|
--- |
|
library_name: transformers |
|
license: mit |
|
language: |
|
- fr |
|
- en |
|
tags: |
|
- french |
|
- chocolatine |
|
datasets: |
|
- jpacifico/french-orca-dpo-pairs-revised |
|
pipeline_tag: text-generation |
|
--- |
|
|
|
### Chocolatine-3B-Instruct-DPO-Revised |
|
|
|
DPO fine-tuned of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) (3.82B params) |
|
using the [jpacifico/french-orca-dpo-pairs-revised](https://huggingface.co/datasets/jpacifico/french-orca-dpo-pairs-revised) rlhf dataset. |
|
Training in French also improves the model in English, surpassing the performances of its base model. |
|
Window context = 4k tokens |
|
|
|
Quantized 4-bit and 8-bit versions are available (see below) |
|
A larger version Chocolatine-14B is also available in its latest [version-1.2](https://huggingface.co/jpacifico/Chocolatine-14B-Instruct-DPO-v1.2) |
|
|
|
### Benchmarks |
|
|
|
Chocolatine is the best-performing 3B model on the [OpenLLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) (august 2024) |
|
[Update 2024-08-22] Chocolatine-3B also outperforms Microsoft's new model Phi-3.5-mini-instruct on the average benchmarks of the 3B category. |
|
|
|
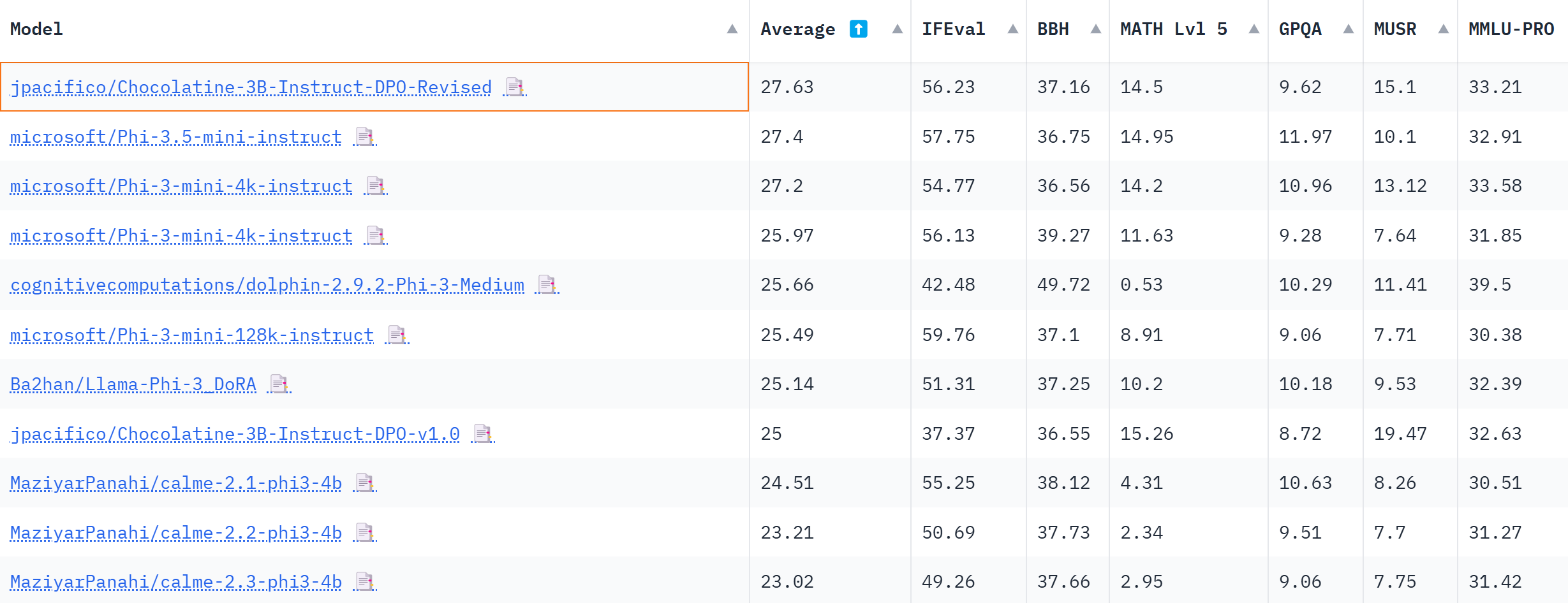 |
|
|
|
|
|
| Metric |Value| |
|
|-------------------|----:| |
|
|**Avg.** |**27.63**| |
|
|IFEval |56.23| |
|
|BBH |37.16| |
|
|MATH Lvl 5 |14.5| |
|
|GPQA |9.62| |
|
|MuSR |15.1| |
|
|MMLU-PRO |33.21| |
|
|
|
|
|
### MT-Bench-French |
|
|
|
Chocolatine-3B-Instruct-DPO-Revised is outperforming GPT-3.5-Turbo on [MT-Bench-French](https://huggingface.co/datasets/bofenghuang/mt-bench-french), used with [multilingual-mt-bench](https://github.com/Peter-Devine/multilingual_mt_bench) and GPT-4-Turbo as LLM-judge. |
|
Notably, this latest version of the Chocolatine-3B model is approaching the performance of Phi-3-Medium (14B) in French. |
|
|
|
``` |
|
########## First turn ########## |
|
score |
|
model turn |
|
gpt-4o-mini 1 9.28750 |
|
Chocolatine-14B-Instruct-DPO-v1.2 1 8.61250 |
|
Phi-3-medium-4k-instruct 1 8.22500 |
|
gpt-3.5-turbo 1 8.13750 |
|
Chocolatine-3B-Instruct-DPO-Revised 1 7.98750 |
|
Daredevil-8B 1 7.88750 |
|
NeuralDaredevil-8B-abliterated 1 7.62500 |
|
Phi-3-mini-4k-instruct 1 7.21250 |
|
Meta-Llama-3.1-8B-Instruct 1 7.05000 |
|
vigostral-7b-chat 1 6.78750 |
|
Mistral-7B-Instruct-v0.3 1 6.75000 |
|
gemma-2-2b-it 1 6.45000 |
|
French-Alpaca-7B-Instruct_beta 1 5.68750 |
|
vigogne-2-7b-chat 1 5.66250 |
|
|
|
########## Second turn ########## |
|
score |
|
model turn |
|
gpt-4o-mini 2 8.912500 |
|
Chocolatine-14B-Instruct-DPO-v1.2 2 8.337500 |
|
Chocolatine-3B-Instruct-DPO-Revised 2 7.937500 |
|
Phi-3-medium-4k-instruct 2 7.750000 |
|
gpt-3.5-turbo 2 7.679167 |
|
NeuralDaredevil-8B-abliterated 2 7.125000 |
|
Daredevil-8B 2 7.087500 |
|
Meta-Llama-3.1-8B-Instruct 2 6.787500 |
|
Mistral-7B-Instruct-v0.3 2 6.500000 |
|
Phi-3-mini-4k-instruct 2 6.487500 |
|
vigostral-7b-chat 2 6.162500 |
|
gemma-2-2b-it 2 6.100000 |
|
French-Alpaca-7B-Instruct_beta 2 5.487395 |
|
vigogne-2-7b-chat 2 2.775000 |
|
|
|
########## Average ########## |
|
score |
|
model |
|
gpt-4o-mini 9.100000 |
|
Chocolatine-14B-Instruct-DPO-v1.2 8.475000 |
|
Phi-3-medium-4k-instruct 7.987500 |
|
Chocolatine-3B-Instruct-DPO-Revised 7.962500 |
|
gpt-3.5-turbo 7.908333 |
|
Daredevil-8B 7.487500 |
|
NeuralDaredevil-8B-abliterated 7.375000 |
|
Meta-Llama-3.1-8B-Instruct 6.918750 |
|
Phi-3-mini-4k-instruct 6.850000 |
|
Mistral-7B-Instruct-v0.3 6.625000 |
|
vigostral-7b-chat 6.475000 |
|
gemma-2-2b-it 6.275000 |
|
French-Alpaca-7B-Instruct_beta 5.587866 |
|
vigogne-2-7b-chat 4.218750 |
|
``` |
|
|
|
|
|
### Quantized versions |
|
|
|
* **4-bit quantized version** is available here : [jpacifico/Chocolatine-3B-Instruct-DPO-Revised-Q4_K_M-GGUF](https://huggingface.co/jpacifico/Chocolatine-3B-Instruct-DPO-Revised-Q4_K_M-GGUF) |
|
|
|
* **8-bit quantized version** also available here : [jpacifico/Chocolatine-3B-Instruct-DPO-Revised-Q8_0-GGUF](https://huggingface.co/jpacifico/Chocolatine-3B-Instruct-DPO-Revised-Q8_0-GGUF) |
|
|
|
* **Ollama**: [jpacifico/chocolatine-3b](https://ollama.com/jpacifico/chocolatine-3b) |
|
|
|
```bash |
|
ollama run jpacifico/chocolatine-3b |
|
``` |
|
|
|
Ollama *Modelfile* example : |
|
|
|
```bash |
|
FROM ./chocolatine-3b-instruct-dpo-revised-q4_k_m.gguf |
|
TEMPLATE """{{ if .System }}<|system|> |
|
{{ .System }}<|end|> |
|
{{ end }}{{ if .Prompt }}<|user|> |
|
{{ .Prompt }}<|end|> |
|
{{ end }}<|assistant|> |
|
{{ .Response }}<|end|> |
|
""" |
|
PARAMETER stop """{"stop": ["<|end|>","<|user|>","<|assistant|>"]}""" |
|
SYSTEM """You are a friendly assistant called Chocolatine.""" |
|
``` |
|
|
|
### Usage |
|
|
|
You can run this model using my [Colab notebook](https://github.com/jpacifico/Chocolatine-LLM/blob/main/Chocolatine_3B_inference_test_colab.ipynb) |
|
|
|
You can also run Chocolatine using the following code: |
|
|
|
```python |
|
import transformers |
|
from transformers import AutoTokenizer |
|
|
|
# Format prompt |
|
message = [ |
|
{"role": "system", "content": "You are a helpful assistant chatbot."}, |
|
{"role": "user", "content": "What is a Large Language Model?"} |
|
] |
|
tokenizer = AutoTokenizer.from_pretrained(new_model) |
|
prompt = tokenizer.apply_chat_template(message, add_generation_prompt=True, tokenize=False) |
|
|
|
# Create pipeline |
|
pipeline = transformers.pipeline( |
|
"text-generation", |
|
model=new_model, |
|
tokenizer=tokenizer |
|
) |
|
|
|
# Generate text |
|
sequences = pipeline( |
|
prompt, |
|
do_sample=True, |
|
temperature=0.7, |
|
top_p=0.9, |
|
num_return_sequences=1, |
|
max_length=200, |
|
) |
|
print(sequences[0]['generated_text']) |
|
``` |
|
|
|
### Limitations |
|
|
|
The Chocolatine model is a quick demonstration that a base model can be easily fine-tuned to achieve compelling performance. |
|
It does not have any moderation mechanism. |
|
|
|
- **Developed by:** Jonathan Pacifico, 2024 |
|
- **Model type:** LLM |
|
- **Language(s) (NLP):** French, English |
|
- **License:** MIT |
