_text=False, legend_location=(0, 0))
fig = c.plotter.plot(figsize="column", truth=list(θ_target), filename=None)
```
___
# Congrats !
You've made it through the core of the tutorial and trained a DELFI ensemble on IMNN-compressed summaries of mock dark matter fields and obtained cosmological parameter posteriors !
### Now what ?
There are lots of things you can do if you have the time -- for one, you could check out the bonus problems below
___
# BONUS: Compare IMNN Compressors
For this whole tutorial we've been using an IMNN ***trained deliberately far*** from our Planck parameters, meaning our compression isn't guaranteed to be optimal. In our accompanying paper (to be released on arXiv on July 16, 2021) we re-trained an IMNN on the mean of the score estimates of a set of four cosmological fields. Since this estimate is closer to the true target parameters, our IMNN compression is guaranteed to improve our inference on the target data.
<img src="https://raw.githubusercontent.com/tlmakinen/FieldIMNNs/master/tutorial/plots/new-four-cosmo-field-comparison.png" alt="drawing" width="700"/>
We've included this newly-trained IMNN in the GitHub repository that you've already cloned into this notebook -- as a bonus, repeat the DELFI posterior estimation using the new (more optimal) compressor and see how your inference shapes up ! You *should* see tighter Gaussian Approximations *and* DELFI contours:
```
# load IMNN state
import cloudpickle as pickle
import os
def unpickle_me(path):
file = open(path, 'rb')
return pickle.load(file)
folder_name = './FieldIMNNs/tutorial/IMNN2-aspects/'
loadstate = unpickle_me(os.path.join(folder_name, 'IMNN_state'))
state2 = jax.experimental.optimizers.pack_optimizer_state(loadstate)
# startup key to get the right state of the weights
startup_key2 = np.load(os.path.join(folder_name, 'IMNN_startup_key.npy'), allow_pickle=True)
# load weights
best_weights2 = np.load(os.path.join(folder_name, 'best_w.npy'), allow_pickle=True)
# load fiducial model that we trained the model at (estimates derived from initial IMNN)
θ_fid_new = np.load(os.path.join(folder_name, 'new_fid_params.npy'), allow_pickle=True)
# initialize IMNN with pre-trained state
IMNN2 = imnn.IMNN(
n_s=n_s,
n_d=n_d,
n_params=n_params,
n_summaries=n_summaries,
input_shape=(1,) + shape + (1,),
θ_fid=θ_fid_new,
model=model,
optimiser=optimiser,
key_or_state=state2, # <---- initialize with state
simulator=lambda rng, θ: simulator(
rng, θ, simulator_args={
**simulator_args,
**{"squeeze": False}}))
# now set weights using the best training weights and startup key (this can take a moment)
IMNN2.set_F_statistics(w=best_weights, key=startup_key2)
print(np.linalg.det(IMNN2.F))
```
---
# BONUS 2:
Alternatively, train a new IMNN from scratch at the target data `estimates` (try with fewer filters on the free version of Colab). You could also try playing with other `stax` layers like `stax.Dense(num_neurons)`. Feel free to also switch up the simulation parameters -- choosing $N=32$ for instance will dramatically increase training speed for testing, etc.
```
fs = 16
new_layers = [
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(4, 4)),
InceptBlock((fs, fs, fs), strides=(2, 2), do_5x5=False, do_3x3=False),
stax.Conv(n_summaries, (1, 1), strides=(1, 1), padding="SAME"),
stax.Flatten,
Reshape((n_summaries,))
]
new_model = stax.serial(*new_layers)
print_model(layers, input_shape, rng)
rng, key = jax.random.split(rng)
IMNN2 = imnn.IMNN(
n_s=n_s,
n_d=n_d,
n_params=n_params,
n_summaries=n_summaries,
input_shape=(1,) + shape + (1,),
θ_fid=np.squeeze(estimates),
model=new_model,
optimiser=optimiser,
key_or_state=key, # <---- initialize with key
simulator=lambda rng, θ: simulator(
rng, θ, simulator_args={
**simulator_args,
**{"squeeze": False}}))
print("now I'm training the IMNN")
rng, key = jax.random.split(rng)
IMNN2.fit(λ=10., ϵ=0.1, rng=key, print_rate=None,
min_iterations=500, patience=100, best=True)
# visualize training trajectory
IMNN2.plot(expected_detF=None);
```
|
github_jupyter
|
```
#hide
from perutils.nbutils import simple_export_all_nb,simple_export_one_nb
```
# Personal Utils (perutils)
> Notebook -> module conversion with #export flags and nothing else
**Purpose:** The purpose and main use of this module is for adhoc projects where a full blown nbdev project is not necessary
**Example Scenario**
Imagine you are working on a kaggle competition. You may not want the full nbdev. For example, you don't need separate documentation from your notebooks and you're never going to release it to pip or conda. This module simplifies the process so you just run one command and it creates .py files from your notebooks. Maybe you are doing an ensemble and to export the dataloaders from a notebook so you can import them into seperate notebooks for your seperate models, or maybe you have a seperate use case.
That's what this module does. it's just the #export flags from nbdev and exporting to a module folder with no setup (ie settings.ini, \_\_nbdev.py, etc.) for fast minimal use
## Install
`pip install perutils`
## How to use
```
#hide
from nbdev.showdoc import *
```
### Shelve Experiment Tracking
This module is designed to assist me in tracking experiments when I am working on data science and machine learning tasks, though is flexible enough to track most things. This allows for easy tracking and plotting of many different types of information and datatypes without requiring a consistent schema so you can add new things without adjusting your dataframe or table.
General access to a shelve db can be reached in one of two ways and behaves similar to a dictionary.
```python
with shelve.open('test.shelve') as d:
print(d['exp'])
d = shelve.open('test.shelve')
print(d['exp']
d.close()
```
This module assumes a certain structure. If we assume: `d = shelve.open('test.shelve')`
```python
assert type(d[key]) == list
assert type(d[key][0]) == dict
```
Additionally:
+ keys in an experiment (`d['exp'][0][key]` must be strings but the values can be anything that can be pickled
+ Plotting functions assumes the value you want to plot (ie `d['exp][0]['batch_loss']` is list like and the name (for the legend) is a string
#### Create and Add Data
The process is:
1. Create a dict with all the information
2. Append dict to database
This will create `filename` if it does not exist
```python
append(filename,new_dict)
```
>note: You can write individual elements at a time as well just like you would in a normal dictionary if that is preferred.
#### Delete
`-1` can be replaced with any index location.
```python
delete(filename,-1)
```
#### What keys are available?
```python
print_keys(filename)
```
#### What were the results?
```python
el,ea,bl = get_stats(filename,-1,['epoch_loss','epoch_accuracy','batch_loss'],display=True)
```
#### Find the experiment with the best results.
```python
print_best(filename,'epoch_loss',best='min')
print_best(filename,'epoch_accuracy',best='max')
```
#### Graph some stats and compare results
```python
graph_stats(filename,['batch_loss','epoch_accuracy'],idxs=[-1,-2,-3])
```
### nb -> py
#### Full Directory Conversion
In python run the `simple_export_all_nb` function. This will:
+ Look through all your notebooks in the directory (nbs_path) for any code cells starting with `#export` or `# export`
+ If any export code cells exist, it will take all the code and put it in a .py file located in `lib_path`
+ The .py module will be named the same as the notebook. There is no option to specify a seperate .py file name from your notebook name
**Any .py files in your lib_path will be removed and replaced. Do not set lib_path to a folder where you are storing other .py files. I recommend lib_path being it's own folder only for these auto-generated modules**
```python
simple_export_all_nb(nbs_path=Path('.'), lib_path=Path('test_example'))```
#### Single Notebook Conversion
In python run the `simple_export_one_nb` function. This will:
+ Look through the specified notebook (nb_path) for any code cells starting with `#export` or `# export`
+ If any export code cells exist, it will take all the code and put it in a .py file located in `lib_path`
+ The .py module will be named the same as the notebook. There is no option to specify a seperate .py file name from your notebook name
```python
simple_export_one_nb(nb_path=Path('./00_core.ipynb'), lib_path=Path('test_example'))```
### py -> nb
#### Full Directory Conversion
In python run the `py_to_nb` function. This will:
+ Look through all your py files in the `py_path`
+ Find the simple breaking points in each file (ie when new functions or classes are defined
+ Create jupyter notebooks in `nb_path` and put code in seperate cells (with `#export` flag)
**This will overwrite notebooks in the `nb_path` if they have the same name other than extension as a python module**
```python
py_to_nb(py_path=Path('./src/'),nb_pth=Path('.')```
### kaggle dataset
#### Uploading Libraries
```python
if __name__ == '__main__':
libraries = ['huggingface','timm','torch','torchvision','opencv-python','albumentations','fastcore']
for library in libraries:
print(f'starting {library}')
dataset_path = Path(library)
print("downloading dataset...")
download_dataset(dataset_path,f'isaacflath/library{library}',f'library{library}',content=False,unzip=True)
print("adding library...")
add_library_to_dataset(library,dataset_path)
print("updating dataset...")
update_datset(dataset_path,"UpdateLibrary")
print('+'*30)
```
#### Custom dataset (ie model weights)
```python
dataset_path = Path(library)
dataset_name = testdataset
download_dataset(dataset_path,f'isaacflath/{dataset_name}',f'{dataset_name}',content=False,unzip=True)
# add files (ie model weights to folder
update_datset(dataset_path,"UpdateLibrary")
```
|
github_jupyter
|
```
import boto3
import botocore
import os
import sagemaker
bucket = sagemaker.Session().default_bucket()
prefix = "sagemaker/ipinsights-tutorial"
execution_role = sagemaker.get_execution_role()
region = boto3.Session().region_name
# check if the bucket exists
try:
boto3.Session().client("s3").head_bucket(Bucket=bucket)
except botocore.exceptions.ParamValidationError as e:
print("Specify your S3 bucket or you gave your bucket an invalid name!")
except botocore.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "403":
print(f"You don't have permission to access the bucket, {bucket}.")
elif e.response["Error"]["Code"] == "404":
print(f"Your bucket, {bucket}, doesn't exist!")
else:
raise
else:
print(f"Training input/output will be stored in: s3://{bucket}/{prefix}")
```
Next we download the modules necessary for synthetic data generation they do not exist.
```
from os import path
tools_bucket = f"jumpstart-cache-prod-{region}" # Bucket containing the data generation module.
tools_prefix = "1p-algorithms-assets/ip-insights" # Prefix for the data generation module
s3 = boto3.client("s3")
data_generation_file = "generate_data.py" # Synthetic data generation module
script_parameters_file = "ip2asn-v4-u32.tsv.gz"
if not path.exists(data_generation_file):
s3.download_file(tools_bucket, f"{tools_prefix}/{data_generation_file}", data_generation_file)
if not path.exists(script_parameters_file):
s3.download_file(tools_bucket, f"{tools_prefix}/{script_parameters_file}", script_parameters_file)
```
### Dataset
Apache Web Server ("httpd") is the most popular web server used on the internet. And luckily for us, it logs all requests processed by the server - by default. If a web page requires HTTP authentication, the Apache Web Server will log the IP address and authenticated user name for each requested resource.
The [access logs](https://httpd.apache.org/docs/2.4/logs.html) are typically on the server under the file `/var/log/httpd/access_log`. From the example log output below, we see which IP addresses each user has connected with:
```
192.168.1.100 - user1 [15/Oct/2018:18:58:32 +0000] "GET /login_success?userId=1 HTTP/1.1" 200 476 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
192.168.1.102 - user2 [15/Oct/2018:18:58:35 +0000] "GET /login_success?userId=2 HTTP/1.1" 200 - "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
...
```
If we want to train an algorithm to detect suspicious activity, this dataset is ideal for SageMaker IP Insights.
First, we determine the resource we want to be analyzing (such as a login page or access to a protected file). Then, we construct a dataset containing the history of all past user interactions with the resource. We extract out each 'access event' from the log and store the corresponding user name and IP address in a headerless CSV file with two columns. The first column will contain the user identifier string, and the second will contain the IPv4 address in decimal-dot notation.
```
user1, 192.168.1.100
user2, 193.168.1.102
...
```
As a side note, the dataset should include all access events. That means some `<user_name, ip_address>` pairs will be repeated.
#### User Activity Simulation
For this example, we are going to simulate our own web-traffic logs. We mock up a toy website example and simulate users logging into the website from mobile devices.
The details of the simulation are explained in the script [here](./generate_data.py).
```
from generate_data import generate_dataset
# We simulate traffic for 10,000 users. This should yield about 3 million log lines (~700 MB).
NUM_USERS = 10000
log_file = "ipinsights_web_traffic.log"
generate_dataset(NUM_USERS, log_file)
# Visualize a few log lines
!head $log_file
```
### Prepare the dataset
Now that we have our logs, we need to transform them into a format that IP Insights can use. As we mentioned above, we need to:
1. Choose the resource which we want to analyze users' history for
2. Extract our users' usage history of IP addresses
3. In addition, we want to separate our dataset into a training and test set. This will allow us to check for overfitting by evaluating our model on 'unseen' login events.
For the rest of the notebook, we assume that the Apache Access Logs are in the Common Log Format as defined by the [Apache documentation](https://httpd.apache.org/docs/2.4/logs.html#accesslog). We start with reading the logs into a Pandas DataFrame for easy data exploration and pre-processing.
```
import pandas as pd
df = pd.read_csv(
log_file,
sep=" ",
na_values="-",
header=None,
names=["ip_address","rcf_id","user","timestamp","time_zone","request", "status", "size", "referer", "user_agent"]
)
df.head()
```
We convert the log timestamp strings into Python datetimes so that we can sort and compare the data more easily.
```
# Convert time stamps to DateTime objects
df["timestamp"] = pd.to_datetime(df["timestamp"], format="[%d/%b/%Y:%H:%M:%S")
```
We also verify the time zones of all of the time stamps. If the log contains more than one time zone, we would need to standardize the timestamps.
```
# Check if they are all in the same timezone
num_time_zones = len(df["time_zone"].unique())
num_time_zones
```
As we see above, there is only one value in the entire `time_zone` column. Therefore, all of the timestamps are in the same time zone, and we do not need to standardize them. We can skip the next cell and go to [1. Selecting a Resource](#1.-Select-Resource).
If there is more than one time_zone in your dataset, then we parse the timezone offset and update the corresponding datetime object.
**Note:** The next cell takes about 5-10 minutes to run.
```
from datetime import datetime
import pytz
def apply_timezone(row):
tz = row[1]
tz_offset = int(tz[:3]) * 60 # Hour offset
tz_offset += int(tz[3:5]) # Minutes offset
return row[0].replace(tzinfo=pytz.FixedOffset(tz_offset))
if num_time_zones > 1:
df["timestamp"] = df[["timestamp", "time_zone"]].apply(apply_timezone, axis=1)
```
#### 1. Select Resource
Our goal is to train an IP Insights algorithm to analyze the history of user logins such that we can predict how suspicious a login event is.
In our simulated web server, the server logs a `GET` request to the `/login_success` page everytime a user successfully logs in. We filter our Apache logs for `GET` requests for `/login_success`. We also filter for requests that have a `status_code == 200`, to ensure that the page request was well formed.
**Note:** every web server handles logins differently. For your dataset, determine which resource you will need to be analyzing to correctly frame this problem. Depending on your usecase, you may need to do more data exploration and preprocessing.
```
df = df[(df["request"].str.startswith("GET /login_success")) & (df["status"] == 200)]
```
#### 2. Extract Users and IP address
Now that our DataFrame only includes log events for the resource we want to analyze, we extract the relevant fields to construct a IP Insights dataset.
IP Insights takes in a headerless CSV file with two columns: an entity (username) ID string and the IPv4 address in decimal-dot notation. Fortunately, the Apache Web Server Access Logs output IP addresses and authentcated usernames in their own columns.
**Note:** Each website handles user authentication differently. If the Access Log does not output an authenticated user, you could explore the website's query strings or work with your website developers on another solution.
```
df = df[["user", "ip_address", "timestamp"]]
```
#### 3. Create training and test dataset
As part of training a model, we want to evaluate how it generalizes to data it has never seen before.
Typically, you create a test set by reserving a random percentage of your dataset and evaluating the model after training. However, for machine learning models that make future predictions on historical data, we want to use out-of-time testing. Instead of randomly sampling our dataset, we split our dataset into two contiguous time windows. The first window is the training set, and the second is the test set.
We first look at the time range of our dataset to select a date to use as the partition between the training and test set.
```
df["timestamp"].describe()
```
We have login events for 10 days. Let's take the first week (7 days) of data as training and then use the last 3 days for the test set.
```
time_partition = (
datetime(2018, 11, 11, tzinfo=pytz.FixedOffset(0))
if num_time_zones > 1
else datetime(2018, 11, 11)
)
train_df = df[df["timestamp"] <= time_partition]
test_df = df[df["timestamp"] > time_partition]
```
Now that we have our training dataset, we shuffle it.
Shuffling improves the model's performance since SageMaker IP Insights uses stochastic gradient descent. This ensures that login events for the same user are less likely to occur in the same mini batch. This allows the model to improve its performance in between predictions of the same user, which will improve training convergence.
```
# Shuffle train data
train_df = train_df.sample(frac=1)
train_df.head()
```
### Store Data on S3
Now that we have simulated (or scraped) our datasets, we have to prepare and upload it to S3.
We will be doing local inference, therefore we don't need to upload our test dataset.
```
# Output dataset as headerless CSV
train_data = train_df.to_csv(index=False, header=False, columns=["user", "ip_address"])
# Upload data to S3 key
train_data_file = "train.csv"
key = os.path.join(prefix, "train", train_data_file)
s3_train_data = f"s3://{bucket}/{key}"
print(f"Uploading data to: {s3_train_data}")
boto3.resource("s3").Bucket(bucket).Object(key).put(Body=train_data)
# Configure SageMaker IP Insights Input Channels
input_data = {
"train": sagemaker.session.s3_input(
s3_train_data, distribution="FullyReplicated", content_type="text/csv"
)
}
```
## Training
---
Once the data is preprocessed and available in the necessary format, the next step is to train our model on the data. There are number of parameters required by the SageMaker IP Insights algorithm to configure the model and define the computational environment in which training will take place. The first of these is to point to a container image which holds the algorithms training and hosting code:
```
from sagemaker.amazon.amazon_estimator import get_image_uri
image = get_image_uri(boto3.Session().region_name, "ipinsights")
```
Then, we need to determine the training cluster to use. The IP Insights algorithm supports both CPU and GPU training. We recommend using GPU machines as they will train faster. However, when the size of your dataset increases, it can become more economical to use multiple CPU machines running with distributed training.
### Training Job Configuration
- **train_instance_type**: the instance type to train on. We recommend `p3.2xlarge` for single GPU, `p3.8xlarge` for multi-GPU, and `m5.2xlarge` if using distributed training with CPU;
- **train_instance_count**: the number of worker nodes in the training cluster.
We need to also configure SageMaker IP Insights-specific hypeparameters:
### Model Hyperparameters
- **num_entity_vectors**: the total number of embeddings to train. We use an internal hashing mechanism to map the entity ID strings to an embedding index; therefore, using an embedding size larger than the total number of possible values helps reduce the number of hash collisions. We recommend this value to be 2x the total number of unique entites (i.e. user names) in your dataset;
- **vector_dim**: the size of the entity and IP embedding vectors. The larger the value, the more information can be encoded using these representations but using too large vector representations may cause the model to overfit, especially for small training data sets;
- **num_ip_encoder_layers**: the number of layers in the IP encoder network. The larger the number of layers, the higher the model capacity to capture patterns among IP addresses. However, large number of layers increases the chance of overfitting. `num_ip_encoder_layers=1` is a good value to start experimenting with;
- **random_negative_sampling_rate**: the number of randomly generated negative samples to produce per 1 positive sample; `random_negative_sampling_rate=1` is a good value to start experimenting with;
- Random negative samples are produced by drawing each octet from a uniform distributed of [0, 255];
- **shuffled_negative_sampling_rate**: the number of shuffled negative samples to produce per 1 positive sample; `shuffled_negative_sampling_rate=1` is a good value to start experimenting with;
- Shuffled negative samples are produced by shuffling the accounts within a batch;
### Training Hyperparameters
- **epochs**: the number of epochs to train. Increase this value if you continue to see the accuracy and cross entropy improving over the last few epochs;
- **mini_batch_size**: how many examples in each mini_batch. A smaller number improves convergence with stochastic gradient descent. But a larger number is necessary if using shuffled_negative_sampling to avoid sampling a wrong account for a negative sample;
- **learning_rate**: the learning rate for the Adam optimizer (try ranges in [0.001, 0.1]). Too large learning rate may cause the model to diverge since the training would be likely to overshoot minima. On the other hand, too small learning rate slows down the convergence;
- **weight_decay**: L2 regularization coefficient. Regularization is required to prevent the model from overfitting the training data. Too large of a value will prevent the model from learning anything;
```
# Set up the estimator with training job configuration
ip_insights = sagemaker.estimator.Estimator(
image,
execution_role,
instance_count=1,
instance_type="ml.p3.2xlarge",
output_path=f"s3://{bucket}/{prefix}/output",
sagemaker_session=sagemaker.Session(),
)
# Configure algorithm-specific hyperparameters
ip_insights.set_hyperparameters(
num_entity_vectors="20000",
random_negative_sampling_rate="5",
vector_dim="128",
mini_batch_size="1000",
epochs="5",
learning_rate="0.01",
)
# Start the training job (should take about ~1.5 minute / epoch to complete)
ip_insights.fit(input_data)
print(f"Training job name: {ip_insights.latest_training_job.job_name}")
```
## Inference
-----
Now that we have trained a SageMaker IP Insights model, we can deploy the model to an endpoint to start performing inference on data. In this case, that means providing it a `<user, IP address>` pair and predicting their compatability scores.
We can create an inference endpoint using the SageMaker Python SDK `deploy()`function from the job we defined above. We specify the instance type where inference will be performed, as well as the initial number of instnaces to spin up. We recommend using the `ml.m5` instance as it provides the most memory at the lowest cost. Verify how large your model is in S3 and pick the instance type with the appropriate amount of memory.
```
predictor = ip_insights.deploy(initial_instance_count=1, instance_type="ml.m5.xlarge")
print(f"Endpoint name: {predictor.endpoint}")
```
### Data Serialization/Deserialization
We can pass data in a variety of formats to our inference endpoint. In this example, we will pass CSV-formmated data. Other available formats are JSON-formated and JSON Lines-formatted. We make use of the SageMaker Python SDK utilities: `csv_serializer` and `json_deserializer` when configuring the inference endpoint
```
from sagemaker.predictor import csv_serializer, json_deserializer
predictor.serializer = csv_serializer
predictor.deserializer = json_deserializer
```
Now that the predictor is configured, it is as easy as passing in a matrix of inference data.
We can take a few samples from the simulated dataset above, so we can see what the output looks like.
```
inference_data = [(data[0], data[1]) for data in train_df[:5].values]
predictor.predict(
inference_data, initial_args={"ContentType": "text/csv", "Accept": "application/json"}
)
```
By default, the predictor will only output the `dot_product` between the learned IP address and the online resource (in this case, the user ID). The dot product summarizes the compatibility between the IP address and online resource. The larger the value, the more the algorithm thinks the IP address is likely to be used by the user. This compatability score is sufficient for most applications, as we can define a threshold for what we constitute as an anomalous score.
However, more advanced users may want to inspect the learned embeddings and use them in further applications. We can configure the predictor to provide the learned embeddings by specifing the `verbose=True` parameter to the Accept heading. You should see that each 'prediction' object contains three keys: `ip_embedding`, `entity_embedding`, and `dot_product`.
```
predictor.predict(
inference_data,
initial_args={"ContentType": "text/csv", "Accept": "application/json; verbose=True"},
)
```
## Compute Anomaly Scores
----
The `dot_product` output of the model provides a good measure of how compatible an IP address and online resource are. However, the range of the dot_product is unbounded. This means to be able to consider an event as anomolous we need to define a threshold. Such that when we score an event, if the dot_product is above the threshold we can flag the behavior as anomolous.However, picking a threshold can be more of an art, and a good threshold depends on the specifics of your problem and dataset.
In the following section, we show how to pick a simple threshold by comparing the score distributions between known normal and malicious traffic:
1. We construct a test set of 'Normal' traffic;
2. Inject 'Malicious' traffic into the dataset;
3. Plot the distribution of dot_product scores for the model on 'Normal' trafic and the 'Malicious' traffic.
3. Select a threshold value which separates the normal distribution from the malicious traffic threshold. This value is based on your false-positive tolerance.
### 1. Construct 'Normal' Traffic Dataset
We previously [created a test set](#3.-Create-training-and-test-dataset) from our simulated Apache access logs dataset. We use this test dataset as the 'Normal' traffic in the test case.
```
test_df.head()
```
### 2. Inject Malicious Traffic
If we had a dataset with enough real malicious activity, we would use that to determine a good threshold. Those are hard to come by. So instead, we simulate malicious web traffic that mimics a realistic attack scenario.
We take a set of user accounts from the test set and randomly generate IP addresses. The users should not have used these IP addresses during training. This simulates an attacker logging in to a user account without knowledge of their IP history.
```
import numpy as np
from generate_data import draw_ip
def score_ip_insights(predictor, df):
def get_score(result):
"""Return the negative to the dot product of the predictions from the model."""
return [-prediction["dot_product"] for prediction in result["predictions"]]
df = df[["user", "ip_address"]]
result = predictor.predict(df.values)
return get_score(result)
def create_test_case(train_df, test_df, num_samples, attack_freq):
"""Creates a test case from provided train and test data frames.
This generates test case for accounts that are both in training and testing data sets.
:param train_df: (panda.DataFrame with columns ['user', 'ip_address']) training DataFrame
:param test_df: (panda.DataFrame with columns ['user', 'ip_address']) testing DataFrame
:param num_samples: (int) number of test samples to use
:param attack_freq: (float) the ratio of negative_samples:positive_samples to generate for test case
:return: DataFrame with both good and bad traffic, with labels
"""
# Get all possible accounts. The IP Insights model can only make predictions on users it has seen in training
# Therefore, filter the test dataset for unseen accounts, as their results will not mean anything.
valid_accounts = set(train_df["user"])
valid_test_df = test_df[test_df["user"].isin(valid_accounts)]
good_traffic = valid_test_df.sample(num_samples, replace=False)
good_traffic = good_traffic[["user", "ip_address"]]
good_traffic["label"] = 0
# Generate malicious traffic
num_bad_traffic = int(num_samples * attack_freq)
bad_traffic_accounts = np.random.choice(list(valid_accounts), size=num_bad_traffic, replace=True)
bad_traffic_ips = [draw_ip() for i in range(num_bad_traffic)]
bad_traffic = pd.DataFrame({"user": bad_traffic_accounts, "ip_address": bad_traffic_ips})
bad_traffic["label"] = 1
# All traffic labels are: 0 for good traffic; 1 for bad traffic.
all_traffic = good_traffic.append(bad_traffic)
return all_traffic
NUM_SAMPLES = 100000
test_case = create_test_case(train_df, test_df, num_samples=NUM_SAMPLES, attack_freq=1)
test_case.head()
test_case_scores = score_ip_insights(predictor, test_case)
```
### 3. Plot Distribution
Now, we plot the distribution of scores. Looking at this distribution will inform us on where we can set a good threshold, based on our risk tolerance.
```
%matplotlib inline
import matplotlib.pyplot as plt
n, x = np.histogram(test_case_scores[:NUM_SAMPLES], bins=100, density=True)
plt.plot(x[1:], n)
n, x = np.histogram(test_case_scores[NUM_SAMPLES:], bins=100, density=True)
plt.plot(x[1:], n)
plt.legend(["Normal", "Random IP"])
plt.xlabel("IP Insights Score")
plt.ylabel("Frequency")
plt.figure()
```
### 4. Selecting a Good Threshold
As we see in the figure above, there is a clear separation between normal traffic and random traffic.
We could select a threshold depending on the application.
- If we were working with low impact decisions, such as whether to ask for another factor or authentication during login, we could use a `threshold = 0.0`. This would result in catching more true-positives, at the cost of more false-positives.
- If our decision system were more sensitive to false positives, we could choose a larger threshold, such as `threshold = 10.0`. That way if we were sending the flagged cases to manual investigation, we would have a higher confidence that the acitivty was suspicious.
```
threshold = 0.0
flagged_cases = test_case[np.array(test_case_scores) > threshold]
num_flagged_cases = len(flagged_cases)
num_true_positives = len(flagged_cases[flagged_cases["label"] == 1])
num_false_positives = len(flagged_cases[flagged_cases["label"] == 0])
num_all_positives = len(test_case.loc[test_case["label"] == 1])
print(f"When threshold is set to: {threshold}")
print(f"Total of {num_flagged_cases} flagged cases")
print(f"Total of {num_true_positives} flagged cases are true positives")
print(f"True Positive Rate: {num_true_positives / float(num_flagged_cases)}")
print(f"Recall: {num_true_positives / float(num_all_positives)}")
print(f"Precision: {num_true_positives / float(num_flagged_cases)}")
```
### SageMaker Automatic Model Tuning
#### Validation Dataset
Previously, we separated our dataset into a training and test set to validate the performance of a single IP Insights model. However, when we do model tuning, we train many IP Insights models in parallel. If we were to use the same test dataset to select the best model, we bias our model selection such that we don't know if we selected the best model in general, or just the best model for that particular dateaset.
Therefore, we need to separate our test set into a validation dataset and a test dataset. The validation dataset is used for model selection. Then once we pick the model with the best performance, we evaluate it the winner on a test set just as before.
#### Validation Metrics
For SageMaker Automatic Model Tuning to work, we need an objective metric which determines the performance of the model we want to optimize. Because SageMaker IP Insights is an usupervised algorithm, we do not have a clearly defined metric for performance (such as percentage of fraudulent events discovered).
We allow the user to provide a validation set of sample data (same format as training data bove) through the `validation` channel. We then fix the negative sampling strategy to use `random_negative_sampling_rate=1` and `shuffled_negative_sampling_rate=0` and generate a validation dataset by assigning corresponding labels to the real and simulated data. We then calculate the model's `descriminator_auc` metric. We do this by taking the model's predicted labels and the 'true' simulated labels and compute the Area Under ROC Curve (AUC) on the model's performance.
We set up the `HyperParameterTuner` to maximize the `discriminator_auc` on the validation dataset. We also need to set the search space for the hyperparameters.
```
test_df["timestamp"].describe()
```
The test set we constructed above spans 3 days. We reserve the first day as the validation set and the subsequent two days for the test set.
```
time_partition = (
datetime(2018, 11, 13, tzinfo=pytz.FixedOffset(0))
if num_time_zones > 1
else datetime(2018, 11, 13)
)
validation_df = test_df[test_df["timestamp"] < time_partition]
test_df = test_df[test_df["timestamp"] >= time_partition]
valid_data = validation_df.to_csv(index=False, header=False, columns=["user", "ip_address"])
```
We then upload the validation data to S3 and specify it as the validation channel.
```
# Upload data to S3 key
validation_data_file = "valid.csv"
key = os.path.join(prefix, "validation", validation_data_file)
boto3.resource("s3").Bucket(bucket).Object(key).put(Body=valid_data)
s3_valid_data = f"s3://{bucket}/{key}"
print(f"Validation data has been uploaded to: {s3_valid_data}")
# Configure SageMaker IP Insights Input Channels
input_data = {"train": s3_train_data, "validation": s3_valid_data}
from sagemaker.tuner import HyperparameterTuner, IntegerParameter
# Configure HyperparameterTuner
ip_insights_tuner = HyperparameterTuner(
estimator=ip_insights, # previously-configured Estimator object
objective_metric_name="validation:discriminator_auc",
hyperparameter_ranges={"vector_dim": IntegerParameter(64, 1024)},
max_jobs=4,
max_parallel_jobs=2,
)
# Start hyperparameter tuning job
ip_insights_tuner.fit(input_data, include_cls_metadata=False)
# Wait for all the jobs to finish
ip_insights_tuner.wait()
# Visualize training job results
ip_insights_tuner.analytics().dataframe()
# Deploy best model
tuned_predictor = ip_insights_tuner.deploy(
initial_instance_count=1,
instance_type="ml.m4.xlarge",
serializer=csv_serializer,
deserializer=json_deserializer,
)
# Make a prediction against the SageMaker endpoint
tuned_predictor.predict(
inference_data, initial_args={"ContentType": "text/csv", "Accept": "application/json"}
)
```
We should have the best performing model from the training job! Now we can determine thresholds and make predictions just like we did with the inference endpoint [above](#Inference).
### Batch Transform
To score all of the login events at the end of the day and aggregate flagged cases for investigators to look at in the morning. If we store the daily login events in S3, we can use IP Insights with to run inference and store the IP Insights scores back in S3 for future analysis.
Below, we take the training job from before and evaluate it on the validation data we put in S3.
```
transformer = ip_insights.transformer(instance_count=1, instance_type="ml.m4.xlarge")
transformer.transform(s3_valid_data, content_type="text/csv", split_type="Line")
# Wait for Transform Job to finish
transformer.wait()
print(f"Batch Transform output is at: {transformer.output_path}")
```
### Stop and Delete the Endpoint
If you are done with this model, then we should delete the endpoint before we close the notebook. Or else you will continue to pay for the endpoint while it is running.
```
ip_insights_tuner.delete_endpoint()
sagemaker.Session().delete_endpoint(predictor.endpoint)
```
|
github_jupyter
|
# Table of Contents
<p><div class="lev1 toc-item"><a href="#ALGO1-:-Introduction-à-l'algorithmique" data-toc-modified-id="ALGO1-:-Introduction-à-l'algorithmique-1"><span class="toc-item-num">1 </span><a href="https://perso.crans.org/besson/teach/info1_algo1_2019/" target="_blank">ALGO1 : Introduction à l'algorithmique</a></a></div><div class="lev1 toc-item"><a href="#Cours-Magistral-6" data-toc-modified-id="Cours-Magistral-6-2"><span class="toc-item-num">2 </span>Cours Magistral 6</a></div><div class="lev2 toc-item"><a href="#Rendu-de-monnaie" data-toc-modified-id="Rendu-de-monnaie-21"><span class="toc-item-num">2.1 </span>Rendu de monnaie</a></div><div class="lev2 toc-item"><a href="#Structure-"Union-Find"" data-toc-modified-id="Structure-"Union-Find"-22"><span class="toc-item-num">2.2 </span>Structure "Union-Find"</a></div><div class="lev3 toc-item"><a href="#Naïve" data-toc-modified-id="Naïve-221"><span class="toc-item-num">2.2.1 </span>Naïve</a></div><div class="lev3 toc-item"><a href="#Avec-compression-de-chemin" data-toc-modified-id="Avec-compression-de-chemin-222"><span class="toc-item-num">2.2.2 </span>Avec compression de chemin</a></div><div class="lev2 toc-item"><a href="#Algorithme-de-Kruskal" data-toc-modified-id="Algorithme-de-Kruskal-23"><span class="toc-item-num">2.3 </span>Algorithme de Kruskal</a></div><div class="lev2 toc-item"><a href="#Algorithme-de-Prim" data-toc-modified-id="Algorithme-de-Prim-24"><span class="toc-item-num">2.4 </span>Algorithme de Prim</a></div><div class="lev3 toc-item"><a href="#File-de-priorité-min" data-toc-modified-id="File-de-priorité-min-241"><span class="toc-item-num">2.4.1 </span>File de priorité min</a></div><div class="lev3 toc-item"><a href="#Prim" data-toc-modified-id="Prim-242"><span class="toc-item-num">2.4.2 </span>Prim</a></div><div class="lev2 toc-item"><a href="#Illustrations" data-toc-modified-id="Illustrations-25"><span class="toc-item-num">2.5 </span>Illustrations</a></div><div class="lev2 toc-item"><a href="#Autres" data-toc-modified-id="Autres-26"><span class="toc-item-num">2.6 </span>Autres</a></div><div class="lev2 toc-item"><a href="#Conclusion" data-toc-modified-id="Conclusion-27"><span class="toc-item-num">2.7 </span>Conclusion</a></div>
# [ALGO1 : Introduction à l'algorithmique](https://perso.crans.org/besson/teach/info1_algo1_2019/)
- [Page du cours](https://perso.crans.org/besson/teach/info1_algo1_2019/) : https://perso.crans.org/besson/teach/info1_algo1_2019/
- Magistère d'Informatique de Rennes - ENS Rennes - Année 2019/2020
- Intervenants :
+ Cours : [Lilian Besson](https://perso.crans.org/besson/)
+ Travaux dirigés : [Raphaël Truffet](http://perso.eleves.ens-rennes.fr/people/Raphael.Truffet/)
- Références :
+ [Open Data Structures](http://opendatastructures.org/ods-python.pdf)
# Cours Magistral 6
- Ce cours traite des algorithmes gloutons.
- Ce notebook sera concis, comparé aux précédents.
## Rendu de monnaie
- Voir https://en.wikipedia.org/wiki/Change-making_problem ou https://fr.wikipedia.org/wiki/Probl%C3%A8me_du_rendu_de_monnaie
```
def binary_coin_change(x, R):
"""Coin change
:param x: table of non negative values
:param R: target value
:returns bool: True if there is a non negative linear combination
of x that has value R
:complexity: O(n*R)
"""
if int(R) != R: # we work with 1/100
R = int(R * 100)
x = [int(xi * 100) for xi in x]
b = [False] * (R + 1)
b[0] = True
for xi in x:
for s in range(xi, R + 1):
b[s] |= b[s - xi]
return b[R]
def constructive_coin_change(values_of_coins, sum_to_find):
"""Coin change
:param values_of_coins: table of non negative values
:param sum_to_find: target value
:returns bool: True if there is a non negative linear combination
of x that has value R
:complexity: O(n*R)
"""
with_cents = False
if int(sum_to_find) != sum_to_find: # we work with 1/100
with_cents = True
sum_to_find = int(sum_to_find * 100)
values_of_coins = [int(pi * 100) for pi in values_of_coins]
n = len(values_of_coins)
number_of_coins = [0] * n
values_of_coins = sorted(values_of_coins, reverse=True)
current_sum = sum_to_find
for i, pi in enumerate(values_of_coins):
assert pi > 0, "Error: a coin with value zero."
if pi > current_sum:
continue # coin is too large, we continue
how_much_pi, rest = divmod(current_sum, pi) # x // y, x % y
number_of_coins[i] = how_much_pi
print("For current sum = {}, coin = {}, was used {} times, now sum = {}.".format(current_sum, pi, how_much_pi, rest))
current_sum = rest
if current_sum != 0:
raise ValueError("Could not write {} in the coin system {} with greedy method.".format(sum_to_find, values_of_coins))
if with_cents:
values_of_coins = [round(pi / 100, 2) for pi in values_of_coins]
return number_of_coins, values_of_coins
```
Avec les pièces des euros :
```
billets = [500, 200, 100, 50, 20, 10, 5]
pieces = [2, 1, 0.5, 0.2, 0.1, 0.05, 0.02, 0.01]
euros = billets + pieces
binary_coin_change(euros, 16.12)
constructive_coin_change(euros, 16.12)
billets = [500, 200, 100, 50, 20, 10, 5]
binary_coin_change(billets, 16)
constructive_coin_change(billets, 16)
```
Avec un autre système de pièce :
```
billets = [19, 13, 7]
pieces = [3, 2]
weird = billets + pieces
if binary_coin_change(weird, 47):
constructive_coin_change(weird, 47)
if binary_coin_change(weird, 49):
constructive_coin_change(weird, 49)
if binary_coin_change(weird, 50):
constructive_coin_change(weird, 50)
```
Cette méthode gourmande ne marche pas pour tous les systèmes !
---
## Structure "Union-Find"
### Naïve
```
class UnionFind:
"""Maintains a partition of {0, ..., n-1}
"""
def __init__(self, n):
self.up_bound = list(range(n))
def find(self, x_index):
"""
:returns: identifier of part containing x_index
:complex_indexity: O(n) worst case, O(log n) in amortized cost.
"""
if self.up_bound[x_index] == x_index:
return x_index
self.up_bound[x_index] = self.find(self.up_bound[x_index])
return self.up_bound[x_index]
def union(self, x_index, y_index):
"""
Merges part that contain x and part containing y
:returns: False if x_index, y_index are already in same part
:complexity: O(n) worst case, O(log n) in amortized cost.
"""
repr_x = self.find(x_index)
repr_y = self.find(y_index)
if repr_x == repr_y: # already in the same component
return False
self.up_bound[repr_x] = repr_y
return True
```
Par exemple avec $S = \{0,1,2,3,4\}$ et les unions suivantes :
```
S = [0,1,2,3,4]
U = UnionFind(len(S))
U.up_bound
U.union(0, 2)
U.up_bound
U.up_bound
U.union(2, 3)
U.up_bound
for i in S:
U.find(i)
```
Cela représente la partition $\{ \{0,2,3\}, \{1\}, \{4\}\}$.
### Avec compression de chemin
```
class UnionFind_CompressedPaths:
"""Maintains a partition of {0, ..., n-1}
"""
def __init__(self, n):
self.up_bound = list(range(n))
self.rank = [0] * n
def find(self, x_index):
"""
:returns: identifier of part containing x_index
:complex_indexity: O(inverse_ackerman(n))
"""
if self.up_bound[x_index] == x_index:
return x_index
self.up_bound[x_index] = self.find(self.up_bound[x_index])
return self.up_bound[x_index]
def union(self, x_index, y_index):
"""
Merges part that contain x and part containing y
:returns: False if x_index, y_index are already in same part
:complexity: O(inverse_ackerman(n))
"""
repr_x = self.find(x_index)
repr_y = self.find(y_index)
if repr_x == repr_y: # already in the same component
return False
if self.rank[repr_x] == self.rank[repr_y]:
self.rank[repr_x] += 1
self.up_bound[repr_y] = repr_x
elif self.rank[repr_x] > self.rank[repr_y]:
self.up_bound[repr_y] = repr_x
else:
self.up_bound[repr_x] = repr_y
return True
```
Par exemple avec $S = \{0,1,2,3,4\}$ et les unions suivantes :
```
S = [0,1,2,3,4]
U = UnionFind_CompressedPaths(len(S))
U.up_bound
U.union(0, 2)
U.up_bound
U.up_bound
U.union(2, 3)
U.up_bound
for i in S:
U.find(i)
```
Cela représente la partition $\{ \{0,2,3\}, \{1\}, \{4\}\}$.
---
## Algorithme de Kruskal
On utilise une des implémentations de la structure Union-Find, et le reste du code est très simple.
```
def kruskal(graph, weight):
"""Minimum spanning tree by Kruskal
:param graph: undirected graph in listlist or listdict format
:param weight: in matrix format or same listdict graph
:returns: list of edges of the tree
:complexity: ``O(|E|log|E|)``
"""
# a UnionFind with n singletons { {0}, {1}, ..., {n-1} }
u_f = UnionFind(len(graph))
edges = [ ]
for u, _ in enumerate(graph):
for v in graph[u]:
# we add the edge (u, v) with weight w(u,v)
edges.append((weight[u][v], u, v))
edges.sort() # sort the edge in increasing order!
min_span_tree = [ ]
for w_idx, u_idx, v_idx in edges: # O(|E|)
if u_f.union(u_idx, v_idx):
# u and v were not in the same connected component
min_span_tree.append((u_idx, v_idx))
# we add the edge (u, v) in the tree, now they are in the same connected component
return min_span_tree
```
---
## Algorithme de Prim
### File de priorité min
On peut utiliser les opérations `heappush` et `heappop` du module `heapq`.
Ou notre implémentation maison des tas, qui permet d'avoir une opération `update` pour efficacement mettre à jour la priorité d'un élément.
```
from heapq import heappop, heappush
from heap_operations import OurHeap
```
### Prim
```
def prim(graph, weight, source=0):
"""Minimum spanning tree by Prim
- param graph: directed graph, connex and non-oriented
- param weight: in matrix format or same listdict graph
- assumes: weights are non-negative
- param source: source vertex
- returns: distance table, precedence table
- complexity: O(|S| + |A| log|A|)
"""
n = len(graph)
assert all(weight[u][v] >= 0 for u in range(n) for v in graph[u])
prec = [None] * n
cost = [float('inf')] * n
cost[source] = 0
# the difference with Dijsktra is that the heap starts with all the nodes!
heap = OurHeap([])
is_in_the_heap = [False for u in range(n)]
for u in range(n):
heap.push((cost[u], u))
is_in_the_heap[u] = True
while heap:
dist_node, node = heap.pop() # Closest node from source
is_in_the_heap[node] = False
# and there is no color white/gray/black
# the node is always visited!
for neighbor in graph[node]:
if is_in_the_heap[neighbor] and cost[neighbor] >= weight[node][neighbor]:
old_cost = cost[neighbor]
cost[neighbor] = weight[node][neighbor]
prec[neighbor] = node
heap.update((old_cost, neighbor), (cost[neighbor], neighbor))
# now we need to construct the min_spanning_tree
edges = [ ]
for u in range(n):
if u != prec[u]:
edges.append((u, prec[u]))
return edges # cost, prec
```
---
## Illustrations
```
import random
import math
def dist(a, b):
"""
distance between point a and point b
"""
return math.sqrt(sum([(a[i] - b[i]) * (a[i] - b[i]) for i in range(len(a))]))
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (10, 7)
mpl.rcParams['figure.dpi'] = 120
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(context="notebook", style="whitegrid", palette="hls", font="sans-serif", font_scale=1.1)
N = 50
points = [[random.random() * 5, random.random() * 5] for _ in range(N)]
weight = [[dist(points[i], points[j]) for j in range(N)]
for i in range(N)]
graph = [[j for j in range(N) if i != j] for i in range(N)]
min_span_tree_kruskal = kruskal(graph, weight)
min_span_tree_prim = prim(graph, weight)
plt.figure()
for u in points:
for v in points:
if u > v: break
xu, yu = u
xv, yv = v
_ = plt.plot([xu, xv], [yu, yv], 'o-')
# print("{} -- {}".format(points[u_idx], points[v_idx]))
plt.title("The whole graph")
plt.show()
plt.figure()
val = 0
for u_idx, v_idx in min_span_tree_kruskal:
val += weight[u_idx][v_idx]
xu, yu = points[u_idx]
xv, yv = points[v_idx]
_ = plt.plot([xu, xv], [yu, yv], 'o-')
# print("{} -- {}".format(points[u_idx], points[v_idx]))
print(val)
plt.title("Minimum spanning with Kruskal tree of cost {}".format(round(val, 2)))
plt.show()
plt.figure()
val = 0
for u_idx, v_idx in min_span_tree_prim:
val += weight[u_idx][v_idx]
xu, yu = points[u_idx]
xv, yv = points[v_idx]
_ = plt.plot([xu, xv], [yu, yv], 'o-')
# print("{} -- {}".format(points[u_idx], points[v_idx]))
print(val)
plt.title("Minimum spanning with Kruskal tree of cost {}".format(round(val, 2)))
plt.show()
```
## Autres
On en écrira plus tard !
## Conclusion
C'est bon pour aujourd'hui !
|
github_jupyter
|
```
import pandas as pd
import numpy as np
```
## Load data from csv file
```
names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','PRICE']
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data',
header=None, names=names , delim_whitespace = True, na_values='?')
"""
Attribute Information:
1. CRIM per capita crime rate by town
2. ZN proportion of residential land zoned for lots over
25,000 sq.ft.
3. INDUS proportion of non-retail business acres per town
4. CHAS Charles River dummy variable (= 1 if tract bounds
river; 0 otherwise)
5. NOX nitric oxides concentration (parts per 10 million)
6. RM average number of rooms per dwelling
7. AGE proportion of owner-occupied units built prior to 1940
8. DIS weighted distances to five Boston employment centres
9. RAD index of accessibility to radial highways
10. TAX full-value property-tax rate per $10,000
11. PTRATIO pupil-teacher ratio by town
12. B 1000(Bk - 0.63)^2 where Bk is the proportion of blocks by town
13. LSTAT % lower status of the population
14. MEDV Median value of owner-occupied homes in $1000's
"""
print ('df is an object of ', type(df))
print ('\n')
print(df.head(5))
print(df.shape)
```
### Store values in the pandas dataframe as numpy arrays
- we want to use the average number of rooms to predict the housing price
- we need to extract the data from df and convert them to numpy arrays
```
y = df['PRICE'].values
x = df['RM'].values
print ('both x and y are now objects of', type(x))
```
### Plot the housing price against the average number of rooms
```
import matplotlib.pyplot as plt
plt.plot(x,y,'o')
plt.xlabel('Average Number of Rooms')
plt.ylabel('Price')
plt.grid()
```
# Guess a line to fit the data
```
w1 = 9
w0 = -30
xplt = np.linspace(3,9,100)
yplt = w1 * xplt + w0
plt.plot(x,y,'o') # Plot the data points
plt.plot(xplt,yplt,'-',linewidth=3) # Plot the line
plt.xlabel('Average number of rooms in a region')
plt.ylabel('Price')
plt.grid()
```
## Calculate the Mean Squared Error (MSE) and Mean Absolute Error (MAE) to determine goodness of fit
### Reminder :
Given :
- a dataset : $(x_i, y_i)$, $i = 1, 2, 3, ..., N$
- a model : $\hat{y} = w_1x + w_0$
We can compute the following two error functions :
- Mean Squared Error: $\displaystyle MSE = \frac{1}{N}\sum_{i=1}^N || y_i - \hat{y_i}||^2$
- Mean Absolute Error: $\displaystyle MAE = \frac{1}{N}\sum_{i=1}^N |y_i - \hat{y_i}|$
```
## To-do
```
|
github_jupyter
|
```
from copy import deepcopy
import json
import pandas as pd
DATA_DIR = 'data'
# Define template payloads
CS_TEMPLATE = {
'resourceType': 'CodeSystem',
'status': 'draft',
'experimental': False,
'hierarchyMeaning': 'is-a',
'compositional': False,
'content': 'fragment',
'concept': []
}
```
# 1. PCGC
## 1.1 Phenotype
### 1.1.1 HP
```
# Copy template
cs_hp = deepcopy(CS_TEMPLATE)
# Set metadata
cs_hp['id'] = 'hp'
cs_hp['url'] = 'http://purl.obolibrary.org/obo/hp.owl'
cs_hp['name'] = 'http://purl.obolibrary.org/obo/hp.owl'
cs_hp['title'] = 'Human Phenotype Ontology'
# Read in phenotype codes
file_path = f'{DATA_DIR}/pcgc_ph_codes.tsv'
ph_codes = pd.read_csv(file_path, sep='\t')
# Populate concept
for i, row in ph_codes.iterrows():
if row.hpo_id_phenotype == 'No Match':
continue
cs_hp['concept'].append({
'code': row.hpo_id_phenotype,
'display': row.source_text_phenotype
})
cs_hp['count'] = len(cs_hp['concept'])
# Output to JSON
with open('CodeSystem-hp.json', 'w') as f:
json.dump(cs_hp, f, indent=2)
```
## 1.2 Diagnosis
```
# Read in phenotype codes
file_path = f'{DATA_DIR}/pcgc_dg_codes.tsv'
dg_codes = pd.read_csv(file_path, sep='\t')
```
### 1.2.1 MONDO
```
# Copy template
cs_mondo = deepcopy(CS_TEMPLATE)
# Set metadata
cs_mondo['id'] = 'mondo'
cs_mondo['url'] = 'http://purl.obolibrary.org/obo/mondo.owl'
cs_mondo['name'] = 'http://purl.obolibrary.org/obo/mondo.owl'
cs_mondo['title'] = 'Mondo Disease Ontology'
# Populate concept
for i, row in dg_codes[[
'source_text_diagnosis',
'mondo_id_diagnosis'
]].iterrows():
if row.mondo_id_diagnosis == 'No Match':
continue
cs_mondo['concept'].append({
'code': row.mondo_id_diagnosis,
'display': row.source_text_diagnosis
})
cs_mondo['count'] = len(cs_mondo['concept'])
# Output to JSON
with open('CodeSystem-mondo.json', 'w') as f:
json.dump(cs_mondo, f, indent=2)
```
### 1.2.2 NCIt
```
# Copy template
cs_ncit = deepcopy(CS_TEMPLATE)
# Set metadata
cs_ncit['id'] = 'ncit'
cs_ncit['url'] = 'http://purl.obolibrary.org/obo/ncit.owl'
cs_ncit['name'] = 'http://purl.obolibrary.org/obo/ncit.owl'
cs_ncit['title'] = 'NCI Thesaurus'
# Populate concept
for i, row in dg_codes[[
'source_text_diagnosis',
'ncit_id_diagnosis'
]].iterrows():
if row.ncit_id_diagnosis == 'No Match':
continue
cs_ncit['concept'].append({
'code': row.ncit_id_diagnosis,
'display': row.source_text_diagnosis
})
cs_ncit['count'] = len(cs_ncit['concept'])
# Output to JSON
with open('CodeSystem-ncit.json', 'w') as f:
json.dump(cs_ncit, f, indent=2)
```
## 1.3 Vital Status
### 1.3.1 SNOMED CT
```
# Copy template
cs_sct = deepcopy(CS_TEMPLATE)
# Set metadata
cs_sct['id'] = 'sct'
cs_sct['url'] = 'http://snomed.info/sct'
cs_sct['name'] = 'http://snomed.info/sct'
cs_sct['title'] = 'SNOMED CT'
cs_sct['concept'] = cs_sct['concept'] + [
{
'code': '438949009',
'display': 'Alive'
},
{
'code': '419099009',
'display': 'Dead'
}
]
cs_sct['count'] = len(cs_sct['concept'])
# Output to JSON
with open('CodeSystem-sct.json', 'w') as f:
json.dump(cs_sct, f, indent=2)
```
# 2. Synthea
## 2.1 SNOMED CT
```
with open(f'{DATA_DIR}/sct.json') as f:
concept_sct = json.load(f)
cs_sct['concept'] += concept_sct
cs_sct['count'] = len(cs_sct['concept'])
# Output to JSON
with open('CodeSystem-sct.json', 'w') as f:
json.dump(cs_sct, f, indent=2)
```
## 2.2 LOINC
```
# Copy template
cs_loinc = deepcopy(CS_TEMPLATE)
# Set metadata
cs_loinc['id'] = 'loinc'
cs_loinc['url'] = 'http://loinc.org'
cs_loinc['name'] = 'http://loinc.org'
cs_loinc['title'] = 'LOINC'
with open(f'{DATA_DIR}/loinc.json') as f:
concept_loinc = json.load(f)
cs_loinc['concept'] += concept_loinc
cs_loinc['count'] = len(cs_loinc['concept'])
# Output to JSON
with open('CodeSystem-loinc.json', 'w') as f:
json.dump(cs_loinc, f, indent=2)
```
|
github_jupyter
|
## AutoGraph: examples of simple algorithms
This notebook shows how you can use AutoGraph to compile simple algorithms and run them in TensorFlow.
It requires the nightly build of TensorFlow, which is installed below.
```
!pip install -U -q tf-nightly-2.0-preview
import tensorflow as tf
tf = tf.compat.v2
tf.enable_v2_behavior()
```
### Fibonacci numbers
https://en.wikipedia.org/wiki/Fibonacci_number
```
@tf.function
def fib(n):
f1 = 0
f2 = 1
for i in tf.range(n):
tmp = f2
f2 = f2 + f1
f1 = tmp
tf.print(i, ': ', f2)
return f2
_ = fib(tf.constant(10))
```
#### Generated code
```
print(tf.autograph.to_code(fib.python_function))
```
### Fizz Buzz
https://en.wikipedia.org/wiki/Fizz_buzz
```
import tensorflow as tf
@tf.function(experimental_autograph_options=tf.autograph.experimental.Feature.EQUALITY_OPERATORS)
def fizzbuzz(i, n):
while i < n:
msg = ''
if i % 3 == 0:
msg += 'Fizz'
if i % 5 == 0:
msg += 'Buzz'
if msg == '':
msg = tf.as_string(i)
tf.print(msg)
i += 1
return i
_ = fizzbuzz(tf.constant(10), tf.constant(16))
```
#### Generated code
```
print(tf.autograph.to_code(fizzbuzz.python_function))
```
### Conway's Game of Life
https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life
#### Testing boilerplate
```
NUM_STEPS = 1
```
#### Game of Life for AutoGraph
Note: the code may take a while to run.
```
#@test {"skip": true}
NUM_STEPS = 75
```
Note: This code uses a non-vectorized algorithm, which is quite slow. For 75 steps, it will take a few minutes to run.
```
import time
import traceback
import sys
from matplotlib import pyplot as plt
from matplotlib import animation as anim
import numpy as np
from IPython import display
@tf.autograph.experimental.do_not_convert
def render(boards):
fig = plt.figure()
ims = []
for b in boards:
im = plt.imshow(b, interpolation='none')
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
ims.append([im])
try:
ani = anim.ArtistAnimation(
fig, ims, interval=100, blit=True, repeat_delay=5000)
plt.close()
display.display(display.HTML(ani.to_html5_video()))
except RuntimeError:
print('Coult not render animation:')
traceback.print_exc()
return 1
return 0
def gol_episode(board):
new_board = tf.TensorArray(tf.int32, 0, dynamic_size=True)
for i in tf.range(len(board)):
for j in tf.range(len(board[i])):
num_neighbors = tf.reduce_sum(
board[tf.maximum(i-1, 0):tf.minimum(i+2, len(board)),
tf.maximum(j-1, 0):tf.minimum(j+2, len(board[i]))]
) - board[i][j]
if num_neighbors == 2:
new_cell = board[i][j]
elif num_neighbors == 3:
new_cell = 1
else:
new_cell = 0
new_board.append(new_cell)
final_board = new_board.stack()
final_board = tf.reshape(final_board, board.shape)
return final_board
@tf.function(experimental_autograph_options=(
tf.autograph.experimental.Feature.EQUALITY_OPERATORS,
tf.autograph.experimental.Feature.BUILTIN_FUNCTIONS,
tf.autograph.experimental.Feature.LISTS,
))
def gol(initial_board):
board = initial_board
boards = tf.TensorArray(tf.int32, size=0, dynamic_size=True)
i = 0
for i in tf.range(NUM_STEPS):
board = gol_episode(board)
boards.append(board)
boards = boards.stack()
tf.py_function(render, (boards,), (tf.int64,))
return i
# Gosper glider gun
# Adapted from http://www.cplusplus.com/forum/lounge/75168/
_ = 0
initial_board = tf.constant((
( _,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,1,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,1,_,1,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,1,1,_,_,_,_,_,_,1,1,_,_,_,_,_,_,_,_,_,_,_,_,1,1,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,1,_,_,_,1,_,_,_,_,1,1,_,_,_,_,_,_,_,_,_,_,_,_,1,1,_ ),
( _,1,1,_,_,_,_,_,_,_,_,1,_,_,_,_,_,1,_,_,_,1,1,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,1,1,_,_,_,_,_,_,_,_,1,_,_,_,1,_,1,1,_,_,_,_,1,_,1,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,1,_,_,_,_,_,1,_,_,_,_,_,_,_,1,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,1,_,_,_,1,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,1,1,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
( _,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_ ),
))
initial_board = tf.pad(initial_board, ((0, 10), (0, 5)))
_ = gol(initial_board)
```
#### Generated code
```
print(tf.autograph.to_code(gol.python_function))
```
|
github_jupyter
|
# T81-558: Applications of Deep Neural Networks
**Module 7: Generative Adversarial Networks**
* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)
* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).
# Module 7 Material
* Part 7.1: Introduction to GANS for Image and Data Generation [[Video]](https://www.youtube.com/watch?v=0QnCH6tlZgc&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_07_1_gan_intro.ipynb)
* Part 7.2: Implementing a GAN in Keras [[Video]](https://www.youtube.com/watch?v=T-MCludVNn4&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_07_2_Keras_gan.ipynb)
* Part 7.3: Face Generation with StyleGAN and Python [[Video]](https://www.youtube.com/watch?v=Wwwyr7cOBlU&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_07_3_style_gan.ipynb)
* **Part 7.4: GANS for Semi-Supervised Learning in Keras** [[Video]](https://www.youtube.com/watch?v=ZPewmEu7644&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_07_4_gan_semi_supervised.ipynb)
* Part 7.5: An Overview of GAN Research [[Video]](https://www.youtube.com/watch?v=cvCvZKvlvq4&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_07_5_gan_research.ipynb)
# Part 7.4: GANS for Semi-Supervised Training in Keras
GANs can also be used to implement semi-supervised learning/training. Normally GANs implement un-supervised training. This is because there are no y's (expected outcomes) provided in the dataset. The y-values are usually called labels. For the face generating GANs, there is typically no y-value, only images. This is unsupervised training. Supervised training occurs when we are training a model to

The following paper describes the application of GANs to semi-supervised training.
* [Odena, A. (2016). Semi-supervised learning with generative adversarial networks. *arXiv preprint* arXiv:1606.01583.](https://arxiv.org/abs/1606.01583)
As you can see, supervised learning is where all data have labels. Supervised learning attempts to learn the labels from the training data to predict these labels for new data. Un-supervised learning has no labels and usually simply clusters the data or in the case of a GAN, learns to produce new data that resembles the training data. Semi-supervised training has a small number of labels for mostly unlabeled data. Semi-supervised learning is usually similar to supervised learning in that the goal is ultimately to predict labels for new data.
Traditionally, unlabeled data would simply be discarded if the overall goal was to create a supervised model. However, the unlabeled data is not without value. Semi-supervised training attempts to use this unlabeled data to help learn additional insights about what labels we do have. There are limits, however. Even semi-supervised training cannot learn entirely new labels that were not in the training set. This would include new classes for classification or learning to predict values outside of the range of the y-values.
Semi-supervised GANs can perform either classification or regression. Previously, we made use of the generator and discarded the discriminator. We simply wanted to create new photo-realistic faces, so we just needed the generator. Semi-supervised learning flips this, as we now discard the generator and make use of the discriminator as our final model.
### Semi-Supervised Classification Training
The following diagram shows how to apply GANs for semi-supervised classification training.

Semi-supervised classification training is laid exactly the same as a regular GAN. The only differences is that it is not a simple true/false classifier as was the case for image GANs that simply classified if the generated image was a real or fake. The additional classes are also added. Later in this module I will provide a link to an example of [The Street View House Numbers (SVHN) Dataset](http://ufldl.stanford.edu/housenumbers/). This dataset contains house numbers, as seen in the following image.

Perhaps all of the digits are not labeled. The GAN is setup to classify a real or fake digit, just as we did with the faces. However, we also expand upon the real digits to include classes 0-9. The GAN discriminator is classifying between the 0-9 digits and also fake digits. A semi-supervised GAN classifier always classifies to the number of classes plus one. The additional class indicates a fake classification.
### Semi-Supervised Regression Training
The following diagram shows how to apply GANs for semi-supervised regression training.

Neural networks can perform both classification and regression simultaneously, it is simply a matter of how the output neurons are mapped. A hybrid classification-regression neural network simply maps groups of output neurons to be each of the groups of classes to be predicted, along with individual neurons to perform any regression predictions needed.
A regression semi-supervised GAN is one such hybrid. The discriminator has two output neurons. The first output neuron performs the requested regression prediction. The second predicts the probability that the input was fake.
### Application of Semi-Supervised Regression
An example of using Keras for Semi-Supervised classification is provided here.
* [Semi-supervised learning with Generative Adversarial Networks (GANs)](https://towardsdatascience.com/semi-supervised-learning-with-gans-9f3cb128c5e)
* [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434)
* [The Street View House Numbers (SVHN) Dataset](http://ufldl.stanford.edu/housenumbers/)
|
github_jupyter
|
```
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
```
<a href="https://colab.research.google.com/github/lmoroney/dlaicourse/blob/master/TensorFlow%20In%20Practice/Course%203%20-%20NLP/Course%203%20-%20Week%202%20-%20Lesson%202.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
```
# Run this to ensure TensorFlow 2.x is used
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
except Exception:
pass
import json
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
vocab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/sarcasm.json \
-O /tmp/sarcasm.json
with open("/tmp/sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# Need this block to get it to work with TensorFlow 2.x
import numpy as np
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_sentence(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
print(decode_sentence(training_padded[0]))
print(training_sentences[2])
print(labels[2])
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')
sentence = ["granny starting to fear spiders in the garden might be real", "game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))
```
|
github_jupyter
|
```
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
import utils
matplotlib.rcParams['figure.figsize'] = (0.89 * 12, 6)
matplotlib.rcParams['lines.linewidth'] = 10
matplotlib.rcParams['lines.markersize'] = 20
```
# The Dataset
$$y = x^3 + x^2 - 4x$$
```
x, y, X, transform, scale = utils.get_base_data()
utils.plotter(x, y)
```
# The Dataset
```
noise = utils.get_noise()
utils.plotter(x, y + noise)
```
# Machine Learning
$$
y = f(\mathbf{x}, \mathbf{w})
$$
$$
f(x, \mathbf{w}) = w_3 x^3 + w_2x^2 + w_1x + w_0
$$
$$
y = \mathbf{w} \cdot \mathbf{x}
$$
# Transforming Features
<center><img src="images/transform_features.png" style="height: 600px;"></img></center>
# Fitting Data with Scikit-Learn
<center><img src="images/sklearn.png"></img></center>
# Fitting Data with Scikit-Learn
Minimize
$$C(\mathbf{w}) = \sum_j (\mathbf{x}_j^T \mathbf{w} - y_j)^2$$
```
def mean_squared_error(X, y, fit_func):
return ((fit_func(X).squeeze() - y.squeeze()) ** 2).mean()
```
# Fitting Data with Scikit-Learn
```
from sklearn.linear_model import LinearRegression
reg = LinearRegression(fit_intercept=False).fit(X, y)
print(reg.coef_ / scale)
print(mean_squared_error(X, y, reg.predict))
utils.plotter(x, y, fit_fn=reg.predict, transform=transform)
```
# Fitting Data with Scikit-Learn
```
reg = LinearRegression(fit_intercept=False).fit(X, y + noise)
print(reg.coef_ / scale)
print(mean_squared_error(X, y + noise, reg.predict))
utils.plotter(x, y + noise, fit_fn=reg.predict, transform=transform)
```
# Exercise 1
# Fitting Data with Numpy
<center><img src="images/numpylogoicon.svg" style="height: 400px;"></img></center>
# Linear Algebra
<center><img src="images/linear_tweet.png" style="height: 400px;"></img></center>
# Linear Algebra!
$$X\mathbf{w} = \mathbf{y}$$
<center><img src="images/row_mult.png" style="height: 500px;"></img></center>
# Linear Algebra!
<center><img src="images/row_mult.png" style="height: 200px;"></img></center>
```
(X.dot(reg.coef_.T) == reg.predict(X)).all()
```
# Fitting Data with Numpy
$$X\mathbf{w} = \mathbf{y}$$
$$\mathbf{w} = X^{-1}\mathbf{y}$$
<center><img src="images/pete-4.jpg" style="height: 400px;"></img></center>
# Fitting Data with Numpy
$$X\mathbf{w} = \mathbf{y}$$
$$X^TX\mathbf{w} = X^T\mathbf{y}$$
$$\mathbf{w} = (X^TX)^{-1}X^T\mathbf{y}$$
# Orthogonal Projections!
$$P = X(X^TX)^{-1}X^T$$
Try to show $$P^2 = P$$
and that
$$(\mathbf{y} - P\mathbf{y})^T P\mathbf{y} = 0$$
<center><img src="images/pete-5.jpg" style="height: 350px;"></img></center>
# Fitting Data with Numpy
$$\mathbf{w} = (X^TX)^{-1}X^T\mathbf{y}$$
```
np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y).T / scale
(np.linalg.inv(X.T @ X) @ X.T @ y).T / scale
np.linalg.pinv(X).dot(y).T / scale
```
# Fitting Data with Numpy
```
class NumpyLinearRegression(object):
def fit(self, X, y):
self.coef_ = np.linalg.pinv(X).dot(y)
return self
def predict(self, X):
return X.dot(self.coef_)
```
# Fitting Data with Numpy
```
linalg_reg = NumpyLinearRegression().fit(X, y)
print(linalg_reg.coef_.T / scale)
print(mean_squared_error(X, y, linalg_reg.predict))
utils.plotter(x, y, fit_fn=linalg_reg.predict, transform=transform)
```
# Fitting Data with Numpy
```
linalg_reg = NumpyLinearRegression().fit(X, y + noise)
print(linalg_reg.coef_.T / scale)
print(mean_squared_error(X, y + noise, linalg_reg.predict))
utils.plotter(x, y + noise, fit_fn=linalg_reg.predict, transform=transform)
```
# Exercise 2
# Regularization
```
x_train, x_test, y_train, y_test, X_train, X_test, transform, scale = utils.get_overfitting_data()
```
# What does overfitting look like?
```
reg = LinearRegression(fit_intercept=False).fit(X_train, y_train)
print((reg.coef_ / scale))
plt.bar(np.arange(len(reg.coef_.squeeze())), reg.coef_.squeeze() / scale);
```
# What does overfitting look like?
```
mean_squared_error(X_train, y_train, reg.predict)
utils.plotter(x_train, y_train, fit_fn=reg.predict, transform=transform)
```
# What does overfitting look like?
```
mean_squared_error(X_test, y_test, reg.predict)
utils.plotter(x_test, y_test, fit_fn=reg.predict, transform=transform)
```
# Ridge Regression
## "Penalize model complexity"
$$C(\mathbf{w}) = \sum_j (\mathbf{x}_j^T \mathbf{w} - y_j)^2$$
$$C(\mathbf{w}) = \sum_j (\mathbf{x}_j^T \mathbf{w} - y_j)^2 + \alpha \sum_j w_j^2$$
# Ridge Regression
```
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=0.02).fit(X_train, y_train)
utils.plotter(x_test, y_test, fit_fn=ridge_reg.predict, transform=transform)
```
# Ridge Regression
```
print(mean_squared_error(X_test, y_test, ridge_reg.predict))
plt.bar(np.arange(len(ridge_reg.coef_.squeeze())), ridge_reg.coef_.squeeze() / scale);
```
# Lasso Regression
```
from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.005, max_iter=100000, fit_intercept=False).fit(X_train, y_train)
utils.plotter(x_test, y_test, fit_fn=lasso_reg.predict, transform=transform)
```
# Lasso Regression
```
print(mean_squared_error(X_test, y_test, lasso_reg.predict))
plt.bar(np.arange(len(lasso_reg.coef_)), lasso_reg.coef_ / scale);
```
# Exercise 3
|
github_jupyter
|
```
#######################################################
# Script:
# trainPerf.py
# Usage:
# python trainPerf.py <input_file> <output_file>
# Description:
# Build the prediction model based on training data
# Pass 1: prediction based on hours in a week
# Authors:
# Jasmin Nakic, [email protected]
# Samir Pilipovic, [email protected]
#######################################################
import sys
import numpy as np
from sklearn import linear_model
from sklearn.externals import joblib
# Imports required for visualization (plotly)
import plotly.graph_objs as go
from plotly import __version__
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
# Script debugging flag
debugFlag = False
# Feature lists for different models
simpleCols = ["dateFrac"]
trigCols = ["dateFrac", "weekdaySin", "weekdayCos", "hourSin", "hourCos"]
hourDayCols = ["dateFrac", "isMonday", "isTuesday", "isWednesday", "isThursday", "isFriday", "isSaturday", "isSunday",
"isHour0", "isHour1", "isHour2", "isHour3", "isHour4", "isHour5", "isHour6", "isHour7",
"isHour8", "isHour9", "isHour10", "isHour11", "isHour12", "isHour13", "isHour14", "isHour15",
"isHour16", "isHour17", "isHour18", "isHour19", "isHour20", "isHour21", "isHour22", "isHour23"]
hourWeekCols = ["dateFrac"]
for d in range(0,7):
for h in range(0,24):
hourWeekCols.append("H_" + str(d) + "_" + str(h))
# Add columns to the existing array and populate with data
def addColumns(dest, src, colNames):
# Initialize temporary array
tmpArr = np.empty(src.shape[0])
cols = 0
# Copy column content
for name in colNames:
if cols == 0: # first column
tmpArr = np.copy(src[name])
tmpArr = np.reshape(tmpArr,(-1,1))
else:
tmpCol = np.copy(src[name])
tmpCol = np.reshape(tmpCol,(-1,1))
tmpArr = np.append(tmpArr,tmpCol,1)
cols = cols + 1
return np.append(dest,tmpArr,1)
#end addColumns
# Generate linear regression model
def genModel(data,colList,modelName):
# Initialize array
X = np.zeros(data.shape[0])
X = np.reshape(X,(-1,1))
# Add columns
X = addColumns(X,data,colList)
if debugFlag:
print("X 0: ", X[0:5])
Y = np.copy(data["cnt"])
if debugFlag:
print("Y 0: ", Y[0:5])
model = linear_model.LinearRegression()
print(model.fit(X, Y))
print("INTERCEPT: ", model.intercept_)
print("COEFFICIENT shape: ", model.coef_.shape)
print("COEFFICIENT values: ", model.coef_)
print("SCORE values: ", model.score(X,Y))
P = model.predict(X)
if debugFlag:
print("P 0-5: ", P[0:5])
joblib.dump(model,modelName)
return P
#end genModel
# Generate linear regression model
def genRidgeModel(data,colList,modelName,ridgeAlpha):
# Initialize array
X = np.zeros(data.shape[0])
X = np.reshape(X,(-1,1))
# Add columns
X = addColumns(X,data,colList)
if debugFlag:
print("X 0: ", X[0:5])
Y = np.copy(data["cnt"])
if debugFlag:
print("Y 0: ", Y[0:5])
model = linear_model.Ridge(alpha=ridgeAlpha)
print(model.fit(X, Y))
print("INTERCEPT: ", model.intercept_)
print("COEFFICIENT shape: ", model.coef_.shape)
print("COEFFICIENT values: ", model.coef_)
print("SCORE values: ", model.score(X,Y))
P = model.predict(X)
if debugFlag:
print("P 0-5: ", P[0:5])
joblib.dump(model,modelName)
return P
#end genModel
# Generate linear regression model
def genLassoModel(data,colList,modelName,lassoAlpha):
# Initialize array
X = np.zeros(data.shape[0])
X = np.reshape(X,(-1,1))
# Add columns
X = addColumns(X,data,colList)
if debugFlag:
print("X 0: ", X[0:5])
Y = np.copy(data["cnt"])
if debugFlag:
print("Y 0: ", Y[0:5])
model = linear_model.Lasso(alpha=lassoAlpha,max_iter=5000)
print(model.fit(X, Y))
print("INTERCEPT: ", model.intercept_)
print("COEFFICIENT shape: ", model.coef_.shape)
print("COEFFICIENT values: ", model.coef_)
print("SCORE values: ", model.score(X,Y))
P = model.predict(X)
if debugFlag:
print("P 0-5: ", P[0:5])
joblib.dump(model,modelName)
return P
#end genModel
# Write predictions to the output file
def writeResult(output,data,p1,p2,p3,p4):
# generate result file
result = np.array(
np.empty(data.shape[0]),
dtype=[
("timeStamp","|U19"),
("dateFrac",float),
("isHoliday",int),
("isSunday",int),
("cnt",int),
("predSimple",int),
("predTrig",int),
("predHourDay",int),
("predHourWeek",int)
]
)
result["timeStamp"] = data["timeStamp"]
result["dateFrac"] = data["dateFrac"]
result["isHoliday"] = data["isHoliday"]
result["isSunday"] = data["isSunday"]
result["cnt"] = data["cnt"]
result["predSimple"] = p1
result["predTrig"] = p2
result["predHourDay"] = p3
result["predHourWeek"] = p4
if debugFlag:
print("R 0-5: ", result[0:5])
hdr = "timeStamp\tdateFrac\tisHoliday\tisSunday\tcnt\tpredSimple\tpredTrig\tpredHourDay\tpredHourWeek"
np.savetxt(output,result,fmt="%s",delimiter="\t",header=hdr,comments="")
#end writeResult
# Start
inputFileName = "train_data.txt"
outputFileName = "train_hourly.txt"
# All input columns - data types are strings, float and int
inputData = np.genfromtxt(
inputFileName,
delimiter='\t',
names=True,
dtype=("|U19","|S10",int,float,int,float,float,int,float,float,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int,
int,int,int,int,int,int,int,int,int,int
)
)
print(inputData[1:5])
# P1 = genRidgeModel(inputData,simpleCols,"modelSimple",0.1)
# P2 = genRidgeModel(inputData,trigCols,"modelTrig",0.1)
# P3 = genRidgeModel(inputData,hourDayCols,"modelHourDay",0.1)
# P4 = genRidgeModel(inputData,hourWeekCols,"modelHourWeek",0.1)
# P1 = genLassoModel(inputData,simpleCols,"modelSimple",0.4)
# P2 = genLassoModel(inputData,trigCols,"modelTrig",0.4)
# P3 = genLassoModel(inputData,hourDayCols,"modelHourDay",0.4)
# P4 = genLassoModel(inputData,hourWeekCols,"modelHourWeek",0.4)
P1 = genModel(inputData,simpleCols,"modelSimple")
P2 = genModel(inputData,trigCols,"modelTrig")
P3 = genModel(inputData,hourDayCols,"modelHourDay")
P4 = genModel(inputData,hourWeekCols,"modelHourWeek")
writeResult(outputFileName,inputData,P1,P2,P3,P4)
# Load the training data from file generated above using correct data types
results = np.genfromtxt(
outputFileName,
dtype=("|U19",float,int,int,int,int,int,int,int),
delimiter='\t',
names=True
)
# Examine training data
print("Shape:", results.shape)
print("Columns:", results.dtype.names)
print(results[1:5])
# Generate chart with predicitons based on training data (using plotly)
print("Plotly version", __version__) # requires plotly version >= 1.9.0
init_notebook_mode(connected=True)
set1 = go.Bar(
x=results["dateFrac"],
y=results["cnt"],
# marker=dict(color='blue'),
name='Actual'
)
set2 = go.Bar(
x=results["dateFrac"],
y=results["predTrig"],
# marker=dict(color='crimson'),
opacity=0.6,
name='Prediction'
)
set3 = go.Bar(
x=results["dateFrac"],
y=results["predHourWeek"],
# marker=dict(color='crimson'),
opacity=0.6,
name='Prediction'
)
barData = [set1, set2, set3]
barLayout = go.Layout(barmode='group', title="Prediction vs. Actual")
fig = go.Figure(data=barData, layout=barLayout)
iplot(fig)
```
|
github_jupyter
|
# Rotation Transformation
We meta-learn how to rotate images so that we can accurately classify rotated images. We use MNIST.
Import relevant packages
```
from operator import mul
from itertools import cycle
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.functional as F
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
import tqdm
from higher.patch import make_functional
from higher.utils import get_func_params
from sklearn.metrics import accuracy_score
%matplotlib inline
matplotlib.rcParams['pdf.fonttype'] = 42
matplotlib.rcParams['ps.fonttype'] = 42
```
Define transformations to create standard and rotated images
```
transform_basic = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
transform_rotate = transforms.Compose([
transforms.RandomRotation([30, 30]),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
```
Load the data and split the indices so that we both standard and rotated images in various sets. We also keep a part of the training data as unrotated test images in case it is useful.
```
train_set = datasets.MNIST(
'data', train=True, transform=transform_basic, target_transform=None, download=True)
train_set_rotated = datasets.MNIST(
'data', train=True, transform=transform_rotate, target_transform=None, download=True)
train_basic_indices = range(40000)
train_test_basic_indices = range(40000, 50000)
val_rotate_indices = range(50000, 60000)
train_basic_set = torch.utils.data.Subset(train_set, train_basic_indices)
train_test_basic_set = torch.utils.data.Subset(train_set, train_test_basic_indices)
val_rotate_set = torch.utils.data.Subset(
train_set_rotated, val_rotate_indices)
test_set = datasets.MNIST(
'data', train=False, transform=transform_rotate, target_transform=None, download=True)
```
Define data loaders
```
batch_size = 128
train_basic_set_loader = torch.utils.data.DataLoader(
train_basic_set, batch_size=batch_size, shuffle=True)
train_test_basic_set_loader = torch.utils.data.DataLoader(
train_test_basic_set, batch_size=batch_size, shuffle=True)
val_rotate_set_loader = torch.utils.data.DataLoader(
val_rotate_set, batch_size=batch_size, shuffle=True)
test_set_loader = torch.utils.data.DataLoader(
test_set, batch_size=batch_size, shuffle=True)
```
Set-up the device to use
```
if torch.cuda.is_available(): # checks whether a cuda gpu is available
device = torch.cuda.current_device()
print("use GPU", device)
print("GPU ID {}".format(torch.cuda.current_device()))
else:
print("use CPU")
device = torch.device('cpu') # sets the device to be CPU
```
Define a function to do rotation by angle theta (in radians). We define the function in a way that allows us to differentiate with respect to theta.
```
def rot_img(x, theta, device):
rot = torch.cat([torch.cat([torch.cos(theta), -torch.sin(theta), torch.tensor([0.], device=device)]),
torch.cat([torch.sin(theta), torch.cos(theta), torch.tensor([0.], device=device)])])
grid = F.affine_grid(rot.expand([x.size()[0], 6]).view(-1, 2, 3), x.size())
x = F.grid_sample(x, grid)
return x
```
Define the model that we use - simple LeNet that will allow us to do fast experiments
```
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.in_channels = 1
self.input_size = 28
self.conv1 = nn.Conv2d(self.in_channels, 6, 5,
padding=2 if self.input_size == 28 else 0)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
```
A function to test a model on the test set
```
def test_classification_net(data_loader, model, device):
'''
This function reports classification accuracy over a dataset.
'''
model.eval()
labels_list = []
predictions_list = []
with torch.no_grad():
for i, (data, label) in enumerate(data_loader):
data = data.to(device)
label = label.to(device)
logits = model(data)
softmax = F.softmax(logits, dim=1)
_, predictions = torch.max(softmax, dim=1)
labels_list.extend(label.cpu().numpy().tolist())
predictions_list.extend(predictions.cpu().numpy().tolist())
accuracy = accuracy_score(labels_list, predictions_list)
return 100 * accuracy
```
A function to test the model on the test set while doing the rotations manually with a specified angle
```
def test_classification_net_rot(data_loader, model, device, angle=0.0):
'''
This function reports classification accuracy over a dataset.
'''
model.eval()
labels_list = []
predictions_list = []
with torch.no_grad():
for i, (data, label) in enumerate(data_loader):
data = data.to(device)
if angle != 0.0:
data = rot_img(data, angle, device)
label = label.to(device)
logits = model(data)
softmax = F.softmax(logits, dim=1)
_, predictions = torch.max(softmax, dim=1)
labels_list.extend(label.cpu().numpy().tolist())
predictions_list.extend(predictions.cpu().numpy().tolist())
accuracy = accuracy_score(labels_list, predictions_list)
return 100 * accuracy
```
Define a model to do the rotations - it has a meta-learnable parameter theta that represents the rotation angle in radians
```
class RotTransformer(nn.Module):
def __init__(self, device):
super(RotTransformer, self).__init__()
self.theta = nn.Parameter(torch.FloatTensor([0.]))
self.device = device
# Rotation transformer network forward function
def rot(self, x):
rot = torch.cat([torch.cat([torch.cos(self.theta), -torch.sin(self.theta), torch.tensor([0.], device=self.device)]),
torch.cat([torch.sin(self.theta), torch.cos(self.theta), torch.tensor([0.], device=self.device)])])
grid = F.affine_grid(rot.expand([x.size()[0], 6]).view(-1, 2, 3), x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
return self.rot(x)
```
We first train a simple model on standard images to see how it performs when applied to rotated images
```
acc_rotate_list = []
acc_basic_list = []
num_repetitions = 5
for e in range(num_repetitions):
print('Repetition ' + str(e + 1))
model = LeNet().to(device=device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss().to(device=device)
num_epochs_meta = 5
with tqdm.tqdm(total=num_epochs_meta) as pbar_epochs:
for epoch in range(0, num_epochs_meta):
for i, batch in enumerate(train_basic_set_loader):
(input_, target) = batch
input_ = input_.to(device=device)
target = target.to(device=device)
logits = model(input_)
loss = criterion(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar_epochs.update(1)
# testing
acc_rotate = test_classification_net(test_set_loader, model, device)
acc_rotate_list.append(acc_rotate)
angle = torch.tensor([-np.pi/6], device=device)
acc_basic = test_classification_net_rot(test_set_loader, model, device, angle)
acc_basic_list.append(acc_basic)
```
Print statistics:
```
print('Accuracy on rotated test images: {:.2f} $\pm$ {:.2f}'.format(np.mean(acc_rotate_list), np.std(acc_rotate_list)))
print('Accuracy on standard position test images: {:.2f} $\pm$ {:.2f}'.format(np.mean(acc_basic_list), np.std(acc_basic_list)))
```
We see there is a large drop in accuracy if we apply the model on rotated images rather the same images without rotations
Now we use EvoGrad and meta-learning to train the model with images that are rotated by the rotation transformer. Rotation transformer is learned jointly alongside the base model. We will use random seeds to improve reproducibility since EvoGrad random noise perturbations depend on sampling of random numbers (but the precise accuracies may differ).
```
acc_rotate_list_evo_2mc = []
acc_basic_list_evo_2mc = []
angles_reps_2mc = []
# define the settings
num_repetitions = 5
torch_seeds = [1, 23, 345, 4567, 56789]
sigma = 0.001
temperature = 0.05
n_model_candidates = 2
num_epochs_meta = 5
for e in range(num_repetitions):
print('Repetition ' + str(e + 1))
torch.manual_seed(torch_seeds[e])
model = LeNet().to(device=device)
model_patched = make_functional(model)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss().to(device=device)
feature_transformer = RotTransformer(device=device).to(device=device)
meta_opt = torch.optim.Adam(feature_transformer.parameters(), lr=1e-2)
angles = []
with tqdm.tqdm(total=num_epochs_meta) as pbar_epochs:
for epoch in range(0, num_epochs_meta):
loaders = zip(train_basic_set_loader, cycle(val_rotate_set_loader))
for i, batch in enumerate(loaders):
((input_, target), (input_rot, target_rot)) = batch
input_ = input_.to(device=device)
target = target.to(device=device)
input_rot = input_rot.to(device=device)
target_rot = target_rot.to(device=device)
# base model training with images rotated using the rotation transformer
logits = model(feature_transformer(input_))
loss = criterion(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# update the model parameters used for patching
model_parameter = [i.detach() for i in get_func_params(model)]
input_transformed = feature_transformer(input_)
# create multiple model copies
theta_list = [[j + sigma * torch.sign(torch.randn_like(j)) for j in model_parameter] for i in range(n_model_candidates)]
pred_list = [model_patched(input_transformed, params=theta) for theta in theta_list]
loss_list = [criterion(pred, target) for pred in pred_list]
baseline_loss = criterion(model_patched(input_transformed, params=model_parameter), target)
# calculate weights for the different model copies
weights = torch.softmax(-torch.stack(loss_list)/temperature, 0)
# merge the model copies
theta_updated = [sum(map(mul, theta, weights)) for theta in zip(*theta_list)]
pred_rot = model_patched(input_rot, params=theta_updated)
loss_rot = criterion(pred_rot, target_rot)
# update the meta-knowledge
meta_opt.zero_grad()
loss_rot.backward()
meta_opt.step()
angles.append(180 / 3.14 * feature_transformer.theta.item())
pbar_epochs.update(1)
angles_reps_2mc.append(angles)
acc = test_classification_net(test_set_loader, model, device)
acc_rotate_list_evo_2mc.append(acc)
angle = torch.tensor([-np.pi/6], device=device)
acc_basic = test_classification_net_rot(test_set_loader, model, device, angle)
acc_basic_list_evo_2mc.append(acc_basic)
```
Print statistics:
```
print('Accuracy on rotated test images: {:.2f} $\pm$ {:.2f}'.format(np.mean(acc_rotate_list_evo_2mc), np.std(acc_rotate_list_evo_2mc)))
print('Accuracy on standard position test images: {:.2f} $\pm$ {:.2f}'.format(np.mean(acc_basic_list_evo_2mc), np.std(acc_basic_list_evo_2mc)))
```
Show what the learned angles look like during training:
```
for angles_list in angles_reps_2mc:
plt.plot(range(len(angles_list)), angles_list, linewidth=2.0)
plt.ylabel('Learned angle', fontsize=14)
plt.xlabel('Number of iterations', fontsize=14)
plt.savefig("RotTransformerLearnedAngles.pdf", bbox_inches='tight')
plt.show()
```
Print the average final meta-learned angle:
```
final_angles_2mc = [angles_list[-1] for angles_list in angles_reps_2mc]
print("{:.2f} $\pm$ {:.2f}".format(np.mean(final_angles_2mc), np.std(final_angles_2mc)))
```
It's great to see the meta-learned angle is typically close to 30 degrees, which is the true value.
|
github_jupyter
|
In Ipython Notebook, I can write down the mathmatical expression with latex, which allows me to understand my codes better.
## q_3 word2vec.py
```
import numpy as np
import random
from q1_softmax import softmax
from q2_gradcheck import gradcheck_naive
from q2_sigmoid import sigmoid, sigmoid_grad
def normalizeRows(x):
"""
Row normalization function
Implement a function that normalizes each row of a matrix to have unit length.
"""
### YOUR CODE HERE
# print (x.sum(axis=1).reshape(-1,1))
x = x/np.sqrt((x**2).sum(axis=1)).reshape(-1,1)
# Equivalent Form:
'''
x = x/np.sqrt((x**2).sum(axis-=1, keepdims = True))
'''
#raise NotImplementedError
### END YOUR CODE
return x
def test_normalize_rows():
print ("Testing normalizeRows...")
x = normalizeRows(np.array([[3.0,4.0],[1, 2]]))
print (x)
ans = np.array([[0.6,0.8],[0.4472136,0.89442719]])
assert np.allclose(x, ans, rtol=1e-05, atol=1e-06)
print ("test passed")
test_normalize_rows()
```
## For the input arguments of the softmaxCostAndGradient function
- ($\hat{y}$) = predicted
- ($\hat{y} - y$) = (predicted[target] -= 1.)
- cost = -log(prob)
- gradPred = $\frac{\partial CE(y, \hat{y})}{\partial \theta}$ = $U (\hat{y} - y)$ = np.dot(prob, $\hat{y} - y$)
- grad = $\frac{\partial CE(y, \hat{y})}{\partial u_w}$
```
def softmaxCostAndGradient(predicted, target, outputVectors, dataset):
""" Softmax cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, assuming the softmax prediction function and cross
entropy loss.
Arguments:
predicted -- numpy ndarray, predicted word vector
target -- integer, the index of the target word
outputVectors -- "output" vectors (as rows) for all tokens
what is the meaning of the output vectors?
dataset -- needed for negative sampling, unused here.
Return:
cost -- cross entropy cost for the softmax word prediction
gradPred -- the gradient with respect to the predicted word
vector
grad -- the gradient with respect to all the other word
vectors
We will not provide starter code for this function, but feel
free to reference the code you previously wrote for this
assignment!
"""
#The math expression of the loss function can be found in the slides,
# to get a better understanding, I will use the same notation same as the paper assignment
### YOUR CODE HERE
# y has the same shape with y_hat but all zero values,
# whereas the target place has a value of 1.
#然后按照slides上的表达式 就直接求出cost
prob = softmax(np.dot(predicted, outputVectors.T))
cost = -np.log(prob[target])
#这一步是用来求出 y_hat - y
prob[target] -= 1.
#跟推导的结果一致,
gradPred = np.dot(prob, outputVectors)
#这里我不是很清楚为什么要这么来写,这三种表达方式等价,我用的是我比较熟悉的一种
#grad = prob[:, np.newaxis] * predicted[np.newaxis, :]
#grad = np.outer(prob, predicted)
grad = np.dot(prob.reshape(-1,1), predicted.reshape(1, -1))
#raise NotImplementedError
### END YOUR CODE
return cost, gradPred, grad
```
'np.out(a,b)' is to combine the a(M, ) and b(N, ) into (M, N) array, where out[i][j] = a[i] * b[j]
```
def getNegativeSamples(target, dataset, K):
""" Samples K indexes which are not the target """
indices = [None] * K
for k in range(K):
newidx = dataset.sampleTokenIdx()
while newidx == target:
newidx = dataset.sampleTokenIdx()
indices[k] = newidx
return indices
```
## This part is designed to execute the part(c) of the assignment problem
$J_{loss}$ = $-log(\sigma(u_O^T v_C)) - \Sigma_{k=1}^K log(\sigma(-u_k^T v_C))$
$\frac{\partial J_{loss}}{\partial v_c}$ = $(\sigma(u_O^T v_C)-1)u_O - \Sigma_{k=1}^K (\sigma(-u_k^T v_C)-1)u_k$
$\frac{\partial J_{loss}}{\partial u_O}$ = $[\sigma(u_O^T v_C) - 1]v_C$
$\frac{\partial J_{loss}}{\partial u_k}$ = $-[\sigma(-u_k^T v_C) - 1]v_C$
```
def negSamplingCostAndGradient(predicted, target, outputVectors, dataset, K=10):
""" Negative sampling cost function for word2vec models
Implement the cost and gradients for one predicted word vector
and one target word vector as a building block for word2vec
models, using the negative sampling technique. K is the sample
size.
Note: See test_word2vec below for dataset's initialization.
Arguments/Return Specifications: same as softmaxCostAndGradient
"""
# Sampling of indices is done for you. Do not modify this if you
# wish to match the autograder and receive points!
indices = [target]
indices.extend(getNegativeSamples(target, dataset, K))
'''so the first space in digit stores the target'''
### YOUR CODE HERE
prob = np.dot(outputVectors, predicted)
cost = -np.log(sigmoid(prob[target])) \
- np.log(sigmoid(-prob[indices[1:]])).sum()
# prob & cost can be derived by myself easily
#gradPred is partial loss function /partial Vc
gradPred = (sigmoid(prob[target]) - 1) * outputVectors[target] \
+ sum(-(sigmoid(-prob[indices[1:]]) - 1).reshape(-1,1) * outputVectors[indices[1:]])
# grad is like partial lss funtion/ partical u
grad = np.zeros_like(outputVectors)# to generate np.zeros with same shape as outputVectors
grad[target] = (sigmoid(prob[target]) - 1) * predicted
for k in indices[1:]:
grad[k] += (1.0 - sigmoid(-np.dot(outputVectors[k], predicted))) * predicted
#raise NotImplementedError
### END YOUR CODE
return cost, gradPred, grad
def skipgram(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
""" Skip-gram model in word2vec
Implement the skip-gram model in this function.
Arguments:
currentWord -- a string of the current center word
C -- integer, context size
contextWords -- list of no more than 2*C strings, the context words
tokens -- a dictionary that maps words to their indices in
the word vector list
inputVectors -- "input" word vectors (as rows) for all tokens
outputVectors -- "output" word vectors (as rows) for all tokens
word2vecCostAndGradient -- the cost and gradient function for
a prediction vector given the target
word vectors, could be one of the two
cost functions you implemented above.
Return:
cost -- the cost function value for the skip-gram model
grad -- the gradient with respect to the word vectors
"""
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
### YOUR CODE HERE
center_word = tokens[currentWord] # vector representation of the center word
for context_word in contextWords:
# index of target word
target = tokens[context_word] # vector representation of the context word
cost_, gradPred_, gradOut_ = word2vecCostAndGradient(inputVectors[center_word], target, outputVectors, dataset)
#sum all the values together
cost += cost_
gradOut += gradOut_
gradIn[center_word] += gradPred_
### END YOUR CODE
return cost, gradIn, gradOut
def cbow(currentWord, C, contextWords, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient=softmaxCostAndGradient):
"""CBOW model in word2vec
Implement the continuous bag-of-words model in this function.
Arguments/Return specifications: same as the skip-gram model
Extra credit: Implementing CBOW is optional, but the gradient
derivations are not. If you decide not to implement CBOW, remove
the NotImplementedError.
"""
cost = 0.0
gradIn = np.zeros(inputVectors.shape)
gradOut = np.zeros(outputVectors.shape)
### YOUR CODE HERE
target = tokens[currentWord]
# context_w correspond to the \hat{v} vector
context_word = sum(inputVectors[tokens[w]] for w in contextWords)
cost, gradPred, gradOut = word2vecCostAndGradient(context_word, target, outputVectors, dataset)
gradIn = np.zeros(inputVectors.shape)
for w in contextWords:
gradIn[tokens[w]] += gradPred
### END YOUR CODE
return cost, gradIn, gradOut
#############################################
# Testing functions below. DO NOT MODIFY! #
#############################################
def word2vec_sgd_wrapper(word2vecModel, tokens, wordVectors, dataset, C,
word2vecCostAndGradient=softmaxCostAndGradient):
batchsize = 50
cost = 0.0
grad = np.zeros(wordVectors.shape)
N = wordVectors.shape[0]
inputVectors = wordVectors[:int(N/2),:]
outputVectors = wordVectors[int(N/2):,:]
for i in range(batchsize):
C1 = random.randint(1,C)
centerword, context = dataset.getRandomContext(C1)
if word2vecModel == skipgram:
denom = 1
else:
denom = 1
c, gin, gout = word2vecModel(
centerword, C1, context, tokens, inputVectors, outputVectors,
dataset, word2vecCostAndGradient)
cost += c / batchsize / denom
grad[:int(N/2), :] += gin / batchsize / denom
grad[int(N/2):, :] += gout / batchsize / denom
return cost, grad
def test_word2vec():
""" Interface to the dataset for negative sampling """
dataset = type('dummy', (), {})()
def dummySampleTokenIdx():
return random.randint(0, 4)
def getRandomContext(C):
tokens = ["a", "b", "c", "d", "e"]
return tokens[random.randint(0,4)], \
[tokens[random.randint(0,4)] for i in range(2*C)]
dataset.sampleTokenIdx = dummySampleTokenIdx
dataset.getRandomContext = getRandomContext
random.seed(31415)
np.random.seed(9265)
dummy_vectors = normalizeRows(np.random.randn(10,3))
dummy_tokens = dict([("a",0), ("b",1), ("c",2),("d",3),("e",4)])
print ("==== Gradient check for skip-gram ====")
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
skipgram, dummy_tokens, vec, dataset, 5, softmaxCostAndGradient),
dummy_vectors)
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
skipgram, dummy_tokens, vec, dataset, 5, negSamplingCostAndGradient),
dummy_vectors)
print ("\n==== Gradient check for CBOW ====")
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
cbow, dummy_tokens, vec, dataset, 5, softmaxCostAndGradient),
dummy_vectors)
gradcheck_naive(lambda vec: word2vec_sgd_wrapper(
cbow, dummy_tokens, vec, dataset, 5, negSamplingCostAndGradient),
dummy_vectors)
print ("\n=== Results ===")
print (skipgram("c", 3, ["a", "b", "e", "d", "b", "c"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset))
print (skipgram("c", 1, ["a", "b"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset,
negSamplingCostAndGradient))
print (cbow("a", 2, ["a", "b", "c", "a"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset))
print (cbow("a", 2, ["a", "b", "a", "c"],
dummy_tokens, dummy_vectors[:5,:], dummy_vectors[5:,:], dataset,
negSamplingCostAndGradient))
if __name__ == "__main__":
test_normalize_rows()
test_word2vec()
def sgd(f, x0, step, iterations, postprocessing=None, useSaved=False,
PRINT_EVERY=10):
""" Stochastic Gradient Descent
Implement the stochastic gradient descent method in this function.
Arguments:
f -- the function to optimize, it should take a single
argument and yield two outputs, a cost and the gradient
with respect to the arguments
x0 -- the initial point to start SGD from
step -- the step size for SGD
iterations -- total iterations to run SGD for
postprocessing -- postprocessing function for the parameters
if necessary. In the case of word2vec we will need to
normalize the word vectors to have unit length
PRINT_EVERY -- specifies how many iterations to output loss
Return:
x -- the parameter value after SGD finishes
"""
# Anneal learning rate every several iterations, annealling(interesting!)
ANNEAL_EVERY = 20000
if useSaved:
start_iter, oldx, state = load_saved_params()
if start_iter > 0:
x0 = oldx
step *= 0.5 ** (start_iter / ANNEAL_EVERY)
if state:
random.setstate(state)
else:
start_iter = 0
x = x0
if not postprocessing:
postprocessing = lambda x: x
expcost = None
for iter in range(start_iter + 1, iterations + 1):
# Don't forget to apply the postprocessing after every iteration!
# You might want to print the progress every few iterations.
cost = None
### YOUR CODE HERE
#raise NotImplementedError
### END YOUR CODE
if (iter % PRINT_EVERY == 0):
if not expcost:
expcost = cost
else:
expcost = .95 * expcost + .05 * cost
print ("iter %d: %f" % (iter, expcost))
if iter % SAVE_PARAMS_EVERY == 0 and useSaved:
save_params(iter, x)
if iter % ANNEAL_EVERY == 0:
step *= 0.5
return x
```
|
github_jupyter
|
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-59152712-8"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-59152712-8');
</script>
# Enforce conformal 3-metric $\det{\bar{\gamma}_{ij}}=\det{\hat{\gamma}_{ij}}$ constraint (Eq. 53 of [Ruchlin, Etienne, and Baumgarte (2018)](https://arxiv.org/abs/1712.07658))
## Author: Zach Etienne
### Formatting improvements courtesy Brandon Clark
[comment]: <> (Abstract: TODO)
**Notebook Status:** <font color='green'><b> Validated </b></font>
**Validation Notes:** This tutorial notebook has been confirmed to be self-consistent with its corresponding NRPy+ module, as documented [below](#code_validation). In addition, its output has been
### NRPy+ Source Code for this module: [BSSN/Enforce_Detgammahat_Constraint.py](../edit/BSSN/Enforce_Detgammahat_Constraint.py)
## Introduction:
[Brown](https://arxiv.org/abs/0902.3652)'s covariant Lagrangian formulation of BSSN, which we adopt, requires that $\partial_t \bar{\gamma} = 0$, where $\bar{\gamma}=\det \bar{\gamma}_{ij}$. Further, all initial data we choose satisfies $\bar{\gamma}=\hat{\gamma}$.
However, numerical errors will cause $\bar{\gamma}$ to deviate from a constant in time. This actually disrupts the hyperbolicity of the PDEs, so to cure this, we adjust $\bar{\gamma}_{ij}$ at the end of each Runge-Kutta timestep, so that its determinant satisfies $\bar{\gamma}=\hat{\gamma}$ at all times. We adopt the following, rather standard prescription (Eq. 53 of [Ruchlin, Etienne, and Baumgarte (2018)](https://arxiv.org/abs/1712.07658)):
$$
\bar{\gamma}_{ij} \to \left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \bar{\gamma}_{ij}.
$$
<a id='toc'></a>
# Table of Contents
$$\label{toc}$$
This notebook is organized as follows:
1. [Step 1](#initializenrpy): Initialize needed NRPy+ modules
1. [Step 2](#enforcegammaconstraint): Enforce the $\det{\bar{\gamma}_{ij}}=\det{\hat{\gamma}_{ij}}$ constraint
1. [Step 3](#code_validation): Code Validation against `BSSN.Enforce_Detgammahat_Constraint` NRPy+ module
1. [Step 4](#latex_pdf_output): Output this notebook to $\LaTeX$-formatted PDF file
<a id='initializenrpy'></a>
# Step 1: Initialize needed NRPy+ modules \[Back to [top](#toc)\]
$$\label{initializenrpy}$$
```
# Step P1: import all needed modules from NRPy+:
from outputC import nrpyAbs,lhrh,outCfunction # NRPy+: Core C code output module
import finite_difference as fin # NRPy+: Finite difference C code generation module
import NRPy_param_funcs as par # NRPy+: parameter interface
import grid as gri # NRPy+: Functions having to do with numerical grids
import indexedexp as ixp # NRPy+: Symbolic indexed expression (e.g., tensors, vectors, etc.) support
import reference_metric as rfm # NRPy+: Reference metric support
import cmdline_helper as cmd # NRPy+: Multi-platform Python command-line interface
import sympy as sp # SymPy, Python's core symbolic algebra package
import BSSN.BSSN_quantities as Bq # NRPy+: BSSN quantities
import os,shutil,sys # Standard Python modules for multiplatform OS-level functions
# Set spatial dimension (must be 3 for BSSN)
DIM = 3
par.set_parval_from_str("grid::DIM",DIM)
# Then we set the coordinate system for the numerical grid
par.set_parval_from_str("reference_metric::CoordSystem","SinhSpherical")
rfm.reference_metric() # Create ReU, ReDD needed for rescaling B-L initial data, generating BSSN RHSs, etc.
```
<a id='enforcegammaconstraint'></a>
# Step 2: Enforce the $\det{\bar{\gamma}_{ij}}=\det{\hat{\gamma}_{ij}}$ constraint \[Back to [top](#toc)\]
$$\label{enforcegammaconstraint}$$
Recall that we wish to make the replacement:
$$
\bar{\gamma}_{ij} \to \left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \bar{\gamma}_{ij}.
$$
Notice the expression on the right is guaranteed to have determinant equal to $\hat{\gamma}$.
$\bar{\gamma}_{ij}$ is not a gridfunction, so we must rewrite the above in terms of $h_{ij}$:
\begin{align}
\left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \bar{\gamma}_{ij} &= \bar{\gamma}'_{ij} \\
&= \hat{\gamma}_{ij} + \varepsilon'_{ij} \\
&= \hat{\gamma}_{ij} + \text{Re[i][j]} h'_{ij} \\
\implies h'_{ij} &= \left[\left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \bar{\gamma}_{ij} - \hat{\gamma}_{ij}\right] / \text{Re[i][j]} \\
&= \left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \frac{\bar{\gamma}_{ij}}{\text{Re[i][j]}} - \delta_{ij}\\
&= \left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \frac{\hat{\gamma}_{ij} + \text{Re[i][j]} h_{ij}}{\text{Re[i][j]}} - \delta_{ij}\\
&= \left(\frac{\hat{\gamma}}{\bar{\gamma}}\right)^{1/3} \left(\delta_{ij} + h_{ij}\right) - \delta_{ij}
\end{align}
Upon inspection, when expressing $\hat{\gamma}$ SymPy generates expressions like `(xx0)^{4/3} = pow(xx0, 4./3.)`, which can yield $\text{NaN}$s when `xx0 < 0` (i.e., in the `xx0` ghost zones). To prevent this, we know that $\hat{\gamma}\ge 0$ for all reasonable coordinate systems, so we make the replacement $\hat{\gamma}\to |\hat{\gamma}|$ below:
```
# We will need the h_{ij} quantities defined within BSSN_RHSs
# below when we enforce the gammahat=gammabar constraint
# Step 1: All barred quantities are defined in terms of BSSN rescaled gridfunctions,
# which we declare here in case they haven't yet been declared elsewhere.
Bq.declare_BSSN_gridfunctions_if_not_declared_already()
hDD = Bq.hDD
Bq.BSSN_basic_tensors()
gammabarDD = Bq.gammabarDD
# First define the Kronecker delta:
KroneckerDeltaDD = ixp.zerorank2()
for i in range(DIM):
KroneckerDeltaDD[i][i] = sp.sympify(1)
# The detgammabar in BSSN_RHSs is set to detgammahat when BSSN_RHSs::detgbarOverdetghat_equals_one=True (default),
# so we manually compute it here:
dummygammabarUU, detgammabar = ixp.symm_matrix_inverter3x3(gammabarDD)
# Next apply the constraint enforcement equation above.
hprimeDD = ixp.zerorank2()
for i in range(DIM):
for j in range(DIM):
# Using nrpyAbs here, as it directly translates to fabs() without additional SymPy processing.
# This acts to simplify the final expression somewhat.
hprimeDD[i][j] = \
(nrpyAbs(rfm.detgammahat)/detgammabar)**(sp.Rational(1,3)) * (KroneckerDeltaDD[i][j] + hDD[i][j]) \
- KroneckerDeltaDD[i][j]
```
<a id='code_validation'></a>
# Step 3: Code Validation against `BSSN.Enforce_Detgammahat_Constraint` NRPy+ module \[Back to [top](#toc)\]
$$\label{code_validation}$$
Here, as a code validation check, we verify agreement in the C code output between
1. this tutorial and
2. the NRPy+ [BSSN.Enforce_Detgammahat_Constraint](../edit/BSSN/Enforce_Detgammahat_Constraint.py) module.
```
##########
# Step 1: Generate enforce_detgammahat_constraint() using functions in this tutorial notebook:
Ccodesdir = os.path.join("enforce_detgammahat_constraint")
# First remove C code output directory if it exists
# Courtesy https://stackoverflow.com/questions/303200/how-do-i-remove-delete-a-folder-that-is-not-empty
shutil.rmtree(Ccodesdir, ignore_errors=True)
# Then create a fresh directory
cmd.mkdir(Ccodesdir)
enforce_detg_constraint_vars = [lhrh(lhs=gri.gfaccess("in_gfs","hDD00"),rhs=hprimeDD[0][0]),
lhrh(lhs=gri.gfaccess("in_gfs","hDD01"),rhs=hprimeDD[0][1]),
lhrh(lhs=gri.gfaccess("in_gfs","hDD02"),rhs=hprimeDD[0][2]),
lhrh(lhs=gri.gfaccess("in_gfs","hDD11"),rhs=hprimeDD[1][1]),
lhrh(lhs=gri.gfaccess("in_gfs","hDD12"),rhs=hprimeDD[1][2]),
lhrh(lhs=gri.gfaccess("in_gfs","hDD22"),rhs=hprimeDD[2][2]) ]
enforce_gammadet_string = fin.FD_outputC("returnstring",enforce_detg_constraint_vars,
params="outCverbose=False,preindent=1,includebraces=False")
desc = "Enforce det(gammabar) = det(gammahat) constraint."
name = "enforce_detgammahat_constraint"
outCfunction(
outfile=os.path.join(Ccodesdir, name + ".h-validation"), desc=desc, name=name,
params="const rfm_struct *restrict rfmstruct, const paramstruct *restrict params, REAL *restrict in_gfs",
body=enforce_gammadet_string,
loopopts="AllPoints,enable_rfm_precompute")
##########
# Step 2: Generate enforce_detgammahat_constraint() using functions in BSSN.Enforce_Detgammahat_Constraint
gri.glb_gridfcs_list = []
import BSSN.Enforce_Detgammahat_Constraint as EGC
EGC.output_Enforce_Detgammahat_Constraint_Ccode(outdir=Ccodesdir,
exprs=EGC.Enforce_Detgammahat_Constraint_symb_expressions())
import filecmp
for file in [os.path.join(Ccodesdir,"enforce_detgammahat_constraint.h")]:
if filecmp.cmp(file,file+"-validation") == False:
print("VALIDATION TEST FAILED on file: "+file+".")
sys.exit(1)
else:
print("Validation test PASSED on file: "+file)
##########
```
<a id='latex_pdf_output'></a>
# Step 4: Output this notebook to $\LaTeX$-formatted PDF file \[Back to [top](#toc)\]
$$\label{latex_pdf_output}$$
The following code cell converts this Jupyter notebook into a proper, clickable $\LaTeX$-formatted PDF file. After the cell is successfully run, the generated PDF may be found in the root NRPy+ tutorial directory, with filename
[Tutorial-BSSN_enforcing_determinant_gammabar_equals_gammahat_constraint.pdf](Tutorial-BSSN_enforcing_determinant_gammabar_equals_gammahat_constraint.pdf) (Note that clicking on this link may not work; you may need to open the PDF file through another means.)
```
import cmdline_helper as cmd # NRPy+: Multi-platform Python command-line interface
cmd.output_Jupyter_notebook_to_LaTeXed_PDF("Tutorial-BSSN_enforcing_determinant_gammabar_equals_gammahat_constraint")
```
|
github_jupyter
|
<div align="center"><h1>Perspectives on Text</h1>
<h3>_Synthesizing Textual Knowledge through Markup_</h3>
<br/>
<h4>Elli Bleeker, Bram Buitendijk, Ronald Haentjens Dekker, Astrid Kulsdom
<br/>R&D - Dutch Royal Academy of Arts and Science</h4>
<h6>Computational Methods for Literary Historical Textual Scholarship - July 3, 2018</h6>
</div>
This talk is not a simple "me and my project"-presentation. Instead I'd like to the topic of computational text modeling by focusing on one instrument: markup.
Markup is cool! It is an instrument to express our understanding of a text to a computer so we can probe that text further, have others probe it, store it and represent it.
### Theory
Definition of text
Expectations of markup; challenges
### Practice
TAGML
Editorial workflow
### Conclusion
### Discussion
# Theory
Before we go on, let's take a closer look at what we're dealing with, exactly. As this is the Computational Methods for Literary-Historical Textual Scholarship, I assume we are primarily working with textual objects.
"Text" has been defined over and over again (see all the publications about "what text is, really") but we propose the following definition that is both very precise and inclusive and takes into account all textual features that textual scholars are interested in.
# What is text?
A multilayered, non-linear object containing information which is at times ordered, partially ordered, or unordered
I'll give three examples of textual features and how they translate informationally.
# Modeling textual features
- Overlapping structures
- Discontinuous elements
- Non-linear elements
# Overlapping structures
<img src="images/Selection-21v.png">
<img src="images/Selection-22v.png">
# Discontinuous elements
<img width="900" height="500" src="images/discontinuity.png">
<img width="300" height="300" src="images/order.jpg">
# Non-linear structures
<img width="500" height="500" src="images/code-nonlinear.png">
<img align="left" width="500" height="300" src="images/order1a.png">
<img align="right" width="500" height="300" src="images/order1b.png">
Now, let's move on to markup. The aims or "potential" of markup is twofold:
# Markup
- Markup helps us to **make explicit implicit notions and interpretations**
- Markup **unites scholarly knowledge**
I don't have to tell you that these promises are not, at least not entirely, fulfilled.
Current markup technology do not permit us to do so, or better: they don't facilitate it in a straightforward manner.
- Simple texts do fit into one hierarchy, but the moment one wants to tag more complex phenomena one has to resort to workarounds. Which work, but they do remain workarounds.
- Transcriptions are usually made on a project basis / idiosyncratic approaches. No shared conception of digital editing.
Let's start with the first point. The moment I mention hierarchies, your mind will automatically spring to "overlap".
Indeed, we can make explicit our understanding of text but the moment we structure a textual object a certain way, there'll be many elements that do not fit into that structure. The easiest example is that of:
Logical structure vs. document structure
<img src="images/Selection-21v.png">
<img src="images/Selection-22v.png">
There are, of course, an infinite amount of structures, as illustrated by the long list of analytical perspectives on text by Allan Renear _et al_. Each of these perspectives implies a different structuring and ordering of the text.
"Analytical perspectives on text" (Renear _et al_. 1993):
- dramatic: act, scene, stage directions, speech
- poetic: poem, verse, stanza, quatrain, couplet, line, half-line, foot
- syntactic: sentence, noun phrase, verb phrase, determiner, adjective, noun, verb
- etc...
The second point, bringing together scholarly knowledge in one file that can be used and reused by others, has also been proven quite unfeasible by our diverging scholarly practices.
<div class="quote" align="center">_"Most texts are made for a special use in a specific context for a limited group of people"_</div><br/><div class="source" align="center">(Hillesund 2005)</div>
<div align="center">A "_shared conception of digital editing_" (Hajo 2010) is abandoned in favor of idiosyncratic approaches</div>
Paraphrasing Erwin Palofsky we can assume that:
<div align="center">A strict formal observation and with it a description of a textual object is a _physical impossibility_</div>
Theoretically, markup is an indispensable instrument:
# Markup allows us to ...
#### ... formally describe our interpretation of text
#### ... create transcriptions that can be shared with others and processed by software
Markup is a powerful technology. But:
# With great power comes great responsibilities.
Apart from the fact that we have to be very conscious about the ways in which we identify and tag textual features (during which we also have to take into account how these features may be processed and addressed in later stages) we have a responsibility to keep questioning the model we use.
<div align="center"> The affordances and limitations of a textual model influence our understanding of text</div>
So what happens if we step outside the framework we've all come know, and start all over again? What if we're no longer compelled to think in terms of monohierarchical structures when modeling text and instead take as point departure a model that provides *native* support for multiple hierarchies, without complicated hacks and workarounds? How would we then markup a text?
# Practice
In the second part of my talk, I'll introduce TAGML, the markup language we've been developing over the past few months. TAGML is based on the definition of text as a multilayered, non-linear object and addresses in a straightforward manner complex textual features like those I just described.
Furthermore, we have developed a system to manage TAGML files and address both the issues of compatibility and interoperability.
First, TAGML.
# TAGML
Markup language of Text-as-Graph (TAG) model
Considers **text** to be **a non-linear and multilayered information object**.
A TAGML file can have multiple **layers**.
A layer is, in principle, a set of markup nodes. A layer is hierarchical.
How does that help us to capture various features of text, both simple and complicated?
Let's focus on one of the textual features I just outlined, the most familiar one: overlapping structures.
Imagine transcribing the poetic structure of the text on this document fragment.
<img src="images/Selection-21v.png">
<img src="images/Selection-22v.png">
```
[tagml>
[page>
[p>
[line>2d. Voice from the Springs<line]
[line>Thunderbolts had parched our water<line]
[line>We had been stained with bitter blood<line]
<p]
<page]
[page>
[p>
[line>And had ran mute 'mid shrieks of <|[sic>slaugter<sic]|[corr>slaughter<]|><line]
[line>Thro' a city & a solitude!<line]
<p]
<page]
<tagml]
```
Let's take a closer look at that last transcription. One could argue that the paragraph isn't really "closed", it just needs to be closed to avoid overlap with the page element. If that weren't necessary, this would be a more intuitive transcription:
(In the following transcripton has been stripped of most tags for readability)
```
[page>
[p>
[line>2d. Voice from the Springs<line]
[line>Thunderbolts had parched our water<line]
[line>We had been stained with bitter blood<line]
<page]
[page>
[line>And had ran mute 'mid shrieks of slaughter<line]
[line>Thro' a city and a multitude!<line]
<p]
<page]
```
This is where the multilayeredness comes in. The moment structures overlap, the user can create a new layer. A layer can be created locally. The layers may be given any name; in this example they are simply referred to as layer A and layer B.
```
[page|+A>
[p|+B>
[line>2d. Voice from the Springs<line]
[line>Thunderbolts had parched our water<line]
[line>We had been stained with bitter blood<line]
<page|A]
[page|A>
[line>And had ran mute 'mid shrieks of slaughter<line]
[line>Thro' a city and a multitude!<line]
<p|B]
<page|A]
```
# _Alexandria_
- Text repository for TAGML files
- Git-like version management
Managing TAGML files with multiple layers is done in a repository called _Alexandria_ which stores the TAGM files.
The workflow is similar to that of Git.
Let's return to the examples I just showed, and let's imagine that the markup is added not by one, but by two editors. We'll name them A and B, or to make it more realistic, Astrid and Bram.
## Astrid
```
[page>
[p>
[line>2d. Voice from the Springs<line]
[line>Thrice three hundred thousand years<line]
[line>We had been stained with bitter blood<line]
<p]
<page]
[page>
[p>
[line>And had ran mute 'mid shrieks of <|[sic>slaugter<sic]|[corr>slaughter<corr]]><line]
[line>Thro' a city and a multitude<line]
<p]
<page]
```
<img width="500" height="400" src="images/astrid-alex-init.png">
<img width="500" height="400" src="images/bram-alexandria-checkout.png">
## View "material"
Includes elements `[page>`, `[line>` and `[corr>`
```
[page>
[line>2d. Voice from the Springs<line]
[line>Thrice three hundred thousand years<line]
[line>We had been stained with bitter blood<line]
<page]
[page>
[line>And had ran mute 'mid shrieks of slaughter<line]
[line>Thro' a city and a multitude<line]
<page]
```
## Bram
```
[page|+A>
[p|+B>
[l>2d. Voice from the Springs<l]
[l>Thrice three hundred thousand years<l]
[l>We had been stained with bitter blood<l]
<page|A]
[page|A>
[l>And had ran mute 'mid shrieks of [corr>slaughter<corr]<l]
[l>Thro' a city & a multitude<l]
<p|B]
<page|A]
```
Both TAGML transcriptions are merged in Alexandria. Usually, the users would not check out the "master file" but if they would, it would look something like this:
# Astrid + Bram
```
[page|+A>
[p|+B>
[p|+C>
[line>[l>2nd. Voice from the Springs.<l]<line]
[line>[l>Thrice three hundred thousand years<l]<line]
[line>[l>We had been stained with bitter blood<l]<line]
<p|C]
<page|A]
[page|A>
[p|C>
[line>[l>And had ran mute 'mid shrieks of <|[sic|C>slaugter<sic|C]|[corr>slaughter<corr]|><l]<line]
[line>[l>Thro' a city and a multitude<l]<line]
<p|B]
<p|C]
<page|A]
```
It may be clear that, in order to properly manage multiple transcriptions with multiple layers, properly documenting transcriptions is key. If we go back to the statement that adding markup is "making explicit what is implicit", we can say that this explicitness exists on several levels. Not only within the _text_, but also in the form of metadata and additional documenting files.
# Conclusion
# Text
- Text is a multilayered, non-linear object
- The information can be ordered, partially ordered, or unordered
# Markup
1. Overlap
2. Discontinuity
3. Non-linearity
4. Compatible
a. Interoperable
b. Reusable
"Natural" or idiomatic: the model needs to be close to our understanding of text
# TAGML
... formal description of complex textual features in a straightforward manner
# Alexandria
... stores and manages TAGML files
# Discussion
- How do we handle the merge of TAGML files? Do we consider changes in markup as replacements or additions?
`[line>` to `[l>`
# Option 1: replacements
Changes made by a user replace the existing markup:
<br/>
```[l>2nd. Voice from the Springs.<l]```
# Option 2: additions
New layers are created to identify changes made by different users:
<br/>
```[line|Astrid>[l|Bram>2nd. Voice from the Springs.<l|Bram]<line|Astrid]```
If changes were to be considered replacements, a merge would imply losing a certain amount of information. Perhaps that's not problematic, but users need to be aware of that. In any case, losses wouldn't be forever as they can always be reverted.
- Is the source text part of a perspective or not? In other words, is a perspective only the markup or also the source text?
<img src="images/Selection-22v.png">
View poetic:
`[rhyme>slaughter<rhyme]`
View material:
`<|[sic>slaugter<sic]|[corr>slaughter<corr]|>`
# References
- Alexandria. https://github.com/HuygensING/alexandria-markup. Information about installing and using the Alexandria command line app is available at links on the TAG portal at https://github.com/HuygensING/TAG.
- Gengnagel, T. 2015. "Marking Up Iconography: Scholarly Editions Beyond Text," in: parergon, 06/11/2015, https://parergon.hypotheses.org/40.
- Haentjens Dekker, R. & Birnbaum, D.J. 2017. "It’s more than just overlap: Text As Graph". In _Proceedings of Balisage: The Markup Conference 201. Balisage Series on Markup Technologies_, vol. 19. doi:10.4242/BalisageVol19.Dekker01. https://www.balisage.net/Proceedings/vol19/html/Dekker01/BalisageVol19-Dekker01.html
- Hajo, C. M. 2010. "The sustainability of the scholarly edition in a digital world". In _Proceedings of the International Symposium on XML for the Long Haul: Issues in the Long-term Preservation of XML_. Balisage Series on Markup Technologies, vol. 6. doi:10.4242/BalisageVol6.Hajo01.
- Hillesund, T. 2005. "Digital Text Cycles: From Medieval Manuscripts to Modern Markup". In _Journal of Digital Information_ 6:1. https://journals.tdl.org/jodi/index.php/jodi/article/view/62/65.
- Panofsky, E. 1932/1964. "Zum Problem der Beschreibung und Inhaltsdeutung von Werken der bildenden Kunst" in _Ikonographie und Ikonologie: Theorien, Entwicklung, Probleme (Bildende Kunst als Zeichensystem; vol. 1)_, ed. by Ekkehard Kaemmerling, Köln 1979, pp.185-206.
- Renear, A. H., Mylonas, E., & Durand, D. 1993. "Refining our notion of what text really is: The problem of overlapping hierarchies". https://www.ideals.illinois.edu/bitstream/handle/2142/9407/RefiningOurNotion.pdf?sequence=2&isAllowed=y
- Sahle, P. 2013. _Digitale Editionsformen-Teil 3: Textbegriffe Und Recodierung_. Norderstedt: Books on Demand. http://kups.ub.uni-koeln.de/5353/
- Shelley, P. B. "Prometheus Unbound, Act I", in The Shelley-Godwin Archive, MS. Shelley e. 1, 21v. Retrieved from http://shelleygodwinarchive.org/sc/oxford/prometheus_unbound/act/i/#/p7
- Shillingsburg, P. 2014. "From physical to digital textuality: Loss and gain in literary projects". In _CEA Critic_ 76:2, pp.158-168.
# Some extra slides
## Just in case ...
<img src="images/cmlhts-18-latest.png">
<img src="images/cmlhts-19-latest.png">
<img src="images/cmlhts-20-latest.png">
# TAG
Data model: non-uniform cyclic property hypergraph of text
- Document Node
- Text Nodes
- Markup Nodes
- Annotation Nodes
<img align="center" width="300" height="200" src="images/hypergraph-general.png">
<img align="center" width="600" height="600" src="images/hypergraph.png">
|
github_jupyter
|
# Import
```
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import TensorDataset, Dataset, DataLoader, random_split
from torch.nn.utils.rnn import pack_padded_sequence, pack_sequence, pad_packed_sequence, pad_sequence
import os
import sys
import pickle
import logging
import random
from pathlib import Path
from math import log, ceil
from typing import List, Tuple, Set, Dict
import numpy as np
import pandas as pd
from sklearn import metrics
import seaborn as sns
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import random
import math
import os
import time
sys.path.append('..')
from src.data import prepare_data, prepare_seq2seq_data, SOURCE_ASSIST0910_SELF, SOURCE_ASSIST0910_ORIG
from src.utils import sAsMinutes, timeSince
sns.set()
sns.set_style('whitegrid')
sns.set_palette('Set1')
# =========================
# PyTorch version & GPU setup
# =========================
print('PyTorch:', torch.__version__)
dev = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# dev = torch.device('cpu')
print('Using Device:', dev)
dirname = Path().resolve()
dirname
# =========================
# Seed
# =========================
SEED = 0
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
# torch.backends.cudnn.deterministic = True
# torch.backends.cudnn.benchmark = False
# =========================
# Parameters
# =========================
# model_name = 'RNN'
sequence_size = 20
epoch_size = 500
lr = 0.1
batch_size, n_hidden, n_skills, n_layers = 100, 200, 124, 1
n_output = n_skills
PRESERVED_TOKENS = 2 # PAD, SOS
onehot_size = n_skills * 2 + PRESERVED_TOKENS
n_input = ceil(log(2 * n_skills))
# n_input = onehot_size #
NUM_EMBEDDIGNS, ENC_EMB_DIM, ENC_DROPOUT = onehot_size, n_input, 0.6
OUTPUT_DIM, DEC_EMB_DIM, DEC_DROPOUT = onehot_size, n_input, 0.6
# OUTPUT_DIM = n_output = 124 # TODO: ほんとはこれやりたい
HID_DIM, N_LAYERS = n_hidden, n_layers
# =========================
# Data
# =========================
train_dl, eval_dl = prepare_seq2seq_data(
SOURCE_ASSIST0910_ORIG, n_skills, PRESERVED_TOKENS, min_n=3, max_n=sequence_size, batch_size=batch_size, device=dev, sliding_window=1)
# 違いを調整する <- ???
#OUTPUT_DIM = eval_dl.dataset.tensors[1].shape
# =========================
# Model
# =========================
class Encoder(nn.Module):
def __init__(self, num_embeddings, emb_dim, hid_dim, n_layers, dropout):
# def __init__(self, dev, model_name, n_input, n_hidden, n_output, n_layers, batch_size, dropout=0.6, bidirectional=False):
super().__init__()
self.num_embeddings = num_embeddings
self.emb_dim = emb_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.dropout = dropout
self.embedding = nn.Embedding(num_embeddings, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, input):
#src = [src sent len, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [src sent len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src sent len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
# def __init__(self, dev, model_name, n_input, n_hidden, n_output, n_layers, batch_size, dropout=0.6, bidirectional=False):
super().__init__()
self.emb_dim = emb_dim
self.hid_dim = hid_dim
self.output_dim = output_dim
self.n_layers = n_layers
self.dropout = dropout
self.embedding = nn.Embedding(output_dim, emb_dim) # 250->6
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout) # 6, 100, 1
self.out = nn.Linear(hid_dim, output_dim) # 100, 250
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
#print(input.shape) #torch.Size([21])
input = input.unsqueeze(0)
#print(input.shape) #torch.Size([1, 21])
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = self.dropout(input)
#print(embedded.shape) # torch.Size([1, 15, 6])
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [sent len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#sent len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
OUTP = None
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, dev):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = dev
assert encoder.hid_dim == decoder.hid_dim, \
"Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, \
"Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, actual_q=None, teacher_forcing_ratio=0.5):
#src = [src sent len, batch size]
#trg = [trg sent len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
max_len = trg.shape[0]
# print(f'target shape: {trg.shape}')
# print(f'batch_size: {batch_size}, max_len: {max_len}')
trg_vocab_size = self.decoder.output_dim
# print(f'vocab size: {trg_vocab_size}')
#tensor to store decoder outputs
outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device) # TODO: fix hard coding
outputs_prob = torch.zeros(max_len, batch_size, 124).to(self.device) # TODO: fix hard coding
# print('s2s outputs shape:', outputs.shape)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
# #first input to the decoder is the <sos> tokens
# input = trg[0,:]
#
# # print(actual_q.shape) # 100, 20, 124
# for t in range(1, max_len):
#
# output, hidden, cell = self.decoder(input, hidden, cell)
# # print(output.shape) # 100, 250
# # つまり100ごとにバッチ処理をしていて、20のSeqを頭から順に処理している段階
# #global OUTP
# #OUTP = output
# outputs[t] = output
# o_wro = torch.sigmoid(output[:, 2:2+124])
# o_cor = torch.sigmoid(output[:, 2+124:])
# outputs_prob[t] = o_cor / (o_cor + o_wro)
# teacher_force = random.random() < teacher_forcing_ratio
# top1 = output.max(1)[1]
# flag = torch.zeros(100, 2) # PRESERVED_TAGS = 2
# flag = torch.cat((flag, actual_q[:,t], actual_q[:,t]), dim=1)
# top1 = torch.max(torch.sigmoid(output) * flag, dim=1)[1]
# input = (trg[t] if teacher_force else top1)
# print(actual_q.shape) # 100, 20, 124
input = trg[-2,:]
output, hidden, cell = self.decoder(input, hidden, cell)
# print(output.shape) # 100, 250
# つまり100ごとにバッチ処理をしていて、20のSeqを頭から順に処理している段階
#global OUTP
#OUTP = output
outputs = output.unsqueeze(0)
o_wro = torch.sigmoid(output[:, 2:2+124])
o_cor = torch.sigmoid(output[:, 2+124:])
outputs_prob = (o_cor / (o_cor + o_wro)).unsqueeze(0)
return outputs, outputs_prob
# =========================
# Prepare and Train
# =========================
enc = Encoder(NUM_EMBEDDIGNS, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT).to(dev)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT).to(dev)
model = Seq2Seq(enc, dec, dev).to(dev)
# Load model
# ----------
load_model = None
epoch_start = 1
load_model = '/home/qqhann/qqhann-paper/ECML2019/dkt_neo/models/s2s_2019_0404_2021.100'
if load_model:
epoch_start = int(load_model.split('.')[-1]) + 1
model.load_state_dict(torch.load(load_model))
model = model.to(dev)
# ----------
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
loss_func = nn.BCELoss()
opt = optim.SGD(model.parameters(), lr=lr)
def train():
pass
def evaluate():
pass
PRED = None
def main():
debug = False
logging.basicConfig()
logger = logging.getLogger('dkt log')
logger.setLevel(logging.INFO)
train_loss_list = []
train_auc_list = []
eval_loss_list = []
eval_auc_list = []
eval_recall_list = []
eval_f1_list = []
x = []
start_time = time.time()
for epoch in range(epoch_start, epoch_size + 1):
print_train = epoch % 10 == 0
print_eval = epoch % 10 == 0
print_auc = epoch % 10 == 0
# =====
# TRAIN
# =====
model.train()
val_pred = []
val_actual = []
current_epoch_train_loss = []
for xs, ys, yq, ya, yp in train_dl:
input = xs
target = ys
input = input.permute(1, 0)
target = target.permute(1, 0)
out, out_prob = model(input, target, yq)
out = out.permute(1, 0, 2)
out_prob = out_prob.permute(1, 0, 2)
pred = torch.sigmoid(out) # [0, 1]区間にする
# _, pred = torch.max(pred, 2)
target = torch.tensor([list(torch.eye(NUM_EMBEDDIGNS)[i]) for i in target.contiguous().view(-1)])\
.contiguous().view(batch_size, -1, NUM_EMBEDDIGNS).to(dev)
# --- 指標評価用データ
# print(out_prob.shape, yq[:,-1,:].unsqueeze(1).shape)
prob = torch.max(out_prob * yq[:,-1,:].unsqueeze(1), 2)[0]
val_pred.append(prob)
val_actual.append(ya[:,-1])
# ---
# print(prob.shape, ya.shape)
loss = loss_func(prob[:,-1], ya[:,-1])
current_epoch_train_loss.append(loss.item())
# バックプロバゲーション
opt.zero_grad()
loss.backward()
opt.step()
# stop at first batch if debug
if debug:
break
if print_train:
loss = np.array(current_epoch_train_loss)
logger.log(logging.INFO + (5 if epoch % 100 == 0 else 0),
'TRAIN Epoch: {} Loss: {}'.format(epoch, loss.mean()))
train_loss_list.append(loss.mean())
# # AUC, Recall, F1
# # TRAINの場合、勾配があるから処理が必要
# y = torch.cat(val_targ).cpu().detach().numpy()
# pred = torch.cat(val_prob).cpu().detach().numpy()
# # AUC
# fpr, tpr, thresholds = metrics.roc_curve(y, pred, pos_label=1)
# logger.log(logging.INFO + (5 if epoch % 100 == 0 else 0),
# 'TRAIN Epoch: {} AUC: {}'.format(epoch, metrics.auc(fpr, tpr)))
# train_auc_list.append(metrics.auc(fpr, tpr))
# =====
# EVAL
# =====
if print_eval:
with torch.no_grad():
model.eval()
val_pred = []
val_actual = []
current_eval_loss = []
for xs, ys, yq, ya, yp in eval_dl:
input = xs
target = ys
input = input.permute(1, 0)
target = target.permute(1, 0)
out, out_prob = model(input, target, yq)
out = out.permute(1, 0, 2)
out_prob = out_prob.permute(1, 0, 2)
pred = torch.sigmoid(out) # [0, 1]区間にする
# _, pred = torch.max(pred, 2)
target = torch.tensor([list(torch.eye(NUM_EMBEDDIGNS)[i]) for i in target.contiguous().view(-1)])\
.contiguous().view(batch_size, -1, NUM_EMBEDDIGNS).to(dev)
# --- 指標評価用データ
prob = torch.max(out_prob * yq[:,-1,:].unsqueeze(1), 2)[0]
val_pred.append(prob)
val_actual.append(ya[:,-1])
# ---
# print(prob.shape, ya.shape)
loss = loss_func(prob[:,-1], ya[:,-1])
current_eval_loss.append(loss.item())
# stop at first batch if debug
if debug:
break
loss = np.array(current_eval_loss)
logger.log(logging.INFO + (5 if epoch % 100 == 0 else 0),
'EVAL Epoch: {} Loss: {}'.format(epoch, loss.mean()))
eval_loss_list.append(loss.mean())
# AUC, Recall, F1
if print_auc:
y = torch.cat(val_actual).view(-1).cpu() # TODO: viewしない? 最後の1個で?
pred = torch.cat(val_pred).view(-1).cpu()
# AUC
fpr, tpr, thresholds = metrics.roc_curve(y, pred, pos_label=1)
logger.log(logging.INFO + (5 if epoch % 100 == 0 else 0),
'EVAL Epoch: {} AUC: {}'.format(epoch, metrics.auc(fpr, tpr)))
eval_auc_list.append(metrics.auc(fpr, tpr))
# # Recall
# logger.debug('EVAL Epoch: {} Recall: {}'.format(epoch, metrics.recall_score(y, pred.round())))
# # F1 score
# logger.debug('EVAL Epoch: {} F1 score: {}'.format(epoch, metrics.f1_score(y, pred.round())))
if epoch % 10 == 0:
x.append(epoch)
logger.info(f'{timeSince(start_time, epoch / epoch_size)} ({epoch} {epoch / epoch_size * 100})')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, train_loss_list, label='train loss')
# ax.plot(x, train_auc_list, label='train auc')
ax.plot(x, eval_loss_list, label='eval loss')
ax.plot(x, eval_auc_list, label='eval auc')
ax.legend()
print(len(train_loss_list), len(eval_loss_list), len(eval_auc_list))
plt.show()
if __name__ == '__main__':
print('Using Device:', dev)
main()
model
import datetime
now = datetime.datetime.now().strftime('%Y_%m%d_%H%M')
torch.save(model.state_dict(), '/home/qqhann/qqhann-paper/ECML2019/dkt_neo/models/s2s_' + now + '.' + str(epoch))
```
|
github_jupyter
|
# NLP - Hotel review sentiment analysis in python
```
#warnings :)
import warnings
warnings.filterwarnings('ignore')
import os
dir_Path = 'D:\\01_DATA_SCIENCE_FINAL\\D-00000-NLP\\NLP-CODES\\AMAN-NLP-CODES\\AMAN_NLP_VIMP-CODE\\Project-6_Sentiment_Analysis_Amn\\'
os.chdir(dir_Path)
```
## Data Facts and Import
```
import pandas as pd
# Local directory
Reviewdata = pd.read_csv('train.csv')
#Data Credit - https://www.kaggle.com/anu0012/hotel-review/data
Reviewdata.head()
Reviewdata.shape
Reviewdata.head()
Reviewdata.info()
Reviewdata.describe().transpose()
```
## Data Cleaning / EDA
```
### Checking Missing values in the Data Set and printing the Percentage for Missing Values for Each Columns ###
count = Reviewdata.isnull().sum().sort_values(ascending=False)
percentage = ((Reviewdata.isnull().sum()/len(Reviewdata)*100)).sort_values(ascending=False)
missing_data = pd.concat([count, percentage], axis=1,
keys=['Count','Percentage'])
print('Count and percentage of missing values for the columns:')
missing_data
print("Missing values count:")
print(Reviewdata.Is_Response.value_counts())
print("*"*12)
print("Missing values %ge:")
print(round(Reviewdata.Is_Response.value_counts(normalize=True)*100),2)
print("*"*12)
import seaborn as sns
sns.countplot(Reviewdata.Is_Response)
plt.show()
### Checking for the Distribution of Default ###
import matplotlib.pyplot as plt
%matplotlib inline
print('Percentage for default\n')
print(round(Reviewdata.Is_Response.value_counts(normalize=True)*100,2))
round(Reviewdata.Is_Response.value_counts(normalize=True)*100,2).plot(kind='bar')
plt.title('Percentage Distributions by review type')
plt.show()
#Removing columns
Reviewdata.drop(columns = ['User_ID', 'Browser_Used', 'Device_Used'], inplace = True)
# Apply first level cleaning
import re
import string
#This function converts to lower-case, removes square bracket, removes numbers and punctuation
def text_clean_1(text):
text = text.lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\w*\d\w*', '', text)
return text
cleaned1 = lambda x: text_clean_1(x)
# Let's take a look at the updated text
Reviewdata['cleaned_description'] = pd.DataFrame(Reviewdata.Description.apply(cleaned1))
Reviewdata.head(10)
# Apply a second round of cleaning
def text_clean_2(text):
text = re.sub('[‘’“”…]', '', text)
text = re.sub('\n', '', text)
return text
cleaned2 = lambda x: text_clean_2(x)
# Let's take a look at the updated text
Reviewdata['cleaned_description_new'] = pd.DataFrame(Reviewdata['cleaned_description'].apply(cleaned2))
Reviewdata.head(10)
```
## Model training
```
from sklearn.model_selection import train_test_split
Independent_var = Reviewdata.cleaned_description_new
Dependent_var = Reviewdata.Is_Response
IV_train, IV_test, DV_train, DV_test = train_test_split(Independent_var, Dependent_var, test_size = 0.1, random_state = 225)
print('IV_train :', len(IV_train))
print('IV_test :', len(IV_test))
print('DV_train :', len(DV_train))
print('DV_test :', len(DV_test))
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
tvec = TfidfVectorizer()
clf2 = LogisticRegression(solver = "lbfgs")
from sklearn.pipeline import Pipeline
model = Pipeline([('vectorizer',tvec),('classifier',clf2)])
model.fit(IV_train, DV_train)
from sklearn.metrics import confusion_matrix
predictions = model.predict(IV_test)
confusion_matrix(predictions, DV_test)
```
## Model prediciton
```
from sklearn.metrics import accuracy_score, precision_score, recall_score
print("Accuracy : ", accuracy_score(predictions, DV_test))
print("Precision : ", precision_score(predictions, DV_test, average = 'weighted'))
print("Recall : ", recall_score(predictions, DV_test, average = 'weighted'))
```
## Trying on new reviews
```
example = ["I'm happy"]
result = model.predict(example)
print(result)
example = ["I'm frustrated"]
result = model.predict(example)
print(result)
# Drawback???
example = ["I'm not happy"]
result = model.predict(example)
print(result)
```
|
github_jupyter
|
## TrainingPhase and General scheduler
Creates a scheduler that lets you train a model with following different [`TrainingPhase`](/callbacks.general_sched.html#TrainingPhase).
```
from fastai.gen_doc.nbdoc import *
from fastai.callbacks.general_sched import *
from fastai.vision import *
show_doc(TrainingPhase)
```
You can then schedule any hyper-parameter you want by using the following method.
```
show_doc(TrainingPhase.schedule_hp)
```
The phase will make the hyper-parameter vary from the first value in `vals` to the second, following `anneal`. If an annealing function is specified but `vals` is a float, it will decay to 0. If no annealing function is specified, the default is a linear annealing for a tuple, a constant parameter if it's a float.
```
jekyll_note("""If you want to use discriminative values, you can pass an numpy array in `vals` (or a tuple
of them for start and stop).""")
```
The basic hyper-parameters are named:
- 'lr' for learning rate
- 'mom' for momentum (or beta1 in Adam)
- 'beta' for the beta2 in Adam or the alpha in RMSprop
- 'wd' for weight decay
You can also add any hyper-parameter that is in your optimizer (even if it's custom or a [`GeneralOptimizer`](/general_optimizer.html#GeneralOptimizer)), like 'eps' if you're using Adam.
Let's make an example by using this to code [SGD with warm restarts](https://arxiv.org/abs/1608.03983).
```
def fit_sgd_warm(learn, n_cycles, lr, mom, cycle_len, cycle_mult):
n = len(learn.data.train_dl)
phases = [(TrainingPhase(n * (cycle_len * cycle_mult**i))
.schedule_hp('lr', lr, anneal=annealing_cos)
.schedule_hp('mom', mom)) for i in range(n_cycles)]
sched = GeneralScheduler(learn, phases)
learn.callbacks.append(sched)
if cycle_mult != 1:
total_epochs = int(cycle_len * (1 - (cycle_mult)**n_cycles)/(1-cycle_mult))
else: total_epochs = n_cycles * cycle_len
learn.fit(total_epochs)
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = Learner(data, simple_cnn((3,16,16,2)), metrics=accuracy)
fit_sgd_warm(learn, 3, 1e-3, 0.9, 1, 2)
learn.recorder.plot_lr()
show_doc(GeneralScheduler)
```
### Callback methods
You don't call these yourself - they're called by fastai's [`Callback`](/callback.html#Callback) system automatically to enable the class's functionality.
```
show_doc(GeneralScheduler.on_batch_end, doc_string=False)
```
Takes a step in the current phase and prepare the hyperparameters for the next batch.
```
show_doc(GeneralScheduler.on_train_begin, doc_string=False)
```
Initiates the hyperparameters to the start values of the first phase.
## Undocumented Methods - Methods moved below this line will intentionally be hidden
|
github_jupyter
|
## Problem Definition
In the following different ways of loading or implementing an optimization problem in our framework are discussed.
### By Class
A very detailed description of defining a problem through a class is already provided in the [Getting Started Guide](../getting_started.ipynb).
The following definition of a simple optimization problem with **one** objective and **two** constraints is considered. The problem has two constants, *const_1* and *const_2*, which can be modified by initiating the problem with different parameters. By default, it consists of 10 variables, and the lower and upper bounds are within $[-5, 5]$ for all variables.
**Note**: The example below uses the `autograd` library, which calculates the gradients through automatic differentiation.
```
import numpy as np
import autograd.numpy as anp
from pymoo.model.problem import Problem
class MyProblem(Problem):
def __init__(self, const_1=5, const_2=0.1):
# define lower and upper bounds - 1d array with length equal to number of variable
xl = -5 * anp.ones(10)
xu = 5 * anp.ones(10)
super().__init__(n_var=10, n_obj=1, n_constr=2, xl=xl, xu=xu, evaluation_of="auto")
# store custom variables needed for evaluation
self.const_1 = const_1
self.const_2 = const_2
def _evaluate(self, x, out, *args, **kwargs):
f = anp.sum(anp.power(x, 2) - self.const_1 * anp.cos(2 * anp.pi * x), axis=1)
g1 = (x[:, 0] + x[:, 1]) - self.const_2
g2 = self.const_2 - (x[:, 2] + x[:, 3])
out["F"] = f
out["G"] = anp.column_stack([g1, g2])
```
After creating a problem object, the evaluation function can be called. The `return_values_of` parameter can be overwritten to modify the list of returned parameters. The gradients for the objectives `dF` and constraints `dG` can be obtained as follows:
```
problem = MyProblem()
F, G, CV, feasible, dF, dG = problem.evaluate(np.random.rand(100, 10),
return_values_of=["F", "G", "CV", "feasible", "dF", "dG"])
```
**Elementwise Evaluation**
If the problem can not be executed using matrix operations, a serialized evaluation can be indicated using the `elementwise_evaluation=True` flag. If the flag is set, then an outer loop is already implemented, an `x` is only a **one**-dimensional array.
```
class MyProblem(Problem):
def __init__(self, **kwargs):
super().__init__(n_var=2, n_obj=1, elementwise_evaluation=True, **kwargs)
def _evaluate(self, x, out, *args, **kwargs):
out["F"] = x.sum()
```
### By Function
Another way of defining a problem is through functions. One the one hand, many function calls need to be performed to evaluate a set of solutions, but on the other hand, it is a very intuitive way of defining a problem.
```
import numpy as np
from pymoo.model.problem import FunctionalProblem
objs = [
lambda x: np.sum((x - 2) ** 2),
lambda x: np.sum((x + 2) ** 2)
]
constr_ieq = [
lambda x: np.sum((x - 1) ** 2)
]
problem = FunctionalProblem(10,
objs,
constr_ieq=constr_ieq,
xl=np.array([-10, -5, -10]),
xu=np.array([10, 5, 10])
)
F, CV = problem.evaluate(np.random.rand(3, 10))
print(f"F: {F}\n")
print(f"CV: {CV}")
# END from_string
```
### By String
In our framework, various test problems are already implemented and available by providing the corresponding problem name we have assigned to it. A couple of problems can be further parameterized by providing the number of variables, constraints, or other problem-dependent constants.
```
from pymoo.factory import get_problem
p = get_problem("dtlz1_-1", n_var=20, n_obj=5)
# create a simple test problem from string
p = get_problem("Ackley")
# the input name is not case sensitive
p = get_problem("ackley")
# also input parameter can be provided directly
p = get_problem("dtlz1_-1", n_var=20, n_obj=5)
```
## API
|
github_jupyter
|
```
import os, platform, pprint, sys
import fastai
import keras
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sn
import sklearn
# from fastai.tabular.data import TabularDataLoaders
# from fastai.tabular.all import FillMissing, Categorify, Normalize, tabular_learner, accuracy, ClassificationInterpretation, ShowGraphCallback
from itertools import cycle
from keras.layers import Dense
from keras.metrics import CategoricalAccuracy, Recall, Precision, AUC
from keras.models import Sequential
from keras.utils import to_categorical, normalize
from math import sqrt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import StratifiedKFold, train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
seed: int = 14
# set up pretty printer for easier data evaluation
pretty = pprint.PrettyPrinter(indent=4, width=30).pprint
# declare file paths for the data we will be working on
file_path_1: str = '../data/prepared/baseline/Benign_vs_DDoS.csv'
file_path_2: str = '../data/prepared/timebased/Benign_vs_DDoS.csv'
modelPath : str = './models'
# print library and python versions for reproducibility
print(
f'''
python:\t{platform.python_version()}
\tfastai:\t\t{fastai.__version__}
\tkeras:\t\t{keras.__version__}
\tmatplotlib:\t{mpl.__version__}
\tnumpy:\t\t{np.__version__}
\tpandas:\t\t{pd.__version__}
\tseaborn:\t{sn.__version__}
\tsklearn:\t{sklearn.__version__}
'''
)
def load_data(filePath: str) -> pd.DataFrame:
'''
Loads the Dataset from the given filepath and caches it for quick access in the future
Function will only work when filepath is a .csv file
'''
# slice off the ./CSV/ from the filePath
if filePath[0] == '.' and filePath[1] == '.':
filePathClean: str = filePath[17::]
pickleDump: str = f'../data/cache/{filePathClean}.pickle'
else:
pickleDump: str = f'../data/cache/{filePath}.pickle'
print(f'Loading Dataset: {filePath}')
print(f'\tTo Dataset Cache: {pickleDump}\n')
# check if data already exists within cache
if os.path.exists(pickleDump):
df = pd.read_pickle(pickleDump)
# if not, load data and cache it
else:
df = pd.read_csv(filePath, low_memory=True)
df.to_pickle(pickleDump)
return df
def show_conf_matrix(model=None, X_test=None, y_test=None, classes=[], file=''):
# Techniques from https://stackoverflow.com/questions/29647749/seaborn-showing-scientific-notation-in-heatmap-for-3-digit-numbers
# and https://stackoverflow.com/questions/35572000/how-can-i-plot-a-confusion-matrix#51163585
predictions = model.predict(X_test)
matrix = [ [ 0 for j in range(len(predictions[0])) ] for i in range(len(predictions[0])) ]
for i in range(len(predictions)):
pred = predictions[i]
test = y_test[i]
guess = np.argmax(pred)
actual = np.argmax(test)
matrix[actual][guess] += 1
df_cm = pd.DataFrame(matrix, range(len(matrix)), range(len(matrix)))
int_cols = df_cm.columns
df_cm.columns = classes
df_cm.index = classes
fig = plt.figure(figsize=(10,7))
sn.set(font_scale=1.5) # for label size
ax = sn.heatmap(df_cm, annot=True, annot_kws={"size": 16}, fmt='g', cmap=sn.color_palette("Blues")) # font size
ax.set_ylabel('Actual')
ax.set_xlabel('Predicted')
plt.tight_layout()
fig.savefig('conf_matrix_{}.png'.format(file))
plt.show()
def show_roc_curve(model=None, X_test=None, y_test=None, classes=[], file=''):
y_score = model.predict(X_test)
n_classes = len(classes)
# Produce ROC curve from https://hackernoon.com/simple-guide-on-how-to-generate-roc-plot-for-keras-classifier-2ecc6c73115a
# Note that I am working through this code and I'm going to clean it up as I learn more about how it works
import numpy as np
from numpy import interp
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn.metrics import roc_curve, auc
# Plot linewidth.
lw = 2
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# Compute macro-average ROC curve and ROC area
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves of all the classes
fig = plt.figure(figsize=(12,12))
colors = cycle(['red', 'blue', 'orange', 'green', 'violet', 'teal', 'turquoise', 'pink'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of {0} (area = {1:0.2f})'.format(classes[i], roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel('True Positive Rate (Sensativity)')
plt.xlabel('False Positive Rate (1-Specificity)')
plt.title('Receiver Operating Characteristic of the Classes')
plt.legend(loc="lower right")
fig.savefig('roc_curve_classes_{}.png'.format(file))
plt.show()
# Plot all ROC curves with micro and macro averages
fig = plt.figure(figsize=(12,12))
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.ylabel('True Positive Rate (Sensativity)')
plt.xlabel('False Positive Rate (1-Specificity)')
plt.title('Receiver Operating Characteristic of the Micro and Macro Averages')
plt.legend(loc="lower right")
fig.savefig('roc_curve_micromacro_{}.png'.format(file))
plt.show()
def get_std(x=[], xbar=0):
o2=0
for xi in x:
o2 += (xi - xbar)**2
o2 /= len(x)-1
return sqrt(o2)
baseline_df : pd.DataFrame = load_data(file_path_1)
timebased_df: pd.DataFrame = load_data(file_path_2)
dep_var = 'Label'
ind_vars_baseline = (baseline_df.columns.difference([dep_var])).tolist()
ind_vars_timebased = (timebased_df.columns.difference([dep_var])).tolist()
baseline_Xy = (baseline_df[ind_vars_baseline], baseline_df[dep_var])
timebased_Xy = (timebased_df[ind_vars_timebased], timebased_df[dep_var])
names: list = ['Benign', 'DDoS']
X = baseline_Xy[0]
x = baseline_Xy[0]
Y = baseline_Xy[1]
num_classes = Y.nunique()
encoder = LabelEncoder()
y = encoder.fit_transform(Y)
# Lists for accuracies collected from models
list_rf = []
list_dt = []
list_knn = []
list_dnn = []
std_rf = []
std_dt = []
std_knn = []
std_dnn = []
# Mean accuracies for each model
mean_rf = 0
mean_dt = 0
mean_knn = 0
mean_dnn = 0
# Keep to calculate std
results_rf = []
results_dt = []
results_knn = []
results_dnn = []
# 10-fold Stratified Cross-Validation
n_splits = 10
skf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=seed)
for train_idxs, test_idxs in skf.split(X, y):
# Define the training and testing sets
X_train, X_test = X.iloc[train_idxs], X.iloc[test_idxs]
y_train, y_test = y[train_idxs], y[test_idxs]
# Create a different version of the y_train and y_test for the Deep Neural Network
# y_train_dnn = to_categorical(y_train, num_classes=num_classes)
# y_test_dnn = to_categorical(y_test, num_classes=num_classes)
# Initialize the sklearn models
rf = RandomForestClassifier(random_state=seed)
dt = DecisionTreeClassifier(random_state=seed)
knn = KNeighborsClassifier()
# # Deep Neural Network
# dnn = Sequential([
# Dense(256, input_shape=(69,)),
# Dense(128, activation='relu'),
# Dense(64, activation='relu'),
# Dense(32, activation='relu'),
# Dense(2, activation='softmax')
# ])
# dnn.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the models
rf.fit(X_train, y_train)
dt.fit(X_train, y_train)
knn.fit(X_train, y_train)
# dnn.fit(x=X_train, y=y_train_dnn, batch_size=25, epochs=100, verbose=0, validation_data=(X_test, y_test_dnn))
# Evaluate the models
results_rf.append(rf.score(X_test, y_test))
results_dt.append(dt.score(X_test, y_test))
results_knn.append(knn.score(X_test, y_test))
# results_dnn.append( (dnn.evaluate(X_test, y_test_dnn, verbose=0) )[1] )
# print('Random Forest')
# show_roc_curve(model=rf, X_test=X_test, y_test=y_test, classes=names)
# print('Decision Tree')
# show_roc_curve(model=dt, X_test=X_test, y_test=y_test, classes=names)
# print('k-Nearest Neighbor')
# show_roc_curve(model=knn, X_test=X_test, y_test=y_test, classes=names)
# # print('Deep Learning')
# show_roc_curve(model=dnn, X_test=X_test, y_test=y_test_dnn, classes=names)
print('Random Forest')
show_conf_matrix(model=rf, X_test=X_test, y_test=y_test, classes=names)
print('Decision Tree')
show_conf_matrix(model=dt, X_test=X_test, y_test=y_test, classes=names)
print('k-Nearest Neighbor')
show_conf_matrix(model=knn, X_test=X_test, y_test=y_test, classes=names)
# print('Deep Learning')
# show_conf_matrix(model=dnn, X_test=X_test, y_test=y_test_dnn, classes=names)
#print('Results from DNN: {}'.format(results_dnn))
# Add the results to the running mean
mean_rf += results_rf[-1] / (n_splits * 1.0)
mean_dt += results_dt[-1] / (n_splits * 1.0)
mean_knn += results_knn[-1] / (n_splits * 1.0)
# mean_dnn += results_dnn[-1] / (n_splits * 1.0)
# Push the mean results from all of the splits to the lists
list_rf.append(mean_rf)
list_dt.append(mean_dt)
list_knn.append(mean_knn)
# list_dnn.append(mean_dnn)
std_rf.append(get_std(results_rf, mean_rf))
std_dt.append(get_std(results_dt, mean_dt))
std_knn.append(get_std(results_knn, mean_knn))
# std_dnn.append(get_std(results_dnn, mean_dnn))
print('done')
print('All trainings complete!')
```
|
github_jupyter
|
# Using AWS Lambda and PyWren for Landsat 8 Time Series
This notebook is a simple demonstration of drilling a timeseries of NDVI values from the [Landsat 8 scenes held on AWS](https://landsatonaws.com/)
### Credits
- NDVI PyWren - [Peter Scarth](mailto:[email protected]?subject=AWS%20Lambda%20and%20PyWren) (Joint Remote Sensing Research Program)
- [RemotePixel](https://github.com/RemotePixel/remotepixel-api) - Landsat 8 NDVI GeoTIFF parsing function
- [PyWren](https://github.com/pywren/pywren) - Project by BCCI and riselab. Makes it easy to executive massive parallel map queries across [AWS Lambda](https://aws.amazon.com/lambda/)
#### Additional notes
The below remotely executed function will deliver results usually in under a minute for the full timeseries of more than 100 images, and we can simply plot the resulting timeseries or do further analysis. BUT, the points may well be cloud or cloud shadow contaminated. We haven’t done any cloud masking to the imagery, but we do have the scene metadata on the probable amount of cloud across the entire scene. We use this to weight a [smoothing spline](https://docs.scipy.org/doc/scipy-0.19.1/reference/generated/scipy.interpolate.UnivariateSpline.html), such that an observation with no reported cloud over the scene has full weight, and an observation with a reported 100% of the scene with cloud has zero weight.
# Step by Step instructions
### Setup Logging (optional)
Only activate the below lines if you want to see all debug messages from PyWren. _Note: The output will be rather chatty and lengthy._
```
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
%env PYWREN_LOGLEVEL=INFO
```
### Setup all the necessary libraries
This will setup all the necessary libraries to properly display our results and it also imports the library that allows us to query Landsat 8 data from the [AWS Public Dataset](https://aws.amazon.com/public-datasets/landsat/):
```
import requests, json, numpy, datetime, os, boto3
from IPython.display import HTML, display, Image
import matplotlib.pyplot as plt
import l8_ndvi
from scipy.interpolate import UnivariateSpline
import pywren
# Function to return a Landsat 8 scene list given a Longitude,Latitude string
# This uses the amazing developmentseed Satellite API
# https://github.com/sat-utils/sat-api
def getSceneList(lonLat):
scenes=[]
url = "https://api.developmentseed.org/satellites/landsat"
params = dict(
contains=lonLat,
satellite_name="landsat-8",
limit="1000")
# Call the API to grab the scene metadata
sceneMetaData = json.loads(requests.get(url=url, params=params).content)
# Parse the metadata
for record in sceneMetaData["results"]:
scene = str(record['aws_index'].split('/')[-2])
# This is a bit of a hack to get around some versioning problem on the API :(
# Related to this issue https://github.com/sat-utils/sat-api/issues/18
if scene[-2:] == '01':
scene = scene[:-2] + '00'
if scene[-2:] == '02':
scene = scene[:-2] + '00'
if scene[-2:] == '03':
scene = scene[:-2] + '02'
scenes.append(scene)
return scenes
# Function to call a AWS Lambda function to drill a single pixel and compute the NDVI
def getNDVI(scene):
return l8_ndvi.point(scene, eval(lonLat))
```
### Run the code locally over a point of interest
Let's have a look at Hong Kong, an urban area with some country parks surrounding the city: [114.1095,22.3964](https://goo.gl/maps/PhDLAdLbiQT2)
First we need to retrieve the available Landsat 8 scenes from the point of interest:
```
lonLat = '114.1095,22.3964'
scenesHK = getSceneList('114.1095,22.3964')
#print(scenesHK)
display(HTML('Total scenes: <b>' + str(len(scenesHK)) + '</b>'))
```
Now let's find out the NDVI and the amount of clouds on a specific scene locally on our machine:
```
lonLat = '114.1095,22.3964'
thumbnail = l8_ndvi.thumb('LC08_L1TP_121045_20170829_20170914_01_T1', eval(lonLat))
display(Image(url=thumbnail, format='jpg'))
result = getNDVI('LC08_L1TP_121045_20170829_20170914_01_T1')
#display(result)
display(HTML('<b>Date:</b> '+result['date']))
display(HTML('<b>Amount of clouds:</b> '+str(result['cloud'])+'%'))
display(HTML('<b>NDVI:</b> '+str(result['ndvi'])))
```
Great, time to try this with an observation on a cloudier day. Please note that the NDVI drops too, as we are not able to actually receive much data fom the land surface:
```
lonLat = '114.1095,22.3964'
thumbnail = l8_ndvi.thumb('LC08_L1GT_122044_20171108_20171108_01_RT', eval(lonLat))
display(Image(url=thumbnail, format='jpg'))
result = getNDVI('LC08_L1GT_122044_20171108_20171108_01_RT')
#display(result)
display(HTML('<b>Date:</b> '+result['date']))
display(HTML('<b>Amount of clouds:</b> '+str(result['cloud'])+'%'))
display(HTML('<b>NDVI:</b> '+str(result['ndvi'])))
```
### Massively Parallel calculation with PyWren
Now let's try this with multiple scenes and send it to PyWren, however to accomplish this we need to change our PyWren AWS Lambda function to include the necessary libraries such as rasterio and GDAL. Since those libraries are compiled C code, PyWren will not be able to pickle it up and send it to the Lambda function. Hence we will update the entire PyWren function to include the necessary binaries that have been compiled on an Amazon EC2 instance with Amazon Linux. We pre-packaged this and made it available via https://s3-us-west-2.amazonaws.com/pywren-workshop/lambda_function.zip
You can simple push this code to your PyWren AWS Lambda function with below command, assuming you named the function with the default name pywren_1 and region us-west-2:
```
lambdaclient = boto3.client('lambda', 'us-west-2')
response = lambdaclient.update_function_code(
FunctionName='pywren_1',
Publish=True,
S3Bucket='pywren-workshop',
S3Key='lambda_function.zip'
)
response = lambdaclient.update_function_configuration(
FunctionName='pywren_1',
Environment={
'Variables': {
'GDAL_DATA': '/var/task/lib/gdal'
}
}
)
```
If you look at the list of available scenes, we have a rather large amount. This is a good use-case for PyWren as it will allows us to have AWS Lambda perform the calculation of NDVI and clouds for us - furthermore it will have a faster connectivity to read and write from Amazon S3. If you want to know more details about the calculation, have a look at [l8_ndvi.py](/edit/Lab-4-Landsat-NDVI/l8_ndvi.py).
Ok let's try this on the latest 200 collected Landsat 8 images GeoTIFFs of Hong Kong:
```
lonLat = '114.1095,22.3964'
pwex = pywren.default_executor()
resultsHK = pywren.get_all_results(pwex.map(getNDVI, scenesHK[:200]))
display(resultsHK)
```
### Display results
Let's try to render our results in a nice HTML table first:
```
#Remove results where we couldn't retrieve data from the scene
results = filter(None, resultsHK)
#Render a nice HTML table to display result
html = '<table><tr><td><b>Date</b></td><td><b>Clouds</b></td><td><b>NDVI</b></td></tr>'
for x in results:
html = html + '<tr>'
html = html + '<td>' + x['date'] + '</td>'
html = html + '<td>' + str(x['cloud']) + '%</td>'
html = html + '<td '
if (x['ndvi'] > 0.5):
html = html + ' bgcolor="#00FF00">'
elif (x['ndvi'] > 0.1):
html = html + ' bgcolor="#FFFF00">'
else:
html = html + ' bgcolor="#FF0000">'
html = html + str(round(abs(x['ndvi']),2)) + '</td>'
html = html + '</tr>'
html = html + '</table>'
display(HTML(html))
```
This provides us a good overview but would quickly become difficult to read as the datapoints expand - let's use [Matplotlib](https://matplotlib.org/) instead to plot this out:
```
timeSeries = filter(None,resultsHK)
# Extract the data trom the list of results
timeStamps = [datetime.datetime.strptime(obs['date'],'%Y-%m-%d') for obs in timeSeries if 'date' in obs]
ndviSeries = [obs['ndvi'] for obs in timeSeries if 'ndvi' in obs]
cloudSeries = [obs['cloud']/100 for obs in timeSeries if 'cloud' in obs]
# Create a time variable as the x axis to fit the observations
# First we convert to seconds
timeSecs = numpy.array([(obsTime-datetime.datetime(1970,1,1)).total_seconds() for obsTime in timeStamps])
# And then normalise from 0 to 1 to avoid any numerical issues in the fitting
fitTime = ((timeSecs-numpy.min(timeSecs))/(numpy.max(timeSecs)-numpy.min(timeSecs)))
# Smooth the data by fitting a spline weighted by cloud amount
smoothedNDVI=UnivariateSpline(
fitTime[numpy.argsort(fitTime)],
numpy.array(ndviSeries)[numpy.argsort(fitTime)],
w=(1.0-numpy.array(cloudSeries)[numpy.argsort(fitTime)])**2.0,
k=2,
s=0.1)(fitTime)
fig = plt.figure(figsize=(16,10))
plt.plot(timeStamps,ndviSeries, 'gx',label='Raw NDVI Data')
plt.plot(timeStamps,ndviSeries, 'y:', linewidth=1)
plt.plot(timeStamps,cloudSeries, 'b.', linewidth=1,label='Scene Cloud Percent')
plt.plot(timeStamps,cloudSeries, 'b:', linewidth=1)
#plt.plot(timeStamps,smoothedNDVI, 'r--', linewidth=3,label='Cloudfree Weighted Spline')
plt.xlabel('Date', fontsize=16)
plt.ylabel('NDVI', fontsize=16)
plt.title('AWS Lambda Landsat 8 NDVI Drill (Hong Kong)', fontsize=20)
plt.grid(True)
plt.ylim([-.1,1.0])
plt.legend(fontsize=14)
plt.show()
```
### Run the code over another location
This test site is a cotton farming area in Queensland, Australia [147.870599,-28.744617](https://goo.gl/maps/GF5szf7vZo82)
Let's first acquire some scenes:
```
lonLat = '147.870599,-28.744617'
scenesQLD = getSceneList(lonLat)
#print(scenesQLD)
display(HTML('Total scenes: <b>' + str(len(scenesQLD)) + '</b>'))
```
Let's first have a look at an individual observation first on our local machine:
```
thumbnail = l8_ndvi.thumb('LC80920802017118LGN00', eval(lonLat))
display(Image(url=thumbnail, format='jpg'))
result = getNDVI('LC80920802017118LGN00')
#display(result)
display(HTML('<b>Date:</b> '+result['date']))
display(HTML('<b>Amount of clouds:</b> '+str(result['cloud'])+'%'))
display(HTML('<b>NDVI:</b> '+str(result['ndvi'])))
```
### Pywren Time
Let's process this across all of the observations in parallel using AWS Lambda:
```
pwex = pywren.default_executor()
resultsQLD = pywren.get_all_results(pwex.map(getNDVI, scenesQLD))
display(resultsQLD)
```
Now let's plot this out again:
```
timeSeries = filter(None,resultsQLD)
# Extract the data trom the list of results
timeStamps = [datetime.datetime.strptime(obs['date'],'%Y-%m-%d') for obs in timeSeries if 'date' in obs]
ndviSeries = [obs['ndvi'] for obs in timeSeries if 'ndvi' in obs]
cloudSeries = [obs['cloud']/100 for obs in timeSeries if 'cloud' in obs]
# Create a time variable as the x axis to fit the observations
# First we convert to seconds
timeSecs = numpy.array([(obsTime-datetime.datetime(1970,1,1)).total_seconds() for obsTime in timeStamps])
# And then normalise from 0 to 1 to avoid any numerical issues in the fitting
fitTime = ((timeSecs-numpy.min(timeSecs))/(numpy.max(timeSecs)-numpy.min(timeSecs)))
# Smooth the data by fitting a spline weighted by cloud amount
smoothedNDVI=UnivariateSpline(
fitTime[numpy.argsort(fitTime)],
numpy.array(ndviSeries)[numpy.argsort(fitTime)],
w=(1.0-numpy.array(cloudSeries)[numpy.argsort(fitTime)])**2.0,
k=2,
s=0.1)(fitTime)
fig = plt.figure(figsize=(16,10))
plt.plot(timeStamps,ndviSeries, 'gx',label='Raw NDVI Data')
plt.plot(timeStamps,ndviSeries, 'g:', linewidth=1)
plt.plot(timeStamps,cloudSeries, 'b.', linewidth=1,label='Scene Cloud Percent')
plt.plot(timeStamps,smoothedNDVI, 'r--', linewidth=3,label='Cloudfree Weighted Spline')
plt.xlabel('Date', fontsize=16)
plt.ylabel('NDVI', fontsize=16)
plt.title('AWS Lambda Landsat 8 NDVI Drill (Cotton Farm QLD, Australia)', fontsize=20)
plt.grid(True)
plt.ylim([-.1,1.0])
plt.legend(fontsize=14)
plt.show()
```
|
github_jupyter
|
```
import xgboost as xgb
import pandas as pd
# 読み出し
data = pd.read_pickle('data.pkl')
nomination_onehot = pd.read_pickle('nomination_onehot.pkl')
selected_performers_onehot = pd.read_pickle('selected_performers_onehot.pkl')
selected_directors_onehot = pd.read_pickle('selected_directors_onehot.pkl')
selected_studio_onehot = pd.read_pickle('selected_studio_onehot.pkl')
selected_scriptwriter_onehot = pd.read_pickle('selected_scriptwriter_onehot.pkl')
review_dataframe = pd.read_pickle('review_dataframe.pkl')
tfidf = pd.read_pickle('tfidf.pkl')
table = pd.concat([
data[['prize', 'title', 'year', 'screen_time']],
nomination_onehot,
selected_performers_onehot,
selected_directors_onehot,
selected_studio_onehot,
selected_scriptwriter_onehot
], axis = 1)
for year in range(1978, 2019 + 1):
rg = xgb.XGBRegressor(silent= True)
X = table.query('year != {}'.format(year)).drop(['prize', 'title', 'year'], axis = 1).values
y = table.query('year != {}'.format(year))['prize'].values
rg.fit(X,y)
result = rg.predict(table.query('year == {}'.format(year)).drop(['prize', 'title', 'year'], axis = 1).values)
prize = table.query('year == {}'.format(year))
title = table.query('year == {}'.format(year))['title'].copy()
title[prize['prize'] == 1] = title[prize['prize'] == 1].map(lambda s: '★' + s)
print(year)
print(pd.Series(result, index = title.values).sort_values(ascending=False) )
print('')
frames = [
data.query('year == 2004')[['title', 'production_studio', 'other_nominates']],
review_dataframe
]
def asdf(s):
s['len'] = len(s['reviews'])
return s
pd.concat(
frames,
axis = 1,
join = 'inner'
).apply(asdf, axis = 1).drop(['reviews'], axis = 1)
from sklearn.decomposition import PCA
pca = PCA(n_components=20)
pca.fit(tfidf.values)
tfidf_df = pd.DataFrame(pca.transform(tfidf.values), index = tfidf.index)
table = pd.concat([
data[['prize', 'title', 'year']],
tfidf
], axis = 1)
for year in range(1978, 2019 + 1):
rg = xgb.XGBRegressor(silent= True)
X = table.query('year != {}'.format(year)).drop(['prize', 'title', 'year'], axis = 1).values
y = table.query('year != {}'.format(year))['prize'].values
rg.fit(X,y)
result = rg.predict(table.query('year == {}'.format(year)).drop(['prize', 'title', 'year'], axis = 1).values)
prize = table.query('year == {}'.format(year))
title = table.query('year == {}'.format(year))['title'].copy()
title[prize['prize'] == 1] = title[prize['prize'] == 1].map(lambda s: '★' + s)
print(year)
print(pd.Series(result, index = title.values).sort_values(ascending=False) )
print('')
```
|
github_jupyter
|
```
%tensorflow_version 2.x
import tensorflow as tf
#from tf.keras.models import Sequential
#from tf.keras.layers import Dense
import os
import io
tf.__version__
```
# Download Data
```
# Download the zip file
path_to_zip = tf.keras.utils.get_file("smsspamcollection.zip",
origin="https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip",
extract=True)
# Unzip the file into a folder
!unzip $path_to_zip -d data
# optional step - helps if colab gets disconnected
# from google.colab import drive
# drive.mount('/content/drive')
# Test data reading
# lines = io.open('/content/drive/My Drive/colab-data/SMSSpamCollection').read().strip().split('\n')
lines = io.open('/content/data/SMSSpamCollection').read().strip().split('\n')
lines[0]
```
# Pre-Process Data
```
spam_dataset = []
count = 0
for line in lines:
label, text = line.split('\t')
if label.lower().strip() == 'spam':
spam_dataset.append((1, text.strip()))
count += 1
else:
spam_dataset.append(((0, text.strip())))
print(spam_dataset[0])
print("Spam: ", count)
```
# Data Normalization
```
import pandas as pd
df = pd.DataFrame(spam_dataset, columns=['Spam', 'Message'])
import re
# Normalization functions
def message_length(x):
# returns total number of characters
return len(x)
def num_capitals(x):
_, count = re.subn(r'[A-Z]', '', x) # only works in english
return count
def num_punctuation(x):
_, count = re.subn(r'\W', '', x)
return count
df['Capitals'] = df['Message'].apply(num_capitals)
df['Punctuation'] = df['Message'].apply(num_punctuation)
df['Length'] = df['Message'].apply(message_length)
df.describe()
train=df.sample(frac=0.8,random_state=42) #random state is a seed value
test=df.drop(train.index)
train.describe()
test.describe()
```
# Model Building
```
# Basic 1-layer neural network model for evaluation
def make_model(input_dims=3, num_units=12):
model = tf.keras.Sequential()
# Adds a densely-connected layer with 12 units to the model:
model.add(tf.keras.layers.Dense(num_units,
input_dim=input_dims,
activation='relu'))
# Add a sigmoid layer with a binary output unit:
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
return model
x_train = train[['Length', 'Punctuation', 'Capitals']]
y_train = train[['Spam']]
x_test = test[['Length', 'Punctuation', 'Capitals']]
y_test = test[['Spam']]
x_train
model = make_model()
model.fit(x_train, y_train, epochs=10, batch_size=10)
model.evaluate(x_test, y_test)
y_train_pred = model.predict_classes(x_train)
# confusion matrix
tf.math.confusion_matrix(tf.constant(y_train.Spam),
y_train_pred)
sum(y_train_pred)
y_test_pred = model.predict_classes(x_test)
tf.math.confusion_matrix(tf.constant(y_test.Spam), y_test_pred)
```
# Tokenization and Stop Word Removal
```
sentence = 'Go until jurong point, crazy.. Available only in bugis n great world'
sentence.split()
!pip install stanza # StanfordNLP has become https://github.com/stanfordnlp/stanza/
import stanza
en = stanza.download('en')
en = stanza.Pipeline(lang='en')
sentence
tokenized = en(sentence)
len(tokenized.sentences)
for snt in tokenized.sentences:
for word in snt.tokens:
print(word.text)
print("<End of Sentence>")
```
## Dependency Parsing Example
```
en2 = stanza.Pipeline(lang='en')
pr2 = en2("Hari went to school")
for snt in pr2.sentences:
for word in snt.tokens:
print(word)
print("<End of Sentence>")
```
## Japanese Tokenization Example
```
jp = stanza.download('ja')
jp = stanza.Pipeline(lang='ja')
jp_line = jp("選挙管理委員会")
for snt in jp_line.sentences:
for word in snt.tokens:
print(word.text)
```
# Adding Word Count Feature
```
def word_counts(x, pipeline=en):
doc = pipeline(x)
count = sum( [ len(sentence.tokens) for sentence in doc.sentences] )
return count
#en = snlp.Pipeline(lang='en', processors='tokenize')
df['Words'] = df['Message'].apply(word_counts)
df.describe()
#train=df.sample(frac=0.8,random_state=42) #random state is a seed value
#test=df.drop(train.index)
train['Words'] = train['Message'].apply(word_counts)
test['Words'] = test['Message'].apply(word_counts)
x_train = train[['Length', 'Punctuation', 'Capitals', 'Words']]
y_train = train[['Spam']]
x_test = test[['Length', 'Punctuation', 'Capitals' , 'Words']]
y_test = test[['Spam']]
model = make_model(input_dims=4)
model.fit(x_train, y_train, epochs=10, batch_size=10)
model.evaluate(x_test, y_test)
```
## Stop Word Removal
```
!pip install stopwordsiso
import stopwordsiso as stopwords
stopwords.langs()
sorted(stopwords.stopwords('en'))
en_sw = stopwords.stopwords('en')
def word_counts(x, pipeline=en):
doc = pipeline(x)
count = 0
for sentence in doc.sentences:
for token in sentence.tokens:
if token.text.lower() not in en_sw:
count += 1
return count
train['Words'] = train['Message'].apply(word_counts)
test['Words'] = test['Message'].apply(word_counts)
x_train = train[['Length', 'Punctuation', 'Capitals', 'Words']]
y_train = train[['Spam']]
x_test = test[['Length', 'Punctuation', 'Capitals' , 'Words']]
y_test = test[['Spam']]
model = make_model(input_dims=4)
#model = make_model(input_dims=3)
model.fit(x_train, y_train, epochs=10, batch_size=10)
```
## POS Based Features
```
en = stanza.Pipeline(lang='en')
txt = "Yo you around? A friend of mine's lookin."
pos = en(txt)
def print_pos(doc):
text = ""
for sentence in doc.sentences:
for token in sentence.tokens:
text += token.words[0].text + "/" + \
token.words[0].upos + " "
text += "\n"
return text
print(print_pos(pos))
en_sw = stopwords.stopwords('en')
def word_counts_v3(x, pipeline=en):
doc = pipeline(x)
count = 0
for sentence in doc.sentences:
for token in sentence.tokens:
if token.text.lower() not in en_sw and \
token.words[0].upos not in ['PUNCT', 'SYM']:
count += 1
return count
print(word_counts(txt), word_counts_v3(txt))
train['Test'] = 0
train.describe()
def word_counts_v3(x, pipeline=en):
doc = pipeline(x)
totals = 0.
count = 0.
non_word = 0.
for sentence in doc.sentences:
totals += len(sentence.tokens) # (1)
for token in sentence.tokens:
if token.text.lower() not in en_sw:
if token.words[0].upos not in ['PUNCT', 'SYM']:
count += 1.
else:
non_word += 1.
non_word = non_word / totals
return pd.Series([count, non_word], index=['Words_NoPunct', 'Punct'])
x = train[:10]
x.describe()
train_tmp = train['Message'].apply(word_counts_v3)
train = pd.concat([train, train_tmp], axis=1)
train.describe()
test_tmp = test['Message'].apply(word_counts_v3)
test = pd.concat([test, test_tmp], axis=1)
test.describe()
z = pd.concat([x, train_tmp], axis=1)
z.describe()
z.loc[z['Spam']==0].describe()
z.loc[z['Spam']==1].describe()
aa = [word_counts_v3(y) for y in x['Message']]
ab = pd.DataFrame(aa)
ab.describe()
```
# Lemmatization
```
text = "Stemming is aimed at reducing vocabulary and aid un-derstanding of" +\
" morphological processes. This helps people un-derstand the" +\
" morphology of words and reduce size of corpus."
lemma = en(text)
lemmas = ""
for sentence in lemma.sentences:
for token in sentence.tokens:
lemmas += token.words[0].lemma +"/" + \
token.words[0].upos + " "
lemmas += "\n"
print(lemmas)
```
# TF-IDF Based Model
```
# if not installed already
!pip install sklearn
corpus = [
"I like fruits. Fruits like bananas",
"I love bananas but eat an apple",
"An apple a day keeps the doctor away"
]
```
## Count Vectorization
```
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
vectorizer.get_feature_names()
X.toarray()
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(X.toarray())
query = vectorizer.transform(["apple and bananas"])
cosine_similarity(X, query)
```
## TF-IDF Vectorization
```
import pandas as pd
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False)
tfidf = transformer.fit_transform(X.toarray())
pd.DataFrame(tfidf.toarray(),
columns=vectorizer.get_feature_names())
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import LabelEncoder
tfidf = TfidfVectorizer(binary=True)
X = tfidf.fit_transform(train['Message']).astype('float32')
X_test = tfidf.transform(test['Message']).astype('float32')
X.shape
from keras.utils import np_utils
_, cols = X.shape
model2 = make_model(cols) # to match tf-idf dimensions
lb = LabelEncoder()
y = lb.fit_transform(y_train)
dummy_y_train = np_utils.to_categorical(y)
model2.fit(X.toarray(), y_train, epochs=10, batch_size=10)
model2.evaluate(X_test.toarray(), y_test)
train.loc[train.Spam == 1].describe()
```
# Word Vectors
```
# memory limit may be exceeded. Try deleting some objects before running this next section
# or copy this section to a different notebook.
!pip install gensim
from gensim.models.word2vec import Word2Vec
import gensim.downloader as api
api.info()
model_w2v = api.load("word2vec-google-news-300")
model_w2v.most_similar("cookies",topn=10)
model_w2v.doesnt_match(["USA","Canada","India","Tokyo"])
king = model_w2v['king']
man = model_w2v['man']
woman = model_w2v['woman']
queen = king - man + woman
model_w2v.similar_by_vector(queen)
```
|
github_jupyter
|
# 3D Partially coherent ODT forward simulation
This forward simulation is based on the SEAGLE paper ([here](https://ieeexplore.ieee.org/abstract/document/8074742)): <br>
```H.-Y. Liu, D. Liu, H. Mansour, P. T. Boufounos, L. Waller, and U. S. Kamilov, "SEAGLE: Sparsity-Driven Image Reconstruction Under Multiple Scattering," IEEE Trans. Computational Imaging vol.4, pp.73-86 (2018).```<br>
and the 3D PODT paper ([here](https://www.osapublishing.org/oe/fulltext.cfm?uri=oe-25-14-15699&id=368361)): <br>
```J. M. Soto, J. A. Rodrigo, and T. Alieva, "Label-free quantitative 3D tomographic imaging for partially coherent light microscopy," Opt. Express 25, 15699-15712 (2017).```<br>
```
import numpy as np
import matplotlib.pyplot as plt
from numpy.fft import fft, ifft, fft2, ifft2, fftshift, ifftshift, fftn, ifftn
import pickle
import waveorder as wo
%load_ext autoreload
%autoreload 2
%matplotlib inline
plt.style.use(['dark_background']) # Plotting option for dark background
```
### Experiment parameters
```
N = 256 # number of pixel in y dimension
M = 256 # number of pixel in x dimension
L = 100 # number of layers in z dimension
n_media = 1.46 # refractive index in the media
mag = 63 # magnification
ps = 6.5/mag # effective pixel size
psz = 0.25 # axial pixel size
lambda_illu = 0.532 # wavelength
NA_obj = 1.2 # objective NA
NA_illu = 0.9 # illumination NA
```
### Sample creation
```
radius = 5
blur_size = 2*ps
sphere, _, _ = wo.gen_sphere_target((N,M,L), ps, psz, radius, blur_size)
wo.image_stack_viewer(np.transpose(sphere,(2,0,1)))
# Physical value assignment
n_sample = 1.50
RI_map = np.zeros_like(sphere)
RI_map[sphere > 0] = sphere[sphere > 0]*(n_sample-n_media)
RI_map += n_media
t_obj = np.exp(1j*2*np.pi*psz*(RI_map-n_media))
wo.image_stack_viewer(np.transpose(np.angle(t_obj),(2,0,1)))
```
### Setup acquisition
```
# Subsampled Source pattern
xx, yy, fxx, fyy = wo.gen_coordinate((N, M), ps)
Source_cont = wo.gen_Pupil(fxx, fyy, NA_illu, lambda_illu)
Source_discrete = wo.Source_subsample(Source_cont, lambda_illu*fxx, lambda_illu*fyy, subsampled_NA = 0.1)
plt.figure(figsize=(10,10))
plt.imshow(fftshift(Source_discrete),cmap='gray')
np.sum(Source_discrete)
z_defocus = (np.r_[:L]-L//2)*psz
chi = 0.1*2*np.pi
setup = wo.waveorder_microscopy((N,M), lambda_illu, ps, NA_obj, NA_illu, z_defocus, chi, \
n_media = n_media, phase_deconv='3D', illu_mode='Arbitrary', Source=Source_cont)
simulator = wo.waveorder_microscopy_simulator((N,M), lambda_illu, ps, NA_obj, NA_illu, z_defocus, chi, \
n_media = n_media, illu_mode='Arbitrary', Source=Source_discrete)
plt.figure(figsize=(5,5))
plt.imshow(fftshift(setup.Source), cmap='gray')
plt.colorbar()
H_re_vis = fftshift(setup.H_re)
wo.plot_multicolumn([np.real(H_re_vis)[:,:,L//2], np.transpose(np.real(H_re_vis)[N//2,:,:]), \
np.imag(H_re_vis)[:,:,L//2], np.transpose(np.imag(H_re_vis)[N//2,:,:])], \
num_col=2, size=8, set_title=True, \
titles=['$xy$-slice of Re{$H_{re}$} at $u_z=0$', '$xz$-slice of Re{$H_{re}$} at $u_y=0$', \
'$xy$-slice of Im{$H_{re}$} at $u_z=0$', '$xz$-slice of Im{$H_{re}$} at $u_y=0$'], colormap='jet')
H_im_vis = fftshift(setup.H_im)
wo.plot_multicolumn([np.real(H_im_vis)[:,:,L//2], np.transpose(np.real(H_im_vis)[N//2,:,:]), \
np.imag(H_im_vis)[:,:,L//2], np.transpose(np.imag(H_im_vis)[N//2,:,:])], \
num_col=2, size=8, set_title=True, \
titles=['$xy$-slice of Re{$H_{im}$} at $u_z=0$', '$xz$-slice of Re{$H_{im}$} at $u_y=0$', \
'$xy$-slice of Im{$H_{im}$} at $u_z=0$', '$xz$-slice of Im{$H_{im}$} at $u_y=0$'], colormap='jet')
I_meas = simulator.simulate_3D_scalar_measurements(t_obj)
wo.image_stack_viewer(np.transpose(np.abs(I_meas),(0,1,2)))
# Save simulations
output_file = '3D_PODT_simulation'
np.savez(output_file, I_meas=I_meas, lambda_illu=lambda_illu, \
n_media=n_media, NA_obj=NA_obj, NA_illu=NA_illu, ps=ps, psz=psz, Source_cont=Source_cont)
```
|
github_jupyter
|
```
#default_exp fastai.dataloader
```
# DataLoader Errors
> Errors and exceptions for any step of the `DataLoader` process
This includes `after_item`, `after_batch`, and collating. Anything in relation to the `Datasets` or anything before the `DataLoader` process can be found in `fastdebug.fastai.dataset`
```
#export
import inflect
from fastcore.basics import patch
from fastai.data.core import TfmdDL
from fastai.data.load import DataLoader, fa_collate, fa_convert
#export
def collate_error(e:Exception, batch):
"""
Raises an explicit error when the batch could not collate, stating
what items in the batch are different sizes and their types
"""
p = inflect.engine()
err = f'Error when trying to collate the data into batches with fa_collate, '
err += 'at least two tensors in the batch are not the same size.\n\n'
# we need to iterate through the entire batch and find a mismatch
length = len(batch[0])
for idx in range(length): # for each type in the batch
for i, item in enumerate(batch):
if i == 0:
shape_a = item[idx].shape
type_a = item[idx].__class__.__name__
elif item[idx].shape != shape_a:
shape_b = item[idx].shape
if shape_a != shape_b:
err += f'Mismatch found within the {p.ordinal(idx)} axis of the batch and is of type {type_a}:\n'
err += f'The first item has shape: {shape_a}\n'
err += f'The {p.number_to_words(p.ordinal(i+1))} item has shape: {shape_b}\n\n'
err += f'Please include a transform in `after_item` that ensures all data of type {type_a} is the same size'
e.args = [err]
raise e
#export
@patch
def create_batch(self:DataLoader, b):
"Collate a list of items into a batch."
func = (fa_collate,fa_convert)[self.prebatched]
try:
return func(b)
except Exception as e:
if not self.prebatched:
collate_error(e, b)
else: raise e
```
`collate_error` is `@patch`'d into `DataLoader`'s `create_batch` function through importing this module, so if there is any possible reason why the data cannot be collated into the batch, it is presented to the user.
An example is below, where we forgot to include an item transform that resizes all our images to the same size:
```
#failing
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2,
label_func=lambda x: x[0].isupper())
x,y = dls.train.one_batch()
#export
@patch
def new(self:TfmdDL, dataset=None, cls=None, **kwargs):
res = super(TfmdDL, self).new(dataset, cls, do_setup=False, **kwargs)
if not hasattr(self, '_n_inp') or not hasattr(self, '_types'):
try:
self._one_pass()
res._n_inp,res._types = self._n_inp,self._types
except Exception as e:
print("Could not do one pass in your dataloader, there is something wrong in it")
raise e
else: res._n_inp,res._types = self._n_inp,self._types
return res
```
|
github_jupyter
|
```
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(5)
y = x
t = x
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.scatter(x, y, c=t, cmap='viridis')
ax2.scatter(x, y, c=t, cmap='viridis_r')
color = "red"
plt.scatter(x, y, c=color)
sequence_of_colors = ["red", "orange", "yellow", "green", "blue","red", "orange", "yellow", "green", "blue"]
plt.scatter(x, y, c=sequence_of_colors)
sample_size = 1000
color_num = 3
X = np.random.normal(0, 1, sample_size)
Y = np.random.normal(0, 1, sample_size)
C = np.random.randint(0, color_num, sample_size)
print("X.shape : {}, \n{}".format(X.shape, X))
print("Y.shape : {}, \n{}".format(Y.shape, Y))
print("C.shape : {}, \n{}".format(C.shape, C))
plt.figure(figsize=(12, 4))
plt.scatter(X, Y, c=C, s=20, cmap=plt.cm.get_cmap('rainbow', color_num), alpha=0.5)
plt.colorbar(ticks=range(color_num), format='color: %d', label='color')
plt.show()
plt.cm.get_cmap('rainbow', color_num)
for a in np.linspace(0, 1.0, 5):
print(plt.cm.rainbow(a))
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import itertools
sample_size = 100
x = np.vstack([
np.random.normal(0, 1, sample_size).reshape(sample_size//2, 2),
np.random.normal(2, 1, sample_size).reshape(sample_size//2, 2),
np.random.normal(4, 1, sample_size).reshape(sample_size//2, 2)
])#50,2
y = np.array(list(itertools.chain.from_iterable([ [i+1 for j in range(0, sample_size//2)] for i in range(0, 3)])))
y = y.reshape(-1, 1)
df = pd.DataFrame(np.hstack([x, y]), columns=['x1', 'x2', 'y'])
print("x : {}, y : {}, df : {}".format(x.shape, y.shape, df.shape))
print(df)
c_lst = [plt.cm.rainbow(a) for a in np.linspace(0.0, 1.0, len(set(df['y'])))]
plt.figure(figsize=(12, 4))
for i, g in enumerate(df.groupby('y')):
plt.scatter(g[1]['x1'], g[1]['x2'], color=c_lst[i], label='group {}'.format(int(g[0])), alpha=0.5)
plt.legend()
plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import itertools
from matplotlib import colors
_cmap = ['#1A90F0', '#F93252', '#FEA250', '#276B29', '#362700',
'#2C2572', '#D25ABE', '#4AB836', '#A859EA', '#65C459',
'#C90B18', '#E02FD1', '#5FAFD4', '#DAF779', '#ECEE25',
'#56B390', '#F3BBBE', '#8FC0AE', '#0F16F5', '#8A9EFE',
'#A23965', '#03F70C', '#A8D520', '#952B77', '#2A493C',
'#E8DB82', '#7C01AC', '#1938A3', '#3C4249', '#BC3D92',
'#DEEDB1', '#3C673E', '#65F3D7', '#77110B', '#D16DD6',
'#08EF68', '#CFFD6F', '#DC6B26', '#912D5D', '#8CA6F8',
'#04EE96', '#54B0C1', '#6CBE38', '#24633B', '#DE41DD',
'#5EF270', '#896991', '#E6D381', '#7B0681', '#D66C07'
]
sample_size = 256
x = np.vstack([
np.random.normal(0, 1, sample_size).reshape(sample_size//2, 2),
np.random.normal(2, 1, sample_size).reshape(sample_size//2, 2),
np.random.normal(4, 1, sample_size).reshape(sample_size//2, 2),
np.random.normal(3, 1, sample_size).reshape(sample_size//2, 2)
])#50,2
print(x.shape)
y = np.array(list(itertools.chain.from_iterable([ [i+1 for j in range(0, int(sample_size/4))] for i in range(0, 8)])))
y = y.reshape(-1, 1)
df = pd.DataFrame(np.hstack([x, y]), columns=['x1', 'x2', 'y'])
c_lst = [plt.cm.rainbow(a) for a in np.linspace(0.0, 1.0, len(set(df['y'])))]
plt.figure(figsize=(12, 4))
print("groupby : ", df.groupby('y'))
for i, g in enumerate(df.groupby('y')):
print(i, "g[1]", g[1])
print(i, "g[0]", g[0])
plt.scatter(g[1]['x1'], g[1]['x2'], color=_cmap[i], label='group {}'.format(int(g[0])), alpha=0.5)
plt.legend()
plt.show()
import matplotlib.pyplot as plt
import numpy as np
from struct import unpack
from sklearn import cluster
import datetime
import seaborn as sns
from sklearn.preprocessing import PowerTransformer, normalize, MinMaxScaler, StandardScaler
from struct import pack
from matplotlib import colors
from sklearn.metrics import silhouette_score, silhouette_samples
import matplotlib.cm as cm
import matplotlib
_cmap = colors.ListedColormap(['#1A90F0', '#F93252', '#FEA250', '#276B29', '#362700',
'#2C2572', '#D25ABE', '#4AB836', '#A859EA', '#65C459',
'#C90B18', '#E02FD1', '#5FAFD4', '#DAF779', '#ECEE25',
'#56B390', '#F3BBBE', '#8FC0AE', '#0F16F5', '#8A9EFE',
'#A23965', '#03F70C', '#A8D520', '#952B77', '#2A493C',
'#E8DB82', '#7C01AC', '#1938A3', '#3C4249', '#BC3D92',
'#DEEDB1', '#3C673E', '#65F3D7', '#77110B', '#D16DD6',
'#08EF68', '#CFFD6F', '#DC6B26', '#912D5D', '#8CA6F8',
'#04EE96', '#54B0C1', '#6CBE38', '#24633B', '#DE41DD',
'#5EF270', '#896991', '#E6D381', '#7B0681', '#D66C07'
])
#matplotlib.colors.ListedColormap(colors, name='from_list', N=None)
test = matplotlib.colors.ListedColormap(_cmap.colors[:5])
print(test.colors)
print(_cmap.colors[:5])
```
|
github_jupyter
|
```
# ==============================================================================
# Copyright 2021 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
#
# Author: Chanchal Chatterjee
# Email: [email protected]
#
# To these first:
# 1. Create a VM with TF 2.1
# 2. Create the following buckets in your project:
# Root Bucket: BUCKET_NAME = 'tuti_asset' 'gs://$BUCKET_NAME'
# Model Results Directory: FOLDER_RESULTS = 'tf_models' 'gs://$BUCKET_NAME/$FOLDER_RESULTS'
# Data directory: FOLDER_DATA = 'datasets' 'gs://$BUCKET_NAME/$FOLDER_DATA'
# The data: INPUT_FILE_NAME = 'mortgage_structured.csv'
# 3. In your VM create directory called ./model_dir
# Uninstall old packages
#!pip3 uninstall -r requirements-uninstall.txt -y
# Install packages
# https://cloud.google.com/ai-platform/training/docs/runtime-version-list
#!pip3 install -r requirements-rt2.1.txt --user --ignore-installed
# If VM created with TF2.1 Enterprise (no GPUs), all you need to install is cloudml-hypertune
!pip3 install cloudml-hypertune --user --ignore-installed
# Import packages
import warnings
warnings.filterwarnings("ignore")
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#0 = all messages are logged (default behavior)
#1 = INFO messages are not printed
#2 = INFO and WARNING messages are not printed
#3 = INFO, WARNING, and ERROR messages are not printed
import numpy as np
from google.cloud import storage
import tensorflow as tf
#import matplotlib.pyplot as plt
#from tensorflow.keras import models
print("TF Version= ", tf.__version__)
print("Keras Version= ", tf.keras.__version__)
# Utility functions
#------
def find_best_model_dir(model_dir, offset=1, maxFlag=1):
# Get a list of model directories
all_models = ! gsutil ls $model_dir
print("")
print("All Models = ")
print(*all_models, sep='\n')
# Check if model dirs exist
if (("CommandException" in all_models[0]) or (len(all_models) <= 1)):
print("Create the models first.")
return ""
# Find the best model from checkpoints
import re
best_acc = -np.Inf
if (maxFlag != 1):
best_acc = np.Inf
best_model_dir = ""
tup_list = []
for i in range(1,len(all_models)):
all_floats = re.findall(r"[-+]?\d*\.\d+|\d+", all_models[i]) #Find the floats in the string
cur_acc = -float(all_floats[-offset]) #which item is the model optimization metric
tup_list.append([all_models[i],cur_acc])
if (maxFlag*(cur_acc > best_acc) or (1-maxFlag)*(cur_acc < best_acc)):
best_acc = cur_acc
best_model_dir = all_models[i]
if maxFlag:
tup_list.sort(key=lambda tup: tup[1], reverse=False)
else:
tup_list.sort(key=lambda tup: tup[1], reverse=True)
#for i in range(len(tup_list)):
# print(tup_list[i][0])
print("Best Accuracy from Checkpoints = ", best_acc)
print("Best Model Dir from Checkpoints = ", best_model_dir)
return best_model_dir
from oauth2client.client import GoogleCredentials
from googleapiclient import discovery
from googleapiclient import errors
import json
#------
# Python module to get the best hypertuned model parameters
def pyth_get_hypertuned_parameters(project_name, job_name, maxFlag):
# Define the credentials for the service account
#credentials = service_account.Credentials.from_service_account_file(<PATH TO CREDENTIALS JSON>)
credentials = GoogleCredentials.get_application_default()
# Define the project id and the job id and format it for the api request
project_id = 'projects/{}'.format(project_name)
job_id = '{}/jobs/{}'.format(project_id, job_name)
# Build the service
cloudml = discovery.build('ml', 'v1', cache_discovery=False, credentials=credentials)
# Execute the request and pass in the job id
request = cloudml.projects().jobs().get(name=job_id)
try:
response = request.execute()
# Handle a successful request
except errors.HttpError as err:
tf.compat.v1.logging.error('There was an error getting the hyperparameters. Check the details:')
tf.compat.v1.logging.error(err._get_reason())
# Get just the best hp values
if maxFlag:
best_model = response['trainingOutput']['trials'][0]
else:
best_model = response['trainingOutput']['trials'][-1]
#print('Best Hyperparameters:')
#print(json.dumps(best_model, indent=4))
nTrials = len(response['trainingOutput']['trials'])
for i in range(0,nTrials):
state = response['trainingOutput']['trials'][i]['state']
trialId = response['trainingOutput']['trials'][i]['trialId']
objV = -1
if (state == 'SUCCEEDED'):
objV = response['trainingOutput']['trials'][i]['finalMetric']['objectiveValue']
print('objective=', objV, ' trialId=', trialId, state)
d = response['trainingOutput']['trials'][i]['hyperparameters']
for key, value in d.items():
print(' ', key, value)
return best_model
```
# Setup
```
# Get the project id
proj_id = !gcloud config list project --format "value(core.project)"
proj_id[0]
USER = 'cchatterj'
PROJECT_ID = proj_id[0]
BUCKET_NAME = 'tuti_asset' #Use a unique name
FOLDER_RESULTS = 'tf_models'
FOLDER_DATA = 'datasets'
REGION = 'us-central1'
ZONE1 = 'us-central1-a'
RUNTIME_VERSION = 2.1
JOB_DIR = 'gs://' + BUCKET_NAME + '/' + FOLDER_RESULTS + '/jobdir'
MODEL_DIR = 'gs://' + BUCKET_NAME + '/' + FOLDER_RESULTS + '/models'
INPUT_FILE_NAME = 'mortgage_structured.csv'
!gcloud config set project $PROJECT_ID
!gcloud config set compute/zone $ZONE1
!gcloud config set compute/region $REGION
!gcloud config list
#!gcloud config config-helper --format "value(configuration.properties.core.project)"
# Clean old job logs, job packages and models
!gsutil -m -q rm $JOB_DIR/packages/**
!gsutil -m -q rm $MODEL_DIR/model**
```
# ML Model
```
# Create the tf_trainer directory and load the trainer files in it
!mkdir -p trainer
%%writefile ./trainer/inputs.py
# Create the train and label lists
import math
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
#------
def load_data(input_file):
# Read the data
print(input_file)
#try:
table_data = pd.read_csv(input_file)
#except:
# print("Oops! That is invalid filename. Try again...")
# return
print(table_data.shape)
# ---------------------------------------
# Pre-processing
# ---------------------------------------
# Drop useless columns
table_data.drop(['LOAN_SEQUENCE_NUMBER'], axis=1, inplace=True)
# Inputs to an XGBoost model must be numeric. One hot encoding was
# previously found to yield better results
# than label encoding for the particular
strcols = [col for col in table_data.columns if table_data[col].dtype == 'object']
table_data = pd.get_dummies(table_data, columns=strcols)
# Train Test Split and write out the train-test files
# Split with a small test size so as to allow our model to train on more data
X_train, X_test, y_train, y_test = \
train_test_split(table_data.drop('TARGET', axis=1),
table_data['TARGET'],
stratify=table_data['TARGET'],
shuffle=True, test_size=0.2
)
# Remove Null and NAN
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)
# Check the shape
print("X_train shape = ", X_train.shape)
print("X_test shape = ", X_test.shape)
y_train_cat = tf.keras.utils.to_categorical(y_train)
y_test_cat = tf.keras.utils.to_categorical(y_test)
print("y_train shape = ", y_train_cat.shape)
print("y_test shape = ", y_test_cat.shape)
# count number of classes
#values, counts = np.unique(y_train, return_counts=True)
#NUM_CLASSES = len(values)
#print("Number of classes ", NUM_CLASSES)
#train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
#train_dataset = train_dataset.shuffle(100).batch(batch_size)
#test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
#test_dataset = test_dataset.shuffle(100).batch(batch_size)
return [X_train, X_test, y_train_cat, y_test_cat]
%%writefile ./trainer/model.py
import tensorflow as tf
import numpy as np
def tf_model(input_dim, output_dim, model_depth: int = 1, dropout_rate: float = 0.02):
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
decr = int((input_dim-output_dim-16)/model_depth) ^ 1
model = Sequential()
model.add(Dense(128, input_dim=input_dim, activation=tf.nn.relu))
for i in range(1,model_depth):
model.add(Dense(input_dim-i*decr, activation=tf.nn.relu, kernel_regularizer='l2'))
model.add(Dropout(dropout_rate))
model.add(Dense(output_dim, activation=tf.nn.softmax))
print(model.summary())
return model
def custom_loss(y_true, y_pred):
custom_loss = mean(square(y_true - y_pred), axis=-1)
return custom_loss
def custom_metric(y_true, y_pred):
custom_metric = mean(square(y_true - y_pred), axis=-1)
return custom_metric
```
## Package for distributed training
```
%%writefile ./setup.py
# python3
# ==============================================================================
# Copyright 2020 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
# https://cloud.google.com/ai-platform/training/docs/runtime-version-list
from setuptools import find_packages
from setuptools import setup
#Runtime 2.1
REQUIRED_PACKAGES = ['tensorflow==2.1.0',
'pandas==0.25.3',
'scikit-learn==0.22',
'google-cloud-storage==1.23.0',
'gcsfs==0.6.1',
'cloudml-hypertune',
]
setup(
name='trainer',
version='0.1',
install_requires=REQUIRED_PACKAGES,
packages=find_packages(),
include_package_data=True,
description='Trainer package for Tensorflow Task'
)
```
## Training functions
```
%%writefile ./trainer/__init__.py
# python3
# ==============================================================================
# Copyright 2020 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
%%writefile ./trainer/train.py
# python3
# ==============================================================================
# Copyright 2020 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
import os
import json
import tensorflow as tf
import numpy as np
import datetime as datetime
from pytz import timezone
import hypertune
import argparse
from trainer import model
from trainer import inputs
import warnings
warnings.filterwarnings("ignore")
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
#0 = all messages are logged (default behavior)
#1 = INFO messages are not printed
#2 = INFO and WARNING messages are not printed
#3 = INFO, WARNING, and ERROR messages are not printed
def parse_arguments():
"""Argument parser.
Returns:
Dictionary of arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('--model_depth', default=3, type=int,
help='Hyperparameter: depth of model')
parser.add_argument('--dropout_rate', default=0.02, type=float,
help='Hyperparameter: Drop out rate')
parser.add_argument('--learning_rate', default=0.0001, type=float,
help='Hyperparameter: initial learning rate')
parser.add_argument('--batch_size', default=4, type=int,
help='batch size of the deep network')
parser.add_argument('--epochs', default=1, type=int,
help='number of epochs.')
parser.add_argument('--model_dir', default="",
help='Directory to store model checkpoints and logs.')
parser.add_argument('--input_file', default="",
help='Directory to store model checkpoints and logs.')
parser.add_argument('--verbosity', choices=['DEBUG','ERROR','FATAL','INFO','WARN'],
default='FATAL')
args, _ = parser.parse_known_args()
return args
def get_callbacks(args, early_stop_patience: int = 3):
"""Creates Keras callbacks for model training."""
# Get trialId
trialId = json.loads(os.environ.get("TF_CONFIG", "{}")).get("task", {}).get("trial", "")
if trialId == '':
trialId = '0'
print("trialId=", trialId)
curTime = datetime.datetime.now(timezone('US/Pacific')).strftime('%H%M%S')
# Modify model_dir paths to include trialId
model_dir = args.model_dir + "/checkpoints/cp-"+curTime+"-"+trialId+"-{val_accuracy:.4f}"
log_dir = args.model_dir + "/log_dir"
tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir, histogram_freq=1)
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(model_dir, monitor='val_accuracy', mode='max',
verbose=0, save_best_only=True,
save_weights_only=False)
earlystop_cb = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3)
return [checkpoint_cb, tensorboard_cb, earlystop_cb]
if __name__ == "__main__":
# ---------------------------------------
# Parse Arguments
# ---------------------------------------
args = parse_arguments()
#args.model_dir = MODEL_DIR + datetime.datetime.now(timezone('US/Pacific')).strftime('/model_%m%d%Y_%H%M')
#args.input_file = 'gs://' + BUCKET_NAME + '/' + FOLDER_DATA + '/' + INPUT_FILE_NAME
print(args)
# ---------------------------------------
# Input Data & Preprocessing
# ---------------------------------------
print("Input and pre-process data ...")
# Extract train_seismic, train_label
train_test_data = inputs.load_data(args.input_file)
X_train = train_test_data[0]
X_test = train_test_data[1]
y_train = train_test_data[2]
y_test = train_test_data[3]
# ---------------------------------------
# Train model
# ---------------------------------------
print("Creating model ...")
print("x_train")
print(X_train.shape[1])
print("y_train")
print(y_train.shape[1])
tf_model = model.tf_model(X_train.shape[1], y_train.shape[1],
model_depth=args.model_depth,
dropout_rate=args.dropout_rate)
tf_model.compile(optimizer=tf.keras.optimizers.Adam(lr=args.learning_rate),
loss='mean_squared_error',
metrics=['accuracy'])
print("Fitting model ...")
callbacks = get_callbacks(args, 3)
histy = tf_model.fit(np.array(X_train), y_train,
epochs=args.epochs,
batch_size=args.batch_size,
validation_data=[np.array(X_test),y_test],
callbacks=callbacks)
# TBD save history for visualization
final_epoch_accuracy = histy.history['accuracy'][-1]
final_epoch_count = len(histy.history['accuracy'])
print('final_epoch_accuracy = %.6f' % final_epoch_accuracy)
print('final_epoch_count = %2d' % final_epoch_count)
%%time
# Run the training manually
# Training parameters
from datetime import datetime
from pytz import timezone
MODEL_DEPTH = 2
DROPOUT_RATE = 0.01
LEARNING_RATE = 0.00005
EPOCHS = 1
BATCH_SIZE = 32
MODEL_DIR_PYTH = MODEL_DIR + datetime.now(timezone('US/Pacific')).strftime('/model_%m%d%Y_%H%M')
INPUT_FILE = 'gs://' + BUCKET_NAME + '/' + FOLDER_DATA + '/' + INPUT_FILE_NAME
print('MODEL_DEPTH = %2d' % MODEL_DEPTH)
print('DROPOUT_RATE = %.4f' % DROPOUT_RATE)
print('LEARNING_RATE = %.6f' % LEARNING_RATE)
print('EPOCHS = %2d' % EPOCHS)
print('BATCH_SIZE = %2d' % BATCH_SIZE)
print("MODEL_DIR =", MODEL_DIR_PYTH)
print("INPUT_FILE =", INPUT_FILE)
# Run training
! python3 -m trainer.train --model_depth=$MODEL_DEPTH --dropout_rate=$DROPOUT_RATE \
--learning_rate=$LEARNING_RATE \
--epochs=$EPOCHS \
--batch_size=$BATCH_SIZE \
--model_dir=$MODEL_DIR_PYTH \
--input_file=$INPUT_FILE
# Test with latest saved model
best_model_dir_pyth = find_best_model_dir(MODEL_DIR_PYTH+'/checkpoints', offset=1, maxFlag=1)
#acc = test_saved_model(best_model_dir_pyth, 0)
%%time
#***CREATE model_dir in local VM***
!mkdir -p model_dir
from trainer import model
# Copy the model from storage to local memory
!gsutil -m cp -r $best_model_dir_pyth* ./model_dir
# Load the model
loaded_model = tf.keras.models.load_model('./model_dir', compile=False)#,
#custom_objects={"custom_loss": model.custom_loss, "custom_mse": model.custom_mse})
print("Signature ", loaded_model.signatures)
print("")
# Display model
tf.keras.utils.plot_model(loaded_model, show_shapes=True)
```
------
# Training
```
# Create the config directory and load the trainer files in it
!mkdir -p config
%%writefile ./config/config.yaml
# python3
# ==============================================================================
# Copyright 2020 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
# https://cloud.google.com/sdk/gcloud/reference/ai-platform/jobs/submit/training#--scale-tier
# https://www.kaggle.com/c/passenger-screening-algorithm-challenge/discussion/37087
# https://cloud.google.com/ai-platform/training/docs/using-gpus
#trainingInput:
# scaleTier: CUSTOM
# masterType: n1-highmem-16
# masterConfig:
# acceleratorConfig:
# count: 2
# type: NVIDIA_TESLA_V100
#trainingInput:
# scaleTier: CUSTOM
# masterType: n1-highmem-8
# masterConfig:
# acceleratorConfig:
# count: 1
# type: NVIDIA_TESLA_T4
# masterType: n1-highcpu-16
# workerType: cloud_tpu
# workerCount: 1
# workerConfig:
# acceleratorConfig:
# type: TPU_V3
# count: 8
#trainingInput:
# scaleTier: CUSTOM
# masterType: complex_model_m
# workerType: complex_model_m
# parameterServerType: large_model
# workerCount: 6
# parameterServerCount: 1
# scheduling:
# maxWaitTime: 3600s
# maxRunningTime: 7200s
#trainingInput:
# runtimeVersion: "2.1"
# scaleTier: CUSTOM
# masterType: standard_gpu
# workerCount: 9
# workerType: standard_gpu
# parameterServerCount: 3
# parameterServerType: standard
#trainingInput:
# scaleTier: BASIC-GPU
#trainingInput:
# region: us-central1
# scaleTier: CUSTOM
# masterType: complex_model_m
# workerType: complex_model_m_gpu
# parameterServerType: large_model
# workerCount: 4
# parameterServerCount: 2
trainingInput:
scaleTier: standard-1
from datetime import datetime
from pytz import timezone
JOBNAME_TRN = 'tf_train_'+ USER + '_' + \
datetime.now(timezone('US/Pacific')).strftime("%m%d%y_%H%M")
JOB_CONFIG = "config/config.yaml"
MODEL_DIR_TRN = MODEL_DIR + datetime.now(timezone('US/Pacific')).strftime('/model_%m%d%Y_%H%M')
INPUT_FILE = 'gs://' + BUCKET_NAME + '/' + FOLDER_DATA + '/' + INPUT_FILE_NAME
print("Job Name = ", JOBNAME_TRN)
print("Job Dir = ", JOB_DIR)
print("MODEL_DIR =", MODEL_DIR_TRN)
print("INPUT_FILE =", INPUT_FILE)
# Training parameters
MODEL_DEPTH = 3
DROPOUT_RATE = 0.02
LEARNING_RATE = 0.0001
EPOCHS = 2
BATCH_SIZE = 32
print('MODEL_DEPTH = %2d' % MODEL_DEPTH)
print('DROPOUT_RATE = %.4f' % DROPOUT_RATE)
print('LEARNING_RATE = %.6f' % LEARNING_RATE)
print('EPOCHS = %2d' % EPOCHS)
print('BATCH_SIZE = %2d' % BATCH_SIZE)
# https://cloud.google.com/sdk/gcloud/reference/ai-platform/jobs/submit/training
TRAIN_LABELS = "mode=train,owner="+USER
# submit the training job
! gcloud ai-platform jobs submit training $JOBNAME_TRN \
--package-path $(pwd)/trainer \
--module-name trainer.train \
--region $REGION \
--python-version 3.7 \
--runtime-version $RUNTIME_VERSION \
--job-dir $JOB_DIR \
--config $JOB_CONFIG \
--labels $TRAIN_LABELS \
-- \
--model_depth=$MODEL_DEPTH \
--dropout_rate=$DROPOUT_RATE \
--learning_rate=$LEARNING_RATE \
--epochs=$EPOCHS \
--batch_size=$BATCH_SIZE \
--model_dir=$MODEL_DIR_TRN \
--input_file=$INPUT_FILE
# check the training job status
! gcloud ai-platform jobs describe $JOBNAME_TRN
# Print Errors
#response = ! gcloud logging read "resource.labels.job_id=$JOBNAME_TRN severity>=ERROR"
#for i in range(0,len(response)):
# if 'message' in response[i]:
# print(response[i])
# Test with latest saved model
best_model_dir_trn = find_best_model_dir(MODEL_DIR_TRN+'/checkpoints', offset=1, maxFlag=1)
#acc = test_saved_model(best_model_dir_trn, 0)
```
------
# Hyper Parameter Tuning
```
# Create the tf directory and load the trainer files in it
!cp ./trainer/train.py ./trainer/train_hpt.py
%%writefile -a ./trainer/train_hpt.py
"""This method updates a CAIP HPTuning Job with a final metric for the job.
In TF2.X the user must either use hypertune or a custom callback with
tf.summary.scalar to update CAIP HP Tuning jobs. This function uses
hypertune, which appears to be the preferred solution. Hypertune also works
with containers, without code change.
Args:
metric_tag: The metric being optimized. This MUST MATCH the
hyperparameterMetricTag specificed in the hyperparameter tuning yaml.
metric_value: The value to report at the end of model training.
global_step: An int value to specify the number of trainin steps completed
at the time the metric was reported.
"""
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=final_epoch_accuracy,
global_step=final_epoch_count
)
%%writefile ./config/hptuning_config.yaml
# python3
# ==============================================================================
# Copyright 2020 Google LLC. This software is provided as-is, without warranty
# or representation for any use or purpose. Your use of it is subject to your
# agreement with Google.
# ==============================================================================
# https://cloud.google.com/ai-platform/training/docs/reference/rest/v1/projects.jobs
# https://cloud.google.com/sdk/gcloud/reference/ai-platform/jobs/submit/training
#trainingInput:
# scaleTier: CUSTOM
# masterType: n1-highmem-8
# masterConfig:
# acceleratorConfig:
# count: 1
# type: NVIDIA_TESLA_T4
#
# masterType: standard_p100
# workerType: standard_p100
# parameterServerType: standard_p100
# workerCount: 8
# parameterServerCount: 1
# runtimeVersion: $RUNTIME_VERSION
# pythonVersion: '3.7'
#trainingInput:
# scaleTier: CUSTOM
# masterType: complex_model_m
# workerType: complex_model_m
# parameterServerType: large_model
# workerCount: 9
# parameterServerCount: 3
# scheduling:
# maxWaitTime: 3600s
# maxRunningTime: 7200s
#trainingInput:
# scaleTier: BASIC-GPU
#trainingInput:
# scaleTier: CUSTOM
# masterType: n1-highmem-16
# masterConfig:
# acceleratorConfig:
# count: 2
# type: NVIDIA_TESLA_V100
trainingInput:
scaleTier: STANDARD-1
hyperparameters:
goal: MAXIMIZE
hyperparameterMetricTag: accuracy
maxTrials: 4
maxParallelTrials: 4
enableTrialEarlyStopping: True
params:
- parameterName: model_depth
type: INTEGER
minValue: 2
maxValue: 4
scaleType: UNIT_LINEAR_SCALE
- parameterName: epochs
type: INTEGER
minValue: 1
maxValue: 3
scaleType: UNIT_LINEAR_SCALE
from datetime import datetime
from pytz import timezone
JOBNAME_HPT = 'tf_hptrn_' + USER + '_' + \
datetime.now(timezone('US/Pacific')).strftime("%m%d%y_%H%M")
JOB_CONFIG = "./config/hptuning_config.yaml"
MODEL_DIR_HPT = MODEL_DIR + datetime.now(timezone('US/Pacific')).strftime('/model_%m%d%Y_%H%M')
INPUT_FILE = 'gs://' + BUCKET_NAME + '/' + FOLDER_DATA + '/' + INPUT_FILE_NAME
print("Job Name = ", JOBNAME_HPT)
print("Job Dir = ", JOB_DIR)
print("MODEL_DIR =", MODEL_DIR_HPT)
print("INPUT_FILE =", INPUT_FILE)
# Training parameters
DROPOUT_RATE = 0.02
LEARNING_RATE = 0.0001
BATCH_SIZE = 32
# submit the training job
HT_LABELS = "mode=hypertrain,owner="+USER
! gcloud ai-platform jobs submit training $JOBNAME_HPT \
--package-path $(pwd)/trainer \
--module-name trainer.train_hpt \
--python-version 3.7 \
--runtime-version $RUNTIME_VERSION \
--region $REGION \
--job-dir $JOB_DIR \
--config $JOB_CONFIG \
--labels $HT_LABELS \
-- \
--dropout_rate=$DROPOUT_RATE \
--learning_rate=$LEARNING_RATE \
--batch_size=$BATCH_SIZE \
--model_dir=$MODEL_DIR_HPT \
--input_file=$INPUT_FILE
# check the hyperparameter training job status
! gcloud ai-platform jobs describe $JOBNAME_HPT
# Print Errors
#response = ! gcloud logging read "resource.labels.job_id=$JOBNAME_HPT severity>=ERROR"
#for i in range(0,len(response)):
# if 'message' in response[i]:
# print(response[i])
# Get the best model parameters from Cloud API
best_model = pyth_get_hypertuned_parameters(PROJECT_ID, JOBNAME_HPT, 1)
MODEL_DEPTH = best_model['hyperparameters']['model_depth']
EPOCHS = best_model['hyperparameters']['epochs']
print('')
print('Objective=', best_model['finalMetric']['objectiveValue'])
print('MODEL_DEPTH =', MODEL_DEPTH)
print('EPOCHS =', EPOCHS)
# Find count of checkpoints
all_models = ! gsutil ls {MODEL_DIR_HPT+'/checkpoints'}
print("Total Hypertrained Models=", len(all_models))
# Test with latest saved model
best_model_dir_hyp = find_best_model_dir(MODEL_DIR_HPT+'/checkpoints', offset=1, maxFlag=1)
#acc = test_saved_model(best_model_dir_hyp, 0)
#import keras.backend as K
#loaded_model = tf.keras.models.load_model(MODEL_DIR_PARAM+'/checkpoints')
#print("learning_rate=", K.eval(loaded_model.optimizer.lr))
#tf.keras.utils.plot_model(loaded_model, show_shapes=True)
```
--------
# Deploy the Model
```
## https://cloud.google.com/ai-platform/prediction/docs/machine-types-online-prediction#available_machine_types
# We need 2 versions of the same model:
# 1. Batch prediction model deployed on a mls1-c1-m2 cluster
# 2. Online prediction model deployed on a n1-standard-16 cluster
# Batch prediction does not support GPU and n1-standard-16 clusters.
# Run the Deploy Model section twice:
# 1. As a BATCH Mode version use MODEL_VERSION = MODEL_VERSION_BATCH
# 2. As a ONLINE Mode version use MODEL_VERSION = MODEL_VERSION_ONLINE
# Regional End points with python
#https://cloud.google.com/ai-platform/prediction/docs/regional-endpoints#python
MODEL_NAME = "loan_model_1"
MODEL_VERSION_BATCH = "batch_v1"
MODEL_VERSION_ONLINE = "online_v1"
#Run this as Batch first then Online
#MODEL_VERSION = MODEL_VERSION_ONLINE
MODEL_VERSION = MODEL_VERSION_BATCH
# List all models
print("\nList of Models in Global Endpoint)")
!gcloud ai-platform models list --region=global
# List all versions of model
print("\nList of Versions in Global Endpoint)")
!gcloud ai-platform versions list --model $MODEL_NAME --region=global
#!gcloud ai-platform versions delete $MODEL_VERSION_BATCH --model $MODEL_NAME --quiet --region=global
#!gcloud ai-platform models delete $MODEL_NAME --quiet --region=global
# List all models
print("\nList of Models in Global Endpoint)")
!gcloud ai-platform models list --region=global
# List all versions of model
print("\nList of Versions in Global Endpoint)")
!gcloud ai-platform versions list --model $MODEL_NAME --region=global
# create the model if it doesn't already exist
modelname = !gcloud ai-platform models list | grep -w $MODEL_NAME
print(modelname)
if (len(modelname) <= 1) or ('Listed 0 items.' in modelname[1]):
print("Creating model " + MODEL_NAME)
# Global endpoint
!gcloud ai-platform models create $MODEL_NAME --enable-logging --regions $REGION
else:
print("Model " + MODEL_NAME + " exist")
print("\nList of Models in Global Endpoint)")
!gcloud ai-platform models list --region=global
%%time
print("Model Name =", MODEL_NAME)
print("Model Versions =", MODEL_VERSION)
# Get a list of model directories
best_model_dir = best_model_dir_hyp
print("Best Model Dir: ", best_model_dir)
MODEL_FRAMEWORK = "TENSORFLOW"
MODEL_DESCRIPTION = "SEQ_MODEL_1"
MODEL_LABELS="team=ourteam,phase=test,owner="+USER
MACHINE_TYPE = "mls1-c1-m2"
if (MODEL_VERSION == MODEL_VERSION_BATCH):
MACHINE_TYPE = "mls1-c1-m2"
MODEL_LABELS = MODEL_LABELS+",mode=batch"
if (MODEL_VERSION == MODEL_VERSION_ONLINE):
MACHINE_TYPE = "mls1-c1-m2" #"n1-standard-32"
MODEL_LABELS = MODEL_LABELS+",mode=online"
# Deploy the model
! gcloud beta ai-platform versions create $MODEL_VERSION \
--model $MODEL_NAME \
--origin $best_model_dir \
--runtime-version $RUNTIME_VERSION \
--python-version=3.7 \
--description=$MODEL_DESCRIPTION \
--labels $MODEL_LABELS \
--machine-type=$MACHINE_TYPE \
--framework $MODEL_FRAMEWORK \
--region global
# List all models
print("\nList of Models in Global Endpoint)")
!gcloud ai-platform models list --region=global
print("\nList of Models in Regional Endpoint)")
!gcloud ai-platform models list --region=$REGION
# List all versions of model
print("\nList of Versions in Global Endpoint)")
!gcloud ai-platform versions list --model $MODEL_NAME --region=global
#print("\nList of Versions in Regional Endpoint)")
#!gcloud ai-platform versions list --model $MODEL_NAME --region=$REGION
```
------
# Predictions with the deployed model
```
%%time
from trainer import model
# Copy the model from storage to local memory
!gsutil -m cp -r $best_model_dir_hyp* ./model_dir
# Load the model
loaded_model = tf.keras.models.load_model('./model_dir', compile=False) #,
#custom_objects={"custom_loss": model.custom_loss,"custom_mse": model.custom_mse})
print("Signature ", loaded_model.signatures)
# Check the model layers
model_layers = [layer.name for layer in loaded_model.layers]
print("")
print("Model Input Layer=", model_layers[0])
print("Model Output Layer=", model_layers[-1])
print("")
from trainer import inputs
input_file = 'gs://' + BUCKET_NAME + '/' + FOLDER_DATA + '/' + INPUT_FILE_NAME
train_test_data = inputs.load_data(input_file)
X_test = train_test_data[1]
y_test = train_test_data[3]
```
## Online Prediction with python
```
%%time
# Online Prediction with Python - works for global end points only
# Use MODEL_VERSION_ONLINE not MODEL_VERSION_BATCH
MODEL_VERSION = MODEL_VERSION_ONLINE
from oauth2client.client import GoogleCredentials
from googleapiclient import discovery
from googleapiclient import errors
import json
#tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
#tf.get_logger().setLevel('ERROR')
print("Project ID =", PROJECT_ID)
print("Model Name =", MODEL_NAME)
print("Model Version =", MODEL_VERSION)
model_name = 'projects/{}/models/{}'.format(PROJECT_ID, MODEL_NAME)
if MODEL_VERSION is not None:
model_name += '/versions/{}'.format(MODEL_VERSION)
credentials = GoogleCredentials.get_application_default()
service = discovery.build('ml', 'v1', cache_discovery=False, credentials=credentials)
print("model_name=", model_name)
pprobas_temp = []
batch_size = 32
n_samples = min(1000,X_test.shape[0])
print("batch_size=", batch_size)
print("n_samples=", n_samples)
for i in range(0, n_samples, batch_size):
j = min(i+batch_size, n_samples)
print("Processing samples", i, j)
request = service.projects().predict(name=model_name, \
body={'instances': np.array(X_test)[i:j].tolist()})
try:
response = request.execute()
pprobas_temp += response['predictions']
except errors.HttpError as err:
# Something went wrong, print out some information.
tf.compat.v1.logging.error('There was an error getting the job info, Check the details:')
tf.compat.v1.logging.error(err._get_reason())
break
# Show the prediction results as an array
nPreds = len(pprobas_temp)
nClasses = y_test.shape[1]
pprobas = np.zeros((nPreds, nClasses))
for i in range(nPreds):
pprobas[i,:] = np.array(pprobas_temp[i][model_layers[-1]])
pprobas = np.round(pprobas, 2)
pprobas
```
## Batch Prediction with GCLOUD
```
# Write batch data to file in GCS
import shutil
# Clean current directory
DATA_DIR = './batch_data'
shutil.rmtree(DATA_DIR, ignore_errors=True)
os.makedirs(DATA_DIR)
n_samples = min(1000,X_test.shape[0])
nFiles = 10
nRecsPerFile = min(1000,n_samples//nFiles)
print("n_samples =", n_samples)
print("nFiles =", nFiles)
print("nRecsPerFile =", nRecsPerFile)
# Create nFiles files with nImagesPerFile images each
for i in range(nFiles):
with open(f'{DATA_DIR}/unkeyed_batch_{i}.json', "w") as file:
for z in range(nRecsPerFile):
print(f'{{"dense_input": {np.array(X_test)[i*nRecsPerFile+z].tolist()}}}', file=file)
#print(f'{{"{model_layers[0]}": {np.array(X_test)[i*nRecsPerFile+z].tolist()}}}', file=file)
#key = f'key_{i}_{z}'
#print(f'{{"image": {X_test_images[z].tolist()}, "key": "{key}"}}', file=file)
# Write batch data to gcs file
!gsutil -m cp -r ./batch_data gs://$BUCKET_NAME/$FOLDER_RESULTS/
# Remove old batch prediction results
!gsutil -m rm -r gs://$BUCKET_NAME/$FOLDER_RESULTS/batch_predictions
from datetime import datetime
from pytz import timezone
DATA_FORMAT="text" # JSON data format
INPUT_PATHS='gs://' + BUCKET_NAME + '/' + FOLDER_RESULTS + '/batch_data/*'
OUTPUT_PATH='gs://' + BUCKET_NAME + '/' + FOLDER_RESULTS + '/batch_predictions'
PRED_LABELS="mode=batch,team=ourteam,phase=test,owner="+USER
SIGNATURE_NAME="serving_default"
JOBNAME_BATCH = 'tf_batch_predict_'+ USER + '_' + \
datetime.now(timezone('US/Pacific')).strftime("%m%d%y_%H%M")
print("INPUT_PATHS = ", INPUT_PATHS)
print("OUTPUT_PATH = ", OUTPUT_PATH)
print("Job Name = ", JOBNAME_BATCH)
# Only works with global endpoint
# Submit batch predict job
# Use MODEL_VERSION_BATCH not MODEL_VERSION_ONLINE
MODEL_VERSION = MODEL_VERSION_BATCH
!gcloud ai-platform jobs submit prediction $JOBNAME_BATCH \
--model=$MODEL_NAME \
--version=$MODEL_VERSION \
--input-paths=$INPUT_PATHS \
--output-path=$OUTPUT_PATH \
--data-format=$DATA_FORMAT \
--labels=$PRED_LABELS \
--signature-name=$SIGNATURE_NAME \
--region=$REGION
# check the batch prediction job status
! gcloud ai-platform jobs describe $JOBNAME_BATCH
# Print Errors
#response = ! gcloud logging read "resource.labels.job_id=$JOBNAME_BATCH severity>=ERROR"
#for i in range(0,len(response)):
# if 'message' in response[i]:
# print(response[i])
print("errors")
!gsutil cat $OUTPUT_PATH/prediction.errors_stats-00000-of-00001
print("batch prediction results")
!gsutil cat $OUTPUT_PATH/prediction.results-00000-of-00010
```
|
github_jupyter
|
# Hertzian conatct 1
## Assumptions
When two objects are brought into contact they intially touch along a line or at a single point. If any load is transmitted throught the contact the point or line grows to an area. The size of this area, the pressure distribtion inside it and the resulting stresses in each solid require a theory of contact to describe.
The first satisfactory theory for round bodies was presented by Hertz in 1880 who worked on it during his christmas holiday at the age of twenty three. He assumed that:
The bodies could be considered as semi infinite elastic half spaces from a stress perspective as the contact area is normally much smaller than the size of the bodies, it is also assumed strains are small. This means that the normal integral equations for surface contact can be used:
The contact is also assumed to be frictionless so the contact equations reduce to:
$\Psi_1=\int_S \int p(\epsilon,\eta)ln(\rho+z)\ d\epsilon\ d\eta$ [1]
$\Psi=\int_S \int \frac{p(\epsilon,\eta)}{\rho}\ d\epsilon\ d\eta$ [2]
$u_x=-\frac{1+v}{2\pi E}\left((1-2v)\frac{\delta\Psi_1}{\delta x}+z\frac{\delta\Psi}{\delta x}\right) $ [3a]
$u_y=-\frac{1+v}{2\pi E}\left((1-2v)\frac{\delta\Psi_1}{\delta y}+z\frac{\delta\Psi}{\delta y}\right) $ [3b]
$u_z=-\frac{1+v}{2\pi E}\left(2(1-v)\Psi+z\frac{\delta\Psi}{\delta z}\right) $ [3c]
```
from IPython.display import Image
Image("figures/hertz_probelm reduction.png")
```
For the shape of the surfaces: it was asumed that they are smooth on both the micro scale and the macro scale. Assuming that they are smooth on the micro scale means that small irregulararities which would cause discontinuous contact and local pressure variations are ignored.
## Geometry
Assuming that the surfaces are smooth on the macro scale implies that the surface profiles are continuous up to their second derivative. Meaning that the surfaces can be described by polynomials:
$z_1=A_1'x+B_1'y+A_1x^2+B_1y^2+C_1xy+...$ [4]
With higher order terms being neglected. By choosing the location of the origin to be at the point of contact and the orientation of the xy plane to be inline wiht the principal radii of the surface the equation above reduces to:
$z_1=\frac{1}{2R'_1}x_1^2+\frac{1}{2R''_1}y_1^2$ [5]
Where $R'_1$ and $R''_1$ are the principal radii of the first surface at the origin.
### They are the maximum and minimum radii of curvature across all possible cross sections
The following widget allows you to change the principal radii of a surface and the angle between it an the coordinate axes
```
from matplotlib import pyplot as plt
from matplotlib.lines import Line2D
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from __future__ import print_function
from ipywidgets import interact, interactive, fixed, interact_manual
import ipywidgets as widgets
plt.rcParams['figure.figsize'] = [15, 10]
@interact(r1=(-10,10),r2=(-10,10),theta=(0,np.pi),continuous_update=False)
def plot_surface(r1=5,r2=0,theta=0):
"""
Plots a surface given two principal radii and the angle relative to the coordinate axes
Parameters
----------
r1,r2 : float
principal radii
theta : float
Angle between the plane of the first principal radius and the coordinate axes
"""
X,Y=np.meshgrid(np.linspace(-1,1,20),np.linspace(-1,1,20))
X_dash=X*np.cos(theta)-Y*np.sin(theta)
Y_dash=Y*np.cos(theta)+X*np.sin(theta)
r1 = r1 if np.abs(r1)>=1 else float('inf')
r2 = r2 if np.abs(r2)>=1 else float('inf')
Z=0.5/r1*X_dash**2+0.5/r2*Y_dash**2
x1=np.linspace(-1.5,1.5)
y1=np.zeros_like(x1)
z1=0.5/r1*x1**2
y2=np.linspace(-1.5,1.5)
x2=np.zeros_like(y2)
z2=0.5/r2*y2**2
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(X, Y, Z)
ax.plot((x1*np.cos(-theta)-y1*np.sin(-theta)),x1*np.sin(-theta)+y1*np.cos(-theta),z1)
ax.plot((x2*np.cos(-theta)-y2*np.sin(-theta)),x2*np.sin(-theta)+y2*np.cos(-theta),z2)
ax.set_xlim(-1, 1)
ax.set_ylim(-1, 1)
ax.set_zlim(-0.5, 0.5)
```
A similar equation defines the second surface:
$z_2=-\left(\frac{1}{2R'_2}x_2^2+\frac{1}{2R''_2}y_2^2\right)$ [6]
The separation between these surfaces is then given as $h=z_1-z_2$.
by writing equation 4 and its counterpart on common axes, it is clear that the gap between the surfaces can be written as:
$h=Ax^2+By^2+Cxy$ [7]
And by a suitable choice of orientation of the xy plane the C term can be made to equal 0. As such when ever two surfaces with parabolic shape are brought into contact (with no load) the gap between them can be defined as a single parabola:
$h=Ax^2+Bx^2=\frac{1}{2R'_{gap}}x^2+\frac{1}{2R''_{gap}}y^2$ [8]
#### The values $R'_{gap}$ and $R''_{gap}$ are called the principal radii of relative curvature.
These relate to the principal radii of each of the bodies through the equations below:
$(A+B)=\frac{1}{2}\left(\frac{1}{R'_{gap}}+\frac{1}{R''_{gap}}\right)=\frac{1}{2}\left(\frac{1}{R'_1}+\frac{1}{R''_1}+\frac{1}{R'_2}+\frac{1}{R''_2}\right)$
The next widget shows the shpae of the gap between two bodies in contact allowing you to set the principal radii of each boday and the angle between them:
```
@interact(top_r1=(-10,10),top_r2=(-10,10),
bottom_r1=(-10,10),bottom_r2=(-10,10),
theta=(0,np.pi),continuous_update=False)
def plot_two_surfaces(top_r1=2,top_r2=5,bottom_r1=4,bottom_r2=-9,theta=0.3):
"""
Plots 2 surfaces and the gap between them
Parameters
----------
top_r1,top_r2,bottom_r1,bottom_r2 : float
The principal radii of the top and bottom surface
theta : float
The angel between the first principal radii of the surfaces
"""
X,Y=np.meshgrid(np.linspace(-1,1,20),np.linspace(-1,1,20))
X_dash=X*np.cos(theta)-Y*np.sin(theta)
Y_dash=Y*np.cos(theta)+X*np.sin(theta)
top_r1 = top_r1 if np.abs(top_r1)>=1 else float('inf')
top_r2 = top_r2 if np.abs(top_r2)>=1 else float('inf')
bottom_r1 = bottom_r1 if np.abs(bottom_r1)>=1 else float('inf')
bottom_r2 = bottom_r2 if np.abs(bottom_r2)>=1 else float('inf')
Z_top=0.5/top_r1*X_dash**2+0.5/top_r2*Y_dash**2
Z_bottom=-1*(0.5/bottom_r1*X**2+0.5/bottom_r2*Y**2)
fig = plt.figure()
ax = fig.add_subplot(121, projection='3d')
ax.set_title("Surfaces")
ax2 = fig.add_subplot(122)
ax2.set_title("Gap")
ax2.axis("equal")
ax2.set_adjustable("box")
ax2.set_xlim([-1,1])
ax2.set_ylim([-1,1])
ax.plot_surface(X, Y, Z_top)
ax.plot_surface(X, Y, Z_bottom)
if top_r1==top_r2==bottom_r1==bottom_r2==float('inf'):
ax2.text(s='Flat surfaces, no gap', x=-0.6, y=-0.1)
else:
ax2.contour(X,Y,Z_top-Z_bottom)
div=((1/top_r2)-(1/top_r1))
if div==0:
lam=float('inf')
else:
lam=((1/bottom_r2)-(1/bottom_r1))/div
beta=-1*np.arctan((np.sin(2*theta))/(lam+np.cos(2*theta)))/2
if beta<=(np.pi/4):
x=1
y=np.tan(beta)
else:
x=np.tan(beta)
y=1
ax2.add_line(Line2D([x,-1*x],[y,-1*y]))
beta-=np.pi/2
if beta<=(np.pi/4):
x=1
y=np.tan(beta)
else:
x=np.tan(beta)
y=1
ax2.add_line(Line2D([x,-1*x],[y,-1*y]))
```
From the form of equation 8 it is clear that the contours of constant gap (the contours plotted by the widget) are elipitcal in shape. With axes in the ratio $(R'_gap/R''_gap)^{1/2}$. In the special case of equal principal radii for each body (spherical contact) the contours of separation will be circular. From the symmetry of this problem it is clear that this will remain true when a load is applied.
Additonally, when two cylinders are brought in to contact with their axes parallel the contours of separation are straight lines parallel to the axes of the cylinders. When loaded the cylinders will also make contact along a narrow strip parallel to the axes of the cylinders.
We might expect, then that for the general case the contour of contact under load will follow the same eliptical shape as the contours of separation. This is infact the case but the proof will have to wait for the next section
|
github_jupyter
|
```
import matplotlib.pyplot as plt
import numpy
from numpy import genfromtxt
import csv
import pandas as pd
from operator import itemgetter
from datetime import*
from openpyxl import load_workbook,Workbook
from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font
import openpyxl
from win32com import client
print('Libraries Imported Successfully......')
#######################################################################
def nearest(items, pivot):
return min(items, key=lambda x: abs(x - pivot))
#######################################################################
def add_one_month(t):
"""Return a `datetime.date` or `datetime.datetime` (as given) that is
one month earlier.
Note that the resultant day of the month might change if the following
month has fewer days:
>>> add_one_month(datetime.date(2010, 1, 31))
datetime.date(2010, 2, 28)
"""
import datetime
one_day = datetime.timedelta(days=1)
one_month_later = t + one_day
while one_month_later.month == t.month: # advance to start of next month
one_month_later += one_day
target_month = one_month_later.month
while one_month_later.day < t.day: # advance to appropriate day
one_month_later += one_day
if one_month_later.month != target_month: # gone too far
one_month_later -= one_day
break
return one_month_later
#######################################################################
def subtract_one_month(t):
"""Return a `datetime.date` or `datetime.datetime` (as given) that is
one month later.
Note that the resultant day of the month might change if the following
month has fewer days:
>>> subtract_one_month(datetime.date(2010, 3, 31))
datetime.date(2010, 2, 28)
"""
import datetime
one_day = datetime.timedelta(days=1)
one_month_earlier = t - one_day
while one_month_earlier.month == t.month or one_month_earlier.day > t.day:
one_month_earlier -= one_day
return one_month_earlier
#######################################################################
print('Custom Functions Loaded into the Current Path')
values=[]
dates=[]
combine=[]
with open('hyatt.csv', 'r') as csvFile:
reader = csv.reader(csvFile)
for row in reader:
values.append(row[1])
dates.append(row[1])
combine.append(row)
csvFile.close()
#print(values)
#print(dates)
#print(combine)
print('Data Loaded into the Program Successfuly')
print('The Number of Values are: ',len(values))
print('The Number of Dates are:',len(dates))
combine = sorted(combine, key=itemgetter(0))
"""for i in combine:
print(i)"""
for i in combine:
m2=i[0]
m2=datetime.strptime(m2,'%d/%m/%y %I:%M %p')
i[0]=m2
combine = sorted(combine, key=itemgetter(0))
"""for i in combine:
print(i)"""
ref_min=combine[0][0].date()
min_time=datetime.strptime('0000','%H%M').time()
ref_min=datetime.combine(ref_min, min_time)
print(type(ref_min))
ref_max=combine[-1][0].date()
max_time=datetime.strptime('2359','%H%M').time()
ref_max=datetime.combine(ref_max, max_time)
print(ref_max)
ref_max = add_one_month(ref_max)
dates=[]
for i in combine:
dates.append(i[0])
i=ref_min
indices=[]
while i<ref_max:
k=nearest(dates,i)
print('The corresponding Lowest time related to this reading is: ',k)
index=dates.index(k)
print(index)
indices.append(index)
i = add_one_month(i)
print(i)
print('The Number of Indices are: ',len(indices))
k=ref_min.date()
consump=[]
lower=[]
upper=[]
for i in range(len(indices)-1):
r_min=float(values[indices[i]])
lower.append(r_min)
r_up=float(values[indices[i+1]])
upper.append(r_up)
consumption=r_up-r_min
consump.append(consumption)
print('The Consumption on ',k.strftime('%d-%m-%Y'),' is : ',consumption)
k = add_one_month(k)
rate=float(input('Enter the Rate per KWH consumed for Cost Calculation: '))
k=ref_min.date()
cost=[]
for i in consump:
r=float(i)*rate
print('The Cost of Electricity for ',k.strftime('%d-%m-%Y'),' is :',r)
cost.append(r)
k = add_one_month(k)
print('\n====================Final Output====================\n')
k=ref_min.date()
date_list=[]
write=[]
write2=[]
cust=input('Please Enter The Customer Name: ')
row=['Customer Name: ',cust]
write.append(row)
row=['Address Line 1: ',"3, National Hwy 9, Premnagar, "]
write.append(row)
row=['Address Line 2: ',"Ashok Nagar, Pune, Maharashtra 411016"]
write.append(row)
row=['']
write.append(row)
row=['Electricity Bill Invoice']
write.append(row)
row=['From: ',ref_min.date()]
write.append(row)
row=['To: ',subtract_one_month(ref_max.date())+timedelta(days=1)]
write.append(row)
row=['']
write.append(row)
row=['Reading Date','Previous Reading','Present Reading','Consumption','Cost']
write.append(row)
for i in range(len(indices)-1):
row=[]
row2=[]
print('--------------------------------------')
print('Date:\t\t',k)
row.append(k)
row2.append(k)
date_list.append(k)
k = add_one_month(k)
print('Lower Reading:\t',lower[i])
row.append(lower[i])
row2.append(lower[i])
print('Upper Reading:\t',upper[i])
row.append(upper[i])
row2.append(upper[i])
print('Consumption:\t',consump[i])
row.append(consump[i])
row2.append(consump[i])
print('Cost:\t\t',cost[i])
row.append(cost[i])
row2.append(cost[i])
write.append(row)
write2.append(row2)
plt.plot(date_list,consump)
plt.show()
plt.savefig('graph.png')
row=['Total Consumption: ', sum(consump)]
write.append(row)
row=['Cost Per Unit: ',rate]
write.append(row)
row=['Total Bill Ammount: ',sum(cost)]
write.append(row)
with open('output.csv', 'w') as csvFile:
for row in write:
writer = csv.writer(csvFile,lineterminator='\n')
writer.writerow(row)
csvFile.close()
print('CSV FILE Generated as Output.csv')
###########################################################################
wb=load_workbook('Book1.xlsx')
ws1=wb.get_sheet_by_name('Sheet1')
# shs is list
ws1['B2']=cust
ws1['B3']='3, National Hwy 9, Premnagar, '
ws1['B4']='Ashok Nagar, Pune, Maharashtra 411016'
ws1['B6']=ref_min.date()
ws1['E6']=subtract_one_month(ref_max.date())+timedelta(days=1)
row=9
column=1
for r in write2:
column=1
for i in r:
ws1.cell(row,column).value=i
column+=1
row+=1
"""
row+=1
column=1
ws1.cell(row,column).value='Total Consumption: '
ws1.cell(row,column).font=Font(bold=True)
column+=1
ws1.cell(row,column).value=sum(consump)
column-=1
row+=1
ws1.cell(row,column).value='Total Cost: '
ws1.cell(row,column).font=Font(bold=True)
column+=1
ws1.cell(row,column).value=sum(cost)
column-=1"""
thick_border_right=Border(right=Side(style='thick'))
ws1['E2'].border=thick_border_right
ws1['E3'].border=thick_border_right
ws1['E4'].border=thick_border_right
thick_border = Border(left=Side(style='thick'), right=Side(style='thick'), top=Side(style='thick'), bottom=Side(style='thick'))
ws1['A15']='Total Consumption'
ws1['A15'].font=Font(bold=True)
ws1['A15'].border=thick_border
ws1['B15'].border=thick_border
ws1['C15'].border=thick_border
ws1['D15'].border=thick_border
ws1['A16']='Total Cost'
ws1['A16'].font=Font(bold=True)
ws1['A16'].border=thick_border
ws1['B16'].border=thick_border
ws1['C16'].border=thick_border
ws1['D16'].border=thick_border
ws1['E15']=sum(consump)
ws1['E16']=sum(cost)
img = openpyxl.drawing.image.Image('logo.jpg')
img.anchor='A1'
ws1.add_image(img)
wb.save('Book1.xlsx')
print('Excel Workbook Generated as Book1.xlsx')
#############################################################################
xlApp = client.Dispatch("Excel.Application")
books = xlApp.Workbooks.Open('E:\Internship\Siemens\EMAPP\Book1.xlsx')
ws = books.Worksheets[0]
ws.Visible = 1
ws.ExportAsFixedFormat(0, 'E:\Internship\Siemens\EMAPP\trial.pdf')
```
|
github_jupyter
|
```
import json
import requests
import numpy as np
import pandas as pd
import pandas as pd
import requests
from requests.auth import HTTPBasicAuth
USERNAME = 'damminhtien'
PASSWORD = '**********'
TARGET_USER = 'damminhtien'
authentication = HTTPBasicAuth(USERNAME, PASSWORD)
import uuid
from IPython.display import display_javascript, display_html, display
class printJSON(object):
def __init__(self, json_data):
if isinstance(json_data, dict):
self.json_str = json.dumps(json_data)
else:
self.json_str = json_data
self.uuid = str(uuid.uuid4())
def _ipython_display_(self):
display_html('<div id="{}" style="height: 100%; width:100%; color:red; background: #2f0743;"></div>'.format(self.uuid), raw=True)
display_javascript("""
require(["https://rawgit.com/caldwell/renderjson/master/renderjson.js"], function() {
document.getElementById('%s').appendChild(renderjson(%s))
});
""" % (self.uuid, self.json_str), raw=True)
user_data = requests.get('https://api.github.com/users/' + TARGET_USER,
auth = authentication)
user_data = user_data.json()
printJSON(user_data)
from PIL import Image
from io import BytesIO
from IPython.display import display, HTML
import tabulate
response = requests.get(user_data['avatar_url'])
ava_img = Image.open(BytesIO(response.content))
display(ava_img)
table = [["Name:", user_data['name']],
["Company:", user_data['company']],
["Bio:", user_data['bio']],
["Public_repos:", user_data['public_repos']],
["Number followers:", user_data['followers']],
["Number following users:", user_data['following']],
["Date joined:", user_data['created_at']]]
display(HTML(tabulate.tabulate(table, tablefmt='html')))
url = user_data['repos_url']
page_no = 1
repos_data = []
while (True):
response = requests.get(url, auth = authentication)
response = response.json()
repos_data = repos_data + response
repos_fetched = len(response)
if (repos_fetched == 30):
page_no = page_no + 1
url = str(user_data['repos_url']) + '?page=' + str(page_no)
else:
break
printJSON(repos_data[0])
_LANGUAGE_IGNORE = ['HTML', 'CSS', 'Jupyter Notebook']
LANGUAGE_USED = []
TIMES_USED = []
STAR_COUNT = []
for rd in repos_data:
if rd['fork']: continue
response = requests.get(rd['languages_url'], auth = authentication)
response = response.json()
language_rd = list(response.keys())
for l in language_rd:
if l in _LANGUAGE_IGNORE: continue
if l not in LANGUAGE_USED:
LANGUAGE_USED.append(l)
TIMES_USED.append(response[l])
else:
TIMES_USED[LANGUAGE_USED.index(l)] += response[l]
language_data = {'Languages': LANGUAGE_USED, 'Times': TIMES_USED}
language_df = pd.DataFrame(language_data).sort_values(by=['Times'])
language_df
import plotly.express as px
fig = px.bar(language_df, x='Languages', y='Times',
color='Languages',
labels={'pop':'Statistic languages were used by user'}, height=400)
fig.show()
repos_information = []
for i, repo in enumerate(repos_data):
data = []
data.append(repo['id'])
data.append(repo['name'])
data.append(repo['description'])
data.append(repo['created_at'])
data.append(repo['updated_at'])
data.append(repo['owner']['login'])
data.append(repo['license']['name'] if repo['license'] != None else None)
data.append(repo['has_wiki'])
data.append(repo['fork'])
data.append(repo['forks_count'])
data.append(repo['open_issues_count'])
data.append(repo['stargazers_count'])
data.append(repo['watchers_count'])
data.append(repo['url'])
data.append(repo['commits_url'].split("{")[0])
data.append(repo['url'] + '/languages')
repos_information.append(data)
repos_df = pd.DataFrame(repos_information, columns = ['Id', 'Name', 'Description', 'Created on', 'Updated on',
'Owner', 'License', 'Includes wiki', 'Is Fork','Forks count',
'Issues count', 'Stars count', 'Watchers count',
'Repo URL', 'Commits URL', 'Languages URL'])
repos_df
repos_df.describe()
star_fig = px.bar(repos_df[repos_df['Stars count']>0].sort_values(by=['Stars count']), x='Name', y='Stars count',
color='Forks count', hover_data=['Description', 'License', 'Owner'],
labels={'pop':'Statistic languages were used by user'})
star_fig.show()
url = repos_df.loc[23, 'Commits URL']
response = requests.get(url, auth = authentication)
response = response.json()
printJSON(response[0])
commits_information = []
for i in range(repos_df.shape[0]):
if repos_df.loc[i, 'Is Fork']: continue
url = repos_df.loc[i, 'Commits URL']
page_no = 1
while (True):
try:
response = requests.get(url, auth = authentication)
response = response.json()
for commit in response:
commit_data = []
commit_data.append(repos_df.loc[i, 'Name'])
commit_data.append(repos_df.loc[i, 'Id'])
commit_data.append(commit['commit']['committer']['date'])
commit_data.append(commit['commit']['message'])
commits_information.append(commit_data)
if (len(response) == 30):
page_no = page_no + 1
url = repos_df.loc[i, 'Commits URL'] + '?page=' + str(page_no)
else:
break
except:
print(url + ' fetch failed')
break
commits_df = pd.DataFrame(commits_information, columns = ['Name', 'Repo Id', 'Date', 'Message'])
commits_df
print("Two most common commit messages: {}".format(' and '.join(commits_df['Message'].value_counts().index[:2])))
commit_per_repo_fig = px.bar(commits_df.groupby('Name').count().reset_index(level=['Name']), x='Name', y='Message',
color='Name',
labels={'pop':'Commit per repositories'})
commit_per_repo_fig.show()
commits_df['Year'] = commits_df['Date'].apply(lambda x: x.split('-')[0])
yearly_stats = commits_df.groupby('Year').count()['Repo Id']
yearly_stats_df = yearly_stats.to_frame().reset_index(level=['Year'])
yearly_stats_df
yearly_stats_fig = px.bar(yearly_stats_df, x='Year', y='Repo Id',
color='Year',
labels={'pop':'Commit per Year'})
yearly_stats_fig.show()
commits_df['Month'] = commits_df['Date'].apply(lambda x: x.split('-')[1])
def commits_in_month_arr(year):
n_commits = [0,0,0,0,0,0,0,0,0,0,0,0,0]
commits_in_month_df = commits_df[commits_df['Year'] == str(year)].groupby('Month').count().reset_index(level=['Month']).drop(['Name', 'Date', 'Message', 'Year'], axis=1)
for i, m in enumerate(commits_in_month_df['Month']):
n_commits[int(m)] = n_commits[int(m)] + commits_in_month_df['Repo Id'][i]
return n_commits
import plotly.graph_objects as go
MONTHS = ['January', 'Febuary', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December']
# Create traces
fig = go.Figure()
fig.add_trace(go.Scatter(x=MONTHS, y=commits_in_month_arr(2017),
mode='lines+markers',
name='2017'))
fig.add_trace(go.Scatter(x=MONTHS, y=commits_in_month_arr(2018),
mode='lines+markers',
name='2018'))
fig.add_trace(go.Scatter(x=MONTHS, y=commits_in_month_arr(2019),
mode='lines+markers',
name='2019'))
fig.show()
```
|
github_jupyter
|
# Missing Data
Missing values are a common problem within datasets. Data can be missing for a number of reasons, including tool/sensor failure, data vintage, telemetry issues, stick and pull, and omissing by choice.
There are a number of tools we can use to identify missing data, some of these methods include:
- Pandas Dataframe summaries
- MissingNo Library
- Visualisations
How to handle missing data is controversial, some argue that data should be filled in using techniques such as: mean imputation, regression imputations, whereas others argue that it is best to remove that data to prevent adding further uncertainty to the final results.
In this notebook, we are going to use: Variable Discarding and Listwise Deletion.
# Importing Libraries & Data
The first step is to import the libraries that we will require for working with the data.
For this notebook, we will be using:
- pandas for loading and storing the data
- matplotlib and seaborn for visualising the data
- numpy for a number of calculation methods
- missingno to visualise where missing data exists
```
import pandas as pd
import matplotlib.pyplot as plt
import missingno as msno
import numpy as np
```
Next, we will load the data in using the pandas `read_csv` function and assign it to the variable `df`. The data will now be stored within a structured object known as a dataframe.
```
df = pd.read_csv('data/spwla_volve_data.csv')
```
As seen in the previous notebook, we can call upon a few methods to check the data quality.
The `.head()` method allows us to view the first 5 rows of the dataframe.
```
df.head()
```
The describe method provides us some summary statistics. To identify if we have missing data using this method, we need to look at the count row. If we assume that MD (measured depth) is the most complete column, we have 27,845 data points. Now, if we look at DT and DTS, we can see we only have 5,493 and 5,420 data points respectively. A number of other columns also have lower numbers, namely: RPCELM, PHIF, SW, VSH.
```
df.describe()
```
To gain a clearer insight, we can call upon the `info()` method to see how many non-null values exist for each column. Right away we can see the ones highlighted previously have lower numbers of non-null values.
```
df.info()
```
## Using missingno to Visualise Data Sparsity
The missingno library is designed to take a dataframe and allow you to visualise where gaps may exist.
We can simply call upon the `.matrix()` method and pass in the dataframe object. When we do, we generate a graphical view of the dataframe.
In the plot below, we can see that there are significant gaps within the DT and DTS columns, with minor gaps in the RPCELM, PHIF, and SW columns.
The sparkline to the right hand side of the plot provides an indication of data completeness. If the line is at the maximum value (to the right) it shows that data row as being complete.
```
msno.matrix(df)
plt.show()
```
Another plot we can call upon is the bar plot, which provides a graphical summary of the number of points in each columns.
```
msno.bar(df)
```
## Using matplotlib
We can generate our own plots to show how the data sparsity varies across each of the wells. In order to do this, we need to manipulate the dataframe.
First we create a copy of the dataframe to work on separately, and then replace each column with a value of 1 if the data is non-null.
To make our plot work, we need to increment each column's value by 1. This allows us to plot each column as an offset to the previous one.
```
data_nan = df.copy()
for num, col in enumerate(data_nan.columns[2:]):
data_nan[col] = data_nan[col].notnull() * (num + 1)
data_nan[col].replace(0, num, inplace=True)
```
When we view the header of the dataframe we now have a series of columns with increasing values from 1 to 14.
```
data_nan.head()
```
Next, we can group the dataframe by the wellName column.
```
grouped = data_nan.groupby('wellName')
```
We can then create multiple subplots for each well using the new dataframe. Rather than creating subplots within subplots, we can shade from the previous column's max value to the current column's max value if the data is present. If data is absent, it will be displayed as a gap.
```
#Setup the labels we want to display on the x-axis
labels = ['BS', 'CALI', 'DT', 'DTS', 'GR', 'NPHI', 'RACEHM', 'RACELM', 'RHOB', 'RPCEHM', 'RPCELM', 'PHIF', 'SW', 'VSH']
#Setup the figure and the subplots
fig, axs = plt.subplots(3, 2, figsize=(20,20))
#Loop through each well and column in the grouped dataframe
for (name, well), ax in zip(grouped, axs.flat):
ax.set_xlim(0,9)
#Setup the depth range
ax.set_ylim(well.MD.max() + 50, well.MD.min() - 50)
ax.set_ylim(well.MD.max() + 50, well.MD.min() - 50)
# Create multiple fill betweens for each curve# This is between
# the number representing null values and the number representing
# actual values
ticks = []
ticks_labels = []
for i, curve in enumerate(labels):
ax.fill_betweenx(well.MD, i, well[curve], facecolor='lightblue')
ticks.append(i)
ticks_labels.append(i+0.5)
# add extra value on to ticks
ticks.append(len(ticks))
#Setup the grid, axis labels and ticks
ax.grid(axis='x', alpha=0.5, color='black')
ax.set_ylabel('DEPTH (m)', fontsize=18, fontweight='bold')
#Position vertical lines at the boundaries between the bars
ax.set_xticks(ticks, minor=False)
#Position the curve names in the centre of each column
ax.set_xticks(ticks_labels, minor=True)
#Setup the x-axis tick labels
ax.set_xticklabels(labels, rotation='vertical', minor=True, verticalalignment='bottom', fontsize=14)
ax.set_xticklabels('', minor=False)
ax.tick_params(axis='x', which='minor', pad=-10)
ax.tick_params(axis='y', labelsize=14 )
#Assign the well name as the title to each subplot
ax.set_title(name, fontsize=16, fontweight='bold')
plt.tight_layout()
plt.subplots_adjust(hspace=0.15, wspace=0.25)
# plt.savefig('missingdata.png', dpi=200)
plt.show()
```
From the plot, we can not only see the data range of each well, but we can also see that 2 of the 5 wells have missing DT and DTS curves, 2 of the wells have missing data within RPCELM, and 2 of the wells have missing values in the PHIF and SW curves.
## Dealing With Missing Data
### Discarding Variables
As DT and DTS are missing in two of the wells, we have the option to remove these wells from the dataset, or we can remove these two columns for all of the wells.
The following is an example of how we remove the two curves from the dataframe. For this we can pass in a list of the columns names to the `drop()` function, the axis, which we want to drop data along, in this case the columns (axis=1), and the `inplace=True` argument allows us to physically remove these values from the dataframe.
```
df.drop(df[['DT', 'DTS']], axis=1, inplace=True)
```
If we view the header of the dataframe, we will see that we have removed the required columns.
```
df.head()
```
However, if we call upon the info method, we can see we still have null values within the dataframe.
```
df.info()
```
### Discarding NaNs
We can drop missing values by calling upon a special function called `dropna()`. This will remove any NaN (Not a Number) values from the dataframe. The `inplace=True` argument allows us to physically remove these values from the dataframe.
```
df.dropna(inplace=True)
df.info()
```
# Summary
This short notebook has shown three separate ways to visualise missing data. The first is by interrogating the dataframe, the second, by using the missingno library and thirdly by creating a custom visualisation with matplotlib.
At the end, we covered two ways in which missing data can be removed from the dataframe. The first by discarding variables, and the second by discarding missing values within the rows.
|
github_jupyter
|
# Applying Chords to 2D and 3D Images
## Importing packages
```
import time
import porespy as ps
ps.visualization.set_mpl_style()
```
Import the usual packages from the Scipy ecosystem:
```
import scipy as sp
import scipy.ndimage as spim
import matplotlib.pyplot as plt
```
## Demonstration on 2D Image
Start by creating an image using the ``blobs`` function in ``generators``. The useful thing about this function is that images can be created with anisotropy. These are exactly the sort of images where chord length distributions are useful, since chords can be drawn in different directions, to probe the anisotropic pore sizes.
```
im = ps.generators.blobs(shape=[400, 400], blobiness=[2, 1])
```
The image can be visualized easily using matplotlib's ``imshow`` function:
```
# NBVAL_IGNORE_OUTPUT
plt.figure(figsize=[6, 6])
fig = plt.imshow(im)
```
Determining chord-length distributions requires first adding chords to the image, which is done using the ``apply_chords`` function. The following code applies chords to the image in the x-direction (along ``axis=0``), then applies them in the y-direction (``axis=1``). The two images are then plotted using ``matplotlib``.
```
# NBVAL_IGNORE_OUTPUT
crds_x = ps.filters.apply_chords(im=im, spacing=4, axis=0)
crds_y = ps.filters.apply_chords(im=im, spacing=4, axis=1)
fig, ax = plt.subplots(1, 2, figsize=[10, 5])
ax[0].imshow(crds_x)
ax[1].imshow(crds_y)
```
Note that none of the chords touch the edge of the image. These chords are trimmed by default since they are artificially shorter than they should be and would skew the results. This behavior is optional and these chords can be kept by setting ``trim_edges=False``.
It is sometimes useful to colorize the chords by their length. PoreSpy includes a function called ``region_size`` which counts the number of voxels in each connected region of an image, and replaces those voxels with the numerical value of the region size. This is illustrated below:
```
# NBVAL_IGNORE_OUTPUT
sz_x = ps.filters.region_size(crds_x)
sz_y = ps.filters.region_size(crds_y)
fig, ax = plt.subplots(1, 2, figsize=[10, 6])
ax[0].imshow(sz_x)
ax[1].imshow(sz_y)
```
Although the above images are useful for quick visualization, they are not quantitative. To get quantitative chord length distributions, pass the chord image(s) to the ``chord_length_distribution`` functions in the ``metrics`` submodule:
```
data_x = ps.metrics.chord_length_distribution(crds_x, bins=25)
data_y = ps.metrics.chord_length_distribution(crds_y, bins=25)
```
This function, like many of the functions in the ``metrics`` module, returns a named tuple containing various arrays. The advantage of the named tuple is that each array can be accessed by name as attributes, such as ``data_x.pdf``. To see all the available attributes (i.e. arrays) use the autocomplete function if your IDE, the following:
```
print(data_x._fields)
```
Now we can print the results of the chord-length distribution as bar graphs:
```
# NBVAL_IGNORE_OUTPUT
plt.figure(figsize=[6, 6])
bar = plt.bar(x=data_y.L, height=data_y.cdf, width=data_y.bin_widths, color='b', edgecolor='k', alpha=0.5)
bar = plt.bar(x=data_x.L, height=data_x.cdf, width=data_x.bin_widths, color='r', edgecolor='k', alpha=0.5)
```
The key point to see here is that the blue bars are for the y-direction, which was the elongated direction, and as expected they show a tendency toward longer chords.
## Application to 3D images
Chords can just as easily be applied to 3D images. Let's create an artificial image of fibers, aligned in the YZ plane, but oriented randomly in the X direction
```
# NBVAL_IGNORE_OUTPUT
im = ps.generators.cylinders(shape=[200, 400, 400], radius=8, ncylinders=200, )
plt.imshow(im[:, :, 100])
```
As above, we must apply chords to the image then pass the chord image to the ``chord_length_distribution`` function:
```
# NBVAL_IGNORE_OUTPUT
crds = ps.filters.apply_chords(im=im, axis=0)
plt.imshow(crds[:, :, 100])
```
|
github_jupyter
|
# Exercise 6
```
# Importing libs
import cv2
import numpy as np
import matplotlib.pyplot as plt
apple = cv2.imread('images/apple.jpg')
apple = cv2.cvtColor(apple, cv2.COLOR_BGR2RGB)
apple = cv2.resize(apple, (512,512))
orange = cv2.imread('images/orange.jpg')
orange = cv2.cvtColor(orange, cv2.COLOR_BGR2RGB)
orange = cv2.resize(orange, (512,512))
plt.figure(figsize=(10,10))
ax1 = plt.subplot(121)
ax1.imshow(apple)
ax2 = plt.subplot(122)
ax2.imshow(orange)
ax1.axis('off')
ax2.axis('off')
ax1.text(0.5,-0.1, "Apple", ha="center", transform=ax1.transAxes)
ax2.text(0.5,-0.1, "Orange", ha="center", transform=ax2.transAxes)
def combine(img1, img2):
result = np.zeros(img1.shape, dtype='uint')
h,w,_ = img1.shape
result[:,0:w//2,:] = img1[:,0:w//2,:]
result[:,w//2:,:] = img2[:,w//2:,:]
return result.astype('uint8')
apple_orange = combine(apple,orange)
plt.imshow(apple_orange)
plt.axis('off')
plt.figtext(0.5, 0, 'Apple + Orange', horizontalalignment='center')
plt.show()
def buildPyramid(levels, left,right=None):
lresult = left
rresult = right if type(right) is np.ndarray else left
for i in range(levels):
lresult = cv2.pyrDown(lresult)
rresult = cv2.pyrDown(rresult)
for i in range(levels):
lresult = cv2.pyrUp(lresult)
rresult = cv2.pyrUp(rresult)
return combine(lresult,rresult)
apple_orange_pyramid = buildPyramid(3, apple_orange)
plt.figure(figsize=(10,10))
ax1 = plt.subplot(121)
ax1.imshow(apple_orange)
ax2 = plt.subplot(122)
ax2.imshow(apple_orange_pyramid)
ax1.axis('off')
ax2.axis('off')
ax1.text(0.5,-0.1, "Raw", ha="center", transform=ax1.transAxes)
ax2.text(0.5,-0.1, "After Pyramid", ha="center", transform=ax2.transAxes)
apple_orange_pyramid = buildPyramid(3, apple, orange)
plt.figure(figsize=(10,10))
ax1 = plt.subplot(121)
ax1.imshow(apple_orange)
ax2 = plt.subplot(122)
ax2.imshow(apple_orange_pyramid)
ax1.axis('off')
ax2.axis('off')
ax1.text(0.5,-0.1, "Raw", ha="center", transform=ax1.transAxes)
ax2.text(0.5,-0.1, "After Pyramid", ha="center", transform=ax2.transAxes)
```
## Another implementation
```
def buildPyramid2(levels, left,right=None):
lresult = left
rresult = right if type(right) is np.ndarray else left
for i in range(levels):
lresult = cv2.pyrDown(lresult)
rresult = cv2.pyrDown(rresult)
result = combine(lresult,rresult)
for i in range(levels):
result = cv2.pyrUp(result)
return result
apple_orange_pyramid = buildPyramid2(3, apple, orange)
plt.figure(figsize=(10,10))
ax1 = plt.subplot(121)
ax1.imshow(apple_orange)
ax2 = plt.subplot(122)
ax2.imshow(apple_orange_pyramid)
ax1.axis('off')
ax2.axis('off')
ax1.text(0.5,-0.1, "Raw", ha="center", transform=ax1.transAxes)
ax2.text(0.5,-0.1, "After Pyramid", ha="center", transform=ax2.transAxes)
```
|
github_jupyter
|
# Offline analysis of a [mindaffectBCI](https://github.com/mindaffect) savefile
So you have successfully run a BCI experiment and want to have a closer look at the data, and try different analysis settings?
Or you have a BCI experiment file from the internet, e.g. MOABB, and want to try it with the mindaffectBCI analysis decoder?
Then you want to do an off-line analysis of this data!
This notebook shows how to such a quick post-hoc analysis of a previously saved dataset. By the end of this tutorial you will be able to:
* Load a mindaffectBCI savefile
* generate summary plots which show; the per-channel grand average spectrum, the data-summary statistics, per-trial decoding results, the raw stimulus-resonse ERPs, the model as trained by the decoder, the per-trial BCI performance plots.
* understand how to use these plots to identify problems in the data (such as artifacts, excessive line-noise) or the BCI operation
* understand how to change analysis parameters and the used classifier to develop improved decoders
```
import numpy as np
from mindaffectBCI.decoder.analyse_datasets import debug_test_dataset
from mindaffectBCI.decoder.offline.load_mindaffectBCI import load_mindaffectBCI
import matplotlib.pyplot as plt
%matplotlib inline
%load_ext autoreload
%autoreload 2
plt.rcParams['figure.figsize'] = [12, 8] # bigger default figures
```
## Specify the save file you wish to analyse.
You can either specify:
* the full file name to load, e.g. '~/Downloads/mindaffectBCI_200901_1154.txt'
* a wildcard filename, e.g. '~/Downloads/mindaffectBCI*.txt', in which case the **most recent** matching file will be loaded.
* `None`, or '-', in which case the most recent file from the default `logs` directory will be loaded.
```
# select the file to load
#savefile = '~/../../logs/mindaffectBCI_200901_1154_ssvep.txt'
savefile = None # use the most recent file in the logs directory
savefile = 'mindaffectBCI_exampledata.txt'
```
## Load the *RAW*data
Load, with minimal pre-processing to see what the raw signals look like. Note: we turn off the default filtering and downsampling with `stopband=None, fs_out=None` to get a true raw dataset.
It will then plot the grand-aver-spectrum of this raw data. This plot shows for each EEG channel the signal power across different signal frequencies. This is useful to check for artifacts (seen as peaks in the spectrum at specific frequencies, such as 50hz), or bad-channels (seen as channels with excessively high or low power in general.)
During loading the system will print some summary information about the loaded data and preprocessing applied. Including:
* The filter and downsampling applied
* The number of trails in the data and their durations
* The trail data-slice used, measured relative to the trial start event
* The EEG and STIMULUS meta-information, in terms of the array shape, e.g. (13,575,4) and the axis labels, e.g. (trials, time, channels) respectively.
```
X, Y, coords = load_mindaffectBCI(savefile, stopband=None, fs_out=None)
# output is: X=eeg, Y=stimulus, coords=meta-info about dimensions of X and Y
print("EEG: X({}){} @{}Hz".format([c['name'] for c in coords],X.shape,coords[1]['fs']))
print("STIMULUS: Y({}){}".format([c['name'] for c in coords[:-1]]+['output'],Y.shape))
# Plot the grand average spectrum to get idea of the signal quality
from mindaffectBCI.decoder.preprocess import plot_grand_average_spectrum
plot_grand_average_spectrum(X, fs=coords[1]['fs'], ch_names=coords[-1]['coords'], log=True)
```
## Reload the data, with standard preprocessing.
This time, we want to analysis the loaded data for the BCI signal. Whilst we can do this after loading, to keep the analysis as similar as possible to the on-line system where the decoder only sees pre-processed data, we will reload wand apply the pre-processing directly. This also has the benefit of making the datafile smaller.
To reproduce the pre-processing done in the on-line BCI we will set the pre-processing to:
* temporally filter the data to the BCI relevant range. Temporal filtering is a standard technique to remove sigal frequencies which we know only contain noise. For the noise-tag brain response we know it is mainly in the frequency range from 3 to about 25 Hz. Thus, we specifcy a bandpass filter to only retain these frequencies with:
`stopband=(3,25,'bandpass')`
* The orginal EEG is sampled 250 times per second. However, the BCI relevant signal changes at most at 25 times per second, thus the EEG is sampled much more rapidly than needed -- so processing it takes undeeded computational resources. Thus, we downsmaple the data to save some computation. To avoid signal-artifacts, as a general 'rule of thumb' you should downsample to about 3 times your maximum signal frequency. In this case we use an output sample rate of 4 times, or 100 h with:
`fs_out=100`
```
X, Y, coords = load_mindaffectBCI(savefile, stopband=(3,25,'bandpass'), fs_out=100)
# output is: X=eeg, Y=stimulus, coords=meta-info about dimensions of X and Y
print("EEG: X({}){} @{}Hz".format([c['name'] for c in coords],X.shape,coords[1]['fs']))
print("STIMULUS: Y({}){}".format([c['name'] for c in coords[:-1]]+['output'],Y.shape))
```
## Analyse the data
The following code runs the standard initial analysis and data-set visualization, in one go with some standard analysis parameters:
* tau_ms : the length of the modelled stimulus response (in milliseconds)
* evtlabs : the type of brain feaatures to transform the stimulus information into prior to fitting the model in this case
* 're' -> rising edge
* 'fe' -> falling edge
see `stim2event.py` for more information on possible transformations
* rank : the rank of the CCA model to fit
* model : the type of model to fit. 'cca' corrospends to the Cannonical Correlation Analysis model.
This generates many visualizations. The most important are:
1. **Summary Statistics**: Summary statistics for the data with,
This has vertically 3 sub-parts.
row 1: Cxx : this is the spatial cross-correlation of the EEG channels
row 2: Cxy : this is the cross-correlation of the stimulus with the EEG. Which for discrete stimuli as used in this BCI is essentially another view of the ERP.
row 3: Cyy : the auto-cross covariance of the stimulus features with the other (time-delayed) stimulus features
<img src='images/SummaryStatistics.png' width=200>
2. **Grand Average Spectrum** : This shows for each data channel the power over different signal frequencies. This is useful to identify artifacts in the data, which tend to show up as peaks in the spectrum at different frequencies, e.g. high power below 3Hz indicate movement artifacts, high power at 50/60hz indicates excessive line-noise interference.
<img src='images/GrandAverageSpectrum.png' width=200>
3. **ERP** : This plot shows for each EEG channel the averaged measured response over time after the triggering stimulus. This is the conventional plot that you find in many neuroscientific publications.
<img src='images/ERP.png' width=200>
4. **Decoding Curve** + **Yerr** : The decoder accumulates information during a trial to make it's predictions better. These pair of plots show this information as a 'decoding curve' which shows two important things:
a) **Yerr** : which is the **true** error-rate of the systems predictions, with increasing trial time.
b) **Perr** : which is the systems own **estimation** of it's prediction error. This estimation is used by the system to identify when it is confident enough to make a selection and stop a trial early. Thus, this should ideally be as accurate as possible, so it's near 1 when Yerr is 1 and near 0 when Yerr is 0. In the DecodingCurve plot Perr is shown by colored dots, with red being Yerr=1 and green being Yerr=0. Thus, if the error estimates are good you should see red dots at the top left (wrong with short trials) and green dots at the bottom right (right with more data).
<img src='images/DecodingCurve.png' width=200> <img src='images/Ycorrect.png' width=200>
5. **Trial Summary** : This plot gives a direct trial-by-trial view of the input data and the BCI performance. With each trial plotted individually running from left to right top to bottom.
<img src='images/TrialSummary.png' width=400>
Zooming in on a single trial, we see that vertically it has 5 sub-parts:
a) **X** : this is the pre-processed input EEG data, with time horizontially, and channels with different colored lines vertically.
b) **Y** : this is the raw stimulus information, with time horizontially and outputs vertically.
c) **Fe** : this is the systems predicted score for each type of stimulus-event, generated by applying the model to the raw EEG (e.g. 're','fe')
d) **Fy** : this is the systems _accumulated_ predicted score for each output, generated by combining the predicted stimulus scores with the stimulus information. Here the **true** output is in black with the other outputs in grey. Thus, if the system is working correctly, the true output has the highest score and will be the highest line.
e) **Py** : this is the systems **estimated** target probability for each output, generated by softmaxing the Fy scores. Again, the true target is in black with the others in grey. So if the system is working well the black line is near 0 when it's incorrect, and then jumps to 1 when it is correct.
<img src='images/TrialSummary_single.png' width=200>
6. *Model*: plot of the fitted model, in two sub-plots with: a) the fitted models spatial-filter -- which shows the importance of each EEG channel, b) the models impulse response -- which shows how the brain responds over time to the different types of stimulus event
<img src='images/ForwardModel.png' width=200>
```
clsfr=debug_test_dataset(X, Y, coords,
model='cca', evtlabs=('re','fe'), rank=1, tau_ms=450)
```
## Alternative Analyse
The basic analysis system has many parameters you can tweak to test different analysis methods. The following code runs the standard initial analysis and data-set visualization, in one go with some standard analysis parameters:
tau_ms : the length of the modelled stimulus response (in milliseconds)
evtlabs : the type of brain feaatures to transform the stimulus information into prior to fitting the model in this case
're' -> rising edge
'fe' -> falling edge see stim2event.py for more information on possible transformations
rank : the rank of the CCA model to fit
model : the type of model to fit. 'cca' corrospends to the Cannonical Correlation Analysis model.
other options include:
* 'ridge' = ridge-regression,
* 'fwd' = Forward Modelling,
* 'bwd' = Backward Modelling,
* 'lr' = logistic-regression,
* 'svc' = support vector machine
See the help for `mindaffectBCI.decoder.model_fitting.BaseSequence2Sequence` or `mindaffectBCI.decoder.analyse_datasets.analyse_dataset` for more details on the other options.
Here we use a Logistic Regression classifier to classify single stimulus-responses into rising-edge (re) or falling-edge (fe) responses.
Note: we also include some additional pre-processing in this case, which consists of:
* **whiten** : this will do a spatial whitening, so that the data input to the classifier is **spatially** decorrelated. This happens automatically with the CCA classifier, and has been found useful to suppress artifacts in the data.
* **whiten_spectrum** : this will approximately decorrelate different frequencies in the data. In effect this flattens the peaks and troughs in the data frequency spectrum. This pre-processing also been found useful to suppress artifacts in the data.
Further, as this is now a classification problem, we set `ignore_unlabelled=True`. This means that samples which are not either rising edges or falling edges will not be given to the classifier -- so in the end we train a simple binary classifier.
```
# test different inner classifier. Here we use a Logistic Regression classifier to classify single stimulus-responses into rising-edge (re) or falling-edge (fe) responses.
debug_test_dataset(X, Y, coords,
preprocess_args=dict(badChannelThresh=3, badTrialThresh=None, whiten=.01, whiten_spectrum=.1),
model='lr', evtlabs=('re', 'fe'), tau_ms=450, ignore_unlabelled=True)
```
|
github_jupyter
|
<div class="alert alert-block alert-info" style="margin-top: 20px">
<a href="https://cocl.us/corsera_da0101en_notebook_top">
<img src="https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/Images/TopAd.png" width="750" align="center">
</a>
</div>
<a href="https://www.bigdatauniversity.com"><img src = "https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/Images/CCLog.png" width = 300, align = "center"></a>
<h1 align=center><font size=5>Data Analysis with Python</font></h1>
<h1>Data Wrangling</h1>
<h3>Welcome!</h3>
By the end of this notebook, you will have learned the basics of Data Wrangling!
<h2>Table of content</h2>
<div class="alert alert-block alert-info" style="margin-top: 20px">
<ul>
<li><a href="#identify_handle_missing_values">Identify and handle missing values</a>
<ul>
<li><a href="#identify_missing_values">Identify missing values</a></li>
<li><a href="#deal_missing_values">Deal with missing values</a></li>
<li><a href="#correct_data_format">Correct data format</a></li>
</ul>
</li>
<li><a href="#data_standardization">Data standardization</a></li>
<li><a href="#data_normalization">Data Normalization (centering/scaling)</a></li>
<li><a href="#binning">Binning</a></li>
<li><a href="#indicator">Indicator variable</a></li>
</ul>
Estimated Time Needed: <strong>30 min</strong>
</div>
<hr>
<h2>What is the purpose of Data Wrangling?</h2>
Data Wrangling is the process of converting data from the initial format to a format that may be better for analysis.
<h3>What is the fuel consumption (L/100k) rate for the diesel car?</h3>
<h3>Import data</h3>
<p>
You can find the "Automobile Data Set" from the following link: <a href="https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data">https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data</a>.
We will be using this data set throughout this course.
</p>
<h4>Import pandas</h4>
```
import pandas as pd
import matplotlib.pylab as plt
```
<h2>Reading the data set from the URL and adding the related headers.</h2>
URL of the dataset
This dataset was hosted on IBM Cloud object click <a href="https://cocl.us/corsera_da0101en_notebook_bottom">HERE</a> for free storage
```
filename = "https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/auto.csv"
```
Python list <b>headers</b> containing name of headers
```
headers = ["symboling","normalized-losses","make","fuel-type","aspiration", "num-of-doors","body-style",
"drive-wheels","engine-location","wheel-base", "length","width","height","curb-weight","engine-type",
"num-of-cylinders", "engine-size","fuel-system","bore","stroke","compression-ratio","horsepower",
"peak-rpm","city-mpg","highway-mpg","price"]
```
Use the Pandas method <b>read_csv()</b> to load the data from the web address. Set the parameter "names" equal to the Python list "headers".
```
df = pd.read_csv(filename, names = headers)
```
Use the method <b>head()</b> to display the first five rows of the dataframe.
```
# To see what the data set looks like, we'll use the head() method.
df.head()
```
As we can see, several question marks appeared in the dataframe; those are missing values which may hinder our further analysis.
<div>So, how do we identify all those missing values and deal with them?</div>
<b>How to work with missing data?</b>
Steps for working with missing data:
<ol>
<li>dentify missing data</li>
<li>deal with missing data</li>
<li>correct data format</li>
</ol>
<h2 id="identify_handle_missing_values">Identify and handle missing values</h2>
<h3 id="identify_missing_values">Identify missing values</h3>
<h4>Convert "?" to NaN</h4>
In the car dataset, missing data comes with the question mark "?".
We replace "?" with NaN (Not a Number), which is Python's default missing value marker, for reasons of computational speed and convenience. Here we use the function:
<pre>.replace(A, B, inplace = True) </pre>
to replace A by B
```
import numpy as np
# replace "?" to NaN
df.replace("?", np.nan, inplace = True)
df.head(5)
```
dentify_missing_values
<h4>Evaluating for Missing Data</h4>
The missing values are converted to Python's default. We use Python's built-in functions to identify these missing values. There are two methods to detect missing data:
<ol>
<li><b>.isnull()</b></li>
<li><b>.notnull()</b></li>
</ol>
The output is a boolean value indicating whether the value that is passed into the argument is in fact missing data.
```
missing_data = df.isnull()
missing_data.head(5)
```
"True" stands for missing value, while "False" stands for not missing value.
<h4>Count missing values in each column</h4>
<p>
Using a for loop in Python, we can quickly figure out the number of missing values in each column. As mentioned above, "True" represents a missing value, "False" means the value is present in the dataset. In the body of the for loop the method ".value_counts()" counts the number of "True" values.
</p>
```
for column in missing_data.columns.values.tolist():
print(column)
print (missing_data[column].value_counts())
print("")
```
Based on the summary above, each column has 205 rows of data, seven columns containing missing data:
<ol>
<li>"normalized-losses": 41 missing data</li>
<li>"num-of-doors": 2 missing data</li>
<li>"bore": 4 missing data</li>
<li>"stroke" : 4 missing data</li>
<li>"horsepower": 2 missing data</li>
<li>"peak-rpm": 2 missing data</li>
<li>"price": 4 missing data</li>
</ol>
<h3 id="deal_missing_values">Deal with missing data</h3>
<b>How to deal with missing data?</b>
<ol>
<li>drop data<br>
a. drop the whole row<br>
b. drop the whole column
</li>
<li>replace data<br>
a. replace it by mean<br>
b. replace it by frequency<br>
c. replace it based on other functions
</li>
</ol>
Whole columns should be dropped only if most entries in the column are empty. In our dataset, none of the columns are empty enough to drop entirely.
We have some freedom in choosing which method to replace data; however, some methods may seem more reasonable than others. We will apply each method to many different columns:
<b>Replace by mean:</b>
<ul>
<li>"normalized-losses": 41 missing data, replace them with mean</li>
<li>"stroke": 4 missing data, replace them with mean</li>
<li>"bore": 4 missing data, replace them with mean</li>
<li>"horsepower": 2 missing data, replace them with mean</li>
<li>"peak-rpm": 2 missing data, replace them with mean</li>
</ul>
<b>Replace by frequency:</b>
<ul>
<li>"num-of-doors": 2 missing data, replace them with "four".
<ul>
<li>Reason: 84% sedans is four doors. Since four doors is most frequent, it is most likely to occur</li>
</ul>
</li>
</ul>
<b>Drop the whole row:</b>
<ul>
<li>"price": 4 missing data, simply delete the whole row
<ul>
<li>Reason: price is what we want to predict. Any data entry without price data cannot be used for prediction; therefore any row now without price data is not useful to us</li>
</ul>
</li>
</ul>
<h4>Calculate the average of the column </h4>
```
avg_norm_loss = df["normalized-losses"].astype("float").mean(axis=0)
print("Average of normalized-losses:", avg_norm_loss)
```
<h4>Replace "NaN" by mean value in "normalized-losses" column</h4>
```
df["normalized-losses"].replace(np.nan, avg_norm_loss, inplace=True)
```
<h4>Calculate the mean value for 'bore' column</h4>
```
avg_bore=df['bore'].astype('float').mean(axis=0)
print("Average of bore:", avg_bore)
```
<h4>Replace NaN by mean value</h4>
```
df["bore"].replace(np.nan, avg_bore, inplace=True)
```
<div class="alert alert-danger alertdanger" style="margin-top: 20px">
<h1> Question #1: </h1>
<b>According to the example above, replace NaN in "stroke" column by mean.</b>
</div>
```
# Write your code below and press Shift+Enter to execute
avg_stroke=df['stroke'].astype('float').mean(axis=0)
df['stroke'].replace(np.nan, avg_stroke, inplace=True)
```
Double-click <b>here</b> for the solution.
<!-- The answer is below:
# calculate the mean vaule for "stroke" column
avg_stroke = df["stroke"].astype("float").mean(axis = 0)
print("Average of stroke:", avg_stroke)
# replace NaN by mean value in "stroke" column
df["stroke"].replace(np.nan, avg_stroke, inplace = True)
-->
<h4>Calculate the mean value for the 'horsepower' column:</h4>
```
avg_horsepower = df['horsepower'].astype('float').mean(axis=0)
print("Average horsepower:", avg_horsepower)
```
<h4>Replace "NaN" by mean value:</h4>
```
df['horsepower'].replace(np.nan, avg_horsepower, inplace=True)
```
<h4>Calculate the mean value for 'peak-rpm' column:</h4>
```
avg_peakrpm=df['peak-rpm'].astype('float').mean(axis=0)
print("Average peak rpm:", avg_peakrpm)
```
<h4>Replace NaN by mean value:</h4>
```
df['peak-rpm'].replace(np.nan, avg_peakrpm, inplace=True)
```
To see which values are present in a particular column, we can use the ".value_counts()" method:
```
df['num-of-doors'].value_counts()
```
We can see that four doors are the most common type. We can also use the ".idxmax()" method to calculate for us the most common type automatically:
```
df['num-of-doors'].value_counts().idxmax()
```
The replacement procedure is very similar to what we have seen previously
```
#replace the missing 'num-of-doors' values by the most frequent
df["num-of-doors"].replace(np.nan, "four", inplace=True)
```
Finally, let's drop all rows that do not have price data:
```
# simply drop whole row with NaN in "price" column
df.dropna(subset=["price"], axis=0, inplace=True)
# reset index, because we droped two rows
df.reset_index(drop=True, inplace=True)
df.head()
```
<b>Good!</b> Now, we obtain the dataset with no missing values.
<h3 id="correct_data_format">Correct data format</h3>
<b>We are almost there!</b>
<p>The last step in data cleaning is checking and making sure that all data is in the correct format (int, float, text or other).</p>
In Pandas, we use
<p><b>.dtype()</b> to check the data type</p>
<p><b>.astype()</b> to change the data type</p>
<h4>Lets list the data types for each column</h4>
```
df.dtypes
```
<p>As we can see above, some columns are not of the correct data type. Numerical variables should have type 'float' or 'int', and variables with strings such as categories should have type 'object'. For example, 'bore' and 'stroke' variables are numerical values that describe the engines, so we should expect them to be of the type 'float' or 'int'; however, they are shown as type 'object'. We have to convert data types into a proper format for each column using the "astype()" method.</p>
<h4>Convert data types to proper format</h4>
```
df[["bore", "stroke"]] = df[["bore", "stroke"]].astype("float")
df[["normalized-losses"]] = df[["normalized-losses"]].astype("int")
df[["price"]] = df[["price"]].astype("float")
df[["peak-rpm"]] = df[["peak-rpm"]].astype("float")
```
<h4>Let us list the columns after the conversion</h4>
```
df.dtypes
```
<b>Wonderful!</b>
Now, we finally obtain the cleaned dataset with no missing values and all data in its proper format.
<h2 id="data_standardization">Data Standardization</h2>
<p>
Data is usually collected from different agencies with different formats.
(Data Standardization is also a term for a particular type of data normalization, where we subtract the mean and divide by the standard deviation)
</p>
<b>What is Standardization?</b>
<p>Standardization is the process of transforming data into a common format which allows the researcher to make the meaningful comparison.
</p>
<b>Example</b>
<p>Transform mpg to L/100km:</p>
<p>In our dataset, the fuel consumption columns "city-mpg" and "highway-mpg" are represented by mpg (miles per gallon) unit. Assume we are developing an application in a country that accept the fuel consumption with L/100km standard</p>
<p>We will need to apply <b>data transformation</b> to transform mpg into L/100km?</p>
<p>The formula for unit conversion is<p>
L/100km = 235 / mpg
<p>We can do many mathematical operations directly in Pandas.</p>
```
df.head()
# Convert mpg to L/100km by mathematical operation (235 divided by mpg)
df['city-L/100km'] = 235/df["city-mpg"]
# check your transformed data
df.head()
```
<div class="alert alert-danger alertdanger" style="margin-top: 20px">
<h1> Question #2: </h1>
<b>According to the example above, transform mpg to L/100km in the column of "highway-mpg", and change the name of column to "highway-L/100km".</b>
</div>
```
# Write your code below and press Shift+Enter to execute
df['highway-mpg'] = 235/df['highway-mpg']
df.rename(columns={'highway-mpg':'highway-L/100km'}, inplace=True)
df.head()
```
Double-click <b>here</b> for the solution.
<!-- The answer is below:
# transform mpg to L/100km by mathematical operation (235 divided by mpg)
df["highway-mpg"] = 235/df["highway-mpg"]
# rename column name from "highway-mpg" to "highway-L/100km"
df.rename(columns={'"highway-mpg"':'highway-L/100km'}, inplace=True)
# check your transformed data
df.head()
-->
<h2 id="data_normalization">Data Normalization</h2>
<b>Why normalization?</b>
<p>Normalization is the process of transforming values of several variables into a similar range. Typical normalizations include scaling the variable so the variable average is 0, scaling the variable so the variance is 1, or scaling variable so the variable values range from 0 to 1
</p>
<b>Example</b>
<p>To demonstrate normalization, let's say we want to scale the columns "length", "width" and "height" </p>
<p><b>Target:</b>would like to Normalize those variables so their value ranges from 0 to 1.</p>
<p><b>Approach:</b> replace original value by (original value)/(maximum value)</p>
```
# replace (original value) by (original value)/(maximum value)
df['length'] = df['length']/df['length'].max()
df['width'] = df['width']/df['width'].max()
```
<div class="alert alert-danger alertdanger" style="margin-top: 20px">
<h1> Questiont #3: </h1>
<b>According to the example above, normalize the column "height".</b>
</div>
```
# Write your code below and press Shift+Enter to execute
df['height'] = df['height']/df['height'].max()
df[["length","width","height"]].head()
```
Double-click <b>here</b> for the solution.
<!-- The answer is below:
df['height'] = df['height']/df['height'].max()
# show the scaled columns
df[["length","width","height"]].head()
-->
Here we can see, we've normalized "length", "width" and "height" in the range of [0,1].
<h2 id="binning">Binning</h2>
<b>Why binning?</b>
<p>
Binning is a process of transforming continuous numerical variables into discrete categorical 'bins', for grouped analysis.
</p>
<b>Example: </b>
<p>In our dataset, "horsepower" is a real valued variable ranging from 48 to 288, it has 57 unique values. What if we only care about the price difference between cars with high horsepower, medium horsepower, and little horsepower (3 types)? Can we rearrange them into three ‘bins' to simplify analysis? </p>
<p>We will use the Pandas method 'cut' to segment the 'horsepower' column into 3 bins </p>
<h3>Example of Binning Data In Pandas</h3>
Convert data to correct format
```
df["horsepower"]=df["horsepower"].astype(int, copy=True)
```
Lets plot the histogram of horspower, to see what the distribution of horsepower looks like.
```
%matplotlib inline
import matplotlib as plt
from matplotlib import pyplot
plt.pyplot.hist(df["horsepower"])
# set x/y labels and plot title
plt.pyplot.xlabel("horsepower")
plt.pyplot.ylabel("count")
plt.pyplot.title("horsepower bins")
```
<p>We would like 3 bins of equal size bandwidth so we use numpy's <code>linspace(start_value, end_value, numbers_generated</code> function.</p>
<p>Since we want to include the minimum value of horsepower we want to set start_value=min(df["horsepower"]).</p>
<p>Since we want to include the maximum value of horsepower we want to set end_value=max(df["horsepower"]).</p>
<p>Since we are building 3 bins of equal length, there should be 4 dividers, so numbers_generated=4.</p>
We build a bin array, with a minimum value to a maximum value, with bandwidth calculated above. The bins will be values used to determine when one bin ends and another begins.
```
bins = np.linspace(min(df["horsepower"]), max(df["horsepower"]), 4)
bins
```
We set group names:
```
group_names = ['Low', 'Medium', 'High']
```
We apply the function "cut" the determine what each value of "df['horsepower']" belongs to.
```
df['horsepower-binned'] = pd.cut(df['horsepower'], bins, labels=group_names, include_lowest=True )
df[['horsepower','horsepower-binned']].head(20)
```
Lets see the number of vehicles in each bin.
```
df["horsepower-binned"].value_counts()
```
Lets plot the distribution of each bin.
```
%matplotlib inline
import matplotlib as plt
from matplotlib import pyplot
pyplot.bar(group_names, df["horsepower-binned"].value_counts())
# set x/y labels and plot title
plt.pyplot.xlabel("horsepower")
plt.pyplot.ylabel("count")
plt.pyplot.title("horsepower bins")
```
<p>
Check the dataframe above carefully, you will find the last column provides the bins for "horsepower" with 3 categories ("Low","Medium" and "High").
</p>
<p>
We successfully narrow the intervals from 57 to 3!
</p>
<h3>Bins visualization</h3>
Normally, a histogram is used to visualize the distribution of bins we created above.
```
%matplotlib inline
import matplotlib as plt
from matplotlib import pyplot
a = (0,1,2)
# draw historgram of attribute "horsepower" with bins = 3
plt.pyplot.hist(df["horsepower"], bins = 3)
# set x/y labels and plot title
plt.pyplot.xlabel("horsepower")
plt.pyplot.ylabel("count")
plt.pyplot.title("horsepower bins")
```
The plot above shows the binning result for attribute "horsepower".
<h2 id="indicator">Indicator variable (or dummy variable)</h2>
<b>What is an indicator variable?</b>
<p>
An indicator variable (or dummy variable) is a numerical variable used to label categories. They are called 'dummies' because the numbers themselves don't have inherent meaning.
</p>
<b>Why we use indicator variables?</b>
<p>
So we can use categorical variables for regression analysis in the later modules.
</p>
<b>Example</b>
<p>
We see the column "fuel-type" has two unique values, "gas" or "diesel". Regression doesn't understand words, only numbers. To use this attribute in regression analysis, we convert "fuel-type" into indicator variables.
</p>
<p>
We will use the panda's method 'get_dummies' to assign numerical values to different categories of fuel type.
</p>
```
df.columns
```
get indicator variables and assign it to data frame "dummy_variable_1"
```
dummy_variable_1 = pd.get_dummies(df["fuel-type"])
dummy_variable_1.head()
```
change column names for clarity
```
dummy_variable_1.rename(columns={'fuel-type-diesel':'gas', 'fuel-type-diesel':'diesel'}, inplace=True)
dummy_variable_1.head()
```
We now have the value 0 to represent "gas" and 1 to represent "diesel" in the column "fuel-type". We will now insert this column back into our original dataset.
```
# merge data frame "df" and "dummy_variable_1"
df = pd.concat([df, dummy_variable_1], axis=1)
# drop original column "fuel-type" from "df"
df.drop("fuel-type", axis = 1, inplace=True)
df.head()
```
The last two columns are now the indicator variable representation of the fuel-type variable. It's all 0s and 1s now.
<div class="alert alert-danger alertdanger" style="margin-top: 20px">
<h1> Question #4: </h1>
<b>As above, create indicator variable to the column of "aspiration": "std" to 0, while "turbo" to 1.</b>
</div>
```
# Write your code below and press Shift+Enter to execute
dummy_variable_2 = pd.get_dummies(df['aspiration'])
dummy_variable_2.head()
```
Double-click <b>here</b> for the solution.
<!-- The answer is below:
# get indicator variables of aspiration and assign it to data frame "dummy_variable_2"
dummy_variable_2 = pd.get_dummies(df['aspiration'])
# change column names for clarity
dummy_variable_2.rename(columns={'std':'aspiration-std', 'turbo': 'aspiration-turbo'}, inplace=True)
# show first 5 instances of data frame "dummy_variable_1"
dummy_variable_2.head()
-->
<div class="alert alert-danger alertdanger" style="margin-top: 20px">
<h1> Question #5: </h1>
<b>Merge the new dataframe to the original dataframe then drop the column 'aspiration'</b>
</div>
```
# Write your code below and press Shift+Enter to execute
# merge data frame "df" and "dummy_variable_1"
df = pd.concat([df, dummy_variable_2], axis=1)
# drop original column "fuel-type" from "df"
df.drop('aspiration', axis = 1, inplace=True)
```
Double-click <b>here</b> for the solution.
<!-- The answer is below:
#merge the new dataframe to the original datafram
df = pd.concat([df, dummy_variable_2], axis=1)
# drop original column "aspiration" from "df"
df.drop('aspiration', axis = 1, inplace=True)
-->
save the new csv
```
df.to_csv('clean_df.csv')
```
<h1>Thank you for completing this notebook</h1>
<div class="alert alert-block alert-info" style="margin-top: 20px">
<p><a href="https://cocl.us/corsera_da0101en_notebook_bottom"><img src="https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/Images/BottomAd.png" width="750" align="center"></a></p>
</div>
<h3>About the Authors:</h3>
This notebook was written by <a href="https://www.linkedin.com/in/mahdi-noorian-58219234/" target="_blank">Mahdi Noorian PhD</a>, <a href="https://www.linkedin.com/in/joseph-s-50398b136/" target="_blank">Joseph Santarcangelo</a>, Bahare Talayian, Eric Xiao, Steven Dong, Parizad, Hima Vsudevan and <a href="https://www.linkedin.com/in/fiorellawever/" target="_blank">Fiorella Wenver</a> and <a href=" https://www.linkedin.com/in/yi-leng-yao-84451275/ " target="_blank" >Yi Yao</a>.
<p><a href="https://www.linkedin.com/in/joseph-s-50398b136/" target="_blank">Joseph Santarcangelo</a> is a Data Scientist at IBM, and holds a PhD in Electrical Engineering. His research focused on using Machine Learning, Signal Processing, and Computer Vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.</p>
<hr>
<p>Copyright © 2018 IBM Developer Skills Network. This notebook and its source code are released under the terms of the <a href="https://cognitiveclass.ai/mit-license/">MIT License</a>.</p>
|
github_jupyter
|
```
import cv2
cap = cv2.VideoCapture(0)
car_model=cv2.CascadeClassifier('cars.xml')
```
# TO DETECT CAR ON LIVE VIDEO OR PHOTO.....
```
while True:
ret,frame=cap.read()
cars=car_model.detectMultiScale(frame)
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
for(x,y,w,h) in cars:
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),1)
cv2.imshow('car',frame)
if cv2.waitKey(10)==13:
break
cv2.destroyAllWindows()
cap.release()
#main start here
import cv2
from matplotlib import pyplot as plt
import numpy as np
import imutils
import easyocr
#main code
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
#FOR REAL USE CASE and LIVE NUMBER PLATE OF CAR
''''while(cap.isOpened()):
ret, frame = cap.read()
gra = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imwrite('carpic.jpg',frame)
cv2.imshow('frame',gra)
if cv2.waitKey(10) == 13:
break
cap.release()
cv2.destroyAllWindows()
plt.imshow(cv2.cvtColor(gra, cv2.COLOR_BGR2RGB))'''
#USING A IMAGE FROM GOOGLE FOR REFERENCE USE CASE
img=cv2.imread('car11 test.jpeg')
gray=cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(cv2.cvtColor(gray, cv2.COLOR_BGR2RGB))
bfilter = cv2.bilateralFilter(gray, 11, 17, 17) #Noise reduction
edged = cv2.Canny(bfilter, 30, 200) #Edge detection
plt.imshow(cv2.cvtColor(edged, cv2.COLOR_BGR2RGB))
keypoints = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(keypoints)
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:10]
location = None
for contour in contours:
approx = cv2.approxPolyDP(contour, 10, True)
if len(approx) == 4:
location = approx
break
mask = np.zeros(gray.shape, np.uint8)
new_image = cv2.drawContours(mask, [location], 0,255, -1)
new_image = cv2.bitwise_and(img,img, mask=mask)
plt.imshow(cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB))
(x,y) = np.where(mask==255)
(x1, y1) = (np.min(x), np.min(y))
(x2, y2) = (np.max(x), np.max(y))
cropped_image = gray[x1:x2+1, y1:y2+1]
plt.imshow(cv2.cvtColor(cropped_image, cv2.COLOR_BGR2RGB))
reader = easyocr.Reader(['en'])
result = reader.readtext(cropped_image)
text = result[0][-2]
font = cv2.FONT_HERSHEY_SIMPLEX
res = cv2.putText(img, text=text, org=(approx[0][0][0], approx[1][0][1]+60), fontFace=font, fontScale=1, color=(0,255,0), thickness=2, lineType=cv2.LINE_AA)
res = cv2.rectangle(img, tuple(approx[0][0]), tuple(approx[2][0]), (0,255,0),3)
plt.imshow(cv2.cvtColor(res, cv2.COLOR_BGR2RGB))
#Removing spaces from the detected number
def remove(text):
return text.replace(" ", "")
extracted_number=remove(text)
print(extracted_number)
#SELENIUM TO EXTRACT DATA FROM THE THIRD PARTY WEBSITE HERE i used CARS24.Com (VALID for some number)
#YOU CAN PAY FOR OTHER THIRD PARTY WEBSITES FOR MORE NUMBER PLATES
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
reg_no=extracted_number;
driver = webdriver.Chrome("C:\\chromedriver\\chromedriver.exe")
driver.get("https://www.cars24.com/rto-vehicle-registration-details/")
driver.maximize_window()
time.sleep(5)
#Cross button
driver.find_element_by_xpath("/html/body/div[1]/div[5]/div/div/h3/div/img").click()
time.sleep(3)
#sending value
driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div/div[1]/div[2]/form/div/input").click()
last=driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div/div[1]/div[2]/form/div/input")
last.send_keys(reg_no)
time.sleep(2)
#button click
driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div/div[1]/button").click()
time.sleep(3)
#data of user
data=driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div[1]/div[1]")
data_in_text=data.text
print(data_in_text)
phone=driver.find_element_by_xpath("/html/body/div[1]/div[2]/div[2]/div[1]/div[1]/div[1]/div/ul/li[4]/span[2]")
phone_number=phone.text
#clossing driver
driver.close()
#saving into a file
text_file = open("sample.txt", "w")
n = text_file.write(data_in_text)
text_file.close()
```
# then you can send sms for the voilation of rule etc if you want ...
```
#Phone Number of user
print(phone_number)
```
|
github_jupyter
|
<h1>datetime library</h1>
<li>Time is linear
<li>progresses as a straightline trajectory from the big bag
<li>to now and into the future
<li>日期库官方说明 https://docs.python.org/3.5/library/datetime.html
<h3>Reasoning about time is important in data analysis</h3>
<li>Analyzing financial timeseries data
<li>Looking at commuter transit passenger flows by time of day
<li>Understanding web traffic by time of day
<li>Examining seaonality in department store purchases
<h3>The datetime library</h3>
<li>understands the relationship between different points of time
<li>understands how to do operations on time
<h3>Example:</h3>
<li>Which is greater? "10/24/2017" or "11/24/2016"
```
d1 = "10/24/2017"
d2 = "11/24/2016"
max(d1,d2)
```
<li>How much time has passed?
```
d1 - d2
```
<h4>Obviously that's not going to work. </h4>
<h4>We can't do date operations on strings</h4>
<h4>Let's see what happens with datetime</h4>
```
import datetime
d1 = datetime.date(2016,11,24)
d2 = datetime.date(2017,10,24)
max(d1,d2)
print(d2 - d1)
```
<li>datetime objects understand time
<h3>The datetime library contains several useful types</h3>
<li>date: stores the date (month,day,year)
<li>time: stores the time (hours,minutes,seconds)
<li>datetime: stores the date as well as the time (month,day,year,hours,minutes,seconds)
<li>timedelta: duration between two datetime or date objects
<h3>datetime.date</h3>
```
import datetime
century_start = datetime.date(2000,1,1)
today = datetime.date.today()
print(century_start,today)
print("We are",today-century_start,"days into this century")
print(type(century_start))
print(type(today))
```
<h3>For a cleaner output</h3>
```
print("We are",(today-century_start).days,"days into this century")
```
<h3>datetime.datetime</h3>
```
century_start = datetime.datetime(2000,1,1,0,0,0)
time_now = datetime.datetime.now()
print(century_start,time_now)
print("we are",time_now - century_start,"days, hour, minutes and seconds into this century")
```
<h4>datetime objects can check validity</h4>
<li>A ValueError exception is raised if the object is invalid</li>
```
some_date=datetime.date(2015,2,29)
#some_date =datetime.date(2016,2,29)
#some_time=datetime.datetime(2015,2,28,23,60,0)
```
<h3>datetime.timedelta</h3>
<h4>Used to store the duration between two points in time</h4>
```
century_start = datetime.datetime(2050,1,1,0,0,0)
time_now = datetime.datetime.now()
time_since_century_start = time_now - century_start
print("days since century start",time_since_century_start.days)
print("seconds since century start",time_since_century_start.total_seconds())
print("minutes since century start",time_since_century_start.total_seconds()/60)
print("hours since century start",time_since_century_start.total_seconds()/60/60)
```
<h3>datetime.time</h3>
```
date_and_time_now = datetime.datetime.now()
time_now = date_and_time_now.time()
print(time_now)
```
<h4>You can do arithmetic operations on datetime objects</h4>
<li>You can use timedelta objects to calculate new dates or times from a given date
```
today=datetime.date.today()
five_days_later=today+datetime.timedelta(days=5)
print(five_days_later)
now=datetime.datetime.today()
five_minutes_and_five_seconds_later = now + datetime.timedelta(minutes=5,seconds=5)
print(five_minutes_and_five_seconds_later)
now=datetime.datetime.today()
five_minutes_and_five_seconds_earlier = now+datetime.timedelta(minutes=-5,seconds=-5)
print(five_minutes_and_five_seconds_earlier)
```
<li>But you can't use timedelta on time objects. If you do, you'll get a TypeError exception
```
time_now=datetime.datetime.now().time() #Returns the time component (drops the day)
print(time_now)
thirty_seconds=datetime.timedelta(seconds=30)
time_later=time_now+thirty_seconds
#Bug or feature?
#But this is Python
#And we can always get around something by writing a new function!
#Let's write a small function to get around this problem
def add_to_time(time_object,time_delta):
import datetime
temp_datetime_object = datetime.datetime(500,1,1,time_object.hour,time_object.minute,time_object.second)
print(temp_datetime_object)
return (temp_datetime_object+time_delta).time()
#And test it
time_now=datetime.datetime.now().time()
thirty_seconds=datetime.timedelta(seconds=30)
print(time_now,add_to_time(time_now,thirty_seconds))
```
<h2>datetime and strings</h2>
<h4>datetime.strptime</h4>
<li>datetime.strptime(): grabs time from a string and creates a date or datetime or time object
<li>The programmer needs to tell the function what format the string is using
<li> See http://pubs.opengroup.org/onlinepubs/009695399/functions/strptime.html for how to specify the format
```
date='01-Apr-03'
date_object=datetime.datetime.strptime(date,'%d-%b-%y')
print(date_object)
#Unfortunately, there is no similar thing for time delta
#So we have to be creative!
bus_travel_time='2:15:30'
hours,minutes,seconds=bus_travel_time.split(':')
x=datetime.timedelta(hours=int(hours),minutes=int(minutes),seconds=int(seconds))
print(x)
#Or write a function that will do this for a particular format
def get_timedelta(time_string):
hours,minutes,seconds = time_string.split(':')
import datetime
return datetime.timedelta(hours=int(hours),minutes=int(minutes),seconds=int(seconds))
```
<h4>datetime.strftime</h4>
<li>The strftime function flips the strptime function. It converts a datetime object to a string
<li>with the specified format
```
now = datetime.datetime.now()
string_now = datetime.datetime.strftime(now,'%m/%d/%y %H:%M:%S')
print(now,string_now)
print(str(now)) #Or you can use the default conversion
```
|
github_jupyter
|
<table class="ee-notebook-buttons" align="left">
<td><a target="_blank" href="https://github.com/giswqs/earthengine-py-notebooks/tree/master/Algorithms/CloudMasking/landsat457_surface_reflectance.ipynb"><img width=32px src="https://www.tensorflow.org/images/GitHub-Mark-32px.png" /> View source on GitHub</a></td>
<td><a target="_blank" href="https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/Algorithms/CloudMasking/landsat457_surface_reflectance.ipynb"><img width=26px src="https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png" />Notebook Viewer</a></td>
<td><a target="_blank" href="https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/Algorithms/CloudMasking/landsat457_surface_reflectance.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" /> Run in Google Colab</a></td>
</table>
## Install Earth Engine API and geemap
Install the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://geemap.org). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.
The following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.
```
# Installs geemap package
import subprocess
try:
import geemap
except ImportError:
print('Installing geemap ...')
subprocess.check_call(["python", '-m', 'pip', 'install', 'geemap'])
import ee
import geemap
```
## Create an interactive map
The default basemap is `Google Maps`. [Additional basemaps](https://github.com/giswqs/geemap/blob/master/geemap/basemaps.py) can be added using the `Map.add_basemap()` function.
```
Map = geemap.Map(center=[40,-100], zoom=4)
Map
```
## Add Earth Engine Python script
```
# Add Earth Engine dataset
# This example demonstrates the use of the Landsat 4, 5 or 7
# surface reflectance QA band to mask clouds.
# cloudMaskL457 = function(image) {
def cloudMaskL457(image):
qa = image.select('pixel_qa')
# If the cloud bit (5) is set and the cloud confidence (7) is high
# or the cloud shadow bit is set (3), then it's a bad pixel.
cloud = qa.bitwiseAnd(1 << 5) \
.And(qa.bitwiseAnd(1 << 7)) \
.Or(qa.bitwiseAnd(1 << 3))
# Remove edge pixels that don't occur in all bands
mask2 = image.mask().reduce(ee.Reducer.min())
return image.updateMask(cloud.Not()).updateMask(mask2)
# }
# Map the function over the collection and take the median.
collection = ee.ImageCollection('LANDSAT/LT05/C01/T1_SR') \
.filterDate('2010-04-01', '2010-07-30')
composite = collection \
.map(cloudMaskL457) \
.median()
# Display the results in a cloudy place.
Map.setCenter(-6.2622, 53.3473, 12)
Map.addLayer(composite, {'bands': ['B3', 'B2', 'B1'], 'min': 0, 'max': 3000})
```
## Display Earth Engine data layers
```
Map.addLayerControl() # This line is not needed for ipyleaflet-based Map.
Map
```
|
github_jupyter
|
```
%%pyspark
df = spark.read.load('abfss://[email protected]/SeattlePublicLibrary/Library_Collection_Inventory.csv', format='csv'
## If header exists uncomment line below
, header=True
)
display(df.limit(10))
%%pyspark
# Show Schema
df.printSchema()
%%pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# Primary storage info
capture_account_name = 'splacceler5lmevhdeon4ym' # fill in your primary account name
capture_container_name = 'capture' # fill in your container name
capture_relative_path = 'SeattlePublicLibrary/Library_Collection_Inventory.csv' # fill in your relative folder path
capture_adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (capture_container_name, capture_account_name, capture_relative_path)
print('Primary storage account path: ' + capture_adls_path)
%%pyspark
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DoubleType, DateType, TimestampType
csvSchema = StructType([
StructField('bibnum', IntegerType(), True),
StructField('title', StringType(), True),
StructField('author', StringType(), True),
StructField('isbn', StringType(), True),
StructField('publication_year', StringType(), True),
StructField('publisher', StringType(), True),
StructField('subjects', StringType(), True),
StructField('item_type', StringType(), True),
StructField('item_collection', StringType(), True),
StructField('floating_item', StringType(), True),
StructField('item_location', StringType(), True),
StructField('reportDate', StringType(), True),
StructField('item_count', IntegerType(), True)
])
CheckByTPI_capture_df = spark.read.format('csv').option('header', 'True').schema(csvSchema).load(capture_adls_path)
display(CheckByTPI_capture_df.limit(10))
%%pyspark
from pyspark.sql.functions import to_date, to_timestamp, col, date_format, current_timestamp
df_final = (CheckByTPI_capture_df.withColumn("report_date", to_date(col("reportDate"),"MM/dd/yyyy")).drop("reportDate")
.withColumn('loadDate', date_format(current_timestamp(), 'MM/dd/yyyy hh:mm:ss aa'))
.withColumn("load_date", to_timestamp(col("loadDate"),"MM/dd/yyyy hh:mm:ss aa")).drop("loadDate")
)
%%pyspark
# Show Schema
df_final.printSchema()
display(df_final.limit(10))
%%pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
# Primary storage info
compose_account_name = 'splacceler5lmevhdeon4ym' # fill in your primary account name
compose_container_name = 'compose' # fill in your container name
compose_relative_path = 'SeattlePublicLibrary/LibraryCollectionInventory/' # fill in your relative folder path
compose_adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (compose_container_name, compose_account_name, compose_relative_path)
print('Primary storage account path: ' + compose_adls_path)
%%pyspark
compose_parquet_path = compose_adls_path + 'CollectionInventory.parquet'
print('parquet file path: ' + compose_parquet_path)
%%pyspark
df_final.write.parquet(compose_parquet_path, mode = 'overwrite')
%%sql
-- Create database SeattlePublicLibrary only if database with same name does not exist
CREATE DATABASE IF NOT EXISTS SeattlePublicLibrary
%%sql
-- Create table CheckoutsByTitlePhysicalItemsschemafinal only if table with same name does not exist
CREATE TABLE IF NOT EXISTS SeattlePublicLibrary.library_collection_inventory
(title STRING
,author STRING
,isbn STRING
,publication_year STRING
,publisher STRING
,subjects STRING
,item_type STRING
,item_collection STRING
,floating_item STRING
,item_location STRING
,report_date DATE
,item_count INTEGER
,load_date TIMESTAMP
)
USING PARQUET OPTIONS (path 'abfss://[email protected]/SeattlePublicLibrary/LibraryCollectionInventory/CollectionInventory.parquet')
%%sql
--DROP TABLE SeattlePublicLibrary.library_collection_inventory
```
|
github_jupyter
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.