

metadata
base_model:
- Qwen/Qwen2.5-3B
datasets:
- MegaScience/MegaScience
language:
- en
license: apache-2.0
metrics:
- accuracy
pipeline_tag: text-generation
library_name: transformers
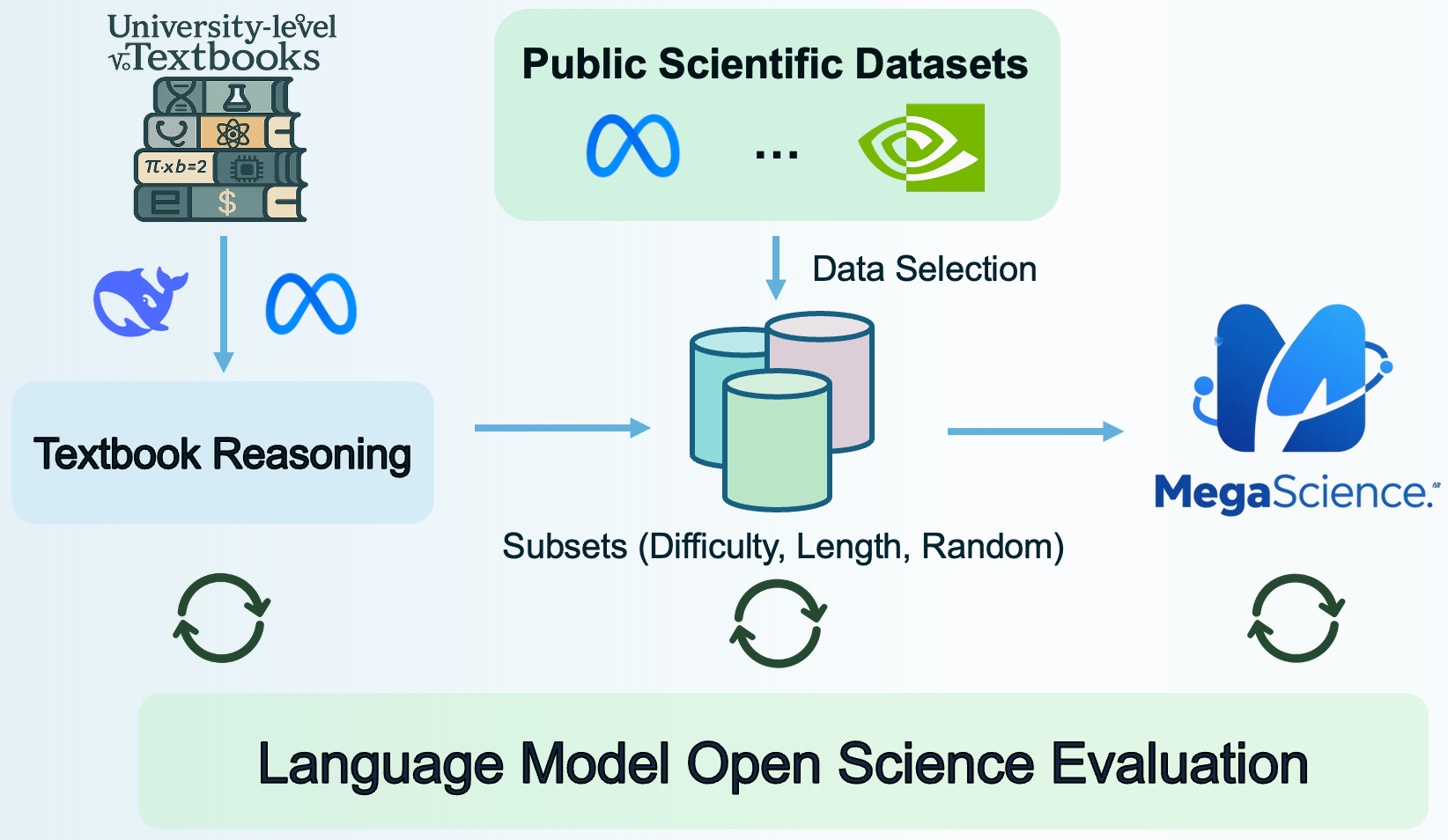
MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
This repository contains the Qwen2.5-3B-MegaScience model, one of the models trained as part of the MegaScience project.
For the official code, data processing pipeline, and evaluation system, please refer to the MegaScience GitHub repository.
Qwen2.5-3B-MegaScience
Usage
You can use this model with the Hugging Face transformers library:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MegaScience/Qwen2.5-3B-MegaScience"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Example text generation
prompt = "The capital of France is"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt")
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=20)
print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0])
Training Recipe
- LR: 5e-6
- LR Schedule: Cosine
- Batch Size: 512
- Max Length: 4,096
- Warm Up Ratio: 0.05
- Epochs: 3
Evaluation Results
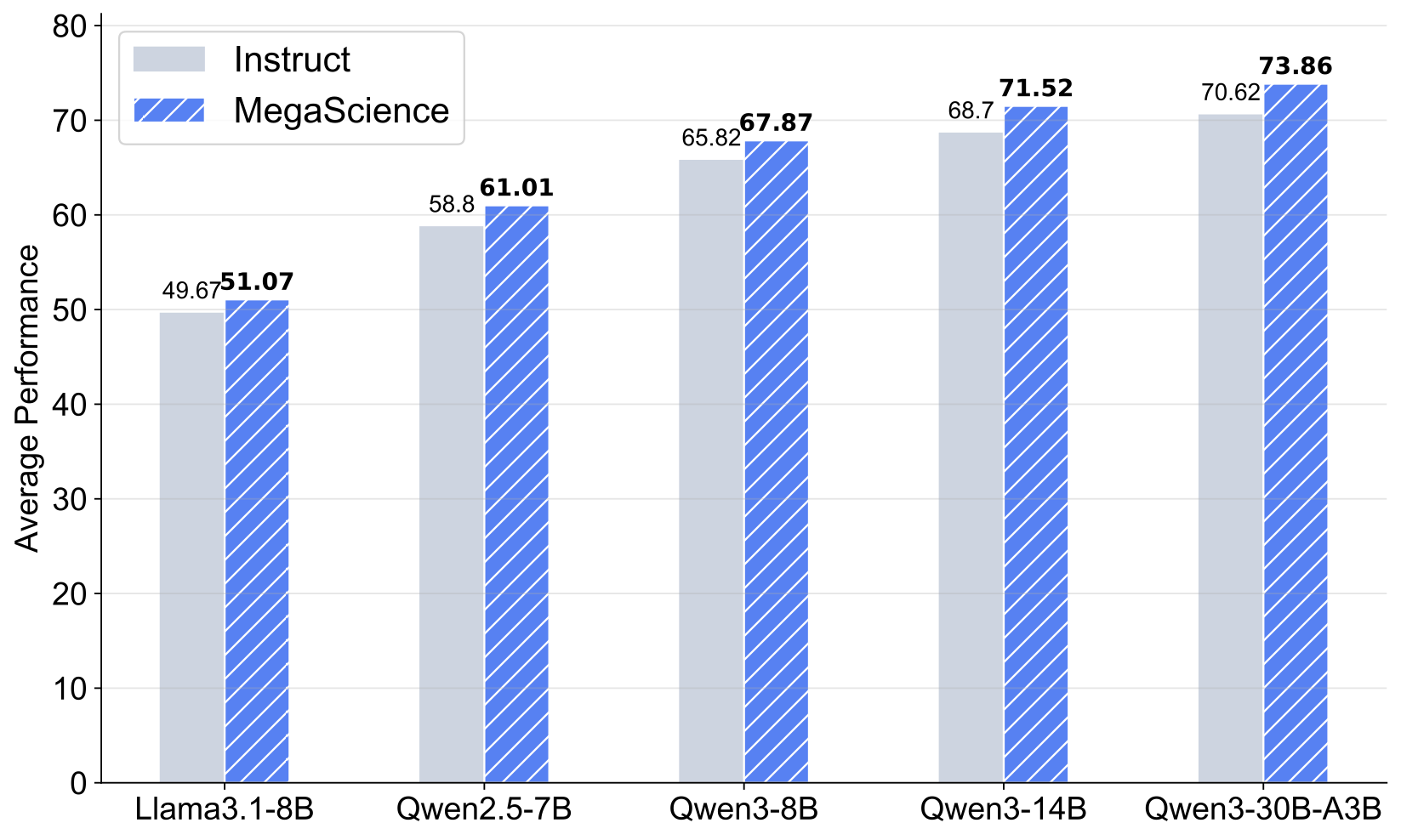
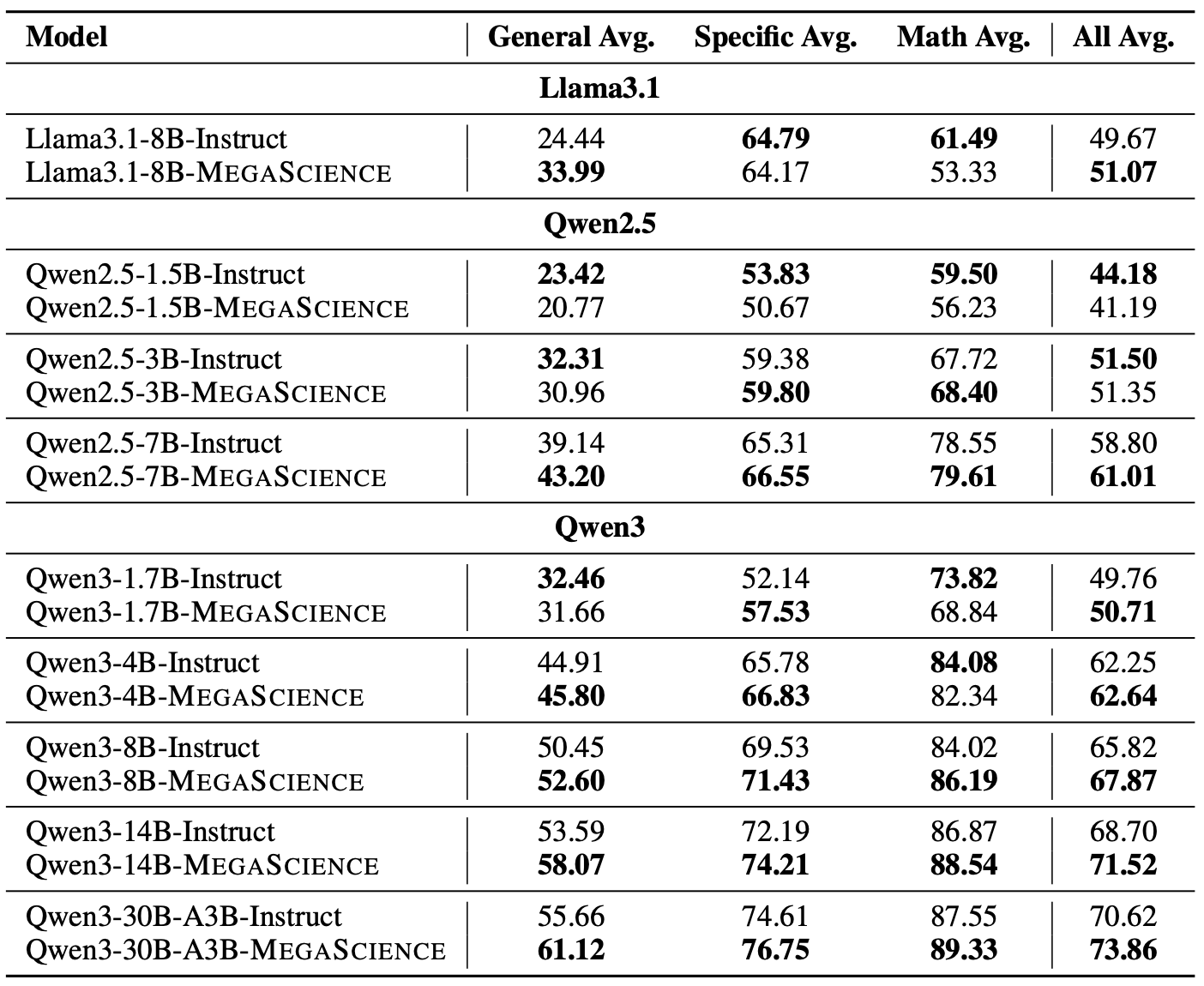
More about MegaScience
Citation
Check out our paper for more details. If you use our dataset or find our work useful, please cite
@article{fan2025megascience,
title={MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning},
author={Fan, Run-Ze and Wang, Zengzhi and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2507.16812},
url={https://arxiv.org/abs/2507.16812}
}