
metadata
license: apache-2.0
tags:
- contrastive learning
- CLAP
- audio classification
- zero-shot classification
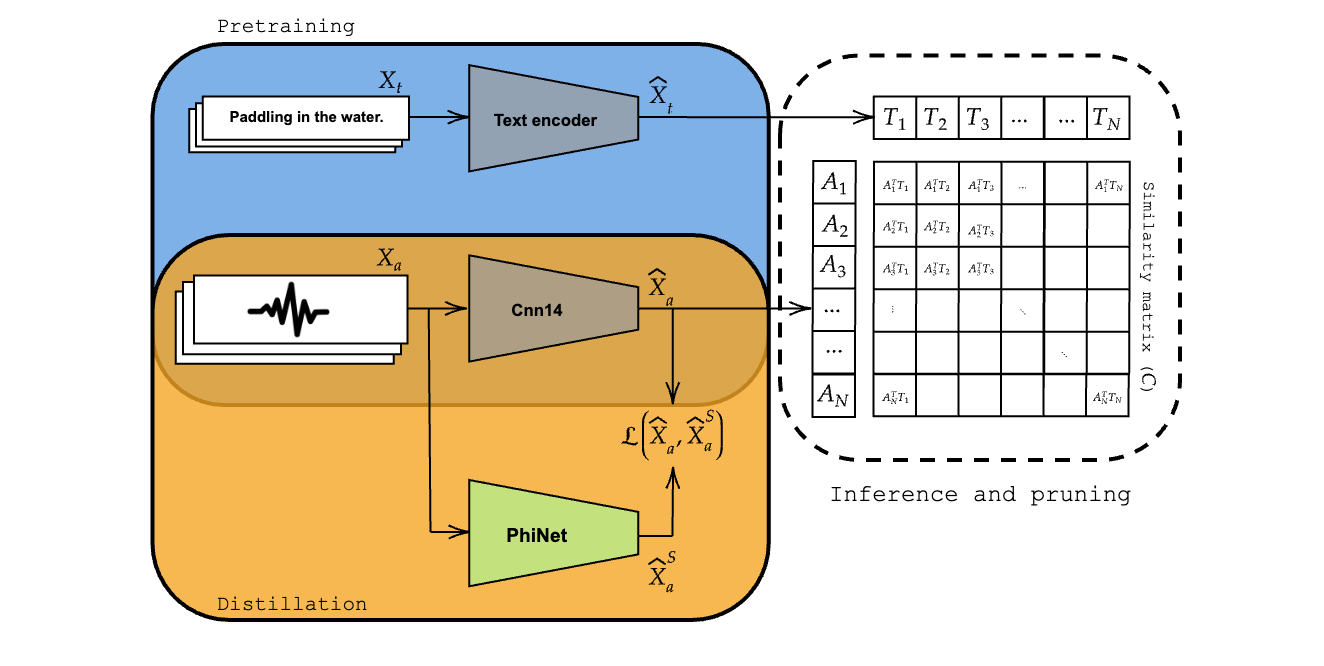
tinyCLAP: Distilling Contrastive Language-Audio Pretrained models
![]()
This repository contains the official implementation of tinyCLAP.
Requirements
To install requirements:
pip install -r extra_requirements.txt
Training
To train the model(s) in the paper, run this command:
MODEL_NAME=phinet_alpha_1.50_beta_0.75_t0_6_N_7
./run_tinyCLAP.sh $MODEL_NAME
Note that MODEL_NAME is formatted such that the script will automatically parse the configuration for the student model.
You can change parameters by changing the model name.
Please note:
- To use the original CLAP encoder in the distillation setting, replace the model name with
Cnn14; - To reproduce the variants of PhiNet from the manuscript, refer to the hyperparameters listed in Table 1.
Evaluation
The command to evaluate the model on each dataset varies slightly among datasets. Below are listed all the necessary commands.
ESC50
python train_clap.py --experiment_name tinyCLAP_$MODEL_NAME --zs_eval True --esc_folder $PATH_TO_ESC
UrbanSound8K
python train_clap.py --experiment_name tinyCLAP_$MODEL_NAME --zs_eval True --us8k_folder $PATH_TO_US8K
TUT17
python train_clap.py --experiment_name tinyCLAP_$MODEL_NAME --zs_eval True --tut17_folder $PATH_TO_TUT17
Pre-trained Models
You can download pretrained models here:
- My awesome model trained on ImageNet using parameters x,y,z.
Citing tinyCLAP
@inproceedings{paissan2024tinyclap,
title={tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models},
author={Paissan, Francesco and Farella, Elisabetta},
journal={Interspeech 2024},
year={2024}
}