
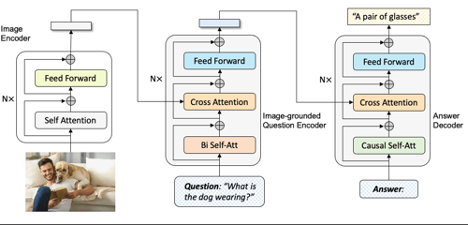
| # Visual Question Answering using BLIP pre-trained model! | |
| This implementation applies the BLIP pre-trained model to solve the icon domain task. | |
|  | |
| | 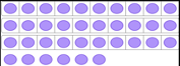| | | |
| |--|--| | |
| | How many dots are there? | 36 | | |
| # Description | |
| **Note: The test dataset does not have labels. I evaluated the model via Kaggle competition and got 96% in accuracy manner. Obviously, you can use a partition of the training set as a testing set. | |
| ## Create data folder | |
| Copy all data following the example form | |
| You can download data [here](https://drive.google.com/file/d/1tt6qJbOgevyPpfkylXpKYy-KaT4_aCYZ/view?usp=sharing) | |
| ## Install requirements.txt | |
| pip install -r requirements.txt | |
| ## Run finetuning code | |
| python finetuning.py | |
| ## Run prediction | |
| python predicting.py | |