
filename
stringlengths 7
140
| content
stringlengths 0
76.7M
|
|---|---|
code/sorting/src/sleep_sort/sleep_sort.jl
|
count = 0
function sleep_and_print(n)
global count
sleep(n)
count += 1
println(n)
end
a = [5, 3, 6, 2, 3, 2, 2];
for i=1:length(a)
@async sleep_and_print(a[i])
end
# wait for all threads to complete
while count != length(a)
sleep(1)
end
|
code/sorting/src/sleep_sort/sleep_sort.js
|
/**
* Sleep Sort Implementation in JavaScript
*
* @author Ahmar Siddiqui <[email protected]>
* @github @ahhmarr
* @date 07/Oct/2017
* Part of Cosmos by OpenGenus Foundation
*/
function sleepNumber(number) {
// The timeout is (n^2) so that close numbers are no longer close.
// Example: 1 is really close to 2, but 1^2 isn't close to 2^2.
setTimeout(function() {
console.log(number);
}, number * number);
}
function sleepSort(array) {
for (i = 0; i < array.length; ++i) {
sleepNumber(array[i]);
}
}
// Generate 100 random numbers for sorting.
randoms = [];
for (var i = 0; i < 100; ++i) {
// Random number between 1 - 100
randomInt = Math.floor(Math.random() * 100 + 1);
randoms.push(randomInt);
}
// Sort said random numbers.
sleepSort(randoms);
|
code/sorting/src/sleep_sort/sleep_sort.m
|
/* Part of Cosmos by OpenGenus Foundation */
//
// sleep_sort.m
// Created by DaiPei on 2017/10/12.
//
#import <Foundation/Foundation.h>
@interface SleepSort : NSObject
- (void)sort:(NSMutableArray<NSNumber *> *)array;
@end
@implementation SleepSort
- (void)sort:(NSMutableArray<NSNumber *> *)array {
dispatch_group_t group = dispatch_group_create();
for (int i = 0; i < array.count; i++) {
dispatch_queue_t queue = dispatch_queue_create("com.my.queue", NULL);
dispatch_group_async(group, queue, ^{
usleep(array[i].unsignedIntValue * 1000);
NSLog(@"%@", array[i]);
});
}
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
}
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
NSMutableArray *array = [NSMutableArray arrayWithCapacity:100];
for (int i = 0; i < 100; i++) {
uint32_t ran = arc4random() % 1000;
[array addObject:@(ran)];
}
SleepSort *ss = [[SleepSort alloc] init];
[ss sort:array];
}
return 0;
}
|
code/sorting/src/sleep_sort/sleep_sort.php
|
<?php
//Sleep Sort in PHP
//Author: Amit Kr. Singh
//Github: @amitsin6h
//Social: @amitsin6h
//OpenGenus Contributor
// Part of Cosmos by OpenGenus Foundation
$list = range(1,10);
shuffle($list);
foreach($list as $li){
$pid = pcntl_fork();
if($pid == -1){
die('could not fork');
}else if($pid == 0){
sleep($li);
echo $li."\n";
exit();
}
}
?>
|
code/sorting/src/sleep_sort/sleep_sort.py
|
# Part of Cosmos by OpenGenus Foundation
import threading
import time
_lk = threading.Lock()
class sleep_sort_thread(threading.Thread):
def __init__(self, val):
self.val = val
threading.Thread.__init__(self)
def run(self):
global _lk
# Thread is made to sleep in proportion to value
time.sleep(self.val * 0.1)
# Acquire lock
_lk.acquire()
print(self.val, end=" ")
# Release lock
_lk.release()
def sleep_sort(list):
ts = []
# Intialize a thread corresponding to each element in list
for i in list:
t = sleep_sort_thread(i)
ts.append(t)
# Start all Threads
for i in ts:
i.start()
# Wait for all threads to terminate
for i in ts:
i.join()
x = [2, 4, 3, 1, 6, 8, 4]
x = sleep_sort(x)
|
code/sorting/src/sleep_sort/sleep_sort.rb
|
# Part of Cosmos by OpenGenus Foundation
def sleep_sort(arr, time = 0.01)
require 'thread'
# We need a semaphore to synchronize the access of the shared resource result
mutex = Mutex.new
result = []
# For each element in the array, create a new thread which will sleep.
threads = arr.collect do |e|
Thread.new do
sleep time * e
mutex.synchronize { result << e }
end
end
# Let all threads finish
threads.each(&:join)
result
end
def test
puts 'Testing sleep_sort on array'
array = [1, 4, 4, 2, 5, 8, 7, 6, 12]
puts ' Before: ' + array.join(',')
array = sleep_sort array, 0.05 # sleeping longer for demonstrative purpose
puts ' After: ' + array.join(',')
end
test if $PROGRAM_NAME == __FILE__
|
code/sorting/src/sleep_sort/sleep_sort.scala
|
object Main
{
def sleep_sort(xs: List[Int]): List[Int] =
{
var r: List[Int] = Nil
var threads: List[Thread] = Nil
for (x <- xs)
{
val t = new Thread(new Runnable
{
def run()
{
Thread.sleep(x)
this.synchronized
{
r = r:+ x
}
}
})
threads = t :: threads
t.start
}
for (t <- threads)
{
t.join()
}
r
}
def main(args: Array[String]) =
{
println(sleep_sort(List(100,99,3,15,2)))
}
}
|
code/sorting/src/sleep_sort/sleep_sort.sh
|
#sleep sort in shell script only for positive numbers
# Part of Cosmos by OpenGenus Foundation
function f(){
sleep "$1"
echo "$1"
}
while [ -n "$1" ]
do
f "$1" &
shift
done
wait
|
code/sorting/src/sleep_sort/sleep_sort.swift
|
/* Part of Cosmos by OpenGenus Foundation */
//
// sleep_sort.swift
// Created by DaiPei on 2017/10/12.
//
import Foundation
import Dispatch
func sleepSort(_ array: [Int]) {
let group = DispatchGroup()
for i in 0..<array.count {
let queue = DispatchQueue(label: "com.my.queue")
queue.async(group: group, execute: {
usleep(UInt32(array[i]))
print(array[i])
})
}
group.wait()
}
|
code/sorting/src/slow_sort/README.md
|
# Slow Sort
Slowsort is a recursive algorithm. It sorts in-place.
It is a stable sort. (It does not change the order of equal-valued keys.)
## Explantation
Input : {4, -9, 5, 8,-2, 4 78}
Output: {-9, -2, 4, 4, 5, 8, 78}
## Algorithm
function slowsort(A[], i, j)
if i ≥ j then
return
m := floor( (i+j)/2 )
slowsort(A, i, m)
slowsort(A, m+1, j)
if A[j] < A[m] then
swap A[j] , A[m]
slowsort(A, i, j-1)
## Complexity
Runtime T(n) = 2T(n/2)+T(n-1)+1
## Wiki Link
https://en.wikipedia.org/wiki/Slowsort
---
<p align="center">
A massive collaborative effort by <a href="https://github.com/OpenGenus/cosmos">OpenGenus Foundation</a>
</p>
---
|
code/sorting/src/slow_sort/slow_sort.cpp
|
/* Part of Cosmos by OpenGenus Foundation */
#pragma once
#include <bits/stdc++.h>
using namespace std;
/**
* @brief implement the slowSort Algorithm
*
* @param vect_ vector to be sorted
* @param i ith index of vector
* @param j jth index of vector
*/
void slowSort( vector<int32_t>& vect_, int i, int j )
{
if( i >= j )
{
return;
}
int m = floor( ( i+j ) / 2 );
slowSort( vect_, i, m );
slowSort( vect_, m+1, j );
if( vect_[j] < vect_[m] )
{
swap( vect_[j], vect_[m] );
}
slowSort( vect_, i, j-1 );
}
/**
* @brief print the contents of vector A
*
* @param vect_ vector whose index has to be printed
*/
void printVector( vector<int32_t>& vect_ )
{
for(const auto& a : vect_)
{
cout << a << " ";
}
}
int main()
{
vector<int32_t> vect_;
cout << " Enter elements of the vector: [Enter any character to end the while loop]\n";
int32_t input;
while(cin>>input)
{
vect_.push_back(input);
}
int i = 0;
int j = vect_.size() - 1;
cout << "Vector before sorting : \n";
printVector( vect_ );
slowSort(vect_, i, j);
cout<<"\n";
cout << "Vector after sorting : \n";
printVector( vect_ );
return 0;
}
|
code/sorting/src/slow_sort/slow_sort.java
|
import java.util.Arrays;
public class slow_sort {
/*
* Function that implements the slow sort algorithm
* @param arr[] Array of elements
* @param i Recursion leftmost index
* @param j Recursion rightmost index
*/
static void slowSort(int arr[], int i, int j)
{
if (i >= j) { // Return on base case
return;
}
int mid = (i + j) / 2; // Calculate midpoint of i and j
// Recursively find maximum with left half
slowSort(arr, i, mid);
// Recursively find maximum with right half
slowSort(arr, mid + 1, j);
if (arr[j] < arr[mid]){ // Swap to keep maximum at end of the array
int temp = arr[j];
arr[j] = arr[mid];
arr[mid] = temp;
}
// Recursive call excluding the last element
slowSort(arr, i, j - 1);
}
/*
* Main method to test slow sort method
*/
public static void main(String[] args)
{
int arr[] = {2, 3, 1, 8, 9, 4, 2, 7, 3};
int N = arr.length;
slowSort(arr, 0, N - 1);
System.out.println(Arrays.toString(arr));
}
}
|
code/sorting/src/stooge_sort/README.md
|
# Stooge Sort
Stooge sort is a recursive sorting algorithm.
The algorithm is defined as follows:
1) If the value at the start is larger than the value at the end, swap them.
2) If there are 3 or more elements in the list, then:
* Stooge sort the initial 2/3 of the list
* Stooge sort the final 2/3 of the list
* Stooge sort the initial 2/3 of the list again
## Explanation

> Image credits: geeksforgeeks
Input: `2 4 5 3 1`
Output: `1 2 3 4 5`
## Algorithm
```
function stoogesort(array L, i = 0, j = length(L)-1)
if L[i] > L[j] then
L[i] ↔ L[j]
if (j - i + 1) > 2 then
t = (j - i + 1) / 3
stoogesort(L, i , j-t)
stoogesort(L, i+t, j)
stoogesort(L, i , j-t)
return L
```
## Complexity
**Time complexity**:
O(n<sup>(log3/log1.5)</sup>) = **O(n<sup>2.709</sup>)**
**Space complexity**:
Worst case space complexity: **O(n)**
---
<p align="center">
A massive collaborative effort by <a href="https://github.com/OpenGenus/cosmos">OpenGenus Foundation</a>
</p>
---
|
code/sorting/src/stooge_sort/stooge_sort.c
|
/* Part of Cosmos by OpenGenus Foundation */
#include <stdio.h>
void stooge_sort(int *input, int firs_num, int last_num)
{
int temp = 0;
int t = 0;
if(input[firs_num] > input[last_num])
{
temp = input[firs_num];
input[firs_num] = input[last_num];
input[last_num] = temp;
}
if((last_num - firs_num + 1) >= 3)
{
t = (last_num - firs_num + 1)/3;
stooge_sort(input, firs_num, last_num - t);
stooge_sort(input, firs_num + t, last_num);
stooge_sort(input, firs_num, last_num - t);
}
}
int main(void)
{
int L[5] = {5, 3, 4, 1, 2};
stooge_sort(L, 0, 4);
int num;
for(num = 0; num < 5; num++)
{
printf("\r\n %d", L[num]);
}
return 0;
}
|
code/sorting/src/stooge_sort/stooge_sort.cpp
|
// Part of Cosmos by OpenGenus
#include <bits/stdc++.h>
using namespace std;
// Function to implement stooge sort
void stoogesort(int arr[],int l, int h)
{
if (l >= h)
return;
// If first element is smaller than last,
// swap them
if (arr[l] > arr[h])
swap(arr[l], arr[h]);
// If there are more than 2 elements in
// the array
if(h-l+1>2)
{
int t = (h-l+1)/3;
// Recursively sort first 2/3 elements
stoogesort(arr, l, h-t);
// Recursively sort last 2/3 elements
stoogesort(arr, l+t, h);
// Recursively sort first 2/3 elements
// again to confirm
stoogesort(arr, l, h-t);
}
}
// Driver Code
int main()
{
int n;
cin>>n;
int arr[n];
for(int i=0;i<n;i++){
cin>>arr[i];
}
// Calling Stooge Sort function to sort
// the array
stoogesort(arr, 0, n-1);
// Display the sorted array
for (int i=0; i<n; i++)
cout << arr[i] << " ";
return 0;
}
/*
Input :
2 4 5 1 3
Output:
1 2 3 4 5
*/
|
code/sorting/src/stooge_sort/stooge_sort.go
|
/* Part of Cosmos by OpenGenus Foundation */
package main
import "fmt"
/*
* If the value at the start is larger than the value at the end, swap them.
* If there are 3 or more elements in the list, then:
* Stooge sort the initial 2/3 of the list
* Stooge sort the final 2/3 of the list
* Stooge sort the initial 2/3 of the list again
*/
func stoogeSort(data []int, start, end int) {
if data[start] > data[end] {
data[start], data[end] = data[end], data[start]
}
if (end - start) >= 2 {
third := (end - start + 1) / 3
stoogeSort(data, start, end-third)
stoogeSort(data, start+third, end)
stoogeSort(data, start, end-third)
}
}
func main() {
data := []int{42, 32, 65, 12345, 41, 52, 23, 1, 25, 1245, 84, 582, 184, 123, 561}
fmt.Println("Before sorting", data)
stoogeSort(data, 0, len(data)-1)
fmt.Println("After orting", data)
}
|
code/sorting/src/stooge_sort/stooge_sort.java
|
//This is a java program to sort numbers using Stooge Sort
import java.util.Random;
public class StoogeSort
{
public static int N = 20;
public static int[] sequence = new int[N];
public static int[] stoogeSort(int[] L, int i, int j)
{
if (L[j] < L[i])
{
int swap = L[i];
L[i] = L[j];
L[j] = swap;
}
if ((j - i + 1) >= 3)
{
int t = (j - i + 1) / 3;
stoogeSort(L, i, j - t);
stoogeSort(L, i + t, j);
stoogeSort(L, i, j - t);
}
return L;
}
public static void printSequence(int[] sorted_sequence)
{
for (int i = 0; i < sorted_sequence.length; i++)
System.out.print(sorted_sequence[i] + " ");
}
public static void main(String[] args)
{
Random random = new Random();
System.out
.println("Sorting of randomly generated numbers using STOOGE SORT");
for (int i = 0; i < N; i++)
sequence[i] = Math.abs(random.nextInt(1000));
System.out.println("\nOriginal Sequence: ");
printSequence(sequence);
System.out.println("\nSorted Sequence: ");
printSequence(stoogeSort(sequence, 0, sequence.length - 1));
}
}
|
code/sorting/src/stooge_sort/stooge_sort.js
|
// Part of Cosmos by OpenGenus Foundation
function stoogeSort(a) {
function sort(left, right) {
if (a[left] > a[right]) {
[a[left], a[right]] = [a[right], a[left]];
}
if (right - left > 1) {
const third = Math.floor((right - left + 1) / 3);
sort(left, right - third);
sort(left + third, right);
sort(left, right - third);
}
}
sort(0, a.length - 1);
}
let l = [4, 7, 2, 8, 1, 9, 3];
stoogeSort(l);
console.log(l);
|
code/sorting/src/stooge_sort/stooge_sort.py
|
#!/usr/bin/env python2
# Part of Cosmos by OpenGenus Foundation
def stooge_sort(a):
def sort(left, right):
if a[left] > a[right]:
a[left], a[right] = a[right], a[left]
if right - left > 1:
third = (right - left + 1) // 3
sort(left, right - third)
sort(left + third, right)
sort(left, right - third)
sort(0, len(a) - 1)
l = [4, 7, 2, 8, 1, 9, 3]
stooge_sort(l)
print(", ".join(str(x) for x in l))
|
code/sorting/src/topological_sort/readme.md
|
# Topological Sort
A topological sort is a simple algorithm that outputs the linear ordering of vertices/nodes of a DAG(Directed Acyclic Graph), where for each directed edge from node A to node B(A :arrow_right: B), node A appears before node B in ordering.
## Explanation:
There are two conditions for this algorithm to work:
1. The graphs should be **directed**, otherwise for any two vertices a & b, there would be two paths from a to b & vice-versa, & hence they cannot be ordered.
2. The graphs should be **acyclic**, otherwise for any three vertices a,b,c on a cycle, there will not be any starting point, & hence, linear ordering can't be done.
> Note: Via this algorithm, multiple orderings are possible.
For example:

> Image Credits: Simpson College Computer Science Faculty
Here, V1, V2, V3, V4 and V1, V3, V2, V4 are possible orderings.
## Algorithm
```
L ← Empty list that will contain the sorted elements
S ← Set of all nodes with no incoming edge
while S is non-empty do
remove a node n from S
add n to tail of L
for each node m with an edge e from n to m do
remove edge e from the graph
if m has no other incoming edges then
insert m into S
if graph has edges then
return error (graph has at least one cycle)
else
return L (a topologically sorted order)
```
## Complexity:
**Time complexity**
`O(V+E)` when we implement it using adjacency list with depth first search.
Where, **V**: No. of vertices & **E**: No. of edges.
---
A large scale collaboration of [OpenGenus](https://github.com/opengenus)
|
code/sorting/src/topological_sort/topological_sort.c
|
#include <stdio.h>
// Part of Cosmos by OpenGenus Foundation
int main(){
int i,j,k,n,a[10][10],indeg[10],flag[10],count=0;
printf("Enter the no of vertices:\n");
scanf("%d",&n);
printf("Enter the adjacency matrix:\n");
for(i=0;i<n;i++){
printf("Enter row %d\n",i+1);
for(j=0;j<n;j++)
scanf("%d",&a[i][j]);
}
for( i = 0; i < n; i++){
indeg[i]=0;
flag[i]=0;
}
for(i=0;i<n;i++)
for(j=0;j<n;j++)
indeg[i]=indeg[i]+a[j][i];
printf("\nThe topological order is:");
while(count<n){
for(k=0;k<n;k++){
if((indeg[k]==0) && (flag[k]==0)){
printf("%d ",(k+1));
flag [k]=1;
}
for(i=0;i<n;i++){
if(a[i][k]==1)
indeg[k]--;
}
}
count++;
}
return 0;
}
|
code/sorting/src/topological_sort/topological_sort.cpp
|
// A C++ program to print topological sorting of a DAG
// Part of Cosmos by OpenGenus Foundation
#include <iostream>
#include <list>
#include <stack>
using namespace std;
// Class to represent a graph
class Graph
{
int V; // No. of vertices'
// Pointer to an array containing adjacency listsList
list<int> *adj;
// A function used by topologicalSort
void topologicalSortUtil(int v, bool visited[], stack<int> &Stack);
public:
Graph(int V); // Constructor
// function to add an edge to graph
void addEdge(int v, int w);
// prints a Topological Sort of the complete graph
void topologicalSort();
};
Graph::Graph(int V)
{
this->V = V;
adj = new list<int>[V];
}
void Graph::addEdge(int v, int w)
{
adj[v].push_back(w); // Add w to v’s list.
}
// A recursive function used by topologicalSort
void Graph::topologicalSortUtil(int v, bool visited[],
stack<int> &Stack)
{
// Mark the current node as visited.
visited[v] = true;
// Recur for all the vertices adjacent to this vertex
list<int>::iterator i;
for (i = adj[v].begin(); i != adj[v].end(); ++i)
if (!visited[*i])
topologicalSortUtil(*i, visited, Stack);
// Push current vertex to stack which stores result
Stack.push(v);
}
// The function to do Topological Sort. It uses recursive
// topologicalSortUtil()
void Graph::topologicalSort()
{
stack<int> Stack;
// Mark all the vertices as not visited
bool *visited = new bool[V];
for (int i = 0; i < V; i++)
visited[i] = false;
// Call the recursive helper function to store Topological
// Sort starting from all vertices one by one
for (int i = 0; i < V; i++)
if (visited[i] == false)
topologicalSortUtil(i, visited, Stack);
// Print contents of stack
while (Stack.empty() == false)
{
cout << Stack.top() << " ";
Stack.pop();
}
}
// Driver program to test above functions
int main()
{
// Create a graph given in the above diagram
Graph g(6);
g.addEdge(5, 2);
g.addEdge(5, 0);
g.addEdge(4, 0);
g.addEdge(4, 1);
g.addEdge(2, 3);
g.addEdge(3, 1);
cout << "Following is a Topological Sort of the given graph n ";
g.topologicalSort();
return 0;
}
|
code/sorting/src/topological_sort/topological_sort.java
|
import java.util.InputMismatchException;
import java.util.Scanner;
import java.util.Stack;
public class TopologicalSort
{
private Stack<Integer> stack;
public TopologicalSort()
{
stack = new Stack<Integer>();
}
public int [] topological(int adjacency_matrix[][], int source) throws NullPointerException
{
int number_of_nodes = adjacency_matrix[source].length - 1;
int[] topological_sort = new int [number_of_nodes + 1];
int pos = 1;
int j ;
int visited[] = new int[number_of_nodes + 1];
int element = source;
int i = source;
visited[source] = 1;
stack.push(source);
while (!stack.isEmpty())
{
element = stack.peek();
while (i <= number_of_nodes)
{
if (adjacency_matrix[element][i] == 1 && visited[i] == 1)
{
if (stack.contains(i))
{
System.out.println("TOPOLOGICAL SORT NOT POSSIBLE");
return null;
}
}
if (adjacency_matrix[element][i] == 1 && visited[i] == 0)
{
stack.push(i);
visited[i] = 1;
element = i;
i = 1;
continue;
}
i++;
}
j = stack.pop();
topological_sort[pos++] = j;
i = ++j;
}
return topological_sort;
}
public static void main(String...arg)
{
int number_no_nodes, source;
Scanner scanner = null;
int topological_sort[] = null;
try
{
System.out.println("Enter the number of nodes in the graph");
scanner = new Scanner(System.in);
number_no_nodes = scanner.nextInt();
int adjacency_matrix[][] = new int[number_no_nodes + 1][number_no_nodes + 1];
System.out.println("Enter the adjacency matrix");
for (int i = 1; i <= number_no_nodes; i++)
for (int j = 1; j <= number_no_nodes; j++)
adjacency_matrix[i][j] = scanner.nextInt();
System.out.println("Enter the source for the graph");
source = scanner.nextInt();
System.out.println("The Topological sort for the graph is given by ");
TopologicalSort toposort = new TopologicalSort();
topological_sort = toposort.topological(adjacency_matrix, source);
System.out.println();
for (int i = topological_sort.length - 1; i > 0; i-- )
{
if (topological_sort[i] != 0)
System.out.print(topological_sort[i]+"\t");
}
}catch(InputMismatchException inputMismatch)
{
System.out.println("Wrong Input format");
}catch(NullPointerException nullPointer)
{
}
scanner.close();
}
}
|
code/sorting/src/topological_sort/topological_sort.py
|
from collections import defaultdict
class Graph:
def __init__(self, vertices):
self.graph = defaultdict(list)
self.V = vertices
def addEdge(self, u, v):
self.graph[u].append(v)
def topologicalSortUtil(self, v, visited, stack):
visited[v] = True # Mark current node as visited
for i in self.graph[v]: # traversing adjacent nodes
if visited[i] == False:
self.topologicalSortUtil(i, visited, stack)
stack.insert(0, v) # pushing current node to stack
def topologicalSort(self):
visited = [False] * self.V
stack = []
for i in range(self.V):
if visited[i] == False:
self.topologicalSortUtil(i, visited, stack)
print(stack)
g = Graph(4)
g.addEdge(0, 2)
g.addEdge(0, 3)
g.addEdge(2, 1)
g.addEdge(1, 3)
g.addEdge(2, 3)
print("Topological Sort of the given graph")
g.topologicalSort()
|
code/sorting/src/tree_sort/README.md
|
# Tree Sort
Tree sort is a sorting algorithm that is based on Binary Search Tree data structure. It first creates a binary search tree from the elements of the input list or array and then performs an in-order traversal on the created binary search tree to get the elements in sorted order.
Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
## Explanation
The following flow chart explains the steps involved in performing tree sort by depicting how every element in a binary search tree is printed in ascending order.
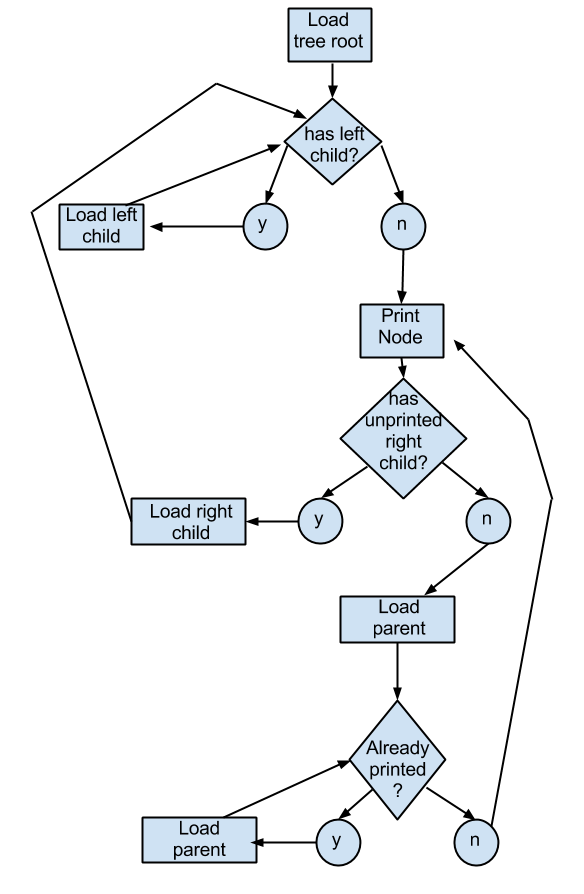
> Image credits: wikipedia
## Algorithm
```
structure BinaryTree
BinaryTree:LeftSubTree
Object:Node
BinaryTree:RightSubTree
procedure Insert(BinaryTree:searchTree, Object:item)
IF searchTree.Node IS NULL THEN
SET searchTree.Node TO item
ELSE
IF item IS LESS THAN searchTree.Node THEN
Insert(searchTree.LeftSubTree, item)
ELSE
Insert(searchTree.RightSubTree, item)
procedure InOrder(BinaryTree:searchTree)
IF searchTree.Node IS NULL THEN
EXIT procedure
ELSE
InOrder(searchTree.LeftSubTree)
EMIT searchTree.Node
InOrder(searchTree.RightSubTree)
procedure TreeSort(Collection:items)
BinaryTree:searchTree
FOR EACH individualItem IN items
Insert(searchTree, individualItem)
InOrder(searchTree)
```
## Complexity
**Time complexity**
- Worst Case:
- **O(n<sup>2</sup>)** (unbalanced)
- **O(n logn)** (balanced)
- Average Case: **O(n logn)**
- Best Case: **O(n logn)**
**Space Complexity**: **O(n)** auxillary space
---
<p align="center">
A massive collaborative effort by <a href="https://github.com/OpenGenus/cosmos">OpenGenus Foundation</a>
</p>
---
|
code/sorting/src/tree_sort/tree_sort.c
|
#include <stdio.h>
#include <alloc.h>
// Part of Cosmos by OpenGenus Foundation
struct btreenode
{
struct btreenode *leftchild ;
int data ;
struct btreenode *rightchild ;
} ;
void insert ( struct btreenode **, int ) ;
void inorder ( struct btreenode * ) ;
void main( )
{
struct btreenode *bt ;
int arr[10] = { 11, 2, 9, 13, 57, 25, 17, 1, 90, 3 } ;
int i ;
bt = NULL ;
printf ( "Binary tree sort.\n" ) ;
printf ( "\nArray:\n" ) ;
for ( i = 0 ; i <= 9 ; i++ )
printf ( "%d\t", arr[i] ) ;
for ( i = 0 ; i <= 9 ; i++ )
insert ( &bt, arr[i] ) ;
printf ( "\nIn-order traversal of binary tree:\n" ) ;
inorder ( bt ) ;
}
void insert ( struct btreenode **sr, int num )
{
if ( *sr == NULL )
{
*sr = malloc ( sizeof ( struct btreenode ) ) ;
( *sr ) -> leftchild = NULL ;
( *sr ) -> data = num ;
( *sr ) -> rightchild = NULL ;
}
else
{
if ( num < ( *sr ) -> data )
insert ( &( ( *sr ) -> leftchild ), num ) ;
else
insert ( &( ( *sr ) -> rightchild ), num ) ;
}
}
void inorder ( struct btreenode *sr )
{
if ( sr != NULL )
{
inorder ( sr -> leftchild ) ;
printf ( "%d\t", sr -> data ) ;
inorder ( sr -> rightchild ) ;
}
}
|
code/sorting/src/tree_sort/tree_sort.cpp
|
//Tree Sort implemented using C++
// Part of Cosmos by OpenGenus Foundation
#include <vector>
#include <iostream>
using namespace std;
struct Node
{
int data;
struct Node *left, *right;
};
//Function to create new Node
struct Node *newnode(int key)
{
struct Node *temp = new Node;
temp->data = key;
temp->left = NULL;
temp->right = NULL;
return temp;
}
Node* insert(Node *node, int key)
{
if (node == NULL)
return newnode(key); //If tree is empty return new node
if (key < node->data)
node->left = insert(node->left, key);
else
node->right = insert(node->right, key);
return node;
}
void store(Node *root, int a[], int &i)
{
if (root != NULL)
{
store(root->left, a, i);
a[i++] = root->data;
store(root->right, a, i);
}
}
void TreeSort(vector<int>& a)
{
struct Node *root = NULL;
//Construct binary search tree
root = insert(root, a[0]);
for (size_t i = 1; i < a.size(); i++)
insert(root, a[i]);
//Sorting the array using inorder traversal on BST
int i = 0;
store(root, a.data(), i);
}
int main()
{
vector<int> a{1, 6, 8, 3, 10, 2, 12};
TreeSort(a);
cout << "The sorted array is :\n";
//Printing the sorted array
for (size_t i = 0; i < a.size(); i++)
cout << a[i] << " ";
return 0;
}
/* output:
* The sorted array is :
* 1 2 3 6 8 10 12
*/
|
code/sorting/src/tree_sort/tree_sort.go
|
package main
import "fmt"
// Part of Cosmos by OpenGenus Foundation
/**************************************
* Structures
**************************************/
// Define binary tree structure
//
// - data : the value in the tree
// - right : the sub-tree of greater or equal values
// - left : the sub-tree of lesser values
type Tree struct {
data int
right *Tree
left *Tree
}
// Create a Tree by initializing its subtree to nil
// and setting it's value.
func createTree(value int) *Tree {
var tree = Tree{}
tree.data = value
tree.right = nil
tree.left = nil
return &tree
}
// Insert the given value in the tree.
//
// The tree is traveled until an empty sub-tree is found:
// If the value is lesser than the one hold by the current node,
// try to insert it to the left.
// If the value is greater or equal than the one hold by the current node,
// try to insert it to the right.
// The value is inserted by creating a new sub-tree.
func (t *Tree) insert(value int) *Tree {
if value < t.data {
if t.left == nil {
t.left = createTree(value)
} else {
t.left.insert(value)
}
} else {
if t.right == nil {
t.right = createTree(value)
} else {
t.right.insert(value)
}
}
return t
}
// Apply the given function to each value in the tree
// from left to right, i.e. from the lesser one to the greater one.
func (t *Tree) forEach(fn func(int)) {
if t.left != nil {
t.left.forEach(fn)
}
fn(t.data)
if t.right != nil {
t.right.forEach(fn)
}
}
/**************************************
* Algorithm
**************************************/
// Perform a binary tree sort of the given array
// and return the created tree.
func binaryTreeSort(array []int) *Tree {
tree := createTree(array[0])
for _, node := range array[1:] {
tree.insert(node)
}
return tree
}
/**************************************
* Tests
**************************************/
// Test the binary tree sort on the given array:
//
// [1, -6, 8, 3, 10, 3, 21]
//
// Should output: -6 1 3 3 8 10 21
//
// NOTE: this will only display the values in the tree by traveling
// it from left to right.
// If you want to fill an array with the values,
// just pass a function that fills it to tree.forEach().
func main() {
var array = [...]int{1,-6,8,3,10,3,21}
tree := binaryTreeSort(array[:])
tree.forEach(func(value int) {
fmt.Print(value, " ")
})
}
|
code/sorting/src/tree_sort/tree_sort.java
|
// Part of Cosmos by OpenGenus Foundation
public class Tree {
public static void main(String[] args) {
TreeSort myTree;
myTree = new TreeSort(4);
myTree.invert(new TreeSort(5));
myTree.invert(new TreeSort(8));
myTree.invert(new TreeSort(1));
myTree.traverse(new KeyPrint());
}
static class TreeSort {
private TreeSort left;
private TreeSort right;
private int key;
public TreeSort(int key) {
this.key = key;
}
private void invert(TreeSort node) {
if (node.key < key) {
if (left != null) left.invert(node);
else {
left = node;
}
} else {
if (right != null) right.invert(node);
else {
right = node;
}
}
}
private void traverse(TreeVisitor visitor) {
if (left != null)
left.traverse(visitor);
visitor.visit(this);
if (right != null)
right.traverse(visitor);
}
}
interface TreeVisitor {
void visit(TreeSort node);
}
static class KeyPrint implements TreeVisitor {
public void visit(TreeSort node) {
System.out.println(" " + node.key);
}
}
}
|
code/sorting/src/tree_sort/tree_sort.js
|
// Part of Cosmos by OpenGenus Foundation
var BinarySearchTree = function(value) {
var instance = Object.create(BinarySearchTree.prototype);
instance.value = value;
// a BST where all values are higher than than the current value.
instance.right = undefined;
// a binary search tree (BST) where all values are lower than than the current value.
instance.left = undefined;
return instance;
};
BinarySearchTree.prototype.insert = function(value) {
// accepts a value and places in the tree in the correct position.
var node = BinarySearchTree(value);
function recurse(bst) {
if (bst.value > value && bst.left === undefined) {
bst.left = node;
} else if (bst.value > value) {
recurse(bst.left);
} else if (bst.value < value && bst.right === undefined) {
bst.right = node;
} else if (bst.value < value) {
recurse(bst.right);
}
}
recurse(this);
};
BinarySearchTree.prototype.contains = function(value) {
var doesContain = false;
//accepts a value and returns a boolean reflecting whether or not the value is contained in the tree.
function recurse(bst) {
if (bst.value === value) {
doesContain = true;
} else if (bst.left !== undefined && value < bst.value) {
recurse(bst.left);
} else if (bst.right !== undefined && value > bst.value) {
recurse(bst.right);
}
}
recurse(this);
return doesContain;
};
BinarySearchTree.prototype.depthFirstLog = function(callback) {
//accepts a callback and executes it on every value contained in the tree.
function recurse(bst) {
callback.call(bst, bst.value);
if (bst.left !== undefined) {
recurse(bst.left);
}
if (bst.right !== undefined) {
recurse(bst.right);
}
}
recurse(this);
};
|
code/sorting/src/tree_sort/tree_sort.php
|
<?php
// Part of Cosmos by OpenGenus
namespace SF;
class TreeSort
{
public static function sort($input, $options = array())
{
$output = array();
$all = array();
$dangling = array();
// Initialize arrays
foreach ($input as $entry) {
$entry['children'] = array();
$entry['active'] = false;
$entry['active_parent'] = false;
$id = $entry['id'];
// If this is a top-level node, add it to the output immediately
if (!$entry['parent_id']) {
$all[$id] = $entry;
$output[] =& $all[$id];
// If this isn't a top-level node, we have to process it later
} else {
$dangling[$id] = $entry;
}
}
// Process all 'dangling' nodes
while (count($dangling) > 0) {
foreach($dangling as $entry) {
$id = $entry['id'];
$pid = $entry['parent_id'];
// If the parent has already been added to the output, it's
// safe to add this node too
if (isset($all[$pid])) {
$all[$id] = $entry;
$all[$pid]['children'][] =& $all[$id];
unset($dangling[$entry['id']]);
}
}
}
// Active
if (isset($options['active_id'])) {
$id = $options['active_id'];
$all[$id]['active'] = true;
do {
$parent_id = $all[$id]['parent_id'];
if (isset($all[$parent_id])) {
$all[$parent_id]['active_parent'] = true;
$id = $parent_id;
} else {
break;
}
} while (true);
}
return $output;
}
public static function sortFlat($items, $addHelpers = true)
{
$children = array(); // Parent's children
$itemsize = array(); // Family sizes
// Get children by parent
foreach ($items as $item) {
if ($item['parent_id'] != 0) {
$children[$item['parent_id']][] = $item['id'];
}
$itemsize[$item['id']] = 1;
}
$adopted = array(); // Children that have been adopted
for ($i = 0; count($children) != 0; $i++) {
$itemId = $items[$i]['id'];
// If I have children
if (isset($children[$itemId])) {
$offset = 1;
// Loop through children and append them after me
foreach ($children[$itemId] as $id) {
$itemsize[$itemId] += $itemsize[$id]; // Update my family size
$adopted[$id] = true;
$childIndex = self::getIndexInArray($items, $id);
// Move child with family
for ($j = 0; $j < $itemsize[$id]; $j++) {
if ($childIndex + $j < $i + $offset) {
$childIndexReal = $childIndex; // When we move a child, the next will come to into position
$i--; // If child is before me, I should adjust my index pointer
} else {
$childIndexReal = $childIndex + $j;
}
$child = array($items[$childIndexReal]);
unset($items[$childIndexReal]);
array_splice($items, $i + $offset++, 0, $child);
}
}
// Resize parent if it has adopted me
$thisId = $itemId;
while (isset($adopted[$thisId])) {
$parentId = $items[self::getIndexInArray($items, $thisId)]['parent_id'];
$itemsize[$parentId] += $itemsize[$itemId];
$thisId = $parentId;
}
unset($children[$itemId]);
}
// Prevent endless loop if the array isn't complete (disconnected parent_ids)
if ($i == count($items) - 1) {
break;
}
}
if ($addHelpers) {
return self::addHelpers($items);
} else {
return $items;
}
}
public static function getIndexInArray(&$items, $id)
{
foreach ($items as $index => $item) {
if ($item['id'] == $id) {
return $index;
}
}
return null;
}
public static function addHelpers($items)
{
$level = 0;
$parentIds = array(0);
$lastParentId = 0;
$last = null; // isset == false
$first = true;
foreach ($items as &$item) {
// If we've gone deeper, or this is the first
if (($item['parent_id'] != $lastParentId && !in_array($item['parent_id'], $parentIds)) || is_null($last)) {
$item['first_child'] = true;
} else {
$item['first_child'] = false;
}
if (isset($last)) {
// If we've gone up one/more level to the surface
if ($item['parent_id'] != $lastParentId && in_array($item['parent_id'], $parentIds)) {
$last['last_child'] = true;
} else {
$last['last_child'] = false;
}
}
if ($item['parent_id'] != $lastParentId) {
// If we've gone up one/more level to the surface
if (in_array($item['parent_id'], $parentIds)) {
if (isset($lastIndex)) {
$items[$lastIndex] = true;
}
for ($i = count($parentIds) - 1; $item['parent_id'] != $parentIds[$i]; $i--) {
$level--;
unset($parentIds[$i]);
}
// If we've gone deeper
} else {
if (isset($last)) {
$last['has_children'] = true;
}
$parentIds[count($parentIds)] = $item['parent_id'];
$level++;
}
}
$item['level'] = $level;
$item['first'] = $first;
$item['has_children'] = false;
$item['last'] = false;
$item['previous'] = &$last;
$last['next'] = &$item;
$lastParentId = $item['parent_id'];
$first = false;
$last = &$item;
}
$last['last'] = true;
$last['last_child'] = true;
return $items;
}
}
|
code/sorting/src/tree_sort/tree_sort.py
|
# Part of Cosmos by OpenGenus Foundation
class Node:
"""Base class to contain the tree metadata per instance of the class"""
def __init__(self, val):
self.l_child = None
self.r_child = None
self.data = val
def binary_insert(root, node):
"""This recursive function will insert the objects into the tree"""
if root is None: # If we don't have a root node
root = (
node
) # Set the root node equal to the first node argument that was provided
else: # We already have a root
if (
root.data > node.data
): # If our current root is bigger than the node we are about to insert
if root.l_child is None: # If we don't have any node to the left of root
root.l_child = node # Insert the node as the left node under root
else: # There's already a node to the left of root
binary_insert(
root.l_child, node
) # Call the insert function recursively with the left node value as the
# temp root for comparison
else: # Node to be inserted is bigger than root (going right side)
if root.r_child is None: # if there's no right child
root.r_child = (
node
) # insert the node as the right child of root (under)
else: #
binary_insert(
root.r_child, node
) # Call the insert function recursively with the right node value as the
# temp root for comparison
def post_sort_print(root):
if not root:
return None
post_sort_print(root.l_child)
print(root.data)
post_sort_print(root.r_child)
def pre_sort_print(root):
if not root:
return None
print(root.data)
pre_sort_print(root.l_child)
pre_sort_print(root.r_child)
r = Node(6)
binary_insert(r, Node(2))
binary_insert(r, Node(8))
binary_insert(r, Node(90))
binary_insert(r, Node(23))
binary_insert(r, Node(12))
binary_insert(r, Node(91))
print("---------")
print("PRE SORT")
pre_sort_print(r)
print("---------")
print("POST SORT")
post_sort_print(r)
|
code/sorting/test/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
|
code/sorting/test/test_sort.cpp
|
/*
* Part of Cosmos by OpenGenus Foundation
*/
/*
* guide
*
* 1. substitute iterator (col:28)
* 2. substitute sort algorithm (col: 70)
* 3. run
*/
#define CATCH_CONFIG_MAIN
#ifndef SORT_TEST
#define SORT_TEST
#include "../../../test/c++/catch.hpp"
#include <forward_list>
#include <list>
#include <deque>
#include <iterator>
#include <iostream>
#include <algorithm>
#include "../src/merge_sort/merge_sort.cpp"
#include "../src/quick_sort/quick_sort.cpp"
#include "../src/insertion_sort/insertion_sort.cpp"
#include "../src/selection_sort/selection_sort.cpp"
#include "../src/bubble_sort/bubble_sort.cpp"
// substitute iterator
// #define AT_LEAST_INPUT_ITERATOR
// #define AT_LEAST_BIDIRECTIONAL_ITERATOR
#define AT_LEAST_RANDOM_ITERATOR
#ifdef AT_LEAST_INPUT_ITERATOR
template<typename _T>
using ContainerType = std::forward_list<_T>;
#endif
#ifdef AT_LEAST_BIDIRECTIONAL_ITERATOR
template<typename _T>
using ContainerType = std::list<_T>;
#endif
#ifdef AT_LEAST_RANDOM_ITERATOR
template<typename _T>
using ContainerType = std::deque<_T>;
#endif
template<typename _Iter1,
typename _Iter2,
typename _Tp = typename std::iterator_traits<_Iter1>::value_type>
bool
isSame(_Iter1 aBegin, _Iter1 aEnd, _Iter2 bBegin)
{
auto aIt = aBegin;
auto bIt = bBegin;
for (; aIt != aEnd; ++aIt, ++bIt)
if (*aIt != *bIt)
return false;
return true;
}
TEST_CASE("sort algorithm")
{
srand(static_cast<unsigned int>(clock()));
void (*psf)(int *, int *);
void (*vsf)(ContainerType<int>::iterator, ContainerType<int>::iterator);
// substitute sort algorithm
vsf = mergeSort;
psf = mergeSort;
// vsf = bubbleSort;
// psf = bubbleSort;
// vsf = insertionSort;
// psf = insertionSort;
// vsf = selectionSort;
// psf = selectionSort;
// vsf = quickSort;
// psf = quickSort;
auto stdSort = [](ContainerType<int>&expectStdContainer)
{
#ifdef AT_LEAST_RANDOM_ITERATOR
std::sort(expectStdContainer.begin(), expectStdContainer.end());
#else
expectStdContainer.sort();
#endif
};
auto testSTLContainer = [&](int sz)
{
ContainerType<int> actualStdContainer, expectStdContainer;
// randomize elems
for (int i = 0; i < sz; ++i)
{
int randomValue = std::rand() % (sz / 2 + 1);
actualStdContainer.push_front(randomValue);
expectStdContainer.push_front(randomValue);
}
stdSort(expectStdContainer);
vsf(actualStdContainer.begin(), actualStdContainer.end());
CHECK(isSame(actualStdContainer.begin(),
actualStdContainer.end(),
expectStdContainer.begin()));
};
auto testPODPtr = [&](int sz)
{
int *actualDynamicArray = new int[sz];
int *actualDynamicArrayEnd = actualDynamicArray + sz;
ContainerType<int> expectStdContainer;
// randomize elems
for (int i = 0; i < sz; ++i)
{
int randomValue = std::rand() % (sz / 2 + 1);
actualDynamicArray[i] = randomValue;
expectStdContainer.push_front(randomValue);
}
stdSort(expectStdContainer);
psf(actualDynamicArray, actualDynamicArrayEnd);
CHECK(isSame(actualDynamicArray,
actualDynamicArrayEnd,
expectStdContainer.begin()));
delete[] actualDynamicArray;
};
SECTION("empty")
{
testPODPtr(0);
testSTLContainer(0);
};
SECTION("1 elem")
{
testPODPtr(1);
testSTLContainer(1);
}
SECTION("2 elems")
{
for (int i = 0; i < 1000; ++i)
{
testPODPtr(2);
testSTLContainer(2);
}
}
SECTION("3 elems") {
for (int i = 0; i < 1000; ++i)
{
testPODPtr(3);
testSTLContainer(3);
}
}
SECTION("large size")
{
testPODPtr(1e6);
testSTLContainer(1e6);
}
SECTION("multiple random size")
{
for (int i = 0; i < 10000; ++i)
{
testPODPtr(100 + std::rand() % 50);
testSTLContainer(100 + std::rand() % 50);
}
}
}
#endif // SORT_TEST
|
code/sorting/test/test_sort.py
|
"""
Part of Cosmos by OpenGenus Foundation
"""
import random
import copy
# import bead_sort # result error
# import bead_sort_numpy # error
# import bucket_sort # error
# import circle_sort # error, tried
# import counting_sort # error, tried
# import radix_sort # error
# sort_func = bead_sort.bead_sort
# sort_func = bead_sort_numpy.bead_sort
# sort_func = bogo_sort.bogo_sort
# sort_func = bubble_sort.bubble_sort
# sort_func = bucket_sort.bucket_sort
# sort_func = circle_sort.circle_sort
# sort_func = counting_sort.counting_sort
# sort_func = cycle_sort.cycle_sort
# sort_func = gnome_sort.gnome_sort
# sort_func = heap_sort.heap_sort
# sort_func = merge_sort.merge_sort
# sort_func = quick_sort.quick_sort
# sort_func = radix_sort.radix_sort
# sort_func = selection_sort.selection_sort
# sort_func = shaker_sort.shaker_sort
ELEM_MODE = "ALLOW_DUPLICATE"
# ELEM_MODE = "UNIQUE"
print(sort_func)
def fill(arr, size):
i = 0
# elems may not be continuous
if ELEM_MODE == "ALLOW_DUPLICATE":
while len(arr) < size:
if random.randint(0, 2) % 2:
arr.extend([i])
if random.randint(0, 2) % 2:
arr.extend([i])
i += 1
if len(arr) > size:
del arr[len(arr) - 1]
elif ELEM_MODE == "UNIQUE":
while len(arr) < size:
if random.randint(0, 2) % 2:
arr.extend([i])
i += 1
def randomize(arr):
LENGTH = len(arr)
for i in range(LENGTH):
r = random.randint(0, LENGTH - 1)
arr[i], arr[r] = arr[r], arr[i]
def is_same(expect, actual):
assert len(expect) == len(actual)
for i in range(len(expect)):
assert expect[i] == actual[i]
def test_size_by_times(size, times):
for i in range(times):
# GIVEN
expect = []
fill(expect, size)
actual = copy.copy(expect)
randomize(actual)
# WHEN
sort_func(actual)
# THEN
is_same(expect, actual)
test_size_by_times(0, 1)
test_size_by_times(1, 1)
test_size_by_times(2, 1000)
test_size_by_times(3, 1000)
test_size_by_times(random.randint(1e4, 1e5), 1)
print("passed")
|
code/sorting/test/test_sort.swift
|
/* Part of Cosmos by OpenGenus Foundation */
import Foundation
let maxSize = 100
class TestSort {
func test() {
let less = { (a: UInt32, b: UInt32) -> Bool in
return a < b
}
var origin = [UInt32](),
expect = origin,
actual = expect
// test with given size
for size in 0..<maxSize {
for duplicate in 0...1 {
if duplicate == 0 {
origin = getRandomElements(UInt32(size), limitBy: UInt32(size * 2))
} else {
// force generate duplicate elements
origin = getRandomElements(UInt32(size), limitBy: UInt32(size / 2))
}
// test with all sort functions
for funcIndex in 0...4 {
expect = origin
actual = expect
switch funcIndex {
case 0:
expect.selectionSort(compareWith: less)
case 1:
expect.insertionSort(compareWith: less)
case 2:
expect.bubbleSort(compareWith: less)
case 3:
expect.mergeSort(compareWith: less)
default:
expect.quickSort(compareWith: less)
}
actual.sort()
assert(expect == actual)
}
}
}
print(0)
}
}
private func countDigit(_ value: UInt32) -> UInt32 {
var v = value
var count = UInt32(1)
while v > 9 {
count += 1
v >>= 1
}
return count
}
private func getRandomElements(_ size: UInt32 = 0, limitBy upperBound: UInt32) -> [UInt32] {
var array = [UInt32]()
for _ in 0..<size {
array.append(arc4random_uniform(upperBound))
}
return array
}
|
code/square_root_decomposition/src/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
|
code/square_root_decomposition/src/mos_algorithm/mos_algorithm.cpp
|
//Time Complexity : O((n+q)*sqrt(n))
#include <bits/stdc++.h>
#include <cmath>
/* Part of Cosmos by OpenGenus Foundation */
#define ll long long int
#define mod 1000000007
#define show(a) for (i = 0; i < a.size(); i++) cout << a[i] << " ";
#define fi first
#define se second
#define vi vector<int>
#define vs vector<string>
#define vll vector<long long int>
#define pb push_back
#define pi pair<int, int>
#define si set<int>
#define sll set<ll>
#define maxheap priority_queue<int>
#define minheap priority_queue<int, vector<int>, greater<int>>
#define mp make_pair
#define fast_io() cin.sync_with_stdio(false); cout.sync_with_stdio(false);
#define long_zero 0ll
#define long_one 1ll
inline int sbt(int x)
{
return __builtin_popcount(x);
}
using namespace std;
int freq[1111111];
int BLOCK;
//Mo Sorting
bool f(pair<int, pi> a, pair<int, pi> b)
{
if (a.se.fi / BLOCK == b.se.fi / BLOCK)
return a.se.se > b.se.se;
return a.se.fi / BLOCK > b.se.fi / BLOCK;
}
int main()
{
system("cls");
//fast_io()
int n;
scanf("%d", &n);
int a[n + 3];
for (int i = 0; i < n; i++)
scanf("%d", &a[i]);
int l, r, s = 0, e = 0, Q;
vector<pair<int, pi>>q;
scanf("%d", &Q);
//block size:SQRT(N)
BLOCK = floor(sqrt(1.0 * double(n)));
for (int i = 0; i < Q; i++)
{
scanf("%d%d", &l, &r);
q.pb(mp(i, mp(l - 1, r - 1)));
}
int v[Q + 4], ans = 0;
sort(q.begin(), q.end(), f); //f is comparator
for (int i = 0; i < Q; i++)
{
l = q[i].se.fi;
r = q[i].se.se;
while (s < l)
{
freq[a[s]]--;
if (!freq[a[s]])
ans--;
s++;
}
while (s > l)
{
freq[a[s - 1]]++;
if (freq[a[s - 1]] == 1)
ans++;
s--;
}
while (e <= r)
{
freq[a[e]]++; // mantains frequency
if (freq[a[e]] == 1)
ans++;
e++;
}
while (e > r + 1)
{
freq[a[e - 1]]--;
if (freq[a[e - 1]] == 0)
ans--;
e--;
}
v[q[i].fi] = ans;
}
for (int i = 0; i < Q; i++)
printf("%d\n", v[i]);
return 0;
}
|
code/square_root_decomposition/src/mos_algorithm/sqrtdecomposition.py
|
# PROBLEM STATEMENT-> You are given an array A of size N and Q queries.(All indexes are 1 based).
# Each query can be of two types
# 1-> 1 i - add 1 to the ith element of the array A
# 2-> 2 K - print the Kth odd number of the array A if it exists, else print -1
def precalculate(n, array):
buckets = int(math.ceil(math.sqrt(n)))
total_odds = [0 for i in range(buckets)]
bucket_size = int(math.ceil(n / buckets))
for bucket in range(buckets):
start = bucket * bucket_size
end = min(n, start + bucket_size)
for index in range(start, end):
if array[index] % 2 != 0:
total_odds[bucket] += 1
return total_odds,bucket_size
def query_sol(typ, k,total_odds,bucket_size):
if typ == 1:
k -= 1
array[k] += 1
bucket = k // bucket_size
if array[k] % 2 != 0:
total_odds[bucket] += 1
else:
total_odds[bucket] += -1
else:
cnt = 0
found_at = -1
for index, count in enumerate(total_odds):
cnt += count
if cnt >= k:
bucket = index
start = bucket * bucket_size
end = min(n, start + bucket_size)
cnt -= count
for j in range(start, end):
if array[j] % 2 != 0:
cnt += 1
if cnt == k:
found_at = j + 1
break
break
return found_at
if __name__ == "__main__":
import math
n, q = list(map(int, input().strip().split(" ")))
array = list(map(int, input().strip().split(" ")))
total_odds,bucket_size = precalculate(n, array)
for i in range(q):
typ, k = list(map(int, input().strip().split(" ")))
if typ==1:
query_sol(typ, k,total_odds,bucket_size)
else:
print(query_sol(typ, k,total_odds,bucket_size))
|
code/square_root_decomposition/test/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
|
code/string_algorithms/src/Longest_common_subsequence/longest_common_subsequence.c
|
#include <stdio.h>
#include <string.h>
/* Part of Cosmos by OpenGenus Foundation */
int i, j, m, n, LCS_table[20][20];
char S1[20] , S2[20], b[20][20];
void lcsAlgo() {
m = strlen(S1);
n = strlen(S2);
// Filling 0's in the matrix
for (i = 0; i <= m; i++)
LCS_table[i][0] = 0;
for (i = 0; i <= n; i++)
LCS_table[0][i] = 0;
// Building the mtrix in bottom-up way
for (i = 1; i <= m; i++)
for (j = 1; j <= n; j++) {
if (S1[i - 1] == S2[j - 1]) {
LCS_table[i][j] = LCS_table[i - 1][j - 1] + 1;
} else if (LCS_table[i - 1][j] >= LCS_table[i][j - 1]) {
LCS_table[i][j] = LCS_table[i - 1][j];
} else {
LCS_table[i][j] = LCS_table[i][j - 1];
}
}
int index = LCS_table[m][n];
char lcsAlgo[index + 1];
lcsAlgo[index] = '\0';
int i = m, j = n;
while (i > 0 && j > 0) {
if (S1[i - 1] == S2[j - 1]) {
lcsAlgo[index - 1] = S1[i - 1];
i--;
j--;
index--;
}
else if (LCS_table[i - 1][j] > LCS_table[i][j - 1])
i--;
else
j--;
}
// Printing the sub sequences
printf("S1 : %s \nS2 : %s \n", S1, S2);
printf("Output: %s", lcsAlgo);
}
int main() {
printf("Enter the first string");
scanf("%s",S1);
printf("Enter the second string");
scanf("%s",S2);
lcsAlgo();
printf("\n");
}
|
code/string_algorithms/src/README.md
|
# cosmos #
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/aho_corasick_algorithm/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/aho_corasick_algorithm/aho_corasick_algorithm.cpp
|
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
const int MAXC = 26;
const int MAXS = 500;
int out[MAXS];
int f[MAXS];
int g[MAXS][MAXC];
int buildMatchingMachine(string arr[], int k)
{
memset(out, 0, sizeof out);
memset(g, -1, sizeof g);
int states = 1;
for (int i = 0; i < k; ++i)
{
const string &word = arr[i];
int currentState = 0;
for (size_t j = 0; j < word.size(); ++j)
{
int ch = word[j] - 'a';
if (g[currentState][ch] == -1)
g[currentState][ch] = states++;
currentState = g[currentState][ch];
}
out[currentState] |= (1 << i);
}
for (int ch = 0; ch < MAXC; ++ch)
if (g[0][ch] == -1)
g[0][ch] = 0;
memset(f, -1, sizeof f);
queue<int> q;
for (int ch = 0; ch < MAXC; ++ch)
if (g[0][ch] != 0)
{
f[g[0][ch]] = 0;
q.push(g[0][ch]);
}
while (q.size())
{
int state = q.front();
q.pop();
for (int ch = 0; ch <= MAXC; ++ch)
if (g[state][ch] != -1)
{
int failure = f[state];
while (g[failure][ch] == -1)
failure = f[failure];
failure = g[failure][ch];
f[g[state][ch]] = failure;
out[g[state][ch]] |= out[failure];
q.push(g[state][ch]);
}
}
return states;
}
int findNextState(int currentState, char nextInput)
{
int answer = currentState;
int ch = nextInput - 'a';
while (g[answer][ch] == -1)
answer = f[answer];
return g[answer][ch];
}
void searchWords(string arr[], int k, string text)
{
buildMatchingMachine(arr, k);
int currentState = 0;
for (size_t i = 0; i < text.size(); ++i)
{
currentState = findNextState(currentState, text[i]);
if (out[currentState] == 0)
continue;
for (int j = 0; j < k; ++j)
if (out[currentState] & (1 << j))
cout << "Word " << arr[j] << " appears from "
<< i - arr[j].size() + 1 << " to " << i << endl;
}
}
int main()
{
cout << "Enter number of test words you want.\n";
int num;
cin >> num;
string arr[num];
cout << "Enter test words.\n";
for (int i = 0; i < num; i++)
cin >> arr[i];
cout << "Enter test sentence.\n";
string text;
cin >> text;
int k = sizeof(arr) / sizeof(arr[0]);
searchWords(arr, k, text);
return 0;
}
|
code/string_algorithms/src/aho_corasick_algorithm/aho_corasick_algorithm.java
|
import java.util.*;
public class AhoCorasick {
static final int ALPHABET_SIZE = 26;
Node[] nodes;
int nodeCount;
public static class Node {
int parent;
char charFromParent;
int suffLink = -1;
int[] children = new int[ALPHABET_SIZE];
int[] transitions = new int[ALPHABET_SIZE];
boolean leaf;
{
Arrays.fill(children, -1);
Arrays.fill(transitions, -1);
}
}
public AhoCorasick(int maxNodes) {
nodes = new Node[maxNodes];
// create root
nodes[0] = new Node();
nodes[0].suffLink = 0;
nodes[0].parent = -1;
nodeCount = 1;
}
public void addString(String s) {
int cur = 0;
for (char ch : s.toCharArray()) {
int c = ch - 'a';
if (nodes[cur].children[c] == -1) {
nodes[nodeCount] = new Node();
nodes[nodeCount].parent = cur;
nodes[nodeCount].charFromParent = ch;
nodes[cur].children[c] = nodeCount++;
}
cur = nodes[cur].children[c];
}
nodes[cur].leaf = true;
}
public int suffLink(int nodeIndex) {
Node node = nodes[nodeIndex];
if (node.suffLink == -1)
node.suffLink = node.parent == 0 ? 0 : transition(suffLink(node.parent), node.charFromParent);
return node.suffLink;
}
public int transition(int nodeIndex, char ch) {
int c = ch - 'a';
Node node = nodes[nodeIndex];
if (node.transitions[c] == -1)
node.transitions[c] = node.children[c] != -1 ? node.children[c] : (nodeIndex == 0 ? 0 : transition(suffLink(nodeIndex), ch));
return node.transitions[c];
}
public static void main(String[] args) {
AhoCorasick ahoCorasick = new AhoCorasick(1000);
ahoCorasick.addString("bc");
ahoCorasick.addString("abc");
String s = "tabcbc";
int node = 0;
List<Integer> positions = new ArrayList<>();
for (int i = 0; i < s.length(); i++) {
node = ahoCorasick.transition(node, s.charAt(i));
if (ahoCorasick.nodes[node].leaf)
positions.add(i);
}
System.out.println(positions);
}
}
|
code/string_algorithms/src/aho_corasick_algorithm/aho_corasick_algorithm2.cpp
|
#include <vector>
#include <fstream>
#include <queue>
using namespace std;
const int MAXN = 1000005;
char word[MAXN];
int n;
struct trie_node
{
int nr;
trie_node *children[26];
trie_node *fail;
vector<trie_node* >out;
trie_node()
{
nr = 0;
for (int i = 0; i < 26; i++)
children[i] = 0;
fail = 0;
out.clear();
}
}*root = new trie_node;
trie_node *fr[MAXN];
queue<trie_node* >coada;
trie_node* trie_insert(trie_node *&node, char *p)
{
if (!*p)
return node;
if (!node->children[*p - 'a'])
node->children[*p - 'a'] = new trie_node;
return trie_insert(node->children[*p - 'a'], p + 1);
}
void traversal(trie_node *t)
{
for (size_t i = 0; i < t->out.size(); i++)
{
traversal(t->out[i]);
t->nr += t->out[i]->nr;
}
}
int main()
{
ifstream in("ahocorasick.in");
ofstream out("ahocorasick.out");
in >> word >> n;
for (int i = 1; i <= n; i++)
{
char s[100000];
in >> s;
fr[i] = trie_insert(root, s);
}
coada.push(root);
while (!coada.empty())
{
trie_node *nod = coada.front();
coada.pop();
for (int i = 0; i < 26; i++)
{
if (!nod->children[i])
continue;
trie_node *f = nod->fail;
while (f && !f->children[i])
f = f->fail;
if (!f)
{
nod->children[i]->fail = root;
root->out.push_back(nod->children[i]);
}
else
{
nod->children[i]->fail = f->children[i];
f->children[i]->out.push_back(nod->children[i]);
}
coada.push(nod->children[i]);
}
}
trie_node *t = root;
for (char *p = word; *p; p++)
{
int ch = *p - 'a';
while (t && !t->children[ch])
t = t->fail;
if (!t)
t = root;
else
t = t->children[ch];
t->nr++;
}
traversal(root);
for (int i = 1; i <= n; i++)
out << fr[i]->nr << '\n';
return 0;
}
|
code/string_algorithms/src/anagram_search/README.md
|
## Anagram Search
An anagram of a string is another string that contains same characters, only the order of characters can be different. For example, “abcd” and “dabc” are anagram of each other.

### There are two methods used to implement the above algortithms -
### Method 1 (Use Sorting) ( used in C program )
- Sort both strings
- Compare the sorted strings
- Time Complexity: Time complexity of this method depends upon the sorting technique used. In the above implementation, quickSort is used which may be O(n^2) in worst case. If we use a O(nLogn) sorting algorithm like merge sort, then the complexity becomes O(nLogn)
### Method 2 (Count characters) ( used in C++ program )
This method assumes that the set of possible characters in both strings is small. In the following implementation, it is assumed that the characters are stored using 8 bit and there can be 256 possible characters.
- Create count arrays of size 256 for both strings. Initialize all values in count arrays as 0.
- Iterate through every character of both strings and increment the count of character in the corresponding count arrays.
- Compare count arrays. If both count arrays are same, then return true.
- Time Complexity - O(n)
### Method 3 (Prime Array Method) ( used in Ruby program )
- This method takes an array of first 26 prime numbers .Each number representing a-z characters accordingly.
- The product of numbers corresponding to each alphabet in counted for both of the string.
- If product is equal then the strings are analgrams.
- Time Complexity - O(n)
|
code/string_algorithms/src/anagram_search/anagram.scala
|
object Anagram {
def isAnagram(a: String, b: String): Boolean = {
val a1 = a.replaceAll("\\s", "")
val b1 = b.replaceAll("\\s", "")
if (a1.length != b1.length)
false
else
frequencyMap(a1.toLowerCase()) == frequencyMap(b1.toLowerCase())
}
def frequencyMap(str: String) = str.groupBy(identity).mapValues(_.length)
def main(args: Array[String]): Unit = {
print(isAnagram("hello", "olleh"))
print(isAnagram("hello world", "woorll lehd"))
println(isAnagram("1", "2"))
}
}
|
code/string_algorithms/src/anagram_search/anagram_search.c
|
#include <stdio.h>
#include <string.h>
int
main(void)
{
char string1[1000], string2[1000], temp;
int length_string1, length_string2;
scanf("%s", string1);
scanf("%s", string2);
length_string1 = strlen(string1);
length_string2 = strlen(string2);
/* If both strings are of different length, then they are not anagrams */
if (length_string1 != length_string2) {
printf("%s and %s are not anagrams! \n", string1, string2);
return (0);
}
/* lets sort both strings first */
for (int i = 0; i < length_string1-1; i++)
for (int j = i+1; j < length_string1; j++) {
if (string1[i] > string1[j]) {
temp = string1[i];
string1[i] = string1[j];
string1[j] = temp;
}
if (string2[i] > string2[j]) {
temp = string2[i];
string2[i] = string2[j];
string2[j] = temp;
}
}
/* Compare both strings character by character */
for (int i = 0; i<length_string1; i++)
if (string1[i] != string2[i]) {
puts("Strings are not anagrams!");
return (0);
}
puts("Strings are anagrams!");
return (0);
}
|
code/string_algorithms/src/anagram_search/anagram_search.cpp
|
/* Part of Cosmos by OpenGenus Foundation */
#include <iostream>
#include <vector>
#include <string>
using namespace std;
/*
* Checks if two strings are anagrams of each other, ignoring any whitespace.
*
* Create maps of the counts of every character in each string.
* As well as keep a set of all characters used in both strings.
*
* Check to ensure every unique character is used in both strings the
* same number of times.
*/
vector<int> getMap(const string& s)
{
vector<int> m(26, 0);
for(char c : s)
{
if(c != ' ')
{
c = tolower(c);
m[c - 'a']++;
}
}
return m;
}
bool isAnagram(const string& s1, const string& s2)
{
vector<int> m1 = getMap(s1);
vector<int> m2 = getMap(s2);
return m1 == m2;
}
int main()
{
cout << isAnagram("anagram", "not a gram") << endl; // false
cout << isAnagram("anagram", "na a marg") << endl; // true
cout << isAnagram("William Shakespeare", "I am \t a weakish speller") << endl; // true
cout << isAnagram("Madam Curie", "Radium came") << endl; // true
cout << isAnagram("notagram", "notaflam") << endl; // false
return 0;
}
|
code/string_algorithms/src/anagram_search/anagram_search.cs
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AnagramSearch
{
class Program
{
static void Main(string[] args)
{
printAnagramResult("Anagram", "Nag A Ram", anagram_search("Anagram", "Nag A Ram"));
printAnagramResult("Nascar", "Battles", anagram_search("Nascar", "Battles"));
printAnagramResult("Lisp", "Clips", anagram_search("Lisp", "Clips"));
printAnagramResult("Angel", "Glean", anagram_search("Angel", "Glean"));
Console.ReadKey();
}
public static bool anagram_search(string first, string second)
{
// Remove all whitespace
first = first.Replace(" ", string.Empty);
second = second.Replace(" ", string.Empty);
if (first.Length != second.Length)
{
return false;
}
// Convert to lowercase and sort
first = first.ToLower();
second = second.ToLower();
char[] _first = first.ToArray();
Array.Sort(_first);
char[] _second = second.ToArray();
Array.Sort(_second);
first = new string(_first);
second = new string(_second);
for (int i = 0; i < first.Length; i++)
{
if (first[i] != second[i])
{
return false;
}
}
return true;
}
public static void printAnagramResult(string first, string second, bool result)
{
if (result)
{
Console.WriteLine(first + " and " + second + " are anagrams.");
}
else
{
Console.WriteLine(first + " and " + second + " are not anagrams.");
}
}
}
}
|
code/string_algorithms/src/anagram_search/anagram_search.go
|
//Part of the Cosmos Project by OpenGenus
//Find out if two strings are angram
//Written by Guilherme Lucas (guilhermeslucas)
package main
import (
"fmt"
"sort"
"strings"
)
func prepareString(w string) string {
s := strings.Split(w, "")
sort.Strings(s)
return strings.Join(s, "")
}
func isAnagram (first_word string, second_word string) bool {
first := prepareString(strings.ToLower(first_word))
second := prepareString(strings.ToLower(second_word))
return first == second
}
func main() {
if (isAnagram("god","dog")) {
fmt.Println("Dog and God are anagrams")
} else {
fmt.Println("Dog and God are not anagrams")
}
if (isAnagram("pie","apple")) {
fmt.Println("Pie and Apple are anagrams")
} else {
fmt.Println("Pie and Apple are not anagrams")
}
}
|
code/string_algorithms/src/anagram_search/anagram_search.java
|
/* Part of Cosmos by OpenGenus Foundation */
import java.util.Arrays;
import java.util.Scanner;
public class anagram_search {
static void isAnagram(String str1, String str2) {
String s1 = str1.replaceAll("\\s", "");
String s2 = str2.replaceAll("\\s", "");
boolean status = true;
if (s1.length() != s2.length()) {
status = false;
} else {
char[] ArrayS1 = s1.toLowerCase().toCharArray();
char[] ArrayS2 = s2.toLowerCase().toCharArray();
Arrays.sort(ArrayS1);
Arrays.sort(ArrayS2);
status = Arrays.equals(ArrayS1, ArrayS2);
}
if (status) {
System.out.println(s1 + " and " + s2 + " are anagrams");
} else {
System.out.println(s1 + " and " + s2 + " are not anagrams");
}
}
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
String str1=sc.next();
String str2=sc.next();
isAnagram(str1, str2);
}
}
|
code/string_algorithms/src/anagram_search/anagram_search.js
|
// Part of Cosmos by OpenGenus Foundation
// Checks if two strings are anagrams of each other, ignoring any whitespace.
//
// Remove whitespaces in both strings.
// Make all characters in both strings lowercase.
// Use .reduce() to create a hash table for each word containing the counts for each letter.
// Compare both hash tables to see if one contains any letters not contained in the other table.
// Check to ensure every unique character is used in both strings the same number of times.
var removeWhiteSpace = str => {
var splitStr = str.split("");
var letters = [];
for (var i = 0; i < splitStr.length; i++) {
if (splitStr[i] !== " ") {
letters.push(splitStr[i]);
}
}
var strNoSpaces = letters.join("");
return strNoSpaces;
};
var charCountTable = str => {
var letters = str.split("");
var counts = letters.reduce((instances, a) => {
if (a in instances) {
instances[a]++;
} else {
instances[a] = 1;
}
return instances;
}, {});
return counts;
};
var checkIfAnagrams = (str1, str2) => {
str1 = removeWhiteSpace(str1.toLowerCase());
str2 = removeWhiteSpace(str2.toLowerCase());
var str1LetterCount = charCountTable(str1);
var str2LetterCount = charCountTable(str2);
var str1LetterKeys = Object.keys(str1LetterCount);
var str2LetterKeys = Object.keys(str2LetterCount);
if (str1LetterKeys.length !== str2LetterKeys.length) {
return false;
} else {
for (var i = 0; i < str1LetterKeys.length; i++) {
if (
str1LetterCount[str1LetterKeys[i]] ===
str2LetterCount[str1LetterKeys[i]]
) {
continue;
} else {
return false;
}
}
return true;
}
};
checkIfAnagrams("bob", " "); // => false
checkIfAnagrams("aabb", "baba"); // => true
checkIfAnagrams("aab", " aa b"); // => true
checkIfAnagrams("bob", "ob oo"); // => false
|
code/string_algorithms/src/anagram_search/anagram_search.py
|
""" Part of Cosmos by OpenGenus Foundation"""
import collections
def removeWhitespace(string):
return "".join(string.split())
"""
Checks if two strings are anagrams of each other, ignoring any whitespace.
First remove any whitespace and lower all characters of both strings.
Then create dictionaries of the counts of every character in each string.
As well as keep a set of all characters used in both strings.
Check to ensure every unique character are used in both strings the
same number of times.
"""
def isAnagram(string1, string2):
charCount1 = collections.Counter(removeWhitespace(string1.lower()))
charCount2 = collections.Counter(removeWhitespace(string2.lower()))
allChars = set(charCount1.keys())
allChars = allChars.union(charCount2.keys())
for c in allChars:
if charCount1[c] != charCount2[c]:
return False
return True
assert isAnagram("anagram", "not a gram") == False
assert isAnagram("anagram", "na a marg") == True
assert isAnagram("William Shakespeare", "I am \t a weakish speller") == True
assert isAnagram("Madam Curie", "Radium came") == True
assert isAnagram("notagram", "notaflam") == False
|
code/string_algorithms/src/anagram_search/anagram_search.rb
|
FIRST_TWENTY_SIX_PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31,
37, 41, 43, 47, 53, 59, 61, 67, 71, 73,
79, 83, 89, 97, 101 ].freeze
def anagram_number(word)
word.downcase.chars.map do |letter|
letter.ord - 'a'.ord
end.reject do |index|
index < 0 || index >= FIRST_TWENTY_SIX_PRIMES.size
end.map do |index|
FIRST_TWENTY_SIX_PRIMES[index]
end.inject(:*)
end
def anagrams?(first_word, second_word)
anagram_number(first_word) == anagram_number(second_word)
end
anagrams?('anagram', 'nag a ram') # true
anagrams?('William Shakespeare', 'I am a weakish speller') # true
anagrams?('Madam Curie', 'Radium came') # true
anagrams?('notagram', 'notaflam') # false
|
code/string_algorithms/src/anagram_search/anagram_search.swift
|
/* Part of Cosmos by OpenGenus Foundation */
import Foundation
extension String {
/*
* Checks if two strings are anagrams of each other,
* ignoring case and whitespaces.
*/
func isAnagram(of other: String) -> Bool {
let selfChars = self.removingWhitespaces().lowercased().characters.sorted()
let otherChars = other.removingWhitespaces().lowercased().characters.sorted()
return selfChars == otherChars;
}
func removingWhitespaces() -> String {
return components(separatedBy: .whitespaces).joined()
}
}
func test() {
print("anagram".isAnagram(of: "not a gram")) // false
print("anagram".isAnagram(of: "na a marg")) // true
print("William Shakespeare".isAnagram(of: "I am \t a weakish speller")) // true
print("Madam Curie".isAnagram(of: "Radium came")) // true
print("notagram".isAnagram(of: "notaflam")) // false
}
test()
|
code/string_algorithms/src/arithmetic_on_large_numbers/string_addition.cpp
|
#include <string>
#include <iostream>
#include <cassert>
std::string strAdd(std::string s, std::string r)
{
int re = 0;
std::string sum;
// precondition for empty strings
assert(s.length() > 0 && r.length() > 0);
if (r.length() < s.length())
r.insert(r.begin(), s.length() - r.length(), '0');
else if (r.length() > s.length())
s.insert(s.begin(), r.length() - s.length(), '0');
for (int i = s.length() - 1; i >= 0; --i)
{
int a = (int(s[i] + r[i]) + re - 96);
sum.insert(sum.begin(), char(a % 10 + 48));
re = a / 10;
}
if (re != 0)
sum.insert(sum.begin(), char(re + 48));
return sum;
}
int main()
{
std::string s;
std::string c;
std::cout << "Enter Number One" << "\n";
std::cin >> s;
std::cout << "Enter Number Two" << "\n";
std::cin >> c;
std::cout << "Addition Result: " << strAdd(s, c) << "\n";
return 0;
}
|
code/string_algorithms/src/arithmetic_on_large_numbers/string_factorial.cpp
|
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int n;
cout << "Enter The Number for Factorial" << endl;
cin >> n;
vector<int> digit;
digit.push_back(1);
for (int j = 1; j < n + 1; j++)
{
int x = 0, y = 0;
for (int i = digit.size() - 1; i >= 0; i--)
{
x = j * digit[i] + y;
digit[i] = x % 10;
y = x / 10;
}
while (y != 0)
{
digit.insert(digit.begin(), y % 10);
y = y / 10;
}
}
cout << "The Factorial is: " << endl;
for (size_t i = 0; i < digit.size(); i++)
cout << digit[i];
cout << endl;
return 0;
}
|
code/string_algorithms/src/arithmetic_on_large_numbers/string_multiplication.cpp
|
#include <string>
#include <iostream>
using namespace std;
string strAdd(string s, string r)
{
int re = 0;
string digit;
if (r.length() < s.length())
r.insert(r.begin(), s.length() - r.length(), '0');
else if (r.length() > s.length())
s.insert(s.begin(), r.length() - s.length(), '0');
for (int i = s.length() - 1; i >= 0; --i)
{
int a = (int(s[i] + r[i]) + re - 96);
digit.insert(digit.begin(), char(a % 10 + 48));
re = a / 10;
}
if (re != 0)
digit.insert(digit.begin(), char(re + 48));
return digit;
}
string strMul(string s, string c)
{
string fina = "";
for (int j = c.length() - 1; j >= 0; j--)
{
string digit = "";
int re = 0;
for (int i = s.length() - 1; i >= 0; i--)
{
int a = int(c[j] - '0') * int(s[i] - '0') + re;
digit.insert(digit.begin(), char(a % 10 + 48));
re = a / 10;
}
if (re != 0)
digit.insert(digit.begin(), char(re + 48));
digit.append((c.length() - j - 1), '0');
fina = strAdd(fina, digit);
}
return fina;
}
int main()
{
string s;
string c;
cout << "Enter Number One" << endl;
cin >> s;
cout << "Enter Number Two" << endl;
cin >> c;
cout << "Multiplication Result: " << strMul(s, c) << endl;
return 0;
}
|
code/string_algorithms/src/arithmetic_on_large_numbers/string_subtract.cpp
|
#include <string>
#include <iostream>
#include <algorithm>
using namespace std;
bool isSmaller(string str1, string str2)
{
int n1 = str1.length(), n2 = str2.length();
if (n1 < n2)
return true;
if (n2 < n1)
return false;
for (int i = 0; i < n1; i++)
{
if (str1[i] < str2[i])
return true;
else if (str1[i] > str2[i])
return false;
}
return false;
}
string strSub(string str1, string str2)
{
if (isSmaller(str1, str2))
swap(str1, str2);
string str = "";
int n1 = str1.length(), n2 = str2.length();
reverse(str1.begin(), str1.end());
reverse(str2.begin(), str2.end());
int carry = 0;
for (int i = 0; i < n2; i++)
{
int sub = ((str1[i] - '0') - (str2[i] - '0') - carry);
if (sub < 0)
{
sub = sub + 10;
carry = 1;
}
else
carry = 0;
str.push_back(sub + '0');
}
for (int i = n2; i < n1; i++)
{
int sub = ((str1[i] - '0') - carry);
carry = 0;
str.push_back(sub + '0');
}
reverse(str.begin(), str.end());
return str;
}
int main()
{
string s;
string c;
cout << "Enter Number One" << endl;
cin >> s;
cout << "Enter Number Two" << endl;
cin >> c;
cout << "Subtraction Result: " << strSub(s, c) << endl;
return 0;
}
|
code/string_algorithms/src/boyer_moore_algorithm/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/boyer_moore_algorithm/boyer_moore_algorithm.c
|
# include <limits.h>
# include <string.h>
# include <stdio.h>
/* Part of Cosmos by OpenGenus Foundation */
# define NO_OF_CHARS 256
int
max(int a, int b)
{
return ((a > b) ? a: b);
}
void
badCharHeuristic(char *str, int size,
int badchar[NO_OF_CHARS])
{
int i;
for (i = 0; i < NO_OF_CHARS; i++)
badchar[i] = -1;
for (i = 0; i < size; i++)
badchar[(int) str[i]] = i;
}
void
search(char *txt, char *pat)
{
int m = strlen(pat);
int n = strlen(txt);
int badchar[NO_OF_CHARS];
badCharHeuristic(pat, m, badchar);
int s = 0;
while (s <= (n - m)) {
int j = m-1;
while(j >= 0 && pat[j] == txt[s+j])
j--;
if (j < 0) {
printf("\n pattern occurs at shift = %d", s);
s += (s+m < n) ? m-badchar[txt[s+m]] : 1;
} else
s += max(1, j - badchar[txt[s+j]]);
}
}
|
code/string_algorithms/src/boyer_moore_algorithm/boyer_moore_algorithm.cpp
|
#include <iostream>
#include <cstring>
#define NO_OF_CHARS 256
int max(int a, int b)
{
return (a > b) ? a : b;
}
void badCharHeuristic(char *str, int size, int badchar[NO_OF_CHARS])
{
int i;
for (i = 0; i < NO_OF_CHARS; i++)
badchar[i] = -1;
for (i = 0; i < size; i++)
badchar[(int) str[i]] = i;
}
void search(char *txt, char *pat)
{
int m = strlen(pat);
int n = strlen(txt);
int badchar[NO_OF_CHARS];
badCharHeuristic(pat, m, badchar);
int s = 0;
while (s <= (n - m))
{
int j = m - 1;
while (j >= 0 && pat[j] == txt[s + j])
j--;
if (j < 0)
{
printf("\n pattern occurs at shift = %d", s);
s += (s + m < n) ? m - badchar[txt[s + m] - char(0)] : 1;
}
else
s += max(1, j - badchar[txt[s + j] - char(0)]);
}
}
int main()
{
using namespace std;
char txt[] = {}, pat[] = {};
cin >> txt;
cin >> pat;
search(txt, pat);
return 0;
}
|
code/string_algorithms/src/boyer_moore_algorithm/boyer_moore_algorithm2.c
|
/* Part of Cosmos by OpenGenus Foundation */
/*
* Pointer based implementation of the Boyer-Moore String Search Algorithm
*/
#include <stdio.h>
#include <string.h>
/*
* Number of characters in the text alphabet used by the search and pattern strings
* For 8-bit strings, use 256
*/
#define NO_OF_CHARS 256
/*
* The core of Boyer-Moore algorithm is the skip value array used to advance more than
* a single character on mismatches encountered while searching
*/
static void
InitSkip(char const *const pattern, int skip[], size_t alphabetLen, int patternLen)
{
/* The length of the pattern is the default skip value */
for (int *skipVal = skip; alphabetLen; --alphabetLen, ++skipVal)
*skipVal = patternLen;
/*
* Examining the search pattern from left to right, set the skip value to the rightmost occurence
* of each unique character in the search pattern
*/
char const *patChar = pattern;
int i = patternLen;
while (*patChar && i)
skip[*patChar++] = --i;
}
static const char *
NextSearchBegin(const char *const curSearch, int skip)
{
return (curSearch + ((skip < 1) ? 1 : skip));
}
/*
* Searches txt for the first occurence of pattern using the Boyer-Moore searching algorithm
* If found return a pointer to the matching string in txt
* If not found return null (0)
* This matches the function declaration of the strstr() function
*/
const char *
BoyerMooreSearch(char const * const txt, char const * const pattern)
{
if (!pattern || !txt)
return (0);
const int patternLen = strlen(pattern);
const int txtLen = strlen(txt);
if (patternLen > txtLen)
return (0);
int skip[NO_OF_CHARS];
InitSkip(pattern, skip, NO_OF_CHARS, patternLen);
const char *const patternEnd = pattern + (patternLen - 1);
const char *const end = txt + (txtLen - patternLen);
const char *searchBegin = txt;
while (searchBegin <= end) {
const char *patternChar = patternEnd;
const char *searchChar = searchBegin + (patternLen - 1);
/* Compare right to left */
while (searchChar >= searchBegin && *searchChar == *patternChar)
--searchChar, --patternChar;
if (searchChar < searchBegin) /* All characters matched the pattern */
return (searchBegin);
searchBegin = NextSearchBegin(searchBegin, skip[*searchChar]);
}
return (0); /* pattern not found in txt */
}
/* Usage Example */
int
main()
{
const char *testText;
const char *testPattern;
const char *result;
int spaces;
char *matchMarker = "^";
testText = "A string searching example consisting of this sentence.";
testPattern = "sting";
result = BoyerMooreSearch(testText, testPattern);
puts(testText);
if (result) {
spaces = result - testText;
while (spaces--)
putc(' ', stdout);
puts(matchMarker);
}
else
puts("Pattern not found.");
return (0);
}
|
code/string_algorithms/src/finite_automata/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/finite_automata/c/c/makefile
|
main: main.c dfa.h dfa.c types.c types.h
gcc -o main main.c dfa.c types.c
|
code/string_algorithms/src/finite_automata/c/dfa.c
|
/*
* Part of Cosmos by OpenGenus.
* Author : ABDOUS Kamel
*/
#include "dfa.h"
#include <stdlib.h>
/* This array is used when doing a dfs */
static dfs_color_t* dfs_colors;
/* Tells if a state is accessible, when removing useless states */
static bool* access_bits;
/* Stores the new ids of states, when removing useless states */
static state_id_t* states_new_ids;
/* Stores the number of coaccessible states of a given DFA */
static int coaccess_states_nb;
/*
* Depth-first search subroutine for accessible states.
*/
static void
not_accessible_subroutine(dfa_t* dfa, state_id_t root, state_link_t* access_list);
/*
* Reverse depth-first search subroutine for coaccessible states.
*/
static state_link_t*
not_coaccessible_subroutine(dfa_t* dfa, state_id_t root, state_link_t* coaccess_list);
/*
* Allocate necessary data structure for the given dfa.
* States ID's are initialized.
* Initialize all transitions to -1.
* @return 0 on success, -1 on failure.
*/
int
allocate_dfa(int states_nb, dfa_t* dfa)
{
dfa->alpha_size = 256;
dfa->states_nb = states_nb;
dfa->states = malloc(sizeof(state_t) * states_nb);
if (dfa->states == NULL)
return (-1);
dfa->transitions = malloc(sizeof(state_id_t*) * states_nb);
if (dfa->transitions == NULL) {
free(dfa->states);
return (-1);
}
int i, j;
for (i = 0; i < states_nb; ++i) {
dfa->states[i].id = i;
dfa->states[i].is_final = false;
dfa->transitions[i] = malloc(sizeof(state_id_t) * dfa->alpha_size);
/* Error, free allocated memory */
if (dfa->transitions[i] == NULL) {
--i;
while (i >= 0) {
free(dfa->transitions[i]);
--i;
}
free(dfa->transitions);
free(dfa->states);
return (-1);
}
else {
for (j = 0; j < dfa->alpha_size; ++j)
dfa->transitions[i][j] = -1;
}
}
return (0);
}
/*
* Free data structures of given DFA.
*/
void
free_dfa(dfa_t* dfa)
{
free(dfa->states);
int i;
for (i = 0; i < dfa->states_nb; ++i)
free(dfa->transitions[i]);
free(dfa->transitions);
}
/*
* Remove not accessible and not co-accessible states of dfa.
* @return -1 if the resulting automaton is empty, 0 otherwise.
*/
int
remove_useless_states(dfa_t* dfa)
{
int i;
dfs_colors = malloc(sizeof(*dfs_colors) * dfa->states_nb);
for (i = 0; i < dfa->states_nb; ++i)
dfs_colors[i] = WHITE;
access_bits = calloc(dfa->states_nb, sizeof(*access_bits));
/* Used to store accessible states */
state_link_t* access_list = alloc_state_link(dfa->start_id);
/* Get all accessible states in access_list */
not_accessible_subroutine(dfa, dfa->start_id, access_list);
/* Now we will get co-accessible states from accessible states */
state_link_t *coaccess_list = NULL, *coaccess_back,
*next_save, *tmp_link;
states_new_ids = malloc(sizeof(state_id_t) * dfa->states_nb);
for (i = 0; i < dfa->states_nb; ++i) {
dfs_colors[i] = WHITE;
states_new_ids[i] = -1;
}
coaccess_states_nb = 0;
/* Loop over accessible states */
while (access_list != NULL) {
next_save = access_list->next;
if (dfa->states[access_list->state].is_final && dfs_colors[access_list->state] == WHITE) {
tmp_link = alloc_state_link(access_list->state);
if (coaccess_list == NULL)
coaccess_list = coaccess_back = tmp_link;
else
coaccess_back->next = tmp_link;
coaccess_back = not_coaccessible_subroutine(dfa, tmp_link->state, tmp_link);
}
/* We don't need this link anymore, so we free it */
free(access_list);
access_list = next_save;
}
/* End of depth-first search */
free(access_bits);
free(dfs_colors);
/* Time to construct the new DFA */
if (coaccess_states_nb == 0) {
free(states_new_ids);
return (-1);
}
else if (coaccess_states_nb == dfa->states_nb) {
free(states_new_ids);
return (0);
}
else {
state_t* old_states = dfa->states;
state_id_t** old_transitions = dfa->transitions;
int new_start_id;
/* Allocate new states and transitions */
dfa->states = malloc(sizeof(state_t) * coaccess_states_nb);
dfa->transitions = malloc(sizeof(state_id_t*) * coaccess_states_nb);
for (i = 0; i < coaccess_states_nb; ++i)
dfa->transitions[i] = malloc(sizeof(state_id_t) * dfa->alpha_size);
i = 0;
int j;
/* Copy coaccessible states and transitions of coaccessible states */
while (coaccess_list != NULL) {
dfa->states[i].id = i;
dfa->states[i].is_final = old_states[coaccess_list->state].is_final;
if (coaccess_list->state == dfa->start_id)
new_start_id = i;
for (j = 0; j < dfa->alpha_size; ++j) {
if (old_transitions[coaccess_list->state][j] != -1)
dfa->transitions[i][j] = states_new_ids[old_transitions[coaccess_list->state][j]];
else
dfa->transitions[i][j] = -1;
}
/* We free this link, we don't need it anymore */
next_save = coaccess_list->next;
free(coaccess_list);
coaccess_list = next_save;
++i;
}
free(old_states);
for (i = 0; i < dfa->states_nb; ++i)
free(old_transitions[i]);
free(old_transitions);
dfa->states_nb = coaccess_states_nb;
dfa->start_id = new_start_id;
free(states_new_ids);
}
return (0);
}
/*
* Depth-first search subroutine for accessible states.
*/
static void
not_accessible_subroutine(dfa_t* dfa, state_id_t root, state_link_t* access_list)
{
state_link_t* new_link;
int new_root;
dfs_colors[root] = BLACK;
access_bits[root] = true;
int i;
for (i = 0; i < dfa->alpha_size; ++i) {
new_root = dfa->transitions[root][i];
if (new_root != -1 && dfs_colors[new_root] == WHITE) {
new_link = alloc_state_link(new_root);
access_list->next = new_link;
not_accessible_subroutine(dfa, new_root, new_link);
}
}
}
/*
* Reverse depth-first search subroutine for coaccessible states.
*/
static state_link_t*
not_coaccessible_subroutine(dfa_t* dfa, state_id_t root, state_link_t* coaccess_list)
{
state_link_t* new_link;
dfs_colors[root] = BLACK;
states_new_ids[root] = coaccess_states_nb;
coaccess_states_nb++;
int i, j;
for (i = 0; i < dfa->states_nb; ++i) {
/* We do nothing if this state isn't accessible */
if (access_bits[i]) {
for (j = 0; j < dfa->alpha_size; ++j) {
if (dfa->transitions[i][j] == root && dfs_colors[i] == WHITE) {
new_link = alloc_state_link(i);
coaccess_list->next = new_link;
coaccess_list = not_coaccessible_subroutine(dfa, i, new_link);
break;
}
}
}
}
return (coaccess_list);
}
/*
* Make the dfa complete (all transitions are defined).
*/
void
complete_dfa(dfa_t* dfa)
{
/* ID of dead state */
state_id_t dead_id = dfa->states_nb;
/* The DFA is complete until we found a -1 transition */
bool complete = true;
int i, j;
for (i = 0; i < dfa->states_nb; ++i) {
for (j = 0; j < dfa->alpha_size; ++j) {
if (dfa->transitions[i][j] == -1) {
complete = false;
dfa->transitions[i][j] = dead_id;
}
}
}
/* The DFA is to be completed */
if (!complete) {
dfa->states_nb++;
dfa->states = realloc(dfa->states, sizeof(state_t) * dfa->states_nb);
dfa->states[dead_id].id = dead_id;
dfa->states[dead_id].is_final = false;
dfa->transitions = realloc(dfa->transitions, sizeof(state_id_t*) * dfa->states_nb);
dfa->transitions[dead_id] = malloc(sizeof(state_id_t) * dfa->alpha_size);
for (i = 0; i < dfa->alpha_size; ++i)
dfa->transitions[dead_id][i] = dead_id;
}
}
/*
* @return 1 if string is on the language of dfa.
* 0 otherwise.
*/
int
recognize_string(dfa_t* dfa, char* string)
{
state_id_t cur_state = dfa->start_id;
int i;
for (i = 0; string[i] != '\0'; ++i) {
cur_state = dfa->transitions[cur_state][(unsigned int)string[i]];
if (cur_state == -1)
return (0);
}
return (dfa->states[cur_state].is_final);
}
/*
* Construct the complement of the given dfa.
*/
void
complement_dfa(dfa_t* dfa)
{
complete_dfa(dfa);
int i;
for (i = 0; i < dfa->states_nb; ++i)
dfa->states[i].is_final = !dfa->states[i].is_final;
}
|
code/string_algorithms/src/finite_automata/c/dfa.h
|
/*
* Part of Cosmos by OpenGenus.
* Author : ABDOUS Kamel
*/
#ifndef AUTOMATA_DFA_H
#define AUTOMATA_DFA_H
#include "types.h"
/*
* Definition of a DFA.
*/
typedef struct dfa_s
{
int alpha_size;
state_t* states;
int states_nb;
state_id_t start_id;
/*
* This is a transition matrix.
* -1 indicates that the transition isn't defined.
*/
state_id_t** transitions;
} dfa_t;
/*
* Allocate necessary data structure for the given dfa.
* States ID's are initialized.
* Initialize all transitions to -1.
* @return 0 on success, -1 on failure.
*/
int
allocate_dfa(int states_nb, dfa_t* dfa);
/*
* Free data structures of given DFA.
*/
void
free_dfa(dfa_t* dfa);
/*
* Remove not accessible and not co-accessible states of dfa.
* @return -1 if the resulting automaton is empty, 0 otherwise.
*/
int
remove_useless_states(dfa_t* dfa);
/*
* Make the dfa complete (all transitions are defined).
*/
void
complete_dfa(dfa_t* dfa);
/*
* @return 1 if string is on the language of dfa.
* 0 otherwise.
*/
int
recognize_string(dfa_t* dfa, char* string);
/*
* Construct the complement of the given dfa.
*/
void
complement_dfa(dfa_t* dfa);
#endif // AUTOMATA_DFA_H
|
code/string_algorithms/src/finite_automata/c/main.c
|
/*
* Part of Cosmos by OpenGenus.
* Author : ABDOUS Kamel
*/
#include <stdio.h>
#include <stdlib.h>
#include "dfa.h"
int
main()
{
dfa_t dfa;
/* A DFA to recognize all strings with 01 as a substring */
allocate_dfa(3, &dfa);
/* States are labelled with positive integers */
dfa.start_id = 0;
dfa.states[2].is_final = true;
dfa.transitions[0]['0'] = 1;
dfa.transitions[0]['1'] = 0;
dfa.transitions[1]['0'] = 1;
dfa.transitions[1]['1'] = 2;
dfa.transitions[2]['0'] = 2;
dfa.transitions[2]['1'] = 2;
printf("%d\n", recognize_string(&dfa, "0111"));
printf("%d\n", recognize_string(&dfa, "10101010"));
printf("%d\n", recognize_string(&dfa, "11110"));
printf("%d\n", recognize_string(&dfa, "001001"));
free_dfa(&dfa);
return (0);
}
|
code/string_algorithms/src/finite_automata/c/types.c
|
/*
* Part of Cosmos by OpenGenus.
* Author : ABDOUS Kamel
*/
#include "types.h"
#include <stdlib.h>
/*
* Allocate a new state_link_t and return a pointer to it.
*/
state_link_t* alloc_state_link(state_id_t id)
{
state_link_t* ret = malloc(sizeof(*ret));
ret->state = id;
ret->next = NULL;
return (ret);
}
|
code/string_algorithms/src/finite_automata/c/types.h
|
/*
* Part of Cosmos by OpenGenus.
* Author : ABDOUS Kamel
*/
#ifndef AUTOMATA_TYPES_H
#define AUTOMATA_TYPES_H
#include <stdbool.h>
/* States are labelled by positive integers instead of strings */
typedef int state_id_t;
/* A symbol is a single char */
typedef char symbol_t;
typedef enum dfs_color_e
{
WHITE,
BLACK
} dfs_color_t;
/*
* State of a finite automaton.
*/
typedef struct state_s
{
state_id_t id;
/* Indicates if this state is a final state */
bool is_final;
} state_t;
/*
* A single link in a linked-list of state ids.
*/
typedef struct state_link_s
{
state_id_t state;
struct state_link_s* next;
} state_link_t;
/*
* Allocate a new state_link_t and return a pointer to it.
*/
state_link_t* alloc_state_link(state_id_t id);
#endif // AUTOMATA_TYPES_H
|
code/string_algorithms/src/finite_automata/searchstringusingdfa.java
|
// Part of Cosmos by OpenGenus Foundation
import java.util.Scanner;
public class SearchStringUsingDFA
{
public static final int NO_OF_CHARS = 256;
public static int getNextState(char[] pat, int M, int state, int x)
{
if (state < M && x == pat[state])
return state + 1;
int ns, i;
for (ns = state; ns > 0; ns--)
{
if (pat[ns - 1] == x)
{
for (i = 0; i < ns - 1; i++)
{
if (pat[i] != pat[state - ns + 1 + i])
break;
}
if (i == ns - 1)
return ns;
}
}
return 0;
}
public static void computeTF(char[] pat, int M, int[][] TF)
{
int state, x;
for (state = 0; state <= M; ++state)
for (x = 0; x < NO_OF_CHARS; ++x)
TF[state][x] = getNextState(pat, M, state, x);
}
public static void search(char[] pat, char[] txt)
{
int M = pat.length;
int N = txt.length;
int[][] TF = new int[M + 1][NO_OF_CHARS];
computeTF(pat, M, TF);
// Process txt over FA.
int i, state = 0;
for (i = 0; i < N; i++)
{
state = TF[state][txt[i]];
if (state == M)
{
System.out.print(pat);
System.out.print(" found at " + (i - M + 1));
}
}
}
public static void main(String[] args)
{
Scanner sc = new Scanner(System.in);
System.out.println("Enter the main string: ");
String main = sc.nextLine();
System.out.println("Enter the pattern string: ");
String pattern = sc.nextLine();
search(pattern.toCharArray(), main.toCharArray());
sc.close();
}
}
|
code/string_algorithms/src/finite_automata/searchstringusingdfa.rs
|
use std::io;
fn search(string: &str, pattern: &str, start: u64, prev_match: bool) -> (bool, u64) {
// Returns if start index is `ge` string length
if start >= string.len() as u64 {
return (false, start);
}
// Checks whether the char at string[start] equals the first char of pattern
if string.chars().nth(start as usize).unwrap() == pattern.chars().nth(0).unwrap() {
// Returns true if pattern's length is 1
if pattern.len() == 1 {
return (true, start);
}
// Creates a new pattern which consists of all the chars of pattern except the first char
let new_pattern = &pattern[pattern.char_indices().nth(1).unwrap().0..];
/*
Returns only if the both the previous and next char match.
Suppose the string is `hello` and the pattern is `ef`.
It will initially match `e`, but since the next char in the pattern
does not match, it should again start checking for an `e` from index 2 of
the string. If we do not check for truthy prev_match, then a string
of the likes of `helfo` will be matched by the pattern `ef`.
*/
if prev_match && search(&string, &new_pattern, start + 1, true).0 {
return (true, start);
}
}
// Passing a falsy prev_match value since the previous char did not match.
return search(&string, &pattern, start + 1, false);
}
fn main() {
println!("Enter a string");
let mut string = String::new();
io::stdin().read_line(&mut string).expect("Error reading string");
println!("Enter a pattern");
let mut pattern = String::new();
io::stdin().read_line(&mut pattern).expect("Error reading pattern");
println!("{:?}", search(&string, &pattern, 0, false));
}
|
code/string_algorithms/src/kasai_algorithm/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/kasai_algorithm/kasai_algorithm.cpp
|
/*
*
* Kasai Algorithm
* https://www.geeksforgeeks.org/%C2%AD%C2%ADkasais-algorithm-for-construction-of-lcp-array-from-suffix-array/
*
*/
#include <iostream>
#include <vector>
#include <string>
std::vector<int> kasaiAlgorithm(std::string s, std::vector<int> suffix_array)
{
size_t m = 0;
std::vector<int> LCP(s.size(), 0);
std::vector<size_t> rank(s.size(), 0);
for (size_t i = 0; i < s.size(); i++)
rank[suffix_array[i]] = i;
for (size_t i = 0; i < s.size(); i++, m ? m-- : 0)
{
if (rank[i] == s.size() - 1)
{
m = 0;
continue;
}
int j = suffix_array[rank[i] + 1];
while (i + m < s.size() && j + m < s.size() && s[i + m] == s[j + m])
m++;
LCP[rank[i]] = m;
}
return LCP;
}
int main()
{
std::string input = "banana";
int indexes[] = {5, 3, 1, 0, 4, 2};
std::vector<int> suffixArray(indexes, indexes + 62);
std::vector<int> lcpArray = kasaiAlgorithm(input, suffixArray);
for (int i = 0; i < lcpArray.size(); i++) // => 1 3 0 0 2 0
std::cout << lcpArray[i] << " ";
return 0;
}
|
code/string_algorithms/src/kmp_algorithm/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/kmp_algorithm/kmp.java
|
class KMP_String_Matching {
void KMPSearch(String pat, String txt)
{
int M = pat.length();
int N = txt.length();
// create lps[] that will hold the longest
// prefix suffix values for pattern
int lps[] = new int[M];
int j = 0; // index for pat[]
// Preprocess the pattern (calculate lps[]
// array)
computeLPSArray(pat, M, lps);
int i = 0; // index for txt[]
while ((N - i) >= (M - j)) {
if (pat.charAt(j) == txt.charAt(i)) {
j++;
i++;
}
if (j == M) {
System.out.println("Found pattern "
+ "at index " + (i - j));
j = lps[j - 1];
}
// mismatch after j matches
else if (i < N && pat.charAt(j) != txt.charAt(i)) {
// Do not match lps[0..lps[j-1]] characters,
// they will match anyway
if (j != 0)
j = lps[j - 1];
else
i = i + 1;
}
}
}
void computeLPSArray(String pat, int M, int lps[])
{
// length of the previous longest prefix suffix
int len = 0;
int i = 1;
lps[0] = 0; // lps[0] is always 0
// the loop calculates lps[i] for i = 1 to M-1
while (i < M) {
if (pat.charAt(i) == pat.charAt(len)) {
len++;
lps[i] = len;
i++;
}
else // (pat[i] != pat[len])
{
// This is tricky. Consider the example.
// AAACAAAA and i = 7. The idea is similar
// to search step.
if (len != 0) {
len = lps[len - 1];
// Also, note that we do not increment
// i here
}
else // if (len == 0)
{
lps[i] = len;
i++;
}
}
}
}
|
code/string_algorithms/src/kmp_algorithm/kmp.py
|
def getLPS(pattern):
m = len(pattern)
lps = [0] * (m + 1)
i = 0
j = -1
lps[i] = j
while i < m:
while j >= 0 and pattern[i] != pattern[j]:
j = lps[j]
i += 1
j += 1
lps[i] = j
return lps
text = "ABC ABCDAB ABCDABCDABDE"
pattern = "ABCDABD"
lps = getLPS(pattern)
# Matching part
i = 0
j = 0
n = len(text)
m = len(pattern)
while i < n - 1:
while j >= 0 and text[i] != pattern[j]:
j = lps[j]
i += 1
j += 1
if j == m:
print("Match found at index: " + str(i - j))
j = lps[j]
|
code/string_algorithms/src/kmp_algorithm/kmp_algorithm.cpp
|
// C++ program for implementation of KMP pattern searching
// algorithm
#include <string>
#include <iostream>
using namespace std;
void computeLPSArray(string pat, int M, int *lps);
// Prints occurrences of txt[] in pat[]
void KMPSearch(string pat, string txt)
{
int M = pat.length();
int N = txt.length();
// create lps[] that will hold the longest prefix suffix
// values for pattern
int lps[M];
// Preprocess the pattern (calculate lps[] array)
computeLPSArray(pat, M, lps);
int i = 0; // index for txt[]
int j = 0; // index for pat[]
while (i < N)
{
if (pat[j] == txt[i])
{
j++;
i++;
}
if (j == M)
{
printf("Found pattern at index %d \n", i - j);
j = lps[j - 1];
}
// mismatch after j matches
else if (i < N && pat[j] != txt[i])
{
// Do not match lps[0..lps[j-1]] characters,
// they will match anyway
if (j != 0)
j = lps[j - 1];
else
i = i + 1;
}
}
}
// Fills lps[] for given patttern pat[0..M-1]
void computeLPSArray(string pat, int M, int *lps)
{
// length of the previous longest prefix suffix
int len = 0;
lps[0] = 0; // lps[0] is always 0
// the loop calculates lps[i] for i = 1 to M-1
int i = 1;
while (i < M)
{
if (pat[i] == pat[len])
{
len++;
lps[i] = len;
i++;
}
else // (pat[i] != pat[len])
{
// This is tricky. Consider the example.
// AAACAAAA and i = 7. The idea is similar
// to search step.
if (len != 0)
len = lps[len - 1];
// Also, note that we do not increment
// i here
else // if (len == 0)
{
lps[i] = 0;
i++;
}
}
}
}
// Driver program to test above function
int main()
{
string txt, pat;
cout << "Enter string to be searched on: ";
cin >> txt;
cout << "Enter pattern to be searched: ";
cin >> pat;
KMPSearch(pat, txt);
return 0;
}
|
code/string_algorithms/src/levenshtein_distance/README.md
|
# Levenshtein Distance
The Levenshtein distance between two strings measures the similarity between them by calculating the **minimum number of one-character insertions, deletions, or substitutions required to change one string into another**. This edit distance is often used in spell chekers, plagiarism detectors, and OCR.
For example, each of these examples have a Levensthein distance of 1 with `cosmos`:
- cosmo**t**s (addition of t in the middle)
- cosmos**k** (addition of k at the end)
- cosms (deletion of o in the middle)
- cosmo (deletion of s at the end)
- cosm**a**s (substitution of o to a)
## Recursive algorithm
Recursively solving this problem is simple, but computationally very inefficient because it recalculates the distance between substrings it has already covered.
Function LevDistance(String S, String T):
1. If either (length of `S`) or (length of `T`) is `0`, return the maximum of (length of `S`) and (length of `T`)
- This is because the minium edit distance between a nonempty string and an empty string is always the length of the nonempty string
2. Else, return minimum of:
- LevDistance(`S` without the last character, `T`)
- LevDistance(`S`, `T` without last character)
- LevDistance(`S` without the last character, `T` without the last character)
## Iterative matrix algorithm
This algorithm is more efficient than the recursive one because the matrix stores the distance calculations for substrings, saving computational time.
Function LevDistance(String S, String T):
1. Variable `SL` = length of `S` and `TL` = length of `T`
2. Create an empty `matrix` (2d array) of height `SL` and width `TL`
3. Fill the first row with numbers from `0` to `TL`
4. Fill the first column with numbres from `0` to `SL`
5. For each character `s` of `S` (from `i` = `1` to `SL`):
- For each character `t` of `T` (from `j` = `1` to `TL`):
- if `s` equals `t`, the `cost` is `0`
- if `s` does not equal `t`, the `cost` is `1`
- set `matrix[i][j]` to the minimum of:
- `matrix[i - 1, j] + 1` (this is for deletion)
- `matrix[i, j - 1] + 1` (this is for insertion)
- `matrix[i - 1, j - 1] + cost` (this is for substitution)
6. Return `matrix[SL, TL]`
Each bottom-up dynamic program works by setting each cell's value to the minimum edit distance between the substrings of S and T.
### Example matrix
This is the final Levenshtein distance matrix for the strings "cosmos" and "catmouse". The minimum edit distance is the value in the bottom right corner: 4.
| | | c | a | t | m | o | u | s | e |
|-------|---|---|---|---|---|---|---|---|---|
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| **c** | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| **o** | 2 | 1 | 1 | 2 | 3 | 3 | 4 | 5 | 6 |
| **s** | 3 | 2 | 2 | 2 | 3 | 4 | 4 | 4 | 5 |
| **m** | 4 | 3 | 3 | 3 | 2 | 3 | 4 | 5 | 5 |
| **o** | 5 | 4 | 4 | 4 | 3 | 2 | 3 | 4 | 5 |
| **s** | 6 | 5 | 5 | 5 | 4 | 3 | 3 | 3 | **4** |
---
<p align="center">
A massive collaborative effort by <a href="https://github.com/OpenGenus/cosmos">OpenGenus Foundation</a>
</p>
---
|
code/string_algorithms/src/levenshtein_distance/levenshteindistance.java
|
// Part of Cosmos by OpenGenus Foundation
class LevenshteinDistance {
private String a, b;
private int n, m;
private int[][] dp;
public LevenshteinDistance(String a, String b) {
this.a = a;
this.b = b;
n = a.length();
m = b.length();
dp = new int[n + 1][m + 1];
initialize();
}
private void initialize() {
for(int i = 0; i <= n; i++) {
dp[i][0] = i;
}
for(int j = 0; j <= m; j++) {
dp[0][j] = j;
}
}
private int min3(int a, int b, int c) {
return Math.min(a, Math.min(b, c));
}
public int compute() {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
int c = (a.charAt(i - 1) == b.charAt(j - 1)) ? 0 : 1;
dp[i][j] = min3(dp[i - 1][j - 1] + c, dp[i - 1][j] + 1, dp[i][j - 1] + 1);
}
}
return dp[n][m];
}
public static void main(String[] args) {
LevenshteinDistance distance = new LevenshteinDistance("ana", "banana");
System.out.println(distance.compute());
}
}
|
code/string_algorithms/src/lexicographically_largest_palindrome_subsequence/Lexicographyically_largest_palindrome_subsequence.cpp
|
/* C++ Program to find lexicographically largest palindrome subsequence
In this Program only input line contains a non-empty string S consisting of lowercase English letters only. Its length does not exceed 10.
Here, Characters in the strings are compared according to their ASCII codes and the one with largest ASCII code is lexicographically largest.
And output contain frequency and all the reoccurrence of that character in string S in a single line.
*/
#include<iostream>
#include<string>
using namespace std;
int main() {
string S, k, a, m;
int i, j, c, max;
//getting user input as string
cin >> S;
//initialising m with character "a"
m = "a";
max = 0;
for(j = 0; j < S.size(); j++) {
//initialising c with 0
c = 0;
for(i = 0; i < S.size(); i++) {
//assigning value of element with index 'i' to a
a = S[i];
//this is for getting the lexicographically largest element (the one with largest ascii value)
if(a >= m)
m = a;
}
}
for(i = 0; i < S.size(); i++) {
a = S[i];
if(a == m) {
//increament c when we find our lexicographically largest character in string more than one time
c++;
//for finding maximum frequency of character
if(c > max)
max = c;
}
}
cout << max << " ";
for(i = 0; i < max; i++) {
//printing subsequence of lexicographically largest character as output
cout << m;
}
return 0;
}
/* SAMPLE
Testcase 1
INPUT startling
OUTPUT 2 tt
Testcase 2
INPUT mississippi
OUTPUT 4 ssss
Testcase 3
INPUT sausage
OUTPUT 1 u
Time Complexity is O(n^2) where n is length of string
Space Complexity is O(1) */
|
code/string_algorithms/src/lipogram_checker/lipogram_checker.cpp
|
// Part of Cosmos by OpenGenus Foundation
#include <iostream>
#include <string>
const std::string alphabets = "abcdefghijklmnopqrstuvwxyz";
void
panLipogramChecker(std::string phrase)
{
using std::cout;
using std::endl;
for (unsigned int i = 0; i < phrase.length(); i++)
phrase[i] = tolower(phrase[i]);
int counter = 0;
for (unsigned int i = 0; i < 26; i++)
{
auto pos = phrase.find(alphabets[i]);
if (pos > phrase.length())
counter += 1;
}
if (counter == 0)
cout << "Pangram" << endl;
else if (counter >= 2)
cout << "Not a pangram but might be a lipogram" << endl;
else
cout << "Pangrammatic Lipogram" << endl;
}
int
main()
{
std::string str = "The quick brown fox jumped over the lazy dog";
panLipogramChecker(str);
str = "The quick brown fox jumps over the lazy dog";
panLipogramChecker(str);
str = "The quick brown fox jum over the lazy dog";
panLipogramChecker(str);
}
|
code/string_algorithms/src/lipogram_checker/lipogram_checker.cs
|
using System;
/*
* Part of cosmos by OpenGenus Foundation
* */
namespace lipogram_checker
{
class Program
{
/// <summary>
/// Method to check if a string is lipogram or not
/// </summary>
/// <param name="str">String To Check</param>
/// <returns>Integer Value</returns>
static int lipogram(string str)
{
int count = 0;
string alphabets = "abcdefghijklmnopqrstuvwxyz";
str = str.ToLower();
for (int i = 0; i < alphabets.Length; i++)
{
int index = str.IndexOf(alphabets[i]);
if (index < 0 || index > str.Length)
count++;
}
return count;
}
static void Main(string[] args)
{
string to_chk = "The quick brown fox jumped over the lazy dog";
int val = lipogram(to_chk);
if (val == 0)
Console.WriteLine("Pangram");
else if (val >= 2)
Console.WriteLine("Not a pangram but might a lipogram");
else
Console.WriteLine("Pangrammatic Lipogram");
Console.ReadKey();
}
}
}
|
code/string_algorithms/src/lipogram_checker/lipogram_checker.js
|
/* Checker */
const alphabet = [..."abcdefghijklmnopqrstuvwxyz"];
const countUnused = str =>
alphabet.reduce(
(unused, char) => unused + !str.toLowerCase().includes(char),
0
);
const checkLipogram = str => {
let unused = countUnused(str);
return unused >= 2
? "Not a pangram but might a lipogram"
: unused == 1
? "Pangrammatic lipogram"
: "Pangram";
};
/* Test */
checkLipogram("The quick brown fox jumps over the lazy dog"); // should return 'Pangram'
checkLipogram("OpenGenus cosmos"); // should return 'Not a pangram but might a lipogram'
checkLipogram(
`A jovial swain should not complain
Of any buxom fair
Who mocks his pain and thinks it gain
To quiz his awkward air.
`
); // should return 'Pangrammatic lipogram'
|
code/string_algorithms/src/lipogram_checker/lipogram_checker.py
|
"""
A pangram or holoalphabetic sentence is a sentence using every letter of a given alphabet at least once.
The best-known English pangram is "The quick brown fox jumps over the lazy dog."
A pangrammatic lipogram is a text that uses every letter of the alphabet but excludes one of them.
"""
# Part of Cosmos by OpenGenus Foundation
#
alphabet = "abcdefghijklmnopqrstuvwxyz"
def pangrammaticChecker(string):
string.lower()
counter = 0
for x in alphabet:
if string.find(x) < 0:
counter += 1
if counter == 0:
result = "Pangram"
elif counter == 1:
result = "Pangrammatic Lipogram"
else:
result = "Not a pangram but might a lipogram"
return result
if __name__ == "__main__":
print(pangrammaticChecker("The quick brown fox jumps over the lazy dog"))
|
code/string_algorithms/src/longest_palindromic_substring/longest_palindromic_substring.cpp
|
// Part of Cosmos by OpenGenus
#include <iostream>
#include <string>
using namespace std;
// expand in both directions of low and high to find
// maximum length palindrome
string expand(string str, int low, int high)
{
int len = str.length();
// run till str[low.high] is a palindrome
while (low >= 0 && high < len && (str[low] == str[high]))
low--, high++; // expand in both directions
// return palindromic substring
return str.substr(low + 1, high - low - 1);
}
// Function to find Longest Palindromic Substring in O(n^2) time
// and O(1) space
string LongestPalindromicSubstring(string str, int len)
{
// max_str stores the maximum length palindromic substring
// found so far
string max_str = "", curr_str;
// max_length stores the length of maximum length palindromic
// substring found so far
int max_length = 0, curr_length;
// consider every character of given string as mid points and expand
// in its both directions to find maximum length palindrome
for (int i = 0; i < len; i++)
{
// find a longest odd length palindrome with str[i] as mid point
curr_str = expand(str, i, i);
curr_length = curr_str.length();
// update maximum length palindromic substring if odd length
// palindrome has greater length
if (curr_length > max_length)
{
max_length = curr_length;
max_str = curr_str;
}
// find a longest even length palindrome with str[i] and str[i+1]
// as mid points. Note that an even length palindrome has two
// mid points
curr_str = expand(str, i, i + 1);
curr_length = curr_str.length();
// update maximum length palindromic substring if even length
// palindrome has greater length
if (curr_length > max_length)
{
max_length = curr_length;
max_str = curr_str;
}
}
return max_str;
}
// main function
int main()
{
string str;
cin>>str;
cout << "Longest Palindromic Substring of " << str << " is "
<< LongestPalindromicSubstring(str, str.length() - 1);
return 0;
}
|
code/string_algorithms/src/longest_palindromic_substring/longest_palindromic_substring.js
|
/*
Path of Cosmos by OpenGenus
To find the longest palindromic substring in JavaScript
Example : Input String : "agbdcdbty" the palindromic substring is "bdcdb"
*/
// A utility function to check if a substring is a palindrome
function isPalindrome(str){
var rev = str.split("").reverse().join("");
return str == rev;
}
// The main function to find the longest palindromic substring
function longestPalindromicSubstring(str){
var maxL=0;
maxp = ' ';
// loop to check each and every substring
for(var i=0; i < str1.length; i++) {
var subs = str1.substr(i, str1.length);
for(var j=subs.length; j>=0; j--) {
var sub_subs_str = subs.substr(0, j);
if (sub_subs_str.length <= 1){
continue;
}
// to check if the substring is a palindrome
if (is_Palindrome(sub_subs_str)){
// if length of palindromic substring is greater than the current maximum length
// then change the value of maximum length and store the corresponding value
// of the substring
if (sub_subs_str.length > max_length) {
max_length = sub_subs_str.length;
maxp = sub_subs_str;
}
}
}
}
return maxp; // return the answer
}
console.log(longest_palindrome("abccbatry")); // print the solution
}
/*
Output String : abccba
*/
|
code/string_algorithms/src/longest_palindromic_substring/longest_palindromic_substring.py
|
def expand_center(s, l, r):
while l >= 0 and r < len(s) and s[l] == s[r]:
l -= 1
r += 1
return s[l + 1 : r]
def longest_pal_substr(s):
ans = ""
for c in range(len(s)):
s1 = expand_center(s, c, c)
s2 = expand_center(s, c, c + 1)
ans = max(ans, s1, s2, key=len)
return ans
if __name__ == "__main__":
print(longest_pal_substr("belle"))
print(longest_pal_substr("racecar"))
|
code/string_algorithms/src/manachar_algorithm/manachar_longest_palindromic_subs.cpp
|
#include <string>
#include <iostream>
#include <cmath>
/* Part of Cosmos by OpenGenus Foundation */
using namespace std;
#define SIZE 100000 + 1
size_t P[SIZE * 2];
// Transform S into new string with special characters inserted.
string convertToNewString(const string &s)
{
string newString = "@";
for (size_t i = 0; i < s.size(); i++)
newString += "#" + s.substr(i, 1);
newString += "#$";
return newString;
}
string longestPalindromeSubstring(const string &s)
{
string Q = convertToNewString(s);
int c = 0;
size_t r = 0; // current center, right limit
for (size_t i = 1; i < Q.size() - 1; i++)
{
// find the corresponding letter in the palidrome subString
int iMirror = c - (i - c);
if (r > i)
P[i] = std::min(r - i, P[iMirror]);
// expanding around center i
while (Q[i + 1 + P[i]] == Q[i - 1 - P[i]])
P[i]++;
// Update c,r in case if the palindrome centered at i expands past r,
if (i + P[i] > r)
{
c = i; // next center = i
r = i + P[i];
}
}
// Find the longest palindrome length in p.
size_t maxPalindrome = 0;
int centerIndex = 0;
for (size_t i = 1; i < Q.size() - 1; i++)
if (P[i] > maxPalindrome)
{
maxPalindrome = P[i];
centerIndex = i;
}
cout << maxPalindrome << "\n";
return s.substr( (centerIndex - 1 - maxPalindrome) / 2, maxPalindrome);
}
int main()
{
string s = "kiomaramol\n";
cout << longestPalindromeSubstring(s);
return 0;
}
|
code/string_algorithms/src/manachar_algorithm/manachar_longest_palindromic_subs.py
|
# Part of Cosmos by OpenGenus Foundation
def get_palindrome_length(string, index):
length = 1
while index + length < len(string) and index - length >= 0:
if string[index + length] == string[index - length]:
length += 1
else:
break
return length - 1
def interleave(string):
ret = []
for s in string:
ret.extend(["#", s])
ret.append("#")
return "".join(ret)
def manacher(string):
right = 0
center = 0
string = interleave(string)
P = list(map(lambda e: 0, range(len(string))))
for i in range(1, len(string)):
mirror = 2 * center - i
if i + P[mirror] <= right and mirror >= len(string) - i:
P[i] = P[mirror]
else:
plength = get_palindrome_length(string, i)
P[i] = plength
if plength > 1:
center = int(i)
right = center + plength
return [e / 2 for e in P]
def get_palindrome_number(string):
return sum(manacher(string))
|
code/string_algorithms/src/morse_code/morsecode.cpp
|
#include <iostream>
#include <string>
#include <vector>
std::pair<char, std::string> pairing(char alpha, std::string morse_code);
std::string finder(const std::vector<std::pair<char, std::string>> &mp, std::string value);
std::string wordToMorse(const std::vector<std::pair<char, std::string>> &mp, std::string input);
std::string morseToWord(const std::vector<std::pair<char, std::string>> &mp, std::string input);
int main()
{
std::vector<std::pair<char, std::string>> key;
key.push_back(pairing('A', ".-"));
key.push_back(pairing('B', "-..."));
key.push_back(pairing('C', "-.-."));
key.push_back(pairing('D', "-.."));
key.push_back(pairing('E', "."));
key.push_back(pairing('F', "..-."));
key.push_back(pairing('G', "--."));
key.push_back(pairing('H', "...."));
key.push_back(pairing('I', ".."));
key.push_back(pairing('J', ".---"));
key.push_back(pairing('K', "-.-"));
key.push_back(pairing('L', ".-.."));
key.push_back(pairing('M', "--"));
key.push_back(pairing('N', "-."));
key.push_back(pairing('O', "---"));
key.push_back(pairing('P', ".--."));
key.push_back(pairing('Q', "--.-"));
key.push_back(pairing('R', ".-."));
key.push_back(pairing('S', "..."));
key.push_back(pairing('T', "-"));
key.push_back(pairing('U', "..-"));
key.push_back(pairing('V', "...-"));
key.push_back(pairing('W', ".--"));
key.push_back(pairing('X', "-..-"));
key.push_back(pairing('Y', "-.--"));
key.push_back(pairing('Z', "--.."));
key.push_back(pairing('1', ".----"));
key.push_back(pairing('2', "..---"));
key.push_back(pairing('3', "...--"));
key.push_back(pairing('4', "....-"));
key.push_back(pairing('5', "....."));
key.push_back(pairing('6', "-...."));
key.push_back(pairing('7', "--..."));
key.push_back(pairing('8', "---.."));
key.push_back(pairing('9', "---."));
key.push_back(pairing('0', "-----"));
std::cout << wordToMorse(key, "shobhit is a programmer") << std::endl;
std::cout << morseToWord(key, "--- .--. . -. --. . -. ..- ...") << std::endl; // prints OPENGENUS
return 0;
}
std::pair<char, std::string> pairing(char alpha, std::string morse_code)
{
return std::make_pair(alpha, morse_code);
}
// returns the corresponding code for both alphabet and numbers & vice versa
std::string finder(const std::vector<std::pair<char, std::string>> &mp, std::string value)
{
// to know where to search on (first index or second index)
if (value[0] == '.' || value[0] == '-')
{
std::string val = "";
for (const auto &it : mp)
if (it.second == value)
{
val += it.first;
return val;
}
}
else
{
// it is used because length of any alphabet is 1
char val = value[0];
for (const auto &it : mp)
if (it.first == val)
return it.second;
}
return std::string{};
}
std::string wordToMorse(const std::vector<std::pair<char, std::string>> &mp, std::string input)
{
std::string tempr, encoded = "";
for (const auto& elem : input)
{
if (elem == ' ')
encoded += '/';
else
{
tempr = std::toupper(elem);
tempr = finder(mp, tempr);
encoded += tempr + " ";
}
}
return encoded;
}
std::string morseToWord(const std::vector<std::pair<char, std::string>> &mp, std::string input)
{
std::string new_input = input + " ", decoded = "", pseudo_morse = "";
for (const auto& elem : input)
{
if (elem != ' ' && elem != '/')
pseudo_morse += elem;
else if (elem == ' ')
{
decoded += finder(mp, pseudo_morse);
pseudo_morse.clear();
}
else
{
decoded += ' ';
decoded += finder(mp, pseudo_morse);
pseudo_morse.clear();
}
}
return decoded;
}
|
code/string_algorithms/src/morse_code/morsecode.go
|
// Part of Cosmos by OpenGenus Foundation
package main
import (
"fmt"
"strings"
)
var (
morseAlphabet = map[rune]string{
'A': ".-", 'B': "-...", 'C': "-.-.", 'D': "-..", 'E': ".", 'F': "..-.",
'G': "--.", 'H': "....", 'I': "..", 'J': ".---", 'K': "-.-", 'L': ".-..",
'M': "--", 'N': "-.", 'O': "---", 'P': ".--.", 'Q': "--.-", 'R': ".-.",
'S': "...", 'T': "-", 'U': "..-", 'V': "...-", 'W': ".--", 'X': "-..-",
'Y': "-.--", 'Z': "--..", '1': ".----", '2': "..---", '3': "...--",
'4': "....-", '5': ".....", '6': "-....", '7': "--...", '8': "---..",
'9': "----.", '0': "-----",
}
inverseAlphabet = make(map[string]rune, len(morseAlphabet))
)
func init() {
for c, m := range morseAlphabet {
inverseAlphabet[m] = c
}
}
// Encode returns the morse coded representation of the message.
func Encode(text string) string {
result := make([]string, 0, len(text))
text = strings.ToUpper(text)
for _, c := range text {
if m, ok := morseAlphabet[c]; ok {
result = append(result, m)
}
}
return strings.Join(result, " ")
}
// Decode returns the text content of a morse coded message.
func Decode(text string) string {
result := make([]rune, 0, len(text)/3)
parts := strings.Split(text, " ")
for _, m := range parts {
if c, ok := inverseAlphabet[m]; ok {
result = append(result, c)
}
}
return string(result)
}
func main() {
if Decode(Encode("TEST")) != "TEST" {
panic("encode/decode failed")
}
fmt.Println(Decode(Encode("HELLO")), Decode(".-- --- .-. .-.. -.."))
}
|
code/string_algorithms/src/morse_code/morsecode.js
|
// String algorithms | morse code | javascript
// Part of OpenGenus Foundation
const TO_MORSE_MAP = {
A: ".-",
B: "-...",
C: "-.-.",
D: "-..",
E: ".",
F: "..-.",
G: "--.",
H: "....",
I: "..",
J: ".---",
K: "-.-",
L: ".-..",
M: "--",
N: "-.",
O: "---",
P: ".--.",
Q: "--.-",
R: ".-.",
S: "...",
T: "-",
U: "..-",
V: "...-",
W: ".--",
X: "-..-",
Y: "-.--",
Z: "--..",
"1": ".----",
"2": "..---",
"3": "...--",
"4": "....-",
"5": ".....",
"6": "-....",
"7": "--...",
"8": "---..",
"9": "----.",
"0": "-----"
};
const FROM_MORSE_MAP = Object.keys(TO_MORSE_MAP).reduce(
(map, key) => Object.assign(map, { [TO_MORSE_MAP[key]]: key }),
{}
);
const fromChar = char => TO_MORSE_MAP[char];
const toChar = seq => FROM_MORSE_MAP[seq];
const encode = input => input.split("").map(fromChar);
const decode = input => input.map(toChar).join("");
// Tests
const assert = require("assert");
assert.deepEqual(encode("FOO"), ["..-.", "---", "---"]);
assert.deepEqual(decode(["..-.", "---", "---"]), "FOO");
|
code/string_algorithms/src/morse_code/morsecode.php
|
<?php
/* Part of Cosmos by OpenGenus Foundation */
/* Example Usage:
echo morseEncode('HELLO');
echo morseDecode('.... . .-.. .-.. ---');
*/
function morseDecode($str)
{
$toCharMorseMap = ["A"=> ".-", "B"=> "-...", "C"=> "-.-.", "D"=> "-..", "E"=> ".", "F"=> "..-.", "G"=> "--.", "H"=> "....", "I"=> "..", "J"=> ".---", "K"=> "-.-", "L"=> ".-..", "M"=> "--", "N"=> "-.", "O"=> "---", "P"=> ".--.", "Q"=> "--.-", "R"=> ".-.", "S"=> "...", "T"=> "-", "U"=> "..-", "V"=> "...-", "W"=> ".--", "X"=> "-..-", "Y"=> "-.--", "Z"=> "--..", "1"=> ".----", "2"=> "..---", "3"=> "...--", "4"=> "....-", "5"=> ".....", "6"=> "-....", "7"=> "--...", "8"=> "---..", "9"=> "----.", "0"=> "-----"];
$fromMorseMap = array_flip($toCharMorseMap);
$charArray = [];
$chars = explode(' ', strtoupper($str));
foreach ($chars as $char) {
$charArray[] = $fromMorseMap[$char];
}
return implode('', $charArray);
}
function morseEncode($str)
{
$toCharMorseMap = ["A"=>".-", "B"=> "-...", "C"=> "-.-.", "D"=> "-..", "E"=> ".", "F"=> "..-.", "G"=> "--.", "H"=> "....", "I"=> "..", "J"=> ".---", "K"=> "-.-", "L"=> ".-..", "M"=> "--", "N"=> "-.", "O"=> "---", "P"=> ".--.", "Q"=> "--.-", "R"=> ".-.", "S"=> "...", "T"=> "-", "U"=> "..-", "V"=> "...-", "W"=> ".--", "X"=> "-..-", "Y"=> "-.--", "Z"=> "--..", "1"=> ".----", "2"=> "..---", "3"=> "...--", "4"=> "....-", "5"=> ".....", "6"=> "-....", "7"=> "--...", "8"=> "---..", "9"=> "----.", "0"=> "-----" ];
$chars = str_split(strtoupper($str));
$morseArray = [];
foreach ($chars as $char) {
$morseArray[] = $toCharMorseMap[$char];
}
return implode(' ', $morseArray);
}
|
code/string_algorithms/src/morse_code/morsecode.py
|
from functools import reduce
morseAlphabet = {
"A": ".-",
"B": "-...",
"C": "-.-.",
"D": "-..",
"E": ".",
"F": "..-.",
"G": "--.",
"H": "....",
"I": "..",
"J": ".---",
"K": "-.-",
"L": ".-..",
"M": "--",
"N": "-.",
"O": "---",
"P": ".--.",
"Q": "--.-",
"R": ".-.",
"S": "...",
"T": "-",
"U": "..-",
"V": "...-",
"W": ".--",
"X": "-..-",
"Y": "-.--",
"Z": "--..",
"1": ".----",
"2": "..---",
"3": "...--",
"4": "....-",
"5": ".....",
"6": "-....",
"7": "--...",
"8": "---..",
"9": "----.",
"0": "-----",
}
inverseAlphabet = reduce(
lambda a, b: dict(list(a.items()) + list(b.items())),
[{morseAlphabet[k]: k} for k in morseAlphabet.keys()],
{},
)
def encode(_text):
return " ".join([morseAlphabet[_c.upper()] for _c in _text[:]])
def decode(_text):
return "".join([inverseAlphabet[_c] for _c in _text.split(" ")])
def test():
print(decode(encode("TEST")) == "TEST")
if __name__ == "__main__":
test()
|
code/string_algorithms/src/naive_pattern_search/README.md
|
# cosmos
Your personal library of every algorithm and data structure code that you will ever encounter
Collaborative effort by [OpenGenus](https://github.com/opengenus)
|
code/string_algorithms/src/naive_pattern_search/naive_pattern_search.cpp
|
// # Part of Cosmos by OpenGenus Foundation
#include <cstddef>
#include <cstring>
int search(const char *pattern, const char *text) {
/**
* @brief Searches for the given pattern in the provided text,
*
*
* @param pat Pattern to search for
* @param txt Text to search in
*
* @returns [int] position if pattern exists, else [bool] false
*/
const size_t M = strlen(pattern); // length of pattern
const size_t N = strlen(text); // length of txt
if (M == 0 || N == 0)
return false; // empty pattern or text provided
for (size_t i = 0; i < (N - M + 1); i++) { // loop along the text
for (size_t j = 0; j < M; j++) { // loop through the pattern
if (text[i + j] != pattern[j]) { // compare elements of pattern and text
break; // break out of loop, if mismatch
}
if (j == M - 1) { // loop through the pattern passes, here we have a match
return i; // return matched text index
}
}
}
return false; // return false, as match not found
}
// int main(int argc, const char **argv) {
// search("xt", "const char *txt");
// return 0;
// }
|
code/string_algorithms/src/naive_pattern_search/naive_pattern_search.py
|
# Part of Cosmos by OpenGenus Foundation
def search(pat, txt):
M = len(pat)
N = len(txt)
# Iterate pat[]
for i in range(N - M + 1):
# For current index i, check for pattern match
for j in range(M):
if txt[i + j] != pat[j]:
break
if j == M - 1: # if pat[0...M-1] = txt[i, i+1, ...i+M-1]
print("Pattern found at index " + str(i))
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.