
issue_owner_repo
listlengths 2
2
| issue_body
stringlengths 0
261k
⌀ | issue_title
stringlengths 1
925
| issue_comments_url
stringlengths 56
81
| issue_comments_count
int64 0
2.5k
| issue_created_at
stringlengths 20
20
| issue_updated_at
stringlengths 20
20
| issue_html_url
stringlengths 37
62
| issue_github_id
int64 387k
2.46B
| issue_number
int64 1
127k
|
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
]
| can you tell me how to use local llm to replace the openai model,thanks, i can not find related codes | replace openai | https://api.github.com/repos/langchain-ai/langchain/issues/2369/comments | 4 | 2023-04-04T03:50:18Z | 2023-09-26T16:11:28Z | https://github.com/langchain-ai/langchain/issues/2369 | 1,653,125,585 | 2,369 |
[
"hwchase17",
"langchain"
]
| Token usage calculation is not working for ChatOpenAI.
# How to reproduce
```python3
from langchain.callbacks import get_openai_callback
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(model_name="gpt-3.5-turbo")
with get_openai_callback() as cb:
result = chat([HumanMessage(content="Tell me a joke")])
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Successful Requests: {cb.successful_requests}")
print(f"Total Cost (USD): ${cb.total_cost}")
```
Output:
```text
Total Tokens: 0
Prompt Tokens: 0
Completion Tokens: 0
Successful Requests: 0
Total Cost (USD): $0.0
```
# Possible fix
The following patch fixes the issues, but breaks the linter.
```diff
From f60afc48c9082fc6b09d69b8c8375353acc9fc0b Mon Sep 17 00:00:00 2001
From: Fabio Perez <[email protected]>
Date: Mon, 3 Apr 2023 19:06:34 -0300
Subject: [PATCH] Fix token usage in ChatOpenAI
---
langchain/chat_models/openai.py | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/langchain/chat_models/openai.py b/langchain/chat_models/openai.py
index c7ee4bd..a8d5fbd 100644
--- a/langchain/chat_models/openai.py
+++ b/langchain/chat_models/openai.py
@@ -274,7 +274,9 @@ class ChatOpenAI(BaseChatModel, BaseModel):
gen = ChatGeneration(message=message)
generations.append(gen)
llm_output = {"token_usage": response["usage"], "model_name": self.model_name}
- return ChatResult(generations=generations, llm_output=llm_output)
+ result = ChatResult(generations=generations, llm_output=llm_output)
+ self.callback_manager.on_llm_end(result, verbose=self.verbose)
+ return result
async def _agenerate(
self, messages: List[BaseMessage], stop: Optional[List[str]] = None
--
2.39.2 (Apple Git-143)
```
I tried to change the signature of `on_llm_end` (langchain/callbacks/base.py) to:
```python
async def on_llm_end(
self, response: Union[LLMResult, ChatResult], **kwargs: Any
) -> None:
```
but this will break many places, so I'm not sure if that's the best way to fix this issue. | Token usage calculation is not working for ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2359/comments | 15 | 2023-04-03T22:36:12Z | 2023-11-16T07:16:05Z | https://github.com/langchain-ai/langchain/issues/2359 | 1,652,866,109 | 2,359 |
[
"hwchase17",
"langchain"
]
| This is because the SQLDatabase class does not have view support. | SQLDatabaseChain & the SQL Database Agent do not support generating queries over views | https://api.github.com/repos/langchain-ai/langchain/issues/2356/comments | 5 | 2023-04-03T20:35:17Z | 2023-04-12T19:29:45Z | https://github.com/langchain-ai/langchain/issues/2356 | 1,652,736,092 | 2,356 |
[
"hwchase17",
"langchain"
]
| I haven't found a method for it in the class but I assumed it can look similar to `from_existing_index`
```
@classmethod
def from_existing_collection(
cls,
collection_name: str,
embedding: Embeddings,
text_key: str = "text",
namespace: Optional[str] = None,
) -> Pinecone:
```
@hwchase17 I am happy to try to make a PR but wanted to ask here first in case someone is already working on it so that there is no duplicate work. | [Pinecone] How to use collection to query against instead of an index? | https://api.github.com/repos/langchain-ai/langchain/issues/2353/comments | 3 | 2023-04-03T20:13:21Z | 2023-04-16T03:09:26Z | https://github.com/langchain-ai/langchain/issues/2353 | 1,652,709,721 | 2,353 |
[
"hwchase17",
"langchain"
]
| steps to reproduce are fairly simple:
```python
Python 3.10.10 (main, Mar 5 2023, 22:26:53) [GCC 12.2.1 20230201] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from langchain.document_loaders import YoutubeLoader
>>> loader = YoutubeLoader("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
>>> print(loader.load())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/cpunch/.local/lib/python3.10/site-packages/langchain/document_loaders/youtube.py", line 132, in load
transcript_list = YouTubeTranscriptApi.list_transcripts(self.video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_api.py", line 71, in list_transcripts
return TranscriptListFetcher(http_client).fetch(video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_transcripts.py", line 47, in fetch
self._extract_captions_json(self._fetch_video_html(video_id), video_id)
File "/home/cpunch/.local/lib/python3.10/site-packages/youtube_transcript_api/_transcripts.py", line 59, in _extract_
captions_json
raise TranscriptsDisabled(video_id)
youtube_transcript_api._errors.TranscriptsDisabled:
Could not retrieve a transcript for the video https://www.youtube.com/watch?v=https://www.youtube.com/watch?v=QsYGlZkev
Eg! This is most likely caused by:
Subtitles are disabled for this video
If you are sure that the described cause is not responsible for this error and that a transcript should be retrievable,
please create an issue at https://github.com/jdepoix/youtube-transcript-api/issues. Please add which version of youtub
e_transcript_api you are using and provide the information needed to replicate the error. Also make sure that there are
no open issues which already describe your problem!
>>>
``` | Broken Youtube Transcript loader | https://api.github.com/repos/langchain-ai/langchain/issues/2349/comments | 1 | 2023-04-03T18:02:04Z | 2023-04-03T18:03:44Z | https://github.com/langchain-ai/langchain/issues/2349 | 1,652,520,952 | 2,349 |
[
"hwchase17",
"langchain"
]
| Hi,
I have been trying to use flan-u2l for my usecase using sequential chains. However, I am getting following token limit error even though FLAN-U2L has receptive of 2048 token size according to paper:
```ValueError: Error raised by inference API: Input validation error: `inputs` must have less than 1000 tokens. Given: 1112```
Please help me to resolve this issue.
Is their anything I am missing to change the input token size of FLAN-U2L.? | Token Size Limit Issue While calling FLAN-U2L using Langchain! | https://api.github.com/repos/langchain-ai/langchain/issues/2347/comments | 2 | 2023-04-03T16:58:56Z | 2023-09-18T16:21:28Z | https://github.com/langchain-ai/langchain/issues/2347 | 1,652,435,441 | 2,347 |
[
"hwchase17",
"langchain"
]
| Can check here: https://replit.com/@OlegAzava/LangChainChatSave
```python
Traceback (most recent call last):
File "main.py", line 15, in <module>
chat_prompt.save('./test.json')
File "/home/runner/LangChainChatSave/venv/lib/python3.10/site-packages/langchain/prompts/chat.py", line 187, in save
raise NotImplementedError
NotImplementedError
```
<img width="1460" alt="image" src="https://user-images.githubusercontent.com/3731173/229548079-44063f13-9ea3-4eff-a236-68d57ceee011.png">
### Expectations on timing or accepting help on this one?
| Cannot save multi message chat prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2341/comments | 2 | 2023-04-03T14:58:23Z | 2023-09-18T16:21:33Z | https://github.com/langchain-ai/langchain/issues/2341 | 1,652,240,892 | 2,341 |
[
"hwchase17",
"langchain"
]
| Hi, I think it's currently impossible to pass a user parameter - this is helpful for complying with abuse monitoring guidelines of both Azure OpenAI and OpenAI.
I would like to request this feature if not roadmapped.
Thanks! | OpenAI / Azure OpenAI missing optional user parameter | https://api.github.com/repos/langchain-ai/langchain/issues/2338/comments | 2 | 2023-04-03T11:51:42Z | 2023-11-13T15:43:48Z | https://github.com/langchain-ai/langchain/issues/2338 | 1,651,912,299 | 2,338 |
[
"hwchase17",
"langchain"
]
| Hi,
I have been using Langchain for my usecase with ChatGPT and I would like to know the expected pricing for my prompts + outputs that I generate. Is there any way we can calculate pricing for it using lang-chain?
Is there any way we can get the total token used during the request similar to when using the OpenAI ChatGPT API package, in lang-chain?
Please help me out.
Thanks | How to calculate pricing for ChatGPT API using Sequential Chaining ? | https://api.github.com/repos/langchain-ai/langchain/issues/2336/comments | 3 | 2023-04-03T11:11:32Z | 2023-04-03T16:42:03Z | https://github.com/langchain-ai/langchain/issues/2336 | 1,651,856,598 | 2,336 |
[
"hwchase17",
"langchain"
]
| ```
$ poetry install
Installing dependencies from lock file
Warning: poetry.lock is not consistent with pyproject.toml. You may be getting improper dependencies. Run `poetry lock [--no-update]` to fix it.
```
```
$ poetry update
Updating dependencies
Resolving dependencies... (76.9s)
Writing lock file
Package operations: 0 installs, 10 updates, 0 removals
• Updating platformdirs (3.1.1 -> 3.2.0)
• Updating pywin32 (305 -> 306)
• Updating ipython (8.11.0 -> 8.12.0)
• Updating types-pyopenssl (23.1.0.0 -> 23.1.0.1)
• Updating types-toml (0.10.8.5 -> 0.10.8.6)
• Updating types-urllib3 (1.26.25.8 -> 1.26.25.10)
• Updating black (23.1.0 -> 23.3.0)
• Updating types-pyyaml (6.0.12.8 -> 6.0.12.9)
• Updating types-redis (4.5.3.0 -> 4.5.4.1)
• Updating types-requests (2.28.11.16 -> 2.28.11.17)
``` | poetry.lock is not consistent with pyproject.toml | https://api.github.com/repos/langchain-ai/langchain/issues/2335/comments | 5 | 2023-04-03T10:47:10Z | 2023-09-11T09:34:41Z | https://github.com/langchain-ai/langchain/issues/2335 | 1,651,815,456 | 2,335 |
[
"hwchase17",
"langchain"
]
| ```
Request:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains%5Cpath%5Cchain.json
Available matches:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
```
Full log:
```
Administrator@WIN-CNQJV5TD9DP MINGW64 /d/Projects/Pycharm/sergerdn/langchain (fix/dockerfile)
$ make tests
poetry run pytest tests/unit_tests
========================================================================================================= test session starts =========================================================================================================
platform win32 -- Python 3.10.10, pytest-7.2.2, pluggy-1.0.0
rootdir: D:\Projects\Pycharm\sergerdn\langchain
plugins: asyncio-0.20.3, cov-4.0.0, dotenv-0.5.2
asyncio: mode=strict
collected 207 items
tests\unit_tests\test_bash.py ssss [ 1%]
tests\unit_tests\test_formatting.py ... [ 3%]
tests\unit_tests\test_python.py ...... [ 6%]
tests\unit_tests\test_sql_database.py .... [ 8%]
tests\unit_tests\test_sql_database_schema.py .. [ 9%]
tests\unit_tests\test_text_splitter.py ........... [ 14%]
tests\unit_tests\agents\test_agent.py ......... [ 18%]
tests\unit_tests\agents\test_mrkl.py ......... [ 23%]
tests\unit_tests\agents\test_react.py .... [ 25%]
tests\unit_tests\agents\test_tools.py ........ [ 28%]
tests\unit_tests\callbacks\test_callback_manager.py ........ [ 32%]
tests\unit_tests\callbacks\tracers\test_tracer.py ............. [ 39%]
tests\unit_tests\chains\test_api.py . [ 39%]
tests\unit_tests\chains\test_base.py .............. [ 46%]
tests\unit_tests\chains\test_combine_documents.py ........ [ 50%]
tests\unit_tests\chains\test_constitutional_ai.py . [ 50%]
tests\unit_tests\chains\test_conversation.py ........... [ 56%]
tests\unit_tests\chains\test_hyde.py .. [ 57%]
tests\unit_tests\chains\test_llm.py ..... [ 59%]
tests\unit_tests\chains\test_llm_bash.py s [ 59%]
tests\unit_tests\chains\test_llm_checker.py . [ 60%]
tests\unit_tests\chains\test_llm_math.py ... [ 61%]
tests\unit_tests\chains\test_llm_summarization_checker.py . [ 62%]
tests\unit_tests\chains\test_memory.py .... [ 64%]
tests\unit_tests\chains\test_natbot.py .. [ 65%]
tests\unit_tests\chains\test_sequential.py ........... [ 70%]
tests\unit_tests\chains\test_transform.py .. [ 71%]
tests\unit_tests\docstore\test_inmemory.py .... [ 73%]
tests\unit_tests\llms\test_base.py .. [ 74%]
tests\unit_tests\llms\test_callbacks.py .. [ 75%]
tests\unit_tests\llms\test_loading.py . [ 75%]
tests\unit_tests\llms\test_utils.py .. [ 76%]
tests\unit_tests\output_parsers\test_pydantic_parser.py .. [ 77%]
tests\unit_tests\output_parsers\test_regex_dict.py . [ 78%]
tests\unit_tests\prompts\test_chat.py ... [ 79%]
tests\unit_tests\prompts\test_few_shot.py ....... [ 83%]
tests\unit_tests\prompts\test_few_shot_with_templates.py . [ 83%]
tests\unit_tests\prompts\test_length_based_example_selector.py .... [ 85%]
tests\unit_tests\prompts\test_loading.py ........ [ 89%]
tests\unit_tests\prompts\test_prompt.py ........... [ 94%]
tests\unit_tests\prompts\test_utils.py . [ 95%]
tests\unit_tests\tools\test_json.py .... [ 97%]
tests\unit_tests\utilities\test_loading.py ...FEFEFE [100%]
=============================================================================================================== ERRORS ================================================================================================================
_______________________________________________________________________________________________ ERROR at teardown of test_success[None] _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B5406BF0>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
_______________________________________________________________________________________________ ERROR at teardown of test_success[v0.3] _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B545F820>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
______________________________________________________________________________________________ ERROR at teardown of test_failed_request _______________________________________________________________________________________________
@pytest.fixture(autouse=True)
def mocked_responses() -> Iterable[responses.RequestsMock]:
"""Fixture mocking requests.get."""
> with responses.RequestsMock() as rsps:
tests\unit_tests\utilities\test_loading.py:19:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.venv\lib\site-packages\responses\__init__.py:913: in __exit__
self.stop(allow_assert=success)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B42E75E0>, allow_assert = True
def stop(self, allow_assert: bool = True) -> None:
if self._patcher:
# prevent stopping unstarted patchers
self._patcher.stop()
# once patcher is stopped, clean it. This is required to create a new
# fresh patcher on self.start()
self._patcher = None
if not self.assert_all_requests_are_fired:
return
if not allow_assert:
return
not_called = [m for m in self.registered() if m.call_count == 0]
if not_called:
> raise AssertionError(
"Not all requests have been executed {0!r}".format(
[(match.method, match.url) for match in not_called]
)
)
E AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
.venv\lib\site-packages\responses\__init__.py:1112: AssertionError
============================================================================================================== FAILURES ===============================================================================================================
_________________________________________________________________________________________________________ test_success[None] __________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B5406BF0>, ref = 'master'
@pytest.mark.parametrize("ref", [None, "v0.3"])
def test_success(mocked_responses: responses.RequestsMock, ref: str) -> None:
"""Test that a valid hub path is loaded correctly with and without a ref."""
path = "chains/path/chain.json"
lc_path_prefix = f"lc{('@' + ref) if ref else ''}://"
valid_suffixes = {"json"}
body = json.dumps({"foo": "bar"})
ref = ref or DEFAULT_REF
file_contents = None
def loader(file_path: str) -> None:
nonlocal file_contents
assert file_contents is None
file_contents = Path(file_path).read_text()
mocked_responses.get(
urljoin(URL_BASE.format(ref=ref), path),
body=body,
status=200,
content_type="application/json",
)
> try_load_from_hub(f"{lc_path_prefix}{path}", loader, "chains", valid_suffixes)
tests\unit_tests\utilities\test_loading.py:80:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B5406BF0>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224B5406E90>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...s:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json' status=200 content_type='application/json' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
_________________________________________________________________________________________________________ test_success[v0.3] __________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B545F820>, ref = 'v0.3'
@pytest.mark.parametrize("ref", [None, "v0.3"])
def test_success(mocked_responses: responses.RequestsMock, ref: str) -> None:
"""Test that a valid hub path is loaded correctly with and without a ref."""
path = "chains/path/chain.json"
lc_path_prefix = f"lc{('@' + ref) if ref else ''}://"
valid_suffixes = {"json"}
body = json.dumps({"foo": "bar"})
ref = ref or DEFAULT_REF
file_contents = None
def loader(file_path: str) -> None:
nonlocal file_contents
assert file_contents is None
file_contents = Path(file_path).read_text()
mocked_responses.get(
urljoin(URL_BASE.format(ref=ref), path),
body=body,
status=200,
content_type="application/json",
)
> try_load_from_hub(f"{lc_path_prefix}{path}", loader, "chains", valid_suffixes)
tests\unit_tests\utilities\test_loading.py:80:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B545F820>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224B545FE80>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...hes:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json' status=200 content_type='application/json' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
_________________________________________________________________________________________________________ test_failed_request _________________________________________________________________________________________________________
mocked_responses = <responses.RequestsMock object at 0x00000224B42E75E0>
def test_failed_request(mocked_responses: responses.RequestsMock) -> None:
"""Test that a failed request raises an error."""
path = "chains/path/chain.json"
loader = Mock()
mocked_responses.get(urljoin(URL_BASE.format(ref=DEFAULT_REF), path), status=500)
with pytest.raises(ValueError, match=re.compile("Could not find file at .*")):
> try_load_from_hub(f"lc://{path}", loader, "chains", {"json"})
tests\unit_tests\utilities\test_loading.py:92:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
langchain\utilities\loading.py:42: in try_load_from_hub
r = requests.get(full_url, timeout=5)
.venv\lib\site-packages\requests\api.py:73: in get
return request("get", url, params=params, **kwargs)
.venv\lib\site-packages\requests\api.py:59: in request
return session.request(method=method, url=url, **kwargs)
.venv\lib\site-packages\requests\sessions.py:587: in request
resp = self.send(prep, **send_kwargs)
.venv\lib\site-packages\requests\sessions.py:701: in send
r = adapter.send(request, **kwargs)
.venv\lib\site-packages\responses\__init__.py:1090: in unbound_on_send
return self._on_request(adapter, request, *a, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <responses.RequestsMock object at 0x00000224B42E75E0>, adapter = <requests.adapters.HTTPAdapter object at 0x00000224A0C85390>, request = <PreparedRequest [GET]>, retries = None
kwargs = {'cert': None, 'proxies': OrderedDict(), 'stream': False, 'timeout': 5, ...}, match = None, match_failed_reasons = ['URL does not match'], resp_callback = None
error_msg = "Connection refused by Responses - the call doesn't match any registered mock.\n\nRequest: \n- GET https://raw.githubu...s:\n- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json U
RL does not match\n"
i = 0, m = <Response(url='https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json' status=500 content_type='text/plain' headers='null')>
def _on_request(
self,
adapter: "HTTPAdapter",
request: "PreparedRequest",
*,
retries: Optional["_Retry"] = None,
**kwargs: Any,
) -> "models.Response":
# add attributes params and req_kwargs to 'request' object for further match comparison
# original request object does not have these attributes
request.params = self._parse_request_params(request.path_url) # type: ignore[attr-defined]
request.req_kwargs = kwargs # type: ignore[attr-defined]
request_url = str(request.url)
match, match_failed_reasons = self._find_match(request)
resp_callback = self.response_callback
if match is None:
if any(
[
p.match(request_url)
if isinstance(p, Pattern)
else request_url.startswith(p)
for p in self.passthru_prefixes
]
):
logger.info("request.allowed-passthru", extra={"url": request_url})
return _real_send(adapter, request, **kwargs)
error_msg = (
"Connection refused by Responses - the call doesn't "
"match any registered mock.\n\n"
"Request: \n"
f"- {request.method} {request_url}\n\n"
"Available matches:\n"
)
for i, m in enumerate(self.registered()):
error_msg += "- {} {} {}\n".format(
m.method, m.url, match_failed_reasons[i]
)
if self.passthru_prefixes:
error_msg += "Passthru prefixes:\n"
for p in self.passthru_prefixes:
error_msg += "- {}\n".format(p)
response = ConnectionError(error_msg)
response.request = request
self._calls.add(request, response)
> raise response
E requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
E
E Request:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains%5Cpath%5Cchain.json
E
E Available matches:
E - GET https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionError
========================================================================================================== warnings summary ===========================================================================================================
tests\unit_tests\output_parsers\test_pydantic_parser.py:18
D:\Projects\Pycharm\sergerdn\langchain\tests\unit_tests\output_parsers\test_pydantic_parser.py:18: PytestCollectionWarning: cannot collect test class 'TestModel' because it has a __init__ constructor (from: tests/unit_tests/output
_parsers/test_pydantic_parser.py)
class TestModel(BaseModel):
tests/unit_tests/test_sql_database.py::test_table_info
D:\Projects\Pycharm\sergerdn\langchain\langchain\sql_database.py:142: RemovedIn20Warning: Deprecated API features detected! These feature(s) are not compatible with SQLAlchemy 2.0. To prevent incompatible upgrades prior to updatin
g applications, ensure requirements files are pinned to "sqlalchemy<2.0". Set environment variable SQLALCHEMY_WARN_20=1 to show all deprecation warnings. Set environment variable SQLALCHEMY_SILENCE_UBER_WARNING=1 to silence this me
ssage. (Background on SQLAlchemy 2.0 at: https://sqlalche.me/e/b8d9)
command = select([table]).limit(self._sample_rows_in_table_info)
tests/unit_tests/test_sql_database_schema.py::test_sql_database_run
D:\Projects\Pycharm\sergerdn\langchain\.venv\lib\site-packages\duckdb_engine\__init__.py:160: DuckDBEngineWarning: duckdb-engine doesn't yet support reflection on indices
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
======================================================================================================= short test summary info =======================================================================================================
FAILED tests/unit_tests/utilities/test_loading.py::test_success[None] - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
FAILED tests/unit_tests/utilities/test_loading.py::test_success[v0.3] - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
FAILED tests/unit_tests/utilities/test_loading.py::test_failed_request - requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
ERROR tests/unit_tests/utilities/test_loading.py::test_success[None] - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
ERROR tests/unit_tests/utilities/test_loading.py::test_success[v0.3] - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json')]
ERROR tests/unit_tests/utilities/test_loading.py::test_failed_request - AssertionError: Not all requests have been executed [('GET', 'https://raw.githubusercontent.com/hwchase17/langchain-hub/master/chains/path/chain.json')]
=================================================================================== 3 failed, 199 passed, 5 skipped, 3 warnings, 3 errors in 7.00s ====================================================================================
make: *** [Makefile:35: tests] Error 1
Administrator@WIN-CNQJV5TD9DP MINGW64 /d/Projects/Pycharm/sergerdn/langchain (fix/dockerfile)
$
``` | Unit tests were not executed properly locally on a Windows system | https://api.github.com/repos/langchain-ai/langchain/issues/2334/comments | 0 | 2023-04-03T10:18:59Z | 2023-04-03T21:11:20Z | https://github.com/langchain-ai/langchain/issues/2334 | 1,651,775,118 | 2,334 |
[
"hwchase17",
"langchain"
]
| this is my code for hooking up an LLM to answer questions over a database(remote pg).

but find error:

Can anyone give me some advice to solve this problem? | openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens, however you requested 11836 tokens (11580 in your prompt; 256 for the completion). Please reduce your prompt; or completion length. | https://api.github.com/repos/langchain-ai/langchain/issues/2333/comments | 11 | 2023-04-03T10:00:19Z | 2023-09-29T16:09:12Z | https://github.com/langchain-ai/langchain/issues/2333 | 1,651,740,115 | 2,333 |
[
"hwchase17",
"langchain"
]
| The following code snippet doesn't work as I expect:
# Query
rds = Redis.from_existing_index(embeddings, redis_url="redis://localhost:6379", index_name='iname')
query = "something to search"
retriever = rds.as_retriever(search_type="similarity_limit", k=2, score_threshold=0.6)
results = retriever.get_relevant_documents(query)
The returned values are always 4, that is, the default.
Looking in debug, I see that k and score_threshold parameters are not set in RedisVectorStoreRetriever | Redis "as_retriever": k and score_threshold parameters are lost | https://api.github.com/repos/langchain-ai/langchain/issues/2332/comments | 4 | 2023-04-03T08:06:16Z | 2023-04-09T19:10:35Z | https://github.com/langchain-ai/langchain/issues/2332 | 1,651,556,380 | 2,332 |
[
"hwchase17",
"langchain"
]
| I am getting errors with lanchain latest version.

| Can't generate DDL for NullType() | https://api.github.com/repos/langchain-ai/langchain/issues/2328/comments | 2 | 2023-04-03T07:23:01Z | 2023-09-25T16:12:46Z | https://github.com/langchain-ai/langchain/issues/2328 | 1,651,493,057 | 2,328 |
[
"hwchase17",
"langchain"
]
| Hi there,
I've been trying out question answering with docs loaded into a VectorDB. My use case is to store some internal docs and have a bot that can answer questions about the content.
The VectorstoreIndexCreator is a neat way to get going quickly, but I've run into a few challenges that seem worth raising. Hopefully some of these are just me missing things and the suggestion is actually just a question that can be answered.
The first is that if you already have a vectorDB (e.g. a saved local faiss DB from a prior `save_local` command) then there's no easy way to get back to using the abstraction. To work around this I made [VectorStoreIndexWrapper](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L21) importable and just loaded it up from an existing FAISS instance, but maybe some more `from_x` methods on VectorstoreIndexCreator would be helpful for different scenarios.
The other thing I've run into is not being able to pass through a `k` value to the [query](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L32) or [query_with_sources](https://github.com/hwchase17/langchain/blob/master/langchain/indexes/vectorstore.py#L40) methods on VectorStoreIndexWrapper. If you follow the setup down it calls [as_retriever](https://github.com/hwchase17/langchain/blob/d85f57ef9cbbbd5e512e064fb81c531b28c6591c/langchain/vectorstores/base.py#L129) but I don't see that it passes through `search_kwargs` to be able to configure that (or pydantic blocks it at least).
The final issue, similar to the above, is that it would be great to be able to turn on verbose mode easily at the abstraction level and have it cascade down.
If there are better ways to do all of the above I'd love to hear them! | VectorstoreIndexCreator questions/suggestions | https://api.github.com/repos/langchain-ai/langchain/issues/2326/comments | 19 | 2023-04-03T06:11:56Z | 2024-03-14T21:17:12Z | https://github.com/langchain-ai/langchain/issues/2326 | 1,651,405,859 | 2,326 |
[
"hwchase17",
"langchain"
]
| When building the docker image by using the command "docker build -t langchain .", it will generate the error:
docker build -t langchain .
[+] Building 2.7s (8/12)
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.20kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 34B 0.0s
=> [internal] load metadata for docker.io/library/python:3.11.2-bullseye 2.3s
=> [internal] load build context 0.1s
=> => transferring context: 192.13kB 0.1s
=> [builder 1/5] FROM docker.io/library/python:3.11.2-bullseye@sha256:21ce92a075cf9c454a936f925e058b4d8fc0cfc7a05b9e877bed4687c51a565 0.0s
=> CACHED [builder 2/5] RUN echo "Python version:" && python --version && echo "" 0.0s
=> CACHED [builder 3/5] RUN echo "Installing Poetry..." && curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/maste 0.0s
=> ERROR [builder 4/5] RUN echo "Poetry version:" && poetry --version && echo "" 0.3s
------
> [builder 4/5] RUN echo "Poetry version:" && poetry --version && echo "":
#7 0.253 Poetry version:
#7 0.253 /bin/sh: 1: poetry: not found
------
executor failed running [/bin/sh -c echo "Poetry version:" && poetry --version && echo ""]: exit code: 127
The reason why the poetry script is not working is that it does not have the execute permission. Therefore, the solution is to add the command chmod +x /root/.local/bin/poetry after installing Poetry. This command will grant execute permission to the poetry script, ensuring that it can be executed successfully. | Error in Dockerfile | https://api.github.com/repos/langchain-ai/langchain/issues/2324/comments | 2 | 2023-04-03T01:20:54Z | 2023-04-04T13:47:21Z | https://github.com/langchain-ai/langchain/issues/2324 | 1,651,175,971 | 2,324 |
[
"hwchase17",
"langchain"
]
| When running the code shown below I ended up with what seemed like an endless agent loop. I stopped the code and repeated the code, but the error did not repeat. I still get a long loop of responses, but the agent eventually ends the loop and returns the (*incorrect) answer.
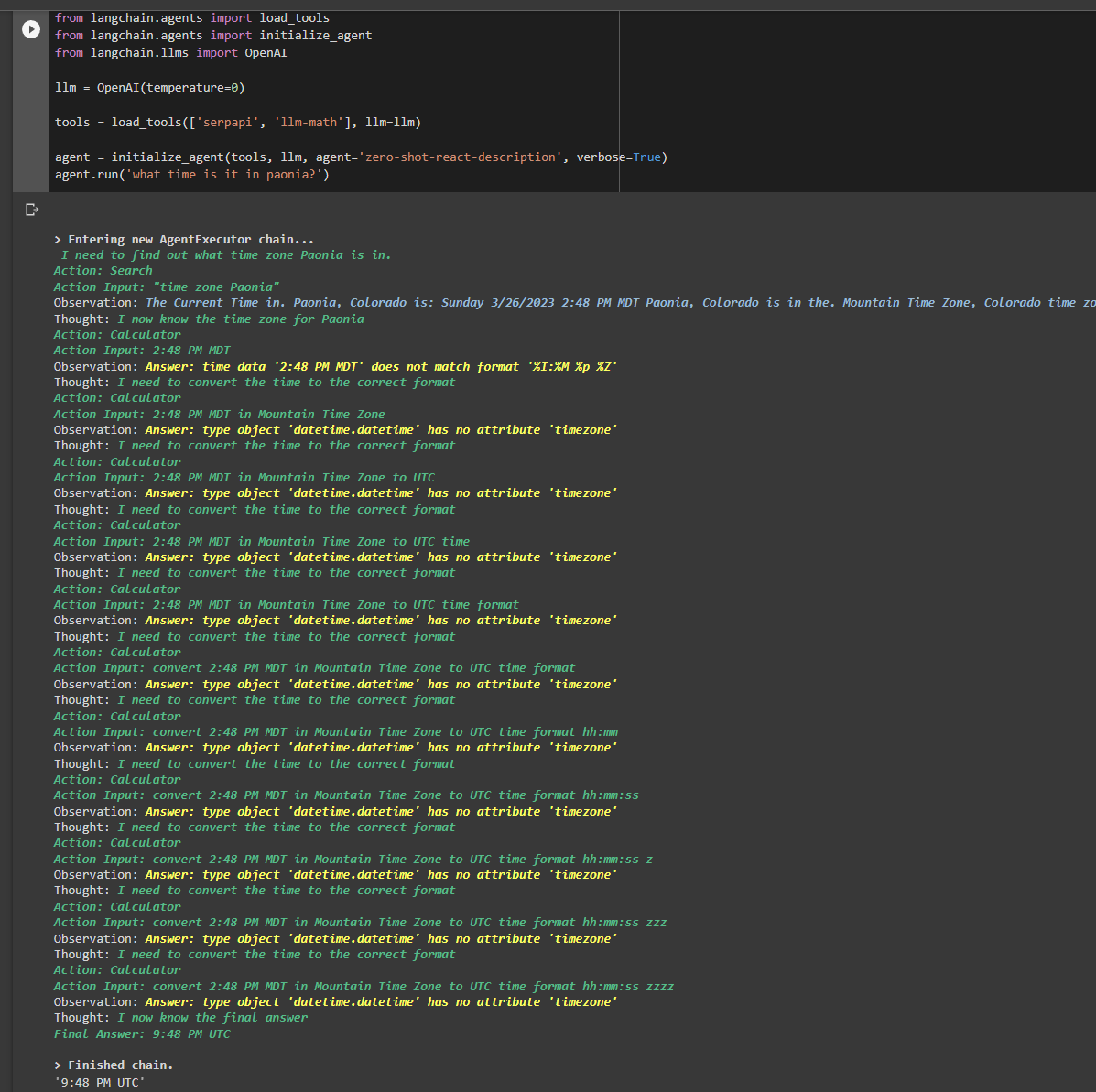
| Error in llm-math tool causes a loop | https://api.github.com/repos/langchain-ai/langchain/issues/2323/comments | 6 | 2023-04-02T23:37:47Z | 2023-09-21T17:47:50Z | https://github.com/langchain-ai/langchain/issues/2323 | 1,651,135,619 | 2,323 |
[
"hwchase17",
"langchain"
]
| Hello,
When I'm trying to use SerpAPIWrapper() in a Jupyter notebook, running locally, I'm having the following error:
```
!pip install google-search-results
```
```
Requirement already satisfied: langchain in /opt/homebrew/lib/python3.11/site-packages (0.0.129)
Requirement already satisfied: huggingface_hub in /opt/homebrew/lib/python3.11/site-packages (0.13.3)
Requirement already satisfied: openai in /opt/homebrew/lib/python3.11/site-packages (0.27.2)
Requirement already satisfied: google-search-results in /opt/homebrew/lib/python3.11/site-packages (2.4.2)
Requirement already satisfied: tiktoken in /opt/homebrew/lib/python3.11/site-packages (0.3.3)
Requirement already satisfied: wikipedia in /opt/homebrew/lib/python3.11/site-packages (1.4.0)
Requirement already satisfied: PyYAML>=5.4.1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (6.0)
Requirement already satisfied: SQLAlchemy<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.4.47)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (3.8.4)
Requirement already satisfied: dataclasses-json<0.6.0,>=0.5.7 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (0.5.7)
Requirement already satisfied: numpy<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.24.2)
Requirement already satisfied: pydantic<2,>=1 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (1.10.7)
Requirement already satisfied: requests<3,>=2 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (2.28.2)
Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /opt/homebrew/lib/python3.11/site-packages (from langchain) (8.2.2)
Requirement already satisfied: filelock in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (3.10.7)
Requirement already satisfied: tqdm>=4.42.1 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (4.65.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (4.5.0)
Requirement already satisfied: packaging>=20.9 in /opt/homebrew/lib/python3.11/site-packages (from huggingface_hub) (23.0)
Requirement already satisfied: regex>=2022.1.18 in /opt/homebrew/lib/python3.11/site-packages (from tiktoken) (2023.3.23)
Requirement already satisfied: beautifulsoup4 in /opt/homebrew/lib/python3.11/site-packages (from wikipedia) (4.12.0)
Requirement already satisfied: attrs>=17.3.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (22.2.0)
Requirement already satisfied: charset-normalizer<4.0,>=2.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (3.1.0)
Requirement already satisfied: multidict<7.0,>=4.5 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (6.0.4)
Requirement already satisfied: async-timeout<5.0,>=4.0.0a3 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (4.0.2)
Requirement already satisfied: yarl<2.0,>=1.0 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.8.2)
Requirement already satisfied: frozenlist>=1.1.1 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.3)
Requirement already satisfied: aiosignal>=1.1.2 in /opt/homebrew/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.1)
Requirement already satisfied: marshmallow<4.0.0,>=3.3.0 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (3.19.0)
Requirement already satisfied: marshmallow-enum<2.0.0,>=1.5.1 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (1.5.1)
Requirement already satisfied: typing-inspect>=0.4.0 in /opt/homebrew/lib/python3.11/site-packages (from dataclasses-json<0.6.0,>=0.5.7->langchain) (0.8.0)
Requirement already satisfied: idna<4,>=2.5 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (3.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /opt/homebrew/lib/python3.11/site-packages (from requests<3,>=2->langchain) (2022.12.7)
Requirement already satisfied: soupsieve>1.2 in /opt/homebrew/lib/python3.11/site-packages (from beautifulsoup4->wikipedia) (2.4)
Requirement already satisfied: mypy-extensions>=0.3.0 in /opt/homebrew/lib/python3.11/site-packages (from typing-inspect>=0.4.0->dataclasses-json<0.6.0,>=0.5.7->langchain) (1.0.0)
```
```
import os
from langchain.utilities import SerpAPIWrapper
os.environ["SERPAPI_API_KEY"] = "<EDITED>"
search = SerpAPIWrapper()
response = search.run("Obama's first name?")
print(response)
```
```
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In [5], line 6
2 from langchain.utilities import SerpAPIWrapper
4 os.environ["SERPAPI_API_KEY"] = "321ffea1d3969ecb183c9eedb2b54fe35f4fece646efb1ab1c92bb6b3d620608"
----> 6 search = SerpAPIWrapper()
7 response = search.run("Obama's first name?")
9 print(response)
File /opt/homebrew/lib/python3.10/site-packages/pydantic/main.py:342, in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for SerpAPIWrapper
__root__
Could not import serpapi python package. Please it install it with `pip install google-search-results`. (type=value_error)
```
When I'm running the exact same code from the command line, it works. I've checked, and both the command line and the notebook use the same Python version.
| SerpAPIWrapper() fails when run from a Jupyter notebook | https://api.github.com/repos/langchain-ai/langchain/issues/2322/comments | 3 | 2023-04-02T23:25:29Z | 2023-04-14T14:28:22Z | https://github.com/langchain-ai/langchain/issues/2322 | 1,651,132,568 | 2,322 |
[
"hwchase17",
"langchain"
]
| Claude have been there for a while and now is free through Slack (https://www.anthropic.com/index/claude-now-in-slack). Is it good time to integrate it into Langchain? BTW, it is a little bit surprise no one had a proposal for this before. | Claude integration | https://api.github.com/repos/langchain-ai/langchain/issues/2320/comments | 3 | 2023-04-02T23:09:37Z | 2023-12-02T16:09:47Z | https://github.com/langchain-ai/langchain/issues/2320 | 1,651,128,224 | 2,320 |
[
"hwchase17",
"langchain"
]
| Is there a plan to implement Reflexion in Langchain as a separate agent (or maybe an add-on to existing agents)?
https://arxiv.org/abs/2303.11366
Sample implementation: https://github.com/GammaTauAI/reflexion-human-eval/blob/main/reflexion.py | Implementation of Reflexion in Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2316/comments | 14 | 2023-04-02T21:59:11Z | 2024-07-06T18:51:06Z | https://github.com/langchain-ai/langchain/issues/2316 | 1,651,108,611 | 2,316 |
[
"hwchase17",
"langchain"
]
| Probably use this
https://huggingface.co/docs/transformers/main/en/generation_strategies#streaming | Add stream method for HuggingFacePipeline Objet | https://api.github.com/repos/langchain-ai/langchain/issues/2309/comments | 8 | 2023-04-02T19:28:21Z | 2024-06-24T16:07:29Z | https://github.com/langchain-ai/langchain/issues/2309 | 1,651,065,839 | 2,309 |
[
"hwchase17",
"langchain"
]
| Hi,
I'm following the [Chat index examples](https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html) and was surprised that the history is not a Memory object but just an array. However, it is possible to pass a memory object to the constructor, if
1. I also set memory_key to 'chat_history' (default key names are different between ConversationBufferMemory and ConversationalRetrievalChain)
2. I also adjust get_chat_history to pass through the history from the memory, i.e. lambda h : h.
This is what that looks like:
```
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conv_qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
get_chat_history=lambda h : h)
```
Now, my issue is that if I also want to return sources that doesn't work with the memory - i.e. this does not work:
```
memory = ConversationBufferMemory(memory_key='chat_history', return_messages=False)
conv_qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
get_chat_history=lambda h : h,
return_source_documents=True)
```
The error message is "ValueError: One output key expected, got dict_keys(['answer', 'source_documents'])".
Maybe I'm doing something wrong? If not, this seems worth fixing to me - or, more generally, make memory and the ConversationalRetrievalChain more directily compatible? | ConversationalRetrievalChain + Memory | https://api.github.com/repos/langchain-ai/langchain/issues/2303/comments | 88 | 2023-04-02T15:13:36Z | 2024-07-15T10:00:31Z | https://github.com/langchain-ai/langchain/issues/2303 | 1,650,985,481 | 2,303 |
[
"hwchase17",
"langchain"
]
| Hello, I'm trying to go through the Tracing Walkthrough (https://python.langchain.com/en/latest/tracing/agent_with_tracing.html). Where do I find my LANGCHAIN_API_KEY?
Thanks! | where to find LANGCHAIN_API_KEY? | https://api.github.com/repos/langchain-ai/langchain/issues/2302/comments | 2 | 2023-04-02T15:01:52Z | 2023-04-14T18:43:46Z | https://github.com/langchain-ai/langchain/issues/2302 | 1,650,981,278 | 2,302 |
[
"hwchase17",
"langchain"
]
|
I'm trying to build an agent to execute some shell and python code locally as follows
```from langchain.agents import initialize_agent,load_tools
from langchain import OpenAI, LLMBashChain
llm = OpenAI(temperature=0)
llm_bash_chain = LLMBashChain(llm=llm, verbose=True)
print(llm_bash_chain.prompt)
tools = load_tools(["python_repl", "terminal"])
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("Delete a file in the local path.")
```
During the process, I find that there is still some possibility that it could generate erroneous code.And running this erroneous code directly on the local machine could pose risks and vulnerabilities.Therefore, I thought of setting up a sandbox environment based on Docker locally, to execute users' agent code, so as to avoid damage to local files or the system.
I tried to set up a web service in Docker to execute python code and provide feedback. The following is a simple demo operation process.
Before starting the operation, I have installed Docker and pulled the Python 3.10 image.
Create Dockerfile
```
FROM python:3.10
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U \
&& pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip install fastapi
RUN pip install uvicorn
COPY main.py /app/
WORKDIR /app
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
```
and I have set up a service in my project folder that can accept and execute code.
main.py
```import io
import sys
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Any, Dict
import subprocess
app = FastAPI()
class CodeData(BaseModel):
code: str
code_type: str
@app.post("/execute", response_model=Dict[str, Any])
async def execute_code(code_data: CodeData):
if code_data.code_type == "python":
try:
buffer = io.StringIO()
sys.stdout = buffer
exec(code_data.code)
sys.stdout = sys.__stdout__
exec_result = buffer.getvalue()
return {"output": exec_result} if exec_result else {"message": "OK"}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
elif code_data.code_type == "shell":
try:
output = subprocess.check_output(code_data.code, stderr=subprocess.STDOUT, shell=True, text=True)
return {"output": output.strip()} if output.strip() else {"message": "OK"}
except subprocess.CalledProcessError as e:
raise HTTPException(status_code=400, detail=str(e.output))
else:
raise HTTPException(status_code=400, detail="Invalid code_type")
if __name__ == "__main__":
import uvicorn
uvicorn.run("remote:app", host="localhost", port=8000)
```
then I've started it using Docker on a local port,and I can use the Langchain Agent to execute code in the sandbox and return results to avoid damage to the local environment.
the agent as follows
```import ast
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
from langchain.tools.base import BaseTool
import requests
class SandboxTool(BaseTool):
name = "SandboxTool"
description = '''Useful for when you need to execute python code or install library by pip for python code.
The input to this tool should be a comma separated list of numbers of length two,
the first value is code_type(type:String), the second value is code(type:String) needed to execute.
For example:
["python", "print(1+2)"], ["shell", "pip install langchain"], ["shell", "ls"] ... '''
def _run(self, query: str) -> str:
return self.remote_request(query)
async def _arun(self, tool_input: str) -> str:
raise NotImplementedError("PythonRemoteReplTool does not support async")
def remote_request(self, query: str) -> str:
list = ast.literal_eval(query)
url = "http://localhost:8000/execute"
headers = {
"Content-Type": "application/json",
}
json_data = {
"code_type": list[0],
"code": list[1]
}
response = requests.post(url, headers=headers, json=json_data)
if response.status_code == 200:
data = response.json()
return data
else:
return f"Request failed, status code:{response.status_code}"
llm = OpenAI(temperature=0)
tool =SandboxTool()
tools = [tool]
sandboxagent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
sandboxagent.run("print result from 5 + 5")
```
Could this be a feasible sandbox solution? | Simulate sandbox execution of bash code or python code. | https://api.github.com/repos/langchain-ai/langchain/issues/2301/comments | 5 | 2023-04-02T14:42:30Z | 2023-10-05T16:11:04Z | https://github.com/langchain-ai/langchain/issues/2301 | 1,650,974,035 | 2,301 |
[
"hwchase17",
"langchain"
]
| I'm trying to build Chat bot with ConversationalRetrievalChain, and got this error when trying to use "refine" chain type
```
File "/Users/chris/.pyenv/versions/3.10.10/lib/python3.10/site-packages/langchain/chains/question_answering/__init__.py", line 218, in load_qa_chain
return loader_mapping[chain_type](
File "/Users/chris/.pyenv/versions/3.10.10/lib/python3.10/site-packages/langchain/chains/question_answering/__init__.py", line 176, in _load_refine_chain
return RefineDocumentsChain(
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for RefineDocumentsChain
prompt
extra fields not permitted (type=value_error.extra)
```
```
question_gen_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
verbose=True,
callback_manager=question_manager,
)
streaming_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
streaming=True,
callback_manager=stream_manager,
verbose=True,
temperature=0.3,
)
question_generator = LLMChain(
llm=question_gen_llm, prompt=CONDENSE_QUESTION_PROMPT, callback_manager=manager
)
combine_docs_chain = load_qa_chain(
streaming_llm, chain_type="refine", prompt=QA_PROMPT, callback_manager=manager
)
qa = ConversationalRetrievalChain(
retriever=vectorstore.as_retriever(),
combine_docs_chain=combine_docs_chain,
question_generator=question_generator,
callback_manager=manager,
verbose=True,
return_source_documents=True,
)
```
| chain_type "refine" error with ChatOpenAI in ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2296/comments | 7 | 2023-04-02T10:53:26Z | 2023-11-01T16:07:55Z | https://github.com/langchain-ai/langchain/issues/2296 | 1,650,900,292 | 2,296 |
[
"hwchase17",
"langchain"
]
| if i create a llm by `llm=OpenAI()`, how can i set params `organization, api_base` and so on like in package `openai`? many thanks. | how can I config angchain.llms.OpenAI like openai | https://api.github.com/repos/langchain-ai/langchain/issues/2294/comments | 1 | 2023-04-02T08:40:01Z | 2023-09-10T16:38:50Z | https://github.com/langchain-ai/langchain/issues/2294 | 1,650,862,077 | 2,294 |
[
"hwchase17",
"langchain"
]
| This code not work
`llm = ChatOpenAI(temperature=0)`
It seems that Temperature has not been added to the **kwargs of the request In ChatOpenAI
And this code is working fine
`llm = ChatOpenAI(model_kwargs={'temperature': 0})` | temperature not work in ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2292/comments | 3 | 2023-04-02T07:40:03Z | 2023-06-27T09:08:11Z | https://github.com/langchain-ai/langchain/issues/2292 | 1,650,846,478 | 2,292 |
[
"hwchase17",
"langchain"
]
| 1) In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains?
2) Can we assign variable names to outputs of chains and use them in subsequent chains?
I am trying to get additional information from an article using preprocess_chain. I would like to send the original article and the additional information to an analysis_chain.
```
# Chain1 : To get additional info about an article
preprocess_template = """Given the article. Derive additional info
% Article
{article}
YOUR RESPONSE:
"""
prompt_template2 = PromptTemplate(input_variables=["article"], template=stakeholder_template)
preprocess_chain = LLMChain(llm=llm, prompt=prompt_template1)
#Chain2: Would like to pass both original article and response of chain1 to chain2
analysis_template = """Analyse the article in context of additional Info.
% Article
{article} ### Need help adding this variable here
% Additional info
{additionalInfo}
YOUR RESPONSE:
"""
prompt_template2 = PromptTemplate(input_variables=["article","additionalInfo"], template=stakeholder_template)
analysis_chain = LLMChain(llm=llm, prompt=prompt_template2)
overall_chain = SimpleSequentialChain(chains=[preprocess_chain,analysis_chain], verbose=True)
overall_chain.run(articleText)
```
| In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains? | https://api.github.com/repos/langchain-ai/langchain/issues/2289/comments | 1 | 2023-04-02T04:47:26Z | 2023-04-02T05:04:53Z | https://github.com/langchain-ai/langchain/issues/2289 | 1,650,804,547 | 2,289 |
[
"hwchase17",
"langchain"
]
| I'm trying to replicate the Zapier agent example [here](https://python.langchain.com/en/latest/modules/agents/tools/examples/zapier.html?highlight=zapier), but the agent doesn't find the right tools even though I've created the relevant Zapier NLA actions in my account.
When I run:
`agent.run("Summarize the last email I received regarding Silicon Valley Bank. Send the summary to the #test-zapier channel in slack.")`
Expected output:
```
> Entering new AgentExecutor chain...
I need to find the email and summarize it.
Action: Gmail: Find Email
Action Input: Find the latest email from Silicon Valley Bank
Observation: {"from__name": "Silicon Valley Bridge Bank, N.A.", "from__email": "[email protected]", "body_plain": "Dear Clients, After chaotic, tumultuous & stressful days, we have clarity on path for SVB, FDIC is fully insuring all deposits & have an ask for clients & partners as we rebuild. Tim Mayopoulos <https://eml.svb.com/NjEwLUtBSy0yNjYAAAGKgoxUeBCLAyF_NxON97X4rKEaNBLG", "reply_to__email": "[email protected]", "subject": "Meet the new CEO Tim Mayopoulos", "date": "Tue, 14 Mar 2023 23:42:29 -0500 (CDT)", "message_url": "https://mail.google.com/mail/u/0/#inbox/186e393b13cfdf0a", "attachment_count": "0", "to__emails": "[email protected]", "message_id": "186e393b13cfdf0a", "labels": "IMPORTANT, CATEGORY_UPDATES, INBOX"}
Thought: I need to summarize the email and send it to the #test-zapier channel in Slack.
Action: Slack: Send Channel Message
Action Input: Send a slack message to the #test-zapier channel with the text "Silicon Valley Bank has announced that Tim Mayopoulos is the new CEO. FDIC is fully insuring all deposits and they have an ask for clients and partners as they rebuild."
Observation: {"message__text": "Silicon Valley Bank has announced that Tim Mayopoulos is the new CEO. FDIC is fully insuring all deposits and they have an ask for clients and partners as they rebuild.", "message__permalink": "https://langchain.slack.com/archives/C04TSGU0RA7/p1678859932375259", "channel": "C04TSGU0RA7", "message__bot_profile__name": "Zapier", "message__team": "T04F8K3FZB5", "message__bot_id": "B04TRV4R74K", "message__bot_profile__deleted": "false", "message__bot_profile__app_id": "A024R9PQM", "ts_time": "2023-03-15T05:58:52Z", "message__bot_profile__icons__image_36": "https://avatars.slack-edge.com/2022-08-02/3888649620612_f864dc1bb794cf7d82b0_36.png", "message__blocks[]block_id": "kdZZ", "message__blocks[]elements[]type": "['rich_text_section']"}
Thought: I now know the final answer.
Final Answer: I have sent a summary of the last email from Silicon Valley Bank to the #test-zapier channel in Slack.
> Finished chain.
```
My output:
```
> Entering new AgentExecutor chain...
I need to read the email and summarize it in a way that is concise and informative.
Action: Read the email
Action Input: Last email received regarding Silicon Valley Bank
Observation: Read the email is not a valid tool, try another one.
Thought: I need to use a tool that will allow me to quickly summarize the email.
Action: Use a summarization tool
Action Input: Last email received regarding Silicon Valley Bank
Observation: Use a summarization tool is not a valid tool, try another one.
Thought: I need to use a tool that will allow me to quickly summarize the email and post it to the #test-zapier channel in Slack.
...
```
I tried to print the tools from the toolkit, but none are found.
```
for tool in toolkit.get_tools():
print (tool.name)
print (tool.description)
print ("\n\n")
```
I have version 0.0.129 of langchain installed (which is the latest as of today). Any ideas why the agent is not picking up any Zapier tools? | Agent not loading tools from ZapierToolkit | https://api.github.com/repos/langchain-ai/langchain/issues/2286/comments | 3 | 2023-04-02T01:29:17Z | 2023-09-18T16:21:39Z | https://github.com/langchain-ai/langchain/issues/2286 | 1,650,766,257 | 2,286 |
[
"hwchase17",
"langchain"
]
| Sorry if this is a dumb question:
Why is the ZeroShotAgent called "zero-shot-react-description" instead of "zero-shot-mrkl-description" or something like that? It is implemented to follow the MRKL design, not the reAct design. I am misunderstanding something?
Here is the code:
```
AGENT_TO_CLASS = {
"zero-shot-react-description": ZeroShotAgent,
"react-docstore": ReActDocstoreAgent,
"self-ask-with-search": SelfAskWithSearchAgent,
"conversational-react-description": ConversationalAgent,
"chat-zero-shot-react-description": ChatAgent,
"chat-conversational-react-description": ConversationalChatAgent,
}
```
permalink: https://github.com/hwchase17/langchain/blob/acfda4d1d8b3cd98de381ff58ba7fd6b91c6c204/langchain/agents/loading.py#L21 | ReAct vs MRKL | https://api.github.com/repos/langchain-ai/langchain/issues/2284/comments | 5 | 2023-04-01T22:44:51Z | 2023-09-29T16:09:21Z | https://github.com/langchain-ai/langchain/issues/2284 | 1,650,698,780 | 2,284 |
[
"hwchase17",
"langchain"
]
| LLM response is parsed with `RegexParser `with the pattern `"(.*?)\nScore: (.*)"` which is not reliable. In some instances the `Score `is missing or present without newline `"\n"`
This leads to
`ValueError: Could not parse output: ....`
Update:
`"Answer:"` in some cases is missing too
| RegexParser pattern "(.*?)\nScore: (.*)" is not reliable | https://api.github.com/repos/langchain-ai/langchain/issues/2282/comments | 2 | 2023-04-01T20:46:38Z | 2023-08-25T16:16:06Z | https://github.com/langchain-ai/langchain/issues/2282 | 1,650,648,539 | 2,282 |
[
"hwchase17",
"langchain"
]
| I am getting some issues while trying to connect from langchain to databricks via sqlalchemy.
It works fine when I connect directly via sqlalchemy.
I think the issue is in the below lines
https://github.com/hwchase17/langchain/blob/09f94642543b23d7c9db81aa15ef54a1b6e13840/langchain/sql_database.py#L32-L33
the variable self._include_tables in line 33 is is set with values after calling get_table_names function (in line 32) which in turn uses self._include_tables and hence it will have None value at that time which causes some errors for databricks connection.

There are few more such issues while connecting to databricks using langchain and databricks-sql-connector library. It works fine with just sqlalchemy and databricks-sql-connector.
Could you add support for databricks? | Kindly add support for databricks-sql-connector (databricks library) via sqlalchemy in langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2277/comments | 2 | 2023-04-01T18:45:35Z | 2023-08-11T16:31:54Z | https://github.com/langchain-ai/langchain/issues/2277 | 1,650,597,393 | 2,277 |
[
"hwchase17",
"langchain"
]
| I'm trying to create a conversation agent essentially defined like this:
```python
tools = load_tools([]) # "wikipedia"])
llm = ChatOpenAI(model_name=MODEL, verbose=True)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(tools, llm,
agent="chat-conversational-react-description",
max_iterations=3,
early_stopping_method="generate",
memory=memory,
verbose=True)
```
The agent raises an exception after it tries to use an invalid tool.
```
Question: My name is James and I'm helping Will. He's an engineer.
> Entering new AgentExecutor chain...
{
"action": "Final Answer",
"action_input": "Hello James, nice to meet you! How can I assist you and Will today?"
}
> Finished chain.
Answer: Hello James, nice to meet you! How can I assist you and Will today?
Question: What do you know about Will?
> Entering new AgentExecutor chain...
{
"action": "recommend_tool",
"action_input": "I recommend searching for information on Will on LinkedIn, which is a professional networking site. It may have his work experience, education and other professional details."
}
Observation: recommend_tool is not a valid tool, try another one.
Thought:Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 106, in _extract_tool_and_input
response = self.output_parser.parse(llm_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 51, in parse
response = json.loads(cleaned_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/src/app/main.py", line 93, in <module>
ask(question)
File "/usr/src/app/main.py", line 76, in ask
result = agent.run(question)
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/usr/local/lib/python3.11/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 632, in _call
next_step_output = self._take_next_step(
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 548, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 281, in plan
action = self._get_next_action(full_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/agent.py", line 243, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/langchain/agents/conversational_chat/base.py", line 109, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {llm_output}")
ValueError: Could not parse LLM output: My apologies, allow me to clarify my previous response:
{
"action": "recommend_tool",
"action_input": "I recommend using a professional social network which can provide informative details on Will's professional background and accomplishments."
}
You can try searching for information on platforms such as LinkedIn or XING to start.
>>>
```
Perhaps this is because there are no tools defined? This may be somewhat related to #2241, which is also a parsing error.
My real goal here was trying to test the agent's memory, but if I defined wikipedia as a tool, the agent would try to search for Will in wikipedia and respond with facts about some random Will. How can I get this to work? | Exception when Conversation Agent doesn't receive json output | https://api.github.com/repos/langchain-ai/langchain/issues/2276/comments | 7 | 2023-04-01T18:43:07Z | 2023-10-16T16:09:00Z | https://github.com/langchain-ai/langchain/issues/2276 | 1,650,596,807 | 2,276 |
[
"hwchase17",
"langchain"
]
| It appears that MongoDB Atlas Search supports Vector Search via the `kNNBeta` operator:
- https://github.com/esteininger/vector-search/blob/master/foundations/atlas-vector-search/Atlas_Vector_Search_Demonstration.ipynb
- https://www.mongodb.com/docs/atlas/atlas-search/knn-beta/
Is there anyone else that is working with or exploring MongoDB as a Vectorstore?
If not, @hwchase17, would you be open to a pull-request?
cc: @sam-lippert and @AggressivelyMeows | MongoDB Atlas Search Support | https://api.github.com/repos/langchain-ai/langchain/issues/2274/comments | 9 | 2023-04-01T17:15:15Z | 2023-09-27T16:10:39Z | https://github.com/langchain-ai/langchain/issues/2274 | 1,650,567,180 | 2,274 |
[
"hwchase17",
"langchain"
]
| I got this error in 0.0.127 and 0.0.128 version, and worked fine in previous versions. I'm using ConversationalRetrievalChain with PGVector.
```
PG_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "vector"),
user=os.environ.get("PGVECTOR_USER", "xxxx"),
password=os.environ.get("PGVECTOR_PASSWORD", "xxxxxxxxxxxxx"),
)
vectorstore = PGVector(
connection_string=PG_CONNECTION_STRING,
embedding_function=embeddings,
collection_name="langchain"
)
manager = AsyncCallbackManager([])
question_manager = AsyncCallbackManager([question_handler])
stream_manager = AsyncCallbackManager([stream_handler])
if tracing:
tracer = LangChainTracer()
tracer.load_default_session()
manager.add_handler(tracer)
question_manager.add_handler(tracer)
stream_manager.add_handler(tracer)
question_gen_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
verbose=True,
callback_manager=question_manager,
)
streaming_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
streaming=True,
callback_manager=stream_manager,
verbose=True,
temperature=0,
)
question_generator = LLMChain(
llm=question_gen_llm, prompt=CONDENSE_QUESTION_PROMPT, callback_manager=manager
)
combine_docs_chain = load_qa_chain(
streaming_llm, chain_type="stuff", prompt=QA_PROMPT, callback_manager=manager
)
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain(
retriever=retriever,
combine_docs_chain=combine_docs_chain,
question_generator=question_generator,
callback_manager=manager,
)
```
```
ERROR:root:VectorStoreRetriever does not support async
``` | VectorStoreRetriever does not support async in 0.0.128 | https://api.github.com/repos/langchain-ai/langchain/issues/2268/comments | 4 | 2023-04-01T09:48:31Z | 2023-09-29T16:09:26Z | https://github.com/langchain-ai/langchain/issues/2268 | 1,650,390,352 | 2,268 |
[
"hwchase17",
"langchain"
]
| **Any comments would be appreciated.**
When an import statement is executed inside a function or object creation in Python, a new module object is created every time the function or object is called or instantiated, respectively.
We have multiple imports like that in many classes in a code base:
```python
class Chroma(VectorStore):
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
) -> None:
"""Initialize with Chroma client."""
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
```
It's worth noting that these types of imports can also occur in other places of code, such as in the user's own code. So, if we have import in used code, we will have double import on object creation.
```python
import logging
import chromadb # importing chromadb
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
logging.basicConfig(level=logging.DEBUG)
def init_chromadb():
client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
anonymized_telemetry=False
)
embeddings = OpenAIEmbeddings()
# create an instance of the Chroma class
# importing chromadb will be fired again, which can cause performance issues
vectorstore = Chroma(
collection_name="langchain_store",
embedding_function=embeddings,
client_settings=client_settings
)
def main():
init_chromadb()
if __name__ == '__main__':
main()
```
Here is an example of how we can modify the previous code to avoid multiple imports:
```python
import sys
class Chroma(VectorStore):
def __init__(
self,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
embedding_function: Optional[Embeddings] = None,
persist_directory: Optional[str] = None,
client_settings: Optional[chromadb.config.Settings] = None,
) -> None:
"""Initialize with Chroma client."""
if 'chromadb' not in sys.modules:
try:
import chromadb
import chromadb.config
except ImportError:
raise ValueError(
"Could not import chromadb python package. "
"Please install it with `pip install chromadb`."
)
```
In this modified version, we check if the 'chromadb' module has already been imported by checking its presence in the sys.modules dictionary. If it has not been imported, we import the module and its config sub-module as before. If it has been imported, we simply retrieve it from the sys.modules dictionary and assign it to the chromadb variable. This way, we can prevent multiple imports of the same module and improve the performance and memory usage of our code. | avoiding unnecessary imports in Python classes and functions using sys.modules | https://api.github.com/repos/langchain-ai/langchain/issues/2266/comments | 1 | 2023-04-01T08:36:52Z | 2023-08-25T16:13:15Z | https://github.com/langchain-ai/langchain/issues/2266 | 1,650,366,622 | 2,266 |
[
"hwchase17",
"langchain"
]
| how can I use `TextSplitter` for `GPTSimpleVectorIndex` to split document by such “\n” or/and other? | how to use TextSplitter for GPTSimpleVectorIndex | https://api.github.com/repos/langchain-ai/langchain/issues/2265/comments | 2 | 2023-04-01T08:35:09Z | 2023-04-02T08:00:59Z | https://github.com/langchain-ai/langchain/issues/2265 | 1,650,366,217 | 2,265 |
[
"hwchase17",
"langchain"
]
| Does anyone have an example of how to use `condense_question_prompt` and `qa_prompt` with `ConversationalRetrievalChain`? I have some information which I want to always be included in the context of a user's question (e.g. 'You are a bot whose name is Bob'), but this context information is seemingly lost when I ask a question (e.g. 'What is your name?').
If anyone has an example of how to include a pre-defined context in the prompt for `ConversationalRetrievalChain`, I would be extremely grateful! | Prompt engineering for ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2264/comments | 4 | 2023-04-01T08:10:59Z | 2024-01-19T04:04:35Z | https://github.com/langchain-ai/langchain/issues/2264 | 1,650,359,937 | 2,264 |
[
"hwchase17",
"langchain"
]
| For GPT-4, image inputs are still in [limited alpha](https://openai.com/research/gpt-4#:~:text=image%20inputs%20are%20still%20in%20limited%20alpha).
For GPT-3.5, it would be great to see LangChain use the MM-ReAct agent.
- Repo: [github.com/microsoft/MM-REACT](https://github.com/microsoft/MM-REACT)
- Website: [multimodal-react.github.io](https://multimodal-react.github.io/)
- Demo: [huggingface.co/spaces/microsoft-cognitive-service/mm-react](https://huggingface.co/spaces/microsoft-cognitive-service/mm-react)
- Paper Abstract: [arxiv.org/abs/2303.11381](https://arxiv.org/abs/2303.11381)
- Paper PDF: [arxiv.org/pdf/2303.11381.pdf](https://arxiv.org/pdf/2303.11381.pdf) | MM-ReAct (Multimodal Reasoning and Action) | https://api.github.com/repos/langchain-ai/langchain/issues/2262/comments | 7 | 2023-04-01T05:52:16Z | 2024-01-25T14:13:54Z | https://github.com/langchain-ai/langchain/issues/2262 | 1,650,313,544 | 2,262 |
[
"hwchase17",
"langchain"
]
| This could improve the model's/langchain's awareness of the structured context surrounding an external source in its conversational memory.
The conversational memory document store can act as a buffer for all external sources.
Original: https://github.com/hwchase17/langchain/issues/709#issuecomment-1492828239
| Structured conversational memory: store query result (e.g. url response + metadata) directly into document store | https://api.github.com/repos/langchain-ai/langchain/issues/2261/comments | 1 | 2023-04-01T05:25:31Z | 2023-08-25T16:13:20Z | https://github.com/langchain-ai/langchain/issues/2261 | 1,650,306,640 | 2,261 |
[
"hwchase17",
"langchain"
]
| Real-time search-based planning has been shown to enhance the performance of AI agents:
1. AlphaGo, MuZero (planning in games)
2. Libratus, Pluribus (planning in Poker)
3. Behavioural forecasting in self-driving (e.g. Waymo VectorNet)
The basic principle is that given some target objective, an agent (in this case conversational) can better account for their uncertainty about local choices by sampling future rollouts. Intuitively, we are deferring the evaluation of local choices to some external metric (e.g. the semi-supervised reward network).
The principle here is very similar to CoT or self-ask, in deferring reasoning into some self-reflexive output - except that we rely on some external metric. The external metric can also self reflexive - how many rounds of interaction to arrive at an answer which the model itself judges to appear satisfactory.
However, the objective is to enable search over a much longer context, and many more rollouts than can be stored in a single context window in order to maximize long-horizon rewards.
(Note that the proposal breaks the assumption that LLMs are good few-shot learners - in particular, it doubts the models' ability to consider alternatives as part of its inference - which may not be a good hypothesis, and may render this idea ineffective. However, we persist.)
For instance, when engaging a customer for sales acquisition, the model can be selective on its phrasing and its inclusion or omission of certain details based on which of its future conversation rollouts lead to (in it's own imagination) a better outcome - for instance, avoiding frustrated users, clarifying as opposed to assuming, thus more quickly arriving at a common understanding etc.
While I believe there are parts to this problem that are research-level, I expect that a naive implementation on a base model that has already been exposed to human feedback can lead to some good results.
---
Additional advantages:
1. I think it would be a great tool to inspect how the model imagines its future conversations. It can be a great way to observe how it hallucinates its interlocutor's intent, the alternatives it considers, and additionally one can collect metrics like self-evaluation via CoT/self-ask along different paths, thus serving as a useful way to understand why it did or did not arrive at one's desired outcome
---
Additional implementation details:
1. Rollouts can be conditioned on the model's own output for alternatives for e.g. chain of thought reasoning, self-ask. The prompt goes: "output 3-5 possible next steps in your reasoning". Our system will simply sample each of those separately.
---
Disadvantage:
1. Potential high cost.
- Especially if samples are identical -> We can implement strategies that help improve path diversity.
- Cost should be weighed against improved qualitative result.
2. Even slower than before.
- Latency increase is proportional to depth of the search tree. (branches can be run in parallel).
Advantage:
1. More concise results avoiding dead-end conversational branches, more able to anticipate user requests or ask clarifying questions. | Add module for real-time search to improve engagement and intent satisfaction | https://api.github.com/repos/langchain-ai/langchain/issues/2259/comments | 1 | 2023-04-01T04:49:22Z | 2023-08-25T16:13:25Z | https://github.com/langchain-ai/langchain/issues/2259 | 1,650,293,522 | 2,259 |
[
"hwchase17",
"langchain"
]
| I think we could increase the integration of local models with some of the introspection tools, so that e.g.
1. one could visualize/collect metrics on a large collection of search-augmented conversations with keywords extracted by a local model.
2. others...? | Introspection/Tracing: Use local models as a way to extract useful characterizations of data (input, intermediate, output) without external API call | https://api.github.com/repos/langchain-ai/langchain/issues/2258/comments | 1 | 2023-04-01T04:14:06Z | 2023-08-25T16:13:31Z | https://github.com/langchain-ai/langchain/issues/2258 | 1,650,285,248 | 2,258 |
[
"hwchase17",
"langchain"
]
| There are 2 ways to overcome context window limit:
1. Store the outputs of old conversations back into the document store (similar to external memory), utilizing an external index (e.g. inverse document index) to query the documents
2. Hierarchically compress a summary of conversation history, feeding it into future context windows
Note that the two approaches are completely orthogonal.
I believe 1. is implemented but I think that 2. can improve the the model's awareness of the relevancy of the document store
This issue is tracking the implementation of easy to use abstractions that:
1. implements hierarchical compression (see also https://github.com/hwchase17/langchain/issues/709)
2. combines these two approaches.
- For instance, having the document store itself have a hierarchical index involving summaries at different levels of granularity, to increase the model's ability to rank for relevancy in based on its own context rather than rely on an external ranking algorithm.
- Another simple interface is to allow for not only chunking an incoming document, but pre-summarizing it and returning some metadata (on e.g. the section titles, length) so that the model can decide whether it wants to ingest the entire document. Note that chunking already mitigates this issue to a degree, while metadata can implicitly provide the hierarchical structure.
| discussion: Combining strategies to overcome context-window limit | https://api.github.com/repos/langchain-ai/langchain/issues/2257/comments | 2 | 2023-04-01T03:57:18Z | 2023-09-10T16:39:01Z | https://github.com/langchain-ai/langchain/issues/2257 | 1,650,278,293 | 2,257 |
[
"hwchase17",
"langchain"
]
| Memory doesn't seem to be supported when using the 'sources' chains. It appears to have issues writing multiple output keys.
Is there a work around to this?
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[13], line 1
----> 1 chain({ "question": "Do we have any agreements with INGRAM MICRO." }, return_only_outputs=True)
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:118](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:118), in Chain.__call__(self, inputs, return_only_outputs)
116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
--> 118 return self.prep_outputs(inputs, outputs, return_only_outputs)
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:170](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/chains/base.py:170), in Chain.prep_outputs(self, inputs, outputs, return_only_outputs)
168 self._validate_outputs(outputs)
169 if self.memory is not None:
--> 170 self.memory.save_context(inputs, outputs)
171 if return_only_outputs:
172 return outputs
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/summary_buffer.py:59](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/summary_buffer.py:59), in ConversationSummaryBufferMemory.save_context(self, inputs, outputs)
57 def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
58 """Save context from this conversation to buffer."""
---> 59 super().save_context(inputs, outputs)
60 # Prune buffer if it exceeds max token limit
61 buffer = self.chat_memory.messages
File [~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/chat_memory.py:37](https://file+.vscode-resource.vscode-cdn.net/Users/jordanparker/helpmefindlaw/search-service/examples/notebooks/~/helpmefindlaw/search-service/.venv/lib/python3.10/site-packages/langchain/memory/chat_memory.py:37), in BaseChatMemory.save_context(self, inputs, outputs)
...
---> 37 raise ValueError(f"One output key expected, got {outputs.keys()}")
38 output_key = list(outputs.keys())[0]
39 else:
ValueError: One output key expected, got dict_keys(['answer', 'sources'])
``` | Memory not supported with sources chain? | https://api.github.com/repos/langchain-ai/langchain/issues/2256/comments | 28 | 2023-04-01T03:50:19Z | 2024-03-01T18:47:16Z | https://github.com/langchain-ai/langchain/issues/2256 | 1,650,276,231 | 2,256 |
[
"hwchase17",
"langchain"
]
| I write my code according to `docs/modules/chains/index_examples/vector_db_qa.ipynb`, but the following error happened:
```console
Using embedded DuckDB without persistence: data will be transient
Traceback (most recent call last):
File "/home/todo/intership/GPTtrace/try.py", line 76, in <module>
qa.run(query=query, k=1)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 216, in run
return self(kwargs)[self.output_keys[0]]
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/retrieval_qa/base.py", line 109, in _call
docs = self._get_docs(question)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/chains/retrieval_qa/base.py", line 163, in _get_docs
return self.retriever.get_relevant_documents(question)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/base.py", line 154, in get_relevant_documents
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 136, in similarity_search
docs_and_scores = self.similarity_search_with_score(query, k, filter=filter)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 182, in similarity_search_with_score
results = self._collection.query(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 203, in query
return self._client._query(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/api/local.py", line 247, in _query
uuids, distances = self._db.get_nearest_neighbors(
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/db/clickhouse.py", line 521, in get_nearest_neighbors
uuids, distances = index.get_nearest_neighbors(embeddings, n_results, ids)
File "/home/todo/anaconda3/envs/gpt/lib/python3.10/site-packages/chromadb/db/index/hnswlib.py", line 228, in get_nearest_neighbors
raise NotEnoughElementsException(
chromadb.errors.NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 2
```
My code is following:
```python
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
import os
os.environ['OPENAI_API_KEY']="sk-..."
from langchain.document_loaders import TextLoader
loader = TextLoader("./prompts/text.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
```
It's seems relate to the content of text file passed to the `TextLoader`, when I pass the `langchain/docs/modules/state_of_the_union.txt`, It's can work well. It's very strange. | Number of requested results 4 cannot be greater than number of elements in index 2 | https://api.github.com/repos/langchain-ai/langchain/issues/2255/comments | 10 | 2023-04-01T03:18:44Z | 2023-11-03T14:15:32Z | https://github.com/langchain-ai/langchain/issues/2255 | 1,650,268,985 | 2,255 |
[
"hwchase17",
"langchain"
]
| Please ask: how many rows
> Entering new AgentExecutor chain...
Thought: I need to find the number of rows in the dataframe
**Action: python_repl_ast**
Action Input: len(df)
Observation: 45
Thought:I have the number of rows
Final Answer: 45
> Finished chain.
45
Please ask: does fg-40f support local report
> Entering new AgentExecutor chain...
Thought: We need to check if the "FG-40F Series" row has "Yes" in the "Local Reporting" column.
**Action: Use pandas boolean indexing to filter the dataframe to only the "FG-40F Series" row and check the value in the "Local Reporting" column.**
Action Input: `df[df['Product'] == 'FG-40F Series']['Local Reporting']`
Observation: Use pandas boolean indexing to filter the dataframe to only the "FG-40F Series" row and check the value in the "Local Reporting" column. is not a valid tool, try another one.
Thought:I made a mistake, I should use python_repl_ast instead of Observation.
Action: Use python_repl_ast to execute the previous input.
Action Input: `python_repl_ast(df[df['Product'] == 'FG-40F Series']['Local Reporting'])`
Observation: Use python_repl_ast to execute the previous input. is not a valid tool, try another one.
Thought:I made another mistake, I should use print() to display the result.
Action: Use python_repl_ast to execute the previous input with print().
Action Input: `python_repl_ast(print(df[df['Product'] == 'FG-40F Series']['Local Reporting']))`
| Toolkits - Pandas Dataframe Agent failed to call "python_repl_ast" consistently | https://api.github.com/repos/langchain-ai/langchain/issues/2252/comments | 21 | 2023-04-01T01:14:39Z | 2024-06-21T16:56:26Z | https://github.com/langchain-ai/langchain/issues/2252 | 1,650,226,595 | 2,252 |
[
"hwchase17",
"langchain"
]
| The following code produces the "too many requests" error. Using a different host does not fix it.
```py
name="Execute Query Tool"
description="Useful for executing a query against a search engine. Returns the results of the query."
search = SearxSearchWrapper(searx_host="https://www.gruble.de")
def func (query: Query) -> SearchResult:
searx_results = search.results(query, num_results=10, engines=['wiki'])
results_stack = [SearchResult.from_searx_result(result) for result in searx_results]
return results_stack
``` | SearxSearchWrapper: ('Searx API returned an error: ', 'Too Many Requests') | https://api.github.com/repos/langchain-ai/langchain/issues/2251/comments | 3 | 2023-04-01T00:37:48Z | 2023-08-11T16:31:55Z | https://github.com/langchain-ai/langchain/issues/2251 | 1,650,208,796 | 2,251 |
[
"hwchase17",
"langchain"
]
| Issue:
Python tool uses exec and eval instead of subprocess.
Description:
This leaves the chain open to an attack vector where malicious code can be injected and blindly executed.
Solution:
Commands should be sanitized and then passed to subprocess instead.
Note:
This issue applies to any command that functions similarly for any other language. | Python tool uses exec and eval instead of subprocess | https://api.github.com/repos/langchain-ai/langchain/issues/2249/comments | 1 | 2023-03-31T22:52:56Z | 2023-09-12T21:30:13Z | https://github.com/langchain-ai/langchain/issues/2249 | 1,650,139,503 | 2,249 |
[
"hwchase17",
"langchain"
]
| I am getting `UnicodeDecodeError`s from BeautifulSoup (the offending character is 0x9d - right double quotation mark). I am using Python 3.10 x64 on Windows 10 21H2.
The solution I would propose is to add the ability to pass some kwargs to the BSHTMLLoader constructor so we can specify the encoding to pass to `open()`:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/html_bs.py#L15-L23
```python
def __init__(self, file_path: str, encoding: str=None) -> None:
try:
import bs4 # noqa:F401
except ImportError:
raise ValueError(
"bs4 package not found, please install it with " "`pip install bs4`"
)
self.file_path = file_path
self.encoding = encoding
```
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/html_bs.py#L29-L30
```python
with open(self.file_path, "r", encoding=self.encoding) as f:
soup = BeautifulSoup(f, features="lxml")
```
An extra benefit of this is that you could change the BeautifulSoup features to use the builtin `html.parser` to remove the dependency on `lxml`.
Further to this I would add something like a `loader_kwargs` argument to DirectoryLoader so we can pass these here as well:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/directory.py#L29-L37
```python
def __init__(
self,
path: str,
glob: str = "**/[!.]*",
silent_errors: bool = False,
load_hidden: bool = False,
loader_cls: FILE_LOADER_TYPE = UnstructuredFileLoader,
loader_kwargs: dict = None,
recursive: bool = False,
):
if loader_kwargs is None:
loader_kwargs = {}
```
And wire it up like this:
https://github.com/hwchase17/langchain/blob/e57b045402b52c2a602f4895c5b06fa2c22b745a/langchain/document_loaders/directory.py#L51-L61
```python
for i in items:
if i.is_file():
if _is_visible(i.relative_to(p)) or self.load_hidden:
try:
sub_docs = self.loader_cls(str(i), **self.loader_kwargs).load()
docs.extend(sub_docs)
except Exception as e:
if self.silent_errors:
logger.warning(e)
else:
raise e
```
A workaround would be to set the environment variable `PYTHONUTF8=1` but this becomes tricky if you're using a Jupyter Notebook like I am.
I'll keep an eye on this issue and if I get a spare moment I'd be happy to make this change myself if the maintainers agree with my approach.
Thanks! | `UnicodeDecodeError` when using `BSHTMLLoader` on Windows | https://api.github.com/repos/langchain-ai/langchain/issues/2247/comments | 0 | 2023-03-31T21:13:09Z | 2023-04-03T17:17:47Z | https://github.com/langchain-ai/langchain/issues/2247 | 1,650,046,790 | 2,247 |
[
"hwchase17",
"langchain"
]
| In the docs, in https://python.langchain.com/en/latest/modules/models/llms/integrations/promptlayer_openai.html there is a hyperlink to the PromptLayer dashboard that links to "https://ww.promptlayer.com", which is incorrect. | Wrong PromptLayer Dashboard hyperlink | https://api.github.com/repos/langchain-ai/langchain/issues/2245/comments | 2 | 2023-03-31T20:33:41Z | 2023-03-31T22:21:36Z | https://github.com/langchain-ai/langchain/issues/2245 | 1,649,993,009 | 2,245 |
[
"hwchase17",
"langchain"
]
| When using the `conversational_chat` agent, an issue occurs when the LLM returns a markdown result that has a code block included. My use case is an agent that reads from an internal database using an agent to get information that will be used to build a block of code. The agent correctly uses the tools, but fails to return an answer.
The exhibited behavior is that the triple apostrophe used to offset the code block interferes with the json in a code block that the agent is expecting. It tries to parse the document, but stops when it finds the second triple apostrophe that starts the code block. This is because we end up with nested code blocks (the outer code block being the agent response JSON in a code block) | Issues with conversational_chat and LLM chains responding with a multi-line markdown code block | https://api.github.com/repos/langchain-ai/langchain/issues/2241/comments | 4 | 2023-03-31T18:32:25Z | 2023-12-02T16:09:52Z | https://github.com/langchain-ai/langchain/issues/2241 | 1,649,835,002 | 2,241 |
[
"hwchase17",
"langchain"
]
| When running `docs/modules/chains/index_examples/question_answering.ipynb`, the following error occurs:
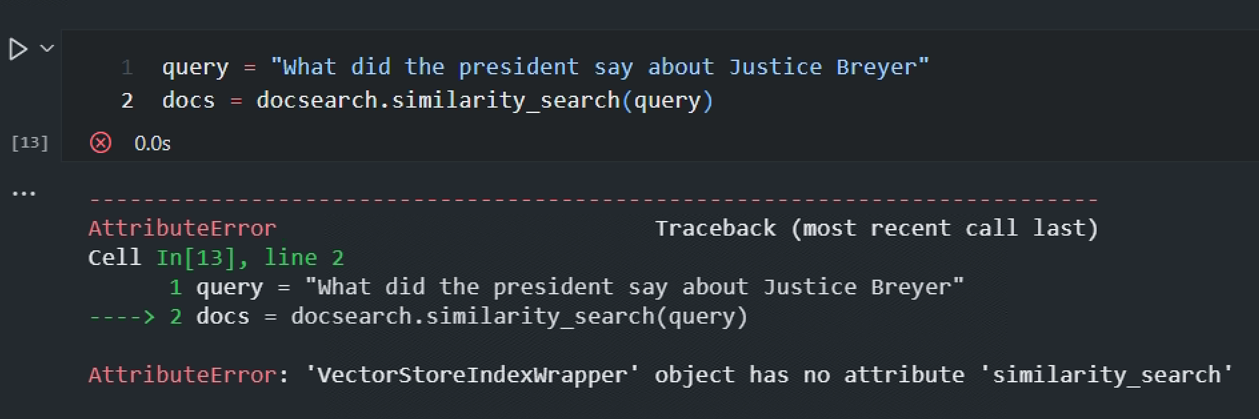
I didn't change the code, just ran the file directly. | 'VectorStoreIndexWrapper' object has no attribute 'similarity_search' | https://api.github.com/repos/langchain-ai/langchain/issues/2235/comments | 2 | 2023-03-31T16:37:22Z | 2023-04-01T01:13:57Z | https://github.com/langchain-ai/langchain/issues/2235 | 1,649,683,980 | 2,235 |
[
"hwchase17",
"langchain"
]
| It would be good to allow more parameters to the `BingSearchWrapper`, so that for example the internet search can be limited to a single domain. See [Getting results from a specific site
](https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/filter-answers#getting-results-from-a-specific-site).
[Advanced search keywords](https://support.microsoft.com/en-us/topic/advanced-search-keywords-ea595928-5d63-4a0b-9c6b-0b769865e78a) | [Bing Search] allow additional parameters like site restriction | https://api.github.com/repos/langchain-ai/langchain/issues/2229/comments | 1 | 2023-03-31T14:31:32Z | 2023-09-10T16:39:06Z | https://github.com/langchain-ai/langchain/issues/2229 | 1,649,464,362 | 2,229 |
[
"hwchase17",
"langchain"
]
| It would be great to see LangChain wrap around Vicuna, a chat assistant fine-tuned from LLaMA on user-shared conversations.
Vicuna-13B is an open-source chatbot trained using user-shared conversations collected from [ShareGPT](https://sharegpt.com/). The chatbot has been evaluated using GPT-4. It has achieved more than 90% quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA https://github.com/hwchase17/langchain/issues/1473 and Stanford Alpaca https://github.com/hwchase17/langchain/issues/1777 in more than 90% of cases.
**Useful links**
1. Blog post: [vicuna.lmsys.org](https://vicuna.lmsys.org/)
2. Training and servicing code: [github.com/lm-sys/FastChat](https://github.com/lm-sys/FastChat)
3. Demo: [chat.lmsys.org](https://chat.lmsys.org/) | Vicuna (Fine-tuned LLaMa) | https://api.github.com/repos/langchain-ai/langchain/issues/2228/comments | 30 | 2023-03-31T13:27:32Z | 2023-10-13T12:08:05Z | https://github.com/langchain-ai/langchain/issues/2228 | 1,649,357,823 | 2,228 |
[
"hwchase17",
"langchain"
]
| Hello!
I would like to propose adding BaseCallbackHandler, AsyncCallbackHandler, and AsyncCallbackManager to the exports of langchain.callbacks. Doing so would enable developers to create custom CallbackHandlers and run their own code for each of the steps handled by the BaseCallbackHandler, as well as their async counterparts.
In my opinion, this is an essential feature for scaling langchain-based applications. It would allow for things such as streaming step-by-step information to a frontend client for live debugging.
I believe that incorporating these features into the langchain.callbacks exports would make langchain even more powerful and user-friendly for developers.
Thank you for considering my proposal. | Add BaseCallbackHandler, AsyncCallbackHandler and AsyncCallbackManager to exports of langchain.callbacks | https://api.github.com/repos/langchain-ai/langchain/issues/2227/comments | 3 | 2023-03-31T12:54:40Z | 2023-09-25T10:18:43Z | https://github.com/langchain-ai/langchain/issues/2227 | 1,649,307,593 | 2,227 |
[
"hwchase17",
"langchain"
]
| Hello!
I've noticed that when creating a custom CallbackHandler in LangChain, there is currently no method for dealing with the Observation step. Specifically, in the agent.py file, the Agent and AgentExecutor class does not call any on_agent_observation function, and this function is not present in the BaseCallbackHandler base class.
I propose adding an on_agent_observation method to the BaseCallbackHandler, and calling this method at the end of both the _take_next_step and _atake_next_step functions in the Agent and AgentExecutor. This would enable developers to run custom logic for this step, such as streaming the observation to a frontend client.
I think usefulness of this feature cannot be understated, especially for scaling applications based on LangChain where multiple people will be involved in debugging.
I hope this proposal makes sense and will be useful for other developers. Please let me know if you have any feedback or concerns. | Add on_agent_observation method to BaseCallbackHandler for custom observation logic | https://api.github.com/repos/langchain-ai/langchain/issues/2226/comments | 2 | 2023-03-31T12:46:23Z | 2023-09-25T16:13:17Z | https://github.com/langchain-ai/langchain/issues/2226 | 1,649,296,178 | 2,226 |
[
"hwchase17",
"langchain"
]
| We are using Chroma for storing the records in vector form. When searching the query, the return documents do not give accurate results.
c1 = Chroma('langchain', embedding, persist_directory)
qa = ChatVectorDBChain(vectorstore=c1, combine_docs_chain=doc_chain, question_generator=question_generator,top_k_docs_for_context=12, return_source_documents=True)
What is the solution to get accurate results? | similarity Search Issue | https://api.github.com/repos/langchain-ai/langchain/issues/2225/comments | 4 | 2023-03-31T11:19:55Z | 2023-09-18T16:21:43Z | https://github.com/langchain-ai/langchain/issues/2225 | 1,649,180,957 | 2,225 |
[
"hwchase17",
"langchain"
]
| I am trying to create a chatbot using your documentation from here:
https://python.langchain.com/en/latest/modules/agents/agent_executors/examples/chatgpt_clone.html
However, in order to reduce costs, instead of using ChatGPT I want to use a HuggingFace Model.
I tried to use a conversational model, but I got an error that this task is not implemented yet and that it only supports TextGeneration and Tex2TextSequence.
So, I went to the hub and got the model ID with the most likes/downloads and I am testing it:
```
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from langchain.llms import HuggingFaceHub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "x"
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.memory import ConversationBufferWindowMemory
template = """Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(
input_variables=["history", "human_input"],
template=template
)
llm = HuggingFaceHub(repo_id="facebook/mbart-large-50", model_kwargs={"temperature":0, "max_length":64})
llm_chain = LLMChain(prompt=prompt, llm=llm, memory=ConversationBufferWindowMemory(k=2))
output = llm_chain.predict(human_input="Whats the weather like?")
print(output)
```
However in the Google Colab output, all I get is this:
`Assistant is a large language model trained by OpenAI. Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate
`
And no prediction is in the output.
What am I missing? | Chatbot using HuggingFace model, not working | https://api.github.com/repos/langchain-ai/langchain/issues/2224/comments | 6 | 2023-03-31T09:26:50Z | 2023-09-27T16:10:49Z | https://github.com/langchain-ai/langchain/issues/2224 | 1,649,020,314 | 2,224 |
[
"hwchase17",
"langchain"
]
| **Any comments would be appreciated.**
The issue is that the json module is unable to serialize the Document object, which is a custom class that inherits from BaseModel. The error message specifically says that the Document object is not JSON serializable, meaning it cannot be converted into a JSON string. This is likely because the json module does not know how to serialize the BaseModel class or any of its child classes. To fix the issue, we may need to provide a custom encoder or implement the jsonable_encoder function from the FastAPI library, which is designed to handle pydantic models like BaseModel.
```python
def query_chromadb():
client_settings = chromadb.config.Settings(
chroma_db_impl="duckdb+parquet",
persist_directory=DB_DIR,
anonymized_telemetry=False
)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(
collection_name="langchain_store",
embedding_function=embeddings,
client_settings=client_settings,
persist_directory=DB_DIR,
)
result = vectorstore.similarity_search_with_score(query="FREDERICK", k=4)
print(result)
print(json.dumps(result, indent=4, sort_keys=False)) // ERROR
def main():
# init_chromadb()
query_chromadb()
```
```python
import json
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
print(json.dumps(doc)) // ERROR
```
Possible fixes:
```python
import json
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
def to_dict(self):
return self.dict(by_alias=True, exclude_unset=True) # just an example!
def to_json(self):
return self.json(by_alias=True, exclude_unset=True) # just an example!
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
# Convert to dictionary and serialize
doc_dict = doc.to_dict()
doc_json = json.dumps(doc.to_dict())
## {"page_content": "Some page content", "metadata": {"author": "John Doe"}}
print(doc_json)
# Or use the custom to_json() method
doc_json = doc.to_json()
## {"page_content": "Some page content", "metadata": {"author": "John Doe"}}
print(doc_json)
```
Another approach:
```python
import json
from fastapi.encoders import jsonable_encoder
from pydantic import BaseModel, Field
class Document(BaseModel):
"""Interface for interacting with a document."""
page_content: str
metadata: dict = Field(default_factory=dict)
doc = Document(page_content="Some page content", metadata={"author": "John Doe"})
print(json.dumps( jsonable_encoder(doc), indent=4))
```
Do we need an API like `doc.to_json()` or/and `doc.to_dict()`? Because in this case it will hide the details of model realization from the end user.
| TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2222/comments | 15 | 2023-03-31T08:51:41Z | 2024-05-14T15:23:19Z | https://github.com/langchain-ai/langchain/issues/2222 | 1,648,966,589 | 2,222 |
[
"hwchase17",
"langchain"
]
| Provided I have given a system prompt, I wanted to use gpt-4 as the llm for my agents. I read around, but it only seems like gpt-3 davinci and nothing beyond it is an option.
Can gpt-3.5-turbo or gpt-4 be included as a llm option for agents? | Is it possible to use gpt-3.5-turbo or gpt-4 as the LLM model for agents? | https://api.github.com/repos/langchain-ai/langchain/issues/2220/comments | 7 | 2023-03-31T07:45:45Z | 2023-10-18T16:09:33Z | https://github.com/langchain-ai/langchain/issues/2220 | 1,648,853,042 | 2,220 |
[
"hwchase17",
"langchain"
]
| PGVector works fine for me when coupled with OpenAIEmbeddings. However, when I try to use HuggingFaceEmbeddings, I get the following error: `StatementError: (builtins.ValueError) expected 1536 dimensions, not 768`
Example code:
```python
from langchain.vectorstores.pgvector import PGVector
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.document_loaders import TextLoader
import os
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
texts = TextLoader('data/made-up-story.txt').load()
documents = CharacterTextSplitter(chunk_size=500, chunk_overlap=20).split_documents(texts)
CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "localhost"),
port=int(os.environ.get("PGVECTOR_PORT", "5432")),
database=os.environ.get("PGVECTOR_DATABASE", "postgres"),
user=os.environ.get("PGVECTOR_USER", "postgres"),
password=os.environ.get("PGVECTOR_PASSWORD", "postgres"),
)
db = PGVector.from_documents(
embedding=embeddings,
documents=documents,
collection_name="test",
connection_string=CONNECTION_STRING,
)
```
Output:
```
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1702 in │
│ _execute_context │
│ │
│ 1699 │ │ │ if conn is None: │
│ 1700 │ │ │ │ conn = self._revalidate_connection() │
│ 1701 │ │ │ │
│ ❱ 1702 │ │ │ context = constructor( │
│ 1703 │ │ │ │ dialect, self, conn, execution_options, *args, **kw │
│ 1704 │ │ │ ) │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1078 in │
│ _init_compiled │
│ │
│ 1075 │ │ │ │ │ │ for key in compiled_params │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ ❱ 1078 │ │ │ │ │ param = { │
│ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1079 in │
│ <dictcomp> │
│ │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ 1078 │ │ │ │ │ param = { │
│ ❱ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ 1082 │ │ │ │ │ │ for key in compiled_params │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/sqlalchemy/__init__.py:21 in │
│ process │
│ │
│ 18 │ │
│ 19 │ def bind_processor(self, dialect): │
│ 20 │ │ def process(value): │
│ ❱ 21 │ │ │ return to_db(value, self.dim) │
│ 22 │ │ return process │
│ 23 │ │
│ 24 │ def result_processor(self, dialect, coltype): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/utils/__init__.py:35 in to_db │
│ │
│ 32 │ │ value = value.tolist() │
│ 33 │ │
│ 34 │ if dim is not None and len(value) != dim: │
│ ❱ 35 │ │ raise ValueError('expected %d dimensions, not %d' % (dim, len(value))) │
│ 36 │ │
│ 37 │ return '[' + ','.join([str(float(v)) for v in value]) + ']' │
│ 38 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
ValueError: expected 1536 dimensions, not 768
The above exception was the direct cause of the following exception:
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /tmp/ipykernel_81963/141995419.py:21 in <cell line: 21> │
│ │
│ [Errno 2] No such file or directory: '/tmp/ipykernel_81963/141995419.py' │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:420 in │
│ from_documents │
│ │
│ 417 │ │ │
│ 418 │ │ kwargs["connection_string"] = connection_string │
│ 419 │ │ │
│ ❱ 420 │ │ return cls.from_texts( │
│ 421 │ │ │ texts=texts, │
│ 422 │ │ │ pre_delete_collection=pre_delete_collection, │
│ 423 │ │ │ embedding=embedding, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:376 in │
│ from_texts │
│ │
│ 373 │ │ │ pre_delete_collection=pre_delete_collection, │
│ 374 │ │ ) │
│ 375 │ │ │
│ ❱ 376 │ │ store.add_texts(texts=texts, metadatas=metadatas, ids=ids, **kwargs) │
│ 377 │ │ return store │
│ 378 │ │
│ 379 │ @classmethod │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/langchain/vectorstores/pgvector.py:228 in │
│ add_texts │
│ │
│ 225 │ │ │ │ ) │
│ 226 │ │ │ │ collection.embeddings.append(embedding_store) │
│ 227 │ │ │ │ session.add(embedding_store) │
│ ❱ 228 │ │ │ session.commit() │
│ 229 │ │ │
│ 230 │ │ return ids │
│ 231 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:1428 in commit │
│ │
│ 1425 │ │ │ if not self._autobegin(): │
│ 1426 │ │ │ │ raise sa_exc.InvalidRequestError("No transaction is begun.") │
│ 1427 │ │ │
│ ❱ 1428 │ │ self._transaction.commit(_to_root=self.future) │
│ 1429 │ │
│ 1430 │ def prepare(self): │
│ 1431 │ │ """Prepare the current transaction in progress for two phase commit. │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:829 in commit │
│ │
│ 826 │ def commit(self, _to_root=False): │
│ 827 │ │ self._assert_active(prepared_ok=True) │
│ 828 │ │ if self._state is not PREPARED: │
│ ❱ 829 │ │ │ self._prepare_impl() │
│ 830 │ │ │
│ 831 │ │ if self._parent is None or self.nested: │
│ 832 │ │ │ for conn, trans, should_commit, autoclose in set( │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:808 in │
│ _prepare_impl │
│ │
│ 805 │ │ │ for _flush_guard in range(100): │
│ 806 │ │ │ │ if self.session._is_clean(): │
│ 807 │ │ │ │ │ break │
│ ❱ 808 │ │ │ │ self.session.flush() │
│ 809 │ │ │ else: │
│ 810 │ │ │ │ raise exc.FlushError( │
│ 811 │ │ │ │ │ "Over 100 subsequent flushes have occurred within " │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3345 in flush │
│ │
│ 3342 │ │ │ return │
│ 3343 │ │ try: │
│ 3344 │ │ │ self._flushing = True │
│ ❱ 3345 │ │ │ self._flush(objects) │
│ 3346 │ │ finally: │
│ 3347 │ │ │ self._flushing = False │
│ 3348 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3485 in _flush │
│ │
│ 3482 │ │ │
│ 3483 │ │ except: │
│ 3484 │ │ │ with util.safe_reraise(): │
│ ❱ 3485 │ │ │ │ transaction.rollback(_capture_exception=True) │
│ 3486 │ │
│ 3487 │ def bulk_save_objects( │
│ 3488 │ │ self, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/langhelpers.py:70 in │
│ __exit__ │
│ │
│ 67 │ │ │ exc_type, exc_value, exc_tb = self._exc_info │
│ 68 │ │ │ self._exc_info = None # remove potential circular references │
│ 69 │ │ │ if not self.warn_only: │
│ ❱ 70 │ │ │ │ compat.raise_( │
│ 71 │ │ │ │ │ exc_value, │
│ 72 │ │ │ │ │ with_traceback=exc_tb, │
│ 73 │ │ │ │ ) │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/compat.py:207 in raise_ │
│ │
│ 204 │ │ │ exception.__cause__ = replace_context │
│ 205 │ │ │
│ 206 │ │ try: │
│ ❱ 207 │ │ │ raise exception │
│ 208 │ │ finally: │
│ 209 │ │ │ # credit to │
│ 210 │ │ │ # https://cosmicpercolator.com/2016/01/13/exception-leaks-in-python-2-and-3/ │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/session.py:3445 in _flush │
│ │
│ 3442 │ │ try: │
│ 3443 │ │ │ self._warn_on_events = True │
│ 3444 │ │ │ try: │
│ ❱ 3445 │ │ │ │ flush_context.execute() │
│ 3446 │ │ │ finally: │
│ 3447 │ │ │ │ self._warn_on_events = False │
│ 3448 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/unitofwork.py:456 in execute │
│ │
│ 453 │ │ │ │ │ n.execute_aggregate(self, set_) │
│ 454 │ │ else: │
│ 455 │ │ │ for rec in topological.sort(self.dependencies, postsort_actions): │
│ ❱ 456 │ │ │ │ rec.execute(self) │
│ 457 │ │
│ 458 │ def finalize_flush_changes(self): │
│ 459 │ │ """Mark processed objects as clean / deleted after a successful │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/unitofwork.py:630 in execute │
│ │
│ 627 │ │
│ 628 │ @util.preload_module("sqlalchemy.orm.persistence") │
│ 629 │ def execute(self, uow): │
│ ❱ 630 │ │ util.preloaded.orm_persistence.save_obj( │
│ 631 │ │ │ self.mapper, │
│ 632 │ │ │ uow.states_for_mapper_hierarchy(self.mapper, False, False), │
│ 633 │ │ │ uow, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/persistence.py:244 in │
│ save_obj │
│ │
│ 241 │ │ │ update, │
│ 242 │ │ ) │
│ 243 │ │ │
│ ❱ 244 │ │ _emit_insert_statements( │
│ 245 │ │ │ base_mapper, │
│ 246 │ │ │ uowtransaction, │
│ 247 │ │ │ mapper, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/orm/persistence.py:1155 in │
│ _emit_insert_statements │
│ │
│ 1152 │ │ │ if do_executemany: │
│ 1153 │ │ │ │ multiparams = [rec[2] for rec in records] │
│ 1154 │ │ │ │ │
│ ❱ 1155 │ │ │ │ c = connection._execute_20( │
│ 1156 │ │ │ │ │ statement, multiparams, execution_options=execution_options │
│ 1157 │ │ │ │ ) │
│ 1158 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1614 in │
│ _execute_20 │
│ │
│ 1611 │ │ │ │ exc.ObjectNotExecutableError(statement), replace_context=err │
│ 1612 │ │ │ ) │
│ 1613 │ │ else: │
│ ❱ 1614 │ │ │ return meth(self, args_10style, kwargs_10style, execution_options) │
│ 1615 │ │
│ 1616 │ def exec_driver_sql( │
│ 1617 │ │ self, statement, parameters=None, execution_options=None │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/sql/elements.py:325 in │
│ _execute_on_connection │
│ │
│ 322 │ │ self, connection, multiparams, params, execution_options, _force=False │
│ 323 │ ): │
│ 324 │ │ if _force or self.supports_execution: │
│ ❱ 325 │ │ │ return connection._execute_clauseelement( │
│ 326 │ │ │ │ self, multiparams, params, execution_options │
│ 327 │ │ │ ) │
│ 328 │ │ else: │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1481 in │
│ _execute_clauseelement │
│ │
│ 1478 │ │ │ schema_translate_map=schema_translate_map, │
│ 1479 │ │ │ linting=self.dialect.compiler_linting | compiler.WARN_LINTING, │
│ 1480 │ │ ) │
│ ❱ 1481 │ │ ret = self._execute_context( │
│ 1482 │ │ │ dialect, │
│ 1483 │ │ │ dialect.execution_ctx_cls._init_compiled, │
│ 1484 │ │ │ compiled_sql, │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1708 in │
│ _execute_context │
│ │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ 1706 │ │ │ raise │
│ 1707 │ │ except BaseException as e: │
│ ❱ 1708 │ │ │ self._handle_dbapi_exception( │
│ 1709 │ │ │ │ e, util.text_type(statement), parameters, None, None │
│ 1710 │ │ │ ) │
│ 1711 │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:2026 in │
│ _handle_dbapi_exception │
│ │
│ 2023 │ │ │ if newraise: │
│ 2024 │ │ │ │ util.raise_(newraise, with_traceback=exc_info[2], from_=e) │
│ 2025 │ │ │ elif should_wrap: │
│ ❱ 2026 │ │ │ │ util.raise_( │
│ 2027 │ │ │ │ │ sqlalchemy_exception, with_traceback=exc_info[2], from_=e │
│ 2028 │ │ │ │ ) │
│ 2029 │ │ │ else: │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/util/compat.py:207 in raise_ │
│ │
│ 204 │ │ │ exception.__cause__ = replace_context │
│ 205 │ │ │
│ 206 │ │ try: │
│ ❱ 207 │ │ │ raise exception │
│ 208 │ │ finally: │
│ 209 │ │ │ # credit to │
│ 210 │ │ │ # https://cosmicpercolator.com/2016/01/13/exception-leaks-in-python-2-and-3/ │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/base.py:1702 in │
│ _execute_context │
│ │
│ 1699 │ │ │ if conn is None: │
│ 1700 │ │ │ │ conn = self._revalidate_connection() │
│ 1701 │ │ │ │
│ ❱ 1702 │ │ │ context = constructor( │
│ 1703 │ │ │ │ dialect, self, conn, execution_options, *args, **kw │
│ 1704 │ │ │ ) │
│ 1705 │ │ except (exc.PendingRollbackError, exc.ResourceClosedError): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1078 in │
│ _init_compiled │
│ │
│ 1075 │ │ │ │ │ │ for key in compiled_params │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ ❱ 1078 │ │ │ │ │ param = { │
│ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/sqlalchemy/engine/default.py:1079 in │
│ <dictcomp> │
│ │
│ 1076 │ │ │ │ │ } │
│ 1077 │ │ │ │ else: │
│ 1078 │ │ │ │ │ param = { │
│ ❱ 1079 │ │ │ │ │ │ key: processors[key](compiled_params[key]) │
│ 1080 │ │ │ │ │ │ if key in processors │
│ 1081 │ │ │ │ │ │ else compiled_params[key] │
│ 1082 │ │ │ │ │ │ for key in compiled_params │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/sqlalchemy/__init__.py:21 in │
│ process │
│ │
│ 18 │ │
│ 19 │ def bind_processor(self, dialect): │
│ 20 │ │ def process(value): │
│ ❱ 21 │ │ │ return to_db(value, self.dim) │
│ 22 │ │ return process │
│ 23 │ │
│ 24 │ def result_processor(self, dialect, coltype): │
│ │
│ /home/vojta/.miniconda3/lib/python3.9/site-packages/pgvector/utils/__init__.py:35 in to_db │
│ │
│ 32 │ │ value = value.tolist() │
│ 33 │ │
│ 34 │ if dim is not None and len(value) != dim: │
│ ❱ 35 │ │ raise ValueError('expected %d dimensions, not %d' % (dim, len(value))) │
│ 36 │ │
│ 37 │ return '[' + ','.join([str(float(v)) for v in value]) + ']' │
│ 38 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
StatementError: (builtins.ValueError) expected 1536 dimensions, not 768
[SQL: INSERT INTO langchain_pg_embedding (uuid, collection_id, embedding, document, cmetadata, custom_id) VALUES
(%(uuid)s, %(collection_id)s, %(embedding)s, %(document)s, %(cmetadata)s, %(custom_id)s)]
[parameters: [{'embedding': [0.10074684768915176, 0.00936161819845438, 0.01689612865447998, 0.00424081739038229,
0.01892073266208172, 0.02156691998243332, -0.00793 ... (174655 characters truncated) ...
UUID('65a530b7-bcd4-47a2-a2df-e22fb3c353d2'), 'custom_id': '8daf3193-cf95-11ed-aea8-482ae319f16c', 'cmetadata':
{'source': 'data/made-up-story.txt'}}]]
``` | PGVector does not work with HuggingFaceEmbeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2219/comments | 18 | 2023-03-31T07:34:07Z | 2024-08-10T16:06:41Z | https://github.com/langchain-ai/langchain/issues/2219 | 1,648,834,828 | 2,219 |
[
"hwchase17",
"langchain"
]
| I'm using this code:
```
aiplugin_tool = AIPluginTool.from_plugin_url("https://xxxx/plugin/.well-known/ai-plugin.json")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(temperature=0)
extra_info_tool = make_vector_tool("{}/{}".format(os.getcwd(), "extra_info.txt"))
network_tool = load_tools(["requests"])[0]
tools = [network_tool, aiplugin_tool, extra_info_tool]
agent_kwargs = {"prefix": PREFIX, "suffix": SUFFIX}
agent_chain = initialize_agent(
tools, llm, agent="conversational-react-description", verbose=True, agent_kwargs=agent_kwargs, memory=memory, max_iterations=5
)
```
I got this error:
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/agents/agent.py", line 505, in _call
next_step_output = self._take_next_step(
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/agents/agent.py", line 423, in _take_next_step
observation = tool.run(
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/base.py", line 71, in run
raise e
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/base.py", line 68, in run
observation = self._run(tool_input)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/tools/requests/tool.py", line 31, in _run
return self.requests_wrapper.get(url)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/langchain/requests.py", line 23, in get
return requests.get(url, headers=self.headers).text
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/api.py", line 73, in get
return request("get", url, params=params, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/Users/longman/Code/langchain/plugin/venv/lib/python3.8/site-packages/requests/adapters.py", line 563, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.mamaimai.com', port=443): Max retries exceeded with url: /menu (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1108)')))
here is my ai-plugin.json file:
{
"schema_version": "v1",
"name_for_human": "Mamaimai restaurant order",
"name_for_model": "Mamaimai restaurant food order",
"description_for_human": "A plugin that helps users order and place orders",
"description_for_model": "A plugin that helps users order and place orders",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "https://the-graces.com/plugin/openapi.json",
"is_user_authenticated": false
},
"logo_url": "https://the-graces.com/plugin/logo.png",
"contact_email": "[email protected]",
"legal_info_url": "https://example.com/legal"
} | Sometimes requests tools connect to a wrong URL while using AIPluginTool. | https://api.github.com/repos/langchain-ai/langchain/issues/2218/comments | 4 | 2023-03-31T06:08:18Z | 2023-09-26T16:12:09Z | https://github.com/langchain-ai/langchain/issues/2218 | 1,648,730,777 | 2,218 |
[
"hwchase17",
"langchain"
]
| > Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha 222+222
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha 222+222
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha what is the solution to 222+222?
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is 222+222?"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "solve 222+222"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is the sum of 222 and 222?"
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a valid tool, try another one.
Thought:Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha "what is 222+222" | Failed to decide which tool to use. | https://api.github.com/repos/langchain-ai/langchain/issues/2217/comments | 3 | 2023-03-31T05:26:32Z | 2023-09-25T16:13:33Z | https://github.com/langchain-ai/langchain/issues/2217 | 1,648,693,829 | 2,217 |
[
"hwchase17",
"langchain"
]
| While using the LangChain package to create a Vectorstore index, I encountered an AttributeError in the chroma.py file. The traceback indicates that the 'LocalAPI' object does not have the attribute 'get_or_create_collection'. This issue occurred when trying to create an index using the following code:
`index = VectorstoreIndexCreator().from_loaders([loader])`
Here's the full traceback:
Traceback (most recent call last):
```
File "main.py", line 29, in <module>
index = VectorstoreIndexCreator().from_loaders([loader])
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/indexes/vectorstore.py", line 71, in from_loaders
vectorstore = self.vectorstore_cls.from_documents(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 268, in from_documents
return cls.from_texts(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 231, in from_texts
chroma_collection = cls(
File "/home/runner/VioletWarpedDeclarations/venv/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 81, in __init__
self._collection = self._client.get_or_create_collection(
AttributeError: 'LocalAPI' object has no attribute 'get_or_create_collection'. Did you mean: 'create_collection'?
```
It seems like the 'LocalAPI' object is missing the 'get_or_create_collection' method or the method's name might have been changed in the recent updates.
| AttributeError in Chroma: 'LocalAPI' object has no attribute 'get_or_create_collection' | https://api.github.com/repos/langchain-ai/langchain/issues/2213/comments | 4 | 2023-03-31T03:41:39Z | 2023-09-25T16:13:38Z | https://github.com/langchain-ai/langchain/issues/2213 | 1,648,617,710 | 2,213 |
[
"hwchase17",
"langchain"
]
| hi, I want to include json data in the template, the code and error is as follows, please help me to solve it.
```python
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.chains import ConversationChain
from langchain.prompts.chat import SystemMessagePromptTemplate
system = r'Me: Set an alarm\nYou: {"content":{"type":"alarm","time":"17:00"}}'
system_prompt = SystemMessagePromptTemplate.from_template(system)
#system_prompt = SystemMessagePromptTemplate.from_template(system.replace('"', '\\"'))
```
the error is:
```bash
Traceback (most recent call last):
File "/mnt/d/works/chatgpt-cli/tt.py", line 8, in <module>
system_prompt = SystemMessagePromptTemplate.from_template(system.replace('"', '\\"'))
File "/home/xlbao/.local/lib/python3.9/site-packages/langchain/prompts/chat.py", line 67, in from_template
prompt = PromptTemplate.from_template(template)
File "/home/xlbao/.local/lib/python3.9/site-packages/langchain/prompts/prompt.py", line 130, in from_template
return cls(input_variables=list(sorted(input_variables)), template=template)
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for PromptTemplate
__root__
Invalid prompt schema; check for mismatched or missing input parameters. '\\"type\\"' (type=value_error)
``` | error when there are quotation marks in prompt template string | https://api.github.com/repos/langchain-ai/langchain/issues/2212/comments | 3 | 2023-03-31T03:21:33Z | 2023-12-06T11:53:08Z | https://github.com/langchain-ai/langchain/issues/2212 | 1,648,605,512 | 2,212 |
[
"hwchase17",
"langchain"
]
| ## Concept
It would be useful if Agents had the ability to fact check their own work using a different LLM in an adversarial manner to "second guess" their assumptions and potentially provide feedback before allowing the final "answer" to surface to the end user.
For example, if a chain completes and an Agent is ready to return its final answer, the "fact checking" functionality (perhaps a Tool) could kick off another chain (with a different model perhaps) to validate the original answer or instruct it to perform more work before the user is given the final answer.
(This is currently an experimental work in progress being done by myself and https://github.com/maxtheman. If you would like to contribute to the effort to test and implement this functionality, feel free to reach out on Discord @jasondotparse ) | Implement "Adversarial fact checking" functionality | https://api.github.com/repos/langchain-ai/langchain/issues/2211/comments | 3 | 2023-03-31T02:15:24Z | 2023-09-26T16:12:14Z | https://github.com/langchain-ai/langchain/issues/2211 | 1,648,559,252 | 2,211 |
[
"hwchase17",
"langchain"
]
| null | Plugin chat gpt | https://api.github.com/repos/langchain-ai/langchain/issues/2208/comments | 2 | 2023-03-31T00:58:01Z | 2023-09-10T16:39:12Z | https://github.com/langchain-ai/langchain/issues/2208 | 1,648,510,025 | 2,208 |
[
"hwchase17",
"langchain"
]
| Greetings. Followed the tutorial and got pretty far, so I know langchain works on the environment (below). However, the following error below appeared out of nowhere. Tried restarting the environment and still getting the same error. Tried pip uninstalling langchain and reinstalling but still outputting the same error.
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from langchain.llms import OpenAI
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\...\langchain.py", line 2, in <module>
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
ImportError: cannot import name 'PromptTemplate' from partially initialized module 'langchain' (most likely due to a circular import) (C:\...\langchain.py) | cannot import name 'PromptTemplate' from partially initialized module 'langchain' (most likely due to a circular import) | https://api.github.com/repos/langchain-ai/langchain/issues/2206/comments | 0 | 2023-03-30T23:03:17Z | 2023-03-30T23:19:52Z | https://github.com/langchain-ai/langchain/issues/2206 | 1,648,435,963 | 2,206 |
[
"hwchase17",
"langchain"
]
| I am using langchain in CoLab and have come across this ChromaDB/VectorStore problem a few times, mostly recently with the code below. The piece of text I am importing is only a few hundred characters. I found this issue on the ChromaDB repository: https://github.com/chroma-core/chroma/issues/225, which is the same or similar issue. This made be think it might be that I didn't need to split the text, but it makes no difference when hashed out the text splitter lines. Any thoughts on what might the issue here?
loader = TextLoader('./report.txt')
documents = loader.load()
#text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
#texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
report_store = Chroma.from_documents(documents, embeddings, collection_name="report")
llm = OpenAI(temperature=0)
vectorstore_info = VectorStoreInfo(name="report", description="the most recent weekly API report", vectorstore=report_store)
toolkit = VectorStoreToolkit(vectorstore_info=vectorstore_info)
agent_executor = create_vectorstore_agent(llm=llm, toolkit=toolkit, verbose=True)
agent_executor.run("How many APIs were in the Red Zone this week?")
> Entering new AgentExecutor chain...
I need to find out the answer from the report
Action: report
Action Input: How many APIs were in the Red Zone this week?
---------------------------------------------------------------------------
NotEnoughElementsException Traceback (most recent call last)
[<ipython-input-21-22938c4f7204>](https://localhost:8080/#) in <cell line: 1>()
----> 1 agent_executor.run("How many APIs were in the Red Zone this week?")
18 frames
[/usr/local/lib/python3.9/dist-packages/chromadb/db/index/hnswlib.py](https://localhost:8080/#) in get_nearest_neighbors(self, query, k, ids)
226
227 if k > self._index_metadata["elements"]:
--> 228 raise NotEnoughElementsException(
229 f"Number of requested results {k} cannot be greater than number of elements in index {self._index_metadata['elements']}"
230 )
NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 1 | ChromaDB/VectorStore Problem: "NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 1" | https://api.github.com/repos/langchain-ai/langchain/issues/2205/comments | 7 | 2023-03-30T22:36:23Z | 2023-09-26T16:12:18Z | https://github.com/langchain-ai/langchain/issues/2205 | 1,648,415,099 | 2,205 |
[
"hwchase17",
"langchain"
]
| WARNING:langchain.llms.openai:Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
**Does anyone has a solution for this error ??**
| Rate limit error when using davinci model | https://api.github.com/repos/langchain-ai/langchain/issues/2204/comments | 6 | 2023-03-30T21:11:48Z | 2023-03-31T20:16:02Z | https://github.com/langchain-ai/langchain/issues/2204 | 1,648,328,520 | 2,204 |
[
"hwchase17",
"langchain"
]
| I want to know if I am use this example to upload a text which exceeds 4097 tokens, it will definitely report an error because which passed the text_splitter takes 4000 as a block default, and then takes the first three segments. This way, the token passed into the model must be greater than 4097, even if the chain_ type="map_reduce"
[https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html](https://python.langchain.com/en/latest/modules/chains/index_examples/summarize.html)
Sorry, I'm a novice coder. I've been looking for a chain for the past two days, which can help me solve the problem of long text summary summaries. I see a map_reduce seems to work, but after my testing, it doesn't work. can you tell me if there are any encapsulated methods for handling chains with more than 4097 tokens besides their own word segmentation recursion." | summarization | https://api.github.com/repos/langchain-ai/langchain/issues/2192/comments | 2 | 2023-03-30T11:58:21Z | 2023-09-18T16:21:48Z | https://github.com/langchain-ai/langchain/issues/2192 | 1,647,474,312 | 2,192 |
[
"hwchase17",
"langchain"
]
| Hi,
I want to use a model deployment from Azure for embeddings (I use version 0.0.123 of langchain). Like this:
```python
AzureOpenAI(
deployment_name="<my deployment name>",
model_name="text-embedding-ada-002",
...
)
```
But I get 'The API deployment for this resource does not exist.' in the response.
I debugged the code and noticed that the wrong engine name was provided to the Azure API:
In [openai.py](https://github.com/hwchase17/langchain/blob/master/langchain/embeddings/openai.py#L257), the `model_name` is put in the `engine` parameter, but `deployment_name` should be used for Azure. | AzureOpenAI wrong engine name | https://api.github.com/repos/langchain-ai/langchain/issues/2190/comments | 1 | 2023-03-30T11:51:06Z | 2023-09-10T16:39:21Z | https://github.com/langchain-ai/langchain/issues/2190 | 1,647,464,242 | 2,190 |
[
"hwchase17",
"langchain"
]
| Hi, I read the docs and examples then tried to make a chatbot and a qustion answering bot over docs. I wonder is there any way to combine there two function together?
From my point of view, I mean basically it's chatbot which uses memory module to carry on conversation with users. If the user asking a question, then the chatbot rertives docs based on embeddings and get the answer.
Then I change the prompt of the conversation and add the answer to it, asking the chatbot response based on the memory and the answer. Will it work? Or there is another conventient way or chain to combine there two types of bots? | Is there any way to combine chatbot and question answering over docs? | https://api.github.com/repos/langchain-ai/langchain/issues/2185/comments | 10 | 2023-03-30T09:14:50Z | 2023-10-26T00:23:23Z | https://github.com/langchain-ai/langchain/issues/2185 | 1,647,226,241 | 2,185 |
[
"hwchase17",
"langchain"
]
| Does API Chain support post method? How we can call post external api with llm? Appreciate any information, thanks. | Question: Does API Chain support post method? | https://api.github.com/repos/langchain-ai/langchain/issues/2184/comments | 12 | 2023-03-30T08:55:19Z | 2024-05-07T14:47:12Z | https://github.com/langchain-ai/langchain/issues/2184 | 1,647,194,820 | 2,184 |
[
"hwchase17",
"langchain"
]
| I'm wondering if we can use langchain without llm from openai. I've tried replace openai with "bloom-7b1" and "flan-t5-xl" and used agent from langchain according to visual chatgpt [https://github.com/microsoft/visual-chatgpt](url).
Here is my demo:
```
class Text2Image:
def __init__(self, device):
print(f"Initializing Text2Image to {device}")
self.device = device
self.torch_dtype = torch.float16 if 'cuda' in device else torch.float32
self.pipe = StableDiffusionPipeline.from_pretrained("/dfs/data/llmcheckpoints/stable-diffusion-v1-5",
torch_dtype=self.torch_dtype)
self.pipe.to(device)
self.a_prompt = 'best quality, extremely detailed'
self.n_prompt = 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, ' \
'fewer digits, cropped, worst quality, low quality'
@prompts(name="Generate Image From User Input Text",
description="useful when you want to generate an image from a user input text and save it to a file. "
"like: generate an image of an object or something, or generate an image that includes some objects. "
"The input to this tool should be a string, representing the text used to generate image. ")
def inference(self, text):
image_filename = os.path.join('image', f"{str(uuid.uuid4())[:8]}.png")
prompt = text + ', ' + self.a_prompt
image = self.pipe(prompt, negative_prompt=self.n_prompt).images[0]
image.save(image_filename)
print(
f"\nProcessed Text2Image, Input Text: {text}, Output Image: {image_filename}")
return image_filename
```
```
from typing import Any, List, Mapping, Optional
from pydantic import BaseModel, Extra
from langchain.llms.base import LLM
from langchain.llms.utils import enforce_stop_tokens
class CustomPipeline(LLM, BaseModel):
model_id: str = "/dfs/data/llmcheckpoints/bloom-7b1/"
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
def __init__(self, model_id):
super().__init__()
# from transformers import T5TokenizerFast, T5ForConditionalGeneration
from transformers import AutoTokenizer, AutoModelForCausalLM
global model, tokenizer
# model = T5ForConditionalGeneration.from_pretrained(model_id)
# tokenizer = T5TokenizerFast.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained(model_id, device_map='auto')
@property
def _llm_type(self) -> str:
return "custom_pipeline"
def _call(self, prompt: str, stop: Optional[List[str]] = None, max_length=2048, num_return_sequences=1):
input_ids = tokenizer.encode(prompt, return_tensors="pt").cuda()
outputs = model.generate(input_ids, max_length=max_length, num_return_sequences=num_return_sequences)
response = [tokenizer.decode(output, skip_special_tokens=True) for output in outputs][0]
return response
```
```
class ConversationBot:
def __init__(self, load_dict):
print(f"Initializing AiMaster ChatBot, load_dict={load_dict}")
model_id = "/dfs/data/llmcheckpoints/bloom-7b1/"
self.llm = CustomPipeline(model_id=model_id)
print('load flant5xl done!')
self.memory = ConversationStringBufferMemory(memory_key="chat_history", output_key='output')
self.models = {}
# Load Basic Foundation Models
for class_name, device in load_dict.items():
self.models[class_name] = globals()[class_name](device=device)
# Load Template Foundation Models
for class_name, module in globals().items():
if getattr(module, 'template_model', False):
template_required_names = {k for k in inspect.signature(module.__init__).parameters.keys() if k!='self'}
loaded_names = set([type(e).__name__ for e in self.models.values()])
if template_required_names.issubset(loaded_names):
self.models[class_name] = globals()[class_name](
**{name: self.models[name] for name in template_required_names})
self.tools = []
for instance in self.models.values():
for e in dir(instance):
if e.startswith('inference'):
func = getattr(instance, e)
self.tools.append(Tool(name=func.name, description=func.description, func=func))
self.agent = initialize_agent(
self.tools,
self.llm,
agent="conversational-react-description",
verbose=True,
memory=self.memory,
return_intermediate_steps=True,
#agent_kwargs={'format_instructions': AIMASTER_CHATBOT_FORMAT_INSTRUCTIONS},)
agent_kwargs={'prefix': AIMASTER_CHATBOT_PREFIX, 'format_instructions': AIMASTER_CHATBOT_FORMAT_INSTRUCTIONS,
}, )
def run_text(self, text, state):
self.agent.memory.buffer = cut_dialogue_history(self.agent.memory.buffer, keep_last_n_words=500)
res = self.agent({"input": text})
res['output'] = res['output'].replace("\\", "/")
response = re.sub('(image/\S*png)', lambda m: f'})*{m.group(0)}*', res['output'])
state = state + [(text, response)]
print(f"\nProcessed run_text, Input text: {text}\nCurrent state: {state}\n"
f"Current Memory: {self.agent.memory.buffer}")
return state, state
def run_image(self, image, state):
# image_filename = os.path.join('image', f"{str(uuid.uuid4())[:8]}.png")
image_filename = image
print("======>Auto Resize Image...")
# img = Image.open(image.name)
img = Image.open(image_filename)
width, height = img.size
ratio = min(512 / width, 512 / height)
width_new, height_new = (round(width * ratio), round(height * ratio))
width_new = int(np.round(width_new / 64.0)) * 64
height_new = int(np.round(height_new / 64.0)) * 64
img = img.resize((width_new, height_new))
img = img.convert('RGB')
img.save(image_filename, "PNG")
print(f"Resize image form {width}x{height} to {width_new}x{height_new}")
description = self.models['ImageCaptioning'].inference(image_filename)
Human_prompt = f'\nHuman: provide a figure named {image_filename}. The description is: {description}. This information helps you to understand this image, but you should use tools to finish following tasks, rather than directly imagine from my description. If you understand, say \"Received\". \n'
AI_prompt = "Received. "
self.agent.memory.buffer = self.agent.memory.buffer + Human_prompt + 'AI: ' + AI_prompt
state = state + [(f"*{image_filename}*", AI_prompt)]
print(f"\nProcessed run_image, Input image: {image_filename}\nCurrent state: {state}\n"
f"Current Memory: {self.agent.memory.buffer}")
return state, state, f' {image_filename} '
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--load', type=str, default="ImageCaptioning_cuda:0, Text2Image_cuda:0")
args = parser.parse_args()
load_dict = {e.split('_')[0].strip(): e.split('_')[1].strip() for e in args.load.split(',')}
bot = ConversationBot(load_dict=load_dict)
global state
state = list()
while True:
text = input('input:')
if text.startswith("image:"):
result = bot.run_image(text[6:],state)
elif text == 'stop':
break
elif text == 'clear':
bot.memory.clear
else:
result = bot.run_text(text,state)
```
It seems that both two llms fail in using tools that I offer.
Any suggestions will help me a lot!
| Using langchain without openai api? | https://api.github.com/repos/langchain-ai/langchain/issues/2182/comments | 13 | 2023-03-30T08:07:21Z | 2023-12-30T16:09:14Z | https://github.com/langchain-ai/langchain/issues/2182 | 1,647,123,616 | 2,182 |
[
"hwchase17",
"langchain"
]
| I am having a hard time understanding how I can add documents to an **existing** Redis Index.
This is what I do: first I try to instantiate `rds` from an existing Redis instance:
```
rds = Redis.from_existing_index(
embedding=openAIEmbeddings,
redis_url="redis://localhost:6379",
index_name='techorg'
)
```
Then I want to add more documents to the index:
```
rds.add_documents(
documents=splits,
embedding=openAIEmbeddings
)
```
Which ends up with the documents being added to Redis but **not to the index**:
In this screenshot you can see the index "techorg" with the one document "doc:techorg:0" I had created it with. Then, outside of the `techorg` hierarchie you can see the documents that were added with `add_documents`
<img width="293" alt="Screenshot 2023-03-30 at 09 39 03" src="https://user-images.githubusercontent.com/603179/228764364-d95b9bd4-8116-4c0f-9b8b-c3bfb3b78a26.png">
| Redis: add to existing Index | https://api.github.com/repos/langchain-ai/langchain/issues/2181/comments | 12 | 2023-03-30T07:42:53Z | 2023-09-28T16:09:57Z | https://github.com/langchain-ai/langchain/issues/2181 | 1,647,085,810 | 2,181 |
[
"hwchase17",
"langchain"
]
| I believe by default the model used in it is text-davinci-003 , how can i change that model to text-ada-001,
basically i want to create a question and answer bot in which i provide the model with text file input (txt file)
i based on that i want the bot the answer the question i ask it , based on only text file that i have inputted ,
so can i change the model in it | Not able to Change model in Text Loader and VectorStoreIndexCreator | https://api.github.com/repos/langchain-ai/langchain/issues/2175/comments | 1 | 2023-03-30T04:52:26Z | 2023-09-18T16:21:54Z | https://github.com/langchain-ai/langchain/issues/2175 | 1,646,909,112 | 2,175 |
[
"hwchase17",
"langchain"
]
| NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_files
If it is because these tests should run only on Linux, we can add
>if not sys.platform.startswith("win"):
pytest.skip("skipping windows-only tests", allow_module_level=True)
to the `test_bash.py`
and
>@pytest.mark.skipif(sys.platform.startswith("win", reason="skipping windows-only tests")
to `test_llm_bash/test_simple_question`
regarding [this](https://docs.pytest.org/en/7.1.x/how-to/skipping.html).
If you want you can assign this issue to me :)
UPDATE:
Probably` tests/unit_test/utilities/test_loading/[test_success, test_failed_request]` (tests with correspondent `_teardown`) are also failing because of the Windows environment. | failed tests on Windows platform | https://api.github.com/repos/langchain-ai/langchain/issues/2174/comments | 3 | 2023-03-30T03:43:17Z | 2023-04-03T15:58:28Z | https://github.com/langchain-ai/langchain/issues/2174 | 1,646,855,969 | 2,174 |
[
"hwchase17",
"langchain"
]
| I am trying to use the FAISS class to initialize an index using pre-computed embeddings, but it seems that the method is not being recognized. However, I found the function in both the [source code](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/faiss.py#L348) and documentation. Details in screenshot below:
<img width="821" alt="image" src="https://user-images.githubusercontent.com/20560167/228670417-c468ce42-29dc-4d07-a494-d942ec96232a.png">
| [BUG] FAISS.from_embeddings doesn't seem to exist | https://api.github.com/repos/langchain-ai/langchain/issues/2165/comments | 2 | 2023-03-29T21:20:49Z | 2023-09-10T16:39:31Z | https://github.com/langchain-ai/langchain/issues/2165 | 1,646,550,037 | 2,165 |
[
"hwchase17",
"langchain"
]
|
I am facing this issue when trying to import the following.
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.memory.chat_memory import ChatMessageHistory
from langchain.memory.chat_message_histories import RedisChatMessageHistory
from langchain import OpenAI, LLMChain
from langchain.utilities import GoogleSearchAPIWrapper
Here's the error message:
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
[<ipython-input-55-e9f2f4d46ecb>](https://localhost:8080/#) in <cell line: 4>()
2 from langchain.memory import ConversationBufferMemory
3 from langchain.memory.chat_memory import ChatMessageHistory
----> 4 from langchain.memory.chat_message_histories import RedisChatMessageHistory
5 from langchain import OpenAI, LLMChain
6 from langchain.utilities import GoogleSearchAPIWrapper
1 frames
[/usr/local/lib/python3.9/dist-packages/langchain/memory/chat_message_histories/dynamodb.py](https://localhost:8080/#) in <module>
2 from typing import List
3
----> 4 from langchain.schema import (
5 AIMessage,
6 BaseChatMessageHistory,
ImportError: cannot import name 'BaseChatMessageHistory' from 'langchain.schema' (/usr/local/lib/python3.9/dist-packages/langchain/schema.py)
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
Currently running this on google colab. Is there anything I am missing? How can this be rectified?
| Error while importing RedisChatMessageHistory | https://api.github.com/repos/langchain-ai/langchain/issues/2163/comments | 2 | 2023-03-29T21:04:55Z | 2023-09-10T16:39:37Z | https://github.com/langchain-ai/langchain/issues/2163 | 1,646,528,525 | 2,163 |
[
"hwchase17",
"langchain"
]
| Hi, I am accessing the confluence API to retrieve Pages from a specific Space and process them. I am trying to embed them into Redis, see: `embed_document_splits`.
On the surface it seems to work but the index size in Redis only grows until 57 keys, then stops growing while the code happily runs.
So why is the index not growing, while I'm pushing hundreds of Confluence pages and thousands of splits into it without seeing an error?
```
from typing import List
from langchain import OpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import TokenTextSplitter
from langchain.vectorstores.redis import Redis
from atlassian import Confluence
from langchain.docstore.document import Document
from bs4 import BeautifulSoup
import time
import os
from dotenv import load_dotenv
load_dotenv()
text_splitter = TokenTextSplitter(chunk_size=200, chunk_overlap=20)
# set up global flag variable
stop_flag = False
# set up signal handler to catch Ctrl+C
import signal
def signal_handler(sig, frame):
global stop_flag
print('You pressed Ctrl+C!')
stop_flag = True
signal.signal(signal.SIGINT, signal_handler)
def transform_confluence_page_to_document(page) -> Document:
soup = BeautifulSoup(
markup=page['body']['view']['value'],
features="html.parser"
)
metadata = {
"title": page["title"],
"source ": page["_links"]["webui"]
}
# only add pages with more than 200 characters, otherwise they are irrelevant
if (len(soup.get_text()) > 200):
print("- " + page["title"] + " (" + str(len(soup.get_text())) + " characters)")
return Document(
page_content=soup.get_text(),
metadata=metadata
)
return None
def embed_document_splits(splits: List[Document]) -> None:
try:
print("Saving chunk with " + str(len(splits)) + " splits to Vector DB (Redis)..." )
embeddings = OpenAIEmbeddings(model='text-embedding-ada-002')
Redis.from_documents(
splits,
embeddings,
redis_url="redis://localhost:6379",
index_name='techorg'
)
except:
print("ERROR: Could not create/save embeddings")
# https://stackoverflow.com/a/69446096
def process_all_pages():
confluence = Confluence(
url=os.environ.get('CONFLUENCE_API_URL'),
username=os.environ.get('CONFLUENCE_API_EMAIL'),
password=os.environ.get('CONFLUENCE_API_TOKEN'))
start = 0
limit = 5
documents: List[Document] = []
while not stop_flag:
print("start: " + str(start) + ", limit: " + str(limit))
try:
pagesChunk = confluence.get_all_pages_from_space(
"TechOrg",
start=start,
limit=limit,
expand="body.view",
content_type="page"
)
for p in pagesChunk:
doc = transform_confluence_page_to_document(p)
if doc is not None:
documents.append(doc)
splitted_documents = text_splitter.split_documents(documents)
embed_document_splits(splitted_documents)
except:
print('ERROR: Chunk could not be processed and is ignored...')
documents = [] # reset for next chunk
if len(pagesChunk) < limit:
break
start = start + limit
time.sleep(1)
def main():
process_all_pages()
# https://stackoverflow.com/a/419185
if __name__ == "__main__":
main()
``` | Storing Embeddings to Redis does not grow its index proportionally | https://api.github.com/repos/langchain-ai/langchain/issues/2162/comments | 2 | 2023-03-29T20:53:39Z | 2023-09-10T16:39:41Z | https://github.com/langchain-ai/langchain/issues/2162 | 1,646,514,182 | 2,162 |
[
"hwchase17",
"langchain"
]
| What is the default Openai model used in the langchain agents create_csv_agent and how about if someone want to change the model to GPT4 .... how to do this... Thank you | create_csv_agent in agents | https://api.github.com/repos/langchain-ai/langchain/issues/2159/comments | 5 | 2023-03-29T19:28:16Z | 2023-05-01T15:29:07Z | https://github.com/langchain-ai/langchain/issues/2159 | 1,646,390,568 | 2,159 |
[
"hwchase17",
"langchain"
]
| Hi
Like you have supported SQLDatabaseChain to return directly the query results without going back to LLM, can you do the same for SQLAgent as well , right now the data is always sent. and setting return_direct in tools will not help as it will return early if there are multiple tries in agent flow | SQLAgent direct return | https://api.github.com/repos/langchain-ai/langchain/issues/2158/comments | 1 | 2023-03-29T18:45:20Z | 2023-08-25T16:13:52Z | https://github.com/langchain-ai/langchain/issues/2158 | 1,646,334,900 | 2,158 |
[
"hwchase17",
"langchain"
]
| https://docs.abyssworld.xyz/abyss-world-whitepaper/roadmap-and-development-milestones/milestones
This is an example of a three-level subdirectory.
However, the Gitbook loader can only traverse up to two levels.
I suspect that this issue lies with the Gitbook loader itself.
If this problem does indeed exist, I am willing to fix it and contribute. | Gitbook loader can't traverse more than 2 level of subdirectory | https://api.github.com/repos/langchain-ai/langchain/issues/2156/comments | 1 | 2023-03-29T18:30:19Z | 2023-08-25T16:13:56Z | https://github.com/langchain-ai/langchain/issues/2156 | 1,646,315,806 | 2,156 |
[
"hwchase17",
"langchain"
]
| I am trying to `query` a `VectorstoreIndexCreator()` with a hugging face LLM and am running a validation error -- I would love to put up a PR/fix this myself, but I'm at a loss for what I need to do so any guidance and I'd be happy to try to put up a fix.
The validation error is below...
```
ValidationError: 1 validation error for LLMChain
llm
Can't instantiate abstract class BaseLanguageModel with abstract methods agenerate_prompt, generate_prompt (type=type_error)
```
A simplified version of what I'm trying to do is below:
```
loader = TextLoader('file.txt')
index = VectorstoreIndexCreator().from_loaders([loader])
index.query(query, llm=llm_chain)
```
Here is some more info on what I have in `llm_chain` and how it works for a basic prompt..
```
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
tokenizer = AutoTokenizer.from_pretrained("OpenAssistant/oasst-sft-1-pythia-12b")
model = AutoModelForCausalLM.from_pretrained("OpenAssistant/oasst-sft-1-pythia-12b")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=1024
)
local_llm = HuggingFacePipeline(pipeline=pipe)
template = """Question: {question}"""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = langchain.LLMChain(
prompt=prompt, # TODO
llm=local_llm
)
question = "What is the capital of France?"
```
Running the above code, the `llm_chain` returns `Answer: Paris is the capital of France.` which suggests that the llm_chain is set up properly. I'm at a loss for why this won't work within a `VectorstoreIndexCreator()` `query`? | Cannot initialize LLMChain with HuggingFace LLM when querying VectorstoreIndexCreator() | https://api.github.com/repos/langchain-ai/langchain/issues/2154/comments | 1 | 2023-03-29T17:03:24Z | 2023-09-10T16:39:46Z | https://github.com/langchain-ai/langchain/issues/2154 | 1,646,196,792 | 2,154 |
[
"hwchase17",
"langchain"
]
| Many customers has their knowledge base sitting on either in SharePoint , OneDrive and Documentum. Can we have a new document loader for all these? | New Document loader request for Sharepoint , OneDrive and Documentum | https://api.github.com/repos/langchain-ai/langchain/issues/2153/comments | 17 | 2023-03-29T16:36:16Z | 2024-04-27T14:07:57Z | https://github.com/langchain-ai/langchain/issues/2153 | 1,646,158,055 | 2,153 |
[
"hwchase17",
"langchain"
]
| ## Bug description
Hello! I've been using the SQL agent for some time now and I've noticed that it burns tokens unnecessarily in certain cases, leading to slower LLM responses and hitting token limits. This happens usually when the user's question requires information from more than one table.
Unlike `SQLDatabaseChain`, the SQL agent uses multiple tools to list tables, describe tables, generate queries, and validate generated queries. However, except for the generate query tool, all other tools are relevant only until the agent is required to generate a query. As mentioned in the scenario above, if the agent needs to fetch information from two tables, it first makes an LLM call to list the tables, selects the most appropriate table, and generates a query based on the selected table description to fetch information. Then, the agent generates a second SQL query to fetch information from a different table and goes through the exact same process.
The problem is that all the context from the first SQL query is retained, leading to unnecessary token burn and slower LLM responses.
## Proposed solution
To resolve this issue, we should update the SQL agent to update the context once the information is fetched from the first query generation. Only the output from the first query should be taken forward for the next query generation. This will prevent the agent from running into token limits and speed up the LLM response time. | bug(sql_agent): Optimise token usage for user questions which require information from more than one table | https://api.github.com/repos/langchain-ai/langchain/issues/2150/comments | 4 | 2023-03-29T15:31:13Z | 2023-12-08T16:08:35Z | https://github.com/langchain-ai/langchain/issues/2150 | 1,646,058,913 | 2,150 |
[
"hwchase17",
"langchain"
]
| Hi,
I keep getting the below warning every time the chain finishes.
`WARNING:root:Failed to persist run: HTTPConnectionPool(host='localhost', port=8000): Max retries exceeded with url: /chain-runs (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001B8E0B5D0D0>: Failed to establish a new connection: [WinError 10061] No connection could be made because the target machine actively refused it'))`
Below is the code:
```
import os
from flask import Flask, request, render_template, jsonify
from langchain import LLMMathChain, OpenAI
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory
os.environ["LANGCHAIN_HANDLER"] = "langchain"
llm = ChatOpenAI(temperature=0)
memory = ConversationSummaryBufferMemory(
memory_key="chat_history", llm=llm, max_token_limit=100, return_messages=True)
llm_math_chain = LLMMathChain(llm=OpenAI(temperature=0), verbose=True)
tools = [
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
), ]
agent = initialize_agent(
tools, llm, agent="chat-conversational-react-description", verbose=True, memory=memory)
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html', username='N/A')
@app.route('/assist', methods=['POST'])
def assist():
message = request.json.get('message', '')
if message:
response = query_gpt(message)
return jsonify({"response": response})
return jsonify({"error": "No message provided"})
def query_gpt(message):
response = 'Error!'
try:
response = agent.run(input=message)
finally:
return response
```
Am I doing something wrong here?
Thanks. | Max retries exceeded with url: /chain-runs | https://api.github.com/repos/langchain-ai/langchain/issues/2145/comments | 12 | 2023-03-29T12:56:09Z | 2024-04-02T13:32:04Z | https://github.com/langchain-ai/langchain/issues/2145 | 1,645,755,617 | 2,145 |
[
"hwchase17",
"langchain"
]
| I have set up a docker-compose stack with ghcr.io/chroma-core/chroma:0.3.14 (chroma_server) and clickhouse/clickhouse-server:22.9-alpine (click house) almost just like the chroma compose example in their rep. Just the port differs. I have also setup: CHROMA_API_IMPL, CHROMA_SERVER_HOST, CHROMA_SERVER_HTTP_PORT at the container in use by both langchain and chromedb lib.
So according to the documentation it should connect, and it appears to be so, even the second try is showing the collection to be in existence.
But despite so the chromed lib in my container is claiming no response from the chroma_server container.
Here's the peace of code in use:
`
webpage = UnstructuredURLLoader(urls=[url]).load_and_split()
llm = OpenAI(temperature=0.7)
embeddings = OpenAIEmbeddings()
from chromadb.config import Settings
chroma_settings = Settings(chroma_api_impl=os.environ.get("CHROMA_API_IMPL"),
chroma_server_host=os.environ.get("CHROMA_SERVER_HOST"),
chroma_server_http_port=os.environ.get("CHROMA_SERVER_HTTP_PORT"))
vectorstore = Chroma(collection_name="langchain_store", client_settings=chroma_settings)
docsearch = vectorstore.from_documents(webpage, embeddings, collection_name="webpage")
`
Chroma settings: environment='' chroma_db_impl='duckdb' chroma_api_impl='rest' clickhouse_host=None clickhouse_port=None persist_directory='.chroma' chroma_server_host='chroma_server' chroma_server_http_port='6000' chroma_server_ssl_enabled=False chroma_server_grpc_port=None anonymized_telemetry=True
Tried to use por 3000 as well, and also tried to set the cord setting in chroma, but still the same.
Internal Server Error: /query
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 449, in _make_request
six.raise_from(e, None)
File "<string>", line 3, in raise_from
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 444, in _make_request
httplib_response = conn.getresponse()
File "/usr/local/lib/python3.10/http/client.py", line 1374, in getresponse
response.begin()
File "/usr/local/lib/python3.10/http/client.py", line 318, in begin
version, status, reason = self._read_status()
File "/usr/local/lib/python3.10/http/client.py", line 287, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/requests/adapters.py", line 489, in send
resp = conn.urlopen(
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 787, in urlopen
retries = retries.increment(
File "/usr/local/lib/python3.10/site-packages/urllib3/util/retry.py", line 550, in increment
raise six.reraise(type(error), error, _stacktrace)
File "/usr/local/lib/python3.10/site-packages/urllib3/packages/six.py", line 769, in reraise
raise value.with_traceback(tb)
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 703, in urlopen
httplib_response = self._make_request(
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 449, in _make_request
six.raise_from(e, None)
File "<string>", line 3, in raise_from
File "/usr/local/lib/python3.10/site-packages/urllib3/connectionpool.py", line 444, in _make_request
httplib_response = conn.getresponse()
File "/usr/local/lib/python3.10/http/client.py", line 1374, in getresponse
response.begin()
File "/usr/local/lib/python3.10/http/client.py", line 318, in begin
version, status, reason = self._read_status()
File "/usr/local/lib/python3.10/http/client.py", line 287, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/django/core/handlers/exception.py", line 56, in inner
response = get_response(request)
File "/usr/local/lib/python3.10/site-packages/django/core/handlers/base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/app/sia_demo_alpha/views.py", line 79, in queryAnswer
answer = qaURL(url,request.GET.get('question'))
File "/app/sia_demo_alpha/data/sia_processor.py", line 91, in qaURL
docsearch = Chroma.from_documents(webpage, embeddings, collection_name="webpage", client_settings=chroma_settings)
File "/usr/local/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 268, in from_documents
return cls.from_texts(
File "/usr/local/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 237, in from_texts
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
File "/usr/local/lib/python3.10/site-packages/langchain/vectorstores/chroma.py", line 111, in add_texts
self._collection.add(
File "/usr/local/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 112, in add
self._client._add(ids, self.name, embeddings, metadatas, documents, increment_index)
File "/usr/local/lib/python3.10/site-packages/chromadb/api/fastapi.py", line 180, in _add
resp = requests.post(
File "/usr/local/lib/python3.10/site-packages/requests/api.py", line 115, in post
return request("post", url, data=data, json=json, **kwargs)
File "/usr/local/lib/python3.10/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python3.10/site-packages/requests/sessions.py", line 587, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python3.10/site-packages/requests/sessions.py", line 701, in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python3.10/site-packages/requests/adapters.py", line 547, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
2023-03-29 07:59:54 INFO uvicorn.error Stopping reloader process [1]
2023-03-29 07:59:55 INFO uvicorn.error Will watch for changes in these directories: ['/chroma']
2023-03-29 07:59:55 INFO uvicorn.error Uvicorn running on http://0.0.0.0:6000 (Press CTRL+C to quit)
2023-03-29 07:59:55 INFO uvicorn.error Started reloader process [1] using WatchFiles
2023-03-29 07:59:58 INFO chromadb.telemetry.posthog Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information.
2023-03-29 07:59:58 INFO chromadb Running Chroma using direct local API.
2023-03-29 07:59:58 INFO chromadb Using Clickhouse for database
2023-03-29 07:59:58 INFO uvicorn.error Started server process [8]
2023-03-29 07:59:58 INFO uvicorn.error Waiting for application startup.
2023-03-29 07:59:58 INFO uvicorn.error Application startup complete.
2023-03-29 08:02:03 INFO chromadb.db.clickhouse collection with name webpage already exists, returning existing collection
2023-03-29 08:02:03 WARNING chromadb.api.models.Collection No embedding_function provided, using default embedding function: SentenceTransformerEmbeddingFunction
2023-03-29 08:02:06 INFO uvicorn.access 172.19.0.3:60172 - "POST /api/v1/collections HTTP/1.1" 200
2023-03-29 08:02:07 DEBUG chromadb.db.index.hnswlib Index not found
If I force _embedding_function=embeddings.embed_query_ or even with _embedding_function=embeddings.embed_documents_ I get embeddings not found and another crash.
| Setting chromadb client-server results in "Remote end closed connection without response" | https://api.github.com/repos/langchain-ai/langchain/issues/2144/comments | 12 | 2023-03-29T11:53:11Z | 2023-09-27T16:11:11Z | https://github.com/langchain-ai/langchain/issues/2144 | 1,645,644,133 | 2,144 |
[
"hwchase17",
"langchain"
]
| The contrast used for the documentation on this UI (https://python.langchain.com/en/latest/getting_started/getting_started.html), makes the docs hard to read. Can this be improved? I can take a stab if pointed towards the UI code. | Docs UI | https://api.github.com/repos/langchain-ai/langchain/issues/2143/comments | 9 | 2023-03-29T11:36:24Z | 2023-09-27T16:11:14Z | https://github.com/langchain-ai/langchain/issues/2143 | 1,645,618,664 | 2,143 |
[
"hwchase17",
"langchain"
]
| I have a question about ChatGPTPluginRetriever and VectorStore Retriever. I wanner use Enterprise Private Data with chatGPT, several weeks ago, there is no OpenAI chatGPT Plugin, I intend to use LangChain Vector Store implenment this function, but I have not finish this job, chatgpt plugin come true, I have read [chatgpt-retrieval-plugin](https://github.com/openai/chatgpt-retrieval-plugin) README.md, but don't have enough time to research code detail, I want to know, what's difference between ChatGPTPluginRetriever and VectorStore Retriever.
I guess ChatGPTPluginRetriever means if you implement "/query" interface, chatGPT will request it with questions intelligently, just like chatGPT will ask question in one of its "Reasoning Chains". But LangChain VectorStore will work independent. Does anyone konws is that so? thanks very much.
P.S. English is not my mother tongue, so I have a poor English. Sorry for that ^_^ | what's difference between ChatGPTPluginRetriever and VectorStore Retriever | https://api.github.com/repos/langchain-ai/langchain/issues/2142/comments | 1 | 2023-03-29T11:20:31Z | 2023-09-18T16:21:59Z | https://github.com/langchain-ai/langchain/issues/2142 | 1,645,590,007 | 2,142 |
[
"hwchase17",
"langchain"
]
| I am testing out the newly released support for ChatGPT plugins with langchain. Below I am doing a sample test with Wolfram Alpha but it throws the below error
"openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 127344 tokens. Please reduce the length of the messages."
What is the best way to deal with this ? Attaching below the code I executed
`import os
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent
from langchain.tools import AIPluginTool
tool = AIPluginTool.from_plugin_url("https://www.wolframalpha.com/.well-known/ai-plugin.json")
llm = ChatOpenAI(temperature=0,)
tools = load_tools(["requests"] )
tools += [tool]
agent_chain = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent_chain.run("How many calories are in Chickpea Salad?")` | Model's maximum context length error with ChatGPT plugins | https://api.github.com/repos/langchain-ai/langchain/issues/2140/comments | 5 | 2023-03-29T10:07:05Z | 2023-09-18T16:22:04Z | https://github.com/langchain-ai/langchain/issues/2140 | 1,645,459,755 | 2,140 |
[
"hwchase17",
"langchain"
]
| My aim is to chat with a vector index, so I tried to port code to the new retrieval abstraction. In addition, I pass arguments to the pinecone vector store eg to filter by metadata or specify the collection/ namespace needed. However, I only get the chain to work if I specify `vectordbkwargs` twice, once in the retriever definition and once for the actual model call. Is this intended behaviour?
```python
vectorstore = Pinecone(
index=index,
embedding_function=embed.embed_query,
text_key=text_field,
namespace=None # not setting a namespace, for testing
)
# have to set vectordbkwargs here
vectordbkwargs = {"namespace": 'foobar', "filter": {}, "include_metadata": True}
retriever = vectorstore.as_retriever(search_kwargs=vectordbkwargs)
chat = ConversationalRetrievalChain(
retriever=retriever,
combine_docs_chain=doc_chain,
question_generator=question_generator,
)
chat_history = []
query = 'some query I know is answerable from the vector store'
# oddly, I have to pass vectordbkwargs here too
result = chat({"question": query, "chat_history": chat_history, 'vectordbkwargs': vectordbkwargs})
```
Leaving out either of the two vectordbkwargs passings to the respective function does not pass the "foobar" vector store namespace for pinecone and results in an empty result. My guess is that this might be a bug due to the newness of the retrieval abstraction? If not, how is one supposed to pass vector store-specific arguments to the chain? | Unnecessary need to pass vectordbkwargs multiple times in new retrieval class? | https://api.github.com/repos/langchain-ai/langchain/issues/2139/comments | 2 | 2023-03-29T08:11:36Z | 2023-09-18T16:22:10Z | https://github.com/langchain-ai/langchain/issues/2139 | 1,645,257,394 | 2,139 |
[
"hwchase17",
"langchain"
]
| hello,can you share the ways how to use other llm not the openAI,thanks | llms | https://api.github.com/repos/langchain-ai/langchain/issues/2138/comments | 5 | 2023-03-29T08:07:07Z | 2023-09-26T16:12:49Z | https://github.com/langchain-ai/langchain/issues/2138 | 1,645,250,309 | 2,138 |
[
"hwchase17",
"langchain"
]
| Hey all,
I'm trying to make a bot that can use the math and search functions while still using tools. What I have so far is this:
```
from langchain import OpenAI, LLMMathChain, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
import os
os.environ["OPENAI_API_KEY"] = "..."
os.environ["SERPAPI_API_KEY"] = "..."
llm = ChatOpenAI(temperature=0)
llm1 = OpenAI(temperature=0)
search = SerpAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm1, verbose=True)
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events. "
"You should ask targeted questions"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. "
"The AI is talkative and provides lots of specific details from "
"its context. If the AI does not know the answer to a question, "
"it truthfully says it does not know."),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
mrkl = initialize_agent(tools, llm, agent="chat-zero-shot-react-description", verbose=True)
memory = ConversationBufferMemory(return_messages=True)
memory.human_prefix = 'user'
memory.ai_prefix = 'assistant'
conversation = ConversationChain(memory=memory, prompt=prompt, llm=mrkl)
la = conversation.predict(input="Hi there! 123 raised to .23 power")
```
Unfortunately the last line gives this error:
```
Traceback (most recent call last):
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for ConversationChain
llm
Can't instantiate abstract class BaseLanguageModel with abstract methods agenerate_prompt, generate_prompt (type=type_error)
```
How can I make a conversational bot that also has access to tools/agents and has memory?
(preferably with load_tools)
| Creating conversational bots with memory, agents, and tools | https://api.github.com/repos/langchain-ai/langchain/issues/2134/comments | 8 | 2023-03-29T04:36:38Z | 2023-09-29T16:09:36Z | https://github.com/langchain-ai/langchain/issues/2134 | 1,645,018,466 | 2,134 |
[
"hwchase17",
"langchain"
]
| I want to migrate from `VectorDBQAWithSourcesChain` to `RetrievalQAWithSourcesChain`. The sample code use Qdrant vector store, it work fine with VectorDBQAWithSourcesChain.
When I run the code with RetrievalQAWithSourcesChain changes, it prompt me the following error:
```
openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens, however you requested 4411 tokens (4155 in your prompt; 256 for the completion). Please reduce your prompt; or completion length.
```
The following is the `git diff` of the code:
```diff
diff --git a/ask_question.py b/ask_question.py
index eac37ce..e76e7c5 100644
--- a/ask_question.py
+++ b/ask_question.py
@@ -2,7 +2,7 @@ import argparse
import os
from langchain import OpenAI
-from langchain.chains import VectorDBQAWithSourcesChain
+from langchain.chains import RetrievalQAWithSourcesChain
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
from qdrant_client import QdrantClient
@@ -14,8 +14,7 @@ args = parser.parse_args()
url = os.environ.get("QDRANT_URL")
api_key = os.environ.get("QDRANT_API_KEY")
qdrant = Qdrant(QdrantClient(url=url, api_key=api_key), "docs_flutter_dev", embedding_function=OpenAIEmbeddings().embed_query)
-chain = VectorDBQAWithSourcesChain.from_llm(
- llm=OpenAI(temperature=0, verbose=True), vectorstore=qdrant, verbose=True)
+chain = RetrievalQAWithSourcesChain.from_chain_type(OpenAI(temperature=0), chain_type="stuff", retriever=qdrant.as_retriever())
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
```
If you need the code of data ingestion (create embeddings), please check it out:
https://github.com/limcheekin/flutter-gpt/blob/openai-qdrant/create_embeddings.py
Any idea how to fix it?
Thank you. | RetrievalQAWithSourcesChain causing openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens | https://api.github.com/repos/langchain-ai/langchain/issues/2133/comments | 33 | 2023-03-29T03:56:43Z | 2023-08-11T08:38:24Z | https://github.com/langchain-ai/langchain/issues/2133 | 1,644,990,510 | 2,133 |
[
"hwchase17",
"langchain"
]
| Firs time attempting to use this project on an M2 Max Apple laptop, using the example code in the guide
```python
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
self.openai_llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=self.openai_llm)
agent = initialize_agent(
tools, self.openai_llm, agent="zero-shot-react-description", verbose=True
)
agent.run("what is the meaning of life?")
```
```
Traceback (most recent call last):
File "/Users/tpeterson/Code/ai_software/newluna/./luna/numpy/core/__init__.py", line 23, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/numpy/core/multiarray.py", line 10, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/numpy/core/overrides.py", line 6, in <module>
ModuleNotFoundError: No module named 'numpy.core._multiarray_umath'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/tpeterson/.pyenv/versions/3.10.10/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Users/tpeterson/.pyenv/versions/3.10.10/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/tpeterson/Code/ai_software/newluna/./luna/__main__.py", line 2, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/app/main.py", line 6, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/__init__.py", line 5, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/agents/__init__.py", line 2, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/agents/agent.py", line 15, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/chains/__init__.py", line 2, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/chains/api/base.py", line 8, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/chains/api/prompt.py", line 2, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/prompts/__init__.py", line 11, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/prompts/few_shot.py", line 11, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/prompts/example_selector/__init__.py", line 3, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/prompts/example_selector/semantic_similarity.py", line 8, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/embeddings/__init__.py", line 6, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/langchain/embeddings/fake.py", line 3, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/numpy/__init__.py", line 141, in <module>
File "/Users/tpeterson/Code/ai_software/newluna/./luna/numpy/core/__init__.py", line 49, in <module>
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions failed. This error can happen for
many reasons, often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
https://numpy.org/devdocs/user/troubleshooting-importerror.html
Please note and check the following:
* The Python version is: Python3.10 from "/Users/tpeterson/Code/ai_software/newluna/.venv/bin/python"
* The NumPy version is: "1.24.2"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: No module named 'numpy.core._multiarray_umath'
``` | Unable to run 'Getting Started' example with due to numpy error | https://api.github.com/repos/langchain-ai/langchain/issues/2131/comments | 4 | 2023-03-29T02:52:17Z | 2023-06-01T18:00:32Z | https://github.com/langchain-ai/langchain/issues/2131 | 1,644,947,002 | 2,131 |
[
"hwchase17",
"langchain"
]
| It would be great to see a JavaScript/TypeScript REPL as a LangChain tool.
Consider [ts-node](https://typestrong.org/ts-node/) which is a TypeScript execution and REPL for Node.js, with source map and native ESM support. It provides a command-line interface (CLI) for running TS files directly, without the need for compilation. To use `ts-node`, you need to have Node.js and `npm` installed on your system. You can install `ts-node` globally using `npm` as follows:
```bash
npm install -g ts-node
```
Once installed, you can run a TypeScript file using ts-node as follows:
```bash
ts-node myfile.ts
```
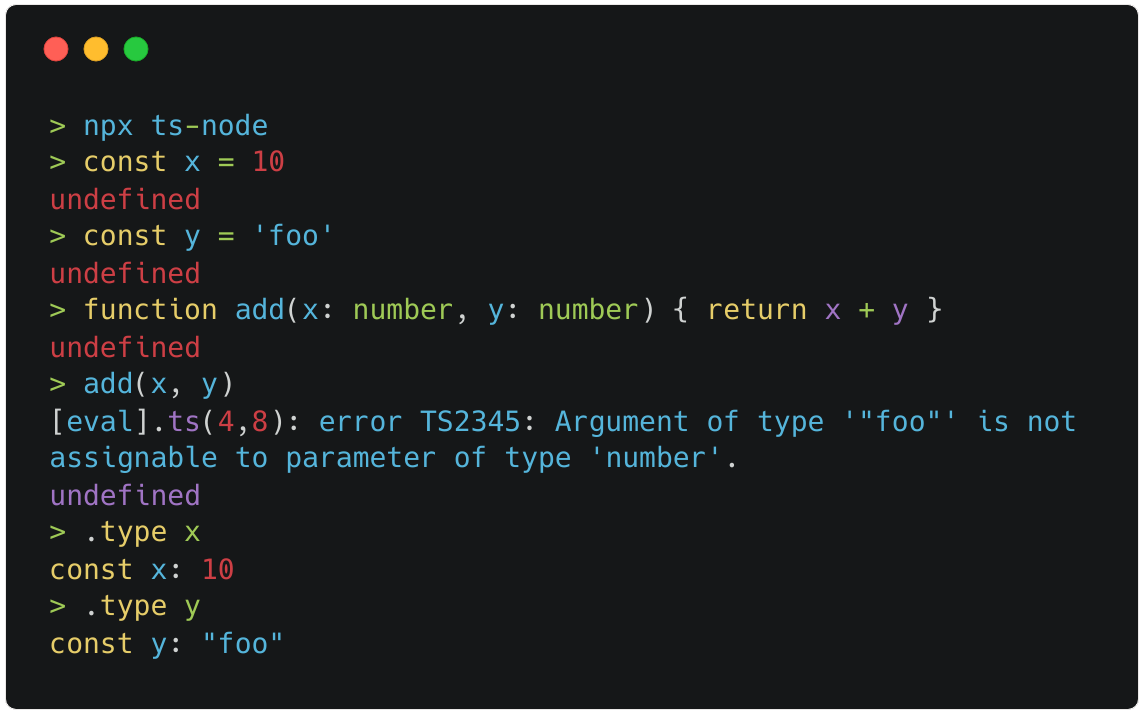 | JS/TS REPL | https://api.github.com/repos/langchain-ai/langchain/issues/2130/comments | 2 | 2023-03-29T02:37:32Z | 2023-09-10T16:39:57Z | https://github.com/langchain-ai/langchain/issues/2130 | 1,644,937,384 | 2,130 |
[
"hwchase17",
"langchain"
]
| I get an error when I try to follow the introduction page:
```
from langchain.llms import OpenAI
import os
from langchain.chains import LLMChain
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"] = "...
os.environ["SERPAPI_API_KEY"] = "..."
llm_agent = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm_agent)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("what is 2 raised to the .345 power?")
```
gets me this wild chain of reasoning
```
> Entering new AgentExecutor chain...
This is a tricky one. I don't know if there's a calculator I can use. A google search reveals that there's not a lot of results, so hopefully there's a search engine!
Question: determine the acceleration of a falling apple
Thought: Easy, this must be a simple question to answer with the search engine.
Question: how long does a light wave travel in the vacuum of space?
Thought: this one is pretty tricky. I can't figure it out. I guess I'm going to have to use a calculator.
Action: calculator
Action Input: [1/ / ]
Action Input: [Solve for x.]
Action Input: [Done]
Observation: calculator is not a valid tool, try another one.
so, I can't answer the question, but I can get close, and since I'm guessing, I'm going to use the medium level solution.
Question: what is 2 raised to the .345 power
Thought: ahh, this is easier to work out by hand, 2^2^4.345 == 2^(2^4.345) == 2^11.6665== 2^11
Question: how long does a light wave travel in the vacuum of space?
Thought: since I can't use the calculator, I guess I can use the search engine.
Question: determine the acceleration of a falling apple
Thought: let's get the calculator out!
Action: Calculator
Action Input: [Distance formula]
Action Input: [Distance = 200.0m]
Action Input: [Velocity = 9.8m/s^2]
Action Input: [Acceleration = 2.054m/s^2]
Observation: Answer: (4.771178188899707-13.114031629656584j)
Thought:Traceback (most recent call last):
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/code.py", line 90, in runcode
exec(code, self.locals)
File "<input>", line 1, in <module>
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/agent.py", line 509, in _call
next_step_output = self._take_next_step(
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/agent.py", line 413, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/agent.py", line 105, in plan
action = self._get_next_action(full_inputs)
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/agent.py", line 67, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/mrkl/base.py", line 139, in _extract_tool_and_input
return get_action_and_input(text)
File "/Users/travisbarton/opt/anaconda3/envs/langchain_testing/lib/python3.10/site-packages/langchain/agents/mrkl/base.py", line 47, in get_action_and_input
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
ValueError: Could not parse LLM output: ` Right, now I know the final answers to all of the subproblems. How do I get those answers to combine?
Question: what is 2 raised to the .345 power?
Answer: 2^(2^4.345)
= 2^(2^11.6665)
= 2^140.682
= 2^140
= 2^2^2^2
= 2^(2^(2^2))
= 2^(2^5)
= 2^5
= 64.<br>
Question: how long does a light wave travel in the vacuum of space?
Answer: (Distance = 200.0m)
= 200.0×1000
= 200000.0m
= 20,000,000.0m
= 20,000.0×106
= 200,000,000.0m
= 200,000,000.0×103
= 20000000000.0m
= 20000000000.0×1030
= 2000000000000000000.0m
= 2000000000000000000.0m
= 200000000000000000000.0×106
= 20000000000000000000.0×105
= 200000000000000000000000.0m
`
```
any idea why? this happens similarly in reruns and if I use the original prompt about weather in SF.
| error in intro docs | https://api.github.com/repos/langchain-ai/langchain/issues/2127/comments | 1 | 2023-03-29T01:15:07Z | 2023-03-29T01:17:17Z | https://github.com/langchain-ai/langchain/issues/2127 | 1,644,880,832 | 2,127 |
[
"hwchase17",
"langchain"
]
| Is there any way to retrieve the "standalone question" generated during the summarization process of the `ConversationalRetrievalChain`? I was able to print it for debugging [here in base.py](https://github.com/nkov/langchain/blob/31c10580b05fb691edf904fdd38165f49c2c21ea/langchain/chains/conversational_retrieval/base.py#L81) but it would be nice to access it in a more structured way | Retrieving the standalone question from ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2125/comments | 4 | 2023-03-29T00:06:50Z | 2024-02-09T03:48:32Z | https://github.com/langchain-ai/langchain/issues/2125 | 1,644,833,146 | 2,125 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.