
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/13147 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13147/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13147/comments | https://api.github.com/repos/huggingface/transformers/issues/13147/events | https://github.com/huggingface/transformers/issues/13147 | 972,406,549 | MDU6SXNzdWU5NzI0MDY1NDk= | 13,147 | Support OpenNMT models | {
"login": "jordimas",
"id": 309265,
"node_id": "MDQ6VXNlcjMwOTI2NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/309265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jordimas",
"html_url": "https://github.com/jordimas",
"followers_url": "https://api.github.com/users/jordimas/followers",
"following_url": "https://api.github.com/users/jordimas/following{/other_user}",
"gists_url": "https://api.github.com/users/jordimas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jordimas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jordimas/subscriptions",
"organizations_url": "https://api.github.com/users/jordimas/orgs",
"repos_url": "https://api.github.com/users/jordimas/repos",
"events_url": "https://api.github.com/users/jordimas/events{/privacy}",
"received_events_url": "https://api.github.com/users/jordimas/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | open | false | null | [] | [
"Hi @jordimas !\r\n\r\nWould you be interested in adding this model to transformers? I briefly looked at the code and it looks similar to [mbart](https://github.com/huggingface/transformers/blob/master/src/transformers/models/mbart/modeling_mbart.py)/[m2m](https://github.com/huggingface/transformers/blob/master/src/transformers/models/m2m_100/modeling_m2m_100.py)/[Marian](https://github.com/huggingface/transformers/blob/master/src/transformers/models/marian/modeling_marian.py) style models in transformers. So it should be fairly straightforward to port this by looking at the design of these models.\r\n\r\nAs you might already know, each model in the library requires 3 files, which will look something like this:\r\n- `configuration_open_nmt.py`\r\n- `modeling_open_nmt.py`\r\n- `tokenization_open_nmt.py`\r\n\r\n\r\nWe provide a template using CookieCutter which lets you set up these files for you, even filling in the names, as explained [here](https://github.com/huggingface/transformers/tree/master/templates/adding_a_new_model). It also creates documentation pages, test files, and so on.\r\n\r\nI would be happy to help with this, so feel free to ping me if you have any issues. Thank you :) "
] | 1,629 | 1,636 | null | CONTRIBUTOR | null | It will be great if OpenNMT (https://opennmt.net/) and CTranslate2 (https://github.com/OpenNMT/CTranslate2) model support is provided out of the box. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13147/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13147/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13146 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13146/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13146/comments | https://api.github.com/repos/huggingface/transformers/issues/13146/events | https://github.com/huggingface/transformers/issues/13146 | 972,390,168 | MDU6SXNzdWU5NzIzOTAxNjg= | 13,146 | Runtime error when training DetForObjectDetection using HFTrainer with GPU. | {
"login": "jnishi",
"id": 836541,
"node_id": "MDQ6VXNlcjgzNjU0MQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/836541?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jnishi",
"html_url": "https://github.com/jnishi",
"followers_url": "https://api.github.com/users/jnishi/followers",
"following_url": "https://api.github.com/users/jnishi/following{/other_user}",
"gists_url": "https://api.github.com/users/jnishi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jnishi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jnishi/subscriptions",
"organizations_url": "https://api.github.com/users/jnishi/orgs",
"repos_url": "https://api.github.com/users/jnishi/repos",
"events_url": "https://api.github.com/users/jnishi/events{/privacy}",
"received_events_url": "https://api.github.com/users/jnishi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @jnishi,\r\n\r\nThanks a lot for your issue!\r\nCould you please try to make a minimum reproducible code example that doesn't force us to manually create a `img_folder` or `annotations` folder? Ideally, you could link to a colab that runs in less than a minute to reproduce the error. \r\n\r\nAlso cc'ing @NielsRogge here for DETR",
"Here is the link to colab.\r\nhttps://colab.research.google.com/drive/1qvasKfJGhxoNn-l_5GZwkvh4FhW59gBS?usp=sharing\r\n\r\nPlease upload sample.jpg and sample.json included below before you run colab.\r\n[detr_samples.tar.gz](https://github.com/huggingface/transformers/files/7011436/detr_samples.tar.gz)\r\n",
"Thanks for the colab! It was indeed easy to reproduce the issue.\r\n\r\nI've fixed it here: https://colab.research.google.com/drive/1oIHGwr1U0sw-6KW-MG60s-ksXA-kYyUO?usp=sharing \r\n\r\nAs you already spotted, the problem is in the `_prepare_inputs()` method of the Trainer, which does not take into account inputs which are lists. For DETR, the `labels` are a list of dictionaries, each dictionary containing the annotations (class labels and boxes) for an example in the batch. I've fixed it by overwriting that method.\r\n\r\ncc'ing @sgugger, as this could be incorporated directly in the Trainer, instead of having to overwrite it.",
"Thanks for a quick response, and suggestion of the fix. It works fine in my scripts too.\r\nI would be more than happy to incorporate it directly.\r\n\r\nBTW, I have another problem with a multi-GPU environment, so I created another issue.\r\nhttps://github.com/huggingface/transformers/issues/13197",
"The PR linked above should solve this problem. It's a bit more general than your solution in the notebook @NielsRogge to handle any nested dict/list of tensors."
] | 1,629 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.2
- Platform: Linux-5.4.0-81-generic-x86_64-with-glibc2.27
- Python version: 3.8.0
- PyTorch version (GPU?): 1.9.0+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <yes>
- Using distributed or parallel set-up in script?: <no>
## Information
Model I am using: DetrForObjectDetection
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
I'm training DetrForObjectDetection by using HFTrainer.
Save a script file below as `mini_example.py`, and run as `python mini_example.py --output_dir mini_model mini_model` after setting `img_folder` to the path to the coco image dataset folder and `annotations` to the path to the coco annotation JSON file.
```python
from typing import Dict, List, Union
import torch
from torchvision.datasets import CocoDetection
from transformers import (
DetrConfig,
DetrFeatureExtractor,
DetrForObjectDetection,
HfArgumentParser,
Trainer,
TrainingArguments,
)
def load_category(category):
id2label = {}
label2id = {}
maxid = 0
for k, v in category.items():
id2label[int(k)] = v["name"]
label2id[v["name"]] = int(k)
maxid = max(maxid, int(k))
for i in range(maxid):
if not (i in id2label):
id2label[i] = None
return id2label, label2id
class DetrData(CocoDetection):
def __init__(self, img_folder, annotations, feature_extractor, train=True):
super(DetrData, self).__init__(img_folder, annotations)
self.feature_extractor = feature_extractor
def __getitem__(self, idx):
# read in PIL image and target in COCO format img, target = super(DetrData, self).__getitem__(idx)
# preprocess image and target (converting target to DETR format, resizing + normalization of both image and target) image_id = self.ids[idx]
target = {'image_id': image_id, 'annotations': target}
encoding = self.feature_extractor(images=img, annotations=target, return_tensors="pt")
encoding["pixel_values"] = encoding["pixel_values"].squeeze() # remove batch dimension encoding["labels"] = encoding["labels"][0] # remove batch dimension return encoding
@dataclass
class DataCollatorDetr:
feature_extractor: DetrFeatureExtractor
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
pixel_values = [item["pixel_values"] for item in features]
encoding = self.feature_extractor.pad_and_create_pixel_mask(pixel_values, return_tensors="pt")
encoding["labels"] = [item["labels"] for item in features]
return encoding
def main():
parser = HfArgumentParser((TrainingArguments))
training_args, = parser.parse_args_into_dataclasses()
feature_extractor = DetrFeatureExtractor()
train_dataset = DetrData(img_folder="path/to/image_folder", annotations="path/to/annotation_file", feature_extractor=feature_extractor)
id2label, label2id = load_category(train_dataset.coco.cats)
config = DetrConfig.from_pretrained("facebook/detr-resnet-50")
config.id2label = id2label
config.label2id = label2id
model = DetrForObjectDetection.from_pretrained(
"facebook/detr-resnet-50",
config=config)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=feature_extractor,
data_collator=DataCollatorDetr(feature_extractor=feature_extractor),
)
train_result = trainer.train()
if __name__ == "__main__":
main()
```
When train without GPU, it works fine, but got RuntimeError below with GPU,
```
Traceback (most recent call last):
File "mini_example.py", line 97, in <module>
main()
File "mini_example.py", line 93, in main
train_result = trainer.train()
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/trainer.py", line 1286, in train
tr_loss += self.training_step(model, inputs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/trainer.py", line 1779, in training_step
loss = self.compute_loss(model, inputs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/trainer.py", line 1811, in compute_loss
outputs = model(**inputs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/models/detr/modeling_detr.py", line 1435, in forward
loss_dict = criterion(outputs_loss, labels)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/models/detr/modeling_detr.py", line 2009, in forward
indices = self.matcher(outputs_without_aux, targets)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/transformers/models/detr/modeling_detr.py", line 2127, in forward
bbox_cost = torch.cdist(out_bbox, tgt_bbox, p=1)
File "/home/christopher/pyenvs/detr/lib/python3.8/site-packages/torch/functional.py", line 1049, in cdist
return _VF.cdist(x1, x2, p, None) # type: ignore[attr-defined]
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking arugment for argument x2 in method wrapper__cdist_forward)
0%| | 0/1875 [00:03<?, ?it/s]
```
This is maybe because `inputs["labels"]` is not sent to GPU here https://github.com/huggingface/transformers/blob/v4.9.2/src/transformers/trainer.py#L1734 which is called at
https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L1771 because it is dict.
Any suggestion on how to fix it?
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Successfully complete training
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13146/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13145 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13145/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13145/comments | https://api.github.com/repos/huggingface/transformers/issues/13145/events | https://github.com/huggingface/transformers/pull/13145 | 972,283,100 | MDExOlB1bGxSZXF1ZXN0NzEzODk5NzA2 | 13,145 | remove unwanted control-flow code from DeBERTa-V2 | {
"login": "kamalkraj",
"id": 17096858,
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalkraj",
"html_url": "https://github.com/kamalkraj",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalkraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamalkraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalkraj/subscriptions",
"organizations_url": "https://api.github.com/users/kamalkraj/orgs",
"repos_url": "https://api.github.com/users/kamalkraj/repos",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamalkraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,629 | 1,631 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
Removes never executed branch from `deberta-v2` code
discussed in https://github.com/huggingface/transformers/pull/13120#issuecomment-899865394
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik @patrickvonplaten @Rocketknight1 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13145/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13145",
"html_url": "https://github.com/huggingface/transformers/pull/13145",
"diff_url": "https://github.com/huggingface/transformers/pull/13145.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13145.patch",
"merged_at": 1629734862000
} |
https://api.github.com/repos/huggingface/transformers/issues/13144 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13144/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13144/comments | https://api.github.com/repos/huggingface/transformers/issues/13144/events | https://github.com/huggingface/transformers/issues/13144 | 972,211,469 | MDU6SXNzdWU5NzIyMTE0Njk= | 13,144 | [Benchmark] | {
"login": "mahmoudcupo",
"id": 59886161,
"node_id": "MDQ6VXNlcjU5ODg2MTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/59886161?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mahmoudcupo",
"html_url": "https://github.com/mahmoudcupo",
"followers_url": "https://api.github.com/users/mahmoudcupo/followers",
"following_url": "https://api.github.com/users/mahmoudcupo/following{/other_user}",
"gists_url": "https://api.github.com/users/mahmoudcupo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mahmoudcupo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mahmoudcupo/subscriptions",
"organizations_url": "https://api.github.com/users/mahmoudcupo/orgs",
"repos_url": "https://api.github.com/users/mahmoudcupo/repos",
"events_url": "https://api.github.com/users/mahmoudcupo/events{/privacy}",
"received_events_url": "https://api.github.com/users/mahmoudcupo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Closing since the issue doesn't seem to have much information. @mahmoudcupo did you mean to submit a benchmark?"
] | 1,629 | 1,629 | 1,629 | NONE | null | # 🖥 Benchmarking `transformers`
## Benchmark
Which part of `transformers` did you benchmark?
## Set-up
What did you run your benchmarks on? Please include details, such as: CPU, GPU? If using multiple GPUs, which parallelization did you use?
## Results
Put your results here!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13144/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13143 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13143/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13143/comments | https://api.github.com/repos/huggingface/transformers/issues/13143/events | https://github.com/huggingface/transformers/pull/13143 | 972,045,169 | MDExOlB1bGxSZXF1ZXN0NzEzNjk3NTIy | 13,143 | fix wrong 'cls' masking for bigbird qa model output | {
"login": "donggyukimc",
"id": 16605764,
"node_id": "MDQ6VXNlcjE2NjA1NzY0",
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/donggyukimc",
"html_url": "https://github.com/donggyukimc",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_url": "https://api.github.com/users/donggyukimc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/donggyukimc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donggyukimc/subscriptions",
"organizations_url": "https://api.github.com/users/donggyukimc/orgs",
"repos_url": "https://api.github.com/users/donggyukimc/repos",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"received_events_url": "https://api.github.com/users/donggyukimc/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @donggyukimc,\r\n\r\nThanks for your PR - this makes sense to me. Do you by any chance have a reference to the original code / paper that shows that the original CLS token should not be masked out? \r\n\r\nAlso cc-ing our expert on BigBird here @vasudevgupta7 ",
"@donggyukimc, I am little unsure about this. In the original code also, they are masking out everything till first `[SEP]` ([see this](https://github.com/tensorflow/models/blob/6de0c8e97f6f658a6387d8b7fa946b070a50e98f/official/nlp/projects/triviaqa/modeling.py#L56)).\r\n\r\nIf we don't mask the `CLS` token, then there is a possibility that `start_token` will point to `CLS` but `end_token` will point to some token in a sequence and hence final answer will have question also. I think cases corresponding to whether answer is present (or not) should be handled by putting a classifier over the pooler layer instead ([something like this](https://github.com/vasudevgupta7/bigbird/blob/ea2ce568f8f55978b3f0808f811de7d2ac0deb6c/src/train_nq_torch.py#L96)). If we make the model point `start_token` & `end_token` to `CLS` during training, it usually leads to infinite/nan loss during training but classifier approach works well.\r\n\r\nCorrect me if you feel I am wrong somewhere.",
"@vasudevgupta7, Thank you for your comment.\r\n\r\nI bring the QA models from other architectures (BERT, ROBERTA)\r\nhttps://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/models/bert/modeling_bert.py#L1831-L1863\r\n\r\nhttps://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/models/roberta/modeling_roberta.py#L1518-L1550\r\nEven though both of them do not apply any mask on predictions for CLS (and also questions), they can be trained without the problems on loss. (actually, CLS shouldn't be masked out because they predict unanswerable probability from CLS)\r\n\r\nAs you can see in, [squad_metrics.py](https://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L384), the QA evaluation pipeline in transformers library,\r\nhttps://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L437-L456\r\nit directly computes unanswerable probability from same MLP logit outputs with answerable spans.\r\nhttps://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L438\r\n\r\nOne of your our concerns (**there is a possibility that start_token will point to CLS but end_token will point to some token in a sequence and hence final answer will have question also**) will be prevented in this part.\r\nhttps://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L453-L456\r\nbecause the positions of questions tokens not exists in feature.token_to_orig_map.\r\n\r\nYour [suggestion](https://github.com/vasudevgupta7/bigbird/blob/ea2ce568f8f55978b3f0808f811de7d2ac0deb6c/src/train_nq_torch.py#L96) using a separate MLP to predict unanswerable probability will also do the work, but you have to use different evaluation code except for [squad_metrics.py](https://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L384).\r\n\r\nActually, this is how i found the problem, i got wrong prediction results when i used bigbirdQA model + [squad_metrics.py](https://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/data/metrics/squad_metrics.py#L384)\r\n\r\nIn my opinion, it is better to use the same prediction mechanism in order to keep compatibility between other QA model architectures and the QA evaluation pipeline in transformers library.\r\n\r\nI'd like to hear your opinion on this.\r\n\r\nThank you for your thoughtful comment again, @vasudevgupta7.\r\n\r\n",
"any thoughts on my [opinion](https://github.com/huggingface/transformers/pull/13143#issuecomment-902547309)? @patrickvonplaten @vasudevgupta7 ",
"Hey @donggyukimc, so sorry I missed your comment earlier. As you pointed out about BERT like models, I think it's fine to unmask `CLS` token to mantain consistency with other models. So, this PR looks alright to me.",
"Awesome merging it then!"
] | 1,629 | 1,630 | 1,630 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
Currently, the bigbird QA model masks out (assign very small value < -1e6) all logits before context tokens as follows.
```
tokens : ['[CLS]', '▁How', '▁old', '▁are', '▁you', '?', '[SEP]', '▁I', "'m", '▁twenty', '▁years', '▁old', '.']
input_ids : [65, 1475, 1569, 490, 446, 131, 66, 415, 1202, 8309, 913, 1569, 114]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
start_logits:
[-1.00000231e+06 -1.00000294e+06 -1.00000794e+06 -1.00000525e+06
-1.00000344e+06 -1.00000288e+06 -9.99994312e+05 -2.53751278e+00
-7.34928894e+00 4.26531649e+00 -6.21708155e+00 -8.17963409e+00
-6.25242186e+00]
end_logits:
[-1.00000169e+06 -1.00000869e+06 -1.00000731e+06 -1.00001088e+06
-1.00000856e+06 -1.00000781e+06 -9.99996375e+05 -9.58227539e+00
-9.81797123e+00 -2.89585280e+00 1.97710574e+00 -9.89597499e-01
-5.21932888e+00]
```
As you can see, it also masks out the logits from [CLS] token. This is because the following function makes question masks based on the position of the first [SEP] token.
https://github.com/huggingface/transformers/blob/14e9d2954c3a7256a49a3e581ae25364c76f521e/src/transformers/models/big_bird/modeling_big_bird.py#L3047
However, this is the wrong mechanism because [CLS] token is used for the prediction of "unanswerable question" in many QA models.
So, I simply change the code so that the masking on [CLS] token is disabled right after the creation of token_type_ids.
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13143/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13143/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13143",
"html_url": "https://github.com/huggingface/transformers/pull/13143",
"diff_url": "https://github.com/huggingface/transformers/pull/13143.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13143.patch",
"merged_at": 1630497797000
} |
https://api.github.com/repos/huggingface/transformers/issues/13142 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13142/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13142/comments | https://api.github.com/repos/huggingface/transformers/issues/13142/events | https://github.com/huggingface/transformers/issues/13142 | 971,954,050 | MDU6SXNzdWU5NzE5NTQwNTA= | 13,142 | Pretrain BART MNLI model on Financial Phrasebank | {
"login": "bartmnli",
"id": 89036539,
"node_id": "MDQ6VXNlcjg5MDM2NTM5",
"avatar_url": "https://avatars.githubusercontent.com/u/89036539?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bartmnli",
"html_url": "https://github.com/bartmnli",
"followers_url": "https://api.github.com/users/bartmnli/followers",
"following_url": "https://api.github.com/users/bartmnli/following{/other_user}",
"gists_url": "https://api.github.com/users/bartmnli/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bartmnli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bartmnli/subscriptions",
"organizations_url": "https://api.github.com/users/bartmnli/orgs",
"repos_url": "https://api.github.com/users/bartmnli/repos",
"events_url": "https://api.github.com/users/bartmnli/events{/privacy}",
"received_events_url": "https://api.github.com/users/bartmnli/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nWe like to keep Github issues for bugs/feature requests. For training-related questions, please use the [forum](https://discuss.huggingface.co/). Many HuggingFace members are happy to help you there! \r\n\r\nThanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,632 | 1,632 | NONE | null | Hi, I am trying to train/finetune the BART large model pretrained on MNLI on Financial Phrasebank but completely lost as I'm just a beginner.
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained('facebook/bart-large-mnli')
tokenizer = AutoTokenizer.from_pretrained('facebook/bart-large-mnli')
I couldnt find any code examples for tokenizing the input text from Financial Phrasebank. Different tutorials show different ways and I'm completely full.
Can anyone please please share any links to examples similar to this?
I was also trying to look for the finetuning code of the BART large MNLI finetuned on yahoo datset by Joe Davison @joeddav (https://huggingface.co/joeddav/bart-large-mnli-yahoo-answers) but couldn't find that code. Any suggestions or advice would be much appreciated.
Thanks in advance. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13142/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13141 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13141/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13141/comments | https://api.github.com/repos/huggingface/transformers/issues/13141/events | https://github.com/huggingface/transformers/issues/13141 | 971,888,530 | MDU6SXNzdWU5NzE4ODg1MzA= | 13,141 | Implement a `batch_size` parameter in the `pipeline` object | {
"login": "xegulon",
"id": 74178038,
"node_id": "MDQ6VXNlcjc0MTc4MDM4",
"avatar_url": "https://avatars.githubusercontent.com/u/74178038?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xegulon",
"html_url": "https://github.com/xegulon",
"followers_url": "https://api.github.com/users/xegulon/followers",
"following_url": "https://api.github.com/users/xegulon/following{/other_user}",
"gists_url": "https://api.github.com/users/xegulon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xegulon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xegulon/subscriptions",
"organizations_url": "https://api.github.com/users/xegulon/orgs",
"repos_url": "https://api.github.com/users/xegulon/repos",
"events_url": "https://api.github.com/users/xegulon/events{/privacy}",
"received_events_url": "https://api.github.com/users/xegulon/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger ?",
"Hello @xegulon, this is in line with some work currently underway by @Narsil ",
"@xegulon,\r\n\r\nBatching on inference is something to be very cautious about, because alignment might heavily penalize the speed of inference.\r\n\r\nSee https://github.com/huggingface/transformers/pull/11251 and https://gist.github.com/Narsil/ee5c09875e74fa6f018dc6d014f6c06c for more information.\r\n\r\nCuda OOM errors are most likely due to the fact that you are padding way too much, and actually showcase the slow down.\r\n\r\nThe big refactor mentionned by @LysandreJik is ready here https://github.com/Narsil/transformers/tree/iterable_pipelines\r\n\r\nWith said PR, you should be able to actually stream all your data to the GPU leading to a massive speedup (like DataLoader), and if you want to do batching because you know it will speedup (please measure real payloads, it's unlikely to be significant, so make sure it is a speedup) you can do it by manually using `Dataloader`, `preprocess`, `forward` and `postprocess`. \r\nThe proposed PR will use DataLoader (for `pt`) by default if you send lists too. You can also send directly Datasets. ",
"Great (useful) work @Narsil thanks a lot. Is it planned to be released in `v4.10.0`?",
"I don't think it will make it in time, it's a pretty massive change, we're pulling in stuff bit by bit to make sure we're not breaking anything (we're in a phase where we're strengthening the tests first)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@xegulon the modifications have landed in master, can you confirm it speeds up inference without the need for `batch_size` ?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,636 | 1,636 | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
Implement a `batch_size` parameter in the `pipeline` object, so that when we call it, it computes the predictions by batches of sentences and then does get CUDA Out of Memory errors.
Ideally, this optional argument would have a good default, computed from the tokenizer's parameters and the hardware the code is running on.
References to this need in the forum:
https://discuss.huggingface.co/t/how-to-make-pipeline-automatically-scale/7432/3
https://discuss.huggingface.co/t/how-to-change-the-batch-size-in-a-pipeline/8738
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
When making inference on very long list of sentences using the `pipeline` object, I often get CUDA OOM errors.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
I could try :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13141/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13140 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13140/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13140/comments | https://api.github.com/repos/huggingface/transformers/issues/13140/events | https://github.com/huggingface/transformers/pull/13140 | 971,864,491 | MDExOlB1bGxSZXF1ZXN0NzEzNTQ0MTI3 | 13,140 | Ci continue through smi failure | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,629 | 1,629 | 1,629 | MEMBER | null | Temporary fix in order to get coverage while we replace the machine: apply the `continue-on-error` option to NVIDIA-SMI runs that run on the multi-gpu machine | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13140/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13140/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13140",
"html_url": "https://github.com/huggingface/transformers/pull/13140",
"diff_url": "https://github.com/huggingface/transformers/pull/13140.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13140.patch",
"merged_at": 1629128438000
} |
https://api.github.com/repos/huggingface/transformers/issues/13139 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13139/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13139/comments | https://api.github.com/repos/huggingface/transformers/issues/13139/events | https://github.com/huggingface/transformers/pull/13139 | 971,750,598 | MDExOlB1bGxSZXF1ZXN0NzEzNDQ4NzA3 | 13,139 | [WIP][Wav2Vec2] Fix Wav2Vec2 Pretraining | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,634 | 1,634 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## 1. Fix Wav2Vec2 Pretraining with PyTorch & Deepspeed
Changes in the initialization and loss calculation seemed to have solved the unstable wav2vec2 pretraining loss problem for now. In a first run, the following loss curves were obtained:
```
{'loss': 4.7028, 'learning_rate': 1.1098409651313401e-05, 'epoch': 0.49}
{'loss': 4.6605, 'learning_rate': 1.443936386052536e-05, 'epoch': 0.99}
{'loss': 4.7504, 'learning_rate': 1.639369678954086e-05, 'epoch': 1.49}
{'loss': 4.5622, 'learning_rate': 1.778031806973732e-05, 'epoch': 1.99}
{'loss': 4.5645, 'learning_rate': 1.885586509341484e-05, 'epoch': 2.49}
{'loss': 4.513, 'learning_rate': 1.9734650998752817e-05, 'epoch': 2.99}
{'loss': 4.5666, 'learning_rate': 2.0477653894913667e-05, 'epoch': 3.49}
{'loss': 4.4167, 'learning_rate': 2.112127227894928e-05, 'epoch': 3.99}
{'loss': 4.5131, 'learning_rate': 2.1742243895858865e-05, 'epoch': 4.49}
{'loss': 4.4049, 'learning_rate': 2.2244779679123014e-05, 'epoch': 4.99}
{'loss': 4.5507, 'learning_rate': 2.269983228781891e-05, 'epoch': 5.49}
{'loss': 4.4056, 'learning_rate': 2.3115605255534444e-05, 'epoch': 5.99}
{'loss': 4.4998, 'learning_rate': 2.349834418215476e-05, 'epoch': 6.49}
{'loss': 4.4116, 'learning_rate': 2.385291414268169e-05, 'epoch': 6.99}
{'loss': 4.539, 'learning_rate': 2.418317878182792e-05, 'epoch': 7.49}
{'loss': 4.3734, 'learning_rate': 2.4492257601320028e-05, 'epoch': 7.99}
{'loss': 4.4986, 'learning_rate': 2.4810810490944393e-05, 'epoch': 8.49}
{'loss': 4.3982, 'learning_rate': 2.5083198105070827e-05, 'epoch': 8.99}
{'loss': 4.4946, 'learning_rate': 2.5341012393499218e-05, 'epoch': 9.49}
{'loss': 4.3938, 'learning_rate': 2.5585733888334973e-05, 'epoch': 9.99}
{'loss': 4.4944, 'learning_rate': 2.5818628371128123e-05, 'epoch': 10.49}
{'loss': 4.4035, 'learning_rate': 2.604078649703087e-05, 'epoch': 10.99}
6%|████████▎ | 227/4000 [16:55<4:45:30, 4.54s/it]
```
The run can be reproduced by doing the following:
**1. Create training folder**
```bash
mkdir wav2vec2_reproduce
cd wav2vec2_reproduce
```
**2. Create data folder**
```
git lfs install
git clone https://huggingface.co/patrickvonplaten/LibriSpeechTest
```
**3. Create model & experiment folder**
```
git lfs install
git clone https://huggingface.co/patrickvonplaten/wav2vec2_libri
```
**4. Prepare training**
We need to create a simlink as follows:
```
ln $(realpath ./LibriSpeechTest) LibriSpeech
```
and the manual data dir as defined in: https://huggingface.co/patrickvonplaten/wav2vec2_libri/blob/main/run_main.sh#L20
should be renamed to the local absolute path that leads to the just created simlink folder `wav2vec2_reproduce/LibriSpeech`.
We have to make sure that the `transformers` is checkout to the branch of this PR: `https://github.com/patrickvonplaten/transformers/tree/wav2vec2-pretraining`
Finally, we can start running the training:
```
cd wav2vec2_libri
./run_main.sh
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13139/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/13139/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13139",
"html_url": "https://github.com/huggingface/transformers/pull/13139",
"diff_url": "https://github.com/huggingface/transformers/pull/13139.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13139.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13138 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13138/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13138/comments | https://api.github.com/repos/huggingface/transformers/issues/13138/events | https://github.com/huggingface/transformers/pull/13138 | 971,676,723 | MDExOlB1bGxSZXF1ZXN0NzEzMzg0NzQw | 13,138 | Fix classifier dropout in RobertaForMultipleChoice | {
"login": "mandelbrot-walker",
"id": 49194488,
"node_id": "MDQ6VXNlcjQ5MTk0NDg4",
"avatar_url": "https://avatars.githubusercontent.com/u/49194488?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandelbrot-walker",
"html_url": "https://github.com/mandelbrot-walker",
"followers_url": "https://api.github.com/users/mandelbrot-walker/followers",
"following_url": "https://api.github.com/users/mandelbrot-walker/following{/other_user}",
"gists_url": "https://api.github.com/users/mandelbrot-walker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mandelbrot-walker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandelbrot-walker/subscriptions",
"organizations_url": "https://api.github.com/users/mandelbrot-walker/orgs",
"repos_url": "https://api.github.com/users/mandelbrot-walker/repos",
"events_url": "https://api.github.com/users/mandelbrot-walker/events{/privacy}",
"received_events_url": "https://api.github.com/users/mandelbrot-walker/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,632 | 1,632 | CONTRIBUTOR | null | # What does this PR do?
Fix as per [PR#13087](https://github.com/huggingface/transformers/pull/13087)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13138/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13138/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13138",
"html_url": "https://github.com/huggingface/transformers/pull/13138",
"diff_url": "https://github.com/huggingface/transformers/pull/13138.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13138.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13137 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13137/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13137/comments | https://api.github.com/repos/huggingface/transformers/issues/13137/events | https://github.com/huggingface/transformers/issues/13137 | 971,550,339 | MDU6SXNzdWU5NzE1NTAzMzk= | 13,137 | how to finetune or test XLM-ProphetNet on XGLUE-NTG task | {
"login": "koukoulala",
"id": 30341159,
"node_id": "MDQ6VXNlcjMwMzQxMTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/30341159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koukoulala",
"html_url": "https://github.com/koukoulala",
"followers_url": "https://api.github.com/users/koukoulala/followers",
"following_url": "https://api.github.com/users/koukoulala/following{/other_user}",
"gists_url": "https://api.github.com/users/koukoulala/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koukoulala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koukoulala/subscriptions",
"organizations_url": "https://api.github.com/users/koukoulala/orgs",
"repos_url": "https://api.github.com/users/koukoulala/repos",
"events_url": "https://api.github.com/users/koukoulala/events{/privacy}",
"received_events_url": "https://api.github.com/users/koukoulala/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"I think XLMProphetNet and ProphetNet training is currently broken, see: https://github.com/huggingface/transformers/issues/9804",
"There might be a PR to fix it though https://github.com/huggingface/transformers/pull/13132",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,632 | 1,632 | NONE | null | # 📚 Migration
## Information
<!-- Important information -->
Model I am using (xprophetnet): 'microsoft/xprophetnet-large-wiki100-cased-xglue-ntg'
Language I am using the model on (English, Chinese ...): multi-language
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [√] my own modified scripts: (give details below)
Just a little change in ./examples/pytorch/summarization/run_summarization_no_trainer.py to suit for NTG task and bleu evaluation metric.
The tasks I am working on is:
* [√ ] an official GLUE/SQUaD task: (give the name): XGLUE-NTG
* [ ] my own task or dataset: (give details below)
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
I have tried to use open xprophetnet checkpoint "https://huggingface.co/microsoft/xprophetnet-large-wiki100-cased-xglue-ntg" to reproduce NTG test results without further training, but I have received very bad blue results. For example, the test.fr can only get 7.7, while the paper claims 11.4. The num_beams and max_source_length parameters in my script (run_summarization_no_trainer.py) are set to 10 and 512, while others are same as original default value.
Now I don't know how to reproduce the NTG results of xprophetnet. Can you show me some related inference scripts or how to fine-tune xprophetnet-ntg from the pre-trained xprophetnet-multi ckpt?
Here are some jupyter notebook examples. You can see that most generated titles are wrong, even have this ',,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,'.
```
for step, batch in enumerate(test_dataloader[lg]):
if step > 5:
break
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
**gen_kwargs,
)
#print("generated_tokens", generated_tokens)
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
#print("generated_tokens", generated_tokens)
labels = batch["labels"]
if not args.pad_to_max_length:
# If we did not pad to max length, we need to pad the labels too
labels = accelerator.pad_across_processes(batch["labels"], dim=1, pad_index=tokenizer.pad_token_id)
generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()
labels = accelerator.gather(labels).cpu().numpy()
if args.ignore_pad_token_for_loss:
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
if isinstance(generated_tokens, tuple):
generated_tokens = generated_tokens[0]
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
input_seq = tokenizer.batch_decode(batch["input_ids"], skip_special_tokens=True)
print("\ninput_seq", input_seq[0][:200])
print("decoded_preds", decoded_preds)
print("decoded_labels", decoded_labels)
# Some simple post-processing
#decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
```
input_seq Vice-présidente de l'Assemblée nationale, la macroniste Carole Bureau-Bonnard était chargée mardi après-midi d'animer la séance d'examen du projet de loi «confiance dans l'action publique». C'était sa
decoded_preds ["Carole Bureau-Bonnard, vice-présidente de l'Assemblée nationale, a connu une séance éprouvante", "Les plus grands fauteuils de l'île d'Antiparos"]
decoded_labels ["Les débuts balbutiants d'une députée LREM provoque la pagaille à l'Assemblée nationale", 'Ces maisons du sud qui nous inspirent']
input_seq Le procès d'un Turc de 17 ans qui avait agressé en janvier 2016 à la machette un enseignant d'une école juive de Marseille portant une kippa, s'ouvre mercredi devant le tribunal pour enfants (TPE) de
decoded_preds [',,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,', 'The S.O.A.A.D.:,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,']
decoded_labels ['Un jeune djihadiste de 17 ans en procès à Paris', 'Canada : la forme de ce nuage est invraisemblable']
input_seq Face à l'inflation des médicaments, le Comité économique des produits de santé alerte les industriels, qui répondent coûts de recherche. Une fatalité? On la surnomme "la pilule du président", car elle
decoded_preds ['Le Keytruda est un espoir pour les malades atteints de la tumeur de Jimmy Carter', 'Les voyageurs qui utilisent Android ou iOS seraient des voyageurs préférés']
decoded_labels ['La vérité sur... la surenchère des anticancéreux', "Dis-moi quel système d'exploitation mobile tu utilises, je te dirai quel voyageur tu es"]
input_seq La République serbe de Bosnie (Republika Srpska) s'est déclarée mercredi "militairement neutre" alors que le gouvernement central de Sarajevo, les Bosniaques musulmans et les Croates de Bosnie-Herzégo
decoded_preds ['La République serbe de Bosnie déclarée "militairement neutre"', 'Les habitudes alimentaires des Français changent, selon une étude']
decoded_labels ['La République serbe de Bosnie proclame sa neutralité militaire', 'Les Français de plus en plus adeptes du grignotage']
input_seq Eva Longoria se livre dans une interview accordée à Hollywood Access au sujet de son mari, José Baston dont elle semble éperdument amoureuse. Grande supportrice de l'ex-candidate présidentielle Hillar
decoded_preds ["Eva Longoria s'est confiée sur le bonheur trouvé dans le bras de José Baston", '3 exercices de respiration simples à mettre en oeuvre pour se détendre']
decoded_labels ['Avec Pepe, Eva Longoria file le parfait amour', '3 exercices de respiration qui vont vous sauver en cas de coup de stress']
input_seq Le kaki fait son grand come-back dans notre dressing. Par petites touches ou en total look, voici 20 tenues repérées sur Pinterest pour être stylée en kaki.. Un blouson satiné kaki avec une jupe fleur
decoded_preds ['20 tenues pour être stylée en kaki', 'La tuerie de Las Vegas relance le débat sur le contrôle des armes à feu aux Etats-Unis']
decoded_labels ['Pinterest : 20 façons de porter du kaki ce printemps', 'Fusillades: Les Etats-Unis pays développé le plus meurtrier au monde']
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- PyTorch version (GPU):
- Using GPU in script?:
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
pytorch-transformers
## Checklist
- [√ ] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [√ ] I checked if a related official extension example runs on my machine.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13137/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13136 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13136/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13136/comments | https://api.github.com/repos/huggingface/transformers/issues/13136/events | https://github.com/huggingface/transformers/pull/13136 | 971,392,559 | MDExOlB1bGxSZXF1ZXN0NzEzMTM5NDM4 | 13,136 | Correct & simplify check_dummies regex | {
"login": "cosine0",
"id": 14046775,
"node_id": "MDQ6VXNlcjE0MDQ2Nzc1",
"avatar_url": "https://avatars.githubusercontent.com/u/14046775?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cosine0",
"html_url": "https://github.com/cosine0",
"followers_url": "https://api.github.com/users/cosine0/followers",
"following_url": "https://api.github.com/users/cosine0/following{/other_user}",
"gists_url": "https://api.github.com/users/cosine0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cosine0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cosine0/subscriptions",
"organizations_url": "https://api.github.com/users/cosine0/orgs",
"repos_url": "https://api.github.com/users/cosine0/repos",
"events_url": "https://api.github.com/users/cosine0/events{/privacy}",
"received_events_url": "https://api.github.com/users/cosine0/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,633 | 1,633 | NONE | null | # What does this PR do?
Add necessary `\` escapes omitted for `()` and remove unnecessary `\` in the check_dummies' code matching regex.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13136/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13136",
"html_url": "https://github.com/huggingface/transformers/pull/13136",
"diff_url": "https://github.com/huggingface/transformers/pull/13136.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13136.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13135 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13135/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13135/comments | https://api.github.com/repos/huggingface/transformers/issues/13135/events | https://github.com/huggingface/transformers/issues/13135 | 971,237,068 | MDU6SXNzdWU5NzEyMzcwNjg= | 13,135 | dtype | {
"login": "tshi04",
"id": 15058453,
"node_id": "MDQ6VXNlcjE1MDU4NDUz",
"avatar_url": "https://avatars.githubusercontent.com/u/15058453?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tshi04",
"html_url": "https://github.com/tshi04",
"followers_url": "https://api.github.com/users/tshi04/followers",
"following_url": "https://api.github.com/users/tshi04/following{/other_user}",
"gists_url": "https://api.github.com/users/tshi04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tshi04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tshi04/subscriptions",
"organizations_url": "https://api.github.com/users/tshi04/orgs",
"repos_url": "https://api.github.com/users/tshi04/repos",
"events_url": "https://api.github.com/users/tshi04/events{/privacy}",
"received_events_url": "https://api.github.com/users/tshi04/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,629 | 1,629 | 1,629 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13135/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13135/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13134 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13134/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13134/comments | https://api.github.com/repos/huggingface/transformers/issues/13134/events | https://github.com/huggingface/transformers/pull/13134 | 971,216,316 | MDExOlB1bGxSZXF1ZXN0NzEyOTk2MzA0 | 13,134 | ✨ Add PyTorch image classification example | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"repos_url": "https://api.github.com/users/nateraw/repos",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Nice!! Relevant for #13080 ",
"I'll review this PR in detail (thanks for working on this!). Regarding the fixtures for the tests, I've recently moved these files to the hf-internal-testing organization on the [hub](https://huggingface.co/hf-internal-testing). This makes it more clear, as otherwise these fixture files are also downloaded when people do a `git clone` of the library.",
"Last nit on my side: can we move the vision folder to be `image-classification`? We will have other kinds of vision examples in the future.",
"Ok, addressed most of the comments. Merging as-is for now.\r\n\r\n@NielsRogge I did not address these two items, however I can in future PRs (if need be):\r\n\r\n- Adding test data to `datasets` library. \r\n- Adjusting train/validation/test split logic. ",
"13134"
] | 1,629 | 1,630 | 1,630 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adds PyTorch image classification example. For now, it uses `torchvision.datasets.ImageFolder` to load local image folders (just like the flax image classification example). In the future, we will switch to using the `datasets` package's image folder (once it exists).
Marking as draft for now as I'm still working through cleaning up changes I made from [this example](https://github.com/nateraw/vision/tree/main/image-classification) I wrote earlier that uses `datasets` instead.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13134/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13134/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13134",
"html_url": "https://github.com/huggingface/transformers/pull/13134",
"diff_url": "https://github.com/huggingface/transformers/pull/13134.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13134.patch",
"merged_at": 1630610982000
} |
https://api.github.com/repos/huggingface/transformers/issues/13133 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13133/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13133/comments | https://api.github.com/repos/huggingface/transformers/issues/13133/events | https://github.com/huggingface/transformers/pull/13133 | 971,148,266 | MDExOlB1bGxSZXF1ZXN0NzEyOTQ2NDg0 | 13,133 | [WIP] Add Few Shot Named Entity Recognition (FSNER) model | {
"login": "sayef",
"id": 9072075,
"node_id": "MDQ6VXNlcjkwNzIwNzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/9072075?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayef",
"html_url": "https://github.com/sayef",
"followers_url": "https://api.github.com/users/sayef/followers",
"following_url": "https://api.github.com/users/sayef/following{/other_user}",
"gists_url": "https://api.github.com/users/sayef/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayef/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayef/subscriptions",
"organizations_url": "https://api.github.com/users/sayef/orgs",
"repos_url": "https://api.github.com/users/sayef/repos",
"events_url": "https://api.github.com/users/sayef/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayef/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nThanks for your contribution! Looking at the code, I'm not sure whether there's a need to add an entire new model for it that includes a modeling file, tokenizer, etc., as the model itself is a just a BERT model, and one can just use `BertTokenizer` to prepare data for the model. The only differences are the `get_start_end_token_scores` and `extract_entity_from_scores` \r\nmethods.\r\n\r\nSo personally, I'd opt to:\r\n- upload the model's weights to the hub under the \"microsoft\" namespace. I see you've already uploaded them under your own name, so we can transfer or copy them for you.\r\n- add a Colab notebook or script under the [research_projects](https://github.com/huggingface/transformers/tree/master/examples/research_projects) directory, that illustrates how FSNER works. ",
"Thanks for your kind reviews and replies. I would like to start with @NielsRogge 's comment. \r\n\r\n- The `get_start_end_token_scores ` method is actually the few shot prediction method. The training method is almost similar (which is not yet included), returning the entity start/end span probability and off-course the proposed loss function etc. Because of the extra special tokens i.e. [E], and [/E] the tokenizer has some modifications inside. Well, end users also can do that by themselves.\r\n\r\n- On the other hand, the `extract_entity_from_scores` method is responsible for choosing the best spans from the start/end probabilities like answer span selection process in question answering task.\r\n\r\n- At the end, we actually achieve a fine-tuned BERT model ready for few-shot named entity recognition task. \r\n\r\nNow, what I am confused about is, how you maintain/support a new model which is not a variation of transformer model, rather uses pretrained BERT model and fine-tunes on new task and data, for example, BertForQuestionAnswering. It would be best, in my opinion, if we could work on something like that, BertForFSNER or something similar.\r\n\r\nIt's totally okay for me to support the model in any format, i.e., new model, colab script or what I discussed above.\r\n\r\nFor your comprehension of the model, I am attaching the class I wrote when I started implementing the proposed architecture.\r\n\r\n<details><summary>FSNER Prototype Code</summary>\r\n<p>\r\n\r\n```python\r\nclass FSNER(nn.Module):\r\n def __init__(self, model_name='bert-base-uncased'):\r\n super(FSNER, self).__init__()\r\n # declare bert tokenizer\r\n self.tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')\r\n # add special tokens for enity boundaries\r\n self.tokenizer.add_special_tokens({'additional_special_tokens': ['[E]','[/E]']})\r\n \r\n # get enitity start and end token ids\r\n self.start_token_id, self.end_token_id = tuple(self.tokenizer.convert_tokens_to_ids(['[E]','[/E]']))\r\n \r\n # declare bert model\r\n self.bert = BertModel.from_pretrained(model_name, return_dict=True)\r\n \r\n # resize model token embeddings\r\n self.bert.resize_token_embeddings(len(self.tokenizer))\r\n\r\n # cosine sim\r\n self.cos = torch.nn.CosineSimilarity(3, 1e-08)\r\n \r\n # softmax\r\n self.softmax = torch.nn.Softmax(dim=1)\r\n \r\n def BERT(self, **inputs):\r\n return self.bert(**inputs).last_hidden_state\r\n \r\n def VectorSum(self, token_embeddings):\r\n return token_embeddings.sum(2, keepdim=True)\r\n \r\n def Atten(self, q_rep, S_rep, T=1):\r\n return self.softmax(T*self.cos(q_rep, S_rep))\r\n \r\n def tokenize(self, x):\r\n return self.tokenizer(x, padding='max_length', max_length=384, truncation=True, return_tensors=\"pt\", return_offsets_mapping=True)\r\n \r\n def save(self):\r\n self.bert.save_pretrained('./fsner-bert-base-uncased/')\r\n\r\n def forward(self, W_query, W_supports):\r\n \r\n q = self.BERT(**W_query)\r\n S = self.BERT(**W_supports)\r\n \r\n # reshape from (batch_size, 384, 784) to (batch_size, 1, 384, 784)\r\n q = q.view(q.shape[0], -1, q.shape[1], q.shape[2])\r\n \r\n # reshape from (batch_size*n_exaples_per_entity, 384, 784) to (batch_size, n_exaples_per_entity, 384, 784)\r\n S = S.view(q.shape[0], -1, S.shape[1], S.shape[2])\r\n \r\n q_rep = self.VectorSum(q)\r\n S_rep = self.VectorSum(S)\r\n \r\n s_start = S[(W_supports['input_ids'] == self.start_token_id).view(S.shape[:3])].view(S.shape[0], -1, 1, S.shape[-1])\r\n s_end = S[(W_supports['input_ids'] == self.end_token_id).view(S.shape[:3])].view(S.shape[0], -1, 1, S.shape[-1])\r\n \r\n atten = self.Atten(q_rep, S_rep)\r\n \r\n P_start = torch.sum(atten * torch.einsum(\"bitf,bejf->bet\", q, s_start), dim=1)\r\n P_end = torch.sum(atten * torch.einsum(\"bitf,bejf->bet\", q, s_end), dim=1)\r\n \r\n \r\n return P_start, P_end\r\n \r\n def decode(self, ids, skip_special_tokens=True):\r\n return self.tokenizer.decode(ids, skip_special_tokens=skip_special_tokens) \r\n```\r\nAs you can see, the forward method takes in BERT pretrained model and does some calculations to provide span predictions. \r\n</p>\r\n</details>\r\n\r\n",
"The [research_projects folder](https://github.com/huggingface/transformers/tree/master/examples/research_projects) is typically used for models that introduce a new technique or model based BERT. Examples are Performer, LXMERT, etc. \r\n\r\nAs mentioned there, they are not actively maintained, one just needs to specify a requirements.txt file, together with a script or Colab notebook. So perhaps you can make a Colab notebook in which you define the `nn.Module` as shown in your prototype above, and illustrate how the model works to perform few-shot NER. You can also fill in the README of that folder as you like.\r\n\r\nDoes that work for you?\r\n\r\n",
"> The [research_projects folder](https://github.com/huggingface/transformers/tree/master/examples/research_projects) is typically used for models that introduce a new technique or model based BERT. Examples are Performer, LXMERT, etc.\r\n> \r\n> As mentioned there, they are not actively maintained, one just needs to specify a requirements.txt file, together with a script or Colab notebook. So perhaps you can make a Colab notebook in which you define the `nn.Module` as shown in your prototype above, and illustrate how the model works to perform few-shot NER. You can also fill in the README of that folder as you like.\r\n> \r\n> Does that work for you?\r\n\r\n- Yeah, that works for me. I just want to keep the trained model's weights and tokenizer under my namespace, since they are not officially from Microsoft. And I also plan to add other BERT variation based fsner. So, I would prefer to keep those under my namespace, if that's not an issue for you.\r\n- So, should I/you close this PR and open a new PR with the suggested procedures you mentioned above?",
"> I just want to keep the trained model's weights and tokenizer under my namespace, since they are not officially from Microsoft. And I also plan to add other BERT variation based fsner. So, I would prefer to keep those under my namespace, if that's not an issue for you.\r\n\r\nMakes sense!\r\n\r\n> So, should I/you close this PR and open a new PR with the suggested procedures you mentioned above?\r\n\r\nYes, indeed. You can perhaps take a look at other research projects to get some inspiration :) ",
"Thanks for your help. Will talk to you in other PR."
] | 1,629 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
- This PR adds a new model FSNER (few shot named entity recognition) which has been implemented and trained based on the paper: [Example-Based Named Entity Recognition](https://arxiv.org/abs/2008.10570) from the researches in Microsoft Dynamics 365 AI.
- It includes only FSNERModel, not any other derivations, i.e., MaskedLM, ForQuestionAnswering etc.
- Doc strings are also updated, but not sure how it would appear visually.
- No additional tests are included.
<details><summary>Usage Example</summary>
<p>
```
from transformers import FSNERModel, FSNERTokenizerFast, FSNERTokenizer
device = 'cpu'
fsner_model = FSNERModel.from_pretrained("sayef/fsner-bert-base-uncased").to(device)
fsner_tokenizer = FSNERTokenizer.from_pretrained("sayef/fsner-bert-base-uncased")
# size of query and supports must be same. If you want to find all the entitites in one particular query, just repeat same query n times where n is the size of supports (or entities).
query = [
'KWE 4000 can reach with a maximum speed from up to 450 P/min an accuracy from 50 mg',
'I would like to order a computer from eBay.',
]
# each list in supports are the examples of one entity type
supports = [
[
'Horizontal flow wrapper [E] Pack 403 [/E] features the new retrofit-kit „paper-ON-form“',
'[E] Paloma Pick-and-Place-Roboter [/E] arranges the bakery products for the downstream tray-forming equipment'
,
'Finally, the new [E] Kliklok ACE [/E] carton former forms cartons and trays without the use of glue',
'We set up our pilot plant with the right [E] FibreForm® [/E] configuration to make prototypes for your marketi
ng tests and package validation',
'The [E] CAR-T5 [/E] is a reliable, purely mechanically driven cartoning machine for versatile application fiel
ds'
],
[
"[E] Walmart [/E] is a leading e-commerce company",
"I recently ordered a book from [E] Amazon [/E]",
"I ordered this from [E] ShopClues [/E]",
"Fridge can be ordered in [E] Amazon [/E]",
"[E] Flipkart [/E] started it's journey from zero"
]
]
def tokenize(x):
return fsner_tokenizer(x, padding='max_length', max_length=384, truncation=True, return_tensors="pt")
W_query = tokenize(query).to(device)
W_supports = tokenize([s for support in supports for s in support]).to(device)
start_prob, end_prob = fsner_model.get_start_end_token_scores(W_query, W_supports)
output = fsner_tokenizer.extract_entity_from_scores(query, W_query, start_prob, end_prob, thresh=0.50)
print(output)
```
</p>
</details>
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@LysandreJik @stas00 @sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13133/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13133/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13133",
"html_url": "https://github.com/huggingface/transformers/pull/13133",
"diff_url": "https://github.com/huggingface/transformers/pull/13133.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13133.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13132 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13132/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13132/comments | https://api.github.com/repos/huggingface/transformers/issues/13132/events | https://github.com/huggingface/transformers/pull/13132 | 971,143,590 | MDExOlB1bGxSZXF1ZXN0NzEyOTQzMDg4 | 13,132 | Fix the loss calculation of ProphetNet | {
"login": "StevenTang1998",
"id": 37647985,
"node_id": "MDQ6VXNlcjM3NjQ3OTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/37647985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StevenTang1998",
"html_url": "https://github.com/StevenTang1998",
"followers_url": "https://api.github.com/users/StevenTang1998/followers",
"following_url": "https://api.github.com/users/StevenTang1998/following{/other_user}",
"gists_url": "https://api.github.com/users/StevenTang1998/gists{/gist_id}",
"starred_url": "https://api.github.com/users/StevenTang1998/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StevenTang1998/subscriptions",
"organizations_url": "https://api.github.com/users/StevenTang1998/orgs",
"repos_url": "https://api.github.com/users/StevenTang1998/repos",
"events_url": "https://api.github.com/users/StevenTang1998/events{/privacy}",
"received_events_url": "https://api.github.com/users/StevenTang1998/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the fix here @StevenTang1998 - did you succesfully run a ProphetNet fine-tuning with this fix? :-)",
"Yes, I have the very close results of my pr and that of the code to calculate loss manually.",
"That sounds great! \r\nI'm running the training command:\r\n\r\n```\r\npython examples/pytorch/summarization/run_summarization.py --learning_rate=3e-5 --do_train --do_eval --evaluation_strategy steps --model_name_or_path microsoft/prophetnet-large-uncased --output_dir myoutputdir --per_device_train_batch_size 8 --per_device_eval_batch_size 16 --eval_accumulation_steps 8 --gradient_accumulation_steps 8 --num_train_epochs=20 --load_best_model_at_end --save_steps 25 --logging_steps 25 --fp16 --overwrite_output_dir --dataset_name cnn_dailymail --dataset_config_name 3.0.0\r\n```\r\n\r\non a single GPU once to verify that training works :-) Will let you know how it goes!",
"I've run training for 5h and the loss goes down nicely which is a very good sign! Maybe this is the long-awaited ProphetNet fix :partying_face: \r\n\r\nMerging!"
] | 1,629 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #9804
## Before submitting
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13132/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13132",
"html_url": "https://github.com/huggingface/transformers/pull/13132",
"diff_url": "https://github.com/huggingface/transformers/pull/13132.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13132.patch",
"merged_at": 1629450114000
} |
https://api.github.com/repos/huggingface/transformers/issues/13131 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13131/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13131/comments | https://api.github.com/repos/huggingface/transformers/issues/13131/events | https://github.com/huggingface/transformers/pull/13131 | 971,132,308 | MDExOlB1bGxSZXF1ZXN0NzEyOTM0NjMx | 13,131 | [WIP] Add Few Shot Named Entity Recognition (FSNER) model | {
"login": "sayef",
"id": 9072075,
"node_id": "MDQ6VXNlcjkwNzIwNzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/9072075?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayef",
"html_url": "https://github.com/sayef",
"followers_url": "https://api.github.com/users/sayef/followers",
"following_url": "https://api.github.com/users/sayef/following{/other_user}",
"gists_url": "https://api.github.com/users/sayef/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayef/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayef/subscriptions",
"organizations_url": "https://api.github.com/users/sayef/orgs",
"repos_url": "https://api.github.com/users/sayef/repos",
"events_url": "https://api.github.com/users/sayef/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayef/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,629 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
- This PR adds a new model FSNER (few shot named entity recognition) which has been implemented and trained based on the paper: [Example-Based Named Entity Recognition](https://arxiv.org/abs/2008.10570) from the researches in Microsoft Dynamics 365 AI.
- It includes only FSNERModel, not any other derivations, i.e., MaskedLM, ForQuestionAnswering etc.
- Doc strings are also updated, but not sure how it would appear visually.
- No additional tests are included.
<details><summary>Usage Example</summary>
<p>
```
from transformers import FSNERModel, FSNERTokenizerFast, FSNERTokenizer
device = 'cpu'
fsner_model = FSNERModel.from_pretrained("sayef/fsner-bert-base-uncased").to(device)
fsner_tokenizer = FSNERTokenizer.from_pretrained("sayef/fsner-bert-base-uncased")
# size of query and supports must be same. If you want to find all the entitites in one particular query, just repeat same query n times where n is the size of supports (or entities).
query = [
'KWE 4000 can reach with a maximum speed from up to 450 P/min an accuracy from 50 mg',
'I would like to order a computer from eBay.',
]
# each list in supports are the examples of one entity type
supports = [
[
'Horizontal flow wrapper [E] Pack 403 [/E] features the new retrofit-kit „paper-ON-form“',
'[E] Paloma Pick-and-Place-Roboter [/E] arranges the bakery products for the downstream tray-forming equipment'
,
'Finally, the new [E] Kliklok ACE [/E] carton former forms cartons and trays without the use of glue',
'We set up our pilot plant with the right [E] FibreForm® [/E] configuration to make prototypes for your marketi
ng tests and package validation',
'The [E] CAR-T5 [/E] is a reliable, purely mechanically driven cartoning machine for versatile application fiel
ds'
],
[
"[E] Walmart [/E] is a leading e-commerce company",
"I recently ordered a book from [E] Amazon [/E]",
"I ordered this from [E] ShopClues [/E]",
"Fridge can be ordered in [E] Amazon [/E]",
"[E] Flipkart [/E] started it's journey from zero"
]
]
def tokenize(x):
return fsner_tokenizer(x, padding='max_length', max_length=384, truncation=True, return_tensors="pt")
W_query = tokenize(query).to(device)
W_supports = tokenize([s for support in supports for s in support]).to(device)
start_prob, end_prob = fsner_model.get_start_end_token_scores(W_query, W_supports)
output = fsner_tokenizer.extract_entity_from_scores(query, W_query, start_prob, end_prob, thresh=0.50)
print(output)
```
</p>
</details>
Would like to have attention of @LysandreJik, @stas00, @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13131/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13131",
"html_url": "https://github.com/huggingface/transformers/pull/13131",
"diff_url": "https://github.com/huggingface/transformers/pull/13131.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13131.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13130 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13130/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13130/comments | https://api.github.com/repos/huggingface/transformers/issues/13130/events | https://github.com/huggingface/transformers/pull/13130 | 971,073,663 | MDExOlB1bGxSZXF1ZXN0NzEyODkxOTI1 | 13,130 | [Flax] Add logging steps, eval steps, and save steps for hybrid CLIP example | {
"login": "galuhsahid",
"id": 10180442,
"node_id": "MDQ6VXNlcjEwMTgwNDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/10180442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galuhsahid",
"html_url": "https://github.com/galuhsahid",
"followers_url": "https://api.github.com/users/galuhsahid/followers",
"following_url": "https://api.github.com/users/galuhsahid/following{/other_user}",
"gists_url": "https://api.github.com/users/galuhsahid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galuhsahid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galuhsahid/subscriptions",
"organizations_url": "https://api.github.com/users/galuhsahid/orgs",
"repos_url": "https://api.github.com/users/galuhsahid/repos",
"events_url": "https://api.github.com/users/galuhsahid/events{/privacy}",
"received_events_url": "https://api.github.com/users/galuhsahid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@galuhsahid could you run `make style` that will fix the failing test. Thanks :) ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"gently pinging @galuhsahid :) ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,629 | 1,635 | 1,635 | NONE | null | # What does this PR do?
This PR enables users to set `logging_steps`, `eval_steps`, and `save_steps` when training a model using the Hybrid CLIP example. `logging_steps` helps to keep the train_metrics small so that we can avoid fragmentation errors. `eval_steps` and `save_steps` enables users to save evaluation results and model checkpoints based on steps instead of epochs which may run for days especially when using large datasets.
Discussed in #13095
## Notes
I'd like to have input on the following:
- I've tested the script using the same dataset as the one described in the readme. The run can be found on [tensorboard.dev](https://tensorboard.dev/experiment/WH8xEX25RVavnizS4VaU8Q/#scalars). I'm not sure if I should update the tensorboard in the readme or not.
- I'm also not sure if we should save the final model once the training is done, or only save the model based on the steps only. Right now the script also saves the final model after the whole training is done.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case. Yes, discussed in #13095
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13130/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13130",
"html_url": "https://github.com/huggingface/transformers/pull/13130",
"diff_url": "https://github.com/huggingface/transformers/pull/13130.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13130.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13129 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13129/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13129/comments | https://api.github.com/repos/huggingface/transformers/issues/13129/events | https://github.com/huggingface/transformers/pull/13129 | 971,066,879 | MDExOlB1bGxSZXF1ZXN0NzEyODg2OTYy | 13,129 | Fix classifier dropout in bertForMultipleChoice | {
"login": "mandelbrot-walker",
"id": 49194488,
"node_id": "MDQ6VXNlcjQ5MTk0NDg4",
"avatar_url": "https://avatars.githubusercontent.com/u/49194488?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandelbrot-walker",
"html_url": "https://github.com/mandelbrot-walker",
"followers_url": "https://api.github.com/users/mandelbrot-walker/followers",
"following_url": "https://api.github.com/users/mandelbrot-walker/following{/other_user}",
"gists_url": "https://api.github.com/users/mandelbrot-walker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mandelbrot-walker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mandelbrot-walker/subscriptions",
"organizations_url": "https://api.github.com/users/mandelbrot-walker/orgs",
"repos_url": "https://api.github.com/users/mandelbrot-walker/repos",
"events_url": "https://api.github.com/users/mandelbrot-walker/events{/privacy}",
"received_events_url": "https://api.github.com/users/mandelbrot-walker/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,629 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
Fix as per [PR#13087](https://github.com/huggingface/transformers/pull/13087)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13129/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13129",
"html_url": "https://github.com/huggingface/transformers/pull/13129",
"diff_url": "https://github.com/huggingface/transformers/pull/13129.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13129.patch",
"merged_at": 1629101857000
} |
https://api.github.com/repos/huggingface/transformers/issues/13128 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13128/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13128/comments | https://api.github.com/repos/huggingface/transformers/issues/13128/events | https://github.com/huggingface/transformers/pull/13128 | 971,003,049 | MDExOlB1bGxSZXF1ZXN0NzEyODQyNDkw | 13,128 | Fix missing `seq_len` in `electra` model when `inputs_embeds` is used. | {
"login": "sararb",
"id": 17721108,
"node_id": "MDQ6VXNlcjE3NzIxMTA4",
"avatar_url": "https://avatars.githubusercontent.com/u/17721108?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sararb",
"html_url": "https://github.com/sararb",
"followers_url": "https://api.github.com/users/sararb/followers",
"following_url": "https://api.github.com/users/sararb/following{/other_user}",
"gists_url": "https://api.github.com/users/sararb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sararb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sararb/subscriptions",
"organizations_url": "https://api.github.com/users/sararb/orgs",
"repos_url": "https://api.github.com/users/sararb/repos",
"events_url": "https://api.github.com/users/sararb/events{/privacy}",
"received_events_url": "https://api.github.com/users/sararb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"LGTM! Did you verify that it works now?",
"Thanks a lot for the PR @sararb !"
] | 1,628 | 1,629 | 1,629 | CONTRIBUTOR | null | ## Before submitting
- [x] This PR Fixes a small bug discussed in #[13122](https://github.com/huggingface/transformers/issues/13122)
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj, @NielsRogge
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13128/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13128/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13128",
"html_url": "https://github.com/huggingface/transformers/pull/13128",
"diff_url": "https://github.com/huggingface/transformers/pull/13128.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13128.patch",
"merged_at": 1629131768000
} |
https://api.github.com/repos/huggingface/transformers/issues/13127 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13127/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13127/comments | https://api.github.com/repos/huggingface/transformers/issues/13127/events | https://github.com/huggingface/transformers/issues/13127 | 970,955,682 | MDU6SXNzdWU5NzA5NTU2ODI= | 13,127 | RuntimeError: Error(s) in loading state_dict for BeitForImageClassification: size mismatch for classifier.weight | {
"login": "dnnxl",
"id": 51223285,
"node_id": "MDQ6VXNlcjUxMjIzMjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/51223285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dnnxl",
"html_url": "https://github.com/dnnxl",
"followers_url": "https://api.github.com/users/dnnxl/followers",
"following_url": "https://api.github.com/users/dnnxl/following{/other_user}",
"gists_url": "https://api.github.com/users/dnnxl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dnnxl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dnnxl/subscriptions",
"organizations_url": "https://api.github.com/users/dnnxl/orgs",
"repos_url": "https://api.github.com/users/dnnxl/repos",
"events_url": "https://api.github.com/users/dnnxl/events{/privacy}",
"received_events_url": "https://api.github.com/users/dnnxl/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nThanks to #12664, it's now possible to load a fine-tuned checkpoint and replace the head which has a different number of classes, by setting `ignore_mismatched_sizes` to `True` when calling the `from_pretrained` method, like so:\r\n\r\n```\r\nfrom transformers import BeitForImageClassification\r\n\r\nmodel = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-224', num_labels=2, ignore_mismatched_sizes=True)\r\n```\r\nThis prints the warning:\r\n\r\n```\r\nSome weights of BeitForImageClassification were not initialized from the model checkpoint at microsoft/beit-base-patch16-224 and are newly initialized because the shapes did not match:\r\n- classifier.weight: found shape torch.Size([1000, 768]) in the checkpoint and torch.Size([2, 768]) in the model instantiated\r\n- classifier.bias: found shape torch.Size([1000]) in the checkpoint and torch.Size([2]) in the model instantiated\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n```\r\n\r\nFrom that PR, I see that only in `modeling_flax_utils.py` users get an error message that says \"use ignore_mismatched_sizes if you really want to load this checkpoint inside this model.\" in case not all keys match. Not sure why this suggestion is not printed for PyTorch models. cc @sgugger ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"size mismatch for model.classifier.weight: copying a param with shape torch.Size([555, 2208]) from checkpoint, the shape in current model is torch.Size([563, 2208]).\r\n\tsize mismatch for model.classifier.bias: copying a param with shape torch.Size([555]) from checkpoint, the shape in current model is torch.Size([563]).\r\n"
] | 1,628 | 1,665 | 1,632 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
Hi trying to run the BEiTForImageClassification with a custom dataset for a binary classification problem in Google Colab and got the following "RuntimeError: Error(s) in loading state_dict for BeitForImageClassification: size mismatch for classifier.weight and classifier.bias". Seems like the last layer doesn't match with the binary output, instead is mapping to the number of 1000 classes from the ImageNet trained. Any suggestion on how to fix it?
- `transformers` version: 4.10.0
- Platform: Google Colab
Models:
- nielsr/beit-base-patch16-224
## To reproduce
Steps to reproduce the behavior:
Based on https://huggingface.co/nielsr/beit-base-patch16-224.
1. Run and using the following code
` ` `
feature_extractor = BeitFeatureExtractor.from_pretrained('nielsr/beit-base-patch16-224')
model = BeitForImageClassification.from_pretrained('nielsr/beit-base-patch16-224', num_labels =2, label2id=label2id, id2label=id2label)
` ` `
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
` ` `
RuntimeError: Error(s) in loading state_dict for BeitForImageClassification:
size mismatch for classifier.weight: copying a param with shape torch.Size([1000, 768]) from checkpoint, the shape in current model is torch.Size([2, 768]).
size mismatch for classifier.bias: copying a param with shape torch.Size([1000]) from checkpoint, the shape in current model is torch.Size([2]).
` ` ` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13127/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13127/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13126 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13126/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13126/comments | https://api.github.com/repos/huggingface/transformers/issues/13126/events | https://github.com/huggingface/transformers/issues/13126 | 970,798,832 | MDU6SXNzdWU5NzA3OTg4MzI= | 13,126 | torch.jit.trace quantized bigbird leads to 0INTERNAL ASSERT FAILED runtime error | {
"login": "matthiaslmz",
"id": 19335932,
"node_id": "MDQ6VXNlcjE5MzM1OTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/19335932?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/matthiaslmz",
"html_url": "https://github.com/matthiaslmz",
"followers_url": "https://api.github.com/users/matthiaslmz/followers",
"following_url": "https://api.github.com/users/matthiaslmz/following{/other_user}",
"gists_url": "https://api.github.com/users/matthiaslmz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/matthiaslmz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/matthiaslmz/subscriptions",
"organizations_url": "https://api.github.com/users/matthiaslmz/orgs",
"repos_url": "https://api.github.com/users/matthiaslmz/repos",
"events_url": "https://api.github.com/users/matthiaslmz/events{/privacy}",
"received_events_url": "https://api.github.com/users/matthiaslmz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Uff trying to `torch.jit(...)` our most complex model BigBird won't be easy I think :-/ Sadly I won't find time to dig deeper into this as it will require a lot of work :-/ Could you maybe try to go wiht `Longformer` for now?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@patrickvonplaten Sadly this error is also raised for me when actually using Longformer.",
"In Longformer, looks like this bug comes from this single line: https://github.com/huggingface/transformers/blob/ee6674d45030161d8d60533b7d469a727d492113/src/transformers/models/longformer/modeling_longformer.py#L1573\r\n```\r\n attention_mask = nn.functional.pad(\r\n attention_mask, (0, padding_len), value=False # <-- should be 0\r\n ) # no attention on the padding tokens\r\n```\r\n`nn.functional.pad` expects a number, not a boolean, value\r\n\r\nIn BigBird, the same bug is here:\r\nhttps://github.com/huggingface/transformers/blob/ee6674d45030161d8d60533b7d469a727d492113/src/transformers/models/big_bird/modeling_big_bird.py#L2252\r\n\r\n",
"Great catch @dadamson - if you want feel free to open a PR for it :-)"
] | 1,628 | 1,639 | 1,632 | CONTRIBUTOR | null | Attempt to torch jit trace and save a quantized bigbird model leads to 0INTERNAL ASSERT FAILED runtime error.
I also ran the same code for BERT and RoBERTa (see `example.ipynb`) but did not encounter the same issue and was able to trace the quantized models for both respectively.
## To Reproduce
Steps to reproduce the behavior:
1. Git clone this [repo](https://github.com/matthiaslmz/quantized_bigbird_issue)
2. Run `example.ipynb`
### Stacktrace:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-4-1dfdd2340788> in <module>
4 )
5
----> 6 traced_model = torch.jit.trace(model, (input_ids, attention_mask))
7 torch.jit.save(traced_model, "traced_bigbird.pt")
/opt/conda/lib/python3.7/site-packages/torch/jit/_trace.py in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
742 strict,
743 _force_outplace,
--> 744 _module_class,
745 )
746
/opt/conda/lib/python3.7/site-packages/torch/jit/_trace.py in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit)
957 strict,
958 _force_outplace,
--> 959 argument_names,
960 )
961 check_trace_method = module._c._get_method(method_name)
RuntimeError: 0INTERNAL ASSERT FAILED at "/pytorch/torch/csrc/jit/ir/alias_analysis.cpp":532, please report a bug to PyTorch. We don't have an op for aten::constant_pad_nd but it isn't a special case. Argument types: Tensor, int[], bool,
```
## Expected behavior
Quantized bigbird should be able to be saved.
## Environment
- PyTorch Version: 1.9.0+cu111
- Transformers Version: 4.9.1
- OS: Debian GNU/Linux 10 (buster)
- Python version: 3.7.9
- CUDA/cuDNN version: 11.0.194
- GPU models and configuration: NVIDIA Tesla V100 16GB
### Who can help
@patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13126/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13126/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13125 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13125/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13125/comments | https://api.github.com/repos/huggingface/transformers/issues/13125/events | https://github.com/huggingface/transformers/issues/13125 | 970,790,566 | MDU6SXNzdWU5NzA3OTA1NjY= | 13,125 | type object 'AutoModelForSequenceClassification' has no attribute 'from_config' | {
"login": "Sujeeth-Shetty",
"id": 55334425,
"node_id": "MDQ6VXNlcjU1MzM0NDI1",
"avatar_url": "https://avatars.githubusercontent.com/u/55334425?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sujeeth-Shetty",
"html_url": "https://github.com/Sujeeth-Shetty",
"followers_url": "https://api.github.com/users/Sujeeth-Shetty/followers",
"following_url": "https://api.github.com/users/Sujeeth-Shetty/following{/other_user}",
"gists_url": "https://api.github.com/users/Sujeeth-Shetty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sujeeth-Shetty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sujeeth-Shetty/subscriptions",
"organizations_url": "https://api.github.com/users/Sujeeth-Shetty/orgs",
"repos_url": "https://api.github.com/users/Sujeeth-Shetty/repos",
"events_url": "https://api.github.com/users/Sujeeth-Shetty/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sujeeth-Shetty/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! I just tried the following code snippet in both `v4.9.2` and `v4.4.2` and both seem to work:\r\n\r\n```py\r\nfrom transformers import AutoConfig, AutoTokenizer, AutoModel, AutoModelForSequenceClassification, Trainer, TrainingArguments\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(\"distilbert-base-uncased\")\r\nconfig = AutoConfig.from_pretrained('distilbert-base-uncased', num_labels=2)\r\n\r\nAutoModelForSequenceClassification.from_config(config)\r\n```\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | I'm using Transformer version 4.4.2 and have been getting "type object 'AutoModelForSequenceClassification' has no attribute 'from_config'" error. Here is my code snippet. I went through the document, the syntax seem to be correct. Your help is very much appreciated.
from transformers import AutoConfig, AutoTokenizer, AutoModel, AutoModelForSequenceClassification, Trainer, TrainingArguments
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
config = AutoConfig.from_pretrained('distilbert-base-uncased', num_labels=2)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13125/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13124 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13124/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13124/comments | https://api.github.com/repos/huggingface/transformers/issues/13124/events | https://github.com/huggingface/transformers/issues/13124 | 970,781,867 | MDU6SXNzdWU5NzA3ODE4Njc= | 13,124 | You must login to the Hugging Face hub on this computer by typing `transformers-cli login` and entering your credentials to use `use_auth_token=True`. Alternatively, you can pass your own token as the `use_auth_token` argument in the translation notebook. | {
"login": "Azitt",
"id": 32965166,
"node_id": "MDQ6VXNlcjMyOTY1MTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/32965166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Azitt",
"html_url": "https://github.com/Azitt",
"followers_url": "https://api.github.com/users/Azitt/followers",
"following_url": "https://api.github.com/users/Azitt/following{/other_user}",
"gists_url": "https://api.github.com/users/Azitt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Azitt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Azitt/subscriptions",
"organizations_url": "https://api.github.com/users/Azitt/orgs",
"repos_url": "https://api.github.com/users/Azitt/repos",
"events_url": "https://api.github.com/users/Azitt/events{/privacy}",
"received_events_url": "https://api.github.com/users/Azitt/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"In order to be able to push to model to the hub after training, make sure to follow these steps:\r\n\r\nAdd the following arguments to `TrainingArguments`:\r\n```\r\npush_to_hub=True,\r\npush_to_hub_model_id=\"name of your model\" # optional, will default to the name of your output directory\r\npush_to_hub_organization=\"name of the organization to which to upload the model\" # optional\r\npush_to_hub_token=\"your authentication token\"\r\n```\r\n\r\n=> your authentication token can be obtained by typing `!huggingface-cli login` in Colab/in a terminal to get your authentication token stored in local cache. Actually, you don't need to pass the `push_to_hub_token` argument, as it will default to the token in the cache folder as stated in the [docs](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments).\r\n\r\nAlso, make sure git LFS is installed, as this is required to upload your model to the hub. In Colab, you can do this as follows:\r\n\r\n```\r\n!sudo apt-get install git-lfs\r\n!git config --global user.email \"your email address\"\r\n# Tip: using the same email than for your huggingface.co account will link your commits to your profile\r\n!git config --global user.name \"your username\"\r\n```",
"Thank you! "
] | 1,628 | 1,629 | 1,629 | NONE | null | I'm trying to run the following but gives me this error. I made an account and login but am not sure about `transformers-cli login`. any help would be appreciated.
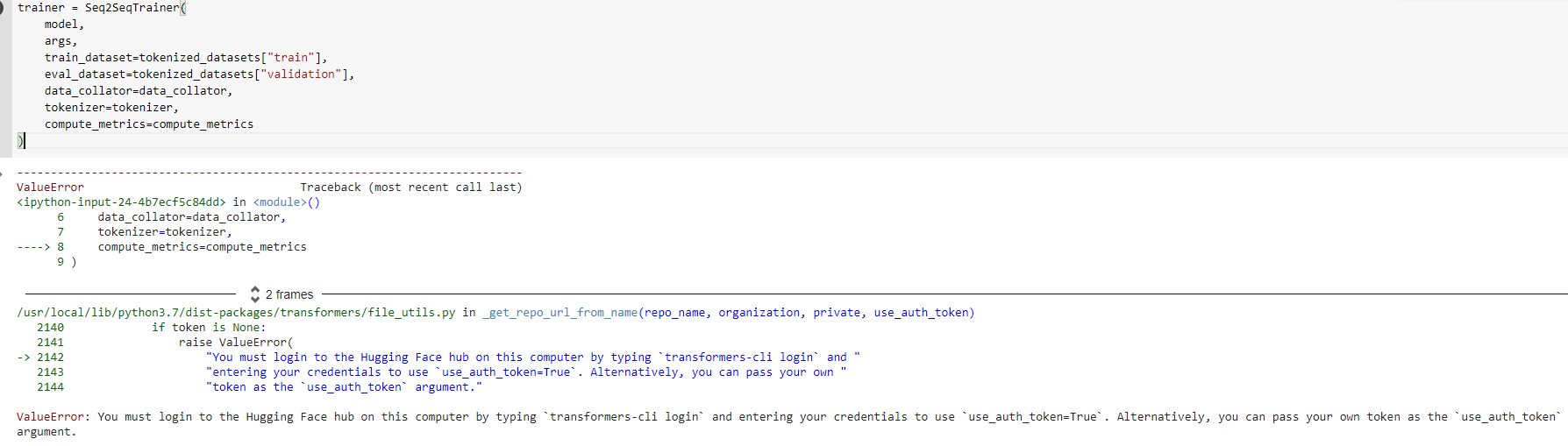
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13124/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13124/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13123 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13123/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13123/comments | https://api.github.com/repos/huggingface/transformers/issues/13123/events | https://github.com/huggingface/transformers/issues/13123 | 970,756,424 | MDU6SXNzdWU5NzA3NTY0MjQ= | 13,123 | Value error while running run_glue.py example with gpt2 | {
"login": "bpraveenk",
"id": 14226904,
"node_id": "MDQ6VXNlcjE0MjI2OTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/14226904?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bpraveenk",
"html_url": "https://github.com/bpraveenk",
"followers_url": "https://api.github.com/users/bpraveenk/followers",
"following_url": "https://api.github.com/users/bpraveenk/following{/other_user}",
"gists_url": "https://api.github.com/users/bpraveenk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bpraveenk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bpraveenk/subscriptions",
"organizations_url": "https://api.github.com/users/bpraveenk/orgs",
"repos_url": "https://api.github.com/users/bpraveenk/repos",
"events_url": "https://api.github.com/users/bpraveenk/events{/privacy}",
"received_events_url": "https://api.github.com/users/bpraveenk/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Is this the exact command you're using? I tried to reproduce but I'm getting an error with the pad token which is not defined in the GPT-2 tokenizer. Did you tweak your GPT-2 tokenizer in order to add a padding token?",
"That's the exact command I am running. The only change I did (see below) was to comment out clipnorm, to fix the error \"ValueError: Gradient clipping in the optimizer (by setting clipnorm or clipvalue) is currently unsupported when using a distribution strategy.\" \r\n\r\n- clipnorm=training_args.max_grad_norm,\r\n+ #clipnorm=training_args.max_grad_norm,",
"@LysandreJik any luck reproducing the error?",
"When I set the dataset_mode to constant_batch, I see the following error. Any idea why the logits output dimension is (batch_size, sequence_length, num_labels) and not (batch_size, num_labels) ?\r\n\r\n ValueError: Shape mismatch: The shape of labels (received (8, 1)) should equal the shape of logits except for the last dimension (received (8, 128, 3)).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.7.0
- Platform: Linux
- Python version: 3.8.1
- PyTorch version (GPU?):
- Tensorflow version (GPU?): 2.3 , GPU : yes
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?:no
Tagging people:
@patrickvonplaten, @LysandreJik, @sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): GPT2
The problem arises when using:
* [ ] the official example scripts: tensorflow/run_glue.py
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name) GLUE (MNLI/SST2)
## Error
ValueError: Dimension size must be evenly divisible by 192 but is 8 for '{{node sparse_categorical_crossentropy_2/Reshape_2}} = Reshape[T=DT_FLOAT, Tshape=DT_INT32](sparse_categorical_crossentropy_2/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits, sparse_categorical_crossentropy_2/strided_slice_1)' with input shapes: [8], [4] and with input tensors computed as partial shapes: input[1] = [2,8,12,?].
## To reproduce
python run_glue.py --model_name_or_path gpt2 --task_name mnli --do_train --do_eval --do_predict --output_dir ./output
## Expected behavior
Successfully complete training
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13123/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13123/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13122 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13122/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13122/comments | https://api.github.com/repos/huggingface/transformers/issues/13122/events | https://github.com/huggingface/transformers/issues/13122 | 970,746,537 | MDU6SXNzdWU5NzA3NDY1Mzc= | 13,122 | Electra raises UnboundLocalError: local variable 'seq_length' referenced before assignment when inputs are pre-computed embeddings | {
"login": "sararb",
"id": 17721108,
"node_id": "MDQ6VXNlcjE3NzIxMTA4",
"avatar_url": "https://avatars.githubusercontent.com/u/17721108?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sararb",
"html_url": "https://github.com/sararb",
"followers_url": "https://api.github.com/users/sararb/followers",
"following_url": "https://api.github.com/users/sararb/following{/other_user}",
"gists_url": "https://api.github.com/users/sararb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sararb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sararb/subscriptions",
"organizations_url": "https://api.github.com/users/sararb/orgs",
"repos_url": "https://api.github.com/users/sararb/repos",
"events_url": "https://api.github.com/users/sararb/events{/privacy}",
"received_events_url": "https://api.github.com/users/sararb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That's indeed a small bug. It can be fixed as follows:\r\n\r\n```diff\r\nif input_ids is not None and inputs_embeds is not None:\r\n raise ValueError(\"You cannot specify both input_ids and inputs_embeds at the same time\")\r\n elif input_ids is not None:\r\n input_shape = input_ids.size()\r\n- batch_size, seq_length = input_shape\r\n elif inputs_embeds is not None:\r\n input_shape = inputs_embeds.size()[:-1]\r\n else:\r\n raise ValueError(\"You have to specify either input_ids or inputs_embeds\")\r\n \r\n+ batch_size, seq_length = input_shape \r\n device = input_ids.device if input_ids is not None else inputs_embeds.device \r\n```\r\n\r\nBtw, I love Github's abilities to showcase this haha. Mind opening a PR to fix this?",
"Sure, I opened a PR #13128. Thank you for your reply ! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
-`transformers` version: 4.9.2
- Platform: Linux-4.15.0-15-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
Models:
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
## Information
Model I am using (ELECTRA):
The problem arises when using:
* [ ] my own modified scripts: (give details below)
I am pre-training the ELECTRA model for session-based recommendation task and directly feeding the inputs embeddings instead of their ids.
## To reproduce
Steps to reproduce the behavior:
1. Load ELECTRA model from config :
```
transformers.MODEL_MAPPING[transformers.ElectraConfig(hidden_size=d_model,
embedding_size=d_model,
num_hidden_layers=n_layer,
num_attention_heads=n_head,...)]
```
2. Apply the model to pre-computed embeddings :
``` model(inputs_embeds=inputs) ```
3. The error raised is :
```
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
batch_size, seq_length = input_shape
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
> buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
E UnboundLocalError: local variable 'seq_length' referenced before assignment
/opt/conda/lib/python3.8/site-packages/transformers/models/electra/modeling_electra.py:869: UnboundLocalError
```
## Expected behavior
- The seq_len value should also be computed when inputs are pre-computed embeddings instead of raw ids.
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13122/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13122/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13121 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13121/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13121/comments | https://api.github.com/repos/huggingface/transformers/issues/13121/events | https://github.com/huggingface/transformers/issues/13121 | 970,611,251 | MDU6SXNzdWU5NzA2MTEyNTE= | 13,121 | AutoModel KeyError: 'layoutlmv2' | {
"login": "nurgel",
"id": 55975187,
"node_id": "MDQ6VXNlcjU1OTc1MTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/55975187?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nurgel",
"html_url": "https://github.com/nurgel",
"followers_url": "https://api.github.com/users/nurgel/followers",
"following_url": "https://api.github.com/users/nurgel/following{/other_user}",
"gists_url": "https://api.github.com/users/nurgel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nurgel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nurgel/subscriptions",
"organizations_url": "https://api.github.com/users/nurgel/orgs",
"repos_url": "https://api.github.com/users/nurgel/repos",
"events_url": "https://api.github.com/users/nurgel/events{/privacy}",
"received_events_url": "https://api.github.com/users/nurgel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@NielsRogge ",
"Hello @nurgel! LayoutLM v2 is not merged yet so it isn't available in the latest version. You can follow the development here https://github.com/huggingface/transformers/pull/12604"
] | 1,628 | 1,629 | 1,629 | NONE | null | ## Environment info
- `transformers` version: 4.9.2
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
## Information
I am trying to run layoutlmv2. When I run the code from documentation:
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
I get the below error:
> KeyError Traceback (most recent call last)
> <ipython-input-7-457d9de7bf01> in <module>()
> 1 from transformers import AutoTokenizer, AutoModel
> 2
> ----> 3 tokenizer = AutoTokenizer.from_pretrained("microsoft/layoutlmv2-base-uncased")
> 4
> 5 model = AutoModel.from_pretrained("microsoft/layoutlmv2-base-uncased")
>
> /usr/local/lib/python3.7/dist-packages/transformers/models/auto/tokenization_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
> 532 if config_tokenizer_class is None:
> 533 if not isinstance(config, PretrainedConfig):
> --> 534 config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
> 535 config_tokenizer_class = config.tokenizer_class
> 536
>
> /usr/local/lib/python3.7/dist-packages/transformers/models/auto/configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
> 450 config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
> 451 if "model_type" in config_dict:
> --> 452 config_class = CONFIG_MAPPING[config_dict["model_type"]]
> 453 return config_class.from_dict(config_dict, **kwargs)
> 454 else:
>
> KeyError: 'layoutlmv2' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13121/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13120 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13120/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13120/comments | https://api.github.com/repos/huggingface/transformers/issues/13120/events | https://github.com/huggingface/transformers/pull/13120 | 970,545,433 | MDExOlB1bGxSZXF1ZXN0NzEyNDgzODk1 | 13,120 | Deberta_v2 tf | {
"login": "kamalkraj",
"id": 17096858,
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalkraj",
"html_url": "https://github.com/kamalkraj",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalkraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamalkraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalkraj/subscriptions",
"organizations_url": "https://api.github.com/users/kamalkraj/orgs",
"repos_url": "https://api.github.com/users/kamalkraj/repos",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamalkraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@Rocketknight1 \r\nhttps://github.com/huggingface/transformers/pull/12972#discussion_r684418611\r\ngather function fails while running `run_glue.py` from examples\r\n\r\n\r\nIf i replace the gather function with experimental NumPy take_along_axis works - https://gist.github.com/kamalkraj/73ad5fa2b84de7e201e05464e11a4fec\r\n ",
"Hi @kamalkraj, do you know what shape the inputs are to the gather/take_along_axis? I'm going to try to construct a small test case that fails for my gather function but not for take_along_axis. If you can find a simple test case that fails, feel free to send that too so I can fix the function!",
"Hi @Rocketknight1 \r\nI have tried few tests for `torch.gather ` when you initially shared the function. notebook link- https://colab.research.google.com/drive/1ujI6zKTuuryAO2Nfw9U1ZftyZyC4VUVS?usp=sharing",
"In all of those cases, it looks like the TF `torch_gather` function gets the same results as the actual `torch.gather`, right? Is there a difference?",
"No. TF `torch_gather` function gets the same output as `torch.gather`.\r\n\r\nActually, in runtime, this branch never gets called https://github.com/huggingface/transformers/blob/e2f07c01e93611fbd96f85204c9a2129bc81862b/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L766-L771\r\n\r\nbecause both query_layer and key_layer are of the same size\r\nhttps://github.com/huggingface/transformers/blob/e2f07c01e93611fbd96f85204c9a2129bc81862b/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L571-L572\r\n\r\n",
"Hi @BigBird01,\r\n\r\nI was going through `deberta-v2` implementation inside huggingface and as per my understanding, for `deberta-v2` the below branch will be never executed.\r\nhttps://github.com/huggingface/transformers/blob/e2f07c01e93611fbd96f85204c9a2129bc81862b/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L766\r\n\r\nBecause query_layer and key_layer shapes are -> \r\n`[batch_size * num_attention_heads, sequence_length, attention_head_size] `\r\n\r\nthe above condition may be needed for `deberta`. But Huggingface has separate implementation for `deberta` and `deberta-v2`\r\nif my assumption is correct we can remove those never executed control flow branches from the `deberta-v2` code. \r\n",
"Yes. We can remove it to make the code clear.\n\nThanks!\nPengcheng\n\nFrom: Kamal Raj ***@***.***>\nSent: Monday, August 16, 2021 1:03 PM\nTo: huggingface/transformers ***@***.***>\nCc: Pengcheng He ***@***.***>; Mention ***@***.***>\nSubject: Re: [huggingface/transformers] Deberta_v2 tf (#13120)\n\n\nHi @BigBird01<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2FBigBird01&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915898630%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=lc6grZfUDwbI8XqIUK4JLTj3W%2F2evr6AkgrG2N27TeY%3D&reserved=0>,\n\nI was going through deberta-v2 implementation inside huggingface and as per my understanding, for deberta-v2 the below branch will be never executed.\nhttps://github.com/huggingface/transformers/blob/e2f07c01e93611fbd96f85204c9a2129bc81862b/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L766<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fblob%2Fe2f07c01e93611fbd96f85204c9a2129bc81862b%2Fsrc%2Ftransformers%2Fmodels%2Fdeberta_v2%2Fmodeling_deberta_v2.py%23L766&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915898630%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=nMC317uM%2Fsa7XTmnF1bvG9Blnabdawhxuu9jayoY8GA%3D&reserved=0>\n\nBecause query_layer and key_layer shapes are ->\n[batch_size * num_attention_heads, sequence_length, attention_head_size]\n\nthe above condition may be needed for deberta. Huggingface has separate implementation for deberta and deberta-v2\nif my assumption is correct we can remove those never executed control flow branches from the deberta-v2 code.\n\n-\nYou are receiving this because you were mentioned.\nReply to this email directly, view it on GitHub<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fhuggingface%2Ftransformers%2Fpull%2F13120%23issuecomment-899782332&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915908587%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=ZWPmlym37Xufrg18IhWl9hLPiz74rzOMrqKZViwC6Bg%3D&reserved=0>, or unsubscribe<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fgithub.com%2Fnotifications%2Funsubscribe-auth%2FAJDNDRTGVQBRQ5QKLPWTKXTT5FVHVANCNFSM5CD4MTLA&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915908587%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=Jtx3lLmO%2FV7%2BUkmH6%2BJgHoLfKXgkPtDK%2FueTvkN4u%2Bs%3D&reserved=0>.\nTriage notifications on the go with GitHub Mobile for iOS<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fapps.apple.com%2Fapp%2Fapple-store%2Fid1477376905%3Fct%3Dnotification-email%26mt%3D8%26pt%3D524675&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915918545%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=a1Gav7n4ZNejVJ4ufuDq0t0QC2G%2FWdsQyTuN2ctyckg%3D&reserved=0> or Android<https://nam06.safelinks.protection.outlook.com/?url=https%3A%2F%2Fplay.google.com%2Fstore%2Fapps%2Fdetails%3Fid%3Dcom.github.android%26utm_campaign%3Dnotification-email&data=04%7C01%7CPengcheng.H%40microsoft.com%7C5d5abaf3549d4964849008d960f0deb8%7C72f988bf86f141af91ab2d7cd011db47%7C1%7C0%7C637647409915918545%7CUnknown%7CTWFpbGZsb3d8eyJWIjoiMC4wLjAwMDAiLCJQIjoiV2luMzIiLCJBTiI6Ik1haWwiLCJXVCI6Mn0%3D%7C1000&sdata=lkAkdc34Y4JxscuaZWrLFjlyn3JrgNzuDNe3GkqZtl8%3D&reserved=0>.\n",
"> @Rocketknight1\r\n> [#12972 (comment)](https://github.com/huggingface/transformers/pull/12972#discussion_r684418611)\r\n> gather function fails while running `run_glue.py` from examples\r\n> \r\n> \r\n> If i replace the gather function with experimental NumPy take_along_axis works - https://gist.github.com/kamalkraj/73ad5fa2b84de7e201e05464e11a4fec\r\n\r\nHi @kamalkraj, can you share the exact glue task / command you used? I still can't reproduce the bug - I tried this:\r\n```\r\npython run_glue.py --model_name_or_path kamalkraj/deberta-v2-xlarge --task_name mnli --do_train --do_eval --do_predict --output_dir output\r\n```\r\n\r\nThis seemed to work fine with `torch_gather`.",
"@Rocketknight1 \r\nthe issue is solved with this commit https://github.com/huggingface/transformers/pull/13120/commits/90c122dedf95e6f4d1ff4395b08783f851e6eb02 .\r\n\r\n`torch_gather` function under those `if` condition was creating the issue. I removed those conditions as it was unnecessary .\r\nYou can see the discussion https://github.com/huggingface/transformers/pull/13120#issuecomment-899782332\r\n\r\nI also opened another pull request to remove from PyTorch model also. https://github.com/huggingface/transformers/pull/13145",
"Hi @Rocketknight1 ,\r\nhttps://github.com/huggingface/transformers/pull/13145 is merged to master. Now the TF implementation is the same as the torch Implementation. and runs without any issues",
"Hi @patrickvonplaten ,\r\nthanks for the review.\r\ncommitted changes. ",
"Hi @LysandreJik,\r\ncommitted changes.",
"Is this code compatible with model.fit?"
] | 1,628 | 1,652 | 1,630 | CONTRIBUTOR | null | # What does this PR do?
Deberta-v2 TF
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@LysandreJik @patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13120/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13120/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13120",
"html_url": "https://github.com/huggingface/transformers/pull/13120",
"diff_url": "https://github.com/huggingface/transformers/pull/13120.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13120.patch",
"merged_at": 1630405967000
} |
https://api.github.com/repos/huggingface/transformers/issues/13119 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13119/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13119/comments | https://api.github.com/repos/huggingface/transformers/issues/13119/events | https://github.com/huggingface/transformers/pull/13119 | 970,518,436 | MDExOlB1bGxSZXF1ZXN0NzEyNDYwNTM3 | 13,119 | Optimizes ByT5 tokenizer | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There's also a way to speed it up even for 100+ special tokens (by using a single cut pass instead of 100 with byt5) but as mentionned in the issue it's more involved and side effects harder to apprehend.",
"With this updated version, I am now getting issues with encoding characters which require multiple bytes, e.g. \"€\" gets tokenized as [8367], where it should be [229, 133, 175]. ",
"cc @Narsil - I had a similar problem as @gggg8000 previously. Are you sure the optimized ByT5 tokenizer correctly takes single characters that are made of multiple unicode bytes into account?",
"Oups, I imagined those were covered in tests so I didn't: \r\n\r\nThe fix is here: https://github.com/huggingface/transformers/pull/13447\r\n"
] | 1,628 | 1,630 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
- Removes unused logic (actual special tokens are handled by super class
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #12884
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13119/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13119/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13119",
"html_url": "https://github.com/huggingface/transformers/pull/13119",
"diff_url": "https://github.com/huggingface/transformers/pull/13119.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13119.patch",
"merged_at": 1629187918000
} |
https://api.github.com/repos/huggingface/transformers/issues/13118 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13118/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13118/comments | https://api.github.com/repos/huggingface/transformers/issues/13118/events | https://github.com/huggingface/transformers/pull/13118 | 970,512,520 | MDExOlB1bGxSZXF1ZXN0NzEyNDU1MDU0 | 13,118 | Fix frameworks table so it's alphabetical | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the PR! Could you run `make fix-copies` to fix the code quality issue?",
"Thanks, I didn't realize there was a script to automatically generate the table. I changed the `sort` call so there is no difference between uppercase and lowercase, hence removing lowercase models from the end of the list. This creates few other diffs, so please let me know if this is ok."
] | 1,628 | 1,629 | 1,629 | MEMBER | null | # What does this PR do?
This is a minor PR to make the frameworks table alphabetical
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13118/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13118",
"html_url": "https://github.com/huggingface/transformers/pull/13118",
"diff_url": "https://github.com/huggingface/transformers/pull/13118.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13118.patch",
"merged_at": 1629121519000
} |
https://api.github.com/repos/huggingface/transformers/issues/13117 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13117/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13117/comments | https://api.github.com/repos/huggingface/transformers/issues/13117/events | https://github.com/huggingface/transformers/issues/13117 | 970,480,986 | MDU6SXNzdWU5NzA0ODA5ODY= | 13,117 | Can we directly replace gpt2LMHeadModel with BertLMHeadModel to see bert's performance? #7 | {
"login": "ZonglinY",
"id": 48231194,
"node_id": "MDQ6VXNlcjQ4MjMxMTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/48231194?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZonglinY",
"html_url": "https://github.com/ZonglinY",
"followers_url": "https://api.github.com/users/ZonglinY/followers",
"following_url": "https://api.github.com/users/ZonglinY/following{/other_user}",
"gists_url": "https://api.github.com/users/ZonglinY/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZonglinY/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZonglinY/subscriptions",
"organizations_url": "https://api.github.com/users/ZonglinY/orgs",
"repos_url": "https://api.github.com/users/ZonglinY/repos",
"events_url": "https://api.github.com/users/ZonglinY/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZonglinY/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | I have a code for gpt2LMHeadModel which runs well, and I want to test my code on BertLMHeadModel.
But when I directly replace gpt2LMHeadModel with BertLMHeadModel and replace gpt2Tokenizer with BertTokenizer, the ppl remains at 1 (the BertLMHeadModel predicts perfectly the same with labels)
So can anyone help me, is there any difference of the input format between gpt2LMHeadModelwith and BertLMHeadModel?
Thanks so much! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13117/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13117/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13116 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13116/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13116/comments | https://api.github.com/repos/huggingface/transformers/issues/13116/events | https://github.com/huggingface/transformers/issues/13116 | 970,425,801 | MDU6SXNzdWU5NzA0MjU4MDE= | 13,116 | Problem about using mBART50 for Russian to Chinese translation | {
"login": "ALUKErnel",
"id": 40779961,
"node_id": "MDQ6VXNlcjQwNzc5OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/40779961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ALUKErnel",
"html_url": "https://github.com/ALUKErnel",
"followers_url": "https://api.github.com/users/ALUKErnel/followers",
"following_url": "https://api.github.com/users/ALUKErnel/following{/other_user}",
"gists_url": "https://api.github.com/users/ALUKErnel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ALUKErnel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ALUKErnel/subscriptions",
"organizations_url": "https://api.github.com/users/ALUKErnel/orgs",
"repos_url": "https://api.github.com/users/ALUKErnel/repos",
"events_url": "https://api.github.com/users/ALUKErnel/events{/privacy}",
"received_events_url": "https://api.github.com/users/ALUKErnel/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Same problem, please have a look~ @patil-suraj",
"Yes I've seen similar issues with mBART50 returning random sentences as output. Related issues are #12104 and #12958 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I don't think this was fixed",
"@patil-suraj - pinging again here. Would be great to take some action here soon",
"Sorry about being super slow here.\r\n\r\nGoing to take look at it this week. First step is to do the same generation with the original model [here](https://github.com/pytorch/fairseq/tree/main/examples/multilingual), the setup is very complicated. Will do it and post the instructions here as well. If the generations match then the issue is with the model itself.\r\n",
"is there a translation from English to Chinese ?\r\nOr From Chinese to English ? ",
"It also happens from Spanish to English, using `mbart50_m2en`.\r\n```\r\nOriginal text: \"un perro rojo con sombrero de colores\"\r\nTranslation to English: \"The Committee recommends that the State party take all necessary measures to ensure the full implementation of the present recommendations, inter alia, by transmitting them to the members of the Council of Ministers, the Parliament, the Parliamentary Assembly and the Senate...\"\r\n```\r\n<details>\r\n <summary> Packages installed </summary>\r\n\r\n```\r\n#\r\n# This file is autogenerated by pip-compile with Python 3.10\r\n# by the following command:\r\n#\r\n# pip-compile\r\n#\r\naiohttp==3.8.4\r\n # via runpod\r\naiosignal==1.3.1\r\n # via aiohttp\r\nanyio==3.6.2\r\n # via\r\n # httpcore\r\n # starlette\r\n # watchfiles\r\nasync-timeout==4.0.2\r\n # via aiohttp\r\nattrs==23.1.0\r\n # via aiohttp\r\nbackoff==2.2.1\r\n # via runpod\r\nboto3==1.26.133\r\n # via runpod\r\nbotocore==1.29.133\r\n # via\r\n # boto3\r\n # s3transfer\r\ncertifi==2023.5.7\r\n # via\r\n # httpcore\r\n # httpx\r\n # requests\r\ncharset-normalizer==3.1.0\r\n # via\r\n # aiohttp\r\n # requests\r\nclick==8.1.3\r\n # via\r\n # nltk\r\n # sacremoses\r\n # uvicorn\r\ncmake==3.27.2\r\n # via triton\r\ndnspython==2.3.0\r\n # via email-validator\r\neasynmt==2.0.2\r\n # via -r requirements.in\r\nemail-validator==2.0.0.post2\r\n # via fastapi\r\nexceptiongroup==1.1.3\r\n # via pytest\r\nfastapi[all]==0.95.1\r\n # via runpod\r\nfasttext==0.9.2\r\n # via easynmt\r\nfilelock==3.12.0\r\n # via\r\n # huggingface-hub\r\n # torch\r\n # transformers\r\n # triton\r\nfrozenlist==1.3.3\r\n # via\r\n # aiohttp\r\n # aiosignal\r\nfsspec==2023.5.0\r\n # via huggingface-hub\r\nh11==0.14.0\r\n # via\r\n # httpcore\r\n # uvicorn\r\nhttpcore==0.17.0\r\n # via httpx\r\nhttptools==0.5.0\r\n # via uvicorn\r\nhttpx==0.24.0\r\n # via fastapi\r\nhuggingface-hub==0.14.1\r\n # via transformers\r\nidna==3.4\r\n # via\r\n # anyio\r\n # email-validator\r\n # httpx\r\n # requests\r\n # yarl\r\niniconfig==2.0.0\r\n # via pytest\r\nitsdangerous==2.1.2\r\n # via fastapi\r\njinja2==3.1.2\r\n # via\r\n # fastapi\r\n # torch\r\njmespath==1.0.1\r\n # via\r\n # boto3\r\n # botocore\r\njoblib==1.2.0\r\n # via\r\n # nltk\r\n # sacremoses\r\nlit==16.0.6\r\n # via triton\r\nmarkupsafe==2.1.2\r\n # via jinja2\r\nmpmath==1.3.0\r\n # via sympy\r\nmultidict==6.0.4\r\n # via\r\n # aiohttp\r\n # yarl\r\nnetworkx==3.1\r\n # via torch\r\nnltk==3.8.1\r\n # via easynmt\r\nnumpy==1.24.3\r\n # via\r\n # easynmt\r\n # fasttext\r\n # transformers\r\nnvidia-cublas-cu11==11.10.3.66\r\n # via\r\n # nvidia-cudnn-cu11\r\n # nvidia-cusolver-cu11\r\n # torch\r\nnvidia-cuda-cupti-cu11==11.7.101\r\n # via torch\r\nnvidia-cuda-nvrtc-cu11==11.7.99\r\n # via torch\r\nnvidia-cuda-runtime-cu11==11.7.99\r\n # via torch\r\nnvidia-cudnn-cu11==8.5.0.96\r\n # via torch\r\nnvidia-cufft-cu11==10.9.0.58\r\n # via torch\r\nnvidia-curand-cu11==10.2.10.91\r\n # via torch\r\nnvidia-cusolver-cu11==11.4.0.1\r\n # via torch\r\nnvidia-cusparse-cu11==11.7.4.91\r\n # via torch\r\nnvidia-nccl-cu11==2.14.3\r\n # via torch\r\nnvidia-nvtx-cu11==11.7.91\r\n # via torch\r\norjson==3.8.12\r\n # via fastapi\r\npackaging==23.1\r\n # via\r\n # huggingface-hub\r\n # pytest\r\n # transformers\r\npillow==9.5.0\r\n # via runpod\r\npluggy==1.0.0\r\n # via pytest\r\nprotobuf==3.20.3\r\n # via\r\n # -r requirements.in\r\n # easynmt\r\npybind11==2.10.4\r\n # via fasttext\r\npydantic==1.10.7\r\n # via fastapi\r\npytest==7.3.1\r\n # via -r requirements.in\r\npython-dateutil==2.8.2\r\n # via botocore\r\npython-dotenv==1.0.0\r\n # via\r\n # runpod\r\n # uvicorn\r\npython-multipart==0.0.6\r\n # via fastapi\r\npyyaml==6.0\r\n # via\r\n # fastapi\r\n # huggingface-hub\r\n # transformers\r\n # uvicorn\r\nregex==2023.5.5\r\n # via\r\n # nltk\r\n # sacremoses\r\n # transformers\r\nrequests==2.30.0\r\n # via\r\n # huggingface-hub\r\n # runpod\r\n # transformers\r\nrunpod==0.9.7\r\n # via -r requirements.in\r\ns3transfer==0.6.1\r\n # via boto3\r\nsacremoses==0.0.53\r\n # via -r requirements.in\r\nsentencepiece==0.1.99\r\n # via easynmt\r\nsix==1.16.0\r\n # via\r\n # python-dateutil\r\n # sacremoses\r\nsniffio==1.3.0\r\n # via\r\n # anyio\r\n # httpcore\r\n # httpx\r\nstarlette==0.26.1\r\n # via fastapi\r\nsympy==1.12\r\n # via torch\r\ntokenizers==0.13.3\r\n # via transformers\r\ntomli==2.0.1\r\n # via pytest\r\ntorch==2.0.1\r\n # via\r\n # easynmt\r\n # triton\r\ntqdm==4.65.0\r\n # via\r\n # easynmt\r\n # huggingface-hub\r\n # nltk\r\n # sacremoses\r\n # tqdm-loggable\r\n # transformers\r\ntqdm-loggable==0.1.3\r\n # via runpod\r\ntransformers==4.29.1\r\n # via easynmt\r\ntriton==2.0.0\r\n # via torch\r\ntyping-extensions==4.5.0\r\n # via\r\n # huggingface-hub\r\n # pydantic\r\n # torch\r\nujson==5.7.0\r\n # via fastapi\r\nurllib3==1.26.15\r\n # via\r\n # botocore\r\n # requests\r\nuvicorn[standard]==0.22.0\r\n # via fastapi\r\nuvloop==0.17.0\r\n # via uvicorn\r\nwatchfiles==0.19.0\r\n # via uvicorn\r\nwebsockets==11.0.3\r\n # via uvicorn\r\nwheel==0.41.2\r\n # via\r\n # nvidia-cublas-cu11\r\n # nvidia-cuda-cupti-cu11\r\n # nvidia-cuda-runtime-cu11\r\n # nvidia-curand-cu11\r\n # nvidia-cusparse-cu11\r\n # nvidia-nvtx-cu11\r\nyarl==1.9.2\r\n # via aiohttp\r\n\r\n# The following packages are considered to be unsafe in a requirements file:\r\n# setuptools\r\n\r\n```\r\n\r\n</details>\r\n\r\nPython 3.9.17",
"See #25425, with an example.\r\n@leandroalbero You would need to give a full reproducer "
] | 1,628 | 1,692 | null | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: ubuntu 18.04
- Python version: 3.6.9.
- PyTorch version (GPU?): 1.8.0
- Tensorflow version (GPU?): 2.3.0
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
mbart-large-50-many-to-many-mmt:@LysandreJik @patrickvonplaten
## Information
Model I am using: mbart-large-50-many-to-many-mmt
The problem arises when using:
* my own modified scripts: (give details below)
We originally wanted to do a Russian-Chinese translation task, but our translation results showed a lot of English. We used a script to test.
## To reproduce
Steps to reproduce the behavior:
1.The code is as follow:
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
text_list = ['Это позволит облегчить транспортировку грузов для Китая и Германии.',
'Россия останется одним из лидеров, возможности для наращивания экспорта есть.',
'Это позволит оптимизировать торговые отношения.']
src_lang = 'ru_RU'
tgt_lang = 'zh_CN'
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
for text in text_list:
tokenizer.src_lang = src_lang
encoded_hi = tokenizer(text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.lang_code_to_id[tgt_lang])
translated = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
print(translated)
```
when the src_lang was ‘ru_RU’ and the tgt_lang was ‘zh_CN’, the results were:
```
['This will facilitate the transport of goods for China and Germany.']
['Russia will remain one of the leaders, there are opportunities to increase export.']
['This will allow to optimize trade relations.']
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
We wanted to obtain a set of Chinese translations. Here are the Chinese translations for reference.
```
['这将使中国和德国更容易运输货物。']
['俄罗斯仍将是一个领导者,有机会增加出口。']
['这将有助于改善贸易关系。']
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13116/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13116/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13114 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13114/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13114/comments | https://api.github.com/repos/huggingface/transformers/issues/13114/events | https://github.com/huggingface/transformers/pull/13114 | 970,266,970 | MDExOlB1bGxSZXF1ZXN0NzEyMjQyODg3 | 13,114 | Migrating conversational pipeline tests to new testing format | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Friendly ping @LysandreJik @sgugger "
] | 1,628 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
Moving the cnversational pipeline tests to new format.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13114/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13114/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13114",
"html_url": "https://github.com/huggingface/transformers/pull/13114",
"diff_url": "https://github.com/huggingface/transformers/pull/13114.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13114.patch",
"merged_at": 1629964245000
} |
https://api.github.com/repos/huggingface/transformers/issues/13113 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13113/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13113/comments | https://api.github.com/repos/huggingface/transformers/issues/13113/events | https://github.com/huggingface/transformers/pull/13113 | 970,113,842 | MDExOlB1bGxSZXF1ZXN0NzEyMTExMjY0 | 13,113 | Fix CircleCI nightly tests | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
The pipelines TF job was not setup properly, so failed in the nightlies. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13113/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13113/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13113",
"html_url": "https://github.com/huggingface/transformers/pull/13113",
"diff_url": "https://github.com/huggingface/transformers/pull/13113.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13113.patch",
"merged_at": 1628837850000
} |
https://api.github.com/repos/huggingface/transformers/issues/13115 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13115/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13115/comments | https://api.github.com/repos/huggingface/transformers/issues/13115/events | https://github.com/huggingface/transformers/issues/13115 | 970,323,245 | MDU6SXNzdWU5NzAzMjMyNDU= | 13,115 | typeerror: textinputsequence must be str | {
"login": "justwangqian",
"id": 55977323,
"node_id": "MDQ6VXNlcjU1OTc3MzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/55977323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/justwangqian",
"html_url": "https://github.com/justwangqian",
"followers_url": "https://api.github.com/users/justwangqian/followers",
"following_url": "https://api.github.com/users/justwangqian/following{/other_user}",
"gists_url": "https://api.github.com/users/justwangqian/gists{/gist_id}",
"starred_url": "https://api.github.com/users/justwangqian/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/justwangqian/subscriptions",
"organizations_url": "https://api.github.com/users/justwangqian/orgs",
"repos_url": "https://api.github.com/users/justwangqian/repos",
"events_url": "https://api.github.com/users/justwangqian/events{/privacy}",
"received_events_url": "https://api.github.com/users/justwangqian/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"by the way ,the same code works when i process the xnli dataset.",
"Hi @justwangqian,\r\n\r\nI think your issue is with the `transformers` library. I guess you should update it, but I prefer transferring your issue to them, so that they can keep the record.\r\n\r\nFeel free to reopen an issue in `datasets` if there is finally a bug here. :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Describe the bug
I use dataset.map() to encode the data, but get this problem.
# I use the code to transfer data to local csv files,.As i use colab, local files are more convenient.
dataset = load_dataset(path='glue', name='mnli')
keys = ['train', 'validation_matched','validation_mismatched']
for k in keys:
result = []
for record in dataset[k]:
c1, c2, c3 = record['premise'], record['hypothesis'], record['label']
if c1 and c2 and c3 in {0,1,2}:
result.append(c1,c2,c3))
result = pd.DataFrame(result, columns=['premise','hypothesis','label'])
result.to_csv('mnli_'+k+'.csv',index=False)
# then I process data like this ,and get the issue.
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
def encode(batch):
return tokenizer(batch['premise'],
batch['hypothesis'],
max_length=MAXLEN,
padding='max_length',
truncation=True
)
train_dict = load_dataset('csv', data_files=train_data_path)
train_dataset = train_dict['train']
train_dataset = train_dataset.map(encode, batched=True)
## Expected results
encode the data successfully.
## Actual results
TypeError Traceback (most recent call last)
<ipython-input-19-00acc2cded49> in <module>()
5 val_dataset = val_dict['train']
6
----> 7 train_dataset = train_dataset.map(encode, batched=True)
8 val_dataset = val_dataset.map(encode, batched=True)
9
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
1680 new_fingerprint=new_fingerprint,
1681 disable_tqdm=disable_tqdm,
-> 1682 desc=desc,
1683 )
1684 else:
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
183 }
184 # apply actual function
--> 185 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
186 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
187 # re-apply format to the output
/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
395 # Call actual function
396
--> 397 out = func(self, *args, **kwargs)
398
399 # Update fingerprint of in-place transforms + update in-place history of transforms
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, disable_tqdm, desc)
2018 indices,
2019 check_same_num_examples=len(input_dataset.list_indexes()) > 0,
-> 2020 offset=offset,
2021 )
2022 except NumExamplesMismatch:
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples, offset)
1904 effective_indices = [i + offset for i in indices] if isinstance(indices, list) else indices + offset
1905 processed_inputs = (
-> 1906 function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
1907 )
1908 if update_data is None:
<ipython-input-11-3dad555201d4> in encode(batch)
6 max_length=MAXLEN,
7 padding='max_length',
----> 8 truncation=True
9 )
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in __call__(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2383 return_length=return_length,
2384 verbose=verbose,
-> 2385 **kwargs,
2386 )
2387 else:
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py in batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)
2568 return_length=return_length,
2569 verbose=verbose,
-> 2570 **kwargs,
2571 )
2572
/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_fast.py in _batch_encode_plus(self, batch_text_or_text_pairs, add_special_tokens, padding_strategy, truncation_strategy, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose)
406 batch_text_or_text_pairs,
407 add_special_tokens=add_special_tokens,
--> 408 is_pretokenized=is_split_into_words,
409 )
410
TypeError: TextInputSequence must be str
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.11.0
- Platform:colab
- Python version:3.7
- PyArrow version:
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13115/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13115/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13112 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13112/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13112/comments | https://api.github.com/repos/huggingface/transformers/issues/13112/events | https://github.com/huggingface/transformers/pull/13112 | 969,364,719 | MDExOlB1bGxSZXF1ZXN0NzExNDEzNTYx | 13,112 | modified roberta source code | {
"login": "raina-kikani",
"id": 88499769,
"node_id": "MDQ6VXNlcjg4NDk5NzY5",
"avatar_url": "https://avatars.githubusercontent.com/u/88499769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/raina-kikani",
"html_url": "https://github.com/raina-kikani",
"followers_url": "https://api.github.com/users/raina-kikani/followers",
"following_url": "https://api.github.com/users/raina-kikani/following{/other_user}",
"gists_url": "https://api.github.com/users/raina-kikani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/raina-kikani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/raina-kikani/subscriptions",
"organizations_url": "https://api.github.com/users/raina-kikani/orgs",
"repos_url": "https://api.github.com/users/raina-kikani/repos",
"events_url": "https://api.github.com/users/raina-kikani/events{/privacy}",
"received_events_url": "https://api.github.com/users/raina-kikani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | NONE | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ #] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13112/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13112/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13112",
"html_url": "https://github.com/huggingface/transformers/pull/13112",
"diff_url": "https://github.com/huggingface/transformers/pull/13112.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13112.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13111 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13111/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13111/comments | https://api.github.com/repos/huggingface/transformers/issues/13111/events | https://github.com/huggingface/transformers/issues/13111 | 969,352,784 | MDU6SXNzdWU5NjkzNTI3ODQ= | 13,111 | `ModelError` when calling SageMaker Endpoint for prediction using the official notebooks | {
"login": "xegulon",
"id": 74178038,
"node_id": "MDQ6VXNlcjc0MTc4MDM4",
"avatar_url": "https://avatars.githubusercontent.com/u/74178038?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xegulon",
"html_url": "https://github.com/xegulon",
"followers_url": "https://api.github.com/users/xegulon/followers",
"following_url": "https://api.github.com/users/xegulon/following{/other_user}",
"gists_url": "https://api.github.com/users/xegulon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xegulon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xegulon/subscriptions",
"organizations_url": "https://api.github.com/users/xegulon/orgs",
"repos_url": "https://api.github.com/users/xegulon/repos",
"events_url": "https://api.github.com/users/xegulon/events{/privacy}",
"received_events_url": "https://api.github.com/users/xegulon/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @philschmid ",
"Hey @xegulon, \r\n\r\nHow have you created your `model.tar.gz` and what does it contain? It looks like that the file structure of it is wrong and the inference toolkit cannot find the `config.json` and `pytorch_model.bin`. \r\n\r\nYou can take a look [here](https://huggingface.co/docs/sagemaker/inference#creating-a-model-artifact-modeltargz-for-deployment) at how to properly create a `model.tar.gz`.\r\nhttps://huggingface.co/docs/sagemaker/inference#creating-a-model-artifact-modeltargz-for-deployment",
"Here are the contents of `model.tar.gz`:\r\n\r\n\r\n\r\nI used the `save_pretrained` method on the model and tokenizer to get that.\r\n\r\nP. S.: after re-checking, I remarked `transformers` version is `4.9.2`",
"How have you created this archive? \r\n\r\nand are you sure the structure is not the one below?\r\n```bash\r\nmodel.tar.gz\r\n directory\r\n pytorch_model.bin\r\n```\r\n\r\nCould you try creating the archive with the following steps? \r\n1. cd and create a tar file\r\n```bash\r\ncd {repository}\r\ntar zcvf model.tar.gz *\r\n```\r\nthe repository should be the directory where your artifacts are stored\r\n\r\n2. Upload model.tar.gz to s3\r\n```Bash\r\naws s3 cp model.tar.gz <s3://{my-s3-path}>\r\n```\r\nAfter that, you can use the S3 uri as model_data.\r\n\r\n\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
- `transformers` version: 4.6.1
- Platform: Linux-4.14.232-123.381.amzn1.x86_64-x86_64-with-glibc2.10
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@sgugger @patil-suraj
## Information
I have trained and saved a BertForSequenceClassification model to S3. I then used [this notebook](https://github.com/huggingface/notebooks/blob/master/sagemaker/10_deploy_model_from_s3/deploy_transformer_model_from_s3.ipynb) to deploy the model to SageMaker Endpoints.
I ran:
```python
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
role = sagemaker.get_execution_role()
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data="s3://XXXXXXXXXXXX/model.tar.gz", # path to your trained sagemaker model
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.6", # transformers version used
pytorch_version="1.7", # pytorch version used
py_version="py36", # python version of the DLC
env={'HF_TASK':'text-classification'}
)
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.m5.xlarge"
)
```
But when I use the provided snippet:
```python
# example request, you always need to define "inputs"
data = {
"inputs": "The new Hugging Face SageMaker DLC makes it super easy to deploy models in production. I love it!"
}
# request
predictor.predict(data)
```
I get the following error:
```bash
ModelError: An error occurred (ModelError) when calling the InvokeEndpoint operation: Received client error (400) from model with message "{
"code": 400,
"type": "InternalServerException",
"message": "Can\u0027t load config for \u0027/.sagemaker/mms/models/model\u0027. Make sure that:\n\n- \u0027/.sagemaker/mms/models/model\u0027 is a correct model identifier listed on \u0027https://huggingface.co/models\u0027\n\n- or \u0027/.sagemaker/mms/models/model\u0027 is the correct path to a directory containing a config.json file\n\n"
}
". See https://us-east-2.console.aws.amazon.com/cloudwatch/home?region=us-east-2#logEventViewer:group=/aws/sagemaker/Endpoints/huggingface-pytorch-inference-XXXXXXXX in account XXXXXXXXXX for more information.
```
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13111/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13111/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13110 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13110/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13110/comments | https://api.github.com/repos/huggingface/transformers/issues/13110/events | https://github.com/huggingface/transformers/pull/13110 | 969,337,360 | MDExOlB1bGxSZXF1ZXN0NzExMzg4MjA1 | 13,110 | adding modified roberta | {
"login": "raina-kikani",
"id": 88499769,
"node_id": "MDQ6VXNlcjg4NDk5NzY5",
"avatar_url": "https://avatars.githubusercontent.com/u/88499769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/raina-kikani",
"html_url": "https://github.com/raina-kikani",
"followers_url": "https://api.github.com/users/raina-kikani/followers",
"following_url": "https://api.github.com/users/raina-kikani/following{/other_user}",
"gists_url": "https://api.github.com/users/raina-kikani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/raina-kikani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/raina-kikani/subscriptions",
"organizations_url": "https://api.github.com/users/raina-kikani/orgs",
"repos_url": "https://api.github.com/users/raina-kikani/repos",
"events_url": "https://api.github.com/users/raina-kikani/events{/privacy}",
"received_events_url": "https://api.github.com/users/raina-kikani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | NONE | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ #] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13110/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13110/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13110",
"html_url": "https://github.com/huggingface/transformers/pull/13110",
"diff_url": "https://github.com/huggingface/transformers/pull/13110.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13110.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13109 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13109/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13109/comments | https://api.github.com/repos/huggingface/transformers/issues/13109/events | https://github.com/huggingface/transformers/pull/13109 | 969,213,690 | MDExOlB1bGxSZXF1ZXN0NzExMjc2Mjgx | 13,109 | Fix flax gpt2 hidden states | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, @patil-suraj , thank you for the suggestions. There is however some issues regarding\r\n\r\n```\r\n if output_hidden_states:\r\n all_hidden_states = outputs[1] + (hidden_states,)\r\n outputs = (hidden_states, all_hidden_states) + outputs[2:]\r\n else:\r\n outputs = (hidden_states,) + outputs[1:]\r\n```\r\nbecause this will change `outputs` to a `tuple` even if it is previously a `FlaxBaseModelOutput`, and this causes problem to the end (i.e. if `return_dict=True`)\r\n\r\n```\r\n return FlaxBaseModelOutput(\r\n last_hidden_state=hidden_states,\r\n hidden_states=outputs.all_hidden_states,\r\n attentions=outputs.attentions,\r\n )\r\n```\r\n\r\nDo you have a good solution to address this while keep your suggestions?",
"Ahh, yeah, you're right!\r\n\r\nI wanted to avoid multiple if/else conds, but seems we will need to add one either way.\r\n\r\nI could see two options:\r\n\r\n- we have already stored `all_hidden_states`, we could store the `all_attentions` using \r\n\r\n```python3\r\nall_attentions = outputs[-1] if output_attentions else None\r\n```\r\n\r\nand then use that in the output class\r\n\r\n- another option is, `FlaxGPT2BlockCollection` is only used internally, so we could also just always return `outputs` (including `None` values) as a `tuple`. So in the `FlaxGPT2Module`, we could do \r\n\r\n```python3\r\nif output_hidden_states:\r\n\tall_hidden_states = outputs[1] + (hidden_states,)\r\n\toutputs = (hidden_states, all_hidden_states) + outputs[2:]\r\nelse:\r\n\toutputs = (hidden_states,) + outputs[1:]\r\n\r\nif not return_dict:\r\n return tuple(v for v in outputs if v is not None)\r\n\r\nreturn FlaxBaseModelOutput(\r\n last_hidden_state=hidden_states,\r\n hidden_states=all_hidden_states,\r\n attentions=outputs[-1],\r\n)\r\n```",
"@patil-suraj I went for option 2, with a slightly change `hidden_states=all_hidden_states,` -> `hidden_states=outputs[1],` (all_hidden_states not always define)."
] | 1,628 | 1,651 | 1,628 | COLLABORATOR | null | # What does this PR do?
Fixes #13102
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)?
[ inconsistency of the last element in hidden_states between PyTorch/Flax GPT2(Neo) #13102 ](https://github.com/huggingface/transformers/issues/13102#issuecomment-897687182)
## Who can review?
@patrickvonplaten @patil-suraj | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13109/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13109",
"html_url": "https://github.com/huggingface/transformers/pull/13109",
"diff_url": "https://github.com/huggingface/transformers/pull/13109.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13109.patch",
"merged_at": 1628844353000
} |
https://api.github.com/repos/huggingface/transformers/issues/13108 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13108/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13108/comments | https://api.github.com/repos/huggingface/transformers/issues/13108/events | https://github.com/huggingface/transformers/issues/13108 | 969,194,099 | MDU6SXNzdWU5NjkxOTQwOTk= | 13,108 | Multi Lang Marian Translator not working (opus_mt_mul_en) | {
"login": "rp13g10",
"id": 37337032,
"node_id": "MDQ6VXNlcjM3MzM3MDMy",
"avatar_url": "https://avatars.githubusercontent.com/u/37337032?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rp13g10",
"html_url": "https://github.com/rp13g10",
"followers_url": "https://api.github.com/users/rp13g10/followers",
"following_url": "https://api.github.com/users/rp13g10/following{/other_user}",
"gists_url": "https://api.github.com/users/rp13g10/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rp13g10/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rp13g10/subscriptions",
"organizations_url": "https://api.github.com/users/rp13g10/orgs",
"repos_url": "https://api.github.com/users/rp13g10/repos",
"events_url": "https://api.github.com/users/rp13g10/events{/privacy}",
"received_events_url": "https://api.github.com/users/rp13g10/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @rp13g10,\r\n\r\nWe are not really familiar with the `sparkNLP` repo...from the issue I assume that the following is the error from our side:\r\n\r\n```python\r\n# opus-mt-mul-en\r\n# opus-mt-en-mul\r\n\r\nfrom transformers import MarianMTModel, MarianTokenizer\r\n\r\nmodel_name = 'Helsinki-NLP/opus-mt-mul-en'\r\ntokenizer = MarianTokenizer.from_pretrained(model_name)\r\n\r\ntokenizer.supported_language_codes # this returns nothing\r\n```\r\n\r\nE.g. the tokenizers should return some supported language codes\r\n\r\n@patil-suraj have you already taken a look at multi-lingual marian models? \r\n\r\nAlso gently pinging the Marian OG @sshleifer - should we update https://huggingface.co/Helsinki-NLP/opus-mt-mul-en/blob/main/tokenizer_config.json analogs to https://huggingface.co/Helsinki-NLP/opus-mt-en-ROMANCE/blob/main/tokenizer_config.json ? ",
"This is still an issue as far as I can tell, and it would be cool if it was fixed. :)",
"Gently pinging @patil-suraj here - do you have an opinion here?",
"Not 100% sure, but language codes are required when there are multiple target languages as for such models we need to prepend the target language code to the source text. \r\n\r\nThe `opus-mt-mul-en` models, translate multiple languages to English, so we do not need to insert any language codes as you can see from this example\r\n\r\n```python3\r\nmodel_name = 'Helsinki-NLP/opus-mt-mul-en'\r\ntokenizer = MarianTokenizer.from_pretrained(model_name)\r\n\r\ntexts = [\r\n \"c'est une phrase en anglais que nous voulons traduire en français\", # french\r\n \"Isto deve ir para o português.\", # portuguese\r\n \"Y esto al español\", # Spanish\r\n]\r\ninputs = tokenizer(texts, return_tensors=\"pt\", padding=True)\r\n\r\ngen_ids = model.generate(**inputs)\r\ntokenizer.batch_decode(gen_ids, skip_special_tokens=True)\r\n# ['is a phrase in English that we want to translate into French',\r\n 'This has to go to Portugal.',\r\n 'And this is in Spanish']\r\n```\r\n\r\nSo it seems there is no issue with the model.\r\n\r\nAnd if you look at `opus-mt-en-mul` or `opus-mt-en-ROMANCE` where there are multiple target languages, it does return non-empty `supported_language_codes` list.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,634 | 1,634 | NONE | null | When attempting to use the [opus_mt_mul_en](https://huggingface.co/Helsinki-NLP/opus-mt-mul-en) model, no translations are generated. Based on [this issue](https://github.com/JohnSnowLabs/spark-nlp/issues/2472) on the SparkNLP repo, this has been happening for a while, but perhaps never raised here.
I'm currently accessing the model through SparkNLP on an Amazon EMR cluster (release 5.30.0). Spark version 2.4.5, SparkNLP version 3.1.0.. The same issue occurs when using SparkNLP 2.7.0.
Code to reproduce the issue:
```python
import os
! apt-get update -qq > /dev/null
# Install java
! apt-get install -y openjdk-8-jdk-headless -qq > /dev/null
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["PATH"] = os.environ["JAVA_HOME"] + "/bin:" + os.environ["PATH"]
! pip install pyspark==2.4.5 spark-nlp==2.7.0
from sparknlp.annotator import *
from sparknlp.common import *
from sparknlp.base import *
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from pyspark.sql.functions import array_contains
from pyspark.ml import Pipeline, PipelineModel
import sparknlp
from sparknlp.annotator import *
from sparknlp.pretrained import PretrainedPipeline
spark = sparknlp.start()
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
sentencerDL = SentenceDetectorDLModel.pretrained("sentence_detector_dl", "xx")\
.setInputCols(["document"])\
.setOutputCol("sentences")
marian = MarianTransformer.pretrained("opus_mt_mul_en", "xx")\
.setInputCols(["sentences"])\
.setOutputCol("translation")
marian_pipeline = Pipeline(stages=[documentAssembler, sentencerDL, marian])
sdf = spark.createDataFrame([[">>deu<< Hallo wie geht es dir Ich bin hubert aus Deutschland"], [">>fra<< Wikipédia est un projet d'encyclopédie collective en ligne, universelle, multilingue et fonctionnant sur le principe du wiki. Ce projet vise à offrir un contenu librement réutilisable, objectif et vérifiable, que chacun peut modifier et améliorer."]]).toDF("text")
m_fit = marian_pipeline.fit(sdf )
res_Df = m_fit.transform(sdf)
res_Df.select('translation').show(truncate=False)
```
I've tried using the `setLangId` method instead of putting the tags inline with the input text, with the same result. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13108/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13108/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13107 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13107/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13107/comments | https://api.github.com/repos/huggingface/transformers/issues/13107/events | https://github.com/huggingface/transformers/pull/13107 | 969,144,123 | MDExOlB1bGxSZXF1ZXN0NzExMjEyMTQ5 | 13,107 | [WIP] Add TFSpeech2Text | {
"login": "will-rice",
"id": 25072137,
"node_id": "MDQ6VXNlcjI1MDcyMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25072137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/will-rice",
"html_url": "https://github.com/will-rice",
"followers_url": "https://api.github.com/users/will-rice/followers",
"following_url": "https://api.github.com/users/will-rice/following{/other_user}",
"gists_url": "https://api.github.com/users/will-rice/gists{/gist_id}",
"starred_url": "https://api.github.com/users/will-rice/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/will-rice/subscriptions",
"organizations_url": "https://api.github.com/users/will-rice/orgs",
"repos_url": "https://api.github.com/users/will-rice/repos",
"events_url": "https://api.github.com/users/will-rice/events{/privacy}",
"received_events_url": "https://api.github.com/users/will-rice/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Gently pinging @stancld to see if he's still working on this :) ",
"@patil-suraj I'm having a little trouble with the generate tests. Should I just do a custom generate function for this model in the modeling file or modify the base generate function to accommodate this model? ",
"Sorry to only reply now.\r\n\r\nWhat is the issue with `generate`? Ideally `generate` should work, so let's try to avoid adding a custom `generate`. \r\n",
"This [assert](https://github.com/huggingface/transformers/blob/596bb85f2fabde6c5611cfa2664ddb357e228ec7/src/transformers/generation_tf_utils.py#L624) is the beginning of the issue. This is probably my interpretation of `input_ids`. Since the `input_ids` is changed to `input_features`, all of the generate functions pop the `input_ids` key. The shape of `input_features` is 3 dimensions though which most other models have a 2 dimension input for encoder-decoder models. I'm going to try to wrap this up today though so I'll figure out what the issue is without doing a custom `generate`."
] | 1,628 | 1,631 | 1,631 | CONTRIBUTOR | null | # What does this PR do?
This PR adds TFSpeech2Text. The issue that requested it was recently closed due to inactivity so I don't think it is being worked on currently. If this is an incorrect assessment, feel free to let me know and I will close this.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patil-suraj
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13107/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13107/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13107",
"html_url": "https://github.com/huggingface/transformers/pull/13107",
"diff_url": "https://github.com/huggingface/transformers/pull/13107.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13107.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13106 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13106/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13106/comments | https://api.github.com/repos/huggingface/transformers/issues/13106/events | https://github.com/huggingface/transformers/pull/13106 | 968,981,196 | MDExOlB1bGxSZXF1ZXN0NzExMDYwODgz | 13,106 | Fix VisualBERT docs | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
This PR fixes VisualBERT docs and adds demo link. Please let me know in case of any issues.
Reviewers @LysandreJik @patil-suraj | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13106/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13106",
"html_url": "https://github.com/huggingface/transformers/pull/13106",
"diff_url": "https://github.com/huggingface/transformers/pull/13106.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13106.patch",
"merged_at": 1628835244000
} |
https://api.github.com/repos/huggingface/transformers/issues/13105 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13105/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13105/comments | https://api.github.com/repos/huggingface/transformers/issues/13105/events | https://github.com/huggingface/transformers/pull/13105 | 968,947,158 | MDExOlB1bGxSZXF1ZXN0NzExMDI5NDE4 | 13,105 | TF/Numpy variants for all DataCollator classes | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"More updates done - please note that tests will fail until all of the data collators are updated, because I removed the top-level imports. I definitely won't be merging this until that's done, don't worry!",
"All the classes are in! Thank you to @aromans and @sdwalker62, whose PR #12199 I cannibalized for MLM and its variants. Next step is finishing tests and making sure all of this actually works.",
"Hi @aromans and @sdwalker62, we're ready to merge now. I just realized I'll need your Github no-reply e-mail addresses to add you though - see the docs [here](https://docs.github.com/en/github/committing-changes-to-your-project/creating-and-editing-commits/creating-a-commit-with-multiple-authors#required-co-author-information). ",
"[email protected]",
"Thanks!",
"[email protected]",
"It's in, and all authors have been properly credited! If you want to delete the messages with your e-mails (in case of spambot harvesting), feel free."
] | 1,628 | 1,630 | 1,630 | MEMBER | null | This is a draft PR again - I've written an example of what a TF variant of one of our data collators would look like. If we're happy with this format, it should be easy to expand it to support Numpy/JAX as well, and to do the same for other data collators, and I'll probably add most of the other data collators to this PR before merging it. Let me know what you think! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13105/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13105/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13105",
"html_url": "https://github.com/huggingface/transformers/pull/13105",
"diff_url": "https://github.com/huggingface/transformers/pull/13105.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13105.patch",
"merged_at": 1630411609000
} |
https://api.github.com/repos/huggingface/transformers/issues/13104 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13104/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13104/comments | https://api.github.com/repos/huggingface/transformers/issues/13104/events | https://github.com/huggingface/transformers/pull/13104 | 968,945,502 | MDExOlB1bGxSZXF1ZXN0NzExMDI3ODcx | 13,104 | Fix VisualBERT docs | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
This PR fixes VisualBERT docs. Please let me know in case on any remaining issues.
Reviewers @patil-suraj @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13104/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13104",
"html_url": "https://github.com/huggingface/transformers/pull/13104",
"diff_url": "https://github.com/huggingface/transformers/pull/13104.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13104.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13103 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13103/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13103/comments | https://api.github.com/repos/huggingface/transformers/issues/13103/events | https://github.com/huggingface/transformers/pull/13103 | 968,926,669 | MDExOlB1bGxSZXF1ZXN0NzExMDEwNDY1 | 13,103 | Ci last fix | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
The GPU/multi-GPU tests for the cuda extensions failed on the last commit on master because there is nothing to report if no tests were run. Changing the condition from always to failure (we don't want to report anything if there is no failure anyway) fixes that. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13103/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13103",
"html_url": "https://github.com/huggingface/transformers/pull/13103",
"diff_url": "https://github.com/huggingface/transformers/pull/13103.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13103.patch",
"merged_at": 1628779506000
} |
https://api.github.com/repos/huggingface/transformers/issues/13102 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13102/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13102/comments | https://api.github.com/repos/huggingface/transformers/issues/13102/events | https://github.com/huggingface/transformers/issues/13102 | 968,920,745 | MDU6SXNzdWU5Njg5MjA3NDU= | 13,102 | inconsistency of the last element in hidden_states between PyTorch/Flax GPT2(Neo) | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @ydshieh,\r\n\r\nThat's a great catch! And we should definitely correct this. The way to go here in my opinion is to remove the second:\r\n\r\n```python\r\nif output_hidden_states:\r\n all_hidden_states += (hidden_states,)\r\n```\r\n\r\nof ```FlaxGPT2BlockCollection``` \r\n\r\nand move it to:\r\n\r\n```FlaxGPT2Module``` \r\n\r\nas you've suggested I think. Would you be interested in opening a PR for this? :-)",
"Hi, yes, I can open a PR for this. But just to be sure\r\n\r\n> my opinion is to remove the second\r\n\r\ndo you mean, in `FlaxGPT2BlockCollection`, we should (if specified) return the tuple containing all the hidden states EXCEPT the last one? And add the last one in `FlaxGPT2Module`.\r\n\r\nI am OK with it - it is just slightly different from what I wrote originally (still add the last one in `FlaxGPT2BlockCollection`, but updating later).",
"Yes I think we should add all hidden states EXCEPT the last one. This class is never used externally without using `FlaxGPT2Module` so it's safe to do IMO. Adding it once is the better option instead of adding it and updating it later IMO.",
"Hi,\r\n\r\nWhile working on a PR for this, it seems there is another bug in `FlaxGPT2BlockCollection`.\r\n\r\nNear the end of its call method,\r\n\r\n```\r\n outputs = (hidden_states,)\r\n\r\n if not return_dict:\r\n return tuple(v for v in outputs if v is not None)\r\n```\r\n\r\nit should be \r\n\r\n```\r\n outputs = (hidden_states, all_hidden_states, all_attentions)\r\n```\r\n\r\nI think. Otherwise, we never get `all_hidden_states` / `all_attentions` in the tuple.\r\n(FlaxBartModel has done the right way.)\r\n\r\nI am going to include a fix for this into the same PR. Is it ok for you?",
"That's a great catch!\r\n\r\n>I am going to include a fix for this into the same PR. Is it ok for you?\r\n\r\nYes! Would be great if you fix it in the same PR."
] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | ### Who can help
@patrickvonplaten @patil-suraj
## Information
The current Flax version of GPT2/GPTNeo give different results for the last element in `hidden_states` if `output_hidden_states=True`. This difference comes from the following fact:
In Flax GPT2 (and GPTNeo similarly), `all_hidden_states` is prepared in `FlaxGPT2BlockCollection` which has no layer norm layer (`ln_f`), therefore the last hidden state is added before applying layer normalization.
While in PyTorch/TF GPT2, it is prepared in `GPT2Model` or `TFGPT2MainLayer`, which contain `ln_f` layer, and the last hidden state is added after applying layer normalization.
This could be fixed by updating the outputs in `FlaxGPT2Module.__call__`, (if it's worth the change), something like
```
hidden_states = outputs[0]
hidden_states = self.ln_f(hidden_states)
all_hidden_states = None
if output_hidden_states:
if not return_dict:
all_hidden_states = outputs[1]
else:
all_hidden_states = outputs.hidden_states
all_hidden_states = all_hidden_states[:-1] + (hidden_states,)
if not return_dict:
if all_hidden_states:
return (hidden_states, all_hidden_states) + outputs[2:]
else:
return (hidden_states,) + outputs[1:]
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
```
### Related places in the source code
PyTroch GPT2
https://github.com/huggingface/transformers/blob/773d386041b2761204dcc67b316904d8d5b412da/src/transformers/models/gpt2/modeling_gpt2.py#L820
```
hidden_states = self.ln_f(hidden_states)
...
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
```
TensorFlow GPT2
https://github.com/huggingface/transformers/blob/773d386041b2761204dcc67b316904d8d5b412da/src/transformers/models/gpt2/modeling_tf_gpt2.py#L397
```
hidden_states = self.ln_f(hidden_states)
...
# Add last hidden state
if inputs["output_hidden_states"]:
all_hidden_states = all_hidden_states + (hidden_states,)
```
Flax GPT2
https://github.com/huggingface/transformers/blob/773d386041b2761204dcc67b316904d8d5b412da/src/transformers/models/gpt2/modeling_flax_gpt2.py#L461
```
# In `FlaxGPT2BlockCollection` which has no `ln_f` (only exist in `FlaxGPT2Module`)
if output_hidden_states:
all_hidden_states += (hidden_states,)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13102/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13101 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13101/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13101/comments | https://api.github.com/repos/huggingface/transformers/issues/13101/events | https://github.com/huggingface/transformers/pull/13101 | 968,739,338 | MDExOlB1bGxSZXF1ZXN0NzEwODM1NjQx | 13,101 | [To Show] Required changes for general multi-modal models | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13101/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13101",
"html_url": "https://github.com/huggingface/transformers/pull/13101",
"diff_url": "https://github.com/huggingface/transformers/pull/13101.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13101.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13100 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13100/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13100/comments | https://api.github.com/repos/huggingface/transformers/issues/13100/events | https://github.com/huggingface/transformers/pull/13100 | 968,727,929 | MDExOlB1bGxSZXF1ZXN0NzEwODI0OTk1 | 13,100 | Rely on huggingface_hub for common tools | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Awesome, wanted to do this for quite some time, thanks!"
] | 1,628 | 1,629 | 1,628 | COLLABORATOR | null | # What does this PR do?
This PR removes the `hf_api` module from Transformers to rely on the one in `huggingface_hub`. It also fully deprecates the `transformers-cli` command lines relying on it (such as `login`, `whoami`, `logout`).
In passing, when `model_list` was used, this PR switches to the new version, `list_models`.
cc @julien-c | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13100/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13100/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13100",
"html_url": "https://github.com/huggingface/transformers/pull/13100",
"diff_url": "https://github.com/huggingface/transformers/pull/13100.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13100.patch",
"merged_at": 1628773142000
} |
https://api.github.com/repos/huggingface/transformers/issues/13099 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13099/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13099/comments | https://api.github.com/repos/huggingface/transformers/issues/13099/events | https://github.com/huggingface/transformers/pull/13099 | 968,696,524 | MDExOlB1bGxSZXF1ZXN0NzEwNzk1NzQ5 | 13,099 | [FlaxCLIP] allow passing params to image and text feature methods | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
Allows passing `params` to `get_text_features` and `get_image_features` methods. This is needed when we use transformations like `pmap/pjit` where we need to pass replicated or sharded params to functions. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13099/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13099",
"html_url": "https://github.com/huggingface/transformers/pull/13099",
"diff_url": "https://github.com/huggingface/transformers/pull/13099.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13099.patch",
"merged_at": 1628773501000
} |
https://api.github.com/repos/huggingface/transformers/issues/13098 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13098/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13098/comments | https://api.github.com/repos/huggingface/transformers/issues/13098/events | https://github.com/huggingface/transformers/pull/13098 | 968,632,743 | MDExOlB1bGxSZXF1ZXN0NzEwNzM1NzEw | 13,098 | Fix Flax params dtype | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | null | [] | [
"I like the design and I think it follows jax-design quite nicely (similar to how optax optimizers mask certain weights: https://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/examples/flax/summarization/run_summarization_flax.py#L588)\r\n\r\nThis PR will necessarly have some breaking changes as after it loading a model with `dtype=bfloat16` won't convert the weights into bfloat16 anymore, so we should announce it well. \r\n\r\nAlso it would be great if @avital could maybe quickly give his opinion on the API here",
"Hi folks, sorry for the radio silence, I'm back now. @jheek has thought carefully about the exact meaning of dtypes in Flax modules so I'd like to hear his take on this confusion. ",
"I think masking is the right approach here. The right dtype is very context dependent. During inference half precision is almost always better while during training it's pretty much never worth it. And then of course there is fine-tuning where the masked weights are basically in inference mode. The mask based API captures this complexity really well. ",
"just noticed a sneaky bug in some flax models, the `dtype` is never passed to some modules, for example here in bart, \r\nhttps://github.com/huggingface/transformers/blob/3fbb55c75779824aacfc43067f0892674a9cfbc6/src/transformers/models/bart/modeling_flax_bart.py#L400-L405\r\nattention never receives `dtype`, so it’s always in `fp32` even if the user passed `bf16` .\r\n\r\nsame with T5 here\r\nhttps://github.com/huggingface/transformers/blob/3fbb55c75779824aacfc43067f0892674a9cfbc6/src/transformers/models/t5/modeling_flax_t5.py#L1368\r\n\r\n@patrickvonplaten @sgugger I propose we make `dtype` required for all modules except user-facing once? So all main model classes will have a default type (`fp32`) but for all other submodules make it required to avoid such bugs.",
"And I think the flax template has to be adapted here as well",
"Hey @patrickvonplaten !\r\n\r\n- added a couple more tests as you suggested\r\n- updated the templates\r\n- ran tests on both GPU and TPU and they pass \r\n\r\nWould be awesome if you could take quick final look :) \r\n",
"Thanks for finishing the PR!",
"Think we just need to update the Flax templates now and we're good to go :-) "
] | 1,628 | 1,636 | 1,636 | MEMBER | null | # What does this PR do?
The `dtype` argument in flax models is used ambiguously. This argument is actually supposed to specify the `dtype` of computation and not the `dtype` of model parameters. But in some models/modules, it's passed to kernel_initializers which causes the `kernel` parameters to be initialized with that `dtype`. This causes the following issues
- in flax models, we don't pass `bias_init` to `Dense` layers since the default value is as expected by our models. So if we pass `dtype=jnp.bfloat16` it's only passed to `kernel_init`, so for a dense layer the kernel params are in `bfloat16` while the `bias` params are in `fp32`
- This also causes issues with saving and loading models as explained in #12534
This PR corrects the usage of `dtype` in flax models and adds `to_bf16`, `to_fp16` and `to_fp32` methods in `FlaxPreTrainedModel`. These methods could accept any arbitrary params tree and change its `dtype`. So if users want they could keep certain params in bf16 and certain others in fp32 however they like, by just passing the right parameters to these methods.
To allow keeping only certain params in half-precision the `to_bf16` method accepts a mask that specifies what params to keep in `bf16` and what params in `fp32`. For example
```python3
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import freeze, unfreeze
from flax.traverse_util import flatten_dict, unflatten_dict
from transformers import FlaxBertModel, BertConfig
config = BertConfig(num_hidden_layers=1)
model = FlaxBertModel(config, dtype=jnp.dtype("bfloat16"))
# keep layer norm in fp32
def mask_fn(params):
flat_params = flatten_dict(params)
flat_mask = {path: (path[-2:] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale")) for path in flat_params}
return unflatten_dict(flat_mask)
mask = mask_fn(model.params)
params = model.to_bf16(model.params, mask)
jax.eval_shape(lambda x : x, freeze(params)) # view the dtypes
```
- This PR also fixes an issue in some models where the `dtype` was never passed to some modules, so those modules were always doing computation in fp32 even if the user passed `bf16` or `fp16` dtype .
- This should now help enable mixed-precision training in flax models as we can keep the params and computation `dtype` separate.
---
🚨 **BREAKING CHANGE** 🚨
**Note that: this will be a breaking change since the meaning of `dtype` is now changed and it's only used to specify the data type of computation and does not influence the data type of model parameters.** | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13098/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13098",
"html_url": "https://github.com/huggingface/transformers/pull/13098",
"diff_url": "https://github.com/huggingface/transformers/pull/13098.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13098.patch",
"merged_at": 1636622120000
} |
https://api.github.com/repos/huggingface/transformers/issues/13097 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13097/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13097/comments | https://api.github.com/repos/huggingface/transformers/issues/13097/events | https://github.com/huggingface/transformers/pull/13097 | 968,450,026 | MDExOlB1bGxSZXF1ZXN0NzEwNTY0MjQz | 13,097 | Reactive test fecthers on scheduled test with proper git install | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
This PR reactivates the test fecther on the scheduled jobs, now that we have debug the root of the issue: PyTorch docker image does not contain a recent `git` version, which in turns does not work properly with GitHub actions, so we need to:
- install it manually
- **then** check out the repo after. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13097/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13097",
"html_url": "https://github.com/huggingface/transformers/pull/13097",
"diff_url": "https://github.com/huggingface/transformers/pull/13097.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13097.patch",
"merged_at": 1628761094000
} |
https://api.github.com/repos/huggingface/transformers/issues/13096 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13096/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13096/comments | https://api.github.com/repos/huggingface/transformers/issues/13096/events | https://github.com/huggingface/transformers/pull/13096 | 968,337,962 | MDExOlB1bGxSZXF1ZXN0NzEwNDYwNzM3 | 13,096 | Optimize Token Classification models for TPU | {
"login": "ibraheem-moosa",
"id": 14109029,
"node_id": "MDQ6VXNlcjE0MTA5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/14109029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibraheem-moosa",
"html_url": "https://github.com/ibraheem-moosa",
"followers_url": "https://api.github.com/users/ibraheem-moosa/followers",
"following_url": "https://api.github.com/users/ibraheem-moosa/following{/other_user}",
"gists_url": "https://api.github.com/users/ibraheem-moosa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibraheem-moosa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibraheem-moosa/subscriptions",
"organizations_url": "https://api.github.com/users/ibraheem-moosa/orgs",
"repos_url": "https://api.github.com/users/ibraheem-moosa/repos",
"events_url": "https://api.github.com/users/ibraheem-moosa/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibraheem-moosa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thank you for your PR! Would you happen to have performance results we can take a look at to see the improvement your PR offers?",
"Sure. I found this issue while running experiments for our paper. I cannot make that code public yet. I will make a colab notebook illustrating the issue.",
"Hi. Sorry for being so late. I have prepared a colab notebook showing the speedup [here](https://colab.research.google.com/drive/1Y9f3BWkTeQS7lFJSGXjcCULURYAJ1NZw?usp=sharing). With this PR we can improve ALBERT Token Classification model training time from 27.5 minutes to 3minutes.",
"Thank you for sharing, I have requested access to the doc",
"I have updated the permission. ",
"Thank you, this looks good! @sgugger, @mfuntowicz, I think you're the most experienced with torch operations - do you have some feedback for this PR?",
"Sure. I will run the code on GPU too :)",
"Here is the [colab notebook](https://colab.research.google.com/drive/1OTBfHNt-ZGqFlz1kFvFEq-oCBRYFEuLw?usp=sharing) comparing the execution of the original implementation and the patched implementation on GPU. As expected, there is no performance degradation on GPU.",
"Thanks for checking! The failing test has been fixed on master so this is good to merge for me.",
"Thanks for your work @ibraheem-moosa, super nice addition!"
] | 1,628 | 1,631 | 1,631 | CONTRIBUTOR | null | As per the XLA [documentation](https://github.com/pytorch/xla/blob/master/TROUBLESHOOTING.md#known-performance-caveats) XLA cannot handle masked indexing well. So token classification
models for BERT and others use an implementation based on `torch.where`. This implementation
works well on TPU.
ALBERT, ELECTRA and LayoutLM token classification model uses the masked indexing which
causes performance issues on TPU.
This PR fixes this issue by following the BERT implementation.
Relevant code in [BERT](https://github.com/huggingface/transformers/blob/c4e1586db8ef6b4102016fc5cb038940fde45325/src/transformers/models/bert/modeling_bert.py#L1741)
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13096/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13096",
"html_url": "https://github.com/huggingface/transformers/pull/13096",
"diff_url": "https://github.com/huggingface/transformers/pull/13096.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13096.patch",
"merged_at": 1631887672000
} |
https://api.github.com/repos/huggingface/transformers/issues/13095 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13095/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13095/comments | https://api.github.com/repos/huggingface/transformers/issues/13095/events | https://github.com/huggingface/transformers/issues/13095 | 967,670,535 | MDU6SXNzdWU5Njc2NzA1MzU= | 13,095 | Memory accumulation when using hybrid clip script | {
"login": "galuhsahid",
"id": 10180442,
"node_id": "MDQ6VXNlcjEwMTgwNDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/10180442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galuhsahid",
"html_url": "https://github.com/galuhsahid",
"followers_url": "https://api.github.com/users/galuhsahid/followers",
"following_url": "https://api.github.com/users/galuhsahid/following{/other_user}",
"gists_url": "https://api.github.com/users/galuhsahid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galuhsahid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galuhsahid/subscriptions",
"organizations_url": "https://api.github.com/users/galuhsahid/orgs",
"repos_url": "https://api.github.com/users/galuhsahid/repos",
"events_url": "https://api.github.com/users/galuhsahid/events{/privacy}",
"received_events_url": "https://api.github.com/users/galuhsahid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks a lot for posting the detailed issue.\r\n\r\nI'm not exactly sure about this, but could you try disabling `persistent_workers` in `DataLoader`, it was causing some issues for another team. \r\n\r\n> if it's OK to add to the existing script, maybe I can make a separate issue to add logging and saving by steps and make a PR for that?\r\n\r\nyes, that would be great! Feel free to open a PR for that :)",
"Along with what @patil-suraj suggested, you should also bring down your `num_workers` to 16 or 32 instead of 96. That should keep your memory in check if you're planning to train your model for 2-3 days.",
"@bhavitvyamalik Yup, for the run I linked in the original thread I've used `num_workers` = 16. I have used 96 earlier which crashed the run almost immediately with ~12M images. Decreasing the `num_workers` helped a lot indeed, although the memory is still seeing an increasing trend.\r\n\r\n@patil-suraj Thank you for the suggestion - disabling `persistent_workers` seems to work, this is how the graph looks like after I disabled it ([wandb run](https://wandb.ai/galuh/clip-indonesian/runs/33dqdxtd/system?workspace=user-galuh)):\r\n\r\n\r\n\r\nIt's still increasing but at a much slower pace than when `persistent_workers` was enabled and somehow drops again much later. Not sure if this is expected though. \r\n\r\n(If it's not expected - this might be somehow related to this issue https://github.com/pytorch/pytorch/issues/13246. I've tried one of the solutions (converting the `examples` list in the DataLoader into np.array) but I'm still seeing the same increasing trend)\r\n\r\nAlso sure would be happy to open a PR later! Thank you",
"Looking at the PyTorch issue it does seem related to the dataloader.\r\n\r\nIn the `ImageTextDataset` in `run_hybrid_clip.py`, all examples, captions, image_paths are stored in python lists\r\n\r\nhttps://github.com/huggingface/transformers/blob/bda1cb02360fc9d290636cfcb6bcbeb4a18484ce/examples/research_projects/jax-projects/hybrid_clip/run_hybrid_clip.py#L220-L228\r\n\r\nAs suggested in that issue, could try storing the examples in a zero-copy object?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: Linux-5.4.0-1043-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cpu (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (cpu)
- Jax version: 0.2.18
- JaxLib version: 0.1.69
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: yes, TPU v3-8
### Who can help
@patil-suraj
## Information
Model I am using (Bert, XLNet ...): BERT + ViT
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
I'm currently working on pretraining CLIP for Indonesian using scripts that are based on the [Hybrid CLIP](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects/hybrid_clip) example. I've run the code using the COCO dataset and it ran with no problem and managed to produce a working model, however I didn't track this run with wandb so I'm not sure how the system looked like with COCO.
Right now I'm trying to train a model on a larger dataset (~12M image-text pairs). However it seems that the memory keeps accumulating as seen on the graph below. During one of my runs it (not tracked) it eventually crashed after ~7 hours which is why I noticed this. After rerunning and tracking it (terminated - [here](https://wandb.ai/galuh/clip-indonesian/runs/2qb4zp6v?workspace=user-galuh) is the wandb run) turns out it's probably because of the memory:

Looks like the sharp jumps happened during evaluation.
Changes on the script compared to the hybrid clip example:
- add wandb logging
- save training, evaluation metrics, and checkpoints in steps instead of epochs -> at first I thought the memory accumulation was due to the training and evaluation metrics, however the issue still persists despite having logged and cleared my training metrics with a 200 step interval <note: if it's OK to add to the existing script, maybe I can make a separate issue to add logging and saving by steps and make a PR for that?>
- use adafactor instead of adamw
## To reproduce
Steps to reproduce the behavior:
1. Run the code in [this folder](https://github.com/galuhsahid/clip-indonesian/tree/main/hybrid_clip) by running `run_training.sh`, with any large image-text dataset that is prepared as instructed in the [readme of the examples folder](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects/hybrid_clip) (jsonl file).
## Expected behavior
Memory stays roughly constant throughout
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13095/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13094 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13094/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13094/comments | https://api.github.com/repos/huggingface/transformers/issues/13094/events | https://github.com/huggingface/transformers/pull/13094 | 967,544,615 | MDExOlB1bGxSZXF1ZXN0NzA5NzEwODc4 | 13,094 | Improve type checker performance | {
"login": "bschnurr",
"id": 1946977,
"node_id": "MDQ6VXNlcjE5NDY5Nzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1946977?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bschnurr",
"html_url": "https://github.com/bschnurr",
"followers_url": "https://api.github.com/users/bschnurr/followers",
"following_url": "https://api.github.com/users/bschnurr/following{/other_user}",
"gists_url": "https://api.github.com/users/bschnurr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bschnurr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bschnurr/subscriptions",
"organizations_url": "https://api.github.com/users/bschnurr/orgs",
"repos_url": "https://api.github.com/users/bschnurr/repos",
"events_url": "https://api.github.com/users/bschnurr/events{/privacy}",
"received_events_url": "https://api.github.com/users/bschnurr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Last failure is not linked to this PR and has been fixed on master already, so we're good to go, thanks again!"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
conditionally declare `TOKENIZER_MAPPING_NAMES` within a `if TYPE_CHECKING` block so that type checkers don't need to evaluate the RHS of the assignment.
this improves performance of the pylance/pyright type checkers
```Python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
```
from 12 seconds, down to 2.5 seconds
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13094/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13094",
"html_url": "https://github.com/huggingface/transformers/pull/13094",
"diff_url": "https://github.com/huggingface/transformers/pull/13094.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13094.patch",
"merged_at": 1628786754000
} |
https://api.github.com/repos/huggingface/transformers/issues/13093 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13093/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13093/comments | https://api.github.com/repos/huggingface/transformers/issues/13093/events | https://github.com/huggingface/transformers/issues/13093 | 967,250,247 | MDU6SXNzdWU5NjcyNTAyNDc= | 13,093 | AttributeError: module 'sacrebleu' has no attribute 'DEFAULT_TOKENIZER' in translation.ipynb notebook | {
"login": "Azitt",
"id": 32965166,
"node_id": "MDQ6VXNlcjMyOTY1MTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/32965166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Azitt",
"html_url": "https://github.com/Azitt",
"followers_url": "https://api.github.com/users/Azitt/followers",
"following_url": "https://api.github.com/users/Azitt/following{/other_user}",
"gists_url": "https://api.github.com/users/Azitt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Azitt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Azitt/subscriptions",
"organizations_url": "https://api.github.com/users/Azitt/orgs",
"repos_url": "https://api.github.com/users/Azitt/repos",
"events_url": "https://api.github.com/users/Azitt/events{/privacy}",
"received_events_url": "https://api.github.com/users/Azitt/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! A new release of sacrebleu was released with breaking changes. Could you reinstall sacrebleu on version 1.5.1 to see if it runs? cc @sgugger ",
"El El jue, ago. 12, 2021 a la(s) 12:28 a.m., Lysandre Debut <\n***@***.***> escribió:\n\n> Hello! A new release of sacrebleu was released with breaking changes.\n> Could you reinstall sacrebleu on version 1.5.1 to see if it runs? cc\n> @sgugger <https://github.com/sgugger>\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/13093#issuecomment-897412269>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ATAWLJIIQSKSOC5FCT6GLULT4NZYVANCNFSM5B7G2BFQ>\n> .\n> Triage notifications on the go with GitHub Mobile for iOS\n> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>\n> or Android\n> <https://play.google.com/store/apps/details?id=com.github.android&utm_campaign=notification-email>\n> .\n>\n",
"installing version 1.5.1 solves the problem. thanks!",
"Removed Sacrebleu 2.0.0 and installed 1.5.1\r\nIt works!",
"I used 1.5.1 but faild"
] | 1,628 | 1,684 | 1,628 | NONE | null | I'm trying to use translation.ipynb notebook. I'm getting below error:

## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.2
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13093/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13092 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13092/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13092/comments | https://api.github.com/repos/huggingface/transformers/issues/13092/events | https://github.com/huggingface/transformers/issues/13092 | 967,014,496 | MDU6SXNzdWU5NjcwMTQ0OTY= | 13,092 | [Benchmark] | {
"login": "Dennis0225",
"id": 83877811,
"node_id": "MDQ6VXNlcjgzODc3ODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/83877811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dennis0225",
"html_url": "https://github.com/Dennis0225",
"followers_url": "https://api.github.com/users/Dennis0225/followers",
"following_url": "https://api.github.com/users/Dennis0225/following{/other_user}",
"gists_url": "https://api.github.com/users/Dennis0225/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dennis0225/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dennis0225/subscriptions",
"organizations_url": "https://api.github.com/users/Dennis0225/orgs",
"repos_url": "https://api.github.com/users/Dennis0225/repos",
"events_url": "https://api.github.com/users/Dennis0225/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dennis0225/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | # 🖥 Benchmarking `transformers`
## Benchmark
Which part of `transformers` did you benchmark?
## Set-up
What did you run your benchmarks on? Please include details, such as: CPU, GPU? If using multiple GPUs, which parallelization did you use?
## Results
Put your results here! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13092/reactions",
"total_count": 1,
"+1": 0,
"-1": 1,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13092/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13091 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13091/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13091/comments | https://api.github.com/repos/huggingface/transformers/issues/13091/events | https://github.com/huggingface/transformers/pull/13091 | 966,961,698 | MDExOlB1bGxSZXF1ZXN0NzA5MTY3MDcy | 13,091 | Install git | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Just added it in the TensorFlow tests that are commented out for now as I'm afraid we will forget otherwise when we uncomment them.\r\n\r\nThanks a lot for adding this!"
] | 1,628 | 1,628 | 1,628 | MEMBER | null | Add git to the installation instructions for pytorch-based images which do not have git installed. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13091/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13091",
"html_url": "https://github.com/huggingface/transformers/pull/13091",
"diff_url": "https://github.com/huggingface/transformers/pull/13091.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13091.patch",
"merged_at": 1628698182000
} |
https://api.github.com/repos/huggingface/transformers/issues/13090 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13090/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13090/comments | https://api.github.com/repos/huggingface/transformers/issues/13090/events | https://github.com/huggingface/transformers/pull/13090 | 966,953,559 | MDExOlB1bGxSZXF1ZXN0NzA5MTU5NTc0 | 13,090 | [Flax/JAX] Run jitted tests at every commit | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger - I'll wait with merging this PR hten until \"efficient testing\" is rolled out for self-push github action",
"Efficient tests are rolled out on `self-push` -> merging the PR"
] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Thanks to @sgugger's PR to run only tests that are affected by the code change, we can re-enable jitted Flax/JAX tests at every commit in my opinion. A jitted Flax/JAX test takes between 20 seconds and 5 minutes per model (only BigBird takes 5 minutes, the second longest test takes 1min), so a total of around 20 minutes (only when files affected all Flax models are pushed).
If just a single Flax model is changed the tests will take a minute or so, see: https://circle-production-customer-artifacts.s3.amazonaws.com/picard/forks/5bdabdd888af1f000130874a/226201271/6113ef4861c2ff26950fd762-0-build/artifacts/~/transformers/reports/tests_flax_durations.txt?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20210811T154534Z&X-Amz-SignedHeaders=host&X-Amz-Expires=60&X-Amz-Credential=AKIAJR3Q6CR467H7Z55A%2F20210811%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Signature=1eae0d3553c5ebf6daac2dfa0db9af4dde96e7fe1630bab6d16e442eb8832cb7
@sgugger I think it's fine to run the jitted Flax/JAX tests now everytime thanks to your PR :-)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13090/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13090",
"html_url": "https://github.com/huggingface/transformers/pull/13090",
"diff_url": "https://github.com/huggingface/transformers/pull/13090.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13090.patch",
"merged_at": 1628772586000
} |
https://api.github.com/repos/huggingface/transformers/issues/13089 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13089/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13089/comments | https://api.github.com/repos/huggingface/transformers/issues/13089/events | https://github.com/huggingface/transformers/issues/13089 | 966,937,172 | MDU6SXNzdWU5NjY5MzcxNzI= | 13,089 | can"t connect ther online datasets.the issue:ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py | {
"login": "jinec",
"id": 39627475,
"node_id": "MDQ6VXNlcjM5NjI3NDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/39627475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jinec",
"html_url": "https://github.com/jinec",
"followers_url": "https://api.github.com/users/jinec/followers",
"following_url": "https://api.github.com/users/jinec/following{/other_user}",
"gists_url": "https://api.github.com/users/jinec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jinec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jinec/subscriptions",
"organizations_url": "https://api.github.com/users/jinec/orgs",
"repos_url": "https://api.github.com/users/jinec/repos",
"events_url": "https://api.github.com/users/jinec/events{/privacy}",
"received_events_url": "https://api.github.com/users/jinec/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nCan you create a Colab/code example to reproduce the issue?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:4.6.1
- Platform:
- Python version:3.6
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy):run_glue.py @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13089/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13088 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13088/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13088/comments | https://api.github.com/repos/huggingface/transformers/issues/13088/events | https://github.com/huggingface/transformers/pull/13088 | 966,907,359 | MDExOlB1bGxSZXF1ZXN0NzA5MTE3MDE3 | 13,088 | Doctests job | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | Add a doctests job that runs on a daily basis.
It currently goes through two files which are cleaned up for doctests (see `documentation_tests.txt`). As files get cleaned up, they should be added to that file to enable the tests.
Once all files are cleaned, this logic can be removed. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13088/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13088",
"html_url": "https://github.com/huggingface/transformers/pull/13088",
"diff_url": "https://github.com/huggingface/transformers/pull/13088.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13088.patch",
"merged_at": 1628754145000
} |
https://api.github.com/repos/huggingface/transformers/issues/13087 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13087/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13087/comments | https://api.github.com/repos/huggingface/transformers/issues/13087/events | https://github.com/huggingface/transformers/pull/13087 | 966,864,208 | MDExOlB1bGxSZXF1ZXN0NzA5MDc2ODc0 | 13,087 | Fix classifier dropout in AlbertForMultipleChoice | {
"login": "ibraheem-moosa",
"id": 14109029,
"node_id": "MDQ6VXNlcjE0MTA5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/14109029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibraheem-moosa",
"html_url": "https://github.com/ibraheem-moosa",
"followers_url": "https://api.github.com/users/ibraheem-moosa/followers",
"following_url": "https://api.github.com/users/ibraheem-moosa/following{/other_user}",
"gists_url": "https://api.github.com/users/ibraheem-moosa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibraheem-moosa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibraheem-moosa/subscriptions",
"organizations_url": "https://api.github.com/users/ibraheem-moosa/orgs",
"repos_url": "https://api.github.com/users/ibraheem-moosa/repos",
"events_url": "https://api.github.com/users/ibraheem-moosa/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibraheem-moosa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Indeed, thank you for fixing it! We'll gladly welcome PRs that update other models that have this issue."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | Classification head of AlbertForMultipleChoice uses `hidden_dropout_prob` instead of `classifier_dropout_prob`.
This is not desirable as we cannot change classifer head dropout probability without changing the dropout
probabilities of the whole model.
As shown in the paper Albert performance is hurt by dropout. So we should be able to change classifier head probability
without changing internal dropout of Albert. Also I wonder if changing the internal dropout of a pretrained model is
a good idea or not.
Also I have seen similar issue in Bert and Roberta multiple choice models. I wonder if this is a conscious choice or an
unintended bug.
This PR fixes this behaviour for Albert.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13087/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13087",
"html_url": "https://github.com/huggingface/transformers/pull/13087",
"diff_url": "https://github.com/huggingface/transformers/pull/13087.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13087.patch",
"merged_at": 1628753852000
} |
https://api.github.com/repos/huggingface/transformers/issues/13086 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13086/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13086/comments | https://api.github.com/repos/huggingface/transformers/issues/13086/events | https://github.com/huggingface/transformers/issues/13086 | 966,841,896 | MDU6SXNzdWU5NjY4NDE4OTY= | 13,086 | Missing `lm_head` parameter in FlaxGPT2LMHeadModel.params | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @ydshieh,\r\n\r\nThanks for the issue! The reason why `lm_head` is missing in the parameters is because the input and output embeddings are tied for `gpt2` which is the default case if not stated otherwise in the specific config -> see: https://github.com/huggingface/transformers/blob/c71f73f438c7848b7d86af5258e886f03ba45f1e/src/transformers/configuration_utils.py#L227\r\n\r\nAs a consequence the jax models run through this line of code: https://github.com/huggingface/transformers/blob/c71f73f438c7848b7d86af5258e886f03ba45f1e/src/transformers/models/gpt2/modeling_flax_gpt2.py#L590 which means that the `lm_head` weights are never used **instead** the `shared_kernel = self.transformer.variables[\"params\"][\"wte\"][\"embedding\"].T` weights are passed through `lm_head` module. When the first were first created, jax therefore did not trace through an uninitialzied `self.lm_head` but just applied existing weights to the `lm_head` which then didn't create any weights for `lm_head`. \r\n\r\n=> In short one can remember that weights are only created if the control flow goes through the `flax.linen.Module.__call__(...)` method. If the control flow just goes through a `flax.linen.Module.apply(...)` method with given weights, then the model does not expect any weights for this model and will never create it. \r\n\r\n ",
"Hi, @patrickvonplaten , thank you for this explanation. Now I feel more sure about the code below (copied from `modeling_hybrid_clip.py`) for the recent work on `FlaxEncoderDecoderModel`\r\n\r\n```\r\nclass FlaxEncoderDecoderModel(FlaxPreTrainedModel):\r\n\r\n @classmethod\r\n def from_encoder_decoder_pretrained(\r\n\r\n ...\r\n\r\n # init model\r\n model = cls(config, dtype=dtype, **kwargs)\r\n model.params[\"encoder\"] = encoder.params\r\n model.params[\"decoder\"] = decoder.params\r\n\r\n return model\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | COLLABORATOR | null | ## Environment info
- `transformers` version: 4.10.0.dev0
- Platform: Linux-5.11.0-25-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cpu (False)
- Tensorflow version (GPU?): 2.5.1 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (cpu)
- Jax version: 0.2.16
- JaxLib version: 0.1.68
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten
## Information
Model I am using: `FlaxGPT2LMHeadModel`
## To reproduce
Steps to reproduce the behavior:
This code snippet
```
from transformers import FlaxGPT2LMHeadModel
model = FlaxGPT2LMHeadModel.from_pretrained('gpt2')
{k for k in model.params}
```
gives
```
{'transformer'}
```
## Expected behavior
I expect the output will be
```
{'transformer', 'lm_head'}
```
because `FlaxGPT2LMHeadModule` has `self.lm_head` as in the code snippet below
```
class FlaxGPT2LMHeadModule(nn.Module):
def setup(self):
self.transformer = FlaxGPT2Module(self.config, dtype=self.dtype)
self.lm_head = nn.Dense(...)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13086/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13085 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13085/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13085/comments | https://api.github.com/repos/huggingface/transformers/issues/13085/events | https://github.com/huggingface/transformers/pull/13085 | 966,790,410 | MDExOlB1bGxSZXF1ZXN0NzA5MDA5Mzc4 | 13,085 | Proper import for unittest.mock.patch | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
Import from `unittest.mock` to avoid errors. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13085/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13085/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13085",
"html_url": "https://github.com/huggingface/transformers/pull/13085",
"diff_url": "https://github.com/huggingface/transformers/pull/13085.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13085.patch",
"merged_at": 1628760181000
} |
https://api.github.com/repos/huggingface/transformers/issues/13084 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13084/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13084/comments | https://api.github.com/repos/huggingface/transformers/issues/13084/events | https://github.com/huggingface/transformers/issues/13084 | 966,700,651 | MDU6SXNzdWU5NjY3MDA2NTE= | 13,084 | やからん | {
"login": "bdr2486",
"id": 86000075,
"node_id": "MDQ6VXNlcjg2MDAwMDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/86000075?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bdr2486",
"html_url": "https://github.com/bdr2486",
"followers_url": "https://api.github.com/users/bdr2486/followers",
"following_url": "https://api.github.com/users/bdr2486/following{/other_user}",
"gists_url": "https://api.github.com/users/bdr2486/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bdr2486/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bdr2486/subscriptions",
"organizations_url": "https://api.github.com/users/bdr2486/orgs",
"repos_url": "https://api.github.com/users/bdr2486/repos",
"events_url": "https://api.github.com/users/bdr2486/events{/privacy}",
"received_events_url": "https://api.github.com/users/bdr2486/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md --> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13084/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13082 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13082/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13082/comments | https://api.github.com/repos/huggingface/transformers/issues/13082/events | https://github.com/huggingface/transformers/issues/13082 | 966,572,457 | MDU6SXNzdWU5NjY1NzI0NTc= | 13,082 | I modified https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py script few days ago for training electra from scratch. But there were some problems(maybe bugs) i had to solve for this task. | {
"login": "apkbala107",
"id": 85219702,
"node_id": "MDQ6VXNlcjg1MjE5NzAy",
"avatar_url": "https://avatars.githubusercontent.com/u/85219702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apkbala107",
"html_url": "https://github.com/apkbala107",
"followers_url": "https://api.github.com/users/apkbala107/followers",
"following_url": "https://api.github.com/users/apkbala107/following{/other_user}",
"gists_url": "https://api.github.com/users/apkbala107/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apkbala107/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apkbala107/subscriptions",
"organizations_url": "https://api.github.com/users/apkbala107/orgs",
"repos_url": "https://api.github.com/users/apkbala107/repos",
"events_url": "https://api.github.com/users/apkbala107/events{/privacy}",
"received_events_url": "https://api.github.com/users/apkbala107/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"location is currently not available...please share the exact location",
"Here's the folder containing the language modeling scripts: https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | I modified https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py script few days ago for training electra from scratch. But there were some problems(maybe bugs) i had to solve for this task.
Currently I´m setting up a clean running version for training a electra language model from scratch with an additional document classification head based on the script.
_Originally posted by @miketrimmel in https://github.com/huggingface/transformers/issues/4425#issuecomment-630715171_ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13082/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13081 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13081/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13081/comments | https://api.github.com/repos/huggingface/transformers/issues/13081/events | https://github.com/huggingface/transformers/issues/13081 | 966,571,222 | MDU6SXNzdWU5NjY1NzEyMjI= | 13,081 | location is currently not available...please share the exact locationDetailed Explanation | {
"login": "apkbala107",
"id": 85219702,
"node_id": "MDQ6VXNlcjg1MjE5NzAy",
"avatar_url": "https://avatars.githubusercontent.com/u/85219702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apkbala107",
"html_url": "https://github.com/apkbala107",
"followers_url": "https://api.github.com/users/apkbala107/followers",
"following_url": "https://api.github.com/users/apkbala107/following{/other_user}",
"gists_url": "https://api.github.com/users/apkbala107/gists{/gist_id}",
"starred_url": "https://api.github.com/users/apkbala107/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/apkbala107/subscriptions",
"organizations_url": "https://api.github.com/users/apkbala107/orgs",
"repos_url": "https://api.github.com/users/apkbala107/repos",
"events_url": "https://api.github.com/users/apkbala107/events{/privacy}",
"received_events_url": "https://api.github.com/users/apkbala107/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"location is currently not available...please share the exact location",
"@apkbala107 mlcom.github.io",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | Detailed Explanation
https://mlcom.github.io/Create-Language-Model/
_Originally posted by @mlcom in https://github.com/huggingface/transformers/issues/4425#issuecomment-774689668_ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13081/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13080 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13080/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13080/comments | https://api.github.com/repos/huggingface/transformers/issues/13080/events | https://github.com/huggingface/transformers/issues/13080 | 966,558,757 | MDU6SXNzdWU5NjY1NTg3NTc= | 13,080 | [Vision Transformers] examples and pretraining | {
"login": "flozi00",
"id": 47894090,
"node_id": "MDQ6VXNlcjQ3ODk0MDkw",
"avatar_url": "https://avatars.githubusercontent.com/u/47894090?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/flozi00",
"html_url": "https://github.com/flozi00",
"followers_url": "https://api.github.com/users/flozi00/followers",
"following_url": "https://api.github.com/users/flozi00/following{/other_user}",
"gists_url": "https://api.github.com/users/flozi00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/flozi00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/flozi00/subscriptions",
"organizations_url": "https://api.github.com/users/flozi00/orgs",
"repos_url": "https://api.github.com/users/flozi00/repos",
"events_url": "https://api.github.com/users/flozi00/events{/privacy}",
"received_events_url": "https://api.github.com/users/flozi00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | CONTRIBUTOR | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
Example scripts for fine-tuning and pretraining for clip and Beit models
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
At the moment I am training ViT and DeiT for several tasks and thought it would be interesting to compare with clip or from scratch pretrained beit model in self supervised way.
I saw there are already examples for training clip using transformers and flax, not sure if there is an specific reason why it's not already in this repo.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
If there is someone out who could give me advice, I would be interested adding the Beit pretraining script for pytorch. Longtime I definitely want to add comparisons for several tasks between ViT and from scratch trained BeiT especially for low resource tasks to the hub | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13080/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/13080/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13079 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13079/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13079/comments | https://api.github.com/repos/huggingface/transformers/issues/13079/events | https://github.com/huggingface/transformers/pull/13079 | 966,494,314 | MDExOlB1bGxSZXF1ZXN0NzA4NzM1Njk4 | 13,079 | fix: keep separate hypothesis for different beam group | {
"login": "ayubSubhaniya",
"id": 20911334,
"node_id": "MDQ6VXNlcjIwOTExMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/20911334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayubSubhaniya",
"html_url": "https://github.com/ayubSubhaniya",
"followers_url": "https://api.github.com/users/ayubSubhaniya/followers",
"following_url": "https://api.github.com/users/ayubSubhaniya/following{/other_user}",
"gists_url": "https://api.github.com/users/ayubSubhaniya/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayubSubhaniya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayubSubhaniya/subscriptions",
"organizations_url": "https://api.github.com/users/ayubSubhaniya/orgs",
"repos_url": "https://api.github.com/users/ayubSubhaniya/repos",
"events_url": "https://api.github.com/users/ayubSubhaniya/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayubSubhaniya/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@ayushtiku5 could you maybe take a look here? :-)",
"@patrickvonplaten @ayushtiku5 doesn't seem to be available, could you please take a look?\r\n\r\nRegarding test failure, It is related to the change itself, there are some assertions on structure of beam hypothesis array, which needs to be changed. Once change seems fine to you I can make test work.",
"@patrickvonplaten If you need some examples I can try to find them.\r\nI tried to debug this issue on my custom trained weights, it would be hard to find an example on public models.",
"Thanks for pinging me again on this @ayubSubhaniya! I finally took some time to look a bit deeper into the PR - IMO it's not really a bug, but just a matter of how to define \"beam_per_group\". If `num_beams` is thought of as the total number of beams for generation then, `num_beams // num_beam_groups` is the number of beams per group. \r\n\r\nIt is questionable whether `num_beams` in this case should represent the overall number of beams across all groups or *per* group - if I understand correctly in your opinion in should be per group. I understand this point, but the problem is that making this change now is a big backwards compatibility breaking change: Image all the users using group beam search in their pipelines now that all of a sudden get different results because the meaning of `num_beams` change. \r\n\r\nSo, I'd prefer to not merge this PR as IMO it doesn't really fix a bug but just re-interprets the meaning of `num_beams` which is a very public API",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | CONTRIBUTOR | null | # What does this PR do?
It fixes the issue in diverse beam search implementation. <be>
# What was the issue?
By definition, diverse beam search is a variant of beam search which tries to group beams and introduce variance between the groups.
After successful decoding, we select beams from each group thus giving diverse solutions.
For example with beam size 3 and group size 3, we will have 1 beam in each group. And finally, if we want the top 3 suggestions, we should select the top suggestion from each group.
This condition was violated in the current implementation thus giving similar generated sequences in some cases.
Paper for reference [Diverse Beam Search](https://arxiv.org/pdf/1610.02424.pdf)
## Who can review?
@patrickvonplaten Please review changes | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13079/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13079",
"html_url": "https://github.com/huggingface/transformers/pull/13079",
"diff_url": "https://github.com/huggingface/transformers/pull/13079.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13079.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13078 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13078/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13078/comments | https://api.github.com/repos/huggingface/transformers/issues/13078/events | https://github.com/huggingface/transformers/pull/13078 | 966,274,902 | MDExOlB1bGxSZXF1ZXN0NzA4NTMzMTky | 13,078 | [Doctest] Setup, quicktour and task_summary | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
This PR starts the work of re-enabling the doc tests and makes sure our documentation uses the latest version of the APIs. For the doctest setup, it registers the options we will need for `doctest` in the setup.cfg.
For the quicktour and task_summary, it tweaks all results to match the output of the code so the doctests pass for those two files, and removes the use of deprecated APIs (AutoModelWithLMHead) as well as favoring the call method of the tokenizers over the encode method. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13078/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13078",
"html_url": "https://github.com/huggingface/transformers/pull/13078",
"diff_url": "https://github.com/huggingface/transformers/pull/13078.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13078.patch",
"merged_at": 1628682325000
} |
https://api.github.com/repos/huggingface/transformers/issues/13077 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13077/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13077/comments | https://api.github.com/repos/huggingface/transformers/issues/13077/events | https://github.com/huggingface/transformers/pull/13077 | 966,178,547 | MDExOlB1bGxSZXF1ZXN0NzA4NDQ0MjA2 | 13,077 | Add MultiBERTs conversion script | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for working on this. Where are the MultiBERT checkpoints in the README you link to?\r\n\r\nNvm, found them here: https://github.com/google-research/language/tree/master/language/multiberts\r\n\r\nAnd question out of interest: was it not possible to use the existing conversion script?",
"@NielsRogge Thanks for taking a look at this. \r\n\r\nThe existing scripts do not consider NLP/MLM heads - which are probably randomly initialized for downstream models, including pre-training, MLM and NSP. I feel, for MultiBERTs, we might want the heads too? I'm not 100% sure of this requirement.\r\n\r\nMaybe @yanaiela can share the exact requirement he has in mind if that is not the case?\r\n\r\nWhat do you think?",
"So, although in my specific use case I don't need the MLM heads, it would be nice to have.\r\n\r\nAlso, I don't think that this is what this PR is doing, but I think it would be beneficial to integrate such function into the standard model loading. There's an increasing interest of researchers in studying the intermediate steps of models, and there's more and more publications that release these checkpoints. It would be good to be able to load these checkpoint seamlessly through the regular api, rather than converting each checkpoint on its own.",
"@yanaiela Are you saying that the checkpoints should be available on the Hub for easy use?\n\nFor example:\n\n```python\n\nfrom transformers import BertModel\nmodel = BertModel.from_pretrained('multiberts-seed-0')\n```\n?\n\nOr, add a custom definition in the modeling file which does something like:\n\n```python\nfrom transformers import BertModel\nmodel = BertModel.from_pretrained_original_tf_url(<URL>)\n```",
"Well, the first option would be super convenient (btw, it should also contain the checkpoint step).",
"I think this conversion script will be needed in order to convert. I can put these models up on the hub after that so the first option can be used.",
"ah sure, but I'm not sure if the best option would be to upload all of them to the hub?\r\nIt may accumulate to a lot of storage (relatively) with all the checkpoints, so maybe a good option would be to integrate the conversion when calling the `from_pretrained` function locally.\r\nWhat do you think?",
"@yanaiela If that is the requirement, then is there an issue with downloading the checkpoint, using conversion script and then using the model? \r\n\r\nI could add another method which downloads from the URL if not present in cache and returns the model.\r\n\r\nFor example\r\n```python\r\nfrom transformers.models.bert.convert_original_multiberts_tf2_checkpoint_to_pytorch import get_pretrained_multiberts_checkpoint\r\n\r\nseed_0_model = get_pretrained_multiberts_checkpoint(seed=0, force_download=True)\r\n```\r\n",
"Ah I mainly was commenting on the comment of putting models on the hub.\r\nIntegrating the script sounds like a good idea though!",
":P Okay. Not sure which is the best way to go, wdyt @NielsRogge?",
"Hi,\r\n\r\n> ah sure, but I'm not sure if the best option would be to upload all of them to the hub?\r\n\r\nStorage is not a problem on the hub. All MultiBERT checkpoints can be uploaded there. In that way, people can do the following:\r\n\r\n```\r\nfrom transformers import BertModel\r\n\r\nmodel = BertModel.from_pretrained(\"google/multibert-...\")\r\n```\r\n\r\nRegarding the conversion script, I wonder whether we could update the existing conversion script in `modeling_bert.py` to also include the MLM and NSP heads, such that we don't need to add a new one. \r\n\r\n> The following weights are not present:\r\n\r\n> cls.predictions.decoder.weight\r\n> cls.predictions.decoder.bias\r\n\r\n=> is that because MultiBERT checkpoints use weight tying (i.e. same embedding layer at the input and output)?",
"@NielsRogge\r\n\r\nSorry I didn't check this earlier. You are right, they [use the input embeddings](https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/run_pretraining.py#L140) to the [`get_masked_lm_output` method](https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/run_pretraining.py#L257).\r\n\r\nShould I edit the bert conversion script with an option to include MLM/NSP heads?\r\n",
"@NielsRogge I checked. The current `convert_bert_original_tf_checkpoint_to_pytorch` script does exactly what I'm doing ;-; Sorry, I was looking at the `tf2` checkpoint script earlier. :/ My bad.\r\n\r\nShould I start pushing the multiberts checkpoints to the hub, then?",
"Yes, you can upload all checkpoints to the hub (under the \"Google\" namespace), and then close this PR.",
"Thanks a lot for working on this @gchhablani!",
"I have pushed all final checkpoints to the hub as `multiberts-seed-x` where x ranges from 0 to 24.\r\n\r\nFor intermediate, I'm thinking something like `multiberts-seed-x-10k` for the 10k-th checkpoint. Does this sound okay?",
"Yes, that's fine!",
"---\r\nlanguage: en\r\ntags:\r\n- exbert\r\n- multiberts\r\nlicense: apache-2.0\r\ndatasets:\r\n- bookcorpus\r\n- wikipedia\r\n---\r\n# MultiBERTs Seed 0 (uncased)\r\nSeed 0 pretrained BERT model on English language using a masked language modeling (MLM) objective. It was introduced in\r\n[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in\r\n[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This model is uncased: it does not make a difference\r\nbetween english and English.\r\n\r\nDisclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).\r\n## Model description\r\nMultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it\r\nwas pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of\r\npublicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it\r\nwas pretrained with two objectives:\r\n- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run\r\n the entire masked sentence through the model and has to predict the masked words. This is different from traditional\r\n recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like\r\n GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the\r\n sentence.\r\n- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes\r\n they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to\r\n predict if the two sentences were following each other or not.\r\nThis way, the model learns an inner representation of the English language that can then be used to extract features\r\nuseful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard\r\nclassifier using the features produced by the BERT model as inputs.\r\n## Intended uses & limitations\r\nYou can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to\r\nbe fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for\r\nfine-tuned versions on a task that interests you.\r\nNote that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)\r\nto make decisions, such as sequence classification, token classification or question answering. For tasks such as text\r\ngeneration you should look at model like GPT2.\r\n### How to use\r\nHere is how to use this model to get the features of a given text in PyTorch:\r\n```python\r\n from transformers import BertTokenizer, BertModel\r\n tokenizer = BertTokenizer.from_pretrained('multiberts-seed-0')\r\n model = BertModel.from_pretrained(\"bert-base-uncased\")\r\n text = \"Replace me by any text you'd like.\"\r\n encoded_input = tokenizer(text, return_tensors='pt')\r\n output = model(**encoded_input)\r\n```\r\n### Limitations and bias\r\nEven if the training data used for this model could be characterized as fairly neutral, this model can have biased\r\npredictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular\r\ncheckpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.\r\n\r\n## Training data\r\nThe MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038\r\nunpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and\r\nheaders).\r\n## Training procedure\r\n### Preprocessing\r\nThe texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are\r\nthen of the form:\r\n```\r\n [CLS] Sentence A [SEP] Sentence B [SEP]\r\n```\r\nWith probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in\r\nthe other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a\r\nconsecutive span of text usually longer than a single sentence. The only constrain is that the result with the two\r\n\"sentences\" has a combined length of less than 512 tokens.\r\nThe details of the masking procedure for each sentence are the following:\r\n- 15% of the tokens are masked.\r\n- In 80% of the cases, the masked tokens are replaced by `[MASK]`.\r\n- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.\r\n- In the 10% remaining cases, the masked tokens are left as is.\r\n### Pretraining\r\nThe model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size\r\nof 256. The sequence length was set to 512 throughout. The optimizer\r\nused is Adam with a learning rate of 1e-4, \\\\(\\beta_{1} = 0.9\\\\) and \\\\(\\beta_{2} = 0.999\\\\), a weight decay of 0.01,\r\nlearning rate warmup for 10,000 steps and linear decay of the learning rate after.\r\n### BibTeX entry and citation info\r\n```bibtex\r\n @article{DBLP:journals/corr/abs-2106-16163,\r\n author = {Thibault Sellam and\r\n Steve Yadlowsky and\r\n Jason Wei and\r\n Naomi Saphra and\r\n Alexander D'Amour and\r\n Tal Linzen and\r\n Jasmijn Bastings and\r\n Iulia Turc and\r\n Jacob Eisenstein and\r\n Dipanjan Das and\r\n Ian Tenney and\r\n Ellie Pavlick},\r\n title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},\r\n journal = {CoRR},\r\n volume = {abs/2106.16163},\r\n year = {2021},\r\n url = {https://arxiv.org/abs/2106.16163},\r\n eprinttype = {arXiv},\r\n eprint = {2106.16163},\r\n timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},\r\n biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},\r\n bibsource = {dblp computer science bibliography, https://dblp.org}\r\n }\r\n```\r\n<a href=\"https://huggingface.co/exbert/?model=multiberts\">\r\n\t<img width=\"300px\" src=\"https://cdn-media.huggingface.co/exbert/button.png\">\r\n</a>\r\n\r\n\r\nAdding this README to all, will just replace `seed-0` with `seed-x` and `Seed 0` with `Seed X`.",
"That looks great @gchhablani !",
"@NielsRogge @patrickvonplaten I have added all the MultiBERTs checkpoints to `google` organization on the hub.\n\n@yanaiela You can access them like:\n\n```python\nfrom transformers import BertModel\nmodel = BertModel.from_pretrained('google/multiberts-seed-0')\nintermediate_checkpoint = BertModel.from_pretrained('google/multiberts-seed-0-20k')\n```\n\nPlease let me know in case of any issues!",
"Awesome, thanks!\r\nbtw, based on the documentation, it seems like the tokenizer uses the `bert-base-uncased` tokenizer. Is there a reason not to allow the same name with the tokenization?",
"Looks good to me!",
"@gchhablani - just to follow-up here...did you manage to correctly convert the mulit-bert checkpoints with an existing conversion script (that also took into account MLM and NSP)? In this case, I might have merged the PR too quickly :sweat_smile: ",
"Hi @patrickvonplaten \r\nSorry, I didn't check this PR was merged. Yes, I had updated the script.\r\n\r\nHowever, we don't need this script as the `load_tf_checkpoint` method works fine for the conversion. Should I create another PR to remove the script? Or should I revert the merge?\r\n\r\nI used the following script for pushing intermediate checkpoints: [MultiBERTs Pushing Script](https://gist.github.com/gchhablani/070d41ec7b02a0b3b0429d04cadee557) and a similar one for the final checkpoints. We don't need a new conversion script.\r\n",
"@yanaiela No, there's no reason why we cannot add the tokenizer files as well to the checkpoints. I can do that if needed. \r\n\r\nWdyt @patrickvonplaten @NielsRogge?",
"Sure it would be nice to add the tokenizer files as well!",
"> Hi @patrickvonplaten Sorry, I didn't check this PR was merged. Yes, I had updated the script.\r\n> \r\n> However, we don't need this script as the `load_tf_checkpoint` method works fine for the conversion. Should I create another PR to remove the script? Or should I revert the merge?\r\n> \r\n> I used the following script for pushing intermediate checkpoints: [MultiBERTs Pushing Script](https://gist.github.com/gchhablani/070d41ec7b02a0b3b0429d04cadee557) and a similar one for the final checkpoints. We don't need a new conversion script.\r\n\r\nYeah it would be great if you could open a new PR to delete the conversion file in this case then :-) Thanks a lot!",
"@patrickvonplaten @yanaiela\r\nI have added the tokenizer files to the checkpoints and updated the model card accordingly.\r\nPlease let me know if you find any issues.",
"It works great btw. Well done, and thanks! "
] | 1,628 | 1,646 | 1,633 | CONTRIBUTOR | null | # What does this PR do?
This PR adds MultiBERTs checkpoint conversion script to the bert model. This PR closes #13069.
Currently the issue is that some weights required in HuggingFace `BertForPreTraining` are not present in the classifier layer.
The `cls` keys present in `BertForPreTraining`:
```python
cls.predictions.bias
cls.predictions.transform.dense.weight
cls.predictions.transform.dense.bias
cls.predictions.transform.LayerNorm.weight
cls.predictions.transform.LayerNorm.bias
cls.predictions.decoder.weight
cls.predictions.decoder.bias
cls.seq_relationship.weight
cls.seq_relationship.bias
```
Name splits starting with `cls` in the MultiBERTs checkpoint `seed_0.zip`:
```python
['cls', 'predictions', 'output_bias']
['cls', 'predictions', 'transform', 'LayerNorm', 'bias']
['cls', 'predictions', 'transform', 'LayerNorm', 'kernel']
['cls', 'predictions', 'transform', 'dense', 'bias']
['cls', 'predictions', 'transform', 'dense', 'kernel']
['cls', 'seq_relationship', 'output_bias']
['cls', 'seq_relationship', 'output_weights']
```
The following weights are not present:
```python
cls.predictions.decoder.weight
cls.predictions.decoder.bias
```
How do I handle this?
EDIT:
------
I checked for the original BERT checkpoints present in the table [here](https://github.com/google-research/bert) , the same issue happens there as well.
EDIT 2:
------
The BERT conversion skip also skips the final layers (pre-training). Specifically, this script does not handle MLM/NSP heads. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13077/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13077",
"html_url": "https://github.com/huggingface/transformers/pull/13077",
"diff_url": "https://github.com/huggingface/transformers/pull/13077.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13077.patch",
"merged_at": 1633020536000
} |
https://api.github.com/repos/huggingface/transformers/issues/13076 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13076/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13076/comments | https://api.github.com/repos/huggingface/transformers/issues/13076/events | https://github.com/huggingface/transformers/issues/13076 | 965,982,220 | MDU6SXNzdWU5NjU5ODIyMjA= | 13,076 | respect dtype of the the model when instiating not working | {
"login": "hwijeen",
"id": 29157715,
"node_id": "MDQ6VXNlcjI5MTU3NzE1",
"avatar_url": "https://avatars.githubusercontent.com/u/29157715?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hwijeen",
"html_url": "https://github.com/hwijeen",
"followers_url": "https://api.github.com/users/hwijeen/followers",
"following_url": "https://api.github.com/users/hwijeen/following{/other_user}",
"gists_url": "https://api.github.com/users/hwijeen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hwijeen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hwijeen/subscriptions",
"organizations_url": "https://api.github.com/users/hwijeen/orgs",
"repos_url": "https://api.github.com/users/hwijeen/repos",
"events_url": "https://api.github.com/users/hwijeen/events{/privacy}",
"received_events_url": "https://api.github.com/users/hwijeen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thank you for the great report, @hwijeen \r\n\r\nI'm able to reproduce both problems:\r\n\r\n```\r\npython -c \"from transformers import GPT2LMHeadModel; GPT2LMHeadModel.from_pretrained('sshleifer/tiny-gpt2', torch_dtype_auto_detect=True)\" \r\npython -c \"import torch; from transformers import AutoModel; AutoModel.from_pretrained('sshleifer/tiny-gpt2', torch_dtype=torch.float16)\"\r\n```\r\n\r\nOnce I get a chance I will work on it and we will sort it out.",
"ok, where did you find `torch_dtype_auto_detect`? The documented syntax is: `torch_dtype='auto'` for auto detection. Perhaps you were looking at the original proposal discussion before the API was selected?\r\n\r\nThis works just fine:\r\n```\r\npython -c \"from transformers import AutoModel; AutoModel.from_pretrained('sshleifer/tiny-gpt2', torch_dtype='auto')\"\r\n```",
"Oh, I see. `torch_dtype` is the right keyword.\r\n\r\nBut setting it \"auto\" does not seem to work:\r\n`python -c \"from transformers import AutoModel; m=AutoModel.from_pretrained('sshleifer/tiny-gpt2', torch_dtype='auto');print(m.dtype)\"` # This gives torch.float32.\r\n\r\nJust for a sanity check, I tried loading my own model whose weight is float16 and the result was the same.\r\n`python -c \"from transformers import AutoModel; m=AutoModel.from_pretrained(my_path, torch_dtype='auto');print(m.dtype)\"` # This gives torch.float32!\r\n\r\nIt seems that `torch_dtype='auto'` is not working as expected?\r\n",
"why do you think it's float16?\r\n\r\nthe auto-detector checks the first entry:\r\n```\r\n$ wget https://huggingface.co/sshleifer/tiny-gpt2/resolve/main/pytorch_model.bin\r\n$ python -c \"import torch; sd=torch.load('pytorch_model.bin'); print(next(iter(sd.values())).dtype)\"\r\ntorch.float32\r\n```\r\nbut we can look at all of them:\r\n```\r\npython -c \"import torch; sd=torch.load('pytorch_model.bin'); print([v.dtype for v in sd.values()])\"\r\n[torch.float32, torch.float32, torch.float32, torch.float32, torch.uint8, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.uint8, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32, torch.float32]\r\n```\r\nAlso I think Sam was making many test models `half()`, perhaps just not this one? Try it on other of his tiny test models?\r\n\r\nYou can see the test that saves as fp16 and then auto-detects it to be fp16:\r\n\r\nhttps://github.com/huggingface/transformers/blob/c89180a9de1fc2e98654812fd1c233c3bc6a8d43/tests/test_modeling_common.py#L1687-L1692",
"I was not sure whether `sshleifer/tiny-gpt2` uses float16 or not, and that's why I tried with my own model (megatronLM) which (mostly) has float16.\r\n```\r\npython -c \"import torch; sd=torch.load('pytorch_model.bin'); print([v.dtype for v in sd.values()])\"\r\n[torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.uint8, torch.float32, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16]\r\n```\r\n\r\nI tried to load this model with two ways, and only one yields the correct result:\r\n```python\r\n# load correctly with specific model class\r\nGPT2LMHeadModel.from_pretrained(\".\", torch_dtype=\"auto\").dtype\r\ntorch.float16\r\n\r\n# but fails with AutoModelForCausalLM\r\nAutoModelForCausalLM.from_pretrained(\".\", torch_dtype=\"auto\").dtype\r\ntorch.float32\r\n```\r\n\r\nThe test cases you linked seem to be using specific model classes, so perhaps this is AutoModel's fault?",
"Yes, clearly `AutoModel` goes through a different path and needs to be better tested and fixed.\r\n\r\n> I tried with my own model (megatronLM) which (mostly) has float16.\r\n\r\nThe question is what to do with models that have mixed dtypes - typically a model is either fp16 or fp32. I can see how a custom buffer may be of fp32 while the params are in fp16.\r\n\r\nCould you explain your situation and how mixed is your model? ",
"I am using [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) by Nvidia. As you may know, this code trains a billion scale language model using various parallelism techniques. One thing to note is that this library does not rely on apex amp to achieve mixed precision training, and it has a complicated and self-contained code to deal with fp16 -- so I would say that models with various data types are not a usual case and is not a higher priority.\r\n\r\nBut the `AutoModel` problem shown above looks like an urgent issue to me.. Are you planning to work on this in the near future? \r\n(I would also be happy to look into the problem if you could share some hints.)",
"> But the AutoModel problem shown above looks like an urgent issue to me\r\n\r\nWhich of the AutoModel problems are you referring to? \r\n\r\nIf it's the pickle issue, then one needs some kind of `to_json` workaround for the `torch.dtype` class. It should be easy to just comment out that code as well, if it gets in the way and it's urgent as you say. Until it's resolved.\r\n\r\nBy all means if you can solve it, it'd be super helpful.\r\n\r\nIf it's the auto-detection failing because it checks the first key entry, then before solving it, as suggested we need to discuss what to do if the model has mixed dtypes. I suppose with just fp16/fp32 it obviously should be auto=fp32, but now we are going to have other types like bf16, so hardcoding is going to be an issue.\r\n\r\nI'm going to be offline for the next 3 days and can follow up next on Friday.",
"> I am using Megatron-LM by Nvidia. As you may know, this code trains a billion scale language model using various parallelism techniques. One thing to note is that this library does not rely on apex amp to achieve mixed precision training, and it has a complicated and self-contained code to deal with fp16 -- so I would say that models with various data types are not a usual case and is not a higher priority.\r\n\r\nRunning on the official checkpoint:\r\n\r\n```\r\nwget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O checkpoint.zip\r\npython3 /hf/transformers-master/src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py checkpoint.zip\r\n\r\npython -c \"from transformers import MegatronBertForMaskedLM; m = MegatronBertForMaskedLM.from_pretrained('.'); d = {p.dtype():1 for p in m.parameters() }; print(d.keys())\"\r\n```\r\n\r\nprints: `dict_keys([torch.float32])`\r\n\r\nso there are only fp32 keys in that official checkpoint. But that's just that checkpoint.\r\n\r\nWhich keys do you get when you run the quick check from above (last line of code with `from_pretrained('.')` adjusted to point to your model.\r\n",
"Ah, of course, the above test is wrong, because it relies on transformers, which by default loads in fp32, need to recode to do it based on the checkpoint. here you go:\r\n\r\n```\r\npython -c \"import torch; sd=torch.load('pytorch_model.bin'); d = {p.dtype:1 for p in sd.values() }; print(d.keys())\"\r\ndict_keys([torch.float16])\r\n```\r\n\r\nso it's all fp16. not mixed. but again, this is just this checkpoint.",
"> so there are only fp32 keys in that official checkpoint. But that's just that checkpoint.\r\n\r\nWhen I opened the official checkpoint with `torch.load`, it seems like it mostly has float16.\r\n\r\n```\r\nwget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O checkpoint.zip\r\nunzip checkpoint.zip\r\npython -c \"import torch; sd = torch.load('model_optim_rng.pt', map_location='cpu'); print([v.dtype for v in sd['model']['language_model']['transformer'].values()])`\r\n\r\n[torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16, torch.float16]\r\n```\r\n\r\nIn my case, I get a mixture of `float32`, `float16`, `uint8`. Most of the params are `float16` with masked_bias being `float32` and bias being `uint8`. I am not 100% sure but I guess this has to do with Megatron version issue..\r\n\r\n",
"As you pointed out, dealing with mixed data type is complicated and needs further discussion.\r\n\r\n\r\n\r\nOn the other hand, I think `AutoModel`'s pickle issue is orthogonal to this, and I will look into it when I have time (perhaps this weekend) and get back to you with if I find a solution :)\r\n\r\n> If it's the pickle issue, then one needs some kind of to_json workaround for the torch.dtype class. It should be easy to just comment out that code as well, if it gets in the way and it's urgent as you say. Until it's resolved.\r\n\r\nThanks for the quick workaround!\r\n\r\n\r\n",
"Right, so my 2nd attempt was potentially wrong too, since the original checkpoint went through a conversion and I guess it could have ignored the original dtypes and made it fp16 all.\r\n\r\nHowever doing it the right way hopefully inspecting the original and based on your code:\r\n```\r\npython -c \"import torch; sd=torch.load('release/mp_rank_00/model_optim_rng.pt'); d = {p.dtype:1 for p in sd['model']['language_model']['transformer'].values() }; print(d.keys())\"\r\ndict_keys([torch.float16])\r\n```\r\nis still fp16 (for this checkpoint).\r\n\r\nPerhaps when the model is mixed, `from_pretrained()` should assert and tell the user to choose one? \r\n\r\nThe problem is not `transformers` by torch which loads the weights under a fixed dtype. Unless we change the dtype context for each key perhaps?\r\n\r\n",
"> As you pointed out, dealing with mixed data type is complicated and needs further discussion.\r\n\r\nPerhaps let's open a new Issue that focuses just on this separate issue and please tag me, sgugger and LysandreJik on it. Thank you!\r\n\r\nYou can use the above one liner to show us the mixed keys your model contains and then it'd be easier to understand what's going on. ",
"> Right, so my 2nd attempt was potentially wrong too since the original checkpoint went through a conversion and I guess it could have ignored the original dtypes and made it fp16 all.\r\n\r\nOh, I double-checked and confirmed that the weights in Megatron-LM checkpoint are all in fp16. It was the [conversion script](https://github.com/huggingface/transformers/blob/master/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py) that made the checkpoint have mixed data type. Specifically, [this line](https://github.com/huggingface/transformers/blob/91ff480e2693f36b11aaebc4e9cc79e4e3c049da/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py#L160) produces `uint8` and this line `float32`. I'll open a new issue to address this.\r\n\r\nSo at least in my case, my model is not a mixed data type -- are there any cases where data types are mixed? If not, I think a new issue is not necessary?",
"> So at least in my case, my model is not a mixed data type -- are there any cases where data types are mixed? If not, I think a new issue is not necessary?\r\n\r\nI asked the same question when working on the original feature and those who followed up, said they didn't think they saw such cases.\r\n\r\nI can only think of a registered buffer which can be of whatever dtype and be different from the weights. \r\n\r\nThat's said perhaps down the road we should check that indeed all the weights have the same dtype, so we don't accidentally set a dtype that is not like the rest. But let's worry about it if it becomes a problem."
] | 1,628 | 1,629 | 1,629 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.2
- Platform: Linux-4.18.0-25-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.0a0+52ea372 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: No
### Who can help
@stas00 as he is the writer of the [#12316](https://github.com/huggingface/transformers/pull/12316)
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
First case:
```python
from transformers import AutoModel
AutoModel.from_pretrained("my_path", torch_dtype=torch.float16)
```
The above code results in
```python
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/models/auto/auto_factory.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) [40/1573]
377 if not isinstance(config, PretrainedConfig):
378 config, kwargs = AutoConfig.from_pretrained(
--> 379 pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
380 )
381
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/models/auto/configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
451 if "model_type" in config_dict:
452 config_class = CONFIG_MAPPING[config_dict["model_type"]]
--> 453 return config_class.from_dict(config_dict, **kwargs)
454 else:
455 # Fallback: use pattern matching on the string.
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/configuration_utils.py in from_dict(cls, config_dict, **kwargs)
579 kwargs.pop(key, None)
580
--> 581 logger.info(f"Model config {config}")
582 if return_unused_kwargs:
583 return config, kwargs
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/configuration_utils.py in __repr__(self)
611
612 def __repr__(self):
--> 613 return f"{self.__class__.__name__} {self.to_json_string()}"
614
615 def to_diff_dict(self) -> Dict[str, Any]:
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/configuration_utils.py in to_json_string(self, use_diff)
675 else:
676 config_dict = self.to_dict()
--> 677 return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
678
679 def to_json_file(self, json_file_path: Union[str, os.PathLike], use_diff: bool = True):
/opt/conda/envs/ml/lib/python3.7/json/__init__.py in dumps(obj, skipkeys, ensure_ascii, check_circular, allow_nan, cls, indent, separators, default, sort_keys, **kw)
236 check_circular=check_circular, allow_nan=allow_nan, indent=indent,
237 separators=separators, default=default, sort_keys=sort_keys,
--> 238 **kw).encode(obj)
239
240
/opt/conda/envs/ml/lib/python3.7/json/encoder.py in encode(self, o)
199 chunks = self.iterencode(o, _one_shot=True)
200 if not isinstance(chunks, (list, tuple)):
--> 201 chunks = list(chunks)
202 return ''.join(chunks)
203
/opt/conda/envs/ml/lib/python3.7/json/encoder.py in _iterencode(o, _current_indent_level)
429 yield from _iterencode_list(o, _current_indent_level)
430 elif isinstance(o, dict):
--> 431 yield from _iterencode_dict(o, _current_indent_level)
432 else:
433 if markers is not None:
/opt/conda/envs/ml/lib/python3.7/json/encoder.py in _iterencode_dict(dct, _current_indent_level)
403 else:
404 chunks = _iterencode(value, _current_indent_level)
--> 405 yield from chunks
406 if newline_indent is not None:
407 _current_indent_level -= 1
/opt/conda/envs/ml/lib/python3.7/json/encoder.py in _iterencode(o, _current_indent_level)
436 raise ValueError("Circular reference detected")
437 markers[markerid] = o
--> 438 o = _default(o)
439 yield from _iterencode(o, _current_indent_level)
440 if markers is not None:
/opt/conda/envs/ml/lib/python3.7/json/encoder.py in default(self, o)
177
178 """
--> 179 raise TypeError(f'Object of type {o.__class__.__name__} '
180 f'is not JSON serializable')
181
TypeError: Object of type dtype is not JSON serializable
```
Second case:
```python
m = GPT2LMHeadModel.from_pretrained(model_path, torch_dtype_auto_detect=True)
```
yields the following error.
```python
/opt/conda/envs/ml/lib/python3.7/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1319 else:
1320 with no_init_weights(_enable=_fast_init):
-> 1321 model = cls(config, *model_args, **model_kwargs)
1322
1323 if from_pt:
TypeError: __init__() got an unexpected keyword argument 'torch_dtype_auto_detect'
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
First case
Regarding the first case, setting torch_dtype works with AutoModel as well as specific model classes.
Can this be fixed?
It would be convenient for me if we could sue "torch_dtype" key-value pair in config.json which [is not supported in the current version](https://github.com/huggingface/transformers/pull/12316/commits/368c71c0978e0d2f731cec72daea2a5a687e7b97).
Second case
Shouldn't the second case run without any errors?
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13076/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/13076/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13075 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13075/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13075/comments | https://api.github.com/repos/huggingface/transformers/issues/13075/events | https://github.com/huggingface/transformers/issues/13075 | 965,403,213 | MDU6SXNzdWU5NjU0MDMyMTM= | 13,075 | Custom Seq2Seq translation model training exits with error | {
"login": "krajasek",
"id": 2865463,
"node_id": "MDQ6VXNlcjI4NjU0NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/2865463?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/krajasek",
"html_url": "https://github.com/krajasek",
"followers_url": "https://api.github.com/users/krajasek/followers",
"following_url": "https://api.github.com/users/krajasek/following{/other_user}",
"gists_url": "https://api.github.com/users/krajasek/gists{/gist_id}",
"starred_url": "https://api.github.com/users/krajasek/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/krajasek/subscriptions",
"organizations_url": "https://api.github.com/users/krajasek/orgs",
"repos_url": "https://api.github.com/users/krajasek/repos",
"events_url": "https://api.github.com/users/krajasek/events{/privacy}",
"received_events_url": "https://api.github.com/users/krajasek/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please use the [forums](https://discuss.huggingface.co/) for help to debug your scripts, and provide all relevant code. The error indicates you are attempting to pass a `encoder_hidden_states` to a model that don't accept that but we don't see our your dataset is or how your model is, so no one can help you understand why.",
"I am not explicitly passing any state to the model at all. I can't share the dataset as it could be proprietary to our organization, but can I at-least know if Roberta to GPT-Neo language translation is possible? I glanced at the code base https://github.com/huggingface/transformers/blob/master/src/transformers/models/gpt_neo/modeling_gpt_neo.py and it looks like the forward() method does not accept encoder_hidden_states as a parameter?",
"The trainer script works fine when a pre-trained Roberta model is used as the source and a custom-trained Roberta model is used as the target model. It only fails when a pre-trained Roberta model is the source and custom-trained GPT-Neo model is the target.",
"Here is the list of combinations tried out for seq2seq translation:\r\n\r\n1) Roberta to Roberta: No issues faced with the seq2seq model training\r\n2) Roberta to GPT-2: No issues faced with the seq2seq model training\r\n3) Roberta to GPT-Neo: Non-recoverable errors during the seq2seq model training",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0.dev0
- Platform: Linux-4.14.238-182.422.amzn2.x86_64-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes, using deepspeed
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten
@sgugger
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ X] my own task or dataset: (give details below)
I am training a custom language translation model with pre-trained Roberta as the source model and custom-trained GPT-Neo as the target model. The training process quickly exits with an error and the error stack trace is pasted below. The custom language translation model has been developed based on the HF example: https://huggingface.co/patrickvonplaten/roberta2roberta-cnn_dailymail-fp16
## To reproduce
Steps to reproduce the behavior:
1. Run an HF Trainer with deepspeed (see below deepspeed script)
2. The Trainer process exits with error (see below stack trace)
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
### Error Stack Trace
```
Traceback (most recent call last):
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 303, in <module>
tr_model.train(model_dir=model_output_dir, epochs=epochs)
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 194, in train
Traceback (most recent call last):
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 303, in <module>
train_results = trainer.train()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1267, in train
Traceback (most recent call last):
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 303, in <module>
tr_model.train(model_dir=model_output_dir, epochs=epochs)
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 194, in train
train_results = trainer.train()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1267, in train
Traceback (most recent call last):
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 303, in <module>
tr_model.train(model_dir=model_output_dir, epochs=epochs)
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 194, in train
tr_loss += self.training_step(model, inputs)
train_results = trainer.train()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1760, in training_step
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1267, in train
tr_model.train(model_dir=model_output_dir, epochs=epochs)
File "src/phase3/language_model/luna_llayla_translator_model_trainer.py", line 194, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1760, in training_step
train_results = trainer.train()
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1267, in train
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1760, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1794, in compute_loss
tr_loss += self.training_step(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1760, in training_step
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1794, in compute_loss
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1794, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
loss = self.compute_loss(model, inputs)
File "/usr/local/lib/python3.6/dist-packages/transformers/trainer.py", line 1794, in compute_loss
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/distributed.py", line 799, in forward
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/distributed.py", line 799, in forward
outputs = model(**inputs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
output = self.module(*inputs[0], **kwargs[0])
output = self.module(*inputs[0], **kwargs[0])
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/distributed.py", line 799, in forward
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/distributed.py", line 799, in forward
output = self.module(*inputs[0], **kwargs[0])
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 450, in forward
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 450, in forward
**kwargs_decoder,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
output = self.module(*inputs[0], **kwargs[0])
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
**kwargs_decoder,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 450, in forward
**kwargs_decoder,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 450, in forward
return forward_call(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
**kwargs_decoder,
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
return forward_call(*input, **kwargs)
TypeError: forward() got an unexpected keyword argument 'encoder_hidden_states'
```
### deepspeed script
```bash
export TOKENIZERS_PARALLELISM=false
export NCCL_IB_DISABLE=1
export NCCL_SOCKET_IFNAME=eth0
export NCCL_DEBUG=INFO
deepspeed --include localhost:0,1,2,3 src/phase3/language_model/luna_llayla_translator_model_trainer.py
```
### Trainer snippet
```python
def train(self, model_dir, epochs=10, learning_rate=5e-05,
clear_cuda_cache=True, metric_name='rouge'):
if clear_cuda_cache and torch.cuda.is_available():
torch.cuda.empty_cache()
print('Loading dataset ...')
if not self.train_raw_dataset:
self.load_raw_dataset(self.dataset_path)
print('Pre-processing dataset ...')
self.preprocess_data()
print('Loading metric data ...')
if not self.metric:
self.load_metric(metric_name=metric_name)
train_config = LunaLlaylaTranslatorTrainingConfig.config
if epochs:
train_config['num_train_epochs'] = epochs
if learning_rate:
train_config['learning_rate'] = learning_rate
if model_dir:
train_config['output_dir'] = model_dir
if self.deepspeed_config:
train_config['deepspeed'] = self.deepspeed_config
train_arguments = Seq2SeqTrainingArguments(**train_config)
print('Training ...')
trainer = Seq2SeqTrainer(
model=self.translator_model,
args=train_arguments,
data_collator=default_data_collator,
train_dataset=self.train_processed_dataset,
eval_dataset=self.validation_processed_dataset,
compute_metrics=self.compute_metrics,
)
train_results = trainer.train()
print('Training completed.')
print('Evaluating model ...')
train_metrics = train_results.metrics
trainer.log_metrics("train", train_metrics)
trainer.save_metrics("train", train_metrics)
print('*** Train metrics ***')
print(train_metrics)
eval_metrics = trainer.evaluate()
try:
perplexity_score = math.exp(eval_metrics['eval_loss'])
except OverflowError:
perplexity_score = float('inf')
eval_metrics['perplexity_score'] = perplexity_score
trainer.log_metrics("eval", eval_metrics)
trainer.save_metrics("eval", eval_metrics)
print('*** Eval metrics ***')
print(eval_metrics)
print('Saving trained model ...')
trainer.save_state()
trainer.save_model(output_dir=model_dir)
print('Evaluating model ...')
self.evaluate()
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
I expect the training process to be complete without errors. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13075/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13074 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13074/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13074/comments | https://api.github.com/repos/huggingface/transformers/issues/13074/events | https://github.com/huggingface/transformers/pull/13074 | 965,318,955 | MDExOlB1bGxSZXF1ZXN0NzA3NjQzNjE4 | 13,074 | Change a parameter name in FlaxBartForConditionalGeneration.decode() | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I made the same change to flax marian and mbart as suggested.",
"Thanks a lot for fixing this!\r\n\r\nMerging, the failing test is un-related. "
] | 1,628 | 1,651 | 1,628 | COLLABORATOR | null | # What does this PR do?
In short: Change a parameter name in `FlaxBartForConditionalGeneration.decode()`: `deterministic` -> `train`.
In the current version of `FlaxBartForConditionalGeneration.decode()` method, it takes an argument `deterministic`, while
`FlaxBartPreTrainedModel.decode()`, `FlaxT5PreTrainedModel.decode()`, `FlaxT5ForConditionalGeneration.decode()`, and similar places in `FlaxGPT2`, they all use `train` as the argument.
It seems to me that there is a (implicit?) convention that, in Flax models, we use `deterministic` parameter for `nn.Module` and parameter `train` for models inheriting from `FlaxPreTrainedModel`.
This PR fix this small inconsistency in `FlaxBartForConditionalGeneration.decode()`. I hope this PR makes sense, despite the change is really small.
## Before submitting
- [ x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests)
## Who can review?
@patrickvonplaten
@patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13074/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13074/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13074",
"html_url": "https://github.com/huggingface/transformers/pull/13074",
"diff_url": "https://github.com/huggingface/transformers/pull/13074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13074.patch",
"merged_at": 1628770788000
} |
https://api.github.com/repos/huggingface/transformers/issues/13073 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13073/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13073/comments | https://api.github.com/repos/huggingface/transformers/issues/13073/events | https://github.com/huggingface/transformers/issues/13073 | 965,190,480 | MDU6SXNzdWU5NjUxOTA0ODA= | 13,073 | t5 base not found. | {
"login": "s4sarath",
"id": 10637096,
"node_id": "MDQ6VXNlcjEwNjM3MDk2",
"avatar_url": "https://avatars.githubusercontent.com/u/10637096?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/s4sarath",
"html_url": "https://github.com/s4sarath",
"followers_url": "https://api.github.com/users/s4sarath/followers",
"following_url": "https://api.github.com/users/s4sarath/following{/other_user}",
"gists_url": "https://api.github.com/users/s4sarath/gists{/gist_id}",
"starred_url": "https://api.github.com/users/s4sarath/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/s4sarath/subscriptions",
"organizations_url": "https://api.github.com/users/s4sarath/orgs",
"repos_url": "https://api.github.com/users/s4sarath/repos",
"events_url": "https://api.github.com/users/s4sarath/events{/privacy}",
"received_events_url": "https://api.github.com/users/s4sarath/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @s4sarath,\r\n\r\nhttps://huggingface.co/t5-base looks normal to me - what exactly is your error?",
"Hi @patrickvonplaten , t5-small is working fine. Transformers version is **4.9.0.dev0**\r\n\r\n```\r\nfrom transformers import TFT5Model\r\nmodel = TFT5Model.from_pretrained(\"t5-base\")\r\n```\r\n\r\nOSError: file t5-base/config.json not found\r\nOSError: Can't load config for 't5-base'. Make sure that:\r\n\r\n- 't5-base' is a correct model identifier listed on 'https://huggingface.co/models'\r\n\r\n- or 't5-base' is the correct path to a directory containing a config.json file",
"Do you have a folder called `t5-base` in your working directory? The `TFT5Model` may be trying to load from that directory rather than from the hub.",
"Hi Lysandre. You were true. My bad.\nClosing this ticket.\n\nThanks for your help.\n\nOn Wed, 11 Aug, 2021, 6:58 pm Lysandre Debut, ***@***.***>\nwrote:\n\n> Do you have a folder called t5-base in your working directory? The\n> TFT5Model may be trying to load from that directory rather than from the\n> hub.\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/13073#issuecomment-896827708>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ACRE6KG7EFEL3Y4QQQCD4Q3T4J3H7ANCNFSM5B4SPOOA>\n> .\n> Triage notifications on the go with GitHub Mobile for iOS\n> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>\n> or Android\n> <https://play.google.com/store/apps/details?id=com.github.android&utm_campaign=notification-email>\n> .\n>\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | - 't5-base' is a correct model identifier listed on 'https://huggingface.co/models'
- or 't5-base' is the correct path to a directory containing a config.json file | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13073/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13072 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13072/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13072/comments | https://api.github.com/repos/huggingface/transformers/issues/13072/events | https://github.com/huggingface/transformers/pull/13072 | 965,121,118 | MDExOlB1bGxSZXF1ZXN0NzA3NDcxOTM0 | 13,072 | Revert to all tests whil we debug what's wrong | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
Remove the use of test_fetcher for GPU and multiGPU tests for now. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13072/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13072",
"html_url": "https://github.com/huggingface/transformers/pull/13072",
"diff_url": "https://github.com/huggingface/transformers/pull/13072.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13072.patch",
"merged_at": 1628613421000
} |
https://api.github.com/repos/huggingface/transformers/issues/13071 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13071/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13071/comments | https://api.github.com/repos/huggingface/transformers/issues/13071/events | https://github.com/huggingface/transformers/pull/13071 | 965,029,142 | MDExOlB1bGxSZXF1ZXN0NzA3Mzk0NTQ4 | 13,071 | Fix fallback of test_fetcher | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
When the `test_fetcher` util fails, it falls back to all tests, which is fine when we have not set any filters, but not fine if we did. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13071/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13071/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13071",
"html_url": "https://github.com/huggingface/transformers/pull/13071",
"diff_url": "https://github.com/huggingface/transformers/pull/13071.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13071.patch",
"merged_at": 1628605026000
} |
https://api.github.com/repos/huggingface/transformers/issues/13070 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13070/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13070/comments | https://api.github.com/repos/huggingface/transformers/issues/13070/events | https://github.com/huggingface/transformers/issues/13070 | 965,026,207 | MDU6SXNzdWU5NjUwMjYyMDc= | 13,070 | top-k sampling for Flax models | {
"login": "khalidsaifullaah",
"id": 26279642,
"node_id": "MDQ6VXNlcjI2Mjc5NjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/26279642?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/khalidsaifullaah",
"html_url": "https://github.com/khalidsaifullaah",
"followers_url": "https://api.github.com/users/khalidsaifullaah/followers",
"following_url": "https://api.github.com/users/khalidsaifullaah/following{/other_user}",
"gists_url": "https://api.github.com/users/khalidsaifullaah/gists{/gist_id}",
"starred_url": "https://api.github.com/users/khalidsaifullaah/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/khalidsaifullaah/subscriptions",
"organizations_url": "https://api.github.com/users/khalidsaifullaah/orgs",
"repos_url": "https://api.github.com/users/khalidsaifullaah/repos",
"events_url": "https://api.github.com/users/khalidsaifullaah/events{/privacy}",
"received_events_url": "https://api.github.com/users/khalidsaifullaah/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | # 🚀 Feature request
We're using a custom (`Flax`) Seq2Seq model (`Bart`) in our `DALL·E mini` project to generate the image tokens, currently, we're doing the following to generate samples (`encoded image`) given a tokenized prompt to the Seq2Seq model:
```
model.generate(
**tokenized_prompt,
do_sample=True,
num_beams=1,
prng_key=subkey
)
```
But, now we're trying to experiment with the generation method (for example `top_k` sampling) to see if it improves our generated samples.
We've tried doing the following:
```
model.generate(
**tokenized_prompt,
do_sample=True,
top_k=50,
prng_key=key,
params=params
)
```
Which throws- `NotImplementedError: Beam sampling is currently not implemented.`
After looking at the source-code for `generation_flax_utils`, it's indeed the case that it hasn't been implemented yet ([here](https://huggingface.co/transformers/_modules/transformers/generation_flax_utils.html)).
I hope the sampling feature will be integrated into the flax models, our project and other (Flax ones) will benefit greatly from the feature (and I'm sure it's already in the todo-list of the amazing HF dev team).
[_project repo_](https://github.com/borisdayma/dalle-mini)
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
We believe that the `top_k` sampling will improve our generations (quite a bit if not a lot), and even in the taming transformers paper, they've used `top_k` sampling for generating tokens with their autoregressive models and have shown higher `top_k` (subjective to the dataset) improves image generations by increasing variance (in a sense). So we just want to experiment with this sampling method and see if we can find something similar for our model.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13070/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13069 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13069/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13069/comments | https://api.github.com/repos/huggingface/transformers/issues/13069/events | https://github.com/huggingface/transformers/issues/13069 | 964,972,037 | MDU6SXNzdWU5NjQ5NzIwMzc= | 13,069 | MultiBerts in Huggingface | {
"login": "yanaiela",
"id": 8031035,
"node_id": "MDQ6VXNlcjgwMzEwMzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8031035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yanaiela",
"html_url": "https://github.com/yanaiela",
"followers_url": "https://api.github.com/users/yanaiela/followers",
"following_url": "https://api.github.com/users/yanaiela/following{/other_user}",
"gists_url": "https://api.github.com/users/yanaiela/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yanaiela/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanaiela/subscriptions",
"organizations_url": "https://api.github.com/users/yanaiela/orgs",
"repos_url": "https://api.github.com/users/yanaiela/repos",
"events_url": "https://api.github.com/users/yanaiela/events{/privacy}",
"received_events_url": "https://api.github.com/users/yanaiela/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | closed | false | null | [] | [] | 1,628 | 1,633 | 1,633 | NONE | null | # 🚀 Feature request
It would be nice to have a script/converter of all the [multiberts](https://arxiv.org/pdf/2106.16163.pdf) checkpoints that were released about a month ago.
It was [released](https://github.com/google-research/language/tree/master/language/multiberts) by Google, thus using tensorflow, and it would be nice to have it under the huggingface library/hub.
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
These checkpoints may be useful to study training dynamics and hypotheses over multiple seeds that were used to train the model.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13069/reactions",
"total_count": 7,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13069/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13068 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13068/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13068/comments | https://api.github.com/repos/huggingface/transformers/issues/13068/events | https://github.com/huggingface/transformers/issues/13068 | 964,958,662 | MDU6SXNzdWU5NjQ5NTg2NjI= | 13,068 | Can not instantiate `PreTrainedTokenizerFast` from instantiated tokenizer object | {
"login": "brand17",
"id": 36546021,
"node_id": "MDQ6VXNlcjM2NTQ2MDIx",
"avatar_url": "https://avatars.githubusercontent.com/u/36546021?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brand17",
"html_url": "https://github.com/brand17",
"followers_url": "https://api.github.com/users/brand17/followers",
"following_url": "https://api.github.com/users/brand17/following{/other_user}",
"gists_url": "https://api.github.com/users/brand17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brand17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brand17/subscriptions",
"organizations_url": "https://api.github.com/users/brand17/orgs",
"repos_url": "https://api.github.com/users/brand17/repos",
"events_url": "https://api.github.com/users/brand17/events{/privacy}",
"received_events_url": "https://api.github.com/users/brand17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The ability to load a tokenizer object directly was introduced in version v4.5.x! Could you upgrade your `transformers` version to a more recent one?"
] | 1,628 | 1,628 | 1,628 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2
- Platform: Windows
- Python version: 3.6.6
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): 2.3.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run the following script:
```
from tokenizers import Tokenizer
tok = Tokenizer(BPE(unk_token="[UNK]"))
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
tok.pre_tokenizer = Whitespace()
def it():
for t in ['one', 'two', 'three']:
yield t
tok.train_from_iterator(it(), trainer)
from transformers import PreTrainedTokenizerFast
tok = PreTrainedTokenizerFast(tokenizer_object=tok)
```
I am getting error:
> Exception has occurred: ValueError (note: full exception trace is shown but execution is paused at: _run_module_as_main)
> Couldn't instantiate the backend tokenizer from one of: (1) a `tokenizers` library serialization file, (2) a slow tokenizer instance to convert or (3) an equivalent slow tokenizer class to instantiate and convert. You need to have sentencepiece installed to convert a slow tokenizer to a fast one.
>
I have sentencepiece installed (0.1.91).
## Expected behavior
No error | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13068/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13067 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13067/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13067/comments | https://api.github.com/repos/huggingface/transformers/issues/13067/events | https://github.com/huggingface/transformers/pull/13067 | 964,792,530 | MDExOlB1bGxSZXF1ZXN0NzA3MTk0Nzgy | 13,067 | Fix ModelOutput instantiation form dictionaries | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
Currently, instantiating a `ModelOutput` from a dictionary does not yield proper results. It nests the dictionary in the first field instead of populating the fields with the content of the dictionary.
This PR fixes that and adds a regression test to make sure this behavior is not accidentally removed. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13067/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13067/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13067",
"html_url": "https://github.com/huggingface/transformers/pull/13067",
"diff_url": "https://github.com/huggingface/transformers/pull/13067.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13067.patch",
"merged_at": 1628590804000
} |
https://api.github.com/repos/huggingface/transformers/issues/13066 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13066/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13066/comments | https://api.github.com/repos/huggingface/transformers/issues/13066/events | https://github.com/huggingface/transformers/pull/13066 | 964,788,360 | MDExOlB1bGxSZXF1ZXN0NzA3MTkxMzQ0 | 13,066 | Model output dict | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Arg, branched from the wrong point. CLosing and reopening."
] | 1,628 | 1,651 | 1,628 | COLLABORATOR | null | # What does this PR do?
Currently, instantiating a `ModelOutput` from a dictionary does not yield proper results. It nests the dictionary in the first field instead of populating the fields with the content of the dictionary.
This PR fixes that and adds a regression test to make sure this behavior is not accidentally removed. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13066/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13066",
"html_url": "https://github.com/huggingface/transformers/pull/13066",
"diff_url": "https://github.com/huggingface/transformers/pull/13066.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13066.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13065 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13065/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13065/comments | https://api.github.com/repos/huggingface/transformers/issues/13065/events | https://github.com/huggingface/transformers/pull/13065 | 964,709,674 | MDExOlB1bGxSZXF1ZXN0NzA3MTI1MTQ0 | 13,065 | [WIP] Add Japanese RoBERTa Model | {
"login": "butsugiri",
"id": 6701836,
"node_id": "MDQ6VXNlcjY3MDE4MzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/6701836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/butsugiri",
"html_url": "https://github.com/butsugiri",
"followers_url": "https://api.github.com/users/butsugiri/followers",
"following_url": "https://api.github.com/users/butsugiri/following{/other_user}",
"gists_url": "https://api.github.com/users/butsugiri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/butsugiri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/butsugiri/subscriptions",
"organizations_url": "https://api.github.com/users/butsugiri/orgs",
"repos_url": "https://api.github.com/users/butsugiri/repos",
"events_url": "https://api.github.com/users/butsugiri/events{/privacy}",
"received_events_url": "https://api.github.com/users/butsugiri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Also it seems that the CircleCI jobs were not triggered - do you mind pushing a new commit (can be empty) to trigger the jobs? Thank you!",
"Hi, @LysandreJik . Thank you very much for your helpful review.\r\nI would really like to work on your suggestions (I have a lot to learn from your comments), but right now I have to deal with my paper deadline. \r\nSo please forgive me that it will take some time to start working on it.\r\n",
"No worries @butsugiri, looking forward to it!",
"I am sorry that it took me so long to address the review comments.\r\n\r\nCurrently, the following tests are not passing on my laptop (and they should fail on CI, too):\r\n- `test_pickle_subword_regularization_tokenizer`\r\n- `test_subword_regularization_tokenizer`\r\n- `test_tokenizer_slow_store_full_signature`\r\n\r\nI am not familiar enough with the internals of the library; so I am not sure how I should deal with them.\r\n\r\nIn addition, I think I have to write document for this new tokenizer (`make quality` command gave me an error).\r\n\r\n",
"Hi @butsugiri - I'm currently in the process of checking with CircleCI why the runs don't trigger on your PRs. Will resolve this problem and work with you to resolve the issues above. Thanks for your patience!",
"I see. Thank you!",
"Hello @butsugiri! It seems that the CircleCI tests aren't run because they try to run with the user @lalitpagaria's credentials. Do you know why that might be so?\r\n\r\n@lalitpagaria, if you receive a notification, from what I understand the CircleCI authentication system tries to authenticate you as a runner for this PR - but your credentials have gone stale and CircleCI cannot manage to run the tests. It was mentioned you should do a full CircleCI [re-authentication](https://support.circleci.com/hc/en-us/articles/360051228052-How-to-perform-a-full-re-authentication). \r\n\r\nPlease let me know if this is expected or not - I don't see any commits from @lalitpagaria so I'm unaware of what might be causing this. I would expect the Hugging Face auth to be used to run these tests.",
"@LysandreJik oh man. I dont have any idea why this happened.\nIn past I added RAG related PRs (around 10 months back) that time to debug CI failure I opened Circles CI. Not sure of that caused this. But how come it automatically update credentials when I don't have permission 🤷🏽♂️\n\nNot receiving any notification from circleCI. I have removed them from my approved app list long time back",
"That's helpful, thank you for sharing @lalitpagaria! Will report back to CircleCI's customer support.",
"@LysandreJik I just enabled circleCI. See if this help at least should unblock existing failing CI meanwhile you work with them to get this sorted. I really apologize if any of my actions caused this.",
"@butsugiri \r\nThank you for making the effort to publish the Japanese Roberta model. \r\nIf it's not a problem, I would like to know the details of how you trained tokenizer. I would like to know what kind of pre-processing you did on the pre-trained corpus and the Mecab dictionary you used.",
"@butsugiri, sorry this slipped through the cracks - could you close the PR and open a new one without touching your branch? Hopefully the CI should trigger, otherwise I'll take care of it. Thank you!",
"@kambehmw Thank you for your interest. My colleagues and I are currently preparing the release page with the details of pretraining including tokenization. I would appreciate if you could wait for it, Thanks!",
"@LysandreJik Absolutely no problem. Thank you for your continuous support, I really appreciate it.\r\nClose this PR and will open new one.",
"@butsugiri Thanks for your reply. I understand that you are preparing a release page, and I look forward to the official release of the Japanese Roberta Model. Thanks."
] | 1,628 | 1,635 | 1,635 | NONE | null | # Add Japanese RoBERTa Model
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
I have recently trained a Japanese version of RoBERTa-base, and would like to make our model publicly available via this wonderful library.
The files are available [here](https://www.dropbox.com/sh/tu5v06ge4hgo2c4/AADdtnrBxh73076onmpt9gUva?dl=0)
I made two major changes:
1. Added a new tokenizer file `tokenization_roberta_japanese.py`
- If one can nicely merge this tokenizer to `tokenization_bert_japanese.py`, that would be the best. (as adding a new file is not ideal)
2. Added `do_zenkaku` option to `tokenization_bert_japanese.py`
- This is because I normalized every hankaku character to zenkaku character in preprocessing
## Background
I have recently trained a Japanese version of RoBERTa-base using [fairseq codebase](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.pretraining.md).
I believe that our Japanese RoBERTa is better than the existing Japanese pre-trained language models (i.e., BERTs) that are publicly available for the following reasons:
- **More data**: Existing BERT models (the one from [NICT](https://alaginrc.nict.go.jp/nict-bert/index.html) and [cl-tohoku](https://huggingface.co/cl-tohoku/bert-base-japanese)) use Wikipedia dump for training. We also use CC-100 corpus, which is about 17.5 times larger than Wikipedia.
- **Better model**: We trained RoBERTa that is empirically better than vanilla BERT.
- **More compute**: In order to take advantage of large training data, we trained our RoBERTa longer than vanilla BERT. The training took 1 month on DGX-2 (V100 32GB x 16).
In fact, my colleagues have conducted experiments on multiple Japanese benchmark datasets, and confirmed that our RoBERTa is indeed superior:
### [amazon_reviews dataset](https://huggingface.co/datasets/amazon_reviews_multi)
| model | accuracy |
| ---- | ---- |
| [NICT_BERT-base](https://alaginrc.nict.go.jp/nict-bert/index.html) | 0.6014 |
| [bert_bert-base-japanese-v2](https://huggingface.co/cl-tohoku/bert-base-japanese) | 0.5980 |
| Our RoBERTa | **0.6198** |
### [paws-x dataset](https://github.com/google-research-datasets/paws/tree/master/pawsx)
| model | accuracy |
| ---- | ---- |
| [NICT_BERT-base](https://alaginrc.nict.go.jp/nict-bert/index.html) | 0.8285 |
| [bert_bert-base-japanese-v2](https://huggingface.co/cl-tohoku/bert-base-japanese) | 0.8305 |
| Our RoBERTa | **0.8440** |
### [JRTE dataset (Macro F1)](https://github.com/megagonlabs/jrte-corpus)
| Model | BASE | ME | MLM |
| ------------- | ------------- | ------------- | ------------- |
| [NICT_BERT-base](https://alaginrc.nict.go.jp/nict-bert/index.html) | 90.3 | **80.0** | 55.5 |
| [bert_bert-base-japanese-v2](https://huggingface.co/cl-tohoku/bert-base-japanese)| 86.1 | 75.2 | 53.8 |
| Our RoBERTa| **92.3** | 77.8 | **58.0** |
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- I read the guideline and ran the `make test` command. However, I am struggling with so many FAILED tests.
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
- I have not written any test yet. (I am not familiar with writing a test, so it may take a while.)
## Who can review?
I would really appreciate if @LysandreJik could review the code. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13065/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13065",
"html_url": "https://github.com/huggingface/transformers/pull/13065",
"diff_url": "https://github.com/huggingface/transformers/pull/13065.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13065.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13064 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13064/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13064/comments | https://api.github.com/repos/huggingface/transformers/issues/13064/events | https://github.com/huggingface/transformers/issues/13064 | 964,646,494 | MDU6SXNzdWU5NjQ2NDY0OTQ= | 13,064 | How to extract the encoded data of feed & forward layer in tfbertmodel? | {
"login": "1148330040",
"id": 34124260,
"node_id": "MDQ6VXNlcjM0MTI0MjYw",
"avatar_url": "https://avatars.githubusercontent.com/u/34124260?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/1148330040",
"html_url": "https://github.com/1148330040",
"followers_url": "https://api.github.com/users/1148330040/followers",
"following_url": "https://api.github.com/users/1148330040/following{/other_user}",
"gists_url": "https://api.github.com/users/1148330040/gists{/gist_id}",
"starred_url": "https://api.github.com/users/1148330040/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/1148330040/subscriptions",
"organizations_url": "https://api.github.com/users/1148330040/orgs",
"repos_url": "https://api.github.com/users/1148330040/repos",
"events_url": "https://api.github.com/users/1148330040/events{/privacy}",
"received_events_url": "https://api.github.com/users/1148330040/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThanks!\r\n\r\ncc @Rocketknight1 ",
"I asked questions where you said, but no one replied to me. I hope you can tell me the answer to this question. Thank you!\r\nhttps://discuss.huggingface.co/t/how-to-extract-the-encoded-data-of-feed-forward-layer-in-tfbertmodel/9320",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,633 | 1,633 | NONE | null | env:tf2.2
model:TFBertModel.from_pretrained('hfl/chinese-bert-wwm-ext')
i'm working on an information extraction project. First, I predict the “**subject**” through Bert CRF, then **tf. Gather ()** the coding layer of shared Bert and the location information corresponding to the “**subject**”, and then predict the “**object**“, but I can't extract the **feed & forward** layer of Bert now
I want to extract the output of the **feed & forward** layer of the Bert model as the shared coding layer, but I can't find the corresponding method. I want to obtain the output similar to the following:
# Tensor("Transformer-11-FeedForward-Add/add:0", shape=(None, None, 768), dtype=float32)
I tried through ”**model.trainable_weights[- 5]**”layer, but the extracted output is obviously not what I need, and I don't want to directly use "model (ids, masks, tokens) [0]", because Bert's last layer is processed by "layerNormal"
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13064/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13064/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13063 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13063/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13063/comments | https://api.github.com/repos/huggingface/transformers/issues/13063/events | https://github.com/huggingface/transformers/pull/13063 | 964,475,555 | MDExOlB1bGxSZXF1ZXN0NzA2OTI5MDgy | 13,063 | [WIP] Correct wav2vec2 flax | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,629 | 1,629 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13063/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13063",
"html_url": "https://github.com/huggingface/transformers/pull/13063",
"diff_url": "https://github.com/huggingface/transformers/pull/13063.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13063.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13062 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13062/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13062/comments | https://api.github.com/repos/huggingface/transformers/issues/13062/events | https://github.com/huggingface/transformers/issues/13062 | 964,443,499 | MDU6SXNzdWU5NjQ0NDM0OTk= | 13,062 | Cannot import name 'BEiTForImageClassification' from 'transformers' | {
"login": "dnnxl",
"id": 51223285,
"node_id": "MDQ6VXNlcjUxMjIzMjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/51223285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dnnxl",
"html_url": "https://github.com/dnnxl",
"followers_url": "https://api.github.com/users/dnnxl/followers",
"following_url": "https://api.github.com/users/dnnxl/following{/other_user}",
"gists_url": "https://api.github.com/users/dnnxl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dnnxl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dnnxl/subscriptions",
"organizations_url": "https://api.github.com/users/dnnxl/orgs",
"repos_url": "https://api.github.com/users/dnnxl/repos",
"events_url": "https://api.github.com/users/dnnxl/events{/privacy}",
"received_events_url": "https://api.github.com/users/dnnxl/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I have encountered the same problem, and solved it by re-installing `transformers` from the source via the following command:\r\n`pip install git+https://github.com/huggingface/transformers` (for further details please see https://huggingface.co/transformers/installation.html). Installing from the source resulted in a `transformers ` version of 4.10.0, and then I could import the Beit models.\r\n\r\nAnother thing that caught my attention in your code sample is that there is a little typo that might also be causing the problem, the module to be imported is written as `BEiTForImageClassification`, however it is supposed to be `BeitForImageClassification`.",
"Thanks it solves the problem. Also for the clarification."
] | 1,628 | 1,628 | 1,628 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
Hi trying to run the BEiTForImageClassification in Google Colab and got the following error Cannot import name 'BEiTForImageClassification' from 'transformers'. Any suggestion on how to fix it?
- `transformers` version: 4.9.2
- Platform: Google Colab
Models:
- nielsr/beit-base-patch16-224
## To reproduce
Steps to reproduce the behavior:
Based on https://huggingface.co/nielsr/beit-base-patch16-224.
1. Run and using the following code
` ` `
from transformers import AutoTokenizer, BEiTForImageClassification
tokenizer = AutoTokenizer.from_pretrained("nielsr/beit-base-patch16-224")
model = BEiTForImageClassification.from_pretrained("nielsr/beit-base-patch16-224")
` ` `
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
An error "Cannot import name 'BEiTForImageClassification' from 'transformers' " | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13062/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13061 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13061/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13061/comments | https://api.github.com/repos/huggingface/transformers/issues/13061/events | https://github.com/huggingface/transformers/pull/13061 | 964,191,808 | MDExOlB1bGxSZXF1ZXN0NzA2Njg3MzU0 | 13,061 | Fix small typo in M2M100 doc | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://api.github.com/users/SaulLu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SaulLu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SaulLu/subscriptions",
"organizations_url": "https://api.github.com/users/SaulLu/orgs",
"repos_url": "https://api.github.com/users/SaulLu/repos",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"received_events_url": "https://api.github.com/users/SaulLu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
Reading the M2M100 documentation, I think a little typo has crept into the code snippet.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed and @patil-suraj :slightly_smiling_face:
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13061/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13061/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13061",
"html_url": "https://github.com/huggingface/transformers/pull/13061",
"diff_url": "https://github.com/huggingface/transformers/pull/13061.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13061.patch",
"merged_at": 1628529426000
} |
https://api.github.com/repos/huggingface/transformers/issues/13060 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13060/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13060/comments | https://api.github.com/repos/huggingface/transformers/issues/13060/events | https://github.com/huggingface/transformers/issues/13060 | 964,181,650 | MDU6SXNzdWU5NjQxODE2NTA= | 13,060 | Exporting Fine tuned T5ForConditionalGeneration model to TF-Serving using ONNX | {
"login": "sekharvth",
"id": 37143160,
"node_id": "MDQ6VXNlcjM3MTQzMTYw",
"avatar_url": "https://avatars.githubusercontent.com/u/37143160?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sekharvth",
"html_url": "https://github.com/sekharvth",
"followers_url": "https://api.github.com/users/sekharvth/followers",
"following_url": "https://api.github.com/users/sekharvth/following{/other_user}",
"gists_url": "https://api.github.com/users/sekharvth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sekharvth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sekharvth/subscriptions",
"organizations_url": "https://api.github.com/users/sekharvth/orgs",
"repos_url": "https://api.github.com/users/sekharvth/repos",
"events_url": "https://api.github.com/users/sekharvth/events{/privacy}",
"received_events_url": "https://api.github.com/users/sekharvth/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
}
] | [
"Also pinging @mfuntowicz here as the expert for everything onnx related. It might be the case that the `lm_head.weight` are not correctly ported to ONNX here. \r\n\r\nCould you try to do the following after training\r\n\r\nAfter line: \r\n```\r\nmodel, optimizer, start_epoch = load_ckp(ckp_path, model, optimizer)\r\n```\r\nadd those two lines \r\n\r\n```\r\nmodel.config.tie_word_embeddings =False # sets `config.tie_word_embeddings=False`\r\nmodel.lm_head.weight = torch.nn.Parameter(model.shared.weight.T.clone()) # clones the correct parameters\r\n```\r\nand try if this works. Not at all sure, but this should at least remove the warning",
"Hey @patrickvonplaten, thanks for getting back.\r\n\r\nI tried running the pipeline with the additional lines of code you'd provided. It gave me a shape mismatch initially in the line where the `model.lm_head.weight` parameter is set, but I was able to get around that by removing the `.T` in the RHS. \r\n\r\nEven after doing this, the `lm_head.weight not initialized` warning still appeared, but I decided to try out the remainder anyway. Curiously, I did notice that the `config.json` file had an additional key-value pair this time, specifically `'decoder_start_token_id': 0`, which I'm hoping was a step in the right direction.\r\n\r\nI converted the onnx file that was generated to the TF SavedModel format with the same command in my original post, and inspected the inputs and outputs to the model with the `saved_model_cli show` command. The outputs of the same are as follows : \r\n\r\n```\r\nsignature_def['serving_default']:\r\n The given SavedModel SignatureDef contains the following input(s):\r\n inputs['attention_mask'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (-1, -1)\r\n name: serving_default_attention_mask:0\r\n inputs['decoder_attention_mask'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (-1, 1)\r\n name: serving_default_decoder_attention_mask:0\r\n inputs['decoder_input_ids'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (-1, 1)\r\n name: serving_default_decoder_input_ids:0\r\n inputs['input_ids'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (-1, -1)\r\n name: serving_default_input_ids:0\r\n The given SavedModel SignatureDef contains the following output(s):\r\n outputs['output_0'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (-1, -1, 768)\r\n name: StatefulPartitionedCall:0\r\n outputs['output_1'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (-1, -1, 768)\r\n name: StatefulPartitionedCall:1\r\n```\r\n\r\nThe outputs section indicates that these are the outputs of a couple of hidden layers which has 768 units (I'm guessing it's the final encoder/decoder hidden states), but what is actually required is the softmax distribution over ~32k tokens for summarization. \r\n\r\nJust out of curiosity, I did try exporting the fine tuned PyTorch model through the standard `torch.onnx.export` pipeline, with the following command:\r\n`torch.onnx.export(model, (model.dummy_inputs['input_ids'], model.dummy_inputs['decoder_input_ids'], model.dummy_inputs['decoder_attention_mask']), 't5-for-serve.onnx')`, and it exited successfully with just a `TracerWarning`.\r\n\r\nOn converting this to the TF SavedModel format, I get these input and output signatures : \r\n\r\n```\r\nsignature_def['serving_default']:\r\n The given SavedModel SignatureDef contains the following input(s):\r\n inputs['0'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (3, 5)\r\n name: serving_default_0:0\r\n inputs['2'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (3, 5)\r\n name: serving_default_2:0\r\n inputs['attention_mask.1'] tensor_info:\r\n dtype: DT_INT64\r\n shape: (3, 5)\r\n name: serving_default_attention_mask.1:0\r\n The given SavedModel SignatureDef contains the following output(s):\r\n outputs['output_0'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 5, 32128)\r\n name: PartitionedCall:0\r\n outputs['output_1'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:1\r\n outputs['output_10'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:2\r\n outputs['output_11'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:3\r\n outputs['output_12'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:4\r\n outputs['output_13'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:5\r\n outputs['output_14'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:6\r\n outputs['output_15'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:7\r\n outputs['output_16'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:8\r\n outputs['output_17'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:9\r\n outputs['output_18'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:10\r\n outputs['output_19'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:11\r\n outputs['output_2'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:12\r\n outputs['output_20'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:13\r\n outputs['output_21'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:14\r\n outputs['output_22'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:15\r\n outputs['output_23'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:16\r\n outputs['output_24'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:17\r\n outputs['output_25'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:18\r\n outputs['output_26'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:19\r\n outputs['output_27'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:20\r\n outputs['output_28'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:21\r\n outputs['output_29'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:22\r\n outputs['output_3'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:23\r\n outputs['output_30'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:24\r\n outputs['output_31'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:25\r\n outputs['output_32'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:26\r\n outputs['output_33'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:27\r\n outputs['output_34'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:28\r\n outputs['output_35'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:29\r\n outputs['output_36'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:30\r\n outputs['output_37'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:31\r\n outputs['output_38'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:32\r\n outputs['output_39'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:33\r\n outputs['output_4'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:34\r\n outputs['output_40'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:35\r\n outputs['output_41'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:36\r\n outputs['output_42'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:37\r\n outputs['output_43'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:38\r\n outputs['output_44'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:39\r\n outputs['output_45'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:40\r\n outputs['output_46'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:41\r\n outputs['output_47'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:42\r\n outputs['output_48'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:43\r\n outputs['output_49'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 5, 768)\r\n name: PartitionedCall:44\r\n outputs['output_5'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:45\r\n outputs['output_6'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:46\r\n outputs['output_7'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:47\r\n outputs['output_8'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:48\r\n outputs['output_9'] tensor_info:\r\n dtype: DT_FLOAT\r\n shape: (3, 12, 5, 64)\r\n name: PartitionedCall:49\r\n```\r\n\r\nAs can be seen, the inputs and outputs differ significantly. The number of inputs have gone down by 1, compared to the `transformers.onnx` export having suggestions from @patrickvonplaten. Plus, the sizes of the inputs and outputs are fixed, which I'm guessing can be overriden with the `dynamic_axes` parameter in the export step. \r\n\r\nBut the first output in this does have what appears to be the softmax distribution over the ~32k tokens. \r\n\r\nIs this the right approach @patrickvonplaten @mfuntowicz ?\r\n",
"Hmm ok :-/ Think we'll have to wait here until @mfuntowicz is back from vacation I'm afraid...he knows better how to debug onnx + tf",
"Sure @patrickvonplaten thanks for the quick turnaround though.",
"Hey @patrickvonplaten, just checking in to see if @mfuntowicz is back :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hey @patrickvonplaten @mfuntowicz , any updates on this?",
"Hi @sekharvth,\r\nIt seems that you are interested in doing seq2seq language modeling (`T5ForConditionalGeneration`), but you do not specify that when exporting to ONNX, so what seems to happen is that you are only exporting a `T5Model`, not a `T5ForConditionalGeneration`, hence the issue.\r\n\r\nFor each architecture, you can find which feature is supported for the ONNX export [here](https://github.com/huggingface/transformers/blob/master/src/transformers/onnx/features.py#L60). \r\n\r\nThe command line utilty takes a feature parameter that defaults to `default` when left unspecified, in your case you want `seq2seq-lm`, could you try this and tell me if this solves the issue:\r\n\r\n```\r\npython -m transformers.onnx --feature=\"seq2seq-lm\" --model=fine-tuned onnx/t5-tf-serving/ output_dir\r\n```\r\n\r\n\r\n\r\n",
"Hey @michaelbenayoun .\r\n\r\nAaah, there's a param to be set then. I'll try this out and let you know :)\r\n\r\nThank you!",
"Hey @michaelbenayoun , thank you so much for pointing out the solution, it works like a charm :)\r\n\r\nSide note : If anyone is else is trying to serve a generative model, you need to make calls to the served model repeatedly with the latest decoded array, until the stop token is generated (much like the usual inference logic). Takeaway being that from limited initial testing, serving the model doesn't necessarily speed up the inference process. \r\n\r\nClosing this issue :)"
] | 1,628 | 1,633 | 1,633 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: Linux-5.4.0-1049-gcp-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* my own modified scripts:
I use a fine tuned version of t5 (fine tuned using Huggingfqce and PyTorch), trained on a custom dataset for summarization. Since PyTorch Serving is no longer an option because of unrelated reasons, I require TF-Serving for a production optimized setting. I'm using the ONNX pipeline detailed here : https://huggingface.co/transformers/serialization.html#converting-an-onnx-model-using-the-transformers-onnx-package, with necessary changes to the paths.
When I serve this model and do inference, it seems the model being loaded isn't the fine tuned one, as it gives output of the following nature : `In In In In In auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf auf`
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: Summarization
## To reproduce
Steps to reproduce the behavior:
```
def load_ckp(checkpoint_fpath, model, optimizer):
checkpoint = torch.load(checkpoint_fpath, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
return model, optimizer, checkpoint['epoch']
import os
tokenizer = T5Tokenizer.from_pretrained("t5-base")
model = T5ForConditionalGeneration.from_pretrained("t5-base")
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
model = model.to(device)
optimizer = torch.optim.Adam(params = model.parameters(), lr=1e-4)
ckp_path = '/checkpoint_dir/checkpoint.pt'
model, optimizer, start_epoch = load_ckp(ckp_path, model, optimizer)
model.save_pretrained('fine-tuned') ##saves it to pytorch_model.bin format and config.json, which is needed for onnx
tokenizer.save_pretrained('fine-tuned')
tokenizer = T5Tokenizer.from_pretrained("fine-tuned")
model = T5ForConditionalGeneration.from_pretrained("fine-tuned")
==== COMMAND LINE====
python -m transformers.onnx --model=fine-tuned onnx/t5-tf-serving/
```
At this point, I get the following warning : `Some weights of the model checkpoint at fine-tuned were not used when initializing T5Model: ['lm_head.weight']`,
but the process completes with the following message : `All good, model saved at: onnx/t5-tf-serving/model.onnx`.
Post this I use `onnx-tf convert -i onnx/t5-tf-serving/model.onnx -o output.pb` to get the corresponding Tensorflow SavedModel, and use standard docker based procedure for deploying it with TF-Serving.
## Expected behavior
I'm able to serve the model using the proper request formats, but the outputs are way off, as shown above. I'm guessing it has to do with the warning message that was displayed when converting the pytorch model to onnx.
Fwiw, I tested out normal inference on the .bin formatted pytorch model that was obtained using the `model.save_pretrained('fine-tuned')` function, and it was generating expected outputs.
Can you please suggest workarounds? @patrickvonplaten, @patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13060/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13059 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13059/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13059/comments | https://api.github.com/repos/huggingface/transformers/issues/13059/events | https://github.com/huggingface/transformers/issues/13059 | 964,178,331 | MDU6SXNzdWU5NjQxNzgzMzE= | 13,059 | RAG: building my own dataset | {
"login": "Arij-Aladel",
"id": 68355048,
"node_id": "MDQ6VXNlcjY4MzU1MDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/68355048?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Arij-Aladel",
"html_url": "https://github.com/Arij-Aladel",
"followers_url": "https://api.github.com/users/Arij-Aladel/followers",
"following_url": "https://api.github.com/users/Arij-Aladel/following{/other_user}",
"gists_url": "https://api.github.com/users/Arij-Aladel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Arij-Aladel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Arij-Aladel/subscriptions",
"organizations_url": "https://api.github.com/users/Arij-Aladel/orgs",
"repos_url": "https://api.github.com/users/Arij-Aladel/repos",
"events_url": "https://api.github.com/users/Arij-Aladel/events{/privacy}",
"received_events_url": "https://api.github.com/users/Arij-Aladel/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Check this script.\n\nhttps://www.github.com/huggingface/transformers/tree/master/examples%2Fresearch_projects%2Frag%2Fuse_own_knowledge_dataset.py",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | @shamanez Hello! My question is about building our own dataset to train RAG from scratch. It was mentioned [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag#finetuning) that we can build our dataset to finetune the model, but the links do not open. Could you please provide us with the steps and examples? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13059/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13058 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13058/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13058/comments | https://api.github.com/repos/huggingface/transformers/issues/13058/events | https://github.com/huggingface/transformers/issues/13058 | 964,170,606 | MDU6SXNzdWU5NjQxNzA2MDY= | 13,058 | Non-English characters not fully supported by GPT-2 HF model | {
"login": "danielricks",
"id": 2449536,
"node_id": "MDQ6VXNlcjI0NDk1MzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2449536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielricks",
"html_url": "https://github.com/danielricks",
"followers_url": "https://api.github.com/users/danielricks/followers",
"following_url": "https://api.github.com/users/danielricks/following{/other_user}",
"gists_url": "https://api.github.com/users/danielricks/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielricks/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielricks/subscriptions",
"organizations_url": "https://api.github.com/users/danielricks/orgs",
"repos_url": "https://api.github.com/users/danielricks/repos",
"events_url": "https://api.github.com/users/danielricks/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielricks/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The `bad_word_ids` argument takes as input the token IDs, it's unrelated to the encoding. If you've trained a GPT-2 model on a larger vocabulary containing characters from other languages, then you should be able to specify the ID of the words you'd like to ignore in your vocabulary.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Ubuntu 20.04
- Python version: 3.7.11
- PyTorch version (GPU?):
- Tensorflow version (GPU?): yes
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): GPT-2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. @patrickvonplaten, @LysandreJik When I try to use the bad_words_ids argument in the generate method, it only takes in a list of ints (per the documentation: transformers.NoBadWordsLogitsProcessor). But if I've trained the GPT-2 model using any characters higher than UTF-8, the encoding for those characters requires more than just an int to represent. Is there any way to use Huggingface transformers for a language other than English and prevent the output from containing those characters as well? Or is there any alternative way to use GPT-2 with UTF-32 that you know of?
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
GPT-2 would be more usable if it could be fully supporting of UTF-32 characters, and not just UTF-8. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13058/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13057 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13057/comments | https://api.github.com/repos/huggingface/transformers/issues/13057/events | https://github.com/huggingface/transformers/pull/13057 | 964,168,881 | MDExOlB1bGxSZXF1ZXN0NzA2NjY3OTM4 | 13,057 | Use original key for label in DataCollatorForTokenClassification | {
"login": "ibraheem-moosa",
"id": 14109029,
"node_id": "MDQ6VXNlcjE0MTA5MDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/14109029?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibraheem-moosa",
"html_url": "https://github.com/ibraheem-moosa",
"followers_url": "https://api.github.com/users/ibraheem-moosa/followers",
"following_url": "https://api.github.com/users/ibraheem-moosa/following{/other_user}",
"gists_url": "https://api.github.com/users/ibraheem-moosa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibraheem-moosa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibraheem-moosa/subscriptions",
"organizations_url": "https://api.github.com/users/ibraheem-moosa/orgs",
"repos_url": "https://api.github.com/users/ibraheem-moosa/repos",
"events_url": "https://api.github.com/users/ibraheem-moosa/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibraheem-moosa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Sure. I will get to it tonight.",
"Failure is unrelated to this PR (linked to sacrebleu release today), so merging. Thanks again!"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | DataCollatorForTokenClassification accepts either `label` or `labels` as key for the labels in it's input. However after padding the label it assigns the padded labels to key `labels`.
If originally `label` was used as key than the original upadded labels still remains in the batch. Then at line 192 when we try to convert the batch elements to torch tensor than these original unpadded labels cannot be converted as the labels for different samples have different lengths.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13057/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13057",
"html_url": "https://github.com/huggingface/transformers/pull/13057",
"diff_url": "https://github.com/huggingface/transformers/pull/13057.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13057.patch",
"merged_at": 1628613588000
} |
https://api.github.com/repos/huggingface/transformers/issues/13056 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13056/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13056/comments | https://api.github.com/repos/huggingface/transformers/issues/13056/events | https://github.com/huggingface/transformers/pull/13056 | 964,165,782 | MDExOlB1bGxSZXF1ZXN0NzA2NjY1MzI4 | 13,056 | Change how "additional_special_tokens" argument in the ".from_pretrained" method of the tokenizer is taken into account | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://api.github.com/users/SaulLu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SaulLu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SaulLu/subscriptions",
"organizations_url": "https://api.github.com/users/SaulLu/orgs",
"repos_url": "https://api.github.com/users/SaulLu/repos",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"received_events_url": "https://api.github.com/users/SaulLu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"LGTM! Thank you for making this cleaner.",
"Feel free to merge after solving the code quality issues!"
] | 1,628 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
This PR is a proposal for the issue #12533.
## Motivation
This change in behavior is motivated in particular by the [`test_special_tokens_initialization` test in `test_tokenization_common`](https://github.com/huggingface/transformers/blob/v4.9.2/tests/test_tokenization_common.py#L3132).
This test consists in loading thanks to the method `from_pretrained` a tokenizer (on the hub) and adding in the arguments `additional_special_tokens=[AddedToken("<special>", lstrip=True)]` then to check that this new special token `"<special>"` was well added.
```python
added_tokens = [AddedToken("<special>", lstrip=True)]
tokenizer_r = self.rust_tokenizer_class.from_pretrained(
pretrained_name, additional_special_tokens=added_tokens, **kwargs
r_output = tokenizer_r.encode("Hey this is a <special> token")
special_token_id = tokenizer_r.encode("<special>", add_special_tokens=False)[0]
self.assertTrue(special_token_id in r_output)
```
This test does not currently work in one case: if the repository on the hub contains a `"special_tokens_map.json"` file that defines the value of `"additional_special_tokens"` then the new argument `additional_special_tokens=[AddedToken("<special>", lstrip=True)]` added in the `.from_pretrained` method is ignored.
## New behavior introduce by this PR
This PR introduces a change that gives priority to arguments provided in the `.from_pretrained` method. Understand that if there is a competition between the definition of an argument in the `.from_pretrained` method and in the repository files, then the definition of the argument in the method will be chosen.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. In particular:
@LysandreJik and @sgugger - It would be awesome if you could validate the new behavior and give your opinion on the PR
@NielsRogge - It would be great if you could look at the proposed change in the tokenization of Luke and possibly the test of Canine
@patil-suraj - It would be great if you could look at the proposed change in the tokenization of M2M-100 and MBart50. For these 2 models, I have proposed changes so that the user can still define additional special tokens even if these templates already define additional special tokens corresponding to the language codes. This behavior was already present in `TokenizerMBart` but not in the tokenizers of these last models. If these are not desirable behaviors for these models, I can reverse the changes and just disable the corresponding tests for these models
@patrickvonplaten - it would be great if you could take a look at the change in the Wave2Vec2 processor test (if you agree with this change, there is the same function used in `test_tokenization_wave2vec2.py` that I didn't change)
Thank you for your time
## Failing Test
One test is currently failing `test_run_seq2seq_no_dist` in `test_trainer_ext.py`. At the moment I'm not sure that I see the link with the changes I introduced, but I'm still investigating.
EDIT: I think this test is failing do to a change in [sacrebleu](https://github.com/mjpost/sacrebleu/) which affects :hugs: datasets library. I understand that the problem is in process to be solved on the datasets side ([PR](https://github.com/huggingface/datasets/pull/2778))
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13056/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13056",
"html_url": "https://github.com/huggingface/transformers/pull/13056",
"diff_url": "https://github.com/huggingface/transformers/pull/13056.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13056.patch",
"merged_at": 1629722118000
} |
https://api.github.com/repos/huggingface/transformers/issues/13055 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13055/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13055/comments | https://api.github.com/repos/huggingface/transformers/issues/13055/events | https://github.com/huggingface/transformers/pull/13055 | 964,085,560 | MDExOlB1bGxSZXF1ZXN0NzA2NTk2OTgy | 13,055 | Roll out the test fetcher on push tests | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
This PR rolls out the test_fetcher script on the merged PR in master, making it so that:
- circleCI only runs the tests that are affected by the diff between the master branch and the last commit
- non slow single and multi GPU tests only runs the tests that are affected by the diff between the master branch and the last commit
The last thing to add is a scheduled job to run all those tests daily to make sure we don't miss anything. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13055/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13055",
"html_url": "https://github.com/huggingface/transformers/pull/13055",
"diff_url": "https://github.com/huggingface/transformers/pull/13055.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13055.patch",
"merged_at": 1628600092000
} |
https://api.github.com/repos/huggingface/transformers/issues/13054 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13054/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13054/comments | https://api.github.com/repos/huggingface/transformers/issues/13054/events | https://github.com/huggingface/transformers/issues/13054 | 964,078,361 | MDU6SXNzdWU5NjQwNzgzNjE= | 13,054 | Is there any convenient way to train a transformer from scratch ? | {
"login": "Hannibal046",
"id": 38466901,
"node_id": "MDQ6VXNlcjM4NDY2OTAx",
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hannibal046",
"html_url": "https://github.com/Hannibal046",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_url": "https://api.github.com/users/Hannibal046/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hannibal046/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hannibal046/subscriptions",
"organizations_url": "https://api.github.com/users/Hannibal046/orgs",
"repos_url": "https://api.github.com/users/Hannibal046/repos",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hannibal046/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThere are a few scripts related to pretraining: [language-modeling examples](https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling)\r\n\r\nThanks!"
] | 1,628 | 1,628 | 1,628 | NONE | null | Hello guys!
`Huggingface/transformers` is such a convenient library to use when it comes to all sorts of pertained model. But I am wondering is there a convenient way to train a model from scratch ?
If I want to rebuild the model in `Attention is all you need` , the first thought came into my mind is change modeling_bart.py to adapt to`Attention is all you need` setting like `three way weight tying`,,and do not using `.from_pretrained`,
Is there any better way to do it ?
I know this is a **pertained_model** library , but isn't is be cool to do something more with it?
I am looking forward to your reply | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13054/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13053 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13053/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13053/comments | https://api.github.com/repos/huggingface/transformers/issues/13053/events | https://github.com/huggingface/transformers/issues/13053 | 964,071,656 | MDU6SXNzdWU5NjQwNzE2NTY= | 13,053 | Is there any way to train a transformer model from scrat | {
"login": "Hannibal046",
"id": 38466901,
"node_id": "MDQ6VXNlcjM4NDY2OTAx",
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hannibal046",
"html_url": "https://github.com/Hannibal046",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_url": "https://api.github.com/users/Hannibal046/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hannibal046/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hannibal046/subscriptions",
"organizations_url": "https://api.github.com/users/Hannibal046/orgs",
"repos_url": "https://api.github.com/users/Hannibal046/repos",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hannibal046/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13053/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13052 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13052/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13052/comments | https://api.github.com/repos/huggingface/transformers/issues/13052/events | https://github.com/huggingface/transformers/pull/13052 | 963,930,671 | MDExOlB1bGxSZXF1ZXN0NzA2NDY0NzMz | 13,052 | Fix omitted lazy import for xlm-prophetnet | {
"login": "minwhoo",
"id": 11580164,
"node_id": "MDQ6VXNlcjExNTgwMTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/11580164?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/minwhoo",
"html_url": "https://github.com/minwhoo",
"followers_url": "https://api.github.com/users/minwhoo/followers",
"following_url": "https://api.github.com/users/minwhoo/following{/other_user}",
"gists_url": "https://api.github.com/users/minwhoo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/minwhoo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/minwhoo/subscriptions",
"organizations_url": "https://api.github.com/users/minwhoo/orgs",
"repos_url": "https://api.github.com/users/minwhoo/repos",
"events_url": "https://api.github.com/users/minwhoo/events{/privacy}",
"received_events_url": "https://api.github.com/users/minwhoo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The failures are unrelated to this PR (and the underlying problem is fixed on master) so can be safely ignored.",
"One last thing: can you run `make style` on your branch to fix the quality issue? We should be good to go after."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
Fixes import code for the xlm-prophetnet model to support lazy import. Continued from #13015.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13052/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13052/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13052",
"html_url": "https://github.com/huggingface/transformers/pull/13052",
"diff_url": "https://github.com/huggingface/transformers/pull/13052.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13052.patch",
"merged_at": 1628850293000
} |
https://api.github.com/repos/huggingface/transformers/issues/13051 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13051/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13051/comments | https://api.github.com/repos/huggingface/transformers/issues/13051/events | https://github.com/huggingface/transformers/pull/13051 | 963,899,379 | MDExOlB1bGxSZXF1ZXN0NzA2NDM3NTM1 | 13,051 | [Feature Processing Sequence] Remove duplicated code | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,629 | 1,629 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR removes redundant code which was overlooked in https://github.com/huggingface/transformers/pull/12804 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13051/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13051",
"html_url": "https://github.com/huggingface/transformers/pull/13051",
"diff_url": "https://github.com/huggingface/transformers/pull/13051.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13051.patch",
"merged_at": 1629122555000
} |
https://api.github.com/repos/huggingface/transformers/issues/13050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13050/comments | https://api.github.com/repos/huggingface/transformers/issues/13050/events | https://github.com/huggingface/transformers/pull/13050 | 963,855,056 | MDExOlB1bGxSZXF1ZXN0NzA2Mzk4NTg2 | 13,050 | docs: add HuggingArtists to community notebooks | {
"login": "AlekseyKorshuk",
"id": 48794610,
"node_id": "MDQ6VXNlcjQ4Nzk0NjEw",
"avatar_url": "https://avatars.githubusercontent.com/u/48794610?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AlekseyKorshuk",
"html_url": "https://github.com/AlekseyKorshuk",
"followers_url": "https://api.github.com/users/AlekseyKorshuk/followers",
"following_url": "https://api.github.com/users/AlekseyKorshuk/following{/other_user}",
"gists_url": "https://api.github.com/users/AlekseyKorshuk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AlekseyKorshuk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AlekseyKorshuk/subscriptions",
"organizations_url": "https://api.github.com/users/AlekseyKorshuk/orgs",
"repos_url": "https://api.github.com/users/AlekseyKorshuk/repos",
"events_url": "https://api.github.com/users/AlekseyKorshuk/events{/privacy}",
"received_events_url": "https://api.github.com/users/AlekseyKorshuk/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
* Add [HuggingArtists](https://github.com/AlekseyKorshuk/huggingartists) project to [Community Notebooks](https://huggingface.co/transformers/master/community.html#community-notebooks) in documentation
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? https://discuss.huggingface.co/t/huggingartists-train-a-model-to-generate-lyrics/9045
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13050/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13050",
"html_url": "https://github.com/huggingface/transformers/pull/13050",
"diff_url": "https://github.com/huggingface/transformers/pull/13050.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13050.patch",
"merged_at": 1628581004000
} |
https://api.github.com/repos/huggingface/transformers/issues/13049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13049/comments | https://api.github.com/repos/huggingface/transformers/issues/13049/events | https://github.com/huggingface/transformers/pull/13049 | 963,850,145 | MDExOlB1bGxSZXF1ZXN0NzA2Mzk0MjQx | 13,049 | Add MBART to models exportable with ONNX | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | Adds MBART to models exportable with ONNX | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13049/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13049",
"html_url": "https://github.com/huggingface/transformers/pull/13049",
"diff_url": "https://github.com/huggingface/transformers/pull/13049.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13049.patch",
"merged_at": 1628513765000
} |
https://api.github.com/repos/huggingface/transformers/issues/13048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13048/comments | https://api.github.com/repos/huggingface/transformers/issues/13048/events | https://github.com/huggingface/transformers/pull/13048 | 963,837,029 | MDExOlB1bGxSZXF1ZXN0NzA2MzgyNTc4 | 13,048 | Add to ONNX docs | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | Complete the ONNX docs with an example
Closes https://github.com/huggingface/transformers/issues/12821#issuecomment-884009576 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13048/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13048",
"html_url": "https://github.com/huggingface/transformers/pull/13048",
"diff_url": "https://github.com/huggingface/transformers/pull/13048.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13048.patch",
"merged_at": 1628517109000
} |
https://api.github.com/repos/huggingface/transformers/issues/13047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13047/comments | https://api.github.com/repos/huggingface/transformers/issues/13047/events | https://github.com/huggingface/transformers/issues/13047 | 963,828,469 | MDU6SXNzdWU5NjM4Mjg0Njk= | 13,047 | How do i pre-train Bert_mlm model [Discussion] | {
"login": "mosh98",
"id": 48658042,
"node_id": "MDQ6VXNlcjQ4NjU4MDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/48658042?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mosh98",
"html_url": "https://github.com/mosh98",
"followers_url": "https://api.github.com/users/mosh98/followers",
"following_url": "https://api.github.com/users/mosh98/following{/other_user}",
"gists_url": "https://api.github.com/users/mosh98/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mosh98/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mosh98/subscriptions",
"organizations_url": "https://api.github.com/users/mosh98/orgs",
"repos_url": "https://api.github.com/users/mosh98/repos",
"events_url": "https://api.github.com/users/mosh98/events{/privacy}",
"received_events_url": "https://api.github.com/users/mosh98/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@NielsRogge \r\n@sgugger \r\n\r\nAny thoughts?\r\n\r\nKind regards,\r\nMosleh",
"Hi there! Please use the [forums](https://discuss.huggingface.co/) for questions like this, as we keep the issues for bugs and feature requests only.\r\n\r\nAs for your question, you can fine-tune any existing model with that `run_mlm` script.",
"Hi,\r\n\r\nAlright thanks, i'll post in forums next time.\r\n\r\n/Mosleh\r\n\r\n"
] | 1,628 | 1,628 | 1,628 | NONE | null | Hi,
i've been able to pre train a Bert model using the run_mlm.py file. Thanks to huggingface team ofc. :D
I do have one question tho, if i want to further pre train a bert_mlm model, do i use the same pre training script such as run_mlm.py for the mlm model. Is that the "correct" way or is there another type of training script i should use.
Any help is much appreciated | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13047/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.