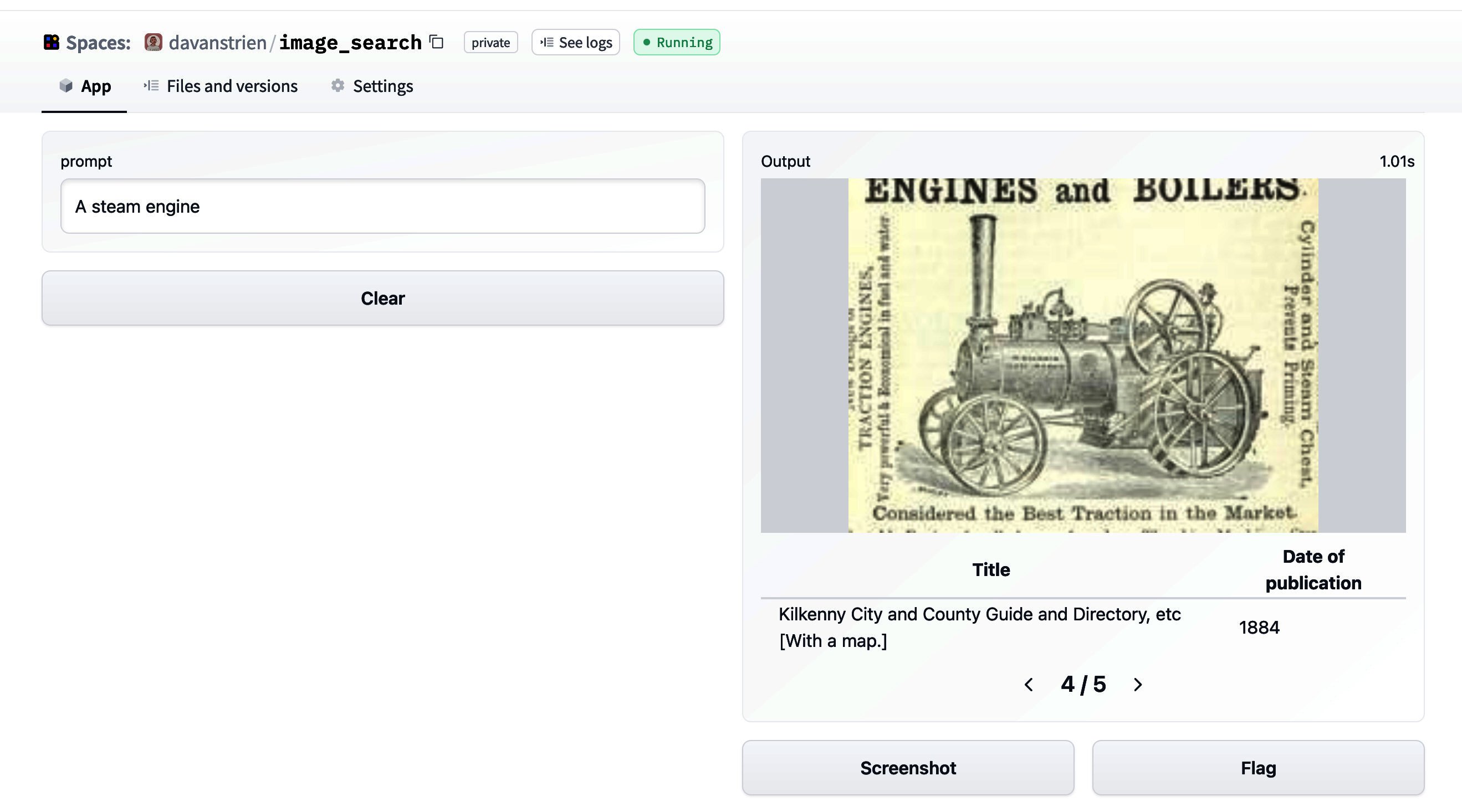
Bigger isn't always better: how to choose the most efficient model for context-specific tasks 🌱🧑🏼💻 By sasha • 6 days ago • 16
*Context Is Gold to Find the Gold Passage*: Evaluating and Training Contextual Document Embeddings By manu and 1 other • 1 day ago • 13
AI Policy @🤗: Response to the 2025 National AI R&D Strategic Plan By evijit and 2 others • about 22 hours ago • 9
System Prompt Learning: Teaching LLMs to Learn Problem-Solving Strategies from Experience By codelion • 1 day ago • 9
Building an Open Ecosystem for Time Series Forecasting: Introducing TimesFM in Hugging Face By Nutanix and 1 other • 15 days ago • 16
OpenEvolve: An Open Source Implementation of Google DeepMind's AlphaEvolve By codelion • 14 days ago • 18
Fine-Tuning Your First Large Language Model (LLM) with PyTorch and Hugging Face By dvgodoy • Feb 11 • 38
DeepSeek-R1 Dissection: Understanding PPO & GRPO Without Any Prior Reinforcement Learning Knowledge By NormalUhr • Feb 7 • 144
Bigger isn't always better: how to choose the most efficient model for context-specific tasks 🌱🧑🏼💻 By sasha • 6 days ago • 16
*Context Is Gold to Find the Gold Passage*: Evaluating and Training Contextual Document Embeddings By manu and 1 other • 1 day ago • 13
AI Policy @🤗: Response to the 2025 National AI R&D Strategic Plan By evijit and 2 others • about 22 hours ago • 9
System Prompt Learning: Teaching LLMs to Learn Problem-Solving Strategies from Experience By codelion • 1 day ago • 9
Building an Open Ecosystem for Time Series Forecasting: Introducing TimesFM in Hugging Face By Nutanix and 1 other • 15 days ago • 16
OpenEvolve: An Open Source Implementation of Google DeepMind's AlphaEvolve By codelion • 14 days ago • 18
Fine-Tuning Your First Large Language Model (LLM) with PyTorch and Hugging Face By dvgodoy • Feb 11 • 38
DeepSeek-R1 Dissection: Understanding PPO & GRPO Without Any Prior Reinforcement Learning Knowledge By NormalUhr • Feb 7 • 144