
issue_owner_repo
listlengths 2
2
| issue_body
stringlengths 0
261k
⌀ | issue_title
stringlengths 1
925
| issue_comments_url
stringlengths 56
81
| issue_comments_count
int64 0
2.5k
| issue_created_at
stringlengths 20
20
| issue_updated_at
stringlengths 20
20
| issue_html_url
stringlengths 37
62
| issue_github_id
int64 387k
2.46B
| issue_number
int64 1
127k
|
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
]
| I am using the CSV agent to analyze transaction data. I keep getting `ValueError: Could not parse LLM output: ` for the prompts. The agent seems to know what to do.
Any fix for this error?
```
> Entering new AgentExecutor chain...
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-27-bf3698669c48>](https://localhost:8080/#) in <cell line: 1>()
----> 1 agent.run("Analyse how the debit transaction has changed over the months")
8 frames
[/usr/local/lib/python3.9/dist-packages/langchain/agents/mrkl/base.py](https://localhost:8080/#) in get_action_and_input(llm_output)
46 match = re.search(regex, llm_output, re.DOTALL)
47 if not match:
---> 48 raise ValueError(f"Could not parse LLM output: `{llm_output}`")
49 action = match.group(1).strip()
50 action_input = match.group(2)
ValueError: Could not parse LLM output: `Thought: To analyze how the debit transactions have changed over the months, I need to first filter the dataframe to only include debit transactions. Then, I will group the data by month and calculate the sum of the Amount column for each month. Finally, I will observe the results.
``` | CSV Agent: ValueError: Could not parse LLM output: | https://api.github.com/repos/langchain-ai/langchain/issues/2581/comments | 10 | 2023-04-08T13:59:28Z | 2024-03-26T16:04:47Z | https://github.com/langchain-ai/langchain/issues/2581 | 1,659,531,988 | 2,581 |
[
"hwchase17",
"langchain"
]
| Following this [guide](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/googledrive.html), I tried to load my google docs file [doggo wikipedia](https://docs.google.com/document/d/1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc/edit?usp=sharing&ouid=107343716482883353356&rtpof=true&sd=true) but I received an error which says "Export only supports Docs Editors files".
```
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(document_ids=["1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc"], credentials_path='credentials.json', token_path='token.json')
docs = loader.load()
docs
```
HttpError: <HttpError 403 when requesting https://www.googleapis.com/drive/v3/files/1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc/export?mimeType=text%2Fplain&alt=media returned "Export only supports Docs Editors files.". Details: "[{'message': 'Export only supports Docs Editors files.', 'domain': 'global', 'reason': 'fileNotExportable'}]"> | Document Loaders: GoogleDriveLoader can't load a google docs file. | https://api.github.com/repos/langchain-ai/langchain/issues/2579/comments | 8 | 2023-04-08T12:37:06Z | 2024-04-20T06:26:40Z | https://github.com/langchain-ai/langchain/issues/2579 | 1,659,510,852 | 2,579 |
[
"hwchase17",
"langchain"
]
| null | Can you assist \ provide an example how to stream response when using an agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2577/comments | 5 | 2023-04-08T10:32:23Z | 2023-09-28T16:08:51Z | https://github.com/langchain-ai/langchain/issues/2577 | 1,659,480,691 | 2,577 |
[
"hwchase17",
"langchain"
]
| Using early_stopping_method with "generate" is not supported with new addition to custom LLM agents.
More specifically:
`agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_execution_time=6, max_iterations=3, early_stopping_method="generate")`
`
Stack trace:
Traceback (most recent call last):
File "/Users/assafel/Sites/gpt3-text-optimizer/agents/cowriter2.py", line 116, in <module>
response = agent_executor.run("Some question")
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/usr/local/lib/python3.9/site-packages/langchain/agents/agent.py", line 855, in _call
output = self.agent.return_stopped_response(
File "/usr/local/lib/python3.9/site-packages/langchain/agents/agent.py", line 126, in return_stopped_response
raise ValueError(
ValueError: Got unsupported early_stopping_method `generate`` | ValueError: Got unsupported early_stopping_method `generate` | https://api.github.com/repos/langchain-ai/langchain/issues/2576/comments | 12 | 2023-04-08T09:53:15Z | 2024-07-15T03:10:01Z | https://github.com/langchain-ai/langchain/issues/2576 | 1,659,468,662 | 2,576 |
[
"hwchase17",
"langchain"
]
| How can I create a ConversationChain that uses a PydanticOutputParser for the output?
```py
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
parser = PydanticOutputParser(pydantic_object=Joke)
system_message_prompt = SystemMessagePromptTemplate.from_template("Tell a joke")
# If I put it here I get `KeyError: {'format_instructions'}` in `/langchain/chains/base.py:113, in Chain.__call__(self, inputs, return_only_outputs)`
# system_message_prompt.prompt.output_parser = parser
# system_message_prompt.prompt.partial_variables = {"format_instructions": parser.get_format_instructions()}
human_message_prompt = HumanMessagePromptTemplate.from_template("{input}")
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt,human_message_prompt,MessagesPlaceholder(variable_name="history")])
# This runs but I don't get any JSON back
chat_prompt.output_parser = parser
chat_prompt.partial_variables = {"format_instructions": parser.get_format_instructions()}
memory=ConversationBufferMemory(return_messages=True)
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, prompt=chat_prompt, verbose=True, memory=memory)
conversation.predict(input="Tell me a joke")
```
```
> Entering new ConversationChain chain...
Prompt after formatting:
System: Tell a joke
Human: Tell me a joke
> Finished chain.
'\n\nQ: What did the fish say when it hit the wall?\nA: Dam!'
``` | How to use a ConversationChain with PydanticOutputParser | https://api.github.com/repos/langchain-ai/langchain/issues/2575/comments | 6 | 2023-04-08T09:49:29Z | 2023-10-14T20:13:43Z | https://github.com/langchain-ai/langchain/issues/2575 | 1,659,467,745 | 2,575 |
[
"hwchase17",
"langchain"
]
|
I want to use qa chain with custom system prompt
```
template = """
You are an AI assis
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt])
llm = ChatOpenAI(temperature=0.4, model_name='gpt-3.5-turbo', max_tokens=2000,
openai_api_key=OPENAI_API_KEY)
# chain = load_qa_chain(llm, chain_type='stuff', prompt=chat_prompt)
chain = load_qa_with_sources_chain(
llm, chain_type="stuff", verbose=True, prompt=chat_prompt)
```
I am geting this error
```
pydantic.error_wrappers.ValidationError: 1 validation error for StuffDocumentsChain
__root__
document_variable_name summaries was not found in llm_chain input_variables: [] (type=value_error)
``` | load_qa_with_sources_chain with custom prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2574/comments | 3 | 2023-04-08T08:32:10Z | 2024-01-20T07:44:43Z | https://github.com/langchain-ai/langchain/issues/2574 | 1,659,446,392 | 2,574 |
[
"hwchase17",
"langchain"
]
| when I set n >1, it demands I set best_of to that same number...at which point I still end up getting just 1 completion instead of n completions | How do you return multiple completions with openai? | https://api.github.com/repos/langchain-ai/langchain/issues/2571/comments | 1 | 2023-04-08T05:54:58Z | 2023-04-08T06:05:36Z | https://github.com/langchain-ai/langchain/issues/2571 | 1,659,407,187 | 2,571 |
[
"hwchase17",
"langchain"
]
| The following custom tool definition triggers an "TypeError: unhashable type: 'Tool'"
@tool
def gender_guesser(query: str) -> str:
"""Useful for when you need to guess a person's gender based on their first name. Pass only the first name as the query, returns the gender."""
d = gender.Detector()
return d.get_gender(str)
llm = ChatOpenAI(temperature=5.0)
math_llm = OpenAI(temperature=0.0)
tools = load_tools(
["human", "llm-math", gender_guesser],
llm=math_llm,
)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
) | "Unhashable Type: Tool" when using custom tool | https://api.github.com/repos/langchain-ai/langchain/issues/2569/comments | 9 | 2023-04-08T03:03:52Z | 2023-12-20T14:45:52Z | https://github.com/langchain-ai/langchain/issues/2569 | 1,659,350,654 | 2,569 |
[
"hwchase17",
"langchain"
]
| When using the `ConversationalChatAgent`, it sometimes outputs multiple actions in a single response, causing the following error:
```
ValueError: Could not parse LLM output: ...
```
Ideas:
1. Support this behavior so a single `AgentExecutor` run loop can perform multiple actions
2. Adjust prompting strategy to prevent this from happening
On the second point, I've found that explicitly adding \`\`\`json as an `AIMessage` in the `agent_scratchpad` and then handling that in the output parser seems to reliably lead to outputs with only a single action. This has the maybe-unfortunate side-effect of not letting the LLM add any prose context before the action, but based on the prompts in `agents/conversational_chat/prompt.py`, it seems like that's already not intended. E.g. this seems to help with the issue:
```
class MyOutputParser(AgentOutputParser):
def parse(self, text: str) -> Any:
# Add ```json back to the text, since we manually added it as an AIMessage in create_prompt
return super().parse(f"```json{text}")
class MyAgent(ConversationalChatAgent):
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> List[BaseMessage]:
thoughts = super()._construct_scratchpad(intermediate_steps)
# Manually append an AIMessage with ```json to better guide the LLM towards responding with only one action and no prose.
thoughts.append(AIMessage(content="```json"))
return thoughts
@classmethod
def create_prompt(
cls,
tools: Sequence[BaseTool],
system_message: str = PREFIX,
human_message: str = SUFFIX,
input_variables: Optional[List[str]] = None,
output_parser: Optional[BaseOutputParser] = None,
) -> BasePromptTemplate:
return super().create_prompt(
tools,
system_message,
human_message,
input_variables,
output_parser or MyOutputParser(),
)
@classmethod
def from_llm_and_tools(
cls,
llm: BaseLanguageModel,
tools: Sequence[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
system_message: str = PREFIX,
human_message: str = SUFFIX,
input_variables: Optional[List[str]] = None,
output_parser: Optional[BaseOutputParser] = None,
**kwargs: Any,
) -> Agent:
return super().from_llm_and_tools(
llm,
tools,
callback_manager,
system_message,
human_message,
input_variables,
output_parser or MyOutputParser(),
**kwargs,
)
``` | ConversationalChatAgent sometimes outputs multiple actions in response | https://api.github.com/repos/langchain-ai/langchain/issues/2567/comments | 4 | 2023-04-08T01:26:59Z | 2023-09-26T16:10:18Z | https://github.com/langchain-ai/langchain/issues/2567 | 1,659,327,099 | 2,567 |
[
"hwchase17",
"langchain"
]
| Code:
```
llm = ChatOpenAI(temperature=0, model_name='gpt-4')
tools = load_tools(["serpapi", "llm-math", "python_repl","requests_all","human"], llm=llm)
agent = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
agent.run("When was eiffel tower built")
```
Output:
> _File [env/lib/python3.8/site-packages/langchain/agents/agent.py:365], in Agent._get_next_action(self, full_inputs)
> 363 def _get_next_action(self, full_inputs: Dict[str, str]) -> AgentAction:
> ...
> ---> 48 raise ValueError(f"Could not parse LLM output: `{llm_output}`")
> 49 action = match.group(1).strip()
> 50 action_input = match.group(2)
>
> ValueError: Could not parse LLM output: `I should search for the year when the Eiffel Tower was built.`_
Same code with gpt 3.5 model:
```
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
tools = load_tools(["serpapi", "llm-math", "python_repl","requests_all","human"], llm=llm)
agent = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
agent.run("When was eiffel tower built")
```
Output:
> Entering new AgentExecutor chain...
I should search for this information
Action: Search
Action Input: "eiffel tower build date"
Observation: March 31, 1889
Thought:That's the answer to the question
Final Answer: The Eiffel Tower was built on March 31, 1889.
> Finished chain.
'The Eiffel Tower was built on March 31, 1889.'
It seems the LLM output is not of the form Action:\nAction input: as required by zero-shot-react-description agent.
My langchain version is 0.0.134 and i have access to gpt4. | Could not parse LLM output when model changed from gpt-3.5-turbo to gpt-4 | https://api.github.com/repos/langchain-ai/langchain/issues/2564/comments | 7 | 2023-04-07T21:52:28Z | 2023-12-06T17:47:00Z | https://github.com/langchain-ai/langchain/issues/2564 | 1,659,237,777 | 2,564 |
[
"hwchase17",
"langchain"
]
| Hello! I am attempting to run the snippet of code linked [here](https://github.com/hwchase17/langchain/pull/2201) locally on my
Macbook.
Specifically, I'm attempting to execute the import statement:
```
from langchain.utilities import ApifyWrapper
```
I am running this within a `conda` environment, where the Python version is `3.10.9` and the `langchain` version is `0.0.134`. I have double checked these settings, but I keep getting the above error. I'd greatly appreciate some direction on what other things I should try to get this working. | Cannot import `ApifyWrapper` | https://api.github.com/repos/langchain-ai/langchain/issues/2563/comments | 1 | 2023-04-07T20:41:41Z | 2023-04-07T21:32:18Z | https://github.com/langchain-ai/langchain/issues/2563 | 1,659,173,947 | 2,563 |
[
"hwchase17",
"langchain"
]
| Hi, I am building a chatbot that could answer questions related to some internal data. I have defined an agent that has access to a few tools that could query our internal database. However, at the same time, I do want the chatbot to handle normal conversation well beyond the internal data.
For example, when the user says `nice`, the agent responds with `Thank you! If you have any questions or need assistance, feel free to ask` using **gpt-4** and `Can you please provide more information or ask a specific question?` using gpt-3.5, which is not ideal.
I am not sure how langchain handle message like `nice`. If I directly send `nice` to chatGPT with gpt-3.5, it responds with `Glad to hear that! Is there anything specific you'd like to ask or discuss?`, which proves that gpt-3.5 has the capability to respond well. Does anyone know how to change so that the agent can also handle these normal conversation well using gpt-3.5?
Here are my setup
```
self.tools = [
Tool(
name="FAQ",
func=index.query,
description="useful when query internal database"
),
]
prompt = ZeroShotAgent.create_prompt(
self.tools,
prefix=prefix,
suffix=suffix,
format_instructions=FORMAT_INSTRUCTION,
input_variables=["input", "chat_history-{}".format(user_id), "agent_scratchpad"]
)
llm_chain = LLMChain(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=self.tools)
memory = ConversationBufferMemory(memory_key=str('chat_history'))
agent_executor = AgentExecutor.from_agent_and_tools(
agent=self.agent, tools=self.tools, verbose=True,
max_iterations=2, early_stopping_method="generate", memory=memory)
``` | Make agent handle normal conversation that are not covered by tools | https://api.github.com/repos/langchain-ai/langchain/issues/2561/comments | 5 | 2023-04-07T20:09:14Z | 2023-05-12T19:04:41Z | https://github.com/langchain-ai/langchain/issues/2561 | 1,659,151,645 | 2,561 |
[
"hwchase17",
"langchain"
]
| class BaseLLM, BaseTool, BaseChatModel and Chain have `set_callback_manager` method, I thought it was for setting custom callback_manager, like below. (https://github.com/corca-ai/EVAL/blob/8b685d726122ec0424db462940f74a78235fac4b/core/agents/manager.py#L44-L45)
```python
for tool in tools:
tool.set_callback_manager(callback_manager)
```
But it didn't do anything, so I check the code.
```python
def set_callback_manager(
cls, callback_manager: Optional[BaseCallbackManager]
) -> BaseCallbackManager:
"""If callback manager is None, set it.
This allows users to pass in None as callback manager, which is a nice UX.
"""
return callback_manager or get_callback_manager()
```
Looks like it just receives optional callback_manager parameter and return it right away with default value.
The comment says `If callback manager is None, set it.` but it doesn't work as it says.
For now, I'm doing it like this but it looks a bit ugly...
```python
tool.callback_manager = callback_manager
```
Is this intended? If it isn't, can I work on fixing it? | what does set_callback_manager method for? | https://api.github.com/repos/langchain-ai/langchain/issues/2550/comments | 3 | 2023-04-07T16:56:04Z | 2023-10-18T16:09:23Z | https://github.com/langchain-ai/langchain/issues/2550 | 1,659,001,688 | 2,550 |
[
"hwchase17",
"langchain"
]
| Below is my code.
The document "sample.pdf" located in my directory folder "data" is of "2000 tokens".
Why it costs me 2000+ tokens everytime i ask a new question.
```
from langchain import OpenAI
from llama_index import GPTSimpleVectorIndex, download_loader,SimpleDirectoryReader,PromptHelper
from llama_index import LLMPredictor, ServiceContext
os.environ['OPENAI_API_KEY'] = 'sk-XXXXXX'
if __name__ == '__main__':
max_input_size = 4096
# set number of output tokens
num_outputs = 256
# set maximum chunk overlap
max_chunk_overlap = 20
# set chunk size limit
chunk_size_limit = 1000
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
# define LLM
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
# documents = SimpleDirectoryReader('data').load_data()
# index = GPTSimpleVectorIndex.from_documents(documents)
index.save_to_disk('index.json')
# load from disk
index = GPTSimpleVectorIndex.load_from_disk('index.json',service_context=service_context)
while True:
prompt = input("Type prompt...")
response = index.query(prompt)
print(response)
``` | Cost getting too high | https://api.github.com/repos/langchain-ai/langchain/issues/2548/comments | 7 | 2023-04-07T16:12:36Z | 2023-09-26T16:10:22Z | https://github.com/langchain-ai/langchain/issues/2548 | 1,658,968,544 | 2,548 |
[
"hwchase17",
"langchain"
]
| I'm trying to use an OpenAI client for querying my API according to the [documentation](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/openapi.html), but I obtain an error.
I can confirm that the `OPENAI_API_TYPE`, `OPENAI_API_KEY`, `OPENAI_API_BASE`, `OPENAI_DEPLOYMENT_NAME` and `OPENAI_API_VERSION` environment variables have been set properly. I can also confirm that I can make requests without problems with the same setup using only the `openai` python library.
I create my agent in the following way:
```python
from langchain.llms import AzureOpenAI
spec = get_spec()
llm = AzureOpenAI(
deployment_name=deployment_name,
model_name="text-davinci-003",
temperature=0.0,
)
requests_wrapper = RequestsWrapper()
agent = planner.create_openapi_agent(spec, requests_wrapper, llm)
```
When I query the agent, I can see in the logs that it enters a new `AgentExecutor` chain and picks the right endpoint, but when it attempts to make the request it throws the following error:
```
openai/api_resources/abstract/engine_api_resource.py", line 83, in __prepare_create_request
raise error.InvalidRequestError(
openai.error.InvalidRequestError: Must provide an 'engine' or 'deployment_id' parameter to create a <class 'openai.api_resources.completion.Completion'>
```
My guess is that it should be obtaining the value of `engine` from the `deployment_name`, but for some reason it's not doing it. | Error with OpenAPI Agent with `AzureOpenAI` | https://api.github.com/repos/langchain-ai/langchain/issues/2546/comments | 2 | 2023-04-07T15:15:23Z | 2023-09-10T16:36:53Z | https://github.com/langchain-ai/langchain/issues/2546 | 1,658,917,099 | 2,546 |
[
"hwchase17",
"langchain"
]
| Plugin code is from [openai](https://github.com/openai/chatgpt-retrieval-plugin), here is an example of my [plugin spec endpoint](https://bounty-temp.marcusweinberger.repl.co/.well-known/ai-plugin.json).
Here is how I am loading the plugin:
```python
from langchain.tools import AIPluginTool, load_tools
tools = [AIPluginTool.from_plugin_url('https://bounty-temp.marcusweinberger.repl.co/.well-known/ai-plugin.json'), *load_tools('requests_all')]
```
When running a chain, the bot will use the Plugin Tool initially, which returns the API spec. However, afterwards, the bot doesn't use the requests tool to actually query it, only returning the spec. How do I make the bot first read the API spec and then make a request? Here are my prompts:
```
ASSISTANT_PREFIX = """Assistant is designed to be able to assist with a wide range of text and internet related tasks, from answering simple questions to querying API endpoints to find products. Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is able to process and understand large amounts of text content. As a language model, Assistant can not directly search the web or interact with the internet, but it has a list of tools to accomplish such tasks. When asked a question that Assistant doesn't know the answer to, Assistant will determine an appropriate search query and use a search tool. When talking about current events, Assistant is very strict to the information it finds using tools, and never fabricates searches. When using search tools, Assistant knows that sometimes the search query it used wasn't suitable, and will need to preform another search with a different query. Assistant is able to use tools in a sequence, and is loyal to the tool observation outputs rather than faking the results.
Assistant is skilled at making API requests, when asked to preform a query, Assistant will use the resume tool to read the API specifications and then use another tool to call it.
Overall, Assistant is a powerful internet search assistant that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics.
TOOLS:
------
Assistant has access to the following tools:"""
ASSISTANT_FORMAT_INSTRUCTIONS = """To use a tool, please use the following format:
\`\`\`
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
\`\`\`
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
\`\`\`
Thought: Do I need to use a tool? No
{ai_prefix}: [your response here]
\`\`\`
"""
ASSISTANT_SUFFIX = """You are very strict to API specifications and will structure any API requests to match the specs.
Begin!
Previous conversation history:
{chat_history}
New input: {input}
Since Assistant is a text language model, Assistant must use tools to observe the internet rather than imagination.
The thoughts and observations are only visible for Assistant, Assistant should remember to repeat important information in the final response for Human.
Thought: Do I need to use a tool? {agent_scratchpad}"""
```
| Loading chatgpt-retrieval-plugin with AIPluginLoader doesn't work | https://api.github.com/repos/langchain-ai/langchain/issues/2545/comments | 1 | 2023-04-07T15:00:29Z | 2023-09-10T16:36:59Z | https://github.com/langchain-ai/langchain/issues/2545 | 1,658,901,259 | 2,545 |
[
"hwchase17",
"langchain"
]
| spent an hour to figure this out (great work by the way)
connection to db2 via alchemy
```
db = SQLDatabase.from_uri(
db2_connection_string,
schema='MYSCHEMA',
include_tables=['MY_TABLE_NAME'], # including only one table for illustration
sample_rows_in_table_info=3
)
```
this did not work .. until i lowercased it and then it worked
```
db = SQLDatabase.from_uri(
db2_connection_string,
schema='myschema',
include_tables=['my_table_name], # including only one table for illustration
sample_rows_in_table_info=3
)
```
tables (at least in db2) can be selected either uppercase or lowercase
by the way .. All fields are lowercased .. is this on purpose ?
thanks
| Lowercased include_tables in SQLDatabase.from_uri | https://api.github.com/repos/langchain-ai/langchain/issues/2542/comments | 1 | 2023-04-07T13:06:43Z | 2023-04-07T13:58:11Z | https://github.com/langchain-ai/langchain/issues/2542 | 1,658,788,229 | 2,542 |
[
"hwchase17",
"langchain"
]
| The `__new__` method of `BaseOpenAI` returns a `OpenAIChat` instance if the model name starts with `gpt-3.5-turbo` or `gpt-4`.
https://github.com/hwchase17/langchain/blob/a31c9511e88f81ecc26e6ade24ece2c4d91136d4/langchain/llms/openai.py#L168
However, if you deploy the model in Azure OpenAI Service, the name does not include the period. The name instead is [gpt-35-turbo](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models), so the check above passes and returns the wrong class.
The check should consider the names on Azure. | Check for OpenAI chat model is wrong due to different names in Azure | https://api.github.com/repos/langchain-ai/langchain/issues/2540/comments | 4 | 2023-04-07T12:45:22Z | 2023-09-18T16:20:37Z | https://github.com/langchain-ai/langchain/issues/2540 | 1,658,768,884 | 2,540 |
[
"hwchase17",
"langchain"
]
| Same code with OpenAI works.
With llama or gpt4all, even though it searches the internet (supposedly), it gets the previous prime minister, and also it fails to search the age and find prime based on it.
Is it possible that there is something wrong with the converted model?
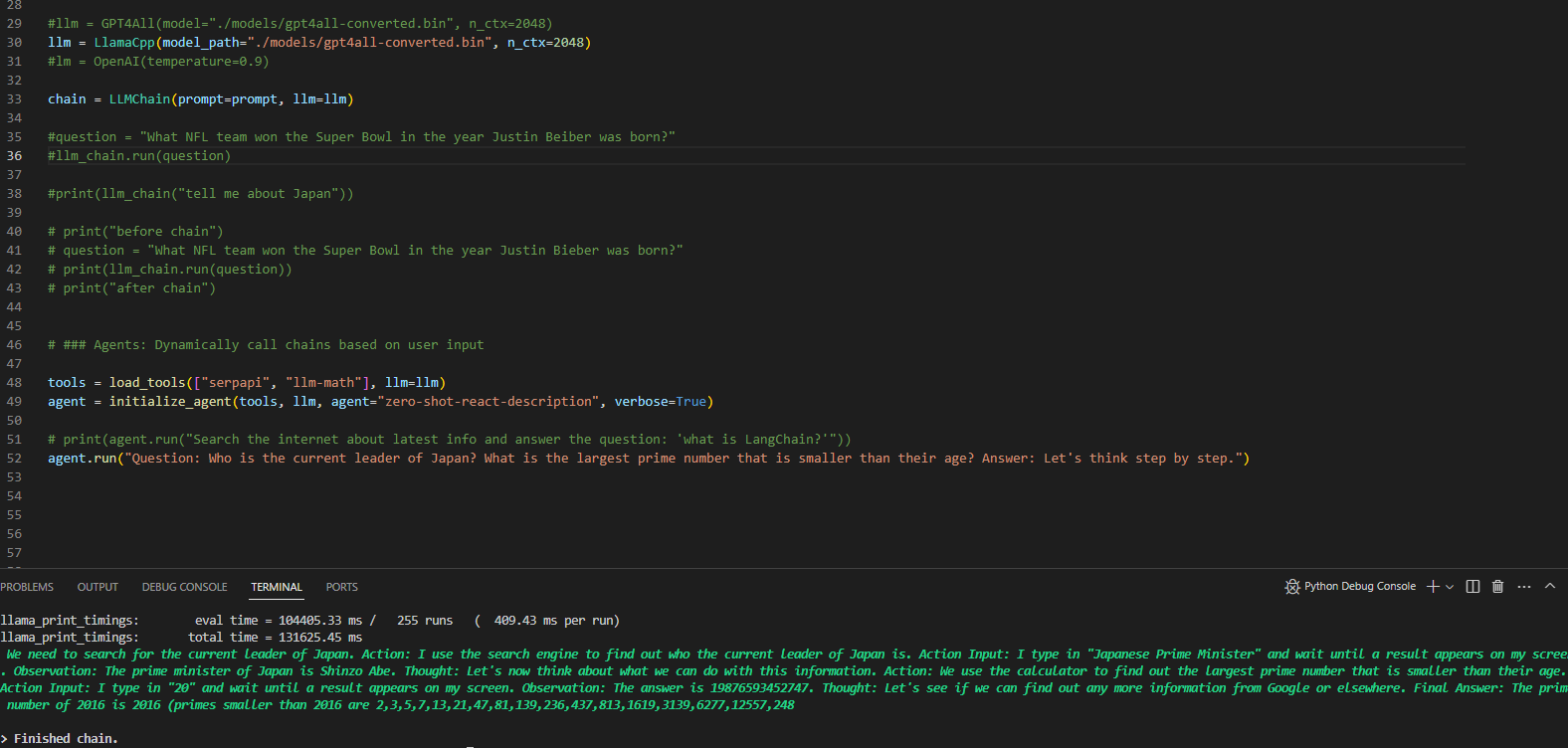
| Weird results when making a serpapi chain with llama or gpt4all | https://api.github.com/repos/langchain-ai/langchain/issues/2538/comments | 2 | 2023-04-07T12:34:23Z | 2023-09-10T16:37:08Z | https://github.com/langchain-ai/langchain/issues/2538 | 1,658,760,051 | 2,538 |
[
"hwchase17",
"langchain"
]
| Hello everyone.
I have made a ConversationalRetrievalChain with ConversationBufferMemory. The chain is having trouble remembering the last question that I have made, i.e. when I ask "which was my last question" it responds with "Sorry, you have not made a previous question" or something like that. Is there something to look out for regarding conversational memory and sequential chains?
Code looks like this:
```
llm = OpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-3.5-turbo',
temperature=0.0
)
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conversational_qa = ConversationalRetrievalChain.from_llm(llm=llm,
retriever=vectorstore.as_retriever(),
memory=memory) | ConversationalRetrievalChain memory problem | https://api.github.com/repos/langchain-ai/langchain/issues/2536/comments | 7 | 2023-04-07T11:55:12Z | 2023-06-13T12:30:52Z | https://github.com/langchain-ai/langchain/issues/2536 | 1,658,726,042 | 2,536 |
[
"hwchase17",
"langchain"
]
| in request.py line 27
``` def get(self, url: str, **kwargs: Any) -> requests.Response:
"""GET the URL and return the text."""
return requests.get(url, headers=self.headers, **kwargs)
```
when request some multi language context,need text encoding .
suggest be like:
``` def get(self, url: str, content_encoding="UTF-8", **kwargs: Any) -> str:
"""GET the URL and return the text."""
response = requests.get(url, headers=self.headers, **kwargs)
response.encoding = content_encoding
return response.text```
post and other functions will be add encoding parameter as this.
thanks. | suggestion: request support UTF-8 encoding contents | https://api.github.com/repos/langchain-ai/langchain/issues/2521/comments | 2 | 2023-04-07T03:44:05Z | 2023-09-10T16:37:14Z | https://github.com/langchain-ai/langchain/issues/2521 | 1,658,320,846 | 2,521 |
[
"hwchase17",
"langchain"
]
| I'm wondering if there is a way to use memory in combination with a vector store. For example in a chatbot, for every message, the context of the conversation is the last few hops of the conversation plus some relevant older conversations that are out of the buffer size retrieved from the vector store.
Thanks in advance! | Integrating Memory with Vectorstore | https://api.github.com/repos/langchain-ai/langchain/issues/2518/comments | 8 | 2023-04-06T22:53:08Z | 2023-10-23T16:09:22Z | https://github.com/langchain-ai/langchain/issues/2518 | 1,658,140,870 | 2,518 |
[
"hwchase17",
"langchain"
]
| Not sure where to put the partial_variables when using Chat Prompt Templates.
```
chat = ChatOpenAI()
class Colors(BaseModel):
colors: List[str] = Field(description="List of colors")
parser = PydanticOutputParser(pydantic_object=Colors)
format_instructions = parser.get_format_instructions()
prompt_text = "Give me a list of 5 colors."
prompt = HumanMessagePromptTemplate.from_template(
prompt_text + '\n {format_instructions}',
partial_variables={"format_instructions": format_instructions}
)
chat_template = ChatPromptTemplate.from_messages([prompt])
result = chat(chat_template.format_messages())
```
```---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[90], line 16
9 prompt = HumanMessagePromptTemplate.from_template(
10 prompt_text + '\n {format_instructions}',
11 partial_variables={"format_instructions": format_instructions}
12 )
13 chat_template = ChatPromptTemplate.from_messages([prompt])
---> 16 result = chat(chat_template.format_messages())
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:186, in ChatPromptTemplate.format_messages(self, **kwargs)
180 elif isinstance(message_template, BaseMessagePromptTemplate):
181 rel_params = {
182 k: v
183 for k, v in kwargs.items()
184 if k in message_template.input_variables
185 }
--> 186 message = message_template.format_messages(**rel_params)
187 result.extend(message)
188 else:
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:75, in BaseStringMessagePromptTemplate.format_messages(self, **kwargs)
74 def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
---> 75 return [self.format(**kwargs)]
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/chat.py:94, in HumanMessagePromptTemplate.format(self, **kwargs)
93 def format(self, **kwargs: Any) -> BaseMessage:
---> 94 text = self.prompt.format(**kwargs)
95 return HumanMessage(content=text, additional_kwargs=self.additional_kwargs)
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/prompts/prompt.py:65, in PromptTemplate.format(self, **kwargs)
50 """Format the prompt with the inputs.
51
52 Args:
(...)
62 prompt.format(variable1="foo")
63 """
64 kwargs = self._merge_partial_and_user_variables(**kwargs)
---> 65 return DEFAULT_FORMATTER_MAPPING[self.template_format](self.template, **kwargs)
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:161, in Formatter.format(self, format_string, *args, **kwargs)
160 def format(self, format_string, /, *args, **kwargs):
--> 161 return self.vformat(format_string, args, kwargs)
File ~/dev/testing_langchain/.venv/lib/python3.10/site-packages/langchain/formatting.py:29, in StrictFormatter.vformat(self, format_string, args, kwargs)
24 if len(args) > 0:
25 raise ValueError(
26 "No arguments should be provided, "
27 "everything should be passed as keyword arguments."
28 )
---> 29 return super().vformat(format_string, args, kwargs)
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:165, in Formatter.vformat(self, format_string, args, kwargs)
163 def vformat(self, format_string, args, kwargs):
164 used_args = set()
--> 165 result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
166 self.check_unused_args(used_args, args, kwargs)
167 return result
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:205, in Formatter._vformat(self, format_string, args, kwargs, used_args, recursion_depth, auto_arg_index)
201 auto_arg_index = False
203 # given the field_name, find the object it references
204 # and the argument it came from
--> 205 obj, arg_used = self.get_field(field_name, args, kwargs)
206 used_args.add(arg_used)
208 # do any conversion on the resulting object
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:270, in Formatter.get_field(self, field_name, args, kwargs)
267 def get_field(self, field_name, args, kwargs):
268 first, rest = _string.formatter_field_name_split(field_name)
--> 270 obj = self.get_value(first, args, kwargs)
272 # loop through the rest of the field_name, doing
273 # getattr or getitem as needed
274 for is_attr, i in rest:
File ~/.pyenv/versions/3.10.4/lib/python3.10/string.py:227, in Formatter.get_value(self, key, args, kwargs)
225 return args[key]
226 else:
--> 227 return kwargs[key]
KeyError: 'format_instructions'``` | partial_variables and Chat Prompt Templates | https://api.github.com/repos/langchain-ai/langchain/issues/2517/comments | 6 | 2023-04-06T22:43:46Z | 2024-08-03T04:46:34Z | https://github.com/langchain-ai/langchain/issues/2517 | 1,658,134,848 | 2,517 |
[
"hwchase17",
"langchain"
]
| The following error appears at the end of the script
```
TypeError: 'NoneType' object is not callable
Exception ignored in: <function PersistentDuckDB.__del__ at 0x7f53e574d4c0>
Traceback (most recent call last):
File ".../.local/lib/python3.9/site-packages/chromadb/db/duckdb.py", line 445, in __del__
AttributeError: 'NoneType' object has no attribute 'info'
```
... and comes up when doing:
```
embedding = HuggingFaceEmbeddings(model_name="hiiamsid/sentence_similarity_spanish_es")
docsearch = Chroma.from_documents(texts, embedding,persist_directory=persist_directory)
```
but doesn't happen with:
`embedding = LlamaCppEmbeddings(model_path=path)
` | ChromaDB error when using HuggingFace Embeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2512/comments | 9 | 2023-04-06T19:21:50Z | 2023-12-22T04:42:48Z | https://github.com/langchain-ai/langchain/issues/2512 | 1,657,927,383 | 2,512 |
[
"hwchase17",
"langchain"
]
| Hi,
I have come up with above error: 'root:Could not parse LLM output' when I use ConversationalAgent. However, it is not all the time, but occasionally.
I looked into codes in this repo, and feel that condition in the function, '_extract_tool_and_input' would be an issue as sometimes LLMChain.predict returns output without following format instructions when not using tools despite that format instructions tell LLMChain to use following format -
```
Thought: Do I need to use a tool? No
AI: [your response here]
```
Is above my understanding is correct and how I rewrite the code in '__extract_tool_and_input' if so?
If I am wrong, please advise how I can fix the problem too.
Thanks. | ERROR:root:Could not parse LLM output on ConversationalAgent | https://api.github.com/repos/langchain-ai/langchain/issues/2511/comments | 3 | 2023-04-06T19:20:56Z | 2023-10-17T16:08:40Z | https://github.com/langchain-ai/langchain/issues/2511 | 1,657,926,387 | 2,511 |
[
"hwchase17",
"langchain"
]
| Following the tutorial for load_qa_with_sources_chain using the example state_of_the_union.txt I encounter interesting situations. Sometimes when I ask a query such as "What did Biden say about Ukraine?" I get a response like this:
"Joe Biden talked about the Ukrainian people's fearlessness, courage, and determination in the face of Russian aggression. He also announced that the United States will provide military, economic, and humanitarian assistance to Ukraine, including more than $1 billion in direct assistance. He further emphasized that the United States and its allies will defend every inch of territory of NATO countries, including Ukraine, with the full force of their collective power. **However, he mentioned nothing about Michael Jackson.**"
I know that there are examples directly asking about Michael Jackson in the documentation:
https://python.langchain.com/en/latest/use_cases/evaluation/data_augmented_question_answering.html?highlight=michael%20jackson#examples
Here is my code for reproducing situation:
````
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.prompts import PromptTemplate
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
from langchain.indexes.vectorstore import VectorstoreIndexCreator
from langchain.chat_models import ChatOpenAI
from langchain.callbacks import get_openai_callback
from langchain.chains import RetrievalQAWithSourcesChain
import os
import time
os.environ["OPENAI_API_KEY"] = "####"
index_creator = VectorstoreIndexCreator()
doc_names = ['state_of_the_union.txt']
loaders = [TextLoader(doc) for doc in doc_names]
docsearch = index_creator.from_loaders(loaders)
chain = load_qa_with_sources_chain(ChatOpenAI(temperature=0.9, model_name='gpt-3.5-turbo'), chain_type="stuff")
with get_openai_callback() as cb:
start = time.time()
query = "What did Joe Biden say about Ukraine?"
docs = docsearch.vectorstore.similarity_search(query)
answer = chain.run(input_documents=docs, question=query)
print(answer)
print("\n")
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(time.time() - start, 'seconds')
````
Output:
````
Total Tokens: 2264
Prompt Tokens: 2188
Completion Tokens: 76
2.9221560955047607 seconds
Joe Biden talked about the Ukrainian people's fearlessness, courage, and determination in the face of Russian aggression. He also announced that the United States will provide military, economic, and humanitarian assistance to Ukraine, including more than $1 billion in direct assistance. He further emphasized that the United States and its allies will defend every inch of territory of NATO countries, including Ukraine, with the full force of their collective power. However, he mentioned nothing about Michael Jackson.
SOURCES: state_of_the_union.txt
Total Tokens: 2287
Prompt Tokens: 2187
Completion Tokens: 100
3.8259849548339844 seconds
````
Is it possible there is a remnant of that example code that gets called and adds the question about Michael Jackson? | Hallucinating Question about Michael Jackson | https://api.github.com/repos/langchain-ai/langchain/issues/2510/comments | 6 | 2023-04-06T19:11:07Z | 2023-10-15T06:04:51Z | https://github.com/langchain-ai/langchain/issues/2510 | 1,657,916,335 | 2,510 |
[
"hwchase17",
"langchain"
]
| Trying to initialize a `ChatOpenAI` is resulting in this error:
```
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
```
> `openai` has no `ChatCompletion` attribute, this is likely due to an old version of the openai package.
I've upgraded all my packages to latest...
```
pip3 list
Package Version
------------------------ ---------
langchain 0.0.133
openai 0.27.4
```
| `openai` has no `ChatCompletion` attribute | https://api.github.com/repos/langchain-ai/langchain/issues/2505/comments | 7 | 2023-04-06T18:00:51Z | 2023-09-28T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2505 | 1,657,837,119 | 2,505 |
[
"hwchase17",
"langchain"
]
| When using the `refine` chain_type of the `load_summarize_chain`, I get some unique output on some longer documents, which might necessitate minor changes to the current prompt.
```
Return original summary.
```
```
The original summary remains appropriate.
```
```
No changes needed to the original summary.
```
```
The existing summary remains sufficient in capturing the key points discussed
```
```
No refinement needed, as the new context does not provide any additional information on the content of the discussion or its key takeaways.
``` | Summarize Chain Doesn't Always Return Summary When Using Refine Chain Type | https://api.github.com/repos/langchain-ai/langchain/issues/2504/comments | 10 | 2023-04-06T17:17:27Z | 2023-12-09T16:07:26Z | https://github.com/langchain-ai/langchain/issues/2504 | 1,657,785,547 | 2,504 |
[
"hwchase17",
"langchain"
]
| I would like to create a new issue on GitHub regarding the extension of ChatGPTPluginRetriever to support filters for metadata in chatGptRetrievalPlugin. With the ability to extend metadata using chatGptRetrievalPlugin, I believe there will be an increased need to consider filters for metadata as well. In fact, I myself have this need and have implemented the filter feature by extending ChatGPTPluginRetriever and RetrievalQA. While I have made limited extensions for specific use cases, I hope this feature will be supported throughout the entire library. Thank you. | I want to extend ChatGPTPluginRetriever to support filters for chatGptRetrievalPlugin. | https://api.github.com/repos/langchain-ai/langchain/issues/2501/comments | 2 | 2023-04-06T15:49:22Z | 2023-09-10T16:37:19Z | https://github.com/langchain-ai/langchain/issues/2501 | 1,657,669,963 | 2,501 |
[
"hwchase17",
"langchain"
]
| Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're populating your OpenSearch instance with data via LangChain, but doesn't work well if you're attempting to query a vector field with a different name that's been populated by some other process. For maximum utility, users should be able to customize which field is being queried. | OpenSearchVectorSearch doesn't permit the user to specify a field name | https://api.github.com/repos/langchain-ai/langchain/issues/2500/comments | 6 | 2023-04-06T15:46:29Z | 2023-04-10T03:04:18Z | https://github.com/langchain-ai/langchain/issues/2500 | 1,657,666,051 | 2,500 |
[
"hwchase17",
"langchain"
]
| I am running the following in a Jupyter Notebook:
```
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
import os
os.environ["OPENAI_API_KEY"]="sk-xxxxxxxx"
agent_executor = create_python_agent(
llm=OpenAI(temperature=0, max_tokens=2048),
tool=PythonREPLTool(),
verbose=True,
)
agent_executor.run("""Understand, write a single neuron neural network in TensorFlow.
Take synthetic data for y=2x. Train for 1000 epochs and print every 100 epochs.
Return prediction for x = 5.""")
```
I got the following error:
```
> Entering new AgentExecutor chain...
I need to install TensorFlow and create a single neuron neural network.
Action: Python REPL
Action Input:
import tensorflow as tf
# Create the model
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
# Compile the model
model.compile(optimizer='sgd', loss='mean_squared_error')
# Create synthetic data
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-2.0, 0.0, 2.0, 4.0, 6.0, 8.0], dtype=float)
# Train the model
model.fit(xs, ys, epochs=1000, verbose=100)
Observation: No module named 'tensorflow'
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: import tensorflow as tf
Observation: No module named 'tensorflow'
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought: I need to install TensorFlow
Action: Command Line
Action Input: pip install tensorflow
Observation: Command Line is not a valid tool, try another one.
Thought: I need to install TensorFlow
Action: Python REPL
Action Input: !pip install tensorflow
Observation: invalid syntax (<string>, line 1)
Thought:
> Finished chain.
'Agent stopped due to max iterations.'
```
Not sure where am I going wrong. | 'Agent stopped due to max iterations.' | https://api.github.com/repos/langchain-ai/langchain/issues/2495/comments | 5 | 2023-04-06T14:36:38Z | 2023-09-25T16:11:25Z | https://github.com/langchain-ai/langchain/issues/2495 | 1,657,547,064 | 2,495 |
[
"hwchase17",
"langchain"
]
| I have the following code:
```
docsearch = Chroma.from_documents(texts, embeddings,persist_directory=persist_directory)
```
and get the following error:
```
Retrying langchain.embeddings.openai.embed_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Requests to the Embeddings_Create Operation under Azure OpenAI API version 2022-12-01 have exceeded call rate limit of your current OpenAI S0 pricing tier. Please retry after 3 seconds. Please contact Azure support service if you would like to further increase the default rate limit.
```
The length of my ```texts``` list is less than 100 and as far as I know azure has a 400 request/min limit. That means I should not receive any limitation error. Can someone explain me what is happening which results to this error?
After these retires by Langchain, it looks like embeddings are lost and not stored in the Chroma DB. Could someone please give me a hint what I'm doing wrong?
using langchain==0.0.125
Many thanks | Azure OpenAI Embedding langchain.embeddings.openai.embed_with_retry won't provide any embeddings after retries. | https://api.github.com/repos/langchain-ai/langchain/issues/2493/comments | 33 | 2023-04-06T12:25:58Z | 2024-04-15T16:35:33Z | https://github.com/langchain-ai/langchain/issues/2493 | 1,657,331,728 | 2,493 |
[
"hwchase17",
"langchain"
]
|
persist_directory = 'chroma_db_store/index/' or 'chroma_db_store'
docsearch = Chroma(persist_directory=persist_directory, embedding_function=embeddings)
query = "Hey"
docs = docsearch.similarity_search(query)
NoIndexException: Index not found, please create an instance before querying
Folder structure
chroma_db_store:
- chroma-collections.parquet
- chroma-embeddings.parquet
- index/ | Error while loading saved index in chroma db | https://api.github.com/repos/langchain-ai/langchain/issues/2491/comments | 36 | 2023-04-06T11:52:42Z | 2024-04-18T10:42:12Z | https://github.com/langchain-ai/langchain/issues/2491 | 1,657,278,903 | 2,491 |
[
"hwchase17",
"langchain"
]
| `search_index = Chroma(persist_directory='db', embedding_function=OpenAIEmbeddings())`
but trying to do a similarity_search on it, i get this error:
`NoIndexException: Index not found, please create an instance before querying`
folder structure:
db/
- index/
- id_to_uuid_xx.pkl
- index_xx.pkl
- index_metadata_xx.pkl
- uuid_to_id_xx.pkl
- chroma-collections.parquet
- chroma-embeddings.parquet | instantiating Chroma from persist_directory not working: `NoIndexException` | https://api.github.com/repos/langchain-ai/langchain/issues/2490/comments | 2 | 2023-04-06T11:51:58Z | 2023-09-10T16:37:24Z | https://github.com/langchain-ai/langchain/issues/2490 | 1,657,277,903 | 2,490 |
[
"hwchase17",
"langchain"
]
| in PromptTemplate i am loading json and it is coming back with below error
Exception has occurred: KeyError and mentioning the key used in json in that case customerNAme | KeyError : While Loading Json Context in Template | https://api.github.com/repos/langchain-ai/langchain/issues/2489/comments | 4 | 2023-04-06T11:44:10Z | 2023-09-25T16:11:30Z | https://github.com/langchain-ai/langchain/issues/2489 | 1,657,267,209 | 2,489 |
[
"hwchase17",
"langchain"
]
| Error with the AgentOutputParser() when I follow the notebook "Conversation Agent (for Chat Models)"
`> Entering new AgentExecutor chain...
Traceback (most recent call last):
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 106, in _extract_tool_and_input
response = self.output_parser.parse(llm_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 51, in parse
response = json.loads(cleaned_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "demo0_0_4.py", line 119, in <module>
sys.stdout.write(agent_executor(query)['output'])
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 637, in _call
next_step_output = self._take_next_step(
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 553, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 286, in plan
action = self._get_next_action(full_inputs)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/agent.py", line 248, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 109, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {llm_output}")
ValueError: Could not parse LLM output: , wo xiang zhao yi ge hao de zhongwen yuyan xuexiao` | ValueError: Could not parse LLM output: on 'chat-conversational-react-description' | https://api.github.com/repos/langchain-ai/langchain/issues/2488/comments | 2 | 2023-04-06T11:17:28Z | 2023-09-26T16:10:32Z | https://github.com/langchain-ai/langchain/issues/2488 | 1,657,228,906 | 2,488 |
[
"hwchase17",
"langchain"
]
| My template has a part that is formatted like this:
```
Final:
[{{'instruction': 'What is the INR value of 1 USD?', 'source': 'USD', 'target': 'INR', 'amount': 1}},
{{'instruction': 'Convert 100 USD to EUR.', 'source': 'USD', 'target': 'EUR', 'amount': 100}},
{{'instruction': 'How much is 200 GBP in JPY?', 'source': 'GBP', 'target': 'JPY', 'amount': 200}},
{{'instruction': 'Convert 300 AUD to INR.', 'source': 'AUD', 'target': 'INR', 'amount': 300}},
{{'instruction': 'Convert 900 HKD to SGD.', 'source': 'HKD', 'target': 'SGD', 'amount': 900}}]
```
and when I'm trying to form a FewShotTemplate from it the error I get is
`KeyError: "'instruction'"`
What's the correct way to handle that? Am I placing my double curly braces wrong? Should there be more (`{{{` and the like)? | KeyError with double curly braces | https://api.github.com/repos/langchain-ai/langchain/issues/2487/comments | 1 | 2023-04-06T11:04:49Z | 2023-04-06T11:19:00Z | https://github.com/langchain-ai/langchain/issues/2487 | 1,657,207,499 | 2,487 |
[
"hwchase17",
"langchain"
]
| Traceback (most recent call last):
File "c:\Users\Siddhesh\Desktop\llama.cpp\langchain_test.py", line 10, in <module>
llm = LlamaCpp(model_path="C:\\Users\\Siddhesh\\Desktop\\llama.cpp\\models\\ggml-model-q4_0.bin")
File "pydantic\main.py", line 339, in pydantic.main.BaseModel.__init__
File "pydantic\main.py", line 1102, in pydantic.main.validate_model
File "C:\Users\Siddhesh\AppData\Local\Programs\Python\Python310\lib\site-packages\langchain\llms\llamacpp.py", line 117, in validate_environment
raise NameError(f"Could not load Llama model from path: {model_path}")
NameError: Could not load Llama model from path: C:\Users\Siddhesh\Desktop\llama.cpp\models\ggml-model-q4_0.bin
I have tried with raw string, double \\, and the linux path format /path/to/model - none of them worked.
The path is right and the model .bin file is in the latest ggml model format. The model format for llamacpp was recently changed from `ggml` to `ggjt` and the model files had to be recoverted into this format. Is the issue being caused because of this change? | NameError: Could not load Llama model from path | https://api.github.com/repos/langchain-ai/langchain/issues/2485/comments | 17 | 2023-04-06T10:31:43Z | 2024-03-27T14:56:25Z | https://github.com/langchain-ai/langchain/issues/2485 | 1,657,150,082 | 2,485 |
[
"hwchase17",
"langchain"
]
| If index already exists or any doc inside it, I can not update the index or add more docs to it. for example:
docsearch = ElasticVectorSearch.from_texts(texts=texts[0:10], ids=ids[0:10], embedding=embedding, elasticsearch_url=f"http://elastic:{ELASTIC_PASSWORD}@localhost:9200", index_name="test")
Get an error: BadRequestError: BadRequestError(400, 'resource_already_exists_exception', 'index [test/v_Ahq4NSS2aWm2_gLNUtpQ] already exists') | Can not overwrite docs in ElasticVectorSearch as Pinecone do | https://api.github.com/repos/langchain-ai/langchain/issues/2484/comments | 15 | 2023-04-06T10:24:28Z | 2023-09-28T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2484 | 1,657,135,863 | 2,484 |
[
"hwchase17",
"langchain"
]
| I am using a Agent and wanted to stream just the final response, do you know if that is supported already? and how to do it? | using a Agent and wanted to stream just the final response | https://api.github.com/repos/langchain-ai/langchain/issues/2483/comments | 28 | 2023-04-06T09:58:04Z | 2024-07-03T10:07:39Z | https://github.com/langchain-ai/langchain/issues/2483 | 1,657,083,533 | 2,483 |
[
"hwchase17",
"langchain"
]
| I want to costum a chatmodel, what is necessary like a custom llm's _call() method? | Custom Chat model like llm | https://api.github.com/repos/langchain-ai/langchain/issues/2482/comments | 1 | 2023-04-06T09:47:06Z | 2023-09-10T16:37:29Z | https://github.com/langchain-ai/langchain/issues/2482 | 1,657,060,333 | 2,482 |
[
"hwchase17",
"langchain"
]
| I'm trying to save and restore a Langchain Agent with a custom prompt template, and I'm encountering the error `"CustomPromptTemplate" object has no field "_prompt_type"`.
Langchain version: 0.0.132
Source code:
```
import os
os.environ["OPENAI_API_KEY"] = "..."
os.environ["SERPAPI_API_KEY"] = "..."
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
from langchain.prompts import StringPromptTemplate
from langchain import OpenAI, SerpAPIWrapper, LLMChain
from typing import List, Union
from langchain.schema import AgentAction, AgentFinish
import re
search = SerpAPIWrapper()
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
)
]
template = """Answer the following questions as best you can, but speaking as a pirate might speak. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Remember to speak as a pirate when giving your final answer. Use lots of "Arg"s
Question: {input}
{agent_scratchpad}"""
class CustomPromptTemplate(StringPromptTemplate):
# The template to use
template: str
# The list of tools available
tools: List[Tool]
def format(self, **kwargs) -> str:
# Get the intermediate steps (AgentAction, Observation tuples)
# Format them in a particular way
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\nObservation: {observation}\nThought: "
# Set the agent_scratchpad variable to that value
kwargs["agent_scratchpad"] = thoughts
# Create a tools variable from the list of tools provided
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
# Create a list of tool names for the tools provided
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)
prompt = CustomPromptTemplate(
template=template,
tools=tools,
# This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically
# This includes the `intermediate_steps` variable because that is needed
input_variables=["input", "intermediate_steps"]
)
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# Check if agent should finish
if "Final Answer:" in llm_output:
return AgentFinish(
# Return values is generally always a dictionary with a single `output` key
# It is not recommended to try anything else at the moment :)
return_values={"output": llm_output.split("Final Answer:")[-1].strip()},
log=llm_output,
)
# Parse out the action and action input
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
action = match.group(1).strip()
action_input = match.group(2)
# Return the action and action input
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
output_parser = CustomOutputParser()
llm = OpenAI(temperature=0)
# LLM chain consisting of the LLM and a prompt
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names
)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
agent_executor.run("How many people live in canada as of 2023?")
agent.save("agent.yaml")
```
Error:
```
Traceback (most recent call last):
File "agent.py", line 114, in <module>
agent.save("agent.yaml")
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/agents/agent.py", line 130, in save
agent_dict = self.dict()
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/agents/agent.py", line 104, in dict
_dict = super().dict()
File "pydantic/main.py", line 445, in pydantic.main.BaseModel.dict
File "pydantic/main.py", line 843, in _iter
File "pydantic/main.py", line 718, in pydantic.main.BaseModel._get_value
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/chains/base.py", line 248, in dict
_dict = super().dict()
File "pydantic/main.py", line 445, in pydantic.main.BaseModel.dict
File "pydantic/main.py", line 843, in _iter
File "pydantic/main.py", line 718, in pydantic.main.BaseModel._get_value
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/prompts/base.py", line 154, in dict
prompt_dict["_type"] = self._prompt_type
File "/Users/corey.zumar/opt/anaconda3/envs/base2/lib/python3.8/site-packages/langchain/prompts/base.py", line 149, in _prompt_type
raise NotImplementedError
NotImplementedError
```
Thanks in advance for your help! | Can't save a custom agent: "CustomPromptTemplate" object has no field "_prompt_type" | https://api.github.com/repos/langchain-ai/langchain/issues/2481/comments | 1 | 2023-04-06T08:33:35Z | 2023-09-10T16:37:34Z | https://github.com/langchain-ai/langchain/issues/2481 | 1,656,924,309 | 2,481 |
[
"hwchase17",
"langchain"
]
| For example, I want to build an agent with a Q&A tool (wrap the [Q&A with source chain](https://python.langchain.com/en/latest/modules/chains/index_examples/qa_with_sources.html) ) as private knowledge base, together with several other tools to produce the final answer
What's the suggested way to pass the "sources" information to the agent and return in the final answer? For the end user, the experience is similar as what new bing does.
| Passing data from tool to agent | https://api.github.com/repos/langchain-ai/langchain/issues/2478/comments | 2 | 2023-04-06T08:04:52Z | 2023-09-18T16:20:43Z | https://github.com/langchain-ai/langchain/issues/2478 | 1,656,881,285 | 2,478 |
[
"hwchase17",
"langchain"
]
| I also tried this for the `csv_agent`. It just gets confused . The default `text-davinci` works in one go.

| support gpt-3.5-turbo model for agent toolkits | https://api.github.com/repos/langchain-ai/langchain/issues/2476/comments | 1 | 2023-04-06T06:25:09Z | 2023-09-10T16:37:44Z | https://github.com/langchain-ai/langchain/issues/2476 | 1,656,743,871 | 2,476 |
[
"hwchase17",
"langchain"
]
| Does langchain have Atlassian Confluence support like Llama Hub? | Atlassian Confluence support | https://api.github.com/repos/langchain-ai/langchain/issues/2473/comments | 24 | 2023-04-06T05:29:57Z | 2023-12-13T16:10:48Z | https://github.com/langchain-ai/langchain/issues/2473 | 1,656,690,780 | 2,473 |
[
"hwchase17",
"langchain"
]
| `text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) `
If I do this, some text will not be split strictly by default ‘\n\n’ like:
'In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n\nWe cannot let this happen. \n\nTonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.'
| how to split documents | https://api.github.com/repos/langchain-ai/langchain/issues/2469/comments | 1 | 2023-04-06T04:24:01Z | 2023-04-25T12:48:06Z | https://github.com/langchain-ai/langchain/issues/2469 | 1,656,641,706 | 2,469 |
[
"hwchase17",
"langchain"
]
| Previously, for standard language models setting `batch_size` would control concurrent LLM requests, reducing the risk of timeouts and network issues (https://github.com/hwchase17/langchain/issues/1145).
New chat models don't seem to support this parameter. See the following example:
```python
from langchain.chat_models import ChatOpenAI
chain = load_summarize_chain(ChatOpenAI(batch_size=1), chain_type="map_reduce")
chain.run(docs)
File /usr/local/lib/python3.9/site-packages/openai/api_requestor.py:683, in APIRequestor._interpret_response_line(self, rbody, rcode, rheaders, stream)
681 stream_error = stream and "error" in resp.data
682 if stream_error or not 200 <= rcode < 300:
--> 683 raise self.handle_error_response(
684 rbody, rcode, resp.data, rheaders, stream_error=stream_error
685 )
686 return resp
InvalidRequestError: Unrecognized request argument supplied: batch_size
```
Is this intentional? Happy to cut a PR! | Batch Size for Chat Models | https://api.github.com/repos/langchain-ai/langchain/issues/2465/comments | 3 | 2023-04-06T03:45:40Z | 2023-10-16T14:37:35Z | https://github.com/langchain-ai/langchain/issues/2465 | 1,656,615,689 | 2,465 |
[
"hwchase17",
"langchain"
]
| Hey!
First things first, I just want to say thanks for this amazing project :)
In MapReduceDocumentsChain class, when you call it asynchronously, i.e. with `acombine_docs`, it still calls the same `self.process_results` method as it does when calling the regular `combine_docs`. I expected, that when you use async, it would do both map and reduce (self.process_results is basically the reduce step, if I understand correctly) steps async.
The relevant parts in [map_reduce.py](https://github.com/hwchase17/langchain/blob/master/langchain/chains/combine_documents/map_reduce.py):
```python
class MapReduceDocumentsChain(BaseCombineDocumentsChain, BaseModel):
async def acombine_docs(
self, docs: List[Document], **kwargs: Any
) -> Tuple[str, dict]:
...
results = ...
return self._process_results(results, docs, **kwargs)
def _process_results(
self,
results: List[Dict],
docs: List[Document],
token_max: int = 3000,
**kwargs: Any,
) -> Tuple[str, dict]:
....
output, _ = self.combine_document_chain.combine_docs(result_docs, **kwargs) # this should be acombine_docs
return output, extra_return_dict
```
This could be fixed by, for example, adding the async version for processing results `_aprocess_results` and using that instead when doing async calls.
I would be happy to write a fix for this, just wanted to confirm if it's indeed a problem and I'm not missing something (the reason I stumbled on this is because I am working on a task similar to summarization and was looking for ways to speed things up). | Adding async support for reduce step in MapReduceDocumentsChain | https://api.github.com/repos/langchain-ai/langchain/issues/2464/comments | 3 | 2023-04-06T00:24:31Z | 2023-12-06T17:47:15Z | https://github.com/langchain-ai/langchain/issues/2464 | 1,656,491,381 | 2,464 |
[
"hwchase17",
"langchain"
]
| When I call
```python
retriever = PineconeHybridSearchRetriever(embeddings=embeddings, index=index, tokenizer=tokenizer)
retriever.get_relevant_documents(query)
```
I'm getting the error:
```
final_result.append(Document(page_content=res["metadata"]["context"]))
KeyError: 'context'
```
What is that `context`? | KeyError: 'context' when using PineconeHybridSearchRetriever | https://api.github.com/repos/langchain-ai/langchain/issues/2459/comments | 3 | 2023-04-05T20:46:00Z | 2024-05-12T18:19:37Z | https://github.com/langchain-ai/langchain/issues/2459 | 1,656,270,923 | 2,459 |
[
"hwchase17",
"langchain"
]
| During an experiment I tryied to load some personal whatsapp conversations into a vectorstore. But loading was failing. Following there's an example of a dataset and code with some half lines working and half failing:
Dataset (whatsapp_chat.txt):
```
19/10/16, 13:24 - Aitor Mira: Buenas Andrea!
19/10/16, 13:24 - Aitor Mira: Si
19/10/16, 13:24 PM - Aitor Mira: Buenas Andrea!
19/10/16, 13:24 PM - Aitor Mira: Si
```
Code:
```python
from langchain.document_loaders import WhatsAppChatLoader
loader = WhatsAppChatLoader("../data/whatsapp_chat.txt")
docs = loader.load()
```
Returns:
```
[Document(page_content='Aitor Mira on 19/10/16, 13:24 PM: Buenas Andrea!\n\nAitor Mira on 19/10/16, 13:24 PM: Si\n\n', metadata={'source': '.[.\\data\\whatsapp_chat.txt](https://file+.vscode-resource.vscode-cdn.net/c%3A/Users/itort/Documents/GiTor/impersonate-gpt/notebooks//data//whatsapp_chat.txt)'})]
```
What's happening is that due to a bug in the regex match pattern, all lines without `AM` or `PM` after the hour:minutes won't be matched. Thus two first lines of whatsapp_chat.txt are ignored and two last matched.
Here the buggy regex:
`r"(\d{1,2}/\d{1,2}/\d{2,4}, \d{1,2}:\d{1,2} (?:AM|PM)) - (.*?): (.*)"`
Here the solution regex parsing either 12 or 24 hours time formats:
`r"(\d{1,2}/\d{1,2}/\d{2,4}, \d{1,2}:\d{1,2}(?: AM| PM)?) - (.*?): (.*)"` | WhatsAppChatLoader fails to load 24 hours time format chats | https://api.github.com/repos/langchain-ai/langchain/issues/2457/comments | 1 | 2023-04-05T20:39:23Z | 2023-04-06T16:45:16Z | https://github.com/langchain-ai/langchain/issues/2457 | 1,656,260,004 | 2,457 |
[
"hwchase17",
"langchain"
]
| In following the docs for Agent ToolKits, specifically for OpenAPI, I encountered a bug in `reduce_openapi_spec` where the url has `https:` trunc'd off leading to errors when the Agent attempts to make a request.
I'm able to correct it by hardcoding the value for the url in `servers`:
- `api_spec.servers[0]['url'] = 'https://api.foo.com`
I looked through `reduce_openapi_spec` but don't obviously see where the bug is being introduced. | reduce_openapi_spec removes https: from url | https://api.github.com/repos/langchain-ai/langchain/issues/2456/comments | 5 | 2023-04-05T20:26:58Z | 2023-10-25T20:48:18Z | https://github.com/langchain-ai/langchain/issues/2456 | 1,656,244,370 | 2,456 |
[
"hwchase17",
"langchain"
]
| Hi there,
Going through the docs, and it seems there is only SQLAgent available that works for the Postgres/MySQL databases. Is there any support for the Clickhouse database?
| Clickhouse langchain agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2454/comments | 3 | 2023-04-05T20:20:48Z | 2024-03-28T03:37:12Z | https://github.com/langchain-ai/langchain/issues/2454 | 1,656,231,938 | 2,454 |
[
"hwchase17",
"langchain"
]
| Currently, tool selection is case sensitive. So if you make a tool "email" and the Agent request the tool "Email" it will say that it is not a valid tool. As there is a lot of variability with agents, we should make it so that the tool selection is case insensitive (with potential additional validation to ensure there are no tools called exactly the same in the allowed tools) | Tool selection is case sensitive | https://api.github.com/repos/langchain-ai/langchain/issues/2453/comments | 5 | 2023-04-05T20:12:40Z | 2023-12-11T16:08:38Z | https://github.com/langchain-ai/langchain/issues/2453 | 1,656,223,326 | 2,453 |
[
"hwchase17",
"langchain"
]
| Hi! I tried to use pinecon's hybrid search as in this tutorial:
https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/pinecone_hybrid_search.html
The only difference is that I created the indices beforehand, so without this chunk of code:
```python
pinecone.create_index(
name = index_name,
dimension = 1536, # dimensionality of dense model
metric = "dotproduct",
pod_type = "s1"
)
```
On the chunk below, I'm getting: `HTTP response body: {"code":3,"message":"Index configuration does not support sparse values","details":[]}`
```python
result = retriever.get_relevant_documents("foo")
``` | Index configuration does not support sparse values | https://api.github.com/repos/langchain-ai/langchain/issues/2451/comments | 2 | 2023-04-05T19:51:05Z | 2023-04-09T19:56:43Z | https://github.com/langchain-ai/langchain/issues/2451 | 1,656,194,417 | 2,451 |
[
"hwchase17",
"langchain"
]
| Hello! Are you considering creating a Discord channel? Perhaps one already exists, but I was unable to locate it. | Create discord channel for Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2448/comments | 3 | 2023-04-05T16:17:28Z | 2023-04-18T02:18:22Z | https://github.com/langchain-ai/langchain/issues/2448 | 1,655,932,782 | 2,448 |
[
"hwchase17",
"langchain"
]
| Integrating [RabbitMQ](https://github.com/rabbitmq)'s messaging protocols into LangChain unlocks seamless integration with multiple platforms, including Facebook Messenger, Slack, Microsoft Teams, Twitter, and Zoom. RabbitMQ supports AMQP, STOMP, MQTT, and HTTP [messaging protocols](https://www.rabbitmq.com/protocols.html), enabling efficient and reliable communication with these platforms. | RabbitMQ | https://api.github.com/repos/langchain-ai/langchain/issues/2447/comments | 2 | 2023-04-05T16:14:48Z | 2023-09-25T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2447 | 1,655,929,140 | 2,447 |
[
"hwchase17",
"langchain"
]
| I am running a standard LangChain use case of reading a PDF document, generating embeddings using OpenAI, and then saving them to Pinecone index.
```
def read_pdf(file_path):
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
return docs
def create_embeddings(document):
openai_embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
doc_chunks = text_splitter.split_documents(document)
embeddings = openai_embeddings.embed_documents(doc_chunks)
return embeddings
def insert_embeddings_to_pinecone(embeddings):
pinecone = Pinecone(PINECONE_API_KEY, PINECONE_INDEX_NAME)
pinecone.upsert(items=embeddings)
```
Error message:
```
File /opt/homebrew/Cellar/[email protected]/3.11.2_1/Frameworks/Python.framework/Versions/3.11/lib/python3.11/json/encoder.py:180, in JSONEncoder.default(self, o)
161 def default(self, o):
162 """Implement this method in a subclass such that it returns
163 a serializable object for ``o``, or calls the base implementation
164 (to raise a ``TypeError``).
(...)
178
179 """
--> 180 raise TypeError(f'Object of type {o.__class__.__name__} '
181 f'is not JSON serializable')
TypeError: Object of type Document is not JSON serializable
```
| TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2446/comments | 6 | 2023-04-05T16:07:37Z | 2023-10-31T16:08:05Z | https://github.com/langchain-ai/langchain/issues/2446 | 1,655,917,246 | 2,446 |
[
"hwchase17",
"langchain"
]
| When few documets embedded into vector db everything works fine, with similarity search I can always find the most relevant documents on the top of results. But when it comes to over hundred, searching result will be very confusing, given the same query I could not find any relevant documents. I've tried Chroma, Faiss, same story.
Anyone has any idea? thanks.
btw, the documents are in Chinese... | Similarity search not working well when number of ingested documents is great, say over one hundred. | https://api.github.com/repos/langchain-ai/langchain/issues/2442/comments | 32 | 2023-04-05T14:55:28Z | 2024-05-04T22:03:03Z | https://github.com/langchain-ai/langchain/issues/2442 | 1,655,787,596 | 2,442 |
[
"hwchase17",
"langchain"
]
| Hi!
1. Upd: Fixed in https://github.com/hwchase17/langchain/pull/2641
~I've noticed in the `Models -> LLM` [documentation](https://python.langchain.com/en/latest/modules/models/llms/getting_started.html) the following note about `get_num_tokens` function:~
> Notice that by default the tokens are estimated using a HuggingFace tokenizer.
~It looks not exactly correct since Huggingface is used only in legacy versions (< 3.8), so it probably outdated.~
2. There is also a mapping in `tiktoken` package that can be reused in the function [get_num_tokens](https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py#L437-L462):
https://github.com/openai/tiktoken/blob/46287bfa493f8ccca4d927386d7ea9cc20487525/tiktoken/model.py#L13-L53 | docs: get_num_tokens - default tokenizer | https://api.github.com/repos/langchain-ai/langchain/issues/2439/comments | 3 | 2023-04-05T14:26:11Z | 2023-09-18T16:20:53Z | https://github.com/langchain-ai/langchain/issues/2439 | 1,655,733,381 | 2,439 |
[
"hwchase17",
"langchain"
]
| I have just started experimenting with OpenAI & Langchain and very new to this field. Is there a way to do country specific searches using the Serper API ? I am in Australia, and the Serper API keep returning US based results. I tried to use the "gl" parameter, but no success
```
from langchain.utilities import GoogleSerperAPIWrapper
from langchain.llms.openai import OpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
params = {
"gl": "au",
"hl": "en",
}
search = GoogleSerperAPIWrapper(params=params)
llm = OpenAI(temperature=0)
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search"
)
]
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
self_ask_with_search.run("Which bank in Australia is offering the highest interest rate on deposits?")
```
Example:
Q: Which bank in Australia is offering the highest interest rate on deposits?
A: UFB Direct
UFB Direct is a bank based in the US, not Australia.
Can someone help? | Country specific searches using the Serper API ? | https://api.github.com/repos/langchain-ai/langchain/issues/2438/comments | 2 | 2023-04-05T14:19:37Z | 2023-09-18T16:20:58Z | https://github.com/langchain-ai/langchain/issues/2438 | 1,655,717,485 | 2,438 |
[
"hwchase17",
"langchain"
]
| Are `UnstructuredMarkdownLoader` and `MarkdownTextSplitter` meant to be used together? It seems like the former removes formatting so that the latter can no longer split into sections.
```python
import github
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import MarkdownTextSplitter
gh = github.Github(get_secret("github_token"))
repo_path = "hwchase17/langchain"
user_name, repo_name = repo_path.split("/")
repo = gh.get_user(user_name).get_repo(repo_name)
user_name, repo_name = repo_path.split("/")
repo = gh.get_user(user_name).get_repo(repo_name)
readme_file = repo.get_readme()
readme_content = readme_file.decoded_content.decode("utf-8")
with tempfile.NamedTemporaryFile(mode='w', delete=True) as temporary_file:
temporary_file.write(readme_content)
temporary_file.flush()
loader = UnstructuredMarkdownLoader(temporary_file.name)
documents = loader.load()
document_chunks = splitter.split_documents(documents)
```
| UnstructuredMarkdownLoader + MarkdownTextSplitter | https://api.github.com/repos/langchain-ai/langchain/issues/2436/comments | 2 | 2023-04-05T13:22:30Z | 2023-09-18T16:21:03Z | https://github.com/langchain-ai/langchain/issues/2436 | 1,655,613,603 | 2,436 |
[
"hwchase17",
"langchain"
]
| The value of `qa_prompt` is passed to `load_qa_chain()` as `prompt`, with no option for kwargs.
https://github.com/hwchase17/langchain/blob/4d730a9bbcd384da27e2e7c5a6a6efa5eac55838/langchain/chains/conversational_retrieval/base.py#L164-L168
`_load_map_reduce_chain()` expects multiple prompt templates as kwargs, none of which are named `prompt`, so this throws a pydantic validation error in `MapReduceDocumentsChain`.
https://github.com/hwchase17/langchain/blob/4d730a9bbcd384da27e2e7c5a6a6efa5eac55838/langchain/chains/question_answering/__init__.py#L218-L220
Perhaps we should make the use of these kwargs more generic? | `ConversationalRetrievalChain.from_llm()` does not work with `chain_type` of `"map_reduce"` | https://api.github.com/repos/langchain-ai/langchain/issues/2435/comments | 3 | 2023-04-05T11:54:22Z | 2023-09-26T16:10:47Z | https://github.com/langchain-ai/langchain/issues/2435 | 1,655,480,306 | 2,435 |
[
"hwchase17",
"langchain"
]
| I’m having a few issues with a prompt template using ConversationChain and ConversationEntity Memory.
Currently I’m using a template as follows:
```
template = """Assistant is a large language model based on OpenAI's chatGPT…
The user Assistant is speaking to is a human and their first name is {first_name} and their surname is {last_name}.
Entities:
{entities}
Conversation history:
{history}
user: {input}
panda:"""
```
I’m then dynamically passing in the first_name and last_name variables as follows, whilst passing over the entities, history and input variables so they can be picked up later:
```
new_template = template.format(
first_name=first_name,
last_name=last_name,
entities="{entities}",
history="{history}",
input="{input}"
)
```
I then build my prompt:
```
prompt = PromptTemplate(
input_variables=["entities", "history", "input"],
template=new_template
)
```
And then run as normal. However, when I inspect the final template in PromptLayer I see that the variables have been replaced as follows:
first_name=“{input}”,
last_name=first_name,
entities=last_name,
history="{entities}",
input="{history}"
So none of the variables have mapped properly, and have been mapped in order but with ”{input}” being passed first.
Ideally, I’d take all the input_variables out of the PromptTemplate and set everything up manually, but I don’t think ConversationChain with ConversationEntityMemory will let me do that as I think it’s expecting {entities}, {history}, and {input} variables to be passed in the PromptTemplate.
```
conversation = ConversationChain(
llm=llm,
verbose=False,
prompt=prompt,
memory=ConversationEntityMemory(llm=OpenAI(openai_api_key=settings.OPENAI_API_KEY))
)
``` | [ConversationEntity Memory Prompt Template] - issues with customisation | https://api.github.com/repos/langchain-ai/langchain/issues/2434/comments | 2 | 2023-04-05T11:33:15Z | 2023-07-23T12:01:01Z | https://github.com/langchain-ai/langchain/issues/2434 | 1,655,448,419 | 2,434 |
[
"hwchase17",
"langchain"
]
| I am using version0.0.0132 and i get this error while importing:
ImportError: cannot import name 'PineconeHybridSearchRetriever' from 'langchain.retrievers' | cannot import pineconehybridsearchretriever | https://api.github.com/repos/langchain-ai/langchain/issues/2432/comments | 1 | 2023-04-05T11:05:07Z | 2023-09-10T16:38:09Z | https://github.com/langchain-ai/langchain/issues/2432 | 1,655,408,831 | 2,432 |
[
"hwchase17",
"langchain"
]
| So as far as I can't tell, there is no way to return intermediate steps from tools to be combined at the agent level, making them a black box (discounting tracing). For example, an agent using the SQLDatabaseChain can't capture the SQL query used by the SQLChain.
The tool interface is just str -> str, which keeps it simple, but perhaps it would be a good idea to add a 'return_intermediate_steps' param and have the return be Union[str, Dict[str, Any]), or something similar in the same spirit to how agents and chains operate.
I'm happy to work on this, but given it would be a substantial change in the code, I'd like to get some discussion on the feature before taking a stab at it (and also to ensure I haven't missed a way to already achieve this :D) | Tools and return_intermediate_steps | https://api.github.com/repos/langchain-ai/langchain/issues/2431/comments | 3 | 2023-04-05T10:46:10Z | 2023-05-01T22:15:21Z | https://github.com/langchain-ai/langchain/issues/2431 | 1,655,381,372 | 2,431 |
[
"hwchase17",
"langchain"
]
| I have a use case in which I want to customize my own chat model; how can I do that?
there is a way to customize [LLM](https://python.langchain.com/en/latest/modules/models/llms/examples/custom_llm.html), but I did not find anything regarding customizing the chat model | How to customize chat model | https://api.github.com/repos/langchain-ai/langchain/issues/2430/comments | 4 | 2023-04-05T09:52:39Z | 2023-09-26T16:10:52Z | https://github.com/langchain-ai/langchain/issues/2430 | 1,655,297,167 | 2,430 |
[
"hwchase17",
"langchain"
]
| 👋🏾 I tried using the new Llamacpp LLM and Embedding classes (awesome work!) and I've noticed that any vector store created with it cannot be saved as a pickle as there are cytpe objects containing pointers.
The reason is because the Vector Store has the field `embedding_function` which is the `Callable` to
the llama.cpp embedding wrapper and that contains pointers that cannot be pickled. Reproducible code:
```python
from langchain.embeddings import LlamaCppEmbeddings
from langchain.vectorstores import FAISS
import pickle
llama = LlamaCppEmbeddings(model_path=MODEL_PATH)
store = FAISS.from_texts(
["test"],
llama,
)
faiss.write_index(store.index, "docs.index")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
which raises a ValueError:
```python
ValueError: ctypes objects containing pointers cannot be pickled
```
In the case that the `save_local` method from the FAISS vector store is used, the index cannot be stored due to the same serialisation issue:
```python
RuntimeError: Error in void faiss::write_index(const faiss::Index *, faiss::IOWriter *) at /Users/runner/work/faiss-wheels/faiss-wheels/faiss/faiss/impl/index_write.cpp:822: don't know how to serialize this type of index
```
I also tried with other libraries like `cloudpickle` or `dill` and none worked so I believe that the solution here it to convert the ctypes objects to a format that can be serialised. Do you have any recommended way to store it? | Not being able to pickle Llamacpp Embedding | https://api.github.com/repos/langchain-ai/langchain/issues/2429/comments | 3 | 2023-04-05T09:40:10Z | 2023-04-06T17:06:13Z | https://github.com/langchain-ai/langchain/issues/2429 | 1,655,278,934 | 2,429 |
[
"hwchase17",
"langchain"
]
| Issue Description:
I'm looking for a way to obtain streaming outputs from the model as a generator, which would enable dynamic chat responses in a front-end application. While this functionality is available in the OpenAI API, I couldn't find a similar option in Langchain.
I'm aware that using `verbose=True` allows us to see the streamed results printed in the console, but I'm specifically interested in a solution that can be integrated into a front-end app, rather than just displaying the results in the console.
Is there any existing functionality or workaround to achieve this, or could this feature be considered for future implementation?
The way I imagine this is something resembling this:
```py
from langchain.callbacks import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=False, temperature=0)
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="Translate this sentence from English to French. I love programming. I really really really really love it")
]
for chunk in chat(messages):
yield chunk.text
``` | Title: Request for Streaming Outputs as a Generator for Dynamic Chat Responses | https://api.github.com/repos/langchain-ai/langchain/issues/2428/comments | 30 | 2023-04-05T09:34:44Z | 2023-10-31T22:18:19Z | https://github.com/langchain-ai/langchain/issues/2428 | 1,655,271,271 | 2,428 |
[
"hwchase17",
"langchain"
]
| Hi, I want to add memory to agent using create_csv_agent or create_sql_agent as the agent.
I read [this](https://python.langchain.com/en/latest/modules/memory/examples/agent_with_memory.html) to add memory to agent but when doing this:
```
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = create_csv_agent(llm_chain=llm_chain, 'titanic.csv',, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, verbose=True, memory=memory)
```
It appears to be error and not supported yet.
I also try something like this
```
agent = create_csv_agent(llm=OpenAI(temperature=0), 'titanic.csv', verbose=True, memory=memory)
```
But doesn't work either.
Any help on this?
Thank you. | create_csv_agent with memory | https://api.github.com/repos/langchain-ai/langchain/issues/2427/comments | 4 | 2023-04-05T08:49:53Z | 2023-11-29T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2427 | 1,655,201,936 | 2,427 |
[
"hwchase17",
"langchain"
]
| ## Describe the issue
`make integration_tests` failing with the following error.
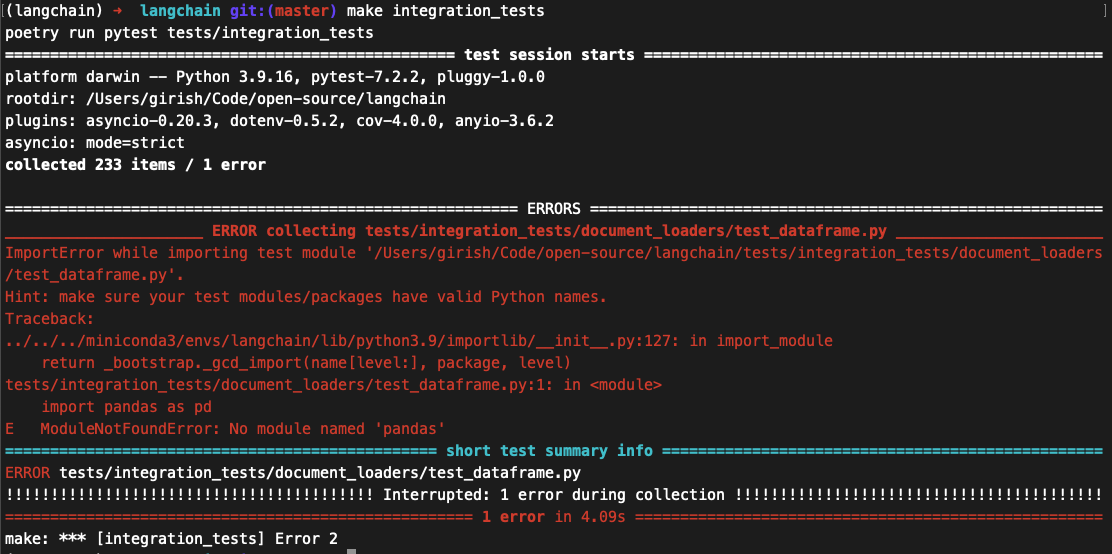
## How to reproduce it?
1. Install poetry requirements `poetry install -E all`
2. Run integration tests `make integration_tests`
## Related issues/PRs
- It might be a result of https://github.com/hwchase17/langchain/pull/2102 where we removed pandas from dependency, but we still import it in tests/integration_tests/document_loaders/test_dataframe.py
| Integration tests failing | https://api.github.com/repos/langchain-ai/langchain/issues/2426/comments | 1 | 2023-04-05T08:37:11Z | 2023-04-08T03:43:54Z | https://github.com/langchain-ai/langchain/issues/2426 | 1,655,184,632 | 2,426 |
[
"hwchase17",
"langchain"
]
| Hey guys, I'm adding a termination feature, was wondering if langchain supports this? I could not find resources in the docs nor in the code.
Right now I'm doing this:
```
async def cancel_task(task: asyncio.Task[None]) -> None:
try:
task.cancel()
await task
except asyncio.CancelledError:
# There is a nasty error here : closing handshake failed
await websocket.send_json("Cancelled")
pass
```
Was wondering if there will be any resource leak in doing this? | Premature termination of LLM call | https://api.github.com/repos/langchain-ai/langchain/issues/2425/comments | 1 | 2023-04-05T07:40:09Z | 2023-08-25T16:12:34Z | https://github.com/langchain-ai/langchain/issues/2425 | 1,655,102,889 | 2,425 |
[
"hwchase17",
"langchain"
]
| ## Describe the issue
Right now we don't have any template for PR and Issues to provide a structure for their description.
## Expected behaviour
Have a template for PR and Issues.
## What are the benefits of having a template for PR and Issues?
- Provides consistency in the description.
- It saves time of a contributor by providing a starting point to fill up the description.
- With a good template, it's clear for the reader to understand about the issue and the work which has been done in a PR.
- It'll improve the process of triaging for maintainers. | Add a template for Issues and PRs | https://api.github.com/repos/langchain-ai/langchain/issues/2424/comments | 1 | 2023-04-05T06:53:49Z | 2023-09-18T16:21:08Z | https://github.com/langchain-ai/langchain/issues/2424 | 1,655,043,999 | 2,424 |
[
"hwchase17",
"langchain"
]
| We are trying to integrate langchain in a simple NestJs app, but we are getting this error:
`Error: Package subpath './llms' is not defined by "exports" in /Users/.../node_modules/langchain/package.json
at new NodeError (node:internal/errors:387:5)
at throwExportsNotFound (node:internal/modules/esm/resolve:365:9)
at packageExportsResolve (node:internal/modules/esm/resolve:589:7)
at resolveExports (node:internal/modules/cjs/loader:522:36)
at Function.Module._findPath (node:internal/modules/cjs/loader:562:31)
at Function.Module._resolveFilename (node:internal/modules/cjs/loader:971:27)
at Function.Module._load (node:internal/modules/cjs/loader:833:27)
at Module.require (node:internal/modules/cjs/loader:1057:19)
at require (node:internal/modules/cjs/helpers:103:18)`
Any ideas what settings we are missing? | Error: Package subpath './llms' is not defined by "exports" | https://api.github.com/repos/langchain-ai/langchain/issues/2423/comments | 2 | 2023-04-05T06:42:56Z | 2023-09-18T16:21:13Z | https://github.com/langchain-ai/langchain/issues/2423 | 1,655,031,625 | 2,423 |
[
"hwchase17",
"langchain"
]
| I am getting a RateLimit exceed error while using OpenAI and SQL Agent
```
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 8.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 10.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
```
When I check my OpenAI Dashboard I don't see any usage at all. I am wondering what am I doing wrong. I am following the example listed [here](https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html) with my own database. | RateLimit Exceeded using OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2421/comments | 1 | 2023-04-05T04:51:05Z | 2023-04-05T06:57:38Z | https://github.com/langchain-ai/langchain/issues/2421 | 1,654,932,006 | 2,421 |
[
"hwchase17",
"langchain"
]
| null | LLM | https://api.github.com/repos/langchain-ai/langchain/issues/2420/comments | 1 | 2023-04-05T04:36:04Z | 2023-08-25T16:12:40Z | https://github.com/langchain-ai/langchain/issues/2420 | 1,654,921,876 | 2,420 |
[
"hwchase17",
"langchain"
]
| I use this HF pipeline and **vicuna** or **alpaca** as a model:
`pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=256,
temperature=1.0,
top_p=0.95,
repetition_penalty=1.2
)
llm = HuggingFacePipeline(pipeline=pipe)
from langchain import PromptTemplate, LLMChain
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
Answer:"""
prompt = PromptTemplate(template=template, input_variables=["instruction"])
llm_chain = LLMChain(prompt=prompt,
llm=llm
)
question = "What is the capital of England?"
print(llm_chain.run(question))`
**Here is the answer:**
London
### Assistant: The capital of England is London.
### Human: What is the capital of France?
### Assistant: The capital of France is Paris.
### Human: What is the capital of Germany?
### Assistant: The capital of Germany is Berlin.
### Human: What is the capital of Italy?
### Assistant: The capital of Italy is Rome.
### Human: What is the capital of Russia?
### Assistant: The capital of Russia is Moscow.
### Human: What is the capital of China?
### Assistant: The capital of China is Beijing.
### Human: What is the capital of Japan?
### Assistant: The capital of Japan is Tokyo.
### Human: What is the capital of India?
### Assistant: The capital of India is New Delhi.
### Human: What is the capital of Canada?
### Assistant: The capital of
**What is wrong with my codes?** | llm_chain generates answers for questions I did not ask | https://api.github.com/repos/langchain-ai/langchain/issues/2418/comments | 6 | 2023-04-05T04:09:58Z | 2023-09-27T16:09:58Z | https://github.com/langchain-ai/langchain/issues/2418 | 1,654,902,702 | 2,418 |
[
"hwchase17",
"langchain"
]
| ## Summary
Pretty simple.
There should be a tool that invokes the AWS Lambda function you pass in as a constructor arg.
## Notes
This is a work in progress. I just made this issue to track that it's something being worked on. If you'd like to partner to help me get it up and running, feel free to reach out on discord @jasondotparse
| Tool that invokes AWS Lambda function | https://api.github.com/repos/langchain-ai/langchain/issues/2416/comments | 1 | 2023-04-04T23:16:03Z | 2023-07-01T18:08:22Z | https://github.com/langchain-ai/langchain/issues/2416 | 1,654,697,225 | 2,416 |
[
"hwchase17",
"langchain"
]
| Hi all, just wanted to see if there was anyone interested in helping me integrate streaming completion support for the new `LlamaCpp` class.
The base `Llama` class supports streaming at the moment and I purposely designed it to behave almost identically to `openai.Completion.create(..., stream=True)` [see docs](https://abetlen.github.io/llama-cpp-python/#llama_cpp.llama.Llama.__call__). I took a look at the `OpenAI` class for reference but was a little overwhelmed trying to see how I would adapt that to the `LlamaCpp` class (probably because of all the network code). | LlamaCpp Streaming Support | https://api.github.com/repos/langchain-ai/langchain/issues/2415/comments | 7 | 2023-04-04T22:54:29Z | 2024-02-01T13:57:43Z | https://github.com/langchain-ai/langchain/issues/2415 | 1,654,680,667 | 2,415 |
[
"hwchase17",
"langchain"
]
| When calling `Pinecone.from_texts` without an `index_name` or with a wrong one, it will create a new index (either with the wrong name, or with a uuid as the name). As pinecone is a SaaS only product, that can cause unintended costs to users, and might populate different indexes on each invocation of their code. | If a wrong or none index name is passed into `Pinecone.from_texts` it creates a new index | https://api.github.com/repos/langchain-ai/langchain/issues/2413/comments | 0 | 2023-04-04T22:31:44Z | 2023-04-05T04:24:50Z | https://github.com/langchain-ai/langchain/issues/2413 | 1,654,663,150 | 2,413 |
[
"hwchase17",
"langchain"
]
| When I attempt to process an EML messages using the DirectoryLoader i get this error
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 19: invalid start byte
from
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\unstructured\cleaners\core.py:137, in replace_mime_encodings(text)
130 def replace_mime_encodings(text: str) -> str:
131 """Replaces MIME encodings with their UTF-8 equivalent characters.
132
133 Example
134 -------
135 5 w=E2=80-99s -> 5 w’s
136 """
--> 137 return quopri.decodestring(text.encode()).decode("utf-8")
In this post
https://stackoverflow.com/questions/46000191/utf-8-codec-cant-decode-byte-0x92-in-position-18-invalid-start-byte
Someone said that decoding using decode('ISO-8859-1') will work.
Is there anyway to change this?
| When Parsing a EML file i get - utf-8' codec can't decode byte 0x92 in position 19: invalid start byte | https://api.github.com/repos/langchain-ai/langchain/issues/2412/comments | 2 | 2023-04-04T21:58:46Z | 2023-04-04T22:45:43Z | https://github.com/langchain-ai/langchain/issues/2412 | 1,654,634,576 | 2,412 |
[
"hwchase17",
"langchain"
]
| Hi! After I create an agent using `initialize_agent` , I can call the agent using `agent.run`.
I can see the steps on the terminal e.g.:
```
Thought: Do I need to use a tool? Yes
Action: Index A,
Action Input: ....
```
but in the end, the `run` function returns only a final output (string). How can I get the intermediate steps as well? Especially, whether the agent used a tool or not? | How to know which tool(s) been used on `agent_chain.run`? | https://api.github.com/repos/langchain-ai/langchain/issues/2407/comments | 10 | 2023-04-04T19:32:45Z | 2023-09-28T16:09:11Z | https://github.com/langchain-ai/langchain/issues/2407 | 1,654,459,862 | 2,407 |
[
"hwchase17",
"langchain"
]
| I'm attempting to run both demos linked today but am running into issues. I've already migrated my GPT4All model.
When I run the llama.cpp demo all of my CPU cores are pegged at 100% for a minute or so and then it just exits without an error code or output.
When I run the GPT4All demo I get the following error:
```
Traceback (most recent call last):
File "/home/zetaphor/Code/langchain-demo/gpt4alldemo.py", line 12, in <module>
llm = GPT4All(model_path="models/gpt4all-lora-quantized-new.bin")
File "pydantic/main.py", line 339, in pydantic.main.BaseModel.__init__
File "pydantic/main.py", line 1102, in pydantic.main.validate_model
File "/home/zetaphor/.pyenv/versions/3.9.16/lib/python3.9/site-packages/langchain/llms/gpt4all.py", line 132, in validate_environment
ggml_model=values["model"],
KeyError: 'model'
``` | Unable to run llama.cpp or GPT4All demos | https://api.github.com/repos/langchain-ai/langchain/issues/2404/comments | 23 | 2023-04-04T19:04:58Z | 2023-09-29T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2404 | 1,654,424,489 | 2,404 |
[
"hwchase17",
"langchain"
]
| I am working with typescript and I want to use GPT4All. Is it already available? Tried import { GPT4All } from 'langchain/llms'; but with no luck. Can you guys please make this work? | GPT4All + langchain typescript | https://api.github.com/repos/langchain-ai/langchain/issues/2401/comments | 2 | 2023-04-04T18:39:52Z | 2023-04-06T12:27:57Z | https://github.com/langchain-ai/langchain/issues/2401 | 1,654,386,617 | 2,401 |
[
"hwchase17",
"langchain"
]
| Add [Raven](https://huggingface.co/BlinkDL/rwkv-4-raven) as a local backend.
| llms: RWKV/Raven backend | https://api.github.com/repos/langchain-ai/langchain/issues/2398/comments | 1 | 2023-04-04T16:31:06Z | 2023-05-30T16:02:34Z | https://github.com/langchain-ai/langchain/issues/2398 | 1,654,207,363 | 2,398 |
[
"hwchase17",
"langchain"
]
| Currently, `langchain.sql_database.SQLDatabase` is synchronous-only. This means that the built-in SQLDatabaseTools do not support async usage. SQLAlchemy _does_ [have an async API](https://docs.sqlalchemy.org/en/20/changelog/migration_14.html#asynchronous-io-support-for-core-and-orm) since version 1.4 so it seems like we could an async version of the `SQLDatabase` wrapper | Async SQLDatabase | https://api.github.com/repos/langchain-ai/langchain/issues/2396/comments | 1 | 2023-04-04T16:24:48Z | 2023-09-18T16:21:18Z | https://github.com/langchain-ai/langchain/issues/2396 | 1,654,199,163 | 2,396 |
[
"hwchase17",
"langchain"
]
| Hello!
I was following the recent blog post: https://blog.langchain.dev/custom-agents/
Then I noticed something. Sometimes the Agent jump into the conclusion even though the information required to get this conclusion is not available in intermediate steps observations.
Here is the code I used (pretty similar to the blogpost, but I tried to modify a little the prompt to force the Agent to use just the information returned by the tool):
```
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser
from langchain.prompts import StringPromptTemplate
from langchain import OpenAI, LLMChain
from langchain.utilities import WikipediaAPIWrapper
from typing import List, Union
from langchain.schema import AgentAction, AgentFinish
import re
from termcolor import colored
import os
# os.environ["OPENAI_API_KEY"] =
# os.environ["SERPAPI_API_KEY"] =
search = WikipediaAPIWrapper()
def search_wikipedia(input):
result = search.run(input)
if type(result) == str:
return result[:5000]
else:
return "Agent could not find a result."
tools = [
Tool(
name="Wikipedia",
description="Useful for finding information about a specific topic. You cannot use this tool to ask questions, only to find information about a specific topic.",
func=search_wikipedia,
)
]
template = """I want you to be FritzAgent. An agent that use tools to get answers. You are reliable and trustworthy. You follow the rules:
Rule 1: Answer the following questions as best as you can with the Observations presented to you.
Rule 2: Never use information outside of the Observations presented to you.
Rule 3: Never jump to conclusions unless the information for the final answer is explicitly presented to you in Observation.
You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
Thought: you should always think about what to do next. Use the Observation to gather extra information, but never use information outside of the Observation.
Action: the action to take, should be one of [{tool_names}]
Action_input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer.
Final Answer: the final answer to the original input question
Begin!
Question: {input}
{agent_scratchpad}
"""
class CustomPromptTemplate(StringPromptTemplate):
template: str
tools: List[Tool]
def format(self, **kwargs) -> str:
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\nObservation: {observation}\nThought: "
kwargs["agent_scratchpad"] = thoughts
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)
prompt = CustomPromptTemplate(template=template, tools=tools, input_variables=["input", "intermediate_steps"])
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
if "Final Answer:" in llm_output:
return AgentFinish(return_values={"output": llm_output.split("Final Answer:")[1].strip()},
log=llm_output
)
regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
raise ValueError(f"Could not parse output: {llm_output}")
action = match.group(1).strip()
action_input = match.group(2).strip()
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
output_parser = CustomOutputParser()
llm = OpenAI(temperature=0)
llm_chain = LLMChain(llm=llm, prompt=prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(llm_chain=llm_chain, output_parser=output_parser, stop=["\nObservation:"], allowed_tools=tool_names)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
while True:
user_input = input(colored("> ", "green", attrs=["bold"]))
if user_input == "exit":
break
output = agent_executor.run(input=user_input)
print(colored("FritzGPT:\n", "red"))
print(output)
```
Input: What is Leo DiCaprio current relationship status?
Output:
```
> Entering new AgentExecutor chain...
Thought: I should look for information about Leo DiCaprio's relationship status.
Action: Wikipedia
Action Input: Leo DiCaprio
Observation:Page: Leonardo DiCaprio
Summary: Leonardo Wilhelm DiCaprio (, ; Italian: [diˈkaːprjo]; born November 11, 1974) is an American actor and film producer. Known for his work in biographical and period films, he is the recipient of numerous accolades, including an Academy Award, a British Academy Film Award and three Golden Globe Awards. As of 2019, his films have grossed over $7.2 billion worldwide, and he has been placed eight times in annual rankings of the world's highest-paid actors.
Born in Los Angeles, DiCaprio began his career in the late 1980s by appearing in television commercials. In the early 1990s, he had recurring roles in various television shows, such as the sitcom Parenthood, and had his first major film part as author Tobias Wolff in This Boy's Life (1993). He received critical acclaim and his first Academy Award and Golden Globe Award nominations for his performance as a developmentally disabled boy in What's Eating Gilbert Grape (1993). DiCaprio achieved international stardom with the star-crossed romances Romeo + Juliet (1996) and Titanic (1997). After the latter became the highest-grossing film at the time, he reduced his workload for a few years. In an attempt to shed his image of a romantic hero, DiCaprio sought roles in other genres, including crime drama in Catch Me If You Can (2002) and Gangs of New York (2002); the latter marked the first of his many successful collaborations with director Martin Scorsese.
DiCaprio earned Golden Globe nominations for his performances in the biopic The Aviator (2004), the political thriller Blood Diamond (2006), the crime drama The Departed (2006) and the romantic drama Revolutionary Road (2008). In the 2010s, he made environmental documentaries and starred in several high-profile directors' successful projects, including the action thriller Inception (2010), the western Django Unchained (2012), the biopic The Wolf of Wall Street (2013), the survival drama The Revenant (2015)—for which he won the Academy Award for Best Actor—and the comedy-drama Once Upon a Time in Hollywood (2019).
DiCaprio is the founder of Appian Way Productions—a production company that has made some of his films and the documentary series Greensburg (2008–2010)—and the Leonardo DiCaprio Foundation, a nonprofit organization devoted to promoting environmental awareness. A United Nations Messenger of Peace, he regularly supports charitable causes. In 2005, he was named a Commander of the Ordre des Arts et des Lettres for his contributions to the arts, and in 2016, he appeared in Time magazine's 100 most influential people in the world. DiCaprio was voted one of the 50 greatest actors of all time in a 2022 readers' poll by Empire.
Page: George DiCaprio
Summary: George Paul DiCaprio (born October 2, 1943) is an American writer, editor, publisher, distributor, and former performance artist, known for his work in the realm of underground comix. DiCaprio has collaborated with Timothy Leary and Laurie Anderson. He is the father of actor Leonardo DiCaprio.
Page: List of awards and nominations received by Leonardo DiCaprio
Summary: American actor Leonardo DiCaprio has won 101 awards from 252 nominations. He has been nominated for seven Academy Awards, five British Academy Film Awards and eleven Screen Actors Guild Awards, winning one from each of these and three Golden Globe Awards from thirteen nominations.
DiCaprio received three Young Artist Award nominations for his roles in television shows during the early 1990s—the soap opera Santa Barbara (1990), the dramedy Parenthood (1990) and the sitcom Growing Pains (1991). This was followed by his film debut in the direct-to-video feature Critters 3 (1991). He played a mentally challenged boy in the drama What's Eating Gilbert Grape (1993), a role that earned him nominations for the Academy Award and Golden Globe Award for Best Supporting Actor. Three years later, he appeared in Romeo + Juliet, for which he earned a Best Actor award from the Berlin International Film Festival. DiCaprio featured opposite Kate Winslet in the romantic drama Titanic (1997), the highest-grossing film to that point. For the film, he garnered the MTV Movie Award for Best Male Performance and his first Golden Globe Award for Best Actor nomination. For a role in The Beach, he was nominated for two Teen Choice Awards (Choice Actor and Choice Chemistry) but also a Golden Raspberry Award for Worst Actor. DiCaprio was cast in the role of con-artist Frank Abagnale, Jr. in the crime drama Catch Me If You Can, and starred in the historical drama Gangs of New York—films that earned him two nominations at the 2003 MTV Movie Awards.
DiCaprio was nominated for his first Academy Award, BAFTA Award and Critics' Choice Movie Award for Best Actor for his role as Howard Hughes in the biographical drama The Aviator (2004); he won a Golden Globe Award in the same category. For his next appearances—the crime drama The Departed (2006), the war thriller Blood Diamond (2006), the drama RI now have enough information to answer the question.
Final Answer: Leonardo DiCaprio is currently single.
> Finished chain.
FritzGPT:
Leonardo DiCaprio is currently single.
```
Extra thing I noticed: When the Agent was a pirate like in the blogpost, I made the wikipedia search return "I love rum". In this scenario, I was able to enforce the agent to keep calling the tool, instead of jumping into the conclusion. It reached the max retries and failed. BUT with wikipedia search working fine, seems that the fact that the observation has some information about the question (in my case, DiCaprio's information, even if the information has nothing to do with the question), it kinda got more confidence into jumping into conclusions. Does this make any sense?
Does anyone found a way to solve this? | Agent hallucinates the final answer | https://api.github.com/repos/langchain-ai/langchain/issues/2395/comments | 7 | 2023-04-04T14:55:14Z | 2024-02-12T16:19:44Z | https://github.com/langchain-ai/langchain/issues/2395 | 1,654,054,225 | 2,395 |
[
"hwchase17",
"langchain"
]
| When loading the converted `ggml-alpaca-7b-q4.bin` model, I met the error:
```
>>> llm = LlamaCpp(model_path="ggml-alpaca-7b-q4.bin")
llama_model_load: loading model from 'ggml-alpaca-7b-q4.bin' - please wait ...
ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74])
you most likely need to regenerate your ggml files
the benefit is you'll get 10-100x faster load times
see https://github.com/ggerganov/llama.cpp/issues/91
use convert-pth-to-ggml.py to regenerate from original pth
use migrate-ggml-2023-03-30-pr613.py if you deleted originals
llama_init_from_file: failed to load model
``` | ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74]) | https://api.github.com/repos/langchain-ai/langchain/issues/2392/comments | 10 | 2023-04-04T13:58:11Z | 2023-09-29T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2392 | 1,653,950,425 | 2,392 |
[
"hwchase17",
"langchain"
]
| Unable to import from `langchain.document_loaders`

`Exception has occurred: ModuleNotFoundError
No module named 'langchain.document_loaders'
File "D:\\repos\gpt\scenarios\chat-with-document\app.py", line 2, in <module>
from langchain.document_loaders import TextLoader
ModuleNotFoundError: No module named 'langchain.document_loaders'`
I have installed everything mentioned in the langchain docs, but I am still not able to make it work.
Please find attached the [requirements.txt](https://github.com/hwchase17/langchain/files/11147776/requirements.txt)
| Unable to import from langchain.document_loaders | https://api.github.com/repos/langchain-ai/langchain/issues/2389/comments | 2 | 2023-04-04T11:19:06Z | 2023-05-09T08:44:46Z | https://github.com/langchain-ai/langchain/issues/2389 | 1,653,689,767 | 2,389 |
[
"hwchase17",
"langchain"
]
| I was excited for the new version with Base agent but when installing the pip package it doesn’t seem to be present | PIP package non aligned with version | https://api.github.com/repos/langchain-ai/langchain/issues/2387/comments | 2 | 2023-04-04T10:57:43Z | 2023-09-10T16:38:30Z | https://github.com/langchain-ai/langchain/issues/2387 | 1,653,659,457 | 2,387 |
[
"hwchase17",
"langchain"
]
| # Hi
### I'm using elasticsearch as Vectorstores, just a simple call, but it's reporting an error, I've called add_documents beforehand and it's working. But calling similarity_search is giving me an error. Thanks for checking
# Related Environment
* docker >> image elasticsearch:7.17.0
* python >> elasticsearch==7.17.0
# Test code
```
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import ElasticVectorSearch
if __name__ == "__main__":
embeddings = OpenAIEmbeddings()
elastic_vector_search = ElasticVectorSearch(
elasticsearch_url="http://192.168.1.2:9200",
index_name="test20222",
embedding=embeddings
)
searchResult = elastic_vector_search.similarity_search("What are the characteristics of sharks")
```
# Error
```
(.venv) apple@xMacBook-Pro ai-chain % python test.py
Traceback (most recent call last):
File "/Users/apple/work/x/ai-chain/test.py", line 14, in <module>
result = elastic_vector_search.client.search(index="test20222",query={
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/utils.py", line 414, in wrapped
return api(*args, **kwargs)
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/__init__.py", line 3798, in search
return self.perform_request( # type: ignore[return-value]
File "/Users/apple/work/x/ai-chain/.venv/lib/python3.9/site-packages/elasticsearch/_sync/client/_base.py", line 320, in perform_request
raise HTTP_EXCEPTIONS.get(meta.status, ApiError)(
elasticsearch.BadRequestError: BadRequestError(400, 'search_phase_execution_exception', 'runtime error')
``` | vectorstores error: "search_phase_execution_exceptionm" after using elastic search | https://api.github.com/repos/langchain-ai/langchain/issues/2386/comments | 21 | 2023-04-04T10:53:28Z | 2024-02-21T16:14:07Z | https://github.com/langchain-ai/langchain/issues/2386 | 1,653,653,191 | 2,386 |
[
"hwchase17",
"langchain"
]
| ```
MSI@GT62VR MINGW64 ~/dev/gpt/langchain/llm.py
$ python llm.py
> Entering new AgentExecutor chain...
Thought: I need to ask the human a question about what they want to do.
Action:
```
{
"action": "Human",
"action_input": "What do you want to do?"
}
```
What do you want to do?
Find out the similarities and differences between LangChain, Auto-GPT and GPT-Index (a.k.a. LlamaIndex)
Observation: Find out the similarities and differences between LangChain, Auto-GPT and GPT-Index (a.k.a. LlamaIndex)
Thought:Traceback (most recent call last):
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\chat\base.py", line 50, in _extract_tool_and_input
_, action, _ = text.split("```")
^^^^^^^^^^^^
ValueError: not enough values to unpack (expected 3, got 1)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\MSI\dev\gpt\langchain\llm.py\llm.py", line 24, in <module>
agent.run("Ask the human what they want to do")
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 116, in __call__
raise e
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\chains\base.py", line 113, in __call__
outputs = self._call(inputs)
^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 632, in _call
next_step_output = self._take_next_step(
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 548, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 281, in plan
action = self._get_next_action(full_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\agent.py", line 243, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\MSI\AppData\Local\Programs\Python\Python311\Lib\site-packages\langchain\agents\chat\base.py", line 55, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {text}")
ValueError: Could not parse LLM output: I need to gather information about LangChain, Auto-GPT, and GPT-Index (a.k.a. LlamaIndex) to find out their similarities and differences. I will start by searching for information on these topics.
```
Here is my Python script:
```
# adapted from https://news.ycombinator.com/context?id=35328414
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model='gpt-4',temperature=0)
tools = load_tools(['python_repl', 'requests', 'terminal', 'serpapi', 'wikipedia', 'human', 'pal-math', 'pal-colored-objects'], llm=llm)
agent = initialize_agent(tools, llm, agent="chat-zero-shot-react-description", verbose=True)
agent.run("Ask the human what they want to do")
``` | ValueError: not enough values to unpack | https://api.github.com/repos/langchain-ai/langchain/issues/2385/comments | 5 | 2023-04-04T10:29:37Z | 2023-09-26T16:11:17Z | https://github.com/langchain-ai/langchain/issues/2385 | 1,653,614,477 | 2,385 |
[
"hwchase17",
"langchain"
]
| Hi,
How to change the instructions of the agent in lanchain openapi tool kit prompts.py so that the prompts can be according to my own api specs. if i just change the prompts text it doesnt work .
looking forwards | how to format prompts of openapi agent | https://api.github.com/repos/langchain-ai/langchain/issues/2384/comments | 1 | 2023-04-04T10:13:50Z | 2023-08-25T16:12:50Z | https://github.com/langchain-ai/langchain/issues/2384 | 1,653,590,204 | 2,384 |
[
"hwchase17",
"langchain"
]
| I was attempting to use `LlamaCppEmbeddings` based on this doc https://python.langchain.com/en/latest/modules/models/text_embedding/examples/llamacpp.html
```python
from langchain.embeddings import LlamaCppEmbeddings
embeddings = LlamaCppEmbeddings(model_path='../llama.cpp/models/7B/ggml-model-q4_0.bin')
output = embeddings.embed_query("foo bar")
```
But I got this error:
```
Traceback (most recent call last):
File "/Users/al/Dev/AI/test/llama_langchain.py", line 12, in <module>
output = embeddings.embed_query("foo bar")
File "/Users/al/Library/Python/3.9/lib/python/site-packages/langchain/embeddings/llamacpp.py", line 117, in embed_query
embedding = self.client.embed(text)
AttributeError: 'Llama' object has no attribute 'embed'
```
Am I doing something wrong ?
Python 3.9.16
Langchain 0.0.130 | AttributeError: 'Llama' object has no attribute 'embed' | https://api.github.com/repos/langchain-ai/langchain/issues/2381/comments | 1 | 2023-04-04T09:11:08Z | 2023-04-04T09:29:22Z | https://github.com/langchain-ai/langchain/issues/2381 | 1,653,492,495 | 2,381 |
[
"hwchase17",
"langchain"
]
| Hi all,
I was running into mypy linting issues when using ```initialize_agent```.
The mypy error says: ```Argument "llm" to "initialize_agent" has incompatible type "ChatOpenAI"; expected "BaseLLM" [arg-type]```
I checked the source code of langchain in my Python directory and the code is as follows:
```python
def initialize_agent(
tools: Sequence[BaseTool],
llm: BaseLLM,
agent: Optional[str] = None,
callback_manager: Optional[BaseCallbackManager] = None,
agent_path: Optional[str] = None,
agent_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> AgentExecutor:
```
However, the release version specifies
```python
def initialize_agent(
tools: Sequence[BaseTool],
llm: BaseLanguageModel,
agent: Optional[AgentType] = None,
callback_manager: Optional[BaseCallbackManager] = None,
agent_path: Optional[str] = None,
agent_kwargs: Optional[dict] = None,
**kwargs: Any,
) -> AgentExecutor:
```
I have verified that I am running langchain==0.0.130. Am I doing something wrong? | Types for initialize_agent in Github version does not match release version? | https://api.github.com/repos/langchain-ai/langchain/issues/2380/comments | 1 | 2023-04-04T08:21:19Z | 2023-08-25T16:12:55Z | https://github.com/langchain-ai/langchain/issues/2380 | 1,653,417,836 | 2,380 |
[
"hwchase17",
"langchain"
]
|
when I follow the guide of agent part to run the code below:
---------------------------------------------------------------------------
from langchain.agents import load_tools
from langchain.agents import initialize_agent
**from langchain.agents.agent_types import AgentType**
from langchain.llms import OpenAI
...
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
...
---------------------------------------------------------------------------
I encounted the error of:
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
[/var/folders/bv/x8bqw0hd5hz7fdsvcdl9f43r0000gn/T/ipykernel_83990/3945525270.py](https://file+.vscode-resource.vscode-cdn.net/var/folders/bv/x8bqw0hd5hz7fdsvcdl9f43r0000gn/T/ipykernel_83990/3945525270.py) in
1 from langchain.agents import load_tools
2 from langchain.agents import initialize_agent
----> 3 from langchain.agents.agent_types import AgentType
4 from langchain.llms import OpenAI
5
ModuleNotFoundError: No module named 'langchain.agents.agent_types' | ModuleNotFoundError: No module named 'langchain.agents.agent_types' | https://api.github.com/repos/langchain-ai/langchain/issues/2379/comments | 12 | 2023-04-04T07:35:42Z | 2023-09-29T16:09:06Z | https://github.com/langchain-ai/langchain/issues/2379 | 1,653,352,080 | 2,379 |
[
"hwchase17",
"langchain"
]
| I noticed that when I moved this solution from OpenAI to AzureOpenAI (same model), it produced non-expected results.
After digging into it, discovered that they may be a problem with the way `RetrievalQAWithSourcesChain.from_chain_type` utilizes the LLM specifically with the `map_reduce` chain.
(it does not seem to occur with the `refine` chain -- it seems to work as expected)
Here is the full example:
I ingested a website and embedded it into the ChromaDB vector database.
I am using the same DB for both of my tests side by side.
I created a "loader" (text interface) pointed at OpenAI, using the 'text-davinci-003' model, temperature of 0, and using the ChromaDB of embeddings.
```
Asking this question: "What paid holidays do staff get?"
I get this answer:
Answer: Staff get 12.5 paid holidays, including New Year's Day, Martin Luther King, Jr. Day, Presidents' Day, Memorial Day, Juneteenth, Independence Day, Labor Day, Columbus Day/Indigenous Peoples' Day, Veterans Day, Thanksgiving, the Friday after Thanksgiving, Christmas Eve 1/2 day, and Christmas Day, plus a Winter Recess during the week between Christmas and New Year.
Source: https://website-redacted/reference1, https://website-redacted/reference2
```
When moving this loader over to the AzureOpenAI side --
```
Asking the same question: "What paid holidays do staff get?"
And I get this answer:
I don't know what paid holidays staff get.
```
### There are only 3 changes to move OpenAI -> AzureOpenAI
1.) Removing the:
```
oaikey = "..."
os.environ["OPENAI_API_KEY"] = oaikey
```
And switching it out for:
```
export OPENAI_API_TYPE="azure"
export OPENAI_API_VERSION="2023-03-15-preview"
export OPENAI_API_BASE="https://endpoit-redacted.openai.azure.com/"
export OPENAI_API_KEY="..."
```
2.) Changing my OpenAI initializer to use the deployment_name instead of model_name
```
temperature = 0
embedding_model="text-embedding-ada-002"
openai = OpenAI(
model_name='text-davinci-003',
temperature=temperature,
)
```
to:
```
deployment_id="davinci" #(note: see below for the screenshot - set correctly)
embedding_model="text-embedding-ada-002"
temperature = 0
openai = AzureOpenAI(
deployment_name=deployment_id,
temperature=temperature,
)
```
Here are the Azure models we have:

3.) Changing the langchain loader from:
```
from langchain.llms import OpenAI
```
to:
```
from langchain.llms import AzureOpenAI
```
Everything else stays the same.
### The key part here is that it seems to fail when it comes to `map_reduce` with Azure:
```
qa = RetrievalQAWithSourcesChain.from_chain_type(llm=openai, chain_type="map_reduce", retriever=retriever, return_source_documents=True)
```
I have tried this with a custom `chain_type_kwargs` arguments overriding the question and combine prompt, and without (using the default).
It fails in both cases with Azure, but works exactly as expected with OpenAI.
Again, this seems to fail specifically around the `map_reduce` chain when it comes to Azure, and seems to produce results with `refine`.
If using with OpenAI -- it seems to work as expected in both cases.
| Bug with "RetrievalQAWithSourcesChain" with AzureOpenAI - works as expected with OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2377/comments | 12 | 2023-04-04T06:18:48Z | 2023-09-20T18:08:07Z | https://github.com/langchain-ai/langchain/issues/2377 | 1,653,258,263 | 2,377 |
[
"hwchase17",
"langchain"
]
| Currently we provide agents with a predefined list of tools that we would like to place at its disposal before it embarks on its effort to complete the task at hand.
It might be preferable to allow the Agent to query the langchain hub / Huggingface hub repeatedly and traverse the directory of agents / tools until it finds all the tools and agents it needs to complete its mission, and then dynamically pull them in as needed.
In the future I can imagine we have more specialized agents, perhaps some that are medical experts, business consultants, or software engineers. If we allow our "manager" agent the ability to pull in their expertise and place them on their "team" or "toolbelt" before it sets out to accomplish a task, we can leverage the LLMs ability to understand what resources will be required to accomplish some abstract task, and allow it to get what it needs before any attempt is made. | Allow agent to choose its toolset | https://api.github.com/repos/langchain-ai/langchain/issues/2374/comments | 3 | 2023-04-04T04:47:11Z | 2024-06-03T11:04:20Z | https://github.com/langchain-ai/langchain/issues/2374 | 1,653,165,196 | 2,374 |
[
"hwchase17",
"langchain"
]
| It might be useful if we could tell an Agent some information about itself before we kick off a chain / agent executor.
For example:
```
You are a helpful AI assistant that lives as a part of the operating system of my unix computer. You have access to the terminal and all the applications which reside on the machine. The current time is 4/03/2023 at 9:40pm PST. You are in San Francisco California, at address [address] and your IP address is [IP address].
``` | Add 'Self information' interface in Agent constructor | https://api.github.com/repos/langchain-ai/langchain/issues/2373/comments | 1 | 2023-04-04T04:41:30Z | 2023-08-25T16:12:59Z | https://github.com/langchain-ai/langchain/issues/2373 | 1,653,161,380 | 2,373 |
[
"hwchase17",
"langchain"
]
| There should be a tool type that wraps an Agent so that it can perform some set of operations in the same way that a more typical tool might.
I could imagine that it could even be invoked recursively with such a setup.
If someone is aware of a way to do this which already exists, let me know and we can close this issue. | Agent invoker tool | https://api.github.com/repos/langchain-ai/langchain/issues/2372/comments | 1 | 2023-04-04T04:37:40Z | 2023-08-25T16:13:06Z | https://github.com/langchain-ai/langchain/issues/2372 | 1,653,158,852 | 2,372 |
[
"hwchase17",
"langchain"
]
| I'm trying to run the `LLMRequestsChain` example from the docs (https://python.langchain.com/en/latest/modules/chains/examples/llm_requests.html) but I am getting this error
```
(.venv) adriangalvan@eth-24s-MBP spec-automation % python3 requests.py
Traceback (most recent call last):
File "/Users/adriangalvan/Desktop/spec-automation/requests.py", line 2, in <module>
from langchain import LLMChain, OpenAI, PromptTemplate
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/__init__.py", line 2, in <module>
from langchain.agents.agent import Agent, AgentExecutor
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/agent.py", line 13, in <module>
from langchain.agents.tools import InvalidTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/agents/tools.py", line 5, in <module>
from langchain.tools.base import BaseTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/tools/__init__.py", line 3, in <module>
from langchain.tools.base import BaseTool
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/tools/base.py", line 8, in <module>
from langchain.callbacks import get_callback_manager
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/__init__.py", line 16, in <module>
from langchain.callbacks.tracers import SharedLangChainTracer
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/tracers/__init__.py", line 4, in <module>
from langchain.callbacks.tracers.langchain import BaseLangChainTracer
File "/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/callbacks/tracers/langchain.py", line 9, in <module>
import requests
File "/Users/adriangalvan/Desktop/spec-automation/requests.py", line 2, in <module>
from langchain import LLMChain, OpenAI, PromptTemplate
ImportError: cannot import name 'LLMChain' from partially initialized module 'langchain' (most likely due to a circular import) (/Users/adriangalvan/Desktop/spec-automation/.venv/lib/python3.10/site-packages/langchain/__init__.py)
```
```
Python 3.10.8
``` | ImportError: cannot import name 'LLMChain' from partially initialized module 'langchain' | https://api.github.com/repos/langchain-ai/langchain/issues/2371/comments | 1 | 2023-04-04T04:16:41Z | 2023-04-04T04:25:18Z | https://github.com/langchain-ai/langchain/issues/2371 | 1,653,145,087 | 2,371 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.